JP4839291B2 - Speech recognition apparatus and computer program - Google Patents
Speech recognition apparatus and computer programDownload PDFInfo
- Publication number
- JP4839291B2 JP4839291B2JP2007252817AJP2007252817AJP4839291B2JP 4839291 B2JP4839291 B2JP 4839291B2JP 2007252817 AJP2007252817 AJP 2007252817AJP 2007252817 AJP2007252817 AJP 2007252817AJP 4839291 B2JP4839291 B2JP 4839291B2
- Authority
- JP
- Japan
- Prior art keywords
- candidate word
- candidate
- words
- word
- recognition result
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images








Abstract
Description
Translated fromJapanese本発明は、音声認識装置およびコンピュータプログラムに関する。 The present invention relates to a speech recognition apparatus and a computer program.
従来、コンピュータを用いた音声認識では、話者の発声方法や音声入力時の背景雑音などの影響により100%の認識率を達成することは困難である。そのために、例えば特許文献1に記載の音声認識装置は、入力音声に含まれる複数の単語を予め辞書に記憶されている複数の単語とそれぞれ比較し、競合候補の中から一番競合確率の高い単語を音声認識結果とし、音声認識結果を複数の単語の単語列として画面に表示し、競合候補の中から一番競合確率の高い単語の競合確率に近い競合確率を持つ1以上の競合単語を選び、対応する一番競合確率の高い単語に隣接して画面上に表示させ、ユーザによるマニュアル操作に応じて、画面上に表示された1以上の競合単語から適切な訂正単語を選択し、選択された競合単語を、音声認識結果の一番競合確率の高い単語と置き換えるようにしている。
しかし、上述した従来の音声認識装置では、以下に示すような問題がある。
特許文献1に記載の音声認識装置は、複数の系列の認識結果を簡略化する過程において、各系列に属する同一の表記ではない候補語をグループ化するときに、時間的な重なりがあれば、異なる系列に属する読みが近い候補語を同一のグループに分類している。しかしながら、例えば“庭には二羽鶏がいた”のように、読みの似た単語が時間的に近い位置にあると、図12に示されるように、同一の単語が複数の区間で候補語となる場合が生じる。すると、音声認識結果から画面に表示される候補語として、同じ単語が複数の区間で表示されることとなり、表示される候補語の個数が多くなる。このため、ユーザは、画面に表示された候補語の中から正解を選んだり、候補語を削除したり、候補語を新規の候補語に変更したりなどすることにより画面上で文章を編集する際に、同じ単語を何度も編集しなければならず、手間や時間がかかる。また、連続する時間区間で同じ候補語が何度も出現するため、候補語を選択するときには前後にある候補語を確認する作業が必要となり、ユーザにとって負担である。However, the conventional speech recognition apparatus described above has the following problems.
In the process of simplifying the recognition results of a plurality of sequences, the speech recognition device described in
本発明は、このような事情を考慮してなされたもので、その目的は、入力音声の音声認識結果から候補語を画面に表示してユーザが画面に表示された候補語を編集するときに、ユーザが候補語を編集する操作の回数を減らすことのできる音声認識装置およびコンピュータプログラムを提供することにある。 The present invention has been made in consideration of such circumstances, and its purpose is to display candidate words on the screen from the speech recognition result of the input speech and when the user edits the candidate words displayed on the screen. Another object of the present invention is to provide a speech recognition apparatus and a computer program that can reduce the number of operations of a user editing a candidate word.
上記の課題を解決するために、本発明に係る音声認識装置は、入力された音声を認識する処理を行い、認識した単語の列から成る認識結果を生成する音声認識手段と、認識結果から候補語を抽出する候補語抽出手段と、候補語をグループ化する候補語グループ化手段と、グループ化された候補語を画面に表示する候補語表示手段と、ユーザが画面に表示された候補語を編集するための編集操作手段と、ユーザによる編集内容に従って認識結果を更新する更新手段と、を備え、前記候補語グループ化手段は、前記認識結果において信頼度が最大である文を構成する候補語の列(第1の候補語列)とそれ以外の候補語の列(第2の候補語列)を抽出する手段と、第1の候補語列中の候補語と第2の候補語列中の候補語の間の時間的距離を算出する手段と、同じグループ内の第1の候補語列中の候補語と第2の候補語列中の候補語の間の時間的距離を合計した値が最小になるように、第1の候補語列と第2の候補語列を構成する候補語同士をグループ化する手段と、を有することを特徴とする。 In order to solve the above problems, a speech recognition apparatus according to the present invention performs processing for recognizing input speech and generates a recognition result including a recognized word sequence, and a candidate based on the recognition result. Candidate word extracting means for extracting words, candidate word grouping means for grouping candidate words, candidate word display means for displaying the grouped candidate words on the screen, and candidate words displayed on the screen by the user An editing operation means for editing, and an updating means for updating the recognition result according to the content edited by the user, wherein the candidate word grouping means is a candidate word constituting a sentence having the maximum reliability in the recognition result Means for extracting a sequence (first candidate word sequence) and a column of other candidate words (second candidate word sequence), candidate words in the first candidate word sequence, and second candidate word sequences The temporal distance between candidate words And the first candidate word so that the sum of temporal distances between the candidate words in the first candidate word string and the candidate words in the second candidate word string in the same group is minimized. And means for grouping candidate words constituting the second candidate word string.
本発明に係る音声認識装置においては、前記時間的距離は、候補語間の時間的な重なりを表すことを特徴とする。 In the speech recognition apparatus according to the present invention, the temporal distance represents temporal overlap between candidate words.
本発明に係る音声認識装置は、入力された音声を認識する処理を行い、認識した単語の列から成る認識結果を生成する音声認識手段と、認識結果から候補語を抽出する候補語抽出手段と、候補語をグループ化する候補語グループ化手段と、グループ化された候補語を画面に表示する候補語表示手段と、ユーザが画面に表示された候補語を編集するための編集操作手段と、ユーザによる編集内容に従って認識結果を更新する更新手段と、を備え、前記候補語グループ化手段は、前記認識結果において信頼度が最大である文を構成する候補語の列(第1の候補語列)とそれ以外の候補語の列(第2の候補語列)を抽出する手段と、第1の候補語列中の候補語と第2の候補語列中の候補語の間の時間的な重なりを算出する手段と、第1の候補語列中の候補語と第2の候補語列中の候補語の間の音素の編集距離を算出する手段と、候補語間の時間的な重なりと候補語間の音素の編集距離を用いて、候補語間の距離を算出する手段と、第1の候補語列中の候補語と第2の候補語列中の候補語の間の距離が最小である候補語同士をグループ化する手段と、を有することを特徴とする。 The speech recognition apparatus according to the present invention performs a process of recognizing input speech, generates speech recognition means including a recognized word sequence, candidate word extraction means for extracting candidate words from the recognition results, , Candidate word grouping means for grouping the candidate words, candidate word display means for displaying the grouped candidate words on the screen, editing operation means for the user to edit the candidate words displayed on the screen, Updating means for updating a recognition result in accordance with contents edited by a user, wherein the candidate word grouping means includes a sequence of candidate words (first candidate word sequence) constituting a sentence having the maximum reliability in the recognition result ) And the other candidate word string (second candidate word string), and the time between the candidate word in the first candidate word string and the candidate word in the second candidate word string Means for calculating overlap and in the first candidate word string Using the means for calculating the phoneme editing distance between the candidate word and the candidate word in the second candidate word string, the temporal overlap between the candidate words and the phoneme editing distance between the candidate words, And a means for grouping candidate words having the shortest distance between the candidate words in the first candidate word string and the candidate words in the second candidate word string. It is characterized by.
本発明に係る音声認識装置においては、前記候補語間の音素の編集距離は、1音素当たりの編集回数であることを特徴とする。 In the speech recognition apparatus according to the present invention, the phoneme edit distance between the candidate words is the number of edits per phoneme.
本発明に係る音声認識装置においては、前記候補語間の音素の編集距離は、候補語間で音素を一致させるために必要な置換の対象の音素の組合せにおける、音素間の音響的な類似度を表すことを特徴とする。 In the speech recognition apparatus according to the present invention, the phoneme editing distance between the candidate words is an acoustic similarity between phonemes in a combination of phonemes to be replaced necessary for matching the phonemes between candidate words. It is characterized by expressing.
本発明に係る音声認識装置においては、前記音素間の音響的な類似度は、音素間の調音位置と調音様式についての一致度であることを特徴とする。 In the speech recognition apparatus according to the present invention, the acoustic similarity between the phonemes is a coincidence between the articulation position and the articulation style between the phonemes.
本発明に係る音声認識装置においては、前記候補語間の音素の編集距離は、音素間の誤認識しやすさを表すことを特徴とする。 In the speech recognition apparatus according to the present invention, the phoneme editing distance between the candidate words represents ease of erroneous recognition between phonemes.
本発明に係る音声認識装置においては、1つの候補語列中の複数の候補語が1つのグループに属すると判定された場合に、該複数の候補語を連結する手段を備えたことを特徴とする。 The speech recognition apparatus according to the present invention is characterized by comprising means for connecting a plurality of candidate words when it is determined that a plurality of candidate words in one candidate word string belongs to one group. To do.
