JP2007336344A - 情報端末装置、その駆動方法及びプログラム - Google Patents
情報端末装置、その駆動方法及びプログラムDownload PDFInfo
- Publication number
- JP2007336344A JP2007336344AJP2006167321AJP2006167321AJP2007336344AJP 2007336344 AJP2007336344 AJP 2007336344AJP 2006167321 AJP2006167321 AJP 2006167321AJP 2006167321 AJP2006167321 AJP 2006167321AJP 2007336344 AJP2007336344 AJP 2007336344A
- Authority
- JP
- Japan
- Prior art keywords
- data
- terminal device
- information terminal
- keyword
- unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images








Landscapes
- Telephonic Communication Services (AREA)
- Two-Way Televisions, Distribution Of Moving Picture Or The Like (AREA)
Abstract
Description
本発明は、音声データ及び画像データを含む各種のデータを伝送路を介して外部装置と送受信可能に構成された情報端末装置、その駆動方法、及び当該駆動方法をコンピュータに実行させるためのプログラムに関する。
従来より、画像データ、音声データ等の各種情報をネットワークを介して端末装置間で授受するTV電話/TV会議システムが提案されている(例えば、下記の特許文献1参照)。
近年、TV電話では、画像データと音声データを端末装置間で送受信することにより、相手側の映像を見ながら会話ができるようになっている。更に、TV電話では、ネットワークの伝送路の大幅な伝送容量の増大に伴い、TV会議システムで提案されている、映像、音声を授受するだけではなく、ファイル転送、描画情報のやり取り、アプリケーションソフトの共有等を多地点間で行うことができるようになっている。これにより、効率的な会議を進めることが可能なシステムが提供されている。
上述したシステムでは、TV会議システムのみならず、個人のTV電話においても、端末装置内に記憶された画像データや各種ドキュメントデータ等をお互いの端末装置上に表示出力させて会話を行うことができるようになっている。これにより、遠隔地間で会話をしながら、各種情報を共有することが可能であり、よりリアルな会議の雰囲気での会話に近づけたシステムも実現されてきている。
上述したシステムにおいては、端末装置の表示画面を見ながら会話を行い、必要に応じて共有すべき情報を端末装置を操作することにより検索、出力して送信を行うことを実現している。
しかしながら、上述したシステムでは、端末装置に設けられたキーボード等の入力手段を操作して所望のデータが格納されている記憶手段を特定し、その中から当該所望のデータを検索して、自装置の表示装置に表示すると共に、相手側の端末装置に対する送信指示を行うことが必要となり、連続的に会話をしている状態である場合、当該操作中は会話が中断してしまうといった問題があった。
また、上述したシステムでは、表示装置に出力されている双方の映像を確認しながら会話が行われるため、通常、映像を撮影するカメラが表示装置上に配設されている関係上、会話者は、表示装置からある程度離れた位置で会話を行う必要がある。また、上述した操作を表示装置を含む端末装置で行う場合は、端末装置の傍に近づき操作を行うため、やはり、会話が一時的に中断されてしまうといった問題があった。
本発明は上述の問題点に鑑みてなされたものであり、連続的な会話を中断することなく、快適なTV電話システム、TV会議システムを実現する情報端末装置、その駆動方法及びプログラムを提供することを目的とする。
本発明の情報端末装置は、音声データ及び画像データを含む各種のデータを伝送路を介して外部装置と送受信可能に構成された情報端末装置であって、検索用のキーワードと関連付けられたデータを記憶する第1の記憶手段と、前記情報端末装置及び前記外部装置のうちの少なくとも何れか一方に対して発声された音声を音声データとして入力する音声入力手段と、前記音声入力手段により入力された音声データに基づいてキーワードを抽出する抽出手段と、前記抽出手段で抽出したキーワードに係るデータを前記第1の記憶手段から読み出す読み出し手段と、前記読み出し手段で読み出したデータを表示媒体に表示する表示手段と、前記読み出し手段で読み出したデータを前記伝送路を介して前記外部装置に送信する送信手段とを有する。
本発明の情報端末装置の駆動方法は、音声データ及び画像データを含む各種のデータを伝送路を介して外部装置と送受信可能に構成され、検索用のキーワードと関連付けられたデータを記憶する第1の記憶手段を具備する情報端末装置の駆動方法であって、前記情報端末装置及び前記外部装置のうちの少なくとも何れか一方に対して発声された音声を音声データとして入力する音声入力ステップと、前記音声入力ステップにより入力された音声データに基づいてキーワードを抽出する抽出ステップと、前記抽出ステップで抽出したキーワードに係るデータを前記第1の記憶手段から読み出す読み出しステップと、前記読み出しステップで読み出したデータを表示媒体に表示する表示ステップと、前記読み出しステップで読み出したデータを前記伝送路を介して前記外部装置に送信する送信ステップとを有する。
また、本発明のプログラムは、前記情報端末装置の駆動方法の各ステップをコンピュータに実行させるためのものである。
本発明によれば、連続的な会話を中断することなく、快適なTV電話システム、TV会議システムを実現することができる。
以下、図面を参照して、本発明の実施形態について説明する。
(第1の実施形態)
図1は、第1の実施形態に係る情報端末装置のハードウエア構成を示すブロック図である。
図1において、制御部11は、情報端末装置のシステム全体の制御を司るものであり、例えば、後述する情報検索出力制御及び情報送信制御等を実行する。ROM12は、制御部11で各種制御を行う際に必要なプログラムなどを格納する。RAM13は、入力データなどの情報やプログラム実行中のデータなどを一時的に記憶する。
図1は、第1の実施形態に係る情報端末装置のハードウエア構成を示すブロック図である。
図1において、制御部11は、情報端末装置のシステム全体の制御を司るものであり、例えば、後述する情報検索出力制御及び情報送信制御等を実行する。ROM12は、制御部11で各種制御を行う際に必要なプログラムなどを格納する。RAM13は、入力データなどの情報やプログラム実行中のデータなどを一時的に記憶する。
画像入力部14は、例えばカメラ装置等からなるものであり、TV電話/TV会議システムにおいて、撮影された映像(画像)を映像データ(画像データ)として入力を行う。音声入力部15は、例えばマイク装置等からなるものであり、TV電話/TV会議システムにおいて、発声された音声を音声データとして入力を行う。ここで、本実施形態の音声入力部15は、当該情報端末装置のみならず、相手側の情報端末装置に対して発声された音声を音声データとして入力するものとする。
