KR20130075380A - Apparatus and method for protecting personal location information in massive user environment - Google Patents
Apparatus and method for protecting personal location information in massive user environmentDownload PDFInfo
- Publication number
- KR20130075380A KR20130075380AKR1020110143731AKR20110143731AKR20130075380AKR 20130075380 AKR20130075380 AKR 20130075380AKR 1020110143731 AKR1020110143731 AKR 1020110143731AKR 20110143731 AKR20110143731 AKR 20110143731AKR 20130075380 AKR20130075380 AKR 20130075380A
- Authority
- KR
- South Korea
- Prior art keywords
- user
- location
- location information
- anonymization
- server group
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images












Classifications
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04W—WIRELESS COMMUNICATION NETWORKS
- H04W12/00—Security arrangements; Authentication; Protecting privacy or anonymity
- H04W12/02—Protecting privacy or anonymity, e.g. protecting personally identifiable information [PII]
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F21/00—Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity
- G06F21/60—Protecting data
- G06F21/62—Protecting access to data via a platform, e.g. using keys or access control rules
- G06F21/6218—Protecting access to data via a platform, e.g. using keys or access control rules to a system of files or objects, e.g. local or distributed file system or database
- G06F21/6245—Protecting personal data, e.g. for financial or medical purposes
- G06F21/6254—Protecting personal data, e.g. for financial or medical purposes by anonymising data, e.g. decorrelating personal data from the owner's identification
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L9/00—Cryptographic mechanisms or cryptographic arrangements for secret or secure communications; Network security protocols
- H04L9/08—Key distribution or management, e.g. generation, sharing or updating, of cryptographic keys or passwords
- H04L9/0816—Key establishment, i.e. cryptographic processes or cryptographic protocols whereby a shared secret becomes available to two or more parties, for subsequent use
- H04L9/0838—Key agreement, i.e. key establishment technique in which a shared key is derived by parties as a function of information contributed by, or associated with, each of these
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04W—WIRELESS COMMUNICATION NETWORKS
- H04W4/00—Services specially adapted for wireless communication networks; Facilities therefor
- H04W4/02—Services making use of location information
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04W—WIRELESS COMMUNICATION NETWORKS
- H04W88/00—Devices specially adapted for wireless communication networks, e.g. terminals, base stations or access point devices
- H04W88/18—Service support devices; Network management devices
Landscapes
- Engineering & Computer Science (AREA)
- Computer Networks & Wireless Communication (AREA)
- Signal Processing (AREA)
- Computer Security & Cryptography (AREA)
- Health & Medical Sciences (AREA)
- Bioethics (AREA)
- General Health & Medical Sciences (AREA)
- Theoretical Computer Science (AREA)
- Databases & Information Systems (AREA)
- Computer Hardware Design (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Medical Informatics (AREA)
- Telephonic Communication Services (AREA)
Abstract
Translated fromKoreanDescription
Translated fromKorean본 발명은 다수 사용자가 존재하는 환경에서 개인의 위치 정보를 보호하는 기술에 관한 것으로, 특히 다수의 사용자가 위치 기반 서비스를 사용하는 환경에서 사용자 개인에게 적합한 프라이버시(privacy) 보호 프레임워크(framework)에 기반한 위치 정보 보호 장치, 방법 및 그 방법을 기록한 기록매체에 관한 것이다.BACKGROUND OF THE
위치 기반 서비스(location based service, LBS)는 사용자의 위치 정보를 이용하여 길 찾기, 주변 친구 검색 등을 제공하는 서비스이다. 과거 피처폰 환경에서는 사용자의 위치만을 사용한 기본적인 서비스만이 제공되던 환경에서는 제한된 수의 사용자만이 서비스를 이용하였다. 그러나 스마트폰이 일반화됨에 따라 사용자의 프로필이나 주변 정보 등을 활용하여 보다 다양한 형태의 위치 기반 서비스가 등장하였고, 이를 사용하는 사람들의 수 역시 급증함에 따라 대용량 데이터를 처리하는 것이 중요한 문제로 부각되었다.A location based service (LBS) is a service that provides directions, search for neighbors, etc. using location information of a user. In the past, only a limited number of users used the service in the environment where only basic services using only the user's location were provided in the feature phone environment. However, as smartphones are becoming more common, various types of location-based services have emerged by utilizing user profiles and surrounding information, and as the number of people using them has increased, processing large data has emerged as an important problem.
한편, 이러한 위치 기반 서비스의 사용은 사용자들에게 생활에서의 편이를 제공하나 사용자의 위치 정보를 직접적으로 사용함에 따른 개인의 프라이버시 침해에 대한 우려 역시 존재한다(예를 들어, 범죄자가 사용자의 현재 위치가 집이 아님을 확인한 뒤 가택 침입을 한다든지, 사용자의 위치 정보 기록을 바탕으로 스토킹을 할 수 있는 수단으로 악용될 수 있다.). 따라서, 이하에서 인용된 비특허문헌을 통해 제시된 바와 같이 위치 기반 서비스 사용에 따른 프라이버시 보호를 위한 연구들이 이루어져 왔다.On the other hand, the use of such location-based services provides users with convenience in their lives, but there are also concerns about personal privacy infringement due to the direct use of the user's location information (e.g., a criminal may have a user's current location). May be used as a means to sneak into your home after confirming you are not home, or to stalk based on your location history). Therefore, studies have been made for privacy protection according to the use of location-based services, as suggested through the non-patent literature cited below.
그러나, 통신사들에 의해 위치 기반 서비스의 제공이 관리되던 과거와 달리 오늘날의 스마트폰 사용 환경에서는 애플의 앱스토어나 안드로이드 마켓과 같은 경로를 통해 서비스 제공자와 사용자들이 직접적으로 연결된다. 또한, 위치 기반 서비스를 사용하는 사용자의 수 역시 과거와는 비교할 수 없을 정도로 증가하였다. 따라서, 많은 수의 사용자가 위치 기반 서비스를 이용하는 환경에서 개인 사용자가 요구하는 수준의 안전하고 유연한 프라이버시 보호 기법이 요구된다.However, unlike in the past when location-based services were managed by telecommunications companies, service providers and users are directly connected in today's smartphone environment through paths such as Apple's App Store and Android Market. In addition, the number of users who use location-based services has also increased beyond the past. Therefore, in an environment where a large number of users use location-based services, a level of safe and flexible privacy protection required by individual users is required.
본 발명의 실시예들이 해결하고자 하는 기술적 과제는, 위치 기반 서비스를 이용하는 사용자의 수가 폭발적으로 증가함에 따라 중앙처리 방식의 서비스 제공자에게 보다 많은 시스템 자원이 요구되고 서비스 제공자의 부하가 증가함으로써 이러한 사용자의 서비스 요청에 대한 응답이 지연되는 문제를 해결하며, 사용자 개인에게 위치 정보 서비스를 제공함에 있어서 사용자 개인의 위치 정보 내지 개인 식별 정보가 노출되는 보안의 취약성을 해소하고자 한다.The technical problem to be solved by the embodiments of the present invention is that, as the number of users using location-based services exploded, more system resources are required for the centralized service provider and the load of the service provider increases. In order to solve the problem of delayed response to the service request and to provide location information service to the user, it is intended to solve the vulnerability of security in which the user's location information or personal identification information is exposed.
상기 기술적 과제를 해결하기 위하여, 본 발명의 일 실시예에 따른 사용자의 위치 정보를 익명화하는 방법은, 클라이언트가 복수 개의 사용자 식별자를 제 1 익명화 서버 그룹에 전송하고, 상기 사용자 식별자와 개별 익명화 서버별로 동일한 값을 갖는 키(key)를 각각 결합한 제 1 데이터 쌍을 상기 제 1 익명화 서버 그룹으로부터 수신받는 단계; 상기 클라이언트가 상기 수신된 제 1 데이터 쌍에 기초하여 상기 키와 사용자의 위치 정보를 각각 결합한 제 2 데이터 쌍을 생성하는 단계; 및 상기 클라이언트가 상기 생성된 제 2 데이터 쌍을 제 2 익명화 서버 그룹에 전송하고, 상기 제 2 데이터 쌍에 대해 동일한 키를 기준으로 그룹화한 키 그룹을 상기 제 2 익명화 서버 그룹으로부터 수신하는 단계;를 포함한다.In order to solve the above technical problem, the method for anonymizing the user's location information according to an embodiment of the present invention, the client transmits a plurality of user identifiers to the first anonymization server group, and the user identifier and each individual anonymization server Receiving from the first anonymization server group a first data pair each combining a key having the same value; Generating, by the client, a second data pair combining the key and location information of the user based on the received first data pair; And transmitting, by the client, the generated second data pair to a second anonymization server group, and receiving, from the second anonymization server group, a key group grouped based on the same key for the second data pair. Include.
일 실시예에 따른 상기 사용자의 위치 정보를 익명화하는 방법에서, 상기 제 1 익명화 서버 그룹과 상기 제 2 익명화 서버 그룹은 서로 분리된 장치로서, 상기 제 1 익명화 서버 그룹은 상기 사용자의 식별자를 수신할 수 있으나 상기 사용자의 위치 정보를 수신할 수 없으며, 상기 제 2 익명화 서버 그룹은 상기 사용자의 위치 정보를 수신할 수 있으나 상기 사용자의 식별자를 수신할 수 없다.In the method of anonymizing the location information of the user according to an embodiment, the first anonymization server group and the second anonymization server group are separated from each other, and the first anonymization server group may receive the identifier of the user. Although the location information of the user may not be received, the second anonymization server group may receive location information of the user, but may not receive an identifier of the user.
일 실시예에 따른 상기 사용자의 위치 정보를 익명화하는 방법에서, 상기 제 1 데이터 쌍을 수신받는 단계는, 상기 클라이언트가 복수의 사용자 각각을 식별할 수 있는 복수 개의 사용자 식별자(ID)를 제 1 익명화 서버 그룹에 전송하는 단계; 및 상기 제 1 익명화 서버 그룹을 구성하는 개별 익명화 서버별로 동일한 값을 갖는 복수 개의 키(key)를 생성하여 상기 수신된 사용자 식별자(ID)와 결합함으로써 상기 제 1 익명화 서버 그룹에 의해 생성된 제 1 데이터 쌍 {key,ID}을 상기 클라이언트가 수신하는 단계를 포함한다.In the method of anonymizing the location information of the user according to an embodiment, the step of receiving the first data pair may include: first anonymizing a plurality of user identifiers (IDs) by which the client may identify each of the plurality of users. Transmitting to a server group; And a first generated by the first anonymization server group by generating a plurality of keys having the same value for each individual anonymization server constituting the first anonymization server group and combining them with the received user identifier (ID). Receiving by the client a data pair {key, ID}.
일 실시예에 따른 상기 사용자의 위치 정보를 익명화하는 방법에서, 상기 제 2 데이터 쌍을 생성하는 단계는, 상기 클라이언트가 상기 제 1 데이터 쌍에 포함된 사용자 식별자(ID)를 상기 사용자의 위치 정보(location)로 대체함으로써, 상기 키(key)와 상기 사용자의 위치 정보(location)를 각각 결합한 제 2 데이터 쌍 {key,location}을 생성한다.In the method of anonymizing the location information of the user according to an embodiment of the present disclosure, the generating of the second data pair may include: generating, by the client, a user identifier (ID) included in the first data pair; By replacing with location, a second data pair {key, location} is generated by combining the key and the location information of the user.
또한, 일 실시예에 따른 상기 사용자의 위치 정보를 익명화하는 방법은, 상기 클라이언트가 상기 수신된 키 그룹에 소정 위치 기반 질의를 결합하여 위치 기반 서비스 제공자에게 전송하고, 상기 질의에 대응하는 복수 개의 질의 결과를 상기 위치 기반 서비스 제공자로부터 수신하는 단계; 및 상기 클라이언트가 상기 수신된 복수 개의 질의 결과로부터 자신의 위치 정보에 대응하는 질의 결과만을 획득하는 단계;를 더 포함한다.In addition, the method of anonymizing the location information of the user according to an embodiment, the client combines a predetermined location-based query to the received key group to transmit to a location-based service provider, a plurality of queries corresponding to the query Receiving a result from the location based service provider; And acquiring, by the client, only query results corresponding to the location information of the plurality of queries from the received query results.
일 실시예에 따른 상기 사용자의 위치 정보를 익명화하는 방법에서, 상기 제 1 익명화 서버 그룹은 맵리듀스(MapReduce) 알고리즘에 따르는 매퍼(mapper)이고, 상기 제 2 익명화 서버 그룹은 상기 맵리듀스 알고리즘에 따르는 리듀서(reducer)이다.In the method of anonymizing the location information of the user according to an embodiment, the first anonymization server group is a mapper according to a MapReduce algorithm, and the second anonymization server group is according to the map reduce algorithm. It is a reducer.
