JP3832693B2 - Structured document search and display method and apparatus - Google Patents
Structured document search and display method and apparatusDownload PDFInfo
- Publication number
- JP3832693B2 JP3832693B2JP19803898AJP19803898AJP3832693B2JP 3832693 B2JP3832693 B2JP 3832693B2JP 19803898 AJP19803898 AJP 19803898AJP 19803898 AJP19803898 AJP 19803898AJP 3832693 B2JP3832693 B2JP 3832693B2
- Authority
- JP
- Japan
- Prior art keywords
- search
- information
- document
- structured document
- highlight
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images











































Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Document Processing Apparatus (AREA)
Description
Translated fromJapanese【0001】
【発明の属する技術分野】
本発明は、SGML、HTMLなどによって作成された構造化文書に対する検索表示技術に係り、特に構造化文書に対して検索を行い、検索結果に対してハイライトして表示する構造化文書検索表示方法および装置に関する。
【0002】
【従来の技術】
ワードプロセッサなどの普及により、作成される文書情報の電子化が進んでいる。これらの電子化文書は、作成される機器、ソフトウェアによって個々のフォーマットを持っており、別の機器あるいはソフトウェアでは、利用できない、あるいは、何らかの変換手段を用意することが必要となっていた。
このような文書交換のための共通フォーマットとして、各種の構造化文書が提案されている。これらの構造化文書は、文書の基本構造である、章、節、項などの階層構造を定義できるだけでなく、レイアウト情報を含む事も可能となっている。
【0003】
構造化文書の記述言語として、標準化が進められているのが、SGML(Standard Generalized Markup Language)=「標準一般化マークアップ言語」である。
SGMLは、構造化文書の構造情報をタグと呼ばれる特定の文字列をテキスト中に埋め込むことで、文書の構造を表現する方法を用いている。SGMLでは、タグの名称、内容、さらに、タグによって示される文書構造をDTD(Document Type Definition)=「文書型定義」によって規定することができる。上記のSGML、DTDについては、「実践SGML」(SGML懇談会実用化WG監訳 1992年4月20日 財団法人 日本規格協会発行)に詳細に説明されている。
これらの構造化文書を検索システムのDBに登録して、構造名を指定して検索しようとする場合を想定する。登録しようとする各文書のDTDが異なる場合、処理方法としては、文書ごとに文書構造を解析して、指定された構造名がどの部分に相当するかを解析した上で、検索対象の文字列を取得して検索する方法が考えられる。
しかし、この方法は、多くの処理時間を必要とする。また、構造名ごとに各文書の対応する箇所をテーブルで持つなどの方法を用いる場合、各文書に出現する構造名を全て一括して管理し、構造名ごとに各文書の対応する部分を登録する必要があり、膨大な管理テーブルが必要となる。
さらに、異なるDTDが混在する文書を登録しても、検索対象の構造をすべての文書が持っているとは限らず、また、例えば、「要約」、「要旨」のように、同じ内容であっても異なる構造名を付けた場合、これらの異なる構造名を全て指定して、検索を行なわなければならず、現実的な構造化文書の検索とは考えられない。
【0004】
したがって、同じ文書型定義で生成された文書だけを登録するように運用することが構造化文書の検索では必要となる。あらかじめ指定された構造名について、各文書の対応する部分を管理する。
検索の際には、検索対象の構造名および検索条件を指定すると、各文書の指定された構造に対応する部分に検索条件に当てはまる文字列が含まれると、検索条件にヒットしたと判断される。
【0005】
構造化文書の検索結果として、文書の内容を表示するための機能の従来技術について以下に述べる。
まず、第1の従来技術として、特開平8-339369「文書表示装置および文書表示方法」が挙げられる。
本従来技術は、SGML文書の構造解析および構造表示用のレイアウトへの変換、さらに指定構造の内容の表示を行う方法について述べられており、本技術を用いることで構造化文書を構造単位で表示することが可能である。さらに、本従来技術においては、指定構造のハイライト表示(強調した表示のことであり、色、字体、字の大きさ等を変えたり、アンダーラインを付したりする)の手段を提供している。
しかし、ここで示されているハイライト表示手段とは、構造毎に表示方法をコントロールする手段であり、構造単位に、表示の有無、ハイライト表示などの指定を行う。したがって、本従来技術において、構造化文書の検索結果の表示を実現する際に必要となる、ヒットした検索タームに対するハイライト表示を実現する方法が示されているわけではない。
【0006】
また、第2の従来技術としては、特開平8-212230「文書検索方法および文書検索装置」で構造化文書以外の文書の検索結果に対するハイライト表示方法が示されている。
しかし、本従来技術は、表示するためのテキストに対するヒット範囲の取得およびハイライト情報の付加を実現するのみであり、構造化文書の検索結果として得られた文書に対してハイライト情報を付加する機能を持つわけではない。
【0007】
上記2つの従来技術を組み合わせただけでは、構造化文書に対する検索結果として出力する文書に対して、ヒットしたタームに対するハイライト情報の付加を実現する事はできない。
つまり、構造化文書において、ハイライト表示を実現するためには、表示対象の文書の作成時のDTDにハイライト用の構造情報を追加したDTDを作成する手段が必要となる。
【0008】
構造化文書にハイライト情報を付加した際の文書型定義の変更方法については、第3の従来技術である、特願平8-159202「構造化文書の版管理方法および装置」に、元のDTDに対して新たな構造を追加したDTDを生成する方法が示されている。
本従来技術を用いる事により、ハイライト情報を付加した文書型定義を作成することができる。
【0009】
第1、第2の従来技術により、構造化文書を構造が分かるように表示すること、さらに構造化されていない文書においては、ヒット範囲のハイライト表示をする事が可能であることがわかる。
さらに、第3の従来技術を用いることにより、構造ごとに取得したハイライト情報を付加した文書型定義が指定できる。
これらの技術を組み合わせることで、構造化文書の特定の構造の検索結果に対してハイライト情報を付加した構造化文書を出力し、ハイライト表示を実現する事ができる。
【0010】
また、最新の情報を入手する方法として、近年インターネットが爆発的に広まっている。インターネット上に存在する数多くの情報から自分が必要とする情報をいち早く知る手段として、Web上の情報の検索機能も充実してきた。
HTML(Hyper Text Markup Language)は、WWW(World Wide Web)上において、文書内容を記述し、他の資源へのリンク情報、文書のフォーマットを表現するための言語である。HTMLは、特定のDTDにしたがって記述されたSGMLとみなすことができる。このHTML文書を作成、加工する手段として、HTMLエディタがある。また、作成されたHTML文書を解析し、表示するHTMLブラウザが存在する。
HTMLブラウザには、検索する文字列(以下、「検索ターム」という。)を入力し、表示中のHTML文書に対して検索を行い、ヒットした箇所を反転表示などの強調表示を行う機能を持つものがある。
SGMLについても、レイアウト表示し、加工する機能を持つSGMLブラウザが存在する。SGMLブラウザには、ブラウザ上に表示中のSGML文書に対して、全文検索し、検索条件に適合する箇所をハイライト表示する。これらのブラウザでは、文書表示の際に文書の解析を行ない、表示用のデータを作成している。検索はこのブラウザ上の表示用のデータに対して検索を行ない、画面上でヒット位置をハイライト表示している。
【0011】
【発明が解決しようとする課題】
上記の従来技術の組み合わせにより、与えられた構造化文書に対して、構造毎に検索した結果を、個々にハイライト表示することが可能である。
しかし、構造情報には、章、節、項のように文書構造そのものを表わしているものだけでなく、アンダーラインの付加などレイアウト用の情報も含まれる場合がある。これらの構造情報は、必ずしも文の切れ目で挿入されるとは限らない。文書検索する際には、このような構造情報を除去しなければ、文書中に含まれている語であるにもかかわらず、検索できないという問題がある。このように、検索時に不要となる構造情報を除去する処理を、以下の説明では「正規化処理」と呼ぶ。
正規化処理を行なった構造化文書を検索対象とし、元の構造化文書に対してハイライト情報を付加した表示を実現するためには、正規化処理を行なった構造化文書に対して、上記の従来技術を用いた方法を利用するだけでは実現できない。つまり、この方法では、検索時には、元の文書の構造情報の一部しか残っていないため、この構造情報に対してハイライト情報を付加するだけでは、元の構造化文書に対してヒットした検索タームのハイライト表示を実現することにならないのである。
【0012】
一方、HTML文書は、ブラウザ依存の独自の拡張により複数のDTDに基づいて作成されたHTML文書が存在し、またどのDTDに基づいて記述されているかがわからない。さらに、SGMLの文法に基づいて正しく記述されていない文書も数多く存在するため、SGMLと同様の方法で構造解析することは困難である。
また、(1)プレーンなテキスト文書に対しては、検索処理を行い、検索ヒット位置の前後にハイライト用のタグを挿入したHTML文書を生成することにより、HTMLブラウザ上で、検索ヒットした文字列を強調表示することが可能である。しかし、タグ内の文字列が検索タームと一致した場合、この検索ヒット位置の前後に対して、ハイライト用のタグを挿入すると、元々のHTMLのタグの内容が変更されるため、正しく表示されなくなるといった問題が起こる。
さらに、(2)HTMLブラウザ上で連続して表示されている文字列の途中に、レイアウトを表現するタグが挿入されている場合があり、HTML文書に対して検索する場合は、タグを除いて検索しなければ正しく検索することができない。
例えば、HTML文書中に「今月の<FONT SIZE=+1>特集</FONT>記事」と書かれており、検索タームを「特集記事」とした場合、HTML文書中では、「特集」と「記事」の間に文字を拡大して表示するための「</FONT>」のタグが記述されているため、タグを飛ばして検索しなければ正しく検索することができない。
【0013】
本発明の目的は、正規化処理された文書に対する検索結果から、元の文書に対するハイライト情報の付加を実現するために、検索用の文書から、元の文書のハイライト範囲情報への変換を実現することにある。
本発明の他の目的は、正規化後のヒットタームが、元の文書において複数の構造にまたがっている場合、各構造ごとに、ヒットした範囲に対してハイライト情報を付加し、ハイライト表示することにある。
本発明のさらに他の目的は、ヒットしたタームが含まれる構造全体のハイライト表示、あるいは、出現位置の距離条件を満たした2つの検索タームを含む領域全体をハイライト表示するなどの処理をするため、階層的なハイライト情報を付加し、異なるハイライト表示形態によりハイライト表示することにある。
本発明のさらに他の目的は、構造化文書の部分構造だけを抽出して表示する場合に、このような部分構造の内容についても、ハイライト情報を付加し、ハイライト表示することにある。
本発明のさらに他の目的は、文書構造を示すHTMLタグが存在する文書から文字列を検索する場合、設定した検索タームと一致した文字列がHTMLタグ内に存在する場合や、検索タームがHTMLタグをまたがって記述されている場合でも検索を可能にすることにある。
本発明のさらに他の目的は、検索条件にヒットした文字列をハイライト表示可能にすることにある。
【0014】
【課題を解決する為の手段】
上記の課題を解決するため、本発明は、
処理装置と、記憶装置と、ファイル装置と、入出力装置を備える情報処理システムにおける構造化文書検索表示方法であり、
前記処理装置は、
入力された構造化文書を解析して解析済み構造化文書を生成し、該解析済み構造化文書を前記ファイル装置に格納し、該解析済み構造化文書から各構造内の内容文字列情報を取得して文書検索用情報を生成し、前記ファイル装置に格納し、入力された検索条件により該ファイル装置に格納された文書検索用情報を検索し、該検索条件を満たす内容文字列情報があるか否か判定し、該検索条件を満たすとみなされる内容文字列情報を持つ文書の解析済み構造化文書を取得し、かつ該文書の検索条件を満たす範囲の情報を取得し、該文書の検索条件を満たす範囲をハイライト表示するための表示用文書型定義(表示用DTD)を作成し、前記文書の検索条件を満たす範囲の情報と表示用文書型定義に基づき構造化文書中にハイライト表示するための情報を付加した表示用構造化文書を作成するようにしている。
【0015】
また、処理装置と、記憶装置と、ファイル装置と、入出力装置を備える情報処理システムにおける構造化文書検索表示方法であり、
前記処理装置は、
入力された構造化文書を解析して解析済み構造化文書を生成し、該解析済み構造化文書を前記ファイル装置に格納し、前記入力された構造化文書から予め与えられた検索対象外の構造情報を除去した文書検索用の正規化処理済み構造化文書を生成し、かつ該除去された構造情報を復元するための復元情報を生成し、前記ファイル装置に格納し、入力された検索条件により該ファイル装置に格納された正規化処理済み構造化文書を検索し、該検索条件を満たす正規化処理済み構造化文書があるか否か判定し、該検索条件を満たすとみなされる文書の正規化処理済み構造化文書を取得し、かつ該文書の検索条件を満たす範囲の情報を取得し、該文書の検索条件を満たす範囲をハイライト表示するための表示用文書型定義を作成し、前記検索により取得された正規化処理済み構造化文書を前記復元情報により、除去された構造情報を有する構造化文書に復元し、前記文書の検索条件を満たす範囲の情報と表示用文書型定義に基づき該復元された構造化文書中にハイライト表示するための情報を付加した表示用構造化文書を作成するようにしている。
【0016】
また、処理装置と、記憶装置と、ファイル装置と、入出力装置を備える情報処理システムにおける構造化文書検索表示方法であり、
前記処理装置は、
入力された構造化文書を解析して解析済み構造化文書を生成し、該解析済み構造化文書を前記ファイル装置に格納し、該解析済み構造化文書から各構造内の内容文字列情報を取得して文書検索用情報を生成し、前記ファイル装置に格納し、入力された検索条件により該ファイル装置に格納された文書検索用情報を検索し、該検索条件を満たす内容文字列情報があるか否か判定し、該検索条件を満たすとみなされる内容文字列情報を持つ文書の解析済み構造化文書を取得し、かつ該文書の検索条件を満たす範囲の情報を取得し、入力された表示対象の部分構造を取得し、該表示対象の部分構造中の前記検索条件を満たす範囲をハイライト表示するための部分構造表示用文書型定義を作成し、該表示対象の部分構造に対して、前記文書の検索条件を満たす範囲の情報と部分構造表示用文書型定義に基づき構造化文書中にハイライト表示するための情報を付加した部分構造表示用構造化文書を作成するようにしている。
【0017】
また、処理装置と、記憶装置と、ファイル装置と、入出力装置を備える構造化文書検索表示装置であり、
前記処理装置は、
入力された構造化文書を解析して解析済み構造化文書を生成し、該解析済み構造化文書を前記ファイル装置に格納する手段と、前記入力された構造化文書から予め与えられた検索対象外の構造情報を除去した文書検索用の正規化処理済み構造化文書を生成し、前記ファイル装置に格納する手段と、該除去された構造情報を復元するための復元情報を生成し、前記ファイル装置に格納する手段と、入力された検索条件により該ファイル装置に格納された正規化処理済み構造化文書を検索し、該検索条件を満たす正規化処理済み構造化文書があるか否か判定し、該検索条件を満たすとみなされる正規化処理済み構造化文書の情報を取得し、かつ該文書の検索条件を満たす範囲の情報を取得する手段と、該文書の検索条件を満たす範囲をハイライト表示するための表示用文書型定義を作成する手段と、前記検索により取得された正規化処理済み構造化文書を前記復元情報により、除去された構造情報を有する構造化文書に復元する手段と、前記文書の検索条件を満たす範囲の情報と表示用文書型定義に基づき該復元された構造化文書中にハイライト表示するための情報を付加した表示用構造化文書を作成する手段を有するようにしている。
【0018】
また、処理装置と、記憶装置と、ファイル装置と、入出力装置を備える情報処理システムにおける構造化文書検索表示方法であり、
前記処理装置は、
入力された特定の文書型定義に従う構造化文書をタグを残したままプレーンテキストとして前記ファイル装置に格納し、
入力された検索条件により該ファイル装置に格納されたプレーンテキストを検索し、該検索条件を満たす範囲があるか否か判定し、該検索条件を満たす範囲を持つ文書をプレーンテキストとして取得し、かつ該文書の検索条件を満たす範囲の情報を取得し、
前記特定の文書型定義を表示用文書型定義とし、前記入力された構造化文書に対して前記検索条件を満たす範囲に対して該表示用文書型定義に基づくハイライト表示するための情報を付加した表示用構造化文書を作成するようにしている。
【0019】
また、処理装置と、記憶装置と、ファイル装置と、入出力装置を備える情報処理システムにおける構造化文書検索表示方法であり、
前記処理装置は、
入力された特定の文書型定義に従う構造化文書をタグを残したままプレーンテキストとして前記ファイル装置に格納し、
入力された検索条件により該ファイル装置に格納されたプレーンテキストを検索し、該検索条件を満たす範囲があるか否か判定し、該検索条件を満たす範囲を持つ文書をプレーンテキストとして取得し、かつ該文書の検索条件を満たす範囲の情報を取得し、
検索条件を満たす範囲が構造化文書において文書構造を示すタグの属性情報中に存在するか否かを判定し、
該検索条件を満たす範囲がタグの属性情報中に存在する場合は、構造化文書の内容文字列中に該検索条件を満たす範囲の文字列を含む文字列を追加し、該文字列において該検索条件を満たす範囲に対して前記特定の文書型定義に基づくハイライト表示するための情報を付加した表示用構造化文書を作成するようにしている。
【0020】
また、処理装置と、記憶装置と、ファイル装置と、入出力装置を備える情報処理システムにおける構造化文書検索表示方法であり、
前記処理装置は、
入力された特定の文書型定義に従う構造化文書をタグを残したままプレーンテキストとして前記ファイル装置に格納し、
予め指定された特定のタグを構成する文字列を検索対象から除去し、該特定のタグを構成する文字列の前後を連結した文字列に対して検索することで得られる検索条件を満たす範囲に対して、前記特定の文書型定義に基づくハイライト表示するための情報を付加した表示用構造化文書を作成するようにしている。
【0021】
また、処理装置と、記憶装置と、ファイル装置と、入出力装置を備える情報処理システムにおける構造化文書検索表示方法であり、
前記処理装置は、
入力された特定の文書型定義に従う構造化文書をタグを残したままプレーンテキストとして前記ファイル装置に格納し、
入力された検索条件により該ファイル装置にプレーンテキストとして格納された構造化文書を検索する際に、検索条件を満たす範囲が予め指定された文書構造の開始を示す特定のタグと文書構造の終わりを示す特定のタグに挟まれるか否かを判定し、
挟まれる場合は、文書構造の開始を示す特定のタグより前もしくは文書構造の終わりを示すタグより後ろの内容文字列中に、該検索条件を満たす範囲の文字列を含む文字列を追加し、該文字列において該検索条件を満たす範囲に対して前記特定の文書型定義に基づくハイライト表示するための情報を付加した表示用構造化文書を作成するようにしている。
【0022】
【発明の実施の形態】
第1の実施例の概略の処理ブロック図を図1に示す。
101は、構造化文書検索表示装置である。登録データファイル(114)に格納された、構造化文書(102)を入力として文書登録の処理を行う事で、構造解析された構造化文書(図3により後述する)と、文書検索のための文書検索用情報(図5により後述)が生成される。
構造解析された構造化文書は、構造化文書データベース(以下、データベースをDBと記述する。)(105)に格納し、検索用情報は、検索用情報DB(106)に格納される。
次に入出力装置(115)から、検索条件(103)が入力されると、検索条件を解析し、文書検索用情報を読み出して、検索処理(108)を行う。検索結果としては、ヒットした文書番号の情報(109)とヒット範囲の情報(110)を出力する。
表示処理は、まず、文書読み出しの処理(107)で、ヒットした文書番号の情報(109)に基づいて、構造化文書DB(105)から、指定された構造解析済構造化文書(111)を読み出す。文書表示(112)の処理では、ヒット範囲情報(110)を基に、構造解析済構造化文書(111)に対して、ヒット情報を埋め込んだ表示用の構造化文書(113)を生成する。生成された表示用の構造化文書は、入出力装置(115)に表示される。
【0023】
図2に構造化文書検索表示の処理フローを示す。
まず、構造化文書の登録処理を行なう(201)。登録処理の内容については、図4のフローチャートを用いて後述する。
次に、指定された検索条件を用いて構造化文書を検索する(202)。検索処理の詳細は、図6のフローチャートを用いて後述する。
検索結果としては、ヒット文書数とヒット文書を識別する番号と各文書毎の検索タームのヒット範囲がある。ヒット範囲の情報は、ヒットした検索タームが含まれる構造を識別するための構造ID(構造識別子)と構造内でのヒット開始位置、テキスト長の情報を出力する。
構造化文書検索の処理で、ヒット文書数が1以上であれば(203)、順次、ヒットした文書の内容を読み出し(204)、読み出した文書のヒット範囲情報を取得し(205)、ハイライト表示を実現する(206)。表示処理の詳細については、図9を用いて後述する。
さらにヒットした文書があれば、204から206の処理を繰り返す。
表示処理を終えると、次の検索処理の有無を確認し(208)、検索条件がなければ、処理を終え、検索条件があれば、202の処理に戻って構造化文書の検索表示処理を繰り返す。
【0024】
図3は、構造化文書登録処理の概要を示した図である。
まず、SGML文書(301)の構造を解析し、木構造(302)を生成する。生成した木構造の各項目の内容をテーブル形式のデータ(303)として出力し、これを解析済み構造化文書として登録する。ここで、CDATAとは文字列データのことである。
【0025】
図4は構造化文書登録処理のフローチャートである。
まず、構造化文書を解析する(401)。解析された構造化文書を解析済構造化文書として登録する(402)。構造化文書の解析には、DTDを利用してSGML文書を解析するSGMLパーサを用いることで実現できる。
次に、解析された構造化文書に対して、検索に不要な構造を除去するための正規化処理を行なう(403)。
正規化処理の手順については、図12を用いて後述する。そして、正規化処理した構造化文書を、文書データベースに登録する(404)。
さらに、データベースに登録された解析済み構造化文書から、構造化文書の検索に必要な検索用情報として、構造情報、構造内のテキストの情報を取り出す(405)。ここで得られた検索用情報を検索用情報DB(106)に登録する(406)。ここで、登録される検索用情報は、SGML文書中の構造情報(タグ)を除去し、各構造ごとに構造情報とその内容を表すテキスト列を格納したものである。
図5に上記検索用情報と正規化した構造化文書からなる検索用のテキストの格納例を示す。上記処理を登録文書に対して繰り返し実行し、登録文書が無くなったとき処理を終了する(407)。登録内容は登録文書の全文検索に用いる。
図5は、検索用のテキストとして、出力される内容の例である。このように文書構造の構造IDとテキスト列を対応付けるテーブルと文字列情報からなる情報を検索用のテキストとして登録する。検索の際には、構造IDを元に必要な文字列を抽出して検索を行なう。
【0026】
図6は、図2の構造化文書検索表示処理の202ステップの構造化文書検索の処理フローである。
検索条件は、「検索対象の構造指定:検索条件式」のように与えられる。
検索対象の構造は、例えば、「<文書.タイトル>」のように、 '<' と '>' で囲まれ、上位構造(例の場合、「文書」)と下位構造(例の場合、「タイトル」)は '.' で区切られ、階層構造中のどの構造に対して、検索を行なうかが指定される。
検索条件式は、例えば、and("検索"、"文書")では、"検索"と"文書"が両方出現する条件を示しており、C<=10("検索","文書")では、"検索"と"文書"が10文字以下の文字を挟んで出現する条件を示している。
【0027】
構造化文書検索は、まず、ヒット文書数のカウンタをクリアし(601)、次に、検索条件中の検索対象の構造指定の部分の解析を行なう(602)。ステップ602では、<文書.タイトル>のように構造を指定する文字列から、解析済み構造化文書の対応する構造を一意に特定できる構造ID(構造識別子)を取得する。構造ID取得の処理内容は、図7のフローチャートを用いて後述する。
次に、検索対象として登録された文書(検索用のテキスト)を読み出し、ステップ602で取得した指定構造IDに対応するテキスト部分を取得する(603)。
検索条件から、検索ターム、さらに複数の検索タームの出現の論理積、距離条件などの論理条件からなる検索条件式を解析し(604)、得られた検索タームによりステップ603で取得されたテキスト部分の全文検索を行ない、検索条件式の論理条件を満たすか否かの判定、すなわち、検索条件にヒットしたか否か判定する(605)。
検索条件にヒットすると(606)、検索結果として文書の番号、検索タームが含まれる構造のIDと、構造中の検索タームがヒットした範囲の情報を出力する(607)。
