JP7406418B2 - Voice quality conversion system and voice quality conversion method - Google Patents
Voice quality conversion system and voice quality conversion methodDownload PDFInfo
- Publication number
- JP7406418B2 JP7406418B2JP2020048518AJP2020048518AJP7406418B2JP 7406418 B2JP7406418 B2JP 7406418B2JP 2020048518 AJP2020048518 AJP 2020048518AJP 2020048518 AJP2020048518 AJP 2020048518AJP 7406418 B2JP7406418 B2JP 7406418B2
- Authority
- JP
- Japan
- Prior art keywords
- voice
- ppg
- conversion
- model
- voice quality
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000006243chemical reactionMethods0.000titleclaimsdescription190
- 238000000034methodMethods0.000titleclaimsdescription33
- 238000004458analytical methodMethods0.000claimsdescription43
- 230000000877morphologic effectEffects0.000claimsdescription21
- 230000010365information processingEffects0.000claimsdescription5
- 230000015572biosynthetic processEffects0.000description23
- 238000003786synthesis reactionMethods0.000description23
- 238000012545processingMethods0.000description22
- 238000000605extractionMethods0.000description12
- 238000010586diagramMethods0.000description11
- 238000005516engineering processMethods0.000description11
- 230000006870functionEffects0.000description11
- 238000012549trainingMethods0.000description9
- 238000010276constructionMethods0.000description6
- 239000000284extractSubstances0.000description5
- 238000004891communicationMethods0.000description4
- 239000013598vectorSubstances0.000description4
- 230000001755vocal effectEffects0.000description4
- 230000000694effectsEffects0.000description3
- 210000000056organAnatomy0.000description3
- 229920001451polypropylene glycolPolymers0.000description3
- 230000004044responseEffects0.000description3
- 238000003491arrayMethods0.000description2
- 238000013528artificial neural networkMethods0.000description2
- 230000015654memoryEffects0.000description2
- 238000011160researchMethods0.000description2
- 230000005236sound signalEffects0.000description2
- 238000013519translationMethods0.000description2
- OSXPVFSMSBQPBU-UHFFFAOYSA-N2-(2-carboxyethoxycarbonyl)benzoic acidChemical compoundOC(=O)CCOC(=O)C1=CC=CC=C1C(O)=OOSXPVFSMSBQPBU-UHFFFAOYSA-N0.000description1
- 101100072002Arabidopsis thaliana ICME geneProteins0.000description1
- 206010013952DysphoniaDiseases0.000description1
- 208000010473HoarsenessDiseases0.000description1
- 238000013473artificial intelligenceMethods0.000description1
- 230000002457bidirectional effectEffects0.000description1
- 230000006835compressionEffects0.000description1
- 238000007906compressionMethods0.000description1
- 238000013461designMethods0.000description1
- 230000002401inhibitory effectEffects0.000description1
- 210000000867larynxAnatomy0.000description1
- 238000004519manufacturing processMethods0.000description1
- 239000011159matrix materialSubstances0.000description1
- 239000000203mixtureSubstances0.000description1
- 230000008447perceptionEffects0.000description1
- 230000000306recurrent effectEffects0.000description1
- 230000000717retained effectEffects0.000description1
- 230000033764rhythmic processEffects0.000description1
- 230000006403short-term memoryEffects0.000description1
- 239000007787solidSubstances0.000description1
- 230000003595spectral effectEffects0.000description1
- 238000001308synthesis methodMethods0.000description1
Images











Landscapes
- Machine Translation (AREA)
Description
Translated fromJapanese本発明は、声質変換システムおよび声質変換方法に係り、特に、音声の声質変換を行うにあたって、安定して高い音質の音質変換を可能にする声質変換システムおよび声質変換方法に関する。 The present invention relates to a voice quality conversion system and a voice quality conversion method, and particularly to a voice quality conversion system and a voice quality conversion method that enable stable and high quality voice quality conversion when performing voice quality conversion.
近年、音声認識、機械翻訳、対話生成などの技術が飛躍的に向上してきたことを背景に、音声翻訳、音声対話サービス、サービスロボットなどの人工知能による音声コミュニケーションの実用化が急激に進んできた。その中に、声質変換(VC: Voice Conversion)技術が重要な技術の一つとして注目されている。声質変換とは、ある話者(source speaker)の発話に対して、含まれる発話内容と話し方を変えずに、別の話者(target speaker)の声に聞こえるように音声を編集する技術である。 In recent years, with the dramatic improvement in technologies such as voice recognition, machine translation, and dialogue generation, the practical application of voice communication using artificial intelligence, such as voice translation, voice dialogue services, and service robots, has progressed rapidly. . Among these, voice conversion (VC) technology is attracting attention as one of the important technologies. Voice quality conversion is a technology that edits the speech of one speaker (source speaker) so that it sounds like the voice of another speaker (target speaker) without changing the utterance content and speaking style. .
近年、各社サービスロボットのプロトタイプが次々と開発され、PoC(概念実証)が実施されている。このようなサービスロボットにおいては、音声認識や音声合成の技術は必須のものとなる。しかしながら、実環境(特に空港や駅など)では音声認識の精度が悪く、対話成功率が非常に低いという問題が生じる。このような結果、サービスロボットでの実戦配備が先延ばしとなり、リアルデータの蓄積ができなくなり、サービスロボットの市場成長を阻害する原因の一つとなっている。そこで、ロボットによる接客サービスの品質向上のために、音声認識や意図理解の精度向上研究と並行して、自動応答とオペレータ対応が連携した、ハイブリッド音声対話サービスが構想されている。 In recent years, prototypes of service robots from various companies have been developed one after another, and proofs of concept (PoC) are being conducted. Speech recognition and speech synthesis technologies are essential for such service robots. However, in real environments (particularly in airports, stations, etc.), the accuracy of voice recognition is poor and the success rate of dialogues is extremely low. As a result, the actual deployment of service robots has been postponed, making it impossible to accumulate real data, which is one of the causes of inhibiting the growth of the service robot market. Therefore, in order to improve the quality of customer service provided by robots, in parallel with research to improve the accuracy of voice recognition and intention understanding, a hybrid voice dialogue service that combines automatic response and operator response is being envisioned.
この構想を実現するためには、TTS(Text To Speech)で生成した自動対応音声とオペレータの肉声とがシームレスに切り替えられるため、オペレータの声をロボットの声に変換する声質変換技術が不可欠となる。 In order to realize this concept, voice quality conversion technology that converts the operator's voice into the robot's voice is essential, since the automatic response voice generated by TTS (Text To Speech) and the operator's real voice can be seamlessly switched. .
このような声質変換技術については、例えば、非特許文献1に、音素事後確率(PPG:Phonetic Posterior Gram)を用いて声質変換を行うことが論じられている。 Regarding such voice quality conversion technology, for example, Non-Patent Document 1 discusses performing voice quality conversion using phonetic posterior probabilities (PPGs).
従来の声質変換技術では、入力音声の収録環境によって、声質変換の性能が著しく低下するなどといった課題があったが、非特許文献1に記載された声質変換技術は、そのような課題を解決することを意図している。非特許文献1の記載された技術は、入力音声の話者性と収録環境音を取り除き、音声認識で学習した音響モデルを用いて、音声特徴量を発話内容にかかわる情報のみが含まれるPPGに変換することによって、安定した声質変換を実現しようとするものである。 Conventional voice quality conversion technology has had issues such as the performance of voice quality conversion being significantly degraded depending on the recording environment of the input voice, but the voice quality conversion technology described in Non-Patent Document 1 solves such problems. is intended. The technology described in Non-Patent Document 1 removes the speaker characteristics of the input speech and recording environment sounds, and uses an acoustic model learned through speech recognition to transform speech features into a PPG that includes only information related to the content of the utterance. By performing this conversion, the aim is to achieve stable voice quality conversion.