操作入力部16は、例えばキーボード装置等からなるものであり、情報端末装置における各種の設定、制御、データ入力手段として機能する。
表示出力部17は、例えば液晶ディスプレイ端末装置やTV表示装置等からなるものであり、画像を出力する手段として機能する。また、音声出力部18は、例えばスピーカ装置等からなるものであり、音声を出力する手段として機能する。これらの表示出力部17及び音声出力部18により、当該情報端末装置と通信可能に構成された情報端末装置の使用者における双方の顔や、会話、共有データの出力再生がなされる。通常、表示出力部17は、同時に複数の情報の出力が可能であり、送信側の映像データや、相手側の映像データ、共有データ、及び各情報端末装置内の情報が同時に出力可能に構成されている。
画像符号化/復号化処理部19及び音声符号化/復号化処理部20は、送信側の情報端末装置と受信側の情報端末装置との間で、それぞれ、映像及び音声、並びにその他の情報を授受する際のこれらの各データの符号化/復号化処理を行なう。多重/分離処理部21は、画像データ、音声データを分離した後、回線インターフェース処理部22を介して、通信ネットワーク23に伝送可能な通信形態に所望の通信プロトコルに準じた変換を行う。これらの一連の処理により、送信側の情報端末装置と受信側の情報端末装置との間で、画像データ及び音声データを含む各種のデータの送受信が行なわれる。
外部記憶部24には、画像やドキュメント等の各種のデータが検索用のキーワードと関連付けられて記憶されている。音声認識処理部25は、音声入力部15より入力された音声データの中から従来より提案されている認識処理を用いてテキスト情報に変換するものであり、このテキスト情報は、キーワードとしてキーワード保持部26へ順次格納される。
制御部11は、キーワード保持部26に格納された各種キーワードを活用して、外部記憶部24内に予めキーワードと関連付けられて格納された画像データや各種のデータの検索を行う。そして、制御部11は、検索された各種のデータを外部記憶部24から読み出して、表示出力部17に表示出力したり、回線インターフェース処理部22を介して、相手の情報端末装置に送信したりする。
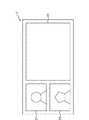
図2は、従来例における表示出力部17の出力表示の一例を示す図である。
図2に示す表示出力部17には、送信側の情報端末装置の画像入力部14で撮影された画像を表示する送信側映像部27と、相手側の情報端末装置で撮影され、通信ネットワーク23を介して伝送される画像を表示する相手側映像部28が設けられている。この場合、また、音声入力部15により音声データを送受信しながら、通信ネットワーク23を介して映像と音声による会話が実現されている。
図2に示す表示出力部17には、送信側の情報端末装置の画像入力部14で撮影された画像を表示する送信側映像部27と、相手側の情報端末装置で撮影され、通信ネットワーク23を介して伝送される画像を表示する相手側映像部28が設けられている。この場合、また、音声入力部15により音声データを送受信しながら、通信ネットワーク23を介して映像と音声による会話が実現されている。
上述のように、映像と音声で会話を行っている際、送信側の情報端末装置内の外部記憶部24に格納された画像やドキュメント等のデータに関して会話を行う場合、外部記憶部24内のデータの格納状態を示すデータ一覧29を表示出力部17の下部に表示させる。このデータ一覧29は、通常、階層構造になっている。
操作者は、会話をしながら操作入力部16の操作によりデータ一覧29の中から所望のデータ「001」30を送信指示することにより、通信ネットワーク23を介して相手側の情報端末装置の表示出力部に当該データ「001」が出力表示される。この際、送信側の情報端末装置では、送信するデータ「001」30を画像符号化/復号化処理部19で圧縮し、回線インターフェース処理部22を介して、相手側の情報端末装置に送信する。また、送信側の情報端末装置の表示出力部17には、送信指示したデータ「001」30がデータ表示部31に表示される。このようにして、送信側と相手側とが表示されたデータ「001」を確認しながら会話を行うことが可能となる。
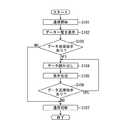
図3は、図2に示す従来例における表示出力部17の出力表示動作を示すフローチャートである。この図3に示す処理は、図1の制御部11で行われる。
まず、ステップS101では、送信側の情報端末装置と相手側(受信側)の情報端末装置とを、通信ネットワーク23を介して画像データや音声データを含む各種のデータの送受信が可能な状態として、通信開始の処理を行う。
続いて、操作者が外部記憶部24内のデータを相手側の情報端末装置に送信する場合、ステップS102では、図2における表示出力部17の下段に示すデータ一覧29を表示出力させる。
続いて、ステップS103では、操作者によりデータ一覧29から相手側の情報端末装置に送信する所望のデータ(図2に示す例では、データ「001」30)が選択され、当該データの送信指示があるか否かを判断する。この判断の結果、データの送信指示がなかった場合には、ステップS107に進む。一方、ステップS103の判断の結果、データの送信指示があった場合には、ステップS104に進む。
ステップS104では、ステップS103で送信指示されたデータ「001」30の元データを外部記憶部24から読み出し、画像符号化/復号化処理部19で圧縮して通信ネットワーク23を介して相手側の情報端末装置に送信する。続いて、ステップS105では、図2に示すように、送信指示したデータ「001」30を当該表示出力部17のデータ表示部31に表示合成する。
続いて、ステップS106では、操作者によりデータ一覧29から相手側の情報端末装置に送信する他のデータが選択され、当該データの送信指示があるか否かを判断する。この判断の結果、他のデータの送信指示があった場合には、ステップS104に戻り、ステップS104で改めて当該他のデータを読み出して、ステップS105で当該他のデータを表示しながら会話を継続することになる。一方、ステップS106の判断の結果、他のデータの送信指示がなかった場合には、ステップS107に進む。
続いて、ステップS107では、一連の会話を終了させるために、通信の切断処理を実行する。以上のステップS101〜ステップS107までの処理を経ることにより、図2に示す表示出力部17の出力表示動作が行われる。
図2及び図3に示す従来例の場合、表示出力部17の相手側映像部28を確認しながら操作入力部16を操作して所望のデータを検索指示することが必要であった。このため、当該所望のデータが格納されている構成が複雑な場合、操作入力部16の操作に手間取り、会話が中断してしまうといった不都合が発生していた。そこで、この課題を解決するための本発明の第1の実施形態に係る情報端末装置の駆動方法を、図4乃至図6を用いて以下に説明する。
図4は、第1の実施形態における表示出力部17の出力表示の一例を示す図である。
