JP2006268428A - Information presenting device, information presentation method and information-presenting program - Google Patents
Information presenting device, information presentation method and information-presenting programDownload PDFInfo
- Publication number
- JP2006268428A JP2006268428AJP2005085592AJP2005085592AJP2006268428AJP 2006268428 AJP2006268428 AJP 2006268428AJP 2005085592 AJP2005085592 AJP 2005085592AJP 2005085592 AJP2005085592 AJP 2005085592AJP 2006268428 AJP2006268428 AJP 2006268428A
- Authority
- JP
- Japan
- Prior art keywords
- information
- character
- voice
- response
- storage means
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 238000000034methodMethods0.000titleclaimsdescription102
- 230000004044responseEffects0.000claimsabstractdescription67
- 230000008859changeEffects0.000claimsabstractdescription15
- 230000006870functionEffects0.000claimsdescription11
- 230000008569processEffects0.000description88
- 239000003795chemical substances by applicationSubstances0.000description29
- 230000015572biosynthetic processEffects0.000description21
- 238000003786synthesis reactionMethods0.000description21
- 230000007704transitionEffects0.000description17
- 238000004458analytical methodMethods0.000description13
- 238000010586diagramMethods0.000description6
- 210000001015abdomenAnatomy0.000description4
- 238000006243chemical reactionMethods0.000description4
- 235000012054mealsNutrition0.000description4
- 206010034719Personality changeDiseases0.000description3
- 239000004065semiconductorSubstances0.000description3
- 230000002194synthesizing effectEffects0.000description3
- 230000009471actionEffects0.000description2
- 238000004364calculation methodMethods0.000description2
- 239000003814drugSubstances0.000description2
- 230000000877morphologic effectEffects0.000description2
- 230000003287optical effectEffects0.000description2
- 208000012886VertigoDiseases0.000description1
- 239000002253acidSubstances0.000description1
- 230000009118appropriate responseEffects0.000description1
- 230000003247decreasing effectEffects0.000description1
- 208000002173dizzinessDiseases0.000description1
- 239000000284extractSubstances0.000description1
- 238000005111flow chemistry techniqueMethods0.000description1
- 230000036541healthEffects0.000description1
- 239000000463materialSubstances0.000description1
- 238000012986modificationMethods0.000description1
- 230000004048modificationEffects0.000description1
- 210000002784stomachAnatomy0.000description1
- 231100000889vertigoToxicity0.000description1
- 238000005406washingMethods0.000description1
Images











Landscapes
- User Interface Of Digital Computer (AREA)
Abstract
Description
Translated fromJapanese本発明は、情報呈示装置、情報呈示方法、および、情報呈示用プログラムに関する。 The present invention relates to an information presentation device, an information presentation method, and an information presentation program.
近年、ユーザ一人ひとりの嗜好に合わせたアドバイスを行ったり、商品またはサービスを紹介したりする、いわゆるエージェント機能が種々提案されている。 In recent years, various so-called agent functions have been proposed that provide advice tailored to each user's preference and introduce products or services.
このようなエージェント機能を有する装置では、例えば、人の形を模したキャラクタ等を表示させ、ユーザからの質問等に当該キャラクタが応答するように構成されているものがある。 Some apparatuses having such an agent function are configured such that, for example, a character imitating a human shape is displayed and the character responds to a question from a user.
ところで、このようなエージェント機能を有する装置の場合、常に同じキャラクタが表示されると、ユーザが飽きを感じてしまう。そこで、特許文献1に示すように、キャラクタを必要に応じて変更することができる技術が提案されている。 By the way, in the case of a device having such an agent function, if the same character is always displayed, the user feels bored. Therefore, as shown in
ところで、特許文献1に示す技術は、キャラクタについては変更することができるが、キャラクタが発生する音声および応答パターンについては変更することができない。このため、ユーザが飽きを感じてしまったり、ユーザが求めているのとは異なる応答がなされてしまったりするという問題点がある。 By the way, although the technique shown in
本発明は、上記の事情に基づきなされたもので、その目的とするところは、ユーザが真に求めている情報を呈示することができるとともに、呈示される情報に飽きを感じにくい情報呈示装置、情報呈示方法、および、情報呈示用プログラムを提供することを目的とする。 The present invention has been made based on the above circumstances, the purpose of which is to present information that the user really wants, and an information presentation device that makes it difficult to feel bored with the information presented, It is an object to provide an information presentation method and an information presentation program.
上述の目的を達成するため、本発明の情報呈示装置は、入力情報に対応する応答情報を記憶する第1の記憶手段と、応答情報を音声として出力するための音声情報を記憶する第2の記憶手段と、音声情報に対応するキャラクタに関する情報を記憶する第3の記憶手段と、ユーザから所定の入力情報が供給された場合には、対応する応答情報、音声情報、および、キャラクタに関する情報を第1〜第3の記憶手段から取得する取得手段と、取得手段によって取得された応答情報、音声情報、キャラクタに関する情報を所定の出力装置にそれぞれ出力する出力手段と、キャラクタを変更する必要が生じた場合には、第3の記憶手段に記憶されているキャラクタに関する情報を変更するとともに、必要に応じて第1および/または第2の記憶手段に記憶されている応答情報および/または音声情報を変更する変更手段と、を有している。 In order to achieve the above-described object, an information presentation apparatus according to the present invention includes a first storage unit that stores response information corresponding to input information, and a second storage that stores audio information for outputting the response information as audio. When predetermined input information is supplied from the storage means, the third storage means for storing information related to the character corresponding to the voice information, and the user, the corresponding response information, voice information, and information about the character are The acquisition means acquired from the first to third storage means, the output means for outputting the response information, the voice information, and the information about the character acquired by the acquisition means to a predetermined output device respectively, and the character need to be changed If it is, the information on the character stored in the third storage means is changed, and the first and / or second storage means are changed if necessary. Has changing means for changing the response information and / or audio information is 憶, the.
また、本発明の情報呈示装置は、上述の発明に加えて、応答情報が、ユーザの入力情報に対する応答パターンを示す情報であり、音声情報が、キャラクタに応じた音声を出力するための情報であり、キャラクタに関する情報が、キャラクタを表示するための画像情報であるようにしている。 In addition to the above-described invention, the information presenting apparatus of the present invention is information for indicating response patterns for user input information, and voice information is information for outputting a sound corresponding to a character. Yes, the information related to the character is image information for displaying the character.
また、本発明の情報呈示装置は、上述の発明に加えて、変更手段が、応答情報、音声情報、および、キャラクタに関する情報を他の記憶装置から取得して変更するようにしている。 In addition to the above-described invention, the information presenting device of the present invention is configured such that the changing means acquires response information, voice information, and information about the character from another storage device and changes the information.
また、本発明の情報呈示装置は、上述の発明に加えて、変更手段が、ユーザの入力情報に対応する専門分野に属する応答情報に変更するとともに、当該専門分野に応じたキャラクタおよび音声情報に変更するようにしている。 In addition to the above-described invention, the information presenting device according to the present invention changes the response means to response information belonging to a specialized field corresponding to the input information of the user, and converts the character and voice information according to the specialized field. I am trying to change it.
また、本発明の情報呈示装置は、上述の発明に加えて、変更手段が、ユーザからの要求に応じてぼけ役またはつっこみ役を示すキャラクタに変更し、応答情報および音声情報についても該当する情報に変更するようにしている。 In addition to the above-described invention, the information presenting apparatus according to the present invention is an information in which the changing means changes to a character indicating a blurring role or a punishment role in response to a request from the user, and the response information and voice information are also applicable. I am trying to change it.
また、本発明の情報呈示方法は、ユーザから所定の入力情報が供給された場合には、入力情報に対応する応答情報、応答情報を音声として出力するための音声情報、音声情報に対応するキャラクタに関する情報を記憶装置から取得し、取得された応答情報、音声情報、キャラクタに関する情報を所定の出力装置にそれぞれ出力し、キャラクタを変更する必要が生じた場合には、記憶装置に記憶されているキャラクタに関する情報を変更するとともに、必要に応じて応答情報および/または音声情報を変更するようにしている。 The information presenting method of the present invention, when predetermined input information is supplied from the user, response information corresponding to the input information, voice information for outputting the response information as voice, and a character corresponding to the voice information Information is obtained from the storage device, and the obtained response information, voice information, and information about the character are respectively output to a predetermined output device, and stored in the storage device when it becomes necessary to change the character. While changing the information regarding a character, the response information and / or audio | voice information are changed as needed.