本発明に係るコンピュータプログラムは、入力された音声を認識する処理を行い、認識した単語の列から成る認識結果を生成する音声認識機能と、認識結果から候補語を抽出する候補語抽出機能と、候補語をグループ化する候補語グループ化機能と、グループ化された候補語を画面に表示する候補語表示機能と、ユーザが画面に表示された候補語を編集するための編集操作機能と、ユーザによる編集内容に従って認識結果を更新する更新機能と、をコンピュータに実現させるコンピュータプログラムであり、前記候補語グループ化機能は、前記認識結果において信頼度が最大である文を構成する候補語の列(第1の候補語列)とそれ以外の候補語の列(第2の候補語列)を抽出し、第1の候補語列中の候補語と第2の候補語列中の候補語の間の時間的距離を算出し、同じグループ内の第1の候補語列中の候補語と第2の候補語列中の候補語の間の時間的距離を合計した値が最小になるように、第1の候補語列と第2の候補語列を構成する候補語同士をグループ化することを特徴とする。 The computer program according to the present invention performs a process for recognizing input speech, generates a recognition result including a recognized word sequence, a candidate word extraction function for extracting a candidate word from the recognition result, A candidate word grouping function for grouping candidate words, a candidate word display function for displaying the grouped candidate words on the screen, an editing operation function for the user to edit the candidate words displayed on the screen, and a user An update function that updates a recognition result in accordance with the edited content by the computer, and the candidate word grouping function includes a sequence of candidate words constituting a sentence having the maximum reliability in the recognition result ( First candidate word string) and other candidate word strings (second candidate word string) are extracted, and between the candidate words in the first candidate word string and the candidate words in the second candidate word string The temporal distance is calculated, and the value obtained by summing the temporal distances between the candidate words in the first candidate word string and the candidate words in the second candidate word string in the same group is minimized. The candidate words constituting one candidate word string and the second candidate word string are grouped together.
本発明に係るコンピュータプログラムは、入力された音声を認識する処理を行い、認識した単語の列から成る認識結果を生成する音声認識機能と、認識結果から候補語を抽出する候補語抽出機能と、候補語をグループ化する候補語グループ化機能と、グループ化された候補語を画面に表示する候補語表示機能と、ユーザが画面に表示された候補語を編集するための編集操作機能と、ユーザによる編集内容に従って認識結果を更新する更新機能と、をコンピュータに実現させるコンピュータプログラムであり、前記候補語グループ化機能は、前記認識結果において信頼度が最大である文を構成する候補語の列(第1の候補語列)とそれ以外の候補語の列(第2の候補語列)を抽出し、第1の候補語列中の候補語と第2の候補語列中の候補語の間の時間的な重なりを算出し、第1の候補語列中の候補語と第2の候補語列中の候補語の間の音素の編集距離を算出し、候補語間の時間的な重なりと候補語間の音素の編集距離を用いて、候補語間の距離を算出し、第1の候補語列中の候補語と第2の候補語列中の候補語の間の距離が最小である候補語同士をグループ化することを特徴とする。
これにより、前述の音声認識装置がコンピュータを利用して実現できるようになる。The computer program according to the present invention performs a process for recognizing input speech, generates a recognition result including a recognized word sequence, a candidate word extraction function for extracting a candidate word from the recognition result, A candidate word grouping function for grouping candidate words, a candidate word display function for displaying the grouped candidate words on the screen, an editing operation function for the user to edit the candidate words displayed on the screen, and a user An update function that updates a recognition result in accordance with the edited content by the computer, and the candidate word grouping function includes a sequence of candidate words constituting a sentence having the maximum reliability in the recognition result ( First candidate word string) and other candidate word strings (second candidate word string) are extracted, and between the candidate words in the first candidate word string and the candidate words in the second candidate word string The temporal overlap is calculated, the phoneme editing distance between the candidate word in the first candidate word string and the candidate word in the second candidate word string is calculated, and the temporal overlap between the candidate words and the candidate The distance between candidate words is calculated using the phoneme editing distance between words, and the distance between the candidate word in the first candidate word string and the candidate word in the second candidate word string is the smallest It is characterized by grouping words together.
As a result, the speech recognition apparatus described above can be realized using a computer.
本発明によれば、同一の単語が複数の区間で候補語となることを防ぐことができ、音声認識結果から画面に表示される候補語として、同じ単語が複数の区間で表示されることを防止することが可能になる。これにより、ユーザが候補語を編集する操作の回数を低減することができるという効果が得られる。 According to the present invention, the same word can be prevented from becoming a candidate word in a plurality of sections, and the same word can be displayed in a plurality of sections as a candidate word displayed on the screen from the speech recognition result. It becomes possible to prevent. Thereby, the effect that the frequency | count of operation which a user edits a candidate word can be reduced is acquired.
以下、図面を参照し、本発明の一実施形態について説明する。
図1は、本発明の一実施形態に係る音声認識装置1の全体構成を示すブロック図である。図1において、音声認識装置1は、音声入力部11、音響特徴量抽出部12、音声認識部13、音響モデル記憶部14、言語モデル記憶部15、候補語生成部16、候補語編集・表示部17及び編集操作部18を備える。Hereinafter, an embodiment of the present invention will be described with reference to the drawings.
FIG. 1 is a block diagram showing the overall configuration of a
音声入力部11は、マイク、増幅器、アナログ−デジタル変換器(AD変換器)などから構成される。音声入力部11は、ユーザが発声した音声をマイクにより入力し、入力したアナログの音声信号を適当なレベルまで増幅してからデジタルの音声データに変換する。この音声データは音響特徴量抽出部12に送られる。 The
なお、音声入力部11は、電話回線、IP(Internet Protocol)網などの通信回線と接続する通信インターフェースを備え、通信回線を介して受信したデジタルの音声データを音響特徴量抽出部12に送るものであってもよい。さらに、音声データが符号化されている場合には、復号化した音声データを音響特徴量抽出部12に送るようにする。 The
音響特徴量抽出部12は、音声入力部11から受け取った音声データから、後段の音声認識処理に用いる音響特徴量を抽出する。この音響特徴量のデータは音声認識部13に送られる。 The acoustic feature
音声認識部13は、音響特徴量抽出部12から受け取った音響特徴量データに対して音声認識処理を行う。この音声認識処理には、音響モデル記憶部14に記憶されている音響モデルと、言語モデル記憶部15に記憶されている言語モデルとを使用する。音響モデル及び言語モデルは、準備段階として事前に、学習データを用いた学習によって構築し、各記憶部14,15に格納しておく。 The
音声認識部13は、音響モデル及び言語モデルを用いた音声認識処理によって、音響特徴量データから単語を認識し、認識した単語の列から成る認識結果を作成する。このとき、最も確からしい単語の列から成る認識結果だけでなく、それ以外の他の認識された単語の列についても認識結果として作成する。音声認識部13は、各認識結果に対して、音響的なスコア(音響尤度)と言語的な確率(言語確率)から認識結果の確からしさ(信頼度)を算出する。言語確率とは、一定数(例えば3個)の単語の並びが出現する確率である。音声認識部13は、作成した認識結果の中から、所定の順位までの信頼度を有する認識結果を用いて、単語のネットワーク形式の認識結果を作成する。 The
図2に、単語のネットワーク形式の認識結果の構成例を示す。図2に示されるような、単語のネットワーク形式は、従来、ラティス形式と呼ばれている。図2の例は、ユーザが“今日の午後3時に会議です”という文章を読んだときの構成例である。図2に示されるように、複数の認識結果(所定の順位までの信頼度の認識結果)を使用し、各認識結果に含まれる時間的に対応する単語の区切りをネットワーク状に連結している。なお、図2の認識結果の内容は、説明の便宜上のものである。 FIG. 2 shows a configuration example of the recognition result of the word network format. The network format of words as shown in FIG. 2 is conventionally called a lattice format. The example of FIG. 2 is a configuration example when the user reads the sentence “It is a meeting at 3 pm today”. As shown in FIG. 2, a plurality of recognition results (recognition results up to a predetermined rank) are used, and temporally corresponding word breaks included in each recognition result are connected in a network form. . The contents of the recognition result in FIG. 2 are for convenience of explanation.
