KR102421159B1 - The methods and systems of copyright infringement analysis through similarity analysis of contents which created by users in virtual reality modeling the real world - Google Patents
The methods and systems of copyright infringement analysis through similarity analysis of contents which created by users in virtual reality modeling the real worldDownload PDFInfo
- Publication number
- KR102421159B1 KR102421159B1KR1020210172838AKR20210172838AKR102421159B1KR 102421159 B1KR102421159 B1KR 102421159B1KR 1020210172838 AKR1020210172838 AKR 1020210172838AKR 20210172838 AKR20210172838 AKR 20210172838AKR 102421159 B1KR102421159 B1KR 102421159B1
- Authority
- KR
- South Korea
- Prior art keywords
- content
- unit
- metaverse
- data
- similarity
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images








Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q50/00—Information and communication technology [ICT] specially adapted for implementation of business processes of specific business sectors, e.g. utilities or tourism
- G06Q50/10—Services
- G06Q50/18—Legal services
- G06Q50/184—Intellectual property management
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q30/00—Commerce
- G06Q30/06—Buying, selling or leasing transactions
- G06Q30/0601—Electronic shopping [e-shopping]
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T19/00—Manipulating 3D models or images for computer graphics
- G06T19/003—Navigation within 3D models or images
Landscapes
- Engineering & Computer Science (AREA)
- Business, Economics & Management (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Software Systems (AREA)
- Economics (AREA)
- Marketing (AREA)
- Strategic Management (AREA)
- General Business, Economics & Management (AREA)
- General Health & Medical Sciences (AREA)
- Tourism & Hospitality (AREA)
- Technology Law (AREA)
- General Engineering & Computer Science (AREA)
- Accounting & Taxation (AREA)
- Finance (AREA)
- Health & Medical Sciences (AREA)
- Evolutionary Computation (AREA)
- Molecular Biology (AREA)
- Remote Sensing (AREA)
- Computer Graphics (AREA)
- Computer Hardware Design (AREA)
- Mathematical Physics (AREA)
- Entrepreneurship & Innovation (AREA)
- Operations Research (AREA)
- Computing Systems (AREA)
- Radar, Positioning & Navigation (AREA)
- Data Mining & Analysis (AREA)
- Human Resources & Organizations (AREA)
- Computational Linguistics (AREA)
- Primary Health Care (AREA)
- Biophysics (AREA)
- Biomedical Technology (AREA)
- Artificial Intelligence (AREA)
- Life Sciences & Earth Sciences (AREA)
- Development Economics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Translated fromKoreanDescription
Translated fromKorean본 발명은 컨텐츠의 유사도 분석을 통한 저작권 침해 분석 방법 및 시스템에 관한 것으로서, 보다 상세하게는 사용자들이 현실세계 혹은 메타버스 등의 가상현실에서 컨텐츠를 창작하고, 창작된 컨텐츠를 등록하고 공유하는 과정에서 컨텐츠의 특징점을 추출하고, 유사도를 분석하여 저작권의 침해 정도를 분석하는 방법 및 시스템에 관한 것이다.The present invention relates to a method and system for analyzing copyright infringement through similarity analysis of content, and more particularly, in the process of creating content in virtual reality such as the real world or metaverse, and registering and sharing the created content by users. It relates to a method and system for extracting feature points of content and analyzing the degree of copyright infringement by analyzing the degree of similarity.
최근 실감 미디어에 대한 사용자 욕구의 증가로 사실감과 몰입감, 입체감을 줄 수 있는 실감 미디어 표출 및 음향 시스템이 중요한 연구분야로 고려되고 있다.With the recent increase in users' desire for sensory media, sensory media expression and sound systems that can provide realism, immersion, and three-dimensional effect are being considered as important research fields.
이러한 서비스를 위하여 1차적으로 가상현실과 게임, 사용자 상호간의 인터렉티브 기술과, 거래의 안정성을 위한 블럭체인 기술, 그리고 네트웍 및 서버 운영기술이 필요하다.For these services, virtual reality and games, interactive technology between users, block chain technology for transaction stability, and network and server operation technology are required.
특히, 최근 컴퓨터 그래픽 기술을 응용한 가상현실(Virtual Reality), 증강현실(Augmented Reality) 및 혼합현실(Mixed Reality) 기술이 발달하고 있다.In particular, recently, virtual reality, augmented reality, and mixed reality technologies to which computer graphic technology is applied have been developed.
이때, 가상현실 기술은 컴퓨터를 이용하여 현실 세계에 존재하지 않는 가상 공간을 구축한 후 그 가상공간을 현실처럼 느끼게 하는 기술을 말하고, 증강현실 또는 혼합현실 기술은 현실 세계 위에 컴퓨터에 의해 생성된 정보를 덧붙여 표현하는 기술, 즉 현실 세계와 가상 세계를 결합함으로써 실시간으로 사용자와 상호작용이 이루어지도록 하는 기술을 말한다.At this time, virtual reality technology refers to a technology that uses a computer to build a virtual space that does not exist in the real world and makes the virtual space feel like reality, and augmented reality or mixed reality technology is information generated by a computer on the real world. It refers to a technology that expresses the user in real time by combining the real world and the virtual world.
이들 중 증강현실과 혼합현실 기술은 다양한 분야의 기술들과 접목되어 활용되고 있다.Among them, augmented reality and mixed reality technologies are being used in combination with technologies in various fields.
예를 들면, TV에서 일기 예보를 하는 기상 캐스터 앞의 날씨 지도가 자연스럽게 바뀌는 경우나, 스포츠 중계에서 경기장에 존재하지 않는 광고 이미지를 경기장에 실제로 존재하는 것처럼 화면에 삽입하여 송출하는 경우가 방송 기술 분야에 증강현실 기술이 접목되어 활용된 대표적인 예이다. 특히, 이러한 증강현실과 혼합현실 기술은 스마트폰(Smart phone)의 등장과 함께 다양한 응용 서비스로 구현되어 제공되고 있다.For example, when the weather map in front of a weather caster who forecasts the weather on TV changes naturally, or when an advertisement image that does not exist in the stadium is inserted and transmitted on the screen as if it actually exists in the stadium during sports broadcasting, the broadcasting technology field It is a representative example of the application of augmented reality technology to the In particular, these augmented reality and mixed reality technologies are being implemented and provided as various application services with the advent of smart phones.
그리고, 증강현실 또는 혼합현실을 사용자에게 제공하는 대표적인 서비스로서, 메타버스(Meta-verse)가 있다. 이 메타버스는 가공, 추상을 의미하는 '메타(Meta)'와 현실세계를 의미하는 '유니버스(Universe)'의 합성어로 3차원 가상세계를 의미한다. 메타버스는 기존의 가상현실 환경(Virtual reality environment)이라는 용어보다 진보된 개념으로서, 웹과 인터넷 등의 가상세계가 현실세계에 흡수된 증강현실 환경을 제공한다.In addition, as a representative service that provides augmented reality or mixed reality to users, there is a meta-verse. This metaverse is a compound word of 'Meta', meaning fictitious and abstract, and 'Universe', meaning the real world, meaning a three-dimensional virtual world. Metaverse is a more advanced concept than the conventional virtual reality environment, and provides an augmented reality environment in which the virtual world such as the web and the Internet is absorbed into the real world.
이러한 메타버스 서비스 시스템에서는 현실세계 체험 솔루션 기술인 온라인과 오프라인 가상체험을 연계하여 쌍방향의 가상체험 공간의 데이터 공유와 네트웍을 통한 가상체험 솔루션을 사용자에게 제공한다.In this metaverse service system, by linking online and offline virtual experience, which are real world experience solution technologies, data sharing of interactive virtual experience space and virtual experience solution through network are provided to users.
이러한 메타버스 플랫폼안에서 가상체험 솔루션은 사용자에게 오프라인의 공간적, 시간적, 나이, 성별에 따른 불편함을 해소시킬 수 있으며, 사용자가 자신의 아이템을 획득 및 판매하여 네트웍 공간안에서의 생태계가 만들어지는 특징을 갖는다.In this metaverse platform, the virtual experience solution can solve the inconvenience of offline spatial, temporal, age, and gender for users, and users acquire and sell their own items to create an ecosystem in the network space. have
그리고, 메타버스 플랫폼에 의하여 가상체험 솔루션을 제공하기 위한 다양한 기술이 개발되고 있는 바, 예를 들면, 사용자가 온라인상에서 박물관, 전시관, 체험관을 간접적으로 체험해 볼 수 있는 기술이다.In addition, various technologies for providing virtual experience solutions are being developed by the metaverse platform, for example, a technology that allows users to indirectly experience museums, exhibition halls, and experience halls online.
또한, 이러한 메타버스 플랫폼에서는 보안을 위한 블록체인 기술과, 가상공간에서의 소통을 위한 공간이 필요하다, 예를 들면, 일반적인 SNS 플랫폼에서와 같이 개인의 클럽이나 샵을 만들고, 이에 대한 아이템 적용, SNS 안에서의 체험과 게임, 그리고 광고 및 게임에 대한 포인트가 안전하게 적립될 수 있는 공간이 필요하다.In addition, in this metaverse platform, block chain technology for security and a space for communication in a virtual space are required. For example, as in a general SNS platform, create a personal club or shop, apply items, There is a need for a space where points can be safely accumulated for experiences, games, advertisements and games within SNS.
이와 더불어, 스마트 Glass, VR 기기, 3D 안경 입체 영상 기술이 발전하여 머리에 장착하거나 안경처럼 착용하여 사용할 수 있는 모니터에 영상을 디스플레이함으로서 게임이나 다양한 응용분야에서 사용될 수 있는 실감영상 표출 및 가상현실에 적용할 수 있는 컨텐츠 제작 및 협업에 의한 컨텐츠 제작에 대한 기술적 연구 및 상용화를 위한 연구개발이 진행되고 있다.In addition, smart glass, VR devices, and 3D glasses stereoscopic image technology has been developed to display images on a monitor that can be worn on the head or worn like glasses, so that it can be used in games and various applications to express realistic images and virtual reality. R&D for technical research and commercialization of applicable content production and content production by collaboration is in progress.
그러나, 종래의 이러한 가상현실 혹은 메타버스 기술은 다음과 같은 문제점이 있다.However, the conventional virtual reality or metaverse technology has the following problems.
첫째, 사용자 단독 또는 협업에 의한 다양한 컨텐츠 공유 및 소비를 위한 플랫폼에서 창작물의 지식재산권에 대한 보호 및 권리 침해에 대하여 지원하는 시스템이 없으며, 빅데이터 분석에 의하여 창작물의 지식재산권의 보호 및 지식재산권에 대한 권리 침해 정도의 분석을 지원하지 못한다는 문제점이 있다.First, there is no system that supports protection of intellectual property rights and infringement of copyrights of creations on platforms for sharing and consuming various contents by users alone or by collaboration, There is a problem in that it cannot support analysis of the degree of infringement of rights.
둘째, 복합 가상현실에서 사용자가 창작한 창작물에 대하여 지식재산권, 지식재산권 침해 등의 창작물(이미지, 사운드, 영상 ,게임 등의 컨텐츠)에 대한 권리를 분석하지 못하므로 다양한 창작물을 거래하지 못한다는 한계가 있으며, 이를 통한 투자와 판매 수익을 분배하고, 매매하기 위한 서비스를 지원하지 못한다는 한계가 있다.Second, the limitation of not being able to trade in various creative works because the rights to creative works (contents such as images, sounds, videos, games, etc.) There is a limit in that it cannot support services for distributing investment and sales profits through this, and for trading.
따라서, 본 발명은 이와 같은 문제점을 해결하기 위하여 안출된 것으로서, 본 발명의 목적은, 사용자들이 현실세계 혹은 메타버스 등의 가상현실에서 창작한 컨텐츠를 등록하고, 공유하는 과정에서 컨텐츠의 특징점을 추출하고, 유사도를 분석하여 저작권의 침해 정도를 분석하는 시스템을 보여주는 기술을 제공하는 것이다.Accordingly, the present invention has been devised to solve such a problem, and an object of the present invention is to extract feature points of content in the process of registering and sharing content created in virtual reality, such as the real world or metaverse, by users. and to provide a technology showing a system that analyzes the degree of copyright infringement by analyzing the degree of similarity.
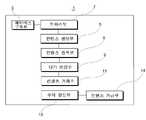
상기한 목적을 달성하기 위하여, 본 발명의 일 실시예는,In order to achieve the above object, an embodiment of the present invention,
가상현실 세계에서 거래되는 다양한 유, 무형의 자산에 대한 정보를 등록 및 관리하고, 영상 및 메타데이터를 수집하고, 수집된 데이터를 전처리한 후 인공지능 알고리즘에 의하여 실시간 분석하고 분류하며, 아이템 혹은 새로운 데이터를 3D 모델링하고, 복합 메타버스 가상현실 공간에 유형의 아이템을 표출하는 메타버스 구축부(3)와;Registers and manages information on various tangible and intangible assets traded in the virtual reality world, collects images and metadata, pre-processes the collected data, and then analyzes and categorizes it in real time by an artificial intelligence algorithm. a metaverse constructing
복합 메타버스 가상현실에서 창작물을 생성하는 컨텐츠 생성부(5);a
컨텐츠 생성부(5)에서 생성된 메타버스 컨텐츠를 인공지능 분석에 의하여 창작물의 표절, 저작권 위배 여부, 컨텐츠와 관련된 정보를 등록하는 컨텐츠 등록부(8);a
컨텐츠 등록부(57)에 의하여 등록된 메타버스 컨텐츠의 단가를 연산하는 단가 연산부(9);a unit
온라인상에서 메타버스 컨텐츠에 대한 거래를 진행시키는 컨텐츠 거래소(11)와; 그리고a
컨텐츠 거래소(11)를 통하여 공표되거나 거래된 메타버스 데이터의 수익을 정산하는 수익 정산부(13)를 포함하며;a
컨텐츠 등록부(57)는 새로 등록예정인 메타버스 컨텐츠와 기존 메타버스 컨텐츠를 비교하는 유사도 분석모듈(45)과; 그리고The
유사도 분석결과에 따라 지재권의 침해여부를 판단하는 침해 판단모듈(47)을 포함하는 컨텐츠의 유사도 분석을 통한 저작권 침해 분석 시스템을 제공한다.A system for analyzing copyright infringement through similarity analysis of content including a
본 발명의 다른 실시예는,Another embodiment of the present invention is
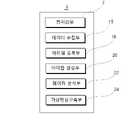
생성된 컨텐츠가 입력되는 입력부(53)와;an
입력된 컨텐츠를 분류하여 특징점을 추출하는 특징점 추출부(55)와;a feature
컨텐츠에 대한 전처리를 실시하는 전처리부(57)와;a pre-processing
컨텐츠 데이터에 시퀀스 처리를 실시하는 시퀀스 변환부(59)와;a
새로 등록예정인 컨텐츠와 기존 등록 컨텐츠를 비교하는 유사도 분석모듈(45)과; 그리고a
유사도 분석결과에 따라 지재권의 침해여부를 판단하는 침해 판단모듈(47)을 포함하는 컨텐츠의 유사도 분석을 통한 저작권 침해 분석 시스템(1)을 제공한다.A copyright infringement analysis system (1) is provided through the similarity analysis of contents including a violation determination module (47) for determining whether intellectual property rights are infringed according to the similarity analysis result.
