JP2023021946A - Data retrieval method and system - Google Patents
Data retrieval method and systemDownload PDFInfo
- Publication number
- JP2023021946A JP2023021946AJP2022121133AJP2022121133AJP2023021946AJP 2023021946 AJP2023021946 AJP 2023021946AJP 2022121133 AJP2022121133 AJP 2022121133AJP 2022121133 AJP2022121133 AJP 2022121133AJP 2023021946 AJP2023021946 AJP 2023021946A
- Authority
- JP
- Japan
- Prior art keywords
- data
- content
- field values
- categories
- vector
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images







Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/901—Indexing; Data structures therefor; Storage structures
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/22—Indexing; Data structures therefor; Storage structures
- G06F16/2228—Indexing structures
- G06F16/2237—Vectors, bitmaps or matrices
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/22—Indexing; Data structures therefor; Storage structures
- G06F16/2228—Indexing structures
- G06F16/2264—Multidimensional index structures
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/22—Indexing; Data structures therefor; Storage structures
- G06F16/2282—Tablespace storage structures; Management thereof
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/31—Indexing; Data structures therefor; Storage structures
- G06F16/316—Indexing structures
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G06F16/334—Query execution
- G06F16/3347—Query execution using vector based model
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/50—Information retrieval; Database structures therefor; File system structures therefor of still image data
- G06F16/58—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually
- G06F16/583—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually using metadata automatically derived from the content
- G06F16/5846—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually using metadata automatically derived from the content using extracted text
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/14—Image acquisition
- G06V30/148—Segmentation of character regions
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/40—Document-oriented image-based pattern recognition
- G06V30/42—Document-oriented image-based pattern recognition based on the type of document
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Databases & Information Systems (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Artificial Intelligence (AREA)
- Computational Linguistics (AREA)
- Mathematical Physics (AREA)
- Evolutionary Computation (AREA)
- Computing Systems (AREA)
- Multimedia (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Library & Information Science (AREA)
- Medical Informatics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Translated fromJapaneseDescription
Translated fromJapanese本発明は、異なるカテゴリーのフィールド値を含むデータを検索するデータ検索方法及びシステムに関する。 The present invention relates to a data retrieval method and system for retrieving data containing field values of different categories.
人工知能の辞書的意味は、人間の学習能力、推論能力、知覚能力、自然言語理解能力などをコンピュータプログラムで実現した技術である。このような人工知能は、マシンラーニングに人間の脳を模倣したニューラルネットワークを加えたディープラーニングにより飛躍的に発展してきた。 The dictionary meaning of artificial intelligence is technology that realizes human learning ability, reasoning ability, perceptual ability, natural language understanding ability, etc. by computer program. Such artificial intelligence has made dramatic progress through deep learning, which is a combination of machine learning and a neural network that mimics the human brain.
ディープラーニング(deep learning)とは、コンピュータが人間のように判断及び学習できるようにし、それにより事物やデータを群集化又は分類する技術をいい、近年、テキストデータだけでなく画像データまで分析できるようになり、非常に多様な産業分野に積極的に活用されている。 Deep learning is a technology that allows computers to make judgments and learn like humans, thereby grouping or classifying objects and data.In recent years, not only text data but also image data can be analyzed. and is actively used in a wide variety of industrial fields.
このような人工知能の発達により、オフィス・オートメーション(office automation)分野においても様々な自動化が行われている。特に、オフィス・オートメーション分野においては、人工知能を活用した画像データ分析技術に基づいて、紙(ペーパ)に印刷されたコンテンツをデータ化するのに多くの努力をしている。その一環として、オフィス・オートメーション分野においては、紙文書をイメージ化し、イメージに含まれるコンテンツを分析するイメージ分析技術(又は画像データ分析技術)により、文書に含まれるコンテンツをデータ化しており、その場合、文書に含まれるコンテンツのタイプによってイメージを分析する技術が必要である。 With the development of such artificial intelligence, various automations are being carried out in the field of office automation. In particular, in the field of office automation, much effort is being made to digitize content printed on paper based on image data analysis technology that utilizes artificial intelligence. As part of this, in the field of office automation, the content contained in the document is converted into data using image analysis technology (or image data analysis technology) that converts paper documents into images and analyzes the content contained in the images. , a technique is needed to analyze images according to the type of content contained in the document.
例えば、領収証(レシート)を含む文書をデータ化する場合、領収証の形式、領収証に含まれるテキストの内容、及び領収証に含まれるテキストの位置などのように、領収証に関連する様々な要素についての正確な分析が必要である。 For example, when digitizing a document containing a receipt, the accuracy of various elements related to the receipt, such as the format of the receipt, the content of the text contained in the receipt, and the location of the text contained in the receipt. Further analysis is required.
よって、イメージに含まれる情報を電子機器で処理できる形態のデータに加工するための様々な技術が開発されている。例えば、特許文献1においては、OCR(Optical Character Reader)データベースを構築する方法が開示されているが、これまで開発された方法は、人が経験的に定めた規則に従ってデータを分類するレベルのものであるので、OCRデータにエラーがある場合、不正確なデータベースが構築されるだけでなく、データベースを用いた検索が円滑に行われないことがある。 Accordingly, various techniques have been developed to process information contained in images into data that can be processed by electronic devices. For example, Patent Document 1 discloses a method for constructing an OCR (Optical Character Reader) database. Therefore, if there is an error in the OCR data, not only is an inaccurate database constructed, but also searches using the database may not be performed smoothly.
一方、近年、各種検索サービスが提供されている。例えば、領収証を用いて当該領収証を使用した場所を検索するサービスが提供されている。よって、イメージ、音声、テキストなどの様々な形式のコンテンツに対してそれに対応するデータを検索する技術の必要性が高まっている。 On the other hand, in recent years, various search services have been provided. For example, a service is provided that uses a receipt to search for the location where the receipt was used. Therefore, there is an increasing need for techniques for retrieving data corresponding to various types of contents such as images, voices, and texts.
従来は、OCR認識エラーを補正するために、正規表現式などを活用した前処理技術に依存していた。このような方法は、時間とコストが多くかかり、補正性能が高くないという問題があった。 Conventionally, in order to correct OCR recognition errors, preprocessing techniques using regular expressions and the like have been relied on. Such a method has the problem that it takes a lot of time and cost, and the correction performance is not high.
また、複数のフィールド値を含むコンテンツの場合、所望の結果を得るために複数のフィールド情報を検索に用いなければならないが、一般的にはヒューリスティックなルールベースのモデルに依存していた。特に、どのフィールドを選択するかによって検索性能が大きく異なるか所望の検索結果が得られないという問題があった。 Also, for content containing multiple field values, multiple field information must be used in the search to obtain the desired results, typically relying on heuristic rule-based models. In particular, there is a problem that the search performance varies greatly depending on which field is selected, or desired search results cannot be obtained.
よって、OCR認識エラーなどによりテキストが誤って認識された場合にも所望の検索結果が得られるようにする技術が求められている。 Therefore, there is a need for a technique that enables desired search results to be obtained even when text is erroneously recognized due to an OCR recognition error or the like.
本発明は、異なるカテゴリーに属するフィールド値を含むデータを電子機器で活用できる形態のデータに埋め込み(embedding)、埋め込みの結果に基づいてデータを検索するための方法及びシステムを提供するものである。 The present invention provides a method and system for embedding data including field values belonging to different categories into data in a format that can be utilized by electronic devices, and for retrieving data based on the embedding result.
具体的には、本発明は、データに含まれる異なるカテゴリーの特徴を維持しながらも電子機器で活用できる形態のデータに埋め込むための方法及びシステムを提供する。 Specifically, the present invention provides a method and system for embedding data in electronic device-friendly form while preserving the characteristics of different categories contained in the data.
また、本発明は、データベースから異なるフィールド値を含むデータに対応するデータを容易に検索できるようにする方法及びシステムを提供するものである。 The present invention also provides a method and system for facilitating retrieval of data corresponding to data containing different field values from a database.
さらに、本発明は、テキスト認識エラーや音声認識エラーなどによりエラー値が含まれるデータに対応するデータを検索する場合にも、データベースから所望の結果を高い正確度で検索できるようにする方法及びシステムを提供するものである。 Furthermore, the present invention provides a method and system for retrieving desired results from a database with high accuracy even when retrieving data corresponding to data containing error values due to text recognition errors, voice recognition errors, etc. It provides
上記課題を解決するために、本発明は、複数のフィールド値を含むコンテンツを受信するステップと、前記コンテンツに含まれるフィールド値を配列するが、前記フィールド値が属するカテゴリーを区分する複数の区分子を追加してモデル入力値を生成するステップと、前記モデル入力値及び学習されたディープラーニングモデルを用いて前記コンテンツのベクトルを生成するステップと、前記生成されたベクトルと既に保存された複数のデータのそれぞれに対応するベクトル間の類似度に基づいて、前記既に保存された複数のデータから検索対象データに対応するデータを検索するステップとを含む、データ検索方法を提供する。 In order to solve the above problems, the present invention provides a step of receiving content including a plurality of field values; generating a model input value using the model input value and the trained deep learning model; generating a vector of the content using the model input value and the trained deep learning model; and searching for data corresponding to search target data from the plurality of data already stored based on the degree of similarity between vectors corresponding to each of .
