KR20090097292A - Voice recognition system and method using user image - Google Patents
Voice recognition system and method using user imageDownload PDFInfo
- Publication number
- KR20090097292A KR20090097292AKR1020080022345AKR20080022345AKR20090097292AKR 20090097292 AKR20090097292 AKR 20090097292AKR 1020080022345 AKR1020080022345 AKR 1020080022345AKR 20080022345 AKR20080022345 AKR 20080022345AKR 20090097292 AKR20090097292 AKR 20090097292A
- Authority
- KR
- South Korea
- Prior art keywords
- user
- voice recognition
- voice
- string
- strings
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images




Landscapes
- Telephonic Communication Services (AREA)
- Telephone Function (AREA)
Abstract
Translated fromKoreanDescription
Translated fromKorean본 발명은 음성인식 기술에 관한 것으로, 보다 상세하게는 사용자 영상을 이용하여 음성인식을 수행하는 기술에 관한 것이다. 특히 본 발명은 영상 통화가 가능한 PDA(Personal Digital Assistants), 셀룰라(cellular) 등과 같은 각종 이동통신 단말기에서 음성 인식 시 사용자의 음성 뿐만 아니라 사용자의 영상을 함께 이용하여 음성 인식을 수행할 수 하도록 하는 음성인식 시스템 및 방법에 관한 것이다.The present invention relates to a voice recognition technology, and more particularly, to a technology for performing voice recognition using a user image. In particular, the present invention can be used to perform voice recognition using not only the user's voice but also the user's video when voice recognition in various mobile communication terminals such as PDA (Personal Digital Assistants), cellular (cellular) capable of video calls A recognition system and method are disclosed.
음성인식 기술이 발전하면서 다양한 기술분야에 이용되고 있다. 특히 최근 이동통신 단말기가 현대인의 필수품이 되면서 이동통신 단말기에도 음성인식 기능이 접목되어 여러 가지 방식으로 이용되고 있다. 예를 들면, 이동통신 단말기는 사용자로부터 메뉴실행 명령 음성을 입력받아 메뉴를 실행하거나, 전화번호를 음성으로 입력받아 전화를 거는 등의 방식으로 음성인식 기술을 이용하고 있다.As voice recognition technology is developed, it is used in various technical fields. In particular, as the mobile communication terminal has become a necessity of the modern man, the voice recognition function is also used in the mobile communication terminal in various ways. For example, the mobile communication terminal uses voice recognition technology by receiving a menu execution command voice from a user, executing a menu, or receiving a phone number by voice and making a phone call.
이와 같이 이동통신 단말기에 음성인식 기술이 적용된 경우 사용자는 이동통신 단말기 사용 시 키패드(keypad), 터치스크린(touch screen) 등의 별도 입력장치 조작 없이 말을 하기만 하면 된다. 따라서 사용자들이 간편함과 동시에 재미를 느낄 수 있는 이점이 있어 이동통신 단말기에서의 음성인식 기능 이용이 활성화되고 있는 추세이다.As such, when the voice recognition technology is applied to the mobile communication terminal, the user only needs to speak without manipulating a separate input device such as a keypad and a touch screen when using the mobile communication terminal. Therefore, there is an advantage that users can enjoy the simplicity and fun, and the use of the voice recognition function is being activated in the mobile communication terminal.
그런데 통상의 음성인식 이동통신 단말기는 주로 음성만으로 음성인식을 수행하기 때문에 소음에 따라 음성인식에 문제가 발생할 수 있다. 다시 말해 이동통신 단말기는 음성인식 시 소음이 없는 상태에서는 90%이상의 음성인식 성공률을 보이나, 소음이 있는 상태에서는 음성인식 성공률이 30%이하로 낮아져 실제 사용에 큰 문제점을 보이는 경우가 많다.However, since the conventional voice recognition mobile communication terminal mainly performs voice recognition only by voice, a problem may occur in voice recognition according to noise. In other words, the mobile communication terminal shows a voice recognition success rate of more than 90% in the absence of noise during voice recognition, but the voice recognition success rate is lowered to less than 30% in the presence of noise, which shows a large problem in actual use.
또한 음성인식 이동통신 단말기는 사용자의 음성인식 시 미리 정해진 정확한 음성이 입력되어야만 음성인식이 가능하므로, 소음이 없는 상태라 하더라도 불명확한 음성이 입력되면 음성인식이 실패하게 되는 문제점이 있다.In addition, since the voice recognition mobile communication terminal can recognize the voice only when a predetermined accurate voice is input at the time of the voice recognition of the user, even if there is no noise, the voice recognition fails.
따라서 본 발명의 목적은 음성인식 시 사용자 음성과 함께 영상을 이용함으로써 소음이 있는 상태에서도 음성인식 성공률을 높일 수 있는 사용자 영상을 이용한 음성인식 시스템 및 방법을 제공하는 데 있다.Therefore, an object of the present invention is to provide a voice recognition system and method using a user image that can increase the voice recognition success rate even in the presence of noise by using the image with the user voice when the voice recognition.
또한 본 발명의 다른 목적은 음성인식 시 사용자 음성 및 사용자 영상에 해 당하는 문자열들을 제공하고 그 중 선택된 문자열을 이용하여 음성인식을 수행하여 개인에게 최적화된 음성인식 수행이 가능한 사용자 영상을 이용한 음성인식 시스템 및 방법을 제공하는 데 있다.In addition, another object of the present invention is to provide a character string corresponding to the user's voice and the user's image when the voice recognition, and to perform the voice recognition using the selected string of the voice recognition system using the user image that can perform the optimized voice recognition for the individual And a method.
상기 목적을 달성하기 위한 본 발명은 사용자 영상을 이용한 음성인식 시스템에 있어서, 사용자의 음성 및 영상 정보가 수신되면 미리 저장된 문자열들 중 상기 수신된 사용자의 음성 및 영상 정보에 대응된 문자열들을 추출하고 미리 정해진 기준에 따른 우선순위로 정렬하여 문자열 리스트를 제공하는 음성인식 DB 서버와, 상기 사용자의 음성 및 영상 정보에 대응된 문자열 리스트를 제공받아 상기 문자열 리스트 중 문자열이 선택되면 선택된 문자열이 음성인식된 것으로 판단하고, 상기 선택된 문자열에 대응된 기능을 수행하는 이동통신 단말기를 포함하여 구성된다.According to the present invention for achieving the above object, in the voice recognition system using the user image, when the user's voice and image information is received, the character strings corresponding to the received user's voice and image information from the pre-stored character strings and extracted in advance Voice recognition DB server that provides a list of strings in order of priority according to a predetermined criterion, and a string list corresponding to the user's voice and video information is received. When a string is selected from the list of strings, the selected string is recognized as a voice. And a mobile communication terminal for determining and performing a function corresponding to the selected character string.
상기 목적을 달성하기 위한 다른 본 발명은 사용자 영상을 이용한 음성인식 방법에 있어서, 다수의 음성 및 영상 정보에 대응된 문자열들을 저장하는 음성인식 DB 서버가 음성인식을 위한 사용자의 음성 및 영상 정보를 수신하여 해당 문자열들을 추출하고, 미리 정해진 기준에 따른 우선순위로 정렬된 문자열 리스트를 생성하여 전송하는 단계와, 이동통신 단말기가 상기 문자열 리스트를 수신하고, 수신된 문자열 리스트 중 어느 하나의 문자열이 선택되면 선택된 문자열이 음성인식된 것으로 판단하고, 상기 선택된 문자열에 해당하는 기능을 수행하는 단계를 포함하여 구성된다.Another object of the present invention to achieve the above object is a voice recognition method using a user image, a voice recognition DB server for storing a plurality of strings corresponding to the voice and video information receives the voice and video information of the user for voice recognition Extracting the strings, generating and transmitting a string list arranged in order of priority according to a predetermined criterion, and when the mobile communication terminal receives the string list and any one of the received string lists is selected, And determining that the selected text string is speech recognized and performing a function corresponding to the selected text string.
