JP4307287B2 - Metadata extraction device - Google Patents
Metadata extraction deviceDownload PDFInfo
- Publication number
- JP4307287B2 JP4307287B2JP2004046611AJP2004046611AJP4307287B2JP 4307287 B2JP4307287 B2JP 4307287B2JP 2004046611 AJP2004046611 AJP 2004046611AJP 2004046611 AJP2004046611 AJP 2004046611AJP 4307287 B2JP4307287 B2JP 4307287B2
- Authority
- JP
- Japan
- Prior art keywords
- attribute
- document
- relevance
- degree
- association
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images


















Landscapes
- Machine Translation (AREA)
- Document Processing Apparatus (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
Translated fromJapaneseこの発明は、電子文書から有用な情報を抽出するメタデータ抽出装置に関するものである。 The present invention relates to a metadata extraction apparatus that extracts useful information from an electronic document.
近年、コンピュータの高性能化とディスク容量の増大、ネットワークインフラの整備などを背景に、ワープロソフト、CAD(Computer Aided Design)ソフト等で作成した文書、図面等をファイルサーバに保存して共有することで、文書、図面等の検索または閲覧を可能にする文書管理方法が増加している。また、文書の電子化・共有化が進み文書数が増加するにつれて、サーバに大量に蓄積された文書群から有用な情報を抽出して活用したいという要求が高まっている。 In recent years, documents, drawings, etc. created with word processing software, CAD (Computer Aided Design) software, etc. are stored on a file server and shared against the background of higher performance computers, increased disk capacity, and network infrastructure. Therefore, there are an increasing number of document management methods that enable searching or browsing of documents, drawings, and the like. Further, as the number of documents increases as the digitization and sharing of documents progresses, there is an increasing demand for extracting and utilizing useful information from a large amount of documents stored in a server.
文書中から有用な情報を抽出する方法として、例えば、非構造化文書を登録時に構造化して文書タイトル、章節タイトルを抽出する方法や、文書中から特定の形式で記述された情報を抽出する方法がある。 As a method of extracting useful information from a document, for example, a method of extracting an unstructured document at the time of registration and extracting a document title and a chapter title, and a method of extracting information described in a specific format from a document There is.
例えば、特許文献1には、非構造化文書をサーバ登録時に構造化して保存する方法が開示されている。具体的には、紙文書をスキャナで読み込んで作成した文書イメージから、テキスト領域、表領域、イメージ領域を検出し、例えばテキスト領域からはテキストを抽出すると共に、文字列のレイアウト情報を利用して文書タイトル、章節タイトルを抽出する。また、表領域からはセル内の文字認識を行って数値データを抽出する。 For example,
また、特許文献2には、有用な情報として文書中から特定の形式の情報を抽出する方法が開示されている。具体的には、抽出する項目と探索範囲を予め定義ファイルに登録しておき、この定義ファイルに従って入力文書から文字抽出を行い、その結果を文書記述言語SGML(Standard Generalized Markup Language)形式で出力する方法である。例えば、タイトルを抽出する場合は、文字列「タイトル:」に続き改行までの文字列を「タイトル」として抽出するように定義ファイルに登録しておき、これに基づいて文字抽出を行う。 Patent Document 2 discloses a method for extracting information in a specific format from a document as useful information. Specifically, the items to be extracted and the search range are registered in the definition file in advance, characters are extracted from the input document according to the definition file, and the result is output in the document description language SGML (Standard Generalized Markup Language) format. Is the method. For example, when extracting a title, the character string “title:” is registered in the definition file so that a character string up to a line feed is extracted as “title”, and character extraction is performed based on this.
特許文献1に記載の発明は上記のように構成されているので、入力文書から抽出できる情報は、例えばテキスト領域からは文書タイトル、章節タイトル等であり、文書画像中の文字列の位置または大きさのみに基づいて抽出できる情報に限定されてしまう。したがって、文書中の文章間・単語間の関係等、文書の内容に関する情報は抽出できないため、文書から抽出できる有用な知識が限られてしまうという課題があった。 Since the invention described in
また、特許文献2に記載の発明では、定型文書に対応するように予め作成された定義ファイルに従って情報抽出が行われるため、非定形文書に対してはそれぞれに応じた抽出形式の定義ファイルを作成しなければならないという課題があった。 Further, in the invention described in Patent Document 2, information extraction is performed according to a definition file created in advance so as to correspond to a standard document. Therefore, for a non-standard document, a definition file of an extraction format corresponding to each is created. There was a problem that had to be done.
この発明は上記のような課題を解決するためになされたもので、文書中の文章間・単語間の関係等、文書から有用な知識を抽出でき、また非定形文書からの定義ファイルを作成しなおすことなく有用な知識が抽出できるメタデータ抽出装置を得ることを目的とする。 The present invention has been made to solve the above-described problems, and can extract useful knowledge from a document, such as the relationship between sentences and words in a document, and can create a definition file from an atypical document. It is an object of the present invention to provide a metadata extraction device that can extract useful knowledge without correction.
