KR102742714B1 - Efficient multi-gpu based deep learning inference using critical-path-based scheduling - Google Patents
Efficient multi-gpu based deep learning inference using critical-path-based schedulingDownload PDFInfo
- Publication number
- KR102742714B1 KR102742714B1KR1020210083671AKR20210083671AKR102742714B1KR 102742714 B1KR102742714 B1KR 102742714B1KR 1020210083671 AKR1020210083671 AKR 1020210083671AKR 20210083671 AKR20210083671 AKR 20210083671AKR 102742714 B1KR102742714 B1KR 102742714B1
- Authority
- KR
- South Korea
- Prior art keywords
- computational
- units
- generated
- model inference
- deep learning
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images




Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/06—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons
- G06N3/063—Physical realisation, i.e. hardware implementation of neural networks, neurons or parts of neurons using electronic means
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/04—Inference or reasoning models
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T1/00—General purpose image data processing
- G06T1/20—Processor architectures; Processor configuration, e.g. pipelining
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Software Systems (AREA)
- Life Sciences & Earth Sciences (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- Computational Linguistics (AREA)
- Artificial Intelligence (AREA)
- Health & Medical Sciences (AREA)
- Evolutionary Computation (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Neurology (AREA)
- Devices For Executing Special Programs (AREA)
- Feedback Control In General (AREA)
Abstract
Translated fromKorean
Description
Translated fromKorean아래의 설명은 딥러닝 모델 추론 기술에 관한 것이다.The description below is about deep learning model inference technology.
딥러닝 시스템은 일반적으로 데이터 셋을 이용하여 모델을 구성하고, 이를 분류하는 일련의 과정을 의미한다. 그러나 데이터 셋의 크기가 증가하고, 정확도를 높이기 위해 모델의 깊이와 크기가 증가하며, 모델을 만들기 위한 시간적인 소모가 증가하게 되었다. 이에 대한 해결책으로, 사람이 직접 모델을 작성하지 않고, 모델을 탐색하여 직접 자동으로 생성하고, 데이터 셋을 이용해 적용해보는 방식이다. 기존의 모델은 직접 사람이 코드로 작성하여, 최적의 정확도를 찾기 위해, 모델 내의 채널(Channel)을 늘리거나 추가로 계층(layer)을 늘리는 방식으로 모델을 변경하였으나, 최적의 모델을 찾기 위해 계층의 수를 변경하거나, 계층 자체의 모양을 자동으로 조절하여 탐색하는 방법을 선택했다. 대표적으로 NASNet으로 대표되는 신경망 탐색은 이러한 방식으로 수행되었으며, 직접 신경망을 탐색하지 않아도, 계층의 수나, 연결 방식을 무작위로 결정하는 Randomly Wired 신경망이 있다. 이러한 신경망들은 딥러닝 시스템을 구현하거나, 특정 데이터 셋의 정확도를 높이기 위해 모델을 작성하기 위한 시간 소모를 크게 줄이고, 신경망 탐색에서 최적의 정확도와 성능을 가져올 수 있게 되었다.Deep learning systems generally refer to a series of processes that use data sets to construct models and classify them. However, as the size of data sets increases, and the depth and size of models increase to improve accuracy, the time consumed to create models increases. As a solution to this, instead of people directly writing models, models are explored and automatically generated, and applied using data sets. Existing models were written directly by people in code, and in order to find the optimal accuracy, the models were changed by increasing the number of channels in the model or adding additional layers, but in order to find the optimal model, a method was chosen to search by changing the number of layers or automatically adjusting the shape of the layers themselves. Representative neural network search represented by NASNet was performed in this way, and there is a Randomly Wired neural network that randomly determines the number of layers or connection method without directly searching the neural network. These neural networks have greatly reduced the time consumed to implement deep learning systems or create models to improve the accuracy of specific data sets, and have been able to bring about optimal accuracy and performance in neural network search.
근래의 불규칙적이고 복잡한 신경망은 직접 데이터 셋에 맞게 구현되기도 하지만, 자동화된 신경망 구조 탐색 기법을 사용하여 높은 정확도와 효율적인 모델 구성에 도달하고 있다. 그러나 리소스 측면에서는 상당한 자원 낭비를 발생하고 있고, 모델 자체의 크기가 기하급수적으로 커지면서, 소규모 서버나 임베디드 환경에서는 제한적인 메모리와 성능으로, 학습된 모델을 구동시키기 어려워 졌다. 최근에 발표되는 모델의 크기는 일반적인 단일 GPU로 구동해도 수일에서 수주가 소요되기 때문에, 쉽게 접근하기 어려운 점이 존재한다. 그러므로 2개 이상의 GPU에서 이러한 큰 신경망에서 요구되는 연산을 적절하게 분배하고, 지원의 사용을 효과적으로 사용할 수 있도록 하는 기술이 필요하다.Recent irregular and complex neural networks are implemented directly to the data set, but they are also using automated neural network structure search techniques to achieve high accuracy and efficient model configuration. However, in terms of resources, they are causing considerable resource waste, and as the size of the model itself grows exponentially, it has become difficult to run the learned model in small servers or embedded environments due to limited memory and performance. The size of recently announced models is difficult to approach easily because it takes several days to several weeks to run on a general single GPU. Therefore, a technology is needed to appropriately distribute the operations required by such large neural networks on two or more GPUs and to effectively utilize the use of support.
중요 경로 기반 스케줄링 및 후처리를 통해 리소스 활용을 극대화할 수 있는 multi-GPU 기반 딥러닝 모델 추론 방법 및 시스템을 제공할 수 있다.A multi-GPU based deep learning model inference method and system can be provided that can maximize resource utilization through critical path-based scheduling and post-processing.
모델 추론 시스템에 의해 수행되는 딥러닝 모델 추론 방법은, 학습을 위해 생성된 그래프 정보로부터 연산 단위들의 핵심 경로(Critical Path)의 탐색을 통해 스케줄링 정보를 생성하는 단계; 및 상기 생성된 스케줄링 정보에 따라 할당된 연산 단위를 서로 다른 복수 개의 연산 장치에 분배하는 단계를 포함할 수 있다.A deep learning model inference method performed by a model inference system may include a step of generating scheduling information by searching for a critical path of computational units from graph information generated for learning; and a step of distributing allocated computational units to a plurality of different computational devices according to the generated scheduling information.
상기 생성하는 단계는, 불규칙 뉴럴 네트워크 연산 학습을 위해 생성된 그래프 정보로부터 서로 다른 복수 개의 연산 장치에서 구동할 연산 단위들의 핵심 경로를 탐색하고, 상기 탐색된 핵심 경로를 연산 단위의 인덱스로 구성된 어레이(Array)로 저장하는 단계를 포함할 수 있다.The above generating step may include a step of searching for a core path of computational units to be driven by different multiple computational devices from graph information generated for irregular neural network computational learning, and storing the searched core path as an array composed of indices of computational units.
상기 생성하는 단계는, 상기 저장된 연산 단위의 인덱스로 구성된 어레이와 상기 생성된 그래프 정보를 이용하여 위상 정렬(Topological Sort)을 수행하고, 상기 수행된 위상 정렬을 통해 연산 단위의 인덱스를 저장한 각 연산 장치별 어레이를 생성하는 단계를 포함할 수 있다.The above generating step may include a step of performing a topological sort using an array composed of indices of the stored operation units and the generated graph information, and generating an array for each operation device storing the indices of the operation units through the performed topological sort.
상기 생성하는 단계는, 각 연산 장치에서 스케줄링 정보를 생성하기 위하여 각 동작에서 실행되어야 할 연산 단위를 쌍으로 묶어서 상기 각 동작에서 수행되는 연산 단위의 쌍을 획득한 어레이를 생성하는 단계를 포함할 수 있다.The above generating step may include a step of generating an array that obtains pairs of computational units performed in each operation by grouping computational units to be executed in each operation into pairs in order to generate scheduling information in each computational device.
