JP2022124765A - 多重制御プログラム、情報処理装置および多重制御方法 - Google Patents
多重制御プログラム、情報処理装置および多重制御方法Download PDFInfo
- Publication number
- JP2022124765A JP2022124765AJP2021022593AJP2021022593AJP2022124765AJP 2022124765 AJP2022124765 AJP 2022124765AJP 2021022593 AJP2021022593 AJP 2021022593AJP 2021022593 AJP2021022593 AJP 2021022593AJP 2022124765 AJP2022124765 AJP 2022124765A
- Authority
- JP
- Japan
- Prior art keywords
- processing
- gpu
- request
- time
- delay
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



















Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/48—Program initiating; Program switching, e.g. by interrupt
- G06F9/4806—Task transfer initiation or dispatching
- G06F9/4843—Task transfer initiation or dispatching by program, e.g. task dispatcher, supervisor, operating system
- G06F9/4881—Scheduling strategies for dispatcher, e.g. round robin, multi-level priority queues
Landscapes
- Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Debugging And Monitoring (AREA)
Abstract

Description
本発明は、多重制御プログラムなどに関する。
近年、GPU(Graphical Processing Unit)を使ってAI(Artificial Intelligence)処理を実行するシステムが増加している。例えば、映像のAI処理により物体検知等を行うシステムがある。
このようなシステムでは、1台のGPUが1台のカメラから転送される映像を処理していたが、映像は一定周期で送られるため、処理の隙間でGPUが空く時間が生じる。そこで、1台のGPUが複数台のカメラから転送される映像を収容して処理することで、相互に隙間を埋めて効率よく利用することが期待される。
しかしながら、1台のGPUで複数の映像を処理する場合、1台のGPUで複数の処理が多重で実行されることがある。このとき、処理同士の干渉により処理時間が増加するという問題がある。
ここで、処理同士の干渉により処理時間が増加する場合について、図22を参照して説明する。図22は、処理同士の干渉による処理時間の増加を説明する図である。図22に示すように、1台のGPUは、複数のタスクを多重で処理することが可能である。ここでは、タスクの処理は、映像の推論処理であり、4個の処理が並列で実行されている。
GPUは、単体で映像の推論処理を実行する場合には、予め定められた一定周期で推論処理を実行する。ところが、GPUが、4並列で映像の推論処理を実行する場合には、推論処理同士が干渉してしまい、処理時間が増加する場合がある。処理時間の増加の程度は、推論処理の内容や重なり方によって異なる。例えば、推論処理間の重なりが大きく、推論処理の重なる数が多い方が、処理時間の増加の程度は大きくなる。推論処理の開始タイミングは別々であるため、偶々開始が近い推論処理が多いと、推論処理の重なる数が多くなり、処理時間の増加の程度が大きくなり、推論処理の処理時間が一定周期を超過してしまう。すなわち、処理同士の干渉により処理時間が増加するという問題が起きる。
本発明は、1つの側面では、1台のGPUが複数の処理を多重で実行しても、処理の重複実行による処理時間の増加を抑制することを目的とする。
1つの態様では、多重制御プログラムは、複数のアプリケーションの処理を多重で実行させる場合に、前記複数のアプリケーションの処理の中で第1の工程の処理時間を閾値として記憶部に記録し、前記複数のアプリケーションのうちいずれかのアプリケーションの処理を実行中に、後続のアプリケーションから実行要求を受け付けると、前記後続のアプリケーションの処理の開始を、先行して実行中のアプリケーションの処理の開始から前記閾値以上遅らせる、処理をコンピュータに実行させる。
1実施態様によれば、1台のGPUが複数の処理を多重で実行しても、処理の重複実行による処理時間の増加を抑制することが可能となる。
以下に、本願の開示する多重制御プログラム、情報処理装置および多重制御方法の実施例を図面に基づいて詳細に説明する。なお、本発明は、実施例により限定されるものではない。
[システムの構成]
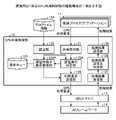
図1は、実施例1に係る実行サーバを含むシステムの機能構成の一例を示す図である。システム9は、実行サーバ1と、ストレージサーバ3と、複数のカメラ5とを有する。システム9は、動画像(映像)に関し、推論処理する推論プロセス11(アプリケーション)を、GPU(Graphics Processing Unit)を搭載する実行サーバ1上で実行する。そして、システム9は、1台のGPU上で複数の推論プロセス11を実行することを想定する。ここでいう推論プロセス11とは、例えば、カメラ5から出力される映像から不審者を推定したり、交通量を推定したりするアプリケーションのことをいう。推論プロセス11は、AIフレームワーク14の所定のライブラリを組み込んで推論モデル32を用いて推論処理を実行する。
図1は、実施例1に係る実行サーバを含むシステムの機能構成の一例を示す図である。システム9は、実行サーバ1と、ストレージサーバ3と、複数のカメラ5とを有する。システム9は、動画像(映像)に関し、推論処理する推論プロセス11(アプリケーション)を、GPU(Graphics Processing Unit)を搭載する実行サーバ1上で実行する。そして、システム9は、1台のGPU上で複数の推論プロセス11を実行することを想定する。ここでいう推論プロセス11とは、例えば、カメラ5から出力される映像から不審者を推定したり、交通量を推定したりするアプリケーションのことをいう。推論プロセス11は、AIフレームワーク14の所定のライブラリを組み込んで推論モデル32を用いて推論処理を実行する。
ストレージサーバ3は、複数のカメラ5からそれぞれ出力される映像のデータソース31と、推論モデル32とを有する。推論モデル32は、推論プロセス11の推論処理に用いられるモデルであり、所定のアルゴリズムに基づくものである。実施例1では、複数の推論プロセス11で同じアルゴリズムに基づく推論モデル32が用いられる場合とする。
実行サーバ1は、複数の推論プロセス11と、GPUドライバ13およびAIフレームワーク14との間にGPU利用制御部12を設ける。加えて、実行サーバ1は、プロファイル情報15を有する。
GPUドライバ13は、GPUを制御するための専用のソフトウェアである。例えば、GPUドライバ13は、GPU利用制御部12から要求されるGPU利用要求をAIフレームワーク14に送信する。GPUドライバ13は、AIフレームワーク14から返却される処理結果をGPU利用制御部12に送信する。
AIフレームワーク14は、推論プロセス11の推論処理を実行する。AIフレームワーク14は、映像に関する推論処理を行うためのライブラリであり、推論プロセス11(アプリケーション)に組み込まれる。AIフレームワーク14は、推論プロセス11から呼び出され、GPUドライバ13を介して推論処理を実行する。AIフレームワーク14としては、一例として、TensorFlow、MXNet、Pytorchなどが挙げられる。
GPU利用制御部12は、推論プロセス11(アプリケーション)からのGPU利用要求を監視して、推論プロセス11におけるGPU利用の開始タイミングを変更する。例えば、GPU利用制御部12は、複数の推論プロセス11を多重で実行させる場合には、所定の閾値に基づいて後続の推論プロセス11の開始を遅延させてGPUの利用を制御する。実施例1では、所定の閾値は、推論プロセス11に含まれる複数のフェーズの中の、重複(干渉)して実行すると処理時間の影響が大きいフェーズの処理時間の値である。言い換えると、所定の閾値は、推論プロセス11に含まれる複数のフェーズの中で重複(干渉)すると処理時間が増加してしまうフェーズの処理時間の値である。GPU利用制御部12は、2つの推論プロセス11が近いタイミングで実行される場合には、先行の推論プロセス11の開始から所定の閾値だけ後続の推論プロセス11の開始を遅延させることで、干渉による処理時間の増加を抑制する。なお、実施例1では、複数の推論プロセス11で用いられる推論モデル32(アルゴリズム)が同じ場合であるので、複数の推論プロセス11のそれぞれの複数のフェーズの処理時間は同一であるとする。
プロファイル情報15は、所定の閾値を記憶する。所定の閾値は、例えば、後述する畳込み処理の処理時間である。一例として、GPU利用制御部12が、予め畳込み処理の処理時間を計測して、プロファイル情報15に記録しておく。なお、プロファイル情報15は、記憶部の一例である。
[実施例1に係る多重制御]
ここで、実施例1に係る多重制御について、図2Aおよび図2Bを参照して説明する。図2Aおよび図2Bは、実施例1に係る多重制御を説明する図である。図2Aに示すように、推論プロセス11は、3つのフェーズを含む。3つのフェーズは、前処理、畳込み処理および後処理であり、各処理の特性は異なる。前処理は、例えば、データソース31等の処理データを用意するCPU処理と、CPUからGPUへデータを転送するデータ転送処理とを含む。畳込み処理は、例えば、ディープラーニングの中核部分である、GPUを利用したデータ処理であり、畳込みニューラルネットワーク(Convolutional neural network)を用いて実行される。後処理は、例えば、GPUからCPUへ処理結果を転送するデータ転送処理と処理結果を取り出して加工するCPU処理とを含む。
ここで、実施例1に係る多重制御について、図2Aおよび図2Bを参照して説明する。図2Aおよび図2Bは、実施例1に係る多重制御を説明する図である。図2Aに示すように、推論プロセス11は、3つのフェーズを含む。3つのフェーズは、前処理、畳込み処理および後処理であり、各処理の特性は異なる。前処理は、例えば、データソース31等の処理データを用意するCPU処理と、CPUからGPUへデータを転送するデータ転送処理とを含む。畳込み処理は、例えば、ディープラーニングの中核部分である、GPUを利用したデータ処理であり、畳込みニューラルネットワーク(Convolutional neural network)を用いて実行される。後処理は、例えば、GPUからCPUへ処理結果を転送するデータ転送処理と処理結果を取り出して加工するCPU処理とを含む。
