JP2009140004A - Distributed recommendation system - Google Patents
Distributed recommendation systemDownload PDFInfo
- Publication number
- JP2009140004A JP2009140004AJP2007312499AJP2007312499AJP2009140004AJP 2009140004 AJP2009140004 AJP 2009140004AJP 2007312499 AJP2007312499 AJP 2007312499AJP 2007312499 AJP2007312499 AJP 2007312499AJP 2009140004 AJP2009140004 AJP 2009140004A
- Authority
- JP
- Japan
- Prior art keywords
- peer
- peer device
- profile
- similarity
- list
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images










Landscapes
- Computer And Data Communications (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Translated fromJapaneseDescription
Translated fromJapanese本発明は、ユーザの嗜好情報であるプロファイルを一つの装置に集中させず、各ユーザが管理する装置に分散させたまま、そのユーザが知らない他のユーザの紹介を通して推薦を受けることが可能な分散型推薦システムに関する。 The present invention can receive a recommendation through introductions of other users that the user does not know, while concentrating the profile that is the user's preference information on one device and distributing it to the devices managed by each user. It relates to a distributed recommendation system.
近年、情報や商品の爆発的な増加やユーザ嗜好の多様化により、ユーザが欲しい情報や商品をお薦めする情報推薦システムの重要性が高まっている。現在の情報推薦システムのアーキテクチャは、サービス事業者が運用する大規模サーバにユーザの嗜好情報であるプロファイルを集中管理する集中処理方式が一般的であり、協調フィルタリングがよく用いられている(例えば、非特許文献1)。 In recent years, with the explosive increase in information and products and the diversification of user preferences, the importance of information recommendation systems that recommend information and products that users want is increasing. The current information recommendation system architecture is generally a centralized processing method that centrally manages profiles that are user preference information on large-scale servers operated by service providers, and collaborative filtering is often used (for example, Non-patent document 1).
このアーキテクチャに基づく推薦においては、サービス事業者がプロファイルをサーバに収集して一括管理し、被推薦ユーザと嗜好がよく似たプロファイルを有する別のユーザのプロファイルを用いて被推薦ユーザに情報や商品を推薦することにより高精度な推薦を可能としている。 In the recommendation based on this architecture, the service provider collects the profiles on the server and manages them collectively, and uses the profile of another user who has a profile similar in taste to the recommended user. Can be recommended with high accuracy.
しかし、大規模サーバでの集中処理方式による協調フィルタリングは、サービスを利用するユーザ数の増加やお薦め対象となるアイテム数の増加によって計算量が非常に大きくなり、それをまかなうために多大な設備投資や維持コストが必要になるという問題点があった。 However, collaborative filtering using a centralized processing method on a large-scale server increases the amount of computation due to the increase in the number of users who use the service and the number of recommended items. In addition, there is a problem that maintenance costs are required.
この集中処理方式の問題点を解決するために、個人の所有する機器(以下、ピアと呼ぶ。)を通じてネットワークを形成するPeer−to−Peer(P2P)アーキテクチャを用いた分散処理方式が提案されている(例えば、特許文献1)。 In order to solve the problems of the centralized processing method, a distributed processing method using a peer-to-peer (P2P) architecture that forms a network through personally owned devices (hereinafter referred to as peers) has been proposed. (For example, Patent Document 1).
このPeer−to−Peerアーキテクチャに基づく協調フィルタリングにおいては、サーバを用いた集中処理が不要であるため運用コスト面で有利であり、各ピアが各自計算を行うため処理の負荷分散が可能である。
しかし、このPeer−to−Peerアーキテクチャに基づく協調フィルタリングにおいては、全体を統括するサーバが存在しないため各ピアが他のピアと通信する必要があり、ネットワーク負荷が高まるという問題点がある。 However, in the collaborative filtering based on the peer-to-peer architecture, there is no server that controls the whole, so each peer needs to communicate with other peers, and there is a problem that the network load increases.
例えば、特許文献1に記載の技術においては、推薦を受けたい第1のピアは自己のプロファイルをネットワーク上にブロードキャストし、このプロファイルを受信した第2のピアから第Nのピアがピア1との類似度を計算し、この類似度を第1のピアに送り返す。 For example, in the technique described in
第1のピアは類似度を返したピアの中から類似度がもっとも高いピアを選択し、コンテンツの推薦を受ける。 The first peer selects the peer with the highest similarity from the peers that returned the similarity, and receives content recommendation.
このようなデータを多人数にブロードキャストする方法は、構内通信網(LAN)のような狭い範囲のネットワークなら問題はない。しかし、インターネットのような大規模な広域ネットワークで用いるのは現実的ではない。 The method of broadcasting such data to a large number of people is not a problem for a narrow range network such as a local area network (LAN). However, it is not realistic to use in a large-scale wide area network such as the Internet.
特許文献1においては、この問題に対して、各ピアが持つ限られた数のピアにクエリをブロードキャストし、クエリを受けたピアはさらにブロードキャストするといったブロードキャストの伝播を行えば広範囲のピアと通信できると示唆している(特許文献1、図7 参照)。 In
しかし、このようなブロードキャストを伝播する方法は、ブロードキャストの伝播回数がわずか数回でも莫大な数のピアに対してクエリを送ることになり、ネットワーク負荷を高めてしまうという問題がある。 However, such a method for propagating broadcasts has a problem that even if the number of broadcast propagations is only a few, queries are sent to an enormous number of peers, increasing the network load.
また、特許文献1に記載の技術においては、推薦依頼のクエリを発するたびに上記の方法で類似ピアを探索するためさらにネットワーク負荷が高まると考えられる。 Further, in the technique described in
本発明は、上記の問題点を鑑み、他のピアから新たにピアの推薦を受ける際のネットワーク負荷を抑えたピア装置及び分散型推薦システムを提供することを目的とする。 In view of the above problems, an object of the present invention is to provide a peer device and a distributed recommendation system in which a network load when receiving a peer recommendation from another peer is suppressed.
本発明の分散型推薦システムは、複数個のピア装置がネットワークを通じて相互に接続された分散型推薦システムにおいて、前記各ピア装置は、ユーザの嗜好情報を表すプロファイルを保存するプロファイル保存部と、嗜好が類似するプロファイルを保存する有限(k)個の隣接ピア装置の識別子情報を保存する隣接ピアリスト保存部と、を備え、前記複数個のピア装置の内の第1のピア装置が、前記隣接ピアリスト保存部に保存されたk個の隣接ピア群である第2のピア装置群に推薦依頼情報を送信し、協調フィルタリングによる推薦情報を受信することを特徴とするものである。 The distributed recommendation system of the present invention is a distributed recommendation system in which a plurality of peer devices are connected to each other through a network. Each of the peer devices includes a profile storage unit that stores a profile representing user preference information, and a preference. A neighbor peer list storage unit that stores identifier information of finite (k) adjacent peer devices that store similar profiles, wherein a first peer device of the plurality of peer devices is configured to store the neighbor peer list storage unit. Recommendation request information is transmitted to a second peer device group that is a group of k adjacent peers stored in a peer list storage unit, and recommendation information by collaborative filtering is received.