処理対象の電子文書を取得する文書取得手段と、文書取得手段が取得した電子文書から、電子文書に記述される文章を構成する要素と、各要素の電子文書内における相対的な位置を示す位置データとを抽出する要素抽出手段と、文章を構成する1または複数の要素からなる要素列の属性を、要素列を構成する要素の品詞に関連付けて定義した属性定義を記憶する属性定義記憶手段と、属性定義を参照して、前記要素列に属性を割り当てる属性割り当て手段と、属性割り当て手段が属性を割り当てた要素列のうち、着目する要素列間の関連性を示す関連度を算出する関連度算出手段と、属性割り当て手段が割り当てた属性を識別子として各要素列に付すと共に、関連度算出手段によって算出された関連度に応じて要素列同士をグループ化し、当該グループに対応する識別子を付すことによって第1の関連度抽出情報を生成する関連度抽出情報生成手段とを備えたものである。A document acquisition unit that acquires an electronic document to be processed, elements that constitute a sentence described in the electronic document from the electronic document acquired by the document acquisition unit, and a position that indicates the relative position of each element in the electronic document Element extraction means for extracting data, and attribute definition storage means for storing an attribute definition in which an attribute of an element sequence composed of one or more elements constituting a sentence is defined in association with a part of speech of an element constituting the element sequence , An attribute assignment unit that assigns an attribute to the element string with reference to the attribute definition, and a degree of association that calculates a degree of association indicating the relation between the element columns of interest among the element columns to which the attribute assignment unit has assigned the attribute The attribute assigned by the calculating means and the attribute assigning means is attached to each element string as an identifier, and element strings are grouped according to the degree of association calculated by the degree of association calculating means. It is obtained by a relation level extraction information generation means for generating afirst relation level extractor information by subjecting an identifier corresponding to the group.
処理対象の電子文書を取得する文書取得手段と、文書取得手段が取得した電子文書から、電子文書に記述される文章を構成する要素と、各要素の電子文書内における相対的な位置を示す位置データとを抽出する要素抽出手段と、文章を構成する1または複数の要素からなる要素列の属性を、要素列を構成する要素の品詞に関連付けて定義した属性定義を記憶する属性定義記憶手段と、属性定義を参照して、前記要素列に属性を割り当てる属性割り当て手段と、属性割り当て手段が属性を割り当てた要素列のうち、着目する要素列間の関連性を示す関連度を算出する関連度算出手段と、属性割り当て手段が割り当てた属性を識別子として各要素列に付すと共に、関連度算出手段によって算出された関連度に応じて要素列同士をグループ化し、当該グループに対応する識別子を付すことによって第1の関連度抽出情報を生成する関連度抽出情報生成手段とを備えるように構成したので、文書中の文章間・単語間の関係等、文書から有用な知識を抽出でき、また非定形文書からの定義ファイルを作成しなおすことなく有用な知識が抽出できる効果がある。A document acquisition unit that acquires an electronic document to be processed, elements that constitute a sentence described in the electronic document from the electronic document acquired by the document acquisition unit, and a position that indicates the relative position of each element in the electronic document Element extraction means for extracting data, and attribute definition storage means for storing an attribute definition in which an attribute of an element sequence composed of one or more elements constituting a sentence is defined in association with a part of speech of an element constituting the element sequence , An attribute assignment unit that assigns an attribute to the element string with reference to the attribute definition, and a degree of association that calculates a degree of association indicating the relation between the element columns of interest among the element columns to which the attribute assignment unit has assigned the attribute The attribute assigned by the calculating means and the attribute assigning means is attached to each element string as an identifier, and element strings are grouped according to the degree of association calculated by the degree of association calculating means. Since it is configured to include a relation level extractor information generating means for generating afirst relation level extractor information by subjecting an identifier corresponding to the group, the relationship or the like between the sentence and inter-word in the document, useful from the document Knowledge can be extracted, and useful knowledge can be extracted without recreating a definition file from a non-standard document.