상기 기술적 과제를 해결하기 위하여, 본 발명의 다른 실시예에 따른 사용자의 위치 정보를 익명화하는 방법은, 클라이언트가 복수 개의 사용자 식별자를 제 1 익명화 서버 그룹에 전송하고, 상기 사용자 식별자와 개별 익명화 서버별로 동일한 값을 갖는 키를 각각 결합한 제 1 데이터 쌍을 상기 제 1 익명화 서버 그룹으로부터 수신받는 단계; 상기 클라이언트가 상기 수신된 제 1 데이터 쌍에 기초하여 상기 키와 사용자의 위치 정보를 각각 결합한 제 2 데이터 쌍을 생성하는 단계; 상기 클라이언트가 상기 생성된 제 2 데이터 쌍을 제 2 익명화 서버 그룹에 전송하고, 상기 제 2 데이터 쌍에 대해 동일한 키를 기준으로 그룹화한 키 그룹을 상기 제 2 익명화 서버 그룹으로부터 수신하는 단계; 상기 클라이언트가 상기 수신된 키 그룹에 소정 위치 기반 질의를 결합하여 위치 기반 서비스 제공자에게 전송하고, 상기 질의에 대응하는 복수 개의 질의 결과를 상기 위치 기반 서비스 제공자로부터 수신하는 단계; 및 상기 클라이언트가 상기 수신된 복수 개의 질의 결과로부터 자신의 위치 정보에 대응하는 질의 결과만을 획득하는 단계;를 포함하고, 상기 위치 기반 질의를 상기 위치 기반 서비스 제공자에게 전송되기 이전에, 상기 사용자의 위치 정보를 인근 위치 정보로 대체함으로써 공간 정보를 익명화하는 단계를 더 포함한다.In order to solve the above technical problem, a method for anonymizing a user's location information according to another embodiment of the present invention, the client transmits a plurality of user identifiers to the first anonymization server group, and the user identifier and each individual anonymization server Receiving from the first anonymizing server group a first data pair each combining a key having the same value; Generating, by the client, a second data pair combining the key and location information of the user based on the received first data pair; Sending, by the client, the generated second data pair to a second anonymization server group, and receiving, from the second anonymization server group, a key group grouped based on the same key for the second data pair; Combining, by the client, a location-based query with the received key group to a location-based service provider, and receiving a plurality of query results corresponding to the query from the location-based service provider; And obtaining, by the client, only query results corresponding to its location information from the received plurality of query results, and before transmitting the location based query to the location based service provider, the location of the user. Anonymizing the spatial information by replacing the information with nearby location information.
일 실시예에 따른 상기 사용자의 위치 정보를 익명화하는 방법에서, 상기 공간 정보를 익명화하는 단계는, 상기 사용자의 위치를 중심으로 소정 범위 내의 공간 중 하나의 위치를 선택하는 단계; 및 상기 선택된 위치에 대한 정보로서 상기 사용자의 위치 정보를 대체하여 상기 위치 기반 질의를 재생성하는 단계;를 포함한다.In the method of anonymizing the location information of the user according to an embodiment, the anonymizing the space information may include selecting one location among spaces within a predetermined range based on the location of the user; And regenerating the location based query by substituting the location information of the user as the information on the selected location.
일 실시예에 따른 상기 사용자의 위치 정보를 익명화하는 방법에서, 상기 대체되는 인근 위치 정보는 상기 사용자의 위치를 중심으로 소정 범위 내의 공간 중 사용자의 밀도가 가장 높은 공간이다.In the method of anonymizing the location information of the user according to an embodiment, the replaced neighboring location information is a space having the highest density of the user among spaces within a predetermined range around the location of the user.
한편, 이하에서는 상기 기재된 사용자의 위치 정보를 익명화하는 방법들을 컴퓨터에서 실행시키기 위한 프로그램을 기록한 컴퓨터로 읽을 수 있는 기록매체를 제공한다.On the other hand, the following provides a computer-readable recording medium having recorded thereon a program for executing on the computer the methods of anonymizing the user's location information described above.
상기 기술적 과제를 해결하기 위하여, 본 발명의 일 실시예에 따른 사용자의 위치 정보를 익명화하는 장치는, 식별 정보를 익명화하는 제 1 익명화 서버 그룹 및 제 2 익명화 그룹과 통신하는 통신부; 및 적어도 하나의 프로세서(processor)를 구비하여 연산을 수행하는 처리부;를 포함하고, 상기 처리부는, 복수 개의 사용자 식별자를 생성하여 상기 통신부를 통해 제 1 익명화 서버 그룹에 전송하고, 상기 사용자 식별자와 개별 익명화 서버별로 동일한 값을 갖는 키를 각각 결합한 제 1 데이터 쌍을 상기 제 1 익명화 서버 그룹으로부터 수신받으며, 상기 수신된 제 1 데이터 쌍에 기초하여 상기 키와 사용자의 위치 정보를 각각 결합한 제 2 데이터 쌍을 생성하고, 상기 생성된 제 2 데이터 쌍을 상기 통신부를 통해 제 2 익명화 서버 그룹에 전송하며, 상기 제 2 데이터 쌍에 대해 동일한 키를 기준으로 그룹화한 키 그룹을 상기 제 2 익명화 서버 그룹으로부터 수신한다.In order to solve the above technical problem, an apparatus for anonymizing a user's location information according to an embodiment of the present invention, the communication unit for communicating with the first anonymization server group and the second anonymization group to anonymize the identification information; And a processor configured to perform an operation with at least one processor, wherein the processor generates a plurality of user identifiers and transmits the plurality of user identifiers to the first anonymized server group through the communication unit. Receiving a first data pair combining a key having the same value for each anonymization server from the first anonymization server group, and a second data pair combining the key and location information of the user based on the received first data pair, respectively. Generate a second data pair, transmit the generated second data pair to the second anonymization server group through the communication unit, and receive a key group grouped based on the same key for the second data pair from the second anonymization server group do.
일 실시예에 따른 상기 사용자의 위치 정보를 익명화하는 장치에서, 상기 제 1 익명화 서버 그룹과 상기 제 2 익명화 서버 그룹은 서로 분리된 장치로서, 상기 제 1 익명화 서버 그룹은 상기 사용자의 식별자를 수신할 수 있으나 상기 사용자의 위치 정보를 수신할 수 없으며, 상기 제 2 익명화 서버 그룹은 상기 사용자의 위치 정보를 수신할 수 있으나 상기 사용자의 식별자를 수신할 수 없다.In the apparatus for anonymizing the location information of the user according to an embodiment, the first anonymization server group and the second anonymization server group are separated from each other, and the first anonymization server group may receive the identifier of the user. Although the location information of the user may not be received, the second anonymization server group may receive location information of the user, but may not receive an identifier of the user.
일 실시예에 따른 상기 사용자의 위치 정보를 익명화하는 장치에서, 상기 처리부는, 상기 수신된 키 그룹에 소정 위치 기반 질의를 결합하여 상기 통신부를 통해 위치 기반 서비스 제공자에게 전송하고, 상기 질의에 대응하는 복수 개의 질의 결과를 상기 위치 기반 서비스 제공자로부터 수신하며, 상기 수신된 복수 개의 질의 결과로부터 자신의 위치 정보에 대응하는 질의 결과만을 획득한다.In the apparatus for anonymizing the location information of the user according to an embodiment, the processing unit combines a location-based query with the received key group and transmits the location-based service provider to the location-based service provider through the communication unit, and corresponds to the query. Receive a plurality of query results from the location-based service provider, and obtains only the query results corresponding to their location information from the received plurality of query results.
일 실시예에 따른 상기 사용자의 위치 정보를 익명화하는 장치에서, 상기 사용자의 위치를 포함하는 인근 위치 정보 및 그에 대한 사용자의 밀도 정보를 저장하는 저장부;를 더 포함하고, 상기 처리부는, 상기 위치 기반 질의를 상기 위치 기반 서비스 제공자에게 전송되기 이전에, 상기 저장부에 저장된 사용자의 밀도 정보를 이용하여 상기 사용자의 위치 정보를 상기 인근 위치 정보 중 어느 하나로 대체함으로써 공간 정보를 익명화한다.In the apparatus for anonymizing the location information of the user according to an embodiment, the storage unit for storing the nearby location information including the location of the user and the density information of the user; further comprising, the processing unit, the location Before the base query is transmitted to the location-based service provider, the spatial information is anonymized by replacing the location information of the user with one of the neighbor location information using the density information of the user stored in the storage unit.
일 실시예에 따른 상기 사용자의 위치 정보를 익명화하는 장치에서, 상기 제 1 익명화 서버 그룹은 맵리듀스 알고리즘에 따르는 매퍼이고, 상기 제 2 익명화 서버 그룹은 상기 맵리듀스 알고리즘에 따르는 리듀서이다.In the apparatus for anonymizing the location information of the user according to an embodiment, the first anonymization server group is a mapper according to a map reduce algorithm, and the second anonymization server group is a reducer according to the map reduce algorithm.
본 발명의 실시예들은 복수 개의 익명화 서버 그룹들을 이용하여 사용자의 식별 정보를 분산 처리를 통해 익명화함으로써, 위치 기반 서비스를 이용하는 사용자의 수가 폭발적으로 증가하더라도 대용량의 데이터를 효과적으로 처리할 수 있으므로 사용자의 서비스 요청에 대한 빠른 응답 속도를 보장할 수 있으며, 개인화된 위치 정보 서비스를 이용함에 있어서 분리된 익명화 서버 그룹을 통해 사용자 개인의 식별자와 위치 정보 간의 연결 관계를 노출시키지 않음으로써 강인한 보안성을 제공할 수 있다.Embodiments of the present invention use a plurality of anonymization server groups to anonymize user identification information through distributed processing, so that a large amount of data can be effectively processed even if the number of users using location-based services increases explosively. Fast response to requests can be assured, and the use of personalized location information service can provide robust security by not exposing the connection relationship between user's personal identifier and location information through a separate anonymized server group. have.
도 1은 본 발명의 실시예들이 활용될 수 있는 위치 기반 서비스의 요청 서비스 제공 구조를 예시한 도면이다.
도 2는 위치 기반 서비스에서, 위치 및 식별 정보의 익명화 수준을 설명하기 위한 도면이다.
도 3은 본 발명의 실시예들이 채택하고 있는 맵리듀스 프레임워크를 예시한 도면이다.
도 4는 본 발명의 실시예들이 제안하는 사용자 위치 정보 익명화 프레임워크의 구조를 도시한 도면이다.
도 5a 내지 도 5b는 본 발명의 실시예들에 따른 도 4의 프레임워크에서 사용자의 위치 정보를 익명화하는 과정을 순차적으로 도시한 도면이다.
도 6은 본 발명의 일 실시예에 따른 사용자의 위치 정보를 익명화하는 방법을 도시한 흐름도이다.
도 7은 본 발명의 일 실시예에 따른 도 6에 이어서 위치 기반 서비스 제공자에게 질의하는 방법을 도시한 흐름도이다.
도 8은 본 발명의 다른 실시예에 따른 사용자의 위치 정보를 익명화하는 방법에서 공간 정보를 익명화하는 방법을 설명하기 위한 도면이다.
도 9는 본 발명의 일 실시예에 따른 사용자의 위치 정보를 익명화하는 장치를 도시한 블록도이다.
도 10은 본 발명의 실시예들에 따라 구현된 위치 정보 익명화 기술과 종래의 익명화 기술의 응답 속도를 비교한 실험 결과를 예시한 도면이다.
도 11은 본 발명의 실시예들에 따라 구현된 위치 정보 익명화 기술과 종래의 익명화 기술의 필터링 수를 비교한 실험 결과를 예시한 도면이다.1 is a diagram illustrating a request service providing structure of a location based service in which embodiments of the present invention can be utilized.
2 is a diagram for describing anonymization level of location and identification information in a location-based service.
3 is a diagram illustrating a map reduce framework adopted by embodiments of the present invention.
4 is a diagram illustrating a structure of a user location information anonymization framework proposed by embodiments of the present invention.
5A through 5B are diagrams sequentially illustrating a process of anonymizing location information of a user in the framework of FIG. 4 according to embodiments of the present invention.
6 is a flowchart illustrating a method of anonymizing user location information according to an embodiment of the present invention.
7 is a flowchart illustrating a method of querying a location-based service provider following FIG. 6 according to an embodiment of the present invention.
8 is a diagram for describing a method of anonymizing spatial information in a method of anonymizing user location information according to another embodiment of the present invention.
9 is a block diagram illustrating an apparatus for anonymizing user location information according to an embodiment of the present invention.
10 is a diagram illustrating an experimental result comparing the response speed of the location information anonymization technique and the conventional anonymization technique implemented according to the embodiments of the present invention.
FIG. 11 is a diagram illustrating an experimental result comparing the number of filtering of the location information anonymization technique and the conventional anonymization technique implemented according to the embodiments of the present invention.