また、本発明の分散型推薦システムは、複数個のピア装置がネットワークを通じて相互に接続された分散型推薦システムにおいて、前記各ピア装置は、ユーザの嗜好情報を表すプロファイルを保存するプロファイル保存部と、嗜好が類似するプロファイルを保存する有限(k)個の隣接ピア装置の識別子情報を保存する隣接ピアリスト保存部と、前記プロファイル保存部に保存されたプロファイルと前記隣接ピアから受信したプロファイルとの類似度を計算する類似度計算部と、を備え、前記複数個のピア装置の内の第1のピア装置は、前記プロファイル保存部に保存されたプロファイルを前記第2のピア装置群に送信し、前記第2のピア装置群はそれらの隣接ピアリストに含まれる第3のピア装置群の識別子情報を前記第1のピア装置に送信し、前記第1のピア装置は受信したこれらの第3のピア装置群のプロファイルとの類似度が前記第1のピア装置内に保存された隣接ピアリストのどのピア装置のプロファイルとの類似度よりも高い場合、前記第1のピア装置に保存された隣接ピアリストを前記第3のピア装置の識別情報により置き換えることを特徴とするものである。 The distributed recommendation system of the present invention is a distributed recommendation system in which a plurality of peer devices are connected to each other through a network. Each of the peer devices includes a profile storage unit that stores a profile that represents user preference information. An adjacent peer list storage unit that stores identifier information of finite (k) adjacent peer devices that store profiles having similar preferences, and a profile stored in the profile storage unit and a profile received from the adjacent peer. A similarity calculation unit that calculates a similarity, and a first peer device among the plurality of peer devices transmits a profile stored in the profile storage unit to the second peer device group. The second peer device group sends the identifier information of the third peer device group included in the neighboring peer list to the first peer device. The similarity between the received first peer device and the profile of the received third peer device group is similar to the profile of any peer device in the neighboring peer list stored in the first peer device. Is higher, the neighboring peer list stored in the first peer device is replaced with the identification information of the third peer device.
さらに、上記の分散型推薦システムにおいては、前記第2のピア装置群は、前記第3のピア装置群のうち、前記第1のピア装置の隣接ピアリストに含まれないピア装置を選択して前記第1のピア装置に送信することを特徴とするものである。 Furthermore, in the above distributed recommendation system, the second peer device group selects a peer device that is not included in the adjacent peer list of the first peer device from the third peer device group. It transmits to said 1st peer apparatus, It is characterized by the above-mentioned.
さらに、上記の分散型推薦システムにおいては、前記第2のピア装置群は、受信した前記第1のピア装置のプロファイルと自己のプロファイルとの類似度を前記類似度計算部により計算し、前記第2のピア装置群の隣接ピアリストに掲載されたどのピア装置のプロファイルよりも類似度が高い場合、前記第2のピア装置群の隣接ピアリストに掲載されたピア装置の識別子情報を前記第1のピア装置の識別子情報で置き換えることを特徴とするものである。 Further, in the distributed recommendation system, the second peer device group calculates a similarity between the received profile of the first peer device and its own profile by the similarity calculation unit, and When the similarity is higher than the profile of any peer device listed in the neighboring peer list of the second peer device group, the identifier information of the peer device listed in the neighboring peer list of the second peer device group is set to the first peer device group. It is characterized in that it is replaced with the identifier information of the peer device.
本発明の上記解決手段をより具体的に説明する。 The above solution of the present invention will be described more specifically.
本発明では、上記の問題を解決するため各ピアが高々k 個のピア情報を格納した隣接ピアリストを持ち、この隣接ピアリストを類似度がより高いピアが含まれるように動的に更新する仕組みを導入した。 In the present invention, in order to solve the above problem, each peer has a neighbor peer list storing at most k pieces of peer information, and this neighbor peer list is dynamically updated so that peers with higher similarity are included. Introduced a mechanism.
隣接ピアリストを動的に更新するために第一の装置は隣接ピアリスト内のk 個の第二の装置群へプロファイルをブロードキャストする。ブロードキャストを受信した第二の装置は、さらなるブロードキャストはせずに、自己の隣接ピアリストに含まれる第三の装置の情報を選択して第一の装置へ送り返す。このとき選ばれる第三の装置は第二の装置との類似度が高く、かつ第一の装置が知らない(第一の装置の隣接ピアリストおよびキャッシュに存在しない)ピアに限る。 To dynamically update the neighbor peer list, the first device broadcasts the profile to the k second devices in the neighbor peer list. The second device that receives the broadcast selects the information of the third device included in its neighbor peer list and sends it back to the first device without further broadcasting. The third device selected at this time is limited to peers that have a high degree of similarity to the second device and that the first device does not know (does not exist in the first device's neighbor peer list and cache).
また第二の装置は第一の装置のプロファイルと自己のプロファイルから類似度を計算し、隣接ピアリストに含まれるいずれかのピアの類似度より第一の装置との類似度が高ければそのピアを第一の装置の情報で置き換える。このように第一の装置からクエリを受けた第二の装置が第一の装置の情報を保存しておくことをバックリンクの記録と呼ぶ。ここで第一の装置と置き換えられるピアはキャッシュと呼ばれる領域に保存しておく。キャッシュに保存されたピアは隣接ピアリスト内のピアより重要ではない類似度の低い既知のピアだと判断できる。 The second device calculates the similarity from the profile of the first device and its own profile, and if the similarity to the first device is higher than the similarity of any peer included in the neighboring peer list, Is replaced with information from the first device. In this way, storing the information of the first device by the second device that has received the query from the first device is referred to as backlink recording. Here, the peer replaced with the first device is stored in an area called a cache. Peers stored in the cache can be determined to be known peers with lower similarity that are less important than peers in the neighbor peer list.
第二の装置から第三の装置の情報を受け取った第一の装置は第三の装置へプロファイルを送信し、第三の装置が計算した類似度を受け取る。そして第三の装置の類似度が自己の隣接ピアリストに含まれるいずれかのピアの類似度より高ければそのピアを第三の装置の情報で置き換える。ここで第三の装置と置き換えられるピアはキャッシュと呼ばれる領域に保存しておく。 The first device receiving the third device information from the second device transmits a profile to the third device and receives the similarity calculated by the third device. If the similarity degree of the third device is higher than the similarity degree of any peer included in its own neighboring peer list, the peer is replaced with the information of the third device. Here, the peer replaced with the third device is stored in an area called a cache.
