CN116386068A - Webpage text extraction method, device, equipment and storage medium based on image text - Google Patents
Webpage text extraction method, device, equipment and storage medium based on image textDownload PDFInfo
- Publication number
- CN116386068A CN116386068ACN202310300637.1ACN202310300637ACN116386068ACN 116386068 ACN116386068 ACN 116386068ACN 202310300637 ACN202310300637 ACN 202310300637ACN 116386068 ACN116386068 ACN 116386068A
- Authority
- CN
- China
- Prior art keywords
- text
- image
- data
- webpage
- picture
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images




Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/40—Document-oriented image-based pattern recognition
- G06V30/41—Analysis of document content
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/33—Querying
- G06F16/3331—Query processing
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/951—Indexing; Web crawling techniques
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/14—Image acquisition
- G06V30/1444—Selective acquisition, locating or processing of specific regions, e.g. highlighted text, fiducial marks or predetermined fields
- G06V30/1448—Selective acquisition, locating or processing of specific regions, e.g. highlighted text, fiducial marks or predetermined fields based on markings or identifiers characterising the document or the area
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/16—Image preprocessing
- G06V30/164—Noise filtering
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/18—Extraction of features or characteristics of the image
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/19—Recognition using electronic means
- G06V30/191—Design or setup of recognition systems or techniques; Extraction of features in feature space; Clustering techniques; Blind source separation
- G06V30/19147—Obtaining sets of training patterns; Bootstrap methods, e.g. bagging or boosting
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/19—Recognition using electronic means
- G06V30/191—Design or setup of recognition systems or techniques; Extraction of features in feature space; Clustering techniques; Blind source separation
- G06V30/19173—Classification techniques
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Multimedia (AREA)
- Databases & Information Systems (AREA)
- Data Mining & Analysis (AREA)
- General Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Artificial Intelligence (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及大数据技术领域,尤其涉及一种基于图文的网页正文提取方法、装置、设备及计算机可读存储介质。The present invention relates to the field of big data technology, and in particular to a method, device, equipment and computer-readable storage medium for extracting webpage text based on graphics and text.
背景技术Background technique
随着计算机网络的发展,大数据受到越来越大的关注,众多企业开始从互联网上获取海量数据进行分析,帮助企业进行决策及进步。With the development of computer networks, big data has received more and more attention. Many companies have begun to obtain massive data from the Internet for analysis to help companies make decisions and make progress.
传统网页正文的提取方法需要懂得网页结构,制定专业模板实施数据爬取。然而如今网络上的网页数量爆发式增长,网页结构也各有不同,难以制定符合各个网络的数据爬取模板,获取网络数据的速度与质量大大降低。The traditional method of extracting webpage text needs to understand the structure of the webpage, and formulate a professional template to implement data crawling. However, the number of webpages on the Internet is growing explosively, and the structure of webpages is also different. It is difficult to formulate data crawling templates suitable for each network, and the speed and quality of obtaining network data are greatly reduced.
发明内容Contents of the invention
本发明提供一种基于图文的网页正文提取方法、装置、设备及存储介质,其主要目的在于通过图文识别定位对网页正文进行提取,增加网络正文爬取的效率及普遍性。The present invention provides a method, device, device and storage medium for extracting webpage text based on images and texts, the main purpose of which is to extract webpage texts by identifying and positioning images and texts, so as to increase the efficiency and universality of web text crawling.
为实现上述目的,本发明提供的一种基于图文的网页正文提取方法,包括:In order to achieve the above object, a method for extracting webpage text based on graphics and text provided by the present invention includes:
根据预设关键词检索得到目标网页,并抓取所述目标网页的超文本标记数据,及截取所述目标网页的网页图像;Retrieving the target webpage according to preset keywords, grabbing the hypertext markup data of the target webpage, and intercepting the webpage image of the target webpage;
利用预训练的图片文本识别模型,对所述网页图像进行对象识别,并对对象识别结果执行标记框选操作,得到正文文本块集合及图片区域集合;Using a pre-trained image text recognition model, object recognition is performed on the webpage image, and a mark-and-frame selection operation is performed on the object recognition result to obtain a body text block set and a picture area set;
根据预设的图文冲突筛选规则及所述正文文本块集合,对所述图片区域集合进行正文区域筛选,得到正文图片区域集合;According to the preset image-text conflict screening rules and the text block set, perform text area screening on the picture area set to obtain a text picture area set;
对所述正文文本块集合中的各个正文文本块进行文本识别,得到正文文本序列,并对各个所述正文文本序列进行文本序号的标记操作;Performing text recognition on each text text block in the text text block set to obtain a text text sequence, and performing a text serial number marking operation on each of the text text sequences;
根据所述正文图片区域集合中各个正文图片区域的上下文相邻的正文文本序列的文本序号,对所述超文本标记数据进行查询,得到正文图像数据;According to the text serial number of the contextually adjacent text text sequence of each text image area in the text image area set, query the hypertext markup data to obtain text image data;
判断各个所述正文文本序列的语句完整性;judging the sentence integrity of each of said body text sequences;
根据语句不完整的正文文本序列,对所述超文本标记数据进行查询,得到正文文本数据;Querying the hypertext markup data according to the text sequence of the incomplete sentence to obtain the text data of the text;
将语句完整的正文文本序列、所述正文文本数据及所述正文图像数据存储至预构建的数据库中。The complete text sequence of the sentence, the text data and image data of the text are stored in a pre-built database.
可选的,所述根据预设的图文冲突筛选规则及所述正文文本块集合,对所述图片区域集合进行正文区域筛选,得到正文图片区域集合,包括:Optionally, according to the preset image-text conflict screening rules and the text text block set, the text area screening is performed on the picture area set to obtain the text picture area set, including:
根据预设的图文冲突筛选规则,构建所述正文文本块集合的最大外切框架;Construct the largest circumscribed frame of the body text block set according to preset image-text conflict screening rules;
识别所述图片区域集合中各个图片区域与所述最大外切框架的位置关系,并根据各个图片区域的位置关系,从所述图片区域集合中提取内置图片集合;identifying the positional relationship between each picture area in the picture area set and the maximum circumscribed frame, and extracting a built-in picture set from the picture area set according to the positional relationship of each picture area;
识别所述内置图片集中各个内置图片的图文覆盖冲突关系,并根据所述图文覆盖冲突关系,从所述内含图片集合中提取未覆盖文本的内置图片,得到正文图片区域集合。Identifying the graphic-text coverage conflict relationship of each built-in picture in the built-in picture set, and extracting the built-in pictures that do not cover text from the set of included pictures according to the graphic-text coverage conflict relationship to obtain a text picture area set.
可选的,所述利用预训练的图片文本识别模型,对所述网页图像进行对象识别,包括:Optionally, using a pre-trained image text recognition model to perform object recognition on the web page image includes:
对所述网页图像进行高斯滤波处理,得到降噪图像;performing Gaussian filter processing on the webpage image to obtain a noise-reduced image;
利用预训练的图片文本识别模型,对所述降噪图像进行特征提取操作,得到图像特征序列;Using a pre-trained image text recognition model, performing feature extraction operations on the noise-reduced image to obtain an image feature sequence;
对所述图像特征序列进行基于文字字体及文字背景的全连接图文分类,得到对象识别结果。Carrying out fully-connected image-text classification based on text fonts and text backgrounds on the image feature sequence to obtain object recognition results.
