KR101435499B1 - Mapreduce cluster node and design method in the virtual cloud environment - Google Patents
Mapreduce cluster node and design method in the virtual cloud environmentDownload PDFInfo
- Publication number
- KR101435499B1 KR101435499B1KR1020120122305AKR20120122305AKR101435499B1KR 101435499 B1KR101435499 B1KR 101435499B1KR 1020120122305 AKR1020120122305 AKR 1020120122305AKR 20120122305 AKR20120122305 AKR 20120122305AKR 101435499 B1KR101435499 B1KR 101435499B1
- Authority
- KR
- South Korea
- Prior art keywords
- block device
- virtual machine
- mapper
- reducer
- device file
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images








Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/22—Microcontrol or microprogram arrangements
- G06F9/28—Enhancement of operational speed, e.g. by using several microcontrol devices operating in parallel
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/16—Combinations of two or more digital computers each having at least an arithmetic unit, a program unit and a register, e.g. for a simultaneous processing of several programs
- G06F15/161—Computing infrastructure, e.g. computer clusters, blade chassis or hardware partitioning
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/16—Combinations of two or more digital computers each having at least an arithmetic unit, a program unit and a register, e.g. for a simultaneous processing of several programs
- G06F15/163—Interprocessor communication
- G06F15/167—Interprocessor communication using a common memory, e.g. mailbox
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3802—Instruction prefetching
- G06F9/3804—Instruction prefetching for branches, e.g. hedging, branch folding
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5061—Partitioning or combining of resources
- G06F9/5066—Algorithms for mapping a plurality of inter-dependent sub-tasks onto a plurality of physical CPUs
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Computer Hardware Design (AREA)
- General Physics & Mathematics (AREA)
- Mathematical Physics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Translated fromKoreanDescription
Translated fromKorean본 발명은 가상 클라우드 환경 내 맵리듀스 클러스터 및 이를 위한 설계방법에 관한 것으로, 특히 대용량 데이터 처리를 위한 맵리듀스 수행 시, 발생되는 네트워크 트래픽 양의 발생을 감소시켜 데이터 처리속도를 향상시킬 수 있는 가상 클라우드 환경 내 맵리듀스 클러스터 및 이를 위한 설계방법에 관한 것이다.
The present invention relates to a MapReduce cluster in a virtual cloud environment and a design method for the same. More particularly, the present invention relates to a method for designing a virtual cloud And a design method for the cluster.
급속도로 증가하는 데이터량으로 인하여, 데이터 병렬 또는 분산 처리를 위한 클러스터 컴퓨팅이 널리 사용되고 있으며, 이러한 클러스터 컴퓨팅 시스템은 다수의 물리 머신을 연결하여 이용하고 있다.Due to the rapidly increasing amount of data, cluster computing for data parallel or distributed processing is widely used, and these cluster computing systems connect and use many physical machines.
최근에는, 가상머신 기반의 클라우드 서비스들이 출현함에 따라, 기존의 클러스터 시스템들이 점차 클라우드 상으로 이동하고 있다.In recent years, with the advent of virtual machine-based cloud services, existing cluster systems are increasingly moving into the cloud.
이처럼, 클라우드 상에서 동작하는 클러스터 시스템은 관리의 유용성, 신뢰성, 가용성, 그리고 클러스터 구성의 용이성 등의 장점을 갖는다. 하지만 이러한 클라우드 기반의 클러스터 시스템이 많이 이용되면서 분산 파일 시스템이나 통신 프로토콜과 같은 클러스터 시스템의 기반 기술들에 있어서, 병목현상이 발생하는 문제점이 발생했다.As such, cluster systems operating in the cloud have advantages such as manageability, reliability, availability, and ease of cluster configuration. However, such a cloud-based cluster system is frequently used, which causes a bottleneck in the underlying technologies of a cluster system such as a distributed file system or a communication protocol.
상술한 바와 같이, 가상 클라우드 환경 내 맵리듀스 클러스터 및 이를 위한 설계방법을 살펴보면 다음과 같다.As described above, a MapReduce cluster in a virtual cloud environment and a design method thereof are as follows.
선행기술 1은 한국등록특허공보 제10-0980599호(2010.09.01)로서, 입출력 공유장치를 이용한 클라우드 서비스 시스템에 관한 것이다. 이러한 선행기술 1은 인터넷에 연결되어 데이터 통신을 수행하는 네트워크 스위치 허브; 네트워크 스위치 허브를 통해 인터넷과 데이터 통신을 수행하는 호스트 네트워크 인터페이스 카드를 구비하며 입출력 공유 장치의 제어에 따라 다수의 가상머신을 실행시키며 실행되는 다수의 가상머신이 호스트 네트워크 인터페이스 카드를 통해 인터넷의 다수의 사용자 단말과 통신을 수행하는 복수의 호스트 컴퓨터; 적어도 하나의 가상머신 이미지를 저장하는 저장장치; 및 네트워크 스위치 허브를 통해 인터넷과 데이터 통신을 수행하는 공유 네트워크 인터페이스 카드를 구비하며 인터넷에 연결된 사용자 단말의 요청에 따라 저장장치 내의 적어도 하나의 가상머신 이미지 중 하나를 선택하여 복수의 호스트 컴퓨터 중 어느 하나에서 실행시키는 입출력 공유장치를 포함한다.
또한, 선행기술 2는 한국공개특허공보 제10-2012-0071979호(2012.07.03)로서, 클라우드 컴퓨팅 시스템의 자원관리장치 및 방법에 관한 것이다. 이러한 선행기술 2는 사용자로부터 사용할 컴퓨팅 자원의 사용시점 및 자원사용량을 포함하는 개인 스케줄링 정보를 입력받아, 입력받은 개인 스케줄링 정보를 기초로 사용자가 사용할 가상머신이 생성될 위치를 배정하고, 사용시점에 자원사용량만큼 컴퓨팅 자원을 사용할 수 있는 가상머신을 배정된 위치에 생성하여 사용자에게 제공함으로써, 사용자의 시간대별로 사용할 컴퓨팅 자원에 관한 개인 스케줄링 정보를 고려하여, 컴퓨팅 자원의 할당 및 관리를 최적화할 수 있다.
상기와 같은 종래 기술의 문제점을 해결하기 위해, 본 발명은 대용량 데이터에 대한 맵리듀스 처리를 위해 발생하는 네트워크 트래픽의 양을 감소시켜 보다 빠른 데이터 분산 처리를 수행하도록 하는 가상 클라우드 환경 내 맵리듀스 클러스터 및 이를 위한 설계방법을 제공하고자 한다.
In order to solve the problems of the prior art as described above, the present invention provides a MapReduce cluster in a virtual cloud environment for reducing the amount of network traffic generated for mapping processing for large amounts of data, And to provide a design method for this.
위와 같은 과제를 해결하기 위한 본 발명의 한 실시 예에 따른 가상 클라우드 환경 내 맵리듀스 클러스터는 매퍼 가상머신에 의해 구동되는 맵 함수의 출력값을 포함하는 블록 장치 파일을 상기 매퍼 가상머신으로부터 분리하여 리듀서 가상머신에 부착하는 것을 특징으로 한다.According to an aspect of the present invention, there is provided a maple devise cluster in a virtual cloud environment, the mapper cluster including a mapper function file including an output value of a map function driven by a mapper virtual machine, And is attached to the machine.
보다 바람직하게는 상기 블록 장치 파일을 송수신하여 가상머신으로 전송하는 드라이버 도메인; 상기 블록 장치 파일에 대하여 임의의 키값을 읽어 이를 필터링하거나, 다른값으로 변환하는 맵 함수를 수행하는 매퍼 가상머신; 상기 키값을 기준으로 하여, 상기 블록 장치 파일을 정렬하고 병합하는 리듀스 함수를 수행하는 리듀서 가상머신;을 포함하며, 상기 드라이버 도메인은 상기 맵 함수의 출력단으로부터 블록 장치 파일을 분리한 후, 분리한 상기 블록 장치 파일을 상기 리듀스 함수의 입력단에 부착하는 블록 장치 재구성 모듈;을 포함하는 맵리듀스 클러스터를 포함할 수 있다.A driver domain for transmitting and receiving the block device file and transmitting the block device file to a virtual machine; A mapper virtual machine that reads an arbitrary key value for the block device file and filters or converts the key value into a different value; And a reducer virtual machine for performing a decreasing function to sort and merge the block device files based on the key value, wherein the driver domain separates the block device file from the output end of the map function, And a block device reconfiguration module for attaching the block device file to the input of the redess function.