本実施形態では、図4に示す送信側映像部27と相手側映像部28を同一画面上に表示しながら会話を行っている時、会話における音声データを音声認識処理部25において順次認識して、キーワードを連続的に抽出する。
本実施形態では、図4に示す送信側映像部27と相手側映像部28を同一画面上に表示しながら会話を行っている時、会話における音声データを音声認識処理部25において順次認識して、キーワードを連続的に抽出する。
そして、連続的に抽出されるキーワードから、予め外部記憶部24内にキーワードと共に格納された複数のデータの中から、抽出されたキーワードと一致するキーワードに係るデータを順次読み出し、これを表示出力部17のデータ表示部33に順次表示する。
これにより、会話を継続しながら、会話の中から関連する情報がデータ表示部33に順次表示されると共に、当該情報を共有させることにより、円滑で効率的なTV会議システムが実現される。
図5は、第1の実施形態に係る情報端末装置の駆動方法を示すフローチャートである。具体的に、図5は、図4に示す表示出力部17の出力表示動作を示すフローチャートである。この図5に示す処理は、図1の制御部11で行われる。
まず、ステップS201では、送信側の情報端末装置と相手側(受信側)の情報端末装置とを、通信ネットワーク23を介して画像データや音声データを含む各種のデータの送受信が可能な状態として、通信開始の処理を行う。
続いて、ステップS202では、会話中の音声からデータ検索のキーワードを抽出する音声認識モードの設定がなされているか否かを判断する。この判断の結果、音声認識モードの設定がなされていない場合には、ステップS210に進む。一方、ステップS202の判断の結果、音声認識モードの設定がなされている場合には、ステップS203に進む。
ステップS202で音声認識モードが設定されていると判断された場合、続いて、ステップS203では、送信者あるいは相手側の会話を音声認識処理部25で順次音声認識を行い、検索対象となるキーワードが発声されたか否かを判断する。この判断の結果、検索対象となるキーワードが発声されていない場合には、検索対象となるキーワードが発声されるまで、ステップS203で待機する。一方、ステップS203の判断の結果、検索対象となるキーワードが発声された場合には、ステップS204に進む。
ステップS204では、キーワードの認識処理を行う。続いて、ステップS205では、予め外部記憶部24にキーワードと共に格納されたデータの中から検索を行う。続いて、ステップS206では、外部記憶部24内に、ステップS204で認識されたキーワードと一致したキーワードに係る元データが存在するか否かを判断する。この判断の結果、ステップS204で認識されたキーワードと一致したキーワードに係る元データが外部記憶部24内に存在しない場合には、ステップS203に戻る。一方、ステップS206の判断の結果、ステップS204で認識されたキーワードと一致したキーワードに係る元データが外部記憶部24内に存在する場合には、ステップS207に進む。
ステップS207では、当該元データを読み出す。続いて、ステップS208では、ステップS207で読み出した元データを表示出力部17のデータ表示部33に表示する。さらに、相手側の情報端末装置にステップS207で読み出された元データを送信し、当該相手側の情報端末装置の表示出力部に当該元データを出力表示させる。
続いて、ステップS209では、次なる検索キーワードが発声されたか否かを判断し、発声された場合には、ステップS204に戻って以降の処理を繰り返す。一方、ステップS209での判断の結果、次なる検索キーワードが発声されなかった場合には、ステップS210に進む。
ステップS210では、一連の会話を終了させるために、通信の切断処理を実行する。以上のステップS201〜ステップS210までの処理を経ることにより、図4に示す表示出力部17の出力表示動作が行われる。
図6は、第1の実施形態における表示出力部17の出力表示の他の一例を示す図である。即ち、図6には、図4に示す表示出力部17の出力表示における別のレイアウトを示したものである。
図6において、表示出力部17の下段には、一連の会話で使用予定、もしくは、外部記憶部24内の一部のデータの縮小データ32が複数表示されている。図6に示す例では、この縮小データ32が複数表示されている状態の中で会話を行いながら、データを指定するものである。
図6に示す例では、会話における音声認識により抽出されたキーワードに合致するデータ「a」34が強調されると共に、その元データ「A」が外部記憶部24から読み出されて、表示出力部17のデータ表示部33に表示される。また、指示部35a及び35bは、縮小データ32の候補の切替を指示する際に操作されるものである。
第1の実施形態によれば、操作者は、予め会話に必要なデータ一覧を確認しながら会話を行うことができ、相手側にも同一表示状態を再現させることにより、より効果的な会話が実現可能となる。これにより、連続的な会話を中断することなく、快適なTV電話システム、TV会議システムを実現することが可能となる。
(第2の実施形態)
図7は、第2の実施形態における表示出力部17の出力表示の一例を示す図である。
第1の実施形態では、送信側の情報端末装置の外部記憶部(第1の記憶手段)24に格納されたデータのみを検索対象としていたが、第2の実施形態では、相手側の情報端末装置の外部記憶部(第2の記憶手段)に格納されたデータも検索対象とするものである。
図7は、第2の実施形態における表示出力部17の出力表示の一例を示す図である。
第1の実施形態では、送信側の情報端末装置の外部記憶部(第1の記憶手段)24に格納されたデータのみを検索対象としていたが、第2の実施形態では、相手側の情報端末装置の外部記憶部(第2の記憶手段)に格納されたデータも検索対象とするものである。
図7において、送信側の情報端末装置における表示出力部17の下段には、当該情報端末装置に格納されている送信側の縮小データ(縮小画像データ)36と、相手側の情報端末装置に格納されている相手側の縮小データ(縮小画像データ)37が表示される。なお、この際、これらの縮小データがそれぞれ両者の情報端末装置に同時に通信ネットワーク23を介して表示されている。このため、会話において認識されたキーワードに合致するデータを、それぞれの情報端末装置内の外部記憶部から検索し、合致したデータ「b」38が強調されると共に、その元データ「B」が表示出力部17のデータ表示部33に表示される。
(第3の実施形態)
図8は、第3の実施形態における表示出力部17の出力表示の一例を示す図である。第3の実施形態は、第2の実施形態の更なる応用を示すものである。
図8は、第3の実施形態における表示出力部17の出力表示の一例を示す図である。第3の実施形態は、第2の実施形態の更なる応用を示すものである。
第2の実施形態では、送信側及び相手側の情報端末装置の各外部記憶部内に格納された縮小データの一覧を、それぞれのデータ表示部に出力表示させていたが、各情報端末装置内に格納されたデータの中で、相手に見せたくないデータも含まれることがある。そこで、第3の実施形態では、図8に示すように、相手側の情報端末装置において送信側の情報端末装置に表示したくない禁止縮小データ40a及び40bは、送信側の情報端末装置からは視認できないように、データ表示部33に表示される。