また、本発明の情報呈示用プログラムは、コンピュータを、入力情報に対応する応答情報を記憶する第1の記憶手段、応答情報を音声として出力するための音声情報を記憶する第2の記憶手段、音声情報に対応するキャラクタに関する情報を記憶する第3の記憶手段、ユーザから所定の入力情報が供給された場合には、対応する応答情報、音声情報、および、キャラクタに関する情報を第1〜第3の記憶手段から取得する取得手段、取得手段によって取得された応答情報、音声情報、キャラクタに関する情報を所定の出力装置にそれぞれ出力する出力手段、キャラクタを変更する必要が生じた場合には、第3の記憶手段に記憶されているキャラクタに関する情報を変更するとともに、必要に応じて第1および/または第2の記憶手段に記憶されている応答情報および/または音声情報を変更する変更手段、として機能させるようにしている。 The information presenting program of the present invention includes a first storage means for storing response information corresponding to input information, a second storage means for storing voice information for outputting the response information as voice, Third storage means for storing information related to the character corresponding to the voice information. When predetermined input information is supplied from the user, the corresponding response information, voice information, and information about the character are first to third. If there is a need to change the character, the output means for outputting the acquisition means acquired from the storage means, the output information obtained by the acquisition means, the voice information, the information relating to the character to the predetermined output device, respectively. The information on the character stored in the storage means is changed and stored in the first and / or second storage means as necessary. In which the response information and / or changing means for changing the sound information, and to function as.
本発明は、ユーザが真に求めている情報を呈示することができるとともに、呈示される情報に飽きを感じにくい情報呈示装置、情報呈示方法、および、情報呈示用プログラムを提供することができる。 The present invention can provide an information presenting apparatus, an information presenting method, and an information presenting program that can present information that the user really wants and are less tired of the presented information.
以下、本発明の一実施の形態について図に基づいて説明する。 Hereinafter, an embodiment of the present invention will be described with reference to the drawings.
図1は、本発明の実施の形態に係る情報呈示装置の構成例を示すブロック図である。この図に示すように、本発明の実施の形態に係る情報呈示装置10は、CPU(Central Processing Unit)10a、ROM(Read Only Memory)10b、RAM(Random Access Memory)10c、HDD(Hard Disk Drive)10d、ビデオ回路10e、I/F(Interface)10f、バス10g、表示装置10h、記憶装置10i、音声入力装置10j、および、音声出力装置10kを有している。 FIG. 1 is a block diagram showing a configuration example of an information presentation apparatus according to an embodiment of the present invention. As shown in this figure, an
ここで、取得手段および変更手段としてのCPU10aは、HDD10dに格納されているプログラムに応じて、各種演算処理を実行するとともに、装置の各部を制御する中央処理装置である。 Here, the CPU 10a as the obtaining unit and the changing unit is a central processing unit that executes various arithmetic processes and controls each unit of the apparatus according to a program stored in the
ROM10bは、CPU10aが実行するプログラムを格納した半導体記憶装置である。RAM10cは、CPU10aが実行するプログラムを一時的に記憶する半導体記憶装置である。 The
第1の記憶手段、第2の記憶手段、および、第3の記憶手段としてのHDD10dは、CPU10aが実行するプログラムおよびデータを格納している。具体的には、HDD10dは、音声処理プログラム10d1、エージェント処理プログラム10d2、キャラクタ情報DB(Data Base)10d3、および、キャラクタ変更プログラム10d4を有している。ここで、音声処理プログラム10d1は、図2を参照して後述するように、音声の入出力および音声認識に関する処理を実行するためのプログラムである。エージェント処理プログラム10d2は、同じく、図2を参照して後述するように、音声処理プログラム10d1の処理に基づいて入力された音声に対応した所定の応答情報を取得し、音声として出力するためのプログラムである。キャラクタ情報DB10d3は、キャラクタに関する情報を格納するデータベースである。キャラクタ変更プログラム10d4は、キャラクタを変更する必要が生じた場合に、キャラクタ情報DB10d3に格納されている情報を他のキャラクタのものに変更するとともに、関連する情報を対応する情報に変更する処理を実行するプログラムである。 The
出力手段としてのビデオ回路10eは、CPU10aから供給された描画コマンドに応じた描画処理を実行するとともに、描画処理の結果として得られた画像を映像信号に変換して表示装置10hへ出力する。 The video circuit 10e serving as an output unit executes a drawing process according to a drawing command supplied from the CPU 10a, converts an image obtained as a result of the drawing process into a video signal, and outputs the video signal to the
出力手段としてのI/F10fは、記憶装置10iおよび音声入力装置10jからの出力される信号の表現形式を変換して入力するとともに、記憶装置10iおよび音声出力装置10kに対して出力する信号の表現形式を変換する。バス10gは、CPU10a、ROM10b、RAM10c、HDD10d、ビデオ回路10e、および、I/F10fを相互に接続し、これらの間で情報の授受を可能とするための信号線群である。 The I / F 10f serving as an output unit converts the representation format of signals output from the storage device 10i and the
表示装置10hは、ビデオ回路10eから出力される映像信号を表示するための装置であり、CRT(Cathode Ray Tube)モニタ等によって構成される。記憶装置10iは、例えば、CD(Compact Disk)−ROM、DVD(Digital Versatile Disk)−ROMに記録された情報を読み出す装置である。また、記憶装置10iとしては、記録可能な記録媒体(例えば、CD−R(Recordable)、DVD−R、DVD−RAM)から情報を読み出すとともに、情報を書き込むことができる装置としてもよい。 The
音声入力装置10jは、ユーザの音声を電気信号に変換した後に、ディジタルデータに変換して出力する装置であり、例えば、マイクロフォンおよびA/D(Analog to Digital)変換器等によって構成される。音声出力装置10kは、ディジタル信号をアナログ信号に変換した後に、音声として出力する装置であり、例えば、D/A(Digital to Analog)変換器およびスピーカ等によって構成される。 The
図2は、図1に示すHDDに記憶されている音声処理プログラム10d1、エージェント処理プログラム10d2、および、キャラクタ変更プログラム10d4によって、実現される機能のブロックを説明するための図である。 FIG. 2 is a diagram for explaining a block of functions realized by the voice processing program 10d1, the agent processing program 10d2, and the character change program 10d4 stored in the HDD shown in FIG.
この図において、音声認識部50は、音声入力装置10jを介して入力された音声データに含まれている雑音を除去する処理等を実行した後、エージェント処理部52の単語データベース52cを参照して、音声データに対する認識処理を施し、この音声データに対応する単語の候補と、それぞれの候補の尤度(スコア)とを出力する。 In this figure, the
具体的には、音声認識部50は、例えば、入力された音声データと、単語データベース52cに登録されているすべての単語とのマッチング処理を行ってスコアを算出し、どの単語のスコアが最も高いかを検討する。例えば、ユーザの発話が「え〜と、???が減ったよ。」である場合に、???の部分が「お腹」とも「お墓」とも認識され得るときは、音声認識部50は、「???」の部分については単語「お腹」に対するスコアが80%で、単語「お墓」に対するスコアが65%のようにスコアを計算する。そして、最も高いスコアを有する単語「お腹」を発話「???」に対する単語であるとして選択する。そして、音声認識部50は、「え〜と、お腹が減ったよ。」というテキスト文字列(または単語ID(Identifier))を生成して、自然言語解析部51に供給する。 Specifically, for example, the
なお、音声認識部50が行う音声認識の手法は任意である。また、スコアの値が所定値を下回る単語については、候補として選択しないようにしてもよい。また、1つの音声入力に対して複数の単語の候補が選択されるようにしてもよい。具体的には、上述のように「お腹」を1つ選択するのではなく、「お腹」と「お墓」の双方を選択して、出力するようにすることも可能である。その場合には、特定した候補とそのスコアを示すデータ(以下、「単語データ」と称する)を生成して出力する。単語データは、単語情報そのものとスコアを含むものとしてもよいが、実際には単語IDとスコアを含むものとした方がデータの取り扱い上有利である。 Note that the speech recognition method performed by the
自然言語解析部51は、音声認識部50から供給された単語データ(またはテキストデータ)に形態素解析処理を施すことにより、単語データを構成する単語を品詞毎に分類し、分類結果を示すデータを単語データに付して、エージェント処理部52に供給する。なお、自然言語解析部51が行う分類の手法は任意であり、例えば、奈良先端技術大学で開発された日本語形態素解析の手法である“Chasen”を用いることができる。具体的には、自然言語解析部51は、入力音声から所定の品詞(例えば、名詞、動詞のみ)を抽出して出力する。この結果、入力音声がユーザの自然な発話である場合(例えば、「あ〜お腹がすいたな。」)でも、処理に必要なキーワード(「お腹」および「すいた」)が抽出される。 The natural
エージェント処理部52は、I/F52a、カテゴリ辞書52b、単語データベース52c、処理項目データベース52d、および、ワイヤデータベース52eを有し、自然言語解析部51から供給された単語の品詞に基づいて、ユーザへの問いかけなどの処理を行う。例えば、ユーザが「お腹がすいたなあ」と発話した場合には、エージェント処理部52はこれに対する問いかけとして「食事に行きますか」を音声合成処理部53に出力する。 The
ここで、I/F52aは、図示せぬ他の処理部との間でデータを授受する場合に、データのフォーマット等を変換する。 Here, the I /
カテゴリ辞書52bは、単語を示すデータと、当該単語が属するカテゴリを示すデータとを相互に関連付けて格納している。例えば、単語「減った」はカテゴリ「食事」に対応付けられている。なお、1個の単語が複数のカテゴリに属するようにしてもよい(例えば、単語「昼食」を、カテゴリ「腹具合」および「時間帯」の双方に対応付けしてもよい)。 The
単語データベース52cは、単語とその発音データとを関連付けして格納しており、音声認識部50が入力された音声データを認識処理する際に利用される。 The
処理項目データベース52dは、エージェント処理部52が実行するトリガ取得処理、判別処理、および、入出力処理の内容を処理項目(ポインタ)毎に記述するデータを格納している。ここで、トリガ取得処理の内容を記述するデータは、一連の処理を開始するきっかけとなるトリガを指定するデータと、後述する進行方向の確率係数とを有している。取得するデータは、任意のものでよく、例えば、自然言語解析部51から供給される単語データ、図示せぬクロックから供給される時刻を示すデータ、または、エージェント処理部52自身が実行する処理から引き渡されるデータ等がある。 The