また、本発明は、複数のフィールド値を含むコンテンツを受信する通信部と、前記コンテンツに含まれるフィールド値を配列するが、前記フィールド値が属するカテゴリーを区分する複数の区分子を追加してモデル入力値を生成し、前記モデル入力値及び学習されたディープラーニングモデルを用いて前記コンテンツのベクトルを生成し、前記生成されたベクトルと既に保存された複数のデータのそれぞれに対応するベクトル間の類似度に基づいて、前記既に保存された複数のデータから検索対象データに対応するデータを検索する制御部とを含む、データ検索システムを提供する。 In addition, the present invention is a communication unit that receives content including a plurality of field values, and arranges the field values included in the content. generating input values, generating vectors of the content using the model input values and the trained deep learning model, and similarity between the generated vectors and vectors corresponding to each of a plurality of data already stored; and a control unit that searches for data corresponding to search target data from the plurality of data that have already been saved, based on the degree of retrieval.
前述したように、本発明は、データに含まれる複数のフィールド値が属するカテゴリーを区分してデータの埋め込みを行うので、データに含まれる異なるカテゴリーの特徴が維持されたベクトルを生成することができる。本発明は、生成された異なるカテゴリーの特徴が維持されたベクトルをデータ検索に活用することにより、既に保存されたデータと同じデータのみを検索することに限定されず、対象文書に含まれる複数のカテゴリーに属する値の類似度を考慮したデータ検索を行うことができる。 As described above, the present invention embeds data by classifying categories to which a plurality of field values included in the data belong, so it is possible to generate a vector that maintains the characteristics of different categories included in the data. . The present invention is not limited to retrieving only the same data as the already stored data by utilizing the generated vectors that maintain the features of different categories for data retrieval, and multiple Data retrieval can be performed in consideration of the similarity of values belonging to categories.
また、本発明によれば、埋め込みの結果で生成されたベクトル間の類似度に基づいてデータを検索するので、データ検索時に人が定めた検索規則に依存して検索を行う必要がなくなる。 Moreover, according to the present invention, data is retrieved based on the similarity between vectors generated as a result of embedding, so there is no need to rely on a human-defined retrieval rule when retrieving data.
さらに、本発明によれば、データのカテゴリー毎の類似度を考慮した検索が可能であるので、ノイズやエラーが頻繁に発生するデータ(例えば、文字認識データ(OCRデータ)、音声認識データ)を用いた検索時にも高い正確度でデータ検索を行うことができる。 Furthermore, according to the present invention, since it is possible to perform a search considering the degree of similarity for each category of data, data in which noise or errors frequently occur (for example, character recognition data (OCR data), voice recognition data) can be searched. Data can be searched with high accuracy even when searching using
以下、添付図面を参照して本発明の実施形態について詳細に説明するが、図面番号に関係なく同一又は類似の構成要素には同一の符号を付し、それについての重複する説明は省略する。以下の説明で用いられる構成要素の接尾辞である「モジュール」や「部」は、明細書の作成を容易にするために付与又は混用されるものであり、それ自体が有意性や有用性を有するものではない。また、本発明の実施形態について説明するにあたり、関連する公知技術についての具体的な説明が本発明の実施形態の要旨を不明にすると判断される場合は、その詳細な説明を省略する。さらに、添付図面は本発明の実施形態の理解を助けるためのものにすぎず、添付図面により本発明の技術的思想が限定されるものではなく、本発明の思想及び技術範囲に含まれるあらゆる変更、均等物乃至代替物を含むものと理解すべきである。 Hereinafter, embodiments of the present invention will be described in detail with reference to the accompanying drawings. The same or similar components are denoted by the same reference numerals regardless of the drawing numbers, and duplicate descriptions thereof will be omitted. The suffixes “module” and “part” used in the following explanation are given or used together to facilitate the preparation of the specification, and themselves have significance and usefulness. does not have In addition, in describing the embodiments of the present invention, detailed descriptions of related known techniques will be omitted if it is determined that they may obscure the gist of the embodiments of the present invention. Furthermore, the accompanying drawings are only for helping understanding of the embodiments of the present invention, and the technical ideas of the present invention are not limited by the accompanying drawings. , equivalents or alternatives.
「第1」、「第2」などのように序数を含む用語は様々な構成要素を説明するために用いられるが、上記構成要素は上記用語により限定されるものではない。上記用語は1つの構成要素を他の構成要素と区別する目的でのみ用いられる。 Terms including ordinal numbers such as "first", "second", etc. are used to describe various components, but the components are not limited by the above terms. The above terms are only used to distinguish one component from another.
ある構成要素が他の構成要素に「連結」又は「接続」されていると言及された場合は、他の構成要素に直接連結又は接続されていてもよく、中間にさらに他の構成要素が存在してもよいものと解すべきである。それに対して、ある構成要素が他の構成要素に「直接連結」又は「直接接続」されていると言及された場合は、中間にさらに他の構成要素が存在しないものと解すべきである。 When a component is referred to as being "coupled" or "connected" to another component, it may be directly coupled or connected to the other component, with additional components in between. It should be interpreted as something that can be done. In contrast, when a component is referred to as being "directly coupled" or "directly connected" to another component, it should be understood that there are no additional components in between.
単数の表現には、特に断らない限り複数の表現が含まれる。 References to the singular include the plural unless specifically stated otherwise.
本明細書において、「含む」や「有する」などの用語は、本明細書に記載された特徴、数字、段階、動作、構成要素、部品又はそれらの組み合わせが存在することを指定しようとするもので、1つ又はそれ以上の他の特徴、数字、段階、動作、構成要素、部品又はそれらの組み合わせの存在や付加可能性を予め排除するものではないと理解すべきである。 As used herein, terms such as "including" and "having" are intended to specify the presence of features, numbers, steps, acts, components, parts, or combinations thereof described herein. and does not preclude the presence or possibility of adding one or more other features, figures, steps, acts, components, parts or combinations thereof.
本明細書において、コンテンツとは、コンピュータで処理可能な各種情報やその内容物を意味し、テキスト、イメージ、音声、ファイルなど、様々な形態であり、特定の形態に限定されない。 In this specification, the term "content" refers to various types of information or contents that can be processed by a computer, and is in various forms such as text, image, sound, and file, and is not limited to any particular form.
カテゴリーとは、定義された分類内で任意のレベルにある項目を意味する。特定のカテゴリーに属するデータと他のカテゴリーに属するデータとを区分する基準は、絶対的であるのではなく、カテゴリーを規定する任意の規則によって異なる。このような規則は、原本コンテンツ(例えば、紙文書、紙文書を撮影したイメージ、音声データ)とそれを構造化したデータとに異なって適用される。 Category means an item at any level within a defined taxonomy. Criteria for distinguishing data belonging to a particular category from data belonging to other categories are not absolute, but vary according to arbitrary rules defining the categories. Such rules apply differently to original content (eg, paper documents, images captured from paper documents, audio data) and structured data thereof.
例えば、様々な種類の領収証などの文書は、売場名、事業者番号、売場電話番号、売場住所、注文商品名、注文商品数量など、販売者及び消費者に関連する複数のカテゴリーを含み、データの効率的な処理のために紙文書に含まれるデータを、同一のカテゴリー同士を関連付けてデータ化する必要がある。 For example, various types of receipts and other documents contain multiple categories related to sellers and consumers, such as store name, business number, store phone number, store address, order item name, order item quantity, etc. For efficient processing of paper documents, it is necessary to convert data contained in paper documents into data by associating the same categories with each other.
例えば、紙文書である特定の領収証は、「売場名」、「注文商品名」、「注文商品数量」という3つのカテゴリーを含むが、当該紙文書に含まれるデータをデジタル化する際には、「売場名」、「注文商品」という2つのカテゴリーに縮小してもよい。 For example, a specific receipt, which is a paper document, contains three categories: "sales area name", "ordered product name", and "ordered product quantity". When digitizing the data contained in the paper document, It may be reduced to two categories of "sales area name" and "ordered product".
一方、本明細書においては、特定のカテゴリーの属性を示すデータをフィールド名(例えば、「売場名:」、「数量:」、「電話番号」など)と定義し、特定のカテゴリーの値を示すデータをフィールド値(例えば、「NLP CAFE」、「S City」、「01-234-568」など)と定義する。 On the other hand, in this specification, data indicating attributes of a specific category are defined as field names (for example, "sales floor name:", "quantity:", "telephone number", etc.), and indicate values of a specific category. Define data as field values (eg, "NLP CAFE", "S City", "01-234-568", etc.).
