JP2005266009A - Data conversion program and data conversion apparatus - Google Patents
Data conversion program and data conversion apparatusDownload PDFInfo
- Publication number
- JP2005266009A JP2005266009AJP2004075166AJP2004075166AJP2005266009AJP 2005266009 AJP2005266009 AJP 2005266009AJP 2004075166 AJP2004075166 AJP 2004075166AJP 2004075166 AJP2004075166 AJP 2004075166AJP 2005266009 AJP2005266009 AJP 2005266009A
- Authority
- JP
- Japan
- Prior art keywords
- data
- tag
- html
- conversion
- computer
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images

















Abstract
Description
Translated fromJapanese本発明は、データ変換プログラムに関し、より特定的には、コンピュータにおいて実行され、HTML(Hyper Text Markup Language)データを、当該HTMLデータの内容を当該コンピュータに音声で出力させるための音声出力データに変換するためのデータ変換プログラムに関する発明である。 The present invention relates to a data conversion program, and more particularly, is executed in a computer, and converts HTML (Hyper Text Markup Language) data into audio output data for causing the computer to output the contents of the HTML data as audio. It is invention regarding the data conversion program for doing.
近年、通信技術の発展や携帯端末の高機能化に伴い、携帯電話やカーナビゲーションシステム等を用いたインターネットのアクセスが増加している。上記携帯電話やカーナビゲーションシステム等では、従来のパーソナルコンピュータを用いた場合と異なり、より容易に操作できるユーザインタフェースが求められる。具体的には、従来では視覚により認識されていたWebページの内容を、音声によりユーザに認識させるユーザインタフェースが求められている。このようなユーザインタフェースを実現するためのシステムとして、VoiceXMLが用いられたシステムが存在する。当該VoiceXMLが用いられたシステムは、HTMLデータにより作成されたWebページが表示された携帯電話やカーナビゲーションシステム等を、音声対話により操作するシステムである。 In recent years, with the development of communication technology and the enhancement of functions of mobile terminals, Internet access using mobile phones, car navigation systems, and the like is increasing. In the cellular phone, the car navigation system, and the like, unlike the case of using a conventional personal computer, a user interface that can be operated more easily is required. Specifically, there is a need for a user interface that allows the user to recognize the contents of a Web page that has been conventionally recognized visually by voice. As a system for realizing such a user interface, there is a system using VoiceXML. The system using the VoiceXML is a system for operating a cellular phone, a car navigation system, or the like on which a Web page created by HTML data is displayed by voice interaction.
ここで、上記VoiceXMLのデータ(以下、VoiceXMLデータと称す)を、HTMLデータに基づいて生成するシステムが、従来から存在している。このようなシステムでは、まず、VoiceXMLデータに変換したいHTMLデータが、コンピュータ(携帯電話やカーナビゲーションシステム)に入力される。HTMLデータを取得したコンピュータは、当該HTMLデータを構文解析する。次に、当該コンピュータは、構文解析したHTMLデータから、文字情報のみを抽出する。最後に、当該コンピュータは、当該文字情報の音声データを生成して、当該音声データに基づいて音声を出力する。これにより、ユーザは、当該HTMLデータに基づいて表示されるべきWebページの内容を、音声により認識することが可能となる。 Here, a system for generating the VoiceXML data (hereinafter referred to as VoiceXML data) based on HTML data has been conventionally available. In such a system, first, HTML data to be converted into VoiceXML data is input to a computer (mobile phone or car navigation system). The computer that has acquired the HTML data parses the HTML data. Next, the computer extracts only character information from the parsed HTML data. Finally, the computer generates voice data of the character information and outputs a voice based on the voice data. Thereby, the user can recognize the content of the Web page to be displayed based on the HTML data by voice.
また、ユーザは、コンピュータから出力される音声に対して、声を発して応答することにより、当該コンピュータを操作することが可能である。具体的には、ユーザは、コンピュータから出力される音声に対して声を発して返事する。応じて、コンピュータは、ユーザが発した声を認識して、文字が入力されたものと擬制して動作を行う。これにより、ユーザは、音声対話によりコンピュータを操作することが可能となる。
ところで、HTMLデータにより表示されるWebページには、さまざまなフォントや色の文字が使用されている。そして、文字のフォントや色は、HTMLデータ中のタグにより設定されている。 By the way, characters of various fonts and colors are used for Web pages displayed by HTML data. The font and color of the characters are set by tags in the HTML data.
しかしながら、上記システムでは、HTMLデータに含まれるタグが無視された状態でVoiceXMLデータが生成されている。そのため、当該システムにおいて、コンピュータから出力される音声は、文字のフォントや色などに関わらず、単調なリズムおよび大きさで出力されていた。そのため、ユーザは、当該Webページにおいてどの部分が重要であるかを判断することが困難であった。 However, in the system described above, VoiceXML data is generated in a state where tags included in the HTML data are ignored. Therefore, in this system, the sound output from the computer is output in a monotonous rhythm and size regardless of the font and color of the characters. Therefore, it is difficult for the user to determine which part is important in the Web page.
また、ユーザがアンケートに答えるために情報を入力することができる形式のWebペ
ージでは、当該ユーザに性別や年齢等を選択させるための選択欄が存在する。このような選択欄も、HTMLデータ中ではタグにより設定されている。そのため、上記従来のシステムにより、このようなHTMLデータがVoiceXMLデータに変換された場合、当該選択欄がうまく音声により表現されない。さらに、コンピュータは、HTMLデータの文字情報のみを抽出しただけである。そのため、コンピュータは、選択欄に対する応答と、画面を介して入力された応答とを結びつけることができない。In addition, a Web page in a format in which a user can input information for answering a questionnaire has a selection column for allowing the user to select gender, age, and the like. Such a selection field is also set by a tag in the HTML data. Therefore, when such HTML data is converted into VoiceXML data by the above-described conventional system, the selection field is not expressed well by voice. Further, the computer only extracts character information of HTML data. Therefore, the computer cannot connect a response to the selection field with a response input via the screen.
すなわち、上記従来のシステムでは、HTMLデータ中のタグを認識せずにVoiceXMLデータが生成されていたので、ユーザにとって、非常に利便性が悪かった。 That is, in the above-described conventional system, VoiceXML data is generated without recognizing a tag in HTML data, which is very inconvenient for the user.
そこで、本発明の目的は、当該HTMLデータに含まれるタグを、VoiceXMLデータに反映させて、HTMLデータをVoiceXMLデータに変換できるデータ変換プログラムを提供することである。 Accordingly, an object of the present invention is to provide a data conversion program capable of converting HTML data into VoiceXML data by reflecting a tag included in the HTML data in VoiceXML data.
本発明は、コンピュータにおいて実行され、HTML(Hyper Text Markup Language)データを、当該HTMLデータの内容を当該コンピュータに音声で出力させるための音声出力データに変換するためのプログラムである。ここで、HTMLデータには、当該HTMLデータが読みこまれてWebページとして表示された際の表示内容の構造を示すタグが含まれており、コンピュータは、HTMLデータのタグと、当該タグの内容に応じた音声を出力するための変換データとの組合せを記憶している。このような環境において、本発明に係るプログラムは、HTMLデータを読みこみ、読みこんだHTMLデータに含まれるタグの内容に応じた変換データを、コンピュータが記憶している組合せを参照して取得し、特定した変換データに基づいて、音声出力データを生成するようにしている。 The present invention is a program that is executed in a computer and converts HTML (Hyper Text Markup Language) data into audio output data for causing the computer to output the contents of the HTML data as audio. Here, the HTML data includes a tag indicating the structure of the display content when the HTML data is read and displayed as a Web page. The computer includes the HTML data tag and the content of the tag. The combination with the conversion data for outputting the sound according to the is stored. In such an environment, the program according to the present invention reads HTML data, and acquires conversion data corresponding to the contents of the tag included in the read HTML data with reference to the combination stored in the computer. The audio output data is generated based on the specified conversion data.