判別処理の内容を記述するデータは、進行方向の確率係数を、とり得る判別結果毎に記述したデータを含んでおり、また、後述する戻り方向の確率係数を含んでいる。なお、エージェント処理部52は、後述するワイヤ(遷移定義データ)に基づいて処理の手順を決定するものであり、どのワイヤが示す遷移を実行するかは、直接的には上述の確率係数に従って決定するのではなく、後述する重み係数に従って決定する。 The data describing the contents of the discrimination processing includes data describing the probability coefficient in the traveling direction for each possible discrimination result, and also includes a probability coefficient in the return direction described later. Note that the
判別処理では、判別に用いるデータを、任意の取得源から取得することができる。例えば、取得源として、自然言語解析部51、エージェント処理部52が実行する他の処理等が考えられる。また、判別処理では、判別に先立って所定の出力先にデータを出力することもできる。例えば、所定の質問を示す音声データを、音声合成処理部53に出力する等である。 In the discrimination process, data used for discrimination can be acquired from an arbitrary acquisition source. For example, other processing executed by the natural
入出力処理の内容を記述するデータは、入力あるいは出力するデータの内容を指定するデータからなっている。入力または出力するデータは、任意の内容を有していてよく、例えば、出力するデータは、音声合成処理部53を介して音声出力装置10kから音声として出力する音声データであってもよいし、入力するデータは外部の機器から供給されるデータであってもよい。 The data describing the contents of the input / output processing consists of data specifying the contents of the data to be input or output. The data to be input or output may have arbitrary contents. For example, the data to be output may be voice data output as voice from the
ワイヤデータベース52eは、複数の処理間の遷移を記述するデータ、つまり、遷移定義データ(以下、定義遷移データを「ワイヤ」と称する)の集合からなっている。ワイヤは、例えば、図3に示すような書式で記述されたデータからなっており、図示するように、先行する処理から後続する処理への遷移について、当該先行する処理と、当該後続する処理と、当該遷移に対して与えられた重み係数と、を指定するデータである。ただし、先行の処理が判別処理である場合には、当該判別処理のどの判別結果からの遷移であるかまで記述される必要がある。 The wire database 52e includes data describing transitions between a plurality of processes, that is, a set of transition definition data (hereinafter, the definition transition data is referred to as “wire”). For example, the wire is made up of data described in a format as shown in FIG. 3, and as shown in the figure, regarding the transition from the preceding process to the subsequent process, the preceding process, the subsequent process, , Data specifying a weighting factor given to the transition. However, when the preceding process is a determination process, it is necessary to describe from which determination result of the determination process the transition is made.
なお、上述した処理項目データが記述する確率係数を、接続されるワイヤが示す遷移が実行された実績に従ってエージェント処理部52等によって書き換えるようにしてもよい。例えば、特定のワイヤが示す遷移が実行される頻度が所定値よりも高い場合、このワイヤが示す遷移元の処理項目を示す処理項目データに記述されている確率係数の値を従前よりも大きな値にエージェント処理部52が書き換えることによって、このワイヤが示す遷移が起こりやすくする等である。そのような方法によれば、結果的にユーザの意図する応答がなされる確率が高くなる。 Note that the probability coefficient described by the above-described process item data may be rewritten by the
エージェント処理部52は、処理項目データベース52dおよびワイヤデータベース52eが全体として表しているフローを実行する。処理項目データベース52dおよびワイヤデータベース52eは、例えば、図4に示すフローチャートとして表すことができる。 The
ここで、エージェント処理部52の処理が、具体的にどのように行われるかについて、図4を参照して説明する。エージェント処理部52は、図示するように、先行する第1の処理P1を実行して後述の第2の処理P2に遷移するようにワイヤW01により定義されており、第2の処理P2を実行して後続の第3の処理P3に遷移するようにワイヤW03によって定義されているとき、以下の処理が実行される。 Here, how the processing of the
なお、処理P1は、単語「痛い」を表す単語データが供給されたか否かを判断する処理であるとし、処理P2は、単語「頭」を表す単語データが供給されたか否かを判断する処理であるとし、処理P3は、「めまい」があるか否かを判定する処理である。なお、図示するように、処理P1〜P3の進行方向の確率係数はいずれも0.5であるものとする。また、エージェント処理部52は、音声認識部50が自然言語と分類された単語データのうち、自然言語解析部51において名詞または動詞に分類された単語データのみを取得するものとする。 The process P1 is a process for determining whether or not the word data representing the word “pain” is supplied, and the process P2 is a process for determining whether or not the word data representing the word “head” is supplied. The process P3 is a process for determining whether or not there is “vertigo”. As shown in the figure, it is assumed that the probability coefficients in the traveling direction of the processes P1 to P3 are all 0.5. In addition, the
まず、エージェント処理部52が第1の処理P1に達したとき、エージェント処理部52は、ワイヤW01,W03,W05のそれぞれの重み係数を計算し、計算結果をワイヤW01,W03,W05に書き込む。これらの値は、各処理に予め設定されている進行方向の確率係数によって決定される。 First, when the
具体的には、処理P1に処理が到達したとき、ワイヤW01の重み係数は、処理P1のワイヤに係る確率係数の値すなわち0.5となる。処理P2のワイヤW03の重み係数は、処理P1のワイヤW01に係る重み係数0.5に処理P2のワイヤW03に係る確率係数0.5を乗じた結果すなわち0.25となる。ワイヤW05の重み係数は、処理P1のワイヤW01に係る確率係数0.5に処理P2のワイヤW03に係る確率係数0.5を乗じた結果にさらに処理P3のワイヤW05に係る確率係数0.5を乗じた結果、すなわち、0.125となる。 Specifically, when the process reaches the process P1, the weight coefficient of the wire W01 becomes the value of the probability coefficient related to the wire of the process P1, that is, 0.5. The weight coefficient of the wire W03 in the process P2 is a result of multiplying the weight coefficient 0.5 related to the wire W01 in the process P1 by the probability coefficient 0.5 related to the wire W03 in the process P2, that is, 0.25. The weight coefficient of the wire W05 is obtained by multiplying the probability coefficient 0.5 related to the wire W01 in the process P1 by the probability coefficient 0.5 related to the wire W03 in the process P2 and the probability coefficient 0.5 related to the wire W05 in the process P3. As a result of multiplication, that is, 0.125.
このようにして、ある処理を基点としたときのそれぞれのワイヤの重み係数が計算される。よって、現在の状況が遷移すると、現在の処理を基点としてその都度重み係数が計算されることになる。 In this way, the weight coefficient of each wire when a certain process is used as a base point is calculated. Therefore, when the current situation changes, the weighting coefficient is calculated each time using the current process as a base point.
具体的には、現在の状態が処理P2に遷移すると、ワイヤW03の重み係数は、処理P2のワイヤW03に係る確率係数に等しい値0.5となり、ワイヤW05の重み係数は、処理P2のワイヤW03に係る確率係数0.5と、処理P3のワイヤW05に係る重み係数0.5との積すなわち0.25となる。また、このとき、エージェント処理部52は、逆方向、つまり処理P1に戻る方向に係るワイヤW01の重み係数も再度書き込む。処理P2に遷移した場合では、ワイヤW01に係る戻り方向の重み係数0.1がそのままワイヤW01の重み係数となる。処理P3に遷移した場合は、さらに、ワイヤW03に係る戻り方向の確率係数0.1がそのままワイヤW03の重み係数となる。そして、処理P3に遷移した状態におけるワイヤW01の重み係数は、処理P3に遷移した状態におけるワイヤW03の重み係数0.1に、処理P2の戻り方向の確率係数0.1を乗じた値すなわち0.01となる。 Specifically, when the current state transitions to the process P2, the weight coefficient of the wire W03 becomes 0.5 equal to the probability coefficient related to the wire W03 of the process P2, and the weight coefficient of the wire W05 is the wire of the process P2. The product of the probability coefficient 0.5 related to W03 and the weighting coefficient 0.5 related to the wire W05 in the process P3, that is, 0.25. At this time, the
重み係数の計算は、関連するフローの処理のみではなく、すべてのフローのすべてのワイヤについて設定される。ここで、現在の処理に関連のないワイヤについては、予め定められた低い計数値を割り当てるようにすればよい。しかし、特に、トリガ取得処理を先行の処理とするワイヤについては、重み係数をある程度高く設定するようにする。そのようにすることで、直前までなされていた会話と著しく異なる内容の会話にもジャンプすることが可能になる。 The weighting factor calculation is set for all wires of all flows, not just the processing of the associated flows. Here, a predetermined low count value may be assigned to a wire that is not related to the current process. However, in particular, for a wire whose trigger acquisition process is the preceding process, the weighting factor is set to be somewhat high. By doing so, it is possible to jump to a conversation having a content that is significantly different from the conversation that has been performed immediately before.
