KR102160117B1 - a real-time broadcast content generating system for disabled - Google Patents
a real-time broadcast content generating system for disabledDownload PDFInfo
- Publication number
- KR102160117B1 KR102160117B1KR1020190047797AKR20190047797AKR102160117B1KR 102160117 B1KR102160117 B1KR 102160117B1KR 1020190047797 AKR1020190047797 AKR 1020190047797AKR 20190047797 AKR20190047797 AKR 20190047797AKR 102160117 B1KR102160117 B1KR 102160117B1
- Authority
- KR
- South Korea
- Prior art keywords
- shorthand
- screen commentary
- unit
- input
- sound source
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images





Classifications
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/43—Processing of content or additional data, e.g. demultiplexing additional data from a digital video stream; Elementary client operations, e.g. monitoring of home network or synchronising decoder's clock; Client middleware
- H04N21/4302—Content synchronisation processes, e.g. decoder synchronisation
- H04N21/4307—Synchronising the rendering of multiple content streams or additional data on devices, e.g. synchronisation of audio on a mobile phone with the video output on the TV screen
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/08—Text analysis or generation of parameters for speech synthesis out of text, e.g. grapheme to phoneme translation, prosody generation or stress or intonation determination
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/40—Client devices specifically adapted for the reception of or interaction with content, e.g. set-top-box [STB]; Operations thereof
- H04N21/47—End-user applications
- H04N21/488—Data services, e.g. news ticker
- H04N21/4884—Data services, e.g. news ticker for displaying subtitles
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/80—Generation or processing of content or additional data by content creator independently of the distribution process; Content per se
- H04N21/85—Assembly of content; Generation of multimedia applications
- H04N21/854—Content authoring
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Computer Security & Cryptography (AREA)
- Two-Way Televisions, Distribution Of Moving Picture Or The Like (AREA)
Abstract
Description
Translated fromKorean본 발명은 실시간 방송에서 시각 장애인 및 청각 장애인을 위한 방송 컨텐츠 제작 시스템에 관한 것이다. 특히, 본 발명은 방송 컨텐츠와 함께 제공되지 않아 별도로 생성해야만 하는 시각 장애인을 위한 화면해설용 음원과 방송 컨텐츠를 동기화하여 시청자에게 원활한 방송 시청이 가능하도록 하는 방송 컨텐츠 제작 시스템에 관한 것이다.The present invention relates to a broadcasting content production system for the visually impaired and the hearing impaired in real-time broadcasting. In particular, the present invention relates to a broadcast content production system that enables a smooth broadcast viewing by a viewer by synchronizing a screen commentary sound source for the visually impaired and broadcast content, which is not provided with broadcast content and must be generated separately.
화면해설방송이란 소리에만 의존하여 TV를 시청하는 시각장애인에게 영상에 대한 이해와 흥미를 높이기 위해 장면의 전황, 등장인물의 표정이나 몸짓, 대사없이 처리되는 영상 등을 해설하는 서비스를 말한다.Screen commentary broadcasting refers to a service that explains the scenes, facial expressions and gestures of characters, and images processed without dialogue in order to increase the understanding and interest in the video for the visually impaired who only rely on sound to watch TV.
화면해설을 위한 음원이 방송 컨텐츠를 방송국에서 송출할 때 같이 송출되는 것이 바람직하겠으나, 화면해설이 필요한 시청자가 제한적이라는 점에서 모든 방송 컨텐츠에 화면해설을 위한 음원이 제작되지 않는 것이 실정이다. 따라서, 시각장애인을 위한 화면해설방송은 속기사의 화면 해설 입력에 의해 실시간으로 원고가 만들어지고 이를 음원으로 변경하여 화면해설방송을 만들어 송출할 수도 있다.It would be desirable that the sound source for screen commentary is transmitted at the same time when broadcasting content is transmitted from the broadcasting station. Therefore, in the screen commentary broadcast for the visually impaired, a manuscript is created in real time by the screen commentary input by a short story, and the screen commentary broadcast may be created and transmitted by changing it to a sound source.
그러나, 속기사가 방송 컨텐츠를 보고 화면해설을 위한 원고를 타이핑하는 시간이 필요하여 결과적으로 최종 출력단에서 본 컨텐츠(오디오를 포함하는 컨텐츠)와 화면해설을 위한 음원간에 동기화가 맞지 않는 문제가 발생하고 있다.However, the shorthand story needs time to view the broadcast content and type the manuscript for screen commentary, and as a result, there is a problem that the synchronization between the content (content including audio) and the sound source for screen commentary viewed at the final output end occurs. .
따라서, 이하에서는 사전에 방송해설용 음원이 제작되지 않은 실시간 방송 환경에서 화면해설을 위한 음원과 컨텐츠간에 동기화를 수행하여 시각장애인이 원활하게 실시간 방송 컨텐츠를 시청할 수 있는 방법을 설명하도록 한다.Accordingly, hereinafter, a method for a visually impaired person to smoothly view real-time broadcast content by synchronizing the sound source for screen commentary and the content in a real-time broadcasting environment in which a sound source for broadcast commentary is not produced in advance will be described.
본 발명의 일 실시 예에 따른 시각 청각 장애인을 위한 컨텐츠 제작 시스템은 실시간 방송에 있어서, 화면해설용 음원과 방송 컨텐츠간 동기화가 어렵다는 문제를 해결하는 것을 목적으로 한다.An object of the present invention is to solve the problem of difficulty in synchronizing a sound source for screen commentary and broadcast content in real-time broadcasting in a content production system for the visually and hearing impaired according to an embodiment of the present invention.
본 발명의 일 실시 예에 따른 장애인을 위한 방송 컨텐츠 제작 시스템은 화면해설용 음원 생성을 위한 속기 입력을 획득하는 속기 입력부, 컨텐츠 제공자로부터 방송 컨텐츠를 수신하는 영상 수신부 및 상기 속기 입력을 화면해설용 음원으로 변환하고, 상기 화면해설용 음원과 상기 방송 컨텐츠를 동기화하는 화면해설 처리부를 포함한다.The broadcasting content production system for the disabled according to an embodiment of the present invention includes a shorthand input unit for obtaining a shorthand input for generating a sound source for screen commentary, an image receiving unit for receiving broadcast content from a content provider, and a sound source for screen commentary. And a screen commentary processing unit configured to convert the sound source to the screen commentary and synchronize the broadcast content.
본 발명의 일 실시 예에 따른 시각 청각 장애인을 위한 컨텐츠 제작 시스템은 방송 컨텐츠를 보면서 입력할 수 밖에 없는 속기 입력의 특성상 발생할 수 밖에 없는 방송 컨텐츠와 화면해설용 음원의 비동기를 해결할 수 있다.The content production system for the visually and hearing impaired according to an embodiment of the present invention can solve the asynchronization of the broadcast content and the sound source for screen commentary, which is inevitable due to the nature of shorthand input that cannot but be input while viewing broadcast content.
