JP2005148727A - Learning support device - Google Patents
Learning support deviceDownload PDFInfo
- Publication number
- JP2005148727A JP2005148727AJP2004309024AJP2004309024AJP2005148727AJP 2005148727 AJP2005148727 AJP 2005148727AJP 2004309024 AJP2004309024 AJP 2004309024AJP 2004309024 AJP2004309024 AJP 2004309024AJP 2005148727 AJP2005148727 AJP 2005148727A
- Authority
- JP
- Japan
- Prior art keywords
- file
- learning
- audio file
- audio
- order
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000012545processingMethods0.000claimsdescription27
- 230000001174ascending effectEffects0.000claimsdescription5
- 238000001514detection methodMethods0.000claimsdescription5
- 230000033458reproductionEffects0.000description33
- 238000007726management methodMethods0.000description32
- 238000010586diagramMethods0.000description16
- 230000006870functionEffects0.000description13
- 238000000034methodMethods0.000description11
- 238000013500data storageMethods0.000description9
- 238000012986modificationMethods0.000description5
- 230000004048modificationEffects0.000description5
- 230000008569processEffects0.000description5
- 230000005540biological transmissionEffects0.000description3
- 230000008859changeEffects0.000description3
- 238000006243chemical reactionMethods0.000description3
- 239000000463materialSubstances0.000description3
- 125000002066L-histidyl groupChemical group[H]N1C([H])=NC(C([H])([H])[C@](C(=O)[*])([H])N([H])[H])=C1[H]0.000description2
- 239000000470constituentSubstances0.000description2
- 230000008929regenerationEffects0.000description2
- 238000011069regeneration methodMethods0.000description2
- 230000008901benefitEffects0.000description1
- 238000004891communicationMethods0.000description1
- 238000004590computer programMethods0.000description1
- 230000033764rhythmic processEffects0.000description1
- 238000012360testing methodMethods0.000description1
- 238000012546transferMethods0.000description1
- 230000001960triggered effectEffects0.000description1
Images








Landscapes
- Electrically Operated Instructional Devices (AREA)
- Signal Processing For Digital Recording And Reproducing (AREA)
- Indexing, Searching, Synchronizing, And The Amount Of Synchronization Travel Of Record Carriers (AREA)
Abstract
Description
Translated fromJapaneseこの発明は学習支援技術に関し、とくに音声再生装置を利用した学習を支援する装置に関する。 The present invention relates to a learning support technique, and more particularly to a device that supports learning using an audio reproduction device.
語学学習を効率的に行うために、ネイティブスピーカの発音を繰り返し聞くことが行われている。例えば、英会話の教材には、ネイティブスピーカの発音が記録されたコンパクトディスクが添付され、学習者はそれを例えばステレオなどの再生装置を利用して何度も聞いて、発音、アクセント、抑揚、リズムなどを学習する。学習者は、何度も聞き返すことができるので、自分のペースで着実に学習を進めることができる。 In order to perform language learning efficiently, the pronunciation of a native speaker is repeatedly heard. For example, English conversation materials are accompanied by a compact disc with native speaker pronunciation recorded, and the learner listens to it many times using a playback device such as a stereo to pronounce, accent, intonation, and rhythm. To learn. The learner can listen back and forth many times, so that the learner can proceed steadily at his / her own pace.
そうした学習は携帯型の再生装置が普及することで、更に身近になり、例えばヘッドホンステレオを使い再生することで、通勤や通学の途中で学習を行うことができるようになった。こうした学習を可能とする装置として、日本語と英語のいずれか一方を学習者の意志で再生言語として選択する機能を備える装置がある(特許文献1)。
多くの学習者は、ステレオやヘッドホンステレオなどの一般的な再生装置を利用して、コンパクトディスクに記録されている音声を聞く。しかしながら、そうした再生装置は、もともと語学学習を意識していないため、例えば音声の再生回数や順序を学習者の学習スタイルに合わせて変えることができない。
本発明は上記課題に鑑みてなされたものであり、その目的は、一般的な再生装置を利用して学習者の学習スタイルに合わせた学習を可能にする技術を提供することにある。Many learners listen to audio recorded on a compact disc using a general playback device such as stereo or headphone stereo. However, since such a playback device is originally not conscious of language learning, for example, the number and order of voice playback cannot be changed according to the learning style of the learner.
The present invention has been made in view of the above problems, and an object of the present invention is to provide a technique that enables learning in accordance with a learner's learning style using a general playback device.
本発明のある態様は、音声を利用した学習を支援する装置である。この装置は、第1種類の音声を記録した第1音声ファイルと、第2種類の音声を記録した第2音声ファイルとを対応づけて格納する格納部と、第1種類を特定する情報と第2種類を特定する情報とにより指定された再生順序に基づいて、互いに対応付けられた前記第1音声ファイルおよび前記第2音声ファイルの再生順序を設定する設定部とを備える。「種類」は、例えば「日本語」と「英語」のように言語であってもよいし、「年号」と「歴史的事柄」のように所定の対応関係を有するものであってもよい。この装置により、個々のファイルに対してひとつずつ再生順序を指定する必要がなくなる。つまり、音声ファイルの種類により指定された再生順序をひとつ用意すれば、複数の組み合わせの音声ファイルに対しても同様の再生順序を設定できる。 One embodiment of the present invention is an apparatus that supports learning using speech. The apparatus includes a storage unit that stores a first audio file in which a first type of audio is recorded and a second audio file in which a second type of audio is recorded, information that specifies the first type, and first information A setting unit configured to set the reproduction order of the first audio file and the second audio file associated with each other based on the reproduction order designated by the information specifying two types. The “type” may be a language such as “Japanese” and “English”, or may have a predetermined correspondence relationship such as “year” and “historical matters”. . This apparatus eliminates the need to designate the playback order for each file one by one. That is, if one reproduction order designated by the type of audio file is prepared, the same reproduction order can be set for a plurality of combinations of audio files.
この装置は、設定された再生順序で前記第1音声ファイルおよび前記第2音声ファイルを再生できるように、前記第1音声ファイルならびに前記第2音声ファイルを所定の記録媒体に書き込む格納処理部を更に備えてもよい。 The apparatus further includes a storage processing unit for writing the first audio file and the second audio file to a predetermined recording medium so that the first audio file and the second audio file can be reproduced in a set reproduction order. You may prepare.