상기 목적을 달성하기 위한 또 다른 본 발명은 사용자 영상을 이용한 음성인식 시스템의 음성인식 DB 서버로서, 다수의 음성 및 영상 정보에 해당하는 문자열들을 저장하는 음성인식 DB와, 이동통신을 통해 외부로부터 음성인식을 위한 사용자의 음성 및 영상 정보를 수신하는 송수신부와, 상기 저장된 문자열들 중 상기 수신된 사용자의 음성 및 영상 정보에 대응된 문자열들을 미리 정해진 기준에 따른 우선순위로 정렬하여 문자열 리스트를 생성하고, 상기 문자열 리스트를 제공하도록 제어하는 음성인식 DB 제어부를 포함한다.Another object of the present invention for achieving the above object is a voice recognition DB server of a voice recognition system using a user image, a voice recognition DB for storing a plurality of strings corresponding to the voice and video information, and voice from the outside through mobile communication A transceiving unit that receives voice and video information of a user for recognition, and strings corresponding to the received voice and video information of the user among the stored text strings in order of priority according to a predetermined criterion to generate a text list; And a voice recognition DB controller for controlling to provide the string list.
상기 목적을 달성하기 위한 또 다른 본 발명은 사용자 영상을 이용한 음성인식 시스템의 음성인식 DB 서버에서 음성인식 방법으로서, 다수의 음성 및 영상 정보에 해당하는 문자열들을 저장하는 단계와, 외부로부터 음성인식을 위한 사용자의 음성 및 영상 정보를 수신하는 단계와, 상기 저장된 문자열들 중 상기 수신된 사용자의 음성 및 영상 정보에 대응된 문자열들을 추출하는 단계와, 상기 추출된 문자열들을 미리 정해진 기준에 따른 우선순위로 정렬하여 문자열 리스트를 생성하는 단계와, 상기 문자열 리스트 중 선택된 문자열이 음성인식된 것으로 판단할 수 있도록 상기 문자열 리스트를 제공하는 단계를 포함한다.Another object of the present invention for achieving the above object is a voice recognition method in a voice recognition DB server of a voice recognition system using a user image, storing the strings corresponding to a plurality of voice and video information, and the voice recognition from the outside Receiving voice and video information of the user, extracting character strings corresponding to the received voice and video information of the user from the stored character strings, and assigning the extracted character strings to priorities according to a predetermined criterion; Generating a list of strings by sorting, and providing the string list to determine that the selected string of the string list is speech recognized.
상기 목적을 달성하기 위한 또 다른 본 발명은 사용자 영상을 이용한 음성인식 시스템의 이동통신 단말기로서, 사용자에 의한 음성인식 요구 및 문자열 선택을 입력받는 사용자 입력부와, 카메라를 통해 촬영된 사용자 영상 정보를 출력하는 영상 처리부와, 마이크를 통해 입력된 사용자 음성 정보를 출력하는 오디오 처리부와, 음성인식을 위한 사용자의 음성 및 영상 정보와 현재 사용중인 기능 정보를 송 신하는 무선부와, 상기 음성인식 요구에 입력에 따라 상기 사용자의 음성 및 영상 정보를 외부 서버로 송신하여 상기 사용자의 음성 및 영상에 대응된 문자열들을 미리 정해진 기준에 따른 우선순위로 정렬한 문자열 리스트를 제공받고, 제공된 문자열 리스트 중 문자열이 선택되면 선택된 문자열에 해당하는 음성인식이 된 것으로 판단하고, 선택된 문자열에 해당하는 기능이 수행되도록 제어하는 단말 제어부를 포함한다.Another embodiment of the present invention for achieving the above object is a mobile communication terminal of a voice recognition system using a user image, a user input unit for receiving a voice recognition request and a string selection by the user, and outputs the user image information taken through the camera An image processing unit configured to output user voice information input through a microphone, a wireless unit transmitting user's voice and video information for voice recognition and function information currently being used, and inputting the voice recognition request Transmits the voice and video information of the user to an external server and receives a string list in which the strings corresponding to the voice and video of the user are sorted in order of priority according to a predetermined criterion. It is determined that the voice recognition corresponds to the selected character string, and selection And a terminal control section for controlling to perform a function corresponding to the character string.
상기 목적을 달성하기 위한 또 다른 본 발명은 사용자 영상을 이용한 음성인식 시스템의 이동통신단말기에서 음성인식 방법으로서, 사용자에 의한 음성인식 요구에 입력에 따라 상기 사용자의 음성 및 영상 정보를 외부로 송신하는 단계와,상기 외부로부터 상기 사용자의 음성 및 영상에 대응된 문자열들을 미리 정해진 기준에 따른 우선순위로 정렬한 문자열 리스트를 제공받는 단계와, 상기 제공된 문자열 리스트 중 문자열이 선택되면 선택된 문자열에 해당하는 음성인식이 된 것으로 판단하고 상기 선택된 문자열에 해당하는 기능을 수행하는 단계를 포함한다.Another object of the present invention for achieving the above object is a voice recognition method in a mobile communication terminal of a voice recognition system using a user image, which transmits the voice and video information of the user to the outside in response to a voice recognition request by the user And receiving a list of strings in which the strings corresponding to the voice and image of the user are sorted in order of priority according to a predetermined criterion from the outside, and when the string is selected from the provided string list, the voice corresponding to the selected string. Determining that it is recognized and performing a function corresponding to the selected character string.
따라서 본 발명은 음성인식 시 사용자의 음성뿐만 아니라 사용자의 영상 정보(입모양, 표정)을 이용하여 음성인식을 하게 되므로 소음이 많은 지역에서도 음성인식 성공률을 높일 수 있는 효과가 있다.Therefore, in the present invention, the voice recognition is performed using not only the user's voice but also the user's image information (mouth shape, facial expression), so that the voice recognition success rate can be increased even in a noisy area.
또한 본 발명은 사용자에 따라 미리 정해진 우선순위를 이용하여 음성인식에 이용될 문자열을 제공하고 이를 이용하여 음성인식을 수행함으로써 사용자 개인 에게 최적화된 음성인식이 가능한 이점이 있다. In addition, the present invention has the advantage that the speech recognition optimized for the individual user by providing a character string to be used for speech recognition using a predetermined priority according to the user and performing the speech recognition using this.
이하 첨부된 도면을 참조하여 본 발명에 따른 바람직한 실시 예를 상세히 설명한다. 도면에서 동일한 구성 요소들에 대해서는 비록 다른 도면에 표시되더라도 가능한 동일한 참조번호 및 부호로 나타내고 있음에 유의해야 한다. 또한 본 발명을 설명함에 있어서, 관련된 공지기능 혹은 구성에 대한 구체적인 설명이 본 발명의 요지를 불필요하게 흐릴 수 있다고 판단되는 경우 그 상세한 설명은 생략한다.Hereinafter, exemplary embodiments of the present invention will be described in detail with reference to the accompanying drawings. Note that the same components in the drawings are represented by the same reference numerals and symbols as much as possible even if shown in different drawings. In describing the present invention, when it is determined that a detailed description of a related known function or configuration may unnecessarily obscure the subject matter of the present invention, the detailed description thereof will be omitted.