上記の手順を繰り返すことで各ピアの隣接ピアリスト内に自己と類似度が高いピアが含まれるようになる。推薦は隣接ピアリスト内のピアにクエリを出し、結果を受け取ることで実現する。 By repeating the above procedure, a peer having a high similarity with itself is included in the adjacent peer list of each peer. The recommendation is realized by querying the peers in the neighbor peer list and receiving the result.
本発明によれば、新規のピア装置の紹介を得る際にネットワーク負荷が低く済むという効果がある。また、既知のピア装置との通信を行うことがなく、無駄な通信が抑えられるという効果がある。 According to the present invention, it is possible to reduce the network load when obtaining an introduction of a new peer device. Further, there is an effect that unnecessary communication is suppressed without performing communication with a known peer device.
以下、本発明によるピア装置及び分散型推薦システムの一実施の形態を、図面を用いて詳細に説明する。なお、各図において同一箇所については同一の符号を付すとともに、重複した説明は省略する。 Hereinafter, an embodiment of a peer device and a distributed recommendation system according to the present invention will be described in detail with reference to the drawings. In addition, while attaching | subjecting the same code | symbol about the same location in each figure, the overlapping description is abbreviate | omitted.
<実施形態の詳細>
<構成の説明>
図1は、本実施形態のピア装置10の構成を示した概要図である。図1に示すように、ピア装置10はネットワーク11を経由して情報を送受信する送受信部17と、あらかじめ設定された変数ごとの値の集合であるプロファイルを格納するプロファイル保存部12と、格納されたプロファイルと、受信したプロファイルの類似度を算出する類似度計算部16と、通信先の識別子を示すピア識別子の集合である隣接ピアリストを格納する隣接ピアリスト保存部14と、受信したピア識別子毎の類似度に従って隣接ピアリストを更新する隣接ピアリスト管理部13と、を備える。ピア識別子を格納するキャッシュ部15をさらに備えるように構成することもできる。<Details of Embodiment>
<Description of configuration>
FIG. 1 is a schematic diagram showing the configuration of the peer device 10 of the present embodiment. As shown in FIG. 1, the peer device 10 stores a transmission /
ピア装置10はさらに、映像や音楽や商品情報等のコンテンツを保存するコンテンツ保存部19と、プロファイルに対応したコンテンツを推薦するコンテンツ推薦部18と、を備える。 The peer device 10 further includes a
隣接ピアリスト管理部13は、ピア識別子を類似度によってソートする隣接ピアリストソート部13Aと、格納されている隣接ピアリストから受信した隣接ピアリストに存在しないピア識別子を検索する未知ピア検索部13Bと、を備える。 The neighboring peer list management unit 13 sorts the peer identifiers according to the similarity, the neighboring peer
ピア装置10は、上述の構成を含んでいればいわゆるパソコン、テレビ、ハードディスクを内蔵するレコーダ、携帯電話、通信機能を備えた携帯音楽端末、携帯型情報端末(PDA:Personal Digital Assistant)など、いずれの機器であってもよい。 The peer device 10 may include a so-called personal computer, a TV, a recorder with a built-in hard disk, a mobile phone, a portable music terminal having a communication function, a personal digital assistant (PDA), etc. It may be a device.
ネットワーク11は、例えばLANやインターネットのような公衆通信回線網を利用したネットワークが挙げられるがこれらに限られるものではない。 Examples of the network 11 include, but are not limited to, a network using a public communication network such as a LAN or the Internet.
ピア識別子とは、ピア装置10をネットワーク上において識別する識別子であり、例えばIPアドレスが挙げられるがこれに限られるものではない。 The peer identifier is an identifier for identifying the peer device 10 on the network and includes, for example, an IP address, but is not limited thereto.
図2は、プロファイルの例を示した図である。プロファイルはユーザの嗜好情報などが挙げられるが、これに限られるものではない。図2のピア装置Aのプロファイル21に示すように、プロファイルはあらかじめ設定された変数、例えば複数のアイテム、すなわち商品や事象に対する、これらの変数ごとの値、例えば好感度を示すレイティングの集合である。 FIG. 2 is a diagram showing an example of a profile. The profile includes user preference information, but is not limited to this. As shown in the profile 21 of the peer device A in FIG. 2, the profile is a set of ratings indicating values for each variable, for example, favorableness, for a plurality of preset items, for example, a product or an event. .
図3は、複数のピア装置10がネットワークによって接続されている様子を模式的に表した図である。図3において、矢印の方向は情報の送信方向を示す。アルファベットはピア装置10を示す。 FIG. 3 is a diagram schematically illustrating a state in which a plurality of peer devices 10 are connected by a network. In FIG. 3, the direction of the arrow indicates the information transmission direction. The alphabet indicates the peer device 10.
ピア装置Aの隣接ピアリスト33に示すように、隣接ピアリストには、あらかじめ定められた数だけピア識別子と類似度の組が格納されている。ピア装置Aの隣接ピアリスト33においては、あらかじめ定められた数が4である。隣接ピアリストは隣接ピアリストソート部13Aによって類似度の降順にソートされている。 As shown in the
ピア装置10を結ぶ矢印32はアクセス可能であることとアクセス方向とを示している。各ピア装置10はピア識別子を持っており、アクセス可能であるとは通信相手のピア識別子を保持していることを意味する。 An
従って、双方向の矢印34は、ピア装置Bの隣接ピアリストにピア装置Cのピア識別子が保持されており、ピア装置Cの隣接ピアリストにピア装置Bのピア識別子が保持されていることを意味する。 Therefore, the
<動作の説明>
<動作の概要>
本実施形態の分散型推薦システムにおいては、各ピア装置10は次のように動作する。第1のピア装置が、第2のピア装置に第1のピア装置の第1の隣接ピアリストに存在しないピア識別子である新規ピア識別子の第1のピア装置への送信を指示する。<Description of operation>
<Overview of operation>
In the distributed recommendation system of the present embodiment, each peer device 10 operates as follows. The first peer device instructs the second peer device to transmit to the first peer device a new peer identifier that is a peer identifier that is not in the first peer list of the first peer device.
次に、第2のピア装置が、新規ピア識別子の送信指示を受信したとき、第1のピア装置に新規ピア識別子を送信する。 Next, when the second peer device receives the transmission instruction of the new peer identifier, the second peer device transmits the new peer identifier to the first peer device.
次に、第1のピア装置が、新規ピア識別子を受信したとき、新規ピア識別子が示す第3のピア装置に第1のピア装置に格納された第1のプロファイルを送信するとともに、第1のプロファイルと第3のピア装置に格納された第3のプロファイルとの類似度の算出と算出した類似度の第1のピア装置への送信を指示する。 Next, when the first peer device receives the new peer identifier, the first peer device transmits the first profile stored in the first peer device to the third peer device indicated by the new peer identifier, and the first peer device Instructing the calculation of the similarity between the profile and the third profile stored in the third peer device and the transmission of the calculated similarity to the first peer device.
次に、第3のピア装置が、類似度の算出と送信の指示を受信したとき、類似度を算出して第1のピア装置に送信する。 Next, when the third peer device receives the similarity calculation and transmission instruction, the third peer device calculates the similarity and transmits it to the first peer device.
さらに、第1のピア装置が、類似度を受信したとき、類似度に従って第1の隣接ピアリストを更新する。 Further, when the first peer device receives the similarity, the first neighboring peer list is updated according to the similarity.
ここで、第1のピア装置は第1のプロファイルを第2のピア装置及び第3のピア装置に送信している。そこで、第2のピア装置及び第3のピア装置は第1のプロファイルと第2のプロファイル及び第3のプロファイルとの類似度をそれぞれ算出し、算出された類似度に従って各隣接ピアリストを更新しておくことにより処理を高速化することが可能となる。この第2のピア装置及び第3のピア装置が各隣接ピアリストを更新する処理をバックリンク処理と呼ぶ。 Here, the first peer device is transmitting the first profile to the second peer device and the third peer device. Therefore, the second peer device and the third peer device respectively calculate the similarity between the first profile, the second profile, and the third profile, and update each neighboring peer list according to the calculated similarity. This makes it possible to speed up the processing. The process in which the second peer apparatus and the third peer apparatus update each neighboring peer list is called a back link process.
バックリンク処理を取り入れると、本実施形態の分散型推薦システムにおいては、各ピア装置10は次のように動作する。 When back link processing is adopted, each peer device 10 operates as follows in the distributed recommendation system of this embodiment.
第1のピア装置が、第2のピア装置に第1のピア装置に格納された第1のプロファイルを送信するとともに第1のピア装置の第1の隣接ピアリストに存在しないピア識別子である新規ピア識別子の第1のピア装置への送信を指示する。 The first peer device transmits a first profile stored in the first peer device to the second peer device and is a new peer identifier that is not present in the first peer list of the first peer device Instructing transmission of the peer identifier to the first peer device.
次に、第2のピア装置が、第1のプロファイルと新規ピア識別子の送信指示を受信したとき、第1のピア装置に新規ピア識別子を送信するとともに、第2のピア装置に格納された第2のプロファイルと第1のプロファイルとの第1の類似度を算出し、第1の類似度に従って第2のピア装置に格納された第2の隣接ピアリストを更新する。 Next, when the second peer device receives the transmission instruction of the first profile and the new peer identifier, the second peer device transmits the new peer identifier to the first peer device and stores the first peer device stored in the second peer device. The first similarity between the two profiles and the first profile is calculated, and the second neighboring peer list stored in the second peer device is updated according to the first similarity.
次に、第1のピア装置が、新規ピア識別子を受信したとき、新規ピア識別子が示す第3のピア装置に第1のプロファイルを送信するとともに、第1のプロファイルと第3のピア装置に格納された第3のプロファイルとの第2の類似度の算出と算出した第2の類似度の第1のピア装置への送信を指示する。 Next, when the first peer device receives the new peer identifier, it transmits the first profile to the third peer device indicated by the new peer identifier, and stores it in the first profile and the third peer device. Instructing the calculation of the second similarity with the calculated third profile and the transmission of the calculated second similarity to the first peer device.
次に、第3のピア装置が、第2の類似度の算出と送信の指示を受信したとき、第2の類似度を算出して第1のピア装置に送信するとともに、第2の類似度に従って第3のピア装置に格納された第3の隣接ピアリストを更新する。 Next, when the third peer device receives the second similarity calculation and transmission instruction, the third peer device calculates the second similarity and transmits it to the first peer device. To update the third neighbor list stored in the third peer device.
さらに、第1のピア装置が、第2の類似度を受信したとき、第2の類似度に従って第1の隣接ピアリストを更新する。 Further, when the first peer device receives the second similarity, it updates the first neighboring peer list according to the second similarity.
このように動作するため、本実施形態のピア装置10及び分散型推薦システムにおいては、各ピア装置10の隣接ピアリストが新規ピア識別子の紹介を受けるたびに更新される。このように動的かつ非同期に隣接ピアリストが更新されるため、新規ピア識別子が得られやすくなり、接続先がマンネリ化しない。 In order to operate in this way, in the peer device 10 and the distributed recommendation system of this embodiment, the neighboring peer list of each peer device 10 is updated every time an introduction of a new peer identifier is received. Since the neighbor peer list is updated dynamically and asynchronously in this way, a new peer identifier can be easily obtained, and the connection destination is not made ruined.
ピア装置10は、あらかじめ定められた数のピア識別子のみを隣接ピアリストに保持するように構成することが望ましい。あらかじめ定められた数は、例えば5以上10以下の自然数から選択されることが望ましい。このように限定することにより、ネットワークの負荷が高まることを防止できる。 The peer device 10 is preferably configured to retain only a predetermined number of peer identifiers in the neighbor peer list. The predetermined number is desirably selected from natural numbers of 5 to 10, for example. By limiting in this way, it is possible to prevent an increase in network load.
隣接ピアリストが保持するピア識別子の数を上回ったピア識別子、またはソートの結果隣接ピアリストから外されることとなったピア識別子は別の格納場所に格納することが望ましい。 It is desirable to store a peer identifier that exceeds the number of peer identifiers held in the neighbor peer list or a peer identifier that has been removed from the neighbor peer list as a result of sorting in a separate storage location.
例えば、ピア装置10が、ピア識別子を格納するキャッシュ部15をさらに備えるように構成することができる。 For example, the peer device 10 may be configured to further include a
この場合、ピア装置10はピア識別子毎の類似度を受信したとき、類似度によって隣接ピアリストのピア識別子をソートし、ピア識別子のうち最も類似度の低いピア識別子の類似度と新規ピア識別子の類似度とを比較し、最も類似度の低いピア識別子の類似度が新規ピア識別子の類似度を下回ったとき、最も類似度の低いピア識別子をキャッシュ部15に移し、新規ピア識別子を隣接ピアリストに追加するように、構成することができる。 In this case, when the peer device 10 receives the similarity for each peer identifier, the peer device 10 sorts the peer identifiers in the adjacent peer list according to the similarity, and the similarity between the peer identifier with the lowest similarity among the peer identifiers and the new peer identifier When the similarity of the peer identifier with the lowest similarity falls below the similarity of the new peer identifier, the peer identifier with the lowest similarity is moved to the
<動作の詳細>
(類似度の計算)
類似度は、プロファイルにヒストグラム、確率分布などを用いても計算することができる。以下に、図2に示した例をベクトルとしてあらわし、類似度を相関係数によって算出する例を説明する。<Details of operation>
(Similarity calculation)
The degree of similarity can also be calculated using a histogram, probability distribution, or the like for the profile. Hereinafter, an example in which the example illustrated in FIG. 2 is represented as a vector and the similarity is calculated using a correlation coefficient will be described.