しかしながら、日本語音声認識で用いる音響モデルから生成されたPPGは、日本語音素の音素事後確率であり、調音構造に関係しない韻律情報や非周期成分情報などの情報は含まれていないとされている。そのため、日本語PPGのみから基本周波数(F0)(音響特徴量の一つ、音声のインパルス列の間隔の逆数と定義される。声の高さに相当する)を推測することは難しい。従来研究では、声道構造に関係するMCEP(メルケプトラム係数、メルケプトラムは、人の聴覚特性に合わせて低周波領域を細かくサンプリングする手法)のみをPPGで変換し、韻律情報(ピッチなど)は線形変換する手法で変換する。そして、別々に変換したパラメータを使って音声を再構築する。しかし、声質変換においては別々で生成した音声パラメータを用いた場合、声質変換音質の劣化につながりやすいと、一般的知られている。特に、F0の抽出が非常に不安定であるため、安定した声質変換ができなかった。 However, the PPG generated from the acoustic model used in Japanese speech recognition is the phoneme posterior probability of Japanese phonemes, and is said to not include information such as prosodic information or aperiodic component information that is not related to articulatory structure. There is. Therefore, it is difficult to estimate the fundamental frequency (F0) (one of the acoustic features, defined as the reciprocal of the interval between speech impulse trains, which corresponds to the pitch of the voice) from only the Japanese PPG. In conventional research, only the MCEP (Melceptrum coefficient, Melceptrum is a method that finely samples the low frequency region according to the human auditory characteristics) related to the vocal tract structure is converted using PPG, and the prosodic information (pitch, etc.) is converted using linear conversion. Convert using the following method. The audio is then reconstructed using the separately converted parameters. However, it is generally known that when separately generated voice parameters are used in voice quality conversion, the voice quality conversion tends to deteriorate the sound quality. In particular, since the extraction of F0 was extremely unstable, stable voice quality conversion was not possible.
本発明の目的は、音声の声質変換を行うにあたって、安定して高い音質の音質変換を可能にする声質変換システムおよび声質変換方法を提供することにある。 An object of the present invention is to provide a voice quality conversion system and a voice quality conversion method that enable stable and high quality voice quality conversion.
本発明の声質変換システムの構成は、好ましくは、情報処理装置により、入力音声から声質を変換した合成音声を出力する声質変換システムであって、声質変換用データ作成装置と、声質変換装置とを備え、声質変換用データ作成装置は、単語辞書とテキストと音声情報を対応付けた音声コーパスとを入力して、PPG変換モデルを生成するPPG(音素事後確率)変換モデル学習部と、音声コーパスとPPG変換モデルを入力して音声パラメータ生成モデルを生成する音声パラメータ生成モデル学習部とよりなり、PPG変換モデル学習部は、単語辞書から韻律情報付き辞書を生成し、音声コーパスに含まれるテキストを形態素解析して、形態素解析の結果と、韻律情報付き辞書に基づいて、韻律情報付き音素配列を生成し、韻律情報付き音素配列と、音声コーパスに含まれる音声情報の特徴量解析の結果として出力される音声特徴量とから、音響モデルを生成し、音響モデルを学習して、PPG変換モデルを生成し、音声パラメータ生成モデル学習部は、PPG変換モデルと音声コーパスより、PPG変換モデルに対応するPPGを生成し、音声コーパスに含まれる音声情報から音声パラメータを抽出し、生成されたPPGと音声パラメータを学習して、音声パラメータ生成モデルを生成し、声質変換装置は、入力音声とPPG変換モデル学習部が生成したPPG変換モデルと音声パラメータ生成モデル学習部が生成した音声パラメータ生成モデルとを入力し、音声コーパスに含まれる音声情報の特徴量解析の結果として出力される音声特徴量とPPG変換モデルとに基づいて、PPGを生成し、生成したPPGと音声パラメータ生成モデルに基づいて、音声パラメータを生成し、音声パラメータによる音声の波形を生成して、出力音声として出力するようにしたものである。
Preferably, the configuration of the voice quality conversion system of the present invention is a voice quality conversion system in which an information processing device outputs a synthesized voice whose voice quality is converted from an input voice, and includes a voice quality conversion data creation device and a voice quality conversion device. The voice quality conversion data creation deviceincludes a PPG (phoneme posterior probability) conversion model learning unit that generates a PPG conversion model by inputting a word dictionary and a speech corpus in which text and speech information are associated, and a speech corpus. It consists of a speech parameter generation model learning section that inputs a PPG conversion model and generates a speech parameter generation model. A phoneme array with prosodic information is generated based on the results of morphological analysis and a dictionary with prosodic information, and the phoneme array with prosodic information and the result of feature analysis of the speech information included in the speech corpus are output. The audio parameter generation model learning unit generates a PPG conversion model corresponding to the PPG conversion model from the PPG conversion model and the audio corpus. , extracts speech parameters from the speech information included in the speech corpus, learns the generated PPG and speech parameters to generate a speech parameter generation model, and the voice quality conversion device uses the input speech and PPG conversion model learning. The PPG conversion model generated by the unit and the audio parameter generation model generated by the audio parameter generation model learning unit are input, and the audio features and PPG conversion model are output as a result of feature analysis of audio information included in the audio corpus. Based on this, a PPG is generated, based on the generated PPG and an audio parameter generation model, audio parameters are generated, and audio waveforms based on the audio parameters are generated and output as output audio. .
本発明によれば、音声の声質変換を行うにあたって、安定して高い音質の音質変換を可能にする声質変換システムおよび声質変換方法を提供することができる。 According to the present invention, it is possible to provide a voice quality conversion system and a voice quality conversion method that enable stable and high quality voice quality conversion when performing voice quality conversion.
以下、本発明に係る各実施形態を、図1ないし図11を用いて説明する。 EMBODIMENT OF THE INVENTION Hereinafter, each embodiment based on this invention is described using FIG. 1 thru|or 11.
〔実施形態1〕
先ず、図1および図3を用いて声質変換システムの構成を説明する。
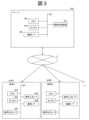
一般的な声質変換システムは、図1に示されるように、声質変換用データ作成装置200と、声質変換装置100により構成されている。声質変換用データ作成装置200は、音声コーパス10から声質変換用データ20を生成装置する装置である。声質変換装置100は、その声質変換用データ20を用いて、入力音声30から所望の声質を有する合成音声40に変換して出力する装置である。[Embodiment 1]
First, the configuration of the voice quality conversion system will be explained using FIGS. 1 and 3.
A typical voice quality conversion system, as shown in FIG. 1, includes a voice quality conversion
音声コーパス10は、音声ファイルとテキストを対応付けたデータである。声質変換用データ20は、PPG変換モデル1~PPG変換モデルNと、音声パラメータ生成モデルである(詳細は後述)。 The
以下では、各装置の機能構成とそれによる処理を主体として述べるが、それらの機能構成部は、ハードウェアとして実現してもよいし、ソフトウェアプログラムとして実現されてもよい。 In the following, the functional configuration of each device and the processing thereof will be mainly described, but these functional components may be realized as hardware or as a software program.
また、以下の説明では、学習時に日本語音声コーパスを例にしているが、ほかの自然言語、あるいは、複数言語の混じっている音声コーパスも用いても処理可能である。ただし、その場合は、その言語に対応したプログラム・データを用いなければならない。 Further, in the following explanation, a Japanese speech corpus is used as an example during learning, but processing can also be performed using other natural languages or speech corpora containing a mixture of multiple languages. However, in that case, program data corresponding to that language must be used.