実施の形態1.
図1はこの発明の実施の形態1によるメタデータ抽出装置のブロック図である。図に示すように、メタデータ抽出装置10は、文書取得手段11、文字抽出手段12、属性割り当て手段(要素抽出手段、属性割り当て手段)13、属性間関連度算出手段(関連度算出手段)14、属性構造化手段(第1の関連度抽出情報生成手段)15、出力手段16、属性定義DB(属性定義記憶手段)17、属性間関連度DB18を備える。
FIG. 1 is a block diagram of a metadata extraction apparatus according to
文書取得手段11は、ユーザが入力した文書を取得し、文字抽出手段12は、文書取得手段11が取得した文書に記述される文章を構成する文字、および各文字の位置座標を抽出する。属性割り当て手段13は、文字抽出手段12が抽出した文字に形態素解析を行い、属性定義DB17を参照して文字列に属性を割り当てる。属性間関連度算出手段14は、属性割り当て手段13が割り当てた文字列間の意味の関連性を示す関連度を算出する。属性構造化手段15は、属性間関連度算出手段14が算出した関連度に基づいて、関連性の高い文字列同士をグループ化して構造化文書を作成する。出力手段16は、作成された構造化文書をファイル形式で出力する。属性定義DB17は、文章を構成する文字列に対して属性を割り当てるために、文字列を構成する文字の品詞に関連付けて属性を定義した属性定義を保持する。属性間関連度DB18は、属性間の関連度を定性的な値で予め定義したテーブルを保持する。 The
図1の文書取得手段11、文字抽出手段12、属性割り当て手段13、属性間関連度算出手段14、属性構造化手段15、出力手段16はメタデータ抽出装置10の中央演算装置を、該中央演算装置の動作を制御するプログラムのモジュールに従って便宜的に分割したものである。 The
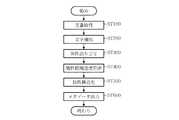
図2は図1のメタデータ抽出装置10の動作を示すフローチャートである。この図を参照してメタデータ抽出装置10の動作について説明する。
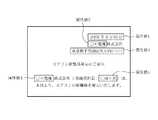
まず、文書取得手段11が、ユーザが指定したコンピュータ読み取り可能な文書を取得する(ステップST100)。例えば、コンピュータで処理可能なワープロソフト等を用いて作成した文書ファイル、CADソフトを用いて作成した図面ファイル、PDF(Portable Document Format)形式のファイル等を取得の対象とする。図3は文書取得手段11が取得した文書の例を示す図である。ここでは、ワープロソフトで作成した文書ファイルを用いるとする。FIG. 2 is a flowchart showing the operation of the
First, the
続いて、文字抽出手段12が文字抽出処理を行う(ステップST200)。文字抽出手段12は文書取得手段11が取得した文書ファイルから、記述されている文字、数字等の各要素の文字コードおよび文書内における位置座標を抽出する。文字コードおよび位置座標の抽出は、PDF等のようにフォーマット仕様が公開されているものについては、それに従って文書ファイルを解析することで文字コード、位置座標を抽出することができる。一方、仕様が公開されていないワープロソフト等で作成された文書については、文書を作成したアプリケーションから擬似的な印刷処理、すなわち、文書、画像等をプリンタが解釈できるページ記述言語で記述したPDFファイルを作成し、これを用いて文書解析を行って、文字コード、位置座標を抽出する。文字抽出手段12は抽出した文字コード、位置座標を属性割り当て手段13に供給する。 Subsequently, the character extraction means 12 performs a character extraction process (step ST200). The
属性割り当て手段13は、取得した文字コードと属性定義DB17が保持する属性定義とに基づいて、文書に記述される文字列に属性を割り当てる(ステップST300)。ここで、属性とは文書中に記述された文字列の意義を示す情報、例えば会社名、人名、地名等の固有表現、または日付、長さ、重さ、状態等の項目付けが可能な情報である。属性割り当て手段13は、属性定義DB17を参照して文字抽出手段12が抽出した文字コードに対応する属性を割り当てる。 The attribute assigning means 13 assigns an attribute to the character string described in the document based on the acquired character code and the attribute definition held in the attribute definition DB 17 (step ST300). Here, the attribute is information indicating the significance of the character string described in the document, for example, a unique expression such as a company name, a person name, or a place name, or information that can be itemized such as date, length, weight, state, etc. It is. The attribute assigning means 13 assigns an attribute corresponding to the character code extracted by the character extracting means 12 with reference to the
図4は属性定義DB17が保持する属性定義の例を示す図である。図には、「日付」、「所在地」、「組織名」、「社長」の属性が記述されている。例えば、属性「日付」は、2〜4桁の数字、記号、1〜2桁の数字、記号および1〜2桁の数字の組み合わせ、または、2〜4桁の数字、「年」、1〜2桁の数字、「月」、1〜2桁の数字および「日」の組み合わせによって表示される文字列であると定義される。また、属性「社長」は、構成文字の品詞および付加情報が[名詞−固有名詞−人名]からなり、かつ文字列「社長」の近くにある文字列であると定義される(詳細は後述する)。 FIG. 4 is a diagram illustrating an example of attribute definitions held in the
図5は属性割り当て手段13の動作を示すフローチャートである。この図を参照して属性割り当て手段13の具体的な動作について説明する。
属性割り当て手段13は、文字抽出手段12から取得した文字コードに対して形態素解析処理を行う(ステップST310)。形態素解析処理は日本文解析の公知の技術であるので詳細な動作の説明は省略するが、自然文を意味のある最小の単位に分解する処理である。属性割り当て手段13は形態素解析処理によって文章を意味のある最小の単位の文字列(以下、最小文字列と呼ぶ)に分け、各文字列に対して品詞を割り当てる。FIG. 5 is a flowchart showing the operation of the attribute assigning means 13. A specific operation of the
The
図6は図3に示す文書に対する属性割り当て手段13の形態素解析処理の結果を示す図である。図に示すように、形態素解析処理の結果、各最小文字列に品詞および必要に応じて付加情報1〜3が付加される。付加情報1は、文字列の品詞が名詞である場合に、その名詞の種類を示す。例えば、一般名詞、固有名詞等である。付加情報2は文字列の品詞が名詞で、かつ付加情報1が固有名詞である場合に、固有名詞の種類を示す。例えば、組織、地域、人名等である。さらに必要な場合は付加情報3が付加される。例えば、付加情報2が人名のとき「姓」、「名」が付加される。 FIG. 6 is a diagram showing the result of the morphological analysis processing of the
属性割り当て手段13はまた、図2のステップST200において文字抽出手段12が抽出した各要素の位置座標から、最小文字列の左上座標、右下座標を算出する。図6に各座標値を示す。ここに示す座標値は、例えば文書の横方向をx軸、縦方向をy軸としたときの原点からの距離を示す。各最小文字列は左上座標と右下座標を対角線とする矩形に収まるように配置される。 The