상기한 바와 같이 본 발명의 일 실시예에 따른 시스템은, 사용자들이 현실세계 혹은 메타버스 등의 가상현실에서 창작한 컨텐츠를 등록하고, 공유하는 과정에서 컨텐츠의 특징점을 추출하고, 유사도를 분석하여 저작권의 침해 정도를 분석할 수 있다.As described above, in the system according to an embodiment of the present invention, users register and share content created in virtual reality such as the real world or metaverse, extract feature points of the content, and analyze the similarity to obtain copyright The degree of infringement can be analyzed.
도 1은 본 발명의 일 실시예에 따른 가상현실 컨텐츠의 유사도 분석을 통한 저작권 침해 분석시스템의 전체 구조를 개략적으로 보여주는 도면이다.
도 2는 도 1에 도시된 메타버스 컨텐츠를 생성하기 위한 서버의 구조를 개략적으로 보여주는 도면이다.
도 3은 도 1에 도시된 시스템의 구조를 개략적으로 보여주는 블록도이다.
도 4는 도 1에 도시된 AI 데이터 수집기의 구조를 개략적으로 보여주는 블록도이다.
도 5는 도 1에 도시된 메타버스 구축부의 구조를 개략적으로 보여주는 블록도이다.
도 6은 도 5에 도시된 컨텐츠 등록부의 구조를 개략적으로 보여주는 블록도이다.
도 7은 아이템 및 컨텐츠 거래 과정을 보여주는 순서도이다.
도 8은 도 2의 유사 분석부에서 인공 지능에 의하여 유사도를 판단하는 과정을 개략적으로 보여주는 도면이다.
도 9는 본 발명의 다른 실시예로서 컨텐츠의 유사도 분석을 통한 저작권 침해 분석시스템의 전체 구조를 개략적으로 보여주는 도면이다.
도 10은 문서의 유사도 분석과정을 개략적으로 보여주는 도면이다.
도 11은 음향의 유사도 분석과정을 개략적으로 보여주는 도면이다.
도 12는 컨텐츠의 유사도 분석 및 침해 분석과정을 보여주는 순서도이다.1 is a diagram schematically showing the overall structure of a copyright infringement analysis system through similarity analysis of virtual reality contents according to an embodiment of the present invention.
FIG. 2 is a diagram schematically showing the structure of a server for generating the metaverse content shown in FIG. 1 .
FIG. 3 is a block diagram schematically showing the structure of the system shown in FIG. 1 .
FIG. 4 is a block diagram schematically showing the structure of the AI data collector shown in FIG. 1 .
FIG. 5 is a block diagram schematically showing the structure of the metaverse constructing unit shown in FIG. 1 .
6 is a block diagram schematically showing the structure of the content registration unit shown in FIG.
7 is a flowchart illustrating an item and content transaction process.
FIG. 8 is a diagram schematically illustrating a process of determining the degree of similarity by artificial intelligence in the similarity analysis unit of FIG. 2 .
9 is a diagram schematically showing the overall structure of a system for analyzing copyright infringement through similarity analysis of content as another embodiment of the present invention.
10 is a diagram schematically showing a similarity analysis process of documents.
11 is a diagram schematically illustrating a sound similarity analysis process.
12 is a flowchart showing the similarity analysis and infringement analysis process of content.
이하, 본 발명에 따른 컨텐츠의 유사도 분석을 통한 저작권 침해 분석 방법 및 시스템을 첨부된 도면을 참조하여 상세하게 설명한다.Hereinafter, a method and system for analyzing copyright infringement through similarity analysis of content according to the present invention will be described in detail with reference to the accompanying drawings.
본 발명은 컨텐츠를 생성 및 등록하고, 네트워크 상에서 거래를 진행하며, 컨텐츠 거래에 대한 수익을 정산하고, 또한 유사한 커텐츠를 식별하여 저작권 침해여부를 판단하는 시스템에 관한 것으로서, 컨텐츠는 메타버스 컨텐츠와 일반 컨텐츠, 즉 음향, 영상, 이미지 컨텐츠로 구분하여 설명한다.The present invention relates to a system that generates and registers content, conducts a transaction on a network, settles revenue for content transaction, and determines whether or not copyright is infringed by identifying similar content. The general contents, ie, sound, video, and image contents, will be divided and explained.
실시예 1 (메타버스 컨텐츠의 저작권 침해 분석 시스템)Example 1 (Metaverse Content Copyright Infringement Analysis System)
도 1 내지 도 8에 도시된 바와 같이, 본 발명이 제안하는 메타버스 컨텐츠의 유사도 분석을 통한 저작권 침해 분석 시스템(1)은, 컨텐츠 관련한 정보를 입출력하는 단말기(2)와, 각종 데이터를 수집하는 센서, 카메라 등의 디바이스(6)와, 이 단말기(2)와 네트워크에 의하여 연결되어 메타버스 컨텐츠를 생성, 관리하고, 거래 및 수익을 정산하며, 저작권 침해여부를 판단하는 서버(4)로 구성된다.1 to 8, the
이러한 메타버스 컨텐츠의 저작권 침해 분석 시스템에 있어서,In this metaverse content copyright infringement analysis system,
서버(4)는, 가상현실 세계에서 거래되는 다양한 유, 무형의 자산에 대한 정보를 등록 및 관리하고, 영상 및 메타데이터를 수집하고, 수집된 데이터를 전처리한 후 인공지능 알고리즘에 의하여 실시간 분석하고 분류하며, 아이템 혹은 새로운 데이터를 3D 모델링하고, 복합 메타버스 가상현실 공간에 유형의 아이템을 표출하는 메타버스 구축부(3)와;The
복합 메타버스 가상현실에서 창작물을 생성하는 컨텐츠 생성부(5);a
컨텐츠 생성부(5)에서 생성된 메타버스 컨텐츠를 인공지능 분석에 의하여 창작물의 표절, 저작권 위배 여부, 컨텐츠와 관련된 정보를 등록하는 컨텐츠 등록부(8);a
컨텐츠 등록부(7)에 의하여 등록된 메타버스 컨텐츠의 단가를 연산하는 단가 연산부(9);a unit
온라인상에서 메타버스 컨텐츠에 대한 거래를 진행시키는 컨텐츠 거래소(11)와;a
컨텐츠 거래소(11)를 통하여 공표되거나 거래된 메타버스 데이터의 수익을 정산하는 수익 정산부(13)를 포함한다.and a
이러한 서버에 있어서,In such a server,
메타버스 구축부(3)는 유무형의 아이템 정보와, 영상, 메타 데이터를 수집, 분류, 분석하여 아이템을 생성하고, 생성된 아이템과 유무형의 아이템 정보를 매칭하여 복합 메타버스 가상현실 공간을 구축한다.The
보다 상세하게 설명하면,In more detail,
메타버스 구축부(3)는, 현실 세계에서 거래되는 다양한 유, 무형의 자산에 대한 정보를 등록하고, 저장 관리되는 아이템 등록부(18)와;The
상기 사용자의 카메라, IoT 센서와 이동형 3D 스캐너로부터 GIS 및 GPS 기반의 실시간 위치에 따라 수신되는 영상 및 메타데이터를 수집하는 데이터 수집부(15)와;a
상기 수집된 데이터를 전처리 한 후 인공지능 알고리즘에 의하여 실시간 분석하고 분류하는 데이터 분석부(22)와;a
상기 데이터 분석부(22)를 통하여 수신된 각종 영상 및 메타데이터를 이용하여 2D 또는 3D 영상으로 등록된 아이템 혹은 새로운 데이터를 3D 모델링하는 아이템 생성부(20)와;an
상기 아이템 생성부(20)에서 모델링된 아이템(건물, 자동차, 시설물, 제품, 상품 등)과 상기 아이템 등록부(18)에서 매칭된 아이템 제품 정보를 연결하여 복합 메타버스 가상현실 공간에 유형의 아이템을 표출하는 복합 메타버스 가상현실 구축부(3)를 포함한다.By linking the item (building, vehicle, facility, product, product, etc.) modeled in the
아이템 등록부(18)는 기존에 생성된 다양한 데이터, 예를 들면 음향 데이터, 영상 데이터, 3D 데이터, 메타버스 데이터 등을 서버의 DB에 저장하고 관리한다.The
그리고 데이터 수집부(15)는 새로운 데이터를 생성하는 바, 예를 들면 카메라, IoT 센서, 이동형 3D 스캐너 등에 의하여 데이터를 생성 및 수집하게 된다.And the
이때, 새로 수집된 데이터는 GIS 및 GPS 기반의 실시간 위치 정보가 추가된다.In this case, real-time location information based on GIS and GPS is added to the newly collected data.
그리고, 데이터 분석부(22)는 수집된 데이터를 전처리 한 후 인공지능 알고리즘에 의하여 실시간 분석하고 분류하게 된다.Then, the
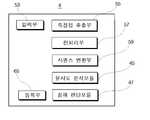
전처리부(7)는 입력된 데이터에 반사광, 화각, Dust 및 노이즈 제거를 진행함으로써 전처리를 진행한다.The
빅데이터(big data) 분석, 데이터 마이닝(data mining)을 위해서는 각 알고리즘의 요구사항에 따라 전처리된 데이터가 필수적이다. 따라서 수집된 데이터들을 목적에 맞게 효과적으로 가공해야 한다.For big data analysis and data mining, preprocessed data according to the requirements of each algorithm is essential. Therefore, it is necessary to effectively process the collected data according to the purpose.
이를 위해 전처리부(7)는 데이터의 측정 오류를 줄이고 잡음(noise), 왜곡, 편차 최소화, 정밀도, 정확도, 이상 값(outlier), 결측 값(missing value), 모순, 불일치, 중복 등을 해소한다.To this end, the
보다 상세하게 설명하면, 전처리부(7)는 도 2에 도시된 바와 같이, 영상 컨텐츠 전처리 모듈(17)과, 이미지 컨텐츠 전처리 모듈(19)과, 메타정보 전처리 모듈(21)과, 음원 컨텐츠 전처리 모듈(23)을 포함하며, 중앙 처리장치와 연결되어 신호를 송수신한다.In more detail, as shown in FIG. 2 , the
따라서, 이러한 전처리부(7)는 데이터 정제(cleansing), 데이터 변환(transformation), 데이터 필터링(filtering), 데이터 통합(integration), 데이터 축소(reduction) 과정을 포함한다.Accordingly, the
데이터 정제(cleansing)는 결측 값(missing value; 빠진 데이터)들을 채워 넣고, 이상치를 식별 또는 제거하고, 잡음 섞인 데이터를 평활화(smoothing)하여 데이터의 불일치성을 교정하는 과정이다.Data cleaning is a process of correcting inconsistencies in data by filling in missing values, identifying or removing outliers, and smoothing noisy data.
데이터 변환(transformation)은 데이터 유형 변환 등 데이터 분석이 쉬운 형태로 변환하는 과정으로서, 정규화(normalization), 집합화(aggregation), 요약(summarization), 계층 생성 등의 방식을 적용한다.Data transformation is a process of converting data into a form that is easy to analyze, such as data type transformation, and methods such as normalization, aggregation, summarization, and layer creation are applied.
데이터 필터링(filtering)은 오류 발견, 보정, 삭제 및 중복성 확인 등의 과정을 통해 데이터의 품질을 향상하는 과정이다.Data filtering is a process of improving data quality through processes such as error detection, correction, deletion, and redundancy check.
데이터 통합(integration)은 데이터 분석이 용이하도록 유사 데이터 및 연계가 필요한 데이터들을 통합하는 과정이다.Data integration is a process of integrating similar data and data requiring linkage to facilitate data analysis.
데이터 축소(reduction)는 분석 시간을 단축할 수 있도록 데이터 분석에 활용되지 않는 항목 등을 제거하는 과정이다.Data reduction is a process of removing items that are not used for data analysis in order to shorten the analysis time.
따라서, 영상 컨텐츠 전처리 모듈(17)과, 이미지 컨텐츠 전처리 모듈(19)과, 메타정보 전처리 모듈(21)과, 음원 컨텐츠 전처리 모듈(23)은 메타 데이터, 영상 데이터, 이미지 데이터, 음원 데이터에 대한 데이터 정제(cleansing), 데이터 변환(transformation), 데이터 필터링(filtering), 데이터 통합(integration), 데이터 축소(reduction) 과정을 진행한다.Accordingly, the image
이와 같이 전처리부(7)에 데이터를 전처리한 후, 아이템 생성부(20)에 의하여 각종 영상 및 메타데이터를 이용하여 2D 또는 3D 영상으로 등록된 아이템 혹은 새로운 데이터를 3D 모델링한다.After the data is pre-processed by the
이러한 아이템 생성부(20)에서는 평면상의 영상 및 메타 데이터를 3D 데이터로 변환하게 된다.The
즉, 아이템 생성부(20)에는 3D 모델링을 위한 소프트웨어가 탑재되며, 입력된 2차원 데이터값을 분석한 후 컴퓨터가 이해할 수 있도록 랜더링 과정을 거쳐서 가상 공간의 3차원 물체로 변환한다.That is, the
먼저 3D 모델링이 진행되는 바, 3D 모델링은 가상공간의 입체적인 모델을 통해 실세계의 물체를 묘사하거나, 혹은 물리적 환경을 만들어 가상환경 속에서 물체의 모습을 만들어낼 수도 있으며 영화, 애니메이션, 광고 등의 엔터테인먼트 분야와 물리적 실험 시뮬레이션, 건축, 디자인 등의 설계 및 예술 분야에 적용된다.First, 3D modeling proceeds, and 3D modeling can depict objects in the real world through a three-dimensional model of virtual space or create a physical environment to create the appearance of an object in a virtual environment. It is applied to design and art fields such as field and physical experiment simulation, architecture, and design.
이러한 3D 모델링은 와이어 프레임 모델링(Wire Frame Modeling), 서페이스 모델링(Surface Modeling), 솔리드 모델링(Solid Modeling) 등 다양한 방식에 의하여 구현될 수 있다.Such 3D modeling may be implemented by various methods such as wire frame modeling, surface modeling, solid modeling, and the like.
와이어프레임 모델링은 직선, 점, 원, 호 등의 기본적인 기하학적인 요소로 철사를 연결한 구조물과 같이 형상을 모델링 하는 방식이다.Wireframe modeling is a method of modeling a shape like a structure in which wires are connected with basic geometric elements such as straight lines, points, circles, and arcs.
서페이스 모델링은 점, 곡선, 곡면을 이용해서 형상을 표현하는 방법으로 표면 모델링이 정밀하고 수학적으로 정의된 곡선표면, NC 가공, 우주항공, 자동차, 조선에 주로 적용하는 방식이다.Surface modeling is a method of expressing shapes using points, curves, and curved surfaces, and is mainly applied to curved surfaces in which surface modeling is precisely and mathematically defined, NC machining, aerospace, automobiles, and shipbuilding.
솔리드 모델링은 곡면 모델에 곡면 간 연결정보를 추가하는 방법으로 3차원으로 형상화된 물체의 내부를 공학적으로 분석할 수 있는 방식으로 물체를 가공하기 전에 가공상태를 미리 예측하거나, 부피, 무게 등의 다양한 정보를 제공할 수 있는 방식이다.Solid modeling is a method that adds connection information between surfaces to a surface model. It is a method that allows engineering analysis of the inside of a three-dimensionally shaped object. A way to provide information.