前記格納処理部は、所定の再生装置において前記設定部により設定された再生順序で再生されるようにファイル名を変更して、前記第1音声ファイルおよび前記第2音声ファイルを前記記録媒体に書き込んでもよい。これにより、再生機能を備える装置であれば、ユーザが所望する順序で音声ファイルを再生できる。 The storage processing unit changes a file name so as to be played back in a playback order set by the setting unit in a predetermined playback device, and writes the first audio file and the second audio file to the recording medium. But you can. Thereby, if it is an apparatus provided with a reproduction | regeneration function, an audio | voice file can be reproduced | regenerated in the order which a user desires.
前記格納処理部は、昇順または降順に連なるように前記ファイル名を変更してもよい。 The storage processing unit may change the file name so as to be in ascending order or descending order.
この装置は、前記記録媒体の空き容量を検出する検出部を更に備え、前記設定部により設定された再生順序で前記第1音声ファイルおよび前記第2音声ファイルを再生するために前記記憶媒体に書き込むべきファイルのデータサイズが前記記憶媒体の空き容量より小さい場合に、前記格納処理部は前記第1音声ファイルならびに前記第2音声ファイルを前記記憶媒体に書き込みを行ってもよい。 The apparatus further includes a detection unit that detects a free space of the recording medium, and writes the first audio file and the second audio file in the storage medium in order to reproduce in the reproduction order set by the setting unit. When the data size of the file to be stored is smaller than the free space of the storage medium, the storage processing unit may write the first audio file and the second audio file to the storage medium.
なお、以上の構成要素の任意の組合せ、本発明の表現を方法、装置、システム、記録媒体、コンピュータプログラムなどの間で変換したものもまた、本発明の態様として有効である。 It should be noted that any combination of the above-described constituent elements and a conversion of the expression of the present invention between a method, an apparatus, a system, a recording medium, a computer program, etc. are also effective as an aspect of the present invention.
本発明によれば、所定の再生装置に学習者の学習スタイルに合わせて音声を再生させることができ、利便的な学習支援装置を提供できる。 ADVANTAGE OF THE INVENTION According to this invention, a predetermined | prescribed reproduction | regeneration apparatus can be made to reproduce | regenerate an audio | voice according to a learner's learning style, and a convenient learning assistance apparatus can be provided.
<第1の実施の形態>
図1は、第1の実施の形態に係る学習支援システム10の構成図である。学習支援装置100は、例えばパーソナルコンピュータなど一般的に普及しているコンピュータで、CD−ROMなどの第1記録媒体12に記録されたプログラムを実行することにより実現される。学習支援装置100は、例えばメモリカードやミニディスクなどの音声データをファイル単位で記録可能な第2記録媒体20に着脱可能に接続し、音声データの書込や削除など一連のファイルアクセスが可能である。<First Embodiment>
FIG. 1 is a configuration diagram of a
再生装置50は、例えばメモリカードを記録媒体とするICレコーダ、ICプレーヤ、MDプレーヤなどの、第2記録媒体20に記録されている音声データを再生可能な装置である。 The playback device 50 is a device capable of playing back audio data recorded on the
学習支援装置100は、例えばモニタなどの表示部に表示画面60を表示して、ユーザからの指示を受け付ける。文章選択領域62は、第2記録媒体20に記録する音声ファイルを選択するための領域であり、ユーザが選択可能な音声ファイルを特定する情報が一覧表示される。詳細は後述するが、学習支援装置100は、所定のストーリ、文章、節、単語など言語の要素毎に、それぞれ複数の言語の音声ファイルを対応付けて保持する。更に学習支援装置100は、それらの音声ファイルと、音声ファイルにより再生されるストーリ、文章、節、単語の文字情報とを対応付けて管理している。 The
ここで、「ストーリ」は、複数の文章で構成された文字列群であり、「文章」は、複数の節で構成された文字列群であり、「節」は複数の単語で構成された文字列群である。例えば、学習支援装置100は、文章とその文章に含まれる節とその文章に含まれる単語の文字情報に対応付けて、それぞれ日本語と英語の音声ファイルを保持する。つまり、学習支援装置100は、階層的に音声ファイルとその音声ファイルにより再生される言葉の文字情報とを対応付けて格納している。こうした音声ファイルの組合せを、以下「音声セット」という。 Here, “story” is a character string group composed of a plurality of sentences, “sentence” is a character string group composed of a plurality of clauses, and “section” is composed of a plurality of words. A string group. For example, the
本図では、最上位の階層である文章の文字情報が、文章選択領域62に一覧表示されており、例えばユーザがマウスやキーボードなどの種々の入力デバイスを操作することにより、所望の文章が選択される。文章選択領域62に一覧表示される内容は、任意であり、例えば語学学習教材の単元でもよいし、熟語、単語などでもよい。要は、文章選択領域62は、音声セットを選択するための情報を表示し、ユーザが文章選択領域62を利用して所望の音声セットを選択できればよい。 In this figure, text information of sentences at the highest hierarchy is displayed in a list in the sentence selection area 62. For example, the user selects a desired sentence by operating various input devices such as a mouse and a keyboard. Is done. The contents displayed in a list in the text selection area 62 are arbitrary, and may be, for example, a unit of language learning materials, idioms, words, or the like. In short, the text selection area 62 only needs to display information for selecting a voice set and the user can select a desired voice set using the text selection area 62.
学習パターン選択領域64は、学習パターンを選択するための領域であり、選択可能な学習パターンが一覧表示される。「学習パターン」は、音声ファイルの再生順序を定義するためのひな形であり、例えば音声セットに含まれるそれぞれの音声ファイルを再生する順番を規定する。ユーザは、学習パターン選択領域64に表示された学習パターンの中から所望のパターンを選択する。 The learning pattern selection area 64 is an area for selecting a learning pattern, and a list of selectable learning patterns is displayed. The “learning pattern” is a template for defining the playback order of audio files, and for example, defines the order in which each audio file included in the audio set is played back. The user selects a desired pattern from the learning patterns displayed in the learning pattern selection area 64.
開始ボタン66は、文章選択領域62および学習パターン選択領域64で選択された内容に基づいて、音声ファイルを第2記録媒体20に格納する処理の開始を指示するためのボタンである。キャンセルボタン68は、開始ボタン66に開始された、音声ファイルの格納処理の中止を指示するためのボタンである。 The start button 66 is a button for instructing the start of the process of storing the audio file in the
開始ボタン66が押下されると、学習支援装置100は、選択された学習パターンに基づいて決められた再生順序で音声を再生できるように音声ファイル70を第2記録媒体20に格納する。再生装置50は、第2記録媒体20から音声ファイル70を通常の再生順序に従って読み込むことにより、音声出力内容54のように各音声ファイルを再生する。本図では、第2学習パターンを選択することにより、学習支援装置100は、「文章−日本語」、「文章−英語」、「第1の単語−日本語」、「第1の単語−英語」、「第1の単語−英語」、「第2の単語−日本語」、「第2の単語−英語」、「第2の単語−英語」、「文章−日本語」、「文章−英語」、「文章−英語」の順番で再生装置50が再生できるように、音声ファイル70を第2記録媒体20に記録する。このように記録されることにより、再生装置50は、通常の再生処理を行うことにより、音声出力内容54のように音声を再生できる。つまり、実施の形態に係る学習支援装置100は、ユーザが学習したい文章について、所望の順番で音声ファイルを再生できるように第2記録媒体20に音声ファイルを格納する。 When the start button 66 is pressed, the
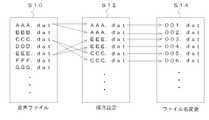
図2は、図1の学習支援装置100における処理を説明するための図である。学習支援装置100は、複数の音声ファイルを保持する(S10)。学習支援装置100は、ユーザからそれぞれの音声ファイルの再生順序を受け付ける(S12)。そして、学習支援装置100は、その再生順序で音声ファイルを再生できるように、再生装置50のファイルシステムの機能に合わせて、それぞれのファイル名を変更して図1の第2記録媒体20に書き込む。つまり、再生装置50が、第2記録媒体20に保持された音声ファイルの再生順を決定する規定に基づいて、学習支援装置100は、ステップ12で指定された再生順序で再生されるようにファイル名を変更する。例えば、再生装置50がファイル名の昇順または降順で再生する場合、学習支援装置100は、指定された再生順序に応じて、昇順または降順で音声ファイルが並ぶようにファイル名を変更する。 FIG. 2 is a diagram for explaining processing in the
例えば、そのファイルシステムが、数字、アルファベット、ひらがな、漢字の順で優先度をもち、それぞれの文字が昇順になるようにソートをする場合、学習支援装置100は、数字の0から順にインクリメントする新たなファイル名を生成し、ファイル名を変更する。例えば音声ファイルの数が999個以内の場合、学習支援装置100は、ファイル名を「001.dat」、「002.dat」、「003.dat」のように変更する。これにより、一般的な再生装置50で、ユーザが所望する順番、すなわちユーザの学習スタイルに合わせて音声ファイルの再生が可能になる。 For example, when the file system has a priority in the order of numbers, alphabets, hiragana, and kanji, and the sort is performed so that each character is in ascending order, the
本実施の形態では、音声ファイルの再生順序を設定する作業を簡便にするために、そのひな形が学習パターンとして予め用意されている。これにより、ユーザが音声セットと学習パターンを選択することにより、自動的に再生順序が設定される。もちろん、他の例として、音声セットおよび学習パターンという概念を排除してもよく、図1の学習支援装置100は、単に複数の音声ファイルを保持し、ユーザが指定した再生順序で再生できるように第2記録媒体20に音声ファイルを格納してもよい。 In the present embodiment, the template is prepared in advance as a learning pattern in order to simplify the task of setting the playback order of audio files. Thus, the playback order is automatically set by the user selecting the voice set and the learning pattern. Of course, as another example, the concept of a voice set and a learning pattern may be excluded, and the
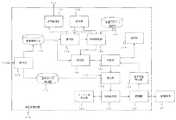
図3は、図1の学習支援装置100の内部構成図である。接続部128は、例えばコネクタなどであり、第2記録媒体20と着脱可能に接続する。また、接続部128は、例えばUSB(Universal Serial Bus)などの装置間のデータ転送規格に準じた方式にて、図1の再生装置50に内蔵された第2記録媒体20と間接的に接続してもよい。要は、接続部128は、外部にある第2記録媒体20に対するファイルアクセスを可能にすればよい。 FIG. 3 is an internal configuration diagram of the
操作部102は、例えばマウス、キーボード、タッチパネルなどのユーザから操作を受け付けるための入力デバイスである。表示処理部101は、例えばモニタなどの表示デバイスに、図1の表示画面60を表示するための処理を行う。 The operation unit 102 is an input device for receiving an operation from a user such as a mouse, a keyboard, or a touch panel. The display processing unit 101 performs processing for displaying the display screen 60 of FIG. 1 on a display device such as a monitor.
管理情報データベース110は、音声ファイルの格納場所、音声ファイルで再生される言葉の文字情報、各音声ファイルの言語要素、すなわち階層構造を決める属性情報などを保持する。学習パターン格納部112は、学習パターンを定義する情報を保持する。管理情報データベース110および学習パターン格納部112のデータ構造について、それぞれ説明する。 The
図4は、図3の管理情報データベース110のデータ構造の一例を示す図である。グループID欄150は、グループを識別する情報(以下、単に「グループID」という)を保持する。このグループIDは、前述した音声セット毎に割り当てられる。属性欄152は、音声ファイルにより再生される言葉の属性を特定する属性情報を保持する。本実施の形態では、属性情報は「ストーリ」、「文章」、「節」、「単語」などである。そして、この属性情報に基づいて、音声セットにおける階層構造が定義されており、最上位の階層から順に「ストーリ」、「文章」、「節」、「単語」として定義されている。 FIG. 4 is a diagram showing an example of the data structure of the
英語テキスト欄154は、英語の文字情報を保持する。日本語テキスト欄156は、日本語の文字情報を保持する。英語音声ファイル名欄158は、英語テキスト欄154に保持された言葉に対応する音声ファイルの格納場所とそのファイル名とを保持する。日本語音声ファイル名欄160は、日本語テキスト欄156に保持された言葉に対応する音声ファイルの格納場所とそのファイル名とを保持する。また、図示していないが、それぞれの音声ファイルのデータサイズと、それぞれの音声ファイルを一意に特定するための情報(以下、単に「音声ID」という)とを対応付けて保持する。本図では、ファイル名のみが記載されているが、音声ファイルを格納するディレクトリを予め決めておくことで、学習支援装置100は、ファイル名のみで必要な音声ファイルにアクセス可能である。要は、英語音声ファイル名欄158および日本語音声ファイル名欄160は、音声ファイルにアクセスするための情報を保持すればよい。 The English text field 154 holds English character information. The Japanese text field 156 holds Japanese character information. The English voice file name column 158 holds the storage location of the voice file corresponding to the words held in the English text column 154 and its file name. The Japanese voice file name column 160 holds the storage location of the voice file corresponding to the words held in the Japanese text column 156 and its file name. Although not shown, the data size of each audio file and information for uniquely identifying each audio file (hereinafter simply referred to as “audio ID”) are stored in association with each other. Although only the file name is shown in this figure, the learning
図5は、学習パターン格納部112に保持されている学習パターンのデータ構造の一例を示す図である。学習パターン格納部112は、XML(eXtensible Markup Language)形式で学習パターンを保持する。パターン名欄180は、学習パターンの名称など学習パターンを識別する情報を保持する。本実施の形態では、パターン名欄180に保持された名称が、図1の学習パターン選択領域64に表示される。一般に文章は複数の単語が組み合わさることにより構成される。このため、所定の文章の音声セットの中には文章の音声データとともに、複数の単語の音声データが含まれる。実施の形態における学習パターンは、この特徴に基づいて再生する音声データを属性と言語種類と再生回数の組み合わせで設定する。このように属性と言語種類と再生回数の組み合わせで学習パターンを定義することにより、学習パターンの一般化が可能になる。 FIG. 5 is a diagram illustrating an example of a data structure of learning patterns held in the learning
本実施の形態では、属性を指定すれば、その属性に該当する言葉を再生するための日本語と英語の2種類の音声ファイルが決まる。このため、再生順序は、まず属性レベルで設定され、更にその属性に該当する音声ファイルの中で、言語レベルで設定される。そして更に、その言語の再生回数が設定される。これをユーザに選択された各音声セットに適用することで、ユーザが所望する学習パターンでの音声ファイルの再生順序を生成できる。 In the present embodiment, if an attribute is designated, two types of audio files, Japanese and English, for reproducing a word corresponding to the attribute are determined. Therefore, the playback order is first set at the attribute level, and further set at the language level in the audio file corresponding to the attribute. Furthermore, the number of times of reproduction of the language is set. By applying this to each voice set selected by the user, it is possible to generate the playback order of the voice files in the learning pattern desired by the user.
具体的には、第1音声指定欄170aおよび第2音声指定欄170b(以下、単に「音声指定欄170」という)は、属性情報を保持する再生言語属性欄174をそれぞれ含んでいる。属性レベルの再生順序は、音声指定欄170の並びにより定義されている。本図では、「文章」属性の音声データの次に、「単語」属性の音声データを再生することが定義されている。 Specifically, the first voice designation field 170a and the second voice designation field 170b (hereinafter simply referred to as “speech designation field 170”) each include a reproduction language attribute field 174 that holds attribute information. The playback order at the attribute level is defined by the arrangement in the voice designation field 170. In this figure, it is defined that the audio data having the “word” attribute is reproduced after the audio data having the “text” attribute.
音声指定欄170は、再生言語属性欄174に加えて、言語レベルの再生順序を設定するために、第1再生データ指定欄172aおよび第2再生データ指定欄172b(以下、単に「再生データ指定欄172」という)を有する。この再生データ指定欄172の並びが、言語レベルの再生順序、つまり日本語音声と英語音声の再生順序になる。再生データ指定欄172は、言語を指定するための情報を保持する再生言語欄176と、再生回数を指定するための情報を保持する再生回数欄178とを有する。 In addition to the reproduction language attribute column 174, the audio designation column 170 is used to set the reproduction order of the language level. The first reproduction data designation column 172a and the second reproduction data designation column 172b (hereinafter simply referred to as “reproduction data designation column”) 172 "). The arrangement of the reproduction data designation field 172 becomes the reproduction order of the language level, that is, the reproduction order of Japanese voice and English voice. The reproduction data designation column 172 includes a
例えば、本図の学習パターンによれば、まず「文章」属性の言葉に該当する日本語が、1回再生され、次に対応する英語が1回再生される。そのあと、「単語」属性に該当する日本語が1回再生され、それに対応する英語が2回続けて再生される。また、同一の属性に該当する言葉が複数存在する場合、その言葉についてそれぞれ再生を行う。つまり、文章中に第1の単語と第2の単語がある場合、まず第1の単語について、日本語と英語の再生を行い、次に、第2の単語について、同様に日本語と英語の再生を行う。こうした、データ構造により、学習パターンを定義することができる。この学習パターンは、ユーザが任意に定義できてもよいし、予め用意されていてもよい。ユーザが学習パターンを任意に定義する場合については後述する。 For example, according to the learning pattern of this figure, first, Japanese corresponding to the word of the “sentence” attribute is reproduced once, and then the corresponding English is reproduced once. Thereafter, the Japanese corresponding to the “word” attribute is played once, and the corresponding English is played twice in succession. Further, when there are a plurality of words corresponding to the same attribute, the words are reproduced respectively. In other words, if there are the first and second words in the sentence, first the Japanese and English are played for the first word, and then the second and the same word are also used for the second word. Perform playback. A learning pattern can be defined by such a data structure. This learning pattern may be arbitrarily defined by the user, or may be prepared in advance. The case where the user arbitrarily defines the learning pattern will be described later.
図3に戻り、選択部104は、管理情報データベース110から再生すべき音声セットを選択して、選択部104に供給する。具体的には、選択部104は、管理情報データベース110に保持されているデータに基づいて、図1の文章選択領域62のように音声セットを選択するためのインターフェースをユーザに提供するとともに、ユーザから再生する音声セットの指定を受け付ける。そして、選択部104は、選択した音声セットを特定するためのグループIDを順序設定部108に出力する。 Returning to FIG. 3, the selection unit 104 selects an audio set to be reproduced from the
順序設定部108は、操作部102を介してユーザに指定された学習パターンを学習パターン格納部112から読み込む。そして、順序設定部108は、受け付けたグループIDで特定される音声セットに含まれる音声ファイルに対して、学習パターンに基づいて再生する順序を設定する。例えば、順序設定部108は、グループIDに基づいて、管理情報データベース110を参照し、再生順序に応じて、音声ファイルの音声IDを並べた順序指定ファイルを生成する。そして、順序設定部108は、順序指定ファイルを推定部106に出力する。他の例では、順序設定部108は、学習パターンによらず、ユーザの指示に応じて、音声ファイルの再生順序を個々に受け付けてもよい。 The order setting unit 108 reads a learning pattern designated by the user via the operation unit 102 from the learning
推定部106は、順序指定ファイルに基づいて、再生すべき各音声ファイルのデータサイズを、管理情報データベース110を参照して特定し、全ての音声ファイルを格納するために必要な空き容量のサイズ(以下、単に「総音声ファイルサイズ」という)を推定する。そして、推定部106は、総音声ファイルサイズを判定部116に供給する。一方、空き容量検出部126は、接続部128を介して接続されている第2記録媒体20の空き容量のサイズを検出し、判定部116に供給する。 The estimation unit 106 specifies the data size of each audio file to be reproduced based on the order designation file with reference to the
判定部116は、総音声ファイルサイズと、空き容量検出部126から供給される第2記録媒体20の空き容量サイズとに基づいて、全ての音声ファイルを第2記録媒体20に格納できるか否かを判断する。そして、全ての音声ファイルを格納できないと判断した場合、その旨を通知部114に通知する。通知部114は、第2記録媒体20の空き容量が足りないことを示すメッセージをユーザに通知する。通知部114は、例えば音声やモニタを利用して、その通知を行えばよい。また、全ての音声ファイルを格納できると判断した場合、判定部116は、順序指定ファイルを読込部120に出力する。つまり、総音声ファイルサイズが、第2記録媒体20の空き容量サイズより大きい場合、判定部116は、全ての音声ファイルを格納できないと判断し、通知部114にエラーメッセージを通知させる。また、総音声ファイルサイズが第2記録媒体20の空き容量サイズ以下の場合、判定部116は、音声ファイルの書込処理をすべく、順序指定ファイルを読込部120に出力する。これにより、音声ファイルを第2記録媒体20に書き込む前に、ユーザに指定された音声ファイルを全て第2記録媒体20に書き込むことができるか否かを判断することができる。 Whether the determination unit 116 can store all the audio files in the
音声データ格納部118は、管理情報データベース110に登録されているそれぞれの音声ファイルを保持する。読込部120は、順序指定ファイルに基づいて、音声データ格納部118から音声ファイルを読み込み、格納処理部124に供給する。具体的には、読込部120は、管理情報データベース110を参照して、順序指定ファイルに含まれる音声IDで特定される音声ファイルの格納場所を特定する。その特定処理は、音声ファイルの再生順に行われる。そして、読込部120は、順次特定し、読み込んだ音声ファイルを格納処理部124に出力する。 The audio
一方、ファイル名生成部122は、図1の再生装置50のファイルシステムにおけるソート条件に応じて、その再生装置50が通常の再生処理を行った場合に、順序指定ファイルに指定された順番で、音声ファイルが並ぶようにファイル名を生成して格納処理部124に供給する。ファイル名生成部122は、例えば、型番や装置名称など再生装置50を特定するための情報をユーザから受け付けてもよいし、再生装置50と通信を行い自動的に取得してもよい。 On the other hand, when the playback device 50 performs normal playback processing according to the sort condition in the file system of the playback device 50 in FIG. File names are generated so that audio files are arranged and supplied to the storage processing unit 124. For example, the file name generation unit 122 may receive information for specifying the playback device 50 such as a model number and a device name from the user, or may automatically acquire the information by communicating with the playback device 50.
格納処理部124は、読込部120から供給された音声ファイルに、ファイル名生成部122から供給されたファイル名を付けて第2記録媒体20に書き込む。これにより、再生装置50は、通常の再生処理を行うことで、第2記録媒体20に格納された音声ファイルを、ユーザが所望する順番で再生することができる。 The storage processing unit 124 adds the file name supplied from the file name generation unit 122 to the audio file supplied from the reading unit 120 and writes the file to the
実施の形態で説明した学習支援装置100により、ユーザは自分の学習スタイルに合わせて音声の再生順序を決めることができる。例えば、英語のヒアリング力を養いたい場合、英語の繰り返し回数を多めに設定して、最後に日本語を再生するようにしたり、日本語を1回再生した後に、英語を複数回連続して再生したりすることができる。 With the learning
図6は、ユーザが任意に学習パターンを定義するための表示画面60の一例を示す図である。学習パターンは、属性、言語種類、および再生回数の組み合わせで定義されるので、これらの値を設定するためのGUI(Graphical User Interface)コンポーネントが表示画面60には設けられている。属性設定欄90は、属性の指定を受け付けるためのGUIコンポーネントである。言語種類設定欄92は、言語種類の指定を受け付けるためのGUIコンポーネントである。再生回数設定欄94は、再生回数の指定を受け付けるためのGUIコンポーネントである。追加ボタン96は、これらのGUIコンポーネントで指定された設定値を学習パターンに追加するためのボタンである。学習パターン表示領域98は、学習パターンを表示するための領域である。本図では、ユーザが認識しやすいように文章形式で学習パターンが表示されているが、図5を用いて説明したXML形式で表示を行ってもよい。図3を用いて説明した順序設定部108は、このようなGUIによりユーザから学習パターンを受け付ける。そして、順序設定部108はこの学習パターンに基づいて順序指定ファイルを生成する。これにより、ユーザは自分で学習パターンを作成することができる。 FIG. 6 is a diagram illustrating an example of a display screen 60 for the user to arbitrarily define a learning pattern. Since the learning pattern is defined by a combination of the attribute, the language type, and the number of times of reproduction, a GUI (Graphical User Interface) component for setting these values is provided on the display screen 60. The
<第2の実施の形態>
図7は、第2の実施の形態に係る学習支援システム200の構成図である。第2の実施の形態に係る学習支援装置210は、ネットワーク202を介してサーバ220から音声ファイルとその音声ファイルに対応づけられた管理情報を取得することができる。これにより、例えばユーザは学習進度に応じて音声ファイルをダウンロードでき、学習支援装置210におけるディスク容量を効率的に使うことができる。また、サーバ側音声データ格納部222およびサーバ側管理情報データベース224に新しい音声ファイルを追加更新することにより、学習支援装置210側の音声ファイルも同様に追加更新することができる。音声ファイルの鮮度を保つことができるので、ユーザの継続的な利用が期待できる。<Second Embodiment>
FIG. 7 is a configuration diagram of a
サーバ側音声データ格納部222は、学習支援装置210に提供可能な音声ファイルを保持する。サーバ側管理情報データベース224は、音声ファイルの管理情報を保持し、そのデータ構造は図4を用いて説明した管理情報データベース110と同様であってよい。サーバ側管理情報データベース224における各音声ファイルの格納場所を示す情報は、サーバ側音声データ格納部222に保持されている音声ファイルを特定する情報である。 The server-side voice data storage unit 222 holds a voice file that can be provided to the learning support apparatus 210. The server-side management information database 224 holds management information for audio files, and the data structure thereof may be the same as that of the
提供部226は、サーバ側管理情報データベース224から管理情報を読み込み、読み込んだ管理情報を学習支援装置210に送信するとともに、送信した管理情報に対応づけられた音声ファイルをサーバ側音声データ格納部222から読み込み学習支援装置210に送信する。提供部226は、サーバ側管理情報データベース224に保持されている管理情報の全体を学習支援装置210を送信してもよいし、一部の管理情報を学習支援装置210に送信してもよい。送信する音声ファイルの選択方法はいろいろと考えられるが、例えば音声ファイルのリストをウェブブラウザなどでユーザが閲覧できるように提供し、ユーザに選択された音声ファイルを学習支援装置210に送信してもよい。また、教材の単元ごとに音声ファイルを管理し、ユーザから単元を特定する情報を受け付けると、受け付けた単元に対応する音声ファイルを学習支援装置210に送信してもよい。こうしたインターフェイスは、提供部226によって提供される。 The providing unit 226 reads the management information from the server-side management information database 224, transmits the read management information to the learning support apparatus 210, and transmits the audio file associated with the transmitted management information to the server-side audio data storage unit 222. Is read and transmitted to the learning support device 210. The providing unit 226 may transmit the entire management information held in the server-side management information database 224 to the learning support apparatus 210 or may transmit some management information to the learning support apparatus 210. There are various methods for selecting an audio file to be transmitted. For example, a list of audio files may be provided so that the user can browse with a web browser, and the audio file selected by the user may be transmitted to the learning support apparatus 210. Good. In addition, when an audio file is managed for each unit of the teaching material and information specifying the unit is received from the user, the audio file corresponding to the received unit may be transmitted to the learning support apparatus 210. Such an interface is provided by the providing unit 226.
図8は、図7の学習支援装置210の内部構成図である。本図で、既に説明した構成と同一の符号が付された構成は、既に説明した同一の符号が付された構成と機能が同一である。以下の説明では、各図の既に説明した構成とは異なる構成について詳細に説明する。取得部212は、ネットワーク202を介して図7のサーバ220から管理情報および音声ファイルを取得して、それぞれ管理情報データベース110並びに音声データ格納部118に格納する。取得部212は、新たに取得した管理情報および音声ファイルを管理情報データベース110並びに音声データ格納部118に追加もしくは更新する。また、取得部212は、取得した音声ファイルの格納場所を管理情報データベース110に書き込む。別の例では、取得部212は、既に格納されているデータを削除した後、新たに取得したデータを追加してもよい。これにより、学習支援装置210は、ネットワーク202を介してサーバ220から新たに音声ファイルを取得することができる。 FIG. 8 is an internal block diagram of the learning support apparatus 210 of FIG. In this figure, the configuration with the same reference numerals as those already described has the same function as the configuration with the same reference numerals already described. In the following description, a configuration different from the configuration already described in each drawing will be described in detail. The acquisition unit 212 acquires management information and audio files from the
<第3の実施の形態>
図9は、第3の実施の形態に係る学習支援システム250の構成図である。学習支援システム250は、第2記録媒体20に記録された音声ファイルに対応づけられた文字情報を携帯電話254に表示させることを可能にする。これにより、ユーザは携帯電話254で文字情報を確認しながら、音声を聞くことができる。<Third Embodiment>
FIG. 9 is a configuration diagram of a learning support system 250 according to the third embodiment. The learning support system 250 allows the mobile phone 254 to display character information associated with the audio file recorded on the
学習支援装置260は、第2記録媒体20に記録した音声ファイルに対応づけられた文字情報を、音声ファイルの再生順序で表示するための学習内容ファイルを生成する。学習支援装置260は、学習内容ファイルをネットワーク202を介してサーバ270に送信する。学習内容ファイルは、ユーザを特定する情報とともにサーバ270に送信される。サーバ270は、学習内容ファイルとユーザを特定する情報とを対応付けて学習内容格納部274に蓄積する。 The learning support device 260 generates a learning content file for displaying the character information associated with the audio file recorded on the
携帯電話254は基地局252を介してネットワーク202に接続し、サーバ270から学習内容ファイルを取得する。携帯電話254は、例えばjava(登録商標)などのプログラムを実行することにより、学習内容ファイルに基づいて文字情報を表示させる。学習内容ファイルの表示方法や表示のためのインターフェイスは任意であり、例えばユーザのキー操作を契機に、音声ファイルの再生順序で文字情報を切り替えて表示してもよいし、一定の間隔で自動的に表示を切り替えてもよい。また、携帯電話254は、文字情報にマークを付けて、後でマーク部分だけを一覧表示する機能やテスト機能などを備えてもよい。 The mobile phone 254 connects to the
図10は、図9の学習支援装置260の内部構成図である。本図の判定部116は、順序指定ファイルを読込部120および学習内容作成部262に出力する。学習内容作成部262は、順序指定ファイルに含まれる音声IDに基づいて、管理情報データベース110を参照し、音声IDに対応づけられた文字情報を取得する。そして、学習内容作成部262は、取得した文字情報を順序指定ファイルに指定された順序で表示できるように学習内容ファイルを作成する。学習内容ファイルは、文字情報とその文字情報を表示する順序とを対応づけている。学習内容ファイルのデータ構造は任意であり、例えば文字情報を順番に並べたものであってもよいし、文字情報に識別情報を割り当て、その識別情報を表示順に並べたものであってもよい。また、学習内容ファイルに含まれる文字情報は、例えばURIであってもよく、動画や静止画などへのリンクであってもよい。リンクを加えることにより、学習形態に自由度をもたせることができる。 FIG. 10 is an internal block diagram of the learning support apparatus 260 of FIG. The determination unit 116 in this figure outputs the order designation file to the reading unit 120 and the learning content creation unit 262. The learning content creation unit 262 refers to the
送信部264は、学習内容作成部262により作成された学習内容ファイルをサーバ270に送信する。送信部264は、すべての音声ファイルが第2記録媒体20に格納されたことを契機に学習内容ファイルをサーバ270に送信してもよい。これにより、第2記録媒体20に格納されている音声ファイルと、学習内容ファイルとが対応していることを保証できる。別の例では、送信部264はIrDA(Infrared Data Association)などの通信手段を利用して、直接的に携帯電話254に学習内容ファイルを送信してもよい。The transmission unit 264 transmits the learning content file created by the learning content creation unit 262 to the server 270. The transmission unit 264 may transmit the learning content file to the server 270 when all the audio files are stored in the
以上、本発明を実施の形態をもとに説明した。この実施の形態は例示であり、それらの各構成要素や各処理プロセスの組合せにいろいろな変形例が可能なこと、またそうした変形例も本発明の範囲にあることは当業者に理解されるところである。こうした変形例として、図3の管理情報データベース110は、様々な国の言語を組み合わせて保持してもよい。こうすることで、任意の言語を取り扱うことができる。学習支援装置100は、ネットワークを介して音声ファイルを取得できるとともに、学習内容ファイルを作成することができる。これにより、学習支援装置100の利便性が更に向上する。 The present invention has been described based on the embodiments. This embodiment is an exemplification, and it will be understood by those skilled in the art that various modifications can be made to combinations of the respective constituent elements and processing processes, and such modifications are also within the scope of the present invention. is there. As such a modification, the
別の変形例として、音声ファイルをデコードして再生装置に出力してもよい。例えばカセットテーププレーヤを再生装置として使う場合、図3の格納処理部124は音声ファイルをデコードしてアナログ信号を接続部128に出力する。接続部128は、アナログ信号を出力するための端子を更に備え、格納処理部124から受け付けたアナログ信号を出力する。このようにデコード機能を備えることで、利用可能な再生装置の種類を広げることができる。また、この場合、学習支援装置100は、デコード機能を有効にするか否かをユーザから受け付けるためのインターフェースを更に備える。 As another modification, an audio file may be decoded and output to a playback device. For example, when a cassette tape player is used as a playback device, the storage processing unit 124 in FIG. 3 decodes the audio file and outputs an analog signal to the connection unit 128. The connection unit 128 further includes a terminal for outputting an analog signal, and outputs the analog signal received from the storage processing unit 124. By providing a decoding function in this way, the types of playback devices that can be used can be expanded. In this case, the learning
再生装置が、音声ファイルを再生する順番を指定する再生リストに準じて、音声ファイルを再生する機能を有することも想定できる。こうした再生装置に対応するため、学習支援装置100は、順序指定ファイルに基づいて、接続中の再生装置で利用できる再生リストを生成して、出力してもよい。つまり、学習支援装置100は、順序指定ファイルを接続中の再生装置における再生リストのファイルフォーマットに変換する機能を備える。例えば、図3の格納処理部124が、このファイルフォーマット変換機能を備えてもよい。 It can also be assumed that the playback device has a function of playing back an audio file according to a play list that specifies the order of playing back the audio file. In order to support such a playback apparatus, the learning
学習支援装置100は、再生装置を特定する情報をユーザから受け付けるためのインタフェースを更に備える。そして、格納処理部124は、受け付けた情報に基づいて接続中の再生装置用のファイルフォーマットを特定し、変換処理を行う。このように、再生リストを生成する機能を備えることで、利用可能な再生装置の種類を広げることができる。 The learning
別の変形例として、図3の選択部104は、管理情報データベース110に保持されているデータから所定の条件に適合するレコードを検索する機能を更に備えてもよい。これにより、例えば所定の単語を含むレコードについて学習をすることができる。 As another modification, the selection unit 104 in FIG. 3 may further include a function of searching for a record that meets a predetermined condition from data held in the
実施の形態では語学学習を例に説明したが、本装置は語学学習に限らず、例えば歴史や地理など様々な学習に利用できる。 Although language learning has been described as an example in the embodiment, the present apparatus is not limited to language learning but can be used for various learning such as history and geography.
10 学習支援システム、12 第1記録媒体、20 第2記録媒体、50 再生装置、54 音声出力内容、60 表示画面、62 文章選択領域、64 学習パターン選択領域、66 開始ボタン、68 キャンセルボタン、70 音声ファイル、100 学習支援装置、101 表示処理部、102 操作部、104 選択部、106 推定部、108 順序設定部、110 管理情報データベース、112 学習パターン格納部、114 通知部、116 判定部、118 音声データ格納部、120 読込部、122 ファイル名生成部、124 格納処理部、126 空き容量検出部、128 接続部、150 グループID欄、152 属性欄、154 英語テキスト欄、156 日本語テキスト欄、158 英語音声ファイル名欄、160 日本語音声ファイル名欄、170 音声指定欄、172 再生データ指定欄、174 再生言語属性欄、176 再生言語欄、178 再生回数欄、180 パターン名欄、182 学習パターン欄。 10 learning support system, 12 first recording medium, 20 second recording medium, 50 playback device, 54 audio output content, 60 display screen, 62 sentence selection area, 64 learning pattern selection area, 66 start button, 68 cancel button, 70 Audio file, 100 learning support device, 101 display processing unit, 102 operation unit, 104 selection unit, 106 estimation unit, 108 order setting unit, 110 management information database, 112 learning pattern storage unit, 114 notification unit, 116 determination unit, 118 Audio data storage unit, 120 reading unit, 122 file name generation unit, 124 storage processing unit, 126 free space detection unit, 128 connection unit, 150 group ID column, 152 attribute column, 154 English text column, 156 Japanese text column, 158 English audio file name field, 160 Japanese Voice file name field, 170 voice designation column, 172 playback data specification field, 174 playback language attribute column, 176 playback language column, 178 Views column, 180 pattern name column, 182 learning pattern column.
Claims (5)
Translated fromJapanese第1種類を特定する情報と第2種類を特定する情報とにより指定された再生順序に基づいて、互いに対応付けられた前記第1音声ファイルおよび前記第2音声ファイルの再生順序を設定する設定部と、
を備えることを特徴とする学習支援装置。A storage unit for storing the first audio file in which the first type of audio is recorded and the second audio file in which the second type of audio is recorded;
A setting unit that sets the playback order of the first audio file and the second audio file that are associated with each other based on the playback order specified by the information that specifies the first type and the information that specifies the second type When,
A learning support apparatus comprising:
Data of a file to be written to the storage medium in order to reproduce the first audio file and the second audio file in the reproduction order set by the setting unit, further comprising a detection unit for detecting the free space of the recording medium 5. The learning support according to claim 2, wherein the storage processing unit writes the first audio file and the second audio file to the storage medium when the size is smaller than the free space of the storage medium. apparatus.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2004309024AJP2005148727A (en) | 2003-10-23 | 2004-10-25 | Learning support device |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003398129 | 2003-10-23 | ||
| JP2004309024AJP2005148727A (en) | 2003-10-23 | 2004-10-25 | Learning support device |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2005148727Atrue JP2005148727A (en) | 2005-06-09 |
Family
ID=34703256
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2004309024APendingJP2005148727A (en) | 2003-10-23 | 2004-10-25 | Learning support device |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2005148727A (en) |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2012017716A1 (en)* | 2010-08-06 | 2012-02-09 | 三洋電機株式会社 | Content playback device for sequentially playing back multiple files |
| JP2012527007A (en)* | 2009-05-13 | 2012-11-01 | ドハン イ | Multimedia file playback method and multimedia playback device |
| JP2013037251A (en)* | 2011-08-10 | 2013-02-21 | Casio Comput Co Ltd | Vocal learning device and vocal learning program |
| JP2015111217A (en)* | 2013-12-06 | 2015-06-18 | カシオ計算機株式会社 | Voice output device and program |
| JP2016048390A (en)* | 2015-11-18 | 2016-04-07 | カシオ計算機株式会社 | Information display device and information display program |
| JP2020144269A (en)* | 2019-03-07 | 2020-09-10 | 理 小山 | Multilingual content reproduction method for learning, and data structure and program for the same |
| WO2021091692A1 (en)* | 2019-11-07 | 2021-05-14 | Square Panda Inc. | Speech synthesizer with multimodal blending |
- 2004
- 2004-10-25JPJP2004309024Apatent/JP2005148727A/enactivePending
Cited By (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012527007A (en)* | 2009-05-13 | 2012-11-01 | ドハン イ | Multimedia file playback method and multimedia playback device |
| WO2012017716A1 (en)* | 2010-08-06 | 2012-02-09 | 三洋電機株式会社 | Content playback device for sequentially playing back multiple files |
| JP2012039376A (en)* | 2010-08-06 | 2012-02-23 | Sanyo Electric Co Ltd | Content reproduction device |
| JP2013037251A (en)* | 2011-08-10 | 2013-02-21 | Casio Comput Co Ltd | Vocal learning device and vocal learning program |
| US9483953B2 (en) | 2011-08-10 | 2016-11-01 | Casio Computer Co., Ltd. | Voice learning apparatus, voice learning method, and storage medium storing voice learning program |
| JP2015111217A (en)* | 2013-12-06 | 2015-06-18 | カシオ計算機株式会社 | Voice output device and program |
| JP2016048390A (en)* | 2015-11-18 | 2016-04-07 | カシオ計算機株式会社 | Information display device and information display program |
| JP2020144269A (en)* | 2019-03-07 | 2020-09-10 | 理 小山 | Multilingual content reproduction method for learning, and data structure and program for the same |
| WO2021091692A1 (en)* | 2019-11-07 | 2021-05-14 | Square Panda Inc. | Speech synthesizer with multimodal blending |
| CN115023758A (en)* | 2019-11-07 | 2022-09-06 | 知识方正有限公司 | Speech synthesizer with multi-mode mixing |
| JP2023501404A (en)* | 2019-11-07 | 2023-01-18 | ラーニング スクエアード インコーポレイテッド | Speech Synthesizer Using Multimodal Mixing |
| JP7686217B2 (en) | 2019-11-07 | 2025-06-02 | ラーニング スクエアード インコーポレイテッド | Speech synthesizer using multimodal mixing |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US4985697A (en) | Electronic book educational publishing method using buried reference materials and alternate learning levels | |
| KR101728699B1 (en) | Service Providing Method For E-Book And System thereof, Portable Device supporting the same | |
| US7779357B2 (en) | Audio user interface for computing devices | |
| TW548609B (en) | Method and system for assisting a user in learning and interactive learning appliance | |
| JPH0973461A (en) | Sentence information reproducing device using voice | |
| KR20090017414A (en) | System for Providing Learning Content through User Word Search History | |
| KR20100005177A (en) | Customized learning system, customized learning method, and learning device | |
| JP2005148727A (en) | Learning support device | |
| CN101097659A (en) | Language Learning System and Method | |
| JP2007528572A (en) | User interface for multimedia file playback devices | |
| JP2010002788A (en) | Learning terminal, and learning program | |
| KR100226946B1 (en) | Data Discs and Data Retrieval Methods | |
| JP2018146961A (en) | Audio playback device and music playback program | |
| JP2010002787A (en) | Learning system, learning terminal, and learning program | |
| KR100882857B1 (en) | Content playback method using identification code | |
| KR100422110B1 (en) | Portable multimedia learning apparatus and method | |
| KR20020006620A (en) | Portable CD player displaying caption data and audio CD having caption index data and System for providing caption data | |
| JP4099907B2 (en) | Information reproducing apparatus and method, and information providing medium | |
| KR100622101B1 (en) | Memorization Learning System Using Sheet Music and Songs and Its Recording Media | |
| JP2005285274A (en) | Title display information generator | |
| JP2003067099A (en) | Device and method for information processing, recording medium and program | |
| KR100738695B1 (en) | Learning content editing system and method | |
| JP2006208514A (en) | Karaoke apparatus having karaoke music selection keyboard into which inputting is conducted in two languages and music selecting method in the apparatus | |
| JP2005326811A (en) | Speech synthesis apparatus and speech synthesis method | |
| KR20080065205A (en) | Custom Learning Systems, Custom Learning Methods, and Learners |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination | Free format text:JAPANESE INTERMEDIATE CODE: A621 Effective date:20061019 | |
| A977 | Report on retrieval | Free format text:JAPANESE INTERMEDIATE CODE: A971007 Effective date:20080716 | |
| A131 | Notification of reasons for refusal | Free format text:JAPANESE INTERMEDIATE CODE: A131 Effective date:20080725 | |
| A521 | Request for written amendment filed | Free format text:JAPANESE INTERMEDIATE CODE: A523 Effective date:20080923 | |
| A02 | Decision of refusal | Free format text:JAPANESE INTERMEDIATE CODE: A02 Effective date:20090216 |