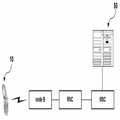
먼저 도 1은 본 발명의 실시 예에 따른 사용자 영상을 이용한 음성인식 시스템에 대한 구성도이다. 도 1을 참조하면, 이동통신 단말기(10)는 예컨대 PDA(Personal Digital Assistants), 셀룰라(Cellular) 등이 될 수 있으며, 단말기와 무선 구간을 연결하는 node B, node B를 제어하는 RNC (Radio Network Controller ; 무선망 제어기), 서버망과 연결하는 MSC (Mobile Switching Center : 이동 스위칭 센터) 를 거쳐 음성인식 DB(DataBase) 서버(50)와 통신을 수행한다.First, Figure 1 is a block diagram of a voice recognition system using a user image according to an embodiment of the present invention. Referring to FIG. 1, the
먼저 이동통신 단말기(10)는 개인음성인식 DB 생성에 필요한 사용자의 음성 및 동영상 정보를 제공하고 그 사용자의 음성 및 동영상 정보에 대응된 문자열 리스트를 제공받는다. 그리고 이동통신 단말기(10)는 문자열 리스트 중 사용자로부터 선택된 특정 문자열을 음성인식 DB 서버(50)로 제공하여 사용자에게 최적화된 개인음성인식 DB가 생성되도록 한다. 이때 이동통신 단말기(10)는 사용자의 음성 및 동영상 정보 전송 시 그에 해당하는 문자열을 함께 음성인식 DB 서버(50)로 제공하여 사용자에게 최적화된 개인음성인식 DB가 생성되도록 할 수도 있다. 또한, 이동통신 단말기(10)는 음성인식이 필요한 경우 사용자의 음성 및 동영상 정보와 현재 사용중인 기능 정보(예컨대 현재 사용중인 특정 기능이나 메뉴 정보 또는 현재 사용중인 무선데이터 통신 기능이나 메뉴 정보 등)를 제공한다. 그리고 이동통신 단말기(10)는 사용자의 음성 및 동영상 정보와 현재 사용중인 기능 정보에 해당하는 문자열 리스트를 제공받으면 문자열 리스트 중 사용자에 의해 선택된 문자열에 해당하는 음성인식을 수행한다. 이러한 본 발명의 실시 예에 따른 음성인식은 사용자 요구에 따라 통상의 음성인식과정과 별도의 과정으로 이루어질 수도 있고 통상의 음성인식 수행 중 그 음성인식이 소음 등으로 이용될 수 없거나, 사용자에 최적화된 음성인식이 필요할 경우 자동적으로 수행될 수 있다.First, the
한편, 음성인식 DB 서버(50)는 개인음성인식 DB 생성을 위한 사용자의 음성 및 동영상 정보가 제공되면, 음성인식 DB에서 그 사용자의 음성 및 동영상 정보에 해당하는 문자열들을 검색한다. 이때 음성인식 DB는 일반 사람들의 음성 및 동영상정보에 대응된 문자열들 저장하는 기본음성인식 DB 또는 이동통신 단말기 사용자의 음성 및 동영상정보에 해당하는 문자열들을 저장하는 개인음성인식 DB가 될 수 있다. 그리고 음성인식 DB 서버(50)는 검색된 문자열들을 미리 정해진 우선순위에 따라 리스트로 생성한다. 이때 문자열 리스트는 얼굴영상 분석에 의한 표정에 부합하는 순서, 음성인식 시 가장 이용횟수가 많은 문자열 순서, 가장 최근 이용된 문자열 순서 등의 우선 순위에 따라 생성될 수 있다. 이러한 음성인식 DB 서버(50)는 이동통신 단말기(10)를 통해 문자열 리스트 중 특정 문자열이 선택되면, 선택된 문 자열과 사용자의 음성 및 동영상 정보를 매칭시켜 개인음성인식 DB를 생성한다.Meanwhile, when the voice and video information of the user for generating the personal voice recognition DB is provided, the voice
또한 음성인식 DB 서버(50)는 음성인식 시 사용자의 음성 및 동영상 정보와 현재 사용중인 기능 정보가 제공되면 음성인식 DB에서 사용자의 음성 및 동영상 정보에 해당하는 문자열들을 추출하여 미리 정해진 우선순위에 따라 문자열 리스트로 생성한다. 이때 음성인식 DB 서버(50)는 현재의 얼굴영상 분석에 의한 표정에 부합하는 순서, 현재까지 선택된 문자열 순서, 최근 선택된 문자열 순서와 함께 현재 사용중인 기능 정보에 부합하는 순서에 따라 문자열 리스트를 생성할 수 있다. 이러한 음성인식 DB 서버(50)는 생성된 문자열 리스트를 이동통신 단말기(10)로 제공하여 사용자에 의해 선택된 문자열에 해당하는 음성인식이 수행되도록 한다.In addition, the voice
상기한 바와 같이 본 발명의 실시 예에 따른 음성인식 시스템은 사용자의 음성 및 동영상 정보를 이용하여 음성인식을 위한 개인음성인식 DB를 생성하고, 음성인식 시 개인음성인식 DB를 이용하여 음성인식을 수행하게 된다. 이하에서는 개인음성인식 DB 생성 과정과 음성인식 과정을 각각 설명한다.As described above, the voice recognition system according to an embodiment of the present invention generates a personal voice recognition DB for voice recognition by using voice and video information of a user, and performs voice recognition using the personal voice recognition DB during voice recognition. Done. Hereinafter, the individual voice recognition DB generation process and the voice recognition process will be described.
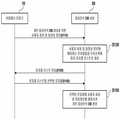
먼저 개인음성인식 DB 생성 과정을 설명하면, 도 2는 본 발명의 실시 예에 따른 사용자 영상을 이용한 음성인식 시스템에서 개인음성인식 DB 생성 흐름도이다.First, a process of generating a personal voice recognition DB will be described. FIG. 2 is a flowchart illustrating a process of generating a personal voice DB in a voice recognition system using a user image according to an exemplary embodiment of the present invention.
