JP2011221840A - Image processor - Google Patents
Image processorDownload PDFInfo
- Publication number
- JP2011221840A JP2011221840AJP2010091233AJP2010091233AJP2011221840AJP 2011221840 AJP2011221840 AJP 2011221840AJP 2010091233 AJP2010091233 AJP 2010091233AJP 2010091233 AJP2010091233 AJP 2010091233AJP 2011221840 AJP2011221840 AJP 2011221840A
- Authority
- JP
- Japan
- Prior art keywords
- image
- value
- input
- layer
- output
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 230000013016learningEffects0.000claimsabstractdescription53
- 238000013528artificial neural networkMethods0.000claimsabstractdescription40
- 238000001514detection methodMethods0.000claimsabstractdescription27
- 238000000034methodMethods0.000claimsabstractdescription16
- 230000008569processEffects0.000claimsabstractdescription15
- 230000008859changeEffects0.000claimsdescription10
- 230000007423decreaseEffects0.000claimsdescription10
- 230000009467reductionEffects0.000claimsdescription6
- 238000010586diagramMethods0.000description10
- 238000004364calculation methodMethods0.000description8
- 230000001629suppressionEffects0.000description6
- 230000008878couplingEffects0.000description2
- 238000010168coupling processMethods0.000description2
- 238000005859coupling reactionMethods0.000description2
- 230000000694effectsEffects0.000description1
- 238000005516engineering processMethods0.000description1
- 239000000284extractSubstances0.000description1
- 230000006870functionEffects0.000description1
- 210000002569neuronAnatomy0.000description1
- 230000004044responseEffects0.000description1
- 238000009966trimmingMethods0.000description1
Images







Landscapes
- Image Processing (AREA)
- Image Analysis (AREA)
Abstract
Description
Translated fromJapanese本発明は、画像処理装置に関し、特に、階層型ニューラルネットワークを用いた画像処理装置に関する。 The present invention relates to an image processing apparatus, and more particularly to an image processing apparatus using a hierarchical neural network.
画像内に含まれる人物の顔を検知するための、階層型ニューラルネットワークを用いた画像処理装置の開発が進められている。当該画像処理装置においては、ニューラルネットワークの入力層に入力画像が入力され、出力層からは、入力画像に含まれる人物の顔の中心位置を示す出力画像(例えば、顔の中心位置に対応する画素が白く表示され、その他の領域の画素が黒く表示された画像)が出力される。 Development of an image processing apparatus using a hierarchical neural network for detecting a human face included in an image is in progress. In the image processing apparatus, an input image is input to an input layer of a neural network, and an output image (for example, a pixel corresponding to the center position of the face) indicating the center position of a human face included in the input image is output from the output layer. Is displayed in white and pixels in other areas are displayed in black).
なお、階層型ニューラルネットワークを用いた顔検知技術については、例えば下記特許文献1,2に開示されている。 Note that face detection technology using a hierarchical neural network is disclosed in, for example, the following
階層型ニューラルネットワークは、それぞれが複数のニューロン(以下「ユニット」と称す)を含む複数の処理層(入力層、中間層、及び出力層)を有する。入力層に含まれる各ユニットと中間層に含まれる各ユニットとの間には、ユニット間の結合強度を示す重み付け値が設定され、同様に、中間層に含まれる各ユニットと出力層に含まれる各ユニットとの間には、ユニット間の結合強度を示す重み付け値が設定される。ニューラルネットワークの学習においては、人物の顔の位置が既知である教師画像を入力層に入力し、その顔の位置が反映された適切な出力画像が出力層から出力されるように、各ユニット間の重み付け値が設定される。 The hierarchical neural network has a plurality of processing layers (input layer, intermediate layer, and output layer) each including a plurality of neurons (hereinafter referred to as “units”). A weighting value indicating the coupling strength between the units is set between each unit included in the input layer and each unit included in the intermediate layer, and similarly included in each unit included in the intermediate layer and the output layer. A weighting value indicating the coupling strength between the units is set between each unit. In neural network learning, a teacher image with a known human face position is input to the input layer, and an appropriate output image reflecting the face position is output from the output layer. Is set.
一般的にニューラルネットワークにおいては、より多くの画像を用いて学習を行うことによって、各ユニット間の重み付け値がより良く設定され、顔検知の精度が向上する。しかしながら、多くの画像を収集することは現実的に困難を伴うことがあり、準備できた画像の数が少ない場合には、各ユニット間の重み付け値の設定が不十分となって、顔検知の精度が低下する。 In general, in a neural network, by performing learning using a larger number of images, weight values between units are set better, and the accuracy of face detection is improved. However, collecting many images may be difficult in practice, and when the number of prepared images is small, the setting of weight values between units becomes insufficient, and face detection is not possible. Accuracy is reduced.
本発明はかかる事情に鑑みて成されたものであり、準備できた画像の数が少ない場合であっても、顔検知の精度を向上することが可能な画像処理装置を得ることを目的とするものである。 The present invention has been made in view of such circumstances, and an object thereof is to obtain an image processing device capable of improving the accuracy of face detection even when the number of prepared images is small. Is.
本発明の第1の態様に係る画像処理装置は、入力層及び出力層を含む複数の処理層を有し、各前記処理層が複数のユニットを含み、前記入力層に入力された入力画像に含まれる人物の顔の位置を示す出力画像を前記出力層から出力する、ニューラルネットワークと、人物の顔を含む第1の画像を取得する取得手段と、前記第1の画像に対して所定の加工処理を施すことにより、人物の顔を含む複数の第2の画像を生成する加工手段と、前記複数の第2の画像を前記入力層に入力することにより、前記複数の第2の画像を教師画像として用いた学習によって、異なる前記処理層に属する各前記ユニット間の重み付け値を設定する設定手段と、を備えることを特徴とするものである。 The image processing apparatus according to the first aspect of the present invention includes a plurality of processing layers including an input layer and an output layer, each of the processing layers includes a plurality of units, and an input image input to the input layer A neural network for outputting an output image indicating the position of the included human face from the output layer, an acquisition means for acquiring a first image including the human face, and a predetermined processing for the first image Processing means for generating a plurality of second images including a human face by performing processing, and inputting the plurality of second images to the input layer, thereby teaching the plurality of second images to the teacher Setting means for setting a weighting value between the units belonging to different processing layers by learning used as an image.
