JP4580206B2 - Compound estimation apparatus, compound estimation method and program thereof - Google Patents
Compound estimation apparatus, compound estimation method and program thereofDownload PDFInfo
- Publication number
- JP4580206B2 JP4580206B2JP2004296917AJP2004296917AJP4580206B2JP 4580206 B2JP4580206 B2JP 4580206B2JP 2004296917 AJP2004296917 AJP 2004296917AJP 2004296917 AJP2004296917 AJP 2004296917AJP 4580206 B2JP4580206 B2JP 4580206B2
- Authority
- JP
- Japan
- Prior art keywords
- information
- compound
- expression
- cell
- pharmacological activity
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images






Landscapes
- Investigating Or Analysing Biological Materials (AREA)
- Organic Low-Molecular-Weight Compounds And Preparation Thereof (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Description
Translated fromJapanese本発明は、特定の疾患等に対して薬理活性を有する化合物(特定の疾患等に対する効き目がある化合物)を推定する化合物推定装置、化合物推定方法及びそのプログラムに関するものである。 The present invention relates to a compound estimation apparatus, a compound estimation method, and a program thereof for estimating a compound having pharmacological activity against a specific disease or the like (a compound having an effect on a specific disease or the like).
創薬スクリーニング技術の1つとして、例えば、化合物の3次元構造情報と薬理活性情報とをデータベースに登録しておき、ユーザが薬理活性の項目を指定することで、リード候補の化合物を抽出するという技術が開示されている(例えば、特許文献1を参照。)。 As one of drug discovery screening techniques, for example, the three-dimensional structure information and pharmacological activity information of a compound are registered in a database, and a user specifies a pharmacological activity item to extract lead candidate compounds. A technique is disclosed (see, for example, Patent Document 1).
ところで、近年では化合物の構造情報や薬理活性情報や毒性情報などの情報だけでなく、細胞情報(細胞の遺伝子情報)と疾患との関連性に関するデータベースも充実して来ている。これにより、それらの情報を基に、化合物の薬理活性又は毒性ついて未知の細胞情報(遺伝子情報は分かっている)に対して、薬理活性又は毒性の有る化合物や、反対に薬理活性又は毒性の低い化合物を推定する技術についても望まれるようになっている。 By the way, in recent years, not only information such as structural information, pharmacological activity information, and toxicity information of compounds, but also databases relating to the relationship between cell information (gene information of cells) and diseases have been enhanced. Thus, based on such information, a compound having pharmacological activity or toxicity, or on the contrary, having low pharmacological activity or toxicity against unknown cell information (genetic information is known) about the pharmacological activity or toxicity of the compound. A technique for estimating a compound is also desired.
本発明は、上述した事情を考慮してなされたもので、化合物の薬理活性や毒性ついて未知の細胞情報に対して、薬理活性又は毒性の有る化合物又は、薬理活性又は毒性の低い化合物を推定することができる化合物推定装置、化合物推定方法及びそのプログラムを提供することを目的とする。 The present invention has been made in view of the above-described circumstances, and estimates a compound having pharmacological activity or toxicity or a compound having low pharmacological activity or toxicity with respect to unknown cell information about the pharmacological activity and toxicity of the compound. An object of the present invention is to provide a compound estimation device, a compound estimation method, and a program thereof.
この発明は、上述した課題を解決すべくなされたもので、本発明による化合物推定装置においては、細胞を特定する細胞特定情報に関連付けて、細胞特定情報で特定される細胞における遺伝子の発現パターンである第1の発現パターンを構成する各遺伝子の発現量を含む第1の発現情報と、細胞特定情報で特定される細胞に対する複数種類の化合物の薬理活性又は毒性に関する情報を含む化合物情報とを格納する関連情報格納手段と、化合物情報が未知である未知細胞における遺伝子の発現パターンである第2の発現パターンを構成する各遺伝子の発現量を含む第2の発現情報を得た場合に、第1の発現パターンと第2の発現パターンとの両方に共通に存在する遺伝子について、第1の発現情報に含まれる発現量と第2の発現情報に含まれる発現量とのユークリッド距離を、次元数により正規化することで距離を算出する距離算出手段と、距離算出手段が算出した未知細胞と各細胞の距離と、関連情報格納手段から参照する各細胞に対する化合物情報とを基に、未知細胞に対して薬理活性又は毒性を有する化合物又は、未知細胞に対して薬理活性又は毒性の低い化合物を推定する化合物推定手段とを具備することを特徴とする。The present invention has been made to solve the above-described problems. In the compound estimation device according to the present invention, the expression pattern of thegene in the cell specified by the cell specifying information is associated with the cell specifying information for specifying the cell. Stores first expression information including theexpression level ofeach gene constituting a certain first expression pattern, and compound information including information on the pharmacological activity or toxicity of a plurality of types of compounds with respect to the cell specified by the cell identification information. a related information storage means for, when a compound information to obtain a second expression information containing theexpression level of each gene constituting the second expression pattern which is the expression pattern of genes in unknown cells is unknown,the first For genes that are commonly present in both the expression pattern and the second expression pattern, the expression level included in the first expression information and the second expression information The Euclidean distance between the current quantity, a distance calculating means for calculating a distanceby normalizing the number of dimensions, and the distance of the unknown cells and each cell of the distance calculating means is calculated, for each cell reference from the related information storage means And a compound estimation means for estimating a compound having pharmacological activity or toxicity to unknown cells or a compound having low pharmacological activity or toxicity to unknown cells based on the compound information.
これにより、本発明による化合物推定装置は、化合物の薬理活性や毒性ついて未知の細胞情報(発現情報を含む細胞に関する情報)に対して、未知細胞と各細胞の距離と、各細胞に対する化合物情報とを基に、未知の細胞情報に対して薬理活性又は毒性の有る化合物又は、薬理活性又は毒性の低い化合物を推定することができる。ここで、薬理活性又は毒性の低い化合物とは、薬理活性値や毒性値が相対的に低い化合物や、薬理活性値や毒性値がある基準値より低い化合物のことを示す。As a result, the compound estimation apparatus according to the present invention providesthe distance between the unknown cell and each cell, the compound information for each cell, and theunknown cell information (information about the cell including expression information) about the pharmacological activity and toxicityof the compound. Based on the above, a compound having pharmacological activity or toxicity against unknown cell information or a compound having low pharmacological activity or toxicity can be estimated. Here, the compound having low pharmacological activity or toxicity refers to a compound having a relatively low pharmacological activity value or toxicity value or a compound having a pharmacological activity value or toxicity value lower than a certain reference value.