さらに、ヒットした文書の数をカウントし(608)、本処理を全文書について行なった後(609)、ヒット文書数を出力する(610)。
【0028】
図7は、図6の検索条件の解析における、構造指定内容の解析処理のフローチャートである。
まず、文書の最上位構造を取得する(701)。次に最上位構造から順に下位構造を取得する。取得した構造が指定構造の下位構造であれば(703)、その構造を検索対象の構造として構造IDを出力する(704)。
下位構造があれば(705)、さらにその下位構造に対して、同様に指定された構造の下位構造か否かを判定し、下位構造であれば構造IDを出力する処理(706)を下位構造がなくなるまで繰り返し(707)、全ての構造について処理が終われば、検索対象の構造IDの一覧が得られる。
図8に検索対象となる構造ID一覧の出力形式を示す。
検索対象となる構造IDの数(801)と、検索対象として得られた数のID(802)が出力される。
【0029】
図9は、表示処理の内容を示すフローチャートである。本フローチャートを用いて、表示処理の内容を以下に述べる。
まず、検索対象の構造化文書は、検索に不要な構造を除去する正規化処理を行なった後の文書であるため、検索によりヒットした構造およびヒット範囲情報は、必ずしも登録した正規化していない構造化文書における構造および範囲と一致するとは限らない(図3の木構造302と図12の木構造1203を参照)。
表示に用いる文書は、登録した正規化していない構造化文書に対して、ヒットした範囲にハイライト情報を付加した文書となる。
したがって、まず、登録文書のDTDから、表示に用いる文書用の表示用DTDの作成処理を行なう(901)。表示用DTD作成処理の内容については、図11を用いて後述する。
さらに、正規化後の構造化文書に対して得られたヒット範囲については、正規化前の登録した構造化文書における構造およびハイライト範囲情報に変換する(902)。正規化後の文書のヒット範囲情報の正規化前の文書のハイライト範囲情報への変換処理の内容については、図15を用いて後述する。
【0030】
次に表示に用いる解析済み文書の最上位構造の情報を読み出し、903から911の処理を順に繰り返すことで、表示用の文書の出力処理を行なう。
まず、構造情報を読み出し(903)、最初に構造の開始タグを出力する(904)。さらに本構造に下位構造が存在するなら(905)、下位構造に対して、表示処理(903から911の処理)を再帰的に行なう(906)。下位構造がなくなれば、構造の終わりを示すタグを出力する処理(911)に移る。
【0031】
ここで、下位構造とは、文字列を含む。したがって、
<文書>
<タイトル>
構造化文書
</タイトル>
<本文>
<強調>構造化文書</強調>の検索は、・・・
</本文>
</文書>
などの構造化文書については、<タイトル>の下位構造として、文字列(SGMLでは、CDATAと表現される)という構造が存在することになる。CDATAは、下位構造を持たず、文字列情報として、上記の例の場合、「構造化文書」という内容を持つのである。
<本文>についても同様に、<強調>という構造と、「の検索は、・・・」という内容を持つ文字列が下位構造として存在することになる。
【0032】
905のステップで下位構造が存在しないと判定された場合は、文字列の構造であるため、本構造の内容に対して、ヒット範囲情報と比較し(908)、ヒット範囲が含まれる構造であれば、ハイライト処理を行なう(909)。ハイライト処理については、図16を用いて後述する。
ヒット範囲が含まれない文字列であれば、内容をそのままテキストとして出力する(910)。出力内容が文字列の場合は、904、911のステップで、開始タグ、終了タグは出力しない。
上記の処理で構造ごとのハイライト表示を実現する。さらに処理すべき構造があれば、903からの処理を繰り返す(912)。
【0033】
図10は、登録用DTD(1001)と、登録するSGML文書(文書インスタンス)の例(1002)、ハイライト表示に用いる表示用DTD(1003)と、表示用に変換したSGML文書(文書インスタンス)の例(1004)である。なお、DTD(Document Type Definition)とは、従来の技術の項で述べたように、タグの名称、内容、さらに、タグによって示される文書構造を規定する文書型定義である。
DTDにおいて、構造を表現する場合は、"<!ELEMENT タグ名"に続いて、"-"または"O"が2つ並べられる。
最初の"-"または、"O"は、構造開始タグの省略の可否を示しており、"-"の場合は、省略できない。"O"の場合は省略可能である。2つめの"-"または"O"は、終了タグの省略の可否を示している。
次に、内容モデルとして、下位構造に出現しうる構造が記述される。
図10のDTD1001の(タイトル,本文)の場合、タイトルは下位構造1、本文は下位構造2である。
"(下位構造1,下位構造2?)"のように記述される場合は、下位構造1の後に下位構造2がそれぞれ1回だけ出現することを示し、"?"は、下位構造2は、出現しなくても良いことを示している。
"(下位構造1|下位構造2)*"の場合は、下位構造1、2が順序不同で複数回(0回を含む)出現することを示す。
ここで、内容モデルに"CDATA"と記述されている場合は、その構造中には、1つだけの文字列が存在することを示している。
#PCDATAも文字列を表わしているが、繰り返し出現が可能である。文字列と、構造が混在する場合は、#PCDATAを用いる必要がある。
【0034】
内容モデルに、"CDATA"の代わりに"RCDATA"が指定される場合がある。CDATAとRCDATAの違いは、CDATAが、構造内にエンティティ参照("&xxxx;"のように記述される。外字への置き換えなどに利用される。)が出現した場合に、エンティティ(外字など)への変換を行なわないで、出現した文字列のまま、文字列として扱うのである。"RCDATA"が指定された場合は、エンティティへの変換を行なった文字列を、文字列として扱う。
【0035】
ハイライト表示するためには、文字列に対してハイライト情報を付加できるように、文書構造を変更する必要がある。1003にアンダーラインで示した変更点のように、各構造の文字列部分に対しては、全てハイライト表示用の構造情報を追加し、さらにハイライト表示用の構造情報(<!ELEMENT ハイライト - -(#PCDATA)>を付加する必要がある。
元のDTDで内容モデルの"CDATA"となっている部分が、"(#PCDATA|ハイライト)*"に変更されているのは、CDATAがその構造中には、文字列が1つしか存在しないことを示しており、繰り返しの要素としては出現し得ないためである。ハイライト用のタグが付加されるため、元の構造がCDATAであっても、#PCDATAに変更した上で、ハイライトが繰り返し出現することが可能なように、"(#PCDATA|ハイライト)*"とするのである。
【0036】
図11は、登録用のDTDからハイライト表示用のDTDを作成するための処理内容を表すフローチャートである。
まず、登録用DTDを読み出し(1101)、DTDの内容を解析して、ELEMENT項目を取得する(1102)。ELEMENT項目の内容モデル中に、CDATA、RCDATA、#PCDATAなどが指定されている場合は、全て、ハイライト用の構造を付加できるように、内容モデルを変更する(1103−1106)。
内容モデルの変更は、まず、"CDATA"、"RCDATA",を"#PCDATA"に変更した上で、"#PCDATA"を"(#PCDATA|ハイライト)*"のように、ハイライトタグで囲まれた文字列と、囲まれていない文字列が繰り返し出現するように定義する。
元の内容モデルが、"(#PCDATA|アンダーライン)*"のように複数の構造が、繰り返し出現するように記述されている場合は、"(#PCDATA|アンダーライン|ハイライト)*"のように、ハイライト構造が出現することを記述するだけで良い。
すべてのELEMENT宣言について変更処理が終わると(1107)、ハイライト用の構造の定義として、"<!ELEMENT ハイライト - - CDATA>"を追加する(1108)。以上の処理で、図10の1003に示したハイライト表示用のDTDが生成される。
【0037】
図12は、構造化文書の正規化処理の内容を示した図である。
図10の1001に示した構造化文書を木構造に表わすと1201のようになる。
不要な構造として"アンダーライン"が指定されている場合、正規化処理の最初の処理として、1202に示すように、アンダーラインという構造を削除し、アンダーラインの下位構造に含まれる文字列は、直接上位構造である"本文"の要素とする。
さらに、"本文"の下位構造として、文字列(CDATA)が2つ並んでいるため、1203のように、文字列を連結して、1つの文字列データとする。
【0038】
図13は、正規化処理前の構造化文書(1301)、正規化処理後の構造化文書(1302)の内容を解析し、テーブル形式に変換して出力した内容である。1303は、構造情報を格納したテーブルであり、0から6までの構造IDが付けられた構造は、正規化前の構造の情報である。0が最上位構造であり、下位構造の情報をたどっていくことで、文書構造が分かる。
7から9までの構造ID(構造識別子)が付けられた構造は、正規化後に変更、追加された構造である。
7が最上位構造であり、下位構造を辿ると正規化後の文書構造が分かる。ここで、変更のない構造である"タイトル"以下の構造である構造ID1,2の構造情報はそのまま残される。
さらに、正規化処理で追加された構造ID7から9の構造については、1304の正規化対応テーブルにより、正規化前の構造との対応関係が格納される。
【0039】
図14は、正規化後の構造化文書に対して、検索した際のヒット範囲の情報を正規化前の構造化文書における範囲情報へ変換した結果を示している。
1401の正規化後の構造情報に基づいて得られたヒット範囲の情報を、図13の1304の正規化対応テーブルの情報を利用して、正規化前の構造化文書における範囲情報(1402)に変換している。
本図の例では、正規化後の構造ID9のヒット範囲が、正規化前の文書では、構造ID5と6に分かれているため、2つの構造中のハイライト対象の範囲情報に変更している。
【0040】
図15に、図9の902ステップの正規化処理後の構造化文書に対するヒット範囲情報を正規化処理前の構造化文書に対するヒット範囲情報に変換する処理内容のフローチャートを示す。
まず、正規化後のヒット範囲情報を順次読み出し(1501)、ヒット範囲情報の構造IDが、正規化後に追加されたものか、正規化前から存在するものであるかを判定する(1502)。
正規化前から存在する構造IDであれば変更はないため、そのまま、正規化前のヒット範囲情報として出力する(1503)。
正規化後に作成された構造IDであれば、図14の正規化対応テーブルの正規化後構造IDを辿り、文字範囲の情報から、対応する正規化前の構造IDと、ヒット範囲を得る(1504)。
正規化処理前の構造におけるヒット範囲を得たら、これを正規化前のヒット範囲として出力する(1505)。
全てのヒット範囲情報について処理を終える(1506)と、表示用のハイライト範囲情報が得られる。
【0041】
図16は、図9の909ステップのハイライト処理のフローチャートである。まず、文書の先頭から、ハイライト開始までの文字列を出力する(1601)。次に、ハイライト表示に用いる構造の開始タグを出力する(1602)。
さらに、ハイライト範囲の文字列を出力し(1603)、ハイライト表示に用いる構造の終了タグを出力する(1604)。
すべてのハイライト処理を終えると(1605)、残ったテキストを出力し、ハイライト処理を終わる(1606)。
【0042】
次に第2の実施例として、ヒット条件によって、ハイライト表示方法を変更する処理、さらに複数のハイライト処理を階層的に行なう場合の処理について説明する。概略処理ブロック図は、図1と同じである。
図17は、本実施例で用いるヒット範囲情報(1701)である。
図14に示したヒット範囲情報に対して追加された情報は、各ヒットした条件を格納する領域(1702)が追加されていることである。
さらに、図14では、ヒットした検索タームの範囲だけを出力しているが、検索条件によって、ヒットした検索タームに加えて、その検索タームが含まれる構造全体に対するハイライトなど、検索タームを含む領域を指定することを可能としている。
これらのヒット条件の情報は、構造化文書の検索処理時に付加する。ここでは、検索条件に用いられた距離条件、各検索タームの出現頻度などの情報を付加しているが、検索ターム毎にあらかじめ、重み付けを行なうなどの方法を用いることもできる。
【0043】
図18は、ヒット条件とハイライト方法(ハイライト表示形態)の対応を定義したテーブル(1801)である。
ヒット条件(1802)に対応するハイライト方法(1803)が記述されている。各ヒット条件によって、ヒットした範囲は、本テーブルの内容に基づいてハイライト表示を行なう。
さらに、階層情報(1804)が与えられており、階層情報の値が大きいほど、構造全体のハイライトなど上位のハイライト構造となっている。
【0044】
図19は、上記のハイライト処理を実現するための、表示用DTD作成の処理内容を示したものである。
登録に用いた元のDTD(1901)に対して、上位のハイライト構造内には下位のハイライト構造を階層的に指定でき、さらに省略も可能なように定義を変更、追加したハイライト表示用のDTD(1902)を生成している。
DTDの作成方法は、図11を用いて前述した処理に対して、1106ステップのハイライト情報付加の際に、複数存在するハイライト情報をすべて付加(1903)し、さらに1108ステップのハイライト用ELEMENT宣言追加の際に、図18の階層情報(1804)を元に、各ハイライト構造の下位構造として、下位のハイライト構造および文字列を内容モデルとして持つようにすれば良い。
下位のハイライト構造がなければ、内容モデルとして、文字列だけが出現する(1904)。
【0045】
図20は、第2の実施例におけるハイライト処理のフローチャートである。
まず、ハイライト情報を開始位置順を第1キー、階層情報の上位から下位の順を第2キーとしてソートする(2001)。次に、ハイライト開始までのテキストを出力し(2002)、ハイライト開始タグを出力する(2003)。
さらに、ハイライト範囲の終わりまでに、次のハイライトが開始していれば、下位の構造情報が存在するため(2004)、その位置までのテキストを出力した上で(2005)、下位のハイライト構造におけるハイライト処理を行なう(2006)。下位構造におけるハイライト処理は、2003から2009の処理と同じである。
下位のハイライト構造に対する処理を終えた後、さらに下位のハイライト構造があれば(2007)、2005ステップの処理に戻って、次のハイライト構造までのテキストを出力し、下位のハイライト構造の処理を行なう。
下位のハイライト構造がなくなれば、構造の終わりまでのテキストを出力して(2008)、ハイライト終了タグを出力する(2009)。
ハイライトの情報が残っていれば、2002のステップに戻り、処理を繰り返す。ハイライトの情報が終われば(2010)、残ったテキストを出力し、処理を終える(2011)。
【0046】
図21は、上記処理により生成されるSGML文書の例である。
図22は、図21のSGML文書の本文の表示例である。重なったハイライト範囲については、複数のハイライトのための表示方法を重複して行なっている。
【0047】
第3の実施例として、構造化文書の部分構造だけを切り出し、ハイライト表示する場合の処理内容を示す。
図23は、本実施例の概略処理ブロック図を示したものである。
図1からの変更点は、表示対象の構造(2301)を指定するようにしていることと、表示対象の構造の指定内容を元に、文書表示(112)の処理の代わりに部分構造表示の処理(2302)を行なっていることである。
【0048】
図24は、部分構造を抽出して、表示する場合の処理手順を示したフローチャートである。
まず、部分構造表示用のDTDを作成する(2401)。部分構造表示用のDTDの作成処理については、図26を用いて後述する。
さらに、正規化後の構造化文書に対して得られたヒット範囲については、正規化前の登録時の文書における、構造IDおよびヒット範囲情報に変換する(2402)。正規化後の文書の情報の正規化前の文書の範囲情報への変換処理の内容については、図16を用いて前述した方法を用いることができる。
次に表示対象となっている解析済み文書の構造の情報を読み出し、2403から2411の処理を順に繰り返すことで、表示用の文書の出力処理を行なう。
まず、表示対象となる構造情報を読み出す(2403)。ここで表示対象の構造であるか否かの判定は、図7を用いて前述した方法を用いて実現する。
表示対象の構造情報であれば、まず、構造の開始タグを出力する(2404)。さらに本構造に下位構造が存在するなら(2405)、下位構造に対して、表示処理(2403から2411の処理)を行なう(2406)。下位構造がなくなれば、構造の終わりを示すタグを出力する処理(2411)に移る。
2405のステップで下位構造が存在しないと判定された場合は、文字列の構造であるため、本構造の内容に対して、ヒット範囲情報と比較し(2408)、ヒット範囲が含まれる構造であれば、ハイライト処理を行なう(2409)。ハイライト処理については、図15を用いて前述した方法を用いる。
ハイライト範囲が含まれない文字列であれば、内容をそのままテキストとして出力する(2410)。出力内容が文字列の場合は、2404、2411のステップで、開始タグ、終了タグは出力しない。
上記の処理で構造ごとのハイライト表示を実現する。さらに処理すべき構造があれば、2403からの処理を繰り返す(2412)。
【0049】
図25は、部分構造表示用のDTDの作成内容である。
部分構造の出力により、元のDTD(2501)で必ず出現しなければならないと定義されている構造が出力されない場合がある。さらに上位構造が必ずしも出力されるとは限らない。
このため、部分構造表示用のDTDは、上位構造の開始タグ、終了タグの出現を必須としない。さらに構造そのものについても、必ずしも出現しなくて良いとするように変更する必要がある。作成された部分構造表示用のDTDは2502に示したようになる。
このDTDを用いて作成したSGML文書は、2503に示したようになる。この例では、タイトルだけを抽出している。
【0050】
図26は、部分構造表示用のDTD作成手順を示したフローチャートである。
まず、登録用のDTDを取得する(2601)。
次にDTD中のELEMENT項目を取り出す(2602)。内容モデルにCDATA、RCDATA、#PCDATAが含まれる場合は、ハイライト情報を付加する(2603−2606)。
ハイライト情報の付加は、図11の1103から1106ステップの処理と同じである。
次に内容モデル中の出現指示子(*、+、?、なし)をチェックし、"+"ならば(2607)、"*"に変更し(2608)、出現指示子がなければ(2609)、"?"を付加する(2610)。
全てのELEMENT宣言に対する処理が終わると(2611)、ハイライト用の構造のELEMENT宣言を追加し(2612)、さらに、下位構造が存在する構造のタグが出現することが必須(-)であれば、不要(O)に変更する。
【0051】
次に、本発明を用いた実施例4について、図面を用いて説明する。
図27は、本実施例のシステム構成図である。
WWW(World Wide Web)検索システム(2700)は、ネットワーク(2702)を使用してクライアント(2701)と接続されている。
クライアント(2701)は、PC,WSなどであり、クライアント(2701)上で動作するWebブラウザ(2703)上の、検索ターム設定画面上で検索タームを入力する。WWW検索システム(2700)では、この検索タームを用いて検索を行い、その検索結果をWebブラウザ(2703)に出力する。
WWW検索システム(2700)は、クライアント(2701)からの検索タームを受け取るHTTPサーバ(2704)と、検索処理およびハイライト用タグを挿入するデータ制御部(2705)と、ハイライトタグの位置情報などを格納しておくメモリ(2706)から成り立ち、検索対象となるHTML文書を格納しておく磁気ディスク装置(2707)が接続されている。
データ制御部(2705)では、HTTPサーバ(2704)で受け取った検索タームを磁気ディスク(2707)中に存在するHTML文書に対して検索処理を行い、検索タームにヒットしたHTML文書の検索ヒット位置にハイライトタグを挿入する。
メモリ(2706)は、各文書ごとの検索ヒット数を格納するハイライト数格納領域(2708)と、検索結果位置情報を格納するハイライト位置情報格納領域(2709)と、挿入するハイライト用タグの内容を格納しておくハイライト用タグ文字格納領域(2710)と、ハイライト用タグを挿入したHTML文書を格納するHTML文書一時格納領域(2711)と、クライアント(2701)で入力した検索タームをWWW検索システム(2700)のHTTPサーバ(2704)で取得し、一時的に格納する検索ターム格納領域(2712)からなる。
WWW検索システム(2700)によってハイライト用タグを挿入したHTML文書は、HTTPサーバ(2704)からネットワーク(2702)を経由して、クライアント(2701)のWebブラウザ(2703)上に表示される。
【0052】
次に、データ制御部(2705)の処理内容について、図28を用いて説明する。
ここでは、クライアント(2701)で設定した検索タームを取得し、検索処理を行い、検索ヒット位置を検出しハイライト位置情報(2709)を作成し、検索条件にヒットしたHTML文書の検索タームにヒットしたHTML文書の検索ヒット位置にハイライト用のタグを埋め込み、クライアント(2701)のWebブラウザ(2703)に表示する。
ステップ2800:
クライアント(2701)で設定した検索タームを、WWW検索システム(2700)では、HTTPサーバ(2704)を用いて取得する。取得した検索タームは、メモリ(2706)の検索ターム格納領域(2712)に格納される。ステップ2801:
ステップ2800で検索ターム格納領域(2712)に格納した検索タームを用いて、磁気ディスク装置(2707)に格納されているHTML文書に対する全文検索を行う。検索ヒットした場合は、HTML文書中の検索ヒット位置や検索ヒット数などを取得し、その情報をハイライト位置情報格納領域(2709)、ハイライト数格納領域(2708)に格納する。この処理については、図29を用いて詳しく説明する。
ステップ2802:
ステップ2801において、作成されたハイライト位置情報格納領域(2709)に格納されている情報を基に、ハイライトタグ文字格納領域(2710)に格納されているハイライト用タグをHTML文書の検索ヒットした位置に挿入し、HTML文書一時格納領域(2711)に格納する。詳細は、図33を用いて説明する。
ステップ2803:
ステップ2802により作成されたHTML文書一時格納領域(2711)に格納されたハイライト用HTML文書を、HTTPサーバ(2704)を用いてクライアント(2701)のWebブラウザ(2703)に表示する。
ステップ2800からステップ2803の処理を繰り返すことにより、クライアント(2701)で入力された検索条件を用いて、磁気ディスク(2707)に格納されているHTML文書を検索し、検索条件にヒットした文書に対して、複数箇所の検索ヒット位置のハイライト表示を可能とする。
【0053】
次に、図29を用いて、図28のステップ2801のハイライト位置情報の作成処理について説明する。
ステップ2900:
磁気ディスク(2707)に格納されているHTML文書を読み出す。図34のHTML文書(3400)は、読み出したHTML文書の例である。
このHTML文書をWebブラウザで表示すると、3401に示すような画面が表示される。
ステップ2901:
ハイライト位置情報を格納する領域であるハイライト位置情報格納領域(2709)をα件数分確保する。αは、任意の正の整数である。またハイライト数を格納するハイライト数格納領域(2708)を確保する。
なお、ハイライト位置情報格納領域(2709)と、ハイライト数格納領域(2708)のデータ形式は、図30および図31に示す。
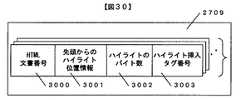
ハイライト位置情報格納領域(2709)は、図30に示すように、HTML文書番号(3000)、先頭からのハイライト位置番号(3001)、ハイライトバイト数(3002)、ハイライト挿入タグ番号(3003)から構成される。
HTML文書番号(3000)は、ステップ2900で読み出したHTML文書の番号である。HTML文書を格納した際に付けられる通し番号などを格納する。
先頭からのハイライト位置番号(3001)は、ステップ2900で読み出したHTML文書にステップ2800で取得した検索タームにヒットした場合、HTML文書中の検索ヒット位置を文書先頭からバイト数で格納する。
ハイライトバイト数(3002)は、ハイライトする長さをバイト数で格納する。つまり、検索タームの文字列長を格納する。
ハイライト挿入タグ番号(3003)は、複数の検索タームでハイライト表示する場合、検索タームごとにハイライト用タグを区別して表示することが可能である。ここに格納されている情報を基にして、ハイライト用タグを区別する。つまり、ここには、ハイライト表示に利用するタグの種類を判別するデータを格納する。
【0054】
ステップ2902:
ハイライト位置情報格納領域(2709)に格納したカウントを示すi_cntを0に初期設定する。
ステップ2903:
ステップ2800で読み出した検索タームとステップ2900で読み出したHTML文書が一致するか否かをチェックをする。検索ヒット箇所が存在する場合は、ステップ2904に進む。また、存在しない場合は、ステップ2908に進む。
ステップ2904:
ステップ2901または2905で確保したハイライト位置情報格納領域(2709)がハイライト格納数を示すi_cntより大きいか否かをチェックする。データを格納する領域がまだ存在する場合、ステップ2906に進む。また、格納する領域が存在しない場合、ステップ2905に進む。
ステップ2905:
ハイライト位置情報格納領域(2709)を一定値拡大して再度確保し直し、ステップ2906に進む。
【0055】
ステップ2906:
ステップ2901または2905で確保したハイライト位置情報格納領域(2709)のi_cnt番目の位置に、HTML文書番号(3000)、HTML文書の先頭からの位置(3001)、ハイライト文字数(3002)、ハイライトタグ挿入番号(3003)を格納する。i_cntは0に初期化されているので、i_cntが0の場合、0番目にデータを格納する。
1つのHTML文書中に複数のハイライト情報を格納する場合は、i_cntが更新されるので、i_cntが示す位置に格納する。
