KR102815465B1 - System and method for extracting knowledge based on graph reading - Google Patents
System and method for extracting knowledge based on graph readingDownload PDFInfo
- Publication number
- KR102815465B1 KR102815465B1KR1020210157084AKR20210157084AKR102815465B1KR 102815465 B1KR102815465 B1KR 102815465B1KR 1020210157084 AKR1020210157084 AKR 1020210157084AKR 20210157084 AKR20210157084 AKR 20210157084AKR 102815465 B1KR102815465 B1KR 102815465B1
- Authority
- KR
- South Korea
- Prior art keywords
- knowledge
- query
- answer
- graph
- generate
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images









Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/3332—Query translation
- G06F16/3334—Selection or weighting of terms from queries, including natural language queries
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/334—Query execution
- G06F16/3347—Query execution using vector based model
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/36—Creation of semantic tools, e.g. ontology or thesauri
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/901—Indexing; Data structures therefor; Storage structures
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/901—Indexing; Data structures therefor; Storage structures
- G06F16/9024—Graphs; Linked lists
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/258—Heading extraction; Automatic titling; Numbering
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
- G06F40/295—Named entity recognition
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/02—Knowledge representation; Symbolic representation
- G06N5/022—Knowledge engineering; Knowledge acquisition
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Artificial Intelligence (AREA)
- Databases & Information Systems (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Software Systems (AREA)
- Evolutionary Computation (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Molecular Biology (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Translated fromKorean
Description
Translated fromKorean본 발명의 기술적 사상은 지식 추출에 관한 것으로서, 자세하게는 그래프 독해(graph reading)에 기초하여 지식을 추출하기 위한 시스템 및 방법에 관한 것이다.The technical idea of the present invention relates to knowledge extraction, and more particularly, to a system and method for extracting knowledge based on graph reading.
본 발명은 과학기술정보통신부 혁신성장동력 프로젝트(인공지능) 사업의 일환으로 (주)솔트룩스에서 주관하여 수행된 연구로부터 도출된 것이다. (연구기간: 2021.01.01~2021.12.31, 연구관리 전문기관: 정보통신기획평가원, 연구과제명: [엑소브레인 2세부과제] WiseKB: 빅데이터 이해 기반 자가학습형 지식베이스 및 추론 기술 개발, 과제 고유번호: 1711126235, 세부과제번호: 2013-2-00109-009)The present invention is derived from research conducted by Saltlux Co., Ltd. as part of the Ministry of Science and ICT's Innovation Growth Engine Project (Artificial Intelligence). (Research Period: 2021.01.01~2021.12.31, Research Management Organization: National IT Industry Promotion Agency, Research Project Name: [Exobrain 2nd Subproject] WiseKB: Development of Self-Learning Knowledge Base and Inference Technology Based on Big Data Understanding, Project Unique Number: 1711126235, Subproject Number: 2013-2-00109-009)
컴퓨터가 인식 가능한 형태로 지식을 저장하는 지식베이스(knowledgebase)는, 저장된 지식을 활용하는 다양한 서비스들을 가능하게 한다. 예를 들면, 사용자의 질의에 대하여 답변을 제공하는 질의 답변 시스템(question and answering system)은 사용자의 질의를 분석한 후, 지식베이스에 저장된 지식을 참조하여 답변을 제공할 수 있다. 이러한 지식베이스를 활용한 서비스의 품질 및 범위는 지식베이스에 포함된 지식의 정확도 및 양에 좌우될 수 있고, 이에 따라 지식베이스에 보강하기 위한 정확한 지식을 확보하는 것이 중요할 수 있다.A knowledge base that stores knowledge in a computer-readable form enables various services that utilize the stored knowledge. For example, a question and answering system that provides answers to user queries can analyze the user's query and then provide an answer by referencing the knowledge stored in the knowledge base. The quality and scope of services utilizing such a knowledge base can depend on the accuracy and quantity of the knowledge contained in the knowledge base, and therefore, it can be important to secure accurate knowledge to supplement the knowledge base.
본 발명의 기술적 사상은, 그래프 독해에 기초하여 표에 포함된 지식을 자동으로 추출하기 위한 시스템 및 방법을 제공한다.The technical idea of the present invention provides a system and method for automatically extracting knowledge contained in a table based on graph interpretation.
상기와 같은 목적을 달성하기 위하여, 본 발명의 기술적 사상의 일측면에 따라, 표를 포함하는 문서로부터 지식을 추출하기 위한 지식 추출 시스템은, 입력 문서로부터 개체(entity)를 추출하는 개체 추출부, 개체의 속성 리스트에 포함된 속성에 기초하여, 개체를 포함하는 질의를 생성하는 질의 생성부, 표로부터 그래프 데이터를 생성하는 그래프 생성부, 그래프 데이터로부터 질의의 답변을 추출하는 그래프 독해 엔진, 및 지식베이스의 형식에 기초하여, 개체, 속성 및 답변으로부터 지식 인스턴스를 생성하는 지식 생성부를 포함할 수 있다.In order to achieve the above purpose, according to one aspect of the technical idea of the present invention, a knowledge extraction system for extracting knowledge from a document including a table may include an entity extraction unit for extracting entities from an input document, a query generation unit for generating a query including the entity based on attributes included in an attribute list of the entity, a graph generation unit for generating graph data from the table, a graph interpretation engine for extracting an answer to the query from the graph data, and a knowledge generation unit for generating a knowledge instance from the entity, the attribute, and the answer based on the format of a knowledge base.
본 발명의 예시적 실시예에 따라, 개체 추출부는, 입력 문서의 제목으로부터 개체를 추출할 수 있다.According to an exemplary embodiment of the present invention, the entity extraction unit can extract entities from the title of an input document.
본 발명의 예시적 실시예에 따라, 질의 생성부는, 속성 리스트에 포함된 복수의 속성들 각각을 순차적으로 선택하고, 개체에 대응하는 제1 워드 벡터 및 선택된 속성에 대응하는 제2 워드 벡터를 생성하는 전처리부, 샘플 객체들 및 샘플 속성들에 따라 샘플 질의들을 생성하도록 학습되고, 제1 워드 벡터 및 제2 워드 벡터로부터 질의에 대응하는 제3 워드 벡터를 생성하도록 제1 딥 러닝 네트워크, 및 제3 워드 벡터로부터 질의를 생성하는 후처리부를 포함할 수 있다.According to an exemplary embodiment of the present invention, the query generation unit may include a preprocessing unit which sequentially selects each of a plurality of attributes included in an attribute list and generates a first word vector corresponding to an object and a second word vector corresponding to the selected attribute, a first deep learning network which is trained to generate sample queries according to sample objects and sample attributes and generates a third word vector corresponding to the query from the first word vector and the second word vector, and a postprocessing unit which generates a query from the third word vector.
본 발명의 예시적 실시예에 따라, 그래프 독해 엔진은, 그래프 데이터를 자연어 처리함으로써 제1 입력 데이터를 생성하고, 질의를 자연어 처리함으로써 제2 입력 데이터를 생성하는 자연어 처리부, 제1 입력 데이터의 샘플들에 따라 샘플 그래프 벡터들을 출력하도록 학습된 제2 딥 러닝 네트워크, 제2 입력 데이터의 샘플들에 따라 샘플 워드 벡터들을 출력하도록 학습된 제3 딥 러닝 네트워크, 샘플 그래프 벡터들 및 샘플 워드 벡터들에 따라 출력 데이터의 샘플들을 출력하도록 학습된 제4 딥 러닝 네트워크, 및 제4 딥 러닝 네트워크의 출력 데이터에 기초하여, 답변을 생성하는 답변 생성부를 포함할 수 있고, 출력 데이터는, 표에서 정답의 포함 여부, 정답의 위치, 정답의 신뢰도 중 적어도 하나를 포함할 수 잇다.According to an exemplary embodiment of the present invention, a graph reading engine may include a natural language processing unit which generates first input data by natural language processing graph data and generates second input data by natural language processing a query, a second deep learning network trained to output sample graph vectors according to samples of the first input data, a third deep learning network trained to output sample word vectors according to samples of the second input data, a fourth deep learning network trained to output samples of output data according to the sample graph vectors and the sample word vectors, and an answer generating unit which generates an answer based on output data of the fourth deep learning network, wherein the output data may include at least one of whether a correct answer is included in a table, a position of the correct answer, and a reliability of the correct answer.
본 발명의 예시적 실시예에 따라, 답변 생성부는, 입력 문서에 정답이 포함되지 아니하거나 신뢰도가 미리 정의된 문턱값 미만인 경우, 답변의 추출 실패를 판정할 수 있다.According to an exemplary embodiment of the present invention, the answer generation unit may determine failure in extracting an answer if the input document does not contain a correct answer or the reliability is below a predefined threshold.
본 발명의 예시적 실시예에 따라, 질의 생성부는, 답변의 추출 실패에 응답하여, 속성 리스트에 포함된 다음 속성에 기초하여 질의를 생성할 수 잇다.According to an exemplary embodiment of the present invention, the query generation unit may, in response to a failure to extract an answer, generate a query based on the following attributes included in the attribute list.
본 발명의 예시적 실시예에 따라, 지식베이스는, 주어(subject), 술어(predicate) 및 목적어(object)를 포함하는 트리플(triple)을 포함할 수 있고, 지식 생성부는, 개체, 속성 및 답변을, 주어, 술어 및 목적어로서 포함하는 트리플을 지식 인스턴스로서 생성할 수 있다.According to an exemplary embodiment of the present invention, a knowledge base may include a triple including a subject, a predicate and an object, and a knowledge generation unit may generate a triple including an entity, an attribute and an answer as a subject, a predicate and an object as a knowledge instance.
본 발명의 예시적 실시예에 따라, 그래프 데이터는, 표에 포함된 셀들 각각의 인덱스, 좌표 및 컨텐츠를 포함하는 노드들, 및 표에 포함된 셀들의 배치에 기초하여, 노드들을 연결하는 에지들을 포함할 수 있다.According to an exemplary embodiment of the present invention, the graph data may include nodes including indices, coordinates, and contents of each of the cells included in the table, and edges connecting the nodes based on the arrangement of the cells included in the table.
본 발명의 예시적 실시예에 따라, 지식 생성부는, 지식베이스에 포함된 지식 인스턴스의 형식에 기초하여 개체, 속성 및 답변을 후처리하고, 개체, 속성 및 답변 중 적어도 하나에 대응하는 식별자를 지식베이스에서 추출함으로써 지식 인스턴스를 생성하는 지식 인스턴스 생성부, 및 생성된 지식 인스턴스를 지식베이스에 포함된 지식 인스턴스들과 비교함으로써 지식베이스에 선택적으로 통합하는 인스턴스 비교부를 포함할 수 있다.According to an exemplary embodiment of the present invention, the knowledge generation unit may include a knowledge instance generation unit that generates a knowledge instance by post-processing objects, properties, and answers based on the formats of knowledge instances included in a knowledge base and extracting an identifier corresponding to at least one of the objects, properties, and answers from the knowledge base, and an instance comparison unit that selectively integrates the generated knowledge instance into the knowledge base by comparing it with knowledge instances included in the knowledge base.
본 발명의 기술적 사상의 일측면에 따라, 문서로부터 지식을 추출하기 위한 지식 추출 방법은, 입력 문서로부터 개체(entity)를 추출하는 단계, 개체의 속성 리스트에 포함된 속성에 기초하여, 개체를 포함하는 질의를 입력 문서로부터 생성하는 단계, 입력 문서에 포함된 표로부터 그래프 데이터를 생성하는 단계, 그래프 데이터로부터 질의의 답변을 추출하는 단계, 지식베이스의 형식에 기초하여, 개체, 속성 및 답변으로부터 지식 인스턴스를 생성하는 단계를 포함할 수 있다.According to one aspect of the technical idea of the present invention, a knowledge extraction method for extracting knowledge from a document may include a step of extracting an entity from an input document, a step of generating a query including the entity from the input document based on an attribute included in an attribute list of the entity, a step of generating graph data from a table included in the input document, a step of extracting an answer to the query from the graph data, and a step of generating a knowledge instance from the entity, the attribute, and the answer based on a format of a knowledge base.
본 발명의 기술적 사상에 따른 시스템 및 방법에 의하면, 지식 추출이 용이하지 아니한 표로부터 지식이 추출될 수 있다.According to the system and method according to the technical idea of the present invention, knowledge can be extracted from a table from which knowledge extraction is not easy.
또한, 본 발명의 기술적 사상에 따른 시스템 및 방법에 의하면, 추출된 지식이 검증될 수 있고, 최종적으로 정확한 지식이 추출될 수 있다.In addition, according to the system and method according to the technical idea of the present invention, the extracted knowledge can be verified, and ultimately accurate knowledge can be extracted.
또한, 본 발명의 기술적 사상에 따른 시스템 및 방법에 의하면, 용이하고 정확하게 추출된 지식에 기인하여 지식베이스가 효율적으로 보강될 수 있고, 이에 따라 지식베이스에 기반한 서비스들의 품질이 향상되고 범위가 확대될 수 있다.In addition, according to the system and method according to the technical idea of the present invention, the knowledge base can be efficiently reinforced due to the knowledge extracted easily and accurately, and accordingly, the quality of services based on the knowledge base can be improved and the scope can be expanded.
본 발명의 예시적 실시예들에서 얻을 수 있는 효과는 이상에서 언급한 효과들로 제한되지 아니하며, 언급되지 아니한 다른 효과들은 이하의 기재로부터 본 발명의 예시적 실시예들이 속하는 기술분야에서 통상의 지식을 가진 자에게 명확하게 도출되고 이해될 수 있다. 즉, 본 발명의 예시적 실시예들을 실시함에 따른 의도하지 아니한 효과들 역시 본 발명의 예시적 실시예들로부터 당해 기술분야의 통상의 지식을 가진 자에 의해 도출될 수 있다.The effects obtainable from the exemplary embodiments of the present invention are not limited to the effects mentioned above, and other effects not mentioned can be clearly derived and understood by those skilled in the art to which the exemplary embodiments of the present invention belong from the following description. That is, unintended effects resulting from practicing the exemplary embodiments of the present invention can also be derived from the exemplary embodiments of the present invention by those skilled in the art.
도 1은 본 발명의 예시적 실시예에 따른 지식 추출 시스템 및 그 입출력을 나타내는 블록도이다.
도 2는 본 발명의 예시적 실시예에 따른 입력 문서 및 입력 문서로부터 추출된 표의 예시들을 나타내는 도면이다.
도 3은 본 발명의 예시적 실시예에 따른 질의 생성부의 예시를 나타내는 블록도이다.
도 4는 본 발명의 예시적 실시예에 따라 질의를 생성하는 동작의 예시를 나타내는 도면이다.
도 5a 및 도 5b는 본 발명의 예시적 실시예들에 따라 표로부터 생성된 구조화된 데이터의 예시들을 나타낸다.
도 6은 본 발명의 예시적 실시예에 따른 그래프 데이터의 예시를 나타내는 도면이다.
도 7은 본 발명의 예시적 실시예에 따른 그래프 독해 엔진의 예시를 나타내는 블록도이다.
도 8은 본 발명의 예시적 실시예에 따라 도 7의 자연어 처리부의 동작의 예시를 나타내는 도면이다.
도 9는 본 발명의 예시적 실시예에 따른 지식 추출을 위한 방법을 나타내는 순서도이다.
도 10은 본 발명의 예시적 실시예에 따른 지식 생성부의 예시를 나타내는 블록도이다.
도 11은 본 발명의 예시적 실시예에 따라 지식 생성부의 동작의 예시를 나타내는 도면이다.
도 12는 본 발명의 예시적 실시예에 따른 지식 추출을 위한 방법을 나타내는 순서도이다.
도 13은 본 발명의 예시적 실시예에 따른 지식 추출을 위한 방법을 나타내는 순서도이다.FIG. 1 is a block diagram showing a knowledge extraction system and its input/output according to an exemplary embodiment of the present invention.
FIG. 2 is a diagram illustrating examples of input documents and tables extracted from the input documents according to an exemplary embodiment of the present invention.
FIG. 3 is a block diagram showing an example of a query generation unit according to an exemplary embodiment of the present invention.
FIG. 4 is a diagram illustrating an example of an operation for generating a query according to an exemplary embodiment of the present invention.
Figures 5a and 5b illustrate examples of structured data generated from a table according to exemplary embodiments of the present invention.