また、本発明による化合物推定装置の一態様例においては、上記化合物情報は、細胞特定情報で特定される細胞に対する複数種類の化合物の薬理活性又は毒性を数値化した薬理活性値又は毒性値を含む情報であり、化合物推定手段は、距離算出手段が算出した距離と、関連情報格納手段から参照する各細胞に対する化合物情報とを基に、未知細胞に対して化合物の薬理活性値又は毒性値を推定することにより、未知細胞に対して薬理活性又は毒性を有する化合物又は、未知細胞に対して薬理活性又は毒性の低い化合物を推定することを特徴とする。In one embodiment of the compound estimation apparatus according to the present invention, the compound information includes a pharmacological activity value or toxicity value obtained by quantifying the pharmacological activity or toxicity of a plurality of types of compounds with respect to the cell specified by the cell specifying information. The compound estimation means estimates the pharmacological activity value or toxicity value of the compound for unknown cells based on thedistance calculated by the distance calculation means and the compound information for each cell referenced from the related information storage means. Thus, a compound having pharmacological activity or toxicity to unknown cells or a compound having low pharmacological activity or toxicity to unknown cells is estimated.
また、本発明による化合物推定装置の一態様例においては、上記第1の発現情報を格納する発現情報データベースと、上記化合物情報を格納する化合物情報データベースと、発現情報データベースから第1の発現情報を参照して、化合物情報データベースから化合物情報を参照することで、関連情報格納手段に対して、細胞を特定する細胞特定情報に関連付けて、第1の発現情報と、化合物情報とを登録する情報登録手段とを更に具備することを特徴とする。 In one embodiment of the compound estimation apparatus according to the present invention, an expression information database for storing the first expression information, a compound information database for storing the compound information, and first expression information from the expression information database. By referring to the compound information from the compound information database, the information registration for registering the first expression information and the compound information in association with the cell specifying information for specifying the cell to the related information storage means And a means.
また、本発明による化合物推定装置の一態様例においては、上記距離算出手段は、第1の発現パターンと第2の発現パターンとの両方に共通に存在する遺伝子をγ(γ=1,2…Γ)で識別し、第1の発現情報に含まれる発現量をcγとし、第2の発現情報に含まれる発現量をxγとし、距離をdとしたときに、式(1)により上記距離を算出することを特徴とする。Further, in one embodiment of the compound estimation apparatus according to the present invention, thedistance calculation means calculates a gene that is commonly present in both the first expression pattern and the second expression pattern as γ (γ = 1, 2,... Γ), the expression level included in the first expression information is cγ, the expression level included in the second expression information is xγ, and the distance is d.It is characterized by calculating.
また、本発明による化合物推定装置の一態様例においては、上記化合物情報データベースは、化合物の構造に関する情報である構造情報を更に格納し、種々の情報を表示する表示手段と、化合物情報データベースより構造情報を参照して、化合物推定手段が推定した未知細胞に対して薬理活性又は毒性を有する化合物の構造又は、未知細胞に対して薬理活性又は毒性の低い化合物の構造を示す推定結果画面を表示手段に表示させる推定結果表示手段とを更に具備することを特徴とする。 Further, in one embodiment of the compound estimation apparatus according to the present invention, the compound information database further stores structure information that is information related to the structure of the compound, and includes a display means for displaying various information, and a structure from the compound information database. Referring to the information, a means for displaying an estimation result screen showing the structure of the compound having pharmacological activity or toxicity to the unknown cell estimated by the compound estimation means or the structure of the compound having low pharmacological activity or toxicity to the unknown cell And an estimation result display means to be displayed.
また、本発明による化合物推定方法においては、細胞を特定する細胞特定情報に関連付けて、細胞特定情報で特定される細胞における遺伝子の発現パターンである第1の発現パターンを構成する各遺伝子の発現量を含む第1の発現情報と、細胞特定情報で特定される細胞に対する複数種類の化合物の薬理活性又は毒性に関する情報を含む化合物情報とを格納する関連情報格納手段と、発現情報取得手段と、距離算出手段と、化合物推定手段とを備える化合物推定装置を用いた化合物推定方法であって、発現情報取得手段が、化合物情報が未知である未知細胞における遺伝子の発現パターンである第2の発現パターンを構成する各遺伝子の発現量を含む第2の発現情報を得る取得ステップと、距離算出手段が、第1の発現パターンと第2の発現パターンとの両方に共通に存在する遺伝子について、第1の発現情報に含まれる発現量と第2の発現情報に含まれる発現量とのユークリッド距離を、次元数により正規化することで距離を算出する距離算出ステップと、化合物推定手段が、距離算出ステップで算出した未知細胞と各細胞の距離と、関連情報格納手段から参照する各細胞に対する化合物情報とを基に、未知細胞に対して薬理活性又は毒性を有する化合物を推定する化合物推定ステップとを有することを特徴とする。In the compound estimation method according to the present invention,the expression level of each gene constituting the first expression pattern that is the expression pattern of thegene in the cell specified by the cell specification information in association with the cell specification information for specifying the cell Related information storage meansfor storing firstexpression information including information, and compound information including information relating to pharmacological activity or toxicity of a plurality of types of compounds for cells specified by the cell specification information, expression information acquisition means, and distance A compound estimation method using a compound estimation apparatus comprising acalculation means and a compound estimation means , wherein theexpression information acquisition means obtainsa second expression pattern that is a gene expression pattern in an unknown cell whose compound information is unknown. an acquisition step of obtaining a second expression information containing theexpression level of each gene constituting,distance calculating means, first expression pattern and the second expression For gene present in common to both the turn, it calculates the distanceby the Euclidean distance between the first expression expression amount included in information and expression level contained in the second expression information, normalized by the number of dimensions Pharmacological activity against unknown cells based on the distance calculation step, thecompound estimation means calculatesthe distance between the unknown cells calculated in the distance calculation step and each cell, and the compound information for each cell referenced from the related information storage means. Or a compound estimation step for estimating a compound having toxicity.
また、本発明によるプログラムは、コンピュータを、細胞を特定する細胞特定情報に関連付けて、細胞特定情報で特定される細胞における遺伝子の発現パターンである第1の発現パターンを構成する各遺伝子の発現量を含む第1の発現情報と、細胞特定情報で特定される細胞に対する複数種類の化合物の薬理活性又は毒性に関する情報を含む化合物情報とを格納する関連情報格納手段と、化合物情報が未知である未知細胞における遺伝子の発現パターンである第2の発現パターンを構成する各遺伝子の発現量を含む第2の発現情報を得た場合に、第1の発現パターンと第2の発現パターンとの両方に共通に存在する遺伝子について、第1の発現情報に含まれる発現量と第2の発現情報に含まれる発現量とのユークリッド距離を、次元数により正規化することで距離を算出する距離算出手段と、距離算出手段が算出した未知細胞と各細胞の距離と、関連情報格納手段から参照する各細胞に対する化合物情報とを基に、未知細胞に対して薬理活性又は毒性を有する化合物又は、未知細胞に対して薬理活性又は毒性の低い化合物を推定する化合物推定手段として機能させるプログラムである。In addition, the program according to the present invention relates to thecomputer with the cell specifying information for specifying the cell, and the expression level of each gene constituting the first expression pattern that is the expression pattern of the gene in the cell specified by the cell specifying information. Related information storage means for storing first expression information including information and compound information including information relating to the pharmacological activity or toxicity of a plurality of types of compounds with respect to the cell specified by the cell specifying information, and the compound information is unknown Common to both the first expression pattern and the second expression pattern when the second expression information including the expression level of each gene constituting the second expression pattern that is the expression pattern of the gene in the cell is obtained. The Euclidean distance between the expression level included in the first expression information and the expression level included in the second expression information is expressed by the number of dimensions. Based on the distance calculation means for calculating the distance by normalization, the distance between the unknown cell calculated by the distance calculation means and each cell, and the compound information for each cell referred from the related information storage means, It isa program thatfunctions as a compound estimation means for estimating a compound having pharmacological activity or toxicity or a compound having low pharmacological activity or toxicity to unknown cells .