ステップ2900で読み出したHTML文書(3400)をHTML文書番号「001」とする。さらに、ステップ2800で抽出した検索タームを「特集」とする。
このHTML文書(3400)で、検索ターム「特集」を検索すると、HTML文書(3400)の先頭から122バイト目(3403)に「特集」の文字を見つけることができる。
この場合、HTML文書番号(3000)にはHTML文書番号である「001」(3404)を格納し、HTML文書の先頭からの位置(3001)には「122」(3405)を格納し、ハイライト文字数(3002)には「特集」のバイト数「4」(3406)を格納する。最後に、ハイライトタグ挿入番号(3003)には、検索結果を強調するためのタグを示す番号を格納する。ここでは、「1」(3407)を格納する。
【0056】
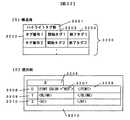
ここで、ハイライト挿入タグ番号と実際に格納するハイライトタグを対応する構成を図32に示す。図32の(1)では、ハイライトタグ文字格納領域(2710)に格納されているハイライト挿入タグ用の構造体3200を示す。
ハイライト挿入タグ用の構造体(3200)は、通し番号を格納するタグ番号1(3202)と、ハイライト開始タグ名を格納する開始タグ1(3203)、ハイライト終了タグ名を格納する終了タグ1(3204)と、タグの個数を格納するハイライトタグ数(3201)から成り立つ。ハイライトタグ数に格納した数分のタグ番号、開始タグ、終了タグが存在する。
【0057】
ハイライトタグ文字格納領域の使用例を(2)に説明する。
ここでは、3種類のハイライトタグを格納する場合を示す。よって、ハイライトタグ数を格納する箇所には、「3」(3205)を格納する。タグ番号「0」(3206)の箇所の開始タグには、赤色を示すタグ「<FONT COLOR=“RED”>」(3207)を、終了タグには「</FONT>」(3208)を格納する。同様に、タグ番号「1」(3209)には、点滅を示すタグ「<BLINK>」を、タグ番号「2」(3210)には、文字を大きく表示する「<H1>」を格納する。
ハイライトタグ文字格納領域(2710)は、ハイライト位置情報格納領域(2709)の作成前に作成する。また、このハイライトタグ文字格納領域(2710)は、ユーザインターフェースを使用して、作成することも可能である。
複数のハイライト用タグを用意することで、異表記や同義語の検索処理を行った場合において、異表記で検索された文字にはタグ番号「1」、同義語で検索された文字にはタグ番号「2」のように、検索条件ごとに異なるハイライト表示が可能となる。
ハイライト用タグに「<BLINK>」を使用する場合は、ハイライト位置情報格納領域(3402)のハイライトタグ挿入番号(3407)に「1」を格納する。
【0058】
ステップ2907:
ステップ2906において、ハイライト位置情報格納領域(2709)にデータを格納したので、i_cntを1を加え、ステップ2903に戻る。
ステップ2908:
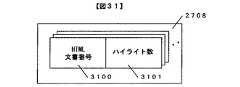
ステップ2900で取得したHTML文書中のハイライト数を取得し、ハイライト数格納領域(2708)に格納する。ハイライト数格納領域(2708)の構造体の内容は図31を用いて説明する。
図31は、ハイライト数格納領域(2708)の構造体の内容である。
3100は、ステップ2900で読み出したHTML文書の文書番号である。また、3101は、取得したハイライト数を格納しておく箇所である。ここでは、文書番号「001」を文書番号3100に格納し、i_cntをハイライト数格納領域(3101)に格納し、処理を終了する。
【0059】
次に、図33を用いて、ハイライト用タグ付のHTML文書作成処理について説明する。
ステップ3300:
ステップ2900で読み出したHTML文書中に、ハイライトタグを挿入する必要があるか否かをチェックする。
ハイライト位置情報格納領域(2709)に格納したHTML文書番号(3000)が存在する場合は、ステップ3301に進む。存在しない場合は、ステップ3309ですべてのテキストを出力し、処理を終了する。
ステップ3301:
処理カウントを示すi_cntを0に初期化する。
ステップ3302:
ハイライトタグを挿入したHTML文書を格納するHTML文書一時格納領域(2711)を確保する。
HTML文書一時格納領域(2711)は、HTML原文書のバイト数は、ハイライト用開始タグと終了タグのバイト数の合計値にハイライト挿入数を乗じたバイト数の領域を確保する。
ハイライトの開始タグと終了タグは、ハイライト位置情報格納領域(2709)のハイライト挿入タグ番号(3003)より、ハイライト用タグのタグ文字列長を計算する。ハイライト数は、ステップ2908でハイライト数格納領域(2708)に格納したハイライト数(3101)を取得する。
ステップ3303:
ハイライト数(3101)がi_cntより小さいか否かをチェックする。
小さい場合は、未処理のハイライト箇所が存在するので、ステップ3304に進む。それ以外は、処理すべき未処理のハイライト箇所を全て終了したので、ステップ3309に進む。
ステップ3304:
ハイライト位置までのHTML文書をステップ3302で確保したHTML文書一時格納領域(2711)に格納する。
【0060】
ステップ3305:
ハイライト開始タグをHTML文書一時格納領域(2711)に格納する。ハイライト開始タグは、ハイライト挿入タグ番号(3003)から抽出した番号より得られるハイライトタグ文字格納領域(2710)に格納されているタグ名である。
図34(3)の場合、ハイライト挿入タグ番号(3003)には「1」が格納されている。図32(2)に示したハイライトタグ文字格納領域(2710)のタグ番号「1」(3209)に格納されている「<BLINK>」をHTML文書一時格納領域(2711)に格納する。
ステップ3306:
検索タームをHTML文書一時格納領域(2711)に格納する。
図34の場合、「特集」をHTML文書一時格納領域(2711)に格納する。
ステップ3307:
ハイライト終了タグをHTML文書一時格納領域(2711)に格納する。ハイライト終了タグは、ステップ3305で処理したハイライト開始タグ同様、ハイライト挿入タグ番号(3003)にて格納された番号から得られるハイライトタグ文字格納領域(2710)に格納されているタグ名を格納する。
図34(3)の場合、「1」が格納されている。したがって、図32(2)のタグ番号「1」に格納されている「</BLINK>」をHTML文書一時格納領域(2711)に格納する。
ステップ3308:
ステップ3305からステップ3307において、データをHTML文書一時格納領域(2711)に格納した後、i_cntに1を加え、ステップ3303に戻る。
ステップ3309:
ハイライト挿入位置からHTML文書最後までテキストをHTML文書一時格納領域(2711)に格納し、ハイライトタグ付きHTML文書の作成処理を終了する。
【0061】
以上の処理を用いることで、クライアント(2701)設定した検索タームから、HTML文書を検索し、検索タームと一致する文書に対して、ハイライト数を格納するハイライト数格納領域(2708)、ハイライト位置を格納するハイライト位置情報格納領域(2709)の内容を作成することが可能である。
上記の処理結果の例を図35に示す。3500は、ハイライト用タグを挿入したHTML文書である。検索ヒットした「特集」の前後(3501,3502)にハイライト用タグが挿入されている。
このHTML文書を画面に表示すると3503のようになり、検索ヒットした「特集」(3504)が点滅表示される。
以上で、本発明の第1実施例として、クライアント(2701)が挿入した検索タームをHTML文書(2707)中から検索し、ヒット位置にハイライト用タグを挿入した、ハイライト用タグ付きHTML文書を作成する方法を説明した。
【0062】
次に、本発明における実施例5について、図36から図42を用いて説明する。
図36は、検索タームがHTML文書のタグで分断されている場合や、検索タームがタグ内に存在する場合のハイライト表示方法におけるシステム構成図である。
図27と同様に、クライアント(2701)のWebブラウザ(2703)上で検索タームを設定する。
【0063】
WWW検索システム(2700)は、検索タームを取得するHTTPサーバ(2704)、検索処理を行うデータの制御(2705)、領域を確保するメモリ(2706)から成り立つ。
メモリ(2706)は、図27の説明で述べた以外に、レイアウト表示などに使用されるタグで、読み飛ばすタグ名を格納した読み飛ばしタグ名格納領域(3600)と、クライアント(2701)が入力した検索タームとHTML文書(2707)が一致した開始位置を一時的に格納しておく開始位置格納領域(3601)と、検索タームとヒットした位置がHTMLタグの開始文字「<」と終了文字「>」の間に存在した場合、目印となるマークを格納しておく再度記述マーク格納領域(3602)と、HTMLタグの開始タグと終了タグの間に検索タームがヒットした場合、検索ヒットした箇所の前後にハイライト用タグを入れることができないHTMLタグを記述しておく、ハイライトタグ挿入不可能タグ名格納領域(3603)からなる。
検索タームがHTML文書のタグをまたがっている場合や、検索タームがタグ内に存在する場合の検索タームの取得、ハイライト位置情報の作成、ハイライト用タグ挿入方法は、図28で示した処理手順で行う。また、各々の処理内容については、図37から図42を用いて説明する。
【0064】
ステップ2800で取得した検索タームを用いて、ステップ2801の処理では、検索処理およびハイライト位置情報作成処理を行う。処理内容は、図37のフローチャートに示す。
ステップ3700:
処理対象となるHTML文書を磁気ディスク(2707)から読みだす。
ステップ3701:
ハイライト位置情報を格納するハイライト位置情報格納領域(2709)とハイライト数格納領域(2708)をメモリ(2706)に確保する。
ステップ3702:
検索ヒット位置の前後に挿入するハイライトタグを読み出す。
図32(2)の使用例に具体例を示したようにハイライトタグ文字格納領域(2710)からハイライト用タグを読み出す。この場合ハイライト挿入タグ番号の個数は、「3」(3205)から「3つ」とわかる。
1番目の「0」(3206)には、「<FONT COLOR=“RED”>」(3207)と「</FONT>」(3208)格納されている。そこで、ハイライト挿入タグ番号0番目の開始タグは「<FONT COLOR=“RED”>」、終了タグは「</FONT>」となる。
同様に、ハイライト挿入タグ番号1番目の開始タグは「<BLINK>」、終了タグは、「</BLINK>」となり、ハイライト挿入タグ番号2番目の開始タグは「<H1>」、終了タグは「</H1>」となる。
ステップ3703:
HTML文書の処理済み文字数のカウントを示すi_cntと、ハイライト数を格納する領域の内容を0に初期設定する。
【0065】
ステップ3704:
検索タームとHTML文書の文字列が一致するか否かをチェックする。チェック方法として、HTML文書のi_cntバイト目から、検索タームの先頭文字と一致する文字を検索する。ステップ3703において、初期設定が0に設定されているため、最初は、HTML文書の0バイト目から一致する文字を検索する。一致した場合は、ステップ3705に進む。不一致の場合は、処理を終了する。
また、ここでは、検索タームを抽出する方法として、指定したタグを飛ばして検索する方法を用いる。具体的には、読み飛ばしタグ名格納領域(3600)に格納してあるタグ名をHTML文書中に存在した場合は、そのタグを読み飛ばし、検索処理を行う。
読み飛ばしタグ名格納領域(3600)に「IMG」を格納しておき、図34のHTML文書(3400)を検索した場合、HTML文書(3400)中の先頭からデータを走査し、「IMG」(3413)が抽出された時点で、タグ内の文字を飛ばす。つまり、タグの終了文字「>」(3414)までを飛ばす。
この読み飛ばしタグ名格納領域(3600)は、検索処理前に設定しておくことにより、読み飛ばし処理が可能となる。
【0066】
ステップ3705:
ステップ3704でHTML文書の先頭から検索タームの先頭文字と一致した文字までの文字数を開始位置格納領域(3601)に一時的に確保する。
ステップ3706:
検索タームの文字列とHTML文書に書かれている文字が一致するか否かをチェックし、一致した場合、一致箇所がHTMLタグ内に存在するかあるいはHTMLタグ外に存在するか否かをチェックする。さらに、検索ヒットした文字列の最後の文字の位置を、HTML文書の先頭からの文字数で確保する。詳細は、図38を用いて説明する。
ステップ3707:
ステップ3706の結果、検索ヒットしたか否かチェックする。HTML文書中に検索タームが存在した場合は、ステップ3708に進む。検索タームが存在しない場合、ステップ3712に進む。
ステップ3708:
ステップ3701で確保したハイライト数格納領域(3708)とハイライト格納数を比較して、確保した領域が格納したハイライト数より多ければ、ステップ3709に進む。少なければ、ステップ3710に進む。
ステップ3709:
ハイライト位置情報格納領域(2709)にデータを格納する領域が足りないため、再度領域設定し直し、ステップ3710に進む。
【0067】
ステップ3710:
ハイライトする文字数とハイライトの位置の情報を、ハイライト位置情報格納領域(3600)に格納する。
具体的には、図30で説明したハイライト位置情報格納領域(3600)のHTML文書番号(3000)には、ステップ3700で読み出したHTML文書の文書番号を格納し、先頭からのハイライト位置情報(3001)には、ステップ3705で取得した開始位置を格納する。
また、ハイライトのバイト数(3002)には、検索タームの文字列長を格納し、ハイライト挿入タグ番号(3003)には、ステップ3702で読み出したタグの番号を格納する。
ハイライト挿入タグ番号(3003)は、デフォルトとして、「0」を設定する。
ステップ3711:
検索タームにヒットする文字列が複数存在する場合、検索ヒットした位置の次文字から再度検索タームとHTML文書中の一致する箇所をチェックする処理を行う。そこで、ステップ3706で確保した検索ヒットの最後の文字が記述されている位置の、HTML文書の先頭からの文字数に1を加えた値をi_cntに代入する。処理位置を更新したら、ステップ3704に戻る。
ステップ3712:
ステップ3705で取得した開始位置格納領域(3600)に格納してある開始位置からの文字列と、検索タームが一致していない場合、開始位置の次文字から再度検索タームとHTML文書中の一致する箇所をチェックする処理を行う。そこで開始位置格納領域(3600)に格納してある開始位置に1を加えた値をi_cntに代入する。処理位置を更新したら、ステップ3704に戻る。
以上で、タグ内およびタグ外のチェックを含む検索処理およびハイライト位置情報作成処理について述べた。
【0068】
次に、図38を用いて、ステップ3706のタグ内の検索およびタグ外の検索処理について説明する。
ここでは、ステップ3705で取得した検索ヒットの開始位置が、文書構造を示すタグの属性中に存在するかあるいはタグの外に存在するかをチェックし、検索ヒットの開始位置からの文字列が検索タームと一致するか否かのチェックを行う。
ステップ3800:
ステップ3705で開始位置格納領域(3600)に格納した検索ヒットの開始位置において、HTMLタグ内かあるいはタグ外かをチェックする。
ステップ3706時点におけるHTML文書のi_cntバイト目から、検索ヒットの開始位置までのデータをチェックする。
タグの開始文字「<」と対応するタグの終了文字「>」をチェックし、タグ内に検索ヒットの開始位置が存在するか否かをチェックする。
タグの開始文字「<」があり、タグの終了文字「>」の前に検索ヒットの開始位置が存在する場合、開始位置はタグ内に存在するとして、ステップ3801に進む。
タグの開始文字「<」とタグの終了文字「>」に囲まれない範囲に、検索ヒットの開始位置が存在する場合、検索ヒットの開始位置は、タグ外に存在するとして、ステップ3804に進む。
【0069】
ステップ3801:
検索タームと、検索ヒットの開始位置からの文字列が一致するか否かをチェックする。検索タームの文字列が複数バイトから成り立つ場合、文字列を1バイト毎にチェックする。検索タームの文字列と検索ヒットした位置からの文字列が一致する場合、ステップ3802に進む。不一致の場合、ステップ3803に進む。
ステップ3802:
ステップ3801において、検索タームと一致した場合、「検索ヒット」したとして、処理を終了する。
また、検索ヒットした文字列の終端位置を求める。終端位置は、検索ヒットした開始文字位置に検索タームの文字列長を加えたバイト数とする。ここで求めた終端位置は、ステップ3711にて使用される。
ステップ3803:
ステップ3801において、検索タームが不一致の場合、「検索ヒットしない」として、処理を終了する。
ステップ3804:
ステップ3800において、検索ヒットの開始位置がタグの外に存在した場合、タグ外用の検索処理を行う。タグ外用の検索処理は、図39を用いて説明する。
ステップ3805:
ステップ3804で検索タームがヒットする箇所がHTML文書中に存在するか否かをチェックする。存在する場合は、ステップ3807に進む。存在しない場合は、ステップ3806に進む。
ステップ3806:
ステップ3805において、検索タームがヒットしない場合、処理を終了する。
ステップ3807:
ステップ3805において、検索タームと一致した場合、「検索ヒット」したとして、処理を終了する。
また、検索ヒットした文字列の終端位置を求める。終端位置は、検索ヒットの開始文字位置に、ステップ3804で検出した検索ヒットの最後の文字が記述されている位置を加えた値とする。ここで求めた終端位置は、ステップ3711にて使用する。
以上で、タグ内検索およびタグ外検索処理について説明した。
【0070】
次に、ステップ3804のタグ外用の検索処理について、図39を用いて説明する。
ステップ3900:
HTML文書中に検索タームが存在するか否かをチェックする。検索タームの文字列がHTML文書中に存在する文字列と一致するか否かをチェックするが、検索ヒットした開始位置から、途中に存在するタグを飛ばすことにより一致する場合があるので、ここでは、検索ヒットした開始位置から1文字ごとに検索タームと合致しているか否かをチェックする。
具体的には、図34を用いて説明する。
検索タームを「特集記事」とした場合、(2)の表示画面では、3408に「特集記事」が表示されている。しかし、HTML文書(3400)では、「特集」(3403)と「記事」(3416)の間に「</H1>」(3417)のタグがある。このように検索タームの途中にHTMLタグが存在する場合、このHTMLタグを読み飛ばして、検索タームと一致する文字列を抽出する。
ここでは、検索タームを1文字ごとHTML文書の文字と照合し、チェックを行う。
検索タームの1文字目とHTML文書中の文字が一致した場合は、検索タームの次文字とHTML文書の次文字について、同処理を繰り返す。
検索タームの文字列のすべての文字が一致した場合、具体的には、「特」(3403)、「集」、と文字の比較を行い、「</H1>」(3417)を読み飛ばし、さらに、「記」(3416)、「事」と文字比較を行う。すべての検索タームを抽出し終わった場合、ステップ3901に進む。
検索タームがHTML文書中の文字列と完全に一致しなかった場合、ステップ3902に進む。
【0071】
ステップ3901:
HTML文書中に検索タームが存在するため、「検索ヒット」したとして、処理を終了する。
また、検索ヒットの終端位置を求める。終端位置は、ステップ3900において、最後に抽出した文字の位置である。
ステップ3902:
ステップ3900で、検索タームの文字とHTML文書の文字が一致しなかった場合、HTML文書の文字が、タグの開始文字「<」か否かをチェックする。
タグの開始文字「<」の場合は、ステップ3903に進む。それ以外の文字の場合は、ステップ3904に進む。
ステップ3903:
ステップ3902において、HTML文書中の文字がタグの開始文字「<」の場合、タグの内容を飛ばして、ステップ3900に戻る。
具体的には、タグの終了文字「>」を抽出し、抽出した文字までを読み飛ばす。図34のHTML文書(3400)で、検索タームを「特集記事」とした場合、「特集」(3403)の次文字にある「<」(3417)からタグの終了文字「>」(3418)までを読み飛ばす。つまり、「</H1>」を読み飛ばす。
ステップ3904:
ステップ3902において、検索タームが不一致の場合、「検索ヒットしない」として、処理を終了する。
以上で、HTML文書中に検索タームの文字列が存在した場合、検索ヒット位置を抽出し、ハイライト位置情報格納領域にハイライト位置情報を格納する処理について説明した。
【0072】
次に、図40を用いて、ハイライト位置情報格納領域に格納したハイライト位置情報を基にして、HTML文書の検索ヒットした文字列を強調表示するため、ハイライト用タグを挿入する方法について説明する。
ステップ4000:
ステップ3710においてハイライト情報格納領域(2709)に格納した、ハイライト位置情報を読み出す。
ステップ4001:
ハイライトタグを挿入したHTML文書を格納するためのHTML文書一時格納領域(2711)を確保する。
確保する領域の大きさは、HTML文書の原文書のデータ、ハイライトタグ数分のハイライト開始タグと終了タグの長さの和を乗じた値のバイト数である。
ハイライトタグ数は、ハイライトタグ数格納領域(2708)から読み出す。また、ハイライトの開始タグと終了タグは、ハイライト位置情報格納領域(2709)のハイライト挿入タグ番号(3003)とハイライトタグ文字格納領域(2710)からタグを検出し、検出したタグの文字列長を求める。
ステップ4002:
HTML文書中の処理済み位置を示すi_cntと、ハイライト処理数を0に初期化する。
【0073】
ステップ4003:
処理済みのハイライト箇所の数であるハイライト処理数と、処理すべきハイライト数を比較する。ハイライト処理数が少ない場合は、ハイライト用タグを挿入する処理を行うため、ステップ4004に進む。それ以外の場合は、ステップ4007に進む。
ステップ4004:
処理済みの位置を示すi_cntから検索ヒットの開始位置までのデータを、HTML文書一時格納領域(2711)に格納する。
具体的には、図34のHTML文書(3400)で、検索タームを「特集記事」とした場合、HTML文書先頭から「特集記事」(3403)前の文字「今月の」までのデータをHTML文書一時格納領域(2711)に格納する。
ステップ4005:
ハイライト用タグを検索ヒット位置に格納する。ハイライト用タグの挿入処理については、図41で説明する。
ステップ4006:
HTML文書の処理済み位置を示すi_cntにハイライト終了タグを挿入した位置の先頭からのバイト数を代入し、ステップ4003に戻る。
ステップ4007:
HTML文書の処理済み位置を示すi_cntから、HTML文書の最後までのデータをHTML文書一時格納領域(2711)に格納し、処理を終了する。
【0074】
次にステップ4005で処理するハイライトタグの挿入処理について、図41を用いて説明する。
ここでは、検索ヒットした位置が、タグの内あるいはタグ外かをチェックし、検索ヒット位置の前後にハイライト用タグを挿入する処理を行う。
ステップ4100:
HTML文書でヒットした位置がHTMLタグ内か、タグ外かをチェックする。
チェック方法は、検索ヒットの開始位置までのHTML文書において、HTMLタグの開始文字「<」とタグの終了文字「>」の対応をとり、タグ内かタグ外かを判断する。検索ヒットの開始位置がタグの開始文字「<」からタグの終了文字「>」の間にある場合は、タグ内に存在するとして、ステップ4101に進む。それ以外の場合は、タグ外に検索ヒット位置の開始位置が存在するとし、ステップ4110に進む。
ステップ4101:
タグの開始文字「<」の次文字から文字を抽出し、タグの種類を取得する。
例えば、図34のHTML文書(3400)の場合、検索タームを「hitachi」とした場合、HTML文書(3400)中の3409に「hitachi」を取得することができる。このHTMLタグの種類を取得すると、タグの開始文字「<」の次に書かれている「A」(3410)とわかる。
ステップ4102:
ステップ4101で取得したタグが、開始用のタグが終了用のタグかをチェックする。終了用のタグの場合、タグの開始文字「<」の次文字が「/(スラッシュ)」である。そこで、タグの開始文字「<」の次文字をチェックし、判別する。このタグ開始文字「<」の次文字が「/」の場合、終了用のタグと判定して、ステップ4105に進む。それ以外の場合は、開始タグと判定し、ステップ4103に進む。
【0075】
ステップ4103:
開始用タグと終了用タグの間にハイライト用のタグを挿入することが可能か否かをチェックする。
挿入することが可能な場合は、ステップ4105に進む。また、不可能な場合は、ステップ4106に進む。
具体的には、図34のHTML文書(3400)で、検索タームが「hitachi」の場合、HTMLタグの種類は、「hitachi」(3409)の前に存在する「A」(3410)である。開始用のタグとは、HTMLタグの種類を囲む「<」と「>」に挟まれた部分の「<A〜>」(3410)であり、終了用のタグとは、「</A>」(3412)である。
このHTMLタグは、開始用タグと終了用タグに書かれた文字列が画面に表示され、この文字列を選択すると、開始用タグ内で指定したURLにリンクするタグである。この「<A〜>」(3410)と「</A>」(3412)の間にハイライト用のタグを挿入すると、強調表示が正しく行われない現象が生じる。そこで「<A〜>」タグと「</A>」タグの間にはハイライト用のタグを挿入することができないとして、ステップ4104に進む。
ハイライトタグの挿入の可能あるいは不可能の判定は、HTMLタグの種類がハイライトタグ挿入不可能タグ名格納領域(3603)に格納されているタグのいずれかと一致すれば、不可能と判定し、いずれとも不一致の場合は、挿入可能と判定する。
なお、ハイライトタグ挿入不可能タグ名格納領域(3603)に格納するタグは、ユーザインタフェースを使用して、データ制御(2705)の処理を行う前に、作成しておく。
【0076】
ステップ4104:
開始用タグと終了用タグの間に検索ヒットした文字列を挿入することが出来ない場合、挿入可能な箇所まで読み飛ばす。
ここでは、終了用タグの終わりの文字「>」まで読み飛ばし、読み飛ばしたデータを取得する。
具体的には、図34のHTML文書(3400)、検索タームを「hitachi」とした場合、HTMLタグは、「A」(3410)である。その終了タグは「</A>」(3412)である。