一方、コンテンツの種類に関係なく、各コンテンツは、フィールド名及びフィールド値を含んでもよい。例えば、紙文書、紙文書のイメージ、音声データのそれぞれは、フィールド名及びフィールド値を含んでもよい。よって、フィールド名及びフィールド値は、テキスト、イメージ、音声データなど、様々な形態を有する。 On the other hand, regardless of the type of content, each content may include field names and field values. For example, each of the paper document, the image of the paper document, and the audio data may include field names and field values. Therefore, field names and field values have various forms such as text, image, and audio data.
一方、機械で処理可能な形式のデータの観点から、前記フィールド名は「属性」と称され、前記フィールド値は「値」と称される。 On the other hand, from the point of view of data in machine-processable form, the field name is called "attribute" and the field value is called "value".
上記用語の定義によれば、コンテンツは、同一のカテゴリーに含まれる「属性-値」対のデータを含んでもよい。ただし、これに限定されるものではなく、コンテンツは、特定のカテゴリーに対しては、フィールド名を含まず、フィールド値のみを含んでもよい。この場合、前記フィールド名が省略されているだけであり、省略されたフィールド名に対応するフィールド値はフィールド名に関連する意味を含む。 According to the definition of the term above, content may include data of "attribute-value" pairs that fall within the same category. However, the content is not limited to this, and the content may not include the field name but only the field value for a particular category. In this case, the field name is just omitted, and the field value corresponding to the omitted field name contains the meaning associated with the field name.
一方、コンテンツは、フィールド値を含まず、フィールド名のみを含んでもよい。この場合、特定の項目に割り当てられた値が存在せず、特定の項目に割り当てられた値が存在しなくても、当該特定の項目が存在することがある。 On the other hand, the content may not contain field values, only field names. In this case, there may be no value assigned to a particular item, and the particular item may exist even though there is no value assigned to the particular item.
上記例示において、紙文書(又は紙文書を撮影したイメージ)は、文字認識により、電子機器で処理可能なテキストに変換され、変換されたテキストは、異なるカテゴリーに分類される。よって、異なるカテゴリーに属するフィールド値を含むデータが生成される。 In the above example, a paper document (or a photographed image of a paper document) is converted by character recognition into text that can be processed by an electronic device, and the converted text is classified into different categories. Thus, data containing field values belonging to different categories is generated.
一方、異なるカテゴリーに属するフィールド値を含むデータは、OCRだけでなく、他の方式で収集されたテキストに基づいて生成することもできる。例えば、音声認識結果物により、異なるカテゴリーに属するフィールド値を含むデータを生成することができる。具体的には、音声認識により認識されたユーザの音声がテキストに変換され、変換されたテキストが異なるカテゴリーに分類されて電算化される。 On the other hand, data containing field values belonging to different categories can be generated based on text collected by other methods besides OCR. For example, speech recognition results can generate data containing field values belonging to different categories. Specifically, the user's voice recognized by voice recognition is converted into text, and the converted text is classified into different categories and computerized.
前述したように、異なるカテゴリーに属するフィールド値を含むデータは、様々な方法で生成することができる。本発明は、既に保存されたデータベースから前記生成されたデータに対応するデータを検索する方法及びシステムを提供する。 As previously mentioned, data containing field values belonging to different categories can be generated in a variety of ways. The present invention provides a method and system for retrieving data corresponding to the generated data from a pre-stored database.
一方、本発明によるデータ検索は、前記コンテンツに対するデータの埋め込みの結果で生成されたベクトルに基づいて行われる。 Data retrieval according to the present invention, on the other hand, is based on vectors generated as a result of embedding data into the content.
本発明は、異なるカテゴリーに属するフィールド値を含むデータの検索を効率的に行う方法を提供する。具体的には、本発明は、異なるカテゴリーに属するフィールド値を含むデータを機械が理解できる形態の情報に変換する効率的な埋め込みによりデータ検索の正確度を向上させる。 The present invention provides a method for efficiently retrieving data containing field values belonging to different categories. Specifically, the present invention improves data retrieval accuracy through efficient embedding that transforms data containing field values belonging to different categories into a machine-understandable form of information.
本発明は、新たな方式のデータの埋め込みにより生成されたベクトルを用いてデータ検索の正確度を向上させるデータ検索方法及びシステムを提供する。 The present invention provides a data retrieval method and system for improving the accuracy of data retrieval using vectors generated by a new type of data embedding.
以下、新たな方式のデータの埋め込みについて、添付図面を参照して具体的に説明する。 The new method of embedding data will be specifically described below with reference to the accompanying drawings.
図1は本発明によるデータ検索システムを説明するための概念図であり、図2は本発明によるデータ検索方法を示す概念図である。 FIG. 1 is a conceptual diagram for explaining a data search system according to the present invention, and FIG. 2 is a conceptual diagram showing a data search method according to the present invention.
本発明によるデータ検索システム100は、アプリケーション又はソフトウェアの形態で実現されてもよい。本発明によるデータ検索システム100のソフトウェア的な実現によれば、本明細書で説明されるプロセスや機能などの実施形態は、別途のソフトウェアモジュールで実現されてもよい。ソフトウェアモジュールのそれぞれは、本明細書で説明される1つ以上の機能及び動作を行うことができる。 The
本発明によるソフトウェア的な実現は、図1に示すデータ検索システム100により実現される。以下、データ検索システム100の構成についてより具体的に説明する。 Software implementation according to the present invention is implemented by the
本発明によるデータ検索システム100は、複数のフィールド値を含むコンテンツを受信することができる。受信されたコンテンツは、データ検索システム100に必要な形態でデータ化される。 A
例えば、本発明によるデータ検索システム100は、紙文書のイメージを受信し、イメージに対するテキスト認識によりOCRデータを生成することができる。本明細書において、OCRデータは、イメージから抽出されたテキスト及び抽出されたテキストに対応する位置情報を含んでもよい。ここで、位置情報は、抽出されたテキストのイメージ(又は紙文書)内の位置を定義する。本発明によるデータ検索システム100は、前記抽出されたテキストを異なるカテゴリーに分類することができる。 For example, the
他の例として、本発明によるデータ検索システム100は、音声データを受信し、音声データをテキストに変換し、その後変換されたテキストを異なるカテゴリーに分類することができる。 As another example, the
一方、本発明によるデータ検索システム100は、図1に示すように、通信部110、保存部120、OCR部130、制御部140及び音声認識部150の少なくとも1つを含む。ただし、これに限定されるものではなく、本発明によるデータ検索システム100は、上記構成要素より多いか又は少ない構成要素を含んでもよく、上記構成要素の少なくとも一部は物理的に離隔した位置に配置されてもよい。 Meanwhile, the
まず、通信部110は、紙文書をスキャンしたイメージ10又は音声データを受信する手段であって、通信部、スキャン部及び入力部の少なくとも1つを含むようにしてもよく、その他のイメージ10を受信する手段からなるようにしてもよい。 First, the
データ検索システム100は、通信部110を介して受信したイメージ10又は音声データなどのコンテンツを受信し、コンテンツに対するデータの埋め込みを行うことができる。 The
次に、保存部120は、本発明による様々な情報を保存するようにしてもよい。保存部120は、その種類が非常に多様であり、少なくとも一部はDB(データベース)160を含んでもよい。DB160は、データ検索システム100から物理的に離隔した外部サーバ又はクラウドサーバであってもよく、データ検索システム100は、DB160との通信によりDB160を保存部120のように活用することができる。 Next, the
すなわち、保存部120は、本発明に関連する情報が保存される空間であればよく、物理的な空間の制約はない。本明細書においては、保存部120とDB160を区分せず、DB160に保存されたデータも保存部120に保存されたデータとして説明する。 That is, the
保存部120には、i)コンテンツの生成に活用されるデータ(紙文書をスキャンしたイメージ10又は音声データ)及びそれに関連するデータ、ii)データ埋め込みモデルの機械学習に活用される学習データ、iii)埋め込まれたデータの少なくとも1つが保存される。 The
次に、OCR部130は、イメージ10に含まれるテキストを認識する手段であって、様々なテキスト認識アルゴリズムの少なくとも1つによりイメージ10に含まれるテキストを認識することができる。OCR部130は、人工知能に基づくアルゴリズムを用いて、テキストを認識することができる。
OCR部130は、イメージ10に含まれるテキスト及びテキストの位置情報を抽出することができる。ここで、テキストの位置情報には、イメージ10内でのテキストの位置に関する情報が含まれる。 The
次に、制御部140は、本発明に関連するデータ検索システム100の全般的な動作を制御する。制御部140は、人工知能アルゴリズムを処理するプロセッサ(又は人工知能プロセッサ)を含んでもよい。 Next, the
また、制御部140は、データの埋め込みのための作業領域を提供し、このような作業領域は、データの埋め込みを行うか、又はデータの埋め込みのための機械学習を行うための「ユーザ環境」又は「ユーザインタフェース」とも命名される。 The
このような作業領域は、電子機器のディスプレイ部に出力(又は提供)されるようにしてもよい。さらに、制御部140は、電子機器に備えられるか又は電子機器と連動するユーザ入力部(例えば、タッチスクリーン、マウスなど)を介して受信されるユーザ入力に基づいて、データの埋め込みを行うか、又はデータの埋め込みのための機械学習を行うことができる。さらに、制御部140は、コンテンツ10を受信し、受信したコンテンツ10に対応するデータを保存部120に保存されたデータ240a、240b及び保存部120に保存された他のデータから検索することができる。 Such a work area may be output (or provided) on the display of the electronic device. In addition, the
なお、本発明において、作業領域が出力される電子機器の種類に特に制限はなく、本発明によるアプリケーションを起動できるものであればよい。例えば、電子機器には、スマートフォン、携帯電話、タブレットPC、コンピュータ、ノートブックコンピュータ、デジタル放送用端末、PDA(Personal Digital Assistants)、PMP(Portable Multimedia Player)、スマートミラー(smart mirror)及びスマートテレビ(smart TV)の少なくとも1つが含まれる。 In the present invention, there is no particular limitation on the type of electronic device to which the work area is output, as long as it can start the application according to the present invention. For example, electronic devices include smart phones, mobile phones, tablet PCs, computers, notebook computers, digital broadcasting terminals, PDA (Personal Digital Assistants), PMP (Portable Multimedia Player), smart mirrors and smart TVs ( smart TV).
本発明において、電子機器又は電子機器に備えられるディスプレイ部、ユーザ入力部に対しては符号を付さない。しかし、本発明における作業領域は、電子機器のディスプレイ部に出力され、ユーザ入力が電子機器に備えられるか又は電子機器と連動するユーザ入力部を介して受信されることは、当業者にとって自明である。 In the present invention, reference numerals are not attached to the electronic equipment or the display unit and the user input unit provided in the electronic equipment. However, it is obvious to those skilled in the art that the working area in the present invention is output to the display unit of the electronic device, and user input is received via a user input unit provided in the electronic device or interlocked with the electronic device. be.
一方、本発明によるデータ検索システムは、既に保存されたデータからコンテンツに対応するデータを検索することができる。 On the other hand, the data search system according to the present invention can search for data corresponding to content from already stored data.
以下、本発明によるデータ検索システムを用いる例として、紙文書のイメージ10を受信して既に保存されたデータから当該イメージに対応するデータを検索する過程について説明する。受信されるコンテンツがイメージに限定されないことは前述した通りである。 Hereinafter, as an example of using the data retrieval system according to the present invention, a process of receiving an
図2に示すように、本発明によるデータ検索システムは、紙文書のイメージ10を受信し、テキスト認識によりイメージ10からテキスト及びテキストの位置情報を抽出220する。ここで、紙文書の損傷210などにより、テキストの文字が正確に認識されないことがあり、このような場合をノイズ221があるという。その後、データ検索システムは、抽出されたテキスト220を異なる複数のカテゴリーのそれぞれに分類し、構造化されたデータ230を生成する。ここで、構造化されたデータは、既に定められた形式(例えば、JSON、XML)で表される。 As shown in FIG. 2, a data retrieval system according to the present invention receives an
データ検索システム100は、それを用いて、既に保存された複数のデータ240a、240b及び保存部120に保存された他のデータからイメージ10に対応するデータ240aを検索する。 The
ここで、本発明は、異なるカテゴリーに属する複数のフィールド値を含むコンテンツに対する埋め込みを行い、データ検索に活用する。以下、コンテンツに対するデータの埋め込み方法についてより具体的に説明する。 Here, the present invention embeds contents including multiple field values belonging to different categories and utilizes them for data retrieval. The method of embedding data in content will be described in more detail below.
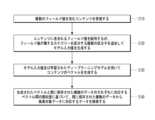
以下、前述したデータ検索システムを用いてデータの埋め込みを行う方法についてより具体的に説明する。特に、以下では、フローチャートを参照して、データの埋め込み方法についてまず説明する。 A method of embedding data using the data search system described above will be described in more detail below. In particular, the method of embedding data will first be described below with reference to flowcharts.
図3は本発明によるデータ検索方法を説明するためのフローチャートであり、図4は本発明によるデータ埋め込みモデルを説明するための概念図であり、図5は本発明によるデータの埋め込みの結果で生成されたベクトルをベクトル空間にフローティングした状態を示す概念図である。 FIG. 3 is a flowchart for explaining the data retrieval method according to the present invention, FIG. 4 is a conceptual diagram for explaining the data embedding model according to the present invention, and FIG. FIG. 10 is a conceptual diagram showing a state in which the obtained vector is floated in the vector space;
本発明によるデータ検索方法においては、コンテンツを受信するステップが行われる(S110)。 In the data search method according to the present invention, a step of receiving content is performed (S110).
前記コンテンツは、複数のフィールド値を含み、前記フィールド値は、複数の異なるカテゴリーにそれぞれ対応するようにしてもよい。前述したように、前記コンテンツは、フィールド値のカテゴリーが区分された形態のデータであるか、又はこのような形態に加工される。例えば、複数のフィールド値とそのカテゴリーは、既に定められた形式(例えば、JSONやXMLなど)で表される。 The content may include a plurality of field values, and the field values may correspond to a plurality of different categories. As described above, the content is data in the form of categorized field values, or is processed in such a form. For example, multiple field values and their categories are represented in a predefined format (eg, JSON, XML, etc.).
すなわち、本発明によるデータ検索システムは、外部からフィールド値のカテゴリーが区分された形態のデータを受信するか、原本データ(紙文書のイメージ又は音声データ)を受信し、その後原本データに基づいてフィールド名-フィールド値で区分された形態のデータを生成して検索に活用することができる。 That is, the data retrieval system according to the present invention receives data in the form of categorized field values from the outside or receives original data (image or voice data of paper documents), and then searches the fields based on the original data. It is possible to generate data in a form classified by name-field value and use it for searching.
次に、前記コンテンツに含まれるフィールド値を配列するが、前記フィールド値が属するカテゴリーに基づいて前記フィールド値のカテゴリーを区分する複数の区分子を追加してモデル入力値を生成するステップが行われる(S120)。 Next, the step of arranging the field values contained in the content, but adding a plurality of partitioning molecules that partition categories of the field values based on the category to which the field values belong, produces a model input value. (S120).
本発明によるデータ検索システム100は、複数のフィールド値を順次配列してデータの埋め込みのためのディープラーニングモデルの入力値を生成する。ここで、データ検索システム100は、複数のフィールド値のそれぞれが属するカテゴリーを区分する区分子を活用して、異なるカテゴリーに属するフィールド値が区分されるようにモデル入力値を生成することができる。カテゴリーを区分するためのカテゴリー区分子の他にも、データ入力の開始又は終了を示す区分子、該当フィールド値がないことを示す区分子などをさらに用いてもよい。 The
例えば、データ検索システム100は、コンテンツに含まれるフィールド値を所定の順序で連結して1つのデータを生成し、フィールド値の前部又は後部に区分子を配列する。よって、モデル入力値は、複数のフィールド値と複数の区分子が所定の順序で一列に配列されたデータであってもよい。 For example, the
一方、前記フィールド値は、複数のカテゴリーにそれぞれ対応し、モデル入力値に追加される前記複数の区分子は、前記複数のカテゴリーにそれぞれ対応する。すなわち、モデル入力値には、複数のカテゴリーのそれぞれに対応するフィールド値及び区分子が含まれる。 On the other hand, the field values respectively correspond to a plurality of categories, and the plurality of partitions added to the model input values respectively correspond to the plurality of categories. In other words, the model input values include field values and section molecules corresponding to each of a plurality of categories.
ここで、同一のカテゴリーに属するフィールド値及び区分子は、互いに隣接して配列される。すなわち、複数のカテゴリーのうち特定のカテゴリーに対応する特定の区分子及び特定のフィールド値は、互いに隣接して配列される。本明細書においては、同一のカテゴリーに属するフィールド値及び区分子のいずれかを称する際に、フィールド値に対応する区分子及び区分子に対応するフィールド値と説明する。 Here, field values and class molecules belonging to the same category are arranged adjacent to each other. That is, a specific segment molecule and a specific field value corresponding to a specific category among a plurality of categories are arranged adjacent to each other. In this specification, when referring to either a field value or a divisional element belonging to the same category, the divisional element corresponding to the field value and the field value corresponding to the divisional element are described.
