JP2010186412A - Document management method and management device - Google Patents
Document management method and management deviceDownload PDFInfo
- Publication number
- JP2010186412A JP2010186412AJP2009031450AJP2009031450AJP2010186412AJP 2010186412 AJP2010186412 AJP 2010186412AJP 2009031450 AJP2009031450 AJP 2009031450AJP 2009031450 AJP2009031450 AJP 2009031450AJP 2010186412 AJP2010186412 AJP 2010186412A
- Authority
- JP
- Japan
- Prior art keywords
- state transition
- transition table
- document
- analysis
- analysis processing
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images






Landscapes
- Machine Translation (AREA)
- Document Processing Apparatus (AREA)
Abstract
Translated fromJapaneseDescription
Translated fromJapanese本発明は、文書管理方法及び管理装置に係り、特に、構造化文書の構文解析処理に要するメモリ使用量を抑制可能とした文書管理方法及び管理装置に関する。 The present invention relates to a document management method and management apparatus, and more particularly to a document management method and management apparatus capable of suppressing the memory usage required for syntax analysis processing of a structured document.
メモリ使用量を抑制可能とした構造化文書管理装置に関する従来技術として、例えば、特許文献1等に記載された技術が知られている。この従来技術は、アプリケーションに含まれる要素のうち、キーとして利用されない要素を1つの要素にまとめるデータ構造変換処理を、構文解析対象である構造化文書に施すことによって、キーとして利用されない要素のメモリ使用量を抑制することを可能としたものである。 For example, a technique described in
前述した従来技術による構造化文書の管理は、アプリケーションに含まれるキーとして利用されない要素についてメモリの使用量を抑制するため、アプリケーションの処理ロジックに特化したものである。このため、前述した従来技術は、アプリケーションの処理ロジックを変更すると、例えば、非キー要素であったものをキー要素として扱うようにロジックを変更すると、メモリ使用量の抑制度合いが変化してしまい、アプリケーションのロジックを変更しなければならない場合に、たとえ、構造化文書の構造に何ら変更を施さなくても、メモリ使用量に影響を及ぼしてしまうという問題点を生じさせてしまう。 The above-described management of structured documents according to the prior art is specialized in application processing logic in order to reduce the amount of memory used for elements that are not used as keys included in the application. For this reason, in the above-described prior art, when the processing logic of the application is changed, for example, when the logic is changed so that what was a non-key element is handled as a key element, the degree of suppression of the memory usage changes, When the logic of the application must be changed, even if no change is made to the structure of the structured document, there is a problem that the memory usage is affected.
本発明の目的は、前述した従来技術の問題点を解決し、メモリ使用量の抑制度合いが、アプリケーションの処理ロジックの変更によって、メモリ使用量の抑制度合いが影響されることを少なくして、構文解析処理におけるメモリ使用量を抑制することを可能とした構造化文書の文書管理方法及び管理装置を提供することにある。 The object of the present invention is to solve the above-mentioned problems of the prior art, and to reduce the amount of memory usage by reducing the amount of memory usage by changing the processing logic of the application. It is an object of the present invention to provide a document management method and management apparatus for structured documents that can suppress memory usage in analysis processing.
本発明は、前述の目的を達成するために、アプリケーションの処理ロジックが変わっても構造化文書の構造が変わらない限り、メモリ使用量の抑制度合いが同程度になるような機能を構造化文書管理装置に対して付加する。 In order to achieve the above-mentioned object, the present invention provides a function for reducing the amount of memory used to the same extent as long as the structure of the structured document does not change even if the processing logic of the application changes. Add to the device.
具体的には、本発明は、入力される構造化文書の構文解析を行う文書管理方法であって、文書管理装置が備える構造化文書の解析処理部が、事前解析処理手段と、該事前解析処理手段が生成した状態遷移テーブルを検索する状態遷移テーブル検索手段とを有し、前記事前解析処理手段は、入力される構造化文書の構造単位の親子兄弟関係パターンを構文解析処理前に事前解析して該親子兄弟関係を格納した状態遷移テーブルを生成し、前記構造化文書の解析処理部は、入力された文書の構文解析処理中に、前記状態遷移テーブル検索手段により前記状態遷移テーブルを参照し、前記状態遷移テーブルに格納済みの文字列の処理が要求されている場合に、前記状態遷移テーブルに格納済みの解析結果を返すことを特徴とする。 Specifically, the present invention is a document management method for performing a syntax analysis of an input structured document, wherein a structured document analysis processing unit provided in the document management apparatus includes a pre-analysis processing unit and the pre-analysis processing unit. A state transition table retrieving unit that retrieves the state transition table generated by the processing unit, and the prior analysis processing unit preliminarily analyzes the parent-child sibling relationship pattern of the structural unit of the input structured document before the parsing process. A state transition table storing the parent-child sibling relationship is generated by analysis, and the structured document analysis processing unit generates the state transition table by the state transition table search means during the parsing process of the input document. When the processing of the character string stored in the state transition table is requested, the analysis result stored in the state transition table is returned.
