JP4370811B2 - Voice display output control device and voice display output control processing program - Google Patents
Voice display output control device and voice display output control processing programDownload PDFInfo
- Publication number
- JP4370811B2 JP4370811B2JP2003143499AJP2003143499AJP4370811B2JP 4370811 B2JP4370811 B2JP 4370811B2JP 2003143499 AJP2003143499 AJP 2003143499AJP 2003143499 AJP2003143499 AJP 2003143499AJP 4370811 B2JP4370811 B2JP 4370811B2
- Authority
- JP
- Japan
- Prior art keywords
- image
- pronunciation
- accent
- word
- display
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images



















Landscapes
- Electrically Operated Instructional Devices (AREA)
Description
Translated fromJapanese【0001】
【発明の属する技術分野】
本発明は、音声,テキスト,画像などのデータを同期して出力するための音声表示出力制御装置、画像表示制御装置、および音声表示出力制御処理プログラム、画像表示制御処理プログラムに関する。
【0002】
【従来の技術】
従来、例えば言語学習装置として、言語の音声を出力しその口型を表示させるものがある。
【0003】
この言語学習装置では、マイクとカメラによって、母国語使用者の音声情報と口型のイメージデータを予めサンプルデータメモリに記録する。そして、学習者の音声情報と口型のイメージデータを前記マイクとカメラによって記録し、この学習者と前記サンプルデータメモリに予め記録された母国語使用者とのそれぞれの音声情報の波形とこれに対応する各口型のイメージデータとを対比しチャート形式で表示する。
【0004】
これにより、母国語使用者と学習者との言語発音の差異を明確に分析し表示しようとするものである(例えば、特許文献1参照。)。
【0005】
【特許文献1】
特開2001−318592号公報
【0006】
【発明が解決しようとする課題】
このような、従来の言語学習装置を用いると、手本である母国語使用者の発音音声とその口型イメージを知ることができるが、各言語のアクセントについては、主にアクセント部分の発音音声が強調されることで知らされるだけであって、口型イメージそのものには明確な違いが現れないため、各学習言語におけるアクセントのタイミングが分かり辛い問題がある。
【0007】
本発明は、前記のような問題に鑑みてなされたもので、音声出力に同期した画像の表示において、アクセントのタイミングを明確に現すことが可能になる音声表示出力制御装置、画像表示制御装置、および音声表示出力制御処理プログラム、画像表示制御処理プログラムを提供することを目的とする。
【0012】
【課題を解決するための手段】
本発明の請求項1に係る音声表示出力制御装置では、単語記憶手段により複数の単語と当該各単語それぞれの正しいアクセント付き発音記号と誤りアクセント付き発音記号とを対応付けて記憶し、音声データ出力手段により前記記憶した単語の正しいアクセントの発音音声データまたは誤りアクセントの発音音声データを出力し、テキスト同期表示制御手段により前記音声出力される単語の発音音声データに同期して当該単語のテキストを表示させ、画像表示制御手段により少なくとも口の部分を含む画像を、前記音声データ出力手段により正しいアクセントの発音音声データが出力される場合と誤りアクセントの発音音声データが出力される場合とで異なる表示形態にして表示させ、さらに、口画像表示制御手段により前記表示画像に含まれる口の部分について、前記音声データ出力手段により出力される発音音声データに同期して当該発音音声データに対応した口型の画像を表示させる。そして、アクセント検出手段により前記テキスト同期表示制御手段による単語テキストの同期表示に伴い、前記単語記憶手段により記憶した該当単語のアクセント付き発音記号から該単語のアクセントを検出し、画像変化表示制御手段により前記アクセント検出に応じて前記画像表示制御手段により表示される画像を変化させる。さらに、正誤アクセント表示制御手段により前記単語記憶した単語と当該単語に対応付けられた正しいアクセント付き発音記号と誤りアクセント付き発音記号とを並べて表示させ、正誤アクセント選択手段により前記並べて表示された単語の正しいアクセント付き発音記号か誤りアクセント付き発音記号かの何れかを選択する。すると、音声データ出力手段は、前記正誤アクセント選択手段による単語アクセントの正誤選択に応じて、該当単語の正しいアクセントの発音音声データまたは誤りアクセントの発音音声データを出力する。
【0013】
これによれば、単語記憶手段により記憶される単語について正しいアクセントの発音音声データと誤りアクセントの発音音声データとを出力できるだけでなく、この発音音声データに同期した単語テキストの表示および表示画像に含まれる口部分についての発音音声データに対応した口型画像を表示でき、しかも単語アクセントの検出に応じて表示画像を変化できるので、単語についての正しいアクセントと誤りアクセントを容易かつ明確なタイミングで学習でき、さらに、単語記憶手段により記憶される単語について正しいアクセント付き発音記号か誤りアクセント付き発音記号かを選択してその発音音声データを出力でき、しかも、この発音音声データに同期した単語テキストの表示および表示画像に含まれる口部分についての発音音声データに対応した口型画像を表示でき、単語アクセントの検出に応じて表示画像を変化できるので、単語についての正しいアクセントと誤りアクセントをさらに容易かつ明確なタイミングで学習できることになる。
【0026】
【発明の実施の形態】
以下、図面を参照して本発明の実施の形態について説明する。
【0027】
(第1実施形態)
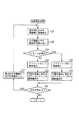
図1は本発明の音声表示出力制御装置(画像表示制御装置)の実施形態に係る携帯機器10の電子回路の構成を示すブロック図である。
【0028】
この携帯機器(PDA:personal digital assistants)10は、各種の記録媒体に記録されたプログラム、又は、通信伝送されたプログラムを読み込んで、その読み込んだプログラムによって動作が制御されるコンピュータによって構成され、その電子回路には、CPU(central processing unit)11が備えられる。
【0029】
CPU11は、メモリ12内のFLASHメモリ12Aに予め記憶されたPDA制御プログラム、あるいはROMカードなどの外部記録媒体13から記録媒体読取部14を介して前記メモリ12に読み込まれたPDA制御プログラム、あるいはインターネットなどの通信ネットワークN上の他のコンピュータ端末(30)から電送制御部15を介して前記メモリ12に読み込まれたPDA制御プログラムに応じて、回路各部の動作を制御するもので、前記メモリ12に記憶されたPDA制御プログラムは、スイッチやキーからなる入力部17aおよびマウスやタブレットからなる座標入力装置17bからのユーザ操作に応じた入力信号、あるいは電送制御部15に受信される通信ネットワークN上の他のコンピュータ端末(30)からの通信信号、あるいはBluetooth(R)による近距離無線接続や有線接続による通信部16を介して受信される外部の通信機器(PC:personal computer)20からの通信信号に応じて起動される。
【0030】
前記CPU11には、前記メモリ12、記録媒体読取部14、電送制御部15、通信部16、入力部17a、座標入力装置17bが接続される他に、LCDからなる表示部18、マイクを備え音声を入力する音声入力部19a、左右チャンネルのスピーカL,Rを備え音声を出力するステレオ音声出力部19bなどが接続される。
【0031】
また、CPU11には、処理時間計時用のタイマが内蔵される。
【0032】
この携帯機器10のメモリ12は、FLASHメモリ(EEP-ROM)12A、RAM12Bを備えて構成される。
【0033】
FLASHメモリ(EEP-ROM)12Aには、当該携帯機器10の全体の動作を司るシステムプログラムや電送制御部15を介して通信ネットワークN上の各コンピュータ端末(30)とデータ通信するためのネット通信プログラム、通信部16を介して外部の通信機器(PC)20とデータ通信するための外部機器通信プログラムが記憶される他に、スケジュール管理プログラムやアドレス管理プログラム、そして辞書の見出語検索や検索見出語に対応する音声・テキスト・顔画像(含む口型合成画像)などの各種データの同期再生、および当該顔画像(キャラクタ)の種類設定、および見出語アクセントの出題テストを行うための辞書処理プログラム12aなど、種々のPDA制御プログラムが記憶される。
【0034】
また、FLASHメモリ(EEP-ROM)12Aにはさらに、辞書データベース12b(図2参照)、辞書音声データ12c、キャラクタ画像データ12d(図3参照)、音声別口(型)画像データ12e(図4参照)、および辞書タイムコードファイル12f(図5・図6参照)が記憶される。
【0035】
辞書データベース12bとしては、英和辞書、和英辞書、国語辞書など、各種の辞書のデータが記憶されると共に、図2に示すように、辞書内の全ての見出語についてそれぞれその見出語No、音声・テキスト・画像の同期再生を簡単に行うためのタイムコードファイルのNoと格納先アドレス、画像再生ウインドウを設定するためのHTMLファイルのNoと格納先アドレス、テキストファイルのNoと格納先アドレス、テキストの各文字,発音記号,口型番号を対応付けたテキスト口同期ファイルのNoと格納先アドレス、音声データであるサウンドファイルのNoと格納先アドレス、辞書内容のデータ番号と格納先アドレスが、それぞれリンク付けられて記憶される。
【0036】
なお、各実施形態において、明細書上で記載される発音記号については、正式な発音記号の入力が困難なため類似の文字を代用し、正式な発音記号については図面上にて記載する。
【0037】
図2は前記携帯機器10のメモリ12に記憶される辞書データベース12bのうち1つの見出語「low」についての同期再生用リンクデータを示す図であり、同図(A)は各ファイルNoと格納先アドレスを示すテーブル、同図(B)は当該テキストファイルNoに従い格納されているテキストデータ「low」を示す図、同図(C)はテキスト口同期ファイルNoに従い格納されているテキストの文字,発音記号,口型番号を示す図である。
【0038】
辞書音声データ12cとしては、前記辞書データベース12bにおける各見出語毎の発音のための音声データがそのサウンドファイルNoとアドレスに対応付けられて記憶される。
【0039】
図3は前記携帯機器10のメモリ12に記憶され、辞書の見出語検索における発音口型画像の同期表示のためにユーザ設定により選択的に使用されるキャラクタ画像データ12dを示す図である。
【0040】
キャラクタ画像データ12dとしては、本実施形態の場合、3種類のキャラクタ画像(顔画像)No1〜No3が用意され、個々のキャラクタ画像No1,No2,No3には、その口型画像の合成矩形領域を対角する2点の座標として指定するための口画像エリアデータ(X1,Y1,X2,Y2)が対応付けられて記憶される。
【0041】
なお、この3種類のキャラクタ画像(顔画像)No1〜No3には、それぞれさらに、辞書検索された見出語のアクセントのタイミングで発音の強調を表現するためのアクセント顔画像No1′〜No3′(図12(C)▲2▼,図13(B)▲2▼参照)が記憶され、さらには、米語または英語の発音音声が指定された場合の米語用キャラクタ画像No1US〜No3US(図15参照)や英語用キャラクタ画像No1UK〜No3UK(図16参照)、およびそのアクセント顔画像No1US′〜No3US′(図15(B)▲2▼参照)やNo1UK′〜No3UK′(図16(B)▲2▼参照)が記憶される。
【0042】
図4は前記携帯機器10のメモリ12に記憶され、辞書の見出語検索における発音口型画像の同期表示のためにキャラクタ画像(12d:No1〜No3)の口画像エリア(X1,Y1,X2,Y2)に合成表示される音声別口画像データ12eを示す図である。
【0043】
音声別口(型)画像データ12eとしては、前記辞書データベース12bに記憶された全ての見出し語の発音に要する各発音記号に対応付けた口型画像12e1,12e2,…がそれぞれその口番号No.nに対応付けられて記憶される。
【0044】
また、前記携帯機器10のメモリ12に記憶される辞書タイムコードファイル12fは、辞書検索された見出語に対応する音声・テキスト・顔画像(含む口型合成画像)の同期再生を行うための指令ファイル(図5参照)であり、全ての見出語毎ではなく、文字数と発音記号数およびその発音タイミングが同じである複数の見出語毎に用意され、所定のアルゴリズムにより圧縮・暗号化されている。
【0045】
図5は前記携帯機器10のメモリ12に格納された辞書タイムコードファイル12fにおける見出語「low」に対応付けられたファイルNo23のタイムコードファイル12f23(12i)を示す図である。
【0046】
タイムコードファイル12fnには、予めヘッダ情報Hとして記述設定される一定時間間隔の基準処理単位時間(例えば25ms)で各種データ(音声・テキスト・画像)を同期再生するコマンド処理を行うためのタイムコードが記述配列されるもので、この各タイムコードは、命令を指示するコマンドコードと、当該コマンドに関わるデータ内容(テキストファイル/サウンドファイル/イメージファイルなど)を対応付けするための参照番号や指定数値からなるパラメータデータとの組み合わせにより構成される。
【0047】
例えば図5で示す見出語「low」のタイムコードファイル12f23によるファイル再生時間は、予め設定された基準処理単位時間が25msである場合、40ステップのタイムコードからなる再生処理を経て1秒間となる。
【0048】
図6は前記携帯機器10の辞書タイムコードファイル12fn(図5参照)にて記述される各種コマンドのコマンドコードとそのパラメータデータに基づき解析処理される命令内容を対応付けて示す図である。
【0049】
タイムコードファイル12fnに使用されるコマンドとしては、標準コマンドと拡張コマンドがあり、標準コマンドには、LT(i番目テキストロード).VD(i番目テキスト文節表示).BL(文字カウンタリセット・i番目文節ブロック指定).HN(ハイライト無し・文字カウンタカウントアップ).HL(i番目文字までハイライト・文字カウント).LS(1行スクロール・文字カウンタカウントアップ).DH(i番目HTMLファイル表示).DI(i番目イメージファイル表示).PS(i番目サウンドファイルプレイ).CS(クリアオールファイル).PP(基本タイムi秒間停止).FN(処理終了).NP(無効)の各コマンドがある。
【0050】
また、メモリ12内のRAM12Bには、辞書データベース12bの検索処理に伴う見出語がその見出語番号に従い読み出されて記憶される検索見出語メモリ12g、検索された見出語に対応する意味内容などの辞書データが前記辞書データベース12bからその辞書データ番号に従い読み出されて記憶される見出語対応辞書データメモリ12h、検索された見出語に対応した音声・テキスト・画像の同期再生を行うためのタイムコードファイル12fn(図5参照)が前記辞書データベース12b内のタイムコードファイルNoに従い辞書タイムコードファイル12fの中から読み出され伸張・復号化されて記憶される再生タイムコードファイルメモリ12iが用意される。
【0051】
さらに、このメモリ12内のRAM12Bには、見出語検索画面G2上でテキスト・画像の同期再生用ウインドウW1,W2(図12・図13参照)を設定するためのHTMLファイルが、前記辞書データベース12bからHTMLファイルNoに従い読み出されて記憶される同期用HTMLファイルメモリ12j、検索見出語のテキストデータが前記辞書データベース12bからそのテキストファイルNoに従い読み出されて記憶される同期用テキストファイルメモリ12k、検索見出語の発音音声データが前記辞書データベース12b内のサウンドファイルNoに従い前記辞書音声データ12cの中から読み出されて記憶される同期用サウンドファイルメモリ12m、検索見出語の発音画像表示用としてユーザ設定されたキャラクタ画像が前記キャラクタ画像データ12d(図3参照)の中から読み出されて記憶される同期用イメージファイルメモリ12n、この同期用イメージファイルメモリ12nに記憶されたキャラクタ画像における口型画像の合成領域を示す口画像エリアデータ(X1,Y1;X2,Y2)が記憶される口画像エリアメモリ12p、そして、前記タイムコードファイルメモリ12iに記憶された検索見出語に対応するタイムコードファイル12fnに従い音声・テキストに同期再生すべきキャラクタ画像と口型画像とが展開合成されて記憶される画像展開バッファ12qなどが用意される。
【0052】
すなわち、この携帯機器(PDA)10のFLASHメモリ12Aに記憶されている辞書処理プログラム12aを起動させて検索された見出語が「low」であり、これに対応して辞書タイムコードファイル12f内から読み出されて再生タイムコードファイルメモリ12iに記憶されたタイムコードファイル12fが、例えば図5で示したタイムコードファイル12f23であり、設定処理単位時間毎のコマンド処理に伴い3番目のコマンドコード“DI”およびパラメータデータ“00”が読み込まれた場合には、このコマンド“DI”はi番目のイメージファイル表示命令であるため、パラメータデータi=00からリンク付けられる同期用イメージファイル12nに記憶されたキャラクタ画像12dnが読み出されて表示される。
【0053】
また、設定処理単位時間毎のコマンド処理に伴い4番目のコマンドコード“PS”およびパラメータデータ“00”が読み込まれた場合には、このコマンド“PS”はi番目のサウンドファイル再生命令であるため、パラメータデータi=00からリンク付けられる同期用サウンドファイル12mに記憶された音声データ12cnが読み出されて出力される。
【0054】
また、設定処理単位時間毎のコマンド処理に伴い6番目のコマンドコード“VD”およびパラメータデータ“00”が読み込まれた場合には、このコマンド“VD”はi番目のテキスト文節表示命令であるため、パラメータデータi=00に従い、テキストの0番目の文節(この場合は、同期用テキストファイルメモリ12kに記憶された検索見出語のテキストファイル「low」が表示される。
【0055】
さらに、設定処理単位時間毎のコマンド処理に伴い9番目のコマンドコード“NP”およびパラメータデータ“00”が読み込まれた場合には、このコマンド“NP”は無効命令であるため、現状のファイル出力状態が維持される。
【0056】
なお、この図5で示したファイル内容のタイムコードファイル12f23(12i)に基づいた検索見出語に対応する発音音声・テキスト・画像(口型画像)の同期再生についての詳細な動作は、後述にて改めて説明する。
【0057】
次に、前記構成の携帯機器10による各種の動作について説明する。
【0058】
図7は前記携帯機器10の辞書処理プログラム12aに従ったメイン処理を示すフローチャートである。
【0059】
図8は前記携帯機器10のメイン処理に伴う見出語同期再生処理を示すフローチャートである。