エージェント処理部52は、判別条件に係る1個または複数個の単語データもしくは状態データが自然言語解析部51等から供給されると、以下の処理を実行する。なお、簡単のため、以下では、単語データが供給された場合を例に挙げて説明するが、状態データが供給された場合においても同様の処理がなされるものとする。 When one or a plurality of word data or state data related to the determination condition is supplied from the natural
まず、前述の処理によって各ワイヤに対して設定された重み係数と、供給された単語データが示すスコアとの積を計算する。例えば、図4に示すフローの処理が実行されている場合において、単語「痛い」を示す単語データがスコア80%で供給され、単語「頭」を示す単語データがスコア50%で供給されたとし、また、単語「痛い」を条件とするワイヤW01の重み係数が0.5、単語「頭」を条件とするワイヤW03の重み係数が0.25であったとする。この場合、ワイヤW01およびW03について求められる判別結果は、以下の式(1)および式(2)のようになる。 First, the product of the weighting coefficient set for each wire by the above-described processing and the score indicated by the supplied word data is calculated. For example, when the processing of the flow shown in FIG. 4 is executed, word data indicating the word “pain” is supplied with a score of 80%, and word data indicating the word “head” is supplied with a score of 50%. Further, it is assumed that the weighting factor of the wire W01 that is conditional on the word “pain” is 0.5, and the weighting factor of the wire W03 that is conditional on the word “head” is 0.25. In this case, the determination results obtained for the wires W01 and W03 are as shown in the following equations (1) and (2).
〔数1〕
ワイヤW01についての判別結果:「痛い」に対するスコア80%×ワイヤW01の重み係数0.5=40[Equation 1]
Discrimination result for wire W01: score 80% for “pain” × weight coefficient 0.5 of wire W01 = 40
〔数2〕
ワイヤW03についての判別結果:「頭」に対するスコア50%×ワイヤW03の重み係数0.25=12.5[Equation 2]
Discrimination result for wire W03: score 50% for “head” × weight coefficient 0.25 = 12.5 for wire W03
エージェント処理部52は、スコアと重み係数との積を求める上述の処理を、フローの処理が有するワイヤのうち、少なくともスコアが設定されたすべてのワイヤについて行う。その結果、例えば、ワイヤW01について求めた積(つまり、判別結果)が最も高い値を示した場合、入力された音声は単語「痛い」を示すものであったと認識して、ワイヤW01が後続の処理としている処理P2に遷移することになる。 The
図2に戻って、音声合成処理部53は、音片合成用データベース53a、音素合成用データベース53b、素片合成用データベース53cを有しており、エージェント処理部52から供給されたテキストデータに対応する音声を合成して出力する。 Returning to FIG. 2, the speech
ここで、音片合成用データベース53aは、音片合成を実行する際に用いる音片データを格納している。ここで、音片とは、1つ以上の音素からなる音声の集合である。例えば、音片として「食事に」と「行きますか?」をそれぞれ格納しておき、これらをつなぎ合わせて合成することにより「食事に行きますか?」という自然な音声を得ることができる。 Here, the sound
音素合成用データベース53bは、音素合成を実行する際に用いる音素データを格納している。ここで、音素とは、語と語の意味を区別する機能を有する音声の最小単位をいう。本実施の形態では、音片合成を優先して音声合成が実行されるが、音片データが存在しない場合には、音素を合成することにより、必要な音声データを生成する。 The
素片合成用データベース53cは、音片合成用データベース53aに格納されている音片と、音素合成用データベース53bに格納されている音素とを用いて音声を合成する場合に、これらを合成するためのデータを格納している。 The
音声出力装置10kは、音声合成処理部53から出力された音声データをD/A変換し、増幅器で増幅した後、スピーカから音声として出力する。 The
つぎに、本発明の実施の形態に係る情報呈示装置の動作について説明する。 Next, the operation of the information presenting apparatus according to the embodiment of the present invention will be described.
図5は、本発明の実施の形態に係る情報呈示装置の動作を説明するためのフローチャートである。このフローチャートの処理が開始されると以下のステップが実行される。 FIG. 5 is a flowchart for explaining the operation of the information presentation apparatus according to the embodiment of the present invention. When the process of this flowchart is started, the following steps are executed.
ステップS10:CPU10aは、音声入力装置10jの出力を参照し、ユーザが発話を行ったことが検出された場合には、音声の入力を開始する。 Step S10: The CPU 10a refers to the output of the
ステップS11:CPU10aは、音声処理プログラム10d1に基づいて音声認識を開始する。具体的には、音声入力装置10jは、ユーザの発話を音声信号(アナログ信号)に変換した後、さらに、ディジタル信号に変換し、音声認識部50に供給する。音声認識部50では、当該発話が、対応するテキストデータに変換され、自然言語解析部51に供給される。自然言語解析部51では、当該発話を形態素(意味を有する最小単位)に分解し、それぞれの形態素の品詞を特定して出力する。 Step S11: The CPU 10a starts voice recognition based on the voice processing program 10d1. Specifically, the
ステップS12:CPU10aは、ステップS11の認識結果に基づいて、キャラクタを表示する。具体的は、CPU10aは、HDD10dのキャラクタ情報DB10d3に格納されているデフォルトのキャラクタ画像データを読み出し、ビデオ回路10eに供給して表示する。その結果、表示装置10hには、図6に示すような画像が表示される。この例では、枠70が表示され、枠70内の最上部には、表示されているキャラクタを説明するタイトル71として「薬の専門家」が表示されている。また、その下には、薬の専門家としてのキャラクタ72が表示されている。なお、キャラクタ72をアニメーション画像(動画像)とし、ユーザから入力された音声情報や時間の経過に応じて所定の動作を行うようにしてもよい。 Step S12: The CPU 10a displays a character based on the recognition result of step S11. Specifically, the CPU 10a reads default character image data stored in the character information DB 10d3 of the
ステップS13:CPU10aは、ステップS11における音声認識処理の結果に応じて応答処理を実行する。例えば、図4のフローを例に挙げると、処理P1においてユーザから音声データ「痛い」が入力されたと判断され、処理P2において音声データ「頭」が入力されたと判断され、さらに、処理P3において「めまい」があると判断された場合には、例えば、エージェント処理部52は、処理項目データベース52dから該当するコメント「薬効成分アセサルチル酸が配合された○○○を食後に1錠服用すると良いでしょう。」を取得し、音声合成処理部53に供給する。その結果、音声出力装置10kからは前述のメッセージが図6に示すキャラクタの音声として出力される。なお、このとき、図6に示すキャラクタが音声に応じて口唇を動かしたり、身体の一部(例えば、手や足等)を動かしたりするようにしてもよい。 Step S13: The CPU 10a executes a response process according to the result of the voice recognition process in step S11. For example, taking the flow of FIG. 4 as an example, it is determined in the process P1 that the voice data “pain” has been input from the user, in the process P2, it is determined that the voice data “head” has been input. If it is determined that there is dizziness, for example, the
ステップS14:CPU10aは、ステップS11の音声認識処理において、キャラクタを変更するようにユーザから要求がなされたか否かを判定し、要求がなされたと判定した場合には、ステップS15に進み、それ以外の場合にはステップS16に進む。例えば、ユーザが「投資の専門家に相談したい。」のような発話を行った場合には、ステップS11においてキャラクタの変更が要求されていると判断し、ステップS15に進む。 Step S14: The CPU 10a determines whether or not a request has been made by the user to change the character in the voice recognition processing in step S11. If it is determined that the request has been made, the process proceeds to step S15. If so, the process proceeds to step S16. For example, when the user utters “I want to consult an investment specialist”, it is determined in step S11 that a character change is requested, and the process proceeds to step S15.
ステップS15:CPU10aは、キャラクタを変更する処理を実行する。この処理の詳細は、図8を参照して後述する。ステップS15に示す処理が実行されてキャラクタが変更されると、表示装置10hには、例えば、図7に示すような画像が表示されることになる。この例では、枠80が表示され、枠80内の最上部には、表示されているキャラクタを説明するためのタイトル81として「投資の専門家」が表示されている。また、その下には、投資の専門家としてのキャラクタ82が表示されている。なお、この新たなキャラクタは、図6のキャラクタと比較すると、キャラクタ自体の姿態が異なるのみならず、声質、話し方、会話に登場する専門用語、および、動作が異なっている。すなわち、後述するように、キャラクタの画像情報のみならず、音声情報、および、応答情報についても併せて変更される。 Step S15: The CPU 10a executes a process of changing the character. Details of this processing will be described later with reference to FIG. When the process shown in step S15 is executed and the character is changed, for example, an image as shown in FIG. 7 is displayed on the
ステップS16:CPU10aは、処理を終了するか否かを判定し、終了しない場合にはステップS10に戻って同様の処理を繰り返し、それ以外の場合には処理を終了する。 Step S16: The CPU 10a determines whether or not to end the process. If not, the CPU 10a returns to step S10 to repeat the same process, and otherwise ends the process.