さらに、以下の説明では、声質変換手法として、例えば、DNN(Deep Neural Network:深層ニューラルネットワーク)を用いることを前提にして説明しているが、他の統計ベース手法を用いてもよい。 Furthermore, although the following description is based on the assumption that, for example, a DNN (Deep Neural Network) is used as the voice quality conversion method, other statistical-based methods may be used.
次に、図2を用いて声質変換装置のハードウェア構成について説明する。
声質変換装置100は、一般的な情報処理装置で実現でき、図2に示されるように、例えば、補助記憶装置101と、音声入力I/F(InterFace)102と、CPU103と、主メモリ104と、音声出力I/F105とからなり、それらがバス107により接続された形態である。Next, the hardware configuration of the voice quality conversion device will be explained using FIG. 2.
The voice
CPU103は、声質変換装置100の各部を制御し、主記憶装置104に必要なプログラムをロードして実行する。
主メモリ104は、通常、RAMなどの揮発メモリで構成され、CPU102が実行するプログラム、参照するデータが記憶される。The
The
音声入力I/F102は、マイクなどと接続されて、音声信号を入力するためのインターフェースである。
音声出力I/F103は、スピーカなどと接続されて、音声信号を入力するためのインターフェースである。The audio input I/F 102 is an interface connected to a microphone or the like to input audio signals.
The audio output I/F 103 is an interface connected to a speaker or the like to input an audio signal.
音声の入出力は、例えば、WAVEファイルやMP3ファイルのようにコード化された音声データを入出力するようにしてもよい。 For audio input/output, for example, encoded audio data such as a WAVE file or an MP3 file may be input/output.
補助記憶装置101は、HDD(Hard Disk Drive)やSSD(Solid State Drive)などの大容量の記憶容量を有する記憶装置である。
補助記憶装置101には、図示しなかったが、本実施形態の声質変換装置100の機能を実行するためのプログラムである特徴量解析プログラム、PPG抽出プログラム、マージプログラム、音声パラメータ生成プログラム、波形生成プログラムがインストールされている。The
Although not shown, the
特徴量解析プログラム、PPG抽出プログラム、マージプログラム、音声パラメータ生成プログラム、波形生成プログラムは、それぞれ特徴量解析部、PPG抽出部、マージ部、音声パラメータ生成部、波形生成部の機能を実行するプログラムである。なお、これらの機能部の処理の詳細については、後述する。 The feature analysis program, PPG extraction program, merge program, audio parameter generation program, and waveform generation program are programs that execute the functions of a feature analysis section, a PPG extraction section, a merging section, an audio parameter generation section, and a waveform generation section, respectively. be. Note that details of the processing of these functional units will be described later.
また、補助記憶装置101には、声質変換装置100で使用される各種データが格納される。声質変換装置100で使用される各種データには、後述するように、音声特徴量、PPG、音声パラメータ生成モデル、音声パラメータがある。 Further, the
同様に、声質変換用データ作成装置200も、図2の声質変換装置100と同様の構成を有する情報処理装置で実現することができる。 Similarly, the voice quality conversion
声質変換用データ作成装置200の補助記憶装置101には、図示しなかったが、本実施形態の声質変換用データ作成装置200の機能を実行するためのプログラムであるPPG変換モデル学習プログラム、音声パラメータ生成モデル学習プログラムがインストールされている。 Although not shown, the
PPG変換モデル学習プログラム、音声パラメータ生成モデル学習プログラムは、それぞれPPG変換モデル学習部、音声パラメータ生成モデル学習部の機能を実行するプログラムである。なお、これらの機能部の処理の詳細については、後述する。 The PPG conversion model learning program and the audio parameter generation model learning program are programs that execute the functions of the PPG conversion model learning section and the audio parameter generation model learning section, respectively. Note that details of the processing of these functional units will be described later.
また、補助記憶装置101には、声質変換用データ作成装置200で使用される各種データが格納される。声質変換用データ作成装置200で使用される各種データには、後述するように、単語辞書、音声コーパス、音声パラメータ生成モデルがある。 Further, the
声質変換装置100は、例えば、カーナビゲーション装置、携帯電話機、パーソナルコンピュータ等のデバイスに、声質変換ユニットとして組み込まれている。そのため、図2に示した各ハードウェアは、声質変換装置100が組み込まれたデバイスにより実現してもよいし、声質変換用データ作成装置200と声質変換装置100が組み込まれたデバイスとは別個に設けられていてもよい。 The voice
声質変換に関するすべての機能を一つあるいは二つのデバイスだけで実現してもよいが、図3に示す変形例のように、サーバ330とクライアント端末400(図3では、400A、400Bと表記)が、ネットワーク5により相互接続されたシステムでも実現することができる。 All the functions related to voice quality conversion may be realized by only one or two devices, but as in the modified example shown in FIG. , can also be realized in a system interconnected by a
この場合には、クライアント端末400は、音声入力I/F402、音声出力I/F405と、通信I/F406を有し、クライアント端末400側で音声を受付け、声質変換に関する機能の一部または全部をサーバ300側で担当し、必要なデータをサーバ300側の通信I/F306とクライアント端末400の通信I/F405でやりとりするようにしてもよい。 In this case, the client terminal 400 has an audio input I/
次に、図4ないし図8を用いて実施形態1に係る声質変換システムの機能と処理について説明する。
先ず、図4を用いて声質変換データ装置の機能構成とデータフローについて説明する。
声質変換用データ作成装置200は、図4に示されるように、機能構成として、PPG変換モデル学習部210と音声パラメータ生成モデル学習部220を有している。Next, the functions and processing of the voice quality conversion system according to the first embodiment will be explained using FIGS. 4 to 8.
First, the functional configuration and data flow of the voice quality conversion data device will be explained using FIG.
As shown in FIG. 4, the voice quality conversion
PPG変換モデル学習部210は、単語辞書500と音声コーパス510を用いた学習により、PPG変換モデル(詳細は後述)700を生成する機能部である。 The PPG conversion
PPG(音素事後確率)とは、非特許文献1に定義されているように、ある発話におけるそれぞれの音素クラスに対する事後確率(非特許文献1では、時間-音素クラスの事後確率の表現行列)である。 PPG (phoneme posterior probability) is the posterior probability for each phoneme class in a certain utterance (in Non-patent document 1, it is an expression matrix of time-phoneme class posterior probability), as defined in Non-patent document 1. be.
音声パラメータ生成モデル学習部220は、生成用音声コープス(音声コープス510とデータ構造は同じ)520とPPG変換モデル600より、音声パラメータ生成モデルを生成する機能部である。 The audio parameter generation
次に、図5を用いてPPG変換モデル学習部の機能とデータフローの詳細について説明する。
PPG変換モデル学習部210では、上述のように単語辞書500と音声コーパス510を用いた学習により、PPG変換モデル700を生成する。このPPG変換モデル700は、入力音声30から発話内容と発話スタイル情報を含むPPGに変換するモデルである。このPPG変換モデル学習部210は、図5に示されるように、形態素解析部211、言語モデル学習部212、特徴量解析部213、辞書読み拡張部214、形態素配列拡張部215、音素配列&音響モデル学習部216、言語モデル考慮音響モデル学習部217のサブ機能部により構成されている。Next, the functions and data flow of the PPG conversion model learning section will be explained in detail using FIG. 5.
