KR102419579B1 - Apparatus and method for generating learning data for determining whether intellectual property is infringed - Google Patents
Apparatus and method for generating learning data for determining whether intellectual property is infringedDownload PDFInfo
- Publication number
- KR102419579B1 KR102419579B1KR1020210188854AKR20210188854AKR102419579B1KR 102419579 B1KR102419579 B1KR 102419579B1KR 1020210188854 AKR1020210188854 AKR 1020210188854AKR 20210188854 AKR20210188854 AKR 20210188854AKR 102419579 B1KR102419579 B1KR 102419579B1
- Authority
- KR
- South Korea
- Prior art keywords
- information channel
- generating
- color
- images
- image
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N5/00—Computing arrangements using knowledge-based models
- G06N5/02—Knowledge representation; Symbolic representation
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T11/00—2D [Two Dimensional] image generation
- G06T11/001—Texturing; Colouring; Generation of texture or colour
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T15/00—3D [Three Dimensional] image rendering
- G06T15/04—Texture mapping
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/10—Segmentation; Edge detection
- G06T7/13—Edge detection
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/43—Processing of content or additional data, e.g. demultiplexing additional data from a digital video stream; Elementary client operations, e.g. monitoring of home network or synchronising decoder's clock; Client middleware
- H04N21/442—Monitoring of processes or resources, e.g. detecting the failure of a recording device, monitoring the downstream bandwidth, the number of times a movie has been viewed, the storage space available from the internal hard disk
- H04N21/44236—Monitoring of piracy processes or activities
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2207/00—Indexing scheme for image analysis or image enhancement
- G06T2207/20—Special algorithmic details
- G06T2207/20084—Artificial neural networks [ANN]
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Computing Systems (AREA)
- General Health & Medical Sciences (AREA)
- Evolutionary Computation (AREA)
- Data Mining & Analysis (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Computational Linguistics (AREA)
- Artificial Intelligence (AREA)
- Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Computer Security & Cryptography (AREA)
- Virology (AREA)
- Computer Networks & Wireless Communication (AREA)
- Databases & Information Systems (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Computer Graphics (AREA)
- Image Analysis (AREA)
Abstract
Description
Translated fromKorean본 발명은 학습 데이터 생성 기술에 관한 것으로, 보다 상세하게는, 지적 재산권 침해 여부를 판별하는 인공신경망을 학습시키기 위한 학습 데이터를 생성하기 위한 장치 및 이를 위한 방법에 관한 것이다.The present invention relates to a technology for generating learning data, and more particularly, to an apparatus for generating learning data for training an artificial neural network to determine whether intellectual property rights are infringed, and a method therefor.
인공지능이 제대로 동작하기 위해서는 학습을 위한 다양한 물품의 이미지를 필요로 한다. 그러나 실제로 학습에 필요한 데이터를 취득하기 위해서는 많은 인력 및 시간적인 소모를 요구하는 것이 대부분이다. 대부분의 경우 인공지능 학습용 데이터 선취를 위한 팀이 존재하는 경우가 일반적이다. 특히, 도면 이미지의 경우 본래 지닌 이미지의 특수성으로 인해, 원하는 학습용 이미지를 취득하기 위해 물품과 대응되는 도면 이미지를 스케치하는 것이 시간 소모량이 크고 다양하지 못하다는 한계점이 존재한다. 또한, 도면 이미지를 포함하여, 이와 직접적으로 대응되는 RGB 이미지 모두 카메라를 통해 직접적으로 선취하는 기대 시간의 비용이 적지 않다는 근본적인 한계가 존재한다.In order for artificial intelligence to work properly, it needs images of various objects for learning. However, most of them require a lot of manpower and time consumption to actually acquire the data required for learning. In most cases, it is common for a team to preempt data for AI learning. In particular, in the case of drawing images, due to the specificity of the original image, there is a limitation in that sketching a drawing image corresponding to an article in order to obtain a desired learning image consumes a large amount of time and is not diverse. In addition, there is a fundamental limitation that the cost of the expected time to directly preempt all RGB images directly corresponding thereto through the camera, including drawing images, is not small.
본 발명의 목적은 지적 재산권 침해 여부를 판별하는 인공신경망을 학습시키기 위한 학습 데이터를 생성하기 위한 장치 및 이를 위한 방법을 제공함에 있다.An object of the present invention is to provide an apparatus for generating learning data for training an artificial neural network to determine whether intellectual property rights are infringed, and a method therefor.
상술한 바와 같은 목적을 달성하기 위한 본 발명의 바람직한 실시예에 따른 학습 데이터를 생성하기 위한 방법은 스캔부가 객체를 스캔하여 3차원 이미지를 생성하는 단계와, 렌더링부가 서로 다른 복수의 위치에 배치된 가상의 카메라를 통해 상기 3차원 이미지에 대한 렌더링을 수행하여 법선정보 채널, 깊이정보 채널 및 컬러정보 채널을 포함하는 복수의 컬러 이미지를 생성하는 단계와, 도면생성부가 상기 복수의 컬러 이미지의 법선정보 채널, 깊이정보 채널 및 컬러정보 채널을 이용하여 복수의 도면 이미지를 생성하는 단계를 포함한다.In a method for generating learning data according to a preferred embodiment of the present invention for achieving the above object, the scanning unit scans an object to generate a three-dimensional image, and the rendering unit is disposed at a plurality of different locations. generating a plurality of color images including a normal information channel, a depth information channel, and a color information channel by performing rendering on the three-dimensional image through a virtual camera; and generating a plurality of drawing images by using the channel, the depth information channel, and the color information channel.
상기 도면 이미지를 생성하는 단계는 상기 도면생성부가 상기 컬러 이미지의 컬러정보 채널을 변환하여 객체의 면이 흰색으로 표현되는 컬러정보 채널을 도출하는 단계와, 상기 도면생성부가 상기 컬러 이미지의 법선정보 채널 및 깊이정보 채널로부터 객체의 윤곽이 검정색으로 표현되는 객체윤곽 특징지도를 도출하는 단계와, 상기 도면생성부가 객체의 면이 흰색으로 표현되는 컬러정보 채널에 객체윤곽 특징지도를 결합하여 도면 이미지를 생성하는 단계를 포함한다.The generating of the drawing image includes: the drawing generating unit converting the color information channel of the color image to derive a color information channel in which the surface of the object is expressed in white; and the drawing generating unit converting the color information channel of the color image; and deriving an object contour characteristic map in which the outline of the object is expressed in black from the depth information channel. The drawing generating unit generates a drawing image by combining the object contour characteristic map in the color information channel in which the surface of the object is expressed in white. including the steps of
상기 객체의 면이 흰색으로 표현되는 컬러정보 채널을 도출하는 단계는 상기 도면생성부가 상기 법선정보 채널을 통해 객체의 면에 해당하는 픽셀을 특정하는 단계와, 상기 도면생성부가 상기 컬러정보 채널에서 상기 특정된 객체의 면에 해당하는 픽셀의 색을 흰색으로 정의하는 단계를 포함한다.The step of deriving the color information channel in which the surface of the object is expressed in white includes the steps of, by the drawing generating unit, specifying a pixel corresponding to the surface of the object through the normal information channel, and the drawing generating unit in the color information channel and defining a color of a pixel corresponding to a surface of the specified object as white.