本発明によれば、構文解析処理を行う前に「要素の親子・兄弟・属性関係が、業務システムで扱う構造化文書と同じであるような、代表的な構造化文書」を元に状態遷移テーブルを一度だけ作成し、構文解析処理中に前記状態遷移テーブルを参照することにより、構文解析処理におけるメモリ使用量を抑制することが可能となる。また、メモリ使用量の抑制度合いが、アプリケーションの処理ロジックの変更に影響されることを少なくすることができる。 According to the present invention, before performing the parsing process, the state transition is based on “a typical structured document whose element parent / child / sibling / attribute relationship is the same as the structured document handled in the business system”. By creating the table only once and referring to the state transition table during the parsing process, it is possible to suppress the memory usage in the parsing process. In addition, it is possible to reduce the degree of suppression of the memory usage amount from being affected by changes in the processing logic of the application.
以下、本発明による構造化文書の文書管理方法及び管理装置の実施形態を図面により詳細に説明する。なお、以下に説明する本発明の実施形態は、構造化文書として、構造化文書を表現する言語の1つであるXML文書を扱うものとしている。 Embodiments of a document management method and management apparatus for structured documents according to the present invention will be described below in detail with reference to the drawings. In the embodiment of the present invention described below, an XML document that is one of languages for expressing a structured document is handled as a structured document.
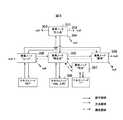
図1は本発明の一実施形態によるXML文書管理装置の機能構成と、その入出力データの流れの概要を示す図である。 FIG. 1 is a diagram showing a functional configuration of an XML document management apparatus according to an embodiment of the present invention and an outline of a flow of input / output data thereof.
本発明の実施形態によるXML文書管理装置は、主記憶装置102と、HDD等の補助記憶装置106と、プログラムにより構成され、本発明のために設けられた各種機能部の処理を実行するCPUてあるプロセッサ104と、図示しないキーボード、マウス等の入力装置及び表示装置、印刷装置等の出力装置とがバス105に接続されて構成されている計算機システムの中に構築されている。そして、補助記憶106には、本発明の実施形態で解析するXML文書107が格納されており、また、主記憶装置102には、本発明の実施形態の文書管理において、文書の解析を行うXML解析処理部103と、アプリケーション115と、XML解析処理部103により生成される状態遷移テーブル119とが格納されている。 An XML document management apparatus according to an embodiment of the present invention includes a
また、XML解析処理部103は、XML構文解析メイン部108、状態遷移テーブル検索部117、要素開始タグ解析部109、要素文字チェック部110、属性解析・ノード生成部111、要素ノード生成部112、コンテンツ解析・テキストノード生成部113、要素終了タグ解析部114、事前解析部116、省メモリ要素ノード生成部118の各機能部を備えて構成されている。前述し各機能部は、プログラムにより構成されており、プロセッサ104により実行されることにより、それぞれの機能が構築されるものである。 The XML analysis processing unit 103 includes an XML syntax analysis
補助記憶装置106に格納されたXML文書107は、XML解析処理部103に入力され、XML解析処理部103により構文解析の処理が行われる。XML文書は、“要素”を基本単位とした階層構造を有する構造化文書の1つである。要素は、親子関係を持つことができる。また、要素には、“属性”という情報を付加することができる。さらに、要素は、その子として他の要素及びテキストを持つことができる。通常、ある1つの要素の子に該当する要素及びテキストを総称して、その要素の“コンテンツ”と呼ぶ。 The
前述において、一般的なXML解析処理部103は、XML文書の基本単位である要素を構文解析する場合、XML構文解析メイン部108を起点として、要素開始タグ解析部109、要素文字チェック部110、属性解析・ノード生成部111、要素ノード生成部112、コンテンツ解析・テキストノード生成部113、要素終了タグ解析部114が順番に呼び出されて構文解析を行う。なお、ノードとは、XML文書を構文解析して認識された要素、属性、テキストをメモリ上に保持する単位のことである。XML文書に含まれる要素、属性、テキストは、構文解析処理を経ることにより、それぞれ要素ノード、属性ノード、テキストノードとしてメモリ上に保持される。XML解析処理部103は、生成された前述のノードをアプリケーション115に渡す。 In the above description, when a general XML analysis processing unit 103 parses an element that is a basic unit of an XML document, an element start
要素開始タグ解析部109、要素終了タグ解析部114は、要素の開始タグ及び終了タグを字句解析する。字句解析とは、XML文書に含まれる文字列を、構造部分(マークアップと呼ばれる)を表す“<”や“>”などと、それ以外の部分とに分解する処理である。要素文字チェック部110は、要素に含まれる文字がXML仕様で定義された文字に合致しているかどうかをチェックする処理である。これらの処理は比較的多くの時間を消費する。 The element start
本発明の実施形態は、前述したような一般的なXML解析処理部の構成に対して、本発明により事前解析部116、状態遷移テーブル検索部117、省メモリ要素ノード生成118を追加し、主記憶装置102の上に状態遷移テーブル119を追加したものである。 In the embodiment of the present invention, a
図2はXML文書の文書構造と、構文解析後のメモリ上のデータ構造とを説明する図であり、次に、これについて説明する。 FIG. 2 is a diagram for explaining the document structure of the XML document and the data structure on the memory after the syntax analysis. Next, this will be described.