또한, 본 발명의 일 실시 예에 따른 시각 청각 장애인을 위한 컨텐츠 제작 시스템은 시각 장애인을 위한 화면해설용 음원과 청각 장애인을 위한 자막을 모두 생성하여 출력할 수 있다.In addition, the content creation system for the visually and hearing impaired according to an embodiment of the present invention may generate and output both a sound source for screen explanation for the visually impaired and a caption for the hearing impaired.
도 1은 본 발명의 일 실시 예에 따른 장애인을 위한 컨텐츠 제작 시스템의 전체 구성도이다.
도 2는 본 발명의 일 실시 예에 따른 음성인식부의 구성을 나타낸다.
도 3은 본 발명의 일 실시 예에 따른 속기입력부의 구성을 나타내는 블록도이다.
도 4는 본 발명의 일 실시 예에 따른 화면해설 처리부의 구성을 나타내는 블록도이다.
도 5는 본 발명의 일 실시 예에 따른 자막 생성 시스템의 동작을 나타내는 흐름도이다.
도 6은 본 발명의 일 실시 예에 따른 화면해설용 음원과 방송 컨텐츠 동기화 방법에 관한 흐름도이다.1 is an overall configuration diagram of a content creation system for a disabled person according to an embodiment of the present invention.
2 shows the configuration of a voice recognition unit according to an embodiment of the present invention.
3 is a block diagram showing the configuration of a shorthand input unit according to an embodiment of the present invention.
4 is a block diagram illustrating a configuration of a screen commentary processing unit according to an embodiment of the present invention.
5 is a flowchart illustrating an operation of a caption generation system according to an embodiment of the present invention.
6 is a flowchart illustrating a method for synchronizing a sound source for screen commentary and broadcast content according to an embodiment of the present invention.
이하에서는 도면을 참조하여 본 발명의 구체적인 실시예를 상세하게 설명한다. 그러나 본 발명의 사상은 이하의 실시예에 제한되지 아니하며, 본 발명의 사상을 이해하는 당업자는 동일한 사상의 범위 내에 포함되는 다른 실시예를 구성요소의 부가, 변경, 삭제, 및 추가 등에 의해서 용이하게 제안할 수 있을 것이나, 이 또한 본 발명 사상의 범위 내에 포함된다고 할 것이다.Hereinafter, specific embodiments of the present invention will be described in detail with reference to the drawings. However, the spirit of the present invention is not limited to the following embodiments, and those skilled in the art who understand the spirit of the present invention can easily add, change, delete, and add components to other embodiments included within the scope of the same idea. It may be suggested, but it will be said that this is also included within the scope of the inventive concept.
첨부 도면은 발명의 사상을 이해하기 쉽게 표현하기 위하여 전체적인 구조를 설명함에 있어서는 미소한 부분은 구체적으로 표현하지 않을 수도 있고, 미소한 부분을 설명함에 있어서는 전체적인 구조는 구체적으로 반영되지 않을 수도 있다. 또한, 설치 위치 등 구체적인 부분이 다르더라도 그 작용이 동일한 경우에는 동일한 명칭을 부여함으로써, 이해의 편의를 높일 수 있도록 한다. 또한, 동일한 구성이 복수 개가 있을 때에는 어느 하나의 구성에 대해서만 설명하고 다른 구성에 대해서는 동일한 설명이 적용되는 것으로 하고 그 설명을 생략한다.In the accompanying drawings, in explaining the overall structure in order to easily understand the spirit of the invention, minute parts may not be specifically expressed, and when describing the minute parts, the overall structure may not be specifically reflected. In addition, even if specific parts such as the installation location are different, if the action is the same, the same name is given, so that the convenience of understanding can be improved. In addition, when there are a plurality of identical configurations, only one configuration will be described, and the same description will be applied to other configurations, and the description will be omitted.
도 1은 본 발명의 일 실시 예에 따른 장애인을 위한 컨텐츠 제작 시스템의 전체 구성도이다.1 is an overall configuration diagram of a content creation system for a disabled person according to an embodiment of the present invention.
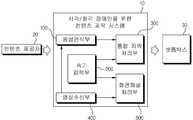
도 1에 도시된 바와 같이, 컨텐츠 제공자(20)가 방송 컨텐츠를 장애인을 위한 컨텐츠 제작 시스템(10)에 전달하고, 장애인을 위한 컨텐츠 제작 시스템(10)은 방송 컨텐츠에 기초하여 방송 자막을 생성하거나, 화면해설용 음원이 포함된 컨텐츠를 생성하여 이를 셋톱박스(30)에 전달한다. 셋톱박스(30)는 전달받은 방송 패킷을 인코딩하여 시청자에게 출력한다.As shown in FIG. 1, the
