KR102176375B1 - System for detecting music from broadcast contents using deep learning - Google Patents
System for detecting music from broadcast contents using deep learningDownload PDFInfo
- Publication number
- KR102176375B1 KR102176375B1KR1020190044882AKR20190044882AKR102176375B1KR 102176375 B1KR102176375 B1KR 102176375B1KR 1020190044882 AKR1020190044882 AKR 1020190044882AKR 20190044882 AKR20190044882 AKR 20190044882AKR 102176375 B1KR102176375 B1KR 102176375B1
- Authority
- KR
- South Korea
- Prior art keywords
- deep learning
- music
- music section
- data
- learning model
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images

Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/20—Servers specifically adapted for the distribution of content, e.g. VOD servers; Operations thereof
- H04N21/23—Processing of content or additional data; Elementary server operations; Server middleware
- H04N21/233—Processing of audio elementary streams
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Computing Systems (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Life Sciences & Earth Sciences (AREA)
- Molecular Biology (AREA)
- Artificial Intelligence (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
Translated fromKorean본 발명은 방송 콘텐츠에서 음악 구간을 검출하는 기술에 관한 것으로서, 더욱 상세하게는 딥러닝을 이용하여 방송 콘텐츠에서 음악 구간을 검출하는 기술에 관한 것이다.The present invention relates to a technology for detecting a music section in broadcast content, and more particularly, to a technology for detecting a music section in broadcast content using deep learning.
TV 혹은 라디오 방송 콘텐츠, 영화 등에는 많은 음원들이 배경 음악(Background Music, BGM)으로 사용된다. 영화, 드라마, 시사교양 프로그램과 같은 방송 콘텐츠 제작 시에 음원의 저작권자와 미리 계약을 체결한 뒤 해당 음원들을 배경 음악으로 사용하게 되며, 방송 사업자는 해당 방송물의 어느 시점에서 어떠한 음원이 사용되었는지에 대해서 큐시트(cue sheet)를 작성하여 저작권자 혹은 저작권 사업자에게 제공해야 한다.Many sound sources are used as background music (BGM) in TV or radio broadcast content, movies, and the like. When producing broadcast content such as movies, dramas, and current affairs programs, after signing a contract with the copyright holder of the sound source in advance, the sound sources are used as background music, and the broadcaster can determine which sound source was used at what point in the broadcast. A cue sheet must be prepared and provided to the copyright holder or copyright provider.
그러나, 방송 콘텐츠의 제작을 위한 시간이 늘 부족하고, 방송 기술의 인프라가 부족한 국내외 현실에서는 수백만 곡에 해당하는 음원 데이터베이스에 대해서 콘텐츠의 어떤 부분에 어느 정도의 길이로 삽입되었는지 제대로 관리하기가 어려워 방송 사업자가 제공하는 큐시트 리스트에는 다수의 음원이 누락되거나, 잘못된 음원이 목록에 포함되거나 배경음의 삽입 시점에 오류가 포함된 경우가 빈번하였다.However, in the domestic and foreign reality where the time for production of broadcasting contents is always insufficient and infrastructure of broadcasting technology is insufficient, it is difficult to properly manage the sound source database of millions of songs in which part of the contents and how long it is inserted. In the cue sheet list provided by the operator, a number of sound sources were omitted, incorrect sound sources were included in the list, or errors were included at the time of insertion of the background sound.
비교적 최근까지도 저작권자 또는 저작권 사업자는 방송 사업자가 제출한 큐시트에 대해 숙련된 음원 모니터링 요원이 해당 방송물의 음악 삽입 시점에서 청음에 의해 큐시트에 표시된 음원을 확인하는 수작업 방식의 검토 작업이 이루어져 왔다. 그러나, 수백 만 곡 이상의 방대한 음원에 대해 콘텐츠에 삽입된 모든 음원을 사람이 일일이 청음으로 검증하는 것은 어려운 일이며, 시간과 비용을 많이 필요로 하는 비효율적인 작업이다.Until relatively recently, the copyright holder or copyright operator has been reviewing the cue sheet submitted by the broadcaster in a manual method in which an experienced sound source monitoring agent checks the sound source displayed on the cue sheet by listening at the time of insertion of the music in the broadcast. However, it is difficult for a person to individually verify all the sound sources inserted in the content for a vast number of sound sources of millions of songs, and it is an inefficient operation that requires a lot of time and cost.
본 발명은 상기와 같은 문제점을 해결하기 위하여 안출된 것으로서, 음악 구간 탐지에 필요한 시간과 비용을 줄이기 위해, 딥러닝 기술을 이용하여 방송 콘텐츠에서 음악 구간을 검출하는 시스템을 제공하는데 그 목적이 있다.The present invention has been devised to solve the above problems, and an object of the present invention is to provide a system for detecting a music section in broadcast content using a deep learning technology in order to reduce the time and cost required for detecting a music section.
