KR102331229B1 - Spatial voice virtual reality server and apparatus - Google Patents
Spatial voice virtual reality server and apparatusDownload PDFInfo
- Publication number
- KR102331229B1 KR102331229B1KR1020170143266AKR20170143266AKR102331229B1KR 102331229 B1KR102331229 B1KR 102331229B1KR 1020170143266 AKR1020170143266 AKR 1020170143266AKR 20170143266 AKR20170143266 AKR 20170143266AKR 102331229 B1KR102331229 B1KR 102331229B1
- Authority
- KR
- South Korea
- Prior art keywords
- voice
- user
- spatial
- location
- signal
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 230000002194synthesizing effectEffects0.000claimsabstractdescription7
- 238000000034methodMethods0.000claimsdescription46
- 238000004891communicationMethods0.000claimsdescription13
- 230000006870functionEffects0.000description15
- 238000010586diagramMethods0.000description13
- 238000012545processingMethods0.000description10
- 238000004590computer programMethods0.000description5
- 230000008569processEffects0.000description5
- 230000014509gene expressionEffects0.000description3
- 230000008901benefitEffects0.000description2
- 230000000694effectsEffects0.000description2
- 239000011521glassSubstances0.000description2
- 230000000007visual effectEffects0.000description2
- 238000003491arrayMethods0.000description1
- 230000008859changeEffects0.000description1
- 238000005516engineering processMethods0.000description1
- 239000000284extractSubstances0.000description1
- 238000004519manufacturing processMethods0.000description1
- 238000012986modificationMethods0.000description1
- 230000004048modificationEffects0.000description1
- 238000012546transferMethods0.000description1
Images




Classifications
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S7/00—Indicating arrangements; Control arrangements, e.g. balance control
- H04S7/30—Control circuits for electronic adaptation of the sound field
- H04S7/302—Electronic adaptation of stereophonic sound system to listener position or orientation
- H04S7/303—Tracking of listener position or orientation
- H04S7/304—For headphones
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2420/00—Techniques used stereophonic systems covered by H04S but not provided for in its groups
- H04S2420/11—Application of ambisonics in stereophonic audio systems
Landscapes
- Engineering & Computer Science (AREA)
- Signal Processing (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Multimedia (AREA)
- Information Transfer Between Computers (AREA)
- Telephonic Communication Services (AREA)
Abstract
Translated fromKoreanDescription
Translated fromKorean본 발명은 공간 음성 VR 서버 및 장치에 관한 것으로서, 보다 자세하게는 동일한 가상 공간에 위치하는 여러 사용자가 발화하는 음성 신호를 기초로 가상 공간 내에서 사용자의 음성이 출력되는 위치를 결정하는 공간 음성 VR 서버 및 장치에 관한 것이다.The present invention relates to a spatial voice VR server and apparatus, and more particularly, to a spatial voice VR server that determines a position at which a user's voice is output in a virtual space based on voice signals uttered by multiple users located in the same virtual space. and devices.
최근 VR(virtual reality) 글래스가 개발됨에 따라, 동일한 가상 공간에 다수의 사용자가 접속하여 서로 상대방의 아바타를 보며 대화를 진행할 수 있는 형태의 가상 공간 대화 서비스가 제공되고 있다.Recently, as virtual reality (VR) glasses have been developed, a virtual space conversation service has been provided in which a plurality of users access the same virtual space to see each other's avatars and have a conversation.
한편, 기존의 가상 공간 대화 서비스는 동일한 가상 공간에 접속한 여러 사용자들의 음성을 서버가 수신하여 하나의 스트림으로 합성한 음성 신호를 모든 사용자들에게 동일하게 제공할 뿐이기에 사용자들은 다른 사용자의 음성이 해당 사용자가 위치하는 공간에서 들린다는 느낌을 경험할 수 없었다.Meanwhile, in the existing virtual space conversation service, the server receives the voices of multiple users connected to the same virtual space and provides the same voice signal synthesized into one stream to all users. I couldn't experience the feeling of being heard in the space where the user was located.
따라서 가상 공간 대화 서비스는 다른 사용자가 위치하는 공간을 고려하여 다른 사용자의 위치에서 음성이 들리는 느낌을 경험할 수 있도록 보다 현실적인 서비스 형태를 제공할 필요가 있다.Therefore, the virtual space conversation service needs to provide a more realistic service form so that the user can experience the feeling of hearing a voice from another user's location in consideration of the space where the other user is located.
본 발명의 실시예에서 해결하고자 하는 과제는 동일한 가상 공간 내의 다른 사용자가 위치하는 공간에서 음성이 들리는 느낌을 경험할 수 있도록 하는 기술을 제공하는 것이다.An object to be solved in an embodiment of the present invention is to provide a technology that allows users to experience the feeling of hearing a voice in a space in which another user in the same virtual space is located.
이와 함께, 모든 사용자의 음성을 각각 처리하는 것이 아니라 여러 사용자들의 음성을 하나의 스트림으로 합성하는 동시에 위와 같은 과제를 해결함으로써 동일한 가상 공간 내에 참여하는 사용자의 수가 증가함에 따라 발생할 수 있는 서버의 과부하를 방지하고자 한다.At the same time, instead of processing the voices of all users individually, the voices of several users are synthesized into one stream and at the same time solving the above problem, the overload of the server that may occur as the number of users participating in the same virtual space increases is reduced. want to prevent
다만, 본 발명의 실시예가 이루고자 하는 기술적 과제는 이상에서 언급한 과제로 제한되지 않으며, 이하에서 설명할 내용으로부터 통상의 기술자에게 자명한 범위 내에서 다양한 기술적 과제가 도출될 수 있다.However, the technical problems to be achieved by the embodiments of the present invention are not limited to the above-mentioned problems, and various technical problems can be derived from the contents to be described below within the scope obvious to those skilled in the art.
본 발명의 일 실시예에 따른 공간 음성 VR 서버는 동일한 가상 공간 내에 위치하는 복수의 사용자의 음성 신호를 전송하는 복수의 공간 음성 VR 장치로부터 각 사용자의 가상 공간 내에서의 위치 정보 및 상기 각 사용자의 음성 신호를 수신하는 정보 수신부, 상기 각 사용자의 음성 신호를 합성한 믹싱 신호를 생성하는 믹싱 신호 생성부, 상기 각 사용자의 음성 신호의 음량 정보 및 상기 위치 정보를 기초로 상기 가상 공간 내에서 상기 믹싱 신호가 출력될 위치인 가상 출력 위치를 결정하는 출력 위치 결정부 및 상기 믹싱 신호 및 상기 가상 출력 위치를 상기 복수의 공간 음성 VR 장치에 제공하는 정보 송신부를 포함한다.The spatial voice VR server according to an embodiment of the present invention includes location information of each user in a virtual space and information of each user from a plurality of spatial voice VR devices that transmit voice signals of a plurality of users located in the same virtual space. An information receiving unit for receiving a voice signal, a mixing signal generating unit for generating a mixed signal synthesizing the voice signals of the respective users, and the mixing in the virtual space based on the volume information and the location information of the voice signals of each user and an output position determining unit for determining a virtual output position, which is a position at which a signal is to be output, and an information transmitting unit for providing the mixing signal and the virtual output position to the plurality of spatial voice VR devices.
본 발명의 일 실시예에 따른 공간 음성 VR 장치는 사용자의 가상 공간 내 위치 정보 및 상기 사용자의 음성 신호를 공간 음성 VR 서버로 송신하고, 상기 가상 공간 내에 위치하는 각 사용자의 음성 신호가 합성된 믹싱 신호를 상기 음성 VR 서버로부터 수신하는 통신부 및 상기 가상 공간 내에서 상기 믹싱 신호가 출력될 위치로서, 상기 각 사용자의 음성 신호의 음량 정보 및 상기 각 사용자의 위치 정보에 기초하여 결정된 가상 출력 위치에서 상기 믹싱 신호가 재생되도록 하는 믹싱 신호 재생부를 포함한다.The spatial voice VR apparatus according to an embodiment of the present invention transmits the user's location information in the virtual space and the user's voice signal to the spatial voice VR server, and mixes the synthesized voice signals of each user located in the virtual space. A communication unit for receiving a signal from the voice VR server and a position at which the mixing signal is output in the virtual space, at a virtual output position determined based on the volume information of each user's voice signal and the position information of each user and a mixed signal reproducing unit for reproducing the mixed signal.
