JP2006120131A - Operation result prediction method and system - Google Patents
Operation result prediction method and systemDownload PDFInfo
- Publication number
- JP2006120131A JP2006120131AJP2005278489AJP2005278489AJP2006120131AJP 2006120131 AJP2006120131 AJP 2006120131AJP 2005278489 AJP2005278489 AJP 2005278489AJP 2005278489 AJP2005278489 AJP 2005278489AJP 2006120131 AJP2006120131 AJP 2006120131A
- Authority
- JP
- Japan
- Prior art keywords
- data
- past
- predicted
- factors
- factor
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images


















Classifications
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02P—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN THE PRODUCTION OR PROCESSING OF GOODS
- Y02P90/00—Enabling technologies with a potential contribution to greenhouse gas [GHG] emissions mitigation
- Y02P90/30—Computing systems specially adapted for manufacturing
Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
Translated fromJapaneseDescription
Translated fromJapanese本発明は、操業結果予測方法及びそのシステムに関し、特に、データベース等の記憶装置を利用した予測モデルにおける近傍データの選択法に関する。 The present invention relates to an operation result prediction method and a system thereof, and more particularly, to a neighborhood data selection method in a prediction model using a storage device such as a database.
従来の操業予測方法としては、例えば現時点の操業因子に対して所定の類似度を有する複数の過去の操業因子に対し、現時点の因子情報を表現する重み付けを決定し、その重み付けを過去の操業結果情報に作用させて、現時点の操業因子情報に対する品質などの操業結果を演算により直接的に予測する方法が提案されている(例えば特許文献1)。 As a conventional operation prediction method, for example, for a plurality of past operation factors having a predetermined similarity to the current operation factor, a weight for expressing the current factor information is determined, and the weight is used as the past operation result. There has been proposed a method in which an operation result such as quality for the current operation factor information is directly predicted by calculation by acting on the information (for example, Patent Document 1).
また、過去の事例をデータベースに多数蓄積し、予測したい未知の出力に対する入力変数が与えられたときに、入力変数を入力変数空間上のベクトルと見なし、予測対象の入力変数ベクトルとの距離の大小によってデータベース内から過去のデータをk個選択し、選択された過去のデータの既知である出力の平均値又は回帰式により、予測した未知の出力を予測する方法において、距離の大小から過去のデータをk個選択する方法を近傍データ選択法と呼ぶが、その近傍データ選択法にはk-NN法及びk-SN法がある。これらの手法は後述の非特許文献1等に詳述されているが、簡単に説明すると以下のとおりである。 In addition, many past cases are accumulated in the database, and when an input variable for an unknown output to be predicted is given, the input variable is regarded as a vector on the input variable space, and the distance from the input variable vector to be predicted is large or small. In the method of selecting k past data from the database by the above, and predicting the unknown output predicted by the average value or regression equation of the known output of the selected past data, the past data from the magnitude of the distance A method of selecting k pieces is referred to as a neighborhood data selection method, and the neighborhood data selection method includes a k-NN method and a k-SN method. These methods are described in detail in
(a)k-NN法
データベース内の全データを距離(ユークリッド距離など)の近い順に並べ替え、距離の近いデータからk個のデータを選択するという方法であり、最も基本的な方法である。但し、本方法はデータの分布によっては選択した近傍データに偏りやすい。このため、平均値法の場合には、予測値にバイアスがかかるという問題がある(後述の図3参照)。(A) k-NN method This is a method of rearranging all data in the database in the order of distance (Euclidean distance, etc.) and selecting k pieces of data from the closest distance, and is the most basic method. However, this method tends to be biased to selected neighborhood data depending on the data distribution. For this reason, in the case of the average value method, there is a problem that the predicted value is biased (see FIG. 3 described later).
(b)k-SN法
k-NN法での問題点を少しでも解決するために、予測対象の入力変数ベクトル(予測要求点)の周囲からバランスよく近傍データを選択できるように、選択すべき近傍の数がk個に達するまで1対ずつデータを選択する方法である。対となる1つ目は、予測要求点に距離が最も近いデータを選択する。2つ目は、予測要求点からの距離d1と1つ目に選択したデータからの距離d2とを比較し、d1<d2を満たすデータの中から要求点に最も近いデータを選択するという方法である。本方法はk-NN法の欠点を多少補うものであるが、後述の図4で示すように対の2つ目の探索領域はハッチング部分となるため不完全である。
上記の特許文献1の方法では、類似度を算出する際に重み付けをしているものの、近傍データの選択方法は類似度の高いものから一定の数を選択する方法なので、データの分布によっては選択した近傍データに偏りが生じ、予測値にバイアスがかかるという問題点がある。また、非特許文献1の方法でも、特許文献1と同様に、k-NN法の場合には、データの分布によっては選択した近傍データに偏りが生じ、予測値にバイアスがかかるという問題点があった。また、k-SN法も、k-NN法を若干は改善するものの、同様の問題点があった。 In the method of
本発明は、かかる事情に鑑みてなされたものであり、シンプルなアルゴリズムであるにもかかわらず、入力変数空間上で予測要求点を取り囲むように、偏りなく近傍データを選択して予測値の精度を格段に向上させた操業結果予測方法及びそのシステムを提供することを目的とする。 The present invention has been made in view of such circumstances, and in spite of being a simple algorithm, the accuracy of the predicted value is selected by selecting neighboring data without bias so as to surround the predicted request point on the input variable space. An object of the present invention is to provide an operation result prediction method and a system thereof that can significantly improve the above.
本発明に係る操業結果予測方法は、過去の操業実績で得られた複数の操業因子と、それに対する操業結果を実績操業データ記憶装置に記憶し、予測対象の複数の操業因子と類似した過去の操業因子を前記実績操業データ記憶装置から選択し、前記選択された過去の操業因子に対する操業結果から、前記予測対象の複数の操業因子に対する操業結果を予測する操業結果予測方法であって、内積を利用して前記類似した過去の操業因子を選択する。 The operation result prediction method according to the present invention stores a plurality of operation factors obtained in the past operation results and the operation results for the same in the actual operation data storage device, and stores past results similar to the plurality of operation factors to be predicted. An operation result prediction method for selecting an operation factor from the actual operation data storage device, and predicting an operation result for the plurality of operation factors to be predicted from an operation result for the selected past operation factor, The similar past operating factors are selected by using them.
本発明に係る操業結果予測方法は、操業結果に影響を与える複数の操業因子を操業因子配列とし、複数ある操業因子配列を操業因子配列群とし、それに対する操業結果を操業結果群とし、過去の操業実績で得られた操業因子配列群と、それに対する操業結果群を実績操業データ記憶装置に記憶し、予測対象の操業因子配列と類似した過去の操業因子配列群を前記実績操業データ記憶装置から複数選択し、前記選択された過去の操業因子配列群に対する操業結果群から、前記予測対象の操業因子配列に対する操業結果を予測する操業結果予測方法であって、過去の操業因子配列群の各々について、過去の操業因子配列と予測対象の操業因子配列の各配列要素の差をとり、得られた新たな配列因子群の間で、各配列要素の積和をとり、得られた値に基づき、予測対象の操業因子配列と類似した過去の操業因子配列群を選択する。 In the operation result prediction method according to the present invention, a plurality of operation factors affecting the operation result are set as an operation factor array, a plurality of operation factor arrays are set as an operation factor array group, and an operation result corresponding thereto is set as an operation result group. The operation factor array group obtained by the operation results and the operation result group corresponding thereto are stored in the actual operation data storage device, and the past operation factor array group similar to the operation factor array to be predicted is stored from the actual operation data storage device. A plurality of selections, an operation result prediction method for predicting an operation result for the operation factor array to be predicted from an operation result group for the selected past operation factor array group, each of the past operation factor array groups , Take the difference of each array element between the previous operation factor array and the predicted operation factor array, take the product sum of each array element between the obtained new array factor groups, the value obtained Based selects operating factor sequence group in the past similar to operation factor sequence of the prediction target.
本発明に係る操業結果予測方法は、過去の操業実績で得られた複数の操業因子を入力変数とし、それに対する操業結果を出力とするデータが記憶された実績操業データ記憶装置から、過去の操業因子と操業結果とを読み出す実績操業データ読み出しステップと、予測対象の複数の操業因子を入力する操業因子入力ステップと、前記操業因子入力ステップで入力された予測対象の複数の操業因子を変数ベクトルqに変換し、前記実績操業データ読み出しステップで読み出された過去の操業因子を変数ベクトルXj(j=1,2,・‥)に変換するベクトル変換ステップと、前記ベクトルXj(j=1,2,・・・)の内、前記ベクトルqに類似したデータを選択する選択ステップと、前記選択された類似データに対応する過去実績の出力値とに基づいて操業結果を予測する操業結果予測ステップとを備える操業結果予測方法であって、前記ベクトルのなす角度から類似データを選択する。 The operation result prediction method according to the present invention uses a plurality of operation factors obtained from past operation results as input variables, and stores past operation data from the operation data storage device in which data is output as the operation results. The actual operation data reading step for reading out factors and operation results, the operation factor input step for inputting a plurality of operation factors to be predicted, and the plurality of operation factors to be predicted input in the operation factor input step are represented by a variable vector q. A vector conversion step of converting the past operation factor read in the actual operation data read step into a variable vector Xj (j = 1, 2,...), And the vector Xj (j = 1, 2 ,...), An operation for predicting an operation result based on a selection step for selecting data similar to the vector q and an output value of a past record corresponding to the selected similar data. A result prediction step, wherein similar data is selected from an angle formed by the vectors.
本発明に係る操業結果予測方法は、過去の操業実績で得られた複数の操業因子を入力変数とし、それに対する操業結果を出力とするデータが記憶された実績操業データ記憶装置から、過去の操業因子と操業結果とを読み出す実績操業データ読み出しステップと、予測対象の複数の操業因子を入力する操業因子入力ステップと、前記操業因子入力ステップで入力された予測対象の複数の操業因子を入力変数空間上の座標qとし、前記実績操業データ読み出しステップで読み出された過去の操業因子を入力空間上の座標Xj(j=1,2,・‥) に変換する座標変換ステップと、前記座標Xj(j=1,2,・・・)の内、前記座標qに類似したデータを選択する選択ステップと、前記選択された類似データに対応する過去実績の出力値とに基づいて操業結果を予測する操業結果予測ステップとを備える操業結果予測方法であって、前記入力変数空間上に仮定する平面の両側から類似データを選択する。 The operation result prediction method according to the present invention uses a plurality of operation factors obtained from past operation results as input variables, and stores past operation data from the actual operation data storage device in which data is output as the operation results. Actual operation data read step for reading out factors and operation results, an operation factor input step for inputting a plurality of operation factors to be predicted, and a plurality of operation factors to be predicted input in the operation factor input step as input variable space A coordinate conversion step for converting the past operating factors read in the actual operation data reading step into coordinates Xj (j = 1, 2,...) On the input space, and the coordinates Xj ( j = 1, 2,...), and the operation result is predicted based on the selection step of selecting data similar to the coordinate q and the past actual output value corresponding to the selected similar data. Operation A operation result prediction method and a prediction step, selecting a similar data from both sides of the assumed plane on the input variable space.
本発明に係る操業結果予測方法は、過去の操業実績で得られた複数の操業因子を入力変数とし、それに対する操業結果を出力とするデータが記憶された実績操業データ記憶装置から、過去の操業因子と操業結果とを読み出す実績操業データ読み出しステップと、予測対象の複数の操業因子を入力する操業因子入力ステップと、前記操業因子入力ステップで入力された予測対象の複数の操業因子を変数ベクトルqに変換し、前記実績操業データ読み出しステップで読み出された過去の操業因子を変数ベクトルXj(j=1,2,・・・)に変換するベクトル変換ステップと、前記予測対象の複数の操業因子の変数ベクトルqと過去の操業因子の変数ベクトルXj(j=1,2,・・・)とのベクトル空間上での距離dを算出する距離算出ステップと、前記過去の操業因子の変数ベクトルXj(j=1,2,・・・)の内、前記距離dが最も小さい過去の操業因子の変数ベクトルデータを選択して第1の近傍データsnaとする第1の選択ステップと、前記第1の近傍データsnaと、前記予測対象の変数ベクトルqと、前記過去の操業因子の変数ベクトルXj(j=1,2,・・・)とから、
内積値(sna−q)・(Xj−q)
を算出する内積演算ステップと、前記算出された内積値が所定値の範囲で、且つ、前記距離dが最も小さい変数ベクトルXj(j=1,2,・・・)を選択して第2の近傍データsnbとする第2の選択ステップと、前記第1の近傍データsnaに対応する過去実績の出力値と、前記第2の近傍データsnbに対応する過去実績の出力値とに基づいて操業結果を予測する操業結果予測ステップとを備え、前記各ステップが電子計算機において実行される。The operation result prediction method according to the present invention uses a plurality of operation factors obtained from past operation results as input variables, and stores past operation data from the operation data storage device in which data is output as the operation results. The actual operation data reading step for reading the factor and the operation result, the operation factor input step for inputting a plurality of operation factors to be predicted, and the plurality of operation factors to be predicted input in the operation factor input step are represented by a variable vector q. A vector conversion step of converting the past operation factor read in the actual operation data read step into a variable vector Xj (j = 1, 2,...), And a plurality of operation factors to be predicted A distance calculating step for calculating a distance d in a vector space between a variable vector q of the current and a variable vector Xj (j = 1, 2,...) Of a past operating factor, and the past operating factor First selection of the variable vector data of the past operation factor with the smallest distance d among the child variable vectors Xj (j = 1, 2,...) As the first neighborhood data sna Step, the first neighborhood data sna , the variable vector q to be predicted, and the variable vector Xj (j = 1, 2,...) Of the past operation factor.