특히, 상기 맵리듀스 클러스터가 하나의 노드에서 구성되었을 때, 블록 장치 파일의 재구성이 수행될 수 있다.Particularly, when the MapReduce cluster is configured in one node, reconstruction of the block device file can be performed.
보다 바람직하게는 상기 블록 장치 파일에 대하여 임의의 키값을 읽어 이를 필터링 또는 다른값으로 변환하는 맵 함수를 수행하는 매퍼 가상머신; 상기 맵 함수의 출력값을 포함하는 블록 장치 파일을 입력받아 출력하는 매퍼 가상머신용 드라이버 도메인; 상기 가상머신용 드라이버 도메인으로부터 출력된 블록 장치 파일을 입력받아 리듀서 가상머신으로 전송하는 리듀서 가상머신용 드라이버 도메인; 및 상기 블록 장치 파일을 수신하여 키값을 기준으로 상기 블록 장치 파일을 정렬하고 병합하는 리듀스 함수를 수행하는 리듀서 가상머신;을 포함하는 맵리듀스 클러스터를 포함할 수 있다.More preferably, the mapper virtual machine reads the arbitrary key value for the block device file and performs a map function for filtering or converting the key value into another value. A driver domain for a mapper virtual machine for receiving and outputting a block device file including an output value of the map function; A driver domain for a reducer virtual machine for receiving a block device file output from the driver domain for the virtual machine and transferring the block device file to the reducer virtual machine; And a reducer virtual machine for receiving the block device file and performing a decrement function for aligning and merging the block device files based on the key value.
보다 바람직하게는 상기 블록 장치 파일을 마운트하고, 마운트된 위치의 컨텐츠를 상기 리듀서 가상머신용 드라이버 도메인으로 전송하는 제1 블록 장치 재구성 모듈; 을 더 포함하는 매퍼 가상머신용 드라이버 도메인을 포함할 수 있다.A first block device reconfiguration module for mounting the block device file and transmitting the contents of the mounted location to the driver domain for the reducer virtual machine; A driver domain for the mapper virtual machine.
특히, 마운트된 블록 장치 파일을 분리하는 리듀서 가상머신용 드라이버 도메인을 포함할 수 있다.In particular, it may include a driver domain for a reducer virtual machine that separates mounted block device files.
보다 바람직하게는 분리한 블록 장치 파일을 상기 리듀서 가상머신에 부착하는 제2 블록 장치 재구성 모듈;을 더 포함하는 리듀서 가상머신용 드라이버 도메인을 포함할 수 있다.And a second block device reconfiguration module for attaching the detached block device file to the reducer virtual machine, more preferably, a driver domain for the reducer virtual machine.
특히, 상기 맵리듀스 클러스터가 다수의 노드에 걸쳐 구성되었을 때의 블록 장치 파일의 재구성이 수행되는 것을 특징으로 한다.Particularly, the reconfiguration of a block device file is performed when the mapping cluster is configured over a plurality of nodes.
위와 같은 과제를 해결하기 위한 본 발명의 다른 실시 예에 따른 가상 클라우드 환경 내 맵리듀스 클러스터 설계방법은 매퍼 가상머신 내 매퍼가 마운트 포인팅 지점에 부착된 블록 장치를 마운트하는 단계; 상기 매퍼가 맵 태스크를 수행하고, 상기 마운트된 위치에서 상기 맵 함수의 출력을 생성하는 단계; 상기 맵 태스크의 수행이 완료되면, 상기 매퍼는 상기 맵 함수의 출력이 생성된 위치에서 마운트를 해제하는 단계; 상기 드라이버 도메인 내 위치하는 블록 장치 재구성모듈이 상기 매퍼 가상머신으로부터 블록 장치 파일을 분리하는 단계; 상기 블록 장치 재구성 모듈이 분리한 상기 블록 장치 파일을 리듀스 가상머신에 부착하는 단계; 상기 리듀서 가상머신 내 리듀서는 상기 블록 장치 파일을 리듀스 함수의 입력위치로 마운트하는 단계; 상기 리듀서가 모든 맵 함수의 출력을 받고, 리듀서 함수를 수행하는 단계;를 포함하는 것을 특징으로 한다.According to another aspect of the present invention, there is provided a method for designing a clustered cluster in a virtual cloud environment, including: mounting a block device attached to a mount pointing point in a mapper virtual machine; The mapper performing a map task and generating an output of the map function at the mounted location; When the mapping task is completed, the mapper releases the mount at the position where the output of the map function is generated; A block device reconfiguration module located in the driver domain separating a block device file from the mapper virtual machine; Attaching the block device file separated by the block device reconfiguration module to a redox virtual machine; Wherein the reducer in the reducer virtual machine mounts the block device file at the input location of the redess function; And the reducer receives the output of all map functions and performs a reducer function.
보다 바람직하게는 상기 리듀서가 상기 매퍼 가상머신의 모든 블록 장치 파일들이 마운트될 때까지 기다리는 것을 더 포함하는 리듀서가 상기 블록 장치 파일을 리듀스 함수의 입력위치로 마운트하는 단계를 포함할 수 있다.More preferably, the reducer may further include mounting the block device file at the input location of the redess function, the reducer further including waiting for the reducer to mount all the block device files of the mapper virtual machine.
위와 같은 과제를 해결하기 위한 본 발명의 다른 실시 예에 따른 가상 클라우드 환경 내 맵리듀스 클러스터 설계방법은 매퍼 가상머신 내 매퍼가 마운트 포인팅 지점에 부착된 블록 장치를 마운트하는 단계; 상기 매퍼가 맵 태스크를 수행하고, 상기 마운트된 위치에서 상기 맵 함수의 출력을 생성하는 단계; 상기 맵 태스크의 수행이 완료되면, 상기 매퍼는 상기 맵 함수의 출력이 생성된 위치에서 마운트를 해제하는 단계; 상기 드라이버 도메인 내 위치하는 블록 장치 재구성 모듈이 상기 매퍼 가상머신으로부터 블록 장치 파일을 분리하는 단계; 상기 매퍼 가상머신은 분리된 블록 장치 파일을 마운트하는 단계; 상기 블록 장치 재구성 모듈이 상기 블록 장치 파일이 마운트된 위치의 컨텐츠를 상기 리듀서 가상머신의 부분 드라이버 도메인으로 전송하는 단계; 상기 리듀서 가상머신의 부분 드라이버 도메인이 마운트된 블록 장치 파일을 분리하는 단계; 상기 블록 장치 재구성 모듈이 상기 리듀서 가상머신의 입력단에 블록 장치 파일을 부착하는 단계; 상기 리듀서 가상머신 내 리듀서는 상기 블록 장치 파일을 리듀스 함수의 입력위치로 마운트하는 단계; 및 상기 리듀서가 모든 맵 함수의 출력을 받고, 리듀서 함수를 수행하는 단계;를 포함하는 것을 특징으로 한다.
According to another aspect of the present invention, there is provided a method for designing a clustered cluster in a virtual cloud environment, including: mounting a block device attached to a mount pointing point in a mapper virtual machine; The mapper performing a map task and generating an output of the map function at the mounted location; When the mapping task is completed, the mapper releases the mount at the position where the output of the map function is generated; A block device reconfiguration module located in the driver domain separating a block device file from the mapper virtual machine; The mapper virtual machine mounting a separate block device file; Wherein the block device reconfiguration module transmits content of a location where the block device file is mounted to a partial driver domain of the reducer virtual machine; Isolating a block device file on which the partial driver domain of the reducer virtual machine is mounted; The block device reconfiguration module attaching a block device file to an input of the reducer virtual machine; Wherein the reducer in the reducer virtual machine mounts the block device file at the input location of the redess function; And receiving the output of all the map functions and performing the reducer function.