よって「</A>」(3412)までデータを取得する。
ステップ4105:
開始用タグと終了用タグの間に文字挿入することができる場合、タグの終わりの文字「>」までデータを取得する。
具体的には、図34のHTML文書(3400)検索タームが「imagefile.gif」(3411)とした場合、HTMLタグの種類は、「IMG」(3413)で、その終わりのタグ文字は、「>」(3414)となる。よって、「>」(3414)まで読み飛ばし、読み飛ばしたデータを取得する。
ステップ4106:
ステップ4104、ステップ4105で取得したデータをHTML文書一時格納領域(2711)に挿入する。また、検索ヒットした文字の終端位置を求める。終端位置は、ステップ4104あるいはステップ4105で読み飛ばした位置のバイト数である。
【0077】
ステップ4107:
ハイライト用の開始タグをHTML文書一時格納領域(2711)に挿入する。図32の開始タグ1(3203)に書かれているタグ名をHTML文書一時格納領域(2711)に挿入する。
ハイライト位置情報格納領域に格納されているデータを3402とし、ハイライトタグ文字格納領域を図32の(2)とした場合、ハイライト位置情報格納領域のハイライト挿入タグ番号(3407)に「1」が記述してあるので、図32の(2)から、「<BLINK>」を取得することができる。よって、ここでは、「<BLINK>」をHTML文書一時格納領域(2711)に挿入する。
ステップ4108:
検索ヒット文字をHTML文書一時格納領域(2711)に挿入する。但し、再度検索ヒット文字を記述するため、再度記述したマークを格納する。ここでは、再度記述マークの格納領域(3602)に格納されているデータを挿入する。
再度記述マークの格納領域(3602)は、データ制御を行う前に、データを格納しておく。例えば、「@」マークを格納しておく。
ステップ4109:
ハイライト用の終了タグをHTML文書一時格納領域(2711)に挿入する。図32の終了タグ1(3204)に書かれているタグ名をHTML文書一時格納領域(2711)に挿入する。ここでは、「</BLINK>」を挿入する。
ステップ4110:
検索ヒットした位置がタグの外に存在する場合、タグ外用ハイライトタグ挿入処理を行う。この処理については、図42を用いて説明する。
次にステップ4110で処理をするタグ外用ハイライト挿入処理について、図42を用いて説明する。
ステップ4200:
「<A〜>」タグの場合、開始用のタグ「<A〜>」と終了用のタグ「</A>」に挟まれている箇所にハイライト用のタグを挿入すると、強調表示が反映されない。ここでは、開始タグと終了タグに囲まれているか否かをチェックし、ステップ4201でハイライトタグを挿入することが可能なタグか否かを判断する。但し、HTML文書には、「<HTML>」と「<BODY>」のタグが存在するが、これらのタグは、文書全体を囲むタグとして使用されているため、ここでは、チェックの対象としない。
図30の先頭からのハイライト位置情報(3001)に格納されている位置が、HTML文書の開始用タグと終了用タグに囲まれているか否かをチェックする。囲まれている場合は、ステップ4201に進む。囲まれていない場合は、ステップ4209に進む。
具体的には、図34のHTML文書(3400)で、検索タームが「日立」とした場合、HTML文書(3400)の「日立」(3415)が抽出される。これは、HTMLタグ「<A〜>」(3410)と「</A>」(3412)に囲まれているので、ここでは、ステップ4201に進む。
ステップ4201:
検索ヒットした文字列の前後にハイライト用タグを挿入することが可能か否かをチェックする。
チェック方法は、検索ヒットした検索文字列に囲まれているHTMLタグを抽出する。抽出したタグの種類とハイライトタグ挿入不可能タグ名格納領域(3603)に格納されているタグと比較する。一致すれば、ステップ4202に進み、不一致の場合、ステップ4209に進む。
ハイライトタグ挿入不可能タグ名格納領域(3603)中に記述されたタグ名は、開始用タグと終了用タグの間に、ハイライト用タグを挿入することができない。
よって、ハイライトタグ挿入不可能タグ名格納領域(3603)に格納されているHTMLタグと比較し、一致すれば、ステップ4202に進む、不一致の場合は、ステップ4209に進む。
このハイライトタグ挿入不可能タグ名格納領域(3603)は、ユーザインタフェースを使用して、データ制御(2705)の前に作成しておく。
ステップ4202:
ハイライト用タグを挿入することが出来ない場合、終了用タグの終わりの文字「>」までのHTML文書を読み飛ばす。
図34において、検索ターム「日立」とした場合、「</A>」(3412)までのHTML文書を読み飛ばす。
【0078】
ステップ4203:
ステップ4202で飛ばしたHTML文書をHTML文書一時格納領域(2711)に格納する。
図34において、検索ターム「日立」とした場合、ステップ4002で設定したi_cnt番目あるいはステップ4006で更新したi_cnt番目にあるHTML文書の文字から「</A>」(3412)のデータをHTML文書一時格納領域(2711)に格納する。
ステップ4204:
ハイライト用タグの開始タグをHTML文書一時格納領域(2711)に挿入する。ハイライト位置情報格納領域を3402として、ハイライトタグ文字格納領域を図32の(2)とした場合、「<BLINK>」が抽出される。よって、ここでは、「<BLINK>」を挿入する。
ステップ4205:
再表示用マークを格納する。ステップ4108同様に、再度記述マークの格納領域(3602)に格納されているHTML文書を読み出し、HTML文書一時格納領域(2711)に格納する。
ステップ4206:
検索ヒットした文字列をもう一度HTML文書一時格納領域(2711)に挿入する。
但し、検索ヒットした文字列の途中にタグが存在する場合は、タグが存在する箇所までの文字列を挿入する。
ステップ4207:
ハイライト用の終了タグをHTML文書一時格納領域(2711)に挿入する。ここでは、「</BLINK>」を挿入する。
ステップ4208:
ステップ4206において、検索タームの文字列をすべて格納したか否かをチェックする。
検索ヒットした文字列中にタグが存在し、検索ヒットした文字をすべて格納していない場合、ステップ4200に戻る。また、すべての文字を格納した場合は、処理を終了する。
【0079】
ステップ4209:
検索ヒットした開始位置までデータを飛ばし、飛ばしたHTML文書をHTML文書一時格納領域(2711)に格納する。
具体的には、図34のHTML文書(3400)で、検索タームが「特集記事」とした場合、検索ヒットした「特集」(3403)の前に存在する「今月の」までのHTML文書をHTML文書一時格納領域(2711)に挿入する。
ステップ4210:
ステップ4205同様に、ハイライト用タグの開始タグをHTML文書一時格納領域(2711)に格納する。ここでは、「<BLINK>」を挿入する。
ステップ4211:
検索ヒットした文字列を、HTML文書一時格納領域(2711)に挿入する。
但し、検索ヒットした文字列の途中にタグが存在する場合は、タグが存在する箇所までの文字列を挿入する。
例えば、HTML文書(3400)で、検索タームが「特集記事」とした場合、「特集」(3403)と「記事」(3416)の間に「</H1>」(3417)が存在する。よって、ここでは、「特集」を格納する。
ステップ4212:
ハイライト用タグの終了タグをHTML文書一時格納領域(2711)に挿入する。ここでは、「</BLINK>」を挿入する。
【0080】
ステップ4213:
ステップ4211において、検索タームの文字列すべてをHTML文書一時格納領域(2711)に挿入したか否かをチェックする。HTMLのタグを除くことにより、検索タームとHTML文書の文字列がヒットし、検索ヒットした先頭位置から検索ターム長の文字列の間に、HTMLのタグが存在する場合、ステップ4211では、HTMLタグまでのHTML文書をHTML文書一時格納領域(2711)に挿入する。この場合、HTMLタグから残りの検索ヒットの文字を処理する必要がある。
すべての検索タームをHTML文書一時格納領域に挿入した場合は、処理を終了する。また、HTMLタグから残りの検索ヒットの文字を処理する場合は、ステップ4200に戻る。
図34のHTML文書(3400)で、検索タームが「特集記事」とした場合、「特集」(3403)と「記事」(3416)の間に「</H1>」(3417)が存在する。ステップ4206では、「特集」のみ挿入した状態で、「記事」を挿入していないため、ステップ4200に戻る。
【0081】
このような処理を行うことで、クライアント(2701)が設定した検索タームを用いて、検索タームと合致するHTML文書にハイライトタグを挿入し、Webブラウザ(2703)にハイライトヒット箇所を表示することが可能である。
ここでは、検索ターム1つに対して、HTML文書をチェックし、検索タームの文字列がHTML文書中に存在すれば、クライアント(2701)のWebブラウザに検索の結果を表示する処理方法を示したが、1つの検索タームに対して、複数のHTML文書から検索し、検索ヒットしたHTML文書数分のハイライト位置情報を格納し、ハイライト用タグを格納した複数HTML文書を一括して作成する事も可能である。
また、複数の検索タームに対して、複数のHTML文書から検索し、検索ヒットしたHTML文書数分のハイライト位置情報を格納し、ハイライト用タグを格納した複数HTML文書を一括して作成することも可能である。
【0082】
次に本発明を用いた実施例6について説明する。
本実施例の実施例2からの変更点は、検索条件中に検索タームなどと共に、検索条件にヒットした場合のハイライト方法を定義することができる点である。これにより、任意の検索条件に対して、検索条件毎にハイライト方法を指定することができる。
本実施例のシステム構成は図1と同じである。ただし、検索条件103の記載方法が異なる。本実施例における検索条件103の記述方法の例を図43を用いて説明する。
【0083】
図43に本実施例における検索条件の例を示す。
本図に示すように、各検索タームや構造条件などの後ろに、「{アンダーライン}」のようにハイライト方法を指定する。
実施例2における検索条件は、「検索対象の構造指定:検索条件式」であったが、「検索対象の構造条件{ハイライト方法}:ハイライト方法付き検索条件式」となる。
ハイライト方法の指定は省略可能である。省略時は、実施例2で示した方法でハイライト表示を行なう。すなわち、ハイライト方法が検索条件中に記載されていない箇所については、図18に示したハイライト方法定義1801を読み出し、本定義情報に記載されているハイライト方法を用いてハイライト表示する。
【0084】
図44に本実施例におけるヒット範囲情報4401の格納内容を示す。
実施例2の図17に示したヒット範囲情報からの変更点は、各ヒット範囲ごとにヒット条件4402だけではなく、ハイライト方法4403を格納する点である。本情報は、図43を用いて前述した検索条件を解析し、検索条件中に記載されたハイライト方法の情報を読み出すことで取得可能である。
【0085】
図45に本実施例におけるハイライト表示用DTDの生成方法を示す。
本例では、検索の度に新規にハイライト方法が変更される可能性があることから、ハイライト表示の度に、必要な構造だけを追加したハイライト表示用DTDを生成することとする。この場合、DTD中に検索条件ではなく、直接ハイライト方法に関する記述を行なうことになる。
本図に示すように、登録に用いた元のDTD(1901)に対して、上位のハイライト構造内には下位のハイライト構造を階層的に指定でき、さらに省略も可能なように定義を変更、追加したハイライト表示用のDTD(4501)を生成している。
【0086】
DTDの作成方法は、まず図44のヒット範囲情報にハイライト方法4403が記載されていない場合に、図18に示したハイライト方法定義からヒット条件に対応するハイライト方法を取得する。まず、元のDTDの各構造に対して、下位構造に出現するハイライト方法を内容モデルに持つことができるように、構造情報を変更する(4502)。
さらに、ヒット範囲情報4401におけるヒット範囲の階層関係から、出現するハイライト用構造の階層関係を得る。ここで得られたハイライト表示用の階層関係を元に、各ハイライト構造の下位構造として、下位のハイライト構造および文字列を内容モデルとして持つようにする。下位のハイライト構造がなければ、内容モデルとして、文字列だけが出現するようにする(4503)。
【0087】
本実施例におけるハイライト処理により、検索条件をハイライト構造とするのではなく、記載されたハイライト方法を記述したハイライト表示用構造化文書と、ハイライト表示用のDTDを生成することになる。
このように、本実施例による処理により、ハイライト表示用の構造化文書が生成される。生成されたハイライト表示用の構造化文書の例を図46に示す。
図46に示すハイライト表示用の構造化文書をハイライト表示すると、図47に示すようになる。
【0088】
【発明の効果】
本発明により、構造化文書の検索結果として、ヒットした文書の内容を表示する際に、各構造ごとに検索タームがヒットした範囲に、ハイライト情報を付加した構造化文書を出力することが可能となる。ブラウザ依存のハイライト情報ではなく、構造化文書中にハイライト情報を埋め込むことで、どのようなブラウザにおいてもハイライト表示が可能となる。
検索時の条件、または、各検索タームの重要度、出現頻度などの条件によって異なるハイライト処理が行え、重要な検索タームについては、高い重み付けであることを明示したハイライト処理を行なうことが可能となる。さらに、検索条件中にハイライト方法を記述することで、ユーザ毎に任意のハイライト表示を行なうことが可能となる。
さらに、部分構造だけを抽出して、ハイライト情報を付加した構造化文書を出力することが可能になる。
また、文書構造を示すHTMLタグが存在する文書から文字列を検索する場合、設定した検索タームと一致した文字列がHTMLタグ内に存在する場合や、検索タームがHTMLタグをまたがって記述されている場合でも容易に検索ヒットすることが可能となる。また、検索ヒットした文字列をハイライト表示することが可能となる。
【図面の簡単な説明】
【図1】実施例1、2の構造化文書検索表示装置の処理ブロック図である。
【図2】構造化文書検索表示処理のフローチャートを示す図である。
【図3】構造化文書登録の内容を示す図である。
【図4】構造化文書登録処理のフローチャートを示す図である。
【図5】検索用のテキストを示す図である。
【図6】更新処理のフローチャートを示す図である。
【図7】指定構造の抽出処理のフローチャートを示す図である。
【図8】構造指定の解析結果として出力される情報を示す図である。
【図9】文書表示処理のフローチャートを示す図である。
【図10】構造化文書およびハイライト処理結果の例を示す図である。
【図11】文書表示用DTD作成処理のフローチャートを示す図である。
【図12】構造化文書検索用の正規化処理の内容を示す図である。
【図13】正規化処理を行なった結果の格納内容を示す図である。
【図14】正規化処理を行なった場合のヒット範囲情報の変換処理内容を示す図である。
【図15】正規化処理を行なった場合のヒット範囲情報の変換処理のフローチャートを示す図である。
【図16】ハイライト情報を付加する処理のフローチャートを示す図である。
【図17】実施例2におけるヒット範囲情報を示す図である。
【図18】実施例2におけるヒット情報ごとのハイライト方法の定義を示す図である。
【図19】実施例2のハイライト表示用DTDへの変換内容を示す図である。
【図20】実施例2におけるハイライト処理のフローチャートを示す図である。
【図21】実施例2によりハイライト情報を付加したSGML文書の例を示す図である。
【図22】ハイライト表示の例を示す図である。
【図23】実施例3の構造化文書検索表示装置の概略処理ブロック図である。
【図24】実施例3の処理内容のフローチャートを示す図である。
【図25】部分構造表示用のDTDへの変換処理を示す図である。
【図26】部分構造表示用のDTD作成処理のフローチャートを示す図である。
【図27】実施例4におけるシステム構成図である。
【図28】データ制御部のフローチャートを示す図である。
【図29】実施例4における文字検索処理およびハイライト位置情報の作成処理のフローチャートを示す図である。
【図30】ハイライト位置情報格納領域の構成である。
【図31】ハイライト数格納領域の構成である。
【図32】ハイライトタグ文字格納領域の構成である。
【図33】実施例4におけるハイライトタグ付きHTML文書の作成処理のフローチャートを示す図である。
【図34】ハイライト挿入例である。
【図35】ハイライト挿入後の例である。
【図36】実施例5におけるシステム構成図である。
【図37】実施例5における検索処理およびハイライト位置情報作成処理2のフローチャートを示す図である。
【図38】実施例5におけるタグ内検索およびタグ外検索処理のフローチャートを示す図である。
【図39】実施例5におけるタグ外用検索処理のフローチャートを示す図である。
【図40】実施例5におけるハイライト用タグの挿入HTML文書の作成処理のフローチャートを示す図である。
【図41】実施例5におけるハイライトタグ挿入処理のフローチャートを示す図である。
【図42】実施例5におけるタグ外ハイライトタグ挿入処理のフローチャートを示す図である。
【図43】実施例6における検索条件の例である。
【図44】実施例6におけるヒット範囲情報の例である。
【図45】実施例6におけるハイライト表示用DTDへの変換処理を示す図である。
【図46】実施例6におけるハイライト表示用のSGML文書の例を示す図である。
【図47】実施例6におけるハイライト表示の例を示す図である。
【符号の説明】
101 構造化文書検索表示装置
102 登録用構造化文書
103 検索条件
104 文書登録処理モジュール
105 構造化文書DB
106 検索用情報DB
107 構造化文書読み出し処理モジュール
108 検索処理モジュール
109 ヒット文書番号情報
110 ヒット範囲情報
111 ヒット文書の文書内容
112 文書表示処理モジュール
113 表示用文書
114 登録用文書格納ファイル
115 入出力装置
2301 表示構造情報
2302 部分構造表示モジュール
2700 WWW検索システム
2701 クライアント
2703 Webブラウザ
2704 HTTPサーバ
2705 データ制御
2706 メモリ
2707 HTML文書
3200 ハイライトタグ文字格納領域の構造
3400 HTML文書例
3401 HTML文書の表示画面例
3500 ハイライトタグ挿入後HTML文書例
3501 ハイライトタグ挿入後表示画面例[0001]
BACKGROUND OF THE INVENTION
The present invention relates to a search and display technique for a structured document created by SGML, HTML, etc., and more particularly to a structured document search and display method for performing a search on a structured document and highlighting and displaying the search result. And device.
[0002]
[Prior art]
With the spread of word processors and the like, digitized document information has been digitized. These electronic documents have individual formats depending on the devices and software to be created, and cannot be used by other devices or software, or some conversion means must be prepared.
Various structured documents have been proposed as a common format for such document exchange. These structured documents can not only define a hierarchical structure such as chapters, sections, and sections, which is the basic structure of the document, but can also include layout information.
[0003]
The standardized markup language (SGML) = “standard generalized markup language” is being standardized as a description language for structured documents.
SGML uses a method of expressing the structure of a document by embedding a specific character string called a tag in the text of structure information of a structured document. In SGML, the name and content of a tag and the document structure indicated by the tag can be defined by DTD (Document Type Definition) = “document type definition”. The above SGML and DTD are described in detail in “Practical SGML” (translated by SGML Social Practical WG April 20, 1992, published by the Japanese Standards Association).
Assume that these structured documents are registered in the DB of the search system, and a structure name is designated to be searched. If each document to be registered has a different DTD, the processing method is to analyze the document structure for each document, analyze which part the specified structure name corresponds to, and then search for the character string to be searched. A method of acquiring and searching for the URL can be considered.
However, this method requires a lot of processing time. Also, when using a method such as having a table with corresponding parts of each document for each structure name, all the structure names appearing in each document are managed together, and the corresponding part of each document is registered for each structure name This requires a huge management table.
Furthermore, even if a document in which different DTDs are mixed is registered, not all documents have the structure to be searched, and the same contents, such as “summary” and “summary”, for example. However, if different structure names are assigned, the search must be performed by designating all of these different structure names, which cannot be considered as a realistic search for structured documents.
[0004]
Therefore, it is necessary to search for structured documents so that only documents generated with the same document type definition are registered. For the structure name designated in advance, the corresponding part of each document is managed.
When searching, if the name of the structure to be searched and the search condition are specified, if a character string that matches the search condition is included in the part corresponding to the specified structure of each document, it is determined that the search condition is hit. .
[0005]
The prior art of the function for displaying the contents of a document as a structured document search result will be described below.