Inner product value (sna −q) ・ (Xj−q)
An inner product calculation step for calculating a second vector by selecting a variable vector Xj (j = 1, 2,...) In which the calculated inner product value is within a predetermined value range and the distance d is the smallest. Based on the second selection step of setting the neighborhood data snb , the past performance output value corresponding to the first neighborhood data sna, and the past performance output value corresponding to the second neighborhood data snb An operation result prediction step for predicting the operation result, and each step is executed in the electronic computer.
本発明に係る操業結果予測方法は、 前記第1の選択ステップ、前記内積演算ステップ及び第2の選択ステップの処理が、前記第1の近傍データと前記第2の近傍データの総和が所定数k(但し、kは2以上の整数)になるまで、既に第1の近傍データ又は第2の近傍データに選択された前記変数ベクトルXj(j=1,2,・・・)を除いて、前記第1の近傍データ及び前記第2の近傍データを選択することを繰り返し、前記所定数の選択された第1の近傍データと第2の近傍データのそれぞれに対応する過去実績の出力値を平均処理又は回帰処理することによって操業結果を予測する。 In the operation result prediction method according to the present invention, the processing of the first selection step, the inner product calculation step, and the second selection step is performed such that a sum of the first neighborhood data and the second neighborhood data is a predetermined number k. Except for the variable vector Xj (j = 1, 2,...) Already selected for the first neighborhood data or the second neighborhood data until k is an integer of 2 or more, Repeating the selection of the first neighborhood data and the second neighborhood data, and averaging the past output values corresponding to the predetermined number of the selected first neighborhood data and the second neighborhood data, respectively Or the operation result is predicted by regression processing.
本発明に係る操業結果予測方法において、前記第2の選択ステップは、前記第1の近傍データsnaと、前記予測対象の変数ベクトルqと、前記過去の換業因子の変数ベクトルXj(j=1,2,・・・)とから、
{(sna−q)・(Xj−q)}/(||sna−q||・||Xj−q||)を算出し、
前記算出された値に基づき変数べクトルXj(j=1,2,・・・)を選択して第2の近傍データsnbとする。In the operation result prediction method according to the present invention, in the second selection step, the first neighborhood data sna , the prediction target variable vector q, and the past conversion factor variable vector Xj (j = 1, 2, ...)
{(Sna −q) · (Xj−q)} / (|| sna −q || • | Xj−q ||)
The base variables based on the calculated value vector Xj (j = 1,2, ···) and second neighboring data snb Select.
本発明に係る操業結果予測方法において、前記第2の選択ステップは、該当する変数べクトルXj(j=1,2,・・・)が存在しない場合には、所定数kに達する前に選択を中止する。 In the operation result prediction method according to the present invention, the second selection step selects before reaching a predetermined number k when there is no corresponding variable vector Xj (j = 1, 2,...). Cancel.
本発明に係る操業結果予測システムは、過去の操業実績で得られた複数の操業因子と、それに対する操業結果を実績操業データ記憶装置に記憶し、予測対象の複数の操業因子と類似した過去の操業因子を前記実績操業データ記憶装置から選択し、前記選択された過去の操業因子に対する操業結果から、前記予測対象の複数の操業因子に対する操業結果を予測する操業結果予測システムであって、内積を利用して前記類似した過去の操業因子を選択する。 The operation result prediction system according to the present invention stores a plurality of operation factors obtained in the past operation results and the operation results for the same in the actual operation data storage device, and stores past operation factors similar to the plurality of operation factors to be predicted. An operation result prediction system for selecting an operation factor from the actual operation data storage device and predicting an operation result for the plurality of operation factors to be predicted from an operation result for the selected past operation factor, The similar past operating factors are selected by using them.
本発明に係る操業結果予測システムは、過去の操業実績で得られた複数の操業因子を入力変数とし、それに対する操業結果を出力とするデータが記憶された実績操業データ記憶装置と、前記実績操業データ記憶装置に記憶されたデータに基づいて、予測対象の複数の操業因子に対応した操業結果を予測する操業結果予測装置とを備え、前記操業結果予測装置は、前記実績操業データ記憶装置から過去の操業因子と操業結果とを読み出す実績操業データ読込部と、予測対象の複数の操業因子を入力する予測対象材データ入力部と、前記予測対象の複数の操業因子を変数ベクトルqに変換し、前記実績操業データ読み出しステップで読み出された過去の操業因子を変数ベクトルXj(j=1,2,・‥)に変換するベクトル変換処理と、前記ベクトル)Xj(j=1,2,・・・)の内、前記ベクトルqに類似したデータを選択する選択処理と、前記選択された類似データに対応する過去実績の出力値とに基づいて操業結果を予測する操業結果予測処理とを実行する予測演算部とを備え、前記予測演算部は、前記ベクトルのなす角度から類似データを選択する。 The operation result prediction system according to the present invention includes a plurality of operation factors obtained from past operation results as input variables, and a result operation data storage device storing data that outputs operation results corresponding thereto, and the result operation data An operation result prediction device for predicting operation results corresponding to a plurality of operation factors to be predicted based on data stored in the data storage device, the operation result prediction device from the actual operation data storage device The actual operation data reading unit for reading the operation factor and the operation result, a prediction target material data input unit for inputting a plurality of operation factors to be predicted, and converting the plurality of operation factors to be predicted into a variable vector q, A vector conversion process for converting the past operation factor read in the actual operation data reading step into a variable vector Xj (j = 1, 2,...), And the vector) Xj (j = 1, 2,. ), A selection process for selecting data similar to the vector q and an operation result prediction process for predicting an operation result based on the past actual output value corresponding to the selected similar data are executed. A prediction calculation unit, and the prediction calculation unit selects similar data from angles formed by the vectors.
本発明に係る操業結果予測システムは、過去の操業実績で得られた複数の操業因子を入力変数とし、それに対する操業結果を出力とするデータが記憶される実績操業データ記憶装置と、前記実績操業データ記憶装置に記憶されたデータに基づいて、予測対象の複数の操業因子に対応した操業結果を予測する操業結果予測装置とを備え、前記操業結果予測装置は、前記実績操業データ記憶装置から過去の操業因子と操業結果とを読み込む過去操業データ読込部と、予測対象の複数の操業因子を入力する予測対象材データ入力部と、前記予測対象の複数の操業因子を変数ベクトルqに変換し、前記過去操業データ読込部により読み込まれた過去の操業因子を変数ベクトルXj(j=1,2,・・・)に変換する処理と、前記予測対象の複数の操業因子の変数ベクトルqと過去の操業因子の変数ベクトルXj(j=1,2,・・・)とのベクトル空間上での距離dを算出する処理と、前記過去の操業因子の変数ベクトルXj(j=1,2,・・・)の内、前記距離dが最も小さい過去の操業因子の変数ベクトルデータを選択して第1の近傍データsnaとする第1の選択処理と、前記第1の近傍データsnaと、前記予測対象の変数ベクトルqと、前記過去の操業因子の変数ベクトルXj(j=1,2,・・・)とから、内積値(sna−q)・(Xj−q)を算出する処理と、前記算出された内積値が所定の範囲で、且つ、前記距離dが最も小さい変数ベクトルXj(j=1,2,・・・)を選択して第2の近傍データsnbとする第2の選択処理と、前記第1の近傍データsnaに対応する過去実績の出力値と、前記第2の近傍データsnbに対応する過去実績の出力値とに基づいて操業結果を予測する処理とを行う予測値演算部とを備えたものである。The operation result prediction system according to the present invention includes a result operation data storage device that stores a plurality of operation factors obtained from past operation results as input variables, and stores data that outputs an operation result corresponding thereto, and the result operation An operation result prediction device for predicting operation results corresponding to a plurality of operation factors to be predicted based on data stored in the data storage device, the operation result prediction device from the actual operation data storage device A past operation data reading unit for reading the operation factor and the operation result of, a prediction target material data input unit for inputting a plurality of operation factors to be predicted, and converting the plurality of operation factors to be predicted into a variable vector q, A process of converting past operation factors read by the past operation data reading unit into a variable vector Xj (j = 1, 2,...), And variables of a plurality of operation factors to be predicted A process of calculating a distance d in the vector space between the kuttle q and the variable vector Xj (j = 1, 2,...) Of the past operating factor, and the variable vector Xj (j = 1 of the past operating factor) , 2,...), A first selection process in which variable vector data of a past operation factor having the smallest distance d is selected as first neighborhood data sna, and the first neighborhood data From the sna , the variable vector q to be predicted, and the variable vector Xj (j = 1, 2,...) of the past operation factor, the inner product value (sna −q) · (Xj−q) And the second neighborhood data sn by selecting the variable vector Xj (j = 1, 2,...) Having the smallest inner product value in the predetermined range and the smallest distance d. a second selection process forb , a past performance output value corresponding to the first neighborhood data sna, and a past performance output value corresponding to the second neighborhood data snb And a predicted value calculation unit that performs a process of predicting the operation result based on the above.
本発明に係る操業結果予測システムにおいて、前記予測値演算部は、前記第1の選択処理、前記内積値を算出する処理及び第2の選択処理が、前記第1の近傍データと前記第2の近傍データの総和が所定数k(但し、kは2以上の整数)になるまで、既に前記第1の近傍データ又は前記第2の近傍データに選択された前記変数ベクトルXj(j=1,2,・・・)を除いて、前記第1の近傍データ及び前記第2の近傍データを選択することを繰り返し、前記所定数の選択された第1の近傍データと第2の近傍データのそれぞれに対応する過去実績の出力値を平均処理又は回帰処理することによって操業結果を予測する。 In the operation result prediction system according to the present invention, the predicted value calculation unit includes the first selection process, the process of calculating the inner product value, and the second selection process. The variable vector Xj (j = 1, 2) already selected for the first neighborhood data or the second neighborhood data until the sum of the neighborhood data reaches a predetermined number k (where k is an integer of 2 or more). ,...), And repeatedly selecting the first neighborhood data and the second neighborhood data to each of the predetermined number of selected first neighborhood data and second neighborhood data. The operation result is predicted by averaging or regression processing the corresponding past performance output value.
本発明に係る操業結果予測システムにおいて、前記予測演算部は、第2の選択処理において、該当する変数べクトルXj(j=1,2,・・・)が存在しない場合には、所定数kに達する前に選択を中止する。なお、本発明において、X・YはベクトルXとYの内積を、||X||はベクトルXのノルム(大きさ)を表すものである。 In the operation result prediction system according to the present invention, the predictive calculation unit determines a predetermined number k when there is no corresponding variable vector Xj (j = 1, 2,...) In the second selection process. Cancel selection before reaching. In the present invention, X · Y represents the inner product of the vectors X and Y, and || X || represents the norm (size) of the vector X.
本発明によれば、過去の操業実績で得られた複数の操業因子から、予測対象の複数の操業因子と類似した過去の操業因子を内積を利用して選択し、その選択された過去の操業因子に対する操業結果から、予測対象の複数の操業因子に対する操業結果を予測するようにしたので、偏りなく類似データ(近傍データ)を選択することができる。
また、本発明によれば、過去の操業因子配列群の各々について、過去の操業因子配列と予測対象の操業因子配列の各配列要素の差をとり、得られた新たな配列因子群の間で、各配列要素の積和をとり、得られた値に基づき前記類似した過去の操業因子を選択するようにしたので、入力変数空間上で予測要求点を取り囲むように、偏りなく類似データ(近傍データ)を選択することができる。このため、予測値の精度を格段に向上させることができる(図11、図12参照)。According to the present invention, a past operation factor similar to a plurality of operation factors to be predicted is selected from a plurality of operation factors obtained from past operation results using an inner product, and the selected past operation is selected. Since the operation results for a plurality of operation factors to be predicted are predicted from the operation results for the factors, similar data (neighboring data) can be selected without bias.
Further, according to the present invention, for each of the past operation factor sequence groups, the difference between the respective array elements of the past operation factor sequence and the predicted operation factor sequence is taken, and the obtained new sequence factor group is obtained. Since the sum of products of each array element is taken and the similar past operation factor is selected based on the obtained value, similar data (neighboring neighbors) is used so as to surround the prediction request point on the input variable space. Data) can be selected. For this reason, the precision of a predicted value can be improved significantly (refer FIG. 11, FIG. 12).
また、本発明によれば、予測対象の複数の操業因子の変数ベクトルqと、過去の操業因子を変数ベクトルXj(j=1,2,・‥)の内、予測対象の複数の操業因子の変数ベクトルqに類似したデータを選択する選択する際に両者ベクトルのなす角度から類似データを選択し、或いは、入力変数空間上に仮定する平面の両側から類似データを選択するようにしたので、入力変数空間上で予測要求点を取り囲むように、偏りなく類似データ(近傍データ)を選択することができる。このため、予測値の精度を格段に向上させることができる。 Further, according to the present invention, a variable vector q of a plurality of operation factors to be predicted and a past operation factor of a plurality of operation factors to be predicted among the variable vectors Xj (j = 1, 2,...). When selecting data similar to the variable vector q, select similar data from the angle formed by both vectors, or select similar data from both sides of the assumed plane in the input variable space. Similar data (neighboring data) can be selected without deviation so as to surround the prediction request point on the variable space. For this reason, the precision of a predicted value can be improved significantly.
