JP2023016504A - Slide playback program, slide playback device, and slide playback method - Google Patents
Slide playback program, slide playback device, and slide playback methodDownload PDFInfo
- Publication number
- JP2023016504A JP2023016504AJP2021120856AJP2021120856AJP2023016504AJP 2023016504 AJP2023016504 AJP 2023016504AJP 2021120856 AJP2021120856 AJP 2021120856AJP 2021120856 AJP2021120856 AJP 2021120856AJP 2023016504 AJP2023016504 AJP 2023016504A
- Authority
- JP
- Japan
- Prior art keywords
- slide
- data
- output
- control unit
- spoken text
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images





















Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T13/00—Animation
- G06T13/20—3D [Three Dimensional] animation
- G06T13/40—3D [Three Dimensional] animation of characters, e.g. humans, animals or virtual beings
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L13/00—Speech synthesis; Text to speech systems
- G10L13/08—Text analysis or generation of parameters for speech synthesis out of text, e.g. grapheme to phoneme translation, prosody generation or stress or intonation determination
- G10L13/10—Prosody rules derived from text; Stress or intonation
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Processing Or Creating Images (AREA)
- User Interface Of Digital Computer (AREA)
Abstract
Description
Translated fromJapanese本発明は、プレゼンテーションデータに含まれる複数のスライドを順次表示出力するスライド再生プログラム等に関する。 The present invention relates to a slide reproduction program and the like for sequentially displaying and outputting a plurality of slides included in presentation data.
近年、商談などにおいて、表示装置に画像を表示し、この画像を順次切り替えながら商材の説明することが行われている。表示される各画像をスライドと呼び、複数のスライドをまとめたものはプレゼンテーションデータと呼ばれている。 2. Description of the Related Art In recent years, in business negotiations and the like, images are displayed on a display device, and products are explained while sequentially switching the images. Each displayed image is called a slide, and a collection of multiple slides is called presentation data.
また、音声合成技術を利用したプレゼンテーション装置が提案されている(特許文献1)。特許文献1に記載のプレゼンテーション装置は、スライドの切り替えと同期して、音声合成でテキストデータの読み上げを自動的に行う。 Also, a presentation device using speech synthesis technology has been proposed (Patent Document 1). The presentation device described in
しかしながら、音声のみでは臨場感に欠け、聴取者は内容を理解しにくくなる場合がある。本発明はこのような状況に鑑みてなされたものである。その目的は、音声合成を用いたプレゼンテーションにおいて、より臨場感を出すことが可能なスライド再生プログラム等を提供することである。 However, the sound alone lacks a sense of realism, and the listener may find it difficult to understand the content. The present invention has been made in view of such circumstances. The object is to provide a slide reproduction program or the like that can give a more realistic feeling in a presentation using speech synthesis.
本願の一態様に係るスライド再生プログラムは、発話テキストと表示要素とを含むスライドデータを複数含むプレゼンテーションデータを取得し、複数の前記スライドデータそれぞれに含む前記表示要素を所定の順番で出力するとともに、出力している前記スライドデータに含む前記発話テキストの読み上げ音声を、人物動画を付して出力する処理をコンピュータに行わせることを特徴とする。 A slide playback program according to an aspect of the present application acquires presentation data including a plurality of slide data including spoken text and display elements, outputs the display elements included in each of the plurality of slide data in a predetermined order, A computer is caused to perform a process of outputting the reading voice of the spoken text included in the output slide data with a moving image of the person.
本願の一観点によれば、人物が話しをしている人物動画を表示することにより、臨場感のあるプレゼンテーションが可能となる。 According to one aspect of the present application, it is possible to give a realistic presentation by displaying a moving image of a person talking.
(実施の形態1)
以下実施の形態を、図面を参照して説明する。以下の説明におけるプレゼンテーションデータについて述べる。プレゼンテーションデータは複数のスライドを含む。スライドは、コンピュータのディスプレイに表示したり、プロジェクターで投影したりするためのプレゼンテーションソフト用の表示データをいう。スライドはオブジェクト(表示要素)を含む。オブジェクトはテキスト、図形、動画、表、グラフ等である。オブジェクトは属性として、大きさ、位置、傾きを有する。スライドには、プロジェクターで投影する際には表示されない、テキスト(発話テキスト)を含めることが可能である。当該テキストは、スピーカーノート、発表者ノート、単にノートともいう。スピーカーノートはプロジェクターで投影する画像には含まれないが、プレゼンテーションソフトを実行するコンピュータのディスプレイには表示可能である。(Embodiment 1)
Embodiments will be described below with reference to the drawings. Presentation data in the following description will be described. Presentation data includes multiple slides. A slide is display data for presentation software to be displayed on a computer display or projected by a projector. A slide contains objects (display elements). Objects are text, figures, animations, tables, graphs, and the like. An object has size, position, and tilt as attributes. Slides can contain text (spoken text) that is not visible when projected by a projector. The text is also called speaker notes, presenter notes, or simply notes. The speaker notes are not included in the image projected by the projector, but can be displayed on the display of the computer running the presentation software.
図1はプレゼンテーションシステムの構成例を示す説明図である。プレゼンテーションシステム100は再生装置1及び音声合成サーバ2を含む。再生装置1及び音声合成サーバ2はネットワークNにより、互いに通信可能に接続されている。図1において、再生装置1は1台のみ記載しているが、2台以上でもよい。図1では、再生装置Kも再生装置1と同様であり、その中身の処理概念図を示す。再生装置1、再生装置Kは共に再生装置と呼ぶ。また、再生装置をプロジェクターに接続しても良い(例えば、USBケーブル、若しくは、VGAケーブル等による有線接続、又は、Wifi若しくはBluetooth(登録商標)などによる無線接続を行なう)。その場合、後述する再生装置の表示部のデータをプロジェクターに送信する。プロジェクターからの出力をスクリーン等に投影し、画像を表示させることになる。 FIG. 1 is an explanatory diagram showing a configuration example of a presentation system. A
再生装置はユーザがプレゼンテーションに用いる装置である。再生装置はノートパソコン、パネルコンピュータ、タブレットコンピュータ、スマートフォン等で構成する。再生装置の論理的な処理は再生装置Kで示す。再生装置は後述のハードウェア構成で、プレゼンテーションデータK1、VR(Virtual Reality:バーチャルリアリティー)モデルDBK2、設定データK3を保持している。本願における一つの実施形態のスライド再生プログラムK4はこれらのデータを読み込み、発表者ノートのテキストを音声合成サーバ2に送信し、音声合成結果を得る。更に、スライドデータからスライド表示プログラムK5(例えば、Microsoft PowerPoint,Googleプレゼンテーションなど)でスライドを表示し、VRエンジンでVRアバターK6を表示させる。スライド再生プログラムK4はスライド表示K5、VRアバターK6及び音声合成結果K7を表示、再生する。また、スライド再生プログラムK4はスライド表示、音声合成結果の再生、アバター表示と同時に、スライドのページ遷移の制御も自動的に行い、これらの要素の表示、再生を同期化する。音声合成サーバ2は音声合成エンジンを備える。音声合成サーバ2は再生装置1からテキストデータを受け付け、音声合成モデルを用いて受け付けたテキストを読み上げる音声を合成し、音声データを再生装置1へ返信する。音声合成サーバ2はサーバコンピュータ、ワークステーション等で構成する。また、音声合成サーバ2を複数のコンピュータからなるマルチコンピュータ、ソフトウェアによって仮想的に構築された仮想マシン又は量子コンピュータで構成してもよい。さらに、音声合成サーバ2の機能をクラウドサービスで実現してもよい。 A playback device is a device that a user uses for a presentation. The playback device consists of a notebook computer, a panel computer, a tablet computer, a smart phone, and the like. The logical processing of the playback device is indicated by playback device K. FIG. The playback device has a hardware configuration to be described later, and holds presentation data K1, a VR (Virtual Reality) model DBK2, and setting data K3. The slide playback program K4 of one embodiment of the present application reads these data, transmits the text of the presenter's notes to the
図2は再生装置のハードウェア構成例を示すブロック図である。再生装置1は制御部11、主記憶部12、補助記憶部13、通信部14、入力部15、表示部16、音声出力部17及び読み取り部18を含む。制御部11、主記憶部12、補助記憶部13、通信部14、入力部15、表示部16、音声出力部17及び読み取り部18はバスBにより接続されている。 FIG. 2 is a block diagram showing a hardware configuration example of the playback device. The