続いて、属性割り当て手段13は属性パタン照合処理を行う(ステップST320)。具体的には、図6に示した形態素解析結果に対して図4の属性定義との照合を行い、属性定義と一致する品詞および付加情報1〜3を有する文字列にその属性を割り当てる。例えば、「日付」の属性を割り当てる場合、図4の「日付」を表す組み合わせと一致する組み合わせからなる文字列を図6から抽出する。まず、「数字2〜4桁」となる文字列を検索する。図6の文頭1〜4文字が「数字2〜4桁」の文字列に当てはまるため、文頭1〜4文字である「2003」を抽出する。続いて、「2003」に続く文字が「記号」または「年」であるかを判定する。図6では、「2003」に続いて「年」が出現するので、ここまで「日付」の照合に成功し、「年」を抽出する。以下、属性割り当て手段13は同様に処理を続行し、「日」まで抽出したところで文字列「2003年9月16日」に属性「日付」を割り当てる。 Subsequently, the
属性割り当て手段13は、同様に他の属性についても図4の属性定義に従って文字列に割り当てる。例えば、「組織名」の属性を割り当てる場合は、品詞−付加情報1−付加情報2が[名詞−固有名詞−組織]となる文字列を抽出して割り当てる。図7、図8は図3に示す文書のうち属性割り当て手段13によって属性が割り当てられた文字列を説明する図である。図8に示すように、属性割り当て手段13は属性「日付」を文字列「2003年9月16日」に、属性「組織名」を文字列「○×電気」に、属性「所在地」を文字列「東京都千代田区丸の内1−1−1」に、属性「社長」の文字列「○田×男」に割り当てた。以降、属性を割り当てた文字列を属性値と称する。図8にはまた抽出した各属性値の左上座標、右上座標も示す。属性割り当て手段13は割り当て結果を属性間関連度算出手段14に供給する(ステップST330)。 Similarly, the
続いて、属性間関連度算出手段14は属性値間の関連度の算出を行う。関連度とは着目する2属性値間の意味、位置関係に基づく関連性を示す値であり、割り当てられた属性の関連度に基づいて算出される。図9は図4に定義された属性間の関連度を記述した属性間関連度テーブルである。各関連度は0から1までの値をとり、数値が大きいほど関連度が高いとする。例えば、図9に示すように「組織名」と、「所在地」、「社長」の関連度がそれぞれ0.8であるのに対し、「日付」と、「組織名」、「所在地」、「社長」の関連度、「所在地」と「社長」の関連度はそれぞれ0.3と低く設定している。属性間関連度テーブルは、ユーザが予め作成して属性間関連度DB18に保存するものであり、ここでは日本文文法と属性内容を参考にヒューリスティックに作成する。 Subsequently, the inter-attribute relevance calculation means 14 calculates the relevance between attribute values. The relevance is a value indicating the relevance based on the meaning and positional relationship between the two attribute values of interest, and is calculated based on the relevance of the assigned attribute. FIG. 9 is an inter-attribute relevance table describing the relevance between attributes defined in FIG. Each degree of association takes a value from 0 to 1, and it is assumed that the degree of association is higher as the numerical value is larger. For example, as shown in FIG. 9, the degree of association between “organization name”, “location”, and “president” is 0.8, whereas “date”, “organization name”, “location”, “ The relevance level of “President” and the relevance level of “Location” and “President” are each set as low as 0.3. The inter-attribute relevance table is created in advance by the user and stored in the
図10は属性間関連度算出手段14の動作を示すフローチャートである。この図を参照して文書属性間関連度の算出手順について説明する。
まず属性間関連度算出手段14は、文章を構成する要素に対して属性割り当て手段13が属性を割り当てた属性値の数を求め変数Nに代入する(ステップST410)。ここでは図8に示すように5つの文字列に属性を割り当てたため、N=5である。続いて、変数iに1を代入し(ステップST420)、変数jをj=i+1からj=Nまで変化させながら各属性との関連度を以下の式を用いて算出する(ステップST430)。FIG. 10 is a flowchart showing the operation of the attribute relevance calculation means 14. A procedure for calculating the degree of association between document attributes will be described with reference to FIG.
First, the inter-attribute
F(PiPj)=a1*f1(PiPj)
+a2*f2(PiPj)+a3*f3(PiPj) …(1)F (Pi Pj ) = a1 * f1 (Pi Pj )
+ A2 * f2 (Pi Pj ) + a3 * f3 (Pi Pj ) (1)
a1+a2+a3=1 …(2)a1 + a2 + a3 = 1 (2)
f2(PiPj)=1/log(ZiZj+1) (ZiZj>0)…(3)
=1 (ZiZj=0)f2 (Pi Pj ) = 1 / log (Zi Zj +1) (Zi Zj > 0) (3)
= 1 (Zi Zj = 0)
f3(PiPj)=1(同一文内) …(4)
=0(上記以外)f3 (Pi Pj ) = 1 (in the same sentence) (4)
= 0 (other than above)
ここで、F(PiPj)は属性値Piと属性値Pjとの関連度、f1(PiPj)は図9に示す属性間関連度テーブルの値、f2(PiPj)は注目する2つの属性値の位置座標の距離を用いた評価値であり、式(3)で表す。式(3)においてZiZjは属性値Piと属性値Pjの距離であり、図8に示す左上座標および右下座標で囲まれる各矩形同士の最短距離である。a1,a2,a3は式(2)を満たすように予め設定される任意の値である。Here, F (Pi Pj ) is the degree of association between the attribute value Pi and the attribute value Pj , f1 (Pi Pj ) is the value of the inter-attribute degree of association table shown in FIG. 9, and f2 (Pi Pj ) is an evaluation value using the distance between the position coordinates of two attribute values of interest, and is expressed by Expression (3). In Expression (3), Zi Zj is the distance between the attribute value Pi and the attribute value Pj , and is the shortest distance between the rectangles surrounded by the upper left coordinates and the lower right coordinates shown in FIG. a1 , a2 , and a3 are arbitrary values set in advance so as to satisfy Expression (2).