본 발명의 실시예들을 설명하기에 앞서, 위치 기반 서비스를 제공함에 있어서 발생하는 문제점들을 검토한 후, 이들 문제점을 해결하기 위해 본 발명의 실시예들이 채택하고 있는 다양한 기술적 배경에 대해 개괄적으로 검토하도록 하겠다.Before describing the embodiments of the present invention, it is necessary to review the problems arising in providing location-based services, and then to outline the various technical backgrounds adopted by the embodiments of the present invention to solve these problems. would.
도 1은 본 발명의 실시예들이 활용될 수 있는 위치 기반 서비스의 요청 서비스 제공 구조를 예시한 도면으로서, 사용자가 자신이 휴대하는 휴대 단말기(10)를 이용하여 위치 기반 서비스를 이용하고 있는 상황을 가정하고 있다. 예를 들어, 사용자가 현재 자신의 위치로부터 목적지까지의 대중교통을 이용하고자 할 경우, 사용자가는 현재 위치와 목적지의 위치를 입력값으로서 제공하고, 이러한 입력값에 기초하여 적절한 대중교통 정보를 수신할 수 있을 것이다. 이러한 위치 기반 서비스는 제공하는 주체는 특정 서비스 제공자(50)가 될 것이며, 물리적으로는 원격지에 위치한 위치 기반 서비스 제공 서버가 될 것이다.FIG. 1 is a diagram illustrating a structure of providing a request service of a location-based service in which embodiments of the present invention can be utilized. FIG. 1 illustrates a situation in which a user uses a location-based service by using a
즉, 사용자 단말기(10)로부터 '사용자의 위치 정보(현재의 위치 정보)'와 '위치 기반 질의(목적지까지의 대중교통 정보)'가 위치 기반 서비스 제공자(50)에게 전송되면, 위치 기반 서비스 제공자(50)는 입력된 정보를 기반으로 필요한 연산을 수행한 후, 그 질의 결과를 사용자 단말기(10)로 회신하게 된다. 이하에서 기술될 본 발명의 실시예들은 이러한 위치 기반 서비스가 이루어지는 환경에서 활용될 수 있는 것으로, 특히 다수의 사용자가 동시 다발적으로 위치 기반 서비스를 요청하는 경우를 가정하고 있다.That is, when the location information (current location information) of the user and the location-based query (public transportation information to the destination) are transmitted from the
위치 기반 서비스에서의 프라이버시 보호는 크게 사용자의 정확한 위치 정보를 숨기는 위치 정보 익명화와 서비스 사용자의 실제 식별 정보(예를 들어, 주민번호 또는 이름 등이 될 수 있다.)를 숨기는 식별 정보의 익명화로 분류될 수 있다. 또한 익명화 과정을 수행하는 주체가 중앙의 익명화 서버인지 개인인지에 따라 중앙집중형과 분산형으로 나뉠 수 있다. 위치 정보의 익명화를 위해서는 사용자의 현재 위치를 일정 크기 이상으로 확장하거나, 더미(dummy)를 생성하여 여러 위치에 분포시키는 기법 등이 활용될 수 있으며, 일정 영역 안에 k 명(단, k는 양의 정수)의 사용자가 존재하거나 k 개 이상의 더미를 생성하는 k-anonymity의 변형이 사용될 수 있다.Privacy protection in location-based services is largely classified into anonymization of location information that hides the user's accurate location information and anonymization of identification information that hides the service user's actual identification information (for example, social security number or name). Can be. In addition, depending on whether the subject performing the anonymization process is a central anonymization server or an individual, it can be divided into centralized and distributed types. For anonymization of location information, the user's current location can be extended beyond a certain size, or a dummy can be created and distributed to multiple locations. A variant of k-anonymity may be used, where there are users of integers) or create k or more dummy.
종래의 기술들은 중앙에 신뢰할 수 있는 익명화 서버를 두어 그리드 형태의 맵으로 사용자의 위치 정보를 일반화한 익명화 영역을 생성하는, 중앙집중형-위치 정보 익명화 영역 생성 방법을 중심으로 연구가 주로 이루어져 왔다. 이는 신뢰할 수 있는 서버를 사용하여 간단한 알고리즘으로 사용자의 위치 정보를 보호할 수 있다는 장점이 있으나 신뢰할 수 있는 익명화 서버가 반드시 존재해야 하며 중앙의 익명화 서버가 단독으로 익명화 직업을 수행하기에 사용자 수가 증가함에 따라 서버측 연산 부하량이 증가하는 단점이 존재한다. 또한 서버측이 임의로 익명화 공간 영역(Anonymized Spatial Region, ASR)을 지정함에 의해 발생하는 개인의 설정에 따른 프라이버시 정도를 조절하지 못하며, 무엇보다 오늘날의 변화된 환경에 적합하지 않다.Conventional techniques have been mainly focused on a method for generating a centralized-location information anonymization area in which a reliable anonymization server is placed at the center to generate an anonymization area that generalizes user's location information in a grid-like map. This has the advantage of using a reliable server to protect the user's location information with a simple algorithm, but a reliable anonymization server must exist and the number of users increases because the centralized anonymization server alone performs anonymization jobs. Therefore, there is a disadvantage that the server-side computational load increases. In addition, the server side cannot arbitrarily control the degree of privacy caused by an individualized Anonymized Spatial Region (ASR), which is not suitable for today's changed environment.
한편, 이를 보완하기 위해 P2P 형태의 익명화 연구들이 수행되어 왔다. P2P 형태의 익명화 기법에서는 서비스 사용자들이 서로의 위치 정보를 공유하여 자신의 위치 정보를 일반화하는 기법이다. 이러한 위치 정보는 암호화 등의 과정을 통해 서로에게 노출되지 않도록 보호되며 중앙의 익명화 서버를 필요로 하지 않는다는 장점이 있다. 그러나 이 경우 네트워크 상황이나 주변 사용자와의 거리에 따라 익명화 영역 구성에 시간이 필요하며, 사용자들간의 위치 정보 교환에 따른 악의적인 사용자에 의한 공격 위협이 존재한다.On the other hand, anonymization studies in the form of P2P have been conducted to compensate for this. In the P2P type anonymization technique, service users share their location information and generalize their location information. Such location information is protected from being exposed to each other through encryption and the like, and does not require a centralized anonymization server. However, in this case, time is required for anonymization zone configuration according to network conditions or distances from neighboring users, and there is an attack threat by malicious users due to location information exchange between users.
이상에서 소개한 바와 같이, 기존의 익명화 기법들은 사용자의 위치 정보를 보호함에 있어서, 일정한 한계를 지닌다. 이하에서는 우선, 위치 기반 서비스에서의 프라이버시를 보호하는 기술들을 평가할 수 있는 객관적인 기준을 제시하고, 궁극적으로 본 발명의 실시예들이 달성하고자 하는 기준과 그에 따른 기술적 수단을 제안하고자 한다.As introduced above, existing anonymization techniques have certain limitations in protecting user location information. In the following, first, objective criteria for evaluating technologies for protecting privacy in location-based services will be presented, and ultimately, the criteria and the technical means to be achieved by the embodiments of the present invention will be proposed.
위치 기반 서비스에서 프라이버시 보호 수준을 측정하는 방법은 크게 위치 익명화와 개인 식별 정보 익명화이다. 위치 익명화는 사용자의 위치를 일반화한 정도로써 익명화 수준을 측정하고 개인 식별 정보 익명화는 일정 영역에 존재하는 특정인을 추론할 수 있는 확률을 바탕으로 익명화 수준을 측정한다. 만약 민감한 위치에 존재하는 사용자가 자신의 위치를 노출하지 않기 위해 일정 수준까지 위치 정보를 일반화하였다고 하자. 그럼에도 인근에 다른 사용자가 없고 민감한 위치에 해당하는 건물이 근처에 유일하다면 해당 사용자가 민감한 위치의 건물에 접근했다는 것이 노출될 수 있으므로 위치 익명화는 만족되나 개인 식별 정보 익명화를 만족시키지 못했다고 할 수 있다. 반대로 특정 영역에 일정 수 이상의 사용자가 존재한다고 하여도 위치 익명화가 충분히 이루어지지 않았다면 해당 사용자가 해당 위치의 건물에 접근하였다는 것이 노출될 수 있다. 따라서 사용자의 프라이버시가 지켜지기 위해서는 두 기준 모두가 만족되어야 한다.The methods for measuring the level of privacy protection in location-based services are location anonymization and personally identifiable information anonymization. Location anonymization measures the level of anonymity by generalizing the user's location, and anonymization of personal identification information measures the level of anonymization based on the probability of inferring a specific person in a certain area. Suppose a user in a sensitive location generalizes location information to a certain level in order not to expose his or her location. Nevertheless, if there is no other user nearby and the building corresponding to the sensitive location is the only one nearby, it can be revealed that the user has accessed the building of the sensitive location. On the contrary, even if a certain number of users exist in a specific area, if the location anonymization is not sufficiently performed, the user may be exposed to accessing the building of the location. Therefore, both standards must be satisfied for the privacy of the user.
도 2는 위치 기반 서비스에서, 위치 및 식별 정보의 익명화 수준을 설명하기 위한 도면으로서, 위치 익명화와 식별 정보 익명화에 따른 각각의 경우를 나타낸다. 도 2에서 음영으로 표시된 영역은 익명화가 수행되는 영역을 나타내고, 사각형 점은 사용자 본인의 위치를 나타내며, 원형 점은 다른 사용자의 위치를 나타낸다.FIG. 2 is a diagram for describing anonymization level of location and identification information in a location-based service, and illustrates each case according to location anonymization and identification information anonymization. In FIG. 2, the shaded area represents an area where anonymization is performed, a square dot represents a user's own location, and a circular dot represents a location of another user.
도 2의 (A)를 참조하면, 익명화 영역은 4개의 블록에 걸쳐 수행되고 있고, 사용자가 위치한 가장 작은 식별 블록 내에는 사용자 외에도 3명의 다른 사용자가 위치해 있음을 알 수 있다. 즉, 도 2의 (A)의 경우는, 익명화 영역이 넓은지 여부를 나타내는 '위치에 따른 익명화 수준'은 높으며, 다수의 사용자에 의해 식별 정보를 감출 수 있는 정도를 나타내는 '식별 정보 익명화 수준'도 높은 것을 알 수 있다.Referring to FIG. 2A, it can be seen that the anonymization region is performed over four blocks, and three other users besides the user are located in the smallest identification block in which the user is located. That is, in the case of FIG. 2A, the 'anonymization level according to the location' indicating whether the anonymization area is wide is high, and the 'identification information anonymization level' indicating the degree to which the identification information can be hidden by a plurality of users. It can be seen that also high.
도 2의 (B)를 참조하면, 익명화 영역은 4개의 블록에 걸쳐 수행되고 있고, 사용자가 위치한 가장 작은 식별 블록 내에는 사용자 1명만이 위치해 있음을 알 수 있다. 즉, 도 2의 (B)의 경우는, '위치에 따른 익명화 수준'은 높으나, '식별 정보 익명화 수준'은 낮은 것을 알 수 있다.Referring to FIG. 2B, it can be seen that the anonymization region is performed over four blocks, and only one user is located in the smallest identification block in which the user is located. That is, in the case of FIG. 2B, the 'anonymization level according to the location' is high, but the 'identification information anonymization level' is low.
도 2의 (C)를 참조하면, 익명화 영역은 1개의 블록에서 수행되고 있고, 사용자가 위치한 가장 작은 식별 블록 내에는 사용자 외에도 3명의 다른 사용자가 위치해 있음을 알 수 있다. 즉, 도 2의 (C)의 경우는, '위치에 따른 익명화 수준'은 낮으나, '식별 정보 익명화 수준'은 높은 것을 알 수 있다.Referring to FIG. 2C, it can be seen that the anonymization region is performed in one block, and three other users besides the user are located in the smallest identification block in which the user is located. That is, in the case of (C) of FIG. 2, it can be seen that 'anonymization level according to location' is low, but 'identification information anonymization level' is high.
도 2의 (D)를 참조하면, 익명화 영역은 1개의 블록에서 수행되고 있고, 사용자가 위치한 가장 작은 식별 블록 내에는 사용자 1명만이 위치해 있음을 알 수 있다. 즉, 도 2의 (D)의 경우는, '위치에 따른 익명화 수준'은 낮고, '식별 정보 익명화 수준'도 낮은 것을 알 수 있다.Referring to FIG. 2D, it can be seen that the anonymization area is performed in one block, and only one user is located in the smallest identification block in which the user is located. That is, in FIG. 2D, it can be seen that the 'anonymization level according to the location' is low and the 'identification information anonymization level' is also low.
도 2의 익명화 수준을 2가지 기준(위치에 따른 익명화 수준, 식별 정보 익명화 수준)에 따라 분류하면 다음의 표 1과 같다.The anonymization level of FIG. 2 is classified according to two criteria (anonymization level according to location, identification information anonymization level) as shown in Table 1 below.