본 발명의 목적은 이상에서 언급한 목적으로 제한되지 않으며, 언급되지 않은 또 다른 목적들은 아래의 기재로부터 통상의 기술자에게 명확하게 이해될 수 있을 것이다.The object of the present invention is not limited to the above-mentioned object, and other objects not mentioned will be clearly understood by those skilled in the art from the following description.
이와 같은 목적을 달성하기 위한 본 발명의 음악 검출 시스템은 방송 콘텐츠에서 음악 구간을 검출하기 위해, 음악 데이터, 잡음 데이터, 음성 데이터를 혼합하여 딥러닝 모델을 학습하도록 하기 위한 학습 모듈 및 상기 학습 모듈에서 생성된 딥러닝 모델을 이용하여 방송 데이터에서 음악 구간을 검출하는 검출 모듈을 포함한다.In order to achieve this object, the music detection system of the present invention includes a learning module for learning a deep learning model by mixing music data, noise data, and voice data to detect a music section in broadcast content, and the learning module. And a detection module that detects a music section from broadcast data by using the generated deep learning model.
상기 학습 모듈은, 음악 데이터, 잡음 데이터, 음성 데이터를 혼합하고, 데이터들을 혼합하기 전 신호가 존재하는 구간을 탐지하여 레이블을 생성하기 위한 혼합 및 레이블 생성부, 상기 혼합 및 레이블 생성부에서 혼합된 데이터를 푸리에 변환하고, 이를 통해 절대값과 로그를 취하여 로그-스케일 스펙트로그램을 추출하기 위한 제1 음향 특징 추출부 및 상기 제1 음향 특징 추출부에서 추출된 로그-스케일 스펙트로그램과 상기 레이블을 이용하여, 방송 데이터에서 음악 구간을 검출하기 위한 딥러닝 모델 학습을 수행하기 위한 딥러닝 모델 학습부를 포함하여 이루어질 수 있다.The learning module includes a mixing and label generation unit for generating a label by mixing music data, noise data, and voice data, and detecting a section in which a signal exists before mixing the data, and the mixing and label generation unit. Using a first acoustic feature extracting unit for extracting a log-scale spectrogram by Fourier transforming the data and taking the absolute value and log through this, and the log-scale spectrogram extracted from the first acoustic feature extracting unit and the label Thus, a deep learning model learning unit for performing deep learning model training for detecting a music section from broadcast data may be included.
상기 검출 모듈은, 입력되는 방송 데이터를 푸리에 변환한 후, 절대값과 로그를 취하여 로그-스케일 스펙트로그램을 추출하기 위한 제2 음향 특징 추출부, 상기 제2 음향 특징 추출부에서 추출된 로그-스케일 스펙트로그램과 상기 딥러닝 모델을 이용하여 프레임 단위의 음악 구간 검출 결과를 출력하기 위한 음악 구간 검출부 및 상기 음악 구간 검출부에서 출력한 프레임 단위의 음악 구간 검출 결과에 존재하는 세그먼트들을 병합하거나 또는 제거하여 스무딩(smoothing)하기 위한 사후 처리부를 포함하여 이루어질 수 있다.The detection module includes a second acoustic feature extracting unit for extracting a log-scale spectrogram by taking an absolute value and a log after Fourier transforming the input broadcast data, and the log-scale extracted from the second acoustic feature extracting unit. Using the spectrogram and the deep learning model, a music section detector for outputting a frame-by-frame music section detection result, and the segments present in the frame-by-frame music section detection result output from the music section detector are merged or removed for smoothing. It may include a post-processing unit for smoothing.
상기 음악 구간 검출부는 상기 딥러닝 모델의 피드포워드 알고리즘을 통해 프레임 단위의 음악 구간을 검출할 수 있다.The music section detection unit may detect a music section in units of frames through a feed forward algorithm of the deep learning model.
상기 딥러닝 모델 학습부는 CNN(Convolutional Neural Network) 방식의 딥러닝 모델 학습을 수행할 수 있다. The deep learning model training unit may perform deep learning model training using a convolutional neural network (CNN) method.
상기 딥러닝 모델 학습부의 딥러닝 구조는 멜스케일 커널로 구성된 컨볼루션 레이어인 멜스케일 레이어, 컨볼루션 레이어 및 풀리 커넥티드 레이어를 포함하여 이루어질 수 있다.The deep learning structure of the deep learning model learning unit may include a melscale layer, a convolutional layer, and a fully connected layer, which are convolutional layers composed of melscale kernels.
상기 멜스케일 레이어의 커널은 주파수의 크기 영역에 따라 크기가 다르게 형성될 수 있으며, 고주파 영역일수록 크게 형성될 수 있다.The kernel of the melscale layer may be formed differently in size according to a frequency region, and may be formed larger in a high frequency region.
본 발명에 의하면 방송 데이터의 음악 구간을 자동으로 검출하여 시간과 비용이 크게 절감할 수 있다는 효과가 있다.According to the present invention, there is an effect that time and cost can be greatly reduced by automatically detecting a music section of broadcast data.
그리고, 본 발명에 의하면, 딥러닝 프레임 워크를 이용하여 음악 구간 검출 시스템을 구현할 수 있으며, 멜스케일 레이어를 이용하여 정확도가 개선된 딥러닝 기반 음악검출기를 구현할 수 있다는 효과가 있다.Further, according to the present invention, there is an effect that a music section detection system can be implemented using a deep learning framework, and a deep learning-based music detector with improved accuracy can be implemented using a melscale layer.
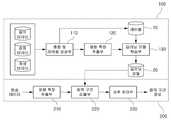
도 1은 본 발명의 일 실시예에 따른 방송 콘텐츠에서 음악 구간 검출 시스템의 전체 구조도이다.
도 2는 본 발명의 일 실시예에 따른 딥러닝 구조를 도시한 도면이다.
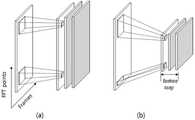
도 3은 종래 컨볼루션 레이어와 본 발명의 일 실시예에 따른 멜스케일 레이러를 도시한 도면이다.1 is an overall structural diagram of a music section detection system in broadcast content according to an embodiment of the present invention.
2 is a diagram showing a deep learning structure according to an embodiment of the present invention.
3 is a view showing a conventional convolutional layer and a melscale radar according to an embodiment of the present invention.
본 발명은 다양한 변경을 가할 수 있고 여러 가지 실시예를 가질 수 있는 바, 특정 실시예들을 도면에 예시하고 상세하게 설명하고자 한다. 그러나, 이는 본 발명을 특정한 실시 형태에 대해 한정하려는 것이 아니며, 본 발명의 사상 및 기술 범위에 포함되는 모든 변경, 균등물 내지 대체물을 포함하는 것으로 이해되어야 한다.In the present invention, various modifications may be made and various embodiments may be provided, and specific embodiments will be illustrated in the drawings and described in detail. However, this is not intended to limit the present invention to a specific embodiment, it is to be understood to include all changes, equivalents, and substitutes included in the spirit and scope of the present invention.
본 출원에서 사용한 용어는 단지 특정한 실시예를 설명하기 위해 사용된 것으로, 본 발명을 한정하려는 의도가 아니다. 단수의 표현은 문맥상 명백하게 다르게 뜻하지 않는 한, 복수의 표현을 포함한다. 본 출원에서, "포함하다" 또는 "가지다" 등의 용어는 명세서 상에 기재된 특징, 숫자, 단계, 동작, 구성요소, 부품 또는 이들을 조합한 것이 존재함을 지정하려는 것이지, 하나 또는 그 이상의 다른 특징들이나 숫자, 단계, 동작, 구성요소, 부품 또는 이들을 조합한 것들의 존재 또는 부가 가능성을 미리 배제하지 않는 것으로 이해되어야 한다.The terms used in the present application are only used to describe specific embodiments, and are not intended to limit the present invention. Singular expressions include plural expressions unless the context clearly indicates otherwise. In the present application, terms such as "comprise" or "have" are intended to designate the presence of features, numbers, steps, actions, components, parts, or combinations thereof described in the specification, but one or more other features. It is to be understood that the presence or addition of elements or numbers, steps, actions, components, parts, or combinations thereof, does not preclude in advance.
다르게 정의되지 않는 한, 기술적이거나 과학적인 용어를 포함해서 여기서 사용되는 모든 용어들은 본 발명이 속하는 기술 분야에서 통상의 지식을 가진 자에 의해 일반적으로 이해되는 것과 동일한 의미를 갖고 있다. 일반적으로 사용되는 사전에 정의되어 있는 것과 같은 용어들은 관련 기술의 문맥 상 갖는 의미와 일치하는 의미를 갖는 것으로 해석되어야 하며, 본 출원에서 명백하게 정의하지 않는 한, 이상적이거나 과도하게 형식적인 의미로 해석되지 않는다.Unless otherwise defined, all terms used herein, including technical or scientific terms, have the same meaning as commonly understood by one of ordinary skill in the art to which the present invention belongs. Terms as defined in a commonly used dictionary should be interpreted as having a meaning consistent with the meaning in the context of the related technology, and should not be interpreted as an ideal or excessively formal meaning unless explicitly defined in this application. Does not.
또한, 첨부 도면을 참조하여 설명함에 있어, 도면 부호에 관계없이 동일한 구성 요소는 동일한 참조 부호를 부여하고 이에 대한 중복되는 설명은 생략하기로 한다. 본 발명을 설명함에 있어서 관련된 공지 기술에 대한 구체적인 설명이 본 발명의 요지를 불필요하게 흐릴 수 있다고 판단되는 경우 그 상세한 설명을 생략한다.In addition, in the description with reference to the accompanying drawings, the same reference numerals are assigned to the same components regardless of the reference numerals, and redundant descriptions thereof will be omitted. In describing the present invention, when it is determined that a detailed description of related known technologies may unnecessarily obscure the subject matter of the present invention, a detailed description thereof will be omitted.
기존에는 음향 정보와 딥러닝 기술을 이용하고, 로그-스펙트로그램 또는 멜스케일-스펙트로그램 등과 같은 특징을 추출하여 입력으로 사용하고, CNN, RNN, DNN 등을 이용한 딥러닝 구조를 구성하여 사용하였다. 여기서 로그-스펙트로그램과 멜스케일-스펙트로그램은 각각 장단점이 존재하기 때문에 해결하려는 문제 또는 임무에 따라 그 성능 차이가 존재한다. 따라서, 본 발명에서는 로그-스펙트로그램과 멜스케일의 장점을 결합할 수 있는 멜스케일 커널의 컨볼루션 레이어를 제안한다.Previously, acoustic information and deep learning technology were used, features such as log-spectrogram or melscale-spectrogram were extracted and used as inputs, and deep learning structures using CNN, RNN, and DNN were constructed and used. Here, the log-spectrogram and melscale-spectrogram each have their strengths and weaknesses, so there is a difference in performance depending on the problem or task to be solved. Accordingly, the present invention proposes a convolution layer of a melscale kernel capable of combining the advantages of a log-spectrogram and melscale.
도 1은 본 발명의 일 실시예에 따른 방송 콘텐츠에서 음악 구간 검출 시스템의 전체 구조도이다.1 is an overall structural diagram of a music section detection system in broadcast content according to an embodiment of the present invention.
도 1을 참조하면, 본 발명의 음악 구간 검출 시스템은 크게 딥러닝 모델을 학습하는 학습 모듈(100)과 방송 데이터에서 음악 구간을 검출하는 검출 모듈(200)로 나뉜다.Referring to FIG. 1, the music section detection system of the present invention is largely divided into a
학습 모듈(100)은 혼합 및 레이블 생성부(110), 제1 음향 특징 추출부(120), 딥러닝 모델 학습부(130)를 포함한다.The
검출 모듈(200)은 제2 음향 특징 추출부(210), 음악 구간 검출부(220), 사후 처리부(230)를 포함한다.The
본 발명에서 제1 음향 특징 추출부(120)와 제2 음향 특징 추출부(210)는 동일한 구성요소로 구현될 수 있다.In the present invention, the first
혼합 및 레이블 생성부(110)는 딥러닝 모델을 학습하기 위하여 음악, 잡음, 음성 데이터를 혼합하고, 레이블(10)을 생성한다.The mixing and
본 발명에서 음악, 잡음, 음성 데이터를 실제 방송 데이터와 비슷하게 혼합하기 위하여 다양한 상대적 신호대비 값으로 혼합하였고, 그 결과 혼합 식은 다음 수학식 1과 같다.In the present invention, music, noise, and voice data are mixed with various relative signal contrast values in order to be similarly mixed with actual broadcast data. As a result, the mixing equation is shown in Equation 1 below.

여기서, s는 혼합할 신호이고, g는 스케일링 팩터(scaling factor)이고, E(s)는 신호 s의 에너지이고, k는 혼합하고자 하는 신호대비 값(dB)이다.Here, s is a signal to be mixed, g is a scaling factor, E(s) is the energy of signal s, and k is a signal contrast value (dB) to be mixed.
수학식 1에서 k가 0이면 신호 s1과 s2가 같은 에너지를 갖도록 s1의 신호를 증폭시켜 혼합하게 되며, k가 n 이면 s1 이 s2 보다 n dB 만큼 더 큰 에너지를 갖도록 혼합하게 된다.And mixed by amplifying a signal s1 is k is 0, the signal s1 and s2 have the same energy in Equation (1), if k is n s1 are mixed so as to have a larger energy as n dB than s2 do.
예를 들어, 수학식 1에서 음성(s1)과 잡음(s2)의 경우, k의 값이 0에서 30 사이의 값을 가지도록 혼합할 수 있으며, 음악(s1)과 잡음(s2)의 경우, k의 값이 0에서 30사이의 값을 가지도록 혼합할 수 있다. 이는 방송 데이터에서 대부분의 잡음이 음성과 음악보다 낮은 에너지로 나타나는 것을 반영한 것이다. 하지만 음악(s1)과 음성(s2)을 혼합하는 경우에는 k의 값이 -30 에서 0 의 값을 가지도록 혼합하며, 이는 방송 데이터에서 음성의 에너지가 음악보다 높게 나타남을 반영한 수치이다.For example, in the case of speech (s1 ) and noise (s2 ) in Equation 1, the values of k can be mixed to have a value between 0 and 30, and music (s1 ) and noise (s2) ), k can be mixed to have a value between 0 and 30. This reflects that most of the noise in broadcast data appears with lower energy than voice and music. However, in the case of mixing music (s1 ) and voice (s2 ), the values of k are mixed to have a value of -30 to 0, which reflects that the energy of the voice is higher than that of the music in broadcast data.
혼합 및 레이블 생성부(110)는 각각의 데이터를 혼합하기 전 신호가 존재하는 구간을 탐지하여 레이블(10)을 생성한다. 혼합하기 전 음악 데이터는 다른 신호가 혼합되어 있지 않은 순수한 신호이기 때문에 에너지의 분포만으로도 음악이 존재하는 구간을 탐지할 수 있으며, 혼합하기 전 탐지한 음악 구간은 혼합 후에도 음악 구간으로 레이블(10)을 생성한다. 즉, 혼합하기 전 음악이 존재하던 구간이 혼합 데이터의 음악 구간으로 표시된다.The mixing and
제1 음향 특징 추출부(120)는 혼합된 신호를 푸리에 변환한 후, 절대 값과 로그를 취하여 로그-스케일 스펙트로그램을 추출한다. 스펙트로그램의 차원은 푸리에 변환 포인터 개수와 시간 영역으로의 프레임 개수로 구성된다.The first
딥러닝 모델 학습부(130)는 혼합 신호의 스펙트로그램과 혼합 시 표시한 음악 구간에 대한 레이블(10)을 이용하여 음악 구간 검출을 위한 딥러닝(deep learning)모델을 학습한다.The deep learning
본 발명에서 딥러닝(deep learning) 기술은 CNN(Convolutional Neural Network)을 사용할 수 있다.In the present invention, the deep learning technology may use a convolutional neural network (CNN).
도 2는 본 발명의 일 실시예에 따른 딥러닝 구조를 도시한 도면이다.2 is a diagram showing a deep learning structure according to an embodiment of the present invention.
도 2를 참조하면, 딥러닝 모델 학습부(130)의 딥러닝 구조는 멜스케일 커널(Mel-scale kernel)로 구성된 컨볼루션 레이어(Convolutional layer)인 멜스케일 레이어(Mel-sclae layer), 컨볼루션 레이어(Convolutional layer), 풀리 커넥티드(fully-connected) 레이어를 이용하여 구성된다.Referring to FIG. 2, the deep learning structure of the deep learning
여기서, 본 발명에서 멜스케일 레이어는 커널의 크기가 고정이라는 기존의 컨볼루션 레이어의 단점을 보완하기 위하여, 주파수의 영역에 따라 커널의 크기를 변화시켜 적용하는 레이어를 말하며, 다음 수학식 2와 같이 나타낼 수 있다.Here, in the present invention, the melscale layer refers to a layer applied by varying the size of the kernel according to the frequency domain in order to compensate for the disadvantage of the existing convolutional layer that the size of the kernel is fixed, as shown in Equation 2 below. Can be indicated.

여기서 x는 입력이고, k는 컨볼루션 레이어의 커널의 가중치이고, b는 컨볼루션 레이어의 커널의 바이어스이고, F는 하이퍼블릭 탄젠트 또는 시그모이드 등의 비활성화 함수이다. 그리고, y 는 멜스케일 레이어의 출력이자 다음 히든 레이어의 입력이고, f는 인덱스이다.Here, x is an input, k is the weight of the kernel of the convolutional layer, b is the bias of the kernel of the convolutional layer, and F is a deactivation function such as hyperblic tangent or sigmoid. And, y is the output of the melscale layer and the input of the next hidden layer, and f is the index.
수학식 2에서 f를 제외하면, 기존의 컨볼루션 레이어의 커널 식이 되며, 이는 i 번째 입력에 컨볼루션 레이어의 커널을 취하여 j 번째 출력을 나타낸 것과 같다. 본 발명에서는 멜스케일 레이어가 추가됨에 따라, 수학식 2에서 기존의 컨볼루션 레이어에서 f라는 인덱스가 추가되며, 이는 주파수 영역에 따라 커널의 종류와 크기가 다름을 의미한다. 즉, 고주파 영역에서의 커널의 크기는 저주파 영역에서의 커널의 크기보다 크게 설정되어 적용된다.Excluding f in Equation 2, it becomes the kernel expression of the existing convolution layer, which is the same as representing the j-th output by taking the kernel of the convolution layer as the i-th input. In the present invention, as the melscale layer is added, the index f is added in the existing convolution layer in Equation 2, which means that the type and size of the kernel are different according to the frequency domain. That is, the size of the kernel in the high frequency region is set and applied larger than the size of the kernel in the low frequency region.
도 2의 실시예에서, 본 발명의 딥러닝 구조는 하나의 멜스케일 레이어와, 세 개의 연속적으로 위치하는 컨볼루션 레이어와, 두 개의 풀리 커넥티드 레이어로 되어 있다.In the embodiment of FIG. 2, the deep learning structure of the present invention includes one melscale layer, three consecutively positioned convolution layers, and two fully connected layers.
세 개의 컨볼루션 레이어는 각각 순차적으로 32개, 64개, 128개의 필터를 갖는다.Each of the three convolutional layers has 32, 64, and 128 filters in sequence.