複数の推論プロセス11が多重で実行される場合には、重なるフェーズの組み合わせにより処理時間の増加の影響が異なる。同種のフェーズが重なる場合には、処理時間の増加が大きくなる。異種のフェーズが重なる場合には、処理時間の増加は少なくなる。図2A左図に示すように、畳込み処理および前処理や、後処理および畳込み処理のように、異なるフェーズ同士が重なる場合には、処理時間の増加は少ない。これに対して、図2A右図に示すように、特に畳込み処理同士が重なる場合には、処理時間の増加は大きくなる。そこで、実施例では、処理時間の影響が大きい畳込み処理同士が重複(干渉)して実行しないように、GPU利用制御部12が、推論プロセス11の開始タイミングを制御する。
具体的には、GPU利用制御部12は、複数の推論プロセス11が近いタイミングで実行される場合には、推論プロセス11の中の畳込み処理の処理時間を閾値として、後続の推論プロセス11の開始を閾値以上遅延させる。ここでいう閾値として用いられる畳込み処理の処理時間は、推論プロセス11が他の推論プロセス11と重複しない状態で計測された畳込み処理の処理時間であり、予め計測されれば良い。
図2Bに示すように、例えば、GPU利用制御部12は、推論プロセス11を示すアプリa、アプリb、アプリcを近いタイミングで実行させるとする。GPU利用制御部12は、アプリaの開始要求(GPU利用要求)をAIフレームワーク14に送り、推論処理を実行させる。アプリaに後続するアプリbについて、GPU利用制御部12は、直前に実行されたアプリaの推論処理の開始よりも閾値以上遅らせて、アプリbの開始要求(GPU利用要求)をAIフレームワーク14に送り、推論処理を実行させる。これにより、GPU利用制御部12は、アプリaおよびアプリbの畳込み処理が重ならないように制御できる。
また、アプリbに後続するアプリcについて、GPU利用制御部12は、直前に実行されたアプリbの推論処理の開始よりも閾値以上遅らせて、アプリcの開始要求(GPU利用要求)をAIフレームワーク14に送り、推論処理を実行させる。これにより、GPU利用制御部12は、アプリa、アプリbおよびアプリcの畳込み処理が重ならないように制御できる。
[GPU利用制御部の機能構成]
図3は、実施例1に係るGPU利用制御部の機能構成の一例を示す図である。図3に示すように、GPU利用制御部12は、利用検知部121、読込部122、遅延実行判定部123、遅延待機中要求管理部124、要求キュー125、利用要求送信部126、処理結果受信部127、処理結果送信先判定部128および処理結果送信部129を有する。なお、遅延実行判定部123および遅延待機中要求管理部124は、遅延待機部の一例である。
図3は、実施例1に係るGPU利用制御部の機能構成の一例を示す図である。図3に示すように、GPU利用制御部12は、利用検知部121、読込部122、遅延実行判定部123、遅延待機中要求管理部124、要求キュー125、利用要求送信部126、処理結果受信部127、処理結果送信先判定部128および処理結果送信部129を有する。なお、遅延実行判定部123および遅延待機中要求管理部124は、遅延待機部の一例である。
利用検知部121は、推論プロセス11(アプリケーション)からGPUの利用要求(アプリの開始要求)を検知する。GPUの利用要求には、推論モデル32の名前と、データソース31の識別子とが含まれる。そして、利用検知部121は、検知したGPUの利用要求における推論プロセス11のプロセスIDを遅延実行判定部123に出力する。
読込部122は、プロファイル情報15から閾値を読み込む。そして、読込部122は、読み込んだ閾値を後述する遅延実行判定部123に出力する。
ここで、実施例1に係るプロファイル情報15の一例を、図4を参照して説明する。図4は、実施例1に係るプロファイル情報の一例を示す図である。図4に示すように、プロファイル情報15には、閾値が設定される。閾値は、予め畳込み処理の処理時間を計測して得られた値である。一例として、閾値として「nn」が設定されている。なお、「nn」は、正の整数である。
図3に戻って、遅延実行判定部123は、GPUの利用要求がされた推論プロセス11の実行までの遅延時間を判定する。例えば、遅延実行判定部123は、GPUの利用要求を蓄積する要求キュー125が空であるか否かを判定する。遅延実行判定部123は、要求キュー125が空である場合には、GPUを最終に利用した時刻(GPU最終利用時刻)を取得する。遅延実行判定部123は、プロファイル情報15から閾値を取得する。遅延実行判定部123は、最終利用時刻に閾値を加えた時刻から現在時刻を引いた時間を待機時間として計算する。そして、遅延実行判定部123は、待機時間が0より大きい場合には、GPUの利用要求を要求キュー125に蓄積するとともに、遅延待機中要求管理部124へ待機時間を設定する。すなわち、遅延実行判定部123は、GPUの利用要求がされた(後続の)推論プロセス11の開始タイミングを先行の推論プロセス11の利用開始から閾値以上遅らせるように制御する。つまり、遅延実行判定部123は、GPUの利用要求がされた推論プロセス11の畳込み処理と先行の推論プロセス11の畳込み処理が重複しないように制御する。また、遅延実行判定部123は、待機時間が0以下の場合には、GPUの利用要求を利用要求送信部126に対して依頼する。すなわち、待機時間が0以下の場合には、GPU最終利用時刻は現在時刻より閾値以上前となる。このため、遅延実行判定部123は、後続の推論プロセス11が先行の推論プロセス11の畳込み処理と重複しないと判断し、後続の推論プロセス11のGPUの利用要求を依頼する。
また、遅延実行判定部123は、要求キュー125が空でない場合には、GPUの利用要求を要求キュー125に蓄積する。ここで、要求キュー125のデータ構造の一例を、図5を参照して説明する。
図5は、要求キューのデータ構造の一例を示す図である。図5に示すように、要求キュー125は、1つのGPU利用要求に対して、GPU利用要求情報および要求元プロセスIDを保持する。GPU利用要求情報には、推論モデル名と入力データ識別子とが含まれる。推論モデル名は、推論モデル32の名前である。入力データ識別子は、データソース31を一意に識別する識別子である。要求元プロセスIDは、推論プロセス11のプロセスIDである。
図3に戻って、遅延待機中要求管理部124は、遅延を待機しているGPUの利用要求を管理する。例えば、遅延待機中要求管理部124は、遅延実行判定部123によって設定された待機時間だけ待機する。遅延待機中要求管理部124は、待機時間だけ待機すると、要求キュー125の先頭のGPUの利用要求を利用要求送信部126に対して依頼する。そして、遅延待機中要求管理部124は、要求キュー125が空であるか否かを判定する。遅延待機中要求管理部124は、要求キュー125が空でない場合には、プロファイル情報15から閾値を取得し、取得した閾値を待機時間に設定する。すなわち、遅延待機中要求管理部124は、後続の推論プロセス11の畳込み処理と先行の推論プロセス11の畳込み処理が重複しないように、現に送信した推論プロセス11の利用開始から閾値分後続の推論プロセス11の開始タイミングを遅らせるように制御する。
利用要求送信部126は、GPUの利用要求を、GPUドライバ13を介してAIフレームワーク14へ送信する。例えば、利用要求送信部126は、GPUを最終に利用した時刻(GPU最終利用時刻)を現在時刻に更新する。そして、利用要求送信部126は、GPUの利用要求の依頼元のプロセスIDをGPU最終利用時刻に対応付けて記録する。なお、GPU最終利用時刻と依頼元のプロセスIDとの対応付けは、図示せぬ記憶部に記録される。そして、利用要求送信部126は、GPUの利用要求をGPUドライバ13へ送信する。
処理結果受信部127は、AIフレームワーク14によって処理された処理結果を、GPUドライバ13を介して受信する。
処理結果送信先判定部128は、処理結果の送信先を判定する。例えば、処理結果送信先判定部128は、利用要求送信部126から、記録された、GPU最終利用時刻に対応付けられた依頼元のプロセスIDを処理結果の送信先として取得する。
処理結果送信部129は、処理結果を、処理結果送信先判定部128によって判定された依頼元のプロセスIDに対応する推論プロセス11へ送信する。
[実行サーバのハードウェア構成]
図6は、実行サーバのハードウェア構成の一例を示す図である。図6に示すように、実行サーバ1は、CPU21に加えてGPU22を有する。そして、実行サーバ1は、メモリ23、ハードディスク24およびネットワークインターフェイス25を有する。図6に示した各部は、例えばバス26で相互に接続される。
図6は、実行サーバのハードウェア構成の一例を示す図である。図6に示すように、実行サーバ1は、CPU21に加えてGPU22を有する。そして、実行サーバ1は、メモリ23、ハードディスク24およびネットワークインターフェイス25を有する。図6に示した各部は、例えばバス26で相互に接続される。
ネットワークインターフェイス25は、ネットワークインターフェイスカード等であり、ストレージサーバ3等の他の装置との通信を行う。ハードディスク24は、図1および図3に示した機能を動作させるプログラムやプロファイル情報15を記憶する。
CPU21は、図1および図3に示した各処理部と同様の処理を実行するプログラムをハードディスク24等から読み出してメモリ23に展開することで、図1および図3等で説明した各機能を実行するプロセスを動作させる。例えば、このプロセスは、実行サーバ1が有する各処理部と同様の機能を実行する。具体的には、CPU21は、推論プロセス11、GPU利用制御部12、GPUドライバ13およびAIフレームワーク14等と同様の機能を有するプログラムをハードディスク24等から読み出す。そして、CPU21は、推論プロセス11、GPU利用制御部12、GPUドライバ13およびAIフレームワーク14等と同様の処理を実行するプロセスを実行する。
GPU22は、図1で示したAIフレームワーク14を用いて推論プロセス11の推論処理を実行するプログラムをハードディスク24等から読み出してメモリ23に展開することで、当該プログラムを実行するプロセスを動作させる。GPU22は、複数の推論プロセス11を多重で動作させる。
[GPU利用制御のフローチャート]
ここで、実施例1に係るGPU利用制御処理のフローチャートを、図7~図10を参照して説明する。
ここで、実施例1に係るGPU利用制御処理のフローチャートを、図7~図10を参照して説明する。
[遅延実行判定処理のフローチャート]
まず、図7は、実施例1に係る遅延実行判定処理のフローチャートの一例を示す図である。図7に示すように、利用検知部121は、GPUの利用要求を検知したか否かを判定する(ステップS11)。GPUの利用要求を検知していないと判定した場合には(ステップS11;No)、利用検知部121は、GPUの利用要求を検知するまで、判定処理を繰り返す。一方、GPUの利用要求を検知したと判定した場合には(ステップS11;Yes)、利用検知部121は、要求送信元のプロセスID(PID)を取得する(ステップS12)。