한편, 본 발명의 실시예들은 사용자의 위치 정보를 익명화함에 있어서, 다수의 사용자로부터 발생하는 서비스 요청을 효과적으로 처리하기 위해 종래의 중앙처리 방식이 아닌 분산/병렬 처리를 활용하고자 한다. 이를 위해 이하에서는 분산/병렬 처리를 위한 기술적 수단으로서 맵리듀스(MapReduce) 알고리즘을 소개하고자 한다.Meanwhile, embodiments of the present invention attempt to utilize distributed / parallel processing rather than a conventional central processing method to effectively process service requests generated from multiple users in anonymizing user location information. To this end, the following introduces a MapReduce algorithm as a technical means for distributed / parallel processing.
오늘날 웹 상의 데이터가 폭발적으로 증가하면서 대용량의 데이터를 효과적으로 관리하기 위한 .여러 시스템들이 도입되고 있다. 이 중 맵리듀스(MapReduce)알고리즘은 구글(Google)이 공개한 기술로써 저가의 컴퓨터로 구성된 클러스터 환경에서 PB 이상의 대용량 데이터를 병렬로 처리하기 위한 분산 프로그래밍 모델이다. 오늘날 맵리듀스의 오픈소스 구현체인 하둡(Hadoop)을 중심으로 아마존, 링크드인, 페이스북과 같은 대용량 데이터를 다루는 서비스에서 맵리듀스 모델을 채용하고 있으며 대용량 데이터를 다루는 것이 요구되는 시스템에서 많은 주목을 받고 있다.With the explosion of data on the Web today, several systems are being introduced to effectively manage large amounts of data. Among them, the MapReduce algorithm is a technology published by Google, which is a distributed programming model for processing large amounts of data in parallel over PB in a low cost computer cluster environment. Today, MapReduce's open source implementation, Hadoop, employs the MapReduce model in services that handle large amounts of data such as Amazon, LinkedIn, and Facebook, and attracts a lot of attention in systems that require large amounts of data. have.
도 3은 본 발명의 실시예들이 채택하고 있는 맵리듀스 프레임워크를 예시한 도면으로서, 맵리듀스의 전체적인 구조를 제시하고 있다. 도 3에서, 맵리듀스 수행 시 파일 시스템은 큰 파일을 블록 단위로 분할하여 맵(Map) 함수를 수행하는 매퍼(Mapper) 태스크들에 할당한다. Map 함수는 임의의 키-값 상을 읽어 이를 필터링하거나 다른 값으로 변환하는 작업을 수행한다. Map 함수의 수행 결과는 Mapper가 수행된 노드의 로컬 디스크에 기록되며 모든 Mapper가 작업을 종료하면 맵리듀스의 스케쥴러가 리듀서(Reducer) 태스크를 수행한다. Reducer는 여러 노드들로부터 키 값을 기준으로 각 Reducer가 처리해야 할 키-값 쌍을 이전 Mapper들의 로컬 디스크로부터 읽어온다. 이후 키(key) 값을 기준으로 정렬 연산을 수행하고 이렇게 정렬된 키-값 쌍 등을 동일 키 값을 기준으로 그룹화를 수행하여 그 결과를 출력한다.3 is a diagram illustrating a map reduce framework adopted by embodiments of the present invention, and shows the overall structure of map reduce. In FIG. 3, when performing MapReduce, the file system divides a large file into blocks and allocates them to mapper tasks that perform a map function. The Map function reads arbitrary key-values and filters them or converts them to other values. The execution result of the Map function is recorded on the local disk of the node where the Mapper is executed. When all Mapper finishes the work, the scheduler of MapReduce performs the reducer task. The reducer reads the key-value pairs from each of the previous mappers' local disks, based on the key values, from different nodes. After that, a sort operation is performed based on key values, and the sorted key-value pairs are grouped based on the same key value and the result is output.
이제, 이하에서 기술될 본 발명의 실시예들은 위치 기반 서비스에서의 프라이버시를 보호하기 위한 맵리듀스 형태의 아이디 배분을 제안함으로써 사용자의 식별 정보가 노출되는 것을 방지함과 동시에 차후 대용량 데이터를 처리해야 할 환경에서의 서비스 확장성을 제공할 수 있는 프레임워크를 제안하고자 한다. 비록 본 발명의 실시예들이 사용자의 위치 정보를 익명화함에 있어서, 맵리듀스 알고리즘을 차용하고는 있으나, 이러한 기술의 활용은 본 발명의 실시예들이 채택하고 있는 아이디어를 구현하기 위한 기술적 수단 중 일례에 불과하며, 단지 맵리듀스 알고리즘에 한정되는 것이 아니다. 따라서, 본 발명이 속하는 기술분야에서 통상의 지식을 가진 자는 이러한 맵리듀스 알고리즘 이외에 본 발명의 실시예들이 제안하고 있는 기술적 사상과 대응하는 다양한 기술적 수단 및 알고리즘을 활용할 수 있음을 알 수 있다.Now, embodiments of the present invention to be described below are proposed to distribute the ID in the form of MapReduce to protect the privacy in location-based services to prevent the user's identification information from being exposed and at the same time to process a large amount of data We propose a framework that can provide service scalability in an environment. Although embodiments of the present invention employ a MapReduce algorithm in anonymizing the user's location information, the use of this technique is only one example of technical means for implementing the idea adopted by the embodiments of the present invention. It is not limited to the map reduce algorithm. Therefore, it will be appreciated by those skilled in the art that various technical means and algorithms corresponding to the technical idea proposed by the embodiments of the present invention may be used in addition to the map reduce algorithm.
도 4는 본 발명의 실시예들이 제안하는 사용자 위치 정보 익명화 프레임워크의 구조를 도시한 도면으로서, 사용자 단말기(10) 및 위치 기반 서비스 제공자(50) 이외에 매퍼(20)와 리듀서(30)를 활용하고 있다.FIG. 4 is a diagram illustrating a structure of an anonymization framework for user location information proposed by embodiments of the present invention, and utilizes a
우선, 사용자는 사용자 단말기(10)를 통해 자신의 식별자(ID)를 매퍼(20)에 전송하고, 매퍼(20)로부터 키(key)를 할당받는다. 그런 다음, 사용자 단말기(10)는 사용자 식별자(ID)를 대신하여 자신의 위치 정보와 키를 결합하여 리듀서(30)에게 전송하게 된다. 이 때, 리듀서(30)는 수신된 데이터를 키 값을 기준으로 그룹화한 후, 사용자 단말기(10)에게 해당 키 그룹을 회신한다. 이제, 사용자는 사용자 단말기(10)를 통해 수신된 키 그룹에 위치 기반 질의를 결합하고, 위치 기반 서비스 제공자(50)에게 질의를 전송한다. 그러면, 위치 기반 서비스 제공자(50)는 질의 결과를 생성하여 사용자 단말기(10)에게 반환한다.First, the user transmits his identifier (ID) to the
도 4에서 매퍼(20)와 리듀서(30)는 복수 개의 분리된 서버 그룹으로서, 다수의 사용자로부터 사용자 식별 정보 내지 위치 정보를 익명화 처리하는 역할을 수행한다. 또한, 매퍼(20)와 리듀서(30)는 각각 사용자 식별자와 위치 정보만을 처리하기 때문에 서로 상대방이 갖는 정보는 접근할 수 없다. 즉, 매퍼(20)는 위치 정보를 알 수 없고, 리듀서(30)는 사용자 식별자를 알 수 없다. 이를 통해 제 3 자가 사용자 식별자와 위치 정보 상호 간의 관계를 유추할 수 없으므로, 견고한 보안성을 제공할 수 있다. 나아가, 위치 기반 서비스 제공자(50)는 다수의 질의를 수신하므로 어떠한 질의가 특정 사용자에 대응하는지를 알 수 없으므로, 개인 사용자의 익명성이 보장될 수 있다.In FIG. 4, the
도 5a 내지 도 5b는 본 발명의 실시예들에 따른 도 4의 프레임워크에서 사용자의 위치 정보를 익명화하는 과정을 순차적으로 도시한 도면이다.5A through 5B are diagrams sequentially illustrating a process of anonymizing location information of a user in the framework of FIG. 4 according to embodiments of the present invention.
도 5a에서, 사용자들은 사용자 단말기(10)를 통해 자신의 ID를 매퍼(20)에게 전송한다. 이 때, 다수의 사용자들마다 자신을 식별할 수 있는 고유의 ID가 생성된다. 매퍼(20)는 사용자의 ID를 받아 같은 값을 지니는 키가 k개(단, k는 양의 정수) 이상 되도록 ID에 key를 할당하여 {ID,KEY} 쌍을 생성하여 사용자에게 돌려준다. 매퍼(20)는 복수 개의 서버로 구성될 수 있으므로, 각각의 개별 매퍼마다 동일한 key가 부여될 수 있다. 이 때, 매퍼에서 생성한 key와 결합하는 사용자의 ID는 임의로 할당되게 된다.In FIG. 5A, the users transmit their IDs to the
도 5b에서, 사용자들은 사용자 단말기(10)를 통해 자신에게 할당된 {ID,key} 쌍에서 ID에 해당하는 정보 대신 자신의 현재 위치 정보를 넣어 리듀서(30)에게 전송한다. 사용자 ID는 각각 개별 사용자를 식별하는 역할을 하므로, 교체되는 위치 정보 역시 개별 사용자의 위치 정보에 해당한다. 리듀서(30)는 수집된 {Key, 위치} 정보들을 key를 기준으로 정렬하고 같은 key 값을 지니는 그룹끼리 하나의 그룹으로 묶어 각 사용자들에게 돌려준다.In FIG. 5B, the users transmit their current location information to the
도 5c에서, 사용자는 사용자 단말기(10)를 통해 자신이 수신한 k명 이상의 {Key,위치 정보} 그룹 정보에 질의를 결합하여 위치 기반 서비스 제공자(50)에게 전송한다. 이러한 key 그룹은 개별 사용자에 대응하는 하나의 질의뿐만 아니라 다수의 질의를 포함하게 되어, 사용자 개인을 은닉하는 효과가 나타나게 된다. 이제, 위치 기반 서비스 제공자(50)는 자신에게 전송된 질의를 처리하여 그 결과를 질의를 한 사용자에게 회신한다. 앞서 설명한 바와 같이 질의가 k개였다면, 회신되는 질의 결과 역시 k개일 것이다. 물론, 이 중 사용자 자신에게 대응되는 질의 및 결과는 하나뿐이다. 마지막으로, 사용자는 k개의 질의 결과 중 자신에게 해당하는 하나의 정보만을 취하고 나머지를 폐기한다.In FIG. 5C, a user combines a query with group information of k or more {Key, location information} groups received by the user through the
이상의 과정을 통해 사용자는 자신의 ID와 위치 정보간의 연관성을 익명화를 수행하는 매퍼(20)나 리듀서(30) 중 어느 쪽에도 노출시키지 않을 수 있으며 위치 기반 서비스의 이용 시에도 k개 이상의 위치 정보를 함께 전송함으로써 서비스 사용자의 정확한 위치 정보가 노출되는 것을 방지할 수 있다. 또한, 맵리듀스 알고리즘을 응용한 프레임워크를 사용하므로 사용자 수 증가에 따른 확장성 문제에도 능동적으로 적용할 수 있다.Through the above process, the user may not expose the association between his ID and the location information to either the
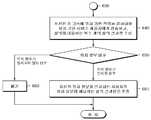
도 6은 본 발명의 일 실시예에 따른 사용자의 위치 정보를 익명화하는 방법을 도시한 흐름도로서, 사용자 단말기, 즉 클라이언트를 중심으로 그 수행 동작을 순차적으로 설명한다. 이하에서, 제 1 익명화 서버 그룹은 맵리듀스(MapReduce) 알고리즘에 따르는 매퍼(mapper)이고, 제 2 익명화 서버 그룹은 상기 맵리듀스 알고리즘에 따르는 리듀서(reducer)로서 구현될 수 있다. 특히, 앞서 도 4 내지 도 5c를 통해 소개한 바와 같이, 상기 제 1 익명화 서버 그룹과 상기 제 2 익명화 서버 그룹은 서로 분리된 장치로서, 상기 제 1 익명화 서버 그룹은 상기 사용자의 식별자를 수신할 수 있으나 상기 사용자의 위치 정보를 수신할 수 없으며, 상기 제 2 익명화 서버 그룹은 상기 사용자의 위치 정보를 수신할 수 있으나 상기 사용자의 식별자를 수신할 수 없는 것이 바람직하다.FIG. 6 is a flowchart illustrating a method of anonymizing user location information according to an embodiment of the present invention, and sequentially describes an operation performed by a user terminal, that is, a client. Hereinafter, the first anonymization server group may be a mapper according to the MapReduce algorithm, and the second anonymization server group may be implemented as a reducer according to the MapReduce algorithm. In particular, as described above with reference to FIGS. 4 through 5C, the first anonymization server group and the second anonymization server group are separated from each other, and the first anonymization server group may receive an identifier of the user. However, the location information of the user may not be received, and the second anonymization server group may receive location information of the user, but may not receive the user's identifier.