制御部11は、一又は複数のCPU(Central Processing Unit)、MPU(Micro-Processing Unit)、GPU(Graphics Processing Unit)等の演算処理装置を有する。制御部11は、補助記憶部13に記憶された制御プログラム1P(スライド再生プログラム、プログラム製品)を読み出して実行することにより、再生装置1に係る種々の情報処理、制御処理等を行い、取得部及び出力部等の機能部を実現する。 The
主記憶部12は、SRAM(Static Random Access Memory)、DRAM(Dynamic Random Access Memory)、フラッシュメモリ等である。主記憶部12は主として制御部11が演算処理を実行するために必要なデータを一時的に記憶する。 The
補助記憶部13はハードディスク又はSSD(Solid State Drive)等であり、制御部11が処理を実行するために必要な制御プログラム1Pや各種DB(Database)を記憶する。補助記憶部13は、基本設定DB131、モデルDB132、発話設定DB133、画面設定DB134及び遷移設定DB135、VRモデルデータ136、並びに、プレゼンテーションデータ137を記憶する。補助記憶部13は再生装置1に接続された外部記憶装置であってもよい。補助記憶部13に記憶する各種DB等を、再生装置1とは異なるデータベースサーバやクラウドストレージに記憶してもよい。一方、基本設定DB131、モデルDB132、発話設定DB133、画面設定DB134及び遷移設定DB135が記憶する内容を、まとめて一つのファイルとして、補助記憶部13に記憶してもよい。 The
通信部14はネットワークNを介して、音声合成サーバ2と通信を行う。また、制御部11が通信部14を用い、ネットワークN等を介して他のコンピュータから制御プログラム1Pをダウンロードし、補助記憶部13に記憶してもよい。 The
入力部15はキーボードやマウス等を含む。表示部16は液晶表示パネル等を含む。表示部16はプレゼンテーションデータ137を構成するスライドなどを表示する。また、入力部15と表示部16とを一体化し、タッチパネルディスプレイを構成してもよい。さらに、再生装置1は外部の表示装置に表示を行ってもよい。 The input unit 15 includes a keyboard, mouse, and the like. The
音声出力部17は音声スピーカを含む。音声出力部17はデジタル音声データをアナログ音声信号に変換し、スピーカから出力する。
読み取り部18はCD(Compact Disc)-ROM及びDVD(Digital Versatile Disc)-ROMを含む可搬型記憶媒体1aを読み取る。制御部11が読み取り部18を介して、制御プログラム1Pを可搬型記憶媒体1aより読み取り、補助記憶部13に記憶してもよい。また、半導体メモリ1bから、制御部11が制御プログラム1Pを読み込んでもよい。 The
次にデータベースについて説明する。図3は基本設定DBの例を示す説明図である。基本設定DB131はスライド再生に関する基本設定を記憶する。基本設定DB131はモデルID列及びURI列を含む。モデルID列は発表者として表示されるVRモデルのIDを記憶する。URI列はプレゼンテーションデータのURI(Uniform Resource Identifier)を記憶する。 Next, the database will be explained. FIG. 3 is an explanatory diagram showing an example of the basic setting DB. The
図4はモデルDBの例を示す説明図である。モデルDB132は発表者として表示されるVRモデルの情報を記憶する。モデルDB132はモデルID列、名称列、写真列及びモデル列を含む。モデルID列はVRモデルを一意に特定するモデルIDを記憶する。モデルIDはモデルDB132の主キーであり、上述の基本設定DB131のモデルID列は、外部キーとしてモデルIDを記憶する。名称列はVRモデルの名称を記憶する。写真列はVRモデルを作成する際に用いた静止画像を記憶する。予め用意されているVRモデルなどの場合、写真列は静止画像を記憶しなくともよい。モデル列はVRモデルの実体についての情報を記憶する。図4に示す例ではVRモデルデータ136に相当するファイルの名称を、モデル列は記憶している。なお、VRモデルは動画より生成してもよい。この場合、写真列に替えて又は加えて、動画列を設ける。動画列はVRモデルを作成する際に用いた動画像を記憶する。 FIG. 4 is an explanatory diagram showing an example of the model DB. The
図5は発話設定DBの例を示す説明図である。発話設定DB133は発話音声の設定を記憶する。発話設定DB133はエンジン列、ピッチ列、速さ列、言語列、性別列及び声モデル列を含む。エンジン列は音声合成に用いる音声合成エンジンの識別情報を記憶する。ピッチ列は合成音声の音程を記憶する。速さ列は発話の速度を記憶する。言語列は発話する言語を記憶する。性別列は発話音声の性別を記憶する。声モデル列は音声合成エンジンが複数の音声モデルを備えている場合、音声合成に用いる音声モデルの識別情報(特定情報)を記憶する。 FIG. 5 is an explanatory diagram showing an example of the speech setting DB. The
図6は画面設定DBの例を示す説明図である。画面設定DB134はアバター画像を表示する発表者画面の設定を記憶する。画面設定DB134は背景画像列、幅列、高さ列、位置列を含む。背景画像列はアバターの背景に表示する画像の情報を記憶する。背景の画像は静止画像でも動画像でもよい。図6に示す例では静止画像または動画画像ファイルの名称を、背景画像列は記憶する。幅列は発表者画面の幅を記憶する。高さ列は発表者画面の高さを記憶する。位置列は画面全体の中で、発表者画面を表示する位置を記憶する。 FIG. 6 is an explanatory diagram showing an example of the screen setting DB. The
図7は遷移設定DBの例を示す説明図である。遷移設定DB135はスライドが次のスライドに遷移する際の設定を記憶する。遷移設定DB135はディレイ列及び切り替え列を含む。ディレイ列は表示しているスライドの発話テキストの音声読み上げが完了してから、次のスライドに遷移するまでの間隔時間(以下、「遷移間隔時間」という。)を記憶する。切り替え列は現在のスライドから次のスライドに切り替える際の効果、モーションを記憶する。 FIG. 7 is an explanatory diagram showing an example of a transition setting DB. The
次に、プレゼンテーションシステム100で行われる処理について説明する。図8はメイン処理の手順例を示すフローチャートである。再生装置1の制御部11は設定を読み込む(ステップS1)。設定は、基本設定DB131、発話設定DB133、画面設定DB134及び遷移設定DB135に記憶されている。制御部11は読み込んだ設定に基づく設定画面を生成し、表示部16に表示する(ステップS2)。設定項目は種々あるため、複数グループに分けられており、設定画面では、設定内容をグループ毎にタブ表示している。制御部11は入力部15を介して、ユーザの操作入力を受け付ける(ステップS3)。制御部11は操作入力が設定画面のタブ切り替えであるか否かを判定する(ステップS4)。制御部11は操作入力が設定画面のタブ切り替えであると判定した場合(ステップS4でYES)、表示するタブを指定されたタブに切り替える(ステップS5)。制御部11は操作入力が設定画面のタブ切り替えでないと判定した場合(ステップS4でNO)、操作入力が設定の入力であるか否かを判定する(ステップS6)。制御部11は操作入力が設定の入力であると判定した場合(ステップS6でYES)、入力を受け付ける(ステップS7)。制御部11は処理をステップS3へ戻す。この際、受け付けた入力内容が設定画面に反映される。制御部11は操作入力が設定の入力でないと判定した場合(ステップS6でNO)、操作入力が終了指示であるか否かを判定する(ステップS8)。制御部11は操作入力が終了指示でないと判定した場合(ステップS8でNO)、入力に応じたコマンドを実行し(ステップS9)、処理をステップS3へ戻す。制御部11は操作入力が終了指示であると判定した場合(ステップS8でYES)、処理を終了する。 Next, processing performed by the
図9はコマンド実行処理の手順例を示すフローチャートである。制御部11は実行するコマンドがスライドの再生であるか否かを判定する(ステップS21)。制御部11は実行するコマンドがスライドの再生であると判定した場合(ステップS21でYES)、スライドの再生を行う(ステップS22)。再生完了後、制御部11は処理を呼び出し元へ戻す。制御部11は実行するコマンドがスライドの再生でないと判定した(ステップS21でNO)、実行するコマンドがVRモデル作成であるか否かを判定する(ステップS23)。制御部11は実行するコマンドがVRモデル作成であると判定した場合(ステップS23でYES)、VRモデル作成を行う(ステップS24)。モデル作成後、制御部11は処理を呼び出し元へ戻す。制御部11は実行するコマンドがVRモデル作成でないと判定した場合(ステップS23でNO)、処理を呼び出し元へ戻す。 FIG. 9 is a flow chart showing an example of the procedure of command execution processing. The
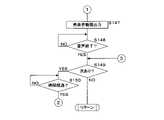
図10は再生処理の手順例を示すフローチャートである。制御部11は再生に必要な設定が済みであるか否かを判定する(ステップS31)。制御部11は再生に必要な設定が済みでないと判定した場合(ステップS31でNO)、エラー表示を行い(ステップS41)、処理を呼び出し元へ戻す。必要な設定が済みでないと判定する場合には、再生するプレゼンテーションデータが指定されているが、当該データの存在を確認できない場合も含む。制御部11は再生に必要な設定が済みであると判定した場合(ステップS31でYES)、VRモデルデータを取得する(ステップS32)。制御部11はスライドデータを取得する(ステップS33)。制御部11はスライドを表示部16に表示する(ステップS34)。制御部11はスライドデータに含まれる発話テキストを、音声合成サーバ2へ送信する(ステップS35)。音声合成サーバ2は発話テキストの読み上げ音声のデータを作成し、作成した音声データを再生装置1へ送信する。制御部11は音声データを音声合成サーバ2から受信する(ステップS36)。制御部11は動画を出力する(ステップS37)。制御部11はVRモデルデータより作成したアバターの動画(人物動画)を作成し、表示部16に表示するとともに、発話テキストの読み上げ音声を音声出力部17から出力する。制御部11は読み上げ音声の出力が終了したか否かを判定する(ステップS38)。制御部11は読み上げ音声の出力が終了していないと判定した場合(ステップS38でNO)、ステップS38を再度、実行する。制御部11は読み上げ音声の出力が終了したと判定した場合(ステップS38でYES)、次のスライドデータがあるか否かを判定する(ステップS39)。制御部11は次のスライドデータがあると判定した場合(ステップS39でYES)、遷移間隔時間(所定時間)が経過した否かを判定する(ステップS40)。制御部11は遷移間隔時間が経過していないと判定した場合(ステップS40でNO)、ステップS40を再度、実行する。制御部11は遷移間隔時間が経過したと判定した場合(ステップS40でYES)、処理をステップS33へ戻す。制御部11は次のスライドデータがないと判定した場合(ステップS39でNO)、処理を呼び出し元へ戻す。 FIG. 10 is a flow chart showing an example of the procedure of reproduction processing. The
図11はVRモデル作成処理の手順例を示すフローチャートである。再生装置1の制御部11はVRモデル作成に用いる画像を取得する(ステップS51)。画像は人物のポートレートの写真画像である。制御部11は取得した画像からVRモデルの作成を行う(ステップS52)。制御部11は、写真画像内の顔を認識し、2次元または3次元のVRモデルを生成する。制御部11は目、口を認識、まばたきや話しをしているかのようなアニメーションを作成する。VRモデルの作成は、公知技術を用いることが可能であるので、詳細な説明は省略する。VRモデルの作成は再生装置1ではなく、外部サーバやクラウドサービスを利用して行ってもよい。制御部11は作成したVRモデルの実体を補助記憶部13に、VRモデルの名称等の属性データをモデルDB132に記憶し(ステップS53)、処理を呼び出し元へ戻す。 FIG. 11 is a flow chart showing an example of the procedure of VR model creation processing. The
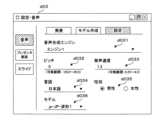
続いて、再生装置1が表示部16に表示する画面の例について説明する。図12は発表設定画面の例を示す説明図である。発表設定画面d01はスライドの再生を行うに当たり、最低限必要な設定を行う画面である。発表設定画面d01はモデル選択メニューd011、プレゼンデータ指定欄d012、参照ボタンd013及び再生ボタンd014を含む。モデル選択メニューd011は、動画表示する発表者のモデルを選択するプルダウンメニューである。プレゼンデータ指定欄d012は再生するプレゼンテーションデータのURIを入力する。参照ボタンd013を選択すると、ファイル選択のダイアログボックスが表示され、再生するプレゼンテーションデータとして、補助記憶部13に記憶しているファイルを選択可能である。再生ボタンd014を選択するとスライドの再生(スライドショー)を開始する。 Next, examples of screens displayed on the