本発明による化合物推定装置、化合物推定方法及びそのプログラムによれば、化合物の薬理活性又は毒性ついて未知の細胞情報に対して、薬理活性又は毒性の有る化合物や、薬理活性又は毒性の低い化合物を推定することができる。 According to the compound estimation apparatus, the compound estimation method and the program according to the present invention, a compound having pharmacological activity or toxicity or a compound having low pharmacological activity or toxicity is estimated with respect to unknown cell information about the pharmacological activity or toxicity of the compound. can do.
以下、本発明の実施の形態を説明する。
本発明の一実施形態における化合物推定装置は、特定の疾患等に対して薬理活性を有する化合物(特定の疾患等に対する効き目がある化合物)を推定する処理を行う装置であり、以下にその概略構成について説明を行う。図1は、本実施形態における化合物推定装置の概略構成を示す図である。Embodiments of the present invention will be described below.
The compound estimation device according to one embodiment of the present invention is a device that performs a process of estimating a compound having pharmacological activity against a specific disease or the like (a compound that has an effect on a specific disease or the like). Will be described. FIG. 1 is a diagram showing a schematic configuration of a compound estimation apparatus in the present embodiment.
図1において、1は、化合物推定装置であり、例えば癌細胞に対して薬理活性を有する化合物を推定する処理を行う。2は、ネットワークであり、例えばインターネットである。3は、NCI(National Cancer Institute)データベースであり、本実施形態で利用するNICが公開しているデータベースであり、具体的には、癌細胞の遺伝子発現パターンに関する情報である発現情報と、癌細胞に対する化合物の薬理活性値に関する情報である化合物情報とが少なくとも格納されているデータベースである。すなわち、化合物推定装置1は、ネットワーク2を介してNCIデータベース3から、上述した発現情報及び化合物情報を取得して利用することで、薬理活性に関して未知の癌細胞に対して、薬理活性を有するであろう化合物を推定する処理を行う。尚、化合物推定装置1は、図示していないが、マウスやキーボードなどの入力装置および、CRT(Cathode Ray Tube)や液晶ディスプレイなどの表示装置を具備する。 In FIG. 1, 1 is a compound estimation apparatus, for example, which performs a process of estimating a compound having pharmacological activity against cancer cells.
ここで、発現情報における、癌細胞の遺伝子発現パターンとは、複数種類の癌細胞毎に複数種類の遺伝子別の発現量(遺伝子が機能しているか否かを示す量)に関する情報である。すなわち、特定の癌細胞においては、特定の遺伝子の組合せ(遺伝子パターン)が発現している。また、化合物情報とは、複数種類の癌細胞毎に複数種類の化合物別の薬理活性値を示す情報である。尚、発現情報及び化合物情報については具体例を後述する。 Here, the gene expression pattern of cancer cells in the expression information is information relating to the expression level (amount indicating whether or not a gene is functioning) for each of a plurality of types of cancer cells. That is, specific gene combinations (gene patterns) are expressed in specific cancer cells. The compound information is information indicating the pharmacological activity value for each of a plurality of types of compounds for each of a plurality of types of cancer cells. Specific examples of expression information and compound information will be described later.
次に、化合物推定装置1の機能構成について説明する。11は、制御部であり、化合物推定装置1内の各処理部やデータの流れの制御を行う。12は、データベースであり、上述した発現情報を格納する発現情報データベース12aと、上述した化合物情報を格納する化合物情報データベース12bと、上記発現情報と化合物情報から遺伝子の発現パターンと化合物の関連に関する情報である関連情報を格納する関連情報データベース12cから構成される。 Next, the functional configuration of the
13は、情報登録処理部であり、後述する送受信処理部18及びネットワーク2を介してNCIデータベース3から発現情報を取得して発現情報データベース12aに登録する処理と、NCIデータベース3から化合物情報を取得して化合物情報データベース12bに登録する処理を行う。本実施形態における情報登録処理部13は、NCIデータベース3から癌細胞の遺伝子発現パターンに関する情報であるT−Matrix(発現情報)を取得して、必要な情報を発現情報データベース12aに登録する。また、情報登録処理部13は、NCIデータベース3から癌細胞の化合物に対する薬理活性値に関する情報であるA−Matrix(化合物情報)を取得して、必要な情報を化合物情報データベース12bに登録する。
ここで、上述した発現情報データベース12a及び化合物情報データベース12bに格納する発現情報及び化合物情報のデータ構成例を図2及び図3を用いて説明する。図2は、図1に示した発現情報データベース12aのデータ構成例を示す図である。図2において、CLIDはClone IDから接頭辞“IMAGE:”を抜いた数値であり、各遺伝子に固有の数値である。NAMEはClone IDのcDNA(Type)に紐付く遺伝子名称ある。また、「ME:MALME−3M」や「ME:SK−MEL−28」は、癌細胞の名称である。また、癌細胞の名称の下には各遺伝子に対する発現量が示されている。尚、これらのCLIDやNAMEはNCIデータベース3から参照するT−Matrix(発現情報)で規定されている。また、図2に示す各遺伝子の発現量は、NCIデータベース3において60種の中から代表的な7種の癌細胞を抜き出し、その平均と分散値で正規化した値である。 Here, a data configuration example of the expression information and the compound information stored in the expression information database 12a and the compound information database 12b described above will be described with reference to FIGS. FIG. 2 is a diagram showing a data configuration example of the expression information database 12a shown in FIG. In FIG. 2, CLID is a numerical value obtained by removing the prefix “IMAGE:” from Clone ID, and is a numerical value unique to each gene. NAME is a gene name associated with Clone ID cDNA (Type). “ME: MALME-3M” and “ME: SK-MEL-28” are names of cancer cells. Moreover, the expression level with respect to each gene is shown under the name of a cancer cell. Note that these CLIDs and NAMEs are defined by T-Matrix (expression information) referenced from the NCI
図3は、図1に示した化合物情報データベース12bのデータ構成例を示す図である。
図3において、“NSC No.”は、化合物を特定する数値である。また、図2と同様に、「ME−MALME−3M」や「ME−SK−MEL−28」などは、癌細胞の名称である。また、癌細胞の名称の下には各化合物に対する薬理活性値が示されている。この薬理活性値は、例えば化合物δの細胞ωに対する薬理活性値a(ω,δ)は以下の式1で算出される。FIG. 3 is a diagram showing a data configuration example of the compound information database 12b shown in FIG.