610 단계에서, 클라이언트는 복수 개의 사용자 식별자를 제 1 익명화 서버 그룹에 전송하고, 상기 사용자 식별자와 개별 익명화 서버별로 동일한 값을 갖는 키(key)를 각각 결합한 제 1 데이터 쌍을 상기 제 1 익명화 서버 그룹으로부터 수신받는다. 보다 구체적으로, 상기 제 1 데이터 쌍을 수신받는 단계는, 상기 클라이언트가 복수의 사용자 각각을 식별할 수 있는 복수 개의 사용자 식별자(ID)를 제 1 익명화 서버 그룹에 전송하고, 상기 제 1 익명화 서버 그룹을 구성하는 개별 익명화 서버별로 동일한 값을 갖는 복수 개의 키(key)를 생성하여 상기 수신된 사용자 식별자(ID)와 결합함으로써 상기 제 1 익명화 서버 그룹에 의해 생성된 제 1 데이터 쌍 {key,ID}을 상기 클라이언트가 수신한다.In
620 단계에서, 상기 클라이언트는 상기 610 단계를 통해 수신된 제 1 데이터 쌍에 기초하여 상기 키와 사용자의 위치 정보를 각각 결합한 제 2 데이터 쌍을 생성한다. 보다 구체적으로, 상기 제 2 데이터 쌍을 생성하는 단계는, 상기 클라이언트가 상기 제 1 데이터 쌍에 포함된 사용자 식별자(ID)를 상기 사용자의 위치 정보(location)로 대체함으로써, 상기 키(key)와 상기 사용자의 위치 정보(location)를 각각 결합한 제 2 데이터 쌍 {key,location}을 생성한다.In
630 단계에서, 상기 클라이언트는 상기 생성된 제 2 데이터 쌍을 제 2 익명화 서버 그룹에 전송하고, 상기 제 2 데이터 쌍에 대해 동일한 키를 기준으로 그룹화한 키 그룹을 상기 제 2 익명화 서버 그룹으로부터 수신한다.In
이상과 같은 과정을 통해 클라이언트는 자신의 식별자와 위치 정보 간의 관계를 익명화 서버에 노출시키지 않고도 익명화를 분산 처리할 수 있다. 이제, 클라이언트는 이렇게 익명화된 위치 정보에 기초하여 다양한 위치 기반 질의를 할 수 있다.Through the above process, the client can distribute anonymization without exposing the relationship between its identifier and location information to the anonymization server. Now, the client can make various location based queries based on this anonymous location information.
도 7은 본 발명의 일 실시예에 따른 도 6에 이어서 위치 기반 서비스 제공자에게 질의하는 방법을 도시한 흐름도로서, 앞서 도 6에서 소개한 610 단계 내지 630 단계에 계속하여 위치 기반 질의를 수행하게 된다.FIG. 7 is a flowchart illustrating a method of querying a location-based service provider following FIG. 6 according to an embodiment of the present invention, and continues to perform location-based
640 단계에서, 클라이언트는 상기 630 단계를 통해 수신된 키 그룹에 특정 위치 기반 질의를 결합하여 위치 기반 서비스 제공자에게 전송하고, 상기 질의에 대응하는 복수 개의 질의 결과를 상기 위치 기반 서비스 제공자로부터 수신한다.In
650 단계에서, 클라이언트는 수신된 복수 개의 질의 결과 중 자신에게 필요한 질의 결과만을 선별하기 위한 검사를 수행한다. 이를 위해 클라이언트는 상기 640 단계를 통해 수신된 복수 개의 질의 결과 중 사용자의 위치 정보를 참조하여 자신의 위치 정보와 비교한다.In
만약, 위치 정보가 서로 일치할 경우에는 661 단계로 진행하여 자신의 위치 정보와 일치하는 사용자의 위치 정보에 해당하는 질의 결과만을 추출하고, 그렇지 않은 경우 662 단계로 진행하여 나머지 질의 결과들을 폐기한다.If the location information coincides with each other, the process proceeds to step 661 to extract only the query result corresponding to the user's location information that matches the user's location information. Otherwise, the process proceeds to step 662 to discard the remaining query results.
이상과 같은 과정을 통해 클라이언트는 자신의 위치 정보를 위치 정보 서비스 제공자에게 노출시키지 않고도 위치 정보 서비스를 제공받을 수 있다. 이하에서는 개인화된 위치 익명화 공간을 달성할 수 있는 기술적 수단에 대해 소개하도록 한다.Through the above process, the client may receive the location information service without exposing his location information to the location information service provider. Hereinafter, the technical means to achieve a personalized location anonymization space will be introduced.
위치 기반 서비스에서 프라이버시 보장을 위해서는 앞서 표 1을 통해 설명한 바와 같이 식별정보 익명화와 위치 익명화가 동시에 달성되어야 할 필요가 있다. 본 발명의 실시예들을 통해 제안된 프레임워크를 통해 식별 정보 익명화의 요구 사항은 만족시킬 수 있음을 보였다. 한편, 기존의 연구에서 위치 익명화는 위치 정보를 보다 넓은 범위로 일반화시킴으로써 사용자의 정확한 위치가 추론되지 못하게 하는 방식을 사용하였다. 이를 위해 주로 그리드 맵(grid map)을 트리 형태로 계층화하거나 힐버트 커브(Hilbert curve)를 사용하여 위치 익명화를 수행하였다. 그러나 기존의 기법들은 사용자 개인이 원하는 수준의 위치 익명화를 수행하지 못한다는 단점이 존재한다. 따라서, 이하에서 제시되는 본 발명의 다른 실시예들은 사용자가 자신이 원하는 수준만큼의 프라이버시 요구에 맞게 위치 정보를 일반화할 수 있는 개인화된 위치 익명화 기법(PASR: Personalized Anonymized Spatial Region Technique)을 제안한다.In order to guarantee privacy in location-based services, it is necessary to simultaneously identify anonymization and location anonymization as described in Table 1 above. Through the proposed framework through the embodiments of the present invention it has been shown that the requirement of anonymizing identification information can be satisfied. On the other hand, in the previous research, location anonymization used a method of generalizing location information to a wider range so that the exact location of the user could not be inferred. For this purpose, grid maps are hierarchically layered or positional anonymization is performed using a Hilbert curve. However, the existing techniques have the disadvantage that the user does not perform the desired level of location anonymization. Accordingly, other embodiments of the present invention, which are presented below, propose a Personalized Anonymized Spatial Region Technique (PASR) that allows a user to generalize location information according to the desired privacy level.
PASR은 자신의 현재 위치를 중심으로 일정 크기만큼의 위치를 일반화하여 위치 기반 서비스 제공자에게 전송할 수 있다. 이 때, 자신의 위치가 익명화 공간의 중심에 위치할 경우 사용자의 위치에 대한 추론이 가능하다. 따라서 이를 피하기 위해 해당 일반화 영역 안의 장소에 랜덤하게 위치를 지정하고 이를 중심으로 PASR을 생성한다.The PASR may generalize a certain amount of location around its current location and transmit it to the location-based service provider. In this case, if the user's location is located in the center of the anonymized space, the user's location can be inferred. Therefore, to avoid this, we randomly assign a location to a place within the generalization area and generate a PASR around it.
즉, 사용자의 위치 정보를 익명화하는 방법에 있어서, 위치 기반 질의를 위치 기반 서비스 제공자에게 전송되기 이전에, 사용자의 위치 정보를 인근 위치 정보로 대체함으로써 공간 정보를 익명화할 수 있다. 이를 위해, 상기 공간 정보를 익명화하는 단계는, 사용자의 위치를 중심으로 일정 범위 내의 공간 중 하나의 위치를 선택하고, 선택된 위치에 대한 정보로서 사용자의 위치 정보를 대체하여 위치 기반 질의를 재생성하게 된다.That is, in the method of anonymizing the location information of the user, the spatial information can be anonymized by replacing the location information of the user with the location information before the location-based query is transmitted to the location-based service provider. To this end, the anonymizing of the spatial information may select one of the spaces within a predetermined range around the user's location, and regenerate the location-based query by replacing the user's location information with the information about the selected location. .
다만, 이 경우 지도 상에서 사람이 전혀 존재하지 않는 공간(예를 들어, 호수나 접근 통제 지역의 경우가 그러하다.)을 중심으로 익명화 영역이 생성될 경우, 공격자는 그러한 익명화 공간 내에 사용자가 존재할 수 없음을 인지함으로써 해당 공간을 배제하고 나머지 공간에 사용자가 존재할 것이라고 추론할 수 있다. 따라서 이러한 상황을 피하기 위하여 사전에 입수된 공간의 밀도 정보를 바탕으로 사용자의 밀도가 가장 높은 공간으로 PASR 영역의 중심을 선정하는 것이 바람직하다.In this case, however, if anonymization zones are created around spaces where no humans exist on the map (for example, in lakes or access control zones), an attacker may have users in those anonymization spaces. By recognizing the absence, it is possible to exclude the space and infer that the user will exist in the remaining space. Therefore, in order to avoid such a situation, it is desirable to select the center of the PASR region as the space having the highest density based on the density information of the previously obtained space.
도 8은 본 발명의 다른 실시예에 따른 사용자의 위치 정보를 익명화하는 방법에서 공간 정보를 익명화하는 방법을 설명하기 위한 도면이다.8 is a diagram for describing a method of anonymizing spatial information in a method of anonymizing user location information according to another embodiment of the present invention.
도 8의 (A)는 사용자의 위치를 기준으로 반지름 R을 프라이버시 수준에 따른 범위로 결정하여 익명화 공간을 설정하는 방법을 예시하고 있다. 이 경우, 반지름 R에 의해 형성된 공간 내의 임의의 위치를 선택하여 사용자의 현재 위치를 대체할 수 있다.8A illustrates a method of setting anonymization space by determining a radius R based on a user's position as a range according to a privacy level. In this case, an arbitrary position in the space formed by the radius R may be selected to replace the user's current position.
도 8의 (B)는 사용자의 위치를 기준으로 일정한 영역을 익명화 공간으로 설정하되, 전체 영역을 소 영역으로 분할(예를 들어, 도 8의 (B)에 도시된 바와 같이 전체 영역의 중심점을 기준으로 특정 각도 θ에 따라 소 영역으로 분할할 수 있을 것이다.)하여 각 영역마다 밀도 정보를 파악하고, 각각의 영역 중 가장 사용자의 밀도가 높은 공간을 선택할 수 있다. 이 때, 사용자의 밀도가 높다는 것은 사용자 개인의 위치 정보를 은닉하기 유리함을 의미한다. 따라서, 위치 익명성을 강화하기 위해 본 발명의 실시예들은 미리 파악된 공간의 밀도 정보에 기초하여 사용자의 밀도가 가장 높은 공간 내의 특정 위치를 선택하여, 자신의 현재 위치를 대체하는 것이 바람직하다. 즉, 대체되는 인근 위치 정보는 사용자의 위치를 중심으로 일정 범위 내의 공간 중 사용자의 밀도가 가장 높은 공간이 된다.In FIG. 8B, a predetermined area is set as anonymized space based on the user's location, but the entire area is divided into small areas (for example, as shown in FIG. 8B) As a reference, it may be divided into small regions according to a specific angle θ.), Density information may be obtained for each region, and a space having the highest user density among each region may be selected. At this time, the high density of the user means that it is advantageous to conceal the location information of the user. Therefore, in order to enhance location anonymity, it is preferable that embodiments of the present invention select a specific location in the space having the highest density of the user based on previously known density information of the space, and replace its current location. That is, the replaced neighboring location information becomes a space having the highest density of the user among the spaces within a predetermined range around the user's location.