【0060】
図9は前記携帯機器10の見出語同期再生処理に伴う各見出語文字のハイライト表示に応じて割り込みで実行されるテキスト対応口表示処理を示すフローチャートである。
【0061】
図10は前記携帯機器10のメイン処理内のキャラクタ設定処理に伴う同期再生用キャラクタ画像の設定表示状態を示す図である。
【0062】
入力部17aの「設定」キー17a1およびカーソルキー17a2の操作によりキャラクタ画像の設定モードに切り替えられると(ステップS1→S2)、FLASHメモリ12Aに記憶されている例えば3種類のキャラクタ画像データ12d1(No1),12d2(No2),12d3(No3)[図3参照]が読み出され、図10に示すように、キャラクタ画像の一覧選択画面G1として表示部18に表示される(ステップS3)。
【0063】
このキャラクタ画像の一覧選択画面G1において、カーソルキー17a3の操作により各キャラクタ画像の選択フレームXが移動操作されてユーザ所望のキャラクタ画像(例えば12d3(No3))が選択されると共に、「訳/決定(音声)」キー17a4による決定操作により当該キャラクタ画像の選択が検知されると(ステップS4)、この選択検知されたキャラクタ画像12dnが読み出され、RAM12B内の同期用イメージファイルメモリ12nに転送格納される(ステップS5)。また、この選択検知されたキャラクタ画像12dnの口型画像の合成領域を示す口画像エリアデータ(X1,Y1;X2,Y2)も読み出され、RAM12B内の口画像エリアメモリ12pに転送格納される(ステップS6)。
【0064】
これにより、見出語検索に伴い、当該見出語の発音音声に同期表示させるべき口型画像合成対象のキャラクタ画像が選択設定される。
【0065】
図11は前記携帯機器10のメイン処理内の見出語検索処理に伴う検索見出語表示画面G2を示す図である。
【0066】
辞書データベース12bに記憶されている例えば英和辞書の辞書データに基づいて見出語検索を行うのに、入力部17aの「英和」キー17a5の操作により英和辞書の検索モードに設定した後に、検索対象の見出語(例えば「low」)を入力すると(ステップS7→S8)、当該入力された見出語と一致及び一致文字を先頭に含む複数の見出語が前記英和辞書の辞書データから検索されて読み出され、検索見出語の一覧(図示せず)として表示部18に表示される(ステップS9)。
【0067】
この検索見出語の一覧画面において、ユーザ入力した検索対象の見出語と一致する見出語(この場合「low」)がカーソルキーにより選択指示されて「訳/決定(音声)」キー17a4が操作されると(ステップS10)、当該選択検知された見出語「low」がRAM12B内の見出語メモリ12gに記憶されると共に、この見出語「low」に対応する発音/品詞/意味内容などの辞書データが読み出されてRAM12B内の見出語対応辞書データメモリ12hに記憶され、図11に示すように、検索見出語表示画面G2として表示部18に表示される(ステップS11)。
【0068】
ここで、前記検索表示された見出語「low」について、その発音音声を出力させるのと同時に、当該見出語の文字,発音記号と発音の口型画像を同期表示させるために、「訳/決定(音声)」キー17a4が操作されると(ステップS12)、図8における同期再生処理に移行される(ステップSA)。
【0069】
図12は前記携帯機器10の見出語検索処理における同期再生処理に伴いキャラクタ画像No3の設定状態において検索見出語表示画面G2上にウインドウ表示される見出語文字表示ウインドウW1および発音口型表示ウインドウW2の表示状態を示す図であり、同図(A)は検索見出語表示画面G2に対する見出語文字表示ウインドウW1および発音口型表示ウインドウW2の設定表示状態を示す図、同図(B)は発音音声の出力に同期した見出語文字表示ウインドウW1およびアクセント未対応の発音口型表示ウインドウW2の変化状態を示す図、同図(C)は発音音声の出力に同期した見出語文字表示ウインドウW1およびアクセント対応の発音口型表示ウインドウW2の変化状態を示す図である。
【0070】
前記検索見出語表示画面G2が表示されている状態での「訳/決定(音声)」キー17a4の操作に伴い、図8における同期再生処理(ステップSA)が起動されると、RAM12B内の各ワークエリアのクリア処理などのイニシャライズ処理が行われ(ステップA1)、まず、辞書データベース12bに記憶されている今回の検索見出語「low」についての同期再生用リンクデータ(図2参照)に基づき、見出語検索画面G2上でテキスト・画像の同期再生用ウインドウW1,W2(図12参照)を設定するためのHTMLファイルがそのHTMLファイルNo3に従い読み出され同期用HTMLファイルメモリ12jに書き込まれる。また、検索見出語のテキストデータ「low(発音記号付)」がそのテキストファイルNo4222に従い読み出され同期用テキストファイルメモリ12kに書き込まれる。また、検索見出語の発音音声データがそのサウンドファイルNo4222に従い読み出され同期用サウンドファイルメモリ12mに書き込まれる(ステップA2)。
【0071】
なお、検索見出語の発音画像表示用としてユーザ設定されたキャラクタ画像(この場合、12d3(No3))は、前記キャラクタ設定処理に伴うステップS5に従って、既にキャラクタ画像データ12d(図3参照)の中から読み出されて同期用イメージファイルメモリ12nに書き込まれ、さらに当該キャラクタ画像12d3(No3)における発音口型画像合成エリアである口画像エリアデータ(X1,Y1;X2,Y2)も前記キャラクタ設定処理に伴うステップS6に従って、既に口画像エリアメモリ12pに書き込まれている。
【0072】
すると、FLASHメモリ12A内に辞書タイムコードファイル12fとして記憶されている各種見出語対応の暗号化された音声・テキスト・画像の同期再生用タイムコードファイル12fnの中から、今回の検索見出語「low」に対応するタイムコードファイル12f23(図5参照)が、前記同期再生用リンクデータ(図2参照)に記述されたタイムコードファイルNo23に従い解読復号化されて読み出され、RAM12B内のタイムコードファイルメモリ12iに転送されて格納される(ステップA3)。
【0073】
こうして、前記検索見出語「low」に対応する発音音声・テキスト・発音口型画像の同期再生用の各種ファイルのRAM12Bへの読み込み設定、およびこれらのファイルを同期再生するためのタイムコードファイル12f23のRAM12Bへの転送設定が完了すると、タイムコードファイルメモリ12iに格納されたタイムコードファイル(CASファイル)12f23(図5参照)のCPU11による処理単位時間(例えば25ms)が当該タイムコードファイル12f23のヘッダ情報Hとして設定される(ステップA4)。
【0074】
そして、前記タイムコードファイルメモリ12iに格納されたタイムコードファイル12f23の先頭に読み出しポインタがセットされると共に、各同期用ファイルメモリ12j,12k,12m,12nに書き込まれた各種ファイルの先頭に読み出しポインタがセットされ(ステップA5)、当該各同期ファイルの再生処理タイミングを計時するためのタイマがスタートされる(ステップA6)。
【0075】
このステップA6において、処理タイマがスタートされると、前記ステップA4にて設定された今回のタイムコードファイル12f23に応じた処理単位時間(25ms)毎に、前記ステップA5にて設定された読み出しポインタの初期位置の当該タイムコードファイル12f23(図5参照)のコマンドコードおよびそのパラメータデータが読み出される(ステップA7)。
【0076】
そして、前記タイムコードファイル12f23(図5参照)から読み出されたコマンドコードが、“FN”か否か判断され(ステップA8)、“FN”と判断された場合には、その時点で当該同期再生処理の停止処理が指示実行される(ステップA8→A9)。
【0077】
一方、前記タイムコードファイル12f23(図5参照)から読み出されたコマンドコードが、“FN”ではないと判断された場合には、当該コマンドコードの内容(図6参照)に対応する処理が実行される(ステップA10)。
【0078】
そして、前記タイマによる計時時間が次の処理単位時間(25ms)に到達したと判断された場合には、RAM12Bに格納されたタイムコードファイル12f23(図5参照)に対する読み出しポインタが次の位置に移動セットされ(ステップA11→A12)、前記ステップA7における当該読み出しポインタの位置のタイムコードファイル12f23(図5参照)のコマンドコードおよびそのパラメータデータ読み出しからの処理が繰り返される(ステップA12→A7〜A10)。
【0079】
ここで、図5で示す検索見出語「low」のタイムコードファイル12f23に基づいた、発音音声・テキスト・発音口型画像ファイルの同期再生出力動作について詳細に説明する。
【0080】
すなわち、このタイムコードファイル12f23は、そのヘッダHに予め記述設定された(基準)処理単位時間(例えば25ms)毎にコマンド処理が実行されるもので、まず、タイムコードファイル12f23(図5参照)の第1コマンドコード“CS”(クリアオールファイル)およびそのパラメータデータ“00”が読み出されると、全ファイルの出力をクリアする指示が行われ、テキスト・音声・画像ファイルの出力がクリアされる(ステップA10)。
【0081】
第2コマンドコード“DH”(i番目HTMLファイル表示)およびそのパラメータデータ“00”が読み出されると、当該コマンドコードDHと共に読み出されたパラメータデータ(i=0)に応じて、RAM12B内の同期用HTMLファイルメモリ12jからHTMLデータの見出語テキスト・画像フレームデータが読み出され、図12(A)に示すように、表示部18に対する見出語検索画面G2上でのテキスト・画像の同期再生用ウインドウW1,W2が設定される(ステップA10)。
【0082】
第3コマンドコード“DI”(i番目イメージファイル表示)およびそのパラメータデータ“00”が読み出されると、当該コマンドコードDIと共に読み出されたパラメータデータ(i=0)に応じて、RAM12B内の同期用イメージファイルメモリ12nから前記キャラクタ設定処理(ステップS2〜S6)にて設定記憶されたキャラクタ画像12d(この場合No3)が読み出され、図12(A)に示すように、前記見出語検索画面G2上でHTMLファイルで設定された画像の同期再生用ウインドウW2に表示される(ステップA10)。
【0083】
第4コマンドコード“PS”(i番目サウンドファイルプレイ)およびそのパラメータデータ“00”が読み出されると、当該コマンドコードPSと共に読み出されたパラメータデータ(i=0)に応じて、RAM12B内の同期用サウンドファイルメモリ12mから前記ステップA2にて設定記憶された検索見出語「low」に対応する発音音声データが読み出され、ステレオ音声出力部19bからの音声出力が開始される(ステップA10)。
【0084】
第5コマンドコード“LT”(i番目テキストロード)およびそのパラメータデータ“00”が読み出されると、当該コマンドコードLTと共に読み出されたパラメータデータ(i=0)に応じて、RAM12B内の同期用テキストファイルメモリ12kに前記ステップA2にて設定記憶された検索見出語「low」に対応する1文節のテキストデータ「l」「o」「w」(含む発音記号)が指定される(ステップA10)。
【0085】
第6コマンドコード“VD”(i番目テキスト文節表示)およびそのパラメータデータ“00”が読み出されると、当該コマンドコードVDと共に読み出されたパラメータデータ(i=0)に応じて、前記第5コマンドコード“LT”に従い指定された1文節のテキストデータ「l」「o」「w」(含む発音記号)が読み出され、図12(A)に示すように、前記見出語検索画面G2上のテキスト同期再生用ウインドウW1に表示される(ステップA10)。
【0086】
第7コマンドコード“BL”(文字カウンタリセット・i番目文節ブロック指定)およびそのパラメータデータ“00”が読み出されると、前記テキスト同期再生用ウインドウW1で表示中の検索見出語「low」の文字カウンタがリセットされる(ステップA10)。
【0087】
そして、第8コマンドコード“HL”(i番目文字までハイライト・文字カウント)およびそのパラメータデータ“01”が読み出されると、当該コマンドコードHLと共に読み出されたパラメータデータ(i=1)に応じて、図12(A)に示すように、テキスト同期再生用ウインドウW1に表示されている検索見出語「low」(含む発音記号)のうち1番目の文字「l」およびこれに対応する発音記号まで、色替え表示,反転表示,下線表示などによるハイライト(識別)表示HLが行われ、文字カウンタが同2番目の文字およびこれに対応する発音記号までカウントアップされる(ステップA10)。
【0088】
このタイムコードファイル12f23による検索見出語「low」の各文字およびこれに対応する発音記号に対するハイライト(識別)表示に際しては、図9におけるテキスト対応口表示処理の割り込みが行われる。
【0089】
すなわち、今回ハイライト(識別)表示HLされた検索見出語「low」の文字「l」が検知されると(ステップB1)、この検知文字「l」に対応する発音口型画像が、辞書データベース12b内のテキスト口同期ファイル(図2(C)参照)により示されるテキスト「l」に対応する口番号「36」に従い、音声別口画像データ12e(図4参照)の中から発音口型画像12e2(No36)として読み出される(ステップB2)。そして、このハイライト(識別)表示された検索見出語「low」の文字「l」に対する発音口型画像12e2(No36)は、図12(A)(図12(B)▲1▼)に示すように、見出語検索画面G2上の画像同期再生用ウインドウW2に表示されているキャラクタ画像12d(No3)の口画像合成領域に対して、RAM12B内の口画像エリアメモリ12pに記憶されている口画像エリア(X1,Y1;X2,Y2)に従い合成されて表示される(ステップB3)。
【0090】
ここで、前記テキスト口同期ファイル(図2(C)参照)により示される今回のハイライト(識別)表示テキスト「l」の発音記号に対するアクセントマークの有無が判断される(ステップB4)。このハイライト(識別)表示テキスト「l」の発音記号[l]の場合にはアクセントマーク無しと判断されるので、キャラクタ画像12d(No3)はその通常の顔画像のままの表示が維持される(ステップB4→B5)。
【0091】
なお、ここでアクセントマーク有りと判断された場合には、前記キャラクタ画像12d(No3)は、発音強調表現用のアクセント顔画像No3′(図12(C)▲2▼参照)に変更表示される(ステップB4→B6)。
【0092】
そして、前記第4コマンドコード“PS”に応じてステレオ音声出力部19bから出力開始されている検索見出語「low」に対応する発音音声データの出力タイミングと、本タイムコードファイル12f23による処理単位時間(25ms)に応じた検索見出語「low」の1文字毎の識別表示タイミングとは、予め対応付けされて当該タイムコードファイル12f23が作成されているので、当該検索見出語「low」の1文字目「l」の識別表示とその発音口型画像12e(No36)の同期合成表示の際には、これに対応する発音記号を読み上げるところの発音音声が同期出力されることになる。
【0093】
これにより、検索見出語「low」の第1文字目「l」の識別表示、その発音口型画像12e3(No36)の設定キャラクタ画像12d(No3)への合成表示、ならびにその発音音声の出力が同期して行われる。
【0094】
そして、第9コマンドコード“NP”が読み出されると、現在の検索見出語「low」に対応するキャラクタ画像およびテキストデータの同期表示画面および発音音声データの同期出力状態が維持される。
【0095】
この後、第12コマンドコード“HL”、第35コマンドコード“HL”に従い、図12(C)▲2▼、図12(C)▲3▼に示すように、テキスト同期再生用ウインドウW1では、検索見出語のテキストデータ「low」とその発音記号が、順次、2番目の文字「o」と発音記号[o]、3番目の文字「w」と発音記号[u]というように、ハイライト(識別)表示HLされて行く(ステップA10)。そして、これと共に、画像同期再生用ウインドウW2では、前記図9におけるテキスト対応の口表示処理に応じて、設定キャラクタ画像12d(No3)の口画像エリア(X1,Y1;X2,Y2)に合成すべき発音口型画像も、前記テキスト口同期ファイル(図2(C)参照)に従い、口番号9に対応する発音口型画像12e(No9)、口番号8に対応する発音口型画像12e(No8)として音声別口画像12eの中から読み出され、順次合成されて同期表示される(ステップB1〜B3)。
【0096】
さらに、前記第4コマンドコード“PS”に応じてステレオ音声出力部19bから出力されている検索見出語「low」の発音音声データも、同テキスト「low」とその発音記号のハイライト(識別)表示部分を読み上げるところの音声が順次同期出力される。
【0097】
なお、前記検索見出語「low」の各文字「l」「o」「w」毎のハイライト(識別)表示HLに同期させたテキスト対応口表示処理による各発音口型画像12e(No36)→12e(No9)→12e(No8)の設定キャラクタ画像12d(No3)に対する合成切り替え表示(ステップB1〜B5)に際し、図12(B)▲2▼で示したように、2番目の文字「o」とその発音記号のハイライト(識別)表示HLに伴い発音口型画像12e(No9)を合成表示させるときには、当該ハイライト(識別)表示テキスト「o」の発音記号にはアクセントマーク有りと判断されるので、図12(C)▲2▼で示したように、このときのキャラクタ画像12d(No3)は、発音強調表現用のアクセント顔画像No3′に変更されて表示される(ステップB4→B6)。
【0098】
つまり、図12で示した検索見出語「Low」のアクセント文字「o」に対する発音音声の出力と同期したハイライト(識別)表示HL、発音口型画像12e(No9)の切り替え合成表示に際しては、当該口型画像12e(No9)の合成先である図12(B)▲2▼で示した通常の設定キャラクタ(顔)画像12d(No3)が、図12(C)▲2▼で示した例えば頭部の発汗や口元の皺によって強く発音している状態を表現するアクセント対応の顔画像12d(No3′)に変更表示されるので、ユーザは検索見出語「Low」の発音音声とその発声タイミングおよび各文字「L」「o」「w」とその発音記号の対応部分、さらには各発音口型画像12e(No36→No9→No8)を、そのそれぞれの同期再生により容易に学習できるばかりでなく、アクセントに応じて発声強調するタイミングをリアルに学習できるようになる。
【0099】
図13は前記携帯機器10の見出語検索処理における同期再生処理に伴いキャラクタ画像No1の設定状態において検索見出語表示画面G2上にウインドウ表示される見出語文字表示ウインドウW1および発音口型表示ウインドウW2の表示状態を示す図であり、同図(A)は検索見出語表示画面G2に対する見出語文字表示ウインドウW1および発音口型表示ウインドウW2の設定表示状態を示す図、同図(B)は発音音声の出力に同期した見出語文字表示ウインドウW1および発音口型表示ウインドウW2の変化状態を示す図である。
【0100】
すなわち、前記図7のステップS1〜S6によるキャラクタ設定処理において、予め記憶された3種類のキャラクタ画像データ12d(No1),12d(No2),12c(No3)[図3参照]の中からアニメ調のキャラクタ画像12d(No1)が選択設定された状態で、前記ステップS7〜SAと同様に検索対象の見出語「low」についての見出語検索処理および同期再生処理、そして図9におけるテキスト対応口表示処理が行われた場合には、図13(A)および図13(B)に示すように、検索見出語表示画面G2に対する見出語文字表示ウインドウW1には、検索見出語「low」およびその発音記号の発音音声出力に同期させたハイライト(識別)表示HLが順次行われる。これに伴い、発音口型表示ウインドウW2には、前記キャラクタ設定処理(ステップS1〜S6)において設定されたアニメ調のキャラクタ画像12d(No1)を基本の顔画像として、前記発音音声出力およびテキスト(含む発音記号)のハイライト表示HLに同期させた各発音口型画像12e(No36→No9→No8)が順次切り替え合成されて表示される。