In FIG. 3, “NSC No.” is a numerical value that identifies a compound. Similarly to FIG. 2, “ME-MALME-3M”, “ME-SK-MEL-28”, and the like are names of cancer cells. Moreover, the pharmacological activity value with respect to each compound is shown under the name of a cancer cell. As for this pharmacological activity value, for example, the pharmacological activity value a (ω, δ) of the compound δ with respect to the cell ω is calculated by the following

上述した式1において、GI50とは増殖抑制濃度であり、ここでは、癌細胞ωの増殖が50%の確率で抑制される化合物δの濃度を意味する。aaverageとasdはそれぞれ指定された化合物に対する癌細胞群の薬理活性値の平均と分散である。これにより、式1で求まる薬理活性値a(ω,δ)は、癌細胞ωに対する化合物δの増殖抑制の効果を意味し、化合物毎に正規化された値となる。In the above-described
14は、関連解析処理部であり、発現情報データベース12aから発現情報、化合物情報データベース12bから化合物情報を参照して、同じ癌細胞における遺伝子発現パターンと薬理活性を有する化合物の関連に関する情報である関連情報を生成して、関連情報データベース12cに登録する。具体的には、関連解析処理部14は、上述した発現情報の癌細胞名と化合物情報の癌細胞名が同じものをキーに遺伝子発現パターンと薬理活性値を紐付けて、関連情報データベース12cに登録する。この際、関連解析処理部14は、本実施形態の化合物推定装置1では薬理活性があると期待できる化合物を推定する処理を行うので、薬理活性値の下限値εを設け、その下限値ε以下の薬理活性値を有する化合物については紐付け処理及び登録処理を行わない。
15は、距離算出処理部であり、薬理活性に関して未知の癌細胞の遺伝子発現パターンと、関連情報データベース12cより参照する薬理活性に関して既知の癌細胞の遺伝子発現パターンとを基に、未知の癌細胞と既知の癌細胞との遺伝子発現パターンの距離を求める。尚、薬理活性に関して未知の癌細胞において、遺伝子の発現パターンは判明しており、その発現パターンに関する情報を距離算出処理部15は取得しているとする。ここで、遺伝子発現パターンの距離とは、双方の癌細胞における遺伝子発現パターンの類似度を示す値であり、双方の癌細胞の発現情報を基に、共通する遺伝子の発現量を比較する(例えば、差分を取る)ことで、遺伝子発現パターンの類似度を算出する。 15 is a distance calculation processing unit, which is based on the gene expression pattern of an unknown cancer cell regarding pharmacological activity and the gene expression pattern of the known cancer cell regarding pharmacological activity referenced from the related information database 12c. And the distance between the gene expression pattern and the known cancer cell. It is assumed that the gene expression pattern is known in cancer cells whose pharmacological activity is unknown, and the distance
具体的には、距離算出処理部15は、例えば薬理活性に関して未知の癌細胞χの遺伝子発現パターンXが観測された場合には、薬理活性に関して既知の癌細胞ωの遺伝子発現パターンCとの距離d(ω,χ)は以下の式2及び式3により求めることができる。 Specifically, the distance
式2及び式3において、γは、発現情報データベース12aに格納する発現情報に含まれるCLIDのいずれかであって、癌細胞ωとχの両方に発現量が存在する遺伝子を特定するCLIDである。Γは、癌細胞ωとχの両方に発現量が存在する遺伝子を示すCLIDの集合である。すなわち、γは集合Γの内のいずれかのCLIDである。また、cγは、CLIDを示すγで特定される遺伝子であって、遺伝子発現パターンCに含まれる遺伝子の癌細胞ωにおける発現量を示す。xγは、CLIDを示すγで特定される遺伝子であって、遺伝子発現パターンXに含まれる遺伝子の癌細胞χにおける発現量を示す。 In
上述した式2及び式3で求める距離d(ω,χ)は、癌細胞ω及びχの遺伝子発現パターンC及びXの内、両方に共通に存在する遺伝子の発現量(cγ及びxγ)の距離としてユークリッド距離を求めて、次元数により正規化した値である。
次元数で正規化する理由は、細胞毎に発現データの存在する遺伝子数が大きく異なるからである。なお、距離算出処理部15は、遺伝子発現パターンXと遺伝子発現パターンCとの間に共通する遺伝子が存在しない場合、すなわち|Γ|=0の場合は距離が算出できないためその癌細胞ωを無視する。The distance d (ω, χ) obtained by the above-described
The reason for normalizing by the number of dimensions is that the number of genes in which expression data exists varies greatly from cell to cell. The distance
16は、化合物推定処理部であり、癌細胞ωに関連する化合物δの未知の癌細胞χに対する薬理活性値を距離算出処理部15が求めた距離を用いて推定し、推定した薬理活性値を基に、未知の癌細胞χに対する化合物δの薬理活性の強さを推定する活性ポイントを求める。
具体的には、化合物推定処理部16は、関連情報データベース12cを参照して癌細胞ωに関連する化合物δを特定して、化合物δの未知の癌細胞χに対する薬理活性値e(ω,χ,δ)を距離算出処理部15が求めた距離d(ω,χ)を用いて、以下の式4を計算することにより推定する。すなわち、例えば特定の癌細胞ω1に対して薬理活性値の高い化合物δ1がある場合に、特定の癌細胞ω1と癌細胞χの遺伝子発現パターンが類似していればいるほど、化合物推定処理部16は、化合物δ1の癌細胞χに対する薬理活性値も高いと推定する。 Specifically, the compound
上述した式4において、α及びβは、距離と薬理活性値の影響度合いを決定するパラメータである。αは推定する薬理活性値の値域に影響を与え、βは値を大きくとることで細胞間の類似性の評価を厳しくする働きがある。 In
次に、化合物推定処理部16は、推定した薬理活性値e(ω,χ,δ)を基に、以下の式5及び式6を用いて未知の癌細胞χに対する化合物δの活性ポイントp(χ,δ)を求める。 Next, the compound
上述した式5及び式6において、Ξは、発現情報データベース12aに格納される全癌細胞ωの集合Ωにおいて癌細胞χとの距離d(ω,χ)が算出できる癌細胞ωの部分集合(上記|Γ|=0でない癌細胞ωの集合)である。この式5の計算により、最終的な活性ポイントp(χ,δ)は、推定した薬理活性値e(ω,χ,δ)の化合物δ別の平均値となる。化合物推定処理部16は、化合物δ別の活性ポイントp(χ,δ)を降順に並べて上位50個の化合物識別情報(“NSC No.”)と活性ポイントの組合せを推定結果として出力する。 In Equation 5 and Equation 6 described above, Ξ is a subset of cancer cells ω that can calculate the distance d (ω, χ) from the cancer cells χ in the set Ω of all cancer cells ω stored in the expression information database 12a ( (A set of cancer cells ω other than | Γ | = 0). According to the calculation of Equation 5, the final active point p (χ, δ) is an average value for each compound δ of the estimated pharmacological activity value e (ω, χ, δ). The compound
17は、結果表示処理部であり、化合物推定処理部16が出力する推定結果を基に、化合物情報データベース12bから化合物δの構造に関する情報を取得して、推定結果画面を化合物推定装置1の表示装置に表示する。図4は、結果表示処理部17が、化合物推定装置1の表示装置に表示する推定結果画面例を示す図である。図4においては、化合物推定処理部16が求めた活性ポイントp(χ,δ)の上位50件中の上位12件の化合物δに関する情報を推定結果として表示している。図4に示すように、化合物δに関する画面情報は、化合物の構造を図示する図示エリア41と、化合物の名称を記載する行42と、化合物を特定する情報である“NSC No.”を記載する行43と、当該化合物の癌細胞χに対する活性ポイントを記載する行44とから構成される。尚、本実施形態においては、現状のNCIデータベース3で公開されている化合物構造情報には化合物名が付与されていないため、化合物名を記載する行42にも、“NSC No.”を記載している。もちろん、化合物名に関する情報も化合物情報データベース12bに格納することができた場合には、行42には化合物名を記載する。