도 9는 본 발명의 일 실시예에 따른 사용자의 위치 정보를 익명화하는 장치를 도시한 블록도로서, 이러한 사용자의 위치 정보를 익명화하는 장치는 일례로서 사용자 단말기(10) 내에 구현될 수 있을 것이다. 따라서, 사용자의 위치 정보를 익명화하는 장치는 매퍼(20), 리듀서(30) 및 위치 기반 서비스 제공자(50)와 상호 작용할 수 있다. 사용자 단말기(10)는 다시 처리부(11) 및 통신부(13)를 포함할 수 있으며, 구현상의 필요에 따라 저장부(15)를 더 포함할 수 있다. 이들 각각의 구성들의 역할은 앞서 기술한 도 6 내지 도 7의 익명화 방법을 통해 수행되는 과정에 대응하는 것으로서, 여기서는 설명의 중복을 피하기 위해 장치적인 구성을 중심으로 그 개요만을 약술하도록 한다.FIG. 9 is a block diagram illustrating an apparatus for anonymizing a user's location information according to an embodiment of the present disclosure. An apparatus for anonymizing the user's location information may be implemented in the
통신부(13)는 식별 정보를 익명화하는 제 1 익명화 서버 그룹 및 제 2 익명화 그룹과 통신하는 수단이다. 이 때, 제 1 익명화 서버 그룹은 맵리듀스 알고리즘에 따르는 매퍼(20)이고, 제 2 익명화 서버 그룹은 상기 맵리듀스 알고리즘에 따르는 리듀서(30)로서 구현될 수 있음은 당연하다. 또한, 상기 제 1 익명화 서버 그룹과 상기 제 2 익명화 서버 그룹은 서로 분리된 장치로서, 상기 제 1 익명화 서버 그룹은 상기 사용자의 식별자를 수신할 수 있으나 상기 사용자의 위치 정보를 수신할 수 없으며, 상기 제 2 익명화 서버 그룹은 상기 사용자의 위치 정보를 수신할 수 있으나 상기 사용자의 식별자를 수신할 수 없는 것이 바람직하다.The
처리부(11)는 적어도 하나의 프로세서(processor)를 구비하여 일련의 사용자 위치 정보 익명화 연산을 수행한다. 보다 구체적으로, 처리부(11)는, 복수 개의 사용자 식별자를 생성하여 상기 통신부(13)를 통해 제 1 익명화 서버 그룹(20)에 전송하고, 상기 사용자 식별자와 개별 익명화 서버별로 동일한 값을 갖는 키를 각각 결합한 제 1 데이터 쌍을 상기 제 1 익명화 서버 그룹(20)으로부터 수신받는다. 그런 다음, 처리부(11)는 상기 수신된 제 1 데이터 쌍에 기초하여 상기 키와 사용자의 위치 정보를 각각 결합한 제 2 데이터 쌍을 생성하고, 상기 생성된 제 2 데이터 쌍을 상기 통신부(13)를 통해 제 2 익명화 서버 그룹(30)에 전송하며, 상기 제 2 데이터 쌍에 대해 동일한 키를 기준으로 그룹화한 키 그룹을 상기 제 2 익명화 서버 그룹(30)으로부터 수신한다.The
나아가, 처리부(11)는, 상기 수신된 키 그룹에 소정 위치 기반 질의를 결합하여 상기 통신부(13)를 통해 위치 기반 서비스 제공자(50)에게 전송하고, 상기 질의에 대응하는 복수 개의 질의 결과를 상기 위치 기반 서비스 제공자(50)로부터 수신한다. 그런 다음, 처리부(11)는 상기 수신된 복수 개의 질의 결과로부터 자신의 위치 정보에 대응하는 질의 결과만을 획득할 수 있다. 이를 위해 처리부(11)는, 상기 수신된 복수 개의 질의 결과 중 사용자의 위치 정보를 참조하여 자신의 위치 정보와 비교하고, 상기 비교 결과 자신의 위치 정보와 일치하는 사용자의 위치 정보에 해당하는 질의 결과만을 추출하며, 나머지 질의 결과들을 폐기하는 것이 바람직하다.Further, the
한편, 위치 익명화를 강화하기 위해, 도 9에 도시된 사용자의 위치 정보를 익명화하는 장치(사용자 단말기, 10)는, 사용자의 위치를 포함하는 인근 위치 정보 및 그에 대한 사용자의 밀도 정보를 저장하는 저장부(15)를 더 포함할 수 있다. 이 경우 처리부(11)는, 상기 위치 기반 질의를 상기 위치 기반 서비스 제공자(50)에게 전송되기 이전에, 상기 저장부(15)에 저장된 사용자의 밀도 정보를 이용하여 상기 사용자의 위치 정보를 상기 인근 위치 정보 중 어느 하나로 대체함으로써 공간 정보를 익명화할 수 있다. 특히, 보다 효과적인 위치 익명화를 위해 상기 대체되는 인근 위치 정보는 상기 사용자의 위치를 중심으로 소정 범위 내의 공간 중 사용자의 밀도가 가장 높은 공간인 것이 바람직하다.On the other hand, in order to enhance location anonymization, the device (user terminal) 10 for anonymizing the location information of the user illustrated in FIG. 9 is configured to store nearby location information including the location of the user and density information of the user thereof. The
이하에서는 본 발명의 실시예들을 통해 구현된 사용자의 위치 정보를 익명화하는 기술의 성능을 검증하기 위해 실시된 실험 결과를 제시하도록 한다. 실험은 질의 시 소요되는 응답 속도와 k값 증가에 따른 필터링 발생 비용을 기존의 중앙집중형 기법과 비교를 통해 제시하도록 한다. 종래의 중앙집중형 기법의 구현을 위해 그리드의 기본 단위는 100m2으로 설정하였으며, 각 그리드의 인구 밀도는 실제 서울시 인구 밀도를 바탕으로 최저 8명에서 최대 30명까지로 랜덤하게 발생시켰다. 실험을 위해 10,000개의 그리드를 실험에 사용되는 영역으로 가정하였다. 실험 환경은 Pentium Dual-Core 2.6GHz 프로세서와 2GB DDR2 메모리가 장착된 마이크로소프트 윈도우7 32bit 운영체제 사양의 컴퓨터로 서버를 구현하였고 삼성 갤럭시탭에 위치 정보 서비스 사용자에 해당하는 클라이언트를 구현하였다.Hereinafter, to present the results of the experiment conducted to verify the performance of the technique of anonymizing the user's location information implemented through the embodiments of the present invention. The experiment suggests the response speed and the cost of filtering due to the increase of k value compared with the existing centralized method. In order to implement the conventional centralized method, the basic unit of the grid was set to 100 m2 , and the population density of each grid was randomly generated from 8 to 30 people based on the actual population density of Seoul. For the experiment, 10,000 grids were assumed as the area used for the experiment. The experimental environment was implemented with a computer of
도 10은 본 발명의 실시예들에 따라 구현된 위치 정보 익명화 기술과 종래의 익명화 기술의 응답 속도를 비교한 실험 결과를 예시한 도면이다. 도 10은 분당 서비스 요청 횟수에 따른 응답 속도를 도시하고 있다. 분당 1,000번부터 30,000번까지의 서비스 요청에 대해 종래의 중앙집중형 기법(New Casper)과 비교하여 실험을 수행하였다. 본 발명의 실시예들에 따른 제안 기법은 매퍼와 리듀서를 두어 서비스 요청을 분산 처리하므로 대량의 데이터 요청에 확장성 있게 대응할 수 있음을 확인할 수 있다. 특히, 서비스 요청 횟수가 증가할 경우 종래의 중앙집중형 기법에서 발생하는 병목 현상이 발생하지 않으므로 보다 좋은 성능을 보인다.10 is a diagram illustrating an experimental result comparing the response speed of the location information anonymization technique and the conventional anonymization technique implemented according to the embodiments of the present invention. 10 shows the response speed according to the number of service requests per minute. Experiments were performed for 1,000 to 30,000 service requests per minute compared to a conventional centralized technique (New Casper). Since the proposed scheme according to the embodiments of the present invention has a mapper and a reducer for distributing the service request, it can be seen that it can respond to a large data request in a scalable manner. In particular, when the number of service requests increases, the bottleneck caused by the conventional centralized technique does not occur, and thus shows better performance.
도 11은 본 발명의 실시예들에 따라 구현된 위치 정보 익명화 기술과 종래의 익명화 기술의 필터링 수를 비교한 실험 결과를 예시한 도면이다. 도 11은 동일한 키의 개수를 의미하는 k 값의 증가에 따라 사용자가 원치 않은 결과에 대한 필터링 발생 개수를 도시하고 있다. 종래의 중앙집중형 기법(New Casper)의 경우, quad-tree의 형태로 익명화 영역을 확장하므로 k 값이 일정 수준 이상을 초과할 시에 급격히 필터링 개수가 증가한다. 반면, 본 발명의 실시예들에 따른 제안 기법은 개인화된 익명화 공간 영역(PASR)을 생성하여 강화된 위치 익명화 성능을 제공하므로 k 값의 증가에 따른 선형적인 필터링 개수 증가를 보인다.FIG. 11 is a diagram illustrating an experimental result comparing the number of filtering of the location information anonymization technique and the conventional anonymization technique implemented according to the embodiments of the present invention. FIG. 11 illustrates the number of filtering occurrences for results that the user does not want according to an increase in the value of k, which means the number of identical keys. In the conventional centralized technique (New Casper), since the anonymization region is extended in the form of a quad-tree, when the k value exceeds a certain level, the number of filtering rapidly increases. On the other hand, the proposed scheme according to the embodiments of the present invention generates a personalized anonymized space region (PASR) to provide enhanced location anonymization performance, so that the linear filtering number increases with the increase of the k value.
상기된 본 발명의 실시예들에 따르면, 복수 개의 익명화 서버 그룹들을 이용하여 사용자의 식별 정보를 분산 처리를 통해 익명화함으로써, 위치 기반 서비스를 이용하는 사용자의 수가 폭발적으로 증가하더라도 대용량의 데이터를 효과적으로 처리할 수 있으므로 사용자의 서비스 요청에 대한 빠른 응답 속도를 보장할 수 있으며, 개인화된 위치 정보 서비스를 이용함에 있어서 분리된 익명화 서버 그룹을 통해 사용자 개인의 식별자와 위치 정보 간의 연결 관계를 노출시키지 않음으로써 강인한 보안성을 제공할 수 있다.According to the embodiments of the present invention described above, by anonymizing the identification information of the user by using a plurality of anonymization server groups through distributed processing, even if the number of users using the location-based service explodes, it is possible to effectively process a large amount of data. This guarantees fast response to user's service request and robust security by not exposing the connection relationship between user's personal identifier and location information through separate anonymized server group in using personalized location service. Can provide sex.
특히, 본 발명의 실시예들은 스마트폰 보급이 일반화된 환경에서의 위치 기반 서비스를 사용할 때의 프라이버시 보호 프레임워크를 제안하고 있으며, 맵리듀스 기법을 응용하여 실제 식별정보와 위치 정보간의 관계를 단절시키면서도 대량의 데이터 처리가 필요할 경우 확장성을 보장할 수 있다. 또한, 개인화된 익명화 공간 생성을 통해 사용자 프라이버시 요구 사항을 만족시키며, 동시에 잘못되거나 불필요한 질의 결과값을 제공받아 이를 사용자 측에서 필터링하는 비용을 최소화하였다.In particular, embodiments of the present invention propose a privacy protection framework when using a location-based service in an environment in which smartphones are popularized, while applying a MapReduce technique to break the relationship between the actual identification information and the location information. Scalability can be guaranteed if a large amount of data processing is required. In addition, by creating a personalized anonymized space, it satisfies user privacy requirements and at the same time minimizes the cost of filtering the user side by receiving wrong or unnecessary query result values.
한편, 본 발명의 실시예들은 컴퓨터로 읽을 수 있는 기록 매체에 컴퓨터가 읽을 수 있는 코드로 구현하는 것이 가능하다. 컴퓨터가 읽을 수 있는 기록 매체는 컴퓨터 시스템에 의하여 읽혀질 수 있는 데이터가 저장되는 모든 종류의 기록 장치를 포함한다.Meanwhile, embodiments of the present invention can be implemented by computer readable codes on a computer readable recording medium. A computer-readable recording medium includes all kinds of recording apparatuses in which data that can be read by a computer system is stored.
컴퓨터가 읽을 수 있는 기록 매체의 예로는 ROM, RAM, CD-ROM, 자기 테이프, 플로피디스크, 광 데이터 저장장치 등이 있으며, 또한 캐리어 웨이브(예를 들어 인터넷을 통한 전송)의 형태로 구현하는 것을 포함한다. 또한, 컴퓨터가 읽을 수 있는 기록 매체는 네트워크로 연결된 컴퓨터 시스템에 분산되어, 분산 방식으로 컴퓨터가 읽을 수 있는 코드가 저장되고 실행될 수 있다. 그리고 본 발명을 구현하기 위한 기능적인(functional) 프로그램, 코드 및 코드 세그먼트들은 본 발명이 속하는 기술 분야의 프로그래머들에 의하여 용이하게 추론될 수 있다.Examples of the computer-readable recording medium include a ROM, a RAM, a CD-ROM, a magnetic tape, a floppy disk, an optical data storage device and the like, and also a carrier wave (for example, transmission via the Internet) . In addition, the computer-readable recording medium may be distributed over network-connected computer systems so that computer readable codes can be stored and executed in a distributed manner. In addition, functional programs, codes, and code segments for implementing the present invention can be easily deduced by programmers skilled in the art to which the present invention belongs.
이상에서 본 발명에 대하여 그 다양한 실시예들을 중심으로 살펴보았다. 본 발명에 속하는 기술 분야에서 통상의 지식을 가진 자는 본 발명이 본 발명의 본질적인 특성에서 벗어나지 않는 범위에서 변형된 형태로 구현될 수 있음을 이해할 수 있을 것이다. 그러므로 개시된 실시예들은 한정적인 관점이 아니라 설명적인 관점에서 고려되어야 한다. 본 발명의 범위는 전술한 설명이 아니라 특허청구범위에 나타나 있으며, 그와 동등한 범위 내에 있는 모든 차이점은 본 발명에 포함된 것으로 해석되어야 할 것이다.The present invention has been described above with reference to various embodiments. It will be understood by those skilled in the art that various changes in form and details may be made therein without departing from the spirit and scope of the invention as defined by the appended claims. Therefore, the disclosed embodiments should be considered in an illustrative rather than a restrictive sense. The scope of the present invention is defined by the appended claims rather than by the foregoing description, and all differences within the scope of equivalents thereof should be construed as being included in the present invention.