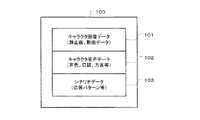
つぎに、図8を参照して、図5のステップS15に示すキャラクタ変更処理の詳細について説明する。なお、1つのキャラクタは、図9に示すような複数のデータによって構成されている。この例では、キャラクタを構成するデータ100としては、例えば、キャラクタ画像データ101、キャラクタ音声データ102、および、シナリオデータ103がある。ここで、キャラクタに関する情報としてのキャラクタ画像データ101は、図6または図7に示すキャラクタ72およびキャラクタ82を表示するための静止画または動画データである。音声情報としてのキャラクタ音声データ102は、キャラクタの音声および発話内容に関するデータであり、声色、口調、方言、使用する専門用語に関するデータである。応答情報としてのシナリオデータ103は、キャラクタのユーザに対する応答パターンを示すデータである。 Next, the details of the character change process shown in step S15 of FIG. 5 will be described with reference to FIG. One character is composed of a plurality of data as shown in FIG. In this example, the
図8のフローチャートの処理が開始されると、以下のステップが実行される。 When the processing of the flowchart of FIG. 8 is started, the following steps are executed.
ステップS30:CPU10aは、例えば、記憶装置10iまたは図示せぬサーバ装置からネットワークを介してキャラクタ画像データ101を受信する。 Step S30: The CPU 10a receives the
ステップS31:CPU10aは、キャラクタ画像データ101の受信が完了したか否かを判定し、終了した場合にはステップS32に進み、それ以外の場合には同様の処理を繰り返す。 Step S31: The CPU 10a determines whether or not the reception of the
ステップS32:CPU10aは、データが正常に受信できたか否かを判定し、受信できたと判定した場合にはステップS33に進み、それ以外の場合にはステップS30に戻って受信処理を繰り返す。 Step S32: The CPU 10a determines whether or not the data has been normally received. If it is determined that the data has been received, the process proceeds to step S33. Otherwise, the process returns to step S30 and the reception process is repeated.
ステップS33:CPU10aは、例えば、記憶装置10iまたは図示せぬサーバ装置からネットワークを介してキャラクタ音声データ102を受信する。 Step S33: For example, the CPU 10a receives the
ステップS34:CPU10aは、キャラクタ音声データ102の受信が完了したか否かを判定し、終了した場合にはステップS35に進み、それ以外の場合には同様の処理を繰り返す。 Step S34: The CPU 10a determines whether or not the reception of the
ステップS35:CPU10aは、データが正常に受信できたか否かを判定し、受信できたと判定した場合にはステップS36に進み、それ以外の場合にはステップS33に戻って受信処理を繰り返す。 Step S35: The CPU 10a determines whether or not the data has been normally received. If it is determined that the data has been received, the CPU 10a proceeds to step S36, and otherwise returns to step S33 to repeat the reception process.
ステップS36:CPU10aは、例えば、記憶装置10iまたは図示せぬサーバ装置からネットワークを介してシナリオデータ103を受信する。 Step S36: The CPU 10a receives the
ステップS37:CPU10aは、シナリオデータ103の受信が完了したか否かを判定し、終了した場合にはステップS38に進み、それ以外の場合には同様の処理を繰り返す。 Step S37: The CPU 10a determines whether or not the reception of the
ステップS38:CPU10aは、データが正常に受信できたか否かを判定し、受信できたと判定した場合にはステップS39に進み、それ以外の場合にはステップS36に戻って受信処理を繰り返す。 Step S38: The CPU 10a determines whether or not the data has been normally received. If it is determined that the data has been received, the process proceeds to step S39. Otherwise, the process returns to step S36 and the reception process is repeated.
ステップS39:CPU10aは、以上の処理により受信したキャラクタ画像データ101、キャラクタ音声データ102、および、シナリオデータ103をHDD10dに格納する。具体的には、CPU10aは、キャラクタ変更処理部54により、単語データベース52c、処理項目データベース52d、ワイヤデータベース52e、音片合成用データベース53a、音素合成用データベース53b、素片合成用データベース53c、および、キャラクタ情報DB10d3に格納されているデータを、新たに受信したキャラクタ画像データ101、キャラクタ音声データ102、および、シナリオデータ103に含まれているデータにより更新する。 Step S39: The CPU 10a stores the
以上の処理によれば、ユーザからの要求がなされた場合には、表示装置10hに表示されるキャラクタの画像が変更されるとともに、キャラクタの発する音声およびシナリオが変更されるので、ユーザの嗜好や目的に合ったキャラクタを選択することが可能になる。 According to the above processing, when a request from the user is made, the character image displayed on the
また、キャラクタとともに対応可能な専門用語およびシナリオを併せて変更することにより、限られた記憶容量で、複数の専門分野に対応することが可能になる。 In addition, by changing the technical terms and scenarios that can be handled together with the character, it is possible to deal with a plurality of specialized fields with a limited storage capacity.
また、それぞれの専門分野に応じたキャラクタが表示されることから、ユーザが親しみ安いインターフェースを提供することが可能になる。 In addition, since a character corresponding to each specialized field is displayed, it is possible to provide a user-friendly interface.
ところで、以上の実施の形態では、ユーザの要求に応じた専門分野に対応するキャラクタが表示されるようにしたが、例えば、漫才等に見られるいわゆる「ぼけ」および「つっこみ」のキャラクタを実現し、それぞれのキャラクタと対話するだけでなく、例えば、漫才の練習等に役立てることも可能である。 By the way, in the above embodiment, the characters corresponding to the specialized field according to the user's request are displayed, but for example, so-called “blur” and “tsutsumi” characters found in comics etc. are realized. In addition to interacting with each character, it is also possible to use it for the practice of comic talent, for example.
図10は、漫才の練習に用いる場合の動作モードの一例を示す図である。この例では、練習モードとしては、ぼけ練習モード、つっこみ練習モード、および、自動実行モードを有している。ここで、ぼけ練習モードは、ユーザがぼけ役であり、情報呈示装置10がつっこみ役であるモードであり、情報呈示装置10がユーザの音声を認識し、その言葉に応じた音声を出力するモードである。また、つっこみ練習モードは、情報呈示装置10がぼけ役であり、ユーザがつっこみ役であるモードであり、情報呈示装置10がユーザの音声を認識し、その言葉に応じた音声を出力するモードである。また、自動実行モードは、ぼけ役およびつっこみ役の双方が情報呈示装置10であるモードであり、ユーザは情報呈示装置10によって呈示されるぼけ役とつっこみ役のやり取りをお手本として参照することが可能なモードである。 FIG. 10 is a diagram illustrating an example of an operation mode when used for the practice of comic talent. In this example, the practice mode includes a blur practice mode, a practice practice mode, and an automatic execution mode. Here, the blur practice mode is a mode in which the user is in a blurring role and the
なお、ぼけ練習モードでは、表示装置10hには、つっこみ役のキャラクタが表示される。また、つっこみ練習モードでは、表示装置10hには、ぼけ役のキャラクタが表示される。さらに、自動実行モードでは、表示装置10hには、ぼけ役とつっこみ役の双方のキャラクタが表示される。 In the blur practice mode, the character that plays the character is displayed on the
図11は、図10に示すぼけ練習モードにおける情報呈示装置の応答パターンの一例を示す図である。この図では、あいづち、つっこみ、終了の3つのパターンが示されている。ここで、「あいづち」は、ユーザの話した内容にあいづちを打つ応答パターンであり、具体的には「ふむふむ」、「それで」等の応答パターンである。このような応答パターンは、例えば、ぼけ役のユーザの発話が終了して、所定時間の無音状態が検出された場合に選択されて呈示される。また、「つっこみ」は、例えば、ぼけ役のユーザの発話が終了し、所定時間の無音状態が検出された場合であって、ユーザの発話の語尾の声量が大きくなったときに選択されて呈示される。声量が大きくなるのはユーザがつっこんで欲しいことを意図している場合が多いためである。また、「終了」は、ネタを披露する時間は予め決まっている場合が多いので、例えば、所定の時間(例えば、開始から5分)が経過し、ユーザの発話が終了した場合に選択されて呈示される。なお、これら以外にもユーザの発話の内容の一部を繰り返す応答パターンを設けることも可能である。例えば、「最近は不景気でんな。」に対して「不景気でんな。」のような応答パターンである。 FIG. 11 is a diagram illustrating an example of a response pattern of the information presentation device in the blur practice mode illustrated in FIG. 10. In this figure, three patterns, i.e., nick, prick, and end are shown. Here, “AIZUCHI” is a response pattern that hits the user's spoken content, specifically “Fumufum”, “So”, and the like. Such a response pattern is selected and presented, for example, when the utterance of the blurring user ends and a silent state for a predetermined time is detected. “Tsukumi” is selected and presented when, for example, the speech of the blurring user ends and a silent state is detected for a predetermined time, and the utterance volume of the user's speech increases. Is done. The amount of voice increases because the user often intends to have it. In addition, “end” is often selected when the user's utterance ends after a predetermined time (for example, 5 minutes from the start) has elapsed since the time to show the material is often predetermined. Presented. In addition to these, it is also possible to provide a response pattern that repeats part of the content of the user's utterance. For example, a response pattern such as “Don't be a recession” to “Recently a recession”.