The PPG conversion
形態素解析部211、言語モデル学習部212、特徴量解析部213、辞書読み拡張部214、形態素配列拡張部215、音素配列&音響モデル学習部216、言語モデル考慮音響モデル学習部217は、それぞれ、PPG変換モデル学習プログラムのサブルーチンとして、形態素解析プログラム、言語モデル学習プログラム、特徴量解析プログラム、辞書読み拡張プログラム、形態素配列拡張プログラム、音素配列&音響モデル学習プログラム、言語モデル考慮音響モデル学習プログラムを実行することにより実現することができる。 The
形態素解析部211は、事前に用意した単語辞書500を用いて、テキストを形態素単位に分割する機能部である。ここで、形態素とは、言語学上で意味を有する最小の表現単位である。この形態素解析部211の機能を実現するために、一般的に使われているMeCabや茶筌などのOSS(Open Source Software)の形態素解析ツールを利用することができる。 The
単語辞書500には、必ずその言語における読みが用意してあるものとする。そして、形態素解析部211により、入力したテキストに対して、読み情報付き形態素配列600が生成される。 It is assumed that the
なお、本実施形態の説明で、形態素解析部211に「単語辞書」を入力するとしたが、辞書の単位は必ず単語ではなく、フレーズや文でもよい。 In the description of this embodiment, it is assumed that a "word dictionary" is input to the
ここで、一例を示すと、テキスト「これは箸です。」に対して、形態素解析した結果は、図6Aに示されるようになり、一方、テキスト「これは橋です。」に対して、形態素解析した結果は、図6Bに示されるようになる。 Here, to give an example, the result of morphological analysis for the text ``This is chopsticks.'' is shown in Figure 6A, while the morphological analysis result for the text ``This is a bridge.'' The analyzed results are shown in FIG. 6B.
言語モデル学習部212は、形態素解析部211から生成された読み情報付き形態素配列600を用いて、言語モデル学習を行い、言語モデルを作成する機能部である。言語モデル学習では、一般的にN-gramと呼ばれる言語モデルが使われることが多い。N-gramとは、任意の文字列や文書を、N個の連続した文字で分割する手法である。なお、近年、RNN(Recurrent Neural Network:再帰型ニューラルネットワーク)を用いた言語モデルなども使われるようになっている。 The language
特徴量解析部213は、音声コーパス520に含まれている音声から、特徴量を抽出する機能部である。音声コーパス520は、図5に示されるように、発話テキスト521と音声522を一対一に対応付けたデータである。音声の特徴量としては、一般的に、MFCCがよく使われているが、一部、LF0などの韻律情報を用いる研究も存在する。MFCC(Mel Frequency Ceastral Coefficient:メル周波数ケプストラム係数)は、対数ケプストラム(声道成分に由来した周波数特性を表現する)の低次成分に対して、ヒトの周波数知覚特性を考慮した重み付けをした特徴量である。LF0は、基本周波数F0の対数である。 The feature
本実施形態で用いる特徴量は、どのような特徴量を用いてもよいが、最低限、調音情報と韻律情報を含まれている必要がある。すなわち、MFCCを用いる場合は、低次元のみを用いる場合は、韻律情報が含まれていないため、全次元(16kHzの音声の場合は、全40次元)を用いることが推奨される。 Although any feature amount may be used in this embodiment, it is necessary to include at least articulatory information and prosody information. That is, when using MFCC, it is recommended to use all dimensions (all 40 dimensions in the case of 16 kHz speech) because prosodic information is not included if only low dimensions are used.
ここで、調音(articulation)とは、喉頭以上の器官の形や動きによって発声器官内の空気の流れを制御したり、発声器官内で発生する音声の共鳴の仕方を変化させたり、新たな音を発生あるいは追加したりして、さまざまな母音や子音を発生させることである。また、韻律(prosody)とは、発話において現れる音声学的性質で、抑揚あるいは音調、強勢、音長、リズムなどのその言語の一般的な書記記録からは予測されないものをいう。 Here, articulation refers to controlling the air flow within the vocal organs by the shape and movement of organs beyond the larynx, changing the way the sounds generated within the vocal organs resonate, and creating new sounds. It is the production of various vowels and consonants by producing or adding . Prosody refers to phonetic properties that occur in speech that are not predicted from the general written record of the language, such as intonation, tone, stress, duration, and rhythm.
辞書読み拡張部214は、事前に用意されている形態素解析用の単語辞書500に付与されている読み情報(音素情報)に対して、韻律シンボルを加えて、韻律情報付き音素に拡張し、韻律情報付き音素辞書602を生成する。なお、日本語の場合は、読み情報として音節を与えられることもあるので、以降単に「音素」と書いた場合でも、「音節」を指すこともあるものとする。ここで、言語学において、音素(phoneme)とは、ある個別言語の中で、同じとみなされる音の集まりをいい、音節(syllable)とは、連続する言語音を区切る文節単位の一種である。 The dictionary
この韻律情報付き音素は、各言語の特徴に合わせる必要があり、言語情報を担う韻律情報を定義することが必要である。例えば、日本語のような高低アクセント言語では、音節間F0の相対位置がアクセントの区別に重要な手がかりとなっているため、すべての母音にHigh Pitchを意味する「H」とLow Pitch を意味する「L」をつけることができる。一方では、中国語のような声調(tone)言語では、音節内のF0パターンが意味の理解に重要な役割を果たしているため、母音音素に4つの声調シンボルとして(いわゆる普通話の場合)、数字1~5(軽声、第1声~第4声)をつけることができる。さらに、アクセントの変形(中国語では変調)のことを考慮し、同じ単語に対しても、複数の韻律パターンを登録することにより、実際に音声の韻律変化を正確にとらえることができる。 This phoneme with prosodic information needs to match the characteristics of each language, and it is necessary to define the prosodic information that carries the linguistic information. For example, in pitch-accented languages such as Japanese, the relative position of F0 between syllables is an important clue to distinguish between accents, so all vowels have an "H" meaning High Pitch and a "H" meaning Low Pitch. You can add "L". On the other hand, in tonal languages such as Chinese, the F0 pattern within a syllable plays an important role in understanding meaning, so the vowel phoneme is represented by the digit 1 as four tonal symbols (in the case of so-called Putonghua). ~5 (light voice, 1st to 4th voice) can be added. Furthermore, by taking into account accent deformation (modulation in Chinese) and registering multiple prosodic patterns for the same word, it is possible to accurately capture the actual prosodic changes in speech.
一例としては、単語「橋」に対して、拡張前は、「表記=橋;読み=/ハ/+/シ/」となっているとして、拡張後は、上記の日本語の場合の韻律シンボルを付加し、「表記=橋;読み1=/ハL/+/シH/:読み2=/ハH/+/シH/」に拡張し、すべての話しうるアクセント型をリストする。一方、単語「箸」に対しては、拡張前は「表記=箸;読み=/ハ/+/シ/」となっていることに対して、拡張後は「表記=箸;読み1=/ハH/+/シL/:読み2=/ハH/+/シしH/」に拡張する。 As an example, for the word "hashi", before expansion, the spelling = bridge; reading = /ha/+/shi/, and after expansion, the prosodic symbol in the Japanese case above is and expands it to ``Notation=Hashi; Reading 1=/HaL/+/ShiH/:
すなわち、従来では、単語辞書500から音素配列を生成するのみであったが、本実施形態では、韻律情報付き辞書602により、韻律情報付き音素配列603を生成する。そのため、従来では音素配列だけでは一意に特定できない同音異義語に対しても、アクセントの違いによって、特定することができるようになる。すなわち、韻律情報付き音素を導入することにより、音声認識時に韻律情報を考慮することとなり、音響モデルの出力であるPPGには韻律情報が含まれることになる。 That is, conventionally, a phoneme array is only generated from the
形態素配列拡張部215は、形態素の読みを複数に展開し、すべての読みうるパターンを用意し、韻律情報付き音素配列603に変換する機能部である。 The morpheme
例えば、「これは橋です。」に対して、「/コL/+/レH/+/ワH/+/ハL/+/シH/+/デH/+/スL/」や「/コL/+/レH/+/ワH/+/ハH/+/シH/+/デH/+/スL/」に展開される。音素配列の数は、各単語に登録されている全読み数の組み合わせとなる。 For example, for "This is a bridge.", "/KOL/+/LeH/+/WAH/+/HaL/+/shiH/+/deH/+/suL/" or "This is a bridge." It is expanded to "/koL/+/ReH/+/WaH/+/HaH/+/ShH/+/DeH/+/SuL/". The number of phoneme arrays is a combination of the total number of readings registered for each word.