可选的,所述利用预训练的图片文本识别模型,对所述网页图像进行对象识别之前,所述方法还包括:Optionally, before performing object recognition on the web page image using the pre-trained image text recognition model, the method further includes:
利用预设埋点抓取海量数据文本并分类得到图片样本及文本样本,并对所述图片样本及所述文本样本标记上类型标签;Using preset buried points to capture massive data texts and classify them to obtain image samples and text samples, and label the image samples and the text samples with type labels;
将标记后的图片样本及所述文本样本混合作为图文样本集合,并将所述图文样本集合根据预设比例进行随机分组,得到训练集及测试集;Mixing the marked picture sample and the text sample as a graphic sample set, and randomly grouping the graphic sample set according to a preset ratio to obtain a training set and a test set;
依次从所述训练集中提取一个训练样本,并利用预构建的图片文本识别模型对所述训练样本进行基于图片及文本的分类,得到测试类别;Extracting a training sample from the training set in turn, and using a pre-built picture text recognition model to classify the training sample based on pictures and text to obtain a test category;
利用交叉熵损失算法,计算所述训练样本的类型标签与所述测试类别之间的损失值,并最小化所述损失值,得到所述损失值最小时所述图片文本识别模型的模型参数,并根据梯度下降方法对所述模型参数进行网络逆向更新,得到更新图片文本识别模型;Using the cross-entropy loss algorithm to calculate the loss value between the type label of the training sample and the test category, and minimize the loss value to obtain the model parameters of the picture text recognition model when the loss value is the smallest, And according to the gradient descent method, the network reverse update is carried out to the model parameters, and an updated picture text recognition model is obtained;
判断所述训练集中的训练样本是否全部参与训练;judging whether all the training samples in the training set participate in the training;
当所述训练集中的训练样本未全部参与训练,则返回上述依次从所述训练集中提取一个训练样本的步骤,对所述更新图片文本识别模型进行迭代训练;When the training samples in the training set do not all participate in the training, return to the above-mentioned step of sequentially extracting a training sample from the training set, and iteratively train the updated image text recognition model;
当所述训练集中的训练样本全部参与训练,则利用所述测试集对所述更新图片文本识别模型进行测试,得到测试准确率;When all the training samples in the training set participate in the training, the test set is used to test the updated picture text recognition model to obtain the test accuracy;
判断所述测试准确率是否大于或等于预设的合格阈值;Judging whether the test accuracy rate is greater than or equal to a preset qualified threshold;
当所述测试准确率小于所述合格阈值时,返回上述将所述图文样本集合根据预设比例进行随机分组的步骤,对所述图文样本集合进行重新分组,并对所述更新图片文本识别模型进行更新;When the test accuracy rate is less than the qualified threshold, return to the above-mentioned step of randomly grouping the graphic sample set according to the preset ratio, regroup the graphic sample set, and update the image text The recognition model is updated;
当所述测试准确率大于或等于所述合格阈值时,得到训练完成的图片文本识别模型。When the test accuracy rate is greater than or equal to the qualified threshold, a trained picture-to-text recognition model is obtained.
可选的,所述抓取所述目标网页的超文本标记数据,包括:Optionally, the crawling the hypertext markup data of the target webpage includes:
利用预构建的请求库向所述目标网页发送了一个请求,得到所述目标网页反馈的状态码,并判断所述状态码是否请求成功;sending a request to the target webpage by using a pre-built request library, obtaining a status code fed back by the target webpage, and judging whether the status code is successfully requested;
当所述状态码请求成功时,根据响应文本属性抓取所述目标网页的加密超文本标记数据,并利用使用预构建的美丽汤库解析所述加密超文本标记数据,得到解密超文本标记数据;When the status code request is successful, grab the encrypted hypertext markup data of the target web page according to the response text attribute, and use the pre-built beautiful soup library to analyze the encrypted hypertext markup data to obtain the decrypted hypertext markup data ;
利用预构建的美化函数,对所述解密超文本标记数据进行格式化输出,得到所述目标网页的超文本标记数据。The pre-built beautification function is used to format and output the decrypted hypertext markup data to obtain the hypertext markup data of the target webpage.
可选的,所述根据所述正文图片区域集合中各个正文图片区域的上下文相邻的正文文本序列的文本序号,对所述超文本标记数据进行查询,得到正文图像数据,包括:Optionally, according to the text number of the context-adjacent text text sequence of each text image area in the text image area set, the hypertext markup data is queried to obtain text image data, including:
在所述超文本标记数据中查询所述上下文相邻的正文文本序列的文本序号,得到所述上下文相邻的正文文本序列的文本序号对应的正文文本块的文件数据位置,并在所述文件数据位置中查找内嵌图片的img标签;Query the text sequence number of the context-adjacent text sequence in the hypertext markup data, obtain the file data position of the text block corresponding to the text sequence number of the context-adjacent text sequence, and add Find the img tag of the embedded image in the data location;
根据所述img标签查询所述超文本标记数据,得到正文图像数据。The hypertext markup data is queried according to the img tag to obtain text image data.
可选的,所述判断各个所述正文文本序列的语句完整性,包括:Optionally, the judging the sentence integrity of each text sequence includes:
识别所述正文文本序列的语法完整性,得到第一完整性分数;identifying grammatical completeness of the body text sequence to obtain a first completeness score;
识别所述正文文本序列的语义完整性,得到第二完整性分数;identifying the semantic integrity of the body text sequence to obtain a second integrity score;
识别所述文本正文序列的上下文知识完整性,得到第三完整性分数;identifying contextual knowledge completeness of said text body sequence to obtain a third completeness score;
根据预设的权重配置规则,对所述第一完整性分数、所述第二完整性分数及所述第三完整性分数进行加权计算,得到所述正文文本序列的语句完整性。Perform weighted calculations on the first integrity score, the second integrity score, and the third integrity score according to preset weight configuration rules to obtain the sentence integrity of the text sequence.
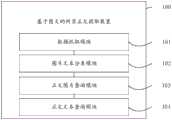
为了解决上述问题,本发明还提供一种基于图文的网页正文提取装置,所述装置包括:In order to solve the above problems, the present invention also provides a device for extracting webpage text based on graphics and text, said device comprising:
数据抓取模块,用于根据预设关键词检索得到目标网页,并抓取所述目标网页的超文本标记数据,及截取所述目标网页的网页图像;The data capture module is used to retrieve the target webpage according to preset keywords, and capture the hypertext markup data of the target webpage, and intercept the webpage image of the target webpage;
图片文本分类模块,用于利用预训练的图片文本识别模型,对所述网页图像进行对象识别,并对对象识别结果执行标记框选操作,得到正文文本块集合及图片区域集合;The picture text classification module is used to utilize the pre-trained picture text recognition model to carry out object recognition to the web page image, and perform a mark and frame selection operation on the object recognition result to obtain a body text block set and a picture area set;
正文图片查询模块,用于对所述正文文本块集合中的各个正文文本块进行文本识别,得到正文文本序列,并对各个所述正文文本序列进行文本序号的标记操作,及根据所述正文图片区域集合中各个正文图片区域的上下文相邻的正文文本序列的文本序号,对所述超文本标记数据进行查询,得到正文图像数据;The text picture query module is used to perform text recognition on each text text block in the text text block set, obtain a text text sequence, and perform a text serial number marking operation on each of the text text sequences, and according to the text image The text serial number of the contextually adjacent text text sequence of each text picture area in the area set is queried to the hypertext tag data to obtain the text image data;
正文文本查询模块,用于判断各个所述正文文本序列的语句完整性,及根据语句不完整的正文文本序列,对所述超文本标记数据进行查询,得到正文文本数据,及将语句完整的正文文本序列、所述正文文本数据及所述正文图像数据存储至预构建的数据库中。The body text query module is used to judge the sentence integrity of each of the body text sequences, and according to the incomplete body text sequence of the sentence, query the hypertext tag data, obtain the text data, and query the complete text of the sentence The text sequence, the text data of the text and the image data of the text are stored in a pre-built database.
为了解决上述问题,本发明还提供一种电子设备,所述电子设备包括:In order to solve the above problems, the present invention also provides an electronic device, which includes:
至少一个处理器;以及,at least one processor; and,
与所述至少一个处理器通信连接的存储器;其中,a memory communicatively coupled to the at least one processor; wherein,
所述存储器存储有可被所述至少一个处理器执行的计算机程序,所述计算机程序被所述至少一个处理器执行,以使所述至少一个处理器能够执行上述所述的基于图文的网页正文提取方法。The memory stores a computer program that can be executed by the at least one processor, and the computer program is executed by the at least one processor, so that the at least one processor can execute the above-mentioned graphic-based webpage Text extraction method.