도 2를 참조하면, 이동통신 단말기(10)는 개인음성인식 DB 생성을 위한 사용자의 음성 및 동영상 정보를 음성인식 DB 서버(50)로 전송한다.(S110) 이때 이동통신 단말기(10)는 영상통화 중 개인음성인식 DB 생성을 위한 사용자 음성 및 동영상 정보를 음성인식 DB 서버(50)로 전송할 수 있다. 이와 같이 영상 통화 중 개인음성 인식 DB를 생성하는 경우, 이동통신 단말기(10)는 영상 통화중인 상대측 단말기와의 영상통화 세션을 끊고(예컨대 3G-324M), 음성인식 DB 서버(50)와 연결한 후, 음성인식 DB 서버(50)를 경유하여 상대측 단말기와 다시 세션을 연결한다. 이러한 경우 음성인식 DB 서버(50)는 이동통신 단말기(10)와 상대측 단말기 간의 영상통화를 포워딩하여 영상통화가 지속되게 하면서 개인음성인식 DB 생성을 수행하게 된다.Referring to FIG. 2, the
사용자의 음성 및 동영상 정보를 수신하면, 음성인식 DB 서버(50)는 기본음성인식 DB 혹은 미리 생성된 개인음성인식 DB로부터 사용자의 음성 및 동영상 정보에 해당하는 문자열들을 추출한다. 여기서 사용자의 동영상정보는 사용자가 말할 때 촬영한 동영상 자체이거나, 그 동영상으로부터 추출된 입모양 벡터 정보, 얼굴 표정 벡터 정보 등을 포함하는 얼굴영상 정보가 될 수 있다. 그리고 음성인식 DB 서버(50)는 추출된 문자열들을 미리 정해진 우선순위에 따라 문자열 리스트로 생성한다.(S120) 여기서 기본음성인식 DB는 통상적인 사람들의 음성 및 동영상정보에 해당하는 문자열들을 미리 저장하는 DB이고, 개인음성인식 DB는 이동통신 단말기 사용자 개인의 음성 및 동영상정보에 해당하는 문자열들을 저장하는 DB이다. 본 발명의 실시 예에 따르면 음성인식 DB 서버(50)는 먼저 개인음성인식 DB를 검색하여 문자열 리스트를 생성하고, 개인음성인식 DB에 문자열이 없으면 기본음성인식 DB를 검색하여 리스트를 생성할 수 있다. 또한 음성인식 DB 서버(50)는 검색된 문자열들을 현재의 얼굴영상 분석에 의한 표정에 부합하는 순서, 현재까지 음성인식에서 선택된 문자열 순서, 최근 선택된 문자열 순서 등의 우선순위에 따라 리스트로 생성할 수 있다. 여기서 상기 우선 순위 기준들은 사전에 무선데이터 통신으로 음성인 식 DB 서버(50)에 접속하여 변경이 가능하며, 음성인식 기능 수행 중에도 변경 가능하다.Upon receiving the voice and video information of the user, the voice
사용자의 음성 및 동영상 정보에 해당하는 문자열 리스트 생성 후, 음성인식 DB 서버(50)는 문자열 리스트를 이동통신 단말기(10)로 전송한다.(S130) 문자열 리스트가 수신되면 이동통신 단말기(10)는 문자열 리스트 중 사용자가 원하는 문자열을 선택받고, 선택된 문자열을 음성인식 DB 서버(50)로 전송한다.(S140) 선택된 문자열이 수신되면 음성인식 DB 서버(50)는 선택된 문자열과 사용자의 음성 및 동영상 정보를 매칭시켜 개인음성인식 DB를 생성한다.(S150)After generating the string list corresponding to the voice and video information of the user, the voice
한편, 상기한 바와 같은 개인음성 인식 DB 생성 과정은 전술한 실시 예에만 한정되지 않으며 다른 방법으로도 수행될 수 있다. 예컨대 음성인식 DB 서버(50)는 사용자의 음성 및 동영상 정보와 그에 해당하는 문자열을 함께 수신하여 바로 저장함으로써 개인음성인식 DB를 생성할 수 있음은 당업자에게 명백하다.On the other hand, the process of generating a personal voice recognition DB as described above is not limited to the above-described embodiment and may be performed by other methods. For example, it will be apparent to those skilled in the art that the voice
한편, 음성인식 과정을 설명하면, 도 3은 본 발명의 실시 예에 따른 사용자 영상을 이용한 음성인식 시스템에서 음성인식 흐름도이다.Meanwhile, referring to the voice recognition process, FIG. 3 is a voice recognition flowchart in a voice recognition system using a user image according to an exemplary embodiment of the present invention.
도 3을 참조하면, 이동통신 단말기(10)는 음성인식이 필요한 경우 음성인식 DB 서버(50)로 사용자 음성 및 동영상정보와 현재 사용중인 기능 정보를 전송한다. (S120) 예를 들면, 이동통신 단말기(10)는 특정 기능이나 메뉴 사용 중 또는 WAP(Wireless Application Protocol)이나 WEP(Wired Equivalent Privacy)을 이용한 무선데이터 통신 기능이나 메뉴 사용 중 음성인식이 필요한 경우 사용자에 의해 음성인식 버튼이 눌려지면 음성인식 DB 서버(50)와 연결한다. 그리고 이동통신 단말 기(10)는 음성인식 DB 서버(50)로 사용자 음성 및 동영상 정보와 현재 사용중인 특정 기능 혹은 메뉴 정보나 현재 사용중인 무선데이터 통신 기능 혹은 메뉴 정보를 전송한다. 여기서도 사용자의 동영상정보는 사용자가 말할 때 촬영한 동영상 자체이거나, 그 동영상으로부터 추출된 입모양 벡터 정보, 얼굴 표정 벡터 정보 등을 포함하는 얼굴영상 정보가 될 수 있다.Referring to FIG. 3, when voice recognition is required, the
사용자 음성 및 동영상정보와 현재 사용중인 기능 정보가 수신되면, 음성인식 DB 서버(50)는 기본음성인식 DB 혹은 미리 생성된 개인음성인식 DB로부터 사용자의 음성 및 동영상 정보에 해당하는 문자열들을 추출한다. 그리고 나서 음성인식 DB 서버(50)는 추출된 문자열들을 미리 정해진 우선순위에 따라 문자열 리스트로 생성한다.(S220) 이때 음성인식 DB 서버(50)는 현재의 얼굴영상 분석에 의한 표정에 부합하는 순서, 현재까지 선택된 문자열 순서, 최근 선택된 문자열 순서와 함께 현재 사용중인 기능 정보에 부합하는 순서에 따라 문자열 리스트를 생성할 수 있다. 여기서 상기 우선 순위 기준들은 사전에 무선데이터 통신으로 음성인식 DB 서버(50)에 접속하여 변경이 가능하며, 음성인식 기능 수행 중에도 변경 가능하다.When the user voice and video information and the function information currently being used are received, the voice
사용자의 음성 및 동영상 정보와 현재 사용중인 기능 정보에 대응된 문자열 리스트 생성이 완료되면, 음성인식 DB 서버(50)는 생성된 문자열 리스트를 이동통신 단말기(10)로 전송한다.(S230) 그리고 문자열 리스트가 수신되면, 이동통신 단말기(10)는 문자열 리스트 중 사용자가 원하는 문자열을 선택받고, 선택된 문자열이 음성인식된 것으로 판단하여 선택된 문자열에 해당하는 기능을 수행한다.(S240)When the generation of the string list corresponding to the user's voice and video information and the function information currently being used is completed, the voice
상기한 바와 같이 본 발명의 실시 예에 따르면 음성인식 시 사용자의 음성 뿐만 아니라 동영상 정보(입모양, 표정)을 이용하여 음성인식을 하게 되므로 음성만으로 음성인식을 수행할 때 보다 음성인식 성공률을 높일 수 있게 된다. 또한, 본 발명의 실시 예에 따르면 사용자 개인별 우선순위에 따라 음성인식에 이용될 문자열을 제공함으로써 개인에게 최적화된 음성인식을 가능하게 할 수 있게 된다.As described above, according to an embodiment of the present invention, the voice recognition is performed using not only the user's voice but also video information (mouth shape, facial expression), so that the voice recognition success rate can be increased more than the voice recognition. Will be. In addition, according to an embodiment of the present invention it is possible to enable the speech recognition optimized for the individual by providing a character string to be used for speech recognition in accordance with the priority of each user.