特定のフィールド値に対応する特定の区分子は、特定のフィールド値の前部又は後部に配列されてもよい。よって、モデル入力値に含まれる一部の区分子は、モデル入力値の前部又は後部に配列されてもよく、異なるフィールド値間に配列されてもよい。 A particular segment molecule corresponding to a particular field value may be aligned to the front or back of the particular field value. Thus, some partitions included in the model input value may be arranged at the front or back of the model input value, or may be arranged between different field values.
図2を参照すると、イメージ10の入力に対して、モデル入力値は、「[CLS]NLP COFFEE[SEP_Name]S City[SEP_Address]」のように生成される。ここで、「[]」(「[]」の内部のテキストを含む)は、特定の役割を果たす区分子又は異なるカテゴリーに属するフィールド値を区分する区分子であり、「[]」で区分されないテキストは、コンテンツに含まれるフィールド値を示す。例示において、[CLS]は、データ全体を代表するクラス区分子、[SEP_Name]は、名称フィールド値の終了を示すカテゴリー区分子、[SEP_Address]は、住所フィールド値の終了を示すカテゴリー区分子である。 Referring to FIG. 2, for the
一方、前記コンテンツに特定のカテゴリーを定義するフィールド名が含まれ、前記特定のカテゴリーに対応するフィールド値が含まれない場合、前記モデル入力値は、前記特定のカテゴリーに対応する特殊な区分子(マスク)を含んでもよい。前記マスクは、前記特定のカテゴリーに対応する区分子に隣接して配列されてもよい。 On the other hand, if the content contains a field name defining a specific category and does not contain a field value corresponding to the specific category, the model input value is a special classifier corresponding to the specific category ( mask). The masks may be arranged adjacent to the partition molecules corresponding to the particular category.
フィールド値がない場合、前記特定のコンテンツから生成されたモデル入力値は、該当カテゴリーに対応するフィールド値が配列されなければならない位置にマスクを代わりに配列することにより構成してもよい。例えば、特定のコンテンツに「事業者登録番号」を定義するフィールド名が含まれるが、フィールド値は、それに対応するマスク([MASK_biz])で表され、モデル入力値は、「[CLS]NLP CAFE[SEP_name]S city[MASK_biz][SEP_biz]」のように生成される。 In the absence of field values, the model input values generated from the specific content may be constructed by instead arranging a mask at the position where the field values corresponding to the category should be arranged. For example, a particular piece of content includes a field name that defines "business registration number", but the field value is represented by its corresponding mask ([MASK_biz]), and the model input value is "[CLS]NLP CAFE [SEP_name] City [MASK_biz] [SEP_biz]".
次に、前記モデル入力値及び学習されたディープラーニングモデルを用いて前記コンテンツのベクトルを生成するステップが行われる(S130)。 Next, a step of generating a vector of the content using the model input values and the trained deep learning model is performed (S130).
ここで、前記モデル入力値に含まれる前記フィールド値のそれぞれを少なくとも1つの第1タイプトークンに変換するステップ、及び前記複数の区分子のそれぞれを第2タイプトークンに変換するステップが行われてもよい。 wherein the steps of converting each of the field values included in the model input value into at least one first type token and converting each of the plurality of classifiers into a second type token are performed. good.
データ検索システム100は、前記複数のカテゴリーのそれぞれに対応する第1タイプトークンが互いに区分されるように、特定のカテゴリーに対応するフィールド値及び区分子から変換された第1及び第2タイプトークンを互いに隣接して配列する。 The
ここで、1つのフィールド値に対応する第1タイプトークンは、1つ以上生成されてもよい。 Here, one or more first type tokens corresponding to one field value may be generated.
一実施形態において、1つのフィールド値から複数の第1タイプトークンが生成されるようにしてもよい。1つの単語又は複数の単語からなるフィールド値は、トークン変換過程で複数のテキストに分割され、分割されたテキストの少なくとも一部には、既に設定されたテキストが結合されるようにしてもよい。例えば、モデル入力値に含まれるフィールド値「NLP COFFEE」は、複数の第1タイプトークン(「NL」、「♯P」、「COFF」、「♯EE」)に変換される。ここで、第1タイプトークンに含まれるテキスト「♯」は、前のトークンとの間が空白でないことを定義するテキストであって、フィールド値から分割された一部のテキストに結合されるようにしてもよい。 In one embodiment, multiple first type tokens may be generated from a single field value. A field value consisting of one word or multiple words may be divided into multiple texts in the token conversion process, and already set text may be combined with at least a part of the divided text. For example, the field value "NLP COFFEE" included in the model input value is converted into a plurality of first type tokens ("NL", "#P", "COFF", "#EE"). Here, the text "#" contained in the first type token is the text that defines that there is no blank space between the token before it, and is to be combined with the partial text split from the field value. may
前記フィールド値のうち特定のフィールド値に対応する第1タイプトークンは、1つ又はそれ以上から構成されてもよく、前記特定のフィールド値に対応する複数の第1タイプトークンは、互いに隣接して配列されてもよい。例えば、フィールド値「NLP COFFEE」から生成された複数の第1タイプトークン(「NL」、「♯P」、「COFF」、「♯EE」)は、順次配列されてもよい。 The first type token corresponding to a specific field value among the field values may consist of one or more, and the plurality of first type tokens corresponding to the specific field value are adjacent to each other. may be arranged. For example, a plurality of first type tokens (“NL”, “#P”, “COFF”, “#EE”) generated from the field value “NLP COFFEE” may be arranged sequentially.
一方、第2タイプトークンは、モデル入力値に含まれる複数の区分子のそれぞれから変換されたものであってもよい。 On the other hand, the second type tokens may be converted from each of the plurality of delimiters included in the model input value.
一実施形態において、第2タイプトークンは、異なるカテゴリーに属するフィールド値を区分するようになっているが、第2タイプトークン自体が特定の意味を含まない形態からなるようにしてもよい。例えば、第2タイプトークンは、[SEP1]、[SEP2]、[SEP3]の形態からなるようにしてもよい。 In one embodiment, the second type token distinguishes between field values belonging to different categories, but the second type token itself may have a form that does not contain a specific meaning. For example, the second type token may be in the form of [SEP1], [SEP2], and [SEP3].
他の一実施形態において、第2タイプトークンのそれぞれは、当該第2タイプトークンに対応するカテゴリーの属性を示す値を含んでもよい。具体的には、複数の第2タイプトークンは、前記複数のカテゴリーを示すテキストをそれぞれ含み、前記第2タイプトークンのうちいずれか1つに含まれるテキストと他の1つに含まれるテキストとは異なるものであってもよい。例えば、第2タイプトークンは、[SEP_Name]、[SEP_Address]のように、特定のカテゴリーのフィールド名を含んでもよい。 In another embodiment, each second type token may include a value indicating an attribute of the category corresponding to the second type token. Specifically, the plurality of second type tokens each include text indicating the plurality of categories, and the text included in any one of the second type tokens and the text included in the other one are It can be different. For example, a second type token may include field names of a particular category, such as [SEP_Name], [SEP_Address].
一方、特定のカテゴリーに属するフィールド値から変換された第1タイプトークンが複数である場合、前記特定のカテゴリーに対応する第2タイプトークンは、前記複数の第1タイプトークンのうち最初に配列された第1タイプトークンの前部又は前記複数の第1タイプトークンのうち最後に配列された第1タイプトークンの後部に配列されるようにしてもよい。 On the other hand, if there are a plurality of first type tokens converted from field values belonging to a specific category, the second type token corresponding to the specific category is arranged first among the plurality of first type tokens. It may be arranged in the front part of the first type token or in the rear part of the last arranged first type token among the plurality of first type tokens.
例えば、モデル入力値「[CLS]NLP_COFFEE[SEP_Name]S City[SEP_Address]」から変換された第1及び第2タイプトークンは、「[CLS]/NL/♯P/COFF/♯EE/[SEP1]/S/Ci/♯ty/[SEP2]」のように配列される。(「/」は単にトークンを区分するための表示である)なお、モデル入力値がマスクを含む場合、マスクトークンは、マスクトークンに対応する第2タイプトークンに隣接して配列される。 For example, the first and second type tokens converted from the model input value "[CLS]NLP_COFFEE[SEP_Name]S City[SEP_Address]" are "[CLS]/NL/#P/COFF/#EE/[SEP1] /S/Ci/#ty/[SEP2]”. (The "/" is merely an indication to separate the tokens.) Note that if the model input value contains a mask, the mask token is arranged adjacent to the second type token corresponding to the mask token.
配列された第1、第2タイプトークン及びマスクトークンが既に学習されたディープラーニングモデルに入力され、コンテンツに対応するベクトルが生成される。 The arranged first and second type tokens and mask tokens are input to the already trained deep learning model to generate a vector corresponding to the content.
データの埋め込みのためのディープラーニングモデルとしては、シーケンスを埋め込む際に活用できるモデル、具体的にはRNN又はTransformer類のモデル(例えば、BERTなど)を活用することができる。 As a deep learning model for data embedding, a model that can be used when embedding a sequence, specifically, a RNN or Transformer class model (eg, BERT, etc.) can be used.
