KR20060037228A - Methods, systems, and programs for speech recognition - Google Patents
Methods, systems, and programs for speech recognitionDownload PDFInfo
- Publication number
- KR20060037228A KR20060037228AKR1020057003948AKR20057003948AKR20060037228AKR 20060037228 AKR20060037228 AKR 20060037228AKR 1020057003948 AKR1020057003948 AKR 1020057003948AKR 20057003948 AKR20057003948 AKR 20057003948AKR 20060037228 AKR20060037228 AKR 20060037228A
- Authority
- KR
- South Korea
- Prior art keywords
- recognition
- word
- user
- selection
- input
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images


























































































































Classifications
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/28—Constructional details of speech recognition systems
- G10L15/32—Multiple recognisers used in sequence or in parallel; Score combination systems therefor, e.g. voting systems
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/28—Constructional details of speech recognition systems
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Telephone Function (AREA)
Abstract
Translated fromKoreanDescription
Translated fromKorean본 발명은 음성인식을 위한 방법, 시스템 및 프로그램에 관한 것이다.The present invention relates to a method, system and program for speech recognition.
본 출원을 작성하는 지금까지 약 10년 동안 이산형 대형 문자(어휘) 음성 인식 시스템이 데스크 탑 개인용 컴퓨터 상에서 이용가능 하였다. 또한, 지금까지 5년동안 연속형 대형 문자(어휘) 음성 인식 시스템이 이러한 컴퓨터 상에서 이용가능 하였다. 이 음성 인식시스템은 상당한 가치가 있는 것임이 증명되었다. 본 발명의 명세서 내용은 주로 대형 문자(어휘) 연속형 음성인식 시스템을 위하여 작성된 것이다.For about 10 years now at the time of writing this application, discrete large text (vocabulary) speech recognition systems have been available on desktop personal computers. In addition, up to five years of continuous large character (vocabulary) speech recognition systems have been available on these computers. This speech recognition system has proved to be of considerable value. The specification of the present invention is mainly written for a large text (vocabulary) continuous speech recognition system.
다음의 명세서 및 청구범위에서 사용하는 바와 같이, 대형 문자(어휘) 음성 인식 시스템이라고 칭할 때, 이 용어는 발성된 단어(워드)에 가장 근접하는 표음모델을 기초로 최소한 2천 이상의 단어 중에서 소정의 발성을 인식하는 능력을 의미한다.As used in the following specification and claims, when referred to as a large character (vocabulary) speech recognition system, the term is based on a phonetic model of at least 2,000 words based on a phonetic model closest to the spoken word. Refers to the ability to recognize speech.
도 1에 표시한 바와 같이, 대형 문자(어휘) 음성 인식은 사용자(100)가 마이크로폰(102)에 말을 함으로써 통상적으로 기능을 하게 되며, 여기서 마이크로폰(102)이란 도 1의 경우 예를 들면 휴대폰(104)의 마이크로폰을 들 수 있다. 마이크 로폰은 워드의 발성에 의해 야기된 시간 상에서의 공기압의 변화를 전기적 신호로 표현된 대응 파형(106)으로 변환한다. 많은 음성인식 시스템에서 이 파형신호는 컴퓨터 프로세서에 의해 또는 특별한 디지털 신호 프로세서(108)에 의해 행해지는 디지털 신호 처리에 의해 시간 도메인 표현으로 변환된다. 때로 이 시간 도메인 표현은 다수의 파라메터 프레임(112)을 가지고 있으며, 이들 각 프레임은 예를 들면 매 100회째의 (시간)초와 같은 다수의 연속 시간 주기 각각에서 상기 파형으로 표현되는 소리특성을 나타낸다.As shown in FIG. 1, large text (vocabulary) speech recognition typically functions by the
도 2에 나타낸 바와 같이, 피인식 발성의 시간 도메인 또는 프레임 표현은 이후 대용량 어휘 중에서 다양한 워드에 대응하는 다수의 개연성 있는 표음모델(200) 시퀀스와 일치시키는 작업을 거친다. 최대 용량 문자(어휘) 음성 인식 시스템에서, 개별워드(202)는 각각 대부분의 사전에서 발견되는 표음 스펠링에 유사한 대응 표음 스펠링(204)으로 표현된다. 표음 스펠링에서 각 음소는 이 것과 연관된 하나 이상의 표음 모델(200)을 갖는다. 많은 시스템에서 이 표음모델(200)은 문맥 내 음소 모델로서, 소정의 워드 표음 스펠링에 있어서 문맥 내에서 전후 음소 사이에 걸려 있는 음소를 독자적인 아닌 연관적으로 모델화한 것이다. 표음모델은 공통적으로 하나 이상의 개연성 있는 모델의 시퀀스로 구성되며, 이들 각각의 모델은 피인식 발성의 시간 도메인 표현(110)의 프레임에서 사용되는 각 파라메터를 위해 다양한 파라메터 값의 개연성을 표현한다.As shown in FIG. 2, the time domain or frame representation of the recognized speech is then matched with a sequence of multiple probable
최근 개인용 컴퓨터 작업에서 주요 경향으로는 컴퓨터 장비의 소형화 및 더욱 간편한 휴대성을 들 수 있다.Recent trends in personal computer work include miniaturization and easier portability of computer equipment.
원래의 개인용 컴퓨터 작업은 대체로 도 3에 나타낸 바와 같이 데스크 탑 형 컴퓨터로 이루어졌다. 이후 랩탑의 형태로 보다 작아진 개인용 컴퓨터의 사용이 증대하였다. 여기서 랩탑 컴퓨터는 데스크 탑 컴퓨터와 컴퓨터 성능이나 사용자 인터페이스라는 측면에서 대체로 동일하므로 도시를 생략한다. 현대 대부분의 대용량 문자(어휘) 음성 인식 시스템은 이러한 시스템 상에서 사용되는 것을 전제로 설계된 것이다.The original personal computer work generally consisted of a desktop computer as shown in FIG. Since then, the use of smaller personal computers in the form of laptops has increased. The laptop computer is omitted here since it is generally the same in terms of computer performance or user interface. Most modern high-volume text (vocabulary) speech recognition systems are designed on the premise of being used on such systems.
최근, 새로운 타입의 컵퓨터 사용이 늘어나고 있으며, 이 새로운 타입의 컴퓨터로는 도 4의 타블렛 컴퓨터, 도 5의 PDA(Personal Digital Assistant), 도 6의 연산능력을 향상한 셀 폰, 도 7의 폰 컴퓨터, 도 8에서와 같이 헤드착용장비에 설치되는 것으로서, 스크린과 아이트랙킹(eyetracking) 및/또는 오디오 출력과 함께 사용자 인터페이스를 제공하는 착복식 컴퓨터를 들 수 있다.Recently, the use of a new type of cup computer is increasing, and the new type of computer includes a tablet computer of FIG. 4, a personal digital assistant (PDA) of FIG. 5, a cell phone with improved computing power of FIG. 6, and a phone of FIG. 7. A computer, which is installed in the head wear equipment as shown in FIG. 8, may be a wearable computer that provides a user interface with a screen and eyetracking and / or audio output.
최근 연산능력의 증대 때문에, 이러한 새로운 타입의 장비는 이산형 대형 문자(어휘) 인식 시스템이 설치된 첫번째 데스크탑의 연산능력과 대등한 연산능력을 갖추고 있으며, 경우에 따라서는 연속형 대형 문자(어휘) 음성 인식을 운영하는 초기 데스크 탑 컴퓨터의 연산능력과 대등한 능력을 갖고 있을 정도이다. 이러한 소형 및/또는 휴대용 개인용 컴퓨터의 연산능력은 시간이 지남에 따라 계속 성장을 거듭할 뿐이다.Due to the recent increase in computing power, this new type of equipment has the computing power equivalent to that of the first desktop with a discrete large text (vocabulary) recognition system, and in some cases continuous large text (vocabulary) speech. It is comparable to the computational power of early desktop computers that run recognition. The computing power of these small and / or portable personal computers will only continue to grow over time.
보다 휴대성향이 큰 컴퓨터에서 효과적인 대형 문자(어휘) 음성 인식을 제공하는데 있어 가장 큰 과제 중 하나는 이러한 장비 상에서 음성인식을 생성, 편집(에디트), 사용하는 것을 보다 쉽고, 보다 빠르게 이룰 수 있는 사용자 인터페이스 를 제공하는 것이다.One of the biggest challenges in providing effective large text (vocabulary) speech recognition on more portable computers is making it easier and faster for users to create, edit (edit) and use speech recognition on these devices. To provide an interface.
본 발명의 일측면은 선택가능한 인식모드를 이용하는 음성인식에 관한 것으로서, 랭귀지 콘텍스트와 함께 또는 랭귀지 콘텍스트 없이 인식모드 사이에서 사용자가 선택을 할 수 있도록 하는 단계와, 연속 또는 이산 대형 어휘 음성 인식 모드 사이에서 사용자가 선택을 할 수 있도록 하는 단계와, 최소한 2개 이상의 서로 다른 알파벳 엔트리 음성 인식 모드 사이에서 사용자가 선택을 할 수 있도록 하는 단계와, 텍스트를 생성할 때 대형 어휘 모드, 레터 인식모드, 수치 인식 모드, 구두 인식 모드를 포함하는 4개 이상의 모드 중에서 사용자가 선택을 할 수 있도록 하는 단계로 구성된다.One aspect of the present invention relates to speech recognition using a selectable recognition mode, comprising: allowing a user to select between recognition modes with or without a language context, and between continuous or discrete large vocabulary speech recognition modes. Allowing the user to make selections in the user, allowing the user to choose between at least two different alphabet entry speech recognition modes, and generating large vocabulary modes, letter recognition modes, and numerical values when generating text. And a step of allowing a user to select from four or more modes including a recognition mode and a verbal recognition mode.
본 발명의 또 다른 측면은 대형 어휘 음성 인식에서 선택분류 리스트를 이용하는 것에 관한 것으로서, 캐릭터 순차 선택분류 리스트를 제공하는 단계와, 수직으로 스크롤 가능한 선택분류 리스트를 제공하는 단계와, 수평으로 스크롤 가능한 선택분류 리스트를 제공하는 단계와, 인식 캔디디트를 제한하기 위해 사용하는 알파벳 필터에서 캐릭터 상에 선택분류 리스트를 제공하는 단계로 구성된다.Another aspect of the invention relates to the use of a classification list in large vocabulary speech recognition, comprising: providing a character sequential selection list, providing a vertically scrollable selection list, and a horizontally scrollable selection Providing a classification list, and providing a selection classification list on the character in an alphabetic filter used to limit recognition candies.
본 발명의 또 다른 측면은 사용자에게 워드 변형(transformation)을 가능하게하는 것에 관한 것으로서, 사용자는 다수의 변형으로부터 하나를 선택할 수 있어 인식된 워드에 대해 원하는 방법으로 변경을 하며, 이 변경으로는 예를들면 단수를 복수로, 워드를 동명사로 변형하는 것 등을 들 수 있다. 또한 사용자는 선택된 워드를 알파벳 폼과 비알파벳 폼 중에서 선택할 수도 있다. 또한 사용자는 인식된 워드에 대응하는 변형 워드의 선택분류 리스트를 제시받고 출력으로서 변형된 워드 중 하나를 선택할 수 있다.Another aspect of the invention relates to enabling a word transformation to a user, wherein the user can select one from a number of variations to make changes in the desired way for the recognized word, with examples of such modifications. For example, a singular number may be used, and a word may be transformed into a same name verb. The user can also select the selected word from alphabetic and nonalphabetic forms. The user may also be presented with a selection classification list of modified words corresponding to the recognized word and select one of the modified words as output.
본 발명의 또 다른 측면은 하나 이상의 특별한 방법으로 자동으로 인식을 턴 오프 하는 음성 인식에 관한 것으로서, 대형 어휘 음성 인식 명령은 인식을 턴 온하고, 다른 명령을 수신하여 인식을 다시 턴 온할 때까지 자동으로 이 인식을 턴 오프한다. 또한 본 발명의 음성 인식에 따르면 버튼을 프레스하는 시간 길이로 결정되는 도중(duration)시간 동안 인식이 이루어지며, 동일 버튼을 클릭할 경우는 이 클릭 시간의 길이에 상관없이 일정 시간길이 동안 인식이 이루어진다.Another aspect of the present invention is directed to speech recognition, which automatically turns off recognition in one or more special ways, wherein a large vocabulary speech recognition command turns on recognition, and receives another command to automatically turn on recognition again. Turn this recognition off. In addition, according to the voice recognition of the present invention, recognition is performed during a duration determined by the length of time for pressing a button, and when the same button is clicked, recognition is performed for a predetermined length of time regardless of the length of the click time. .
본 발명의 또 다른 측면은 대형 어휘 음성 인식의 폰 키 제어(콘트롤)에 관한 것으로서, 폰 키를 이용하여 선택분류 리스트로부터 워드를 선택하고, 이 키를 사용하는 중에 차후 프레스 키에 대하여 설명을 제공하며, 폰 키에 현재 연관된 펑크션 리스트를 선택한다. 또한 본 발명에 따르면 텍스트 내비게이션 모드를 갖는 개선된 음성 인식으로 다중 수치부여 폰키가 동시에 이 폰키와 연관된 다중의 여러 키 맵핑을 가지며, 이러한 키를 프레스하여 수치부여 폰키와 연관된 펑크션이 프레스된 키와 연관된 맵핑에 변경을 하도록 작용한다.Another aspect of the present invention relates to phone key control (control) of large vocabulary speech recognition, wherein a phone key is used to select a word from a selection list and provides a description of future press keys while using this key. Select the function list currently associated with the phone key. Also, according to the present invention, improved speech recognition with text navigation mode allows multiple numeric phone keys to have multiple multiple key mappings associated with this phone key at the same time. It acts to make changes to the associated mapping.
본 발명의 또 다른 측면은 폰키 알파벳 필터링 및 스펠링을 이용하는 음성 인식에 관한 것으로서, 알파벳 필터링이란 레터 시퀀스, 통상은 사용자 입력에 의해 표시된 레터 시퀀스에 대응하는 초기 레터 시퀀스를 포함하는 음성인식을 의미한다. 본 발명의 이러한 측면에 있어서는 필터 입력으로서 폰키의 프레스를 이용하며, 각 키 프레스가 모호이고, 목표 워드에서의 대응 캐릭터 위치가 이 폰키와 함께 식별된 다수의 레터 중 하나와 대응한다. 또한 본 발명에 따르면, 필터 입력으로서 폰 키 프레스 시퀀스를 사용하며, 소정의 키의 0번 이상의 반복적 프레스의 개수가 비모호 인디케이션(표시)을 제공하며, 이 인디케이션의 키와 연관된 다중 레터는 필터에서 사용되기 위한 것이다. 또한 본 발명에 따르면, 음성 인식으로 생성된 텍스트 이외에 사용될 수 있는 텍스트를 스펠링하기 위해 이와같은 모호 및 비모호 폰 키 입력을 사용한다.Another aspect of the invention relates to speech recognition using phonekey alphabet filtering and spelling, wherein alphabetic filtering refers to speech recognition comprising an initial letter sequence corresponding to a letter sequence, typically a letter sequence indicated by user input. In this aspect of the present invention, a press of the phone keys is used as the filter input, each key press is ambiguous, and the corresponding character position in the target word corresponds to one of the plurality of letters identified with this phone key. Also in accordance with the present invention, a phone key press sequence is used as the filter input, where the number of zero or more repetitive presses of a given key provides an unambiguous indication (multiple letters) associated with the key of the indication. It is intended to be used in filters. Also in accordance with the present invention, such ambiguous and unambiguous phone keystrokes are used to spell text that may be used in addition to text generated by speech recognition.
본 발명의 또 다른 측면은 사용자가 재발성 인식을 행할 수 있는 음성인식에 관한 것으로서, 하나 이상의 워드 시퀀스의 1초의 말과, 같은 시퀀스의 초기 말에서 이 음성 인식이 수행되어 음성인식을 통해 발성을 위한 하나 이상의 베스트 스코어링 텍스트 시퀀스를 보다 양호하게 선택할 수 있도록 지원한다.Another aspect of the present invention relates to speech recognition, in which a user can perform recurrent recognition, wherein the speech recognition is performed at the end of one second of one or more word sequences, and at the beginning of the same sequence to generate speech through speech recognition. To better select one or more best scoring text sequences.
본 발명의 또 다른 측면은 음성인식과 TTS(Text-To-Speech)발생의 조합에 관한 것으로서, 음성인식과 TTS 소프트웨어는 표음 스펠링과 레터 대 사운드 루울과 같은 자원을 공유한다. 본 발명에 따르면 하나 이상의 모드를 갖는 대형 어휘 음성인식 시스템을 포함하며, 여기서 하나 이상의 모드는 자동으로 TTS를 사용하여 텍스트 인식 이후 그 텍스트를 말하고, TTS 또는 레코드된 오디오를 이용하여 명령 인식 이후 그 명령의 네임을 말한다. 또한 본 발명에 따르면 각 발성 이후 TTS를 이용하여 인식된 텍스트를 자동으로 반복하는 대형어휘 시스템을 포함한다. 또한 본 발명에 따르면, 사용자는 커런트 위치에서 하나 이상의 워드로 인식된 텍스트에서 앞 뒤로 이동하며, 이 이동은 상기 각 이동을 TTS가 말한 이후가 된다. 또한 본 발명에 따르면, 음성 인식을 이용하여 선택분류 리스트를 생성하고 이 리스트의 선택분류 중 하나 이상의 TTS 출력을 제공하는 대형 어휘 시스템을 제공한다.Another aspect of the invention relates to a combination of speech recognition and text-to-speech generation, wherein speech recognition and TTS software share resources such as phonetic spelling and letter-to-sound loops. According to the invention there is provided a large lexical speech recognition system having one or more modes, wherein one or more modes automatically speak the text after text recognition using TTS, and the command after command recognition using TTS or recorded audio. Says the name. In addition, according to the present invention includes a large vocabulary system that automatically repeats the recognized text using the TTS after each voice. In addition, according to the present invention, the user moves back and forth in the text recognized as one or more words in the current position, which movement is after the TTS has said each movement. According to the present invention, there is also provided a large vocabulary system that generates a classification list using speech recognition and provides the output of one or more of the classifications of the list.
본 발명의 또 다른 측면은 음성인식과 수기 및/또는 캐릭터 인식의 조합에 관한 것으로서, 인식될 하나 이상의 워드 시퀀스 수기 및 발성 표현 모두의 인식 펑크션으로서 하나 이상의 베스트 스코어링 인식 캔디디트를 선택한다. 본 발명에 따르면, 하나 이상의 레터의 캐릭터 또는 수기 인식을 이용하여 알파벳 방식으로 하나 이상의 워드의 음성 인식을 필터링한다. 또한 본 발명에 따르면 하나 이상의 레터 식별 워드의 음성 인식을 사용하여 알파벳 방식으로 수기 인식을 필터링하며, 음성인식을 이용하여 하나 이상의 수기 인식을 교정한다.Another aspect of the invention relates to a combination of speech recognition and handwriting and / or character recognition, selecting one or more best scoring recognition candies as a recognition function of both one or more word sequence handwriting and utterance expressions to be recognized. According to the present invention, the speech recognition of one or more words is filtered in an alphabetical manner using character or handwriting recognition of one or more letters. In addition, according to the present invention, handwriting recognition is filtered in alphabetical manner using speech recognition of one or more letter identification words, and one or more handwriting recognition is corrected using speech recognition.
본 발명의 또 다른 측면은 대형 어휘 음성 인식과 오디오 레코딩 및 플레이백의 조합에 관한 것으로서, 대형 어휘 음성 인식과 오디오 레코딩을 갖는 핸드헬드 장치를 포함하고, 이 장치에서 사용자는 사운드 입력을 레코딩하는 2가지 이상의 모드 사이에서 전환을 할 수 있으며, 그 하나는 대응 음성 인식 출력이 없는 오디오를 기록(레코드)하는 모드이고, 다른 하나는 대응 오디오 없이 오디오 음성 인식 출력을 기록(레코드)하는 모드이다. 본 발명에 따르면, 핸드헬드 장치는 대형 어휘 음성 인식과 오디오 레코드 능력 모두를 가지고 있으며, 사용자가 미리 기록한 사운드 부분을 선택할 수 있고, 이 부분에 대해 음성 인식을 수행할 수 있다. 본 발명에 따르면, 대형 어휘 음성 인식 시스템은 사용자가 대형 어휘 음성 인식을 사용하여 대응 음성 인식 출력 없이 레코드된 사운드 부분을 위해 텍스트 라벨을 제공할 수 있고, 라벨의 워드를 발성하고, 이 발성을 인식하고, 이들 워드를 포함한 텍스트를 조사(서치)하여 비인식 레코드 사운드 부분과 관련된 텍스트 라벨을 조사할 수 있다. 본 발명에 따르면, 대형 어휘 시스템을 통해 사용자는 미리 레코드된 오디오의 플레이 백 동작과 단일 입력과 함께 음성인식을 수행하는 동작 사이에서 전환이 가능하며, 여기서 연속적인 오디오 플레이백은 자동으로 선행 플레이백의 종료 약간 앞에서 시작된다. 또한 본 발명은 대형 어휘 음성 인식과 오디오 레코딩 및 플레이백 능력을 모두 갖는 셀 폰을 포함한다.Another aspect of the invention relates to a combination of large vocabulary speech recognition and audio recording and playback, comprising a handheld device having large vocabulary speech recognition and audio recording, in which a user records two sound inputs. It is possible to switch between the above modes, one of which is a mode for recording (recording) audio without a corresponding speech recognition output, and the other is a mode for recording (recording) audio speech recognition output without corresponding audio. According to the present invention, the handheld device has both large vocabulary speech recognition and audio recording capability, and the user can select a prerecorded sound portion, and perform speech recognition on this portion. According to the present invention, a large vocabulary speech recognition system enables a user to provide a text label for a portion of a recorded sound without a corresponding speech recognition output using large vocabulary speech recognition, utter a word of the label, and recognize this speech. The text label associated with the unrecognized record sound portion can be examined by searching (searching) the text including these words. According to the present invention, a large vocabulary system allows a user to switch between playback of prerecorded audio and speech recognition with a single input, where continuous audio playback is automatically Start slightly before exit. The invention also includes a cell phone having both large vocabulary speech recognition and audio recording and playback capabilities.
본 발명의 그 밖의 특징 및 이점은 다음에 첨부도면과 함께 설명하는 본 발명의 바람직한 실시예를 통해 보다 명백히 이해할 수 있을 것이다.Other features and advantages of the present invention will be more clearly understood from the preferred embodiments of the present invention described in conjunction with the accompanying drawings in the following.
도 1은 음성 인식 소프트웨어에 의해 발성된 소리가 음향 파라메터 프레임으로 어떻게 변환될 수 있는가를 나타낸 개략도.1 is a schematic diagram showing how sound produced by speech recognition software can be converted into an acoustic parameter frame.
도 2는 도 1에 표시한 파라메터 프레임의 시퀀스에 의해 표현되는 워드를 표음 스펠링을 사용하여, 어떻게 음성인식을 통해 인식되는가를 나타내고, 워드의 표음모델간의 시간 정렬을 이용하여 파라메터 프레임이 도출된 원래의 음향 신호에 대해 이들 워드를 시간 정렬하는 방법을 나타낸 개략도.FIG. 2 illustrates how words are recognized by phonetic spelling using word phonetic spelling as represented by the sequence of parameter frames shown in FIG. 1, and the parameter frames are derived using time alignment between phonetic models of words. Schematic showing how to time align these words with respect to the acoustic signal.
도 3 내지 도 8은 본 발명의 여러 특징이 사용되는 다양한 타입의 연산 플랫폼의 진행을 도시하고, 보다 소형이면서 보다 휴대성을 갖는 컴퓨터장치의 경향을 표현한 도면.3-8 illustrate the progress of various types of computing platforms in which various features of the present invention are employed, and represent the trend of smaller, more portable computing devices.
도 9는 PDA(Personal Digital Assistant), SIP(Software Input Panel)을 표시하는 터치 스크린을 갖는 장비를 나타낸 것으로서, 이러한 장비에서 운영되는 응용 프로그램으로 음성인식을 통해 텍스트를 입력하여 본 발명의 여러가지 특징을 구현할 수 있음을 설명한 도면.FIG. 9 illustrates a device having a touch screen displaying a personal digital assistant (PDA) and a software input panel (SIP). Various features of the present invention are provided by inputting text through voice recognition as an application program operated by the device. A drawing explaining that it can be implemented.
도 10은 도 9에 도시한 타입의 PDA에서 발견될 수 있는 여러 하드웨어 및 소프트웨어 성분을 나타낸 개략도.FIG. 10 is a schematic diagram illustrating various hardware and software components that may be found in a PDA of the type shown in FIG. 9.
도 11은 도 9에 도시한 음성인식 SIP의 여러 특정 엘리멘트를 지적하기 위해 사용되는 스크린 이미지의 확대도.11 is an enlarged view of a screen image used to point out various specific elements of the voice recognition SIP shown in FIG.
도 12는 음성인식 SIP에 의해 생성된 교정 창과 여러 도형상의 사용자 인터페이스 엘리멘트를 제외하고는 도 11과 유사한 도면.FIG. 12 is a view similar to FIG. 11 except for the calibration window generated by the voice recognition SIP and the user interface elements on the various figures.
도 13 내지 도 17은 여러 가지 입력, 특히 도형상의 사용자 인터페이스로부터 수신된 입력으로 음성인식 SIP가 행하는 반응에 관한 의사코드의 개략 설명도.13 to 17 are schematic explanatory diagrams of pseudo codes relating to reactions performed by voice recognition SIP with various inputs, especially inputs received from a user interface on a graphic.
도 18은 하나 이상의 사용자 인터페이스 버튼의 가압에 반응하거나 도 9의 음성인식 SIP에서 또는 도 59의 시작에서 보여주는 셀 폰의 실시예에서 음성인식이 턴온되는 시간길이를 판별하기 위해 사용되는 인식지속논리의 의사코드의 개략 설명도.FIG. 18 is a diagram of recognition persistence logic used to determine the length of time voice recognition is turned on in response to a press of one or more user interface buttons or in a cell phone embodiment shown in the speech recognition SIP of FIG. 9 or at the beginning of FIG. Schematic explanatory diagram of a pseudo code.
도 19는 단순 터치에 의해 도 9의 음성인식 SIP의 각 엘리멘트와 연관된 기능설명을 사용자가 볼 수 있도록 허락하는 헬프모드의 의사코드의 개략 설명도.FIG. 19 is a schematic illustration of a pseudo code in a help mode allowing a user to view the functional description associated with each element of the voice recognition SIP of FIG. 9 by a simple touch; FIG.
도 20 및 도 21은 도 19에서 설명한 헬프모드에 생성된 스크린 이미지를 나타낸 도면.20 and 21 illustrate screen images generated in the help mode described with reference to FIG. 19.
도 22는 교정창을 표시하기 위하여 도 9의 음성인식 SIP와 도 59의 셀폰의 실시예가 여러 가지 형태로 사용하는 표시 선택분류 루틴의 의사코드의 개략 설명도.Fig. 22 is a schematic explanatory diagram of a pseudo code of a display selection classification routine used in various forms by the embodiments of the voice recognition SIP of Fig. 9 and the cell phone of Fig. 59 to display a calibration window;
도 23은 도 22의 표시 선택분류 리스트 루틴에 의해 하나 이상의 선택분류 리스트를 생성하기 위해 음성인식 SIP와 셀폰 실시예에 의해 여러가지 형태로 사용되는 겟 선택분류 루틴의 의사코드의 개략 설명도.FIG. 23 is a schematic explanatory diagram of a pseudo code of a get selection classification routine used in various forms by a voice recognition SIP and a cell phone embodiment to generate one or more selection classification lists by the display selection list routine of FIG. 22; FIG.
도 24 및 도 25는 겟선택분류 루틴에 의해 사용되는 발성 리스트 데이터 구조를 나타낸 도면.24 and 25 show a speech list data structure used by the get selection classification routine.
도 26은 사용자에 의해 입력된 필터 입력을 매치시키도록 교정창 선택분류를 제한하기 위해 겟선택분류 루틴에 의해 사용된 필터 매치 루틴의 개략 설명도.Fig. 26 is a schematic illustration of a filter match routine used by the get selection classification routine to limit the calibration window selection to match the filter input entered by the user.
도 27은 소정의 워드 또는 선택의 여러 가지 다른 형태를 표시하는 워드 형태 교정리스트를 생성하기 위해 음성인식 SIP와 셀폰 실시예에 의해 여러 가지 형태로 사용된 워드형태 리스트 루틴의 의사코드 개략설명도.Fig. 27 is a schematic diagram of a pseudo code of a word form list routine used in various forms by a voice recognition SIP and cell phone embodiment to generate a word form correction list indicating a given word or various other forms of selection;
도 28 및 도 29는 사용자가 입력한 알파벳 필터정보에 반응하여 도 26의 필터매치 루틴에 의해 사용된 필터 스트링을 편집하기 위해 음성인식 SIP와 셀폰 실시예에 의해 여러 가지 형태로 사용되는 필터편집 루틴의 의사코드의 개략 설명도.28 and 29 are filter editing routines used in various forms by voice recognition SIP and cell phone embodiments to edit filter strings used by the filter matching routine of FIG. 26 in response to alphabetic filter information entered by a user. Schematic diagram of the pseudo-code of the user.
도 30은 필터 스트링의 개별 캐릭터를 위해 선택분류 리스트를 표시하도록 음성인식 SIP와 셀폰 실시예에 의해 여러 가지 형태로 상용되는 필터 캐릭터 선택분류 루틴의 의사코드의 개략 설명도.30 is a schematic explanatory diagram of a pseudo code of a filter character selection classification routine commonly used in various forms by the voice recognition SIP and cell phone embodiments to display a selection classification list for each character of the filter string.
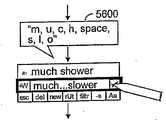
도 31 내지 도 35는 한번에 한번형 이산 음성인식 방법을 이용하여 사용자가 워드의 인식을 입력 및 교정하는 사용자와 음성인식 SIP 간의 상호작용 시퀀스를 나타낸 도면. 31 to 35 are diagrams illustrating an interaction sequence between a user and a voice recognition SIP in which a user inputs and corrects a word recognition using a discrete voice recognition method at a time.
도 36은 SIP 사용자가 텍스트로 입력하기 전에 목표워드를 찾고, 이어서 이 것은 문자버튼을 통해 문자화할 때까지 교정창에 제시된 선택분류 리스트를 스크롤하여 도 35의 끝에 표시한 오류인식의 교정을 하는 방법을 나타낸 설명도.36 shows a target word before the SIP user inputs the text, and then scrolls through the selection list presented in the correction window until the text is input through the character button to correct the error recognition indicated at the end of FIG. Explanatory diagram showing.
도 37은 SIP 사용자가 교정창에서 대체 선택분류의 일부를 선택하고, 이것을 목표 음성 인식 출력을 선택하기 위한 필터로서 사용하여 이러한 오류인식을 교정하는 방법을 나타낸 설명도.FIG. 37 is an explanatory diagram showing how a SIP user selects a part of an alternative selection classification in a calibration window and uses this as a filter for selecting a target speech recognition output to correct such error recognition; FIG.
도 38은 SIP 사용자가 알파벳으로 2개의 선택 선택분류 사이에 위치하는 캐릭터 시퀀스와 함께 시작하는 출력에 음성인식 출력을 제한하도록 작용하기 위해 2개의 연속 알파벳 순서의 대체 선택분류를 선택할 수 있는 방법을 나타낸 설명도.FIG. 38 illustrates a method by which a SIP user can select alternate selection classifications of two consecutive alphabetical sequences to act to limit speech recognition output to output starting with a character sequence located between two selection selections alphabetically. Explanatory diagram.
도 39는 필터 캐릭터를 입력하기 위해 SIP 사용자가 레터 이름을 사용하는 방법과, 이러한 필터 캐릭터의 인식에서 에러를 교정하기 위한 필터 캐릭터 선택분류 리스트를 사용하는 방법을 나타낸 도면.FIG. 39 illustrates a method by which a SIP user uses a letter name for inputting filter characters, and a method of using a filter character classification list for correcting errors in recognition of such filter characters. FIG.
도 40은 SIP 사용자가 국제 통신 알파벳을 이용하여 하나 이상의 필터시작 캐릭터를 입력하는 방법과 SIP 인터페이스가 사용자에게 이 알파벳으로부터 워드를 제시하는 방법을 나타낸 도면.FIG. 40 shows how a SIP user enters one or more filter start characters using the international communication alphabet and how the SIP interface presents words from the alphabet to the user.
도 41은 사용자가 교정창에서 대체 선택분류로부터 캐릭터 초기 시퀀스를 선택하고, 이어서 국제 통신 알파벳을 이용하여 캐릭터를 이 시퀀스에 부가하여 목표출력 스펠링을 완성하는 방법을 나타낸 도면.FIG. 41 illustrates a method for a user selecting a character initial sequence from an alternative selection classification in a calibration window, and then adding a character to this sequence using an international communication alphabet to complete a target output spelling; FIG.
도 42 내지 도 43은 사용자가 연속음성인식을 사용하여 텍스트를 SIP로 입력 및 편집하는 사용자 상호작용 시퀀스를 나타낸 도면.42-43 illustrate user interaction sequences in which a user enters and edits text into SIP using continuous speech recognition.
도 45는 연속 레터 이름 인식을 이용하여 목표출력의 일부 또는 전부를 모호 (또는 다가)필터로 스펠링하여 사용자가 오류인식을 교정하는 방법과, 사용자가 필터 캐릭터 선택 리스트를 이용하여 이러한 연속 레터 이름 인식에 생성된 에러를 신속하게 교정하는 방법을 나타낸 도면.45 illustrates a method of correcting error recognition by a user by spelling a part or all of a target output with an ambiguous (or multivalent) filter using continuous letter name recognition, and recognizing such a continuous letter name using a filter character selection list. Showing a method for quickly correcting errors generated in the system.
도 46은 도출된 캐릭터 인식에 의해 음성 인식 SIP가 또한 사용자에게 캐릭터를 입력시킬 수 있는 방법을 나타낸 도면. FIG. 46 illustrates how the speech recognition SIP may also input characters to the user by derived character recognition. FIG.
도 47은 도 46에 도시한 타입의 도출 캐릭터 인식을 수행할 때 SIP에 의해 사용되는 캐릭터 인식 모드의 의사코드에 관한 개략 설명도.FIG. 47 is a schematic explanatory diagram of a pseudo code of a character recognition mode used by SIP when performing derived character recognition of the type shown in FIG. 46; FIG.
도 48은 수기인식을 이용하여 음성인식 SIP가 사용자에게 텍스트를 입력시키는 방법을 나타낸 도면.FIG. 48 is a diagram illustrating how voice recognition SIP inputs text to a user using handwriting recognition; FIG.
도 49는 도 48에 도시한 타입의 수기인식을 수행할 때 SIP에 의해 사용된 수기 인식모드의 의사코드에 관한 개략 설명도.FIG. 49 is a schematic illustration of a pseudo code of a handwriting recognition mode used by SIP when performing handwriting recognition of the type shown in FIG. 48; FIG.
도 50은 음성인식시스템이 소프트웨어 키보드로 사용자에게 텍스트를 입력시키는 방법을 나타낸 도면.50 illustrates a method in which a voice recognition system inputs text to a user with a software keyboard.
도 51은 음성인식, 캐릭터인식, 수기인식, 및 소프트웨어 키보드입력 등 필터정보를 입력하는 여러가지 방법 중 선택이 가능하게하는 필터 엔트리 모드 메뉴를 도시한 도면.FIG. 51 shows a filter entry mode menu allowing selection of various methods of inputting filter information such as voice recognition, character recognition, handwriting recognition, and software keyboard input. FIG.
도 52 내지 도 54는 SIP 교정창에서 생성된 음성인식 선택분류를 필터하는데 캐릭터 인식, 수기인식, 소프트웨어 키보드 입력을 사용하는 방법을 나타낸 도면.52 to 54 illustrate a method of using character recognition, handwriting recognition, and software keyboard input to filter the voice recognition selection classification generated in the SIP calibration window.
도 55 및 도 56은 SIP를 통해 워드 또는 필터 캐릭터가 수기인식입력을 어떻게 교정하는가를 나타낸 도면.55 and 56 illustrate how a word or filter character corrects handwriting recognition input through SIP;
도 58은 도 22의 표시 선택 리스트의 대체 실시예의 개략도로서, 도 22의 알파벳 순서가 아니라 인식 스코어에 의해서만 선택분류 리스트가 순서 선택분류를 생성하는 것을 나타낸 도면.FIG. 58 is a schematic diagram of an alternative embodiment of the display selection list of FIG. 22, showing that the selection classification list generates the order selection classification only based on the recognition scores, not the alphabetical order of FIG.
도 59는 본 발명의 여러가지 특징을 구현한 셀폰을 나타낸 도면.59 illustrates a cell phone implementing various aspects of the present invention.
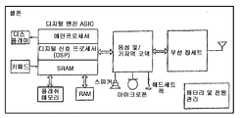
도 60은 도 59에 도시한 셀폰과 같은 형태의 전형적인 셀폰에 있어 그 주요구성요소를 나타낸 개략구성도.Fig. 60 is a schematic diagram showing the main components of a typical cell phone of the same type as the cell phone shown in Fig. 59;
도 61은 도 59의 셀폰에서 하나 이상의 대량 저장장치에 포함된 여러가지 프로그램 및 데이터 구조를 나타낸 개략 구성도.FIG. 61 is a schematic structural diagram illustrating various programs and data structures included in one or more mass storage devices in the cell phone of FIG. 59; FIG.
도 62는 수자형 폰 키를 가압하여 통상의 다이얼링을 행하는 것을 보여주는 도 59의 셀폰을 나타낸 도면.FIG. 62 is a view of the cell phone of FIG. 59 showing normal phone dialing by pressing a digital phone key; FIG.
도 63은 도 62의 상부에 도시한 스크린에 의해 도시한 바와 같이 상부레벨 폰 모드에서 있을 때, 도 59의 셀폰의 통상의 구조를 나타낸 개략구조도.FIG. 63 is a schematic structural diagram showing a typical structure of the cell phone of FIG. 59 when in the top level phone mode as shown by the screen shown at the top of FIG. 62; FIG.
도 64는 도 59의 셀폰의 사용자가 셀폰 상에서 메뉴키를 가압하여 메인 메뉴의 명령을 신속하게 액세스 및 관찰하는 방법을 나타낸 도면.FIG. 64 shows how a user of the cell phone of FIG. 59 quickly presses a menu key on the cell phone to quickly access and observe commands of the main menu; FIG.
도 65 및 도 66은 도 64에 도시한 메인메뉴의 동작에 관한 의사코드를 설명한 개략도.65 and 66 are schematic views for explaining pseudo codes relating to the operation of the main menu shown in FIG. 64;
도 67 내지 도 74는 도 59의 셀폰 상에서 동작하는 음성인식 텍스트 에디터와 연관된 여러 가지 중요한 모드 및 메뉴 각각에서의 셀폰의 수자 키의 명령 맵핑을 도시한 도면.67-74 illustrate command mapping of the numeric keys of a cell phone in each of several important modes and menus associated with the speech recognition text editor operating on the cell phone of FIG. 59;
도 75는 도 64에 도시한 타입의 메뉴와 같은 메뉴에서 사용되는 명령 리스트 를 통해 메뉴버튼을 가압하고 스크롤링하여 비메뉴 모드에서 하나 이상의 키와 연관된 기능을 셀폰의 텍스트 에디팅 소프트웨어의 사용자가 신속하게 볼 수 있는 방법을 나타낸 도면.FIG. 75 shows the function of one or more keys in a non-menu mode by quickly pressing and scrolling through the menu buttons used in a menu such as the menu of the type shown in FIG. A diagram showing how it can be done.
도 66 내지 도 68은 텍스트 윈도우, 데이터 모드 일때 셀폰의 음성인식 프로그램의 반응에 관한 의사코드을 설명하는 개략도.66 to 68 are schematic diagrams illustrating pseudo codes relating to the response of the voice recognition program of the cell phone in the text window and data mode.
도 79 및 도 80은 텍스트를 입력할 수 있는 여러 가지 방법 중에서 선택할 수 있도록 여러 가지 음성인식 모드로부터 액세스 가능한 엔트리 모드 메뉴의 의사코드를 설명하는 개략도.79 and 80 are schematic diagrams illustrating pseudo codes of an entry mode menu accessible from various voice recognition modes for selecting among various methods for entering text.
도 81 내지 도 83은 교정창을 표시하고, 이러한 교정창이 표시될 때 사용자 입력에 반응하도록 셀폰에 의해 사용되는 교정 윈도우 루틴의 의사코드를 설명하기 위한 도면.81 to 83 illustrate the pseudocode of a calibration window routine used by the cell phone to display a calibration window and to respond to user input when such a calibration window is displayed.
도 84는 에디트 모드의 텍스트 창이 표시될 때 셀폰의 내비게이션 키와 함께 사용자가 여러가지 내비게이션 방법을 선택하는 것을 가능하게 하는 에디트 내비게이션 메뉴의 의사코드를 설명하기 위한 도면.FIG. 84 is a view for explaining pseudo code of an edit navigation menu that enables a user to select various navigation methods together with a navigation key of a cell phone when a text window of an edit mode is displayed; FIG.
도 85는 교정창에 있을 때, 셀폰의 내비게이션 키와 함께 여러 가지 방법의 내비게이션을 사용자가 선택하는 것을 가능하게 하는 교정창 내비게이션 메뉴의 의사코드를 설명하기 위한 도면.FIG. 85 is a view for explaining the pseudo code of the calibration window navigation menu which enables the user to select various ways of navigation with the cell phone navigation keys when in the calibration window; FIG.
도 86 내지 도 88은 키 알파모드의 약간 다른 3개의 실시예를 설명하는 의사코드의 개략 설명도로서, 사용자가 한 문자와 함께 시작하는 워드를 말하여 이 문자를 입력하고, 가압된 키와 연관된 3개 또는 4개의 문자 중 하나로 시작하는 워드 로 인식을 제한하여 폰키의 가압에 반응하는 방법을 나타낸 도면.86 to 88 are schematic explanatory diagrams of pseudocodes for explaining three slightly different embodiments of the key alpha mode, in which a user inputs a word starting with one letter and associated with the pressed key. A diagram illustrating how to respond to pressurization of a phone key by limiting recognition to words starting with one of three or four characters.
도 89 및 도 90은 많은 셀폰 음성인식 프로그램 모드로부터 액세스 가능한 에디트 옵션 메뉴 하에서 유용한 일부 옵션의 의사코드에 관한 개략 설명도.89 and 90 are schematic explanatory diagrams of pseudocodes of some options useful under an edit option menu accessible from many cell phone voice recognition program modes.
도 91 및 도 92는 특정 문법형 워드와 같은 특정형 워드에 인식 선택분류를 제한하도록 사용될 수 있는 워드형 메뉴에 관한 개략 설명도.91 and 92 are schematic explanatory diagrams of a word type menu that can be used to limit recognition selection classification to a specific word such as a specific grammatical word.
도 93은 여러 가지 음성인식기능을 위한 디폴트 인식 세팅을 설정하거나 인식지속 세팅을 설정하는데 사용될 수 있는 엔트리 기준 메뉴의 의사코드에 관한 설명도.FIG. 93 is an explanatory diagram of a pseudo code of an entry criterion menu that can be used to set default recognition settings or set recognition duration settings for various voice recognition functions; FIG.
도 94는 셀폰 상에서 유용한 음성 플레이백 동작대한 텍스트의 의사코드에 관한 설명도.Fig. 94 is an illustration of pseudo code of text for useful voice playback operation on a cell phone.
도 95는 셀폰의 음성인식에 의해 또한 이용되는 프로그램 및 데이터구조를 음성생성에 대응하는 셀폰의 텍스트가 어떻게 이용하는가를 나타낸 의사코드에 관한 설명도.FIG. 95 is an explanatory diagram of a pseudo code showing how the text of a cell phone corresponding to voice generation uses a program and a data structure also used by the voice recognition of the cell phone; FIG.
도 96은 장비의 음성인식능력을 이용하여 셀폰 상에서 기록되는 오디오를 사용자가 보다 쉽게 표기하도록 셀폰의 표기모드의 의사코드에 관한 설명도.FIG. 96 is an explanatory diagram of a pseudo code of a display mode of a cell phone so that a user can more easily display audio recorded on the cell phone using the voice recognition capability of the device; FIG.
도 97은 셀폰의 음성인식 에디터가 셀폰에 제시된 다이얼로그 박스에서 텍스트를 입력 및 편집하는데 사용될 수 있고, 이러한 다이얼로그 박스에서 리스트 박스, 체크박스 및 무선버튼과 같은 제어 상태를 변화시킬 수 있는 프로그램의 의사코드에 관한 간략 설명도.FIG. 97 shows a pseudo code of a program that can be used by a voice recognition editor of a cell phone to input and edit text in a dialog box presented to the cell phone, and to change control states such as a list box, a check box, and a radio button in the dialog box. Brief description of the.
도 98은 셀폰의 명령구조에서 여러 가지 위치의 설명을 여러 가지 위치의 설 명을 사용자가 신속하게 찾을 수 있도록 하는 셀 폰에서 유용한 헬프 루틴의 의사코드의 간략 설명도.FIG. 98 is a simplified illustration of pseudocode of a help routine useful in a cell phone for allowing a user to quickly find descriptions of various locations in the cell phone command structure.
도 99 및 도 100은 도 98의 프로그램으로 디스플레이되는 타입의 헬프 메뉴의 예를 예시하는 도면.99 and 100 illustrate examples of the help menu of the type displayed by the program of FIG. 98;
도 101 및 도 102는 도 98의 헬프 프로그램을 사용자가 이용하여 셀 폰의 명령구조의 여러 가지 부분과 연관된 펑크션을 신속하게 조사하고 그 설명을 수신하는 방법을 설명한 예시도.101 and 102 illustrate an example of a method of quickly examining a function associated with various parts of a command structure of a cell phone by using the help program of FIG. 98 and receiving a description thereof.
도 103 및 도 104는 사용자가 연속 음성 인식을 이용하여 텍스트를 입력하고 교정하는 셀폰의 음성인식 에디터 사용자 인터페이스와, 그 사용자 간의 상호작용 시퀀스를 나타낸 예시도.103 and 104 illustrate exemplary speech recognition editor user interfaces of a cell phone in which a user inputs and corrects text using continuous speech recognition, and an interaction sequence between the users.
도 105는 셀폰 상에서 디스플레이되는 교정창에서 수평으로 사용자가 스크롤하는 방법을 설명한 예시도.105 is an exemplary view illustrating a user scrolling horizontally in a calibration window displayed on a cell phone.
도 107은 도 86에 도시한 키 알파 모드의 동작을 나타낸 예시도.FIG. 107 is an exemplary diagram showing operation of a key alpha mode shown in FIG. 86;
도 108 및 도 109는 셀폰의 음성인식 에디터를 통해 사용자가 셀폰의 무선 통신 능력으로 송신될 수 있는 e-메일 메시지에서 텍스트를 어드레스, 엔터 및 에디트하는 방법을 설명한 예시도.108 and 109 illustrate how a user can address, enter, and edit text in an e-mail message that can be transmitted to the cell phone's wireless communication capability through the cell phone's voice recognition editor.
도 110은 셀폰의 음성인식을 통해 하나 이상의 워드의 이산 인식으로부터의 스코어와 이들 워드의 선행 연속 인식으로부터의 스코어를 조합하여 목표 출력을 생성하는 것을 도울 수 있는 방법을 설명한 예시도.FIG. 110 illustrates an example of how a cell phone's speech recognition may help to generate a target output by combining scores from discrete recognition of one or more words with scores from prior consecutive recognition of these words.
도 111은 셀폰의 음성인식 소프트웨어를 통해 셀폰의 무선 통신 능력을 이용 하여 월드 와이드 웹(www)사이트를 액세스하기 위해 URL을 엔터할 수 있는 방법을 설명한 예시도.111 illustrates an example of how a URL can be entered to access a World Wide Web (www) site using the cell phone's wireless communication capability via the cell phone's voice recognition software.
도 112 및 도 113은 셀폰의 음성 인식 사용자 인터페이스의 엘리멘트를 통해 사용자가 월드 와이드 웹(www) 페이지를 내비게이션하고 이 웹 페이지 필드에서 아이템을 선택하고, 텍스트를 엔터 및 에디트하는 방법을 설명한 예시도.112 and 113 illustrate how a user navigates a World Wide Web (www) page, selects items in this web page field, enters and edits text through elements of the voice recognition user interface of the cell phone.
도 114는 셀폰의 음성 인식 사용자 인터페이스의 엘리멘트를 통해 사용자가 웹 페이지의 텍스트 필드나 다이얼로그 박스와 같이 셀폰의 스크린에 디스플레이되는 텍스트 필드에서 한번에 보기에는 매우 큰 텍스트 스트링을 보다 용이하게 독출할 수 있는 방법을 설명한 예시도.FIG. 114 illustrates how a user may more easily read a text string that is very large for viewing at a time in a text field displayed on a screen of a cell phone, such as a text field of a web page or a dialog box, through an element of the voice recognition user interface of the cell phone. Illustrated diagram also described.
도 115는 셀폰의 파인드 다이얼로그 박스를 통해 사용자가 음성인식으로 다이얼로그 박스에 서치 스트링을 엔터하는 방법, 이후 파인트 펑크션이 엔터된 스트링의 서치를 행하는 방법, 그리고 발견된 텍스트를 셀폰에 레코드된 오디오에 라벨을 하기 위한 텍스트로 사용하는 방법을 설명한 예시도.115 illustrates a method for a user to enter a search string into a dialog box by voice recognition through a find dialog box of a cell phone, a method of performing a search of a string in which a pint function is entered, and the found text to audio recorded in the cell phone. An illustration showing how to use it as text for labeling.
도 116은 도 97에 도시한 다이얼로그 박스 에디터 프로그램을 통해 음성인식이 리스트 박스와 연관되어 있을 수 있는 값을 선택하는데 사용되는 방법을 설명한 예시도.FIG. 116 is an exemplary view for explaining a method used for selecting a value in which speech recognition may be associated with a list box through the dialog box editor program shown in FIG. 97;
도 117은 음성인식을 통해 네임으로 사람에게 다이얼을 하고, 셀폰의 오디오 플레이백과 레코드 능력을 이러한 셀폰 호출 중에 이용할 수 있는 방법을 설명한 예시도.117 illustrates an example of how a person may dial a person via voice recognition and use the cell phone's audio playback and record capabilities during such a cell phone call.
도 118은 셀폰이 오디오를 레코드하면서 텍스트 라벨 또는 텍스트 코멘트를 레코드된 오디오로 삽입할 때 음성인식이 턴온 및 턴오프되는 방법을 설명한 예시도.118 illustrates an example of how speech recognition is turned on and turned off when a cell phone inserts a text label or text comment into the recorded audio while recording audio.
도 119는 셀폰을 통해 사용자가 미리 레코드된 오디오 부분에서 음성 인식을 수행하는 방법을 설명한 예시도.FIG. 119 is a view for explaining a method of performing voice recognition on an audio portion recorded in advance by a user through a cell phone; FIG.
도 120은 셀폰을 통해 사용자가 사운드의 오디오 레코딩으로부터 이 사운드의 소정의 세그멘트를 위해 인식된 텍스트를 스트립하는 방법을 설명하는 예시도.120 illustrates an example of how a user strips recognized text for a given segment of the sound from an audio recording of the sound via a cell phone.
도 121은 셀폰을 통해 사용자가 표시(인디케이션)를 턴온 또는 오프하는 방법을 설명한 것으로서, 상기 표시의 텍스트의 선택된 세그멘트 부분은 오디오 레코드를 관련시키는 것을 보여주는 예시도.FIG. 121 illustrates a method of turning a display (indication) on or off by a user via a cell phone, wherein the selected segment portion of the text of the display relates to an audio record.
도 122 내지 도 125는 셀폰 음성인식 소프트웨어를 통해 사용자가 음성인식에 의해 전화번호를 입력(엔터)하고, 잘못되었을 때 이 번호의 인식을 교정하는 방법을 설명한 예시도.122 to 125 are exemplary views for explaining how a user inputs (enters) a phone number by voice recognition through cell phone voice recognition software and corrects the recognition of this number when it is wrong.
도 126은 도 59 내지 도 125에 도시한 셀폰 실시예의 여러 특징을 셀폰 실시예의 TTS 및 도중 로직 특징을 포함하는 자동환경에서 이용하는 방법을 설명한 예시도.126 is an exemplary view illustrating a method of using various features of the cell phone embodiments shown in FIGS. 59 to 125 in an automatic environment including the TTS and middle logic features of the cell phone embodiment.
도 127 및 도 128은 도 59 내지 도 129에 도시한 셀폰 실시예의 대부분의 특징을 코드리스 폰 또는 랜드라인 폰에서 이용하는 방법을 설명한 예시도.127 and 128 illustrate a method of using most of the features of the cell phone embodiment shown in FIGS. 59 to 129 in a cordless phone or a landline phone.
도 129는 도 117에서 부분적으로 예시한 셀폰 실시예의 네임 다이얼링 프로그램의 의사코드를 개략적으로 설명한 도면.129 schematically illustrates pseudo code of a name dialing program of the cell phone embodiment partially illustrated in FIG. 117;
도 130은 도 122 내지 도 125에 예시한 셀폰의 디지트 다이얼 프로그램의 의 사코드를 개략적으로 설명한 도면.FIG. 130 is a view schematically illustrating a pseudo code of a digit dial program of the cell phone illustrated in FIGS. 122 to 125.
도 9는 본 발명의 여러 특징이 적용될 수 있는 개인용 디지털 어시스턴트(PDA : Personal Digital Assistant)를 도시한다. 도시된 PDA는 현재 시판되고 있는 iPAQ H3650 포켓 PC, 카시오 카시오페아, 휴렛패커드 조르나도 525 와 같은 제품에 상당하는 것이다.9 illustrates a Personal Digital Assistant (PDA) to which various features of the present invention may be applied. The PDA shown is equivalent to products such as the iPAQ H3650 Pocket PC, Casio Cassiopeia, and Hewlett-Packard Girdona 525.
PDA900은 상대적으로 고해상도 터치 스크린을 가지고 있어, 스타일러스 904 또는 손가락 등으로 터치스크린을 터치하여 소프트웨어 버튼 뿐만 아니라 텍스트도 사용자가 선택할 수 있다. PDA는 또한 한 세트(일조)의 입력버튼(906)과 2차원 내비게이션 콘트롤(908)을 포함한다. The PDA900 has a relatively high-resolution touch screen that allows the user to select text as well as software buttons by touching the touch screen with a
본 명세서 및 청구범위에서 하나 이상의 차원에서 이동하는 이산유니트를 사용자가 선택할 수 있도록 하는 내비게이션 입력장비는 버튼에 의한 입력과 같은 범주에 포함되는 것으로 간주될 것이다. 이것은 특히 전화 인터페이스에서 실질적으로 적용되며, 이 경우 내비게이션 장비의 상,하 좌,우 입력이 폰키 또는 폰 버튼으로 간주된다.Navigation input devices that allow a user to select discrete units moving in one or more dimensions in this specification and claims will be considered to be included in the same category as input by a button. This is particularly true in the telephone interface, in which case the up, down, left and right inputs of the navigation equipment are regarded as phone keys or phone buttons.
도 10은 PDA (900)의 개략적 시스템 다이어그램으로서, 터치스크린(200) 및 입력버튼(906)(내비게이션 입력(908)을 포함한다)을 나타내고 있다. 또한, 도 10은 이 장비가 마이크로프로세서(1002)와 같은 중앙처리장치(CPU)를 포함하는 것을 보여주고 있다. 이 CPU(1002)는 하나 이상의 전기통신버스(1004)를 통해 ROM(106)(때로는 플래시 ROM), RAM(1008), 하나 이상의 I/O 장치(1010), 터치 스크린(902) 상 에서의 디스플레이를 제어하는 비디오 콘트롤러(1012), 마이크로폰(1015)으로부터 입력을 수신하고 스피커(1016)에 오디오 출력을 공급하는 오디오장치(1014)에 접속된다.FIG. 10 is a schematic system diagram of a
PDA는 또한 휴대전원을 갖춘 배터리(1018), 오디오 회로(1014)에 접속된 헤드폰 인, 헤드폰 아웃 잭(1020), PDA와 데스크탑과 같은 다른 컴퓨터 사이에 접속을 제공하는 독킹 커넥터(1022), 부가성 플래시 ROM, 모뎀, 무선 송수신기(1025), 매스 저장 디바이스와 같이 PDA에 사용자가 회로를 추가할 수 있도록 하는 애드온 커넥터(1024)를 포함한다.The PDA also includes a
도 10은 매스 저장 디바이스(1017)를 나타낸다. 실질적으로, 이 매스 저장 디바이스는 어떠한 형태도 가능하며, 예를들면 플래쉬 ROM(1006)의 일부나 전부, 또는 소형 하드 디스크를 들 수 있다. 이러한 매스 저장 디바이스에 있어서, PDA는 통상적으로 디바이스의 기본적 기능성을 최대한으로 제공하기 위한 운영체계(OS)(1026)를 저장한다. 공통적으로 이 매스 저장 디바이스는 운영체계외에도, 그리고 다음부터 설명하는 음성 인식 관련 기능과, 하나 이상의 응용 프로그램이 포함되며, 응용 프로그램의 예로는 워드 프로세서, 스프레드시트, 웹 브라우저, 또는 개인 정보 관리 시스템을 들 수 있다.10 shows a
PDA(900)는 본 발명에 적용되는 경우 통상적으로 음성인식 프로그램(1030)을 포함하게 되며, 이 프로그램은 도 1 및 도 2와 관련하여 위에서 설명한 일반적 타입의 워드 매칭을 행하기 위한 프로그램을 포함한다. 음성 인식 프로그램은 또한 통상 하나 이상의 어휘 또는 어휘군을 포함하며, 이 어휘 또는 어휘군은 최소한 2 천 워드 이상을 포함하는 대형 어휘가 담겨있다. 많은 대형 어휘 시스템은 5천에서 수만 워드에 이르는 어휘를 갖는다. 각 어휘는 통상 텍스트 스펠링(1036)과 하나 이상의 어휘군(1036)을 가지며, 여기에 워드가 포함된다(예를들면, 텍스트 출력, "·"은 일부 시스템에서 실질적으로 대형 어휘 인식 어휘, 즉 스펠링 어휘와 구두 어휘군 모두에 존재한다). 각 어휘는 워드를 분류할 수 있는 음성(1038)의 하나 이상의 부분에 대한 인디케이션(표시)과, 음성의 이들 부분 각각에 대한 워드를 위한 표음 스펠링(1040)을 가진다.
음성 인식 프로그램은 공통적으로 시스템에 부가되는 신규 워드의 발음을 추정하는 발음추정자(1042)를 가지고 있고, 이 신규 워드는 시스템에 부가되며, 따라서 미리 정의된 표음 스펠링을 갖지는 않는다. 음성 인식 프로그램은 공통적으로 하나 이상의 표음 어휘 트리(1044)를 포함한다. 표음 어휘 트리는 트리형 데이터 구조로서 음소의 동일 시퀀스와 함께 시작하는 모든 표음 스펠링을 트리 루트로부터 공통 통로에서 함께 그룹화한다. 이러한 어휘 트리는 인식 성능을 향상시키는데 그 이유는 이것이 동일 초기 표음 스펠링을 공유하는 여러 상이한 워드의 모든 부분이 함께 스코어링되도록 하기 때문이다.The speech recognition program has a
바람직하게는, 음성 인식 프로그램이 또한 폴리그램 랭귀지 모델(1045)을 포하며, 이것은 텍스트에서 여러 가지 워드의 발생 가능성을 표시(인디케이션)하며, 이 가능성으로는 예를들면 하나 이상의 선행 및/또는 폴로윙 워드가 주어지는 텍스트에서 발생하는 워드의 가능성을 들 수 있다.Preferably, the speech recognition program also includes a
통상, 음성 인식 프로그램은 랭귀지 모델 갱신 데이터(1046)를 저장하며, 이 것은 바로 설명한 폴리그램 랭귀지 모델(1045)을 갱신(이하 "업데이트"와 혼용하여 사용함)하기 위해 사용되는 정보를 포함한다. 통상, 이 랭귀지 모델 갱신 데이터는 사용자가 생성하거나 사용자가 지적하는 텍스트로부터 도출된 통계정보를 포함하며, 이 텍스트는 사용자가 발생시키기를 원하는 것과 유사한 것이다. 도 10에서와 같이, 음성 인식 프로그램은 콘택트(접촉) 정보(1048)를 저장하고 있으며, 이 정보로는 네임, 어드레스, 폰 번호, e-메일 주소, 이러한 정보의 일부 또는 전부를 위한 표음 스펠링을 들 수 있다. 이 데이터는 음성 인식 프로그램이 이러한 콘택트 정보의 스피킹을 인식하는 것을 돕는다. 정보에 관한 여러 실시예에서 이러한 콘택트 정보는 응용 프로그램(1028) 또는 운영체계(1026)에 대한 부속 프로그램과 같은 외부 프로그램에 포함되지만, 이러한 경우에서조차, 음성인식 프로그램은 통상 이러한 네임, 주소, 폰 번호, e-메일 주소, 이러한 것들의 표음적 표현에 대한 액세스가 필요할 것이다.Typically, the speech recognition program stores language
음성 인식 프로그램은 또한 통상 도 2에 도시한 표음 모델(200)과 유사할 수 있는 표음 음향 모델(1050)을 포함한다. 공통적으로 음성 인식 프로그램은 음향 모델 갱신 데이터(1052)를 포함하며, 이 데이터는 시스템에 의해 미리 인식된 음향 신호로부터의 정보를 포함한다. 공통적으로, 이러한 음향 모델 갱신 데이터는 도 1 및 도 2에 도시한 파라메터 프레임(110)과 같은 형태, 또는 이러한 파라메터 프레임으로부터 유출된 통계적 데이터 형태로 되어 있다.The speech recognition program also typically includes a phonetic
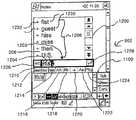
도 11은 도 9에 도시한 터치 스크린(902)에 의해 제공된 사용자 인터페이스의 확대도이며, 여기서 PDA는 본 발명의 여러 측면을 구현하는 소프트웨어 입력 패 널(또는 SIP)(1100)을 사용한다.FIG. 11 is an enlarged view of the user interface provided by the
도 12는 음성인식 SIP가 교정창(1200)을 디스플레이 할 때 터치 스크린을 나타낸 것을 제외하고는 도 11과 유사하다.FIG. 12 is similar to FIG. 11 except that the voice recognition SIP shows a touch screen when displaying the
도 13 내지 도 17은 음성인식 SIP가 그 그래픽 상의 사용자 인터페이스에서 여러 가지 입력에 대해 반응하는 방법의 의사코드 설명에 관한 연속 페이지를 나타낸 것이다. 간단 명료함을 위해, 이 의사코드는 사용자 입력에 반응하는 SIP 프로그램에서는 하나의 메인 이벤트 루프(1300)로서 표현된다.13-17 show consecutive pages of pseudocode descriptions of how voice recognition SIP responds to various inputs in its graphical user interface. For simplicity, this pseudocode is represented as one main event loop 1300 in a SIP program that responds to user input.
도 13 내지 도 17에서 이 이벤트 루프는 2개의 주요 스위치 스테이트(또는 "전환 상태"로도 사용함)를 갖는 것을 설명하며, 도 13의 스위치 스테이트는 교정창(1200)이 디스플레이되는지의 여부에 상관없이 발생할 수 있는 사용자 인터페이스 상에서의 입력에 반응하고, 도 15의 스위치 스테이트(1542)는 교정창(1200)이 디스플레이될 때만 발생할 수 있는 사용자 입력에 반응한다.In FIGS. 13-17 this event loop describes two main switch states (also used as "switched states"), where the switch state of FIG. 13 occurs regardless of whether or not the
사용자가 도 11에 도시한 대화 버튼(1102)을 프레스하면, 도 13의 펑크션(1302)은 펑크션 (1304 - 1308)이 수행되도록 한다. 펑크션(1304)은 도 11에서의 창(1104)에 의해 도시한 SIP 버퍼에서 임의 텍스트가 있는지를 검사한다. 도면에 도시한 SIP 실시예에서, SIP버퍼는 상대적으로 작은 개수의 텍스트 라인을 유지하도록 설계되며, SIP 소프트웨어는 음향 입력의 트랙을 유지하고 각 워드의 인식과 연관된 베스트 선택분류, 그리고 이러한 텍스트에 의해 생성된 언어 콘텍스트의 트랙을 유지한다. 이러한 텍스트 버퍼가 사용되는 이유는 음성 인식 SIP가 도 11의 창(1106)에 도시한 원격 응용에서 텍스트에 관한 지식을 갖지 않기 때문이며, 도 11의 창(1106)으로 SIP가 실질응용에서 커런트 커서(1108)의 위치에 텍스트를 출력한다. 본 발명의 다른 실시예에 따라서는, 매우 큰 SIP 버퍼가 사용될 수도 있다. 또 다른 실시예에 따라서, 본 발명의 여러 가지 특징이 독립적인 음성인식 텍스트 생성 응용분야에 적용될 수 있으며, 이 경우, 텍스트 입력을 위한 SIP가 필요없게 된다. SIP로서 기능하는 음성 인식자를 이용하는 주요 장점은 PDA에서 동작하도록 설계된 대부분의 응용분야에서 입력기능을 제공할 수 있기 때문이다.When the user presses the
도 13으로 돌아가면, 펑크션(1304)은 SIP 버퍼(1104)로부터 임의 텍스트를 제거하는데 그 이유는 대화 버튼(1102)이 다음 콘텍스트에서 사용자가 텍스트를 딕테이트하고 있다는 것을 SIP에게 사용자가 지적하는 수단으로 사용되기 때문이다. 따라서, SIP 사용자가 도 11의 응용창(1106)에서 커서(1108)를 이동시키면, 이 사용자는 대화 버튼(1102)을 프레스하여 다음 딕테이션을 시작한다.Returning to FIG. 13, function 1304 removes random text from
도 13의 펑크션(1306)은 음성 인식 시스템이 현재 교정 모드에 있는가를 검사하여 대화버튼에서 프레스에 반응하다. 그러면, 이 모드를 빠져나와서 도 12에 도시한 타입의 교정창(1200)을 제거한다.The function 1306 of FIG. 13 checks if the speech recognition system is currently in calibration mode and responds to the press at the interactive button. Then, this mode is exited and the
도면에서 도시한 SIP는 교정창이 디스플레이될 때 교정모드에 있지 않지만, 메인 SIP 인터페이스의 대부분의 버튼으로부터의 투입 입력을 수신하도록 선택되지 않았으며, 이 교정창이 디스플레이될 때 교정모드에 있고 이러한 많은 버튼으로부터 입력을 수신하도록 선택된다. 이 차이는 바람직한 것이라 할 수 있으며, 그 이유는 도시한 특정 SIP가 한번에 한번 모드(원@어타임)에서 동작하도록 선택될 수 있기 때문이다. 한번에 한번 모드에서는 워드가 이산적으로 발성 및 인식되고, 사 용자가 더욱 신속하게 선택분류 리스트를 보거나 교정 입력을 제공할 수 있도록 워드가 인식됨에 따라 각 워드에 대해 교정창이 디스플레이 된다. 한번에 한번 모드에서 특별이 교정을 하는데 관련되지 않은 사용자 입력의 대부부의 폼은 목표 워드로서 커런트 선택분류 리스트에 디스플레이된 제1선택분류를 확인하는 추가 기능을 수행하는데 사용된다. 시스템이 한번에 한번 모드에 있지않으면, 사용자가 선행 입력을 교정하기 원한다는 표시의 입력을 제공할 때 통상 교정창이 디스플레이된다. 이러한 경우에 교정창이 교정모드에서 디스플레이되는 이유는 사용자가 교정하는 것을 선택함에 따라 대부분의 입력 폼이 교정창으로 향해야 하기 때문이다.Although the SIP shown in the figure is not in calibration mode when the calibration window is displayed, it has not been selected to receive input input from most of the buttons of the main SIP interface, and it is in calibration mode when this calibration window is displayed and from many of these buttons. It is selected to receive the input. This difference may be desirable, since the particular SIP shown may be selected to operate in one mode at a time (one-time). In one mode at a time, words are spoken and recognized discretely, and a calibration window is displayed for each word as the word is recognized so that the user can view the classification list more quickly or provide calibration input. Most forms of user input that are not involved in making special corrections once in a mode are used to perform the additional function of confirming the first classification displayed in the current classification list as the target word. If the system is not in one mode at a time, the normal calibration window is displayed when the user provides an input indicating that he wants to calibrate the preceding input. In this case the reason why the calibration window is displayed in calibration mode is that most input forms must be directed to the calibration window as the user chooses to calibrate.
한번에 한번 인식 모드만을 사용하는 시스템에서 또는 이것을 전혀 사용하지 않는 시스템에서 교정모드의 스위칭과 관련된 부차적으로 복잡한 문제를 가져야할 필요가 없음을 이해할 수 있을 것이다.It will be appreciated that in systems using only one recognition mode at a time, or in systems that do not use it at all, there is no need to have a secondary complication associated with switching the calibration mode.
펑크션(1306)으로 돌아가면, 커런트 교정창을 모두 제거한다. 그 이유는 대화버튼(1302)의 프레스가 올드 딕테이션을 교정하는데 흥미가 있다기 보다는 신규 딕테이션을 시작하기 원한다고 표시하기 때문이다.Returning to function 1306, remove all current calibration windows. The reason is that the press of the dialog button 1302 indicates that it wants to start a new dictation rather than interested in correcting the old dictation.
도 13의 펑크션(1308)은 미리 선택된 커런트 인식도중모드에 따라서 SIP 버퍼 인식이 시작되도록 하여 대화버튼의 프레스에 응답한다. 이 인식은 제1워드를 위한 선행 랭귀지 콘텍스트 없이 일어난다. 바람직한 형태로는 랭귀지 모델 콘텍스트는 대화버튼의 일회 프레스에 반응하여 인식되는 워드로부터 도출되며, 이러한 인식에서 제2워드 그리고 이후 워드의 인식을 위한 랭귀지 콘텍스트를 제공한다.The function 1308 of FIG. 13 responds to the press of the conversation button by starting the SIP buffer recognition according to the preselected current recognition mode. This recognition takes place without a prior language context for the first word. In a preferred form, the language model context is derived from a word recognized in response to a single press of the dialog button, which provides a language context for the recognition of the second word and subsequent words.
도 18은 음성 인식을 시작하는데 사용될 수 있는 SIP 인터페이스에서 임의 버튼의 프레스 또는 클릭에 반응하여 음성인식을 활성화하는 여러 모드를 사용자가 선택할 수 있도록 하는 인식 도중 프로그램(1800)의 개략도이다. 도시한 실시예에서, 대화버튼을 포함하는 다수의 버튼이 있으며, 이들은 각각 음성인식을 시작하는데 이용될 수 있다. 이러한 구조는 사용자가 소정의 인식모드를 선택할 수 있고, 이 모드에서 버튼의 1회 프레스로 인식을 시작할 수 있도록 해준다.18 is a schematic diagram of a program 1800 during recognition that allows a user to select various modes of activating speech recognition in response to a press or click of any button in a SIP interface that may be used to initiate speech recognition. In the illustrated embodiment, there are a number of buttons, including a dialog button, each of which can be used to initiate speech recognition. This structure allows the user to select a predetermined recognition mode and in this mode can start recognition with a single press of a button.
펑크션(1802)은 커런트 인식 도중 모드에 따라서 도 18의 어느 펑크션이 수행되는가를 판정하는 것을 돕는다. 이 모드는 여러 가지 다양한 방법으로 설정될 수 있으며, 그 방법으로는 디폴트에 의한 것, 도 46에 도시한 펑크션 메뉴에서 엔트리 프레퍼런스 옵션 하에서의 선택에 의한 것 등을 들 수 있다.Function 1802 helps determine which function of FIG. 18 is performed in accordance with the mode during current recognition. This mode can be set in a variety of ways, including by default, by selection under the entry preference option in the function menu shown in FIG. 46, and the like.
프레스 온리 인식 도중 타입(press only recongnition duration type)이 선택되면, 펑크션(1804)은 평크션(1806)(1808)이 음성 버튼의 프레스 도중에 발성된 음성 사운드를 인식하도록 작용한다. 이 인식 도중 타입은 간단하면서도 유연성을 가질 수 있는데, 그 이유는 이 타입이 사용자로 하여금 하나의 단순한 루울로 인식 길이를 제어하는 것을 가능하게 하기 때문이다. 여기서 인식은 음성 버튼을 프레스하는 도중 및 오로지 프레스하는 도중에 발생한다. 바람직하게는 발성 및/또는 발성 종료 검출을 임의 인식모드 중에 이용하여 배경잡음이 발성으로서 인식될 가능성을 감소시킨다.If a press only recongnition duration type is selected during the press only recognition, the function 1804 acts to allow the sections 1806 and 1808 to recognize the spoken sound during the press of the voice button. During this recognition, the type can be simple and flexible because this type allows the user to control the recognition length with a single simple loop. The recognition here occurs during the press of the voice button and only during the press. Preferably, phonation and / or utterance end detection is used during any recognition mode to reduce the likelihood of background noise being recognized as phonation.
커런트 인식 도중 타입이 발성종료에 대한 프레스 앤드 클릭 투 발성 종료(Press And Click To Utterance End) 타입이면, 펑크션(1810)은 음성 버튼의 프레스 도중에 이 프레스에 펑크션(1812)(1814)이 반응하도록 작용시킨다. 이 경우, 음 성 버튼의 "프레스"는 소정의 기간, 예를들면 1/4초 또는 1/3초 이상 길게 버튼을 가압하는 것으로 정의한다. 사용자가 이것 보다 짧은 시간 동안 음성 버튼을 누르면, 이 가압은 "프레스"가 아니라 "클릭"으로 간주되며, 펑크션(1816)(1818)은 발성 검출의 다음 종료 때까지 이 클릭 시간부터 시작하여 인식을 초기화한다.If the type is Press and Click To Utterance End type during current recognition, the function 1810 responds to this press during the press of the voice button. To work. In this case, the "press" of the audio button is defined as pressing the button for a predetermined period of time, for example, 1/4 second or 1/3 second or longer. If the user presses the voice button for a shorter time than this, this press is considered to be a "click" rather than a "press" and the function 1816 (1818) recognizes starting from this click time until the next end of speech detection. Initialize
발성종료에 대한 프레스 앤드 클릭 인식 도중 타입은 여러 가지 길이 확대 인식을 사용자가 선택할 수 있도록 하는 모드와, 단일 발성만을 인식하는 모드 사이에서 단일 버튼만을 사용하여 신속하고도 용이하게 선택을 할 수 있도록 하는 이점이 있다.During the press-and-click recognition of the end of speech, the type allows the user to select between different length-expansion recognition modes and a mode that allows the user to select quickly and easily using a single button only. There is an advantage.
커런트 인식 도중 타입이 발성종료에 대한 연속 프레스 또는 이산 클릭이면, 펑크션(1820)은 평크션(1822 - 1828)이 기능하도록 작용한다. 정의한 바와 같이 음성 버튼이 클릭되면 펑크션(1822)(1824)은 발성의 다음 종료 때까지 이산 인식을 수행한다. 한편, 앞서 정의한 바와 같이 음성 버튼이 프레스되면, 펑크션(1826)(1828)은 음성 버튼이 프레스된 채로 남아있는한 연속 인식을 수행한다.If the type is a continuous press or discrete click on utterance end during current recognition, function 1820 acts to allow functions 1822-1828 to function. As defined, when a voice button is clicked, functions 1822 and 1824 perform discrete recognition until the next end of utterance. On the other hand, when the voice button is pressed as defined above, the functions 1826 and 1828 perform continuous recognition as long as the voice button remains pressed.
이 인식 도중 타입은 소정의 음성 버튼에서 여러 가지 다양한 타입의 프레스를 이용하여 연속 인식과 이산 인식 사이에서 신속한 스위칭(전환)을 사용자가 용이하게 할 수 있도록 하는 장점이 있다. 도시한 SIP 실시예에서, 기타 다른 인식 도중 타입은 연속 인식과 이산 인식 사이에서 전환(스위칭)하지 않는다.This type of recognition has the advantage of allowing the user to facilitate rapid switching (switching) between continuous recognition and discrete recognition using various different types of presses on a given voice button. In the illustrated SIP embodiment, the type during other recognition does not switch (switching) between continuous and discrete recognition.
커런트 인식 도중 타입이 타임 아웃 클릭 타입이면, 펑크션(1830)은 펑크션(1832 - 1840)이 수행되도록 작용한다. 음성 버튼이 클릭되면, 기능(1833 - 1836)은 정상적으로는 오프와 온 사이에서 인식을 토글한다. 펑크션(1834)은 음성 인식 이 현재 온인가의 여부를 검사하여 클릭에 반응한다. 그러하면, 클릭되는 음성 버튼이 어휘를 변경하는 것 이외의 것이면 음성 인식을 턴 오프하여 클릭에 반응한다. 한편, 음성 버튼이 클릭될 때 음성 인식이 오프이면 기능(1836)은 타임 아웃 도중이 경과할 때까지 음성인식을 턴온한다. 이 타임 아웃 도중의 길이는 도 46에 도시한 펑크션 메뉴(4602)에서 엔트리 프레퍼런스 옵션 하에서 사용자에 의해 설정될 수 있다. 전술한 바와 같이 음성 버튼이 소정의 도중 보다 길게 프레스되면, 펑크션(1838)(1840)은 프레스 도중에 인식이 온이 되도록 작용하며, 그 종료에서는 턴 오프가 되도록 한다.If the type is a time-out click type during current recognition, the function 1830 acts to perform the functions 1832-1840. When the voice button is clicked, the functions 1833-1836 normally toggle recognition between off and on. Function 1834 checks whether speech recognition is currently on and responds to the click. Then, if the voice button being clicked is other than changing the vocabulary, voice recognition is turned off to respond to the click. On the other hand, if the speech recognition is off when the speech button is clicked, the function 1836 turns on speech recognition until the time-out middle elapses. The length during this timeout can be set by the user under the entry preference option in the
이 인식 도중 타입은 신속하고도 용이하게 사용자가 음성 인식을 온, 오프하는 토클 사이에서 한번의 버튼으로 선택을 가능하게 하며, 음성 버튼의 확대 프레스 도중에만 음성인식이 턴 온되도록 한다.This type of recognition allows the user to quickly and easily select a single button between toggles for turning on and off the voice recognition, and turn on the voice recognition only during the enlarged press of the voice button.
도 13의 펑크션(1308)으로 돌아가면(리턴하면), 여러 가지 인식 도중 타입의 선택을 통해 대화 버튼과 기타 음성 버튼이 인식을 초기화하는 방법을 사용자가 선택할 수 있도록 한다.Returning to the function 1308 of FIG. 13 (returning), the user can select how the conversation button and other voice buttons initiate recognition through the selection of types during various recognitions.
사용자가 도 11에 도시한 클리어 버튼(1112)을 선택하면, 펑크션(1309 - 1314)은 디스플레이된 교정창을 제거하고 운영체게 텍스트 입력에 어떠한 딜리션(deletion)(또는 삭제)을 보내지 않고 SIP 버퍼의 콘텐츠를 클리어한다. 상기와 같이, 도시한 음성 SIP에서, 도 11에 도시한 SIP 텍스트 창(1104)은 상대적으로 작은 텍스트 바디를 유지하도록 설계된다. SIP버퍼에서 텍스트가 엔터되거가 에디트되면, 캐릭터가 PDA의 운영체계에 공급되고, 이에 상응하는 변경사항이 도 11에 도시 한 응용창(1006)에서의 텍스트에 반영된다. 클리어 버튼은 사용자가 SIP버퍼로부터 텍스트를 클리어할 수 있도록 하여 이것이 오버로드되는 것을 방지하는 한편, 응용 창에서의 텍스트에는 이에 상응하는 삭제(딜리션)가 발생하지 않도록 한다.When the user selects the
도 11에 도시한 연속 버튼(1114)은 최후 딕테이트된 텍스트의 연속, 또는 SIP 버퍼창(1104)에서 커런트 위치에 삽입될 텍스트의 연속을 사용자가 딕테이트하기 원할 때 사용되기 위한 것이다. 이 버튼이 프레스되면, 펑크션(1316)은 펑크션(1318 - 1330)이 수행되도록 작용한다. 펑크션(1318)은 임의 교정창을 제거하는데, 그 이유는 연속 버튼의 프레스를 통해 사용자가 교정창을 사용하는데 흥미가 없다는 것을 표시하기 때문이다. 다음에, 펑크션(1132)은 SIP 버퍼창에서 커런트 커서가 선행 랭귀지 콘텍스트를 가지고 있는가의 여부를 검사하며, 여기서 선행 랭귀지 콘텍스는 연속버튼의 프레스 결과로서 인식된 임의 발성의 제1워드 또는 이들 워드들의 개연성을 예측하는데 도움을 줄 수 있다. 여기서 선행 랭귀지 콘텍스트가 있으면, 이것을 사용하도록 작용하고, 없다면 그리고 현재 SIP 버퍼에 텍스트가 없다면, 펑크션(1326)은 연속 버튼에 의해 초기화된 인식 시작에서 랭귀지 콘텍스트로서 SIP 버퍼에 이미 엔터된 최후 하나 이상의 워드를 사용한다. 다음에, 펑크션(1330)은 SIP 버퍼 인식 즉, SIP 버퍼에서 커서로 출력될 텍스트의 인식을 커런트 인식도중모드를 이용하여 시작한다.The
사용자가 도 11에 도시한 백스페이스 버튼(1116)을 선택하면, 펑크션(1132 - 1336)을 수행한다. 펑크션(1134)은 SIP가 현재 교정모드에 있는가의 여부를 검사한다. 있다면, 백스페이스를 교정창의 필터 에디터로 엔터한다. 도 12에 도시한 교정 창(1200)은 제1 선택분류창(1202)을 포함한다. 아래 상세히 설명하는 바와 같이, 교정창 인터페이스는 필터 스트링의 일부로서 제1선택분류창에서 사용자가 하나 이상의 캐릭터를 선택 또는 에디트하는 것을 가능하게 하며, 여기서 필터 스트링은 목표 교정 인식 워드에 속하는 초기 캐릭터 시퀀스를 식별한다. SIP가 교정모드에 있으면, 백페이스를 프레스하는 것으로 제1 선택분류창에서 현재 선택된 필터 스트링과 캐릭터로부터 삭제되고, 캐릭터가 선택되지 않으면 필터 커서(1204)의 좌측으로 캐릭터를 삭제한다.When the user selects the
SIP가 현재 교정모드에 없으면, 펑크션(1136)은 SIP버퍼로 백스페이스 캐릭터를 엔터하고 운영체계로 동일 캐릭터를 출력하여 백스페이스의 프레스에 반응하며, 동일한 변경을 도 11에 도시한 응용창(1106)에서 대응 텍스트에 반영한다.If the SIP is not currently in the calibration mode, the
사용자가 도 11에 도시한 신규 패러그래프 버튼(1118)을 선택하면, 도 13의 펑크션(1338 -1342)은 교정모드를 빠져나오며, SIP가 현재 그곳에 있으면, 신규 패러그래프 캐릭터를 SIP 버퍼로 엔터하고 대응출력을 운영체계에 제공한다.When the user selects the
펑크션(1344 - 1338)으로 표시한 바와 같이, SIP는 백스페이스에 반응하는 것과 실질적으로 동일한 방법으로, 즉, SIP가 교정모드에 있으면 필터 에디터에 엔터하고, 그렇지 않으면 SIP버퍼 및 운영체계로 출력하는 것으로 스페이스 버튼(1120)의 사용자 선택에 반응한다.As indicated by functions 1344-1338, SIP is substantially the same as responding to backspace, ie enters the filter editor if SIP is in calibration mode, otherwise outputs to the SIP buffer and operating system. In response to user selection of the
사용자가 도 11에 도시한 어휘 선택 버튼(1122 - 1132) 중 하나를 선택하면, 도 13의 펑크션(1350 - 1370), 도 14의 펑크션(1402 - 1416)은 적절한 인식모드의 어휘를 선택된 버튼에 대응하는 어휘로 설정하고 커런트 인식 도중 모드와 인식 모 드를 위한 기타 셋팅에 따라서 이 모드에서 음성인식을 시작한다.When the user selects one of the vocabulary selection buttons 1122-1132 shown in FIG. 11, the functions 1350-1370 of FIG. 13 and the functions 1402-1416 of FIG. 14 select a vocabulary of an appropriate recognition mode. Set to the vocabulary corresponding to the button and start voice recognition in this mode according to the mode during current recognition and other settings for recognition mode.
사용자가 네임 인식 버튼(1122)을 선택하면, 펑크션(1350)(1356)이 커런트 모드의 인식어휘를 네임 인식 어휘로 설정하고, 커런트 인식 도중 셋팅 및 기타 적절한 음성 셋팅에 따라서 인식을 시작한다. 네임과 대형 어휘 버튼 이외에 모든 어휘 버튼과 함께, 이들 펑크션은 SIP가 교정모드에 있는가에 따라서 필터 또는 SIP버퍼 인식으로서 커런트 인식 모드를 취급(간주)한다. 이것은 이들 기타 어휘버튼이 필터 스트링을 규정하거나 SIP버퍼로 직접 진입하기에 적절한 캐릭터 시퀀스를 입력하는데 사용되는 어휘와 연관이 있다. 그러나, 대형 어휘와 네임 어휘를 필터 스트링 에디트에서는 부적절한 것으로 간주된다. 따라서 개시된 실시예에서 커런트 인식 모드는 SIP가 교정 모드에 있는가의 여부에 따라서 재발성 또는 SIP 버퍼 인식으로 간주된다. 다른 실시예에서, 네임과 대형 어휘 인식은 다중 워드 필터를 에디트 하기위한 것으로 사용될 수 있다.When the user selects the
어휘 버튼의 프레스와 연관된 표준 반응 외에, 알파브라보 어휘 버튼이 프레스되면, 도 40에서의 번호 4002에 도시한 바와 같이 펑크션(1404 - 1406)은 ICA(International Communication Alphabet)에 의해 사용되는 모든 워드의 리스트를 디스플레이 하도록 작용한다.In addition to the standard response associated with the press of the vocabulary button, when the Alpha Bravo vocabulary button is pressed, the functions 1404-1406 are used for all words used by the International Communication Alphabet (ICA) as shown by the
사용자가 도 11에 도시한 연속/이산 인식 버튼(1134)을 선택하면, 도 14의 펑크션(1418 - 1422)이 수행되며, 이들 펑크션은 연속 인식 모드와 이산 인식 모드 사이에서 토글된다. 여기서의 연속인식모드는 연속 음성 음향 모델을 이용하여 다중워드 인식 캔디디트가 소정의 단일 발성에 매치되는 것을 가능하게 하고, 이산 인식 모드는 이산 인식 음향 모델을 사용하고, 단일 발성을 위해 단일 워드 인식 캔디디트 만을 인식할 수 있는 것이다. 펑크션은 또한 연속/이산 버튼의 프레스에 의해 바로 선택된 바와 같이 이산 또는 연속 인식을 이용하여 음성 인식을 시작한다.When the user selects the continuous /
사용자가 프레스에 의해 펑크션 키(1110)를 선택하면 펑크션(1424)(1426)은 도 46에 도시한 펑크션 메뉴(4602)를 호출한다. 이 펑크션 메뉴는 사용자가 도 11 및 도 12에 도시한 버튼으로부터 직접 이용가능한 것 이외에 다른 옵션을 선택할 수 있도록 한다.When the user selects the
사용자가 도 11에 도시한 헬프 버튼(1136)을 선택하면 도 14의 펑크션(1432)(1434)은 헬프 모드를 호출한다.When the user selects the
도 19에 도시한 바와 같이, 헬프버튼의 초기 가압에 따라서 헬프 모드가 엔터될 때, 펑크션(1902)은 도 20에 도시한 바와 같이 헬프 모드를 이용하는 것에 대한 정보를 제공하는 헬프 창(2000)을 디스플레이 한다. 헬프 모드의 연속 동작 중에 사용자가 SIP 인터페이스 부분을 터치하면, 펑크션(1904)(1906)은 사용자가 터치를 연속하고 있는 한에서 디스플레이를 연속하는 인터페이스의 터치된 부분에 대한 정보와 함께 헬프창을 디스플레이한다. 이 것을 도 21에 도시한다. 여기서 사용자는 스타일러스(904)를 사용하여 교정창의 필터 버튼(1218)을 프레스한다. 반응으로서, 도시된 헬프창(2100)은 필터 버튼의 펑크션을 설명하고 있다. 헬프 모드 중에 사용자가 디스플레이 부분에서 더블클릭을 하면, 펑크션(1908)(1910)은 헬프창을 디스플레이하며, 이 헬프창은 인터페이스의 다른 부분을 사용자가 프레스 할 때 까지 유지된다. 이것은 사용자가 도 21에 도시한 헬프 창에서 도시한 스크롤 바(2102)를 사용할 수 있도록 하여 이 스크롤 바를 통해 한번에 헬프 창(2102)에서 끼워지기에는 너무 큰 헬프 정보를 읽는 것을 가능하게 한다.As shown in FIG. 19, when the help mode is entered according to the initial press of the help button, the function 1902 provides a
도 19에 도시하였지만, 헬프창은 킵 업 버튼(2100)을 가지고 있으며, 이것을 통해 사용자는 흥미있는 SIP 사용자 인터페이스의 일부분에서 초기 다운 프레스를 드래그하고 또한 SIP 사용자 인터페이스의 다른 부분의 터치가 있을 때까지 헬프 창을 유지하도록 선택할 수 있다.As shown in FIG. 19, the help window has a keep up
헬프 모드의 초기 엔트리 이후, 사용자가 다시 도 11, 20, 21에 도시한 헬프 버튼(1136)을 터치하면, 펑크션(1912)(1914)은 임의 헬프 창을 제거하면서 헬프 모드에서 빠져나오고, 헬프 버튼의 하일라이트를 턴오프한다.After the initial entry of the help mode, if the user touches the
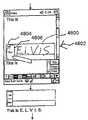
사용자가 SIP 버퍼에서 워드를 탭하면 도 14의 펑크션(1436 - 1438)은 선택된 워드를 커런트 선택으로 하고 커런트 선택으로서의 탭된 워드와, 탭된 워드의 인식과 연관된 음향 데이터, 임의로 커런트 선택과 연관된 음향 데이터를 유지하는 발성 리스트에서의 제1 엔트리와 함께 도 22에 도시한 디스플레이 선택분류 리스트 루틴을 호출한다.When the user taps a word in the SIP buffer, the functions 1436-1438 of FIG. 14 make the selected word the current selection and the tapped word as the current selection, the acoustic data associated with the recognition of the tapped word, and optionally the acoustic data associated with the current selection. A display selection classification list routine shown in FIG. 22 is called along with the first entry in the utterance list that maintains.
도 22에 도시한 바와 같이, 디스플레이 선택분류 리스트가 선택 파라메터, 필터 스트링 파라메터, 낱 선택분류 리스트 플랙 등으로 호출된다. 선택 파라메터는 루틴이 호출되는 SIP 버퍼에서의 텍스트를 표시한다. 필터 스트링은 하나 이상의 캐릭터 시퀀스를 표시하며, 이것은 목표 인식 출력이 시작되는 하나 이상의 가능한 스펠링 세트를 규정하는 엘리멘트를 지시한다. 필터 레인지 파라메터는 2개의 캐릭터 시퀀스를 규정하며, 이들은 목표 인식 출력이 떨어지는 알파벳 섹션을 바운드한다. 워드 타입 파라메터는 목표인식출력이 목표 문법 타입과 같이 특정한 타입이라는 것을 표시한다. 낱 선택분류 리스트 플랙은 사용자 액션이 표시하는 하나 이상의 워드 리스트가 목표워드가 아님을 표시한다.As shown in Fig. 22, the display classification list is called with selection parameters, filter string parameters, single selection list flags, and the like. The selection parameter displays the text in the SIP buffer in which the routine is called. The filter string represents one or more character sequences, which indicate an element that defines one or more possible spelling sets from which the goal recognition output begins. The filter range parameter defines two character sequences, which bound the alphabetic section where the target recognition output falls. The word type parameter indicates that the target recognition output is of a specific type, such as the target grammar type. The single sort list flag indicates that the list of one or more words that the user action represents is not a target word.
디스플레이 선택분류 리스트 루틴의 펑크션(2202)은 도 23에 도시한 겟 선택분류 루틴을 호출하며, 이와 함께 디스플레이 선택분류 리스트 루틴이 호출되는 필터 스트링 및 필터 레인지 파라메터와 선택 파라메터와 연관된 발성 리스트로 동반된다.The function 2202 of the display classification list routine calls the get classification routine shown in FIG. 23, and is accompanied by a speech string associated with the filter string and the filter range parameter and the selection parameter in which the display classification list routine is called. do.
도 24 및 도 25에 도시한 바와같이, 발성리스트(2404)는 하나 이상의 발성에대한 사운드 표현을 저장하며, 여기서의 발성은 커런트 선택과 연관된 하나 이상의 워드의 목표 시퀀스 일부로서 발음된 것을 말한다. 앞에 설명한 바와 같이, 도 22의 펑크션(2202)이 겟 선택분류 루틴을 호출할 때, 도 24에 도시한 바와 같이 사운드(2402)의 그 부분의 표현(representation)(2400)이 나타나며, 이것으로부터 커런트 선택의 워드가 인식되었다. 도 2에 지적한 바와 같이, 음성인식 프로세스는 오디오 신호의 표현에 대해 음향 모델을 시간정렬한다. 바람직한 일실시예로서, 인식시스템이 이 시간정렬을 저장하여 선택된 텍스트의 교정 또는 플레이백이 요구될 때, 이러한 시간정렬로부터 대응 오디오 표현을 발견할 수 있도록 할 수 있다.As shown in Figures 24 and 25,
도 24에서, 발성 리스트에서의 제1엔트리(2004)는 연속 발성(2402)의 일부이다. 본 발명에 따르면 사용자가 하나 이상의 워드로된 목표 시퀀스의 추가 발성을 선택의 발성 리스트에 부가할 수 있고, 이들 발성 모두에 대해 인식을 수행하여 목 표출력을 올바르게 인식할 수 있는 확율을 높일 수 있다. 도 24에 도시한 바와 같이, 이러한 부가 발성은 엔트리(2400A)와 같은 이산 발성 뿐만아니라 엔트리(2400A)와 같은 이산 발성 모두를 포함할 수 있다. 각 부가발성은 참조부호 2406 및 2408로 표시된 바와 같은 정보를 포함하며, 이것은 연속 또는 이산 발성인가의 여부, 딕테이트된 어휘 모드를 표시한다.In FIG. 24, the first entry 2004 in the speech list is part of the
도 24 및 도 25에 있어서는, 음향 리스트에서 발성의 음향 표현이 파형으로서 나타나 있다. 실시예에 따라서, 음향 표현을 다른 형태, 즉 도 1 및 도 2의 표현(110)과 같은 파라메터 프레임 등으로 나타낼 수 있음은 자명한 것이다.In FIG. 24 and FIG. 25, the acoustic representation of speech in the acoustic list is shown as a waveform. According to embodiments, it is obvious that the acoustic representation may be represented in another form, that is, a parameter frame such as the
도 25는 원래의 발성 리스트 엔트리가 이산 발성 시퀀스라는 것 외에는 도 24와 유사하다. 도 25에 있어서는 하나 이상의 이산 발성의 초기 시퀀스의 인식 교정을 위해 사용되는 부가 발성 엔트리가 이산 또는 연속 발성(2500A)(2500B)을 각각 포함할 수도 있음을 나타내고 있다.FIG. 25 is similar to FIG. 24 except that the original speech list entry is a discrete speech sequence. 25 shows that additional speech entries used for recognition correction of one or more discrete speech initial sequences may include discrete or
도 23에 도시한 바와 같이, 겟분류선택 루틴(2300)은 펑크션(2302)을 포함하며, 이 펑크션(2302)은 상기 루틴을 호출한 선택에 관하여 선행인식이 있는가의 여부를 검사한다. 그리고 이 선행인식은 커런트 리스트와 필터값(즉, 필터 스트링과 필터 레인지 값)과 함께 수행된 것을 말한다. 그래서 선행 인식이 있다면 이 선행인식이 발생된 시간이래로 인식 파라메터에 변화가 없으므로 펑크션(2304)으로 하여금 선행인식으로부터 분류선택과 함께 리턴하도록 작용한다.As shown in Fig. 23, the get classification selection routine 2300 includes a function 2302, which checks whether there is an advance recognition with respect to the selection invoking the routine. This precedence is done with the current list and filter values (ie, filter string and filter range values). Thus, if there is a prior recognition, since the recognition parameter has not changed since the time when the preceding recognition occurred, the function 2304 acts to return with the classification selection from the preceding recognition.
펑크션(2302)의 검사가 충족되지 않으면, 펑크션(2306)은 필터 레인지 파라메터가 널(null)인가의 여부를 검사한다. 널이 아니면 펑크션(2308)은 필터 레인지 가 커런트 필터 스트링 보다 더욱 특별한 것인가를 검사하며, 특별한 것이면 필터 스트링을 필터 레인지의 공통 레터로 변경한다. 특별하지 않으면 필터 스트링이 행해야할 더욱 상세한 정보를 포함하고 있으므로 펑크션(2312)은 필터 레인지를 무효화(null)한다.If the check of function 2302 is not satisfied, function 2306 checks whether the filter range parameter is null. If not null, function 2308 checks whether the filter range is more special than the current filter string, and if so, changes the filter string to a common letter in the filter range. Function 2312 nullifies the filter range because the filter string contains more detailed information to be done unless otherwise specified.
이하에서 설명하는 바와 같이, 사용자가 알파벳 순서로 목표 인식 출력이 속하는 범위의 표시(인디케이션)로서 선택분류 리스트에서 2개의 선택분류를 선택할 때 필터 레인지가 선택된다. 초기 레터를 공유하는 2개의 선택분류를 사용자가 선택할 때, 펑크션(2310)은 필터 스트링으로 하여금 이들 공유 레터에 대응하도록 한다. 이렇게 하여 선택분류 리스트가 디스플레이될 때 공유 레터는 목표 출력의 초기 캐릭터에 대응하는 것으로 확인된 것으로서 사용자에게 표시된다.As described below, the filter range is selected when the user selects two selection classifications from the selection classification list as an indication (indication) of the range to which the target recognition output belongs in alphabetical order. When the user selects two classifications that share the initial letter, function 2310 causes the filter string to correspond to these shared letters. In this way, when the selection classification list is displayed, the shared letter is displayed to the user as confirmed to correspond to the initial character of the target output.
사용자가 신규 필터 레인지 또는 필터 스트링을 선택하는 명령을 수행할 때 이들 2개의 파라메터 중 신규로 선택된 것이 다른 것과는 모순되는 값을 가지면 이들 2 파라메터 중 보다 오래된 것의 값을 무효화(null)한다.When the user performs a command to select a new filter range or filter string, if the new one of these two parameters has a value that is inconsistent with the other, then the value of the older of these two parameters is null.
커런트 발성 리스트 중 선행 인식으로부터 어느 캔디디트가 있으면 펑크션(2316)은 펑크션(2318)(2320)이 수행되도록 작용한다. 펑크션(2318)은 캔디디트의 선행 인식 스코어와 커런트 필터 정의와 함께 각 선행 인식 캔디디트를 위해 도 26의 필터 매치 루틴을 호출하고, 펑크션(2320)은 특정 임계값 이하의 스코어를 갖는 이러한 호출의 결과로서 리턴된 이들 캔디디트를 삭제(딜리션)한다.If there is any candy from the preceding recognition in the current utterance list, the function 2316 acts so that the functions 2318 and 2320 are performed. Function 2318 invokes the filter match routine of FIG. 26 for each prior recognition candite, with Candid's prior recognition score and current filter definition, and function 2320 has a score below a certain threshold. Delete (delete) these candy deets returned as a result of the call.
도 26에 도시한 바와 같이, 필터 매치 루틴(2600)은 워드 캔디디트 상에서 필터링을 행한다. 도시한 본 발명의 실시예에서, 이들 필터링 프로세서는 필터 스 트링, 필터 레인지 또는 워드 타입으로 필터를 규정하는 것을 가능하게 하므로 매우 유연하다. 또한 이 필터링 프로세는 워드 타입, 필터 스트링 또는 필터 레인지 사양의 조합을 가능하게 하고, 한편으로 필터 스트링에서의 엘리멘트가 그 연관 캐릭터의 값에 대해 모호할 뿐만 아니라 연관 캐릭터 시퀀스에서의 캐릭터 개수에 대해서도 모호한 경우의 모호 필터에 대해서도 모호 필터링을 허용한다는 점에서 유연하다고 할 수 있다.As shown in FIG. 26, filter match routine 2600 performs filtering on word candies. In the illustrated embodiment of the present invention, these filtering processors are very flexible as it makes it possible to define filters by filter string, filter range or word type. This filtering process also allows for combinations of word types, filter strings, or filter range specifications, while on the other hand elements in the filter string are not only ambiguous about the value of the associative character, but also ambiguous as to the number of characters in the associative character sequence. The ambiguity filter in the case is also flexible in that it allows ambiguity filtering.
여기서 필터 스트링 또는 필터 스트링의 일부분이 모호하다고 말할 때, 이 말의 의미는 다수의 있을 수 있는 캐릭터 시퀀스가 매치될 수 있는 것으로 간주된다는 뜻이다. 모호 필터링은 신뢰가 되지만 단일 캐릭터로서 유일하게 규정되지는 않는 필터 스트링 입력과 함께 사용될 때 효용가치가 있으며, 이것은 본 발명의 여러 특징이 반영된 셀 폰 실시예와 관련하여 이하에서 설명하는 타입의 모호 폰 키 필터링에 경우에도 적용된다.When we say that a filter string or part of a filter string is ambiguous, this means that a number of possible character sequences are considered to be matchable. Ambiguous filtering is useful when used with a filter string input that is trusted but not uniquely defined as a single character, which is the type of ambiguous phone described below in connection with a cell phone embodiment in which various aspects of the invention are incorporated. The same applies to key filtering.
모호 필터링은 특히 인식이 연속으로 수행될 때 레터 네임의 인식 등과 같이 높은 특정성을 가지고 인식될 수 없는 필터 스트링 입력에 대해서도 효용가치가 있다. 이러한 경우로는, 캐릭터 시퀀스의 인식에 대한 베스트 선택분류가 하나 이상의 에러를 포함할 수 있는 높은 가능성이 있을 뿐만 아니라 베스트 스코어링 인식 캔디디트에서 인식된 캐릭터의 개수가 발음된 개수와 다를 수 있는 합리적인 개연성이 있을 때를 들 수 있다. 비록 이러한 인식으로부터 베스트 선택분류가 때로는 부정확하고, 특히 이러한 부정확성은 열악한 조건하에서 딕테이트가 행해질 때 나타남에도 불구하고 목표 출력의 모든 캐릭터 또는 초기 캐릭터를 스펠링하는 것은 필터링 정보를 입력하는 매우 신속하고도 직감적인 방법이라 할 수 있다.Ambiguous filtering is especially useful for filter string inputs that cannot be recognized with high specificity, such as the recognition of letter names when the recognition is performed continuously. In this case, there is a high likelihood that the best selection classification for the recognition of character sequences may include one or more errors, as well as the reasonable probability that the number of characters recognized in the best scoring recognition candid may differ from the pronounced number. When there is this. Although the best selection classification from this perception is sometimes inaccurate, and in particular this inaccuracy appears when the dictate is made under poor conditions, spelling all characters or initial characters in the target output is very quick and intuitive. It can be said that.
필터 매치 루틴은 각 개별 워드 캔디디트를 위해 호출되며, 이 호출은 워드 캔디디트의 선행 인식 스코어를 임의로 또는 1의 스코어로 하여 이루어진다. 이 루틴은 캔디디트가 커런트 필터 값을 매치한다는 개연성에 의해 증배된 스코어와 동일한 인식 스코어로 리턴(복귀)시킨다.A filter match routine is called for each individual word candidit, which call is made with a random recognition score of 1 or a prior recognition score of the word candidit. This routine returns (returns) a recognition score equal to the score multiplied by the probability that Candidet matches the current filter value.
필터 매치 루틴의 펑크션(2602 - 2606)은 워드 타입 파라메터가 규정(정의)되었나의 여부를 검사하며, 정의되었다면 그리고 워드 캔디디트가 정의된 워드 타입이 아니라면 스코어 0과 함께 필터 매치 펑크션으로부터 리턴하며, 여기서 스코어 0은 워드 캔디디트가 커런트 필터 값과 명백히 호환할 수 없다는 것을 표시하는 값이다.Functions in the filter match routine (2602-2606) check whether the word type parameter is defined (define) and return from the filter match function with a score of 0 if defined and if the word candid is not a defined word type. Where
펑크션 (2608 - 2614)은 커런트 값이 필터 레인지를 위해 정의되었나의 여부를 검사한다. 정의되었다면 그리고 커런트 워드 캔디디트가 알파벳 순으로 이 필터 레인지의 시작과 종료 워드 사이에 위치한다면, 이들 펑크션은 변경없는 스코어 값으로 리턴하며, 그렇지 않으면 스코어 0의 값으로 리턴한다.Functions 2608-2614 check whether the current value is defined for the filter range. If defined and if the current word candies are placed alphabetically between the start and end words of this filter range, these functions return unchanged score values, otherwise they return a value of score zero.
펑크션(2616)은 정의된 필터 스트링이 있는가의 여부를 판정한다. 있다면 펑크션(2618 - 2653)으로 하여금 수행을 하도록 작용한다. 펑크션(2618)은 다음(폴로윙) 루프에서 사용될 변수인 커런트 캔디디트 캐릭터를 필터 매치가 호출된 워드 캔디디트에서의 제1 캐릭터로 설정한다. 다음에, 루프(2602)는 그 순환반복이 필터 스트링의 종료에 도달할 때까지 수행된다. 이 루프는 펑크션(2622 - 2651)을 포함한다.Function 2616 determines whether there is a defined filter string. If present, it causes functions 2618-2653 to perform the operation. Function 2618 sets the current Candidate character, which is a variable to be used in the next (following) loop, as the first character in the word Candidate for which the filter match was called. Next, loop 2602 is performed until its recursion reaches the end of the filter string. This loop contains functions 2622-2651.
이 루프의 각 순환반복에서의 제1펑크션은 스텝(2622)에 의한 검사이며, 이 검사를 통해 제1 필터 스트링에서 다음 엘리멘트의 특성(nature)을 판정한다. 도시한 실시예에서는 3 타입의 필터 스트링 엘리멘트를 허용하며, 그 3타입은 비모호 캐릭터, 모호 캐릭터, 길이가 다를 수 있는 모호 캐릭터 시쿼스 세트를 표현하는 모호 엘리멘트를 말한다.The first function in each loop iteration of this loop is a check by step 2622, which determines the nature of the next element in the first filter string. In the illustrated embodiment, three types of filter string elements are allowed, and the three types refer to an ambiguous element representing an unambiguous character, an ambiguous character, and an ambiguous character sequence set which may be different in length.
비모호 캐릭터는 모호하지 않게 알파벳 레터나 공간과 같은 다른 캐릭터를 식별하며, 이 것은 임의 형태의 알파벳 입력에 대한 비모호 인식으로 생성될 수 있지만 대체로 레터, ICA 워드 인식, 키보드 입력, 또는 폰 동작 중에 비모호 폰키 입력과 관련이 있다. 알파벳 입력의 임의 인식은 비모호 캐릭터 시퀀스로서 인식에 의해 출력된 단일 베스트 스코어링 스펠링을 단순이 수용하여 비모호로서 취급(또는 간주)할 수 있다.Unambiguous characters unambiguously identify other characters, such as alphabetic letters or spaces, which can be generated by unambiguous recognition of any type of alphabetic input, but are typically used during letter, ICA word recognition, keyboard input, or phone operation. Related to unambiguous phone key input. Any recognition of the alphabet input can simply accept (or regard) it as unambiguous by simply accepting a single best scoring spelling output by recognition as an unambiguous character sequence.
모호 캐릭터는 다중 레터값을 가질 수 있지만 일 캐릭터의 정의된 길이를 갖는 것을 말한다. 상술한 바와 같이, 이 모호 캐릭터는 전화실시예에서 키에 대한 모호 프레스에 의해, 또는 음성에 의해 또는 레터의 캐릭터 인식에 의해 발생할 수 있다. 또한 모호 캐릭터는 모든 베스트 스코어링 캐릭터 시퀀스가 동일한 캐릭터 길이를 갖는 레터 네임의 연속 인식에 의해서도 생성될 수 있다.Ambiguous characters can have multiple letter values, but have a defined length of one character. As described above, this ambiguity character may be generated by an ambiguity press on a key in a telephone embodiment, or by voice or by character recognition of a letter. Ambiguous characters can also be generated by successive recognition of letter names in which all best scoring character sequences have the same character length.
모호 길이 엘리멘트는 공통적으로 연속 레터 네임 인식 또는 수기 인식의 출력과 관련이 있다. 모호 길이 엘리멘트는 수기 또는 발음된 입력에 대해 다중 베스트 스코어링 레터 시퀀스를 표현하며, 이 시퀀스의 일부는 서로 다른 길이를 가질 수 있다.Ambiguous length elements are commonly associated with the output of continuous letter name recognition or handwriting recognition. Ambiguous length elements represent multiple best scoring letter sequences for handwritten or pronounced inputs, some of which may have different lengths.
필터 스트링에서 다음 엘리멘트가 비모호 캐릭터이면 펑크션(2644)은 펑크션(2626 - 2606)이 수행되도록 작용한다. 펑크션(2626)은 커런트 캔디디트 캐릭터가 커런트 비모호 캐릭터와 매치되는가의 여부를 검사한다. 매치되지 않으면 필터 매치에 대한 호출이 커런트 워드 캔디디트를 위해 스코어 0과 함께 리턴한다. 매치되면 펑크션(2630)은 커런트 캔디디트 캐릭터의 위치를 증대시킨다.If the next element in the filter string is an unambiguous character, function 2644 acts to cause functions 2626-2606 to be performed. The function 2626 checks whether the current candy character is matched with the current unambiguous character. If no match is found, a call to filter match returns with a score of 0 for the current word candite. If matched, function 2630 augments the position of the current candy candite character.
필터 스트링에서 다음 엘리멘트가 모호 캐릭터이면 펑크션(2632)은 펑크션(2634 - 2636)이 수행되도록 작용한다. 펑크션(2634)은 커런트 캐릭터가 모호 캐릭터의 인식 값 중 하나와 매치하는 것에 실패하였나의 여부를 검사한다. 실패하면, 펑크션(2636)은 스코어 0과 함께 필터매치에 대한 호출로부터 리턴한다. 실패하지 않으면, 펑크션(2638 - 2642)은 커런트 캔디디트 캐릭터의 값을 매치하는 모호 캐릭터의 개연성의 기능으로서 커런트 워드 캔디디트의 스코어를 변경하고, 커런트 캔디디트 캐릭터의 위치를 증대시킨다.If the next element in the filter string is an ambiguous character, function 2632 acts to cause functions 2634-2636 to be performed. Function 2634 checks whether the current character failed to match one of the ambiguous character's recognition values. If unsuccessful, function 2636 returns from a call to the filter match with a score of zero. If unsuccessful, functions 2638-2642 change the score of the current word candid as a function of the probability of the ambiguous character matching the value of the current candidite character, and increase the position of the current candidite character.
필터 스트링에서 다음 엘리멘트가 모호 길이 엘리멘트이면 펑크션(2644)은 모호 길이 엘리멘트에 의해 표현된 각 캐릭터 시퀀스를 위해 루프(2646)가 수행되도록 작용한다. 이 루프는 펑크션(2648 - 2652)을 포함한다. 펑크션(2648)은 루프(2646)의 커런트 캐릭터 시퀀스와 매치하는 커런트 캔디디트 캐릭터 위치에서 시작하는 캐릭터의 매칭 시퀀스가 있는가를 검사한다. 있다면 펑크션(2649)은 모호 길이 엘리멘트에 의해 표현된 인식된 매칭 시퀀스의 개연성 기능으로서 워드 캔디디트의 스코어를 변경하고, 이후 펑크션(2650)은 매칭 모호 길이 엘리멘트 시퀀스에서 캐릭터 수 만큼 커런트 캔디디트 캐릭터의 커런트 위치를 증대시킨다. 모호 길 이 엘리멘트와 관련된 임의 캐릭터 시퀀스와 매치하는 커런트 워드 캔디디트의 캐릭터 위치에서 시작하는 캐릭터 시퀀스가 없으면, 펑크션(2651)(2652)은 스코어 0과 함께 필터 매치에 대한 호출로부터 리턴한다.If the next element in the filter string is an ambiguous length element, function 2644 acts to cause loop 2646 to be performed for each character sequence represented by the ambiguous length element. This loop contains functions 2648-2652. Function 2648 checks whether there is a matching sequence of characters starting at the current candy character position that matches the current character sequence of loop 2646. If present, function 2649 changes the score of the word candid as a probable function of the recognized matching sequence represented by the obscure length element, and then the function 2650 performs current candite as many characters as the number of characters in the matching ambiguous length element sequence. Increase the current position of the character. If there is no character sequence starting at the character position of the current word candite that matches any character sequence associated with the ambiguity length element, functions 2601 and 2652 return from the call to filter match with a score of zero.
루프(2620)가 완료되면, 커런트 워드 캔디디트는 전체 필터 스트링에 대해서 매치된다. 이 경우, 펑크션(2653)은 루프(2620)에 의해 생성된 커런트 워드의 스코어와 함께 필터 매치로부터 리턴한다.When loop 2620 is complete, the current word candite is matched against the entire filter string. In this case, function 2653 returns from the filter match with the score of the current word generated by loop 2620.
스텝(2616)의 검사가 정의된 필터 스트링이 없다는 것을 발견하면 스텝(2654)은 단지 변경되지 않은 커런트 워드 캔디디트의 스코어와 함께 필터 매치로부터 리턴한다.If the check at step 2616 finds that no filter string is defined, step 2654 simply returns from the filter match with the score of the unchanged current word candice.
도 23의 펑크션(2318)을 참조하면, 각 워드 캔디디트를 위한 필터 매치에 대한 호출이 캔디디트를 위한 스코어를 리턴하는 것을 알 수 있다. 이것은 펑크션(2320)에서 어느 워드 캔디디트를 삭제할 것인가를 결정하는데 사용되는 스코어이다.Referring to function 2318 of FIG. 23, it can be seen that a call to a filter match for each word candidite returns a score for candidit. This is the score used to determine which word candies to delete in function 2320.
이 삭제(딜리션)가 일어나면, 펑크션(2320)의 임의 딜리션이 캔디디트의 목표 수 이하가된 이후 선행 인식 캔디디트의 남은 수를 펑크션(2322)이 검사한다. 통상, 이 목표수는 선택분류 리스트에서 사용하기 위한 선택분류의 목표수를 표현한다. 선행 인식 캔디디트의 수가 이 목표수 이하이면 펑크션(2324 - 2336)이 수행된다. 펑크션(2324)은 도 24 및 도 25에 도시한 바와 같이 발성 리스트에서 하나 이상의 엔트리의 매 하나당 음성인식을 수행한다. 펑크션(2326)(2328)으로 표시한 바와 같이, 이 인식 프로세스는 발성 리스트에서 연속 및 이산 엔트리 모두가 있는 가를 판정하는 검사를 포함하며, 이 검사에서 모두 있다면 연속 엔트리의 인식에서 있을 수 있는 워드 캔디디트의 수를 하나 이상의 이산 엔트리에서 검출된 개별 발성 수만큼 제한한다. 펑크션(2324)의 인식은 또한 연속 또는 이산 인식과 함께 발성 리스트에서 각 엔트리를 인식하는 단계를 포함하며, 이 인식단계는 도 24 및 도 25에 도시한 연속 또는 이산 인식 표시(인디케이션)(2406)에 의해 표시된 바와 같이 각각이 받아들여질 때 유효한 각 모드에 따라 이루어진다. 2332로 표시한 바와 같이, 각 발성 리스트 엔트리의 인식은 또한 앞서 설명한 바와 같이 필터 매치 루틴을 사용하는 단계와, 이러한 각 발성의 인식을 위한 베스트 스코어링 수용가능 캔디디트의 리스트를 선택하는데 있어 랭귀지 모델을 사용하는 단계를 포함한다. 필터 매치 루틴에 있어서, 발성 리스트에서 최신 발성을 표시하는 도 24 및 도 25의 어휘 인디케이터(2408)는 워드 타입 필터로서 사용되어 목표 워드 시퀀스가 특정 어휘로부터 하나 이상의 워드에 제한된다는 임의 표시(인디케이션)를 사용자에 의해 반영한다. 사용된 랭귀지 모델은 비그램(bigram) 또는 트리그램(trigram) 랭귀지 모델과 같은 폴리그램 랭귀지 모델이며, 베스트 스코어링 캔디디트 선택을 돕는데 유용한 임의 선행 랭귀지 콘텍스트를 사용한다.If this deletion (delivery) occurs, then the function 2322 checks the remaining number of preceding recognition candy edits after any delivery of function 2320 is less than or equal to the target number of candy edits. Typically, this target number represents the target number of the selection classification for use in the selection classification list. If the number of preceding recognition candies is less than or equal to this target, functions 2324-2336 are performed. The function 2324 performs voice recognition for every one or more entries in the speech list as shown in FIGS. 24 and 25. As indicated by functions 2326 and 2328, this recognition process includes a check to determine if there are both consecutive and discrete entries in the speech list, and if there is both a word that can be in the recognition of the consecutive entries The number of candies is limited by the number of individual utterances detected in one or more discrete entries. Recognition of function 2324 also includes the step of recognizing each entry in the speech list with continuous or discrete recognition, which is the continuous or discrete recognition indication (indication) shown in FIGS. As indicated by 2406, each is made according to each mode in effect when accepted. Recognition of each utterance list entry, as indicated by 2332, also includes the use of a filter match routine, as described above, and a language model for selecting a list of best scoring acceptable candies for recognition of each utterance. Using steps. In the filter match routine, the
발성 리스트에서 하나 이상의 엔트리 인식을 수행한 후, 발성 리스트에 하나 이상의 엔트리가 있으면, 펑크션(2334)(2336)은 여러가지 인식으로부터의 스코어를 조합한 것을 근거로 발성 리스트를 위한 베스트 스코어링 인식 캔디디트 리스트를 뽑는다. 본 발명의 이러한 특징과 관련한 일부 실시예에서, 스코어의 조합이 여러 가지 발성의 인식으로부터 사용될 수 있으며, 그 결과 하나 이상의 발성을 이용하 여 인식의 효과를 향상시킬 수 있음을 이해할 수 있다.After performing one or more entry recognitions in the utterance list, and if there is one or more entries in the utterance list, functions 2334 and 2336 are the best scoring recognition candies for the utterance list based on combining scores from various recognitions. Pull the list. In some embodiments relating to this aspect of the invention, it can be appreciated that a combination of scores may be used from the recognition of various utterances, and as a result, one or more utterances may be used to enhance the effectiveness of the recognition.
펑크션(2314 - 2366)에 의해 생성된 인식 캔디디트의 수가 목표 수 이하이면, 그리고 넌 널(non-null) 필터 스트링 필터 레인지 정의(디피니션)가 있다면, 펑크션(2338)(2340) 필터 매치를 사용하여 발성 리스트에서 최근 엔트리와 관련된 어휘로부터, 또는 이 발성리스트에서 엔트리가 없다면 커런트 인식 어휘로부터 부가(추가) 선택분류의 목표 수를 선택한다.If the number of recognition candies generated by functions 2314-2366 is less than or equal to the target number, and there is a non-null filter string filter range definition (definition), then the functions (2338) (2340) filter The match is used to select the target number of additional (additional) classifications from the vocabulary associated with the most recent entry in the utterance list, or from the current recognition vocabulary if there is no entry in the utterance list.
도 23의 겟 선택분류 루틴이 펑크션(2342)에 도달하는 시간에 인식 또는 커런트 어휘로부터 캔디디트가 없으면, 펑크션(2344)은 목표개수까지의 선택분류로서 커런트 필터 스트링을 매치하는 베스트 스코어링 캐릭터 시퀀스를 사용한다. 필터 스트링이 비모호 캐릭터만을 포함할 때, 이들 비모호 캐릭터를 매치하는 단일 캐릭터 시퀀스를 가능한 선택분류로서 선택한다. 그러나, 필터 스트링에서 모호 캐릭터 및 모호 길이 엘리멘트가 있으면 이러한 캐릭터 시퀀스 선택분류가 다수 있다. 모호 길이 엘리멘트를 갖는 모호 캐릭터가 하나 이상의 캐릭터로된 여러 가지 있을 수 있는 대응 시퀀스와 연관된 여러 가지 개연성을 가지고 있으면, 펑크션(2344)에 의해 생성된 선택분류는 도 26에서와 같이 펑크션(2616 -2606)에서 도시한 것과 같은 스코어링 기구에 대응하는 스코어가 된다.If there is no candy from recognition or current vocabulary at the time when the get selection classification routine of FIG. 23 reaches function 2342, function 2344 is the best scoring character that matches the current filter string as the selection classification up to the target number. Use sequences When the filter string contains only unambiguous characters, a single character sequence matching these unambiguous characters is selected as a possible selection. However, there are many such character sequence selection classifications if there is an ambiguous character and an ambiguous length element in the filter string. If an ambiguous character with an ambiguous length element has various probabilities associated with various possible correspondence sequences of one or more characters, the selection classification generated by function 2344 is a function 2616 as shown in FIG. A score corresponding to a scoring mechanism as shown at -2606).
겟 선택분류에 대한 호출이 리턴되면, 인식에 의해, 또는 필터에 따른 어휘로부터의 선택에 의해, 또는 있을 수 있는 필터의 리스트로부터의 선택에 의해 통상 리턴된다.When a call to get selection is returned, it is normally returned by recognition, by selection from the vocabulary according to the filter, or by selection from a list of possible filters.
도 22를 참조하면, 펑크션(2202)에서 겟 선택분류에 대한 호출이 디스플레이 선택분류 리스트 루틴으로 리턴하면, 펑크션(2204)은 필터가 커런트 선택을 위해 정의되었는가의 여부, 커런트 선택의 발성 리스트에 부가된 임의 발성이 있는가의 여부, 디스플레이 선택분류 리스트가 호출되기 위한 선택이 낱 선택분류 리트스에 없는가의 여부를 검사한다. 여기서 낱 선택분류 리스트는 사용자 입력이 표시하는 하나 이상의 워드 리스트로서 인식 캔디디트로서 필요하지 않은 것을 말한다.Referring to Fig. 22, when the call to get selection classification returns from the function 2202 to the display selection list routine, the function 2204 determines whether the filter is defined for current selection, the voice list of the current selection. It is checked whether or not there is any utterance added to the list, and whether the selection for the display selection list is called is not in the selection list. Here, the selection list is a list of one or more words that the user input indicates, which is not needed as a recognition candy.
이들 조건이 충족되지 않으면, 펑크션(2206)은 이 선택을 루틴이 생성하는 교정창에서 디스플레이를 위한 제1선택분류로 만든다. 다음에, 펑크션(2210)은 낱 선택분류 리스트에 포함되는 동시에 겟 선택분류에 대한 호출 루틴에 의해 생성된 캔디디트 리스트로부터 기타 다른 캔디디트를 제거한다. 다음에, 제1 선택분류가 이미 펑크션(2206)에 의해 선택되면 펑크션(2212)은 겟 선택분류에 대한 호출에 의해 리턴된 베스트 스코어링 캔디디트를 차후 교정창 디스플레이를 위한 제1선택분류로 만든다. 단일 베스트 스코어링 인식 캔디디트가 없으면, 알파벳 순차를 사용하여 제1선택분류가 될 캔디디트를 선택할 수 있다. 다음에, 펑크션(2218)은 특별 디스플레이를 위해 임의로 필터 스트링에 대응하는 제1선택분류의 이들 캐릭터를 선택한다. 아래 설명하는 바와 같이, 바람직한 실시예에서 비모호 필터에 대응하는 제1선택분류에서의 캐릭터는 한가지 방법으로 표시되며, 모호 필터에 대응하는 제1선택분류에서의 캐릭터는 여러가지 방법으로 표시되며, 사용자는 필터 스트링의 어느 부분이 필터 엘리멘트의 어느 타입과 대응하는 가를 이해할 수 있다. 다음에, 펑크션(2220)은 필터 스트링과 대응하지 않는 제1선택분류의 제1캐릭터 앞에 필터 커서를 둔다. 정의된 필터 스트링이 없을 때 이 커서는 제1선택분류의 제1캐릭터 앞에 놓인다.If these conditions are not met, function 2206 makes this selection the first selection for display in the calibration window that the routine creates. Function 2210 then removes any other candy from the candy list that is included in the individual classification list and created by the calling routine for the get selection. Next, if the first selection is already selected by function 2206, function 2212 returns the best scoring candid returned by the call to get selection to the first selection for display of the calibration window. Make. If there is no single best scoring recognition candid, then the alphabet sequence can be used to select the candidite to be the first classification. Function 2218 then arbitrarily selects these characters of the first selection class corresponding to the filter string for special display. As described below, in the preferred embodiment, the character in the first selective classification corresponding to the unambiguous filter is displayed in one way, and the character in the first selective classification corresponding to the ambiguous filter is displayed in various ways, and the user Can understand which part of the filter string corresponds to which type of filter element. Next, the function 2220 places the filter cursor in front of the first character of the first selection classification that does not correspond to the filter string. When no filter string is defined, this cursor is placed before the first character of the first classification.
다음에, 커런트 제1 선택분류 이외의 임의 캔디디트를 켓선택분류 루틴이 리턴하면, 펑크션(2222)은 스텝(2224-2228)을 수행시킨다. 이 경우, 펑크션(2224)은 한번에 교정창에 모두 끼워지는 베스트 스코어링 캔디디트 세트로부터 제1 캐릭터 순차 선택분류를 생성한다. 그 이상의 다른 인식 캔디디트가 있으면, 펑크션(2226)(2228)은 나머지 베스트 스코어링 캔디디트로부터 모드 선택분류를 위한 기설정 개수의 스크린 만큼 제2 캐릭터 순차 선택분류 리스트를 생성한다.Next, if the KET selection classification routine returns any candy other than the current first selection classification, the function 2222 performs steps 2224-2228. In this case, function 2224 generates a first character sequential selection classification from the best scoring candy set that fits all in the calibration window at once. If there is more recognition recognition than that, functions 2226 and 2228 generate a second character sequential classification list from the remaining best scoring candies as many as a predetermined number of screens for mode selection.
이러한 과정이 모두 이루어지면, 펑크션(2230)은 교정창을 디스플레이하며, 이 교정창에는 커런트 제1선택분류, 임의 또는 특정 필터에서 캐릭터를 받아들이는 표시(인디케이션), 커런트 커서 위치의 표시(인디케이션), 그리고 제1선택분류 리스트를 함께 담고 있다. 도 12에서 제1선택분류(1206)는 제1선택분류의 제1캐릭터 앞에 놓이는데 그 이유는 현재 정의된 필터가 없기 때문이다.When all of these processes are performed, function 2230 displays a calibration window, which includes a current first selection classification, an indication to accept a character from an arbitrary or specific filter, an indication of the current cursor position ( Indication), and the first classification list. In Fig. 12, the first selection classification 1206 is placed before the first character of the first selection classification because there is no filter currently defined.
커런트 선택 뿐만 아니라 관련 발성이 없는 텍스트 선택을 위해서도 널(null)값과 함께 디스플레이 선택분류 리스트 루틴을 호출할 수 있음을 알 수 있다. 이 경우, 펑크션(2338)(2340)의 동작을 기초로 워드 완성을 행하여 알파벳 입력에 대응한다. 이에따라 필터링이나 재발성을 사용하지 않고 발성 인식을 위한 선택분류를 선택하고, 선행 인식을 교정하는 것을 돕는 필터링 및/또는 재발성을 이용하고, 알파벳 필터링 입력에 따라 워드 완성을 행하며, 필요하다면, 차후 발성의 입력에 의해 이와같은 알파벳 완성 프로세스를 지원하고, 알파벳 입력과 함께 커런트 어휘에 있지 않은 워드를 스펠링하고, 캐릭터에 대해 모호 또는 비모호이거나 길이에 대해 모호인 폼을 포함하는 알파벳 입력의 여러가지 폼을 혼합 및 매치할 수 있다.It can be seen that the display classification list routine can be called with a null value for text selection as well as current selection. In this case, word completion is performed based on the operations of the functions 2338 and 2340 to correspond to the alphabet input. This allows you to select a classification for speech recognition without using filtering or recurrence, use filtering and / or recurrence to help correct previous recognition, perform word completion based on alphabetic filtering input, and if necessary, later Various forms of alphabetic input, including support for this alphabetic completion process by vocal input, spelling words that are not in the current vocabulary with alphabetical input, and forms that are ambiguous, unambiguous, or ambiguous for characters. Can be mixed and matched.
도 14를 참조하면, 디스플레이 선택분류 리스트 루틴을 호출하여 SIP 버퍼에서 워드 상에서의 탭에 펑크션(1436)(1438)이 반응하고, 이어서, 결과로서 도 12에 도시한 바와 같은 교정창이 디스플레이되는 방법을 설명하였다. 단지 한 워드 상에서의 탭에 의해 그 연관 선택분류 리스트와 함께 교정창을 디스플레이하는 능력은 사용자가 단일 워드 에러를 교정하도록 하기 위한 신속하고도 편리한 방법을 제공한다.Referring to FIG. 14, a function 1436 and 1438 reacts to a tap on a word in a SIP buffer by invoking a display classification list routine, and subsequently a calibration window as shown in FIG. 12 is displayed as a result. Explained. The ability to display the calibration window along with its associated classification list by tapping on just one word provides a quick and convenient way for the user to correct a single word error.
사용자가 SIP 버퍼에서 선택 상에서 더블 탭을 하면, 펑크션(1440 - 1444)은 디스플레이 되어 있을 임의 커런트 교정창으로부터 빠져나오고(이스케이프), 커런트 선택의 커런트 랭귀지 콘텍스트를 이용하여 커런트 인식도중모드 및 셋팅에 따라서 SIP 버퍼 인식을 시작한다. 도 18과 관련하여 위에서 설명한 목적을 위한 프레스 또는 클릭이 있는가의 여부에 대해 반응하는가를 판별하는데 있어서, 인식도중 로직은 이러한 더블 클릭과 연관된 키 프레스 타입의 도중에 반응한다. 임의 인식의 출력은 커런트 선택을 재개한다. 도면에 도시하지 않았지만, 사용자가 SIP 버퍼에서 한 워드에 더블 탭하면, 이것은 펑크션(1444)의 목적을 위한 커런트 선택으로 취급(간주)된다.When the user double taps on the selection in the SIP buffer, the functions 1440-1444 exit from any current calibration window to be displayed (escape) and use the current language context of the current selection to enter current recognition mode and settings. Therefore, SIP buffer recognition starts. In determining whether there is a press or click for the purpose described above with respect to FIG. 18, the recognition logic responds during the key press type associated with this double click. The output of random recognition resumes current selection. Although not shown in the figure, if a user double taps on a word in the SIP buffer, this is treated as current selection for the purpose of function 1444.
사용자가 텍스트를 포함하지 않는 SIP 버퍼의 임의 부분, 이를테면 워드 사이, 버퍼에서의 텍스트 전후에 탭을 하면, 펑크션(1446)은 펑크션(1448 - 1452)을 수행하도록 작용한다. 펑크션(1448)은 탭의 위치에서 커서를 플랜트한다. SIP 버퍼 에서 텍스트의 종료 이후에 있는 SIP 버퍼의 임의 부분에 탭이 위치하면, 커서는 이 버퍼에서 최후 워드 이후에 놓인다. 탭이 더블 팁이면, 펑크션(1450)(1452)은 커런트 인식 도중 모드 또는 기타 셋팅에 따라서 신규 커서 위치에서 SIP 버퍼 인식을 시작하며, 이때 프레스 또는 클릭에 대해 반응하는가의 여부를 판별하기 위한 더블 탭의 제2 터치 도중의 시간을 이용하게 된다.If the user taps on any portion of the SIP buffer that does not contain text, such as between words, before and after the text in the buffer, function 1446 acts to perform functions 1448-1452. Function 1484 plants the cursor at the position of the tab. If a tab is placed in any part of the SIP buffer after the end of the text in the SIP buffer, the cursor is placed after the last word in this buffer. If the tap is a double tip, functions 1450 and 1452 begin SIP buffer recognition at the new cursor position depending on the mode or other setting during current recognition, with a double to determine whether to respond to a press or click. The time during the second touch of the tap is used.
도 15는 도 13 및 도 14에 관하여 설명한 의사코드의 연속이다.FIG. 15 is a continuation of the pseudo code described with reference to FIGS. 13 and 14.
사용자가 SIP 버퍼에서 하나 이상의 워드 부분을 가로질러 드래그하면, 펑크션(1502)(1504)은 도 223에 관해 위에 설명한 디스플레이 선택분류 리스트 루틴을 호출하며, 모든 워드는 커런트 선택으로서 전체 또는 부분적으로 드래그되며 이들 워드의 인식과 연관된 음향 데이터는 임의로 발성 리스트에서의 제1엔트리로서 함께 표시된다.When the user drags across one or more word portions in the SIP buffer, functions 1502 and 1504 invoke the display classification list routine described above with respect to FIG. 223, with all words dragged in whole or in part as current selections. And acoustic data associated with the recognition of these words are optionally displayed together as the first entry in the speech list.
SIP 버퍼에서 개별 워드의 초기 부분에 대해 사용자가 드래그하면, 펑크션(1506)(1508)은 선택으로서 이 워드와 함께 디스플레이 선택분류 리스트 기능을 호출하며, 이 워드는 낱 선택분류 리스트에 부가되고, 워드의 드래그된 초기부분은 필터 스트링으로서 함께 표시되고, 이 워드와 연관된 음향 데이터는 발성 리스트에서의 제1 엔트리로서 표시된다. 이 진행 프로그램은 워드가 낱 선택분류 리스트에 부가되었다는 사실에 의해 표시된 바와 같이, 전체 워드가 목표 선택분류가 아니라는 표시(인디케이션)로서, 사용자가 워드의 초기 부분만을 드래그 하였다고 해석한다.When the user drags on the initial portion of an individual word in the SIP buffer, functions 1506 and 1508 invoke the display classification list function with this word as a selection, which word is added to the single classification list, The dragged initial portion of the word is displayed together as a filter string, and the acoustic data associated with this word is displayed as the first entry in the speech list. This progression program interprets that the user drags only the initial portion of the word as an indication that the entire word is not the target classification, as indicated by the fact that the word has been added to the individual classification list.
사용자가 SIP 버퍼에서 개별 워드의 종료를 드래그하면 펑크션(1510)(1512) 은 선택으로서 워드와 함께 디스플레이 선택분류 리스트 루틴을 호출하며, 이 선택은 낱 선택분류 리스트에 부가되고, 워드의 드래그 안된 초기부분을 필터 스트링으로서, 선택된 워드와 연관된 음향데이터는 발성 리스트에서 제1 엔트리로서 표시된다.When the user drags the end of an individual word in the SIP buffer, functions 1510 and 1512 call the display classification list routine with the word as a selection, which is added to the single classification list and the word is not dragged. The initial portion is the filter string, and the acoustic data associated with the selected word is displayed as the first entry in the speech list.
SIP 버퍼가 특정량 이상의 텍스트를 가졌다는 인디케이션을 수신하면, 펑크션(1514)(1516)은 버퍼가 풀 상태에 가깝다고 사용자에게 경고한다. 본 개시 실시예에서, 이 경고는 추가 캐릭터가 버퍼에 부가되면 버퍼가 자동으로 클리어될 것임을 사용자에게 통보하는 한편 사용자에게 버퍼에서의 현재 텍스트가 옳바른가를 검사하도록 하고 옳바르면 대화나 연속을 프레스하여 버퍼를 클리어할 것을 요청한다.Upon receiving an indication that the SIP buffer has more than a certain amount of text, functions 1514 and 1516 alert the user that the buffer is near full. In the present embodiment, this warning notifies the user that the buffer will be automatically cleared when additional characters are added to the buffer, while allowing the user to check whether the current text in the buffer is correct, and if it is correct, press the dialog or sequence to buffer Request to clear
SIP 버퍼가 텍스트 입력을 수신하였다는 인디케이션을 수신하면, 펑크션(1518)은 스텝(1520-1528)을 수행시킨다. 펑크션(1520)은 커서가 현재 SIP 버퍼의 종료에 있는가를 검사한다. 종료에 없으면, 펑크션(1522)은 SIP 버퍼 내에서 이 SIP 버퍼의 최후 레터로부터 커런트 커서 위치까지의 간격만큼의 백스페이스의 수를 운영체계 쪽으로 출력한다. 다음에, 펑크션(1526)은 하나 이상의 캐릭터로 구성될 수 있는 텍스트 입력으로 하여금 그 커런트 커서 위치에서 SIP 버퍼로 출력되도록 한다. 스텝(1527)(1528)은 SIP 버퍼에서의 동일한 텍스트 시퀀스 및 임의의 다음(폴로윙) 텍스트를 운영체계(OS)의 텍스트 입력으로 출력한다.Upon receiving an indication that the SIP buffer has received text input, function 1518 performs steps 1520-1528. Function 1520 checks if the cursor is at the end of the current SIP buffer. If not present, the function 1522 outputs the number of backspaces in the SIP buffer by the interval from the last letter of the SIP buffer to the current cursor position to the operating system. Function 1526 then causes text input, which may consist of one or more characters, to be output to the SIP buffer at its current cursor position. Steps 1527 and 1528 output the same text sequence and any next (following) text in the SIP buffer to the text input of the operating system (OS).
인식된 텍스트를 OS에 보내기 전에 OS에 백스페이스를 펑크션(1522)이 공급하였다는 사실과, 수신된 텍스트 이후의 임의 텍스트를 OS에 공급하였다는 사실로 인해 응용창에 미리 공급된 텍스트에 대응하는 SIP 버퍼의 텍스트에서의 임의 변경이 응용창에서 이 텍스트에도 야기되도록 한다.Responding to text pre-supplied to the application window due to the fact that function 1522 supplied backspace to the OS before sending the recognized text to the OS, and that the OS supplied arbitrary text after the received text. Any change in the text of the SIP buffer is caused to this text in the application window.
SIP 프로그램은 신규 SIP 버퍼 텍스트 입력의 인디케이션이 수신될 때 한번에 한번 모드(one-at-a-time)에 있으면, 펑크션(1536)은 텍스트 입력이 음성인식에 따라 발생하였는가의 여부를 검사한다. 그렇다면, 펑크션(1537)은 인식된 텍스트를 위해 디스플레이 선택분류 리스트 루틴을 호출하고, 펑크션(1538)은 교정모드를 턴오프한다. 통상, 디스플레이 선택분류 리스트 루틴의 호출은 시스템을 교정모드로 변환하지만 펑크션(1538)은 한번에 한번 모드가 사용될 때와 같은 경우가 되는 것을 방지한다. 전술한 바와 같이, 이렇게 하는 이유는 한번에 한번 모드에서 교정창이 워드의 발성에 대해 음성 인식이 수행될 때마다 자동으로 디스플레이되고, 그 결과 교정창으로의 입력 이외의 목적으로 사용되도록 SIP 인터페이스의 비교정창 측에 대해 사용자가 입력을 공급할 의도가 상대적으로 높다. 한편, 교정창은 하나 이상의 워드를 교정하기 원한다는 표시를 하는 특별 사용자 입력의 결과로서 디스플레이 되고 있으며 교정 모드가 엔터되어 특정 비교정창 입력은 교정창으로 향하게된다.If the SIP program is in one-at-a-time mode when an indication of a new SIP buffer text input is received, the function 1536 checks whether the text input occurred according to voice recognition. . If so, function 1537 calls the display classification list routine for the recognized text, and function 1538 turns off the calibration mode. Normally, the call to the display classification list routine converts the system to the calibration mode but the function 1538 prevents the same case as when the mode is used once. As mentioned above, the reason for this is that in the mode once at a time, the calibration window is automatically displayed each time a speech recognition is performed on the utterance of the word, so that the comparison window of the SIP interface is used for purposes other than input to the calibration window. The user intends to provide input to the side relatively. The calibration window, on the other hand, is displayed as a result of a special user input indicating that one or more words are desired to be calibrated and the calibration mode is entered so that a particular comparison window input is directed to the calibration window.
펑크션(1539)은 다음의 조건 세트가 충족되는가를 검사한다. 이 조건 세트로는 SIP가 한번에 한번 모드에 있고, 교정창이 디스플레이되지만 시스템은 교정모드에 있지 않은 조건을 말한다. 이러한 조건은 통상 한번에 한번 모드에서 워드의 각 발성 이후에 존재하는 스테이트(상태)를 말한다. 상기 조건이 존재하면, 펑크션(1540)은 교정창에서 제1선택분류의 인식을 확인하여 도 13, 도 14 및 도 15에서 상기 임의 입력에 반응하며, 그 이유는 이 선택분류가 텍스트 출력으로서 SIP 버퍼및 OS에 도입될 목적과, 하나 이상의 차후 워드의 인식을 위해 커런트 랭귀지 콘텍스트를 갱신할 목적과, 랭귀지 모델을 갱신하는데 사용하기 위한 데이터를 제공할 목적, 음향 모델을 갱신하기 위해 데이터를 제공할 목적 때문이다. 이에 따라 사용자는 많은 입력 중 임의의 하나로 한번에 한번 모드에서 워드의 선행 인식을 확인할 수 있으며, 이것은 또한 인식 프로세스를 향상시키는데도 사용될 수 있다.Function 1539 checks if the next set of conditions is met. This set of conditions is a condition where the SIP is in the mode once at a time and the calibration window is displayed but the system is not in the calibration mode. This condition usually refers to the state (state) that exists after each speech of a word in mode once at a time. If the above conditions exist, function 1540 confirms the recognition of the first selective classification in the calibration window and responds to the arbitrary input in FIGS. 13, 14 and 15, because this selective classification is a text output. Provide data for updating the acoustic model, for the purpose of being introduced into the SIP buffer and OS, for updating the current language context for the recognition of one or more subsequent words, for providing data for use in updating the language model For the purpose. This allows the user to verify prior recognition of a word in a mode one at a time with any of a number of inputs, which can also be used to enhance the recognition process.
사용자가 한번에 한번 모드에 있고, 선택분류 리스트에서 도시한 워드 교정을 희망하는 표시를 하는 입력을 발생시키면, SIP는 교정모드로 설정되고, 이 모드의 연속 도중에 이어지는 입력이 펑크션(1540)의 동작을 야기하지 않을 것임을 알 수 있다.If the user is in one mode at a time and generates an input that marks the desired word correction shown in the classification list, then the SIP is set to the calibration mode, and subsequent inputs to the function 1540 continue to operate. It will be understood that it will not cause.
도 15의 펑크션(1542)은 SIP 프로그램의 메인 반응 루프 중 일부의 시작을 표시하며, 이 SIP 프로그램은 교정창이 디스플레이될 때 수신되는 입력에 관한 것이다. 이 부분은 도 15의 나머지, 그리고 도 16 및 도 17의 모두를 통해 확대된다.Function 1542 of FIG. 15 marks the beginning of some of the main response loops of a SIP program, which relates to input received when a calibration window is displayed. This portion extends through the rest of FIG. 15 and through both FIGS. 16 and 17.
도 12에 도시한 교정창의 이스케이프(Escape) 버튼(1210)을 프레스하면, 펑크션(1544)(1546)은 SIP 프로그램이 교정 선택 없이 교정창을 빠져나가도록 한다.When the
도 12에 도시한 교정창의 딜리션 버튼(1212)을 프레스하면, 펑크션(1548)(1550)은 SIP 버퍼에서 커런트 선택을 삭제하고, 출력을 OS로 보내며, 이것으로인해 SIP버퍼에서의 텍스트에 대응하는 응용창에서의 임의 텍스트에 대응하는 변경이 이루어진다.When pressing the
도 12에 도시한 신규 버튼(1214)이 프레스되면, 펑크션(1552)은 펑크션(1553 - 1556)이 수행되도록 한다. 펑크션(1553)이 교정창에 대응하는 SIP 버퍼에서 커런트 선택을 삭제(딜리션)하고, 출력을 OS에 보내어 응용창에서의 텍스트에 대응 변경이 일어나도록 한다. 펑크션(1554)은 인식모드를 신규 발성 디폴트로 설정하며,, 이것은 통상 대형 어휘인식모드가 되며, 사용자에 의해 연속 또는 이산 인식모드로 설정될 수 있다. 펑크션(1556)은 커런트 인식 도중 모드 및 기타 다른 인식 세팅을 이용하여 SIP 버퍼인식을 시작한다. 전술한 바와 같이 펑크션(1518 - 1538)에 따라서 SIP 버퍼 인식은 입력을 SIP 버퍼로 입력을 제공하는 인식이다.When the
도 16은 교정창의 디스플레이 도중에 수신된 입력에 대해 SIP 프로그램의 메인 루프의 반응을 나타낸 연속도면이다.16 is a continuous diagram illustrating the response of the main loop of the SIP program to input received during the display of the calibration window.
도 12의 재발성 버튼(1216)이 프레스되면, 펑크션(1602)은 펑크션(1603 - 1610)이 수행하도록 작용한다. 펑크션(1603)은 SIP 프로그램이 교정모드에 있지않다면 그 프로그램을 이 모드로 설정한다. 이 모드 설정은 한번에 한번 모드에서 이산 워드 인식의 결과로서, 교정창에서 버튼을 프레스함에 의한 사용자 반응 결과로서, 교정창이 디스플레이되면 발생되며, 상기 버튼 프레스의 경우는 재발성 버튼으로서 교정목적을 위해 교정창을 사용할 의도를 표시한다. 이후 펑크션(1606)은 커런트 재발성 인식도중모드 및 기타 인식 세팅에 따라서 어휘를 포함한 하나 이상의 발성을 수신한다. 다음에 펑크션(1608)은 펑크션(1606)에서 수신된 하나 이상의 발성을 교정창 선택을 위해 발성 리스트에 부가하며, 이와 아울러 이들 발성 시간에 어휘모드와 연속 또는 이산 인식이 유효한가의 여부를 표시(인디케이션)한다.When
이후 펑크션(1610)이 상술한 바와 같이 도 22의 디스플레이 선택분류 리스트 루틴을 호출한다. 이것은 차례로 도 23과 관련하여 위에 설명한 겟 선택분류 펑크션을 호출하고, 펑크션(2306 - 2336)이 신규 발성 리스트 엔트리를 이용하여 재발성 인식을 수행하도록 작용한다.Thereafter, the function 1610 calls the display selection list routine of FIG. 22 as described above. This in turn invokes the get selection classification function described above with respect to FIG. 23, and functions 2306-2336 to perform recurrent recognition using the new speech list entry.
도 12에 도시한 필터 버튼(1218)이 프레스되면, 도 16의 펑크션(1612)은 펑크션(1613 - 1620)이 수행되도록 작용한다. 펑크션(1613)은 SIP 프로그램이 현재 없으면 교정모드로 진입(엔터)하며, 펑크션(1603)과 관련하여 위에 설명한 바와 같이, 펑크션(1614)은 커런트 엔트리 모드가 음성인식모드인가를 검사하며, 음성모드이면 커런트 필터 인식 도중 모드 및 셋팅에 따라서 펑크션(1616)이 필터 인식을 시작하도록 작용한다. 이 것은 그 인식에 의해 발생된 임의 입력이 커런트 필터 스트링의 커서로 향하도록 작용한다. 한편, 커런트 필터 엔트리 모드가 비음성 인식엔트리 창 모드이면, 펑크션(1618)(1620)은 적절한 엔트리 창을 호출한다. 전술한 바와 같이, 도시한 본 발명의 실시예에서 이들 비음성 엔트리 창모드는 캐릭터 인식 엔트리 모드, 수기 인식 엔트리 모드 및 키보드 엔트리 모드에 대응한다.When the
사용자가 도 12에 도시한 워드 폼 버튼(1220)을 프레스하면, 펑크션(1622 - 1624)은 SIP 프로그램이 현재 없다면 교정모드에 진입하도록 작용하며, 도 27의 워드 폼 리스트 루틴이 커런트 제1 선택분류 워드를 위해 호출되도록 작용한다. 사용자가 교정창 재디스플레이를 발생시키는 교정창에 대한 입력을 제공할 때까지 커런트 제1 선택분류는 통상 이제까지의 교정창을 호출하기 위한 선택이 된다. 이것은 SIP 버퍼에서 하나 이상의 워드를 선택하는 것으로 그리고, 교정창에서 워드 폼 버튼을 프레스하는 것으로 사용자가 신속하게 임의의 선택을 위한 대체 폼 리스트를 선택할 수 있다는 것을 의미한다.When the user presses the
도 25는 워드 폼 리스트의 기능을 도시한다. 호출될 때 교정창이 이미 디스플레이되면 펑크션(2702)(2704)은 커런트 베스트 선택분류를 워드 폼 리스트가 디스플레이될 선택으로서 간주(취급)한다. 커런트 선택이 일 워드이면, 펑크션(2706)은 펑크션(2708-2714)을 수행하도록 작용한다. 커런트 선택이 임의 동의어이면, 펑크션(2708)은 워드 폼 선택분류 리스트의 시작에 이들 동의어를 둔다. 다음에 스텝(2710)은 선택된 워드의 루트 폼을 찾고, 펑크션(2712)은 워드를 위한 대체 문법 폼의 리스트를 생성한다. 이후 펑크션(2714)을 알파벳순으로 임의 동의어 이후 선택분류 리스트에서 이들 모든 문법 폼을 정렬하며, 이것을 펑크션(2708)에 의해 리스트에 부가할 수도 있다.25 shows the function of the word form list. If a calibration window is already displayed when invoked, functions 2702 and 2704 consider (handle) the current best selection classification as the selection for which the word form list is to be displayed. If the current selection is one word, function 2706 acts to perform functions 2708-2714. If the current selection is any synonym, function 2708 places these synonyms at the beginning of the word form classification list. Step 2710 then finds the root form of the selected word, and function 2712 creates a list of alternative grammar forms for the word. Function 2714 then sorts all of these grammar forms in a sort list after any synonym in alphabetical order, which may be added to the list by function 2708.
한편, 선택이 다중 워드로 구성되면, 펑크션(2716)은 펑크션(2718 - 2728)이 수행되도록 작용한다. 펑크션(2718)은 선택이 그 워드 간에 임의 공간을 갖는가를 검사한다. 공간을 가지면, 펑크션(2720)은 선택분류 리스트에 선택의 카피를 부가하며, 이것은 워드 간에 상기 공간을 갖지 않는다. 그리고, 펑크션(2222)은 하이픈으로 대체된 공간을 갖는 선택의 카피를 부가한다. 도 27에 도시하지 않았지만, 부가 기능이 수행되어 하이픈을 공간으로 또는 공간이 없는 것으로 할 수도 있다. 선택이 동일 스펠링/비스펠링 변형을 받는 다중 엘리멘트를 가지면, 변형(2726)은 선택 및 모든 선행 선택분류 변형의 카피를 선택분류 리스트에 부가한다. 이것은 예를들면 일련 번호 네임을 수치 등가물로 변형하는 것, 이를테면 워드 "period" 를 대응구두 마크로 변형하는 등의 작용을 가능하게 한다. 다음에, 펑크션(2728)은 알 파벳 순으로 선택분류 리스트를 순차정렬한다.On the other hand, if the selection consists of multiple words, function 2716 acts to perform functions 2718-2728. Function 2718 checks if the selection has any space between the words. With space, function 2720 adds a copy of the selection to the classification list, which has no space between words. Function 2222 then adds a copy of the selection with spaces replaced by hyphens. Although not shown in FIG. 27, the additional function may be performed to make the hyphen a space or no space. If the selection has multiple elements that are subject to the same spelling / non-spelling variant, variant 2726 adds a copy of the selection and all of the preceding classification classification variants to the classification list. This makes it possible, for example, to transform serial number names into numerical equivalents, such as converting the word "period" into a corresponding phrase mark. Next, function 2728 sequentially sorts the selection list in alphabetical order.
선택분류 리스트가 단일 워드 또는 다중 워드 선택을 위해 생성되면, 펑크션(2730)은 제1선택분류로서 선택을 보여주는 교정창을 디스플레이하며, 이 교정창은 또한 제1 선택분류의 시작에서의 필터커서, 스크롤 가능 선택분류 리스트 및 스크롤 가능 리스트를 보여준다. 선택이 단일 워드이고, 그 필터가 모든 문법적 폼에서 발생하는 단일 시퀀스 캐릭터를 갖는 일부 실시예에서, 필터커서는 비모호 필터 스트링으로 표시된 공통(코몬) 시퀀스 이후에 놓일 수 있다.If the classification list is created for single word or multiple word selection, function 2730 displays a calibration window showing the selection as the first selection classification, which also displays the filter cursor at the beginning of the first selection classification. Displays a scrollable selection list and a scrollable list. In some embodiments where the selection is a single word and the filter has a single sequence character that occurs in all grammatical forms, the filter cursor may be placed after a common (common) sequence indicated by an unambiguous filter string.
본 발명의 일부 실시예에서, 워드 폼은 옵션 워드 폼의 단일 알파벳 순차 리스트를 제공한다. 다른 실시예에서, 옵션은 사용빈도에 따라 순차정렬될 수도 있고, 제1 및 제2 알파벳 순차 선택분류 리스트가 있을 수 있으며, 이 경우 제1선택분류 리스트는 가장 공통적으로 선택된 옵션폼으로서 한번에 교정창에서 끼워질 수 있는 형태가 되고, 제2리스트는 공통성이 떨어지는 정도의 워드 폼을 포함할 수 있을 것이다.In some embodiments of the invention, the word form provides a single alphabetical ordered list of optional word forms. In another embodiment, the options may be ordered according to frequency of use, and there may be first and second alphabetical ordered classification lists, in which case the first selection list is the most commonly selected option form at one time. It can be embedded in the form, and the second list may contain a word form with less commonality.
아래 설명하는 바와 같이, 워드 폼 리스트는 매우 공통적인 타입의 음성 인식 에러, 즉 제1 선택분류가 목표 워드의 동의어이거나 교체 문법적 폼일 경우의 에러를 교정하는 매우 신속한 방법이다.As described below, the word form list is a very common way to correct very common types of speech recognition errors, i.e. errors when the first classification is a synonym of the target word or an alternate grammatical form.
사용자가 도 12의 캐피털라이제이션 버튼(1222)을 프레스하면, 펑크션(1626 - 1628)은 시스템이 교정모드에 없다면 이곳으로 들어가며 교정창 커런트 제1 선택분류를 위해 캐피털라이즈 싸이클 펑크션을 호출한다. 캐피털라이즈 교정 싸이클은 초기 캐피털라이제이션을 갖지 않는 하나 이상의 워드 시퀀스가 각 워드의 초기 캐 피털라지제이션을 갖도록 하며, 초기 캐피털라이제이션을 갖는 하나 이상의 워드 시퀀스가 모든 캐피털라이제이션 폼으로 변경되도록 하고, 또한 모든 캐피털라이제이션 폼을 갖는 하나 이상의 워드 시퀀스가 모두 하위 케이스 폼으로 변경되도록 작용한다. 캐피털라이제이션 버튼을 반복적으로 프레스하면, 사용자는 신속하게 이들 폼 사이에서 선택을 할 수 있다.When the user presses the
사용자가 도 12에 도시한 플레이 버튼(1224)을 선택하면, 제1엔트리가 있다면 펑크션(1630)(1632)은 교정창 연관 선택과 관련된 발성리스트에서 제1엔트리의 오디오 플레이백에 작용한다. 그 결과, 하나 이상의 워드에 대한 미인식 시퀀스에 대하여 무엇이 발성되었나를 사용자가 정확하게 들을 수 있게 된다. 도시하지 않았지만, 바람직한 실시예로서 교정창이 먼저 디스플레이될 때 사용자는 오디오가 자동으로 플레이되도록 작용하는 셋팅을 선택할 수도 있다.When the user selects the
그레이 상태에서 디스플레이되지 않은 경우 도 12에 도시한 애드 워드 버튼(Add Word Button)(1226)을 프레스하면, 펑크션(1634)(1636)은 다이얼로그 박스를 호출하며, 이 다이얼로그 박스는 사용자가 커런트 제1선택분류 워드를 액티브 또는 백업 어휘로 진입할 수 있도록 한다. SIP 인식자의 특정 실시예에서, 시스템은 대형어휘모드를 사용하는 정상 인식 도중에 인식에 유용한 액티브 어휘로서 그 전체 어휘의 서브세트를 사용한다. 펑크션(1636)은 사용자가 워드를 만드는 것을 가능하게 하며, 이 워드는 정상상태에서 액티브 어휘의 백업 어휘 일부에 있다. 또한 이 펑크션은 워드를 액티브 또는 백업 어휘에 부가하는 것을 가능하게 하며, 이 부가 워드는 어휘에 속하지는 않지만 알파벳 입력에 의해 제1선택분류창에 스펠링된 것 을 말한다. 보다 큰 하드웨어 자원을 갖는 본 발명의 다른 실시예에 있어서는, 액티브와 백업 어휘 간의 구별이 필요없음을 이해할 수 있을 것이다.If it is not displayed in the gray state, when the
애드 워드 버튼(1226)은 제1선택분류 워드가 액티브 어휘에 현재 있지 않으면 넌 그레이 스테이트(non-grayed state)에만 있다. 이러한 구조는 사용자가 제1선택분류를 액티브 또는 백업 어휘에 부가하기 원한다는 인디케이션을 그 사용자에게 제공한다.
사용자가 도 12에 도시한 체크 버튼(1228)을 선택하면, 펑크션(1638 - 1648)은 커런트 교정창을 제거하고, 그 제1선택분류를 SIP 버퍼에 제공하며, 응용창에서 텍스트에 대응 변경을 주는데 필요한 키스트로크 시퀀스를 OS에 공급한다.When the user selects the
도 12에 도시한 교정창에서의 선택분류 중 하나를 사용자가 선택하면, 펑크션(1650 - 1653)은 커런트 교정창을 제거하고, SIP 버퍼에 선택된 선택분류를 출력하며, 응용창에서 대응 변경을 주는데 필요한 키스트로크의 시쿼스를 OS에 공급한다.When the user selects one of the selection categories in the calibration window shown in FIG. 12, the functions 1650-1653 remove the current calibration window, output the selected classification to the SIP buffer, and change the corresponding change in the application window. It supplies the OS with a sequence of keystrokes needed to give it.
도 12에 도시한 선택분류 에디트 버튼(1232) 중 하나는 사용자가 탭하면, 펑크션(1654)은 펑크션(1656 - 1658)이 수행되도록 작용한다. 펑크션(1656)은 시스템이 교정모드에 없으면 교정모드로 변경한다. 펑크션(1656)은 탭이된 선택분류 에디트 버튼과 연관된 선택분류가 제1선택분류가되고, 커런트 필터 스트링이 되도록 한다. 이후 펑크션(1658)은 신규 필터 스트링과 함께 디스플레이 선택분류 리스트를 호출한다. 아래 설명하는 바와 같이, 이 펑크션을 통해 사용자는 커런트 필터 스트링으로서 선택분류 워드 또는 워드 시퀀스를 선택하고, 이후 필터 스트링을 에디트 (편집)할 수 있으며, 이 에디트는 통상 목표 워드와 일치하지 않는 캐릭터를 그 종료 부분에서 삭제하는 것으로 행해진다.When one of the selection
제1 선택분류를 포함하는 임의 선택분류 중 하나 이상의 초기 캐릭터를 사용자가 드래그하면, 펑크션(1664-1666)은 교정모드에 없으면 시스템을 이 교정모드로 변경하고, 드래그된 선택분류를 선택분류 리스트에 부가하고, 필터 스트링으로서 선택분류 중 드래그된 초기부분과 함께 디스플레이 선택분류 리스트를 호출한다. 이들 펑크션은 커런트 선택분류가 목표 제1선택분류가 아니지만 이 것의 드래그된 초기부분이 목표 선택분류를 찾는데 도움을 주도록 필터로서 사용되어야 한다는 표시를 사용자가 할 수 있도록 해준다.If the user drags one or more initial characters of the arbitrary selection that includes the first selection, the functions 1664-1666 change the system to this calibration mode if not in calibration mode, and the dragged classification is selected. In addition to, call the display selection list with the initial portion dragged out of the selection as a filter string. These functions allow the user to indicate that the current classification is not the target first classification but the dragged initial portion of it should be used as a filter to help find the target selection.
도 17은 SIP 인식자가 교정창 입력에 반응하여 만든 펑크션 리스트의 최종 연속물을 보여준다.Figure 17 shows the final sequence of function lists created by the SIP identifier in response to the calibration window input.
사용자가 제1선택분류를 포함하는 선택분류의 종료를 드래그하면, 펑크션(1702)(1704)은 교정모드에 없으면 시스템을 교정모드로 진입시키고 부분 드래그된 선택분류를 낱선택분류 리스트에 부가시키고, 선택분류 중 드래그안된 초기부분은 필터 스트링으로 하여 디스플레이 선택분류 리스트를 호출한다.When the user drags the end of the selection including the first selection, the functions 1702 and 1704 enter the calibration mode if not in calibration mode and add the partially dragged selection to the single selection list. In the selection classification, the initial dragged portion is called a filter string and the display selection classification list is called.
사용자가 선택분류에서 2개의 선택분류를 드래그하면, 펑크션(1706 - 1708)은 교정모드에 없으면 시스템을 교정모드로 진입시키고 2개의 선택분류를 낱선택분류 리스트에 부가시키고, 이 2개의 선택분류를 커런트 필터 레인지의 정의(디피니션)에서의 시작과 종료로 하여 디스플레이 선택분류 리스트를 호출한다.If the user drags two selections from the selection, the functions 1706-1708 enter the calibration mode if not in the calibration mode, add the two selections to the single selection list, and add these two selections. Call the display selection list with the start and end of the current filter range definition (definition).
사용자가 제1선택분류에서 캐릭터 상에서 탭을 하면, 펑크션(1710 - 1712)은 SIP가 교정모드에 없다면 교정모드에 진입하고 필터 커서를 탭이된 위치로 이동시킨다. 이 때 디스플레이 선택분류 리스트에 대한 호출은 없는데, 그 이유는 사용자가 필터에 대해 어떠한 변화도 주지않기 때문이다.If the user taps on the character in the first classification, functions 1710-1712 enter calibration mode if the SIP is not in calibration mode and move the filter cursor to the tapped position. There is no call to the display classification list because the user does not make any changes to the filter.
도 13의 펑크션(1334)에 대하여 위에 설명한 바와 같이, 교정모드에 있을 때 사용자가 백스페이스 버튼(1116)을 프레스하여 백스페이스를 엔터하면, 펑크션(1714)은 펑크션(1718 - 1720)이 수행하도록 작용한다. 펑크션(1718)은 백스페이스가 입력될 때 도 28 및 도 29의 필터 에디트 루틴을 호출한다.As described above with respect to the function 1334 of FIG. 13, when the user presses the
도 28에 도시된 바와 같이, 필터에디트 루틴(2800)은 비모호, 모호 및/또는 모호 길이 필터 엘리멘트와 함께 필터 에디트(편집)에 있어서 사용자에게 유연성을 주도록 구성되어 있다.As shown in FIG. 28, filter edit routine 2800 is configured to give the user flexibility in filter editing with unambiguous, ambiguous and / or obscure length filter elements.
이 루틴은 펑크션(2802)을 포함하여 필터 커서의 커런트 위치 이전에 호출된 선택분류의 임의 캐릭터가 있는가를 검사하고, 있다면, 펑크션(2804)으로 하여금 루틴이 호출된 필터 스트링을 올드 필터 스트링으로서 정의하도록 작용한다. 펑크션(2806)은 필터커서 위치 앞에서 루틴이 호출된 선택분류에서의 캐릭터를 신규 필터 커서로하여 이 스트링에서 모든 캐릭터를 비모호한 것으로 정의한다. 그 결과 사용자는 제1 선택분류의 임의 부분을 정의할 수 있게 되는데 그 이유는 교정필터 캐릭터로서 자동 확인된 에디트의 위치 때문이다.This routine checks whether there is any character of the selection classification called before the current position of the filter cursor, including function 2802, and if so, causes function 2804 to use the filter string from which the routine was called as the old filter string. Act to define. Function 2806 defines all characters in this string as unambiguous, with the new filter cursor as the character in the selection classification whose routine is called before the filter cursor position. As a result, the user can define any part of the first selection classification because of the position of the edit automatically identified as the correction filter character.
다음에, 펑크션(2807)은 필터 에디트가 호출되도록 한 입력 백스페이스인가의 여부를 검사하며, 백스페이스이면 펑크션(2808 - 2812)이 수행되도록 작용한다. 펑크션(2808)(2810)은 필터 커서가 비선택 커서이면 신규 필터 스트링의 최후 캐릭 터를 삭제(딜리션)한다. 필터 커서가 커런트 제1 선택분류에서 하나 이상의 캐릭터 선택에 대응하면, 이들 캐릭터는 바로 설명한 펑크션(2806)의 동작에 의해 신규필터에 이미 포함되지 않은 것이다. 그러면, 올드 필터 스트링을 클리어하게되는데 그 이유는 필터 에디트에 대한 입력이 백스페이스일 때 백스페이스의 위치 우측에 대한 선행 필터 부분이 이 필터에서 장래의 포함을 의도하고 있지 않기 때문이다. 이 작용으로 인해, 필터커서 위치의 우측에 미리 존재할 수 있는 필터 스트링에서 임의 모호 뿐만 아니라 비모호 엘리멘트도 삭제된다.Next, function 2807 checks whether it is an input backspace that caused the filter edit to be called, and if so, functions 2808-2812 are performed. Functions 2808 and 2810 delete (deliver) the last character of the new filter string if the filter cursor is an unselected cursor. If the filter cursor corresponds to one or more character selections in the current first selection classification, these characters are not already included in the new filter by the operation of the function 2806 described immediately. The old filter string is then cleared because the preceding filter portion to the right of the position of the backspace is not intended for future inclusion in this filter when the input to the filter edit is backspace. This action eliminates any ambiguity as well as any ambiguity in the filter string that may already exist to the right of the filter cursor position.
필터 에디트 루틴을 호출시키는 입력이 하나 이상의 비모호 캐릭터이면, 펑크션(2814)(2816)은 하나 이상의 비모호 캐릭터를 신규 필터 스트링의 종료에 부가한다.If the input to call the filter edit routine is one or more unambiguous characters, functions 2814 and 2816 add one or more unambiguous characters to the end of the new filter string.
필터 에디트 루틴에 대한 입력이 고정된 길이를 갖는 하나 이상의 모호 캐릭터 시퀀스이면, 펑크션(2818)(2820)은 신규 필터의 종료에서 시퀀스에 각 모호 캐릭터를 표현하는 엘리멘트를 둔다.If the input to the filter editing routine is one or more ambiguous character sequences of fixed length, functions 2818 and 2820 place an element representing each ambiguous character in the sequence at the end of the new filter.
필터 에디트 루틴에 대한 입력이 모호 길이 엘리멘트이면 펑크션(2822)은 펑크션(2824 - 2832)이 수행되도록 작용한다. 펑크션(2824)은 모호 입력와 연관된 레터의 베스트 스코어가 되는 시퀀스를 선택하며, 이것은 필터의 선행 비모호 부분에 부가되면, 어휘 워드의 모두 또는 초기부분에 대응한다. 이 기능이 수행될 때 신규 필터 스트링의 선행 부분 모두가 상기 설명한 펑크션(2806)의 동작에 의해 확인되었음을 이해해야 한다. 다음에, 펑크션(2826)은 특정 최소 스코어 이상으로 펑크션(2824)에 의해 선택된 임의 시퀀스가 있는가를 검사하며, 있다면 기능(2828)이 어 휘와는 무관하게 베스트 스코어링 레터 시퀀스를 선택하도록 작용한다. 이와같이 하는 이유는 펑크션(2826)에서 검사(본 명세서에서는 "테스트"와 같은 의미로 사용함)의 조건이 충족되면 모호 필터가 사용되어 어휘 워드를 스펠링하기 때문이다. 다음에 펑크션(2830)(2832)은 펑크션(2824 -2828)에 의해 선택된 캐릭터 시퀀스를 신규 모호 필터 엘리멘트와 연관시키고, 이 신규 모호 필터 엘리멘트를 신규 필터 스트링의 종료에 부가시킨다.If the input to the filter edit routine is an ambiguous length element, function 2822 acts to cause functions 2824-2832 to be performed. Function 2824 selects a sequence that is the best score of the letter associated with the ambiguity input, which, when added to the preceding unambiguous portion of the filter, corresponds to all or the initial portion of the lexical word. It should be understood that when this function is performed, all of the preceding portions of the new filter string have been identified by the operation of the function 2806 described above. Next, function 2826 checks whether there is any sequence selected by function 2824 above a certain minimum score, and if so, function 2828 acts to select the best scoring letter sequence regardless of the vocabulary. . The reason for doing this is because an obfuscal filter is used to spell the lexical word if the condition of the test (in the present specification, used in the sense of "test") is satisfied in function 2826. Functions 2830 and 2832 then associate the character sequence selected by functions 2824-2828 with the new ambiguity filter element and add this new ambiguity filter element to the end of the new filter string.
다음에, 올드 필터 스트링에서 루프(2834)가 각 필터 엘리멘트를 위해 수행된다. 이 루프는 도 28 나머지에 도시한 기능(2836 - 2850)과 도 29에 도시한 기능(2900 - 2922)을 포함한다.Next, a loop 2834 in the old filter string is performed for each filter element. This loop includes the functions 2836-2850 shown in the rest of FIG. 28 and the functions 2900-2922 shown in FIG. 29.
루프(2834)의 커런트 올드 필터 스트링 엘리멘트가 펑크션(2814 - 2820)에 의해 신규 필터 스트링에 부가된 신규 고정 길이 엘리멘트를 벗어난 모호 고정 길이 엘리멘트이면, 펑크션(2836)(2838)은 올드 엘리멘트가 이들 신규 엘리멘트의 범위를 벗어난 것이라면 이 올드 엘리멘트를 신규엘리멘트에 부가한다. 이렇게 하는 이유는 백스페이스 버튼을 사용하는 것 이외의 필터 스트링의 에디트가 미리 진입된(엔터된) 필터 정보를 삭제하지 않고 또한 이 필터정보가 신규 에디트의 우측에 대한 선행 필터의 일부에 상당하기 때문이다.If the current old filter string element of the loop 2834 is an ambiguous fixed length element outside of the new fixed length element added to the new filter string by the functions 2814-2820, the functions 2836 and 2838 are delimited by the old element. If the new element is out of range, the old element is added to the new element. The reason for doing this is that an edit in the filter string other than using the backspace button does not delete the filter information that was entered (entered) beforehand, and that this filter information corresponds to part of the preceding filter for the right side of the new edit. to be.
루프(2834)의 커런트 올드 엘리멘트가 펑크션(2822 - 2832)의 동작에 의해 신규 필터 스트링의 종료에 부가된 신규 모호 길이 엘리멘트에서 일부 시퀀스를 벗어나는 모호 고정 길이 엘리멘트이면, 펑크션(2840)은 펑크션(2842 - 2850)이 수행하도록 작용한다. 펑크션(2842)은 필터 스트링에 부가되는 신규 모호 길이 엘리멘 트에 의해 표현된 각 캐릭터 시퀀스를 위해 루프를 실행한다. 신규 모호 길이 엘리멘트의 상기 캐릭터 시퀀스 각각을 위해 수행되는 상기 루프는 루프(2834)의 커런트 올드 모호 고정 길이 엘리멘트와 일치하는 각 캐릭터 시퀀스를 위해 수행되는 루프(2844)를 포함한다. 이 내부 루프(2844)에 포함된 펑크션(2846)은 올드 엘리멘트가 매치되는가 그리고 신규 엘리멘트에서 커런트 시퀀스을 벗어나는 가를 검사(테스트)한다. 벗어나면, 펑크션(2848)은 신규 모호 길이 엘리멘트에 의해 표현된 캐릭터 시퀀스 리스트에 신규 캐릭터 시퀀스를 부가하며, 이 신규캐릭터 시퀀스는 신규 엘리멘트로부터 커런트 시퀀스를 벗어나는 올드 엘리멘트로부터 시퀀스의 일부를 더한 신규 엘리멘트로부터 커런트 시퀀스에 대응한다.If the current old element of loop 2834 is an ambiguous fixed length element that deviates from some sequence in the new ambiguity length element added to the end of the new filter string by the operation of functions 2822-2832, then function 2840 is a puncture. Options 2842-2850 serve to perform. Function 2842 executes a loop for each character sequence represented by the new ambiguity length element added to the filter string. The loop executed for each of the character sequences of the new ambiguity length element includes a loop 2844 performed for each character sequence that matches the current old ambiguity fixed length element of the loop 2834. The function 2846 included in this inner loop 2844 checks (tests) whether the old element matches and whether it exits the current sequence in the new element. Once off, function 2848 adds the new character sequence to the character sequence list represented by the new obscure length element, which is a new element that adds a portion of the sequence from the old element that deviates from the new element. Corresponds to the current sequence from.
커런트 올드 엘리멘트가 신규 필터에 부가된 신규 고정 길이 엘리멘트를 벗어난 임의 캐릭터 시퀀스를 포함하는 모호 길이 엘리멘트이면, 도 29의 펑크션(2900)은 펑크션(2902 - 2910)이 수행되도록 작용한다.If the current old element is an ambiguous length element that includes an arbitrary character sequence that deviates from the new fixed length element added to the new filter, then the function 2900 of FIG. 29 serves to perform the functions 2902-2910.
펑크션(2902)는 하나의 루프로서 올드 모호 길이 엘리멘트에 의해 표현된 각 시퀀스를 위해 수행된다. 이 펑크션은 올드 엘리멘트로부터의 커런트 시퀀스가 매치되는가의 여부 및 신규 고정 길이 엘리멘트를 벗어나는가를 검사하는 테스트(검사)(2904)를 포함한다. 벗어나면, 펑크션(2906)은 신규 엘리멘트를 벗어나는 올드 엘리멘트로부터의 그 확대분량에 대응하는 신규 캐릭터 시퀀스를 생성한다. 이 루프가 완료되면, 펑크션(2908)은 임의의 신규 시퀀스가 펑크션(2906)에 의해 생성되었나의 여부를 검사하며, 생성되었다면, 펑크션(2910)으로 하여금 이 신규 모호 길일 엘리멘트를 신규 엘리멘트 이후의 신규 필터의 종료에 부가시키도록 한다. 이 신규 모호 길이 엘리멘트는 펑크션(2906)에 의해 생성된 각 시퀀스의 가능성을 표현한다. 바람직하게는 개연성 스코어는 커런트 신규 고정 길이 엘리멘트를 매치시키기 위해 루프(2902)에 의해 발견된 캐릭터 시퀀스 각각의 상대 개연성 스코어에 기초하여 상기 신규 시퀀스 각각과 연관시킨다. 커런트 올드 엘리멘트가 신규 길이 엘리멘트에서의 일부 캐릭터 시퀀스을 벗어난 일부 캐릭터 시퀀스를 갖는 모호 길이 엘리멘트 이면, 펑크션(2912)은 펑크션(2914 - 2920)을 수행하도록 작용한다. 펑크션(2914)은 신규 모호 길이 엘리멘트에서 각 캐릭터 시퀀스를 위해 수행되는 루프이며, 올드 모호 길이 엘리멘트에서 각 캐릭터 시퀀스를 위해 수행되는 내부 루프(2916)로 구성된다. 이 내부루프는 펑크션(2928)(2920)으로 구성되며, 올드 엘리멘트로부터의 캐릭터 시퀀스가 매치되면서 신규 엘리멘트로부터의 커런트 캐릭터 시퀀스를 벗어나는가를 검사하고, 벗어나면, 신규 모호 길이 엘리멘트와 신규 캐릭터 시퀀스를 연관시키며, 여기서 신규 캐릭터 시퀀스는 커런트 올드 엘리메트 캐릭터 시퀀스로부터 확대된(벗어난) 분량을 더한 신규 엘리멘트로부터의 커런트 시퀀스에 대응하는 것이다.Function 2902 is performed for each sequence represented by the old obscure length element as a loop. This function includes a test (inspection) 2904 that checks whether the current sequence from the old element matches and leaves the new fixed length element. Upon departure, function 2906 creates a new character sequence corresponding to the amount of expansion from the old element leaving the new element. When this loop is complete, function 2908 checks whether any new sequence was generated by function 2906, and if so, causes function 2910 to send this new ambiguous Gil element to a new element. To the end of the new filter afterwards. This new ambiguity length element represents the likelihood of each sequence generated by function 2906. Preferably the probability score is associated with each of the new sequences based on the relative probability scores of each of the character sequences found by loop 2902 to match the current new fixed length elements. If the current old element is an ambiguous length element with some character sequence outside of some character sequence in the new length element, function 2912 acts to perform functions 2914-2920. Function 2914 is a loop performed for each character sequence in the new obscure length element and consists of an inner loop 2916 performed for each character sequence in the old obscure length element. This inner loop consists of functions 2928 and 2920, and checks whether the character sequence from the old element matches the current character sequence from the new element and if so, the new ambiguity length element and the new character sequence Where the new character sequence corresponds to the current sequence from the new element plus the enlarged (away) amount from the current old element character sequence.
루프(2834)에서의 모든 펑크션이 완료되면, 펑크션(2924)은 호츨로부터 필터 에디트로 리턴하며, 이때 상기 호출에 의해 생성된 신규 필터 스트링이 함께 수반된다.Once all of the functions in loop 2834 are complete, function 2924 returns from the call to the filter edit, accompanied by the new filter string generated by the call.
본 발명의 여러 가지 측면(또는 특징)을 갖는 많은 실시예를 통해, 다양하면서도 보다 간단한 구조의 필터 에디트 스킴(scheme)을 사용할 수 있음을 알 수 있다. 그러나, 도 28 및 도 29에 도시한 필터 에디트 스킴의 가장 중요한 이점은 연 속 레터 인식에 의해 신속하에 모호 필터를 진입(엔터)할 수 있도록 하고, 이어서 연속하여 이것을 보다 신뢰성 있는 알파벳 엔트리 모드나 심지어 차후 연속 레터 인식으로도 편집할 수 있다는 점이다. 예를들면, 이 스킴은 연속 레터 인식에 의해 엔터된 필터를 이산 레터 인식, ICA 워드 인식, 심지어 수기 인식을 통한 입력으로 모두 또는 부분적으로 대체할 수 있도록 한다. 이 스킴 하에서, 사용자가 필터 스트링의 초기부분을 에디트할 때, 필터 스트링의 이후 부분에 포함된 정보는 사용자가 그 의도를 표시하지 않는한 파괴되지 않으며, 이것은 도시한 실시예서는 백스페이스 캐릭터를 사용하여 이루어진다.Through many embodiments having various aspects (or features) of the present invention, it can be seen that a variety of simpler filter edit schemes can be used. However, the most important advantage of the filter editing schemes shown in Figs. 28 and 29 is that it is possible to enter (enter) an ambiguous filter quickly by successive letter recognition, which in turn can lead to a more reliable alphabet entry mode or even It can also be edited with subsequent letter recognition. For example, this scheme makes it possible to replace all or part of a filter entered by continuous letter recognition with input through discrete letter recognition, ICA word recognition, or even handwriting recognition. Under this scheme, when the user edits the initial part of the filter string, the information contained in the later part of the filter string is not destroyed unless the user indicates its intention, which is illustrated in the illustrated embodiment using a backspace character. It is done by
도 17을 참조하면, 펑크션(1718)에서 필터 에디트에 대한 호출이 리턴할 때, 펑크션(1724)은 이 호출에 의해 리턴된 신규 필터 스트링과 함께 디스플레이 선택분류 리스트를 호출한다.Referring to FIG. 17, when a call to filter edit returns in function 1718, function 1724 calls the display selection list with the new filter string returned by this call.
필터 입력이 수신될 때마다, 도 16의 펑크션(1612)에 대하여 상기 설명한 필터키의 프레스에 반응하여 수행되는 인식 결과에 의해서, 그리고 그 밖의 다른 수단에 의해서, 펑크션(1722 - 1738)이 수행된다.Each time a filter input is received, by means of a recognition result performed in response to the press of the filter key described above with respect to the function 1612 of FIG. Is performed.
펑크션(1724)은 시스템이 한번에 한번 인식 모드에 있는가의 여부, 그리고 필터 입력이 음성 인식에 의해 수행되는가의 여부를 검사하며, 그렇다면, 펑크션(1726 - 1730)이 수행되도록 작용한다. 펑크션(1726)은 필터 캐릭터 선택분류 창, 이를테면 도 39에 도시한 창(3906)이 현재 디스플레이되었나를 테스트(검사)하여, 그렇다면 펑크션(1728)은 필터 선택분류 창을 폐쇄하고, 펑크션(1730)은 입력으로서 제1 선택분류 필터 캐릭터와 함께 필터 에디트를 호출한다. 그 결과, 필터 스트 링에서 모든 선행 캐릭터가 비모호로 정의된 필터 시퀀스로서 취급(간주)되도록 한다. 펑크션(1726)의 테스트(검사)의 결과에 관계없이, 펑크션(1732)은 펑크션(1722) 및 그 아래에 리스트된 다른 펑크션의 동작을 촉발하는 신규 필터 입력을 위해 필터 에디트를 호출한다. 이후, 펑크션(1734)은 커런트 선택과 신규 필터 스트링을 위해 디스플레이 선택분류 리스트를 호출한다. 이후, 시스템이 한번에 한번 모드에 있으면, 펑크션(1736)(1738)은 필터 캐릭터 선택분류 루틴을 호출하며, 이와 아울러 필터 스트링은 필터 에디트에 의해 리턴되고, 신규 인식된 필터 입력 캐릭터는 선택된 필터 캐릭터로서 간주된다.Function 1724 checks whether the system is in recognition mode one at a time and whether the filter input is performed by speech recognition, and if so, functions 1726-1730 are performed. Function 1726 tests (checks) whether a filter character selection window, such as
도 30은 필터 캐릭터 선택분류 서브루틴(3000)의 동작을 나타낸다. 이 서브루틴의 기능(3002)은 루틴을 호출하는 선택된 필터 캐릭터가 다중 베스트 선택분류 캐릭터를 갖는 커런트 필터에서 모호 캐릭터 또는 비모호 캐릭터에 대응하는가를 검사한다. 대응하면, 펑크션(3004)은 이 캐릭터에 연관된 모든 캐릭터로 필터 캐릭터 선택분류 리스트를 설정한다. 캐릭터의 수가 한번에 필터 캐릭터 선택 분류 리스트상에 끼워질 범위 이상이면, 선택분류 리스트는 스크롤 가능하는 버튼을 가지고 이러한 부가 캐릭터을 사용자가 볼 수 있도록 해준다. 바람직하게는 목표 캐릭터에 대해 사용자가 더욱 신속하게 스캔을 하는 것을 용이하게 하기 위해 알파벳 순차로 선택분류 리스트를 디스플레이 한다. 도 30의 필터 캐릭터 선택분류 루틴은 또다른 펑크션(3006)을 포함하며, 이 펑크션은 커런트 필터 스트링에서 모호 길이 필터 스트링 엘리멘트의 캐릭터에 선택된 필터 캐릭터가 대응하는가를 검사하고, 대응하면, 이 펑크션은 펑크션(3008 - 3014)이 수행하도록 작용한다. 펑크션(3008) 은 선택된 필터 캐릭터가 모호 길이 엘리멘트의 제1 캐릭터인가의 여부를 검사하고, 그렇다면 펑크션(3010)은 모호 엘리멘트의 연관 캐릭터 시퀀스 중 임의의 것에서 모든 제1 캐릭터와 동일하게 필터 캐릭터 선택 분류 리스트를 설정한다. 선택된 필터 캐릭터가 모호 길이 엘리멘트의 제1 캐릭터에 대응하지 않으면, 펑크션(3012)(3014)은 커런트 제1 선택분류에서 선택된 필터 캐릭터에서와 같은 동일 캐릭터가 선행하는 모호 엘리멘트에 의해 표현되는 임의 캐릭터 시퀀스에 있어 그 모든 캐릭터와 동일하게 필터 캐릭터 선택분류 리스트를 설정한다. 펑크션(3002)(3004) 또는 펑크션(3006-3014)가 필터 캐릭터 선택분류 리스트를 생성하면 펑크션(3016)은 도 39에 도시한 창(3906)과 같은 창에서 이 선택분류 리스트를 디스플레이한다.30 shows the operation of the filter character selection classification subroutine 3000. The function 3002 of this subroutine checks whether the selected filter character invoking the routine corresponds to an ambiguous character or an unambiguous character in a current filter having multiple best selection classification characters. Correspondingly, function 3004 sets the filter character selection classification list to all characters associated with this character. If the number of characters is more than a range to fit on the filter character selection classification list at one time, the classification list allows the user to see these additional characters with scrollable buttons. Preferably, the selection classification list is displayed in alphabetical order to facilitate the user's faster scanning of the target character. The filter character selection classification routine of FIG. 30 includes another function 3006, which checks whether the selected filter character corresponds to the character of the obscure length filter string element in the current filter string, and if so, The function acts to cause the functions 3008-3014 to perform. Function 3008 checks whether the selected filter character is the first character of the ambiguous length element, and if so, function 3010 is the same as any first character in any of the associative character sequences of the ambiguous element. Sets the selection classification list. If the selected filter character does not correspond to the first character of the ambiguous length element, the functions 3012 and 3014 are arbitrary characters represented by an ambiguous element preceded by the same character as in the filter character selected in the current first selection. Set the filter character selection list to be the same as all of the characters in the sequence. If functions 3002, 3004 or functions 3006-3014 generate a filter character selection list, function 3016 displays this selection list in a window such as
SIP 프로그램이 필터 캐릭터 선택분류 창에서 필터 캐릭터 선택분류의 사용자에 의해 선택을 수신하면, 펑크션(1740)은 펑크션(1742 - 1746)이 수행되도록 작용한다. 펑크션(1742)은 선택이 이루어지는 필터 선택분류 창을 폐쇄한다. 펑크션(1744)이 신규 입력으로서 필터 선택 창에서 선택된 캐릭터와 함께 커런트 필터 스트링을 위해 필터 에디트 펑크션을 호출한다. 그러면, 펑크션(1746)은 필터 에디트에 의해 리턴된 신규 필터 스트링과 함께 디스플레이 선택분류 리스트 루틴을 디스플레이 한다.When the SIP program receives a selection by the user of the filter character selection classification in the filter character selection classification window, the function 1740 functions to perform the functions 1742-1746. Function 1742 closes the filter selection window in which the selection is made. Function 1744 calls the filter edit function for the current filter string with the character selected in the filter selection window as a new input. Function 1746 then displays the display classification list routine with the new filter string returned by the filter edit.
도 45의 교정창(4526)(4538)에 도시한 타입으로 필터 스트링에서 캐릭터로부터의 드래그가 업워드되면, 펑크션(1747)은 펑크션(1748 - 1750)이 수행하도록 작용한다. 펑크션(1748)은 드래그가 이루어진 캐릭터를 위해 필터 캐릭터 선택분류 루틴을 호출하며, 이것은 이 캐릭터에 연관된 임의 다른 캐릭터 선택분류가 있다면 필터 캐릭터 선택분류 창이 생성되도록 한다. 이 창에서 필터 선택분류 캐릭터에 대해 드래그가 해제되면, 펑크션(1749)은 해제가 발생한 필터 캐릭터 선택분류의 선택을 생성한다. 따라서 바로 설명한 펑크션(1740 - 1746)의 동작을 일으킨다. 필터 캐릭터 선택분류 창에서 선택분류 이외에서 드래그가 해제되면 펑크션(1750)은 필터 선택분류 창을 폐쇄한다.If the drag from the character in the filter string is upwarded to the type shown in the
도 13 및 도 14의 펑크션(1350)(1356)(1414)(1416)에 대해 상기 설명한 바와 같이, 교정모드 중에 대형 어휘 버튼이나 네임 어휘 버튼을 프레스 하는 것과 같이, 펑크션(1602)(1610)에 대하여 상기한 바와 같이, 재발성 버튼의 프레스에 의한 것 이외의 것으로 재발성이 수신되면, 도 17의 펑크션(1752)은 펑크션(1754)(1756)이 수행되도록 작용한다. 펑크션(1754)은 교정창의 선택 발성 리스트에 이러한 신규 발성을 부가한다. 그리고 펑크션(1756)은 선택을 위해 디스플레이 선택분류 리스트 루틴을 호출하여 신규 발성을 이용하여 재인식을 수행한다.As described above with respect to the functions 1350, 1356, 1414, and 1416 of FIGS. 13 and 14, the
도 31 내지 도 41을 참조하여 바로 설명한 사용자 인터페이스가 텍스트 시퀀스를 틱테이드하는데 사용되는 방법을 설명한다. 이 특정 시퀀스에서 인터페이스는 한번에 한번 모드로 예시하며, 이 모드는 이산이식모드로서, 선택분류 리스트를 갖는 교정창이 이산 발성이 인식될 때마다 디스플레이되도록 한다.31 to 41, a description will be given of a method in which the immediately described user interface is used to tick a text sequence. In this particular sequence, the interface is illustrated in one mode at a time, which is a discrete transplant mode, which allows a calibration window with a classification list to be displayed whenever discrete speech is recognized.
도 31에서, 부호 3100은 신규 언어 콘텍스트에서 시작하는 디텍이션을 개시하도록 사용자가 대화버튼(1102)을 탭핑하는 것을 보여준다. 대형 어휘버튼(1132)의 하일라이트로 표시된 바와 같이, SIP 인식자는 대형 어휘모드에 있다. 연속/이 산 버튼(1134) 상에서의 개별 도트 시퀀스는 인식자가 이산 인식모드에 있음을 표시한다. 도 18의 부호 1810 내지 1816에 대하여 설명한 발성인식도중의 종료에 대해 프레스 및 클릭 모드에 SIP가 있다고 가정한다. 그 결과, 대화버튼의 클릭을 통해 인식이 다음 발성의 종료때까지 발생하게된다. 부호 3102는 워드 "this"의 사용자에 의해 이 발성을 표현한다. 부호 3104는 SIP 텍스트 창(1104)에 인식된 텍스트(3016)를 두고, "this" 텍스트는 응용창(1106)에 출력시키고, 제1 선택분류 창(1202)과 제1선택분류 리스트(1208)에서 인식된 워드를 포함하는 교정창(1200)을 디스플레이하여 "this" 발성에 반응한 후 PDA의 스크린 이미지(영상)를 표시한다.In FIG. 31, reference numeral 3100 shows the user tapping
도 31의 예에서, 사용자는 부호 3108로 표시한 바와 같이 캐피털라이제이션 버튼(1222)을 탭한다. 그 결과 PDA 스크린은 3110으로 표시된 외관을 갖게되며, 여기서 커런트 제1선택분류 및 텍스트가 SIP버퍼에서 출력되고, 응용창이 초기 캐피털라이제이션을 갖도록 변경된다.In the example of FIG. 31, the user taps the
실시예에서 사용자가 부호 3102에 표시한 바와같이 연속 버튼(1104)을 클릭하고, 이어서 워드 "is"를 부호 3114에 표시한 바와 같이 발성한다. 본 예에서, 상기 발성은 "its"로 오인식된 것으로 가정하며 이에 따라 PDA 스크린은 부호 3116으로 표시된 바와 같은 외관을 가지며, 제1선택분류(3118)로서 그리고, 이 인식(1208)을 위한 신규 선택분류 리스트로서 오인식 워드를 갖는 신규 교정창(1200)이 디스플레이된다. In the embodiment, the user clicks on the
도 32는 본 예의 연속을 표현하며, 여기서 사용자는 부호 3202로 표시된 이미지에서 선분분류 워드 "is" (3200)를 클릭한다. 그 결과, PDA 스크린은 부호 3204로 표시된 외관을 가지며, 여기서 교정창이 제거되고, 교정 텍스트가 SIP 버퍼 창과 응용창에 나타난다.32 represents a continuation of this example, in which the user clicks on line classification word "is" 3200 in the image indicated by
부호 3206으로 표시된 스크린숏에서 사용자는 레터 네임 어휘 버튼(1130)을 탭하며, 그 결과 버튼(1130)의 하일라이트로 표시된 바와 같이 커런트 인식 모드가 레터 네임 어휘로 변경된다. 펑크션(1410)(1412)에 대해 설명한 바와 같이 이 버튼 탭으로 커런트 인식도중 모드에 따라서 음성인식을 시작하게 한다. 그 결과 시스템은 부호 3208로 표시한 바와 같이 레터 네임 "e"의 차후 발성을 인식하게 된다.In the screenshot indicated by 3206, the user taps the letter
인식오류를 신속하게 교정하는 본 발명의 인터페이스 능력을 강조하기 위해, 본 예에서는 시스템이 교정창에 표시된 바와 같이 "p"(3211)와 같은 레터를 오인식하였다고 가정하며, 여기서의 교정창은 발성(3208)에 반응하여 한번에 한번 모드에서 디스플레이된 것이다. 그러나, 부호 3210으로 표시한 교정창에서 볼 수 있는 바와 같이, 교정레터 "e"는 교정창에 도시한 선택분류 중 하나이다. 부호 3214에 표시된 교정창을 보면, 사용자는 선택분류(3212)를 탭하며, 이것은 PDA 스크린이 부호 3215에 표시된 외관을 갖도록 하며, 여기서 교정 레터는 SIP버터와 응용창 모두에 진입한다.In order to emphasize the interface ability of the present invention to quickly correct a recognition error, this example assumes that the system has misrecognized a letter such as "p" 3211 as indicated in the calibration window, where the calibration window is called speech ( In response to 3208). However, as can be seen in the calibration window indicated by
도 33은 본 예의 연속을 도시하며, 여기서 사용자는 버튼(11024)으로 표시한 스크린 숏으로 나타낸 바와 같은 발음 어휘 버튼(11024)에 탭을 한다. 그 결과 부호 3300으로 표시되는 워드 "period"의 발성을 야기하는 발성인식을 시작하며, 이에 따라 인식어휘를 하일라이트 부호 3302로 표시한 바와 같은 발음 어휘로 변경하여 부호 3304에 표시한 교정을 행하며, 여기서 구두 마크 "." 가 제1 선택분류 창 에 표시되고, 이어서 구두의 네임이 이어지면서 사용자가 인식을 보다 용이하게 행다도록 한다.33 illustrates a continuation of this example, where the user taps on the phonetic vocabulary button 11024 as shown in the screen shot indicated by button 11024. As a result, speech recognition that causes utterance of the word "period" indicated by 3300 is started, thereby changing the recognition vocabulary to a pronunciation vocabulary such as indicated by the
본 예에서는 교정 인식이므로 사용자가 그것을 확인하고 스크린숏 부호 3306으로 도시한 바와 같이 버튼(1130)을 프레스하고, 레터 "1."의 발성(3308)을 말하여 레터 네임 어휘를 이용하면서 신규 발성의 인식을 시작한다. 주기가 이어지는 레터를 입력하는 이 프로세는 PDA 스크린이 부호 3312로 도시한 외관을 가질 때까지 반복되며, 이 시점에서 스크린 숏(3314)으로 도시한 바와같이 사용자는 텍스트 "e.l.v.i.s."를 드래그한다고 가정하며, 그 결과 이 텍스트가 선택되고, 도 34의 상부 좌측 핸드 코너 부근의 스크린 숏(3400)에서 교정창(1200)이 디스플레이 되도도록 한다. 커런트 어휘에 선택된 텍스트 스트링이 없다고 가정하므로, 이 선택분류 리스트에서 디스플레이된 대체 선택분류는 없다. 3402로 표시한 교정창을 보면, 사용자는 워드 폼 버튼(1220)을 탭하며, 이에 따라 도 27에 대하여 전술한 워드 폼 리스트 루틴을 호출하게 된다. 선택된 텍스트 스트링이 스페이스를 포함하므로, 이것은 펑크션(2716 - 1728) 예시한 도 27의 루틴 부분이 수행되도록 하는 다중 워드 선택으로 간주되며, 이것은 교정창의 선택으로부터 공간이 제거되는 선택분류(3406)을 포함하는 3404로 표시되는 선택분류 리스트를 포함한다. 본 예에서, 사용자는 최근접 선택분류(3406) 옆의 에디트 버튼(1232)를 탭한다. 부호 3410으로 표시된 교정창에서 보면, 선택분류(3406)는 제1선택분류로서 선택되며, 이것은 3412로 표시한 교정창에서 표시한 바와 같다. 교정창이 스크린 숏(3414)에 표시한 외관을 갖는 시점으로서 제1 선택분류가 모든 캐피털라이즈가 될 때까지 사용자는 캐피 털라이제이션 버튼(1222)을 탭한다. 이 시점에서 사용자는 3416으로 표시한 바와 같이 발음어휘버튼(1124)에 사용자는 클릭을 하고, 3418로 표시된 바와같이 발성 "comma"라는 말을 한다. 본 예에서 이 발성은 올바르게 인식되어 부호 3420으로 표시된 교정창(1200)이 디스플레이되고, 이전 제1 선택분류 "e.l.v.i.s."가 텍스트로서 출력된다고 가정한다.In this example, the calibration is recognized, so the user confirms it and presses the
도 35는 본 예의 연속이다. 여기서, 사용자는 부호 3500으로 표시된 대형 어휘 버튼을 클릭하고, 발성 "the"(3502)을 말한다고 가정한다. 그 결과 교정창(3504)이 디스플레이된다. 사용자는 다시 3506으로 표시된 대형 어휘 버튼을 프레스하여 이 인식을 확인하여 반응하면서 3508로 표시된 발성 "embedded"를 말한다. 본 예에서는 이에 따라 교정창(3510)이 디스플레이되고, 여기서 상기 발성은 워드 "imbedded"로 오인식되고, 또한 여기서 목표 워드가 제1선택분류 리스트에 도시되지 않는다. 코멘트 3512로 표시한 바와 같이 이 시점부터 시작하여 다수의 여러가지 교정 옵션이 예시된다.35 is the continuation of this example. Here, it is assumed that the user clicks on the large vocabulary button denoted by the
도 36은 오인식과 연관된 제1 및 제2선택분류 리스트를 스크롤하는 교정 옵션을 예시한다. 부호 3604로 표시한 교정창에 있어서, 교정창의 스크롤 바(3602)에서 페이지 다운 스크롤 버튼(3600)를 사용자가 탭핑하며, 그 결과 교정창(3606)에 표시한 제2선택분류 리스트(3605)의 제1스크릴 풀로 제1선택분류 리스트(3603)가 교체된다. 이 장면에서 볼 수 있는 바와 같이 교정창의 슬라이드 바(3608)은 수평바(3609) 아래에서 하향 이동하며, 이 수평바는 제1 선택분류 리스트의 종료와 연관된 스크롤 바에서 위치를 규정(정의)한다. 본예에서는 목표 워드가 3606으로 도 시한 알파벳 순차 제2 선택분류 리스트의 부분에 없으며, 이에 따라 사용자는 3610으로 표시한 바와 같이 스크롤 바의 페이지 다운 버튼을 프레스한다. 그 결과 교정창은 3612로 표시된 외관을 가지며, 여기서 알파벳으로 리스트된 선택분류의 신규 스크린 풀이 표시된다. 본 예에서는 3616으로 표시된 바와 같이, 이 선택분류 리스트 상에 목표 워드 "embedded"가 도시된다. 본 예에서, 3618로 표시된 교정창에서와 같은 목표 선택분류와 연관된 이 선택분류 버튼(3619)에 사용자가 클릭한다. 그 결과, 교정창이 3620에 표시된 장면을 갖게되며, 여기서 이 선택분류는 제1선택분류 창에서 디스플레이 된다. 본 예에서 사용자는 부호 3622로 표시된 캐피털라이즈 버튼을 탭하며, 이 버튼은 상기 제1선택분류가 스크린숏(3624)에 도시한 바와 같이 초기 캐피털라이제이션을 갖도록 한다.36 illustrates a calibration option for scrolling through the first and second classification lists associated with misperception. In the calibration window indicated by
따라서, SIP 사용자 인터페이스는 상대적으로 다수의 인식 선택분류 중에서 사용자가 선택을 행하는 신속한 방법을 제공하는 것을 알 수 있다. 도시한 실시예에서 제1선택분류 리스트는 6개의 선택분류로 구성되고, 제2선택분류 리스트는 18 개 까지의 추가 선택분류의 3개까지의 추가 스크린을 포함한다. 선택분류가 알파벳으로 정렬되어 있고, 모든 4개의 스크린을 일초 이하에서 볼 수 있으므로 사용자는 24개 까지의 선택분류 중에서 매우 신속하게 선택이 가능하다.Thus, it can be seen that the SIP user interface provides a quick way for the user to make a selection among a relatively large number of recognition choices. In the illustrated embodiment, the first selection classification list consists of six selection classifications, and the second selection classification list includes up to three additional screens of up to 18 additional selection classifications. The selections are sorted alphabetically and all four screens can be viewed in less than a second, allowing the user to quickly select from up to 24 selections.
도 37은 선택분류의 초기 부분을 드래그하여 선택분류를 필터링하는 방법을 예시하며, 이것은 도 16의 펑크션(1664 - 1666)에 대하여 전술한 바와 같다. 본 실시예에서, 제1선택분류 리스트는 3700으로 표시한 교정창의 선택분류(3702)를 포함하는 것으로 가정하며, 이 선택분류는 목표 워드 "embedded"의 제1 6-캐릭터를 포 함한다. 교정창(3704)에 예시한 바와같이, 사용자는 이들 초기 6-레터에 대해 드래그하며, 시스템은 인식 캔디디트로 제한된 신규 교정창을 디스플레이하는 것으로 반응을 보이며, 여기서 인식 캔디디트는 스크린숏(3706)에 디스플레이된 바와 같이, 6 캐릭터에 대응하는 비모호 필터와 함께 시작한다. 이 스크린숏에서, 목표워드는 제1선택분류이고, 제1선택분류의 제1 6-비모호 확인 레터는 박스(3708)에 표시한 바와 같이 하일라이트되고, 필터커서(3710)도 또한 예시된다.FIG. 37 illustrates a method of filtering a selection classification by dragging an initial portion of the selection classification, as described above with respect to functions 1664-1666 of FIG. 16. In this embodiment, it is assumed that the first selection classification list includes the
도 38은 도 17의 펑크션(1706 - 1708)에 대하여 전술한 선택분류 리스트에서 2개의 선태분류를 드래그하여 선택분류를 필터링하는 방법을 예시한다. 본 예에서, 교정창(3800)은 목표 선택분류 "embedded"를 디스플레이하며, 이것은 2개의 디스플레이된 부호 3802와 3804 사이에 알파벳 순으로 발생한다. 3806으로 도시한 바와 같이, 이들 2개의 선택분류를 드래그하여 알파벳 상의 이 범위에 목표 워드가 속하는 것임을 사용자가 표시한다. 그 결과 신규 교정창이 디스플레이되며, 여기서 있을 수 있는 선택분류는 스크린숏(3808)으로 표시한 바와 같이 선택된 알파벳 범위에서 발생하는 워드로 제한된다. 본 예에서 목표워드는 제1선택분류로서, 그리고 3806에 도시한 선택에 의해 야기된 필터링의 결과로서 선택된다고 가정한다. 이 스크린숏에서 3806에서 선택된 2개의 선택분류의 초기부분을 형성하는 제1선택분류의 부분은 필터 스트링(3810)의 비모호 확인 부분으로 표시되며, 필터커서(3812)는 이 확인된 필터부 이후에 위치한다.FIG. 38 illustrates a method of filtering selection classification by dragging two selection classifications from the selection classification list described above with respect to the functions 1706-1708 of FIG. 17. In this example, the
도 39는 목표 워드 선택분류를 선택하는 것을 돕기 위해 한번에 한번모드에서 알파벳 필터링이 사용되느 방법을 예시한다. 본 실시예에서, 사용자는 교정창 (3900)에서 표시한 필터 버튼을 프레스한다. 디폴트 필터 어휘는 레터 네임 어휘로 가정한다. 필터 버튼을 프레스하면, 다음 발성을 위한 음성인식을 시작하게 되고, 사용자는 3902로 표시한 레터 "e"를 말한다. 그 결과 교정창(3904)이 표시되며, 여기서는 필터 캐릭터가 "p."로서 오인식된 것으로 가정한다. 도시한 실시예에 있어서는 한번에 한번 모드에서 알파벳 입력 또한 그 인식을 위해 디스플레이된 선택분류 리스트를 갖는다. 이 경우, 이 리스트가 도 30의 필터 캐릭터 선택분류 서브루틴에 대하여 전술한 타입의 필터 캐릭터 선택분류 리스트 창(3906)일 수 있다. 본 예에서, 사용자는 목표 필터링 캐릭터로서 3908에 도시한 레터 "e,"를 선택하며, 이것에 의해 신규 교정창(3900)이 디스플레이 된다. 본 예에서, 사용자는 다시 3912에 도시한 바와같이 필터 버튼을 프레스하여 부가 필터링 레터를 입력할 것을 결정하고, 발성 "m"(3914)을 말한다. 그 결과 교정창(3916)이 디스플레이되어 필터 캐릭터 선택분류 창(3918)을 디스플레이한다. 교정창에서, 필터링 캐릭터는 바르게 인식되고, 사용자는 추가 필터링 캐릭터를 말하거나 창(3916)에 나타낸 바와 같이 교정 레터를 선택하여 이 필터링 캐릭터를 확인할 수 있다. 이러한 목표 필터링 캐릭터의 확인으로 인해 신규교정창이 디스플레이되며, 이 창에는 비모호로 확인된 필터의 스트링으로서 간주되는 필터 스트링 "em" 이 표시된다. 스크린 숏(3920)에서 도시한 예에서, 이것으로 인해 목표워드가 인식된다.39 illustrates how alphabetic filtering is used in one mode at a time to help select a target word selection. In this embodiment, the user presses the filter button displayed in the
도 40은 알파브라보 또는 ICA 워드, 알파벳 스펠링과 함께 알파벳 필터링 방법을 예시한다. 스크린숏(4000)에서, 사용자는 알파브라보 버튼(1128)을 탭한다. 이것으로 인해 알파벳이 ICA 워드 알파벳으로 변경되며, 이것에 대해서는 도 14의 펑크션(1402 - 1408)에 설명한 바와 같다. 본 예에서, 디스플레이_알파_온_더블_클릭_변수는 설정되지 않은 것으로 가정한다. 따라서 도 14의 펑크션(1406)은 알파브라보 버튼(1128)의 프레스 중에 스크린숏(4004)에서 도시한 ICA 워드(4002)의 리스트를 디스플레이한다. 본예에서, 사용자는 ICA 워드 "에코"를 엔터하며, 이것은 레터 "e"를 표현하고, 이어서 4008로 나타낸 알파브라보 키로부터 제2 프레스가 이어진다. 그리고 "m"으로 표현되는 제2 ICA 워드 "Mike"의 발성도 이어진다. 본 예에서, 이들 2개의 알파벳 필터링 캐릭터를 연속하여 입력하여 목표 레터 "em"으로 구성된 비모호 필터 스트링을 생성하고, 목표 워드 "embedded"의 인식을 생성한다.40 illustrates an alpha filtering method with alpha bravo or ICA word, alphabet spelling. In
도 41은 사용자가 필터로서 선택분류의 일부를 선택하고, 알파브라보 스펠링을 이용하여 시스템의 어휘, 이 경우는 만들어진 워드 "embedded"에 없은 한 워드의 선택을 완성하는 방법을 예시한다.Figure 41 illustrates how a user selects a portion of a selection classification as a filter and uses alpha bravo spelling to complete the selection of a word that is not in the system's vocabulary, in this case the word "embedded" created.
본 예에서, 사용자에게는 교정창(4100)에 제시되며, 이 교정창은 하나의 선택분류(4100)를 포함하는 동시에 목표워드의 제1 6-레터를 포함한다. 교정창(4104)에서 도시한 바와 같이, 사용자는 제1 6-레터를 드래그하여 이들 레터가 커런트 필터 스트링의 비모호 확인 캐릭터가 되도록 한다. 그 결과로 교정창(4106)이 생성된다. 스크린숏(4108)은 이 교정창의 디스플레이를 도시하는 것으로서 사용자는 필터 버튼(1218)으로부터 드래그를 행하고 이산/연속 버튼(1134)상에서 해제를 하면서 스크린 숏(4108)에서 도시한 버튼 상에 연속 라인으로 표시한 바와 같이 이산 필터 딕테이션 모드로부터 연속 필터 딕테이션 모드로 변경한다. 스크린 숏(4110)에서, 사용자는 알파 버튼을 다시 프레스하고, "Echo, Delta, Echo, Sierra, Tango"와 같 은 ICA 워드을 포함하는 발성을 행한다. 그 결과 커런트 필터 스트링은 목표 워드의 스펠링에 대응한다. 이 필터 스트링에 대응하는 매치하는 어휘에 워드가 없기 때문에 필터 스트링 자체는 교정창(4114)로 표시한 바와 같이 제1 선택분류가 되고, 4116에 도시한 바와 같이, 사용자는 체크 버튼 상에 탭을 하여 제1 선택분류의 선택을 표시하는 한편 PDA 스크린은 4108에 도시한 외관을 갖는다.In this example, the user is presented to the
도 42 내지 도 44는 연속 음성의 딕테이션, 인식 및 교정을 보여준다. 스크린숏(4200)에서, 사용자는 도 13의 펑크션(1310 - 1314)에 대하여 설명한 클리어 버튼(1112)을 클릭한다. 그 결과 SIP 버퍼(1104)에서의 텍스트가 클리어되며, 이때 스크린숏(4204)에 표시한 바와 같이, 응용창(1106)에서 대응 텍스트와 연관된 변화는 전혀 발생하지 않는다. 스크린 숏(4204)에서 사용자는 연속/이산 버튼(1134)을 클릭하며, 이것으로 스크린숏(4002)에 도트 시퀀스로 버튼 상에 표시한 이산 인식으로부터 스크린숏(4204)에 도시한 연속라인을 행하는 것으로 변경된다. 그러므로, 커런트 인식 도중 모드에 따라서 음성인식이 시작되고, 사용자는 부호 4206으로 표시한 바와 같이 "large vocabulary interface system from voice signal technologies period"라는 연속 발성을 행하게 된다. 스크린숏(4208)에 표시한 바와 같이 이러한 발성을 인식하고, SIP 버퍼(1004)에 인식된 텍스트를 두는 한편 OS를 통해 응용창(1106)에도 두는 것으로 시스템이 반응한다. 인식된 텍스트가 한번에 SIP창 내에 끼워질 수 있는 분량 보다 다소 크기 때문에 사용자는 부호 4210에 표시한 바와 같이 SIP창에서 스크롤을 하고, 워드 "vocabularies"(4214)에 탭을 하여 도 14의 펑크션(1436 - 1438)이 상기 워드를 선택하는 한편 이것을 위한 교정창 을 생성하도록 작용한다. 이에 대한 반응으로 교정창(4216)이 디스플레이된다. 본예에서, 목표 워드 "vocabulary"(4218)가 상기 교정창의 선택분류 리스트에 있다. 교정창(4220)에서 사용자는 상기 워드에 탭을 하여 이것을 선택하며, 그 결과 SIP버퍼와 응용창 모두에 있는 워드 "vocabularies"가 상기 선택된 워드로 교체된다.42-44 show dictation, recognition and correction of continuous speech. In
도 43을 참조로 연속설명한다. 상기 교정창은 스크린숏(4300)으로 예시되어 있다. 본 예에서, 사용자는 4302에 표시한 바와 같이 4개의 오류 워드 "enter faces men rum"을 드래그하면서 선택한다. 그 결과 4304로 표시한 바와 같이, 펑크션(1502)(1504)이 선택으로서 드래그된 워드와 함께 선택분류 창을 디스플레이한다.Continuous description will be given with reference to FIG. The calibration window is illustrated by
도 44는 도 43의 바닥에 도시한 교정창이 선택분류 리스트와 함께 수평, 수직 스크롤의 조합으로 교정되는 방법을 예시한 것이다. 부호 4400은 도 43의 4304에서 도시한 것과 같은 교정창을 나타낸다. 여기에는 디스플레이된 수직 스크롤 바(4602) 뿐만 아니라 수평 스크롤 바(4402)도 있다. 사용자는 수직 스크롤 바에서 페이지 다운 버튼(3006)을 탭하여 디스플레이된 선택분류 리스트 부분이 4400에 도시한 일 페이지 알파벳 순차 제1 선택분류 리스트의 디스플레이로부터 4404에 도시한 제2 알파벳 순차 선택분류 리스트의 제1페이지로 이동하도록 한다. 본 예에서, 제2선택분류 리스트의 상기 부분에서 인식 캔디디트는 "interface system from"이라는 목표 인식출력과 매치하는 캐릭터 시퀀스와 함께 시작하지 않는다. 따라서 사용자는 다시 부호 4408과 같이 페이지 다운 스크롤 버튼(3600)을 탭한다. 그 결과 교정창이 4410에 도시한 외관을 가지며, 여기서 2개의 디스플레이된 선택분류 (4412)가 목표인식출력과 매치하는 캐릭터 시퀀스와 함께 시작한다. 이들 인식 캔디디트의 종료가 목표 출력과 매치되었다면 사용자는 4414에 도시한 바와 같이 수평 스크롤 바(4402)에서 유사 워드를 스크롤한다. 그러면 사용자는 이 선택분류(4418)가 목표 출력과 매치하는 것을 볼 수 있다. 4420에 도시한 바와 같이, 사용자는 이 선택분류에서 탭을 하여 4422에 도시한 바와 같이 이 선택분류가 SIP 창(1104)과 응용창(1106) 모두에서 딕테이트된 텍스트에 삽입되도록 한다.FIG. 44 illustrates a method in which the calibration window shown at the bottom of FIG. 43 is calibrated by a combination of horizontal and vertical scrolling together with the selection classification list.
도 45는 연속 발음된 레터 네임의 인식에 의해 생성되고, 필터 캐릭터 선택분류 창에 의해 에디트된 모호 필터의 사용으로 에러 딕테이션을 신속하게 교정하는 방법을 예시한 것이다. 본 예에서, 사용자는 4500에 도시한 바와 같은 대화 버튼(1102)을 프레스하고, 4502에 표시한 바와 같이 워드 "trobule"를 발성한다. 본 예에서, 4504에 워드 "treble"와 같이 상기 발성이 오인식 되었다고 가정한다. 본 예에서 사용자는 4506과 같이 워드 "treble"를 탭하며, 이 탭으로 4508의 교정창이 디스플레이된다. 목표 워드는 임의의 선택분류로 보여준 것이 아니므로, 사용자는 4510에서와 같이 필터 버튼(1218)을 캡하여 목표 워드 "trouble"에서 각 레터 네임을 포함하는 연속 발성(4512)을 한다. 본 예에서, 필터인식모드는 연속 레터 네임 인식을 포함하는 것으로 설정된다.FIG. 45 illustrates a method for quickly correcting error dictation by use of an ambiguous filter generated by the recognition of successively pronounced letter names and edited by a filter character selection classification window. In this example, the user presses a
본 예에서 선택분류 리스트(4518)를 디스플레이하는 것으로 발성(4512)의 인식에 시스템이 반응한다. 본 에에서는 상기 발성의 인식 결과에 의해 필터 스트레인이 생성되고, 이 필터 스트레인은 하나의 모호 길이 엘리멘트로 구성되는 것으로 가정한다. 펑크션(2644 - 2652)에 대해 전술한 바와 같이, 모호 길이 필터 엘리멘 트는 초기 캐릭터 시퀀스의 대응 부분에 포함된 임의 캔디디트를 허용하며, 여기서 캐릭터 시퀀스 중 하나는 모호 엘리멘트로 표현된다. 교정창(4518)에서, 모호 필터 엘리멘트에 대응하는 제1선택분류 워드(4519) 부분은 모호 필터 인디케이터(4520)으로 표시된다. 필터가 모호 엘리멘트를 사용하므로, 디스플레이된 선택분류 리스트는 여러 가지 초기 캐릭터 시퀀스와 함께 시작되는 베스트 스코어링 인식 캔디디트를 포함하며, 상기 여러가지 초기 캐릭터 시퀀스는 모호 엘리멘트에 의해 표현된 매칭 캐릭터 시퀀스에 대응하는 제1 선택분류 부분 보다 작은 길이의 시퀀스를 포함한다.In this example, the system responds to the recognition of the
본 예에서, 사용자는 제1선택분류의 제1캐릭터로부터 상향(업워드) 드래그를 하며, 그 결과 도 17와 함께 설명한 펑크션(1747 -1750)의 동작을 촉발한다. 또한 이어서 필터 선택분류 창(4526)이 디스플레이된다. 교정창(4524)에 도시한 바와 같이, 사용자는 초기 목표 캐릭터인 레터 "t,"에 드래그하고 펑크션(1749)(1740 - 1746)이 수행되는 위치에서 드래그를 해제한다. 상기 기능으로 필터 선택분류 창이 폐쇄되고, 비모호 교정으로서 선택된 캐릭터와 함께 선행 모호 필터 엘리멘트에 부가된 필터를 호출하고, 4528에 표시된 바와 같이 신규 필터와 함께 신규 교정창을 디스플레이한다. 교정창에 도시한 바와 같이, 제1 레터 "t"를 위한 비모호 필터 인디케이터(4532), 그리고 나머지 캐릭터를 위한 모호 필터 인디케이터(4534)와 함께 제1선택분류(4530)를 보여준다. 다음에 4536에서와 같은 교정창에서와 같이 사용자는 신규 제1선택분류의 제5번 레터 "p"로부터 업워드(상향) 드래그를 행하여, 신규 교정창(4538)이 디스플레이된다. 사용자가 캐릭터 "p"에서 상기 드래그를 행할 때, 이 캐릭터 그리고 제1선택분류에서 선행하는 모든 캐릭터가 커런트 필터 스트레인에서 비모호로 정의될 때, 이러한 것이 신규 교정창(4540)에 표시되며, 이 신규교정창은 제1선택분류(4542)가 목표 워드가 되는 선택의 결과로서 보여진 것이고, 필터의 비모호 부분은 비모호 필터 인디케이터(4544)로 표시되고, 모호 필터 엘리멘트의 나머지 부분은 도 29의 펑크션(2900 - 2910) 동작으로 필터 스트링에 존재한다.In this example, the user drags upward (upward) from the first character of the first selection classification, and as a result, triggers the operation of the functions 1747-1750 described with reference to FIG. 17. Also,
도 46은 SIP 인식자를 통해 사용자가 캐릭터 인식자를 이용하여 텍스트 및 필터 정보를 입력하는 것을 예시하는 것이며, 여기서 캐릭터 인식자는 위도우 CE 운영체계(Window CE operation system)의 표준규격과 같은 캐릭터 인식자와 유사하다.FIG. 46 illustrates that a user inputs text and filter information using a character identifier through a SIP identifier, where the character identifier is similar to a character recognizer such as a standard standard of the Windows CE operation system. Do.
도면의 스크린숏(4600)에 도시한 바와 같이, 도 14의 펑크션 키 펑크션(1428)(1430)을 통해 사용자가 드래그 업을 하면, 펀치 및 메뉴(4602)가 디스플레이되고, 사용자가 메뉴의 캐릭터 인식 엔트리(4604)에서 해제하면 도 47의 캐릭터 인식 모드가 턴온 된다.As shown in the
도 47에 도시한 바와 같이, 이것은 펑크션(4702)이 도 46에 도시한 캐릭터 인식창(4608)을 디스플레이 하도록 작용하며, 이후 입력 루프(4704)로 진입하는데, 이 입력루프는 사용자가 펑크션 메뉴(4602)에서 다른 입력옵션을 선택하여 창을 빠져나오는 선택을 할 때까지 반복된다. 이 루프에서, 사용자가 캐릭터 인식창을 터치하면, 펑크션(4906)은 상기 터치의 연속 도중에 "ink"를 레코드하며, 이것으로 캐릭터 인식 창에 대응하는 디스플레이 터치 스크린 부분의 표면 상에서 터치 운동 을 레코드한다. 사용자가 이 창에서 터치를 해제하면, 펑크션(4708-4714)이 수행된다. 펑크션(4710)은 창에서 현재 "ink" 상에 캐릭터 인식을 수행한다. 펑크션(4712)은 도 46의 부호 4610으로 표시한 바와 같이, 캐릭터 인식 창을 클리어한다. 펑크션(4708)이 대응 인식 캐릭터를 SIP 버퍼 및 OS로 공급한다.As shown in FIG. 47, this acts to cause the function 4702 to display the
도 48은 사용자가 스크린숏(4600)으로 표시한 펑크션 메뉴에서 수기인식 옵션을 선택하면 수기인식 엔트리 창(4008)이 스크린숏(4802)으로 표시한 바와 같이 SIP와 연관되어 디스플레이되는 것을 예시한다.FIG. 48 illustrates that when a user selects a handwriting recognition option from the function menu displayed by the
수기모드의 동작을 도 49에 제공한다. 이 모드가 엔터되면, 펑크션(4902)은 수기인식창을 디스플레이하며, 이후 사용자가 다른 입력옵션을 선택할 때까지 루프(4903)가 반복된다. 이 루프에서 사용자가 도 48에 도시한 딜리트 버튼(4804) 이외의 위치에서 수기 인식 창을 터치하면 터치 도중 임의 운동이 펑크션(4904)에 의해 "ink"로서 레코드된다. 사용자가 도 48에 도시한 우측 버튼 영역(4806)에 터치다운하면, 펑크션(4905)은 펑크션(4906 - 4910)이 수행되도록 작용한다. 펑크션(4906)은 수기 인식 창에 미리 진입한(엔터) 임의 "ink"에 대해 수기인식을 수행한다. 펑크션(4908)은 SIP 버퍼 및 OS에 인식된 출력을 공급하고, 펑크션(4910)은 인식창을 클리어한다. 사용자가 도 48에 도시한 딜리트 버튼(4804)을 프레스하면, 펑크션(4912)(4914)은 임의 "ink"의 인식창을 클리어한다.Operation in handwriting mode is provided in FIG. When this mode is entered, function 4902 displays a handwriting recognition window, and then loop 4904 repeats until the user selects another input option. In this loop, when the user touches the handwriting recognition window at a position other than the dealt
인식 버튼(4806)을 사용하여 사용자는 수기인식에 미리 존재하는 "ink"를 인식하도록 시스템에 지시할 수도 있고, 신규 워드의 기입에대해 인식을 시작할 수 도 있다.Using the
도 50은 펑크션 메뉴로부터 선택될 수 있는 키패드(5000)를 도시한다.50 shows a
음성 인식 SIP의 일부로서 신속하게 이용가능한 캐릭터 인식, 수기 인식 및 키보드 입력 인식 방법은 종종 매우 유리한 이점이 있다고 할 수 있는데, 그 이유는 이 방법을 통해 사용자가 다양한 모드 사이를 전환하면서, 현재 가장 편리한 방법을 그때 그때 마다 선택할 수 있기 때문이다. 그리고, 이러한 모드 모두에 대한 출력이 SIP 버퍼의 에디트 텍스트를 통해 가능하다.Rapidly available character recognition, handwriting recognition, and keyboard input recognition methods as part of speech recognition SIP are often very advantageous because they allow users to switch between different modes, Because you can choose the method every time. And output for both of these modes is available via the edit text in the SIP buffer.
도 51에 도시한 바와 같이, SIP 버퍼의 일실시예로서, 사용자가 필터 버튼(1218)으로부터 드래그 업을 하면, 창(5100)이 디스플레이되어 사용자에게 선택가능한 필터 엔트리 모드 옵션을 제시한다. 이 옵션에는 레터 네임 음성 인식, 알파브라보 음성 인식, 캐릭터 인식, 수기 인식, 캐보드 창 등 필터링 스펠링을 입력하는 여러가지 대체 방법이 있다. 또한, 이때 사용자는 음성인식모드를 이산 또는 연속으로 할지의 여부, 레터 네임 인식, 캐릭터인식, 수기 인식 엔트리가 필터 스트링에서 모호로서 취급(간주)될 것인지의 여부를 선택할 수 있다. 이러한 사용자 인터페이스를 통해 사용자는 신속하게 현재 시간 및 장소에 적합한 필터 엔트리 모드를 선택할 수 있다. 예를들면, 사람 말소리가 방해가되는 문제 때문에 근심할 필요가 없는 조용한 장소에서는 연속 레터 네임 인식이 매우 유용하다. 그러나, 많은 소음이 있고, 사용자는 이웃에게 말소리가 방해가 되지 않는다고 느끼는 경우, 알파브라보 인식이 보다 적합할 것이다. 말소리가 다른 사람에게 방해가되는 도서관 같은 장소에서는 캐릭터 인식, 수기 인식, 또는 키보드 인식과 같은 침묵형 필터 엔트리 방법이 보다 적합할 것이다.As shown in FIG. 51, as an embodiment of the SIP buffer, when the user drags up from the
도 52는 인식을 필터링하기 위해 캐릭터 인식을 신속하게 선택할 수 있는 방법을 예시하고 있다. 5200은 교정창 부분으로서, 여기서 사용자는 필터 버튼을 프레스하고 드래그 업하여 도 51의 필터 엔트리 모드 메뉴(5100)가 디스플레이되도록 하고, 이어서 캐릭터 인식 옵션을 선택한다. 스크린숏(5202)에서 도시한 바와 같이 이것은 캐릭터 인식 엔트리 창(4608)이 전체 교정창을 사용자가 볼 수 있는 위치에서 디스플레이되도록 한다. 스크린숏(5202)에서 사용자는 캐릭터 "e"를 드로윙하고, 이 캐릭터의 드로윙으로부터 그 스타일러스를 해제할 때 레터 "e"가 필터 스트링으로 진입하여 교정창(5204)이 예시와 같이 디스플레이된다. 이후 사용자는 추가 캐릭터 "m"을 5206으로 표시한 바와 같이 캐릭터 인식창으로 진입시킨다. 이 레터의 드로윙으로부터 그의 스라일러스를 해제할 때, 캐릭터 "m"의 인식을 통해 필터 스트링이 5208에 도시한 "e"를 포함하게 된다.52 illustrates a method for quickly selecting character recognition to filter recognition. 5200 is a calibration window portion where the user presses and drags up the filter button to display the filter
도 53은 부분 스크린숏(5300)으로 시작하며, 여기서 사용자는 필터 키(1218)로부터 탭과 드래그 업을 하여 필터 엔트리 모드 메뉴의 디스플레이를 실행시키고, 수기옵션을 선택한다. 그 결과 교정창의 모습을 막지 않는 위치에 수기 엔트리 창(4800)이 디스플레이되는 동시에 5302와 같은 스크린이 디스플레이된다. 스크린숏5302에서 사용자는 연속 흘림체로 레터 "embed"을 쓰고, 이후 "REC" 버튼을 프레스하여 이들 캐릭터의 인식을 실행한다. 사용자가 이 버튼을 탭하면, 모호 필터 인디케이터(5304)에 의해 표시된 모호 필터 스트링을 교정창(5306)에 도시한 인식 캐릭터에 대응하는 제1 선택분류창에 디스플레이한다. 도 54는 사용자가 키패드 창(5000)을 사용하여 알파벳 필터링 정보에 진입할 수 있는 방법을 도시한다.53 begins with
도 55는 음성인식을 사용하여 수기인식을 수집하는 방법을 예시한다. 스크린숏(5500)은 SIP 버퍼창(1104)으로 텍스트를 진입하기 위한 위치에서 수기 엔트리 창(4800)이 디스플레이되는 것을 보여준다. 이 스크린숏에서, 사용자는 한 워드의 기입을 바로 끝마쳤다. 부호 5502 - 5510은 5개의 추가 워드의 수기를 표시한다. 이들 모습 각각에서의 워드는 "REC" 버튼의 터치다운과 함께 시작하여 선행 기입 워드의 인식을 실행한다. 부호 5512는 수기 인식창을 나타내며, 여기서 사용자는 "REC"버튼에 최종 탭을 하여 최후 수기 워드 "speech"의 인식을 실행한다. 도 55의 예에서, 수기입력의 시퀀스가 인식된 후, 응용창(1106)에서의 SIP 버퍼창(1104)이 5516에 표시한 스크린숏(5514)의 외관을 갖는다. 사용자는 오인식 워드 "snack shower"를 드래그한다. 그러면 교정창(5518)이 표시된다. 본 예에서, 사용자는 재발성 버튼(1216)을 탭하고 이산적으로 목표 워드 "much... slower."를 재발성한다. 도 23과 함께 전술한 바 있는 "겟(get)" 선택분류의 약간의 변형 버젼의 동작으로 인해 재발성(5520) 인식을 통한 인식 스코어가 부호 5504, 5506으로 표시한 입력에서의 수기 "REC"를 조합한 인식결과와 결합하여 베스트 스코어링 인식 캔디디트를 선택하며, 이 캔디디트는 본 예에서 부호 5522로 표시한 목표 워드가 된다.55 illustrates a method of collecting handwriting recognition using speech recognition.
부호 5516으로 표시한 바와 같이 선택된 수기출력을 교체하기 위해 발성(5520)이 음성인식의 출력을 사용하는 리애드 버튼(Re-Add button) 대신에 사용자가 교정창(5518)에서 신규 버튼을 프레스할 수도 있음을 알 수 있다.Instead of the Re-Add button where the
도 56에 표시한 바와 같이, 사용자가 교정창(5518)에서 재발성 버튼 대신에 필터 버튼(1218)을 프레스하면, 사용자는 도 56의 발성(5600)과 같이 알려진 워드 의 음성인식을 사용하여 알파벳으로 도 55의 5516에 선택된 2개의 워드 중 수기 인식을 필터할 수 있다.As shown in FIG. 56, when the user presses the
도 57은 SIP 음성인식 인터페이스의 대체 실시예(5700)를 예시하며, 여기서는 2개의 별도 탑 레벨 버튼(5702)(5704)이 있어 이산과 연속 음성 인식을 각각 선택할 수 있다. 음성인식 사용자 인터페이스의 탑레벨에 어느 선택분류 버튼이 배치될 것인지는 설계상의 문제일 뿐이다. 그러나, 보다 신속하고, 보다 자연스러운 연속 음성 인식과, 보다 신뢰성을 두는 인식 사이의 신속한 전환 능력은, 보다 정지적이고 느린 이산 음성 인식 매우 바람직한 것일 수도 있지만, 일부 실시예에서 이산 선택을 위한 별도의 탑레벨 키와 연속 인식을 위한 선택의 할당이 적절한 것임을 확인시켜준다.57 illustrates an
도 58은 도 22의 디스플레이 선택분류 리스트의 대체 실시예로서, 도 22의 루틴에 의해 생성된 2개의 알파벳 순차 선택분류 리스트가 아니라 단일 스크롤 가능 스코어 순차 선택분류 리스트를 생성한다는 점에서 도 22의 것과 다르다. 도 22에 포함된 랭귀지와 다른 부분은 밑줄친 부분 뿐이며, 펑크션(2226)(2228)이 도 58의 루틴 버젼에서는 삭제되었다는 점은 예외가 된다.FIG. 58 is an alternative embodiment of the display classification list of FIG. 22, and is different from that of FIG. 22 in that it produces a single scrollable score sequential classification list rather than the two alphabetic sequential classification lists generated by the routine of FIG. different. The language and other parts included in FIG. 22 are only underlined parts, except that functions 2226 and 2228 have been deleted in the routine version of FIG. 58.
도 67 내지 도 74는 개시된 셀폰 음성인식 에디터의 여러 가지 모드 또는 메뉴에서 사용되는 펑크션에 대해 베이직(기본) 폰 번호 키패드의 여러가지 맵핑을 디스플레이한 것이다. 에디터 모드에서 메인 번호할당 폰 키 맵핑은 도 67에 도시하고, 도 68은 에디터 모드에 있을 때 사용자가 한 키를 프레스하면 선택되는 엔트리 모드의 폰 키 부분을 도시한다. 엔트리 모드 메뉴는 시스템 상에서 이용가능한 여러가지 텍스트 및 알파벳 엔트리 모드 중에서 선택을 하기 위해 사용된다. 도 6 9는 "2" 키를 프레스하여 에디터 모드로부터 열릴 수 있는 교정창을 사용자가 디스플레이할 때 수치 폰 키 패드 상에서 이용가능한 펑크션을 디스플레이 한다. 도 70은 도 67의 에디트 모드에 있을 때, "3" 키를 프레스하여 선택되는 에디트 메뉴로부터 이용가능한 수치 폰 키 명령을 디스플레이 한다. 이 메뉴는 폰 키패드의 내비게이션 키를 프레스하여 수행되는 내비게이션 펑크션을 변경하는데 사용된다. 도 71은 "3"키를 프레스 하여 교정창에서 이용가능한 내비게이션 옵션을 디스플레이하는 다소 유사한 교정 내비게이션 메뉴를 예시한다. 교정창에 있는 동안 내비게이션 모드를 변경하는 것 외에도 선택분류가 선택될 때 수행되는 펑크션을 사용자가 변경할 수 있다.67-74 show various mappings of a basic (basic) phone number keypad for functions used in various modes or menus of the disclosed cell phone speech recognition editor. The main number assignment phone key mapping in editor mode is shown in FIG. 67, and FIG. 68 shows the phone key portion of the entry mode selected when the user presses a key while in editor mode. The entry mode menu is used to select from the various text and alphabet entry modes available on the system. 6 9 displays the functions available on the numeric phone keypad when the user displays a calibration window that can be opened from the editor mode by pressing the "2" key. FIG. 70 displays numeric phone key commands available from the edit menu selected by pressing the "3" key when in the edit mode of FIG. This menu is used to change the navigation function performed by pressing the navigation key on the phone keypad. 71 illustrates a somewhat similar calibration navigation menu that presses the "3" key to display the navigation options available in the calibration window. In addition to changing the navigation mode while in the calibration window, the user can change the function performed when the selection is selected.
도 72는 키 알파 모드 도중의 수치 폰 키 맵핑을 예시하며, 여기서 연관된 레터를 갖는 폰 키의 프레스를 통해 프롬프트가 셀 폰 디스플레이 상에 표시되며, 이 표시는 사용자에게 프레스 키와 연관된 레터 세트 중 원하는 것과 연관된 ICA 워드를 말할 것을 요구한다. 이 모드는 도 68의 엔트리 모드 메뉴에 있을 때 "3" 폰 키를 더블 클릭하여 선택된다.FIG. 72 illustrates numerical phone key mapping during key alpha mode, where a prompt is displayed on a cell phone display via a press of a phone key with an associated letter, which indicates to the user the desired set of letter sets associated with the press key. Ask for the ICA word associated with the This mode is selected by double clicking on the "3" phone key when in the entry mode menu of FIG.
도 73은 기본(베이직) 키 메뉴를 도시하며, 이것을 통해 사용자는 텍스트 에디트에 사용되는 최공통 구두 및 펑크션 키 세트 중에서 어느 것을 신속하게 선택하거나 "1"을 프레스하여 선택을 함으로써 보다 공통성이 없이 사용되는 구두 마크의 선택을 허락하는 메뉴를 보게된다. 기본 키 메뉴는 도 67의 에디터 모드에서 "9"를 프레스하여 선택된다. 도 74는 도 67의 에디터에서 "0"을 프레스하여 선택되 는 에디트 옵션 메뉴를 예시한다. 이것은 다른 모드나 메뉴에서 이용가능하지 않은 에디터의 사용과 연관된 기본(베이직) 태스크를 사용자가 수행할 수 있는 메뉴를 포함한다.FIG. 73 shows the Basic (Basic) Key Menu, which allows the user to quickly select which of the most common shoe and function key sets used for text editing or by selecting "1" to make them more common. You will see a menu that allows you to select the verbal mark used. The default key menu is selected by pressing "9" in the editor mode of FIG. 74 exemplifies an edit option menu selected by pressing “0” in the editor of FIG. 67. This includes menus that allow the user to perform basic (basic) tasks associated with the use of the editor that are not available in other modes or menus.
도 67 내지 74에 도시한 수치 폰 키 맵핑 각각의 상부(top)에는 타이틀 바가 있으며, 이 타이틀 바는 메뉴 또는 명령 리스트가 보여질 때 셀 폰 디스플레이의 상부에 표시된다. 도면에서 알 수 있는 바와 같이, 도 67, 69 및 72에 예시되며, 레터 "Cmds"와 함께 시작하여 디스플레이된 옵션이 명령 리스트의 일부임을 표시하며, 도 68, 70, 71, 73, 74에서와 같이 타이틀 바i는 "메뉴(MENU)"와 함께 시작한다. 이것은 도 67, 69 및 72에 도시한 명령 리스트와 이들 도면 이외의 도면에서 도시한 메뉴 사이를 구별하는 표시로 사용된다. 명령 리스트는 디스플레이가 되지 않은 경우에도 모드에서 유용한 명령을 디스플레이한다. 도 67의 명령 리스트와 연관된 에디터 모드나, 도 72와 연관된 키 알파 모드에 있을 때, 폰 키가 이들 도면에 도시한 기능적 맵핑을 가지고 있음에도 텍스트 에디터 창이 디스플레이 된다. 정상적으로 도 69에 도시한 명령 리스트와 연관된 교정창 모드에 있을 때, 셀폰 디스플레이에 교정창이 도시된다. 이들 모든 모드에서, 사용자는 명령 리스트를 액세스하여 도면에 부호 7500으로 지적한 바와 같이 단지 메뉴 키를 프레스 하는 것으로 도 75에 예시한 커런트 폰 키 맵핑을 볼 수 있다. 도 75의 예에서, 디스플레이 스크린(7502)은 메뉴 버튼의 프레스 이전에 에디터 모드의 창을 보여준다. 사용자가 메뉴 버튼을 프레스하면 에디터 명령 리스트의 제1 페이지가 7504로 도시한 바와 같이 표시되며, 사용자는 이때 명령 리스트에서의 스크롤 업 또는 다운할 수 있 는 옵션을 가지고 수치 폰 키로 맵핑된 명령 뿐만 아니라 스크린(7506)의 메뉴 "대화(talk)" 및 "종료(end)" 키, 그리고 스크린(7510)에 의해 부호 7508로 표시한 내비게이션 키 버튼 "OK" 및 "메뉴(MENU)"도 볼 수 있다. 명령 리스트가 엔터될 때 커런트 모드와 연관된 추가 옵션이 있으면, 하일라이트(7512)를 스크롤하거나 "OK"키를 사용하여 명령 리스트에서 이것들을 선택할 수 있다. 도 75에 도시한 예에서, 텔레폰 핸드세트의 일반 형상을 갖는 폰 콜 인디케이터(7514)가 각 타이틀 바의 좌측에 표시되어 셀 폰이 현재 텔레폰 호출 중에 있다는 것을 사용자에게 표시한다. 이 경우, 에디터에서 추가의 펑크션 사용이 가능하며, 이 추가의 펑크션을 통해 발견된 셀의 마이크로폰을 무트(mute)하는 것, 폰 대화의 사용자측으로부터 오디오만을 레코드하는 것, 폰 대화의 사용자 측에게만 플레이백을 플레이하는 것을 사용자는 신속하게 선택할 수 있다.At the top of each of the numerical phone key mappings shown in FIGS. 67 to 74 is a title bar, which is displayed at the top of the cell phone display when a menu or command list is shown. As can be seen in the figures, illustrated in FIGS. 67, 69 and 72, starting with the letter "Cmds" to indicate that the options displayed are part of the command list, as shown in FIGS. 68, 70, 71, 73 and 74. Likewise, the title bar starts with "MENU". This is used as an indication for distinguishing between the command list shown in Figs. 67, 69 and 72 and the menu shown in the drawings other than these drawings. The command list displays useful commands in mode even when not displayed. When in the editor mode associated with the command list of FIG. 67 or in the key alpha mode associated with FIG. 72, a text editor window is displayed even though the phone key has the functional mapping shown in these figures. When in the calibration window mode normally associated with the command list shown in FIG. 69, a calibration window is shown on the cell phone display. In all of these modes, the user can access the command list and see the current phone key mapping illustrated in FIG. 75 by simply pressing a menu key as indicated by
도 76 내지 도 78은 도 67 및 도 75에 도시한 단순 명령 리스트 보다 자세한 에디터 모드의 펑크션에 관한 의사코드 설명을 제공한다. 이 의사코드는 에디터가 여러 가지 사용자 입력에 반응하는 한 입력 루프(7602)로서 표현된다.76 to 78 provide a pseudo code description of functions of the editor mode in more detail than the simple command list shown in FIGS. 67 and 75. This pseudocode is represented as input loop 7802 as long as the editor responds to various user inputs.
사용자가 부호 7603에 표시한 내비게이션 명령 중 하나를 내비게이션 키 중 하나를 프레스하거나 대응 내비게이션 명령을 말하는 것으로 입력하면, 도 76에서와 같이 본 발명의 펑크션이 수행된다.If the user inputs one of the navigation commands indicated by
이 평크션 중에는 에디터가 현재 워드/라인 내비게이션 모드에 있는가의 여부를 검사하는 펑크션(7604)이 들어있다. 이 것은 에디터에서 내비게이션의 최대공통 모드이며, 에디터에서 "3"키를 2번 프레스하여 신속하게 선택될 수 있다. 제1 프레스는 도 70의 내비게이션 모드 메뉴를 선택하고, 제2프레스는 이 메뉴로부터 워드/라인 내비게이션 모드를 선택한다. 에디터가 워드/라인 모드에 있으면 펑크션(7606 - 7624)가 수행된다.Among these functions is a function 7604 that checks whether the editor is currently in word / line navigation mode. This is the maximum common mode of navigation in the editor, which can be selected quickly by pressing the "3" key twice in the editor. The first press selects the navigation mode menu of FIG. 70, and the second press selects the word / line navigation mode from this menu. Functions (7606-7624) are performed when the editor is in word / line mode.
내비게이션 입력이 워드 좌 또는 워드 우 명령이면, 펑크션(7606)은 펑크션(7608)(7610)이 확대된 선택이 온인가의 여부를 검사하고, 그렇다면 커서를 일 워드 좌측이나 우측으로 각각 이동하고, 선행 선택을 그 워드만큼 확대한다. 확대된 선택이 온이면, 펑크션(7612)은 펑크션(7614 - 7617)이 수행되도록 작용한다. 펑크션(7614)(7615)은 선행 입력이 커런트 명령과는 다른 방향으로 워드 좌/우 명령인가의 여부, 커런트 명령이 텍스트 종료의 전후에 커서를 두는 것인가의 여부를 검사한다. 이들 조건중 하나가 진리(true)이면, 커서는 미리 선택된 워드로부터 좌 또는 우로 이동하여 두고, 상기 미리 선택된 워드를 불선택으로 한다. 펑크션(7614)의 테스트에서 조건이 충족되지 않으면, 펑크션(7617)은 커서를 커런트 위치로부터 일 워드 좌 또는 우로 이동시키고 이동된 워드를 커런트 선택으로 한다.If the navigation input is a word left or word right command, function 7706 checks whether functions 7608 and 7610 are enlarged selections, and if so, moves the cursor one word left or right, respectively. , Expands the preceding selection by that word. If the enlarged selection is on, function 7612 acts to cause functions 7614-7617 to be performed. Functions 7714 and 7715 check whether the preceding input is a word left / right instruction in a direction different from the current instruction, and whether the current instruction places the cursor before or after the end of the text. If one of these conditions is true, the cursor moves left or right from the preselected word and makes the preselected word nonselective. If the condition is not met in the test of the function 7614, the function 7417 moves the cursor one word left or right from the current position and makes the moved word the current selection.
펑크션(7612 - 7617)의 동작은 워드 좌, 워드 우 내비게이션을 통해 사용자가 일 워드 만큼 커서를 이동할 수 있도록 할 뿐만 아니라 필요에 따라 각 이동에대해 커런트 워드를 선택하도록 한다. 따라서 선택된 워드에 대응하는 커서와 미리 선택된 워드 전후 삽입 위치를 표현하는 선택된 워드 또는 커서 사이에서 사용자는 신속하게 전환을 할 수 있다.The operations of functions 7612-7617 allow the user to move the cursor by one word through word left and word navigation, as well as select the current word for each movement as needed. Thus, the user can quickly switch between the cursor corresponding to the selected word and the selected word or cursor representing the insertion position before and after the preselected word.
사용자 입력이 라인 업 또는 라인 다운이며, 펑크션(7620)은 커런트 커서 위치로부터 최근접 워드로 라인 업 또는 다운으로 커서를 이동하며, 확대된 선택이 온이면, 펑크션(7624)은 이 신규 커런트 워드를 통해 커런트 선택을 확대한다.If the user input is line up or line down, function 7620 moves the cursor line up or down from the current cursor position to the nearest word, and if expanded selection is on, function 7624 causes this new current. Expand the current selection through the word.
부호 7626로 나타낸 바와 같이, 도 70의 에디트 내비게이션 메뉴로부터 선택될 수 있는 기타 다른 내비게이션 모드에 에디터가 있을 때 내비게이션 입력에 반응하기 위한 프로그램을 에디터는 가지고 있다.As indicated by the sign 7626, the editor has a program for responding to navigation input when the editor is in another navigation mode that can be selected from the edit navigation menu of FIG.
사용자가 버튼을 프레스하거나 음성명령을 사용하여 "OK"를 선택하면, 펑크션(7630)은 웹 도큐먼트 또는 다이얼로그 박스 필드로 텍스트가 진입하는 것과 같이, 텍스트가 다른 프로그램으로 진입하도록 에디터가 호출되었나의 여부를 검사하고, 그렇다면, 펑크션(7632)은 이 다른 프로그램에서 커런트 텍스트 엔트리 위치에서 이 다른 프로그램으로 에디터의 커런트 콘텍스트를 진입시키고 리턴한다. 검사(테스트)(7630)가 충족되지 않으면, 펑크션(7634)은 있을 수 있는 추후의 사용을 위해 커런트 콘텐츠 및 스테이트를 세이브하고 에디터를 빠져나온다.When the user presses a button or uses voice commands to select "OK", the function 7730 calls the editor to enter text into another program, such as entering text into a web document or dialog box field. If so, function 7632 enters and returns the editor's current context from this current program to this other program at the current text entry location. If check (test) 7630 is not satisfied, function 7634 saves the current content and state and exits the editor for possible future use.
사용자가 에디터에 있을 때 메뉴키를 사용자가 프레스하면, 펑크션(7638)은 에디터 명령을 위한 디스플레이 메뉴 루틴을 호출하며, 그 결과 도 75를 참조로 전술한 바와같이 에디터를 위해 명령 리스트가 디스플레이된다. 전술한 바와 같이, 이 기능을 통해 사용자는 1, 2초 내에 에디터 모드를 위해 모든 커런트 명령 맵핑을 스크롤 할 수 있다. 에디터에 있을 때 메뉴 키에 사용자가 더블 클릭을 하면 펑크션(7642 - 7646)은 디스플레이 메뉴를 호출하여 에디터를 위한 명령 리스트를 보여주며, 인식 어휘를 에디터 명령 어휘로 설명하고, 더블 클릭의 최후 프레스를 사용하여 음성 인식을 명령하여 이 인식의 (진행)도중을 판별한다.When the user presses a menu key while the user is in the editor, function 7738 calls a display menu routine for the editor command, and as a result, a list of commands is displayed for the editor as described above with reference to FIG. . As mentioned above, this feature allows the user to scroll through all current command mappings for the editor mode in one or two seconds. When the user double-clicks on a menu key while in the editor, functions (7642-7646) invoke the display menu to show a list of commands for the editor, describe the recognized vocabulary as the editor command vocabulary, and press the end of the double-click. Command speech recognition to determine the progress of this recognition.
사용자가 메뉴 키를 지속적으로 프레스하면, 펑크션(7650)은 에디터를 위한 헬프 모드로 진행한다. 헬프모드에서는 에디터 모드의 펑크션(기능)에 대한 신속한 설명을 제공하며, 키를 프레스하여 에디터의 우선순위 명령구조를 사용자가 탐색할 수 있도록 하며, 또한 이러한 키가 각각 프레스되는 결과로서 도달하는 우선순위 명령 구조 부분을 위해 간략한 설명도 제시된다.If the user continues to press the menu key, function 7650 proceeds to the help mode for the editor. The help mode provides a quick description of the editor mode's functions, allows you to navigate through the editor's priority command structure by pressing keys, and also gives you the priority to reach each of these keys as a result of being pressed. A brief description is also given for the rank command structure part.
사용자가 에디터에 있을 때 대화버튼을 프레스하면, 펑크션(7654)은 어휘, 인식 도중 모드 등의 커런트 인식 셋팅에 따라서 인식을 턴온한다. 대화버튼은 셀폰 실시예에서 음성 인식을 초기화 하기 위한 주요 버튼으로서 사용된다.If the user presses a dialog button while in the editor, function 7764 turns on recognition according to current recognition settings such as vocabulary, mode during recognition, and the like. The talk button is used as the main button for initiating voice recognition in the cell phone embodiment.
사용자가 종료 버튼(End button)을 선택하면, 펑크션(7658)은 폰 모드로 가서 예를들면 신속하게 폰 호출을 하거나 이에 응답한다. 이 기능을 통해 에디터의 커런트 스테이트(현재 상태)를 세이브하여 폰 호출이 종료되었을 때 사용자가 그 세이븐한 곳으로 리턴(복귀)할 수 있다.If the user selects an End button, function 7584 goes to phone mode and, for example, makes a phone call or responds quickly. This feature saves the editor's current state (current state), allowing the user to return (return) to the saved place when the phone call ends.
도 77에 도시한 바와 같이, 사용자가 도 68의 엔트리 모드 메뉴를 선택하면, 펑크션(7702)은 이 메뉴를 디스플레이 한다. 보다 상세히 아래 설명한 바와 같이, 이 메뉴를 통해 사용자는 딕테이션 모드 사이를 신속하게 선택할 수 있으며, 이것은 PDA 실시예에서 도 11에 도시한 버튼(1122 -1134)이 작용하는 것과 같다. 도시한 실시예에서, 엔트리 모드 메뉴는 "1" 키와 관련이 있는데 그 이유는 "1"키가 대화 키와 근사하기 때문이다. 이에 따라 사용자는 신속하게 딕테이션 모드를 전환할 수 있고, 이후 대화 버튼을 이용하여 딕테이션을 계속할 수 있다.As shown in FIG. 77, when the user selects the entry mode menu of FIG. 68, function 7702 displays this menu. As described in more detail below, this menu allows the user to quickly select between dictation modes, which is the same as the buttons 1122-1134 shown in FIG. 11 in the PDA embodiment. In the illustrated embodiment, the entry mode menu is associated with the "1" key because the "1" key is close to the conversation key. This allows the user to quickly switch to dictation mode and then continue the dictation using the conversation button.
사용자가 "선택분류 리스트"를 선택하면, 펑크션(7706)(7708)은 교정창 내비게이션 모드를 인식 캔디디트 선택분류를 스크롤 하고 선택하기 위한 베스트가 되 는 페이지/아이템 내비게이션 모드로 설정한다. 이후 상기 펑크션은 커런트 선택을 위한 교정창 루틴을 호출하며, 그 결과 도 12의 교정창(1200)과 다소 유사한 교정창이 셀폰의 스크린에 디스플레이 된다. 현재 커서가 없으면, 빈공간 선택과 함께 교정창이 호출된다. 호출이 되면, 알파벳 입력, 워드 완료(completion), 및/또는 추가 발성의 부가 등을 통해 하나 이상의 워드를 선택할 수 있다. 이하에는 교정창 루틴을 보다 상세히 설명한다.When the user selects the "selection classification list", the functions 7706 and 7780 set the calibration window navigation mode to the page / item navigation mode which is the best for scrolling and selecting the recognition candy selection classification. The function then calls the calibration window routine for current selection, with the result that a calibration window somewhat similar to the
사용자가 "2"키 상에 더블 클릭을 하는 등으로 "필터 선택분류"를 선택하면, 펑크션(7712-7716)은 교정창 내비게이션 모드를 제1선택분류 또는 필터 스트링에서 내비게이션을 위해 사용되는 워드/캐릭터 모드로 설정한다. 그러면, 커런트 선택을 위한 교정창을 호출하고, 더블 클릭 중 한 번이 엔터되면, 두번째 프레스를 인식 도중 목적을 위한 음성키로서 간주한다.If the user selects "Filter Selection", such as by double clicking on the "2" key, the functions 7712-7716 will switch the calibration window navigation mode to the word used for navigation in the first selection classification or filter string. Set to character mode. This invokes the calibration window for current selection, and when one of the double clicks is entered, the second press is considered as the voice key for the purpose during recognition.
대부분의 셀 폰에서 "2"키는 통상 내비게이션 키 아래에 직접 위치한다. 이 키를 통해 사용자는 에디터에서 교정이 필요한 목표 워드를 내비게이션할 수 있고, 이어서 근처 "2"키를 단일 프레스하여 선택을 위한 대체 선택분류와 함께 교정창을 볼 수 있거나, "2"키를 더블클릭하여 즉시 필터링 정보를 엔터하고 올바른 선택분류를 인식자가 선택할 수 있도록 도울 수도 있다.In most cell phones, the "2" key is usually located directly under the navigation key. This key allows the user to navigate to the target word in the editor that needs to be corrected, then single press a nearby "2" key to view the calibration window with alternative selections for selection, or double-click the "2" key. You can also click to immediately enter filtering information and help the recognizer choose the correct classification.
사용자가 도 70에 도시한 내비게이션 모드 메뉴를 선택하면, 펑크션(7720)은 이것을 디스플레이 한다. 아래 보다 상세히 설명하는 바와 같이, 이 기능을 통해 사용자는 좌, 우 업, 다운 내비게이션 버튼을 프레스하여 수행되는 내비게이션을 변경할 수 있다. 이러한 변경(또는 전환)을 보다 용이하게 하기 위해, 내비게이션 버튼이 수자 배열된 폰 키의 상부열에 배치된다.If the user selects the navigation mode menu shown in Fig. 70, the function 7720 displays this. As described in more detail below, this feature allows the user to change the navigation that is performed by pressing the left, right, up and down navigation buttons. To make this change (or changeover) easier, a navigation button is arranged in the upper row of the numbered phone keys.
사용자가 이산 인식 입력을 선택하면, 펑크션(7724)은 프레스 및 클릭을 이용하여 커런트 어휘에 따라서 이산 인식을 턴온함으로써 커런트 인식 도중 셋팅으로서 도중 모드를 발성 및 전송한다. 이 버튼을 통해 "1"버튼을 프레스하는 형태로 요구할 때마다 사용자는 신속하게 이산 발성 인식으로 전환할 수 있다. 전술한 바와 같이, 이산 인식은 보다 정지성향이 있다고 하여도 실질적으로 연속 인식 보다는 더욱 정밀하다. 이 명령키의 위치는 대화 버튼과 엔트리 모드 메뉴 버튼에 가깝도록 선택된다. 이산 인식 키의 유용성 때문에 정상적으로는 대화 버튼에 맵핑이 되는 인식모드는 연속성이 된다. 이러한 셋팅으로 사용자는 대화버튼과 "4"키 사이에서 프레스를 변경하여 연속과 이산 인식 사이에서 전환할 수 있다.When the user selects a discrete recognition input, function 7724 utters and transmits the intermediate mode as a setting during current recognition by turning on discrete recognition according to the current vocabulary using press and click. This button allows the user to quickly switch to discrete speech recognition whenever required by pressing the "1" button. As mentioned above, discrete recognition is substantially more precise than continuous recognition even if it is more stationary. The position of this command key is chosen to be close to the dialog button and entry mode menu button. Because of the usefulness of discrete recognition keys, the recognition mode that normally maps to a conversation button is continuity. This setting allows the user to switch between continuous and discrete recognition by changing the press between the dialog button and the "4" key.
사용자가 "5" 키를 토글하여 선택 시작과 선택 정지를 선택하면, 펑크션(7728)은 이 모드가 현재 온 또는 오프에 있는가에 따라서 확대된 선택 온, 오프를 토글한다. 이후 펑크션(7730)은 확대된 선택이 턴 오프되었나의 여부를 검사하며, 턴오프 되었다면, 펑크션(7732)은 커런트 커서에서 임의로 하나 이외의 임의 선행 선택을 선택해제한다. 본 실시예에서, "5"키는 확대된 선택 명령을 위해 선택되었는데 그 이유는 이것이 내비게이션 콘트롤과, 그리고 교정창을 지지하는데 사용되는 "2"키와 근사하기 때문이다.When the user toggles the "5" key to select start and stop selection, function 7728 toggles the enlarged select on and off depending on whether this mode is currently on or off. The function 7730 then checks whether the enlarged selection is turned off, and if turned off, the function 7732 randomly deselects any other preceding selection at the current cursor. In this embodiment, the "5" key has been selected for the enlarged selection command because it approximates the "2" key used to support the navigation control and the calibration window.
사용자가 "5"키에 더블클릭하는 등으로 모든 명령을 선택하면 펑크션(7736)은 커런트 도큐먼트에서 모든 텍스트를 선택한다.If the user selects all commands, such as by double-clicking on the " 5 " key, the function 7736 selects all the text in the current document.
사용자가 "6"키를 선택하거나, 플레이 스타트(플레이 시작), 플레이 스톱(플 레이 시작) 또는 레코드 스톱(레코드 스톱)과 같이 현재 활성 중인 임의의 관련 명령을 선택하면, 펑크션(7740)은 시스템이 현재 오디오를 플레이하는가의 여부를 검사한다. 플레이하면, 펑크션(7742)은 오디오 플레이 모드와 오디오 플레이 모드가 오프되는 모드 사이에서 토글을 한다. 오디오 플레이가 없으면, 펑크션(7742)은 오디오 플레이 모드와 오디오 플레이 오프 사이에서 토글한다. 셀폰이 폴 호출 중에 있고, 도 75에 도시한 플레이 온리 투 미(play only to me) 옵션(7513)이 오프 모드에 설정되어 있으면, 펑크션(7746)은 플레이 오버 폰 라인(play over phone line)으로부터 폰 대화 중인 타측으로 또한 셀폰 자체의 스피커 또는 헤드폰으로 오디오를 송신한다.If the user selects the "6" key, or selects any relevant command that is currently active, such as Play Start (Play Start), Play Stop (Play Start), or Record Stop (Record Stop), the function 7770 will Check whether the system is currently playing audio. Upon playing, function 7774 toggles between the audio play mode and the mode in which the audio play mode is turned off. If there is no audio play, function 7742 toggles between the audio play mode and the audio play off. If the cell phone is in a poll call and the play only to me option 7513 shown in FIG. 75 is set to the off mode, the function 7748 is a play over phone line. Audio is sent from the phone to the other side of the phone conversation and to the speaker or headphones of the cell phone itself.
한편, "6" 버튼이 프레스될 때 시스템이 레코드를 하고 있으면, 펑크션(7750)은 레코딩을 오프한다.On the other hand, if the system is recording when the "6" button is pressed, the function 7750 turns off recording.
사용자가 "6"키를 더블 클릭하거나 레코드 명령으로 들어가면, 펑크션(7754)은 오디오 레코딩을 온으로 한다. 이후 펑크션(7756)은 시스템이 현재 폰 호출에 있는가의 여부 및 도 75에 도시한 레코드 온리 미 셋팅(record only me setting)(7511)이 오프 상태인가를 검사한다. 그렇다면, 펑크션(7758)은 폰 라인의 타측으로부터 그리고 폰의 마이크로폰이나 마이크로폰 입력 잭으로부터 오디오를 레코드한다.When the user double-clicks the "6" key or enters the record command, function 7754 turns on audio recording. Function 7566 then checks whether the system is currently in a phone call and whether record only me setting 7511 shown in FIG. 75 is off. If so, function 7758 records audio from the other side of the phone line and from the microphone or microphone input jack of the phone.
사용자가 "7"키를 프레스하거나 캐피털라이즈 메뉴 명령을 선택하면, 펑크션(7762)은 캐피털라이즈 메뉴를 제공한다. 이 메뉴는 사용자에게 선택분류를 제공하며, 이 선택분류를 통해 모든 일련의 엔터된 텍스트를 모두 하위 케이스, 모두 초 기 캡 또는 모두 캐피털라이즈에 있도록 작용하는 모드들 중에서 선택을 할 수있게 된다.If the user presses the "7" key or selects the Capitalize Menu command, function 7762 provides a Capitalize menu. This menu provides the user with a classification, which allows the user to choose from a set of modes that operate to ensure that all the series of entered text is in all subcases, all initial caps, or all capitalized.
사용자가 "7" 키를 더블클릭 하거나 캐피털라이즈 싸이클 키를 선택하면, 캐피털라이즈된 싸이클 루틴은 한번 이상 호출될 수 있어 임의로 커런트 선택을 모두 캡, 모두 캐피털라이즈, 모두 하위케이스 폼(형태)으로 변경할 수 있다.When the user double-clicks the "7" key or selects the capitalize cycle key, the capitalized cycle routine can be called more than once, arbitrarily changing the current selection to all caps, all capitalizes, and all subcase forms. Can be.
사용자가 "8"키 또는 워드 폼 리스트를 선택하면, 펑크션(7770)은 도 27과 함께 상기 설명한 워드 폼 리스트 루틴을 호출한다.If the user selects the " 8 " key or the word form list, function 7777 calls the word form list routine described above in conjunction with FIG.
사용자가 "8"키를 더블클릭 하거나 워드 타입 명령을 선택하면, 펑크션(7774)은 워드 타입 메뉴를 디스플레이한다. 이 워드 타입 메뉴를 통해 사용자는 선택된 워드에 대해 도 26의 필터 매치 루틴과 관련하여 상기 설명한 워드 타입 제한을 선택한다. 도시한 실시예에서, 이 메뉴는 도 91에 도시한 일반 형태를 갖는 우선순위 메뉴이며, 워드 종료 타입, 워드 시작 타입, 워드 텐스(tense) 타입, 음성의 워드부분 타입, 기타 타입으로서, 소유격 또는 비소유격 폼, 단수 또는 복수, 주격폼, 단수, 복수 동사 폼, 스펠링 또는 비스펠링 폼, 동의어, 기타 존재할 수 있는 워드 타입 중에서 사용자가 원하는 것을 규정할 수 있도록 해준다.If the user double-clicks the "8" key or selects a word type command, function 7748 displays a word type menu. Through this word type menu, the user selects the word type restriction described above with respect to the filter match routine of FIG. 26 for the selected word. In the illustrated embodiment, this menu is a priority menu having the general form shown in Fig. 91, and is a word ending type, a word starting type, a word tension type, a word part type of voice, or other type. It allows you to define what you want from non-proprietary forms, singular or plural, subject forms, singular, plural verb forms, spelling or non-spelling forms, synonyms, and other word types that may exist.
도 78에 도시한 바와 같이, 사용자가 "9"키를 프레스하거나 또는 기본 키 메뉴 명령을 프레스하면, 펑크션(7802)은 도 73에 도시한 기본 키 메뉴를 디스플레이하며, 이것을 통해 사용자는 텍스트 입력으로서 이 메뉴로부터 선택될 수 있는 구두 마크 또는 입력 캐릭터 중 한 엔트리를 선택할 수 있다.As shown in FIG. 78, when the user presses the "9" key or presses a basic key menu command, function 7802 displays the basic key menu shown in FIG. 73, through which the user enters text. As an entry one can select a punctuation mark or input character that can be selected from this menu.
사용자가 "*"키 또는 이스케이프 명령을 선택하면, 펑크션(7810 - 7824)이 수행된다. 펑크션(7810)은 다른 프로그램에서 텍스트를 입력 또는 에디트하도록 에디터가 호출되었나의 여부를 검사하며, 호출되었다면, 펑크션(7812)은 이 프로그램으로의 삽입을 위해 에디트된(편집된) 텍스트와 함께 상기 호출로부터 에디터로 리턴한다. 에디터가 이러한 목적으로 호출되지 않았다면, 펑크션(7820)은 에디터에서 빠져나오도록 선택분류의 제시와 함께 사용자에게 프롬프트하고 그 콘텐츠의 세이브 및/또는 이스케이프 취소를 행한다. 사용자가 이스케이프를 선택하면, 펑크션(7822)(7824)은 도 63과 관련하여 앞서 설명한 폰 모드의 탑 레벨로 이스케이프한다. 사용자가 "*" 키를 더블 클릭하거나 태스크 리스트 펑크션을 선택하면, 펑크션(7828)은 태스크 리스트로 가며, 상기 더블 클릭이 대체로 셀폰에서 이루어 질 경우가 많으므로 이 경우는 동작모드 및 메뉴로 간다.When the user selects the "*" key or the escape command, functions 7810-7824 are performed. Function 7810 checks whether the editor has been called to input or edit text in another program, and if so, function 7812 with the edited (edited) text for insertion into this program. Return to the editor from this call. If the editor has not been called for this purpose, function 7820 prompts the user with the presentation of the selection classification to exit the editor and saves and / or escapes the content. When the user selects an escape, functions 7822 and 7824 escape to the top level of the phone mode described above with respect to FIG. If the user double-clicks the "*" key or selects the task list function, the function 7828 goes to the task list, and in this case, the double click is usually performed in the cell phone. Goes.
사용자가 "0"키를 프레스하고 에디트 옵션 메뉴 명령을 선택하면, 펑크션(7832)은 도 74에서 간략하게 설명한 편집된(에디트된) 옵션메뉴이다. 사용자가 "0"키를 더블클릭하거나 부수행 명령을 선택하면 펑크션(7836)은 임의로 에디터에서 최후 명령을 불수행한다.If the user presses the "0" key and selects the edit option menu command, function 7832 is an edited (edited) option menu as briefly described in FIG. If the user double-clicks the "0" key or selects a sub-execution command, the function 7836 arbitrarily fails the last command in the editor.
사용자가 "#"키를 프레스하거나 백스페이스 명령을 선택하면, 펑크션(7840)은 커런트 선택이 있는가를 검사한다. 있다면 펑크션(7842)은 이것을 삭제(딜리션)한다. 커런트 선택이 없고, 커런트 최소 내비게이션 유니트가 캐릭터, 워드, 또는 아웃라인 아이템이면, 펑크션(7846)(7848)은 이 최소 커런트 내비게이션 유니트로 백워드를 삭제한다.When the user presses the "#" key or selects the backspace command, the function 7840 checks whether there is a current selection. Function 7784 deletes (delete) this if it exists. If there is no current selection, and the current minimum navigation unit is a character, word, or outline item, functions 7846 and 7838 delete the backwards with this minimum current navigation unit.
도 79 및 도 80은 도 68과 관련하여 상기 설명한 엔트리 모드에 의해 제공되 는 옵션을 예시한다.79 and 80 illustrate the options provided by the entry mode described above in connection with FIG. 68.
이 메뉴에서, 사용자가 "1"키를 프레스 하거나 대형 어휘 인식을 선택하면, 펑크션(7906 - 7914)가 수행된다. 이 펑크션들은 인식 어휘를 대형 어휘로 설정한다. 그리고 "1"키의 프레스를 인식 도중 목적을 위한 음성 키로서 취급한다. 또한 이들 펑크션은 교정창이 디스플레이되었나의 여부를 검사한다. 디스플레이 되었으면, 교정창에서 사용자가 보다 정밀한 이산 인식을 원한다는 가정하에서 인식모드를 이산 인식모드로 설정한다. 이 모드에서 수신된 임의 신규 발성은 상기한 타입의 발성 리스트에 부가하고, 도 22의 선택분류 리스트 루틴의 디스플레이를 호출하여 수신된 임의 재발성을 위한 신규 교정창을 디스플레이한다.In this menu, when the user presses the "1" key or selects large vocabulary recognition, functions 7806-7914 are performed. These functions set the recognition vocabulary to a large vocabulary. And the press of the "1" key is treated as a voice key for the purpose during recognition. These functions also check whether the calibration window is displayed. If displayed, set the recognition mode to discrete recognition mode on the assumption that the user wants more precise discrete recognition in the calibration window. Any new speech received in this mode is added to the above-mentioned type of speech list and invokes the display of the classification list routine of FIG. 22 to display the new calibration window for the received random recurrence.
도시한 셀 폰 실시예에서, "1"키가 엔트리 모드 메뉴에서 대형 어휘를 위해 선택되었는데 그 이유는 이것이 최대 공통(모스트 코몬 : most common)인식 어휘이고, 이에따라 사용자는 "1"키를 2번 클릭하여 에디터로부터 용이하게 선택을 할 수 있기 때문이다. 제1 클릭은 엔트리 모드 메뉴를 선택하고, 제2클릭은 대형 어휘 인식을 선택한다.In the illustrated cell phone embodiment, the "1" key was selected for the large vocabulary in the entry mode menu because this is the most common (most common) recognition vocabulary, so that the user presses the "1" key twice. This is because you can easily select from the editor by clicking. The first click selects the entry mode menu and the second click selects large vocabulary recognition.
엔트리 모드에 있을 때 사용자가 "2"키를 프레스하면, 시스템은 전술한 타입의 레터 네임 인식으로 설정된다. 사용자가 고정창에 있고 엔트리 모드 메뉴가 디스플레이 될 때 사용자가 이 키를 더블클릭하면, 펑크션(7926)은 인식어휘를 레터네임 어휘로 설정하고, 이 인식의 출력이 모호 필터로서 취급(간주)됨을 표시한다. 바람직한 실시예에서, 사용자는 이러한 필터가 모호 길이 필터로서 간주되었나의 여부를 메뉴의 "9"키와 관련된 엔트리 프레퍼런스 옵션 하에서 표시하는 능력을 가 지고 있다. 디폴트 셋팅은 이러한 인식이 연속 레터 네임 인식에서 모호 길이 필터로서 취급되고, 이산 레터 네임 인식에 반응하여서는 고정 길이 모호 필터로서 취급되도록 한다.If the user presses the "2" key when in the entry mode, the system is set to letter name recognition of the type described above. If the user double-clicks this key when the user is in the fixed window and the entry mode menu is displayed, function 7926 sets the recognition vocabulary to the letter vocabulary, and the output of this recognition is treated as an ambiguous filter. Is displayed. In a preferred embodiment, the user has the ability to indicate whether such a filter has been considered as an ambiguous length filter under the entry preference option associated with the "9" key in the menu. The default setting allows this recognition to be treated as an ambiguous length filter in continuous letter name recognition and as a fixed length ambiguous filter in response to discrete letter name recognition.
사용자가 "3"키를 프레스함에 따라, 인식은 알파브라보 모드로 설정된다. 사용자가 "3"키에 더블 클릭을 하면, 인식은 도 72와 함께 설명한 키 "알파" 모드로 설정된다. 이 모드는 알파브라보 모드와 유사하며, 다만 다음과 같은 차이점이 서로에게 있다. 즉 알파모드에서는 번호 키 "2" 내지 "9" 중 하나를 프레스하면 사용자는 프레스된 키에서의 레터와 연관된 ICA워드 중 하나에 프롬프트되며, 인식은 ICA 워드의 제한된 세트 중 하나의 인식을 선호하게 되고, 그 결과 상대적으로 심한 소음 조건 하에서도 매우 신뢰성 있는 알파벳 엔트리를 제공하게 된다는 점이다.As the user presses the "3" key, recognition is set to alpha bravo mode. If the user double-clicks on the "3" key, recognition is set to the key "alpha" mode described with reference to FIG. 72. This mode is similar to the Alpha Bravo mode, with the following differences: In alpha mode, pressing one of the number keys "2" to "9" will prompt the user to one of the ICA words associated with the letter in the pressed key, and the recognition will favor recognition of one of a limited set of ICA words. The result is a very reliable alphabet entry even under relatively noisy conditions.
사용자가 "4"키를 프레스하면, 어휘가 디지트 어휘로 변경된다. 사용자가 "4"키에 더블클릭하면, 시스템은 에디터 텍스트에 대응 번호를 입력하여 번호부여 폰 키의 프레스에 대응한다.When the user presses the "4" key, the vocabulary is changed to the digit vocabulary. When the user double clicks on the "4" key, the system enters the corresponding number in the editor text to correspond to the press of the numbered phone key.
사용자가 "5"키를 프레스하면, 인식 어휘는 구두어휘로 제한된다.When the user presses the "5" key, the recognition vocabulary is limited to the oral vocabulary.
사용자가 "6"키를 프레스하면, 인식 어휘는 전술한 콘택트 네임 어휘로 제한된다.When the user presses the "6" key, the recognition vocabulary is limited to the contact name vocabulary described above.
도 86은 도 72의 함께 어느 정도 설명한 바 있는 키 알파 모드를 예시한다. 도 86에 표시한 바와 같이, 이 노트가 엔터될 때, 내비게이션 모드가 알파 엔트리와 통상 연관된 워드/캐릭터 내비게이션 모드로 설정된다. 이후 펑크션(8604)은 이 아래에 리스트된 키를 그 키 각각으로 표시된 펑크션에 중첩(오버레이)한다. 이 모드에서, 대화키를 프레스하면 커런트 인식 셋팅에 따라서 알파브라보 어휘와 함께 인식을 턴온하고, 커런트 인식 도중 셋팅에 따라서 키 프레스에 반응한다. "1"키는 엔트리 에디트 모드로서 동작을 지속하여 사용자가 이것을 프레스하여 키 알파 모드를 빠져나올 수 있도록 한다. 수자부여 폰 키"2" 내지 "9"를 프레스 하면, 펑크션(8618 - 8624)이 수행되며, 이 때 동시에 폰키의 프레스로 인해 폰키 레터에 대응하는 ICA 워드의 프롬프트를 디스플레이한다. 그 결과 인식으로 하여금 3개 또는 4개의 ICA 워드 중 하나의 인식을 선호하게 하여, 프레스 도중(지속)을 위한 인식을 턴온하며, 에디트 모드에 있으면 에디터의 텍스트로, 필터 에디트 모드에 있으면 필터 스트링으로, 인식된 ICA 워드에 대응하는 레터를 출력한다.FIG. 86 illustrates the key alpha mode described in conjunction with FIG. 72 to some extent. As shown in Fig. 86, when this note is entered, the navigation mode is set to the word / character navigation mode normally associated with the alpha entry. Function 8604 then overlays (overlays) the keys listed below with the function represented by each of those keys. In this mode, pressing the dialogue key turns on recognition with the alpha bravo vocabulary according to the current recognition setting, and responds to the key press according to the setting during the current recognition. The "1" key continues to operate as an entry edit mode, allowing the user to press it to exit key alpha mode. When pressing the numbering phone keys " 2 " to " 9 ", functions 8618-8624 are performed, at the same time displaying the prompt of the ICA word corresponding to the phone key letter due to the press of the phone keys. The result is that recognition is preferred to one of three or four ICA words, turning on recognition for the duration of the press (persistent), to the text of the editor if in edit mode, to the filter string if in filter edit mode. The letter corresponding to the recognized ICA word is output.
사용자가 제로(0) 버튼을 프레스하면, 펑크션(8628)이 키 구두 모드로 진입하며, 이 모드는 폰키와 연관된 레터 세트 중 하나와 함께 시작하는 모든 구두 마크 중에서 스크롤 가능 리스트를 디스플레이 함으로써 폰키에 연관된 레터를 갖는 임의 폰키의 프레스에 반응하며, 구두 워드 중 하나의 인식을 선호한다.When the user presses the zero button, function 8828 enters key verbal mode, which displays a scrollable list of all verbal marks that start with one of the letter sets associated with the phone key. Responds to the press of any phone key with an associated letter and prefers recognition of one of the spoken words.
도 87은 그 밑줄친 의사코드 부분만을 제외하고는 도 86의 것과 동일한 키 알파 모드의 변형 실시예이다. 이 모드에서, 사용자가 탑 버튼을 프레스하면, 대형 어휘 인식이 턴온하지만 펑크션(8608A)으로 표시한 바와 같이, 각 인식된 워드의 초기 레터만이 출력된다. 펑크션(8618A)(8620B)이 표시하는 바와 같이, 사용자가 폰키와 연관된 3 또는 4 레터 세트를 갖는 폰키를 프레스하면, 사용자에게 프롬프트가 제시되어 목표 레터와 함께 시작할 워드를 말할 것을 요청한다. 그리고 인식 어휘는 실질적으로 키 연관 레터 중 하나와 시작한 워드로 제한되며, 펑크션(8624A)이 인식된 워드에 대응하는 초기 레터를 출력한다.87 is a variation of the same key alpha mode as that of FIG. 86 except for the underlined pseudocode portion. In this mode, when the user presses the top button, large lexical recognition is turned on but only the initial letter of each recognized word is output, as indicated by function 8608A. As the functions 8618A and 8620B indicate, when the user presses a phone key with a set of 3 or 4 letters associated with the phone key, the user is prompted to say a word to start with the target letter. The recognition vocabulary is substantially limited to words that begin with one of the key association letters, and function 8624A outputs an initial letter corresponding to the recognized word.
본 발명의 일부 실시예에서, 제3의 대체 키 알파 모드를 사용할 수 있는 데 이 경우 워드의 제한 세트가 알파벳의 각 레터와 연관을 가지며, 키의 프레스 도중에 인식이 실질적으로 키 연관 레터와 연관된 워드 세트 중 한 인식으로 제한된다. 일부 실시예에서, 5 이하의 워드 세트가 이러한 각 레터에 연관된다.In some embodiments of the present invention, a third alternative key alpha mode may be used, in which case the limit set of words is associated with each letter of the alphabet, and recognition is substantially associated with the key association letter during the press of the key. Limited to one recognition of the set. In some embodiments, a word set of 5 or less is associated with each of these letters.
도 89 및 도 90은 사고(thought) 에디트 옵션에서 유용한 옵션 중 일부를 나타내며, 이 사고 에디트 옵션은 에디터 및 교정창 모드에서 0 버튼을 프레스하여 액세스할 수 있다. 이 메뉴에서, 사용자가 1 키를 프레스하면, 펑크션(8902)에 표시한 파일 옵션 메뉴를 볼 수 있다. 사용자가 2 키를 프레스하면, 펑크션(8904)에 표시한 바와 같이 대부분의 에디트 프로그램에서 공통인 에디트 옵션 메뉴를 볼 수 있다. 사용자가 3 버튼을 프레스하면, 펑크션(8906)은 도 68 및 도 79와 관련하여 위에서 설명한 엔트리 모드 메뉴에서 키 9를 프레스하여 액세스되는 것과 동일한 엔트리 프레퍼런스 메뉴를 디스플레이한다.89 and 90 show some of the options available in the think edit option, which can be accessed by pressing the 0 button in the editor and proofreading modes. In this menu, when the user presses the 1 key, the file option menu displayed in the function 8902 can be viewed. When the user presses 2 keys, as shown in the function 8904, the edit option menu common to most edit programs can be viewed. If the user presses the 3 button, function 8906 displays the same entry preference menu that is accessed by pressing key 9 in the entry mode menu described above with respect to FIGS. 68 and 79.
에디트 옵션 메뉴에 있을 때, "4"키를 프레스하면, 텍스트 투 스피치(TTS : Text-To-Speech) 즉 TTS 메뉴를 디스플레이한다. 이 메뉴에서, "4"키는 온 또는 오프로 TTS 플레이를 토글한다. 이 키가 TTS를 온으로 토글하고 커런트 선택이 있으면, 펑크션(8916)(8918)은 TTS에게 선택을 말하도록 작용하며, 바람직하게는 이 선택 보다 TTS가 미리 존재하고 있거나 워드 "selection"이라는 레코드된 말이 미리 존재할 수 도 있다. TTS가 온으로 토클될 때 선택이 없으면, 커런트 도큐먼트의 종 료 때까지 또는 이 도큐먼트 내에서 커서 이동 이외의 입력을 사용자가 제공할 때까지 커런트 커서 위치에서 TTS는 커런트 텍스트를 말한다. 도 99와 관련하여 아래에 설명하는 바와 같이, TTS 모드가 온이면, 사용자에게 오디오 프롬프트 및 텍스트의 TTS 플레이백이 제공되어 시스템 기능의 실질적 부분이 사용되면서도 셀폰 스크린을 볼 필요가 없도록 한다.When in the Edit Options menu, pressing the "4" key displays a Text-To-Speech (TTS) menu. In this menu, the "4" key toggles TTS play on or off. If this key toggles the TTS on and there is a current selection, the functions 8916 and 8918 act to tell the TTS a choice, preferably a record with the TTS pre-existing or word "selection" above this selection. It may be said beforehand. If no selection is made when the TTS is toggled on, the TTS refers to the current text at the current cursor position until the end of the current document or until the user provides input other than cursor movement within the document. As described below with respect to FIG. 99, if the TTS mode is on, the user is provided with TTS playback of audio prompts and text so that a substantial portion of system functionality is used while not having to view the cell phone screen.
TTS 서브메뉴는 또한 펑크션(8924)(8926)(8928)(8930)으로 표시한 바와 같이 사용자가 원할 때마다 커런트 선택을 플레이할 수 있도록 하는 선택분류를 포함하며, 이들 평크션은 기기가 TTS 온 모드 또는 TTS 오프 모드 중 어디에 있든지 상관없이 사용자가 연속 플레이를 온 또는 오프할 수 있도록 한다. 8932에서 에디트 옵션 메뉴로 탑 레벨 선택분류로 표시한 바와 같이, "4"키의 더블클릭으로 TTS를 온 또는 오프하며, 이것은 마치 사용자가 "4"키를 프레스하고, 이후 TTS 메뉴가 디스플레이되기를 기다리고, 다시 "4"키를 프레스한 것과 같다.The TTS submenu also includes a selection classification that allows the user to play the current selection whenever desired, as indicated by functions 8924, 8926, 8928, 8930, and these features are used by the device to TTS. Allows the user to turn continuous play on or off, whether in on mode or TTS off mode. As indicated by the top level selection in the Edit Options menu at 8932, double-clicking on the "4" key turns the TTS on or off, which waits for the user to press the "4" key and then display the TTS menu. , Again like pressing the "4" key.
에디트 옵션 메뉴에서 "5"키는 아웃라인 메뉴를 선택하며, 이 아웃라인 메뉴는 확대 및 콘트랙트 헤딩 그리고 아웃라인 모드에서 사용자가 내비게이션을 할 수 있도록 하는 다수의 펑크션을 포함한다. 사용작 "5"키를 더블클릭하면 시스템은 전체적으로 확대 에디터의 커서가 위치하는 커런트 아웃라인 엘리멘트를 전체적으로 콘트랙트하는 기능 사이에서 시스템이 토글하게 된다.The "5" key in the Edit Options menu selects the Outline menu, which includes zoom and contract headings and a number of functions that allow the user to navigate in outline mode. Double-clicking on the "5" key will cause the system to toggle between the ability to globally contract the current outline element where the cursor in the global editor is positioned.
사용자가 "6"키를 선택하고, 오디오 메뉴가 서브메뉴로서 디스플레이될 때, 이들 서브 메뉴 중 일부는 도 89 및 도 90의 조합으로 오디오 메뉴 아이템(8938) 하에서 톱니모양으로 디스플레이된다. 이 오디오 메뉴는 "1"키로 선택되는 아이템 을 포함하며, 이 아이템을 통해 도 84 및 도 70에서 상기 설명한 에디트 나우 메뉴(edit now menu)에서 "6"버튼을 이용하여 행하는 오디오 내비게이션 속도에 대해 보다 미세한 제어(콘트롤)를 사용자가 할 수 있도록 한다. 사용자가 "2"키를 선택하면, 볼륨 및 속도와 같은 오디오 플레이백 셋팅의 호출, 인식된 워드와 관계된 오디오가 플레이되는가의 여부 호출, 및 또는 연관된 인식 워드없이 레코드된 오디오 호출을 사용자에게 허용하는 서브메뉴를 볼 수 있다.When the user selects the "6" key and the audio menu is displayed as a submenu, some of these submenus are jagged under the audio menu item 8938 in a combination of FIGS. 89 and 90. This audio menu includes an item selected with the "1" key, and through this item, the audio navigation speed made using the "6" button in the edit now menu described above in FIGS. 84 and 70 can be obtained. Allows the user to perform fine control. When the user selects the "2" key, the user is allowed to call audio playback settings such as volume and speed, call whether audio associated with the recognized word is to be played, or call the recorded audio without an associated recognition word. You can see the submenu.
도 90은 상기 설명한 오디오 메뉴 하에서 "3", "4", "5", "6", "7" 키로 선택되는 아이템과 함께 그리고 도 89의 부호 8938과 함께 시작한다. 사용자가 "3"키를 프레스하면, 인식된 오디오 옵션 다이얼로그 박스(9002 - 9014)가 디스플레이되며, 이것은 부호 9002 - 9014로 설명한 바와 같이, 사용자에게 옵션을 제공하며, 이 옵션을 통해, 에디터에서 커런트 선택에 포함된 임의 오디오에서 속도 인식을 수행하는 선택과, 커런트 도큐먼트에서 모든 오디오를 인식하는 선택과, 미리 인식된 오디오가 인식된 것으로 독출되는가의 여부를 결정하는 선택과, 이러한 인식의 질, 이러한 인식이 요구하는 시간을 판별하는 파라메터를 설정하는 선택을 할 수 있다. 펑크션(9012)에서 표시한 바와 같이, 이 다이얼로그 박스는 커런트 질 셋팅과 함께 커런트 선택을 인식하기 위한 에스티메이트(estimate)를 제공하며, 선택을 인식하는 태스크가 현재 진행중이라면, 커런트 잡(job)에서의 스테이터스(status)를 제공한다. 백그라운드의 태스크로서, 또는 폰이 다른 목적으로 사용되지 않을 때, 그리고 보조 전원에 플러그가 되어 있을 때 상기 다이얼로그 박스를 통해 사용자는 상대적으로 큰 양의 오디오 상에서 인식을 수행할 수 있다.FIG. 90 begins with an item selected with the keys "3", "4", "5", "6", "7" under the above-described audio menu and with reference numeral 8938 of FIG. When the user presses the "3" key, a recognized audio options dialog box 9002-9014 is displayed, which gives the user the option, as described by the symbols 9002-9014, through which the current in the editor The choice to perform speed recognition on any audio included in the selection, the choice to recognize all audio in the current document, the choice to determine whether the pre-recognized audio is read as recognized, and the quality of this recognition, such as You can choose to set a parameter to determine the time required for recognition. As indicated by function 9012, this dialog box provides an estimator for recognizing the current selection along with the current quality settings, and if the task recognizing the selection is currently in progress, the current job Provide the status at. As a background task, or when the phone is not used for any other purpose and when the auxiliary power supply is plugged in, the dialog box allows the user to perform recognition on a relatively large amount of audio.
사용자가 오디오 메뉴에서 "4"키를 선택하면, 사용자에게 커런트 선택으로부터 특정 정보를 제거하는 것을 선택할 수 있는 서브메뉴를 제공한다. 이 서브메뉴를 통해 인식된 워드와 관련이 없는 모든 오디오를 제거하거나, 인식된 워드와 함께 선택된 모드 오디오, 목표 선택으로부터의 텍스트를 선택적으로 제거(딜리션)할 수 있다. 인식된 텍스트로부터 인식 오디오를 삭제하는 것은 이러한 텍스트의 저장과 관련된 메모리를 크게 줄이게 하고, 때로는 사용자가 텍스트관련 오디오가 필요없다고 결정하면 그 의도한 의미를 결정하는 것을 돕는데 매우 유용하다. 텍스트가 오디오로부터 음성인식으로 생성되었고 매우 부정확하여 소용이 없는 경우 미디어 부분으로부터의 오디오를 제외한 텍스트를 삭제하는 것은 때로 매우 유용하다.When the user selects the "4" key in the audio menu, the user is presented with a submenu from which to choose to remove specific information from the current selection. This submenu allows you to remove all audio not related to the recognized word or to selectively remove (select) the selected mode audio, text from the target selection, along with the recognized word. Deleting recognized audio from recognized text greatly reduces the memory associated with storing such text, and is sometimes very useful to help determine the intended meaning if the user decides that text-related audio is not needed. It is sometimes very useful to delete text except audio from the media part if the text is generated from audio by speech recognition and is very inaccurate.
오디오 메뉴에서 "5"키는 사용자에게 인식 오디오를 연관시키는 텍스트가 마크되었나의 여부를 선택하도록 하며, 이 경우 상기 마크여부는 언더라인을 통해 사용자가 이러한 텍스트가 플레이백을 가지고 있다는 것을 알리게되며, 여기서의 플레이백은 텍스트의 이해를 돕거나 일부 실시예에서는 대체 인식 선택분류를 발생시키는 근거가 되는 음향을 가질 수 있다. "6"키는 사용자에게 인식 오디오가 인식된 텍스트를 위해 캡이 되었나의 여부를 선택하도록 한다. 많은 실시예에서 인식 오디오의 레코딩이 턴오프되어도, 이러한 오디오가 가장 최근의 인식 워드의 일부 개수를 위해 캡이되어 교정 플레이백 목적을 위해 유용하게 사용된다.The "5" key in the audio menu allows the user to select whether or not the text associated with the recognized audio has been marked, in which case the underline tells the user that such text has a playback, The playback herein may have a sound that aids in understanding the text or, in some embodiments, is the basis for generating alternative recognition classification. The "6" key allows the user to select whether the recognized audio has been capped for the recognized text. In many embodiments, even if recording of recognition audio is turned off, this audio is capped for some number of the most recent recognition words and is useful for calibration playback purposes.
오디오메뉴에서, "7"키는 트랜스크립션 모드 다이얼로그 박스를 선택한다. 이 기능을 통해 다이얼로그 박스가 디스플레이되고, 사용자는 도 94와 함께 아래 설명하는 트랜스크립션 모드에 사용되는 셋팅을 선택할 수 있다. 이것은 사용자가 음성인식에 의해 미리 레코드된 오디오를 트랜스크라이브(transcribe)하는 것을 용이하게 하도록 설계된 모드이다.In the audio menu, the "7" key selects the transcription mode dialog box. This function displays a dialog box and allows the user to select the settings used for the transcription mode described below in conjunction with FIG. 94. This is a mode designed to facilitate the user to transscribe audio prerecorded by voice recognition.
사용자가 "8"키를 프레스하면 펑크션(9036)이 수행되어, 서치 스트링으로서 임의로 커런트 선택과 함께 서치 다이얼로그 박스를 호출한다. 아래 설명하는 바와 같이, 음성 인식 텍스트 에디터는 필요하다면 여러가지 다른 서치스트링을 입력(엔터)할 수 있다. 사용자가 "8"키에 더블 클릭하면 이 키값은 미리 엔터된 서치 스트링을 위해 다시 서치를 하게될 "파인드 어게인(find again)" 명령으로서 해석된다.When the user presses the " 8 " key, function 9036 is performed to invoke a search dialog box with an optional current selection as a search string. As described below, the speech recognition text editor can enter (enter) various other searchstrings as needed. When the user double clicks on the "8" key, this key value is interpreted as a "find again" command that will search again for the previously entered search string.
사용자가 에디트 옵션 메뉴에서 "9"키를 선택하면, 어휘 메뉴가 디스플레이되어 커런트 어휘에 어떤 워드가 있는가를 판별하고, 여러가지 다른 어휘를 선택하고, 워드를 소저의 어휘에 부가하는 것을 사용자가 할 수 있도록 한다. 에디트 옵션 메뉴에 있을 때 사용자가 "0"버튼을 프레스 하거나 더블클릭하면, 불수행 펑크션이 수행된다. 더블클릭으로 인해 에디트 옵션 메뉴 내에서 불수행 펑크션을 액세스하게 되며, 이것은 "0"에 대한 더블클릭으로 에디터 또는 교정창으로부터 불수행 펑크션을 액세스하는 것과 유사한 기능을 제공한다. 에디트 옵션 메뉴에서 파운드 키는 재개(리두 : redo)버튼으로서 작용한다. When the user selects the "9" key from the Edit Options menu, the Vocabulary menu is displayed so that the user can determine which words are in the current vocabulary, select different vocabularies, and add words to the source vocabulary. do. If the user presses or double-clicks the "0" button when in the Edit Options menu, the default function is performed. Double-clicking accesses the default function within the Edit Options menu, which provides a function similar to accessing the default function from the editor or correction window with a double-click on "0". In the Edit Options menu, the pound key acts as a resume (redo) button.
도 94는 TTS 플레이 룰을 예시한다. 도 89의 펑크션 8908 내지 8932와 관련하여 상기 설명한 TTS 옵션을 통해 TTS 동작이 선택될 때, TTS 발생의 동작을 지배하는 루울이 있다.94 illustrates the TTS play rules. When a TTS operation is selected through the TTS option described above with respect to functions 8908 to 8932 of FIG. 89, there is a rule that governs the operation of the TTS generation.
펑크션(1909)로 표시한 바와 같이 TTS에 있을 때 TTS 키 모드가 1 키의 동작으로 턴온이되면, 펑크션(9404)은 펑크션(9406 - 9414)가 수행되도록 작용한다. 이 들 기능을 통해 사용자는 운전을 하거나 다른 일을 할 때와 같은 경우에 폰 키를 보지 않고도 안전하게 선택을 할 수 있다. 이 모드는 셀폰 동작의 임의 모드에서 사용될 수 있는 음성 인식 에디터에서의 동작에만 한정되지 않는 것이 바람직하다. 임의 폰 키가 프레스되면 펑크션(9408)은 1/4 또는 1/3와 같은 짧은 기간이되는 TTS 키 타임 내에 동일한 키가 프레스 되었나의 여부를 검사(테스트)한다. 이 테스트 목적을 위해, 동일 키의 최후 키 프레스 해제 이후부터의 시간이 측정된다. 이 짧은 시간 내에 동일키가 프레스 되지 않았다면, 펑크션(9410)(9412)은 텍스트가 발성되도록 하거나, 일부 실시예에서는 레코드된 오디오 플레이백을 동작시키며, 키의 번호와 그 커런트 명령 네임을 말한다. 이 오디오 피드백은 사용자가 키를 프레스하고 있는 한에서만 지속된다. 키가 더블클릭 명령을 가지면 사용자가 충분히 길게 키를 프레스하고 있는가의 여부를 알려준다. 펑크션(9408)의 테스트를 통해 동일키의 최후 키 프레스 해제 이후의 시간이 TTS 키 타임 펑크션(9414) 이하 인가를 발견하고, 셀폰 소프트웨어가 키프레스에 반응하며, 이 키프레스에는 TTS 모드가 온이 아닌 것처럼 작용하는 임의 더블클릭도 포함되는 개념이다.As indicated by function 1909, when the TTS key mode is turned on by the operation of the 1 key when in the TTS, the
따라서, TTS 키모드를 통해 사용자는 터치로 셀폰 키를 발견할 수 있고, 키를 프레스하여 이것이 목표 키인지의 여부를 판별할 수 있으며, 목표키이면 신속하게 한번 이상 다시 프레스하여 키의 목표기능을 달성할 수 있다. 펑크션(9410)(9412)에 의해 반응하는 키의 프레스가 그 연관된 기능을 말하는 것외에는 어떠한 반응도 하지 않으므로, 이 모드를 통해 사용자는 목표키를 조사할 수 있으면서도 뜻하지 않는 결과를 전혀 야기하지 않을 수 있다.Thus, through the TTS key mode, the user can find the cell phone key by touch, and can determine whether it is the target key by pressing the key, and if the target key is pressed again, the target function of the key can be quickly pressed once more. Can be achieved. Since the press of the key responding by the functions 9410 and 9212 does not react to anything other than saying its associated function, this mode allows the user to examine the target key while not causing any unexpected results. .
일부 셀폰 실시예에서, 셀폰 키는 가압이 아니라 단지 터치에 의해 펑크션(9412)이 제공하는 것과 유사하게 키가 어떠한 것이고, 커런트(현재)기능은 무엇인가 등의 오디오 피드백을 제공할 수 있다. 이 기능은 예를들면 전도 물질로 된 폰키 물질를 갖는것, 이들 키와는 별도로 되어 사용자 몸체를 통해 키에 도전된다면 키와 연결된 회로에 의해 검출될 수 잇는 전압을 발생시키는 폰의 별체 부분을 통해 이룰 수 있다. 이러한 시스템은 터치를 통해 사용자가 보다 신속하게 목표키를 발견할 수 있도록 하여주는데 그 이유는 사용자가 목표 키 부근에서 키패드 위에 핑거를 단지 스캐닝하여 터치하는 키가 어떠한 키인가에 대해 피드백을 받을 수 있기 때문이다. 이 기능은 또한 목표 명령이 발견될 때까지 연속 키위에 사용자가 그 손가락을 스캐닝하는 것에 의해 목표 명령 네임을 신속하게 스캔할 수 있도록 해준다.In some cell phone embodiments, the cell phone key may provide audio feedback such as what the key is, what the current (current) function is, and so on, similar to that provided by function 9412 only by touch, not by pressing. This function is achieved by means of a separate part of the phone, for example having a phone material of conductive material, separate from these keys and generating a voltage that can be detected by a circuit connected to the key if the keys are challenged through the user's body. Can be. This system allows the user to find the target key more quickly through touch because the user can receive feedback as to which key to touch by just scanning the finger on the keypad near the target key. Because. This feature also allows the user to quickly scan the target command name by scanning the finger over successive keys until the target command is found.
TTS가 온일 때, 시스템이 명령입력을 인식하거나 수신하면, 펑크션(9416)(9418)은 TTS가 또는 레코드된 오디오 플레이백이 인식된 명령의 네임을 말하도록 작용한다. 이러한 명령의 확인은 관련된 사운드 질을 갖는 것이 바람직하며, 그 사운드 질은 이를테면, 음성의 여러 가지 톤의 형태로, 여러 가지 관련 사운드 형태로 되어 인식된 텍스트의 말과 명령워드의 말을 구별할 수 있도록 한다. TTS가 온이면 텍스트 발성이 인식될 때 펑크션(9420 - 9424)은 발성의 종료, 그 인식의 완료를 통보할 수 있으며, 이후 TTS를 이용하여 발성을 위해 제1 선택분류로서 인식된 워드를 말한다.When the TTS is on, when the system recognizes or receives a command input, functions 9416 and 9418 act to say the name of the command from which the TTS or recorded audio playback was recognized. The confirmation of such a command preferably has an associated sound quality, for example in the form of various tones of speech, in the form of several related sounds, which can distinguish between words of recognized text and words of command words. Make sure If the TTS is on, when the text utterance is recognized, the functions 9220-9424 may notify the end of the utterance and the completion of the recognition, and then the word recognized as the first selection classification for the utterance using the TTS. .
펑크션(9426 - 9430)으로 표시한 바와 같이, TTS는 유사 방법으로 필터링 발 성의 재인식에 반응한다.As indicated by functions 9942-9430, the TTS responds to the recognition of filtering speech in a similar manner.
TTS에 있을 때, 사용자가 커서를 이동하여 신규 워드나 캐릭터를 선택하면, 펑크션(9432 -9438)은 TTS를 사용하여 이 새롭게 선택된 워드 또는 캐릭터를 말한다. 신규워드 또는 캐릭터 위치로의 이러한 커서의 이동이 이미 시작된 선택을 확대하면, 신규 커서위치를 말한 후, 펑크션(9436)(9438)은 인식된 텍스트의 일부가 아니라고 표시하는 방법으로 워드 "selection"을 말하고, 이후 커런트 선택의 워드를 말하게 된다. 사용자가 커서를 이동시켜 도 76의 펑크션(7614)(7615)에 설명한 바와 같이 비선택 커서로 하면 도 94의 펑크션(9440)(9442)가 TTS를 사용하여 2 워드를 발하며 이 2 워드 사이에 커서가 위치하게 된다.When in the TTS, if the user moves the cursor to select a new word or character, the functions 9432-9438 speak this newly selected word or character using the TTS. If you magnify a selection that has already begun to move this cursor to a new word or character position, then after referring to the new cursor position, functions 9436 and 9438 indicate that the word "selection" is not part of the recognized text. This is followed by the word of current selection. If the user moves the cursor to a non-select cursor as described in the functions 7714 and 7715 of FIG. 76, the functions 9440 and 9442 of FIG. 94 issue two words using TTS, and between these two words. The cursor will be placed at.
TTS 모드에 있고, 신규 교정창이 디스플레이 되면, 펑크션(9444)(9446)은 TTS를 사용하여 교정창에서 제1 선택분류를 말하고, 임의로 커런트 필터를 쫓아내면서 그 중 어느 부분이 비모호이고, 어느 부분이 모호인가를 표시하며, 이후 TTS를 사용하여 선택분류 리스트의 현재 디스플레이된 부분에서 각 캔디디트를 말한다. 속도를 위해서는 톤과 사운드에 차이를 두어 필터의 어느 부분이 절대적이거나 모호한 것인가를 표시하는 것이 최선이다.When in the TTS mode and a new calibration window is displayed, functions 9444 and 9464 speak the first selective classification in the calibration window using TTS, and optionally kick out the current filter, some of which are unambiguous, and which Indicates whether the part is ambiguous, and then uses TTS to speak each candy det in the currently displayed part of the classification list. For speed it is best to make a difference in tone and sound to indicate which part of the filter is absolute or ambiguous.
사용자가 교정창에서 아이템을 스크롤하면, 펑크션(9448)(9450)은 TTS를 사용하여 각 스크롤에 따라서 현재 하일라이트된 선택분류와 그 선택번호를 말한다. 사용자가 교정창에서 페이지를 스크롤하면 펑크션(9452)(9454)은 TTS를 사용하여 새롭게 디스플레이된 선택분류 뿐만 아니라 현재 하일라이트된 선택분류의 표시를 말한다.As the user scrolls through the items in the calibration window, functions 9482 and 9450 refer to the currently highlighted selection classification and its selection number according to each scroll using the TTS. When the user scrolls the page in the calibration window, functions 9942 and 9444 refer to the display of the currently highlighted selection as well as the newly displayed selection.
수정 모드에 있을 때에 사용자가 메뉴에 들어가면, 펑크션(9456 및 9458)은 TTS 또는 자유로이 녹음된 오디오를 사용하여 현 메뉴의 이름 및 그 메뉴 내의 모든 선택 항목과 그에 딸린 번호를 말하여 현 선택 위치를 지시한다. 그것은 말해지고 있는 단어들이 메뉴 옵션임을 사용자에게 지시하는 오디오 큐에 의해 이뤄지는 것이 바람직하다.When the user enters a menu while in edit mode, functions 9944 and 9458 use TTS or freely recorded audio to tell the current selection position by telling the name of the current menu and all the selections and accompanying numbers within that menu. Instruct. It is preferably done by an audio cue instructing the user that the words being spoken are menu options.
사용자가 메뉴에 있는 항목을 상하로 스크롤하면, 펑크션(9460 및 9462)은 TTS 또는 미리 녹음된 오디오를 사용하여 하이라이트된 선택 항목을 말하고 나서, 잠시 멈춘 후에 메뉴의 디스플레이된 현 페이지 상에 있는 임의의 후속 선택을 말한다.When the user scrolls up or down through the items in the menu, functions 9460 and 9462 speak the highlighted selection using TTS or pre-recorded audio, and then pause and then any of the items on the displayed current page of the menu. Says the subsequent choice.
도 95는 TTS 생성에 사용되는 프로그래밍의 몇 가지 양태를 나타낸 것이다. 텍스트-투-스피치(TTS)에 의해 생성하려는 단어가 음성 인식 프로그램의 표음 철자된 단어들의 어휘 중에 있으면, 펑크션(9502)은 펑크션(9504 내지 9512)이 실행되게끔 한다. 펑크션(9504)은 그 단어가 음성의 상이한 부분과 연관된 다중 표음 철자를 갖는지의 여부와, TTS를 사용하여 설정하려는 단어가 그 현 음성 부분을 지시하는 통용 언어 컨텍스트를 갖는지의 여부를 알아보기 위한 검사를 한다. 그 양자의 조건이 충족되면, 펑크션(9506)은 음성 인식 프로그래밍의 코드 지시 음성 부분을 사용하여 현 단어에 대한 TTS 생성에 있어 그 코드 지시 음성 부분에 의해 표음 철자로서 찾아질 가능성이 가장 높은 음성 부분과 연관된 표음 철자를 선택한다. 한편, 그 단어와 연관된 표음 철자가 단 하나만 있거나, 그 단어에 대해 가장 유망한 음성 부분을 식별하는데 충분한 컨텍스트가 없으면, 펑크션(9510)은 그 단어에 대해 단일의 표음 철자 또는 그 가장 통상적인 표음 철자를 선택한다. 펑크션(9506) 또는 펑크션(9510)에 의해 그 단어에 대해 표음 철자가 선택되고 나면, 펑크션(9512)은 그 단어에 대해 표음 철자로서 선택된 그 표음 철자를 채용하여 TTS 생성에 사용한다. 펑크션(9514)에 나타낸 바와 같이, 텍스트-투-스피치에 의해 생성하려는 단어가 표음 철자를 갖지 않으면, 펑크션(9514 및 9516)은 그 단어의 텍스트-투-스피치 생성을 위해 음성 인식기가 사용하는 발음 추정 소프트웨어를 사용하여 이름 및 새로 편입된 단어에 표음 철자를 할당한다.95 illustrates some aspects of programming used to generate TTS. If the word to be generated by the text-to-speech (TTS) is in the vocabulary of phonetic spelled words of a speech recognition program, function 9502 causes functions 9504 to 9512 to be executed. Function 9504 is used to determine whether the word has multiple phonetic spellings associated with different parts of the speech, and whether the word to be set using TTS has a common language context indicating the current speech portion. Do an inspection. If both conditions are met, function 9506 uses the code directed voice portion of the speech recognition programming to generate the TTS for the current word, the voice most likely to be found as phonetic spelling by the code directed voice portion. Select the phonetic spelling associated with the part. On the other hand, if there is only one phonetic spelling associated with that word, or if there is not enough context to identify the most promising phonetic part for that word, function 9510 may spell a single phonetic spelling or its most common phonetic spelling for that word. Select. After phonetic spelling is selected for the word by function 9506 or function 9510, function 9512 employs the phonetic spelling selected as the phonetic spelling for the word and uses it to generate the TTS. As shown in function 9514, if words to be produced by text-to-speech do not have phonetic spelling, functions 9514 and 9516 are used by the speech recognizer to generate text-to-speech of the words. Phonetic spelling software assigns phonetic spellings to names and newly incorporated words.
도 96은 도 89 및 도 90에 도시된 편집 옵션 메뉴의 오디오 메뉴 중에서 도 90의 번호 "7"과 연관하여 전술된 편집 옵션 메뉴의 오디오 메뉴 옵션 하에 활성화되는 표기 모드 대화 박스의 동작에 의해 선택될 수 있는 표기 모드의 동작을 나타낸 것이다.FIG. 96 is selected by the operation of the notation mode dialog box activated under the audio menu option of the editing option menu described above in connection with the number “7” of FIG. 90 among the audio menus of the editing option menu shown in FIGS. 89 and 90. It shows the behavior of the notation mode.
표기 모드에 들어가면, 펑크션(9602)은 통상적으로 내비게이션 모드를 오디오 내비게이션 모드로 바꾸는데, 그러한 오디오 내비게이션 모드는 좌우 내비게이션 키 입력에 응하여 전후 5초를 경과시켜 오디오 녹음을 진행하고, 상하 내비게이션 키 입력에 응하여 전후 1초를 경과시킨다. 그들은 표기 모드 대화 박스로 바뀔 수 있는 디폴트값들이다. 그러한 모드 동안, 사용자가 편집기에 있는 "6"번 키인 플레이 키를 클릭하면, 펑크션(9606 내지 9614)이 실행된다. 펑크션(9607 및 9608)은 플레이를 온/오프 간으로 토글링한다. 펑크션(9610)은 토글링에 의해 플레이가 온으로 켜지면 펑크션(9612)이 실행되게끔 한다. 그 경우, 마지막 사운드가 플레이된 이래로 사운드 내비게이션이 없었으면, 펑크션(9614)은 플레이의 마지막 종료 전의 일정 기간을 재생하기 시작한다. 그것은 사용자가 표기를 실행하고 있을 때에 마지막 것이 종료되기 약간 전에 각각의 순차적 재생이 시작되어 사용자가 선행 재생에서 단지 부분적으로만 말해진 단어를 인식할 수 있게 하고, 사용자가 앞선 언어 컨텍스트를 조금 인지할 수 있으면 음성 사운드를 단어로서 보다 잘 번역할 수 있게 하도록 이뤄진다. 사용자가 플레이 키를 1초의 1/3과 같은 정해진 기간보다 더 오래 누르면, 펑크션(9616)은 펑크션(9618 내지 9622)가 실행되게끔 한다. 그들 펑크션은 플레이가 온으로 켜져 있는지의 여부를 알아보기 위한 검사를 하고, 그렇다면 플레이를 오프로 끈다. 또한, 그들 펑크션은 플레이 키를 누르는 동안 현재의 세팅에 따라 연속 모드 또는 불연속 모드로 대어휘 인식을 개시한다. 이어서, 그들 펑크션은 표기되는 오디오에 있어 플레이의 마지막 종료가 일어난 위치에서 인식 텍스트를 편집기에 삽입한다. 사용자가 플레이 버튼을 이중 클릭하면, 펑크션(9624 및 9626)은 표기 모드에 오디오 녹음이 가용될 수 없다는 것과 부가 옵션 메뉴 하의 오디오 메뉴에서 표기 모드를 끝낼 수 있음을 사용자에게 일러준다.Upon entering the notation mode, function 9602 typically changes the navigation mode to the audio navigation mode, which proceeds with audio recording after 5 seconds of forward and backward in response to the left and right navigation key inputs, and enters the up and down navigation key inputs. In response, 1 second is passed before and after. They are the default values that can be changed in the notation mode dialog box. During such a mode, when the user clicks on the play key, which is the "6" key in the editor, the functions 9660 to 9614 are executed. Functions 9607 and 9608 toggle play between on and off. Function 9610 causes function 9612 to execute when play is turned on by toggling. In that case, if there has been no sound navigation since the last sound was played, the function 9614 begins to play a period of time before the last end of the play. It starts each sequential playback a little before the end of the last one when the user is executing the notation, allowing the user to recognize only partially spoken words in the preceding playback, and allow the user to recognize some of the preceding language contexts. If so, the speech sounds better translated into words. If the user presses the play key for longer than a predetermined period, such as one third of a second, function 9616 causes functions 9618 to 9622 to be executed. Their function checks to see if play is on and if so, turns play off. In addition, these functions initiate large vocabulary recognition in continuous mode or discontinuous mode depending on the current setting while pressing the play key. These functions then insert the recognition text into the editor at the location where the last end of play in the audio to be marked occurred. When the user double-clicks the play button, functions 9624 and 9626 tell the user that no audio recording is available for the display mode and that the display mode can be exited from the audio menu under the additional options menu.
그러한 표기 모드는 사용자로 하여금 "6"번 전화 키인 플레이 키를 단지 클릭하는 것과 누른 채로 유지하는 것 사이를 교대함으로써 이전에 녹음된 오디오의 일부를 플레이하는 것과 이어서 음성 인식을 사용하여 그것을 표기하는 것 사이를 오갈 수 있게끔 하는 것을 알 수 있다. 사용자는 편집기의 다른 펑크션을 사용하여 표기 과정 동안 인식에 있어 이뤄진 임의의 오류를 자유롭게 수정하고, 이어서 "6"번 키를 다시 눌러 플레이로 돌아가서 표기하려는 오디오의 다음 분절을 플레이하기만 하면 된다. 물론, 사용자가 오디오로부터 문자 표기를 실행하려 하지 않을 경 우도 종종 있다. 예컨대, 사용자는 전화 통화의 일부를 재생하여 좀더 주목할만한 부분의 개요를 표기하기만 하려 할 수 있다.Such a notation mode allows a user to play a portion of previously recorded audio by alternately between simply clicking and holding down the play key, which is the "6" phone key, followed by notation using speech recognition. You can see that it allows you to switch between them. The user simply uses the editor's other functions to freely correct any errors made in recognition during the marking process, then press "6" key again to return to play and play the next segment of the audio to be marked. Of course, there are often times when the user does not want to execute character notation from audio. For example, a user may only want to play part of a phone call to display an outline of a more noteworthy part.
도 97은 전술된 편집 모드의 다수의 특징을 사용하여 사용자로 하여금 텍스트 및 다른 정보를 셀룰러폰 스크린에 디스플레이된 대화 박스 내에 들여보낼 수 있게끔 하는 대화 박스 편집 프로그래밍의 동작을 나타낸 것이다.97 illustrates the operation of dialog box editing programming to allow a user to import text and other information into a dialog box displayed on a cellular phone screen using a number of features of the above-described editing mode.
우선, 대화 박스에 들어갔을 때에 펑크션(9702)은 대화 박스의 제1 부분을 보이는 편집기 창을 디스플레이한다. 대화 박스가 너무 커서 단번에 하나의 스크린에 맞춰질 수 없으면, 대화 박스는 스크롤 가능한 창에 디스플레이된다. 펑크션(9704)에 지시된 바와 같이, 대화 박스는 펑크션(9704 내지 9726)에 의해 지시된 바와 같은 것을 제외하고는 도 76 내지 도 78과 관련하여 전술된 편집 모드가 하는 것과 동일하게 모든 입력에 응한다. 펑크션(9707 및 9708)에 지시된 바와 같이, 사용자가 대화 박스에 있을 때에 내비게이션 입력을 제공하면, 커서 이동은 그것이 통상적으로 이동되기만 할 수 있다는 점을 제외하고는 편집기에서 그러한 것과 유사하게 그로 사용자가 입력을 제공할 수 있는 컨트롤에 응한다. 따라서, 사용자가 단어의 좌우로 이동한다면, 커서는 좌우로 다음 대화 박스 컨트롤로 이동하여 그러한 컨트롤을 찾는데 필요한 경우에 라인을 상하로 이동시킨다. 사용자가 라인을 상하로 이동시킨다면, 커서는 현 커서 위치의 상하로 라인에 가장 가깝게 이동한다. 사용자가 컨트롤을 전혀 담고 있지 않을 수도 있는 텍스트의 확장된 부분을 읽을 수 있도록 하기 위해, 커서는 통상적으로 한 페이지의 간격 내에 컨트롤이 없더라도 한 페이지를 넘게 이동하지는 않는다.First, when entering a dialog box function 9702 displays an editor window showing the first portion of the dialog box. If the dialog is too large to fit on one screen at a time, the dialog is displayed in a scrollable window. As indicated by function 9704, the dialog box has all the same inputs as the edit mode described above with respect to Figs. 76-78, except as indicated by functions 9704-9726. Respond to. As indicated by functions 9707 and 9708, if a user provides navigation input when in a dialog box, the cursor movement is similar to that in the editor except that it can only be moved normally. Responds to a control that can provide input. Thus, if the user moves left and right of the word, the cursor moves left and right to the next dialog box control and moves the line up and down as necessary to find that control. If the user moves the line up and down, the cursor moves up and down the current cursor position closest to the line. To allow the user to read an extended portion of text that may not contain the control at all, the cursor typically does not move more than one page even if there is no control within the interval of one page.
펑크션(9700 내지 9716)에 의해 지시된 바와 같이, 커서가 필드로 이동되고 나서 사용자가 텍스트를 편집기에 입력하는 유형의 어떠한 입력이라도 제공하면, 펑크션(9712)은 그 필드에 대해 별개의 편집 창을 디스플레이하는데, 그 별개의 편집 창은 혹시 있다면 그 필드에 현재 있는 텍스트를 디스플레이한다. 그 필드가 그에 딸린 어떠한 어휘 제한을 갖고 있으면, 펑크션(9714 및 9716)은 편집기에서의 인식을 그 어휘에 한정시킨다. 예컨대, 필드가 상태 이름에 한정되어 있다면, 그 필드에서의 인식은 그와 같이 한정된다. 그러한 필드 편집 창이 디스플레이되어 있는 동안, 펑크션(9718)은 모든 편집 명령을 할애하여 그 필드 편집 창 내의 편집을 실행한다. 사용자는 OK를 선택함으로써 그 필드 편집 창으로부터 나갈 수 있는데, 그에 의해 그 필드 편집 창에 그때 현재 있는 텍스트가 대화 박스 창에 있는 해당 필드로 들어가게 된다.As indicated by functions 9700 to 9716, if the cursor is moved to a field and the user then provides any input of the type that the user enters text into the editor, function 9712 can edit a separate edit for that field. Displays a window, which displays the text currently in that field, if any. If the field has any vocabulary restrictions that accompany it, functions 9714 and 9716 limit the recognition in the editor to that vocabulary. For example, if a field is limited to a state name, the recognition in that field is so limited. While such a field edit window is displayed, function 9718 dedicates all edit commands to execute the edits in that field edit window. The user can exit the field edit window by selecting OK, whereby the text currently in that field edit window enters the corresponding field in the dialog window.
대화 박스에 있는 커서가 선택 항목 리스트로 이동하고 사용자가 텍스트입력 명령을 선택하면, 펑크션(9722)은 리스트 박스 내에 있는 제1 선택 항목으로서의 현 값과 스크롤 가능한 리스트에 나타내진 다른 가용 선택 항목으로서 리스트 박스에 제공된 다른 옵션을 보이는 수정 창을 디스플레이한다. 그러한 특정의 선택 항목 리스트에서는 스크롤 가능한 옵션이 연관 번호를 선택함으로써 액세스될 수 있을 뿐만 아니라, 그 옵션에 한정된 어휘를 사용하는 음성 인식에 의해서도 가용될 수 있다.When the cursor in the dialog box moves to the list of choices and the user selects a text input command, function 9722 can act as the current value as the first choice in the list box and the other available choices shown in the scrollable list. Displays a modification window showing the different options provided in the list box. In such a specific selection item list, scrollable options can be accessed by selecting an association number, as well as speech recognition using a vocabulary limited to that option.
커서가 체크 박스 또는 무선 버튼에 있고 사용자가 임의의 편집 텍스트 명령을 선택하면, 펑크션(9724 및 9726)은 체크 박스 또는 무선 버튼이 선택되었는지의 여부를 토글링함으로써 체크 박스 또는 무선 버튼의 상태를 바꾼다.If the cursor is on a checkbox or radio button and the user selects any edit text command, functions 9724 and 9726 toggle the state of the checkbox or radio button by toggling whether the checkbox or radio button is selected. Change.
도 98은 PDA 실시예에서 도 19와 관련하여 전술된 도움말 모드와 유사한 셀룰러폰 실시예의 도움말 루틴(9800)을 나타낸 것이다. 셀룰러폰이 동작의 주어진 상태 또는 모드에 있을 때에 그러한 도움말 모드가 호출되면, 펑크션(9802)은 도움말 옵션과 모든 상태 명령 중의 선택 가능한 리스트와 함께 그 상태에 관한 설명을 포함하고 있는 그 상태에 대한 스크롤 가능한 도움말 메뉴를 디스플레이한다. 도 99는 도 67 및 도 76 내지 도 78과 관련하여 전술된 편집 모드에 대한 그러한 도움말 메뉴를 나타낸 것이다. 도 100은 도 68, 도 79 및 도 80과 관련하여 전술된 엔트리 모드에 대한 그러한 도움말 메뉴를 나타낸 것이다. 도 99 및 도 100에 도시된 바와 같이, 그러한 각각의 도움말 메뉴는 스크롤 가능한 하이라이트 및 도움말 키의 동작에 의해 선택될 수 있는 도움말 옵션 선택을 포함하고 있는데, 그것은 사용자로 하여금 도움말 메뉴 및 기타의 도움말 관련 펑크션의 여러 부분으로 신속하게 건너뛸 수 있게끔 한다. 또한, 각각의 도움말 메뉴는 그 셀룰러폰이 처해 있는 현 명령 상태에 관한 약술(9904)을 포함하고 있다. 아울러, 각각의 도움말 메뉴는 폰 키에 의해 액세스될 수 있는 모든 옵션을 망라한 스크롤 가능하고 선택 가능한 메뉴(9906)를 포함하고 있다. 뿐만 아니라, 각각의 도움말 메뉴는 도움말 펑크션을 사용하는 방법에 관한 설명 및 일부의 경우에 현 모드에서 가용될 수 있는 스크린의 다른 부분의 펑크션에 관한 도움말을 비롯한 다른 도움말 펑크션에 사용자가 액세스할 수 있게끔 하는 펑크션(9908)을 포함하고 있다.98 illustrates a help routine 9800 of a cellular phone embodiment similar to the help mode described above with respect to FIG. 19 in a PDA embodiment. If such a help mode is invoked when the cellular phone is in a given state or mode of operation, function 9802 will include a description of that state along with a help list and a selectable list of all state commands. Display the scrollable help menu. FIG. 99 shows such a help menu for the edit mode described above with respect to FIGS. 67 and 76-78. FIG. 100 illustrates such a help menu for the entry mode described above in connection with FIGS. 68, 79, and 80. As shown in Figures 99 and 100, each such help menu includes a selection of help options that can be selected by scrollable highlighting and the operation of the help key, which allows the user to relate to the help menu and other help. This allows you to quickly jump to different parts of the function. Each help menu also includes an
도 101에 도시된 바와 같이, 편집 모드에 있는 사용자가 펑크션(10100)에 지 시된 바와 같이 메뉴 키를 누른 채로 유지하고 있으면, 편집 모드를 위한 도움말 모드에 들어가져서 셀룰러폰이 스크린(10102)을 디스플레이하게 된다. 그 스크린(10102)은 선택 가능한 도움말 옵션인 옵션(9902)을 디스플레이하고, 도 99에 도시된 바와 같은 다른 모드(9900)의 동작에 관한 요약 설명의 도입부를 디스플레이한다. 도움말 메뉴에서 내비게이션 모드가 스크린(10102)에 나타내진 문자 "<P^L"로써 지시된 바와 같은 페이지/라인 내비게이션 모드로 된 이래로 사용자가 페이지 라이트 버튼으로서 동작하는 셀룰러폰의 라이트 화살표 키를 누르면, 디스플레이는 스크린(10104)에 의해 지시된 바와 같이 페이지를 스크롤 다운한다. 사용자가 페이지 라이트 키를 다시 누르면, 스크린은 페이지를 다시 스크롤 다운하여 스크린으로 하여금 도면 부호 "10106"에 나타내진 모습을 갖게끔 한다. 본 예에서는 사용자가 페이지 라이트 키를 단 두 번만 클릭함으로써 도 99에 도시된 편집 모드의 펑크션에 관한 요약을 읽을 수 있었다.As shown in FIG. 101, if a user in edit mode is holding down a menu key as indicated in
사용자가 페이지 라이트 키를 다시 클릭하여 스크린으로 하여금 스크린 샷(10108)에 나타내진 바와 같이 페이지를 스크롤 다운하게끔 하면, 편집 모드와 연관된 명령 리스트의 도입부를 볼 수 있게 된다. 사용자는 그러기를 원한다면 내비게이션 키를 사용하여 도움말 메뉴의 전체의 길이를 스크롤 할 수 있다. 도시된 예에서는 사용자가 엔트리 모드 메뉴에 딸린 키 번호를 찾았을 때에 도면 부호 "10110"에 나타내진 바와 같이 그 키를 눌러 도움말 메뉴로 하여금 스크린(10112)에 나타내진 바와 같은 엔트리 모드 메뉴와 연관된 도움말 메뉴를 디스플레이하게끔 한다.If the user clicks the page light key again to cause the screen to scroll down the page as shown in screen shot 10108, the entry of the list of commands associated with the edit mode is visible. The user can use the navigation keys to scroll through the entire length of the help menu if desired. In the example shown, when the user finds a key number that accompanies the entry mode menu, pressing the key as indicated by
사용자는 도움말 메뉴에 있을 때마다 도 99에 도시된 "키에 의한 선택" 라인 아래에 리스트된 명령을 즉시 선택할 수 있음을 알아야 할 것이다. 즉, 그 펑크션을 알아보기 위한 명령과 연관된 키를 누르기 위해 명령이 리스트된 도움말 메뉴의 부분을 사용자가 스크롤 다운할 필요가 없다. 실제로, 키와 관련된 펑크션을 이해하고 있다고 생각하는 사용자는 단지 메뉴 키를 누른 채로 유지하고 나서 원하는 키를 타이핑하여 그 펑크션에 관한 요약 설명 및 그 펑크션 하에 가용될 수 있는 명령의 리스트를 알 수 있게 된다.It will be appreciated that the user can immediately select the commands listed under the "Select by key" line shown in FIG. 99 whenever he is in the Help menu. In other words, the user does not have to scroll down to the portion of the help menu that lists the command to press a key associated with the command for identifying the function. Indeed, a user who thinks he understands the function associated with a key can simply hold down the menu key and then type in the desired key to get a brief description of the function and a list of commands available under that function. It becomes possible.
도 99 및 도 100에 도시된 "OK에 의한 선택" 라인 아래에 리스트된 명령은 메뉴에 있는 명령 라인에 하이라이트를 스크롤하고 OK 명령을 사용하여 선택함으로써 모여져야 한다. 그것은 라인(9912) 아래에 리스트된 명령이 도움말 메뉴 그 자체의 동작에 사용되는 키와 연관되어 있기 때문이다. 그것은 도 75에 도시된 편집 모드 명령의 스크린(7506)에 리스트된 명령과 유사한데, 그러한 명령도 역시 그 명령 리스트에 있는 OK 명령을 선택함으로써만 선택될 수 있는 것이다.The commands listed below the "Select by OK" lines shown in Figures 99 and 100 must be gathered by scrolling the highlights on the command line in the menu and selecting using the OK command. This is because the commands listed below
도 101의 예에서는 사용자가 엔트리 모드 메뉴에 있는 "9"번 키를 누름으로써 엔트리 선호 메뉴를 선택할 수 있음을 알고 있음으로 해서 도면 부호 "10114"에 의해 지시된 바와 같이 엔트리 모드 메뉴에 대한 도움말에 들어오자마자 그 키를 누른다고 가정하기로 한다. 그에 의해, 도면 부호 "10116"에 나타내진 바와 같이 엔트리 선호 메뉴에 대한 도움말 메뉴가 보이게 된다.In the example of FIG. 101, since the user knows that the user can select the entry preference menu by pressing the "9" key in the entry mode menu, the help for the entry mode menu is indicated as indicated by reference numeral "10114". Assume that you press the key as soon as you come in. Thereby, the help menu for the entry preference menu is shown as indicated by
본 예에서는 사용자가 "1"번 키를 누르고, 뒤따라 이스케이프 키를 누른다고 하기로 한다. 그 "1"번 키는 구술 디폴트 옵션에 대한 도움말 메뉴를 잠시 불러내 고, 이스케이프 키는 스크린(10118)에 의해 나타내진 바와 같이 엔트리 선호 메뉴 및 구술 디폴트 옵션이 딸린 메뉴로 되돌린다. 이스케이프가 뒤따르는 그러한 키 옵션의 선택은 사용자가 단지 도움말 메뉴의 명령 리스트 중의 원하는 명령 리스트의 부분에 있는 키 번호를 누르고 뒤따라 이스케이프 키를 누르기만 하면 그 원하는 부분으로 신속하게 내비게이션할 수 있게끔 한다.In this example, the user presses the "1" key followed by the escape key. The "1" key momentarily invokes the help menu for the dictation default option, and the escape key returns to the menu with the entry preference menu and the dictation default option as indicated by
본 예에서는 사용자가 도면 부호 "10120"에 나타내진 바와 같은 페이지 라이트 키를 눌러 스크린(10122)에 의해 지시된 바와 같이 명령 리스트에서 페이지를 스크롤 다운한다. 본 예에서는 사용자가 도면 부호 "10124"에 지시된 바와 같이 "5"번 키를 눌러 그 키와 연관된 옵션을 선택하여 발음 옵션으로 계속 누르든지 불연속적으로 클릭하는 것에 관한 설명을 얻는다고 가정하기로 한다. 그에 의해, 스크린(10126)에 나타내진 바와 같이 그 옵션에 대한 도움말이 디스플레이된다. 본 예에서는 사용자가 2개를 넘는 스크린을 스크롤 다운하여 그 옵션의 펑크션에 관한 요약 설명을 읽고 나서 도면 부호 "10128"에 나타내진 바와 같이 이스케이프 키를 눌러 스크린(10130)에 나타내진 바와 같이 엔트리 선호 메뉴에 대한 도움말 메뉴로 돌아간다.In this example, the user presses the page write key as indicated by
도 102에 도시된 바와 같이, 본 예에서는 사용자가 엔트리 선호 메뉴에 대한 도움말로 돌아갔을 때에 도면 부호 "10200"에 의해 지시된 바와 같이 "4"번 키를 선택하여 스크린(10202)에 나타내진 바와 같이 발음 옵션으로 누르고 클릭하는 동안에 관한 도움말 메뉴가 디스플레이되게끔 한다. 이어서, 사용자는 2개를 넘는 스크린을 스크롤 다운하여 그 모드에 관한 설명을 숙독함으로써 그 펑크션을 이해하 고 난 다음에, 도면 부호 "10204"에 나타내진 바와 같이 이스케이프 키를 눌러 스크린 "10206"에 나타내진 바와 같이 엔트리 선호 메뉴에 대한 도움말로 돌아간다. 이어서, 사용자는 이스케이프를 다시 눌러 그로부터 엔트리 선호 메뉴를 불러왔던 도움말 메뉴, 즉 스크린(10210)에 나타내진 바와 같은 엔트리 모드 메뉴에 대한 도움말 메뉴로 돌아간다. 사용자는 이스케이프를 다시 눌러 그로부터 엔트리 모드 메뉴에 대한 도움말을 불러왔던 도움말 메뉴, 즉 스크린(10214)에 나타내진 바와 같은 편집 모드에 도움말 메뉴로 돌아간다.As shown in FIG. 102, in this example, when the user returns to the help for the entry preference menu, as shown by
본 예에서는 사용자가 페이지 라이트 키를 6번 눌러 편집 모드에 대한 도움말 메뉴 중에서 도 99에 도시된 하단 부분(9908)까지 스크롤 다운하는 것으로 가정하기로 한다. 사용자는 그가 원한다면 플레이스 명령을 사용하여 도움말 메뉴의 그 부분에 있는 옵션에 보다 더 신속하게 액세스할 수 있다. 도움말 메뉴의 "다른 도움말" 부분에 있다면, 사용자는 도면 부호 "10220"에 나타내진 바와 같이 다운 라인 버튼을 눌러 스크린(10222)에 나타내진 편집 스크린 옵션(10224)을 선택한다. 그 시점에, 사용자는 OK 버튼을 선택하여 스크린(10228)에 나타내진 바와 같이 편집 스크린 그 자체에 대한 도움말이 디스플레이되게끔 한다. 그러한 스크린이 보이는 모드에서는 폰 키 번호 지시기(10230)를 사용하여 편집 스크린의 부분을 표식한다. 도 102의 예에서는 사용자가 4"번 키를 눌러 편집 스크린 도움말 스크린(10228)의 상단에 나타내어진 내비게이션 모드 지시기 "<W^L"의 펑크션을 설명하는 편집 스크린 도움말 스크린(10234)이 디스플레이되게끔 한다.In this example, it is assumed that the user presses the page light key six times to scroll down to the
본 예에서는 사용자가 도면 부호 "10236"으로 나타내진 바와 같이 이스케이 프 키를 세 번 누른다. 그와 같이 이스케이프 키를 누르는 것 중의 첫 번째 누름은 스크린(10234)으로부터 도로 스크린(10228)으로 빠져나와 설명되고 있는 스크린의 번호가 달린 다른 부분의 설명을 선택할 옵션을 사용자에게 제공하는 것이다. 본 예에서는 사용자가 그러한 다른 선택을 하는 것에 관심이 없어 이스케이프 키를 첫 번째로 누른 다음에 바로 연달아 이스케이프 키를 또다시 2번 눌렀는데, 그 중의 첫 번째 누름은 편집 모드에 대한 도움말 메뉴로 도로 빠져나오는 것이고, 두 번째 누름은 편집 모드 그 자체로 도로 빠져나오는 것이다.In this example, the user presses the escape key three times, as indicated by reference numeral “10236”. The first press of such an escape key is to exit the
도 101 및 도 102에서 알 수 있는 바와 같이, 도움말 메뉴의 그러한 계층적 동작은 사용자로 하여금 셀룰러폰에서의 명령 구조를 신속하게 조사할 수 있게끔 한다. 그것은 원하는 펑크션을 실행하는 명령을 검색하는데 또는 단지 선형적 순서대로 명령 구조를 습득하는데 사용될 수 있다.As can be seen in FIGS. 101 and 102, such a hierarchical operation of the help menu allows the user to quickly examine the command structure in the cellular phone. It can be used to retrieve instructions that execute the desired function or to learn the instruction structure only in linear order.
도 103 및 도 104는 사용자가 편집 모드에서 몇 가지 음성을 연속적으로 구술하고 나서 그 편집 모드의 인터페이스를 사용하여 결과적으로 나온 텍스트 출력을 수정하는 것의 예를 설명하고 있다.103 and 104 illustrate an example in which a user continuously dictates some voices in the edit mode and then uses the edit mode's interface to modify the resulting text output.
그러한 시퀀스는 도 103에서 도면 부호 "10300"에 지시된 바와 같이 사용자가 토크 버튼을 누른 채로 유지하는 것으로 시작되는데, 그동안 사용자는 발음(10302)을 말한다. 그 결과, 그 발음이 인식되고, 그것은 본 예에서는 스크린(10304)에 나타내진 텍스트가 편집 모드의 텍스트 창(10305)에 디스플레이되게끔 한다. 도면 부호 "10306"은 그와 같이 인식된 텍스트의 끝에 있는 커서의 위치를 지시하고 있는데, 그것은 연속적인 구술의 종료 시에 생기는 비 선택적 커서이다.Such a sequence begins with the user pressing and holding the talk button as indicated by
본 시스템이 연속적인 대어휘 음성 인식을 사용하여 발음이 인식되게끔 하는 모드로 설정되어 있다고 가정하기로 한다. 그것은 스크린(10304)에 나타내진 편집 창의 타이틀 바에 문자 "_LV"로 지시되어 있다.It is assumed that the system is set to a mode in which pronunciation is recognized using continuous large vocabulary speech recognition. It is indicated by the character "_LV" in the title bar of the edit window shown on
본 예에서는 사용자가 "3"번 키를 눌러 도 70 및 도 84에 도시된 부가 내비게이션 메뉴에 액세스하고 나서 "1"번 버튼을 눌러 그들 도면에 도시된 발음 옵션을 선택한다. 그에 의해, 스크린(10310)에 도면 부호 "10308"에 의해 지시된 바와 같이 커서가 가장 최근의 발음에 대해 인식된 텍스트의 첫 번째 단어에 대응하게 된다. 그런 다음, 사용자는 "7"번 키를 더블 클릭하여 도 77에서 설명된 대문자로 시작되는 사이클 펑크션을 선택한다. 그에 의해, 도면 부호 "10312"에 나타내진 바와 같이 선택된 단어가 대문자로 시작되게 된다.In this example, the user presses the "3" key to access the additional navigation menu shown in Figs. 70 and 84, and then presses the "1" button to select the pronunciation option shown in those figures. Thereby, the cursor corresponds to the first word of the text recognized for the most recent pronunciation as indicated by
다음으로, 사용자는 내비게이션 모드 지시기에 의해 지시된 현재의 단어/라인 내비게이션 모드에서 단어 라이트 버튼으로서 동작하는 라이트 버튼을 누른다. 그에 의해, 커서가 우측으로 다음 단어로 이동한다. 그런 다음, 사용자는 "5"번 키를 눌러 편집기를 도 77의 펑크션(7728 내지 7732)과 연관하여 전술된 확장 선택 모드로 설정한다. 이어서, 사용자는 단어 라이트 버튼을 다시 눌러 커서로 하여금 단어(10318)로 이동하게끔 하고, 확장 선택(10320)으로 하여금 "got it"이란 텍스트를 담게끔 한다.Next, the user presses a light button that acts as a word light button in the current word / line navigation mode indicated by the navigation mode indicator. Thereby, the cursor moves to the next word to the right. Then, the user presses a key "5" to set the editor to the extended selection mode described above in association with functions 7728-7732 of FIG. Then, the user presses the word light button again to cause the cursor to move to
다음으로, 사용자는 "2"번 키를 눌러 도 77의 선택 항목 리스트 명령을 선택하는데, 그에 의해 제1 선택 항목으로서의 선택(10320)에 대해 도면 부호 "10324"에 디스플레이된 것과 같이 나타내지는 알파벳 순서의 제1 선택 항목 리스트를 동 반한 수정 창이 디스플레이되게 된다. 그러한 선택 항목 리스트에서는 각각의 선택 항목이 그것을 선택하는데 사용될 수 있는 그에 딸린 폰 키 번호와 함께 나타내진다.Next, the user presses the "2" key to select the selection item list command in FIG. 77, whereby the alphabetical order indicated as indicated by
본 예에서는 원하는 선택 항목이 제1 선택 항목 리스트에 나타내지지 않아서 사용자가 라이트 키를 세 번 눌러 원하는 단어 "product"가 위치되어 있는 도면 부호 "10328"에 나타내진 알파벳 순서의 제2 선택 항목 리스트의 세 번째 스크린까지 스크롤 다운한다고 가정하기로 한다.In this example, since the desired selection item is not shown in the first selection item list, the user presses the right key three times to display the alphabetical second selection item list indicated by reference numeral "10328" in which the desired word "product" is located. Suppose you scroll down to the third screen.
도 77의 펑크션(7706)에 의해 지시되어 있는 바와 같이, 사용자가 선택 항목 리스트 버튼을 한 번 눌러 수정 창에 들어갔을 때에 수정 창의 내비게이션은 스크린(10332)에 나타내진 내비게이션 모드 지시기(10326)에 의해 지시된 바와 같이 페이지l/항목 내비게이션 모드로 설정된다.As indicated by the function 7706 of FIG. 77, when the user enters the modification window by pressing the selection item list button once, the navigation of the modification window is displayed on the
본 예에서는 사용자가 "6"번 키를 눌러 원하는 선택 항목을 선택하고, 그에 의해 그 선택 항목이 커서 선택의 위치에 있는 편집기의 텍스트 창 내에 삽입되어 편집 텍스트 창이 도면 부호 "10330"에 나타내진 것과 같은 모습을 갖게끔 한다.In this example, the user presses the "6" key to select the desired selection, whereby the selection is inserted into the text window of the editor at the cursor selection position so that the edit text window is indicated by reference numeral "10330". Have the same look.
다음으로, 사용자는 단어 라이트 키를 세 번 눌러 커서를 도면 부호 "10332"의 위치에 위치시킨다. 그 경우, 인식된 단어는 "results"이고, 원하는 단어는 그 단어의 단수형 "result"이다. 그 때문에, 사용자는 단어형 리스트 버튼을 눌러 단어형 리스트 수정 창(10334)이 디스플레이되게끔 하는데, 그 리스트 수정 창(10334)은 그 디스플레이된 선택 항목 중의 하나로서 원하는 바의 변형된 단어형을 갖는다. 사용자는 그에 딸린 폰 키를 누름으로써 원하는 선택 항목을 선택하여 편 집 텍스트 창이 도면 부호 "10336"에 나타내진 모습을 갖게끔 한다.Next, the user presses the word write key three times to position the cursor at the position "10332". In that case, the recognized word is "results" and the desired word is the singular form "result". Thus, the user presses a word list button to cause the word list modify
도 104에 도시된 바와 같이, 사용자는 그런 다음에 라인 다운 버튼을 눌러 커서를 아래쪽으로 도면 부호 "10400"의 위치로 이동시킨다. 이어서, 사용자는 "5"번s 키를 눌러 확장 선택을 시작하고, 단어 키를 눌러 커서를 "도면 부호 "10402"의 위치까지 우측으로 한 단어 이동시켜 현 선택(10404)이 우측으로 한 단어만큼 확장되게끔 한다.As shown in FIG. 104, the user then presses a line down button to move the cursor downward to the location of
다음으로, 사용자는 "2"번 키를 더블 클릭하여도 77에서 펑크션(7712 내지 7716)과 연관하여 전술된 필터 선택 항목 옵션을 선택한다. "2"번 키의 두 번째 클릭은 하향 화살표(10406)에 의해 지시된 바와 같이 긴 클릭이다. 그와 같이 길게 누르는 동안, 사용자는 원하는 단어 "painstaking"의 처음 문자인 문자열 "p, a, i, n, s, t"를 발음한다.Next, the user selects the filter selection item option described above in association with the functions 7712-7716 in FIG. 77 by double-clicking the "2" key. The second click of the "2" key is a long click, as indicated by the
본 예에서는 수정 창이 수정(10412)의 타이틀 바에 문자 "_abc로 지시된 바와 같이 연속 문자 이름 인식 모드에 있는 것으로 가정하기로 한다.In this example, it is assumed that the modification window is in the continuous character name recognition mode as indicated by the character "_abc" in the title bar of the
본 예에서는 발음(10408)을 필터 입력으로서 인식함으로써 수정 창(10412)으로 하여금 연속적으로 말해진 문자 이름의 문자열을 인식하는 것으로부터의 인식 결과에 해당하는 다의적 필터에 대해 필터링된 일련의 선택 항목을 나타내게끔 한다. 수정 창은 다의적 필터 요소와 연관된 문자 시퀀스 중의 하나로 시작하는 제1 선택 항목(10414)을 갖는다. 다의적 필터와 연관된 문자 시퀀스에 대응하는 제1 선택 항목의 부분은 다의적 필터 지시기(10416)에 의해 지시된다. 필터 커서(10418)는 제1 선택 항목의 그 부분의 끝 이후에 위치된다.In this example, by recognizing the
본 시점에서는 사용자가 단어 라이트 키를 눌러 필터 커서로 하여금 도 81에서의 펑크션(8124 및 8126)의 동작에 의해 현 단어의 제1 문자(10420)로 이동하여 그를 선택하게끔 한다. 도 81의 펑크션(8151 및 8162)은 필터 문자 선택 항목 창(10422)이 디스플레이되게끔 한다. 원하는 문자가 "p"이기 때문에, 사용자는 "7"번 키를 눌러 그것을 선택함으로써 그 문자가 필터 문자열의 명확한 문자로 되게끔 하고, 필터에서의 그러한 변화의 결과로서 새로운 수정 창(10424)이 디스플레이되게끔 한다.At this point, the user presses the word write key to cause the filter cursor to move to and select the
다음으로, 사용자는 문자 다운 버튼을 4번 눌러 필터 커서의 선택이 도 81의 펑크션(8150)의 동작에 의해 제1 선택 항목에서 4 문자만큼 우측으로 이동되게끔 하는데, 본 예에서는 그에 해당하는 문자가 문자 "f"(10426)이다. 그 문자는 다의적 필터 표시자(10428)에 의해 지시된 바와 같은 필터 문자열의 다의적 부분에 해당하는 제1 선택 항목의 일부이기 때문에, 도 81의 라인(8152)에 있는 필터 문자 선택 항목을 불러내어 도시된 바와 같이 다른 문자 선택 항목 창이 디스플레이되게끔 한다.Next, the user presses the letter down button four times to cause the selection of the filter cursor to be moved to the right by four characters in the first selection item by the operation of the function 8150 of FIG. 81. The character is the letter "f" (10426). Since the character is part of the first selection that corresponds to the multiplicative portion of the filter string as indicated by the
본 예에서는 원하는 문자인 문자 "s가 선택 항목 리스트 중의 "5"번 키에 딸려 있고, 사용자는 그 키를 눌러 도면 부호 "10432"에 의해 지시된 바와 같이 정확한 문자(10430)가 현 필터 문자열 내에 삽입되게끔 하고, 명확한 것으로 확인되기 전에 있는 모든 문자가 그처럼 되게끔 한다.In this example, the desired character "s" is attached to the "5" key in the selection item list, and the user presses the key to insert the
본 시점에서는 정확한 선택 항목이 "6"번 키에 딸려 있고, 사용자는 그 폰 키를 눌러 도면 부호 "10434"에 나타내진 바와 같이 원하는 단어가 편집 텍스트 창 내에 삽입되게끔 한다.At this point, the correct selection is attached to the key "6", and the user presses the phone key to cause the desired word to be inserted into the edit text window as indicated by reference numeral "10434".
다음으로, 본 예에서는 사용자가 라인 다운 및 단어 라이트 키를 눌러 도면 부호 "10436"에 나타내진 텍스트 "period"를 선택하기 위해 커서 선택을 한 라인 아래로, 그리고 우측으로 이동시킨다. 이어서, 사용자는 "8"번 키 또는 단어형 리스트 키를 눌러 단어형 리스트 수정 창(10438)이 디스플레이되게끔 한다. 원하는 출력인 "period" 표시는 "4"번 폰 키에 딸려 있다. 사용자는 그 키를 눌러 도면 부호 "10440"에 나타내진 바와 같이 원하는 단어가 편집 창의 텍스트 내에 삽입되게끔 한다.Next, in this example, the user presses the line down and word write keys to move the cursor selection down one line and to the right in order to select the text “period” indicated by reference numeral “10436”. Then, the user presses the "8" key or the word list key to cause the word list edit window 10438 to be displayed. The desired output "period" is attached to the "4" phone key. The user presses the key to cause the desired word to be inserted into the text of the edit window as indicated by
도 105는 사용자가 도 81과 연관하여 전술된 펑크션(8132 및 8135)의 동작에 의해 어떻게 선택 항목 리스트를 수평으로 스크롤할 수 있는지를 나타낸 것이다.FIG. 105 illustrates how a user can scroll the selection item list horizontally by operation of the functions 8132 and 8135 described above in connection with FIG. 81.
도 106은 "Key Alpha" 모드가 알파벳 입력을 편집 텍스트 창 내에 들여보내는데 어떻게 사용될 수 있는지를 나타낸 것이다. 스크린(10600)은 그 안에 커서(10602)가 보이는 편집 텍스트 창을 나타낸다. 본 예에서는 사용자가 "1"번 키를 눌러 도 79 및 도 68과 연관하여 전술된 엔트리 모드 메뉴를 열어서 스크린(10604)이 나타나게끔 한다. 그러한 모드에 있으면, 사용자는 "3"번 키를 더블 클릭하여 도 79의 펑크션(7938)과 연관하여 전술된 "Key Alpha" 인식 모드를 선택한다. 그에 의해, 시스템이 도 86과 연관하여 전술된 "Key Alpha" 모드로 설정되고, 편집 창이 도 106에 도시된 프롬프트(prompt)를 디스플레이하게 된다.106 illustrates how the "Key Alpha" mode can be used to import alphabetic input into the edit text window.
본 예에서는 사용자가 도면 부호 "10608"에 지시된 바와 같이 폰 키를 길게 눌러 프롬프트 창(10610)이 눌려진 폰 키 상의 각각의 문자에 딸린 ICA 단어를 디 스플레이하게끔 한다. 그에 응하여, 사용자는 "charley"라는 발음(10612)을 낸다. 그에 의해, 해당 문자 "c가 커서의 이전 위치에서 텍스트 창 내에 들어가게 되어 텍스트 창이 스크린(10614)에 나타내진 모습을 갖게 된다.In this example, the user presses and holds the phone key as indicated by
다음으로, 본 예에서는 사용자가 토크 키를 누르면서 도면 부호 "10616"에 지시된 바와 같이 2개의 ICA 단어 "alpha" 및"bravo"를 연속적으로 발음하는 것으로 가정하기로 한다. 그에 의해, 그 2개의 ICA 단어에 딸린 문자 "a 및 "b"가 스크린(10618)에 의해 지시된 바와 같이 커서에서 텍스트 창 내에 들어가게 된다. 다음으로, 본 예에서는 사용자가 "8"번 키를 눌러 그 키에 딸린 3개의 ICA 단어 중의 하나를 말하도록 촉구받고, 그에 따라 "uniform"이란 단어를 발음하여 도면 부호 "10620"에 나타내진 바와 같이 문자 "u"가 편집 텍스트 창 내에 삽입되게끔 한다.Next, it is assumed in this example that the user pronounces the two ICA words "alpha" and "bravo" consecutively as indicated by reference numeral "10616" while pressing the talk key. Thereby, the letters "a" and "b" accompanying the two ICA words enter the text window at the cursor as indicated by
도 107은 알파벳 필터링 입력을 들여보내는데 사용되는 동일한 "key Alpha" 인식 모드를 나타낸 것이다. 그 도면은 수정 창에 있을 때에 도 106에 나타내진 바와 같이 텍스트 편집기로부터 될 수 있는 것과 마찬가지로 "1"키를 누르고 뒤따라 "3"키를 더블 클릭함으로써 "Key Alpha" 모드에 들어갈 수 있음을 나타내고 있다.107 illustrates the same "key Alpha" recognition mode used to import alphabetic filtering input. The figure shows that when in the edit window you can enter the "Key Alpha" mode by pressing the "1" key followed by a double-click on the "3" key as can be done from a text editor as shown in FIG. .
도 106 및 도 109는 셀룰러폰 실시예에서 사용자가 전술된 음성 인식 텍스트 편집기를 사용하여 어떻게 텍스트 및 이-메일의 주소를 지정하고 그것에 들어가서 그것을 수정하는지를 나타낸 것이다.106 and 109 illustrate how in a cellular phone embodiment a user may address and enter text and e-mail using the voice recognition text editor described above.
도 108에서는 스크린(10800)이 사용자가 도 66에 도시된 바와 같은 메인 메뉴에 있을 때에 "4"키를 더블 클릭함으로써 이-메일 옵션을 선택한 경우에 그가 액세스한 이-메일 옵션 스크린을 나타내고 있다.108 shows an e-mail option screen that he accessed when
도시된 예에서는 사용자가 새로운 이-메일 메시지를 작성하기를 원하여 "1"번 옵션을 선택한 것으로 가정하기로 한다. 그에 의해, 새로운 이-메일 메시지 창(10802)이 그 창에 있는 제1 편집 가능한 위치에 커서가 위치된 채로 디스플레이 되게 된다. 그것은 이-메일 메시지 중에서 메시지의 주소와 연관된 부분에 있는 첫 번째 문자이다. 본 예에서는 사용자가 토크 버튼을 길게 누르면서 도면 부호 "10804"에 의해 지시된 바와 같이 이름 "Dan Roth"를 발음한다.In the example shown, it is assumed that the user has selected option "1" in order to create a new e-mail message. Thereby, a new
본 예에서는 그로 인해 도면 부호 "10806"에 나타내진 바와 같이 약간 틀린 이름 "Stan Roth"가 메시지의 주소 내에 삽입되었다고 하기로 한다. 그에 응하여, 사용자는 "2"번 키를 눌러 선택을 위한 선택 항목 리스트(10806)를 선택한다. 본 예에서는 원하는 이름이 선택 항목 리스트 상에 나타내지고, 사용자는 "5"번 키를 눌러 그것을 선택하여 도면 부호 "10808"에 나타내진 바와 같이 원하는 이름이 주소 라인에 삽입되게끔 한다.In this example, it is assumed that a slightly wrong name "Stan Roth" has been inserted into the address of the message, as indicated by
다음으로, 사용자는 다운 라인 버튼을 두 번 눌러 커서를 아래쪽으로 제목 라인의 시작 부분으로 이동시킨다. 이어서, 사용자는 토크 버튼을 누르면서 "cell phonee speech interface"(10812)라는 발음을 말한다. 본 예에서는 그것이 "sell phone speech interface"로서 약간 잘못 인식되고, 그 텍스트가 제목 라인 상의 커서 위치에 삽입되어 이-메일 편집 창이 도면 부호 "10814"에 나타내진 모습을 갖게 된다고 하기로 한다. 그에 응하여, 사용자는 라인 업 버튼 및 단어 레프트 버튼을 눌러 커서 선택을 도면 부호 "10816"의 위치에 위치시킨다. 이어서, 사용자는 "8"번s 키를 눌러 단어형 수정 리스트 창(10818)이 디스플레이되게끔 한다. 본 예에서 는 원하는 출력이 "4"번 키에 딸려 있고, 사용자는 그 키를 선택하여 원하는 출력이 스크린(10820)에 지시된 바와 같은 커서 위치에 놓이게끔 한다.Next, the user presses the downline button twice to move the cursor downward to the beginning of the title line. The user then speaks the pronunciation of “cell phonee speech interface” 10812 while pressing the talk button. In this example it is assumed that it is slightly misrecognized as the "sell phone speech interface" and the text is inserted at the cursor position on the subject line so that the e-mail editing window has the appearance indicated by reference numeral "10814". In response, the user presses the line up button and the word left button to place the cursor selection at the location of reference numeral “10816”. Then, the user presses the "8" key to cause the worded
다음으로, 사용자는 라인 다운 버튼을 두 번 눌러 스크린(10822)에 나타내진 바와 같이 커서를 이-메일 메시지의 본문의 시작 부분에 놓는다. 그것이 이뤄지면, 사용자는 토크 버튼을 누르면서 "the new Elvis interface is working really well"이란 발음을 연속적으로 말한다. 그로 인해, 스크린(10824)에 의해 지시된 바와 같이 다소 잘못 인식된 "he knew elfish interface is working really well"이란 문자열이 커서 위치에 삽입된다고 하기로 한다.Next, the user presses the line down button twice to place the cursor at the beginning of the body of the e-mail message as shown on
그에 응하여, 사용자는 라인 업 키를 한 번, 그리고 단어 레프트 키를 두 번 눌러 커서를 도 109의 스크린(10900)에 의해 나타내진 위치에 놓는다. 이어서, 사용자는 "5"번 키를 눌러 확장 선택을 시작하고, 단어 레프트 키를 두 번 눌러 커서를 도면 부호 "10902"의 위치에 놓고서 도면 부호 "10904"에 의해 나타내진 바와 같이 선택이 확장되게끔 한다. 본 시점에서는 사용자가 "2"번 키를 더블 클릭하여 현 선택에 대한 수정 창(10906)에 들어가고, 그 키를 누르는 동안 문자 "t, h, e, 스페이스, n"을 연속적으로 말한다. 그에 의해, 연속적으로 들어간 자구 이름 문자 시퀀스에 해당하는 명확한 필터(10910)와 함께 새로운 수정 창(10908)이 디스플레이되게 된다.In response, the user presses the line up key once and the word left key twice to place the cursor at the location indicated by
다음으로, 사용자는 단어 라이트 키를 눌러 도면 부호 "10912"에 의해 지시된 바와 같이 필터 커서를 우측으로 다음 단어의 첫 번째 문자로 이동시킨다. 이어서, 사용자는 "1"번 키를 눌러 엔트리 모드 메뉴에 들어가고, "3"번 키를 눌러 "AlphaBravo", 또는 ICA 단어, 입력 어휘를 선택한다. "3"번 키를 계속 누르는 동안, 사용자는 "echo, lima, victor, india, sierra"라는 발음(10914)을 연속적으로 말한다. 그것은 검출 시퀀스 "ELVIS"로서 인식되고, 다시 그것은 앞선 필터 커서 위치로부터 시작하여 수정 창의 제1 선택 항목 창(10916) 내에 삽입되게 된다. 본 예에서는 "AlphaBravo" 인식이 그 신뢰성으로 인해 명확한 것으로서 다뤄짐으로써, 스크린(10916)에 나타내진 명확한 확인 표시(10918)에 의해 지시된 바와 같이 들어간 문자 및 제1 선택 항목 창에 있기 전의 모든 문자를 명확하게 확인된 것으로 다루게끔 하는 것으로 가정하기로 한다.Next, the user presses the word write key to move the filter cursor to the right to the first letter of the next word as indicated by reference numeral “10912”. Then, the user presses the "1" key to enter the entry mode menu and press the "3" key to select "AlphaBravo", or ICA word, input vocabulary. While continuing to press the "3" key, the user continuously speaks the pronunciation 10714 of "echo, lima, victor, india, sierra". It is recognized as the detection sequence "ELVIS" and again it is inserted into the first
본 예에서는 사용자가 "OK" 키를 눌러 그것이 원하는 출력이기 때문에 현 제1 선택 항목을 선택한다.In this example, the user presses the "OK" key to select the current first selection because that is the desired output.
도 110은 재발음이 원하는 인식 출력을 얻는 것을 돕는데 어떻게 사용되는지를 나타낸 것이다. 그것은 도 109의 스크린(10906)에 의해 지시된 것과 동일한 상태에 있는 수정 창으로 시작된다. 그러나, 도 110의 예에서는 사용자가 "1"번 키를 두 번 눌러 엔트리 메뉴 모드에 들어가고, 다시 1초 동안 눌러 대어휘 인식을 선택한다. 도 79의 펑크션(7908 내지 7914)에 의해 지시된 바와 같이, 수정 창이 디스플레이되었을 때에 엔트리 메뉴 모드에서 대어휘 인식이 선택되면, 시스템은 그것을 사용자가 재발음을 실행하고자 하는, 즉 원하는 출력에 대한 새로운 발음을 원하는 출력을 선택하는 것을 돕는데 사용하기 위한 발음 리스트 내에 부가시키고자 하는 지시로서 해석한다. 본 예에서는 사용자가 "1"번 키의 두 번째 누름을 계속하면서 불연속 음성을 사용하여 언하는 출력에 해당하는 3개의 단어 "the", "new", "Elvis"를 말한다. 상기 예에서는 그러한 새로운 발음 리스트 엔트리에 의해 제공되는 부가의 불연속 발음 정보가 시스템으로 하여금 3개의 단어 중의 처음 2개를 정확하게 인식하게끔 하는 것으로 가정하기로 한다. 본 예에서는 3개의 단어 중의 세 번째 것이 현 어휘에 있지 않아서 사용자가 그 세 번째 단어를 도 109의 발음(10914)에 의해 이뤄졌던 것과 같은 필터링 입력으로 철자하는 것이 필요한 것으로 가정하기로 한다.110 illustrates how retones are used to help obtain the desired recognition output. It begins with a modification window in the same state as indicated by
도 111은 셀룰러폰의 소프트웨어 중의 일부인 웹 브라우저 상에서 원하는 웹 페이지에 액세스하기 위해 편집 기능이 URL 텍스트 문자열에 들어가는데 어떻게 사용될 수 있는지를 나타낸 것이다.111 shows how an editing function can be used to enter a URL text string to access a desired web page on a web browser that is part of the cellular phone's software.
브라우저 옵션 스크린(11100)은 사용자가 도 66에 도시된 바와 같은 메인 메뉴에서 "7"번 키에 딸린 웹 브라우저 옵션을 선택하면 디스플레이되는 스크린을 나타낸다. 본 예에서는 사용자가 원하는 웹 사이트의 URL에 들어가서 "1"번 키를 누름으로써 그 키에 딸린 URL 창 옵션을 선택하고자 하는 것으로 가정하기로 한다. 그에 의해, 스크린(11102)은 사용자에게 지시를 하는 요약 프롬프트를 디스플레이한다. 그에 응하여, 사용자는 토크 버튼을 계속 누르는 동안 연속 문자 이름 철자를 사용하여 원하는 웹 사이트의 이름을 철자한다. 도시된 예에서는 URL 편집기가 항상 수정 모드로 있어 발음(11103)의 인식에 의해 수정 창(11104)이 디스플레이되게끔 한다. 이어서, 사용자는 전술된 타입의 필터 문자열 편집 기법을 사용하여 스크린(11106)에 지시된 바와 같이 처음에 잘못 인식된 URL을 원하는 철자로 수정하는데, 그때에 사용자는 제1 선택 항목을 선택하여 시스템으로 하여금 원하는 웹 사 이트에 액세스하게끔 한다.The
도 112 내지 도 114는 편집 인터페이스가 어떻게 텍스트를 내비게이션하여 그 텍스트를 웹 페이지의 필드 내에 들여보내는지를 나타낸 것이다.112 through 114 illustrate how the editing interface navigates text and imports the text into the fields of a web page.
스크린(11200)은 셀룰러폰의 웹 브라우저가 새로운 웹 사이트에 최초로 액세스할 때에 그 웹 브라우저의 모습을 나타내고 있다. 웹 페이지의 상단 이전에 URL 필드(11201)가 나타내져 사용자가 현 웹 페이지를 식별하는데 도움을 준다. 사용자가 디스플레이된 현 웹 페이지의 URL을 알고 싶을 때에는 언제라도 도로 그 위치로 스크롤할 수 있다. 웹 페이지에 최초로 들어갔을 때에는 그 웹 페이지가 레프트 키 및 라이트 키를 이동시킴으로써 대부분의 웹 브라우저 상의 페이지 백 및 페이지 포워드 컨트롤과 같이 동작하는 문서/페이지 내비게이션 모드에 있게 된다. 그 경우,"페이지"라는 단어는 다른 내비게이션 모드에서 셀룰러폰 디스플레이 상의 매체로 채워진 스크린을 지칭하는데 사용되기 때문에, "문서"라는 단어가 "페이지"를 대체하게 된다. 사용자가 업 키 또는 다운 키를 누르면, 웹 페이지의 디스플레이는 풀 스크린 페이지(또는 스크린)에 의해 스크롤되게 된다.
도 116은 도시된 셀룰러폰 실시예가 도 115와 연관하여 전술된 타입의 대화 박스를 편집할 때에 어떻게 특수한 형태의 수정 창이 리스트 박스로서 사용될 수 있게끔 하는지를 나타낸 것이다.FIG. 116 illustrates how the cellular phone embodiment shown allows a special type of modification window to be used as a list box when editing a dialog box of the type described above in connection with FIG. 115.
도 116의 예는 도 115의 스크린(11504)에 나타내진 상태에 있는 대화 박스를 찾는 것으로부터 시작된다. 그 상태로부터, 사용자는 다운 라인 키를 두 번 눌러 커서를 "In:" 리스트 박스에 놓는데, 그 리스트 박스는 대화 박스를 찾는 것에 응 하여 실행되는 검색이 셀룰러폰의 데이터 중의 어느 부분에서 일어나는지를 규정짓는다. 사용자가 커서를 그 창에 위치시킨 채로 토크 버튼을 누르면, 리스트 박스 수정 창(11512)이 디스플레이되어 리스트 박스 내의 현 선택을 현 제1 선택 항목으로서 나타내고, 다른 리스트 박스 선택 항목의 스크롤 가능한 리스트를 제공하는데, 그러한 다른 각각의 선택 항목은 그에 딸린 폰 키 번호와 함께 나타내진다. 사용자는 그 리스트를 통해 스크롤하여 폰 키 번호에 의해 또는 하이라이트된 선택을 사용하여 원하는 선택 항목을 선택할 수 있다. 본 예에서는 사용자가 토크 키를 계속 누르면서 발음(11514)으로써 원하는 리스트 박스 값을 말한다. 리스트 박스 수정 창에서는 유효한 어휘가 리스트 값에 한정된다. 그러한 한정된 어휘에 있어서는 원하는 리스트 값이 제1 선택 항목인 예에서 지시된 바와 같이 인식이 상당히 정확할만하다. 그에 응하여, 사용자는 OK 키를 눌러 도면 부호 "11518"에 지시된 바와 같이 원하는 리스트 값이 대화 박스의 리스트 박스에 놓이게끔 한다.The example of FIG. 116 begins with finding a dialog box that is in the state shown on
도 117은 전화를 걸 때에 셀룰러폰 인터페이스가 사용자에게 실행을 허용하는 펑크션 중의 몇 가지를 디스플레이한, 사용자와 셀루러 폰 인터페이스 사이의 일련의 상호 동작을 나타낸 것이다.117 illustrates a series of interactions between a user and a cellular phone interface, displaying some of the functions the cellular phone interface allows the user to execute when making a call.
도 117에 나타내진 스크린(6400)은 도 64와 연관하여 전술된 것과 동일한 최상위 레벨의 폰 모드 스크린이다. 그 스크린이 디스플레이되었을 때에 사용자가 이름 다이얼 명령이 되도록 맵핑된 마지막 내비게이션 버튼을 선택하면, 시스템은 이름 다이얼 모드에 들어가게 되는데, 그 모드의 기본 펑크션은 도 119의 의사 코드에 나타내진 것들이다. 그 도면으로부터 알 수 있는 바와 같이, 그 모드는 사용자 로 하여금 연락 리스트에 이름을 부가함으로써 그 연락 리스트로부터 이름을 선택할 수 있게끔 하고, 잘못된 인식이 있으면 전술된 것과 유사한 수정 창의 잠재적 스크롤 가능한 선택 항목으로부터 선택 항목을 선택함으로써 알파벳 필터링에 의해 그것을 수정할 수 있게끔 한다.The
셀룰러폰이 이름 다이얼 모드에 들어갔을 때에는 도 117에 지시된 바와 같이 초기 프롬프트 스크린(11700)이 나타내진다. 본 예에서는 사용자가 토크 기를 누르는 동안 이름(11702)을 발음한다. 이름 다이얼에서는 그러한 발음이 자동으로 그 이름 어휘에 한정된 어휘로써 인식되고, 결과적으로 생긴 인식에 의해 수정 창(11704)이 디스플레이되게 된다. 본 예에서는 제1 선택 항목이 정확하여 사용자가 "OK" 키를 선택함으로써 폰이 사용자의 연락 리스트에 있는 거명된 당사자에 딸린 전화 번호로 통화를 개시하게끔 한다.When the cellular phone enters the name dial mode, the initial prompt screen 11700 is shown as indicated in FIG. In this example, the user pronounces the
전화 통화가 접속되면, 도 75와 연관하여 전술된 것과 동일한 발신 통화 지시기(7414)를 갖는 스크린(11706)이 디스플레이된다. 발신 통화 동안, 그 스크린의 하단에는 도면 부호 "11708"에 의해 지시된 바와 같이 각각의 내비게이션에 딸린 펑크션에 대한 표시가 주어진다. 본 예에서는 사용자가 도 64와 연관하여 전술된 것과 동일한 노트 펑크션이 딸린 다운 버튼을 선택한다. 그에 응하여, 노트 개요에 대한 편집 창(11710)이 디스플레이되어 현 통화에 대한 노트 개요에 자동으로 생성된 표제 항목(11712)이 생성되고, 그 통화가 이뤄진 상대방 및 그 시작 시간과 최종적인 종료 시간을 그 노트 개요에 표식하게 된다.Once the telephone call is connected,
본 예에서는 스크린(11716)에 지시된 바와 같이 발음에 해당하는 인식된 텍 스트가 커서에서 노트 개요에 삽입되어야 하기 때문에 사용자가 토크 버튼을 누르는 동안 연속적인 발음(11714)을 말하게 된다. 이어서, 사용자는 "6"번 키를 더블 클릭하여 녹음을 시작하고, 그에 의해 커서의 현 위치에서 소리의 오디오 그래프 표현이 편집 창으로 노트에 넣어지게 된다. 도면 부호 "11718"에 지시된 바와 같이, 오디오 그래프에서 셀룰러폰 사용자가 전화 통화에서 말한 부분으로부터의 오디오에 밑줄이 그어져 사용자가 그 통화에서 얼마나 오랫동안 이야기했는지를 좀더 용이하게 기억하게끔 해주고, 원한다면 그 전화 통화의 당사자들 중의 일방 또는 상대방이 말한 녹음된 오디오의 부분을 더 잘 검색할 수 있게끔 해준다.In this example, as indicated on the screen 1716, the recognized text corresponding to the pronunciation must be inserted in the note outline at the cursor, so that the user speaks the continuous pronunciation 1714 while the user presses the talk button. Then, the user double-clicks the "6" key to start recording, whereby an audio graph representation of the sound at the current position of the cursor is put in the note into the editing window. As indicated by reference numeral 111718, the audio graph underlines the audio from the part the cellular phone user said in the phone call, making it easier to remember how long the user has talked on the call, and if desired the phone This allows you to better search for portions of the recorded audio spoken by one or the other party of the call.
다음으로, 도 117의 예에서는 사용자가 별표 키를 더블 클릭하여 태스크 리스트를 선택한다. 그에 의해, 셀룰러폰에서 현재 열려있는 태스크를 리스트한 스크린(11720)이 나타난다. 본 예에서는 사용자가 "4"번 폰 키에 딸린 태스크를 선택하는데, 그것은 노트 개요에 있는 다른 위치를 디스플레이하는 다른 노트 편빕 창이다. 그에 응하여, 폰 키 디스플레이는 개괄된 노트의 그 부분의 스크린(11722)을 나타낸다.Next, in the example of FIG. 117, the user double-clicks the star key to select a task list. Thereby, a screen 1720 listing the tasks currently open in the cellular phone appears. In this example, the user selects a task attached to the phone key "4", which is another note navigation window displaying different positions in the note outline. In response, the phone key display shows screen 1722 of that portion of the outlined note.
본 예에서는 사용자가 업 키를 세 번 눌러 커서를 도면 부호 "11724"의 위치로 이동시키고 나서 "6"번 키를 눌러 스크린(11726)과 스크린(11728)의 커서 사이의 이동에 의해 지시된 바와 같이 커서에서의 오디오 그래프 표현과 연관된 사운드를 플레이하기 시작한다. 도 75와 연관하여 전술된 나만의 플레이 옵션(75130이 켜져 있지 않으면, 스크린(11728)에서의 오디오 재생은 현 전화 통화의 양방에 플레이되어 셀룰러폰의 사용자가 셀룰러폰 통화 동안 상대방과 오디오 녹음을 공유할 수 있게끔 한다.In this example, the user presses the up key three times to move the cursor to the position "11724" and then presses the "6" key as indicated by the movement between the cursors of screen 1172 and screen 1117. Likewise, it starts playing the sound associated with the audio graph representation at the cursor. If the My Play option 75130 described above in connection with FIG. 75 is not turned on, audio playback on screen 1117 is played on both sides of the current phone call so that the user of the cellular phone shares the audio recording with the other party during the cellular phone call. Make it possible.
도 118은 편집 창이 도 117의 하단 중앙 부근에서 스크린(11717)에 나타내진 것과 같은 오디오를 녹음할 때에 사용자가 그러한 오디오의 녹음 동안 음성 인식을 켜서 그 부분 동안 녹음된 오디오에 대해서도 역시 음성 인식이 실행되게끔 할 수 있음을 나타낸 것이다. 도시된 본 예에서는 스크린(11717)에 나타내진 녹음 동안 사용자가 토크 버튼을 눌러 발음(11800)을 말한다. 그에 의해, 그 발음에 딸린 텍스트가 편집 창(11806)에 삽입되게 된다. 음성 인식의 지속 시간 후에 녹음된 오디오는 단지 오디오 그래프로만 녹음된다. 통상적으로, 그것은 전술된 발음(11800)과 같은 인식시키려는 발음 동안 사용자가 명확하게 말하려고 애쓰는 방법으로 사용될 것이고, 단지 오디오로만 녹음되는 대화 또는 구술의 부분 동안에는 좀더 일상적으로 말해도 좋을 것이다. 통상적으로, 오디오는 음성 인식과 연계하여 녹음되어 사용자가 녹음 동안 부정확하게 인식된 구술(11802)과 같은 구술로 되돌아가 그것을 듣고 수정할 수 있게끔 한다.118 shows that when the editing window records audio such as that shown on screen 11117 near the bottom center of FIG. 117, the user turns on speech recognition during recording of such audio so that speech recognition is also performed for the audio recorded during that portion. It can be done. In this example shown, the user presses the talk button to speak
도 119는 시스템이 사용자로 하여금 어떻게 확장 선택 키와 플레이 또는 내비게이션의 조합에 의해 그 도면에 도시된 부분(11900)과 같은 오디오의 부분을 선택하고 나서 선택된 텍스트가 도면 부호 "11902"에 지시된 바와 같이 인식되도록 도 90의 펑크션(9000 내지 9014)과 연관하여 전술된 바와 같은 인식된 오디오 대화 박스를 선택할 수 있게끔 하는지를 나타낸 것이다. 도 119의 예에서는 사용자가 도 90에 나타내진 인식된 오디오 표시 옵션(9026)을 선택했고, 그에 의해 그 인식된 텍스트(11902)에 밑줄이 그어져 그것이 그와 연관된 플레이 가능한 오디오를 가짐 을 나타내게 된다.119 shows how the system selects a portion of audio, such as
도 120은 사용자가 어떻게 인식된 텍스트 중에서 녹음된 연관 오디오를 갖는 부분(12000)을 선택하고 나서 편집 옵션 메뉴 하의 서브메뉴에서 도 90에 도시된 옵션(9024)을 선택함으로써 그 인식된 연관 오디오로부터 그 텍스트를 떼어 내지도록 선택할 수 있는지를 나타낸 것이다. 그것은 단지 오디오(12002)와 그에 대응하는 오디오 그래프 표현만이 인식된 텍스트가 이전에 있던 미디어의 부분에 잔존하도록 남겨두는 것이다.FIG. 120 illustrates how the user selects a
도 121은 편집 옵션 메뉴의 오디오 메뉴 아래로부터 있는 도 90의 펑크션(9020)이 사용자로 하여금 어떻게 도 121의 도면 부호 "12102"에 지시된 바와 같이 텍스트로부터 인식된 텍스트의 부분(12100)과 연관되었던 인식 오디오를 떼어낼 수 있게끔 하는지를 나타낸 것이다.FIG. 121 shows how the function 9020 of FIG. 90 from below the Audio menu of the Edit Options menu allows a user to associate a
도 122 내지 도 125는 도 126의 의사 코드에 기재된 숫자 다이얼 모드의 동작을 나타낸 것이다. 사용자가 도 65의 펑크션(6552)에 나타내진 바와 같은 메인 메뉴에 있을 때에 "2"번 폰 키를 누르거나 시스템이 도 64의 스크린(6400)에 나타내진 최상위 레벨 폰 모드에 있을 때에 레프트 내비게이션 버튼을 선택하는 것 등에 의해 숫자 다이얼 모드를 선택하면, 시스템은 도 126에 나타내진 숫자 다이얼 모드에 들어가서 사용자에게 전화 번호를 말할 것을 촉구하는 프롬프트 스크린(12202)를 디스플레이하게 된다. 사용자가 도면 부호 "12204"에 지시된 바와 같이 전화 번호의 발음을 말했을 때에 그 발음이 인식되게 된다. 시스템이 전화 번호의 인식이 정확하다고 매우 확신하면, 시스템은 자동으로 도면 부호 "12206"에 지시된 바와 같이 그 인식된 전화 번호로 전화를 건다. 시스템이 전화 번호의 인식에 대해 그러한 확신이 없으면, 시스템은 수정 창(12208)을 디스플레이하게 된다. 수정 창이 도면 부호 "12210"에 지시된 바와 같이 원하는 번호를 제1 선택 항목으로서 가지면, 사용자는 단지 OK 키를 누름으로써 그것을 선택할 수 있고, 그에 의해 도면 부호 "12212"에 지시된 바와 같이 시스템이 그 번호로 전화를 걸게 된다. 도면 부호 "12214"에 지시된 바와 같이 정확한 선택 항목이 제1 선택 항목 리스트 상에 있으면, 사용자는 도면 부호 "12216"에 지시된 바와 같이 시스템이 그 번호에 전화를 걸기 때문에 단지 그 선택 항목에 딸린 폰 키 번호만을 누를 수 있다.122 to 125 show the operation of the numeric dial mode described in the pseudo code of FIG. Left navigation when the user presses the "2" phone key when in the main menu as shown in function 6652 of FIG. 65 or when the system is in the top level phone mode shown on
도 123의 상단에 나타내진 스크린(12300)에 지시된 바와 같이 정확한 번호가 제1 선택 항목에도 없고 제1 선택 항목 리스트에도 없으면, 사용자는 원하는 번호가 도면 부호 "12302"에 의해 지시된 바와 같이 페이지 다운 키를 반복해서 누름든지 도면 부호 "12304"에 지시된 바와 같이 항목 다운 키를 반복해서 누름으로써 제2 선택 항복 리스트의 스크린 중의 하나 상에 원하는 번호가 있는지를 찾아내기 위한 체크를 할 수 있다. 사용자가 그러한 방법 중의 하나로 선택 항목 리스트를 통해 스크롤함으로써 원하는 번호를 찾아내면, 사용자는 그에 딸린 폰 키를 누르든지 선택 항목 하이라이트를 그로 이동시키고 나서 OK 키를 누름으로써 그것을 선택할 수 있다. 그에 의해, 시스템이 스크린(12308)에 지시된 바와 같이 그 번호로 전화를 걸게 된다. 선택 항목 리스트에 있는 전화 번호가 숫자 순으로 정리되어 있기 때문에, 사용자는 그 리스트를 통해 스크롤함으로써 신속하게 원하는 번호를 찾을 수 있음을 알아야 할 것이다. 그들 도면에 도시된 실시예에서는 숫자 변동 지시기 (12310)가 마련되어 어떠한 선택 항목이 리스트 상에서 그에 앞선 선택 항목과 상이한 가장 뚜렷한 숫자의 숫자 칼럼을 지시하게 된다. 그것은 눈으로 원하는 전화 번호를 훑어보는 것을 좀더 용이하게 해준다.If the correct number is not in the first selection item and also in the first selection item list as indicated on
도 124는 숫자 다이얼 모드가 사용자로 하여금 어떻게 제1 선택 항목에 있는 숫자 위치로 내비게이션하여 그 안에 존재하는 임의의 오류를 수정할 수 있게끔 하는지를 나타낸 것이다. 도 124에서는 그것이 원하는 숫자를 말함으로써 이뤄지지만, 사용자는 적절한 폰 키를 누름으로써 원하는 번호를 수정할 수도 있다.124 illustrates how the numeric dial mode allows a user to navigate to the numeric position in the first selection item to correct any errors present therein. In FIG. 124 it is accomplished by saying the desired number, but the user may modify the desired number by pressing the appropriate phone key.
도 125에 도시된 바와 같이, 사용자는 잘못 인식된 전화 번호를 상실된 숫자를 삽입함으로써는 물론 잘못 인식된 것을 대체함으로써 편집할 수도 있다.As shown in FIG. 125, the user may edit the misrecognized telephone number by inserting the lost digit as well as replacing the misrecognized one.
전술된 본 발명은 도 3 내지 도 8에 도시된 것을 비롯한 여러 다른 타입의 컴퓨팅 플랫폼에서 음성 인식은 물론 기타 유형의 인식에 들어가 그것을 수정하는데 사용될 수 있는 다수의 특징을 갖는다. 도 94와 연관하여 설명된 본 발명의 많은 특징은 사용자가 해당 태스크에 면밀한 시각적 주의를 기울임이 없이 텍스트에 들어가서/들어가거나 그것을 편집하고자 하는 상황에 사용될 수 있다. 예컨대, 그것은 사용자로 하여금 공원을 거닐면서 이-메일을 듣고서 그의 셀룰러폰 또는 다른 구술 장치를 면밀하게 볼 필요가 없이 답신을 구술할 수 있게끔 한다. 그러한 오디오 피드백이 음성 인식 및 폰 다이얼링과 폰 제어와 같은 다른 제어 펑크션에 유용한 한가지 특정의 환경은 도 126에 도시된 것과 같은 자동차 분야에서이다.The invention described above has a number of features that can be used to enter and modify speech recognition as well as other types of recognition in many other types of computing platforms, including those shown in FIGS. Many features of the invention described in connection with FIG. 94 can be used in situations where a user wishes to enter / enter text or edit it without paying close attention to the task. For example, it allows a user to walk through the park, listen to e-mail and dictate a reply without having to look closely at his cellular phone or other dictation device. One particular environment where such audio feedback is useful for speech recognition and other control functions such as phone dialing and phone control is in the automotive field as shown in FIG. 126.
도 126에 도시된 실시예에서는 자동차가 셀룰러 무선 통신 시스템(12602)에 접속된 컴퓨터(12600)를 자동차 오디오 시스템(12604) 내에 내장하고 있다. 다수의 실시예에서는 자동차의 전자 시스템이 "Blue Tooth"와 같은 단파 범위의 무선 송수신기 또는 기타의 단파 범위 송수신기(12606)를 구비한다. 그것은 무선 헤드폰(12608) 또는 사용자의 셀룰러폰(12610)과 통신할 수 있어 사용자가 그가 차량을 사용하면서 그의 통상의 셀룰러폰에 저장된 정보에 액세스하는 장점을 누릴 수 있다.In the embodiment shown in FIG. 126, a vehicle 12 incorporates a
셀룰러폰/무선 송수신기(12602)는 셀룰러폰 통화를 송신 및 수신하는데 사용될 수 있을 뿐만 아니라, 이-메일, 전술된 기능으로 청취하고 편집할 수 있는 것과 같은 디지털 파일, 및 오디오 웹 페이지를 송신 및 수신하는데도 사용될 수 있는 것이 바람직하다.The cellular phone /
도시된 셀룰러폰 실시예와 연관하여 전술된 다수의 펑크션을 제어하기 위한 입력 장치에는 자동차의 스티어링 휠 상의 위치와 같은 위치에 배치되는 것이 바람직한 폰 키패드(12212)에 의해 액세스할 수 있고, 그것은 사용자로 하여금 운전 기능으로부터 그의 주의를 과도하게 흩뜨림이 없이 그 키패드에 액세스할 수 있게끔 한다. 실제로, 도 126에 도시된 것과 유사한 위치를 갖는 키패드에 의해, 사용자는 한 손의 집게 손가락 스티어링 휠의 림 둘레에 대고서 같은 손의 엄지로 키패드 버튼을 선택할 수 있다. 그러한 실시예에서는 시스템이 도 94의 펑크션(9404 내지 9414)과 연관하여 전술된 TTS 키 펑크션을 가져서 사용자로 하여금 키패드를 볼 필요가 없이 그가 어떤 키를 누르고 있는지와 그 키의 펑크션을 판단할 수 있게끔 하는 것이 바람직하다. 다른 실시예에서는 단지 그러한 정보를 갖는 그 폰 키를 만지 는 것만으로도 응답하여 사용하기 한층 더 쉽고 더욱 신속한 터치 감지 키패드가 마련될 수도 있다.The input device for controlling the plurality of functions described above in connection with the illustrated cellular phone embodiment is accessible by
도 127 및 도 128은 셀룰러폰 실시예와 연관하여 전술된 대부분의 성능이 도 127에 도시된 무선 전화 또는 도 128에 지시된 지상 통신선 파운드와 같은 다른 타입의 전화에도 사용될 수 있음을 나타낸 것이다.127 and 128 illustrate that most of the capabilities described above in connection with cellular phone embodiments may be used for other types of phones, such as the wireless telephone shown in FIG. 127 or the landline pounds indicated in FIG. 128.
전술된 설명 및 첨부 도면은 단지 본 발명을 설명하고 예시하기 위해 주어진 것으로, 본 발명은 첨부된 청구의 범위의 해석이 그처럼 한정되지 않은 한에는 그에 한정되는 것이 아님을 알아야 할 것이다. 본 명세서에 직면한 당업자라면 본 발명의 범위를 벗어남이 없이 본 발명에 변경 및 수정을 가할 수 있을 것이다.It is to be understood that the foregoing description and the accompanying drawings are merely given to illustrate and illustrate the invention, and the invention is not limited thereto unless the interpretation of the appended claims is so limited. Those skilled in the art having the benefit of this specification may make changes and modifications to the invention without departing from the scope of the invention.
폭넓게 청구된 본 출원의 발명은 어떠한 하나의 타입의 우녕 시스템a, 컴퓨터 하드웨어, 또는 컴퓨터 망과의 사용에 한정되지 않고, 그에 따라 본 발명의 다른 실시예는 상이한 소프트웨어와 하드웨어 시스템을 사용할 수도 있다.The broadly claimed invention of the present application is not limited to use with any one type of well-known system a, computer hardware, or computer network, so that other embodiments of the present invention may use different software and hardware systems.
또한, 거의 모든 프로그램 거동과 같은 아래의 청구의 범위에 기재된 프로그램 거동은 상당히 상이한 편제 및 시퀀싱을 사용하는 다수의 상이한 프로그래밍 및 데이터 구조에 의해 실행될 수 있음을 알아야 할 것이다. 그것은 프로그래밍이란 일단 당업자가 이해하게 되면 주어진 어떠한 복잡한 사상이라도 거의 무제한의 수의 방도로 명료화될 수 있는 극히 가변적인 기술이기 때문이다. 따라서, 청구의 범위는 첨부 도면에 기재된 바로 그 펑크션 및/또는 펑크션의 시퀀스에 한정되는 것으로 의도된 것이 아니다. 특히, 그것은 본문 중에 전술된 의사 코드가 극히 단순화되어 당업자에게 불필요한 세부 사항으로 부담을 줌이 없이 당업자가 본 발명의 실시를 아는데 필요로 하는 것에 보다 더 효율적으로 소통하게끔 하기 때문에 그러하다. 그러한 단순화를 위해, 전술된 의사 코드의 구조는 숙련도니 프로그래머가 본 발명을 실시할 때에 사용하는 실제의 코드의 구조와는 종종 상당히 다르게 된다. 아울러, 명세서에서 소프트웨어로 실행되는 것으로 나타내진 프로그램화된 다수의 거동은 다른 실시예에서는 하드웨어로 실행될 수도 있다.It should also be appreciated that the program behavior described in the claims below, such as almost all program behavior, can be implemented by a number of different programming and data structures using significantly different organization and sequencing. That's because programming is an extremely variable technique that, once understood by one of ordinary skill in the art, can give any complex idea clarification in an almost unlimited number of ways. Accordingly, the claims are not intended to be limited to the very functions and / or sequences of functions described in the accompanying drawings. In particular, this is because the pseudo code described above in the text is extremely simplified to enable those skilled in the art to communicate more efficiently than what is needed to know the practice of the present invention without burdening the skilled person with unnecessary detail. For the sake of simplicity, the structure of the pseudo code described above is often quite different from the actual structure of code used by skilled programmers in practicing the present invention. In addition, many of the programmed behaviors shown herein as being executed in software may be implemented in hardware in other embodiments.
전술된 본 발명의 다수의 실시예에서는 본 발명의 다양한 양태가 본 발명의 그러한 양태의 다른 실시예에서 별도로 일어날 수 있는 사안과 함께 예시되어 있다.In a number of embodiments of the invention described above, various aspects of the invention are illustrated together with issues that can occur separately in other embodiments of such aspects of the invention.
본 발명은 방법, 장치 시스템, 및 기계 판독 가능한 형태로 기록된 프로그래밍으로 확장되고, 그 때문에 본 출원에 기재된 본 발명의 모든 특징 및 양태는 그것의 명세서, 그것의 도면, 및 그것의 최초 청구의 범위를 포함하여 출원되어 있다.The present invention extends to methods, apparatus systems, and programming recorded in machine readable form, whereby all features and aspects of the invention described in this application are set forth in its specification, its drawings, and its original claims. It is filed including.
Claims (248)
Translated fromKoreanApplications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/US2002/028590WO2004023455A2 (en) | 2002-09-06 | 2002-09-06 | Methods, systems, and programming for performing speech recognition |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20060037228Atrue KR20060037228A (en) | 2006-05-03 |
| KR100996212B1 KR100996212B1 (en) | 2010-11-24 |
Family
ID=34271640
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020057003948AExpired - Fee RelatedKR100996212B1 (en) | 2002-09-06 | 2002-09-06 | Methods, systems, and programs for speech recognition |
Country Status (5)
| Country | Link |
|---|---|
| EP (1) | EP1604350A4 (en) |
| JP (1) | JP2006515073A (en) |
| KR (1) | KR100996212B1 (en) |
| CN (1) | CN1864204A (en) |
| AU (1) | AU2002336458A1 (en) |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20120013032A (en)* | 2010-08-04 | 2012-02-14 | 엘지전자 주식회사 | Speech recognition method and image display device accordingly |
| KR101218332B1 (en)* | 2011-05-23 | 2013-01-21 | 휴텍 주식회사 | Method and apparatus for character input by hybrid-type speech recognition, and computer-readable recording medium with character input program based on hybrid-type speech recognition for the same |
| US8407039B2 (en) | 2008-08-11 | 2013-03-26 | Lg Electronics Inc. | Method and apparatus of translating language using voice recognition |
| KR20140045181A (en)* | 2012-10-08 | 2014-04-16 | 삼성전자주식회사 | Method and apparatus for action of preset performance mode using voice recognition |
| KR20170003580A (en)* | 2014-04-17 | 2017-01-09 | 소프트뱅크 로보틱스 유럽 | Method of performing multi-modal dialogue between a humanoid robot and user, computer program product and humanoid robot for implementing said method |
| KR20180054902A (en)* | 2010-01-05 | 2018-05-24 | 구글 엘엘씨 | Word-level correction of speech input |
| KR20230096122A (en)* | 2013-06-07 | 2023-06-29 | 애플 인크. | Intelligent automated assistant |
| US12087308B2 (en) | 2010-01-18 | 2024-09-10 | Apple Inc. | Intelligent automated assistant |
| US12165635B2 (en) | 2010-01-18 | 2024-12-10 | Apple Inc. | Intelligent automated assistant |
Families Citing this family (140)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7720682B2 (en)* | 1998-12-04 | 2010-05-18 | Tegic Communications, Inc. | Method and apparatus utilizing voice input to resolve ambiguous manually entered text input |
| US8645137B2 (en) | 2000-03-16 | 2014-02-04 | Apple Inc. | Fast, language-independent method for user authentication by voice |
| US8677377B2 (en) | 2005-09-08 | 2014-03-18 | Apple Inc. | Method and apparatus for building an intelligent automated assistant |
| US7697827B2 (en)* | 2005-10-17 | 2010-04-13 | Konicek Jeffrey C | User-friendlier interfaces for a camera |
| JP4672686B2 (en)* | 2007-02-16 | 2011-04-20 | 株式会社デンソー | Voice recognition device and navigation device |
| US8977255B2 (en) | 2007-04-03 | 2015-03-10 | Apple Inc. | Method and system for operating a multi-function portable electronic device using voice-activation |
| US8457946B2 (en)* | 2007-04-26 | 2013-06-04 | Microsoft Corporation | Recognition architecture for generating Asian characters |
| JP4862740B2 (en)* | 2007-05-14 | 2012-01-25 | ソニー株式会社 | Imaging apparatus, information display apparatus, display data control method, and computer program |
| US9330720B2 (en) | 2008-01-03 | 2016-05-03 | Apple Inc. | Methods and apparatus for altering audio output signals |
| US8996376B2 (en) | 2008-04-05 | 2015-03-31 | Apple Inc. | Intelligent text-to-speech conversion |
| US10496753B2 (en) | 2010-01-18 | 2019-12-03 | Apple Inc. | Automatically adapting user interfaces for hands-free interaction |
| US20100030549A1 (en) | 2008-07-31 | 2010-02-04 | Lee Michael M | Mobile device having human language translation capability with positional feedback |
| WO2010067118A1 (en) | 2008-12-11 | 2010-06-17 | Novauris Technologies Limited | Speech recognition involving a mobile device |
| US9858925B2 (en) | 2009-06-05 | 2018-01-02 | Apple Inc. | Using context information to facilitate processing of commands in a virtual assistant |
| US10241644B2 (en) | 2011-06-03 | 2019-03-26 | Apple Inc. | Actionable reminder entries |
| US10241752B2 (en) | 2011-09-30 | 2019-03-26 | Apple Inc. | Interface for a virtual digital assistant |
| US20120309363A1 (en) | 2011-06-03 | 2012-12-06 | Apple Inc. | Triggering notifications associated with tasks items that represent tasks to perform |
| US9431006B2 (en) | 2009-07-02 | 2016-08-30 | Apple Inc. | Methods and apparatuses for automatic speech recognition |
| US10705794B2 (en) | 2010-01-18 | 2020-07-07 | Apple Inc. | Automatically adapting user interfaces for hands-free interaction |
| US10679605B2 (en) | 2010-01-18 | 2020-06-09 | Apple Inc. | Hands-free list-reading by intelligent automated assistant |
| US10553209B2 (en) | 2010-01-18 | 2020-02-04 | Apple Inc. | Systems and methods for hands-free notification summaries |
| DE112011100329T5 (en) | 2010-01-25 | 2012-10-31 | Andrew Peter Nelson Jerram | Apparatus, methods and systems for a digital conversation management platform |
| US8682667B2 (en) | 2010-02-25 | 2014-03-25 | Apple Inc. | User profiling for selecting user specific voice input processing information |
| US20120110456A1 (en)* | 2010-11-01 | 2012-05-03 | Microsoft Corporation | Integrated voice command modal user interface |
| US10762293B2 (en) | 2010-12-22 | 2020-09-01 | Apple Inc. | Using parts-of-speech tagging and named entity recognition for spelling correction |
| US9262612B2 (en) | 2011-03-21 | 2016-02-16 | Apple Inc. | Device access using voice authentication |
| US10057736B2 (en) | 2011-06-03 | 2018-08-21 | Apple Inc. | Active transport based notifications |
| US8994660B2 (en) | 2011-08-29 | 2015-03-31 | Apple Inc. | Text correction processing |
| US8762156B2 (en)* | 2011-09-28 | 2014-06-24 | Apple Inc. | Speech recognition repair using contextual information |
| US9256396B2 (en) | 2011-10-10 | 2016-02-09 | Microsoft Technology Licensing, Llc | Speech recognition for context switching |
| US10134385B2 (en) | 2012-03-02 | 2018-11-20 | Apple Inc. | Systems and methods for name pronunciation |
| US9483461B2 (en) | 2012-03-06 | 2016-11-01 | Apple Inc. | Handling speech synthesis of content for multiple languages |
| US9280610B2 (en) | 2012-05-14 | 2016-03-08 | Apple Inc. | Crowd sourcing information to fulfill user requests |
| US9721563B2 (en) | 2012-06-08 | 2017-08-01 | Apple Inc. | Name recognition system |
| US9576574B2 (en) | 2012-09-10 | 2017-02-21 | Apple Inc. | Context-sensitive handling of interruptions by intelligent digital assistant |
| US9547647B2 (en) | 2012-09-19 | 2017-01-17 | Apple Inc. | Voice-based media searching |
| KR101330671B1 (en)* | 2012-09-28 | 2013-11-15 | 삼성전자주식회사 | Electronic device, server and control methods thereof |
| US8994681B2 (en)* | 2012-10-19 | 2015-03-31 | Google Inc. | Decoding imprecise gestures for gesture-keyboards |
| CN103823547B (en)* | 2012-11-16 | 2017-05-17 | 中国电信股份有限公司 | Mobile terminal and cursor control method thereof |
| EP2945052B1 (en)* | 2013-01-08 | 2017-12-20 | Clarion Co., Ltd. | Voice recognition device, voice recognition program, and voice recognition method |
| DE212014000045U1 (en) | 2013-02-07 | 2015-09-24 | Apple Inc. | Voice trigger for a digital assistant |
| US9368114B2 (en) | 2013-03-14 | 2016-06-14 | Apple Inc. | Context-sensitive handling of interruptions |
| AU2014233517B2 (en) | 2013-03-15 | 2017-05-25 | Apple Inc. | Training an at least partial voice command system |
| WO2014144579A1 (en) | 2013-03-15 | 2014-09-18 | Apple Inc. | System and method for updating an adaptive speech recognition model |
| US9582608B2 (en) | 2013-06-07 | 2017-02-28 | Apple Inc. | Unified ranking with entropy-weighted information for phrase-based semantic auto-completion |
| WO2014197334A2 (en) | 2013-06-07 | 2014-12-11 | Apple Inc. | System and method for user-specified pronunciation of words for speech synthesis and recognition |
| WO2014197336A1 (en) | 2013-06-07 | 2014-12-11 | Apple Inc. | System and method for detecting errors in interactions with a voice-based digital assistant |
| WO2014197335A1 (en) | 2013-06-08 | 2014-12-11 | Apple Inc. | Interpreting and acting upon commands that involve sharing information with remote devices |
| US10176167B2 (en) | 2013-06-09 | 2019-01-08 | Apple Inc. | System and method for inferring user intent from speech inputs |
| DE112014002747T5 (en) | 2013-06-09 | 2016-03-03 | Apple Inc. | Apparatus, method and graphical user interface for enabling conversation persistence over two or more instances of a digital assistant |
| AU2014278595B2 (en) | 2013-06-13 | 2017-04-06 | Apple Inc. | System and method for emergency calls initiated by voice command |
| DE112014003653B4 (en) | 2013-08-06 | 2024-04-18 | Apple Inc. | Automatically activate intelligent responses based on activities from remote devices |
| US9620105B2 (en) | 2014-05-15 | 2017-04-11 | Apple Inc. | Analyzing audio input for efficient speech and music recognition |
| US10592095B2 (en) | 2014-05-23 | 2020-03-17 | Apple Inc. | Instantaneous speaking of content on touch devices |
| US9502031B2 (en) | 2014-05-27 | 2016-11-22 | Apple Inc. | Method for supporting dynamic grammars in WFST-based ASR |
| US10078631B2 (en) | 2014-05-30 | 2018-09-18 | Apple Inc. | Entropy-guided text prediction using combined word and character n-gram language models |
| US9760559B2 (en) | 2014-05-30 | 2017-09-12 | Apple Inc. | Predictive text input |
| CN110797019B (en) | 2014-05-30 | 2023-08-29 | 苹果公司 | Multi-command single speech input method |
| US9734193B2 (en) | 2014-05-30 | 2017-08-15 | Apple Inc. | Determining domain salience ranking from ambiguous words in natural speech |
| US9715875B2 (en) | 2014-05-30 | 2017-07-25 | Apple Inc. | Reducing the need for manual start/end-pointing and trigger phrases |
| US9785630B2 (en) | 2014-05-30 | 2017-10-10 | Apple Inc. | Text prediction using combined word N-gram and unigram language models |
| US9430463B2 (en) | 2014-05-30 | 2016-08-30 | Apple Inc. | Exemplar-based natural language processing |
| US9842101B2 (en) | 2014-05-30 | 2017-12-12 | Apple Inc. | Predictive conversion of language input |
| US10170123B2 (en) | 2014-05-30 | 2019-01-01 | Apple Inc. | Intelligent assistant for home automation |
| US9633004B2 (en) | 2014-05-30 | 2017-04-25 | Apple Inc. | Better resolution when referencing to concepts |
| US10289433B2 (en) | 2014-05-30 | 2019-05-14 | Apple Inc. | Domain specific language for encoding assistant dialog |
| US9338493B2 (en) | 2014-06-30 | 2016-05-10 | Apple Inc. | Intelligent automated assistant for TV user interactions |
| US10659851B2 (en) | 2014-06-30 | 2020-05-19 | Apple Inc. | Real-time digital assistant knowledge updates |
| US10446141B2 (en) | 2014-08-28 | 2019-10-15 | Apple Inc. | Automatic speech recognition based on user feedback |
| US9818400B2 (en) | 2014-09-11 | 2017-11-14 | Apple Inc. | Method and apparatus for discovering trending terms in speech requests |
| US10789041B2 (en) | 2014-09-12 | 2020-09-29 | Apple Inc. | Dynamic thresholds for always listening speech trigger |
| CN104267922B (en)* | 2014-09-16 | 2019-05-31 | 联想(北京)有限公司 | A kind of information processing method and electronic equipment |
| US9606986B2 (en) | 2014-09-29 | 2017-03-28 | Apple Inc. | Integrated word N-gram and class M-gram language models |
| US10074360B2 (en) | 2014-09-30 | 2018-09-11 | Apple Inc. | Providing an indication of the suitability of speech recognition |
| US9886432B2 (en) | 2014-09-30 | 2018-02-06 | Apple Inc. | Parsimonious handling of word inflection via categorical stem + suffix N-gram language models |
| US10127911B2 (en) | 2014-09-30 | 2018-11-13 | Apple Inc. | Speaker identification and unsupervised speaker adaptation techniques |
| US9668121B2 (en) | 2014-09-30 | 2017-05-30 | Apple Inc. | Social reminders |
| US9646609B2 (en) | 2014-09-30 | 2017-05-09 | Apple Inc. | Caching apparatus for serving phonetic pronunciations |
| US10552013B2 (en) | 2014-12-02 | 2020-02-04 | Apple Inc. | Data detection |
| US9711141B2 (en) | 2014-12-09 | 2017-07-18 | Apple Inc. | Disambiguating heteronyms in speech synthesis |
| US9865280B2 (en) | 2015-03-06 | 2018-01-09 | Apple Inc. | Structured dictation using intelligent automated assistants |
| US10567477B2 (en) | 2015-03-08 | 2020-02-18 | Apple Inc. | Virtual assistant continuity |
| US9886953B2 (en) | 2015-03-08 | 2018-02-06 | Apple Inc. | Virtual assistant activation |
| US9721566B2 (en) | 2015-03-08 | 2017-08-01 | Apple Inc. | Competing devices responding to voice triggers |
| US9899019B2 (en) | 2015-03-18 | 2018-02-20 | Apple Inc. | Systems and methods for structured stem and suffix language models |
| US9842105B2 (en) | 2015-04-16 | 2017-12-12 | Apple Inc. | Parsimonious continuous-space phrase representations for natural language processing |
| US10083688B2 (en) | 2015-05-27 | 2018-09-25 | Apple Inc. | Device voice control for selecting a displayed affordance |
| US10127220B2 (en) | 2015-06-04 | 2018-11-13 | Apple Inc. | Language identification from short strings |
| US10101822B2 (en) | 2015-06-05 | 2018-10-16 | Apple Inc. | Language input correction |
| US9578173B2 (en) | 2015-06-05 | 2017-02-21 | Apple Inc. | Virtual assistant aided communication with 3rd party service in a communication session |
| US11025565B2 (en) | 2015-06-07 | 2021-06-01 | Apple Inc. | Personalized prediction of responses for instant messaging |
| US10255907B2 (en) | 2015-06-07 | 2019-04-09 | Apple Inc. | Automatic accent detection using acoustic models |
| US10186254B2 (en) | 2015-06-07 | 2019-01-22 | Apple Inc. | Context-based endpoint detection |
| US10747498B2 (en) | 2015-09-08 | 2020-08-18 | Apple Inc. | Zero latency digital assistant |
| US10671428B2 (en) | 2015-09-08 | 2020-06-02 | Apple Inc. | Distributed personal assistant |
| US9787819B2 (en)* | 2015-09-18 | 2017-10-10 | Microsoft Technology Licensing, Llc | Transcription of spoken communications |
| US9697820B2 (en) | 2015-09-24 | 2017-07-04 | Apple Inc. | Unit-selection text-to-speech synthesis using concatenation-sensitive neural networks |
| US11010550B2 (en) | 2015-09-29 | 2021-05-18 | Apple Inc. | Unified language modeling framework for word prediction, auto-completion and auto-correction |
| US10366158B2 (en) | 2015-09-29 | 2019-07-30 | Apple Inc. | Efficient word encoding for recurrent neural network language models |
| US11587559B2 (en) | 2015-09-30 | 2023-02-21 | Apple Inc. | Intelligent device identification |
| US10691473B2 (en) | 2015-11-06 | 2020-06-23 | Apple Inc. | Intelligent automated assistant in a messaging environment |
| US10049668B2 (en) | 2015-12-02 | 2018-08-14 | Apple Inc. | Applying neural network language models to weighted finite state transducers for automatic speech recognition |
| US10223066B2 (en) | 2015-12-23 | 2019-03-05 | Apple Inc. | Proactive assistance based on dialog communication between devices |
| US10446143B2 (en) | 2016-03-14 | 2019-10-15 | Apple Inc. | Identification of voice inputs providing credentials |
| US9934775B2 (en) | 2016-05-26 | 2018-04-03 | Apple Inc. | Unit-selection text-to-speech synthesis based on predicted concatenation parameters |
| US9972304B2 (en) | 2016-06-03 | 2018-05-15 | Apple Inc. | Privacy preserving distributed evaluation framework for embedded personalized systems |
| US10249300B2 (en) | 2016-06-06 | 2019-04-02 | Apple Inc. | Intelligent list reading |
| US10049663B2 (en) | 2016-06-08 | 2018-08-14 | Apple, Inc. | Intelligent automated assistant for media exploration |
| DK179309B1 (en) | 2016-06-09 | 2018-04-23 | Apple Inc | Intelligent automated assistant in a home environment |
| US10192552B2 (en) | 2016-06-10 | 2019-01-29 | Apple Inc. | Digital assistant providing whispered speech |
| US10586535B2 (en) | 2016-06-10 | 2020-03-10 | Apple Inc. | Intelligent digital assistant in a multi-tasking environment |
| US10490187B2 (en) | 2016-06-10 | 2019-11-26 | Apple Inc. | Digital assistant providing automated status report |
| US10067938B2 (en) | 2016-06-10 | 2018-09-04 | Apple Inc. | Multilingual word prediction |
| US10509862B2 (en) | 2016-06-10 | 2019-12-17 | Apple Inc. | Dynamic phrase expansion of language input |
| DK179343B1 (en) | 2016-06-11 | 2018-05-14 | Apple Inc | Intelligent task discovery |
| DK201670540A1 (en) | 2016-06-11 | 2018-01-08 | Apple Inc | Application integration with a digital assistant |
| DK179049B1 (en) | 2016-06-11 | 2017-09-18 | Apple Inc | Data driven natural language event detection and classification |
| DK179415B1 (en) | 2016-06-11 | 2018-06-14 | Apple Inc | Intelligent device arbitration and control |
| CN106126156B (en)* | 2016-06-13 | 2019-04-05 | 北京云知声信息技术有限公司 | Pronunciation inputting method and device based on hospital information system |
| US10043516B2 (en) | 2016-09-23 | 2018-08-07 | Apple Inc. | Intelligent automated assistant |
| TWI610294B (en)* | 2016-12-13 | 2018-01-01 | 財團法人工業技術研究院 | Speech recognition system and method thereof, vocabulary establishing method and computer program product |
| US10593346B2 (en) | 2016-12-22 | 2020-03-17 | Apple Inc. | Rank-reduced token representation for automatic speech recognition |
| DK201770439A1 (en) | 2017-05-11 | 2018-12-13 | Apple Inc. | Offline personal assistant |
| DK179496B1 (en) | 2017-05-12 | 2019-01-15 | Apple Inc. | USER-SPECIFIC Acoustic Models |
| DK179745B1 (en) | 2017-05-12 | 2019-05-01 | Apple Inc. | SYNCHRONIZATION AND TASK DELEGATION OF A DIGITAL ASSISTANT |
| DK201770431A1 (en) | 2017-05-15 | 2018-12-20 | Apple Inc. | Optimizing dialogue policy decisions for digital assistants using implicit feedback |
| DK201770432A1 (en) | 2017-05-15 | 2018-12-21 | Apple Inc. | Hierarchical belief states for digital assistants |
| DK179549B1 (en) | 2017-05-16 | 2019-02-12 | Apple Inc. | Far-field extension for digital assistant services |
| GB2564668B (en)* | 2017-07-18 | 2022-04-13 | Vision Semantics Ltd | Target re-identification |
| CN108899016B (en)* | 2018-08-02 | 2020-09-11 | 科大讯飞股份有限公司 | Voice text normalization method, device and equipment and readable storage medium |
| JP2020042074A (en)* | 2018-09-06 | 2020-03-19 | トヨタ自動車株式会社 | Voice interaction device, voice interaction method, and voice interaction program |
| JP7159756B2 (en)* | 2018-09-27 | 2022-10-25 | 富士通株式会社 | Audio playback interval control method, audio playback interval control program, and information processing device |
| CN110211576B (en)* | 2019-04-28 | 2021-07-30 | 北京蓦然认知科技有限公司 | Voice recognition method, device and system |
| CN110808035B (en)* | 2019-11-06 | 2021-11-26 | 百度在线网络技术(北京)有限公司 | Method and apparatus for training hybrid language recognition models |
| US11455148B2 (en) | 2020-07-13 | 2022-09-27 | International Business Machines Corporation | Software programming assistant |
| KR102494627B1 (en)* | 2020-08-03 | 2023-02-01 | 한양대학교 산학협력단 | Data label correction for speech recognition system and method thereof |
| CN112259100B (en)* | 2020-09-15 | 2024-04-09 | 科大讯飞华南人工智能研究院(广州)有限公司 | Speech recognition method, training method of related model, related equipment and device |
| CN115376506A (en)* | 2021-05-21 | 2022-11-22 | 佛山市顺德区美的电子科技有限公司 | Voiceprint registration method, server, home appliance terminal equipment, and readable storage medium |
| CN114454164B (en)* | 2022-01-14 | 2024-01-09 | 纳恩博(北京)科技有限公司 | Robot control method and device |
| US11880645B2 (en) | 2022-06-15 | 2024-01-23 | T-Mobile Usa, Inc. | Generating encoded text based on spoken utterances using machine learning systems and methods |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE19635754A1 (en)* | 1996-09-03 | 1998-03-05 | Siemens Ag | Speech processing system and method for speech processing |
| US6122613A (en)* | 1997-01-30 | 2000-09-19 | Dragon Systems, Inc. | Speech recognition using multiple recognizers (selectively) applied to the same input sample |
| US6526380B1 (en)* | 1999-03-26 | 2003-02-25 | Koninklijke Philips Electronics N.V. | Speech recognition system having parallel large vocabulary recognition engines |
- 2002
- 2002-09-06EPEP02773307Apatent/EP1604350A4/ennot_activeWithdrawn
- 2002-09-06CNCNA028298519Apatent/CN1864204A/enactivePending
- 2002-09-06AUAU2002336458Apatent/AU2002336458A1/ennot_activeAbandoned
- 2002-09-06JPJP2004533998Apatent/JP2006515073A/enactivePending
- 2002-09-06KRKR1020057003948Apatent/KR100996212B1/ennot_activeExpired - Fee Related
Cited By (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8407039B2 (en) | 2008-08-11 | 2013-03-26 | Lg Electronics Inc. | Method and apparatus of translating language using voice recognition |
| KR20180054902A (en)* | 2010-01-05 | 2018-05-24 | 구글 엘엘씨 | Word-level correction of speech input |
| US12087308B2 (en) | 2010-01-18 | 2024-09-10 | Apple Inc. | Intelligent automated assistant |
| US12165635B2 (en) | 2010-01-18 | 2024-12-10 | Apple Inc. | Intelligent automated assistant |
| US12431128B2 (en) | 2010-01-18 | 2025-09-30 | Apple Inc. | Task flow identification based on user intent |
| KR20120013032A (en)* | 2010-08-04 | 2012-02-14 | 엘지전자 주식회사 | Speech recognition method and image display device accordingly |
| KR101218332B1 (en)* | 2011-05-23 | 2013-01-21 | 휴텍 주식회사 | Method and apparatus for character input by hybrid-type speech recognition, and computer-readable recording medium with character input program based on hybrid-type speech recognition for the same |
| KR20140045181A (en)* | 2012-10-08 | 2014-04-16 | 삼성전자주식회사 | Method and apparatus for action of preset performance mode using voice recognition |
| US10825456B2 (en) | 2012-10-08 | 2020-11-03 | Samsung Electronics Co., Ltd | Method and apparatus for performing preset operation mode using voice recognition |
| KR20230096122A (en)* | 2013-06-07 | 2023-06-29 | 애플 인크. | Intelligent automated assistant |
| KR20170003580A (en)* | 2014-04-17 | 2017-01-09 | 소프트뱅크 로보틱스 유럽 | Method of performing multi-modal dialogue between a humanoid robot and user, computer program product and humanoid robot for implementing said method |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2006515073A (en) | 2006-05-18 |
| AU2002336458A1 (en) | 2004-03-29 |
| CN1864204A (en) | 2006-11-15 |
| EP1604350A4 (en) | 2007-11-21 |
| KR100996212B1 (en) | 2010-11-24 |
| AU2002336458A8 (en) | 2004-03-29 |
| EP1604350A2 (en) | 2005-12-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR100996212B1 (en) | Methods, systems, and programs for speech recognition | |
| US7225130B2 (en) | Methods, systems, and programming for performing speech recognition | |
| US7505911B2 (en) | Combined speech recognition and sound recording | |
| US7809574B2 (en) | Word recognition using choice lists | |
| US7313526B2 (en) | Speech recognition using selectable recognition modes | |
| US7577569B2 (en) | Combined speech recognition and text-to-speech generation | |
| US7526431B2 (en) | Speech recognition using ambiguous or phone key spelling and/or filtering | |
| US7444286B2 (en) | Speech recognition using re-utterance recognition | |
| US7467089B2 (en) | Combined speech and handwriting recognition | |
| US7634403B2 (en) | Word recognition using word transformation commands | |
| US7716058B2 (en) | Speech recognition using automatic recognition turn off | |
| JP4829901B2 (en) | Method and apparatus for confirming manually entered indeterminate text input using speech input | |
| JP5166255B2 (en) | Data entry system | |
| US6314397B1 (en) | Method and apparatus for propagating corrections in speech recognition software | |
| TWI266280B (en) | Multimodal disambiguation of speech recognition | |
| US6321196B1 (en) | Phonetic spelling for speech recognition | |
| US8150699B2 (en) | Systems and methods of a structured grammar for a speech recognition command system | |
| US8954329B2 (en) | Methods and apparatus for acoustic disambiguation by insertion of disambiguating textual information | |
| EP3091535A2 (en) | Multi-modal input on an electronic device | |
| CN102272827B (en) | Method and device for solving ambiguous manual input text input by voice input | |
| JP2002116796A (en) | Voice processor and method for voice processing and storage medium | |
| JP2003015803A (en) | Japanese input mechanism for small keypad | |
| JP2001184088A (en) | Recording medium that computer can freely read and background audio recovery system | |
| JP3476007B2 (en) | Recognition word registration method, speech recognition method, speech recognition device, storage medium storing software product for registration of recognition word, storage medium storing software product for speech recognition | |
| JP3762300B2 (en) | Text input processing apparatus and method, and program |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application | St.27 status event code:A-0-1-A10-A15-nap-PA0105 | |
| P11-X000 | Amendment of application requested | St.27 status event code:A-2-2-P10-P11-nap-X000 | |
| P13-X000 | Application amended | St.27 status event code:A-2-2-P10-P13-nap-X000 | |
| PG1501 | Laying open of application | St.27 status event code:A-1-1-Q10-Q12-nap-PG1501 | |
| A201 | Request for examination | ||
| E13-X000 | Pre-grant limitation requested | St.27 status event code:A-2-3-E10-E13-lim-X000 | |
| P11-X000 | Amendment of application requested | St.27 status event code:A-2-2-P10-P11-nap-X000 | |
| P13-X000 | Application amended | St.27 status event code:A-2-2-P10-P13-nap-X000 | |
| PA0201 | Request for examination | St.27 status event code:A-1-2-D10-D11-exm-PA0201 | |
| P11-X000 | Amendment of application requested | St.27 status event code:A-2-2-P10-P11-nap-X000 | |
| P13-X000 | Application amended | St.27 status event code:A-2-2-P10-P13-nap-X000 | |
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection | St.27 status event code:A-1-2-D10-D21-exm-PE0902 | |
| T11-X000 | Administrative time limit extension requested | St.27 status event code:U-3-3-T10-T11-oth-X000 | |
| T11-X000 | Administrative time limit extension requested | St.27 status event code:U-3-3-T10-T11-oth-X000 | |
| E13-X000 | Pre-grant limitation requested | St.27 status event code:A-2-3-E10-E13-lim-X000 | |
| P11-X000 | Amendment of application requested | St.27 status event code:A-2-2-P10-P11-nap-X000 | |
| P13-X000 | Application amended | St.27 status event code:A-2-2-P10-P13-nap-X000 | |
| E90F | Notification of reason for final refusal | ||
| PE0902 | Notice of grounds for rejection | St.27 status event code:A-1-2-D10-D21-exm-PE0902 | |
| T11-X000 | Administrative time limit extension requested | St.27 status event code:U-3-3-T10-T11-oth-X000 | |
| P11-X000 | Amendment of application requested | St.27 status event code:A-2-2-P10-P11-nap-X000 | |
| P13-X000 | Application amended | St.27 status event code:A-2-2-P10-P13-nap-X000 | |
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration | St.27 status event code:A-1-2-D10-D22-exm-PE0701 | |
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment | St.27 status event code:A-2-4-F10-F11-exm-PR0701 | |
| PR1002 | Payment of registration fee | St.27 status event code:A-2-2-U10-U12-oth-PR1002 Fee payment year number:1 | |
| PG1601 | Publication of registration | St.27 status event code:A-4-4-Q10-Q13-nap-PG1601 | |
| P14-X000 | Amendment of ip right document requested | St.27 status event code:A-5-5-P10-P14-nap-X000 | |
| P16-X000 | Ip right document amended | St.27 status event code:A-5-5-P10-P16-nap-X000 | |
| Q16-X000 | A copy of ip right certificate issued | St.27 status event code:A-4-4-Q10-Q16-nap-X000 | |
| P22-X000 | Classification modified | St.27 status event code:A-4-4-P10-P22-nap-X000 | |
| FPAY | Annual fee payment | Payment date:20131017 Year of fee payment:4 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:4 | |
| FPAY | Annual fee payment | Payment date:20141023 Year of fee payment:5 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:5 | |
| FPAY | Annual fee payment | Payment date:20151016 Year of fee payment:6 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:6 | |
| FPAY | Annual fee payment | Payment date:20161110 Year of fee payment:7 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:7 | |
| LAPS | Lapse due to unpaid annual fee | ||
| PC1903 | Unpaid annual fee | St.27 status event code:A-4-4-U10-U13-oth-PC1903 Not in force date:20171118 Payment event data comment text:Termination Category : DEFAULT_OF_REGISTRATION_FEE | |
| PC1903 | Unpaid annual fee | St.27 status event code:N-4-6-H10-H13-oth-PC1903 Ip right cessation event data comment text:Termination Category : DEFAULT_OF_REGISTRATION_FEE Not in force date:20171118 |