図2(a)はXML文書における要素と、要素から生成されるノードとを説明するものである。要素は、開始タグ201で始まり、終了タグ202で終わる。開始タグと終了タグとの間にはコンテンツが含まれていてもよい。コンテンツは、コンテンツ203(「001」)のようにテキストだけであってもよく、コンテンツ204のように要素205(開始タグ201を<コード>、コンテンツ203を「001」、終了タグを</コード>とした要素)を含んでもよい。例えば、要素205は、テキストだけを含み、要素206(開始タグが<仕入品>、終了タグが</仕入品>)は、要素とテキストの両方を含むものとしている。また、要素は属性207を保持することができる。 FIG. 2A illustrates the elements in the XML document and the nodes generated from the elements. The element begins with a
一般に、業務システムでXML文書を処理するアプリケーションには、図2(a)に示しているような要素を複数個持ったXML文書が、数百〜数万といったオーダで入力される。そして、図1に示して説明したXML解析処理部103は、これらのXML文書を構文解析処理する。構文解析結果は、図2(b)に示すようなノードツリー208としてメモリ上に構築される。図2(b)に示すノードツリー208は、図2(a)に示すXML文書の要素206に対応するノードツリーの例である。 In general, an XML document having a plurality of elements as shown in FIG. 2A is input to an application that processes an XML document in a business system on the order of hundreds to tens of thousands. Then, the XML analysis processing unit 103 described with reference to FIG. 1 performs a syntax analysis process on these XML documents. The parsing result is constructed on a memory as a
図3は図2(b)に示したノードツリーを詳細に示した図である。 FIG. 3 shows the details of the node tree shown in FIG.
図2により説明したように、要素には親子兄弟関係及び要素−属性関係があり、これらに対応するノード間の関係をメモリ上で表現する必要があり、そのために、一般的には“参照”が使用される。参照の実装例としては、Java(登録商標)言語における参照、C言語におけるポインタ等ががある。参照がメモリ上に占めるサイズは、プロセッサのバス幅に応じて32ビットあるいは64ビットであることが多い。 As described with reference to FIG. 2, an element has a parent-child sibling relationship and an element-attribute relationship, and the relationship between nodes corresponding to these must be expressed in a memory. Therefore, generally, “reference” is used. Is used. Examples of the reference implementation include a reference in Java (registered trademark) language, a pointer in C language, and the like. The size of the reference on the memory is often 32 bits or 64 bits depending on the bus width of the processor.
図3に示すノード群の最上位要素ノードである“仕入品”の要素ノード301は、属性及び兄弟ノードを持たないため、属性関係及び兄弟関係を表す参照302、303、304がnullを指している。“商品名”要素ノード305は、子要素ノード306及び属性ノード307を持つので、それらを参照している。また、“コード”要素ノード308の属性ノードへの参照はnullとなり、“備考”要素ノード309の子要素ノード及び属性ノードへの参照はnullとなる。通常、nullを参照していても、参照を確保するためには、メモリ領域(32ビットあるいは64ビット等)を確保する必要があるが、本発明の実施形態は、nullへの参照を確保しないようにすることによってメモリ使用量を抑制している。 Since the
図4は本発明の実施形態によりメモリ使用量を抑制したノードの例について説明する図である。 FIG. 4 is a diagram illustrating an example of a node in which the memory usage is suppressed according to the embodiment of the present invention.
本発明の実施形態では、図4(b)のテーブル401に示すように、要素ノードの種別を、兄弟要素ノードの有無、子要素ノードの有無、属性ノードの有無の組み合わせにより、type1〜type8の8つに分類する。要素ノードの種類をこのように分類しておくことにより、本発明の実施形態は、兄弟要素ノード、子要素ノード、属性ノードを持たない要素に対応するノードにnull参照を持たせる必要がなくなり、結果としてメモリ使用量を抑制した要素ノード(これを省メモリ要素ノードと称する)を生成することができる。 In the embodiment of the present invention, as shown in the table 401 of FIG. 4B, the type of element node is set to type 1 to type 8 depending on the combination of the presence / absence of sibling element nodes, the presence / absence of child element nodes and the presence / absence of attribute nodes. Classify into 8 categories. By classifying the types of element nodes in this way, the embodiment of the present invention does not need to have a null reference for nodes corresponding to elements that do not have sibling element nodes, child element nodes, and attribute nodes. As a result, it is possible to generate an element node (referred to as a memory-saving element node) in which the memory usage is suppressed.
図4(a)には、図3に示したノードツリーの各ノードに前述したような分類を行った場合のノードツリーを示している。この図4(a)において、例えば、“備考”ノード402は子要素及び属性を持たないtype5のノードで表現されるため、図3に示して説明した“備考”ノード309と比較して、null参照2つ分のメモリを節約することができる。省メモリ要素ノードを生成するためには、要素ノード生成部において、兄弟要素の有無、子要素の有無、属性の有無に応じて8種類の中から適切なノードを生成する必要がある。しかし、単に適切な要素ノードを選択的に生成する処理を、従来の解析処理部の中に挿入して増加させると、従来のXML解析処理部の処理と比較して処理ステップが多くなり、処理性能が劣化してしまう。このため、本発明の実施形態は、予め、状態遷移テーブルを119を作成しておき、この状態遷移テーブルを用いて、要素ノードを高速に生成することを可能としたものである。 FIG. 4A shows a node tree when the above-described classification is performed on each node of the node tree shown in FIG. In FIG. 4A, for example, the “remarks”
図5は代表的なXML文書を入力として、XML構文解析処理の前に図1に示す事前解析部116の処理で作成した状態遷移テーブルの構成を示す図である。ここで示している代表的なXML文書は、「要素の親子・兄弟・属性関係が、アプリケーションが扱うXML文書と同じであるようなXML文書」であり、図2に示して説明したXML文書を例としている。図5に示す状態遷移テーブルの作成方法については後述するが、ここでは状態遷移テーブルの意味を説明する。ここに示している状態遷移テーブルは、構文解析すべき文書を事前解析部116に入力して事前解析部116が予め作成しておくものであり、実際の構文解析は、事前解析の処理の後に、構文解析すべき文書がXML構文解析メイン部108に入力されて開始される。そして、図5に示す状態遷移テーブルは、構文解析時に次に説明するように利用される。 FIG. 5 is a diagram showing the configuration of the state transition table created by the processing of the
構文解析処理の初期状態S(501)において、“<仕入品”という要素開始タグ502が入力されると、状態1(503)に遷移し、図4により説明したtype3の要素ノード404を省メモリ要素ノードとして生成する。状態1(503)において、タグの終端文字である“>”504が入力されると、状態2(505)に遷移し、図4により説明したtype7の要素ノード403を省メモリ要素ノードとして生成する。続いて、“<コード”という要素開始タグ506が入力されると、状態3(507)に遷移する。そして、状態3(507)において、タグの終端文字である“>”とそれに続く任意のテキスト508が入力されると、状態4(509)に遷移する。状態4(509)において、“</コード>”という要素終了タグ510が入力されると、状態5(511)に遷移する。状態5(511)において、“<商品名”という要素開始タグ512が入力されると、状態6(513)に遷移し、図4により説明したtype8の要素ノード405を省メモリ要素ノードとして生成する。状態6(513)において、任意の属性の並び及び任意のテキスト514が入力された場合、状態7(515)に遷移する。状態7(515)において、“</商品名>”という要素終了タグ516が入力されると、状態8(517)に遷移する。状態8(517)において、“</備考/>”という空要素タグ518が入力されると、状態9(519)に遷移し、図4により説明したtype5の要素ノード402を省メモリ要素ノードとして生成する。状態9(519)において、“</仕入品>”という要素終了タグ520が入力されると、状態10(521)に遷移する。 In the initial state S (501) of the parsing process, when the element start tag 502 “<purchased product” is input, the state transitions to the state 1 (503), and the
前述したような図4に示す状態遷移図において、横方向への遷移と、縦方向への遷移とは、特に意味を持つものではない。 In the state transition diagram shown in FIG. 4 as described above, the transition in the horizontal direction and the transition in the vertical direction are not particularly significant.
前述したように、「解析中にXML文書から切り出した文字列」が、状態遷移テーブルの矢印上に記載された「遷移文字列」と一致すれば状態を進め、一致しなければ状態遷移テーブルの使用を終了する。一致した場合、図1における要素開始タグ解析部109及び要素文字チェック部110の処理が不要になる。なぜなら、状態遷移テーブル作成時にこれらの処理は済んでおり、必要なデータは、状態遷移テーブルが“遷移用文字列”として保持しているからである。従って、状態遷移テーブルの遷移が成功し続ければ、すなわち、入力文字列と遷移用文字列とが一致し続ければ、従来の構文解析処理が行う特定の処理をスキップすることにより構文解析処理を高速に進めつつ、メモリ使用量が少ない省メモリ要素ノードを生成することができる。 As described above, if the “character string cut out from the XML document during analysis” matches the “transition character string” described on the arrow of the state transition table, the state is advanced. End use. If they match, the processing of the element start
なお、状態遷移テーブルの遷移が失敗したとき、すなわち、入力文字列と遷移用文字列とが一致しなかった場合、従来からの通常の構文解析処理と同じように、図1における要素開始タグ解析部109、要素文字チェック部110、要素ノード生成部112を実行する必要がある。このため、遷移の失敗が頻発すると構文解析処理性能は劣化し、メモリ使用量も従来技術と同じというペナルティが生じることになる。しかし、前述で説明したように、本発明は、「アプリケーションの入力となる構造化文書は似通ったものになる」ことを前提としているため、ペナルティが発生する頻度は非常に少ない。 When the transition of the state transition table fails, that is, when the input character string and the character string for transition do not match, the element start tag analysis in FIG. The
図6は事前解析部116が状態遷移テーブルを作成する処理の動作を説明するフローチャートであり、次に、これについて説明する。 FIG. 6 is a flowchart for explaining the operation of the process in which the
(1)まず、状態遷移テーブル中に初期状態を作成し登録する。この初期状態の作成登録し、図5に示した初期状態S(501)を作成し登録することである(ステップ601)。(1) First, an initial state is created and registered in the state transition table. The initial state is created and registered, and the initial state S (501) shown in FIG. 5 is created and registered (step 601).