상기 생성하는 단계는, 미리 측정된 연산 시간 및 데이터 전달과 데이터 복사 지연 시간을 포함하는 성능 지표를 이용하여 복수 개의 서로 다른 연산 장치 간의 데이터 이동 및 복사로 성능에 따라 각 연산 장치에 대한 연산 단위의 인덱스를 변경하는 단계를 포함할 수 있다.The generating step may include a step of changing an index of a computational unit for each computational device according to performance of data movement and copying between a plurality of different computational devices, using performance indicators including pre-measured computational times and data transmission and data copy delay times.
상기 분배하는 단계는, 상기 생성된 스케줄링 정보 따라 딥러닝 모델 추론을 위한 연산 단위들의 실행 순서와 연산 단위들을 할당하는 단계를 포함할 수 있다.The above distributing step may include a step of allocating the execution order of the computational units and the computational units for deep learning model inference according to the generated scheduling information.
상기 분배하는 단계는, 상기 생성된 스케줄링 정보에 포함된 어레이 정보에 기초하여 각 연산 장치의 인덱스와 연결된 연산 단위를 묶어서 딥러닝 컴파일러를 기반으로 각 연산 장치의 구조에 따른 모듈을 생성하고, 상기 생성된 모듈을 상기 각 연산 장치에서 실행함에 따라 상기 생성된 그래프 정보에 기초하여 각 모듈에서 출력값을 도출하고, 필요한 입력값을 가져올 수 있도록 상기 도출된 출력값을 어레이로 저장하는 단계를 포함할 수 있다.The above distributing step may include a step of generating a module according to the structure of each computational device based on a deep learning compiler by grouping computational units linked to the indexes of each computational device based on array information included in the generated scheduling information, and deriving an output value from each module based on the generated graph information as the generated module is executed on each computational device, and storing the derived output values as an array so that required input values can be obtained.
딥러닝 모델 추론 방법을 상기 추론 시스템에 실행시키기 위해 비-일시적인 컴퓨터 판독가능한 기록 매체에 저장되는 컴퓨터 프로그램을 포함할 수 있다.It may include a computer program stored in a non-transitory computer-readable recording medium to execute the deep learning model inference method in the above inference system.
모델 추론 시스템은, 학습을 위해 생성된 그래프 정보로부터 연산 단위들의 핵심 경로(Critical Path)의 탐색을 통해 스케줄링 정보를 생성하는 스케줄 생성부; 및 상기 생성된 스케줄링 정보에 따라 할당된 연산 단위를 서로 다른 복수 개의 연산 장치에 분배하는 분배부를 포함할 수 있다.The model inference system may include a schedule generation unit that generates scheduling information by searching for critical paths of computational units from graph information generated for learning; and a distribution unit that distributes allocated computational units to a plurality of different computational devices according to the generated scheduling information.
상기 스케줄 생성부는, 불규칙 뉴럴 네트워크 연산 학습을 위해 생성된 그래프 정보로부터 서로 다른 복수 개의 연산 장치에서 구동할 연산 단위들의 핵심 경로를 탐색하고, 상기 탐색된 핵심 경로를 연산 단위의 인덱스로 구성된 어레이(Array)로 저장할 수 있다.The above schedule generation unit can search for core paths of operation units to be driven by different multiple operation devices from graph information generated for irregular neural network operation learning, and store the searched core paths as an array composed of indexes of operation units.
상기 스케줄 생성부는, 상기 저장된 연산 단위의 인덱스로 구성된 어레이와 상기 생성된 그래프 정보를 이용하여 위상 정렬(Topological Sort)을 수행하고, 상기 수행된 위상 정렬을 통해 연산 단위의 인덱스를 저장한 각 연산 장치별 어레이를 생성할 수 있다.The above schedule generation unit can perform a topological sort using an array composed of the indexes of the stored operation units and the generated graph information, and generate an array for each operation device that stores the indexes of the operation units through the performed topological sort.
상기 스케줄 생성부는, 각 연산 장치에서 스케줄링 정보를 생성하기 위하여 각 동작에서 실행되어야 할 연산 단위를 쌍으로 묶어서 상기 각 동작에서 수행되는 연산 단위의 쌍을 획득한 어레이를 생성할 수 있다.The above schedule generation unit can generate an array that obtains pairs of computational units performed in each operation by grouping computational units to be executed in each operation into pairs in order to generate scheduling information in each computational device.
상기 스케줄 생성부는, 미리 측정된 연산 시간 및 데이터 전달과 데이터 복사 지연 시간을 포함하는 성능 지표를 이용하여 복수 개의 서로 다른 연산 장치 간의 데이터 이동 및 복사로 성능에 따라 각 연산 장치에 대한 연산 단위의 인덱스를 변경할 수 있다.The above schedule generation unit can change the index of the operation unit for each operation device according to the performance of data movement and copying between a plurality of different operation devices by using performance indicators including pre-measured operation time and data transmission and data copy delay time.
상기 분배부는, 상기 생성된 스케줄링 정보 따라 딥러닝 모델 추론을 위한 연산 단위들의 실행 순서와 연산 단위들을 할당할 수 있다.The above distribution unit can allocate the execution order and operation units of the operation units for deep learning model inference according to the generated scheduling information.
상기 분배부는, 상기 생성된 스케줄링 정보에 포함된 어레이 정보에 기초하여 각 연산 장치의 인덱스와 연결된 연산 단위를 묶어서 딥러닝 컴파일러를 기반으로 각 연산 장치의 구조에 따른 모듈을 생성하고, 상기 생성된 모듈을 상기 각 연산 장치에서 실행함에 따라 상기 생성된 그래프 정보에 기초하여 각 모듈에서 출력값을 도출하고, 필요한 입력값을 가져올 수 있도록 상기 도출된 출력값을 어레이로 저장할 수 있다.The above distribution unit generates a module according to the structure of each computational device based on a deep learning compiler by grouping computational units linked to the indexes of each computational device based on array information included in the generated scheduling information, and by executing the generated module on each computational device, derives an output value from each module based on the generated graph information, and can store the derived output values as an array so that necessary input values can be obtained.
종래 기술이 지연되는 연산 시간과 많은 리소스 소모를 유발하기 때문에, 딥러닝 모델의 연산 단위를 나누어 다수의 연산 장치에 배분하는 방법을 이용함으로써 효과적인 리소스 사용과 병렬적인 연산 수행을 통해 성능 개선을 도모할 수 있다.Since conventional technologies cause delayed computation time and large resource consumption, a method of dividing the computational units of a deep learning model and distributing them to multiple computational devices can be used to improve performance through effective resource use and parallel computation.
다중 GPU의 경우, 연산 단위로 각 GPU에 자원을 할당할 경우, 각 연산을 동시에 수행하므로, 연산 단위만큼의 성능 개선(Latency Hiding)을 수행할 수 있으며, 불규칙한 연산 의존성을 나타낼 경우, 적절한 연산 분배는 보다 높은 성능 개선을 유도할 수 있기 때문에, 중요 경로 기반 스케줄링 및 후처리를 통해 리소스 활용을 극대화할 수 있다.In the case of multi-GPUs, if resources are allocated to each GPU as a computational unit, each computation is performed simultaneously, so performance improvement (latency hiding) can be performed as much as the computational unit, and if irregular computational dependencies are shown, appropriate computation distribution can lead to higher performance improvement, so resource utilization can be maximized through critical path-based scheduling and postprocessing.
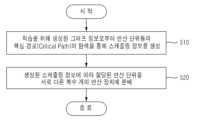
도 1은 일 실시예에 따른 모델 추론 시스템의 동작을 설명하기 위한 도면이다.
도 2는 일 실시예에 따른 모델 추론 시스템에서 훈련된 모델, 데이터 셋, 정확도를 나타낸 표이다.
도 3은 일 실시예에 따른 모델 추론 시스템에서 스케줄링 적용 전과 스케줄링 적용 후를 비교한 것을 나타낸 그래프이다.
도 4는 일 실시예에 따른 모델 추론 시스템의 구성을 설명하기 위한 블록도이다.
도 5는 일 실시예에 따른 모델 추론 시스템에서 딥러닝 모델 추론 방법을 설명하기 위한 흐름도이다.
도 6은 일 실시예에 따른 모델 추론 시스템에서 스케줄링 동작을 설명하기 위한 흐름도이다.FIG. 1 is a diagram for explaining the operation of a model inference system according to one embodiment.
