CN116415196A - Data anomaly detection method, storage medium and terminal based on smart industry - Google Patents
Data anomaly detection method, storage medium and terminal based on smart industryDownload PDFInfo
- Publication number
- CN116415196A CN116415196ACN202310181817.2ACN202310181817ACN116415196ACN 116415196 ACN116415196 ACN 116415196ACN 202310181817 ACN202310181817 ACN 202310181817ACN 116415196 ACN116415196 ACN 116415196A
- Authority
- CN
- China
- Prior art keywords
- covariance matrix
- neural network
- anomaly detection
- detection method
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000001514detection methodMethods0.000titleclaimsabstractdescription53
- 239000011159matrix materialSubstances0.000claimsabstractdescription72
- 238000004422calculation algorithmMethods0.000claimsabstractdescription48
- 238000012545processingMethods0.000claimsabstractdescription35
- 238000003062neural network modelMethods0.000claimsabstractdescription34
- 238000000034methodMethods0.000claimsabstractdescription31
- 230000008569processEffects0.000claimsabstractdescription13
- 230000005284excitationEffects0.000claimsabstractdescription7
- 230000007246mechanismEffects0.000claimsdescription14
- 238000001914filtrationMethods0.000claimsdescription12
- 238000013528artificial neural networkMethods0.000claimsdescription11
- 230000015654memoryEffects0.000claimsdescription10
- 230000000306recurrent effectEffects0.000claimsdescription8
- 230000006870functionEffects0.000claimsdescription6
- 238000010606normalizationMethods0.000claimsdescription6
- 230000006403short-term memoryEffects0.000claimsdescription5
- 230000007704transitionEffects0.000claimsdescription5
- 230000007787long-term memoryEffects0.000claims2
- 230000002159abnormal effectEffects0.000abstractdescription17
- 238000005259measurementMethods0.000abstractdescription5
- 230000005856abnormalityEffects0.000abstractdescription2
- 230000008859changeEffects0.000description10
- 230000004913activationEffects0.000description2
- 238000010586diagramMethods0.000description2
- 230000000694effectsEffects0.000description2
- 238000005516engineering processMethods0.000description2
- 238000000605extractionMethods0.000description2
- 238000009434installationMethods0.000description2
- 238000003064k means clusteringMethods0.000description2
- 230000009286beneficial effectEffects0.000description1
- 238000007635classification algorithmMethods0.000description1
- 238000004891communicationMethods0.000description1
- 238000010276constructionMethods0.000description1
- 238000009795derivationMethods0.000description1
- 238000011161developmentMethods0.000description1
- 230000004927fusionEffects0.000description1
- 230000006872improvementEffects0.000description1
- 238000012804iterative processMethods0.000description1
- 238000010801machine learningMethods0.000description1
- 230000003287optical effectEffects0.000description1
- 238000007781pre-processingMethods0.000description1
- 230000009467reductionEffects0.000description1
- 230000000717retained effectEffects0.000description1
- 230000002441reversible effectEffects0.000description1
- 238000006467substitution reactionMethods0.000description1
- 230000002123temporal effectEffects0.000description1
- 230000009466transformationEffects0.000description1
Images



Landscapes
- Testing And Monitoring For Control Systems (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及异常检测技术领域,尤其涉及基于智慧工业的数据异常检测方法、存储介质及终端。The invention relates to the technical field of anomaly detection, in particular to a data anomaly detection method, storage medium and terminal based on smart industry.
背景技术Background technique
随着工业大数据、工业物联网等技术的应用,工业界开始数字化转型,世界各国出台了对应的发展战略,如美国工业互联网、中国制造2025、德国工业4.0等。工业活动中,传感器短时间内产生的数据是海量的,人工难以基于海量传感器数据分析设备的潜在异常。With the application of technologies such as industrial big data and industrial Internet of Things, the industry has begun to undergo digital transformation, and countries around the world have introduced corresponding development strategies, such as the American Industrial Internet, Made in China 2025, and German Industry 4.0. In industrial activities, the data generated by sensors in a short period of time is massive, and it is difficult for humans to analyze potential abnormalities of equipment based on massive sensor data.
近年来,已经有大量的研究者研究机器学习方法,提取数据流的特征进行数据流异常检测。根据异常检测的建模类型,数据流的异常检测方法分为三类:统计建模方法、时序特征建模方法、空间特征建模方法。按照异常检测算法安装是否需要人工标注好数据集,则可分为有监督学习异常检测算法和无监督学习异常检测算法。In recent years, a large number of researchers have studied machine learning methods to extract the characteristics of data streams for data stream anomaly detection. According to the modeling type of anomaly detection, anomaly detection methods for data streams are divided into three categories: statistical modeling methods, temporal feature modeling methods, and spatial feature modeling methods. According to whether the installation of anomaly detection algorithm needs to manually label the data set, it can be divided into supervised learning anomaly detection algorithm and unsupervised learning anomaly detection algorithm.