図11に示す応答パターンは、図4に示すようなフローに係る処理項目データベース52dおよびワイヤデータベース52eをそれぞれの応答毎に準備することにより、実現できる。 The response pattern shown in FIG. 11 can be realized by preparing the
図12は、図10に示すつっこみ練習モードにおける情報呈示装置10の応答パターンの一例を示す図である。この図では、つっこみ練習モードには、「固定モード」、「半固定モード」、および、「自動モード」の3種類がある。ここで、固定モードは、シナリオは固定であり、情報呈示装置10は、ユーザからの応答があった場合に、シナリオに定められた会話を次々に呈示していく。また、半固定モードは、シナリオはほとんど決まっているが、ユーザから呈示されるキーワードに応じて、シナリオをある程度変更することが可能なモードである。自動モードは、シナリオは予め決まっておらず、ユーザの呈示する情報に応じて、応答する情報をその都度決定するモードである。 FIG. 12 is a diagram illustrating an example of a response pattern of the
具体的には、固定モードは、情報呈示装置10から所定の発話がなされた後に、ユーザから所定の反応がなされた場合には、シナリオに基づいてつぎの発話に移行するように図4に示すようなフローを形成する。例えば、情報呈示装置10が「最近は、雨がぎょうさん降りますなあ。」を呈示した場合に、ユーザが「そうですな。」と対応した場合には、予め設定されているつぎの発話「洗濯物が乾かんから、ええかげんにして欲しいですわ。」が情報呈示装置10によって呈示される。 Specifically, the fixed mode is shown in FIG. 4 so that when a predetermined reaction is made by the user after a predetermined utterance is made from the
また、半固定モードは、情報呈示装置10から所定の発話がなされた後に、ユーザから所定の反応がなされた場合には、当該反応に含まれている所定の情報(例えば、キーワード)に対応した発話を行うようにする。例えば、情報呈示装置10が「最近は、雨がぎょうさん降りますなあ。」を呈示した場合に、ユーザが「雨と言えば、梅雨ですな。」と対応した場合には、情報呈示装置10は予めキーワードとして設定されている「梅雨」を検出し、「梅雨」に対応するつぎの発話「しかし、今年の梅雨は長うおますなあ。」を呈示する。また、情報呈示装置10が「最近は、雨がぎょうさん降りますなあ。」を呈示した場合に、ユーザが「カビが生えてこまりますわ。」と対応した場合には、情報呈示装置10は予めキーワードとして設定されている「カビ」を検出し、「カビ」に対応するつぎの発話「おまえんとこはカビだらけやからな。」を呈示する。なお、半固定モードでは、情報呈示装置10が呈示する応答の選択肢は、例えば、2〜3個と予め定まっているので、ユーザは、このキーワードを予め記憶しておき、状況に応じてキーワードを会話の中に織り交ぜて発言する必要がある。 The semi-fixed mode corresponds to predetermined information (for example, a keyword) included in the reaction when a predetermined reaction is made by the user after a predetermined utterance is made from the
また、自動モードは、図4に示すようなフローを複数準備しておき、ユーザの発話に応じて適切な応答を選択して呈示するようにする。例えば、ユーザが応答としてあいづちだけを打った場合(例えば、「ふむふむ」と発言した場合)には、予め準備されているシナリオに従って発言し、ユーザの応答に所定のキーワードが含まれている場合には、当該キーワードに関連する応答を検索して呈示する。なお、自動モードでは、シナリオは予め決まっていないため、ユーザは情報呈示装置10の発話にあいづちを打ったり、つっこみを入れたり、話題を転換するためにキーワードを含むと考えられる情報を呈示したりして、会話を発展させる。 In the automatic mode, a plurality of flows as shown in FIG. 4 are prepared, and an appropriate response is selected and presented according to the user's utterance. For example, when the user hits only Aizuchi as a response (for example, when saying “Fum Fumu”), the user responds according to a scenario prepared in advance, and the user's response includes a predetermined keyword Search for and present a response related to the keyword. In the automatic mode, since the scenario is not determined in advance, the user may make a brief introduction to the utterance of the
ところで、以上のような処理は、図10に示す各モードが選択された場合に、選択されたモードに対応するキャラクタ画像データ101、キャラクタ音声データ102、および、シナリオデータ103を記憶装置10iまたは図示せぬサーバ装置から検索して取得し、図2に示すエージェント処理部52および音声合成処理部53の各部に格納することにより実現できる。 By the way, in the processing as described above, when each mode shown in FIG. 10 is selected, the
なお、上述の実施の形態は、本発明の好適な例であるが、本発明は、これらに限定されるものではなく、本発明の要旨を逸脱しない範囲において、種々の変形、変更が可能である。 The above-described embodiments are preferred examples of the present invention, but the present invention is not limited to these, and various modifications and changes can be made without departing from the scope of the present invention. is there.
例えば、以上の実施の形態では、キャラクタに関する情報(キャラクタ画像データ)とともに、キャラクタ音声データおよびシナリオデータを併せて変更するようにしたが、これらのいずれか一方のみを変更するようにしてもよい。 For example, in the above embodiment, the character voice data and the scenario data are changed together with the information about the character (character image data), but only one of these may be changed.
また、以上の各実施の形態では、音声の入力に対して音声で出力するようにしたが、例えば、音声とともにテキスト情報を併せて出力するようにしてもよい。 Further, in each of the embodiments described above, voice is output in response to voice input. However, for example, text information may be output together with voice.
また、以上の各実施の形態では、例えば、情報呈示装置10をパーソナルコンピュータとして実施する場合を例に挙げて説明したが、例えば、携帯電話、PDA(Personal Digital Assistant)、または、カーナビゲーション装置として実施することも可能であることはいうまでもない。 In each of the above embodiments, for example, the case where the
また、以上の実施の形態では、処理項目データベース52dおよびワイヤデータベース52eに基づき、図4に示すフローを用いて処理を実現するようにしたが、これ以外の方法によって実現することも可能である。 In the above embodiment, the processing is realized using the flow shown in FIG. 4 based on the
また、以上の実施の形態では、ユーザからの音声による要請に基づいてキャラクタ等を変更するようにしたが、例えば、図示せぬ入力装置から所定の入力がなされた場合に、キャラクタ等を変更するようにしてもよい。また、明示的に要求がなされない場合であっても、例えば、ユーザの発話に含まれている専門用語によって専門分野を判断し、それに応じてキャラクタ等を変更することも可能である。 In the above embodiment, the character or the like is changed based on a voice request from the user. For example, when a predetermined input is made from an input device (not shown), the character or the like is changed. You may do it. Further, even when no explicit request is made, for example, it is possible to determine a specialized field based on technical terms included in a user's utterance and change a character or the like accordingly.
また、以上の実施の形態では、キャラクタ等を変更する際には、記憶装置10iから新たなキャラクタに関する情報を読み込んでHDD10dの内容を更新するようにしたが、HDD10dに予め複数のキャラクタ等に関する情報を記憶しておき、これらの中から所望のキャラクタを選択するようにしてもよい。また、その場合に、HDD10dに格納されていないキャラクタが選択された場合には記憶装置10iから取得して、いずれかのキャラクタ(例えば、使用されていないキャラクタ)と置換するようにしてもよい。 Further, in the above embodiment, when changing a character or the like, information related to a new character is read from the storage device 10i and the content of the
なお、上記の処理機能は、例えば、図1に示すようなコンピュータによって実現される。その場合、情報呈示装置が有すべき機能の処理内容を記述したプログラムが提供される。そのプログラムをコンピュータで実行することにより、処理機能がコンピュータ上で実現される。処理内容を記述したプログラムは、コンピュータで読み取り可能な記録媒体に記録しておくことができる。コンピュータで読み取り可能な記録媒体としては、磁気記録装置、光ディスク、光磁気記録媒体、半導体メモリなどがある。磁気記録装置には、ハードディスク装置(HDD)、フレキシブルディスク(FD)、磁気テープなどがある。光ディスクには、DVD、DVD−RAM、CD−ROM、CD−R(Recordable)/RW(Rewritable)などがある。光磁気記録媒体には、MO(Magneto-Optical disk)などがある。 The above processing functions are realized by a computer as shown in FIG. 1, for example. In that case, a program describing the processing content of the function that the information presenting apparatus should have is provided. By executing the program on the computer, the processing function is realized on the computer. The program describing the processing contents can be recorded on a computer-readable recording medium. Examples of the computer-readable recording medium include a magnetic recording device, an optical disk, a magneto-optical recording medium, and a semiconductor memory. Examples of the magnetic recording device include a hard disk device (HDD), a flexible disk (FD), and a magnetic tape. Optical disks include DVD, DVD-RAM, CD-ROM, CD-R (Recordable) / RW (Rewritable), and the like. Magneto-optical recording media include MO (Magneto-Optical disk).