また、本発明によれば、予測対象の複数の操業因子と過去の操業因子とのベクトル空間上での距離dを算出し、その距離dが最も小さい過去の操業因子の変数ベクトルデータを第1の近傍データsnaとして選択し、更に、その第1の近傍データsnaと、予測対象の変数ベクトルqと、過去の操業因子の変数ベクトルXj(j=1,2,・・・)とから内積値(sna−q)・(Xj−q)を算出し、その内積値が所定値の範囲で、且つ、距離dが最も小さい変数ベクトルXjを第2の近傍データsnbとして選択するようにしたので、入力変数空間上で予測要求点を取り囲むように、偏りなく近傍データを選択することができ、予測値の精度が格段に向上することが可能となる(例えば図18参照)。Further, according to the present invention, the distance d in the vector space between the plurality of operation factors to be predicted and the past operation factor is calculated, and the variable vector data of the past operation factor having the smallest distance d is obtained as the first. selected as proximate data sna of further first and neighborhood data sna of the variable vector q of the prediction target, the variable vector Xj (j = 1,2, ···) of past operation factor from the The inner product value (sna −q) · (Xj−q) is calculated, and the variable vector Xj having the inner product value in the range of the predetermined value and the smallest distance d is selected as the second neighborhood data snb. Therefore, it is possible to select neighboring data without deviation so as to surround the prediction request point in the input variable space, and the accuracy of the prediction value can be remarkably improved (see, for example, FIG. 18).
実施形態1.
図1は本発明の実施形態1に係る操業結果予測方法を概念的に示した説明図であり、同図に基づいてその概要を説明する。まず、出力を予測したいシステム(操業)に関して、そのシステムの1又は複数個からなる入力変数(操業因子)を与えると(Step11)、予め操業因子と操業結果が記憶、蓄積された過去の事例データベース(:実績操業データ記憶装置)から、前記与えられた出力を予測したい入力変数(操業因子)を、その入力変数空間上(例えば、ベクトル空間)で、与えられた入力変数(操業因子)と距離が近い近傍データ(つまり、類似していることを意味する)の過去の事例を複数個抽出して(Step12)、その選択された過去の事例の複数のデータの平均値や回帰式に基づいて予測値を計算する(Step13)。
FIG. 1 is an explanatory diagram conceptually showing an operation result prediction method according to
また、この近傍データの選択におけるデータの流れの概要を後述の図9に基づいて説明すると、予測対象材(これから製造する製品)の入力変数(操業因子データ)から、出力(操業条件)を算出する際に、入力変数{x(1), x(2),x(3)……x(n)}に対して、過去の実績データ{x1(1), x1(2),x1(3)……x1(n)}、{x2(1), x2(2),x2(3)……x2(n)} ……,{xm(1), xm(2),xm(3),……、xm(n)}の中から予測対象材の入力変数に類似した近傍データを複数個抽出して、そのデータに基づいて平均値又は回帰式に基づいて、出力を求めようとするものである。本実施形態1においては上記の処理(Step12)即ち近傍データ選択法の処理に特徴があるので、その詳細を図2を用いて説明する。 In addition, the outline of the data flow in the selection of the neighborhood data will be described with reference to FIG. 9 to be described later. The output (operation condition) is calculated from the input variable (operation factor data) of the material to be predicted (product to be manufactured). The past data {x1 (1), x1 (2), x1 (3) for the input variable {x (1), x (2), x (3) ... x (n)} ) ... x1 (n)}, {x2 (1), x2 (2), x2 (3) ... x2 (n)} ..., {xm (1), xm (2), xm (3), ......, xm (n)} extracts a plurality of neighboring data similar to the input variable of the material to be predicted, and attempts to obtain an output based on the average value or regression equation based on that data It is. The first embodiment is characterized by the above process (Step 12), that is, the process of the neighborhood data selection method, and the details will be described with reference to FIG.
図2は本実施形態1の近傍データ選択法の説明図であり、同図に基づいて本実施形態1の特徴である近傍データ選択法の概念の詳細を説明する。従来の近傍データを抽出する方法では、例えば距離が近いものを複数個抽出して、その抽出されたデータに基づいて平均値や回帰式から予測していたが、場合によってデータが偏ることがあった。従来の近傍データを抽出する方法を図2のデータに適用した場合には、図2の例では、要求点(予測対象の入力変数)ベクトルqに対して、距離が近いデータは、右下の位置に集中しており、それらのデータを元に平均値を取れば、右下に偏ったデータに基づいて結果を予測するため、それだけ偏った結果が算出されることになる(図3及び図4参照)。これに対して、本実施形態1では、その偏りをなくすために、少なくとも2つのデータを1対とするように選択し、対の1つ目のデータ(第1の近傍データ)(ベクトル空間上の点、図2のsna)は、要求点の近傍の値を選択し、対の2つ目のデータ(第2の近傍データ)(ベクトル空間上の点、図2のsnb)は、対の1つ目のデータに対して要求点qを挟んで、反対側に位置するデータを選択する。そして、上記の従来技術と比較すると、選択すべき近傍データの数がk個に達するまで1対ずつデータを選択する方法と、対となる1つ目は、残されたデータの中から距離の最も近いデータを選択するという方法は、従来のk-SN法と同じであるが、対となる2つ目のデータの選択法において、予測要求点の入力変数ベクトルq、対の1つ目として選択したデータの入力変数ベクトルsna、まだ選択されてない残り
のデータの入力変数ベクトルXに対して、ベクトル(sna−q)と(X−q)の内積を計算し、残りのデータにおいて内積がある値以上又は以下(或いは所定範囲)を満足するデータの中から予測要求点に最も近いデータを対の2つ目のデータsnbとして選択する点に特徴がある。FIG. 2 is an explanatory diagram of the neighborhood data selection method according to the first embodiment, and details of the concept of the neighborhood data selection method, which is a feature of the first embodiment, will be described based on FIG. In the conventional method of extracting neighboring data, for example, a plurality of objects with close distances are extracted and predicted based on the extracted data based on the average value or regression equation. However, the data may be biased in some cases. It was. When the conventional method of extracting neighboring data is applied to the data of FIG. 2, in the example of FIG. 2, data that is close to the request point (predicted input variable) vector q If the average value is obtained based on the data, the result is predicted based on the data biased to the lower right, so that the biased result is calculated (FIG. 3 and FIG. 3). 4). On the other hand, in the first embodiment, in order to eliminate the bias, at least two pieces of data are selected as one pair, and the first data of the pair (first neighborhood data) (on the vector space) 2, sna ) in FIG. 2 selects a value in the vicinity of the request point, and the second data of the pair (second neighborhood data) (point on the vector space, snb in FIG. 2) is The data located on the opposite side with respect to the first data of the pair across the request point q is selected. Compared with the above-described prior art, the method of selecting data one by one until the number of neighboring data to be selected reaches k, and the first pair is the distance between the remaining data. The method of selecting the closest data is the same as the conventional k-SN method. However, in the method of selecting the second data to be paired, the input variable vector q of the prediction request point is used as the first of the pair. The inner product of the vectors (sna−q) and (X−q) is calculated for the input variable vector sna of the selected data and the input variable vector X of the remaining data that has not yet been selected. It is characterized in that the data closest to the prediction request point is selected as the second data snb of the pair from data satisfying a certain value or more or less (or a predetermined range).
その方法としては、1つ目に選択したベクトル(図2のsna)と要求点(図2のq)との差ベクトルと、2つ目に選択されるベクトルと要求点との差ベクトルとの内積値を算出し、図2の例で示される内積(sna−q)・(X−q)の値が、所定の閾値(例えば、内積の閾値を-(sna−q)2とすれば、図においてハッチングをかけた部分が対の2つ目の探索領域となる。)より離れた領域にあり、且つ最も小さい値を選択するようにしたものである。図2の例では、所定の値は、内積-(sna−q)2としている。なお、図2の所定の閾値は予測対象に応じて任意に設定される。As the method, a difference vector between the first to the selected vector and the required point (sna in FIG. 2) (q in Fig. 2), the difference vector between the request point vector selected in the second 2, and the value of the inner product (sna −q) · (X−q) shown in the example of FIG. 2 is a predetermined threshold (for example, the inner product threshold is − (sna −q)2 In this figure, the hatched portion is the second search area of the pair.) The smallest value is selected in the area farther away. In the example of FIG. 2, the predetermined value is an inner product − (sna −q)2 . Note that the predetermined threshold in FIG. 2 is arbitrarily set according to the prediction target.
以上のように、本実施形態1においては上記の近傍データの選択法により、非常にシンプルなアルゴリズムでありながら、入力変数空間上で予測要求点を取り囲むように、偏りなく近傍データを選択するようにしているので、予測値の精度が格段に向上することが可能になっている。 As described above, in the first embodiment, the neighborhood data is selected without bias so as to surround the prediction request points in the input variable space by the above-described neighborhood data selection method, although it is a very simple algorithm. Therefore, the accuracy of the predicted value can be greatly improved.
実施形態2.
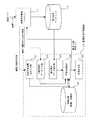
図5は本発明の実施形態2に係る操業結果予測システム構成図である。このシステムは、操業を管理及び制御するための操業用計算機(プロセスコンピュータ)11、過去操業データを蓄積、記憶するための過去操業データベース(:実績操業データ記憶装置)12、操業結果を予測するための操業結果予測装置13から構成される。操業用計算機11は、例えば、1つの製品が製造完了するたびに、製造ラインから操業データを入力し、過去操業データベース12に記憶する。また、操業用計算機11は、次の操業結果を予測するために、操業結果予測装置13に対して操業予測演算要求の指令を出力する。また、その予測に当たって、予測の対象となる材料(例えば、鋼板や鋼材)の諸元データ等も、操業結果予測装置13に出力する。また、操業用計算機11は操業結果予測装置13で算出された計算結果を入力して操業に反映する。過去操業データベース12は、操業結果予測装置13が操業を予測するに当たって必要となる、過去の操業データ(実績操業データ)が記憶されており、このデータが操業結果予測装置13によって読み込まれる。
FIG. 5 is an operation result prediction system configuration diagram according to
操業結果予測装置13は電子計算機から構成されており、本実施形態の機能に着目すると、操業予測演算要求入力部21、予測対象材データ入力部22、過去操業データ読込部23、予測値演算部24、結果表示部25及び記憶装置26から構成されている。操業予測演算要求入力部21は、操業用計算機11からの操業予測演算要求(予測計算開始指令)の指令を受け付け、これを予測値演算部24に出力することで、予測演算が実行される。過去操業データ読込部23は、過去操業データベース12から予測演算の為に必要な過去の操業データを読み込む処理を行い、予測値演算部24に出力する。予測対象材データ入力部22は、これから製造される製品(例えば、鋼板や鋼材)のデータを操業用計算機11から入力し、予測値演算部24に出力する。予測値演算部24では、これから製造される製品の操業結果を予測するために必要となる諸元データと、過去の操業データとを入力して、これらのデータに基づいて、操業結果を予測する。また、記憶装置26は、例えばメモリ、ハードディスク等から構成されており、予測値演算部24で算出された演算値を一次記憶する。また、予測値演算部24は、演算結果(操業結果の予測値)を結果表示部25に出力して表示すると共に、操業用計算機11に出力して操業条件を設定する。 The operation result prediction apparatus 13 is composed of an electronic computer, and paying attention to the function of this embodiment, the operation prediction calculation
図6は過去操業データベース12のデータ構造を示した図である。過去操業データベース12は同図に示されるように、入力変数(操業因子データ)と出力値(操業条件)とが対となっているテーブル形式のデータ構造からなっており、そのデータが過去操業データ読込部23により読み込まれる。
図7は予測対象材の入力データの構成例を示した図である。この入力データは、図6の入力変数(操業因子データ)に対応した複数の入力変数から構成されている。FIG. 6 is a diagram showing the data structure of the
FIG. 7 is a diagram illustrating a configuration example of input data of a prediction target material. This input data is composed of a plurality of input variables corresponding to the input variables (operation factor data) in FIG.
図8は操業結果予測装置13の処理過程を示したフローチャートであり、同図に基づいて操業結果予測装置13の処理過程の詳細を説明する。
操業予測演算要求入力部21が操業用計算機11から操業予測演算要求の指令を入力すると、操業結果予測装置13の演算がスタートする。過去操業データベース12には上述のように、1つの製品の製造が完了する毎に、その製品の諸元データ及びそのときの操業条件が操業用計算機11により記憶されており、ここでは、先ず、過去操業データ読込部23が過去操業データベース12から過去の操業データを読み込んで予測値演算部24に出力し、予測値演算部24ではベクトル変換(Xj(j=1,2,…)への変換)や正規化処理が実行される(Step101)。過去操業データベース12内の過去の事例データは入力変数空間上のベクトルとして捉え、FIG. 8 is a flowchart showing the process of the operation result predicting apparatus 13, and details of the process of the operation result predicting apparatus 13 will be described with reference to FIG.