ピア装置AのプロファイルをA(1,5,2,4)とする。ここで、レイティングしていないアイテムは省略する。これに対応するアイテムのピア装置BのプロファイルはB(4,2,5,1)と表現できる。 The profile of the peer device A is A (1, 5, 2, 4). Here, items not rated are omitted. The corresponding profile of the peer device B of the item can be expressed as B (4, 2, 5, 1).
このとき相関係数は、次のように計算できる。
ここで、Covは共分散、AiはAのアイテムiへのレイティング、A’はAのレイティングの平均値を意味する。Here, Cov means covariance, Ai means the rating of A to item i, and A ′ means the average value of A's rating.
(コマンドの説明)
図4は、本実施形態のピア装置10が使用するコマンドと、各コマンドとともに送信される情報を示した図である。(Command explanation)
FIG. 4 is a diagram illustrating commands used by the peer device 10 of the present embodiment and information transmitted together with the commands.
類似度計算クエリ41はコマンドがREQ_SIMであり、コマンドとともに送信される情報が送信元ピア識別子、送信先ピア識別子、プロファイルである。このコマンドは送信先のピア装置10に、送信元のプロファイルと送信先のプロファイルとの類似度を計算させ、計算した類似度を送信元に送り返させる旨の指示を意味する。 In the similarity calculation query 41, a command is REQ_SIM, and information transmitted together with the command is a transmission source peer identifier, a transmission destination peer identifier, and a profile. This command means an instruction to cause the transmission destination peer device 10 to calculate the similarity between the transmission source profile and the transmission destination profile and to send the calculated similarity back to the transmission source.
類似度計算レスポンス42はコマンドがRES_SIMであり、コマンドとともに送信される情報が送信先ピア識別子、類似度である。このコマンドは計算した類似度を、類似度計算クエリ41を送信したピア装置10に返信するためのコマンドである。 In the similarity calculation response 42, the command is RES_SIM, and information transmitted together with the command is a transmission destination peer identifier and similarity. This command is a command for returning the calculated similarity to the peer device 10 that has transmitted the similarity calculation query 41.
新規ピア探索クエリ43はコマンドがNEW_PEERであり、コマンドとともに送信される情報が送信元ピア識別子、送信先ピア識別子、プロファイル、既知ピアリストである。このコマンドは送信先のピア装置10に送信元のピア装置10が保持していないピア識別子であって送信先のピア装置10が保持しているピア識別子を検索して返信させる旨の指示を意味する。 In the new peer search query 43, the command is NEW_PEER, and information transmitted with the command is a source peer identifier, a destination peer identifier, a profile, and a known peer list. This command means an instruction to cause the destination peer device 10 to search for and return a peer identifier that is not held by the source peer device 10 but held by the destination peer device 10. To do.
ピア紹介レスポンス44はコマンドがINTRO_PEERであり、コマンドとともに送信される情報が送信先ピア識別子、新規ピア識別子である。このコマンドは新規ピア探索クエリ43を受信したピア装置10が検索した新規ピア識別子を、新規ピア探索クエリ43を送信したピア装置10に返信するためのコマンドである。 In the peer introduction response 44, the command is INTRO_PEER, and information transmitted together with the command is a destination peer identifier and a new peer identifier. This command is a command for returning a new peer identifier searched by the peer device 10 that has received the new peer search query 43 to the peer device 10 that has transmitted the new peer search query 43.
推薦クエリ45はコマンドがREQ_RECOMであり、コマンドとともに送信される情報が送信元ピア識別子、送信先ピア識別子である。このコマンドは送信先のピア装置10にコンテンツを推薦させ、送信元のピア装置10に返信させる旨の指示を意味する。 In the recommendation query 45, a command is REQ_RECOM, and information transmitted together with the command is a transmission source peer identifier and a transmission destination peer identifier. This command means an instruction to make the destination peer device 10 recommend content and send it back to the source peer device 10.
推薦レスポンス46はコマンドがRES_RECOMであり、コマンドとともに送信される情報が送信先ピア識別子、推薦コンテンツである。このコマンドは推薦クエリ45を送信したピア装置10に推薦するコンテンツを返信するためのコマンドである。 In the recommendation response 46, the command is RES_RECOM, and information transmitted together with the command is a transmission destination peer identifier and recommended content. This command is a command for returning the recommended content to the peer device 10 that has transmitted the recommendation query 45.
(第1のピア装置23の動作)
(メインフロー)
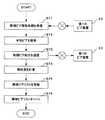
図5は、第1のピア装置23の動作を表したフローチャートである。ステップS51において、第1のピア装置23は最初に接続する隣接ピアすなわち他のピア装置10の決定を行う。この決定は、任意のサーバから接続先の候補をダウンロードし、その中から適宜選択することにより行う。(Operation of the first peer device 23)
(Main flow)
FIG. 5 is a flowchart showing the operation of the
ステップS52において、第1のピア装置23は第1のピア装置23の第1の隣接ピアリストの更新処理を行う。この処理については後述する。 In step S <b> 52, the
ステップS53において、第1のピア装置23は第1の隣接ピアリストが収束したか判定する。第1の隣接ピアリストが収束していない場合は、第1のピア装置23はステップS52に戻る。第1の隣接ピアリストが収束した場合は、ステップS54に進む。 In step S53, the
なお、ここで収束するとは隣接ピアリストの更新が行われなくなった状態を指す。 Here, convergence means a state where the neighbor peer list is no longer updated.
ステップS54において、第1のピア装置23はユーザからコンテンツ推薦の指示があったか判定する。コンテンツの推薦指示があった場合には、ステップS55に進む。コンテンツの推薦の指示がなかった場合には、ステップS57に進む。 In step S54, the
ステップS55において、第1のピア装置23は隣接ピアリストの各ピア装置10へ推薦クエリ45を送信する。ステップS56において、第1のピア装置23は推薦レスポンス46を受信してコンテンツの推薦を受け、ステップS57に進む。 In step S55, the
ステップS57において、第1のピア装置23はネットワークからの離脱の指示の入力を受けたか判定する。離脱指示がない場合にはステップS52に戻る。離脱指示があった場合には、処理を終了する。 In step S57, the
(隣接ピアリストの更新処理サブフロー)
図6は、第1のピア装置23の隣接ピアリストの更新処理における動作を表したフローチャートである。(Neighbor peer list update processing subflow)
FIG. 6 is a flowchart showing the operation of the
ステップS601において、第1のピア装置23はステップS51において決定した初期隣接ピア識別子を有するピア装置10に新規ピア探索クエリ43をブロードキャストする。送信するプロファイルは第1のピア装置23の第1のプロファイルである。また、送信する既知ピアリストは第1のピア装置23の第1の隣接ピアリストとキャッシュ部15に格納されているピア識別子である。 In step S601, the
既知ピアリストはBloom Filterと呼ばれるデータ構造に圧縮して送信することが、通信量を削減する上で望ましい。Bloom Filterとは、データのインデックスリストを小さな記憶容量で効率的に表現するための手法である。Bloom Filterを用いると、あるインデックスがインデックスリストに含まれているか、含まれていないかを元のインデックスリストを参照せずに検査できる。 In order to reduce the amount of communication, it is desirable that the known peer list is transmitted after being compressed into a data structure called a Bloom Filter. The Bloom Filter is a method for efficiently expressing an index list of data with a small storage capacity. Using the Bloom Filter, it is possible to check whether an index is included in the index list without referring to the original index list.