18は、送受信処理部であり、ネットワーク2を介してNCIデータベース3と通信を行う。尚、本実施形態の化合物推定装置1においては、外部にあるNCIデータベース3に格納されるデータを利用するため、ネットワーク2に接続する機能を有しているが、この限りではなく、外部のデータベースを利用することなく、例えば入力手段から内部のデータベース12に予め発現情報や化合物情報を登録して格納していてもよい。この場合には、化合物推定装置1は、ネットワーク2に接続するための機能を必要としない。 A transmission /
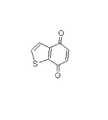
次に、図1に示した化合物推定装置1における癌細胞に有効な化合物の推定処理について、具体例を示して説明する。図5は、図1に示した化合物推定装置1における癌細胞に有効な化合物の推定処理を示す図である。尚、図5の処理を説明するに当たり、具体例として、癌細胞の一種であるMEL−UACC−257を薬理活性のある化合物が未知であり、遺伝子発現パターンが既知である癌細胞と仮定する。尚、実際には癌細胞「MEL−UACC−257」に対しては図6に示すようなBenzothiophenedioneの構造をもつ化合物が薬理活性を有することが分かっている。すなわち、癌細胞「MEL−UACC−257」の遺伝子発現パターンから図6に示すBenzothiophenedioneの構造をもつ化合物を推定できれば、本実施形態における化合物推定装置1は、適正な化合物を推定できているといえる。 Next, the estimation process of a compound effective for cancer cells in the
図5に示すように、ステップS1において、情報登録処理部13は、ネットワーク2を介してNCIデータベース3から発現情報及び化合物情報を取得し、それぞれ発現情報データベース12a及び化合物情報データベース12bに登録する。具体的には、情報登録処理部13は、NCIデータベース3から発現情報として60種の癌細胞に対する4463種の化合物(データが存在するのは4444種)の薬理活性値を含むデータテーブルであるA−Matrixを取得して、発現情報データベース12aに登録する。 As shown in FIG. 5, in step S1, the information
また、情報登録処理部13は、60種の癌細胞に対する9704種の遺伝子(データが存在するのは9073種)の発現量を含むデータテーブルであるT−Matrixを取得して、化合物情報データベース12bに登録する。但し、情報登録処理部13は、T−Matrixと上記A−Matrixとでは同一の癌細胞における細胞名の表記法が異なるのでどちらかの細胞名に統一する変換を行う(例:ME:MALME−3M → MEL−MALME−3M)。また、発現情報データベース12a及び化合物情報データベース12bに登録した癌細胞のデータの内、本実施形態では未知の癌細胞と仮定した癌細胞MEL−UACC−257(癌細胞χ)を除いた59種の癌細胞(癌細胞ω)について、以降の処理を行う。 Further, the information
また、情報登録処理部13は、NCIデータベース3から4463種の化合物の構造情報を取得して、化合物情報データベース12bに登録する。 Further, the information
次に、ステップS2において、関連解析処理部14は、上述した発現情報の癌細胞名と化合物情報の癌細胞名が同じものをキーに遺伝子発現パターンと薬理活性値を紐付けて、関連情報データベース12cに登録する。この時、関連解析処理部14は、薬理活性値の下限値ε=1.0を設け、その下限値ε以下の薬理活性値を有する化合物については紐付け処理及び登録処理を行わない。 Next, in step S2, the association
次に、ステップS3において、距離算出処理部15は、未知の癌細胞χと薬理活性に関して既知の癌細胞ωとの遺伝子発現パターンの距離d(ω,χ)を上述した式2及び式3により求める。尚、本実施形態では、癌細胞「MEL−UACC−257」を、化合物情報が未知であると仮定して処理したので、未知の癌細胞「MEL−UACC−257」の遺伝子発現パターンに関する情報は発現情報データベース12aから参照できたが、発現情報データベース12aに未知の癌細胞の遺伝子発現パターンが格納されていない場合には、図示していない入力装置からの入力したりネットワーク2を介して受信することなどにより、未知の癌細胞の遺伝子発現パターンを取得する必要がある。 Next, in step S3, the distance
次に、ステップS4において、化合物推定処理部16は、関連情報データベース12cを参照して癌細胞ωに紐付けられた化合物δの未知の癌細胞χに対する薬理活性値e(ω,χ,δ)を距離算出処理部15が求めた距離d(ω,χ)と、上述した式4を用いて計算することにより推定する。尚、本実施形態における化合物推定処理部16は、式4の係数α=9、β=10と設定する。 Next, in step S4, the compound
次に、ステップS5において、化合物推定処理部16は、ステップS4で推定した薬理活性値e(ω,χ,δ)を基に、上述した式5及び式6を用いて未知の癌細胞χに対する化合物δの活性ポイントp(χ,δ)を求める。本実施形態の化合物推定処理部16は、求めた活性ポイントを降順に並べて上位50件の化合物識別情報(“NSC No.”)と活性ポイントの組合せを推定結果として出力する。すなわち、化合物推定処理部16は、活性ポイントの高い化合物を、癌細胞χに対して薬理活性を有する化合物と推定して出力している。 Next, in step S5, the compound
次に、ステップS6において、結果表示処理部17は、結果表示処理部であり、化合物推定処理部16が出力する推定結果を基に、化合物情報データベース12bから化合物δの構造に関する情報を取得して、上位50件の化合物の一覧となる図7に示すような推定結果画面を化合物推定装置1の表示装置に表示する。 Next, in step S6, the result
図7は、上述した具体的な処理フローにより、実際に推定された50件の化合物の一覧表示例を示す図である。図7において、点線で囲んである化合物は、図6に示すBenzothiophenedioneの構造をもつ化合物であり、50件中10件が該当している。尚、推定の対象となった全化合物(4444種)の内、Benzothiophenedioneの構造をもつ化合物は23件存在し、その存在確率は0.52%(小数点第2以下四捨五入)であり、化合物推定装置1は、そのような存在確率に対して20%の確率でBenzothiophenedioneの構造をもつ化合物を推定できている。すなわち、本実施形態における化合物推定装置1は、癌細胞「MEL−UACC−257」の遺伝子発現パターンから図6に示すBenzothiophenedioneの構造をもつ化合物を精度良く推定できる。また、この図7の結果は、本実施形態の化合物推定装置1における化合物の推定方法が有効であることを示している。 FIG. 7 is a diagram showing a list display example of 50 compounds actually estimated by the specific processing flow described above. In FIG. 7, compounds surrounded by a dotted line are compounds having the structure of Benzothiopheneion shown in FIG. Of all the compounds subject to estimation (4444 species), there are 23 compounds having the structure of Benzothiopheneion, and the existence probability is 0.52% (rounded to the second decimal place). 1 can estimate a compound having a Benzothiopheneion structure with a probability of 20% with respect to such existence probability. That is, the
尚、図7に表示される化合物に関する情報の種類は、図4に示した情報の種類(化合物の構造、化合物名、NSC No.)と同様であり、表示している化合物の数が異なるのみである。また、化合物の表示方法は、図4や図7に示した表示方法に限定されるものではなく、少なくとも化合物が特定できる情報と、その化合物が癌細胞χに対してどれだけの薬理活性を有するか推定した値(上述の活性ポイント)とが表示される画面であればよい。 7 is the same as the information type (compound structure, compound name, NSC No.) shown in FIG. 4 except for the number of displayed compounds. It is. In addition, the display method of the compound is not limited to the display method shown in FIG. 4 or 7, and at least information that can identify the compound and how much pharmacological activity the compound has against the cancer cell χ. Any screen that displays the estimated value (the above-mentioned active points) may be used.