When the operation prediction calculation

と表される。あるいは、Step101では、過去の事例データをベクトルとして扱ったが、配列、あるいは、入力変数空間における座標として扱い、変換してもよい。なお、過去操業データベース12のデータ構造は、上述の図6のようになっており、入力変数(操業因子データ)に対して、出力結果(操業条件結果)が対応付けされたテーブル構造となっている。It is expressed. Alternatively, in Step 101, past case data is treated as a vector, but it may be treated as an array or coordinates in the input variable space and converted. The data structure of the
次に、予測したい、これから製造する製品に関する諸元データである操業因子データを操業用計算機11から予測対象材データ入力部22で入力し、予測値演算部24に出力し、ベクトル変換(q、図2の例では★印に対応)、正規化処理を実行する(Step102)。ここで入力されるのは、予測したい未知の出力(これから製造される製品の操業条件、たとえば、鋼板や鋼材等の製造操業条件)に対する入力変数q1,q2,q3,・・・,qn(nは入力変数の個数で、予め指定する、例えば鋼板のサイズ(幅、長さ、厚さ、鋼種等))であり、与えられた複数の入力変数を入力変数空間上のベクトルとして捉え、 Next, operation factor data, which is specification data relating to a product to be manufactured, to be predicted is input from the
と表し、これを予測要求点(図2の例では★の点、要求点q)と呼ぶことにする。あるいは、Step101と同様に、配列、あるいは、入力変数空間における座標として扱い、変換してもよい。そして、qとそれぞれの過去実績ベクトルデータXj(図2中の■印、●印に位置するデータ、j=1〜n:nは記憶されている過去実績データの数)との距離d(例えば、ユークリッド距離)を算出し、それぞれに過去実績ベクトルデータXj(j=1〜n)に対応づけて距離dの値を記憶装置26に記憶する(Step103)。例えば、予測要求点からの入力変数空間上の距離を算出する例として以下の式で表されるユークリッド距離dがある。この距離dによって対の1つ目のデータの候補が決定されることになる。This is called a predicted request point (in the example of FIG. 2, a star point, a request point q). Alternatively, as in Step 101, it may be handled and converted as an array or coordinates in the input variable space. A distance d between the q and each past result vector data Xj (data located at the mark ■ and ● in FIG. 2, j = 1 to n: n is the number of stored past result data) (for example, , Euclidean distance) is calculated, and the value of the distance d is stored in the
その他の距離としては重みつきl次ノルム(l≧1、ただし重みつきユークリッド距離はl=2に相当)等があり、それを用いてもよい。あるいは、距離として扱わず、どれだけデータが類似しているかを示す適当な指標を類似度として定義し、それを用いてもよい。一例として、以下に示すような指標があげられる。
次に、所定の個数(k個)まで算出するためのカウント用のパラメータに用いる変数iを1にセットする(Step104)。そして、上記の距離dが最も小さいデータ(図2の例で●印のsn2i-1に位置するデータ)を対の1つ目のデータとして選択し、これを第1の近傍データsnaとして決定する(Step105)。なお、sn2i-1は、この段階ではi=1なのでsn1である。ここで、選択された近傍データの個数(2i−1)が所定数k(近傍データの設定個数)個以上になったか(2i−1≧k)どうかを判断し(Step106)、k個になっている場合(Step106・yes)にはStep110に進む。k個になっていない場合(step106・no)にはstep107に進む。Next, a variable i used as a count parameter for calculating up to a predetermined number (k) is set to 1 (Step 104). Then, the data with the smallest distance d (the data located at the sn2i-1 marked with ● in the example of FIG. 2) is selected as the first data of the pair, and this is set as the first neighborhood data sna. Determine (Step 105). Note that sn2i-1 is sn1 because i = 1 at this stage. Here, it is determined whether or not the number (2i-1) of the selected neighborhood data is equal to or greater than a predetermined number k (a set number of neighborhood data) (2i-1 ≧ k) (Step 106). If yes (
要求点qと上記の第1の近傍データsnaとして決定されたsn2i-1(i=1の段階では、=sn1)とに基づいて、内積値(sn2i-1−q)・(Xj−q)を過去実績ベクトルデータXj(j=1〜n)のそれぞれのデータについて算出し、記憶装置26に記憶する(Step107)。そうして算出され、記憶されたデータ中で、内積値が所定の条件(例えば、内積値<−(sn2i-1−q)2)を満足し、かつ、qから最も距離dが小さいもの(図2の例では●印sn2iに位置するデータ)を対の2つ目のデータとして選択し(Step103で記憶したデータから選択)、これを第2の近傍データsnbとして決定する(Step108)。なお、sn2iは、この段階ではi=1なのでsn2である。選択された近傍データの個数(2i)が所定の値(k)未満であれば(Step109・no)、次のStep111に進む。Step111では、前記Step105及びStep108で選択されたsn2i-1、sn2i(i=1であるので、sn1、sn2)を次の選択演算対象Xjから除き(Step111)、iをインクリメント(Step112)して、上記のStep105の処理に戻り、上記の処理を再び繰り返し、sn3、sn4、…snkまでの近傍データを順次第1及び第2の近傍データとして選択する。選択された近傍データの個数(2i)が所定数k以上であれば(Step109・yes)、選択されたk個の第1及び第2の近傍データ(sn1、sn2、・・・snk)の過去実績操業データに基づき、その出力結果の平均値又は回帰式に基づいて対象となる予測操業結果を算出する(Step110)。なお、上記の近傍データの設定個数「k」は2以上の整数であり、「k」が偶数の場合には、上記の1又は複数の対のデータ(第1及び第2の近傍データ)が選択されることになるが、奇数の場合には1又は複数の対のデータと上記の対の1つ目のデータ(第1の近傍データ)とが選択されることになる。Based on the required point q and the above-described first neighborhood data sna , sn2i-1 (= sn1 at the stage where i =1 ), the inner product value (sn2i-1 −q) · ( Xj−q) is calculated for each piece of past performance vector data Xj (j = 1 to n) and stored in the storage device 26 (Step 107). Of the data calculated and stored in this way, the inner product value satisfies a predetermined condition (for example, inner product value <− (sn2i−1 −q)2 ), and the distance d is the shortest from q (In the example of FIG. 2, the data located at the mark “sn2i” ) is selected as the second data of the pair (selected from the data stored in Step 103), and this is determined as the second neighboring data snb (Step 108). ). Note that sn2i is sn2 because i = 1 at this stage. If the number (2i) of the selected neighborhood data is less than the predetermined value (k) (Step 109 · no), the process proceeds to the next Step 111. In Step 111, sn2i-1 and sn2i selected in Step 105 and Step 108 (because i = 1, sn1 and sn2 ) are excluded from the next selection calculation target Xj (Step 111), and i is incremented (Step 112). Then, the process returns to the process of Step 105, and the above process is repeated again, and the neighborhood data up to sn3 , sn4 ,..., Snk are sequentially selected as the first and second neighborhood data. If the number (2i) of the selected neighborhood data is greater than or equal to the predetermined number k (Step 109 · yes), the selected k first and second neighborhood data (sn1, sn2, ... Snk ) Based on the past actual operation data, the target predicted operation result is calculated based on the average value of the output results or the regression equation (Step 110). Note that the set number “k” of the neighborhood data is an integer of 2 or more, and when “k” is an even number, the above one or plural pairs of data (first and second neighborhood data) are In the case of an odd number, one or a plurality of pairs of data and the first data of the pair (first neighborhood data) are selected.
出力結果の平均値を求める平均値の算出方法としては、例えば選択された過去実績データの出力値yi(図9参照)から As an average value calculation method for obtaining an average value of output results, for example, from the output value yi (see FIG. 9) of selected past performance data.
回帰式としては、p個の独立変数があるので、重回帰分析により求める。その重回帰分析で使用するデータを本願発明の方法により選択する。重回帰分析を行う場合は選択するデータの所定数を多めにし、例えば、近傍データを数10点から100点程度を選択するようにして、下記の重回帰式に基づいて偏回帰係数を求める。 Since there are p independent variables, the regression equation is obtained by multiple regression analysis. Data used in the multiple regression analysis is selected by the method of the present invention. When performing multiple regression analysis, the predetermined number of data to be selected is increased. For example, the local regression coefficient is obtained based on the following multiple regression equation by selecting about several tens to 100 of the neighboring data.
上記の重回帰式により予測要求点(Xj=q)に対する出力予測値を求める。 The output prediction value for the prediction request point (Xj = q) is obtained by the multiple regression equation.
図9は予測対象材の入力変数、過去の操業データ(入力変数・出力)及び予測値の関係を示した説明図である。k=3とし、予測対象材の入力変数(x(1)……x(n))により、例えば対の1つ目の近傍データsn1(sna)としてXi-2が選択され、更に、対の2つ目の近傍データsn2(snb)としてXiが選択され、更に、対の1つ目の近傍データsn3(sna)としてXi+1が選択されると、例えばそれらの出力Yi-2、Yi、Yi+1の平均値が予測値として求められる。なお、図9の説明では、近傍データの並び(sn1、sn2、sn3の並び)は、過去の操業データの並び順(Xi-2、Xi、Xi+1)となる例で説明しているが、通常は、近傍データの並びは過去の操業データの並び順と一致する必要は無く(選択の制約は特に設けない)、選択条件に見合ったものをデータの並びとは関係なく選択される。FIG. 9 is an explanatory diagram showing the relationship between the input variable of the prediction target material, the past operation data (input variable / output), and the predicted value. For example, Xi−2 is selected as thefirst neighboring data sn1 (sna ) of the pair by using k = 3 and the input variable (x (1)... x (n)) of the prediction target material. When Xi is selected as thesecond neighboring data sn2 (snb ) of the pair, and Xi + 1 is selected as thefirst neighboring data sn3 (sna ) of the pair, An average value of these outputs Yi-2 , Yi , Yi + 1 is obtained as a predicted value. In the description of FIG. 9, an example in which the arrangement of neighboring data (the arrangement of sn1 , sn2 , and sn3 ) is the arrangement order of past operation data (Xi−2 , Xi , Xi + 1 ). However, normally, it is not necessary for the arrangement of neighboring data to match the arrangement order of past operation data (there is no special restriction on selection), and the arrangement of data that meets the selection conditions is It is selected regardless.
以上のように本実施形態2によれば、予測値演算部24が、予測対象の複数の操業因子と過去の操業因子とのベクトル空間上での距離dを算出し、その距離dが最も小さい過去の操業因子の変数ベクトルデータを対の1つ目の近傍データ(第1の近傍データsna)として選択し、更に、その対の1つ目の近傍データ(第1の近傍データsna)と、予測対象の変数ベクトルqと、過去の操業因子の変数ベクトルXj(j=1,2,・・・)とから内積値(sna−q)・(Xj−q)を算出し、内積値が所定値の範囲で、且つ、距離dが最も小さい変数ベクトルXjを対の2つ目の近傍データ(第2の近傍データsnb)として選択するようにし、これらの選択された変数ベクトルに対応した過去の操業実績の出力に基づいて操業結果を予測するようにしており、このため、入力変数空間上で予測要求点qを取り囲むように、偏りなく近傍データを選択することができ、予測値の精度が格段に向上することが可能となっている。As described above, according to the second embodiment, the predicted value calculation unit 24 calculates the distance d on the vector space between the plurality of operation factors to be predicted and the past operation factors, and the distance d is the smallest. Variable vector data of past operating factors is selected as the first neighborhood data (first neighborhood data sna ) of the pair, and the first neighborhood data (first neighborhood data sna ) of the pair is further selected. And the inner product value (sna −q) · (Xj−q) is calculated from the variable vector q to be predicted and the variable vector Xj (j = 1, 2,...) A variable vector Xj having a value within a predetermined value range and having the smallest distance d is selected as the second neighboring data (second neighboring data snb ) of the pair, and the selected variable vectors The operation results are predicted based on the output of the corresponding past operation results. , So as to surround the predicted request point q on the input variable space, without any bias can be selected proximate data, the accuracy of the predicted value it is possible to remarkably improved.
実施形態3.
図10は本発明の実施形態3に係る処理過程を示したフローチャートであり、図11はk=4としたときに近傍データの選択方法の概念図である。以下、これらの図に基づいて操業結果予測装置13の処理過程の詳細を説明する。
操業予測演算要求入力部21が操業用計算機11から操業予測演算要求の指令を受信すると、操業結果予測装置13の演算がスタートする。過去操業データベース12には上述のように、1つの製品の製造が完了する毎に、その製品の諸元データ及びそのときの操業条件が記憶されており、ここでは、先ず、過去操業データ読込部23が過去操業データベース12から過去の操業データを読み込んで予測値演算部24に出力し、予測値演算部24ではベクトル変換(Xj(j=1,2,・・・)への変換)や正規化処理が実行される(Step201)。過去操業データベース12内の過去の事例データは入力変数空間上のベクトルとして捉え、
FIG. 10 is a flowchart showing a process according to the third embodiment of the present invention, and FIG. 11 is a conceptual diagram of a neighborhood data selection method when k = 4. Hereinafter, the details of the process of the operation result prediction apparatus 13 will be described based on these drawings.