본 발명의 일 실시예에 따른 공간 음성 VR 서버가 수행하는 공간 음성 VR 제공 방법은 동일한 가상 공간 내에 위치하는 복수의 사용자의 음성 신호를 전송하는 복수의 공간 음성 VR 장치로부터 각 사용자의 가상 공간 내에서의 위치 정보 및 상기 각 사용자의 음성 신호를 수신하는 단계, 상기 각 사용자의 음성 신호를 합성한 믹싱 신호를 생성하는 단계, 상기 각 사용자의 음성 신호의 음량 정보 및 상기 위치 정보를 기초로 상기 가상 공간 내에서 상기 믹싱 신호가 출력될 위치인 가상 출력 위치를 결정하는 단계 및 상기 믹싱 신호 및 상기 가상 출력 위치를 상기 복수의 공간 음성 VR 장치에 제공하는 단계를 포함한다.In the method for providing spatial voice VR performed by the spatial voice VR server according to an embodiment of the present invention, a plurality of spatial voice VR devices that transmit voice signals of a plurality of users located in the same virtual space are transmitted in the virtual space of each user. Receiving the location information of each user and the voice signal of each user, generating a mixed signal synthesizing the voice signal of each user, the virtual space based on the volume information of each user's voice signal and the location information determining a virtual output position, which is a position at which the mixing signal is to be output, within the space, and providing the mixing signal and the virtual output position to the plurality of spatial voice VR devices.
본 발명의 일 실시예에 따른 공간 음성 VR 장치가 수행하는 공간 음성 VR 제공 방법은 사용자의 가상 공간 내 위치 정보 및 상기 사용자의 음성 신호를 공간 음성 VR 서버로 송신하고, 상기 가상 공간 내에 위치하는 각 사용자의 음성 신호가 합성된 믹싱 신호를 상기 음성 VR 서버로부터 수신하는 단계 및 상기 가상 공간 내에서 상기 믹싱 신호가 출력될 위치로서, 상기 각 사용자의 음성 신호의 음량 정보 및 상기 각 사용자의 위치 정보에 기초하여 결정된 가상 출력 위치에서 상기 믹싱 신호가 재생되도록 하는 단계를 포함한다.The spatial voice VR providing method performed by the spatial voice VR device according to an embodiment of the present invention transmits the user's location information in the virtual space and the user's voice signal to the spatial voice VR server, and each Receiving a mixed signal in which a user's voice signal is synthesized from the voice VR server, and a location at which the mixed signal is output in the virtual space, to the volume information of each user's voice signal and the location information of each user and causing the mixed signal to be reproduced at the virtual output position determined based on the determined virtual output position.
본 발명의 실시예에 따르면, 동일한 가상 공간 내의 다른 사용자가 위치하는 공간에서 음성이 들리는 서비스를 제공할 수 있다.According to an embodiment of the present invention, it is possible to provide a service in which a voice is heard in a space where another user is located in the same virtual space.
이와 함께, 본 발명의 실시예는 여러 사용자들의 음성을 하나의 스트림으로 합성한 믹싱 신호를 이용하면서도 가상 공간 내의 위치 정보를 고려하여 믹싱 신호가 출력될 가상 공간 내의 위치를 결정하기 때문에, 각 사용자의 음성을 별개로 전송하지 않으면서도 다른 사용자가 위치하는 곳에서 음성이 들리는 효과를 달성함으로써, 동일한 가상 공간 내에 참여하는 사용자의 수의 증가에 따른 서버의 과부하를 방지할 수 있다.In addition, in the embodiment of the present invention, the location in the virtual space where the mixed signal is output is determined in consideration of the location information in the virtual space while using the mixed signal synthesized from the voices of several users into one stream. It is possible to prevent overload of the server due to an increase in the number of users participating in the same virtual space by achieving the effect of hearing voices from where other users are located without separately transmitting the voices.
도 1은 본 발명의 일 실시예에 따른 공간 음성 VR 서버 및 공간 음성 VR 장치를 포함하는 전체 시스템을 나타낸 도면이다.
도 2는 도 1의 실시예에 따른 공간 음성 VR 서버의 기능 블럭도이다.
도 3은 본 발명의 다른 실시예에 따른 공간 음성 VR 서버 및 공간 음성 VR 장치를 포함하는 전체 시스템을 나타낸 도면이다.
도 4는 도 3의 실시예에 따른 공간 음성 VR 장치의 기능 블럭도이다.
도 5는 도 1의 실시예에 따른 공간 음성 VR 서버가 수행하는 공간 음성 VR 제공 방법의 프로세스를 도시하는 흐름도이다.
도 6은 도 3의 실시예에 따른 공간 음성 VR 장치가 수행하는 공간 음성 VR 제공 방법의 프로세스를 도시하는 흐름도이다.1 is a diagram illustrating an entire system including a spatial voice VR server and a spatial voice VR device according to an embodiment of the present invention.
FIG. 2 is a functional block diagram of a spatial voice VR server according to the embodiment of FIG. 1 .
3 is a diagram illustrating an entire system including a spatial voice VR server and a spatial voice VR device according to another embodiment of the present invention.
4 is a functional block diagram of the spatial voice VR apparatus according to the embodiment of FIG. 3 .
5 is a flowchart illustrating a process of a spatial voice VR providing method performed by the spatial voice VR server according to the embodiment of FIG. 1 .
6 is a flowchart illustrating a process of a spatial voice VR providing method performed by the spatial voice VR apparatus according to the embodiment of FIG. 3 .
본 발명의 이점 및 특징, 그리고 그것들을 달성하는 방법은 첨부되는 도면과 함께 상세하게 후술되어 있는 실시예들을 참조하면 명확해질 것이다. 그러나 본 발명은 이하에서 개시되는 실시예들에 한정되는 것이 아니라 다양한 형태로 구현될 수 있으며, 단지 본 실시예들은 본 발명의 개시가 완전하도록 하고, 본 발명이 속하는 기술분야에서 통상의 지식을 가진 자에게 발명의 범주를 완전하게 알려주기 위해 제공되는 것이며, 본 발명의 범주는 청구항에 의해 정의될 뿐이다.Advantages and features of the present invention, and a method of achieving them will become apparent with reference to the embodiments described below in detail in conjunction with the accompanying drawings. However, the present invention is not limited to the embodiments disclosed below and can be implemented in various forms, only these embodiments make the disclosure of the present invention complete, and Those of ordinary skill in the art to which the present invention pertains It is provided to fully inform the person of the scope of the invention, and the scope of the present invention is only defined by the claims.
본 발명의 실시예들을 설명함에 있어서 공지 기능 또는 구성에 대한 구체적인 설명은 본 발명의 실시예들을 설명함에 있어 실제로 필요한 경우 외에는 생략될 것이다. 그리고 후술되는 용어들은 본 발명의 실시예에서의 기능을 고려하여 정의된 용어들로서 이는 사용자, 운용자의 의도 또는 관례 등에 따라 달라질 수 있다. 그러므로 그 정의는 본 명세서 전반에 걸친 내용을 토대로 내려져야 할 것이다.In describing the embodiments of the present invention, detailed descriptions of well-known functions or configurations will be omitted unless it is actually necessary to describe the embodiments of the present invention. In addition, the terms to be described later are terms defined in consideration of functions in an embodiment of the present invention, which may vary according to intentions or customs of users and operators. Therefore, the definition should be made based on the content throughout this specification.
도면에 표시되고 아래에 설명되는 기능 블록들은 가능한 구현의 예들일 뿐이다. 다른 구현들에서는 상세한 설명의 사상 및 범위를 벗어나지 않는 범위에서 다른 기능 블록들이 사용될 수 있다. 또한 본 발명의 하나 이상의 기능 블록이 개별 블록들로 표시되지만, 본 발명의 기능 블록들 중 하나 이상은 동일 기능을 실행하는 다양한 하드웨어 및 소프트웨어 구성들의 조합일 수 있다.The functional blocks shown in the drawings and described below are merely examples of possible implementations. Other functional blocks may be used in other implementations without departing from the spirit and scope of the detailed description. Also, although one or more functional blocks of the present invention are represented as separate blocks, one or more of the functional blocks of the present invention may be combinations of various hardware and software configurations that perform the same function.
또한 어떤 구성 요소들을 포함한다는 표현은 개방형의 표현으로서 해당 구성 요소들이 존재하는 것을 단순히 지칭할 뿐이며, 추가적인 구성 요소들을 배제하는 것으로 이해되어서는 안 된다.In addition, the expression including certain components is an open expression and merely refers to the existence of the corresponding components, and should not be construed as excluding additional components.
나아가 어떤 구성 요소가 다른 구성 요소에 연결되어 있다거나 접속되어 있다고 언급될 때에는, 그 다른 구성 요소에 직접적으로 연결 또는 접속되어 있을 수도 있지만, 중간에 다른 구성 요소가 존재할 수도 있다고 이해되어야 한다.Furthermore, when it is said that a component is connected or connected to another component, it may be directly connected or connected to the other component, but it should be understood that another component may exist in the middle.
또한 '제1, 제2' 등과 같은 표현은 복수의 구성들을 구분하기 위한 용도로만 사용된 표현으로써, 구성들 사이의 순서나 기타 특징들을 한정하지 않는다.In addition, expressions such as 'first, second', etc. are used only for distinguishing a plurality of components, and do not limit the order or other characteristics between the components.
이하에서는 도면들을 참조하여 본 발명의 실시예들에 대해 설명하도록 한다.Hereinafter, embodiments of the present invention will be described with reference to the drawings.
도 1은 본 발명의 일 실시예에 따른 공간 음성 VR 서버(100) 및 공간 음성 VR 장치(200)를 포함하는 전체 시스템(10)을 나타낸 도면이다.1 is a diagram illustrating an entire system 10 including a spatial
도 1에 도시된 실시예에 따른 전체 시스템(10)은 공간 음성 VR 서버(100) 및 공간 음성 VR 장치(200, 200a, 200b, 200c)를 포함한다. 이때 공간 음성 VR 서버(100) 및 공간 음성 VR 장치(200)는 유무선 통신망을 통해 정보를 송수신할 수 있다.The entire system 10 according to the embodiment shown in Fig. 1 includes a spatial
공간 음성 VR 장치(200)는 사용자에게 가상 공간(virtual reality)을 경험하게 하는 장치이다. 가상 공간이란, 사용자에게 시각 및 청각 정보 등을 제공하는 장치를 통해 사용자에게 시각 및 청각 등으로 표현되는 공간 속에 위치하는 것처럼 느끼게 하는 가상의 공간을 말한다.The spatial voice VR device 200 is a device that allows a user to experience a virtual reality. The virtual space refers to a virtual space that makes the user feel as if he or she is located in a space expressed in visual and auditory sense through a device that provides visual and auditory information to the user.
한편, 공간 음성 VR 장치(200)는 동일한 가상 공간에 접속한 다수의 사용자가 서로 상대방의 아바타를 보며 대화를 진행할 수 있는 형태의 서비스를 제공할 수 있다. 이러한 공간 음성 VR 장치(200)는 일 예로 VR 글래스가 있으나 이러한 예시에 한정되는 것은 아니다.Meanwhile, the spatial voice VR device 200 may provide a service in which a plurality of users accessing the same virtual space can communicate while viewing each other's avatars. The spatial voice VR device 200 is, for example, VR glasses, but is not limited thereto.
도 1의 실시예에 따른 공간 음성 VR 장치(200)는 사용자의 가상 공간 내 위치 정보 및 사용자의 음성 신호를 공간 음성 VR 서버(100)로 송신하고, 가상 공간 내에 위치하는 각 사용자의 음성 신호가 합성된 믹싱 신호 및 믹싱 신호가 가상 공간 내에서 출력될 위치에 대한 정보인 가상 출력 위치를 음성 VR 서버로부터 수신할 수 있다.The spatial voice VR apparatus 200 according to the embodiment of FIG. 1 transmits the user's location information in the virtual space and the user's voice signal to the spatial
이에 따라, 공간 음성 VR 장치(200a)는 가상 공간 내에서 가상 출력 위치에 해당하는 위치에서 믹싱 신호를 재생하여 공간 음성 VR 장치(200a)의 사용자로 하여금 동일한 가상 공간 내의 다른 사용자(가령, 200b의 사용자)가 위치하는 위치에서 음성이 들리는 느낌을 제공할 수 있다.Accordingly, the spatial
도 1의 실시예에 따른 공간 음성 VR 서버(100)는 동일한 가상 공간 내에 접속한 각 사용자의 공간 음성 VR 장치(200, 200a, 200b, 200c)로부터 수신한 음성 신호를 하나의 스트림으로 합성한 믹싱 신호를 생성할 수 있다. 또한 공간 음성 VR 장치(200)로부터 수신한 각 사용자의 가상 공간 내 위치 정보 및 음성 신호의 음량 정보를 기초로 가상 공간 내에서 믹싱 신호가 재생될 출력 위치를 결정하여 동일한 가상 공간 내의 모든 공간 음성 VR 장치(200)에 제공할 수 있다. 이와 같은, 공간 음성 VR 서버(100)의 상세한 구성을 도 2와 함께 설명한다.The spatial
도 2는 도 1의 실시예에 따른 공간 음성 VR 서버(100)의 기능 블럭도이다.FIG. 2 is a functional block diagram of the spatial
도 2를 참조하면, 본 발명의 일 실시예에 따른 공간 음성 VR 서버(100)는 정보 수신부(110), 믹싱 신호 생성부(120), 출력 위치 결정부(130) 및 정보 송신부(140)를 포함한다.Referring to FIG. 2 , the spatial
정보 수신부(110)는 동일한 가상 공간 내에 위치하는 사용자가 착용한 공간 음성 VR 장치(200)로부터 가상 공간 내에서 각 사용자의 위치 정보 및 각 사용자의 음성 신호를 수신한다. 예를 들어, 위치 정보는 사용자의 아바타가 위치하는 지점일 수 있고, 이러한 위치 정보는 가상 공간 내의 좌표를 통해 표현될 수 있다. 또한 사용자의 음성 신호는 공간 음성 VR 장치(200)에 구비된 마이크 등의 음향 입력 수단을 통해 측정될 수 있다.The
믹싱 신호 생성부(120)는 정보 수신부(110)가 수신한 각 사용자의 음성 신호를 합성한 믹싱 신호를 생성한다. 이때 믹싱 신호 생성부(120)는 실시간으로 수신하는 각 사용자의 음성 신호를 하나의 스트림으로 된 믹싱 신호를 생성한다. 각 사용자의 음성 신호를 별개로 처리하는 방식과는 달리, 믹싱 신호를 이용한 방식은 믹싱 신호라는 동일한 정보를 동일한 가상 공간 내에 참여하는 공간 음성 VR 장치(200)에 송신하므로, 가상 공간 내에 참여하는 사용자의 수가 많아져도 공간 음성 VR 서버(100)에 과부하를 발생시킬 가능성이 낮다는 이점이 있다.The mixed
출력 위치 결정부(130)는 동일한 가상 공간 내 각 사용자의 음성 신호의 음량 정보 및 위치 정보를 기초로 가상 공간 내에서 믹싱 신호가 출력될 위치인 가상 출력 위치를 결정한다.The output
예를 들어, 출력 위치 결정부(130)는 동일한 가상 공간에 위치하는 사용자 중에서 음성이 가장 큰 사용자가 가상 공간 내에서 위치하는 지점을 믹싱 신호가 출력될 가상 출력 위치로 결정할 수 있다. 이때 출력 위치 결정부(130)는 각 공간 음성 VR 장치(200)로부터 수신한 음성 신호의 음량 정보(예를 들면, 데시벨 크기)를 기초로 각 사용자의 음성의 크기를 비교할 수 있다. 이때 음성 신호의 음량 정보(예를 들면, 데시벨 정보)는 공간 음성 VR 장치(200)의 음향 입력 수단을 통해 측정되거나, 공간 음성 VR 서버(100)가 음성 신호의 신호 크기로부터 음량 정보를 추출할 수 있다.For example, the output position determiner 130 may determine a point in the virtual space where the user with the highest voice among users located in the same virtual space is located in the virtual space as the virtual output position to which the mixing signal is output. At this time, the
또한 다른 일 예로서, 출력 위치 결정부(130)는 동일한 가상 공간에 위치하는 사용자의 공간 음성 VR 장치(200)로부터 수신한 음성 신호의 음량 정보가 가장 큰 값과 두번째로 큰 값과의 차이가 소정의 값 이하인 경우, 음성이 가장 큰 사용자가 가상 공간 내에서 위치하는 지점과 음성이 두번째로 큰 사용자가 가상 공간 내에서 위치하는 지점의 중간 지점을 믹싱 신호가 출력될 가상 출력 위치로 결정할 수 있다. 이때에도 출력 위치 결정부(130)는 각 공간 음성 VR 장치(200)로부터 수신한 음성 신호의 음량 정보를 기초로 각 사용자의 음성의 크기를 비교할 수 있다.Also, as another example, the
정보 송신부(140)는 믹싱 신호 생성부(120)가 생성한 믹싱 신호 및 출력 위치 결정부(130)가 결정한 가상 출력 위치를 동일한 가상 공간 내의 사용자가 사용하는 공간 음성 VR 장치(200)에 제공한다. 이에 따라, 공간 음성 VR 장치(200)는 가상 공간 내에서 가상 출력 위치에 해당하는 위치에서 믹싱 신호를 재생시킴으로써 사용자로 하여금 동일한 가상 공간 내의 다른 사용자가 위치하는 지점에서 음성이 들리는 느낌을 받도록 할 수 있다.The
한편 상술한 실시예가 포함하는 정보 수신부(110), 믹싱 신호 생성부(120), 출력 위치 결정부(130) 및 정보 송신부(140)는 이들의 기능을 수행하도록 프로그램된 명령어를 포함하는 메모리, 및 이들 명령어를 수행하는 마이크로프로세서를 포함하는 연산 장치에 의해 구현될 수 있다.Meanwhile, the
도 3은 본 발명의 다른 실시예에 따른 공간 음성 VR 서버(300) 및 공간 음성 VR 장치(400)를 포함하는 전체 시스템(30)을 나타낸 도면이다.3 is a diagram illustrating the entire system 30 including the spatial
도 3에 도시된 실시예에 따른 전체 시스템(30)은 공간 음성 VR 서버(300) 및 공간 음성 VR 장치(400, 400a, 400b, 400c)를 포함한다. 이때 공간 음성 VR 서버(300) 및 공간 음성 VR 장치(400)는 유무선 통신망을 통해 정보를 송수신할 수 있다.The entire system 30 according to the embodiment shown in Fig. 3 includes a spatial
도 3의 실시예에 따른 공간 음성 VR 장치(400)는 사용자의 가상 공간 내 위치 정보 및 사용자의 음성 신호를 공간 음성 VR 서버(300)로 송신하고, 가상 공간 내에 위치하는 각 사용자의 음성 신호가 합성된 믹싱 신호를 음성 VR 서버로부터 수신하여, 가상 공간 내의 가상 출력 위치에서 믹싱 신호를 재생한다. 이때 도 1의 실시예에서는 공간 음성 VR 서버(100)가 가상 출력 위치를 결정하지만, 도 3의 실시예에서는 공간 음성 VR 장치(400a)가 공간 음성 VR 서버(300)로부터 수신한 위치 정보 및 다른 공간 음성 VR 장치(400b, 400c)로부터 수신한 음량 정보를 기초로 가상 출력 위치를 결정할 수 있다.The spatial
도 3의 실시예에 따른 공간 음성 VR 서버(300)는 동일한 가상 공간 내에 접속한 각 사용자의 공간 음성 VR 장치(400, 400a, 400b, 400c)로부터 수신한 음성 신호를 하나의 스트림으로 합성한 믹싱 신호를 생성할 수 있다. 또한 공간 음성 VR 서버(300)는 공간 음성 VR 장치(400)로부터 수신한 각 사용자의 가상 공간 내 위치 정보를 동일한 가상 공간 내에 참여한 공간 음성 VR 장치(400)에 제공할 수 있다.The spatial
도 4는 도 3의 실시예에 따른 공간 음성 VR 장치(400)의 기능 블럭도이다.4 is a functional block diagram of the spatial
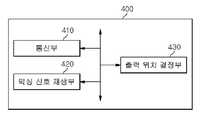
도 4를 참조하면, 도 3의 실시예에 따른 공간 음성 VR 장치(400)는 통신부(410), 믹싱 신호 재생부(420) 및 출력 위치 결정부(430)를 포함할 수 있다. 다만, 도 1의 실시예에 따른 공간 음성 VR 장치(200)는 출력 위치 결정부(430)를 포함하지 않을 수 있다.Referring to FIG. 4 , the spatial
통신부(410)는 공간 음성 VR 장치(400)를 착용한 사용자의 가상 공간 내 위치 정보 및 사용자의 음성 신호를 공간 음성 VR 서버(300)로 송신하고, 가상 공간 내에 위치하는 각 사용자의 음성 신호가 합성된 믹싱 신호 및 각 사용자의 위치 정보를 공간 음성 VR 서버(300)로부터 수신한다.The
이에 더하여, 통신부(410)는 동일한 가상 공간 내에 위치하는 다른 사용자의 음성 신호의 음량 정보를 다른 사용자의 공간 음성 VR 장치(400)로부터 수신할 수 있다. 예를 들어, 각 사용자의 음성 신호의 음량 정보는 브로드캐스트(broadcast) 방식을 통해 모든 사용자의 공간 음성 VR 장치(400)로 송신될 수 있다.In addition, the
믹싱 신호 재생부(420)는 각 사용자의 음성 신호의 음량 정보 및 각 사용자의 위치 정보에 기초하여 결정된 가상 출력 위치에서 믹싱 신호가 재생되도록 한다. 이때 믹싱 신호 재생부(420)는 좌우 스테레오의 음량을 조절하는 기술 또는 귀의 모양에 따른 음성 신호 변화를 모델링한 HRTF(head related transfer function) 등의 기법을 사용하여 믹싱 신호를 가상 출력 위치에서 재생되는 것으로 들리도록 할 수 있으나, 이러한 기술은 특정 위치에서 소리가 재생되는 것으로 들리게 하는 공간 오디오 기술의 예시일 뿐, 믹싱 신호의 재생 기술이 앞에 열거된 예시로 한정되는 것은 아니다. 또한 믹싱 신호 재생부(420)는 믹싱 신호의 음성 중 사용자 자신의 음성은 제거된 채로 믹싱 신호가 재생되도록 할 수 있으며, 이러한 기술은 공지된 기술로서 자세한 설명은 생략한다.The mixed
한편, 가상 출력 위치는 도 1에 도시된 실시예인 공간 음성 VR 서버(100)가 각 사용자의 음성 신호의 음량 정보 및 각 사용자의 위치 정보를 기초로 생성하여, 공간 음성 VR 서버(100)로부터 제공받은 정보일 수 있다. 이와 달리, 도 3의 실시예에 따르면 공간 음성 VR 장치(400)가 가상 출력 위치를 결정할 수 있고, 이를 위해 공간 음성 VR 장치(400)는 출력 위치 결정부(430)를 더 포함할 수 있다.On the other hand, the virtual output location is generated by the spatial
출력 위치 결정부(430)는 통신부(410)가 수신한 동일한 가상 공간 내 다른 사용자의 음성 신호의 음량 정보 및 위치 정보를 기초로 가상 공간 내에서 믹싱 신호가 출력될 위치인 가상 출력 위치를 결정할 수 있다.The output
예를 들어, 출력 위치 결정부(430)는 다른 사용자의 음량 정보 중에서 음성이 가장 큰 사용자가 가상 공간 내에서 위치하는 지점을 믹싱 신호가 출력될 가상 출력 위치로 결정할 수 있다. 이때 출력 위치 결정부(430)는 통신부(410)가 다른 공간 음성 VR 장치(400)로부터 수신한 음성 신호의 음량(예를 들면, 데시벨 크기)을 기초로 각 사용자의 음성의 크기를 비교할 수 있다.For example, the
또한 다른 일 예로서, 출력 위치 결정부(430)는 다른 사용자의 음량 정보 중 음량이 가장 큰 값과 두번째로 큰 값과의 차이가 소정의 값 이하인 경우, 음량이 가장 큰 사용자가 가상 공간 내에서 위치하는 지점과 음량이 두번째로 큰 사용자가 가상 공간 내에서 위치하는 지점의 중간 지점을 믹싱 신호가 출력될 가상 출력 위치로 결정할 수 있다. 이때에도 출력 위치 결정부(430)는 통신부(410)가 다른 공간 음성 VR 장치(400)로부터 수신한 음성 신호의 음량(예를 들면, 데시벨 크기)을 기초로 각 사용자의 음성의 크기를 비교할 수 있다.Also, as another example, when the difference between the largest value and the second largest value among the volume information of other users is less than or equal to a predetermined value, the output
더하여 다른 일 예로서, 출력 위치 결정부(430)는 다른 사용자의 음량 정보 중 음량이 가장 큰 값과 두번째로 큰 값과의 차이가 소정의 값 이하인 경우, 음량이 가장 큰 사용자와 두번째로 음량이 큰 사용자 중 사용자 자신과 더 가까운 사용자의 위치를 가상 출력 위치로 결정할 수 있다.In addition, as another example, when the difference between the largest value and the second largest value among the volume information of other users is less than or equal to a predetermined value, the output
한편 상술한 실시예가 포함하는 통신부(410), 믹싱 신호 재생부(420)및 출력 위치 결정부(430)는 이들의 기능을 수행하도록 프로그램된 명령어를 포함하는 메모리, 및 이들 명령어를 수행하는 마이크로프로세서를 포함하는 연산 장치에 의해 구현될 수 있다.Meanwhile, the
도 5는 도 1의 실시예에 따른 공간 음성 VR 서버(100)가 수행하는 공간 음성 VR 제공 방법의 프로세스를 도시하는 흐름도이다. 도 5에 따른 공간 음성 VR 제공 방법의 각 단계는 도 1 및 도 2를 통해 설명된 공간 음성 VR 서버(100)에 의해 수행될 수 있으며, 각 단계를 설명하면 다음과 같다.5 is a flowchart illustrating a process of a spatial voice VR providing method performed by the spatial
우선, 공간 음성 VR 서버(100)는 동일한 가상 공간 내에 위치하는 복수의 사용자의 음성 신호를 전송하는 복수의 공간 음성 VR 장치(200)로부터 각 사용자의 가상 공간 내에서의 위치 정보 및 각 사용자의 음성 신호를 수신한다(S510). 이후, 각 사용자의 음성 신호를 합성한 믹싱 신호를 생성한다(S520). 다음으로, 각 사용자의 음성 신호의 음량 정보 및 위치 정보를 기초로 가상 공간 내에서 믹싱 신호가 출력될 위치인 가상 출력 위치를 결정한다(S530). 이에 따라, 믹싱 신호 및 가상 출력 위치를 복수의 공간 음성 VR 장치(200)에 제공하여(S540), 믹싱 신호 및 가상 출력 위치를 수신한 공간 음성 VR 장치(200)는 가상 공간 내에서 가상 출력 위치에 해당하는 위치에서 믹싱 신호를 재생할 수 있다.First, the spatial
한편, 각 단계를 수행하기 위해 공간 음성 VR 서버(100)의 각 구성이 수행하는 구체적인 설명은 도 1 및 도 2와 함께 설명하였으므로 중복된 설명을 생략한다.On the other hand, detailed descriptions performed by each configuration of the spatial
도 6은 도 3의 실시예에 따른 공간 음성 VR 장치(400)가 수행하는 공간 음성 VR 제공 방법의 프로세스를 도시하는 흐름도이다. 도 6에 따른 공간 음성 VR 제공 방법의 각 단계는 도 3 및 도 4를 통해 설명된 공간 음성 VR 장치(400)에 의해 수행될 수 있으며, 각 단계를 설명하면 다음과 같다.6 is a flowchart illustrating a process of a spatial voice VR providing method performed by the spatial
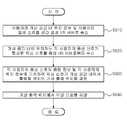
우선, 공간 음성 VR 장치(400)는 사용자의 가상 공간 내 위치 정보 및 사용자의 음성 신호를 공간 음성 VR 서버(300)로 송신한다(S610). 또한, 가상 공간 내에 위치하는 각 사용자의 음성 신호가 합성된 믹싱 신호를 음성 VR 서버로부터 수신한다(S620). 다음으로, 각 사용자의 음성 신호의 음량 정보 및 각 사용자의 위치 정보에 기초하여 믹싱 신호가 가상 공간 내에서 출력될 위치인 가상 출력 위치를 결정한다(S630). 이에 따라, 공간 음성 VR 장치(400)는 가상 출력 위치에서 믹싱 신호를 재생할 수 있다(S640). 이때 도 1의 실시예에 따른 공간 음성 VR 장치(200)가 수행하는 공간 음성 VR 제공 방법은 도 6에 도시된 단계 중 S630 단계를 포함하지 않을 수 있다.First, the spatial
한편, 각 단계를 수행하기 위해 공간 음성 VR 장치(400)의 각 구성이 수행하는 구체적인 설명은 도 3 및 도 4와 함께 설명하였으므로 중복된 설명을 생략한다.Meanwhile, a detailed description performed by each component of the spatial
상술한 실시예에 따르면, 동일한 가상 공간 내의 다른 사용자가 위치하는 공간에서 음성이 들리는 서비스를 제공할 수 있다.According to the above-described embodiment, it is possible to provide a service in which a voice is heard in a space in which another user is located in the same virtual space.
이와 함께, 본 발명의 실시예는 여러 사용자들의 음성을 하나의 스트림으로 합성한 믹싱 신호를 이용하면서도 가상 공간 내의 위치 정보를 고려하여 믹싱 신호가 출력될 가상 공간 내의 위치를 결정하기 때문에, 각 사용자의 음성을 별개로 전송하지 않으면서도 다른 사용자가 위치하는 곳에서 음성이 들리는 효과를 달성함으로써, 동일한 가상 공간 내에 참여하는 사용자의 수의 증가에 따른 서버의 과부하를 방지할 수 있다.In addition, in the embodiment of the present invention, the location in the virtual space where the mixed signal is output is determined in consideration of the location information in the virtual space while using the mixed signal synthesized from the voices of several users into one stream. It is possible to prevent overload of the server due to an increase in the number of users participating in the same virtual space by achieving the effect of hearing voices from where other users are located without separately transmitting voices.
상술한 본 발명의 실시예들은 다양한 수단을 통해 구현될 수 있다. 예를 들어, 본 발명의 실시예들은 하드웨어, 펌웨어(firmware), 소프트웨어 또는 그것들의 결합 등에 의해 구현될 수 있다.The above-described embodiments of the present invention may be implemented through various means. For example, embodiments of the present invention may be implemented by hardware, firmware, software, or a combination thereof.
하드웨어에 의한 구현의 경우, 본 발명의 실시예들에 따른 방법은 하나 또는 그 이상의 ASICs(Application Specific Integrated Circuits), DSPs(Digital Signal Processors), DSPDs(Digital Signal Processing Devices), PLDs(Programmable Logic Devices), FPGAs(Field Programmable Gate Arrays), 프로세서, 컨트롤러, 마이크로 컨트롤러, 마이크로 프로세서 등에 의해 구현될 수 있다.In case of implementation by hardware, the method according to embodiments of the present invention may include one or more Application Specific Integrated Circuits (ASICs), Digital Signal Processors (DSPs), Digital Signal Processing Devices (DSPDs), Programmable Logic Devices (PLDs). , FPGAs (Field Programmable Gate Arrays), processors, controllers, microcontrollers, microprocessors, and the like.
펌웨어나 소프트웨어에 의한 구현의 경우, 본 발명의 실시예들에 따른 방법은 이상에서 설명된 기능 또는 동작들을 수행하는 모듈, 절차 또는 함수 등의 형태로 구현될 수 있다. 소프트웨어 코드 등이 기록된 컴퓨터 프로그램은 컴퓨터 판독 가능 기록 매체 또는 메모리 유닛에 저장되어 프로세서에 의해 구동될 수 있다. 메모리 유닛은 프로세서 내부 또는 외부에 위치하여, 이미 공지된 다양한 수단에 의해 프로세서와 데이터를 주고 받을 수 있다.In the case of implementation by firmware or software, the method according to the embodiments of the present invention may be implemented in the form of a module, procedure, or function that performs the functions or operations described above. A computer program in which a software code or the like is recorded may be stored in a computer-readable recording medium or a memory unit and driven by a processor. The memory unit may be located inside or outside the processor, and may send and receive data to and from the processor by various known means.
또한 본 발명에 첨부된 블록도의 각 블록과 흐름도의 각 단계의 조합들은 컴퓨터 프로그램 인스트럭션들에 의해 수행될 수도 있다. 이들 컴퓨터 프로그램 인스트럭션들은 범용 컴퓨터, 특수용 컴퓨터 또는 기타 프로그램 가능한 데이터 프로세싱 장비의 인코딩 프로세서에 탑재될 수 있으므로, 컴퓨터 또는 기타 프로그램 가능한 데이터 프로세싱 장비의 인코딩 프로세서를 통해 수행되는 그 인스트럭션들이 블록도의 각 블록 또는 흐름도의 각 단계에서 설명된 기능들을 수행하는 수단을 생성하게 된다. 이들 컴퓨터 프로그램 인스트럭션들은 특정 방법으로 기능을 구현하기 위해 컴퓨터 또는 기타 프로그램 가능한 데이터 프로세싱 장비를 지향할 수 있는 컴퓨터 이용 가능 또는 컴퓨터 판독 가능 메모리에 저장되는 것도 가능하므로, 그 컴퓨터 이용가능 또는 컴퓨터 판독 가능 메모리에 저장된 인스트럭션들은 블록도의 각 블록 또는 흐름도 각 단계에서 설명된 기능을 수행하는 인스트럭션 수단을 내포하는 제조 품목을 생산하는 것도 가능하다. 컴퓨터 프로그램 인스트럭션들은 컴퓨터 또는 기타 프로그램 가능한 데이터 프로세싱 장비 상에 탑재되는 것도 가능하므로, 컴퓨터 또는 기타 프로그램 가능한 데이터 프로세싱 장비 상에서 일련의 동작 단계들이 수행되어 컴퓨터로 실행되는 프로세스를 생성해서 컴퓨터 또는 기타 프로그램 가능한 데이터 프로세싱 장비를 수행하는 인스트럭션들은 블록도의 각 블록 및 흐름도의 각 단계에서 설명된 기능들을 실행하기 위한 단계들을 제공하는 것도 가능하다.Also, combinations of each block in the block diagram attached to the present invention and each step in the flowchart may be performed by computer program instructions. These computer program instructions may be embodied in an encoding processor of a general purpose computer, special purpose computer, or other programmable data processing equipment, such that the instructions executed by the encoding processor of the computer or other programmable data processing equipment may correspond to each block of the block diagram or Each step of the flowchart creates a means for performing the functions described. These computer program instructions may also be stored in a computer-usable or computer-readable memory that may direct a computer or other programmable data processing equipment to implement a function in a particular manner, and thus the computer-usable or computer-readable memory. The instructions stored in the block diagram may also produce an item of manufacture containing instruction means for performing the functions described in each block in the block diagram or in each step in the flowchart. The computer program instructions may also be mounted on a computer or other programmable data processing equipment, such that a series of operational steps are performed on the computer or other programmable data processing equipment to create a computer-executed process to create a computer or other programmable data processing equipment. It is also possible that instructions for performing the processing equipment provide steps for carrying out the functions described in each block of the block diagram and each step of the flowchart.
더불어 각 블록 또는 각 단계는 특정된 논리적 기능을 실행하기 위한 하나 이상의 실행 가능한 인스트럭션들을 포함하는 모듈, 세그먼트 또는 코드의 일부를 나타낼 수 있다. 또한 몇 가지 대체 실시예들에서는 블록들 또는 단계들에서 언급된 기능들이 순서를 벗어나서 발생하는 것도 가능함을 주목해야 한다. 예컨대, 잇달아 도시되어 있는 두 개의 블록들 또는 단계들은 사실 실질적으로 동시에 수행되는 것도 가능하고 또는 그 블록들 또는 단계들이 때때로 해당하는 기능에 따라 역순으로 수행되는 것도 가능하다.In addition, each block or each step may represent a module, segment, or part of code including one or more executable instructions for executing a specified logical function. It should also be noted that in some alternative embodiments it is also possible for the functions recited in blocks or steps to occur out of order. For example, it is possible that two blocks or steps shown one after another may in fact be performed substantially simultaneously, or that the blocks or steps may sometimes be performed in the reverse order according to the corresponding function.
이와 같이, 본 발명이 속하는 기술분야의 당업자는 본 발명이 그 기술적 사상이나 필수적 특징을 변경하지 않고서 다른 구체적인 형태로 실시될 수 있다는 것을 이해할 수 있을 것이다. 그러므로 이상에서 기술한 실시예들은 모든 면에서 예시적인 것이며 한정적인 것이 아닌 것으로서 이해해야만 한다. 본 발명의 범위는 상세한 설명보다는 후술하는 특허청구범위에 의하여 나타내어지며, 특허청구범위의 의미 및 범위 그리고 그 등가개념으로부터 도출되는 모든 변경 또는 변형된 형태가 본 발명의 범위에 포함되는 것으로 해석되어야 한다.As such, those skilled in the art to which the present invention pertains will understand that the present invention may be embodied in other specific forms without changing the technical spirit or essential characteristics thereof. Therefore, it should be understood that the embodiments described above are illustrative in all respects and not restrictive. The scope of the present invention is indicated by the following claims rather than the detailed description, and all changes or modifications derived from the meaning and scope of the claims and their equivalent concepts should be construed as being included in the scope of the present invention. .
10: 공간 음성 VR 서버 및 공간 음성 VR 장치를 포함하는 전체 시스템
100: 공간 음성 VR 서버
110: 정보 수신부
120: 믹싱 신호 생성부
130: 출력 위치 결정부
140: 정보 송신부
200, 200a, 200b, 200c: 공간 음성 VR 장치
30: 공간 음성 VR 서버 및 공간 음성 VR 장치를 포함하는 전체 시스템
300: 공간 음성 VR 서버
400, 400a, 400b, 400c: 공간 음성 VR 장치
410: 통신부
420: 믹싱 신호 재생부
430: 출력 위치 결정부10: Full system including spatial voice VR server and spatial voice VR device
100: Spatial Voice VR Server
110: information receiving unit
120: mixing signal generator
130: output positioning unit
140: information transmitter
200, 200a, 200b, 200c: Spatial Voice VR Device
30: Full system including spatial voice VR server and spatial voice VR device
300: Spatial Voice VR Server
400, 400a, 400b, 400c: Spatial Voice VR Device
410: communication department
420: mixing signal reproducing unit
430: output positioning unit
Claims (20)
Translated fromKorean상기 각 사용자의 음성 신호를 합성한 믹싱 신호를 생성하는 믹싱 신호 생성부;
상기 각 사용자의 음성 신호의 음량 정보 중, 기 설정된 조건을 만족하는 음성 크기를 가지는 사용자의 상기 가상 공간 내에서의 위치 정보를 기초로 상기 가상 공간 내에서 상기 믹싱 신호가 출력될 위치인 가상 출력 위치를 결정하는 출력 위치 결정부; 및
상기 믹싱 신호 및 상기 가상 출력 위치를 상기 복수의 공간 음성 VR 장치에 제공하는 정보 송신부를 포함하는
공간 음성 VR 서버.an information receiver configured to receive location information of each user in a virtual space and a voice signal of each user from a plurality of spatial voice VR devices that transmit voice signals of a plurality of users located in the same virtual space;
a mixing signal generator for generating a mixed signal obtained by synthesizing the voice signals of the respective users;
A virtual output position that is a position at which the mixing signal is to be output in the virtual space based on position information in the virtual space of a user having a voice level that satisfies a preset condition among the volume information of each user's voice signal an output position determining unit to determine and
and an information transmitter providing the mixing signal and the virtual output location to the plurality of spatial voice VR devices.
Spatial Voice VR Server.
상기 출력 위치 결정부는,
상기 복수의 공간 음성 VR 장치 중 상기 음성 신호의 음량 정보가 가장 큰 공간 음성 VR 장치의 사용자의 위치를 상기 가상 출력 위치로 결정하는
공간 음성 VR 서버.According to claim 1,
The output positioning unit,
and determining, as the virtual output location, a location of a user of a spatial voice VR device having the largest volume information of the voice signal among the plurality of spatial voice VR devices.
Spatial Voice VR Server.
상기 출력 위치 결정부는,
상기 복수의 공간 음성 VR 장치 중 상기 음성 신호의 음량 정보가 가장 큰 값과 두번째로 큰 값과의 차이가 소정의 값 이하인 경우, 상기 음량 정보가 가장 큰 사용자의 위치와 상기 음량 정보가 두번째로 큰 사용자의 위치의 중간 위치를 상기 가상 출력 위치로 결정하는
공간 음성 VR 서버.According to claim 1,
The output positioning unit,
When the difference between the largest value and the second largest value of the volume information of the voice signal among the plurality of spatial voice VR devices is less than a predetermined value, the location of the user having the largest volume information and the second largest volume information determining an intermediate position of the user's position as the virtual output position
Spatial Voice VR Server.
상기 가상 공간 내에서 상기 믹싱 신호가 출력될 위치로서, 상기 각 사용자의 음성 신호의 음량 정보 중, 기 설정된 조건을 만족하는 음성 크기를 가지는 사용자의 상기 가상 공간 내에서의 위치 정보에 기초하여 결정된 가상 출력 위치에서 상기 믹싱 신호가 재생되도록 하는 믹싱 신호 재생부를 포함하는
공간 음성 VR 장치.a communication unit that transmits the user's location information in the virtual space and the user's voice signal to the spatial voice VR server, and receives a mixed signal in which the voice signals of each user located in the virtual space are synthesized from the voice VR server; and
As a position in the virtual space where the mixing signal is to be output, the virtual space determined based on position information of a user having a voice level satisfying a preset condition among the volume information of each user's voice signal in the virtual space A mixing signal reproducing unit configured to reproduce the mixed signal at an output position
Spatial voice VR device.
상기 장치는,
상기 각 사용자의 음성 신호의 음량 정보 및 상기 각 사용자의 위치 정보에 기초하여 상기 가상 출력 위치를 결정하는 출력 위치 결정부를 더 포함하는
공간 음성 VR 장치.5. The method of claim 4,
The device is
Further comprising an output position determining unit for determining the virtual output position based on the volume information of each user's voice signal and the position information of each user
Spatial voice VR device.
상기 통신부는,
상기 가상 공간 내에 위치하는 다른 사용자의 음성 신호의 음량 정보를 상기 다른 사용자의 공간 음성 VR 장치로부터 수신하고, 상기 각 사용자의 위치 정보를 상기 음성 VR 서버로부터 더 수신하는
공간 음성 VR 장치.7. The method of claim 6,
The communication unit,
Receiving the volume information of the voice signal of another user located in the virtual space from the spatial voice VR device of the other user, and further receiving the location information of each user from the voice VR server
Spatial voice VR device.
상기 출력 위치 결정부는,
상기 각 사용자 중 상기 음성 신호의 음량 정보가 가장 큰 사용자의 위치를 상기 가상 출력 위치로 결정하는
공간 음성 VR 장치.7. The method of claim 6,
The output positioning unit,
Determining the location of the user having the largest volume information of the voice signal among the users as the virtual output location
Spatial voice VR device.
상기 출력 위치 결정부는,
상기 각 사용자의 음성 신호의 음량 정보가 가장 큰 값과 두번째로 큰 값과의 차이가 소정의 값 이하인 경우, 상기 각 사용자 중 상기 음성 신호의 음량 정보가 가장 큰 사용자의 위치와 상기 음성 신호의 음량 정보가 두번째로 큰 사용자의 위치의 중간 위치를 상기 가상 출력 위치로 결정하는
공간 음성 VR 장치.7. The method of claim 6,
The output positioning unit,
When the difference between the largest value and the second largest value of the volume information of each user's voice signal is less than or equal to a predetermined value, the location of the user having the largest volume information of the voice signal among the users and the volume of the voice signal determining an intermediate position of the user's position with the second largest information as the virtual output position
Spatial voice VR device.
상기 출력 위치 결정부는,
상기 각 사용자의 음성 신호의 음량 정보가 가장 큰 값과 두번째로 큰 값과의 차이가 소정의 값 이하인 경우, 상기 음성 신호의 음량 정보가 가장 큰 사용자와 상기 음성 신호의 음량 정보가 두번째로 큰 사용자 중 사용자 자신과 더 가까운 사용자의 위치를 상기 가상 출력 위치로 결정하는
공간 음성 VR 장치.7. The method of claim 6,
The output positioning unit,
When the difference between the largest value and the second largest value of the volume information of each user's voice signal is less than a predetermined value, the user having the largest volume information of the voice signal and the user having the second largest volume information of the voice signal determining the location of the user closer to the user as the virtual output location
Spatial voice VR device.
동일한 가상 공간 내에 위치하는 복수의 사용자의 음성 신호를 전송하는 복수의 공간 음성 VR 장치로부터 각 사용자의 가상 공간 내에서의 위치 정보 및 상기 각 사용자의 음성 신호를 수신하는 단계;
상기 각 사용자의 음성 신호를 합성한 믹싱 신호를 생성하는 단계;
상기 각 사용자의 음성 신호의 음량 정보 중, 기 설정된 조건을 만족하는 음성 크기를 가지는 사용자의 상기 가상 공간 내에서의 위치 정보를 기초로 상기 가상 공간 내에서 상기 믹싱 신호가 출력될 위치인 가상 출력 위치를 결정하는 단계; 및
상기 믹싱 신호 및 상기 가상 출력 위치를 상기 복수의 공간 음성 VR 장치에 제공하는 단계를 포함하는
공간 음성 VR 제공 방법.A method for providing spatial voice VR performed by a spatial voice VR server, the method comprising:
receiving location information of each user in a virtual space and a voice signal of each user from a plurality of spatial voice VR devices that transmit voice signals of a plurality of users located in the same virtual space;
generating a mixed signal obtained by synthesizing the voice signals of the respective users;
A virtual output position that is a position at which the mixing signal is to be output in the virtual space based on position information in the virtual space of a user having a voice level that satisfies a preset condition among the volume information of each user's voice signal determining a; and
providing the mixing signal and the virtual output location to the plurality of spatial voice VR devices;
How to provide spatial voice VR.
상기 가상 출력 위치를 결정하는 단계는,
상기 복수의 공간 음성 VR 장치 중 상기 음성 신호의 음량 정보가 가장 큰 공간 음성 VR 장치의 사용자의 위치를 상기 가상 출력 위치로 결정하는 단계를 포함하는
공간 음성 VR 제공 방법.12. The method of claim 11,
Determining the virtual output location comprises:
determining, as the virtual output position, a location of a user of a spatial voice VR device having the largest volume information of the voice signal among the plurality of spatial voice VR devices as the virtual output location
How to provide spatial voice VR.
상기 가상 출력 위치를 결정하는 단계는,
상기 복수의 공간 음성 VR 장치 중 상기 음성 신호의 음량 정보가 가장 큰 값과 두번째로 큰 값과의 차이가 소정의 값 이하인 경우, 상기 음량 정보가 가장 큰 사용자의 위치와 상기 음량 정보가 두번째로 큰 사용자의 위치의 중간 위치를 상기 가상 출력 위치로 결정하는 단계를 포함하는
공간 음성 VR 제공 방법.12. The method of claim 11,
Determining the virtual output location comprises:
When the difference between the largest value and the second largest value of the volume information of the voice signal among the plurality of spatial voice VR devices is less than a predetermined value, the location of the user having the largest volume information and the second largest volume information determining an intermediate position of the user's position as the virtual output position
How to provide spatial voice VR.
사용자의 가상 공간 내 위치 정보 및 상기 사용자의 음성 신호를 공간 음성 VR 서버로 송신하고, 상기 가상 공간 내에 위치하는 각 사용자의 음성 신호가 합성된 믹싱 신호를 상기 음성 VR 서버로부터 수신하는 단계; 및
상기 가상 공간 내에서 상기 믹싱 신호가 출력될 위치로서, 상기 각 사용자의 음성 신호의 음량 정보 중, 기 설정된 조건을 만족하는 음성 크기를 가지는 사용자의 상기 가상 공간 내에서의 위치 정보에 기초하여 결정된 가상 출력 위치에서 상기 믹싱 신호가 재생되도록 하는 단계를 포함하는
공간 음성 VR 제공 방법.A method for providing spatial voice VR performed by a spatial voice VR device, the method comprising:
transmitting the user's location information in the virtual space and the user's voice signal to the spatial voice VR server, and receiving a mixed signal in which the voice signals of each user located in the virtual space are synthesized from the voice VR server; and
A location in the virtual space where the mixing signal is to be output, and a virtual location determined based on location information in the virtual space of a user having a voice level that satisfies a preset condition among the volume information of each user's voice signal. causing the mixed signal to be reproduced at the output location;
How to provide spatial voice VR.