音声認識部13は、単語のネットワーク形式の認識結果に、各単語の品詞の種類を示す品詞情報と、各単語の音響尤度、言語確率及び信頼度の情報とを含める。単語のネットワーク形式の認識結果は、候補語生成部16に送られる。 The
候補語生成部16は、音声認識部13から受け取った単語のネットワーク形式の認識結果から候補語を抽出し、抽出した候補語をグループ化する。候補語生成部16は、単語のネットワーク形式の認識結果から生成した候補語の列から成る候補語データを候補語編集・表示部17に出力する。候補語データは、認識結果が候補語の列として表され、且つ、候補語がグループ化されたものである。 The candidate
候補語編集・表示部17は、候補語生成部16から受け取った候補語データを画面に表示する。編集操作部18は、各種の編集用の操作キーを備える。例えば、画面に表示された候補語の中からユーザが正解の候補語を選択するための操作キー、ユーザが候補語を削除する操作キー、ユーザが新規の候補語を入力するための操作キー、ユーザが認識結果の編集の終了を指示する操作キーなどを備える。編集操作部18は、ユーザが操作キーで行った編集内容を候補語編集・表示部17に通知する。候補語編集・表示部17は、編集操作部18から通知された編集内容に従って、認識結果を更新する。そして、更新後の認識結果に対応する候補語データで画面の表示内容を更新する。これにより、ユーザが編集した内容を反映した認識結果が、画面に表示される。 The candidate word editing /
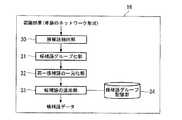
図3は、図1に示す候補語生成部16の構成例である。図3において、候補語生成部16は、候補語抽出部30、候補語グループ化部31、同一候補語の一元化部32、候補語の追加部33及び候補語グループ記憶部34を有する。 FIG. 3 is a configuration example of the candidate
候補語抽出部30は、単語のネットワーク形式の認識結果に含まれる単語の中から、候補語を抽出する。候補語抽出部30は、個々の単語、又は、連続する複数の単語を、一つの候補語として抽出する。 The candidate
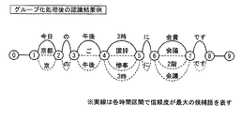
候補語グループ化部31は、単語のネットワーク形式の認識結果から抽出された候補語について、グループ化を行う。候補語のグループ化は、読みの近さや時間情報などに基づいて行う。候補語グループ化部31は、同一グループの候補語の開始時刻および終了時刻を、信頼度が最大の候補語の開始時刻および終了時刻に揃える。これにより、図2に示された単語のネットワーク形式の認識結果は、図4に示されるような、候補語のネットワーク形式になる。図4は、候補語グループ化処理後の認識結果の構成例である。図2では単語単位でネットワーク状に連結されていたが、図4では、候補語単位でネットワーク状に連結されていると共に、候補語がグループ化されている。これにより、認識結果が簡略化される。 The candidate
同一候補語の一元化部32は、候補語のグループ化処理後の認識結果に対して、同一グループに含まれる表記の同じ候補語を1つの候補語にまとめ、その候補語の信頼度を再計算する。一元化処理後の候補語の信頼度は、一元化処理前の候補語の信頼度の平均、加算、最大値などによって求める。同一候補語の一元化部32は、さらに、各時間区間の候補語の数を、確率の高いものから所定個数までに制限する。これにより、図4に示された候補語グループ化処理後の認識結果は、図5に示されるように簡略化される。図5は、同一候補語の一元化処理後の認識結果の構成例である。なお、図5の例では、各時間区間で、信頼度の高い順に候補語を上から並べている。 The
候補語の追加部33は、同一候補語の一元化処理後の認識結果に対して、過去の候補語のグループの履歴に基づき、候補語を追加する。候補語グループ記憶部34は、過去の候補語のグループの履歴を記憶している。候補語の追加部33は、同一候補語の一元化処理後の認識結果中の最大の信頼度を有する候補語についてのグループの履歴を、候補語グループ記憶部34から読み出す。候補語の追加部33は、読み出したグループの履歴中に、同一候補語の一元化処理後の認識結果中のグループ内には存在しない候補語があった場合には、該候補語を同一候補語の一元化処理後の認識結果中のグループに追加する。逆に、同一候補語の一元化処理後の認識結果中のグループ内に存在する候補語が、候補語グループ記憶部34から読み出したグループの履歴中に存在しない場合には、該候補語を候補語グループ記憶部34内のグループの履歴に追加する。 The candidate
候補語生成部16は、候補語の追加処理後の認識結果に対応する候補語データを、候補語編集・表示部17に出力する。 The candidate
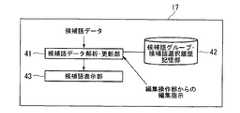
図6は、図1に示す候補語編集・表示部17の構成例である。図6において、候補語編集・表示部17は、候補語データ解析・更新部41、候補語グループ・候補語選択履歴記憶部42及び候補語表示部43を有する。 FIG. 6 is a configuration example of the candidate word editing /
候補語データ解析・更新部41は、候補語データを解析し、各時間区間で信頼度が最大の候補語を連結することにより、暫定的な認識結果を作成し、保持する。その暫定的な認識結果、及び、各候補語と同一グループの候補語のデータは、候補語表示部43に送られる。このとき候補語表示部43には、画面に表示可能な分量のみが送られる。 The candidate word data analysis /
候補語表示部43は、候補語データ解析・更新部41から受け取った認識結果を表示装置の画面に表示する。このとき、候補語の境界を空白などにより明示する。さらに、各候補語に対してグループ化された他の候補語がある場合は、その旨を下線などにより示す。さらに、同一グループの候補語を、認識結果を表示する画面とは別の画面に表示し、その画面内で候補語を信頼度の高い順に表示する。 The candidate
候補語データ解析・更新部41は、編集操作部18からユーザの編集内容を受け取ると、その編集内容に従って認識結果を更新する。例えば、正解の候補語の選択、候補語の削除、候補語の並びの変更、新規の候補語の入力などの編集内容に従って、認識結果を変更する。正解の候補語の選択がなされた場合は、編集箇所を正解の候補語に置き換え、他の候補語を削除する。候補語の削除がなされた場合には、編集箇所の候補語を全て削除する。新規の候補語が入力された場合には、編集箇所に入力された候補語を挿入する。候補語データ解析・更新部41は、編集後の認識結果、及び、各候補語と同一グループの候補語のデータを候補語表示部43に送る。 When the candidate word data analysis /
候補語データ解析・更新部41は、編集操作部18から編集箇所を移動する指示を受け取ると、移動先に対応する認識結果、及び、各候補語と同一グループの候補語のデータを候補語表示部43に送る。 When the candidate word data analyzing / updating
候補語グループ・候補語選択履歴記憶部42は、候補語のグループと、ユーザが候補語を選択した確率(ユーザ選択確率)を保持する。候補語データ解析・更新部41は、候補語グループ・候補語選択履歴記憶部42を参照し、編集箇所にあたる候補語のグループの候補語の表示を、候補語グループ・候補語選択履歴記憶部42内のユーザ選択確率の高い順に並び替える処理を行うことができる。なお、ユーザ選択確率による表示順序の変更処理については、実行の可否を選択することができるようにする。 The candidate word group / candidate word selection
次に、本実施形態に係る候補語グループ化処理について、いくつかの実施例を挙げて詳細に説明する。 Next, the candidate word grouping processing according to the present embodiment will be described in detail with some examples.
候補語グループ化部31は、候補語抽出部30によって単語のネットワーク形式の認識結果から抽出された候補語から、単語のネットワーク形式の認識結果において、信頼度が最大である文を構成する候補語の列(以下、「第1の候補語列」と称する)と、それ以外の候補語の列(以下、「第2の候補語列」と称する)を抽出する。図2の例では、第1の候補語列は図2中の実線部分“今日の午後3時に会費です”であり、第2の候補語列は該“今日の午後3時に会費です”以外の候補語列である。 The candidate
次いで、候補語グループ化部31は、第1の候補語列中の候補語と第2の候補語列中の候補語の間の時間的距離を算出する。次いで、候補語グループ化部31は、同じグループ内の第1の候補語列中の候補語と第2の候補語列中の候補語の間の時間的距離を合計した値が最小になるように、第1の候補語列と第2の候補語列を構成する候補語同士をグループ化する。なお、時間的距離が最小となる候補語の組合せは、DTW(Dynamic Time Warping)により効率的に求めることができる。 Next, the candidate
第1の候補語列中の候補語と第2の候補語列中の候補語との間の時間的距離としては、例えば、候補語の時間的な重なりを1から減算した値を用いることができる。候補語wiと候補語wjの時間的な重なりO(wi,wj)は、例えば、(1)式によって計算することができる。(1)式においては、候補語wi,wjの時間長l(wi),l(wj)の合計に対する時間的な重なりl(wi∩wj)の占める割合として、時間的な重なりO(wi,wj)を定義している。図7には、候補語wiの時間長l(wi)、候補語wjの時間長l(wj)及びその時間的な重なりl(wi∩wj)の関係が示されている。As a temporal distance between the candidate word in the first candidate word string and the candidate word in the second candidate word string, for example, a value obtained by subtracting the temporal overlap of candidate words from 1 is used. it can. The temporal overlap O (wi , wj ) between the candidate word wi and the candidate word wj can be calculated by, for example, equation (1). In equation (1), the temporal overlap l (wi ∩wj ) occupies the temporal length l (wi ) and l (wj ) of the candidate words wi and wj in terms of time. Defined overlap O (wi , wj ). 7, the time length l of candidate words wi (wi), the time length l (wj) of the candidate word wj and in relation temporal overlapping l (wi ∩wj) is shown Yes.

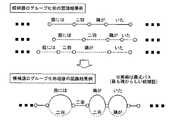
図8は、実施例1に係る候補語グループ化処理の一例である。図8の例は、図2の認識結果を処理する一例である。図8では、第1の候補語列“今日の午後3時に会費です”と、第2の候補語列“京の午後3時に会議です”を処理対象にしている。そして、時間的な重なりの大きい、“今日の”と“京の”、“午後”と“午後”、“3時に”と“3時に”、“会費”と“会議”、“です”と“です”をそれぞれに同じグループとし、合計5つのグループ1〜5を形成している。 FIG. 8 is an example of candidate word grouping processing according to the first embodiment. The example of FIG. 8 is an example of processing the recognition result of FIG. In FIG. 8, the first candidate word string “Meeting fee at 3 pm today” and the second candidate word string “Meeting at 3 pm in Kyoto” are processed. And “Today” and “Kyoto”, “Afternoon” and “Afternoon”, “3 o'clock” and “3 o'clock”, “Meeting fee” and “Conference”, “Is” and “ "Is the same group for each", forming a total of five groups 1-5.
本実施例1によれば、第1の候補語列中の候補語と第2の候補語列中の候補語との間の時間的距離を合計した値が最小になるように、第1の候補語列と第2の候補語列を構成する候補語同士をグループ化する。これにより、候補語の並び順を維持しながら候補語のグループ化を行うと共に、同一の単語が複数の区間で候補語となることを防ぐことができる。これにより、音声認識結果から画面に表示される候補語として、同じ単語が複数の区間で表示されることを防止することが可能になる。 According to the first embodiment, the first value is set so that the sum of the temporal distances between the candidate words in the first candidate word string and the candidate words in the second candidate word string is minimized. The candidate words constituting the candidate word string and the second candidate word string are grouped. Thereby, it is possible to group candidate words while maintaining the order of arrangement of candidate words, and to prevent the same word from becoming a candidate word in a plurality of sections. This makes it possible to prevent the same word from being displayed in a plurality of sections as candidate words displayed on the screen from the speech recognition result.