FIG. 2 is a table showing a trained model, data set, and accuracy in a model inference system according to one embodiment.
Figure 3 is a graph comparing before and after scheduling application in a model inference system according to one embodiment.
FIG. 4 is a block diagram illustrating the configuration of a model inference system according to one embodiment.
FIG. 5 is a flowchart for explaining a deep learning model inference method in a model inference system according to one embodiment.
FIG. 6 is a flowchart for explaining a scheduling operation in a model inference system according to one embodiment.
이하, 실시예를 첨부한 도면을 참조하여 상세히 설명한다.Hereinafter, the present invention will be described in detail with reference to the attached drawings.
실시예에서는 핵심 경로(Critical-Path) 기반 스케줄링 및 후처리(post-process)를 통한 리소스 활용(Resource-utilization)을 극대화할 수 있는 다중 GPU(multi-GPU) 기반 딥러닝 모델 추론(Deep-learning Model Inference) 동작에 대하여 설명하기로 한다. 기존의 딥러닝 시스템에서 성능 개선을 위한 데이터 병렬화(Datal-Parallel) 기법을 사용하고, 복잡하고 불규칙한 딥러닝 모델 추론이 다중 GPU에서 낮은 리소스 활용과 낮은 성능을 가져온다는 한계를 극복하기 위하여, 딥러닝 모델 병렬화(Model-Parallel)를 위한 핵심 경로(Critical-Path) 기반 스케줄링 기법과 연산의 지연시간(latency) 측정값과 가용 리소스를 고려한 후처리 기법 개발을 통해 다중 GPU 위에서의 연산의 실행 순서와 리소스 사용량을 변화시킴으로써 효과적인 딥러닝 모델 추론을 수행할 수 있다.In this embodiment, we describe a multi-GPU based Deep-learning Model Inference operation that can maximize resource utilization through critical-path based scheduling and post-processing. In order to overcome the limitations of using data parallelism techniques for performance improvement in existing deep learning systems and the low resource utilization and low performance of complex and irregular deep-learning model inference in multi-GPUs, a critical-path based scheduling technique for model parallelism and a post-processing technique that considers the latency measurement value and available resources of operations are developed to change the execution order and resource usage of operations on multi-GPUs, thereby enabling effective deep-learning model inference.
도 1은 일 실시예에 따른 모델 추론 시스템의 동작을 설명하기 위한 도면이다.FIG. 1 is a diagram for explaining the operation of a model inference system according to one embodiment.
모델 추론 시스템은 학습을 위해 생성된 그래프 정보로부터 연산 단위들의 핵심 경로(Critical Path)의 탐색을 통해 스케줄링 정보를 생성할 수 있고, 생성된 스케줄링 정보에 따라 할당된 연산 단위를 서로 다른 복수 개의 연산 장치(예를 들면, 2개)에 분배할 수 있다. 예를 들면, 연산 장치는 GPU, CPU 등이 해당될 수 있다. 실시예에서는 연산 장치가 GPU라고 가정하여 설명하기로 한다. 각 연산의 경우, 연산 장치(GPU)의 구조에 따라 연산 시간이 달라질 수 있다. 이때, 실험을 통해 데이터를 획득하여, 연산 시간을 적절하게 분배하는 것이 중요하다. 다만, 이러한 연산 분배가 이루어지면, 각 연산이 수행되기 전 후에 발생하는 입력값과 출력값의 전달 오버헤드가 복수 개의 연산 장치(GPU) 간의 연산 분배에 큰 걸림돌이 될 수 있다.The model inference system can generate scheduling information by exploring the critical path of the computational units from the graph information generated for learning, and can distribute the allocated computational units to different multiple computational devices (for example, two) according to the generated scheduling information. For example, the computational devices may be GPUs, CPUs, etc. In the embodiment, it will be explained assuming that the computational device is a GPU. For each operation, the computation time may vary depending on the structure of the computational device (GPU). At this time, it is important to appropriately distribute the computational time by acquiring data through experiments. However, if such computational distribution is made, the overhead of transmitting input and output values that occurs before and after each operation is performed may become a major obstacle to the computational distribution between multiple computational devices (GPUs).
모델 추론 시스템은 불규칙하고 무작위적인 뉴럴 네트워크 구조에서 확장 가능성(scalable)이 높은 스케줄러(도 1의 그래프 스케줄러)를 제공할 수 있다. 기존의 신경망 구조는 계층과 계층 간의 의존성(Dependency)이 순차적인(Serial) 구조로 되어 있었으나, 최근의 신경망 구조는 서로 다른 계층을 교차하여 불규칙하고 무작위로 데이터를 받으며, 성능 혹은 정확도의 높은 수준을 달성한다. 그러나 이러한 방식의 불규칙 네트워크 모델은 리소스가 제한적인 상황에서는 모델의 크기가 크기 때문에 단일 연산 장치에서 구동하기 어렵다. 이에, 서로 다른 연산 장치가 다수 필요하게 되었으며, 서버 혹은 임베디드 환경에서 연산을 적절히 분배해야 하는 상황이다. 실시예에 따른 스케줄러는, 연산 단위 간의 의존성과 연산 후에 발생하는 데이터 입출력과 데이터 크기를 고려하여, 데이터 이동 및 복사로 발생하는 지연시간을 고려한 최적의 연산 분배(distribution)와 연산의 실행 순서(Order)를 제공한다. 이러한 불규칙 연산은 대부분 그래프 형태로 구성되어 있기 때문에, 어떤 그래프 형태의 신경망에도 적용 가능하도록 제공할 수 있다. 모델 추론 시스템은 그래프의 중요 경로를 고려한 스케줄링 기법을 제공할 수 있다.The model inference system can provide a highly scalable scheduler (graph scheduler in Fig. 1) in irregular and random neural network structures. While the existing neural network structure has a serial structure in which the dependency between layers is intersected, recent neural network structures receive data irregularly and randomly by crossing different layers, and achieve a high level of performance or accuracy. However, this type of irregular network model is difficult to operate on a single computational device in a situation where resources are limited because the model size is large. Therefore, multiple different computational devices are required, and it is a situation where computations must be appropriately distributed in a server or embedded environment. The scheduler according to the embodiment provides an optimal computational distribution and computational execution order that considers the dependency between computational units, the data input/output that occurs after the computation, and the data size, and the delay time that occurs due to data movement and copying. Since most of these irregular computations are configured in the form of graphs, they can be provided so that they can be applied to any graph-type neural network. The model inference system can provide a scheduling technique that considers the critical path of the graph.
모델 추론 시스템에서 복수 개의 연산 장치는 주로 사용하는 주 연산 장치(main-GPU) 및 주로 사용하지 않는 부 연산 장치(Sub-GPU)로 구성될 수 있고, 또는 동일한 역할을 수행하는 복수 개의 연산 장치로 구성될 수 있다. 모델 추론 시스템은 연산 장치들 중 어느 하나의 연산 장치가 연산 장치 간 데이터 이동으로 인해 추가적으로 발생하는 지연시간에 의한 오버헤드가 기 설정된 기준값 이상일 경우, 어느 하나의 특정 연산 장치에 연산 단위를 할당할 경우 성능적으로 이득이 있는지 여부를 판단할 수 있다. 이때, 성능적으로 이득이 있는지 여부는 성능 비교를 위한 기준값을 통해 판단이 가능하며, 사전에 설정되어 있을 수 있다. 예를 들면, 연산 장치에 연산 단위를 할당할 경우 성능적으로 예상되는 이득값과 기준값을 비교할 수 있고, 이득값이 기준값 이상일 경우 성능적으로 이득이 있는 것으로 판단할 수 있다. 연산 장치에 성능적으로 이득이 있다고 판단될 경우 연산 단위를 어느 하나의 연산 장치에 할당하고, 성능적으로 이득이 없다고 판단될 경우 연산 단위를 다른 연산 장치에 할당할 수 있다. 실시예에서는 주로 사용하지 않는 GPU(Sub-GPU)에 할당된 연산 단위가 GPU 간 데이터 이동으로 인해 추가적으로 발생하는 지연시간에 의한 오버헤드보다 거대하여 Sub-GPU에 할당하는 경우 성능적으로 이득이 있는지 여부를 고려하여, 만약 성능 증가에 큰 기여를 하는 경우 해당 연산 단위를 Sub-GPU에 할당하고, 반대의 경우에는 해당 연산 단위를 다시 주로 사용하는 GPU(Main-GPU)에서 연산을 수행하도록 복구하는 후처리 과정을 수행할 수 있다. 모델 추론 시스템은 모델 병렬화(Model-Parallel)에서 분배로 발생하는 데이터 송수신 문제를 고려하여, 효과적인 스케줄링을 수행할 수 있다. 또한, 모델 추론 시스템은 제안한 데이터 전송/복사 기법과 스케줄러 및 후처리 과정을 사용하여 최적의 리소스 활용과 병렬화된 연산을 제공할 수 있다.In a model inference system, multiple computational units can be composed of a main computational unit (main-GPU) that is mainly used and a sub-computational unit (Sub-GPU) that is not mainly used, or can be composed of multiple computational units that perform the same role. If the overhead due to the additional delay time caused by data movement between computational units of any one of the computational units exceeds a preset reference value, the model inference system can determine whether there is a performance gain when assigning a computational unit to any specific computational unit. At this time, whether there is a performance gain can be determined through a reference value for performance comparison, which can be set in advance. For example, when assigning a computational unit to a computational unit, the expected performance gain can be compared with the reference value, and if the gain value is greater than the reference value, it can be determined that there is a performance gain. If it is determined that there is a performance gain to the computational unit, the computational unit can be assigned to one computational unit, and if it is determined that there is no performance gain, the computational unit can be assigned to another computational unit. In the embodiment, the computational unit assigned to the mainly unused GPU (Sub-GPU) is larger than the overhead due to the additional delay time caused by data movement between GPUs, and whether there is a performance benefit when assigning it to the Sub-GPU is considered. If it contributes greatly to the performance increase, the computational unit is assigned to the Sub-GPU, and if not, the computational unit is restored to perform the computation on the mainly used GPU (Main-GPU) again. The model inference system can perform effective scheduling by considering the data transmission and reception problem caused by distribution in model parallelism. In addition, the model inference system can provide optimal resource utilization and parallelized computation by using the proposed data transmission/copying technique, scheduler, and postprocessing process.
도 1은 모델 추론 시스템의 시스템 구성을 나타낸 것으로, 그래프 스케줄러(Graph Scheduler)의 동작에 대하여 상세하게 설명하기로 한다. 그래프 스케줄러는 총 4단계로 구성될 수 있다.Figure 1 shows the system configuration of the model inference system, and the operation of the graph scheduler will be described in detail. The graph scheduler can be composed of a total of four stages.
제1 단계에서, 그래프 스케줄러는 학습을 위해 사전에 생성된 그래프 정보로부터 주로 사용하는 GPU (Main-GPU)에서 구동할 연산 단위들의 핵심 경로를 탐색하고, 탐색된 핵심 경로를 연산 단위의 인덱스(Index)로 구성된 어레이(Array)로 저장할 수 있다. 이때, 그래프 정보는 0, 1, 2와 같은 숫자 형태의 인덱스가 순차적으로 저장되어 있으며, 각 인덱스에는 적어도 하나 이상의 연산(Add, Sub, Mul, Convolution, Relu, etc.)으로 구성된 연산 단위가 연결되어 있다.In the first stage, the graph scheduler can search for the core paths of the computational units to be driven on the GPU (Main-GPU) mainly used for learning from the graph information generated in advance, and store the searched core paths as an array consisting of the indexes of the computational units. At this time, the graph information is sequentially stored as indexes in the form of numbers such as 0, 1, and 2, and each index is connected to a computational unit consisting of at least one operation (Add, Sub, Mul, Convolution, Relu, etc.).
제2 단계에서, 그래프 스케줄러는 연산 단위의 인덱스로 구성된 어레이 정보와 그래프 정보를 활용하여 위상 정렬(Topological Sort) 기법을 사용하여, 연산 간의 의존성(Dependency)을 고려하여 연산 단위의 인덱스를 저장한 각 연산 장치(GPU) 별 어레이를 생성할 수 있다. 여기서, 위상 정렬은 어떤 일을 하는 순서를 찾는 알고리즘으로 방향 그래프에 존재하는 각 정점들의 선행 순서를 위배하지 않으면서도 모든 정점을 나열하는 것을 의미한다.In the second stage, the graph scheduler can use the topological sort technique to create an array for each computational device (GPU) that stores the indices of computational units by considering the dependency between operations, using the array information composed of the indices of the computational units and the graph information. Here, the topological sort is an algorithm for finding the order in which work is done, and means listing all vertices without violating the precedence order of each vertex in the directed graph.
제3 단계에서, 그래프 스케줄러는 각 연산 장치(GPU)에서 스케줄링 정보를 생성하기 위하여 각 단계(Stage) 마다 실행되어야 할 연산 단위를 쌍(Pair) 형태로 묶어서 모든 단계에서 수행되는 연산 단위 쌍을 획득한 어레이를 생성할 수 있다. 예를 들면, 한 개의 쌍은 (0, 1), (2, 4)와 같이 제1 연산 장치(예를 들면, Main-GPU)와 제2 연산 장치(예를 들면, Sub-GPU)에서 구동할 연산 단위의 인덱스가 묶음으로 포함되어 있으며, 이를 바탕으로 모듈 형태로 빌드할 수 있다. 이 후, 모듈이 할당된 연산 장치(GPU)에서 구동될 수 있다. 특정 단계에서의 연산 장치(GPU)에서 구동되는 연산이 없다면, (3, -1)과 같이 -1 값을 추가하여 단계별로 구동되는 연산 단위를 명확하게 구분할 수 있도록 한다.In the third stage, the graph scheduler can generate an array that obtains pairs of computational units performed in all stages by grouping computational units to be executed in each stage in the form of a pair in order to generate scheduling information in each computational unit (GPU). For example, one pair includes a bundle of indices of computational units to be driven in the first computational unit (e.g., Main-GPU) and the second computational unit (e.g., Sub-GPU), such as (0, 1) and (2, 4), and can be built in the form of a module based on this. After this, the module can be driven in the allocated computational unit (GPU). If there is no operation driven in the computational unit (GPU) in a specific stage, a -1 value is added, such as (3, -1), so that the computational unit driven in each stage can be clearly distinguished.
제4단계에서, 그래프 스케줄러는 미리 측정된 연산 시간 및 데이터 전달/복사 지연시간 등의 성능(Profiled Performance) 지표를 이용하여 복수 개의 서로 다른 연산 장치(GPU) 간의 데이터 이동 및 복사로 성능 측면에서 제2 연산 장치(예를 들면, Sub-GPU)에서 구동하는 것이 성능 개선이 아닌 손실에 기여한다면, 제1 연산 장치(예를 들면, Main-GPU)에서 구동할 수 있도록 각 연산 장치에 대한 연산 단위의 인덱스를 변경할 수 있다. 예를 들면, 그래프 스케줄러는 성능 지표를 이용하여 서로 다른 GPU에서 내부 데이터 이동에 따른 성능 측면에서 더 크다면 기존의 중요 경로에 대한 연산 단위의 인덱스로 변경할 수 있다. 이러한 탐색을 반복적으로 수행함에 따라 연산 단위를 구동하는데 있어, 인덱스 쌍들의 최적의 순서로 구성된 어레이를 도출할 수 있다.In the fourth step, the graph scheduler can change the index of the computational unit for each computational unit so that it can be driven on the first computational unit (e.g., Main GPU) if the performance of data movement and copying between multiple different computational units (GPUs) contributes to loss rather than performance improvement by driving on the second computational unit (e.g., Sub GPU) using the profiled performance indicators such as the pre-measured computation time and data transfer/copy latency. For example, the graph scheduler can change the index of the computational unit for the existing critical path if the performance due to internal data movement in different GPUs is greater using the performance indicators. By repeatedly performing this search, an array composed of the optimal order of index pairs can be derived for driving the computational units.