본 발명의 가상 클라우드 환경 내 맵리듀스 클러스터 및 이를 위한 설계방법은 맵 함수의 출력값을 포함하는 블록 장치 파일을 매퍼 가상머신으로부터 분리하여 리듀스 함수로 입력되도록 리듀스 가상머신에 부착함으로써, 리듀서가 네트워크 전송을 통해 맵 함수의 출력값에 접근할 필요가 없어지게 되어, 네트워크의 부하를 감소시킬 수 있는 효과가 있다.The MapReduce cluster in the virtual cloud environment of the present invention and the design method therefor can be realized by attaching the block device file including the output value of the map function to the Reduce virtual machine so as to be input as a Reduce function from the mapper virtual machine, There is no need to access the output value of the map function through transmission, and the load on the network can be reduced.
또한 본 발명의 가상 클라우드 환경 내 맵리듀스 클러스터 및 이를 위한 설계방법은 가상머신들간에 자원 경쟁으로 인해, 데이터 복제 시, 성능 병목현상이 발생하는 것을 미연에 방지할 수 있는 효과가 있다.
In addition, the MapReduce cluster and the design method thereof in the virtual cloud environment of the present invention can prevent performance bottlenecks in data replication due to resource competition between virtual machines.
도 1은 맵리듀스 프레임워크를 나타낸 도면이다.
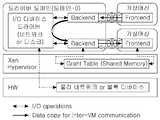
도 2는 일반적인 가상머신 기반의 클라우드 노드를 나타낸 도면이다.
도 3은 본 발명의 일 실시 예에 따른 하나의 노드에서 구성된 클러스터에 대한 구조를 나타낸 도면이다.
도 4는 본 발명의 다른 실시 예에 따른 다수의 노드에 걸쳐 구성된 클러스터에 대한 구조를 나타낸 도면이다.
도 5는 블록 장치 재구성 모듈이 없는 경우의 단어 계수 맵리듀스의 실행시간을 나타낸 그래프이다.
도 6은 블록 장치 재구성 모듈이 있는 경우의 단어 계수 맵리듀스의 실행시간을 나타낸 그래프이다.
도 7은 두 개의 물리노드를 교차하는 가상머신간 데이터 전송시간을 나타낸 그래프이다.
도 8은 리듀서 가상머신이 탑재된 노드의 가상머신들의 CPU 활용도를 나타낸 누적 그래프이다.
도 9는 리듀서 가상머신이 탑재되지 않은 노드의 가상머신들의 CPU 활용도를 나타낸 누적 그래프이다.
도 10은 리듀서 가상머신이 탑재된 노드의 가상머신들의 디스크 입출력 지연대기시간을 나타낸 누적 그래프이다.
도 11은 리듀서 가상머신이 탑재되지 않은 노드의 가상머신들의 디스크 입출력 지연대기시간을 나타낸 누적 그래프이다.1 is a diagram showing a MapReduce framework.
2 is a diagram illustrating a general virtual machine-based cloud node.
3 is a diagram illustrating a structure of a cluster configured at one node according to an embodiment of the present invention.
4 is a diagram illustrating a structure of a cluster configured over a plurality of nodes according to another embodiment of the present invention.
5 is a graph showing the execution time of the word coefficient map deuce in the case where there is no block device reconfiguration module.
6 is a graph showing the execution time of the word coefficient map deuce in the case of the block device reconfiguration module.
7 is a graph showing data transfer time between virtual machines crossing two physical nodes.
8 is a cumulative graph showing the CPU utilization of the virtual machines of the node on which the reducer virtual machine is mounted.
9 is a cumulative graph showing the CPU utilization of the virtual machines of the node on which the reducer virtual machine is not mounted.
10 is an accumulated graph showing disk I / O latency waiting time of virtual machines of a node equipped with a reducer virtual machine.
11 is an accumulated graph showing disk I / O latency waiting time of virtual machines of a node on which a reducer virtual machine is not mounted.
이하, 본 발명을 바람직한 실시 예와 첨부한 도면을 참고로 하여 본 발명이 속하는 기술 분야에서 통상의 지식을 가진 자가 용이하게 실시할 수 있도록 상세히 설명한다. 그러나 본 발명은 여러 가지 상이한 형태로 구현될 수 있으며, 여기에서 설명하는 실시 예에 한정되는 것은 아니다.DETAILED DESCRIPTION OF THE PREFERRED EMBODIMENT Hereinafter, the present invention will be described in detail with reference to preferred embodiments and accompanying drawings, which will be easily understood by those skilled in the art. The present invention may, however, be embodied in many different forms and should not be construed as limited to the embodiments set forth herein.
먼저, 본 발명에 대해 설명하기에 앞서, 대용량 데이터의 분산 또는 병렬 처리를 수행하기 위해 사용되는 맵리듀스(MapReduce) 알고리즘에 대하여 자세히 살펴보도록 한다.Before describing the present invention, the MapReduce algorithm used for performing distributed or parallel processing of large-capacity data will be described in detail.
상기 맵리듀스(MapReduce)알고리즘은 구글(Google)이 공개한 기술로서, 저가의 컴퓨터로 구성된 클러스터 환경에서 페타바이트 이상의 대용량 데이터를 병렬로 처리하기 위한 분산 프로그래밍 모델을 나타낸다. 이에 따라, 맵리듀스의 오픈소스 구현체인 하둡(Hadoop)을 중심으로 아마존, 링크드인, 페이스북과 같은 대용량 데이터를 다루는 서비스에서 맵리듀스 모델을 채용하고 있으며 대용량 데이터를 처리하는 많은 시스템에서 주목을 받고 있다.The MapReduce algorithm disclosed by Google is a distributed programming model for parallel processing petabytes or larger data in a cluster environment composed of low-cost computers. As a result, Hadoop, the open source implementation of MapReduce, is using the MapReduce model for services that deal with large amounts of data such as Amazon, LinkedIn, and Facebook, and has attracted attention in many systems that process large amounts of data have.
도 1은 맵리듀스 프레임워크를 나타낸 도면이다.1 is a diagram showing a MapReduce framework.
도 1에 도시된 바와 같이, 맵리듀스 수행 시 파일 시스템은 큰 파일을 블록 단위로 분할하여 맵(Map) 함수를 수행하는 매퍼(Mapper) 태스크들에 할당한다. 맵 함수는 임의의 키-값 상을 읽어 이를 필터링하거나 다른 값으로 변환하는 작업을 수행한다. 맵 함수의 수행 결과는 매퍼가 수행된 노드의 로컬 디스크에 기록되며 모든 매퍼가 작업을 종료하면 맵리듀스의 스케쥴러가 리듀서(Reducer) 태스크를 수행한다. 리듀서는 여러 노드들로부터 키 값을 기준으로 각 리듀서가 처리해야 할 키-값 쌍을 이전 매퍼들의 로컬 디스크로부터 읽어온다. 이후 키(key) 값을 기준으로 정렬 연산을 수행하고 이렇게 정렬된 키-값 쌍 등을 동일 키 값을 기준으로 병합 연산을 수행하여 그 결과를 출력한다.As shown in FIG. 1, the file system divides a large file into blocks and allocates them to mapper tasks that perform a map function. The map function reads an arbitrary key-value, filters it, or converts it to another value. The result of the map function is recorded on the local disk of the node where the mapper is executed. When all the mapper has finished the task, the scheduler of the Mapper task performs the task of Reducer. The reducer reads key-value pairs from each node's local disk based on the key value that each reducer must process. Then, the sorting operation is performed based on the key value, and the merged operation is performed based on the same key value as the sorted key-value pair, and the result is output.
도 2는 일반적인 가상머신 기반의 클라우드 노드를 나타낸 도면이다.2 is a diagram illustrating a general virtual machine-based cloud node.
도 2에 도시된 바와 같이, 가상머신 기반의 클라우드 환경에서, 하나의 동일한 물리 노드 상에 가상머신이 네트워크를 통해 각각 통신할 때, 상기 가상머신은 드라이버 도메인을 교차하여 복사하도록 하고, 또한 다른 물리 노드와 교차하는 곳에 위치하는 가상머신들 간의 통신은 각 노드의 드라이버 도메인에 의해 중개되어 이루어진다. 이러한 중개과정의 수행 시, 입출력 가상화 오버헤드와, 가상머신들간에 입출력 간섭이 발생된다.As shown in FIG. 2, in a virtual machine-based cloud environment, when a virtual machine communicates through a network on one and the same physical node, the virtual machine crosses the driver domain, Communication between virtual machines located at intersections with nodes is mediated by the driver domain of each node. When performing this mediation process, input / output virtualization overhead and input / output interference occur between virtual machines.