即ち、第3の実施形態では、それぞれの会話の中から認識されたキーワードに合致するデータが禁止縮小データ40aの場合は、当該データを格納している相手側の情報端末装置にはその元データが表示されるが、当該データを未格納な送信側の情報端末装置では、図8に示すように、元データがデータ表示部33に表示されない。
この第3の実施形態の具体的な形態としては、例えば、図5のステップS207において相手側の情報端末装置の外部記憶部(第2の記憶手段)から読み出したデータに対して表示禁止の設定がなされていた場合、ステップS208では、当該データの表示出力部17への表示を行わないようにする。また、例えば、ステップS207において自装置の外部記憶部(第1の記憶手段)24から読み出したデータに対して表示禁止の設定がなされていた場合、ステップS207では、当該データの相手側の情報端末装置への送信を行わないようにする。
第3の実施形態によれば、一連の縮小データを基に会話をする際に、相手側に見られたくないデータを当該相手側に誤って見られてしまうということを回避でき、当該データを当該相手側に対して自動的に隠蔽することができる。なお、予め見れないように指示がされている場合でも、キーワード検索により一致した元データが自分の情報端末装置に表示された後、特定の操作処理を行って相手側に送信することにより、相手側で当該元データを表示可能とするように構成しても良い。
(第4の実施形態)
図9は、第4の実施形態に係る情報端末装置の駆動方法を示すフローチャートである。具体的に、この図9に示す処理は、図1の制御部11で行われる。
図9は、第4の実施形態に係る情報端末装置の駆動方法を示すフローチャートである。具体的に、この図9に示す処理は、図1の制御部11で行われる。
まず、ステップS201では、送信側の情報端末装置と相手側(受信側)の情報端末装置とを、通信ネットワーク23を介して画像データや音声データを含む各種のデータの送受信が可能な状態として、通信開始の処理を行う。
続いて、ステップS302では、会話中の音声からデータ検索のキーワードを抽出する音声認識モードの設定がなされているか否かを判断する。この判断の結果、音声認識モードの設定がなされていない場合には、ステップS311に進む。一方、ステップS302の判断の結果、音声認識モードの設定がなされている場合には、ステップS303に進む。
ステップS302で音声認識モードが設定されていると判断された場合、続いて、ステップS303では、送信者あるいは相手側の会話を音声認識処理部25で順次音声認識を行い、検索対象となるキーワードが発声されたか否かを判断する。この判断の結果、検索対象となるキーワードが発声されていない場合には、検索対象となるキーワードが発声されるまで、ステップS303で待機する。一方、ステップS303の判断の結果、検索対象となるキーワードが発声された場合には、ステップS304に進む。
ステップS304では、キーワードの認識処理を行う。そして、認識されたキーワードがキーワード保持部26にその認識回数と共に格納される。
続いて、ステップS305では、キーワード保持部26に格納されたステップS304で認識されたキーワードがN回(Nは、自然数)以上発声されたか否かを判断する。この判断の結果、ステップS304で認識されたキーワードがN回以上発声されていない場合には、ステップS303に戻る。一方、ステップS305の判断の結果、ステップS304で認識されたキーワードがN回以上発声された場合には、ステップS306に進む。
ステップS306では、予め外部記憶部24にキーワードと共に格納されたデータの中から検索を行う。続いて、ステップS307では、外部記憶部24内に、ステップS304で認識されたキーワードと一致したキーワードに係る元データが存在するか否かを判断する。この判断の結果、ステップS304で認識されたキーワードと一致したキーワードに係る元データが外部記憶部24内に存在しない場合には、ステップS303に戻る。一方、ステップS307の判断の結果、ステップS304で認識されたキーワードと一致したキーワードに係る元データが外部記憶部24内に存在する場合には、ステップS308に進む。
ステップS308では、当該元データを読み出す。続いて、ステップS309では、ステップS308で読み出した元データを表示出力部17のデータ表示部33に表示する。さらに、相手側の情報端末装置にステップS308で読み出された元データを送信し、当該相手側の情報端末装置の表示出力部に当該元データを出力表示させる。
続いて、ステップS310では、次なる検索キーワードが発声されたか否かを判断し、発声された場合には、ステップS304に戻って以降の処理を繰り返す。一方、ステップS310での判断の結果、次なる検索キーワードが発声されなかった場合には、ステップS311に進む。
ステップS311では、一連の会話を終了させるために、通信の切断処理を実行する。以上のステップS301〜ステップS311までの処理を経ることにより、第4の実施形態における表示出力部17の出力表示動作が行われる。
第4の実施形態によれば、会話の中で連続的に発声される異なるキーワードに対して、所定回数(N回)発声されたキーワードの元データを検索することにより、処理が遅くなったり、不要な元データを読み出してしまうといった問題を回避することができる。これにより、検索する元データの精度を向上させることができる。なお、本実施形態において、当該キーワードの発声は、送信側、相手側のそれぞれの発声回数を計上する形態であっても良い。
(第5の実施形態)
図10は、第5の実施形態に係る情報端末装置の駆動方法を示すフローチャートである。具体的に、この図5に示す処理は、図1の制御部11で行われる。
図10は、第5の実施形態に係る情報端末装置の駆動方法を示すフローチャートである。具体的に、この図5に示す処理は、図1の制御部11で行われる。
図6で示した表示出力部17の表示例では、検索対象となる縮小データ群を予め指定して会話を行う必要があった。第5の実施形態では、検索対象となるデータ群に対して、予め話者を対応させて記憶させておく。そして、送信側の情報端末装置に対して、話者が会話を開始することにより、音声認識処理部25で話者が特定され、話者に対応したデータ群が呼び出されるように構成したものである。
まず、ステップS401では、送信側の情報端末装置と相手側(受信側)の情報端末装置とを、通信ネットワーク23を介して画像データや音声データを含む各種のデータの送受信が可能な状態として、通信開始の処理を行う。
続いて、ステップS402では、会話中の音声からデータ検索のキーワードを抽出する音声認識モードの設定がなされているか否かを判断する。この判断の結果、音声認識モードの設定がなされていない場合には、ステップS411に進む。一方、ステップS402の判断の結果、音声認識モードの設定がなされている場合には、ステップS403に進む。
ステップS402で音声認識モードが設定されていると判断された場合、続いて、ステップS403では、送信者あるいは相手側の会話を音声認識処理部25で順次音声認識を行い、検索対象となるキーワードが発声されたか否かを判断する。この判断の結果、検索対象となるキーワードが発声されていない場合には、検索対象となるキーワードが発声されるまで、ステップS403で待機する。一方、ステップS403の判断の結果、検索対象となるキーワードが発声された場合には、ステップS404に進む。