実施例2では、実施例1と同様に、第1の候補語列中の候補語wiと第2の候補語列中の候補語wjとの時間的な重なりO(wi,wj)を用い、さらに、候補語間の読みの近さを表すものとして、候補語間の音素の編集距離(レーベンシュタイン距離)L(wi,wj)を用いる。In the second embodiment, as in the first embodiment, the temporal overlap O (wi , wj between the candidate word wi in the first candidate word string and the candidate word wj in the second candidate word string. ), And the phoneme editing distance (Levenstein distance) L (wi , wj ) between candidate words is used to represent the proximity of reading between candidate words.
候補語グループ化部31は、実施例1と同様に、第1の候補語列中の候補語wiと第2の候補語列中の候補語wjとの時間的な重なりO(wi,wj)を算出する。次いで、候補語グループ化部31は、第1の候補語列中の候補語wiと第2の候補語列中の候補語wjについて候補語間の音素の編集距離L(wi,wj)を算出する。候補語間の音素の編集距離L(wi,wj)は、1音素当たりの編集回数である。編集回数とは、候補語wiと候補語wjの間で音素を一致させるために必要となる、音素の削除、挿入、置換の回数の合計である。候補語wiの音素の数をNwi、候補語wjの音素の数をNwj、編集回数をNeとすると、候補語間の音素の編集距離L(wi,wj)は、(2)式により算出できる。Similar to the first embodiment, the candidate
候補語グループ化部31は、(2)式により候補語wi,wj間の音素の編集距離L(wi,wj)を算出する際に、候補語wiの音素数Nwi及び候補語wjの音素数Nwjを調べる。さらに、候補語グループ化部31は、候補語wiと候補語wjの間で音素を一致させるために必要な編集回数Neを調べる。次いで、候補語グループ化部31は、音素数Nwiと音素数Nwjのうち大きい方の音素数を(2)式の分母に代入し、編集回数Neを(2)式の分子に代入し、(2)式の値を計算する。When the candidate
図9に、編集距離L(wi,wj)の計算例が示されている。図9の例は、“神田”と“蒲田”の間の編集距離L(wi,wj)を求めている。図9に示されるように“神田”と“蒲田”では、編集回数が4回であり、1音素当りの編集距離は、4/6となる。FIG. 9 shows a calculation example of the edit distance L (wi , wj ). In the example of FIG. 9, the edit distance L (wi , wj ) between “Kanda” and “Iwata” is obtained. As shown in FIG. 9, in “Kanda” and “Iwata”, the number of edits is 4, and the edit distance per phoneme is 4/6.
次いで、候補語グループ化部31は、候補語間の時間的な重なりO(wi,wj)と候補語間の音素の編集距離L(wi,wj)を用いて、候補語間の距離D(wi,wj)を算出する。候補語間の距離D(wi,wj)は、(3)式により算出できる。但し、(3)式において、α,βは、0から1の範囲の値を持つ重み付け係数であり、D(wi,wj)が0から1の範囲の値になるように設定する。候補語間の距離D(wi,wj)は、候補語間の時間的な重なりO(wi,wj)と候補語間の音素の編集距離L(wi,wj)の重み付け加算値となっている。Next, the candidate
次いで、候補語グループ化部31は、第1の候補語列中の候補語wiと第2の候補語列中の候補語wjの間の距離D(wi,wj)が最小である候補語同士をグループ化する。Next, the candidate
図10は、実施例2に係る候補語グループ化処理の一例である。図10の例は、図2の認識結果を処理する一例である。図10では、第1の候補語列“今日の午後3時に会費です”と、第2の候補語列“京都ご讃辞に会議です”を処理対象にしている。図10に示されるように、第2の候補語列中の候補語“ご讃辞に”に対して、第1の候補語列の中で時間的に重なりのある候補語は、“午後”と“3時に”と“会費”の3つある。図10の例では、本実施例2の候補語グループ化処理の結果、候補語“3時に”と候補語“ご讃辞に”が同一グループに属するように判定されている。 FIG. 10 is an example of candidate word grouping processing according to the second embodiment. The example of FIG. 10 is an example of processing the recognition result of FIG. In FIG. 10, the first candidate word string “Meeting fee is 3:00 pm today” and the second candidate word string “Meeting in Kyoto!” Are targeted for processing. As shown in FIG. 10, the candidate word that overlaps in time in the first candidate word string is “afternoon” with respect to the candidate word “congratulations” in the second candidate word string. And “3 o'clock” and “membership”. In the example of FIG. 10, as a result of the candidate word grouping process of the second embodiment, it is determined that the candidate word “3 o'clock” and the candidate word “comment” belong to the same group.
図11は、実施例2に係る候補語グループ化処理の他の例である。図11の例では、第1の候補語列が“京都ご讃辞に会議です”であり、第2の候補語列が“今日の午後3時に会費です”である。図11に示されるように、第2の候補語列中の候補語“午後”と候補語“3時に”に対して、第1の候補語列の中で、時間的に重なりがあり且つ編集距離が短い候補語は“ご讃辞に”のみである。そのため、候補語“午後”も候補語“3時に”も、“ご讃辞に”とグループ化される。このように、1つの候補語列に含まれる複数の候補語が1つのグループに属すると判定された場合は、該複数の候補語を連結する。図11の例では、候補語“午後”と候補語“3時に”を連結して、1つの候補語“午後3時に”を生成する。この候補語“午後3時に”は、候補語“ご讃辞に”と同じグループ2を形成する。 FIG. 11 is another example of candidate word grouping processing according to the second embodiment. In the example of FIG. 11, the first candidate word string is “Meeting in Kyoto” and the second candidate word string is “Meeting fee at 3 pm today”. As shown in FIG. 11, the candidate word “afternoon” and the candidate word “3 o'clock” in the second candidate word string are temporally overlapped and edited in the first candidate word string. The only candidate word that has a short distance is “comments”. For this reason, the candidate word “afternoon” and the candidate word “3 o'clock” are grouped together as “congratulations”. In this way, when it is determined that a plurality of candidate words included in one candidate word string belong to one group, the plurality of candidate words are connected. In the example of FIG. 11, the candidate word “afternoon” and the candidate word “3 o'clock” are connected to generate one candidate word “3 o'clock”. This candidate word “3 pm” forms the same group 2 as the candidate word “congratulations”.
本実施例2によれば、第1の候補語列中の候補語wiと第2の候補語列中の候補語wjとの間の時間的な重なりO(wi,wj)及び音素の編集距離L(wi,wj)の重み付け加算値である、距離D(wi,wj)が最小である候補語同士をグループ化する。これにより、候補語の並び順を維持しながら候補語のグループ化を行うと共に、同一の単語が複数の区間で候補語となることを防ぐことができる。これにより、音声認識結果から画面に表示される候補語として、同じ単語が複数の区間で表示されることを防止することが可能になる。According to the second embodiment, the temporal overlap O (wi , wj ) between the candidate word wi in the first candidate word string and the candidate word wj in the second candidate word string and Candidate words having the smallest distance D (wi , wj ), which is a weighted addition value of the phoneme editing distance L (wi , wj ), are grouped. Thereby, it is possible to group candidate words while maintaining the order of arrangement of candidate words, and to prevent the same word from becoming a candidate word in a plurality of sections. This makes it possible to prevent the same word from being displayed in a plurality of sections as candidate words displayed on the screen from the speech recognition result.
なお、実施例2の変形として、以下に示すいくつかの方法が挙げられる。 In addition, some methods shown below are mentioned as a modification of Example 2.
[実施例2−1]
実施例2−1では、候補語間の音素の編集距離L(wi,wj)を算出する際に、編集回数Neの代わりに、候補語間の読みの近さを表すものとして「候補語wiと候補語wjの間で音素を一致させるために必要な置換の対象の音素の組合せにおける、音素間の音響的な類似度」を用いる。例えば、読みの似た3つの単語として“/n/a/k/a/d/a/(中田)”と“/n/a/k/a/t/a/(中田)”と“/n/a/k/a/m/a/(仲間)”では、音素“/d/”と音素“/t/”、音素“/d/”と音素“/m/”、音素“/t/”と音素“/m/”が、それぞれの単語間で音素を一致させるために必要な置換の対象の音素の組合せである。[Example 2-1]
In Example 2-1, the edit distance L (wi, wj) of the phonemes between the candidate word when calculating, instead of editing the number Ne, as representing the closeness of the readings between the candidate word " The “acoustic similarity between phonemes in the combination of phonemes to be replaced necessary for matching phonemes between candidate word wi and candidate word wj ” is used. For example, “/ n / a / k / a / d / a / (Nakada)”, “/ n / a / k / a / t / a / (Nakada)” and “/ n / a / k / a / m / a / (companies), phonemes “/ d /” and phonemes “/ t /”, phonemes “/ d /” and phonemes “/ m /”, phonemes “/ t” “/” And phoneme “/ m /” are combinations of phonemes to be replaced necessary to match phonemes between the respective words.
まず準備段階として事前に、すべての音素の組み合わせに対して、音響的な類似度に応じた編集コストCpi,pjを決定し、メモリに保持しておく。編集コストCpi,pjは、音素piと音素pjの間の音響的な類似度を表す。First, as a preparation stage, the editing cost Cpi, pj corresponding to the acoustic similarity is determined in advance for all phoneme combinations and stored in the memory. The editing cost Cpi, pj represents the acoustic similarity between the phoneme pi and the phoneme pj .
