JP7257349B2 - Program, device and method for estimating characteristic gesture of target person - Google Patents
Program, device and method for estimating characteristic gesture of target personDownload PDFInfo
- Publication number
- JP7257349B2 JP7257349B2JP2020040481AJP2020040481AJP7257349B2JP 7257349 B2JP7257349 B2JP 7257349B2JP 2020040481 AJP2020040481 AJP 2020040481AJP 2020040481 AJP2020040481 AJP 2020040481AJP 7257349 B2JP7257349 B2JP 7257349B2
- Authority
- JP
- Japan
- Prior art keywords
- time
- target
- series
- point coordinates
- target person
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






Landscapes
- Processing Or Creating Images (AREA)
- Image Analysis (AREA)
Description
Translated fromJapanese本発明は、ユーザと対話するエージェントの技術に関する。 The present invention relates to technology for agents that interact with users.
スマートフォンやタブレットのような端末を用いて、ユーザに対して自然に対話するエージェントが広く普及している。エージェントとは、コンピュータグラフィックスによって表現されたアバター(キャラクタ)と、テキストや音声によって対話する対話機能とからなる。エージェントは、ユーザにとって対話相手として存在し、その時点の状況に応じた対話内容を進行させる。
エージェントは、ユーザプロファイルと同様に、個性(年齢、性別等)を持つ。趣味趣向や感情に応じて対話するエージェントに対して、ユーザは親近感を持つことができる。Agents that interact naturally with users using terminals such as smartphones and tablets are widely used. An agent consists of an avatar (character) represented by computer graphics and a dialogue function that interacts with text or voice. The agent exists as a conversational partner for the user, and advances the content of the conversation according to the situation at that time.
Agents, like user profiles, have personalities (age, gender, etc.). A user can have a sense of familiarity with an agent who interacts according to his or her tastes and emotions.
エージェントは、実在しない仮想キャラクタを想定したものであってもよいし、実在する他人を模したものであってもよい。他人を模したエージェントの場合、そのアバターは、その他人の姿を表現した画像となっていることが好ましい。ユーザは、そのようなアバターと対話することによって、更にその性格や人物らしさを感じることができる。
例えば寂しさを感じているシニア層ユーザに対して、エージェントは、対話を通じて活力を与えるであろう、と考えられる。ユーザは、想定する人物と対話した気分になれることで寂しさが解消されるであろう、と考えられる。The agent may be a hypothetical virtual character that does not exist, or may be an imitation of a real person. In the case of an agent that imitates another person, the avatar is preferably an image representing the appearance of the other person. By interacting with such an avatar, the user can further feel the character and personality of the avatar.
For example, it is conceivable that the agent will energize senior users who are feeling lonely through dialogue. It is thought that the loneliness of the user will be relieved by being able to feel that he or she has interacted with an assumed person.
従来、エージェントの発話に応じて、アバターの視覚表現(表情や身振りなど)を自動生成する技術がある(例えば非特許文献1参照)。この技術によれば、学習段階として、人間同士の「発話文」及び「視覚表現」を収録したマルチモーダルコーパスを教師データとして、視覚表現学習エンジンを学習させる。そして、運用段階として、実際の「発話文」を視覚表現学習エンジンに入力することによって、「視覚表現」が出力される。 Conventionally, there is a technique for automatically generating a visual expression (facial expression, gesture, etc.) of an avatar according to an agent's utterance (see, for example, Non-Patent Document 1). According to this technique, in the learning stage, a multimodal corpus containing "spoken sentences" and "visual expressions" between humans is used as teacher data to train a visual expression learning engine. Then, as an operation stage, a "visual expression" is output by inputting an actual "spoken sentence" into the visual expression learning engine.
非特許文献1に記載の技術によれば、汎用的な視覚表現しか生成できないため、アバターの視覚表現の表現能力が少ない。そのために、実在の人物を模したアバターであっても、その人物特有の特徴的な身振りをアバターに表現することができず、ユーザは、大きな違和感が持ってしまっていた。 According to the technology described in Non-Patent
これに対し、本願の発明者は、対象人物の特徴的な身振りを推定すること自体が困難であったのではないか、と考えた。対象人物が映り込む映像から、その特徴的な身振りを推定することができれば、その身振りをアバターに反映させることができるのではないか、と考えた。 On the other hand, the inventor of the present application thought that it might have been difficult to estimate the characteristic gesture of the target person. We thought that if we could estimate the characteristic gestures of the target person from the video in which they appear, we might be able to reflect those gestures in the avatar.
そこで、本発明は、対象人物の特徴的な身振りを推定するプログラム、装置及び方法を提供することを目的とする。また、推定された特徴的な身振りをアバターに反映させることによって、エージェントと対話するユーザは、そのアバターの身振りから、その対象人物の性格や人物らしさを感じることができる。 SUMMARY OF THE INVENTION Accordingly, it is an object of the present invention to provide a program, apparatus, and method for estimating a characteristic gesture of a target person. In addition, by reflecting the estimated characteristic gestures on the avatar, the user interacting with the agent can feel the character and personality of the target person from the gestures of the avatar.
本発明によれば、対象人物の特徴的な身振りを推定するようにコンピュータを機能させるプログラムであって、
対象人物が映り込む対象部分映像と、異なる非対象人物が映り込む複数の非対象部分映像とのそれぞれについて、時系列のフレーム毎に人物の複数の骨格点を抽出し、当該骨格点の時系列の座標変位を表す時系列骨格点座標を推定する姿勢推定手段と、
対象部分映像の時系列骨格点座標と複数の非対象部分映像の時系列骨格点座標の全てとを、所定条件に基づいて複数のクラスタに分類するクラスタリング手段と、
各クラスタに含まれる対象人物の時系列骨格点座標の個数と非対象人物の時系列骨格点座標の個数とを比較して、対象人物に特有に出現する特徴クラスタを推定する特徴クラスタ推定手段と、
特徴クラスタに含まれる時系列骨格点座標を、対象人物の特徴的な身振りとして推定する身振り推定手段と
してコンピュータを機能させることを特徴とする。According to the present invention, a program that causes a computer to estimate a characteristic gesture of a target person, comprising:
For each of a target partial video in which a target person is captured and a plurality of non-target partial videos in which different non-target people are captured, a plurality of skeletal points of a person are extracted for each time-series frame, and the time series of the skeletal points is obtained. posture estimation means for estimating time-series skeletal point coordinates representing coordinate displacement of
clustering means for classifying the time-series skeleton point coordinates of the target partial video and all of the time-series skeleton point coordinates of the plurality of non-target partial videos into a plurality of clusters based on a predetermined condition;
feature cluster estimating means for estimating a feature cluster that appears uniquely to a target person by comparingthe number of time-series skeletal point coordinates of the target person andthe number of time-series skeletal point coordinates of the non-target person included in each cluster; ,
The feature is that the computer functions as gesture estimation means for estimating the time-series skeletal point coordinates included in the feature cluster as the characteristic gesture of the target person.
本発明のプログラムにおける他の実施形態によれば、
身振り推定手段は、特徴クラスタに含まれる全ての時系列骨格点座標の中で重心に最も近い時系列骨格点座標、又は、特徴クラスタに含まれる全ての時系列骨格点座標から算出された重心となる時系列骨格点座標を、対象人物の特徴的な身振りとして推定する
ようにコンピュータを更に機能させることも好ましい。According to another embodiment of the program of the present invention,
The gesture estimating means calculates the time-series skeleton point coordinates closest to the center of gravity among all the time-series skeleton point coordinates contained in the feature cluster, or the center of gravity calculated from all the time-series skeleton point coordinates contained in the feature cluster. It is also preferred that the computer is further operable to estimate the time-series skeletal point coordinates as a characteristic gesture of the target person.