现有技术利用K-means聚类算法检测无线传感网络(WSN)的入侵异常,具体通过分析数据流的统计特征,计算出正常数据和异常数据的聚类中心,并通过计算WSN数据与聚类中心的欧式距离进行异常检测,对特定种类的入侵异常有较高的检测准确率。现有技术还提出将SOM算法与K-means聚类结合,实现了在线异常检测;该算法通过实时更新的网络结构,并利用新数据的适应程度重建异常簇或拆分正常簇,实现了对新型异常的检测。上述两种算法在检测统计异常时具有较高的检测准确率,并且不需要提前标注数据集,是无监督异常检测算法。然而上述算法也有一些缺点:The prior art uses the K-means clustering algorithm to detect the intrusion anomaly of the wireless sensor network (WSN). Specifically, by analyzing the statistical characteristics of the data stream, the cluster center of the normal data and the abnormal data is calculated, and the WSN data and the clustering center are calculated. The Euclidean distance of the class center is used for anomaly detection, and it has a high detection accuracy for specific types of intrusion anomalies. The existing technology also proposes to combine the SOM algorithm with K-means clustering to realize online anomaly detection; this algorithm uses the real-time updated network structure and uses the adaptability of new data to reconstruct abnormal clusters or split normal clusters, and realizes the detection of abnormal clusters. Detection of novel anomalies. The above two algorithms have high detection accuracy when detecting statistical anomalies, and do not need to label the data set in advance. They are unsupervised anomaly detection algorithms. However, the above algorithm also has some disadvantages:
1、容易受到噪声点和孤立点影响,在计算各个簇的中心点时,计算出的均值与实际的均值会有很大的误差;1. It is easily affected by noise points and isolated points. When calculating the center point of each cluster, there will be a large error between the calculated mean and the actual mean;
2、算法中的K值不容易获得,一般是通过个人经验来选取K值,或采用误平方和和轮廓系数法来获取,但这些方法往往不能得到真实的聚类数目,导致降低了聚类效果;2. The K value in the algorithm is not easy to obtain. Generally, the K value is selected through personal experience, or obtained by using the error sum of squares and the contour coefficient method, but these methods often cannot obtain the real number of clusters, resulting in a reduction in the number of clusters. Effect;
3、只适用于簇为凸型状和数值型的数据集,对于其他数据集,性能仍待提高;3. It is only applicable to data sets whose clusters are convex and numerical. For other data sets, the performance still needs to be improved;
4、初始聚类中心的选取对最后结果的分类影响较大,若初始聚类中心选取不当,可能导致聚类失败。4. The selection of the initial clustering center has a great influence on the classification of the final result. If the initial clustering center is not selected properly, the clustering may fail.
不同于上述聚类算法,现有技术还提出将长短期记忆(LSTM)算法应用至工业物联网传感器数据流异常检测中。具体地,使用LSTM模型预测未来数据,通过预测值与实际值的误差检测异常数据。此外,现有技术还提出利用LSTM模型提取工业控制系统数据的时序特征,并使用Softmax分类异常数据。上述方法利用RNN提取数据流的时序特征,通过预测算法预测未来数据,并利用预测值与真实值的误差检测异常值;或者使用分类算法检测异常数据。这类算法对于具有确定时序特征的数据流具有良好的检测准确率,而针对不具有确定时序特征的数据流无法实现准确检测,检测性能仍待进一步提高。Different from the above-mentioned clustering algorithm, the prior art also proposes to apply the long-short-term memory (LSTM) algorithm to anomaly detection of sensor data streams in the Industrial Internet of Things. Specifically, use the LSTM model to predict future data, and detect abnormal data through the error between the predicted value and the actual value. In addition, the prior art also proposes to use LSTM model to extract time series features of industrial control system data, and use Softmax to classify abnormal data. The above method uses RNN to extract the time series features of the data stream, predicts future data through a prediction algorithm, and uses the error between the predicted value and the real value to detect abnormal values; or uses a classification algorithm to detect abnormal data. This type of algorithm has good detection accuracy for data streams with definite timing characteristics, but cannot achieve accurate detection for data streams without definite timing characteristics, and the detection performance still needs to be further improved.
另外,工业场景中,由于多种数据采集器问题造成信息源不统一,各数据采集器如传感器的精度不同、工况不同,针对同一单位的测量可能出现不同结果,降低了后续异常检测准确度。In addition, in industrial scenarios, the information sources are inconsistent due to the problems of various data collectors. The accuracy of each data collector such as sensors is different, and the working conditions are different. Different results may appear for the measurement of the same unit, which reduces the accuracy of subsequent anomaly detection. .
发明内容Contents of the invention
本发明的目的在于克服现有技术的问题,提供了一种基于智慧工业的数据异常检测方法、存储介质及终端。The purpose of the present invention is to overcome the problems of the prior art and provide a data anomaly detection method, storage medium and terminal based on smart industry.