候補語グループ化部31は、(2)式により候補語wi,wj間の音素の編集距離L(wi,wj)を算出する際に、候補語wiと候補語wjの間で音素を一致させるために必要な置換の対象の音素の組合せを調べる。次いで、候補語グループ化部31は、その各音素の組合せについて編集コストCpi,pjをメモリから読み出す。次いで、候補語グループ化部31は、その編集コストCpi,pjの合計を計算する。次いで、候補語グループ化部31は、その編集コストCpi,pjの合計値を編集回数Neの代わりに(2)式の分子に代入し、候補語wiの音素数Nwiと候補語wjの音素数Nwjのうち大きい方の音素数を(2)式の分母に代入し、(2)式の値を計算する。次いで、候補語グループ化部31は、(3)式により、候補語間の距離D(wi,wj)を計算する。なお、候補語間の時間的な重なりO(wi,wj)は、実施例1と同様に算出する。Candidate word grouping unit 31 (2) by the candidate words wi, edit phonemes between wj distance L (wi, wj) in calculating, the candidate words wi and candidate word wj The combination of phonemes to be replaced necessary for matching phonemes between them is examined. Next, the candidate
本実施例2−1によれば、候補語間の編集回数が同じ場合であっても、編集距離が異なることがある。例えば、読みの似た3つの単語として“/n/a/k/a/d/a/(中田)”と“/n/a/k/a/t/a/(中田)”と“/n/a/k/a/m/a/(仲間)”では、どの単語の組合せでも編集回数は1である。このとき、もし、音素“/d/”と音素“/t/”の編集コストC/d/,/t/が、音素“/d/”と音素“/m/”の編集コストC/d/,/m/、及び、音素“/t/”と音素“/m/”の編集コストC/t/,/m/より小さい場合には、“/n/a/k/a/d/a/(中田)”と“/n/a/k/a/t/a/(中田)”の組の編集距離は、他の単語の組に比べて、小さくなる。According to the present Example 2-1, even when the number of edits between candidate words is the same, the edit distance may be different. For example, “/ n / a / k / a / d / a / (Nakada)”, “/ n / a / k / a / t / a / (Nakada)” and “/ In “n / a / k / a / m / a / (friend)”, the number of editing is 1 for any combination of words. In this case, if, phoneme "/ d /" and the phoneme "/ t /" of editing cost C/ d /, / t / is, phoneme "/ d /" and the phoneme "/ m /" Edit cost C/ d of/, / m / and the editing cost C/ t /, / m / of the phonemes “/ t /” and “/ m /” is “/ n / a / k / a / d / The editing distance of the pair “a / (Nakada)” and “/ n / a / k / a / t / a / (Nakada)” is smaller than the other word pairs.
なお、音素間の音響的な類似度としては、例えば、子音の調音に必要な閉鎖が起きる声道の位置(調音位置)とその閉鎖の方法(調音様式)を音素毎に調べ、音素間の調音位置と調音様式についての一致度を用いることが挙げられる。 As the acoustic similarity between phonemes, for example, the position of the vocal tract (articulation position) where the closure required for articulation of consonants and the closing method (articulation style) are examined for each phoneme. For example, the degree of coincidence between the articulation position and the articulation style is used.
[実施例2−2]
実施例2−2では、候補語間の音素の編集距離L(wi,wj)として、音素間の誤認識しやすさ(Confusion Matrix)を用いる。[Example 2-2]
In Example 2-2, the ease of misrecognition between phonemes (Confusion Matrix) is used as the phoneme editing distance L (wi , wj ) between candidate words.
まず準備段階として事前に音声認識処理によって、すべての音素の組み合わせに対して、音素間の誤認識しやすさを求め、音素の組合せ毎に編集距離を決定しメモリに保持しておく。編集距離としては、誤認識しやすい音素間ほど編集距離が短い値、誤認識し難い音素間ほど編集距離が長い値を与える。 First, as a preparation stage, the ease of misrecognition between phonemes is obtained for all phoneme combinations in advance by speech recognition processing, and the edit distance is determined for each phoneme combination and stored in the memory. As the editing distance, a value that is shorter in the editing distance is given to a phoneme that is easily misrecognized, and a longer value is given to a phoneme that is hard to be erroneously recognized.
候補語グループ化部31は、(2)式により候補語wi,wj間の音素の編集距離L(wi,wj)を算出する際に、候補語wiと候補語wjの間の音素の組合せを抽出する。次いで、候補語グループ化部31は、その各音素の組合せについて編集距離をメモリから読み出す。次いで、候補語グループ化部31は、その編集距離の合計を計算する。次いで、候補語グループ化部31は、その編集距離の合計値を編集回数Neの代わりに(2)式の分子に代入し、候補語wiの音素数Nwiと候補語wjの音素数Nwjのうち大きい方の音素数を(2)式の分母に代入し、(2)式の値を計算する。次いで、候補語グループ化部31は、(3)式により、候補語間の距離D(wi,wj)を計算する。なお、候補語間の時間的な重なりO(wi,wj)は、実施例1と同様に算出する。Candidate word grouping unit 31 (2) by the candidate words wi, edit phonemes between wj distance L (wi, wj) in calculating, the candidate words wi and candidate word wj Extract phoneme combinations between. Next, the candidate
上述したように本実施形態によれば、候補語の並び順を維持しながら候補語のグループ化を行うと共に、同一の単語が複数の区間で候補語となることを防ぎ、音声認識結果から画面に表示される候補語として、同じ単語が複数の区間で表示されることを防止することができる。 As described above, according to the present embodiment, the candidate words are grouped while maintaining the arrangement order of the candidate words, and the same word is prevented from becoming a candidate word in a plurality of sections, and the screen from the voice recognition result is displayed. It is possible to prevent the same word from being displayed in a plurality of sections as the candidate words displayed on the screen.
なお、本実施形態に係る音声認識装置1は、専用のハードウェアにより実現されるものであってもよく、あるいはパーソナルコンピュータ等のコンピュータシステムにより構成され、図1に示される装置の各機能を実現するためのプログラムを実行することによりその機能を実現させるものであってもよい。 Note that the
また、その音声認識装置1には、周辺機器として入力装置、表示装置等(いずれも図示せず)が接続されるものとする。ここで、入力装置とはキーボード、マウス、携帯電話端末のキー等の入力デバイスのことをいう。表示装置とはCRT(Cathode Ray Tube)や液晶表示装置等のことをいう。
また、上記周辺機器については、音声認識装置1に直接接続するものであってもよく、あるいは通信回線を介して接続するようにしてもよい。In addition, an input device, a display device, and the like (none of which are shown) are connected to the
The peripheral device may be connected directly to the
また、図1に示す音声認識装置1の機能を実現するためのプログラムをコンピュータ読み取り可能な記録媒体に記録して、この記録媒体に記録されたプログラムをコンピュータシステムに読み込ませ、実行することにより、音声認識に係る処理を行ってもよい。なお、ここでいう「コンピュータシステム」とは、OSや周辺機器等のハードウェアを含むものであってもよい。
また、「コンピュータシステム」は、WWWシステムを利用している場合であれば、ホームページ提供環境(あるいは表示環境)も含むものとする。
また、「コンピュータ読み取り可能な記録媒体」とは、フレキシブルディスク、光磁気ディスク、ROM、フラッシュメモリ等の書き込み可能な不揮発性メモリ、DVD(Digital Versatile Disk)等の可搬媒体、コンピュータシステムに内蔵されるハードディスク等の記憶装置のことをいう。Further, by recording a program for realizing the function of the
Further, the “computer system” includes a homepage providing environment (or display environment) if a WWW system is used.
“Computer-readable recording medium” refers to a flexible disk, a magneto-optical disk, a ROM, a writable nonvolatile memory such as a flash memory, a portable medium such as a DVD (Digital Versatile Disk), and a built-in computer system. A storage device such as a hard disk.
さらに「コンピュータ読み取り可能な記録媒体」とは、インターネット等のネットワークや電話回線等の通信回線を介してプログラムが送信された場合のサーバやクライアントとなるコンピュータシステム内部の揮発性メモリ(例えばDRAM(Dynamic Random Access Memory))のように、一定時間プログラムを保持しているものも含むものとする。
また、上記プログラムは、このプログラムを記憶装置等に格納したコンピュータシステムから、伝送媒体を介して、あるいは、伝送媒体中の伝送波により他のコンピュータシステムに伝送されてもよい。ここで、プログラムを伝送する「伝送媒体」は、インターネット等のネットワーク(通信網)や電話回線等の通信回線(通信線)のように情報を伝送する機能を有する媒体のことをいう。
また、上記プログラムは、前述した機能の一部を実現するためのものであっても良い。さらに、前述した機能をコンピュータシステムにすでに記録されているプログラムとの組み合わせで実現できるもの、いわゆる差分ファイル(差分プログラム)であっても良い。Further, the “computer-readable recording medium” means a volatile memory (for example, DRAM (Dynamic DRAM) in a computer system that becomes a server or a client when a program is transmitted through a network such as the Internet or a communication line such as a telephone line. Random Access Memory)), etc., which hold programs for a certain period of time.
The program may be transmitted from a computer system storing the program in a storage device or the like to another computer system via a transmission medium or by a transmission wave in the transmission medium. Here, the “transmission medium” for transmitting the program refers to a medium having a function of transmitting information, such as a network (communication network) such as the Internet or a communication line (communication line) such as a telephone line.
The program may be for realizing a part of the functions described above. Furthermore, what can implement | achieve the function mentioned above in combination with the program already recorded on the computer system, and what is called a difference file (difference program) may be sufficient.