なお、表示内容は、文字の情報である場合には、タグは、表示内容に該当する文字の情報の表示形式を示しており、変換データは、タグが付された文字の情報の表示形式に応じた音声出力方式で、当該文字の情報を前記コンピュータに音声出力させるためのデータであることが望ましい。 When the display content is character information, the tag indicates the display format of the character information corresponding to the display content, and the conversion data is displayed in the display format of the character information with the tag. It is desirable that the data is data for causing the computer to output the information of the character in a voice output method according to the method.
また、タグは、コンピュータがユーザに対して操作を要求するための情報を含み、変換データは、タグにおいてコンピュータが要求している操作に応じた音声が出力されるためのデータであってもよい。 The tag may include information for the computer to request an operation from the user, and the conversion data may be data for outputting a sound corresponding to the operation requested by the computer in the tag. .
また、音声出力データは、メインデータとサブデータとを含んでいてもよい。この場合には、メインデータには、HTMLデータの表示内容が音声として出力されるための情報が含まれており、サブデータには、タグにおいてコンピュータが要求している操作に応じた音声が出力されるための情報が含まれており、メインデータのコンピュータがユーザに対して操作を要求するポイントには、サブデータが読みこまれるべき指示が存在している。 The audio output data may include main data and sub data. In this case, the main data includes information for outputting the display contents of the HTML data as sound, and the sub data outputs sound corresponding to the operation requested by the computer in the tag. There is an instruction to read the sub data at the point where the computer of the main data requests the user to perform an operation.
また、音声出力データは、VoiceXML(eXtension Markup Language)データであることが望ましい。 The audio output data is preferably VoiceXML (extension Markup Language) data.
なお、本発明は、プログラムのみならず、当該プログラムを格納したデータ変換装置に対しても向けられている。 The present invention is directed not only to a program but also to a data conversion apparatus that stores the program.
本発明に係るデータ変換プログラムによれば、当該HTMLデータに含まれるタグを、
当該タグの内容に応じた音声出力に変換して音声出力データを生成している。そのため、ユーザは、当該音声出力データによりコンピュータから出力される音声に基づいて、タグの情報を取得することが可能となる。その結果、ユーザは、聴覚により、よりHTMLデータの内容を正確に把握することができるようになる。According to the data conversion program of the present invention, the tag included in the HTML data is
Audio output data is generated by converting the audio output according to the contents of the tag. Therefore, the user can acquire tag information based on the sound output from the computer using the sound output data. As a result, the user can grasp the content of the HTML data more accurately by hearing.
なお、HTMLデータによりWebページに表示される表示内容が文字の情報であり、タグは、当該文字の情報の表示方式を示している。そして、変換データが、タグに付された文字の情報の表示形式に応じた音声出力方式を示すデータである。そのため、ユーザは、Webページ中の文字情報の重要度等を音声の速度、大きさあるいは高さにより認識することができるようになる。 The display content displayed on the Web page by the HTML data is character information, and the tag indicates the display method of the character information. The conversion data is data indicating an audio output method according to the display format of the character information attached to the tag. Therefore, the user can recognize the importance of the character information in the Web page by the speed, size or height of the voice.
また、タグは、コンピュータがユーザに対して操作を要求するための情報を含み、変換データは、タグにおいてコンピュータが要求している操作に応じた音声が出力されるためのデータである。そのため、ユーザは、送信ボタンを示すタグ等といったユーザに操作を要求するタグを音声により認識することができるようになる。 The tag includes information for the computer to request an operation from the user, and the conversion data is data for outputting a sound corresponding to the operation requested by the computer in the tag. Therefore, the user can recognize a tag that requests an operation from the user, such as a tag indicating a transmission button, by voice.
また、Webページの表示内容を音声出力するためのメインデータとユーザに対して要求される操作内容を示すサブデータとが関連付けられているので、これらの2つのデータが連動させることができる。 In addition, since the main data for outputting the display content of the Web page as audio and the sub data indicating the operation content requested for the user are associated with each other, these two data can be linked.
(第1の実施形態)
以下に、本発明の第1の実施形態に係るデータ変換プログラムについて図面を参照しながら説明する。ここで、図1は、当該データ変換プログラムが格納されたコンピュータ(以下、データ変換装置と称す)の構成を示した機能ブロック図である。図1に示すデータ変換装置は、当該データ変換装置は、例えば、携帯電話やカーナビゲーションシステムのコンピュータにデータ変換プログラムがインストールされたものである。当該データ変換装置は、図2に示すようなWebページの文字情報を音声出力するためのVoiceXMLデータを、当該WebページのHTMLデータに基づいて生成する装置である。なお、当該データ変換装置は、VoiceXMLデータがデータ変換装置において実行された場合に、図2の太字の部分を通常よりも大きな音声で出力したり、下線が付された部分の読む速度を遅くしたりできるようにして、当該VoiceXMLデータを生成する。かかる動作を実現するために、当該データ変換装置は、HTMLデータのタグを読み出して、当該タグの内容に基づいてVoiceXMLデータを生成している。なお、図2は、Webページの一例を示した図である。(First embodiment)
The data conversion program according to the first embodiment of the present invention will be described below with reference to the drawings. Here, FIG. 1 is a functional block diagram showing a configuration of a computer (hereinafter referred to as a data conversion apparatus) in which the data conversion program is stored. The data conversion apparatus shown in FIG. 1 is a data conversion apparatus in which a data conversion program is installed in, for example, a mobile phone or a car navigation system computer. The data conversion device is a device that generates VoiceXML data for outputting the character information of the Web page as shown in FIG. 2 based on the HTML data of the Web page. Note that when the VoiceXML data is executed in the data converter, the data converter outputs the bolded part in FIG. 2 with a voice larger than usual, or slows down the reading speed of the underlined part. The VoiceXML data is generated. In order to realize such an operation, the data conversion apparatus reads a tag of HTML data and generates VoiceXML data based on the contents of the tag. FIG. 2 is a diagram showing an example of a Web page.
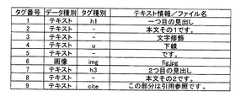
以下に、図面を参照しながら、当該データ変換プログラムの各構成部の説明を行う。なお、図3は、図2のWebページのソースであるHTMLデータである。また、図4は、図3のHTMLデータを構文解析して得られる中間データである。具体的には、図3の中間データは、HTMLデータを各記述内容(テキスト情報や画像情報)を順番に読み出して、各記述内容のデータ種別、タグ種別およびテキスト情報等の情報を、表にまとめたデータである。なお、タグ番号は、HTMLデータの記述内容の番号を示している。データ種別は、記述内容がテキストデータであるか画像データであるかを示している。タグ種別は、記述内容に付されたタグの種別を示している。また、テキスト情報/ファイル名は、記述内容を示している。具体的には、記述内容がテキスト情報の場合には、文章が記述され。記述内容が画像の場合には、ファイル名が記述される。 Hereinafter, each component of the data conversion program will be described with reference to the drawings. FIG. 3 shows HTML data that is the source of the Web page of FIG. FIG. 4 is intermediate data obtained by parsing the HTML data of FIG. Specifically, the intermediate data in FIG. 3 is obtained by reading out the HTML data from each description content (text information and image information) in order, and displaying information such as the data type, tag type, and text information of each description content in a table. This is a summary of data. The tag number indicates the number of the description content of HTML data. The data type indicates whether the description content is text data or image data. The tag type indicates the type of tag attached to the description content. The text information / file name indicates the description content. Specifically, when the description content is text information, a sentence is described. When the description content is an image, the file name is described.
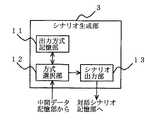
ここで、図1のデータ変換装置は、ドキュメント解析部1、中間データ記憶部2、シナリオ生成部3、対話シナリオ記憶部4および対話処理部5を備える。ドキュメント解析部1は、入力されてきた図3に示すHTMLデータを構文解析して、図4に示す中間データ
を生成する。なお、当該ドキュメント解析部1は、例えばインターネットエクスプローラのパーサー機能により実現される。中間データ記憶部2は、ドキュメント解析部1が生成した中間データを一時的に記憶する部分である。シナリオ生成部3は、中間データに基づいて、VoiceXMLを生成し、図5に示すように、出力方式記憶部11、方式選択部12およびシナリオ出力部13を備える。なお、図5は、シナリオ生成部3の構成を示したブロック図である。1 includes a
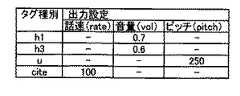
出力方式記憶部11は、HTMLデータのタグと、当該タグに対応する音声の出力設定との組合せを示す対応テーブルを記憶している。図6は、当該対応テーブルの構成の一例を示した図である。図6に示す対応テーブルは、タグ種別と、当該タグ種別に対応する出力設定とが記述されている。具体的には、タイトルを示す「h1」のタグが付されたテキスト情報は、音量を0.7(通常音量よりも大きい音量)に設定されて出力される。また、タイトルを示す「h3」のタグが付されたテキスト情報は、音量を0.6(通常音量よりも大きい音量)に設定されて出力される。また、下線が付されていることを示す「u」のタグが付されたテキスト情報は、ピッチ(音の高さ)が250に設定されて出力される。また、出典・参照先を示す「cite」のタグが付されたテキスト情報は、読出し速度が100(通常速度よりも遅い速度)に設定される。 The output method storage unit 11 stores a correspondence table indicating combinations of HTML data tags and audio output settings corresponding to the tags. FIG. 6 is a diagram showing an example of the configuration of the correspondence table. The correspondence table shown in FIG. 6 describes a tag type and an output setting corresponding to the tag type. Specifically, the text information with the tag “h1” indicating the title is output with the volume set to 0.7 (volume larger than the normal volume). The text information with the tag “h3” indicating the title is output with the volume set to 0.6 (volume higher than the normal volume). In addition, text information with a tag “u” indicating that it is underlined is output with a pitch (pitch) set to 250. Further, the text information with the tag “cite” indicating the source / reference destination is set to a reading speed of 100 (a speed slower than the normal speed).
方式選択部12は、図6に示す対応テーブルを参照して、図4に示す中間データに含まれるタグに対応する出力設定を特定する。シナリオ出力部13は、方式選択部12が選択した出力設定に対応するVoiceXMLデータ用のタグを生成して、図7に示すVoiceXMLデータを生成する。ここで、図7は、方式選択部12で生成されるVoiceXMLデータの一例を示した図である。対話シナリオ記憶部4は、VoiceXMLデータを記憶する。 The method selection unit 12 refers to the correspondence table shown in FIG. 6 and specifies the output setting corresponding to the tag included in the intermediate data shown in FIG. The scenario output unit 13 generates a VoiceXML data tag corresponding to the output setting selected by the method selection unit 12, and generates VoiceXML data shown in FIG. Here, FIG. 7 is a diagram illustrating an example of VoiceXML data generated by the method selection unit 12. The dialogue
対話処理部5は、音声認識部6と音声出力部7とを備える。音声認識部6は、ユーザが発した音声を認識し、当該音声をユーザからの指示として、指示に応じた動作をコンピュータに行わせる。音声出力部7は、対話シナリオ記憶部4が記憶しているVoiceXMLデータを読み出して、図3に示すWebページの内容を音声により読上げる。 The
以上のように構成されたデータ変換装置について、以下に動作を説明する。なお、本実施形態で示す各処理は、コンピュータを用いてソフトウェア的に実現するか、あるいはそれら各処理を行う専用のハードウェア回路を用いて実現することができる。 The operation of the data converter configured as described above will be described below. Each process shown in the present embodiment can be realized by software using a computer, or can be realized by using a dedicated hardware circuit that performs each process.
まず、ドキュメント解析部1に図3に示すHTMLデータが入力されてから、図4に示す中間データが生成されるところまでの間に、当該データ変換装置が行う動作について説明する。 First, an operation performed by the data conversion apparatus from when the HTML data shown in FIG. 3 is input to the
データ変換装置は、インターネット等のネットワークを介して、もしくはローカルのファイルシステムよりHTMLデータを読み込む。応じて、ドキュメント解析部1は、当該HTMLデータの構文解析を行い、中間データを生成する。具体的には、ドキュメント解析部1は、当該HTMLデータに含まれるテキスト情報あるいは画像ファイルのファイル名を読み出して、中間データのテキスト情報/ファイル名の欄に記入する。次に、ドキュメント解析部1は、各テキスト情報がテキスト情報であるのか画像情報であるのかを判定し、判定結果を中間データのデータ種別の欄に記入する。次に、ドキュメント解析部1は、テキスト情報あるいは画像ファイルのファイル名に付されたタグを読み出して、読み出したタグを中間データのタグ種別の欄に記入する。以上の動作により、図4に示す中間データが生成される。なお、当該構文解析は、前述の通り、インターネットエクスプローラのパーサー機能などを用いて実現することが可能である。 The data converter reads HTML data via a network such as the Internet or from a local file system. In response, the
次に、データ変換装置が中間データに基づいて、VoiceXMLデータを生成する際に行う動作について、図面を参照しながら説明する。なお、図8は、このときに、方式選択部12が行う動作を示したフローチャートである。 Next, an operation performed when the data conversion apparatus generates VoiceXML data based on the intermediate data will be described with reference to the drawings. FIG. 8 is a flowchart showing the operation performed by the method selection unit 12 at this time.
まず、方式選択部12は、中間データ中から次のタグ番号のデータを取り出す(ステップS1)。なお、最初の取り出し動作の場合には、方式選択部12は、タグ番号が1番のデータを取り出す。 First, the method selection unit 12 extracts data of the next tag number from the intermediate data (step S1). In the case of the first extraction operation, the method selection unit 12 extracts the data with the
次に、方式選択部12は、取り出したデータが最後のタグ番号のデータであるか否かを判定する(ステップS3)。取り出したデータが最後のタグ番号のデータである場合には、本処理は、終了する。取り出したデータが最後のタグ番号のデータでない場合には、本処理は、ステップS5に進む。 Next, the method selection unit 12 determines whether or not the extracted data is data of the last tag number (step S3). If the extracted data is the data of the last tag number, this process ends. If the extracted data is not the data of the last tag number, the process proceeds to step S5.
取り出したタグが最後のタグ番号のデータでない場合には、方式選択部12は、取り出したデータがテキスト情報であるか否かを判定する(ステップS5)。取り出したデータがテキスト情報である場合には、本処理はステップS7に進む。一方、取り出したデータがテキストデータでない場合には、本処理はステップS17に進む。 If the extracted tag is not the data of the last tag number, the method selection unit 12 determines whether or not the extracted data is text information (step S5). If the extracted data is text information, the process proceeds to step S7. On the other hand, if the extracted data is not text data, the process proceeds to step S17.
タグ情報がテキスト情報である場合、方式選択部12は、出力方式の選択を行う。具体的には、方式選択部12は、図4の中間データのタグ種別の欄を参照し、HTMLのマークアップによるタグ修飾がされているか否かを判定する(ステップS7)。タグ修飾がされている場合には、本処理はステップS9に進む。一方、タグ修飾がされていない場合には、本処理はステップS17に進む。 When the tag information is text information, the method selection unit 12 selects an output method. Specifically, the method selection unit 12 refers to the tag type column of the intermediate data in FIG. 4 and determines whether or not tag modification by HTML markup is performed (step S7). If the tag is modified, the process proceeds to step S9. On the other hand, if the tag is not modified, the process proceeds to step S17.
タグ修飾がされている場合には、方式選択部12は、中間データのタグ種別の欄からタグを取り出す(ステップ9)。タグを取得した方式選択部12は、図6に示す対応テーブルを参照して、当該タグが登録されているか否かを判定する(ステップS11)。タグが登録されている場合には、本処理はステップS13に進む。一方、タグが登録されていない場合には、本処理はステップS17に進む。 If the tag is modified, the method selection unit 12 takes out the tag from the tag type column of the intermediate data (step 9). The method selection unit 12 that has acquired the tag refers to the correspondence table shown in FIG. 6 and determines whether or not the tag is registered (step S11). If the tag is registered, the process proceeds to step S13. On the other hand, if the tag is not registered, the process proceeds to step S17.
タグが登録されている場合、方式選択部12は、図6の対応テーブルを参照して、取得したタグに対応する出力設定の情報を取得する(ステップS13)。出力設定の情報を取得した方式選択部12は、当該出力設定の情報をテキスト情報に付加して、シナリオ出力部13に出力する(ステップS15)。応じて、当該シナリオ出力部13は、出力設定の情報とテキスト情報とを取得する。 When the tag is registered, the method selection unit 12 refers to the correspondence table in FIG. 6 and acquires output setting information corresponding to the acquired tag (step S13). The method selection unit 12 that has acquired the output setting information adds the output setting information to the text information and outputs it to the scenario output unit 13 (step S15). In response, the scenario output unit 13 acquires output setting information and text information.
上記ステップS17において、シナリオ出力部13は、当該出力設定の情報の内容に応じたVoiceXMLデータ用の韻律変更のタグを生成して、テキスト情報に付加して、VoiceXMLデータに対して出力する(ステップS17)。なお、当該ステップS17において、出力設定の情報が付加されていない場合には、当該シナリオ出力部13は、テキスト情報または画像情報をそのままVoiceXMLデータに出力する。この後、本処理は、ステップS1に戻る。そして、ステップS1〜17の処理は、最後のタグ番号に到達するまで繰り返し行われる。 In step S17, the scenario output unit 13 generates a prosody change tag for VoiceXML data according to the content of the output setting information, adds the tag to the text information, and outputs the tag to the VoiceXML data (step S17). S17). If no output setting information is added in step S17, the scenario output unit 13 outputs the text information or the image information as it is to the VoiceXML data. Thereafter, the process returns to step S1. And the process of step S1-17 is repeatedly performed until it reaches the last tag number.
ここで、上記フローチャートに示す動作の具体例として、図3のHTMLデータの3行目の「<h1>一つ目の見出し</h1>」を例にとって説明する。図3に示すHTMLデータの「<h1>一つ目の見出し</h1>」の行は、図4の中間データの1番のタグ番号の欄に格納されている。ここで、1番のタグ番号のデータは、テキスト情報であり、タグ種別の欄には、タグが記入されている。そのため、方式選択部12は、タグ種別である「h1」を読み出す。 Here, as a specific example of the operation shown in the flowchart, “<h1> first heading </ h1>” in the third line of the HTML data in FIG. 3 will be described as an example. The row of “<h1> first heading </ h1>” of the HTML data shown in FIG. 3 is stored in the first tag number column of the intermediate data in FIG. Here, the data of the first tag number is text information, and a tag is entered in the tag type column. Therefore, the method selection unit 12 reads “h1” which is the tag type.
次に、方式選択部12は、読出したタグ「h1」に対応する出力設定の情報を、対応テーブルから読み出す。なお、タグ「h1」に対応する出力設定の情報は、音量0.7が登録されている。そこで、方式選択部12は、音量0.7の出力設定の情報を、「一つ目の見出し」というテキスト情報に付加して、シナリオ出力部13に出力する。 Next, the method selection unit 12 reads out the output setting information corresponding to the read tag “h1” from the correspondence table. Note that the volume 0.7 is registered as the output setting information corresponding to the tag “h1”. Therefore, the method selection unit 12 adds the output setting information of the volume 0.7 to the text information “first heading” and outputs it to the scenario output unit 13.
次に、シナリオ出力部13は、テキスト情報「一つ目の見出し」を0.7の音量で出力することを示すタグを生成して、当該テキスト情報「一つ目の見出し」に付加して、VoiceXMLデータに出力する。具体的には、シナリオ出力部13は、最初に音声出力することを示すタグである「prompt」を付する。次に、当該シナリオ出力部13は、出力する韻律を設定するためのタグ「pros」を付したの後に、音量を0.7に設定する「vol=”0.7”」を付して、VoiceXMLデータに出力する。以上の作業が、各タグ番号のデータに対して行われて、図7に示すVoiceXMLデータが完成する。 Next, the scenario output unit 13 generates a tag indicating that the text information “first headline” is output at a volume of 0.7, and adds the tag to the text information “first headline”. , Output to VoiceXML data. Specifically, the scenario output unit 13 attaches “prompt” which is a tag indicating that audio is output first. Next, the scenario output unit 13 adds a tag “pros” for setting the prosody to be output, and then adds “vol =“ 0.7 ”” for setting the volume to 0.7, Output to VoiceXML data. The above operation is performed on the data of each tag number, and the VoiceXML data shown in FIG. 7 is completed.
なお、シナリオ生成部では、VoiceXMLデータのルート要素やその他のドキュメントとしての体裁を整えるためのタグ要素の出力も行うが、本発明の主眼ではないので、省略する。 The scenario generation unit also outputs a root element of VoiceXML data and a tag element for adjusting the appearance as another document, but is omitted because it is not the main point of the present invention.
なお、対話処理部5では、生成したVoiceXMLデータを読み込み、音声認識、音声合成などの音声入出力機能を用いて、シナリオに基づいたユーザとの音声対話処理を実行する。 The
以上のように、本実施形態に係るデータ変換装置によれば、HTMLデータ中のタグが、当該タグに対応した出力方式を持ったVoiceXMLデータ用のタグに変換される。その結果、タグの内容に応じた音声出力が実現されるようになり、ユーザは、音声によりHTMLデータの内容を容易に認識できるようになった。 As described above, according to the data conversion apparatus according to the present embodiment, tags in HTML data are converted into tags for VoiceXML data having an output method corresponding to the tags. As a result, voice output according to the contents of the tag is realized, and the user can easily recognize the contents of the HTML data by voice.
なお、本実施の形態では、HTMLデータが解析され、中間データに格納された後に対話シナリオの生成が行われたが、HTMLデータの解析処理と並行してシナリオが生成されてもよい。 In the present embodiment, the HTML scenario is generated after the HTML data is analyzed and stored in the intermediate data. However, the scenario may be generated in parallel with the analysis processing of the HTML data.
また、出力設定をタグ種別ごととしたが、タグ要素と属性値との組合せによって、出力設定を行うことも可能である。 Further, although the output setting is made for each tag type, the output setting can be performed by a combination of the tag element and the attribute value.
(第2の実施形態)
以下に、本発明の第2の実施形態に係るデータ変換プログラムについて図面を参照しながら説明する。ここで、図9は、当該データ変換プログラムが格納されたコンピュータ(以下、データ変換装置と称す)の構成を示した機能ブロック図である。図9に示すデータ変換装置は、第1の実施形態と同様にWebページの文字情報を音声出力するためのVoiceXMLデータを、当該WebページのHTMLデータに基づいて生成する装置である。ただし、本実施形態に係るデータ変換装置は、第1の実施形態と異なり、ユーザに対して一方的にWebページの内容を読上げるのではなく、読上げと応答受け付けとをWebページの内容に応じて行うことができる。具体的には、当該データ変換装置は、図10に示すような辞書検索の画面において、音声により入力を促すと共に、ユーザからの入力を待ちうけることができるVoiceXMLデータを生成する。かかる動作を実現するために、当該データ変換装置は、HTMLデータのタグを読み出して、当該タグの内容に基づいてVoiceXMLデータを生成している。なお、図10は、Webページの一例を示した図である。図10の2行目の空欄は、検索する単語が入力される欄である。また、図10の「クエリ送信」は、ユーザがクリックして検索する単語を送信するためのボタン
である。(Second Embodiment)
The data conversion program according to the second embodiment of the present invention will be described below with reference to the drawings. Here, FIG. 9 is a functional block diagram showing a configuration of a computer (hereinafter referred to as a data conversion apparatus) in which the data conversion program is stored. The data conversion apparatus shown in FIG. 9 is an apparatus that generates VoiceXML data for outputting the text information of a Web page as a voice based on the HTML data of the Web page, as in the first embodiment. However, unlike the first embodiment, the data conversion apparatus according to the present embodiment does not read the contents of the Web page unilaterally to the user, but performs reading and response acceptance according to the contents of the Web page. Can be done. Specifically, the data conversion apparatus generates VoiceXML data that prompts input by voice and waits for input from the user on the dictionary search screen as shown in FIG. In order to realize such an operation, the data conversion apparatus reads a tag of HTML data and generates VoiceXML data based on the contents of the tag. FIG. 10 is a diagram illustrating an example of a Web page. The blank in the second line in FIG. 10 is a column in which a word to be searched is input. In addition, “query transmission” in FIG. 10 is a button for transmitting a word that the user clicks to search.