図13はモデル作成画面の例を示す説明図である。モデル作成画面d02はVRモデルを作成する際に使用する画面である。モデル作成画面d02は名称入力欄d021、ファイル選択ボタンd022及び作成ボタンd023を含む。名称入力欄d021には、新たに作成するVRモデルの名称を入力する。ファイル選択ボタンd022を選択すると、ファイル選択のダイアログボックスが表示され、VRモデルの基となる人物の写真ファイルを選択することが可能となる。作成ボタンd023を選択すると、写真ファイルを基にVRデータが作成される。この際、再生装置1は写真内で人が写っている領域を認識して、人の領域以外は、背景画像として設定し、記憶する。 FIG. 13 is an explanatory diagram showing an example of the model creation screen. The model creation screen d02 is a screen used when creating a VR model. The model creation screen d02 includes a name input field d021, a file selection button d022 and a create button d023. The name of the newly created VR model is entered in the name entry field d021. When the file selection button d022 is selected, a file selection dialog box is displayed, and it becomes possible to select a person's photo file as the basis of the VR model. When the create button d023 is selected, VR data is created based on the photo file. At this time, the reproducing
図14は発話設定画面の例を示す説明図である。発話設定画面d03は発話テキストの読み上げ音声についての設定を行う画面である。発話設定画面d03はエンジン選択メニューd031、ピッチ入力欄d032、速度入力欄d033、言語選択メニューd034、性別設定欄d035及びモデル選択メニューd036を含む。エンジン選択メニューd031は発話テキストから読み上げ音声を作成する際に、利用する音声合成エンジンを選択するプルダウンメニューである。ピッチ入力欄d032には音声のピッチ(高さ)の設定を入力する。0を入力すると既定の声の高さで音声が作成される。正の値を入力すると既定よりも高い声の高さで音声が作成される。負の値を入力すると既定よりも低い声の高さで音声が作成される。速度入力欄d033は発話の速度設定を行う。0を入力すると既定の速度で、音声が再生される。正の値を入力すると既定よりも速い速度で音声が再生される。負の値を入力すると既定よりも遅い速度で音声が再生される。言語選択メニューd034は作成する音声の言語を選択メニューである。選択する言語は発話テキストが記述されている言語と一致する必要がある。性別設定欄d035は音声の性別を設定する。モデル選択メニューd036は音声のモデルを選択するプルダウンメニューである。モデル選択メニューd036により選択可能な音声のモデルは、エンジン選択メニューd031、言語選択メニューd034及び性別設定欄d035の設定によって、変動する。 FIG. 14 is an explanatory diagram showing an example of the speech setting screen. The utterance setting screen d03 is a screen for setting the reading voice of the utterance text. The speech setting screen d03 includes an engine selection menu d031, a pitch input field d032, a speed input field d033, a language selection menu d034, a gender setting field d035, and a model selection menu d036. The engine selection menu d031 is a pull-down menu for selecting a speech synthesis engine to be used when creating read-out speech from the spoken text. The setting of the voice pitch (height) is entered in the pitch input field d032. Entering 0 creates a voice with the default pitch. Entering a positive value creates a voice with a higher pitch than the default. Entering a negative value creates a voice with a lower pitch than the default. The speed input field d033 sets the speech speed. Entering 0 will play the audio at the default speed. Entering a positive value plays the audio at a faster speed than the default. Entering a negative value will play the audio at a slower speed than the default. The language selection menu d034 is a menu for selecting the language of the voice to be created. The language you select must match the language in which the spoken text is written. The gender setting field d035 sets the gender of the voice. The model selection menu d036 is a pull-down menu for selecting an audio model. The voice models that can be selected from the model selection menu d036 vary depending on the settings in the engine selection menu d031, language selection menu d034, and sex setting field d035.
なお、音声のモデルとして、発表する人間の声のモデルを音声合成エンジンに登録しておけば、発表者自身の声が利用可能となる。この場合、発話設定DB133の声モデル列に氏名等の識別情報(話者識別情報)を記憶する。声のモデルの作成は、例えば、WaveNetを利用する。WaveNetはDNN(Deep Neural Network)により構成され、話者の声の特徴を学習し、音声を合成することが可能である。 As a speech model, if a model of the voice of a person presenting is registered in the speech synthesis engine, the presenter's own voice can be used. In this case, identification information (speaker identification information) such as name is stored in the voice model column of the
図15は発表者設定画面の例を示す説明図である。発表者設定画面d04は発表者画面の設定を行う画面である。発表者設定画面d04は背景選択メニューd041、幅設定欄d042、高さ設定欄d043及び位置選択メニューd044を含む。背景選択メニューd041は発表者画面において、発表者の背景として表示する画像を選択するプルダウンメニューである。幅設定欄d042には発表画面の幅を入力する。高さ設定欄d043には発表者画面の高さを入力する。幅、高さの単位は例えばピクセルである。位置選択メニューd044は発表者画面の表示位置を選択するプルダウンメニューである。表示位置は、スライドを表示する画面を基準とした相対的な位置である。表示位置と例えば、右上、右下、左上又は左下である。 FIG. 15 is an explanatory diagram showing an example of the presenter setting screen. The presenter setting screen d04 is a screen for setting the presenter screen. The presenter setting screen d04 includes a background selection menu d041, a width setting field d042, a height setting field d043, and a position selection menu d044. The background selection menu d041 is a pull-down menu for selecting an image to be displayed as the background of the presenter on the presenter screen. The width of the presentation screen is entered in the width setting field d042. The height of the presenter screen is entered in the height setting field d043. The units of width and height are pixels, for example. The position selection menu d044 is a pull-down menu for selecting the display position of the presenter's screen. The display position is a position relative to the screen on which the slide is displayed. Display position and, for example, upper right, lower right, upper left, or lower left.
図16はスライドショー設定画面の例を示す説明図である。スライドショー設定画面d05はスライドの再生設定を行う画面である。スライドショー設定画面d05は時間設定欄d051を含む。再生装置1は表示しているスライドに対応する発話テキストの読み上げ音声の再生が終わると、次のスライドを表示するが、音声の再生終了後から次のスライドを表示するまでに時間を置くことが可能である。時間設定欄d051には、再生終了後から次のスライドを表示するまでの時間を秒単位で入力する。 FIG. 16 is an explanatory diagram showing an example of the slide show setting screen. The slide show setting screen d05 is a screen for setting reproduction of slides. The slide show setting screen d05 includes a time setting field d051. When the reproducing
図17はスライド再生画面及び発表者画面の例を示す説明図である。図17では、スライド再生画面d06の右上に発表者画面d07を表示している。発表者画面d07は閉じるボタンd071、音量アイコンd072、進行バーd073、再生/一時停止アイコンd074及び表示頁アイコンd075を含む。これらはマウスポインタを発表者画面d07上に移動させた場合に表示される。閉じるボタンd071を選択すると、スライドの再生は停止され、発表者画面d07は閉じられる。音量アイコンd072を選択すると、トラックバーが表示され、トラックバーのつまみをドラッグすることより、音量を調整可能である。進行バーd073はスライドの再生位置をトラックバーにより表示する。つまみd0731をドラッグすることより、表示するスライドを戻したり、先へ進めたりすることが可能である。また、キーボードの左矢印キー、右矢印キーを押しても、表示するスライドを切り替える同様の操作が可能である。再生/一時停止アイコンd074は再生時に選択すると一時停止し、一時停止時に選択する再生を再開する。表示頁アイコンd075はスライド再生画面d06に表示しているスライドの順番号を表示する。 FIG. 17 is an explanatory diagram showing examples of a slide playback screen and a presenter screen. In FIG. 17, the presenter screen d07 is displayed on the upper right of the slide reproduction screen d06. The presenter screen d07 includes a close button d071, a volume icon d072, a progress bar d073, a play/pause icon d074, and a display page icon d075. These are displayed when the mouse pointer is moved onto the presenter's screen d07. When the close button d071 is selected, the slide playback is stopped and the presenter screen d07 is closed. When the volume icon d072 is selected, a track bar is displayed, and the volume can be adjusted by dragging the knob on the track bar. The progress bar d073 displays the playback position of the slide using a track bar. By dragging the knob d0731, it is possible to return or advance the displayed slide. Also, pressing the left arrow key and the right arrow key on the keyboard can perform the same operation of switching the slide to be displayed. The play/pause icon d074 pauses when selected during playback, and resumes the selected playback when paused. The display page icon d075 displays the order number of the slide displayed on the slide reproduction screen d06.