以上、本発明の実施形態について図面を参照して詳述してきたが、具体的な構成はこの実施形態に限られるものではなく、本発明の要旨を逸脱しない範囲の設計変更等も含まれる。
例えば、上述の音声認識装置1は、ワードプロセッサー装置、電子メール装置などの文書作成を行う各種の装置と組合せて構成するようにしてもよい。As mentioned above, although embodiment of this invention was explained in full detail with reference to drawings, the specific structure is not restricted to this embodiment, The design change etc. of the range which does not deviate from the summary of this invention are included.
For example, the
1…音声認識装置、11…音声入力部、12…音響特徴量抽出部、13…音声認識部、14…音響モデル記憶部、15…言語モデル記憶部、16…候補語生成部、17…候補語編集・表示部、18…編集操作部、30…候補語抽出部、31…候補語グループ化部DESCRIPTION OF
Claims (10)
Translated fromJapanese認識結果から候補語を抽出する候補語抽出手段と、
候補語をグループ化する候補語グループ化手段と、
グループ化された候補語を画面に表示する候補語表示手段と、
ユーザが画面に表示された候補語を編集するための編集操作手段と、
ユーザによる編集内容に従って認識結果を更新する更新手段と、を備え、
前記候補語グループ化手段は、
前記認識結果において信頼度が最大である文を構成する候補語の列(第1の候補語列)とそれ以外の候補語の列(第2の候補語列)を抽出する手段と、
第1の候補語列中の候補語と第2の候補語列中の候補語の間の時間的距離を算出する手段と、
同じグループ内の第1の候補語列中の候補語と第2の候補語列中の候補語の間の時間的距離を合計した値が最小になるように、第1の候補語列と第2の候補語列を構成する候補語同士をグループ化する手段と、を有し、
前記時間的距離は次式で定義され、
時間的距離=1−O(wi,wj)、
ことを特徴とする音声認識装置。Performs processing to recognize the input speech, generatesa recognition result consisting of a sequence of recognized words,and confirms the accuracy of the recognition result from the acoustic score (acoustic likelihood) and linguistic probability (language probability) (trust) Voice recognition meansfor calculating the degree)
Candidate word extracting means for extracting candidate words from the recognition result;
Candidate word grouping means for grouping candidate words;
Candidate word display means for displaying grouped candidate words on the screen;
Editing operation means for the user to edit the candidate words displayed on the screen;
Updating means for updating the recognition result in accordance with the contents edited by the user,
The candidate word grouping means includes:
Means for extracting a sequence of candidate words (first candidate word sequence) and a sequence of other candidate words (second candidate word sequence) constituting a sentence having the maximum reliability in the recognition result;
Means for calculating a temporal distance between a candidate word in the first candidate word string and a candidate word in the second candidate word string;
The first candidate word sequence and the first candidate word sequence are arranged such that the sum of temporal distances between the candidate words in the first candidate word sequence and the second candidate word sequence in the same group is minimized. It means for grouping the candidate words that constitute the second candidate word string, thepossess,
The temporal distance is defined by the following equation:
Temporal distance = 1−O (wi, wj),
A speech recognition apparatus characterized by that.
認識結果から候補語を抽出する候補語抽出手段と、
候補語をグループ化する候補語グループ化手段と、
グループ化された候補語を画面に表示する候補語表示手段と、
ユーザが画面に表示された候補語を編集するための編集操作手段と、
ユーザによる編集内容に従って認識結果を更新する更新手段と、を備え、
前記候補語グループ化手段は、
前記認識結果において信頼度が最大である文を構成する候補語の列(第1の候補語列)とそれ以外の候補語の列(第2の候補語列)を抽出する手段と、
第1の候補語列中の候補語と第2の候補語列中の候補語の間の時間的な重なりを算出する手段と、
第1の候補語列中の候補語と第2の候補語列中の候補語の間の音素の編集距離を算出する手段と、
候補語間の時間的な重なりと候補語間の音素の編集距離を用いて、候補語間の距離を算出する手段と、
第1の候補語列中の候補語と第2の候補語列中の候補語の間の距離が最小である候補語同士をグループ化する手段と、を有し、
前記時間的な重なり「O(wi,wj)」は次式で定義され、
前記音素の編集距離「L(wi,wj)」は次式で定義され、
前記候補語間の距離「D(wi,wj)」は次式で定義され、
ことを特徴とする音声認識装置。Performs processing to recognize the input speech, generatesa recognition result consisting of a sequence of recognized words,and confirms the accuracy of the recognition result from the acoustic score (acoustic likelihood) and linguistic probability (language probability) (trust) Voice recognition meansfor calculating the degree)
Candidate word extracting means for extracting candidate words from the recognition result;
Candidate word grouping means for grouping candidate words;
Candidate word display means for displaying grouped candidate words on the screen;
Editing operation means for the user to edit the candidate words displayed on the screen;
Updating means for updating the recognition result in accordance with the contents edited by the user,
The candidate word grouping means includes:
Means for extracting a sequence of candidate words (first candidate word sequence) and a sequence of other candidate words (second candidate word sequence) constituting a sentence having the maximum reliability in the recognition result;
Means for calculating a temporal overlap between candidate words in the first candidate word string and candidate words in the second candidate word string;
Means for calculating a phoneme editing distance between a candidate word in the first candidate word string and a candidate word in the second candidate word string;
Means for calculating a distance between candidate words using temporal overlap between candidate words and a phoneme editing distance between candidate words;
Means the distance between the first candidate word candidate word in the string and the candidate word in the second candidate word in column group the candidate word with each other is minimal, andpossess,
The temporal overlap “O (wi, wj)” is defined by the following equation:
The phoneme editing distance `` L (wi, wj) '' is defined by the following equation:
The distance “D (wi, wj)”between the candidate wordsis defined by the following equation:
A speech recognition apparatus characterized by that.
認識結果から候補語を抽出する候補語抽出手段と、
候補語をグループ化する候補語グループ化手段と、
グループ化された候補語を画面に表示する候補語表示手段と、
ユーザが画面に表示された候補語を編集するための編集操作手段と、
ユーザによる編集内容に従って認識結果を更新する更新手段と、を備え、
前記候補語グループ化手段は、
前記認識結果において信頼度が最大である文を構成する候補語の列(第1の候補語列)とそれ以外の候補語の列(第2の候補語列)を抽出する手段と、
第1の候補語列中の候補語と第2の候補語列中の候補語の間の時間的な重なりを算出する手段と、
第1の候補語列中の候補語と第2の候補語列中の候補語の間の音素の編集距離を算出する手段と、
候補語間の時間的な重なりと候補語間の音素の編集距離を用いて、候補語間の距離を算出する手段と、
第1の候補語列中の候補語と第2の候補語列中の候補語の間の距離が最小である候補語同士をグループ化する手段と、を有し、
前記時間的な重なり「O(wi,wj)」は次式で定義され、
前記音素の編集距離「L(wi,wj)」は次式で定義され、
前記編集コストCpi,pjは、候補語wiと候補語wjの間で音素を一致させるために必要な置換の対象の音素piと音素pjの間の音響的な類似度であり、
すべての音素の組み合わせに対して前記編集コストを予め記憶する記憶手段を設け、
前記候補語間の距離「D(wi,wj)」は次式で定義され、
ことを特徴とする音声認識装置。Performs processing to recognize the input speech, generatesa recognition result consisting of a sequence of recognized words,and confirms the accuracy of the recognition result from the acoustic score (acoustic likelihood) and linguistic probability (language probability) (trust) Voice recognition meansfor calculating the degree)
Candidate word extracting means for extracting candidate words from the recognition result;
Candidate word grouping means for grouping candidate words;
Candidate word display means for displaying grouped candidate words on the screen;
Editing operation means for the user to edit the candidate words displayed on the screen;
Updating means for updating the recognition result in accordance with the contents edited by the user,
The candidate word grouping means includes:
Means for extracting a sequence of candidate words (first candidate word sequence) and a sequence of other candidate words (second candidate word sequence) constituting a sentence having the maximum reliability in the recognition result;
Means for calculating a temporal overlap between candidate words in the first candidate word string and candidate words in the second candidate word string;
Means for calculating a phoneme editing distance between a candidate word in the first candidate word string and a candidate word in the second candidate word string;
Means for calculating a distance between candidate words using temporal overlap between candidate words and a phoneme editing distance between candidate words;
Means the distance between the first candidate word candidate word in the string and the candidate word in the second candidate word in column group the candidate word with each other is minimal, andpossess,
The temporal overlap “O (wi, wj)” is defined by the following equation:
The phoneme editing distance `` L (wi, wj) '' is defined by the following equation:
The editing cost Cpi, pjisan acoustic similarity between thephoneme piand the phoneme pj tobe replaced necessary to match the phonemes between thecandidate word wiand the candidate word wj. ,
A storage means for storing the editing cost in advance for all phoneme combinations is provided,
The distance “D (wi, wj)”between the candidate wordsis defined by the following equation:
A speech recognition apparatus characterized by that.