가상화된 클라우드에서의 맵리듀스 클러스터는 상기 가상머신들을 포함하여 수행하는데, 각 가상머신은 매퍼 가상머신 또는 리듀서 가상머신을 통해, 개별적인 맵 또는 리듀스 태스크를 수행한다.A MapReduce cluster in a virtualized cloud is run including the virtual machines, where each virtual machine performs a separate map or reduce task through a mapper virtual machine or a reducer virtual machine.
이와 같이, 가상화된 클라우드 환경에서 맵리듀스 클러스터는 디바이스 드라이버의 입출력 중개와, 가상머신들 간에 자원 경쟁으로 인한 병목현상이 발생한다. 특히, 매퍼와 리듀서간 데이터 전달 시, 많은 양의 네트워크 트래픽이 발생하여 맵 리듀스 처리량을 감소시키게 된다.As described above, in the virtualized cloud environment, the MapReduce cluster becomes a bottleneck due to the input / output brokering of the device driver and resource competition between the virtual machines. In particular, when data is transferred between the mapper and the reducer, a large amount of network traffic is generated to reduce the map throughput.
도 3은 본 발명의 일 실시 예에 따른 하나의 노드에서 구성된 클러스터에 대한 구조를 나타낸 도면이다.3 is a diagram illustrating a structure of a cluster configured at one node according to an embodiment of the present invention.
도 3에 도시된 바와 같이, 본 발명의 일 실시 예에 따른 하나의 노드에서 구성된 클러스터는 드라이버 도메인(110), 매퍼 가상머신(120), 리듀서 가상머신(130)을 포함한다.As shown in FIG. 3, a cluster configured at one node according to an embodiment of the present invention includes a
매퍼 가상머신(120)은 상기 블록 장치 파일에 대하여 임의의 키값을 읽어 이를 필터링하거나, 다른값으로 변환하는 맵 함수를 수행한다.The mapper
리듀서 가상머신(130)은 상기 키값을 기준으로 하여, 상기 블록 장치 파일을 정렬하고 병합하는 리듀스 함수를 수행한다.The reducer
드라이버 도메인(110)은 매퍼 가상머신의 상기 블록 장치 파일을 리듀서 가상머신으로 전달한다. 이러한 드라이버 도메인은 상기 맵 함수의 출력단으로부터 블록 장치 파일을 분리한 후, 분리한 상기 블록 장치 파일을 상기 리듀스 함수의 입력단에 부착하는 블록 장치 재구성 모듈(112)을 포함한다.The
이러한 맵리듀스 클러스터의 구조를 설계하는 방법은 다음과 같다. 먼저, 매퍼 가상머신 내 매퍼가 마운트 포인팅 지점에 부착된 블록 장치를 마운트하고(1), 상기 매퍼가 맵 태스크를 수행하고, 상기 마운트된 위치에서 상기 맵 함수의 출력을 생성한다(2). 이후, 상기 맵 태스크의 수행이 완료되면, 상기 매퍼는 상기 맵 함수의 출력이 생성된 위치에서 마운트를 해제하고(3), 상기 드라이버 도메인 내 위치하는 블록 장치 재구성 모듈이 상기 매퍼 가상머신으로부터 블록 장치 파일을 분리한다(4). 이처럼, 상기 블록 장치 재구성 모듈이 분리한 상기 블록 장치 파일을 리듀스 가상머신에 부착한다(5).A method for designing the structure of the MapReduce cluster is as follows. First, a mapper in a mapper virtual machine mounts a block device attached to a mount pointing point (1), the mapper performs a map task, and generates an output of the map function at the mounted position (2). Thereafter, when the map task is completed, the mapper releases the mount at the position where the output of the map function is generated (3), and the block device reconfiguration module located in the driver domain receives the map function from the mapper virtual machine, Separate the files (4). In this way, the block device file separated by the block device reconfiguration module is attached to the redox virtual machine (5).
이에 따라, 상기 리듀서 가상머신 내 리듀서는 상기 블록 장치 파일을 리듀스 함수의 입력위치로 마운트하고(6), 상기 리듀서가 모든 맵 함수의 출력을 받아, 리듀서 함수를 수행한다(7).Accordingly, the reducer in the reducer virtual machine mounts the block device file at the input position of the redaction function (6), and the reducer receives the output of all map functions and performs the reducer function (7).
도 4는 본 발명의 다른 실시 예에 따른 다수의 노드에 걸쳐 구성된 클러스터에 대한 구조를 나타낸 도면이다.4 is a diagram illustrating a structure of a cluster configured over a plurality of nodes according to another embodiment of the present invention.
도 4에 도시된 바와 같이, 본 발명에 따른 다수의 노드에 걸쳐 구성된 클러스터는 매퍼 가상머신(220), 매퍼 가상머신용 드라이버 도메인(210), 리듀서 가상머신용 드라이버 도메인(240) 및 리듀서 가상머신(250)을 포함한다.As shown in FIG. 4, a cluster configured across multiple nodes according to the present invention includes a mapper
매퍼 가상머신(220)은 블록 장치 파일에 대하여 임의의 키값을 읽어 이를 필터링 또는 다른값으로 변환하는 맵 함수를 수행한다.The mapper
매퍼 가상머신용 드라이버 도메인(210)은 상기 맵 함수의 출력값을 포함하는 블록 장치 파일을 입력받아 출력한다. 이러한 매퍼 가상머신용 드라이버 도메인(210)은 상기 블록 장치 파일을 마운트하고, 마운트된 위치의 컨텐츠를 상기 리듀서 가상머신용 드라이버 도메인으로 전송하는 제1 블록 장치 재구성 모듈(212)을 포함할 수 있다.The mapper virtual
리듀서 가상머신용 드라이버 도메인(240)은 상기 매퍼 가상머신용 드라이버 도메인으로부터 출력된 블록 장치 파일을 입력받아 리듀서 가상머신으로 전송하며, 마운트된 블록 장치 파일을 마운트 해제한다. 이러한 리듀서 가상머신용 드라이버 도메인(240)은 마운트 해제한 블록 장치 파일을 상기 리듀서 가상머신에 부착하는 제2 블록 장치 재구성 모듈(242)을 포함할 수 있다.The
리듀서 가상머신(250)은 상기 블록 장치 파일을 수신하여 키값을 기준으로 상기 블록 장치 파일을 정렬하고 병합한다.The reducer
이러한 다수의 노드에 걸쳐 구성된 클러스터를 설계하는 방법은 다음과 같다. 먼저, 매퍼 가상머신 내 매퍼가 마운트 포인팅 지점에 부착된 블록 장치를 마운트한다(1). 상기 매퍼가 맵 태스크를 수행하고, 상기 마운트된 위치에서 상기 맵 함수의 출력을 생성한다(2).A method of designing a cluster composed of such a plurality of nodes is as follows. First, the mapper in the mapper virtual machine mounts the block device attached to the mount pointing point (1). The mapper performs a map task and generates an output of the map function at the mounted position (2).
상기 맵 태스크의 수행이 완료되면, 상기 매퍼는 상기 맵 함수의 출력이 생성된 위치에서 마운트를 해제한다(3).When the execution of the map task is completed, the mapper releases the mount at the position where the output of the map function is generated (3).
상기 드라이버 도메인 내 위치하는 블록 장치 재구성 모듈이 상기 매퍼 가상머신으로부터 블록 장치 파일을 분리한다(4).A block device reconfiguration module located in the driver domain separates a block device file from the mapper virtual machine (4).
상기 매퍼 가상머신은 분리된 블록 장치 파일을 마운트한다(5).The mapper virtual machine mounts a separate block device file (5).
상기 블록 장치 재구성 모듈이 상기 블록 장치 파일이 마운트된 위치의 컨텐츠를 상기 리듀서 가상머신의 부분 드라이버 도메인으로 전송한다(6).The block device reconfiguration module transfers the contents of the location where the block device file is mounted to the partial driver domain of the reducer virtual machine (6).
상기 리듀서 가상머신의 부분 드라이버 도메인이 마운트된 블록 장치 파일을 마운트 해제한다(7).The partial driver domain of the reducer virtual machine dismounts the mounted block device file (7).