ステップS602において、第1のピア装置23は第2のピア装置24からピア紹介レスポンス44を受信する。ここで、新規ピア識別子を有するピア装置10を第3のピア装置25とする。 In step S <b> 602, the
ステップS603において、第1のピア装置23は第3のピア装置25に類似度計算クエリ41を送信する。 In step S <b> 603, the
ステップS604において、第1のピア装置23は第3のピア装置25から類似度計算レスポンス42を受信する。 In step S <b> 604, the
ステップS605において、第1のピア装置23は第1の隣接ピアリストを更新する。更新は次のように行う。 In step S605, the
第1の隣接ピアリストはすでにソートされている。ここで、第1のピア装置23は第1の隣接ピアリストの中で最小の類似度を持つピア識別子である第1の最小類似度ピア識別子の類似度と受信した類似度とを比較する。 The first neighbor peer list is already sorted. Here, the
受信した類似度の方が大きい場合には、第1のピア装置23は第1の最小類似度ピア識別子をキャッシュ部15に移動し、受信したピア識別子を第1の隣接ピアリストに追加する。 If the received similarity is greater, the
ステップS606において、第1のピア装置23は隣接ピアリストソート部13Aを用いて第1の隣接ピアリストをソートし、処理を抜け出る。 In step S606, the
(第2のピア装置24の動作)
図7は、第2のピア装置24の動作を表したフローチャートである。ステップS71において、第2のピア装置24は第1のピア装置23から新規ピア探索クエリ43を受信する。(Operation of the second peer device 24)
FIG. 7 is a flowchart showing the operation of the
ステップS72において、第2のピア装置24は未知ピア検索部13Bを用いて、第2のピア装置24の第2の隣接ピアリストに含まれており、受信した既知ピアリストに含まれていないピア識別子の中から、第2のピア装置との類似度がもっとも高いピア識別子を検索する。この検索乃至選択されたピア識別子を新規ピア識別子とする。 In step S72, the
ステップS73において、第2のピア装置24は第1のピア装置23にピア紹介レスポンス44を送信する。 In step S <b> 73, the
ステップS74において、第2のピア装置24は受信した第1のプロファイルと第2のピア装置24の第2のプロファイルとの第1の類似度を、類似度計算部16を用いて計算する。 In step S <b> 74, the
ステップS75において、第2のピア装置24は計算した第1の類似度に従って第2の隣接ピアリストを更新する。更新は次のように行う。 In step S75, the
第2の隣接ピアリストはすでにソートされている。ここで、第2のピア装置24は第2の隣接ピアリストの中で最小の類似度を持つピア識別子である第2の最小類似度ピア識別子の類似度と第1の類似度とを比較する。 The second neighbor peer list is already sorted. Here, the
第1の類似度の方が大きい場合には、第2のピア装置24は第2の最小類似度ピア識別子をキャッシュ部15に移動し、第1のピア装置23のピア識別子を第2の隣接ピアリストに追加する。 If the first similarity is greater, the
ステップS76において、第2のピア装置24は隣接ピアリストソート部13Aを用いて第2の隣接ピアリストをソートし、処理を終了する。 In step S76, the
(第3のピア装置25の動作)
図8は、第3のピア装置25の動作を表したフローチャートである。ステップS81において、第3のピア装置25は第1のピア装置23から類似度計算クエリ41を受信する。(Operation of the third peer device 25)
FIG. 8 is a flowchart showing the operation of the
ステップS82において、第3のピア装置25は類似度計算部16を用いて第3のピア装置25の第3のプロファイルと、受信した第1のピア装置23の第1のプロファイルとの第2の類似度を算出する。 In step S <b> 82, the
ステップS83において、第3のピア装置25は第1のピア装置23に類似度計算レスポンス42を送信する。 In step S <b> 83, the
ステップS84において、第3のピア装置25は計算した第2の類似度に従って第3の隣接ピアリストを更新する。更新は次のように行う。 In step S84, the
第3の隣接ピアリストはすでにソートされている。ここで、第3のピア装置25は第3の隣接ピアリストの中で最小の類似度を持つピア識別子である第3の最小類似度ピア識別子の類似度と第2の類似度とを比較する。 The third neighbor peer list is already sorted. Here, the
第2の類似度の方が大きい場合には、第3のピア装置25は第3の最小類似度ピア識別子をキャッシュ部15に移動し、第1のピア装置23のピア識別子を第3の隣接ピアリストに追加する。 If the second similarity is greater, the
ステップS85において、第3のピア装置25は隣接ピアリストソート部13Aを用いて第3の隣接ピアリストをソートし、処理を終了する。 In step S85, the
(相互作用)
図9は、第1乃至第3のピア装置の相互作用をまとめた図である。図9に示すように、第1のピア装置23は第2のピア装置24から第3のピア装置25の紹介を受け、第3のピア装置25と通信を開始する。(Interaction)
FIG. 9 is a diagram summarizing the interaction of the first to third peer devices. As shown in FIG. 9, the
以上の説明においては、第1のピア装置23を中心に説明したが、ピア装置10は役割が固定されているわけではない。すなわち、あるとき第1のピア装置23の役割をしたピア装置10は、別のときに第2のピア装置24の役割をしたり第3のピア装置25の役割をしたりすることもある。 In the above description, the description has focused on the
図10は、ネットワークで見た動作例の初期状態を示した図である。また、図11は、ネットワークで見た動作例の隣接ピアリスト更新後の状態を示した図である。ピア装置Aは第1のピア装置23、ピア装置Bは第2のピア装置24、ピア装置Cは第3のピア装置25の役割をする。 FIG. 10 is a diagram illustrating an initial state of an operation example viewed from the network. FIG. 11 is a diagram illustrating a state after the adjacent peer list is updated in the operation example as viewed on the network. Peer device A serves as the
第1のピア装置23の第1の隣接ピアリスト101は{B,E,F,G}であり、第2のピア装置24の第2の隣接ピアリスト102は{C,D,F,H}であり、第3のピア装置25の第3の隣接ピアリスト103は{D,B,I,J}である。 The first
これらの隣接ピアリストは、類似度が高い順にソートされている。よって、例えば第1のピアリストにおいてはピア装置Bが最も類似度が高いこととなっている。 These adjacent peer lists are sorted in descending order of similarity. Therefore, for example, in the first peer list, the peer device B has the highest similarity.