【0101】
そして、図13(B)▲2▼で示したように、検索見出語「low」の2番目の文字「o」とその発音記号のハイライト(識別)表示HLに伴い発音口型画像12e(No9)を合成表示させるときには、当該ハイライト(識別)表示テキスト「o」の発音記号にはアクセントマーク有りと判断されるので、このときのアニメ調キャラクタ画像12d(No1)は、発音強調表現用のアクセント顔画像No1′に変更されて表示される(ステップB4→B6)。
【0102】
つまり、図13で示したアニメ調のキャラクタ画像12d(No1)を選択設定した場合の、検索見出語「Low」のアクセント文字「o」に対する発音音声の出力と同期したハイライト(識別)表示HL、発音口型画像12e(No9)の切り替え合成表示に際しても、当該口型画像12e(No9)の合成先である通常のアニメ調キャラクタ(顔)画像12d(No1)が、例えば頭部の発汗や身体の動揺によって強く発音している状態を表現するアクセント対応の顔画像12d(No1′)に変更表示されるので、ユーザは検索見出語「Low」の発音音声とその発声タイミングおよび各文字「L」「o」「w」とその発音記号の対応部分、さらには各発音口型画像12e(No36→No9→No8)を、そのそれぞれの同期再生により容易に学習できるばかりでなく、アクセントに応じて発声強調するタイミングをリアルに学習できるようになる。
【0103】
なお、前記図11〜図13を参照して説明した見出語検索に伴うテキスト・発音音声・発音口型画像の同期再生処理では、辞書データベース12bとして予め記憶される英和辞書データの内容が、米国系1国の発音にのみ対応する内容である場合について説明したが、例えば、次の図14〜図16を参照して説明するように、辞書データベース12bとして予め記憶される英和辞書データの内容が、米国系および英国系の2国の発音に対応する内容を有する場合に、米国系または英国系の何れか1国の発音形態を指定して見出語検索に伴うテキスト・発音音声・発音口型画像の同期再生処理を行うようにしてもよい。
【0104】
図14は前記携帯機器10のメイン処理内の見出語検索処理に伴い米国/英国の2国の発音形態を収録した英和辞書を利用した場合の検索見出語表示画面G2を示す図である。
【0105】
辞書データベース12bに記憶されている例えば米国/英国の2国の発音形態を収録した英和辞書の辞書データに基づいて見出語検索を行うのに、入力部17aの「英和」キー17a5の操作により英和辞書の検索モードに設定した後に、検索対象の見出語(例えば「laugh」)を入力すると(ステップS7→S8)、当該入力された見出語と一致及び一致文字を先頭に含む複数の見出語が前記英和辞書の辞書データから検索されて読み出され、検索見出語の一覧(図示せず)として表示部18に表示される(ステップS9)。
【0106】
この検索見出語の一覧画面において、ユーザ入力した検索対象の見出語と一致する見出語(この場合「laugh」)がカーソルキーにより選択指示されて「訳/決定(音声)」キー17a4が操作されると(ステップS10)、当該選択検知された見出語「laugh」がRAM12B内の見出語メモリ12gに記憶されると共に、この見出語「laugh」に対応する米国/英国の2国の発音/品詞/意味内容などの辞書データが読み出されてRAM12B内の見出語対応辞書データメモリ12hに記憶され、図14に示すように、検索見出語表示画面G2として表示部18に表示される(ステップS11)。
【0107】
ここで、前記検索表示された見出語「laugh」について、その米国式発音[laef]または英国式発音[la:f]の何れか一方の発音音声を選択的に出力させるのと同時に、これに対応した見出語の文字,発音記号と発音の口型画像を同期表示させるために、検索見出語表示画面G2上の辞書データに表示されている米国方言または英国方言の識別子[米]または[英]の何れかが指定されると共に(ステップS11a)、「訳/決定(音声)」キー17a4が操作されると(ステップS12)、図8における同期再生処理に移行される(ステップSA)。
【0108】
図15は前記携帯機器10の見出語検索処理における同期再生処理に伴い米国式発音[米]を指定した場合に検索見出語表示画面G2上にウインドウ表示される見出語文字表示ウインドウW1および発音口型表示ウインドウW2の表示状態を示す図であり、同図(A)は検索見出語表示画面G2に対する見出語文字表示ウインドウW1および発音口型表示ウインドウW2の設定表示状態を示す図、同図(B)は米国式発音音声の出力に同期した見出語文字表示ウインドウW1および発音口型表示ウインドウW2の変化状態を示す図である。
【0109】
すなわち、前記検索見出語表示画面G2上の辞書データに表示されている米国方言または英国方言の識別子[米]または[英]の何れかが指定されて、図8における同期再生処理に移行されると、当該同期再生処理のステップA2では、例えば米国方言識別子[米]が指定された場合は、キャラクタ設定処理(ステップS2〜S6)において予め設定されたアニメ調キャラクタ画像12d(No1)に対応して米語用キャラクタ画像12d(No1US)が読み出され、RAM12B内の同期用イメージファイルメモリ12nに転送される。またこれと共に、辞書データベース12bに記憶されている今回の検索見出語「laugh」についての同期再生用リンクデータ(図2参照)に基づき、見出語検索画面G2上でテキスト・画像の同期再生用ウインドウW1,W2(図15参照)を設定するためのHTMLファイルがそのHTMLファイルNoに従い読み出され同期用HTMLファイルメモリ12jに書き込まれる。また、検索見出語のテキストデータ「laugh(米国方言発音記号付)」がそのテキストファイルNoに従い読み出され同期用テキストファイルメモリ12kに書き込まれる。また、検索見出語の米国方言の発音音声データがそのサウンドファイルNoに従い読み出され同期用サウンドファイルメモリ12mに書き込まれる(ステップA2)。
【0110】
すると、FLASHメモリ12A内に辞書タイムコードファイル12fとして記憶されている各種見出語対応の暗号化された音声・テキスト・画像の同期再生用タイムコードファイル12fnの中から、今回の検索見出語「laugh」に対応するタイムコードファイル12fn(図5参照)が、前記同期再生用リンクデータ(図2参照)に記述されたタイムコードファイルNoに従い解読復号化されて読み出され、RAM12B内のタイムコードファイルメモリ12iに転送されて格納される(ステップA3)。
【0111】
そして、前記検索見出語「laugh」に対応するタイムコードファイル12fnに従った発音音声・見出語文字・発音口型画像の同期再生処理が、既に説明した検索見出語「low」の場合と同様に、ステップA7〜A12による各コマンドコードに応じた再生処理および図9におけるテキスト対応口表示処理により開始されると、検索見出語表示画面G2上のテキスト同期再生用ウインドウW1には、検索見出語「laugh」と共に米国方言の発音記号が表示され、また、画像同期再生用ウインドウW2には、設定されたアニメ調キャラクタ画像で例えば米国旗Fを持っているデザインの米語用キャラクタ画像12d(No1US)が口型画像合成の対象画像として表示される。
【0112】
これにより、検索見出語「laugh」の米国方言の発音音声出力に同期して、図15(B)▲1▼〜▲3▼に示すように、テキスト同期再生用ウインドウW1では、当該検索見出語「laugh」およびその発音記号の先頭文字からのハイライト(識別)表示HLが順次なされると共に、画像同期再生用ウインドウW2では、前記米語用キャラクタ画像12d(No1US)をベースとして、その口画像エリア(X1,Y1;X2,Y2)に対し、各発音記号の口番号に対応した発音口型画像12e(Non1→Non2→Non3)が音声別口画像データ12eの中から読み出され順次切り替え合成されて表示される。
【0113】
そして、この場合にも前記同様のテキスト対応口表示処理に従って、検索見出語「Laugh」のアクセント文字「au」に対する発音音声の出力と同期したハイライト(識別)表示HL、発音口型画像12e(Non2)の切り替え合成表示に際し、当該口型画像12e(Non2)の合成先である米語用キャラクタ(顔)画像12d(No1US)が、例えば頭部の発汗や身体の動揺によって強く発音している状態を表現するアクセント対応の顔画像12d(No1US′)に変更表示されるので、ユーザは検索見出語「Laugh」の米国方言の発音音声とその発声タイミングおよび各文字「L」「au」「gh」とその発音記号の対応部分、さらには各発音口型画像12e(Non1→Non2→Non3)を、そのそれぞれの同期再生により容易に学習できるばかりでなく、米国方言アクセントに応じて発声強調するタイミングをリアルに学習できるようになる。
【0114】
図16は前記携帯機器10の見出語検索処理における同期再生処理に伴い英国式発音[英]を指定した場合に検索見出語表示画面G2上にウインドウ表示される見出語文字表示ウインドウW1および発音口型表示ウインドウW2の表示状態を示す図であり、同図(A)は検索見出語表示画面G2に対する見出語文字表示ウインドウW1および発音口型表示ウインドウW2の設定表示状態を示す図、同図(B)は英国式発音音声の出力に同期した見出語文字表示ウインドウW1および発音口型表示ウインドウW2の変化状態を示す図である。
【0115】
すなわち、前記図14で示した検索見出語表示画面G2上の辞書データに表示されている米国方言または英国方言の識別子[米]または[英]のうち、例えば英国方言識別子[英]が指定されて(ステップS11a)、図8における同期再生処理(ステップSA)に移行されると、当該同期再生処理のステップA2では、キャラクタ設定処理(ステップS2〜S6)において予め設定されたアニメ調キャラクタ画像12d(No1)に対応して英語用キャラクタ画像12d(No1UK)が読み出され、RAM12B内の同期用イメージファイルメモリ12nに転送される。またこれと共に、辞書データベース12bに記憶されている今回の検索見出語「laugh」についての同期再生用リンクデータ(図2参照)に基づき、見出語検索画面G2上でテキスト・画像の同期再生用ウインドウW1,W2(図16参照)を設定するためのHTMLファイルがそのHTMLファイルNoに従い読み出され同期用HTMLファイルメモリ12jに書き込まれる。また、検索見出語のテキストデータ「laugh(英国方言発音記号付)」がそのテキストファイルNoに従い読み出され同期用テキストファイルメモリ12kに書き込まれる。また、検索見出語の英国方言の発音音声データがそのサウンドファイルNoに従い読み出され同期用サウンドファイルメモリ12mに書き込まれる(ステップA2)。
【0116】
すると、FLASHメモリ12A内に辞書タイムコードファイル12fとして記憶されている各種見出語対応の暗号化された音声・テキスト・画像の同期再生用タイムコードファイル12fnの中から、今回の検索見出語「laugh」に対応するタイムコードファイル12fn(図5参照)が、前記同期再生用リンクデータ(図2参照)に記述されたタイムコードファイルNoに従い解読復号化されて読み出され、RAM12B内のタイムコードファイルメモリ12iに転送されて格納される(ステップA3)。
【0117】
そして、前記検索見出語「laugh」に対応するタイムコードファイル12fnに従った発音音声・見出語文字・発音口型画像の同期再生処理が、既に説明した検索見出語「low」の場合と同様に、ステップA7〜A12による各コマンドコードに応じた再生処理および図9におけるテキスト対応口表示処理により開始されると、検索見出語表示画面G2上のテキスト同期再生用ウインドウW1には、検索見出語「laugh」と共に英国方言の発音記号が表示され、また、画像同期再生用ウインドウW2には、設定されたアニメ調キャラクタ画像で例えば英国帽M1をかぶりステッキM2を持っているデザインの英語用キャラクタ画像12d(No1UK)が口型画像合成の対象画像として表示される。
【0118】
これにより、検索見出語「laugh」の英国方言の発音音声出力に同期して、図16(B)▲1▼〜▲3▼に示すように、テキスト同期再生用ウインドウW1では、当該検索見出語「laugh」およびその発音記号の先頭文字からのハイライト(識別)表示HLが順次なされると共に、画像同期再生用ウインドウW2では、前記英語用キャラクタ画像12d(No1UK)をベースとして、その口画像エリア(X1,Y1;X2,Y2)に対し、各発音記号の口番号に対応した発音口型画像12e(Non1→Non2→Non3)が音声別口画像データ12eの中から読み出され順次切り替え合成されて表示される。
【0119】
そして、この場合にも前記同様のテキスト対応口表示処理に従って、検索見出語「Laugh」のアクセント文字「au」に対する発音音声の出力と同期したハイライト(識別)表示HL、発音口型画像12e(Non2)の切り替え合成表示に際し、当該口型画像12e(Non2)の合成先である英語用キャラクタ(顔)画像12d(No1UK)が、例えば頭部の発汗や身体の動揺によって強く発音している状態を表現するアクセント対応の顔画像12d(No1UK′)に変更表示されるので、ユーザは検索見出語「Laugh」の英国方言の発音音声とその発声タイミングおよび各文字「L」「au」「gh」とその発音記号の対応部分、さらには各発音口型画像12e(Non1→Non2→Non3)を、そのそれぞれの同期再生により容易に学習できるばかりでなく、英国方言のアクセントに応じて発声強調するタイミングをリアルに学習できるようになる。
【0120】
次に、前記構成の携帯機器10のメイン処理に伴い、例えば英単語アクセントの正解/不正解を当てるテストを行うことができるアクセントテスト処理について説明する。
【0121】
図17は前記携帯機器10のアクセントテスト処理に伴い不正解を選択した場合の操作表示状態を示す図であり、同図(A)はアクセントテスト出題表示画面G3を示す図、同図(B)は出題対象の見出語表示画面G2に対する見出語文字表示ウインドウW1および発音口型表示ウインドウW2の設定表示状態を示す図、同図(C)は誤りアクセントの発音音声の出力に同期した見出語文字表示ウインドウW1および発音口型表示ウインドウW2の変化状態を示す図である。
【0122】
図18は前記携帯機器10のアクセントテスト処理に伴い正解を選択した場合の操作表示状態を示す図であり、同図(A)はアクセントテスト出題表示画面G3を示す図、同図(B)は出題対象の見出語表示画面G2に対する見出語文字表示ウインドウW1および発音口型表示ウインドウW2の設定表示状態を示す図、同図(C)は正解アクセントの発音音声の出力に同期した見出語文字表示ウインドウW1および発音口型表示ウインドウW2の変化状態を示す図である。
【0123】
すなわち、入力部17aにおける「アクセントテスト」キー17a6が操作されアクセントテストモードに設定されると(ステップS13)、辞書データベース12cに予め記憶されている辞書データの中からランダムに見出単語が選択され(ステップS14)、図17(A)に示すように、ランダム選択された単語「low」について「o」部分にアクセントのある正しいアクセントの発音記号と「u」部分にアクセントのある誤ったアクセントの発音記号とを選択項目Et/Efとして出題したアクセントテスト出題表示画面G3が表示部18に表示される(ステップS15)。
【0124】
このアクセントテスト出題表示画面G3において、カーソルキー17a2の操作により選択フレームXを移動させ、例えば誤ったアクセントの発音記号のある選択項目Efが選択検知されると(ステップS16)、前記キャラクタ設定処理(ステップS2〜S6)において予め発音口型画像の合成先として選択設定されていたキャラクタ画像およびその関連画像(この場合はアニメ調キャラクタ画像12d(No1)およびそのアクセント対応画像(No1′))が、例えば黄色の通常色から青色のキャラクタ画像(No1BL)(No1BL′)に変更設定される(ステップS17→S18)。
【0125】
またこれと共に、出題単語「low」に対応して辞書音声データ12cの中から読み出される発音音声データが、前記ユーザ選択された誤ったアクセントの発音記号に応じた音声データに補正される(ステップS19)。
【0126】
すると、出題単語「low」がRAM12B内の見出語メモリ12gに記憶されると共に、この見出語「low」に対応する発音/品詞/意味内容などの辞書データが読み出されてRAM12B内の見出語対応辞書データメモリ12hに記憶され、図17(B)に示すように、出題単語に対応した検索見出語表示画面G2として表示部18に表示される(ステップS20)。
【0127】
ここで、前記ユーザにより選択したアクセントの出題単語「low」について、その発音音声を出力させるのと同時に、当該見出単語の文字,発音記号と発音の口型画像を同期表示させるために、「訳/決定(音声)」キー17a4が操作されると(ステップS21)、図8における同期再生処理に移行される(ステップSA)。
【0128】
すると、同期再生処理のステップA2では、前記誤ったアクセントのユーザ選択に応じて青色に変更されたアニメ調キャラクタ画像12d(No1BL)が読み出され、RAM12B内の同期用イメージファイルメモリ12nに転送される。またこれと共に、辞書データベース12bに記憶されている今回の出題単語「low」についての同期再生用リンクデータ(図2参照)に基づき、検索見出語表示画面G2上でテキスト・画像の同期再生用ウインドウW1,W2(図17(B)参照)を設定するためのHTMLファイルがそのHTMLファイルNoに従い読み出され同期用HTMLファイルメモリ12jに書き込まれる。また、出題単語のテキストデータ「low(誤り発音記号付)」が読み出され同期用テキストファイルメモリ12kに書き込まれる。また、出題単語の誤りアクセントに応じて補正した発音音声データが読み出され同期用サウンドファイルメモリ12mに書き込まれる(ステップA2)。
【0129】
すると、FLASHメモリ12A内に辞書タイムコードファイル12fとして記憶されている各種見出語対応の暗号化された音声・テキスト・画像の同期再生用タイムコードファイル12fnの中から、今回の出題単語「low」に対応するタイムコードファイル12fn(図5参照)が、前記同期再生用リンクデータ(図2参照)に記述されたタイムコードファイルNoに従い解読復号化されて読み出され、RAM12B内のタイムコードファイルメモリ12iに転送されて格納される(ステップA3)。
【0130】
そして、前記出題単語「low」に対応するタイムコードファイル12fnに従った誤りアクセントの発音音声・見出語文字・発音口型画像の同期再生処理が、既に説明した検索見出語「low」の場合と同様に、ステップA7〜A12による各コマンドコードに応じた再生処理および図9におけるテキスト対応口表示処理により開始される。すると、図17(B)に示すように、検索見出語表示画面G2上のテキスト同期再生用ウインドウW1(Ef)には、出題単語「low」と共にユーザ選択による誤ったアクセントの発音記号が表示され、また、画像同期再生用ウインドウW2には、誤りアクセントのユーザ選択により青色変更されたアニメ調キャラクタ画像12d(No1BL)が口型画像合成の対象画像として表示される。
【0131】