尚、上述した実施形態における化合物推定装置1は、癌細胞に対して薬理活性を有する化合物を推定する処理を行ったが、その他にも、健常細胞に対して毒性の少ない化合物を推定する処理などに応用して好適である。この場合には、例えば健常細胞の遺伝子発現パターンに関する情報を発現情報として、健常細胞に対する化合物の毒性値に関する情報を化合物情報とすればよい。 In addition, although the
また、上述した実施形態のように未知の癌細胞に対して薬理活性のある化合物を推定する場合には、癌細胞における遺伝子発現に関係する情報を発現情報として発現情報データベース12aに登録するが、未知の健常細胞に対して毒性のある化合物を推定する場合には、化合物情報データベース12bには、健常細胞における遺伝子発現に関係する情報を発現情報として登録する。同様に、上述した実施形態のように未知の癌細胞に対して薬理活性のある化合物を推定する場合には、癌細胞に対して何らかの薬理活性が認められている化合物を化合物情報データベース12bに登録するが、未知の健常細胞に対して毒性のある化合物を推定する場合には、化合物情報データベース12bには、健常細胞に対して何らかの毒性が認められている化合物を登録する。これにより、関連解析処理部14は、同一の健常細胞における発現情報と化合物情報を関連付けて関連情報データベース12cに格納する。 Moreover, when estimating a compound having pharmacological activity against an unknown cancer cell as in the above-described embodiment, information related to gene expression in the cancer cell is registered as expression information in the expression information database 12a. When estimating a compound that is toxic to an unknown healthy cell, information related to gene expression in the healthy cell is registered as expression information in the compound information database 12b. Similarly, when estimating a compound having pharmacological activity against an unknown cancer cell as in the above-described embodiment, a compound having some pharmacological activity with respect to the cancer cell is registered in the compound information database 12b. However, when estimating a compound that is toxic to an unknown healthy cell, the compound information database 12b registers a compound that is recognized to be toxic to the healthy cell. Thereby, the association
また、上述した実施形態において、図1に示した化合物推定装置1の各処理部は、ハードウェアとしてはメモリ及びCPU(中央演算装置)により構成され、各処理部の機能を実現する為のプログラムをメモリに読み込んでCPUが実行することによりその機能を実現させるものである。また、これに限定されるものではなく、各処理部の一部の処理又は全部の処理を専用のハードウェアにより実現されるものであってもよい。
また、上記メモリは、ハードディスク装置や光磁気ディスク装置、フラッシュメモリ等の不揮発性のメモリや、CD−ROM等の読み出しのみが可能な記録媒体、RAM(Random Access Memory)のような揮発性のメモリ、あるいはこれらの組合せによるコンピュータ読み取り、書き込み可能な記録媒体より構成されるものとする。Further, in the above-described embodiment, each processing unit of the
The memory includes a non-volatile memory such as a hard disk device, a magneto-optical disk device, and a flash memory, a recording medium such as a CD-ROM that can only be read, and a volatile memory such as a RAM (Random Access Memory). Or a computer-readable / writable recording medium based on a combination thereof.
また、図1に示した化合物推定装置1の各処理部は、上述したようにコンピュータがプログラムを実行することによって実現しているが、そのプログラムをコンピュータに供給するための手段、例えばかかるプログラムを記録したコンピュータ読み取り可能な記録媒体又はかかるプログラムを伝送する伝送媒体も本発明の実施形態として適用することができる。また、上記のプログラムを記録したコンピュータ読み取り可能な記録媒体等のプログラムプロダクトも本発明の実施形態として適用することができる。上記のプログラム、記録媒体、伝送媒体及びプログラムプロダクトは、本発明の範疇に含まれる。 Further, each processing unit of the
また、「コンピュータ読み取り可能な記録媒体」とは、フレキシブルディスク、光磁気ディスク、ROM、CD−ROM等の可搬媒体、コンピュータシステムに内蔵されるハードディスク等の記憶装置のことをいう。さらに「コンピュータ読み取り可能な記録媒体」とは、インターネット等のネットワークや電話回線等の通信回線を介してプログラムが送信された場合のサーバやクライアントとなるコンピュータシステム内部の揮発メモリ(RAM)のように、一定時間プログラムを保持しているものも含むものとする。 The “computer-readable recording medium” refers to a storage device such as a flexible medium, a magneto-optical disk, a portable medium such as a ROM and a CD-ROM, and a hard disk incorporated in a computer system. Further, the “computer-readable recording medium” refers to a volatile memory (RAM) in a computer system serving as a server or a client when a program is transmitted via a network such as the Internet or a communication line such as a telephone line. In addition, those holding a program for a certain period of time are also included.
また、上記プログラムは、このプログラムを記憶装置等に格納したコンピュータシステムから、伝送媒体を介して、あるいは、伝送媒体中の伝送波により他のコンピュータシステムに伝送されてもよい。ここで、プログラムを伝送する「伝送媒体」は、インターネット等のネットワーク(通信網)や電話回線等の通信回線(通信線)のように情報を伝送する機能を有する媒体のことをいう。 The program may be transmitted from a computer system storing the program in a storage device or the like to another computer system via a transmission medium or by a transmission wave in the transmission medium. Here, the “transmission medium” for transmitting the program refers to a medium having a function of transmitting information, such as a network (communication network) such as the Internet or a communication line (communication line) such as a telephone line.
また、上記プログラムは、前述した機能の一部を実現する為のものであっても良い。さらに、前述した機能をコンピュータシステムに既に記録されているプログラムとの組み合わせで実現できるもの、いわゆる差分ファイル(差分プログラム)であっても良い。 The program may be for realizing a part of the functions described above. Furthermore, what can implement | achieve the function mentioned above in combination with the program already recorded on the computer system, and what is called a difference file (difference program) may be sufficient.