상기 객체의 윤곽이 검정색으로 표현되는 객체윤곽 특징지도를 도출하는 단계는 상기 도면생성부가 상기 법선정보 채널 및 상기 깊이정보 채널 각각에 라플라시안 필터를 이용한 합성곱 연산을 수행하여 법선정보 특징지도 및 깊이정보 특징지도를 생성하는 단계와, 상기 도면생성부가 상기 법선정보 특징지도 및 상기 깊이정보 특징지도를 결합하여 객체의 윤곽이 검정색으로 표현되는 객체윤곽 특징지도를 도출하는 단계를 포함한다.In the step of deriving an object contour feature map in which the outline of the object is expressed in black, the drawing generating unit performs a convolution operation using a Laplacian filter on each of the normal information channel and the depth information channel to obtain a normal information feature map and depth information. generating a feature map; and combining the normal information feature map and the depth information feature map by the drawing generating unit to derive an object contour feature map in which the outline of the object is expressed in black.
상기 방법은 분류부가 복수의 도면 이미지에 대응하는 상기 가상의 카메라의 위치의 상관도에 따라 복수의 도면 이미지를 복수의 도면 이미지 그룹으로 클러스터링하는 단계와, 상기 분류부가 상기 복수의 도면 이미지 그룹 별로 해당 그룹에 속하는 복수의 도면 이미지를 소정 비율에 따라 학습용 데이터와 검증용 데이터로 분류하여 학습용 데이터와 검증용 데이터를 포함하는 학습 데이터를 생성하는 단계를 더 포함한다.The method includes: clustering, by a classifying unit, a plurality of drawing images into a plurality of drawing image groups according to a degree of correlation of positions of the virtual camera corresponding to the plurality of drawing images; and the classifying unit corresponding to each of the plurality of drawing image groups The method further includes generating training data including training data and verification data by classifying a plurality of drawing images belonging to a group into training data and verification data according to a predetermined ratio.
상술한 바와 같은 목적을 달성하기 위한 본 발명의 바람직한 실시예에 따른 학습 데이터를 생성하기 위한 장치는 객체를 스캔하여 3차원 이미지를 생성하는 스캔부와, 서로 다른 복수의 위치에 배치된 가상의 카메라를 통해 상기 3차원 이미지에 대한 렌더링을 수행하여 법선정보 채널, 깊이정보 채널 및 컬러정보 채널을 포함하는 복수의 컬러 이미지를 생성하는 렌더링부와, 상기 복수의 컬러 이미지의 법선정보 채널, 깊이정보 채널 및 컬러정보 채널을 이용하여 복수의 도면 이미지를 생성하는 도면생성부를 포함한다.An apparatus for generating learning data according to a preferred embodiment of the present invention for achieving the object as described above includes a scan unit for generating a three-dimensional image by scanning an object, and a virtual camera arranged at a plurality of different positions a rendering unit generating a plurality of color images including a normal information channel, a depth information channel, and a color information channel by performing rendering on the three-dimensional image through a normal information channel and a depth information channel of the plurality of color images and a drawing generating unit that generates a plurality of drawing images by using the color information channel.
상기 도면생성부는 상기 컬러 이미지의 컬러정보 채널을 변환하여 객체의 면이 흰색으로 표현되는 컬러정보 채널을 도출하고, 상기 컬러 이미지의 법선정보 채널 및 깊이정보 채널로부터 객체의 윤곽이 검정색으로 표현되는 객체윤곽 특징지도를 도출하고, 객체의 면이 흰색으로 표현되는 컬러정보 채널에 객체윤곽 특징지도를 결합하여 도면 이미지를 생성하는 것을 특징으로 한다.The drawing generator converts the color information channel of the color image to derive a color information channel in which the surface of the object is expressed in white, and the object in which the outline of the object is expressed in black from the normal information channel and the depth information channel of the color image It is characterized in that a drawing image is generated by deriving a contour characteristic map and combining the object contour characteristic map with a color information channel in which the surface of the object is expressed in white.
상기 도면생성부는 상기 법선정보 채널을 통해 객체의 면에 해당하는 픽셀을 특정하고, 상기 컬러정보 채널에서 상기 특정된 객체의 면에 해당하는 픽셀의 색을 흰색으로 정의하는 것을 특징으로 한다.The drawing generator specifies a pixel corresponding to the surface of the object through the normal information channel, and defines a color of the pixel corresponding to the surface of the specified object in the color information channel as white.
상기 도면생성부는 상기 객체의 윤곽이 검정색으로 표현되는 객체윤곽 특징지도를 도출하고, 상기 법선정보 채널 및 상기 깊이정보 채널 각각에 라플라시안 필터를 이용한 합성곱 연산을 수행하여 법선정보 특징지도 및 깊이정보 특징지도를 생성하고, 상기 법선정보 특징지도 및 상기 깊이정보 특징지도를 결합하여 객체의 윤곽이 검정색으로 표현되는 객체윤곽 특징지도를 도출하는 것을 특징으로 한다.The drawing generating unit derives an object contour characteristic map in which the outline of the object is expressed in black, and performs a convolution operation using a Laplacian filter on each of the normal information channel and the depth information channel to obtain a normal information characteristic map and a depth information characteristic It is characterized in that a map is generated, and an object contour characteristic map in which the outline of an object is expressed in black is derived by combining the normal information characteristic map and the depth information characteristic map.
상기 장치는 복수의 도면 이미지에 대응하는 상기 가상의 카메라의 위치의 상관도에 따라 복수의 도면 이미지를 복수의 도면 이미지 그룹으로 클러스터링한 후, 상기 복수의 도면 이미지 그룹 별로 해당 그룹에 속하는 복수의 도면 이미지를 소정 비율에 따라 학습용 데이터와 검증용 데이터로 분류하여 학습용 데이터와 검증용 데이터를 포함하는 학습 데이터를 생성하는 분류부를 더 포함한다.The device clusters a plurality of drawing images into a plurality of drawing image groups according to the correlation of the positions of the virtual cameras corresponding to the plurality of drawing images, and then a plurality of drawings belonging to the group for each of the plurality of drawing image groups. It further includes a classification unit for classifying the image into training data and verification data according to a predetermined ratio to generate training data including the training data and the verification data.
본 발명에 따르면, 실제 객체로부터 복수의 서로 다른 위치에서 바라본 도면 이미지를 생성할 수 있으며, 이를 기초로 학습 데이터를 생성하고, 생성된 학습 데이터를 통해 인공신경망을 학습시키는 경우, 그 인공신경망을 이용하여 지적 재산권 침해 여부를 용이하게 판별할 수 있다.According to the present invention, drawing images viewed from a plurality of different positions can be generated from a real object, and learning data is generated based on this, and when an artificial neural network is trained through the generated learning data, the artificial neural network is used. This makes it easier to determine whether intellectual property rights are infringed.
도 1은 본 발명의 실시예에 따른 지적 재산권 침해 여부를 판별하기 위한 학습 데이터를 생성하기 위한 장치의 구성을 설명하기 위한 도면이다.
도 2는 본 발명의 실시예에 따른 지적 재산권 침해 여부를 판별하기 위한 학습 데이터를 생성하기 위한 방법을 설명하기 위한 흐름도이다.
도 3은 본 발명의 실시예에 따른 실제 객체를 스캔하기 위한 방법을 설명하기 위한 도면이다.
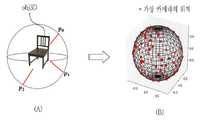
도 4는 본 발명의 실시예에 따른 가상의 카메라의 위치를 설명하기 위한 도면이다.
도 5는 본 발명의 실시예에 따른 깊이정보 채널 및 법선정보 채널을 설명하기 위한 도면이다.
도 6은 본 발명의 실시예에 따른 객체의 면에 해당하는 픽셀을 흰색으로 변환하는 방법을 설명하기 위한 도면이다.