为了解决上述问题,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一个计算机程序,所述至少一个计算机程序被电子设备中的处理器执行以实现上述所述的基于图文的网页正文提取方法。In order to solve the above problems, the present invention also provides a computer-readable storage medium, at least one computer program is stored in the computer-readable storage medium, and the at least one computer program is executed by a processor in an electronic device to realize the above-mentioned The text-based text extraction method of web pages described above.
本发明实施例通过截取目标网页的网页图像,并识别出网页图像中的正文文本块与图片区域,再通过图文冲突筛选规则,提取正文图片区域,其中,所述图文冲突筛选规则,可以根据文本最大外切边界,剔除较多广告等不规范的图片,也能将图文覆盖冲突的图片进行删除,得到较为准确的正文图片区域;根据语句完整性对不完整的正文文本进行数据提取,得到全部的网页正文。因此,本发明实施例提供的一种基于图文的网页正文提取方法、装置、设备及存储介质,能够在于通过图文识别定位对网页正文进行提取,增加网络正文爬取的效率及普遍性。The embodiment of the present invention intercepts the webpage image of the target webpage, and recognizes the text block and the picture area in the webpage image, and then extracts the text picture area through the picture-text conflict screening rule, wherein the picture-text conflict screening rule can be According to the maximum circumscribed boundary of the text, many non-standard pictures such as advertisements are eliminated, and pictures with graphic and text coverage conflicts can also be deleted to obtain a more accurate text image area; data extraction is performed on incomplete texts according to the completeness of sentences , to get the full text of the web page. Therefore, an image-text-based webpage text extraction method, device, device, and storage medium provided by the embodiments of the present invention can extract webpage text through image-text recognition and positioning, and increase the efficiency and universality of webpage text crawling.
附图说明Description of drawings
图1为本发明一实施例提供的基于图文的网页正文提取方法的流程示意图;Fig. 1 is a schematic flow chart of a web page text extraction method based on graphics and text provided by an embodiment of the present invention;
图2为本发明一实施例提供的基于图文的网页正文提取方法中一个步骤的详细流程示意图;Fig. 2 is a detailed schematic flow diagram of a step in the method for extracting webpage text based on graphics and text provided by an embodiment of the present invention;
图3为本发明一实施例提供的基于图文的网页正文提取方法中一个步骤的详细流程示意图;Fig. 3 is a detailed schematic flow diagram of a step in the graphic-text-based webpage text extraction method provided by an embodiment of the present invention;
图4为本发明一实施例提供的基于图文的网页正文提取方法中一个步骤的详细流程示意图;Fig. 4 is a detailed schematic flow diagram of a step in a graphic-text-based webpage text extraction method provided by an embodiment of the present invention;
图5为本发明一实施例提供的基于图文的网页正文提取装置的功能模块图;FIG. 5 is a functional block diagram of a device for extracting webpage text based on graphics and text according to an embodiment of the present invention;
图6为本发明一实施例提供的实现所述基于图文的网页正文提取方法的电子设备的结构示意图。FIG. 6 is a schematic structural diagram of an electronic device implementing the image-text-based webpage text extraction method provided by an embodiment of the present invention.
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。The realization of the purpose of the present invention, functional characteristics and advantages will be further described in conjunction with the embodiments and with reference to the accompanying drawings.
具体实施方式Detailed ways
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
本申请实施例提供一种基于图文的网页正文提取方法。本申请实施例中,所述基于图文的网页正文提取方法的执行主体包括但不限于服务端、终端等能够被配置为执行本申请实施例提供的该方法的电子设备中的至少一种。换言之,所述基于图文的网页正文提取方法可以由安装在终端设备或服务端设备的软件或硬件来执行,所述软件可以是区块链平台。所述服务端包括但不限于:单台服务器、服务器集群、云端服务器或云端服务器集群等。所述服务器可以是独立的服务器,也可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、内容分发网络(ContentDelivery Network,CDN)、以及大数据和人工智能平台等基础云计算服务的云服务器。An embodiment of the present application provides a method for extracting webpage text based on graphics and text. In the embodiment of the present application, the execution subject of the image-text-based web page text extraction method includes but is not limited to at least one of electronic devices such as a server and a terminal that can be configured to execute the method provided in the embodiment of the present application. In other words, the image-text-based web page text extraction method can be executed by software or hardware installed on a terminal device or a server device, and the software can be a block chain platform. The server includes, but is not limited to: a single server, a server cluster, a cloud server or a cloud server cluster, and the like. The server can be an independent server, or it can provide cloud service, cloud database, cloud computing, cloud function, cloud storage, network service, cloud communication, middleware service, domain name service, security service, content distribution network (ContentDelivery Network) , CDN), and cloud servers for basic cloud computing services such as big data and artificial intelligence platforms.
参照图1所示,为本发明一实施例提供的基于图文的网页正文提取方法的流程示意图。在本实施例中,所述基于图文的网页正文提取方法包括:Referring to FIG. 1 , it is a schematic flowchart of a method for extracting webpage text based on images and texts according to an embodiment of the present invention. In this embodiment, the method for extracting webpage text based on graphic and text includes:
S1、根据预设关键词检索得到目标网页,并抓取所述目标网页的超文本标记数据,及截取所述目标网页的网页图像。S1. Retrieve a target webpage according to a preset keyword, capture hypertext markup data of the target webpage, and intercept a webpage image of the target webpage.
本发明实施例中,可以根据*查查、*博、*度等平台型关键词及企业、管理、用户画像等事件型关键词对互联网进行检索,得到目标网页列表,然后从列表中的各个目标网页进行正文抓取,得到超文本标记数据及截取网页图像。In the embodiment of the present invention, the Internet can be retrieved according to platform-type keywords such as *chacha, *bo, *degree, and event-type keywords such as enterprise, management, and user portraits to obtain a list of target web pages, and then from each The text of the target webpage is captured to obtain hypertext markup data and intercept webpage images.
其中,所述超文本标记数据(HyperText Mark-up Language,简称HTML),是一种制作万维网页面的标准语言,可以通过各种标签,将数据展示出来,本发明实施例中的超文本标记数据为解密后的数据。Wherein, the hypertext markup data (HyperText Mark-up Language, HTML for short) is a standard language for making World Wide Web pages, and data can be displayed through various tags. The hypertext markup data in the embodiment of the present invention is the decrypted data.
详细的,本发明实施例中,所述抓取所述目标网页的超文本标记数据,包括:In detail, in the embodiment of the present invention, the crawling of the hypertext markup data of the target webpage includes:
利用预构建的请求库向所述目标网页发送了一个请求,得到所述目标网页反馈的状态码,并判断所述状态码是否请求成功;sending a request to the target webpage by using a pre-built request library, obtaining a status code fed back by the target webpage, and judging whether the status code is successfully requested;
当所述状态码请求成功时,根据响应文本属性抓取所述目标网页的加密超文本标记数据,并利用使用预构建的美丽汤库解析所述加密超文本标记数据,得到解密超文本标记数据;When the status code request is successful, grab the encrypted hypertext markup data of the target web page according to the response text attribute, and use the pre-built beautiful soup library to analyze the encrypted hypertext markup data to obtain the decrypted hypertext markup data ;
利用预构建的美化函数,对所述解密超文本标记数据进行格式化输出,得到所述目标网页的超文本标记数据。The pre-built beautification function is used to format and output the decrypted hypertext markup data to obtain the hypertext markup data of the target webpage.
其中,所述请求库(requests库)及所述美丽汤库(BeautifulSoup库)均为Python中的库。Wherein, both the requests library (requests library) and the beautiful soup library (BeautifulSoup library) are libraries in Python.
例如,本发明实施例先通过requests库向*查查平台的一个企业网页发送GET请求,得到响应的状态码。当所述状态码是200时,表示请求通过,则可以通过响应文本(response.text)属性,抓取所述企业网页的HTML代码,然后利用所述BeautifulSoup库对所述HTML代码进行解析,得到解密HTML代码,最后通过美化函数(prettify())对所述解密HTML代码进行格式化输出,得到超文本标记数据。For example, the embodiment of the present invention first sends a GET request to an enterprise webpage of the *chacha platform through the requests library, and obtains a response status code. When the status code is 200, it means that the request is passed, then the HTML code of the enterprise webpage can be grabbed through the response text (response.text) attribute, and then the HTML code is analyzed by using the BeautifulSoup library to obtain The HTML code is decrypted, and finally the decrypted HTML code is formatted and output by a prettify function (prettify()) to obtain hypertext markup data.
此外,本发明实施例在爬取超文本标记数据时,还需要截取企业网页的网页图像,其中,所述网页图像是将所述企业网页完全展开,并滚动截取的图像。In addition, when the embodiment of the present invention crawls the hypertext markup data, it is also necessary to intercept the webpage image of the enterprise webpage, wherein the webpage image is an image captured by fully unfolding the enterprise webpage and scrolling.
S2、利用预训练的图片文本识别模型,对所述网页图像进行对象识别,并对对象识别结果执行标记框选操作,得到正文文本块集合及图片区域集合。S2. Using the pre-trained image text recognition model, perform object recognition on the web page image, and perform a mark-and-frame selection operation on the object recognition result to obtain a body text block set and a picture area set.
本发明实施例中,所述图片文本识别模型是一种用于识别文本及图片的图像卷积神经网络模型,包括文字识别、文字意图识别及文本背景范围识别的功能。In the embodiment of the present invention, the picture text recognition model is an image convolutional neural network model for recognizing text and pictures, including functions of character recognition, character intention recognition and text background range recognition.
详细的,本发明实施例中,所述利用预训练的图片文本识别模型,对所述网页图像进行对象识别,包括:In detail, in the embodiment of the present invention, the use of the pre-trained picture text recognition model to perform object recognition on the web page image includes:
对所述网页图像进行高斯滤波处理,得到降噪图像;performing Gaussian filter processing on the webpage image to obtain a noise-reduced image;
利用预训练的图片文本识别模型,对所述降噪图像进行特征提取操作,得到图像特征序列;Using a pre-trained image text recognition model, performing feature extraction operations on the noise-reduced image to obtain an image feature sequence;
对所述图像特征序列进行基于文字字体及文字背景的全连接图文分类,得到对象识别结果。Carrying out fully-connected image-text classification based on text fonts and text backgrounds on the image feature sequence to obtain object recognition results.
本发明实施例中,通过滤波器对网页图像进行高斯滤波,其中,所述高斯滤波是指对图像各像素之间的平滑处理。In the embodiment of the present invention, a filter is used to perform Gaussian filtering on the webpage image, wherein the Gaussian filtering refers to smoothing processing between pixels of the image.
本发明实施例通过所述图片文本识别模型中的特征提取网络,对所述降噪图像进行卷积、池化及扁平化处理,得到降维的图像特征序列,其中,所述图像特征序列中的元素个数与卷积过程的卷积核数量相同,每种卷积核负责识别一种特征。其中,池化及扁平化过程均是特征降维的过程,此处不加以赘述。The embodiment of the present invention uses the feature extraction network in the picture text recognition model to perform convolution, pooling, and flattening processing on the noise-reduced image to obtain a dimension-reduced image feature sequence, wherein the image feature sequence The number of elements is the same as the number of convolution kernels in the convolution process, and each convolution kernel is responsible for identifying a feature. Among them, the pooling and flattening processes are both feature dimensionality reduction processes, which will not be described here.
进一步地,本发明实施例利用所述图片文本识别模型的全连接层对所述图像特征序列进行全连接分类判断,得到对象识别结果,并利用最后的输出网络中的标记函数对对象识别结果进行标记框选,得到正文文本块集合及图片区域集合。Further, the embodiment of the present invention utilizes the fully-connected layer of the picture text recognition model to perform fully-connected classification and judgment on the image feature sequence to obtain the object recognition result, and uses the labeling function in the final output network to carry out the object recognition result Mark the box to get the body text block set and picture area set.
进一步的,参阅图2所示,本发明实施例中,所述利用预训练的图片文本识别模型,对所述网页图像进行对象识别之前,所述方法还包括:Further, referring to FIG. 2 , in the embodiment of the present invention, before performing object recognition on the web page image using the pre-trained image text recognition model, the method further includes:
S201、利用预设埋点抓取海量数据文本并分类得到图片样本及文本样本,并对所述图片样本及所述文本样本标记上类型标签;S201. Use preset buried points to capture massive data texts and classify them to obtain image samples and text samples, and label the image samples and the text samples with type labels;
S202、将标记后的图片样本及所述文本样本混合作为图文样本集合,并将所述图文样本集合根据预设比例进行随机分组,得到训练集及测试集;S202. Mix the marked image sample and the text sample as a graphic sample set, and randomly group the graphic sample set according to a preset ratio to obtain a training set and a test set;
S203、依次从所述训练集中提取一个训练样本,并利用预构建的图片文本识别模型对所述训练样本进行基于图片及文本的分类,得到测试类别;S203, sequentially extracting a training sample from the training set, and using a pre-built picture-text recognition model to classify the training sample based on pictures and texts to obtain a test category;
S204、利用交叉熵损失算法,计算所述训练样本的类型标签与所述测试类别之间的损失值,并最小化所述损失值,得到所述损失值最小时所述图片文本识别模型的模型参数,并根据梯度下降方法对所述模型参数进行网络逆向更新,得到更新图片文本识别模型;S204. Using the cross-entropy loss algorithm, calculate the loss value between the type label of the training sample and the test category, and minimize the loss value to obtain the model of the image text recognition model when the loss value is the smallest Parameters, and perform network reverse update on the model parameters according to the gradient descent method to obtain an updated image text recognition model;
S205、判断所述训练集中的训练样本是否全部参与训练;S205. Determine whether all the training samples in the training set participate in the training;
当所述训练集中的训练样本未全部参与训练,则返回上述S203的步骤,对所述更新图片文本识别模型进行迭代训练;When the training samples in the training set do not all participate in the training, return to the step of S203 above, and iteratively train the updated image text recognition model;
当所述训练集中的训练样本全部参与训练,则S206、利用所述测试集对所述更新图片文本识别模型进行测试,得到测试准确率;When all the training samples in the training set participate in the training, then S206, use the test set to test the updated image text recognition model to obtain the test accuracy;
S207、判断所述测试准确率是否大于或等于预设的合格阈值;S207. Determine whether the test accuracy rate is greater than or equal to a preset qualified threshold;
当所述测试准确率小于所述合格阈值时,返回上述S202的步骤,对所述图文样本集合进行重新分组,并对所述更新图片文本识别模型进行更新;When the test accuracy rate is less than the qualified threshold, return to the step of S202 above, regroup the image-text sample set, and update the updated image-text recognition model;
当所述测试准确率大于或等于所述合格阈值时,S208、得到训练完成的图片文本识别模型。When the test accuracy rate is greater than or equal to the qualified threshold, S208. Obtain a trained picture-to-text recognition model.
其中,本发明实施例中获取到的图片样本及文本样本均是图片形式的,并进行预处理操作,即:对图像、裁剪、归一化等操作,以及对文本分词、去除停用词等操作。Among them, the picture samples and text samples obtained in the embodiment of the present invention are all in the form of pictures, and preprocessing operations are performed, that is, operations on images, cropping, normalization, etc., and text segmentation, removal of stop words, etc. operate.
本发明在训练过程中,通过交叉熵损失算法及梯度下降方法对训练方向进行把控,并通过测试准确率的方式对模型的训练效果进行把控。当准确率达到预设的合格阈值为N,例如95%时,可以认为模型的训练过程完成,得到图片文本识别模型。其中,所述交叉熵损失算法是用于计算所述类型标签(真实标签)与所述测试类别(预测标签)之间的差异来衡量模型的预测准确性;所述梯度下降方法是一种最小化损失函数的方法,用于找到最小损失值时的模型参数,进而实现反向更新。During the training process, the present invention controls the training direction through the cross-entropy loss algorithm and the gradient descent method, and controls the training effect of the model by testing the accuracy rate. When the accuracy rate reaches the preset qualified threshold value N, for example, 95%, it can be considered that the training process of the model is completed, and the image text recognition model is obtained. Among them, the cross-entropy loss algorithm is used to calculate the difference between the type label (true label) and the test category (predicted label) to measure the prediction accuracy of the model; the gradient descent method is a minimum The method of optimizing the loss function is used to find the model parameters at the time of the minimum loss value, and then realize the reverse update.
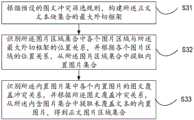
S3、根据预设的图文冲突筛选规则及所述正文文本块集合,对所述图片区域集合进行正文区域筛选,得到正文图片区域集合。S3. According to the preset image-text conflict screening rule and the text block set, perform text area screening on the picture area set to obtain a text picture area set.
详细的,参阅图3所示,本发明实施例中,所述根据预设的图文冲突筛选规则及所述正文文本块集合,对所述图片区域集合进行正文区域筛选,得到正文图片区域集合,包括:In detail, as shown in FIG. 3, in the embodiment of the present invention, according to the preset image-text conflict screening rules and the text text block set, the text area screening is performed on the picture area set to obtain the text picture area set ,include:
S31、根据预设的图文冲突筛选规则,构建所述正文文本块集合的最大外切框架;S31. Construct the largest circumscribed frame of the body text block set according to the preset image-text conflict screening rules;
S32、识别所述图片区域集合中各个图片区域与所述最大外切框架的位置关系,并根据各个图片区域的位置关系,从所述图片区域集合中提取内置图片集合;S32. Identify the positional relationship between each picture area in the picture area set and the maximum circumscribed frame, and extract a built-in picture set from the picture area set according to the positional relationship of each picture area;
S33、识别所述内置图片集中各个内置图片的图文覆盖冲突关系,并根据所述图文覆盖冲突关系,从所述内含图片集合中提取未覆盖文本的内置图片,得到正文图片区域集合。S33. Identify the graphic-text coverage conflict relationship of each built-in picture set in the built-in picture set, and extract the built-in pictures that do not cover text from the set of included pictures according to the graphic-text coverage conflict relationship to obtain a text picture area set.
本发明实施例中,所述图文冲突筛选规则是指判别图片与文本的位置是否规范,文本与图片、图片与图片相互之间是否嵌入或覆盖,进而区分广告等非正文图片。In the embodiment of the present invention, the image-text conflict screening rule refers to judging whether the position of the picture and the text is standardized, whether the text and the picture, or the picture and the picture are embedded or covered with each other, and then distinguish non-text pictures such as advertisements.
本发明实施例构建正文本块集合的最大外切框架,然后将与所述最大外切框架相交或之外的图片区域作为无效图片,并保留所述最大外切框架中完全包含的内置图片,得到内置图片集合。例如,当企业网页中出现人物正面照片时,可能位于正文文本的段落之间,也可能如报纸、论文排版形式,嵌入正文文本之中,但广告这类图像大多超出文章框架,会对阅读造成干扰。因此,通过内置图片集合能够排除大多数广告干扰。最后对内置图片集合进行是否相互覆盖的冲突性检测,得到正文图片区域集合。The embodiment of the present invention constructs the maximum circumscribed frame of the body text block set, and then regards the picture area intersecting or outside the maximum circumscribed frame as an invalid picture, and retains the built-in pictures completely contained in the maximum circumscribed frame, Get the built-in image collection. For example, when a person’s frontal photo appears on a corporate webpage, it may be located between paragraphs of the main text, or it may be embedded in the main text in the form of a newspaper or a thesis layout. interference. Therefore, most advertising distractions can be excluded by the built-in image collection. Finally, check whether the built-in picture set overlaps with each other to obtain a set of text picture areas.
S4、对所述正文文本块集合中的各个正文文本块进行文本识别,得到正文文本序列,并对各个所述正文文本序列进行文本序号的标记操作。S4. Perform text recognition on each text text block in the text text block set to obtain a text sequence, and perform a text sequence number marking operation on each text text sequence.
本发明实施例中,识别到各个正文文本块后,对各个正文文本块进行文本识别,将图像文本数据转变为文本数据,得到正文文本序列,并对各个正文文本序列进行文本序号标记。其中,所述文本序号可以包含数字序号、段落位置等网页显示信息。In the embodiment of the present invention, after each text block is identified, text recognition is performed on each text block, image text data is converted into text data, a text sequence is obtained, and a text serial number is marked on each text sequence. Wherein, the text serial number may include web page display information such as digital serial number and paragraph position.
S5、根据所述正文图片区域集合中各个正文图片区域的上下文相邻的正文文本序列的文本序号,对所述超文本标记数据进行查询,得到正文图像数据。S5. According to the text number of the context-adjacent text text sequence of each text image area in the text image area set, query the hypertext markup data to obtain text image data.
详细的,参阅图4所示,本发明实施例中,所述根据所述正文图片区域集合中各个正文图片区域的上下文相邻的正文文本序列的文本序号,对所述超文本标记数据进行查询,得到正文图像数据,包括:In detail, as shown in FIG. 4, in the embodiment of the present invention, the hypertext markup data is queried according to the text serial number of the context-adjacent text text sequence of each text image area in the text image area set. , get the text image data, including:
S51、在所述超文本标记数据中查询所述上下文相邻的正文文本序列的文本序号,得到所述上下文相邻的正文文本序列的文本序号对应的正文文本块的文件数据位置,并在所述文件数据位置中查找内嵌图片的img标签;S51. Query the text sequence number of the context-adjacent text sequence in the hypertext markup data, obtain the file data position of the text block corresponding to the text sequence number of the context-adjacent text sequence, and set the Find the img tag of the embedded image in the data location of the above file;
S52、根据所述img标签查询所述超文本标记数据,得到正文图像数据。S52. Query the hypertext markup data according to the img tag to obtain text image data.
本发明实施例可以通过开发者工具,根据文本序号,将鼠标位置自动锁定在网页的固定位置,进而HTML文件中的对应文本标签会被高亮显示,进而查询高亮部分,得到对应的<img>标签,从而查询得到正文图像数据。In the embodiment of the present invention, the mouse position can be automatically locked at a fixed position on the web page according to the text serial number through the developer tool, and then the corresponding text tag in the HTML file will be highlighted, and then the highlighted part can be queried to obtain the corresponding <img > label, so as to query and get the text image data.
S6、判断各个所述正文文本序列的语句完整性。S6. Judging the sentence integrity of each text sequence in the text.
详细的,本发明实施例中,所述判断各个所述正文文本序列的语句完整性,包括:In detail, in the embodiment of the present invention, the judging the sentence integrity of each text sequence includes:
识别所述正文文本序列的语法完整性,得到第一完整性分数;identifying grammatical completeness of the body text sequence to obtain a first completeness score;
识别所述正文文本序列的语义完整性,得到第二完整性分数;identifying the semantic integrity of the body text sequence to obtain a second integrity score;
识别所述文本正文序列的上下文知识完整性,得到第三完整性分数;identifying contextual knowledge completeness of said text body sequence to obtain a third completeness score;
根据预设的权重配置规则,对所述第一完整性分数、所述第二完整性分数及所述第三完整性分数进行加权计算,得到所述正文文本序列的语句完整性。Perform weighted calculations on the first integrity score, the second integrity score, and the third integrity score according to preset weight configuration rules to obtain the sentence integrity of the text sequence.