이러한 3D 모델링 방식은 다양한 방식에 의하여 구현이 가능한 바, 예를 들면 폴리곤 방식(Polygon), 넙스 방식(Nurbs), 스컬핑 방식(Sculpting) 등에 의하여 모델링이 가능하다.This 3D modeling method can be implemented by various methods, for example, modeling is possible by a polygon method (Polygon), a NURBS method (Nurbs), a sculpting method (Sculpting), and the like.
이와 같이 3D 모델의 기본 골격을 형성한 후, 렌더링을 실시함으로써 골격 표면을 처리하게 되는 바, 예를 들면 질감, 음영, 색상을 입히고 광학효과를 추가한다.In this way, after the basic skeleton of the 3D model is formed, the surface of the skeleton is processed by rendering, for example, texture, shade, color, and optical effects are added.
렌더링 과정은 변환과정과 채색과정으로 구분할 수 있는 바, 변환과정은 3차원 모델 좌표계의 꼭지점들을 2차원 모델 화면 좌표계로 변환한다. 그리고, 채색과정은 면에 그려지는 객체의 색체와, 조명, 매핑 등으로 목표하는 효과를 구현한다.The rendering process can be divided into a transformation process and a coloring process. The transformation process transforms the vertices of the 3D model coordinate system into the 2D model screen coordinate system. And, the coloring process implements the target effect with the color of the object drawn on the surface, lighting, and mapping.
랜더링 과정은 투영(Projection), 클리핑(Clipping), 은면처리(Hidden Surface), 세이딩(Shading), 매핑(Mapping)의 순서로 진행된다.The rendering process proceeds in the order of Projection, Clipping, Hidden Surface, Shading, and Mapping.
투영은 3차원 오브젝트를 2차원 스크린에 비추는 과정이고, 클리핑은 디스플레이의 외측에 위치하여 보이지 않는 오브젝트 부분을 처리하는 과정이다.Projection is a process of projecting a three-dimensional object onto a two-dimensional screen, and clipping is a process of processing a part of an object that is located outside the display and is invisible.
또한, 은면처리는 오브젝트의 보이는 부분과 보이지 않는 부분을 처리하는 과정이고, 셰이딩은 음영, 조명 빛, 광원의 빛, 반사광, 투명한 효과 등을 처리하는 과정이며, 매핑은 오브젝트의 표면에 텍스처 등을 씌워 질감과 반사된 풍경 등을 처리하는 과정이다.In addition, hidden surface processing is a process of processing the visible and invisible parts of an object, shading is a process of processing shading, illumination light, light from a light source, reflected light, transparent effect, etc. It is the process of covering the texture and the reflected landscape.
이러한 3D 모델링 과정을 통하여 다양한 아이템들을 생성할 수 있는 바, 예를 들면 아바타, 건물, 자동차, 시설물, 제품 등의 아이템을 생성할 수 있다.Various items can be created through this 3D modeling process, for example, items such as avatars, buildings, cars, facilities, and products can be created.
이와 같이 3D 모델링을 실시한 후, 모델링된 아이템과 상기 아이템 등록부(18)에서 매칭된 아이템 제품 정보를 연결하여 복합 메타버스 가상현실 공간에 유형의 아이템을 표출하는 과정이 진행된다.After the 3D modeling is performed in this way, the process of expressing the tangible item in the complex metaverse virtual reality space is performed by connecting the modeled item and the item product information matched in the
이러한 과정은 메타버스 가상현실 구축부(3)에 의하여 진행됨으로써 가상 공간에 아이템을 거래할 수 있는 메타버스를 구축하게 된다.This process is carried out by the metaverse virtual
즉, 메타버스의 구축하기 위하여 엔진을 이용하여 플랫폼을 생성하게 된다. 이때, 엔진으로는 유니티와 언리얼 등 다양한 엔진이 사용된다.That is, a platform is created using the engine to build the metaverse. In this case, various engines such as Unity and Unreal are used as engines.
그리고, 플랫폼상에 가상의 세계를 구현하는 바, 이 가상의 세계에서 아이템이나 컨텐츠를 거래하거나, 할 수 있다.In addition, a virtual world is implemented on the platform, and items or contents can be traded or performed in the virtual world.
즉, 플랫폼상에 메타버스를 구현하고, 이 메타버스에 가맹점이 입점할 수 있도록 한다.In other words, the metaverse is implemented on the platform, and affiliated stores are allowed to enter the metaverse.
그리고, 메타버스 이용자들은 도우미(NPC;Non-Player Character)에 의하여 메타버스 내에서 가맹점 안내, 제품 설명 및 판매, 컨텐츠 생성, 거래 등의 전반적인 활동을 하게 된다. 이러한 도우미는 일종의 아바타이며, 이용자들은 단말기를 통하여 실시간 위치기반 정보에 의하여 복합 가상현실 메타버스내에 NPC로 나타난다.In addition, metaverse users perform overall activities such as merchant guidance, product description and sales, content creation, and transaction within the metaverse by a non-player character (NPC). This helper is a kind of avatar, and users appear as NPCs in the complex virtual reality metaverse through real-time location-based information through the terminal.
그리고, 이용자가 맵을 벗어난 지역으로 이동할 경우 가상현실 메터버스내의 NPC도 이동을 하면서 맵에서 사라지게 되며, 사용자의 단말을 통하여 로그인하였을 경우 NPC가 활성화 되어 가상현실 메타버스 시스템에서 활동을 할 수 있는 방식이다.And, if the user moves to an area outside the map, the NPC in the virtual reality metaverse will also disappear from the map while moving. to be.
이와 같이, 위치기반 실시간 위치가 가상현실 메터버스의 맵이 아니어도 이용자는 장소의 구애없이 가상현실 메타버스 시스템의 모든 서비스를 이용할 수 있다.In this way, even if the location-based real-time location is not a map of the virtual reality metaverse, the user can use all the services of the virtual reality metaverse system regardless of location.
또한, 사용자가 실시간 위치정보 기반으로 복합 가상현실 메타버스 서비스의 맵 내에 들어오게 되면, 사용자와 관계를 맺고 있는 크루들에게 알림 정보를 자동으로 제공하여 실시간 사용자와 맵안의 사용자와 상호작용을 함으로써 서비스의 몰입을 증대시킬 수 있다.In addition, when a user enters the map of the complex virtual reality metaverse service based on real-time location information, notification information is automatically provided to crews having a relationship with the user, and the service is performed by interacting with the real-time user and the user in the map. can increase immersion.
한편, 메타버스에 입점한 각 가맹정에서는 컨텐츠 생성부(5)에 의하여 다양한 창작물을 생성하게 된다.On the other hand, each affiliate that enters the metaverse generates various creative works by the
그리고, 입점한 가맹점의 카메라에 의하여 영상을 획득하고 3D 모델링하게 된다. 이때, 메타버스내에 입점한 가맹점의 가맹점 내에는 다양한 디바이스(6)가 설치되어 데이터를 생성하는 바, 카메라, IoT 센서, 이동형 3D 스캐너 등의 센싱부 및 입력부를 포함한다.Then, the image is acquired by the camera of the affiliated store and 3D modeling is performed. In this case,
이러한 다양한 디바이스(6)에 의하여 얻어진 컨텐츠는 컨텐츠 등록부(7)에 의하여 데이터 베이스(DB)에 등록된다.The contents obtained by these
컨텐츠 등록부(7)는 생성된 메타버스의 컨텐츠 데이터를 등록하고, 등록된 컨텐츠를 인공지능 분석에 의하여 창작물의 표절, 저작권 위배 여부, 컨텐츠와 관련된 정보 및 컨텐츠 생성 과정 등의 컨텐츠 데이터를 등록한다.The
보다 상세하게 설명하면, 컨텐츠 등록부(8)는 도 6에 도시된 바와 같이, 새로 등록예정인 메타버스 컨텐츠와 기존 메타버스 컨텐츠를 비교하는 유사도 분석모듈(45)과; 그리고More specifically, as shown in FIG. 6 , the
유사도 분석결과에 따라 지재권의 침해여부를 판단하는 침해 판단모듈(47)을 포함한다.and a
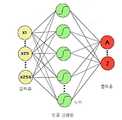
유사도 분석모듈(45)은 메타버스 데이터간의 유사도를 판단하는 바, 이러한 유사도 분석모듈(45)은 중앙처리장치(32)에 의하여 컨텐츠의 유사도 분석을 다양한 알고리즘을 사용할 수 있는 바, 예를 들면 딥러닝(Deep learning) 방식에 의하여 유사도를 판단하는 방식이다.The
중앙처리장치(32)는 유사도 분석엔진(34)과, GPU(35)와, ALSA(Advanced Linux Sound Architecture;36), ALVA(38), RTSP(Real Time Streaming Protocol;40), API(42), 통신모듈에 의하여 신호를 송수신하게 된다.The
그리고, 이러한 중앙처리장치(32)에는 딥러닝 프로그램이 탑재됨으로써 메타버스 컨텐츠간의 유사도를 판단하는 바, 딥러닝은 컴퓨터가 여러 데이터를 이용해 인간처럼 스스로 학습할 수 있게 하기 위해 인공 신경망(ANN: artificial neural network)을 기반으로 구축한 한 기계 학습방법이다.In addition, the
인공 신경망을 이용하면 컨텐츠 데이터의 분류(classification) 및 군집화(clustering)가 가능한 바, 분류나 군집화를 원하는 데이터 위에 여러 가지 층(layer)을 얹어서 유사도 판단을 실시할 수 있다.When the artificial neural network is used, classification and clustering of content data is possible, and thus, similarity can be determined by placing various layers on the data for which classification or clustering is desired.
즉, 도 8에 도시된 바와 같이, 인공 신경망은 입력층, 다수의 노드, 출력층으로 구성된다. 이러한 인공 신경망은 메타버스 컨텐츠 데이터의 형상 특징을 추출하고 그 특징을 다시 다른 기계학습 알고리즘의 입력값으로 사용하여 형상 별로 분류나 군집화를 함으로써 유사도를 판단할 수 있다.That is, as shown in FIG. 8 , the artificial neural network consists of an input layer, a plurality of nodes, and an output layer. Such an artificial neural network can determine similarity by extracting shape features of metaverse content data and classifying or clustering them for each shape by using the features as input values for other machine learning algorithms.
이러한 인공 신경망은 심층 신경망을 포함하는 바, 심층 신경망은 신경망 알고리즘 중에서 여러 개의 층으로 이루어진 신경망을 의미한다.The artificial neural network includes a deep neural network, and the deep neural network means a neural network composed of several layers among neural network algorithms.
즉, 인공 신경망은 다층으로 구성되는 바, 각각의 층은 여러 개의 노드로 구성되고, 각 노드에서는 실제로 형상을 분류하는 연산이 일어나며, 이 연산 과정은 인간의 신경망을 구성하는 뉴런에서 일어나는 과정을 모사하도록 설계된다.That is, the artificial neural network is composed of multiple layers, each layer is composed of several nodes, and an operation of actually classifying a shape occurs at each node. designed to do
노드는 일정 크기 이상의 자극을 받으면 반응을 하는데, 그 반응의 크기는 입력 값과 노드의 계수(또는 가중치, weights)를 곱한 값과 대략 비례한다.When a node receives a stimulus of a certain size or more, it responds, and the magnitude of the response is roughly proportional to the value multiplied by the input value and the node's coefficient (or weights).
일반적으로 노드는 여러 개의 입력을 받으며 입력 갯수만큼의 계수를 갖는다. 따라서, 이 계수를 조절함으로써 여러 입력에 서로 다른 가중치를 부여할 수 있다.In general, a node receives multiple inputs and has as many coefficients as the number of inputs. Therefore, different weights can be given to different inputs by adjusting this coefficient.
최종적으로 곱한 값들은 전부 더해지고 그 합은 활성 함수(activation function)의 입력으로 들어가게 된다. 활성 함수의 결과가 노드의 출력에 해당하며 이 출력값이 궁극적으로 분류나 회귀 분석에 쓰인다.Finally, all the multiplied values are added and the sum is input to the activation function. The result of the activation function corresponds to the output of the node, and this output is ultimately used for classification or regression analysis.
각 층은 여러 개의 노드로 이루어지며 입력값에 따라 각 노드의 활성화/비활성화 여부가 결정된다. 이때, 입력 데이터는 첫 번째 층의 입력이 되며, 그 이후엔 각 층의 출력이 다시 다음 층의 입력이 되는 방식이다.Each layer consists of several nodes, and whether each node is activated/deactivated is determined according to the input value. At this time, the input data becomes the input of the first layer, and after that, the output of each layer becomes the input of the next layer again.
모든 계수는 메타버스 컨텐츠 데이터의 형상 학습 과정에서 계속 조금씩 변하는데, 결과적으로 각 노드가 어떤 입력을 중요하게 여기는지를 반영한다. 그리고 신경망의 학습(training)은 이 계수를 업데이트하는 과정이다.All coefficients change little by little during the shape learning process of metaverse content data, and as a result, reflect which input each node considers important. And training of the neural network is the process of updating this coefficient.
메타버스 컨텐츠 데이터의 형상 학습시 이러한 심층 신경망에서는 각 층마다 서로 다른 층위의 특징이 학습된다.When learning the shape of metaverse content data, different layer characteristics are learned for each layer in such a deep neural network.
즉, 낮은 층위의 특징은 단순하고 구체적인 특징이 학습되며 {예: 컨텐츠 데이터의 형상을 구성하는 형상}, 높은 층위의 특징은 더욱 복잡하고 추상적인 특징이 학습된다. {예: 가상현실의 맵, 가맹점, 아이템 형상 등}That is, simple and specific features are learned for low-level features, {eg, a shape constituting the shape of content data}, and more complex and abstract features are learned for high-level features. {Example: Virtual reality map, merchant, item shape, etc.}
이런 추상화 학습과정을 통해 심층 신경망이 고차원의 데이터를 이해하며, 이 과정에는 수 억, 수 십억 개의 계수가 관여하게 된다. (이 과정에서 비선형함수가 사용된다.)Through this abstraction learning process, deep neural networks understand high-dimensional data, and hundreds of millions or billions of coefficients are involved in this process. (A non-linear function is used in this process.)
또한, 심층 신경망은 데이터를 이용해 데이터의 잠재적인 구조(latent structures)를 파악할 수 있다. 즉, 컨텐츠 데이터의 문서, 음향, 영상 등의 잠재적인 구조를 파악할 수 있다. 이를 통해 데이터가 라벨링되어 있지 않아도 데이터간의 유사성을 효과적으로 파악할 수 있으며, 결과적으로 심층 신경망은 컨텐츠 데이터의 군집화에 효과적이다.In addition, deep neural networks can use the data to identify the latent structures of the data. That is, it is possible to grasp a potential structure of the content data, such as documents, sounds, and images. Through this, similarity between data can be effectively identified even if the data is not labeled, and as a result, deep neural networks are effective for clustering content data.
예를 들어, 신경망을 이용해 대량의 컨텐츠 데이터를 입력받아 비슷한 메타버스 컨텐츠 데이터끼리 모아서 분류할 수 있다.For example, a large amount of content data may be input using a neural network, and similar metaverse content data may be collected and classified.
이러한 심층 신경망이 일반적인 기계 학습과 다른 점은 특징 추출(feature extraction)이 자동적으로 이루어진다는 점이다.The difference between this deep neural network and general machine learning is that feature extraction is performed automatically.
기존에는 효과적인 특징을 추출하기 위해 관련 분야 전문가가 오랜 시간동안 직접 특징을 추출하는 수식이나 방법을 고안해서 적용해야 했다. 이 방법은 개발, 평가 및 보완에 많은 시간이 걸리는 문제점이 있다.In the past, in order to extract effective features, experts in the relevant field had to devise and apply formulas or methods for extracting features directly for a long time. This method has a problem in that it takes a lot of time to develop, evaluate, and supplement.
심층 신경망은 이런 과정을 컴퓨터가 대신 하도록 알고리즘을 짠 것으로, 사람에 비해 훨씬 빠르고 효과적으로 수행하도록 학습시킨다.A deep neural network is an algorithm designed to make a computer perform this process, and it trains it to perform much faster and more effectively than humans.
라벨링이 되어있지 않은 데이터를 학습하는 경우에도 신경망은 컨텐츠 데이터의 특징을 자동적으로 추출할 수 있다. 이 자동 추출은 여러 가지 방법이 있는데, 보통 이 과정은 신경망을 통과시켰을 때의 출력이 입력과 같아지도록 학습하게 된다.Even when learning unlabeled data, the neural network can automatically extract features of content data. There are several methods for this automatic extraction, and in general, this process learns to make the output equal to the input when passed through the neural network.
라벨이 어떤 종류이든지(입력을 그대로 사용/별도의 라벨을 사용) 신경망은 입력과 출력의 상관관계를 찾는다. 경우에 따라서는 라벨링된 데이터로 신경망을 어느 정도 학습시킨 뒤 라벨링이 되어있지 않은 데이터를 추가하여 계속 학습시킬 수도 있다. 이 방법을 이용하면 신경망의 성능을 극대화할 수 있다.No matter what kind of label is (use the input as is/use a separate label), the neural network finds the correlation between the input and the output. In some cases, after training the neural network to some extent with labeled data, it is possible to continue learning by adding unlabeled data. Using this method, the performance of the neural network can be maximized.
심층 신경망의 마지막 층은 출력층이다. 출력층의 활성 함수는 로지스틱(logistic) 혹은 소프트 맥스(softmax)인 경우가 대부분이며 출력층에서는 최종적으로 특정 라벨의 확률을 구할 수 있다. 예를 들어 컨텐츠 데이터를 입력하였을 때 2개의 문서가 서로 유사한지, 음향이 유사한지, 동영상이 서로 유사한지 등을 각각의 확률로 구할 수 있다.The last layer of a deep neural network is the output layer. In most cases, the activation function of the output layer is logistic or softmax, and the probability of a specific label can be finally obtained from the output layer. For example, when content data is input, whether two documents are similar to each other, sounds are similar, or videos are similar to each other can be obtained with respective probabilities.
우선 학습이 시작되기 전에 뉴럴넷의 모든 계수를 초기화한다. 그리고 메타버스 컨텐츠 데이터를 반복적으로 입력하여 학습을 진행한다. 만일 학습이 원활하게 진행되었다면 계수는 적절한 값으로 업데이트 되어 있을 것이고, 이 인공 신경망으로 각종 분류와 예측이 가능하다.First, all coefficients of the neural net are initialized before training starts. Then, learning is carried out by repeatedly inputting metaverse content data. If the learning proceeds smoothly, the coefficients will be updated to appropriate values, and various classifications and predictions are possible with this artificial neural network.
학습 과정 내부에선 이러한 계수의 업데이트 과정이 반복적으로 일어난다.In the learning process, the updating process of these coefficients occurs repeatedly.
계수 업데이트의 원리는 우선 계수를 추정하고 그 계수를 사용했을 때 발생하는 에러를 측정한 뒤 그 에러에 기반해서 계수를 약간씩 업데이트 하는 방식이다.The principle of coefficient update is to first estimate the coefficient, measure the error that occurs when the coefficient is used, and then slightly update the coefficient based on the error.
이때, 신경망의 여러 계수를 합쳐서 모델이라고 부르며, 모델은 초기화 된 상태일 수도 있고, 학습이 완료된 상태일 수도 있다.At this time, the multiple coefficients of the neural network are collectively called a model, and the model may be in an initialized state or in a state in which learning is completed.
초기화된 모델은 의미 있는 작업을 못하지만 학습이 진행될수록 모델은 임의의 값이 아닌, 실제와 유사한 결과를 출력하게 된다.The initialized model does not work meaningfully, but as the learning progresses, the model outputs results similar to the actual value rather than a random value.
이는 인공 신경망이 데이터가 입력되기 전에는 아무것도 모르는 상태이기 때문이며, 계수를 임의의 값으로 초기화하는 이유도 마찬가지이다. 그리고 데이터를 읽어가면서 계수를 조금씩 올바른 방향으로 업데이트하게 된다.This is because the artificial neural network does not know anything before data is input, and the reason for initializing coefficients to arbitrary values is also the same. And as the data is read, the coefficients are updated little by little in the correct direction.
이러한 업데이트 과정을 통하여 인공 신경망은 입력된 메타버스 컨텐츠 데이터들을 분류함으로써 유사한 컨텐츠 데이터들을 군집화할 수 있다. 그리고, 군집화된 메타버스 컨텐츠 데이터는 데이터 베이스에 등록된다.Through this update process, the artificial neural network can group similar content data by classifying the input metaverse content data. And, the clustered metaverse content data is registered in the database.
한편, 컨텐츠가 유사도 분석모듈(45)에 의하여 유사하다고 판단되면, 침해 판단모듈(47)에 의하여 침해여부를 판단하게 된다.On the other hand, if the content is determined to be similar by the
이러한 침해 판단모듈(47)은 도 6에 도시된 바와 같이, 유사범위에 포함된다고 판단된 복수의 컨텐츠들을 로딩하여 복수의 컨텐츠들의 유사도에 의하여 침해여부를 판단하고, 침해시 정당한 컨텐츠 등록자에게 알림모듈(49)을 통하여 알린다.As shown in FIG. 6 , the
로딩된 컨텐츠는 등록 예정인 컨텐츠와 유사하다고 판단된 복수의 컨텐츠들을 포함하며, 이때, 복수의 컨텐츠는 1개 혹은 그 이상일 수 있다.The loaded contents include a plurality of contents determined to be similar to contents to be registered, and in this case, the plurality of contents may be one or more.
판단모듈(47)은 로딩된 컨텐츠들의 침해여부를 판단하는 바, 유사도 분석모듈(45)에 의하여 연산된 유사도값을 비교하게 된다. 그리고, 비교된 유사도값의 차이가 침해기준값의 초과여부를 판단하게 된다.The
예를 들면, 등록 예정인 메타버스 컨텐츠와 유사하다고 판단된 복수의 컨텐츠의 유사도가 80%이고, 해당 컨텐츠 분야의 침해 기준값은 70%인 경우, 판단모듈(47)은 침해로 판단하게 된다.For example, when the similarity of the plurality of contents determined to be similar to the metaverse contents to be registered is 80% and the infringement reference value of the corresponding contents field is 70%, the
반면에 유사도가 60%인 경우에는 비침해라고 판단하게 된다.On the other hand, if the similarity is 60%, it is judged as non-infringement.
그리고, 침해 기준은 컨텐츠 분야마다 차이가 있을 수 있는 바, 예를 들면, 맵 구조의 경우 침해기준값은 90%, 아이템의 경우 80%, 가맹점 형상의 경우 70%와 같이 차등적으로 설정될 수 있다.In addition, the infringement standard may be different for each content field. For example, in the case of a map structure, the infringement standard value may be set differentially such as 90%, in the case of an item, 80%, and in the case of a member store shape, 70%. .
판단모듈(47)에 의하여 침해로 판단되는 경우에는 알림모듈(49)을 통하여 침해임을 안내하게 되고, 비침해로 판단되는 경우에는 등록부(65)에 의하여 컨텐츠를 데이터베이스에 저장한다.If the
알림모듈(49)은 침해인 경우에는 등록 예정인 사용자에게 침해임을 안내하게 되고, 이러한 안내를 접수한 사용자는 해당 컨텐츠의 등록을 포기하거나, 컨텐츠를 보다 개량하여 재등록을 시도하게 된다.In the case of infringement, the
한편, 메타버스 컨텐츠의 등록 후, 해당 컨텐츠를 온라인상에서 거래하여 수익을 창출하기 위하여 단가를 산정할 필요가 있다.Meanwhile, after registering metaverse content, it is necessary to calculate a unit price in order to generate revenue by transacting the content online.
그리고, 단가는 단가 연산부(9)에 의하여 연산되는 바, 단가 연산부(9)는 가맹점별로 고객 정보를 분석하여 단가를 연산하게 된다.In addition, the unit price is calculated by the unit
이러한 단가 연산부(9)는 가맹점을 방문한 고객을 성별, 연령별, 지역별로 분류하고 각 방문자수에 의하여 단가를 산출한다.The unit
이때, 방문자수를 일별, 주간, 월별로 분석하여 단가를 산출할 수도 있다.In this case, the unit price may be calculated by analyzing the number of visitors by day, week, or month.
예를 들면, 화장품 판매점을 방문한 고객이 여성이고, 젊은층이며, 1일 100명이라면 소정의 금액을 단가로 산정하는 방식이다. 이때, 동일한 방문수인 경우라도 고객이 남성이고 노년층인 경우 효과가 상대적으로 높다고 판단되어 단가를 낮추는 것도 가능하다.For example, if the customers who visit the cosmetics store are women, young people, and 100 people per day, a predetermined amount is calculated as a unit price. In this case, even in the case of the same number of visits, if the customer is a male and an elderly person, the effect is determined to be relatively high, so it is possible to lower the unit price.
그리고, 단가 연산부(9)는 상기한 단가 연상 방식 뿐만 아니라 다양한 방식에 의하여 산정가능하다.And, the unit
예를 들면, 각 컨텐츠 창작자가 산정한 단가를 입력받아서 저장한 후, 해당 컨텐츠의 거래시 단가에 의하여 거래금액을 연산하는 방식이다.For example, after receiving and storing the unit price calculated by each content creator, the transaction amount is calculated based on the unit price when the corresponding content is traded.
그리고, 해당 컨텐츠의 거래시 변동하는 단가를 시세에 따라 추가로 반영할 수도 있다.In addition, the unit price that fluctuates during the transaction of the corresponding content may be additionally reflected according to the market price.
또한, 저작권의 침해 판단시, 이 단가를 손해배상액의 산정에 적용할 수 있다.Also, when determining copyright infringement, this unit price can be applied to the calculation of the amount of compensation.
그리고, 상기한 바와 같이 메타버스 컨텐츠는 온라인 상에서 거래가 이루어지는 바, 컨텐츠 거래소(11)는 이러한 거래를 진행하게 된다.And, as described above, the metaverse content is traded online, and the
즉, 컨텐츠 등록부(7)를 통하여 등록된 컨텐츠를 복합 메타버스 가상현실 및 현실 세계에 공표하고, 이를 공유 및 소비하게 된다.That is, the content registered through the
그리고, 컨텐츠 거래소(11)는 다양한 방식의 거래를 중계하는 바, 예를 들면 투자, 매매, 임대, 보상 등을 포함한다.In addition, the
그리고, 컨텐츠 거래소(11)를 통하여 공표되거나 거래된 메타버스 데이터는 수익 정산부(13)에 의하여 매출이 정산될 수 있다.In addition, sales of metaverse data published or traded through the
즉, 수익 정산부(13)는 메타버스 컨텐츠를 이용하는 이용자에게 컨텐츠 과금부(14)를 통하여 이용 횟수 혹은 시간만큼의 수수료를 청구하여 수익을 정산하게 된다.That is, the
이때, 수익을 정산하는 방식은 다양한 바, 예를 들면 온라인상에 노출로 인하여 발생하는 매출액 증감 혹은 각 가맹점 혹은 총 가맹점의 성별 연령별 방문자수에 의한 노출 횟수 및 노출 시간으로 정산하는 방식이 가능하다.At this time, there are various methods of calculating the revenue, for example, a method of calculating the increase or decrease in sales caused by online exposure or the number of exposures and exposure time according to the number of visitors by gender and age of each affiliated store or total affiliated stores is possible.
즉, 매출액 증감에 의하여 정산하는 방식의 경우는, 해당 가맹점에 메타버스 컨텐츠를 제공한 기간 동안 발생한 매출액의 증감을 연산하고, 단가를 적용하여 수익을 정산하는 방식이다.That is, in the case of the method of settlement based on the increase or decrease in sales, the increase or decrease in sales generated during the period of providing the metaverse contents to the corresponding affiliated store is calculated, and the profit is settled by applying the unit price.
이때, 수익 정산부(13)는 수익을 보다 객관적으로 산출하기 위하여 포스기, 카드결제기, 전자 금고 등의 단말기 등에 의하여 산출할 수 있다.In this case, the
따라서, 단말기에 의하여 판매된 컨텐츠 종류 및 매출액을 파악할 수 있고, 노출시간을 파악하여 서로 비교함으로써 구체적으로 해당 메타버스 컨텐츠로 인한 매출액의 증감을 실시간으로 파악할 수 있다.Therefore, it is possible to grasp the type of content sold by the terminal and the sales, and by understanding the exposure time and comparing them with each other, the increase or decrease in sales due to the corresponding metaverse content can be grasped in real time.
방문자수로 정산하는 방식의 경우는, 가맹점을 방문한 고객을 성별, 연령별, 로 분류하고 이때 노출되는 횟수 및 노출 시간에 따른 단가를 적용함으로써 수익을 정산하는 방식이다.In the case of the method of calculating the number of visitors, the revenue is settled by classifying the customers who visited the affiliated store by gender, age, and applying the unit price according to the number of times and exposure time at this time.
이와 같이 각 가맹점별로 메타버스 컨텐츠에 대한 단가를 연산하고, 수익을 정산할 수 있다.In this way, it is possible to calculate the unit price for the metaverse content for each affiliate store and settle the profit.
상기 서버(4)를 구성하는 요소, 즉 메타버스 구축부(3)와, 컨텐츠 생성부(5)와, 컨텐츠 등록부(8)와, 단가 연산부(9)와, 컨텐츠 거래소(11)와, 수익 정산부(13)와, 유사도 분석모듈(45), 침해 판단모듈(47)은 입력된 데이터에 대한 해석, 명령의 실행, 연산 등을 실시하는 마이크로 프로세서(Micro processor)를 의미한다.The elements constituting the
이하, 상기한 메타버스 컨텐츠에 있어서 아이템을 생성하고 거래하는 과정을 첨부된 도면을 참조하여 보다 상세하게 설명한다.Hereinafter, the process of creating and transacting items in the metaverse content will be described in more detail with reference to the accompanying drawings.
도 7에 도시된 바와 같이, 먼저 아이템 생성부(20) 및 등록부에 의하여 아이템을 인증 및 저장한다(S100).As shown in FIG. 7 , the item is first authenticated and stored by the
즉, 다양한 유, 무형의 자산에 대한 정보를 생성 및 등록하는 바, 예를 들면 아이템 생성부(20)에 의하여 가상현실에서 사용할 수 있는 아이템을 생성하거나 구매하고, 아이템 등록부(18)에 의하여 아이템을 인증 및 등록한다.That is, information on various tangible and intangible assets is created and registered, for example, an item that can be used in virtual reality is created or purchased by the
이때, 아이템은 다양한 아이템이 가능하며, 예를 들면, 건물, 자동차, 시설물, 제품, 상품 등이다.In this case, various items are possible as the item, for example, a building, a vehicle, a facility, a product, a product, and the like.