이하 상기한 바와 같은 음성인식 시스템에서의 이동통신 단말기(10)와 음성인식 DB 서버(50)의 구성 및 동작을 좀더 구체적으로 설명한다.Hereinafter, the configuration and operation of the
먼저 음성인식 DB 서버(50)의 구성과 음성인식 DB 서버(50)가 개인음성인식 DB를 생성할 때의 동작을 도 4 및 도 5를 참조하여 설명하기로 한다.First, the configuration of the voice
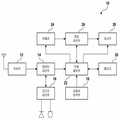
도 4는 본 발명의 실시 예에 따른 음성인식 DB 서버(50)의 구성도이다. 도 4를 참조하면, 본 발명의 실시 예에 따른 음성인식 DB 서버(50)는 송수신부(52), 기본음성인식 DB(54), 개인음성인식 DB(56), 음성인식 DB 제어부(58)를 포함한다.4 is a configuration diagram of a voice
송수신부(52)는 무선통신 기능을 수행하며, 본 발명의 실시 예에서는 이동통신 단말기(10)와의 통신에 이용된다. 기본음성인식 DB(54) 통상적인 사람들의 음성 및 동영상정보에 해당하는 문자열들을 미리 저장한다. 개인음성인식 DB(56)는 이동통신 단말기 사용자 개인의 음성 및 동영상정보에 해당하는 문자열들을 저장한다. 음성인식 DB 제어부(58)는 음성인식 DB 서버(50)의 전반적인 동작을 제어하며, 본 발명의 실시 예에 따라 개인음성인식 DB를 생성하고, 음성인식 시 개인음성인식 DB 정보를 제공한다. The
도 5는 본 발명의 실시 예에 따른 음성인식 DB 서버(50)의 개인음성인식 DB 생성 흐름도이다. 도 5를 참조하면, 음성인식 DB 제어부(58)는 이동통신 단말(10) 로부터 개인음성인식 DB 생성 요구 수신에 따라 송수신부(52)를 통해 이동통신 단말(10)과 세션을 연결한다.(S510)5 is a flowchart for generating a personal voice recognition DB of the voice
세션이 연결되면, 음성인식 DB 제어부(58)는 송수신부(52)를 통해 단말(10)로부터 사용자 음성 및 얼굴영상 정보를 수신한다.(S515) 이때 사용자 동영상 정보를 수신한 후, 사용자 동영상으로부터 얼굴영상 정보(입모양 벡터정보, 표정 벡터 정보 등)를 추출할 수도 있다.When the session is connected, the voice recognition
사용자 음성 및 얼굴영상 정보가 수신되면 음성인식 DB 제어부(58)는 미리 저장된 음성인식 정보를 읽어온다.(S520) 예컨대 음성인식 DB 제어부(58)는 기본음성인식 DB(54) 혹은 미리 생성된 개인음성인식 DB(56)에 저장된 정보를 읽어온다.When the user voice and face image information is received, the voice recognition
그리고 음성인식 DB 제어부(58)는 사용자 음성에 포함된 소음이 임계치 이상인지 판단한다.(S525) 만약 소음이 임계치 이상이면 음성인식 DB 제어부(58)는 읽어온 기본음성인식 DB(54) 혹은 미리 생성된 개인음성인식 DB(56)에 저장된 정보로부터 얼굴영상 정보에 대응된 문자열을 추출한다.(S530) 그리고 나서 음성인식 DB 제어부(58)는 추출된 문자열들 중 음성 정보에 대응된 문자열을 추출한다.(S535) 이때 음성인식 DB 제어부(58)는 먼저 개인음성인식 DB(54)를 검색한 후, 개인음성인식 DB(54)에 문자열이 없으면 기본음성인식 DB(56)를 검색할 수 있다.The voice recognition
만약 소음이 임계치 이상이 아니면 음성인식 DB 제어부(58)는 읽어온 기본음성인식 DB(54) 혹은 미리 생성된 개인음성인식 DB(56)에 저장된 정보로부터 음성 정보에 대응된 문자열들을 추출한다.(S540) 그리고 나서 음성인식 DB 제어부(58)는 추출된 문자열들 중 얼굴영상 정보에 대응된 문자열을 추출한다.(S545)If the noise is not greater than the threshold, the voice recognition
문자열이 추출되면, 음성인식 DB 제어부(58)는 미리 정해진 기준에 따라 추출된 문자열들의 우선순위를 결정한다.(S550) 이때 미리 정해진 기준은 현재의 얼굴영상 분석에 의한 표정에 부합하는 순서(예컨대 긍정/부정), 현재까지 선택된 문자열 순서, 최근 선택된 문자열 등이 될 수 있다. 그리고 상기 우선 순위 기준들은 사전에 사용자의 요구에 따라 새로운 기준들로 등록이 가능하며 기 등록된 기준의 변경이 가능하다.When the character string is extracted, the voice recognition
우선순위가 결정되면, 음성인식 DB 제어부(58)는 우선순위에 따라 문자열 리스트를 생성하고, 문자열 리스트를 송수신부(52)를 통해 이동통신 단말기(10)로 전송한다.(S555) 이때 이동통신 단말(10)은 문자열 리스트가 수신되면 사용자가 원하는 문자열을 선택받아 다시 음성인식 DB 서버(50)로 전송하게 된다.When the priority is determined, the voice
이에 따라 음성인식 DB 제어부(58)는 송수신부(52)를 통해 이동통신 단말기(10)로부터 사용자에 의해 선택된 문자열을 수신한다.(S560) 선택된 문자열이 수신되면 음성인식 DB 제어부(58)는 사용자 음성 및 얼굴영상 정보와 선택된 문자열을 매칭시켜 저장함으로써 개인음성인식 DB를 생성한다.(S565) 이에 따라 이동통신 단말기(10)는 상기 생성된 개인음성인식 DB를 이용하여 음성인식 기능을 수행할 수 있게 된다. 개인음성인식 DB에 저장된 정보가 증가할수록 개인 음성인식 DB는 최적화되며, 인식성공률이 상승하게 된다.Accordingly, the voice recognition
개인 음성인식 DB의 구성단위에는 음성정보 (예컨대 음성 특징벡터 등), 영상정보 (예컨대 입모양 특징벡터, 표정 특징벡터 등), 음성 및 영상정보에 대응하는 문자열 등이 포함될 수 있다. 또한 이동통신 단말기는 음성인식 시 사용자와 음 성 및 영상정보와 현재 사용중인 기능정보 (예컨대 현재 사용중인 특정 기능이나 메뉴정보 또는 현재 사용중인 무선데이터 통신 기능이나 메뉴 정보 등)를 제공하므로 개인 음성인식 DB에는 이러한 정보도 함께 저장될 수 있다. 그 밖에도 현재까지 사용자에 의하여 음성인식에서 선택된 횟수와 최근 선택날짜도 함께 저장되어 있어 개인 음성인식 DB에서 음성 또는 영상 정보에 맞는 문자열 리스트를 추출할 때 함께 전송할 수 있다.The structural unit of the personal voice recognition DB may include voice information (eg, a voice feature vector, etc.), image information (eg, a mouth feature vector, facial expression feature vectors, etc.), and a character string corresponding to voice and image information. In addition, the mobile communication terminal provides the user with voice and video information and the currently used function information (for example, the specific function or menu information currently being used or the wireless data communication function or menu information currently being used). This information can also be stored in the DB. In addition, the number of times selected by the user and the latest selection date are stored together so far, so that when the user extracts a list of strings suitable for voice or video information from the personal voice recognition DB, they can be transmitted together.