(2)次に「要素の親子・兄弟・属性関係が、アプリケーションが扱うXML文書と同じであるような、代表的なXML文書」の先頭から入力文字列を読み込み、入力文字列の種別を判定する。入力文字列の種別としては、1.要素開始タグ(“<”から始まる)、2.要素終了タグ(“<”から始まる)、3.テキスト(“<”以外で始まる)のどれかである(ステップ602)。(2) Next, the input character string is read from the head of “a typical XML document whose element parent / child / sibling / attribute relationship is the same as that of the XML document handled by the application”, and the type of the input character string is determined. To do. The types of input character strings are: Element start tag (starts with “<”), 2. 2. Element end tag (starts with “<”); Any text (beginning with something other than “<”) (step 602).
(2)ステップ602の入力文字列の種別を判定で、入力文字列の種別が要素開始タグ、または、要素終了タグであった場合、現在の状態(最初は初期状態)においてその入力文字列が指す遷移先状態が既に遷移テーブル内に存在するか否かを内判定する(ステップ603)。(2) When the type of the input character string is determined in
(3)ステップ603の判定で、入力文字列が指す遷移先状態が既に遷移テーブル内に存在していた場合、新たな状態を作成せずに既存の状態に遷移し(604)、存在しなかった場合、入力文字列である開始・終了タグを遷移先文字列とした新たな遷移先の状態を作成する(ステップ604〜606)。(3) If it is determined in
(4)そして、ステップ602の入力文字列の種別を判定で、入力文字列の種別が要素開始タグであった場合、次の文字列が属性である場合があるが、属性に関する情報は状態遷移テーブルに保持しないので単にスキップし、次に、タグの終端文字である“>”が入力されるので遷移先の状態を作成し、その状態の遷移用文字列として“>”を設定する(ステップ607、608)。(4) When the input character string type is determined in
(5)ステップ602の入力文字列の種別を判定で、入力文字列の種別がテキストであった場合、現在の状態において「任意のテキスト」が指す遷移先状態が既に存在するか否かを判定し、存在しなかった場合、「任意のテキスト」を表す特殊記号を遷移用文字列入力設定して、新たな状態を遷移先の状態として作成する(ステップ609〜611)。(5) When the type of the input character string is determined in
(6)ステップ607、608、611の処理の後、あるいは、ステップ609の判定で、現在の状態において「任意のテキスト」が指す遷移先状態が既に存在していた場合、前述まての処理を、全ての要素の読み込みが終了するまで行ったか否かを判定し、終了したいなかった場合、ステップ602からの処理に戻って処理を繰り返し、そうでなければ、ここでの処理を終了する(ステップ612)。(6) After the processing in
前述したような事前解析部116での処理により、図5に説明したような遷移テーブルが生成されることになる。 The transition table as illustrated in FIG. 5 is generated by the processing in the
図7は本発明の実施形態でのXML文書の解析処理の動作を説明するフローチャートであり、次に、これについて説明する。なお、ここでの処理の開始時には、事前解析部116での処理により、図5に説明したような遷移テーブルが生成されている。 FIG. 7 is a flowchart for explaining the operation of the XML document analysis processing according to the embodiment of the present invention. Next, this will be described. At the start of the processing here, the transition table as described in FIG. 5 is generated by the processing in the
(1)まず、XML解析処理部103は、現在の状態を初期状態にリセットする。これは、カレントステートに「S」をセットする処理である(ステップ701)。(1) First, the XML analysis processing unit 103 resets the current state to the initial state. This is a process of setting “S” in the current state (step 701).