컨텐츠 제공자(20)는 대표적인 예로 방송국이 있을 수 있으며, 방송국 외 컨텐츠를 제작하여 제공하는 사업자 또는 중간 분배자를 포함할 수도 있다. 컨텐츠 제공자(20)는 오디오와 영상을 포함하는 컨텐츠를 장애인을 위한 컨텐츠 제작 시스템(10)에 전달한다. 여기에서 컨텐츠 제공자(20)가 전달하는 방송 데이터에는 일반적으로 청각장애인을 위한 자막이나, 시각장애인을 위한 화면해설용 음원이 포함되어 있지 않으며, 따라서, 속기사가 실시간으로 방송을 보면서 속기 입력을 통해 자막을 생성하거나, 화면해설원고를 타이핑하여 화면해설용 음원을 생성하는 것이 필요하다.The
장애인을 위한 컨텐츠 제작 시스템(10)은 컨텐츠 제공자(20)로부터 전달받은 컨텐츠에 기초하여 방송 자막 및 화면해설용 음원을 생성한다. 구체적으로 장애인을 위한 컨텐츠 제작 시스템(10)은 음성인식부(100), 속기입력부(200), 통합자막처리부(300), 영상수신부(400) 및 화면해설 처리부(500)를 포함할 수 있다.The
음성인식부(100)는 컨텐츠 제공자(20)로부터 전달받은 컨텐츠가 재생될 때, 음성을 자동 인식하여 문자로 변환한다. 음성인식부(100)는 일반적으로 사용되는 음성 문자 변환 도구일 수 있으며, 구체적인 예로 구글 클라우드 스피치 API나 Amazon Transcirbe일 수 있다. 음성인식부(100)의 구체적인 구성에 대하여는 이하에서 따로 설명하기로 한다.When the content delivered from the
도 2는 본 발명의 일 실시 예에 따른 음성인식부(100)의 구성을 나타낸다.2 shows the configuration of the
도 2에 도시된 바와 같이, 본 발명의 일 실시 예에 따른 음성인식부(100)는 음성수신부(110), 음성-문자 변환부(120) 및 정확도 산출부(130)를 포함할 수 있다.As shown in FIG. 2, the
음성수신부(110)는 컨텐츠로부터 음성 신호를 획득한다. 예를 들어 음성수신부(110)는 마이크일 수 있다. 음성수신부(110)는 컨텐츠로부터 전달되는 모든 음성 신호를 수집하고, 수집한 음성 신호를 디지털 신호로 변환하여 음성-문자 변환부(120)로 전달할 수 있다.The
또 다른 실시 예에서 음성수신부(110)는 속기사의 음성을 수신할 수도 있다. 속기사가 특정 상황에서 속기키보드를 통한 속기 입력이 어려운 경우, 음성수신부(110)는 속기사의 음성을 수신하여 문자로 변환할 수 있다. 단, 속기사의 음성을 문자로 변환한 데이터는 컨텐츠의 음성 신호를 문자로 변환한 것과 다르게 처리되어 통합 자막 처리부(300)로 전달될 수 있다. 통합 자막 처리부(300)는 속기사의 음성으로부터 변환되는 문자 데이터를 보완 속기 입력과 동일하게 취급하여 최종 자막 생성에 사용할 수 있다.In another embodiment, the
음성-문자 변환부(120)는 음성수신부(110)로부터 전달받은 음성 신호를 문자로 변환한다. 구체적으로 음성-문자 변환부(120)는 딥러닝을 통한 자동 음성 인식을 위한 기계 학습 애플리케이션일 수 있다. 음성-문자 변환부(120)는 WAV 및 MP3와 같은 일반적인 형식으로 저장된 오디오 파일을 트랜스크립션하고 단어마다 타임스탬프를 추가할 수 있다.The voice-to-
정확도 산출부(130)는 자동 음성 인식 간에 음성 인식의 정확도를 산출할 수 있다. 구체적으로, 정확도 산출부(130)는 음성 신호에서 사람의 목소리(육성)와 노이즈를 구별할 수 있으며, 사람의 목소리 크기, 사람의 목소리와 노이즈간 비율 또는 음성 인식 결과에 기초하여 정확도를 산출할 수 있다.The
일 실시 예에서, 정확도 산출부(130)는 음성 신호 중에서 사람의 목소리가 작으면 정확도를 낮은 것으로 볼 수 있으며, 사람의 목소리가 크면 정확도가 높을 것으로 볼 수 있다. 다시 말해서 정확도 산출부(130)는 사람의 목소리 크기에 비례하여 정확도를 산출할 수 있다. 예를 들어, 컨텐츠 속 화자가 마이크에서 떨어져 발언하거나 말소리가 상대적으로 작은 경우가 있을 수 있다. 사람의 목소리가 크고 작은지 여부를 판단하는 기준은 일반적인 컨텐츠에서의 사람 목소리 크기가 될 수 있으며, 구체적인 값은 기계학습을 통해 얻을 수도 있다.In an embodiment, the
또 다른 실시 예에서, 정확도 산출부(130)는 음성 신호 중에서 사람 목소리와 노이즈간 비율에서 노이즈 비율이 높을수록 정확도가 낮은 것으로 볼 수 있다. 다시 말해서, 정확도 산출부(130)는 노이즈 비율과 반비례하여 정확도를 산출할 수 있다. 예를 들어 컨텐츠 속에서 장내가 소란스럽다거나 비음성적인 소리가 중심이 되는 경우가 있을 수 있다.In another embodiment, the
또 다른 실시 예에서, 정확도 산출부(130)는 인식 결과에 기초하여 정확도를 산출할 수 있다. 정확도 산출부(130)는 음성을 인식하여 문자로 변환한 결과가 표준어 표기에 맞는지 여부를 판단하여 정확도를 산출할 수 있다. 예를 들어 정확도 산출부(130)의 변환 결과가 맞춤법에 맞지 않는 경우가 있을 수 있으며, 컨텐츠 속 화자가 방언을 구사하는 경우가 있을 수 있다.In another embodiment, the
정확도 산출부(130)는 음성 인식 결과가 특정 값 이하인 경우 해당 단어 또는 구간의 타임스탬프를 따로 기록할 수 있다. 여기에서 기록된 타임스탬프는 통합 자막 처리부(300)로 전달되거나, 속기 입력부(200)에 전달될 수 있다.The
다시 도 1로 돌아온다.It comes back to FIG. 1 again.
속기입력부(200)는 속기입력을 획득한다. 속기입력부(200)는 속기사로부터 속기입력을 획득할 수 있다. 속기입력부(200)의 구체적인 구성에 대하여는 이하에서 따로 설명하기로 한다.The
도 3은 본 발명의 일 실시 예에 따른 속기입력부(200)의 구성을 나타내는 블록도이다.3 is a block diagram showing the configuration of a
도 3에 도시된 바와 같이, 본 발명의 일 실시 예에 따른 속기입력부(200)는 알림표시부(210) 및 속기입력장치(220)를 포함할 수 있다.As shown in FIG. 3, the
알림표시부(210)는 속기사에게 알림을 표시한다. 여기에서 속기사에게 표시되는 알림은 음성인식부(100)에서 인식 정확도가 일정 값 이하임을 알리는 것일 수 있다. 음성 인식 정확도가 일정 값 이하인 경우 음성-문자 변환의 결과가 정확하지 않을 확률이 높은 바, 이때 속기사가 직접 자막을 입력하여 자동 음성 인식의 결과를 보정할 수 있다. 알림표시부(210)는 디스플레이장치 또는 오디오 장치일 수 있으며, 알림표시부(210)는 시각적 또는 청각적 알림을 속기사에게 제공할 수 있다.The
속기입력장치(220)는 속기사로부터 속기 입력을 획득한다. 속기입력장치(220)는 속기키보드로부터 속기 입력을 획득하여 문자 데이터화할 수 있다. 속기입력장치(220)는 일반적으로 사용되는 속기키보드일 수 있다. 또한, 속기키보드는 영한 겸용 속기키보드일 수도 있다. 속기입력장치(220)는 디스플레이 장치를 더 포함할 수 있다. 디스플레이 장치는 속기키보드를 통한 자막 입력이 표시될 수 있다.The
다시 도 1로 돌아온다.It comes back to FIG. 1 again.
통합 자막 처리부(300)는 음성인식부(100) 및 속기입력부(200)로부터 전달받은 문자를 통합하여 최종 자막을 생성한다. 구체적으로 통합 자막 처리부(300)는 음성인식부(100)로부터 전달받은 음성-문자 변환 데이터와 속기입력부(200)로부터 전달받은 속기입력 데이터를 통합하여 최종 자막을 생성한다.The integrated
일 실시 예에서, 통합 자막 처리부(300)는 음성인식부(100)로부터 전달받은 음성 문자 변환 데이터를 기초로 하고, 음성 문자 변환 데이터의 일부를 속기입력부(200)로부터 전달받은 속기입력 데이터로 보완하여 최종 자막을 생성할 수 있다. 상술한 바와 같이, 특정의 상황에서 음성인식부(100)의 인식 정확도가 낮아 문자 변환 결과가 부정확할 수 있는바, 이 경우 부정확한 문자 변환 결과를 속기사의 직접 입력으로 보완하여 최종 자막을 생성할 수 있다.In one embodiment, the integrated
통합 자막 처리부(300)는 음성인식부(100)로부터 정확도가 일정 값 이하인 보완 대상 단어 또는 보완 대상 구간의 타임스탬프 정보를 획득할 수 있다. 그리고 통합 자막 처리부(300)는 보완 대상 단어 또는 구간의 타임스탬프와 속기입력 시작 시간을 비교하여 속기입력 데이터와 음성 문자 변환 데이터를 동기화하여 최종 자막을 생성할 수 있다.The integrated
구체적인 실시 예에서, 통합 자막 처리부(300)는 보완 대상 단어 또는 구간의 타임스탬프와 보완 속기입력이 시작된 시간을 비교하고, 그 차이가 가장 작은 보완 대상 단어 또는 구간과 보완 속기입력을 매칭하여 최종 자막을 생성한다.In a specific embodiment, the integrated
또 다른 실시 예에서, 통합 자막 처리부(300)는 하나 이상의 보완 대상 단어 또는 구간의 시간 순서와 하나 이상의 보완 속기 입력의 시간 순서만을 비교 매칭하여 최종 자막을 생성한다. 보완 대상 단어 또는 구간의 수와 보완 속기 입력의 수가 동일할 것인바, 각 순서만을 비교하여 순서대로 보완 대상 단어 또는 구간을 보완 속기 입력으로 대신하여 최종 자막이 생성될 수 있다.In another embodiment, the integrated
영상수신부(400)는 컨텐츠 제공자(20)로부터 방송 컨텐츠를 수신한다. 영상수신부(400)는 방송 수신기 및 인코더를 포함할 수 있다. 영상수신부(400)는 지상파, 케이블, 인터넷 중 적어도 하나를 통해 컨텐츠 제공자(20)로부터 방송 컨텐츠를 수신할 수 있다.The
영상수신부(400)는 방송 컨텐츠를 음성인식부(100)로 전달하여 음성인식을 수행하게 하거나, 방송 컨텐츠를 속기사가 볼 수 있도록 디코딩하여 디스플레이 장치에 전달할 수 있다. 또한, 영상수신부(400)는 방송 컨텐츠를 화면해설 처리부(500)로 전달할 수도 있다.The
화면해설 처리부(500)는 화면해설용 음원을 생성하고 화면해설용 음원과 영상수신부(400)로부터 전달되는 방송 컨텐츠간 동기화를 수행한다. 더하여, 화면해설 처리부(500)는 방송 컨텐츠와 화면해설용 음원을 하나의 방송 데이터로 인코딩할 수도 있다. 화면해설 처리부(500)에 관하여는 이하에서 따로 자세하게 설명한다.The screen
화면해설 처리부(500)는 속기입력부(200)로부터 화면해설 음원 생성용 원고를 획득하고, 원고에 기초하여 음원을 생성할 수 있다.The screen
도 4는 본 발명의 일 실시 예에 따른 화면해설 처리부의 구성을 나타내는 블록도이다.4 is a block diagram showing a configuration of a screen commentary processing unit according to an embodiment of the present invention.
도 4에 도시되어 있는 바와 같이, 본 발명의 일 실시 예에 따른 화면해설 처리부(500)는 문자-음성 변환부(510), 이미지 객체 인식부(520) 및 동기화부(530)을 포함할 수 있다.4, the screen
문자-음성 변환부(510)는 속기입력부(200)로부터 획득한 화면해설 원고를 음성으로 변환한다. 문자-음성 변환부(510)는 일반적으로 사용되는 문자-음성 변환 도구일 수 있다. 예를 들어 문자-음성 변환부(510)는 구글 TTS API, select and speak, amazon polly와 같은 애플리케이션일 수 있다.The text-to-
속기사는 영상을 보면서 화면해설 원고를 타이핑할 수 있다. 예를 들어 속기사는 대사가 아닌 음성에 대한 해설, 장면에 대한 해설, 장면 변환에 대한 해설, 등장하는 인물에 대한 해설 또는 기타 시각 장애인이 컨텐츠를 즐기는데 있어서 필요한 화면해설 원고를 타이핑할 수 있다.The stenographer can type the on-screen commentary while watching the video. For example, a stenographer can type a commentary on a voice, not a dialogue, a commentary on a scene, a commentary on a scene change, a commentary on a person appearing, or other screen commentary manuscripts necessary for the visually impaired to enjoy the content.
문자-음성 변환부(510)는 생성한 음원을 동기화부(530)로 전달한다.The text-to-
이미지 객체 인식부(520)는 영상수신부(400)로부터 획득한 방송 컨텐츠에서 이미지 객체를 인식한다. 구체적으로 이미지 객체 인식부(520)는 방송 컨텐츠의 비디오 이미지로부터 객체를 인식한다. 여기에서 이미지 객체 인식부(520)는 일반적으로 사용되는 이미지 객체 인식 도구일 수 있다. 예를 들어 이미지 객체 인식부(520)는 클라우드 비전 API와 같은 애플리케이션일 수 있다.The image
객체 인식이란 이미지 또는 비디오 상의 객체를 식별하는 컴퓨터 비전 기술로서, 딥러닝과 머신 러닝 알고리즘을 통해 수행되는 것일 수 있다. 객체 인식을 통해 이미지에 포함된 객체를 인식할 수 있다.Object recognition is a computer vision technology that identifies an object on an image or video, and may be performed through deep learning and machine learning algorithms. Objects included in images can be recognized through object recognition.
예를 들어, 이미지 객체 인식부(520)는 특정의 이미지 프레임에서 파란 하늘을 추출하여 인식하거나, 특정의 이미지 프레임에서 추출된 객체 중에서 사람으로 인식되는 객체가 없는 경우 해당 이미지에는 사람이 등장하지 않는 것으로 인식할 수 있다.For example, the image
동기화부(530)는 문자-음성 변화부(510)로부터 획득한 화면해설용 음원과 방송 컨텐츠를 동기화한다. 또한 동기화부(530)는 화면해설용 음원과 방송 컨텐츠를 동기화하여 새로운 방송 데이터를 인코딩할 수도 있다. 구체적으로 동기화부(530)는 화면해설용 음원의 키워드와 이미지 객체 인식부(520)에서 인식된 이미지 객체를 비교하여 동기화를 수행할 수 있다.The
일 실시 예에서, 동기화부(530)는 화면해설 원고로부터 키워드를 추출할 수 있다. 동기화부(530)가 화면해설 원고로부터 키워드를 추출하는 방법은 일반적으로 널리 알려진 키워드 추출 방법에 의한다. 구체적인 예를 들면 동기화부(530)는 빅데이터 또는 AI 기반의 키워드 추출 도구를 포함할 수 있다.In one embodiment, the
또 다른 실시 예에서, 동기화부(530)는 특성의 화면해설 부분에 대한 키워드를 획득할 수 있다. 예를 들어, 속기사가 특정의 단어를 입력하기 전 특정의 키를 입력하여 해당 단어가 키워드임을 표시할 수 있다.In another embodiment, the
또 다른 예를 들어 속기사가 약어 입력을 사용하여 입력한 단어의 경우 해당 단어가 키워드로 처리되어 동기화부(530)에 전달될 수 있다. 여기에서 약어 입력이란, 속기사가 특정의 단어를 모두 입력하는 것이 아닌 특정의 자음의 조합만을 입력하여도 기 저장된 단어가 입력되도록 약속된 입력을 말한다. 약어 입력을 통해 입력되는 단어는 일반적으로 많이 사용되는 단어로서, 키워드로 사용될 여지가 높을 수 있다.For another example, in the case of a word input by a shorthand article using an abbreviation input, the word may be processed as a keyword and transmitted to the
동기화부(530)는 화면해설용 음원의 기초가 되는 원고의 생성 시간과 영상에서의 이미지 프레임 타임라인을 비교하여 그 차이가 특정 시간 이하인 것을 선정하고, 선정된 이미지 프레임에서 인식된 객체와 화면해설 음원의 키워드를 비교하여 동기화를 수행할 수 있다.The
더하여 동기화부(530)는 방송 컨텐츠와 동기화된 화면해설용 음원을 통합하여 새로운 방송 컨텐츠를 생성할 수 있다. 이때, 동기화부(530)는 방송 컨텐츠의 오디오와 겹치지 않도록 화면해설용 음원의 동기화 정도를 조정할 수도 있다.In addition, the
결과적으로, 본 발명의 일 실시 예에 따른 시각 청각 장애인을 위한 컨텐츠 제작 시스템은 방송 컨텐츠를 보면서 입력할 수 밖에 없는 속기 입력의 특성상 발생할 수 밖에 없는 방송 컨텐츠와 화면해설용 음원의 비동기를 해결할 수 있다.As a result, the content creation system for the visually and hearing impaired according to an embodiment of the present invention can solve the asynchrony between the broadcast content and the sound source for screen commentary, which is inevitable due to the nature of shorthand input that is forced to input while viewing broadcast content. .
다시 도 1로 돌아온다.It comes back to FIG. 1 again.
본 발명의 일 실시 예에 따른 시각 청각 장애인을 위한 컨텐츠 제작 시스템(10)은 출력부(미도시)를 더 포함할 수 있다. 출력부는 생성된 통합 자막, 화면해설용 음원 또는 화면해설용 음원이 동기화된 시각 장애인용 방송 컨텐츠를 출력할 수 있다. 출력부는 통합 자막과 화면해설용 음원을 각각 별도로 태깅하고 패키타이징하여 출력할 수 있다. 셋톱박스(30)는 사용자의 설정에 따라 통합 자막을 출력하거나, 화면해설용 음원을 출력하거나, 두가지를 한번에 출력할 수 있다.The
도 5는 본 발명의 일 실시 예에 따른 자막 생성 시스템의 동작을 나타내는 흐름도이다.5 is a flowchart illustrating an operation of a caption generation system according to an embodiment of the present invention.
여기에서 자막 생성 시스템은 음성인식부(100)와 속기입력부(200) 및 통합자막 처리부(300)만을 포함하는 것일 수 있다.Here, the caption generation system may include only the
자막 생성 시스템은 자동 음성 인식 도구를 통해 제1 구간에 포함된 음성을 문자로 변환한다(S10). 여기에서 자동 음성 인식 도구는 상술한 바와 같이 현재 사용되고 있는 자동 음성 인식 도구일 수 있다. 제 1 구간은 음성 인식의 대상이 되는 컨텐츠의 전체 타임라인 중 일부 구간을 의미한다.The caption generation system converts the voice included in the first section into text through an automatic voice recognition tool (S10). Here, the automatic speech recognition tool may be an automatic speech recognition tool currently used as described above. The first section means a partial section of the entire timeline of the content subject to speech recognition.
자막 생성 시스템은 자동 음성 인식의 정확도를 획득하고, 정확도가 특정 값 이상인지 여부를 판단한다(S20). 자동 음성 인식의 정확도는 음성 신호의 크기, 사람의 목소리와 노이즈간 비율 또는 자동 음성 인식의 결과 중 적어도 하나에 기초하여 판단될 수 있다. 그리고 여기에서 임계값으로 사용되는 특정의 기준 값은 임의적으로 입력된 값이거나, 기계학습을 통해 획득되는 값일 수 있다.The caption generation system acquires the accuracy of automatic speech recognition, and determines whether the accuracy is greater than or equal to a specific value (S20). The accuracy of automatic speech recognition may be determined based on at least one of a size of a speech signal, a ratio between a human voice and noise, or a result of automatic speech recognition. In addition, the specific reference value used as the threshold value here may be a randomly input value or a value obtained through machine learning.
자막 생성 시스템은 제 1 구간의 음성-문자 변환의 정확도가 특정 값 이상인 경우 또 다른 제 구간에 포함된 음성을 자동 음성 인식하여 문자로 변환한다(S30).When the accuracy of the voice-to-text conversion of the first section is greater than or equal to a specific value, the subtitle generation system automatically recognizes the voice included in the second section and converts it into text (S30).
한편, 자막 생성 시스템은 제 1 구간의 음성-문자 변환의 정확도가 특정 값 이하인 경우, 제 1 구간의 시작시간을 기록한다(S40). 일반적으로 자동 음성 인식 도구는 문자로 변환된 음성을 획득한 타임스탬프를 기록하고 있으며, 자막 생성 시스템은 정확도가 특정 값 이하인 단어 또는 구간에 대하여 별도로 타임스탬프를 기록하여 관리할 수 있다.Meanwhile, when the accuracy of the voice-to-text conversion of the first section is less than a specific value, the caption generation system records the start time of the first section (S40). In general, an automatic speech recognition tool records a timestamp obtained by acquiring a voice converted into a text, and the caption generation system may separately record and manage a timestamp for a word or section whose accuracy is less than a specific value.
자막 생성 시스템은 제1 구간의 변환 정확도가 특정 값 이하인 경우, 속기사에게 알림을 출력한다(S50). 자막 생성 시스템은 시각적 또는 청각적 방식으로 속기사에게 알림을 출력할 수 있다.When the conversion accuracy of the first section is less than or equal to a specific value, the caption generation system outputs a notification to the shorthand (S50). The caption generation system may output a notification to the stenographer in a visual or audible manner.
자막 생성 시스템은 제 1 음성에 대한 속기 입력을 획득한다(S60). 자막 생성 시스템은 제 1 음성에 대한 속기 입력을 속기키보드를 통해 획득할 수 있다. 또한, 자막 생성 시스템은 제 1 음성에 대한 속기 입력을 음성 인식을 통해 획득할 수도 있다. 여기에서 음성 인식의 대상은 속기사의 음성일 수 있다.The caption generation system acquires a shorthand input for the first voice (S60). The caption generation system may obtain a shorthand input for the first voice through a shorthand keyboard. In addition, the caption generating system may obtain a shorthand input for the first voice through voice recognition. Here, the object of speech recognition may be the speech of a shorthand article.
자막 생성 시스템은 기록된 제 1 구간의 시작시간과 속기입력이 시작된 시간에 기초하여 음성 인식 결과와 속기 입력 결과를 통합하여 최종 자막을 생성한다(S70).The caption generation system generates a final caption by integrating the voice recognition result and the shorthand input result based on the recorded start time of the first section and the shorthand input start time (S70).
일 실시 예에서, 자막 생성 시스템은 변환 정확도가 특정 값 이하인 구간(이하 보완 구간)의 시작 시간과 보완 구간에 대한 속기입력이 시작된 시간을 비교하고, 그 차이가 가장 작은 보완 구간과 보완 속기입력을 매칭하여 최종 자막을 생성한다. 보완 속기입력은 속기사가 알림에 따라 입력한 속기입력 데이터를 지칭한다.In an embodiment, the caption generation system compares the start time of a section (hereinafter referred to as supplementary section) whose conversion accuracy is less than a certain value and a time when shorthand input for the supplementary section is started, and compares the supplementary section with the smallest difference and the supplementary shorthand input. Matching to generate final subtitles. Supplementary shorthand input refers to shorthand input data input by a shorthand by a shorthand notice.
또 다른 실시 예에서, 자막 생성 시스템은 하나 이상의 보완 구간의 시작 시간과 하나 이상의 보완 속기 입력의 시간 순서만을 비교 매칭하여 최종 자막을 생성한다. 보완 대상 단어 또는 구간의 수와 보완 속기 입력의 수가 동일할 것인바, 각 순서만을 비교하여 순서대로 보완 대상 단어 또는 구간을 보완 속기 입력으로 대신하여 최종 자막이 생성될 수 있다.In another embodiment, the caption generation system generates a final caption by comparing and matching only the start times of one or more supplementary sections and a time sequence of one or more supplementary shorthand inputs. Since the number of supplementary words or sections and the number of supplementary shorthand inputs will be the same, a final subtitle may be generated by comparing only each order and replacing the supplementary words or sections in order with supplementary shorthand input.
자막 생성 시스템은 생성된 최종 자막을 셋톱박스로 전달한다. 셋톱박스는 전달받은 자막을 영상과 함께 표시하여 청각장애인을 위한 자막 방송을 출력할 수 있다.The subtitle generation system delivers the final subtitles generated to the set-top box. The set-top box can output closed caption broadcasting for the hearing impaired by displaying the transmitted caption together with the image.
도 6은 본 발명의 일 실시 예에 따른 화면해설용 음원과 방송 컨텐츠 동기화 방법에 관한 흐름도이다.6 is a flowchart illustrating a method for synchronizing a sound source for screen commentary and broadcast content according to an embodiment of the present invention.
장애인을 위한 방송 컨텐츠 제작 시스템은 시각 장애인을 위한 화면 해설에 관한 속기입력을 획득한다(S110). 상술한 바와 같이, 시각 장애인을 위해 장면이나, 등장 인물에 대한 해설과 같은 부분에 대하여 화면 해설이 필요하며, 이러한 화면 해설을 컨텐츠 제공자가 제공하지 않는 것이 일반적인 바, 화면 해설을 위한 속기 입력을 획득하여 화면해설용 음원을 생성할 수 있다.The broadcasting content production system for the disabled acquires a shorthand input for the screen commentary for the visually impaired (S110). As described above, for the visually impaired, screen commentary is required for parts such as commentary on scenes or characters, and it is common that content providers do not provide such screen commentary, so a shorthand input for screen commentary is obtained. Thus, a sound source for screen commentary can be created.
장애인을 위한 방송 컨텐츠 제작 시스템은 속기사가 작성한 화면해설 원고로부터 키워드를 추출한다(S120). 일 실시 예에서, 장애인을 위한 방송 컨텐츠 제작 시스템은 화면해설 원고로부터 일반적으로 널리 사용되는 키워드 추출 알고리즘을 통해 키워드를 추출할 수 있다. 또 다른 실시 예에서, 장애인을 위한 방송 컨텐츠 제작 시스템은 속기 입력간에 특정 키 입력을 통해 태그된 특정의 단어를 키워드로 추출할 수 있다. 또 다른 실시 예에서, 장애인을 위한 방송 컨텐츠 제작 시스템은 약어 입력을 통해 입력된 단어를 키워드로 추출할 수 있다.The broadcasting content production system for the disabled extracts keywords from the screen commentary manuscript written by a short story (S120). In one embodiment, the broadcast content production system for the disabled may extract keywords from a screen commentary manuscript through a commonly used keyword extraction algorithm. In another embodiment, the broadcast content production system for the disabled may extract a specific word tagged through a specific key input between shorthand inputs as a keyword. In another embodiment, the broadcast content production system for the disabled may extract a word input through an abbreviation input as a keyword.
장애인을 위한 방송 컨텐츠 제작 시스템은 화면해설에 관한 속기 입력을 음성으로 변환한다(S130). 여기에서 화면해설에 관한 속기 입력을 음성으로 변환하는 알고리즘은 일반적으로 널리 알려진 문자-음성 변환 알고리즘에 의한다.The broadcasting content production system for the disabled converts shorthand input for screen commentary into voice (S130). Here, the algorithm for converting the shorthand input for screen commentary into speech is based on the generally known text-to-speech algorithm.
장애인을 위한 방송 컨텐츠 제작 시스템은 방송 컨텐츠의 비디오 프레임으로부터 이미지 객체를 인식한다(S140). 장애인을 위한 방송 컨텐츠 제작 시스템은 이미지 객체 인식을 통해 이미지를 구성하고 있는 객체를 판단할 수 있다. 여기에서 이미지 객체 인식은 일반적으로 널리 알려진 이미지 객체 알고리즘에 의한다.The broadcast content production system for the disabled recognizes an image object from the video frame of the broadcast content (S140). The broadcasting content production system for the disabled may determine an object constituting an image through image object recognition. Here, image object recognition is generally based on a widely known image object algorithm.
장애인을 위한 방송 컨텐츠 제작 시스템은 화면해설 음원과 방송 컨텐츠를 동기화한다(S150). 구체적으로 장애인을 위한 방송 컨텐츠 제작 시스템은 화면해설 음원에 대한 키워드와 방송 컨텐츠에 포함된 영상의 이미지 객체 인식 결과에 기초하여 동기화를 수행할 수 있다.The broadcast content production system for the disabled synchronizes the screen commentary sound source and the broadcast content (S150). In more detail, the broadcast content production system for the disabled may perform synchronization based on a keyword for a screen commentary sound source and an image object recognition result of an image included in the broadcast content.
장애인을 위한 방송 컨텐츠 제작 시스템은 화면해설 음원의 기초가 되는 원고가 생성된 시간과 영상 프레임 타임라인을 먼저 비교하고, 그 차이가 특정 시간 이하인 것들을 선정하여, 선정된 화면해설 음원의 키워드와 영상 프레임의 이미지 객체 결과를 비교하여 동기화를 수행할 수 있다.The broadcasting content production system for the disabled first compares the timeline of the creation of the manuscript, which is the basis of the screen commentary sound source, and the image frame timeline, and selects those whose difference is less than a certain time, and selects keywords and image frames of the screen commentary sound source. Synchronization can be performed by comparing the results of the image objects of.
전술한 본 발명은, 프로그램이 기록된 매체에 컴퓨터가 읽을 수 있는 코드로서 구현하는 것이 가능하다. 컴퓨터가 읽을 수 있는 매체는, 컴퓨터 시스템에 의하여 읽혀질 수 있는 데이터가 저장되는 모든 종류의 기록장치를 포함한다. 컴퓨터가 읽을 수 있는 매체의 예로는, HDD(Hard Disk Drive), SSD(Solid State Disk), SDD(Silicon Disk Drive), ROM, RAM, CD-ROM, 자기 테이프, 플로피 디스크, 광 데이터 저장 장치 등이 있으며, 또한 캐리어 웨이브(예를 들어, 인터넷을 통한 전송)의 형태로 구현되는 것도 포함한다.The present invention described above can be implemented as a computer-readable code in a medium on which a program is recorded. The computer-readable medium includes all types of recording devices that store data that can be read by a computer system. Examples of computer-readable media include HDD (Hard Disk Drive), SSD (Solid State Disk), SDD (Silicon Disk Drive), ROM, RAM, CD-ROM, magnetic tape, floppy disk, optical data storage device, etc. There is also a carrier wave (e.g., transmission over the Internet).
상기의 상세한 설명은 모든 면에서 제한적으로 해석되어서는 아니되고 예시적인 것으로 고려되어야 한다. 본 발명의 범위는 첨부된 청구항의 합리적 해석에 의해 결정되어야 하고, 본 발명의 등가적 범위 내에서의 모든 변경은 본 발명의 범위에 포함된다.The above detailed description should not be construed as restrictive in all respects and should be considered as illustrative. The scope of the present invention should be determined by rational interpretation of the appended claims, and all changes within the equivalent scope of the present invention are included in the scope of the present invention.
Claims (8)
Translated fromKorean자동 음성 인식의 결과를 보정하기 위한 속기 입력 혹은 화면해설용 음원 생성을 위한 속기 입력을 획득하는 속기 입력부와;
상기 음성 인식부로부터 전달받은 음성 문자 변환 데이터와 상기 자동 음성 인식의 결과를 보정하기 위해 상기 속기 입력부로부터 입력된 속기 입력 데이터를 통합하여 최종 자막을 생성하는 통합 자막 처리부와;
컨텐츠 제공자로부터 방송 컨텐츠를 수신하고 디코딩 처리하여 표시장치에 전달하는 영상 수신부와;
화면 해설을 위해 상기 속기 입력부로부터 입력되는 속기 입력을 화면해설용 음원으로 변환하고, 상기 화면해설용 음원과 상기 방송 컨텐츠를 동기화하는 화면해설 처리부;를 포함하되, 상기 화면해설 처리부는,
상기 방송 컨텐츠에 포함된 비디오 이미지로부터 객체를 인식하고 그 인식된 이미지 객체와 화면해설용 음원의 키워드를 비교하여 동기화를 수행함을 특징으로 하는 장애인을 위한 방송 컨텐츠 제작 시스템.A voice recognition unit for automatically recognizing the voice of the played broadcast content and converting it into text, but providing a visual or audible notification to the stenographer when the accuracy of the voice recognition is less than a certain value;
A shorthand input unit for acquiring a shorthand input for correcting a result of automatic speech recognition or a shorthand input for generating a sound source for screen commentary;
An integrated caption processing unit for generating a final caption by integrating the speech text conversion data received from the speech recognition unit with the shorthand input data input from the shorthand input unit to correct a result of the automatic speech recognition;
An image receiving unit that receives broadcast content from a content provider, decodes it, and delivers it to a display device;
Including a screen commentary processing unit for converting the shorthand input input from the shorthand input unit for screen commentary into a sound source for screen commentary, and synchronizing the sound source for screen commentary and the broadcast content; wherein, the screen commentary processing unit,
Recognizing an object from a video image included in the broadcast content, comparing the recognized image object with a keyword of a sound source for screen description, and performing synchronization.
상기 속기 입력이 수행된 시간과 이미지 프레임의 타임라인을 비교하여 일정 시간 이하인 것들을 선정하고, 선정된 이미지 프레임에서 인식된 이미지 객체와 화면해설용 음원의 키워드를 비교하여 동기화를 수행하는 장애인을 위한 방송 컨텐츠 제작 시스템.The method of claim 1, wherein the screen commentary processing unit,
Broadcasting for the disabled, which compares the time when the shorthand input was performed and the timeline of the image frame to select those that are less than a certain time, and compares the image object recognized in the selected image frame with the keyword of the sound source for screen commentary to perform synchronization Content creation system.
상기 화면해설 처리부는
화면해설 원고로부터 키워드를 추출하는
장애인을 위한 방송 컨텐츠 제작 시스템.The method of claim 1,
The screen commentary processing unit
Extracting keywords from the screen commentary manuscript
Broadcasting content production system for the disabled.
상기 화면해설 처리부는
속기 입력간에 특정 키 입력에 의해 태그된 특정의 단어를 키워드로 추출하는
장애인을 위한 방송 컨텐츠 제작 시스템.The method of claim 1,
The screen commentary processing unit
Extracts specific words tagged by specific keystrokes as keywords between shorthand inputs
Broadcasting content production system for the disabled.