FIG. 6 is a diagram showing an example of graph data according to an exemplary embodiment of the present invention.
FIG. 7 is a block diagram illustrating an example of a graph reading engine according to an exemplary embodiment of the present invention.
FIG. 8 is a diagram showing an example of the operation of the natural language processing unit of FIG. 7 according to an exemplary embodiment of the present invention.
FIG. 9 is a flowchart illustrating a method for knowledge extraction according to an exemplary embodiment of the present invention.
FIG. 10 is a block diagram showing an example of a knowledge generation unit according to an exemplary embodiment of the present invention.
FIG. 11 is a diagram showing an example of the operation of a knowledge generation unit according to an exemplary embodiment of the present invention.
FIG. 12 is a flowchart illustrating a method for knowledge extraction according to an exemplary embodiment of the present invention.
FIG. 13 is a flowchart illustrating a method for knowledge extraction according to an exemplary embodiment of the present invention.
이하, 첨부한 도면을 참조하여 본 발명의 실시 예에 대해 상세히 설명한다. 본 발명의 실시 예는 당 업계에서 평균적인 지식을 가진 자에게 본 발명을 보다 완전하게 설명하기 위하여 제공되는 것이다. 본 발명은 다양한 변경을 가할 수 있고 여러 가지 형태를 가질 수 있는 바, 특정 실시 예들을 도면에 예시하고 상세하게 설명하고자 한다. 그러나, 이는 본 발명을 특정한 개시 형태에 대해 한정하려는 것이 아니며, 본 발명의 사상 및 기술 범위에 포함되는 모든 변경, 균등물 내지 대체물을 포함하는 것으로 이해되어야 한다. 각 도면을 설명하면서 유사한 참조부호를 유사한 구성요소에 대해 사용한다. 첨부된 도면에 있어서, 구조물들의 치수는 본 발명의 명확성을 기하기 위하여 실제보다 확대하거나 축소하여 도시한 것이다.Hereinafter, embodiments of the present invention will be described in detail with reference to the attached drawings. Embodiments of the present invention are provided to more completely explain the present invention to a person having average knowledge in the art. Since the present invention can have various modifications and can have various forms, specific embodiments will be illustrated in the drawings and described in detail. However, this is not intended to limit the present invention to a specific disclosed form, but should be understood to include all modifications, equivalents, or substitutes included in the spirit and technical scope of the present invention. In describing each drawing, similar reference numerals are used for similar components. In the attached drawings, the dimensions of structures are illustrated enlarged or reduced from the actual size in order to ensure clarity of the present invention.
본 출원에서 사용한 용어는 단지 특정한 실시 예를 설명하기 위해 사용된 것으로, 본 발명을 한정하려는 의도가 아니다. 단수의 표현은 문맥상 명백하게 다르게 뜻하지 않는 한, 복수개의 표현을 포함한다. 본 출원에서, "포함하다" 또는 "가지다" 등의 용어는 명세서 상에 기재된 특징, 숫자, 단계, 동작, 구성요소, 부분품 또는 이들을 조합한 것이 존재함을 지정하려는 것이지, 하나 또는 그 이상의 다른 특징들이나 숫자, 단계, 동작, 구성 요소, 부분품 또는 이들을 조합한 것들의 존재 또는 부가 가능성을 미리 배제하지 않는 것으로 이해되어야 한다.The terminology used in this application is only used to describe specific embodiments and is not intended to limit the present invention. The singular expression includes the plural expression unless the context clearly indicates otherwise. In this application, the terms "comprises" or "has" and the like are intended to specify the presence of a feature, number, step, operation, component, part, or combination thereof described in the specification, but should be understood to not exclude in advance the possibility of the presence or addition of one or more other features, numbers, steps, operations, components, parts, or combinations thereof.
다르게 정의되지 않는 한, 기술적이거나 과학적인 용어를 포함해서 여기서 사용되는 모든 용어들은 본 발명이 속하는 기술분야에서 통상의 지식을 가진 자에 의해 일반적으로 이해되는 것과 동일한 의미를 갖는다. 일반적으로 사용되는 사전에 정의되어 있는 것과 같은 용어들은 관련 기술의 문맥상 가지는 의미와 일치하는 의미를 가지는 것으로 해석되어야 하며, 본 출원에서 명백하게 정의하지 아니하는 한, 이상적이거나 과도하게 형식적인 의미로 해석되지 않는다.Unless otherwise defined, all terms used herein, including technical or scientific terms, have the same meaning as commonly understood by one of ordinary skill in the art to which this invention belongs. Terms defined in commonly used dictionaries, such as those defined in common dictionaries, should be interpreted as having a meaning consistent with the meaning they have in the context of the relevant art, and shall not be interpreted in an idealized or overly formal sense, unless explicitly defined in this application.
이하 도면 및 설명에서, 하나의 블록으로 표시 또는 설명되는 구성요소는 하드웨어 블록 또는 소프트웨어 블록일 수 있다. 예를 들면, 구성요소들 각각은 서로 신호를 주고 받는 독립적인 하드웨어 블록일 수도 있고, 또는 하나의 프로세서에서 실행되는 소프트웨어 블록일 수도 있다. 소프트웨어 블록은, 프로그램 코드 또는 프로그램 코드가 컴파일된, 적어도 하나의 프로세서에 의해서 실행가능한 일련의 명령어들을 포함할 수 있다. 소프트웨어 블록은, 비일시적인(non-transitory) 컴퓨터 판독가능 매체, 예컨대 반도체 메모리 장치, 자기 디스크 장치, 광학 디스크 장치 등에 저장될 수 있다. 또한, 본 명세서에서 "시스템" 또는 "데이터베이스"는 적어도 하나의 프로세서 및 프로세서에 의해서 액세스되는 메모리를 포함하는 컴퓨팅 시스템을 지칭할 수 있다.In the drawings and descriptions below, a component represented or described as a single block may be a hardware block or a software block. For example, each of the components may be an independent hardware block that transmits and receives signals from each other, or may be a software block executed by one processor. A software block may include a program code or a series of instructions that are executable by at least one processor, into which the program code is compiled. A software block may be stored in a non-transitory computer-readable medium, such as a semiconductor memory device, a magnetic disk device, an optical disk device, etc. In addition, a "system" or a "database" in this specification may refer to a computing system including at least one processor and a memory accessed by the processor.
도 1은 본 발명의 예시적 실시예에 따른 지식 추출 시스템 및 그 입출력을 나타내는 블록도이다. 도 1에 도시된 바와 같이, 지식 추출 시스템(100)은 입력 문서(DIN) 및 속성 리스트(PL)를 수신할 수 있고, 지식베이스(knowledgebase)(200)와 통신할 수 있으며, 네트워크(300)에 접속할 수 있다.FIG. 1 is a block diagram showing a knowledge extraction system and its input/output according to an exemplary embodiment of the present invention. As shown in FIG. 1, the knowledge extraction system (100) can receive an input document (DIN) and an attribute list (PL), communicate with a knowledge base (200), and connect to a network (300).
지식 추출 시스템(100)은, 이하에서 도면들을 참조하여 후술되는 바와 같이, 입력 문서(DIN)에 포함된 표로부터 지식을 추출할 수 있고, 추출된 지식을 지식베이스(200)에 보강할 수 있다. 도 1에 도시된 바와 같이, 지식 추출 시스템(100)은 개체 추출부(110), 질의 생성부(120), 그래프 생성부(130), 그래프 독해 엔진(140), 지식 생성부(150) 및 지식 검증부(160)를 포함할 수 있다. 일부 실시예들에서, 도 1에 도시된 바와 상이하게 지식 추출 시스템(100)은, 지식베이스(200)와 통신하는 대신 추출된 지식을 다른 시스템, 예컨대 지식베이스(200)의 보강을 위한 시스템에 제공할 수도 있다. 또한, 일부 실시예들에서, 도 1에 도시된 바와 상이하게 지식 검증부(160)는 지식 추출 시스템(100)의 외부에 있을 수 있고, 지식 추출 시스템(100)은 외부의 지식 검증부와 (예컨대, 네트워크를 통해서) 통신함으로써 지식의 검증을 수행할 수도 있다. 또한, 일부 실시예들에서, 도 1에 도시된 바와 상이하게, 그래프 생성부(130) 및 그래프 독해 엔진(140)은 지식 추출 시스템(100)의 외부에 있을 수 있고, 지식 추출 시스템(100)은 외부의 그래프 생성부(130) 및 그래프 독해 엔진(140)과 (예컨대, 네트워크를 통해서) 통신함으로써 질의(QUE)를 제공하거나 답변(ANS)을 수신할 수도 있다.The knowledge extraction system (100) can extract knowledge from a table included in an input document (DIN), as described below with reference to the drawings, and can reinforce the extracted knowledge to the knowledge base (200). As illustrated in FIG. 1, the knowledge extraction system (100) can include an entity extraction unit (110), a query generation unit (120), a graph generation unit (130), a graph reading engine (140), a knowledge generation unit (150), and a knowledge verification unit (160). In some embodiments, unlike as illustrated in FIG. 1, instead of communicating with the knowledge base (200), the knowledge extraction system (100) can provide the extracted knowledge to another system, for example, a system for reinforcing the knowledge base (200). In addition, in some embodiments, unlike as illustrated in FIG. 1, the knowledge verification unit (160) may be external to the knowledge extraction system (100), and the knowledge extraction system (100) may perform knowledge verification by communicating with the external knowledge verification unit (e.g., via a network). In addition, in some embodiments, unlike as illustrated in FIG. 1, the graph generation unit (130) and the graph interpretation engine (140) may be external to the knowledge extraction system (100), and the knowledge extraction system (100) may provide a query (QUE) or receive an answer (ANS) by communicating with the external graph generation unit (130) and the graph interpretation engine (140) (e.g., via a network).
지식베이스(200)는 온톨로지(ontology)에 기초하여 구조화된 지식들, 즉 지식 인스턴스들을 포함할 수 있다. 온톨로지는 실존하거나 사람이 인식 가능한 것들을 컴퓨터에서 다룰 수 있는 형태로 표현한 것으로서, 온톨로지 구성요소들은, 예컨대 개체(entity), 클래스(class), 속성(property), 값(value) 등을 포함할 수 있다. 추가적으로, 온톨로지 구성요소들은, 관계(relation), 함수 텀(function term), 제한(restriction), 규칙(rule), 사건(event) 등을 더 포함할 수 있다. 엔티티에 대한 특정 정보, 즉 지식은 지식 인스턴스(또는 단순하게 인스턴스)로서 지칭될 수 있고, 지식베이스(200)는 방대한 지식 인스턴스들을 저장할 수 있다. 일부 실시예들에서, 지식베이스(200)는 RDF(Resource Description Framework)에 기초하여 표현되는 지식 인스턴스들을 포함할 수 있고, 지식 인스턴스는 트리플(triple)로 표현될 수 있다. 지식베이스(200)는 쿼리, 예컨대 SPARQL(SPARQL Protocol and RDF Query Language) 쿼리에 응답하여 지식 인스턴스, 즉 트리플을 반환할 수 있다. 트리플은 "주어(subject; S)-술어(predicate; P)-목적어(object; O)"로 구성될 수 있고, 지식 인스턴스는 트리플의 주어뿐만 아니라 목적어도 될 수 있으며, 술어도 될 수 있다. 예를 들면, 지식베이스(200)는 개체 "이순신"을 포함하는 지식 인스턴스로서 "이순신(S)-국적(P)-조선(O)"이라는 트리플을 가질 수 있다.The knowledge base (200) may include structured knowledge based on ontology, that is, knowledge instances. Ontology is a representation of things that exist or can be recognized by humans in a form that can be handled by a computer, and ontology components may include, for example, entities, classes, properties, values, etc. In addition, ontology components may further include relations, function terms, restrictions, rules, events, etc. Specific information about entities, that is, knowledge, may be referred to as knowledge instances (or simply instances), and the knowledge base (200) may store a large number of knowledge instances. In some embodiments, the knowledge base (200) may include knowledge instances expressed based on RDF (Resource Description Framework), and the knowledge instances may be expressed as triples. The knowledge base (200) can return a knowledge instance, i.e., a triple, in response to a query, for example, a SPARQL (SPARQL Protocol and RDF Query Language) query. A triple can be composed of "subject (S)-predicate (P)-object (O)", and a knowledge instance can be not only the subject of the triple, but also the object, and can also be the predicate. For example, the knowledge base (200) can have a triple called "Yi Sun-shin (S)-nationality (P)-Joseon (O)" as a knowledge instance that includes the entity "Yi Sun-shin."
개체 추출부(110)는 입력 문서(DIN)로부터 개체(ENT)를 추출할 수 있다. 개체(ENT)는 지식의 대상이 되는 것으로서, 지식베이스(200)에 포함되는 지식 인스턴스를 구성할 수 있다. 입력 문서(DIN)는 개체(ENT) 및 개체(ENT)에 대한 정보를 포함하는 임의의 데이터를 지칭할 수 있다. 예를 들면, 입력 문서(DIN)는 위키백과(wikipedia.org)와 같이 백과사전 서비스(또는 서버)로부터 제공되는 문서일 수도 있고, 신문이나 포털 등으로부터 제공되는 기사들일 수도 있으며, 소셜 네트워크 서비스(Social Network Service; SNS) 상에서 작성된 문서들일 수도 있다. 또한, 인터넷과 같은 네트워크를 통해서 획득되는 전술된 예시들과 상이하게, 입력 문서(DIN)는 로컬 스토리지에 저장된 데이터일 수도 있다. 입력 문서(DIN)는 정형 데이터일 수도 있고, 비정형 데이터일 수도 있다.The entity extraction unit (110) can extract an entity (ENT) from an input document (DIN). The entity (ENT) is an object of knowledge and can constitute a knowledge instance included in the knowledge base (200). The input document (DIN) can refer to an entity (ENT) and any data including information about the entity (ENT). For example, the input document (DIN) may be a document provided from an encyclopedia service (or server) such as Wikipedia (wikipedia.org), articles provided from a newspaper or portal, or documents created on a social network service (SNS). In addition, unlike the above-described examples obtained through a network such as the Internet, the input document (DIN) may be data stored in a local storage. The input document (DIN) may be structured data or unstructured data.
도 1에 도시된 바와 같이, 입력 문서(DIN)는 표를 포함할 수 있다. 표는 복수의 셀들을 포함할 수 있고, 셀의 위치 및 컨텐츠에 따라 지식을 포함할 수 있다. 이와 같이, 표에 포함된 지식은 표의 구조에 기초할 수 있고, 자연어 문장들과 같은 텍스트로부터 시맨틱 분석을 통해 지식을 추출하는 방법을 통해 표로부터 지식을 추출하는 것은 용이하지 아니할 수 있다. 후술되는 바와 같이, 지식 추출 시스템(100)은 표로부터 지식을 추출하기 위하여 그래프를 이용할 수 있고, 이에 따라 표로부터 지식이 용이하게 추출될 수 있다. 이를 위하여, 도 1에 도시된 바와 같이, 입력 문서(DIN)는 개체 추출부(110)뿐만 아니라 그래프 생성부(130)에도 제공될 수 있다. 입력 문서(DIN)의 예시가 도 2를 참조하여 후술될 것이다.As illustrated in FIG. 1, the input document (DIN) may include a table. The table may include a plurality of cells, and may include knowledge according to the location and content of the cells. As such, the knowledge included in the table may be based on the structure of the table, and it may not be easy to extract knowledge from the table through a method of extracting knowledge through semantic analysis from text such as natural language sentences. As described below, the knowledge extraction system (100) may utilize a graph to extract knowledge from the table, and thus knowledge may be easily extracted from the table. To this end, as illustrated in FIG. 1, the input document (DIN) may be provided to not only the entity extraction unit (110) but also the graph generation unit (130). An example of the input document (DIN) will be described below with reference to FIG. 2.