ステップS404では、キーワードが認識処理を行う。そして、認識されたキーワードがキーワード保持部26にその話者の情報と共に格納される。
続いて、ステップS405では、ステップS404で認識されたキーワードに基づいて、キーワード保持部26を参照することにより、話者を特定する。話者が特定されると、続いて、ステップS406では、外部記憶部24に予め話者と関連させて記憶させていたデータ群が検索され、図6に示す縮小データ32が表示される。
続いて、ステップS407では、外部記憶部24内に、ステップS404で認識されたキーワードと一致したキーワードに係る元データが存在するか否かを判断する。この判断の結果、ステップS404で認識されたキーワードと一致したキーワードに係る元データが外部記憶部24内に存在しない場合には、ステップS403に戻る。一方、ステップS407の判断の結果、ステップS404で認識されたキーワードと一致したキーワードに係る元データが外部記憶部24内に存在する場合には、ステップS408に進む。
ステップS408では、当該元データを読み出す。続いて、ステップS409では、ステップS408で読み出した元データを表示出力部17のデータ表示部33に表示する。さらに、相手側の情報端末装置にステップS408で読み出された元データを送信し、当該相手側の情報端末装置の表示出力部に当該元データを出力表示させる。
続いて、ステップS410では、次なる検索キーワードが発声されたか否かを判断し、発声された場合には、ステップS404に戻って以降の処理を繰り返す。一方、ステップS410での判断の結果、次なる検索キーワードが発声されなかった場合には、ステップS411に進む。
ステップS411では、一連の会話を終了させるために、通信の切断処理を実行する。以上のステップS401〜ステップS411までの処理を経ることにより、第5の実施形態における表示出力部17の出力表示動作が行われる。
第5の実施形態によれば、音声認識処理部25の機能を利用して話者の特定をキーワードの認識と共に行うことにより、話者特定のデータを検索することができ、更なる会話の有効性が高められる。なお、本実施形態において、相手の話者を認識して、相手の話者と予め関連付けられたデータ群を読み出しても良いことは言うまでもない。
前述した各実施形態に係る情報端末装置を構成する図1の各手段、並びに情報端末装置の駆動方法を示した図5、図9及び図10の各ステップは、コンピュータのRAMやROMなどに記憶されたプログラムが動作することによって実現できる。このプログラム及び当該プログラムを記録したコンピュータ読み取り可能な記憶媒体は本発明に含まれる。
具体的に、前記プログラムは、例えばCD−ROMのような記憶媒体に記録し、或いは各種伝送媒体を介し、コンピュータに提供される。前記プログラムを記録する記憶媒体としては、CD−ROM以外に、フレキシブルディスク、ハードディスク、磁気テープ、光磁気ディスク、不揮発性メモリカード等を用いることができる。他方、前記プログラムの伝送媒体としては、プログラム情報を搬送波として伝搬させて供給するためのコンピュータネットワーク(LAN、インターネットの等のWAN、無線通信ネットワーク等)システムにおける通信媒体を用いることができる。また、この際の通信媒体としては、光ファイバ等の有線回線や無線回線などが挙げられる。
また、コンピュータが供給されたプログラムを実行することにより各実施形態に係る情報端末装置の機能が実現されるだけでなく、そのプログラムがコンピュータにおいて稼働しているOS(オペレーティングシステム)或いは他のアプリケーションソフト等と共同して各実施形態に係る情報端末装置の機能が実現される場合や、供給されたプログラムの処理の全て、或いは一部がコンピュータの機能拡張ボードや機能拡張ユニットにより行われて各実施形態に係る情報端末装置の機能が実現される場合も、かかるプログラムは本発明に含まれる。
11:制御部
12:ROM
13:RAM
14:画像入力部
15:音声入力部
16:操作入力部
17:表示出力部
18:音声出力部
19:画像符号化/復号化処理部
20:音声符号化/復号化処理部
21:多重/分離処理部
22:回線インターフェース処理部
23:通信ネットワーク
24:外部記憶部
25:音声認識処理部
26:キーワード保持部
27:送信側映像部
28:相手側映像部
29:データ一覧
30、34、38:データ
31、33:データ表示部
32:縮小データ
35a、35b:指示部
36:送信側の縮小データ
37:相手側の縮小データ
40a、40b:禁止縮小データ
12:ROM
13:RAM
14:画像入力部
15:音声入力部
16:操作入力部
17:表示出力部
18:音声出力部
19:画像符号化/復号化処理部
20:音声符号化/復号化処理部
21:多重/分離処理部
22:回線インターフェース処理部
23:通信ネットワーク
24:外部記憶部
25:音声認識処理部
26:キーワード保持部
27:送信側映像部
28:相手側映像部
29:データ一覧
30、34、38:データ
31、33:データ表示部
32:縮小データ
35a、35b:指示部
36:送信側の縮小データ
37:相手側の縮小データ
40a、40b:禁止縮小データ
Claims (8)
- 音声データ及び画像データを含む各種のデータを伝送路を介して外部装置と送受信可能に構成された情報端末装置であって、
検索用のキーワードと関連付けられたデータを記憶する第1の記憶手段と、
前記情報端末装置及び前記外部装置のうちの少なくとも何れか一方に対して発声された音声を音声データとして入力する音声入力手段と、
前記音声入力手段により入力された音声データに基づいてキーワードを抽出する抽出手段と、
前記抽出手段で抽出したキーワードに係るデータを前記第1の記憶手段から読み出す読み出し手段と、
前記読み出し手段で読み出したデータを表示媒体に表示する表示手段と、
前記読み出し手段で読み出したデータを前記伝送路を介して前記外部装置に送信する送信手段と
を有することを特徴とする情報端末装置。 - 前記外部装置には、検索用のキーワードと関連付けられたデータを記憶する第2の記憶手段が具備されており、
前記読み出し手段は、前記抽出手段で抽出したキーワードに係るデータを、前記第1の記憶手段及び前記第2の記憶手段から読み出すことを特徴とする請求項1に記載の情報端末装置。 - 前記読み出し手段において前記第2の記憶手段から読み出したデータに対して表示禁止の設定がなされていた場合、前記表示手段は、当該データの前記表示媒体への表示を行わないことを特徴とする請求項2に記載の情報端末装置。
- 前記読み出し手段において前記第1の記憶手段から読み出したデータに対して表示禁止の設定がなされていた場合、前記送信手段は、当該データの前記外部装置への送信を行わないことを特徴とする請求項2又は3に記載の情報端末装置。
- 前記読み出し手段は、前記抽出手段により抽出された前記キーワードの回数が既定回数となった場合に、当該キーワードに係るデータを読み出すことを特徴とする請求項1乃至4の何れか1項に記載の情報端末装置。
- 前記第1の記憶手段及び前記第2の記憶手段に記憶されているデータには、話者に係る前記音声データの音声属性コードが関連付けられており、