プログラムを流通させる場合には、たとえば、そのプログラムが記録されたDVD、CD−ROMなどの可搬型記録媒体が販売される。また、プログラムをサーバコンピュータの記憶装置に格納しておき、ネットワークを介して、サーバコンピュータから他のコンピュータにそのプログラムを転送することもできる。 When the program is distributed, for example, portable recording media such as a DVD and a CD-ROM on which the program is recorded are sold. It is also possible to store the program in a storage device of a server computer and transfer the program from the server computer to another computer via a network.
プログラムを実行するコンピュータは、たとえば、可搬型記録媒体に記録されたプログラムもしくはサーバコンピュータから転送されたプログラムを、自己の記憶装置に格納する。そして、コンピュータは、自己の記憶装置からプログラムを読み取り、プログラムに従った処理を実行する。なお、コンピュータは、可搬型記録媒体から直接プログラムを読み取り、そのプログラムに従った処理を実行することもできる。また、コンピュータは、サーバコンピュータからプログラムが転送される毎に、逐次、受け取ったプログラムに従った処理を実行することもできる。 The computer that executes the program stores, for example, the program recorded on the portable recording medium or the program transferred from the server computer in its own storage device. Then, the computer reads the program from its own storage device and executes processing according to the program. The computer can also read the program directly from the portable recording medium and execute processing according to the program. In addition, each time the program is transferred from the server computer, the computer can sequentially execute processing according to the received program.
本発明は、ユーザの入力に応じた応答情報を呈示する情報呈示装置に利用することができる。 INDUSTRIAL APPLICABILITY The present invention can be used for an information presentation apparatus that presents response information according to a user input.
10 情報呈示装置
10a CPU(取得手段、変更手段)
10d HDD(第1の記憶手段、第2の記憶手段、第3の記憶手段)
10e ビデオ回路(出力手段)
10f I/F(出力手段)10 Information Presentation Device 10a CPU (Acquisition means, change means)
10d HDD (first storage means, second storage means, third storage means)
10e Video circuit (output means)
10f I / F (output means)
Claims (7)
Translated fromJapanese上記入力情報に対応する応答情報を記憶する第1の記憶手段と、
上記応答情報を音声として出力するための音声情報を記憶する第2の記憶手段と、
上記音声情報に対応するキャラクタに関する情報を記憶する第3の記憶手段と、
上記ユーザから所定の入力情報が供給された場合には、対応する応答情報、音声情報、および、キャラクタに関する情報を上記第1〜第3の記憶手段から取得する取得手段と、
上記取得手段によって取得された応答情報、音声情報、キャラクタに関する情報を所定の出力装置にそれぞれ出力する出力手段と、
上記キャラクタを変更する必要が生じた場合には、上記第3の記憶手段に記憶されているキャラクタに関する情報を変更するとともに、必要に応じて上記第1および/または第2の記憶手段に記憶されている応答情報および/または音声情報を変更する変更手段と、
を有することを特徴とする情報呈示装置。In an information presentation device for presenting information corresponding to user input information,
First storage means for storing response information corresponding to the input information;
Second storage means for storing voice information for outputting the response information as voice;
Third storage means for storing information relating to the character corresponding to the voice information;
When predetermined input information is supplied from the user, acquisition means for acquiring corresponding response information, voice information, and information about the character from the first to third storage means,
Output means for outputting response information acquired by the acquisition means, voice information, and information about the character to a predetermined output device, respectively;
When it is necessary to change the character, information on the character stored in the third storage means is changed and stored in the first and / or second storage means as necessary. Changing means for changing the response information and / or voice information,
An information presentation device characterized by comprising:
前記音声情報は、キャラクタに応じた音声を出力するための情報であり、
前記キャラクタに関する情報は、キャラクタを表示するための画像情報である、
ことを特徴とする請求項1記載の情報呈示装置。The response information is information indicating a response pattern for user input information,
The voice information is information for outputting voice according to the character,
The information about the character is image information for displaying the character.
The information presentation apparatus according to claim 1, wherein:
上記ユーザから所定の入力情報が供給された場合には、上記入力情報に対応する応答情報、上記応答情報を音声として出力するための音声情報、上記音声情報に対応するキャラクタに関する情報を記憶装置から取得し、
取得された応答情報、音声情報、キャラクタに関する情報を所定の出力装置にそれぞれ出力し、
上記キャラクタを変更する必要が生じた場合には、上記記憶装置に記憶されているキャラクタに関する情報を変更するとともに、必要に応じて応答情報および/または音声情報を変更する、
ことを特徴とする情報呈示方法。In an information presentation method for presenting information corresponding to user input information,
When predetermined input information is supplied from the user, response information corresponding to the input information, voice information for outputting the response information as voice, and information regarding a character corresponding to the voice information are stored from the storage device. Acquired,
Output the acquired response information, voice information, and information about the character to a predetermined output device,
When it is necessary to change the character, the information on the character stored in the storage device is changed, and the response information and / or the voice information is changed as necessary.
An information presentation method characterized by that.
コンピュータを、
上記入力情報に対応する応答情報を記憶する第1の記憶手段、
上記応答情報を音声として出力するための音声情報を記憶する第2の記憶手段、
上記音声情報に対応するキャラクタに関する情報を記憶する第3の記憶手段、
上記ユーザから所定の入力情報が供給された場合には、対応する応答情報、音声情報、および、キャラクタに関する情報を上記第1〜第3の記憶手段から取得する取得手段、
上記取得手段によって取得された応答情報、音声情報、キャラクタに関する情報を所定の出力装置にそれぞれ出力する出力手段、
上記キャラクタを変更する必要が生じた場合には、上記第3の記憶手段に記憶されているキャラクタに関する情報を変更するとともに、必要に応じて上記第1および/または第2の記憶手段に記憶されている応答情報および/または音声情報を変更する変更手段、
として機能させるコンピュータ読み取り可能な情報呈示用プログラム。In a computer-readable information presentation program for causing a computer to function to present information corresponding to user input information,
Computer
First storage means for storing response information corresponding to the input information;
Second storage means for storing voice information for outputting the response information as voice;
Third storage means for storing information relating to the character corresponding to the voice information;
An acquisition unit that acquires corresponding response information, audio information, and information about a character from the first to third storage units when predetermined input information is supplied from the user;
Output means for outputting the response information, voice information, and information about the character acquired by the acquisition means to a predetermined output device,
When it is necessary to change the character, information on the character stored in the third storage means is changed and stored in the first and / or second storage means as necessary. Changing means for changing the response information and / or voice information,
A computer-readable information presentation program that functions as a computer.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005085592AJP4508917B2 (en) | 2005-03-24 | 2005-03-24 | Information presenting apparatus, information presenting method, and information presenting program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005085592AJP4508917B2 (en) | 2005-03-24 | 2005-03-24 | Information presenting apparatus, information presenting method, and information presenting program |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2006268428Atrue JP2006268428A (en) | 2006-10-05 |
| JP4508917B2 JP4508917B2 (en) | 2010-07-21 |
Family
ID=37204335
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2005085592AExpired - Fee RelatedJP4508917B2 (en) | 2005-03-24 | 2005-03-24 | Information presenting apparatus, information presenting method, and information presenting program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4508917B2 (en) |
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2014020835A1 (en)* | 2012-07-31 | 2014-02-06 | 日本電気株式会社 | Agent control system, method, and program |
| JP2018072765A (en)* | 2016-11-04 | 2018-05-10 | 株式会社カプコン | Voice generation program and game device |
| JP2019185242A (en)* | 2018-04-05 | 2019-10-24 | 株式会社サウスポイント | Automatic music selection system |
| JP2020034626A (en)* | 2018-08-27 | 2020-03-05 | Kddi株式会社 | Program, server and method for alternating agent according to user utterance text |
| WO2020158171A1 (en)* | 2019-01-28 | 2020-08-06 | ソニー株式会社 | Information processor for selecting responding agent |
| JP2020161121A (en)* | 2019-03-27 | 2020-10-01 | ダイコク電機株式会社 | Video output system |
| JP2020160341A (en)* | 2019-03-27 | 2020-10-01 | ダイコク電機株式会社 | Video output system |
| JP2021015547A (en)* | 2019-07-16 | 2021-02-12 | 株式会社博報堂 | Dialogue agent system |
| JP2022531057A (en)* | 2020-03-31 | 2022-07-06 | 北京市商▲湯▼科技▲開▼▲發▼有限公司 | Interactive target drive methods, devices, devices, and recording media |
Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0866558A (en)* | 1994-08-26 | 1996-03-12 | Susumu Imai | Cassette for game |
| JP2000067047A (en)* | 1998-08-24 | 2000-03-03 | Toshiba Corp | Dialogue control device and dialogue control method |