(2)次に、XML解析処理部103は、XML文書107を読み込んで、XML構文解析メイン部108が要素の読み込みを開始する(ステップ702)。(2) Next, the XML analysis processing unit 103 reads the
(3)状態遷移テーブル検索部117は、読み込み中の要素開始タグが状態遷移テーブルの現在状態から出る遷移用文字列と一致するか否かを判定し、一致していなければ、現在の状態を初期状態にリセットする。この場合、図1において、要素開始タグ解析部109、要素文字チェック部110の処理に移行して、従来技術の場合と同様な処理となる(ステップ703、704)。(3) The state transition table search unit 117 determines whether or not the element start tag being read matches the transition character string output from the current state of the state transition table. Reset to the initial state. In this case, in FIG. 1, the process proceeds to the process of the element start
(4)ステップ703の判定で、読み込み中の要素開始タグが状態遷移テーブルの現在状態から出る遷移用文字列と一致した場合、遷移用文字列に従って状態遷移し、省メモリ要素ノード生成部118が遷移先状態の要素typeに従って、省メモリ要素ノードを生成する(ステップ705、706)。(4) If it is determined in
(5)次に、属性解析・ノード生成部111が属性があれば解析して属性ノードを生成する(ステップ707)。(5) Next, if there is an attribute, the attribute analysis /
(6)次に、タグの終端を表す文字“>”が必ず出現し、その後、場合によってはテキストが出現するので、これらの文字列、すなわち、“>”と任意のテキストを表す特殊文字とを遷移用文字列とする状態が現在の状態に隣接している場合、隣接している状態に遷移し、さもなければ現在の状態を初期状態にリセットする。ここでの処理は、コンテンツ解析・テキストノード生成部113により行われる(ステップ708)。(6) Next, since the character “>” representing the end of the tag always appears, and then the text appears in some cases, these character strings, that is, “>” and a special character representing any text, If the state having the character string for transition is adjacent to the current state, the state transitions to the adjacent state, otherwise the current state is reset to the initial state. This processing is performed by the content analysis / text node generation unit 113 (step 708).
(7)次に、これまでのステップにより省メモリ要素ノードが生成されたか否かを判定し、省メモリ要素ノードが生成されていなかった場合、通常の要素ノードを生成する(ステップ709、710)。(7) Next, it is determined whether or not a memory-saving element node has been generated by the above steps. If no memory-saving element node has been generated, a normal element node is generated (
(8)ステップ710の処理の後、あるいは、ステップ709の判定で、省メモリ要素ノードが生成されていた場合、要素終了タグ解析部114が、読み込み中の要素終了タグを表す文字列が、状態遷移図中の現在状態における遷移用文字列と一致するか否かを判定する(ステップ711)。(8) After the processing of
(9)ステップ711の判定で、読み込み中の要素終了タグを表す文字列が、状態遷移図中の現在状態における遷移用文字列と一致した場合、遷移用文字列に従って状態遷移し、一致しなければ、現在の状態を初期状態にリセットする(ステップ712、713)。(9) If the character string representing the element end tag being read matches the character string for transition in the current state in the state transition diagram in the determination in
(10)ステップ712、713の処理の終了後、全ての要素の読み込みが終了し、前述の処理を行ったか否かを判定し、全ての要素に対する処理がすんでいなかった場合、ステップ702からの処理に戻って処理を繰り返し、全ての要素に対する処理がすんでいた場合、ここでの処理を終了する(ステップ714)。(10) After completion of the processing in
前述した本発明の実施形態での各処理は、プログラムにより構成し、本発明が備えるCPUに実行させることができ、また、それらのプログラムは、FD、CDROM、DVD等の記録媒体に格納して提供することができ、また、ネットワークを介してディジタル情報により提供することができる。 Each process in the above-described embodiment of the present invention is configured by a program and can be executed by a CPU included in the present invention. These programs are stored in a recording medium such as an FD, CDROM, or DVD. It can be provided and can be provided by digital information via a network.
前述した処理において、読み込み中の要素開始タグが状態遷移テーブルの現在状態から出る遷移用文字列と一致するかどうかを判定するステップ703の処理は、状態遷移テーブルに登録された文字列と現在解析中の入力文字列とを単純に文字列比較するだけであり、負荷の低い処理である。従来技術によるXML構文解析処理は、要素開始タグ解析部109による要素タグの解析(XMLとしての字句規則に合致していることを確認する処理)及び要素文字チェック部110による要素文字チェック(XMLの要素名として許される文字だけが使われていることを確認する処理)という比較的負荷が高い処理が必要であった。 In the processing described above, the processing in
前述した本発明の実施形態によれば、入力文字列が図5に示して説明した事前解析処理で生成した状態遷移図に沿ったものであれば、言い換えると、入力XML文書が状態遷移テーブル生成の入力となった「要素の親子・兄弟・属性関係が、アプリケーションが扱うXML文書と同じであるような、代表的なXML文書」と同一構造であるという条件を満たせば、負荷が低い処理で省メモリ要素ノードを数多く生成することができる。本発明の実施形態は、これにより、高速かつメモリ使用量を抑制した構文解析処理を行うXML文書管理装置を実現することができる。 According to the above-described embodiment of the present invention, if the input character string is in accordance with the state transition diagram generated by the pre-analysis processing described with reference to FIG. 5, in other words, the input XML document is generated as a state transition table. If the condition that the same structure as the “representative XML document in which the parent-child / sibling / attribute relationship of the element is the same as that of the XML document handled by the application” is satisfied is satisfied, Many memory-saving element nodes can be generated. Accordingly, the embodiment of the present invention can realize an XML document management apparatus that performs syntax analysis processing at high speed and with reduced memory usage.
一般に、アプリケーションの入力となる個々の構造化文書は、同じ構造を持つものであり、親子・兄弟・属性関係が等しいことが多い。例えば、「“仕入品”要素の子要素が、“商品名”要素」といった構造が繰り返し出現する。また、アプリケーションの入力となる複数の構造化文書が、すべて同一構造を持っていることも多い。このため、前出の例を再度用いることとすると、アプリケーションが1000個の構造化文書を受け取った場合、個々の構造化文書のすべてが「“仕入品”要素の子要素は、“商品名”要素である」という構造をしていることが多い。 In general, each structured document that is an input of an application has the same structure and often has the same parent-child / sibling / attribute relationship. For example, a structure such as “a child element of the“ purchased product ”element is a“ product name ”element” repeatedly appears. In many cases, a plurality of structured documents serving as application inputs all have the same structure. Therefore, if the above example is used again, when the application receives 1000 structured documents, all of the individual structured documents are “children of the“ purchase ”element are“ product names ”. In many cases, the structure is “element”.
本発明の実施形態は、アプリケーションの入力となる構造化文書の前述のような性質に着目して処理を行っているため、構文解析の処理を高速化することができる。 In the embodiment of the present invention, processing is performed by paying attention to the above-described property of the structured document that is an input of the application, so that the parsing process can be speeded up.
101 計算機システム
102 主記憶装置
103 XML解析処理部
104 プロセッサ
105 バス
106 補助記憶装置
107 XML文書
108 XML構文解析メイン部
109 要素開始タグ解析部
110 要素文字チェック部
111 属性解析・ノード生成部
112 要素ノード生成部
113 コンテンツ解析・テキストノード生成部
114 要素終了タグ解析部
115 アプリケーション
116 事前解析部
117 状態遷移テーブル検索部
118 省メモリ要素ノード生成
119 状態遷移テーブルDESCRIPTION OF
Claims (4)
Translated fromJapanese文書管理装置が備える構造化文書の解析処理部が、事前解析処理手段と、該事前解析処理手段が生成した状態遷移テーブルを検索する状態遷移テーブル検索手段とを有し、
前記事前解析処理手段は、入力される構造化文書の構造単位の親子兄弟関係パターンを構文解析処理前に事前解析して該親子兄弟関係を格納した状態遷移テーブルを生成し、
前記構造化文書の解析処理部は、入力された文書の構文解析処理中に、前記状態遷移テーブル検索手段により前記状態遷移テーブルを参照し、前記状態遷移テーブルに格納済みの文字列の処理が要求されている場合に、前記状態遷移テーブルに格納済みの解析結果を返すことを特徴とする文書管理方法。A document management method for parsing an input structured document,
The analysis processing unit of the structured document provided in the document management apparatus has a pre-analysis processing unit and a state transition table search unit that searches for a state transition table generated by the pre-analysis processing unit,
The pre-analysis processing unit generates a state transition table storing the parent-child sibling relationship by pre-analyzing the parent-child sibling relationship pattern of the structural unit of the input structured document before syntax analysis processing;
The analysis processing unit of the structured document refers to the state transition table by the state transition table search means during the parsing process of the input document, and requests processing of a character string stored in the state transition table. If it is, the document management method returns the analysis result stored in the state transition table.
前記事前解析処理手段は、出現し得ない兄弟構造や属性構造を省いたメモリ構造を、前記状態遷移テーブルに格納することを特徴とする文書管理方法。The document management method according to claim 1,
The pre-analysis processing means stores a memory structure in which sibling structures and attribute structures that cannot appear in the state transition table are stored in the state transition table.
前記解析処理部は、入力された文書の構文解析処理中に、構文解析中の文字列と前記状態遷移テーブルに格納した要素文字列との文字列の比較を行って文書の構文解析を実現することを特徴とする文書管理方法。A document management method according to claim 1 or 2, wherein
The parsing unit performs parsing of the document by comparing the character string being parsed with the element character string stored in the state transition table during the parsing process of the input document. A document management method characterized by the above.
文書管理装置が備える構造化文書の解析処理部が、事前解析処理手段と、該事前解析処理手段が生成した状態遷移テーブルを検索する状態遷移テーブル検索手段とを有し、
前記事前解析処理手段は、入力される構造化文書の構造単位の親子兄弟関係パターンを構文解析処理前に事前解析して該親子兄弟関係を格納した状態遷移テーブルを生成し、
前記構造化文書の解析処理部は、入力された文書の構文解析処理中に、前記状態遷移テーブル検索手段により前記状態遷移テーブルを参照し、前記状態遷移テーブルに格納済みの文字列の処理が要求されている場合に、前記状態遷移テーブルに格納済みの解析結果を返すことを特徴とする文書管理装置。A document management device for parsing an input structured document,
The analysis processing unit of the structured document provided in the document management apparatus has a pre-analysis processing unit and a state transition table search unit that searches for a state transition table generated by the pre-analysis processing unit,
The pre-analysis processing unit generates a state transition table storing the parent-child sibling relationship by pre-analyzing the parent-child sibling relationship pattern of the structural unit of the input structured document before syntax analysis processing;
The analysis processing unit of the structured document refers to the state transition table by the state transition table search means during the parsing process of the input document, and requests processing of a character string stored in the state transition table. If it is, the document management apparatus returns an analysis result stored in the state transition table.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009031450AJP2010186412A (en) | 2009-02-13 | 2009-02-13 | Document management method and management device |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009031450AJP2010186412A (en) | 2009-02-13 | 2009-02-13 | Document management method and management device |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2010186412Atrue JP2010186412A (en) | 2010-08-26 |
Family
ID=42767015
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2009031450APendingJP2010186412A (en) | 2009-02-13 | 2009-02-13 | Document management method and management device |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2010186412A (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE102011081370A1 (en) | 2010-08-23 | 2012-05-03 | Denso Corporation | Apparatus for assisting the travel of a mobile object based on its desired locus |
| KR101222486B1 (en) | 2012-04-13 | 2013-01-16 | 주식회사 페타바이 | Method, server, terminal, and computer-readable recording medium for selectively eliminating nondeterministic element of nondeterministic finite automata |
| CN108234347A (en)* | 2017-12-29 | 2018-06-29 | 北京神州绿盟信息安全科技股份有限公司 | A kind of method, apparatus, the network equipment and storage medium for extracting feature string |
- 2009
- 2009-02-13JPJP2009031450Apatent/JP2010186412A/enactivePending
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| DE102011081370A1 (en) | 2010-08-23 | 2012-05-03 | Denso Corporation | Apparatus for assisting the travel of a mobile object based on its desired locus |
| KR101222486B1 (en) | 2012-04-13 | 2013-01-16 | 주식회사 페타바이 | Method, server, terminal, and computer-readable recording medium for selectively eliminating nondeterministic element of nondeterministic finite automata |
| WO2013154252A1 (en)* | 2012-04-13 | 2013-10-17 | 주식회사 페타바이 | Method, server, terminal device, and computer-readable recording medium for selectively removing nondeterminism of nondeterministic finite automata |
| US9251290B2 (en) | 2012-04-13 | 2016-02-02 | Infnis Networks, Inc. | Method, server, terminal device, and computer-readable recording medium for selectively removing nondeterminism of nondeterministic finite automata |
| CN108234347A (en)* | 2017-12-29 | 2018-06-29 | 北京神州绿盟信息安全科技股份有限公司 | A kind of method, apparatus, the network equipment and storage medium for extracting feature string |
| CN108234347B (en)* | 2017-12-29 | 2020-04-07 | 北京神州绿盟信息安全科技股份有限公司 | Method, device, network equipment and storage medium for extracting feature string |
| US11379687B2 (en) | 2017-12-29 | 2022-07-05 | Nsfocus Technologies Group Co., Ltd. | Method for extracting feature string, device, network apparatus, and storage medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP3832830B2 (en) | XPath evaluation method, XPath evaluation apparatus and information processing apparatus using the same | |
| US7725923B2 (en) | Structured-document processing | |
| US8181105B2 (en) | Apparatus, method, and program that performs syntax parsing on a structured document in the form of electronic data | |
| US7941417B2 (en) | Processing structured electronic document streams using look-ahead automata | |
| Lam et al. | XML document parsing: Operational and performance characteristics | |
| US8838642B2 (en) | Generating and navigating binary XML data | |
| CN106294493B (en) | Method and device for realizing document format conversion | |
| JP4365162B2 (en) | Apparatus and method for retrieving structured document data | |
| CN107357817B (en) | It is a kind of towards the Web page module design of JSON and its Asynchronous loading method | |
| US7822788B2 (en) | Method, apparatus, and computer program product for searching structured document | |
| US8880557B2 (en) | Method, program, and system for dividing tree structure of structured document | |
| US7865481B2 (en) | Changing documents to include changes made to schemas | |
| US20080235193A1 (en) | Apparatus, method, and computer program product for processing query | |
| US20090083294A1 (en) | Efficient xml schema validation mechanism for similar xml documents | |
| JP2010186412A (en) | Document management method and management device | |
| US20060253430A1 (en) | Method and apparatus for approximate projection of XML documents | |
| US8200714B2 (en) | Apparatus, systems and methods for configurable defaults for XML data | |
| KR20010055959A (en) | Storing and recovering apparatus and method of sgml/xml entities for information reuse in document management system | |
| JP4982154B2 (en) | Structured document parsing method and apparatus | |
| JP4313698B2 (en) | Electronic document processing apparatus, electronic document processing method, and electronic document processing program | |
| US20110093774A1 (en) | Document transformation | |
| Yang | Parsers | |
| CN120688476A (en) | Text generation method, device, computer equipment, product and storage medium | |
| Yue et al. | Architecture and design of the parser used in the embedded browser based on DFA | |
| Cheng et al. | Approximate Validity of XML Streaming Data |