まず、図7は、実施例1に係る遅延実行判定処理のフローチャートの一例を示す図である。図7に示すように、利用検知部121は、GPUの利用要求を検知したか否かを判定する(ステップS11)。GPUの利用要求を検知していないと判定した場合には(ステップS11;No)、利用検知部121は、GPUの利用要求を検知するまで、判定処理を繰り返す。一方、GPUの利用要求を検知したと判定した場合には(ステップS11;Yes)、利用検知部121は、要求送信元のプロセスID(PID)を取得する(ステップS12)。
続いて、遅延実行判定部123は、待機中の利用要求を蓄積する要求キュー125が空であるか否かを判定する(ステップS13)。要求キュー125が空であると判定した場合には(ステップS13;Yes)、遅延実行判定部123は、図示せぬ記憶部に記録されているGPU最終利用時刻を取得する(ステップS14)。GPU最終利用時刻は、GPUを最終に利用した時刻であり、具体的には直近でGPUの利用要求を送信した時刻である。GPU最終利用時刻は、利用要求送信部126によって記録される。
遅延実行判定部123は、プロファイル情報15から閾値を取得する(ステップS15)。遅延実行判定部123は、システム(OS)から現在時刻を取得する(ステップS16)。そして、遅延実行判定部123は、以下の式(1)から待機時間を計算する(ステップS17)。
待機時間=(GPU最終利用時刻+閾値)-現在時刻・・・(1)
待機時間=(GPU最終利用時刻+閾値)-現在時刻・・・(1)
そして、遅延実行判定部123は、待機時間が0より大きいか否かを判定する(ステップS18)。待機時間が0以下であると判定した場合には(ステップS18;No)、遅延実行判定部123は、GPU利用要求で検知した要求とPIDを利用要求送信部126へ出力して当該要求の送信を依頼する(ステップS19)。すなわち、待機時間が0以下の場合には、GPU最終利用時刻が現在時刻より閾値以上前である。このため、遅延実行判定部123は、後続の推論プロセス11が先行の推論プロセス11の畳込み処理と重複しないと判断し、後続の推論プロセス11のGPU利用要求を依頼する。そして、遅延実行判定部123は、遅延実行判定処理を終了する。
一方、待機時間が0より大きいと判定した場合には(ステップS18;Yes)、遅延実行判定部123は、要求キュー125にGPU利用要求情報およびPIDを追加する(ステップS20)。そして、遅延実行判定部123は、遅延待機中要求管理部124へ待機時間を設定する(ステップS21)。すなわち、遅延実行判定部123は、GPUの利用要求が検知された(後続の)推論プロセス11の開始タイミングを先行の推論プロセス11の利用開始から閾値以上遅らせるように制御する。つまり、遅延実行判定部123は、GPUの利用要求がされた推論プロセス11の畳込み処理と先行の推論プロセス11の畳込み処理が重複しないように制御する。そして、遅延実行判定部123は、遅延実行判定処理を終了する。
また、ステップS13において、要求キュー125が空でないと判定した場合には(ステップS13;No)、遅延実行判定部123は、要求キュー125の末尾にGPU利用要求情報およびPIDを追加する(ステップS22)。そして、遅延実行判定部123は、遅延実行判定処理を終了する。
[遅延待機中要求管理処理のフローチャート]
次に、図8は、実施例1に係る遅延待機中要求管理処理のフローチャートの一例を示す図である。図8に示すように、遅延待機中要求管理部124は、待機時間が設定されたか否かを判定する(ステップS31)。待機時間が設定されていないと判定した場合には(ステップS31;No)、遅延待機中要求管理部124は、待機時間が設定されるまで、判定処理を繰り返す。
次に、図8は、実施例1に係る遅延待機中要求管理処理のフローチャートの一例を示す図である。図8に示すように、遅延待機中要求管理部124は、待機時間が設定されたか否かを判定する(ステップS31)。待機時間が設定されていないと判定した場合には(ステップS31;No)、遅延待機中要求管理部124は、待機時間が設定されるまで、判定処理を繰り返す。
一方、待機時間が設定されていると判定した場合には(ステップS31;Yes)、遅延待機中要求管理部124は、設定された時間だけ待機する(ステップS32)。設定された時間だけ待機した後、遅延待機中要求管理部124は、要求キュー125の先頭の要求とPIDを利用要求送信部126へ出力して当該要求の送信を依頼する(ステップS33)。
そして、遅延待機中要求管理部124は、要求キュー125が空であるか否かを判定する(ステップS34)。要求キュー125が空でないと判定した場合には(ステップS34;No)、遅延待機中要求管理部124は、プロファイル情報15から閾値を取得する(ステップS35)。そして、遅延待機中要求管理部124は、次の要求を待機させるべく、閾値を待機時間に設定する(ステップS36)。すなわち、遅延待機中要求管理部124は、次のGPUの利用要求の推論プロセス11の開始タイミングを先行の推論プロセス11の利用開始から閾値以上遅らせるように制御する。そして、遅延待機中要求管理部124は、ステップS32に移行する。
一方、要求キュー125が空であると判定した場合には(ステップS34;Yes)、遅延待機中要求管理部124は、遅延待機中要求管理処理を終了する。
[利用要求送信処理のフローチャート]
次に、図9は、実施例1に係る利用要求送信処理のフローチャートの一例を示す図である。図9に示すように、利用要求送信部126は、GPU利用要求の送信依頼があったか否かを判定する(ステップS41)。GPU利用要求の送信依頼がなかったと判定した場合には(ステップS41;No)、利用要求送信部126は、送信依頼があるまで、判定処理を繰り返す。
次に、図9は、実施例1に係る利用要求送信処理のフローチャートの一例を示す図である。図9に示すように、利用要求送信部126は、GPU利用要求の送信依頼があったか否かを判定する(ステップS41)。GPU利用要求の送信依頼がなかったと判定した場合には(ステップS41;No)、利用要求送信部126は、送信依頼があるまで、判定処理を繰り返す。
一方、GPU利用要求の送信依頼があったと判定した場合には(ステップS41;Yes)、利用要求送信部126は、システム(OS)から現在時刻を取得する(ステップS42)。そして、利用要求送信部126は、GPU最終利用時刻を現在時刻に更新する(ステップS43)。利用要求送信部126は、GPU最終利用時刻に対応付けて依頼元のPIDを記録する(ステップS44)。
そして、利用要求送信部126は、GPUドライバ13へGPU利用要求を送信する(ステップS45)。そして、利用要求送信部126は、利用要求送信処理を終了する。
[処理結果送信先判定処理のフローチャート]
次に、図10は、実施例1に係る処理結果送信先判定処理のフローチャートの一例を示す図である。図10に示すように、処理結果送信先判定部128は、処理結果を受信したか否かを判定する(ステップS51)。処理結果を受信していないと判定した場合には(ステップS51;No)、処理結果送信先判定部128は、処理結果を受信するまで、判定処理を繰り返す。
次に、図10は、実施例1に係る処理結果送信先判定処理のフローチャートの一例を示す図である。図10に示すように、処理結果送信先判定部128は、処理結果を受信したか否かを判定する(ステップS51)。処理結果を受信していないと判定した場合には(ステップS51;No)、処理結果送信先判定部128は、処理結果を受信するまで、判定処理を繰り返す。
一方、処理結果を受信したと判定した場合には(ステップS51;Yes)、処理結果送信先判定部128は、利用要求送信部126から、記録された依頼元のPIDを取得する(ステップS52)。そして、処理結果送信先判定部128は、取得したPIDに対応するアプリケーション(推論プロセス11)へ処理結果を送信する(ステップS53)。そして、処理結果送信先判定部128は、処理結果送信先判定処理を終了する。
[実施例1の効果]
このようにして、上記実施例1では、実行サーバ1は、複数のアプリケーションの処理を多重で実行させる場合に、複数のアプリケーションの処理の中で第1の工程の処理時間を閾値としてプロファイル情報15に記録する。実行サーバ1は、複数のアプリケーションのうちいずれかのアプリケーションの処理を実行中に、後続のアプリケーションから実行要求を受け付けると、後続のアプリケーションの処理の開始を、先行して実行中のアプリケーションの処理の開始から閾値以上遅らせる。かかる構成によれば、実行サーバ1は、第1の工程が重複しないように制御できることとなり、第1の工程の重複実行による処理時間の増加を抑制することができる。
このようにして、上記実施例1では、実行サーバ1は、複数のアプリケーションの処理を多重で実行させる場合に、複数のアプリケーションの処理の中で第1の工程の処理時間を閾値としてプロファイル情報15に記録する。実行サーバ1は、複数のアプリケーションのうちいずれかのアプリケーションの処理を実行中に、後続のアプリケーションから実行要求を受け付けると、後続のアプリケーションの処理の開始を、先行して実行中のアプリケーションの処理の開始から閾値以上遅らせる。かかる構成によれば、実行サーバ1は、第1の工程が重複しないように制御できることとなり、第1の工程の重複実行による処理時間の増加を抑制することができる。
また、上記実施例1では、実行サーバ1は、後続のアプリケーションの処理の開始を、先行して実行中のアプリケーションの開始時刻に閾値を加えた値から後続のアプリケーションの実行要求のタイミングの時刻を差し引いた値以上遅らせる。かかる構成によれば、実行サーバ1は、後続のアプリケーションの処理の開始を第1の工程が重複しないような長さ以上遅らせることができる。
また、上記実施例1では、実行サーバ1は、複数のアプリケーションの処理が同一のアルゴリズムを用いる場合には、第1の工程の処理時間を測定して得られる値を閾値とする。かかる構成によれば、実行サーバ1は、第1の工程の処理時間を測定して得られる値を閾値として用いることで、第1の工程の重複実行による処理時間の増加を抑制することができる。
ところで、実施例1では、複数の推論プロセス11を多重で実行させる場合に、各推論プロセス11で用いられる推論モデル32(アルゴリズム)が同じ場合であるとした。すなわち、実行サーバ1は、いずれかの推論プロセス11の畳込み処理の処理時間を計測して閾値としてプロファイル情報15に記録しておき、後続の推論プロセス11の開始タイミングを、先行の推論プロセス11の利用開始から閾値以上遅らせる。しかしながら、実施例1では、これに限定されず、複数の推論プロセス11を多重で実行させる場合に、各推論プロセス11で用いられる推論モデル32(アルゴリズム)が異なる場合であっても良い。
そこで、実施例2では、複数の推論プロセス11を多重で実行させる場合に、各推論プロセス11で用いられる推論モデル32(アルゴリズム)が異なる場合を説明する。
[GPU利用制御部の機能構成]
図11は、実施例2に係るGPU利用制御部の機能構成の一例を示す図である。なお、図3に示すGPU利用制御部と同一の構成については同一符号を示すことで、その重複する構成および動作の説明ついては省略する。実施例1と実施例2とが異なるところは、プロファイル情報15をプロファイル情報15Aに変更した点にある。また、実施例1と実施例2とが異なるところは、遅延実行判定部123、遅延待機中要求管理部124をそれぞれ遅延実行判定部123A、遅延待機中要求管理部124Aに変更した点にある。
図11は、実施例2に係るGPU利用制御部の機能構成の一例を示す図である。なお、図3に示すGPU利用制御部と同一の構成については同一符号を示すことで、その重複する構成および動作の説明ついては省略する。実施例1と実施例2とが異なるところは、プロファイル情報15をプロファイル情報15Aに変更した点にある。また、実施例1と実施例2とが異なるところは、遅延実行判定部123、遅延待機中要求管理部124をそれぞれ遅延実行判定部123A、遅延待機中要求管理部124Aに変更した点にある。
プロファイル情報15Aは、推論モデル32(アルゴリズム)ごとの、前処理の処理時間と、畳込み処理の処理時間を記憶する。一例として、GPU利用制御部12が、予め推論モデル32ごとの、前処理および畳込み処理の処理時間を計測して、プロファイル情報15Aに記録しておく。
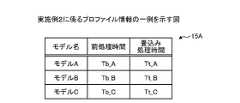
ここで、実施例2に係るプロファイル情報15Aの一例を、図12を参照して説明する。図12は、実施例2に係るプロファイル情報の一例を示す図である。図12に示すように、プロファイル情報15Aは、モデル名、前処理時間および畳込み処理時間を対応付けて記憶する。モデル名は、推論プロセス11の推論処理に用いられる推論モデル32の名前である。前処理時間は、モデル名が示す推論モデル32を用いた推論プロセス11の前処理の処理時間である。畳込み処理時間は、モデル名が示す推論モデル32を用いた推論プロセス11の畳込み処理の処理時間である。モデル名ごとの前処理時間および畳込み処理時間は、予め計測して得られた値である。
一例として、モデル名が「モデルA」である場合に、前処理時間として「Tb_A」、畳込み処理時間として「Tt_A」と記憶している。モデル名が「モデルB」である場合に、前処理時間として「Tb_B」、畳込み処理時間として「Tt_B」と記憶している。モデル名が「モデルC」である場合に、前処理時間として「Tb_C」、畳込み処理時間として「Tt_C」と記憶している。なお、「Tb_A」、「Tt_A」、「Tb_B」、「Tt_B」、「Tb_C」および「Tt_C」は、正の整数である。
図11に戻って、遅延実行判定部123Aは、GPUの利用要求がされた推論プロセス11の実行までの遅延時間を判定する。
例えば、遅延実行判定部123Aは、GPUの利用要求に含まれる推論モデル32のモデル名を取得する。そして、遅延実行判定部123Aは、GPUの利用要求を蓄積する要求キュー125が空であるか否かを判定する。遅延実行判定部123Aは、要求キュー125が空である場合には、GPUを最終に利用した時刻(GPU最終利用時刻)と最終に利用した推論モデル32のモデル名を取得する。つまり、遅延実行判定部123Aは、直前に実行された(先行した)推論プロセス11で用いられる推論モデル32のモデル名を取得する。遅延実行判定部123Aは、プロファイル情報15Aから、先行した推論プロセス11で用いられる推論モデル32のモデル名に対応する前処理時間および畳込み処理時間を取得する。遅延実行判定部123Aは、プロファイル情報15Aから、要求された(後続の)推論プロセス11で用いられる推論モデル32のモデル名に対応する前処理時間および畳込み処理時間を取得する。
そして、遅延実行判定部123Aは、先行した推論プロセス11で用いられる推論モデル32に対応する前処理時間と畳込み処理時間とを加えた値から、後続の推論プロセス11で用いられる推論モデル32に対応する前処理時間を引いた値を閾値として計算する。すなわち、遅延実行判定部123Aは、先行の推論プロセス11で用いられる推論モデル32と後続の推論プロセス11で用いられる推論モデル32との組み合わせに基づいて閾値を計算する。
そして、遅延実行判定部123Aは、最終利用時刻に閾値を加えた時刻から現在時刻を引いた時間を待機時間として計算する。そして、遅延実行判定部123Aは、待機時間が0より大きい場合には、GPUの利用要求を要求キュー125に蓄積するとともに、遅延待機中要求管理部124Aへ待機時間を設定する。すなわち、遅延実行判定部123Aは、GPUの利用要求がされた(後続の)推論プロセス11の開始タイミングを先行の推論プロセス11の利用開始から閾値以上遅らせるように制御する。つまり、遅延実行判定部123Aは、GPUの利用要求がされた推論プロセス11の畳込み処理と先行の推論プロセス11の畳込み処理が重ならないように制御する。また、遅延実行判定部123Aは、待機時間が0以下の場合には、GPUの利用要求を利用要求送信部126に対して依頼する。すなわち、待機時間が0以下の場合には、GPU最終利用時刻が現在時刻より閾値以上前である。このため、遅延実行判定部123Aは、後続の推論プロセス11が先行の推論プロセス11の畳込み処理と重複しないと判断し、後続の推論プロセス11のGPUの利用要求を依頼する。
遅延待機中要求管理部124Aは、遅延を待機しているGPUの利用要求を管理する。例えば、遅延待機中要求管理部124Aは、遅延実行判定部123Aによって設定された待機時間だけ待機する。遅延待機中要求管理部124Aは、待機時間だけ待機すると、要求キュー125の先頭のGPUの利用要求を利用要求送信部126に対して依頼する。そして、遅延待機中要求管理部124Aは、要求キュー125が空であるか否かを判定する。遅延待機中要求管理部124Aは、要求キュー125が空でない場合には、要求キュー125の先頭にある要求の推論モデル名を取得する。遅延待機中要求管理部124Aは、直前に実行された(先行した)推論プロセス11で用いられる推論モデル32のモデル名を取得する。遅延待機中要求管理部124Aは、プロファイル情報15Aから、要求の推論モデル名に対応する前処理時間および畳込み処理時間を取得する。遅延待機中要求管理部124Aは、プロファイル情報15Aから、先行した推論プロセス11で用いられる推論モデル32のモデル名に対応する前処理時間および畳込み処理時間を取得する。
そして、遅延待機中要求管理部124Aは、先行した推論プロセス11で用いられる推論モデル32に対応する前処理時間と畳込み処理時間とを加えた値から、要求の推論モデル名に対応する前処理時間を引いた値を閾値として計算する。すなわち、遅延待機中要求管理部124Aは、先行の推論プロセス11で用いられる推論モデル32と要求の推論プロセス11で用いられる推論モデル32との組み合わせに基づいて閾値を計算する。
そして、遅延待機中要求管理部124Aは、計算した閾値を待機時間に設定する。すなわち、遅延待機中要求管理部124Aは、後続の推論プロセス11の畳込み処理と先行の推論プロセス11の畳込み処理が重複しないように、現に送信した推論プロセス11の利用開始から閾値分後続の推論プロセス11の開始タイミングを遅らせるように制御する。
[GPU利用制御のフローチャート]
ここで、実施例2に係る遅延実行判定処理のフローチャートを、図13を参照して説明する。図13は、実施例2に係る遅延実行判定処理のフローチャートの一例を示す図である。図13に示すように、利用検知部121は、GPUの利用要求を検知したか否かを判定する(ステップS61)。GPUの利用要求を検知していないと判定した場合には(ステップS61;No)、利用検知部121は、GPUの利用要求を検知するまで、判定処理を繰り返す。一方、GPUの利用要求を検知したと判定した場合には(ステップS61;Yes)、利用検知部121は、要求送信元のプロセスID(PID)と要求に対応するモデル名を取得する(ステップS62)。ここでは、要求に対応するモデル名は、「モデルA」であるとする。
ここで、実施例2に係る遅延実行判定処理のフローチャートを、図13を参照して説明する。図13は、実施例2に係る遅延実行判定処理のフローチャートの一例を示す図である。図13に示すように、利用検知部121は、GPUの利用要求を検知したか否かを判定する(ステップS61)。GPUの利用要求を検知していないと判定した場合には(ステップS61;No)、利用検知部121は、GPUの利用要求を検知するまで、判定処理を繰り返す。一方、GPUの利用要求を検知したと判定した場合には(ステップS61;Yes)、利用検知部121は、要求送信元のプロセスID(PID)と要求に対応するモデル名を取得する(ステップS62)。ここでは、要求に対応するモデル名は、「モデルA」であるとする。
続いて、遅延実行判定部123Aは、待機中の利用要求を蓄積する要求キュー125が空であるか否かを判定する(ステップS63)。要求キュー125が空であると判定した場合には(ステップS63;Yes)、遅延実行判定部123Aは、記録されているGPU最終利用時刻と最終利用モデル名を取得する(ステップS64)。ここでは、最終利用モデル名は、「モデルB」であるとする。GPU最終利用時刻および最終利用モデル名は、利用要求送信部126によって記録される。
遅延実行判定部123Aは、プロファイル情報15Aからモデル名に対応する情報を取得する(ステップS65)。ここでは、遅延実行判定部123Aは、プロファイル情報15Aから、最終利用モデル名(モデルB)に対応する前処理時間および畳込み処理時間を取得する。遅延実行判定部123Aは、プロファイル情報15Aから、要求に対応するモデル名(モデルA)に対応する前処理時間および畳込み処理時間を取得する。
遅延実行判定部123Aは、システム(OS)から現在時刻を取得する(ステップS66)。そして、遅延実行判定部123は、以下の式(2)から閾値を計算し、計算した閾値を用いて、式(3)から待機時間を計算する(ステップS67)。なお、式(3)は、式(1)と同じ式である。
閾値=モデルB前処理時間+モデルB畳込み処理時間-モデルA前処理時間・・・(2)
待機時間=(GPU最終利用時刻+閾値)-現在時刻・・・・・・・・・・・・・(3)
閾値=モデルB前処理時間+モデルB畳込み処理時間-モデルA前処理時間・・・(2)
待機時間=(GPU最終利用時刻+閾値)-現在時刻・・・・・・・・・・・・・(3)
そして、遅延実行判定部123Aは、待機時間が0より大きいか否かを判定する(ステップS68)。待機時間が0以下であると判定した場合には(ステップS68;No)、遅延実行判定部123Aは、GPU利用要求で検知した要求とPIDを利用要求送信部126へ出力して当該要求の送信を依頼する(ステップS69)。すなわち、待機時間が0以下の場合には、GPU最終利用時刻が現在時刻より閾値以上前である。このため、遅延実行判定部123Aは、後続の推論プロセス11が先行の推論プロセス11の畳込み処理と重複しないと判断し、後続の推論プロセス11のGPU利用要求を依頼する。そして、遅延実行判定部123Aは、遅延実行判定処理を終了する。
一方、待機時間が0より大きいと判定した場合には(ステップS68;Yes)、遅延実行判定部123Aは、要求キュー125にGPU利用要求情報およびPIDを追加する(ステップS70)。そして、遅延実行判定部123Aは、遅延待機中要求管理部124Aへ待機時間を設定する(ステップS71)。すなわち、遅延実行判定部123Aは、後続の推論プロセス11が先行の推論プロセス11の処理時間の影響が大きい畳込み処理と重複しないように、先行の推論プロセス11の利用開始から閾値以上後続の推論プロセス11の開始タイミングを遅らせるように制御する。そして、遅延実行判定部123Aは、遅延実行判定処理を終了する。
また、ステップS63において、要求キュー125が空でないと判定した場合には(ステップS63;No)、遅延実行判定部123Aは、要求キュー125の末尾にGPU利用要求情報およびPIDを追加する(ステップS72)。そして、遅延実行判定部123Aは、遅延実行判定処理を終了する。
次に、図14は、実施例2に係る遅延待機中要求管理処理のフローチャートの一例を示す図である。図14に示すように、遅延待機中要求管理部124Aは、待機時間が設定されたか否かを判定する(ステップS81)。待機時間が設定されていないと判定した場合には(ステップS81;No)、遅延待機中要求管理部124Aは、待機時間が設定されるまで、判定処理を繰り返す。
一方、待機時間が設定されていると判定した場合には(ステップS81;Yes)、遅延待機中要求管理部124Aは、設定された時間だけ待機する(ステップS82)。設定された時間だけ待機した後、遅延待機中要求管理部124Aは、要求キュー125の先頭の要求とPIDを利用要求送信部126へ出力して当該要求の送信を依頼する(ステップS83)。
そして、遅延待機中要求管理部124Aは、要求キュー125が空であるか否かを判定する(ステップS84)。要求キュー125が空でないと判定した場合には(ステップS84;No)、遅延待機中要求管理部124Aは、要求キュー125の先頭にある要求のモデル名を取得する(ステップS85)。ここでは、先頭にある要求のモデル名は、モデルAであるとする。遅延待機中要求管理部124Aは、直前の送信依頼に対応するモデル名を取得する(ステップS86)。ここでは、直前の送信依頼に対応するモデル名は、モデルBであるとする。なお、遅延待機中要求管理部124Aは、直前の送信依頼に対応するモデル名として、GPU最終利用時刻に対応付けられたモデル名を取得すれば良い。
そして、遅延待機中要求管理部124Aは、プロファイル情報15Aからモデル名に対応する情報を取得する(ステップS87)。ここでは、遅延待機中要求管理部124Aは、プロファイル情報15Aから、モデルAに対応する前処理時間および畳込み処理時間を取得し、モデルBに対応する前処理時間および畳込み処理時間を取得する。
そして、遅延待機中要求管理部124Aは、前述した式(2)から閾値を計算する(ステップS88)。そして、遅延待機中要求管理部124Aは、次の要求を待機させるべく、閾値を待機時間に設定する(ステップS89)。そして、遅延待機中要求管理部124Aは、ステップS82に移行する。
一方、要求キュー125が空であると判定した場合には(ステップS84;Yes)、遅延待機中要求管理部124Aは、遅延待機中要求管理処理を終了する。
[実施例2の効果]
このようにして、上記実施例2では、実行サーバ1は、複数のアプリケーションの処理が異なるアルゴリズムを用いる場合には、アルゴリズムごとに第1の工程と第1の工程より前の第2の工程の処理時間をプロファイル情報15Aに記録する。実行サーバ1は、先行して実行中のアプリケーションの処理におけるアルゴリズムに対応する第1の工程の処理時間と第2の工程の処理時間と、後続のアプリケーションの処理におけるアルゴリズムに対応する第1の工程の処理時間とから閾値を算出する。そして、実行サーバ1は、後続のアプリケーションの処理の開始を、先行して実行中のアプリケーションの処理の開始から閾値以上遅らせる。かかる構成によれば、実行サーバ1は、複数のアプリケーションの処理が異なるアルゴリズムを用いる場合であっても、第1の工程の重複実行による処理時間の増加を抑制することが可能となる。
このようにして、上記実施例2では、実行サーバ1は、複数のアプリケーションの処理が異なるアルゴリズムを用いる場合には、アルゴリズムごとに第1の工程と第1の工程より前の第2の工程の処理時間をプロファイル情報15Aに記録する。実行サーバ1は、先行して実行中のアプリケーションの処理におけるアルゴリズムに対応する第1の工程の処理時間と第2の工程の処理時間と、後続のアプリケーションの処理におけるアルゴリズムに対応する第1の工程の処理時間とから閾値を算出する。そして、実行サーバ1は、後続のアプリケーションの処理の開始を、先行して実行中のアプリケーションの処理の開始から閾値以上遅らせる。かかる構成によれば、実行サーバ1は、複数のアプリケーションの処理が異なるアルゴリズムを用いる場合であっても、第1の工程の重複実行による処理時間の増加を抑制することが可能となる。
ところで、実施例1では、実行サーバ1は、予めいずれかの推論プロセス11の畳込み処理の処理時間を計測して閾値としてプロファイル情報15に記録しておき、後続の推論プロセス11の開始タイミングを遅らせる制御をこの閾値を読み込んで利用した。しかしながら、予め閾値を計測するGPUと実際にGPU利用制御処理を実行するGPUとが異なる場合がある。
そこで、実施例3では、予め閾値を計測するGPUと実際に実行するGPUとが異なる場合のGPU利用制御処理について説明する。
[GPU利用制御部の機能構成]
図15は、実施例3に係るGPU利用制御部の機能構成の一例を示す図である。なお、図3に示すGPU利用制御部と同一の構成については同一符号を示すことで、その重複する構成および動作の説明ついては省略する。実施例1と実施例3とが異なるところは、プロファイル情報15をプロファイル情報15Bに変更した点にある。また、実施例1と実施例3とが異なるところは、遅延実行判定部123、遅延待機中要求管理部124、利用要求送信部126、処理結果送信先判定部128をそれぞれ遅延実行判定部123B、遅延待機中要求管理部124B、利用要求送信部126B、処理結果送信先判定部128Bに変更した点にある。
図15は、実施例3に係るGPU利用制御部の機能構成の一例を示す図である。なお、図3に示すGPU利用制御部と同一の構成については同一符号を示すことで、その重複する構成および動作の説明ついては省略する。実施例1と実施例3とが異なるところは、プロファイル情報15をプロファイル情報15Bに変更した点にある。また、実施例1と実施例3とが異なるところは、遅延実行判定部123、遅延待機中要求管理部124、利用要求送信部126、処理結果送信先判定部128をそれぞれ遅延実行判定部123B、遅延待機中要求管理部124B、利用要求送信部126B、処理結果送信先判定部128Bに変更した点にある。
プロファイル情報15Bは、所定の閾値のほか、処理時間を記憶する。加えて、プロファイル情報15Bは、推論プロセス11ごとの係数を記憶する。閾値は、予め第1のGPUを用いて畳込み処理の処理時間を計測して得られた値である。処理時間は、予め第1のGPUを用いて推論プロセス11を実行した場合の全体の実行時間である。係数は、予め第1のGPUを用いて計測した際の全体の実行時間と、実際に第2のGPUを用いて実行した際の実処理時間との比率である。なお、実処理時間および係数は、処理結果送信先判定部128Bによって計算される。
ここで、実施例3に係るプロファイル情報15Bの一例を、図16を参照して説明する。図16は、実施例3に係るプロファイル情報の一例を示す図である。図16に示すように、プロファイル情報15Bには、閾値に加えて処理時間が設定される。また、プロファイル情報15Bには、PIDと係数とが対応付けて設定される。PIDは、推論プロセス11を実行した際のプロセスIDである。
一例として、閾値として「nn」が記憶されている。処理時間として「t0」が記憶されている。なお、「nn」、「t0」は、正の整数である。また、PIDが「PID_A」である場合には、係数として「係数A」が記憶されている。
図15に戻って、遅延実行判定部123Bは、GPUの利用要求がされた推論プロセス11の実行までの遅延時間を判定する。例えば、遅延実行判定部123Bは、GPUの利用要求を蓄積する要求キュー125が空であるか否かを判定する。遅延実行判定部123Bは、要求キュー125が空である場合には、GPUを最終に利用した時刻(GPU最終利用時刻)を取得する。遅延実行判定部123は、プロファイル情報15Bから、閾値および推論プロセス11のプロセスIDに対応する係数を取得する。遅延実行判定部123Bは、閾値に係数を乗じて得られた新たな閾値を計算する。遅延実行判定部123Bは、最終利用時刻に新たな閾値を加えた時刻から現在時刻を引いた時間を待機時間として計算する。そして、遅延実行判定部123Bは、待機時間が0より大きい場合には、GPUの利用要求を要求キュー125に蓄積するとともに、遅延待機中要求管理部124Bへ待機時間を設定する。また、遅延実行判定部123Bは、待機時間が0以下の場合には、GPUの利用要求を利用要求送信部126Bに対して依頼する。
また、遅延実行判定部123Bは、要求キュー125が空でない場合には、GPUの利用要求を要求キュー125に蓄積する。
なお、プロセスIDに対応する係数がプロファイル情報15Bに設定されていない場合には、遅延実行判定部123Bは、GPUが空いていれば、GPUの利用要求の実行を利用要求送信部126Bへ依頼する。これは、GPUに負荷がかかっていないタイミングで対象の利用要求を実行させて実処理時間を計算させ、対象の利用要求を発行した推論プロセス11のプロセスIDに対応する係数を計算させるためである。
遅延待機中要求管理部124Bは、遅延を待機しているGPUの利用要求を管理する。例えば、遅延待機中要求管理部124Bは、遅延実行判定部123Bによって設定された待機時間だけ待機する。遅延待機中要求管理部124Bは、待機時間だけ待機すると、要求キュー125の先頭のGPUの利用要求を利用要求送信部126Bに対して依頼する。そして、遅延待機中要求管理部124Bは、要求キュー125が空であるか否かを判定する。遅延待機中要求管理部124Bは、要求キュー125が空でない場合には、プロファイル情報15Bから、閾値および要求キュー125に蓄積された先頭のプロセスIDに対応する係数を取得する。遅延待機中要求管理部124Bは、閾値に係数を乗じて得られた新たな閾値を待機時間に設定する。
なお、プロセスIDに対応する係数がプロファイル情報15Bに設定されていない場合には、遅延待機中要求管理部124Bは、GPUが空いていれば、GPUの利用要求の実行を利用要求送信部126Bへ依頼する。これは、GPUに負荷がかかっていないタイミングで対象の利用要求を実行させて実処理時間を計算させ、対象の利用要求を発行した推論プロセス11のプロセスIDに対応する係数を計算させるためである。
利用要求送信部126Bは、GPUの利用要求を、GPUドライバ13を介してAIフレームワーク14へ送信する。例えば、利用要求送信部126Bは、GPUを最終に利用した時刻(GPU最終利用時刻)を現在時刻に更新する。そして、利用要求送信部126Bは、GPUの利用要求の依頼元のプロセスIDをGPU最終利用時刻に対応付けて記録する。そして、利用要求送信部126Bは、GPUの利用要求をGPUドライバ13へ送信する。そして、利用要求送信部126Bは、GPUの処理状態を「処理中」に記録する。
処理結果送信先判定部128Bは、処理結果の送信先を判定する。
例えば、処理結果送信先判定部128Bは、GPUの処理状態を、GPUが処理していないことを示す「空き」に記録する。処理結果送信先判定部128Bは、利用要求送信部126Bから、記録された、GPU最終利用時刻に対応付けられた依頼元のプロセスIDを処理結果の送信先として取得する。そして、処理結果送信先判定部128Bは、処理結果送信部129を介して、依頼元のプロセスIDに対応する推論プロセス11へ送信する。
また、処理結果送信先判定部128Bは、プロセスIDに対応する係数がプロファイル情報15Bに設定されていない場合には、プロセスIDに対応する係数を計算する。一例として、処理結果送信先判定部128Bは、現在時刻から最終利用時刻を引いた実処理時間を計算する。そして、利用要求送信部126Bは、実処理時間を、プロファイル情報15Bに設定された処理時間で割った値を係数として計算し、プロファイル情報15Bに記録する。
[遅延実行判定処理のフローチャート]
図17は、実施例3に係る遅延実行判定処理のフローチャートの一例を示す図である。図17に示すように、利用検知部121は、GPUの利用要求を検知したか否かを判定する(ステップS91)。GPUの利用要求を検知していないと判定した場合には(ステップS91;No)、利用検知部121は、GPUの利用要求を検知するまで、判定処理を繰り返す。一方、GPUの利用要求を検知したと判定した場合には(ステップS91;Yes)、利用検知部121は、要求送信元のプロセスID(PID)を取得する(ステップS92)。
図17は、実施例3に係る遅延実行判定処理のフローチャートの一例を示す図である。図17に示すように、利用検知部121は、GPUの利用要求を検知したか否かを判定する(ステップS91)。GPUの利用要求を検知していないと判定した場合には(ステップS91;No)、利用検知部121は、GPUの利用要求を検知するまで、判定処理を繰り返す。一方、GPUの利用要求を検知したと判定した場合には(ステップS91;Yes)、利用検知部121は、要求送信元のプロセスID(PID)を取得する(ステップS92)。
続いて、遅延実行判定部123Bは、待機中の利用要求を蓄積する要求キュー125が空であるか否かを判定する(ステップS93)。要求キュー125が空であると判定した場合には(ステップS93;Yes)、遅延実行判定部123Bは、記録されているGPU最終利用時刻を取得する(ステップS94)。GPU最終利用時刻は、GPUを最終に利用した時刻であり、具体的には直近でGPUの利用要求を送信した時刻である。GPU最終利用時刻は、利用要求送信部126Bによって記録される。
遅延実行判定部123Bは、プロファイル情報15Bから閾値を取得する(ステップS95)。遅延実行判定部123Bは、システム(OS)から現在時刻を取得する(ステップS96)。遅延実行判定部123Bは、プロファイル情報15BからPIDに対応する係数を取得する(ステップS97)。
遅延実行判定部123Bは、係数が空であるか否かを判定する(ステップS98)。係数が空であると判定した場合には(ステップS98;Yes)、遅延実行判定部123Bは、GPUの処理状態を取得する(ステップS99)。そして、遅延実行判定部123Bは、処理状態が「処理中」であるか否かを判定する(ステップS100)。処理状態が「処理中」でないと判定した場合には(ステップS100;No)、遅延実行判定部123Bは、GPU利用要求の送信を依頼すべく、ステップS102に移行する。これは、GPUに負荷がかかっていないタイミングで対象の利用要求を実行させて実処理時間を計算させ、対象の利用要求を発行した推論プロセス11のプロセスIDに対応する係数を計算させるためである。
一方、処理状態が「処理中」であると判定した場合には(ステップS100;Yes)、遅延実行判定部123Bは、要求キュー125にGPU利用要求情報、要求元プロセスIDを追加する(ステップS101)。かかる場合には、係数が設定されていないので、遅延実行判定部123Bは、待機時間を計算できず、遅延待機中要求管理部124Bに待機時間を設定しない。そして、遅延実行判定部123Bは、遅延実行判定処理を終了する。
ステップS98において、係数が空でないと判定した場合には(ステップS98;No)、遅延実行判定部123Bは、以下の式(4)から待機時間を計算する(ステップS103)。
待機時間=(GPU最終利用時刻+閾値×係数)-現在時刻・・・(4)
待機時間=(GPU最終利用時刻+閾値×係数)-現在時刻・・・(4)
そして、遅延実行判定部123Bは、待機時間が0より大きいか否かを判定する(ステップS104)。待機時間が0以下であると判定した場合には(ステップS104;No)、遅延実行判定部123Bは、GPU利用要求で検知した要求とPIDを利用要求送信部126Bへ出力して当該要求の送信を依頼する(ステップS102)。そして、遅延実行判定部123Bは、遅延実行判定処理を終了する。
一方、待機時間が0より大きいと判定した場合には(ステップS104;Yes)、遅延実行判定部123Bは、要求キュー125にGPU利用要求情報およびPIDを追加する(ステップS105)。そして、遅延実行判定部123Bは、遅延待機中要求管理部124Bへ待機時間を設定する(ステップS106)。そして、遅延実行判定部123Bは、遅延実行判定処理を終了する。
また、ステップS93において、要求キュー125が空でないと判定した場合には(ステップS93;No)、遅延実行判定部123Bは、要求キュー125の末尾にGPU利用要求情報およびPIDを追加する(ステップS107)。そして、遅延実行判定部123Bは、遅延実行判定処理を終了する。
[遅延待機中要求管理処理のフローチャート]
図18は、実施例3に係る遅延待機中要求管理処理のフローチャートの一例を示す図である。図18に示すように、図18に示すように、遅延待機中要求管理部124Bは、待機時間が設定されたか否かを判定する(ステップS111)。待機時間が設定されていないと判定した場合には(ステップS111;No)、遅延待機中要求管理部124Bは、待機時間が設定されるまで、判定処理を繰り返す。
図18は、実施例3に係る遅延待機中要求管理処理のフローチャートの一例を示す図である。図18に示すように、図18に示すように、遅延待機中要求管理部124Bは、待機時間が設定されたか否かを判定する(ステップS111)。待機時間が設定されていないと判定した場合には(ステップS111;No)、遅延待機中要求管理部124Bは、待機時間が設定されるまで、判定処理を繰り返す。
一方、待機時間が設定されていると判定した場合には(ステップS111;Yes)、遅延待機中要求管理部124Bは、設定された時間だけ待機する(ステップS112)。設定された時間だけ待機した後、遅延待機中要求管理部124Bは、要求キュー125の先頭の要求とPIDを利用要求送信部126Bへ出力して当該要求の送信を依頼する(ステップS113)。
そして、遅延待機中要求管理部124Bは、要求キュー125が空であるか否かを判定する(ステップS114)。要求キュー125が空でないと判定した場合には(ステップS114;No)、遅延待機中要求管理部124Bは、プロファイル情報15Bから閾値を取得する(ステップS115)。加えて、遅延待機中要求管理部124Bは、要求キュー125の先頭の要求におけるPIDに対応する係数を取得する(ステップS116)。
そして、遅延待機中要求管理部124Bは、係数が空であるか否かを判定する(ステップS117)。係数が空でないと判定した場合には(ステップS117;No)、遅延待機中要求管理部124Bは、次の要求を待機させるべく、閾値に係数を乗じて得られる値を待機時間に設定する(ステップS117A)。そして、遅延待機中要求管理部124Bは、ステップS112に移行する。
一方、係数が空であると判定した場合には(ステップS117;Yes)、遅延待機中要求管理部124Bは、GPUの処理状態を取得する(ステップS118A)。遅延待機中要求管理部124Bは、処理状態が「処理中」であるか否かを判定する(ステップS118B)。処理状態が「処理中」であると判定した場合には(ステップS118B;Yes)、遅延待機中要求管理部124Bは、遅延待機中要求管理処理を終了する。
一方、処理状態が「処理中」でないと判定した場合には(ステップS118B;No)、遅延待機中要求管理部124Bは、要求キュー125の先頭の要求のPIDを利用要求送信部126Bへ出力して当該要求の送信を依頼する(ステップS118C)。これは、GPUに負荷がかかっていないタイミングで対象の利用要求を実行させて実処理時間を計算させ、対象の利用要求を発行した推論プロセス11のプロセスIDに対応する係数を計算させるためである。そして、遅延待機中要求管理部124Bは、遅延待機中要求管理処理を終了する。
ステップS114において、要求キュー125が空であると判定した場合には(ステップS114;Yes)、遅延待機中要求管理部124Bは、遅延待機中要求管理処理を終了する。
[利用要求送信処理のフローチャート]
次に、図19は、実施例3に係る利用要求送信処理のフローチャートの一例を示す図である。図19に示すように、利用要求送信部126Bは、GPU利用要求の送信依頼があったか否かを判定する(ステップS121)。GPU利用要求の送信依頼がなかったと判定した場合には(ステップS121;No)、利用要求送信部126Bは、送信依頼があるまで、判定処理を繰り返す。
次に、図19は、実施例3に係る利用要求送信処理のフローチャートの一例を示す図である。図19に示すように、利用要求送信部126Bは、GPU利用要求の送信依頼があったか否かを判定する(ステップS121)。GPU利用要求の送信依頼がなかったと判定した場合には(ステップS121;No)、利用要求送信部126Bは、送信依頼があるまで、判定処理を繰り返す。
一方、GPU利用要求の送信依頼があったと判定した場合には(ステップS121;Yes)、利用要求送信部126Bは、システム(OS)から現在時刻を取得する(ステップS122)。そして、利用要求送信部126は、GPU最終利用時刻を現在時刻に更新する(ステップS123)。利用要求送信部126Bは、GPU最終利用時刻に対応付けて依頼元のPIDを記録する(ステップS124)。
そして、利用要求送信部126Bは、GPUドライバ13へGPU利用要求を送信する(ステップS125)。加えて、利用要求送信部126Bは、GPUの処理状態を「処理中」と記録する(ステップS126)。そして、利用要求送信部126Bは、利用要求送信処理を終了する。
[処理結果送信先判定処理のフローチャート]
図20は、実施例3に係る処理結果送信先判定処理のフローチャートの一例を示す図である。図20に示すように、処理結果送信先判定部128Bは、処理結果を受信したか否かを判定する(ステップS131)。処理結果を受信していないと判定した場合には(ステップS131;No)、処理結果送信先判定部128Bは、処理結果を受信するまで、判定処理を繰り返す。
図20は、実施例3に係る処理結果送信先判定処理のフローチャートの一例を示す図である。図20に示すように、処理結果送信先判定部128Bは、処理結果を受信したか否かを判定する(ステップS131)。処理結果を受信していないと判定した場合には(ステップS131;No)、処理結果送信先判定部128Bは、処理結果を受信するまで、判定処理を繰り返す。
一方、処理結果を受信したと判定した場合には(ステップS131;Yes)、処理結果送信先判定部128Bは、GPUの処理状態を「空き」と記録する(ステップS132)。そして、処理結果送信先判定部128Bは、利用要求送信部126Bから、記録された依頼元のPIDを取得する(ステップS133)。そして、処理結果送信先判定部128Bは、プロファイル情報15Bから取得したPIDに対応する係数を取得する(ステップS134)。
続いて、処理結果送信先判定部128Bは、係数が空であるか否かを判定する(ステップS135)。係数が空であると判定した場合には(ステップS135;Yes)、処理結果送信先判定部128Bは、システム(OS)から現在時刻を取得する(ステップS136)。そして、処理結果送信先判定部128Bは、現在時刻からGPU最終利用時刻を引いて得られる値を実処理時間として算出する(ステップS137)。
さらに、処理結果送信先判定部128Bは、プロファイル情報15Bから処理時間を取得する(ステップS138)。そして、処理結果送信先判定部128Bは、(実処理時間/処理時間)をPIDに対応する係数としてプロファイル情報15Bに記録する(ステップS139)。
処理結果送信先判定部128Bが、要求キューが空であるか否かを判定する(ステップS140)。要求キューが空であると判定した場合には(ステップS140;Yes)、処理結果送信先判定部128Bは、ステップS142に移行する。
一方、要求キューが空でないと判定した場合には(ステップS140;No)、処理結果送信先判定部128Bは、次の要求を即座に開始すべく、遅延待機中要求管理部124Bへ待機時間を0に設定する(ステップS141)。そして、処理結果送信先判定部128Bは、ステップS142に移行する。
ステップS142において、処理結果送信先判定部128Bは、取得したPIDに対応するアプリケーション(推論プロセス11)へ処理結果を送信する(ステップS142)。そして、処理結果送信先判定部128Bは、処理結果送信先判定処理を終了する。
[多重制御の用途]
図21は、実施例1~3に係る多重制御の用途の一例を示す図である。図21左に示すように、従来では、1台のGPUが1台のカメラから転送される動画(映像)を処理していた。実施例1~3に係る多重制御では、図21右に示すように、実行サーバ1は、1台のGPU22が複数台のカメラから転送される動画(映像)を処理することができる。例えば、実行サーバ1は、複数の推論アプリ(推論プロセス)(11)を近いタイミングで実行させる場合に、推論アプリ(11)の中の、重複して実行すると処理時間への影響が大きい処理の処理時間を閾値として、後続の推論アプリ(11)の開始を閾値以上遅延させる。これにより、実行サーバ1は、1台のGPU22が複数の推論アプリ(11)を多重で実行しても、処理の重複実行による処理時間の増加を抑制することが可能になる。
図21は、実施例1~3に係る多重制御の用途の一例を示す図である。図21左に示すように、従来では、1台のGPUが1台のカメラから転送される動画(映像)を処理していた。実施例1~3に係る多重制御では、図21右に示すように、実行サーバ1は、1台のGPU22が複数台のカメラから転送される動画(映像)を処理することができる。例えば、実行サーバ1は、複数の推論アプリ(推論プロセス)(11)を近いタイミングで実行させる場合に、推論アプリ(11)の中の、重複して実行すると処理時間への影響が大きい処理の処理時間を閾値として、後続の推論アプリ(11)の開始を閾値以上遅延させる。これにより、実行サーバ1は、1台のGPU22が複数の推論アプリ(11)を多重で実行しても、処理の重複実行による処理時間の増加を抑制することが可能になる。
[実施例3の効果]
このようにして、上記実施例3では、実行サーバ1は、複数のアプリケーションの処理が同一のアルゴリズムを用いる場合に、第1のGPUで第1の工程の処理時間を測定して得られる値を閾値とする。そして、実行サーバ1は、第1のGPUで実行した場合のいずれかのアプリケーションの処理の総処理時間を、さらにプロファイル情報15Bに記録する。実行サーバ1は、第1のGPUと異なる第2のGPUで実行する場合に、初回のアプリケーションの処理時に、他のアプリケーションの処理と重ならないように制御して、処理の総処理時間を測定する。実行サーバ1は、プロファイル情報15Bに記憶された総処理時間と測定された総処理時間との比率を算出し、算出した比率を閾値に乗じた値を新たな閾値として用いる。かかる構成によれば、実行サーバ1は、実行するGPUが変わった場合であっても、重複実行による処理時間の増加を抑制することができる。
このようにして、上記実施例3では、実行サーバ1は、複数のアプリケーションの処理が同一のアルゴリズムを用いる場合に、第1のGPUで第1の工程の処理時間を測定して得られる値を閾値とする。そして、実行サーバ1は、第1のGPUで実行した場合のいずれかのアプリケーションの処理の総処理時間を、さらにプロファイル情報15Bに記録する。実行サーバ1は、第1のGPUと異なる第2のGPUで実行する場合に、初回のアプリケーションの処理時に、他のアプリケーションの処理と重ならないように制御して、処理の総処理時間を測定する。実行サーバ1は、プロファイル情報15Bに記憶された総処理時間と測定された総処理時間との比率を算出し、算出した比率を閾値に乗じた値を新たな閾値として用いる。かかる構成によれば、実行サーバ1は、実行するGPUが変わった場合であっても、重複実行による処理時間の増加を抑制することができる。
[その他]
なお、実施例3では、実行サーバ1は、複数の推論プロセス11が同一のアルゴリズムを用いる場合の多重制御について説明した。しかしながら、実行サーバ1が行う多重制御は、複数の推論プロセス11が異なるアルゴリズムを用いる場合であっても良い。例えば、実行サーバ1は、複数のアプリケーションの処理が異なるアルゴリズムを用いる場合に、第1のGPUで実行した場合のアルゴリズムごとのアプリケーションの処理の総処理時間を測定し、プロファイル情報15Bに記録する。実行サーバ1は、第1のGPUと異なる第2のGPUで実行する場合に、初回のアプリケーションの処理時に、他のアプリケーションの処理と重ならないように制御して、アルゴリズムごとの処理の総処理時間を測定する。そして、実行サーバ1は、プロファイル情報15Bに記憶されたアルゴリズムごとの総処理時間と測定されたアルゴリズムごとの総処理時間とからアルゴリズムごとの比率(係数)を算出し、算出したアルゴリズムごとの比率と閾値を用いて新たな閾値を算出する。そして、実行サーバ1は、アルゴリズムに応じた新たな閾値を用いて該当する推論プロセス11の待機時間を求めれば良い。これにより、実行サーバ1は、複数の推論プロセス11が異なるアルゴリズムを用いる場合に、実行する際のGPUが変わった場合であっても、重複実行による処理時間の増加を抑制することができる。
なお、実施例3では、実行サーバ1は、複数の推論プロセス11が同一のアルゴリズムを用いる場合の多重制御について説明した。しかしながら、実行サーバ1が行う多重制御は、複数の推論プロセス11が異なるアルゴリズムを用いる場合であっても良い。例えば、実行サーバ1は、複数のアプリケーションの処理が異なるアルゴリズムを用いる場合に、第1のGPUで実行した場合のアルゴリズムごとのアプリケーションの処理の総処理時間を測定し、プロファイル情報15Bに記録する。実行サーバ1は、第1のGPUと異なる第2のGPUで実行する場合に、初回のアプリケーションの処理時に、他のアプリケーションの処理と重ならないように制御して、アルゴリズムごとの処理の総処理時間を測定する。そして、実行サーバ1は、プロファイル情報15Bに記憶されたアルゴリズムごとの総処理時間と測定されたアルゴリズムごとの総処理時間とからアルゴリズムごとの比率(係数)を算出し、算出したアルゴリズムごとの比率と閾値を用いて新たな閾値を算出する。そして、実行サーバ1は、アルゴリズムに応じた新たな閾値を用いて該当する推論プロセス11の待機時間を求めれば良い。これにより、実行サーバ1は、複数の推論プロセス11が異なるアルゴリズムを用いる場合に、実行する際のGPUが変わった場合であっても、重複実行による処理時間の増加を抑制することができる。
また、図示した実行サーバ1に含まれるGPU利用制御部12の各構成要素は、必ずしも物理的に図示の如く構成されていることを要しない。すなわち、各装置の分散・統合の具体的態様は図示のものに限られず、その全部または一部を、各種の負荷や使用状況などに応じて、任意の単位で機能的または物理的に分散・統合して構成することができる。例えば、読込部122と遅延実行判定部123とを1つの部として統合しても良い。また、遅延待機中要求管理部124を、GPUの利用要求を設定された待機時間だけ待機する待機部と、次のGPUの利用要求の待機時間を計算し設定する設定部とに分散しても良い。また、プロファイル情報15などを記憶する記憶部(図示しない)を実行サーバ1の外部装置としてネットワーク経由で接続するようにしても良い。
1 実行サーバ
3 ストレージサーバ
5 カメラ
9 システム
11 推論プロセス
12 GPU利用制御部
13 GPUドライバ
14 AIフレームワーク
15、15A、15B プロファイル情報
21 CPU
22 GPU
23 メモリ
24 ハードディスク
25 ネットワークインターフェイス
26 バス
31 データソース
32 推論モデル
121 利用検知部
122 読込部
123、123A、123B 遅延実行判定部
124、124A、124B 遅延待機中要求管理部
125 要求キュー
126、126B 利用要求送信部
127 処理結果受信部
128、128B 処理結果送信先判定部
129 処理結果送信部
3 ストレージサーバ
5 カメラ
9 システム
11 推論プロセス
12 GPU利用制御部
13 GPUドライバ
14 AIフレームワーク
15、15A、15B プロファイル情報
21 CPU
22 GPU
23 メモリ
24 ハードディスク
25 ネットワークインターフェイス
26 バス
31 データソース
32 推論モデル
121 利用検知部
122 読込部
123、123A、123B 遅延実行判定部
124、124A、124B 遅延待機中要求管理部
125 要求キュー
126、126B 利用要求送信部
127 処理結果受信部
128、128B 処理結果送信先判定部
129 処理結果送信部
Claims (10)
- 複数のアプリケーションの処理を多重で実行させる場合に、前記複数のアプリケーションの処理の中で第1の工程の処理時間を閾値として記憶部に記録し、
前記複数のアプリケーションのうちいずれかのアプリケーションの処理を実行中に、後続のアプリケーションから実行要求を受け付けると、前記後続のアプリケーションの処理の開始を、先行して実行中のアプリケーションの処理の開始から前記記憶部に記憶された閾値以上遅らせる
処理をコンピュータに実行させることを特徴とする多重制御プログラム。 - 前記記憶部に記憶された閾値以上遅らせる処理は、先行して実行中のアプリケーションの開始時刻に前記閾値を加えた値から前記後続のアプリケーションの実行要求のタイミングの時刻を差し引いた値以上遅らせる
ことを特徴とする請求項1に記載の多重制御プログラム。 - 前記複数のアプリケーションの処理が同一のアルゴリズムを用いる場合には、前記第1の工程の処理時間を測定した値を閾値とする
ことを特徴とする請求項1に記載の多重制御プログラム。 - 前記記録する処理は、複数のアプリケーションの処理が異なるアルゴリズムを用いる場合には、アルゴリズムごとに前記第1の工程と前記第1の工程より前の第2の工程の処理時間を前記記憶部に記録し、
先行して実行中のアプリケーションの処理におけるアルゴリズムに対応する前記第1の工程の処理時間と前記第2の工程の処理時間と、後続のアプリケーションの処理におけるアルゴリズムに対応する前記第1の工程の処理時間とから、前記閾値を算出し、
前記記憶部に記憶された閾値以上遅らせる処理は、前記後続のアプリケーションの処理の開始を、先行して実行中のアプリケーションの処理の開始から前記閾値以上遅らせる
ことを特徴とする請求項1に記載の多重制御プログラム。 - 前記記録する処理は、第1のGPUで実行した場合のいずれかのアプリケーションの処理の総処理時間を、さらに前記記憶部に記録し、
前記第1のGPUと異なる第2のGPUで実行する場合に、初回のアプリケーションの処理時に、他のアプリケーションの処理と重ならないように制御して、処理の総処理時間を測定し、
前記記憶部に記憶された総処理時間と測定された総処理時間との比率を算出し、
前記比率を前記閾値に乗じた値を新たな閾値として用いる
ことを特徴とする請求項3に記載の多重制御プログラム。 - 前記記録する処理は、第1のGPUで実行した場合のアルゴリズムごとのアプリケーションの処理の総処理時間を、さらに前記記憶部に記録し、
前記第1のGPUと異なる第2のGPUで実行する場合に、初回のアプリケーションの処理時に、他のアプリケーションの処理と重ならないように制御して、アルゴリズムごとの処理の総処理時間を測定し、
前記算出する処理は、前記記憶部に記憶されたアルゴリズムごとの総処理時間と測定されたアルゴリズムごとの総処理時間とからアルゴリズムごとの比率を算出し、
前記アルゴリズムごとの比率と前記閾値を用いて新たな閾値を算出する
ことを特徴とする請求項4に記載の多重制御プログラム。 - 前記第1の工程の処理は、前記アプリケーションが映像に関する推論アプリである場合には、畳込み処理である
ことを特徴とする請求項1に記載の多重制御プログラム。 - 前記複数のアプリケーションの処理は、GPUを使用した推論であることを特徴とする請求項1に記載の多重制御プログラム。
- 複数のアプリケーションの処理を多重で実行させる場合に、前記複数のアプリケーションの処理の中で第1の工程の処理時間を閾値として記憶する記憶部と、
前記複数のアプリケーションのうちいずれかのアプリケーションの処理を実行中に、後続のアプリケーションから実行要求を受け付けると、前記後続のアプリケーションの処理の開始を、先行して実行中のアプリケーションの処理の開始から前記記憶部に記憶された閾値以上遅らせる遅延待機部と、
を有することを特徴とする情報処理装置。 - 複数のアプリケーションの処理を多重で実行させる場合に、前記複数のアプリケーションの処理の中で第1の工程の処理時間を閾値として記憶部に記録し、
前記複数のアプリケーションのうちいずれかのアプリケーションの処理を実行中に、後続のアプリケーションから実行要求を受け付けると、前記後続のアプリケーションの処理の開始を、先行して実行中のアプリケーションの処理の開始から前記記憶部に記憶された閾値以上遅らせる
処理をコンピュータが実行することを特徴とする多重制御方法。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021022593AJP2022124765A (ja) | 2021-02-16 | 2021-02-16 | 多重制御プログラム、情報処理装置および多重制御方法 |
| US17/528,310US20220261279A1 (en) | 2021-02-16 | 2021-11-17 | Storage medium, information processing apparatus, and multiple control method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021022593AJP2022124765A (ja) | 2021-02-16 | 2021-02-16 | 多重制御プログラム、情報処理装置および多重制御方法 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2022124765Atrue JP2022124765A (ja) | 2022-08-26 |
Family
ID=82800437
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2021022593APendingJP2022124765A (ja) | 2021-02-16 | 2021-02-16 | 多重制御プログラム、情報処理装置および多重制御方法 |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US20220261279A1 (ja) |
| JP (1) | JP2022124765A (ja) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2022187116A (ja)* | 2021-06-07 | 2022-12-19 | 富士通株式会社 | 多重制御プログラム、情報処理装置および多重制御方法 |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7399043B2 (en)* | 2002-12-02 | 2008-07-15 | Silverbrook Research Pty Ltd | Compensation for uneven printhead module lengths in a multi-module printhead |
| US9852150B2 (en)* | 2010-05-03 | 2017-12-26 | Panzura, Inc. | Avoiding client timeouts in a distributed filesystem |
| JP5949506B2 (ja)* | 2012-11-30 | 2016-07-06 | 富士通株式会社 | 分散処理方法、情報処理装置、及びプログラム |
| JP6387747B2 (ja)* | 2013-09-27 | 2018-09-12 | 日本電気株式会社 | 情報処理装置、障害回避方法およびコンピュータプログラム |
- 2021
- 2021-02-16JPJP2021022593Apatent/JP2022124765A/jaactivePending
- 2021-11-17USUS17/528,310patent/US20220261279A1/ennot_activeAbandoned
Also Published As
| Publication number | Publication date |
|---|---|
| US20220261279A1 (en) | 2022-08-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8533729B2 (en) | Distributed task system and distributed task management method | |
| US8533718B2 (en) | Batch job assignment apparatus, program, and method that balances processing across execution servers based on execution times | |
| US8560667B2 (en) | Analysis method and apparatus | |
| JP6233413B2 (ja) | タスク割り当て判定装置、制御方法、及びプログラム | |
| JP5664098B2 (ja) | 複合イベント分散装置、複合イベント分散方法および複合イベント分散プログラム | |
| CN111367651B (zh) | 服务限流系统、方法、装置及电子设备 | |
| CN112262559B (zh) | 数据服务过载检测和缓解 | |
| US20100100645A1 (en) | Storage System and Method for Controlling Activation of Command | |
| CN106775949B (zh) | 感知复合应用特征与网络带宽的虚拟机在线迁移优化方法 | |
| JP2022187116A (ja) | 多重制御プログラム、情報処理装置および多重制御方法 | |
| KR20150001146A (ko) | 스토리지 시스템 및 그의 동작 방법 | |
| US20180173473A1 (en) | Method for operating a print server for digital high-capacity printing systems | |
| CN116566805B (zh) | 一种面向体系容灾抗毁的节点跨域调度方法、装置 | |
| JP2022124765A (ja) | 多重制御プログラム、情報処理装置および多重制御方法 | |
| US9983911B2 (en) | Analysis controller, analysis control method and computer-readable medium | |
| TWI584667B (zh) | 多請求的排程方法及排程裝置 | |
| KR102177440B1 (ko) | 빅데이터 처리 장치 및 방법 | |
| CN111737010A (zh) | 任务处理方法和装置、图形任务处理系统以及存储介质 | |
| JP2022172927A (ja) | 情報処理装置、集約制御プログラムおよび集約制御方法 | |
| US20190250961A1 (en) | Information processing device and distributed system | |
| JP2009252050A (ja) | サーバ負荷管理システム、サーバ負荷管理方法、サーバ負荷管理プログラム | |
| WO2013027332A1 (ja) | 情報処理装置、情報処理方法、及びプログラム | |
| JP5751372B2 (ja) | データ処理システム、そのコンピュータプログラムおよびデータ処理方法 | |
| CN116263705A (zh) | 内核的负荷控制方法及装置、计算机可读存储介质 | |
| US20220004432A1 (en) | Process request management apparatus, process request management method and program |