前記抽出手段は、前記音声属性コードに対応したキーワードを抽出することを特徴とする請求項2乃至4の何れか1項に記載の情報端末装置。 - 音声データ及び画像データを含む各種のデータを伝送路を介して外部装置と送受信可能に構成され、検索用のキーワードと関連付けられたデータを記憶する第1の記憶手段を具備する情報端末装置の駆動方法であって、
前記情報端末装置及び前記外部装置のうちの少なくとも何れか一方に対して発声された音声を音声データとして入力する音声入力ステップと、
前記音声入力ステップにより入力された音声データに基づいてキーワードを抽出する抽出ステップと、
前記抽出ステップで抽出したキーワードに係るデータを前記第1の記憶手段から読み出す読み出しステップと、
前記読み出しステップで読み出したデータを表示媒体に表示する表示ステップと、
前記読み出しステップで読み出したデータを前記伝送路を介して前記外部装置に送信する送信ステップと
を有することを特徴とする情報端末装置の駆動方法。 - 請求項7に記載の情報端末装置の駆動方法の各ステップをコンピュータに実行させるためのプログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006167321AJP2007336344A (ja) | 2006-06-16 | 2006-06-16 | 情報端末装置、その駆動方法及びプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006167321AJP2007336344A (ja) | 2006-06-16 | 2006-06-16 | 情報端末装置、その駆動方法及びプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2007336344Atrue JP2007336344A (ja) | 2007-12-27 |
Family
ID=38935377
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006167321APendingJP2007336344A (ja) | 2006-06-16 | 2006-06-16 | 情報端末装置、その駆動方法及びプログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2007336344A (ja) |
Cited By (22)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2009171336A (ja)* | 2008-01-17 | 2009-07-30 | Nec Corp | 携帯通信端末 |
| JP2009294237A (ja)* | 2008-06-02 | 2009-12-17 | Konica Minolta Business Technologies Inc | 会議システム、データ処理装置、画像送信方法および画像送信プログラム |
| JP2010081016A (ja)* | 2008-09-24 | 2010-04-08 | Fuji Xerox Co Ltd | 画像送信装置、画像送信プログラム、及び画像通信システム |
| JP2014518594A (ja)* | 2011-03-29 | 2014-07-31 | ティーアイ スクエア テクノロジー リミテッド | コミュニケーションサービスの遂行中のマルチメディアコンテンツ共有サービス提供方法及びシステム |
| JP2017091535A (ja)* | 2015-11-10 | 2017-05-25 | 株式会社リコー | 電子会議システム |
| US10510051B2 (en) | 2016-10-11 | 2019-12-17 | Ricoh Company, Ltd. | Real-time (intra-meeting) processing using artificial intelligence |
| US10552546B2 (en) | 2017-10-09 | 2020-02-04 | Ricoh Company, Ltd. | Speech-to-text conversion for interactive whiteboard appliances in multi-language electronic meetings |
| US10553208B2 (en) | 2017-10-09 | 2020-02-04 | Ricoh Company, Ltd. | Speech-to-text conversion for interactive whiteboard appliances using multiple services |
| US10572858B2 (en) | 2016-10-11 | 2020-02-25 | Ricoh Company, Ltd. | Managing electronic meetings using artificial intelligence and meeting rules templates |
| US10757148B2 (en) | 2018-03-02 | 2020-08-25 | Ricoh Company, Ltd. | Conducting electronic meetings over computer networks using interactive whiteboard appliances and mobile devices |
| US10860985B2 (en) | 2016-10-11 | 2020-12-08 | Ricoh Company, Ltd. | Post-meeting processing using artificial intelligence |
| US10956875B2 (en) | 2017-10-09 | 2021-03-23 | Ricoh Company, Ltd. | Attendance tracking, presentation files, meeting services and agenda extraction for interactive whiteboard appliances |
| US11030585B2 (en) | 2017-10-09 | 2021-06-08 | Ricoh Company, Ltd. | Person detection, person identification and meeting start for interactive whiteboard appliances |
| US11062271B2 (en) | 2017-10-09 | 2021-07-13 | Ricoh Company, Ltd. | Interactive whiteboard appliances with learning capabilities |
| US11080466B2 (en) | 2019-03-15 | 2021-08-03 | Ricoh Company, Ltd. | Updating existing content suggestion to include suggestions from recorded media using artificial intelligence |