그리고, 2048 크기의 풀리 커넥티드 레이어와, 1028 크기의 풀리 커넥트디 레이어가 순차적으로 위치하는 구조이다.In addition, it is a structure in which a 2048-size fully connected layer and a 1028-size pulley-connected layer are sequentially located.
도 3은 종래 컨볼루션 레이어와 본 발명의 일 실시예에 따른 멜스케일 레이러를 도시한 도면이다.3 is a view showing a conventional convolutional layer and a melscale radar according to an embodiment of the present invention.
도 3을 참조하면, 기존의 컨볼루션 레이어의 커널 (a) 과 제안한 멜스케일 커널 (b)의 차이를 확인할 수 있다.Referring to FIG. 3, the difference between the conventional convolutional layer kernel (a) and the proposed melscale kernel (b) can be confirmed.
도 3에서 기존의 컨볼루션 레이어의 커널은 주파수 영역에 상관 없이 모두 같은 크기이지만, 멜스케일 레이어의 커널은 주파수의 영역에 따라 그 크기가 다르게 적용되는 것을 볼 수 있다. 즉, 도 3 (b)에서 저주파에서는 상대적으로 멜스케일 레이어의 커널의 크기가 작고, 고주파에서는 상대적으로 멜스케일 레이어의 커널의 크기가 큰 것을 확인할 수 있다.In FIG. 3, it can be seen that the kernels of the conventional convolution layer are all the same size regardless of the frequency domain, but the kernels of the melscale layer are applied differently according to the frequency domain. That is, in FIG. 3B, it can be seen that the size of the kernel of the melscale layer is relatively small at low frequencies, and the size of the kernel of the melscale layer is relatively large at high frequencies.
도 3의 실시예에서, 멜스케일 레이어가 위치한 좌표의 가로축은 프레임의 크기를 나타내며, 세로축은 주파수 영역의 크기를 나타낸다.In the embodiment of FIG. 3, the horizontal axis of the coordinates where the melscale layer is located represents the size of the frame, and the vertical axis represents the size of the frequency domain.
이렇게 구성된 멜스케일 레이어의 커널의 가중치와 바이어스는 딥러닝의 역전파(backpropagation) 알고리즘을 통하여 학습되어 음악 구간 검출의 성능을 개선시키는 역할을 한다.The weight and bias of the kernel of the melscale layer configured in this way are learned through a backpropagation algorithm of deep learning to improve the performance of music section detection.
딥러닝 모델 학습부(130)는 최종적으로 학습된 딥러닝 모델(20)을 출력하게 되며, 이 딥러닝 모델(20)은 음악 구간 검출을 위하여 검출 모듈(200)에서 사용된다.The deep learning
제2 음향 특징 추출부(210)는 입력되는 방송 데이터를 푸리에 변환한 후, 절대 값과 로그를 취하여 로그-스케일 스펙트로그램을 추출한다The second
음악 구간 검출부(220)는 로그-스케일 스펙트로그램과 학습 모듈(100)에서 학습한 딥러닝 모델(20)을 이용하여 딥러닝의 피드포워드(feedforward) 알고리즘을 통해 프레임 단위의 음악 구간 검출 결과를 출력한다.The music
사후 처리부(230)는 음악 구간 검출부(220)에서 출력한 프레임 단위의 음악 구간 검출 결과를 스무딩(smoothing)하는 역할을 한다. 프레임 단위의 음악 구간 검출 결과는 작은 세그먼트들이 존재하게 되며, 이는 방송 데이터의 음악의 특성과 맞지 않기 때문에 병합 또는 제거가 필요하다. 예를 들어, 방송 데이터의 음악은 최소 5초 이상 지속되기 때문에 사후 처리부(230)에서는 5초 길이의 메디안(median) 필터를 이용하여 작은 세그먼트들을 병합 또는 제거하여 최종적인 음악 구간 검출 결과를 출력하게 된다.The
이상 본 발명을 몇 가지 바람직한 실시예를 사용하여 설명하였으나, 이들 실시예는 예시적인 것이며 한정적인 것이 아니다. 본 발명이 속하는 기술분야에서 통상의 지식을 지닌 자라면 본 발명의 사상과 첨부된 특허청구범위에 제시된 권리범위에서 벗어나지 않으면서 다양한 변화와 수정을 가할 수 있음을 이해할 것이다.The present invention has been described above using several preferred embodiments, but these embodiments are illustrative and not limiting. Those of ordinary skill in the art to which the present invention pertains will understand that various changes and modifications can be made without departing from the spirit of the present invention and the scope of the rights presented in the appended claims.
100 학습 모듈200 검출 모듈
110 혼합 및 레이블 생성부120 제1 음향 특징 추출부
130 딥러닝 모델 학습부210 제2 음향 특징 추출부
220 음악 구간 검출부230 사후 처리부100
110 Mixing and
130 Deep learning
220 Music
Claims (8)
Translated fromKorean상기 학습 모듈에서 생성된 딥러닝 모델을 이용하여 방송 데이터에서 음악 구간을 검출하는 검출 모듈을 포함하며,
상기 학습 모듈은,
음악 데이터, 잡음 데이터, 음성 데이터를 혼합하고, 데이터들을 혼합하기 전 신호가 존재하는 구간을 탐지하여 레이블을 생성하기 위한 혼합 및 레이블 생성부;
상기 혼합 및 레이블 생성부에서 혼합된 데이터를 푸리에 변환하고, 이를 통해 절대값과 로그를 취하여 로그-스케일 스펙트로그램을 추출하기 위한 제1 음향 특징 추출부; 및
상기 제1 음향 특징 추출부에서 추출된 로그-스케일 스펙트로그램과 상기 레이블을 이용하여, 방송 데이터에서 음악 구간을 검출하기 위한 딥러닝 모델 학습을 수행하기 위한 딥러닝 모델 학습부를 포함하여 이루어지고,
상기 딥러닝 모델 학습부는 CNN(Convolutional Neural Network) 방식의 딥러닝 모델 학습을 수행하며,
상기 딥러닝 모델 학습부의 딥러닝 구조는 멜스케일 커널로 구성된 컨볼루션 레이어인 멜스케일 레이어, 컨볼루션 레이어 및 풀리 커넥티드 레이어를 포함하여 이루어지는 것을 특징으로 하는 음악 구간 검출 시스템.
A learning module for learning a deep learning model by mixing music data, noise data, and voice data to detect a music section in broadcast content; And
A detection module for detecting a music section in broadcast data using the deep learning model generated by the learning module,
The learning module,
A mixer and label generator configured to generate a label by mixing music data, noise data, and voice data, and detecting a section in which a signal exists before mixing the data;
A first acoustic feature extraction unit for Fourier transforming the data mixed by the mixing and label generation unit, and extracting a log-scale spectrogram by taking an absolute value and a log through this; And
And a deep learning model learning unit for performing a deep learning model training for detecting a music section in broadcast data using the log-scale spectrogram extracted by the first acoustic feature extraction unit and the label,
The deep learning model learning unit performs CNN (Convolutional Neural Network) type deep learning model training,
The deep learning structure of the deep learning model learning unit includes a melscale layer, a convolutional layer, and a fully connected layer, which are convolutional layers composed of melscale kernels.
상기 검출 모듈은,
입력되는 방송 데이터를 푸리에 변환한 후, 절대값과 로그를 취하여 로그-스케일 스펙트로그램을 추출하기 위한 제2 음향 특징 추출부;
상기 제2 음향 특징 추출부에서 추출된 로그-스케일 스펙트로그램과 상기 딥러닝 모델을 이용하여 프레임 단위의 음악 구간 검출 결과를 출력하기 위한 음악 구간 검출부; 및
상기 음악 구간 검출부에서 출력한 프레임 단위의 음악 구간 검출 결과에 존재하는 세그먼트들을 병합하거나 또는 제거하여 스무딩(smoothing)하기 위한 사후 처리부를 포함하여 이루어지는 것을 특징으로 하는 음악 구간 검출 시스템.
The method according to claim 1,
The detection module,
A second acoustic feature extracting unit configured to extract a log-scale spectrogram by Fourier transforming the input broadcast data and then taking an absolute value and a log;
A music section detector configured to output a frame-by-frame music section detection result using the log-scale spectrogram extracted by the second acoustic feature extractor and the deep learning model; And
And a post-processing unit for smoothing by merging or removing segments present in a result of detecting a music section for each frame output from the music section detection unit.
상기 음악 구간 검출부는 상기 딥러닝 모델의 피드포워드 알고리즘을 통해 프레임 단위의 음악 구간을 검출하는 것을 특징으로 하는 음악 구간 검출 시스템.
The method of claim 3,
And the music section detection unit detects a music section in units of frames through a feed forward algorithm of the deep learning model.
상기 멜스케일 레이어의 커널은 주파수 영역에 따라 크기가 다르게 형성되는 것을 특징으로 하는 음악 구간 검출 시스템.
The method according to claim 1,
The music section detection system, characterized in that the size of the kernel of the melscale layer is formed differently according to the frequency domain.
상기 멜스케일 레이어의 커널은 고주파 영역일수록 크게 형성되어 있는 것을 특징으로 하는 음악 구간 검출 시스템.
The method of claim 7,
The music section detection system, characterized in that the kernel of the melscale layer is formed larger in a high frequency region.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020190044882AKR102176375B1 (en) | 2019-04-17 | 2019-04-17 | System for detecting music from broadcast contents using deep learning |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020190044882AKR102176375B1 (en) | 2019-04-17 | 2019-04-17 | System for detecting music from broadcast contents using deep learning |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR102176375B1true KR102176375B1 (en) | 2020-11-09 |
Family
ID=73429375
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020190044882AActiveKR102176375B1 (en) | 2019-04-17 | 2019-04-17 | System for detecting music from broadcast contents using deep learning |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR102176375B1 (en) |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20060082465A (en)* | 2005-01-12 | 2006-07-18 | 삼성전자주식회사 | Method and device for distinguishing speech and non-voice using acoustic model |
| KR101858675B1 (en) | 2016-11-30 | 2018-05-24 | 주식회사 이룸에스엔에스 | A emergency bell system having auto warning broadcast function in a abnormal sound source detection |
- 2019
- 2019-04-17KRKR1020190044882Apatent/KR102176375B1/enactiveActive
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20060082465A (en)* | 2005-01-12 | 2006-07-18 | 삼성전자주식회사 | Method and device for distinguishing speech and non-voice using acoustic model |
| KR101858675B1 (en) | 2016-11-30 | 2018-05-24 | 주식회사 이룸에스엔에스 | A emergency bell system having auto warning broadcast function in a abnormal sound source detection |
Non-Patent Citations (1)
| Title |
|---|
| Melendez-Catalan, B., Molina, E., & Gomez, E. (2018). Music and/or speech detection MIREX 2018 submission. https://www.music-ir.org/mirex/abstracts/2018/MMG.pdf(2018.12.31.) 국외논문 사본 1부** |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Liu et al. | Separate anything you describe | |
| Cramer et al. | Look, listen, and learn more: Design choices for deep audio embeddings | |
| Pan et al. | Selective listening by synchronizing speech with lips | |
| CN104252861B (en) | Video speech conversion method, device and server | |
| CN114025216B (en) | Media material processing method, device, server and storage medium | |
| CN113923521B (en) | Video scripting method | |
| Wand et al. | Investigations on end-to-end audiovisual fusion | |
| Wang et al. | Multi-source domain adaptation for text-independent forensic speaker recognition | |
| CN114363531A (en) | H5-based case comment video generation method, device, equipment and medium | |
| CN114143479A (en) | Video abstract generation method, device, equipment and storage medium | |
| CN114842858A (en) | Audio processing method and device, electronic equipment and storage medium | |
| WO2025043996A1 (en) | Human-computer interaction method and apparatus, computer readable storage medium and terminal device | |
| WO2023218268A1 (en) | Generation of closed captions based on various visual and non-visual elements in content | |
| KR102176375B1 (en) | System for detecting music from broadcast contents using deep learning | |
| CN113035236B (en) | Quality inspection method and device for voice synthesis data | |
| CN111785236A (en) | Automatic composition method based on motivational extraction model and neural network | |
| US11523186B2 (en) | Automated audio mapping using an artificial neural network | |
| CN115914742B (en) | Character recognition method, device and equipment for video captions and storage medium | |
| CN117727312A (en) | A target noise separation method, system and terminal equipment | |
| CN104200812B (en) | A kind of audio-frequency noise real-time detection method based on Its Sparse Decomposition | |
| CN117457030A (en) | A speech emotion recognition method and application based on multi-source features | |
| CN114049887B (en) | Real-time voice activity detection method and system for audio and video conferencing | |
| Wang et al. | Contextual Paralinguistic Data Creation for Multi-Modal Speech-LLM: Data Condensation and Spoken QA Generation | |
| Liu et al. | Cross-modal Speech Separation Without Visual Information During Testing | |
| Busso et al. | The MSP-Podcast Corpus |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application | St.27 status event code:A-0-1-A10-A12-nap-PA0109 | |
| PA0201 | Request for examination | St.27 status event code:A-1-2-D10-D11-exm-PA0201 | |
| PE0902 | Notice of grounds for rejection | St.27 status event code:A-1-2-D10-D21-exm-PE0902 | |
| E13-X000 | Pre-grant limitation requested | St.27 status event code:A-2-3-E10-E13-lim-X000 | |
| P11-X000 | Amendment of application requested | St.27 status event code:A-2-2-P10-P11-nap-X000 | |
| P13-X000 | Application amended | St.27 status event code:A-2-2-P10-P13-nap-X000 | |
| PN2301 | Change of applicant | St.27 status event code:A-3-3-R10-R13-asn-PN2301 St.27 status event code:A-3-3-R10-R11-asn-PN2301 | |
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration | St.27 status event code:A-1-2-D10-D22-exm-PE0701 | |
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment | St.27 status event code:A-2-4-F10-F11-exm-PR0701 | |
| PR1002 | Payment of registration fee | St.27 status event code:A-2-2-U10-U11-oth-PR1002 Fee payment year number:1 | |
| P22-X000 | Classification modified | St.27 status event code:A-4-4-P10-P22-nap-X000 | |
| PG1601 | Publication of registration | St.27 status event code:A-4-4-Q10-Q13-nap-PG1601 | |
| R18-X000 | Changes to party contact information recorded | St.27 status event code:A-5-5-R10-R18-oth-X000 | |
| R18-X000 | Changes to party contact information recorded | St.27 status event code:A-5-5-R10-R18-oth-X000 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:4 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:5 | |
| P22-X000 | Classification modified | St.27 status event code:A-4-4-P10-P22-nap-X000 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:6 |