When the operation prediction calculation
と表される。あるいは、Step201では、過去の事例データをベクトルとして扱ったが、配列、あるいは、入力変数空間における座標として扱い、変換してもよい。なお、過去操業データベース12のデータ構造は、上述の図6のようになっており、入力変数(操業因子データ)に対して、出力結果(操業条件結果)が対応付けされたテーブル構造となっている。It is expressed. Alternatively, in Step 201, past case data is treated as a vector, but it may be treated as an array or coordinates in the input variable space and converted. The data structure of the
次に、予測したい、これから製造する製品に関する諸元データである操業因子データを予測対象材データ入力部22で入力し、予測値演算部24に出力し、ベクトル変換(q、図11の例では★印に対応)、正規化処理を実行する(Step202)。ここで入力されるのは、予測したい未知の出力(これから製造される製品の操業条件、たとえば、鋼板や鋼材等の製造操業条件)に対する入力変数q1,q2,q3,・・・,qn(nは入力変数の個数で、予め指定する、例えば鋼板のサイズ(幅、長さ、厚さ、鋼種等))であり、与えられた複数の入力変数を入力変数空間上のベクトルとして捉え、 Next, operation factor data, which is specification data relating to a product to be manufactured, which is to be predicted, is input by the prediction target material
と表し、これを予測要求点(図11の例では★の点、要求点q)と呼ぶことにする。あるいは、Step201と同様に、配列、あるいは、入力変数空間における座標として扱い、変換してもよい。This is called a predicted request point (in the example of FIG. 11, a star point, a request point q). Alternatively, as in Step 201, it may be handled and converted as an array or coordinates in the input variable space.
次に、qとそれぞれの過去実績データXj(図11中の■印、●印に位置するデータ、j=1〜m、mは記憶されている過去実績データの個数)との距離dを算出し、それぞれに過去実績ベクトルデータXj(j=1〜m)に対応づけて距離dの値を記憶装置26に記憶する(Step203)。例えば、予測要求点からの入力変数空間上の距離を算出する例として以下の式で表される重みつきユークリッド距離dがある。この距離dによって近傍データの候補が決定されることになる。 Next, the distance d between q and the respective past performance data Xj (the data located at the ■ and ● marks in FIG. 11, j = 1 to m, m is the number of stored past performance data) is calculated. Then, the value of the distance d is stored in the
その他の距離としては重みつきl次ノルム(l≧1、ただし重みつきユークリッド距離はl=2に相当)等があり、それを用いてもよい。あるいは、距離として扱わず、どれだけデータが類似しているかを示す適当な指標を類似度として定義し、それを用いてもよい。一例として、以下に示すような指標があげられる。
次に所定の個数(k個)まで算出するためのカウント用のパラメータに用いる変数iを1にセットする(Step204)。 Next, a variable i used as a count parameter for calculating up to a predetermined number (k) is set to 1 (Step 204).
次に、上記の距離dが最も小さいデータ、あるいは類似度が最も大きいデータを1つ目のデータとして選択し、これを第1の近傍データsn4i-3として決定し、次の選択演算対象Xjからsn4i-3を削除する(Step205)。なお、sn4i-3は、この段階ではi=1なのでsn1である。ここで、選択された近傍データの総個数が所定数k個以上になったかどうかを判断し(Step206)、k個になっている場合(Step206・yes)にはStep215に進む。k個になっていない場合(Step206・no)にはStep207に進む。Next, the data having the smallest distance d or the data having the largest similarity is selected as the first data, determined as the first neighborhood data sn4i-3 , and the next selection calculation target Xj Sn4i-3 is deleted from (Step 205). Note that sn4i-3 is sn1 because i = 1 at this stage. Here, it is determined whether or not the total number of selected neighborhood data has reached a predetermined number k or more (Step 206), and if it is k (Step 206 · yes), the process proceeds to Step 215. If not k (Step 206 / no), the process proceeds to Step 207.
次に、要求点qと上記の第1の近傍データとして決定されたsn4i-3とに基づいて、内積演算(sn4i-3−q)・(Xj−q)を過去実績データXjのそれぞれにデータについて算出し、記憶装置26に記憶する(Step207)。そうして算出され、記憶されたデータ中で、内積演算値が第1の所定の条件(例えば、内積値<-||sn4i-3−q||2)を満足し、かつ、qから最も距離dが小さいものを選択し、これを第2の近傍データsn4i-2として決定し、次の選択演算対象Xjからsn4i-2を削除する(Step208)。なお、sn4i-2は、この段階ではi=1なのでsn2である。ここで、選択された近傍データの総個数が所定数k個以上になったかどうかを判断し(Step209)、k個になっている場合(Step209・yes)にはStep215に進む。k個になっていない場合(Step209・no)にはStep210に進む。Next, based on the request point q and the above-described sn4i-3 determined as the first neighborhood data, the inner product calculation (sn4i-3 −q) · (Xj−q) is performed on each of the past performance data Xj. The data is calculated and stored in the storage device 26 (Step 207). In the data thus calculated and stored, the inner product operation value satisfies a first predetermined condition (for example, inner product value <-|| sn4i-3 -q ||2 ), and from q The one with the shortest distance d is selected, determined assecond neighborhood data sn4i-2 , and sn4i-2 is deleted from the next selection calculation target Xj (Step 208). Note that sn4i-2 is sn2 because i = 1 at this stage. Here, it is determined whether or not the total number of selected neighborhood data has reached a predetermined number k or more (Step 209), and if it is k (Step 209 / yes), the process proceeds to Step 215. If not k (Step 209 / no), the process proceeds to Step 210.
次に、記憶されたデータ中(上述のとおり、既に選択され、削除したデータは除く)で、内積演算値((sn4i-3−q)・(xj−q))が第2の所定の条件(例えば、内積演算値がゼロに最も近いもの)を選択し、これを第3の近傍データsn4i-1として決定し、次の選択演算対象Xjからsn4i-1を削除する(Step210)。なお、sn4i-1は、この段階ではi=1なのでsn3である。ここで、選択された近傍データの総個数が所定数(k個)以上になったかどうかを判断し(Step211)、所定数(k個)になっている場合(Step211・yes)にはStep215に進む。所定数(k個)になっていない場合(Step211・no)にはStep212に進む。Next, in the stored data (excluding data already selected and deleted as described above), the inner product operation value ((sn4i−3 −q) · (xj −q)) is the second predetermined value. (For example, the inner product operation value closest to zero) is selected as third neighborhood data sn4i-1 , and sn4i-1 is deleted from the next selection operation object Xj (Step 210). ). Note that sn4i-1 is sn3 because i = 1 at this stage. Here, it is determined whether or not the total number of selected neighborhood data has reached a predetermined number (k) or more (Step 211), and if it is the predetermined number (k) (Step 211 / yes), the process goes to Step 215. move on. When the predetermined number (k) is not reached (Step 211 / no), the process proceeds to Step 212.
次に、要求点qと上記の第3の近傍データとして決定されたsn4i-1とに基づいて、内積演算(sn4i-1−q)・(Xj−q)を過去実績データXjのそれぞれにデータについて算出し、記憶装置26に記憶する(Step212)。そうして算出され、記憶されたデータ中で、内積演算値が第3の所定の条件(例えば、内積値<-|| sn4i-1−q||2)を満足し、かつ、qから最も距離dが小さいものを選択し、これを第4の近傍データsn4iとして決定し、次の選択演算対象Xjからsn4iを削除する(step213)。なお、sn4iは、この段階ではi=1なのでsn4である。ここで、選択された近傍データの総個数が所定数k個以上になったかどうかを判断し(Step214)、k個になっている場合(Step214・yes)にはStep215に進む。k個になっていない場合(Step214・no)にはi=i+1としてStep205に進み、近傍データの総個数が所定数k個になるまで繰返す。k=4(p=2)と設定された場合には、この例では、図11に示されるように、要求点qを4方向から囲むようにして4個の近傍データsn1〜sn4が選択される。Next, based on the request point q and the above-described third neighborhood data sn4i-1 , the inner product calculation (sn4i-1 -q) · (Xj-q) is performed on each of the past performance data Xj. The data is calculated and stored in the storage device 26 (Step 212). In the data thus calculated and stored, the inner product operation value satisfies a third predetermined condition (for example, inner product value <-|| sn4i-1 -q ||2 ), and from q The one with the shortest distance d is selected, determined as fourth neighborhood data sn4i , and sn4i is deleted from the next selection calculation target Xj (step 213). Note that sn4i is sn4 because i = 1 at this stage. Here, it is determined whether or not the total number of selected neighborhood data has reached a predetermined number k or more (Step 214), and if it is k (Step 214 · yes), the process proceeds to Step 215. If it is not k (Step 214 · no), i = i + 1 and the process proceeds to Step 205 and is repeated until the total number of neighboring data reaches a predetermined number k. When k = 4 (p = 2) is set, in this example, as shown in FIG. 11, four neighboring data sn1 to sn4 are selected so as to surround the request point q from four directions. The
このようにして決定した近傍データに基づき、重みつき平均、重みつき回帰等を用いることにより、対象となる予測操業結果を算出する(Step215)。出力結果の重みつき平均値を求める算出方法としては、例えば、選択された過去実績データの出力値Yiから
また、Step210では、第1の近傍データsn4i-3(i=1の場合、sn1)を用いた内積値を用いて、ε1≦内積値(sn4i-3―q)・(Xj―q)≦ε2(εは小さな値)を満足し、かつ、qから最も距離dが小さいものを、第3の近傍データsn4i-1(i=1の場合、sn3)として決定してもよい。そして、Step213では、その対として第3の近傍データsn4i-1を基準にした内積値(sn4i-1―q)・(Xj―q)が、所定の範囲内(例えば、−||sn4i-1―q||2より小さい)であり、かつ、qから距離dが最も小さいものを第4の近傍データとして選択するようにしてもよい。また、上記の例では第1〜第4の近傍データとして4個を選択したが、4個以上の近傍データを選択する方法として、図12にその処理のフローチャートを示す。Step501からStep508における第1、第2の近傍データの選択はStep201からStep208までと同じにする(ただし、図10と図12とでは、sn4i-3がsn2i-1等、データ表記は変更している)が、Step510からの第3の近傍データ以降の選択処理において、内積条件(例えば、内積値範囲を示す、上記ε1、ε2に該当する値の組合せ)を(p−1)個用意する(第1、第2の近傍データ選択の条件とあわせて、合計でp個の内積条件となる)。iをインクリメント(Step510)したのち、内積条件LL(i)≦内積値(sn1―q)・(Xj―q)≦UL(i )(i=2,・・・,p)を満足し、かつ、qから最も距離dが小さいものを、第(2i-1)の近傍データとして選択する(Step511)。近傍データ数が所定数以上か判断し(Step512)、所定数より小さい場合は、その対となる第(2i)の近傍データは、Step513で内積値(sn2i-1―q)・(Xj―q)も求め、その値が所定の範囲内(例えば、−||sn1―q||2より小さい)であり、かつ、qから距離dが最も小さいものを選択し(Step514)、選択した近傍データから対象となる予測操業結果を算出してもよい。また、近傍データの選択順番を入替えてもよい。In Step 210, using the inner product value using the first neighborhood data sn4i-3 (in the case of i = 1, sn1 ), ε1 ≦ inner product value (sn4i-3 −q) · (Xj −q) ≦ ε2 (ε is a small value) and the smallest distance d from q is determined as the third neighborhood data sn4i-1 (in the case of i = 1, sn3 ). May be. In Step 213, the inner product value (sn4i-1 -q) · (Xj -q) based on the third neighboring data sn4i-1 as a pair falls within a predetermined range (for example, − || sn4i-1 -q ||2 ) and the smallest distance d from q may be selected as the fourth neighborhood data. In the above example, four are selected as the first to fourth neighborhood data. As a method of selecting four or more neighborhood data, a flowchart of the processing is shown in FIG. The selection of the first and second neighborhood data in Step 501 to Step 508 is the same as in Step 201 to Step 208 (however, in FIG. 10 and FIG. 12, sn4i-3 is sn2i-1, etc., and the data notation is changed. However, in the selection processing after the third neighborhood data from Step 510, (p-1) inner product conditions (for example, combinations of values corresponding to the above ε1 and ε2 indicating the inner product value range) are set. Prepared (a total of p inner product conditions, together with the first and second neighborhood data selection conditions). After i is incremented (Step 510), the inner product condition LL (i) ≦ the inner product value (sn1 −q) · (Xj −q) ≦ UL (i) (i = 2,..., p) is satisfied And the one having the smallest distance d from q is selected as the (2i-1) -th neighborhood data (Step 511). Number neighboring data it is determined whether more than a predetermined number (Step512), is smaller than the predetermined number, the neighborhood data of the (2i) to be its pair inner product value inStep513 (sn 2i-1 -q) · (X j -Q) is also obtained, and the value is within a predetermined range (for example, smaller than-|| sn1 -q ||2 ) and the distance d is the smallest from q (Step 514) and selected. The target predicted operation result may be calculated from the obtained neighborhood data. Further, the selection order of the neighborhood data may be changed.
例えば図13はk=8(p=4)とし、内積値範囲の条件を、同図に示されるように第2i−1の近傍データを選択するための内積範囲条件1〜4に設定して、、8個の近傍データsn1〜sn8を選択する例である。まず、qから距離が最も小さいとして選択された第1の近傍データsn1(図13中の●印)のペアを選択するため、前述のStep508の処理により内積範囲条件1を満たす第2の近傍データsn2(図13中の▲印)を選択する。また、要求点qと第1の近傍データsn1を用いた内積演算値(sn1―q)・(X―q)が内積範囲条件2を満たし、かつ、qからの距離が最も小さいデータを第3の近傍データsn3(図13中の破線○印)として選択する。この第3の近傍データのペアとして、内積値(sn3―q)・(X―q)の値を算出し、値が−||sn3―q||2(つまり、qを挟んで反対側に位置する)であり、かつ、qから距離dが最も小さいものを選択して、第4の近傍データsn4(図13中の破線△印)とする。続いて、同様に、要求点qと第1の近傍データsn1を用いた内積演算値(sn1―q)・(X―q)の値が内積範囲条件3を満たし、かつ、qからの距離が最も小さいデータを第5の近傍データsn5(図13中の○印)として選択する。この第5の近傍データのペアとして、内積値(sn5―q)・(X―q)の値を算出し、値が−||sn3―q||2(つまり、qを挟んで反対側に位置する)であり、かつ、qから距離dが最も小さいものを選択して、sn6(図13中の△印)する。同様に、第7の近傍データsn7、第8の近傍データsn8を求めることにより、図13の各近傍データが得られる。なお、前述のとおり、選択されたデータは、逐次候補データから除外(データを削除)されて、複数回選択されることはない。For example, in FIG. 13, k = 8 (p = 4), and the inner product value range condition is set to inner
以上のように、本実施形態3においては4方向、あるいは、2p方向から要求点を取り囲むように近傍データを選択するので、より一層予測値の精度が向上できる。 As described above, in the third embodiment, the neighborhood data is selected so as to surround the request point from the four directions or the 2p direction, so that the accuracy of the predicted value can be further improved.