f3(PiPj)は文脈に依存する評価値であり、式(4)で表す。すなわち、属性間関連度算出手段14は注目する2つの属性値が同一文内に存在するか否かを判定し、存在する場合は1を、存在しない場合は0を割り当てる。同一文内に存在するか否かは、注目する2属性値間に存在する文字列中の助詞または句点の有無から判定する。2属性値間の文字列中に助詞を含み、かつ句点、ピリオド等の文書の終了を示す記号を含まない場合には同一文内にあると判定する。例えば、図7で属性値1「2003年9月16日」を含む行と属性値2「○×電気」を含む行との間には助詞が存在しないため、同一文ではないと判定する。f3 (Pi Pj ) is an evaluation value depending on the context, and is represented by Expression (4). That is, the inter-attribute relevance calculation means 14 determines whether or not two attribute values of interest exist in the same sentence, and assigns 1 if they exist and 0 if they do not exist. Whether or not they exist in the same sentence is determined from the presence or absence of particles or phrases in the character string existing between the two attribute values of interest. If the character string between the two attribute values includes a particle and does not include a symbol indicating the end of the document such as a punctuation mark or a period, it is determined that they are in the same sentence. For example, in FIG. 7, since there is no particle between the line including
式(1)から、関連度F(PiPj)はPiとPjとの属性間関連度テーブルに示される属性間関連度の値が大きいほど、また位置座標の距離が小さいほど、さらに同一文中にあるほど高くなる。From Expression (1), the degree of association F (Pi Pj ) is larger as the value of the degree of association between attributes shown in the attribute degree of association table between Pi and Pj is larger, and as the position coordinate distance is smaller. Furthermore, it becomes higher as it is in the same sentence.
属性間関連度算出手段14は関連度Fを算出すると、算出した関連度Fが閾値よりも高いか否かを判定し(ステップST440)、高い場合はグループ化処理を行う(ステップST450)。例えば、閾値を0.6とする。i=1のときj=i+1〜Nの関連度Fをそれぞれ算出し、PiとPjの関連度Fが0.6以上であるものを同一の属性グループであると認定する。続いて、i=Nであるか否かを判定し(ステップST460)、i=Nの場合は処理を終了し、i≠Nの場合はiをインクリメントして(ステップST470)、ステップST430に戻る。After calculating the relevance F, the inter-attribute relevance calculation means 14 determines whether or not the calculated relevance F is higher than the threshold (step ST440), and if it is higher, performs a grouping process (step ST450). For example, the threshold is 0.6. When i = 1, the degree of association F of j = i + 1 to N is calculated, respectively, and those having a degree of association F of Pi and Pj of 0.6 or more are recognized as the same attribute group. Subsequently, it is determined whether or not i = N (step ST460). If i = N, the process ends. If i ≠ N, i is incremented (step ST470), and the process returns to step ST430. .
例えば、a1=a2=0.4、a3=0.2として属性値間のf1〜f3および関連度Fの値を計算する。図11〜図14は計算結果を示す図であり、図11はf1の値、図12はf2の値、図13はf3の値、図14は関連度Fの値をそれぞれ示す。図11〜図14の属性値1〜5は図7の属性値1〜5にそれぞれ対応する。For example, the values of f1 to f3 and the degree of association F between the attribute values are calculated as a1 = a2 = 0.4 and a3 = 0.2. 11 to 14 are views showing calculation results, Fig. 11 shows the value off 1, 12 the value off 2, FIG. 13 is the value off 3, Figure 14 the value of the relevance F respectively. The attribute values 1 to 5 in FIGS. 11 to 14 correspond to the attribute values 1 to 5 in FIG. 7, respectively.
図14においてi=1(属性値1)とj=2〜5(属性値2〜属性値5)との関連度はそれぞれ0.42,0.33,0.26,0.29であり、全て0.6未満であるためグループ化処理は行わない。i=2(属性値2),j=3(属性値3)のとき、図14より関連度F=0.62であり、閾値0.6以上であるためグループ化処理を行う。属性間関連度算出手段14は、属性値2と属性値3とが同一の属性グループである旨の情報を保持しておく。また、図14から、属性値4と属性値5の関連度F=0.67であり、閾値0.6以上であるため属性値4と属性値5も同一グループであるとの情報を保持しておく。 In FIG. 14, the relevance between i = 1 (attribute value 1) and j = 2 to 5 (attribute value 2 to attribute value 5) is 0.42, 0.33, 0.26, and 0.29, respectively. Since all of them are less than 0.6, the grouping process is not performed. When i = 2 (attribute value 2) and j = 3 (attribute value 3), the relevance F = 0.62 as shown in FIG. The attribute relevance calculation means 14 holds information indicating that the attribute value 2 and the attribute value 3 are the same attribute group. Further, from FIG. 14, the degree of association F = 0.67 between the attribute value 4 and the attribute value 5 and the threshold value 0.6 or more holds information indicating that the attribute value 4 and the attribute value 5 are also in the same group. Keep it.