| JP2001034451A (en)* | 1999-06-15 | 2001-02-09 | Lucent Technol Inc | Method, system and device for automatically generating human machine dialog |
| JP2001273473A (en)* | 2000-03-24 | 2001-10-05 | Atr Media Integration & Communications Res Lab | Conversation agent and conversation system using it |
| JP2002132804A (en)* | 2000-10-24 | 2002-05-10 | Sanyo Electric Co Ltd | User support system |
| JP2002163109A (en)* | 2000-11-28 | 2002-06-07 | Sanyo Electric Co Ltd | User supporting device and system |
| JP2002169818A (en)* | 2000-12-04 | 2002-06-14 | Sanyo Electric Co Ltd | Device and system for supporting user |
| JP2002189732A (en)* | 2000-12-21 | 2002-07-05 | Sanyo Electric Co Ltd | User support device and system |
| JP2002523828A (en)* | 1998-08-24 | 2002-07-30 | ビーシーエル コンピューターズ, インコーポレイテッド | Adaptive natural language interface |
| JP2002342049A (en)* | 2001-05-15 | 2002-11-29 | Canon Inc | Voice-compatible print processing system, control method therefor, recording medium, and computer program |
| JP2003526120A (en)* | 2000-03-09 | 2003-09-02 | コーニンクレッカ フィリップス エレクトロニクス エヌ ヴィ | Dialogue processing method with consumer electronic equipment system |
| JP2003323388A (en)* | 2002-05-01 | 2003-11-14 | Omron Corp | Information providing method and information providing system |
- 2005
- 2005-03-24JPJP2005085592Apatent/JP4508917B2/ennot_activeExpired - Fee Related
Patent Citations (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0866558A (en)* | 1994-08-26 | 1996-03-12 | Susumu Imai | Cassette for game |
| JP2000067047A (en)* | 1998-08-24 | 2000-03-03 | Toshiba Corp | Dialogue control device and dialogue control method |
| JP2002523828A (en)* | 1998-08-24 | 2002-07-30 | ビーシーエル コンピューターズ, インコーポレイテッド | Adaptive natural language interface |
| JP2001034451A (en)* | 1999-06-15 | 2001-02-09 | Lucent Technol Inc | Method, system and device for automatically generating human machine dialog |
| JP2003526120A (en)* | 2000-03-09 | 2003-09-02 | コーニンクレッカ フィリップス エレクトロニクス エヌ ヴィ | Dialogue processing method with consumer electronic equipment system |
| JP2001273473A (en)* | 2000-03-24 | 2001-10-05 | Atr Media Integration & Communications Res Lab | Conversation agent and conversation system using it |
| JP2002132804A (en)* | 2000-10-24 | 2002-05-10 | Sanyo Electric Co Ltd | User support system |
| JP2002163109A (en)* | 2000-11-28 | 2002-06-07 | Sanyo Electric Co Ltd | User supporting device and system |
| JP2002169818A (en)* | 2000-12-04 | 2002-06-14 | Sanyo Electric Co Ltd | Device and system for supporting user |
| JP2002189732A (en)* | 2000-12-21 | 2002-07-05 | Sanyo Electric Co Ltd | User support device and system |
| JP2002342049A (en)* | 2001-05-15 | 2002-11-29 | Canon Inc | Voice-compatible print processing system, control method therefor, recording medium, and computer program |
| JP2003323388A (en)* | 2002-05-01 | 2003-11-14 | Omron Corp | Information providing method and information providing system |
Cited By (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2014020835A1 (en)* | 2012-07-31 | 2014-02-06 | 日本電気株式会社 | Agent control system, method, and program |
| JP2018072765A (en)* | 2016-11-04 | 2018-05-10 | 株式会社カプコン | Voice generation program and game device |
| JP2019185242A (en)* | 2018-04-05 | 2019-10-24 | 株式会社サウスポイント | Automatic music selection system |
| JP7409628B2 (en) | 2018-04-05 | 2024-01-09 | 株式会社サウスポイント | Automatic music selection system for music selection at weddings |
| JP2020034626A (en)* | 2018-08-27 | 2020-03-05 | Kddi株式会社 | Program, server and method for alternating agent according to user utterance text |
| WO2020158171A1 (en)* | 2019-01-28 | 2020-08-06 | ソニー株式会社 | Information processor for selecting responding agent |
| CN113382831A (en)* | 2019-01-28 | 2021-09-10 | 索尼集团公司 | Information processor for selecting response agent |
| JP2020161121A (en)* | 2019-03-27 | 2020-10-01 | ダイコク電機株式会社 | Video output system |
| JP2020160341A (en)* | 2019-03-27 | 2020-10-01 | ダイコク電機株式会社 | Video output system |
| JP2021015547A (en)* | 2019-07-16 | 2021-02-12 | 株式会社博報堂 | Dialogue agent system |
| JP7294924B2 (en) | 2019-07-16 | 2023-06-20 | 株式会社博報堂 | dialogue agent system |
| JP2022531057A (en)* | 2020-03-31 | 2022-07-06 | 北京市商▲湯▼科技▲開▼▲發▼有限公司 | Interactive target drive methods, devices, devices, and recording media |
Also Published As
| Publication number | Publication date |
|---|---|
| JP4508917B2 (en) | 2010-07-21 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8103510B2 (en) | Device control device, speech recognition device, agent device, on-vehicle device control device, navigation device, audio device, device control method, speech recognition method, agent processing method, on-vehicle device control method, navigation method, and audio device control method, and program | |
| JP4533845B2 (en) | Audio device control apparatus, audio device control method, and program | |
| CN108962217A (en) | Phoneme synthesizing method and relevant device | |
| JP6483578B2 (en) | Speech synthesis apparatus, speech synthesis method and program | |
| CN111653265A (en) | Speech synthesis method, device, storage medium and electronic device | |
| JP2015169698A (en) | Speech retrieval device, speech retrieval method, and program | |
| JP4508917B2 (en) | Information presenting apparatus, information presenting method, and information presenting program | |
| JP2004086001A (en) | Conversation processing system, conversation processing method, and computer program | |
| JP2003114692A (en) | Sound source data providing system, terminal, toy, providing method, program, and medium | |
| JP2007264569A (en) | Retrieval device, control method, and program | |
| CN110524547B (en) | Conversational device, robot, method for controlling a conversational device, and storage medium | |
| JP6466391B2 (en) | Language learning device | |
| JP2007304489A (en) | Musical piece practice supporting device, control method, and program | |
| JP2007256619A (en) | Evaluation device, control method and program | |
| JP2006337667A (en) | Pronunciation evaluation method, phoneme sequence model learning method, apparatus, program, and recording medium using these methods. | |
| US20060084047A1 (en) | System and method of segmented language learning | |
| KR102479023B1 (en) | Apparatus, method and program for providing foreign language learning service | |
| JP2001188782A (en) | Device and method for processing information and recording medium | |
| JP2002342206A (en) | Information providing program, information providing method, and recording medium | |
| JP6672707B2 (en) | Playlist generation method, playlist generation device, program, and list generation method | |
| JP6625089B2 (en) | Voice generation program and game device | |
| JP2007188175A (en) | Server device, terminal device, and program | |
| JP6170604B1 (en) | Speech generator | |
| JP7653828B2 (en) | Robots and robot systems | |
| JP2005241767A (en) | Speech recognition device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination | Free format text:JAPANESE INTERMEDIATE CODE: A621 Effective date:20070412 | |
| A131 | Notification of reasons for refusal | Free format text:JAPANESE INTERMEDIATE CODE: A131 Effective date:20091124 | |
| A521 | Request for written amendment filed | Free format text:JAPANESE INTERMEDIATE CODE: A523 Effective date:20100119 | |
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) | Free format text:JAPANESE INTERMEDIATE CODE: A01 Effective date:20100420 | |
| A01 | Written decision to grant a patent or to grant a registration (utility model) | Free format text:JAPANESE INTERMEDIATE CODE: A01 | |
| A61 | First payment of annual fees (during grant procedure) | Free format text:JAPANESE INTERMEDIATE CODE: A61 Effective date:20100427 | |
| FPAY | Renewal fee payment (event date is renewal date of database) | Free format text:PAYMENT UNTIL: 20130514 Year of fee payment:3 | |
| R150 | Certificate of patent or registration of utility model | Free format text:JAPANESE INTERMEDIATE CODE: R150 | |
| FPAY | Renewal fee payment (event date is renewal date of database) | Free format text:PAYMENT UNTIL: 20130514 Year of fee payment:3 | |
| S111 | Request for change of ownership or part of ownership | Free format text:JAPANESE INTERMEDIATE CODE: R313111 | |
| FPAY | Renewal fee payment (event date is renewal date of database) | Free format text:PAYMENT UNTIL: 20130514 Year of fee payment:3 | |
| R350 | Written notification of registration of transfer | Free format text:JAPANESE INTERMEDIATE CODE: R350 | |
| LAPS | Cancellation because of no payment of annual fees |