本発明のプログラムにおける他の実施形態によれば、
姿勢推定手段の前段として、対象人物が映り込む対象映像について発話音声が含まれる対象部分映像を抽出すると共に、異なる非対象人物が映り込む複数の非対象映像それぞれについて発話音声が含まれる非対象部分映像とを抽出する部分映像抽出手段と
してコンピュータを更に機能させることも好ましい。According to another embodiment of the program of the present invention,
As the preceding stage of the posture estimation means, extracting a target portion video including speech voice from a target video in which a target person is captured, and extracting a non-target portion including speech voice in each of a plurality of non-target videos in which different non-target persons are captured. It is also preferable to cause the computer to further function as partial image extracting means for extracting images.
本発明のプログラムにおける他の実施形態によれば、
対象人物のアバターを、ディスプレイに表示するアバター表示手段と
してコンピュータを更に機能させ、
アバター表示手段は、身振り推定手段によって推定された時系列骨格点座標を、当該アバターの骨格点位置に合わせて、当該アバターを時系列に動作させて表示する
ようにコンピュータを機能させることも好ましい。According to another embodiment of the program of the present invention,
making the computer further function as avatar display means for displaying the target person's avatar on the display;
It is also preferable that the avatar display means cause the computer to operate and display the avatar in chronological order by aligning the time-series skeletal point coordinates estimated by the gesture estimating means with the skeletal point positions of the avatar.
本発明のプログラムにおける他の実施形態によれば、
対象部分映像の発話音声と複数の非対象部分映像の発話音声とのそれぞれを、発話テキストに変換する音声テキスト変換手段と、
対象部分映像の発話テキストと複数の非対象部分映像の群の発話テキストとのそれぞれについて、発話意図フラグを付与する発話意図推定手段と
してコンピュータを更に機能させ、
クラスタリング手段は、所定条件として発話意図フラグ毎のクラスタに分類し、
特徴クラスタ推定手段は、発話意図フラグ毎に、特徴クラスタを推定し、
身振り推定手段は、発話意図フラグ毎に、対象人物の特徴的な身振りを推定する
ようにコンピュータを機能させることも好ましい。According to another embodiment of the program of the present invention,
speech-to-text conversion means for converting each of the speech sound of the target partial video and the speech sounds of the plurality of non-target partial videos into speech text;
causing the computer to further function as an utterance intention estimation means for adding an utterance intention flag to each of the utterance text of the target partial video and the utterance text of the group of the plurality of non-target partial videos;
The clustering means classifies into clusters for each utterance intention flag as a predetermined condition,
The feature cluster estimation means estimates a feature cluster for each utterance intention flag,
It is also preferable that the gesture estimation means causes the computer to estimate the characteristic gesture of the target person for each speech intention flag.
本発明のプログラムにおける他の実施形態によれば、
発話意図推定手段は、発話テキストと発話意図フラグとを対応付けて予め学習し、発話テキストを入力することによって発話意図フラグを推定するものであり、
発話意図フラグは、用例に基づくフラグ、又は、感情に基づくフラグである
ようにコンピュータを機能させることも好ましい。According to another embodiment of the program of the present invention,
The utterance intention estimation means learns in advance the utterance text and the utterance intention flag in association with each other, and estimates the utterance intention flag by inputting the utterance text,
It is also preferred to have the computer act like the speech intent flag is an example-based flag or an emotion-based flag.
本発明のプログラムにおける他の実施形態によれば、
対象人物と対話する対話制御手段と
して更に機能させ、
対話制御手段によってアバターが発話すべき発話テキストに対応する当該発話意図フラグに応じた特徴クラスタを用いて、対象人物の特徴的な身振りを決定する
ようにコンピュータを機能させることも好ましい。According to another embodiment of the program of the present invention,
Further functioning as dialogue control means for interacting with the target person,
It is also preferred that the interaction control means causes the computer to determine characteristic gestures of the target person using feature clusters corresponding to said speech intent flags corresponding to speech texts to be spoken by the avatar.
本発明のプログラムにおける他の実施形態によれば、
特徴クラスタ推定手段は、赤池情報量規準(AIC:Akaike's Information Criterion)を用いて、各クラスタについて、対象人物の時系列骨格点座標の個数P1に対する非対象人物の時系列骨格点座標の個数P2の評価値V(P1,P2)を算出し、当該評価値V(P1,P2)が所定閾値以上となる、又は、当該評価値V(P1,P2)が大きいものから順に所定数となる、任意のクラスタを抽出する
p11:任意のクラスタの中で、対象人物の時系列骨格点座標の個数
p12:任意のクラスタの中で、非対象人物の時系列骨格点座標の個数
p21:任意のクラスタ以外のクラスタについて、対象人物の時系列骨格点座標の個数
p22:任意のクラスタ以外のクラスタについて、非対象人物の時系列骨格点座標の個数
p11+p12+p21+p22=対象人物及び非対象人物全ての時系列骨格点座標の個数
MLL_IM(P1,P2)=(p11+p12) log(p11+p12)
+(p11+p21) log(p11+p21)
+(p21+p22) log(p21+p22)
+(p12+p22) log(p12+p22)-2N log N
MLL_DM(P1,P2)=p11 log p11+p12 log p12+p21 log p21+p22 log p22-N log N
但し、N=p11+p12+p21+p22
AIC_IM(P1,P2)=-2 × MLL_IM(P1,P2) + 2×2
AIC_IM(P1,P2):対象人物の時系列骨格点座標の群と、非対象人物の時系列骨格点座標の群との組の従属AIC
AIC_DM(P1,P2)=-2 × MLL_DM(P1,P2) + 2×3
AIC_DM(P1,P2):対象人物の時系列骨格点座標の群と、非対象人物の時系列骨格点座標の群との組の独立AIC
V(P1,P2)=AIC_IM(P1,P2) - AIC_DM(P1,P2)
としてコンピュータを機能させることも好ましい。According to another embodiment of the program of the present invention,
The feature cluster estimating means uses the Akaike's Information Criterion (AIC) to determine the number P2of the time-series skeleton point coordinates of the non-target person with respect to the number P1 of the time-series skeleton point coordinatesof the target person for each cluster. Calculate the evaluation value V (P1, P2), and the evaluation value V (P1, P2) is equal to or greater than a predetermined threshold value, or the evaluation value V (P1, P2) is a predetermined number in descending order, optional extract clusters of
p11:Number of time-series skeletal point coordinates of the target person in an arbitrary cluster
p12:Number of time-series skeletal point coordinates of non-target persons in an arbitrary cluster
p21:Number of time-series skeletal point coordinates of the target person for clusters other than arbitrary clusters
p22:Number of time-series skeletal point coordinates of non-target persons for clusters other than arbitrary clusters
p11 + p12 + p21 + p22 =number of time-series skeletal point coordinates of all target and non-target persons
MLL_IM(P1,P2) = (p11+p12) log(p11+p12)
+(p11+p21) log(p11+p21)
+(p21+p22) log(p21+p22)
+(p12+p22) log(p12+p22)-2N logN
MLL_DM(P1,P2) = p11 log p11 + p12 log p12 + p21 log p21 + p22 log p22 - N log N
However, N = p11 + p12 + p21 + p22
AIC_IM(P1, P2) = -2 × MLL_IM(P1, P2) + 2 × 2
AIC_IM(P1,P2): Dependent AIC of a group of time-series skeletal point coordinates of a target person and a group of time-series skeletal point coordinates of a non-target person
AIC_DM(P1, P2) = -2 × MLL_DM(P1, P2) + 2 × 3
AIC_DM(P1,P2): Independent AIC of a group of time-series skeletal point coordinates of a target person and a group of time-series skeletal point coordinates of a non-target person
V(P1,P2) = AIC_IM(P1,P2) - AIC_DM(P1,P2)
It is also preferable to have the computer function as a
本発明のプログラムにおける他の実施形態によれば、
特徴クラスタ推定手段は、
評価値が高い複数の特徴クラスタを推定し、
複数の特徴クラスタから、ランダムに、又は、先に出力された特徴クラスタと異なる特徴クラスタ、を1つ選択して出力する
ようにコンピュータを機能させることも好ましい。According to another embodiment of the program of the present invention,
The feature cluster estimation means is
Estimate multiple feature clusters with high evaluation values,
It is also preferable to have the computer function to select and output one feature cluster from a plurality of feature clusters, either randomly or different from the previously output feature cluster.