도 7은 본 발명의 실시예에 따른 객체의 윤곽에 해당하는 픽셀을 검색색으로 표현하는 방법을 설명하기 위한 도면이다.
도 8은 본 발명의 실시예에 따른 컴퓨팅 장치를 나타내는 도면이다.1 is a diagram for explaining the configuration of an apparatus for generating learning data for determining whether intellectual property rights are infringed according to an embodiment of the present invention.
2 is a flowchart illustrating a method for generating learning data for determining whether intellectual property rights are infringed according to an embodiment of the present invention.
3 is a diagram for explaining a method for scanning a real object according to an embodiment of the present invention.
4 is a diagram for explaining a location of a virtual camera according to an embodiment of the present invention.
5 is a diagram for explaining a depth information channel and a normal information channel according to an embodiment of the present invention.
6 is a diagram for explaining a method of converting a pixel corresponding to a surface of an object to white according to an embodiment of the present invention.
7 is a diagram for explaining a method of expressing a pixel corresponding to the outline of an object as a search color according to an embodiment of the present invention.
8 is a diagram illustrating a computing device according to an embodiment of the present invention.
본 발명의 상세한 설명에 앞서, 이하에서 설명되는 본 명세서 및 청구범위에 사용된 용어나 단어는 통상적이거나 사전적인 의미로 한정해서 해석되어서는 아니 되며, 발명자는 그 자신의 발명을 가장 최선의 방법으로 설명하기 위해 용어의 개념으로 적절하게 정의할 수 있다는 원칙에 입각하여 본 발명의 기술적 사상에 부합하는 의미와 개념으로 해석되어야만 한다. 따라서 본 명세서에 기재된 실시예와 도면에 도시된 구성은 본 발명의 가장 바람직한 실시예에 불과할 뿐, 본 발명의 기술적 사상을 모두 대변하는 것은 아니므로, 본 출원시점에 있어서 이들을 대체할 수 있는 다양한 균등물과 변형 예들이 있을 수 있음을 이해하여야 한다.Prior to the detailed description of the present invention, the terms or words used in the present specification and claims described below should not be construed as being limited to their ordinary or dictionary meanings, and the inventors should develop their own inventions in the best way. It should be interpreted as meaning and concept consistent with the technical idea of the present invention based on the principle that it can be appropriately defined as a concept of a term for explanation. Therefore, the embodiments described in the present specification and the configurations shown in the drawings are only the most preferred embodiments of the present invention, and do not represent all the technical spirit of the present invention, so various equivalents that can be substituted for them at the time of the present application It should be understood that there may be water and variations.
이하, 첨부된 도면을 참조하여 본 발명의 바람직한 실시예들을 상세히 설명한다. 이때, 첨부된 도면에서 동일한 구성 요소는 가능한 동일한 부호로 나타내고 있음을 유의해야 한다. 또한, 본 발명의 요지를 흐리게 할 수 있는 공지 기능 및 구성에 대한 상세한 설명은 생략할 것이다. 마찬가지의 이유로 첨부 도면에 있어서 일부 구성요소는 과장되거나 생략되거나 또는 개략적으로 도시되었으며, 각 구성요소의 크기는 실제 크기를 전적으로 반영하는 것이 아니다.Hereinafter, preferred embodiments of the present invention will be described in detail with reference to the accompanying drawings. In this case, it should be noted that in the accompanying drawings, the same components are denoted by the same reference numerals as much as possible. In addition, detailed descriptions of well-known functions and configurations that may obscure the gist of the present invention will be omitted. For the same reason, some components are exaggerated, omitted, or schematically illustrated in the accompanying drawings, and the size of each component does not fully reflect the actual size.
먼저, 본 발명의 실시예에 따른 지적 재산권 침해 여부를 판별하기 위한 학습 데이터를 생성하기 위한 장치에 대해서 설명하기로 한다. 도 1은 본 발명의 실시예에 따른 지적 재산권 침해 여부를 판별하기 위한 학습 데이터를 생성하기 위한 장치의 구성을 설명하기 위한 도면이다.First, an apparatus for generating learning data for determining whether intellectual property rights are infringed according to an embodiment of the present invention will be described. 1 is a diagram for explaining the configuration of an apparatus for generating learning data for determining whether intellectual property rights are infringed according to an embodiment of the present invention.
도 1을 참조하면, 본 발명의 실시예에 따른 지적 재산권 침해 여부를 판별하기 위한 학습 데이터를 생성하기 위한 장치(10, 이하, '도면생성장치'로 칭함)는 객체에 대한 지적 재산권 침해 여부를 판별하기 위해 도면을 생성한다. 이러한 도면생성장치(10)는 스캔부(100), 렌더링부(200), 도면생성부(300) 및 분류부(400)를 포함한다.Referring to FIG. 1 , an apparatus for generating learning data for determining whether intellectual property rights are infringed according to an embodiment of the present invention (10, hereinafter referred to as a 'drawing generating device') determines whether intellectual property rights are infringed on an object. Create a drawing to determine. The
스캔부(100)는 객체를 스캔하여 3차원 이미지를 생성하기 위한 것이다. 스캔부(100)는 3차원 스캐너를 포함하며, 이러한 3차원 스캐너를 통해 객체를 스캔하여 3차원 이미지를 생성할 수 있다.The
렌더링부(200)는 3차원 이미지에 대한 렌더링을 수행하여 복수의 컬러 이미지를 생성한다. 렌더링부(300)는 가상의 카메라를 통해 3차원 이미지에 대한 렌더링을 수행한다. 이때, 렌더링부(300)는 가상의 카메라를 서로 다른 복수의 위치에 배치시키고, 이를 통해 3차원 이미지에 대해 렌더링을 수행함으로써, 가상의 카메라의 위치 별로 복수의 컬러 이미지를 생성할 수 있다. 복수의 컬러 이미지 각각은 법선정보 채널, 깊이정보 채널 및 컬러정보 채널을 포함한다. 컬러정보 채널의 각 픽셀은 컬러값을 가진다. 법선벡터 채널의 각 픽셀은 가상의 카메라로부터 픽셀까지의 법선벡터(normal: Normal Vector)를 나타낸다. 깊이정보 채널의 각 픽셀은 가상의 카메라로부터 픽셀까지의 깊이(d: depth)를 나타낸다.The rendering
도면생성부(300)는 복수의 컬러 이미지의 법선정보 채널, 깊이정보 채널 및 컬러정보 채널을 이용하여 복수의 도면 이미지를 생성한다. 이를 위하여, 도면생성부(300)는 복수의 컬러 이미지 각각에 대해 컬러 이미지의 컬러정보 채널을 변환하여 객체의 면이 흰색으로 표현되는 컬러정보 채널을 도출한다. 또한, 도면생성부(300)는 복수의 컬러 이미지 각각에 대해 컬러 이미지의 법선정보 채널 및 깊이정보 채널로부터 객체의 윤곽이 검정색으로 표현되는 객체윤곽 특징지도를 도출한다. 그런 다음, 도면생성부(300)는 복수의 컬러 이미지 각각에 대해 객체의 면이 흰색으로 표현되는 컬러정보 채널에 객체윤곽 특징지도를 결합함으로써, 복수의 도면 이미지를 생성할 수 있다.The drawing generating unit 300 generates a plurality of drawing images by using the normal information channel, the depth information channel, and the color information channel of the plurality of color images. To this end, the drawing generating unit 300 converts the color information channel of the color image for each of the plurality of color images to derive a color information channel in which the surface of the object is expressed in white. Also, for each of the plurality of color images, the drawing generating unit 300 derives an object contour feature map in which the contour of the object is expressed in black from the normal information channel and the depth information channel of the color image. Then, for each of the plurality of color images, the drawing generating unit 300 may generate a plurality of drawing images by combining the object contour feature map with a color information channel in which the surface of the object is expressed in white.