以上、この発明の実施形態について図面を参照して詳述してきたが、具体的な構成はこの実施形態に限られるものではなく、この発明の要旨を逸脱しない範囲の設計等も含まれる。 The embodiment of the present invention has been described in detail with reference to the drawings. However, the specific configuration is not limited to this embodiment, and includes designs and the like that do not depart from the gist of the present invention.
1 化合物推定装置
2 ネットワーク
3 NCIデータベース
11 制御部
12 データベース
12a 発現情報データベース
12b 化合物情報データベース
12c 関連情報データベース
13 情報登録処理部
14 関連解析処理部
15 距離算出処理部
16 化合物推定処理部
17 結果表示処理部
18 送受信処理部DESCRIPTION OF
Claims (7)
Translated fromJapanese前記化合物情報が未知である未知細胞における遺伝子の発現パターンである第2の発現パターンを構成する各遺伝子の発現量を含む第2の発現情報を得た場合に、前記第1の発現パターンと前記第2の発現パターンとの両方に共通に存在する遺伝子について、前記第1の発現情報に含まれる発現量と前記第2の発現情報に含まれる発現量とのユークリッド距離を、次元数により正規化することで距離を算出する距離算出手段と、
前記距離算出手段が算出した前記未知細胞と各細胞の前記距離と、前記関連情報格納手段から参照する各細胞に対する前記化合物情報とを基に、前記未知細胞に対して前記薬理活性又は毒性を有する化合物又は、前記未知細胞に対して前記薬理活性又は毒性の低い化合物を推定する化合物推定手段と
を具備することを特徴とする化合物推定装置。First expression information includingan expression level ofeach gene constituting a first expression pattern, which is an expression pattern of a gene in a cell identified by the cell identification information, in association with cell identification information for identifying a cell; Related information storage means for storing compound information including information relating to the pharmacological activity or toxicity of a plurality of types of compounds for the cells specified by the cell specifying information;
When the second expression information including theexpression level ofeach gene constituting the second expression pattern that is a gene expression pattern in an unknown cell in which the compound information is unknown is obtained,the first expression pattern and the For genes that are common to both the second expression pattern, the Euclidean distance between the expression level included in the first expression information and the expression level included in the second expression information is normalized by the number of dimensions. A distance calculating means for calculating the distance by
The pharmacological activity or toxicity to the unknown cell based on the distance between the unknown cell and each cell calculated by the distance calculation means and the compound information for each cell referenced from the related information storage means And a compound estimation means for estimating the compound or the compound having low pharmacological activity or toxicity against the unknown cell.
前記化合物推定手段は、前記距離算出手段が算出した前記距離と、前記関連情報格納手段から参照する各細胞に対する前記化合物情報とを基に、前記未知細胞に対して前記化合物の前記薬理活性値又は毒性値を推定することにより、前記未知細胞に対して前記薬理活性又は毒性を有する化合物又は、前記未知細胞に対して前記薬理活性又は毒性の低い化合物を推定すること
を特徴とする請求項1に記載の化合物推定装置。The compound information is information including a pharmacological activity value or toxicity value obtained by quantifying the pharmacological activity or toxicity of a plurality of types of compounds against the cell specified by the cell identification information,
The compounds estimating means, andthe distance that the distance calculating means is calculated, based on said compound information for each cell referenced from the related information storage unit, the pharmacological activity value of the compound against the unknown cell or The compound having a pharmacological activity or toxicity to the unknown cell or a compound having a low pharmacological activity or toxicity to the unknown cell is estimated by estimating a toxicity value. The compound estimation apparatus of description.
前記化合物情報を格納する化合物情報データベースと、
前記発現情報データベースから前記第1の発現情報を参照して、前記化合物情報データベースから前記化合物情報を参照することで、前記関連情報格納手段に対して、前記細胞を特定する細胞特定情報に関連付けて、前記第1の発現情報と、前記化合物情報とを登録する情報登録手段と
を更に具備することを特徴とする請求項1又は2に記載の化合物推定装置。An expression information database for storing the first expression information;
A compound information database for storing the compound information;
By referring to the first expression information from the expression information database and referring to the compound information from the compound information database, the related information storage means is associated with cell specifying information for specifying the cell. The compound estimation apparatus according to claim 1, further comprising: information registration means for registering the first expression information and the compound information.
種々の情報を表示する表示手段と、
前記化合物情報データベースより前記構造情報を参照して、前記化合物推定手段が推定した前記未知細胞に対して前記薬理活性又は毒性を有する化合物の構造又は、前記未知細胞に対して前記薬理活性又は毒性の低い化合物の構造を示す推定結果画面を前記表示手段に表示させる推定結果表示手段と
を更に具備することを特徴とする請求項3に記載の化合物推定装置。The compound information database further stores structure information that is information related to the structure of the compound,
Display means for displaying various information;
Referring to the structure information from the compound information database, the structure of the compound having the pharmacological activity or toxicity to the unknown cell estimated by the compound estimation means, or the pharmacological activity or toxicity to the unknown cell The compound estimation apparatus according to claim3 , further comprising: an estimation result display unit that displays an estimation result screen showing a structure of a low compound on the display unit.
前記発現情報取得手段が、前記化合物情報が未知である未知細胞における遺伝子の発現パターンである第2の発現パターンを構成する各遺伝子の発現量を含む第2の発現情報を得る取得ステップと、
前記距離算出手段が、前記第1の発現パターンと前記第2の発現パターンとの両方に共通に存在する遺伝子について、前記第1の発現情報に含まれる発現量と前記第2の発現情報に含まれる発現量とのユークリッド距離を、次元数により正規化することで距離を算出する距離算出ステップと、
前記化合物推定手段が、前記距離算出ステップで算出した前記未知細胞と各細胞の前記距離と、前記関連情報格納手段から参照する各細胞に対する前記化合物情報とを基に、前記未知細胞に対して前記薬理活性又は毒性を有する化合物を推定する化合物推定ステップと
を有することを特徴とする化合物推定方法。First expression information includingan expression level ofeach gene constituting a first expression pattern, which is an expression pattern of a gene in a cell identified by the cell identification information, in association with cell identification information for identifying a cell; Related information storage means for storing compound information including information on the pharmacological activity or toxicity of a plurality of types of compounds with respect to the cells specified by the cell identification information, expression information acquisition means, distance calculation means, and compound estimation means A compound estimation method using a compound estimation apparatus comprising:
The step of obtaining the second expression information including theexpression level ofeach gene constituting the second expression pattern that is the expression pattern of thegene in an unknown cell in which the compound information is unknown;
The distance calculation means includes, in the expression level included in the first expression information and the second expression information, a gene that is commonly present in both the first expression pattern and the second expression pattern. A distance calculation step of calculating the distanceby normalizing the Euclidean distance from the expressed amount by the number of dimensions ;
The compound estimation unit is configured to calculate the unknown cell based on the distance between the unknown cell and each cell calculated in the distance calculation step, and the compound information for each cell referenced from the related information storage unit. And a compound estimation step for estimating a compound having pharmacological activity or toxicity.