これにより、出題単語「low」に対応する誤ったアクセントの発音音声出力に同期して、図17(C)▲1▼〜▲3▼に示すように、テキスト同期再生用ウインドウW1(Ef)では、当該出題単語「low」およびその誤った発音記号の先頭文字からのハイライト(識別)表示HLが順次なされると共に、画像同期再生用ウインドウW2では、前記誤ったアクセントの選択により青色変更されたアニメ調キャラクタ画像12d(No1BL)をベースとして、その口画像エリア(X1,Y1;X2,Y2)に対し、各発音記号の口番号に対応した発音口型画像12e(No36→No9→No8)が音声別口画像データ12eの中から読み出され順次切り替え合成されて表示される。
【0132】
そして、この場合にも前記同様のテキスト対応口表示処理に従って、見出単語「Low」の誤ったアクセント文字「u」に対する発音音声の出力と同期したハイライト(識別)表示HL、発音口型画像12e(No8)の切り替え合成表示に際し、当該口型画像12e(No8)の合成先である青色変更されたアニメ調キャラクタ(顔)画像12d(No1BL)が、例えば頭部の発汗や身体の動揺によって強く発音している状態を表現するアクセント対応の青色顔画像12d(No1BL′)に変更表示されるので、ユーザは出題単語「Low」の誤ったアクセントの発音音声とその誤った発声タイミングおよび各対応する発音口型画像12e(No36→No9→No8)を、誤ったアクセントによるものとして明確に学習できるようになる。
【0133】
一方、図18(A)に示すように、アクセントテスト出題表示画面G3において、カーソルキー17a2の操作により選択フレームXを移動させ、例えば正しいアクセントの発音記号のある選択項目Etが選択検知されると(ステップS16)、前記キャラクタ画像12d(No1)の青色変更処理(ステップS18)や誤りアクセントに応じた発音音声の補正処理(ステップS19)が行われることなく、図8における同期再生処理に移行される(ステップS17→SA)。
【0134】
すると、前記図13を参照して前述した、アニメ調キャラクタ画像12e(No1)が設定されている状態での検索見出語「low」に対応する発音音声・テキスト・発音口型画像の同期再生処理と同様にして、図18(B)に示すように、検索見出語表示画面G2上のテキスト同期再生用ウインドウW1(Et)には、出題単語「low」と共にユーザ選択による正しいアクセントの発音記号が表示され、また、画像同期再生用ウインドウW2には、予め設定された通りの通常色のアニメ調キャラクタ画像12d(No1)が口型画像合成の対象画像として表示される。
【0135】
これにより、出題単語「low」に対応する正しいアクセントの発音音声出力に同期して、図18(C)▲1▼〜▲3▼に示すように、テキスト同期再生用ウインドウW1(Et)では、当該出題単語「low」およびその正しい発音記号の先頭文字からのハイライト(識別)表示HLが順次なされると共に、画像同期再生用ウインドウW2では、予め設定された通りの通常色のアニメ調キャラクタ画像12d(No1)をベースとして、その口画像エリア(X1,Y1;X2,Y2)に対し、各発音記号の口番号に対応した発音口型画像12e(No36→No9→No8)が音声別口画像データ12eの中から読み出され順次切り替え合成されて表示される。
【0136】
そして、この場合にも前記同様のテキスト対応口表示処理に従って、見出単語「Low」の正しいアクセント文字「o」に対する発音音声の出力と同期したハイライト(識別)表示HL、発音口型画像12e(No9)の切り替え合成表示に際し、当該口型画像12e(No9)の合成先であるアニメ調キャラクタ(顔)画像12d(No1)が、例えば頭部の発汗や身体の動揺によって強く発音している状態を表現するアクセント対応の顔画像12d(No1′)に変更表示されるので、ユーザは出題単語「Low」の正しいアクセントの発音音声とその正しい発声タイミングおよび各対応する発音口型画像12e(No36→No9→No8)を明確に学習できるようになる。
【0137】
したがって、前記構成の第1実施形態の携帯機器10による見出語検索に伴う発音音声・テキスト・発音口型画像の同期再生機能によれば、検索対象の見出語「low」を入力して当該検索見出語に対応する辞書データを検索し、検索見出語表示画面G2として表示させた状態で、「訳/決定(音声)」キー17a4を操作すると、当該検索見出語「low」のタイムコードファイル12f23に従い、ステレオ音声出力部19bから出力される発音音声に同期して、テキスト同期再生用ウインドウW1において、検索見出語「low」およびその発音記号のハイライト(識別)表示HLが順次なされると共に、画像同期再生用ウインドウW2では、予め設定されたキャラクタ画像12d(No3)をベースとして、その口画像エリア(X1,Y1;X2,Y2)に対し、各発音記号の口番号に対応した発音口型画像12e(No36→No9→No8)が音声別口画像データ12eの中から読み出され順次切り替え合成されて表示される。
【0138】
しかも、前記検索見出語「Low」のアクセント文字「o」に対する発音音声の出力と同期したハイライト(識別)表示HL、発音口型画像12e(No9)の切り替え合成表示に際しては、当該口型画像12e(No9)の合成先であるキャラクタ(顔)画像12d(No3)が、例えば頭部の発汗や口元の動揺によって強く発音している状態を表現するアクセント対応の顔画像12d(No3′)に変更表示されるので、ユーザは検索見出語「Low」の発音音声とその発声タイミングおよび各文字「L」「o」「w」とその発音記号の対応部分、さらには各発音口型画像12e(No36→No9→No8)を、そのそれぞれの同期再生により容易に学習できるばかりでなく、アクセントに応じて発声強調するタイミングをリアルに学習できるようになる。
【0139】
さらに、前記構成の第1実施形態の携帯機器10による見出語検索に伴う発音音声・テキスト・発音口型画像の同期再生機能によれば、例えば米国方言と英国方言の発音記号を有する辞書データベース12bに基づき見出語検索を行った際に、図15または図16で示したように、米音[米]または英音[英]を指定して「訳/決定(音声)」キー17a4を操作すると、指定された米音または英音の発音音声に同期して、テキスト同期再生用ウインドウW1において、検索見出語「laugh」およびその米音または英音発音記号のハイライト(識別)表示HLが順次なされると共に、画像同期再生用ウインドウW2では、予め設定されたキャラクタ画像12d(No1)が米音表現用(No1US)または英音表現用(No1UK)としてベース表示され、その口画像エリア(X1,Y1;X2,Y2)に対し、米音または英音の各発音記号の口番号に対応した発音口型画像12e(Non1→Non2→Non3)が音声別口画像データ12eの中から読み出され順次切り替え合成されて表示されるので、検索見出語に対応する米国方言の発音音声およびその発音記号・発音口型と英国方言の発音音声およびその発音記号・発音口型とを明確に区別して学習できるようになる。
【0140】
また、前記構成の第1実施形態の携帯機器10による見出語検索に伴う発音音声・テキスト・発音口型画像の同期再生機能によれば、辞書データベース12bに収録される各見出単語には、正しいアクセントの発音記号と共に誤ったアクセントの発音記号を有し、図17および図18で示すように、「アクセントテスト」キー17a6が操作されると、ランダム選択された見出単語「low」が正しいアクセントの発音記号および誤ったアクセントの発音記号と共にアクセントテスト出題表示画面G3として表示される。そして、正しいアクセントの発音記号が選択された場合には、その正しい発音音声出力に同期して通常の設定キャラクタ画像12d(No1)をベースとした各発音口型画像12e(No36→No9→No8)の切り替え合成表示が行われ、誤ったアクセントの発音記号が選択された場合には、その誤った発音音声出力に同期して青色変更されたキャラクタ画像12d(No1BL)をベースとした各発音口型画像12e(No36→No9→No8)の切り替え合成表示が行われ、しかも正誤何れのアクセント部分の同期再生時にも、前記口型画像合成ベースとしてのキャラクタ画像12e(No1)(No1BL)がアクセント対応のキャラクタ画像12e(No1′)(No1BL′)に変更表示されるので、各種単語の正しいアクセントの発音と、誤ったアクセントの発音とを、そのそれぞれに応じた音声・テキスト・画像の同期再生により明確に学習できるようになる。
【0141】
なお、前記第1実施形態では、検索見出語に対応する発音音声・テキスト(発音記号付き)・発音口型画像の同期生再処理を、タイムコードファイル12fに従った同期再生処理による発音音声出力に同期させたテキスト文字の順次ハイライト(識別)表示、および当該1文字ずつの順次識別表示に伴い割り込みで実行されるテキスト対応口表示処理による識別表示文字対応の発音記号に応じた発音口型画像の切り替え合成表示により行う構成としたが、次の第2実施形態おいて説明するように、アクセント記号付きの発音記号を含む各種の発音記号とそのそれぞれの発音音声データおよび発音顔画像を予め対応付けて複数組み記憶させ、再生すべき見出語の文字を先頭から順番に強調表示させるのに伴い、順次その強調表示文字の発音記号に対応付けられた発音音声データの出力および顔画像データの表示を行う構成としてもよい。
【0142】
(第2実施形態)
図19は前記携帯機器10の第2実施形態の見出語同期再生処理を示すフローチャートである。
【0143】
すなわち、この第2実施形態の携帯機器10では、アクセント記号付きの発音記号を含む各種の発音記号と、そのそれぞれの発音音声データ、および当該各種の発音記号に応じた発音音声データに対応して異なる形態の口部分や表情からなる発音顔画像を、予めメモリ12内に複数組み記憶させる。
【0144】
そして、例えば辞書データベース12bとして予め記憶される英和辞書を対象に、任意の見出語「low」が入力されて検索され、前記図11で示したように、検索見出語表示画面G2として表示された状態で、その発音音声および発音顔画像の同期再生を行わせるべく「訳/決定(音声)」キー17a4が操作されると、図19に示す第2実施形態の同期再生処理が開始される。
【0145】
この第2実施形態の同期再生処理が開始されると、前記図12または図13で示すように、まず、検索見出語表示画面G2上にテキスト同期再生用ウインドウW1が開かれ検索見出語「low」の各文字と発音記号がその発音順に先頭から強調識別表示HLされる(ステップC1)。そして、この強調識別表示HLされた見出文字の発音記号が読み出されて(ステップC2)、アクセント記号付きであるか否か判断される(ステップC3)。
【0146】
ここで、図12(B)▲1▼または図13(B)▲1▼で示すように、今回強調表示HLされた見出単語「low」における文字「l」の発音記号がアクセント記号無しである場合には、前記メモリ12に予め記憶された当該発音記号に対応するアクセント無しの発音音声データが読み出されてステレオ音声出力部19bから出力されるのと共に(ステップC3→C4)、これに対応付けられたアクセント無しの発音顔画像が読み出されて画像同期再生用ウインドウW2に表示される(ステップC5)。
【0147】
すると、現在出力中の検索見出語「low」の次の文字「o」が読み出され(ステップC6→C7)、再び前記ステップC1からの処理に戻り、図12(B)▲2▼または図13(B)▲2▼で示すように、その発音記号と共に強調識別表示HLされる(ステップC1)。
【0148】
そして、今回強調表示HLされた見出単語「low」における文字「o」の発音記号がアクセント記号有りであると判断された場合には(ステップC2,C3)、前記メモリ12に予め記憶された当該発音記号に対応するアクセント有りの発音音声データが読み出されてステレオ音声出力部19bから出力されるのと共に(ステップC3→C8)、図12(C)▲2▼または図13(B)▲2▼で示すように、これに対応付けられた例えば頭部の発汗や身体の動揺によってアクセント有り表現する発音顔画像が読み出されて画像同期再生用ウインドウW2に表示される(ステップC9)。
【0149】
したがって、この第2実施形態の携帯機器10による場合でも、検索見出語「Low」のアクセント文字「o」をハイライト(識別)表示HLしたことに伴う、発音音声の出力および発音顔画像の表示に際しては、そのアクセント付きの発音記号に基づき当該発音顔画像が、例えば頭部の発汗や身体の動揺によって強く発音している状態を表現するアクセント対応の顔画像として表示されるので、ユーザは検索見出語「Low」の各文字「L」「o」「w」と発音音声、さらには各発音顔画像を、そのそれぞれの対応出力により容易に学習できるばかりでなく、アクセントに応じて発声強調する部分をリアルに学習できるようになる。
【0150】
なお、この第2実施形態において、前記メモリ12に予め記憶されたアクセント記号付きの発音記号を含む各種の発音記号と、そのそれぞれの発音音声データ、および当該各種の発音記号に応じた発音音声データに対応して異なる形態の口部分や表情からなる発音顔画像について、アクセント付き発音記号に対応付けられた発音音声の出力はアクセント無し発音記号に対応付けられた発音音声より大きく設定され、また、アクセント付き発音記号に対応付けられた発音顔画像の口部分の開き具合はアクセント無し発音記号に対応付けられた発音顔画像の口部分の開き具合より大きく設定される。さらに、この顔画像における表情は、アクセント付き発音記号に対応付けられた発音顔画像の表情の方が、アクセント無し発音記号に対応付けられた発音顔画像の表情よりも強調されて設定される。
【0151】
なお、前記第2実施形態では、アクセント記号付きの発音記号を含む各種の発音記号と、そのそれぞれの発音音声データ、および当該各種の発音記号に応じた発音音声データに対応して異なる形態の口部分や表情からなる発音顔画像を予め記憶し、検索見出語の各文字をその発音順に強調表示すると共に、その発音記号に対応付けられた発音音声を読み出して出力し、また同発音記号に対応付けられ発音顔画像を読み出して表示する構成としたが、次の第3実施形態において説明するように、辞書データベース12bにある各見出語のそれぞれに対応して当該見出し語の発音音声と発音顔画像とを予め組み合わせて記憶させ、検索見出語の文字表示に伴いその発音音声および発音顔画像を読み出して出力し、この際の発音音声信号のピークレベルを検出してアクセント部分を判断し、前記発音顔画像の口や表情の形態を異なる表示形態に変更制御する構成としてもよい。
【0152】
(第3実施形態)
図20は前記携帯機器10の第3実施形態の見出語同期再生処理を示すフローチャートである。
【0153】
すなわち、この第3実施形態の携帯機器10では、辞書データベース12bの各辞書データにある各見出語のそれぞれに対応して当該見出し語の発音音声と発音顔画像とを予め組み合わせて記憶させる。
【0154】
そして、例えば辞書データベース12bとして予め記憶される英和辞書を対象に、任意の見出語「low」が入力されて検索され、前記図11で示したように、検索見出語表示画面G2として表示された状態で、その発音音声および発音顔画像の同期再生を行わせるべく「訳/決定(音声)」キー17a4が操作されると、図20に示す第3実施形態の同期再生処理が開始される。
【0155】
この第3実施形態の同期再生処理が開始されると、前記図12または図13で示すように、まず、検索見出語表示画面G2上にテキスト同期再生用ウインドウW1が開かれ検索見出語「low」の各文字がその発音順に先頭から強調識別表示HLされる(ステップD1)。そして、この強調識別表示HLされた見出文字に対応する部分の発音音声データが読み出され(ステップD2)、ステレオ音声出力部19bから出力される(ステップD3)。
【0156】
ここで、例えば今回強調表示HLされた見出単語「low」における文字「l」に対応する部分の発音音声データの信号(波形)レベルが一定値以上の音声信号レベル(アクセント部分)か否か判断されるもので(ステップD4)、一定音声信号レベル以上ではない、つまりアクセント部分ではないと判断された場合には、当該検索見出語に対応付けられて記憶された発音顔画像が読み出されてそのまま画像同期再生用ウインドウW2に表示される(ステップD5)。
【0157】
すると、現在出力中の検索見出語「low」の次の文字「o」が読み出され(ステップD6→D7)、再び前記ステップD1からの処理に戻り、強調識別表示HLされる(ステップD1)。
【0158】
すると、今回強調識別表示HLされた見出文字「o」に対応する部分の発音音声データが読み出され(ステップD2)、ステレオ音声出力部19bから出力されると共に(ステップD3)、当該強調表示HLされた単語文字「o」に対応する部分の発音音声データの信号(波形)レベルが一定値以上の音声信号レベル(アクセント部分)か否か判断される(ステップD4)。
【0159】
ここで、一定音声信号レベル以上である、つまりアクセント部分であると判断された場合には、当該検索見出語に対応付けられて記憶された発音顔画像が読み出されると共に、当該顔画像はその口部分の開き具合が大きくまたその表情が強い顔画像に変更制御(例えば図12(B)▲2▼→図12(C)▲2▼)され、画像同期再生用ウインドウW2に表示される(ステップD4→D8)。
【0160】
なお、前記発音音声の音声信号波形レベルが一定値以上と判断されてアクセント部分であると判断された場合には、強調表示されている検索見出語の対応文字をさらに表示色の変更や付加あるいは文字フォントの変更などにより、アクセント部分の文字であることを示す形態に変更制御して表示させる構成としてもよい。
【0161】
したがって、この第3実施形態の携帯機器10による場合でも、検索見出語「Low」のアクセント文字「o」をハイライト(識別)表示HLしたことに伴う、発音音声の出力および発音顔画像の表示に際しては、そのときの発音音声信号レベルが一定値以上であることに基づき当該発音顔画像が、例えば口部分の開き具合が大きくまたその表情が強いアクセント対応の顔画像に変更制御されて表示されるので、ユーザは検索見出語「Low」の各文字「L」「o」「w」とその発音音声、さらには発音顔画像を、そのそれぞれの対応出力により容易に学習できるばかりでなく、アクセントに応じて発声強調する部分をリアルに学習できるようになる。
【0162】
なお、前記各実施形態における検索見出語の各文字(テキスト)・発音音声・発音顔画像(含む発音口型画像)の同期再生機能の説明では、当該見出語のアクセントが1箇所に存在する場合について説明したが、検索見出語のアクセントが第1アクセントと第2アクセントの2箇所に存在する場合には、各アクセント部分に対応して表示するアクセント対応の発音顔画像(含む発音口型画像)を、第1アクセントの場合と第2アクセントの場合とで、例えば口の開き具合の大小や表情の強弱などによって異なる形態にして表示させる構成としてもよい。
【0163】
なお、前記各実施形態において記載した携帯機器10による各処理の手法、すなわち、図7のフローチャートに示す第1実施形態での辞書処理プログラム12aに従ったメイン処理、図8のフローチャートに示す前記メイン処理に伴う見出語同期再生処理、図9のフローチャートに示す前記見出語同期再生処理に伴う各見出語文字のハイライト表示に応じて割り込みで実行されるテキスト対応口表示処理、図19のフローチャートに示す第2実施形態での見出語同期再生処理、図20のフローチャートに示す第3実施形態での見出語同期再生処理などの各手法は、何れもコンピュータに実行させることができるプログラムとして、メモリカード(ROMカード、RAMカード、DATA・CARD等)、磁気ディスク(フロッピディスク、ハードディスク等)、光ディスク(CD−ROM、DVD等)、半導体メモリ等の外部記録媒体13に格納して配布することができる。そして、通信ネットワーク(インターネット)Nとの通信機能を備えた種々のコンピュータ端末は、この外部記録媒体13に記憶されたプログラムを記録媒体読取部14によってメモリ12に読み込み、この読み込んだプログラムによって動作が制御されることにより、前記各実施形態において説明した検索見出語に対応する各文字(テキスト)・発音音声・発音顔画像(含む発音口型画像)の同期再生機能を実現し、前述した手法による同様の処理を実行することができる。