以下に、図面を参照しながら、当該データ変換プログラムの各構成部の説明を行う。なお、図11は、図10のWebページのソースであるHTMLデータである。また、図12は、図11のHTMLデータを構文解析して得られる中間データである。具体的には、図11の中間データは、HTMLデータを各記述内容(テキスト情報や画像情報)を順番に読み出して、各記述内容のデータ種別、タグ種別およびテキスト情報等の情報を、表にまとめたデータである。なお、タグ番号は、HTMLデータの記述内容の番号を示している。データ種別は、記述内容がテキストデータであるか画像データであるかを示している。タグ種別は、記述内容に付されたタグの種別を示している。また、テキスト情報/ファイル名は、記述内容を示している。具体的には、記述内容がテキスト情報の場合には、文章が記述され。記述内容が画像の場合には、ファイル名が記述される。 Hereinafter, each component of the data conversion program will be described with reference to the drawings. FIG. 11 shows HTML data that is the source of the Web page of FIG. FIG. 12 shows intermediate data obtained by parsing the HTML data of FIG. Specifically, the intermediate data in FIG. 11 reads out the HTML data from each description content (text information and image information) in order, and displays information such as the data type, tag type, and text information of each description content in a table. This is a summary of data. The tag number indicates the number of the description content of HTML data. The data type indicates whether the description content is text data or image data. The tag type indicates the type of tag attached to the description content. The text information / file name indicates the description content. Specifically, when the description content is text information, a sentence is described. When the description content is an image, the file name is described.
図9に示すデータ変換装置は、ドキュメント解析部1、中間データ記憶部2、シナリオ生成部33、対話シナリオ記憶部34、操作ポイント保存部35および対話処理部5を備える。ドキュメント解析部1は、入力されてきた図11に示すHTMLデータを構文解析して、図12に示す中間データを生成する。なお、当該ドキュメント解析部1は、例えばインターネットエクスプローラのパーサー機能により実現される。中間データ記憶部2は、ドキュメント解析部1が生成した中間データを一時的に記憶する部分である。シナリオ生成部33は、中間データに基づいて、読上げ用ファイルと操作用ファイルとの2種類のVoiceXMLデータを生成し、図13に示すように、読上げ用ファイル生成部40と操作用ファイル生成部41とを備える。 The data conversion apparatus shown in FIG. 9 includes a
ここで、読上げ用ファイルと操作用ファイルとについて、図面を参照しながら説明する。図14は、読上げ用ファイルの一例を示した図である。また、図15は、操作用ファイルの一例を示した図である。 Here, the reading file and the operation file will be described with reference to the drawings. FIG. 14 is a diagram showing an example of a reading file. FIG. 15 is a diagram showing an example of the operation file.
読上げ用ファイルは、図10に示すWebページを音声により読上げる際のメインルーチンの役割を果たす。操作用ファイルは、図10に示すWebページを音声により読上げる際のサブルーチンの役割を果たす。以下に、図10に示すWebページを例にとって説明する。 The reading file plays the role of the main routine when reading the Web page shown in FIG. 10 by voice. The operation file serves as a subroutine for reading out the Web page shown in FIG. 10 by voice. Hereinafter, the Web page shown in FIG. 10 will be described as an example.
図10に示すWebページには、通常のテキスト情報と、文字入力の為の空欄と、送信ボタンとが含まれている。このようなWebページでは、図11に示すように、通常のテキスト情報の部分(すなわち、「辞書検索」の部分)と、「form」のタグにより囲まれた部分(すなわち、空欄と送信ボタンの部分)とが存在する。このような場合には、読上げ用ファイルに、「form」のタグにより囲まれた部分以外のテキスト情報の読上げが書き込まれると共に、「form」に囲まれた部分については、操作用ファイルを読みこむ旨が書きこまれる。そして、当該操作用ファイルには、「form」に囲まれた部分のテキスト情報と空欄と送信ボタンとに関する情報が、音声情報として書きこまれる。 The Web page shown in FIG. 10 includes normal text information, a blank space for character input, and a send button. In such a Web page, as shown in FIG. 11, a normal text information part (that is, a “dictionary search” part) and a part surrounded by a “form” tag (that is, a blank and a send button) Part) and exist. In such a case, reading of text information other than the portion surrounded by the “form” tag is written in the reading file, and the operation file is read for the portion surrounded by “form”. The effect is written. Then, in the operation file, text information in a portion surrounded by “form”, blank information, and information on the send button are written as audio information.
以下に、図14に示す読上げ用ファイルの詳細について説明する。まず、図14の(1)の部分では、Webページに表示されている「辞書検索」の文字が読上げられる為の記述がなされる。次に、図14の(2)の部分では、ユーザが「はい」か「いいえ」の返事をすることを示す記述がなされる。図14の(3)の部分では、ユーザに対して文字を入力するか否かを問い掛ける音声をデータ変換装置が発するためのテキスト情報が記述される。図14の(4)の部分では、図14の(3)の部分での問い掛けに対するユーザの応答が、「はい」の場合には、操作ファイル「form.vxml」に含まれる操作フォームの部分に進む為の指示が記入される。次に、図15に示す操作ファイルの詳細について説明する。 Details of the reading file shown in FIG. 14 will be described below. First, in part (1) of FIG. 14, a description for reading out the word “dictionary search” displayed on the Web page is provided. Next, in the part (2) of FIG. 14, a description indicating that the user answers “yes” or “no” is made. In part (3) of FIG. 14, text information is described for the data converter to emit a voice asking whether or not to input characters to the user. In the part (4) of FIG. 14, if the user's response to the question in the part (3) of FIG. 14 is “Yes”, the operation form part included in the operation file “form.vxml” is displayed. Instructions to proceed are entered. Next, details of the operation file shown in FIG. 15 will be described.
まず、図15の(1)の部分では、ユーザに文字の入力を開始することを通知する音声を出力するため記述がなされる。次に、図15の(2)の部分では、図10のWebページに示した「検索する言葉を入力して下さい。」のテキスト情報を音声出力させるための記述がなされる。次に、図15の(3)の部分では、ユーザにテキスト情報の入力を促す音声を出力するための記述がなされる。次に、図15の(4)の部分では、ユーザに対して、入力したテキスト情報を送信する否かを問い掛ける音声を出力するための記述がなされる。また、併せて、ユーザからの応答が「はい」の場合には、当該ユーザが入力したテキスト情報を送信する操作を行うための記述がなされる。 First, in the part (1) of FIG. 15, description is made to output a voice notifying the user that character input is started. Next, in the part (2) of FIG. 15, a description for outputting the text information “Please input the word to be searched” shown in the Web page of FIG. 10 is made. Next, in part (3) of FIG. 15, a description for outputting a voice prompting the user to input text information is provided. Next, in part (4) of FIG. 15, a description for outputting a voice asking whether to transmit the input text information to the user is made. In addition, when the response from the user is “Yes”, a description for performing an operation of transmitting the text information input by the user is made.