앞선 4단계로 구성된 스케줄링 과정으로 생성된 어레이 정보를 바탕으로 빌드 모듈에서 각 인덱스와 연결된 연산 단위를 묶어서 딥러닝 컴파일러를 기반으로 연산 장치(GPU)의 구조에 맞게 모듈을 생성할 수 있다. 할당된 연산 단위를 묶어서 TVM 프레임워크를 사용하여 연산 장치(GPU)의 구조에 맞게 빌드를 수행할 수 있다. 추론 데이터 셋이 사전에 학습된 데이터가 모듈을 통해 로드될 수 있다. 각 모듈을 연산 장치(GPU)에서 실행한 후, 그래프 정보를 바탕으로 각 모듈에서 도출된 출력값을 필요한 입력값을 가져올 수 있도록 어레이 형태로 저장할 수 있다. 각 연산 장치에서 연산 장치에 대한 인덱스에 기초하여 연산이 수행될 수 있다.Based on the array information generated by the scheduling process consisting of the previous four steps, the build module can be used to group the computational units associated with each index and generate a module according to the structure of the computational device (GPU) based on the deep learning compiler. The allocated computational units can be grouped and the build can be performed according to the structure of the computational device (GPU) using the TVM framework. The inference data set can be loaded through the module as pre-learned data. After executing each module on the computational device (GPU), the output values derived from each module can be stored in an array format so that the necessary input values can be obtained based on the graph information. In each computational device, an operation can be performed based on the index for the computational device.
도 1은 전체 딥러닝 추론(Inference)에서 연산을 수행하기 전에 연산 단위들의 실행 순서(Order)와 분배(distribution)를 수행하는 전체 과정의 일부분을 나타낸 것일 뿐, 이에 한정되는 것은 아니다.Figure 1 shows only a part of the entire process of performing the execution order and distribution of computational units before performing operations in the overall deep learning inference, but is not limited thereto.
도 2는 일 실시예에 따른 모델 추론 시스템에서 훈련된 모델, 데이터 셋, 정확도를 나타낸 표이다.FIG. 2 is a table showing a trained model, data set, and accuracy in a model inference system according to one embodiment.
실시예에 따른 결과를 보여주기 위해 CIFAR10, ImageNet 데이터 셋이 사용되어 네트워크 구조 Randomly Wired, NASNet이 사용될 수 있다. 네트워크 훈련을 위해 파이토치(Pytorch) 프레임워크가 사용될 수 있으며, 정확도 검증은 TVM 프레임워크를 이용하고, 파이선(Python)을 이용하여 스케줄러를 작성할 수 있다. 성능 측정을 위해 NVIDIA에서 제공하는 Profiler와 파이선 내장 Time API를 사용할 수 있다To show the results according to the embodiment, CIFAR10, ImageNet data sets are used, and network structures Randomly Wired and NASNet can be used. The Pytorch framework can be used for network training, the TVM framework can be used for accuracy verification, and the scheduler can be written using Python. For performance measurement, the Profiler provided by NVIDIA and the Python built-in Time API can be used.
도 2를 참고하면, 실시예에서 사용된 사전 훈련된(pre-trained) 모델, 데이터 셋, 정확도를 나타낸 표이다. Model Name에서의 WS, ER, BA는 각 모델에서 사용된 무작위 그래프를 의미하며, 순서대로 Watts-strogatz, Erdos-Renyi, Barabasi-Albert Graph Model을 의미한다. 도 2에 도시된 표는 실시예에서 사용된 스케줄러가 기존에 도출된 정확도를 훼손하지 않고, 보존된 상태에서 효과적으로 스케줄링 되었다는 점을 나타낸다.Referring to Fig. 2, a table showing the pre-trained models, data sets, and accuracies used in the embodiment is provided. WS, ER, and BA in the Model Name represent random graphs used in each model, and represent Watts-strogatz, Erdos-Renyi, and Barabasi-Albert Graph Models, respectively. The table shown in Fig. 2 shows that the scheduler used in the embodiment effectively scheduled without damaging the previously derived accuracy and in a preserved state.
도 3은 일 실시예에 따른 모델 추론 시스템에서 스케줄링 적용 전과 스케줄링 적용 후를 비교한 것을 나타낸 그래프이다.Figure 3 is a graph comparing before and after scheduling application in a model inference system according to one embodiment.
도 3은 실시예에서 NASNet-A-Mobile 모델과 2개의 GPU (NVIDIA GeForce RTX 2080Ti, 동종 2개) 에서 스케줄링 적용 전과 후를 비교하는 그래프이다. 그래프를 통해 실시예에서 제안된 스케줄러가 약 71.375%의 성능 향상이 있다는 것을 확인할 수 있다.Figure 3 is a graph comparing the NASNet-A-Mobile model and two GPUs (NVIDIA GeForce RTX 2080Ti, two of the same type) before and after applying scheduling in an embodiment. The graph shows that the scheduler proposed in the embodiment has a performance improvement of about 71.375%.
도 4는 일 실시예에 따른 모델 추론 시스템의 구성을 설명하기 위한 블록도이고, 도 5는 일 실시예에 따른 모델 추론 시스템에서 딥러닝 모델 추론 방법을 설명하기 위한 흐름도이다.FIG. 4 is a block diagram for explaining the configuration of a model inference system according to one embodiment, and FIG. 5 is a flowchart for explaining a deep learning model inference method in a model inference system according to one embodiment.
모델 추론 시스템(100)의 프로세서는 스케줄 생성부(410) 및 분배부(420)를 포함할 수 있다. 이러한 프로세서의 모델 추론 시스템에 저장된 프로그램 코드가 제공하는 제어 명령에 따라 프로세서에 의해 수행되는 서로 다른 기능들(different functions)의 표현들일 수 있다. 프로세서 및 프로세서의 구성요소들은 도 5의 딥러닝 모델 추론 방법이 포함하는 단계들(510 내지 520)을 수행하도록 모델 추론 시스템을 제어할 수 있다. 이때, 프로세서 및 프로세서의 구성요소들은 메모리가 포함하는 운영체제의 코드와 적어도 하나의 프로그램의 코드에 따른 명령(instruction)을 실행하도록 구현될 수 있다.The processor of the model inference system (100) may include a schedule generation unit (410) and a distribution unit (420). The different functions performed by the processor according to the control commands provided by the program code stored in the model inference system of the processor may be expressions of different functions. The processor and the components of the processor may control the model inference system to perform the steps (510 to 520) included in the deep learning model inference method of FIG. 5. At this time, the processor and the components of the processor may be implemented to execute instructions according to the code of the operating system included in the memory and the code of at least one program.
프로세서는 딥러닝 모델 추론 방법을 위한 프로그램의 파일에 저장된 프로그램 코드를 메모리에 로딩할 수 있다. 예를 들면, 모델 추론 시스템에서 프로그램이 실행되면, 프로세서는 운영체제의 제어에 따라 프로그램의 파일로부터 프로그램 코드를 메모리에 로딩하도록 모델 추론 시스템을 제어할 수 있다. 이때, 스케줄 생성부(410) 및 분배부(420) 각각은 메모리에 로딩된 프로그램 코드 중 대응하는 부분의 명령을 실행하여 이후 단계들(510 내지 520)을 실행하기 위한 프로세서의 서로 다른 기능적 표현들일 수 있다.The processor can load the program code stored in the program file for the deep learning model inference method into the memory. For example, when the program is executed in the model inference system, the processor can control the model inference system to load the program code from the program file into the memory under the control of the operating system. At this time, each of the schedule generation unit (410) and the distribution unit (420) can be different functional expressions of the processor for executing the instructions of the corresponding part of the program code loaded into the memory to execute subsequent steps (510 to 520).