認識結果から候補語を抽出する候補語抽出手段と、
候補語をグループ化する候補語グループ化手段と、
グループ化された候補語を画面に表示する候補語表示手段と、
ユーザが画面に表示された候補語を編集するための編集操作手段と、
ユーザによる編集内容に従って認識結果を更新する更新手段と、を備え、
前記候補語グループ化手段は、
前記認識結果において信頼度が最大である文を構成する候補語の列(第1の候補語列)とそれ以外の候補語の列(第2の候補語列)を抽出する手段と、
第1の候補語列中の候補語と第2の候補語列中の候補語の間の時間的な重なりを算出する手段と、
第1の候補語列中の候補語と第2の候補語列中の候補語の間の音素の編集距離を算出する手段と、
候補語間の時間的な重なりと候補語間の音素の編集距離を用いて、候補語間の距離を算出する手段と、
第1の候補語列中の候補語と第2の候補語列中の候補語の間の距離が最小である候補語同士をグループ化する手段と、を有し、
前記時間的な重なり「O(wi,wj)」は次式で定義され、
前記音素の編集距離「L(wi,wj)」は次式で定義され、
Neは、候補語wiと候補語wjの間の音素の組合せ毎の音素間の誤認識しやすさの合計値であり、
すべての音素の組み合わせに対して、誤認識しやすい音素間ほど小さい値、誤認識し難い音素間ほど大きい値である前記音素間の誤認識しやすさを予め記憶する記憶手段を設け、
前記候補語間の距離「D(wi,wj)」は次式で定義され、
ことを特徴とする音声認識装置。Performs processing to recognize the input speech, generatesa recognition result consisting of a sequence of recognized words,and confirms the accuracy of the recognition result from the acoustic score (acoustic likelihood) and linguistic probability (language probability) (trust) Voice recognition meansfor calculating the degree)
Candidate word extracting means for extracting candidate words from the recognition result;
Candidate word grouping means for grouping candidate words;
Candidate word display means for displaying grouped candidate words on the screen;
Editing operation means for the user to edit the candidate words displayed on the screen;
Updating means for updating the recognition result in accordance with the contents edited by the user,
The candidate word grouping means includes:
Means for extracting a sequence of candidate words (first candidate word sequence) and a sequence of other candidate words (second candidate word sequence) constituting a sentence having the maximum reliability in the recognition result;
Means for calculating a temporal overlap between candidate words in the first candidate word string and candidate words in the second candidate word string;
Means for calculating a phoneme editing distance between a candidate word in the first candidate word string and a candidate word in the second candidate word string;
Means for calculating a distance between candidate words using temporal overlap between candidate words and a phoneme editing distance between candidate words;
Means the distance between the first candidate word candidate word in the string and the candidate word in the second candidate word in column group the candidate word with each other is minimal, andpossess,
The temporal overlap “O (wi, wj)” is defined by the following equation:
The phoneme editing distance `` L (wi, wj) '' is defined by the following equation:
Neisa total value of the ease of misrecognition between phonemes for each phoneme combination betweencandidate word wiand candidate word wj,
For all phoneme combinations, there is provided storage means for storing in advance the ease of misrecognition between the phonemes, which is a smaller value between easy-to-recognize phonemes, and a larger value between phonemes that are difficult to misrecognize,
The distance “D (wi, wj)”between the candidate wordsis defined by the following equation:
A speech recognition apparatus characterized by that.
認識結果から候補語を抽出する候補語抽出機能と、
候補語をグループ化する候補語グループ化機能と、
グループ化された候補語を画面に表示する候補語表示機能と、
ユーザが画面に表示された候補語を編集するための編集操作機能と、
ユーザによる編集内容に従って認識結果を更新する更新機能と、をコンピュータに実現させるコンピュータプログラムであり、
前記候補語グループ化機能は、
前記認識結果において信頼度が最大である文を構成する候補語の列(第1の候補語列)とそれ以外の候補語の列(第2の候補語列)を抽出し、
第1の候補語列中の候補語と第2の候補語列中の候補語の間の時間的距離を算出し、
同じグループ内の第1の候補語列中の候補語と第2の候補語列中の候補語の間の時間的距離を合計した値が最小になるように、第1の候補語列と第2の候補語列を構成する候補語同士をグループ化し、
前記時間的距離は次式で定義され、
時間的距離=1−O(wi,wj)、
ことを特徴とするコンピュータプログラム。Performs processing to recognize the input speech, generatesa recognition result consisting of a sequence of recognized words,and confirms the accuracy of the recognition result from the acoustic score (acoustic likelihood) and linguistic probability (language probability) (trust) Voice recognition functionto calculate the degree)
A candidate word extraction function for extracting candidate words from the recognition result;
A candidate word grouping function for grouping candidate words;
Candidate word display function to display the grouped candidate words on the screen,
An editing operation function for the user to edit the candidate words displayed on the screen;
A computer program for causing a computer to implement an update function for updating a recognition result in accordance with editing contents by a user;
The candidate word grouping function is:
Extracting candidate word strings (first candidate word strings) and other candidate word strings (second candidate word strings) constituting a sentence having the maximum reliability in the recognition result,
Calculating a temporal distance between a candidate word in the first candidate word string and a candidate word in the second candidate word string;
The first candidate word sequence and the first candidate word sequence are arranged such that the sum of temporal distances between the candidate words in the first candidate word sequence and the second candidate word sequence in the same group is minimized. the candidate words that constitute 2 of the candidate word stringgrouping,
The temporal distance is defined by the following equation:
Temporal distance = 1−O (wi, wj),
A computer program characterized by the above.
認識結果から候補語を抽出する候補語抽出機能と、
候補語をグループ化する候補語グループ化機能と、
グループ化された候補語を画面に表示する候補語表示機能と、
ユーザが画面に表示された候補語を編集するための編集操作機能と、
ユーザによる編集内容に従って認識結果を更新する更新機能と、をコンピュータに実現させるコンピュータプログラムであり、
前記候補語グループ化機能は、
前記認識結果において信頼度が最大である文を構成する候補語の列(第1の候補語列)とそれ以外の候補語の列(第2の候補語列)を抽出し、
第1の候補語列中の候補語と第2の候補語列中の候補語の間の時間的な重なりを算出し、
第1の候補語列中の候補語と第2の候補語列中の候補語の間の音素の編集距離を算出し、
候補語間の時間的な重なりと候補語間の音素の編集距離を用いて、候補語間の距離を算出し、
第1の候補語列中の候補語と第2の候補語列中の候補語の間の距離が最小である候補語同士をグループ化し、
前記時間的な重なり「O(wi,wj)」は次式で定義され、
前記音素の編集距離「L(wi,wj)」は次式で定義され、
前記候補語間の距離「D(wi,wj)」は次式で定義され
ことを特徴とするコンピュータプログラム。Performs processing to recognize the input speech, generatesa recognition result consisting of a sequence of recognized words,and confirms the accuracy of the recognition result from the acoustic score (acoustic likelihood) and linguistic probability (language probability) (trust) Voice recognition functionto calculate the degree)
A candidate word extraction function for extracting candidate words from the recognition result;
A candidate word grouping function for grouping candidate words;
Candidate word display function to display the grouped candidate words on the screen,
An editing operation function for the user to edit the candidate words displayed on the screen;
A computer program for causing a computer to implement an update function for updating a recognition result in accordance with editing contents by a user;
The candidate word grouping function is:
Extracting candidate word strings (first candidate word strings) and other candidate word strings (second candidate word strings) constituting a sentence having the maximum reliability in the recognition result,
Calculating a temporal overlap between the candidate words in the first candidate word string and the candidate words in the second candidate word string;
Calculating a phoneme editing distance between a candidate word in the first candidate word string and a candidate word in the second candidate word string;
Using the temporal overlap between candidate words and the phoneme editing distance between candidate words, calculate the distance between candidate words,
The distance between the first candidate word in the candidate words in columns and candidate word in the second candidate word in column groupsthe candidate word with each other is minimal,
The temporal overlap “O (wi, wj)” is defined by the following equation:
The phoneme editing distance `` L (wi, wj) '' is defined by the following equation:
The distance “D (wi, wj)”between the candidate wordsis defined as
A computer program characterized by the above.
認識結果から候補語を抽出する候補語抽出機能と、
候補語をグループ化する候補語グループ化機能と、
グループ化された候補語を画面に表示する候補語表示機能と、
ユーザが画面に表示された候補語を編集するための編集操作機能と、
ユーザによる編集内容に従って認識結果を更新する更新機能と、をコンピュータに実現させるコンピュータプログラムであり、
前記候補語グループ化機能は、
前記認識結果において信頼度が最大である文を構成する候補語の列(第1の候補語列)とそれ以外の候補語の列(第2の候補語列)を抽出し、
第1の候補語列中の候補語と第2の候補語列中の候補語の間の時間的な重なりを算出し、
第1の候補語列中の候補語と第2の候補語列中の候補語の間の音素の編集距離を算出し、
候補語間の時間的な重なりと候補語間の音素の編集距離を用いて、候補語間の距離を算出し、
第1の候補語列中の候補語と第2の候補語列中の候補語の間の距離が最小である候補語同士をグループ化し、
前記時間的な重なり「O(wi,wj)」は次式で定義され、
前記音素の編集距離「L(wi,wj)」は次式で定義され、
前記編集コストCpi,pjは、候補語wiと候補語wjの間で音素を一致させるために必要な置換の対象の音素piと音素pjの間の音響的な類似度であり、
すべての音素の組み合わせに対して前記編集コストを予め記憶する記憶手段を前記コンピュータに設け、
前記候補語間の距離「D(wi,wj)」は次式で定義され、
ことを特徴とするコンピュータプログラム。Performs processing to recognize the input speech, generatesa recognition result consisting of a sequence of recognized words,and confirms the accuracy of the recognition result from the acoustic score (acoustic likelihood) and linguistic probability (language probability) (trust) Voice recognition functionto calculate the degree)
A candidate word extraction function for extracting candidate words from the recognition result;
A candidate word grouping function for grouping candidate words;
Candidate word display function to display the grouped candidate words on the screen,
An editing operation function for the user to edit the candidate words displayed on the screen;
A computer program for causing a computer to implement an update function for updating a recognition result in accordance with editing contents by a user;
The candidate word grouping function is:
Extracting candidate word strings (first candidate word strings) and other candidate word strings (second candidate word strings) constituting a sentence having the maximum reliability in the recognition result,
Calculating a temporal overlap between the candidate words in the first candidate word string and the candidate words in the second candidate word string;
Calculating a phoneme editing distance between a candidate word in the first candidate word string and a candidate word in the second candidate word string;
Using the temporal overlap between candidate words and the phoneme editing distance between candidate words, calculate the distance between candidate words,
The distance between the first candidate word in the candidate words in columns and candidate word in the second candidate word in column groupsthe candidate word with each other is minimal,
The temporal overlap “O (wi, wj)” is defined by the following equation:
The phoneme editing distance `` L (wi, wj) '' is defined by the following equation:
The editing cost Cpi, pjisan acoustic similarity between thephoneme piand the phoneme pj tobe replaced necessary to match the phonemes between thecandidate word wiand the candidate word wj. ,
The computer is provided with storage means for storing the editing cost in advance for all phoneme combinations,
The distance “D (wi, wj)”between the candidate wordsis defined by the following equation:
A computer program characterized by the above.