개체 추출부(110)는 임의의 방식으로 입력 문서(DIN)로부터 개체를 추출할 수 있다. 일부 실시예들에서, 개체 추출부(110)는 입력 문서(DIN)에 포함된 텍스트에 대하여 형태소 분석을 수행할 수 있고, 형태소들 중 명사에 대응하는 단어들 중 하나를 개체(ENT)로서 추출할 수 있다. 일부 실시예들에서, 개체 추출부(110)는 지식베이스(200)에 포함된 개체들 및/또는 지식 인스턴스들을 참조하여 명사에 대응하는 단어들을 필터링할 수 있고, 필터링된 단어를 개체(ENT)로서 추출할 수 있다. 일부 실시예들에서, 개체 추출부(110)는 의존성 파싱(dependency parsing) 및/또는 SRL(Semantic Role Labeling)에 기초하여 입력 문서(DIN)의 텍스트에 포함된 문장 분석을 통해서 개체를 추출할 수도 있다. 일부 실시예들에서, 개체 추출부(110)는, 도 2에 도시된 바와 같이, 입력 문서(DIN)의 제목으로부터 개체(ENT)를 추출할 수도 있다.The entity extraction unit (110) can extract entities from the input document (DIN) in any manner. In some embodiments, the entity extraction unit (110) can perform morphological analysis on the text included in the input document (DIN) and extract one of the words corresponding to a noun among the morphemes as an entity (ENT). In some embodiments, the entity extraction unit (110) can filter words corresponding to a noun by referencing entities and/or knowledge instances included in the knowledge base (200) and extract the filtered word as an entity (ENT). In some embodiments, the entity extraction unit (110) can extract entities by analyzing sentences included in the text of the input document (DIN) based on dependency parsing and/or Semantic Role Labeling (SRL). In some embodiments, the entity extraction unit (110) can extract entities (ENT) from the title of the input document (DIN), as illustrated in FIG. 2.
질의 생성부(120)는 개체 추출부(110)로부터 추출된 개체(ENT)를 수신할 수 있고, 속성 리스트(PL)를 수신할 수 있다. 속성 리스트(PL)는 지식베이스(200)에서 클래스들이 각각 가지는 속성들을 정의할 수 있다. 예를 들면, 속성 리스트(PL)는 클래스 "사람"은 "나이", "성별", "이름", "출생", "직업", "국적", "배우자" 등의 속성들을 정의할 수 있고, 이에 따라 클래스 "사람"에 속하는 개체로서 "이순신"을 포함하는 지식 인스턴스는, 전술된 속성들 중 하나의 속성 및 속성에 대응하는 다른 개체(예컨대, 직업, 국적 또는 배우자에 대응하는 개체) 또는 값(예컨대, 나이, 성별, 이름, 출생에 대응하는 개체) 을 포함할 수 있다. 일부 실시예들에서, 질의 생성부(120)는 입력 문서(DIN) 및/또는 지식베이스(200)를 참조하여 개체 추출부(110)로부터 제공되는 개체(ENT)가 속하는 클래스를 획득할 수 있고, 속성 리스트(PL)로부터 획득된 클래스에 대응하는 속성 그룹을 추출할 수 있다. 질의 생성부(120)는 개체(ENT) 및 속성 그룹에 포함된 복수의 속성들 중 하나의 속성(PRO)에 기초하여 질의(QUE)를 생성할 수 있다. 도 1에 도시된 바와 같이, 질의 생성부(120)는 질의(QUE)를 그래프 독해 엔진(140)에 제공할 수 있고, 속성(PRO)을 지식 생성부(150)에 제공할 수 있다. 후술되는 바와 같이, 그래프 독해 엔진(140)에 제공된 질의(QUE)는 답변(ANS)을 생성하는데 사용될 수도 있고, 지식 검증부(160)에 의해서 지식 인스턴스(INS)를 검증하는데 사용될 수도 있다. 일부 실시예들에서, 질의 생성부(120)는 지식베이스(200)로부터 속성 리스트(PL)를 수신할 수도 있다. 질의 생성부(120)에 대한 예시들이 도 3 및 도 4를 참조하여 후술될 것이다.The query generation unit (120) can receive an entity (ENT) extracted from the entity extraction unit (110) and can receive an attribute list (PL). The attribute list (PL) can define attributes that each class has in the knowledge base (200). For example, the attribute list (PL) of the class "person" can define attributes such as "age", "gender", "name", "birth", "occupation", "nationality", and "spouse", and accordingly, a knowledge instance including "Yi Sun-shin" as an entity belonging to the class "person" can include one of the attributes described above and another entity (e.g., an entity corresponding to an occupation, nationality, or spouse) or value (e.g., an entity corresponding to age, gender, name, and birth) corresponding to the attribute. In some embodiments, the query generation unit (120) may obtain a class to which an entity (ENT) provided from the entity extraction unit (110) belongs by referring to an input document (DIN) and/or a knowledge base (200), and may extract an attribute group corresponding to the class obtained from the attribute list (PL). The query generation unit (120) may generate a query (QUE) based on one attribute (PRO) among a plurality of attributes included in the entity (ENT) and the attribute group. As illustrated in FIG. 1, the query generation unit (120) may provide the query (QUE) to the graph reading engine (140) and may provide the attribute (PRO) to the knowledge generation unit (150). As described below, the query (QUE) provided to the graph reading engine (140) may be used to generate an answer (ANS) or may be used to verify a knowledge instance (INS) by the knowledge verification unit (160). In some embodiments, the query generator (120) may also receive a property list (PL) from the knowledge base (200). Examples of the query generator (120) will be described below with reference to FIGS. 3 and 4.
그래프 생성부(130)는 입력 문서(DIN)로부터 그래프 데이터(GRA)를 생성할 수 있다. 전술된 바와 같이, 입력 문서(DIN)에 포함된 표에 포함된 지식은 셀의 위치에 의존할 수 있고, 이에 따라 일반적인 텍스트로부터 지식을 추출하는 방법으로 표에서 지식을 추출하는 것은 용이하지 아니할 수 있다. 셀의 위치를 고려하기 위하여, 그래프 생성부(130)는 그래프 데이터(GRA)를 생성할 수 있고, 그래프 데이터(GRA)는 셀의 위치에 대한 정보를 포함할 수 있다. 그래프 생성부(130)의 동작 및 그래프 데이터(GRA)의 예시들이 도 5a, 도 5b 및 도 6을 참조하여 후술될 것이다.The graph generation unit (130) can generate graph data (GRA) from the input document (DIN). As described above, knowledge included in a table included in the input document (DIN) may depend on the location of cells, and therefore, it may not be easy to extract knowledge from the table in the same way as extracting knowledge from general text. In order to consider the location of cells, the graph generation unit (130) can generate graph data (GRA), and the graph data (GRA) may include information about the location of cells. Examples of the operation of the graph generation unit (130) and the graph data (GRA) will be described below with reference to FIGS. 5A, 5B, and 6.
그래프 독해 엔진(140)은 그래프 생성부(130)로부터 그래프 데이터(GRA)를 수신할 수 있고, 질의 생성부(120)로부터 질의(QUE)를 수신할 수 있으며, 그래프 데이터(GRA)에서 질의(QUE)에 대한 답변(ANS)을 추출할 수 있다. 일부 실시예들에서, 그래프 독해 엔진(140)은 적어도 하나의 딥 러닝 네트워크(deep learning network)를 포함할 수 있고, 적어도 하나의 딥 러닝 네트워크는 샘플 그래프 데이터들 및 샘플 질의들에 따라 샘플 답변들을 출력하도록 학습된 상태일 수 있다. 본 명세서에서, 딥 러닝 네트워크는 기계 학습(machine learning) 모델의 일예로서 설명되며, 딥 러닝 네트워크는 기계 학습 모델의 다른 예시로 대체될 수 있다. 그래프 독해 엔진(140)은 답변(ANS)을 지식 생성부(150)에 제공할 수 있다.The graph reading engine (140) can receive graph data (GRA) from the graph generation unit (130), can receive a query (QUE) from the query generation unit (120), and can extract an answer (ANS) to the query (QUE) from the graph data (GRA). In some embodiments, the graph reading engine (140) can include at least one deep learning network, and the at least one deep learning network can be trained to output sample answers according to sample graph data and sample queries. In this specification, the deep learning network is described as an example of a machine learning model, and the deep learning network can be replaced with another example of a machine learning model. The graph reading engine (140) can provide the answer (ANS) to the knowledge generation unit (150).
일부 실시예들에서, 그래프 독해 엔진(140)은 추출된 지식을 검증하는데 사용될 수 있다. 예를 들면, 도 1에 도시된 바와 같이, 그래프 독해 엔진(140)은 지식 검증부(160)와 통신할 수 있고, 답변(ANS)뿐만 아니라 그래프 데이터(GRA) 및 질의(QUE)와 관련된 추가적인 정보를 생성할 수 있다. 지식 생성부(150) 및/또는 지식 검증부(160)는 추가적인 정보를 이용할 수도 있다. 그래프 독해 엔진(140)의 예시들이 도 7을 참조하여 후술될 것이다.In some embodiments, the graph reading engine (140) may be used to verify the extracted knowledge. For example, as illustrated in FIG. 1, the graph reading engine (140) may communicate with the knowledge verification unit (160) and generate additional information related to the graph data (GRA) and the query (QUE) in addition to the answer (ANS). The knowledge generation unit (150) and/or the knowledge verification unit (160) may also utilize the additional information. Examples of the graph reading engine (140) will be described below with reference to FIG. 7.
지식 생성부(150)는 개체 추출부(110)로부터 개체(ENT)를 수신할 수 있고, 질의 생성부(120)로부터 속성(PRO)을 수신할 수 있으며, 그래프 독해 엔진(140)으로부터 답변(ANS)을 수신할 수 있다. 지식 생성부(150)는 개체(ENT), 속성(PRO) 및 답변(ANS)으로부터 지식 인스턴스(INS)(예컨대, 트리플)을 생성할 수 있다. 예를 들면, 지식 생성부(150)는 개체(ENT), 속성(PRO) 및 답변(ANS)을 지식베이스(200)의 형식에 따라 후처리할 수 있고, 개체(ENT), 속성(PRO) 및 답변(ANS) 중 적어도 하나의 식별자를 지식베이스(200)로부터 추출함으로써 지식 인스턴스(INS)를 생성할 수 있다. 또한, 지식 생성부(150)는 지식 인스턴스(INS)를 지식 검증부(160)에 제공함으로써 지식 인스턴스(INS)를 검증할 수 있고, 검증된 지식 인스턴스(INS)를 지식베이스(200)에 보강할 수 있다. 지식 생성부(150)의 예시들은 도 10 및 도 11을 참조하여 설명될 것이다.The knowledge generation unit (150) can receive an entity (ENT) from the entity extraction unit (110), an attribute (PRO) from the query generation unit (120), and an answer (ANS) from the graph reading engine (140). The knowledge generation unit (150) can generate a knowledge instance (INS) (e.g., a triple) from the entity (ENT), the attribute (PRO), and the answer (ANS). For example, the knowledge generation unit (150) can post-process the entity (ENT), the attribute (PRO), and the answer (ANS) according to the format of the knowledge base (200), and can generate the knowledge instance (INS) by extracting an identifier of at least one of the entity (ENT), the attribute (PRO), and the answer (ANS) from the knowledge base (200). In addition, the knowledge creation unit (150) can verify the knowledge instance (INS) by providing the knowledge instance (INS) to the knowledge verification unit (160) and can reinforce the verified knowledge instance (INS) to the knowledge base (200). Examples of the knowledge creation unit (150) will be described with reference to FIGS. 10 and 11.
지식 검증부(160)는 지식 생성부(150)로부터 지식 인스턴스(INS)를 수신할 수 있고, 지식 인스턴스(INS)를 검증함으로써 검증 결과를 지식 생성부(150)에 제공할 수 있다. 도 1에 도시된 바와 같이, 지식 검증부(160)는 네트워크(300)에 접속할 수 있으며, 그래프 독해 엔진(140)과 통신할 수 있다. 네트워크(300)는 인터넷과 같은 광역 네트워크뿐만 아니라 로컬 네트워크를 포함할 수 있고, 지식 검증부(160)는 네트워크(300)에 접속된 다른 시스템들과 통신함으로써 지식 인스턴스(INS)의 검증에 요구되는 데이터(예컨대, 문서)를 획득할 수 있다. 일부 실시예들에서, 지식 검증부(160)는 기계 독해에 기초하여 지식 인스턴스(INS)를 검증할 수 있다. 기계 독해(Machine Reading Comprehension; MRC)는 기계가 다양한 주제의 글을 읽어서 뜻을 이해하는 것을 지칭할 수 있다. 지식 검증부(160)는 기계 독해 엔진을 포함하거나 기계 독해 엔진과 통신할 수 있다. 지식 검증부(160)는, 네트워크(300)를 통해서 획득한 문서 및 지식 인스턴스(INS)를 검증하기 위한 질의를 기계 독해 엔진에 제공할 수 있고, 질의에 대응하는 응답을 기계 독해 엔진으로부터 획득할 수 있다. 예를 들면, SQuAD(Stanford Question Answering Dataset)은 영어 환경에서 기계 독해를 위한 데이터 셋을 제공한다. 이와 같은 기계 독해는 매우 복잡한 질문에 대해서도 응답을 제공하는 장점을 가질 수 있다. 지식 검증부(160)는 기계 독해 엔진의 응답에 기초하여 지식 인스턴스(INS)에 대한 검증의 성공 여부를 판정할 수 있다. 지식 검증부(160)의 예시는 도 10을 참조하여 후술될 것이다.The knowledge verification unit (160) can receive a knowledge instance (INS) from the knowledge creation unit (150), and can verify the knowledge instance (INS) and provide the verification result to the knowledge creation unit (150). As illustrated in FIG. 1, the knowledge verification unit (160) can be connected to a network (300) and can communicate with a graph reading engine (140). The network (300) can include a local network as well as a wide area network such as the Internet, and the knowledge verification unit (160) can obtain data (e.g., documents) required for verification of the knowledge instance (INS) by communicating with other systems connected to the network (300). In some embodiments, the knowledge verification unit (160) can verify the knowledge instance (INS) based on machine reading comprehension. Machine reading comprehension (MRC) can refer to a machine reading texts on various topics and understanding their meaning. The knowledge verification unit (160) may include a machine reading engine or communicate with the machine reading engine. The knowledge verification unit (160) may provide a query to the machine reading engine for verifying documents and knowledge instances (INS) acquired through the network (300), and may obtain a response corresponding to the query from the machine reading engine. For example, SQuAD (Stanford Question Answering Dataset) provides a data set for machine reading in an English environment. Such machine reading may have the advantage of providing a response even to very complex questions. The knowledge verification unit (160) may determine whether verification of the knowledge instance (INS) is successful or not based on the response of the machine reading engine. An example of the knowledge verification unit (160) will be described below with reference to FIG. 10.
도 2는 본 발명의 예시적 실시예에 따른 입력 문서 및 입력 문서로부터 추출된 표의 예시들을 나타내는 도면이다. 도 1을 참조하여 전술된 바와 같이, 입력 문서(DIN')는 표를 포함할 수 있고, 표로부터 그래프 데이터(GRA)가 생성될 수 있다. 일부 실시예들에서, 도 1의 그래프 생성부(130)는 입력 문서(DIN')로부터 표를 추출할 수 있고, 이하에서 도 2는 도 1을 참조하여 설명될 것이다.FIG. 2 is a diagram showing examples of input documents and tables extracted from the input documents according to an exemplary embodiment of the present invention. As described above with reference to FIG. 1, the input document (DIN') may include a table, and graph data (GRA) may be generated from the table. In some embodiments, the graph generation unit (130) of FIG. 1 may extract a table from the input document (DIN'), and FIG. 2 will be described below with reference to FIG. 1.
도 2를 참조하면, 입력 문서(DIN')는 인물 "손흥민"에 대한 정보를 포함할 수 있다. 예를 들면, 입력 문서(DIN')는 위키백과, 나무위키(namu.wiki) 등과 같은 백과사전 서비스로부터 제공될 수 있다. 도 2에 도시된 바와 같이, 입력 문서(DIN')는 제목으로서 인물의 이름을 나타내는 "손흥민"을 포함할 수 있고, 해당 인물을 설명하는 텍스트 "손흥민은 대한민국의 ..."를 포함할 수 있다. 입력 문서(DIN')의 내용은 갱신될 수 있고, 이에 따라 입력 문서(DIN')로부터 지식 추출이 완료된 이후에도, 개체 추출부(110)는 갱신된 입력 문서로부터 동일하거나 상이한 개체를 다시 추출할 수도 있다. 이에 따라, 개체 추출부(110)가 추출하는 개체(ENT')는 지식베이스(200)에 포함된 개체들에 제한되지 아니할 수 있고, 결과적으로 지식베이스(200)에 포함된 개체에 대한 정보를 문서로부터 검색함으로써 지식을 생성하는 방식들보다 효과적인 지식 확장이 달성될 수 있다.Referring to FIG. 2, the input document (DIN') may include information about the person "Son Heung-min". For example, the input document (DIN') may be provided from an encyclopedia service such as Wikipedia, Namu Wiki (namu.wiki), etc. As illustrated in FIG. 2, the input document (DIN') may include "Son Heung-min" as a title, indicating the name of the person, and may include the text "Son Heung-min is a ..." describing the person. The content of the input document (DIN') may be updated, and accordingly, even after knowledge extraction from the input document (DIN') is completed, the entity extraction unit (110) may re-extract the same or different entities from the updated input document. Accordingly, the entities (ENT') extracted by the entity extraction unit (110) may not be limited to entities included in the knowledge base (200), and as a result, more effective knowledge expansion can be achieved than methods of generating knowledge by searching for information about entities included in the knowledge base (200) from documents.
일부 실시예들에서, 그래프 생성부(130)는 입력 문서(DIN')로부터 표를 추출할 수 있다. 예를 들면, 그래프 생성부(130)는 HTML, XML 등과 같이 구조화된 데이터에서 표를 나타내는 구분자들을 식별할 수 있고, 식별된 구분자들에 기초하여 표를 추출할 수 있다. 또한, 그래프 생성부(130)는 OCR(optical character recognition)을 통해 이미지로부터 텍스트 및 표의 테두리를 식별할 수 있고, 식별된 텍스트 및 표의 테두리에 기초하여 표를 추출할 수 있다. 이에 따라, 도 2에 도시된 바와 같이, 입력 문서(DIN')로부터 표(T20)가 추출될 수 있고, 표(T20)의 셀들 각각은 컨텐츠로서 텍스트를 포함할 수 있다.In some embodiments, the graph generation unit (130) can extract a table from the input document (DIN'). For example, the graph generation unit (130) can identify delimiters representing a table in structured data such as HTML, XML, etc., and extract the table based on the identified delimiters. In addition, the graph generation unit (130) can identify text and table borders from an image through OCR (optical character recognition), and extract the table based on the identified text and table borders. Accordingly, as illustrated in FIG. 2, a table (T20) can be extracted from the input document (DIN'), and each cell of the table (T20) can include text as content.
일부 실시예들에서, 도 1의 개체 추출부(110)는 입력 문서(DIN')의 제목으로부터 개체(ENT)를 추출할 수 있다. 예를 들면, 입력 문서(DIN')는 제목에 대한 정보를 포함할 수 있고, 이에 따라 제목으로부터 추출된 개체를 포함하는 다양한 지식 인스턴스들이 입력 문서(DIN')로부터 추출될 수 있다. 이에 따라, 개체 추출부(110)는 도 2의 입력 문서(DIN')로부터 개체(ENT)로서 "손흥민"을 추출할 수 있다.In some embodiments, the entity extraction unit (110) of FIG. 1 can extract an entity (ENT) from the title of the input document (DIN'). For example, the input document (DIN') can include information about the title, and thus, various knowledge instances including the entity extracted from the title can be extracted from the input document (DIN'). Accordingly, the entity extraction unit (110) can extract "Son Heung-min" as an entity (ENT) from the input document (DIN') of FIG. 2.
도 3은 본 발명의 예시적 실시예에 따른 질의 생성부의 예시를 나타내는 블록도이고, 도 4는 본 발명의 예시적 실시예에 따라 질의를 생성하는 동작의 예시를 나타내는 도면이다. 도 1을 참조 하여 전술된 바와 같이, 도 3의 질의 생성부(120')는 개체(ENT) 및 속성 리스트(PL)를 수신할 수 있고, 질의(QUE)를 생성할 수 있다. 이하에서, 도 3 및 도 4는 도 1을 참조하여 설명할 것이다.FIG. 3 is a block diagram showing an example of a query generation unit according to an exemplary embodiment of the present invention, and FIG. 4 is a diagram showing an example of an operation of generating a query according to an exemplary embodiment of the present invention. As described above with reference to FIG. 1, the query generation unit (120') of FIG. 3 can receive an entity (ENT) and a property list (PL), and can generate a query (QUE). Hereinafter, FIG. 3 and FIG. 4 will be described with reference to FIG. 1.
도 3을 참조하면, 질의 생성부(120')는 전처리부(122), 딥 러닝 네트워크(124) 및 후처리부(126)를 포함할 수 있다. 전처리부(122)는 개체(ENT) 및 속성(PRO)을 수신할 수 있다. 일부 실시예들에서, 전처리부(122)는 개체(ENT)의 클래스에 대응하는 속성 그룹에 포함된 속성들 각각을 순차적으로 선택할 수 있다. 예를 들면, 전처리부(122)는 도 1의 지식 생성부(150)에 의해서 지식 인스턴스(INS)의 생성이 완료되거나, 지식 인스턴스(INS)의 생성이 실패한 것으로 판정된 경우, 동일한 개체(ENT)에 대한 속성들, 즉 속성 그룹에 포함된 속성들 중 기존 속성과 다른 속성을 속성 리스트(PL)로부터 획득할 수 있다.Referring to FIG. 3, the query generation unit (120') may include a preprocessing unit (122), a deep learning network (124), and a postprocessing unit (126). The preprocessing unit (122) may receive an entity (ENT) and an attribute (PRO). In some embodiments, the preprocessing unit (122) may sequentially select each attribute included in an attribute group corresponding to a class of the entity (ENT). For example, when the knowledge generation unit (150) of FIG. 1 determines that the generation of a knowledge instance (INS) is completed or that the generation of a knowledge instance (INS) has failed, the preprocessing unit (122) may obtain attributes for the same entity (ENT), that is, attributes included in an attribute group that are different from existing attributes, from the attribute list (PL).
전처리부(122)는 워드 벡터 모델(400)을 참조하여 개체(ENT) 및 속성(PRO)에 대응하는 제1 워드 벡터(V1) 및 제2 워드 벡터(V2)를 생성할 수 있다. 워드 벡터 모델(400)은, 의미를 가지는 워드(또는 토큰, 단어 등)가 하나의 좌표, 즉 워드 벡터로 표현되는 다차원 공간, 또는 워드 벡터들을 포함하고 워드 벡터들을 갱신하는 시스템을 지칭할 수 있다. 의미상 유사한 워드들은 다차원 공간에서 인접하게 배치될 수 있고, 이에 따라 의미상 유사한 워드들에 대응하는 워드 벡터들은 유사한 값들을 가질 수 있다. 이에 따라, 제1 워드 벡터(V1)는 개체(ENT)에 대응하는 좌표 값들을 가질 수 있고, 제2 워드 벡터(V2)는 속성(PRO)에 대응하는 좌표 값들을 가질 수 있으며, 제1 워드 벡터(V1) 및 제2 워드 벡터(V2)에 기초하여 딥 러닝 네트워크(124)는 수학적 연산들을 수행할 수 있다. 워드 벡터 모델(400)은 도 1의 지식 추출 시스템(100)에 포함될 수도 있고, 질의 생성부(120')가 지식 추출 시스템(100)의 외부에 있는 워드 벡터 모델(400)에 액세스할 수도 있다.The preprocessing unit (122) can generate a first word vector (V1) and a second word vector (V2) corresponding to an entity (ENT) and an attribute (PRO) by referring to the word vector model (400). The word vector model (400) can refer to a multidimensional space in which a word (or token, word, etc.) having a meaning is expressed as a single coordinate, i.e., a word vector, or a system that includes word vectors and updates the word vectors. Words that are similar in meaning can be arranged adjacently in the multidimensional space, and thus, word vectors corresponding to words that are similar in meaning can have similar values. Accordingly, the first word vector (V1) can have coordinate values corresponding to the entity (ENT), and the second word vector (V2) can have coordinate values corresponding to the attribute (PRO), and the deep learning network (124) can perform mathematical operations based on the first word vector (V1) and the second word vector (V2). The word vector model (400) may be included in the knowledge extraction system (100) of FIG. 1, or the query generation unit (120') may access the word vector model (400) located outside the knowledge extraction system (100).
딥 러닝 네트워크(124)는 전처리부(122)로부터 제1 워드 벡터(V1) 및 제2 워드 벡터(V2)를 수신할 수 있고, 제3 워드 벡터(V3)를 출력할 수 있다. 딥 러닝 네트워크(124)는 샘플 객체들 및 샘플 속성들에 따라 샘플 질의들을 생성하도록, 예컨대 강화 학습(reinforcement learning; RL)에 기초하여 학습된 상태일 수 있고, 임의의 구조를 가질 수 있다. 본 명세서에서, 도 3의 딥 러닝 네트워크(124)를 포함하는 딥 러닝 네트워크들은 하드웨어 또는 하드웨어와 소프트웨어의 조합으로서 구현될 수 있으며, 인공 신경망(artificial neural network; ANN)으로서 지칭될 수 있다. 딥 러닝 네트워크들은, 비제한적인 예시로서 심층 신경망(Deep Neural Network; DNN), 합성곱 신경망(Convolution Neural Network; CNN), 순환 신경망(Recurrent Neural Network; RNN), 제한 볼츠만 머신(Restricted Boltzmann Machine; RBM), 심층 신뢰 신경망(Deep Belief Network; DBN), 심층 Q-네트워크(Deep Q-Network)를 포함할 수 있다. 이에 따라, 도 3의 딥 러닝 네트워크(124)는 제1 워드 벡터(V1) 및 제2 워드 벡터(V2)로부터 질의(QUE)의 생성을 위한 제3 워드 벡터(V3)를 생성할 수 있다. 본 명세서에서, 질의 생성부(120')에 포함된 딥 러닝 네트워크(124)는 제1 딥 러닝 네트워크로서 지칭될 수 있다.The deep learning network (124) can receive a first word vector (V1) and a second word vector (V2) from the preprocessing unit (122), and can output a third word vector (V3). The deep learning network (124) can be trained, for example, based on reinforcement learning (RL), to generate sample queries according to sample objects and sample properties, and can have an arbitrary structure. In this specification, deep learning networks including the deep learning network (124) of FIG. 3 can be implemented as hardware or a combination of hardware and software, and can be referred to as an artificial neural network (ANN). Deep learning networks may include, but are not limited to, a Deep Neural Network (DNN), a Convolution Neural Network (CNN), a Recurrent Neural Network (RNN), a Restricted Boltzmann Machine (RBM), a Deep Belief Network (DBN), and a Deep Q-Network. Accordingly, the deep learning network (124) of FIG. 3 may generate a third word vector (V3) for generating a query (QUE) from the first word vector (V1) and the second word vector (V2). In this specification, the deep learning network (124) included in the query generation unit (120') may be referred to as a first deep learning network.
후처리부(126)는 워드 벡터 모델(400)을 참조하여 제3 워드 벡터(V3)로부터 질의(QUE)를 생성할 수 있다. 예를 들면, 도 4에 도시된 바와 같이, 딥 러닝 네트워크(124)는 개체(ENT') 및 속성(PRO')으로부터 전처리부(122)에 의해서 생성된 제1 워드 벡터(V1) 및 제2 워드 벡터(V2)를 수신할 수 있다. 딥 러닝 네트워크(124)는 제1 워드 벡터(V1) 및 제2 워드 벡터(V2)에 응답하여 제3 워드 벡터(V3)를 생성할 수 있고, 후처리부(126)는 제3 워드 벡터(V3)로부터 일련의 단어들(W1 내지 W4)을 획득할 수 있고, 일련의 단어들(W1 내지 W4)을 조합함으로써 질의(QUE)로서 "손흥민의 직업은?"을 생성할 수 있다.The post-processing unit (126) can generate a query (QUE) from the third word vector (V3) by referring to the word vector model (400). For example, as illustrated in FIG. 4, the deep learning network (124) can receive the first word vector (V1) and the second word vector (V2) generated by the pre-processing unit (122) from the entity (ENT') and the attribute (PRO'). The deep learning network (124) can generate the third word vector (V3) in response to the first word vector (V1) and the second word vector (V2), and the post-processing unit (126) can obtain a series of words (W1 to W4) from the third word vector (V3) and generate "What is Son Heung-min's occupation?" as a query (QUE) by combining the series of words (W1 to W4).
도 5a 및 도 5b는 본 발명의 예시적 실시예들에 따라 표로부터 생성된 구조화된 데이터의 예시들을 나타낸다. 구체적으로, 도 5a 및 도 5b는 도 2의 표(T20)로부터 생성된 제1 데이터(D51) 및 제2 데이터(D52)를 나타낸다. 일부 실시예들에서, 도 1의 그래프 생성부(130)는 입력 문서(DIN)로부터 추출된 표(예컨대, 도 2의 T20)로부터 제1 데이터(D51) 및 제2 데이터(D52)를 생성할 수 있다. 이하에서, 도 5a 및 도 5b는 도 1 및 도 2를 참조하여 설명될 것이다.FIGS. 5A and 5B illustrate examples of structured data generated from a table according to exemplary embodiments of the present invention. Specifically, FIGS. 5A and 5B illustrate first data (D51) and second data (D52) generated from a table (T20) of FIG. 2. In some embodiments, the graph generation unit (130) of FIG. 1 may generate the first data (D51) and the second data (D52) from a table (e.g., T20 of FIG. 2) extracted from an input document (DIN). Hereinafter, FIGS. 5A and 5B will be described with reference to FIGS. 1 and 2.
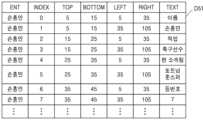
도 5a를 참조하면, 그래프 생성부(130)는 표에 포함된 셀들의 정보를 추출할 수 있고, 추출된 정보를 포함하는 데이터를 생성할 수 있다. 예를 들면, 도 5a에 도시된 바와 같이, 그래프 생성부(130)는 도 2의 표(T20)로부터 제1 데이터(D51)를 생성할 수 있고, 제1 데이터(D51)에서 하나의 행은 표(T20)에 포함된 하나의 셀에 대응하는 정보를 포함할 수 있다. 제1 데이터(D51)에서 열 'ENT'는 엔티티를 나타낼 수 있고, 열 'INDEX'는 셀의 인덱스를 나타낼 수 있고, 열들 'TOP, BOTTOM, LEFT, RIGHT'는 셀의 상위 테두리, 하위 테두리, 좌측 테두리 및 우측 테두리의 좌표들을 각각 나타내고, 열 'TEXT'는 셀에 포함된 컨텐츠를 나타낸다. 이에 따라, 동일한 행에 포함된 셀들은 열들 'TOP, BOTTOM'에서 동일한 값들을 각각 가질 수 있고, 동일한 열에 포함된 셀들은 열들 'LEFT, RIGHT'에서 동일한 값들을 각각 가질 수 있다. 도 6을 참조하여 후술되는 바와 같이, 하나의 셀, 즉 제1 데이터(D51)의 하나의 행은 그래프에서 하나의 노드에 대응할 수 있다.Referring to FIG. 5A, the graph generation unit (130) can extract information of cells included in the table, and can generate data including the extracted information. For example, as illustrated in FIG. 5A, the graph generation unit (130) can generate first data (D51) from the table (T20) of FIG. 2, and one row in the first data (D51) can include information corresponding to one cell included in the table (T20). In the first data (D51), the column 'ENT' can represent an entity, the column 'INDEX' can represent an index of a cell, the columns 'TOP, BOTTOM, LEFT, RIGHT' represent coordinates of the upper border, lower border, left border, and right border of the cell, respectively, and the column 'TEXT' represents content included in the cell. Accordingly, cells included in the same row can have the same values in the columns 'TOP, BOTTOM', respectively, and cells included in the same column can have the same values in the columns 'LEFT, RIGHT', respectively. As described below with reference to Fig. 6, one cell, i.e., one row of the first data (D51), can correspond to one node in the graph.
도 5b를 참조하면, 그래프 생성부(130)는 셀들의 관계들을 나타내는 데이터를 생성할 수 있다. 예를 들면, 그래프 생성부(130)는 도 5a의 제1 데이터(D51)로부터 셀들 사이 관계를 식별할 수 있고, 식별된 셀들 사이 관계에 기초하여 도 5b의 제2 데이터(D52)를 생성할 수 있다. 제2 데이터(D52)에서 하나의 행은 2개의 셀들의 인덱스들을 나타낼 수 있고, 2개의 셀들은 행방향 또는 열방향으로 상호 인접한 관계에 있을 수 있다. 예를 들면, 도 2의 표(T20)에서 "이름"을 포함하는 셀은 인덱스 "0"을 가질 수 있고, "손흥민"을 포함하는 인덱스 "1"의 셀 및 "직업"을 포함하는 인덱스"2"의 셀과 행방향 및 열방향으로 각각 인접할 수 있다. 이에 따라, 도 5b에 도시된 바와 같이, 인덱스 "0" 및 인덱스 "1"이 하나의 행에 포함될 수 있고, 인덱스 "0" 및 인덱스 "2"가 하나의 행에 포함될 수 있다. 도 6을 참조하여 후술되는 바와 같이, 행방향 또는 열방향으로 상호 인접한 셀들, 즉 제2 데이터(D52)의 하나의 행에 포함된 2개의 셀들은 그래프에서 에지로 연결될 수 있다.Referring to FIG. 5b, the graph generation unit (130) can generate data representing relationships between cells. For example, the graph generation unit (130) can identify relationships between cells from the first data (D51) of FIG. 5a, and can generate second data (D52) of FIG. 5b based on the identified relationships between cells. In the second data (D52), one row can represent indices of two cells, and the two cells can be in a relationship that is adjacent to each other in the row direction or the column direction. For example, in the table (T20) of FIG. 2, a cell including "name" can have an index "0", and can be adjacent to a cell having an index "1" including "Son Heung-min" and a cell having an index "2" including "occupation" in the row direction and the column direction, respectively. Accordingly, as illustrated in FIG. 5b, indexes "0" and "1" can be included in one row, and indexes "0" and "2" can be included in one row. As described later with reference to FIG. 6, cells that are adjacent to each other in the row or column direction, i.e., two cells included in one row of the second data (D52), can be connected as edges in the graph.
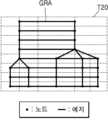
도 6은 본 발명의 예시적 실시예에 따른 그래프 데이터의 예시를 나타내는 도면이다. 구체적으로, 도 6은 도 2의 표(T20)로부터 생성된 그래프 데이터(GRA)가 나타내는 그래프를 나타낸다.Fig. 6 is a diagram showing an example of graph data according to an exemplary embodiment of the present invention. Specifically, Fig. 6 shows a graph represented by graph data (GRA) generated from the table (T20) of Fig. 2.
일부 실시예들에서, 그래프 데이터(GRA)는 표에 포함된 셀들에 대응하는 노드들 및 상호 인접한 셀들을 연결하는 에지들을 포함하는 그래프를 정의할 수 있다. 예를 들면, 표(T20)은 도 6에서 점선으로 도시된 바와 같이 셀들을 포함할 수 있고, 그래프 데이터(GRA)는 셀들에 각각 대응하는 노드들 및 상호 인접한 셀들을 연결하는 에지들을 포함하는 그래프들을 정의할 수 있다. 일부 실시예들에서, 노드는 대응하는 셀에 대한 정보, 예컨대 셀의 인덱스, 셀의 좌표 정보, 컨텐츠(예컨대, 텍스트) 등을 포함할 수 있다. 이에 따라, 표에서 셀들의 위치에 관련된 정보가 그래프 데이터(GRA)에 포함될 수 있다. 그래프 데이터(GRA)는 그래프를 정의하는 임의의 형식을 가질 수 있다.In some embodiments, the graph data (GRA) may define a graph including nodes corresponding to cells included in the table and edges connecting adjacent cells. For example, the table (T20) may include cells as illustrated by the dotted lines in FIG. 6, and the graph data (GRA) may define graphs including nodes respectively corresponding to the cells and edges connecting adjacent cells. In some embodiments, a node may include information about a corresponding cell, such as an index of the cell, coordinate information of the cell, content (e.g., text), etc. Accordingly, information related to the positions of cells in the table may be included in the graph data (GRA). The graph data (GRA) may have any format that defines a graph.
도 7은 본 발명의 예시적 실시예에 따른 그래프 독해 엔진의 예시를 나타내는 블록도이고, 도 8은 본 발명의 예시적 실시예에 따라 도 7의 자연어 처리부의 동작의 예시를 나타내는 도면이다. 도 1을 참조하여 전술된 바와 같이, 도 7의 그래프 독해 엔진(140')은 질의(QUE) 및 그래프 데이터(GRA)를 수신할 수 있고, 답변(ANS)을 생성할 수 있다. 이하에서, 도 7 및 도 8은 도 1을 참조하여 설명될 것이다.FIG. 7 is a block diagram showing an example of a graph reading engine according to an exemplary embodiment of the present invention, and FIG. 8 is a diagram showing an example of the operation of a natural language processing unit of FIG. 7 according to an exemplary embodiment of the present invention. As described above with reference to FIG. 1, the graph reading engine (140') of FIG. 7 can receive a query (QUE) and graph data (GRA), and can generate an answer (ANS). Hereinafter, FIG. 7 and FIG. 8 will be described with reference to FIG. 1.
도 7을 참조하면, 그래프 독해 엔진(140')은 자연어 처리부(141), 그래프 임베딩 모델(143), 텍스트 임베딩 모델(145), 분류(classification) 모델(147) 및 답변 생성부(149)를 포함할 수 있다. 일부 실시예들에서, 그래프 임베딩 모델(143), 텍스트 임베딩 모델(145), 분류 모델(147)은 딥 러닝 네트워크에 기초할 수 있고, 본 명세서에서 제2 내지 제4 딥 러닝 네트워크로서 각각 지칭될 수 있다.Referring to FIG. 7, the graph reading engine (140') may include a natural language processing unit (141), a graph embedding model (143), a text embedding model (145), a classification model (147), and an answer generation unit (149). In some embodiments, the graph embedding model (143), the text embedding model (145), and the classification model (147) may be based on a deep learning network, and may be referred to as the second to fourth deep learning networks, respectively, herein.
자연어 처리부(141)는 그래프 데이터(GRA), 즉 그래프 데이터(GRA)의 노드들에 각각 포함된 컨텐츠들을 자연어 처리함으로써 제1 입력 데이터(IN1)를 생성할 수 있고, 질의(QUE)를 자연어 처리함으로써 제2 입력 데이터(IN2)를 생성할 수 있다. 일부 실시예들에서, 자연어 처리부(141)는 그래프 데이터(GRA) 및 질의(QUE)에 대하여 형태소 분석을 수행할 수 있다. 예를 들면, 도 8에 도시된 바와 같이, 자연어 처리부(141)는 질의(QUE)로서 "손흥민의 직업은?"을 수신할 수 있고, 질의(QUE)의 형태소 분석을 통해 도 8에 도시된 바와 같은 제2 입력 데이터(IN2)를 생성할 수 있다. 도 8의 제2 입력 데이터(IN2)에서, 단어에 후속하는 사선(/) 및 알파벳은 해당 단어의 형태소를 나타낸다. 예를 들면, 제2 입력 데이터(IN2)에서 "손흥민/NNP"은 단어 "손흥민"이 고유 명사임을 나타낼 수 있고, 단어 "직업/NNG"은 "직업"이 일반 명사임을 나타낼 수 있다. 또한, "의/JKG"는 단어 "의"가 소유격을 나타내는 조사임을 나타낼 수 있다. 유사하게, 자연어 처리부(141)는 그래프 데이터(GRA)의 노드들에 각각 포함된 컨텐츠들의 형태소 분석을 통해 제1 입력 데이터(IN1)를 생성할 수 있다. 일부 실시예들에서, 자연어 처리부(141)는 도 7에 도시된 바와 상이하게, 도 1의 지식 추출 시스템(100)의 외부에 있을 수 있고, 그래프 독해 엔진(140')은 외부의 자연어 처리부에 그래프 데이터(GRA) 및 질의(QUE)를 제공함으로써 제1 입력 데이터(IN1) 및 제2 입력 데이터(IN2)를 수신할 수도 있다.The natural language processing unit (141) can generate the first input data (IN1) by performing natural language processing on the graph data (GRA), that is, the contents included in each node of the graph data (GRA), and can generate the second input data (IN2) by performing natural language processing on the query (QUE). In some embodiments, the natural language processing unit (141) can perform morphological analysis on the graph data (GRA) and the query (QUE). For example, as illustrated in FIG. 8, the natural language processing unit (141) can receive “What is Son Heung-min’s occupation?” as the query (QUE), and can generate the second input data (IN2) as illustrated in FIG. 8 through morphological analysis of the query (QUE). In the second input data (IN2) of FIG. 8, the diagonal line (/) and the alphabet following a word represent the morpheme of the word. For example, in the second input data (IN2), "Son Heung-min/NNP" may indicate that the word "Son Heung-min" is a proper noun, and the word "job/NNG" may indicate that "job" is a common noun. In addition, "의/JKG" may indicate that the word "의" is a particle indicating a possessive case. Similarly, the natural language processing unit (141) may generate the first input data (IN1) through morphological analysis of contents included in each node of the graph data (GRA). In some embodiments, the natural language processing unit (141) may be external to the knowledge extraction system (100) of FIG. 1, differently from that illustrated in FIG. 7, and the graph reading engine (140') may receive the first input data (IN1) and the second input data (IN2) by providing the graph data (GRA) and a query (QUE) to the external natural language processing unit.
그래프 임베딩 모델(143)은 자연어 처리부(141)로부터 제1 입력 데이터(IN1)를 수신할 수 있고, 제1 입력 데이터(IN1)에 응답하여 그래프 벡터(GV)를 생성할 수 있다. 그래프 임베딩 모델(143)은 제1 입력 데이터(IN1)의 샘플들에 따라 샘플 그래프 벡터들을 출력하도록 학습된 상태일 수 있고, 이에 따라 표에 대응하는 제1 입력 데이터(IN1)에 내재된 지식에 대응하는 그래프 벡터(GV)가 생성될 수 있다. 이와 같이, 표에 포함된 셀들의 컨텐츠들뿐만 아니라 셀들 사이 관계를 고려한 그래프 데이터(GRA)에 기초하여 지식이 추출될 수 있고, 이에 따라 표에서 용이하게 지식이 추출될 수 있다.The graph embedding model (143) can receive first input data (IN1) from the natural language processing unit (141) and generate a graph vector (GV) in response to the first input data (IN1). The graph embedding model (143) can be trained to output sample graph vectors according to samples of the first input data (IN1), and thus a graph vector (GV) corresponding to knowledge inherent in the first input data (IN1) corresponding to the table can be generated. In this way, knowledge can be extracted based on graph data (GRA) that considers not only the contents of cells included in the table but also the relationships between cells, and thus knowledge can be easily extracted from the table.
텍스트 임베딩 모델(145)은 자연어 처리부(141)로부터 제2 입력 데이터(IN2)를 수신할 수 있고, 제2 입력 데이터(IN2)에 응답하여 워드 벡터(WV)를 생성할 수 있다. 텍스트 임베딩 모델(145)은 제2 입력 데이터(IN2)의 샘플들에 따라 샘플 워드 벡터들을 출력하도록 학습된 상태일 수 있고, 이에 따라 질의(QUE)에 대응하는 제2 입력 데이터(IN2)의 의미에 대응하는 워드 벡터(WV)가 생성될 수 있다. 일부 실시예들에서, 텍스트 임베딩 모델(145)은 하나의 질의(QUE)에 대응하는 제2 입력 데이터(IN2)로부터 하나의 워드 벡터(WV)를 생성하여 후술되는 분류 모델(147)에 제공할 수 있다. 또는, 일부 실시예들에서, 제2 입력 데이터(IN2)는 질의(QUE)를 자연어 처리함으로써 생성된 복수의 단어들을 포함할 수 있고, 텍스트 임베딩 모델(145)은 복수의 단어들 각각에 대응하는 복수의 워드 벡터들을 생성할 수 있고, 복수의 워드 벡터들을 분류 모델(147)에 제공할 수 있다.The text embedding model (145) can receive second input data (IN2) from the natural language processing unit (141) and generate a word vector (WV) in response to the second input data (IN2). The text embedding model (145) can be trained to output sample word vectors according to samples of the second input data (IN2), and accordingly, a word vector (WV) corresponding to the meaning of the second input data (IN2) corresponding to the query (QUE) can be generated. In some embodiments, the text embedding model (145) can generate one word vector (WV) from the second input data (IN2) corresponding to one query (QUE) and provide the generated word vector to a classification model (147) described below. Alternatively, in some embodiments, the second input data (IN2) may include a plurality of words generated by natural language processing a query (QUE), and the text embedding model (145) may generate a plurality of word vectors corresponding to each of the plurality of words, and provide the plurality of word vectors to the classification model (147).
일부 실시예들에서, 그래프 독해 엔진(140')에서 텍스트 임베딩 모델(145)은 생략될 수 있다. 예를 들면, 그래프 독해 엔진(140')은 도 3의 질의 생성부(120')로부터 질의(QUE)를 수신하는 대신, 딥 러닝 네트워크(124)가 출력하는 제3 워드 벡터(V3)를 수신할 수 있고, 제3 워드 벡터(V3)는 도 7의 워드 벡터(WV)로서 분류 모델(147)에 제공될 수 있다. 이 경우, 자연어 처리부(141)가 질의(QUE)로부터 제2 입력 데이터(IN2)를 생성하는 동작이 생략될 수 있고, 제2 입력 데이터(IN2)로부터 워드 벡터(WV)를 생성하는 텍스트 임베딩 모델(145)이 생략될 수 있다.In some embodiments, the text embedding model (145) in the graph reading engine (140') may be omitted. For example, instead of receiving a query (QUE) from the query generation unit (120') of FIG. 3, the graph reading engine (140') may receive a third word vector (V3) output by the deep learning network (124), and the third word vector (V3) may be provided to the classification model (147) as a word vector (WV) of FIG. 7. In this case, the operation of the natural language processing unit (141) generating the second input data (IN2) from the query (QUE) may be omitted, and the text embedding model (145) generating the word vector (WV) from the second input data (IN2) may be omitted.
분류 모델(147)은 그래프 임베딩 모델(143)로부터 그래프 벡터(GV)를 수신할 수 있고, 텍스트 임베딩 모델(145)로부터 적어도 하나의 워드 벡터(WV)를 수신할 수 있다. 분류 모델(147)은 그래프 벡터(GV) 및 적어도 하나의 워드 벡터(WV)에 응답하여 출력 데이터(OUT)를 출력할 수 있다. 분류 모델(147)은 샘플 그래프 벡터들 및 샘플 워드 벡터들에 따라 출력 데이터(OUT)의 샘플들을 출력하도록 학습된 상태일 수 있고, 출력 데이터(OUT)는 그래프 벡터(GV)로부터 추출된, 워드 벡터(WV)에 대응하는 응답에 대한 정보를 포함할 수 있다. 일부 실시예들에서, 출력 데이터(OUT)는 답변(ANS)에 대응하는 내용뿐만 아니라, 추가적인 정보를 더 포함할 수 있다. 예를 들면, 출력 데이터(OUT)는 답변을 포함하는 셀의 위치(예컨대, 인덱스) 등을 더 포함할 수 있다.The classification model (147) can receive a graph vector (GV) from the graph embedding model (143) and can receive at least one word vector (WV) from the text embedding model (145). The classification model (147) can output output data (OUT) in response to the graph vector (GV) and the at least one word vector (WV). The classification model (147) can be trained to output samples of the output data (OUT) according to the sample graph vectors and the sample word vectors, and the output data (OUT) can include information about a response corresponding to the word vector (WV) extracted from the graph vector (GV). In some embodiments, the output data (OUT) can further include additional information in addition to the content corresponding to the answer (ANS). For example, the output data (OUT) can further include the location (e.g., index) of a cell including the answer.
답변 생성부(149)는 분류 모델(147)로부터 출력 데이터(OUT)를 수신할 수 있고, 출력 데이터(OUT)에 기초하여 답변(ANS)을 생성할 수 있다. 예를 들면, 출력 데이터(OUT)는 자연어 처리된 제1 입력 데이터(IN1)에서 "축구/NNG 선수/NNG"를 포함하는 셀의 인덱스, 즉 "3"을 포함할 수 있고, 답변 생성부(149)는 출력 데이터(OUT)에 포함된 셀의 인덱스에 기초하여 "축구선수"를 답변(ANS)으로서 생성할 수 있다. 또한, 답변 생성부(149)는 출력 데이터(OUT)에 포함된 추가적인 정보에 기초하여 답변 추출의 성공 여부를 나타내는 판정 결과(DET)를 생성할 수 있다. 일부 실시예들에서, 판정 결과(DET)는 지식 추출 시스템(100)의 다른 구성요소들, 예컨대 개체 추출부(110), 질의 생성부(120) 및 지식 생성부(150) 중 적어도 하나에 제공될 수 있다. 답변 생성부(149)의 동작의 예시가 도 9를 참조하여 후술될 것이다.The answer generation unit (149) can receive output data (OUT) from the classification model (147) and generate an answer (ANS) based on the output data (OUT). For example, the output data (OUT) can include an index of a cell including “soccer/NNG player/NNG” in the first input data (IN1) that has been subjected to natural language processing, that is, “3,” and the answer generation unit (149) can generate “soccer player” as the answer (ANS) based on the index of the cell included in the output data (OUT). In addition, the answer generation unit (149) can generate a judgment result (DET) indicating whether answer extraction is successful or not based on additional information included in the output data (OUT). In some embodiments, the judgment result (DET) can be provided to at least one of other components of the knowledge extraction system (100), such as the entity extraction unit (110), the query generation unit (120), and the knowledge generation unit (150). An example of the operation of the answer generation unit (149) will be described later with reference to Fig. 9.
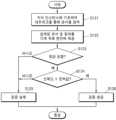
도 9는 본 발명의 예시적 실시예에 따른 지식 추출을 위한 방법을 나타내는 순서도이다. 구체적으로, 도 9의 순서도는 그래프 독해의 결과에 기초하여 지식 추출을 위한 답변을 생성하는 방법을 나타낸다. 일부 실시예들에서, 도 9의 방법은 도 7의 답변 생성부(149)에 의해서 수행될 수 있고, 답변 생성부(149)의 동작 방법으로 지칭될 수도 있다. 도 9에 도시된 바와 같이, 지식 추출을 위한 방법은 복수의 단계들(S92, S94, S96, S98)을 포함할 수 있고, 이하에서 도 9은 도 7을 참조하여 설명될 것이다.FIG. 9 is a flowchart illustrating a method for knowledge extraction according to an exemplary embodiment of the present invention. Specifically, the flowchart of FIG. 9 illustrates a method for generating an answer for knowledge extraction based on a result of graph reading. In some embodiments, the method of FIG. 9 may be performed by the answer generating unit (149) of FIG. 7, and may also be referred to as an operation method of the answer generating unit (149). As illustrated in FIG. 9, the method for knowledge extraction may include a plurality of steps (S92, S94, S96, S98), and FIG. 9 will be described below with reference to FIG. 7.
단계 S92에서, 정답의 포함 여부를 판정하는 동작이 수행될 수 있다. 예를 들면, 분류 모델(147)은 그래프 데이터(GRA)에 질의(QUE)에 대한 정답이 포함되어 있는지 여부를 나타내는 정보를 포함하는 출력 데이터(OUT)를 생성할 수 있고, 답변 생성부(149)는 출력 데이터(OUT)에 포함된 정보에 기초하여, 정답의 포함 여부를 판정할 수 있다. 도 9에 도시된 바와 같이, 그래프 데이터(GRA)에 정답이 포함되지 아니한 것으로 판정된 경우 단계 S96가 후속하여 수행될 수 있는 한편, 그래프 데이터(GRA)에 정답이 포함된 것으로 판정된 경우 단계 S94이 후속하여 수행될 수 있다.In step S92, an operation for determining whether a correct answer is included may be performed. For example, the classification model (147) may generate output data (OUT) including information indicating whether a correct answer to a query (QUE) is included in the graph data (GRA), and the answer generation unit (149) may determine whether a correct answer is included based on the information included in the output data (OUT). As illustrated in FIG. 9, if it is determined that the graph data (GRA) does not include a correct answer, step S96 may be performed subsequently, while if it is determined that the graph data (GRA) includes a correct answer, step S94 may be performed subsequently.
단계 S94에서, 답변(ANS)의 신뢰도를 미리 정의된 문턱값과 비교하는 동작이 수행될 수 있다. 예를 들면, 분류 모델(147)은 답변(ANS)의 위치 정보와 함께 답변(ANS)의 신뢰도를 포함하는 출력 데이터(OUT)를 생성할 수 있고, 답변 생성부(149)는 출력 데이터(OUT)에 포함된 신뢰도를 문턱값과 비교할 수 있다. 도 9에 도시된 바와 같이, 신뢰도가 문턱값 미만인 경우 단계 S96이 후속하여 수행될 수 있는 한편, 신뢰도가 문턱값 이상인 경우 단계 S98이 후속하여 수행될 수 있다.In step S94, an operation of comparing the reliability of the answer (ANS) with a predefined threshold value may be performed. For example, the classification model (147) may generate output data (OUT) including the reliability of the answer (ANS) together with the location information of the answer (ANS), and the answer generation unit (149) may compare the reliability included in the output data (OUT) with the threshold value. As illustrated in FIG. 9, if the reliability is less than the threshold value, step S96 may be performed subsequently, while if the reliability is greater than or equal to the threshold value, step S98 may be performed subsequently.
그래프 데이터(GRA)에 정답이 포함되지 아니한 것으로 판정되거나 답변(ANS)의 신뢰도가 문턱값 미만인 경우, 단계 S96에서 답변의 추출 실패를 판정하는 동작이 수행될 수 있다. 예를 들면, 답변 생성부(1549)는 답변의 추출 실패를 나타내는 판정 결과(DET)를 생성할 수 있고, 지식 추출 시스템(100)에 포함된 다른 구성요소들에 판정 결과(DET)를 제공할 수 있다. 지식 추출 시스템(100)에 포함된 구성요소들은 추출 실패를 나타내는 판정 결과(DET)에 응답하여, 다음 지식을 추출하기 위한 동작을 수행될 수 있다. 예를 들면, 개체 추출부(110)는 이전 개체와 다른 개체를 입력 문서(DIN)로부터 추출할 수도 있고, 다른 입력 문서(DIN)를 수신할 수도 있다. 질의 생성부(120)는 터 이전 속성과 다른 속성을 속성 리스트(PL)로부터 획득함으로써 질의(QUE)를 생성할 수 있다. 지식 생성부(150)는 현재 개체(ENT) 및 속성(PRO)에 대한 지식 인스턴스의 생성을 중단할 수 있다.If it is determined that the graph data (GRA) does not include a correct answer or the reliability of the answer (ANS) is below a threshold, an operation for determining a failure in extracting the answer may be performed in step S96. For example, the answer generation unit (1549) may generate a determination result (DET) indicating a failure in extracting the answer, and may provide the determination result (DET) to other components included in the knowledge extraction system (100). The components included in the knowledge extraction system (100) may perform an operation for extracting the next knowledge in response to the determination result (DET) indicating a failure in extraction. For example, the entity extraction unit (110) may extract an entity different from a previous entity from the input document (DIN), or may receive another input document (DIN). The query generation unit (120) may generate a query (QUE) by obtaining an attribute different from a previous attribute from the attribute list (PL). The knowledge generation unit (150) can stop generating knowledge instances for the current entity (ENT) and attribute (PRO).
다른 한편으로, 그래프 데이터(GRA)에 정답이 포함된 것으로 판정되고 답변(ANS)의 신뢰도가 문턱값 이상인 경우, 단계 S98에서 답변(ANS)을 생성하는 동작이 수행될 수 있다. 예를 들면, 답변 생성부(149)는 도 7 및 도 8을 참조하여 전술된 바와 같이, 출력 데이터(OUT)에 포함된 정답의 위치 정보에 기초하여 그래프 데이터(GRA)로부터 답변(ANS)을 추출할 수 있다.On the other hand, if it is determined that the graph data (GRA) contains the correct answer and the reliability of the answer (ANS) is higher than the threshold, an operation of generating the answer (ANS) may be performed in step S98. For example, the answer generating unit (149) may extract the answer (ANS) from the graph data (GRA) based on the location information of the correct answer contained in the output data (OUT), as described above with reference to FIGS. 7 and 8.
도 10은 본 발명의 예시적 실시예에 따른 지식 생성부의 예시를 나타내는 블록도이고, 도 11은 본 발명의 예시적 실시예에 따라 지식 생성부의 동작의 예시를 나타내는 도면이다. 도 1을 참조하여 전술된 바와 같이, 도 10의 지식 생성부(150')는 개체(ENT), 속성(PRO) 및 답변(ANS)으로부터 지식 인스턴스(INS)(예컨대, 트리플)을 생성할 수 있다. 이하에서, 도 10 및 도 11는 도 1을 참조하여 설명될 것이다.FIG. 10 is a block diagram showing an example of a knowledge generation unit according to an exemplary embodiment of the present invention, and FIG. 11 is a diagram showing an example of the operation of the knowledge generation unit according to an exemplary embodiment of the present invention. As described above with reference to FIG. 1, the knowledge generation unit (150') of FIG. 10 can generate a knowledge instance (INS) (e.g., a triple) from an entity (ENT), an attribute (PRO), and an answer (ANS). Hereinafter, FIG. 10 and FIG. 11 will be described with reference to FIG. 1.
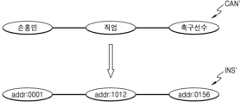
도 10을 참조하면, 지식 생성부(150')는 후보 인스턴스 생성부(152) 및 인스턴스 비교부(154)를 포함할 수 있다. 후보 인스턴스 생성부(152)는 개체(ENT), 속성(PRO) 및 답변(ANS)을 수신할 수 있고, 후보 지식 인스턴스(CAN)를 생성할 수 있다. 일부 실시예들에서, 후보 인스턴스 생성부(152)는 지식베이스(200)의 형식, 즉 지식베이스(200)에 포함된 지식 인스턴스들(예컨대 트리플들)의 형식에 기초하여 개체(ENT), 속성(PRO) 및 답변(ANS)을 후처리할 수 있다. 예를 들면, 개체(ENT), 속성(PRO) 및 답변(ANS)으로서 "이순신", "생일" 및 "1545년 4월 28일"이 수신된 경우, 후보 인스턴스 생성부(152)는 지식베이스(200)에서 날짜를 나타내기 위한 형식 "YYYY-MM-DD"에 기초하여 답변(ANS)인 "1545년 4월 28일"을 "1545-04-28"으로 변환할 수 있다.Referring to FIG. 10, the knowledge generation unit (150') may include a candidate instance generation unit (152) and an instance comparison unit (154). The candidate instance generation unit (152) may receive an entity (ENT), an attribute (PRO) and an answer (ANS), and may generate a candidate knowledge instance (CAN). In some embodiments, the candidate instance generation unit (152) may post-process the entity (ENT), the attribute (PRO) and the answer (ANS) based on the format of the knowledge base (200), that is, the format of the knowledge instances (e.g., triples) included in the knowledge base (200). For example, if “Yi Sun-sin,” “birthday,” and “April 28, 1545” are received as entities (ENT), attributes (PRO), and answers (ANS), the candidate instance generation unit (152) can convert the answer (ANS) “April 28, 1545” to “1545-04-28” based on the format “YYYY-MM-DD” for representing dates in the knowledge base (200).
인스턴스 비교부(154)는 후보 지식 인스턴스(CAN)를 수신할 수 있고, 지식베이스(200)에 포함된 지식 인스턴스들에 기초하여 지식 인스턴스(INS)를 생성할 수 있다. 일부 실시예들에서, 인스턴스 비교부(154)는, 본원과 동일한 출원인에 의해서 출원되고 본 명세서에 전체로서 참조되어 포함되는 한국특허출원 제10-2018-0151222호에서 설명된 "유사도 계산부"와 같이, 후보 지식 인스턴스(CAN)와 지식베이스(200)에 포함된 지식 인스턴스들 사이 유사도를 계산할 수 있다. 인스턴스 비교부(154)는 계산된 유사도에 기초하여 후보 인스턴스에 포함된 주어, 술어 및 목적어에 대응하는 지식베이스(200)의 개체들을 검출할 수 있고, 검출 결과에 기초하여 주어, 술어 및 목적어에 대응하는 식별자, 예컨대 URI(Uniform Resource Identifier)를 지식베이스(200)로부터 추출함으로써 지식 인스턴스(INS)를 생성할 수 있다.The instance comparison unit (154) can receive a candidate knowledge instance (CAN) and generate a knowledge instance (INS) based on the knowledge instances included in the knowledge base (200). In some embodiments, the instance comparison unit (154) can calculate a similarity between the candidate knowledge instance (CAN) and the knowledge instances included in the knowledge base (200), such as the “similarity calculation unit” described in Korean Patent Application No. 10-2018-0151222, filed by the same applicant as the present application and incorporated herein by reference in its entirety. The instance comparison unit (154) can detect entities of the knowledge base (200) corresponding to the subject, predicate, and object included in the candidate instance based on the calculated similarity, and can generate the knowledge instance (INS) by extracting an identifier, for example, a Uniform Resource Identifier (URI), corresponding to the subject, predicate, and object from the knowledge base (200) based on the detection result.
도 11를 참조하면, 개체(ENT'), 속성(PRO') 및 답변(ANS')으로서 "손흥민", "직업" 및 "축구선수"가 수신된 경우, 후보 인스턴스 생성부(152)는 "손흥민-직업-축구선수"에 대응하는 후보 지식 인스턴스(CAN')를 생성할 수 있다. 또한, 지식베이스(200)는 "손흥민", "직업" 및 "축구선수"를 모두 포함하는 반면, 인물 "손흥민"의 직업이 축구선수임을 의미하는 지식, 즉 지식 인스턴스는 포함하지 아니할 수 있다. 이 경우, 인스턴스 비교부(154)는 지식베이스(200)에 포함된 지식 인스턴스들 중 후보 지식 인스턴스(CAN')와 유사한 지식 인스턴스들, 예컨대, 동일하거나 유사한 명칭을 포함하는 지식 인스턴스, 후보 지식 인스턴스(CAN')와 유사한 종류(예컨대, 클래스)의 개체들을 포함하는 지식 인스턴스 등을 추출할 수 있다. 인스턴스 비교부(154)는 추출된 지식 인스턴스들에 기초하여 "손흥민", "직업" 및 "축구선수"에 각각 대응하는 식별자들 "addr:0001", "addr:1012" 및 "addr:0156"을 획득할 수 있고, 이에 따라 지식 인스턴스(INS')로서 "addr:0001-addr:1012-addr:0156"을 생성할 수 있다. 이와 같이, 지식 인스턴스(INS)는 개체들 사이 혹은 개체와 값 사이 관계를 정의할 수 있고, 이에 따라 지식 인스턴스들을 포함하는 지식베이스(200)는 지식 그래프를 포함하는 것으로서 지칭될 수도 있다.Referring to FIG. 11, if “Son Heung-min”, “occupation”, and “soccer player” are received as entities (ENT’), attributes (PRO’), and answers (ANS’), the candidate instance generation unit (152) can generate a candidate knowledge instance (CAN’) corresponding to “Son Heung-min-occupation-soccer player”. In addition, while the knowledge base (200) includes all of “Son Heung-min”, “occupation”, and “soccer player”, it may not include knowledge, i.e., a knowledge instance, indicating that the occupation of the person “Son Heung-min” is a soccer player. In this case, the instance comparison unit (154) can extract knowledge instances similar to the candidate knowledge instance (CAN’) from among the knowledge instances included in the knowledge base (200), for example, knowledge instances including identical or similar names, knowledge instances including entities of a similar type (e.g., class) to the candidate knowledge instance (CAN’), etc. The instance comparison unit (154) can obtain identifiers "addr:0001", "addr:1012" and "addr:0156" corresponding to "Son Heung-min", "occupation" and "soccer player", respectively, based on the extracted knowledge instances, and accordingly can generate "addr:0001-addr:1012-addr:0156" as a knowledge instance (INS'). In this way, the knowledge instance (INS) can define a relationship between entities or between entities and values, and accordingly, the knowledge base (200) including the knowledge instances can be referred to as including a knowledge graph.
도 11의 예시와 상이하게, 후보 지식 인스턴스(CAN)의 주어, 술어 및 목적어 중 적어도 하나가 지식베이스(200)에 포함되지 아니한 대상인 경우, 인스턴스 비교부(154)는 지식베이스(200)에 포함되지 아니한 신규 식별자를 생성함으로써 지식 인스턴스(INS)를 생성할 수도 있다. 이에 따라, 인스턴스 비교부(154)는 식별자들을 포함하는 지식 인스턴스(INS')를 생성할 수 있다. 또한, 인스턴스 비교부(154)는 후보 지식 인스턴스(CAN')와 매우 유사한 지식 인스턴스가 지식베이스(200)에서 검색된 경우, 입력 문서(DIN)로부터 추출된 지식이 중복된 지식으로 판정할 수 있고, 지식 인스턴스의 생성을 중단할 수도 있다. 일부 실시예들에서, 인스턴스 비교부(154)는 중복되지 아니한 지식 인스턴스(INS)를 지식베이스(200)에 추가함으로써 지식베이스(200)를 보강할 수도 있다.Unlike the example of FIG. 11, if at least one of the subject, predicate, and object of the candidate knowledge instance (CAN) is a target that is not included in the knowledge base (200), the instance comparison unit (154) may generate a knowledge instance (INS) by generating a new identifier that is not included in the knowledge base (200). Accordingly, the instance comparison unit (154) may generate a knowledge instance (INS') including the identifiers. In addition, if a knowledge instance that is very similar to the candidate knowledge instance (CAN') is searched for in the knowledge base (200), the instance comparison unit (154) may determine that the knowledge extracted from the input document (DIN) is duplicated knowledge and may stop generating the knowledge instance. In some embodiments, the instance comparison unit (154) may also supplement the knowledge base (200) by adding a non-duplicated knowledge instance (INS) to the knowledge base (200).
도 12는 본 발명의 예시적 실시예에 따른 지식 추출을 위한 방법을 나타내는 순서도이다. 구체적으로, 도 12의 순서도는 추출된 지식에 대응하는 지식 인스턴스를 검증하는 방법을 나타낸다. 일부 실시예들에서, 도 12의 방법은 도 1의 지식 검증부(160)에 의해서 수행될 수 있고, 지식 검증부(160)의 동작 방법으로 지칭될 수도 있다. 도 12에 도시된 바와 같이, 도 12의 방법은 복수의 단계들(S121, S122, S123, S124, S125, S126)을 포함할 수 있고, 이하에서 도 12는 도 1을 참조하여 설명될 것이며, 도 12에 대한 설명 중 도 9에 대한 설명과 중복되는 내용은 생략될 것이다.FIG. 12 is a flowchart illustrating a method for knowledge extraction according to an exemplary embodiment of the present invention. Specifically, the flowchart of FIG. 12 illustrates a method for verifying a knowledge instance corresponding to extracted knowledge. In some embodiments, the method of FIG. 12 may be performed by the knowledge verification unit (160) of FIG. 1, and may also be referred to as an operation method of the knowledge verification unit (160). As illustrated in FIG. 12, the method of FIG. 12 may include a plurality of steps (S121, S122, S123, S124, S125, S126), and FIG. 12 will be described below with reference to FIG. 1, and any content that overlaps with the description of FIG. 9 in the description of FIG. 12 will be omitted.
단계 S121에서, 지식 인스턴스(INS)게 기초하여 네트워크(300)를 통해 문서를 검색하는 동작이 수행될 수 있다. 예를 들면, 지식 검증부(160)는 지식 인스턴스(INS)의 명칭들, 예컨대 "손흥민", "직업" 및 "축구선수" 중 적어도 하나를 포함하는 문서를 네트워크(300)에 접속된 시스템들에서 검색할 수 있다. 일부 실시예들에서, 입력 문서(DIN)를 제공하는 소스들과 유사하게, 지식 검증부(160)는 다양한 정보를 포함하는 문서들을 제공하는 시스템들에 접속함으로써 문서를 검색할 수 있다.In step S121, an operation of searching for a document through the network (300) based on a knowledge instance (INS) may be performed. For example, the knowledge verification unit (160) may search for a document including at least one of the names of the knowledge instance (INS), such as “Son Heung-min,” “occupation,” and “soccer player,” from systems connected to the network (300). In some embodiments, similar to sources providing an input document (DIN), the knowledge verification unit (160) may search for a document by connecting to systems providing documents including various information.
단계 S122에서, 검색된 문서 및 질의(QUE)를 기계 독해 엔진에 제공하는 동작이 수행될 수 있다. 예를 들면, 지식 검증부(160)는 단계 S121에서 검색된 문서를 기계 독해 엔진에 제공할 수 있는 한편, 지식 인스턴스(INS)의 생성에 사용된 질의(QUE)를 기계 독해 엔진에 직접 제공하거나 질의 생성부(120)로 하여금 제공하게 할 수 있다. 이에 따라, 기계 독해 엔진은 검색된 문서에서 질의(QUE)의 정답을 찾을 수 있다.In step S122, an operation of providing the searched document and query (QUE) to the machine reading engine may be performed. For example, the knowledge verification unit (160) may provide the document searched in step S121 to the machine reading engine, while directly providing the query (QUE) used in generating the knowledge instance (INS) to the machine reading engine or causing the query generation unit (120) to provide it. Accordingly, the machine reading engine may find the correct answer to the query (QUE) in the searched document.
단계 S123에서, 정답의 포함 여부를 판정하는 동작이 수행될 수 있다. 예를 들면, 지식 검증부(160)는 도 7의 출력 데이터(OUT)를 직접 수신할 수 있고, 출력 데이터(OUT)에 기초하여 정답의 포함 여부를 판정할 수 있다. 다른 예시로서, 지식 검증부(160)는 도 7의 답변 생성부(149)가 제공하는 판정 결과(DET)에 기초하여 정답의 포함 여부를 판정할 수도 있다. 도 12에 도시된 바와 같이, 검색된 문서에 정답이 포함되지 아니한 것으로 판정된 경우 단계 S125가 후속하여 수행될 수 있는 한편, 검색된 문서에 정답이 포함된 것으로 판정된 경우 단계 S126이 후속하여 수행될 수 있다.In step S123, an operation for determining whether the correct answer is included may be performed. For example, the knowledge verification unit (160) may directly receive the output data (OUT) of FIG. 7 and determine whether the correct answer is included based on the output data (OUT). As another example, the knowledge verification unit (160) may determine whether the correct answer is included based on the determination result (DET) provided by the answer generation unit (149) of FIG. 7. As shown in FIG. 12, if it is determined that the searched document does not include the correct answer, step S125 may be performed subsequently, while if it is determined that the searched document includes the correct answer, step S126 may be performed subsequently.
단계 S124에서, 검색된 문서에서 추출된 답변의 신뢰도를 미리 정의된 문턱값과 비교하는 동작이 수행될 수 있다. 일부 실시예들에서, 도 12의 문턱값은 도 9의 문턱값과 상이할 수 있고, 예컨대 도 12의 문턱값이 도 9의 문턱값 보다 높을 수 있다. 도 12에 도시된 바와 같이, 신뢰도가 문턱값 미만인 경우 단계 S125가 후속하여 수행될 수 있는 한편, 신뢰도가 문턱값 이상인 경우 단계 S126이 후속하여 수행될 수 있다.In step S124, an operation of comparing the reliability of an answer extracted from a searched document with a predefined threshold may be performed. In some embodiments, the threshold of FIG. 12 may be different from the threshold of FIG. 9, for example, the threshold of FIG. 12 may be higher than the threshold of FIG. 9. As illustrated in FIG. 12, if the reliability is less than the threshold, step S125 may be performed subsequently, while if the reliability is greater than or equal to the threshold, step S126 may be performed subsequently.
검색된 문서에 정답이 포함되지 아니하거나, 검색된 문서로부터 추출된 답변의 신뢰도가 낮은 경우, 단계 S125에서 지식 인스턴스(INS)의 검증 실패가 판정될 수 있다. 예를 들면, 지식 검증부(160)는 검증 실패가 판정된 경우, 다른 검색된 문서를 사용하여 지식 인스턴스(INS)의 검증을 다시 수행할 수 있다. 검색된 문서들 전부 혹은 미리 정의된 양의 문서들을 사용하여 지식 인스턴스(INS)의 검증이 실패하는 경우, 지식 검증부(160)는 최종적으로 지식 인스턴스(INS)의 검증 실패를 판정할 수 있고, 이를 지식 생성부(150)에 알릴 수 있다.If the searched document does not contain the correct answer or the reliability of the answer extracted from the searched document is low, the verification failure of the knowledge instance (INS) may be determined in step S125. For example, if the knowledge verification unit (160) determines that the verification has failed, it may perform the verification of the knowledge instance (INS) again using other searched documents. If the verification of the knowledge instance (INS) fails using all of the searched documents or a predefined amount of documents, the knowledge verification unit (160) may finally determine that the verification of the knowledge instance (INS) has failed and may notify the knowledge creation unit (150) of this.
다른 한편으로, 검색된 문서에 정답이 포함되거나 검색된 문서로부터 추출된 답변의 신뢰도가 높은 경우, 단계 S126에서 지식 인스턴스(INS)의 검증 성공이 판정될 수 있다. 예를 들면, 지식 검증부(160)는 하나의 검색된 문서를 사용하여 검증 성공이 판정된 경우, 최종적으로 지식 인스턴스(INS)의 검증 성공을 판정할 수 있다. 다른 예시로서, 지식 검증부(160)는 미리 정의된 개수나 비율의 검색된 문서들을 사용하여 검증 성공이 판정된 경우, 최종적으로 지식 인스턴스(INS)의 검증 성공을 판정할 수도 있다.On the other hand, if the searched document contains the correct answer or the reliability of the answer extracted from the searched document is high, the verification success of the knowledge instance (INS) can be determined in step S126. For example, if the knowledge verification unit (160) determines that the verification success is determined using one searched document, the knowledge verification unit (160) can finally determine that the verification success is determined using a predefined number or ratio of searched documents. As another example, the knowledge verification unit (160) can also finally determine that the verification success is determined using a predefined number or ratio of searched documents.
도 13은 본 발명의 예시적 실시예에 따른 지식 추출을 위한 방법을 나타내는 순서도이다. 일부 실시예들에서, 도 13의 방법은 도 1의 지식 추출 시스템(100)에 의해서 수행될 수 있다. 도 13에 도시된 바와 같이, 도 13의 방법은 복수의 단계들(S100, S300, S500, S700, S900)을 포함할 수 있고, 이하에서 도 13은 도 1을 참조하여 설명될 것이다.FIG. 13 is a flowchart illustrating a method for knowledge extraction according to an exemplary embodiment of the present invention. In some embodiments, the method of FIG. 13 may be performed by the knowledge extraction system (100) of FIG. 1. As illustrated in FIG. 13, the method of FIG. 13 may include a plurality of steps (S100, S300, S500, S700, S900), and FIG. 13 will be described below with reference to FIG. 1.
단계 S100에서, 입력 문서(DIN)로부터 개체(ENT)가 추출될 수 있다. 예를 들면, 입력 문서(DIN)는 제목을 포함할 수 있고, 개체 추출부(110)는 입력 문서(DIN)의 제목으로부터 개체(ENT)를 추출할 수 있다.In step S100, an entity (ENT) can be extracted from an input document (DIN). For example, the input document (DIN) can include a title, and the entity extraction unit (110) can extract an entity (ENT) from the title of the input document (DIN).
단계 S300에서, 개체(ENT)를 포함하는 질의(QUE)가 생성될 수 있다. 예를 들면, 질의 생성부(120)는 속성 리스트(PL)에서 개체(ENT)의 클래스가 가질 수 있는 속성들 중 하나를 선택할 수 있다. 질의 생성부(120)는 워드 벡터 모델을 참조하여 선택된 속성(PRO) 및 개체(ENT)로부터 워드 벡터들(예컨대, 도 3의 V1, V2)을 생성할 수 있고, 딥 러닝 네트워크(예컨대, 도 3의 124)에 워드 벡터들을 제공함으로써 획득된 워드 벡터(예컨대, 도 3의 V3)에 기초하여 질의(QUE)를 생성할 수 있다.In step S300, a query (QUE) including an entity (ENT) can be generated. For example, the query generation unit (120) can select one of the attributes that the class of the entity (ENT) can have from the attribute list (PL). The query generation unit (120) can generate word vectors (e.g., V1 and V2 of FIG. 3) from the selected attribute (PRO) and entity (ENT) by referring to the word vector model, and can generate the query (QUE) based on the word vector (e.g., V3 of FIG. 3) obtained by providing the word vectors to a deep learning network (e.g., 124 of FIG. 3).
단계 S500에서, 표로부터 그래프 데이터(GRA)가 생성될 수 있다. 예를 들면, 그래프 생성부(130)는 입력 문서(DIN)로부터 표를 추출할 수 있고, 표의 내용 및 구조에 대한 정보를 포함하는 그래프 데이터(GRA)를 생성할 수 있다. 도면들을 참조하여 전술된 바와 같이, 표에 포함된 지식은 셀들의 컨텐츠 뿐만 아니라 셀들의 위치에도 의존할 수 있고, 이에 따라 셀들의 위치 정보를 포함하는 그래프 데이터(GRA)가 지식 추출을 위해 사용될 수 있다.In step S500, graph data (GRA) can be generated from a table. For example, the graph generation unit (130) can extract a table from an input document (DIN) and generate graph data (GRA) including information on the contents and structure of the table. As described above with reference to the drawings, the knowledge included in the table can depend not only on the contents of the cells but also on the locations of the cells, and thus, graph data (GRA) including location information of the cells can be used for knowledge extraction.
단계 S700에서, 그래프 데이터(GRA)로부터 질의(QUE)의 답변(ANS)이 추출될 수 있다. 예를 들면, 그래프 독해 엔진(140)은 그래프 데이터(GRA) 및 질의(QUE)를 자연어 처리함으로서 입력 데이터를 생성할 수 있고, 적어도 하나의 학습된 모델을 사용하여 입력 데이터로부터 출력 데이터(OUT)를 생성할 수 있다. 출력 데이터(OUT)는 답변(ANS)에 대한 정보뿐만 아니라 추가적인 정보를 포함할 수 있고, 출력 데이터(OUT)에 기초하여 답변(ANS)이 생성될 수 있다.In step S700, an answer (ANS) to a query (QUE) can be extracted from graph data (GRA). For example, the graph reading engine (140) can generate input data by natural language processing the graph data (GRA) and the query (QUE), and can generate output data (OUT) from the input data using at least one learned model. The output data (OUT) can include additional information as well as information about the answer (ANS), and the answer (ANS) can be generated based on the output data (OUT).
단계 S900에서, 개체(ENT), 속성(PRO) 및 답변(ANS)에 기초하여 지식 인스턴스(INS)를 생성하는 동작이 수행될 수 있다. 예를 들면, 지식 생성부(150)는 개체(ENT), 속성(PRO) 및 답변(ANS)에 기초하여 후보 지식 인스턴스(예컨대, 도 10의 CAN)를 생성할 수 있다. 지식 생성부(150)는 후보 지식 인스턴스를 지식베이스(200)에 포함된 지식 인스턴스들과 비교함으로써, 후보 지식 인스턴스로부터 지식 인스턴스(INS)를 생성할 수도 있고, 지식 인스턴스(INS)에 기초한 지식베이스(200)가 보강 여부를 판정할 수도 있다. 일부 실시예들에서, 단계 S900에 후속하여, 단계 S900에서 생성된 지식 인스턴스(INS)를 검증하는 동작이 더 수행될 수도 있다.In step S900, an operation of generating a knowledge instance (INS) based on an entity (ENT), an attribute (PRO), and an answer (ANS) may be performed. For example, the knowledge generation unit (150) may generate a candidate knowledge instance (e.g., CAN of FIG. 10) based on the entity (ENT), the attribute (PRO), and the answer (ANS). The knowledge generation unit (150) may generate a knowledge instance (INS) from the candidate knowledge instance by comparing the candidate knowledge instance with knowledge instances included in the knowledge base (200), and may determine whether the knowledge base (200) based on the knowledge instance (INS) is reinforced. In some embodiments, an operation of verifying the knowledge instance (INS) generated in step S900 may be further performed subsequent to step S900.