【0164】
また、前記各手法を実現するためのプログラムのデータは、プログラムコードの形態として通信ネットワーク(インターネット)N上を伝送させることができ、この通信ネットワーク(インターネット)Nに接続されたコンピュータ端末から前記のプログラムデータを取り込み、前述した検索見出語に対応する各文字(テキスト)・発音音声・発音顔画像(含む発音口型画像)の同期再生機能を実現することもできる。
【0165】
なお、本願発明は、前記各実施形態に限定されるものではなく、実施段階ではその要旨を逸脱しない範囲で種々に変形することが可能である。さらに、前記各実施形態には種々の段階の発明が含まれており、開示される複数の構成要件における適宜な組み合わせにより種々の発明が抽出され得る。例えば、各実施形態に示される全構成要件から幾つかの構成要件が削除されたり、幾つかの構成要件が組み合わされても、発明が解決しようとする課題の欄で述べた課題が解決でき、発明の効果の欄で述べられている効果が得られる場合には、この構成要件が削除されたり組み合わされた構成が発明として抽出され得るものである。
【0168】
【発明の効果】
以上のように、本発明の請求項1(請求項2)に係る音声表示出力制御装置(音声表示出力制御処理プログラム)によれば、単語記憶手段により記憶される単語について正しいアクセントの発音音声データと誤りアクセントの発音音声データとを出力できるだけでなく、この発音音声データに同期した単語テキストの表示および表示画像に含まれる口部分についての発音音声データに対応した口型画像を表示でき、しかも単語アクセントの検出に応じて表示画像を変化できるので、単語についての正しいアクセントと誤りアクセントを容易かつ明確なタイミングで学習でき、さらに、単語記憶手段により記憶される単語について正しいアクセント付き発音記号か誤りアクセント付き発音記号かを選択してその発音音声データを出力でき、しかも、この発音音声データに同期した単語テキストの表示および表示画像に含まれる口部分についての発音音声データに対応した口型画像を表示でき、単語アクセントの検出に応じて表示画像を変化できるので、単語についての正しいアクセントと誤りアクセントをさらに容易かつ明確なタイミングで学習できるようになる。
【0175】
よって、本発明によれば、音声出力に同期した画像の表示において、アクセントのタイミングを明確に現すことが可能になる音声表示出力制御装置、画像表示制御装置、および音声表示出力制御処理プログラム、画像表示制御処理プログラムを提供できる。
【図面の簡単な説明】
【図1】本発明の音声表示出力制御装置(画像表示制御装置)の実施形態に係る携帯機器10の電子回路の構成を示すブロック図。
【図2】前記携帯機器10のメモリ12に記憶される辞書データベース12bのうち1つの見出語「low」についての同期再生用リンクデータを示す図であり、同図(A)は各ファイルNoと格納先アドレスを示すテーブル、同図(B)は当該テキストファイルNoに従い格納されているテキストデータ「low」を示す図、同図(C)はテキスト口同期ファイルNoに従い格納されているテキストの文字,発音記号,口型番号を示す図。
【図3】前記携帯機器10のメモリ12に記憶され、辞書の見出語検索における発音口型画像の同期表示のためにユーザ設定により選択的に使用されるキャラクタ画像データ12dを示す図。
【図4】前記携帯機器10のメモリ12に記憶され、辞書の見出語検索における発音口型画像の同期表示のためにキャラクタ画像(12d:No1〜No3)の口画像エリア(X1,Y1,X2,Y2)に合成表示される音声別口画像データ12eを示す図。
【図5】前記携帯機器10のメモリ12に格納された辞書タイムコードファイル12fにおける見出語「low」に対応付けられたファイルNo23のタイムコードファイル12f23(12i)を示す図。
【図6】前記携帯機器10の辞書タイムコードファイル12fn(図5参照)にて記述される各種コマンドのコマンドコードとそのパラメータデータに基づき解析処理される命令内容を対応付けて示す図。
【図7】前記携帯機器10の辞書処理プログラム12aに従ったメイン処理を示すフローチャート。
【図8】前記携帯機器10のメイン処理に伴う見出語同期再生処理を示すフローチャート。
【図9】前記携帯機器10の見出語同期再生処理に伴う各見出語文字のハイライト表示に応じて割り込みで実行されるテキスト対応口表示処理を示すフローチャート。
【図10】前記携帯機器10のメイン処理内のキャラクタ設定処理に伴う同期再生用キャラクタ画像の設定表示状態を示す図。
【図11】前記携帯機器10のメイン処理内の見出語検索処理に伴う検索見出語表示画面G2を示す図。
【図12】前記携帯機器10の見出語検索処理における同期再生処理に伴いキャラクタ画像No3の設定状態において検索見出語表示画面G2上にウインドウ表示される見出語文字表示ウインドウW1および発音口型表示ウインドウW2の表示状態を示す図であり、同図(A)は検索見出語表示画面G2に対する見出語文字表示ウインドウW1および発音口型表示ウインドウW2の設定表示状態を示す図、同図(B)は発音音声の出力に同期した見出語文字表示ウインドウW1およびアクセント未対応の発音口型表示ウインドウW2の変化状態を示す図、同図(C)は発音音声の出力に同期した見出語文字表示ウインドウW1およびアクセント対応の発音口型表示ウインドウW2の変化状態を示す図。
【図13】前記携帯機器10の見出語検索処理における同期再生処理に伴いキャラクタ画像No1の設定状態において検索見出語表示画面G2上にウインドウ表示される見出語文字表示ウインドウW1および発音口型表示ウインドウW2の表示状態を示す図であり、同図(A)は検索見出語表示画面G2に対する見出語文字表示ウインドウW1および発音口型表示ウインドウW2の設定表示状態を示す図、同図(B)は発音音声の出力に同期した見出語文字表示ウインドウW1および発音口型表示ウインドウW2の変化状態を示す図。
【図14】前記携帯機器10のメイン処理内の見出語検索処理に伴い米国/英国の2国の発音形態を収録した英和辞書を利用した場合の検索見出語表示画面G2を示す図。
【図15】前記携帯機器10の見出語検索処理における同期再生処理に伴い米国式発音[米]を指定した場合に検索見出語表示画面G2上にウインドウ表示される見出語文字表示ウインドウW1および発音口型表示ウインドウW2の表示状態を示す図であり、同図(A)は検索見出語表示画面G2に対する見出語文字表示ウインドウW1および発音口型表示ウインドウW2の設定表示状態を示す図、同図(B)は米国式発音音声の出力に同期した見出語文字表示ウインドウW1および発音口型表示ウインドウW2の変化状態を示す図。
【図16】前記携帯機器10の見出語検索処理における同期再生処理に伴い英国式発音[英]を指定した場合に検索見出語表示画面G2上にウインドウ表示される見出語文字表示ウインドウW1および発音口型表示ウインドウW2の表示状態を示す図であり、同図(A)は検索見出語表示画面G2に対する見出語文字表示ウインドウW1および発音口型表示ウインドウW2の設定表示状態を示す図、同図(B)は英国式発音音声の出力に同期した見出語文字表示ウインドウW1および発音口型表示ウインドウW2の変化状態を示す図。
【図17】前記携帯機器10のアクセントテスト処理に伴い不正解を選択した場合の操作表示状態を示す図であり、同図(A)はアクセントテスト出題表示画面G3を示す図、同図(B)は出題対象の見出語表示画面G2に対する見出語文字表示ウインドウW1および発音口型表示ウインドウW2の設定表示状態を示す図、同図(C)は誤りアクセントの発音音声の出力に同期した見出語文字表示ウインドウW1および発音口型表示ウインドウW2の変化状態を示す図。
【図18】前記携帯機器10のアクセントテスト処理に伴い正解を選択した場合の操作表示状態を示す図であり、同図(A)はアクセントテスト出題表示画面G3を示す図、同図(B)は出題対象の見出語表示画面G2に対する見出語文字表示ウインドウW1および発音口型表示ウインドウW2の設定表示状態を示す図、同図(C)は正解アクセントの発音音声の出力に同期した見出語文字表示ウインドウW1および発音口型表示ウインドウW2の変化状態を示す図。
【図19】前記携帯機器10の第2実施形態の見出語同期再生処理を示すフローチャート。
【図20】前記携帯機器10の第3実施形態の見出語同期再生処理を示すフローチャート。
【符号の説明】
10 …携帯機器
11 …CPU
12 …メモリ
12A…FLASHメモリ
12B…RAM
12a…辞書処理プログラム
12b…辞書データベース
12c…辞書音声データ
12d…キャラクタ画像データ
12d(No.n)…設定キャラクタ画像
12d(No.n′)…アクセント対応顔画像
12d(No.nUS)…米語用設定キャラクタ画像
12d(No.nUS′)…米語用アクセント対応顔画像
12d(No.nUK)…英語用設定キャラクタ画像
12d(No.nUK′)…英語用アクセント対応顔画像
12d(No.nBL)…青色変更設定キャラクタ画像
12d(No.nBL′)…アクセント対応の青色顔画像
12e…音声別口画像データ
12f…辞書タイムコードファイル
12g…見出語データメモリ
12h…見出語対応辞書データメモリ
12i…タイムコードファイルNo23
12j…同期用HTMLファイルメモリ
12k…同期用テキストファイルメモリ
12m…同期用サウンドファイルメモリ
12n…同期用イメージファイルメモリ
12p…口画像エリアメモリ
12q…画像展開バッファ
13 …外部記録媒体
14 …記録媒体読取部
15 …電送制御部
16 …通信部
17a…入力部
17b…座標入力装置
18 …表示部
19a…音声入力部
19b…ステレオ音声出力部
20 …通信機器(自宅PC)
30 …Webサーバ
N …通信ネットワーク(インターネット)
X …選択フレーム
H …タイムコードテーブルのヘッダ情報
G1 …キャラクタ画像の一覧選択画面
G2 …見出語検索画面
G3 …アクセントテスト出題表示画面
W1 …見出語文字表示ウインドウ(テキスト同期再生用ウインドウ)
W2 …発音口型表示ウインドウ(画像同期再生用ウインドウ)
HL …ハイライト(識別)表示
Et …正解アクセント選択項目
Ef …誤りアクセント選択項目[0001]
BACKGROUND OF THE INVENTION
The present invention relates to a voice display output control device, an image display control device, a voice display output control processing program, and an image display control processing program for outputting data such as voice, text, and images in synchronization.
[0002]
[Prior art]
2. Description of the Related Art Conventionally, for example, there is a language learning device that outputs language speech and displays its mouth shape.
[0003]
In this language learning apparatus, voice information of a native language user and mouth-shaped image data are recorded in a sample data memory in advance by a microphone and a camera. Then, the learner's voice information and mouth-shaped image data are recorded by the microphone and the camera, and the waveforms of the respective voice information of the learner and the native language user recorded in advance in the sample data memory and Corresponding image data of each corresponding mouth shape is displayed in a chart format.
[0004]
Thereby, it is intended to clearly analyze and display the difference in language pronunciation between the native language user and the learner (see, for example, Patent Document 1).
[0005]
[Patent Document 1]
JP 2001-318592 A
[0006]
[Problems to be solved by the invention]
Using such a conventional language learning device, it is possible to know the voice of the native language user who is a model and its mouth image, but the accent of each language is mainly the voice of the accent part. However, there is a problem that the timing of accents in each learning language is difficult to understand because there is no clear difference in the mouth image itself.
[0007]
The present invention has been made in view of the above problems, and in the display of an image synchronized with the audio output, an audio display output control device, an image display control device, which can clearly show the timing of accents, Another object of the present invention is to provide an audio display output control processing program and an image display control processing program.
[0012]
[Means for solving the problem]
Claims of the invention1In the voice display output control device according to the above, the word storage means stores a plurality of words and the correct accented phonetic symbols and the phonetic symbols with error accents of each word in association with each other, and the voice data output means stores the stored words. Output the voice data of the correct accent or the voice data of the error accent, and display the text of the word in synchronism with the pronunciation voice data of the word output by the text synchronization display control means, and the image display control means The image including at least the mouth part is displayed in different display forms when the sound data of correct accent is output by the sound data output means and when the sound data of error accent is output, and The mouth image display control means connects the mouth portion included in the display image. Te, the audio data outputting means in synchronism with the sound audio data output by displaying an image of the mouth type corresponding to the sound speech data. Then, along with the synchronous display of the word text by the text synchronous display control means by the accent detection means, the accent of the word is detected from the accented phonetic symbol stored by the word storage means, and the image change display control means The image displayed by the image display control means is changed according to the accent detection.Further, the word stored by the correct / incorrect accent display control means, the correct accented phonetic symbol associated with the word and the phonetic symbol with the error accent are displayed side by side, and the correct / incorrect accent selection means displays the words displayed side by side. Select either the correct accented phonetic or the error accented phonetic. Then, the voice data output means outputs correct voice pronunciation data or correct accent voice data of the corresponding word in accordance with the correct / incorrect word accent selection by the correct / incorrect accent selection means.