次に、操作ポイント保存部35について説明する。操作ポイント保存部35は、図16に示すような対応表を記憶している。当該対応表は、HTMLデータ中にどのような操作をユーザに促すためのタグがどこに存在のかを示す表である。具体的には、タグ番号は、ユーザに操作を促すタグが存在する場所を示す。操作種別は、ユーザに促される操作が何であるのかを示す。また、操作フォーム名は、このようなタグがHTMLデータ中に複数存在する場合に、それぞれを識別可能とするために付される名前である。なお、当該対応表は、データ選択部62が、中間データを読み出した際に、当該データ選択部62により生成される。 Next, the operation
ここで、図9および図13の説明に戻る。図13は、シナリオ生成部33の詳細な構成を示した機能ブロック図である。当該シナリオ生成部33は、読上げ用ファイル生成部40と操作用ファイル生成部41とを含む。 Here, it returns to description of FIG. 9 and FIG. FIG. 13 is a functional block diagram showing a detailed configuration of the scenario generation unit 33. The scenario generation unit 33 includes a reading
まず、操作用ファイル生成部41について説明する。操作用ファイル生成部41は、中間データおよび図18に示す対応表に基づいて、操作用ファイルを生成し、テーブル記憶部61とデータ選択部62とを含む。テーブル記憶部61は、図17に示す変換テーブルを記憶している。当該変換テーブルは、HTMLデータ中に含まれるタグと、当該タグに対応するVoiceXMLデータ用のタグを含むデータとが関連付けられて格納されている。当該VoiceXMLデータ用のタグを含むデータは、HTMLデータ中のタグの内容に対応する音声を出力させるためのデータである。データ選択部62は、HTMLデータ中のタグを読み出して、当該タグに対応するVoiceXMLデータ用のタグを含むデータを選択し、操作用ファイルに記入する。 First, the operation file generation unit 41 will be described. The operation file generation unit 41 generates an operation file based on the intermediate data and the correspondence table shown in FIG. 18, and includes a table storage unit 61 and a data selection unit 62. The table storage unit 61 stores a conversion table shown in FIG. In the conversion table, a tag included in the HTML data and data including a tag for VoiceXML data corresponding to the tag are stored in association with each other. The data including the tag for the VoiceXML data is data for outputting sound corresponding to the content of the tag in the HTML data. The data selection unit 62 reads out a tag in the HTML data, selects data including a tag for VoiceXML data corresponding to the tag, and writes it in the operation file.
読上げ用ファイル生成部40は、中間データに基づいて、読上げ用ファイルを生成し、遷移用ファイル記憶部51とファイル選択部52とを含む。遷移用ファイル記憶部51は、図18に示す遷移用ファイルを複数パターン記憶している。ここで、遷移用ファイルについて説明する。図18は、遷移用ファイルの一例を示した図である。遷移用ファイルは、ユーザに操作を促すためタグがHTMLデータ中にある場合に、その旨を音声出力させると共に、操作用ファイルに進むための指示を出すためのVoiceXMLデータ用の記述である。なお、図18に示す遷移用ファイルは、ユーザに対して空欄に文字を入力させると共に当該文字の送信させるWebページにおいて、ユーザに文字の入力を促す音声を出力すると共に、操作用ファイルに進む指示を出すための記述がなされたものである。なお、図18は、遷移ファイルの一例である。そのため、遷移用ファイル記憶部51は、「form」以外の複数のタグに対しても、同様の遷移ファイルを記憶している。ファイル選択部52は、ユーザに操作を促すタグがHTMLデータ中に含まれている場合には、当該タグに対応する遷移ファイルを読み出して、読上げ用ファイルに記入する。 The reading
図9の対話シナリオ記憶部34は、読上げ用ファイルと操作用ファイルとを記憶する。 The dialogue scenario storage unit 34 in FIG. 9 stores a reading file and an operation file.
対話処理部5は、音声認識部6と音声出力部7とを備える。音声認識部6は、ユーザが
発した音声を認識し、当該音声をユーザからの指示として、指示に応じた動作をコンピュータに行わせる。音声出力部7は、対話シナリオ記憶部34が記憶しているVoiceXMLデータを読み出して、図10に示すWebページの内容を音声により読上げる。The
以上のように構成されたデータ変換装置について、以下に動作を説明する。なお、本実施形態で示す各処理は、コンピュータを用いてソフトウェア的に実現するか、あるいはそれら各処理を行う専用のハードウェア回路を用いて実現することができる。 The operation of the data converter configured as described above will be described below. Each process shown in the present embodiment can be realized by software using a computer, or can be realized by using a dedicated hardware circuit that performs each process.
まず、ドキュメント解析部1に図10に示すHTMLデータが入力されてから、図11に示す中間データが生成されるところまでの間に、当該データ変換装置が行う動作について説明する。 First, an operation performed by the data conversion apparatus from when the HTML data shown in FIG. 10 is input to the
データ変換装置は、インターネット等のネットワークを介して、もしくはローカルのファイルシステムよりHTMLデータを読み込む。応じて、ドキュメント解析部1は、当該HTMLデータの構文解析を行い、中間データを生成する。具体的には、ドキュメント解析部1は、当該HTMLデータに含まれる各テキスト情報を読み出して、中間データのテキスト情報/ファイル名の欄に記入する。次に、ドキュメント解析部1は、各テキスト情報がテキスト情報であるのか画像情報であるのかを判定し、判定結果を中間データのデータ種別の欄に記入する。次に、ドキュメント解析部1は、各テキスト情報に付されたタグを読み出して、読み出したタグを中間データのタグ種別の欄に記入する。以上の動作により、図11に示す中間データが生成される。なお、当該構文解析は、前述の通り、インターネットエクスプローラのパーサー機能などを用いて実現することが可能である。 The data converter reads HTML data via a network such as the Internet or from a local file system. In response, the
次に、データ変換装置が、中間データに基づいて操作用ファイルと読上げ用ファイルとを生成する際に行う動作について、図面を参照しながら説明する。なお、図19は、操作用ファイルが生成される際に、操作用ファイル生成部41が行う動作を示したフローチャートである。また、図20は、読上げ用ファイル「form.vxml」が生成される際に、読上げ用ファイル生成部40が行う動作を示したフローチャートである。まず、操作用ファイルの生成について説明する。 Next, an operation performed when the data conversion apparatus generates the operation file and the reading file based on the intermediate data will be described with reference to the drawings. FIG. 19 is a flowchart illustrating an operation performed by the operation file generation unit 41 when an operation file is generated. FIG. 20 is a flowchart showing an operation performed by the reading
まず、データ選択部62は、操作フォームの識別子である「form id」を操作用ファイルに記入する(ステップS51)。なお、本実施形態では、「form1」が、「form id」として記入される。これは、本実施形態では、操作ファイル中の操作フォームが一つだけしか存在しないからである。なお、操作フォームが複数存在する場合には、順次、「form2」、「form3」と識別子が付与されていく。 First, the data selection unit 62 writes “form id”, which is an identifier of the operation form, in the operation file (step S51). In this embodiment, “form1” is entered as “form id”. This is because there is only one operation form in the operation file in this embodiment. When there are a plurality of operation forms, identifiers “form2” and “form3” are sequentially assigned.
次に、データ選択部62は、中間データ記憶部2の中間データから、前回読出したタグ番号の次のタグ番号のデータを取り出す(ステップS53)。なお、データ選択部62は、初回の場合には、タグ番号が1のデータを取り出す。次に、データ選択部62は、取り出したデータのタグ番号が最後であるか否かを判定する(ステップS55)。取り出したデータのタグ番号が最後のタグ番号である場合には、本処理は終了する。一方、取り出したデータのタグ番号が最後のタグ番号でない場合には、本処理はステップS57に進む。 Next, the data selection unit 62 takes out the data of the tag number next to the tag number read last time from the intermediate data in the intermediate data storage unit 2 (step S53). Note that the data selection unit 62 takes out data with a tag number of 1 in the first case. Next, the data selection unit 62 determines whether or not the tag number of the extracted data is the last (step S55). If the tag number of the extracted data is the last tag number, this process ends. On the other hand, if the tag number of the extracted data is not the last tag number, the process proceeds to step S57.
タグ番号が最後のタグでない場合、データ選択部62は、図12の中間データのタグ種別の欄を参照し、HTMLのマークアップによるタグ修飾がされているか否かを判定する(ステップS57)。タグ修飾がされている場合には、本処理はステップS59に進む。一方、タグ修飾がされていない場合には、本処理はステップS65に進む。 If the tag number is not the last tag, the data selection unit 62 refers to the tag type column of the intermediate data in FIG. 12 and determines whether or not tag modification by HTML markup has been performed (step S57). If the tag is modified, the process proceeds to step S59. On the other hand, if the tag is not modified, the process proceeds to step S65.