まず、第1のピア装置23であるピア装置Aは第1の隣接ピアリスト内の4つのピア装置10に新規ピア探索クエリ43をブロードキャストする。ここでは、特にピア装置Bに注目して処理を見てゆく。 First, peer device A, which is the
新規ピア探索クエリ43を受信したピア装置Bは、第2の隣接ピアリストにおいて最も類似度が高く、第1の隣接ピアリストに存在しないピア装置Cを新規ピアすなわち第3のピア装置25として、ピア紹介レスポンス44に格納し、ピア装置Aに送信する。 The peer device B that has received the new peer search query 43 has the highest similarity in the second neighbor peer list and the peer device C that does not exist in the first neighbor peer list is the new peer, that is, the
次に、ピア装置Bは第1のプロファイルと第2のプロファイルとの第1の類似度を算出する。ピア装置Bは第1の類似度と第2の最小類似度ピア識別子Hの類似度を比較する。ピア装置Aとの類似度がピア装置Hとの類似度よりも高い場合にはピア識別子Hをキャッシュ部15に移動し、ピア識別子Aを第2の隣接ピアリスト102に追加し、ソートする。この結果、第2の隣接ピアリスト102{A,C,D,F}になったとする。 Next, the peer device B calculates a first similarity between the first profile and the second profile. The peer device B compares the similarity of the first similarity and the second minimum similarity peer identifier H. When the similarity with the peer device A is higher than the similarity with the peer device H, the peer identifier H is moved to the
図11に示すように、ピア識別子Hが第2の隣接ピアリスト102から除外され(点線矢印111)、ピア識別子Aが第2のピアリスト102に追加される(矢印112)。 As shown in FIG. 11, the peer identifier H is excluded from the second neighboring peer list 102 (dotted arrow 111), and the peer identifier A is added to the second peer list 102 (arrow 112).
ピア装置Aはピア装置Bからピア紹介レスポンス44により、ピア装置Cのピア識別子を受信する。ピア装置Aはピア装置Cとの類似度を保持していないため、類似度計算クエリ41をピア装置Cに送信する。 The peer device A receives the peer identifier of the peer device C by the peer introduction response 44 from the peer device B. Since the peer device A does not hold the similarity with the peer device C, the similarity calculation query 41 is transmitted to the peer device C.
類似度計算クエリ41を受信したピア装置Cは第1のプロファイルと第3のプロファイルの第2の類似度を計算し、類似度計算レスポンス42をピア装置Aに送信する。 The peer device C that has received the similarity calculation query 41 calculates the second similarity between the first profile and the third profile, and transmits a similarity calculation response 42 to the peer device A.
次に、ピア装置Cは第2の類似度が第3のプロファイルと第3の最小類似度ピア識別子Jのプロファイルとの類似度よりも高いかを判定する。第2の類似度が第3のプロファイルとピア装置Jのプロファイルとの類似度よりも高いとき、ピア装置Cはピア識別子Jをキャッシュ部15に移動させ、ピア識別子Aを第3の隣接ピアリストに追加し、ソートする。 Next, the peer device C determines whether the second similarity is higher than the similarity between the third profile and the profile of the third minimum similarity peer identifier J. When the second similarity is higher than the similarity between the third profile and the profile of the peer device J, the peer device C moves the peer identifier J to the
ここでは、第2の類似度が第3のプロファイルとピア装置Jのプロファイルとの類似度よりも高くなく、第3の隣接ピアリストに変化がないとする。 Here, it is assumed that the second similarity is not higher than the similarity between the third profile and the profile of the peer device J, and there is no change in the third adjacent peer list.
ピア装置Cから第2の類似度を受信したピア装置Aは、受信した第2の類似度が第1の最小類似度ピア識別子Gとの類似度より高いかを判定する。第2の類似度が第3のプロファイルとピア装置Gのプロファイルとの類似度よりも高い時、ピア識別子Gをキャッシュ部15に移動し、ピア識別子Cを第1の隣接ピアリストに追加し、ソートする。 The peer device A that has received the second similarity from the peer device C determines whether the received second similarity is higher than the similarity with the first minimum similarity peer identifier G. When the second similarity is higher than the similarity between the third profile and the profile of the peer device G, the peer identifier G is moved to the
この場合、ピア装置Aの第1の隣接ピアリスト101は、{C,B,E,F}になったとする。 In this case, it is assumed that the first neighboring
図11に示すように、ピア装置Aの第1の隣接ピアリスト101においては、ピア識別子Gが除外され(点線矢印113)、ピア識別子Cが追加される(矢印114)。 As shown in FIG. 11, in the first neighboring
<本実施形態の効果>
以上述べたように、本実施形態のピア装置10及び分散型推薦システムは、1回の新規ピアの紹介において1回のあらかじめ限られた数のピア装置10にブロードキャストを行い、ブロードキャストを受信したピア装置10がさらにブロードキャストすることはない。このため、本実施形態の本実施形態のピア装置10及び分散型推薦システムは、ブロードキャストが連鎖的に生じることがなく、ネットワーク負荷が低く済むという効果がある。<Effect of this embodiment>
As described above, the peer device 10 and the distributed recommendation system of the present embodiment broadcast to a limited number of peer devices 10 once in a single introduction of a new peer, and the peer that has received the broadcast. The device 10 will not broadcast further. For this reason, the peer device 10 and the distributed recommendation system of the present embodiment of the present embodiment have an effect that the broadcast is not generated in a chain and the network load is low.
また、新規ピア探索クエリ43を使用するため、既知ピアリストにあるピア装置10との通信を行うことがなく、無駄な通信が抑えられるという効果がある。 Moreover, since the new peer search query 43 is used, there is an effect that unnecessary communication is suppressed without performing communication with the peer device 10 in the known peer list.
さらに、バックリンク処理を加えることにより、処理速度を向上させることができるという効果がある。 Furthermore, the processing speed can be improved by adding the back link processing.
<本発明の具体化における可能性>
なお、本発明は上記実施形態そのままに限定されるものではなく、実施段階ではその要旨を逸脱しない範囲で構成要素を変形して具体化できる。また、上記実施形態に開示されている複数の構成要素の適宜な組み合わせにより、種々の発明を形成できる。例えば、実施形態に示される全構成要素から幾つかの構成要素を削除してもよい。さらに、異なる実施形態にわたる構成要素を適宜組み合わせてもよい。<Possibility in the embodiment of the present invention>
Note that the present invention is not limited to the above-described embodiment as it is, and can be embodied by modifying the constituent elements without departing from the scope of the invention in the implementation stage. In addition, various inventions can be formed by appropriately combining a plurality of components disclosed in the embodiment. For example, some components may be deleted from all the components shown in the embodiment. Furthermore, constituent elements over different embodiments may be appropriately combined.