第1の態様に係る画像処理装置によれば、加工手段は、取得手段が取得した第1の画像に対して所定の加工処理を施すことにより、人物の顔を含む複数の第2の画像を生成する。そして、設定手段は、加工手段が生成した複数の第2の画像を入力層に入力することにより、複数の第2の画像を教師画像として用いた学習によって、異なる処理層に属する各ユニット間の重み付け値を設定する。従って、準備できた第1の画像の数が少ない場合であっても、第1の画像を元に生成した複数の第2の画像を教師画像として用いて学習を行うことができる。従って、各ユニット間の重み付け値を適切に設定することができ、その結果、顔検知の精度を向上することが可能となる。 According to the image processing apparatus according to the first aspect, the processing unit performs a predetermined processing on the first image acquired by the acquisition unit, thereby obtaining a plurality of second images including a human face. Generate. Then, the setting means inputs a plurality of second images generated by the processing means to the input layer, thereby learning between the units belonging to different processing layers by learning using the plurality of second images as a teacher image. Set the weight value. Therefore, even when the number of prepared first images is small, learning can be performed using a plurality of second images generated based on the first images as teacher images. Therefore, the weighting value between each unit can be set appropriately, and as a result, the accuracy of face detection can be improved.
本発明の第2の態様に係る画像処理装置は、第1の画像処理装置において特に、前記所定の加工処理には、画像の拡大又は縮小、画像の回転、画像内における顔位置の変更、レンズ歪みの付与、ノイズの付与、及び光源変更の少なくとも一つが含まれることを特徴とするものである。 The image processing apparatus according to the second aspect of the present invention is the image processing apparatus in the first image processing apparatus, and the predetermined processing includes enlargement or reduction of the image, rotation of the image, change of the face position in the image, lens It includes at least one of imparting distortion, imparting noise, and changing the light source.
第2の態様に係る画像処理装置によれば、取得手段が取得した第1の画像に対する加工処理として、画像の拡大又は縮小、画像の回転、画像内における顔位置の変更、レンズ歪みの付与、ノイズの付与、及び光源変更等の加工処理を行うことにより、第1の画像を元に複数の第2の画像を生成することが可能となる。 According to the image processing apparatus according to the second aspect, as the processing for the first image acquired by the acquisition unit, the enlargement or reduction of the image, the rotation of the image, the change of the face position in the image, the application of lens distortion, By performing processing such as applying noise and changing the light source, a plurality of second images can be generated based on the first image.
本発明の第3の態様に係る画像処理装置は、第1又は第2の態様に係る画像処理装置において特に、各前記ユニットの出力値Yは、パラメータμ(≧1)と自身のユニット値Xとを用いて、
と定義され、前記設定手段は、パラメータμの値が互いに異なる値に設定された複数の処理系統によって、前記重み付け値の組をそれぞれ求め、得られた複数の組の中から最適な組を選択することを特徴とするものである。In the image processing apparatus according to the third aspect of the present invention, in particular, in the image processing apparatus according to the first or second aspect, the output value Y of each unit has a parameter μ (≧ 1) and its own unit value X. And
The setting means obtains each set of the weight values by a plurality of processing systems in which the value of the parameter μ is set to a different value, and selects the optimum set from the obtained plurality of sets. It is characterized by doing.
第3の態様に係る画像処理装置によれば、設定手段は、パラメータμの値が互いに異なる値に設定された複数の処理系統によって、各ユニット間の重み付け値の組をそれぞれ求める。そして、得られた複数の組の中から最適な組を選択する。従って、パラメータμの値が固定された一つの処理系統のみによって重み付け値を設定する場合と比較すると、より良い重み付け値を設定することが可能となる。 According to the image processing apparatus according to the third aspect, the setting means obtains a set of weight values between the units by a plurality of processing systems in which the value of the parameter μ is set to a different value. Then, an optimum group is selected from the obtained plurality of groups. Therefore, it is possible to set a better weighting value as compared with the case where the weighting value is set only by one processing system in which the value of the parameter μ is fixed.
本発明の第4の態様に係る画像処理装置は、第3の態様に係る画像処理装置において特に、前記設定手段は、前記複数の組のうち、学習回数の増加に伴って教師信号と出力信号との誤差が低下し、かつ人物の顔の検知率が最も高い組を、前記最適な組として選択することを特徴とするものである。 An image processing apparatus according to a fourth aspect of the present invention is the image processing apparatus according to the third aspect, in which the setting means includes a teacher signal and an output signal as the number of learnings increases in the plurality of sets. And a group having the highest human face detection rate is selected as the optimum group.
第4の態様に係る画像処理装置によれば、設定手段は、複数の組のうち、学習回数の増加に伴って教師信号と出力信号との誤差が低下し、かつ人物の顔の検知率が最も高い組を、最適な組として選択する。これにより、顔検知の精度を向上することが可能となる。 According to the image processing apparatus of the fourth aspect, the setting means includes a plurality of sets in which the error between the teacher signal and the output signal decreases with an increase in the number of learnings, and the human face detection rate increases. The highest set is selected as the optimal set. As a result, the accuracy of face detection can be improved.