本发明的目的是通过以下技术方案来实现的:一种基于智慧工业的数据异常检测方法,该方法包括以下步骤:The purpose of the present invention is achieved through the following technical solutions: a data anomaly detection method based on smart industry, the method includes the following steps:
将各种工业数据分别进行卡尔曼滤波处理,再输入第一神经网络模型进行异常预测,所述卡尔曼滤波处理的协方差矩阵更新包括:Various industrial data are subjected to Kalman filter processing, and then input into the first neural network model for abnormal prediction. The covariance matrix update of the Kalman filter processing includes:
通过第二神经网络模型学习卡尔曼滤波算法的协方差矩阵的变化趋势,进而更新协方差矩阵。The change trend of the covariance matrix of the Kalman filter algorithm is learned through the second neural network model, and then the covariance matrix is updated.
在一示例中,所述协方差矩阵

其中,函数f(·)是通过第二神经网络模型学习拟合协方差矩阵的变化趋势;Pk-1表示上一时刻协方差矩阵。Among them, the function f(·) is the change trend of the covariance matrix learned and fitted by the second neural network model; Pk-1 represents the covariance matrix at the previous moment.
在一示例中,所述学习卡尔曼滤波算法的协方差矩阵的变化趋势包括:In an example, the change trend of the covariance matrix of the learning Kalman filter algorithm includes:
根据k-1时刻的状态

由k-1时刻的误差协方差矩阵Pk-1推出中间变量
通过中间变量
根据卡尔曼增益系数Kk获得k时刻状态最优估计
更新k时刻的协方差矩阵Pk。Update the covariance matrix Pk at time k.
在一示例中,所述通过第二神经网络模型学习卡尔曼滤波算法的协方差矩阵的变化趋势前还包括:In an example, before learning the change trend of the covariance matrix of the Kalman filter algorithm through the second neural network model, it also includes:
将状态转移矩阵、过程激励噪声协方差矩阵、初始协方差矩阵作为输入,对第二神经网络模型进行训练,进而得到能够预测更新协方差矩阵的第二神经网络模型。The state transition matrix, the process excitation noise covariance matrix, and the initial covariance matrix are used as inputs to train the second neural network model, and then the second neural network model capable of predicting and updating the covariance matrix is obtained.
在一示例中,所述第一神经网络模型为应用注意力机制的门控循环神经网络,或应用注意力机制的长短期记忆网络。In an example, the first neural network model is a gated recurrent neural network applying an attention mechanism, or a long short-term memory network applying an attention mechanism.
在一示例中,所述应用注意力机制的门控循环神经网络进行预测时,包括:In an example, when the gated recurrent neural network applying the attention mechanism performs prediction, it includes:
采用注意力机制将门控循环神经网络中各隐藏单元的输出结果与权重矩阵进行点乘处理。The output of each hidden unit in the gated recurrent neural network is multiplied by the weight matrix by using the attention mechanism.
在一示例中,所述第二神经网络模型为门控循环神经网络或长短期记忆网络。In an example, the second neural network model is a gated recurrent neural network or a long short-term memory network.
在一示例中,所述将采集的工业数据进行卡尔曼滤波处理前还包括:In an example, before performing Kalman filter processing on the collected industrial data, it also includes:
对工业数据进行异常值处理、缺失值处理以及归一化处理。Perform abnormal value processing, missing value processing and normalization processing on industrial data.
需要进一步说明的是,上述各示例对应的技术特征可以相互组合或替换构成新的技术方案。It should be further explained that the technical features corresponding to the above examples can be combined or replaced to form new technical solutions.
本发明还包括一种存储介质,其上存储有计算机指令,所述计算机指令运行时执行上述任一示例或多个示例组成形成的所述基于智慧工业的数据异常检测方法的步骤。The present invention also includes a storage medium on which computer instructions are stored, and when the computer instructions are run, the steps of the smart industry-based data anomaly detection method formed by any one or more of the above-mentioned examples are executed.
本发明还包括一种终端,包括存储器和处理器,所述存储器上存储有可在所述处理器上运行的计算机指令,所述处理器运行所述计算机指令时执行上述任一示例或多个示例组成形成的所述基于智慧工业的数据异常检测方法的步骤。The present invention also includes a terminal, including a memory and a processor, the memory stores computer instructions that can run on the processor, and the processor executes any one or more of the above-mentioned examples when running the computer instructions. The steps of the smart industry-based data anomaly detection method formed by an example.
与现有技术相比,本发明有益效果是:Compared with prior art, the beneficial effect of the present invention is:
本发明通过第一神经网络模型捕捉KF算法的协方差矩阵的变化趋势,能够动态调整过程激励噪声协方差矩阵Q,使更新后的协方差矩阵P更加接近真实值,以此降低噪声对KF算法的影响,提高了卡尔曼滤波处理精度,进而保证了后续神经网络模型的异常预测准确性与可靠性;同时,采用改进KF算法对工业数据进行处理,能够剔除冗余数据,对各信息源进行统一处理,以此保证测量准确性;同时改进的KF算法还能够确定工业数据流的时序特征,进而使本方法能够对不具有时序特征的数据流进行准确异常检测。The present invention captures the change trend of the covariance matrix of the KF algorithm through the first neural network model, and can dynamically adjust the process excitation noise covariance matrix Q, so that the updated covariance matrix P is closer to the real value, thereby reducing the impact of noise on the KF algorithm. The impact of Kalman filtering improves the processing accuracy of the Kalman filter, thereby ensuring the accuracy and reliability of the abnormal prediction of the subsequent neural network model. Unified processing to ensure measurement accuracy; at the same time, the improved KF algorithm can also determine the timing characteristics of industrial data streams, so that this method can accurately detect anomalies for data streams that do not have timing characteristics.