분류부(400)는 복수의 도면 이미지를 학습용 데이터 및 검증용 데이터로 분류하여 학습용 데이터 및 검증용 데이터를 포함하는 학습 데이터를 생성한다. 이때, 분류부(400)는 복수의 도면 이미지에 대응하는 가상의 카메라의 위치의 상관도에 따라 복수의 도면 이미지를 복수의 도면 이미지 그룹으로 클러스터링한다. 그리고 분류부(400)는 복수의 도면 이미지 그룹 별로 해당 그룹에 속하는 복수의 도면 이미지를 소정 비율에 따라 학습용 데이터와 검증용 데이터로 분류하여 학습용 데이터와 검증용 데이터를 포함하는 학습 데이터를 생성한다.The classification unit 400 classifies the plurality of drawing images into training data and verification data to generate training data including training data and verification data. In this case, the classification unit 400 clusters the plurality of drawing images into a plurality of drawing image groups according to the degree of correlation of positions of virtual cameras corresponding to the plurality of drawing images. The classification unit 400 classifies a plurality of drawing images belonging to a corresponding group for each of the plurality of drawing image groups into learning data and verification data according to a predetermined ratio to generate learning data including the learning data and the verification data.
다음으로, 본 발명의 실시예에 따른 지적 재산권 침해 여부를 판별하기 위한 학습 데이터를 생성하기 위한 방법에 대해서 설명하기로 한다. 도 2는 본 발명의 실시예에 따른 지적 재산권 침해 여부를 판별하기 위한 학습 데이터를 생성하기 위한 방법을 설명하기 위한 흐름도이다. 도 3은 본 발명의 실시예에 따른 실제 객체를 스캔하기 위한 방법을 설명하기 위한 도면이다. 도 4는 본 발명의 실시예에 따른 가상의 카메라의 위치를 설명하기 위한 도면이다. 도 5는 본 발명의 실시예에 따른 깊이정보 채널 및 법선정보 채널을 설명하기 위한 도면이다. 도 6은 본 발명의 실시예에 따른 객체의 면에 해당하는 픽셀을 흰색으로 변환하는 방법을 설명하기 위한 도면이다. 도 7은 본 발명의 실시예에 따른 객체의 윤곽에 해당하는 픽셀을 검색색으로 표현하는 방법을 설명하기 위한 도면이다.Next, a method for generating learning data for determining whether intellectual property rights are infringed according to an embodiment of the present invention will be described. 2 is a flowchart illustrating a method for generating learning data for determining whether intellectual property rights are infringed according to an embodiment of the present invention. 3 is a diagram for explaining a method for scanning a real object according to an embodiment of the present invention. 4 is a diagram for explaining a location of a virtual camera according to an embodiment of the present invention. 5 is a diagram for explaining a depth information channel and a normal information channel according to an embodiment of the present invention. 6 is a diagram for explaining a method of converting a pixel corresponding to a surface of an object to white according to an embodiment of the present invention. 7 is a diagram for explaining a method of expressing a pixel corresponding to an object outline as a search color according to an embodiment of the present invention.
먼저, 도 2를 참조하면, 스캔부(100)는 S110 단계에서 객체를 스캔하여 3차원 이미지를 생성한다. 이를 위하여, 스캔부(100)는 도 3에 도시된 바와 같이, 턴테이블(31) 상의 객체(obj)가 회전하는 동안 해당 객체를 3차원 스캔할 수 있다. 이때, 스캔부(100)는 3차원 스캔을 통해 객체의 표면의 점들을 자동으로 측정하여, 점구름(Point Cloud)형태로 3차원 유클리디안 공간 좌표 정보(*.obj) 및 표면 정보(*.stl)를 포함하는 3차원 이미지를 생성한다. 이러한 스캔부(100)는 공간 좌표 정보(*.obj) 및 표면 정보(*.stl)를 포함하는 3차원 이미지를 저장부(400)에 저장한다. 공간 좌표 정보(*.obj)는 3차원 유클리디안(x, y, z) 좌표를 포함하며, 표면 정보(*.stl)는 객체의 재질(material) 정보를 포함한다.First, referring to FIG. 2 , the
다음으로, 렌더링부(200)는 S120 단계에서 서로 다른 복수의 위치에 배치된 카메라를 통해 3차원 이미지에 대한 렌더링을 수행하여 법선정보 채널, 깊이정보 채널 및 컬러정보 채널을 포함하는 복수의 컬러 이미지를 도출한다.Next, in step S120 , the
렌더링부(200)는 도 4의 (A)에 도시된 바와 같이, 3차원 이미지의 객체(obj3D)를 중심으로 가상의 카메라를 서로 다른 위치(P0, P1, P2, ...)에 배치시켜 렌더링을 수행할 수 있다. 이러한 가상의 카메라는 도 4의 (B)에 도시된 바와 같이, 전방위(omnidirectional)에 배치될 수 있다. 여기서, 렌더링 기법은 광선추적법(Ray tracing)을 이용할 수 있다.The
특히, 도 5에 도시된 바와 같이, 어느 하나의 가상의 카메라의 위치에서의 3차원 이미지의 객체(obj3D)에 대한 렌더링을 통해 생성된 컬러 이미지는 각 픽셀이 컬러값을 가지는 컬러정보 채널, 각 픽셀이 가상의 카메라로부터 픽셀까지의 법선벡터(normal: Normal Vector)를 나타내는 법선벡터 채널 및 각 픽셀이 가상의 카메라로부터 픽셀까지의 깊이(d: depth)를 나타내는 깊이정보 채널을 포함한다.In particular, as shown in FIG. 5, a color image generated through rendering of an object (obj3D) of a three-dimensional image at the position of any one virtual camera is a color information channel in which each pixel has a color value, each A pixel includes a normal vector channel representing a normal vector (normal vector) from a virtual camera to a pixel, and a depth information channel in which each pixel represents a depth (d: depth) from the virtual camera to the pixel.
도면생성부(300)는 복수의 컬러 이미지의 법선정보 채널, 깊이정보 채널 및 컬러정보 채널을 이용하여 복수의 컬러 이미지로부터 복수의 도면 이미지를 생성한다. 이때, 도면생성부(300)는 컬러 이미지의 객체의 면을 흰색으로 정의하고, 그 객체의 윤곽을 검정색으로 표현함으로써 면이 흰색이고, 윤곽이 검정색인 도면 이미지를 생성할 수 있다.The drawing generating unit 300 generates a plurality of drawing images from the plurality of color images by using the normal information channel, the depth information channel, and the color information channel of the plurality of color images. In this case, the drawing generating unit 300 may generate a drawing image having a white surface and a black outline by defining the surface of the object of the color image as white and expressing the outline of the object in black.