[0013]
According to this, it is possible not only to output correct accent pronunciation voice data and error accent pronunciation voice data for the words stored by the word storage means, but also to display the word text synchronized with the pronunciation voice data and to display the display image. Mouth-shaped images corresponding to the pronunciation speech data for the mouth part can be displayed, and the display image can be changed according to the detection of the word accent, so you can learn the correct accent and error accent for the word easily and clearlyFurther, it is possible to select the correct accented phonetic symbol or the error accented phonetic symbol for the word stored by the word storage means and output the pronunciation voice data, and display the word text synchronized with the pronunciation voice data and Mouth-shaped images corresponding to pronunciation speech data for the mouth part included in the display image can be displayed, and the display image can be changed according to the detection of word accents, making it easier and clearer to correct and accent correct words You can learn at the timing.
[0026]
DETAILED DESCRIPTION OF THE INVENTION
Embodiments of the present invention will be described below with reference to the drawings.
[0027]
(First embodiment)
FIG. 1 is a block diagram showing a configuration of an electronic circuit of a
[0028]
The portable device (PDA: personal digital assistants) 10 is configured by a computer that reads a program recorded on various recording media or a program transmitted by communication and whose operation is controlled by the read program. The electronic circuit includes a CPU (central processing unit) 11.
[0029]
The
[0030]
The
[0031]
The
[0032]
The
[0033]
The FLASH memory (EEP-ROM) 12A has a network communication for data communication with each computer terminal (30) on the communication network N via the system program that controls the overall operation of the
[0034]
Further, the FLASH memory (EEP-ROM) 12A further includes a
[0035]
As the
[0036]
In each embodiment, for phonetic symbols described in the specification, it is difficult to input formal phonetic symbols, so similar characters are substituted, and formal phonetic symbols are described on the drawings.
[0037]
FIG. 2 is a diagram showing synchronous reproduction link data for one headword “low” in the
[0038]
As the
[0039]
FIG. 3 is a diagram showing
[0040]
In this embodiment, three types of character images (face images) No1 to No3 are prepared as the
[0041]
The three types of character images (face images) No1 to No3 are further accented face images No1 'to No3' (for expressing pronunciation emphasis at the timing of the accent of the found word searched in the dictionary. 12 (C) (2) and FIG. 13 (B) (2)) are stored, and further, American character images No1US to No3US (see FIG. 15) when American or English pronunciation sounds are designated. And English character images No1UK to No3UK (see FIG. 16), and accent face images No1US 'to No3US' (see (2) in FIG. 15B) and No1UK 'to No3UK' (see FIG. 16B) (2) Reference) is stored.
[0042]
FIG. 4 is stored in the
[0043]
As the mouth-specific
[0044]
Further, the dictionary time code file 12f stored in the
[0045]
FIG. 5 is a diagram showing a time code file 12f23 (12i) of the file No. 23 associated with the headword “low” in the dictionary time code file 12f stored in the
[0046]
In the time code file 12fn, a time code for performing command processing for synchronously reproducing various data (speech, text, and images) at a reference processing unit time (for example, 25 ms) at a predetermined time interval described and set as header information H in advance. Each time code is a reference number or a specified numerical value for associating a command code indicating an instruction with data contents (text file / sound file / image file etc.) related to the command. It consists of a combination with parameter data consisting of
[0047]
For example, the file playback time by the time code file 12f23 of the headword “low” shown in FIG. 5 is 1 second after a playback process consisting of a time code of 40 steps when a preset reference processing unit time is 25 ms. Become.
[0048]
FIG. 6 is a diagram in which command codes of various commands described in the dictionary time code file 12fn (see FIG. 5) of the
[0049]
Commands used for the time code file 12fn include standard commands and extended commands. The standard commands include LT (i-th text load). VD (i-th text phrase display). BL (Character counter reset / i-th phrase block designation). HN (no highlight, character counter count up). HL (up to i-th character, character count). LS (1 line scrolling / character counter count up). DH (i-th HTML file display). DI (i-th image file display). PS (i-th sound file play). CS (Clear All File). PP (pause for basic time i seconds). FN (end of processing). There are NP (invalid) commands.
[0050]
Further, in the
[0051]
Further, in the
[0052]
That is, the headword searched by activating the
[0053]
When the fourth command code “PS” and parameter data “00” are read in accordance with the command processing for each set processing unit time, this command “PS” is the i-th sound file playback command. The audio data 12cn stored in the
[0054]
When the sixth command code “VD” and parameter data “00” are read in accordance with the command processing for each set processing unit time, this command “VD” is the i-th text phrase display command. According to the parameter data i = 00, the 0th clause of the text (in this case, the text file “low” of the search word stored in the synchronization
[0055]
Further, when the ninth command code “NP” and parameter data “00” are read in accordance with the command processing for each set processing unit time, this command “NP” is an invalid instruction, and therefore the current file output State is maintained.
[0056]
The detailed operation of the synchronized playback of pronunciation speech / text / image (mouth-shaped image) corresponding to the search word based on the time code file 12f23 (12i) having the file contents shown in FIG. 5 will be described later. I will explain it again.
[0057]
Next, various operations performed by the
[0058]
FIG. 7 is a flowchart showing main processing according to the
[0059]
FIG. 8 is a flowchart showing a headword synchronized reproduction process accompanying the main process of the
[0060]
FIG. 9 is a flowchart showing a text corresponding mouth display process executed by interruption in accordance with the highlight display of each entry word character accompanying the entry synchronized playback process of the
[0061]
FIG. 10 is a diagram showing a setting display state of the character image for synchronous reproduction accompanying the character setting process in the main process of the
[0062]
When the mode is switched to the character image setting mode by operating the “setting” key 17a1 and the cursor key 17a2 of the
[0063]
In this character image list selection screen G1, the selection frame X of each character image is moved by the operation of the cursor key 17a3 to select a user desired character image (for example, 12d3 (No 3)). When the selection of the character image is detected by the determination operation using the (voice) key 17a4 (step S4), the character image 12dn detected by the selection is read out and stored in the synchronization image file memory 12n in the
[0064]
Thus, the character image to be synthesized with the mouth-shaped image to be displayed in synchronization with the pronunciation sound of the headword is selected and set along with the headword search.
[0065]
FIG. 11 is a diagram showing a search word entry display screen G2 accompanying the word search process in the main process of the
[0066]
For example, in order to perform a headword search based on dictionary data of an English-Japanese dictionary stored in the
[0067]
In this search headword list screen, the headword (in this case, “low”) that matches the search target headword input by the user is selected and instructed by the cursor key, and the “translation / decision (voice)” key 17a4. Is operated (step S10), the selected and detected headword "low" is stored in the
[0068]
Here, for the headword “low” displayed in the search, the pronunciation voice is output, and at the same time, the character of the headword, the phonetic symbol, and the mouth-shaped image of the pronunciation are displayed in synchronization. When the “/ decision (voice)” key 17a4 is operated (step S12), the process proceeds to the synchronous reproduction process in FIG. 8 (step SA).
[0069]
FIG. 12 shows a headword character display window W1 displayed on the search headword display screen G2 in the setting state of the character image No3 in accordance with the synchronous reproduction processing in the headword search processing of the
[0070]
When the synchronous reproduction process (step SA) in FIG. 8 is started in accordance with the operation of the “translation / decision (voice)” key 17a4 in the state where the search headword display screen G2 is displayed, Initialization processing such as clear processing of each work area is performed (step A1). First, the synchronous reproduction link data (refer to FIG. 2) for the current search term “low” stored in the
[0071]
It should be noted that the character image (in this case, 12d3 (No 3)) set by the user for displaying the search headline pronunciation image is already stored in the
[0072]
Then, from the time code file 12fn for synchronized playback of encrypted voice / text / image corresponding to various headwords stored as the dictionary time code file 12f in the
[0073]
In this manner, settings for reading various files for synchronous reproduction of the pronunciation voice / text / speaking mouth type image corresponding to the search headword “low” into the
[0074]
A read pointer is set at the head of the time code file 12f23 stored in the time
[0075]
In step A6, when the processing timer is started, the read pointer set in step A5 is set every processing unit time (25 ms) corresponding to the current time code file 12f23 set in step A4. The command code and parameter data of the time code file 12f23 (see FIG. 5) at the initial position are read (step A7).
[0076]
Then, it is determined whether or not the command code read from the time code file 12f23 (see FIG. 5) is “FN” (step A8). If “FN” is determined, the synchronization is performed at that time. A reproduction process stop process is instructed (step A8 → A9).
[0077]
On the other hand, when it is determined that the command code read from the time code file 12f23 (see FIG. 5) is not “FN”, processing corresponding to the content of the command code (see FIG. 6) is executed. (Step A10).
[0078]
If it is determined that the time measured by the timer has reached the next processing unit time (25 ms), the read pointer for the time code file 12f23 (see FIG. 5) stored in the
[0079]
Here, the synchronized playback output operation of the pronunciation voice / text / speech mouth image file based on the time code file 12f23 of the search headword “low” shown in FIG. 5 will be described in detail.
[0080]
That is, the time code file 12f23 is a command process executed every (reference) processing unit time (for example, 25ms) preset in the header H. First, the time code file 12f23 (see FIG. 5). When the first command code “CS” (clear all file) and its parameter data “00” are read out, an instruction to clear the output of all the files is given, and the output of the text / audio / image file is cleared ( Step A10).
[0081]
When the second command code “DH” (i-th HTML file display) and its parameter data “00” are read, synchronization in the
[0082]
When the third command code “DI” (i-th image file display) and its parameter data “00” are read, synchronization in the
[0083]
When the fourth command code “PS” (i-th sound file play) and its parameter data “00” are read, synchronization in the
[0084]
When the fifth command code “LT” (i-th text load) and its parameter data “00” are read, the synchronization data in the
[0085]
When the sixth command code “VD” (i-th text phrase display) and its parameter data “00” are read, the fifth command is determined according to the parameter data (i = 0) read together with the command code VD. The text data “l”, “o”, “w” (including phonetic symbols) specified according to the code “LT” is read out, and as shown in FIG. Are displayed in the text synchronized playback window W1 (step A10).
[0086]
When the seventh command code “BL” (character counter reset / i-th clause block designation) and its parameter data “00” are read, the character of the search term “low” displayed in the text synchronous playback window W1 The counter is reset (step A10).
[0087]
When the eighth command code “HL” (highlight / character count up to i-th character) and its parameter data “01” are read, the parameter data (i = 1) read together with the command code HL is read. Then, as shown in FIG. 12A, the first character “l” of the search headword “low” (including phonetic symbols) displayed in the text synchronized playback window W1 and the pronunciation corresponding thereto. Up to the symbol, highlight (identification) display HL by color change display, reverse display, underline display, etc. is performed, and the character counter counts up to the second character and the corresponding phonetic symbol (step A10).
[0088]
At the time of highlight (identification) display for each character of the search headword “low” and its corresponding phonetic symbol by the time code file 12f23, the text corresponding mouth display processing in FIG. 9 is interrupted.
[0089]
That is, when the character “l” of the search headword “low” that is highlighted (identified) HL this time is detected (step B1), the pronunciation type image corresponding to the detected character “l” is converted into the dictionary. According to the mouth number “36” corresponding to the text “l” indicated by the text mouth synchronization file (see FIG. 2C) in the
[0090]
Here, it is determined whether or not there is an accent mark for the phonetic symbol of the current highlight (identification) display text “l” indicated by the text mouth synchronization file (see FIG. 2C) (step B4). In the case of the phonetic symbol [l] of the highlight (identification) display text “l”, it is determined that there is no accent mark, so that the
[0091]
If it is determined that there is an accent mark, the
[0092]
Then, the output timing of the pronunciation voice data corresponding to the search headword “low” started to be output from the stereo voice output unit 19b according to the fourth command code “PS”, and the processing unit by this time code file 12f23 Since the time code file 12f23 is created in association with the identification display timing for each character of the search word “low” corresponding to the time (25 ms), the search word “low” is created. When the first character “l” is identified and displayed, and the
[0093]
Thus, the identification display of the first character “l” of the search headword “low”, the synthesized display of the pronunciation mouth image 12e3 (No36) to the
[0094]
When the ninth command code “NP” is read, the character image and text data synchronous display screen and the sound output data synchronous output state corresponding to the current search headword “low” are maintained.
[0095]
Thereafter, according to the twelfth command code “HL” and the thirty-fifth command code “HL”, as shown in FIG. 12 (C) {circle around (2)} and FIG. 12 (C) {circle around (3)}, The text data “low” of the search headword and its phonetic symbol are sequentially high, such as the second character “o” and the phonetic symbol [o], the third character “w” and the phonetic symbol [u]. The light (identification) display HL is displayed (step A10). At the same time, in the image synchronous reproduction window W2, the mouth image area (X1, Y1; X2, Y2) of the set
[0096]
Furthermore, the pronunciation voice data of the search headword “low” output from the stereo voice output unit 19b according to the fourth command code “PS” is also highlighted (identification) of the text “low” and its phonetic symbol. ) The sound of reading out the display part is sequentially output synchronously.
[0097]
Note that each sound
[0098]
That is, when the combined display of the highlight (identification) display HL synchronized with the output of the pronunciation sound for the accent character “o” of the search headword “Low” shown in FIG. 12 and the
[0099]
FIG. 13 shows a headword character display window W1 and a pronunciation type that are displayed on the search headword display screen G2 in the setting state of the character image No1 in accordance with the synchronized playback processing in the headword search processing of the
[0100]
That is, in the character setting process in steps S1 to S6 in FIG. 7, the animation style is selected from the three types of
[0101]
Then, as shown in (2) in FIG. 13B, the pronunciation
[0102]
That is, the highlight (identification) display synchronized with the output of the pronunciation voice for the accent character “o” of the search headword “Low” when the anime-
[0103]
In the synchronous reproduction process of the text, pronunciation sound, and pronunciation mouth image associated with the headword search described with reference to FIGS. 11 to 13, the contents of the English-Japanese dictionary data stored in advance as the
[0104]
FIG. 14 is a diagram showing a search headword display screen G2 when an English-Japanese dictionary containing pronunciation forms of two countries of the United States / UK is used in the headword search process in the main process of the
[0105]
In order to search for a word based on dictionary data of an English-Japanese dictionary that records pronunciation forms of, for example, two countries of the US / UK stored in the
[0106]
On this search headword list screen, the headword (in this case, “laugh”) that matches the search target headword input by the user is selected and instructed by the cursor key, and the “translation / decision (voice)” key 17a4. Is operated (step S10), the selected and detected headword “laugh” is stored in the
[0107]
Here, for the headword “laugh” displayed in the search, the pronunciation sound of either the American pronunciation [laef] or the English pronunciation [la: f] is selectively output at the same time. In order to synchronize and display the headword characters, phonetic symbols and pronunciation mouth images corresponding to the US dialect or English dialect identifier [US] displayed in the dictionary data on the search headword display screen G2 When either [English] is specified (step S11a) and the “translation / decision (voice)” key 17a4 is operated (step S12), the process proceeds to the synchronous reproduction process in FIG. 8 (step SA). ).
[0108]
FIG. 15 shows a headword character display window W1 displayed on the search headword display screen G2 when the American pronunciation [US] is designated in accordance with the synchronized playback processing in the headword search processing of the
[0109]
That is, either the US dialect or the English dialect identifier [US] or [English] displayed in the dictionary data on the search headword display screen G2 is designated, and the process proceeds to the synchronous playback process in FIG. Then, in step A2 of the synchronous reproduction process, for example, when the US dialect identifier [US] is designated, it corresponds to the
[0110]
Then, from the time code file 12fn for synchronized playback of encrypted voice / text / image corresponding to various headwords stored as the dictionary time code file 12f in the
[0111]
In the case where the synchronized playback process of the pronunciation voice, the headword character, and the pronunciation type image according to the time code file 12fn corresponding to the search headword “laugh” is the search headword “low” already described. In the same manner as described above, when the reproduction process corresponding to each command code in steps A7 to A12 and the text corresponding mouth display process in FIG. 9 are started, the text synchronized reproduction window W1 on the search word display screen G2 includes The phonetic symbol of the US dialect is displayed together with the search headword “laugh”, and the character synchronization image for American English designed to have, for example, the US flag F in the image-synchronized playback window W2. 12d (No1US) is displayed as the target image for the mouth image synthesis.