タグ修飾されている場合には、データ選択部62は、中間データからタグ種別を取得する(ステップS59)。次に、データ選択部62は、テーブル記憶部61に格納されてい
る変換テーブルを参照して、当該タグに対応するVoiceXMLデータ用のタグを含むデータが登録されているか否かを判定する(ステップS61)。データが登録されている場合には、本処理はステップS63に進む。一方、データが登録されていない場合には、本処理はステップS65に進む。If the tag is modified, the data selection unit 62 acquires the tag type from the intermediate data (step S59). Next, the data selection unit 62 refers to the conversion table stored in the table storage unit 61, and determines whether or not data including a tag for VoiceXML data corresponding to the tag is registered (step S1). S61). If data is registered, the process proceeds to step S63. On the other hand, if the data is not registered, the process proceeds to step S65.
データが登録されている場合には、データ選択部62は、当該VoiceXMLデータ用のタグを含むデータを取得する(ステップS63)。さらに、データ選択部62は、図16に示す対応表を生成する(ステップS64)。具体的には、データ選択部62は、処理中のデータのタグ番号と、操作種別を対応表に対して記入する。さらに、データ選択部62は、操作フォーム名を対応表に対して入力する。なお、当該操作フォーム名は、「form1」、「form2」・・・と順次付されていく。この後、本処理はステップS65に進む。 If the data is registered, the data selection unit 62 acquires data including the tag for the VoiceXML data (step S63). Further, the data selection unit 62 generates a correspondence table shown in FIG. 16 (step S64). Specifically, the data selection unit 62 enters the tag number of the data being processed and the operation type in the correspondence table. Further, the data selection unit 62 inputs the operation form name to the correspondence table. The operation form names are sequentially assigned as “form1,” “form2,”... Thereafter, the process proceeds to step S65.
上記ステップS65において、データ選択部62は、テキスト情報または上記VoiceXMLデータ用のタグを含むデータを、操作用ファイルに出力する。この後、本処理は、ステップS53に戻る。そして、ステップS53〜65に示す処理が繰り返されることにより、操作用ファイルが完成する。 In step S65, the data selection unit 62 outputs the text information or data including the VoiceXML data tag to the operation file. Thereafter, the process returns to step S53. And the file for operation is completed by repeating the process shown to step S53-65.
次に、図20を用いて、操作用ファイルの生成について説明する。最初に、ファイル選択部52は、中間データ記憶部2の中間データから、前回読出したタグ番号の次のタグ番号のデータを取り出す(ステップS31)。なお、ファイル選択部52は、初回の場合には、タグ番号が1のデータを取り出す。次に、ファイル選択部52は、取り出したデータのタグ番号が最後であるか否かを判定する(ステップS33)。取り出したデータのタグ番号が最後のタグ番号である場合には、本処理は終了する。一方、取り出したデータのタグ番号が最後のタグ番号でない場合には、本処理はステップS35に進む。 Next, generation of an operation file will be described with reference to FIG. First, the file selection unit 52 extracts the data of the tag number next to the tag number read last time from the intermediate data in the intermediate data storage unit 2 (step S31). Note that the file selection unit 52 takes out data with a tag number of 1 for the first time. Next, the file selection unit 52 determines whether or not the tag number of the extracted data is the last (step S33). If the tag number of the extracted data is the last tag number, this process ends. On the other hand, if the tag number of the extracted data is not the last tag number, the process proceeds to step S35.
取り出したデータのタグ番号が最後のタグ番号でない場合には、ファイル選択部52は、データ種別を参照して、データ形式がいずれのデータであるかを判定する(ステップS35)。データ種別がフォームである場合には、本処理はステップS37に進む。データ種別がテキストである場合には、本処理はステップS39に進む。データ種別がフォームでもテキストでもない場合には、本処理はステップS31に戻る。 If the tag number of the extracted data is not the last tag number, the file selection unit 52 refers to the data type and determines which data format is the data (step S35). If the data type is form, the process proceeds to step S37. If the data type is text, the process proceeds to step S39. If the data type is neither form nor text, the process returns to step S31.
データ種別がテキストである場合には、ファイル選択部52は、テキスト情報/ファイル名の欄に記入されているテキスト情報を、読上げ用ファイルに出力する(ステップS39)。この後、本処理はステップS31に戻る。 If the data type is text, the file selection unit 52 outputs the text information entered in the text information / file name column to the reading file (step S39). Thereafter, the process returns to step S31.
一方、データ種別がフォームである場合には、ファイル選択部52は、図12の中間データを参照して、範囲最終タグまで中間データを読み飛ばす(ステップS37)。そして、ファイル選択部52は、当該フォームに該当する図17に示す遷移ファイルを遷移用ファイル記憶部51から取得し、読上げ用ファイルに出力する(ステップS41)。さらに、ファイル選択部52は、図16に示す対応表を参照して、遷移用ファイル中の操作フォーム名を入力すべき場所に、操作フォーム名を入力する(ステップS43)。なお、本実施形態では、ファイル選択部52は、操作ポイント保存部35の対応表から操作種別としてフォーム操作、操作フォーム名としてform1を取り出す。そして、ファイル選択部52は、取得した操作フォーム名「form1」を、遷移用ファイルに出力する。これにより、読上げ用ファイルと操作ファイルとが関連付けられる。この後、本処理は、ステップS31に戻る。 On the other hand, when the data type is form, the file selection unit 52 refers to the intermediate data in FIG. 12 and skips the intermediate data up to the range final tag (step S37). Then, the file selection unit 52 acquires the transition file shown in FIG. 17 corresponding to the form from the transition
なお、対話処理部5では、生成した読上げ用ファイルおよび操作ファイルを読み込み、音声認識、音声合成などの音声入出力機能を用いて、シナリオに基づいたユーザとの音声
対話処理を実行する。The
以上のように、本実施形態に係るデータ変換装置によれば、HTMLデータ中のタグに基づいて、VoiceXMLデータ用のタグや、当該VoiceXMLデータ用のタグとテキスト情報とを含んだデータが新たに生成される。その結果、従来では、音声として読上げることができなかった送信ボタンの有無を音声で出力することや、当該送信ボタンを押すことを促す音声を出力することといった複雑な動作をすることが可能となった。 As described above, according to the data conversion apparatus according to the present embodiment, based on the tags in the HTML data, the new tags including the tags for VoiceXML data and the tags for the VoiceXML data and text information are newly added. Generated. As a result, it is possible to perform complicated operations such as outputting the presence / absence of a transmission button that could not be read out as voice, or outputting a voice prompting the user to press the transmission button. became.
なお、本実施形態では、読上げ用ファイルと操作ファイルとの2種類のファイルが用いられているが、ファイルの種類はこれに限らない。例えば、読上げ用ファイルと操作ファイルとが一つのファイルにまとめられていてもよい。 In this embodiment, two types of files, a reading file and an operation file, are used, but the type of file is not limited to this. For example, the reading file and the operation file may be combined into one file.
本発明に係るデータ変換プログラムは、聴覚により、HTMLデータの内容をユーザがより正確に把握することができる効果を有し、コンピュータにおいて実行され、HTML(Hyper Text Markup Language)データを、当該HTMLデータの内容を当該コンピュータに音声で出力させるための音声出力データに変換するためのプログラム等として有用である。 The data conversion program according to the present invention has the effect that the user can grasp the contents of HTML data more accurately by hearing, and is executed in a computer to convert HTML (Hyper Text Markup Language) data into the HTML data. Is useful as a program or the like for converting the contents of the above into sound output data for outputting the sound to the computer.
1 ドキュメント解析部
2 中間データ記憶部
3 シナリオ生成部
4 対話シナリオ記憶部
5 対話処理部
6 音声認識部
7 音声出力部
11 出力方式記憶部
12 方式選択部
13 シナリオ出力部
33 シナリオ生成部
34 対話シナリオ記憶部
35 操作ポイント保存部
40 読上げ用ファイル生成部
41 操作用ファイル生成部
51 遷移用ファイル記憶部
52 ファイル選択部
61 テーブル記憶部
62 データ選択部1
Claims (6)
Translated fromJapanese前記HTMLデータには、当該HTMLデータが読みこまれてWebページとして表示された際の表示内容の構造を示すタグが含まれており、
前記コンピュータは、前記HTMLデータのタグと、当該タグの内容に応じた音声を出力するための変換データとの組合せを記憶しており、
前記HTMLデータを読みこむプログラムステップと、
読みこんだHTMLデータに含まれるタグの内容に応じた前記変換データを、前記コンピュータが記憶している組合せを参照して取得するプログラムステップと、
取得した前記変換データに基づいて、前記音声出力データを生成するプログラムステップとを備える、データ変換プログラム。A program that is executed in a computer and converts HTML (Hyper Text Markup Language) data into audio output data for causing the computer to output the contents of the HTML data as audio.
The HTML data includes a tag indicating the structure of display content when the HTML data is read and displayed as a web page.
The computer stores a combination of a tag of the HTML data and conversion data for outputting a sound corresponding to the content of the tag,
A program step for reading the HTML data;
A program step of acquiring the conversion data according to the contents of the tag included in the read HTML data with reference to a combination stored in the computer;
A data conversion program comprising: a program step for generating the audio output data based on the acquired conversion data.
前記タグは、前記表示内容に該当する文字の情報の表示形式を示しており、
前記変換データは、前記タグが付された文字の情報の表示形式に応じた音声出力方式で、当該文字の情報を前記コンピュータに音声出力させるためのデータであることを特徴とする、請求項1に記載のデータ変換プログラム。The display content is character information,
The tag indicates a display format of character information corresponding to the display content,
2. The conversion data according to claim 1, wherein the conversion data is data for causing the computer to output the information of the character in a sound output method according to a display format of the information of the character with the tag. Data conversion program described in 1.
前記変換データは、前記タグにおいて前記コンピュータが要求している操作に応じた音声が出力されるためのデータであることを特徴とする、請求項1に記載のデータ変換プログラム。The tag includes information for the computer to request an operation from the user,
The data conversion program according to claim 1, wherein the conversion data is data for outputting a sound corresponding to an operation requested by the computer in the tag.
前記メインデータには、前記HTMLデータの表示内容が音声として出力されるための情報が含まれており、
前記サブデータには、前記タグにおいて前記コンピュータが要求している操作に応じた音声が出力されるための情報が含まれており、
前記メインデータのコンピュータがユーザに対して操作を要求するポイントには、前記サブデータが読みこまれるべき指示が存在することを特徴とする、請求項3に記載のデータ変換プログラム。The audio output data includes main data and sub data,
The main data includes information for outputting the display content of the HTML data as sound,
The sub-data includes information for outputting a sound corresponding to an operation requested by the computer in the tag,
The data conversion program according to claim 3, wherein an instruction to read the sub data is present at a point at which the computer of the main data requests an operation from a user.
前記HTMLデータには、当該HTMLデータが読みこまれてWebページとして表示された際の表示内容の構造を示すタグが含まれており、
前記HTMLデータを読みこむ読みこみ手段と、
前記HTMLデータのタグと、当該タグの内容に応じた音声を出力するための変換データとの組合せを記憶する記憶手段と、
前記読みこみ手段が読みこんだHTMLデータに含まれるタグの内容に応じた前記変換データを、前記記憶手段が記憶している組合せを参照して取得する取得手段と、
前記取得手段が取得した前記変換データに基づいて、前記音声出力データを生成する生成手段とを備える、データ変換装置。A device that converts HTML (Hyper Text Markup Language) data into audio output data for outputting the contents of the HTML data as audio,
The HTML data includes a tag indicating the structure of display content when the HTML data is read and displayed as a web page.
Reading means for reading the HTML data;
Storage means for storing a combination of the HTML data tag and conversion data for outputting sound according to the content of the tag;
Obtaining means for obtaining the conversion data corresponding to the content of the tag included in the HTML data read by the reading means with reference to a combination stored in the storage means;
A data conversion apparatus comprising: generation means for generating the audio output data based on the conversion data acquired by the acquisition means.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004075166AJP2005266009A (en) | 2004-03-16 | 2004-03-16 | Data conversion program and data conversion apparatus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004075166AJP2005266009A (en) | 2004-03-16 | 2004-03-16 | Data conversion program and data conversion apparatus |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2005266009Atrue JP2005266009A (en) | 2005-09-29 |
Family
ID=35090665
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004075166APendingJP2005266009A (en) | 2004-03-16 | 2004-03-16 | Data conversion program and data conversion apparatus |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2005266009A (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007172597A (en)* | 2005-11-28 | 2007-07-05 | Canon Inc | Speech processing apparatus and speech processing method |
| WO2014117645A1 (en)* | 2013-01-29 | 2014-08-07 | 华为终端有限公司 | Information identification method and apparatus |
| WO2016151761A1 (en)* | 2015-03-24 | 2016-09-29 | 株式会社東芝 | Text-to-speech conversion support device, text-to-speech conversion support method, and text-to-speech conversion support program |
| CN112069775A (en)* | 2020-08-21 | 2020-12-11 | 完美世界控股集团有限公司 | Data conversion method and device, storage medium and electronic device |
- 2004
- 2004-03-16JPJP2004075166Apatent/JP2005266009A/enactivePending
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2007172597A (en)* | 2005-11-28 | 2007-07-05 | Canon Inc | Speech processing apparatus and speech processing method |
| WO2014117645A1 (en)* | 2013-01-29 | 2014-08-07 | 华为终端有限公司 | Information identification method and apparatus |
| US9390711B2 (en) | 2013-01-29 | 2016-07-12 | Huawei Device Co., Ltd. | Information recognition method and apparatus |
| WO2016151761A1 (en)* | 2015-03-24 | 2016-09-29 | 株式会社東芝 | Text-to-speech conversion support device, text-to-speech conversion support method, and text-to-speech conversion support program |
| JPWO2016151761A1 (en)* | 2015-03-24 | 2017-06-15 | 株式会社東芝 | Transliteration support device, transliteration support method, and transliteration support program |
| US10373606B2 (en) | 2015-03-24 | 2019-08-06 | Kabushiki Kaisha Toshiba | Transliteration support device, transliteration support method, and computer program product |
| CN112069775A (en)* | 2020-08-21 | 2020-12-11 | 完美世界控股集团有限公司 | Data conversion method and device, storage medium and electronic device |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8073700B2 (en) | Retrieval and presentation of network service results for mobile device using a multimodal browser | |
| US7546382B2 (en) | Methods and systems for authoring of mixed-initiative multi-modal interactions and related browsing mechanisms | |
| JP2000137596A (en) | Interactive voice response system | |
| US20060136220A1 (en) | Controlling user interfaces with voice commands from multiple languages | |
| US20030187656A1 (en) | Method for the computer-supported transformation of structured documents | |
| EP1215656A2 (en) | Idiom handling in voice service systems | |
| CN109543021B (en) | Intelligent robot-oriented story data processing method and system | |
| CN110232921A (en) | Voice operating method, apparatus, smart television and system based on service for life | |
| JP7200533B2 (en) | Information processing device and program | |
| JPH10124293A (en) | Speech commandable computer and medium for the same | |
| JP2005266009A (en) | Data conversion program and data conversion apparatus | |
| JP2003157095A (en) | Speech recognition apparatus and method, and program | |
| Rössler et al. | Multimodal interaction for mobile environments | |
| CN116956826A (en) | Data processing method and device, electronic equipment and storage medium | |
| KR102020341B1 (en) | System for realizing score and replaying sound source, and method thereof | |
| JP2004334369A (en) | Voice dialog scenario conversion method, voice dialog scenario conversion device, voice dialog scenario conversion program | |
| JP2005181358A (en) | Speech recognition and synthesis system | |
| US20240046035A1 (en) | Program, file generation method, information processing device, and information processing system | |
| JP2002229578A (en) | Speech synthesis apparatus, speech synthesis method, and computer-readable recording medium recording speech synthesis program | |
| WO2011004000A2 (en) | Information distributing system with feedback mechanism | |
| US20030167168A1 (en) | Automatic generation of efficient grammar for heading selection | |
| JP2004029457A (en) | Sound conversation device and sound conversation program | |
| JP2002288170A (en) | Support system for communications in multiple languages | |
| KR20240132995A (en) | A civil format writing software based an AI self-learning engine | |
| JP2013097033A (en) | Apparatus for providing text data with synthesized voice information and method for providing text data |