本発明の第5の態様に係る画像処理装置は、第1〜第4のいずれか一つの態様に係る画像処理装置において特に、第3の画像を記憶する記憶手段をさらに備え、前記設定手段は、学習回数の増加に伴う教師信号と出力信号との誤差の低下の度合いが所定値未満となった場合に、前記記憶手段から読み出した前記第3の画像を前記入力層に入力することにより、前記重み付け値の設定処理を継続することを特徴とするものである。 The image processing apparatus according to a fifth aspect of the present invention is the image processing apparatus according to any one of the first to fourth aspects, and further includes a storage unit that stores a third image, and the setting unit includes The third image read from the storage means is input to the input layer when the degree of decrease in error between the teacher signal and the output signal with the increase in the number of learning is less than a predetermined value, The weighting value setting process is continued.
第5の態様に係る画像処理装置によれば、設定手段は、学習回数の増加に伴う教師信号と出力信号との誤差の低下の度合いが所定値未満となった場合に、記憶手段から読み出した第3の画像を入力層に入力することにより、重み付け値の設定処理を継続する。このように、誤差特性が収束してきた場合に新たな教師画像を自動で追加することによって、学習をさらに進めることができ、その結果、さらに適切な重み付け値を設定することが可能となる。 According to the image processing apparatus of the fifth aspect, the setting unit reads from the storage unit when the degree of reduction in the error between the teacher signal and the output signal due to the increase in the number of learnings is less than a predetermined value. By inputting the third image to the input layer, the weighting value setting process is continued. As described above, when the error characteristic has converged, by automatically adding a new teacher image, learning can be further advanced, and as a result, a more appropriate weighting value can be set.
本発明の第6の態様に係る画像処理装置は、第5の態様に係る画像処理装置において特に、前記第3の画像は、人物の顔を含まない画像であることを特徴とするものである。 The image processing apparatus according to a sixth aspect of the present invention is characterized in that, in the image processing apparatus according to the fifth aspect, the third image is an image that does not include a human face. .
第6の態様に係る画像処理装置によれば、誤差特性が収束してきた場合に新たに追加される第3の画像は、人物の顔を含まない画像である。人物の顔を含まない画像を用いることにより、抑制学習を行うことができる。また、人物の顔を含まない画像に関しては、画像内における人物の顔の位置を教師信号として教示する処理が不要であるため、新たな画像の追加に伴う処理の負荷を軽減することが可能となる。 According to the image processing apparatus of the sixth aspect, the third image newly added when the error characteristic has converged is an image that does not include a human face. Suppression learning can be performed by using an image that does not include a human face. In addition, for an image that does not include a person's face, it is not necessary to teach the position of the person's face in the image as a teacher signal, so the processing load associated with the addition of a new image can be reduced. Become.
本発明の第7の態様に係る画像処理装置は、入力層及び出力層を含む複数の処理層を有し、各前記処理層が複数のユニットを含み、前記入力層に入力された入力画像に含まれる人物の顔の位置を示す出力画像を前記出力層から出力する、ニューラルネットワークと、人物の顔を含む第1の画像を取得する取得手段と、前記第1の画像を前記入力層に入力することにより、前記第1の画像を教師画像として用いた学習によって、異なる前記処理層に属する各前記ユニット間の重み付け値を設定する設定手段と、を備え、各前記ユニットの出力値Yは、パラメータμ(≧1)と自身のユニット値Xとを用いて、
と定義され、前記設定手段は、パラメータμの値が互いに異なる値に設定された複数の処理系統によって、前記重み付け値の組をそれぞれ求め、得られた複数の組の中から最適な組を選択することを特徴とするものである。An image processing apparatus according to a seventh aspect of the present invention includes a plurality of processing layers including an input layer and an output layer, each of the processing layers includes a plurality of units, and an input image input to the input layer A neural network for outputting an output image indicating the position of the included human face from the output layer, an acquisition means for acquiring a first image including the human face, and the first image being input to the input layer And setting means for setting a weight value between the units belonging to different processing layers by learning using the first image as a teacher image, and the output value Y of each unit is: Using the parameter μ (≧ 1) and its own unit value X,
The setting means obtains each set of the weight values by a plurality of processing systems in which the value of the parameter μ is set to a different value, and selects the optimum set from the obtained plurality of sets. It is characterized by doing.
第7の態様に係る画像処理装置によれば、設定手段は、パラメータμの値が互いに異なる値に設定された複数の処理系統によって、各ユニット間の重み付け値の組をそれぞれ求める。そして、得られた複数の組の中から最適な組を選択する。従って、パラメータμの値が固定された一つの処理系統のみによって重み付け値を設定する場合と比較すると、より良い重み付け値を設定することが可能となる。 According to the image processing apparatus of the seventh aspect, the setting means obtains a set of weight values between the units by a plurality of processing systems in which the value of the parameter μ is set to a different value. Then, an optimum group is selected from the obtained plurality of groups. Therefore, it is possible to set a better weighting value as compared with the case where the weighting value is set only by one processing system in which the value of the parameter μ is fixed.
本発明の第8の態様に係る画像処理装置は、入力層及び出力層を含む複数の処理層を有し、各前記処理層が複数のユニットを含み、前記入力層に入力された入力画像に含まれる人物の顔の位置を示す出力画像を前記出力層から出力する、ニューラルネットワークと、人物の顔を含む第1の画像を取得する取得手段と、前記第1の画像を前記入力層に入力することにより、前記第1の画像を教師画像として用いた学習によって、異なる前記処理層に属する各前記ユニット間の重み付け値を設定する設定手段と、第2の画像を記憶する記憶手段と、を備え、前記設定手段は、学習回数の増加に伴う教師信号と出力信号との誤差の低下の度合いが所定値未満となった場合に、前記記憶手段から読み出した前記第2の画像を前記入力層に入力することにより、前記重み付け値の設定処理を継続することを特徴とするものである。 An image processing apparatus according to an eighth aspect of the present invention has a plurality of processing layers including an input layer and an output layer, each of the processing layers includes a plurality of units, and an input image input to the input layer A neural network for outputting an output image indicating the position of the included human face from the output layer, an acquisition means for acquiring a first image including the human face, and the first image being input to the input layer Accordingly, a setting unit that sets a weighting value between the units belonging to different processing layers by learning using the first image as a teacher image, and a storage unit that stores the second image, And the setting means outputs the second image read from the storage means when the degree of decrease in error between the teacher signal and the output signal with the increase in the number of learnings is less than a predetermined value. To enter More, it is characterized in that to continue setting processing of the weighting value.