이제부터는 이동통신 단말기(10)의 구성과 이동통신 단말기(10)가 개인음성인식 DB를 이용하여 음성인식을 수행할 때의 동작을 도 6 및 도 7을 참조하여 설명하기로 한다.Hereinafter, a configuration of the
도 6은 본 발명의 실시 예에 따른 이동통신 단말기(10)의 구성도이다. 도 6을 참조하면, 무선부(12)는 송신되는 신호의 주파수를 상승변환 및 증폭하는 송신기와, 수신되는 신호를 저잡음 증폭하고 주파수를 하강 변환하는 수신기 등을 포함하며, 무선 통신 기능을 수행한다. 본 발명의 실시 예에서는 음성인식 DB 서버(50)와의 통신에 이용된다.6 is a block diagram of a
데이터 처리부(14)는 송신되는 신호를 부호화 및 변조하는 변조기 및 수신되는 신호를 복조 및 복호화하는 복조기 등을 구비한다. 데이터 처리부(14)는 모뎀(modem) 및 코덱(codec)으로 구성될 수 있으며, 코덱은 패킷 데이터등을 처리하는 데이터 코덱과 음성 등의 오디오 신호를 처리하는 오디오 코텍으로 이루어질 수 있다. 이러한 데이터 처리부(14)는 영상 통화 시 또는 사용자 동영상 촬영 시 영상 데이터와 음성 데이터를 코덱을 사용하여 디지털 신호와 아날로그 신호로 변환한 다.The
오디오 처리부(16)는 데이터 처리부(14)의 오디오 코덱에서 출력되는 오디오 신호를 재생하거나, 마이크로부터 발생되는 송신 오디오 신호를 데이터 처리부(14)의 오디오 코덱에 전송한다. 즉, 사용자의 음성 신호를 입력받아 데이터 처리부(14)의 오디오 코덱에 전송하게 된다.The
사용자 입력부(18)는 키패드 또는 터치스크린 등으로 구성될 수 있으며, 사용자에 의해 버튼이 눌려지거나 터치되면, 사용자 입력 신호를 제어부(22)로 전달한다.The
메모리(20)는 프로그램 메모리 및 데이터 메모리들로 구성될 수 있으며, 프로그램 메모리에는 이동통신 단말기의 일반적인 동작을 제어하기 위한 프로그램들이 저장되고, 데이터 메모리에는 프로그램들을 수행하는 중에 발생되는 데이터들을 일시 저장한다. 본 발명의 실시 예에 따르면 메모리(20)에는 개인음성인식 DB 생성에 필요한 사용자 음성 및 동영상 정보가 저장될 수 있다.The
단말 제어부(22)는 이동통신 단말기(10)의 전반적인 동작을 제어하며, 본 발명의 실시 예에 따라 개인음성인식 DB 생성과정을 제어하고, 개인음성인식 DB를 이용한 음성인식 과정을 제어한다.The
카메라(24)는 사용자의 영상을 촬영하여 영상신호를 출력하고, 영상 처리부(26)는 카메라(24)로부터 출력되는 영상신호를 이미지 신호로 변환한다. 또한 영상 처리부(26)는 이미지 신호를 표시하기 위한 화면 데이터를 출력하고, 단말 제어부(22)의 제어 하에 이미지 신호 및 화면 데이터를 표시부(28)이 규격에 맞춰 전송 한다.The
표시부(28)는 LCD(Liquid Crystal Display:액정 표시 장치)등으로 구성될 수 있으며, 제어부(22)의 제어 하에 이동통신 단말기 기능 수행 중 발생하는 표시 데이터를 표시한다. 이러한 표시부(114)는 특히 영상통화 시 영상 처리부 (26)로부터 출력되는 영상 신호를 영상통화 화면으로 표시한다.The
도 7은 본 발명의 실시 예에 따른 이동통신 단말기(10)의 음성인식 흐름도이다. 도 7을 참조하면, 제어부(22)는 사용자로부터 개인음성인식 DB를 이용한 음성인식 요구를 입력받는다.(S710) 이때 제어부(22)는 특정 기능이나 메뉴 사용 중 또는 WAP이나 WEP을 이용한 무선데이터 통신기능이나 메뉴 이용중 사용자에 의한 사용자 입력부(18)의 버튼 누름에 의해 음성인식 요구를 입력 받을 수 있다.7 is a flowchart of voice recognition of the
음성인식 요구가 있으면, 제어부(22)는 현재 사용중인 기능을 파악한다.(S720) 즉, 사용자가 현재 이동통신 단말기의 어떤 기능을 사용하고 있었는지를 판단한다. 예컨대 만약 사용자가 아무 기능도 이용하고 있지 않은 상태라면 대기 상태로 판단하고, 특정 기능이나 메뉴를 이용하고 있었다면 해당 기능을 현재 사용중인 기능으로 파악한다.If there is a voice recognition request, the
현재 사용중인 기능이 파악되면, 제어부(22)는 카메라(24)를 통해 사용자의 음성을 녹음하고 동영상을 촬영한다.(S730) 이때 사용자의 음성발음에 의한 얼굴 표정 및 입모양이 명확히 촬영되는 것이 바람직하다.If the current function is used, the
사용자 음성 녹음과 동영상 촬영이 완료되면, 제어부(22)는 사용자 동영상으로부터 사용자 얼굴영상 정보를 추출한다.(S740) 예컨대 사용자가 말할 때의 입모 양 벡터정보 및 얼굴 표정 벡터정보를 추출한다.When the user voice recording and video recording are completed, the
그리고 제어부(22)는 미리 파악된 현재 사용중인 기능 정보와 녹음된 사용자 음성 그리고 추출된 얼굴영상 정보를 무선부(12)를 통해 음성인식 DB 서버(50)로 전송한다.(S750) 그러면 음성인식 DB 서버(50)는 사용자의 음성 및 동영상 정보에 해당하는 문자열들을 추출한다. 그리고 음성인식 DB 서버(50)는 추출된 문자열들을 현재의 얼굴영상 분석에 의한 표정에 부합하는 순서, 현재까지 선택된 문자열 순서, 최근 선택된 문자열 순서와 함께 현재 사용중인 기능 정보에 부합하는 순서에 따라 문자열 리스트를 생성하여 다시 단말(10)로 전송하게 된다.The
이에 따라 제어부(22)는 해당 문자열 리스트가 수신되는지 판단한다.(S760) 만약 해당 문자열 리스트가 수신되면, 제어부(22)는 사용자 입력부(18)를 통해 문자열 리스트 중 사용자로부터 특정 문자열을 선택받는다.(S770) 그리고 특정 문자열이 선택되면 제어부(22)는 선택된 문자열이 음성인식된 것으로 판단하고,선택된 문자열에 해당하는 기능을 수행한다.(S780)Accordingly, the
그러나 해당 문자열 리스트가 수신되지 않으면, 제어부(22)는 화자독립방식의 음성인식을 수행한다. 화자독립방식의 음성인식이란 이동통신 단말기 내에 통상적인 사람들의 음성 및 동영상정보에 해당하는 문자열들을 미리 저장하는 기본음성인식 DB를 구비하고 이를 이용하여 음성인식을 수행하는 것을 말한다. 이러한 화자독립방식의 음성인식을 위해 제어부(22)는 기본음성인식 DB에서 음성 및 얼굴 영상 정보에 대응된 문자열을 추출한다.(S762) 이때 제어부(22)는 음성 정보에 대응된 문자열들을 추출한 후, 추출된 문자열들 중 얼굴 영상 정보에 대응된 문자열을 추 출하는 것이 바람직하다.However, if the corresponding string list is not received, the
그리고 문자열이 추출되면, 제어부(22)는 미리 정해진 기준에 따라 추출된 문자열들의 우선순위를 결정한다.(S764) 이때 미리 정해진 기준은 현재의 얼굴영상 분석에 의한 표정에 부합하는 순서(예컨대 긍정/부정), 현재까지 선택된 문자열 순서, 최근 선택된 문자열 등이 될 수 있다. 그리고 상기 우선 순위 기준들은 사전에 사용자의 요구에 따라 새로운 기준들로 등록이 가능하며 기 등록된 기준의 변경이 가능하다.When the character string is extracted, the
또한 우선순위가 결정되면, 제어부(22)는 우선순위에 따라 문자열 리스트를 생성하고, 문자열 리스트를 표시부(28)를 통해 표시한다.(S766)If the priority is determined, the
그리고 나서 제어부(2)는 전술한 바와 같은 S770 단계 내지 S780단계를 수행함으로써 음성 인식을 수행하게 된다.Then, the control unit 2 performs voice recognition by performing steps S770 to S780 as described above.