First, as the first prior art, Japanese Patent Laid-Open No. 8-339369 “Document Display Device and Document Display Method” can be cited.
This prior art describes a method for analyzing the structure of an SGML document, converting it to a layout for structure display, and displaying the contents of a specified structure. By using this technique, a structured document is displayed in units of structure. Is possible. Furthermore, in this prior art, there is provided a means for highlighting a specified structure (highlighted display, changing the color, font, character size, etc., or adding an underline). Yes.
However, the highlight display means shown here is means for controlling the display method for each structure, and designates the presence / absence of display, highlight display, and the like for each structural unit. Therefore, this prior art does not show a method for realizing a highlight display for a hit search term, which is necessary when displaying a search result of a structured document.
[0006]
As a second prior art, Japanese Patent Application Laid-Open No. 8-212230 “Document Search Method and Document Search Device” shows a highlight display method for search results of documents other than structured documents.
However, this conventional technique only realizes the acquisition of hit ranges and the addition of highlight information to text to be displayed, and adds highlight information to a document obtained as a search result of a structured document. It does not have a function.
[0007]
Only by combining the above two conventional techniques, it is impossible to add highlight information to a hit term for a document output as a search result for a structured document.
That is, in order to realize highlight display in a structured document, means for creating a DTD in which structure information for highlight is added to the DTD at the time of creating a document to be displayed is required.
[0008]
For the method of changing the document type definition when highlight information is added to a structured document, refer to Japanese Patent Application No. 8-159202 “Method and apparatus for managing version of structured document”, which is the third prior art. A method for generating a DTD with a new structure added to the DTD is shown.
By using this conventional technique, it is possible to create a document type definition to which highlight information is added.
[0009]
According to the first and second prior arts, it can be seen that a structured document can be displayed so that the structure can be understood, and that a hit range can be highlighted in an unstructured document.
Furthermore, by using the third prior art, it is possible to specify a document type definition to which highlight information acquired for each structure is added.
By combining these techniques, it is possible to output a structured document in which highlight information is added to a search result of a specific structure of the structured document, thereby realizing a highlight display.
[0010]
In addition, the Internet has exploded in recent years as a method for obtaining the latest information. As a means to quickly find out the information that you need from a lot of information on the Internet, the information search function on the Web has been enhanced.
HTML (Hyper Text Markup Language) is a language for describing document contents on the WWW (World Wide Web) and expressing link information to other resources and the format of the document. HTML can be considered SGML written according to a specific DTD. As a means for creating and processing this HTML document, there is an HTML editor. There is also an HTML browser that analyzes and displays the created HTML document.
The HTML browser has a function of inputting a character string to be searched (hereinafter referred to as “search term”), performing a search on the HTML document being displayed, and highlighting the hit location in reverse video. There is something.
Regarding SGML, there is an SGML browser having a function of displaying and processing a layout. The SGML browser performs a full text search on the SGML document being displayed on the browser, and highlights a portion that matches the search condition. These browsers analyze the document when the document is displayed, and create display data. The search is performed on the display data on the browser, and the hit position is highlighted on the screen.
[0011]
[Problems to be solved by the invention]
With the combination of the above-described conventional techniques, it is possible to individually highlight the search results for each structure of a given structured document.
However, the structure information may include not only information representing the document structure itself such as chapters, sections and sections but also layout information such as underline addition. Such structure information is not always inserted at a break between sentences. When searching for a document, there is a problem that unless such structure information is removed, the search cannot be performed even though the word is included in the document. In this way, the process of removing unnecessary structure information at the time of retrieval is called “normalization process” in the following description.
In order to realize the display with the highlight information added to the original structured document, the structured document that has been subjected to the normalization process is used as a search target. It cannot be realized only by using the conventional method. In other words, in this method, only a part of the structure information of the original document remains at the time of the search. Therefore, simply by adding highlight information to the structure information, a search that hits the original structured document. It does not realize the highlighting of terms.
[0012]
On the other hand, there is an HTML document created based on a plurality of DTDs by browser-specific extension, and it is not known which DTD is described. Furthermore, since there are many documents that are not correctly described based on the SGML grammar, it is difficult to analyze the structure in the same way as SGML.
(1) For plain text documents, search processing is performed, and an HTML document in which highlight tags are inserted before and after the search hit position is generated. It is possible to highlight a column. However, when the character string in the tag matches the search term, if the highlight tag is inserted before and after the search hit position, the content of the original HTML tag is changed, so that it is displayed correctly. The problem of disappearing occurs.
Furthermore, (2) a tag representing a layout may be inserted in the middle of a character string continuously displayed on the HTML browser. When searching for an HTML document, remove the tag. You cannot search correctly without searching.
For example, in the HTML document, “This month's <FONT SIZE = + 1> special feature </ FONT> article” is written, and when the search term is “special article”, in the HTML document, “special feature” and “article” Since the tag “</ FONT>” for enlarging and displaying the characters between “” is described, the search cannot be performed correctly unless the tag is skipped and searched.
[0013]
An object of the present invention is to perform conversion from a search document to highlight range information of the original document in order to realize the addition of highlight information to the original document from the search result for the normalized document. It is to be realized.
Another object of the present invention is to add highlight information to the hit range for each structure when the normalized hit term spans multiple structures in the original document, and highlight the display. There is to do.
Still another object of the present invention is to perform processing such as highlighting the entire structure including the hit term or highlighting the entire region including two search terms that satisfy the distance condition of the appearance position. Therefore, hierarchical highlight information is added and highlight display is performed in different highlight display forms.
Still another object of the present invention is to add highlight information to highlight the partial structure contents when only the partial structure of the structured document is extracted and displayed.
Still another object of the present invention is to search a character string from a document having an HTML tag indicating the document structure, when a character string that matches a set search term exists in the HTML tag, or when the search term is HTML. The purpose is to enable searching even if the description is written across tags.
Still another object of the present invention is to make it possible to highlight a character string that hits a search condition.
[0014]
[Means for solving the problems]
In order to solve the above problems, the present invention provides:
A structured document search and display method in an information processing system including a processing device, a storage device, a file device, and an input / output device,
The processor is
Analyzes the input structured document to generate an analyzed structured document, stores the analyzed structured document in the file device, and obtains content string information in each structure from the analyzed structured document The document search information is generated, stored in the file device, the document search information stored in the file device is searched according to the input search condition, and there is content string information satisfying the search condition. Determining whether or not, obtaining an analyzed structured document of a document having content character string information regarded as satisfying the search condition, and acquiring information in a range satisfying the search condition of the document, and obtaining the search condition of the document Creates a display document type definition (display DTD) for highlighting a range that satisfies the conditions, and highlights it in the structured document based on the information on the range that satisfies the document search conditions and the display document type definition To do And so as to create a display for structured document added with information.
[0015]
Further, there is a structured document search and display method in an information processing system including a processing device, a storage device, a file device, and an input / output device.
The processor is
The input structured document is analyzed to generate an analyzed structured document, the analyzed structured document is stored in the file device, and a structure not to be searched given in advance from the input structured document Generate a normalized structured document for document retrieval from which information has been removed, and generate restoration information for restoring the removed structure information, store it in the file device, and input the search conditions The normalized structured document stored in the file device is searched, it is determined whether there is a normalized structured document that satisfies the search condition, and normalization of the document that is regarded as satisfying the search condition Acquire a processed structured document, acquire information on a range satisfying the search condition of the document, create a display document type definition for highlighting a range satisfying the search condition of the document, and execute the search By The obtained normalized structured document is restored to the structured document having the removed structure information by the restoration information, and the restoration is performed based on the range information satisfying the search condition of the document and the display document type definition. A structured document for display is created by adding information for highlighting to the structured document.
[0016]
Further, there is a structured document search and display method in an information processing system including a processing device, a storage device, a file device, and an input / output device.
The processor is
Analyzes the input structured document to generate an analyzed structured document, stores the analyzed structured document in the file device, and obtains content string information in each structure from the analyzed structured document The document search information is generated, stored in the file device, the document search information stored in the file device is searched according to the input search condition, and there is content string information satisfying the search condition. Whether or not, obtain an analyzed structured document of a document having content character string information that is regarded as satisfying the search condition, acquire information of a range satisfying the search condition of the document, and input the display target A partial structure display document type definition for highlighting a range satisfying the search condition in the display target partial structure, and for the display target partial structure, Document search criteria And so as to create a range of information and partial structure displaying document type substructure displaying structured document by adding the information to the structured document highlighted in based on the definition satisfying.
[0017]
A structured document search and display device comprising a processing device, a storage device, a file device, and an input / output device;
The processor is
The input structured document is analyzed to generate an analyzed structured document, the analyzed structured document is stored in the file device, and the search object given in advance from the input structured document is excluded. Generating a normalized structured document for document search from which the structure information is removed, storing the document in the file device, and generating restoration information for restoring the removed structure information, and the file device A normalization-processed structured document stored in the file device according to the input search condition, and determining whether there is a normalized structured document that satisfies the search condition; Means for obtaining information on a normalized structured document that is regarded as satisfying the search condition and acquiring information on a range satisfying the search condition of the document, and highlighting a range satisfying the search condition of the document Means for creating a display document type definition for showing, means for restoring the normalized structured document acquired by the search into a structured document having the removed structure information by the restoration information; Means for creating a display structured document to which information for highlighting is added in the restored structured document based on the range information satisfying the search condition of the document and the display document type definition. ing.
[0018]
Further, there is a structured document search and display method in an information processing system including a processing device, a storage device, a file device, and an input / output device.
The processor is
Store the structured document according to the input specific document type definition as plain text in the file device while leaving the tag,
Search plain text stored in the file device according to the input search condition, determine whether there is a range satisfying the search condition, obtain a document having a range satisfying the search condition as plain text, and Obtain information of the range that satisfies the search condition of the document,
The specific document type definition is used as a display document type definition, and information for highlight display based on the display document type definition is added to a range satisfying the search condition for the input structured document. A structured document for display is created.
[0019]
Further, there is a structured document search and display method in an information processing system including a processing device, a storage device, a file device, and an input / output device.
The processor is
Store the structured document according to the input specific document type definition in the file device as plain text while leaving the tag,
Search plain text stored in the file device according to the input search condition, determine whether there is a range satisfying the search condition, obtain a document having a range satisfying the search condition as plain text, and Obtain information of the range that satisfies the search condition of the document,
Determine whether a range that satisfies the search condition exists in the attribute information of the tag indicating the document structure in the structured document,
If a range satisfying the search condition exists in the tag attribute information, a character string including a character string in the range satisfying the search condition is added to the content character string of the structured document, and the search is performed in the character string. A structured document for display is created in which information for highlight display based on the specific document type definition is added to a range that satisfies the conditions.
[0020]
Further, there is a structured document search and display method in an information processing system including a processing device, a storage device, a file device, and an input / output device.
The processor is
Store the structured document according to the input specific document type definition in the file device as plain text while leaving the tag,
A range that satisfies a search condition obtained by removing a character string that constitutes a specific tag specified in advance from a search target and performing a search for a character string that concatenates the character string that constitutes the specific tag. On the other hand, a display structured document to which information for highlight display based on the specific document type definition is added is created.
[0021]
Further, there is a structured document search and display method in an information processing system including a processing device, a storage device, a file device, and an input / output device.
The processor is
Store the structured document according to the input specific document type definition in the file device as plain text while leaving the tag,
When searching for a structured document stored as plain text in the file device according to the input search condition, a specific tag indicating the start of the document structure in which the range satisfying the search condition is designated in advance and the end of the document structure are displayed. Determine whether it is sandwiched between the specific tags shown,
In the case of being sandwiched, a character string including a character string in a range satisfying the search condition is added to the content character string before the specific tag indicating the start of the document structure or after the tag indicating the end of the document structure, A display structured document to which information for highlight display based on the specific document type definition is added to a range satisfying the search condition in the character string is created.
[0022]
DETAILED DESCRIPTION OF THE INVENTION
A schematic processing block diagram of the first embodiment is shown in FIG.
The structured document subjected to the structural analysis is stored in a structured document database (hereinafter, the database is referred to as DB) (105), and the search information is stored in the search information DB (106).
Next, when the search condition (103) is input from the input / output device (115), the search condition is analyzed, the document search information is read, and the search process (108) is performed. As a search result, information on the hit document number (109) and information on the hit range (110) are output.
In the display process, first, in the document reading process (107), based on the information (109) of the hit document number, the designated structurally analyzed structured document (111) is read from the structured document DB (105). read out. In the document display (112) processing, based on the hit range information (110), a structured document (113) for display in which hit information is embedded in the structured document (111) that has been analyzed. The generated structured document for display is displayed on the input / output device (115).
[0023]
FIG. 2 shows a processing flow of structured document search display.
First, a structured document registration process is performed (201). The contents of the registration process will be described later with reference to the flowchart of FIG.
Next, the structured document is searched using the specified search condition (202). Details of the search processing will be described later with reference to the flowchart of FIG.
Search results include the number of hit documents, a number identifying the hit document, and the hit range of the search term for each document. As the hit range information, a structure ID (structure identifier) for identifying a structure including a hit search term, hit start position in the structure, and text length information are output.
If the number of hit documents is 1 or more in the structured document search process (203), the contents of the hit documents are sequentially read (204), the hit range information of the read documents is acquired (205), and highlighting is performed. Display is realized (206). Details of the display processing will be described later with reference to FIG.
If there is a further hit document, the processing from 204 to 206 is repeated.
When the display process is finished, the presence or absence of the next search process is confirmed (208). If there is no search condition, the process is finished. If there is a search condition, the process returns to 202 and the structured document search and display process is repeated. .
[0024]
FIG. 3 is a diagram showing an outline of the structured document registration process.
First, the structure of the SGML document (301) is analyzed to generate a tree structure (302). The contents of each item of the generated tree structure are output as table format data (303), and this is registered as an analyzed structured document. Here, CDATA is character string data.
[0025]
FIG. 4 is a flowchart of the structured document registration process.
First, the structured document is analyzed (401). The analyzed structured document is registered as an analyzed structured document (402). The analysis of the structured document can be realized by using an SGML parser that analyzes the SGML document using DTD.
Next, a normalization process is performed on the analyzed structured document to remove structures unnecessary for the search (403).
The normalization processing procedure will be described later with reference to FIG. The normalized structured document is registered in the document database (404).
Further, from the analyzed structured document registered in the database, structure information and text information in the structure are extracted as search information necessary for searching the structured document (405). The search information obtained here is registered in the search information DB (106) (406). Here, the registered search information is obtained by removing the structure information (tag) in the SGML document and storing the structure information and the text string representing the content for each structure.
FIG. 5 shows a storage example of search text composed of the search information and the normalized structured document. The above process is repeatedly performed on the registered document, and when there is no registered document, the process ends (407). The registered contents are used for full-text search of registered documents.
FIG. 5 is an example of the content output as the search text. In this way, information including a table for associating a structure ID of a document structure with a text string and character string information is registered as a search text. When searching, a necessary character string is extracted based on the structure ID and the search is performed.
[0026]
FIG. 6 is a process flow of the structured document search in
The search condition is given as “structure specification of search target: search condition expression”.
The search target structure is, for example, “ <Document.Title>'' Surrounded by <'and'>', the superstructure ("Document" in the example) and substructure ("Title" in the example) are separated by'. ' Specifies whether to search.
The search condition expression indicates, for example, a condition in which both “search” and “document” appear in and (“search”, “document”), and C <= 10 (“Search”, “Document”) indicates a condition in which “Search” and “Document” appear across 10 or fewer characters.
[0027]
In the structured document search, first, the counter of the hit document number is cleared (601), and then the structure designation portion of the search target in the search condition is analyzed (602). In
Next, a document (search text) registered as a search target is read, and a text portion corresponding to the designated structure ID acquired in
From the search condition, a search condition expression including a search term and logical conditions such as a logical product of a plurality of search terms and a distance condition is analyzed (604), and the text portion obtained in
When the search condition is hit (606), the document number as the search result, the ID of the structure including the search term, and information on the range where the search term in the structure is hit are output (607).
Further, the number of hit documents is counted (608), and after performing this processing for all documents (609), the number of hit documents is output (610).
[0028]
FIG. 7 is a flowchart of the structure designation content analysis processing in the analysis of the search condition of FIG.
First, the top structure of the document is acquired (701). Next, the lower structure is acquired in order from the highest structure. If the acquired structure is a subordinate structure of the designated structure (703), the structure ID is output with the structure as the structure to be searched (704).
If there is a lower structure (705), it is further determined whether or not the lower structure is a lower structure of the designated structure. If it is a lower structure, a process (706) for outputting a structure ID is performed. The process is repeated until there is no more (707). When all the structures are processed, a list of structure IDs to be searched is obtained.
FIG. 8 shows an output format of the list of structure IDs to be searched.
The number of structure IDs to be searched (801) and the number of IDs (802) obtained as search targets are output.
[0029]
FIG. 9 is a flowchart showing the contents of the display process. The contents of the display process will be described below using this flowchart.
First, since the structured document to be searched is a document after performing a normalization process for removing structures unnecessary for the search, the hit structure and hit range information are not necessarily registered normal structures. It does not always match the structure and range in the document (see the
A document used for display is a document in which highlight information is added to a hit range with respect to a registered unnormalized structured document.
Therefore, first, a display DTD for a document used for display is created from the DTD of the registered document (901). The contents of the display DTD creation process will be described later with reference to FIG.
Further, the hit range obtained for the structured document after normalization is converted into the structure and highlight range information in the registered structured document before normalization (902). The content of the conversion process of the hit range information of the normalized document to the highlight range information of the document before normalization will be described later with reference to FIG.
[0030]
Next, the information of the highest structure of the analyzed document used for display is read, and the processing of 903 to 911 is repeated in order to perform the output processing of the document for display.
First, structure information is read out (903), and a structure start tag is output first (904). Further, if there is a lower structure in this structure (905), display processing (processing from 903 to 911) is recursively performed on the lower structure (906). If there is no lower structure, the process proceeds to a process (911) for outputting a tag indicating the end of the structure.
[0031]
Here, the substructure includes a character string. Therefore,
<Document>
<Title>
Structured document
</ Title>
<Text>
<Emphasis> structured document Search for </ emphasis> ...
</ Text>
</ Document>
For structured documents such as As a substructure of <title>, there is a structure of a character string (expressed as CDATA in SGML). CDATA does not have a subordinate structure, but has the content “structured document” as character string information in the above example.
Similarly for <text> A character string having a structure of <emphasis> and a content of "Search for ..." exists as a substructure.
[0032]
If it is determined in
If the character string does not include the hit range, the content is output as text as it is (910). When the output content is a character string, the start tag and the end tag are not output in steps 904 and 911.
The highlight display for each structure is realized by the above processing. If there is a structure to be further processed, the processing from 903 is repeated (912).
[0033]
FIG. 10 shows a registration DTD (1001), an example of an SGML document (document instance) to be registered (1002), a display DTD (1003) used for highlight display, and an SGML document (document instance) converted for display. (1004). Note that the DTD (Document Type Definition) is a document type definition that defines the name and content of a tag and the document structure indicated by the tag, as described in the section of the related art.
In DTD, when expressing a structure, <! ELEMENT tag name "is followed by two"-"or" O ".
The first "-" or "O" indicates whether or not the structure start tag can be omitted. If it is "-", it cannot be omitted. If "O", it can be omitted. The second “-” or “O” indicates whether the end tag can be omitted.
Next, a structure that can appear in the lower structure is described as the content model.
In the case of (title, text) of the
When it is described as "(
“(
Here, when “CDATA” is described in the content model, it indicates that there is only one character string in the structure.
#PCDATA also represents a character string, but it can appear repeatedly. When character strings and structures are mixed, it is necessary to use #PCDATA.
[0034]
"RCDATA" may be specified in the content model instead of "CDATA". The difference between CDATA and RCDATA is that when CDATA appears in the structure, an entity reference (described as "&xxxx;". Used for replacement with external characters, etc.) appears to an entity (external characters, etc.) It is treated as a character string as it is without appearing. When "RCDATA" is specified, the character string converted to an entity is handled as a character string.
[0035]
In order to perform highlight display, it is necessary to change the document structure so that highlight information can be added to a character string. As indicated by the underline in 1003, the structure information for highlight display is added to the character string portion of each structure, and the structure information for highlight display ( <! ELEMENT highlight--(# PCDATA)> needs to be added.
The part of the content model that is "CDATA" in the original DTD has been changed to "(#PCDATA | highlight) *" because CDATA has only one character string in its structure. This is because it cannot appear as a repetitive element. Since a highlight tag is added, even if the original structure is CDATA, change it to #PCDATA, and "(#PCDATA | highlight) * ".
[0036]
FIG. 11 is a flowchart showing the processing contents for creating a DTD for highlight display from the DTD for registration.
First, the registration DTD is read (1101), the contents of the DTD are analyzed, and the ELEMENT item is acquired (1102). When CDATA, RCDATA, #PCDATA, etc. are specified in the ELEMENT item content model, the content model is changed so that a highlight structure can be added (1103-1106).
To change the content model, first change "CDATA", "RCDATA", to "#PCDATA", then change the "#PCDATA" to "#PCDATA | highlight" * " It is defined so that the enclosed character string and the unenclosed character string appear repeatedly.
If the original content model is described so that multiple structures appear repeatedly, such as "(#PCDATA | underline) *", the "(#PCDATA | underline | highlight) *" Thus, it is only necessary to describe the appearance of the highlight structure.
Once all ELEMENT declarations have been changed (1107), the highlight structure definition is "<! ELEMENT Highlight --- CDATA>"is added (1108). With the above processing, the DTD for highlight display indicated by 1003 in FIG. 10 is generated.
[0037]
FIG. 12 is a diagram showing the contents of the normalization processing of the structured document.
When the structured document indicated by 1001 in FIG. 10 is represented in a tree structure, it becomes 1201.
When “underline” is specified as an unnecessary structure, the underline structure is deleted as shown in 1202 as the first process of normalization processing, and the character string included in the underline substructure is It is an element of “text” that is a direct superstructure.
Further, since two character strings (CDATA) are arranged as a substructure of the “text”, the character strings are concatenated as one character string data as in 1203.
[0038]
FIG. 13 shows the contents of the structured document (1301) before normalization processing and the contents of the structured document (1302) after normalization processing, converted into a table format and output. A table 1303 stores structure information. A structure to which
Structures with structure IDs (structure identifiers) 7 to 9 are structures that have been changed and added after normalization.
Further, for the structures with
[0039]
FIG. 14 shows a result of converting the hit range information at the time of retrieval to the range information in the structured document before normalization for the structured document after normalization.
The information on the hit range obtained based on the structure information after
In the example of this figure, the hit range of the
[0040]
FIG. 15 shows a flowchart of processing contents for converting hit range information for the structured document after the normalization process in
First, the hit range information after normalization is sequentially read (1501), and it is determined whether the structure ID of the hit range information is added after normalization or exists before normalization (1502).
Since there is no change if the structure ID exists before normalization, it is output as it is as hit range information before normalization (1503).
If the structure ID is created after normalization, the structure ID after normalization in the normalization correspondence table in FIG. 14 is traced, and the corresponding structure ID before normalization and the hit range are obtained from the information on the character range (1504). ).
When the hit range in the structure before normalization processing is obtained, this is output as the hit range before normalization (1505).
When the processing for all hit range information is completed (1506), highlight range information for display is obtained.
[0041]
FIG. 16 is a flowchart of the highlight process in
Further, the character string in the highlight range is output (1603), and the end tag of the structure used for highlight display is output (1604).
When all the highlight processes are completed (1605), the remaining text is output and the highlight process is terminated (1606).