상기 화면해설 처리부는
약어 입력을 통해 입력된 단어를 키워드로 추출하는
장애인을 위한 방송 컨텐츠 제작 시스템.The method of claim 1,
The screen commentary processing unit
Extracting the entered word as a keyword through abbreviation input
Broadcasting content production system for the disabled.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020190047797AKR102160117B1 (en) | 2019-04-24 | 2019-04-24 | a real-time broadcast content generating system for disabled |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020190047797AKR102160117B1 (en) | 2019-04-24 | 2019-04-24 | a real-time broadcast content generating system for disabled |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR102160117B1true KR102160117B1 (en) | 2020-09-25 |
Family
ID=72707669
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020190047797AExpired - Fee RelatedKR102160117B1 (en) | 2019-04-24 | 2019-04-24 | a real-time broadcast content generating system for disabled |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR102160117B1 (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102292552B1 (en)* | 2021-02-27 | 2021-08-24 | 주식회사 케이에스컨버전스 | Video synchronization system to improve viewing rights for the disabled |
| CN114339074A (en)* | 2021-10-29 | 2022-04-12 | 腾讯科技(深圳)有限公司 | Explanatory video generation method, device, computer equipment and storage medium |
| KR20240074553A (en) | 2022-11-21 | 2024-05-28 | 씨제이올리브네트웍스 주식회사 | Method for automatically generating screen commentary broadcasting using artificial intelligence algorithm and system therefor |
| KR102746801B1 (en) | 2024-05-30 | 2024-12-27 | 주식회사 에스티엔미디어 | Assistance system for improving the performance of disabled golf players through media broadcasting |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20050066488A (en)* | 2003-12-26 | 2005-06-30 | 한국전자통신연구원 | Data service apparatus for digital broadcasting receiver |
| KR20060089922A (en)* | 2005-02-03 | 2006-08-10 | 에스케이 텔레콤주식회사 | Apparatus and method for extracting data using speech recognition |
| KR20070031597A (en)* | 2005-09-15 | 2007-03-20 | (주)동원에스앤에스 | DVR system linked with shorthand system |
- 2019
- 2019-04-24KRKR1020190047797Apatent/KR102160117B1/ennot_activeExpired - Fee Related
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20050066488A (en)* | 2003-12-26 | 2005-06-30 | 한국전자통신연구원 | Data service apparatus for digital broadcasting receiver |
| KR20060089922A (en)* | 2005-02-03 | 2006-08-10 | 에스케이 텔레콤주식회사 | Apparatus and method for extracting data using speech recognition |
| KR20070031597A (en)* | 2005-09-15 | 2007-03-20 | (주)동원에스앤에스 | DVR system linked with shorthand system |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102292552B1 (en)* | 2021-02-27 | 2021-08-24 | 주식회사 케이에스컨버전스 | Video synchronization system to improve viewing rights for the disabled |
| CN114339074A (en)* | 2021-10-29 | 2022-04-12 | 腾讯科技(深圳)有限公司 | Explanatory video generation method, device, computer equipment and storage medium |
| KR20240074553A (en) | 2022-11-21 | 2024-05-28 | 씨제이올리브네트웍스 주식회사 | Method for automatically generating screen commentary broadcasting using artificial intelligence algorithm and system therefor |
| KR102786445B1 (en)* | 2022-11-21 | 2025-03-26 | 씨제이올리브네트웍스 주식회사 | Method for automatically generating screen commentary broadcasting using artificial intelligence algorithm and system therefor |
| KR102746801B1 (en) | 2024-05-30 | 2024-12-27 | 주식회사 에스티엔미디어 | Assistance system for improving the performance of disabled golf players through media broadcasting |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11887578B2 (en) | Automatic dubbing method and apparatus | |
| US12387741B2 (en) | Automated transcript generation from multi-channel audio | |
| KR102160117B1 (en) | a real-time broadcast content generating system for disabled | |
| US11463779B2 (en) | Video stream processing method and apparatus, computer device, and storage medium | |
| US10991380B2 (en) | Generating visual closed caption for sign language | |
| US7047191B2 (en) | Method and system for providing automated captioning for AV signals | |
| US8620139B2 (en) | Utilizing subtitles in multiple languages to facilitate second-language learning | |
| US20140372100A1 (en) | Translation system comprising display apparatus and server and display apparatus controlling method | |
| US20060136226A1 (en) | System and method for creating artificial TV news programs | |
| US20120105719A1 (en) | Speech substitution of a real-time multimedia presentation | |
| US9767825B2 (en) | Automatic rate control based on user identities | |
| EP3839953A1 (en) | Automatic caption synchronization and positioning | |
| US20250104715A1 (en) | Media System with Closed-Captioning Data and/or Subtitle Data Generation Features | |
| KR20180119101A (en) | System and method for creating broadcast subtitle | |
| US9666211B2 (en) | Information processing apparatus, information processing method, display control apparatus, and display control method | |
| JP2012181358A (en) | Text display time determination device, text display system, method, and program | |
| CN110933485A (en) | Video subtitle generating method, system, device and storage medium | |
| WO2023218268A1 (en) | Generation of closed captions based on various visual and non-visual elements in content | |
| KR101618777B1 (en) | A server and method for extracting text after uploading a file to synchronize between video and audio | |
| KR102185183B1 (en) | a broadcast closed caption generating system | |
| Mocanu et al. | Automatic subtitle synchronization and positioning system dedicated to deaf and hearing impaired people | |
| JP4500957B2 (en) | Subtitle production system | |
| KR102292552B1 (en) | Video synchronization system to improve viewing rights for the disabled | |
| WO2021157192A1 (en) | Control device, control method, computer program, and content playback system | |
| US20230362452A1 (en) | Distributor-side generation of captions based on various visual and non-visual elements in content |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application | St.27 status event code:A-0-1-A10-A12-nap-PA0109 | |
| PA0201 | Request for examination | St.27 status event code:A-1-2-D10-D11-exm-PA0201 | |
| D13-X000 | Search requested | St.27 status event code:A-1-2-D10-D13-srh-X000 | |
| D14-X000 | Search report completed | St.27 status event code:A-1-2-D10-D14-srh-X000 | |
| PE0902 | Notice of grounds for rejection | St.27 status event code:A-1-2-D10-D21-exm-PE0902 | |
| E13-X000 | Pre-grant limitation requested | St.27 status event code:A-2-3-E10-E13-lim-X000 | |
| P11-X000 | Amendment of application requested | St.27 status event code:A-2-2-P10-P11-nap-X000 | |
| P13-X000 | Application amended | St.27 status event code:A-2-2-P10-P13-nap-X000 | |
| E90F | Notification of reason for final refusal | ||
| PE0902 | Notice of grounds for rejection | St.27 status event code:A-1-2-D10-D21-exm-PE0902 | |
| P11-X000 | Amendment of application requested | St.27 status event code:A-2-2-P10-P11-nap-X000 | |
| P13-X000 | Application amended | St.27 status event code:A-2-2-P10-P13-nap-X000 | |
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration | St.27 status event code:A-1-2-D10-D22-exm-PE0701 | |
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment | St.27 status event code:A-2-4-F10-F11-exm-PR0701 | |
| PR1002 | Payment of registration fee | St.27 status event code:A-2-2-U10-U11-oth-PR1002 Fee payment year number:1 | |
| PG1601 | Publication of registration | St.27 status event code:A-4-4-Q10-Q13-nap-PG1601 | |
| P22-X000 | Classification modified | St.27 status event code:A-4-4-P10-P22-nap-X000 | |
| PC1903 | Unpaid annual fee | St.27 status event code:A-4-4-U10-U13-oth-PC1903 Not in force date:20230922 Payment event data comment text:Termination Category : DEFAULT_OF_REGISTRATION_FEE | |
| PC1903 | Unpaid annual fee | St.27 status event code:N-4-6-H10-H13-oth-PC1903 Ip right cessation event data comment text:Termination Category : DEFAULT_OF_REGISTRATION_FEE Not in force date:20230922 |