[0112]
As a result, in synchronization with the pronunciation voice output of the US dialect of the search headline “laugh”, as shown in (1) to (3) in FIG. The word “laugh” and the highlight (identification) display HL from the first character of the phonetic symbol are sequentially displayed, and in the image synchronous reproduction window W2, the
[0113]
Also in this case, according to the same text corresponding mouth display processing, the highlight (identification) display HL synchronized with the output of the pronunciation sound for the accent character “au” of the search word “Laugh”, the
[0114]
FIG. 16 shows a headword character display window W1 displayed on the search headword display screen G2 when English pronunciation [English] is designated in accordance with the synchronized playback processing in the headword search processing of the
[0115]
That is, among the dialect identifiers [US] or [English] displayed in the dictionary data on the search word display screen G2 shown in FIG. 14, for example, the English dialect identifier [English] is designated. When the process proceeds to the synchronized playback process (step SA) in FIG. 8 (step S11a), in step A2 of the synchronized playback process, the animation character image preset in the character setting process (steps S2 to S6). The
[0116]
Then, from the time code file 12fn for synchronized playback of encrypted voice / text / image corresponding to various headwords stored as the dictionary time code file 12f in the
[0117]
In the case where the synchronized playback process of the pronunciation voice, the headword character, and the pronunciation type image according to the time code file 12fn corresponding to the search headword “laugh” is the search headword “low” already described. In the same manner as described above, when the reproduction process corresponding to each command code in steps A7 to A12 and the text corresponding mouth display process in FIG. 9 are started, the text synchronized reproduction window W1 on the search word display screen G2 includes The phonetic symbol of the English dialect is displayed together with the search headword “laugh”, and the image synchronized playback window W2 is designed to have, for example, a British cap M1 and a walking stick M2 with a set animation-like character image. An
[0118]
As a result, in synchronization with the pronunciation voice output of the English dialect of the search word “laugh”, as shown in (1) to (3) in FIG. The word “laugh” and the highlight (identification) display HL from the first character of the phonetic symbol are sequentially displayed, and the image synchronized playback window W2 uses the
[0119]
Also in this case, according to the same text corresponding mouth display processing, the highlight (identification) display HL synchronized with the output of the pronunciation sound for the accent character “au” of the search word “Laugh”, the
[0120]
Next, with reference to the main process of the
[0121]
FIG. 17 is a diagram showing an operation display state when an incorrect answer is selected in accordance with the accent test process of the
[0122]
FIG. 18 is a diagram showing an operation display state when a correct answer is selected in accordance with the accent test process of the
[0123]
That is, when the “accent test” key 17a6 in the
[0124]
In this accent test question display screen G3, when the selection frame X is moved by operating the cursor key 17a2, and a selection item Ef having a phonetic symbol with an incorrect accent is selected and detected (step S16), the character setting process ( In step S2 to S6), the character image and its related image (in this case, the anime-
[0125]
At the same time, the pronunciation voice data read out from the
[0126]
Then, the question word “low” is stored in the
[0127]
Here, with respect to the accented question word “low” selected by the user, at the same time that the pronunciation sound is output, the characters of the found word, the pronunciation symbol and the mouth-shaped image of the pronunciation are displayed synchronously. When the “translation / decision (voice)” key 17a4 is operated (step S21), the process proceeds to the synchronous reproduction process in FIG. 8 (step SA).
[0128]
Then, in step A2 of the synchronous reproduction process, the
[0129]
Then, the current question word “low” is selected from the timecode file 12fn for synchronized playback of encrypted voice / text / image corresponding to various headwords stored as the dictionary timecode file 12f in the
[0130]
Then, the synchronized reproduction processing of the pronunciation sound of the accented accent, the headword character, and the pronunciation type image in accordance with the time code file 12fn corresponding to the question word “low” is performed for the search headword “low” already described. As in the case, the process is started by the reproduction process corresponding to each command code in steps A7 to A12 and the text corresponding mouth display process in FIG. Then, as shown in FIG. 17B, in the synchronized text reproduction window W1 (Ef) on the search word display screen G2, the phonetic symbol of the wrong accent by the user selection is displayed together with the question word “low”. In addition, in the image synchronized playback window W2, the animation-
[0131]
Thus, in synchronism with the output of the pronunciation sound of the wrong accent corresponding to the question word “low”, as shown in (1) to (3) in FIG. 17 (C), in the text synchronous reproduction window W1 (Ef). The highlighting (identification) display HL from the question word “low” and the head character of the incorrect phonetic symbol is sequentially performed, and in the image synchronous reproduction window W2, the blue color is changed by the selection of the incorrect accent. On the basis of the anime-
[0132]
In this case as well, according to the same text corresponding mouth display process, the highlight (identification) display HL synchronized with the output of the pronunciation sound for the erroneous accent character “u” of the found word “Low”, the pronunciation type image When switching and displaying 12e (No8), the blue-colored animated character (face)
[0133]
On the other hand, as shown in FIG. 18A, when the selection frame X is moved by operating the cursor key 17a2 on the accent test question display screen G3, for example, the selection item Et having a correct phonetic symbol is selected and detected. (Step S16) The process proceeds to the synchronous reproduction process in FIG. 8 without performing the blue color changing process (Step S18) of the
[0134]
Then, as described above with reference to FIG. 13, the synchronized reproduction of the pronunciation speech / text / speech-type image corresponding to the search word “low” in the state where the
[0135]
As a result, in synchronism with the sound output of the correct accent corresponding to the question word “low”, as shown in (1) to (3) in FIG. 18 (C), in the text synchronous reproduction window W1 (Et), Highlight (identification) display HL from the first word of the question word “low” and its correct phonetic symbol is sequentially performed, and in the image synchronous reproduction window W2, a normal-color anime character image as set in advance. On the basis of 12d (No1), for the mouth image area (X1, Y1; X2, Y2), the sound
[0136]
In this case as well, according to the same text corresponding mouth display processing, the highlight (identification) display HL synchronized with the output of the pronunciation sound for the correct accent character “o” of the found word “Low”, the
[0137]
Therefore, according to the synchronized playback function of pronunciation speech / text / speech mouth type image associated with the search for the headword by the
[0138]
In addition, when switching and displaying the highlight (identification) display HL and the
[0139]
Furthermore, according to the synchronized playback function of pronunciation voice / text / speaking mouth type image accompanying the search for the headword by the
[0140]
Further, according to the synchronized playback function of pronunciation speech / text / speech mouth type image accompanying the search for the entry word by the
[0141]
In the first embodiment, the synchronized live reprocessing of the pronunciation speech / text (with pronunciation symbols) / speech mouth type image corresponding to the search headword is performed by the synchronized playback processing according to the time code file 12f. Pronunciation type corresponding to the phonetic symbol corresponding to the identification display character by the text corresponding mouth display processing executed by interruption in accordance with the sequential identification display of the text characters synchronized with each other and the sequential identification display of each character As described in the second embodiment, various phonetic symbols including phonetic symbols with accent symbols and their respective phonetic voice data and phonetic face images are stored in advance. A plurality of sets are stored in association with each other, and as the headword characters to be reproduced are highlighted in order from the top, the phonetic symbols of the highlighted characters are sequentially It may be configured to perform display of output and face image data of the sound speech data correlated.
[0142]
(Second Embodiment)
FIG. 19 is a flowchart showing a headword synchronized reproduction process of the
[0143]
That is, in the
[0144]
For example, an arbitrary headword “low” is input and searched for an English-Japanese dictionary stored in advance as the
[0145]
When the synchronous playback process of the second embodiment is started, as shown in FIG. 12 or FIG. 13, the text synchronous playback window W1 is first opened on the search word display screen G2, and the search word search is started. The characters “low” and the phonetic symbols are highlighted and displayed HL from the top in the order of their pronunciation (step C1). Then, the phonetic symbol of the found character that has been highlighted and displayed HL is read (step C2), and it is determined whether or not it has an accent symbol (step C3).
[0146]
Here, as shown in FIG. 12 (B) (1) or FIG. 13 (B) (1), the phonetic symbol of the character “l” in the found word “low” highlighted HL this time is without an accent symbol. In some cases, unaccented pronunciation voice data corresponding to the phonetic symbol stored in advance in the
[0147]
Then, the character “o” next to the search word “low” currently being output is read (step C6 → C7), and the process returns to step C1 again. As shown by (2) in FIG. 13B, the emphasis identification display HL is displayed together with the phonetic symbol (step C1).
[0148]
If it is determined that the phonetic symbol of the letter “o” in the found word “low” highlighted HL this time has an accent symbol (
[0149]
Therefore, even in the case of the
[0150]
In the second embodiment, various phonetic symbols including accented phonetic symbols stored in advance in the
[0151]
In the second embodiment, various phonetic symbols including accented phonetic symbols, their respective phonetic speech data, and different forms of mouth corresponding to the phonetic speech data corresponding to the various phonetic symbols. Pre-recorded pronunciation face images consisting of parts and facial expressions, highlight each character of the search headword in the order of its pronunciation, and read out and output the pronunciation sound associated with the pronunciation symbol, Although the corresponding pronunciation face image is read and displayed, as described in the next third embodiment, the pronunciation sound of the entry word corresponding to each entry word in the
[0152]
(Third embodiment)
FIG. 20 is a flowchart showing a headword synchronized reproduction process of the
[0153]
That is, in the
[0154]
For example, an arbitrary headword “low” is input and searched for an English-Japanese dictionary stored in advance as the
[0155]
When the synchronous playback process of the third embodiment is started, as shown in FIG. 12 or FIG. 13, the text synchronous playback window W1 is first opened on the search word display screen G2, and the search word search is started. Each character “low” is highlighted and displayed HL from the top in the order of pronunciation (step D1). Then, the pronunciation sound data of the portion corresponding to the found character that has been highlighted and displayed HL is read (step D2) and output from the stereo sound output unit 19b (step D3).
[0156]
Here, for example, whether the signal (waveform) level of the pronunciation sound data of the portion corresponding to the character “l” in the found word “low” highlighted this time HL is a sound signal level (accent portion) of a certain value or more. If it is determined (step D4) and it is determined that it is not higher than a certain audio signal level, that is, it is not an accent part, a pronunciation face image stored in association with the search word is read out. Then, it is displayed as it is on the image synchronous reproduction window W2 (step D5).
[0157]
Then, the character “o” next to the search headword “low” currently being output is read (step D6 → D7), and the process returns to the processing from step D1 again, and the highlight identification display HL is displayed (step D1). ).
[0158]
Then, the pronunciation sound data of the portion corresponding to the found character “o” that has been highlighted and displayed this time is displayed (step D2), output from the stereo sound output unit 19b (step D3), and the highlighted display. It is determined whether or not the signal (waveform) level of the pronunciation sound data of the portion corresponding to the word character “o” subjected to the HL is a sound signal level (accent portion) equal to or higher than a certain value (step D4).
[0159]
Here, when it is determined that the sound signal level is equal to or higher than a certain audio signal level, that is, an accent portion, the pronunciation face image stored in association with the search headword is read and the face image is The face image is controlled to be changed to a face image with a large opening degree and a strong expression (for example, FIG. 12 (B) (2) → FIG. 12 (C) (2)) and displayed on the image synchronous reproduction window W2 ( Step D4 → D8).
[0160]
If the sound signal waveform level of the pronunciation sound is determined to be a certain value or more and is determined to be an accent part, the display color of the highlighted search word is further changed or added. Or it is good also as a structure which changes and displays in the form which shows that it is a character of an accent part by changing a character font.
[0161]
Therefore, even in the case of the
[0162]
In the description of the synchronized playback function for each character (text), pronunciation sound, and pronunciation face image (including pronunciation mouth image) of the search headword in each of the embodiments, the accent of the headword exists in one place. In the case where the accent of the search word is present in two places, the first accent and the second accent, the accent-corresponding pronunciation face image (corresponding pronunciation mouth to be displayed) corresponding to each accent portion is described. The type image) may be displayed in different forms depending on, for example, the size of the opening of the mouth, the strength of the facial expression, or the like depending on whether the first accent or the second accent.
[0163]
Note that each processing method by the
[0164]
The program data for realizing each of the above methods can be transmitted on a communication network (Internet) N in the form of a program code, and the above-mentioned data can be transmitted from a computer terminal connected to the communication network (Internet) N. It is also possible to capture the program data and realize a synchronized reproduction function of each character (text), pronunciation sound, and pronunciation face image (including pronunciation mouth image) corresponding to the search headword described above.
[0165]
Note that the present invention is not limited to the above-described embodiments, and various modifications can be made without departing from the scope of the invention at the stage of implementation. Further, each of the embodiments includes inventions at various stages, and various inventions can be extracted by appropriately combining a plurality of disclosed constituent elements. For example, even if some constituent requirements are deleted from all the constituent requirements shown in each embodiment or some constituent features are combined, the problems described in the column of the problem to be solved by the invention can be solved. When the effects described in the column of the effect of the invention can be obtained, a configuration in which these constituent elements are deleted or combined can be extracted as an invention.
[0168]
[The invention's effect]
As aboveClaims of the invention1(Claims2) Related voice display output control device (voice display output control processing program)In addition to outputting correct accent pronunciation data and erroneous accent pronunciation data for words stored by the word storage means, the display of word text synchronized with the pronunciation sound data and the mouth portion included in the display image Mouth-shaped images corresponding to phonetic sound data can be displayed, and the display image can be changed according to the detection of word accents, so that correct and incorrect accents can be learned easily and clearly, and word storage It is possible to select the correct accented phonetic symbol or the error accented phonetic symbol for the word stored by the means and output the pronunciation voice data, and the word text synchronized with the pronunciation voice data is displayed and included in the display image Corresponds to pronunciation voice data for mouth part Can display mouth type images, it is possible to change a display image in response to the detection of a word accent, so the correct accents and error accent of the word can be learned more easily and clearly timing.
[0175]
Therefore, according to the present invention, an audio display output control device, an image display control device, and an audio display output control processing program that can clearly show the timing of accents in the display of an image synchronized with audio output, an image A display control processing program can be provided.
[Brief description of the drawings]
FIG. 1 is a block diagram showing a configuration of an electronic circuit of a
FIG. 2 is a diagram showing link data for synchronous playback for one headword “low” in the
FIG. 3 is a diagram showing
FIG. 4 is stored in the
5 is a view showing a time code file 12f23 (12i) of a file No. 23 associated with the headword “low” in the dictionary time code file 12f stored in the
6 is a diagram showing the command codes of various commands described in the dictionary time code file 12fn (see FIG. 5) of the
FIG. 7 is a flowchart showing main processing according to the
FIG. 8 is a flowchart showing a headword synchronized reproduction process accompanying a main process of the
FIG. 9 is a flowchart showing a text corresponding mouth display process executed by interruption in accordance with the highlight display of each headword character accompanying the headword synchronized playback process of the
10 is a view showing a setting display state of a character image for synchronous reproduction accompanying a character setting process in the main process of the
FIG. 11 is a diagram showing a search headword display screen G2 associated with the headword search process in the main process of the
12 is a headword character display window W1 and a pronunciation window that are displayed on a search headword display screen G2 in the setting state of the character image No3 in accordance with the synchronized playback processing in the headword search processing of the
13 shows a headword character display window W1 and a pronunciation window displayed on the search headword display screen G2 in the setting state of the character image No1 in accordance with the synchronous reproduction processing in the headword search processing of the
FIG. 14 is a diagram showing a search headword display screen G2 when an English-Japanese dictionary containing pronunciation forms of two countries of the United States / UK is used in the headword search process in the main process of the
FIG. 15 is a headword character display window that is displayed on the search headword display screen G2 when an American pronunciation [US] is designated in accordance with the synchronized playback process in the headword search process of the
FIG. 16 is a headword character display window that is displayed on the search headword display screen G2 when English pronunciation [English] is designated in accordance with the synchronized playback processing in the headword search processing of the
FIG. 17 is a diagram showing an operation display state when an incorrect answer is selected in accordance with the accent test process of the
FIG. 18 is a diagram showing an operation display state when a correct answer is selected in accordance with the accent test process of the
FIG. 19 is a flowchart showing a headword synchronized playback process of the second embodiment of the
FIG. 20 is a flowchart showing a headword synchronized reproduction process of the third embodiment of the
[Explanation of symbols]
10 ... Mobile device
11 ... CPU
12 ... Memory
12A ... FLASH memory
12B ... RAM
12a ... Dictionary processing program
12b ... Dictionary database
12c ... Dictionary voice data
12d: Character image data
12d (No. n) ... set character image
12d (No. n ') ... face image corresponding to accent
12d (No. nUS) ... set character image for American language
12d (No. nUS ') ... Face image for American accent
12d (No. nUK) ... English set character image
12d (No. nUK ') ... Face image for English accents
12d (No. nBL) ... Blue change setting character image
12d (No. nBL ') ... Blue face image corresponding to accent
12e ... Voice-specific mouth image data
12f ... Dictionary time code file
12g ... Yomi word data memory
12h ... Dictionary data memory for headwords
12i Time code file No23
12j ... HTML file memory for synchronization
12k ... Text file memory for synchronization
12m ... Sound file memory for synchronization
12n ... Image file memory for synchronization
12p ... Mouth image area memory
12q ... Image development buffer
13: External recording medium
14 ... Recording medium reader
15 ... Transmission control unit
16: Communication department
17a ... Input section
17b ... Coordinate input device
18 ... Display section
19a ... Voice input part
19b ... Stereo audio output unit
20 ... Communication equipment (home PC)
30: Web server
N ... Communication network (Internet)
X: Selected frame
H ... Header information of time code table
G1 ... Character image list selection screen
G2 ... Yomi terms search screen
G3 ... Accent test questions display screen
W1 ... Headword character display window (text synchronous playback window)
W2… Speaking mouth type display window (window for synchronized playback of images)
HL ... Highlight (identification) display
Et ... Correct accent selection item
Ef: Error accent selection item
Claims (2)
Translated fromJapaneseこの単語記憶手段により記憶した単語の正しいアクセントの発音音声データまたは誤りアクセントの発音音声データを出力する音声データ出力手段と、
この音声データ出力手段により出力される単語の発音音声データに同期して当該単語のテキストを表示させるテキスト同期表示制御手段と、
少なくとも口の部分を含む画像を、前記音声データ出力手段により正しいアクセントの発音音声データが出力される場合と誤りアクセントの発音音声データが出力される場合とで異なる表示形態にして表示させる画像表示制御手段と、
この画像表示制御手段により表示される画像に含まれる口の部分について、前記音声データ出力手段により出力される発音音声データに同期して当該発音音声データに対応した口型の画像を表示させる口画像表示制御手段と、
前記テキスト同期表示制御手段による単語テキストの同期表示に伴い、前記単語記憶手段により記憶した該当単語のアクセント付き発音記号から該単語のアクセントを検出するアクセント検出手段と、
このアクセント検出手段によるアクセントの検出に応じて前記画像表示制御手段により表示される画像を変化させる画像変化表示制御手段と、
前記単語記憶手段により記憶した単語と当該単語に対応付けられた正しいアクセント付き発音記号と誤りアクセント付き発音記号とを並べて表示させる正誤アクセント表示制御手段と、
この正誤アクセント表示制御手段により表示された単語の正しいアクセント付き発音記号か誤りアクセント付き発音記号かの何れかを選択する正誤アクセント選択手段とを備え、
前記音声データ出力手段は、前記正誤アクセント選択手段による単語アクセントの正誤選択に応じて、該当単語の正しいアクセントの発音音声データまたは誤りアクセントの発音音声データを出力する、
ことを特徴とする音声表示出力制御装置。A word storage means for storing a plurality of words and phonetic symbols with correct accents and phonetic symbols with error accents for each of the words,
Voice data output means for outputting correct accent pronunciation voice data or erroneous accent pronunciation voice data of the word stored by the word storage means;
Text synchronous display control means for displaying the text of the word in synchronism with pronunciation voice data of the word output by the voice data output means;
Image display control for displaying an image including at least a mouth portion in different display forms when the sound data of correct accent is output by the sound data output means and when sound data of error accent is output Means,
A mouth image that displays a mouth-shaped image corresponding to the pronunciation sound data in synchronism with the pronunciation sound data output by the sound data output means for the mouth portion included in the image displayed by the image display control means Display control means;
Accent detection means for detecting the accent of the word from the accented phonetic symbol stored by the word storage means in accordance with the synchronous display of the word text by the text synchronization display control means,
An image change display control means for changing an image displayed by the image display control means in response to detection of an accent by the accent detection means;
Correct / incorrect accent display control means for displaying a word stored by the word storage means and a correct accented pronunciation symbol and an error accented pronunciation symbol associated with the word side by side;
A correct / incorrect accent selection means for selecting either a correct accented phonetic symbol or an error accented phonetic symbol of the word displayed by the correct / incorrect accent display control means,
The voice data output means outputs correct voice pronunciation data or correct accent voice data of the corresponding word in accordance with correct / incorrect word accent selection by the correct / incorrect accent selection means.