[0042]
Next, as a second embodiment, processing for changing a highlight display method according to hit conditions and processing for performing a plurality of highlight processing hierarchically will be described. The schematic processing block diagram is the same as FIG.
FIG. 17 shows hit range information (1701) used in this embodiment.
Information added to the hit range information shown in FIG. 14 is that an area (1702) for storing each hit condition is added.
Furthermore, in FIG. 14, only the range of the search terms that have been hit is output, but depending on the search conditions, in addition to the search terms that have been hit, an area that includes the search terms, such as highlights for the entire structure that contains the search terms Can be specified.
Information on these hit conditions is added at the time of structured document search processing. Here, information such as the distance condition used for the search condition and the appearance frequency of each search term is added, but a method of performing weighting in advance for each search term can also be used.
[0043]
FIG. 18 is a table (1801) defining the correspondence between hit conditions and highlight methods (highlight display form).
A highlight method (1803) corresponding to the hit condition (1802) is described. Depending on the hit conditions, the hit range is highlighted based on the contents of this table.
Furthermore, hierarchical information (1804) is given, and the higher the hierarchical information value, the higher the highlight structure such as the highlight of the entire structure.
[0044]
FIG. 19 shows the processing contents of display DTD creation for realizing the above highlight processing.
Highlight display that has been modified and added to the original DTD (1901) used for registration, so that the lower highlight structure can be specified hierarchically and further omitted in the upper highlight structure. DTD (1902) is generated.
The DTD creation method adds all of the plurality of existing highlight information (1903) when highlight information is added in 1106 steps to the processing described above with reference to FIG. When an ELEMENT declaration is added, a lower highlight structure and a character string may be included as a content model as a lower structure of each highlight structure based on the hierarchical information (1804) in FIG.
If there is no lower highlight structure, only a character string appears as a content model (1904).
[0045]
FIG. 20 is a flowchart of highlight processing in the second embodiment.
First, the highlight information is sorted using the first key as the starting position order and the second key from the top to the bottom of the hierarchy information (2001). Next, the text up to the highlight start is output (2002), and the highlight start tag is output (2003).
Furthermore, if the next highlight has been started by the end of the highlight range, lower structure information exists (2004), so the text up to that position is output (2005), and the lower highlight is displayed. A highlight process in the write structure is performed (2006). The highlight processing in the lower structure is the same as the processing from 2003 to 2009.
After the processing for the lower-level highlight structure is completed, if there is a lower-level highlight structure (2007), the process returns to the processing in
If there is no lower highlight structure, the text up to the end of the structure is output (2008), and the highlight end tag is output (2009).
If highlight information remains, the process returns to step 2002 to repeat the process. When the highlight information is finished (2010), the remaining text is output and the processing is finished (2011).
[0046]
FIG. 21 is an example of an SGML document generated by the above processing.
FIG. 22 is a display example of the text of the SGML document of FIG. For the overlapped highlight range, the display method for a plurality of highlights is repeated.
[0047]
As a third embodiment, processing contents when only a partial structure of a structured document is cut out and highlighted are shown.
FIG. 23 shows a schematic processing block diagram of this embodiment.
The changes from FIG. 1 are that the structure (2301) to be displayed is designated and the display contents of the structure to be displayed are based on the designated contents of the structure to be displayed instead of the document display (112) process. The processing (2302) is being performed.
[0048]
FIG. 24 is a flowchart showing a processing procedure for extracting and displaying a partial structure.
First, a DTD for partial structure display is created (2401). The process for creating the DTD for displaying the partial structure will be described later with reference to FIG.
Further, the hit range obtained for the structured document after normalization is converted into the structure ID and hit range information in the document at the time of registration before normalization (2402). With respect to the content of the conversion processing of the normalized document information into the document range information before normalization, the method described above with reference to FIG. 16 can be used.
Next, the information of the structure of the analyzed document to be displayed is read, and the processing of 2403 to 2411 is repeated in order to perform the output processing of the document for display.
First, structural information to be displayed is read (2403). Here, the determination of whether or not the structure is a display target is realized using the method described above with reference to FIG.
If it is structure information to be displayed, first, a structure start tag is output (2404). Further, if there is a subordinate structure in this structure (2405), display processing (
If it is determined in
If the character string does not include the highlight range, the content is output as text as it is (2410). When the output content is a character string, the start tag and the end tag are not output in
The highlight display for each structure is realized by the above processing. If there is a structure to be further processed, the processing from 2403 is repeated (2412).
[0049]
FIG. 25 shows the contents of creating a DTD for displaying a partial structure.
Depending on the output of the partial structure, there may be a case where a structure defined to necessarily appear in the original DTD (2501) is not output. Furthermore, the upper structure is not always output.
For this reason, the DTD for displaying the partial structure does not require the appearance of the start tag and end tag of the upper structure. Furthermore, the structure itself needs to be changed so that it does not necessarily appear. The created DTD for displaying the partial structure is as shown in 2502.
An SGML document created using this DTD is as shown in 2503. In this example, only the title is extracted.
[0050]
FIG. 26 is a flowchart showing a DTD creation procedure for displaying a partial structure.
First, a DTD for registration is acquired (2601).
Next, an ELEMENT item in the DTD is taken out (2602). When CDATA, RCDATA, and #PCDATA are included in the content model, highlight information is added (2603-2606).
The addition of highlight information is the same as the processing in
Next, the appearance indicator (*, +,?, None) in the content model is checked. If it is “+” (2607), it is changed to “*” (2608), and if there is no appearance indicator (2609). , “?” Is added (2610).
When processing for all ELEMENT declarations is completed (2611), an ELEMENT declaration with a structure for highlighting is added (2612), and if a tag with a structure with a subordinate structure must appear (-) Change to unnecessary (O).
[0051]
Next, Example 4 using the present invention will be described with reference to the drawings.
FIG. 27 is a system configuration diagram of this embodiment.
A WWW (World Wide Web) search system (2700) is connected to a client (2701) using a network (2702).
The client (2701) is a PC, WS or the like, and inputs a search term on a search term setting screen on a web browser (2703) operating on the client (2701). The WWW search system (2700) performs a search using this search term, and outputs the search result to the web browser (2703).
The WWW search system (2700) includes an HTTP server (2704) that receives a search term from the client (2701), a data control unit (2705) that inserts a search processing and highlight tag, and location information of the highlight tag. Is connected to a magnetic disk device (2707) for storing an HTML document to be searched.
In the data control unit (2705), the search term received by the HTTP server (2704) is searched for the HTML document existing in the magnetic disk (2707), and the search hit position of the HTML document hit in the search term is set. Insert a highlight tag.
The memory (2706) includes a highlight number storage area (2708) for storing the number of search hits for each document, a highlight position information storage area (2709) for storing search result position information, and a highlight tag to be inserted. Tag character storage area (2710) for storing the contents of HTML, HTML document temporary storage area (2711) for storing the HTML document into which the highlight tag is inserted, and search term input by the client (2701) Is acquired by the HTTP server (2704) of the WWW search system (2700) and is temporarily stored in a search term storage area (2712).
The HTML document in which the highlight tag is inserted by the WWW search system (2700) is displayed on the Web browser (2703) of the client (2701) via the network (2702) from the HTTP server (2704).
[0052]
Next, processing contents of the data control unit (2705) will be described with reference to FIG.
Here, the search term set in the client (2701) is acquired, search processing is performed, the search hit position is detected, highlight position information (2709) is created, and the search term of the HTML document hit with the search condition is hit. A highlight tag is embedded at the search hit position of the HTML document and displayed on the Web browser (2703) of the client (2701).
Step 2800:
The search term set by the client (2701) is acquired by using the HTTP server (2704) in the WWW search system (2700). The acquired search terms are stored in the search term storage area (2712) of the memory (2706). Step 2801:
Using the search terms stored in the search term storage area (2712) in
Step 2802:
In
Step 2803:
The highlight HTML document stored in the HTML document temporary storage area (2711) created in
By repeating the processing from
[0053]
Next, the highlight position information creation process in
Step 2900:
The HTML document stored in the magnetic disk (2707) is read out. The HTML document (3400) in FIG. 34 is an example of a read HTML document.
When this HTML document is displayed by a Web browser, a screen as shown in 3401 is displayed.
Step 2901:
The number of highlight position information storage areas (2709), which are areas for storing the highlight position information, are secured for the number of α. α is an arbitrary positive integer. A highlight number storage area (2708) for storing the number of highlights is secured.
The data formats of the highlight position information storage area (2709) and the highlight number storage area (2708) are shown in FIGS.
As shown in FIG. 30, the highlight position information storage area (2709) includes an HTML document number (3000), a highlight position number from the beginning (3001), the number of highlight bytes (3002), and a highlight insertion tag number ( 3003).
The HTML document number (3000) is the number of the HTML document read in
The highlight position number (3001) from the top stores the search hit position in the HTML document as the number of bytes from the top of the document when the HTML document read out in
The number of highlight bytes (3002) stores the length to be highlighted as the number of bytes. That is, the character string length of the search term is stored.
When the highlight insertion tag number (3003) is highlighted in a plurality of search terms, the highlight tag can be displayed separately for each search term. Based on the information stored here, the highlight tag is distinguished. That is, data for determining the type of tag used for highlight display is stored here.
[0054]
Step 2902:
I_cnt indicating the count stored in the highlight position information storage area (2709) is initialized to zero.
Step 2903:
It is checked whether or not the search term read in
Step 2904:
It is checked whether the highlight position information storage area (2709) secured in
Step 2905:
The highlight position information storage area (2709) is enlarged by a fixed value and secured again, and the process proceeds to step 2906.
[0055]
Step 2906:
The HTML document number (3000), the position from the beginning of the HTML document (3001), the number of highlighted characters (3002), the highlight are added to the i_cnt-th position in the highlight position information storage area (2709) secured in
When a plurality of highlight information is stored in one HTML document, i_cnt is updated, and is stored at a position indicated by i_cnt.
The HTML document (3400) read in
When the search term “special feature” is searched in this HTML document (3400), the character “special feature” can be found in the 122nd byte (3403) from the top of the HTML document (3400).
In this case, “001” (3404) which is the HTML document number is stored in the HTML document number (3000), and “122” (3405) is stored in the position (3001) from the head of the HTML document. The number of characters (3002) stores the number of bytes of “special feature” “4” (3406). Finally, the highlight tag insertion number (3003) stores a number indicating a tag for emphasizing the search result. Here, “1” (3407) is stored.
[0056]
Here, FIG. 32 shows a configuration corresponding to the highlight insertion tag number and the actually stored highlight tag. FIG. 32 (1) shows a
The structure for the highlight insertion tag (3200) includes a tag number 1 (3202) for storing a serial number, a start tag 1 (3203) for storing a highlight start tag name, and an end tag for storing a highlight end tag name. 1 (3204) and the number of highlight tags (3201) for storing the number of tags. There are as many tag numbers, start tags, and end tags as the number of highlight tags stored.
[0057]
An example of using the highlight tag character storage area will be described in (2).
Here, a case where three types of highlight tags are stored is shown. Therefore, “3” (3205) is stored in the location where the number of highlight tags is stored. A tag “<FONT COLOR =“ RED ”>” (3207) indicating a red color is stored in the start tag of the tag number “0” (3206), and “</ FONT>” (3208) is stored in the end tag. To do. Similarly, a tag “<BLINK>” indicating blinking is stored in the tag number “1” (3209), and “<H1>” that displays a large character is stored in the tag number “2” (3210).
The highlight tag character storage area (2710) is created before the highlight position information storage area (2709) is created. The highlight tag character storage area (2710) can also be created using a user interface.
By preparing a plurality of highlight tags, when searching for different notations and synonyms, the tag number “1” is used for characters searched using different notations, and characters searched using synonyms are used. Different tag display is possible for each search condition, such as tag number “2”.
When “<BLINK>” is used for the highlight tag, “1” is stored in the highlight tag insertion number (3407) of the highlight position information storage area (3402).
[0058]
Step 2907:
In
Step 2908:
The number of highlights in the HTML document acquired in
FIG. 31 shows the contents of the structure of the highlight number storage area (2708).
Reference numeral 3100 denotes the document number of the HTML document read in
[0059]
Next, an HTML document creation process with a highlight tag will be described with reference to FIG.
Step 3300:
It is checked whether or not it is necessary to insert a highlight tag in the HTML document read in
If the HTML document number (3000) stored in the highlight position information storage area (2709) exists, the process proceeds to step 3301. If not, all texts are output in
Step 3301:
I_cnt indicating the processing count is initialized to zero.
Step 3302:
An HTML document temporary storage area (2711) for storing the HTML document in which the highlight tag is inserted is secured.
In the HTML document temporary storage area (2711), the number of bytes of the HTML original document is secured by multiplying the total number of bytes of the highlight start tag and the end tag by the number of highlight insertions.
For the highlight start tag and end tag, the tag character string length of the highlight tag is calculated from the highlight insertion tag number (3003) of the highlight position information storage area (2709). As the number of highlights, the number of highlights (3101) stored in the highlight number storage area (2708) in
Step 3303:
It is checked whether the highlight number (3101) is smaller than i_cnt.
If it is smaller, there is an unprocessed highlight portion, so the process proceeds to step 3304. Otherwise, all the unprocessed highlight portions to be processed are completed, and the process advances to step 3309.
Step 3304:
The HTML document up to the highlight position is stored in the HTML document temporary storage area (2711) secured in
[0060]
Step 3305:
The highlight start tag is stored in the HTML document temporary storage area (2711). The highlight start tag is a tag name stored in the highlight tag character storage area (2710) obtained from the number extracted from the highlight insertion tag number (3003).
In the case of FIG. 34 (3), “1” is stored in the highlight insertion tag number (3003). “<BLINK>” stored in the tag number “1” (3209) of the highlight tag character storage area (2710) shown in FIG. 32 (2) is stored in the HTML document temporary storage area (2711).
Step 3306:
The search term is stored in the HTML document temporary storage area (2711).
In the case of FIG. 34, the “special feature” is stored in the HTML document temporary storage area (2711).
Step 3307:
The highlight end tag is stored in the HTML document temporary storage area (2711). The highlight end tag is the tag name stored in the highlight tag character storage area (2710) obtained from the number stored in the highlight insertion tag number (3003), like the highlight start tag processed in
In the case of FIG. 34 (3), “1” is stored. Therefore, “</ BLINK>” stored in the tag number “1” in FIG. 32B is stored in the HTML document temporary storage area (2711).
Step 3308:
In
Step 3309:
The text is stored in the HTML document temporary storage area (2711) from the highlight insertion position to the end of the HTML document, and the process of creating the HTML document with the highlight tag is finished.
[0061]
By using the above processing, the HTML document is searched from the search term set by the client (2701), and the highlight number storage area (2708) for storing the highlight number for the document that matches the search term is displayed. The contents of the highlight position information storage area (2709) for storing the write position can be created.
An example of the processing result is shown in FIG.
When this HTML document is displayed on the screen, it becomes like 3503, and the search hit “special feature” (3504) blinks.
As described above, as a first embodiment of the present invention, a search term inserted by a client (2701) is searched from an HTML document (2707), and a highlight tag is inserted at a hit position. Explained how to create.
[0062]
Next, a fifth embodiment of the present invention will be described with reference to FIGS.
FIG. 36 is a system configuration diagram in the highlight display method when the search term is divided by the tag of the HTML document or when the search term exists in the tag.
Similarly to FIG. 27, a search term is set on the Web browser (2703) of the client (2701).
[0063]
The WWW search system (2700) includes an HTTP server (2704) that acquires a search term, data control (2705) for search processing, and a memory (2706) that secures an area.
The memory (2706) is a tag used for layout display and the like, as described in the description of FIG. 27, and is input by a skip tag name storage area (3600) storing a tag name to be skipped and a client (2701). The start position storage area (3601) for temporarily storing the start position where the search term and the HTML document (2707) match, and the search term and the hit position are the start character “<” and end character “ > ”, The description mark storage area (3602) for storing a mark as a mark again, and the search term hit between the start tag and the end tag of the HTML tag, the search hit location Write an HTML tag that cannot contain a highlight tag before or after the highlight tag insertion impossible tag name storage area (3603). It made.
The search term acquisition, creation of highlight position information, and highlight tag insertion method when the search term spans the HTML document tag or when the search term exists in the tag are the processing shown in FIG. Follow the procedure. Each processing content will be described with reference to FIGS.
[0064]
Using the search terms acquired in
Step 3700:
The HTML document to be processed is read from the magnetic disk (2707).
Step 3701:
A highlight position information storage area (2709) for storing the highlight position information and a highlight number storage area (2708) are secured in the memory (2706).
Step 3702:
Reads highlight tags to be inserted before and after the search hit position.
As shown in the usage example of FIG. 32 (2), the highlight tag is read from the highlight tag character storage area (2710). In this case, the number of highlight insertion tag numbers is known as “3” from “3” (3205).
The first “0” (3206) stores “<FONT COLOR =“ RED ”>” (3207) and “</ FONT>” (3208). Therefore, the highlight
Similarly, the first insertion tag of the highlight insertion tag number is “<BLINK>”, the end tag is “</ BLINK>”, the second start tag of the highlight insertion tag number is “<H1>”, and the end. The tag is “</ H1>”.
Step 3703:
The i_cnt indicating the count of the number of processed characters of the HTML document and the contents of the area for storing the number of highlights are initialized to 0.
[0065]
Step 3704:
It is checked whether the search term and the character string of the HTML document match. As a check method, a character matching the first character of the search term is searched from the i_cnt byte of the HTML document. In
In addition, here, as a method for extracting the search terms, a method of searching by skipping a designated tag is used. Specifically, if the tag name stored in the skipped tag name storage area (3600) is present in the HTML document, the tag is skipped and search processing is performed.
When “IMG” is stored in the skip tag name storage area (3600) and the HTML document (3400) of FIG. 34 is searched, data is scanned from the head in the HTML document (3400), and “IMG” ( When 3413) is extracted, characters in the tag are skipped. That is, it skips to the end character “>” (3414) of the tag.
By setting this skipping tag name storage area (3600) before search processing, skipping processing can be performed.
[0066]
Step 3705:
In step 3704, the number of characters from the beginning of the HTML document to the character that matches the first character of the search term is temporarily secured in the start position storage area (3601).
Step 3706:
Checks whether the character string of the search term and the character written in the HTML document match. If they match, check whether the matching part exists in the HTML tag or outside the HTML tag. To do. Further, the position of the last character of the character string hit by the search is secured by the number of characters from the head of the HTML document. Details will be described with reference to FIG.
Step 3707:
As a result of
Step 3708:
The highlight number storage area (3708) secured in
Step 3709:
Since there is not enough area to store data in the highlight position information storage area (2709), the area is set again and the process proceeds to step 3710.
[0067]
Step 3710:
Information on the number of characters to be highlighted and the highlight position is stored in the highlight position information storage area (3600).
Specifically, the HTML document number (3000) in the highlight position information storage area (3600) described with reference to FIG. 30 stores the document number of the HTML document read in
The number of highlight bytes (3002) stores the character string length of the search term, and the highlight insertion tag number (3003) stores the tag number read in
The highlight insertion tag number (3003) is set to “0” as a default.
Step 3711:
If there are a plurality of character strings that hit the search term, the process of checking again the search term and the matching part in the HTML document is performed again from the next character at the position of the search hit. Therefore, a value obtained by adding 1 to the number of characters from the beginning of the HTML document at the position where the last character of the search hit secured in
Step 3712:
If the character string from the start position stored in the start position storage area (3600) acquired in
The search process including the check inside and outside the tag and the highlight position information creation process have been described above.
[0068]
Next, with reference to FIG. 38, the search processing within the tag and the search processing outside the tag in
Here, it is checked whether the start position of the search hit acquired in
Step 3800:
In
The data from the i_cnt byte of the HTML document at the time of
The tag end character “>” corresponding to the tag start character “<” is checked, and it is checked whether or not the search hit start position exists in the tag.
If there is a tag start character “<” and the start position of the search hit exists before the tag end character “>”, it is determined that the start position exists in the tag, and the process proceeds to step 3801.
If the search hit start position exists within the range not surrounded by the tag start character “<” and the tag end character “>”, the search hit start position is assumed to be outside the tag, and the process advances to step 3804. .
[0069]
Step 3801:
It is checked whether the search term matches the character string from the start position of the search hit. If the search term string consists of multiple bytes, the string is checked for each byte. If the character string of the search term and the character string from the search hit position match, the process proceeds to step 3802. If not, the process proceeds to step 3803.
Step 3802:
In step 3801, if it matches the search term, it is determined that a “search hit” has been made, and the process ends.
Further, the end position of the character string hit by the search is obtained. The end position is the number of bytes obtained by adding the character string length of the search term to the start character position where the search hit was made. The end position obtained here is used in step 3711.
Step 3803:
In step 3801, if the search terms do not match, the processing ends as “no search hit”.
Step 3804:
In
Step 3805:
In
Step 3806:
If the search term is not hit in
Step 3807:
In
Further, the end position of the character string hit by the search is obtained. The end position is a value obtained by adding the position where the last character of the search hit detected in
The tag search and tag search process has been described above.
[0070]
Next, the external tag search process in
Step 3900:
Check whether a search term exists in the HTML document. It is checked whether or not the character string of the search term matches the character string existing in the HTML document. However, since there is a case where the search term is hit by skipping a tag existing in the middle, here Then, it is checked whether the character matches the search term for each character from the start position where the search hit occurs.
Specifically, this will be described with reference to FIG.
When the search term is “special article”, “special article” is displayed in 3408 on the display screen of (2). However, in the HTML document (3400), there is a tag “</ H1>” (3417) between “special feature” (3403) and “article” (3416). Thus, when an HTML tag exists in the middle of a search term, this HTML tag is skipped and a character string that matches the search term is extracted.
Here, the search term is checked for each character against the characters of the HTML document.
When the first character of the search term matches the character in the HTML document, the same processing is repeated for the next character of the search term and the next character of the HTML document.
When all the characters in the search term string match, specifically, the characters are compared with “special” (3403) and “collection”, and “</ H1>” (3417) is skipped. Further, the character comparison is made with “Note” (3416) and “Thing”. If all search terms have been extracted, the process proceeds to step 3901.
If the search term does not completely match the character string in the HTML document, the process proceeds to step 3902.
[0071]
Step 3901:
Since there is a search term in the HTML document, it is determined that a “search hit” has occurred, and the process is terminated.
Further, the end position of the search hit is obtained. The end position is the position of the character extracted last in
Step 3902:
In
If the tag start character is “<”, the process proceeds to step 3903. In the case of other characters, the process proceeds to step 3904.
Step 3903:
If the character in the HTML document is the tag start character “<” in
Specifically, the end character “>” of the tag is extracted, and the extracted characters are skipped. In the HTML document (3400) of FIG. 34, when the search term is “special article”, from “<” (3417) in the next character of “special feature” (3403) to the end character “>” (3418) of the tag. Skip. That is, “</ H1>” is skipped.
Step 3904:
In
The process of extracting the search hit position and storing the highlight position information in the highlight position information storage area when the character string of the search term exists in the HTML document has been described above.
[0072]
Next, referring to FIG. 40, a method for inserting a highlight tag to highlight a character string that has been searched for in an HTML document based on highlight position information stored in a highlight position information storage area will be described. explain.
Step 4000:
In step 3710, the highlight position information stored in the highlight information storage area (2709) is read.
Step 4001:
An HTML document temporary storage area (2711) for storing the HTML document in which the highlight tag is inserted is secured.
The size of the area to be secured is the number of bytes of a value obtained by multiplying the original document data of the HTML document and the sum of the lengths of highlight start tags and end tags corresponding to the number of highlight tags.