상기 블록 장치 재구성 모듈이 상기 리듀서 가상머신의 입력단에 블록 장치 파일을 부착한다(8).The block device reconfiguration module attaches the block device file to the input of the reducer virtual machine (8).
상기 리듀서 가상머신 내 리듀서는 상기 블록 장치 파일을 리듀스 함수의 입력위치로 마운트한다(9).The reducer in the reducer virtual machine mounts the block device file to the input position of the reduction function (9).
상기 리듀서가 모든 맵 함수의 출력을 받아, 리듀서 함수를 수행한다(10).The reducer receives the output of all map functions and performs a reducer function (10).
이하에서는 본 발명에 따른 가상 클라우드 환경 내 맵리듀스 클러스터를 이용하여 데이터 분산 및 병렬 처리를 수행하는 실험에 대하여 자세히 살펴보도록 한다. 실험조건으로는 두 개의 물리 머신과 두 개의 intel xeon 2.3GHz 쿼드코어 프로세서 및 16GB 메모리를 사용하며, 이때 상기 물리 머신은 Ubuntu 11.10과 커널 3.0.0-12 및 Xen hypervisor 4.1.1에서 구동한다. 또한, 각각의 물리 머신은 7개의 가상머신을 포함하고, 각각의 가상머신은 1개의 VCPU와 1GB 메모리를 포함한다.Hereinafter, experiments for performing data distribution and parallel processing using a MapReduce cluster in a virtual cloud environment according to the present invention will be described in detail. Experimental conditions use two physical machines, two intel xeon 2.3GHz quad core processors and 16GB memory, where the physical machine runs on Ubuntu 11.10, kernel 3.0.0-12 and Xen hypervisor 4.1.1. In addition, each physical machine includes seven virtual machines, and each virtual machine includes one VCPU and one GB memory.
특히, 본 실험은 xen의 기본 관리 툴인 xm 툴을 사용하여, 블록 장치를 분리 및 부착하도록 한다.In particular, this experiment uses the xm tool, xen's basic management tool, to isolate and attach the block devices.
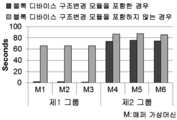
또한, "윌리엄 셰익스피어 전집"을 테스트 데이터로서 사용하여, 약 300MB 테스트 데이터를 300회 복제하여 생성한다. 이때, 상기 데이터는 각 매퍼의 입력으로 사용된다. 예를 들어, 매퍼가 두 개와 세 개가 존재한다면, 전체 입력 데이터의 크기는 각각 600MB 및 900MB이다. 이때, 맵함수의 출력 크기는 약 400MB이고, 상기 400MB 데이터는 각 매퍼로부터 리듀서로 전송된다. 이러한 실험과정을 10번 반복수행하였고, 이후 실험결과의 평균을 연산하여 맵리듀스의 시행횟수에 대한 그래프를 작성하였다.Using "William Shakespeare's Complete Works" as test data, 300 MB of test data is reproduced 300 times. At this time, the data is used as an input of each mapper. For example, if there are two and three mappers, the total input data size is 600MB and 900MB respectively. At this time, the output size of the map function is about 400 MB, and the 400 MB data is transmitted from each mapper to the reducer. This experimental procedure was repeated 10 times, and then the average of the experimental results was calculated, and a graph of the number of times of implementation of the MapReduce was made.
도 5는 블록 장치 재구성 모듈을 사용하지 않는 경우의 단어 계수 맵리듀스의 실행시간을 나타낸 그래프이고, 도 6은 본 발명에 따른 블록 장치 재구성 모듈을 사용하는 경우의 단어 계수 맵리듀스의 실행시간을 나타낸 그래프이다.FIG. 5 is a graph showing the execution time of the word coefficient map deuce when the block device reconfiguration module is not used, and FIG. 6 is a graph showing the execution time of the word coefficient map deuce in the case of using the block device reconfiguration module according to the present invention Graph.
맵리듀스 클러스터가 하나의 물리노드의 가상머신에서 구동될 때, 상기 가상머신 중 하나의 가상머신이 리듀스 태스크를 수행하고, 다른 가상머신들이 맵 태스크를 수행한다.When a MapReduce cluster is run in a virtual machine of one physical node, one virtual machine of the virtual machine performs the resume task, and the other virtual machines perform the map task.
도 5 내지 도 6에 도시된 바와 같이, 매퍼 가상머신의 수와 입력 데이터의 전체 크기가 증가할수록 데이터 전송 시간이 이에 비례하여 증가하는 것을 알 수 있다. 이에 따라, 매퍼 가상머신에서 네트워크 전송이 많아지거나, 데이터 전송을 위한 디스크 입출력이 시행될 때, 드라이버 도메인 상에서 입출력 간섭이 발생하는 것을 알 수 있다.As shown in FIGS. 5 to 6, it can be seen that as the number of mapper virtual machines and the total size of input data increase, the data transfer time increases proportionally. As a result, when the number of network transfers increases in the mapper virtual machine or disk input / output for data transfer is performed, input / output interference occurs in the driver domain.
하지만 본 발명에 따라, 블록 장치 재구성을 사용하는 경우, 매퍼로부터 리듀서로의 맵 함수의 출력전송 소요시간이 급격하게 감소하는 것을 알 수 있다. 특히, 도 5와 비교하여 살펴보면, 매퍼의 수와 입력 데이터의 전체 크기가 증가할 때, 데이터 전송시간이 거의 일정하게 유지되는 것을 알 수 있다.However, according to the present invention, when the block device reconfiguration is used, it can be seen that the time required for the output transmission of the map function from the mapper to the reducer is drastically reduced. In particular, as compared with FIG. 5, it can be seen that the data transmission time is kept substantially constant when the number of mappers and the total size of the input data increase.
또한, 다수의 노드에 걸쳐 구성된 클러스터를 이용한 데이터 전송시간을 평가할 수 있다.In addition, it is possible to evaluate a data transmission time using a cluster composed of a plurality of nodes.
도 7은 두 개의 물리노드에서 구성된 클러스터의 가상머신간 데이터 전송시간을 나타낸 그래프이다.7 is a graph showing data transfer time between virtual machines in a cluster configured in two physical nodes.
데이터 전송결과를 평가하기 위해, 맵리듀스 클러스터가 다수의 물리노드 상에서 구성되어 구동할 때, 하나의 가상머신은 리듀스 태스크를 수행하고, 물리노드 각각에서 세 개의 가상머신은 맵 태스크를 수행하며, 나머지 가상머신들(이들을 D가상머신이라고 한다.)은 일반적인 맵 태스트와 유사한 디스크 입출력 구동을 수행한다. 이러한 D가상머신들은 맵리듀스 클러스터에 포함되지 않고, dbench를 수행한다. 이때, 상기 dbench는 디스크 입출력 벤치마크 툴이고, 디폴트 구성을 사용하였으며, 하나의 dbench 클라이언트를 이용하였다.In order to evaluate the data transfer result, when a MapReduce cluster is configured and running on multiple physical nodes, one virtual machine performs a resume task, three virtual machines at each physical node perform a map task, The rest of the virtual machines (called D virtual machines) perform disk I / O drives similar to the normal map test. These D virtual machines are not included in the MapReduce cluster and do dbench. At this time, the dbench is a disk input / output benchmark tool, uses a default configuration, and uses one dbench client.
도 7에 도시된 바와 같이, 매퍼 가상머신의 제1 그룹은 리듀서 가상머신과 동일한 물리노드에 위치하고, 매퍼 가상머신의 제2 그룹은 다른 물리노드에서 구동된다. 따라서, 제2 그룹 내 가상머신들은 제1 그룹에서 블록 장치 파일들이 분리되고 부착되는 동안, 드라이버 도메인간에 네트워크를 통해 맵 함수의 출력이 전송된다.As shown in FIG. 7, the first group of mapper virtual machines is located at the same physical node as the reducer virtual machine, and the second group of mapper virtual machines is driven at the other physical node. Thus, the virtual machine in the second group transfers the output of the map function over the network between the driver domains while the block device files are detached and attached in the first group.