本发明实施例中通过语法完整性、语义完整性及上下文知识完整性,综合识别正文文本序列的语句完整性。其中,语法完整性是检查短语语句是否符合语法规则,如果短语语句的语法结构不完整,可能表明其不完整或者存在语法错误;语义完整性是指识别文本意图是否完整,若意图存在歧义或者用词不恰当,可以认为语义完整性不足;上下文知识完整性是指根据领域知识和常识推理,判断短语语句是否完整。例如,如果短语语句描述的是一个事件或者行为,那么它可能需要包含事件或者行为的主语、谓语和宾语等信息,否则可能是不完整的。In the embodiment of the present invention, the sentence integrity of the text sequence is comprehensively identified through grammatical integrity, semantic integrity and context knowledge integrity. Among them, grammatical integrity is to check whether the phrase statement conforms to the grammatical rules. If the grammatical structure of the phrase statement is incomplete, it may indicate that it is incomplete or has grammatical errors; semantic integrity refers to identifying whether the intent of the text is complete. If the word is inappropriate, it can be considered that the semantic integrity is insufficient; the context knowledge integrity refers to judging whether the phrase sentence is complete or not based on domain knowledge and common sense reasoning. For example, if a phrase statement describes an event or behavior, it may need to contain information such as the subject, predicate, and object of the event or behavior, or it may be incomplete.
本发明实施例中企业可以根据场景不同为各个完整性分配适当的权重,进而加权计算,得到语句完整性。In the embodiment of the present invention, the enterprise can assign appropriate weights to each completeness according to different scenarios, and then perform weighted calculations to obtain sentence completeness.
S7、根据语句不完整的正文文本序列,对所述超文本标记数据进行查询,得到正文文本数据。S7. Query the hypertext markup data according to the text sequence of the incomplete sentence to obtain the text data of the text.
本发明实施例中,当语句完整时,可以直接通过识别图片的方式获取正文文本数据,而当语句不完整时,仍需要通过超文本标记数据进行对应文本提取,得到对应的正文文本数据。In the embodiment of the present invention, when the sentence is complete, the text data of the text can be obtained directly by recognizing the picture, but when the sentence is incomplete, it is still necessary to extract the corresponding text through the hypertext markup data to obtain the corresponding text data.
S8、将语句完整的正文文本序列、所述正文文本数据及所述正文图像数据存储至预构建的数据库中。S8. Store the complete text sequence of the sentence, the text data and the text image data in a pre-built database.
本发明实施例将语句完整的正文文本序列、所述正文文本数据及所述正文图像数据存储至预构建的数据库中,完成网络正文的提取过程。In the embodiment of the present invention, the complete text sequence of sentences, the text data and the text image data are stored in a pre-built database to complete the network text extraction process.
之后,可以通过前端设计等方式,从所述数据库中提取数据,构建人物画像等、企业结构画像等。Afterwards, data can be extracted from the database by means of front-end design, etc., and portraits of people, enterprise structure portraits, etc. can be constructed.
本发明实施例通过截取目标网页的网页图像,并识别出网页图像中的正文文本块与图片区域,再通过图文冲突筛选规则,提取正文图片区域,其中,所述图文冲突筛选规则,可以根据文本最大外切边界,剔除较多广告等不规范的图片,也能将图文覆盖冲突的图片进行删除,得到较为准确的正文图片区域;进而根据正文文本的文本序号,提取正文图像数据,根据语句完整性对不完整的正文文本进行数据提取,得到全部的网页正文。因此,本发明实施例提供的一种基于图文的网页正文提取方法,能够在于通过图文识别定位对网页正文进行提取,增加网络正文爬取的效率及普遍性。The embodiment of the present invention intercepts the webpage image of the target webpage, and recognizes the text block and the picture area in the webpage image, and then extracts the text picture area through the picture-text conflict screening rule, wherein the picture-text conflict screening rule can be According to the maximum circumscribed boundary of the text, many non-standard pictures such as advertisements are eliminated, and pictures with graphic and text coverage conflicts can also be deleted to obtain a more accurate text image area; then, according to the text sequence number of the text, the text image data is extracted, Data extraction is performed on the incomplete body text according to the completeness of the sentence to obtain the entire web page text. Therefore, the image-text-based webpage text extraction method provided by the embodiment of the present invention can extract the webpage text through image-text recognition and positioning, and increase the efficiency and universality of webpage text crawling.
如图5所示,是本发明一实施例提供的基于图文的网页正文提取装置的功能模块图。As shown in FIG. 5 , it is a functional block diagram of an image-text-based webpage text extraction device provided by an embodiment of the present invention.
本发明所述基于图文的网页正文提取装置100可以安装于电子设备中。根据实现的功能,所述基于图文的网页正文提取装置100可以包括数据抓取模块101、图片文本分类模块102、正文图片查询模块103及正文文本查询模块104。本发明所述模块也可以称之为单元,是指一种能够被电子设备处理器所执行,并且能够完成固定功能的一系列计算机程序段,其存储在电子设备的存储器中。The image-text-based webpage
在本实施例中,关于各模块/单元的功能如下:In this embodiment, the functions of each module/unit are as follows:
所述数据抓取模块101,用于根据预设关键词检索得到目标网页,并抓取所述目标网页的超文本标记数据,及截取所述目标网页的网页图像;The
所述图片文本分类模块102,用于利用预训练的图片文本识别模型,对所述网页图像进行对象识别,并对对象识别结果执行标记框选操作,得到正文文本块集合及图片区域集合;The picture
所述正文图片查询模块103,用于对所述正文文本块集合中的各个正文文本块进行文本识别,得到正文文本序列,并对各个所述正文文本序列进行文本序号的标记操作,及根据所述正文图片区域集合中各个正文图片区域的上下文相邻的正文文本序列的文本序号,对所述超文本标记数据进行查询,得到正文图像数据;The text
所述正文文本查询模块104,用于判断各个所述正文文本序列的语句完整性,及根据语句不完整的正文文本序列,对所述超文本标记数据进行查询,得到正文文本数据,及将语句完整的正文文本序列、所述正文文本数据及所述正文图像数据存储至预构建的数据库中。The body
详细地,本申请实施例中所述基于图文的网页正文提取装置100中所述的各模块在使用时采用与上述图1至图4中所述的基于图文的网页正文提取方法一样的技术手段,并能够产生相同的技术效果,这里不再赘述。In detail, each module described in the image-text-based webpage
如图6所示,是本发明一实施例提供的实现基于图文的网页正文提取方法的电子设备1的结构示意图。As shown in FIG. 6 , it is a schematic structural diagram of an electronic device 1 for implementing a method for extracting webpage text based on images and texts provided by an embodiment of the present invention.