学習されたディープラーニングモデルは、異なるカテゴリーに属するフィールド値を含む構造化されたデータのベクトルを生成する。具体的には、前記学習されたディープラーニングモデルは、保存部120に保存されたデータのそれぞれのベクトルを生成し、受信したコンテンツのベクトルを生成する。すなわち、コンテンツ及び前記コンテンツを用いて検索しようとする既に保存されたデータをベクトル化する。 A trained deep learning model produces a vector of structured data containing field values belonging to different categories. Specifically, the trained deep learning model generates vectors for each of the data stored in the
図5を参照してコンテンツのベクトルを生成する一実施形態について説明すると、例えば、制御部140は、対象文書のイメージ510に対してOCR520を行ってOCRデータを生成し、OCRデータから異なるカテゴリーに属する複数のフィールド値を含む構造化されたデータ530を生成し、データの埋め込み540によりコンテンツ530のベクトルを生成する。 Referring to FIG. 5, describing one embodiment for generating content vectors, for example, the
一方、既に保存されたデータも、学習されたディープラーニングモデルによりベクトル化される。既に保存されたデータのそれぞれに対応するベクトル551a~553a、551b~554b、551c~554cは、ベクトル平面上に示される。既に保存されたデータのベクトルの生成時に既に保存されたデータを構造化されたデータに変換するステップ(例えば、510及び520)は省略される。 On the other hand, already stored data is also vectorized by trained deep learning models.
図5においては、説明の便宜上、データの埋め込みにより生成されるベクトルを2次元的に示すが、データの埋め込みにより生成されるベクトルは2次元より大きい次元のベクトルであってもよい。 In FIG. 5, for convenience of explanation, the vector generated by embedding data is shown two-dimensionally, but the vector generated by embedding data may be a vector of more than two dimensions.
一方、図5においては、説明の便宜上、データの埋め込みが行われるデータを2種類のカテゴリー(name、tel)のみを含むものとして説明するが、データの埋め込みが行われるデータはそれより多い数のフィールドを含んでもよい。 On the other hand, in FIG. 5, for convenience of explanation, it is assumed that the data to be embedded includes only two types of categories (name, tel). May contain fields.
同図に示すように、フローティングされた複数のベクトルのうち、一部のベクトル551a~553aは、第1領域550a内で互いに隣室して配置される。なお、他の一部のベクトル551b~554bは、第2領域550b内で互いに隣室して配置される。さらに他のベクトル551c~554cは、第3領域550c内で互いに隣室して配置される。 As shown in the figure, some of the floating
ディープラーニングモデルは、データ間の類似度に応じてベクトル間の距離が異なるように訓練される。具体的には、ディープラーニングモデルは、データ間の類似度が高いほど近い位置に配置され、データ間の類似度が低いほど遠い位置に配置されるように訓練される。 A deep learning model is trained to vary the distance between vectors according to the similarity between the data. Specifically, the deep learning model is trained so that the higher the similarity between data, the closer the data, and the farther the data, the lower the similarity between the data.
OCRデータに基づいて生成されたコンテンツ530に対するデータの埋め込みの結果で生成されたベクトルは、第1領域550a上にフローティングされる。 A vector generated as a result of embedding data into the
前述したように、本発明は、データに含まれる複数のフィールド値が属するカテゴリーを区分してデータの埋め込みを行うので、データに含まれる異なるカテゴリーの特徴が維持されたベクトルを生成することができる。 As described above, the present invention embeds data by classifying categories to which a plurality of field values included in the data belong, so it is possible to generate a vector that maintains the characteristics of different categories included in the data. .
また、本発明は、生成された異なるカテゴリーの特徴が維持されたベクトルをデータ検索に活用することにより、既に保存されたデータと同じデータのみを検索することに限定されず、対象文書に含まれる複数のカテゴリーに属する値の類似度を考慮したデータ検索を行うことができる。以下、前記ベクトルを活用したデータ検索について具体的に説明する。 In addition, the present invention is not limited to searching only the same data as the already stored data by utilizing the generated vector that maintains the features of different categories for data search, and is included in the target document Data retrieval can be performed considering the similarity of values belonging to multiple categories. Data retrieval using the vector will be described in detail below.
図6a及び図6bはOCRデータを用いてデータを検索する一実施形態を示す概念図であり、図7はデータの埋め込みの結果で生成されたベクトルを用いてデータを検索する一実施形態を示す概念図である。 6a and 6b are conceptual diagrams illustrating one embodiment of retrieving data using OCR data, and FIG. 7 illustrates one embodiment of retrieving data using vectors generated as a result of data embedding. It is a conceptual diagram.
ディープラーニングを用いて前記コンテンツのベクトルを生成し、その後前記生成されたベクトルと既に保存された複数のデータのそれぞれに対応するベクトル間の類似度に基づいて、前記既に保存された複数のデータから検索対象データに対応するデータを検索するステップが行われる(S140)。 using deep learning to generate a vector of the content, and then based on the similarity between the generated vector and a vector corresponding to each of the previously stored data, from the previously stored data. A step of searching for data corresponding to the search target data is performed (S140).
前述した作業領域には、イメージを用いてデータを検索するためのインタフェース画面を表示することができる。 The aforementioned work area can display an interface screen for retrieving data using images.
図6a及び図6bを参照すると、作業領域には、検索対象コンテンツ、例えば領収証のイメージ600が出力される。イメージ600は、既に保存されたイメージのいずれかであるか、作業領域を表示する電子機器に内蔵されたカメラにより撮影されたイメージであるか、作業領域を表示する電子機器以外の他の装置から受信されたイメージであってもよい。 Referring to Figures 6a and 6b, the work area is populated with content to be searched, for example, an
一方、作業領域には、イメージ600に対するOCRの結果で抽出されたテキストを表示することができる。OCRの結果で抽出されたテキストのうちフィールド名に分類されたデータは、前記抽出されたテキストがそのまま表示されるのではなく、既に保存されたテキストが表示されるようにしてもよく、また、抽出されたテキストに存在しなくても作業領域上に表示されるようにしてもよい。 On the other hand, the work area can display the text extracted from the OCR results for the
例えば、図6aを参照すると、イメージ600には、売場名に関するカテゴリーが存在するが、当該カテゴリーに関するフィールド名は含まれていない。制御部140は、フィールド値「HLP Coffee」の意味に基づいて、イメージ600に売場名に関するカテゴリーが存在すると判断し、作業領域に既に保存されたフィールド名(「name」611)を表示することができる。 For example, referring to FIG. 6a,
一方、制御部140は、第2タイプのデータ「カフェラッテ(hot)」に基づいて、イメージ600に商品名に関するカテゴリーが存在すると判断する。ここで、制御部140は、抽出されたテキストに商品名に関するカテゴリーに対応するフィールド名「商品名」が存在するが、既に保存されたフィールド名「item1」を作業領域上に表示することができる。 On the other hand, the
前述したように、作業領域には、OCRの結果で抽出されたテキストを、フィールド名611~615及びフィールド値621~625に区分して表示することができる。ここで、制御部140は、同一のカテゴリーに属するフィールド名及びフィールド値をマッチングさせ、そのマッチングの結果に基づいてデータを表示することができる。例えば、同一のカテゴリーに属するフィールド名「name」及びフィールド値「HLP Coffee」がマッチングされ、作業領域上で互いに隣接して表示される。 As described above, the work area can display the text extracted as a result of OCR by dividing it into field names 611-615 and field values 621-625. Here, the
制御部140は、抽出されたテキストの意味に基づいて同一のカテゴリーに属するデータをマッチングさせてコンテンツを生成し、生成されたコンテンツ及びディープラーニングモデルを用いてベクトルを生成する。その後、生成されたベクトルと既に保存された複数のデータのベクトル間の距離を比較し、その比較の結果に基づいて、前記既に保存された複数のデータのベクトルから少なくとも1つを選択する。 The
制御部140は、学習されたディープラーニングモデルを用いてデータベースに既に保存された「属性-値」形式のデータを前述したベクトルに変換する。データベースに既に保存されたデータは、図5で説明したように、ベクトル空間に表すことができる。 The
制御部140は、前記コンテンツのベクトルと既に保存された他のベクトル間の距離を算出し、既に保存された他のベクトルから少なくとも1つのベクトルをベクトル間の距離が小さい順に選択することができる。 The
その後、制御部140は、前記選択されたベクトルに対応するデータを出力することができる。前記選択されたベクトルに対応するデータは、前述した作業領域上に表示することができる。 After that, the
このために、本発明によるデータ埋め込みモデルは、前述したベクトルを「属性-値」対からなる形式のデータに変換するデコーダ(decoder)を含んでもよい。前記デコーダは、特定のベクトルの生成時に入力データとして活用されたデータと同じ形態のデータに変換するように機械学習される。よって、前記デコーダは、複数のフィールド値が属するカテゴリーが区分された形態のデータ(例えば、JSON、XML)を出力する。 To this end, the data embedding model according to the invention may include a decoder that converts the aforementioned vectors into data in the form of "attribute-value" pairs. The decoder is machine-learned to convert the data into the same form as the data used as the input data when generating a specific vector. Accordingly, the decoder outputs data (eg, JSON, XML) in which categories to which a plurality of field values belong are divided.