단계(510)에서 스케줄 생성부(410)는 학습을 위해 생성된 그래프 정보로부터 연산 단위들의 핵심 경로(Critical Path)의 탐색을 통해 스케줄링 정보를 생성할 수 있다. 도 6을 참고하면, 스케줄링 동작을 설명하기 위한 흐름도이다. 단계(610)에서 스케줄 생성부(410)는 불규칙 뉴럴 네트워크 연산 학습을 위해 생성된 그래프 정보로부터 서로 다른 복수 개의 연산 장치에서 구동할 연산 단위들의 핵심 경로를 탐색하고, 탐색된 핵심 경로를 연산 단위의 인덱스로 구성된 어레이(Array)로 저장할 수 있다. 단계(620)에서 스케줄 생성부(410)는 저장된 핵심 경로의 어레이와 생성된 그래프 정보를 이용하여 위상 정렬(Topological Sort)을 수행하고, 수행된 위상 정렬을 통해 연산 단위의 인덱스를 저장한 각 연산 장치별 어레이를 생성할 수 있다. 단계(630)에서 스케줄 생성부(410)는 각 연산 장치에서 스케줄링 정보를 생성하기 위하여 각 동작에서 실행되어야 할 연산 단위를 쌍으로 묶어서 각 동작에서 수행되는 연산 단위의 쌍을 획득한 어레이를 생성할 수 있다. 단계(640)에서 스케줄 생성부(410)는 성능 지표를 이용하여 복수 개의 서로 다른 연산 장치 간의 데이터 이동 및 복사로 성능에 따라 각 연산 장치에 대한 연산 단위의 인덱스를 변경할 수 있다. 이때, 성능 지표는 기 지정된 지표를 이용할 수 있으며, 사전에 지정되어 있을 수 있다. 예를 들면, 스케줄 생성부(410)는 각 연산 장치 중 어느 하나의 연산 장치에 할당된 연산 단위가 연산 장치 간의 데이터 이동으로 인해 미리 측정된 연산 시간 및 데이터 전달과 데이터 복사 지연 시간을 포함하는 성능 지표를 이용하여 복수 개의 서로 다른 연산 장치 간의 데이터 이동 및 복사로 성능에 따라 각 연산 장치에 대한 연산 단위의 인덱스를 변경할 수 있다.In step (510), the schedule generation unit (410) can generate scheduling information by searching for critical paths of operation units from graph information generated for learning. Referring to FIG. 6, a flowchart for explaining a scheduling operation is provided. In step (610), the schedule generation unit (410) can search for critical paths of operation units to be driven in different operation devices from graph information generated for irregular neural network operation learning, and store the searched critical paths as an array composed of indexes of operation units. In step (620), the schedule generation unit (410) can perform topological sorting using the stored array of critical paths and the generated graph information, and can generate an array for each operation device that stores the indexes of operation units through the performed topological sorting. In step (630), the schedule generation unit (410) can generate an array that obtains pairs of operation units to be executed in each operation by pairing operation units to be executed in each operation in order to generate scheduling information in each operation device. In step (640), the schedule generation unit (410) can change the index of the computational unit for each computational device according to the performance of data movement and copying between the plurality of different computational devices by using the performance indicator. At this time, the performance indicator can use a pre-specified indicator and can be pre-specified. For example, the schedule generation unit (410) can change the index of the computational unit for each computational device according to the performance of data movement and copying between the plurality of different computational devices by using the performance indicator including the computation time and the data transmission and data copy delay time measured in advance due to data movement between the computational devices of the computational unit allocated to any one of the computational devices.
단계(520)에서 분배부(420)는 생성된 스케줄링 정보에 따라 할당된 연산 단위를 서로 다른 복수 개의 연산 장치에 분배할 수 있다. 분배부(420)는 생성된 스케줄링 정보 따라 딥러닝 모델 추론을 위한 연산 단위들의 실행 순서와 연산 단위들을 할당할 수 있다. 분배부(420)는 생성된 스케줄링 정보에 포함된 어레이 정보에 기초하여 각 연산 장치의 인덱스와 연결된 연산 단위를 묶어서 딥러닝 컴파일러를 기반으로 각 연산 장치의 구조에 따른 모듈을 생성하고, 생성된 모듈을 각 연산 장치에서 실행함에 따라 생성된 그래프 정보에 기초하여 각 모듈에서 출력값을 도출하고, 필요한 입력값을 가져올 수 있도록 도출된 출력값을 어레이로 저장할 수 있다.In step (520), the distribution unit (420) can distribute the allocated operation units to a plurality of different operation devices according to the generated scheduling information. The distribution unit (420) can allocate the execution order of the operation units and the operation units for deep learning model inference according to the generated scheduling information. The distribution unit (420) can group the operation units connected to the index of each operation device based on the array information included in the generated scheduling information, generate a module according to the structure of each operation device based on the deep learning compiler, and derive an output value from each module based on the generated graph information as the generated module is executed on each operation device, and store the derived output values as an array so that the required input values can be obtained.
이상에서 설명된 장치는 하드웨어 구성요소, 소프트웨어 구성요소, 및/또는 하드웨어 구성요소 및 소프트웨어 구성요소의 조합으로 구현될 수 있다. 예를 들어, 실시예들에서 설명된 장치 및 구성요소는, 예를 들어, 프로세서, 콘트롤러, ALU(arithmetic logic unit), 디지털 신호 프로세서(digital signal processor), 마이크로컴퓨터, FPGA(field programmable gate array), PLU(programmable logic unit), 마이크로프로세서, 또는 명령(instruction)을 실행하고 응답할 수 있는 다른 어떠한 장치와 같이, 하나 이상의 범용 컴퓨터 또는 특수 목적 컴퓨터를 이용하여 구현될 수 있다. 처리 장치는 운영 체제(OS) 및 상기 운영 체제 상에서 수행되는 하나 이상의 소프트웨어 애플리케이션을 수행할 수 있다. 또한, 처리 장치는 소프트웨어의 실행에 응답하여, 데이터를 접근, 저장, 조작, 처리 및 생성할 수도 있다. 이해의 편의를 위하여, 처리 장치는 하나가 사용되는 것으로 설명된 경우도 있지만, 해당 기술분야에서 통상의 지식을 가진 자는, 처리 장치가 복수 개의 처리 요소(processing element) 및/또는 복수 유형의 처리 요소를 포함할 수 있음을 알 수 있다. 예를 들어, 처리 장치는 복수 개의 프로세서 또는 하나의 프로세서 및 하나의 콘트롤러를 포함할 수 있다. 또한, 병렬 프로세서(parallel processor)와 같은, 다른 처리 구성(processing configuration)도 가능하다.The devices described above may be implemented as hardware components, software components, and/or a combination of hardware components and software components. For example, the devices and components described in the embodiments may be implemented using one or more general-purpose computers or special-purpose computers, such as, for example, a processor, a controller, an arithmetic logic unit (ALU), a digital signal processor, a microcomputer, a field programmable gate array (FPGA), a programmable logic unit (PLU), a microprocessor, or any other device capable of executing instructions and responding to them. The processing device may execute an operating system (OS) and one or more software applications running on the operating system. In addition, the processing device may access, store, manipulate, process, and generate data in response to the execution of the software. For ease of understanding, the processing device is sometimes described as being used alone, but those skilled in the art will appreciate that the processing device may include multiple processing elements and/or multiple types of processing elements. For example, the processing device may include multiple processors, or a processor and a controller. Other processing configurations, such as parallel processors, are also possible.
소프트웨어는 컴퓨터 프로그램(computer program), 코드(code), 명령(instruction), 또는 이들 중 하나 이상의 조합을 포함할 수 있으며, 원하는 대로 동작하도록 처리 장치를 구성하거나 독립적으로 또는 결합적으로(collectively) 처리 장치를 명령할 수 있다. 소프트웨어 및/또는 데이터는, 처리 장치에 의하여 해석되거나 처리 장치에 명령 또는 데이터를 제공하기 위하여, 어떤 유형의 기계, 구성요소(component), 물리적 장치, 가상 장치(virtual equipment), 컴퓨터 저장 매체 또는 장치에 구체화(embody)될 수 있다. 소프트웨어는 네트워크로 연결된 컴퓨터 시스템 상에 분산되어서, 분산된 방법으로 저장되거나 실행될 수도 있다. 소프트웨어 및 데이터는 하나 이상의 컴퓨터 판독 가능 기록 매체에 저장될 수 있다.The software may include a computer program, code, instructions, or a combination of one or more of these, which may configure a processing device to perform a desired operation or may independently or collectively command the processing device. The software and/or data may be embodied in any type of machine, component, physical device, virtual equipment, computer storage medium, or device for interpretation by the processing device or for providing instructions or data to the processing device. The software may be distributed over network-connected computer systems and stored or executed in a distributed manner. The software and data may be stored on one or more computer-readable recording media.
실시예에 따른 방법은 다양한 컴퓨터 수단을 통하여 수행될 수 있는 프로그램 명령 형태로 구현되어 컴퓨터 판독 가능 매체에 기록될 수 있다. 상기 컴퓨터 판독 가능 매체는 프로그램 명령, 데이터 파일, 데이터 구조 등을 단독으로 또는 조합하여 포함할 수 있다. 상기 매체에 기록되는 프로그램 명령은 실시예를 위하여 특별히 설계되고 구성된 것들이거나 컴퓨터 소프트웨어 당업자에게 공지되어 사용 가능한 것일 수도 있다. 컴퓨터 판독 가능 기록 매체의 예에는 하드 디스크, 플로피 디스크 및 자기 테이프와 같은 자기 매체(magnetic media), CD-ROM, DVD와 같은 광기록 매체(optical media), 플롭티컬 디스크(floptical disk)와 같은 자기-광 매체(magneto-optical media), 및 롬(ROM), 램(RAM), 플래시 메모리 등과 같은 프로그램 명령을 저장하고 수행하도록 특별히 구성된 하드웨어 장치가 포함된다. 프로그램 명령의 예에는 컴파일러에 의해 만들어지는 것과 같은 기계어 코드뿐만 아니라 인터프리터 등을 사용해서 컴퓨터에 의해서 실행될 수 있는 고급 언어 코드를 포함한다.The method according to the embodiment may be implemented in the form of program commands that can be executed through various computer means and recorded on a computer-readable medium. The computer-readable medium may include program commands, data files, data structures, etc., alone or in combination. The program commands recorded on the medium may be those specially designed and configured for the embodiment or may be those known to and available to those skilled in the art of computer software. Examples of the computer-readable recording medium include magnetic media such as hard disks, floppy disks, and magnetic tapes, optical media such as CD-ROMs and DVDs, magneto-optical media such as floptical disks, and hardware devices specially configured to store and execute program commands such as ROMs, RAMs, and flash memories. Examples of the program commands include not only machine language codes generated by a compiler, but also high-level language codes that can be executed by a computer using an interpreter, etc.
이상과 같이 실시예들이 비록 한정된 실시예와 도면에 의해 설명되었으나, 해당 기술분야에서 통상의 지식을 가진 자라면 상기의 기재로부터 다양한 수정 및 변형이 가능하다. 예를 들어, 설명된 기술들이 설명된 방법과 다른 순서로 수행되거나, 및/또는 설명된 시스템, 구조, 장치, 회로 등의 구성요소들이 설명된 방법과 다른 형태로 결합 또는 조합되거나, 다른 구성요소 또는 균등물에 의하여 대치되거나 치환되더라도 적절한 결과가 달성될 수 있다.Although the embodiments have been described above by way of limited examples and drawings, those skilled in the art can make various modifications and variations from the above description. For example, appropriate results can be achieved even if the described techniques are performed in a different order than the described method, and/or components of the described system, structure, device, circuit, etc. are combined or combined in a different form than the described method, or are replaced or substituted by other components or equivalents.
그러므로, 다른 구현들, 다른 실시예들 및 특허청구범위와 균등한 것들도 후술하는 특허청구범위의 범위에 속한다.Therefore, other implementations, other embodiments, and equivalents to the claims are also included in the scope of the claims described below.
Claims (15)
Translated fromKorean학습을 위해 생성된 그래프 정보로부터 연산 단위들의 핵심 경로(Critical Path)의 탐색을 통해 스케줄링 정보를 생성하는 단계; 및
상기 생성된 스케줄링 정보에 따라 할당된 연산 단위를 서로 다른 복수 개의 연산 장치에 분배하는 단계
를 포함하고,
상기 생성하는 단계는,
불규칙 뉴럴 네트워크 연산 학습을 위해 생성된 그래프 정보로부터 서로 다른 복수 개의 연산 장치에서 구동할 연산 단위들의 핵심 경로를 탐색하고, 상기 탐색된 핵심 경로를 연산 단위의 인덱스로 구성된 어레이(Array)로 저장하고, 상기 저장된 연산 단위의 인덱스로 구성된 어레이와 상기 생성된 그래프 정보를 이용하여 위상 정렬(Topological Sort)을 수행하고, 상기 수행된 위상 정렬을 통해 연산 단위의 인덱스를 저장한 각 연산 장치별 어레이를 생성하고, 각 연산 장치에서 스케줄링 정보를 생성하기 위하여 각 동작에서 실행되어야 할 연산 단위를 쌍으로 묶어서 상기 각 동작에서 수행되는 연산 단위의 쌍을 획득한 어레이를 생성하고, 미리 측정된 연산 시간 및 데이터 전달과 데이터 복사 지연 시간을 포함하는 성능 지표를 이용하여 복수 개의 서로 다른 연산 장치 간의 데이터 이동 및 복사로 인한 성능 비교를 통해 각 연산 장치에 대한 연산 단위의 인덱스를 변경하는 단계
를 포함하는 딥러닝 모델 추론 방법.In a deep learning model inference method performed by a model inference system,
A step of generating scheduling information by searching for the critical path of the computational units from the graph information generated for learning; and
A step of distributing the allocated operation units to multiple different operation devices according to the above-mentioned generated scheduling information.
Including,
The above generating steps are:
A step of searching for core paths of computational units to be driven on multiple different computational devices from graph information generated for irregular neural network computational learning, storing the searched core paths as an array composed of indices of computational units, performing a topological sort using the array composed of the stored indices of computational units and the generated graph information, generating an array for each computational device storing the indices of computational units through the performed topological sort, generating an array obtaining pairs of computational units to be executed in each operation by grouping computational units to be executed in each operation in order to generate scheduling information in each computational device, and changing the index of the computational unit for each computational device through a performance comparison due to data movement and copying between multiple different computational devices using a performance indicator including a pre-measured computation time and data transfer and data copy delay time.
A deep learning model inference method including:
상기 분배하는 단계는,
상기 생성된 스케줄링 정보 따라 딥러닝 모델 추론을 위한 연산 단위들의 실행 순서와 연산 단위들을 할당하는 단계
를 포함하는 딥러닝 모델 추론 방법.In the first paragraph,
The above distributing step is,
Step of allocating the execution order and operation units for deep learning model inference according to the above-mentioned generated scheduling information.
A deep learning model inference method including:
상기 분배하는 단계는,
상기 생성된 스케줄링 정보에 포함된 어레이 정보에 기초하여 각 연산 장치의 인덱스와 연결된 연산 단위를 묶어서 딥러닝 컴파일러를 기반으로 각 연산 장치의 구조에 따른 모듈을 생성하고, 상기 생성된 모듈을 상기 각 연산 장치에서 실행함에 따라 상기 생성된 그래프 정보에 기초하여 각 모듈에서 출력값을 도출하고, 필요한 입력값을 가져올 수 있도록 상기 도출된 출력값을 어레이로 저장하는 단계
를 포함하는 딥러닝 모델 추론 방법.In Article 6,
The above distributing step is,
A step of generating a module according to the structure of each computational device based on a deep learning compiler by grouping computational units linked to the index of each computational device based on array information included in the above-mentioned generated scheduling information, and deriving an output value from each module based on the generated graph information as the generated module is executed on each computational device, and storing the derived output value as an array so that the required input value can be obtained.