그리고, 생성 또는 구매한 아이템으로 커뮤니티(Community)를 꾸민다(S110).Then, the community is decorated with the created or purchased item (S110).
아이템으로 커뮤니티를 꾸민 후, 아이템 생성부(20)에서 아이템을 모델링 처리한다(S120).After decorating the community with the item, the
즉, 아이템을 아이템 생성부(20)에 탑재된 3D 모델링을 위한 소프트웨어에 의하여 랜더링 과정을 거쳐서 가상 공간의 3차원 물체로 변환한다.That is, the item is converted into a 3D object in a virtual space through a rendering process by software for 3D modeling mounted on the
그리고, 모델링 된 아이템에 의하여 복합 가상현실을 생성하게 된다(S130).Then, the composite virtual reality is generated by the modeled item (S130).
즉, 아이템에 대하여 3D 모델링을 실시한 후, 모델링된 아이템과 아이템 등록부(18)에서 매칭된 아이템 제품 정보를 연결하여 복합 메타버스 가상현실 공간에 유형의 아이템을 표출하는 과정이 진행된다.That is, after 3D modeling is performed on the item, the process of expressing the tangible item in the complex metaverse virtual reality space by linking the modeled item and the item product information matched in the
이러한 과정은 메타버스 가상현실 구축부(3)에 의하여 진행됨으로써 가상 공간에 아이템을 거래할 수 있는 메타버스를 구축하게 된다.This process is carried out by the metaverse virtual
즉, 메타버스의 구축하기 위하여 엔진을 이용하여 플랫폼을 생성하게 된다. 이때, 엔진으로는 유니티와 언리얼 등 다양한 엔진이 사용된다.That is, a platform is created using the engine to build the metaverse. In this case, various engines such as Unity and Unreal are used as engines.
그리고, 플랫폼상에 가상의 세계를 구현하는 바, 이 가상의 세계에서 아이템이나 컨텐츠를 거래하거나, 할 수 있다.In addition, a virtual world is implemented on the platform, and items or contents can be traded or performed in the virtual world.
즉, 플랫폼상에 메타버스를 구현하고, 이 메타버스에 가맹점이 입점할 수 있도록 한다.In other words, the metaverse is implemented on the platform, and affiliated stores are allowed to enter the metaverse.
그리고, 메타버스 이용자들은 도우미(NPC;Non-Player Character)에 의하여 메타버스 내에서 가맹점 안내, 제품 설명 및 판매, 컨텐츠 생성, 거래 등의 전반적인 활동을 하게 된다.In addition, metaverse users perform overall activities such as merchant guidance, product description and sales, content creation, and transaction within the metaverse by a non-player character (NPC).
이와 같이, 생성된 메타버스 컨텐츠는 컨텐츠 등록부(7)에 의하여 등록된다(S140).In this way, the generated metaverse content is registered by the content registration unit 7 (S140).
그리고, 등록된 메타버스는 컨텐츠 거래소(11)에 의하여 온라인 상에서 거래가 이루어진다(S150). 컨텐츠 거래소(11)는 다양한 방식의 거래를 중계하는 바, 예를 들면 투자, 매매, 임대, 보상 등을 포함한다.Then, the registered metaverse is transacted online by the content exchange 11 (S150). The
그리고, 컨텐츠 거래소(11)를 통하여 공표되거나 거래된 메타버스 데이터는 수익 정산부(13)에 의하여 매출이 정산될 수 있다(S160).In addition, sales of metaverse data published or traded through the
즉, 수익 정산부(13)는 메타버스 컨텐츠를 이용하는 이용자에게 컨텐츠 과금부(14)를 통하여 이용 횟수 혹은 시간만큼의 수수료를 청구하여 수익을 정산하게 된다.That is, the
실시예 2 (기타 컨텐츠에 대한 저작권 침해 분석 시스템)Example 2 (Copyright Infringement Analysis System for Other Content)
본 발명이 제안하는 저작권 침해 분석 시스템은 메타버스 컨텐츠 뿐만 아니라 기타 컨텐츠, 예를 들면 음원, 영상, 이미지 등의 컨텐츠에도 적용가능하다.The copyright infringement analysis system proposed by the present invention is applicable not only to metaverse contents but also to other contents, for example, contents such as sound sources, images, and images.
도 9 내지 도 12에 도시된 바와 같이, 본 발명의 다른 실시예는 일반 컨텐츠의 유사도 분석을 통한 저작권 침해 분석 시스템(1)에 관한 것으로서, 전술한 실시예와 동일하며, 서버(4)에 있어서 아래와 같은 차이점이 있다.9 to 12, another embodiment of the present invention relates to a copyright
이러한 서버(4)는, 생성된 컨텐츠가 입력되는 입력부(53)와; 입력된 컨텐츠를 분류하여 특징점을 추출하는 특징점 추출부(55)와; 컨텐츠에 대한 전처리를 실시하는 전처리부(57)와; 시퀀스 변환부(59)와; 새로 등록예정인 컨텐츠와 기존 등록 컨텐츠를 비교하는 유사도 분석모듈(45)과; 유사도 분석결과에 따라 지재권의 침해여부를 판단하는 침해 판단모듈(47)과; 침해 판단모듈(47)에 의하여 비침해라고 판단되는 경우 컨텐츠를 등록하는 등록부(65)를 포함한다.The
이러한 저작권 침해 분석 시스템(1)의 서버(4)에 있어서,In the
컨텐츠 입력부(53)는 사용자 단독 혹은 협업으로 생산한 유, 무형의 창작물을 입력받아 관리한다. 창작물로는 다양한 컨텐츠를 포함하는 바, 예를 들면 이미지, 음원, 영상, 게임 등이다.The
이러한 컨텐츠 입력부(53)는 문서 입력기, 스캐너, 마이크 등의 음성 수집기, 카메라 등의 영상 획득장치에 의하여 사용자가 입력한 문서, 이미지 데이터, 영상 데이터, 음원 데이터, 게임 데이터 등을 온라인 혹은 오프라인을 통하여 입력받는다.The
그리고, 입력된 컨텐츠 데이터는 특징점 추출부(55)에 의하여 특징점을 추출한다.Then, the inputted content data extracts a feature point by the feature
이러한 특징 추출부(55)는 다양한 컨텐츠에 적합하도록 구성된다.The
예를 들면, 문서 컨텐츠인 경우, 도 10에 도시된 바와 같이, 문서에서 어휘 분석기(65)에 의하여 색인어로 사용될 수 있는 단어들을 추출한다. 어휘 분석기(65)는 특정 품사, 예를 들면 명사만을 추출하고 불필요한 단어들은 제거한다.For example, in the case of document content, as shown in FIG. 10 , words that can be used as index words are extracted from the document by the
그리고, 색인 변환기(67)은 어휘 분석과장이 완료되면 문서의 비교를 위하여 추출된 명사들을 색인으로 변환하게 된다. 이때 두 문서간에 공통적인 단어에 대해 같은 색인이 필요한데 공통 색인 테이블(71)이 필요하다. 색인 테이블은 일반적으로 해시테이블로 구성된다.Then, the
이러한 색인 변환기(67)을 통하여 추출된 색인어는 후술하는 시퀀스 추출모듈(69)를 통하여 시퀀스 변환된다.The index word extracted through the
그리고, 음원 컨텐츠인 경우, 도 11에 도시된 바와 같이, 음원 데이터에서 멜로디를 추출하고(55), 시퀀스를 생성한 후(59), 데이터베이스의 다른 음원과 비교함으로써 유사여부를 판단하게 된다(61).And, in the case of sound source content, as shown in FIG. 11 , a melody is extracted from the sound source data (55), a sequence is generated (59), and the similarity is determined by comparing it with other sound sources in the database (61). ).
음원 데이터는 다양한 포멧으로 형성되는 바, 예를 들면, MIDI 포멧, PCM 포멧 등이다.The sound source data is formed in various formats, for example, a MIDI format, a PCM format, and the like.
이러한 음원 데이터를 추출하는 경우, 여러음들이 복합적으로 존재하는 음원에서 멜로디를 추출하게 된다.In the case of extracting such sound source data, a melody is extracted from a sound source in which several sounds are complexly present.
이와 같이 특징점이 추출된 컨텐츠 데이터는 전처리부(57)에 의하여 전처리과정을 거치게 된다.The content data from which the feature points are extracted in this way is subjected to a pre-processing process by the
전처리부(57)는 입력된 데이터에 반사광, 화각, Dust 및 노이즈 제거를 진행함으로써 전처리를 진행한다.The
이러한 전처리부(57)는 도 4에 도시된 바와 같이, 영상 컨텐츠 전처리 모듈(17)과, 이미지 컨텐츠 전처리 모듈(19)과, 메타정보 전처리 모듈(21)과, 음원 컨텐츠 전처리 모듈(23)을 포함하며, 중앙 처리장치와 연결되어 신호를 송수신한다.As shown in FIG. 4, the
빅데이터(big data) 분석, 데이터 마이닝(data mining)을 위해서는 각 알고리즘의 요구사항에 따라 전처리된 데이터가 필수적이다. 따라서 수집된 데이터들을 목적에 맞게 효과적으로 가공해야 한다. 이를 위해 데이터의 측정 오류를 줄이고 잡음(noise), 왜곡, 편차 최소화, 정밀도, 정확도, 이상 값(outlier), 결측 값(missing value), 모순, 불일치, 중복 등을 해소한다.For big data analysis and data mining, preprocessed data according to the requirements of each algorithm is essential. Therefore, it is necessary to effectively process the collected data according to the purpose. To this end, data measurement errors are reduced and noise, distortion, deviation minimization, precision, accuracy, outliers, missing values, contradictions, inconsistencies, and duplicates are eliminated.
이러한 전처리는 데이터 정제(cleansing), 데이터 변환(transformation), 데이터 필터링(filtering), 데이터 통합(integration), 데이터 축소(reduction) 과정을 포함하며, 상기한 실시예 1의 메타버스 컨텐츠의 전처리 과정과 동일하므로 이하 상세한 설명은 생략한다.Such pre-processing includes data cleaning, data transformation, data filtering, data integration, and data reduction processes, and includes the pre-processing process of the metaverse content of the first embodiment and Since they are the same, a detailed description will be omitted below.
이와 같이 컨텐츠 데이터를 전처리한 후, 시퀀스 변환부(59)에 의하여 시퀀스 변환을 실시한다.After preprocessing the content data in this way, the
시퀀스 변환 과정은 전처리된 데이터 파일을 맵(Map) 함수를 통해 병렬 처리하여, 이벤트 레코드를 추출하고, 데이터 파일에 설정된 시간을 시퀀스 번호로 변환하고, 시퀀스 번호로 변환된 데이터를 리듀스(Reduce) 함수를 통해 병렬로 취합하여 시퀀스를 생성한다.The sequence conversion process parallelly processes the preprocessed data file through the Map function, extracts event records, converts the time set in the data file into a sequence number, and reduces the data converted to the sequence number. A sequence is created by assembling in parallel through a function.
이러한 시퀀스 변환부(59)에 의하여 컨텐츠 데이터를 시퀀스 변환을 실시하는 바, 예를 들면 문서 컨텐츠 데이터를 시퀀스 변환을 실시하는 과정을 설명한다.The sequence conversion of the content data is performed by the
도 10에 도시된 바와 같이, 상기한 특징부 추출부(55)에서 문자 컨텐츠는 색인 변환기(67)을 통하여 색인어가 추출되며, 추출된 색인어가 시퀀스 변환된다.As shown in FIG. 10 , an index word is extracted from the character content through an
즉, 색인 변환기(67)를 통하여 문자 컨텐츠 데이터를 색인 테이블로 구성하며(71), 색인 테이블의 구성이 완료되면 문자 컨텐츠 데이터 중 명사들이 순차적으로 나열된다. 나열된 문서를 색인의 나열인 시퀀스 A,B로 변환한다(69).That is, the text content data is configured into an index table through the index converter 67 (71), and when the configuration of the index table is completed, nouns in the text content data are sequentially arranged. Converts the listed documents into sequences A, B, which are lists of indexes (69).
이때, 시퀀스 변환하는 과정에서 역파일 색인 테이블(73)을 만들어 줄 수 있는 바, 이는 유사도 판단에서 비교횟수를 줄일 수 있다.In this case, the inverse file index table 73 can be created in the sequence conversion process, which can reduce the number of comparisons in determining the degree of similarity.
음원 데이터를 시퀀스 변환하는 경우 2단계로 구성되는 바, 멜로디 근사구간과, 멜로디 시퀀스 결정 구간으로 구성된다.When the sound source data is sequence-converted, it consists of two steps: a melody approximation section and a melody sequence determination section.
멜로디 근사구간에서는 하모닉 모델을 이용하여 후보를 연산한다. 그 전에 정확도와 계산 복잡도를 줄이기 위해 음 범위를 결정하게 된다.In the melody approximation section, candidates are calculated using the harmonic model. Before that, the note range is determined to reduce accuracy and computational complexity.
하모닉 구조는 일반적인 멜로디 소리가 가지는 하모닉 구조로서 아래 수식 1로 표현될 수 있다.The harmonic structure is a harmonic structure of a general melody sound and can be expressed by

(Am : m번째 하모닉 성분의 진폭,Hω(k): 기본 주파수 (fundamental frequency)가ω인 하모닉 구조 모델)(Am : amplitude of the mth harmonic component,Hω(k) : harmonic structure model with fundamental frequencyω )
k는 주파수 단위로써 cent이며, 그 정의는 아래 수식 2와 같으며,G는 가우시안 함수로서 수식 3과 같이 정의된다.k is a cent as a frequency unit, the definition is as in


이와 같이 멜로디 근사가 진행된 후, 멜로디 시퀀스를 결정하게 된다.After the melody approximation is performed in this way, the melody sequence is determined.
흔히 발생하는 옥타브(octave) 에러나 잘못된 피치가 결정되는 경우를 막기 위해 후보 음들에 음악적 특징과음 전이의 통계적 정보를 이용하여 가중치를 다르게 주어 정확하게 결정한다.In order to prevent a common octave error or incorrect pitch determination, candidate notes are accurately determined by giving different weights using statistical information on musical characteristics and transitions.
시퀀스 변환 구간에서는 이미 뽑힌 멜로디는 비브라 토(vibrato)등과 약간의 에러들로 바로 사용하기는 부적합하다. 그래서 스무딩(smoothing) 과정을 거쳐서 유사도 비교에 적합 형태로 시퀀스를 변환하게 된다.In the sequence conversion section, the melody that has already been selected is inappropriate to use immediately due to vibrato and some errors. Therefore, the sequence is converted into a form suitable for similarity comparison through a smoothing process.
상기한 바와 같이 데이터를 시퀀스 변환 과정을 완료한 후, 유사도 분석모듈(45)에 의하여 컨텐츠간의 유사도를 비교한다.After completing the data sequence conversion process as described above, the
이러한 유사도 분석과정에 있어서는, 시퀀스 변환된 데이터와 데이터베이스의 데이터간의 유사도를 계산하여 유사여부를 구하게 된다.In this similarity analysis process, the similarity is obtained by calculating the similarity between the sequence-converted data and the data in the database.