例えば、図6bを参照すると、作業領域には、図6aで説明したイメージから生成されたコンテンツに対応するベクトルからの距離が最も近い第1ベクトル及び2番目に近い第2ベクトルのそれぞれに対応する「属性-値」対からなるデータ631、632が表示される。前記データのうち、図6aで説明したイメージ600に対応するデータ631が含まれる。 For example, referring to FIG. 6b, the work area includes a first vector and a second closest vector, respectively, corresponding to the vector corresponding to the content generated from the image described in FIG. 6a.
より具体的には、図7を参照すると、制御部140は、既に保存された複数のデータに対応するベクトル551a~553cと前記コンテンツに対応するベクトル560間の距離を算出する。その結果、既に保存された複数のデータに対応するベクトル551a~553cのそれぞれに対する距離d1~d3が算出される。制御部140は、既に保存されたデータに対応するベクトル551a~553cからコンテンツに対応するベクトル560からの距離が最も近いベクトル552aを選択し、ベクトル552aを「属性-値」対のデータ(Name:NLP COFFEE、Tel:01-234-567)に変換して出力することができる。 More specifically, referring to FIG. 7, the
前述したように、本発明によれば、埋め込みの結果で生成されたベクトル間の類似度に基づいてデータを検索するので、データ検索時に人が定めた検索規則に依存して検索を行う必要がなくなる。 As described above, according to the present invention, data is searched based on the degree of similarity between vectors generated as a result of embedding. Gone.
また、本発明によれば、データのカテゴリー毎の類似度を考慮した検索が可能であるので、ノイズやエラーが頻繁に発生するデータ(例えば、OCRデータ、音声認識データ)を用いた検索時にも高い正確度でデータ検索を行うことができる。 Further, according to the present invention, it is possible to perform a search considering the degree of similarity for each data category. Data retrieval can be performed with high accuracy.
一方、前述した本発明は、コンピュータで1つ以上のプロセスにより実行され、コンピュータ可読媒体(又は記録媒体)に格納可能なプログラムとして実現することができる。 On the other hand, the present invention described above can be implemented as a program that is executed by one or more processes on a computer and can be stored in a computer-readable medium (or recording medium).
また、前述した本発明は、プログラム記録媒体にコンピュータ可読コード又はコマンドとして実現することができる。すなわち、本発明は、プログラムの形態で提供することができる。 Also, the present invention described above can be implemented as computer readable codes or commands on a program recording medium. That is, the present invention can be provided in the form of a program.
一方、コンピュータ可読媒体は、コンピュータシステムにより読み取り可能なデータが記録されるあらゆる種類の記録装置を含む。コンピュータ可読媒体の例としては、HDD(Hard Disk Drive)、SSD(Solid State Disk)、SDD(Silicon Disk Drive)、ROM、RAM、CD-ROM、磁気テープ、フロッピー(登録商標)ディスク、光データ記憶装置などが挙げられる。 A computer-readable medium, on the other hand, includes any type of recording device on which data readable by a computer system is recorded. Examples of computer readable media include HDDs (Hard Disk Drives), SSDs (Solid State Disks), SDDs (Silicon Disk Drives), ROMs, RAMs, CD-ROMs, magnetic tapes, floppy disks, optical data storage device and the like.
また、コンピュータ可読媒体は、ストレージを含み、電子機器が通信によりアクセスできるサーバ又はクラウドストレージであり得る。この場合、コンピュータは、有線又は無線通信により、サーバ又はクラウドストレージから本発明によるプログラムをダウンロードすることができる。 Computer-readable media also includes storage, which may be a server or cloud storage communicatively accessible by the electronic device. In this case, the computer can download the program according to the present invention from a server or cloud storage via wired or wireless communication.
さらに、本発明において、前述したコンピュータは、プロセッサ、すなわち中央処理装置(Central Processing Unit,CPU)が搭載された電子機器であり、その種類は特に限定されない。 Furthermore, in the present invention, the aforementioned computer is an electronic device equipped with a processor, that is, a central processing unit (CPU), and its type is not particularly limited.
一方、本発明の詳細な説明は例示的なものであり、あらゆる面で限定的に解釈されてはならない。本発明の範囲は添付の特許請求の範囲の合理的解釈により定められるべきであり、本発明の均等の範囲内でのあらゆる変更が本発明の範囲に含まれる。 On the other hand, the detailed description of the present invention is illustrative and should not be construed as limiting in any respect. The scope of the present invention should be determined by rational interpretation of the appended claims, and all changes within the scope of equivalents of the present invention are included in the scope of the present invention.
10 イメージ
100 データ検索システム
110 通信部
120 保存部
130 OCR部
140 制御部
150 音声認識部
160 DB(データベース)10
Claims (15)
Translated fromJapanese前記コンテンツに含まれるフィールド値を配列するが、前記フィールド値が属するカテゴリーを区分する複数の区分子を追加してモデル入力値を生成するステップと、
前記モデル入力値及び学習されたディープラーニングモデルを用いて前記コンテンツのベクトルを生成するステップと、
前記生成されたベクトルと既に保存された複数のデータのそれぞれに対応するベクトル間の類似度に基づいて、前記既に保存された複数のデータから検索対象データに対応するデータを検索するステップとを含む、データ検索方法。receiving content that includes multiple field values;
arranging the field values contained in the content, but adding a plurality of division molecules that divide categories to which the field values belong to generate model input values;
generating a vector of the content using the model input values and a trained deep learning model;
searching for data corresponding to search target data from the plurality of already stored data based on the degree of similarity between the generated vector and the vectors corresponding to each of the plurality of already stored data. , data retrieval methods.
前記複数の区分子は、前記複数のカテゴリーにそれぞれ対応することを特徴とする請求項1に記載のデータ検索方法。the field values respectively correspond to a plurality of categories;
2. The data search method according to claim 1, wherein the plurality of segment molecules correspond to the plurality of categories, respectively.
前記複数の区分子のそれぞれを第2タイプトークンに変換するステップとをさらに含み、
前記複数のカテゴリーのそれぞれに対応する第1タイプトークンが互いに区分されるように、前記特定のカテゴリーに対応する前記フィールド値及び前記区分子から変換された前記第1及び前記第2タイプトークンは、互いに隣接して配列されることを特徴とする請求項4に記載のデータ検索方法。converting each of the field values included in the model input value into at least one first type token;
and converting each of the plurality of segmented molecules into a second type token;
The first and second type tokens converted from the field value and the classifier corresponding to the specific category such that the first type tokens corresponding to each of the plurality of categories are separated from each other, 5. The data retrieval method of claim 4, wherein the data are arranged adjacent to each other.
前記複数のカテゴリーを示すテキストをそれぞれ含み、
前記第2タイプトークンのうちいずれか1つに含まれるテキストと他の1つに含まれるテキストとが異なることを特徴とする請求項5に記載のデータ検索方法。The second type token is
each including text indicating the plurality of categories;
6. The data retrieval method of claim 5, wherein the text included in one of the second type tokens is different from the text included in the other one.
前記マスクトークンは、前記特定のカテゴリーに対応する区分子に隣接して配列されることを特徴とする請求項1に記載のデータ検索方法。if the content includes a field name that defines a particular category and does not include the field value corresponding to the particular category, the model input value includes a mask token corresponding to the particular category;
2. The data retrieval method of claim 1, wherein the mask tokens are arranged adjacent to the block corresponding to the specific category.
前記コンテンツのベクトルと前記既に保存された複数のデータのそれぞれに対応するベクトル間の距離を比較するステップと、
前記比較の結果に基づいて、前記既に保存された複数のデータのそれぞれに対応するベクトルから少なくとも1つを選択するステップと、
前記選択されたベクトルに対応するデータを出力するステップとをさらに含むことを特徴とする請求項1に記載のデータ検索方法。The step of searching for data corresponding to search target data from a plurality of data already saved,
comparing a distance between a vector of the content and a vector corresponding to each of the plurality of previously stored data;
selecting at least one from vectors corresponding to each of the plurality of previously stored data based on the result of the comparison;
2. The data retrieval method of claim 1, further comprising outputting data corresponding to the selected vector.
異なるカテゴリーに属する複数のフィールド値を含み、
前記複数のフィールド値が属するカテゴリーが区分された形態のデータであることを特徴とする請求項10に記載のデータ検索方法。The data corresponding to the selected vectors are:
containing multiple field values belonging to different categories,
11. The data search method according to claim 10, wherein the data is in a form in which categories to which the plurality of field values belong are divided.