따라서 상기한 바와 같은 본 발명의 실시 예에 다른 음성인식 기능을 이용하면, 사용자 개인마다 다른 다양한 조건에 따라 음성인식이 수행되므로 개인에게 최적화된 음성인식 수행이 가능하다.Therefore, using the voice recognition function according to the embodiment of the present invention as described above, it is possible to perform the voice recognition optimized for the individual because the voice recognition is performed according to various conditions for each user.
상술한 본 발명의 설명에서는 구체적인 실시 예에 관해 설명하였으나, 여러 가지 변형이 본 발명의 범위에서 벗어나지 않고 실시할 수 있다. 따라서 본 발명의 범위는 설명된 실시 예에 의하여 정할 것이 아니고 특허청구범위와 특허청구범위의 균등한 것에 의해 정해져야 한다.In the above description of the present invention, specific embodiments have been described, but various modifications may be made without departing from the scope of the present invention. Therefore, the scope of the present invention should not be defined by the described embodiments, but should be determined by the equivalent of claims and claims.
전술한 본 발명은 이동통신 단말기 또는 이동통신 단말기 내에 탑재되어 음성인식 서비스를 제공하는 어플리케이션에 적용될 수 있으며, 특히 영상통화가 가능한 이동통신 단말기에서 사용자의 음성뿐만 아니라 얼굴 영상에 대응된 문자열을 이용하여 음성인식을 수행함으로써 소음이 있는 경우 음성인식 서비스를 제공하는데 이용될 수 있다. 또한 음성인식 시 이용되는 문자열을 사용자 개인의 조건에 따른 우선순위에 따라 제공함으로써 사용자에 최적화된 음성인식 서비스를 제공하도록 하는 데 활용될 수 있다.The present invention described above may be applied to a mobile communication terminal or an application mounted in a mobile communication terminal to provide a voice recognition service. In particular, a mobile communication terminal capable of video calling may use a character string corresponding to a face image as well as a user's voice. By performing the voice recognition can be used to provide a voice recognition service when there is noise. In addition, it can be used to provide an optimized speech recognition service to the user by providing a string used in speech recognition according to the priority according to the condition of the user.
도 1은 본 발명의 실시 예에 따른 사용자 영상을 이용한 음성인식 시스템 구성도1 is a block diagram of a speech recognition system using a user image according to an embodiment of the present invention
도 2는 본 발명의 실시 예에 따른 사용자 영상을 이용한 음성인식 시스템에서 개인음성인식 DB 생성 흐름도2 is a flowchart for generating a personal voice recognition DB in a voice recognition system using a user image according to an exemplary embodiment of the present invention.
도 3은 본 발명의 실시 예에 따른 사용자 영상을 이용한 음성인식 시스템에서 음성인식 흐름도3 is a voice recognition flowchart in a voice recognition system using a user image according to an embodiment of the present invention.
도 4는 본 발명의 실시 예에 따른 음성인식 DB 서버의 구성도4 is a block diagram of a voice recognition DB server according to an embodiment of the present invention
도 5는 본 발명의 실시 예에 따른 음성인식 DB 서버의 개인음성인식 DB 생성 동작 흐름도5 is a flowchart illustrating an operation of generating a personal voice recognition DB of a voice recognition DB server according to an embodiment of the present invention.
도 6은 본 발명의 실시 예에 따른 이동통신 단말기의 구성도6 is a block diagram of a mobile communication terminal according to an embodiment of the present invention;
도 7은 본 발명의 실시 예에 따른 이동통신 단말기의 음성인식 동작 흐름도7 is a flowchart illustrating voice recognition of a mobile communication terminal according to an exemplary embodiment of the present invention.
<도면의 주요 부분에 대한 부호의 설명><Explanation of symbols for the main parts of the drawings>
10 : 이동통신 단말기22 : 단말 제어부10: mobile communication terminal 22: terminal control unit
12 : 무선부 24 : 카메라12: wireless unit 24: camera
14 : 데이터 처리부 26 : 영상처리부14: data processing unit 26: image processing unit
16 : 오다오 처리부 28 : 표시부16: Odao processing part 28: Display part
18 : 사용자 입력부 50 : 음성인식 DB 서버18: user input unit 50: voice recognition DB server
20 : 메모리 52 : 송수신부20: memory 52: transceiver
54 : 기본 음성인식 DB54: basic voice recognition DB
56 : 개인 음성인식 DB56: personal voice recognition DB
58 : 음성인식 DB58: voice recognition DB
Claims (35)
Translated fromKoreanPriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR20080022345AKR101170612B1 (en) | 2008-03-11 | 2008-03-11 | Method and system for providing speech recognition by using user images |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR20080022345AKR101170612B1 (en) | 2008-03-11 | 2008-03-11 | Method and system for providing speech recognition by using user images |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20090097292Atrue KR20090097292A (en) | 2009-09-16 |
| KR101170612B1 KR101170612B1 (en) | 2012-08-03 |
Family
ID=41356669
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR20080022345AExpired - Fee RelatedKR101170612B1 (en) | 2008-03-11 | 2008-03-11 | Method and system for providing speech recognition by using user images |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR101170612B1 (en) |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8442820B2 (en) | 2009-09-22 | 2013-05-14 | Hyundai Motor Company | Combined lip reading and voice recognition multimodal interface system |
| WO2015005679A1 (en)* | 2013-07-09 | 2015-01-15 | 주식회사 윌러스표준기술연구소 | Voice recognition method, apparatus, and system |
| WO2011084998A3 (en)* | 2010-01-05 | 2015-06-18 | Google Inc. | Word-level correction of speech input |
| KR101701952B1 (en)* | 2015-07-27 | 2017-02-02 | 오드컨셉 주식회사 | Method, apparatus and computer program for displaying serch information |
| US10354647B2 (en) | 2015-04-28 | 2019-07-16 | Google Llc | Correcting voice recognition using selective re-speak |
| WO2020112377A1 (en)* | 2018-11-30 | 2020-06-04 | Fujifilm Sonosite, Inc. | Touchless input ultrasound control |
| WO2020122677A1 (en)* | 2018-12-14 | 2020-06-18 | Samsung Electronics Co., Ltd. | Method of performing function of electronic device and electronic device using same |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102826450B1 (en)* | 2018-11-15 | 2025-06-27 | 삼성전자 주식회사 | Apparatus and method for generating personalization lip reading model |
| KR102171751B1 (en)* | 2020-01-10 | 2020-10-29 | 최혜린 | Providing method for voice service based on special catrgory telecommunication and apparatus therefor |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007199552A (en) | 2006-01-30 | 2007-08-09 | Toyota Motor Corp | Speech recognition apparatus and speech recognition method |
- 2008
- 2008-03-11KRKR20080022345Apatent/KR101170612B1/ennot_activeExpired - Fee Related
Cited By (22)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8442820B2 (en) | 2009-09-22 | 2013-05-14 | Hyundai Motor Company | Combined lip reading and voice recognition multimodal interface system |
| US11037566B2 (en) | 2010-01-05 | 2021-06-15 | Google Llc | Word-level correction of speech input |
| US9087517B2 (en) | 2010-01-05 | 2015-07-21 | Google Inc. | Word-level correction of speech input |
| US9263048B2 (en) | 2010-01-05 | 2016-02-16 | Google Inc. | Word-level correction of speech input |
| US9466287B2 (en) | 2010-01-05 | 2016-10-11 | Google Inc. | Word-level correction of speech input |
| US9542932B2 (en) | 2010-01-05 | 2017-01-10 | Google Inc. | Word-level correction of speech input |
| US9711145B2 (en) | 2010-01-05 | 2017-07-18 | Google Inc. | Word-level correction of speech input |
| US9881608B2 (en) | 2010-01-05 | 2018-01-30 | Google Llc | Word-level correction of speech input |
| WO2011084998A3 (en)* | 2010-01-05 | 2015-06-18 | Google Inc. | Word-level correction of speech input |
| US12148423B2 (en) | 2010-01-05 | 2024-11-19 | Google Llc | Word-level correction of speech input |