이를 위하여, 도면생성부(300)는 S130 단계에서 복수의 컬러 이미지 각각에 대해 컬러 이미지의 컬러정보 채널을 변환하여 객체의 면이 흰색으로 표현되는 컬러정보 채널을 도출한다. 이때, 도면생성부(300)는 법선정보 채널을 통해 객체의 면에 해당하는 픽셀을 특정한 후, 컬러정보 채널에서 객체의 면에 해당하는 픽셀의 색을 흰색으로 정의한다. 법선정보 채널은 각 픽셀의 값은 법선벡터이며, 법선벡터를 통해 해당 픽셀이 객체의 면에 해당하는지 여부를 알 수 있다. 이에 따라, 도면생성부(300)는 도 6의 (A)에 도시된 바와 같이, 컬러정보 채널에서 객체의 면에 해당하는 픽셀의 픽셀값 중 색을 나타내는 픽셀값(61)을 6의 (B)에 도시된 바와 같이, 흰색(63)으로 변환한다.To this end, the drawing generating unit 300 converts the color information channel of the color image for each of the plurality of color images in step S130 to derive a color information channel in which the surface of the object is expressed in white. At this time, the drawing generating unit 300 specifies a pixel corresponding to the surface of the object through the normal information channel, and then defines the color of the pixel corresponding to the surface of the object in the color information channel as white. In the normal information channel, the value of each pixel is a normal vector, and it can be known whether the pixel corresponds to the surface of the object through the normal vector. Accordingly, as shown in FIG. 6(A), the drawing generating unit 300 sets the
이어서, 도면생성부(300)는 S140 단계에서 복수의 컬러 이미지 각각에 대해 컬러 이미지의 법선정보 채널 및 깊이정보 채널로부터 객체의 윤곽이 검정색으로 표현되는 객체윤곽 특징지도를 도출한다. 이러한 S140 단계에서, 도면생성부(300)는 도 7의 (A)에 도시된 바와 같이, 깊이정보 채널(71)의 픽셀값(72)에 필터(73)를 합성곱(convolution)하여 깊이정보 특징지도(74)를 생성한다. 여기서, 깊이정보 채널(71)의 픽셀값(72)은 깊이(d: depth)를 나타낸다. 이와 함께, 도면생성부(300)는 도 7의 (B)에 도시된 바와 같이, 법선정보 채널(75)의 픽셀값(76)에 필터(77)를 합성곱(convolution)하여 법선정보 특징지도(78)를 생성한다. 여기서, 법선정보 채널(75)의 픽셀값(76)은 법선벡터를 나타낸다. 도 8의 (A) 및 도 8의 (B)에서 사용되는 필터(73, 77)는 라플라시안(Laplacian) 필터를 사용할 수 있다. 그리고 도면생성부(300)는 깊이정보 특징지도(74) 및 법선정보 특징지도(78)를 결합함으로써 객체의 윤곽이 검정색으로 표현되는 객체윤곽 특징지도(79)를 도출할 수 있다.Next, in step S140 , the drawing generating unit 300 derives an object contour feature map in which the outline of the object is expressed in black from the normal information channel and the depth information channel of the color image for each of the plurality of color images. In this step S140, the drawing generating unit 300 convolutions the
그런 다음, 도면생성부(300)는 S150 단계에서 복수의 컬러 이미지 각각에 대해 객체의 면이 흰색으로 표현되는 컬러정보 채널에 객체윤곽 특징지도(79)를 결합하여 복수의 도면 이미지를 생성할 수 있다.Then, the drawing generating unit 300 generates a plurality of drawing images by combining the object
다음으로, 분류부(400)는 S160 단계에서 복수의 도면 이미지에 대응하는 가상의 카메라의 위치의 상관도에 따라 복수의 도면 이미지를 복수의 도면 이미지 그룹으로 클러스터링한다.Next, the classification unit 400 clusters the plurality of drawing images into a plurality of drawing image groups according to the degree of correlation of positions of virtual cameras corresponding to the plurality of drawing images in step S160 .
그런 다음, 분류부(400)는 S170 단계에서 복수의 도면 이미지 그룹 별로 해당 그룹에 속하는 복수의 도면 이미지를 소정 비율에 따라 학습용 데이터와 검증용 데이터로 분류하여 학습용 데이터와 검증용 데이터를 포함하는 학습 데이터를 생성한다.Then, the classification unit 400 classifies the plurality of drawing images belonging to the corresponding group for each group of the plurality of drawing images into learning data and verification data according to a predetermined ratio in step S170 to learn including the learning data and the verification data. create data
예를 들면, 복수의 도면 이미지 그룹은 복수의 도면 이미지에 대응하는 가상의 카메라의 위치의 상관도에 따라 클러스터링되기 때문에 정면도와 유사한 가상의 카메라의 위치를 기준으로 클러스터링된 제1 그룹, 측면도와 유사한 가상의 카메라의 위치를 기준으로 클러스터링된 제2 그룹, 평면도와 유사한 가상의 카메라의 위치를 기준으로 클러스터링된 제3 그룹 및 사시도와 유사한 가상의 카메라의 위치를 기준으로 클러스터링된 제4 그룹을 포함할 수 있다. 또한, 학습용 데이터와 검증용 데이터의 비율은 8 대 2로 설정되었다고 가정한다. 여기서, 도출된 전체 도면 이미지의 수는 400개이고, 제1 내지 제4 그룹 각각에 100개씩 포함된다고 가정한다. 그러면, 제1 내지 제4 그룹 각각에서 80개의 학습용 데이터와 20개의 검증용 데이터를 추출하여, 전체 320개의 학습용 데이터와, 80개의 검증용 데이터를 추출할 수 있다.For example, since the plurality of drawing image groups are clustered according to the correlation of the positions of the virtual cameras corresponding to the plurality of drawing images, the first group clustered based on the positions of the virtual cameras similar to the front view, similar to the side view a second group clustered based on the location of the virtual camera, a third group clustered based on the location of the virtual camera similar to the plan view, and a fourth group clustered based on the location of the virtual camera similar to the perspective view. can In addition, it is assumed that the ratio of the training data to the verification data is set to 8 to 2. Here, it is assumed that the total number of derived drawing images is 400, and 100 is included in each of the first to fourth groups. Then, 80 pieces of data for training and 20 pieces of data for verification are extracted from each of the first to fourth groups, and a total of 320 pieces of data for training and 80 pieces of data for verification can be extracted.
여기서, 학습용 데이터는 인공신경망의 최적화에 사용되며, 검증용 데이터는 인공신경망이 과대적합(Overfitting) 혹은 과소적합(Underfitting)되지 않게 학습이 이루어지도록 학습 종료 시점을 판별하기 위해 사용된다. 지적 재산권 침해 여부를 판별하기 위해 대상 객체의 평면도, 측면도, 사시도 및 정면도 모두에 대한 판단이 요구되며, 학습 데이터 중 학습용 데이터 혹은 검증용 데이터가 평면도, 측면도, 사시도, 정면도 중 어느 일부에만 집중되어 있다면, 해당 학습 데이터를 이용하여 학습된 인공신경망은 평면도, 측면도, 사시도, 정면도 중 어느 일부는 과대적합되거나, 과소적합될 수 있다. 따라서 본 발명은 복수의 도면 이미지를 렌더링 시, 사용되는 가상 카메라의 위치의 상관도에 따라 클러스터링하고, 각 클러스터, 즉, 각 도면 이미지 그룹에서 학습용 데이터와 검증용 데이터를 일정 비율로 추출하여 학습 데이터를 생성하고, 이러한 학습 데이터를 이용하여 인공신경망을 학습시키면, 평면도, 측면도, 사시도, 정면도 등의 모든 방향의 도면에 대해 과대적합(Overfitting) 혹은 과소적합(Underfitting)되지 않게 최적의 학습이 이루어지도록 할 수 있다.Here, the training data is used for optimizing the artificial neural network, and the validation data is used to determine the learning end time so that the artificial neural network is not overfitted or underfitted. In order to determine whether or not intellectual property rights are infringed, judgment on all of the top view, side view, perspective view, and front view of the target object is required, and among the learning data, the learning data or verification data is concentrated only on any part of the plan view, side view, perspective view, and front view If it is, the artificial neural network learned using the corresponding training data may be overfitted or underfitted in any part of a plan view, a side view, a perspective view, and a front view. Therefore, the present invention clusters a plurality of drawing images according to the degree of correlation of the positions of the virtual cameras used when rendering, and extracts learning data and verification data from each cluster, that is, each drawing image group at a certain ratio to obtain training data. When the artificial neural network is trained using this learning data, optimal learning is achieved without overfitting or underfitting drawings in all directions, such as plan view, side view, perspective view, and front view. can make it go away
도 8은 본 발명의 실시예에 따른 컴퓨팅 장치를 나타내는 도면이다. 컴퓨팅 장치(TN100)는 본 명세서에서 기술된 장치(예, 도면생성장치(10) 등) 일 수 있다.8 is a diagram illustrating a computing device according to an embodiment of the present invention. The computing device TN100 may be a device described herein (eg, the
도 8의 실시예에서, 컴퓨팅 장치(TN100)는 적어도 하나의 프로세서(TN110), 송수신 장치(TN120), 및 메모리(TN130)를 포함할 수 있다. 또한, 컴퓨팅 장치(TN100)는 저장 장치(TN140), 입력 인터페이스 장치(TN150), 출력 인터페이스 장치(TN160) 등을 더 포함할 수 있다. 컴퓨팅 장치(TN100)에 포함된 구성 요소들은 버스(bus)(TN170)에 의해 연결되어 서로 통신을 수행할 수 있다.In the embodiment of FIG. 8 , the computing device TN100 may include at least one processor TN110 , a transceiver device TN120 , and a memory TN130 . In addition, the computing device TN100 may further include a storage device TN140 , an input interface device TN150 , an output interface device TN160 , and the like. Components included in the computing device TN100 may be connected by a bus TN170 to communicate with each other.