音素配列決定&音響モデル学習部216は、形態素配列拡張部215が生成した複数の韻律情報付き音素配列603から、最も確率の高い組み合わせを決定したうえ、各音素の特徴(音声特徴量であるMFCCの平均と分散)を計算し、音響モデル620を生成する機能部である。一般的に、最適系列の決定にHMM(Hidden Markov Model:隠れマルコフモデル)がよく使われているが、音響モデルの学習では、DNNを用いることが主流となっている。 The phoneme sequence determination & acoustic
言語モデル考慮音響モデル学習部213は、言語モデル学習部212が生成した言語モデル610と、音素配列決定&音響モデル学習部210が生成した音響モデル620を用いて、音声コーパス520に対してエラー率最小化の基準で再学習を行い、PPG変換モデル700を生成する機能部である。このように学習したPPG変換モデル700は、言語情報の伝達に必要な韻律情報を表現できるため、言語の特徴によって、表現できる韻律情報が異なる。 The language model consideration acoustic
例えば、高低アクセント言語(音節間のF0相対位置が単語の区別に寄与する言語)である日本語なら広域(複数シラブルにまたいだ範囲)のF0変動、声調言語(音節内のF0パターンの形状の違いが単語の区別に寄与する言語)である中国語なら局所的な(音節内の)F0変動をとらえることができる。それに対して、強弱アクセント言語である英語では音の強弱を表現することができると考えられる。 For example, in Japanese, which is a pitch-accented language (a language in which the relative F0 position between syllables contributes to word distinction), there is a wide range of F0 fluctuations (a range that spans multiple syllables), and a tonal language (a language in which the relative position of F0 between syllables contributes to word distinction). In Chinese, a language in which differences contribute to word distinction, local F0 fluctuations (within a syllable) can be detected. In contrast, English, which is a language with a strong accent, is thought to be able to express the strength of sounds.
次に、図7を用いて音声パラメータ生成モデル学習部の機能とデータフローの詳細について説明する。
音声パラメータ生成モデル学習部220では、上述のように、生成用音声コープス520とPPG変換モデル700より、音声パラメータ生成モデル1000を生成する機能部である。Next, the functions and data flow of the audio parameter generation model learning section will be explained in detail using FIG. 7.
The audio parameter generation
音声パラメータ生成モデル学習部220は、図7に示されるように、PPG抽出部221、PPGマージ部222、音声パラメータ抽出部223、音声モデル学習部224、特徴量解析部225のサブ機能部で構成されている。 As shown in FIG. 7, the audio parameter generation
PPG抽出部221、PPGマージ部222、音声パラメータ抽出部223、モデル学習部224、特徴量解析部225は、それぞれ、音声パラメータ生成モデル学習プログラムのサブルーチンとして、PPG抽出プログラム、PPGマージプログラム、音声パラメータ抽出プログラム、音声モデル学習プログラム、特徴量解析プログラムを実行することにより実現することができる。 The
PPG抽出部221は、図5で説明したPPG変換モデル学習部210で得られたPPG変換モデル700(図7では、PPG変換モデル1:700-1~PPG変換モデルN:700-Nと表記)を用いて、生成用音声コーパス511から特徴量解析部225により取り出された音声特徴量640に対して、PPG800(図7では、PPG1:800-1~PPGN:800-Nと表記)を抽出する機能部である。なお、特徴量解析部225は、図5に示した特徴量解析部213と同様である。ここで、複数のPPG変換モデルを用いることによって、正確な韻律表現が可能となる。具体的には、音節をまたいでゆっくり変化するF0の動きを表現できる日本語PPGと、音節内の局所的なF0変化をとらえられる中国語PPGとを組み合わせることにより、F0パターンを充実して表現することができる。すなわち、複数の特徴の異なる言語を組み合わせることによって、入力音声のどの特徴を出力音声に残したいのかを、デザインすることができる。この点で、本発明者の実証では、日本語、中国語、英語の3言語を用いることにより、発音の強弱や発話のイントネーションを精度よく再現できることを確認することができた。 The
PPGマージ部222は、PPG抽出部221から得られた複数のPPG800を一つのベクトルにマージする機能部である。ここでは、単に複数のベクトルをつなげ合わせて、次元数の大きなベクトルにすることも考えられるが、AutoEncoderなどの次元圧縮技術を使って、小さいベクトルに圧縮することもできる。 The
音声パラメータ抽出部223は、生成用音声コーパス511の音声から音声合成用の音声パラメータ223を抽出する。この部分は、一般的に、音声合成にも使われている技術であり、StraightやWorldなどのOSSを利用すれば、高品質な合成音声を得ることができる。 The speech
音声モデル学習部224は、同じ音声から抽出され、PPGマージ部222によりマージされたPPG800と音声パラメータ抽出部223が抽出した音声パラメータ900に対して、変換用DNNの学習により、音声パラメータ生成モデル1000を生成する。すなわち、入力がPPG800と音声パラメータ900であり、その出力として、入力した音声パラメータ900の音声パラメータ生成モデル1000が得られる。一般的に音声のような時系列信号に対しては、Bi-LSTM(Bidirectional Long Short Term Memory:双方向長期短期記憶)を用いたほうがより高い性能が得られる。 The voice
次に、図8を用いて声質変換装置の機能とデータフローについて説明する。
声質変換装置100は、図8に示されるように、特徴量解析部110、PPG抽出部111、PPGマージ部112、音声パラメータ生成部113、波形生成部114を有している。Next, the functions and data flow of the voice quality conversion device will be explained using FIG.
As shown in FIG. 8, the voice
特徴量解析部110は、図5に示した声質変換用データ作成装置200のPPG変換モデル学習部210の特徴量解析部213と同じ機能構成部である。PPG抽出部111とPPGマージ部112は、図7に示した声質変換用データ作成装置200の音声パラメータ生成モデル学習部210のPPG抽出部221とPPGマージ部222と、それぞれ同じ機能構成部である。 The feature
音声パラメータ生成部113は、声質変換用データ作成装置200の音声パラメータ生成モデル学習部210で得られた音声パラメータ生成モデル1000と、入力音声30とPPG変換モデル700から得られたPPG800を入力し、音声パラメータ900を生成する。音声パラメータ900は、例えば、音声の高さに相当する基本周波数、音色に相当するスペクトル包絡、有声音のかすれに相当する非周期性指標(Aperiodicity)がある。 The voice
波形生成部(ボコーダーともいう)114は、生成された音声パラメータ900を用いて、音声波形を生成し、変換した音声を出力音声40として出力する。 The waveform generation unit (also referred to as a vocoder) 114 generates a voice waveform using the generated
本実施形態の声質変換システムによれば、韻律情報を含んだPPG変換モデルによって、PPGを生成し、そのPPGを用いて音声パラメータを生成する。したがって、その音声パラメータによった声質変換により、話者の言語特有の韻律が考慮され、安定して高い音質の音質変換が可能となる。 According to the voice quality conversion system of this embodiment, a PPG is generated using a PPG conversion model that includes prosody information, and voice parameters are generated using the PPG. Therefore, by converting the voice quality using the voice parameters, the prosody peculiar to the language of the speaker is taken into consideration, and it becomes possible to convert the voice quality with stable high quality.