附图说明Description of drawings
下面结合附图对本发明的具体实施方式作进一步详细的说明,此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,在这些附图中使用相同的参考标号来表示相同或相似的部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。The specific embodiments of the present invention will be described in further detail below in conjunction with the accompanying drawings. The accompanying drawings described here are used to provide a further understanding of the application and constitute a part of the application. In these drawings, the same reference numerals are used to indicate the same Or similar parts, the exemplary embodiments of the application and their descriptions are used to explain the application, and do not constitute an undue limitation to the application.
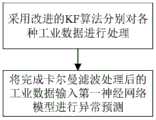
图1为本发明一示例中的异常检测方法流程图;Fig. 1 is a flowchart of an anomaly detection method in an example of the present invention;
图2为本发明一示例中的改进KF算法结构图;Fig. 2 is an improved KF algorithm structural diagram in an example of the present invention;
图3为本发明优选示例异常检测方法结构图;Fig. 3 is a structural diagram of a preferred example of an anomaly detection method in the present invention;
图4为本发明优选示例异常检测方法流程图。Fig. 4 is a flow chart of an anomaly detection method in a preferred example of the present invention.
具体实施方式Detailed ways
下面结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。The technical solutions of the present invention will be clearly and completely described below in conjunction with the accompanying drawings. Apparently, the described embodiments are part of the embodiments of the present invention, but not all of them. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
在本发明的描述中,需要说明的是,属于“中心”、“上”、“下”、“左”、“右”、“竖直”、“水平”、“内”、“外”等指示的方向或位置关系为基于附图所述的方向或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,使用序数词(例如,“第一和第二”、“第一至第四”等)是为了对物体进行区分,并不限于该顺序,而不能理解为指示或暗示相对重要性。In the description of the present invention, it needs to be explained that, belonging to "center", "upper", "lower", "left", "right", "vertical", "horizontal", "inner", "outer" etc. The indicated direction or positional relationship is based on the direction or positional relationship described in the drawings, and is only for the convenience of describing the present invention and simplifying the description, rather than indicating or implying that the device or element referred to must have a specific orientation, or in a specific orientation. construction and operation, therefore, should not be construed as limiting the invention. Furthermore, the use of ordinal numbers (eg, "first and second," "first to fourth," etc.) is for the purpose of distinguishing objects, is not limited to that order, and should not be construed to indicate or imply relative importance.
在本发明的描述中,需要说明的是,除非另有明确的规定和限定,属于“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。In the description of the present invention, it should be noted that, unless otherwise specified and limited, "installation", "connection" and "connection" should be understood in a broad sense, for example, it can be a fixed connection or a detachable connection. Connected, or integrally connected; it can be mechanically connected or electrically connected; it can be directly connected or indirectly connected through an intermediary, and it can be the internal communication of two components. Those of ordinary skill in the art can understand the specific meanings of the above terms in the present invention in specific situations.
此外,下面所描述的本发明不同实施方式中所涉及的技术特征只要彼此之间未构成冲突就可以相互结合。In addition, the technical features involved in the different embodiments of the present invention described below may be combined with each other as long as there is no conflict with each other.
在一示例中,如图1所示,一种基于智慧工业的数据异常检测方法,该方法具体包括以下步骤:In an example, as shown in Figure 1, a data anomaly detection method based on smart industry, the method specifically includes the following steps:
S1’:通过第二神经网络模型学习卡尔曼滤波算法的协方差矩阵的变化趋势,进而更新协方差矩阵P,以此实现对KF算法(卡尔曼滤波算法)的改进,再采用改进的KF算法分别对各种工业数据进行处理,完成局部特征提取;S1': Learn the change trend of the covariance matrix of the Kalman filter algorithm through the second neural network model, and then update the covariance matrix P, so as to realize the improvement of the KF algorithm (Kalman filter algorithm), and then adopt the improved KF algorithm Process various industrial data separately to complete local feature extraction;
S2’:将完成卡尔曼滤波处理后的工业数据输入第一神经网络模型,完成多种数据的数据融合,进一步挖掘各数据间的关系,进而实现异常预测。S2': Input the industrial data processed by Kalman filter into the first neural network model, complete the data fusion of various data, further mine the relationship between each data, and then realize the abnormal prediction.