프로세서(TN110)는 메모리(TN130) 및 저장 장치(TN140) 중에서 적어도 하나에 저장된 프로그램 명령(program command)을 실행할 수 있다. 프로세서(TN110)는 중앙 처리 장치(CPU: central processing unit), 그래픽 처리 장치(GPU: graphics processing unit), 또는 본 발명의 실시예에 따른 방법들이 수행되는 전용의 프로세서를 의미할 수 있다. 프로세서(TN110)는 본 발명의 실시예와 관련하여 기술된 절차, 기능, 및 방법 등을 구현하도록 구성될 수 있다. 프로세서(TN110)는 컴퓨팅 장치(TN100)의 각 구성 요소를 제어할 수 있다.The processor TN110 may execute a program command stored in at least one of the memory TN130 and the storage device TN140. The processor TN110 may mean a central processing unit (CPU), a graphics processing unit (GPU), or a dedicated processor on which methods according to an embodiment of the present invention are performed. The processor TN110 may be configured to implement procedures, functions, and methods described in connection with an embodiment of the present invention. The processor TN110 may control each component of the computing device TN100.
메모리(TN130) 및 저장 장치(TN140) 각각은 프로세서(TN110)의 동작과 관련된 다양한 정보를 저장할 수 있다. 메모리(TN130) 및 저장 장치(TN140) 각각은 휘발성 저장 매체 및 비휘발성 저장 매체 중에서 적어도 하나로 구성될 수 있다. 예를 들어, 메모리(TN130)는 읽기 전용 메모리(ROM: read only memory) 및 랜덤 액세스 메모리(RAM: random access memory) 중에서 적어도 하나로 구성될 수 있다.Each of the memory TN130 and the storage device TN140 may store various information related to the operation of the processor TN110. Each of the memory TN130 and the storage device TN140 may be configured as at least one of a volatile storage medium and a nonvolatile storage medium. For example, the memory TN130 may include at least one of a read only memory (ROM) and a random access memory (RAM).
송수신 장치(TN120)는 유선 신호 또는 무선 신호를 송신 또는 수신할 수 있다. 송수신 장치(TN120)는 네트워크에 연결되어 통신을 수행할 수 있다.The transceiver TN120 may transmit or receive a wired signal or a wireless signal. The transceiver TN120 may be connected to a network to perform communication.
한편, 전술한 본 발명의 실시예에 따른 방법은 다양한 컴퓨터수단을 통하여 판독 가능한 프로그램 형태로 구현되어 컴퓨터로 판독 가능한 기록매체에 기록될 수 있다. 여기서, 기록매체는 프로그램 명령, 데이터 파일, 데이터구조 등을 단독으로 또는 조합하여 포함할 수 있다. 기록매체에 기록되는 프로그램 명령은 본 발명을 위하여 특별히 설계되고 구성된 것들이거나 컴퓨터 소프트웨어 당업자에게 공지되어 사용 가능한 것일 수도 있다. 예컨대 기록매체는 하드 디스크, 플로피 디스크 및 자기 테이프와 같은 자기 매체(magnetic media), CD-ROM, DVD와 같은 광 기록 매체(optical media), 플롭티컬 디스크(floptical disk)와 같은 자기-광 매체(magneto-optical media) 및 롬(ROM), 램(RAM), 플래시 메모리 등과 같은 프로그램 명령을 저장하고 수행하도록 특별히 구성된 하드웨어 장치를 포함한다. 프로그램 명령의 예에는 컴파일러에 의해 만들어지는 것과 같은 기계어 와이어뿐만 아니라 인터프리터 등을 사용해서 컴퓨터에 의해서 실행될 수 있는 고급 언어 와이어를 포함할 수 있다. 이러한 하드웨어 장치는 본 발명의 동작을 수행하기 위해 하나 이상의 소프트웨어 모듈로서 작동하도록 구성될 수 있으며, 그 역도 마찬가지이다.Meanwhile, the method according to the embodiment of the present invention described above may be implemented in the form of a program readable by various computer means and recorded in a computer readable recording medium. Here, the recording medium may include a program command, a data file, a data structure, etc. alone or in combination. The program instructions recorded on the recording medium may be specially designed and configured for the present invention, or may be known and available to those skilled in the art of computer software. For example, the recording medium includes magnetic media such as hard disks, floppy disks and magnetic tapes, optical recording media such as CD-ROMs and DVDs, and magneto-optical media such as floppy disks ( magneto-optical media) and hardware devices specially configured to store and execute program instructions such as ROM, RAM, flash memory, and the like. Examples of program instructions may include not only machine language wires such as those generated by a compiler, but also high-level language wires that can be executed by a computer using an interpreter or the like. Such hardware devices may be configured to operate as one or more software modules to perform the operations of the present invention, and vice versa.
이상 본 발명을 몇 가지 바람직한 실시예를 사용하여 설명하였으나, 이들 실시예는 예시적인 것이며 한정적인 것이 아니다. 이와 같이, 본 발명이 속하는 기술분야에서 통상의 지식을 지닌 자라면 본 발명의 사상과 첨부된 특허청구범위에 제시된 권리범위에서 벗어나지 않으면서 균등론에 따라 다양한 변화와 수정을 가할 수 있음을 이해할 것이다.Although the present invention has been described above using several preferred embodiments, these examples are illustrative and not restrictive. As such, those of ordinary skill in the art to which the present invention pertains will understand that various changes and modifications can be made in accordance with the doctrine of equivalents without departing from the spirit of the present invention and the scope of rights set forth in the appended claims.
10: 도면생성장치
100: 스캔부
200: 렌더링부
300: 도면생성부
400: 분류부10: Drawing generation device
100: scan unit
200: rendering unit
300: drawing generation unit
400: classification unit
Claims (10)
Translated fromKorean스캔부가 객체를 스캔하여 3차원 이미지를 생성하는 단계;
렌더링부가 서로 다른 복수의 위치에 배치된 가상의 카메라를 통해 상기 3차원 이미지에 대한 렌더링을 수행하여 법선정보 채널, 깊이정보 채널 및 컬러정보 채널을 포함하는 복수의 컬러 이미지를 생성하는 단계; 및
도면생성부가 상기 복수의 컬러 이미지의 법선정보 채널, 깊이정보 채널 및 컬러정보 채널을 이용하여 복수의 도면 이미지를 생성하는 단계;
를 포함하며,
상기 도면 이미지를 생성하는 단계는
상기 도면생성부가 상기 컬러 이미지의 컬러정보 채널을 변환하여 객체의 면이 흰색으로 표현되는 컬러정보 채널을 도출하는 단계;
상기 도면생성부가 상기 컬러 이미지의 법선정보 채널 및 깊이정보 채널로부터 객체의 윤곽이 검정색으로 표현되는 객체윤곽 특징지도를 도출하는 단계; 및
상기 도면생성부가 객체의 면이 흰색으로 표현되는 컬러정보 채널에 객체윤곽 특징지도를 결합하여 도면 이미지를 생성하는 단계;
를 포함하는 것을 특징으로 하는
학습 데이터를 생성하기 위한 방법.A method for generating training data, comprising:
generating a three-dimensional image by a scanning unit scanning the object;
generating, by a rendering unit, a plurality of color images including a normal information channel, a depth information channel, and a color information channel by rendering the 3D image through virtual cameras disposed at a plurality of different positions; and
generating, by a drawing generating unit, a plurality of drawing images using a normal information channel, a depth information channel, and a color information channel of the plurality of color images;
includes,
The step of generating the drawing image is
converting the color information channel of the color image by the drawing generator to derive a color information channel in which the surface of the object is expressed in white;
deriving, by the drawing generating unit, an object contour feature map in which an object contour is expressed in black from a normal information channel and a depth information channel of the color image; and
generating, by the drawing generating unit, a drawing image by combining an object contour feature map with a color information channel in which the surface of the object is expressed in white;
characterized in that it comprises
A method for generating training data.
상기 객체의 면이 흰색으로 표현되는 컬러정보 채널을 도출하는 단계는
상기 도면생성부가 상기 법선정보 채널을 통해 객체의 면에 해당하는 픽셀을 특정하는 단계; 및
상기 도면생성부가 상기 컬러정보 채널에서 상기 특정된 객체의 면에 해당하는 픽셀의 색을 흰색으로 정의하는 단계;
를 포함하는 것을 특징으로 하는
학습 데이터를 생성하기 위한 방법.The method of claim 1,
The step of deriving a color information channel in which the surface of the object is expressed in white is
specifying, by the drawing generating unit, a pixel corresponding to the surface of the object through the normal information channel; and
defining, by the drawing generating unit, a color of a pixel corresponding to the surface of the specified object in the color information channel as white;
characterized in that it comprises
A method for generating training data.
상기 객체의 윤곽이 검정색으로 표현되는 객체윤곽 특징지도를 도출하는 단계는
상기 도면생성부가 상기 법선정보 채널 및 상기 깊이정보 채널 각각에 라플라시안 필터를 이용한 합성곱 연산을 수행하여 법선정보 특징지도 및 깊이정보 특징지도를 생성하는 단계; 및
상기 도면생성부가 상기 법선정보 특징지도 및 상기 깊이정보 특징지도를 결합하여 객체의 윤곽이 검정색으로 표현되는 객체윤곽 특징지도를 도출하는 단계;
를 포함하는 것을 특징으로 하는
학습 데이터를 생성하기 위한 방법.According to claim 1,
The step of deriving an object contour feature map in which the outline of the object is expressed in black is
generating, by the drawing generating unit, a normal information feature map and a depth information feature map by performing a convolution operation using a Laplacian filter on each of the normal information channel and the depth information channel; and
deriving an object contour characteristic map in which the outline of an object is expressed in black by combining the normal information characteristic map and the depth information characteristic map by the drawing generating unit;
characterized in that it comprises
A method for generating training data.
분류부가 복수의 도면 이미지에 대응하는 상기 가상의 카메라의 위치의 상관도에 따라 복수의 도면 이미지를 복수의 도면 이미지 그룹으로 클러스터링하는 단계; 및
상기 분류부가 상기 복수의 도면 이미지 그룹 별로 해당 그룹에 속하는 복수의 도면 이미지를 소정 비율에 따라 학습용 데이터와 검증용 데이터로 분류하여 학습용 데이터와 검증용 데이터를 포함하는 학습 데이터를 생성하는 단계;
를 더 포함하는 것을 특징으로 하는
학습데이터를 생성하기 위한 방법.According to claim 1,
clustering, by a classification unit, a plurality of drawing images into a plurality of drawing image groups according to a degree of correlation of positions of the virtual cameras corresponding to the plurality of drawing images; and
generating, by the classification unit, learning data including learning data and verification data by classifying, by the classification unit, a plurality of drawing images belonging to a corresponding group into learning data and verification data according to a predetermined ratio;
characterized in that it further comprises
A method for generating training data.
객체를 스캔하여 3차원 이미지를 생성하는 스캔부;
서로 다른 복수의 위치에 배치된 가상의 카메라를 통해 상기 3차원 이미지에 대한 렌더링을 수행하여 법선정보 채널, 깊이정보 채널 및 컬러정보 채널을 포함하는 복수의 컬러 이미지를 생성하는 렌더링부; 및
상기 복수의 컬러 이미지의 법선정보 채널, 깊이정보 채널 및 컬러정보 채널을 이용하여 복수의 도면 이미지를 생성하는 도면생성부;
를 포함하며,
상기 도면생성부는
상기 컬러 이미지의 컬러정보 채널을 변환하여 객체의 면이 흰색으로 표현되는 컬러정보 채널을 도출하고,
상기 컬러 이미지의 법선정보 채널 및 깊이정보 채널로부터 객체의 윤곽이 검정색으로 표현되는 객체윤곽 특징지도를 도출하고,
객체의 면이 흰색으로 표현되는 컬러정보 채널에 객체윤곽 특징지도를 결합하여 도면 이미지를 생성하는 것을 특징으로 하는
학습 데이터를 생성하기 위한 장치.An apparatus for generating training data, comprising:
a scan unit that scans an object to generate a three-dimensional image;
a rendering unit that performs rendering on the three-dimensional image through virtual cameras disposed at a plurality of different locations to generate a plurality of color images including a normal information channel, a depth information channel, and a color information channel; and
a drawing generator for generating a plurality of drawing images by using a normal information channel, a depth information channel, and a color information channel of the plurality of color images;
includes,
The drawing generating unit
Transform the color information channel of the color image to derive a color information channel in which the surface of the object is expressed in white,
Deriving an object contour feature map in which the contour of the object is expressed in black from the normal information channel and the depth information channel of the color image,
A drawing image is generated by combining an object contour feature map with a color information channel in which the surface of the object is expressed in white.
A device for generating training data.
상기 도면생성부는
상기 법선정보 채널을 통해 객체의 면에 해당하는 픽셀을 특정하고,
상기 컬러정보 채널에서 상기 특정된 객체의 면에 해당하는 픽셀의 색을 흰색으로 정의하는 것을 특징으로 하는
학습 데이터를 생성하기 위한 장치.7. The method of claim 6,
The drawing generating unit
specifying a pixel corresponding to the surface of the object through the normal information channel;
In the color information channel, a color of a pixel corresponding to the surface of the specified object is defined as white
A device for generating training data.
상기 도면생성부는
상기 객체의 윤곽이 검정색으로 표현되는 객체윤곽 특징지도를 도출하고,
상기 법선정보 채널 및 상기 깊이정보 채널 각각에 라플라시안 필터를 이용한 합성곱 연산을 수행하여 법선정보 특징지도 및 깊이정보 특징지도를 생성하고,
상기 법선정보 특징지도 및 상기 깊이정보 특징지도를 결합하여 객체의 윤곽이 검정색으로 표현되는 객체윤곽 특징지도를 도출하는 것을 특징으로 하는
학습 데이터를 생성하기 위한 장치.7. The method of claim 6,
The drawing generating unit
Deriving an object contour feature map in which the outline of the object is expressed in black,
generating a normal information feature map and a depth information feature map by performing a convolution operation using a Laplacian filter on each of the normal information channel and the depth information channel;
Combining the normal information characteristic map and the depth information characteristic map to derive an object contour characteristic map in which the outline of the object is expressed in black
A device for generating training data.
복수의 도면 이미지에 대응하는 상기 가상의 카메라의 위치의 상관도에 따라 복수의 도면 이미지를 복수의 도면 이미지 그룹으로 클러스터링한 후,
상기 복수의 도면 이미지 그룹 별로 해당 그룹에 속하는 복수의 도면 이미지를 소정 비율에 따라 학습용 데이터와 검증용 데이터로 분류하여 학습용 데이터와 검증용 데이터를 포함하는 학습 데이터를 생성하는 분류부;
를 더 포함하는 것을 특징으로 하는
학습 데이터를 생성하기 위한 장치.7. The method of claim 6,
After clustering a plurality of drawing images into a plurality of drawing image groups according to the correlation of the positions of the virtual cameras corresponding to the plurality of drawing images,
a classification unit for classifying a plurality of drawing images belonging to a corresponding group for each of the plurality of drawing image groups into training data and verification data according to a predetermined ratio to generate training data including the training data and the verification data;
characterized in that it further comprises
A device for generating training data.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020210188854AKR102419579B1 (en) | 2021-12-27 | 2021-12-27 | Apparatus and method for generating learning data for determining whether intellectual property is infringed |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020210188854AKR102419579B1 (en) | 2021-12-27 | 2021-12-27 | Apparatus and method for generating learning data for determining whether intellectual property is infringed |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR102419579B1true KR102419579B1 (en) | 2022-07-11 |
Family
ID=82396353
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020210188854AActiveKR102419579B1 (en) | 2021-12-27 | 2021-12-27 | Apparatus and method for generating learning data for determining whether intellectual property is infringed |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR102419579B1 (en) |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20200087310A (en) | 2018-12-28 | 2020-07-21 | 소프트온넷(주) | System and method for generation and augmentation of annotation learning data for deep learning in artificial intelligence picture reading |
| KR20210049783A (en)* | 2018-08-24 | 2021-05-06 | 소니 주식회사 | Image processing apparatus, image processing method and image processing program |
| KR20210064115A (en)* | 2019-08-23 | 2021-06-02 | 상 하이 이워 인포메이션 테크놀로지 컴퍼니 리미티드 | 3D modeling system and method based on shooting, automatic 3D modeling apparatus and method |
- 2021
- 2021-12-27KRKR1020210188854Apatent/KR102419579B1/enactiveActive
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20210049783A (en)* | 2018-08-24 | 2021-05-06 | 소니 주식회사 | Image processing apparatus, image processing method and image processing program |
| KR20200087310A (en) | 2018-12-28 | 2020-07-21 | 소프트온넷(주) | System and method for generation and augmentation of annotation learning data for deep learning in artificial intelligence picture reading |
| KR20210064115A (en)* | 2019-08-23 | 2021-06-02 | 상 하이 이워 인포메이션 테크놀로지 컴퍼니 리미티드 | 3D modeling system and method based on shooting, automatic 3D modeling apparatus and method |
Non-Patent Citations (3)
| Title |
|---|
| Ning, Guanghan, et al. Data augmentation for object detection via differentiable neural rendering. arXiv preprint arXiv:2103.02852. 2021.4.5.** |
| Sarkar, Kripasindhu, Alain Pagani, and Didier Stricker. Feature-augmented Trained Models for 6DOF Object Recognition and Camera Calibration. VISIGRAPP (4: VISAPP). 2016.** |
| Sarkar, Kripasindhu, et al. Trained 3D Models for CNN based Object Recognition. VISIGRAPP (5: VISAPP). 2017.* |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN115699114B (en) | Method and apparatus for image augmentation for analysis | |
| CN110675487B (en) | Three-dimensional face modeling and recognition method and device based on multi-angle two-dimensional face | |
| Zhao et al. | FLIC: Fast linear iterative clustering with active search | |
| US10489970B2 (en) | 2D image processing for extrusion into 3D objects | |
| TWI810818B (en) | A computer-implemented method and system of providing a three-dimensional model and related storage medium | |
| US10410354B1 (en) | Method and apparatus for multi-model primitive fitting based on deep geometric boundary and instance aware segmentation | |
| US10204447B2 (en) | 2D image processing for extrusion into 3D objects | |
| US20220108422A1 (en) | Facial Model Mapping with a Neural Network Trained on Varying Levels of Detail of Facial Scans | |
| US10832095B2 (en) | Classification of 2D images according to types of 3D arrangement | |
| CN116205978A (en) | Three-dimensional target object mapping image determination method, device, equipment and storage medium | |
| KR20160051804A (en) | Expanding a digital representation of a physical plane | |
| KR102393801B1 (en) | Apparatus for generating training data through background synthesis and method therefor | |
| US12236639B2 (en) | 3D object detection using random forests | |
| CN112236778A (en) | Object recognition from images using CAD models as priors | |
| KR102419579B1 (en) | Apparatus and method for generating learning data for determining whether intellectual property is infringed | |
| CN112257548B (en) | Method, device and storage medium for generating pedestrian images | |
| Yang et al. | Capsule based image synthesis for interior design effect rendering | |
| Pohle-Fröhlich et al. | Roof Segmentation based on Deep Neural Networks. | |
| Cai et al. | Deep point-based scene labeling with depth mapping and geometric patch feature encoding | |
| Hu et al. | Point sets joint registration and co-segmentation | |
| KR102793008B1 (en) | System and Method for generating training images and labels for deep learning-based segmentation model using point cloud-to-image conversion technique | |
| US20250265778A1 (en) | System and method for generating a bird-eye view map | |
| Löfgren et al. | Generating synthetic data for evaluation and improvement of deep 6D pose estimation | |
| KR102866088B1 (en) | Method for generating and rendering a 3 dimensional model associated with | |
| Beer | Automatic generation of lod1 city models and building segmentation from single aerial orthographic images using conditional generative adversarial networks |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application | Patent event code:PA01091R01D Comment text:Patent Application Patent event date:20211227 | |
| PA0201 | Request for examination | ||
| PA0302 | Request for accelerated examination | Patent event date:20211228 Patent event code:PA03022R01D Comment text:Request for Accelerated Examination Patent event date:20211227 Patent event code:PA03021R01I Comment text:Patent Application | |
| PE0902 | Notice of grounds for rejection | Comment text:Notification of reason for refusal Patent event date:20220328 Patent event code:PE09021S01D | |
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration | Patent event code:PE07011S01D Comment text:Decision to Grant Registration Patent event date:20220705 | |
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment | Comment text:Registration of Establishment Patent event date:20220706 Patent event code:PR07011E01D | |
| PR1002 | Payment of registration fee | Payment date:20220706 End annual number:3 Start annual number:1 | |
| PG1601 | Publication of registration | ||
| PR1001 | Payment of annual fee | Payment date:20250703 Start annual number:4 End annual number:4 |