10 : 사용자 단말기
11 : 처리부13 : 통신부
15 : 저장부
20 : 매퍼(MAPPER)30 : 리듀서(REDUCER)
50 : 위치 기반 서비스 제공자(location based service provider)10: User terminal
11
15:
20: MAPPER 30: REDUCER
50: location based service provider
Claims (18)
Translated fromKorean클라이언트가 복수 개의 사용자 식별자를 제 1 익명화 서버 그룹에 전송하고, 상기 사용자 식별자와 개별 익명화 서버별로 동일한 값을 갖는 키(key)를 각각 결합한 제 1 데이터 쌍을 상기 제 1 익명화 서버 그룹으로부터 수신받는 단계;
상기 클라이언트가 상기 수신된 제 1 데이터 쌍에 기초하여 상기 키와 사용자의 위치 정보를 각각 결합한 제 2 데이터 쌍을 생성하는 단계; 및
상기 클라이언트가 상기 생성된 제 2 데이터 쌍을 제 2 익명화 서버 그룹에 전송하고, 상기 제 2 데이터 쌍에 대해 동일한 키를 기준으로 그룹화한 키 그룹을 상기 제 2 익명화 서버 그룹으로부터 수신하는 단계;를 포함하는 방법.In the method of anonymizing the user's location information,
The client sends a plurality of user identifiers to the first anonymization server group, and receives a first data pair combining the user identifier and a key having the same value for each individual anonymization server from the first anonymization server group. ;
Generating, by the client, a second data pair combining the key and location information of the user based on the received first data pair; And
And transmitting, by the client, the generated second data pair to a second anonymization server group, and receiving a key group from the second anonymization server group grouped based on the same key for the second data pair. How to.
상기 제 1 익명화 서버 그룹과 상기 제 2 익명화 서버 그룹은 서로 분리된 장치로서,
상기 제 1 익명화 서버 그룹은 상기 사용자의 식별자를 수신할 수 있으나 상기 사용자의 위치 정보를 수신할 수 없으며,
상기 제 2 익명화 서버 그룹은 상기 사용자의 위치 정보를 수신할 수 있으나 상기 사용자의 식별자를 수신할 수 없는 것을 특징으로 하는 방법.The method of claim 1,
The first anonymization server group and the second anonymization server group are separated from each other.
The first anonymization server group may receive an identifier of the user but cannot receive location information of the user.
The second anonymization server group may receive location information of the user but cannot receive an identifier of the user.
상기 제 1 데이터 쌍을 수신받는 단계는,
상기 클라이언트가 복수의 사용자 각각을 식별할 수 있는 복수 개의 사용자 식별자(ID)를 제 1 익명화 서버 그룹에 전송하는 단계; 및
상기 제 1 익명화 서버 그룹을 구성하는 개별 익명화 서버별로 동일한 값을 갖는 복수 개의 키(key)를 생성하여 상기 수신된 사용자 식별자(ID)와 결합함으로써 상기 제 1 익명화 서버 그룹에 의해 생성된 제 1 데이터 쌍 {key,ID}을 상기 클라이언트가 수신하는 단계를 포함하는 방법.The method of claim 1,
Receiving the first data pair,
Sending, by the client, a plurality of user identifiers (IDs) for identifying each of the plurality of users to a first anonymization server group; And
First data generated by the first anonymization server group by generating a plurality of keys having the same value for each individual anonymization server constituting the first anonymization server group and combining them with the received user identifier (ID) Receiving by the client a pair {key, ID}.
상기 제 2 데이터 쌍을 생성하는 단계는,
상기 클라이언트가 상기 제 1 데이터 쌍에 포함된 사용자 식별자(ID)를 상기 사용자의 위치 정보(location)로 대체함으로써, 상기 키(key)와 상기 사용자의 위치 정보(location)를 각각 결합한 제 2 데이터 쌍 {key,location}을 생성하는 것을 특징으로 하는 방법.The method of claim 1,
Generating the second data pair may include:
A second data pair combining the key and the location information of the user by replacing the user identifier (ID) included in the first data pair with the location information of the user; generating {key, location}.
상기 클라이언트가 상기 수신된 키 그룹에 소정 위치 기반 질의를 결합하여 위치 기반 서비스 제공자에게 전송하고, 상기 질의에 대응하는 복수 개의 질의 결과를 상기 위치 기반 서비스 제공자로부터 수신하는 단계; 및
상기 클라이언트가 상기 수신된 복수 개의 질의 결과로부터 자신의 위치 정보에 대응하는 질의 결과만을 획득하는 단계;를 더 포함하는 방법.The method of claim 1,
Combining, by the client, a location-based query with the received key group to a location-based service provider, and receiving a plurality of query results corresponding to the query from the location-based service provider; And
Obtaining, by the client, only query results corresponding to its location information from the received plurality of query results.
상기 자신의 위치 정보에 대응하는 질의 결과만을 획득하는 단계는,
상기 수신된 복수 개의 질의 결과 중 사용자의 위치 정보를 참조하여 자신의 위치 정보와 비교하는 단계; 및
상기 비교 결과, 자신의 위치 정보와 일치하는 사용자의 위치 정보에 해당하는 질의 결과만을 추출하고, 나머지 질의 결과들을 폐기하는 단계;를 포함하는 방법.The method of claim 5, wherein
Acquiring only the query result corresponding to the own location information,
Comparing location information of the user with location information of the user from among the plurality of received query results; And
And extracting only query results corresponding to the location information of the user that matches the location information of the user, and discarding the remaining query results.
상기 제 1 익명화 서버 그룹은 맵리듀스(MapReduce) 알고리즘에 따르는 매퍼(mapper)이고,
상기 제 2 익명화 서버 그룹은 상기 맵리듀스 알고리즘에 따르는 리듀서(reducer)인 것을 특징으로 하는 방법.The method of claim 1,
The first anonymization server group is a mapper according to a MapReduce algorithm,
And the second anonymization server group is a reducer according to the map reduce algorithm.
클라이언트가 복수 개의 사용자 식별자를 제 1 익명화 서버 그룹에 전송하고, 상기 사용자 식별자와 개별 익명화 서버별로 동일한 값을 갖는 키를 각각 결합한 제 1 데이터 쌍을 상기 제 1 익명화 서버 그룹으로부터 수신받는 단계;
상기 클라이언트가 상기 수신된 제 1 데이터 쌍에 기초하여 상기 키와 사용자의 위치 정보를 각각 결합한 제 2 데이터 쌍을 생성하는 단계;
상기 클라이언트가 상기 생성된 제 2 데이터 쌍을 제 2 익명화 서버 그룹에 전송하고, 상기 제 2 데이터 쌍에 대해 동일한 키를 기준으로 그룹화한 키 그룹을 상기 제 2 익명화 서버 그룹으로부터 수신하는 단계;
상기 클라이언트가 상기 수신된 키 그룹에 소정 위치 기반 질의를 결합하여 위치 기반 서비스 제공자에게 전송하고, 상기 질의에 대응하는 복수 개의 질의 결과를 상기 위치 기반 서비스 제공자로부터 수신하는 단계; 및
상기 클라이언트가 상기 수신된 복수 개의 질의 결과로부터 자신의 위치 정보에 대응하는 질의 결과만을 획득하는 단계;를 포함하고,
상기 위치 기반 질의를 상기 위치 기반 서비스 제공자에게 전송되기 이전에, 상기 사용자의 위치 정보를 인근 위치 정보로 대체함으로써 공간 정보를 익명화하는 단계를 더 포함하는 방법.In the method of anonymizing the user's location information,
Transmitting, by the client, a plurality of user identifiers to a first anonymization server group, and receiving, from the first anonymization server group, a first data pair combining the user identifier and a key having the same value for each individual anonymization server;
Generating, by the client, a second data pair combining the key and location information of the user based on the received first data pair;
Sending, by the client, the generated second data pair to a second anonymization server group, and receiving, from the second anonymization server group, a key group grouped based on the same key for the second data pair;
Combining, by the client, a location-based query with the received key group to a location-based service provider, and receiving a plurality of query results corresponding to the query from the location-based service provider; And
Acquiring, by the client, only query results corresponding to the location information of the plurality of queries from the received query results;
Anonymizing spatial information by replacing the location information of the user with nearby location information before the location based query is sent to the location based service provider.
상기 공간 정보를 익명화하는 단계는,
상기 사용자의 위치를 중심으로 소정 범위 내의 공간 중 하나의 위치를 선택하는 단계; 및
상기 선택된 위치에 대한 정보로서 상기 사용자의 위치 정보를 대체하여 상기 위치 기반 질의를 재생성하는 단계;를 포함하는 방법.The method of claim 8,
Anonymizing the spatial information,
Selecting one location among spaces within a predetermined range based on the location of the user; And
Regenerating the location based query by replacing the user's location information with the information about the selected location.
상기 대체되는 인근 위치 정보는 상기 사용자의 위치를 중심으로 소정 범위 내의 공간 중 사용자의 밀도가 가장 높은 공간인 것을 특징으로 하는 방법.The method of claim 8,
The replaced neighboring location information is characterized in that the space of the highest density of the user among the space within a predetermined range around the user's location.
식별 정보를 익명화하는 제 1 익명화 서버 그룹 및 제 2 익명화 그룹과 통신하는 통신부; 및
적어도 하나의 프로세서(processor)를 구비하여 연산을 수행하는 처리부;를 포함하고,
상기 처리부는,
복수 개의 사용자 식별자를 생성하여 상기 통신부를 통해 제 1 익명화 서버 그룹에 전송하고, 상기 사용자 식별자와 개별 익명화 서버별로 동일한 값을 갖는 키를 각각 결합한 제 1 데이터 쌍을 상기 제 1 익명화 서버 그룹으로부터 수신받으며,
상기 수신된 제 1 데이터 쌍에 기초하여 상기 키와 사용자의 위치 정보를 각각 결합한 제 2 데이터 쌍을 생성하고, 상기 생성된 제 2 데이터 쌍을 상기 통신부를 통해 제 2 익명화 서버 그룹에 전송하며, 상기 제 2 데이터 쌍에 대해 동일한 키를 기준으로 그룹화한 키 그룹을 상기 제 2 익명화 서버 그룹으로부터 수신하는 것을 특징으로 하는 장치.An apparatus for anonymizing a user's location information,
A communication unit for communicating with a first anonymization server group and a second anonymization group for anonymizing identification information; And
And a processor configured to perform an operation having at least one processor.
Wherein,
Generate a plurality of user identifiers and transmit them to the first anonymization server group through the communication unit, and receive from the first anonymization server group a first data pair combining each of the user identifier and a key having the same value for each individual anonymization server. ,
Generate a second data pair combining the key and the location information of the user based on the received first data pair, and transmit the generated second data pair to a second anonymization server group through the communication unit; And receive from the second anonymization server group a group of keys grouped on the same key for a second data pair.
상기 제 1 익명화 서버 그룹과 상기 제 2 익명화 서버 그룹은 서로 분리된 장치로서,
상기 제 1 익명화 서버 그룹은 상기 사용자의 식별자를 수신할 수 있으나 상기 사용자의 위치 정보를 수신할 수 없으며,
상기 제 2 익명화 서버 그룹은 상기 사용자의 위치 정보를 수신할 수 있으나 상기 사용자의 식별자를 수신할 수 없는 것을 특징으로 하는 장치.13. The method of claim 12,
The first anonymization server group and the second anonymization server group are separated from each other.
The first anonymization server group may receive an identifier of the user but cannot receive location information of the user.
And the second anonymization server group may receive location information of the user but cannot receive an identifier of the user.
상기 처리부는,
상기 수신된 키 그룹에 소정 위치 기반 질의를 결합하여 상기 통신부를 통해 위치 기반 서비스 제공자에게 전송하고, 상기 질의에 대응하는 복수 개의 질의 결과를 상기 위치 기반 서비스 제공자로부터 수신하며,
상기 수신된 복수 개의 질의 결과로부터 자신의 위치 정보에 대응하는 질의 결과만을 획득하는 것을 특징으로 하는 장치.13. The method of claim 12,
Wherein,
Combining a location-based query with the received key group and transmitting the location-based query to the location-based service provider through the communication unit, receiving a plurality of query results corresponding to the query from the location-based service provider,
And obtaining only query results corresponding to location information of the plurality of queries from the received query results.