第8の態様に係る画像処理装置によれば、設定手段は、学習回数の増加に伴う教師信号と出力信号との誤差の低下の度合いが所定値未満となった場合に、記憶手段から読み出した第2の画像を入力層に入力することにより、重み付け値の設定処理を継続する。このように、誤差特性が収束してきた場合に新たな教師画像を自動で追加することによって、学習をさらに進めることができ、その結果、さらに適切な重み付け値を設定することが可能となる。 According to the image processing apparatus of the eighth aspect, the setting unit reads from the storage unit when the degree of reduction in the error between the teacher signal and the output signal with the increase in the number of learnings is less than a predetermined value. By inputting the second image to the input layer, the weighting value setting process is continued. As described above, when the error characteristic has converged, by automatically adding a new teacher image, learning can be further advanced, and as a result, a more appropriate weighting value can be set.
本発明によれば、準備できた画像の数が少ない場合であっても、顔検知の精度を向上することが可能な画像処理装置を得ることができる。 According to the present invention, it is possible to obtain an image processing apparatus capable of improving the accuracy of face detection even when the number of prepared images is small.
以下、本発明の実施の形態について、図面を用いて詳細に説明する。なお、異なる図面において同一の符号を付した要素は、同一又は相応する要素を示すものとする。 Hereinafter, embodiments of the present invention will be described in detail with reference to the drawings. In addition, the element which attached | subjected the same code | symbol in different drawing shall show the same or corresponding element.
図1は、本発明の実施の形態に係る画像処理装置1の構成を示すブロック図である。図1の接続関係で示すように、画像処理装置1は、ニューラルネットワーク2、記憶部3、取得部4、加工部5、設定部6、及び検知率算出部7を備えて構成されている。 FIG. 1 is a block diagram showing a configuration of an
ニューラルネットワーク2は、入力画像S6に人物の顔が含まれている場合に、その顔の位置を示す出力画像S7を出力する。記憶部3には、複数の画像が記憶されている。記憶部3には、人物の顔を含む画像のほか、人物の顔を含まない画像も記憶されている。取得部4は、記憶部3に記憶されている画像を画像データS1として読み出し、読み出した画像を画像データS2として加工部5に入力する。加工部5は、取得部4から入力された画像に対して所定の加工処理(詳細は後述する)を施すことにより、複数の画像を画像データS3として設定部6に入力する。ここで、加工部5は、取得部4から入力された画像自身も設定部6に入力してもよい。設定部6は、加工部5から入力された画像に基づいて、ニューラルネットワーク2の学習のために用いる教師画像を、画像データS5としてニューラルネットワーク2に入力する。検知率算出部7は、複数の入力画像S6をニューラルネットワーク2に入力し、入力画像S6の総数に対する、人物の顔の位置を正しく検知できた出力画像S7の数の割合(検知率)を求め、その検知率に関するデータS4を設定部6に入力する。 When the input image S6 includes a human face, the
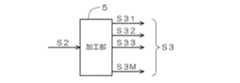
図2は、図1に示した加工部5を示す図である。加工部5には、図1に示した取得部4から画像データS2が入力される。加工部5は、人物の顔が含まれる画像データS2に対して様々な加工処理(ランダマイズ)を施すことにより、人物の顔が含まれる複数の画像データS31,S32,S33,・・・,S3M(図1に示した画像データS3に相当する)を出力する。ランダマイズには、例えば、画像を拡大又は縮小する処理(アスペクト比の変更や解像度の変更を含む)、画像を任意の角度で回転させる処理、画像内における顔位置を変更する処理(トリミング領域の位置や大きさの変更を含む)、画像においてレンズ歪みを恣意的に付与する処理、画像においてノイズを恣意的に付与する処理、及び、画像において光源を恣意的に変更する処理(照度の変更や色温度の変更を含む)が含まれる。これらの各処理は、周知の画像処理技術によって実現することが可能である。 FIG. 2 is a diagram illustrating the
図3は、図1に示したニューラルネットワーク2の構成を示す図である。ニューラルネットワーク2は、複数の処理層を有する階層型のニューラルネットワークであり、複数の入力ユニットを含む入力層10と、複数の中間ユニットを含む中間層11と、複数の出力ユニットを含む出力層12とを備えている。各入力ユニットには、設定部6から入力された画像データS5の各画素値(例えば輝度値)が入力される。各出力ユニットは、画像データS7の各画素値(例えば白又は黒)を出力する。 FIG. 3 is a diagram showing a configuration of the
図4は、入力層10に入力される画像20と、出力層12から出力される画像21とを示す図である。画像20には人物の顔が含まれている。画像21は、画像20に含まれる人物の顔の中心位置を示している。図4に示した画像21の例では、顔の中心位置に対応する画素が白く表示され、その他の領域の画素が黒く表示されている。 FIG. 4 is a diagram illustrating an
図5は、ニューラルネットワーク2における複数の入力ユニット401,402,・・・,40Nと一つの中間ユニット50とを抜き出して示す図である。中間ユニット50には、各入力ユニット401,402,・・・,40Nからの出力値Y1,Y2,・・・,YNが入力される。また、中間ユニット50と各入力ユニット401,402,・・・,40Nとの間には、重み付け値W1,W2,・・・,WNがそれぞれ設定されている。 FIG. 5 is a diagram showing a plurality of
中間ユニット50は、
なる演算を実行することにより、自身のユニット値Xを求める。ここで、θは、各中間ユニット50に設定されたオフセット値である。The
The unit value X is obtained by executing the following calculation. Here, θ is an offset value set for each
また、中間ユニット50は、
なる演算を実行することにより、自身の出力値Yを求めて出力する。ここで、μは、ニューラルネットワーク2に設定されたパラメータである。なお、図5では複数の入力ユニットと一つの中間ユニットとの関係を示したが、複数の中間ユニットと一つの出力ユニットとの関係もこれと同様である。The
Is executed to obtain and output its own output value Y. Here, μ is a parameter set in the
画像処理装置1では、教師画像内に含まれる人物の顔の位置は既知であるため、その顔の位置を教師信号として与えることにより、各教師画像から適切な出力画像(図4参照)が得られるように、ニューラルネットワーク2の学習(つまり各ユニット間の重み付け値Wの設定)が行われる。 In the
つまり、各出力ユニットに関して、教師信号と出力信号との誤差E(二乗誤差)を、
なる演算によって求める。ここで、Tは教師信号の値であり、Yは出力信号の値である。そして、誤差Eを用いて、重み付け値Wの修正量を、
なる演算によって求める。ここで、αは修正係数である。That is, for each output unit, the error E (square error) between the teacher signal and the output signal is
Is obtained by the following calculation. Here, T is the value of the teacher signal, and Y is the value of the output signal. Then, using the error E, the correction amount of the weighting value W is
Is obtained by the following calculation. Here, α is a correction coefficient.