本実施の形態は以下の効果を奏する。本実施の形態においては、プレゼンテーションデータを構成する各スライドデータに発話テキストを設定しておくことにより、発話テキストの読み上げ音声を出力しながら各スライドを順に再生するので、発表(プレゼンテーション)を自動化することが可能となる。また、VRモデルの動画を表示する発表者画面をスライドと共に表示するので、単に動画を視聴する場合に比べて、臨場感を与えることが可能となる。また、スライドの再生を一時停止することが可能であるので、スライドや発話テキストには含まれていない事柄について、補足説明が可能である。また、プレゼンテーション中に質問を受け付けて、回答することも可能である。さらに、VRモデルは写真から作成可能であるので、VRモデルを実際の発表者の写真から生成し、発表者の声を学習したWaveNetを用いて、音声合成を行うことにより、発表者自身の動画(人物動画)と発表者自身の声による発話テキストの読み上げが可能となる。それにより、発表者自身がその場で発表しているかのような印象を視聴者に与えることが可能となる。そして、発話テキストはスピーカーノートに記述するので、内容の修正が容易であり、修正をしたらすぐに発表に反映することが可能である。そのため、即座の対応や微修正の繰り返しが容易に可能となる。 This embodiment has the following effects. In the present embodiment, by setting spoken text in each slide data constituting the presentation data, each slide is reproduced in order while outputting the reading voice of the spoken text, thereby automating the presentation. becomes possible. In addition, since the presenter's screen displaying the moving image of the VR model is displayed together with the slides, it is possible to give a sense of realism compared to simply viewing the moving image. In addition, since it is possible to pause the playback of the slides, it is possible to provide supplementary explanations about matters not included in the slides or the spoken text. It is also possible to receive questions during the presentation and answer them. Furthermore, since a VR model can be created from a photograph, a VR model is generated from an actual presenter's photograph, and by using WaveNet, which has learned the presenter's voice, to synthesize the presenter's own video. It is possible to read aloud the spoken text (personal video) and the presenter's own voice. As a result, it is possible to give the viewer the impression that the presenter himself/herself is presenting on the spot. Since the spoken text is written in the speaker notes, it is easy to modify the content, and the modification can be immediately reflected in the presentation. Therefore, immediate response and repetition of minor corrections are easily possible.
(実施の形態2)
本実施の形態は発話テキストの翻訳を行う形態に関する。以下の説明において、上述の実施の形態と異なる点を主に説明する。本実施の形態では、発話テキストの記述言語と読み上げ音声の言語(出力言語)とが異なる場合について述べる。本実施の形態は、例えば、発話テキストが日本語で記述し、発話設定画面d03において、言語選択メニューd034で英語を選択して、発表を行う。(Embodiment 2)
This embodiment relates to a mode of translating a spoken text. In the following description, differences from the above-described embodiment will be mainly described. In the present embodiment, a description will be given of a case where the description language of the spoken text and the language of the reading voice (output language) are different. In this embodiment, for example, the speech text is written in Japanese, and English is selected in the language selection menu d034 on the speech setting screen d03 to make the presentation.
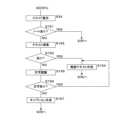
図18は再生処理の他の手順例を示すフローチャートである。図18に示すフローチャートの一部は、図10と同様である。制御部11は再生に必要な設定が済みであるか否かを判定する(ステップS61)。制御部11は再生に必要な設定が済みでないと判定した場合(ステップS61でNO)、エラー表示を行い(ステップS74)、処理を呼び出し元へ戻す。制御部11は再生に必要な設定が済みであると判定した場合(ステップS61でYES)、VRモデルデータを取得する(ステップS62)。制御部11はスライドデータを取得する(ステップS63)。制御部11はスライドを表示部16に表示する(ステップS64)。制御部11はスライドデータに含まれる発話テキストの記述言語を判定する(ステップS65)。言語の判定は周知技術により可能である。例えば、言語の判定はその言語における文字数を数えて、割合を計算するなどの手法があるが、公知の技術であるので説明を省略する。制御部11は判定した記述言語が読み上げ音声の言語と一致するか否かを判定する(ステップS66)。制御部11は記述言語が読み上げ音声の言語と一致しないと判定した場合(ステップS66でNO)、発話テキストの翻訳を行う(ステップS67)。翻訳は再生装置1が行ってもよいが、公知のクラウドサービスを用いて行ってもよい。制御部11は発話テキストを翻訳サービスサイトに送信し、翻訳された発話テキストを受信する。制御部11は記述言語が読み上げ音声の言語と一致すると判定した場合(ステップS66でYES)、ステップS68へ処理を進める。制御部11は発話テキスト又は翻訳された発話テキストを、音声合成サーバ2へ送信する(ステップS68)。ステップS69からS73の処理内容は、図10に示したステップS36からS40の処理内容と同様であるから、説明を省略する。なお、上述した、言語の判定については、グェン トアン ドゥク,“Latent Relational Web Search Engine Based on the Relational Similarity between Entity Pairs.”,2012年,東京大学,博士論文甲28480等に開示されている。 FIG. 18 is a flow chart showing another procedure example of the reproduction process. A part of the flowchart shown in FIG. 18 is the same as in FIG. The
本実施の形態は上述の実施の形態が奏する効果に加えて、以下の効果を奏する。本実施の形態では、発話テキストの記述言語と読み上げ音声の言語とが異なる場合であっても、発表が可能となる。なお、スライドに含まれるテキストデータを抽出し、当該テキストデータを読み上げ音声の言語へ翻訳して表示してもよい。 This embodiment has the following effects in addition to the effects of the above-described embodiments. In this embodiment, even if the description language of the uttered text and the language of the reading voice are different, the presentation can be made. It is also possible to extract text data contained in the slide, translate the text data into the language of the reading voice, and display it.
(実施の形態3)
本実施の形態はスライド再生中にポインティングデバイスのポインタの制御を行う形態に関する。以下の説明において、上述の実施の形態と異なる点を主に説明する。本実施の形態において、発話テキスト内にポインタの制御を行うための命令(制御命令)を記述可能とする。例えば、発話テキストを以下のように記述する。(Embodiment 3)
This embodiment relates to a form of controlling a pointer of a pointing device during slide reproduction. In the following description, differences from the above-described embodiment will be mainly described. In this embodiment, an instruction (control instruction) for controlling the pointer can be described in the spoken text. For example, the spoken text is described as follows.
「AMトークはマルチモーダルAIと、アアル・ピイ・エイの技術を利用するバーチャルプレゼンターのアプリケーションです。AMトークはスライドを自動的に再生できます。合成音声でスライドの内容を読み上げ、スライドのページ送りを自動的に制御します。<script>mouse_move(PRESENWIN, CENTER)</script>発表者の顔アニメーションを生成できます。」 “AM Talk is a virtual presenter application that uses multimodal AI and AAL PI A technology. AM Talk can automatically play slides. Synthetic voice reads out the content of the slides and turns the pages of the slides. <script>mouse_move(PRESENWIN, CENTER)</script> can generate presenter face animation."
<script>はスクリプトが始まることを示し、</script>はスクリプトが終わることを示す。関数mouse_move(引数1,引数2)はポインティングデバイスのポインタを引数でしてした位置を移動させるコマンドである。例えば、引数1は表示されているウィンドウやスライドに含まれるオブジェクトを指定する。引数2は引数1で指定した表示要素内での位置をさらに指定するオプショナル引数であり指定しなくともよい。上述の例では、RESENWINは発表者画面を示し、CENTERは表示要素の中心を示す。mouse_move(PRESENWIN, CENTER)を実行すると、ポインタが発表者画面の中心に移動する。 <script> indicates the beginning of the script, and </script> indicates the end of the script. The function mouse_move (
図19は再生処理の他の手順例を示すフローチャートである。図19に示すフローチャートの一部は、図10と同様である。制御部11は再生に必要な設定が済みであるか否かを判定する(ステップS91)。制御部11は再生に必要な設定が済みでないと判定した場合(ステップS91でNO)、エラー表示を行い(ステップS104)、処理を呼び出し元へ戻す。制御部11は再生に必要な設定が済みであると判定した場合(ステップS91でYES)、VRモデルデータを取得する(ステップS92)。制御部11はスライドデータを取得する(ステップS93)。制御部11はスライドを表示部16に表示する(ステップS94)。制御部11はスライドデータに含まれる発話テキストにスクリプトが記述されていないか探索する(ステップS95)。制御部11は探索結果からスクリプトが発話テキストにスクリプトが記述されているか否かを判定する(ステップS96)。制御部11は発話テキストにスクリプトが記述されていないと判定した場合(ステップS96でNO)、処理をステップS97へ進める。ステップS97からS102の処理内容は、図10に示したステップS35からS40の処理内容と同様であるから、説明を省略する。制御部11は発話テキストにスクリプトが記述されていると判定した場合(ステップS96でYES)、サブルーチン・スクリプト実行を行う(ステップS103)。制御部11はステップS101以降を実行する。 FIG. 19 is a flow chart showing another procedure example of the reproduction process. A part of the flowchart shown in FIG. 19 is the same as that in FIG. The
図20はスクリプト実行処理の手順例を示すフローチャートである。制御部11はスライドデータに含まれる発話テキストをスクリプトの前後で分割する(ステップS111)。制御部11は分割した発話テキストを個別に音声合成サーバ2へ送信する(ステップS112)。制御部11は音声合成サーバ2から音声データを受信する(ステップS113)。この際、制御部11はスクリプト前の発話テキストに対応する音声データと、スクリプト後の発話テキストに対応する音声データとを判別可能なように、主記憶部12又は補助記憶部13に設けた一時記憶領域に記載順に記憶する。また、スクリプトの実行タイミングが判定可能なデータも一時記憶領域に記憶しておくことが望ましい。例えば、「TEXT1, SCRIPT1,TEXT2」という配列を記憶しておく。TEXT1はスクリプト前の発話テキストを、TEXT2はスクリプト後の発話テキストを、SCRIPT1はスクリプトを示す。当該配列を参照することにより、制御部11は音声出力の途中に、スクリプトの実行を行うことが可能である。制御部11は動画出力を開始する(ステップS114)。制御部11は実行データを選択する(ステップS115)。制御部11は実行データが音声データであり、音声出力を行うか否かを判定する(ステップS116)。制御部11は音声出力を行うと判定した場合(ステップS116でYES)、音声出力を行う(ステップS117)。制御部11は音声出力が終了したか否かを判定する(ステップS118)。制御部11は音声出力が終了してないと判定した場合(ステップS118でNO)、ステップS118を再度行う。制御部11は音声出力が終了したと判定した場合(ステップS118でYES)、次に実行すべき処理があるか否かを判定する(ステップS119)。実行すべき処理は、音声出力又はスクリプト実行である。制御部11は次に実行すべき処理があると判定した場合(ステップS119でYES)、処理をステップS115へ戻す。制御部11は次に実行すべき処理がないと判定した場合(ステップS119でNO)、処理を呼び出し元へ戻す。制御部11は音声出力を行なわないと判定した場合(ステップS116でNO)、スクリプトを実行し(ステップS120)、処理をステップS119へ移す。ステップS116やステップS119の判定は、例えば、上述した配列を参照することにより可能である。 FIG. 20 is a flow chart showing an example of the procedure of script execution processing. The
再生処理により、上述の発話テキストでは、まず、「AMトークはマルチモーダルAIと、…スライドのページ送りを自動的に制御します。」の読み上げ音声が出力される。次にスクリプトが実行され、ポインティングデバイスのポインタが、発表者画面の中心に移動する。そして「発表者の顔アニメーションを生成できます。」の読み上げ音声が出力される。 By the playback processing, first, reading voice of "AM Talk automatically controls multimodal AI and slide page turning." is output. A script is then executed to move the pointer of the pointing device to the center of the presenter's screen. Then, a reading voice saying "You can generate the presenter's face animation" is output.
本実施の形態は上述の実施の形態が奏する効果に加えて、以下の効果を奏する。本実施の形態においては、スクリプトにより、ポインティングデバイスのポインタ移動等の制御が可能となる。スライド内で注目すべき箇所を視聴者に示すので、発表の効果を高めることが可能となる。なお、ポインティングデバイスのポインタ移動制御は、スクリプトの一例であり、他の制御も可能である。例えば、スライドの効果として、スライド内の複数テキストを一気に表示するのではなく、マウスクリックする毎に、表示するテキストを追加する効果がある。このような効果を実行する場合、発話テキストの中に、マウスクリックするスクリプトを記述し、当該スクリプトを実行することにより、人手を介すことなく実行可能である。なお、本実施の形態において、実施の形態2で示した翻訳機能を設けてもよい。また、スクリプトにより、キーボードの操作をエミュレートしてもよい。 This embodiment has the following effects in addition to the effects of the above-described embodiments. In this embodiment, it is possible to control the movement of the pointer of the pointing device by using a script. It is possible to enhance the effectiveness of the presentation by showing the audience the points of interest within the slides. Note that the pointer movement control of the pointing device is an example of a script, and other controls are also possible. For example, the effect of the slide is to add text to be displayed each time the mouse is clicked, instead of displaying multiple texts in the slide at once. When executing such an effect, it is possible to execute without human intervention by writing a mouse-clicking script in the spoken text and executing the script. Note that the translation function shown in the second embodiment may be provided in this embodiment. A script may also emulate keyboard operations.
(実施の形態4)
本実施の形態はVRモデルを用いた発表者の制御を行う形態に関する。以下の説明において、上述の実施の形態と異なる点を主に説明する。本実施の形態は実施の形態3に関連する形態である。(Embodiment 4)
This embodiment relates to a mode of controlling a presenter using a VR model. In the following description, differences from the above-described embodiment will be mainly described. This embodiment is a form related to the third embodiment.
上述の実施の形態では、発表者画面に表示するVRモデルを用いた発表者は、目と口を動作させている。本実施の形態においては、ジェスチャーも可能とする。ジェスチャーを行わせるためには、発話テキストにスクリプトを記載する。 In the embodiment described above, the presenter using the VR model displayed on the presenter screen moves his eyes and mouth. In this embodiment, gestures are also possible. In order to make gestures, a script is written in the spoken text.
発表者に行わせるジェスチャーは、例えば、所定方向を指し示すコマンドと通常の姿勢に戻るコマンドとが想定される。所定方向は、右上、真上、左上、左下、真下及び右下等である。例えば、スクリプトに記述する関数として、prstr_pose(引数)を設ける。引数はUR(右上)、DA(真上)、UL(左上)、LL(左下)、DB(真下)、LR(右下)及びNR(通常)。引数LLを指定すると、発表者は発表者画面の左下方向を指し示す。引数NRを指定すると、発表者は指し示す姿勢を通常の姿勢に戻す。 Gestures made by the presenter are assumed to be, for example, a command to point in a predetermined direction and a command to return to a normal posture. The predetermined direction is upper right, right up, upper left, lower left, right down, right down, and the like. For example, set prstr_pose (argument) as a function to be written in the script. The arguments are UR (top right), DA (top right), UL (top left), LL (bottom left), DB (bottom), LR (bottom right) and NR (normal). If the argument LL is specified, the presenter points to the lower left direction of the presenter's screen. The argument NR causes the presenter to return the pointing pose to normal.
本実施の形態において、再生装置1が行なう再生処理は上述の実施の形態と同様であるから、説明を省略する。また、VRモデルにより発表者にジェスチャーを行わせる制御は公知の技術で可能であるので、説明を省略する。 In the present embodiment, the reproducing process performed by the reproducing
図21はスライド再生画面及び発表者画面の他の例を示す説明図である。図21では、スライド再生画面d06の中央下に発表者画面d07を表示している。そして、発表者画面d07に表示している発表者は、真上方向を指し示している。なお、図21の発表者画面d07において、発表者は指し棒(指示棒)を持っているが、指し棒は必ずしも表示する必要はない。 FIG. 21 is an explanatory diagram showing another example of the slide playback screen and the presenter screen. In FIG. 21, the presenter screen d07 is displayed at the lower center of the slide reproduction screen d06. The presenter displayed on the presenter screen d07 points directly upward. In the presenter screen d07 of FIG. 21, the presenter has a pointing stick (pointing stick), but the pointing stick does not necessarily have to be displayed.
本実施の形態は上述の実施の形態が奏する効果に加えて、以下の効果を奏する。発表者にジェスチャーを行わせることより、視聴者がスライドの内容に注目することを期待できる。 This embodiment has the following effects in addition to the effects of the above-described embodiments. By having the presenter make gestures, the audience can be expected to pay attention to the contents of the slide.
(実施の形態5)
本実施の形態は他のアプリケーションソフトとの連携動作を行なう形態に関する。以下の説明において、上述の実施の形態と異なる点を主に説明する。(Embodiment 5)
The present embodiment relates to a form of cooperative operation with other application software. In the following description, differences from the above-described embodiment will be mainly described.
まず、スライドの表示要素に動画が含まれている場合の処理について説明する。図22及び図23は再生処理の他の手順例を示すフローチャートである。図22及び図23に示すフローチャートの一部は、図19と同様である。制御部11は再生に必要な設定が済みであるか否かを判定する(ステップS131)。制御部11は再生に必要な設定が済みでないと判定した場合(ステップS131でNO)、エラー表示を行い(ステップS151)、処理を呼び出し元へ戻す。制御部11は再生に必要な設定が済みであると判定した場合(ステップS131でYES)、VRモデルデータを取得する(ステップS132)。制御部11はスライドデータを取得する(ステップS133)。制御部11はスライドデータに含まれる表示要素に動画があるか探索する(ステップS134)。制御部11は探索結果から表示要素に動画があるか否かを判定する(ステップS135)。制御部11は探索結果から表示要素に動画があると判定した場合(ステップS135でYES)、発話テキストにスクリプトが記述されていないか探索する(ステップ136)。制御部11は探索結果からスクリプトが発話テキストにスクリプトが記述されているか否かを判定する(ステップS137)。制御部11は発話テキストにスクリプトが記述されていないと判定した場合(ステップS137でNO)、スライドを表示する共に表示要素である動画の再生を開始する(ステップS138)。制御部11は必要に応じて、動画再生のアプリケーションを起動し、動画を再生する。この際、スライド再生画面及び発表者画面を最小化し、動画再生画面を全画面表示とすることが望ましい。制御部11は動画再生が終了したか否かを判定する(ステップS139)。制御部11は動画再生が終了していないと判定した場合(ステップS139でNO)、再度、ステップS119を実行する。制御部11は動画再生が終了したと判定した場合(ステップS139でYES)、画面の表示状態を動画再生前の状態へ戻し、処理をステップS149(図23)へ進める。なお、ステップS137でNOと判定された場合、発話テキストは書かれていないことが前提である。もし、発話テキストに何か書かれていても、その内容は無視されて、読み上げ音声は出力されない。発話テキストにスクリプトが含まれていない場合、動画を再生するタイミングを制御部11は判定できないからである。 First, the processing when the display element of the slide includes a moving image will be described. 22 and 23 are flowcharts showing another procedure example of the reproduction process. A part of the flow charts shown in FIGS. 22 and 23 are the same as in FIG. The
制御部11は発話テキストにスクリプトが記述されていると判定した場合(ステップS137でYES)、制御部11はスライドを表示部16に表示する(ステップS140)。制御部11はサブルーチン・スクリプト実行を行う(ステップS141)。なお、ここでは発話テキストに記載されたスクリプトの中には、動画再生の命令が書かれていることが前提である。発話テキストに動画再生の命令が書かれていない場合は、動画は再生されない。また、スクリプト実行処理において、動画再生の命令が実行される場合、当該命令は動画再生が完了するまで、処理を完了しない。動画再生が完了すると、処理を完了する。制御部11はサブルーチン・スクリプト実行後、処理をステップS149へ移す。 When the
制御部11は探索結果から表示要素に動画がないと判定した場合(ステップS135でNO)、制御部11はスライドデータに含まれる発話テキストにスクリプトが記述されていないか探索する(ステップS142)。制御部11は探索結果からスクリプトが発話テキストにスクリプトが記述されているか否かを判定する(ステップS143)。制御部11は発話テキストにスクリプトが記述されていないと判定した場合(ステップS143でNO)、発話テキストを音声合成サーバ2へ送信する(ステップS144)。制御部11は音声合成サーバ2から音声データを受信する(ステップS145)。制御部11はスライドを表示部16に表示する(ステップS146)。制御部11は処理をステップS147(図23)へ移す。制御部11は発表者動画を出力する(ステップS147)。ステップS148からステップS150は、図10のステップS38からS40と同様であるから説明を省略する。制御部11は発話テキストにスクリプトが記述されていると判定した場合(ステップS143でYES)、処理をステップS140へ移す。 When the
以上、動画の再生について説明したが、URL(リンク情報)が表示要素に含まれている場合も同様である。ただし、動画の場合と異なり、発話テキストにスクリプトが含まれていない場合でも、URLで指定されたデータを出力するために、直ちにインターネットブラウザを起動はしない。発話テキストにURLが含まれている否かを探索する。探索の結果、発話テキストにURLが含まれているときは、記載されたURLを出力するために、インターネットブラウザを起動するスクリプトが記載されていると解釈する。なお、動画再生時と同様に、インターネットブラウザを表示する際、スライド再生画面及び発表者画面を最小化し、インターネットブラウザを全画面表示とすることが望ましい。また、インターネットブラウザでの表示を終了し、スライド再生に戻るスクリプトが発話テキストに書かれていない場合、制御部11は所定時間が経過したら、インターネットブラウザでの表示を終了し、スライド再生に戻す。 Although the reproduction of moving images has been described above, the same applies to the case where the URL (link information) is included in the display element. However, unlike the case of moving images, even if the spoken text does not contain a script, the Internet browser is not immediately activated to output the data specified by the URL. Search if the spoken text contains a URL. As a result of the search, when URL is included in the spoken text, it is interpreted that a script for activating an Internet browser is described in order to output the described URL. As with video playback, when displaying the Internet browser, it is desirable to minimize the slide playback screen and the presenter screen and display the Internet browser in full screen. In addition, when a script for ending display on the Internet browser and returning to slide reproduction is not written in the utterance text, the
本実施の形態は上述の実施の形態が奏する効果に加えて、以下の効果を奏する。スライドの再生途中で、他のアプリケーションの実行が可能となるので、発表内容をより充実させることが可能となる。なお、他のアプリケーションにおいても、スクリプトの実行が可能である場合、他のアプリケーションでもスクリプトを実行させれば、スライド再生で行える動作が多彩となり、発表内容をさらに充実させることが可能となる。 This embodiment has the following effects in addition to the effects of the above-described embodiments. Since it is possible to execute other applications while the slide is being reproduced, it is possible to enrich the content of the presentation. If other applications can also execute the script, if the script is executed in the other application as well, the operations that can be performed in the slide playback will be diversified, making it possible to further enhance the content of the presentation.
なお、表示要素に動画を含めていない場合でも、URLで動画ファイル等を指定すれば、インターネットブラウザを、利用して又は介して、動画の再生が可能である。また、動画再生中にスクリプトの実行を可能とし、スクリプトでマウスポインタの位置制御とクリック操作を行えば、動画を一時停止して、発話テキストを読み上げ音声を出力し、音声が終了したら、動画の再生を再開するなどの動作も可能である。 Even if the display element does not include a moving image, if a moving image file or the like is specified by a URL, the moving image can be reproduced using or via an Internet browser. In addition, it is possible to execute a script during video playback, and if the script controls the position of the mouse pointer and clicks, the video will be paused, the spoken text will be read aloud, and the audio will be output. Operations such as resuming playback are also possible.
(実施の形態6)
本実施の形態はスライドデータに発表者ノートが含まれていない場合の動作に関する形態である。以下の説明において、上述の実施の形態と異なる点を主に説明する。本実施の形態においては、スライドデータに発表者ノートが含まれていない場合、スライドデータに含まれるオブジェクトを利用して、発話テキストを作成する。(Embodiment 6)
This embodiment relates to the operation when the slide data does not contain the presenter's notes. In the following description, differences from the above-described embodiment will be mainly described. In this embodiment, if the slide data does not contain the presenter's notes, the objects included in the slide data are used to create the spoken text.
図24は再生処理の他の手順例を示すフローチャートである。図24は、図10に示した再生処理に新たな処理を追加することを示している。再生処理において、制御部11はスライド表示(ステップS34)を行った後、スライドデータに発表者ノートが含まれているか否かを判定する(ステップS161)。制御部11はスライドデータに発表者ノートが含まれていると判定した場合(ステップS161でYES)、処理を図10のステップS35へ移す。制御部11はスライドデータに発表者ノートが含まれていないと判定した場合(ステップS161でNO)、スライドを構成するオブジェクトを対象に、テキストオブジェクトを探索する(ステップS162)。制御部11はテキストオブジェクトがあるか否かを判定する(ステップS163)。制御部11はテキストオブジェクトがあると判定した場合(ステップS163でYES)、テキストオブジェクトのテキストから発話テキストを作成する(ステップS164)。例えば、箇条書きのテキストが得られた場合、助詞や助動詞等を補い、文章作成し、発話テキストとする。制御部11は処理を図10のステップS35へ移す。制御部11はテキストオブジェクトがないと判定した場合(ステップS163でNO)、画像オブジェクトに対して文字認識を行なう(ステップS165)。例えば、OCR(Optical character recognition)技術を用いる。制御部11は認識処理の結果、文字が得られたか否かを判定する(ステップS166)。制御部11は文字が得られたと判定した場合(ステップS166でYES)、処理をステップS164へ移す。制御部11は文字が得られなかったと判定した場合(ステップS166でNO)、スライドデータに含まれる画像オブジェクトを選択し、画像を説明するキャプションを生成し(ステップS167)、処理を図10のステップS35へ移す。キャプションの生成には、画像キャプション自動生成AIを用いる。例えば、画像キャプション自動生成AIはCNN(Convolutional Neural Network)とLSTM(Long Short Term Memory)とを組み合わせた深層学習モデルを用いる。当該学習モデルでは次の手順で学習を行なう。学習済みCNNで画像の特徴量を抽出する。LSTMで文章の特徴量を抽出する。CNNとLSTMの特徴量を結合する。Softmax関数で次に来る単語を予測する。これらのステップを繰り返すことで、画像のキャプションを学習モデルは生成する。学習モデルが生成したキャプションが正解のキャプションに近づくように、学習モデルを訓練する。訓練済みの学習モデルにおいて、CNNに画像を入力し、LSTMに文開始記号を入力すると、キャプションを生成することができる。 FIG. 24 is a flow chart showing another procedure example of the reproduction process. FIG. 24 shows addition of new processing to the reproduction processing shown in FIG. In the reproduction process, after displaying the slide (step S34), the
上述の説明において、実施の形態1の再生処理を変形する例を述べたが、それに限らない。他の実施形態の再生処理を変形することも可能である。 In the above description, an example of modifying the reproduction processing of the first embodiment was described, but the present invention is not limited to this. It is also possible to modify the playback process of other embodiments.
本実施の形態は上述の実施の形態が奏する効果に加えて、以下の効果を奏する。発表者ノートを用意しなくとも、VRモデルを用いた発表者による発表の自動化が可能となる。 This embodiment has the following effects in addition to the effects of the above-described embodiments. It is possible to automate the presentation by the presenter using the VR model without preparing the presenter's notes.
各実施の形態で記載されている技術的特徴(構成要件)はお互いに組み合わせ可能であり、組み合わせすることにより、新しい技術的特徴を形成することができる。
今回開示された実施の形態はすべての点で例示であって、制限的なものではないと考えられるべきである。本発明の範囲は、上記した意味ではなく、特許請求の範囲によって示され、特許請求の範囲と均等の意味及び範囲内でのすべての変更が含まれることが意図される。The technical features (components) described in each embodiment can be combined with each other, and new technical features can be formed by combining them.
The embodiments disclosed this time are illustrative in all respects and should not be considered restrictive. The scope of the present invention is indicated by the scope of the claims rather than the above-described meaning, and is intended to include all modifications within the scope and meaning equivalent to the scope of the claims.
100 プレゼンテーションシステム
1 再生装置
1P 制御プログラム
11 制御部
12 主記憶部
13 補助記憶部
131 基本設定DB
132 モデルDB
133 発話設定DB
134 画面設定DB
135 遷移設定DB
136 VRモデルデータ
137 プレゼンテーションデータ
14 通信部
15 入力部
16 表示部
17 音声出力部
18 読み取り部
1a 可搬型記憶媒体
1b 半導体メモリ
2 音声合成サーバ
B バス
N ネットワークREFERENCE SIGNS
132 Model DB
133 Utterance setting DB
134 Screen setting DB
135 Transition setting DB
136
本願の一態様に係るスライド再生プログラムは、発話テキストと表示要素とを含むスライドデータを複数含むプレゼンテーションデータを取得し、被写体に人物を含む1枚の静止画像を取得し、取得した前記静止画像において人物の領域を認識し、前記領域以外を背景として設定し、前記静止画像に基づいて、人物動画を作成し、複数の前記スライドデータそれぞれに含む前記表示要素を所定の順番で出力するとともに、出力している前記スライドデータに含む前記発話テキストの読み上げ音声を、前記人物動画を付して出力する処理をコンピュータに行わせることを特徴とする。A slide reproduction program according to an aspect of the present application obtains presentation data including a plurality of slide data including spoken text and display elements, obtainsone still image including a person as a subject, and in the obtained still image recognizing an area of a person, setting an area other than the area as a background, creating a moving image of the person based on the still image, outputting the display elements included in each of the plurality of slide data in a predetermined order, and outputting A computer is caused to perform a process of outputting the reading voice of the spoken text included in the slide data, with the moving image ofthe person added.
再生装置はユーザがプレゼンテーションに用いる装置である。再生装置はノートパソコン、パネルコンピュータ、タブレットコンピュータ、スマートフォン等で構成する。再生装置の論理的な処理は再生装置Kで示す。再生装置は後述のハードウェア構成で、プレゼンテーションデータK1、VR(Virtual Reality:バーチャルリアリティー)モデルDBK2、設定データK3を保持している。本願における一つの実施形態のスライド再生プログラムK4はこれらのデータを読み込み、発表者ノートのテキストを音声合成サーバ2に送信し、音声合成結果を得る。更に、スライドデータからスライド表示プログラム(例えば、Microsoft PowerPoint,Googleプレゼンテーションなど)でスライドを表示し、VRエンジンでVRアバターK6を表示させる。スライド再生プログラムK4はスライド表示K5、VRアバターK6及び音声合成結果K7を表示、再生する。また、スライド再生プログラムK4はスライド表示、音声合成結果の再生、アバター表示と同時に、スライドのページ遷移の制御も自動的に行い、これらの要素の表示、再生を同期化する。音声合成サーバ2は音声合成エンジンを備える。音声合成サーバ2は再生装置1からテキストデータを受け付け、音声合成モデルを用いて受け付けたテキストを読み上げる音声を合成し、音声データを再生装置1へ返信する。音声合成サーバ2はサーバコンピュータ、ワークステーション等で構成する。また、音声合成サーバ2を複数のコンピュータからなるマルチコンピュータ、ソフトウェアによって仮想的に構築された仮想マシン又は量子コンピュータで構成してもよい。さらに、音声合成サーバ2の機能をクラウドサービスで実現してもよい。A playback device is a device that a user uses for a presentation. The playback device consists of a notebook computer, a panel computer, a tablet computer, a smart phone, and the like. The logical processing of the playback device is indicated by playback device K. FIG. The playback device has a hardware configuration to be described later, and holds presentation data K1, a VR (Virtual Reality) model DBK2, and setting data K3. The slide playback program K4 of one embodiment of the present application reads these data, transmits the text of the presenter's notes to the
Claims (14)
Translated fromJapanese複数の前記スライドデータそれぞれに含む前記表示要素を所定の順番で出力するとともに、出力している前記スライドデータに含む前記発話テキストの読み上げ音声を、人物動画を付して出力する
処理をコンピュータに行わせることを特徴とするスライド再生プログラム。obtaining presentation data including a plurality of slide data including spoken text and display elements;
performing a process of outputting the display elements included in each of the plurality of slide data in a predetermined order, and outputting the reading voice of the spoken text included in the output slide data with a moving image of the person. A slide playback program characterized by
取得した前記静止画像に基づいて、前記人物動画を作成する
ことを特徴とする請求項1に記載のスライド再生プログラム。Acquire a single still image,
2. The slide reproduction program according to claim 1, wherein the moving image of the person is created based on the obtained still image.
前記発話テキストを前記出力言語に翻訳し、翻訳した発話テキストの読み上げ音声を出力する
ことを特徴とする請求項1又は請求項2に記載のスライド再生プログラム。get the output language,
3. The slide reproduction program according to claim 1, wherein the spoken text is translated into the output language, and a reading voice of the translated spoken text is output.
ことを特徴とする請求項1から請求項3のいずれか一項に記載のスライド再生プログラム。4. The display element of the slide data following the slide data is output after completion of the output of the reading voice of the spoken text corresponding to the display element being output. or the slide playback program according to item 1.
ことを特徴とする請求項4に記載のスライド再生プログラム。5. The slide reproduction program according to claim 4, further comprising outputting the display element of the slide data next to the slide data after a predetermined time has elapsed after the output of the reading voice is completed.
前記特定情報に対応した前記音声合成モデルに基づき、受け付けた声の高さ、及び、発話の速さで、前記発話テキストの読み上げ音声を出力する
ことを特徴とする請求項1から請求項5のいずれか一項に記載のスライド再生プログラム。receiving specific information identifying the speech synthesis model, including gender, and pitch and rate of speech;
Based on the speech synthesis model corresponding to the specific information, reading voice of the uttered text is output at the received voice pitch and utterance speed. The slide playback program according to any one of the items.
前記特定情報は話者を特定する話者識別情報を含み、該話者識別情報に対応する前記音声合成モデルに基づき、前記読み上げ音声を出力する
ことを特徴とする請求項6に記載のスライド再生プログラム。The speech synthesis model includes a model generated by learning the utterance speech of a specific speaker,
7. The slide reproduction according to claim 6, wherein the specific information includes speaker identification information that identifies a speaker, and the reading voice is output based on the speech synthesis model corresponding to the speaker identification information. program.
ことを特徴とする請求項1から請求項7のいずれか一項に記載のスライド再生プログラム。8. The slide reproduction program according to any one of claims 1 to 7, wherein when the display element is a moving image, the moving image is reproduced.
出力対象となっている前記スライドデータにポインティングデバイスにより制御されるポインタの前記制御命令が含まれている場合、当該制御命令に従い、前記ポインタを制御する
ことを特徴とする請求項1から請求項8のいずれか一項に記載のスライド再生プログラム。The slide data can include control instructions,
9. When the slide data to be output includes the control instruction for a pointer controlled by a pointing device, the pointer is controlled according to the control instruction. The slide playback program according to any one of 1.
出力対象となっている前記スライドデータに、他のアプリケーションソフトへ遷移するリンク情報が含まれている場合、前記表示要素を表示している画面を最小化し、前記アプリケーションソフトへ制御を渡し、
前記アプリケーションソフトから制御が戻った場合、前記表示要素を全画面表示で再出力する
ことを特徴とする請求項1から請求項9のいずれか一項に記載のスライド再生プログラム。outputting the display element in full screen display;
if the slide data to be output contains link information for transitioning to other application software, minimizing the screen displaying the display element and passing control to the application software;
10. The slide playback program according to any one of claims 1 to 9, wherein when control is returned from the application software, the display elements are re-output in full-screen display.
ことを特徴とする請求項1から請求項10のいずれか一項に記載のスライド再生プログラム。3. When the slide data to be output includes a control command for causing a person to perform a predetermined gesture, the video of the person performing the gesture according to the control command is output. 11. The slide reproducing program according to any one of claims 1 to 10.
ことを特徴とする請求項1から請求項11のいずれか一項に記載のスライド再生プログラム。12. The method according to any one of claims 1 to 11, wherein the presentation data includes slide data that does not include the spoken text, and the spoken text is generated from the display elements included in the slide data. slide playback program.
複数の前記スライドデータそれぞれに含む前記表示要素を所定の順番で出力するとともに、出力している前記スライドデータに含む前記発話テキストの読み上げ音声を、人物動画を付して出力する出力部と
を備えることを特徴とするスライド再生装置。an acquisition unit for acquiring presentation data including a plurality of slide data including spoken text and display elements;
an output unit for outputting the display elements included in each of the plurality of slide data in a predetermined order, and for outputting the reading voice of the spoken text included in the output slide data with a person moving image attached. A slide playback device characterized by:
発話テキストと表示要素とを含むスライドデータを複数含むプレゼンテーションデータを取得し、
複数の前記スライドデータそれぞれに含む前記表示要素を所定の順番で出力するとともに、出力している前記スライドデータに含む前記発話テキストの読み上げ音声を、人物動画を付して出力する
処理を行うことを特徴とするスライド再生方法。the computer
obtaining presentation data including a plurality of slide data including spoken text and display elements;
outputting the display elements included in each of the plurality of slide data in a predetermined order, and outputting the reading voice of the spoken text included in the output slide data with a moving image of a person. A slide playback method characterized by:
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021120856AJP2023016504A (en) | 2021-07-21 | 2021-07-21 | Slide playback program, slide playback device, and slide playback method |
| PCT/IB2022/056404WO2023002300A1 (en) | 2021-07-21 | 2022-07-12 | Slide playback program, slide playback device, and slide playback method |
| JP2023124775AJP2023162179A (en) | 2021-07-21 | 2023-07-31 | Slide playback program, slide playback device, and slide playback method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021120856AJP2023016504A (en) | 2021-07-21 | 2021-07-21 | Slide playback program, slide playback device, and slide playback method |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2023124775ADivisionJP2023162179A (en) | 2021-07-21 | 2023-07-31 | Slide playback program, slide playback device, and slide playback method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2023016504Atrue JP2023016504A (en) | 2023-02-02 |
Family
ID=84980196
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2021120856APendingJP2023016504A (en) | 2021-07-21 | 2021-07-21 | Slide playback program, slide playback device, and slide playback method |
| JP2023124775APendingJP2023162179A (en) | 2021-07-21 | 2023-07-31 | Slide playback program, slide playback device, and slide playback method |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2023124775APendingJP2023162179A (en) | 2021-07-21 | 2023-07-31 | Slide playback program, slide playback device, and slide playback method |
Country Status (2)
| Country | Link |
|---|---|
| JP (2) | JP2023016504A (en) |
| WO (1) | WO2023002300A1 (en) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US12367641B2 (en)* | 2023-05-02 | 2025-07-22 | Microsoft Technology Licensing, Llc | Artificial intelligence driven presenter |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004128614A (en)* | 2002-09-30 | 2004-04-22 | Toshiba Corp | Image display control device and image display control program |
| JP2006163871A (en)* | 2004-12-08 | 2006-06-22 | Sony Corp | Image processing apparatus, image processing method, and program |
| JP2007072528A (en)* | 2005-09-02 | 2007-03-22 | Internatl Business Mach Corp <Ibm> | Method, program and device for analyzing document structure |
| JP2009157677A (en)* | 2007-12-27 | 2009-07-16 | Fuji Xerox Co Ltd | Recording and reproducing device and program |
| JP2011090100A (en)* | 2009-10-21 | 2011-05-06 | National Institute Of Information & Communication Technology | Speech translation system, controller, speech recognition device, translation device, and speech synthesizer |
| KR20110055957A (en)* | 2009-11-20 | 2011-05-26 | 김학식 | How to create a voice synthesized PowerPoint document and various video files by plugging in a TTS module to PowerPoint and the corresponding system |
| JP2014140135A (en)* | 2013-01-21 | 2014-07-31 | Kddi Corp | Information reproduction terminal |
- 2021
- 2021-07-21JPJP2021120856Apatent/JP2023016504A/enactivePending
- 2022
- 2022-07-12WOPCT/IB2022/056404patent/WO2023002300A1/ennot_activeCeased
- 2023
- 2023-07-31JPJP2023124775Apatent/JP2023162179A/enactivePending
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004128614A (en)* | 2002-09-30 | 2004-04-22 | Toshiba Corp | Image display control device and image display control program |
| JP2006163871A (en)* | 2004-12-08 | 2006-06-22 | Sony Corp | Image processing apparatus, image processing method, and program |
| JP2007072528A (en)* | 2005-09-02 | 2007-03-22 | Internatl Business Mach Corp <Ibm> | Method, program and device for analyzing document structure |
| JP2009157677A (en)* | 2007-12-27 | 2009-07-16 | Fuji Xerox Co Ltd | Recording and reproducing device and program |
| JP2011090100A (en)* | 2009-10-21 | 2011-05-06 | National Institute Of Information & Communication Technology | Speech translation system, controller, speech recognition device, translation device, and speech synthesizer |
| KR20110055957A (en)* | 2009-11-20 | 2011-05-26 | 김학식 | How to create a voice synthesized PowerPoint document and various video files by plugging in a TTS module to PowerPoint and the corresponding system |
| JP2014140135A (en)* | 2013-01-21 | 2014-07-31 | Kddi Corp | Information reproduction terminal |
Non-Patent Citations (4)
| Title |
|---|
| "LOGOSWARE STORM XE 操作マニュアル", vol. 第8版, JPN6022041147, 15 April 2021 (2021-04-15), pages 1 - 165, ISSN: 0005177537* |
| 久保田秀和 他: ""「知球」:持続的に発展可能な時空間記憶の構築"", 情報処理学会研究報告, vol. 2004, no. 90, JPN6022041149, 10 September 2004 (2004-09-10), pages 1 - 8, ISSN: 0004889393* |
| 吉岡理 他: ""対話型自動プレゼンテーションシステム"", 日本音響学会研究発表会議講演論文集, JPN6022041150, 15 March 2000 (2000-03-15), pages 181 - 182, ISSN: 0005177538* |
| 荒井翔真 他: ""発表スライドの構造的・言語的解釈に基づく発話生成"", 言語処理学会第17回年次大会発表論文集, JPN6022041151, 7 March 2011 (2011-03-07), pages 737 - 740, ISSN: 0005177539* |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2023002300A1 (en) | 2023-01-26 |
| JP2023162179A (en) | 2023-11-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10580319B2 (en) | Interactive multimedia story creation application | |
| US5689618A (en) | Advanced tools for speech synchronized animation | |
| US9332100B2 (en) | Portable communications device | |
| US20110319160A1 (en) | Systems and Methods for Creating and Delivering Skill-Enhancing Computer Applications | |
| US9984724B2 (en) | System, apparatus and method for formatting a manuscript automatically | |
| US20120276504A1 (en) | Talking Teacher Visualization for Language Learning | |
| US20220301250A1 (en) | Avatar-based interaction service method and apparatus | |
| JP2001014306A (en) | Method and device for electronic document processing, and recording medium where electronic document processing program is recorded | |
| CN112750187A (en) | Animation generation method, device and equipment and computer readable storage medium | |
| US20180276185A1 (en) | System, apparatus and method for formatting a manuscript automatically | |
| IL302350A (en) | Convert text to dynamic video | |
| CN115497448A (en) | Method and device for synthesizing voice animation, electronic equipment and storage medium | |
| JP2023162179A (en) | Slide playback program, slide playback device, and slide playback method | |
| Ariya et al. | Enhancing textile heritage engagement through generative AI-based virtual assistants in virtual reality museums | |
| Lamberti et al. | A multimodal interface for virtual character animation based on live performance and natural language processing | |
| CN119299800A (en) | Video generation method, device, computing device, storage medium and program product | |
| KR102281298B1 (en) | System and method for video synthesis based on artificial intelligence | |
| KR20180042116A (en) | System, apparatus and method for providing service of an orally narrated fairy tale | |
| CN110362675A (en) | A foreign language teaching content display method and system | |
| TWI897163B (en) | Device for creating digital persona | |
| US20250193477A1 (en) | Streaming a segmented artificial intelligence virtual assistant with probabilistic buffering | |
| TW202526584A (en) | Device for creating digital persona | |
| CN119415655A (en) | Display device and reply generation method | |
| JP2004102764A (en) | Conversation expression generating apparatus and conversation expression generating program | |
| CN116741177A (en) | Nozzle type generating method, device, equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination | Free format text:JAPANESE INTERMEDIATE CODE: A621 Effective date:20220513 | |
| A131 | Notification of reasons for refusal | Free format text:JAPANESE INTERMEDIATE CODE: A131 Effective date:20221004 | |
| A521 | Request for written amendment filed | Free format text:JAPANESE INTERMEDIATE CODE: A523 Effective date:20221205 | |
| A02 | Decision of refusal | Free format text:JAPANESE INTERMEDIATE CODE: A02 Effective date:20230404 | |
| A521 | Request for written amendment filed | Free format text:JAPANESE INTERMEDIATE CODE: A523 Effective date:20230731 | |
| A521 | Request for written amendment filed | Free format text:JAPANESE INTERMEDIATE CODE: A821 Effective date:20230731 | |
| A911 | Transfer to examiner for re-examination before appeal (zenchi) | Free format text:JAPANESE INTERMEDIATE CODE: A911 Effective date:20230828 | |
| A912 | Re-examination (zenchi) completed and case transferred to appeal board | Free format text:JAPANESE INTERMEDIATE CODE: A912 Effective date:20231020 |