前記複数のフィールド値が属するカテゴリーが区分された形態のデータであることを特徴とする請求項1に記載のデータ検索方法。The content is
2. The data search method according to claim 1, wherein the data are in a form in which the categories to which the plurality of field values belong are divided.
前記コンテンツに含まれるフィールド値を配列するが、前記フィールド値が属するカテゴリーを区分する複数の区分子を追加してモデル入力値を生成し、
前記モデル入力値及び学習されたディープラーニングモデルを用いて前記コンテンツのベクトルを生成し、
前記生成されたベクトルと既に保存された複数のデータのそれぞれに対応するベクトル間の類似度に基づいて、前記既に保存された複数のデータから検索対象データに対応するデータを検索する制御部とを含む、データ検索システム。a communication unit that receives content including multiple field values;
arranging the field values contained in the content, but adding a plurality of division molecules that divide categories to which the field values belong to generate a model input value;
generating a vector of the content using the model input values and the trained deep learning model;
a control unit that searches for data corresponding to search target data from the plurality of already-stored data based on the degree of similarity between the generated vector and the vectors corresponding to each of the plurality of already-stored data; Including, data retrieval system.
命令が実行されると、
複数のフィールド値を含むコンテンツを受信するステップと、
前記コンテンツに含まれるフィールド値を配列するが、前記フィールド値が属するカテゴリーを区分する複数の区分子を追加してモデル入力値を生成するステップと、
前記モデル入力値及び学習されたディープラーニングモデルを用いて前記コンテンツのベクトルを生成するステップと、
前記生成されたベクトルと既に保存された複数のデータのそれぞれに対応するベクトル間の類似度に基づいて、前記既に保存された複数のデータから検索対象データに対応するデータを検索するステップとを、
コンピュータで実行する、コンピュータプログラム。A computer program comprising a plurality of instructions,
When the instruction is executed
receiving content that includes multiple field values;
arranging the field values contained in the content, but adding a plurality of segmentation molecules that segment categories to which the field values belong to generate model input values;
generating a vector of the content using the model input values and a trained deep learning model;
searching for data corresponding to search target data from the plurality of already stored data based on the degree of similarity between the generated vector and the vectors corresponding to each of the plurality of already stored data;
A computer program that runs on a computer.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR10-2021-0101660 | 2021-08-02 | ||
| KR1020210101660AKR102684423B1 (en) | 2021-08-02 | 2021-08-02 | Method and system for data searching |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2023021946Atrue JP2023021946A (en) | 2023-02-14 |
| JP7367139B2 JP7367139B2 (en) | 2023-10-23 |
Family
ID=85201539
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2022121133AActiveJP7367139B2 (en) | 2021-08-02 | 2022-07-29 | Data search method and system |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP7367139B2 (en) |
| KR (1) | KR102684423B1 (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR102708124B1 (en)* | 2023-05-17 | 2024-09-19 | 주식회사 티빙 | Method and apparatus for searching contents in contents streaming system |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004013813A (en)* | 2002-06-11 | 2004-01-15 | Megasoft Kk | Information management system and method |
| JP2005301786A (en)* | 2004-04-14 | 2005-10-27 | Internatl Business Mach Corp <Ibm> | Evaluating apparatus, cluster generating apparatus, program, recording medium, evaluation method, and cluster generation method |
| US20060088214A1 (en)* | 2004-10-22 | 2006-04-27 | Xerox Corporation | System and method for identifying and labeling fields of text associated with scanned business documents |
| WO2018070026A1 (en)* | 2016-10-13 | 2018-04-19 | 楽天株式会社 | Commodity information display system, commodity information display method, and program |
| JP2019144771A (en)* | 2018-02-19 | 2019-08-29 | 株式会社ミラボ | Business form processing system and business form processing program |
| JP2020177507A (en)* | 2019-04-19 | 2020-10-29 | 株式会社サイトビジット | Exam question prediction system and exam question prediction method |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR101592670B1 (en)* | 2014-02-17 | 2016-02-11 | 포항공과대학교 산학협력단 | Apparatus for searching data using index and method for using the apparatus |
| KR20210083706A (en)* | 2019-12-27 | 2021-07-07 | 삼성전자주식회사 | Apparatus and method for classifying a category of data |
- 2021
- 2021-08-02KRKR1020210101660Apatent/KR102684423B1/enactiveActive
- 2022
- 2022-07-29JPJP2022121133Apatent/JP7367139B2/enactiveActive
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004013813A (en)* | 2002-06-11 | 2004-01-15 | Megasoft Kk | Information management system and method |
| JP2005301786A (en)* | 2004-04-14 | 2005-10-27 | Internatl Business Mach Corp <Ibm> | Evaluating apparatus, cluster generating apparatus, program, recording medium, evaluation method, and cluster generation method |
| US20060088214A1 (en)* | 2004-10-22 | 2006-04-27 | Xerox Corporation | System and method for identifying and labeling fields of text associated with scanned business documents |
| WO2018070026A1 (en)* | 2016-10-13 | 2018-04-19 | 楽天株式会社 | Commodity information display system, commodity information display method, and program |
| JP2019144771A (en)* | 2018-02-19 | 2019-08-29 | 株式会社ミラボ | Business form processing system and business form processing program |
| JP2020177507A (en)* | 2019-04-19 | 2020-10-29 | 株式会社サイトビジット | Exam question prediction system and exam question prediction method |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7367139B2 (en) | 2023-10-23 |
| KR102684423B1 (en) | 2024-07-12 |
| KR20230019745A (en) | 2023-02-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109783635B (en) | Automatically classify documents and identify metadata hierarchically using machine learning and fuzzy matching | |
| RU2678716C1 (en) | Use of autoencoders for learning text classifiers in natural language | |
| US8243988B1 (en) | Clustering images using an image region graph | |
| US20240404308A1 (en) | Systems and Methods for Extracting Information from a Physical Document | |
| CN113469067B (en) | Document analysis method, device, computer equipment and storage medium | |
| WO2014050774A1 (en) | Document classification assisting apparatus, method and program | |
| KR20220039075A (en) | Electronic device, contents searching system and searching method thereof | |
| US11854537B2 (en) | Systems and methods for parsing and correlating solicitation video content | |
| CN116932730B (en) | Document question-answering method and related equipment based on multi-way tree and large-scale language model | |
| CN112036176B (en) | Text clustering method and device | |
| CN115545036A (en) | Reading order detection in documents | |
| JP2015069256A (en) | Character identification system | |
| WO2023177723A1 (en) | Apparatuses and methods for querying and transcribing video resumes | |
| JP7367139B2 (en) | Data search method and system | |
| JP2016027493A (en) | Document classification support apparatus, method and program | |
| KR102732830B1 (en) | Method and system for extracting information from semi-structured documents | |
| JP2025087598A (en) | Method and system for processing tables of prompts for large language models - Patents.com | |
| CN119066179A (en) | Question and answer processing method, computer program product, device and medium | |
| CN114239569A (en) | Analysis method and device for evaluation text and computer readable storage medium | |
| US11983228B1 (en) | Apparatus and a method for the generation of electronic media | |
| US12437505B2 (en) | Generating templates using structure-based matching | |
| JP7453731B2 (en) | Method and system for extracting information from semi-structured documents | |
| US12210566B1 (en) | Apparatus and method for generation of an integrated data file | |
| EP4524808A1 (en) | Apparatus and method for generation of an integrated data file | |
| KR102649429B1 (en) | Method and system for extracting information from semi-structured documents |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination | Free format text:JAPANESE INTERMEDIATE CODE: A621 Effective date:20220729 | |
| A711 | Notification of change in applicant | Free format text:JAPANESE INTERMEDIATE CODE: A711 Effective date:20230817 | |
| A977 | Report on retrieval | Free format text:JAPANESE INTERMEDIATE CODE: A971007 Effective date:20230818 | |
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) | Free format text:JAPANESE INTERMEDIATE CODE: A01 Effective date:20230912 | |
| A61 | First payment of annual fees (during grant procedure) | Free format text:JAPANESE INTERMEDIATE CODE: A61 Effective date:20231011 | |
| R150 | Certificate of patent or registration of utility model | Ref document number:7367139 Country of ref document:JP Free format text:JAPANESE INTERMEDIATE CODE: R150 | |
| S533 | Written request for registration of change of name | Free format text:JAPANESE INTERMEDIATE CODE: R313533 | |
| R350 | Written notification of registration of transfer | Free format text:JAPANESE INTERMEDIATE CODE: R350 | |
| S531 | Written request for registration of change of domicile | Free format text:JAPANESE INTERMEDIATE CODE: R313531 | |
| R350 | Written notification of registration of transfer | Free format text:JAPANESE INTERMEDIATE CODE: R350 |