상기 처리부는,
상기 수신된 복수 개의 질의 결과 중 사용자의 위치 정보를 참조하여 자신의 위치 정보와 비교하고, 상기 비교 결과 자신의 위치 정보와 일치하는 사용자의 위치 정보에 해당하는 질의 결과만을 추출하며, 나머지 질의 결과들을 폐기하는 것을 특징으로 하는 장치.15. The method of claim 14,
Wherein,
Among the plurality of received query results, the user's location information is compared with reference to the user's location information, and only the query results corresponding to the user's location information matching the location information of the comparison result are extracted, and the remaining query results are extracted. Discard the device.
상기 사용자의 위치를 포함하는 인근 위치 정보 및 그에 대한 사용자의 밀도 정보를 저장하는 저장부;를 더 포함하고,
상기 처리부는,
상기 위치 기반 질의를 상기 위치 기반 서비스 제공자에게 전송되기 이전에, 상기 저장부에 저장된 사용자의 밀도 정보를 이용하여 상기 사용자의 위치 정보를 상기 인근 위치 정보 중 어느 하나로 대체함으로써 공간 정보를 익명화하는 것을 특징으로 하는 장치.13. The method of claim 12,
And a storage unit which stores nearby location information including the location of the user and density information of the user.
Wherein,
Before the location-based query is transmitted to the location-based service provider, anonymize spatial information by replacing the location information of the user with any one of the neighbor location information using density information of the user stored in the storage. Device.
상기 대체되는 인근 위치 정보는 상기 사용자의 위치를 중심으로 소정 범위 내의 공간 중 사용자의 밀도가 가장 높은 공간인 것을 특징으로 하는 장치.17. The method of claim 16,
And the replaced neighboring location information is a space having the highest density of the user among spaces within a predetermined range around the user's location.
상기 제 1 익명화 서버 그룹은 맵리듀스 알고리즘에 따르는 매퍼이고,
상기 제 2 익명화 서버 그룹은 상기 맵리듀스 알고리즘에 따르는 리듀서인 것을 특징으로 하는 장치.13. The method of claim 12,
The first anonymization server group is a mapper according to the map reduce algorithm,
And the second anonymization server group is a reducer according to the map reduce algorithm.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020110143731AKR101287096B1 (en) | 2011-12-27 | 2011-12-27 | Apparatus and method for protecting personal location information in massive user environment |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020110143731AKR101287096B1 (en) | 2011-12-27 | 2011-12-27 | Apparatus and method for protecting personal location information in massive user environment |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20130075380Atrue KR20130075380A (en) | 2013-07-05 |
| KR101287096B1 KR101287096B1 (en) | 2013-07-16 |
Family
ID=48989280
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020110143731AActiveKR101287096B1 (en) | 2011-12-27 | 2011-12-27 | Apparatus and method for protecting personal location information in massive user environment |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR101287096B1 (en) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20170052266A (en)* | 2015-11-04 | 2017-05-12 | 에스케이텔레콤 주식회사 | Apparatus and Computer Program for Managing Query Path and Data Path |
| KR20200002969A (en)* | 2017-04-27 | 2020-01-08 | 스냅 인코포레이티드 | Location privacy management for map-based social media platforms |
| US11418906B2 (en) | 2017-04-27 | 2022-08-16 | Snap Inc. | Selective location-based identity communication |
| US11842411B2 (en) | 2017-04-27 | 2023-12-12 | Snap Inc. | Location-based virtual avatars |
| US12113760B2 (en) | 2016-10-24 | 2024-10-08 | Snap Inc. | Generating and displaying customized avatars in media overlays |
| US12363056B2 (en) | 2017-01-23 | 2025-07-15 | Snap Inc. | Customized digital avatar accessories |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101479498B1 (en) | 2013-02-13 | 2015-01-09 | 아주대학교산학협력단 | A secure monitoring technique for moving k-nearest neighbor queries in road networks |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4339776B2 (en) | 2004-11-02 | 2009-10-07 | 日本電信電話株式会社 | Communication device and communication method having position anonymity |
| US9065908B2 (en) | 2010-02-12 | 2015-06-23 | Broadcom Corporation | Method and system for ensuring user and/or device anonymity for location based services (LBS) |
- 2011
- 2011-12-27KRKR1020110143731Apatent/KR101287096B1/enactiveActive
Cited By (25)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20170052266A (en)* | 2015-11-04 | 2017-05-12 | 에스케이텔레콤 주식회사 | Apparatus and Computer Program for Managing Query Path and Data Path |
| US12316589B2 (en) | 2016-10-24 | 2025-05-27 | Snap Inc. | Generating and displaying customized avatars in media overlays |
| US12113760B2 (en) | 2016-10-24 | 2024-10-08 | Snap Inc. | Generating and displaying customized avatars in media overlays |
| US12363056B2 (en) | 2017-01-23 | 2025-07-15 | Snap Inc. | Customized digital avatar accessories |
| US11418906B2 (en) | 2017-04-27 | 2022-08-16 | Snap Inc. | Selective location-based identity communication |
| US12058583B2 (en) | 2017-04-27 | 2024-08-06 | Snap Inc. | Selective location-based identity communication |
| US11392264B1 (en) | 2017-04-27 | 2022-07-19 | Snap Inc. | Map-based graphical user interface for multi-type social media galleries |
| US11451956B1 (en) | 2017-04-27 | 2022-09-20 | Snap Inc. | Location privacy management on map-based social media platforms |
| US11474663B2 (en) | 2017-04-27 | 2022-10-18 | Snap Inc. | Location-based search mechanism in a graphical user interface |
| US11556221B2 (en) | 2017-04-27 | 2023-01-17 | Snap Inc. | Friend location sharing mechanism for social media platforms |
| US11782574B2 (en) | 2017-04-27 | 2023-10-10 | Snap Inc. | Map-based graphical user interface indicating geospatial activity metrics |
| CN111010882B (en)* | 2017-04-27 | 2023-11-03 | 斯纳普公司 | Location privacy relevance on map-based social media platforms |
| US11842411B2 (en) | 2017-04-27 | 2023-12-12 | Snap Inc. | Location-based virtual avatars |
| US11893647B2 (en) | 2017-04-27 | 2024-02-06 | Snap Inc. | Location-based virtual avatars |
| US11995288B2 (en) | 2017-04-27 | 2024-05-28 | Snap Inc. | Location-based search mechanism in a graphical user interface |
| US11409407B2 (en) | 2017-04-27 | 2022-08-09 | Snap Inc. | Map-based graphical user interface indicating geospatial activity metrics |
| US12086381B2 (en) | 2017-04-27 | 2024-09-10 | Snap Inc. | Map-based graphical user interface for multi-type social media galleries |
| US12112013B2 (en) | 2017-04-27 | 2024-10-08 | Snap Inc. | Location privacy management on map-based social media platforms |
| US11385763B2 (en) | 2017-04-27 | 2022-07-12 | Snap Inc. | Map-based graphical user interface indicating geospatial activity metrics |
| US12131003B2 (en) | 2017-04-27 | 2024-10-29 | Snap Inc. | Map-based graphical user interface indicating geospatial activity metrics |
| US12223156B2 (en) | 2017-04-27 | 2025-02-11 | Snap Inc. | Low-latency delivery mechanism for map-based GUI |
| CN111010882A (en)* | 2017-04-27 | 2020-04-14 | 斯纳普公司 | Location privacy associations on map-based social media platforms |
| US12340064B2 (en) | 2017-04-27 | 2025-06-24 | Snap Inc. | Map-based graphical user interface indicating geospatial activity metrics |
| KR20200002969A (en)* | 2017-04-27 | 2020-01-08 | 스냅 인코포레이티드 | Location privacy management for map-based social media platforms |
| US12393318B2 (en) | 2017-04-27 | 2025-08-19 | Snap Inc. | Map-based graphical user interface for ephemeral social media content |
Also Published As
| Publication number | Publication date |
|---|---|
| KR101287096B1 (en) | 2013-07-16 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Vellela et al. | Strategic survey on security and privacy methods of cloud computing environment | |
| KR101287096B1 (en) | Apparatus and method for protecting personal location information in massive user environment | |
| Dhar et al. | Advanced security model for multimedia data sharing in Internet of Things | |
| Sen et al. | Double cache approach with wireless technology for preserving user privacy | |
| Mouratidis et al. | Shortest path computation with no information leakage | |
| Hu et al. | An access control scheme for big data processing | |
| KR20200121583A (en) | Method and Apparatus for Distributed Processing of Data using De-identification of Data | |
| US9298808B2 (en) | Encrypted search acceleration | |
| Praveena et al. | Anonymization in social networks: a survey on the issues of data privacy in social network sites | |
| Khan | A formal method for privacy‐preservation in cognitive smart cities | |
| Bandara et al. | Blockchain and self-sovereign identity empowered cyber threat information sharing platform | |
| Abouelmehdi et al. | Big data emerging issues: Hadoop security and privacy | |
| Franco et al. | WeTrace: A privacy-preserving tracing approach | |
| Yadav et al. | Big data hadoop: Security and privacy | |
| Kwon et al. | A secure and efficient audit mechanism for dynamic shared data in cloud storage | |
| Deb et al. | CovChain: Blockchain-enabled identity preservation and anti-infodemics for COVID-19 | |
| de Fuentes et al. | Privacy models in wireless sensor networks: A survey | |
| Rao et al. | A novel framework for privacy preserving in location based services | |
| Pandit et al. | Conceptual framework and a critical review for privacy preservation in context aware systems | |
| Djilali et al. | Enhanced dynamic team access control for collaborative Internet of Things using context | |
| Anand et al. | Data security and privacy in 5g-enabled IoT | |
| ALSAIARI et al. | A Review on Security and Privacy of Smart Cities | |
| Almtrafi et al. | Security threats and attacks in internet of things (iots) | |
| Gomes et al. | Privacy preserving on trajectories created by wi-fi connections in a university campus | |
| Ghafghazi et al. | Classification of technological privacy techniques for LTE-based public safety networks |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| PA0109 | Patent application | St.27 status event code:A-0-1-A10-A12-nap-PA0109 | |
| PA0201 | Request for examination | St.27 status event code:A-1-2-D10-D11-exm-PA0201 | |
| D13-X000 | Search requested | St.27 status event code:A-1-2-D10-D13-srh-X000 | |
| D14-X000 | Search report completed | St.27 status event code:A-1-2-D10-D14-srh-X000 | |
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration | St.27 status event code:A-1-2-D10-D22-exm-PE0701 | |
| PG1501 | Laying open of application | St.27 status event code:A-1-1-Q10-Q12-nap-PG1501 | |
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment | St.27 status event code:A-2-4-F10-F11-exm-PR0701 | |
| PR1002 | Payment of registration fee | St.27 status event code:A-2-2-U10-U11-oth-PR1002 Fee payment year number:1 | |
| PG1601 | Publication of registration | St.27 status event code:A-4-4-Q10-Q13-nap-PG1601 | |
| PN2301 | Change of applicant | St.27 status event code:A-5-5-R10-R11-asn-PN2301 | |
| PN2301 | Change of applicant | St.27 status event code:A-5-5-R10-R14-asn-PN2301 | |
| PN2301 | Change of applicant | St.27 status event code:A-5-5-R10-R11-asn-PN2301 | |
| PN2301 | Change of applicant | St.27 status event code:A-5-5-R10-R14-asn-PN2301 | |
| FPAY | Annual fee payment | Payment date:20160704 Year of fee payment:4 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:4 | |
| R18-X000 | Changes to party contact information recorded | St.27 status event code:A-5-5-R10-R18-oth-X000 | |
| P22-X000 | Classification modified | St.27 status event code:A-4-4-P10-P22-nap-X000 | |
| FPAY | Annual fee payment | Payment date:20170707 Year of fee payment:5 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:5 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:6 | |
| PN2301 | Change of applicant | St.27 status event code:A-5-5-R10-R13-asn-PN2301 St.27 status event code:A-5-5-R10-R11-asn-PN2301 | |
| FPAY | Annual fee payment | Payment date:20190710 Year of fee payment:7 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:7 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:8 | |
| P14-X000 | Amendment of ip right document requested | St.27 status event code:A-5-5-P10-P14-nap-X000 | |
| P22-X000 | Classification modified | St.27 status event code:A-4-4-P10-P22-nap-X000 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:9 | |
| R18-X000 | Changes to party contact information recorded | St.27 status event code:A-5-5-R10-R18-oth-X000 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:10 | |
| PN2301 | Change of applicant | St.27 status event code:A-5-5-R10-R13-asn-PN2301 St.27 status event code:A-5-5-R10-R11-asn-PN2301 | |
| R18-X000 | Changes to party contact information recorded | St.27 status event code:A-5-5-R10-R18-oth-X000 | |
| R18-X000 | Changes to party contact information recorded | St.27 status event code:A-5-5-R10-R18-oth-X000 | |
| R18-X000 | Changes to party contact information recorded | St.27 status event code:A-5-5-R10-R18-oth-X000 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:11 | |
| R18-X000 | Changes to party contact information recorded | St.27 status event code:A-5-5-R10-R18-oth-X000 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:12 | |
| R18-X000 | Changes to party contact information recorded | St.27 status event code:A-5-5-R10-R18-oth-X000 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:13 |