〔実施形態2〕
以下、本発明の実施形態2を、図9を用いて説明する。
本実施形態では、実施形態1に示した声質変換装置を用いた応用の一つとして、敵対的生成ネットワーク(GAN:Generative adversarial network)学習を用いた音声特徴量学習システムの処理とそのデータフローを説明する。[Embodiment 2]
In this embodiment, as one of the applications using the voice quality conversion device shown in Embodiment 1, we will explain the processing and data flow of a voice feature learning system using generative adversarial network (GAN) learning. explain.
本実施形態の音声特徴量学習システムは、敵対的生成ネットワークに基づいた学習を行うものであり、Generator Training Stage Generator Training StageとDiscriminator Training Stageの二つの段階よりなる。 The audio feature learning system of this embodiment performs learning based on an adversarial generative network, and consists of two stages: Generator Training Stage, Generator Training Stage, and Discriminator Training Stage.
本実施形態の音声特徴量学習システムは、異なる発話者から収録した多言語音声コーパス2010から、統一した声質の音声特徴量を抽出することができるシステムである。これにより最適化された音声特徴量を用いて、マルチリンガル音声合成システムを構築することができる。 The speech feature learning system of this embodiment is a system that can extract speech features of uniform voice quality from a
先ず、音声特徴量学習システムでは、言語が異なり、声質も異なる多言語音声コーパス2010(図9では、音声コーパス2010-1,音声コーパス2010-2,…と表記)から、実施形態1の声質変換装置100による声質変換処理150を実行し、各々の言語に対して、目標の声質Zを有する多言語音声コーパス2060(図9では、音声コーパス2060-1,音声コーパス2060-2,…と表記)を生成する。 First, in the speech feature learning system, the voice quality conversion of the first embodiment is performed from a multilingual speech corpus 2010 (denoted as speech corpus 2010-1, speech corpus 2010-2, ... in FIG. 9) with different languages and different voice qualities. A multilingual speech corpus 2060 (denoted as speech corpus 2060-1, speech corpus 2060-2, etc. in FIG. 9) having a target voice quality Z for each language by executing voice
一方、音声特徴量学習システムでは、Generator Training Stageで、多言語音声コーパス2010から言語特徴量解析処理2002により、言語特徴量2020を生成し、音声特徴量解析処理2003により、収録音声の音声特徴量2030を生成する。 On the other hand, in the speech feature learning system, the Generator Training Stage generates language features 2020 from the
次に、その言語特徴量2020と収録音声の音声特徴量2030を入力してモデル学習処理2000を行い、Generator(生成ネットワーク)による処理2001によって結果を出力する。Generatorによる処理2001では、ノイズを含んだデータによる合成音声特徴量2040を出力する。いわば、次に説明するDiscriminator(識別ネットワーク)をだますようなデータを生成する。 Next, the
また、Discriminator Training Stageでは、目標の声質Zを有する多言語音声コーパス2060から、言語特徴量解析処理2006により、変換後音声の音声特徴量2050を生成する。そして、Generator2001が生成した合成音声の特徴量2040と変換後音声の音声特徴量2050を入力してモデル学習処理2005を実行し、その結果をDiscriminatorに出力する。Discriminatorによる処理2004では、その真偽を識別し、真偽を判定するラベルを生成して、Generator Training Stageのモデル学習処理2000にフィードバックする。これによって、Generatorによる処理2001によって、自然でかつ声質Zの話者の声質に近い音声特徴量を生成することができる。 Further, in the Discriminator Training Stage, the
すなわち、このGenerator Training Stageと、Discriminator Training Stageを反復し、お互いの学習処理をループ処理させることにより、高い音質を維持したターゲットの声質Zの合成音声の音声特徴量を得ることができ、その音声特徴量を用いて複数の言語をサポートするターゲット話者の多言語音声合成システムを構築可能となる。 In other words, by repeating this Generator Training Stage and Discriminator Training Stage and looping the learning processes of each other, it is possible to obtain the voice features of the synthesized voice of the target voice quality Z that maintains high sound quality. It becomes possible to construct a multilingual speech synthesis system for target speakers that supports multiple languages using features.
本の実施形態においては、声質変換装置100に用いるPPGは、多言語音声コーパス2010に含まれる全ての言語のPPGをマージするものを利用することが望ましい。例えば、日中英の3言語バイリンガル音声合成システムを構築する場合は、図8に示したPPG抽出部において、日本語PPG、中国語PPG、英語PPGを抽出することが望ましい。 In this embodiment, it is desirable that the PPG used in the voice
なお、本実施形態の説明には、入力とする多言語音声コーパス2010には複数言語と複数の声質を含まれているものとして説明したが、単一言語単一声質でもよい。その場合には、音声合成の声質カスタマイズの効果を得ることができる。 Although the present embodiment has been described on the assumption that the input
〔実施形態3〕
以下、本発明に係る実施形態3を、図10を用いて説明する。
本実施形態では、実施形態1の声質変換装置100を用いた応用の一つとして、マルチリンガル音声合成システムを生成する処理について説明する。
先ず、言語が異なり、声質も異なる多言語音声コーパス3010(図10では、音声コーパス3010-1,音声コーパス3010-2,…と表記)から、実施形態1の声質変換装置100による声質変換処理150を実行し、各々の言語に対して、目標の声質Zを有する多言語音声コーパス3020(図9では、音声コーパス3020-1,音声コーパス3020-2,…と表記)を生成する。[Embodiment 3]
Embodiment 3 according to the present invention will be described below using FIG. 10.
In this embodiment, a process for generating a multilingual speech synthesis system will be described as one of the applications using the voice
First, voice
次に、多言語音声コーパス3020より、言語特徴量解析処理3001により、言語特徴量3030を生成し、音声特徴量解析処理3002により、収録音声の音声特徴量3040を生成する。
そして、それらを入力とする合成システム構築処理3000により、マルチリンガル音声合成システム3050を構築する。Next, a
Then, a multilingual
この音声合成システムを構築処理では、合成システム構築処理3000の合成手法によらず、音声合成システムを構築することができる。 In this speech synthesis system construction processing, a speech synthesis system can be constructed regardless of the synthesis method of the synthesis
なお、本実施形態の説明には、入力とする多言語音声コーパス2010には複数言語と複数の声質を含まれているものとして説明したが、単一言語単一声質でもよい。その場合には、音声合成の声質カスタマイズの効果を得ることができる。 Although the present embodiment has been described on the assumption that the input
〔実施形態4〕
以下、本発明に係る実施形態4を、図11を用いて説明する。
図11は、声質変換により変換された音声コーパスを用いて、入力テキストに対する音声合成をするシステムを構築する処理の流れとデータフローを示す図である。
本実施形態の処理は、音声合成システム構築処理と音声合成処理の二段階よりなる。[Embodiment 4]
Embodiment 4 of the present invention will be described below using FIG. 11.
FIG. 11 is a diagram showing a processing flow and a data flow for constructing a system that synthesizes speech for input text using a speech corpus converted by voice quality conversion.
The processing of this embodiment consists of two stages: speech synthesis system construction processing and speech synthesis processing.