이에 따라, 제1 및 제2 그룹에서 작업속도가 향상되는 것을 알 수 있으며, 본 발명에 따른 블록 장치 재구성에 의해, 제1 그룹의 매퍼 가상머신의 데이터 전송이 약 97%가 향상되었다. 또한, 다른 물리 노드에서 구동되는 제 2 그룹의 매퍼 가상머신의 데이터 전송이 약 15% 향상된 것을 알 수 있다.Thus, it can be seen that the work speed is improved in the first and second groups, and by the block device reconfiguration according to the present invention, the data transfer of the first group of mapper virtual machines is improved by about 97%. It can also be seen that the data transfer of the second group of mapper virtual machines driven by other physical nodes is improved by about 15%.
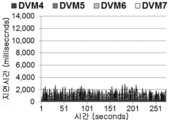
도 8은 리듀서 가상머신이 탑재된 노드의 가상머신들의 CPU 활용도를 나타낸 누적 그래프이고, 도 9는 리듀서 가상머신이 탑재되지 않은 노드의 가상머신들의 CPU 활용도를 나타낸 누적 그래프이다.FIG. 8 is an accumulated graph showing the CPU utilization of the virtual machines of the node on which the reducer virtual machine is mounted, and FIG. 9 is a cumulative graph showing the CPU utilization of the virtual machines of the node on which the reducer virtual machine is not mounted.
이처럼, 도 8 내지 도 9에 도시된 두 개의 그래프는 세 개의 페이즈로 구성되는데, 본 발명에 따라 블록 장치 재구성을 사용하는 첫 번째 전송 페이즈와, 블록 장치 재구성을 사용하지 않는 두 번째 전송 페이즈, 그리고 나머지 안정적 페이즈를 나타낸다.Thus, the two graphs shown in FIGS. 8-9 are organized into three phases, the first transmission phase using block device reconfiguration, the second transmission phase not using block device reconfiguration, and And the remaining stable phases.
도 8 내지 도 9에 도시된 바와 같이, 블록 장치 재구성을 갖는 데이터 전송의 경우에는 블록 장치 재구성이 이루어지지 않는 데이터 전송보다 CPU 자원을 덜 사용되는 것을 알 수 있다. 이러한 현상은 블록 장치 재구성을 수행하지 않는 데이터 전송이 드라이버 도메인을 거쳐, 네트워크 전송이 이루어져야 하기 때문이다.As shown in FIGS. 8 to 9, it can be seen that, in the case of data transfer with block device reconfiguration, less CPU resources are used than data transfers where block device reconfiguration is not performed. This is because the data transfer that does not perform the block device reconfiguration must be performed through the driver domain and the network transfer must be performed.
하지만, 본 발명에 따라, 블록 장치 재구성을 수행하는 데이터 전송은 가상머신이 동일한 물리노드에서 구동될 경우 네트워크 전송이 필요없고, 여러 노드에 걸쳐 구동될 경우 드라이버 도메인간에 네트워크 전송이 이루어지기 때문에 CPU 자원이 덜 사용된다.However, according to the present invention, data transmission for performing block device reconfiguration does not require network transmission when a virtual machine is run on the same physical node, and network transmission is performed between driver domains when running across multiple nodes, Is less used.
도 10은 리듀서 가상머신의 디스크 입출력 지연대기시간을 나타낸 그래프이고, 도 11은 리듀서 가상머신을 제외한 다른 가상머신의 디스크 입출력 지연대기시간을 나타낸 그래프이다. FIG. 10 is a graph showing disk I / O delay waiting time of a reducer virtual machine, and FIG. 11 is a graph showing disk I / O delay waiting time of a virtual machine other than a reducer virtual machine.
도 10과 도 11에 도시된 바와 같이, D가상머신의 디스크 입출력 작업속도는 맵리듀스 클러스터가 블록 장치 재구성을 사용할 때 보다 빠른 것을 알 수 있다. 왜냐하면, 맵리듀스 클러스터가 블록 장치 재구성을 사용하지 않는 경우에, 입출력 간섭이 발생하기 때문이다. 따라서, 블록 장치 재구성이 이루어지지 않는 노드의 D가상머신은 이러한 입출력 간섭으로 인하여 입출력의 작업속도가 감소하게 된다.As shown in FIGS. 10 and 11, it can be seen that the disk I / O operation speed of the D virtual machine is faster than that of the MapReduce cluster when using block device reconfiguration. This is because I / O interference occurs when the MapReduce cluster does not use block device reconfiguration. Therefore, in the D virtual machine of the node in which the block device reconfiguration is not performed, the input / output operation speed is reduced due to such input / output interference.
결과적으로, 본 발명에 의해 셔플 페이즈 내 발생하는 데이터 전송을 위한 오버헤드를 감소시키고, 데이터 송수신 시간을 감소시켜 맵리듀스의 작업속도를 향상시킬 수 있다.As a result, according to the present invention, overhead for data transmission occurring in the shuffle phase can be reduced, and data transmission / reception time can be reduced, thereby improving the working speed of the MapReduce.
더불어, 맵리듀스 클러스터를 구성하는 가상머신 외 다른 가상머신들의 작업속도 또한 향상시킬 수 있다.In addition, the operation speed of virtual machines other than the virtual machines constituting the MapReduce cluster can be improved.
본 발명의 가상 클라우드 환경 내 맵리듀스 클러스터 및 이를 위한 설계방법은 매퍼 함수의 출력값을 포함하는 블록 장치 파일을 매퍼 가상머신으로부터 분리하여 리듀스 함수로 입력되도록 리듀서 가상머신에 부착함으로써, 리듀서가 네트워크를 이용하여 매퍼함수의 출력값에 접근할 필요가 없어지게 되어, 네트워크의 부하를 감소시킬 수 있는 효과가 있다.In the virtual cluster environment of the present invention, a MapReduce cluster and a design method for the virtual cluster environment include attaching the block device file including the output value of the mapper function to the reducer virtual machine so as to be input as a reduction function from the mapper virtual machine, There is no need to access the output value of the mapper function by using it, and the load on the network can be reduced.
또한 본 발명의 가상 클라우드 환경 내 맵리듀스 클러스터 및 이를 위한 설계방법은 가상머신들간에 자원 경쟁으로 인해, 데이터 전송 시, 성능 병목현상이 발생하는 것을 미연에 방지할 수 있는 효과가 있다.In addition, the MapReduce cluster and the design method thereof in the virtual cloud environment of the present invention can prevent performance bottlenecks in data transmission due to resource competition between virtual machines.
상기에서는 본 발명의 바람직한 실시 예에 대하여 설명하였지만, 본 발명은 이에 한정되는 것이 아니고 본 발명의 기술 사상 범위 내에서 여러 가지로 변형하여 실시하는 것이 가능하고 이 또한 첨부된 특허청구범위에 속하는 것은 당연하다.
While the present invention has been described in connection with what is presently considered to be practical exemplary embodiments, it is to be understood that the invention is not limited to the disclosed embodiments, but, on the contrary, Do.
110: 드라이버 도메인120: 매퍼 가상머신
130: 리듀서 가상머신140: 디스크110: Driver Domain 120: Mapper Virtual Machine
130: Reducer virtual machine 140: Disk
Claims (12)
Translated fromKorean상기 블록 장치 파일에 대하여 임의의 키값을 읽어 이를 필터링하거나, 다른값으로 변환하는 맵 함수를 수행하는 매퍼 가상머신;
상기 키값을 기준으로 하여, 상기 블록 장치 파일을 정렬하고 병합하는 리듀스 함수를 수행하는 리듀서 가상머신;을 포함하며,
상기 드라이버 도메인은
상기 맵 함수의 출력단으로부터 블록 장치 파일을 분리한 후, 분리한 상기 블록 장치 파일을 상기 리듀스 함수의 입력단에 부착하는 블록 장치 재구성 모듈;
을 포함하는 것을 특징으로 하는 가상 클라우드 환경 내 맵리듀스 클러스터.
A driver domain that sends and receives block device files and sends them to the virtual machine;
A mapper virtual machine that reads an arbitrary key value for the block device file and filters or converts the key value into a different value;
And a reducer virtual machine for performing a reduction function to sort and merge the block device files based on the key value,
The driver domain
A block device reconfiguration module for separating a block device file from an output end of the map function and attaching the separated block device file to an input end of the redess function;
Wherein the clustered cluster is a clustered cluster.
상기 맵리듀스 클러스터가 하나의 노드에서 구성된 클러스터일 때, 블록 장치 파일의 재구성이 수행되는 것을 특징으로 하는 가상 클라우드 환경 내 맵리듀스 클러스터.