図6は、図5に示したユニット値Xと出力値Yとの関係を示す図である。パラメータμ(≧1)の値の大小に応じて、ユニット値Xに対する出力値Yの反応の度合いが異なる。パラメータμの値が大きいほど、ユニット値Xが「0」の付近における曲線の傾斜は緩くなる。つまり、曲線の傾斜は、特性L1>特性L2>特性L3である。ニューラルネットワークにおいては、パラメータμの値を大きく設定するほど、学習に要する時間は増加するものの、汎化能力を高めることができる。 FIG. 6 is a diagram showing the relationship between the unit value X and the output value Y shown in FIG. The degree of response of the output value Y to the unit value X varies depending on the value of the parameter μ (≧ 1). The larger the value of the parameter μ, the gentler the slope of the curve near the unit value X of “0”. That is, the slope of the curve is characteristic L1> characteristic L2> characteristic L3. In the neural network, the larger the value of the parameter μ, the higher the generalization ability, although the time required for learning increases.
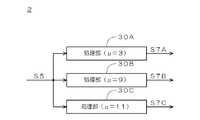
そこで、本実施の形態に係る画像処理装置1では、パラメータμの値が異なる複数の処理系統をニューラルネットワーク2に設け、それぞれの処理系統において並列に学習を行う。図7は、ニューラルネットワーク2の構成を示す図である。この例において、ニューラルネットワーク2は、パラメータμの値が「3」に設定された処理部30Aと、パラメータμの値が「9」に設定された処理部30Bと、パラメータμの値が「11」に設定された処理部30Cとを備える。処理部30A〜30Cは、図3に示した入力層10、中間層11、及び出力層12をそれぞれ有する。処理部30A〜30Cは、設定部6から画像データS5をそれぞれ入力し、画像データS7A〜S7Cをそれぞれ出力する。そして、図1に示した設定部6は、処理部30A〜30Cによって重み付け値Wの組をそれぞれ求め、得られた複数の組の中から最適な組を選択する。 Therefore, in the
一例として設定部6は、得られた複数の組のうち、学習回数の増加に伴って誤差Eが低下し、かつ人物の顔の検知率が最も高い組を、最適な組として選択する。 As an example, the
図8は、学習回数に応じた誤差Eの変化状況の一例を示す図である。図8に示した例では、パラメータμの値が「9」,「11」に設定された処理部30B,30Cに対応する誤差特性K2,K3に関しては、学習回数Pの増加に伴って誤差Eが低下している。一方、パラメータμの値が「3」に設定された処理部30Aに対応する誤差特性K1に関しては、学習回数Pが増加しても誤差Eは低下していない。従って、設定部6は、処理部30Aによって求めた重み付け値Wの組を、選択の候補から除外する。なお、実際には誤差特性K1〜K3は小刻みに振動しているが、図面の簡略化のため、図8ではその振動の図示を省略している。 FIG. 8 is a diagram illustrating an example of a change state of the error E according to the number of learnings. In the example shown in FIG. 8, with respect to the error characteristics K2 and K3 corresponding to the
次に、図1に示した検知率算出部7は、学習回数Pが所定値(例えば1000回)に達した時点で、複数の入力画像S6(望ましくは既に使用した教師画像とは異なる画像)を、処理部30B,30Cにそれぞれ入力する。そして、各処理部30B,30Cに関して、入力画像S6の総数に対する、人物の顔の位置を正しく検知できた出力画像S7の数の割合(検知率)を求める。そして、検知率算出部7は、各処理部30B,30Cの検知率に関するデータS4を設定部6に入力する。 Next, when the learning count P reaches a predetermined value (for example, 1000), the detection
設定部6は、処理部30B,30Cのうち検知率が高いほうの重み付け値Wの組を、上記最適な組として選択し、ニューラルネットワーク2に設定する。なお、この段階で選択の候補が三つ以上残っている場合には、三つ以上の組のうち検知率が最も高い組を上記最適な組として選択する。 The
また、本実施の形態に係る画像処理装置1は、ニューラルネットワーク2(又は図7に示した処理部30A〜30C)の学習が進んで誤差特性が収束してきた場合に、新たな教師画像を自動的に追加することにより、ニューラルネットワーク2の学習をさらに継続させる機能を有する。 The
図9は、学習回数に応じた誤差Eの変化状況の一例を示す図である。図1,9を参照して、学習が進んで誤差特性Kが収束してきた場合(つまり、学習回数Pの増加に伴う誤差Eの低下の度合いΔEが所定値未満となった場合)には、その旨の情報が取得部4に入力されることにより、取得部4は、既に教師画像として使用した画像とは異なる新たな画像を記憶部3から読み出す。ここで、取得部4が記憶部3から読み出す画像は、人物の顔を含まない画像であることが望ましい。これにより、顔でないパターンを顔でないと認識させる抑制学習を行うことができる。抑制学習を行う場合の教師信号は、全ての出力ユニットに関して例えば「0」となる。また、上述した検知率の算出のために使用した複数の入力画像S6のうち、顔でないのに顔であると誤検知されたパターンを含む画像を記憶部3に記憶しておき、その画像を抑制学習に使用してもよい。さらに、人物の顔に類似するが顔でないパターンを含む画像を記憶部3に記憶しておき、その画像を抑制学習に使用してもよい。 FIG. 9 is a diagram illustrating an example of a change state of the error E according to the number of learnings. Referring to FIGS. 1 and 9, when the learning progresses and the error characteristic K has converged (that is, when the degree ΔE of decrease in error E accompanying the increase in the number of learnings P is less than a predetermined value), When the information to that effect is input to the
取得部4は、記憶部3から読み出した画像を新たな教師画像としてニューラルネットワーク2に入力し、ニューラルネットワーク2は、取得部4から入力された新たな教師画像に基づいて学習を継続する。 The
図9を参照して、学習回数PがP1〜P3の各時点で、新たな教示画像が追加されている。新たな教師画像が追加された直後において誤差Eは上昇するが、学習が進むにつれて誤差Eは徐々に低下し、やがて追加前の値よりも小さくなる。誤差特性Kが収束する度に新たな教師画像を追加して学習を継続させることにより、全体として誤差Eは徐々に低下する。 Referring to FIG. 9, a new teaching image is added at each time point where the learning frequency P is P1 to P3. The error E increases immediately after a new teacher image is added, but the error E gradually decreases as learning progresses, and eventually becomes smaller than the value before the addition. By adding a new teacher image and continuing learning whenever the error characteristic K converges, the error E gradually decreases as a whole.