具体地,步骤S1中,第二神经网络模型可以为门控循环神经网络(GRU网络)或长短期记忆网络(LSTM网络),本示例优选为GRU网络。进一步地,将不同数据采集器如传感器采集的数据作为一种工业数据,包括温度数据、气压数据、流量数据等,本步骤中各种工业数据可以是一种类型的数据,如均为温度数据,区别在于通过不同数据采集器进行采集,可以为不同装置或相同装置不同部位的温度数据等。Specifically, in step S1, the second neural network model may be a gated recurrent neural network (GRU network) or a long short-term memory network (LSTM network). In this example, it is preferably a GRU network. Further, the data collected by different data collectors such as sensors is used as a kind of industrial data, including temperature data, air pressure data, flow data, etc. In this step, various industrial data can be one type of data, such as temperature data , the difference is that it is collected by different data collectors, which can be temperature data of different devices or different parts of the same device.
进一步地,卡尔曼滤波算法为现有算法,包括预测部分与更新部分,预测部分的具体数据处理公式包括:Furthermore, the Kalman filtering algorithm is an existing algorithm, including a prediction part and an update part, and the specific data processing formula of the prediction part includes:


其中,


状态更新部分的具体数据处理公式包括:The specific data processing formulas in the status update section include:



其中,Kk表示卡尔曼系数;Pk表示k时刻的协方差矩阵;C表示观测矩阵;T表示矩阵转置;R表示观测噪声协方差矩阵;yk表示观测量;I表示单位矩阵。Among them, Kk is the Kalman coefficient; Pk is the covariance matrix at time k; C is the observation matrix; T is the matrix transpose; R is the observation noise covariance matrix; yk is the observation quantity; I is the identity matrix.
KF算法在推测时考虑了噪声的影响,噪声通过协方差矩阵P传递给下个状态值。如果能够精准的更新协方差矩阵P,就能提高滤波精度,防止滤波发散。本发明中,改进的KF算法,是利用神经网络模型超强的表征能力,准确捕捉协方差矩阵的状态变更,即利用神经网络模型捕捉KF算法的协方差矩阵的变化趋势,能够动态调整过程激励噪声协方差矩阵Q(现有KF算法中,Q为经验定值),使更新后的协方差矩阵P更加接近真实值,以此降低噪声对KF算法的影响,提高了卡尔曼滤波处理精度,进而保证了后续神经网络模型的异常预测准确性与可靠性。同时,需要说明的是,本发明方法基于改进KF算法结合神经网络模型进行异常检测,由于未采用聚类算法,因此不存在现有基于聚类算法进行异常检测的无监督算法中存在的缺点。且卡尔曼滤波对初值友好,通常情况可以随机选取初值或用初始时刻测量值代替,即使有偏差,经过慢慢迭代,也会使偏差急剧缩小。在迭代过程中,卡尔曼滤波考虑观测噪声和系统噪声,结合观测值与估计值综合考虑,得到最优估计值,不易受到噪声与孤立点的影响。The KF algorithm takes into account the influence of noise when inferring, and the noise is passed to the next state value through the covariance matrix P. If the covariance matrix P can be updated accurately, the filtering accuracy can be improved and the filtering divergence can be prevented. In the present invention, the improved KF algorithm is to use the super strong representation ability of the neural network model to accurately capture the state change of the covariance matrix, that is, to use the neural network model to capture the change trend of the covariance matrix of the KF algorithm, and to dynamically adjust the process incentives. The noise covariance matrix Q (in the existing KF algorithm, Q is an empirically determined value), makes the updated covariance matrix P closer to the real value, thereby reducing the impact of noise on the KF algorithm and improving the processing accuracy of Kalman filtering. This ensures the accuracy and reliability of the abnormal prediction of the subsequent neural network model. At the same time, it should be noted that the method of the present invention is based on the improved KF algorithm combined with the neural network model for anomaly detection. Since the clustering algorithm is not used, there are no shortcomings in the existing unsupervised algorithm for anomaly detection based on the clustering algorithm. Moreover, the Kalman filter is friendly to the initial value. Usually, the initial value can be randomly selected or replaced by the measured value at the initial time. Even if there is a deviation, after slow iterations, the deviation will be sharply reduced. In the iterative process, the Kalman filter considers the observation noise and system noise, and combines the observation value and the estimated value to obtain the optimal estimated value, which is not easily affected by noise and isolated points.
进一步地,本发明采用改进KF算法对工业数据进行处理,能够剔除冗余数据,对各信息源进行统一处理,以此保证测量准确性;同时改进的KF算法还能够确定工业数据流的时序特征,进而使本方法能够对不具有时序特征的数据流进行准确异常检测。Further, the present invention uses the improved KF algorithm to process industrial data, which can eliminate redundant data and uniformly process each information source, so as to ensure measurement accuracy; at the same time, the improved KF algorithm can also determine the timing characteristics of industrial data streams , so that the method can perform accurate anomaly detection on data streams that do not have timing characteristics.
在一示例中,协方差矩阵

其中,函数f(·)是通过第二神经网络模型学习拟合协方差矩阵的变化趋势。Wherein, the function f(·) is the variation trend of the fitted covariance matrix learned through the second neural network model.
在一示例中,如图2所示,利用第二神经网络模型学习卡尔曼滤波算法的协方差矩阵的变化趋势包括:In an example, as shown in FIG. 2, using the second neural network model to learn the variation trend of the covariance matrix of the Kalman filter algorithm includes:
S11’:根据k-1时刻的状态

S12’:由k-1时刻的误差协方差矩阵Pk-1推出中间变量
S13’:通过中间变量
S14’:根据卡尔曼增益系数Kk获得k时刻状态最优估计
S15’:更新k时刻的协方差矩阵Pk,具体基于上述公式(5)进行更新。需要进一步说明的是,图2中,“predict”表示预测,“update”表示更新。S15': Update the covariance matrix Pk at time k, specifically based on the above formula (5). It should be further explained that in Figure 2, "predict" means prediction, and "update" means update.
在一示例中,通过第二神经网络模型学习卡尔曼滤波算法的协方差矩阵的变化趋势前还包括:In an example, before learning the change trend of the covariance matrix of the Kalman filter algorithm through the second neural network model, it also includes:
将状态转移矩阵A、过程激励噪声协方差矩阵Q、初始协方差矩阵P作为输入,对第二神经网络模型进行训练,进而得到能够预测更新协方差矩阵的第二神经网络模型,基于第二神经网络模型的非线性处理能力进而动态调整过程激励噪声协方差矩阵Q。The state transition matrix A, the process excitation noise covariance matrix Q, and the initial covariance matrix P are used as input to train the second neural network model, and then a second neural network model capable of predicting and updating the covariance matrix is obtained. Based on the second neural network The nonlinear processing capability of the network model can then dynamically adjust the process excitation noise covariance matrix Q.
在一示例中,第一神经网络模型为应用注意力机制的门控循环神经网络,即GRU_Attention网络。当然,作为一选项,也可采用应用注意力机制的长短期记忆网络,即LSTM_Attention网络。In an example, the first neural network model is a gated recurrent neural network applying an attention mechanism, that is, a GRU_Attention network. Of course, as an option, a long-short-term memory network with an attention mechanism, that is, the LSTM_Attention network, can also be used.
在一示例中,将完成卡尔曼滤波处理后的工业数据输入第一神经网络模型前还包括:In an example, before inputting the industrial data processed by the Kalman filter into the first neural network model, it also includes:
S02’:构建GRU_Attention网络。具体地,工业数据具有较强的时序性,时间特征的充分准确提取对于精确预测未来数据十分关键,因此本发明采用能够处理时序数据的GRU网络,并在GRU的基础上应用Attention机制,将各隐藏单元的输出结果与一个相关性权重矩阵进行点乘,获得更完整的时间特征,进一步保证了本发明对不具有时序特征的数据流进行异常检测的准确度,提高了网络的异常检测性能。根据样本数据序列的长度,设置GRU中隐藏层单元个数为g。本发明采用一层激活函数为Softmax的全连层来实现Attention机制,其输入为GRU隐藏层各单元的输出,其输出为各隐藏层输出结果与最后预测目标的相关性权重。S02': Build a GRU_Attention network. Specifically, industrial data has a strong time sequence, and sufficient and accurate extraction of time features is critical for accurate prediction of future data. Therefore, the present invention adopts a GRU network capable of processing time series data, and applies the Attention mechanism on the basis of the GRU to combine each The output result of the hidden unit is dot-multiplied with a correlation weight matrix to obtain a more complete time feature, which further ensures the accuracy of the present invention for anomaly detection on data streams that do not have timing characteristics, and improves the anomaly detection performance of the network. According to the length of the sample data sequence, set the number of hidden layer units in the GRU to be g. The present invention adopts a fully connected layer whose activation function is Softmax to realize the Attention mechanism, whose input is the output of each unit of the GRU hidden layer, and whose output is the correlation weight between the output results of each hidden layer and the final prediction target.
采用GRU_Attention网络提取数据的时间特征具体实现方式为:The specific implementation of the time features of the data extracted by the GRU_Attention network is as follows:
GRU网络中每一个重复模块都包含了更新门和重置门。重置门的输入为上一时刻的隐藏状态ht-1和当前时刻的输入Xt,经过合并之后,得到[ht-1,Xt],再乘上权重之后重新输入到sigmoid函数中,得到一个0~1之间的向量rt,公式如下:Each repeating module in the GRU network contains an update gate and a reset gate. The input of the reset gate is the hidden state ht-1 of the previous moment and the input Xt of the current moment. After merging, [ht-1 , Xt ] is obtained, and then multiplied by the weight and re-input into the sigmoid function , to get a vector rt between 0 and 1, the formula is as follows:
rt=σ(Wr·[ht-1,xt]) (7)rt = σ(Wr ·[ht-1 , xt ]) (7)
rt决定了上一时刻传来的隐藏状态中的信息,哪些需要被剔除,哪些需要被保留。若值为1时,表示隐藏状态信息全部被保留。计算备选隐藏状态

其中,tanh()为双曲线激活函数,W为权重参数。更新门用于控制上一个GRU单元的状态变量ht-1和新进入GRU单元的向量
Zt=σ(Wz·[ht-1,xt]) (9)Zt = σ(Wz ·[ht-1 , xt ]) (9)

其中Wz为更新门参数,通过GRU得到不同时刻的隐藏状态hn,将其作为Attention机制层的输入。Attention机制层的权重系数具体通过以下几个公式进行计算:Among them, Wz is the update gate parameter, and the hidden state hn at different moments is obtained through GRU, which is used as the input of the Attention mechanism layer. The weight coefficient of the Attention mechanism layer is calculated by the following formulas:
et=utanh(wht+b) (11)et = utanh(wht +b) (11)


其中,et、ej表示由GRU输出向量在t、j时刻确定的注意力概率分布的值,u和w是权重系数,b是偏置系数,st表示attention层在时间t的输出。输出层实现公式如下:Among them, et and ej represent the value of the attention probability distribution determined by the GRU output vector at time t and j, u and w are the weight coefficients, b is the bias coefficient, andst represents the output of the attention layer at time t. The output layer implementation formula is as follows:
yt=softmax(wst+b1) (14)yt =softmax(wst +b1 ) (14)
其中,w表示全连层的权重矩阵,b1表示全连层的偏置,yt为输出的预测标签,进而得到当前异常检测结果。Among them, w represents the weight matrix of the fully connected layer, b1 represents the bias of the fully connected layer, and yt is the output prediction label, and then the current anomaly detection result is obtained.
在一示例中,将采集的工业数据进行卡尔曼滤波处理前还包括数据预处理:In an example, data preprocessing is also included before the collected industrial data is processed by Kalman filtering:
S0’:对工业数据进行异常值处理、缺失值处理以及归一化处理。具体地,可将与平均值的偏差超过三倍标准差的测定值称为高度异常的异常值,异常值处理即剔除异常值,以此保证数据流的可靠性。缺失值处理即填补缺失的数据,可通过相同状态下历史值或者前后相邻数据平均值进行填补。归一化处理即将数据流转换为标量,便于后续数据处理。S0': Perform abnormal value processing, missing value processing and normalization processing on industrial data. Specifically, the measurement value whose deviation from the average value exceeds three times the standard deviation can be called a highly abnormal outlier, and the outlier processing is to eliminate the outlier, so as to ensure the reliability of the data stream. Missing value processing is to fill in missing data, which can be filled by historical values in the same state or the average value of adjacent data before and after. Normalization processing is to convert the data stream into a scalar, which is convenient for subsequent data processing.
将上述示例进行组合,得到本发明的优选示例,如图3-4所示,此时该异常检测方法包括以下步骤:Combining the above examples to obtain a preferred example of the present invention, as shown in Figure 3-4, at this time, the anomaly detection method includes the following steps:
S1:采集工业样本数据;S1: Collect industrial sample data;
S2:对工业数据进行异常值处理、缺失值处理以及归一化处理;S2: Perform abnormal value processing, missing value processing and normalization processing on industrial data;
S3:将各种完成预处理的数据分别输入改进的卡尔曼滤波器进行处理;S3: Input various preprocessed data into the improved Kalman filter for processing;
S4:构建GRU_Attention网络;S4: Build a GRU_Attention network;
S5:将完成卡尔曼滤波的不同数据数据进行拼接,并输入GRU_Attention网络进行异常预测;S5: Splice the different data data that have completed the Kalman filter, and input it into the GRU_Attention network for abnormal prediction;
S6:对预测数据进行逆向归一化变化处理得到最终异常检测结果。S6: Perform reverse normalization change processing on the predicted data to obtain the final anomaly detection result.
当然,作为一选项,S4构建GRU_Attention网络也可在步骤S3前执行。Of course, as an option, S4 constructing the GRU_Attention network can also be performed before step S3.
本申请还包括一种存储介质,与上述任一示例或多个示例组成的基于智慧工业的数据异常检测方法具有相同的发明构思,其上存储有计算机指令,所述计算机指令运行时执行上述基于智慧工业的数据异常检测方法的步骤。The present application also includes a storage medium, which has the same inventive concept as the intelligent industry-based data anomaly detection method composed of any one or more of the above-mentioned examples, on which computer instructions are stored, and when the computer instructions are run, the above-mentioned Steps of data anomaly detection method for smart industry.
基于这样的理解,本实施例的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(Read-Only Memory,ROM)、随机存取存储器(Random AccessMemory,RAM)、磁碟或者光盘等各种可以存储程序代码的介质。Based on this understanding, the technical solution of this embodiment is essentially or the part that contributes to the prior art or the part of the technical solution can be embodied in the form of a software product, and the computer software product is stored in a storage medium. Several instructions are included to make a computer device (which may be a personal computer, server, or network device, etc.) execute all or part of the steps of the method described in each embodiment of the present invention. The above-mentioned storage medium includes: U disk, mobile hard disk, read-only memory (Read-Only Memory, ROM), random access memory (Random Access Memory, RAM), magnetic disk or optical disk and other various media that can store program codes.
本申请还包括一种终端,与上述任一示例或多个示例组成的基于智慧工业的数据异常检测方法具有相同的发明构思,包括存储器和处理器,所述存储器上存储有可在所述处理器上运行的计算机指令,所述处理器运行所述计算机指令时执行上述基于智慧工业的数据异常检测方法的步骤。处理器可以是单核或者多核中央处理单元或者特定的集成电路,或者配置成实施本发明的一个或者多个集成电路。The present application also includes a terminal, which has the same inventive concept as the smart industry-based data anomaly detection method composed of any one or more of the above examples, including a memory and a processor, and the memory stores information that can be used in the processing computer instructions running on the processor, and the processor executes the steps of the above-mentioned smart industry-based data anomaly detection method when running the computer instructions. The processor may be a single-core or multi-core central processing unit or a specific integrated circuit, or one or more integrated circuits configured to implement the present invention.
在本发明提供的实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。Each functional unit in the embodiments provided by the present invention may be integrated into one processing unit, or each unit may physically exist separately, or two or more units may be integrated into one unit.
以上具体实施方式是对本发明的详细说明,不能认定本发明的具体实施方式只局限于这些说明,对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演和替代,都应当视为属于本发明的保护范围。The above specific embodiment is a detailed description of the present invention, and it cannot be determined that the specific embodiment of the present invention is only limited to these descriptions. For those of ordinary skill in the technical field of the present invention, they can also Making some simple deduction and substitution should be regarded as belonging to the protection scope of the present invention.
Claims (10)







Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310181817.2ACN116415196A (en) | 2023-02-28 | 2023-02-28 | Data anomaly detection method, storage medium and terminal based on smart industry |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310181817.2ACN116415196A (en) | 2023-02-28 | 2023-02-28 | Data anomaly detection method, storage medium and terminal based on smart industry |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN116415196Atrue CN116415196A (en) | 2023-07-11 |
Family
ID=87050570
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202310181817.2APendingCN116415196A (en) | 2023-02-28 | 2023-02-28 | Data anomaly detection method, storage medium and terminal based on smart industry |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN116415196A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN119131140A (en)* | 2024-09-04 | 2024-12-13 | 南京信息工程大学 | A robust UAV-unmanned ship collaborative relative visual positioning method and system |
- 2023
- 2023-02-28CNCN202310181817.2Apatent/CN116415196A/enactivePending
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN119131140A (en)* | 2024-09-04 | 2024-12-13 | 南京信息工程大学 | A robust UAV-unmanned ship collaborative relative visual positioning method and system |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20230094389A1 (en) | Quantum computing based deep learning for detection, diagnosis and other applications | |
| Xia et al. | Deciphering spatio-temporal graph forecasting: A causal lens and treatment | |
| CN109766992B (en) | Anomaly detection and attack classification method for industrial control based on deep learning | |
| CN112765896A (en) | LSTM-based water treatment time sequence data anomaly detection method | |
| WO2022160902A1 (en) | Anomaly detection method for large-scale multivariate time series data in cloud environment | |
| CN111914873A (en) | Two-stage cloud server unsupervised anomaly prediction method | |
| CN115168443B (en) | Anomaly detection method and system based on GCN-LSTM and attention mechanism | |
| CN111142501A (en) | Fault detection method based on semi-supervised autoregressive dynamic latent variable model | |
| CN114048546B (en) | Method for predicting residual service life of aeroengine based on graph convolution network and unsupervised domain self-adaption | |
| CN116520806A (en) | Intelligent fault diagnosis system and method for industrial system | |
| CN116340796B (en) | Time sequence data analysis method, device, equipment and storage medium | |
| CN115184054B (en) | Mechanical equipment semi-supervised fault detection and analysis method, device, terminal and medium | |
| CN114528547B (en) | ICPS unsupervised online attack detection method and device based on community feature selection | |
| CN117676099B (en) | Security early warning method and system based on Internet of things | |
| CN117909881A (en) | Fault diagnosis method and device for multi-source data fusion pumping unit | |
| CN119475328B (en) | Data stream intelligent reconstruction method, device and intelligent chip for integrated module | |
| CN116244647A (en) | Unmanned aerial vehicle cluster running state estimation method | |
| CN117612277A (en) | Unsupervised Internet of Vehicles anomaly detection method and system based on physically invariant subspace | |
| CN118520397A (en) | Data anomaly detection method and system for distributed network | |
| Qin et al. | Remaining useful life prediction using temporal deep degradation network for complex machinery with attention-based feature extraction | |
| CN116680613A (en) | Human activity recognition comprehensive optimization method based on multi-scale metric learning | |
| CN116415196A (en) | Data anomaly detection method, storage medium and terminal based on smart industry | |
| Yang et al. | Lightweight fault prediction method for edge networks | |
| CN118133435A (en) | Complex spacecraft on-orbit anomaly detection method based on SVR and clustering | |
| CN118193954A (en) | A method and system for detecting abnormal data in distribution network based on edge computing |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |