KR102484218B1 - Apparatus and method for validating results of similarity based classification model - Google Patents
Apparatus and method for validating results of similarity based classification modelDownload PDFInfo
- Publication number
- KR102484218B1 KR102484218B1KR1020220075119AKR20220075119AKR102484218B1KR 102484218 B1KR102484218 B1KR 102484218B1KR 1020220075119 AKR1020220075119 AKR 1020220075119AKR 20220075119 AKR20220075119 AKR 20220075119AKR 102484218 B1KR102484218 B1KR 102484218B1
- Authority
- KR
- South Korea
- Prior art keywords
- similarity
- classification model
- classification
- input data
- result
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images



Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/19—Recognition using electronic means
- G06V30/19007—Matching; Proximity measures
- G06V30/19093—Proximity measures, i.e. similarity or distance measures
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/19—Recognition using electronic means
- G06V30/191—Design or setup of recognition systems or techniques; Extraction of features in feature space; Clustering techniques; Blind source separation
- G06V30/1916—Validation; Performance evaluation
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/19—Recognition using electronic means
- G06V30/191—Design or setup of recognition systems or techniques; Extraction of features in feature space; Clustering techniques; Blind source separation
- G06V30/19173—Classification techniques
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Software Systems (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Computation (AREA)
- Medical Informatics (AREA)
- Data Mining & Analysis (AREA)
- Computing Systems (AREA)
- General Engineering & Computer Science (AREA)
- Mathematical Physics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Translated fromKoreanDescription
Translated fromKorean본 발명은 유사도 기반의 분류 모델 결과 검증 장치 및 방법에 관한 발명으로서, 더욱 상세하게는 분류 모델이 분류한 분류 결과의 검증을 수행하여 분류 모델이 정상적으로 동작하는지 여부를 평가하는 유사도 기반의 분류 모델 결과 검증 장치 및 방법에 관한 것이다.The present invention relates to an apparatus and method for verifying a classification model result based on similarity, and more particularly, by performing verification of a classification result classified by a classification model to evaluate whether or not the classification model operates normally. It relates to a verification device and method.
인공지능 시스템은 인간 수준의 지능을 구현하는 컴퓨터 시스템으로서 기계가 스스로 학습하고 판단하며, 사용할수록 인식률이 향상되는 시스템이다.An artificial intelligence system is a computer system that implements human-level intelligence, and a machine learns and judges itself, and the recognition rate improves as it is used.
인공지능 기술은 입력 데이터들의 특징을 스스로 분류/학습하는 알고리즘을 이용하는 기계학습(딥러닝) 기술 및 기계학습 알고리즘을 활용하여 인간 두뇌의 인지, 판단 등의 기능을 모사하는 요소 기술들로 구성된다.Artificial intelligence technology consists of machine learning (deep learning) technology using an algorithm that classifies/learns the characteristics of input data by itself, and elemental technologies that mimic functions such as recognition and judgment of the human brain using machine learning algorithms.
요소 기술들은, 예로, 인간의 언어/문자를 인식하는 언어적 이해 기술, 사물을 인간의 시각처럼 인식하는 시각적 이해 기술, 정보를 판단하여 논리적으로 추론하고 예측하는 추론/예측 기술, 인간의 경험 정보를 지식데이터로 처리하는 지식 표현 기술 및 차량의 자율 주행, 로봇의 움직임을 제어하는 동작 제어 기술 중 적어도 하나를 포함할 수 있다.Elemental technologies include, for example, linguistic understanding technology that recognizes human language/characters, visual understanding technology that recognizes objects as human eyes, reasoning/prediction technology that logically infers and predicts information by judging information, and human experience information. It may include at least one of a knowledge expression technology for processing as knowledge data and a motion control technology for controlling the autonomous driving of a vehicle and the movement of a robot.
일반적으로 분류 모델은 입력되는 데이터에 기반하여 클래스를 분류하기 위해 학습 데이터를 이용하여 생성될 수 있다.In general, a classification model may be created using training data to classify a class based on input data.
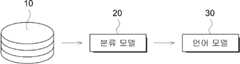
도1은 일반적인 분류 모델의 동작을 설명하기 위해 나타낸 예시도로서, 입력되는 데이터(10)는 다양한 파라미터가 설정된 상태의 분류 모델(20)에서 입력 데이터를 처리하고, 분류 결과와 지정된 값(예: 레이블)에 기반하여 파라미터를 조정함으로써 학습을 수행할 수 있다.1 is an exemplary diagram for explaining the operation of a general classification model. The
또한, 학습된 분류 모델(20)의 분류 결과는 언어 모델(30)의 입력으로 제공된다.In addition, the classification result of the learned
그러나, 레이블에 오류가 있는 경우 잘못된 결과에 대하여 학습을 수행함으로써, 오류를 갖는 분류 모델을 생성할 가능성이 있다.However, when there is an error in the label, there is a possibility of generating a classification model with an error by performing learning on an incorrect result.
예를 들어, 학습 데이터는 사람에 의하여 레이블링될 수 있으며, 인간의 실수에 의하여 잘못된 레이블이 학습 데이터에 부여될 가능성이 있어 해당 레이블에 대한 학습을 통해 제공되는 분류 모델의 분류 정확도가 저하될 가능성이 있다.For example, the training data may be labeled by a human, and there is a possibility that an incorrect label may be assigned to the training data due to human error, which reduces the classification accuracy of the classification model provided through learning on the corresponding label. there is.
또한, 분류 모델의 분류 정확도를 사람이 분석할 경우, 많은 시간과 비용이 발생하는 문제점이 있다.In addition, when a person analyzes the classification accuracy of the classification model, there is a problem in that a lot of time and cost are incurred.
또한, 분류 모델이 입력된 신규 데이터의 분류를 제대로 분류하는지 확인하는지 어려운 문제점이 있다.In addition, there is a difficult problem in checking whether the classification model correctly classifies the input new data.
이러한 문제점을 해결하기 위하여, 본 발명은 분류 모델이 분류한 분류 결과의 검증을 수행하여 분류 모델이 정상적으로 동작하는지 여부를 평가하는 유사도 기반의 분류 모델 결과 검증 장치 및 방법을 제공하는 것을 목적으로 한다.In order to solve this problem, an object of the present invention is to provide a similarity-based classification model result verification apparatus and method for evaluating whether or not the classification model operates normally by performing verification of the classification result classified by the classification model.
상기한 목적을 달성하기 위하여 본 발명의 일 실시 예는 유사도 기반의 분류 모델 결과 검증 장치로서, 임의의 입력 데이터에 대하여 분류 모델이 예측한 분류 결과를 이용하되, 상기 분류 결과에서 예측된 레이블(Lable)이 동일한 데이터들을 분류하여 분류된 데이터들 간의 유사도를 측정하고, 상기 예측된 레이블이 동일한 분류 데이터들 간의 유사도 측정 결과를 미리 설정된 기준 값과 비교하여 결과에 따라 상기 분류 모델이 정상적으로 동작하는지 여부를 평가하는 분류 모델 결과 검증부;를 포함한다.In order to achieve the above object, an embodiment of the present invention is a similarity-based classification model result verification device, using a classification result predicted by a classification model for arbitrary input data, but using a label predicted from the classification result (Label ) classifies the same data, measures the similarity between the classified data, compares the similarity measurement result between the classification data having the same predicted label with a preset reference value, and determines whether the classification model operates normally according to the result. It includes; a classification model result verification unit to be evaluated.
또한, 상기 실시 예에 따른 분류 모델 결과 검증부는 분류 모델이 입력 데이터에 대하여 예측한 분류 결과에서, 예측된 레이블이 동일한 분류 데이터들 간에 유사도를 측정하는 유사도 분석부; 및 상기 유사도의 측정 결과를 미리 설정된 분류 모델의 정상 동작 판단용 기준 값과 비교하여 상기 유사도 측정 결과가 기준 값 이상이면, 상기 분류 모델이 정상 동작하는 것으로 판단하는 성능 평가부;를 포함하는 것을 특징으로 한다.In addition, the classification model result verification unit according to the embodiment may include a similarity analyzer for measuring a similarity between classification data having the same predicted label in the classification result predicted by the classification model for the input data; and a performance evaluation unit that compares the similarity measurement result with a reference value for determining normal operation of a preset classification model, and determines that the classification model operates normally if the similarity measurement result is equal to or greater than the reference value. to be
또한, 상기 실시 예에 따른 유사도 분석부는 분류 모델이 입력 데이터에 대하여 예측한 분류 결과에서 예측된 레이블이 동일한 데이터 별로 분류하는 분류부; 및 상기 예측된 레이블이 동일한 분류 데이터들 간의 유사도를 측정하되, 트랜스포머 기반의 사전학습 언어 모델로 구성된 유사도 전용 언어 모델을 이용하여 추출되는 텍스트 데이터 간의 유사도를 측정하고, 상기 측정된 유사도의 평균값을 계산하는 유사도 계산부;를 포함하는 것을 특징으로 한다.In addition, the similarity analysis unit according to the embodiment includes a classification unit for classifying data having the same predicted label in the classification result predicted by the classification model for the input data; and measuring similarity between classification data having the same predicted label, using a similarity-only language model composed of a transformer-based pretraining language model to measure similarity between extracted text data, and calculating an average value of the measured similarity. It is characterized in that it comprises a; similarity calculator to.
또한, 본 발명의 일 실시 예는 유사도 기반의 분류 모델 결과 검증 방법으로서, a) 분류 모델 결과 검증부가 임의의 입력 데이터에 대하여 분류 모델이 예측한 분류 결과를 이용하되, 상기 분류 결과에서 예측된 레이블(Lable)이 동일한 데이터들을 분류하는 단계; b) 상기 분류 모델 결과 검증부가 예측된 레이블이 동일한 분류 데이터들 간의 유사도를 측정하는 단계; 및 c) 상기 분류 모델 결과 검증부(100)가 예측된 레이블이 동일한 분류 데이터들 간의 유사도 측정 결과를 미리 설정된 기준 값과 비교하고, 비교 결과에 따라 상기 분류 모델(20)이 정상적으로 동작하는지 여부를 평가하는 단계;를 포함한다.In addition, an embodiment of the present invention is a similarity-based classification model result verification method, a) a classification model result verification unit uses a classification result predicted by the classification model for arbitrary input data, and a label predicted from the classification result Classifying data having the same label; b) measuring a similarity between classification data items having the same predicted label by the classification model result verification unit; and c) the classification model
또한, 상기 실시 예에 따른 b) 단계의 유사도는 트랜스포머 기반의 사전학습 언어 모델로 구성된 유사도 전용 언어 모델을 이용하여 추출되는 텍스트 데이터 간의 유사도 평균값으로 계산되는 것을 특징으로 한다.In addition, the similarity in step b) according to the above embodiment is characterized in that it is calculated as an average value of similarity between text data extracted using a similarity-only language model composed of a transformer-based pre-learning language model.
또한, 상기 실시 예에 따른 c) 단계는 유사도 측정 결과가 기준 값 이상이면 상기 분류 모델을 정상으로 판단하는 것을 특징으로 한다.Further, step c) according to the embodiment is characterized in that the classification model is determined to be normal if the similarity measurement result is equal to or greater than a reference value.
본 발명은 분류 모델이 분류한 분류 결과의 검증을 수행하여 분류 모델이 정상적으로 동작하는지 여부를 평가할 수 있는 장점이 있다.The present invention has an advantage in that it is possible to evaluate whether or not the classification model operates normally by performing verification of classification results classified by the classification model.
또한, 본 발명은 실제 분류된 텍스트들끼리의 유사도 비교를 통해 분류 모델의 분류 결과에 대한 검증을 수행하여 분류 모델의 성능을 평가할 수 있는 장점이 있다.In addition, the present invention has the advantage of evaluating the performance of the classification model by performing verification of the classification result of the classification model through similarity comparison between actually classified texts.
도1은 일반적인 분류 모델의 동작을 설명하기 위해 나타낸 예시도.
도2는 본 발명의 일 실시 예에 따른 유사도 기반의 분류 모델 결과 검증 장치를 나타낸 블록도.
도3은 도2의 실시 예에 따른 유사도 기반의 분류 모델 결과 검증 장치의 유사도 분석부 구성을 나타낸 블록도.
도4는 본 발명의 일 실시 예에 따른 유사도 기반의 분류 모델 결과 검증 방법을 설명하기 위해 나타낸 흐름도.1 is an exemplary view illustrating the operation of a general classification model;
2 is a block diagram illustrating a similarity-based classification model result verification apparatus according to an embodiment of the present invention.
FIG. 3 is a block diagram showing the configuration of a similarity analyzer of the similarity-based classification model result verification device according to the embodiment of FIG. 2;
4 is a flowchart illustrating a similarity-based classification model result verification method according to an embodiment of the present invention.
이하에서는 본 발명의 바람직한 실시 예 및 첨부하는 도면을 참조하여 본 발명을 상세히 설명하되, 도면의 동일한 참조부호는 동일한 구성요소를 지칭함을 전제하여 설명하기로 한다.Hereinafter, the present invention will be described in detail with reference to preferred embodiments of the present invention and accompanying drawings, but the same reference numerals in the drawings will be described on the premise that they refer to the same components.
본 발명의 실시를 위한 구체적인 내용을 설명하기에 앞서, 본 발명의 기술적 요지와 직접적 관련이 없는 구성에 대해서는 본 발명의 기술적 요지를 흩뜨리지 않는 범위 내에서 생략하였음에 유의하여야 할 것이다.Prior to describing specific details for the implementation of the present invention, it should be noted that configurations not directly related to the technical subject matter of the present invention are omitted within the scope of not disturbing the technical subject matter of the present invention.
또한, 본 명세서 및 청구범위에 사용된 용어 또는 단어는 발명자가 자신의 발명을 최선의 방법으로 설명하기 위해 적절한 용어의 개념을 정의할 수 있다는 원칙에 입각하여 발명의 기술적 사상에 부합하는 의미와 개념으로 해석되어야 할 것이다.In addition, the terms or words used in this specification and claims are meanings and concepts consistent with the technical idea of the invention based on the principle that the inventor can define the concept of appropriate terms to best describe his/her invention. should be interpreted as
본 명세서에서 어떤 부분이 어떤 구성요소를 "포함"한다는 표현은 다른 구성요소를 배제하는 것이 아니라 다른 구성요소를 더 포함할 수 있다는 것을 의미한다.In this specification, the expression that a certain part "includes" a certain component means that it may further include other components, rather than excluding other components.
또한, "‥부", "‥기", "‥모듈" 등의 용어는 적어도 하나의 기능이나 동작을 처리하는 단위를 의미하며, 이는 하드웨어나 소프트웨어, 또는 그 둘의 결합으로 구분될 수 있다.In addition, terms such as ".. unit", ".. unit", and ".. module" refer to units that process at least one function or operation, which may be classified as hardware, software, or a combination of the two.
또한, "적어도 하나의" 라는 용어는 단수 및 복수를 포함하는 용어로 정의되고, 적어도 하나의 라는 용어가 존재하지 않더라도 각 구성요소가 단수 또는 복수로 존재할 수 있고, 단수 또는 복수를 의미할 수 있음은 자명하다 할 것이다.In addition, the term "at least one" is defined as a term including singular and plural, and even if at least one term does not exist, each component may exist in singular or plural, and may mean singular or plural. would be self-evident.
또한, 각 구성요소가 단수 또는 복수로 구비되는 것은, 실시 예에 따라 변경가능하다 할 것이다.In addition, the singular or plural number of each component may be changed according to embodiments.
이하, 첨부된 도면을 참조하여 본 발명의 일 실시 예에 따른 유사도 기반의 분류 모델 결과 검증 장치 및 방법의 바람직한 실시예를 상세하게 설명한다.Hereinafter, a preferred embodiment of a similarity-based classification model result verification apparatus and method according to an embodiment of the present invention will be described in detail with reference to the accompanying drawings.
도2는 본 발명의 일 실시 예에 따른 유사도 기반의 분류 모델 결과 검증 장치를 나타낸 블록도이고, 도3은 도2의 실시 예에 따른 유사도 기반의 분류 모델 결과 검증 장치의 유사도 분석부 구성을 나타낸 블록도이다.Figure 2 is a block diagram showing a similarity-based classification model result verification apparatus according to an embodiment of the present invention, Figure 3 is a similarity analysis unit configuration of the similarity-based classification model result verification apparatus according to the embodiment of FIG. It is a block diagram.
도2 및 도3을 참조하면, 본 발명의 일 실시 예에 따른 유사도 기반의 분류 모델 결과 검증 장치는 분류 모델(20)이 실제로 분류한 데이터(예를 들어, 텍스트)들끼리의 유사도 비교를 통해 분류 모델(20)의 분류 결과에 대한 검증을 수행함으로써, 분류 모델(20)의 성능을 평가할 수 있다.2 and 3, the similarity-based classification model result verification apparatus according to an embodiment of the present invention compares the similarity between data (eg, text) actually classified by the
분류 모델 결과 검증 장치는 임의의 입력 데이터(10)에 대하여 분류 모델(20)이 예측한 분류 결과를 이용하되, 상기 분류 결과에서 예측된 레이블(Lable)이 동일한 데이터들을 분류하고, 분류된 예측 레이블이 동일한 데이터들 간의 유사도를 측정하는 분류 모델 결과 검증부(100)를 포함하여 구성될 수 있다.The classification model result verification device uses the classification result predicted by the
또한, 분류 모델 결과 검증부(100)는 예측된 레이블이 동일한 분류 데이터들 간의 유사도 측정 결과를 미리 설정된 기준 값과 비교하여 결과에 따른 분류 모델(20)의 성능을 평가할 수 있다.In addition, the classification
이를 위해 분류 모델 결과 검증부(100)는 유사도 분석부(110)와, 성능 평가부(120)를 포함하여 구성될 수 있다.To this end, the classification model
또한, 분류 모델(20)의 성능 평가를 위해 입력되는 데이터는 레이블된 데이터일 수 있다.Also, data input for performance evaluation of the
유사도 분석부(110)는 특정 채널에서 신규 입력되는 데이터(10)에 대하여 분류 모델(20)이 예측한 분류 결과에서, 예측된 레이블이 동일한 분류 데이터들 간에 유사도를 측정하는 구성으로서, 분류부(111)와, 유사도 계산부(112)를 포함하여 구성될 수 있다.The
분류부(111)는 분류 모델(20)이 입력 데이터(10)에 대하여 예측한 분류 결과를 분석하여 예측된 레이블 별로 구분하고, 예측된 레이블이 동일한 데이터 별로 분류할 수 있다.The
예를 들어, 10개의 문서에 대하여 분류 모델(20)이 '상품', '고객 반응', '투자 상담' 등과 같이 레이블을 예측하여 분류하면, 분류부(111)는 예측된 레이블 별로 해당 문서의 텍스트 데이터들을 제1 분류부(111a), 제2 분류부(111b) 내지 제n 분류부(111c) 등에 분류하여 저장되도록 한다.For example, if the
또한, 분류부(111)는 분류 모델(20)의 분류 결과에 기반하여 분류한 예측 레이블이 '상품'인 경우, 분류 모델(20)이 '상품'으로 분류한 키워드 데이터들, 예를 들어, 입력 데이터(10)의 문서 내용이 'XXX 펀드의 목표 수익률을 안내 드림. 단기적인 자금 사용 예정으로 지금 가입중인 YYY 펀드는 해지하고 싶어함.'인 경우, 키워드인 'XXX 펀드', '안내 드림', 'YYY 펀드', '해지' 등을 저장할 수도 있다.In addition, when the prediction label classified based on the classification result of the
유사도 계산부(112)는 분류부(111)에서 분류된 예측 레이블이 동일한 분류 데이터들 간의 유사도를 측정하는 구성으로써, 예를 들어 '상품'으로 분류된 데이터들끼리의 텍스트적인 유사도를 계산한다.The
즉, 유사도 계산부(112)는 예를 들어 10개의 문서 데이터에 대한 분류 모델(20)의 분류 결과 중에서, '상품'으로 예측된 3개의 문서 데이터가 있는 경우, '상품'으로 분류된 3개의 문서에 포함된 텍스트 데이터들 간의 유사도를 분석한다.That is, the
예를 들어, 제1 문서는 'XXX 펀드의 목표 수익률을 안내 드림. 단기적인 자금 사용 예정으로 지금 가입중인 YYY 펀드는 해지하고 싶어함.'이고, 제2 문서는 '가입중인 YYY 펀드의 현재 수익률을 안내 드림. 추가 펀드에 대한 수익률을 문의함'이며, 제3 문서는 'XXX 펀드에 대한 목표 수익률을 안내 드림. 고객에게 추가 수익률에 대하여 안내 드림.'인 경우, 유사도 계산부(112)는 제1 내지 제3 문서들에 포함된 텍스트 데이터들 간의 유사도를 측정하여 측정 결과를 출력할 수 있다.For example, the first document is 'a guide to the target rate of return of the XXX fund. I want to cancel the YYY fund I am currently subscribed to for a short-term use of funds.' The second document is 'Information on the current rate of return of the YYY fund I am subscribed to. Inquiry about the rate of return for additional funds', and the third document is 'Guide you to the target rate of return for the XXX fund. In the case of 'Information about additional profit rate to the customer.', the
또한, 유사도 계산부(112)는 제1 내지 제3 문서들에 포함된 'XXX 펀드', 'YYY 펀드', '목표 수익률', '해지', '현재 수익률', '추가 펀드', '문의함', '추가 수익률' 등의 키워드 데이터를 추출하여 유사도를 계산할 수도 있다.In addition, the
또한, 유사도 계산부(112)는 제1 내지 제3 문서 데이터에 대하여 문서 내의 텍스트 값들을 벡터 값으로 변환한 임베딩 벡터를 산출할 수 있다.Also, the
이때, 임베딩 벡터는 빈도 기반의 TF-IDF(Term Frequency - Inverse Document Frequency)를 통해 산출될 수 있다.In this case, the embedding vector may be calculated through frequency-based term frequency-inverse document frequency (TF-IDF).
또한, TF-IDF는 문서 별로 주요 키워드에 빈도 기반 가중치를 주어 자동으로 주요 키워드를 설정할 수 있고, 문서 별로 등장하는 주요 키워드가 한정적인 타겟 데이터에 적절한 임베딩(Embedding)을 제공할 수도 있다.In addition, TF-IDF can automatically set main keywords by giving frequency-based weights to main keywords for each document, and can provide appropriate embedding for target data in which main keywords appearing in each document are limited.
또한, 유사도 계산부(112)는 단어의 빈도를 벡터로 사용하여 단어-문서 행렬(Term-Document Matrix)로 제공할 수도 있다.Also, the
또한, 유사도 계산부(112)는 제1 내지 제3 문서 데이터의 임베딩 매트릭스 간의 행렬 연산을 통해 각 문서 간의 유사도 행렬을 산출할 수 있다.Also, the
즉, 제1 내지 제3 문서 데이터의 임베딩 벡터 값을 사용해 벡터간 각도의 코사인 값에 기반한 코사인 유사도를 계산하여 벡터의 유사도를 측정할 수 있다.That is, the similarity of the vectors may be measured by calculating the cosine similarity based on the cosine value of the angle between the vectors using the embedding vector values of the first to third document data.
또한, 유사도 계산부(112)는 분류 모델(20)이 예측한 레이블 중에서 입력 데이터(10)의 레이블과 동일하지 않은 레이블의 데이터들 사이의 유사도를 측정할 수도 있다.Also, the
또한, 유사도 계산부(112)는 측정된 텍스트 데이터 간의 유사도 측정 결과 값의 평균 값을 계산하여 출력할 수 있다.Also, the
즉, 유사도 계산부(112)는 모든 벡터들을 더한 후 벡터의 개수로 나눈 값으로 평균 값을 산출하여, 분류 모델(20)이 정상적으로 동작하지 않아 예측 레이블을 잘못 분류하면 각 벡터들의 격차가 크게 발생하거나 또는 이상치를 갖는 벡터로 인해 평균 값에 영향을 준 결과가 반영될 수 있도록 한다.That is, the
또한, 유사도 계산부(112)는 미리 저장된 유사도 전용 언어 모델을 이용하여 제1 내지 제3 문서 데이터 사이의 유사도를 측정할 수도 있다.Also, the
유사도 전용 언어 모델은 트랜스포머 기반의 사전학습 언어 모델로 구성될 수 있고, 범용 데이터(General data)로 학습한 모델보다 특정 도메인, 또는 특정 회사 등에서 사용하는 텍스트 데이터로 학습한 사전학습 언어 모델로 구성될 수 있다.Similarity-only language models can be composed of transformer-based pre-trained language models, and rather than models trained with general data, they can be composed of pre-trained language models trained with text data used by specific domains or specific companies. can
유사도 계산부(112)는 이러한 유사도 전용 언어 모델을 이용하여 텍스트 데이터, 키워드 데이터 등을 추출하고, 추출된 데이터들을 기반으로 문서(또는 문장) 데이터 간의 유사도 계산을 수행함으로써, 빠른 속도와 정확한 예측 성능을 제공할 수 있다.The
성능 평가부(120)는 유사도 계산부(112)에서 출력되는 유사도의 측정 결과 값을 미리 설정된 분류 모델의 정상 동작 판단용 기준 값과 비교하여 결과에 따라 분류 모델(20)의 정상 또는 비정상을 판단할 수 있다.The
이때, 성능 평가부(120)는 입력 데이터(10)의 레이블과 분류 모델(20)에서 예측한 레이블이 동일하고, 예측된 레이블이 동일한 데이터들 간의 유사도 측정 결과 값이 기준 값 이상이면, 분류 모델(20)의 성능이 정상 동작하는 것으로 평가할 수 있다.At this time, if the label of the
또한, 성능 평가부(120)는 분류 모델(20)이 예측한 레이블 중에서 입력 데이터(10)의 레이블과 동일하지 않은 레이블의 데이터들 사이의 유사도 측정 결과를 분류 모델의 정상 동작 판단용 기준 값과 비교하여 기준 값 이상이면, 분류 모델(20)의 성능이 정상 동작하는 것으로 평가할 수도 있다.In addition, the
즉, 성능 평가부(120)는 데이터들 간의 유사도 측정 결과 값이 높을 수록 분류 모델(20)이 정상으로 동작하고 있는 것으로 판단하고, 반대인 경우 분류 모델(20)이 정상적으로 동작하지 않는 것으로 판단할 수 있다.That is, the
다음은 본 발명의 일 실시 예에 따른 유사도 기반의 분류 모델 결과 검증 방법을 설명한다.Next, a similarity-based classification model result verification method according to an embodiment of the present invention will be described.
도4는 본 발명의 일 실시 예에 따른 유사도 기반의 분류 모델 결과 검증 방법을 설명하기 위해 나타낸 흐름도이다.4 is a flowchart illustrating a similarity-based classification model result verification method according to an embodiment of the present invention.
도2 내지 도4를 참조하면, 본 발명의 일 실시 예에 따른 유사도 기반의 분류 모델 결과 검증 방법은 분류 모델 결과 검증부(100)가 레이블된 임의의 입력 데이터(10)에 대하여 분류 모델(20)이 예측한 분류 결과를 입력(S100)받아 예측된 레이블(Lable)이 동일한 데이터들을 분류(S200)한다.2 to 4, in the similarity-based classification model result verification method according to an embodiment of the present invention, the classification model
분류 모델 결과 검증부(100)는 S200 단계에서 분류 모델(20)에 의해 예측된 레이블이 동일한 분류 데이터들 간의 유사도를 측정(S300)한다.The classification model
S300 단계에서 분류 모델 결과 검증부(100)는 분류 모델(20)이 레이블된 입력 데이터(10)에 대해 예측한 분류 결과를 분석하여 예측된 레이블 별로 구분하고, 예측된 레이블이 동일한 데이터 별로 분류할 수 있다.In step S300, the classification model
또한, 분류 모델 결과 검증부(100)는 분류된 예측 레이블이 동일한 분류 데이터들 간의 유사도를 측정하여 동일 레이블로 분류된 데이터들 끼리의 텍스트적인 유사도를 계산한다.In addition, the classification model
또한, S300 단계에서 분류 모델 결과 검증부(100)는 분류 모델(20)이 예측한 레이블 중에서 입력 데이터(10)의 레이블과 동일하지 않은 레이블의 데이터들 사이의 유사도를 측정할 수도 있다.In addition, in step S300 , the classification model
또한, 분류 모델 결과 검증부(100)는 유사도를 측정한 텍스트 데이터 간의 유사도 측정 결과 값의 평균값을 계산하여 출력할 수 있다.In addition, the classification model
계속해서, 분류 모델 결과 검증부(100)는 예측된 레이블이 동일한 분류 데이터들 간의 유사도 측정 결과를 미리 설정된 기준 값과 비교하고, 비교 결과에 따라 상기 분류 모델(20)이 정상적으로 동작하는지 여부를 평가(S400)한다.Subsequently, the classification model
S400 단계에서, 분류 모델 결과 검증부(100)는 입력 데이터(10)의 레이블과 분류 모델(20)에서 예측한 레이블이 동일하고, 예측된 레이블이 동일한 데이터들 간의 유사도 측정 결과 값이 정상 동작 판단용 기준 값 이상이면, 분류 모델(20)의 성능이 정상 동작하는 것으로 평가할 수 있다.In step S400, the classification model
또한, 분류 모델 결과 검증부(100)는 분류 모델(20)이 예측한 레이블 중에서 입력 데이터(10)의 레이블과 동일하지 않은 레이블, 즉 예측된 레이블이 다른 데이터들의 유사도 측정을 수행하고, 각 수행 결과에 따라 산출되는 유사도 측정 결과 값을 분류 모델의 정상 동작 판단용 기준 값과 비교한 결과가 정상 동작 판단용 기준 값 이상이면, 분류 모델(20)이 정상 동작하는 것으로 분류 모델(20)의 성능을 평가할 수도 있다.In addition, the classification model
즉, S400 단계에서 분류 모델 결과 검증부(100)는 예측된 레이블의 데이터들 간의 유사도 측정 결과 값이 높을수록 분류 모델(20)이 정상으로 동작하고 있는 것으로 판단할 수 있다.That is, in step S400 , the classification model
따라서, 분류 모델 결과 검증부는 분류 모델이 실제로 분류한 텍스트 데이터들끼리의 유사도 비교를 통해 분류 모델의 분류 결과에 대한 검증을 수행함으로써, 분류 모델의 성능을 평가할 수 있다.Accordingly, the classification model result verification unit may evaluate the performance of the classification model by performing verification of the classification result of the classification model through similarity comparison between text data actually classified by the classification model.
상기와 같이, 본 발명의 바람직한 실시 예를 참조하여 설명하였지만 해당 기술 분야의 숙련된 당업자라면 하기의 특허청구범위에 기재된 본 발명의 사상 및 영역으로부터 벗어나지 않는 범위 내에서 본 발명을 다양하게 수정 및 변경시킬 수 있음을 이해할 수 있을 것이다.As described above, although it has been described with reference to the preferred embodiments of the present invention, those skilled in the art will variously modify and change the present invention within the scope not departing from the spirit and scope of the present invention described in the claims below. You will understand that it can be done.
또한, 본 발명의 특허청구범위에 기재된 도면번호는 설명의 명료성과 편의를 위해 기재한 것일 뿐 이에 한정되는 것은 아니며, 실시예를 설명하는 과정에서 도면에 도시된 선들의 두께나 구성요소의 크기 등은 설명의 명료성과 편의상 과장되게 도시되어 있을 수 있다.In addition, the drawing numbers described in the claims of the present invention are only described for clarity and convenience of explanation, but are not limited thereto, and in the process of describing the embodiments, the thickness of lines or the size of components shown in the drawings, etc. may be exaggerated for clarity and convenience of description.
또한, 상술된 용어들은 본 발명에서의 기능을 고려하여 정의된 용어들로서 이는 사용자, 운용자의 의도 또는 관례에 따라 달라질 수 있으므로, 이러한 용어들에 대한 해석은 본 명세서 전반에 걸친 내용을 토대로 내려져야 할 것이다.In addition, the above-mentioned terms are terms defined in consideration of functions in the present invention, which may change according to the intention or custom of the user or operator, so the interpretation of these terms should be made based on the contents throughout this specification. .
또한, 명시적으로 도시되거나 설명되지 아니하였다 하여도 본 발명이 속하는 기술분야에서 통상의 지식을 가진 자가 본 발명의 기재사항으로부터 본 발명에 의한 기술적 사상을 포함하는 다양한 형태의 변형을 할 수 있음은 자명하며, 이는 여전히 본 발명의 권리범위에 속한다.In addition, even if it is not explicitly shown or described, a person skilled in the art to which the present invention belongs can make various modifications from the description of the present invention to the technical idea according to the present invention. Obviously, it is still within the scope of the present invention.
또한, 첨부하는 도면을 참조하여 설명된 상기의 실시예들은 본 발명을 설명하기 위한 목적으로 기술된 것이며 본 발명의 권리범위는 이러한 실시예에 국한되지 아니한다.In addition, the above embodiments described with reference to the accompanying drawings are described for the purpose of explaining the present invention, and the scope of the present invention is not limited to these embodiments.
10 : 데이터
20 : 분류 모델
100 : 분류 모델 결과 검증부
110 : 유사도 분석부
111 : 분류부
111a : 제1 분류부
111b : 제2 분류부
111c : 제n 분류부
112 : 유사도 계산부
120 : 성능 평가부10: data
20: classification model
100: classification model result verification unit
110: similarity analysis unit
111: classification unit
111a: first classification unit
111b: second classification unit
111c: nth classification unit
112: similarity calculator
120: performance evaluation unit
Claims (6)
Translated fromKorean상기 분류 모델(20)의 분류 결과에서 예측된 레이블이 동일한 입력 데이터(10) 별로 분류하고, 상기 분류된 입력 데이터(10)들 간의 유사도를 측정하며, 상기 유사도의 측정 결과를 미리 설정된 기준 값과 비교하여 결과에 따라 상기 분류 모델(20)이 입력 데이터(10)를 정상적으로 분류하는지 여부를 평가하는 분류 모델 결과 검증부(100);를 포함하는 유사도 기반의 분류 모델 결과 검증 장치.A classification model 20 that performs classification on arbitrary input data 10, predicts a label for the input data 10, and classifies the input data 10 according to the predicted label; and
In the classification result of the classification model 20, each input data 10 having the same predicted label is classified, the similarity between the classified input data 10 is measured, and the measurement result of the similarity is compared with a preset reference value. A classification model result verification unit (100) that evaluates whether the classification model (20) classifies the input data (10) normally according to the comparison result; a classification model result verification device based on similarity.
상기 분류 모델 결과 검증부(100)는 상기 분류 모델(20)의 분류 결과에서 예측된 레이블이 동일한 입력 데이터(10) 별로 분류하고, 상기 분류된 입력 데이터(10)들 간의 유사도를 측정하는 유사도 분석부(110); 및
상기 유사도의 측정 결과를 미리 설정된 분류 모델의 정상 동작 판단용 기준 값과 비교하여 상기 유사도 측정 결과가 기준 값 이상이면, 상기 분류 모델(20)이 입력 데이터(10)를 정상적으로 분류하는 것으로 판단하는 성능 평가부(120);를 포함하는 것을 특징으로 하는 유사도 기반의 분류 모델 결과 검증 장치.According to claim 1,
The classification model result verification unit 100 classifies each input data 10 having the same label predicted from the classification result of the classification model 20, and analyzes similarity to measure the similarity between the classified input data 10. section 110; and
Performance of comparing the similarity measurement result with a reference value for determining normal operation of a preset classification model and determining that the classification model 20 classifies the input data 10 normally if the similarity measurement result is equal to or greater than the reference value Evaluation unit 120; Similarity-based classification model result verification device comprising a.
상기 유사도 분석부(110)는 상기 분류 모델(20)의 분류 결과에서 예측된 레이블이 동일한 입력 데이터(10) 별로 분류하여 제1 분류부(111a), 제2 분류부(111b) 내지 제n 분류부(111c) 중 어느 하나에 저장하는 분류부(111); 및
상기 예측된 레이블이 동일한 분류 데이터들 간의 유사도를 측정하되, 트랜스포머 기반의 사전학습 언어 모델로 구성된 유사도 전용 언어 모델을 이용하여 추출되는 텍스트 데이터 간의 유사도를 측정하고, 상기 측정된 유사도의 평균값을 계산하는 유사도 계산부(112);를 포함하는 것을 특징으로 하는 유사도 기반의 분류 모델 결과 검증 장치.According to claim 2,
The similarity analysis unit 110 classifies the input data 10 having the same label predicted from the classification result of the classification model 20, and classifies the first classification unit 111a, the second classification unit 111b to nth classification. a classification unit 111 that is stored in any one of the units 111c; and
Measuring similarity between classification data having the same predicted label, measuring similarity between extracted text data using a similarity-only language model composed of a transformer-based pretraining language model, and calculating an average value of the measured similarity A similarity-based classification model result verification device comprising a similarity calculation unit 112.
b) 분류 모델 결과 검증부(100)가 상기 분류 모델(20)의 분류 결과에서 예측된 레이블이 동일한 입력 데이터(10) 별로 분류하고, 상기 분류된 입력 데이터(10)들 간의 유사도를 측정하는 단계; 및
c) 상기 분류 모델 결과 검증부(100)가 상기 유사도 측정 결과를 미리 설정된 기준 값과 비교하고, 비교 결과에 따라 상기 분류 모델(20)이 입력 데이터(10)를 정상적으로 분류하는지 여부를 평가하는 단계;를 포함하는 유사도 기반의 분류 모델 결과 검증 방법.a) The classification model 20 performs classification on arbitrary input data 10, predicts a label for the input data 10, and converts the input data 10 according to the predicted label. classifying;
b) Classifying, by the classification model result verification unit 100, each input data 10 having the same label predicted from the classification result of the classification model 20, and measuring a similarity between the classified input data 10 ; and
c) comparing, by the classification model result verification unit 100, the similarity measurement result with a preset reference value, and evaluating whether the classification model 20 normally classifies the input data 10 according to the comparison result A similarity-based classification model result verification method including ;
상기 b) 단계의 유사도는 트랜스포머 기반의 사전학습 언어 모델로 구성된 유사도 전용 언어 모델을 이용하여 추출되는 텍스트 데이터 간의 유사도 평균값으로 계산되는 것을 특징으로 하는 유사도 기반의 분류 모델 결과 검증 방법.According to claim 4,
The similarity in step b) is calculated as an average value of similarity between text data extracted using a similarity-only language model composed of a transformer-based pre-learning language model.