즉, 유사도 분석모듈(45)에서는 도 4에 도시된 바와 같이, 실시예 1의 메타버스 컨텐츠와 유사한 구조이다.That is, the
이러한 유사도 분석모듈(45)은 중앙처리장치(32)에 의하여 컨텐츠의 유사도 분석을 다양한 알고리즘을 사용할 수 있는 바, 예를 들면 딥러닝(Deep learning) 방식에 의하여 유사도를 판단하는 방식이다.The
중앙처리장치(32)는 유사도 분석엔진(34)과, GPU(35)와, ALSA(Advanced Linux Sound Architecture;36), ALVA(38), RTSP(Real Time Streaming Protocol;40), API(42), 통신모듈에 의하여 신호를 송수신하게 된다.The
그리고, 이러한 중앙처리장치(32)에는 딥러닝 프로그램이 탑재됨으로써 컨텐츠간의 유사도를 판단하는 바, 딥러닝은 컴퓨터가 여러 데이터를 이용해 인간처럼 스스로 학습할 수 있게 하기 위해 인공 신경망(ANN: artificial neural network)을 기반으로 구축한 한 기계 학습방법이다.In addition, the
인공 신경망을 이용하면 컨텐츠 데이터의 분류(classification) 및 군집화(clustering)가 가능한 바, 분류나 군집화를 원하는 데이터 위에 여러 가지 층(layer)을 얹어서 유사도 판단을 실시할 수 있다.When the artificial neural network is used, classification and clustering of content data is possible, and thus, similarity can be determined by placing various layers on the data for which classification or clustering is desired.
즉, 도 8에 도시된 바와 같이, 인공 신경망은 입력층, 다수의 노드, 출력층으로 구성된다. 이러한 인공 신경망은 컨텐츠 데이터의 형상 특징을 추출하고 그 특징을 다시 다른 기계학습 알고리즘의 입력값으로 사용하여 형상 별로 분류나 군집화를 함으로써 유사도를 판단할 수 있다.That is, as shown in FIG. 8 , the artificial neural network consists of an input layer, a plurality of nodes, and an output layer. Such an artificial neural network can determine similarity by extracting shape features of content data and classifying or clustering them by shape using the features as input values for other machine learning algorithms.
이러한 인공 신경망은 심층 신경망을 포함하는 바, 심층 신경망은 신경망 알고리즘 중에서 여러 개의 층으로 이루어진 신경망을 의미한다.The artificial neural network includes a deep neural network, and the deep neural network means a neural network composed of several layers among neural network algorithms.
즉, 인공 신경망은 다층으로 구성되는 바, 각각의 층은 여러 개의 노드로 구성되고, 각 노드에서는 실제로 형상을 분류하는 연산이 일어나며, 이 연산 과정은 인간의 신경망을 구성하는 뉴런에서 일어나는 과정을 모사하도록 설계된다.That is, the artificial neural network is composed of multiple layers, each layer is composed of several nodes, and an operation of actually classifying a shape occurs at each node. designed to do
노드는 일정 크기 이상의 자극을 받으면 반응을 하는데, 그 반응의 크기는 입력 값과 노드의 계수(또는 가중치, weights)를 곱한 값과 대략 비례한다.When a node receives a stimulus of a certain size or more, it responds, and the magnitude of the response is roughly proportional to the value multiplied by the input value and the node's coefficient (or weights).
일반적으로 노드는 여러 개의 입력을 받으며 입력 갯수만큼의 계수를 갖는다. 따라서, 이 계수를 조절함으로써 여러 입력에 서로 다른 가중치를 부여할 수 있다.In general, a node receives multiple inputs and has as many coefficients as the number of inputs. Therefore, different weights can be given to different inputs by adjusting this coefficient.
최종적으로 곱한 값들은 전부 더해지고 그 합은 활성 함수(activation function)의 입력으로 들어가게 된다. 활성 함수의 결과가 노드의 출력에 해당하며 이 출력값이 궁극적으로 분류나 회귀 분석에 쓰인다.Finally, all the multiplied values are added and the sum is input to the activation function. The result of the activation function corresponds to the output of the node, and this output is ultimately used for classification or regression analysis.
각 층은 여러 개의 노드로 이루어지며 입력값에 따라 각 노드의 활성화/비활성화 여부가 결정된다. 이때, 입력 데이터는 첫 번째 층의 입력이 되며, 그 이후엔 각 층의 출력이 다시 다음 층의 입력이 되는 방식이다.Each layer consists of several nodes, and whether each node is activated/deactivated is determined according to the input value. At this time, the input data becomes the input of the first layer, and after that, the output of each layer becomes the input of the next layer again.
모든 계수는 컨텐츠 데이터의 형상 학습 과정에서 계속 조금씩 변하는데, 결과적으로 각 노드가 어떤 입력을 중요하게 여기는지를 반영한다. 그리고 신경망의 학습(training)은 이 계수를 업데이트하는 과정이다.All coefficients change little by little during the shape learning process of content data, and as a result, reflect which input each node considers important. And training of the neural network is the process of updating this coefficient.
컨텐츠 데이터의 형상 학습시 이러한 심층 신경망에서는 각 층마다 서로 다른 층위의 특징이 학습된다.When learning the shape of content data, in such a deep neural network, features of different layers are learned for each layer.
즉, 낮은 층위의 특징은 단순하고 구체적인 특징이 학습되며 {예: 컨텐츠 데이터의 형상을 구성하는 형상}, 높은 층위의 특징은 더욱 복잡하고 추상적인 특징이 학습된다. {예: 명사, 음향, 영상}That is, simple and specific features are learned for low-level features, {eg, a shape constituting the shape of content data}, and more complex and abstract features are learned for high-level features. {Example: noun, sound, image}
이런 추상화 학습과정을 통해 심층 신경망이 고차원의 데이터를 이해하며, 이 과정에는 수 억, 수 십억 개의 계수가 관여하게 된다. (이 과정에서 비선형함수가 사용된다.)Through this abstraction learning process, deep neural networks understand high-dimensional data, and hundreds of millions or billions of coefficients are involved in this process. (A non-linear function is used in this process.)
또한, 심층 신경망은 데이터를 이용해 데이터의 잠재적인 구조(latent structures)를 파악할 수 있다. 즉, 컨텐츠 데이터의 문서, 음향, 영상 등의 잠재적인 구조를 파악할 수 있다. 이를 통해 데이터가 라벨링되어 있지 않아도 데이터간의 유사성을 효과적으로 파악할 수 있으며, 결과적으로 심층 신경망은 컨텐츠 데이터의 군집화에 효과적이다.In addition, deep neural networks can use the data to identify the latent structures of the data. That is, it is possible to grasp a potential structure of the content data, such as documents, sounds, and images. Through this, similarity between data can be effectively identified even if the data is not labeled, and as a result, deep neural networks are effective for clustering content data.
예를 들어, 신경망을 이용해 대량의 컨텐츠 데이터를 입력받아 비슷한 컨텐츠 데이터끼리 모아서 분류할 수 있다.For example, a large amount of content data may be input using a neural network, and similar content data may be collected and classified.
이러한 심층 신경망이 일반적인 기계 학습과 다른 점은 특징 추출(feature extraction)이 자동적으로 이루어진다는 점이다.The difference between this deep neural network and general machine learning is that feature extraction is performed automatically.
기존에는 효과적인 특징을 추출하기 위해 관련 분야 전문가가 오랜 시간동안 직접 특징을 추출하는 수식이나 방법을 고안해서 적용해야 했다. 이 방법은 개발, 평가 및 보완에 많은 시간이 걸리는 문제점이 있다.In the past, in order to extract effective features, experts in the relevant field had to devise and apply formulas or methods for extracting features directly for a long time. This method has a problem in that it takes a lot of time to develop, evaluate, and supplement.
심층 신경망은 이런 과정을 컴퓨터가 대신 하도록 알고리즘을 짠 것으로, 사람에 비해 훨씬 빠르고 효과적으로 수행하도록 학습시킨다.A deep neural network is an algorithm designed to make a computer perform this process, and it trains it to perform much faster and more effectively than humans.
라벨링이 되어있지 않은 데이터를 학습하는 경우에도 신경망은 컨텐츠 데이터의 특징을 자동적으로 추출할 수 있다. 이 자동 추출은 여러 가지 방법이 있는데, 보통 이 과정은 신경망을 통과시켰을 때의 출력이 입력과 같아지도록 학습하게 된다.Even when learning unlabeled data, the neural network can automatically extract features of content data. There are several methods for this automatic extraction, and in general, this process learns to make the output equal to the input when passed through the neural network.
라벨이 어떤 종류이든지(입력을 그대로 사용/별도의 라벨을 사용) 신경망은 입력과 출력의 상관관계를 찾는다. 경우에 따라서는 라벨링된 데이터로 신경망을 어느 정도 학습시킨 뒤 라벨링이 되어있지 않은 데이터를 추가하여 계속 학습시킬 수도 있다. 이 방법을 이용하면 신경망의 성능을 극대화할 수 있다.No matter what kind of label is (use the input as is/use a separate label), the neural network finds the correlation between the input and the output. In some cases, after training the neural network to some extent with labeled data, it is possible to continue learning by adding unlabeled data. Using this method, the performance of the neural network can be maximized.
심층 신경망의 마지막 층은 출력층이다. 출력층의 활성 함수는 로지스틱(logistic) 혹은 소프트 맥스(softmax)인 경우가 대부분이며 출력층에서는 최종적으로 특정 라벨의 확률을 구할 수 있다. 예를 들어 컨텐츠 데이터를 입력하였을 때 2개의 문서가 서로 유사한지, 음향이 유사한지, 동영상이 서로 유사한지 등을 각각의 확률로 구할 수 있다.The last layer of a deep neural network is the output layer. In most cases, the activation function of the output layer is logistic or softmax, and the probability of a specific label can be finally obtained from the output layer. For example, when content data is input, whether two documents are similar to each other, sounds are similar, or videos are similar to each other can be obtained with respective probabilities.
우선 학습이 시작되기 전에 뉴럴넷의 모든 계수를 초기화한다. 그리고 컨텐츠 데이터를 반복적으로 입력하여 학습을 진행한다. 만일 학습이 원활하게 진행되었다면 계수는 적절한 값으로 업데이트 되어 있을 것이고, 이 인공 신경망으로 각종 분류와 예측이 가능하다.First, all coefficients of the neural net are initialized before training starts. Then, the learning proceeds by repeatedly inputting the content data. If the learning proceeds smoothly, the coefficients will be updated to appropriate values, and various classifications and predictions are possible with this artificial neural network.
학습 과정 내부에선 이러한 계수의 업데이트 과정이 반복적으로 일어난다.In the learning process, the updating process of these coefficients occurs repeatedly.
계수 업데이트의 원리는 우선 계수를 추정하고 그 계수를 사용했을 때 발생하는 에러를 측정한 뒤 그 에러에 기반해서 계수를 약간씩 업데이트 하는 방식이다.The principle of coefficient update is to first estimate the coefficient, measure the error that occurs when the coefficient is used, and then slightly update the coefficient based on the error.
이때, 신경망의 여러 계수를 합쳐서 모델이라고 부르며, 모델은 초기화 된 상태일 수도 있고, 학습이 완료된 상태일 수도 있다.At this time, the multiple coefficients of the neural network are collectively called a model, and the model may be in an initialized state or in a state in which learning is completed.
초기화된 모델은 의미있는 작업을 못하지만 학습이 진행될수록 모델은 임의의 값이 아닌, 실제와 유사한 결과를 출력하게 된다.The initialized model does not perform any meaningful work, but as the learning progresses, the model outputs results similar to the actual value rather than a random value.
이는 인공 신경망이 데이터가 입력되기 전에는 아무것도 모르는 상태이기 때문이며, 계수를 임의의 값으로 초기화하는 이유도 마찬가지이다. 그리고 데이터를 읽어가면서 계수를 조금씩 올바른 방향으로 업데이트하게 된다.This is because the artificial neural network does not know anything before data is input, and the reason for initializing coefficients to arbitrary values is also the same. And as the data is read, the coefficients are updated little by little in the correct direction.
이러한 업데이트 과정을 통하여 인공 신경망은 입력된 컨텐츠 데이터들을 분류함으로써 유사한 컨텐츠 데이터들을 군집화할 수 있다. 그리고, 군집화된 컨텐츠 데이터는 데이터 베이스에 등록된다.Through this update process, the artificial neural network can group similar content data by classifying the input content data. Then, the clustered content data is registered in the database.
한편, 상기에서는 인공지능에 의하여 유사도를 판단하는 방법에 의하여 설명하였지만, 본 발명은 이에 한정되는 것은 아니고 다른 방법으로도 유사여부를 판단할 수 있다.Meanwhile, although the method for determining the degree of similarity by artificial intelligence has been described above, the present invention is not limited thereto, and the similarity may be determined by other methods.
예를 들면, 문서 컨텐츠의 유사도를 평가하는 경우, AST 방식에 의하여 유사도를 평가할 수 있다.For example, when evaluating the similarity of document content, the similarity may be evaluated by the AST method.
즉, 2개의 문서 컨텐츠의 노드 스트링을 입력받고, 각 노드 스트링의 첫 번째로 일치하는 스트링을 검색한다. 이때 가장 길게 매칭되는 스트링(MMS: Maximun Match String)을 알고리즘을 통하여 검색한다.That is, node strings of two document contents are input, and the first matching string of each node string is searched. At this time, the longest matching string (MMS: Maximun Match String) is searched through an algorithm.
이 알고리즘에 있어서는, 가능한 최대 크기의 토큰 스트링을 검색하기 위하여 지속적으로 비교하여 가장 긴 스트링을 찾게 된다.In this algorithm, the longest string is found by continuously comparing in order to search for the largest possible size of the token string.
예를 들면, 제 1문서 컨텐츠와 제 2문서 컨텐츠의 노드 스트링이 아래와 같다고 가정한다.For example, it is assumed that node strings of the first document content and the second document content are as follows.
P1 : 23, 34, 25, 54, 55, 44, 45, 49, 81, 83, 84, 22, 55, 44, 33, 90P1: 23, 34, 25, 54, 55, 44, 45, 49, 81, 83, 84, 22, 55, 44, 33, 90
P2 : 34, 25, 54, 46, 47, 81, 83, 84, 22, 55, 44, 33, 90, 93, 92, 95P2: 34, 25, 54, 46, 47, 81, 83, 84, 22, 55, 44, 33, 90, 93, 92, 95
그리고, 이 2개의 노드 스트링에서 일치된 부분을 검사하는 바, (34,25,54), (81,83,84,22,55,44,33,90)를 찾아낸다. 이때 가장 긴 스트링을 찾는다,And, (34,25,54) and (81,83,84,22,55,44,33,90) are found by examining the matched part in these two node strings. At this time, find the longest string,
이와 같이 검색된 스트링을 알고리즘의 Set 집합에 추가한 후, P1,P2 노드 스트링에서 이를 제거한다.After adding the searched string to the set set of the algorithm, it is removed from the P1 and P2 node strings.
제거하지 않으면 이 스트링이 반복하여 길게 매칭되는 스트링을 검색하는 작업에 반복하여 입력된다.If not removed, this string is repeatedly entered into the task of searching for a long matching string.