所述电子设备1可以包括处理器10、存储器11、通信总线12以及通信接口13,还可以包括存储在所述存储器11中并可在所述处理器10上运行的计算机程序,如基于图文的网页正文提取程序。The electronic device 1 may include a
其中,所述处理器10在一些实施例中可以由集成电路组成,例如可以由单个封装的集成电路所组成,也可以是由多个相同功能或不同功能封装的集成电路所组成,包括一个或者多个中央处理器(Central Processing Unit,CPU)、微处理器、数字处理芯片、图形处理器及各种控制芯片的组合等。所述处理器10是所述电子设备1的控制核心(ControlUnit),利用各种接口和线路连接整个电子设备的各个部件,通过运行或执行存储在所述存储器11内的程序或者模块(例如执行基于图文的网页正文提取程序等),以及调用存储在所述存储器11内的数据,以执行电子设备的各种功能和处理数据。Wherein, the
所述存储器11至少包括一种类型的可读存储介质,所述可读存储介质包括闪存、移动硬盘、多媒体卡、卡型存储器(例如:SD或DX存储器等)、磁性存储器、磁盘、光盘等。所述存储器11在一些实施例中可以是电子设备的内部存储单元,例如该电子设备的移动硬盘。所述存储器11在另一些实施例中也可以是电子设备的外部存储设备,例如电子设备上配备的插接式移动硬盘、智能存储卡(Smart Media Card,SMC)、安全数字(Secure Digital,SD)卡、闪存卡(Flash Card)等。进一步地,所述存储器11还可以既包括电子设备的内部存储单元也包括外部存储设备。所述存储器11不仅可以用于存储安装于电子设备的应用软件及各类数据,例如基于图文的网页正文提取程序的代码等,还可以用于暂时地存储已经输出或者将要输出的数据。The
所述通信总线12可以是外设部件互连标准(Peripheral ComponentInterconnect,简称PCI)总线或扩展工业标准结构(Extended Industry StandardArchitecture,简称EISA)总线等。该总线可以分为地址总线、数据总线、控制总线等。所述总线被设置为实现所述存储器11以及至少一个处理器10等之间的连接通信。The
所述通信接口13用于上述电子设备1与其他设备之间的通信,包括网络接口和用户接口。可选地,所述网络接口可以包括有线接口和/或无线接口(如WI-FI接口、蓝牙接口等),通常用于在该电子设备与其他电子设备之间建立通信连接。所述用户接口可以是显示器(Display)、输入单元(比如键盘(Keyboard)),可选地,用户接口还可以是标准的有线接口、无线接口。可选地,在一些实施例中,显示器可以是LED显示器、液晶显示器、触控式液晶显示器以及OLED(Organic Light-Emitting Diode,有机发光二极管)触摸器等。其中,显示器也可以适当的称为显示屏或显示单元,用于显示在电子设备中处理的信息以及用于显示可视化的用户界面。The
图6仅示出了具有部件的电子设备,本领域技术人员可以理解的是,图6示出的结构并不构成对所述电子设备1的限定,可以包括比图示更少或者更多的部件,或者组合某些部件,或者不同的部件布置。FIG. 6 only shows an electronic device with components. Those skilled in the art can understand that the structure shown in FIG. 6 does not constitute a limitation to the electronic device 1, and may include fewer or more components, or combinations of certain components, or different arrangements of components.
例如,尽管未示出,所述电子设备1还可以包括给各个部件供电的电源(比如电池),优选地,电源可以通过电源管理装置与所述至少一个处理器10逻辑相连,从而通过电源管理装置实现充电管理、放电管理、以及功耗管理等功能。电源还可以包括一个或一个以上的直流或交流电源、再充电装置、电源故障检测电路、电源转换器或者逆变器、电源状态指示器等任意组件。所述电子设备1还可以包括多种传感器、蓝牙模块、Wi-Fi模块等,在此不再赘述。For example, although not shown, the electronic device 1 can also include a power supply (such as a battery) for supplying power to various components. Preferably, the power supply can be logically connected to the at least one
应该了解,所述实施例仅为说明之用,在专利申请范围上并不受此结构的限制。It should be understood that the embodiments are only for illustration, and are not limited by the structure in the scope of the patent application.
所述电子设备1中的所述存储器11存储的基于图文的网页正文提取程序是多个指令的组合,在所述处理器10中运行时,可以实现:The graphic-based web page text extraction program stored in the
根据预设关键词检索得到目标网页,并抓取所述目标网页的超文本标记数据,及截取所述目标网页的网页图像;Retrieving the target webpage according to preset keywords, grabbing the hypertext markup data of the target webpage, and intercepting the webpage image of the target webpage;
利用预训练的图片文本识别模型,对所述网页图像进行对象识别,并对对象识别结果执行标记框选操作,得到正文文本块集合及图片区域集合;Using a pre-trained image text recognition model, object recognition is performed on the webpage image, and a mark-and-frame selection operation is performed on the object recognition result to obtain a body text block set and a picture area set;
根据预设的图文冲突筛选规则及所述正文文本块集合,对所述图片区域集合进行正文区域筛选,得到正文图片区域集合;According to the preset image-text conflict screening rules and the text block set, perform text area screening on the picture area set to obtain a text picture area set;
对所述正文文本块集合中的各个正文文本块进行文本识别,得到正文文本序列,并对各个所述正文文本序列进行文本序号的标记操作;Performing text recognition on each text text block in the text text block set to obtain a text text sequence, and performing a text serial number marking operation on each of the text text sequences;
根据所述正文图片区域集合中各个正文图片区域的上下文相邻的正文文本序列的文本序号,对所述超文本标记数据进行查询,得到正文图像数据;According to the text serial number of the contextually adjacent text text sequence of each text image area in the text image area set, query the hypertext markup data to obtain text image data;
判断各个所述正文文本序列的语句完整性;judging the sentence integrity of each of said body text sequences;
根据语句不完整的正文文本序列,对所述超文本标记数据进行查询,得到正文文本数据;Querying the hypertext markup data according to the text sequence of the incomplete sentence to obtain the text data of the text;
将语句完整的正文文本序列、所述正文文本数据及所述正文图像数据存储至预构建的数据库中。The complete text sequence of the sentence, the text data and image data of the text are stored in a pre-built database.
具体地,所述处理器10对上述指令的具体实现方法可参考附图对应实施例中相关步骤的描述,在此不赘述。Specifically, for the specific implementation method of the above instructions by the
进一步地,所述电子设备1集成的模块/单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读存储介质中。所述计算机可读存储介质可以是易失性的,也可以是非易失性的。例如,所述计算机可读介质可以包括:能够携带所述计算机程序代码的任何实体或装置、记录介质、U盘、移动硬盘、磁碟、光盘、计算机存储器、只读存储器(ROM,Read-Only Memory)。Further, if the integrated modules/units of the electronic device 1 are realized in the form of software function units and sold or used as independent products, they can be stored in a computer-readable storage medium. The computer-readable storage medium may be volatile or non-volatile. For example, the computer-readable medium may include: any entity or device capable of carrying the computer program code, a recording medium, a U disk, a removable hard disk, a magnetic disk, an optical disk, a computer memory, a read-only memory (ROM, Read-Only Memory).
本发明还提供一种计算机可读存储介质,所述可读存储介质存储有计算机程序,所述计算机程序在被电子设备的处理器所执行时,可以实现:The present invention also provides a computer-readable storage medium, the readable storage medium stores a computer program, and when the computer program is executed by a processor of an electronic device, it can realize:
根据预设关键词检索得到目标网页,并抓取所述目标网页的超文本标记数据,及截取所述目标网页的网页图像;Retrieving the target webpage according to preset keywords, grabbing the hypertext markup data of the target webpage, and intercepting the webpage image of the target webpage;
利用预训练的图片文本识别模型,对所述网页图像进行对象识别,并对对象识别结果执行标记框选操作,得到正文文本块集合及图片区域集合;Using a pre-trained image text recognition model, object recognition is performed on the webpage image, and a mark-and-frame selection operation is performed on the object recognition result to obtain a body text block set and a picture area set;
根据预设的图文冲突筛选规则及所述正文文本块集合,对所述图片区域集合进行正文区域筛选,得到正文图片区域集合;According to the preset image-text conflict screening rules and the text block set, perform text area screening on the picture area set to obtain a text picture area set;
对所述正文文本块集合中的各个正文文本块进行文本识别,得到正文文本序列,并对各个所述正文文本序列进行文本序号的标记操作;Performing text recognition on each text text block in the text text block set to obtain a text text sequence, and performing a text serial number marking operation on each of the text text sequences;
根据所述正文图片区域集合中各个正文图片区域的上下文相邻的正文文本序列的文本序号,对所述超文本标记数据进行查询,得到正文图像数据;According to the text serial number of the contextually adjacent text text sequence of each text image area in the text image area set, query the hypertext markup data to obtain text image data;
判断各个所述正文文本序列的语句完整性;judging the sentence integrity of each of said body text sequences;
根据语句不完整的正文文本序列,对所述超文本标记数据进行查询,得到正文文本数据;Querying the hypertext markup data according to the text sequence of the incomplete sentence to obtain the text data of the text;
将语句完整的正文文本序列、所述正文文本数据及所述正文图像数据存储至预构建的数据库中。The complete text sequence of the sentence, the text data and image data of the text are stored in a pre-built database.
在本发明所提供的几个实施例中,应该理解到,所揭露的设备,装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述模块的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式。In the several embodiments provided by the present invention, it should be understood that the disclosed devices, devices and methods can be implemented in other ways. For example, the device embodiments described above are only illustrative. For example, the division of the modules is only a logical function division, and there may be other division methods in actual implementation.