이상에서와 같이 도면과 명세서에서 예시적인 실시예들이 개시되었다. 본 명세서에서 특정한 용어를 사용하여 실시예들이 설명되었으나, 이는 단지 본 발명의 기술적 사상을 설명하기 위한 목적에서 사용된 것이지 의미 한정이나 특허청구범위에 기재된 본 발명의 범위를 제한하기 위하여 사용된 것은 아니다. 그러므로 본 기술분야의 통상의 지식을 가진 자라면 이로부터 다양한 변형 및 균등한 타 실시예가 가능하다는 점을 이해할 것이다. 따라서, 본 발명의 진정한 기술적 보호범위는 첨부된 특허청구범위의 기술적 사상에 의해 정해져야 할 것이다.As described above, exemplary embodiments have been disclosed in the drawings and the specification. Although the embodiments have been described using specific terms in this specification, these have been used only for the purpose of explaining the technical idea of the present invention and have not been used to limit the meaning or the scope of the present invention described in the claims. Therefore, those skilled in the art will understand that various modifications and equivalent other embodiments are possible from this. Accordingly, the true technical protection scope of the present invention should be determined by the technical idea of the appended claims.
Claims (10)
Translated fromKorean입력 문서로부터 개체(entity)를 추출하도록 구성된 개체 추출부;
상기 개체의 속성 리스트에 포함된 속성에 기초하여, 상기 개체를 포함하는 질의를 생성하도록 구성된 질의 생성부;
상기 표로부터 그래프 데이터를 생성하도록 구성된 그래프 생성부;
상기 그래프 데이터로부터 상기 질의의 답변을 추출하도록 구성된 그래프 독해 엔진; 및
지식베이스의 형식에 기초하여, 상기 개체, 상기 속성 및 상기 답변으로부터 지식 인스턴스를 생성하도록 구성된 지식 생성부를 포함하고,
상기 질의 생성부는,
상기 속성 리스트에 포함된 복수의 속성들 각각을 순차적으로 선택하고, 상기 개체에 대응하는 제1 워드 벡터 및 선택된 속성에 대응하는 제2 워드 벡터를 생성하도록 구성된 전처리부;
샘플 객체들 및 샘플 속성들에 따라 샘플 질의들을 생성하도록 학습되고, 상기 제1 워드 벡터 및 상기 제2 워드 벡터로부터 상기 질의에 대응하는 제3 워드 벡터를 생성하도록 제1 딥 러닝 네트워크; 및
상기 제3 워드 벡터로부터 상기 질의를 생성하도록 구성된 후처리부를 포함하는 것을 특징으로 하는 지식 추출 시스템.A knowledge extraction system for extracting knowledge from a document containing a table,
An entity extraction unit configured to extract entities from an input document;
A query generation unit configured to generate a query including the object based on attributes included in the attribute list of the object;
A graph generation unit configured to generate graph data from the above table;
a graph reading engine configured to extract an answer to the query from the graph data; and
A knowledge generation unit configured to generate a knowledge instance from the object, the property and the answer based on the format of the knowledge base,
The above query generation part,
A preprocessing unit configured to sequentially select each of a plurality of attributes included in the above attribute list and generate a first word vector corresponding to the object and a second word vector corresponding to the selected attribute;
A first deep learning network trained to generate sample queries based on sample objects and sample properties, and generating a third word vector corresponding to the query from the first word vector and the second word vector; and
A knowledge extraction system characterized by including a post-processing unit configured to generate the query from the third word vector.
상기 개체 추출부는, 상기 입력 문서의 제목으로부터 상기 개체를 추출하도록 구성된 것을 특징으로 하는 지식 추출 시스템.In claim 1,
A knowledge extraction system, characterized in that the above entity extraction unit is configured to extract the entity from the title of the input document.
입력 문서로부터 개체(entity)를 추출하도록 구성된 개체 추출부;
상기 개체의 속성 리스트에 포함된 속성에 기초하여, 상기 개체를 포함하는 질의를 생성하도록 구성된 질의 생성부;
상기 표로부터 그래프 데이터를 생성하도록 구성된 그래프 생성부;
상기 그래프 데이터로부터 상기 질의의 답변을 추출하도록 구성된 그래프 독해 엔진; 및
지식베이스의 형식에 기초하여, 상기 개체, 상기 속성 및 상기 답변으로부터 지식 인스턴스를 생성하도록 구성된 지식 생성부를 포함하고,
상기 그래프 독해 엔진은,
상기 그래프 데이터를 자연어 처리함으로써 제1 입력 데이터를 생성하고, 상기 질의를 자연어 처리함으로써 제2 입력 데이터를 생성하도록 구성된 자연어 처리부;
제1 입력 데이터의 샘플들에 따라 샘플 그래프 벡터들을 출력하도록 학습된 제2 딥 러닝 네트워크;
제2 입력 데이터의 샘플들에 따라 샘플 워드 벡터들을 출력하도록 학습된 제3 딥 러닝 네트워크;
상기 샘플 그래프 벡터들 및 상기 샘플 워드 벡터들에 따라 출력 데이터의 샘플들을 출력하도록 학습된 제4 딥 러닝 네트워크; 및
상기 제4 딥 러닝 네트워크의 출력 데이터에 기초하여, 상기 답변을 생성하도록 구성된 답변 생성부를 포함하고,
상기 출력 데이터는, 상기 표에서 정답의 포함 여부, 정답의 위치, 정답의 신뢰도 중 적어도 하나를 포함하는 것을 특징으로 하는 지식 추출 시스템.A knowledge extraction system for extracting knowledge from a document containing a table,
An entity extraction unit configured to extract entities from an input document;
A query generation unit configured to generate a query including the object based on attributes included in the attribute list of the object;
A graph generation unit configured to generate graph data from the above table;
a graph reading engine configured to extract an answer to the query from the graph data; and
A knowledge generation unit configured to generate a knowledge instance from the object, the property and the answer based on the format of the knowledge base,
The above graph reading engine,
A natural language processing unit configured to generate first input data by natural language processing the above graph data and to generate second input data by natural language processing the above query;
A second deep learning network trained to output sample graph vectors based on samples of the first input data;
A third deep learning network trained to output sample word vectors based on samples of the second input data;
A fourth deep learning network trained to output samples of output data according to the sample graph vectors and the sample word vectors; and
An answer generation unit configured to generate the answer based on the output data of the fourth deep learning network,
A knowledge extraction system, characterized in that the above output data includes at least one of whether the correct answer is included in the above table, the location of the correct answer, and the reliability of the correct answer.
상기 답변 생성부는, 상기 입력 문서에 정답이 포함되지 아니하거나 상기 신뢰도가 미리 정의된 문턱값 미만인 경우, 상기 답변의 추출 실패를 판정하도록 구성된 것을 특징으로 하는 지식 추출 시스템.In claim 4,
A knowledge extraction system characterized in that the answer generation unit is configured to determine failure in extracting the answer if the input document does not contain a correct answer or the reliability is below a predefined threshold.
상기 질의 생성부는, 상기 답변의 추출 실패에 응답하여, 상기 속성 리스트에 포함된 다음 속성에 기초하여 상기 질의를 생성하도록 구성된 것을 특징으로 하는 지식 추출 시스템.In claim 5,
A knowledge extraction system, characterized in that the query generation unit is configured to generate the query based on the next attribute included in the attribute list in response to a failure in extracting the answer.
상기 지식베이스는, 주어(subject), 술어(predicate) 및 목적어(object)를 포함하는 트리플(triple)을 포함하고,
상기 지식 생성부는, 상기 개체, 상기 속성 및 상기 답변을, 상기 주어, 술어 및 상기 목적어로서 포함하는 트리플을 상기 지식 인스턴스로서 생성하도록 구성된 것을 특징으로 하는 지식 추출 시스템.In claim 1,
The above knowledge base includes a triple including a subject, a predicate, and an object.
A knowledge extraction system, characterized in that the knowledge generation unit is configured to generate a triple including the entity, the property, and the answer as the subject, the predicate, and the object as the knowledge instance.
상기 그래프 데이터는,
상기 표에 포함된 셀들 각각의 인덱스, 좌표 및 컨텐츠를 포함하는 노드들; 및
상기 표에 포함된 셀들의 배치에 기초하여, 상기 노드들을 연결하는 에지들을 포함하는 것을 특징으로 하는 지식 추출 시스템.In claim 1,
The above graph data is,
Nodes containing the index, coordinates and contents of each cell included in the above table; and
A knowledge extraction system characterized by including edges connecting the nodes based on the arrangement of cells included in the above table.
상기 지식 생성부는,
상기 지식베이스에 포함된 지식 인스턴스의 형식에 기초하여 상기 개체, 상기 속성 및 상기 답변을 후처리하고, 상기 개체, 상기 속성 및 상기 답변 중 적어도 하나에 대응하는 식별자를 상기 지식베이스에서 추출함으로써 상기 지식 인스턴스를 생성하도록 구성된 지식 인스턴스 생성부; 및
생성된 상기 지식 인스턴스를 상기 지식베이스에 포함된 지식 인스턴스들과 비교함으로써 상기 지식베이스에 선택적으로 통합하도록 구성된 인스턴스 비교부를 포함하는 것을 특징으로 하는 지식 추출 시스템.In claim 1,
The above knowledge generation unit,
A knowledge instance generation unit configured to generate the knowledge instance by post-processing the object, the property and the answer based on the format of the knowledge instance included in the knowledge base, and extracting an identifier corresponding to at least one of the object, the property and the answer from the knowledge base; and
A knowledge extraction system characterized by including an instance comparison unit configured to selectively integrate the generated knowledge instance into the knowledge base by comparing it with knowledge instances included in the knowledge base.
입력 문서로부터 개체(entity)를 추출하는 단계;
상기 개체의 속성 리스트에 포함된 속성에 기초하여, 상기 개체를 포함하는 질의를 상기 입력 문서로부터 생성하는 단계;
상기 입력 문서에 포함된 표로부터 그래프 데이터를 생성하는 단계;
상기 그래프 데이터로부터 상기 질의의 답변을 추출하는 단계; 및
지식베이스의 형식에 기초하여, 상기 개체, 상기 속성 및 상기 답변으로부터 지식 인스턴스를 생성하는 단계를 포함하고,
상기 질의를 상기 입력 문서로부터 생성하는 단계는,
상기 속성 리스트에 포함된 복수의 속성들 각각을 순차적으로 선택하고, 상기 개체에 대응하는 제1 워드 벡터 및 선택된 속성에 대응하는 제2 워드 벡터를 생성하는 단계;
샘플 객체들 및 샘플 속성들에 따라 샘플 질의들을 생성하도록 학습된 제1 딥 러닝 네트워크에 기초하여, 상기 제1 워드 벡터 및 상기 제2 워드 벡터로부터 상기 질의에 대응하는 제3 워드 벡터를 생성하는 단계; 및
상기 제3 워드 벡터로부터 상기 질의를 생성하는 단계를 포함하는 것을 특징으로 하는 지식 추출 방법.A knowledge extraction method performed by a computing system to extract knowledge from a document,
A step of extracting entities from an input document;
A step of generating a query including the object from the input document based on attributes included in the attribute list of the object;
A step of generating graph data from a table included in the above input document;
A step of extracting an answer to the query from the above graph data; and
Based on the format of the knowledge base, a step of generating a knowledge instance from the object, the property and the answer is included.
The step of generating the above query from the above input document is:
A step of sequentially selecting each of a plurality of attributes included in the above attribute list, and generating a first word vector corresponding to the object and a second word vector corresponding to the selected attribute;
A step of generating a third word vector corresponding to the query from the first word vector and the second word vector based on a first deep learning network trained to generate sample queries according to sample objects and sample properties; and
A knowledge extraction method, characterized by comprising a step of generating the query from the third word vector.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020210157084AKR102815465B1 (en) | 2021-11-15 | 2021-11-15 | System and method for extracting knowledge based on graph reading |
| PCT/KR2021/018458WO2023085500A1 (en) | 2021-11-15 | 2021-12-07 | System and method for knowledge extraction based on graph reading |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020210157084AKR102815465B1 (en) | 2021-11-15 | 2021-11-15 | System and method for extracting knowledge based on graph reading |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20230070968A KR20230070968A (en) | 2023-05-23 |
| KR102815465B1true KR102815465B1 (en) | 2025-06-02 |
Family
ID=86336222
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020210157084AActiveKR102815465B1 (en) | 2021-11-15 | 2021-11-15 | System and method for extracting knowledge based on graph reading |
Country Status (2)
| Country | Link |
|---|---|
| KR (1) | KR102815465B1 (en) |
| WO (1) | WO2023085500A1 (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN119832579B (en)* | 2025-03-17 | 2025-06-13 | 中国科学技术大学 | MTU data decoupling synthesis and model training method, system, equipment and medium |
Family Cites Families (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8229883B2 (en)* | 2009-03-30 | 2012-07-24 | Sap Ag | Graph based re-composition of document fragments for name entity recognition under exploitation of enterprise databases |
| US9817823B2 (en)* | 2013-09-17 | 2017-11-14 | International Business Machines Corporation | Active knowledge guidance based on deep document analysis |
| CN109271525A (en)* | 2018-08-08 | 2019-01-25 | 北京百度网讯科技有限公司 | For generating the method, apparatus, equipment and computer readable storage medium of knowledge mapping |
| KR102309375B1 (en)* | 2019-06-26 | 2021-10-06 | 주식회사 카카오 | Apparatus and method for knowledge graph indexing |
| KR102292040B1 (en)* | 2019-10-11 | 2021-08-23 | 주식회사 솔트룩스 | System and method for extracting knowledge based on machine reading |
- 2021
- 2021-11-15KRKR1020210157084Apatent/KR102815465B1/enactiveActive
- 2021-12-07WOPCT/KR2021/018458patent/WO2023085500A1/ennot_activeCeased
Also Published As
| Publication number | Publication date |
|---|---|
| KR20230070968A (en) | 2023-05-23 |
| WO2023085500A1 (en) | 2023-05-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12399893B2 (en) | Question-answering system for answering relational questions by utilizing two paths where at least one path uses BERT model | |
| US20220405484A1 (en) | Methods for Reinforcement Document Transformer for Multimodal Conversations and Devices Thereof | |
| KR102292040B1 (en) | System and method for extracting knowledge based on machine reading | |
| AU2017272243B2 (en) | Method and system for creating an instance model | |
| RU2628436C1 (en) | Classification of texts on natural language based on semantic signs | |
| US20220300831A1 (en) | Context-aware entity linking for knowledge graphs | |
| WO2019229769A1 (en) | An auto-disambiguation bot engine for dynamic corpus selection per query | |
| US10289717B2 (en) | Semantic search apparatus and method using mobile terminal | |
| RU2626555C2 (en) | Extraction of entities from texts in natural language | |
| US20190392035A1 (en) | Information object extraction using combination of classifiers analyzing local and non-local features | |
| US10503830B2 (en) | Natural language processing with adaptable rules based on user inputs | |
| CN116127090B (en) | Aviation system knowledge graph construction method based on fusion and semi-supervision information extraction | |
| US12141179B2 (en) | System and method for generating ontologies and retrieving information using the same | |
| US11537797B2 (en) | Hierarchical entity recognition and semantic modeling framework for information extraction | |
| RU2640297C2 (en) | Definition of confidence degrees related to attribute values of information objects | |
| Sarkhel et al. | Visual segmentation for information extraction from heterogeneous visually rich documents | |
| US20220358379A1 (en) | System, apparatus and method of managing knowledge generated from technical data | |
| CN110765256B (en) | Method and equipment for generating online legal consultation automatic reply | |
| Sarkhel et al. | Improving information extraction from visually rich documents using visual span representations | |
| CN120086427B (en) | A method and system for intelligently collecting and analyzing web merchant information | |
| KR20240020166A (en) | Method for learning machine-learning model with structured ESG data using ESG auxiliary tool and service server for generating automatically completed ESG documents with the machine-learning model | |
| Safar | Digital library of online PDF sources: An ETL approach | |
| KR102815465B1 (en) | System and method for extracting knowledge based on graph reading | |
| JP5812534B2 (en) | Question answering apparatus, method, and program | |
| US11017172B2 (en) | Proposition identification in natural language and usage thereof for search and retrieval |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application | Patent event code:PA01091R01D Comment text:Patent Application Patent event date:20211115 | |
| PA0201 | Request for examination | ||
| PG1501 | Laying open of application | ||
| PE0902 | Notice of grounds for rejection | Comment text:Notification of reason for refusal Patent event date:20240924 Patent event code:PE09021S01D | |
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration | Patent event code:PE07011S01D Comment text:Decision to Grant Registration Patent event date:20250513 | |
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment | Comment text:Registration of Establishment Patent event date:20250527 Patent event code:PR07011E01D | |
| PR1002 | Payment of registration fee | Payment date:20250528 End annual number:3 Start annual number:1 | |
| PG1601 | Publication of registration |