続いて、属性構造化手段15が属性構造化処理を行う(ステップST500)。ここでは、属性割り当て手段13の出力結果、すなわち図7、図8に示す結果と、属性間関連度算出手段14の算出結果、すなわち図14に示す結果とに基づいて処理を行い、関連度が高い属性同士を同一タグ(識別子)、例えば「グループ」タグで囲んで出力する。上述のように、属性間関連度算出手段14は属性値2と属性値3、属性値4と属性値5をそれぞれ同一グループと判定している。また、属性値2と属性値4は同一値(「○×電機」)であるため、属性構造化手段15は属性値2、属性値3および属性値5が同一グループであると判定し、これら3つの属性値について構造化処理を行う。ここでは、各属性値をその属性に対応するタグによって囲み、ファイル形式の文書を作成する。 Subsequently, the attribute structuring means 15 performs an attribute structuring process (step ST500). Here, processing is performed based on the output result of the
図15は属性構造化手段15による文書属性構造化処理の結果を示す図である。図に示すように、各属性値をその属性を示すタグで囲み、さらに属性間関連度算出手段14が同一グループと判定した「○×電機」、「東京都千代田区丸の内1−1−1」および「○田×男」を「グループ」タグで囲む。一方、グループ化されない「2003年9月16日」については「グループ」タグで囲まない。属性構造化手段15は、グループ化した結果をファイル形式で出力手段16に供給する。出力手段16は、取得した処理結果をファイル形式でメタデータ保存領域に登録したり、文書保存サーバ(図示せず)に出力したりする(ステップST600)。 FIG. 15 is a diagram showing the result of the document attribute structuring process by the attribute structuring means 15. As shown in the figure, each attribute value is enclosed by a tag indicating the attribute, and the inter-attribute relevance calculation means 14 determines that the group is the same group, “○ × Denki”, “1-1-1 Marunouchi, Chiyoda-ku, Tokyo” Enclose "* da x man" with a "group" tag. On the other hand, “September 16, 2003” that is not grouped is not surrounded by a “group” tag. The
以上のように、この実施の形態1によれば、属性を品詞に関連付けて定義した属性定義に従って属性割り当て手段13が文書に記述される文字列に属性を割り当て、属性間関連度算出手段14が属性値間の関連度を判定してグループ化し、属性構造化手段15が構造化してメタデータを出力するようにしたので、定型文書のみでなく非定形文書からもメタデータの抽出が行えると共に、関連度の高い属性値同士をグループ化することで属性値間の関連を示すことができるため、検索、閲覧等においてユーザにとって使い勝手のよいメタデータを抽出することができるという効果が得られる。 As described above, according to the first embodiment, the
実施の形態2.
この実施の形態2では、上記実施の形態1で説明した単一文書に対して属性を割り当てて属性値間の関連度を判定することに加えて、他の文書またはデータベース中の文字列の属性とも照合を行い、関連度の高い属性値を同一グループ化する処理について説明する。Embodiment 2. FIG.
In the second embodiment, in addition to determining an association between attribute values by assigning an attribute to the single document described in the first embodiment, the attribute of a character string in another document or database. In the following, a process for performing collation and grouping attribute values having high relevance to the same group will be described.
図16はこの発明の実施の形態2によるメタデータ抽出装置のブロック図である。図に示すように、このメタデータ抽出装置10’は実施の形態1の図1に示す構成に加えて、属性追加手段19と文書DB20とを備える。属性追加手段19は、文書取得手段11が取得した文書が含む属性グループを他の文書が含む属性グループと比較して、他の文書に同一の属性グループが存在する場合はそこから属性値を取り込む処理を行う。文書DB20は、文書とそのメタデータを保持する。 FIG. 16 is a block diagram of a metadata extraction apparatus according to Embodiment 2 of the present invention. As shown in the figure, the
図17は、この発明の実施の形態2によるメタデータ抽出装置の動作を示すフローチャートである。この図は実施の形態1の図2に示すフローチャートのステップST500とステップST600の間に属性追加処理(ステップST600)を追加し、メタデータ出力処理をステップST700としたものである。この図を参照してメタデータ抽出装置の動作について説明する。 FIG. 17 is a flowchart showing the operation of the metadata extraction apparatus according to the second embodiment of the present invention. In this figure, attribute addition processing (step ST600) is added between step ST500 and step ST600 of the flowchart shown in FIG. 2 of the first embodiment, and metadata output processing is made step ST700. The operation of the metadata extraction apparatus will be described with reference to this figure.
文書取得手段11が文書の取得処理を行う(ステップST100)。ここでは、実施の形態1と同様に、図3に示す文書を取得するとする。以降、ステップST200からステップST600まで実施の形態1と同様の処理を行い、図15に示す結果を取得する。 The
続いて、属性追加手段19が属性追加処理を行う(ステップST600)。図18は属性追加手段19の動作を示すフローチャートである。この図を参照して属性追加手段19の動作について説明する。
属性追加手段19は属性構造化手段15から図15に示す構造化処理結果を取得すると、文書DB20が蓄積する文書数Nをカウントして取得する。図19は、文書DB20に格納されるメタデータの例を示す図である。ここでは、文書DB20には図19に示すメタデータとこのメタデータに対応する1文書のみが格納されているとする。したがって、N=1とする(ステップST710)。Subsequently, the attribute adding means 19 performs an attribute adding process (step ST600). FIG. 18 is a flowchart showing the operation of the
When the
続いて、属性追加手段19は、変数kに1を代入し(ステップST720)、蓄積文書D1のメタデータ数mを取得する(ステップST730)。メタデータ数とは「グループ」タグの数であり、図19のメタデータにおいてはm=1である。続いて、属性追加手段19は蓄積文書D1の各メタデータのグループと文書中のグループとの同一性を判定する。 Subsequently, the
同一性の判定は、文書中のグループと蓄積文書のメタデータのグループとを比較し、属性名と属性値とが共に一致する属性値がグループ内で一定数α以上である場合は同一であると判定する。図19と図15に示す属性グループを比較すると、「組織名」、「所在地」、「社長」の3つの属性名およびその属性値が一致する(ステップST740)。ここで、Mは取得文書中のメタデータ数である。属性追加手段19はこの同一属性値数3に基づいて同一性の判定を行う(ステップST750)。例えば、閾値α=2とすると、同一の属性グループであると判断される。 The identity determination is the same when the group in the document is compared with the metadata group of the stored document, and the attribute value having the same attribute name and attribute value is equal to or greater than a certain number α in the group. Is determined. When the attribute groups shown in FIGS. 19 and 15 are compared, the three attribute names “organization name”, “location”, and “president” and their attribute values match (step ST740). Here, M is the number of metadata in the acquired document. The attribute adding means 19 determines the identity based on the same attribute value number 3 (step ST750). For example, if the threshold value α = 2, it is determined that they are the same attribute group.