The number of highlight tags is read from the highlight tag number storage area (2708). The highlight start tag and end tag are detected from the highlight insertion tag number (3003) and highlight tag character storage area (2710) of the highlight position information storage area (2709), and the detected tag Find the string length.
Step 4002:
The i_cnt indicating the processed position in the HTML document and the number of highlight processes are initialized to zero.
[0073]
Step 4003:
The number of highlight processing, which is the number of processed highlight locations, is compared with the number of highlights to be processed. When the number of highlight processes is small, the process proceeds to step 4004 in order to perform a process of inserting a highlight tag. Otherwise, go to
Step 4004:
Data from i_cnt indicating the processed position to the start position of the search hit is stored in the HTML document temporary storage area (2711).
Specifically, in the HTML document (3400) of FIG. 34, when the search term is “special article”, the data from the beginning of the HTML document to the character “this month” before the “special article” (3403) is the HTML document. Store in the temporary storage area (2711).
Step 4005:
The highlight tag is stored in the search hit position. The highlight tag insertion processing will be described with reference to FIG.
Step 4006:
The number of bytes from the beginning of the position where the highlight end tag is inserted is substituted into i_cnt indicating the processed position of the HTML document, and the process returns to step 4003.
Step 4007:
The data from i_cnt indicating the processed position of the HTML document to the end of the HTML document is stored in the HTML document temporary storage area (2711), and the processing is terminated.
[0074]
Next, highlight tag insertion processing to be processed in
Here, it is checked whether the search hit position is inside or outside the tag, and processing for inserting a highlight tag before and after the search hit position is performed.
Step 4100:
It is checked whether the hit position in the HTML document is inside the HTML tag or outside the tag.
In the check method, in the HTML document up to the start position of the search hit, the correspondence between the start character “<” of the HTML tag and the end character “>” of the tag is taken and it is determined whether the tag is inside or outside the tag. If the start position of the search hit is between the start character “<” of the tag and the end character “>” of the tag, the process proceeds to step 4101 assuming that the search hit exists. In other cases, it is assumed that the start position of the search hit position exists outside the tag, and the process proceeds to Step 4110.
Step 4101:
The character is extracted from the next character after the tag start character “<”, and the tag type is acquired.
For example, in the case of the HTML document (3400) of FIG. 34, if the search term is “hitachi”, “hitachi” can be acquired in 3409 of the HTML document (3400). When the type of the HTML tag is acquired, it is understood that “A” (3410) is written after the tag start character “<”.
Step 4102:
It is checked whether the tag acquired in
[0075]
Step 4103:
It is checked whether a highlight tag can be inserted between the start tag and the end tag.
If it can be inserted, the process proceeds to step 4105. If this is not possible, the process proceeds to step 4106.
Specifically, in the HTML document (3400) of FIG. 34, when the search term is “hitachi”, the type of the HTML tag is “A” (3410) existing before “hitachi” (3409). The start tag is “<A to>” (3410) between “<” and “>” surrounding the types of HTML tags, and the end tag is “</A>”. (3412).
The HTML tag is a tag that is displayed on the screen with a character string written in the start tag and the end tag, and links to the URL specified in the start tag when this character string is selected. If a highlight tag is inserted between “<A˜>” (3410) and “</A>” (3412), a phenomenon in which highlighting is not performed correctly occurs. Accordingly, it is determined that a highlight tag cannot be inserted between the “<A˜>” tag and the “</A>” tag, and the process advances to step 4104.
Whether or not the highlight tag can be inserted is determined to be impossible if the type of the HTML tag matches one of the tags stored in the highlight tag insertion impossible tag name storage area (3603). If they do not match, it is determined that insertion is possible.
Note that the tags to be stored in the highlight tag non-insertable tag name storage area (3603) are created before the data control (2705) processing is performed using the user interface.
[0076]
Step 4104:
If the search hit character string cannot be inserted between the start tag and the end tag, skip to the insertable part.
Here, reading is skipped to the character “>” at the end of the end tag, and the skipped data is acquired.
Specifically, when the HTML document (3400) in FIG. 34 and the search term is “hitachi”, the HTML tag is “A” (3410). The end tag is “</A>” (3412).
Therefore, data is acquired up to “</A>” (3412).
Step 4105:
If a character can be inserted between the start tag and the end tag, data is acquired up to the character “>” at the end of the tag.
Specifically, if the HTML document (3400) search term in FIG. 34 is “imagefile.gif” (3411), the type of HTML tag is “IMG” (3413), and the tag character at the end is “ > ”(3414). Therefore, skip to “>” (3414) and acquire the skipped data.
Step 4106:
The data acquired in
[0077]
Step 4107:
A highlight start tag is inserted into the HTML document temporary storage area (2711). The tag name written in the start tag 1 (3203) in FIG. 32 is inserted into the HTML document temporary storage area (2711).
When the data stored in the highlight position information storage area is 3402 and the highlight tag character storage area is (2) in FIG. 32, the highlight insertion tag number (3407) in the highlight position information storage area is “ Since “1” is described, “<BLINK>” can be acquired from (2) of FIG. Therefore, “<BLINK>” is inserted into the HTML document temporary storage area (2711).
Step 4108:
The search hit character is inserted into the HTML document temporary storage area (2711). However, since the search hit character is described again, the mark described again is stored. Here, the data stored in the description mark storage area (3602) is inserted again.
The description
Step 4109:
An end tag for highlighting is inserted into the HTML document temporary storage area (2711). The tag name written in the end tag 1 (3204) in FIG. 32 is inserted into the HTML document temporary storage area (2711). Here, “</ BLINK>” is inserted.
Step 4110:
If the search hit position exists outside the tag, the tag external highlight tag insertion processing is performed. This process will be described with reference to FIG.
Next, the tag highlight highlight insertion processing performed in
Step 4200:
In the case of the “<A˜>” tag, if a highlight tag is inserted at a location between the start tag “<A˜>” and the end tag “</A>”, a highlight is displayed. Not reflected. Here, it is checked whether or not it is surrounded by a start tag and an end tag, and in
It is checked whether or not the position stored in the highlight position information (3001) from the top of FIG. 30 is surrounded by the start tag and the end tag of the HTML document. If so, the process proceeds to step 4201. If not, the process proceeds to Step 4209.
Specifically, in the HTML document (3400) of FIG. 34, when the search term is “Hitachi”, “Hitachi” (3415) of the HTML document (3400) is extracted. Since this is surrounded by HTML tags “<A˜>” (3410) and “</A>” (3412), the process proceeds to step 4201 here.
Step 4201:
Check whether it is possible to insert a highlighting tag before and after the character string hit in the search.
In the check method, an HTML tag surrounded by a search character string hit by the search is extracted. The type of the extracted tag is compared with the tag stored in the tag name storage area (3603) where the highlight tag cannot be inserted. If they match, the process proceeds to step 4202, and if they do not match, the process proceeds to step 4209.
As for the tag name described in the tag name storage area (3603) where the highlight tag cannot be inserted, a highlight tag cannot be inserted between the start tag and the end tag.
Therefore, it compares with the HTML tag stored in the highlight tag non-insertable tag name storage area (3603). If they match, the process proceeds to step 4202, and if they do not match, the process proceeds to step 4209.
This highlight tag insertion impossible tag name storage area (3603) is created before data control (2705) using the user interface.
Step 4202:
If the highlight tag cannot be inserted, the HTML document up to the character “>” at the end of the end tag is skipped.
In FIG. 34, when the search term “Hitachi” is selected, HTML documents up to “</A>” (3412) are skipped.
[0078]
Step 4203:
The HTML document skipped in
In FIG. 34, when the search term is “Hitachi”, the data “</A>” (3412) from the character of the HTML document at the i_cnt-th set at
Step 4204:
The start tag of the highlight tag is inserted into the HTML document temporary storage area (2711). When the highlight position information storage area is 3402 and the highlight tag character storage area is (2) in FIG. 32, “<BLINK>” is extracted. Therefore, “<BLINK>” is inserted here.
Step 4205:
Stores the mark for redisplay. Similarly to step 4108, the HTML document stored in the description mark storage area (3602) is read again and stored in the HTML document temporary storage area (2711).
Step 4206:
The search hit character string is inserted once again into the HTML document temporary storage area (2711).
However, if a tag exists in the middle of the character string that has been searched for, the character string up to the location where the tag exists is inserted.
Step 4207:
An end tag for highlighting is inserted into the HTML document temporary storage area (2711). Here, “</ BLINK>” is inserted.
Step 4208:
In
If there is a tag in the character string hit for the search and not all the characters hit for the search are stored, the process returns to step 4200. If all characters have been stored, the process ends.
[0079]
Step 4209:
The data is skipped to the start position where the search hit occurs, and the skipped HTML document is stored in the HTML document temporary storage area (2711).
Specifically, in the HTML document (3400) of FIG. 34, if the search term is “special feature article”, the HTML documents up to “this month” existing before the “special feature” (3403) that has been searched for are HTML. It is inserted into the temporary document storage area (2711).
Step 4210:
Similarly to step 4205, the start tag of the highlight tag is stored in the HTML document temporary storage area (2711). Here, “<BLINK>” is inserted.
Step 4211:
The search hit character string is inserted into the HTML document temporary storage area (2711).
However, if a tag exists in the middle of the character string that has been searched for, the character string up to the location where the tag exists is inserted.
For example, in the HTML document (3400), when the search term is “special article”, “</ H1>” (3417) exists between “special feature” (3403) and “article” (3416). Therefore, the “special feature” is stored here.
Step 4212:
The end tag of the highlight tag is inserted into the HTML document temporary storage area (2711). Here, “</ BLINK>” is inserted.
[0080]
Step 4213:
In step 4211, it is checked whether or not all character strings of the search terms have been inserted into the HTML document temporary storage area (2711). By removing the HTML tag, the search term and the character string of the HTML document are hit, and if there is an HTML tag between the search hit character string and the search term length character string, in step 4211 the HTML tag The HTML document up to is inserted into the HTML document temporary storage area (2711). In this case, it is necessary to process the remaining search hit characters from the HTML tag.
If all the search terms are inserted into the HTML document temporary storage area, the process is terminated. When processing the remaining search hit characters from the HTML tag, the process returns to step 4200.
In the HTML document (3400) of FIG. 34, when the search term is “special article”, “</ H1>” (3417) exists between “special feature” (3403) and “article” (3416). In
[0081]
By performing such processing, using the search term set by the client (2701), the highlight tag is inserted into the HTML document that matches the search term, and the highlight hit location is displayed on the web browser (2703). It is possible.
Here, a processing method is shown in which an HTML document is checked for one search term, and if the character string of the search term exists in the HTML document, the search result is displayed on the Web browser of the client (2701). However, a single search term is searched from a plurality of HTML documents, highlight position information corresponding to the number of HTML documents hit by the search is stored, and a plurality of HTML documents storing highlight tags are collectively created. Things are also possible.
In addition, for a plurality of search terms, a search is made from a plurality of HTML documents, highlight position information corresponding to the number of search hit HTML documents is stored, and a plurality of HTML documents storing highlight tags are collectively created. It is also possible.
[0082]
Next, Example 6 using the present invention will be described.
The change from the second embodiment of the present embodiment is that a highlight method when the search condition is hit can be defined together with the search term in the search condition. Thereby, it is possible to specify a highlight method for each search condition for an arbitrary search condition.
The system configuration of this embodiment is the same as that shown in FIG. However, the description method of the search condition 103 is different. An example of the description method of the search condition 103 in this embodiment will be described with reference to FIG.
[0083]
FIG. 43 shows an example of search conditions in the present embodiment.
As shown in this figure, the highlight method is specified after each search term and structure condition, such as “{underline}”.
The search condition in the second embodiment is “search target structure designation: search condition formula”, but “search target structure condition {highlight method}: search condition formula with highlight method”.
Specifying the highlight method can be omitted. When omitted, the highlight display is performed by the method shown in the second embodiment. That is, for a portion where the highlight method is not described in the search condition, the
[0084]
FIG. 44 shows the contents stored in the
The change from the hit range information shown in FIG. 17 of the second embodiment is that not only the hit condition 4402 but also the
[0085]
FIG. 45 shows a method for generating a highlight display DTD in this embodiment.
In this example, since there is a possibility that a highlight method is newly changed every time a search is performed, a highlight display DTD in which only a necessary structure is added is generated each time a highlight is displayed. In this case, a description relating to the highlight method is made directly in the DTD, not the search condition.
As shown in this figure, for the original DTD (1901) used for registration, the lower highlight structure can be specified hierarchically in the upper highlight structure and further defined so that it can be omitted. The DTD (4501) for highlight display that has been changed or added is generated.
[0086]
44. First, when the
Further, the hierarchical relationship of the highlight structure that appears is obtained from the hierarchical relationship of the hit ranges in the
[0087]
By the highlight processing in this embodiment, instead of making the search condition a highlight structure, a structured document for highlight display describing the described highlight method and a DTD for highlight display are generated. Become.
As described above, the structured document for highlight display is generated by the processing according to this embodiment. An example of the generated structured document for highlight display is shown in FIG.
When the structured document for highlight display shown in FIG. 46 is highlighted, the result is as shown in FIG.
[0088]
【The invention's effect】
According to the present invention, when displaying the contents of a hit document as a search result of a structured document, it is possible to output a structured document with highlight information added to the range where the search term is hit for each structure. It becomes. By embedding highlight information in a structured document instead of browser-dependent highlight information, highlight display is possible in any browser.
Different highlight processing can be performed depending on the search conditions or the conditions such as importance and appearance frequency of each search term. For important search terms, it is possible to perform highlight processing clearly indicating high weighting. It becomes. Furthermore, by describing the highlight method in the search condition, it becomes possible to perform arbitrary highlight display for each user.
Furthermore, it becomes possible to extract only a partial structure and output a structured document to which highlight information is added.
Also, when searching for a character string from a document having an HTML tag indicating the document structure, a character string that matches the set search term exists in the HTML tag, or the search term is described across the HTML tag. It is possible to easily hit a search even when In addition, it is possible to highlight the character string that has been searched for.
[Brief description of the drawings]
FIG. 1 is a processing block diagram of a structured document search / display apparatus according to
FIG. 2 is a flowchart of a structured document search / display process.
FIG. 3 is a diagram showing the contents of structured document registration.
FIG. 4 is a flowchart of a structured document registration process.
FIG. 5 is a diagram showing text for search.
FIG. 6 is a flowchart of update processing.
FIG. 7 is a diagram illustrating a flowchart of a specified structure extraction process;
FIG. 8 is a diagram illustrating information output as an analysis result of structure designation.
FIG. 9 is a diagram illustrating a flowchart of document display processing.
FIG. 10 is a diagram illustrating an example of a structured document and a highlight processing result.
FIG. 11 is a diagram illustrating a flowchart of document display DTD creation processing;
FIG. 12 is a diagram showing the contents of normalization processing for structured document search.
FIG. 13 is a diagram showing the contents stored as a result of normalization processing;
FIG. 14 is a diagram showing the contents of conversion processing of hit range information when normalization processing is performed.
FIG. 15 is a diagram illustrating a flowchart of hit range information conversion processing when normalization processing is performed.
FIG. 16 is a diagram illustrating a flowchart of processing for adding highlight information.
FIG. 17 is a diagram illustrating hit range information according to the second embodiment.
FIG. 18 is a diagram illustrating a definition of a highlight method for each hit information according to the second embodiment.
FIG. 19 is a diagram illustrating the contents of conversion to highlight display DTD according to the second embodiment.
FIG. 20 is a flowchart illustrating highlight processing according to the second embodiment.
FIG. 21 is a diagram illustrating an example of an SGML document to which highlight information is added according to the second embodiment.
FIG. 22 is a diagram illustrating an example of highlight display.
FIG. 23 is a schematic processing block diagram of a structured document search / display apparatus according to a third embodiment;
FIG. 24 is a diagram illustrating a flowchart of processing contents of a third embodiment.
FIG. 25 is a diagram showing a conversion process to DTD for displaying a partial structure.
FIG. 26 is a diagram illustrating a flowchart of a DTD creation process for displaying a partial structure.
27 is a system configuration diagram according to
FIG. 28 is a diagram illustrating a flowchart of a data control unit.
FIG. 29 is a diagram illustrating a flowchart of a character search process and highlight position information creation process according to the fourth embodiment.
FIG. 30 is a configuration of a highlight position information storage area.
FIG. 31 is a configuration of a highlight number storage area.
FIG. 32 is a configuration of a highlight tag character storage area.
FIG. 33 is a diagram illustrating a flowchart of processing for creating an HTML document with a highlight tag according to the fourth embodiment.
FIG. 34 is an example of highlight insertion.
FIG. 35 is an example after highlight insertion.
36 is a system configuration diagram according to
FIG. 37 is a diagram illustrating a flowchart of search processing and highlight position
FIG. 38 is a flowchart illustrating in-tag search and out-tag search processing according to the fifth embodiment.
FIG. 39 is a diagram showing a flowchart of tag external search processing according to the fifth embodiment.
FIG. 40 is a flowchart of a highlight tag insertion HTML document creation process according to the fifth embodiment.
FIG. 41 is a flowchart of highlight tag insertion processing according to the fifth embodiment.
42 is a diagram showing a flowchart of tag highlight tag insertion processing in
FIG. 43 is an example of a search condition in the sixth embodiment.
44 is an example of hit range information in
FIG. 45 is a diagram illustrating conversion processing to highlight display DTD in the sixth embodiment;
FIG. 46 is a diagram illustrating an example of an SGML document for highlight display according to the sixth embodiment.
47 is a diagram showing an example of highlight display in Example 6. FIG.
[Explanation of symbols]
101 Structured document search and display device
102 Structured document for registration
103 Search conditions
104 Document registration processing module
105 Structured document DB
106 Information DB for search
107 Structured Document Reading Processing Module
108 Search processing module
109 Hit document number information
110 Hit range information
111 Document contents of hit document
112 Document display processing module
113 Document for display
114 Document storage file for registration
115 I / O device
2301 Display structure information
2302 Partial structure display module
2700 WWW search system
2701 clients
2703 Web browser
2704 HTTP server
2705 Data control
2706 memory
2707 HTML document
3200 Highlight Tag Character Storage Area Structure
3400 HTML document example
3401 Display example of HTML document
3500 Example of HTML document after highlight tag insertion
3501 Display screen example after highlight tag insertion
Claims (14)
Translated fromJapanese前記処理装置が、入力された構造化文書を解析して木構造を生成し、該木構造の各項目の内容を、構造識別子、構造種別、タグ、内容を有する解析済み構造化文書を生成し、該解析済み構造化文書を前記ファイル装置に格納し、
前記処理装置が、前記ファイル装置から前記解析済み構造化文書を読み込み、読み込んだ解析済み構造化文書を構成するデータから前記項目の構造種別が文字列である各項目の構造識別子と内容(文字列情報)を抽出して、抽出した文字列情報を順番に連ねて内容文字列情報を取得し、前記各項目の構造識別子と、該構造識別子に対応する文字列情報の位置情報とを有するデータを生成し、該生成したデータと前記取得した内容文字列情報とからなる文書検索用情報を生成し、前記ファイル装置に格納し、
前記処理装置が、入力された検索条件により該ファイル装置に格納された文書検索用情報を検索し、該検索条件を満たす内容文字列情報があるか否か判定し、該検索条件を満たすとみなされる内容文字列情報を持つ文書の解析済み構造化文書を取得し、かつ該文書の検索条件を満たす範囲の情報を取得し、
前記処理装置が、前記文書の検索条件を満たす範囲の情報に基づき構造化文書中にハイライト表示するための情報を付加した表示用構造化文書を、前記内容文字列情報中の前記検索条件を満たす範囲に属する最初の文字情報の前にハイライト開始タグを挿入すると共に最後の文字情報の後にハイライト終了タグを挿入することにより作成することを特徴とする構造化文書検索表示方法。A structured document search and display method in an information processing system including a processing device, a storage device, a file device, and an input / output device,
The processing apparatusgenerates atree structure by analyzing the input structured document,and generates an analyzed structured documenthaving a structure identifier, a structure type, a tag, and contents for each item of thetree structure. Storing the analyzed structured document in the file device;
The processing devicereads the analyzed structured document from the file device, and the structure identifier and contents (character string) of each item whose structure type is a character string from the data constituting the read analyzed structured document Information), content character string information is obtained by sequentially connecting the extracted character string information, and data having a structure identifier of each item and position information of character string information corresponding to the structure identifier is obtained. Generating document search informationcomposed of the generated data and the acquired content character string information, and storing it in the file device,
The processing device searches the document search information stored in the file device according to the input search condition, determines whether there is content character string information that satisfies the search condition, and is regarded as satisfying the search condition. To obtain a parsed structured document of a document having content string information to be acquired, and to acquire information in a range that satisfies the search condition of the document,
The processing device, the display structured document obtained by adding the information to highlight in the structured document based on the information of the search range satisfying thedocument, the search condition in the content character string information A structured document search / display method comprising: creating ahighlight start tag before the first character information belonging to a range to be satisfied and inserting a highlight end tag after the last character information .
前記処理装置が、入力された構造化文書を解析して木構造を生成し、該木構造の各項目の内容を、構造識別子、構造種別、タグ、内容からなる解析済み構造化文書を生成し、該解析済み構造化文書を前記ファイル装置に格納し、
前記処理装置が、前記入力された構造化文書から予め与えられた検索対象外の構造情報を除去した文書検索用の正規化処理済み構造化文書を生成して前記ファイル装置に格納し、
該正規化処理済み構造化文書を解析して木構造を生成し、該木構造の各項目の内容を、構造識別子、構造種別、タグ、内容からなるデータとし、該データと正規化処理前の構造化文書についての前記解析済み構造化文書(以下、正規化前解析済み構造化文書という)を比較して変更、追加された部分のデータを正規化前解析済み構造化文書に追加して正規化後解析済み構造化文書とし、前記変更、追加された部分のデータと正規化前解析済み構造化文書とにおける正規化前後での構造識別子の対応関係および正規化前後での文字列範囲の対応関係を示す正規化対応情報を生成し、前記正規化後解析済み構造化文書および正規化対応情報を前記除去された構造情報を復元するための復元情報として前記ファイル装置に格納し、
前記処理装置が、入力された検索条件により該ファイル装置に格納された正規化処理済み構造化文書を検索し、該検索条件を満たす正規化処理済み構造化文書があるか否か判定し、該検索条件を満たすとみなされる文書の正規化処理済み構造化文書を取得し、かつ該文書の検索条件を満たす範囲の情報を取得し、
前記処理装置が、前記検索により取得された正規化処理済み構造化文書を前記復元情報である前記正規化後解析済み構造化文書および正規化対応情報を参照して、除去された構造情報を有する構造化文書に復元し、前記文書の検索条件を満たす範囲の情報に基づき前記復元情報の正規化対応情報を参照して正規化処理前の構造化文書における検索条件を満たす範囲の情報を取得し、該取得した文書の検索条件を満たす範囲の情報に基づき該復元された構造化文書中にハイライト表示するための情報を付加した表示用構造化文書を、前記取得した検索条件を満たす範囲に属する最初の文字情報の前にハイライト開始タグを挿入すると共に最後の文字情報の後にハイライト終了タグを挿入することにより作成することを特徴とする構造化文書検索表示方法。A structured document search and display method in an information processing system including a processing device, a storage device, a file device, and an input / output device,
The processing devicegenerates atree structure by analyzing the input structured document,and generates an analyzed structured document includinga structure identifier, a structure type, a tag, and contents of each item of thetree structure. Storing the analyzed structured document in the file device;
The processing device generates a normalized structured document for document search in which the structure information that is not previously searched is removed from the input structured document,and stores it in the file device.