이러한 방식으로 2개의 문서 컨텐츠의 스트링을 비교하여 긴 길이를 갖는 스트링을 순차적으로 제거함으로써 아래 수식 4에 의하여 유사도를 판단할 수 있다.In this way, the similarity can be determined by

상기 수식에 의하여 유사도를 연산하면 다음과 같다.Calculating the degree of similarity using the above formula is as follows.
sim(P1,P2)=2*(3+8)/(16+16)=0.6875sim(P1,P2)=2*(3+8)/(16+16)=0.6875
그리고, 유사도는 0 내지 1사이의 값으로 정해지며, 0은 2개의 컨텐츠가 전혀 다른 경우이며, 1은 일치하는 경우를 의미한다.In addition, the similarity is determined as a value between 0 and 1, where 0 is a case in which two contents are completely different, and 1 is a case in which they are identical.
상기의 경우 0.6875이므로 약 68%정도의 유사도를 갖는다.In the above case, since it is 0.6875, it has a similarity of about 68%.
한편, 음향의 유사도 판단의 경우, 먼저 전체 음악 간의 유사도를 비교한다.Meanwhile, in the case of judging the similarity of sound, first, the similarity between all songs is compared.
멜로디 시퀀스에서 각각의 노트는 피치(pitch)와 듀레이션(duration)으로 이루어져 있다. 하지만 절대적인 피치와 듀레이션을 사용하게 되면 조와 박자 변화에 취약하게 되는 바, 조와 박자 변화에 강인한 directed pitch interval 방식과 directed duration ratio 방식을 사용한다.Each note in a melody sequence consists of a pitch and a duration. However, if absolute pitch and duration are used, they are vulnerable to changes in key and time, so the directed pitch interval method and directed duration ratio method, which are strong against changes in key and time, are used.
이와 같이 처리된 두 시퀀스가 주어지면 edit distance에 기반하여 계산을 하게 된다. 제안된 알고리 즘에서는 음악 유사도를 Smith-Waterman Algorithm과 Mongeau-Sankoff Algorithm를 기초하여 표절의 특성을 고려하여 아래 수식 5와 같이 연산한다.Given the two sequences processed in this way, the calculation is performed based on the edit distance. In the proposed algorithm, the musical similarity is calculated as shown in

Xi는 전단에서 처리된 멜로디 시퀀스의 i번째 요소 이고, 阿Yj는 DB에 저장되어있는 멜로디 시퀀스의 ?번째 요소이다. d i,j는 edit distance 행렬의 (i,j)번째 요소를, ω(Xi, Yj)는 Xi와 Yj간의 가중치를 나타낸다.Xi is the i-th element of the melody sequence processed in the previous stage, and 阿Yj is the ?-th element of the melody sequence stored in the DB. d i,j represents the (i,j)-th element of the edit distance matrix, and ω(Xi, Yj) represents the weight between Xi and Yj.
이 가중치를 계산한테 위에서 언급한 표절의 특징들을 고려하게 된다. 다음과 같은 조건을 고려하여 가중치를 달리 주었다.The calculation of this weight takes into account the characteristics of plagiarism mentioned above. Different weights were given in consideration of the following conditions.
예를 들면, 10,000곡의 노래를 분석하여 노래의 음전이 빈도를 계산하여 빈도가 드문 음을 전이하였을 경우 높은 가중치를 주고, 연속된 음이 같은 경우에 더 큰 가중치를 주고, 음악학을 고려하여 Xi와 Yj의 음간에 피치간격에 따른 협화음과 불협화음을 고려하여 협화음 경우에는 가중치를 크게 주고, 불협화음일 경우에 가중치를 적게 주게 된다.For example, by analyzing 10,000 songs and calculating the tone transition frequency of the song, a higher weight is given to the case where the infrequent tone is transitioned, a higher weight is given to the case where consecutive tones are the same, and a greater weight is given in consideration of musicology. Considering the consonant and dissonant sounds according to the pitch interval between the notes of Yj and Yj, a larger weight is given in the case of a consonant, and a smaller weight is given in the case of a dissonance.
유사구간 탐색 구간에서는 유사구간과 유사도를 확정하게 된다. 위와 같은 과정으로 Edit distance 행렬을 완성을 하고 Smith-Waterman 알고리즘을 이용하여 유사 구간을 검출한 이후에 하고 유사구간을 검출한 이후에 유사 구간 간의 유사도를 다시 계산하여 유사 구간을 확정하고 유사구간의 유사도, 길이, 전체 유사도, 길이 대비 유사 도 등을 종합적으로 고려하여 최종유사도를 계산하고 표절 의심 음악을 찾게 된다.In the similar section search section, the similarity section and the degree of similarity are determined. After completing the Edit distance matrix in the same way as above, using the Smith-Waterman algorithm to detect the similar section, and after detecting the similar section, recalculate the similarity between the similar sections to determine the similar section , length, overall similarity, length-to-length similarity, etc. are comprehensively considered to calculate the final similarity and find music suspected of plagiarism.
한편, 컨텐츠가 유사도 분석모듈(45)에 의하여 유사하다고 판단되면, 침해 판단모듈(47)에 의하여 침해여부를 판단하게 된다.On the other hand, if it is determined that the content is similar by the
이러한 침해 판단모듈(47)은 도 6에 도시된 바와 같이, 유사범위에 포함된다고 판단된 복수의 컨텐츠들을 로딩하고, 로딩된 복수의 컨텐츠들의 유사도에 의하여 침해여부를 판단한다.As shown in FIG. 6 , the
로딩된 컨텐츠는 등록 예정인 컨텐츠와 유사하다고 판단된 복수의 컨텐츠들을 포함하며, 복수의 컨텐츠는 1개 혹은 그 이상일 수 있다.The loaded contents include a plurality of contents determined to be similar to contents to be registered, and the plurality of contents may be one or more.
판단모듈(47)은 로딩된 컨텐츠들의 침해여부를 판단하는 바, 유사도 분석모듈(45)에 의하여 연산된 유사도값을 비교하게 된다. 그리고, 비교된 유사도값의 차이가 침해기준값의 초과여부를 판단하게 된다.The
예를 들면, 등록 예정인 컨텐츠와 유사하다고 판단된 복수의 컨텐츠의 유사도가 80%이고, 해당 컨텐츠 분야의 침해 기준값은 70%인 경우, 판단모듈(47)은 침해로 판단하게 된다.For example, when the similarity of the plurality of contents determined to be similar to the contents to be registered is 80% and the infringement reference value of the corresponding contents field is 70%, the
반면에 유사도가 60%인 경우에는 비침해라고 판단하게 된다.On the other hand, if the similarity is 60%, it is judged as non-infringement.
그리고, 침해 기준은 컨텐츠 분야마다 차이가 있을 수 있는 바, 예를 들면, 문서 분야의 경우 침해기준값은 90%, 음향 분야의 경우 80%, 영상 분야의 경우 70%와 같이 차등적으로 설정될 수 있다.In addition, the infringement standard may be different for each content field. For example, in the case of the document field, the infringement standard value may be set differentially such as 90%, in the case of the sound field, 80%, and in the case of the image field, 70%. have.
판단모듈(47)에 의하여 침해로 판단되는 경우에는 알림모듈(49)을 통하여 침해임을 안내하게 되고, 비침해로 판단되는 경우에는 등록부(65)에 의하여 컨텐츠를 데이터베이스에 저장한다.If the
알림모듈(49)은 침해인 경우에는 등록 예정인 사용자에게 침해임을 안내하게 되고, 이러한 안내를 접수한 사용자는 해당 컨텐츠의 등록을 포기하거나, 컨텐츠를 보다 개량하여 재등록을 시도하게 된다.In case of infringement, the
한편, 온라인상에서 거래된 컨텐츠는 공표되거나 거래되는 경우 수익 정산부(13)에 의하여 매출이 정산될 수 있다.On the other hand, when the content traded online is published or traded, the sales may be settled by the
즉, 수익 정산부(13)는 일반 컨텐츠를 이용하는 이용자에게 컨텐츠 과금부(14)를 통하여 이용 횟수 혹은 시간만큼의 수수료를 청구하여 수익을 정산하게 된다. 이러한 정산 방식은 전술한 실시예와 동일한 방식으로 정산한다.That is, the
상기 서버(4)를 구성하는 요소, 즉, 입력부(53)와, 특징점 추출부(55)와, 전처리부(57)와, 시퀀스 변환부(59)와, 유사도 분석모듈(45)과, 침해 판단모듈(47)은 입력된 데이터에 대한 해석, 명령의 실행, 연산 등을 실시하는 마이크로 프로세서(Micro processor)를 의미한다.The elements constituting the
한편, 도 12에는 일반 컨텐츠를 생성, 등록하고, 유사도를 비교하는 과정이 도시된다.Meanwhile, FIG. 12 shows a process of generating and registering general content and comparing the degree of similarity.
도시된 바와 같이, 먼저 컨텐츠를 등록하고 이용하기 위한 인증을 요청한다(S20). 이러한 과정은 통상적인 회원인증절차에 의하여 진행될 수 있다.As shown, first, authentication is requested to register and use the content (S20). This process can be carried out according to the normal member authentication procedure.
등록된 사용자 여부가 확인된 경우(S22), 입력부(53)를 통하여 컨텐츠를 입력한다(S24).When the registered user is checked (S22), the content is input through the input unit 53 (S24).
그리고, 입력된 컨텐츠는 특징점 추출, 전처리, 시퀀스 변환의 과정을 순차적으로 거치면서 처리될 수 있다(S26).Then, the input content may be processed while sequentially going through the processes of feature point extraction, pre-processing, and sequence conversion (S26).
먼저, 특징점 추출부(55)에 의하여 컨텐츠에 대한 특징점을 추출한다.First, the feature
이때, 다양한 컨텐츠에 대한 특징점 추출이 가능한 바, 문서 컨텐츠인 경우, 상기한 바와 같이, 어휘 분석기(65)에 의하여 문서에서 색인어로 사용될 수 있는 단어들을 추출하고, 색인 변환기(67)에 의하여 추출된 명사들을 색인으로 변환하게 된다.At this time, it is possible to extract key points for various contents. In the case of document contents, as described above, words that can be used as index words are extracted from the document by the
그리고, 색인 변환기(67)을 통하여 추출된 색인어는 시퀀스 추출모듈(69)에 의하여 시퀀스 변환된다.Then, the index word extracted through the
이와 같이 특징점이 추출된 컨텐츠 데이터는 전처리부(57)에 의하여 전처리과정을 거치게 된다.The content data from which the feature points are extracted as described above is subjected to a pre-processing process by the
이러한 전처리 과정은 상기한 바와 같이 데이터에 반사광, 화각, Dust 및 노이즈 제거를 진행하는 바, 데이터 정제(cleansing), 데이터 변환(transformation), 데이터 필터링(filtering), 데이터 통합(integration), 데이터 축소(reduction) 과정을 통하여 처리될 수 있다.This pre-processing process removes reflected light, angle of view, dust, and noise from the data as described above, and data cleaning, data transformation, data filtering, data integration, and data reduction ( reduction) process.
이와 같이 컨텐츠 데이터를 전처리한 후, 시퀀스 변환부(59)에 의하여 시퀀스 변환을 실시한다.After pre-processing the content data in this way, the
시퀀스 변환 과정은 전처리된 데이터 파일을 맵(Map) 함수를 통해 병렬 처리하여, 이벤트 레코드를 추출하고, 데이터 파일에 설정된 시간을 시퀀스 번호로 변환하고, 시퀀스 번호로 변환된 데이터를 리듀스(Reduce) 함수를 통해 병렬로 취합하여 시퀀스를 생성한다.The sequence conversion process parallelly processes the preprocessed data file through the Map function to extract event records, converts the time set in the data file into a sequence number, and reduces the data converted to the sequence number. A sequence is created by assembling in parallel through a function.
이와 같이 컨텐츠 데이터에 대한 처리가 완료되면 유사도를 비교 분석할지 여부를 판단하게 된다(S28).As such, when the processing of the content data is completed, it is determined whether to compare and analyze the similarity (S28).
유사도를 비교하지 않는 경우에는 컨텐츠를 저장 및 등록하는 과정이 진행된다(S30).When the similarity is not compared, the process of storing and registering the content is performed (S30).
반대로, 유사도를 비교하는 경우에는, 유사도 분석모듈(45)에 의하여 진행된다(S32).Conversely, in the case of comparing the degree of similarity, the
즉, 유사도 분석모듈(45)은 중앙처리장치(32)에 의하여 컨텐츠의 유사도 분석을 다양한 알고리즘을 사용할 수 있는 바, 예를 들면 딥러닝(Deep learning) 방식에 의하여 유사도를 판단할 수 있다.That is, the
이와 같이, 유사도 판단과정이 완료되면, 산출된 유사도를 사용자에게 통지하게 된다(S34).In this way, when the similarity determination process is completed, the calculated similarity is notified to the user (S34).
Claims (8)
Translated fromKorean서버(4)는, 가상현실 세계에서 거래되는 유, 무형의 자산에 대한 정보를 등록 및 관리하고, 영상 및 메타데이터를 수집하고, 수집된 데이터를 전처리부(7)에 의하여 전처리한 후 인공지능 알고리즘에 의하여 실시간 분석하고 분류하며, 아이템 혹은 새로운 데이터를 3D 모델링하고, 복합 메타버스 가상현실 공간에 유형의 아이템을 표출하는 메타버스 구축부(3)와;
복합 메타버스 가상현실에서 창작물을 생성하는 컨텐츠 생성부(5);
컨텐츠 생성부(5)에서 생성된 메타버스 컨텐츠를 인공지능 분석에 의하여 창작물의 표절, 저작권 위배 여부, 컨텐츠와 관련된 정보를 등록하는 컨텐츠 등록부(8);
컨텐츠 등록부(57)에 의하여 등록된 메타버스 컨텐츠의 단가를 연산하는 단가 연산부(9);
온라인상에서 메타버스 컨텐츠에 대한 거래를 진행시키는 컨텐츠 거래소(11)와; 그리고
컨텐츠 거래소(11)를 통하여 공표되거나 거래된 메타버스 데이터의 수익을 정산하는 수익 정산부(13)를 포함하며;
컨텐츠 등록부(57)는 새로 등록예정인 메타버스 컨텐츠와 기존 메타버스 컨텐츠를 비교하는 유사도 분석모듈(45)과; 그리고
유사도 분석결과에 따라 지재권의 침해여부를 판단하는 침해 판단모듈(47)을 포함하며,
메타버스 구축부(3)는, 현실 세계에서 거래되는 유, 무형의 자산에 대한 정보를 등록하고, 저장 관리되는 아이템 등록부(18)와;
사용자의 디바이스(6) 및 위치 기반신호에 따라 수신되는 영상 및 메타데이터를 수집하는 데이터 수집부(15)와;
상기 수집된 데이터를 전처리 한 후 인공지능 알고리즘에 의하여 실시간 분석하고 분류하는 데이터 분석부(22)와;
상기 데이터 분석부(22)를 통하여 수신된 영상 및 메타데이터를 이용하여 2D 또는 3D 영상으로 등록된 아이템 혹은 새로운 데이터를 3D 모델링하는 아이템 생성부(20)와;
상기 아이템 생성부(20)에서 모델링된 아이템과 상기 아이템 등록부(18)에서 매칭된 아이템 제품 정보를 연결하여 복합 메타버스 가상현실 공간에 유형의 아이템을 표출하는 가상현실 구축부(3)를 포함하는 메타버스 컨텐츠의 유사도 분석을 통한 저작권 침해 분석 시스템.A terminal (2), a device (6) for collecting various data, and a server ( 4) As a copyright infringement analysis system through the similarity analysis of contents including,
The server 4 registers and manages information on tangible and intangible assets traded in the virtual reality world, collects images and metadata, and pre-processes the collected data by the pre-processing unit 7, followed by artificial intelligence a metaverse construction unit 3 that analyzes and categorizes items in real time by an algorithm, 3D models items or new data, and expresses tangible items in a complex metaverse virtual reality space;
a content generation unit 5 that generates a creation in the complex metaverse virtual reality;
a content registration unit 8 for registering information related to plagiarism, copyright violation, and content related to the metaverse content generated by the content generating unit 5 through artificial intelligence analysis;
a unit price calculation unit 9 for calculating a unit price of metaverse contents registered by the contents registration unit 57;
a content exchange 11 that conducts transactions for metaverse content online; and
a revenue settlement unit 13 for calculating the revenue of metaverse data published or traded through the content exchange 11;
The content registration unit 57 includes a similarity analysis module 45 for comparing newly registered metaverse content with existing metaverse content; and
and a infringement determination module 47 for determining whether intellectual property rights are infringed according to the similarity analysis result,
The metaverse construction unit 3 includes: an item registration unit 18 that registers, stores and manages information on tangible and intangible assets traded in the real world;
a data collection unit 15 for collecting images and metadata received according to the user's device 6 and location-based signals;
a data analysis unit 22 that pre-processes the collected data and then analyzes and classifies the collected data in real time by an artificial intelligence algorithm;
an item generating unit 20 for 3D modeling an item or new data registered as a 2D or 3D image using the image and metadata received through the data analysis unit 22;
A virtual reality construction unit (3) that connects the item modeled in the item creation unit (20) and the item product information matched in the item registration unit (18) to express a tangible item in a complex metaverse virtual reality space; Copyright infringement analysis system through similarity analysis of metaverse contents.