本発明によれば、対象人物の特徴的な身振りを推定する推定装置であって、
対象人物が映り込む対象部分映像と、異なる非対象人物が映り込む複数の非対象部分映像とのそれぞれについて、時系列のフレーム毎に人物の複数の骨格点を抽出し、当該骨格点の時系列の座標変位を表す時系列骨格点座標を推定する姿勢推定手段と、
対象部分映像の時系列骨格点座標と複数の非対象部分映像の時系列骨格点座標の全てとを、所定条件に基づいて複数のクラスタに分類するクラスタリング手段と、
各クラスタに含まれる対象人物の時系列骨格点座標の個数と非対象人物の時系列骨格点座標の個数とを比較して、対象人物に特有に出現する特徴クラスタを推定する特徴クラスタ推定手段と、
特徴クラスタに含まれる時系列骨格点座標を、対象人物の特徴的な身振りとして推定する身振り推定手段と
を有することを特徴とする。According to the present invention, an estimation device for estimating a characteristic gesture of a target person,
For each of a target partial video in which a target person is captured and a plurality of non-target partial videos in which different non-target people are captured, a plurality of skeletal points of a person are extracted for each time-series frame, and the time series of the skeletal points is obtained. posture estimation means for estimating time-series skeletal point coordinates representing coordinate displacement of
clustering means for classifying the time-series skeleton point coordinates of the target partial video and all of the time-series skeleton point coordinates of the plurality of non-target partial videos into a plurality of clusters based on a predetermined condition;
feature cluster estimating means for estimating a feature cluster that appears uniquely to a target person by comparingthe number of time-series skeletal point coordinates of the target person andthe number of time-series skeletal point coordinates of the non-target person included in each cluster; ,
and gesture estimation means for estimating the time-series skeletal point coordinates included in the feature cluster as a characteristic gesture of the target person.
本発明によれば、対象人物の特徴的な身振りを推定する装置の推定方法であって、
装置は、
対象人物が映り込む対象部分映像と、異なる非対象人物が映り込む複数の非対象部分映像とのそれぞれについて、時系列のフレーム毎に人物の複数の骨格点を抽出し、当該骨格点の時系列の座標変位を表す時系列骨格点座標を推定する第1のステップと、
対象部分映像の時系列骨格点座標と複数の非対象部分映像の時系列骨格点座標の全てとを、所定条件に基づいて複数のクラスタに分類する第2のステップと、
各クラスタに含まれる対象人物の時系列骨格点座標の個数と非対象人物の時系列骨格点座標の個数とを比較して、対象人物に特有に出現する特徴クラスタを推定する第3のステップと、
特徴クラスタに含まれる時系列骨格点座標を、対象人物の特徴的な身振りとして推定する第4のステップと
を実行することを特徴とする。According to the present invention, a method for estimating a device for estimating a characteristic gesture of a target person, comprising:
The device
For each of a target partial video in which a target person is captured and a plurality of non-target partial videos in which different non-target people are captured, a plurality of skeletal points of a person are extracted for each time-series frame, and the time series of the skeletal points is obtained. a first step of estimating time-series skeletal point coordinates representing coordinate displacements of
a second step of classifying the time-series skeleton point coordinates of the target partial video and all of the time-series skeleton point coordinates of the plurality of non-target partial videos into a plurality of clusters based on a predetermined condition;
a third step of estimating a feature cluster that appears uniquely to the target person by comparingthe number of time-series skeletal point coordinates of the target person andthe number of time-series skeletal point coordinates of the non-target person included in each cluster; ,
and a fourth step of estimating the time-series skeletal point coordinates included in the feature cluster as a characteristic gesture of the target person.
本発明のプログラム、装置及び方法によれば、対象人物の特徴的な身振りを推定することができる。また、推定された特徴的な身振りをアバターに反映させることによって、エージェントと対話するユーザは、そのアバターの身振りから、その対象人物の性格や人物らしさを感じることができる。 According to the program, device and method of the present invention, it is possible to estimate the characteristic gesture of the target person. In addition, by reflecting the estimated characteristic gestures on the avatar, the user interacting with the agent can feel the character and personality of the target person from the gestures of the avatar.
以下、本発明の実施の形態について、図面を用いて詳細に説明する。 BEST MODE FOR CARRYING OUT THE INVENTION Hereinafter, embodiments of the present invention will be described in detail with reference to the drawings.
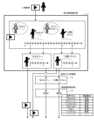
図1は、ユーザとアバターとの間の対話システムの構成図である。 FIG. 1 is a configuration diagram of a dialogue system between a user and an avatar.
図1によれば、対話装置(推定装置)1は、ユーザ操作に基づく端末2とネットワークを介して通信し、ユーザに対するエージェントとして機能する。
端末2は、例えばスマートフォンやタブレットであって、マイク、スピーカ及びディスプレイを搭載する。端末2には、ユーザとの対話インタフェースとなるユーザプログラムが実装されており、対話装置1から受信したエージェントの「アバター」をディスプレイに表示する。また、端末2は、マイクによって収音したユーザの発話音声を音声認識によって発話テキストへ変換し、その発話テキストを対話装置1へ送信する。更に、端末2は、対話装置1から受信したエージェントの対話テキストをスピーカから発声する。According to FIG. 1, a dialogue device (estimation device) 1 communicates with a
The
図2は、本発明における対話装置の機能構成図である。 FIG. 2 is a functional configuration diagram of the interactive device in the present invention.
対話装置1は、一般的な機能として、端末2からユーザ発話テキストを受信し、エージェント発話テキストを端末2へ返答する。対話装置1のエージェント機能は、ユーザとの間で、できる限り自然な対話を進行させる。
特に、本発明の対話装置1は、対象人物が映り込んでいる映像から、その対象人物に特徴的な身振りを推定することができる。また、対話装置1は、エージェントのアバターに、その対象人物に特徴的な身振りを反映させて動作させることができる。As a general function, the
In particular, the
図2によれば、対話装置1は、非対象人物映像データベース10と、部分映像抽出部11、音声テキスト変換部12と、発話意図推定部13と、姿勢推定部14と、クラスタリング部15と、特徴クラスタ推定部16と、身振り推定部17と、対話制御部18と、アバター表示部19とを有する。これら機能構成部は、装置に搭載されたコンピュータを機能させるプログラムを実行することによって実現される。また、これら機能構成部の処理の流れは、装置の対話方法としても理解できる。 According to FIG. 2, the
最初に、対象人物が映り込んだ対象映像を用意する。対象映像には、対象人物における様々な発話音声も含まれている。 First, a target video in which a target person is captured is prepared. The target video also includes various speech sounds of the target person.
[非対象人物映像データベース10]
非対象人物映像データベース10は、対象人物以外の多様な人物が映り込んだ非対象映像を蓄積したものである。また、非対象映像には、人物における様々な発話音声も含まれている。[Non-target person video database 10]
The non-target
「対象映像」及び「非対象映像」のいずれも、例えばスマートフォンのカメラによって人物を撮影した映像であってもよい。また、具体的には、YouTube(登録商標)やSNS(Instagram(登録商標)、Twitter(登録商標)、facebook(登録商標))のようなインターネット上にアップされた映像コンテンツであってもよい。勿論、これらに限らず、宅内やオフィスに設置されたカメラ(宅内であれば見守りサービス用、オフィスであれば社員の健康状態監視用)で撮影された映像であってもよい。 Both the “target video” and the “non-target video” may be video of a person captured by a smartphone camera, for example. More specifically, it may be video content uploaded on the Internet such as YouTube (registered trademark) or SNS (Instagram (registered trademark), Twitter (registered trademark), facebook (registered trademark)). Of course, the images are not limited to these, and may be images captured by cameras installed in homes or offices (for home monitoring services, or in offices for health condition monitoring of employees).
[部分映像抽出部11]
部分映像抽出部11は、対象人物が映り込んだ「対象映像」と、非対象人物映像データベース10に蓄積された複数の「非対象映像」とを入力し、以下のように対象部分映像と非対象部分映像とを抽出する。
(a)対象人物が映り込む対象映像について、「発話音声が含まれる対象部分映像」を抽出する。
(b)異なる非対象人物が映り込む複数の非対象映像それぞれについて、「発話音声が含まれる非対象部分映像」を抽出する。
本発明によれば、抽出された部分映像のみが、姿勢推定部14へ出力される。
尚、オプション的に、抽出された部分映像は、音声テキスト変換部12へ出力されるものであってもよい。[Partial video extraction unit 11]
The partial
(a) For a target video in which a target person is captured, a "target partial video including an utterance voice" is extracted.
(b) For each of a plurality of non-target videos in which different non-target persons are captured, a "non-target partial video containing uttered voice" is extracted.
According to the present invention, only the extracted partial video is output to posture
Optionally, the extracted partial video may be output to the speech-to-
図3は、本発明における部分映像抽出部の説明図である。 FIG. 3 is an explanatory diagram of the partial video extracting unit in the present invention.
例えば、入力した映像(対象人物又は非対象人物が映り込んだ対象映像又は非対象映像)の中で、発話音声の部分を検出し、その発話音声を含む部分映像を抽出する。
(他者) 「おはようー!」
(対象人物/非対象人物)「おはよう~」
(他者) 「どこに行くの?」
(対象人物/非対象人物)「公園に行くよ」
この場合、以下の2箇所の部分映像が抽出される。
対象人物/非対象人物が映り込んでおり、「おはよう~」と発話した部分映像
対象人物/非対象人物が映り込んでおり、「公園に行くよ」と発話した部分映像For example, in the input video (target video or non-target video in which the target person or non-target person is reflected), the part of the spoken voice is detected, and the partial video containing the spoken voice is extracted.
(Others) "Good morning!"
(Target person/non-target person) "Good morning~"
(Other) "Where are you going?"
(Target person/Non-target person) "Let's go to the park"
In this case, the following two partial videos are extracted.
A partial image of the target person/non-target person and saying "Good morning~" A partial image of the target person/non-target person and saying "Let's go to the park"
[音声テキスト変換部12]
音声テキスト変換部12は、「対象部分映像の発話音声」と「複数の非対象部分映像の発話音声」とのそれぞれを、発話テキストに変換する。具体的には、Google(登録商標)が提供しているCloud Speech-to-Text(登録商標)や、Microsoft(登録商標)が提供しているSpeech to Text(登録商標)がある。
図3によれば、映像に映り込む人物が発話した「おはよう~」「公園に行くよ」が抽出されている。
変換された発話テキストは、発話意図推定部13へ出力される。[Speech-to-text converter 12]
The voice-to-
According to FIG. 3, "Good morning~" and "Let's go to the park" uttered by the person reflected in the video are extracted.
The converted speech text is output to the speech
[発話意図推定部13]
発話意図推定部13は、「対象部分映像の発話テキスト」と「複数の非対象部分映像の群の発話テキスト」とのそれぞれについて、「発話意図フラグ」を付与する。尚、発話意図フラグは、オプション的であってもよい。
推定された発話意図フラグは、姿勢推定部14へ出力される。[Speech intention estimation unit 13]
The utterance
The estimated speech intention flag is output to posture
発話意図推定部13は、非特許文献2に開示されたSVM(Support Vector Machine)を用いて、発話テキストと発話意図フラグとを対応付けて予め学習させたものであってもよい。推定段階では、発話テキストをSVMへ入力することによって、発話意図フラグを推定することができる。 The utterance
発話意図フラグは、「用例に基づくフラグ」又は「感情に基づくフラグ」であってもよい。
用例に基づくフラグであれば、例えば「挨拶」「意見」「質問」のようなものを想定できる。また、感情に基づくフラグであれば、例えば「喜び」「悲しみ」「怒り」のようなものであってもよいし、簡単には「Positive」「Negative」「Neutral」のようなものであってもよい。The utterance intention flag may be an "example-based flag" or an "emotion-based flag."
Example-based flags can be assumed to be, for example, "greetings", "opinions", and "questions". Flags based on emotions may be, for example, "joy,""sadness," and "anger," or simply "positive,""negative," and "neutral." good too.
図3によれば、発話意図フラグは、具体的には、非特許文献3に開示された33種類の意図(挨拶、相槌、感謝、質問など)を対象とする。発話意図推定部13が機械学習エンジンである場合、発話テキスト毎に予め発話意図フラグを対応付けた教師データを用意する必要がある。
(発話テキスト) (発話意図フラグ)
「おはよう~」 挨拶
「どこに~?」 質問
「こんにちは」 挨拶
「ひどいね」 意見
「なぜ」 質問
「~に行くよ」 意見According to FIG. 3, the utterance intention flag specifically targets 33 types of intentions (greetings, backtracking, gratitude, questions, etc.) disclosed in Non-Patent Document 3. If the utterance
(utterance text) (utterance intention flag)
"Good morning~" Greeting "Where~?" Question "Hello" Greeting "That's terrible" Opinion "Why"
[姿勢推定部14]
姿勢推定部14は、対象人物が映り込む「対象部分映像」と、異なる非対象人物が映り込む「複数の非対象部分映像」とのそれぞれについて、時系列のフレーム毎に人物の複数の骨格点を抽出し、当該骨格点の時系列の座標変位を表す「時系列骨格点座標(スケルトン座標)」を推定する。
推定された時系列骨格点座標は、クラスタリング部15へ出力される。[Posture estimation unit 14]
The
The estimated time-series skeleton point coordinates are output to the
図4は、本発明における姿勢推定部の説明図である。 FIG. 4 is an explanatory diagram of a posture estimator in the present invention.
映像は、時系列の複数のフレームから構成される。そして、各フレームについて、映り込む人物の骨格を捉える。
具体的には、特許文献1に開示された技術を用いて、骨格点の座標を推定することができる。この技術によれば、骨格点は、関節における2次元座標に基づくものである。例えばOpenPose(登録商標)のようなスケルトンモデルを用いて、人の関節の特徴点を抽出する(例えば非特許文献4、5及び6参照)。OpenPoseとは、画像から複数の人間の体/手/顔のキーポイントをリアルタイムに検出可能なソフトウェアであって、GitHubによって公開されている。撮影映像に映る人の身体全体であれば、例えば15点のキーポイントを検出できる。A video consists of a plurality of time-series frames. Then, for each frame, the skeleton of the person reflected is captured.
Specifically, the technique disclosed in
図4によれば、映像データに1人の人物が映り込んでいる。各関節(Nose, Neck, RShoulder, RElbow,・・・)に対して、信頼度(0~1)が算出される。スケルトン情報とは、18個の各関節の2次元座標点(x,y)とその信頼度とを、各フレームで結び付けた情報をいう。
また、図4によれば、骨格点毎に、その座標を時系列に並べた「時系列骨格点座標(スケルトン座標)」として表している。According to FIG. 4, one person is reflected in the video data. A reliability (0 to 1) is calculated for each joint (Nose, Neck, RShoulder, RElbow, . . . ). Skeleton information is information in which two-dimensional coordinate points (x, y) of each of the 18 joints and their reliability are linked in each frame.
Further, according to FIG. 4, the coordinates of each skeleton point are represented in chronological order as "time-series skeleton pointcoordinates (skeleton coordinates)".
尚、図4によれば、骨格点同士を線で結び、その距離を算出し、各骨格点座標を正規化する。正規化した後、映像における全フレームの時系列骨格点座標を取得する。ここでは、人物が小さく映り込んだものもあれば、大きく映り込んだものもあるために、正規化している。 According to FIG. 4, the skeleton points are connected by lines, the distance between them is calculated, and the coordinates of each skeleton point are normalized. After normalization, time-series skeletal point coordinates of all frames in the video are obtained. Here, normalization is performed because there are some images in which a person is reflected in a small size and others in which a person is reflected in a large size.
[クラスタリング部15]
クラスタリング部15は、「対象部分映像の時系列骨格点座標」と「複数の非対象部分映像の時系列骨格点座標の全て」とを、所定条件に基づいて複数のクラスタに分類する。時系列骨格点座標をベクトルとして、類似度に応じてクラスタに分類することができる。
所定条件としては、オプション的には、発話意図フラグ毎のクラスタに分類するものであってもよい。[Clustering unit 15]
The
As an option, the predetermined condition may be to classify into clusters for each utterance intention flag.
図5は、本発明におけるクラスタリング部の説明図である。 FIG. 5 is an explanatory diagram of the clustering unit in the present invention.
図5(a)によれば、全ての時系列骨格点座標を、例えばk-meansを用いてクラスタに分類したものである。ここでは、人物の発話中における身振りが類似したもの同士が、同じクラスタに含まれている。この場合、例えば最も小さいクラスタに属する時系列骨格点座標に基づく身振りの集合は、極めて特徴的なものであって、他人があまりしないような挙動の集合となる。図5(a)によれば、各クラスタの中に、対象人物の身振りとなる特徴クラスタも内在する。 According to FIG. 5A, all time-series skeleton point coordinates are classified into clusters using k-means, for example. Here, the same cluster includes similar gestures during speech of a person. In this case, for example, a set of gestures based on time-series skeletal point coordinates belonging to the smallest cluster is a very characteristic set of behaviors that other people do not often do. According to FIG. 5(a), each cluster also includes feature clusters that are gestures of the target person.
図5(b)によれば、全ての時系列骨格点座標を、発話意図フラグ毎に、クラスタに分類したものである。各発話意図フラグのクラスタ毎に、対象人物の身振りの時系列骨格点座標の群となる特徴クラスタも含まれる。例えば発話意図フラグ「挨拶」のクラスタの中に、対象人物の身振りとなる特徴クラスタも内在する。図5(b)によれば、対象人物の3つの身振りは、発話意図フラグ毎に、不特定多数の非対象人物の身振りに応じた複数のクラスタに分散されて存在する。 According to FIG. 5B, all time-series skeleton point coordinates are classified into clusters for each speech intention flag. Each cluster of utterance intention flags also includes a feature cluster that is a group of time-series skeletal point coordinates of the target person's gesture. For example, the cluster of the utterance intention flag “greeting” also includes a feature cluster that is the gesture of the target person. According to FIG. 5B, the three gestures of the target person are distributed among a plurality of clusters corresponding to the gestures of an unspecified number of non-target persons for each speech intention flag.
[特徴クラスタ推定部16]
特徴クラスタ推定部16は、各クラスタに含まれる「対象人物の時系列骨格点座標の数」と「非対象人物の時系列骨格点座標の数」とを比較して、対象人物に特有に出現する特徴クラスタを推定する。
ここで、特徴クラスタ推定部16は、発話意図フラグ毎に、特徴クラスタを推定するものであってもよい。即ち、対象人物に高頻度に偏って出現するクラスタを算出し、発話意図フラグ毎に算出度合いの大きいクラスタを決定する。[Feature cluster estimation unit 16]
The feature
Here, the feature
図6は、本発明における特徴クラスタ推定部の説明図である。 FIG. 6 is an explanatory diagram of the feature cluster estimator in the present invention.
特徴クラスタ推定部16は、赤池情報量規準(AIC:Akaike's Information Criterion)を用いて、各クラスタについて、対象人物の時系列骨格点座標の数P1に対する非対象人物の時系列骨格点座標の数P2の評価値V(P1,P2)を算出し、当該評価値V(P1,P2)が所定閾値以上となる、又は、当該評価値V(P1,P2)が大きいものから順に所定数となる、任意のクラスタを抽出する。
p11:任意のクラスタの中で、対象人物の時系列骨格点座標の数
p12:任意のクラスタの中で、非対象人物の時系列骨格点座標の数
p21:任意のクラスタ以外のクラスタについて、対象人物の時系列骨格点座標の数
p22:任意のクラスタ以外のクラスタについて、非対象人物の時系列骨格点座標の数
p11+p12+p21+p22=対象人物及び非対象人物全ての時系列骨格点座標の数
MLL_IM(P1,P2)=(p11+p12) log(p11+p12)
+(p11+p21) log(p11+p21)
+(p21+p22) log(p21+p22)
+(p12+p22) log(p12+p22)-2N log N
MLL_DM(P1,P2)=p11 log p11+p12 log p12+p21 log p21+p22 log p22-N log N
但し、N=p11+p12+p21+p22
AIC_IM(P1,P2)=-2 × MLL_IM(P1,P2) + 2×2
AIC_IM(P1,P2):対象人物の時系列骨格点座標の群と、非対象人物の時系列骨格点座標の群との組の従属AIC
AIC_DM(P1,P2)=-2 × MLL_DM(P1,P2) + 2×3
AIC_DM(P1,P2):対象人物の時系列骨格点座標の群と、非対象人物の時系列骨格点座標の群との組の独立AIC
V(P1,P2)=AIC_IM(P1,P2) - AIC_DM(P1,P2)The feature
p11: Number of time-series skeletal point coordinates of the target person in any cluster
p12: Number of time-series skeletal point coordinates of non-target persons in any cluster
p21: Number of time-series skeletal point coordinates of the target person for clusters other than arbitrary clusters
p22: Number of time-series skeletal point coordinates of non-target persons for clusters other than arbitrary clusters
p11 + p12 + p21 + p22 = number of time-series skeletal point coordinates of all target and non-target persons
MLL_IM(P1,P2) = (p11+p12) log(p11+p12)
+(p11+p21) log(p11+p21)
+(p21+p22) log(p21+p22)
+(p12+p22) log(p12+p22)-2N logN
MLL_DM(P1,P2) = p11 log p11 + p12 log p12 + p21 log p21 + p22 log p22 - N log N
However, N = p11 + p12 + p21 + p22
AIC_IM(P1, P2) = -2 × MLL_IM(P1, P2) + 2 × 2
AIC_IM(P1,P2): Dependent AIC of a group of time-series skeletal point coordinates of a target person and a group of time-series skeletal point coordinates of a non-target person
AIC_DM(P1, P2) = -2 × MLL_DM(P1, P2) + 2 × 3
AIC_DM(P1,P2): Independent AIC of a group of time-series skeletal point coordinates of a target person and a group of time-series skeletal point coordinates of a non-target person
V(P1,P2) = AIC_IM(P1,P2) - AIC_DM(P1,P2)
そして、評価値に基づいて抽出された対象人物の身振りにおける特徴クラスタは、身振り推定部17へ出力する。 Then, the feature cluster in the target person's gesture extracted based on the evaluation value is output to the
ここで、前述した実施形態によれば、アバターの発話行為に対して毎回同じような身振りとなる場合があり、ユーザが飽きてしまう可能性がある。
そこで、他の実施形態として、特徴クラスタ推定部16は、複数の特徴クラスタを推定した後、いずれか1つの特徴クラスタを出力するものであってもよい。例えば以下のステップを実行する。
(S1)評価値が高い複数(例えば上位3個)の特徴クラスタを推定する。
(S2)S1の複数の特徴クラスタから、ランダムに、又は、先に出力された特徴クラスタと異なる特徴クラスタ、を1つ選択して出力する。
これによって、アバターの発話行為に対して適宜異なる身振りとなり、ユーザに対して新たな個性を見せることができる。Here, according to the above-described embodiment, the same gesture may be made every time the avatar speaks, and the user may become bored.
Therefore, as another embodiment, the feature
(S1) Estimate a plurality of (for example, top three) feature clusters with high evaluation values.
(S2) Select and output one feature cluster that is different from the previously output feature cluster, or at random, from the plurality of feature clusters in S1.
As a result, the avatar behaves differently in response to the utterance action, and a new individuality can be shown to the user.
[身振り推定部17]
身振り推定部17は、特徴クラスタに含まれる(対象人物の)時系列骨格点座標を、対象人物の特徴的な身振りとして推定する。[Gesture estimation unit 17]
The
身振り推定部17は、特徴クラスタに含まれる全ての時系列骨格点座標の中で重心に最も近い時系列骨格点座標、又は、特徴クラスタに含まれる全ての時系列骨格点座標から算出された重心となる時系列骨格点座標を、対象人物の特徴的な身振りとして推定する
また、身振り推定部17は、発話意図フラグ毎に、対象人物の特徴的な身振りを推定するものであってもよい。The
また、身振り推定部17は、対話制御部18によってアバターが発話するキーワードの発話意図に対応する発話意図フラグに応じた特徴クラスタの中で、対象人物の特徴的な身振りを決定するものであってもよい。 The
[対話制御部18]
対話制御部18は、例えばスマートフォンやタブレットのような端末2に予めインストールされたアプリケーションと通信する。例えば最初に、ユーザが対話を所望する「対象人物の名前」を発話した際に、対話制御部18は、アバター表示部19へ、その対象人物のアバターを表示するように指示する。[Dialogue control unit 18]
The
対話制御部18は、ユーザと音声によって対話するものであり、以下のように動作する。
(S1)対話時に、端末2のマイクによって収音されたユーザの発話音声を受信する。
(S2)次に、ユーザの発話音声を、音声認識によって発話テキストに変換する。勿論、音声認識は、端末2によって実行されるものであってもよい。
(S3)次に、対話シナリオを用いて、発話テキストに応じた対話テキストを生成する。
(S4)次に、対話テキストを音声合成し、その対話音声を生成する(例えば非特許文献8参照)。勿論、音声合成は、端末2によって実行されるものであってもよい。
(S5)対話音声を、端末2へ送信する。端末2は、対話音声をスピーカによってユーザへ出力する。
尚、S1及びS2について、ユーザが入力フォームにキー入力した発話テキストを端末2から受信し、S4及びS5について、端末2のディスプレイにアバターの吹き出しとして表示する対話テキストを送信するものであってもよい。The
(S1) Receives the user's uttered voice picked up by the microphone of the
(S2) Next, the user's uttered voice is converted into uttered text by voice recognition. Of course, speech recognition may also be performed by
(S3) Next, using the dialogue scenario, a dialogue text is generated according to the spoken text.
(S4) Next, speech synthesis is performed on the dialogue text to generate dialogue speech (see, for example, Non-Patent Document 8). Of course, speech synthesis may also be performed by
(S5) Transmit the dialogue voice to the
It should be noted that for S1 and S2, it is possible to receive from the
[アバター表示部19]
アバター表示部19は、「対象人物のアバター」(画像)を端末2へ送信し、端末2のディスプレイに表示する。
ここで、アバター表示部19は、身振り推定部17によって推定された時系列骨格点座標を、当該アバターの骨格点位置に合わせて、当該アバターを時系列に動作させて表示する(例えば非特許文献7参照)。
対話制御部18によってアバターが発話すべき発話テキストに対応する当該発話意図フラグに応じた特徴クラスタを用いて、対象人物の特徴的な身振りを決定する。これによって、端末2のスピーカからユーザへ対話テキストが発話されると共に、その端末2のディスプレイに表示されるアバターが、その対象人物の特徴的な身振りで動作するようになる。[Avatar display unit 19]
The
Here, the
The characteristic gesture of the target person is determined by using the feature cluster corresponding to the speech intention flag corresponding to the speech text to be spoken by the avatar by the
図7は、本発明におけるアバターの身振りを表す説明図である。 FIG. 7 is an explanatory diagram showing gestures of avatars in the present invention.
図7によれば、ユーザaは、端末2のディスプレイに表示されたアバターと対話している。アバターは、ユーザbを模したものであるとする。
ここで、ユーザbは、[挨拶]時に、腕を組む癖があるとする。また、挨拶時に腕を組む動作は、第三者はあまりしない特徴的な身振りであるとする。
このような場合、本発明によれば、アバターが「おはよう~」と挨拶をする際に、アバターは腕を組むように動作する。このようなアバターと対話しているユーザaは、あたかもユーザbと対話しているかのような感覚を持つことができる。According to FIG. 7, user a is interacting with an avatar displayed on the display of
Here, it is assumed that user b has a habit of folding his arms during [greeting]. It is also assumed that the action of folding one's arms in greeting is a characteristic gesture that third parties do not seldom do.
In such a case, according to the present invention, when the avatar greets with "Good morning~", the avatar acts like folding its arms. User a who is interacting with such an avatar can feel as if he is interacting with user b.
以上、詳細に説明したように、本発明のプログラム、装置及び方法によれば、対象人物の特徴的な身振りを推定することができる。また、推定された特徴的な身振りをアバターに反映させることによって、エージェントと対話するユーザは、そのアバターの身振りから、その対象人物の性格や人物らしさを感じることができる。 As described in detail above, according to the program, device and method of the present invention, it is possible to estimate the characteristic gesture of the target person. In addition, by reflecting the estimated characteristic gestures on the avatar, the user interacting with the agent can feel the character and personality of the target person from the gestures of the avatar.
前述した本発明の種々の実施形態について、本発明の技術思想及び見地の範囲の種々の変更、修正及び省略は、当業者によれば容易に行うことができる。前述の説明はあくまで例であって、何ら制約しようとするものではない。本発明は、特許請求の範囲及びその均等物として限定するものにのみ制約される。 For the various embodiments of the present invention described above, various changes, modifications and omissions within the spirit and scope of the present invention can be easily made by those skilled in the art. The foregoing description is exemplary only and is not intended to be limiting. The invention is to be limited only as limited by the claims and the equivalents thereof.
1 対話装置、推定装置
10 非対象人物映像データベース
11 部分映像抽出部
12 音声テキスト変換部
13 発話意図推定部
14 姿勢推定部
15 クラスタリング部
16 特徴クラスタ推定部
17 身振り推定部
18 対話制御部
19 アバター表示部
2 端末
1 dialogue device,
Claims (11)
Translated fromJapanese対象人物が映り込む対象部分映像と、異なる非対象人物が映り込む複数の非対象部分映像とのそれぞれについて、時系列のフレーム毎に人物の複数の骨格点を抽出し、当該骨格点の時系列の座標変位を表す時系列骨格点座標を推定する姿勢推定手段と、
対象部分映像の時系列骨格点座標と複数の非対象部分映像の時系列骨格点座標の全てとを、所定条件に基づいて複数のクラスタに分類するクラスタリング手段と、
各クラスタに含まれる対象人物の時系列骨格点座標の個数と非対象人物の時系列骨格点座標の個数とを比較して、対象人物に特有に出現する特徴クラスタを推定する特徴クラスタ推定手段と、
特徴クラスタに含まれる時系列骨格点座標を、対象人物の特徴的な身振りとして推定する身振り推定手段と
してコンピュータを機能させることを特徴とするプログラム。A program that causes a computer to infer a characteristic gesture of a subject, comprising:
For each of a target partial video in which a target person is captured and a plurality of non-target partial videos in which different non-target people are captured, a plurality of skeletal points of a person are extracted for each time-series frame, and the time series of the skeletal points is obtained. posture estimation means for estimating time-series skeletal point coordinates representing coordinate displacement of
clustering means for classifying the time-series skeleton point coordinates of the target partial video and all of the time-series skeleton point coordinates of the plurality of non-target partial videos into a plurality of clusters based on a predetermined condition;
feature cluster estimating means for estimating a feature cluster that appears uniquely to a target person by comparingthe number of time-series skeletal point coordinates of the target person andthe number of time-series skeletal point coordinates of the non-target person included in each cluster; ,
A program for causing a computer to function as gesture estimation means for estimating time-series skeletal point coordinates included in a feature cluster as a characteristic gesture of a target person.
ようにコンピュータを更に機能させることを特徴とする請求項1に記載のプログラム。The gesture estimating means calculates the time-series skeleton point coordinates closest to the center of gravity among all the time-series skeleton point coordinates contained in the feature cluster, or the center of gravity calculated from all the time-series skeleton point coordinates contained in the feature cluster. 2. The program according to claim 1, further causing the computer to estimate the time-series skeletal point coordinates as a characteristic gesture of the target person.
してコンピュータを更に機能させることを特徴とする請求項1又は2に記載のプログラム。As the preceding stage of the posture estimation means, extracting a target portion video including speech voice from a target video in which a target person is captured, and extracting a non-target portion including speech voice in each of a plurality of non-target videos in which different non-target persons are captured. 3. The program according to claim 1, further causing the computer to function as partial video extracting means for extracting a video.
してコンピュータを更に機能させ、
アバター表示手段は、身振り推定手段によって推定された時系列骨格点座標を、当該アバターの骨格点位置に合わせて、当該アバターを時系列に動作させて表示する
ようにコンピュータを機能させることを特徴とする請求項1から3のいずれか1項に記載のプログラム。making the computer further function as avatar display means for displaying the target person's avatar on the display;
The avatar display means is characterized in that the time-series skeleton point coordinates estimated by the gesture estimation means are aligned with the skeletal point positions of the avatar, and the computer is caused to operate and display the avatar in chronological order. 4. The program according to any one of claims 1 to 3.
対象部分映像の発話テキストと複数の非対象部分映像の群の発話テキストとのそれぞれについて、発話意図フラグを付与する発話意図推定手段と
してコンピュータを更に機能させ、
クラスタリング手段は、所定条件として発話意図フラグ毎のクラスタに分類し、
特徴クラスタ推定手段は、発話意図フラグ毎に、特徴クラスタを推定し、
身振り推定手段は、発話意図フラグ毎に、対象人物の特徴的な身振りを推定する
ようにコンピュータを機能させることを特徴とする請求項1から3のいずれか1項に記載のプログラム。speech-to-text conversion means for converting each of the speech sound of the target partial video and the speech sounds of the plurality of non-target partial videos into speech text;
causing the computer to further function as an utterance intention estimation means for adding an utterance intention flag to each of the utterance text of the target partial video and the utterance text of the group of the plurality of non-target partial videos;
The clustering means classifies into clusters for each utterance intention flag as a predetermined condition,
The feature cluster estimation means estimates a feature cluster for each utterance intention flag,
4. The program according to any one of claims 1 to 3, wherein the gesture estimation means causes the computer to estimate the characteristic gesture of the target person for each utterance intention flag.
発話意図フラグは、用例に基づくフラグ、又は、感情に基づくフラグである
ようにコンピュータを機能させることを特徴とする請求項5に記載のプログラム。The utterance intention estimation means learns in advance the utterance text and the utterance intention flag in association with each other, and estimates the utterance intention flag by inputting the utterance text,
6. The program according to claim 5, wherein the speech intention flag causes the computer to behave like an example-based flag or an emotion-based flag.
して更に機能させ、
対話制御手段によってアバターが発話すべき発話テキストに対応する当該発話意図フラグに応じた特徴クラスタを用いて、対象人物の特徴的な身振りを決定する
ようにコンピュータを機能させることを特徴とする請求項5又は6に記載のプログラム。Further functioning as dialogue control means for interacting with the target person,
The computer is operated to determine the characteristic gesture of the target person by using the feature cluster corresponding to the speech intention flag corresponding to the speech text to be spoken by the avatar by the dialogue control means. 7. The program according to 5 or 6.
p11:任意のクラスタの中で、対象人物の時系列骨格点座標の個数
p12:任意のクラスタの中で、非対象人物の時系列骨格点座標の個数
p21:任意のクラスタ以外のクラスタについて、対象人物の時系列骨格点座標の個数
p22:任意のクラスタ以外のクラスタについて、非対象人物の時系列骨格点座標の個数
p11+p12+p21+p22=対象人物及び非対象人物全ての時系列骨格点座標の個数
MLL_IM(P1,P2)=(p11+p12) log(p11+p12)
+(p11+p21) log(p11+p21)
+(p21+p22) log(p21+p22)
+(p12+p22) log(p12+p22)-2N log N
MLL_DM(P1,P2)=p11 log p11+p12 log p12+p21 log p21+p22 log p22-N log N
但し、N=p11+p12+p21+p22
AIC_IM(P1,P2)=-2 × MLL_IM(P1,P2) + 2×2
AIC_IM(P1,P2):対象人物の時系列骨格点座標の群と、非対象人物の時系列骨格点座標の群との組の従属AIC
AIC_DM(P1,P2)=-2 × MLL_DM(P1,P2) + 2×3
AIC_DM(P1,P2):対象人物の時系列骨格点座標の群と、非対象人物の時系列骨格点座標の群との組の独立AIC
V(P1,P2)=AIC_IM(P1,P2) - AIC_DM(P1,P2)
としてコンピュータを機能させることを特徴とする請求項1から7のいずれか1項に記載のプログラム。The feature cluster estimating means uses the Akaike's Information Criterion (AIC) to determine the number P2 of the time-series skeleton point coordinatesof the non-target person with respect to the number P1 of the time-series skeleton point coordinatesof the target person for each cluster. Calculate the evaluation value V (P1, P2), and the evaluation value V (P1, P2) is equal to or greater than a predetermined threshold value, or the evaluation value V (P1, P2) is a predetermined number in descending order, optional extract clusters of
p11:Number of time-series skeletal point coordinates of the target person in an arbitrary cluster
p12:Number of time-series skeletal point coordinates of non-target persons in an arbitrary cluster
p21:Number of time-series skeletal point coordinates of the target person for clusters other than arbitrary clusters
p22:Number of time-series skeletal point coordinates of non-target persons for clusters other than arbitrary clusters
p11 + p12 + p21 + p22 =number of time-series skeletal point coordinates of all target and non-target persons
MLL_IM(P1,P2) = (p11+p12) log(p11+p12)
+(p11+p21) log(p11+p21)
+(p21+p22) log(p21+p22)
+(p12+p22) log(p12+p22)-2N logN
MLL_DM(P1,P2) = p11 log p11 + p12 log p12 + p21 log p21 + p22 log p22 - N log N
However, N = p11 + p12 + p21 + p22
AIC_IM(P1, P2) = -2 × MLL_IM(P1, P2) + 2 × 2
AIC_IM(P1,P2): Dependent AIC of a group of time-series skeletal point coordinates of a target person and a group of time-series skeletal point coordinates of a non-target person
AIC_DM(P1, P2) = -2 × MLL_DM(P1, P2) + 2 × 3
AIC_DM(P1,P2): Independent AIC of a group of time-series skeletal point coordinates of a target person and a group of time-series skeletal point coordinates of a non-target person
V(P1,P2) = AIC_IM(P1,P2) - AIC_DM(P1,P2)
8. The program according to any one of claims 1 to 7, which causes a computer to function as a program.
評価値が高い複数の特徴クラスタを推定し、
複数の特徴クラスタから、ランダムに、又は、先に出力された特徴クラスタと異なる特徴クラスタ、を1つ選択して出力する
ようにコンピュータを機能させることを特徴とする請求項8に記載のプログラム。The feature cluster estimation means is
Estimate multiple feature clusters with high evaluation values,
9. The program according to claim 8, causing a computer to select and output one feature cluster that is different from the previously output feature cluster, either randomly or from a plurality of feature clusters.
対象人物が映り込む対象部分映像と、異なる非対象人物が映り込む複数の非対象部分映像とのそれぞれについて、時系列のフレーム毎に人物の複数の骨格点を抽出し、当該骨格点の時系列の座標変位を表す時系列骨格点座標を推定する姿勢推定手段と、
対象部分映像の時系列骨格点座標と複数の非対象部分映像の時系列骨格点座標の全てとを、所定条件に基づいて複数のクラスタに分類するクラスタリング手段と、
各クラスタに含まれる対象人物の時系列骨格点座標の個数と非対象人物の時系列骨格点座標の個数とを比較して、対象人物に特有に出現する特徴クラスタを推定する特徴クラスタ推定手段と、
特徴クラスタに含まれる時系列骨格点座標を、対象人物の特徴的な身振りとして推定する身振り推定手段と
を有することを特徴とする推定装置。An estimation device for estimating a characteristic gesture of a target person,
For each of a target partial video in which a target person is captured and a plurality of non-target partial videos in which different non-target people are captured, a plurality of skeletal points of a person are extracted for each time-series frame, and the time series of the skeletal points is obtained. posture estimation means for estimating time-series skeletal point coordinates representing coordinate displacement of
clustering means for classifying the time-series skeleton point coordinates of the target partial video and all of the time-series skeleton point coordinates of the plurality of non-target partial videos into a plurality of clusters based on a predetermined condition;
feature cluster estimating means for estimating a feature cluster that appears uniquely to a target person by comparingthe number of time-series skeletal point coordinates of the target person andthe number of time-series skeletal point coordinates of the non-target person included in each cluster; ,
and gesture estimation means for estimating time-series skeletal point coordinates included in the feature cluster as a characteristic gesture of a target person.
装置は、
対象人物が映り込む対象部分映像と、異なる非対象人物が映り込む複数の非対象部分映像とのそれぞれについて、時系列のフレーム毎に人物の複数の骨格点を抽出し、当該骨格点の時系列の座標変位を表す時系列骨格点座標を推定する第1のステップと、
対象部分映像の時系列骨格点座標と複数の非対象部分映像の時系列骨格点座標の全てとを、所定条件に基づいて複数のクラスタに分類する第2のステップと、
各クラスタに含まれる対象人物の時系列骨格点座標の個数と非対象人物の時系列骨格点座標の個数とを比較して、対象人物に特有に出現する特徴クラスタを推定する第3のステップと、
特徴クラスタに含まれる時系列骨格点座標を、対象人物の特徴的な身振りとして推定する第4のステップと
を実行することを特徴とする推定方法。A method for estimating a device for estimating a characteristic gesture of a target person, comprising:
The device
For each of a target partial video in which a target person is captured and a plurality of non-target partial videos in which different non-target people are captured, a plurality of skeletal points of a person are extracted for each time-series frame, and the time series of the skeletal points is obtained. a first step of estimating time-series skeletal point coordinates representing coordinate displacements of
a second step of classifying the time-series skeleton point coordinates of the target partial video and all of the time-series skeleton point coordinates of the plurality of non-target partial videos into a plurality of clusters based on a predetermined condition;
a third step of estimating a feature cluster that appears uniquely to the target person by comparingthe number of time-series skeletal point coordinates of the target person andthe number of time-series skeletal point coordinates of the non-target person included in each cluster; ,
and a fourth step of estimating the time-series skeletal point coordinates included in the feature cluster as a characteristic gesture of the target person.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020040481AJP7257349B2 (en) | 2020-03-10 | 2020-03-10 | Program, device and method for estimating characteristic gesture of target person |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020040481AJP7257349B2 (en) | 2020-03-10 | 2020-03-10 | Program, device and method for estimating characteristic gesture of target person |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2021144263A JP2021144263A (en) | 2021-09-24 |
| JP7257349B2true JP7257349B2 (en) | 2023-04-13 |
Family
ID=77766540
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2020040481AActiveJP7257349B2 (en) | 2020-03-10 | 2020-03-10 | Program, device and method for estimating characteristic gesture of target person |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP7257349B2 (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115115963A (en)* | 2022-01-14 | 2022-09-27 | 长城汽车股份有限公司 | Three-dimensional virtual motion generation method and device, electronic equipment and vehicle |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001202379A (en) | 2000-01-21 | 2001-07-27 | Kobe University | Virtual Person Motion Data Browsing Device in Virtual Space |
| JP2012533134A (en) | 2009-07-13 | 2012-12-20 | マイクロソフト コーポレーション | Method and system for making visual display live-action through input learned from user |
| JP2018169494A (en) | 2017-03-30 | 2018-11-01 | トヨタ自動車株式会社 | Utterance intention estimation apparatus and utterance intention estimation method |
| WO2019204651A1 (en) | 2018-04-20 | 2019-10-24 | Facebook Technologies, Llc | Personalized gesture recognition for user interaction with assistant systems |
| JP2020027548A (en) | 2018-08-16 | 2020-02-20 | Kddi株式会社 | Program, device and method for creating dialog scenario corresponding to character attribute |
- 2020
- 2020-03-10JPJP2020040481Apatent/JP7257349B2/enactiveActive
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001202379A (en) | 2000-01-21 | 2001-07-27 | Kobe University | Virtual Person Motion Data Browsing Device in Virtual Space |
| JP2012533134A (en) | 2009-07-13 | 2012-12-20 | マイクロソフト コーポレーション | Method and system for making visual display live-action through input learned from user |
| JP2018169494A (en) | 2017-03-30 | 2018-11-01 | トヨタ自動車株式会社 | Utterance intention estimation apparatus and utterance intention estimation method |
| WO2019204651A1 (en) | 2018-04-20 | 2019-10-24 | Facebook Technologies, Llc | Personalized gesture recognition for user interaction with assistant systems |
| JP2020027548A (en) | 2018-08-16 | 2020-02-20 | Kddi株式会社 | Program, device and method for creating dialog scenario corresponding to character attribute |
Non-Patent Citations (1)
| Title |
|---|
| 服部裕介他,コミュニケーションキャラクタの感情的振る舞い生成,情報処理学会研究報告,日本,社団法人情報処理学会,2006年05月04日,第2006巻 第39号,pp.1-8 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2021144263A (en) | 2021-09-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20220254343A1 (en) | System and method for intelligent initiation of a man-machine dialogue based on multi-modal sensory inputs | |
| CN108000526B (en) | Dialogue interaction method and system for intelligent robot | |
| US11551804B2 (en) | Assisting psychological cure in automated chatting | |
| KR101925440B1 (en) | Method for providing vr based live video chat service using conversational ai | |
| US11468894B2 (en) | System and method for personalizing dialogue based on user's appearances | |
| WO2023226914A1 (en) | Virtual character driving method and system based on multimodal data, and device | |
| JP7105749B2 (en) | Agent program, device and method for uttering text corresponding to character | |
| JP7423490B2 (en) | Dialogue program, device, and method for expressing a character's listening feeling according to the user's emotions | |
| CN114495927A (en) | Multimodal interactive virtual digital human generation method and device, storage medium and terminal | |
| CN107704612A (en) | Dialogue exchange method and system for intelligent robot | |
| CN115167656A (en) | Interactive service method and device based on artificial intelligence virtual image | |
| CN115145434A (en) | Virtual image-based interactive service method and device | |
| WO2020027073A1 (en) | Information processing device and information processing method | |
| CN112910761A (en) | Instant messaging method, device, equipment, storage medium and program product | |
| JP6909189B2 (en) | Programs, servers and methods to switch agents according to user utterance text | |
| KR20210015977A (en) | Apparatus for realizing coversation with died person | |
| JP7575977B2 (en) | Program, device and method for agent that interacts with multiple characters | |
| JP7257349B2 (en) | Program, device and method for estimating characteristic gesture of target person | |
| KR20250090933A (en) | Method for real-time empathy expression of virtual human based on multimodal emotion recognition and Artificial Intelligence using the Method | |
| JP2021051693A (en) | Utterance system, utterance recommendation device, utterance recommendation program, and utterance recommendation method | |
| US12266151B2 (en) | Information processing apparatus, information processing method, and program | |
| Babu et al. | Marve: a prototype virtual human interface framework for studying human-virtual human interaction | |
| CN113379879A (en) | Interaction method, device, equipment, storage medium and computer program product | |
| JP7474211B2 (en) | Dialogue program, device and method for forgetting nouns spoken by a user | |
| WO2020087534A1 (en) | Generating response in conversation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination | Free format text:JAPANESE INTERMEDIATE CODE: A621 Effective date:20220118 | |
| A977 | Report on retrieval | Free format text:JAPANESE INTERMEDIATE CODE: A971007 Effective date:20230131 | |
| A131 | Notification of reasons for refusal | Free format text:JAPANESE INTERMEDIATE CODE: A131 Effective date:20230210 | |
| A521 | Request for written amendment filed | Free format text:JAPANESE INTERMEDIATE CODE: A523 Effective date:20230221 | |
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) | Free format text:JAPANESE INTERMEDIATE CODE: A01 Effective date:20230327 | |
| A61 | First payment of annual fees (during grant procedure) | Free format text:JAPANESE INTERMEDIATE CODE: A61 Effective date:20230403 | |
| R150 | Certificate of patent or registration of utility model | Ref document number:7257349 Country of ref document:JP Free format text:JAPANESE INTERMEDIATE CODE: R150 |