このように本実施の形態に係る画像処理装置1によれば、加工部5は、取得部4から入力された画像(画像データS2)に対して所定の加工処理を施すことにより、人物の顔を含む複数の画像(画像データS3)を生成する。そして、設定部6は、加工部5が生成した複数の画像(画像データS3)をニューラルネットワーク2の入力層10に入力することにより、当該複数の画像を教師画像として用いた学習によって、各ユニット間の重み付け値Wを設定する。従って、準備できた画像(つまり記憶部3に記憶された画像)の数が少ない場合であっても、その画像を元に生成した複数の画像を教師画像として用いて学習を行うことができる。従って、各ユニット間の重み付け値Wを適切に設定することができ、その結果、顔検知の精度を向上することが可能となる。 As described above, according to the
また、本実施の形態に係る画像処理装置1によれば、取得部4から入力された画像(画像データS2)に対して加工部5が行う加工処理として、画像の拡大又は縮小、画像の回転、画像内における顔位置の変更、レンズ歪みの付与、ノイズの付与、及び光源変更等の加工処理を行うことにより、入力された画像(画像データS2)を元に複数の画像(画像データS3)を生成することが可能となる。 Further, according to the
また、本実施の形態に係る画像処理装置1によれば、設定部6は、パラメータμの値が互いに異なる値に設定された複数の処理部30A〜30C(図7参照)によって、各ユニット間の重み付け値Wの組をそれぞれ求める。そして、得られた複数の組の中から最適な組を選択する。従って、パラメータμの値が固定された一つの処理系統のみによって重み付け値Wを設定する場合と比較すると、より良い重み付け値Wを設定することが可能となる。 Further, according to the
また、本実施の形態に係る画像処理装置1によれば、設定部6は、複数の組のうち、学習回数Pの増加に伴って教師信号と出力信号との誤差Eが低下し、かつ人物の顔の検知率が最も高い組を、最適な組として選択する。これにより、顔検知の精度を向上することが可能となる。 Further, according to the
また、本実施の形態に係る画像処理装置1によれば、設定部6は、学習回数Pの増加に伴う教師信号と出力信号との誤差Eの低下の度合いが所定値未満となった場合に、記憶部3から読み出した新たな画像をニューラルネットワーク2の入力層10に入力することにより、重み付け値Wの設定処理を継続する。このように、誤差特性Kが収束してきた場合に新たな教師画像を自動で追加することによって、学習をさらに進めることができ、その結果、さらに適切な重み付け値Wを設定することが可能となる。 Further, according to the
また、本実施の形態に係る画像処理装置1によれば、誤差特性Kが収束してきた場合に新たに追加される画像は、人物の顔を含まない画像である。人物の顔を含まない画像を用いることにより、抑制学習を行うことができる。また、人物の顔を含まない画像に関しては、画像内における人物の顔の位置を教師信号として教示する処理が不要であるため、新たな画像の追加に伴う処理の負荷を軽減することが可能となる。 Further, according to the
1 画像処理装置
2 ニューラルネットワーク
3 記憶部
4 取得部
5 加工部
6 設定部
7 検知率算出部
10 入力層
11 中間層
12 出力層
30A〜30C 処理部
DESCRIPTION OF
Claims (8)
Translated fromJapanese人物の顔を含む第1の画像を取得する取得手段と、
前記第1の画像に対して所定の加工処理を施すことにより、人物の顔を含む複数の第2の画像を生成する加工手段と、
前記複数の第2の画像を前記入力層に入力することにより、前記複数の第2の画像を教師画像として用いた学習によって、異なる前記処理層に属する各前記ユニット間の重み付け値を設定する設定手段と、
を備える、画像処理装置。An output image having a plurality of processing layers including an input layer and an output layer, each processing layer including a plurality of units, and indicating the position of a human face included in the input image input to the input layer Output from layer, neural network,
An acquisition means for acquiring a first image including a person's face;
Processing means for generating a plurality of second images including a person's face by applying a predetermined processing to the first image;
A setting for setting a weight value between the units belonging to different processing layers by learning using the plurality of second images as a teacher image by inputting the plurality of second images to the input layer. Means,
An image processing apparatus comprising:
と定義され、
前記設定手段は、パラメータμの値が互いに異なる値に設定された複数の処理系統によって、前記重み付け値の組をそれぞれ求め、得られた複数の組の中から最適な組を選択する、請求項1又は2に記載の画像処理装置。The output value Y of each unit is obtained by using the parameter μ (≧ 1) and its own unit value X,
Defined as
The setting means obtains each set of the weight values by a plurality of processing systems in which the value of the parameter μ is set to a value different from each other, and selects an optimal set from the obtained plurality of sets. The image processing apparatus according to 1 or 2.