The normalized structured document is analyzed to generate a tree structure, and the contents of each item of the tree structure are data including a structure identifier, a structure type, a tag, and contents. Compare and modify the analyzed structured document (hereinafter referred to as pre-normalized structured document) for the structured document, and add the added data to the pre-normalized structured document for normalization. Correspondence between structure identifiers before and after normalization, and correspondence of character string ranges before and after normalization in the modified and added part of the structured document after normalization and the structured document analyzed before normalization Normalization correspondence information indicating a relationship is generated, and the post-normalization analyzed structured document and normalization correspondence information are stored in the file device as restoration information for restoring the removed structure information,
The processing device searches for a normalized structured document stored in the file device according to an input search condition, determines whether there is a normalized structured document that satisfies the search condition, Obtain a normalized structured document of a document that is considered to satisfy the search condition, and acquire information in a range that satisfies the search condition of the document,
The processing apparatusrefers to the normalized structured document obtained by the searchwith reference to the post-normalized analyzed structured document and the normalization correspondence information as the restoration information, and has the removed structure information Restoring to a structured document,referring to the normalization correspondence information of the restoration information based on the information of the range satisfying the search conditionof the document, and acquiring the information of the range satisfying the search condition in the structured document before normalization processing The structured document for display to which information for highlight display is added in the restored structured document based on the information of the range satisfying the search condition of the acquired document is set to the range satisfying the acquired search condition. structured document search, characterized in that to createby inserting the highlight end tag after the last character information is inserted the highlight start tag before the first character information belonging How to Display.
前記処理装置が、入力された構造化文書を解析して木構造を生成し、該木構造の各項目の内容を、構造識別子、構造種別、タグ、内容からなる解析済み構造化文書を生成し、該解析済み構造化文書を前記ファイル装置に格納し、
前記処理装置が、前記ファイル装置から前記解析済み構造化文書を読み込み、読み込んだ解析済み構造化文書を構成するデータから前記項目の構造種別が文字列である各項目の構造識別子と内容(文字列情報)を抽出して、抽出した文字列情報を順番に連ねて内容文字列情報を取得し、前記各項目の構造識別子と、該構造識別子に対応する文字列情報の位置情報とを有するデータを生成し、該生成したデータと前記取得した内容文字列情報とからなる文書検索用情報を生成し、前記ファイル装置に格納し、
前記処理装置が、入力された検索条件により該ファイル装置に格納された文書検索用情報を検索し、該検索条件を満たす内容文字列情報があるか否か判定し、該検索条件を満たすとみなされる内容文字列情報を持つ文書の解析済み構造化文書を取得し、かつ該文書の検索条件を満たす範囲の情報を取得し、
前記処理装置が、入出力装置から表示対象情報が入力されたとき、前記ファイル装置装置から前記解析済み構造化文書を読み込み、前記表示対象に対応する部分構造を該解析済み構造化文書から抽出し、
前記処理装置が、前記抽出した部分構造に対して、前記文書の検索条件を満たす範囲の情報に基づき構造化文書中にハイライト表示するための情報を付加した部分構造表示用構造化文書を、前記内容文字列情報中の前記検索条件を満たす範囲に属する最初の文字情報の前にハイライト開始タグを挿入すると共に最後の文字情報の後にハイライト終了タグを挿入することにより作成することを特徴とする構造化文書検索表示方法。A structured document search and display method in an information processing system including a processing device, a storage device, a file device, and an input / output device,
The processing devicegenerates atree structure by analyzing the input structured document,and generates an analyzed structured document includinga structure identifier, a structure type, a tag, and contents of each item of thetree structure. Storing the analyzed structured document in the file device;
The processing devicereads the analyzed structured document from the file device, and the structure identifier and contents (character string) of each item whose structure type is a character string from the data constituting the read analyzed structured document Information), content character string information is obtained by sequentially connecting the extracted character string information, and data having a structure identifier of each item and position information of character string information corresponding to the structure identifier is obtained. Generating document search informationcomposed of the generated data and the acquired content character string information, and storing it in the file device,
The processing device searches the document search information stored in the file device according to the input search condition, determines whether there is content character string information that satisfies the search condition, and is regarded as satisfying the search condition. To obtain a parsed structured document of a document having content string information to be acquired, and to acquire information in a range that satisfies the search condition of the document,
When thedisplay target information is input from theinput / output device , the processing devicereads the analyzed structured document from the file device, and extracts a partial structure corresponding to the display target from the analyzed structured document. ,
A structured document for partial structure display in which the processing device adds information for highlighting in the structured document based on information in a range that satisfies the search condition of the document with respectto the extracted partial structure.The content character string information is created byinserting a highlight start tag before the first character information belonging to the range satisfying the search condition and inserting a highlight end tag after the last character information. Structured document search and display method.
前記処理装置が、検索結果のハイライト表示を行う場合、メモリに予め記憶されヒットした条件(以下、ヒット条件という)に対するハイライト方法を定義したハイライト方法定義情報を該メモリから読み込み、検索時のヒット条件に対応するハイライト方法を該情報から抽出し、抽出したハイライト方法を用いて前記入出力装置にハイライト表示することを特徴とする構造化文書検索表示方法。In the structured document search and display method according to claim 1, claim 2, or claim 3,
When the processing deviceperforms highlight display of a search result, it reads highlight method definition information defining a highlight method for a hit condition (hereinafter referred to as a hit condition) stored in advance in a memory from the memory, A structured document search and display method, wherein a highlight method corresponding to a hit condition is extracted from the information, and is highlighted on the input / output device using theextracted highlight method.
前記処理装置が、ヒット条件中の2つの検索タームについて、各検索タームの相対的な出現位置に関するヒット条件がある場合は、ヒット条件を構成する各検索タームに対するハイライト表示とその2つの検索タームを含む最小の文字列範囲に対するハイライト表示とをそれぞれ異なったハイライト方法を用いて前記入出力装置にハイライト表示することを特徴とする構造化文書検索表示方法。The structured document search and display method according toclaim 4 ,
The processing device, the two search terms inthe hit condition,if there hit condition to the relative occurrence position of each search term are highlighted and the two search terms for each search term that constitutes ahit condition structured document search display wherein the highlighting to the input-output device with a minimum of highlightinghow the highlighting for string ranges different from each including.
前記処理装置が、ヒット条件に複数の検索タームを含む場合について、ヒット条件を構成する各検索タームに対するハイライト表示と該検索タームを含む構造全体に対するハイライト表示をそれぞれ異なつたハイライト方法を用いて前記入出力装置にハイライト表示することを特徴とする構造化文書検索表示方法。The structured document search and display method according toclaim 4 ,
The processing device, thecase where thehit conditionincludes a plurality of search terms, using the highlighthow the highlight for the entire structure including the highlighting and the search term for each search term that constitute thehit conditions different from one each A structured document search and display method characterized by highlighting on the input / output device.
前記処理装置が、ヒット条件の各検索ターム毎のハイライト表示のハイライト方法を、各検索タームの出現頻度の情報に基づき決定することを特徴とする構造化文書検索表示方法。The structured document search and display method according to claim 4,
A structured document search and display method, wherein the processing device determines a highlight display highlightmethod for each search term in thehit condition based on information on an appearance frequency of each search term.
前記処理装置が、ヒット条件の各検索ターム毎のハイライト表示のハイライト方法を、各検索タームごとに予め与えられた重み付けの情報に基づき決定することを特徴とする構造化文書検索表示方法。The structured document search and display method according to claim 4,
A structured document search and display method, wherein the processing device determines a highlight display highlightmethod for each search term of ahit condition based on weighting information given in advance for each search term.
前記処理装置は、入力された構造化文書を解析して木構造を生成し、該木構造の各項目の内容を、構造識別子、構造種別、タグ、内容からなる解析済み構造化文書を生成し、該解析済み構造化文書を前記ファイル装置に格納する手段と、
前記入力された構造化文書から予め与えられた検索対象外の構造情報を除去した文書検索用の正規化処理済み構造化文書を生成して前記ファイル装置に格納する手段と、
該正規化処理済み構造化文書を解析して木構造を生成し、該木構造の各項目の内容を、構造識別子、構造種別、タグ、内容からなるデータとし、該データと正規化処理前の構造化文書についての前記解析済み構造化文書(以下、正規化前解析済み構造化文書という)を比較して変更、追加された部分のデータを正規化前解析済み構造化文書に追加して正規化後解析済み構造化文書とし、前記変更、追加された部分のデータと正規化前解析済み構造化文書とにおける正規化前後での構造識別子の対応関係および正規化前後での文字列範囲の対応関係を示す正規化対応情報を生成し、前記正規化後解析済み構造化文書および正規化対応情報を前記除去された構造情報を復元するための復元情報として前記ファイル装置に格納する手段と、
入力された検索条件により該ファイル装置に格納された正規化処理済み構造化文書を検索し、該検索条件を満たす正規化処理済み構造化文書があるか否か判定し、該検索条件を満たすとみなされる文書の正規化処理済み構造化文書を取得し、かつ該文書の検索条件を満たす範囲の情報を取得する手段と、
前記検索により取得された正規化処理済み構造化文書を前記復元情報である前記正規化後解析済み構造化文書および正規化対応情報を参照して、除去された構造情報を有する構造化文書に復元する手段と、
前記文書の検索条件を満たす範囲の情報に基づき前記復元情報の正規化対応情報を参照して正規化処理前の構造化文書における検索条件を満たす範囲の情報を取得し、該取得した文書の検索条件を満たす範囲の情報に基づき該復元された構造化文書中にハイライト表示するための情報を付加した表示用構造化文書を、前記取得した検索条件を満たす範囲に属する最初の文字情報の前にハイライト開始タグを挿入すると共に最後の文字情報の後にハイライト終了タグを挿入することにより作成する手段を有することを特徴とする構造化文書検索表示装置。A structured document search and display device comprising a processing device, a storage device, a file device, and an input / output device,
The processing devicegenerates atree structure by analyzing the input structured document,and generates an analyzed structured document includinga structure identifier, a structure type, a tag, and the contents of each item of thetree structure. Means for storing the analyzed structured document in the file device;
Means for generating a normalized structured document for document search obtained by removing structure information that is not previously searched from the input structured document and storing it in the file device;
The normalized structured document is analyzed togenerate atree structure, and the contents of each item of thetree structure are data including a structure identifier, a structure type, a tag, and contents. Compare and modify the analyzed structured document (hereinafter referred to as pre-normalized structured document) for the structured document, and add the added data to the pre-normalized structured document for normalization. Correspondence of structure identifiers before and after normalization, and correspondence of character string range before and after normalization in the modified and added structured data and the normalized structured data before normalization Meansfor generating normalized correspondence information indicating a relationship and storing thepost-normalized analyzed structured document and normalized correspondence information in the file deviceas restoration information for restoring the removed structure information ;
A search is made for a normalized structured document stored in the file device according to the input search condition, and it is determined whether there is a normalized structured document that satisfies the search condition. Means for obtaining a normalized structured document of the document to be considered and obtaining information in a range that satisfies the search condition of the document;
The normalized structured document obtained by the searchis restored to the structured document having the removed structure information withreference to the post-normalized analyzed structured document and the normalization correspondence information as the restoration information. Means to
Based on the information on the range satisfying the search condition of the document, the information on the range satisfying the search condition inthe structured document before normalization processing is acquired by referring to the normalization correspondence information of the restoration information, and the search of the acquired document Based on the information of the range satisfying the condition, the display structured document to which information for highlight display is added in the restored structured document is displayed before the first character information belonging to the range satisfying the acquired search condition. A structured document search / display apparatus comprising: ahighlight start tag inserted into the first character information and a highlight end tag inserted after the last character information .
前記処理装置が、入力された特定の文書型定義に従う構造化文書をタグを残したままプレーンテキストとして前記ファイル装置に格納し、
前記処理装置が、入力された検索条件により該ファイル装置に格納されたプレーンテキストを検索し、該検索条件を満たす範囲があるか否か判定し、該検索条件を満たす範囲を持つ文書をプレーンテキストとして取得し、かつ該文書の検索条件を満たす範囲の情報を取得し、
前記処理装置が、前記入力された構造化文書に対して前記検索条件を満たす範囲に対して開始タグ、終了タグ、ハイライト表示するための情報を付加した表示用構造化文書を作成することを特徴とする構造化文書検索表示方法。A structured document search and display method in an information processing system including a processing device, a storage device, a file device, and an input / output device,
The processingdevice, stored in the file system a structured document according to a specific document type definition input step, while plain text leaving the tag,
The processing device searches the plain text stored in the file device according to the input search condition, determines whether there is a range satisfying the search condition, and selects a document having the range satisfying the search condition as plain text And obtain information of a range satisfying the search condition of the document,
The processing apparatus creates a structured document for display to which astart tag, an end tag, and information for highlight display are added to a range satisfying the search condition for the input structured document. A featured structured document search and display method.
前記処理装置が、検索条件を満たす範囲が構造化文書において文書構造を示すタグの属性情報中に存在するか否かを判定し、
前記処理装置が、該検索条件を満たす範囲がタグの属性情報中に存在する場合は、構造化文書の内容文字列中に該検索条件を満たす範囲の文字列を含む文字列を追加し、該文字列において該検索条件を満たす範囲に対して前記特定の文書型定義に基づく開始タグ、終了タグ、ハイライト表示するための情報を付加した表示用構造化文書を作成することを特徴とする構造化文書検索表示方法。The structured document search / display method according to claim 10.
The processor determines whether a range satisfying the search condition exists in the attribute information of the tag indicating the document structure in the structured document;
When a range satisfying the search condition exists in the tag attribute information, the processing device adds a character string including a character string in the range satisfying the search condition to the content character string of the structured document, and A structure for generating a structured document for display to which astart tag, an end tag based on the specific document type definition, and information for highlight display are added to a range satisfying the search condition in a character string Document search display method.
前記処理装置が、入力された検索条件により該ファイル装置にタグを残したままプレーンテキストとして格納された構造化文書を検索する際に、予め指定された特定のタグを構成する文字列を検索対象から除去し、該特定のタグを構成する文字列の前後を連結した文字列に対して検索することで得られる検索条件を満たす範囲に対して、前記特定の文書型定義に基づく開始タグ、終了タグ、ハイライト表示するための情報を付加した表示用構造化文書を作成することを特徴とする構造化文書検索表示方法。The structured document search / display method according to claim 10.
When the processing device searches for a structured document stored as plain text while leaving the tag in the file device according to the input search condition, a character string constituting a specific tag specified in advance is searched. Thestart tag based on the specific document type definition andthe end for a range satisfying a search condition obtained by searching for a character string concatenated before and after the character string constituting the specific tag A structured document search and display method characterized by creating a structured document for display to whichtags and information for highlight display are added.
前記処理装置が、入力された検索条件により該ファイル装置にプレーンテキストとして格納された構造化文書を検索する際に、検索条件を満たす範囲が予め指定された文書構造の開始を示す特定のタグと文書構造の終わりを示す特定のタグに挟まれるか否かを判定し、挟まれる場合は、文書構造の開始を示す特定のタグより前もしくは文書構造の終わりを示すタグより後ろの内容文字列中に、該検索条件を満たす範囲の文字列を含む文字列を追加し、該文字列において該検索条件を満たす範囲に対して前記特定の文書型定義に基づく開始タグ、終了タグ、ハイライト表示するための情報を付加した表示用構造化文書を作成することを特徴とする構造化文書検索表示方法。The structured document search / display method according to claim 10.
When the processing device searches for a structured document stored as plain text in the file device according to an input search condition, a specific tag indicating the start of a document structure in which a range satisfying the search condition is designated in advance Judge whether or not to be sandwiched between specific tags indicating the end of the document structure, and if so, in the content string before the specific tag indicating the start of the document structure or after the tag indicating the end of the document structure In addition, a character string including a character string in a range satisfying the search condition is added, and astart tag, an end tag, and a highlight based on the specific document type definition are highlighted for the range satisfying the search condition in the character string. A structured document search and display method, characterized in that a structured document for display to which information for adding information is added is created.
前記処理装置が、開始タグ、終了タグ、ハイライト表示するための情報を付加した表示用構造化文書を作成する際に、開始タグ、終了タグ、ハイライト表示するための情報は、検索条件中に指定された方法を用いて付加することを特徴とする構造化文書検索表示方法。In the structured document search and display method according to claim 1, claim 2, claim 3, or claim 10,
When the processing device creates a structured document for display to which astart tag, an end tag, and information for highlight display are added, thestart tag, end tag, and information for highlight display are in search conditions. A method for displaying and displaying a structured document, which is added by using a method specified in the above.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP19803898AJP3832693B2 (en) | 1997-07-01 | 1998-06-29 | Structured document search and display method and apparatus |
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP19071697 | 1997-07-01 | ||
| JP9-195408 | 1997-07-22 | ||
| JP19540897 | 1997-07-22 | ||
| JP9-190716 | 1997-07-22 | ||
| JP19803898AJP3832693B2 (en) | 1997-07-01 | 1998-06-29 | Structured document search and display method and apparatus |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPH11110384A JPH11110384A (en) | 1999-04-23 |
| JP3832693B2true JP3832693B2 (en) | 2006-10-11 |
Family
ID=27326376
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP19803898AExpired - Fee RelatedJP3832693B2 (en) | 1997-07-01 | 1998-06-29 | Structured document search and display method and apparatus |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP3832693B2 (en) |
Families Citing this family (13)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3580481B2 (en)* | 1999-10-06 | 2004-10-20 | インターナショナル・ビジネス・マシーンズ・コーポレーション | Method and apparatus for specifying speech reading range |
| JP3794882B2 (en)* | 1999-10-28 | 2006-07-12 | 富士通株式会社 | Information processing device |
| JP4573402B2 (en)* | 2000-06-28 | 2010-11-04 | 大日本印刷株式会社 | Document server, document processing system, and recording medium |
| US6963865B2 (en)* | 2001-04-05 | 2005-11-08 | International Business Machines Corporation | Method system and program product for data searching |
| JP2003157249A (en)* | 2001-11-21 | 2003-05-30 | Degital Works Kk | Document compression storage method |
| JP4646289B2 (en)* | 2004-07-14 | 2011-03-09 | 株式会社リコー | Database management system |
| JP4796970B2 (en)* | 2004-11-17 | 2011-10-19 | 株式会社ターボデータラボラトリー | Tree data search / aggregation / sorting method and program |
| JP4786907B2 (en)* | 2005-01-25 | 2011-10-05 | キヤノン株式会社 | Information processing apparatus, information processing method, system, and system control method |
| JP2007241482A (en)* | 2006-03-06 | 2007-09-20 | National Institute Of Information & Communication Technology | Data display apparatus and method |
| WO2006137412A1 (en)* | 2005-06-20 | 2006-12-28 | National Institute Of Information And Communications Technology, Incorporated Administrative Agency | Data display device and method |
| JP4498333B2 (en)* | 2006-09-21 | 2010-07-07 | 株式会社沖データ | Image processing device |
| JP5765452B2 (en)* | 2014-01-20 | 2015-08-19 | 富士通株式会社 | Annotation addition / restoration method and annotation addition / restoration apparatus |
| CN108090057A (en)* | 2016-11-21 | 2018-05-29 | 阿里巴巴集团控股有限公司 | Information displaying method and device |
- 1998
- 1998-06-29JPJP19803898Apatent/JP3832693B2/ennot_activeExpired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JPH11110384A (en) | 1999-04-23 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US7707139B2 (en) | Method and apparatus for searching and displaying structured document | |
| US6931590B2 (en) | Method and system for managing documents | |
| US7480859B2 (en) | Tree construction for XML to XML document transformation | |
| US7293018B2 (en) | Apparatus, method, and program for retrieving structured documents | |
| US7730104B2 (en) | Extraction of information from structured documents | |
| US20070078889A1 (en) | Method and system for automated knowledge extraction and organization | |
| JPH07325827A (en) | Hypertext automatic generator | |
| CN101211336B (en) | Visualized system and method for generating inquiry file | |
| JP2002297602A (en) | Method and device for structured document retrieval, structured document managing device, program, and recording medium | |
| CN106960058B (en) | Webpage structure change detection method and system | |
| JP3832693B2 (en) | Structured document search and display method and apparatus | |
| JP4042830B2 (en) | Content attribute information normalization method, information collection / service provision system, and program storage recording medium | |
| CN101154241A (en) | A data retrieval method and a data retrieval system | |
| JP2008090403A (en) | Document search apparatus, document search method, and document search program | |
| JP2008107904A (en) | Text and animation service device and computer program | |
| Joshi et al. | Web document text and images extraction using DOM analysis and natural language processing | |
| KR101069278B1 (en) | Apparatus and Method for visualization of patent claim | |
| US20080015843A1 (en) | Linguistic Image Label Incorporating Decision Relevant Perceptual, Semantic, and Relationships Data | |
| JP2003281149A (en) | Access authority setting method and structured document management system | |
| JP2004334382A (en) | Structured document summarizing apparatus, program, and recording medium | |
| JPH117452A (en) | Method and apparatus for collecting information via network and recording medium recording program for implementing the method | |
| JP2002297662A (en) | Method and device for editing structured document, terminal, and program | |
| YesuRaju et al. | A language independent web data extraction using vision based page segmentation algorithm | |
| JP2000250930A (en) | Structured document search system | |
| JP4352840B2 (en) | Program, data processing method and data processing system |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| RD04 | Notification of resignation of power of attorney | Free format text:JAPANESE INTERMEDIATE CODE: A7424 Effective date:20040317 | |
| A977 | Report on retrieval | Free format text:JAPANESE INTERMEDIATE CODE: A971007 Effective date:20040414 | |
| A131 | Notification of reasons for refusal | Free format text:JAPANESE INTERMEDIATE CODE: A131 Effective date:20050125 | |
| A521 | Written amendment | Free format text:JAPANESE INTERMEDIATE CODE: A523 Effective date:20050328 | |
| A02 | Decision of refusal | Free format text:JAPANESE INTERMEDIATE CODE: A02 Effective date:20051220 | |
| A521 | Written amendment | Free format text:JAPANESE INTERMEDIATE CODE: A523 Effective date:20060217 | |
| A911 | Transfer to examiner for re-examination before appeal (zenchi) | Free format text:JAPANESE INTERMEDIATE CODE: A911 Effective date:20060512 | |
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) | Free format text:JAPANESE INTERMEDIATE CODE: A01 Effective date:20060711 | |
| A61 | First payment of annual fees (during grant procedure) | Free format text:JAPANESE INTERMEDIATE CODE: A61 Effective date:20060713 | |
| R150 | Certificate of patent or registration of utility model | Free format text:JAPANESE INTERMEDIATE CODE: R150 | |
| FPAY | Renewal fee payment (event date is renewal date of database) | Free format text:PAYMENT UNTIL: 20090728 Year of fee payment:3 | |
| FPAY | Renewal fee payment (event date is renewal date of database) | Free format text:PAYMENT UNTIL: 20100728 Year of fee payment:4 | |
| FPAY | Renewal fee payment (event date is renewal date of database) | Free format text:PAYMENT UNTIL: 20100728 Year of fee payment:4 | |
| FPAY | Renewal fee payment (event date is renewal date of database) | Free format text:PAYMENT UNTIL: 20110728 Year of fee payment:5 | |
| FPAY | Renewal fee payment (event date is renewal date of database) | Free format text:PAYMENT UNTIL: 20110728 Year of fee payment:5 | |
| FPAY | Renewal fee payment (event date is renewal date of database) | Free format text:PAYMENT UNTIL: 20120728 Year of fee payment:6 | |
| FPAY | Renewal fee payment (event date is renewal date of database) | Free format text:PAYMENT UNTIL: 20130728 Year of fee payment:7 | |
| LAPS | Cancellation because of no payment of annual fees |