先ず、音声合成システム構築処理では、言語が異なり、声質も異なる多言語音声コーパス4010(図10では、音声コーパス4010-1,音声コーパス4010-2,…と表記)から、言語特徴量解析処理4001により、言語特徴量4020を生成し、音声特徴量解析処理4002により、収録音声の音声特徴量4030を生成する。
そして、それらを入力とする合成システム構築処理4000により、マルチリンガル音声合成システム5000を構築する。First, in the speech synthesis system construction process, a language
Then, a multilingual
次に、音声合成処理では、音声合成システム5000に入力テキスト5010を入力して、合成音声5020を生成し、それを入力して、実施形態1の声質変換装置100の声質変換処理150により、目標とする声質Zの合成音声5030を出力する。 Next, in the speech synthesis process, the
本実施形態では、言語が異なり、声質も異なる多言語音声コーパス4010から、入力テキストに対応した統一した声質Zの声質の合成音声を出力することができる。 In this embodiment, it is possible to output synthesized speech with a unified voice quality Z corresponding to the input text from a
なお、本実施形態の説明には、入力とする多言語音声コーパス2010には複数言語と複数の声質を含まれているものとして説明したが、単一言語単一声質でもよい。その場合には、音声合成の声質カスタマイズの効果を得ることができる。 Although the present embodiment has been described on the assumption that the input
Claims (8)
Translated fromJapanese声質変換用データ作成装置と、
声質変換装置とを備え、
前記声質変換用データ作成装置は、
単語辞書とテキストと音声情報を対応付けた音声コーパスとを入力して、PPG変換モデルを生成するPPG(音素事後確率)変換モデル学習部と、
音声コーパスと前記PPG変換モデルを入力して音声パラメータ生成モデルを生成する音声パラメータ生成モデル学習部とよりなり、
前記PPG変換モデル学習部は、
前記単語辞書から韻律情報付き辞書を生成し、
前記音声コーパスに含まれるテキストを形態素解析して、形態素解析の結果と、前記韻律情報付き辞書に基づいて、韻律情報付き音素配列を生成し、
前記韻律情報付き音素配列と、前記音声コーパスに含まれる音声情報の特徴量解析の結果として出力される音声特徴量とから、音響モデルを生成し、
前記音響モデルを学習して、前記PPG変換モデルを生成し、
前記音声パラメータ生成モデル学習部は、
前記PPG変換モデルと音声コーパスより、前記PPG変換モデルに対応するPPGを生成し、
前記音声コーパスに含まれる音声情報から音声パラメータを抽出し、
前記生成されたPPGと前記音声パラメータを学習して、音声パラメータ生成モデルを生成し、
前記声質変換装置は、前記入力音声と前記PPG変換モデル学習部が生成したPPG変換モデルと前記音声パラメータ生成モデル学習部が生成した音声パラメータ生成モデルとを入力し、
前記音声コーパスに含まれる音声情報の特徴量解析の結果として出力される音声特徴量と前記PPG変換モデルとに基づいて、PPGを生成し、
生成した前記PPGと前記音声パラメータ生成モデルに基づいて、音声パラメータを生成し、
前記音声パラメータによる音声の波形を生成して、出力音声として出力することを特徴とする声質変換システム。A voice quality conversion system that outputs a synthesized voice whose voice quality is converted from an input voice using an information processing device,
a data creation device for voice quality conversion;
Equipped with a voice quality conversion device,
The voice quality conversion data creation device includes:
a PPG (phoneme posterior probability) conversion model learning unit that generates a PPG conversion model by inputting a word dictionary and a speech corpus that associates text and speech information;
comprising a speech parameter generation model learning unit that inputs the speech corpus and the PPG conversion model to generate a speech parameter generation model;
The PPG conversion model learning unit includes:
generating a dictionary with prosody information from the word dictionary;
morphologically analyzing the text included in the speech corpus and generating a phoneme array with prosodic information based on the result of the morphological analysis and the dictionary with prosodic information;
generating an acoustic model from the phoneme array with prosody information and a speech feature output as a result of feature analysis of speech information included in the speech corpus;
learning the acoustic model to generate the PPG conversion model;
The audio parameter generation model learning unit includes:
generating a PPG corresponding to the PPG conversion model from the PPG conversion model and the speech corpus;
extracting speech parameters from speech information included in the speech corpus;
learning the generated PPG and the audio parameters to generate an audio parameter generation model;
The voice quality conversion device receives the input voice, the PPG conversion model generated by the PPG conversion model learning unit, and the voice parameter generation model generated by the voice parameter generation model learning unit,
generating a PPG based on the PPG conversion model and a voice feature output as a result of feature analysis of voice information included in the voice corpus;
Generate audio parameters based on the generated PPG and the audio parameter generation model,
A voice quality conversion system that generates a voice waveform based on the voice parameters and outputs it as output voice.
前記音響モデルと前記言語モデルの学習により、前記PPG変換モデルを生成することを特徴とする請求項1記載の声質変換システム。The PPG conversion model learning unit morphologically analyzes the text of the speech corpus, performs language model learning, and generates a language model;
2. The voice quality conversion system according to claim 1, wherein the PPG conversion model is generated by learning the acoustic model and the language model.
前記声質変換システムは、
声質変換用データ作成装置と、
声質変換装置とを備え、
前記声質変換用データ作成装置が、単語辞書とテキストと音声情報を対応付けた音声コーパスとを入力して、PPG変換モデルを生成するPPG(音素事後確率)変換モデル学習ステップと、
前記声質変換用データ作成装置が、音声コーパスと前記PPG変換モデルを入力して音声パラメータ生成モデルを生成する音声パラメータ生成モデル学習ステップとを有し、
前記PPG変換モデル学習ステップは、
前記声質変換用データ作成装置が、前記単語辞書から韻律情報付き辞書を生成するステップと、
前記声質変換用データ作成装置が、前記音声コーパスに含まれるテキストを形態素解析して、形態素解析の結果と、前記韻律情報付き辞書に基づいて、韻律情報付き音素配列を生成するステップと、
前記声質変換用データ作成装置が、前記韻律情報付き音素配列と、前記音声コーパスに含まれる音声情報の特徴量解析の結果として出力される音声特徴量とから、音響モデルを生成するステップと、
前記声質変換用データ作成装置が、前記音響モデルを学習して、前記PPG変換モデルを生成するステップとからなり、
前記音声パラメータ生成モデル学習ステップは、
前記声質変換用データ作成装置が、前記PPG変換モデルと音声コーパスより、前記PPG変換モデルに対応するPPGを生成するステップと、
前記声質変換用データ作成装置が、前記音声コーパスに含まれる音声情報から音声パラメータを抽出するステップと、
前記声質変換用データ作成装置が、前記生成されたPPGと前記音声パラメータを学習して、音声パラメータ生成モデルを生成するステップとからなり、
前記声質変換装置が、前記入力音声と前記PPG変換モデル学習ステップにより生成されたPPG変換モデルと前記音声パラメータ生成モデル学習ステップにより生成された音声パラメータ生成モデルとを入力するステップと、
前記声質変換装置が、前記音声コーパスに含まれる音声情報の特徴量解析の結果として出力される音声特徴量と前記PPG変換モデルとに基づいて、PPGを生成するステップと、
前記声質変換装置が、生成した前記PPGと前記音声パラメータ生成モデルに基づいて、音声パラメータを生成するステップと、
前記声質変換装置が、前記音声パラメータによる音声の波形を生成して、出力音声として出力するステップとを有することを特徴とする声質変換方法。A voice quality conversion method that performs voice quality conversion using a voice quality conversion system that outputs a synthesized voice whose voice quality has been converted from an input voice using an information processing device, the method comprising:
The voice quality conversion system includes:
a data creation device for voice quality conversion;
Equipped with a voice quality conversion device,
a PPG (phoneme posterior probability) conversion model learning step in which the voice quality conversion data creation device generates a PPG conversion model by inputting a word dictionary and a speech corpus in which text and speech information are associated;
The voice quality conversion data creation device has a voice parameter generation model learning step of inputting a voice corpus and the PPG conversion model to generate a voice parameter generation model,
The PPG conversion model learning step includes:
a step in which the voice quality conversion data creation device generates a dictionary with prosody information from the word dictionary;
a step in which the voice quality conversion data creation device morphologically analyzes the text included in the speech corpus and generates a phoneme array with prosody information based on the result of the morphological analysis and the dictionary with prosody information;
a step in which the voice quality conversion data creation device generates an acoustic model from the phoneme array with prosody information and voice features output as a result of feature analysis of voice information included in the speech corpus;
the voice quality conversion data creation device learning the acoustic model and generating the PPG conversion model;
The audio parameter generation model learning step includes:
a step in which the voice quality conversion data creation device generates a PPG corresponding to the PPG conversion model from the PPG conversion model and the speech corpus;
the voice quality conversion data creation device extracting voice parameters from voice information included in the voice corpus;
the voice quality conversion data creation device learning the generated PPG and the voice parameters to generate a voice parameter generation model;
the voice quality conversion device inputting the input voice, the PPG conversion model generated by the PPG conversion model learning step, and the voice parameter generation model generated by the voice parameter generation model learning step;
a step in which the voice quality conversion device generates a PPG based on the PPG conversion model and a voice feature output as a result of feature analysis of voice information included in the voice corpus;
a step in which the voice quality conversion device generates voice parameters based on the generated PPG and the voice parameter generation model;
A voice quality conversion method comprising the step of the voice quality conversion device generating a voice waveform based on the voice parameters and outputting it as output voice.
前記音響モデルと前記言語モデルの学習により、前記PPG変換モデルを生成するステップとからなることを特徴とする請求項5記載の声質変換方法。The PPG conversion model learning step includes a step of morphologically analyzing the text of the speech corpus, and a step of performing language model learning and generating a language model based on the result of the morphological analysis.
6. The voice quality conversion method according to claim 5, further comprising the step of generating the PPG conversion model by learning the acoustic model and the language model.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020048518AJP7406418B2 (en) | 2020-03-19 | 2020-03-19 | Voice quality conversion system and voice quality conversion method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020048518AJP7406418B2 (en) | 2020-03-19 | 2020-03-19 | Voice quality conversion system and voice quality conversion method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2021148942A JP2021148942A (en) | 2021-09-27 |
| JP7406418B2true JP7406418B2 (en) | 2023-12-27 |
Family
ID=77848520
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2020048518AActiveJP7406418B2 (en) | 2020-03-19 | 2020-03-19 | Voice quality conversion system and voice quality conversion method |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP7406418B2 (en) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113450759A (en)* | 2021-06-22 | 2021-09-28 | 北京百度网讯科技有限公司 | Voice generation method, device, electronic equipment and storage medium |
| CN114464162B (en)* | 2022-04-12 | 2022-08-02 | 阿里巴巴达摩院(杭州)科技有限公司 | Speech synthesis method, neural network model training method, and speech synthesis model |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180012613A1 (en) | 2016-07-11 | 2018-01-11 | The Chinese University Of Hong Kong | Phonetic posteriorgrams for many-to-one voice conversion |
| JP2020190605A (en) | 2019-05-21 | 2020-11-26 | 株式会社 ディー・エヌ・エー | Voice processing device and voice processing program |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019008120A (en)* | 2017-06-23 | 2019-01-17 | 株式会社日立製作所 | Voice quality conversion system, voice quality conversion method and voice quality conversion program |
- 2020
- 2020-03-19JPJP2020048518Apatent/JP7406418B2/enactiveActive
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180012613A1 (en) | 2016-07-11 | 2018-01-11 | The Chinese University Of Hong Kong | Phonetic posteriorgrams for many-to-one voice conversion |
| JP2020190605A (en) | 2019-05-21 | 2020-11-26 | 株式会社 ディー・エヌ・エー | Voice processing device and voice processing program |
Non-Patent Citations (3)
| Title |
|---|
| YI Zhou, et al.,CROSS-LINGUAL VOICE CONVERSION WITH BILINGUAL PHONETIC POSTERIORGRAM AND AVERAGE MODELING,ICASSP 2019,IEEE,2019年05月,pp.6790-6794 |
| YOW-Bang Wang, et al.,An Experimental Analysis on Integrating Multi-Stream Spectro-Temporal, Cepstral and Pitch Information for Mandarin Speech Recognition,IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING,Vol.21, No.10,2013年10月,pp.2006-2014 |
| 齋藤佑樹他,音素事後確率を用いた多対一音声変換のための音声認識・生成モデルの同時敵対学習,日本音響学会2019年秋季研究発表会講演論文集[CD-ROM],2019年09月,pp.963-966 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2021148942A (en) | 2021-09-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7500020B2 (en) | Multilingual text-to-speech synthesis method | |
| US12020687B2 (en) | Method and system for a parametric speech synthesis | |
| Mache et al. | Review on text-to-speech synthesizer | |
| CN104217713A (en) | Tibetan-Chinese speech synthesis method and device | |
| JP7406418B2 (en) | Voice quality conversion system and voice quality conversion method | |
| Jalin et al. | Text to speech synthesis system for tamil using HMM | |
| Yin | An overview of speech synthesis technology | |
| Chiang et al. | The speech labeling and modeling toolkit (slmtk) version 1.0 | |
| Chettri et al. | Nepali text to speech synthesis system using esnola method of concatenation | |
| Nair et al. | Indian text to speech systems: A short survey | |
| JPWO2010104040A1 (en) | Speech synthesis apparatus, speech synthesis method and speech synthesis program based on one model speech recognition synthesis | |
| Bonafonte et al. | The UPC TTS system description for the 2008 blizzard challenge | |
| Begum et al. | Text-to-speech synthesis system for Mymensinghiya dialect of Bangla language | |
| Charoenrattana et al. | Pali speech synthesis using HMM | |
| Khalil et al. | Arabic speech synthesis based on HMM | |
| Louw | Cross-lingual transfer using phonological features for resource-scarce text-to-speech | |
| Nadeem et al. | Designing a model for speech synthesis using HMM | |
| Sulír et al. | Development of the Slovak HMM-based tts system and evaluation of voices in respect to the used vocoding techniques | |
| Ekpenyong et al. | Tone modelling in Ibibio speech synthesis | |
| Allen | Speech synthesis from text | |
| Kaur et al. | BUILDING AText-TO-SPEECH SYSTEM FOR PUNJABI LANGUAGE | |
| Yin | A Simplified Overview of TTS Techniques | |
| Narupiyakul et al. | A stochastic knowledge-based Thai text-to-speech system | |
| Hosn et al. | New resources for brazilian portuguese: Results for grapheme-to-phoneme and phone classification | |
| Balyan et al. | Development and implementation of Hindi TTS |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination | Free format text:JAPANESE INTERMEDIATE CODE: A621 Effective date:20220714 | |
| A977 | Report on retrieval | Free format text:JAPANESE INTERMEDIATE CODE: A971007 Effective date:20230530 | |
| A131 | Notification of reasons for refusal | Free format text:JAPANESE INTERMEDIATE CODE: A131 Effective date:20230711 | |
| A521 | Request for written amendment filed | Free format text:JAPANESE INTERMEDIATE CODE: A523 Effective date:20230901 | |
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) | Free format text:JAPANESE INTERMEDIATE CODE: A01 Effective date:20231212 | |
| A61 | First payment of annual fees (during grant procedure) | Free format text:JAPANESE INTERMEDIATE CODE: A61 Effective date:20231215 | |
| R150 | Certificate of patent or registration of utility model | Ref document number:7406418 Country of ref document:JP Free format text:JAPANESE INTERMEDIATE CODE: R150 |