実施形態4.
図14は本発明の実施形態4に係る近傍データ選択法の処理を示した概念図であり、同図に基づいてその詳細を説明する。対の1つ目のデータ(第1の近傍データ)は最も距離が近いデータを選択し、対の2つ目のデータ(第2の近傍データ)は対の1つ目のデータに対して要求点qを挟んで、反対側に位置するデータを選択する。このとき、cosθj=(sn2i-1−q)・(Xj−q)/||sn2i-1−q||・||Xj−q||
からθjを算出し、θjが最も180°に近いXjを第2の近傍データとして決定する。あるいは、図15に示されるように、θjの条件を予め用意し、θL≦θj≦θUを満足し、かつ、qから最も距離dが小さいものを第2の近傍データとして決定してもよい。また、本実施の形態4は、上述した実施形態3における内積演算に替わって代用することができる。
FIG. 14 is a conceptual diagram showing processing of the neighborhood data selection method according to the fourth embodiment of the present invention, and details thereof will be described with reference to FIG. The first data in the pair (first neighborhood data) selects the data with the shortest distance, and the second data in the pair (second neighborhood data) is requested for the first data in the pair The data located on the opposite side across the point q is selected. At this time, cos θj = (sn2i−1 −q) · (Xj−q) / || sn2i−1 −q || • | Xj−q ||
Θj is calculated from Xj, and Xj that is closest to 180 ° is determined as second neighborhood data. Alternatively, as shown in FIG. 15, the condition of θj may be prepared in advance, and the data satisfying θL ≦ θj ≦ θU and having the smallest distance d from q may be determined as the second neighborhood data. The fourth embodiment can be substituted for the inner product calculation in the third embodiment described above.
以上のように、本実施形態4においては、対の2つ目のデータは対の1つ目のデータに対して要求点qを挟んで、より一層反対側に位置するデータを選択することができるので、より一層予測値の精度が向上できる。 As described above, in the fourth embodiment, the second data in the pair can select data located on the opposite side of the first data in the pair with the request point q interposed therebetween. Therefore, the accuracy of the predicted value can be further improved.
実施形態5.
図16は本発明の実施形態5に係る処理過程を示したフローチャートであり、同図に基づいて操業結果予測装置13の処理過程の詳細を説明する。なお、Step301〜Step304は図10のStep201〜Step204と同等なので、Step305から説明する。
Step303で算出された距離dが最も小さいデータ、あるいは類似度が最も大きいデータを1つ目のデータとして選択し、これを第1の近傍データsn2i-1として決定し、次の選択演算対象Xjからsn2i-1を削除する(Step305)。なお、sn2i-1は、この段階ではi=1なのでsn1である。ここで、選択された近傍データの総個数が所定数k個以上になったかどうかを判断し(Step306)、k個になっている場合(Step306・yes)にはStep310に進む。k個になっていない場合(Step306・no)にはStep307に進む。Embodiment 5. FIG.
FIG. 16 is a flowchart showing a processing process according to the fifth embodiment of the present invention, and details of the processing process of the operation result prediction apparatus 13 will be described based on FIG. Step 301 to Step 304 are equivalent to Step 201 to Step 204 in FIG.
The data with the smallest distance d calculated at Step 303 or the data with the largest similarity is selected as the first data, determined as the first neighborhood data sn2i-1 , and the next selection calculation target Xj Sn2i-1 is deleted from (Step 305). Note that sn2i-1 is sn1 because i = 1 at this stage. Here, it is determined whether or not the total number of selected neighborhood data has reached a predetermined number k or more (Step 306), and if it is k (Step 306 / yes), the process proceeds to Step 310. If not k (Step 306 / no), the process proceeds to Step 307.
次に、(sn2i-1−q)に直交する平面方程式を以下の式により決定する(Step307)。
f=a1(Xj1−q1)+a2(Xj2−q2) +・・・+an(Xjn−qn) +offset=0
ここで、a1,a2,・・・は(sn2i-1−q)の要素として決めることができる。また、offsetは予め任意に指定することができる。Next, a plane equation orthogonal to (sn2i-1 −q) is determined by the following equation (Step 307).
f = a1 (Xj1-q1) + a2 (Xj2-q2) + ... + an (Xjn-qn) + offset = 0
Here, a1, a2,... Can be determined as elements of (sn2i-1 −q). Further, offset can be arbitrarily designated in advance.
次に、Step307で決定した平面を挟んで第1の近傍データとして決定されたsn2i-1と逆のサイドに位置するXjのうちqから最も距離dが小さいものを選択し、これを第2の近傍データsn2iとして決定し、次の選択演算対象Xjからsn2iを削除する(Step308)。なお、sn2iは、この段階ではi=1なのでsn2である。ここで、選択された近傍データの総個数が所定数k個以上になったかどうかを判断し(Step309)、k個になっている場合(Step309・yes)にはStep310に進む。k個になっていない場合(Step309・no)にはi=i+1としてStep305に進み、近傍データの総個数が所定数k個になるまで繰り返す。
次に、このようにして決定した近傍データに基づき、重みつき平均、重みつき回帰等を用いることにより、対象となる予測操業結果を算出する(Step310)。Next, Xj located on the opposite side to sn2i-1 determined as the first neighborhood data across the plane determined in Step 307 is selected from qj having the smallest distance d from q. determined as proximate data sn2i of deleting the sn2i from the next selection operation object Xj (STEP 308). Note that sn2i is sn2 because i = 1 at this stage. Here, it is determined whether or not the total number of selected neighborhood data has reached a predetermined number k or more (Step 309), and if it is k (Step 309 / yes), the process proceeds to Step 310. If it is not k (Step 309, no), i = i + 1 and the process proceeds to Step 305 and is repeated until the total number of neighboring data reaches a predetermined number k.
Next, based on the neighborhood data determined in this way, a predicted operation result as a target is calculated by using weighted average, weighted regression, or the like (Step 310).
以上のように本実施形態5においては、入力変数空間上に仮定する平面の両側から類似データを選択するようにしたので、入力変数空間上で予測要求点を取り囲むように、偏りなく類似データ(近傍データ)を選択することができる。このため、予測値の精度を格段に向上させることができる。 As described above, in the fifth embodiment, the similar data is selected from both sides of the assumed plane on the input variable space. Therefore, the similar data (with no bias) is selected so as to surround the prediction request point on the input variable space. Neighboring data) can be selected. For this reason, the precision of a predicted value can be improved significantly.
実施形態6.
図17は本発明の実施形態6に係る処理過程を示したフローチャートであり、同図に基づいて操業結果予測装置13の処理過程の詳細を説明する。なお、Step401〜Step404は図10のStep201〜Step204と同等なので、Step405から説明する。
FIG. 17 is a flowchart showing a processing process according to
Step403で算出された距離dが最も小さいデータ、あるいは類似度が最も大きいデータを1つ目のデータとして選択し、これを第1の近傍データsn2i-1として決定し、次の選択演算対象Xjからsn2i-1を削除する(Step405)。なお、sn2i-1は、この段階ではi=1なのでsn1である。The data with the smallest distance d calculated at Step 403 or the data with the largest similarity is selected as the first data, determined as the first neighborhood data sn2i-1 , and the next selection calculation object Xj Sn2i-1 is deleted from (Step 405). Note that sn2i-1 is sn1 because i = 1 at this stage.
次に、要求点qと上記の第1の近傍データとして決定されたsn2i-1とに基づいて、内積演算(sn2i-1−q)・(Xj−q)を過去実績データXjのそれぞれにデータについて算出し、記憶装置26に記憶する(Step406)。ここで、内積演算値が所定の条件(例えば、内積値<-|| sn2i-1−q||2)を満足するXjが存在するかしないかを判断し(Step407)、存在しない場合(Step407・yes)にはStep409に進む。存在する場合にはStep408に進む。内積演算値が所定の条件を満足するXjが存在する場合には、内積演算値が所定の条件を満足し、かつ、qから最も距離dが小さいものを選択し、これを第2の近傍データsn2iとして決定し、次の選択演算対象Xjからsn2iを削除する(Step408)。なお、sn2iは、この段階ではi=1なのでsn2である。Next, based on the request point q and the above-described sn2i-1 determined as the first neighborhood data, the inner product calculation (sn2i-1 −q) · (Xj−q) is performed on each of the past performance data Xj. The data is calculated and stored in the storage device 26 (Step 406). Here, it is determined whether or not there exists Xj that satisfies the predetermined condition (for example, inner product value <-|| sn2i-1 −q ||2 ) (Step 407). In Step 407 / yes), go to Step 409. When it exists, it progresses to Step408. If there is Xj in which the inner product operation value satisfies the predetermined condition, the one having the inner product operation value that satisfies the predetermined condition and having the smallest distance d from q is selected, and this is selected as the second neighborhood data. determined as sn2i, to remove the sn2i from the next selection operation object Xj (Step408). Note that sn2i is sn2 because i = 1 at this stage.
ここで、選択された近傍データの総個数が所定数k個以上になったかどうかを判断し(Step410)、k個になっている場合(Step410・yes)にはStep411に進む。k個になっていない場合(Step410・no)にはi=i+1としてStep405に進み、近傍データの総個数が所定数k個になるまで、あるいは、Step407において近傍データの選択中止が処理されるまで繰り返す。内積演算値が所定の条件を満足するXjが存在しない場合には、既に決定した第1の近傍データsn2i-1を棄却し(Step409)、Step411に進む。Here, it is determined whether or not the total number of selected neighborhood data has reached a predetermined number k or more (Step 410), and if it is k (Step 410 · yes), the process proceeds to Step 411. If it is not k (Step 410 · no), i = i + 1 and proceed to Step 405, and the selection of neighboring data is processed until the total number of neighboring data reaches the predetermined number k or in Step 407. Repeat until If there is no Xj whose inner product calculation value satisfies the predetermined condition, the already determined first neighborhood data sn2i-1 is rejected (Step 409) and the process proceeds to Step 411.
次に、このようにして決定した近傍データに基づき、重みつき平均、重みつき回帰等を用いることにより、対象となる予測操業結果を算出する(Step411)。また、近傍データを決定したとき、決定したデータを次の選択演算対象Xjから除外したが、i=i+1とするときにまとめて除外することもできる。また、近傍データの選択を中止する場合、中止が発生したときのiループで既に決定済みの近傍データを破棄し、常に、対の近傍データで予測操業結果を算出するようにしたが、Step409の処理を省略することもできる。また、Step405の後に、近傍データがk個に達したかどうかを判断し、k個になっている場合にはStep411に進み、k個になっていない場合にはStep406へ進む処理を追加することもできる。 Next, based on the neighborhood data determined in this way, a predicted operation result as a target is calculated by using a weighted average, a weighted regression, or the like (Step 411). Further, when the neighborhood data is determined, the determined data is excluded from the next selection calculation target Xj. However, it is also possible to exclude it when i = i + 1. Also, when canceling the selection of neighboring data, the neighboring data already determined in the i loop when the cancellation occurred is discarded, and the predicted operation result is always calculated with the pair of neighboring data. Processing can be omitted. In addition, after Step 405, it is determined whether or not the number of neighboring data has reached k, and if k, proceed to Step 411, and if not, add processing to proceed to Step 406. You can also.
また、上述の実施形態3,4,5において、所定数k個に達せずとも、内積演算値が所定の条件を満足するXjが存在しない場合には、実施形態6と同様に近傍データの選択を中止し、常に、4個、あるいは、p個のセットで予測操業結果を算出することもできる。 In the third, fourth, and fifth embodiments described above, if there is no Xj whose inner product calculation value satisfies a predetermined condition even if the predetermined number k is not reached, selection of neighboring data is performed as in the sixth embodiment. The prediction operation result can always be calculated with a set of 4 or p.
以上のように、本実施形態6においては、対の2つ目のデータが存在しない場合は近傍データの選択を中止するので、要求点を取り囲むようにして選択される近傍データの空間配置のバランスがより一層よくなり、例えば、予測操業結果の算出に重みつき平均法を用いる場合は、より一層予測値の精度が向上できる。 As described above, in the sixth embodiment, when the second data of the pair does not exist, the selection of the neighboring data is stopped, so the balance of the spatial arrangement of the neighboring data selected so as to surround the request point. For example, when the weighted average method is used to calculate the predicted operation result, the accuracy of the predicted value can be further improved.
上述の実施形態2に対応した実施例として、鋼板の熱間圧延でのエッジャーロール開度調整による幅制御への適用例について説明する。 As an example corresponding to the above-described second embodiment, an application example to width control by edger roll opening adjustment in hot rolling of a steel plate will be described.