細胞を特定する細胞特定情報に関連付けて、前記細胞特定情報で特定される細胞における遺伝子の発現パターンである第1の発現パターンを構成する各遺伝子の発現量を含む第1の発現情報と、前記細胞特定情報で特定される細胞に対する複数種類の化合物の薬理活性又は毒性に関する情報を含む化合物情報とを格納する関連情報格納手段と、
前記化合物情報が未知である未知細胞における遺伝子の発現パターンである第2の発現パターンを構成する各遺伝子の発現量を含む第2の発現情報を得た場合に、前記第1の発現パターンと前記第2の発現パターンとの両方に共通に存在する遺伝子について、前記第1の発現情報に含まれる発現量と前記第2の発現情報に含まれる発現量とのユークリッド距離を、次元数により正規化することで距離を算出する距離算出手段と、
前記距離算出手段が算出した前記未知細胞と各細胞の前記距離と、前記関連情報格納手段から参照する各細胞に対する前記化合物情報とを基に、前記未知細胞に対して前記薬理活性又は毒性を有する化合物又は、前記未知細胞に対して前記薬理活性又は毒性の低い化合物を推定する化合物推定手段と
して機能させるプログラム。Computer
First expression information including an expression level of each gene constituting a first expression pattern, which is an expression pattern of a gene in a cell identified by the cell identification information, in association with cell identification information for identifying a cell; Related information storage means for storing compound information including information relating to the pharmacological activity or toxicity of a plurality of types of compounds for the cells specified by the cell specifying information;
When the second expression information including the expression level of each gene constituting the second expression pattern that is a gene expression pattern in an unknown cell in which the compound information is unknown is obtained, the first expression pattern and the For genes that are common to both the second expression pattern, the Euclidean distance between the expression level included in the first expression information and the expression level included in the second expression information is normalized by the number of dimensions. A distance calculating means for calculating the distance by
The pharmacological activity or toxicity to the unknown cell based on the distance between the unknown cell and each cell calculated by the distance calculation means and the compound information for each cell referenced from the related information storage means A compound estimation means for estimating a compound or a compound having low pharmacological activity or toxicity against the unknown cell;
Programto make it work .
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004296917AJP4580206B2 (en) | 2004-10-08 | 2004-10-08 | Compound estimation apparatus, compound estimation method and program thereof |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004296917AJP4580206B2 (en) | 2004-10-08 | 2004-10-08 | Compound estimation apparatus, compound estimation method and program thereof |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2006107395A JP2006107395A (en) | 2006-04-20 |
| JP4580206B2true JP4580206B2 (en) | 2010-11-10 |
Family
ID=36377027
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004296917AExpired - Fee RelatedJP4580206B2 (en) | 2004-10-08 | 2004-10-08 | Compound estimation apparatus, compound estimation method and program thereof |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4580206B2 (en) |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CA2425488A1 (en)* | 2000-10-12 | 2002-04-18 | Iconix Pharmaceuticals, Inc | Interactive correlation of compound information and genomic information |
| EP1520032A4 (en)* | 2001-11-02 | 2007-07-18 | Pfizer Prod Inc | THERAPEUTIC AND DIAGNOSTIC MEANS APPLICABLE TO LUNG CANCER |
- 2004
- 2004-10-08JPJP2004296917Apatent/JP4580206B2/ennot_activeExpired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2006107395A (en) | 2006-04-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN107292424B (en) | Anti-fraud and credit risk prediction method based on complex social network | |
| Chari et al. | The hammer and the scalpel: On the economics of indiscriminate versus targeted isolation policies during pandemics | |
| JP5633080B2 (en) | Attribute value estimation device, attribute value estimation method, program, and recording medium | |
| JPH10326286A (en) | Similarity search device and recording medium storing similarity search program | |
| US20120253960A1 (en) | Methods, software arrangements, storage media, and systems for providing a shrinkage-based similarity metric | |
| CN113192605A (en) | Medical image classification method, medical image retrieval method and medical image retrieval device | |
| Elbasyoni et al. | Evaluation of a global spring wheat panel for stripe rust: Resistance loci validation and novel resources identification | |
| CN110852589A (en) | Crowdsourcing task matching method based on capability evaluation | |
| Cheng et al. | A novel weighted distance threshold method for handling medical missing values | |
| CN112735542A (en) | Data processing method and system based on clinical trial data | |
| JP2008003842A (en) | Test manhour estimation device and program | |
| JP4580206B2 (en) | Compound estimation apparatus, compound estimation method and program thereof | |
| US20240038330A1 (en) | Computer-implemented method and apparatus for analysing genetic data | |
| Baumgartner et al. | A novel network-based approach for discovering dynamic metabolic biomarkers in cardiovascular disease | |
| GB2608738A (en) | Automated actions in a security platform | |
| CN111368910B (en) | Internet of things equipment cooperative sensing method | |
| JP2003157439A (en) | Image Feature Correlation Extraction Method by Image Categorization and Correlation Extraction Device | |
| CN116467524A (en) | Cold start recommendation method and device, storage medium and computer equipment | |
| KR102361615B1 (en) | Method for drug repositioning based on drug responding gene expression features | |
| Yourganov et al. | Estimating the statistical significance of spatial maps for multivariate lesion-symptom analysis | |
| Fleming et al. | Sensitivity of a white‐tailed deer habitat‐suitability index model to error in satellite land‐cover data: implications for wildlife habitat‐suitability studies | |
| CN112733582B (en) | Crop yield determination method and device and nonvolatile storage medium | |
| JP6352761B2 (en) | Data processing system, data processing method, and program | |
| EP3683735A1 (en) | Learning method, learning program, and learning device | |
| Cheng et al. | Population genomic scans for natural selection and demography |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination | Free format text:JAPANESE INTERMEDIATE CODE: A621 Effective date:20070829 | |
| A131 | Notification of reasons for refusal | Free format text:JAPANESE INTERMEDIATE CODE: A131 Effective date:20100427 | |
| A521 | Request for written amendment filed | Free format text:JAPANESE INTERMEDIATE CODE: A523 Effective date:20100623 | |
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) | Free format text:JAPANESE INTERMEDIATE CODE: A01 Effective date:20100810 | |
| A01 | Written decision to grant a patent or to grant a registration (utility model) | Free format text:JAPANESE INTERMEDIATE CODE: A01 | |
| A61 | First payment of annual fees (during grant procedure) | Free format text:JAPANESE INTERMEDIATE CODE: A61 Effective date:20100827 | |
| FPAY | Renewal fee payment (event date is renewal date of database) | Free format text:PAYMENT UNTIL: 20130903 Year of fee payment:3 | |
| R150 | Certificate of patent or registration of utility model | Free format text:JAPANESE INTERMEDIATE CODE: R150 | |
| R250 | Receipt of annual fees | Free format text:JAPANESE INTERMEDIATE CODE: R250 | |
| R250 | Receipt of annual fees | Free format text:JAPANESE INTERMEDIATE CODE: R250 | |
| R250 | Receipt of annual fees | Free format text:JAPANESE INTERMEDIATE CODE: R250 | |
| R250 | Receipt of annual fees | Free format text:JAPANESE INTERMEDIATE CODE: R250 | |
| LAPS | Cancellation because of no payment of annual fees |