| US10672394B2 (en) | 2010-01-05 | 2020-06-02 | Google Llc | Word-level correction of speech input |
| WO2015005679A1 (en)* | 2013-07-09 | 2015-01-15 | 주식회사 윌러스표준기술연구소 | Voice recognition method, apparatus, and system |
| US10354647B2 (en) | 2015-04-28 | 2019-07-16 | Google Llc | Correcting voice recognition using selective re-speak |
| KR101701952B1 (en)* | 2015-07-27 | 2017-02-02 | 오드컨셉 주식회사 | Method, apparatus and computer program for displaying serch information |
| WO2020112377A1 (en)* | 2018-11-30 | 2020-06-04 | Fujifilm Sonosite, Inc. | Touchless input ultrasound control |
| US10863971B2 (en) | 2018-11-30 | 2020-12-15 | Fujifilm Sonosite, Inc. | Touchless input ultrasound control |
| US11331077B2 (en) | 2018-11-30 | 2022-05-17 | Fujifilm Sonosite, Inc. | Touchless input ultrasound control |
| US11678866B2 (en) | 2018-11-30 | 2023-06-20 | Fujifilm Sonosite, Inc. | Touchless input ultrasound control |
| US12016727B2 (en) | 2018-11-30 | 2024-06-25 | Fujifilm Sonosite, Inc. | Touchless input ultrasound control |
| US12364461B2 (en) | 2018-11-30 | 2025-07-22 | Fujifilm Sonosite, Inc. | Touchless input ultrasound control |
| US11551682B2 (en) | 2018-12-14 | 2023-01-10 | Samsung Electronics Co., Ltd. | Method of performing function of electronic device and electronic device using same |
| WO2020122677A1 (en)* | 2018-12-14 | 2020-06-18 | Samsung Electronics Co., Ltd. | Method of performing function of electronic device and electronic device using same |
Also Published As
| Publication number | Publication date |
|---|---|
| KR101170612B1 (en) | 2012-08-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101170612B1 (en) | Method and system for providing speech recognition by using user images | |
| CN108289244B (en) | Video subtitle processing method, mobile terminal and computer readable storage medium | |
| JP6110503B2 (en) | TV call equipment | |
| JP2004349851A (en) | Mobile terminal, image communication program, and image communication method | |
| CN107464557A (en) | Call recording method, device, mobile terminal and storage medium | |
| JP2008544629A (en) | Mobile communication terminal and method for providing a hyperlink function to a telephone number included in a text message | |
| CN102170617A (en) | Mobile terminal and remote control method thereof | |
| KR20070111270A (en) | Screen display method using voice recognition during multi-party video call | |
| CN104394265A (en) | Automatic session method and device based on mobile intelligent terminal | |
| CN107786427B (en) | Information interaction method, terminal and computer readable storage medium | |
| CN109302528B (en) | Photographing method, mobile terminal and computer readable storage medium | |
| CN112489647A (en) | Voice assistant control method, mobile terminal and storage medium | |
| CN112600815B (en) | Video display method, terminal and computer readable storage medium | |
| KR100678212B1 (en) | Emotional Information Control Method of Mobile Terminal | |
| KR20100115960A (en) | Mobile terminal capable of providing information by speech recognition during speaking over the terminal and method for providing information | |
| CN112612598A (en) | Anti-addiction method, mobile terminal and computer-readable storage medium | |
| CN109167880B (en) | Double-sided screen terminal control method, double-sided screen terminal and computer readable storage medium | |
| CN109453526B (en) | Sound processing method, terminal and computer readable storage medium | |
| CN112700783A (en) | Communication sound changing method, terminal equipment and storage medium | |
| CN112887195A (en) | Voice calling method, voice calling device and computer readable storage medium | |
| KR102058190B1 (en) | Apparatus for providing character service in character service system | |
| US20180315423A1 (en) | Voice interaction system and information processing apparatus | |
| CN113329263B (en) | Game video highlight production method, equipment and computer readable storage medium | |
| CN112562639B (en) | Audio processing method, terminal and computer readable storage medium | |
| KR101264797B1 (en) | Method for searching photo by facial recognition in mobile terminal |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application | St.27 status event code:A-0-1-A10-A12-nap-PA0109 | |
| P22-X000 | Classification modified | St.27 status event code:A-2-2-P10-P22-nap-X000 | |
| PG1501 | Laying open of application | St.27 status event code:A-1-1-Q10-Q12-nap-PG1501 | |
| A201 | Request for examination | ||
| PA0201 | Request for examination | St.27 status event code:A-1-2-D10-D11-exm-PA0201 | |
| D13-X000 | Search requested | St.27 status event code:A-1-2-D10-D13-srh-X000 | |
| D14-X000 | Search report completed | St.27 status event code:A-1-2-D10-D14-srh-X000 | |
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection | St.27 status event code:A-1-2-D10-D21-exm-PE0902 | |
| E13-X000 | Pre-grant limitation requested | St.27 status event code:A-2-3-E10-E13-lim-X000 | |
| P11-X000 | Amendment of application requested | St.27 status event code:A-2-2-P10-P11-nap-X000 | |
| P13-X000 | Application amended | St.27 status event code:A-2-2-P10-P13-nap-X000 | |
| R17-X000 | Change to representative recorded | St.27 status event code:A-3-3-R10-R17-oth-X000 | |
| E701 | Decision to grant or registration of patent right | ||
| P22-X000 | Classification modified | St.27 status event code:A-2-2-P10-P22-nap-X000 | |
| PE0701 | Decision of registration | St.27 status event code:A-1-2-D10-D22-exm-PE0701 | |
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment | St.27 status event code:A-2-4-F10-F11-exm-PR0701 | |
| PR1002 | Payment of registration fee | St.27 status event code:A-2-2-U10-U11-oth-PR1002 Fee payment year number:1 | |
| PN2301 | Change of applicant | St.27 status event code:A-5-5-R10-R13-asn-PN2301 St.27 status event code:A-5-5-R10-R11-asn-PN2301 | |
| PG1601 | Publication of registration | St.27 status event code:A-4-4-Q10-Q13-nap-PG1601 | |
| R18-X000 | Changes to party contact information recorded | St.27 status event code:A-5-5-R10-R18-oth-X000 | |
| R18-X000 | Changes to party contact information recorded | St.27 status event code:A-5-5-R10-R18-oth-X000 | |
| FPAY | Annual fee payment | Payment date:20150625 Year of fee payment:4 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:4 | |
| FPAY | Annual fee payment | Payment date:20160701 Year of fee payment:5 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:5 | |
| P22-X000 | Classification modified | St.27 status event code:A-4-4-P10-P22-nap-X000 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:6 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:7 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:8 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:9 | |
| PC1903 | Unpaid annual fee | St.27 status event code:A-4-4-U10-U13-oth-PC1903 Not in force date:20210728 Payment event data comment text:Termination Category : DEFAULT_OF_REGISTRATION_FEE | |
| PC1903 | Unpaid annual fee | St.27 status event code:N-4-6-H10-H13-oth-PC1903 Ip right cessation event data comment text:Termination Category : DEFAULT_OF_REGISTRATION_FEE Not in force date:20210728 |