認識結果から候補語を抽出する候補語抽出機能と、
候補語をグループ化する候補語グループ化機能と、
グループ化された候補語を画面に表示する候補語表示機能と、
ユーザが画面に表示された候補語を編集するための編集操作機能と、
ユーザによる編集内容に従って認識結果を更新する更新機能と、をコンピュータに実現させるコンピュータプログラムであり、
前記候補語グループ化機能は、
前記認識結果において信頼度が最大である文を構成する候補語の列(第1の候補語列)とそれ以外の候補語の列(第2の候補語列)を抽出し、
第1の候補語列中の候補語と第2の候補語列中の候補語の間の時間的な重なりを算出し、
第1の候補語列中の候補語と第2の候補語列中の候補語の間の音素の編集距離を算出し、
候補語間の時間的な重なりと候補語間の音素の編集距離を用いて、候補語間の距離を算出し、
第1の候補語列中の候補語と第2の候補語列中の候補語の間の距離が最小である候補語同士をグループ化し、
前記時間的な重なり「O(wi,wj)」は次式で定義され、
前記音素の編集距離「L(wi,wj)」は次式で定義され、
Neは、候補語wiと候補語wjの間の音素の組合せ毎の音素間の誤認識しやすさの合計値であり、
すべての音素の組み合わせに対して、誤認識しやすい音素間ほど小さい値、誤認識し難い音素間ほど大きい値である前記音素間の誤認識しやすさを予め記憶する記憶手段を前記コンピュータに設け、
前記候補語間の距離「D(wi,wj)」は次式で定義され、
ことを特徴とするコンピュータプログラム。Performs processing to recognize the input speech, generatesa recognition result consisting of a sequence of recognized words,and confirms the accuracy of the recognition result from the acoustic score (acoustic likelihood) and linguistic probability (language probability) (trust) Voice recognition functionto calculate the degree)
A candidate word extraction function for extracting candidate words from the recognition result;
A candidate word grouping function for grouping candidate words;
Candidate word display function to display the grouped candidate words on the screen,
An editing operation function for the user to edit the candidate words displayed on the screen;
A computer program for causing a computer to implement an update function for updating a recognition result in accordance with editing contents by a user;
The candidate word grouping function is:
Extracting candidate word strings (first candidate word strings) and other candidate word strings (second candidate word strings) constituting a sentence having the maximum reliability in the recognition result,
Calculating a temporal overlap between the candidate words in the first candidate word string and the candidate words in the second candidate word string;
Calculating a phoneme editing distance between a candidate word in the first candidate word string and a candidate word in the second candidate word string;
Using the temporal overlap between candidate words and the phoneme editing distance between candidate words, calculate the distance between candidate words,
The distance between the first candidate word in the candidate words in columns and candidate word in the second candidate word in column groupsthe candidate word with each other is minimal,
The temporal overlap “O (wi, wj)” is defined by the following equation:
The phoneme editing distance `` L (wi, wj) '' is defined by the following equation:
Neisa total value of the ease of misrecognition between phonemes for each phoneme combination betweencandidate word wiand candidate word wj,
The computer is provided with storage means for storing in advance the ease of misrecognition between the phonemes, which is a smaller value between phonemes that are easily misrecognized, and a larger value between phonemes that are difficult to misrecognize, for all combinations of phonemes. ,
The distance “D (wi, wj)”between the candidate wordsis defined by the following equation:
A computer program characterized by the above.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007252817AJP4839291B2 (en) | 2007-09-28 | 2007-09-28 | Speech recognition apparatus and computer program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007252817AJP4839291B2 (en) | 2007-09-28 | 2007-09-28 | Speech recognition apparatus and computer program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2009086063A JP2009086063A (en) | 2009-04-23 |
| JP4839291B2true JP4839291B2 (en) | 2011-12-21 |
Family
ID=40659613
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007252817AExpired - Fee RelatedJP4839291B2 (en) | 2007-09-28 | 2007-09-28 | Speech recognition apparatus and computer program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4839291B2 (en) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5476811B2 (en)* | 2009-06-23 | 2014-04-23 | 富士ゼロックス株式会社 | Document processing apparatus and program |
| US8229965B2 (en)* | 2009-06-30 | 2012-07-24 | Mitsubishi Electric Research Laboratories, Inc. | System and method for maximizing edit distances between particles |
| US8494852B2 (en)* | 2010-01-05 | 2013-07-23 | Google Inc. | Word-level correction of speech input |
| EP3089159B1 (en) | 2015-04-28 | 2019-08-28 | Google LLC | Correcting voice recognition using selective re-speak |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2005084436A (en)* | 2003-09-09 | 2005-03-31 | Advanced Telecommunication Research Institute International | Speech recognition apparatus and computer program |
| JP4236597B2 (en)* | 2004-02-16 | 2009-03-11 | シャープ株式会社 | Speech recognition apparatus, speech recognition program, and recording medium. |
| JP4604178B2 (en)* | 2004-11-22 | 2010-12-22 | 独立行政法人産業技術総合研究所 | Speech recognition apparatus and method, and program |
- 2007
- 2007-09-28JPJP2007252817Apatent/JP4839291B2/ennot_activeExpired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2009086063A (en) | 2009-04-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP3944159B2 (en) | Question answering system and program | |
| JP6251958B2 (en) | Utterance analysis device, voice dialogue control device, method, and program | |
| US6910012B2 (en) | Method and system for speech recognition using phonetically similar word alternatives | |
| US6973427B2 (en) | Method for adding phonetic descriptions to a speech recognition lexicon | |
| US20200082808A1 (en) | Speech recognition error correction method and apparatus | |
| JP2009098490A (en) | Speech recognition result editing apparatus, speech recognition apparatus, and computer program | |
| JP5753769B2 (en) | Voice data retrieval system and program therefor | |
| JP6580882B2 (en) | Speech recognition result output device, speech recognition result output method, and speech recognition result output program | |
| CN105426362A (en) | Speech Translation Apparatus And Method | |
| CN108630200B (en) | Voice keyword detection device and voice keyword detection method | |
| Kadyan et al. | Refinement of HMM model parameters for Punjabi automatic speech recognition (PASR) system | |
| JP5164922B2 (en) | Personal information deleting apparatus and method, program and recording medium | |
| CN114420159B (en) | Audio evaluation method and device, and non-transient storage medium | |
| KR20200026295A (en) | Syllable-based Automatic Speech Recognition | |
| CN118098290A (en) | Reading evaluation method, device, equipment, storage medium and computer program product | |
| JP4089861B2 (en) | Voice recognition text input device | |
| JP5068225B2 (en) | Audio file search system, method and program | |
| JP4839291B2 (en) | Speech recognition apparatus and computer program | |
| JP2006053906A (en) | Efficient multi-modal method for providing input to computing device | |
| JP4764203B2 (en) | Speech recognition apparatus and speech recognition program | |
| CN113707178A (en) | Audio evaluation method and device and non-transient storage medium | |
| JP4966324B2 (en) | Speech translation apparatus and method | |
| JP5590549B2 (en) | Voice search apparatus and voice search method | |
| Thennattil et al. | Phonetic engine for continuous speech in Malayalam | |
| JP2004133003A (en) | Method and apparatus for creating speech recognition dictionary and speech recognition apparatus |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination | Free format text:JAPANESE INTERMEDIATE CODE: A621 Effective date:20100201 | |
| A521 | Request for written amendment filed | Free format text:JAPANESE INTERMEDIATE CODE: A821 Effective date:20100202 | |
| A977 | Report on retrieval | Free format text:JAPANESE INTERMEDIATE CODE: A971007 Effective date:20110609 | |
| A131 | Notification of reasons for refusal | Free format text:JAPANESE INTERMEDIATE CODE: A131 Effective date:20110614 | |
| A521 | Request for written amendment filed | Free format text:JAPANESE INTERMEDIATE CODE: A523 Effective date:20110810 | |
| A521 | Request for written amendment filed | Free format text:JAPANESE INTERMEDIATE CODE: A821 Effective date:20110811 | |
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) | Free format text:JAPANESE INTERMEDIATE CODE: A01 Effective date:20110906 | |
| A01 | Written decision to grant a patent or to grant a registration (utility model) | Free format text:JAPANESE INTERMEDIATE CODE: A01 | |
| A61 | First payment of annual fees (during grant procedure) | Free format text:JAPANESE INTERMEDIATE CODE: A61 Effective date:20111003 | |
| FPAY | Renewal fee payment (event date is renewal date of database) | Free format text:PAYMENT UNTIL: 20141007 Year of fee payment:3 | |
| R150 | Certificate of patent or registration of utility model | Free format text:JAPANESE INTERMEDIATE CODE: R150 | |
| LAPS | Cancellation because of no payment of annual fees |