3. The method of claim 2,
Wherein the reconfiguration of the block device file is performed when the mapping priority cluster is a cluster configured in one node.
상기 맵 함수의 출력값을 포함하는 블록 장치 파일을 입력받아 출력하는 매퍼 가상머신용 드라이버 도메인;
상기 매퍼 가상머신용 드라이버 도메인으로부터 출력된 블록 장치 파일을 입력받아 리듀서 가상머신으로 전송하는 리듀서 가상머신용 드라이버 도메인; 및
상기 블록 장치 파일을 수신하여 키값을 기준으로 상기 블록 장치 파일을 정렬하고 병합하는 리듀스 함수를 수행하는 리듀서 가상머신;
을 포함하는 것을 특징으로 하는 가상 클라우드 환경 내 맵리듀스 클러스터.
A mapper virtual machine that reads a key value from a block device file and performs a map function to convert the key value to a filter or to another value;
A driver domain for a mapper virtual machine for receiving and outputting a block device file including an output value of the map function;
A driver domain for a reducer virtual machine that receives a block device file output from the driver domain for the mapper virtual machine and transmits the block device file to the reducer virtual machine; And
A reducer virtual machine for receiving the block device file and performing a decrement function for sorting and merging the block device files based on a key value;
Wherein the clustered cluster is a clustered cluster.
상기 매퍼 가상머신용 드라이버 도메인은
상기 블록 장치 파일을 마운트하고, 마운트된 위치의 컨텐츠를 상기 리듀서 가상머신용 드라이버 도메인으로 전송하는 제1 블록 장치 재구성 모듈;
을 더 포함하는 것을 특징으로 하는 가상 클라우드 환경 내 맵리듀스 클러스터.
5. The method of claim 4,
The driver domain for the mapper virtual machine
A first block device reconfiguration module for mounting the block device file and transferring the contents of the mounted location to the driver domain for the reducer virtual machine;
Wherein the virtual cluster environment includes at least one virtual cluster.
상기 리듀서 가상머신용 드라이버 도메인은
마운트된 블록 장치 파일을 마운트 해제하는 것을 특징으로 하는 가상 클라우드 환경 내 맵리듀스 클러스터.
5. The method of claim 4,
The driver domain for the reducer virtual machine
Wherein the unmounted block device file is unmounted in a virtual cloud environment.
상기 리듀서 가상머신용 드라이버 도메인은
마운트 해제한 블록 장치 파일을 상기 리듀서 가상머신에 부착하는 제2 블록 장치 재구성모듈;
을 더 포함하는 것을 특징으로 하는 가상 클라우드 환경 내 맵리듀스 클러스터.
The method according to claim 6,
The driver domain for the reducer virtual machine
A second block device reconfiguration module for attaching the unmounted block device file to the reducer virtual machine;
Wherein the virtual cluster environment includes at least one virtual cluster.
상기 맵리듀스 클러스터가 다수의 노드에 걸쳐 구성된 클러스터일 때의 블록 장치 파일의 재구성이 수행되는 것을 특징으로 하는 가상 클라우드 환경 내 맵리듀스 클러스터.
5. The method of claim 4,
Wherein reconfiguration of a block device file is performed when the MapReduce cluster is a cluster configured across a plurality of nodes.
매퍼 가상머신 내 매퍼가 마운트 포인팅 지점에 부착된 블록 장치를 마운트하는 단계;
상기 매퍼가 맵 태스크를 수행하고, 상기 마운트된 위치에 상기 맵 함수의 출력을 생성하는 단계;
상기 맵 태스크의 수행이 완료되면, 상기 매퍼는 상기 맵 함수의 출력이 생성된 위치에서 마운트를 해제하는 단계;
드라이버 도메인 내 위치하는 블록 장치 재구성 모듈이 상기 매퍼 가상머신으로부터 블록 장치 파일을 분리하는 단계;
상기 블록 장치 재구성 모듈이 분리한 상기 블록 장치 파일을 리듀서 가상머신에 부착하는 단계;
상기 리듀서 가상머신 내 리듀서는 상기 블록 장치 파일을 리듀스 함수의 입력위치로 마운트하는 단계; 및
상기 리듀서가 모든 맵 함수의 출력을 받고, 리듀스 함수를 수행하는 단계;
를 포함하는 것을 특징으로 하는 가상 클라우드 환경 내 맵리듀스 클러스터 의 데이터 병렬 처리 방법.
1. A method for designing a MapReduce cluster in a virtual cloud environment,
Mounting a block device attached to a mount pointing point in a mapper virtual machine mapper;
The mapper performing a map task and generating an output of the map function at the mounted location;
When the mapping task is completed, the mapper releases the mount at the position where the output of the map function is generated;
A block device reconfiguration module located in a driver domain separating a block device file from the mapper virtual machine;
Attaching the block device file separated by the block device reconfiguration module to a reducer virtual machine;
Wherein the reducer in the reducer virtual machine mounts the block device file at the input location of the redess function; And
Receiving the output of all the map functions and performing a reduction function;
Wherein the data parallel processing in the virtual cluster environment comprises:
상기 리듀서가 상기 블록 장치 파일을 리듀스 함수의 입력위치로 마운트하는 단계는
상기 리듀서가 상기 매퍼 가상머신의 모든 블록 장치 파일들이 마운트될 때까지 기다리는 것을 더 포함하는 것을 특징으로 하는 가상 클라우드 환경 내 맵리듀스 클러스터의 데이터 병렬 처리 방법.
10. The method of claim 9,
Wherein the step of mounting the block device file at the input location of the redess function comprises:
Further comprising waiting for the reducer to mount all block device files of the mapper virtual machine. ≪ Desc / Clms Page number 19 >
매퍼 가상머신 내 매퍼가 마운트 포인팅 지점에 부착된 블록 장치를 마운트하는 단계;
상기 매퍼가 맵 태스크를 수행하고, 상기 마운트된 위치에서 상기 맵 함수의 출력을 생성하는 단계;
상기 맵 태스크의 수행이 완료되면, 상기 매퍼는 상기 맵 함수의 출력이 생성된 위치에서 마운트를 해제하는 단계;
드라이버 도메인 내 위치하는 블록 장치 재구성 모듈이 상기 매퍼 가상머신으로부터 블록 장치 파일을 분리하는 단계;
상기 매퍼 가상머신의 드라이버 도메인이 분리된 블록 장치 파일을 마운트하는 단계;
상기 블록 장치 재구성 모듈이 상기 블록 장치 파일이 마운트된 위치의 컨텐츠를 리듀서 가상머신의 드라이버 도메인으로 전송하는 단계;
상기 리듀서 가상머신의 부분 드라이버 도메인이 마운트된 블록 장치 파일을 마운트 해제하는 단계;
상기 블록 장치 재구성 모듈이 상기 리듀서 가상머신의 입력단에 블록 장치 파일을 부착하는 단계;
상기 리듀서 가상머신 내 리듀서는 상기 블록 장치 파일을 리듀스 함수의 입력위치로 마운트하는 단계; 및
상기 리듀서가 모든 맵 함수의 출력을 받고, 리듀서 함수를 수행하는 단계;
를 포함하는 것을 특징으로 하는 가상 클라우드 환경 내 맵리듀스 클러스터 의 데이터 병렬 처리 방법.