前記設定手段は、学習回数の増加に伴う教師信号と出力信号との誤差の低下の度合いが所定値未満となった場合に、前記記憶手段から読み出した前記第3の画像を前記入力層に入力することにより、前記重み付け値の設定処理を継続する、請求項1〜4のいずれか一つに記載の画像処理装置。A storage means for storing the third image;
The setting means inputs the third image read from the storage means to the input layer when the degree of decrease in the error between the teacher signal and the output signal with the increase in the number of learnings is less than a predetermined value. The image processing apparatus according to claim 1, wherein the weighting value setting process is continued.
人物の顔を含む第1の画像を取得する取得手段と、
前記第1の画像を前記入力層に入力することにより、前記第1の画像を教師画像として用いた学習によって、異なる前記処理層に属する各前記ユニット間の重み付け値を設定する設定手段と、
を備え、
各前記ユニットの出力値Yは、パラメータμ(≧1)と自身のユニット値Xとを用いて、
と定義され、
前記設定手段は、パラメータμの値が互いに異なる値に設定された複数の処理系統によって、前記重み付け値の組をそれぞれ求め、得られた複数の組の中から最適な組を選択する、画像処理装置。An output image having a plurality of processing layers including an input layer and an output layer, each processing layer including a plurality of units, and indicating the position of a human face included in the input image input to the input layer Output from layer, neural network,
An acquisition means for acquiring a first image including a person's face;
Setting means for setting a weight value between the units belonging to different processing layers by learning using the first image as a teacher image by inputting the first image to the input layer;
With
The output value Y of each unit is obtained by using the parameter μ (≧ 1) and its own unit value X,
Defined as
The setting means obtains the set of weight values by a plurality of processing systems in which the value of the parameter μ is set to a different value, and selects an optimal set from the plurality of obtained sets. apparatus.
人物の顔を含む第1の画像を取得する取得手段と、
前記第1の画像を前記入力層に入力することにより、前記第1の画像を教師画像として用いた学習によって、異なる前記処理層に属する各前記ユニット間の重み付け値を設定する設定手段と、
第2の画像を記憶する記憶手段と、
を備え、
前記設定手段は、学習回数の増加に伴う教師信号と出力信号との誤差の低下の度合いが所定値未満となった場合に、前記記憶手段から読み出した前記第2の画像を前記入力層に入力することにより、前記重み付け値の設定処理を継続する、画像処理装置。
An output image having a plurality of processing layers including an input layer and an output layer, each processing layer including a plurality of units, and indicating the position of a human face included in the input image input to the input layer Output from layer, neural network,
An acquisition means for acquiring a first image including a person's face;
Setting means for setting a weight value between the units belonging to different processing layers by learning using the first image as a teacher image by inputting the first image to the input layer;
Storage means for storing a second image;
With
The setting means inputs the second image read from the storage means to the input layer when the degree of reduction in error between the teacher signal and the output signal with the increase in the number of learnings is less than a predetermined value. By doing so, the image processing apparatus continues the setting process of the weighting value.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2010091233AJP5513960B2 (en) | 2010-04-12 | 2010-04-12 | Image processing device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2010091233AJP5513960B2 (en) | 2010-04-12 | 2010-04-12 | Image processing device |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2011221840Atrue JP2011221840A (en) | 2011-11-04 |
| JP5513960B2 JP5513960B2 (en) | 2014-06-04 |
Family
ID=45038739
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2010091233AActiveJP5513960B2 (en) | 2010-04-12 | 2010-04-12 | Image processing device |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP5513960B2 (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3410351A1 (en) | 2017-05-31 | 2018-12-05 | Fujitsu Limited | Learning program, learning method, and object detection device |
| JP2019185359A (en)* | 2018-04-09 | 2019-10-24 | トヨタ自動車株式会社 | Machine learning device |
| US12205352B2 (en) | 2021-02-24 | 2025-01-21 | Panasonic Intellectual Property Management Co., Ltd. | Image identifying apparatus, video reproducing apparatus, image identifying method, and recording medium |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US10127439B2 (en) | 2015-01-15 | 2018-11-13 | Samsung Electronics Co., Ltd. | Object recognition method and apparatus |
| WO2023149649A1 (en)* | 2022-02-07 | 2023-08-10 | 삼성전자 주식회사 | Electronic device and method for improving image quality |
Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH04266153A (en)* | 1991-02-20 | 1992-09-22 | Honda Motor Co Ltd | Neural network |
| JP2000048187A (en)* | 1998-07-29 | 2000-02-18 | Fuji Photo Film Co Ltd | Method for image transform |
| JP2005253031A (en)* | 2004-02-04 | 2005-09-15 | Sharp Corp | Image printing apparatus, control method for image printing apparatus, control program for image printing apparatus, and recording medium recording control program for image printing apparatus |
| JP2006065447A (en)* | 2004-08-25 | 2006-03-09 | Nippon Telegr & Teleph Corp <Ntt> | Classifier setting device, attention level measuring device, classifier setting method, attention level measuring method, and program |
| JP2007087345A (en)* | 2005-09-26 | 2007-04-05 | Canon Inc | Information processing apparatus and control method therefor, computer program, and storage medium |
| JP2007122362A (en)* | 2005-10-27 | 2007-05-17 | Toyota Motor Corp | State estimation method using neural network and state estimation device using neural network |
| JP2009237632A (en)* | 2008-03-25 | 2009-10-15 | Seiko Epson Corp | Object detection method, object detection device, object detection program and printer |
| JP2009282699A (en)* | 2008-05-21 | 2009-12-03 | Seiko Epson Corp | Detection of organ area corresponding to image of organ of face in image |
- 2010
- 2010-04-12JPJP2010091233Apatent/JP5513960B2/enactiveActive
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH04266153A (en)* | 1991-02-20 | 1992-09-22 | Honda Motor Co Ltd | Neural network |
| JP2000048187A (en)* | 1998-07-29 | 2000-02-18 | Fuji Photo Film Co Ltd | Method for image transform |
| JP2005253031A (en)* | 2004-02-04 | 2005-09-15 | Sharp Corp | Image printing apparatus, control method for image printing apparatus, control program for image printing apparatus, and recording medium recording control program for image printing apparatus |
| JP2006065447A (en)* | 2004-08-25 | 2006-03-09 | Nippon Telegr & Teleph Corp <Ntt> | Classifier setting device, attention level measuring device, classifier setting method, attention level measuring method, and program |
| JP2007087345A (en)* | 2005-09-26 | 2007-04-05 | Canon Inc | Information processing apparatus and control method therefor, computer program, and storage medium |
| JP2007122362A (en)* | 2005-10-27 | 2007-05-17 | Toyota Motor Corp | State estimation method using neural network and state estimation device using neural network |
| JP2009237632A (en)* | 2008-03-25 | 2009-10-15 | Seiko Epson Corp | Object detection method, object detection device, object detection program and printer |
| JP2009282699A (en)* | 2008-05-21 | 2009-12-03 | Seiko Epson Corp | Detection of organ area corresponding to image of organ of face in image |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3410351A1 (en) | 2017-05-31 | 2018-12-05 | Fujitsu Limited | Learning program, learning method, and object detection device |
| US10803357B2 (en) | 2017-05-31 | 2020-10-13 | Fujitsu Limited | Computer-readable recording medium, training method, and object detection device |
| JP2019185359A (en)* | 2018-04-09 | 2019-10-24 | トヨタ自動車株式会社 | Machine learning device |
| US12205352B2 (en) | 2021-02-24 | 2025-01-21 | Panasonic Intellectual Property Management Co., Ltd. | Image identifying apparatus, video reproducing apparatus, image identifying method, and recording medium |
Also Published As
| Publication number | Publication date |
|---|---|
| JP5513960B2 (en) | 2014-06-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6946831B2 (en) | Information processing device and estimation method for estimating the line-of-sight direction of a person, and learning device and learning method | |
| JP6766839B2 (en) | Inspection system, image identification system, identification system, classifier generation system, and learning data generation device | |
| CN102273208B (en) | Image processing device and image processing method | |
| WO2013089265A1 (en) | Dictionary creation device, image processing device, image processing system, dictionary creation method, image processing method, and program | |
| CN108229526A (en) | Network training, image processing method, device, storage medium and electronic equipment | |
| JP2020060879A (en) | Learning device, image generator, method for learning, and learning program | |
| JP5513960B2 (en) | Image processing device | |
| JP7512150B2 (en) | Information processing device, information processing method, and program | |
| JP2017010475A (en) | PROGRAM GENERATION DEVICE, PROGRAM GENERATION METHOD, AND GENERATION PROGRAM | |
| JP2021179833A (en) | Information processing equipment, information processing methods and programs | |
| US8873839B2 (en) | Apparatus of learning recognition dictionary, and method of learning recognition dictionary | |
| JP7741654B2 (en) | Learning device, image processing device, learning processing method, and program | |
| JP2020024612A (en) | Image processing device, image processing method, processing device, processing method and program | |
| JPWO2019188573A1 (en) | Arithmetic logic unit, arithmetic method and program | |
| WO2020240760A1 (en) | Difference detection device, difference detection method, and program | |
| WO2020194378A1 (en) | Image processing system, image processing device, image processing method, and computer-readable medium | |
| JP7403995B2 (en) | Information processing device, control method and program | |
| CN109671055A (en) | Pulmonary nodule detection method and device | |
| JP2020003879A (en) | Information processing device, information processing method, watermark detection device, watermark detection method, and program | |
| JP5617841B2 (en) | Image processing apparatus, image processing method, and image processing program | |
| JP2019074496A (en) | Crack detector, crack detection method, and computer program | |
| CN113269812B (en) | Training and application method, device, equipment and storage medium of image prediction model | |
| CN119206369A (en) | Zero-shot image anomaly detection and localization method based on pre-trained vision-language model | |
| JP2021089493A (en) | Information processing apparatus and learning method thereof | |
| CN118365693A (en) | Target object size detection method, device, equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination | Free format text:JAPANESE INTERMEDIATE CODE: A621 Effective date:20130329 | |
| A977 | Report on retrieval | Free format text:JAPANESE INTERMEDIATE CODE: A971007 Effective date:20131211 | |
| A131 | Notification of reasons for refusal | Free format text:JAPANESE INTERMEDIATE CODE: A131 Effective date:20131217 | |
| A521 | Written amendment | Free format text:JAPANESE INTERMEDIATE CODE: A523 Effective date:20140131 | |
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) | Free format text:JAPANESE INTERMEDIATE CODE: A01 Effective date:20140228 | |
| A61 | First payment of annual fees (during grant procedure) | Free format text:JAPANESE INTERMEDIATE CODE: A61 Effective date:20140328 | |
| R150 | Certificate of patent or registration of utility model | Ref document number:5513960 Country of ref document:JP Free format text:JAPANESE INTERMEDIATE CODE: R150 | |
| R250 | Receipt of annual fees | Free format text:JAPANESE INTERMEDIATE CODE: R250 | |
| R250 | Receipt of annual fees | Free format text:JAPANESE INTERMEDIATE CODE: R250 | |
| R250 | Receipt of annual fees | Free format text:JAPANESE INTERMEDIATE CODE: R250 |