同一の属性グループである場合、属性追加手段19はタグ取り込み処理を行う(ステップST760)。具体的には、属性追加手段19は文書DB20内のメタデータの「グループ」タグ内に存在して、文書取得手段11が取得した文書中の「グループ」タグ内に存在しない属性を検出する。図15と図19を比較すると「資本金」および「2002年度売上」の2つの属性がこれに該当する。そこで、属性追加手段19はこれら2つの属性を図15に示す「グループ」タグ内に加える。図20は属性追加手段19によるタグ取り込み処理の結果を示す図である。属性追加手段19は図15の「グループ」タグ内に「資本金」および「2002年度売上」を追加した。 If they are the same attribute group, the attribute adding means 19 performs a tag capturing process (step ST760). Specifically, the
また、文書中の「グループ」タグ内に存在して蓄積文書のメタデータの「グループ」タグ内に存在しない属性値がある場合は、その属性値をメタデータの「グループ」タグ内に取り込む。ここでは、図15の「グループ」タグ内に存在して図19の「グループ」タグ内には存在しない属性値はないので、取り込み処理は行わない。続いて、変数kと変数Nを比較し(ステップST770)、k=Nである場合は処理を終了し、k≠Nである場合はkをインクリメントして(ステップST780)、ステップST730に戻る。ここではk=N=1であるため、処理を終了する。 If there is an attribute value that exists in the “group” tag in the document but does not exist in the “group” tag of the metadata of the stored document, the attribute value is taken into the “group” tag of the metadata. Here, since there is no attribute value that exists in the “group” tag in FIG. 15 but does not exist in the “group” tag in FIG. 19, the import process is not performed. Subsequently, the variable k and the variable N are compared (step ST770). If k = N, the process ends. If k ≠ N, k is incremented (step ST780), and the process returns to step ST730. Here, since k = N = 1, the process ends.
以上のように、この実施の形態2によれば、属性追加手段19が、文書入力手段11が取得した文書のメタデータのグループと文書DB20が保持する文書のメタデータのグループとを比較し、同一グループと判定した場合には各グループ間で属性値の取り込みを行うようにしたので、文書中に記述のない属性値についても他の文書またはデータベースから取り込むことができるため、文書中に記述のない内容についてもメタデータとして保持・活用できる効果が得られる。 As described above, according to the second embodiment, the
10,10’ メタデータ抽出装置、11 文書取得手段、12 文字抽出手段、13 属性割り当て手段(要素抽出手段、属性割り当て手段)、14 属性間関連度算出手段(関連度判定手段)、15 属性構造化手段(第1の関連度抽出情報生成手段)、16 出力手段、17 属性定義DB(属性定義記憶手段)、18 属性間関連度DB、19 属性追加手段、20 文書DB。10, 10 'metadata extraction device, 11 document acquisition means, 12 character extraction means, 13 attribute assignment means (element extraction means, attribute assignment means), 14 inter-attribute relevance calculation means (relevance degree determination means), 15 attribute structure Conversion means (first relevance degree extraction information generation means), 16 output means, 17 attribute definition DB (attribute definition storage means), 18 inter-attribute relevance DB, 19 attribute addition means, 20 document DB.
Claims (4)
Translated fromJapanese前記文書取得手段が取得した電子文書から、当該電子文書に記述される文章を構成する要素と、各要素の電子文書内における相対的な位置を示す位置データとを抽出する要素抽出手段と、
前記文章を構成する1または複数の要素からなる要素列の属性を、当該要素列を構成する要素の品詞に関連付けて定義した属性定義を記憶する属性定義記憶手段と、
前記属性定義を参照して、前記要素列に属性を割り当てる属性割り当て手段と、
前記属性割り当て手段が属性を割り当てた要素列のうち、着目する要素列間の関連性を示す関連度を算出する関連度算出手段と、
前記属性割り当て手段が割り当てた属性を識別子として各要素列に付すと共に、前記関連度算出手段によって算出された関連度に応じて要素列同士をグループ化し、当該グループに対応する識別子を付すことによって第1の関連度抽出情報を生成する関連度抽出情報生成手段とを備えたメタデータ抽出装置。Document acquisition means for acquiring an electronic document to be processed;
Element extracting means for extracting elements constituting the text described in the electronic document and position data indicating the relative position of each element in the electronic document from the electronic document acquired by the document acquiring means;
Attribute definition storage means for storing an attribute definition in which the attribute of an element sequence composed of one or more elements constituting the sentence is defined in association with the part of speech of the element constituting the element sequence;
Referring to the attribute definition, attribute assigning means for assigning an attribute to the element sequence;
Of the element strings to which the attribute assigning means has assigned attributes, a relevance degree calculating means for calculating a relevance degree indicating the relevance between the element strings of interest;
The attribute assignment unit assigns the attribute assigned to each element column as an identifier, groups the element sequences according to the degree of association calculated by the association degree calculation unit, and attaches an identifier corresponding to the group. A metadata extraction device comprising: relevance level extraction information generating means for generating1 relevance level extraction information.