1. A method for designing a MapReduce cluster in a virtual cloud environment,
Mounting a block device attached to a mount pointing point in a mapper virtual machine mapper;
The mapper performing a map task and generating an output of the map function at the mounted location;
When the mapping task is completed, the mapper releases the mount at the position where the output of the map function is generated;
A block device reconfiguration module located in a driver domain separating a block device file from the mapper virtual machine;
Mounting a separate block device file in a driver domain of the mapper virtual machine;
Wherein the block device reconfiguration module transmits content of a location where the block device file is mounted to a driver domain of a reducer virtual machine;
Unmounting a block device file in which the partial driver domain of the reducer virtual machine is mounted;
The block device reconfiguration module attaching a block device file to an input of the reducer virtual machine;
Wherein the reducer in the reducer virtual machine mounts the block device file at the input location of the redess function; And
The reducer receiving the output of all map functions and performing a reducer function;
Wherein the data parallel processing in the virtual cluster environment comprises:
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020120122305AKR101435499B1 (en) | 2012-10-31 | 2012-10-31 | Mapreduce cluster node and design method in the virtual cloud environment |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020120122305AKR101435499B1 (en) | 2012-10-31 | 2012-10-31 | Mapreduce cluster node and design method in the virtual cloud environment |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20140056743A KR20140056743A (en) | 2014-05-12 |
| KR101435499B1true KR101435499B1 (en) | 2014-08-29 |
Family
ID=50887828
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020120122305AExpired - Fee RelatedKR101435499B1 (en) | 2012-10-31 | 2012-10-31 | Mapreduce cluster node and design method in the virtual cloud environment |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR101435499B1 (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023128013A1 (en)* | 2021-12-30 | 2023-07-06 | (주)페르세우스 | Operating system performance interference preventing apparatus of hypervisor system |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2019032123A1 (en) | 2017-08-11 | 2019-02-14 | Visa International Service Association | Systems and methods for generating distributed software packages using non-distributed source code |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2009059377A1 (en)* | 2007-11-09 | 2009-05-14 | Manjrosoft Pty Ltd | Software platform and system for grid computing |
| KR100907533B1 (en)* | 2007-12-17 | 2009-07-14 | 한국전자통신연구원 | Distributed Distributed Processing Systems and Methods |
| KR100946987B1 (en)* | 2007-12-18 | 2010-03-15 | 한국전자통신연구원 | Multi-map task intermediate result sorting and combining device, and method in a distributed parallel processing system |
| US20110283277A1 (en)* | 2010-05-11 | 2011-11-17 | International Business Machines Corporation | Virtualization and dynamic resource allocation aware storage level reordering |
- 2012
- 2012-10-31KRKR1020120122305Apatent/KR101435499B1/ennot_activeExpired - Fee Related
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2009059377A1 (en)* | 2007-11-09 | 2009-05-14 | Manjrosoft Pty Ltd | Software platform and system for grid computing |
| KR100907533B1 (en)* | 2007-12-17 | 2009-07-14 | 한국전자통신연구원 | Distributed Distributed Processing Systems and Methods |
| KR100946987B1 (en)* | 2007-12-18 | 2010-03-15 | 한국전자통신연구원 | Multi-map task intermediate result sorting and combining device, and method in a distributed parallel processing system |
| US20110283277A1 (en)* | 2010-05-11 | 2011-11-17 | International Business Machines Corporation | Virtualization and dynamic resource allocation aware storage level reordering |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2023128013A1 (en)* | 2021-12-30 | 2023-07-06 | (주)페르세우스 | Operating system performance interference preventing apparatus of hypervisor system |
Also Published As
| Publication number | Publication date |
|---|---|
| KR20140056743A (en) | 2014-05-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11269669B2 (en) | Providing data that is remotely stored to an operating system responsive to a local access request | |
| Zhang et al. | {FlashShare}: Punching Through Server Storage Stack from Kernel to Firmware for {Ultra-Low} Latency {SSDs} | |
| US11573831B2 (en) | Optimizing resource usage in distributed computing environments by dynamically adjusting resource unit size | |
| US8832688B2 (en) | Kernel bus system with a hyberbus and method therefor | |
| Peng et al. | {MDev-NVMe}: A {NVMe} storage virtualization solution with mediated {Pass-Through} | |
| US9569245B2 (en) | System and method for controlling virtual-machine migrations based on processor usage rates and traffic amounts | |
| AU2013206117B2 (en) | Hierarchical allocation of network bandwidth for quality of service | |
| TWI408934B (en) | Network interface technology | |
| US10366046B2 (en) | Remote direct memory access-based method of transferring arrays of objects including garbage data | |
| EP3350700B1 (en) | Multi root i/o virtualization system | |
| US10873630B2 (en) | Server architecture having dedicated compute resources for processing infrastructure-related workloads | |
| CN105556473A (en) | I/O task processing method, device and system | |
| CN118871890A (en) | An AI system, memory access control method and related equipment | |
| US11928517B2 (en) | Feature resource self-tuning and rebalancing | |
| Li et al. | A novel disk I/O scheduling framework of virtualized storage system | |
| KR101435499B1 (en) | Mapreduce cluster node and design method in the virtual cloud environment | |
| Wu et al. | iShare: Balancing I/O performance isolation and disk I/O efficiency in virtualized environments | |
| KR101701378B1 (en) | Apparatus and method of virtualization for file sharing with virtual machine | |
| Thaha et al. | Data location aware scheduling for virtual Hadoop cluster deployment on private cloud computing environment | |
| US9176910B2 (en) | Sending a next request to a resource before a completion interrupt for a previous request | |
| Wu et al. | I/O stack optimization for efficient and scalable access in FCoE-based SAN storage | |
| CN113760798A (en) | RDMA device allocation method, computing device and storage medium | |
| KR20160063711A (en) | Tenant Based Dynamic Processor Mapping Device and Method for Operating Thereof | |
| Cohen et al. | Applying Amdahl's Other Law to the data center | |
| WO2018173300A1 (en) | I/o control method and i/o control system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| PA0109 | Patent application | St.27 status event code:A-0-1-A10-A12-nap-PA0109 | |
| PA0201 | Request for examination | St.27 status event code:A-1-2-D10-D11-exm-PA0201 | |
| D13-X000 | Search requested | St.27 status event code:A-1-2-D10-D13-srh-X000 | |
| D14-X000 | Search report completed | St.27 status event code:A-1-2-D10-D14-srh-X000 | |
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection | St.27 status event code:A-1-2-D10-D21-exm-PE0902 | |
| T11-X000 | Administrative time limit extension requested | St.27 status event code:U-3-3-T10-T11-oth-X000 | |
| E13-X000 | Pre-grant limitation requested | St.27 status event code:A-2-3-E10-E13-lim-X000 | |
| P11-X000 | Amendment of application requested | St.27 status event code:A-2-2-P10-P11-nap-X000 | |
| P13-X000 | Application amended | St.27 status event code:A-2-2-P10-P13-nap-X000 | |
| PG1501 | Laying open of application | St.27 status event code:A-1-1-Q10-Q12-nap-PG1501 | |
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration | St.27 status event code:A-1-2-D10-D22-exm-PE0701 | |
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment | St.27 status event code:A-2-4-F10-F11-exm-PR0701 | |
| PR1002 | Payment of registration fee | St.27 status event code:A-2-2-U10-U11-oth-PR1002 Fee payment year number:1 | |
| PG1601 | Publication of registration | St.27 status event code:A-4-4-Q10-Q13-nap-PG1601 | |
| R18-X000 | Changes to party contact information recorded | St.27 status event code:A-5-5-R10-R18-oth-X000 | |
| FPAY | Annual fee payment | Payment date:20170801 Year of fee payment:4 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:4 | |
| PR1001 | Payment of annual fee | St.27 status event code:A-4-4-U10-U11-oth-PR1001 Fee payment year number:5 | |
| PN2301 | Change of applicant | St.27 status event code:A-5-5-R10-R13-asn-PN2301 St.27 status event code:A-5-5-R10-R11-asn-PN2301 | |
| PC1903 | Unpaid annual fee | St.27 status event code:A-4-4-U10-U13-oth-PC1903 Not in force date:20190823 Payment event data comment text:Termination Category : DEFAULT_OF_REGISTRATION_FEE | |
| PC1903 | Unpaid annual fee | St.27 status event code:N-4-6-H10-H13-oth-PC1903 Ip right cessation event data comment text:Termination Category : DEFAULT_OF_REGISTRATION_FEE Not in force date:20190823 | |
| R18-X000 | Changes to party contact information recorded | St.27 status event code:A-5-5-R10-R18-oth-X000 | |
| PN2301 | Change of applicant | St.27 status event code:A-5-5-R10-R13-asn-PN2301 St.27 status event code:A-5-5-R10-R11-asn-PN2301 | |
| R18-X000 | Changes to party contact information recorded | St.27 status event code:A-5-5-R10-R18-oth-X000 | |
| R18-X000 | Changes to party contact information recorded | St.27 status event code:A-5-5-R10-R18-oth-X000 | |
| R18-X000 | Changes to party contact information recorded | St.27 status event code:A-5-5-R10-R18-oth-X000 | |
| R18-X000 | Changes to party contact information recorded | St.27 status event code:A-5-5-R10-R18-oth-X000 |