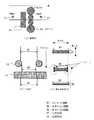
図18は本発明の実施例が適用される熱間圧延における幅制御の全体構成図であり、(a)側面図、(b)は上面図、(c)は板断面形状図である。図19は圧延方向における板幅の変化を示した特性図である。エッジャーロール31で幅方向に圧下した後、水平ミル32で厚さ方向に圧下する。エッジャーロール31の入側及び水平ミル32の出側に板幅計33をそれぞれ配置して、エッジャーロール31の入側の板幅及び水平ミル32の出側の板幅をそれ計測する。ここで、鋼板を幅方向に圧下したとき、鋼板の端部にはドッグボーンが生じるので、厚さ方向の圧下では、矩形部分の塑性変更(矩形幅広がり)に加えてドッグボーン部の幅広がり(ドッグボーン幅広がり)が現象として生じる。このとき、水平ミル32の出側での幅WOは、エッジャーロール31の入側幅WI、入側厚HI、エッジャーロール開度WE、水平ミル出側での厚HO等の変数で決まり、一般的に以下の式で表される。 FIG. 18 is an overall configuration diagram of width control in hot rolling to which an embodiment of the present invention is applied, (a) a side view, (b) a top view, and (c) a plate cross-sectional shape diagram. FIG. 19 is a characteristic diagram showing changes in the sheet width in the rolling direction. After being reduced in the width direction by the
WO=f(WI,HI,WE,HO)
実際に圧延を行うときは、目標の幅が得られるようにエッジャー開度を設定(セットアップ)するため、上式を逆に解き、
WE=f-1(WI,HI,WO,HO)
によりエッジャー開度の設定値を求めることになる。あるいは、fの逆関数を求めることが困難なときはWOが目標値となるまで、収束計算を行う。WO = f (WI, HI, WE, HO)
When actually rolling, in order to set (setup) the edger opening so that the target width can be obtained, solve the above equation in reverse,
WE = f-1 (WI, HI, WO, HO)
Thus, the set value of the edger opening is obtained. Alternatively, when it is difficult to obtain an inverse function of f, convergence calculation is performed until WO reaches a target value.
本実施例では、入力変数として上記のエッジャー入側板幅(WI)、エッジャー入側板幅−水平ミル出側板幅(WI−WO)、エッジャー入側板厚−水平ミル出側板厚(HI−HO)を、出力として幅戻り量(WO−WE)を選んだ。このときはモデルの出力WO−WEに対して水平ミル出側板幅WOの設定値を加算することにより設定すべきエッジャー開度WEを求めることができる。或いは、出力にWI−WEを選んでもよい。このときはエッジャー入側板幅WIの設定値からモデルの出力WI−WEを減算することにより設定すべきエッジャー開度WEを求めることができる。また、入力変数として、入側板温度TIを加えるとさらに精度が向上する。 In this example, the above-mentioned edger inlet side plate width (WI), edger inlet side plate width-horizontal mill outlet side plate width (WI-WO), edger inlet side plate thickness-horizontal mill outlet side plate thickness (HI-HO) as input variables. The width return amount (WO-WE) was selected as the output. At this time, the edger opening WE to be set can be obtained by adding the set value of the horizontal mill outlet side plate width WO to the output WO-WE of the model. Alternatively, WI-WE may be selected for output. At this time, the edger opening WE to be set can be obtained by subtracting the model output WI-WE from the set value of the edger entry side plate width WI. Further, when the input side plate temperature TI is added as an input variable, the accuracy is further improved.
本実施例では、過去の圧延事例1000点をデータベース化し、入力変数として上記のWI,WI−WO,HI−HO,TIを、出力として上記のWO−WEを選んだ。本実施例では、入力変数は予め正規化されており、入力変数間重み係数はすべて1としたが、入力変数-出力間で回帰をとり、その回帰係数を入力変数間重み係数にするなどの処置をすれば、正規化をしなくてもよい。また、選択した近傍データ数(k)は20〜30であり、これに対して空間重みつき平均法により予測を行った。重み関数としては、以下に示すガウシアン型を用い、パラメータσには0.3を用いた。 In this example, 1000 points of past rolling cases were made into a database, the above WI, WI-WO, HI-HO, TI were selected as input variables, and the above-mentioned WO-WE were selected as outputs. In this embodiment, the input variables are normalized in advance, and all the input variable weighting coefficients are set to 1. However, regression is performed between the input variables and the output, and the regression coefficient is used as the input variable weighting coefficient. If treatment is performed, normalization is not necessary. Further, the number of neighboring data selected (k) is 20 to 30, and prediction was performed by the space weighted average method. As the weight function, the Gaussian type shown below was used, and 0.3 was used as the parameter σ.
図20本発明の実施例における予測シミュレーション結果を示す図であり、本発明における近傍データ選択法を適用した場合と従来の近傍データ選択法のk-NN法とk-SN法を適用した場合の比較である。本発明による方法により従来法に比べて大幅な精度向上を達成することが可能となる。 20 is a diagram showing the prediction simulation results in the embodiment of the present invention, when the neighborhood data selection method according to the present invention is applied and when the k-NN method and the k-SN method of the conventional neighborhood data selection method are applied. It is a comparison. The method according to the present invention makes it possible to achieve a significant improvement in accuracy compared to the conventional method.
11 操業用計算機、12 過去操業データベース、13 操業結果予測装置、21 操業予測演算要求入力部、22 予測対象材データ入力部、23 過去操業データ読込部、24 予測値演算部、25 結果表示部、26 記憶装置、31 エッジャーロール、32 水平ミル、33 板幅計。 DESCRIPTION OF
Claims (13)
Translated fromJapanese内積を利用して前記類似した過去の操業因子を選択することを特徴とする操業結果予測方法。A plurality of operation factors obtained in the past operation results and the operation results for the same are stored in the result operation data storage device, and past operation factors similar to the plurality of operation factors to be predicted are stored from the actual operation data storage device. Selecting an operation result prediction method for predicting operation results for a plurality of operation factors to be predicted, from operation results for the selected past operation factors,
An operation result prediction method, wherein the similar past operation factor is selected using an inner product.
過去の操業因子配列群の各々について、過去の操業因子配列と予測対象の操業因子配列の各配列要素の差をとり、得られた新たな配列因子群の間で、各配列要素の積和をとり、得られた値に基づき、予測対象の操業因子配列と類似した過去の操業因子配列群を選択することを特徴とする操業結果予測方法。Multiple operating factors that affect operational results are defined as operational factor arrays, multiple operational factor arrays are defined as operational factor array groups, and the corresponding operational results are defined as operational result groups, and operational factor array groups obtained from past operational results. And an operation result group corresponding thereto are stored in the actual operation data storage device, a plurality of past operation factor array groups similar to the operation factor array to be predicted are selected from the actual operation data storage device, and the selected past An operation result prediction method for predicting an operation result for an operation factor array to be predicted from an operation result group for an operation factor array group,
For each of the past operating factor array groups, take the difference of each array element between the past operating factor array and the predicted operating factor array, and calculate the product sum of each array element between the obtained new array factor groups. And a past operation factor array group similar to the operation factor array to be predicted is selected based on the obtained value.
予測対象の複数の操業因子を入力する操業因子入力ステップと、
前記操業因子入力ステップで入力された予測対象の複数の操業因子を変数ベクトルqに変換し、前記実績操業データ読み出しステップで読み出された過去の操業因子を変数ベクトルXj(j=1,2,・‥)に変換するベクトル変換ステップと、
前記ベクトルXj(j=1,2,・・・)の内、前記ベクトルqに類似したデータを選択する選択ステップと、
前記選択された類似データに対応する過去実績の出力値とに基づいて操業結果を予測する操業結果予測ステップとを備える操業結果予測方法であって、
前記ベクトルのなす角度から類似データを選択することを特徴とする操業結果予測方法。Actual operation data that reads past operation factors and operation results from the actual operation data storage device that stores multiple operation factors obtained from past operation results as input variables and outputs the operation results for the input variables. A read step;
An operation factor input step for inputting a plurality of operation factors to be predicted;
A plurality of operation factors to be predicted input in the operation factor input step is converted into a variable vector q, and past operation factors read in the actual operation data read step are converted into variable vectors Xj (j = 1, 2, A vector conversion step to convert to
A selection step of selecting data similar to the vector q in the vector Xj (j = 1, 2,...);
An operation result prediction method comprising an operation result prediction step for predicting an operation result based on an output value of a past record corresponding to the selected similar data,
Similarity data is selected from the angle which the vector makes, The operation result prediction method characterized by the above-mentioned.
予測対象の複数の操業因子を入力する操業因子入力ステップと、
前記操業因子入力ステップで入力された予測対象の複数の操業因子を入力変数空間上の座標qとし、前記実績操業データ読み出しステップで読み出された過去の操業因子を入力空間上の座標Xj(j=1,2,・‥) に変換する座標変換ステップと、
前記座標Xj(j=1,2,・・・)の内、前記座標qに類似したデータを選択する選択ステップと、
前記選択された類似データに対応する過去実績の出力値とに基づいて操業結果を予測する操業結果予測ステップとを備える操業結果予測方法であって、
前記入力変数空間上に仮定する平面の両側から類似データを選択することを特徴とする 操業結果予測方法。Actual operation data that reads past operation factors and operation results from the actual operation data storage device that stores multiple operation factors obtained from past operation results as input variables and outputs the operation results for the input variables. A read step;
An operation factor input step for inputting a plurality of operation factors to be predicted;
The plurality of operation factors to be predicted input in the operation factor input step is set as a coordinate q on the input variable space, and the past operation factor read in the actual operation data read step is a coordinate Xj (j = 1,2, ...), the coordinate conversion step to convert to
A selection step of selecting data similar to the coordinate q in the coordinates Xj (j = 1, 2,...);
An operation result prediction method comprising an operation result prediction step for predicting an operation result based on an output value of a past record corresponding to the selected similar data,
The operation result prediction method, wherein similar data is selected from both sides of a plane assumed on the input variable space.
予測対象の複数の操業因子を入力する操業因子入力ステップと、
前記操業因子入力ステップで入力された予測対象の複数の操業因子を変数ベクトルqに変換し、前記実績操業データ読み出しステップで読み出された過去の操業因子を変数ベクトルXj(j=1,2,・・・)に変換するベクトル変換ステップと、
前記予測対象の複数の操業因子の変数ベクトルqと過去の操業因子の変数ベクトルXj(j=1,2,・・・)とのベクトル空間上での距離dを算出する距離算出ステップと、
前記過去の操業因子の変数ベクトルXj(j=1,2,・・・)の内、前記距離dが最も小さい過去の操業因子の変数ベクトルデータを選択して第1の近傍データsnaとする第1の選択ステップと、
前記第1の近傍データsnaと、前記予測対象の変数ベクトルqと、前記過去の操業因子の変数ベクトルXj(j=1,2,・・・)とから、
内積値(sna−q)・(Xj−q)
を算出する内積演算ステップと、
前記算出された内積値が所定値の範囲で、且つ、前記距離dが最も小さい変数ベクトルXj(j=1,2,・・・)を選択して第2の近傍データsnbとする第2の選択ステップと、
前記第1の近傍データsnaに対応する過去実績の出力値と、前記第2の近傍データsnbに対応する過去実績の出力値とに基づいて操業結果を予測する操業結果予測ステップと
を備え、前記各ステップが電子計算機において実行されることを特徴とする操業結果予測方法。Actual operation data that reads past operation factors and operation results from the actual operation data storage device that stores multiple operation factors obtained from past operation results as input variables and outputs the operation results for the input variables. A read step;
An operation factor input step for inputting a plurality of operation factors to be predicted;
A plurality of operation factors to be predicted input in the operation factor input step are converted into a variable vector q, and past operation factors read in the actual operation data read step are converted into variable vectors Xj (j = 1, 2, ... a vector conversion step to convert to
A distance calculating step of calculating a distance d in a vector space between the variable vector q of the plurality of operation factors to be predicted and the variable vector Xj (j = 1, 2,...) Of the past operation factor;
Among the past operating factor variable vectors Xj (j = 1, 2,...), The past operating factor variable vector data having the smallest distance d is selected as first neighborhood data sna . A first selection step;
From the first neighborhood data sna , the variable vector q to be predicted, and the variable vector Xj (j = 1, 2,...) Of the past operation factor,
Inner product value (sna −q) ・ (Xj−q)
An inner product calculation step for calculating
Second variable data Xj (j = 1, 2,...) In which the calculated inner product value is within a predetermined value range and the distance d is the smallest is selected as second neighborhood data snb . A selection step of
An operation result prediction step for predicting an operation result based on an output value of a past record corresponding to the first neighborhood data sna and an output value of a past record corresponding to the second neighborhood data snb A method for predicting an operation result, wherein each step is executed in an electronic computer.
{(sna−q)・(Xj−q)}/(||sna−q||・||Xj−q||)を算出し、
前記算出された値に基づき変数べクトルXj(j=1,2,・・・)を選択して第2の近傍データsnbとする請求項5又6記載の操業結果予測方法。The second selection step includes the first neighborhood data sna , the variable vector q to be predicted, and the variable vector Xj (j = 1, 2,...) Of the past operation factor.
{(Sna −q) · (Xj−q)} / (|| sna −q || • | Xj−q ||)
Operation result prediction method according to claim 5 also 6 wherein said base variable based on the calculated value vector Xj (j = 1,2, ···) and second neighboring data snb Select.