An audio display output control device characterized by the above.
前記コンピュータを、
複数の単語と当該各単語それぞれの正しいアクセント付き発音記号と誤りアクセント付き発音記号とを対応付けて記憶する単語記憶手段、
この単語記憶手段により記憶した単語の正しいアクセントの発音音声データまたは誤りアクセントの発音音声データを出力する音声データ出力手段、
この音声データ出力手段により出力される単語の発音音声データに同期して当該単語のテキストを表示させるテキスト同期表示制御手段、
少なくとも口の部分を含む画像を、前記音声データ出力手段により正しいアクセントの発音音声データが出力される場合と誤りアクセントの発音音声データが出力される場合とで異なる表示形態にして表示させる画像表示制御手段、
この画像表示制御手段により表示される画像に含まれる口の部分について、前記音声データ出力手段により出力される発音音声データに同期して当該発音音声データに対応した口型の画像を表示させる口画像表示制御手段、
前記テキスト同期表示制御手段による単語テキストの同期表示に伴い、前記単語記憶手段により記憶した該当単語のアクセント付き発音記号から該単語のアクセントを検出するアクセント検出手段、
このアクセント検出手段によるアクセントの検出に応じて前記画像表示制御手段により表示される画像を変化させる画像変化表示制御手段、
前記単語記憶手段により記憶した単語と当該単語に対応付けられた正しいアクセント付き発音記号と誤りアクセント付き発音記号とを並べて表示させる正誤アクセント表示制御手段、
この正誤アクセント表示制御手段により表示された単語の正しいアクセント付き発音記号か誤りアクセント付き発音記号かの何れかを選択する正誤アクセント選択手段、
として機能させ、
前記音声データ出力手段を、前記正誤アクセント選択手段による単語アクセントの正誤選択に応じて、該当単語の正しいアクセントの発音音声データまたは誤りアクセントの発音音声データを出力するように機能させる、
ようにしたコンピュータ読み込み可能な音声表示出力制御処理プログラム。An audio display output control processing program for controlling a computer of an electronic device to synchronously reproduce audio data, text, and an image,
The computer,
Word storage means for storing a plurality of words and phonetic symbols with correct accents and phonetic symbols with error accents associated with each of the words,
Voice data output means for outputting correct accent pronunciation voice data or error accent pronunciation voice data of the word stored by the word storage means;
Text synchronized display control means for displaying the text of the word in synchronization with the pronunciation voice data of the word output by the voice data output means;
Image display control for displaying an image including at least a mouth portion in different display forms when the sound data of correct accent is output by the sound data output means and when sound data of error accent is output means,
A mouth image that displays a mouth-shaped image corresponding to the pronunciation sound data in synchronism with the pronunciation sound data output by the sound data output means for the mouth portion included in the image displayed by the image display control means Display control means,
Accent detection means for detecting the accent of the word from the accented phonetic symbol of the corresponding word stored by the word storage means in accordance with the synchronous display of the word text by the text synchronous display control means,
Image change display control means for changing the image displayed by the image display control means in accordance with the detection of accents by the accent detection means;
Correct / incorrect accent display control means for displaying the word stored by the word storage means and the correct accented pronunciation symbol and the error accented pronunciation symbol associated with the word side by side;
Correct / incorrect accent selection means for selecting either correct accented phonetic symbols or error accented phonetic symbols of the words displayed by the correct / incorrect accent display control means,
Function as
The voice data output means functions to output correct accent pronunciation voice data or erroneous accent pronunciation voice data of the corresponding word according to correct / incorrect word accent selection by the correct / incorrect accent selection means,
A computer-readable audio display output control processing program.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003143499AJP4370811B2 (en) | 2003-05-21 | 2003-05-21 | Voice display output control device and voice display output control processing program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003143499AJP4370811B2 (en) | 2003-05-21 | 2003-05-21 | Voice display output control device and voice display output control processing program |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2009140670ADivisionJP4985714B2 (en) | 2009-06-12 | 2009-06-12 | Voice display output control device and voice display output control processing program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2004347786A JP2004347786A (en) | 2004-12-09 |
| JP4370811B2true JP4370811B2 (en) | 2009-11-25 |
Family
ID=33531274
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2003143499AExpired - Fee RelatedJP4370811B2 (en) | 2003-05-21 | 2003-05-21 | Voice display output control device and voice display output control processing program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4370811B2 (en) |
Families Citing this family (58)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4626310B2 (en)* | 2005-01-12 | 2011-02-09 | ヤマハ株式会社 | Pronunciation evaluation device |
| WO2006085719A1 (en)* | 2005-02-14 | 2006-08-17 | Hay Kyung Yoo | Foreign language studying device for improving foreign language studying efficiency, and on-line foreign language studying system using the same |
| KR100593757B1 (en) | 2005-02-14 | 2006-06-30 | 유혜경 | Foreign language learning device to improve foreign language learning efficiency and online foreign language learning system using it |
| JP4678672B2 (en)* | 2005-03-09 | 2011-04-27 | 誠 後藤 | Pronunciation learning device and pronunciation learning program |
| JP2006301063A (en)* | 2005-04-18 | 2006-11-02 | Yamaha Corp | Content provision system, content provision device, and terminal device |
| US8677377B2 (en) | 2005-09-08 | 2014-03-18 | Apple Inc. | Method and apparatus for building an intelligent automated assistant |
| US9318108B2 (en) | 2010-01-18 | 2016-04-19 | Apple Inc. | Intelligent automated assistant |
| JP4840052B2 (en)* | 2006-09-28 | 2011-12-21 | カシオ計算機株式会社 | Pronunciation learning support device and pronunciation learning support program |
| KR100816378B1 (en) | 2006-11-15 | 2008-03-25 | 주식회사 에듀왕 | Learning English Pronunciation Using Representative Word Pronunciation |
| WO2009066963A2 (en)* | 2007-11-22 | 2009-05-28 | Intelab Co., Ltd. | Apparatus and method for indicating a pronunciation information |
| US8996376B2 (en) | 2008-04-05 | 2015-03-31 | Apple Inc. | Intelligent text-to-speech conversion |
| CN101383102A (en)* | 2008-10-24 | 2009-03-11 | 无敌科技(西安)有限公司 | Simulation video and audio synchronous display apparatus and method |
| US10241644B2 (en) | 2011-06-03 | 2019-03-26 | Apple Inc. | Actionable reminder entries |
| US10241752B2 (en) | 2011-09-30 | 2019-03-26 | Apple Inc. | Interface for a virtual digital assistant |
| US8682667B2 (en) | 2010-02-25 | 2014-03-25 | Apple Inc. | User profiling for selecting user specific voice input processing information |
| KR101153736B1 (en) | 2010-05-31 | 2012-06-05 | 봉래 박 | Apparatus and method for generating the vocal organs animation |
| US9483461B2 (en)* | 2012-03-06 | 2016-11-01 | Apple Inc. | Handling speech synthesis of content for multiple languages |
| US9721563B2 (en) | 2012-06-08 | 2017-08-01 | Apple Inc. | Name recognition system |
| US9547647B2 (en) | 2012-09-19 | 2017-01-17 | Apple Inc. | Voice-based media searching |
| WO2014197334A2 (en) | 2013-06-07 | 2014-12-11 | Apple Inc. | System and method for user-specified pronunciation of words for speech synthesis and recognition |
| US9338493B2 (en) | 2014-06-30 | 2016-05-10 | Apple Inc. | Intelligent automated assistant for TV user interactions |
| US9668121B2 (en) | 2014-09-30 | 2017-05-30 | Apple Inc. | Social reminders |
| US10567477B2 (en) | 2015-03-08 | 2020-02-18 | Apple Inc. | Virtual assistant continuity |
| US9578173B2 (en) | 2015-06-05 | 2017-02-21 | Apple Inc. | Virtual assistant aided communication with 3rd party service in a communication session |
| US10747498B2 (en) | 2015-09-08 | 2020-08-18 | Apple Inc. | Zero latency digital assistant |
| US10671428B2 (en) | 2015-09-08 | 2020-06-02 | Apple Inc. | Distributed personal assistant |
| US10366158B2 (en) | 2015-09-29 | 2019-07-30 | Apple Inc. | Efficient word encoding for recurrent neural network language models |
| US11010550B2 (en) | 2015-09-29 | 2021-05-18 | Apple Inc. | Unified language modeling framework for word prediction, auto-completion and auto-correction |
| US10691473B2 (en) | 2015-11-06 | 2020-06-23 | Apple Inc. | Intelligent automated assistant in a messaging environment |
| US10049668B2 (en) | 2015-12-02 | 2018-08-14 | Apple Inc. | Applying neural network language models to weighted finite state transducers for automatic speech recognition |
| US10223066B2 (en) | 2015-12-23 | 2019-03-05 | Apple Inc. | Proactive assistance based on dialog communication between devices |
| US10446143B2 (en) | 2016-03-14 | 2019-10-15 | Apple Inc. | Identification of voice inputs providing credentials |
| US9934775B2 (en) | 2016-05-26 | 2018-04-03 | Apple Inc. | Unit-selection text-to-speech synthesis based on predicted concatenation parameters |
| US9972304B2 (en) | 2016-06-03 | 2018-05-15 | Apple Inc. | Privacy preserving distributed evaluation framework for embedded personalized systems |
| US10249300B2 (en) | 2016-06-06 | 2019-04-02 | Apple Inc. | Intelligent list reading |
| US10049663B2 (en) | 2016-06-08 | 2018-08-14 | Apple, Inc. | Intelligent automated assistant for media exploration |
| DK179309B1 (en) | 2016-06-09 | 2018-04-23 | Apple Inc | Intelligent automated assistant in a home environment |
| US10490187B2 (en) | 2016-06-10 | 2019-11-26 | Apple Inc. | Digital assistant providing automated status report |
| US10586535B2 (en) | 2016-06-10 | 2020-03-10 | Apple Inc. | Intelligent digital assistant in a multi-tasking environment |
| US10192552B2 (en) | 2016-06-10 | 2019-01-29 | Apple Inc. | Digital assistant providing whispered speech |
| US10067938B2 (en) | 2016-06-10 | 2018-09-04 | Apple Inc. | Multilingual word prediction |
| US10509862B2 (en) | 2016-06-10 | 2019-12-17 | Apple Inc. | Dynamic phrase expansion of language input |
| DK179415B1 (en) | 2016-06-11 | 2018-06-14 | Apple Inc | Intelligent device arbitration and control |
| DK179049B1 (en) | 2016-06-11 | 2017-09-18 | Apple Inc | Data driven natural language event detection and classification |
| DK179343B1 (en) | 2016-06-11 | 2018-05-14 | Apple Inc | Intelligent task discovery |
| DK201670540A1 (en) | 2016-06-11 | 2018-01-08 | Apple Inc | Application integration with a digital assistant |
| US10043516B2 (en) | 2016-09-23 | 2018-08-07 | Apple Inc. | Intelligent automated assistant |
| US10593346B2 (en) | 2016-12-22 | 2020-03-17 | Apple Inc. | Rank-reduced token representation for automatic speech recognition |
| DK201770439A1 (en) | 2017-05-11 | 2018-12-13 | Apple Inc. | Offline personal assistant |
| DK179745B1 (en) | 2017-05-12 | 2019-05-01 | Apple Inc. | SYNCHRONIZATION AND TASK DELEGATION OF A DIGITAL ASSISTANT |
| DK179496B1 (en) | 2017-05-12 | 2019-01-15 | Apple Inc. | USER-SPECIFIC Acoustic Models |
| DK201770431A1 (en) | 2017-05-15 | 2018-12-20 | Apple Inc. | Optimizing dialogue policy decisions for digital assistants using implicit feedback |
| DK201770432A1 (en) | 2017-05-15 | 2018-12-21 | Apple Inc. | Hierarchical belief states for digital assistants |
| DK179549B1 (en) | 2017-05-16 | 2019-02-12 | Apple Inc. | Far-field extension for digital assistant services |
| CN109147430A (en)* | 2018-10-19 | 2019-01-04 | 渭南师范学院 | A kind of teleeducation system based on cloud platform |
| US11361760B2 (en) | 2018-12-13 | 2022-06-14 | Learning Squared, Inc. | Variable-speed phonetic pronunciation machine |
| EP4283577A3 (en)* | 2019-01-18 | 2024-02-14 | Snap Inc. | Text and audio-based real-time face reenactment |
| CN113066347B (en)* | 2021-04-06 | 2022-04-22 | 湖北师范大学 | An interactive English education device and method of using the same |
- 2003
- 2003-05-21JPJP2003143499Apatent/JP4370811B2/ennot_activeExpired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2004347786A (en) | 2004-12-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4370811B2 (en) | Voice display output control device and voice display output control processing program | |
| US8352269B2 (en) | Systems and methods for processing indicia for document narration | |
| US20190196666A1 (en) | Systems and Methods Document Narration | |
| US8346557B2 (en) | Systems and methods document narration | |
| JP2024117780A (en) | Electronic device, learning support system, learning processing method and program | |
| JP2012098753A (en) | Audio display output control device, image display control device, audio display output control process program and image display control process program | |
| JP4985714B2 (en) | Voice display output control device and voice display output control processing program | |
| JP4591481B2 (en) | Display control apparatus and display control processing program | |
| JP4534557B2 (en) | Information display control device and information display control processing program | |
| JP7379968B2 (en) | Learning support devices, learning support methods and programs | |
| JP4407119B2 (en) | Instruction code creation device | |
| JP2006236037A (en) | Spoken dialogue content creation method, apparatus, program, and recording medium | |
| JP2008058678A (en) | Audio output device and audio output program | |
| KR102656262B1 (en) | Method and apparatus for providing associative chinese learning contents using images | |
| JP4111005B2 (en) | Voice display output control device and voice display output control processing program | |
| JP5057764B2 (en) | Speech synthesis apparatus and speech synthesis program | |
| JP4677869B2 (en) | Information display control device with voice output function and control program thereof | |
| JP2004302286A (en) | Information output device, information output program | |
| JPH06332934A (en) | Device for referring to electronic dictionary | |
| JP2004212646A (en) | Voice display output control device and voice display output control processing program | |
| KR20140087955A (en) | Apparatus and method for learning English prepositions using image data and pronunciation data of native speakers | |
| WO2010083354A1 (en) | Systems and methods for multiple voice document narration | |
| JP2007225999A (en) | Electronic dictionary | |
| JP2008171208A (en) | Audio output device and audio output program |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination | Free format text:JAPANESE INTERMEDIATE CODE: A621 Effective date:20060502 | |
| A977 | Report on retrieval | Free format text:JAPANESE INTERMEDIATE CODE: A971007 Effective date:20090402 | |
| A131 | Notification of reasons for refusal | Free format text:JAPANESE INTERMEDIATE CODE: A131 Effective date:20090421 | |
| A521 | Request for written amendment filed | Free format text:JAPANESE INTERMEDIATE CODE: A523 Effective date:20090612 | |
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) | Free format text:JAPANESE INTERMEDIATE CODE: A01 Effective date:20090811 | |
| A01 | Written decision to grant a patent or to grant a registration (utility model) | Free format text:JAPANESE INTERMEDIATE CODE: A01 | |
| A61 | First payment of annual fees (during grant procedure) | Free format text:JAPANESE INTERMEDIATE CODE: A61 Effective date:20090824 | |
| FPAY | Renewal fee payment (event date is renewal date of database) | Free format text:PAYMENT UNTIL: 20120911 Year of fee payment:3 | |
| R150 | Certificate of patent or registration of utility model | Ref document number:4370811 Country of ref document:JP Free format text:JAPANESE INTERMEDIATE CODE: R150 Free format text:JAPANESE INTERMEDIATE CODE: R150 | |
| FPAY | Renewal fee payment (event date is renewal date of database) | Free format text:PAYMENT UNTIL: 20130911 Year of fee payment:4 | |
| LAPS | Cancellation because of no payment of annual fees |