10:ピア装置、
11:ネットワーク、
12:プロファイル保存部、
13:隣接ピアリスト管理部、
13A:隣接ピアリストソート部、
13B:未知ピア検索部、
14:隣接ピアリスト保存部、
15:キャッシュ部、
18:コンテンツ推薦部、
19:コンテンツ保存部、
23:第1のピア装置、
24:第2のピア装置、
25:第3のピア装置10: Peer device,
11: Network,
12: Profile storage unit
13: Neighboring peer list manager
13A: Adjacent peer list sort part,
13B: Unknown peer search unit,
14: Neighboring peer list storage unit,
15: Cache part
18: Content recommendation section,
19: Content storage unit,
23: first peer device,
24: second peer device,
25: Third peer device
Claims (4)
Translated fromJapanese前記各ピア装置は、
ユーザの嗜好情報を表すプロファイルを保存するプロファイル保存部と、
嗜好が類似するプロファイルを保存する有限(k)個の隣接ピア装置の識別子情報を保存する隣接ピアリスト保存部と、を備え、
前記複数個のピア装置の内の第1のピア装置が、前記隣接ピアリスト保存部に保存されたk個の隣接ピア群である第2のピア装置群に推薦依頼情報を送信し、協調フィルタリングによる推薦情報を受信することを特徴とする分散型推薦システム。In a distributed recommendation system in which a plurality of peer devices are connected to each other through a network,
Each of the peer devices is
A profile storage unit for storing a profile representing user preference information;
An adjacent peer list storage unit that stores identifier information of finite (k) adjacent peer devices that store profiles having similar preferences,
A first peer device of the plurality of peer devices transmits recommendation request information to a second peer device group which is a group of k adjacent peers stored in the adjacent peer list storage unit, and performs collaborative filtering. A decentralized recommendation system characterized by receiving recommendation information.
前記各ピア装置は、
ユーザの嗜好情報を表すプロファイルを保存するプロファイル保存部と、
嗜好が類似するプロファイルを保存する有限(k)個の隣接ピア装置の識別子情報を保存する隣接ピアリスト保存部と、
前記プロファイル保存部に保存されたプロファイルと前記隣接ピアから受信したプロファイルとの類似度を計算する類似度計算部と、
を備え、
前記複数個のピア装置の内の第1のピア装置は、前記プロファイル保存部に保存されたプロファイルを前記第2のピア装置群に送信し、前記第2のピア装置群はそれらの隣接ピアリストに含まれる第3のピア装置群の識別子情報を前記第1のピア装置に送信し、前記第1のピア装置は受信したこれらの第3のピア装置群のプロファイルとの類似度が前記第1のピア装置内に保存された隣接ピアリストのどのピア装置のプロファイルとの類似度よりも高い場合、前記第1のピア装置に保存された隣接ピアリストを前記第3のピア装置の識別情報により置き換えることを特徴とする分散型推薦システム。In a distributed recommendation system in which a plurality of peer devices are connected to each other through a network,
Each of the peer devices is
A profile storage unit for storing a profile representing user preference information;
An adjacent peer list storage unit for storing identifier information of finite (k) adjacent peer devices that store profiles having similar preferences;
A similarity calculation unit for calculating a similarity between the profile stored in the profile storage unit and the profile received from the neighboring peer;
With
A first peer device of the plurality of peer devices transmits a profile stored in the profile storage unit to the second peer device group, and the second peer device group includes their neighboring peer list. Identifier information of the third peer device group included in the first peer device is transmitted to the first peer device, and the first peer device has a similarity to the received profile of the third peer device group. If the neighbor peer list stored in the peer device is higher than the similarity with the profile of any peer device, the neighbor peer list stored in the first peer device is identified by the identification information of the third peer device. A decentralized recommendation system characterized by replacement.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007312499AJP2009140004A (en) | 2007-12-03 | 2007-12-03 | Distributed recommendation system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2007312499AJP2009140004A (en) | 2007-12-03 | 2007-12-03 | Distributed recommendation system |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2009140004Atrue JP2009140004A (en) | 2009-06-25 |
Family
ID=40870585
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007312499APendingJP2009140004A (en) | 2007-12-03 | 2007-12-03 | Distributed recommendation system |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2009140004A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2013508878A (en)* | 2009-10-27 | 2013-03-07 | テレフオンアクチーボラゲット エル エム エリクソン(パブル) | Co-occurrence serendipity recommender |
- 2007
- 2007-12-03JPJP2007312499Apatent/JP2009140004A/enactivePending
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2013508878A (en)* | 2009-10-27 | 2013-03-07 | テレフオンアクチーボラゲット エル エム エリクソン(パブル) | Co-occurrence serendipity recommender |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9237199B2 (en) | Contiguous location-based user networks | |
| US7483925B2 (en) | Selecting data for synchronization | |
| CN100428233C (en) | Method and apparatus for search | |
| US10754503B2 (en) | Methods and apparatus for providing recommendations to a user of a cloud computing service | |
| US9251525B2 (en) | Device for determining potential future interests to be introduced into profile(s) of user(s) of communication equipment(s) | |
| US8224899B2 (en) | Method and system for aggregating media collections between participants of a sharing network | |
| US8285811B2 (en) | Aggregating media collections to provide a primary list and sorted sub-lists | |
| US20130007208A1 (en) | Method and Apparatus for Transferring Digital Content between Mobile Devices Using a Computing Cloud | |
| US20090265416A1 (en) | Aggregating media collections between participants of a sharing network utilizing bridging | |
| EP1610529A1 (en) | Information transmission system by collaborative filtering | |
| US8787336B1 (en) | System and method for establishing a local chat session | |
| US9208239B2 (en) | Method and system for aggregating music in the cloud | |
| CN104008193B (en) | A kind of information recommendation method based on group of typical user discovery technique | |
| Xiaoqiang et al. | An in-network caching scheme based on betweenness and content popularity prediction in content-centric networking | |
| US7764701B1 (en) | Methods, systems, and products for classifying peer systems | |
| JP2009140004A (en) | Distributed recommendation system | |
| Kang et al. | A Semantic Service Discovery Network for Large‐Scale Ubiquitous Computing Environments | |
| CN114003727B (en) | A knowledge graph path retrieval method and system | |
| KR101332834B1 (en) | A method for providing service related exhibition based on the ontology | |
| JP2011216021A (en) | Clustering device, clustering method and clustering program | |
| Cui et al. | A probabilistic top-n algorithm for mobile applications recommendation | |
| Bsoul et al. | An enhanced bandwidth hierarchy based replication strategy for dynamic replication in data grid | |
| Nakauchi et al. | Exploiting semantics in unstructured peer-to-peer networks | |
| KR20120046608A (en) | Apparatus and method for sharing contents | |
| Zhang et al. | Efficient high-dimensional retrieval in structured P2P networks |