상기 c) 단계는 유사도 측정 결과가 기준 값 이상이면 상기 분류 모델(20)이 입력 데이터(10)를 정상적으로 분류하는 것으로 판단하는 것을 특징으로 하는 유사도 기반의 분류 모델 결과 검증 방법.According to claim 4,
In the step c), if the similarity measurement result is equal to or greater than a reference value, it is determined that the classification model 20 classifies the input data 10 normally.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020220075119AKR102484218B1 (en) | 2022-06-20 | 2022-06-20 | Apparatus and method for validating results of similarity based classification model |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020220075119AKR102484218B1 (en) | 2022-06-20 | 2022-06-20 | Apparatus and method for validating results of similarity based classification model |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR102484218B1true KR102484218B1 (en) | 2023-01-04 |
Family
ID=84924895
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020220075119AActiveKR102484218B1 (en) | 2022-06-20 | 2022-06-20 | Apparatus and method for validating results of similarity based classification model |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR102484218B1 (en) |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20150049511A (en)* | 2013-10-30 | 2015-05-08 | 삼성에스디에스 주식회사 | Apparatus and method for classifying data and system for collecting data of using the same |
| KR20200131185A (en) | 2019-05-13 | 2020-11-23 | 삼성전자주식회사 | Method for verifying and learning of classification result using verification neural network, and computing device for performing the method |
| KR20210119041A (en)* | 2020-03-24 | 2021-10-05 | 경북대학교 산학협력단 | Device and Method for Cluster-based duplicate document removal |
| KR20220001204A (en)* | 2020-06-29 | 2022-01-05 | (주)휴톰 | Method, electronic device and program for estimating annotator and ananlyzing anotation using a plurarity of traning models |
- 2022
- 2022-06-20KRKR1020220075119Apatent/KR102484218B1/enactiveActive
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20150049511A (en)* | 2013-10-30 | 2015-05-08 | 삼성에스디에스 주식회사 | Apparatus and method for classifying data and system for collecting data of using the same |
| KR20200131185A (en) | 2019-05-13 | 2020-11-23 | 삼성전자주식회사 | Method for verifying and learning of classification result using verification neural network, and computing device for performing the method |
| KR20210119041A (en)* | 2020-03-24 | 2021-10-05 | 경북대학교 산학협력단 | Device and Method for Cluster-based duplicate document removal |
| KR20220001204A (en)* | 2020-06-29 | 2022-01-05 | (주)휴톰 | Method, electronic device and program for estimating annotator and ananlyzing anotation using a plurarity of traning models |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11734519B2 (en) | Systems and methods for slot relation extraction for machine learning task-oriented dialogue systems | |
| Bishop | Neural networks for pattern recognition | |
| CN111881722B (en) | Cross-age face recognition method, system, device and storage medium | |
| KR102413518B1 (en) | Multy classification system and method using secondary verification | |
| CN111027717A (en) | Model training method and system | |
| CN118885611B (en) | Enterprise business management method and system based on big data | |
| Somogyi | The Application of Artificial Intelligence | |
| Guidotti et al. | Verification and repair of neural networks: a progress report on convolutional models | |
| CN119049682B (en) | Medical asset management big data analysis method and system | |
| Bharti et al. | How confident was your reviewer? estimating reviewer confidence from peer review texts | |
| Montesuma et al. | Lighter, better, faster multi-source domain adaptation with gaussian mixture models and optimal transport | |
| KR102484218B1 (en) | Apparatus and method for validating results of similarity based classification model | |
| KR102575603B1 (en) | User review analysis device by artificial intelligence and method thereof | |
| US20240232626A1 (en) | Machine learning based file ranking methods and systems | |
| Roisenzvit | From Euclidean distance to spatial classification: unraveling the technology behind GPT models | |
| Laurelli | Adaptive meta-domain transfer learning (AMDTL): A novel approach for knowledge transfer in AI | |
| KR102403428B1 (en) | Dpression measurement device by artificial intelligence | |
| Padró-Ferragut et al. | Noise Tolerance and Robustness Ranking in Machine Learning Models | |
| Sheth et al. | Causal domain generalization | |
| Bałazy et al. | r-softmax: Generalized Softmax with Controllable Sparsity Rate | |
| US20230289533A1 (en) | Neural Topic Modeling with Continuous Learning | |
| Gönç et al. | User feedback-based online learning for intent classification | |
| Sowndarya et al. | KEYWORD BASED HYBRID APPROACH FOR ASPECT BASED SENTIMENT ANALYSIS OF COURSE FEEDBACK DATA IN EDUCATION. | |
| CN119441445B (en) | Interaction method, device and medium based on AIGC robots | |
| US12008080B1 (en) | Apparatus and method for directed process generation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application | St.27 status event code:A-0-1-A10-A12-nap-PA0109 | |
| PA0201 | Request for examination | St.27 status event code:A-1-2-D10-D11-exm-PA0201 | |
| PA0302 | Request for accelerated examination | St.27 status event code:A-1-2-D10-D17-exm-PA0302 St.27 status event code:A-1-2-D10-D16-exm-PA0302 | |
| D13-X000 | Search requested | St.27 status event code:A-1-2-D10-D13-srh-X000 | |
| D14-X000 | Search report completed | St.27 status event code:A-1-2-D10-D14-srh-X000 | |
| PE0902 | Notice of grounds for rejection | St.27 status event code:A-1-2-D10-D21-exm-PE0902 | |
| P11-X000 | Amendment of application requested | St.27 status event code:A-2-2-P10-P11-nap-X000 | |
| P13-X000 | Application amended | St.27 status event code:A-2-2-P10-P13-nap-X000 | |
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration | St.27 status event code:A-1-2-D10-D22-exm-PE0701 | |
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment | St.27 status event code:A-2-4-F10-F11-exm-PR0701 | |
| PR1002 | Payment of registration fee | St.27 status event code:A-2-2-U10-U11-oth-PR1002 Fee payment year number:1 | |
| PG1601 | Publication of registration | St.27 status event code:A-4-4-Q10-Q13-nap-PG1601 | |
| R18-X000 | Changes to party contact information recorded | St.27 status event code:A-5-5-R10-R18-oth-X000 |