前記実績操業データ記憶装置に記憶されたデータに基づいて、予測対象の複数の操業因子に対応した操業結果を予測する操業結果予測装置とを備え、
前記操業結果予測装置は、
前記実績操業データ記憶装置から過去の操業因子と操業結果とを読み出す実績操業データ読込部と、
予測対象の複数の操業因子を入力する予測対象材データ入力部と、
前記予測対象の複数の操業因子を変数ベクトルqに変換し、前記実績操業データ読み出しステップで読み出された過去の操業因子を変数ベクトルXj(j=1,2,・‥)に変換するベクトル変換処理と、前記ベクトル)Xj(j=1,2,・・・)の内、前記ベクトルqに類似したデータを選択する選択処理と、前記選択された類似データに対応する過去実績の出力値とに基づいて操業結果を予測する操業結果予測処理とを実行する予測演算部とを備え、
前記予測演算部は、前記ベクトルのなす角度から類似データを選択することを特徴とする操業結果予測システム。A plurality of operation factors obtained from past operation results as input variables, and a result operation data storage device in which data is output as the operation result for that, and
An operation result prediction device that predicts operation results corresponding to a plurality of operation factors to be predicted, based on the data stored in the actual operation data storage device;
The operation result prediction apparatus is
A performance operation data reading unit for reading past operation factors and operation results from the performance operation data storage device,
A prediction target material data input unit for inputting a plurality of operation factors to be predicted;
A vector conversion that converts a plurality of operation factors to be predicted into a variable vector q, and converts past operation factors read in the actual operation data read step into a variable vector Xj (j = 1, 2,...). Processing, selection processing for selecting data similar to the vector q in the vector) Xj (j = 1, 2,...), And past output values corresponding to the selected similar data, A prediction calculation unit that executes an operation result prediction process for predicting an operation result based on
The said prediction calculating part selects similar data from the angle which the said vector makes, The operation result prediction system characterized by the above-mentioned.
前記実績操業データ記憶装置に記憶されたデータに基づいて、予測対象の複数の操業因子に対応した操業結果を予測する操業結果予測装置とを備え、
前記操業結果予測装置は、
前記実績操業データ記憶装置から過去の操業因子と操業結果とを読み込む過去操業データ読込部と、
予測対象の複数の操業因子を入力する予測対象材データ入力部と、
前記予測対象の複数の操業因子を変数ベクトルqに変換し、前記過去操業データ読込部により読み込まれた過去の操業因子を変数ベクトルXj(j=1,2,・・・)に変換する処理と、前記予測対象の複数の操業因子の変数ベクトルqと過去の操業因子の変数ベクトルXj(j=1,2,・・・)とのベクトル空間上での距離dを算出する処理と、前記過去の操業因子の変数ベクトルXj(j=1,2,・・・)の内、前記距離dが最も小さい過去の操業因子の変数ベクトルデータを選択して第1の近傍データsnaとする第1の選択処理と、前記第1の近傍データsnaと、前記予測対象の変数ベクトルqと、前記過去の操業因子の変数ベクトルXj(j=1,2,・・・)とから、内積値(sna−q)・(Xj−q)を算出する処理と、前記算出された内積値が所定の範囲で、且つ、前記距離dが最も小さい変数ベクトルXj(j=1,2,・・・)を選択して第2の近傍データsnbとする第2の選択処理と、前記第1の近傍データsnaに対応する過去実績の出力値と、前記第2の近傍データsnbに対応する過去実績の出力値とに基づいて操業結果を予測する処理とを行う予測値演算部と
を備えたことを特徴とする操業結果予測システム。A plurality of operation factors obtained from past operation results as input variables, and a result operation data storage device that stores data that outputs operation results for the input variables;
An operation result prediction device that predicts operation results corresponding to a plurality of operation factors to be predicted based on the data stored in the actual operation data storage device;
The operation result prediction apparatus is
A past operation data reading unit that reads past operation factors and operation results from the actual operation data storage device;
A prediction target material data input unit for inputting a plurality of operation factors to be predicted;
A process of converting the plurality of operation factors to be predicted into a variable vector q, and converting a past operation factor read by the past operation data reading unit into a variable vector Xj (j = 1, 2,...); A process of calculating a distance d on a vector space between a variable vector q of the plurality of operation factors to be predicted and a variable vector Xj (j = 1, 2,...) Of a past operation factor; The first variable data Xa (j = 1, 2,...) Of the operating factors of the past is selected as the first neighborhood data sna by selecting the variable vector data of the past operating factors with the smallest distance d. Of the first neighborhood data sna , the variable vector q to be predicted, and the variable vector Xj (j = 1, 2,...) Of the past operation factor, sna -q) a process of calculating a · (Xj-q), the inner product value the calculated is in a predetermined range, and the distance d The smallest variable vector Xj (j = 1,2, ···) and second selection processing for the second neighboring data snb Select, historical experience corresponding to the first neighboring data sna An operation result prediction system comprising: a predicted value calculation unit that performs an output value and a process of predicting an operation result based on an output value of a past performance corresponding to the second neighborhood data snb .
In the second selection process, when the corresponding variable vector Xj (j = 1, 2,...) Does not exist, the prediction calculation unit stops the selection before reaching the predetermined number k. The operation result prediction system according to claim 11 or 12.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005278489AJP4821232B2 (en) | 2004-09-27 | 2005-09-26 | Operation result prediction method and system |
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004279927 | 2004-09-27 | ||
| JP2004279927 | 2004-09-27 | ||
| JP2005278489AJP4821232B2 (en) | 2004-09-27 | 2005-09-26 | Operation result prediction method and system |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2006120131Atrue JP2006120131A (en) | 2006-05-11 |
| JP4821232B2 JP4821232B2 (en) | 2011-11-24 |
Family
ID=36537920
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2005278489AActiveJP4821232B2 (en) | 2004-09-27 | 2005-09-26 | Operation result prediction method and system |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4821232B2 (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2009086706A (en)* | 2007-09-27 | 2009-04-23 | Fujitsu Ltd | Model creation support system, model creation support method, model creation support program |
| JP2011221990A (en)* | 2010-03-25 | 2011-11-04 | Jfe Steel Corp | Operation condition prediction method and operation condition prediction program |
| JP2022170101A (en)* | 2021-04-28 | 2022-11-10 | Jfeスチール株式会社 | Rolling load prediction method, rolling control method and rolling load prediction device |
| JP2022170100A (en)* | 2021-04-28 | 2022-11-10 | Jfeスチール株式会社 | Rolling load prediction method, rolling control method and rolling load prediction device |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH08286727A (en)* | 1995-02-17 | 1996-11-01 | Nippon Steel Corp | Operation control automatic preset device |
| JP2001290508A (en)* | 2000-04-04 | 2001-10-19 | Nippon Steel Corp | Result prediction apparatus, method, and computer-readable storage medium |
| JP2002099916A (en)* | 2000-09-25 | 2002-04-05 | Olympus Optical Co Ltd | Pattern-classifying method, its device, and computer- readable storage medium |
| JP2003122845A (en)* | 2001-10-09 | 2003-04-25 | Shinkichi Himeno | Retrieval system for medical information, and program for carrying out the system |
| JP2003162563A (en)* | 2001-11-27 | 2003-06-06 | Nippon Steel Corp | Operation result prediction apparatus and method |
| JP2004117663A (en)* | 2002-09-25 | 2004-04-15 | Matsushita Electric Ind Co Ltd | Speech synthesis system |
- 2005
- 2005-09-26JPJP2005278489Apatent/JP4821232B2/enactiveActive
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH08286727A (en)* | 1995-02-17 | 1996-11-01 | Nippon Steel Corp | Operation control automatic preset device |
| JP2001290508A (en)* | 2000-04-04 | 2001-10-19 | Nippon Steel Corp | Result prediction apparatus, method, and computer-readable storage medium |
| JP2002099916A (en)* | 2000-09-25 | 2002-04-05 | Olympus Optical Co Ltd | Pattern-classifying method, its device, and computer- readable storage medium |
| JP2003122845A (en)* | 2001-10-09 | 2003-04-25 | Shinkichi Himeno | Retrieval system for medical information, and program for carrying out the system |
| JP2003162563A (en)* | 2001-11-27 | 2003-06-06 | Nippon Steel Corp | Operation result prediction apparatus and method |
| JP2004117663A (en)* | 2002-09-25 | 2004-04-15 | Matsushita Electric Ind Co Ltd | Speech synthesis system |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2009086706A (en)* | 2007-09-27 | 2009-04-23 | Fujitsu Ltd | Model creation support system, model creation support method, model creation support program |
| US8473260B2 (en) | 2007-09-27 | 2013-06-25 | Fujitsu Limited | Model creation support system, model creation support method, and model creation support program |
| JP2011221990A (en)* | 2010-03-25 | 2011-11-04 | Jfe Steel Corp | Operation condition prediction method and operation condition prediction program |
| JP2022170101A (en)* | 2021-04-28 | 2022-11-10 | Jfeスチール株式会社 | Rolling load prediction method, rolling control method and rolling load prediction device |
| JP2022170100A (en)* | 2021-04-28 | 2022-11-10 | Jfeスチール株式会社 | Rolling load prediction method, rolling control method and rolling load prediction device |
Also Published As
| Publication number | Publication date |
|---|---|
| JP4821232B2 (en) | 2011-11-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CA2636898C (en) | Apparatus and method for constructing prediction model | |
| CN109317522B (en) | Equipment control device, rolling mill control device, control method thereof, and recording medium | |
| JP5682484B2 (en) | Thick steel plate cooling control method, cooling control device, and thick steel plate manufacturing method | |
| JP5604945B2 (en) | Quality prediction apparatus, quality prediction method, computer program, and computer-readable recording medium | |
| JP5488140B2 (en) | Quality prediction apparatus, quality prediction method, computer program, and computer-readable recording medium | |
| JP6569497B2 (en) | Prediction device, method and program | |
| JP5867349B2 (en) | Quality prediction apparatus, operation condition determination method, quality prediction method, computer program, and computer-readable storage medium | |
| JP2012137813A (en) | Quality prediction device, quality prediction method, program and computer readable recording medium | |
| JP2012027683A (en) | Quality prediction device, quality prediction method, program and computer readable recording medium | |
| CN115099459B (en) | Workshop multi-row layout method considering gaps and loading and unloading points | |
| Saada et al. | Finite element model updating approach to damage identification in beams using particle swarm optimization | |
| JP2018077823A (en) | Physical model parameter identification device, method, and program, and manufacturing process control system | |
| CN118123304A (en) | Laminate modeling path generation device, laminate modeling path generation method, and machine learning device | |
| JP7471162B2 (en) | EVALUATION APPARATUS, PLANT CONTROL SUPPORT SYSTEM, EVALUATION METHOD, AND PROGRAM | |
| JP5195331B2 (en) | Quality prediction apparatus, prediction method, program, and computer-readable recording medium in manufacturing process | |
| JP4821284B2 (en) | Operation result prediction method and system | |
| EP2881874A1 (en) | System and method for searching for new material | |
| JP7449776B2 (en) | Hot rolling line control system and hot rolling line control method | |
| Pian et al. | A hybrid soft sensor for measuring hot-rolled strip temperature in the laminar cooling process | |
| JP2011085970A (en) | Quality prediction device, quality prediction method, program and computer-readable recording medium | |
| JP4821232B2 (en) | Operation result prediction method and system | |
| JP2009072807A (en) | Plane shape control method and planer shape control apparatus for rolled material, and method for manufacturing thick steel plate | |
| JP5375506B2 (en) | Quality prediction apparatus, quality prediction method, program, and computer-readable recording medium | |
| CN112839746A (en) | Folding produces prediction system | |
| CN118709574A (en) | A buckling-resistance design optimization method for large-size corrugated steel webs |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination | Free format text:JAPANESE INTERMEDIATE CODE: A621 Effective date:20080725 | |
| A131 | Notification of reasons for refusal | Free format text:JAPANESE INTERMEDIATE CODE: A131 Effective date:20110517 | |
| A521 | Request for written amendment filed | Free format text:JAPANESE INTERMEDIATE CODE: A523 Effective date:20110713 | |
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) | Free format text:JAPANESE INTERMEDIATE CODE: A01 Effective date:20110809 | |
| A01 | Written decision to grant a patent or to grant a registration (utility model) | Free format text:JAPANESE INTERMEDIATE CODE: A01 | |
| A61 | First payment of annual fees (during grant procedure) | Free format text:JAPANESE INTERMEDIATE CODE: A61 Effective date:20110822 | |
| R150 | Certificate of patent or registration of utility model | Ref document number:4821232 Country of ref document:JP Free format text:JAPANESE INTERMEDIATE CODE: R150 Free format text:JAPANESE INTERMEDIATE CODE: R150 | |
| FPAY | Renewal fee payment (event date is renewal date of database) | Free format text:PAYMENT UNTIL: 20140916 Year of fee payment:3 | |
| R250 | Receipt of annual fees | Free format text:JAPANESE INTERMEDIATE CODE: R250 | |
| R250 | Receipt of annual fees | Free format text:JAPANESE INTERMEDIATE CODE: R250 | |
| R250 | Receipt of annual fees | Free format text:JAPANESE INTERMEDIATE CODE: R250 | |
| R250 | Receipt of annual fees | Free format text:JAPANESE INTERMEDIATE CODE: R250 |