| US11120342B2 (en) | 2015-11-10 | 2021-09-14 | Ricoh Company, Ltd. | Electronic meeting intelligence |
| US11263384B2 (en) | 2019-03-15 | 2022-03-01 | Ricoh Company, Ltd. | Generating document edit requests for electronic documents managed by a third-party document management service using artificial intelligence |
| US11270060B2 (en) | 2019-03-15 | 2022-03-08 | Ricoh Company, Ltd. | Generating suggested document edits from recorded media using artificial intelligence |
| US11307735B2 (en) | 2016-10-11 | 2022-04-19 | Ricoh Company, Ltd. | Creating agendas for electronic meetings using artificial intelligence |
| US11392754B2 (en) | 2019-03-15 | 2022-07-19 | Ricoh Company, Ltd. | Artificial intelligence assisted review of physical documents |
| US11573993B2 (en) | 2019-03-15 | 2023-02-07 | Ricoh Company, Ltd. | Generating a meeting review document that includes links to the one or more documents reviewed |
| US11720741B2 (en) | 2019-03-15 | 2023-08-08 | Ricoh Company, Ltd. | Artificial intelligence assisted review of electronic documents |
- 2006
- 2006-06-16JPJP2006167321Apatent/JP2007336344A/jaactivePending
Cited By (27)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2009171336A (ja)* | 2008-01-17 | 2009-07-30 | Nec Corp | 携帯通信端末 |
| JP2009294237A (ja)* | 2008-06-02 | 2009-12-17 | Konica Minolta Business Technologies Inc | 会議システム、データ処理装置、画像送信方法および画像送信プログラム |
| JP2010081016A (ja)* | 2008-09-24 | 2010-04-08 | Fuji Xerox Co Ltd | 画像送信装置、画像送信プログラム、及び画像通信システム |
| JP2014518594A (ja)* | 2011-03-29 | 2014-07-31 | ティーアイ スクエア テクノロジー リミテッド | コミュニケーションサービスの遂行中のマルチメディアコンテンツ共有サービス提供方法及びシステム |
| US11120342B2 (en) | 2015-11-10 | 2021-09-14 | Ricoh Company, Ltd. | Electronic meeting intelligence |
| US10062057B2 (en) | 2015-11-10 | 2018-08-28 | Ricoh Company, Ltd. | Electronic meeting intelligence |
| US10268990B2 (en) | 2015-11-10 | 2019-04-23 | Ricoh Company, Ltd. | Electronic meeting intelligence |
| US10445706B2 (en) | 2015-11-10 | 2019-10-15 | Ricoh Company, Ltd. | Electronic meeting intelligence |
| US11983637B2 (en) | 2015-11-10 | 2024-05-14 | Ricoh Company, Ltd. | Electronic meeting intelligence |
| JP2017091535A (ja)* | 2015-11-10 | 2017-05-25 | 株式会社リコー | 電子会議システム |
| US10510051B2 (en) | 2016-10-11 | 2019-12-17 | Ricoh Company, Ltd. | Real-time (intra-meeting) processing using artificial intelligence |
| US11307735B2 (en) | 2016-10-11 | 2022-04-19 | Ricoh Company, Ltd. | Creating agendas for electronic meetings using artificial intelligence |
| US10572858B2 (en) | 2016-10-11 | 2020-02-25 | Ricoh Company, Ltd. | Managing electronic meetings using artificial intelligence and meeting rules templates |
| US10860985B2 (en) | 2016-10-11 | 2020-12-08 | Ricoh Company, Ltd. | Post-meeting processing using artificial intelligence |
| US11030585B2 (en) | 2017-10-09 | 2021-06-08 | Ricoh Company, Ltd. | Person detection, person identification and meeting start for interactive whiteboard appliances |
| US10956875B2 (en) | 2017-10-09 | 2021-03-23 | Ricoh Company, Ltd. | Attendance tracking, presentation files, meeting services and agenda extraction for interactive whiteboard appliances |
| US11062271B2 (en) | 2017-10-09 | 2021-07-13 | Ricoh Company, Ltd. | Interactive whiteboard appliances with learning capabilities |
| US10553208B2 (en) | 2017-10-09 | 2020-02-04 | Ricoh Company, Ltd. | Speech-to-text conversion for interactive whiteboard appliances using multiple services |
| US11645630B2 (en) | 2017-10-09 | 2023-05-09 | Ricoh Company, Ltd. | Person detection, person identification and meeting start for interactive whiteboard appliances |
| US10552546B2 (en) | 2017-10-09 | 2020-02-04 | Ricoh Company, Ltd. | Speech-to-text conversion for interactive whiteboard appliances in multi-language electronic meetings |
| US10757148B2 (en) | 2018-03-02 | 2020-08-25 | Ricoh Company, Ltd. | Conducting electronic meetings over computer networks using interactive whiteboard appliances and mobile devices |
| US11080466B2 (en) | 2019-03-15 | 2021-08-03 | Ricoh Company, Ltd. | Updating existing content suggestion to include suggestions from recorded media using artificial intelligence |
| US11263384B2 (en) | 2019-03-15 | 2022-03-01 | Ricoh Company, Ltd. | Generating document edit requests for electronic documents managed by a third-party document management service using artificial intelligence |
| US11270060B2 (en) | 2019-03-15 | 2022-03-08 | Ricoh Company, Ltd. | Generating suggested document edits from recorded media using artificial intelligence |
| US11392754B2 (en) | 2019-03-15 | 2022-07-19 | Ricoh Company, Ltd. | Artificial intelligence assisted review of physical documents |
| US11573993B2 (en) | 2019-03-15 | 2023-02-07 | Ricoh Company, Ltd. | Generating a meeting review document that includes links to the one or more documents reviewed |
| US11720741B2 (en) | 2019-03-15 | 2023-08-08 | Ricoh Company, Ltd. | Artificial intelligence assisted review of electronic documents |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2007336344A (ja) | 情報端末装置、その駆動方法及びプログラム | |
| US9148586B2 (en) | Terminal apparatus for combining images from two different cameras based on detected sound | |
| EP1465423A1 (en) | Videophone device and data transmitting/receiving method applied thereto | |
| JP6374854B2 (ja) | 画面共有システム及び画面共有方法 | |
| JP4973908B2 (ja) | 通信端末およびその表示方法 | |
| JP2008113331A (ja) | 電話システム、電話機、サーバ装置およびプログラム | |
| JP2010219969A (ja) | 検索機能を有する通話録音装置および電話機 | |
| JP2008147950A (ja) | 情報処理装置 | |
| KR100380829B1 (ko) | 에이전트를 이용한 대화 방식 인터페이스 운영 시스템 및방법과 그 프로그램 소스를 기록한 기록 매체 | |
| JPWO2003038759A1 (ja) | 携帯端末、携帯端末におけるアニメーション作成方法、コンピュータを用いてアニメーションを作成するためのプログラム、そのプログラムを記録した記録媒体およびアニメーション作成システム | |
| JP2010193495A (ja) | 通訳通話システム | |
| JPH11355747A (ja) | 映像・音声通信装置と同装置を用いたテレビ会議装置 | |
| JP2006074376A (ja) | 放送受信機能付き携帯電話装置、プログラム、及び記録媒体 | |
| JP2010087950A (ja) | シンクライアントシステム、シンクライアント端末、シンクライアントサーバ、プログラム | |
| KR101355050B1 (ko) | 영상 카드 제작방법 | |
| JP2006191436A (ja) | 携帯電話装置 | |
| JP6387205B2 (ja) | コミュニケーションシステム、コミュニケーション方法及びプログラム | |
| KR101364844B1 (ko) | 화상통화기능을 갖는 이동통신단말기 및 그 제어방법 | |
| JP2005277884A (ja) | 通信端末装置 | |
| JP4658569B2 (ja) | 情報送信装置、情報受信装置及び情報送受信システム | |
| WO2006106671A1 (ja) | 画像処理装置、画像表示装置、受信装置、送信装置、通信システム、画像処理方法、画像処理プログラム、画像処理プログラムを記録した記録媒体 | |
| JP2003008747A (ja) | 携帯端末のユーザサポートシステムおよびユーザサポート方法 | |
| KR20050077682A (ko) | 명함 관리장치 | |
| JPH09200712A (ja) | 音声・画像伝送装置 | |
| JP2005157950A (ja) | 情報処理装置 |