상기 방법은,
상기 각 사용자의 음성 신호의 음량 정보 및 상기 각 사용자의 위치 정보에 기초하여 상기 가상 출력 위치를 결정하는 단계를 더 포함하는
공간 음성 VR 제공 방법.15. The method of claim 14,
The method is
The method further comprising the step of determining the virtual output location based on the volume information of each user's voice signal and the location information of each user
How to provide spatial voice VR.
상기 가상 출력 위치를 결정하는 단계는,
상기 가상 공간 내에 위치하는 다른 사용자의 음성 신호의 음량 정보를 상기 다른 사용자의 공간 음성 VR 장치로부터 수신하고, 상기 각 사용자의 위치 정보를 상기 음성 VR 서버로부터 더 수신하는 단계를 포함하는
공간 음성 VR 제공 방법.17. The method of claim 16,
Determining the virtual output location comprises:
Receiving the volume information of the voice signal of another user located in the virtual space from the spatial voice VR device of the other user, and further receiving the location information of each user from the voice VR server
How to provide spatial voice VR.
상기 가상 출력 위치를 결정하는 단계는,
상기 각 사용자 중 상기 음성 신호의 음량 정보가 가장 큰 사용자의 위치를 상기 가상 출력 위치로 결정하는 단계를 포함하는
공간 음성 VR 제공 방법.17. The method of claim 16,
Determining the virtual output location comprises:
and determining, as the virtual output location, a location of a user having the greatest volume information of the voice signal among the users.
How to provide spatial voice VR.
상기 가상 출력 위치를 결정하는 단계는,
상기 각 사용자의 음성 신호의 음량 정보가 가장 큰 값과 두번째로 큰 값과의 차이가 소정의 값 이하인 경우, 상기 각 사용자 중 상기 음성 신호의 음량 정보가 가장 큰 사용자의 위치와 상기 음성 신호의 음량 정보가 두번째로 큰 사용자의 위치의 중간 위치를 상기 가상 출력 위치로 결정하는 단계를 포함하는
공간 음성 VR 제공 방법.17. The method of claim 16,
Determining the virtual output location comprises:
When the difference between the largest value and the second largest value of the volume information of each user's voice signal is less than or equal to a predetermined value, the location of the user having the largest volume information of the voice signal among the users and the volume of the voice signal determining, as the virtual output location, an intermediate location of a location of a user having the second largest information
How to provide spatial voice VR.
상기 가상 출력 위치를 결정하는 단계는,
상기 각 사용자의 음성 신호의 음량 정보가 가장 큰 값과 두번째로 큰 값과의 차이가 소정의 값 이하인 경우, 상기 음성 신호의 음량 정보가 가장 큰 사용자와 상기 음성 신호의 음량 정보가 두번째로 큰 사용자 중 사용자 자신과 더 가까운 사용자의 위치를 상기 가상 출력 위치로 결정하는 단계를 포함하는
공간 음성 VR 제공 방법.17. The method of claim 16,
Determining the virtual output location comprises:
When the difference between the largest value and the second largest value of the volume information of each user's voice signal is less than a predetermined value, the user having the largest volume information of the voice signal and the user having the second largest volume information of the voice signal and determining a location of a user closer to the user himself as the virtual output location.
How to provide spatial voice VR.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020170143266AKR102331229B1 (en) | 2017-10-31 | 2017-10-31 | Spatial voice virtual reality server and apparatus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020170143266AKR102331229B1 (en) | 2017-10-31 | 2017-10-31 | Spatial voice virtual reality server and apparatus |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20190048359A KR20190048359A (en) | 2019-05-09 |
| KR102331229B1true KR102331229B1 (en) | 2021-11-25 |
Family
ID=66545958
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020170143266AActiveKR102331229B1 (en) | 2017-10-31 | 2017-10-31 | Spatial voice virtual reality server and apparatus |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR102331229B1 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12015658B1 (en) | 2023-03-15 | 2024-06-18 | Clicked, Inc | Apparatus and method for transmitting spatial audio using multicast |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006180251A (en)* | 2004-12-22 | 2006-07-06 | Yamaha Corp | Voice signal processor for enabling callers to perform simultaneous utterance, and program |
| JP2006254167A (en)* | 2005-03-11 | 2006-09-21 | Hitachi Ltd | Audio conference system, conference terminal and audio server |
| JP2017028343A (en)* | 2015-07-15 | 2017-02-02 | サクサ株式会社 | Conference system and terminal |
- 2017
- 2017-10-31KRKR1020170143266Apatent/KR102331229B1/enactiveActive
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2006180251A (en)* | 2004-12-22 | 2006-07-06 | Yamaha Corp | Voice signal processor for enabling callers to perform simultaneous utterance, and program |
| JP2006254167A (en)* | 2005-03-11 | 2006-09-21 | Hitachi Ltd | Audio conference system, conference terminal and audio server |
| JP2017028343A (en)* | 2015-07-15 | 2017-02-02 | サクサ株式会社 | Conference system and terminal |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12015658B1 (en) | 2023-03-15 | 2024-06-18 | Clicked, Inc | Apparatus and method for transmitting spatial audio using multicast |
| KR20240139670A (en) | 2023-03-15 | 2024-09-24 | 클릭트 주식회사 | Apparatus and method for transmitting spatial audio using multicast |
Also Published As
| Publication number | Publication date |
|---|---|
| KR20190048359A (en) | 2019-05-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10979842B2 (en) | Methods and systems for providing a composite audio stream for an extended reality world | |
| CN112602053B (en) | Audio devices and methods of audio processing | |
| US11109177B2 (en) | Methods and systems for simulating acoustics of an extended reality world | |
| US20190313199A1 (en) | Controlling Audio In Multi-Viewpoint Omnidirectional Content | |
| CN117041607A (en) | Method and apparatus for audio rendering | |
| US11223920B2 (en) | Methods and systems for extended reality audio processing for near-field and far-field audio reproduction | |
| CN105594227A (en) | Matrix decoder with constant-power pairwise panning | |
| JP2024166232A (en) | Signal processing device, method, and program | |
| CN108269460B (en) | Electronic screen reading method and system and terminal equipment | |
| JP2019208185A (en) | Information processing unit and sound generation method | |
| KR102331229B1 (en) | Spatial voice virtual reality server and apparatus | |
| US10419870B1 (en) | Applying audio technologies for the interactive gaming environment | |
| CN108574925A (en) | Method and device for controlling audio signal output in virtual auditory environment | |
| CN112770228A (en) | Audio playing method and device, audio playing equipment, electronic equipment and medium | |
| US20240406669A1 (en) | Metadata for Spatial Audio Rendering | |
| RU2798414C2 (en) | Audio device and audio processing method | |
| US20220270626A1 (en) | Method and apparatus in audio processing | |
| RU2823573C1 (en) | Audio device and audio processing method | |
| RU2815621C1 (en) | Audio device and audio processing method | |
| RU2815366C2 (en) | Audio device and audio processing method | |
| CN117492686A (en) | Data processing method and related device | |
| WO2025036422A1 (en) | Audio processing method and electronic device | |
| WO2025011361A1 (en) | Decoding method and electronic device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application | Patent event code:PA01091R01D Comment text:Patent Application Patent event date:20171031 | |
| PG1501 | Laying open of application | ||
| A201 | Request for examination | ||
| PA0201 | Request for examination | Patent event code:PA02012R01D Patent event date:20200312 Comment text:Request for Examination of Application Patent event code:PA02011R01I Patent event date:20171031 Comment text:Patent Application | |
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection | Comment text:Notification of reason for refusal Patent event date:20210225 Patent event code:PE09021S01D | |
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration | Patent event code:PE07011S01D Comment text:Decision to Grant Registration Patent event date:20210830 | |
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment | Comment text:Registration of Establishment Patent event date:20211122 Patent event code:PR07011E01D | |
| PR1002 | Payment of registration fee | Payment date:20211123 End annual number:3 Start annual number:1 | |
| PG1601 | Publication of registration | ||
| PR1001 | Payment of annual fee | Payment date:20240919 Start annual number:4 End annual number:4 |