前記関連度抽出情報蓄積手段が蓄積する第2の関連度抽出情報と、関連度抽出情報生成手段が生成した第1の関連度抽出情報とを比較して各関連度抽出情報が保持するグループの同一性を判定し、同一とみなしたグループ間において一方のグループに存在して他方のグループに存在しない属性を存在しないグループに追加する属性追加手段とを備えたことを特徴とする請求項1または請求項2記載のメタデータ抽出装置。Asecond relation level extractor information relevant degree extraction information storage means and the relation level extraction information storage means for storing asecond relation level extractor information storingfirst relevance generated is relevance extraction information generation means Compare the extracted information to determine the identity of the group held by each relevance degree extracted information, and add the attributes that exist in one group and do not exist in the other group to the non-existing group The metadata extraction device according to claim 1, further comprising: an attribute addition unit configured to perform the attribute addition.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004046611AJP4307287B2 (en) | 2004-02-23 | 2004-02-23 | Metadata extraction device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004046611AJP4307287B2 (en) | 2004-02-23 | 2004-02-23 | Metadata extraction device |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2005235099A JP2005235099A (en) | 2005-09-02 |
| JP4307287B2true JP4307287B2 (en) | 2009-08-05 |
Family
ID=35017972
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004046611AExpired - Fee RelatedJP4307287B2 (en) | 2004-02-23 | 2004-02-23 | Metadata extraction device |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4307287B2 (en) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4807618B2 (en) | 2006-03-06 | 2011-11-02 | 富士ゼロックス株式会社 | Image processing apparatus and image processing program |
| WO2010061813A1 (en) | 2008-11-26 | 2010-06-03 | 日本電気株式会社 | Active metric learning device, active metric learning method, and active metric learning program |
| KR101204039B1 (en)* | 2012-06-28 | 2012-11-23 | (주) 사이냅소프트 | Character string extraction system and method thereof |
| JP7581148B2 (en) | 2021-08-03 | 2024-11-12 | 株式会社東芝 | Information processing device, information processing method, and information processing program |
- 2004
- 2004-02-23JPJP2004046611Apatent/JP4307287B2/ennot_activeExpired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2005235099A (en) | 2005-09-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US7958444B2 (en) | Visualizing document annotations in the context of the source document | |
| CN110377560B (en) | Method and device for structuring resume information | |
| TWI536181B (en) | Language identification in multilingual text | |
| US20070055493A1 (en) | String matching method and system and computer-readable recording medium storing the string matching method | |
| JP4502615B2 (en) | Similar sentence search device, similar sentence search method, and program | |
| CN106980664A (en) | A kind of bilingual comparable corpora mining method and device | |
| CN104077346A (en) | Document creation support apparatus, method and program | |
| US7359896B2 (en) | Information retrieving system, information retrieving method, and information retrieving program | |
| CN115203445B (en) | Multimedia resource search method, device, equipment and medium | |
| CN115794995A (en) | Target answer obtaining method and related device, electronic equipment and storage medium | |
| CN101308512B (en) | Mutual translation pair extraction method and device based on web page | |
| US20130013604A1 (en) | Method and System for Making Document Module | |
| JP5577546B2 (en) | Computer system | |
| CN119808752A (en) | Document comparison and tracing method, device and computer storage medium | |
| JP2018136900A (en) | Sentence analysis device and sentence analysis program | |
| JP4307287B2 (en) | Metadata extraction device | |
| CN119272756A (en) | Management method, device and storage medium of multimodal knowledge base | |
| EP3432161A1 (en) | Information processing system and information processing method | |
| US20140358522A1 (en) | Information search apparatus and information search method | |
| JP2016018279A (en) | Document file search program, document file search apparatus, document file search method, document information output program, document information output apparatus, and document information output method | |
| JP2009277099A (en) | Similar document retrieval device, method and program, and computer readable recording medium | |
| CN114281979A (en) | Text processing method, device and equipment for generating text abstract and storage medium | |
| JP4486324B2 (en) | Similar word search device, method, program, and information search system | |
| WO2010103916A1 (en) | Device for presentation of characteristic words in document and program giving priority of characteristic words | |
| JP5285491B2 (en) | Information retrieval system, method and program, index creation system, method and program, |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination | Free format text:JAPANESE INTERMEDIATE CODE: A621 Effective date:20070124 | |
| RD04 | Notification of resignation of power of attorney | Free format text:JAPANESE INTERMEDIATE CODE: A7424 Effective date:20071016 | |
| RD04 | Notification of resignation of power of attorney | Free format text:JAPANESE INTERMEDIATE CODE: A7424 Effective date:20080714 | |
| A977 | Report on retrieval | Free format text:JAPANESE INTERMEDIATE CODE: A971007 Effective date:20090129 | |
| A131 | Notification of reasons for refusal | Free format text:JAPANESE INTERMEDIATE CODE: A131 Effective date:20090210 | |
| A521 | Written amendment | Free format text:JAPANESE INTERMEDIATE CODE: A523 Effective date:20090323 | |
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) | Free format text:JAPANESE INTERMEDIATE CODE: A01 Effective date:20090421 | |
| A01 | Written decision to grant a patent or to grant a registration (utility model) | Free format text:JAPANESE INTERMEDIATE CODE: A01 | |
| A61 | First payment of annual fees (during grant procedure) | Free format text:JAPANESE INTERMEDIATE CODE: A61 Effective date:20090428 | |
| R150 | Certificate of patent or registration of utility model | Free format text:JAPANESE INTERMEDIATE CODE: R150 | |
| FPAY | Renewal fee payment (event date is renewal date of database) | Free format text:PAYMENT UNTIL: 20120515 Year of fee payment:3 | |
| FPAY | Renewal fee payment (event date is renewal date of database) | Free format text:PAYMENT UNTIL: 20120515 Year of fee payment:3 | |
| FPAY | Renewal fee payment (event date is renewal date of database) | Free format text:PAYMENT UNTIL: 20130515 Year of fee payment:4 | |
| LAPS | Cancellation because of no payment of annual fees |