서버(4)는,
생성된 컨텐츠가 입력되는 입력부(53)와;
입력된 컨텐츠를 분류하여 특징점을 추출하는 특징점 추출부(55)와;
컨텐츠에 대한 전처리를 실시하는 전처리부(57)와;
컨텐츠 데이터에 시퀀스 처리를 실시하는 시퀀스 변환부(59)와;
새로 등록예정인 컨텐츠와 기존 등록 컨텐츠를 비교하는 유사도 분석모듈(45)과; 그리고
유사도 분석결과에 따라 지재권의 침해여부를 판단하는 침해 판단모듈(47)을 포함하며,
시퀀스 변환부(59)는 전처리된 데이터 파일을 맵(Map) 함수를 통해 병렬 처리하여, 이벤트 레코드를 추출하고, 데이터 파일에 설정된 시간을 시퀀스 번호로 변환하고, 시퀀스 번호로 변환된 데이터를 리듀스(Reduce) 함수를 통해 병렬로 취합하여 시퀀스를 생성하는 컨텐츠의 유사도 분석을 통한 저작권 침해 분석 시스템(1).A terminal (2), a device (6) for collecting various data, and a server ( 4) As a copyright infringement analysis system through the similarity analysis of contents including,
The server 4 is
an input unit 53 to which the generated content is input;
a feature point extraction unit 55 for classifying the inputted content and extracting feature points;
a pre-processing unit 57 for pre-processing the content;
a sequence conversion unit 59 that performs sequence processing on the content data;
a similarity analysis module 45 for comparing newly registered content with existing registered content; and
and a infringement determination module 47 for determining whether intellectual property rights are infringed according to the similarity analysis result,
The sequence converter 59 parallel-processes the preprocessed data file through a map function, extracts an event record, converts the time set in the data file into a sequence number, and reduces the data converted to the sequence number Copyright infringement analysis system (1) through similarity analysis of contents that generate sequences by collecting them in parallel through the (Reduce) function.
전처리부(7,57)는 영상 컨텐츠를 처리하는 영상 컨텐츠 전처리 모듈(17)과; 이미지 컨텐츠를 전처리하는 이미지 컨텐츠 전처리 모듈(19)과; 메타정보를 전처리하는 전처리 모듈(21)과; 음원 컨텐츠를 처리하는 음원 컨텐츠 전처리 모듈(23)을 포함하며, 중앙 처리장치(32)와 연결되어 신호를 송수신하는 컨텐츠의 유사도 분석을 통한 저작권 침해 분석 시스템(1).3. The method of claim 1 or 2,
The pre-processing units 7 and 57 include an image content pre-processing module 17 for processing image content; an image content pre-processing module 19 for pre-processing image content; a pre-processing module 21 for pre-processing meta information; A copyright infringement analysis system (1) including a sound source content pre-processing module 23 for processing sound source content, and through a similarity analysis of content that is connected to a central processing unit (32) to transmit and receive signals.
유사도 분석모듈(45)에서는 중앙처리장치(32)에 딥러닝(Deep learning)을 탑재하여 유사도를 판단하는 바,
중앙처리장치(32)는 유사도 분석엔진(34)과, GPU(35)와, ALSA(Advanced Linux Sound Architecture;36), ALVA(38), RTSP(Real Time Streaming Protocol;40), API(42), 통신모듈를 포함하는 컨텐츠의 유사도 분석을 통한 저작권 침해 분석 시스템(1).3. The method of claim 1 or 2,
In the similarity analysis module 45, the central processing unit 32 is equipped with deep learning to determine the similarity,
The central processing unit 32 includes a similarity analysis engine 34, GPU 35, ALSA (Advanced Linux Sound Architecture; 36), ALVA 38, RTSP (Real Time Streaming Protocol; 40), API (42). , a copyright infringement analysis system (1) through similarity analysis of contents including a communication module.
침해 판단모듈(47)은 유사범위에 포함된다고 판단된 복수의 컨텐츠들을 로딩하고, 로딩된 복수의 컨텐츠들의 유사도에 의하여 침해여부를 판단하며, 침해시 알림모듈(49)에 의하여 정당한 컨텐츠 등록자에게 안내하는 컨텐츠의 유사도 분석을 통한 저작권 침해 분석 시스템(1).7. The method of claim 6,
The infringement determination module 47 loads a plurality of contents determined to be included in the similarity range, determines whether there is an infringement based on the similarity of the plurality of loaded contents, and informs a legitimate content registrant by the notification module 49 in case of infringement Copyright infringement analysis system (1) through similarity analysis of contents.
수익 정산부(13)는 메타버스 컨텐츠를 이용하는 이용자에게 컨텐츠 과금부(14)를 통하여 이용 횟수 혹은 시간만큼의 수수료를 청구하여 수익을 정산하는 컨텐츠의 유사도 분석을 통한 저작권 침해 분석 시스템(1).
The method of claim 1,
The revenue settlement unit 13 charges the user who uses the metaverse contents a fee for the number of times or time used through the contents billing unit 14 to settle the revenue.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020210172838AKR102421159B1 (en) | 2021-12-06 | 2021-12-06 | The methods and systems of copyright infringement analysis through similarity analysis of contents which created by users in virtual reality modeling the real world |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020210172838AKR102421159B1 (en) | 2021-12-06 | 2021-12-06 | The methods and systems of copyright infringement analysis through similarity analysis of contents which created by users in virtual reality modeling the real world |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR102421159B1true KR102421159B1 (en) | 2022-07-14 |
Family
ID=82406880
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020210172838AActiveKR102421159B1 (en) | 2021-12-06 | 2021-12-06 | The methods and systems of copyright infringement analysis through similarity analysis of contents which created by users in virtual reality modeling the real world |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR102421159B1 (en) |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102551872B1 (en)* | 2022-08-12 | 2023-07-05 | 한국전자인증 주식회사 | The Music-NFT Generating System based on AI Performed in Metaverse |
| WO2024019228A1 (en)* | 2022-07-21 | 2024-01-25 | 김성희 | Sales management system according to patent for sponsorship call sales business |
| WO2024043391A1 (en)* | 2022-08-25 | 2024-02-29 | 자오보잉 | Metaverse-based luxury item experiencing system and method |
| KR20240044050A (en)* | 2022-09-28 | 2024-04-04 | 정기영 | Method, device and computer-readable recording medium for determining and displaying whether uploaded images are exposed |
| US20240144571A1 (en)* | 2022-10-26 | 2024-05-02 | At&T Intellectual Property I, L.P. | System for Derivation of Consistent Avatar Appearance Across Metaverse Ecosystems |
| KR20240117865A (en)* | 2023-01-26 | 2024-08-02 | 주식회사 고브이알 | Apparatus and method for implementing metaverse based on photogrammetry |
| KR102748722B1 (en)* | 2024-05-28 | 2024-12-31 | 주식회사 메타버즈 | Method of Providing a User 3d Virtual Space Construction and Operation Platform Using AI NPC |
| CN119293909A (en)* | 2024-09-26 | 2025-01-10 | 中建八局第二建设有限公司 | A 3D model design optimization method and system based on deep learning |
| KR102770341B1 (en)* | 2023-11-29 | 2025-02-21 | 주식회사 비욘드테크 | Method for identifying original content to prevent unauthorized use of assets in the metaverse and apparatus |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20010026397A (en) | 1999-09-06 | 2001-04-06 | 박종섭 | Method for comparing similarity of two images and method and apparatus for searching images using the same |
| KR20110007419A (en)* | 2009-07-16 | 2011-01-24 | 한국전자통신연구원 | Content Delivery System in Multi Metaverse Environments and Content Management Method Using the Same |
| KR20210032136A (en)* | 2019-09-16 | 2021-03-24 | 유건우 | Method for providing copyright management service coordinating authorship relation between copyright owner and user |
- 2021
- 2021-12-06KRKR1020210172838Apatent/KR102421159B1/enactiveActive
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20010026397A (en) | 1999-09-06 | 2001-04-06 | 박종섭 | Method for comparing similarity of two images and method and apparatus for searching images using the same |
| KR20110007419A (en)* | 2009-07-16 | 2011-01-24 | 한국전자통신연구원 | Content Delivery System in Multi Metaverse Environments and Content Management Method Using the Same |
| KR20210032136A (en)* | 2019-09-16 | 2021-03-24 | 유건우 | Method for providing copyright management service coordinating authorship relation between copyright owner and user |
Cited By (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2024019228A1 (en)* | 2022-07-21 | 2024-01-25 | 김성희 | Sales management system according to patent for sponsorship call sales business |
| KR102551872B1 (en)* | 2022-08-12 | 2023-07-05 | 한국전자인증 주식회사 | The Music-NFT Generating System based on AI Performed in Metaverse |
| WO2024043391A1 (en)* | 2022-08-25 | 2024-02-29 | 자오보잉 | Metaverse-based luxury item experiencing system and method |
| KR20240044050A (en)* | 2022-09-28 | 2024-04-04 | 정기영 | Method, device and computer-readable recording medium for determining and displaying whether uploaded images are exposed |
| KR102762342B1 (en)* | 2022-09-28 | 2025-02-04 | 로지트코리아 유한회사 | Method, device and computer-readable recording medium for determining and displaying whether uploaded images are exposed |
| US20240144571A1 (en)* | 2022-10-26 | 2024-05-02 | At&T Intellectual Property I, L.P. | System for Derivation of Consistent Avatar Appearance Across Metaverse Ecosystems |
| KR20240117865A (en)* | 2023-01-26 | 2024-08-02 | 주식회사 고브이알 | Apparatus and method for implementing metaverse based on photogrammetry |
| KR102831576B1 (en)* | 2023-01-26 | 2025-07-08 | 주식회사 고브이알 | Apparatus and method for implementing metaverse based on photogrammetry |
| KR102770341B1 (en)* | 2023-11-29 | 2025-02-21 | 주식회사 비욘드테크 | Method for identifying original content to prevent unauthorized use of assets in the metaverse and apparatus |
| KR102748722B1 (en)* | 2024-05-28 | 2024-12-31 | 주식회사 메타버즈 | Method of Providing a User 3d Virtual Space Construction and Operation Platform Using AI NPC |
| CN119293909A (en)* | 2024-09-26 | 2025-01-10 | 中建八局第二建设有限公司 | A 3D model design optimization method and system based on deep learning |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102421159B1 (en) | The methods and systems of copyright infringement analysis through similarity analysis of contents which created by users in virtual reality modeling the real world | |
| Ranjan et al. | Learning multi-human optical flow | |
| Doulamis et al. | Transforming Intangible Folkloric Performing Arts into Tangible Choreographic Digital Objects: The Terpsichore Approach. | |
| US20190354744A1 (en) | Detection of counterfeit items based on machine learning and analysis of visual and textual data | |
| EP3446263A1 (en) | Systems and methods for sensor data analysis through machine learning | |
| CN111784845A (en) | Artificial intelligence-based virtual try-on method, device, server and storage medium | |
| KR20220113248A (en) | System and method for providing virtual reality service based on artificial intelligence | |
| KR20210144330A (en) | Method and apparatus for recommending item based on collaborative filtering neural network | |
| KR102459466B1 (en) | Integrated management method for global e-commerce based on metabus and nft and integrated management system for the same | |
| CN113362852B (en) | User attribute identification method and device | |
| US20100169184A1 (en) | Communication integration between users in a virtual universe | |
| Liu et al. | Digital twins by physical education teaching practice in visual sensing training system | |
| KR102600832B1 (en) | Method of operating art gallery community platform that forms virtual reality art gallery with atmosphere matching exhibition art data and provides art transaction and user community services | |
| KR20240169164A (en) | artificial intelligence learning method | |
| CN116932798A (en) | Virtual speaker generation method, device, equipment and storage medium | |
| Mitsouras et al. | U-sketch: An efficient approach for sketch to image diffusion models | |
| Kumar et al. | An Effective Pre-Owned Car Price Prediction Based on Multi Linear Regression Technique | |
| El-Din et al. | Multimodal data challenge in metaverse technology | |
| CN117034133A (en) | Data processing method, device, equipment and medium | |
| JP2023101452A (en) | Recommendation program, recommendation method, and recommendation apparatus | |
| Rijayana et al. | Development E-Commerce Applications | |
| María-Arribas et al. | The ETS2 Dataset, Synthetic Data from Video Games for Monocular Depth Estimation | |
| CN119620869B (en) | User interaction experience optimization method and system based on meta universe | |
| CN117079336B (en) | Training method, device, equipment and storage medium for sample classification model | |
| KR102669435B1 (en) | System for providing non-fungible token market management service |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application | Patent event code:PA01091R01D Comment text:Patent Application Patent event date:20211206 | |
| PA0201 | Request for examination | ||
| PA0302 | Request for accelerated examination | Patent event date:20211221 Patent event code:PA03022R01D Comment text:Request for Accelerated Examination Patent event date:20211206 Patent event code:PA03021R01I Comment text:Patent Application | |
| PE0902 | Notice of grounds for rejection | Comment text:Notification of reason for refusal Patent event date:20220322 Patent event code:PE09021S01D | |
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration | Patent event code:PE07011S01D Comment text:Decision to Grant Registration Patent event date:20220629 | |
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment | Comment text:Registration of Establishment Patent event date:20220711 Patent event code:PR07011E01D | |
| PR1002 | Payment of registration fee | Payment date:20220711 End annual number:3 Start annual number:1 | |
| PG1601 | Publication of registration | ||
| PR1001 | Payment of annual fee | Payment date:20250519 Start annual number:4 End annual number:4 |