A deep learning model inference method including:
학습을 위해 생성된 그래프 정보로부터 연산 단위들의 핵심 경로(Critical Path)의 탐색을 통해 스케줄링 정보를 생성하는 스케줄 생성부; 및
상기 생성된 스케줄링 정보에 따라 할당된 연산 단위를 서로 다른 복수 개의 연산 장치에 분배하는 분배부
를 포함하고,
상기 스케줄 생성부는,
불규칙 뉴럴 네트워크 연산 학습을 위해 생성된 그래프 정보로부터 서로 다른 복수 개의 연산 장치에서 구동할 연산 단위들의 핵심 경로를 탐색하고, 상기 탐색된 핵심 경로를 연산 단위의 인덱스로 구성된 어레이(Array)로 저장하고, 상기 저장된 연산 단위의 인덱스로 구성된 어레이와 상기 생성된 그래프 정보를 이용하여 위상 정렬(Topological Sort)을 수행하고, 상기 수행된 위상 정렬을 통해 연산 단위의 인덱스를 저장한 각 연산 장치별 어레이를 생성하고, 각 연산 장치에서 스케줄링 정보를 생성하기 위하여 각 동작에서 실행되어야 할 연산 단위를 쌍으로 묶어서 상기 각 동작에서 수행되는 연산 단위의 쌍을 획득한 어레이를 생성하고, 미리 측정된 연산 시간 및 데이터 전달과 데이터 복사 지연 시간을 포함하는 성능 지표를 이용하여 복수 개의 서로 다른 연산 장치 간의 데이터 이동 및 복사로 인한 성능 비교를 통해 각 연산 장치에 대한 연산 단위의 인덱스를 변경하는
모델 추론 시스템.In model inference systems,
A schedule generation unit that generates scheduling information by searching for the critical path of the operation units from the graph information generated for learning; and
A distribution unit that distributes the allocated operation units to multiple different operation devices according to the above-mentioned generated scheduling information.
Including,
The above schedule generation section,
For irregular neural network operation learning, a core path of operation units to be driven on multiple different operation devices is searched for from graph information generated, and the searched core path is stored as an array composed of indexes of operation units, and a topological sort is performed using the array composed of the stored indexes of operation units and the generated graph information, and an array for each operation device storing the indexes of operation units is generated through the performed topological sort, and in order to generate scheduling information in each operation device, operation units to be executed in each operation are grouped into pairs to generate an array obtaining pairs of operation units to be performed in each operation, and the index of the operation unit for each operation device is changed through a performance comparison due to data movement and copying between multiple different operation devices using a performance indicator including a pre-measured operation time and data transmission and data copy delay time.
Model inference system.
상기 분배부는,
상기 생성된 스케줄링 정보 따라 딥러닝 모델 추론을 위한 연산 단위들의 실행 순서와 연산 단위들을 할당하는
것을 특징으로 하는 모델 추론 시스템.In Article 9,
The above distribution unit,
The execution order of the computational units and the allocation of computational units for deep learning model inference according to the above-mentioned generated scheduling information.
A model inference system characterized by:
상기 분배부는,
상기 생성된 스케줄링 정보에 포함된 어레이 정보에 기초하여 각 연산 장치의 인덱스와 연결된 연산 단위를 묶어서 딥러닝 컴파일러를 기반으로 각 연산 장치의 구조에 따른 모듈을 생성하고, 상기 생성된 모듈을 상기 각 연산 장치에서 실행함에 따라 상기 생성된 그래프 정보에 기초하여 각 모듈에서 출력값을 도출하고, 필요한 입력값을 가져올 수 있도록 상기 도출된 출력값을 어레이로 저장하는
것을 특징으로 하는 모델 추론 시스템.
In Article 14,
The above distribution unit,
Based on the array information included in the above-mentioned generated scheduling information, the computational units connected to the indexes of each computational device are grouped to generate a module according to the structure of each computational device based on a deep learning compiler, and as the generated module is executed on each computational device, an output value is derived from each module based on the generated graph information, and the derived output value is stored as an array so that the necessary input value can be obtained.
A model inference system characterized by:
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020210083671AKR102742714B1 (en) | 2021-06-28 | 2021-06-28 | Efficient multi-gpu based deep learning inference using critical-path-based scheduling |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020210083671AKR102742714B1 (en) | 2021-06-28 | 2021-06-28 | Efficient multi-gpu based deep learning inference using critical-path-based scheduling |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20230001132A KR20230001132A (en) | 2023-01-04 |
| KR102742714B1true KR102742714B1 (en) | 2024-12-16 |
Family
ID=84925218
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020210083671AActiveKR102742714B1 (en) | 2021-06-28 | 2021-06-28 | Efficient multi-gpu based deep learning inference using critical-path-based scheduling |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR102742714B1 (en) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20240148151A (en) | 2023-04-03 | 2024-10-11 | 고려대학교 산학협력단 | Method and apparatus for searching graph of deep learning model |
| CN118313458B (en)* | 2024-03-22 | 2025-07-08 | 上海壁仞科技股份有限公司 | Data processing method, data processor, electronic device, storage medium |
- 2021
- 2021-06-28KRKR1020210083671Apatent/KR102742714B1/enactiveActive
Non-Patent Citations (2)
| Title |
|---|
| Apolinar Velarde Martinez, "Scheduling in Heterogeneous Distributed Computing Systems Based on Internal Structure of Parallel Tasks Graphs with Meta-Heuristics," applied sciences (2020.09.22.)* |
| Tianqi Chen et al., "TVM: An Automated End-to-End Optimizing Compiler for Deep Learning," arXiv:1802.04799v3 [cs.LG] 5 Oct 2018 (2018.10.05.)* |
Also Published As
| Publication number | Publication date |
|---|---|
| KR20230001132A (en) | 2023-01-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6898496B2 (en) | Computation graph processing | |
| KR102860886B1 (en) | Scheduler, method for operating the same and accelerator system including the same | |
| KR102765048B1 (en) | Neural network instruction set architecture | |
| US11907770B2 (en) | Method and apparatus for vectorized resource scheduling in distributed computing systems using tensors | |
| KR102860332B1 (en) | Accelerator, method for operating the same and accelerator system including the same | |
| US12314851B2 (en) | Microservice-based training systems in heterogeneous graphic processor unit (GPU) cluster and operating method thereof | |
| US11809849B1 (en) | Global modulo allocation in neural network compilation | |
| JP2018533795A (en) | Stream based accelerator processing of calculation graph | |
| CN111488177A (en) | Data processing method, data processing device, computer equipment and storage medium | |
| KR102860210B1 (en) | Machine Learning Inference Time-spatial SW Scheduler Based on Multiple GPU | |
| JP2016042284A (en) | Parallel computer system, management device, method for controlling parallel computer system, and management device control program | |
| CN116680063B (en) | Task scheduling method, device, computing system, electronic equipment and storage medium | |
| KR102742714B1 (en) | Efficient multi-gpu based deep learning inference using critical-path-based scheduling | |
| Phillips et al. | A cuda implementation of the high performance conjugate gradient benchmark | |
| US12367076B2 (en) | Method for process allocation on multicore systems | |
| KR20230135923A (en) | Method and apparatus for configuring cluster for machine learning service | |
| CN119783812A (en) | Parallel training and reasoning optimization method for large models in next-generation heterogeneous supercomputers | |
| KR102831990B1 (en) | Microservice-based training systems in heterogeneous graphic processor unit(gpu) cluster and operating method thereof | |
| CN110415162B (en) | Adaptive Graph Partitioning Method for Heterogeneous Fusion Processors in Big Data | |
| Yan | Building a productive domain-specific cloud for big data processing and analytics service | |
| KR101470695B1 (en) | Method and system of biogeography based optimization for grid computing scheduling | |
| Czajkowski et al. | Hybrid parallelization of evolutionary model tree induction | |
| Yamashita et al. | Bulk execution of the dynamic programming for the optimal polygon triangulation problem on the GPU | |
| US20240169200A1 (en) | Profiling-based job ordering for distributed deep learning | |
| Bai et al. | Parallelization of matrix partitioning in hierarchical matrix construction on distributed memory systems |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application | Patent event code:PA01091R01D Comment text:Patent Application Patent event date:20210628 | |
| PA0201 | Request for examination | ||
| PG1501 | Laying open of application | ||
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection | Comment text:Notification of reason for refusal Patent event date:20240227 Patent event code:PE09021S01D | |
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration | Patent event code:PE07011S01D Comment text:Decision to Grant Registration Patent event date:20241022 | |
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment | Comment text:Registration of Establishment Patent event date:20241210 Patent event code:PR07011E01D | |
| PR1002 | Payment of registration fee | Payment date:20241211 End annual number:3 Start annual number:1 | |
| PG1601 | Publication of registration |