所述作为分离部件说明的模块可以是或者也可以不是物理上分开的,作为模块显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。The modules described as separate components may or may not be physically separated, and the components shown as modules may or may not be physical units, that is, they may be located in one place, or may be distributed to multiple network units. Part or all of the modules can be selected according to actual needs to achieve the purpose of the solution of this embodiment.
另外,在本发明各个实施例中的各功能模块可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用硬件加软件功能模块的形式实现。In addition, each functional module in each embodiment of the present invention may be integrated into one processing unit, or each unit may physically exist separately, or two or more units may be integrated into one unit. The above-mentioned integrated units can be implemented in the form of hardware, or in the form of hardware plus software function modules.
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。It will be apparent to those skilled in the art that the invention is not limited to the details of the above-described exemplary embodiments, but that the invention can be embodied in other specific forms without departing from the spirit or essential characteristics of the invention.
因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化涵括在本发明内。不应将权利要求中的任何附关联图标记视为限制所涉及的权利要求。Accordingly, the embodiments should be regarded in all points of view as exemplary and not restrictive, the scope of the invention being defined by the appended claims rather than the foregoing description, and it is therefore intended that the scope of the invention be defined by the appended claims rather than by the foregoing description. All changes within the meaning and range of equivalents of the elements are embraced in the present invention. Any reference sign in a claim should not be construed as limiting the claim concerned.
本发明所指区块链是分布式数据存储、点对点传输、共识机制、加密算法等计算机技术的新型应用模式。区块链(Blockchain),本质上是一个去中心化的数据库,是一串使用密码学方法相关联产生的数据块,每一个数据块中包含了一批次网络交易的信息,用于验证其信息的有效性(防伪)和生成下一个区块。区块链可以包括区块链底层平台、平台产品服务层以及应用服务层等。The block chain referred to in the present invention is a new application mode of computer technologies such as distributed data storage, point-to-point transmission, consensus mechanism, and encryption algorithm. Blockchain (Blockchain), essentially a decentralized database, is a series of data blocks associated with each other using cryptographic methods. Each data block contains a batch of network transaction information, which is used to verify its Validity of information (anti-counterfeiting) and generation of the next block. The blockchain can include the underlying platform of the blockchain, the platform product service layer, and the application service layer.
本申请实施例可以基于人工智能技术对相关的数据进行获取和处理。其中,人工智能(Artificial Intelligence,AI)是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。The embodiments of the present application may acquire and process relevant data based on artificial intelligence technology. Among them, artificial intelligence (AI) is the theory, method, technology and application system that uses digital computers or machines controlled by digital computers to simulate, extend and expand human intelligence, perceive the environment, acquire knowledge and use knowledge to obtain the best results. .
此外,显然“包括”一词不排除其他单元或步骤,单数不排除复数。系统权利要求中陈述的多个单元或装置也可以由一个单元或装置通过软件或者硬件来实现。第一、第二等词语用来表示名称,而并不表示任何特定的顺序。In addition, it is obvious that the word "comprising" does not exclude other elements or steps, and the singular does not exclude the plural. A plurality of units or devices stated in the system claims may also be realized by one unit or device through software or hardware. The terms first, second, etc. are used to denote names and do not imply any particular order.
最后应说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或等同替换,而不脱离本发明技术方案的精神和范围。Finally, it should be noted that the above embodiments are only used to illustrate the technical solutions of the present invention without limitation. Although the present invention has been described in detail with reference to the preferred embodiments, those of ordinary skill in the art should understand that the technical solutions of the present invention can be Modifications or equivalent replacements can be made without departing from the spirit and scope of the technical solutions of the present invention.
Claims (10)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310300637.1ACN116386068B (en) | 2023-03-24 | 2023-03-24 | Web page text extraction method, device, equipment and storage medium based on image and text |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310300637.1ACN116386068B (en) | 2023-03-24 | 2023-03-24 | Web page text extraction method, device, equipment and storage medium based on image and text |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN116386068Atrue CN116386068A (en) | 2023-07-04 |
| CN116386068B CN116386068B (en) | 2025-06-06 |
Family
ID=86978063
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202310300637.1AActiveCN116386068B (en) | 2023-03-24 | 2023-03-24 | Web page text extraction method, device, equipment and storage medium based on image and text |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN116386068B (en) |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110147817A (en)* | 2019-04-11 | 2019-08-20 | 北京搜狗科技发展有限公司 | Training data set creation method and device |
| CN110309392A (en)* | 2019-03-21 | 2019-10-08 | 广州国音智能科技有限公司 | A kind of method and relevant apparatus obtaining Web page text content |
| CN112861648A (en)* | 2021-01-19 | 2021-05-28 | 平安科技(深圳)有限公司 | Character recognition method and device, electronic equipment and storage medium |
- 2023
- 2023-03-24CNCN202310300637.1Apatent/CN116386068B/enactiveActive
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN110309392A (en)* | 2019-03-21 | 2019-10-08 | 广州国音智能科技有限公司 | A kind of method and relevant apparatus obtaining Web page text content |
| CN110147817A (en)* | 2019-04-11 | 2019-08-20 | 北京搜狗科技发展有限公司 | Training data set creation method and device |
| CN112861648A (en)* | 2021-01-19 | 2021-05-28 | 平安科技(深圳)有限公司 | Character recognition method and device, electronic equipment and storage medium |
Non-Patent Citations (1)
| Title |
|---|
| 常红要;朱征宇;: "网页正文提取中与正文无关的图像清除技术", 计算机技术与发展, no. 07, 10 July 2010 (2010-07-10)* |
Also Published As
| Publication number | Publication date |
|---|---|
| CN116386068B (en) | 2025-06-06 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN112101335B (en) | APP violation monitoring method based on OCR and transfer learning | |
| US20250182217A1 (en) | Ai-augmented auditing platform including techniques for automated document processing | |
| CN113051356A (en) | Open relationship extraction method and device, electronic equipment and storage medium | |
| WO2019218514A1 (en) | Method for extracting webpage target information, device, and storage medium | |
| CN110033018A (en) | Graphic similarity judgment method, device and computer-readable storage medium | |
| CN113360654B (en) | Text classification method, apparatus, electronic device and readable storage medium | |
| CN113626576B (en) | Method, device, terminal and storage medium for extracting relational features in remote supervision | |
| CN112464927B (en) | Information extraction method, device and system | |
| WO2023178798A1 (en) | Image classification method and apparatus, and device and medium | |
| CN114416939A (en) | Intelligent question answering method, device, equipment and storage medium | |
| CN114398557A (en) | Information recommendation method and device based on double portraits, electronic equipment and storage medium | |
| CN117831056A (en) | Bill information extraction method, device and bill information extraction system | |
| CN112818200A (en) | Data crawling and event analyzing method and system based on static website | |
| US20240411795A1 (en) | Method and apparatus for calculating text semantic similarity, device and storage medium | |
| CN114969385B (en) | Knowledge graph optimization method and device based on document attribute assignment entity weight | |
| CN117859122A (en) | AI-enhanced audit platform including techniques for automated document processing | |
| CN115238670A (en) | Information text extraction method, device, equipment and storage medium | |
| CN114780773A (en) | Document and picture classification method and device, storage medium and electronic equipment | |
| US11803796B2 (en) | System, method, electronic device, and storage medium for identifying risk event based on social information | |
| CN114492446A (en) | Legal document processing method and device, electronic equipment and storage medium | |
| CN110020120A (en) | Feature word treatment method, device and storage medium in content delivery system | |
| CN118211102A (en) | Intelligent disease category analysis method and device, electronic equipment and storage medium | |
| CN113885984B (en) | Method, device, equipment and medium for generating operation instructions based on image recognition | |
| CN116386068B (en) | Web page text extraction method, device, equipment and storage medium based on image and text | |
| CN116774973A (en) | Data rendering method, device, computer equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |