CN116258976A - A Hierarchical Transformer Semantic Segmentation Method and System for High Resolution Remote Sensing Images - Google Patents
A Hierarchical Transformer Semantic Segmentation Method and System for High Resolution Remote Sensing ImagesDownload PDFInfo
- Publication number
- CN116258976A CN116258976ACN202310298438.1ACN202310298438ACN116258976ACN 116258976 ACN116258976 ACN 116258976ACN 202310298438 ACN202310298438 ACN 202310298438ACN 116258976 ACN116258976 ACN 116258976A
- Authority
- CN
- China
- Prior art keywords
- remote sensing
- resolution remote
- sensing image
- resolution
- semantic segmentation
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images





Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/10—Terrestrial scenes
- G06V20/13—Satellite images
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/20—Image preprocessing
- G06V10/26—Segmentation of patterns in the image field; Cutting or merging of image elements to establish the pattern region, e.g. clustering-based techniques; Detection of occlusion
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/7715—Feature extraction, e.g. by transforming the feature space, e.g. multi-dimensional scaling [MDS]; Mappings, e.g. subspace methods
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/80—Fusion, i.e. combining data from various sources at the sensor level, preprocessing level, feature extraction level or classification level
- G06V10/806—Fusion, i.e. combining data from various sources at the sensor level, preprocessing level, feature extraction level or classification level of extracted features
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Physics & Mathematics (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Multimedia (AREA)
- Evolutionary Computation (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Computing Systems (AREA)
- Databases & Information Systems (AREA)
- General Health & Medical Sciences (AREA)
- Medical Informatics (AREA)
- Software Systems (AREA)
- Remote Sensing (AREA)
- Astronomy & Astrophysics (AREA)
- Image Analysis (AREA)
Abstract
Description
Translated fromChinese技术领域Technical Field
本发明涉及遥感图像语义分割技术领域,更具体地,涉及一种分层次Transformer的高分辨率遥感图像语义分割方法及系统。The present invention relates to the technical field of remote sensing image semantic segmentation, and more specifically, to a hierarchical Transformer high-resolution remote sensing image semantic segmentation method and system.
背景技术Background Art
遥感技术可以用来获取地球表面的各种信息,例如地形、气象、水文、植被等等。这些信息可以用于农业、林业、城市规划、资源管理、灾害监测等多个领域。随着遥感技术的不断进步和应用领域的不断扩展,它对人们的生活和工作产生了越来越深远的影响。Remote sensing technology can be used to obtain various information about the earth's surface, such as topography, meteorology, hydrology, vegetation, etc. This information can be used in agriculture, forestry, urban planning, resource management, disaster monitoring and other fields. With the continuous advancement of remote sensing technology and the continuous expansion of its application fields, it has had an increasingly profound impact on people's lives and work.
遥感图像处理包括语义分割、变化监测、覆盖分类等。其中,高分辨率遥感图像语义分割是遥感图像处理中一个十分重要和基础的研究。高分辨率遥感图像语义分割是对图像中待分割区域进行处理,使用不同位置的光谱和抽象的语义特征,将每个像素点分配标签类别,为遥感图像分析和理解奠定坚实基础。传统图像处理算法在进行高分辨率遥感图像语义分割时,存在诸多难点。这些难点包括特征设计的复杂性、大规模数据的处理困难、复杂多变的场景、算法的适应性差等。因此,使用传统图像处理算法进行高分辨率遥感图像语义分割不仅需要耗费大量时间和精力,而且往往难以取得满意的效果。Remote sensing image processing includes semantic segmentation, change monitoring, and coverage classification. Among them, semantic segmentation of high-resolution remote sensing images is a very important and basic research in remote sensing image processing. Semantic segmentation of high-resolution remote sensing images processes the area to be segmented in the image, uses the spectrum at different positions and abstract semantic features, assigns label categories to each pixel, and lays a solid foundation for remote sensing image analysis and understanding. Traditional image processing algorithms have many difficulties in performing semantic segmentation of high-resolution remote sensing images. These difficulties include the complexity of feature design, the difficulty in processing large-scale data, complex and changeable scenes, and poor adaptability of algorithms. Therefore, using traditional image processing algorithms for semantic segmentation of high-resolution remote sensing images not only takes a lot of time and effort, but also often fails to achieve satisfactory results.
近年来,深度学习的蓬勃发展为高分辨率遥感图像的语义分割任务带来了明显的进步。与传统的图像处理算法相比,基于深度学习的神经网络在计算机视觉的各个领域表现卓越,因此受到越来越多的学者关注和研究。随着遥感图像分辨率的提高,传统的遥感影像分割和机器学习方法已经无法有效处理大量的特征提取。这一问题经过深度卷积神经网络不断的探索,在一定程度上已经得到了有效的解决,但是直接应用通用的语义分割方法于高分辨率遥感图像,其结果并不尽如人意。因此,近年来,为了解决遥感图像分割中的四个主要问题,即获取空间信息、重构边缘细节、建立全局关系以及设计轻量化架构,不断发展了针对遥感图像的深度学习语义分割方法,其中包括基于CNNs的模型和基于Transformer的模型。In recent years, the vigorous development of deep learning has brought significant progress to the semantic segmentation task of high-resolution remote sensing images. Compared with traditional image processing algorithms, neural networks based on deep learning have performed well in various fields of computer vision, and therefore have attracted more and more attention and research from scholars. With the improvement of the resolution of remote sensing images, traditional remote sensing image segmentation and machine learning methods can no longer effectively handle a large number of feature extractions. This problem has been effectively solved to a certain extent through the continuous exploration of deep convolutional neural networks, but the direct application of general semantic segmentation methods to high-resolution remote sensing images has not yielded satisfactory results. Therefore, in recent years, in order to solve the four main problems in remote sensing image segmentation, namely, obtaining spatial information, reconstructing edge details, establishing global relationships, and designing lightweight architectures, deep learning semantic segmentation methods for remote sensing images have been continuously developed, including CNNs-based models and Transformer-based models.
基于CNNs结构的网络常常被用于图像分割任务中,CNNs结构简单,训练速度较快,且可以处理大量的数据。此外,CNNs可以通过使用池化、卷积、注意力机制等技术,来提高模型的准确性。然而,由于CNNs只能捕捉局部的图像特征,因此在处理一些全局的信息时,可能存在不足。因此,CNNs模型在一定程度上解决了空间信息提取、边缘重构、轻量化设计等问题;然而,全局关系的建立远未解决。Networks based on CNNs are often used in image segmentation tasks. CNNs have a simple structure, fast training speed, and can process large amounts of data. In addition, CNNs can improve the accuracy of the model by using techniques such as pooling, convolution, and attention mechanisms. However, since CNNs can only capture local image features, they may be insufficient when processing some global information. Therefore, the CNNs model has solved the problems of spatial information extraction, edge reconstruction, and lightweight design to a certain extent; however, the establishment of global relationships is far from being solved.
随着Transformer在计算机视觉中的应用越来越多,它也逐渐在遥感图像语义分割中得到了应用。Transformer结构具有全局注意力机制,可以捕捉到全局的上下文信息,并且不受卷积核大小的限制。这使得Transformer在处理遥感图像语义分割中能够更好地理解图像的全局信息。Transformer架构擅长建立全局关系,因为基于注意力机制的设计构成了基本的Transformer单元,但在提取局部信息方面不太健壮。As Transformer is increasingly used in computer vision, it has also been gradually applied in remote sensing image semantic segmentation. The Transformer structure has a global attention mechanism that can capture global contextual information and is not limited by the size of the convolution kernel. This enables Transformer to better understand the global information of the image when processing remote sensing image semantic segmentation. The Transformer architecture is good at establishing global relationships because the design based on the attention mechanism constitutes the basic Transformer unit, but it is not very robust in extracting local information.
综上所述,基于CNNs架构的分割模型通常是由基础卷积神经网络和特征提取、聚合策略构成,在一定程度上解决了多尺度信息提取、边缘增强、高效分割等问题。但是随着图像的分辨率增大,网络模型参数量激增,基于CNNs架构的模型在语义分割任务上将会达到一个阈值。相反Transformer却能够不断提高性能,在于它具有全局自注意力机制,可以捕捉到全局的上下文信息,并且不受卷积核大小的限制,在处理遥感图像语义分割中能够更好地理解图像的全局信息。但是庞大的计算开销限制其在高分辨率遥感图像语义分割领域的发展。In summary, the segmentation model based on CNNs architecture is usually composed of basic convolutional neural networks and feature extraction and aggregation strategies, which solves the problems of multi-scale information extraction, edge enhancement, and efficient segmentation to a certain extent. However, as the resolution of the image increases, the number of network model parameters increases sharply, and the model based on CNNs architecture will reach a threshold in the semantic segmentation task. On the contrary, Transformer can continuously improve its performance because it has a global self-attention mechanism that can capture global contextual information and is not limited by the size of the convolution kernel. It can better understand the global information of the image when processing the semantic segmentation of remote sensing images. However, the huge computational overhead limits its development in the field of high-resolution remote sensing image semantic segmentation.
发明内容Summary of the invention
本发明针对现有技术中存在的传统图像处理算法在进行高分辨率遥感图像语义分割时,特征设计的复杂性、大规模数据的处理困难、复杂多变的场景、算法的适应性差等的技术问题。The present invention aims to solve the technical problems of traditional image processing algorithms in the prior art when performing semantic segmentation of high-resolution remote sensing images, such as the complexity of feature design, the difficulty in processing large-scale data, complex and changeable scenes, and poor adaptability of algorithms.
本发明提供了一种分层次Transformer的高分辨率遥感图像语义分割方法,包括以下步骤:The present invention provides a high-resolution remote sensing image semantic segmentation method based on a hierarchical Transformer, comprising the following steps:
S1,获取原始遥感影像,进行初步处理得到统一大小的高分辨率遥感图像;S1, obtain the original remote sensing image and perform preliminary processing to obtain a high-resolution remote sensing image of uniform size;
S2,数据预处理构建样本集;S2, data preprocessing to construct sample set;
S3,搭建分层次高效Transformer的高分辨率遥感图像语义分割模型;S3, builds a hierarchical and efficient Transformer model for high-resolution remote sensing image semantic segmentation;
S4,对高分辨遥感图像语义分割模型按照预先设定好的训练方案进行训练,得到改进模型;S4, training the semantic segmentation model of the high-resolution remote sensing image according to a pre-set training scheme to obtain an improved model;
S5,将需要进行分割处理的高分遥感图像按固定尺寸裁切后加载到改进模型中实现快速分割。S5, the high-resolution remote sensing image that needs to be segmented is cropped to a fixed size and loaded into the improved model to achieve fast segmentation.
优选地,所述S1具体包括:Preferably, the S1 specifically includes:
S11,使用无人机搭载的高分辨率遥感传感器对预定地面进行扫描和拍摄,获取得到原始遥感影像;S11, using a high-resolution remote sensing sensor carried by a drone to scan and photograph the predetermined ground to obtain an original remote sensing image;
S12,对原始遥感影像进行图像校正、拼接、去噪,以生成高质量的高分辨率遥感图像;S12, performing image correction, stitching, and denoising on the original remote sensing images to generate high-quality, high-resolution remote sensing images;
S13,对部分高分辨率遥感图像数据集进行人工目视标注,用以提高模型在采集数据集样本下的泛化能力;S13, manually visually annotate some high-resolution remote sensing image datasets to improve the generalization ability of the model under the collected dataset samples;
S14,将高分辨率遥感数据集图像进行大小统一,将原图和对应标签裁剪为512×512大小以适应网络输入。S14, unify the size of the high-resolution remote sensing dataset images, and crop the original images and corresponding labels to 512×512 size to adapt to the network input.
优选地,所述S2具体包括:Preferably, the S2 specifically includes:
S21,为了方便训练,对处理过的所有图像进行归一化处理;S21, for the convenience of training, all processed images are normalized;
S22,使用one-hot编码为标签的每个像素类别进行向量化编码;S22, uses one-hot encoding to vectorize each pixel category of the label;
S23,采用空间数据增强方式对图像进行增强得到数据集;S23, enhancing the image by using a spatial data enhancement method to obtain a data set;
S24,按照3:1:1将数据集划分为训练集、验证集和测试集。S24, divide the dataset into training set, validation set and test set according to 3:1:1.
优选地,所述S3具体包括:Preferably, S3 specifically includes:
S31,搭建一个轻量化设计的主干网络,上面是一个多尺度特征聚合分割头,下面是于主干对应连接的残差轴向注意力块(ResidualAxial Attention,RAA),主干网络包括四个阶段,每个阶段包含一个卷积嵌入块(Convolutional tokens Embedding,ConvS2)和一个EST块(ESwin Transformer Blocks);S31, build a lightweight backbone network, with a multi-scale feature aggregation segmentation head on top and a residual axial attention block (RAA) connected to the backbone. The backbone network consists of four stages, each of which contains a convolutional tokens embedding (ConvS2) and an EST block (ESwin Transformer Blocks);
S32,将H×W×3的图像输入主干网络中以建立全局关系,其中,H和W是输入的尺寸,3是代表RGB三个通道。S32, input the H×W×3 image into the backbone network to establish a global relationship, where H and W are the input sizes and 3 represents the three RGB channels.
S33,卷积嵌入块在每个阶段之前调整特征分辨率以生成具有合适分辨率的特征;EST块采用轻量化的自注意力设计来减少参数量,通过线性嵌入层将输入尺寸缩小一半,然后经过自注意力计算、层归一化(LN)、多层向量感知(MLP),保持分辨率不变,输入到下一个阶段;重复步骤S33总共4次在四个阶段分别输出(C1,C2,C3,C4);S33, the convolution embedding block adjusts the feature resolution before each stage to generate features with appropriate resolution; the EST block adopts a lightweight self-attention design to reduce the number of parameters, reduces the input size by half through the linear embedding layer, and then goes through self-attention calculation, layer normalization (LN), and multi-layer vector perception (MLP), keeping the resolution unchanged and inputting it to the next stage; repeat step S33 for a total of 4 times and output (C1 , C2 , C3 , C4 ) in four stages respectively;
S34,使用深度可分离卷积(DWConv)分别对(C1,C2,C3,C4)进行分层多尺度特征聚合,C4经过PPM模块上采样与各层特征进行矩阵相加;然后经过3×3卷积将各层分辨率都映射到
S35,采用残差轴向注意力机制方法来弥补边缘损失。即将注意力机制分解为两个注意力模块,第一个注意力模块在特征图高度轴上执行自注意力,第二个注意力模块在宽度轴上运行;S35, adopts the residual axial attention mechanism method to compensate for the edge loss. That is, the attention mechanism is decomposed into two attention modules, the first attention module performs self-attention on the height axis of the feature map, and the second attention module operates on the width axis;
S36,将Uperhead分割头与RAA结果进行concat融合,送入1×1卷积进行通道合并,最后经过softmaxt归一化处理,得到目标类别的预测值,组合成预测分割图,用以评价分割性能。S36, concat the Uperhead segmentation head with the RAA result, send it to 1×1 convolution for channel merging, and finally undergo softmaxt normalization to obtain the predicted value of the target category, which is combined into a predicted segmentation map to evaluate the segmentation performance.
优选地,所述S32具体包括:Preferably, the S32 specifically includes:
首先利用卷积嵌入块将图像分割成若干个4H×4W×C的窗口,并将其展平成长度为4×4×3=48的序列;First, the convolutional embedding block is used to split the image into several 4H×4W×C windows and flatten them into a sequence of
然后经过线性嵌入层将特征维度从48映射到C,并将特征馈送到EST块以建立全局关系。The feature dimension is then mapped from 48 to C through a linear embedding layer, and the features are fed to the EST block to establish global relationships.
优选地,所述S33具体包括:Preferably, the S33 specifically includes:
S331,使用步长为2的3×3卷积将大小为

S332,EST块采用轻量化的自注意力设计来减少参数量,通过线性嵌入层将输入尺寸(H×W)映射到(H’×W’),然后经过投影+变形+相乘、层归一化(LN)、多层向量感知(MLP),保持分辨率不变,输入到下一个阶段;S332, EST block uses a lightweight self-attention design to reduce the number of parameters. It maps the input size (H×W) to (H'×W') through a linear embedding layer, and then goes through projection + deformation + multiplication, layer normalization (LN), and multi-layer vector perception (MLP) to keep the resolution unchanged and input it to the next stage;
重复上述步骤,在四个阶段分别输出(C1,C2,C3,C4),对应尺度为
优选地,所述S35具体包括:Preferably, the S35 specifically includes:
对于竖直条纹轴(高度轴)向注意力,X被均匀地划分为等宽度sw的非重叠水平条纹[X1,..,XM],并且每个条纹包含(sw×W)个tokens,其中sw是条带宽度;For vertical stripe axis (height axis) attention, X is evenly divided into non-overlapping horizontal stripes [X1 ,..,XM ] of equal width sw, and each stripe contains (sw×W) tokens, where sw is the stripe width;
经过竖直轴(高度轴)注意力特征后将特征图重新进行合并,输入进水平轴(宽度轴)注意力进行水平方向的特征聚合,只需对进行水平划分。After the vertical axis (height axis) attention features, the feature maps are merged again and input into the horizontal axis (width axis) attention for horizontal feature aggregation. It is only necessary to divide horizontally.
本发明还提供了一种分层次Transformer的高分辨率遥感图像语义分割,所述系统用于实现如前所述的分层次Transformer的高分辨率遥感图像语义分割方法,包括:The present invention also provides a hierarchical Transformer high-resolution remote sensing image semantic segmentation system, the system is used to implement the hierarchical Transformer high-resolution remote sensing image semantic segmentation method as described above, comprising:
图像获取模块,用于获取原始遥感影像,进行初步处理得到统一大小的高分辨率遥感图像;The image acquisition module is used to acquire the original remote sensing images and perform preliminary processing to obtain high-resolution remote sensing images of uniform size;
数据预处理模块,用于数据预处理构建样本集;Data preprocessing module, used for data preprocessing to construct sample sets;
模型建立模块,用于搭建分层次高效Transformer的高分辨率遥感图像语义分割模型;Model building module, used to build a hierarchical and efficient Transformer model for high-resolution remote sensing image semantic segmentation;
模型训练模块,用于对高分辨遥感图像语义分割模型按照预先设定好的训练方案进行训练,得到改进模型;The model training module is used to train the semantic segmentation model of high-resolution remote sensing images according to a pre-set training scheme to obtain an improved model;
语义分割模块,用于将需要进行分割处理的高分遥感图像按固定尺寸裁切后加载到改进模型中实现快速分割。The semantic segmentation module is used to crop the high-resolution remote sensing images that need to be segmented into fixed sizes and load them into the improved model to achieve fast segmentation.
本发明还提供了一种电子设备,包括存储器、处理器,所述处理器用于执行存储器中存储的计算机管理类程序时实现分层次Transformer的高分辨率遥感图像语义分割方法的步骤。The present invention also provides an electronic device, including a memory and a processor, wherein the processor is used to implement the steps of a hierarchical Transformer high-resolution remote sensing image semantic segmentation method when executing a computer management program stored in the memory.
本发明还提供了一种计算机可读存储介质,其上存储有计算机管理类程序,所述计算机管理类程序被处理器执行时实现如前所述的分层次Transformer的高分辨率遥感图像语义分割方法的步骤。The present invention also provides a computer-readable storage medium on which a computer management program is stored. When the computer management program is executed by a processor, the steps of the high-resolution remote sensing image semantic segmentation method of the hierarchical Transformer as described above are implemented.
有益效果:本发明提供的一种分层次Transformer的高分辨率遥感图像语义分割方法及系统,其中方法包括:获取原始遥感影像,进行初步处理得到统一大小的高分辨率遥感图像;数据预处理构建样本集;搭建分层次高效Transformer的高分辨率遥感图像语义分割模型;对高分辨遥感图像语义分割模型按照预先设定好的训练方案进行训练,得到改进模型;将需要进行分割处理的高分遥感图像按固定尺寸裁切后加载到改进模型中实现快速分割。通过设计轻量化高效的Transformer块作为主干网络,能够减少模型计算开销,并获得有效的全局特征映射。对主干网络添加注意力机制、多尺度特征聚合策略;用以增强对不同尺度大小目标类分辨,提高边界精细度,从而取得更好的综合性能。Beneficial effects: The present invention provides a hierarchical Transformer method and system for semantic segmentation of high-resolution remote sensing images, wherein the method includes: obtaining the original remote sensing image, performing preliminary processing to obtain a high-resolution remote sensing image of uniform size; constructing a sample set by data preprocessing; building a hierarchical and efficient Transformer semantic segmentation model for high-resolution remote sensing images; training the high-resolution remote sensing image semantic segmentation model according to a pre-set training scheme to obtain an improved model; and loading the high-resolution remote sensing image that needs to be segmented into a fixed size after being cropped into the improved model to achieve fast segmentation. By designing a lightweight and efficient Transformer block as the backbone network, the model computational overhead can be reduced and an effective global feature map can be obtained. Adding an attention mechanism and a multi-scale feature aggregation strategy to the backbone network can enhance the resolution of target classes of different scales and improve the fineness of boundaries, thereby achieving better overall performance.
附图说明BRIEF DESCRIPTION OF THE DRAWINGS
图1为本发明提供的一种分层次Transformer的高分辨率遥感图像语义分割方法流程图;FIG1 is a flow chart of a high-resolution remote sensing image semantic segmentation method using a hierarchical Transformer provided by the present invention;
图2为本发明提供的分层次Transformer的高分辨率遥感图像语义分割方法原理图;FIG2 is a schematic diagram of a high-resolution remote sensing image semantic segmentation method using a hierarchical Transformer provided by the present invention;
图3为本发明提供的高效主干结构图;FIG3 is a diagram of an efficient backbone structure provided by the present invention;
图4为本发明提供的Uperhead多尺度特征聚合模块图;FIG4 is a diagram of an Uperhead multi-scale feature aggregation module provided by the present invention;
图5为本发明提供的残差轴向注意力图;FIG5 is a residual axial attention diagram provided by the present invention;
图6为本发明提供的一种可能的电子设备的硬件结构示意图;FIG6 is a schematic diagram of a possible hardware structure of an electronic device provided by the present invention;
图7为本发明提供的一种可能的计算机可读存储介质的硬件结构示意图;FIG7 is a schematic diagram of a possible hardware structure of a computer-readable storage medium provided by the present invention;
图8为本发明提供的Swin transformer主干结构图。FIG8 is a structural diagram of the Swin transformer backbone provided by the present invention.
具体实施方式DETAILED DESCRIPTION
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。The specific implementation of the present invention is further described in detail below in conjunction with the accompanying drawings and examples. The following examples are used to illustrate the present invention, but are not intended to limit the scope of the present invention.
图1为本发明提供的一种分层次Transformer的高分辨率遥感图像语义分割方法,包括:FIG1 is a high-resolution remote sensing image semantic segmentation method of a hierarchical Transformer provided by the present invention, comprising:
S1,获取原始遥感影像,进行初步处理得到统一大小的高分辨率遥感数据集图像。一般通过无人机自主获取数据,先要进行人工手动标注,然后进行数据裁剪,裁剪到模型输入大小512×512。S1, obtain the original remote sensing image, perform preliminary processing to obtain a high-resolution remote sensing dataset image of uniform size. Generally, the data is obtained autonomously by drones, and manual annotation is performed first, and then the data is cropped to the model input size of 512×512.
S2,数据预处理构建样本集。通用数据集预处理,包括数据分类、裁切、增强等。S2, data preprocessing to build sample sets. General data set preprocessing, including data classification, cropping, enhancement, etc.
S3,搭建分层次高效transformer的高分辨率遥感图像语义分割模型。S3, builds a hierarchical and efficient transformer model for high-resolution remote sensing image semantic segmentation.
S4,对高分辨遥感图像语义分割模型按照预先设定好的训练方案进行训练。训练时的高分辨遥感图像语义分割模型的输入为512×512大小的高分辨遥感裁剪图,输出为与输入图相同大小的最终分割图。S4, the high-resolution remote sensing image semantic segmentation model is trained according to a pre-set training scheme. The input of the high-resolution remote sensing image semantic segmentation model during training is a high-resolution remote sensing cropped image of size 512×512, and the output is a final segmentation image of the same size as the input image.
S5,将训练好的模型搭载到pc端上,pc端接收需要进行分割处理的高分遥感图像,将图按固定尺寸裁切后加载到模型中,模型对输入图像实现快速分割。S5, load the trained model onto the PC, which receives the high-resolution remote sensing image that needs to be segmented, cuts the image into a fixed size and loads it into the model, so that the model can quickly segment the input image.
本方案解决了四个问题,以实现对高分辨率遥感图像的精细分割。具体内容概括如下:This solution solves four problems to achieve fine segmentation of high-resolution remote sensing images. The specific contents are summarized as follows:
提出一种Transformer与CNN融合语义分割模型,采用Transformer块进行特征提取、CNN的注意力机制和多尺度聚合策略来实现全局到局部的特征融合。提出了轻量级的Efficient Transformer主干网,以减少SwinTransformer的计算量,加快推理速度。引入多尺度特征聚合网络作为分割头,增强图像目标类别像素分类性能。将残差轴向注意力融入分层网络,以处理Transformer架构中的对象边缘提取问题。A Transformer and CNN fusion semantic segmentation model is proposed, which uses Transformer blocks for feature extraction, CNN's attention mechanism and multi-scale aggregation strategy to achieve global-to-local feature fusion. A lightweight Efficient Transformer backbone network is proposed to reduce the computational complexity of SwinTransformer and speed up the inference speed. A multi-scale feature aggregation network is introduced as the segmentation head to enhance the pixel classification performance of image target categories. The residual axial attention is integrated into the hierarchical network to handle the object edge extraction problem in the Transformer architecture.
如下表1所示给出了在Vaihingen和Potsdam通用高分辨率遥感图像上分割指标对比:Table 1 below shows the comparison of segmentation indicators on Vaihingen and Potsdam general high-resolution remote sensing images:

优选的方案,步骤S1具体包括一下步骤The preferred solution, step S1 specifically includes the following steps:
S11,使用无人机搭载的高分辨率遥感传感器对预定地面进行扫描和拍摄,获取得到原始遥感影像。S11, use the high-resolution remote sensing sensor carried by the UAV to scan and photograph the predetermined ground to obtain the original remote sensing image.
S12,进行数据初步处理,包括图像校正、拼接、去噪等,以生成高质量的高分辨率遥感图像。S12, perform preliminary data processing, including image correction, stitching, denoising, etc., to generate high-quality high-resolution remote sensing images.
S13,对部分高分辨率遥感图像数据集进行人工目视标注,用以提高模型在采集数据集样本下的泛化能力。S13, perform manual visual annotation on some high-resolution remote sensing image datasets to improve the generalization ability of the model under the collected dataset samples.
S14,将高分辨率遥感数据集图像进行大小统一,将原图和对应标签裁剪为512×512大小以适应网络输入。S14, unify the size of the high-resolution remote sensing dataset images, and crop the original images and corresponding labels to 512×512 size to adapt to the network input.
优选的方案S2具体包括以下步骤:The preferred solution S2 specifically comprises the following steps:
S21,为了方便训练,对处理过的所有图像进行归一化处理。S21, in order to facilitate training, all processed images are normalized.
S22,使用one-hot编码为标签的每个像素类别进行向量化编码。S22, uses one-hot encoding to vectorize each pixel category of the label.
S23,采用空间数据增强方式对图像进行增强得到数据集,包括不同角度的随机旋转(90°、180°、270°、360°)和垂直或水平的随机镜像翻转。S23, the data set is obtained by enhancing the image using spatial data enhancement, including random rotation at different angles (90°, 180°, 270°, 360°) and vertical or horizontal random mirror flipping.
S24,按照3:1:1将数据集划分为训练集、验证集和测试集。S24, divide the dataset into training set, validation set and test set according to 3:1:1.
优选的方案,步骤S3具体包括以下步骤:In a preferred solution, step S3 specifically comprises the following steps:
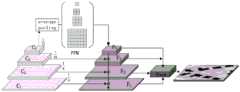
S31,为了更高效地处理大量的特征提取,本文提出了高效的分层视觉转换器(Efficient Swin TransformerBlock),为了方便介绍以下简称ESWin,其中包含卷积操作进行分阶段降低特征图像分辨率,以获取更多的空间信息。搭建分层次高效transformer的高分辨率遥感图像语义分割模型,如图2所示。该模型主要包含一个轻量化设计的主干网络(四个级联的EST块(ESwin Transformer Blocks))、上面是一个多尺度特征聚合分割头、下面是于主干对应连接的残差轴向注意力(Residual Axial Attention,RAA)块。EST模块结构图如图3所示,共有四个阶段,每个阶段的块数(N1,N2,N3,N4)分别为(2,2,2,2),其中每个阶段包含一个卷积嵌入块(ConvS2)和一个EST块。S31, in order to more efficiently process a large number of feature extractions, this paper proposes an efficient hierarchical visual transformer (Efficient Swin TransformerBlock), which is referred to as ESWin for the convenience of introduction. It contains convolution operations to reduce the feature image resolution in stages to obtain more spatial information. A hierarchical and efficient transformer high-resolution remote sensing image semantic segmentation model is built, as shown in Figure 2. The model mainly includes a lightweight backbone network (four cascaded EST blocks (ESwin Transformer Blocks)), a multi-scale feature aggregation segmentation head above, and a residual axial attention (RAA) block connected to the backbone. The EST module structure is shown in Figure 3. There are four stages in total, and the number of blocks in each stage (N1 , N2 , N3 , N4 ) is (2, 2, 2, 2), respectively, where each stage contains a convolution embedding block (ConvS2) and an EST block.
S32,给定一个H×W×3的图像(3代表RGB通道)输入主干网络中。如图3所示,首先利用卷积嵌入(Convolutional tokens Embedding,Conv S2)块将图像分割成若干个(4H)×(4W)×C的窗口,并将其展平成长度为4×4×3=48的序列。因此,原来的H×W分辨率变为
S33,对两个块分别进行处理,过程如下:S33, the two blocks are processed separately, and the process is as follows:
S331,卷积嵌入块在每个阶段之前调整特征分辨率以生成具有合适分辨率的特征。具体是使用步长为2的3×3卷积将大小为

S332,EST块采用轻量化的自注意力设计来减少参数量,通过线性嵌入层(LinearEmbedding)将输入尺寸(H×W)映射到(H’×W’),然后经过自注意力计算(投影+变形+相乘)、层归一化(LN)、多层向量感知(MLP),保持分辨率不变,输入到下一个阶段。S332, the EST block uses a lightweight self-attention design to reduce the number of parameters. The input size (H×W) is mapped to (H'×W') through a linear embedding layer (LinearEmbedding), and then after self-attention calculation (projection+deformation+multiplication), layer normalization (LN), and multi-layer vector perception (MLP), the resolution is kept unchanged and input to the next stage.
重复上述步骤,在四个阶段分别输出(C1,C2,C3,C4),对应尺度为
本实施例的编码器与ViT[]不同,在给定输入图像的情况下生成多级多尺度特征,实现了分层特征表示。这些特征层提供了高分辨率的粗特征和低分辨率的细粒度特征,可以提高语义分割的性能。具体来说,给定大小为H×W×3的输入图像,执行步幅为2的卷积生成分层特征图Fi,分辨率为
S34,UPerhead结构如图4所示,使用深度可分离卷积(DWConv)分别对(C1,C2,C3,C4)进行分层多尺度特征聚合,C4经过PPM模块上采样与各层特征进行矩阵相加,然后经过3×3卷积将各层分辨率都映射到
如图4所示,语义分割模型通常由主干和分割头组成。骨干网络用于从图像中提取特征,以便模型可以区分不同的像素类别。分割头将从主干中提取的特征映射到特定的分类类别,并将下采样的特征恢复为输入图像的分辨率。As shown in Figure 4, a semantic segmentation model usually consists of a backbone and a segmentation head. The backbone network is used to extract features from the image so that the model can distinguish different pixel categories. The segmentation head maps the features extracted from the backbone to specific classification categories and restores the downsampled features to the resolution of the input image.
Uperhead的提出是为了解决语义分割任务中,纹理和类别的重要性不同而产生的问题。在这项任务中,纹理和类别对于区分不同对象同样重要,因此需要融合不同阶段的特征图以提高模型的性能。与此同时,Uperhead也借鉴了UperNet的思想,即使用不同分辨率的特征对不同字符敏感,从而提高模型对不同类别的区分能力。Uperhead was proposed to solve the problem of different importance of texture and category in semantic segmentation tasks. In this task, texture and category are equally important for distinguishing different objects, so it is necessary to fuse feature maps of different stages to improve the performance of the model. At the same time, Uperhead also borrows the idea of UperNet, that is, using features of different resolutions to be sensitive to different characters, thereby improving the model's ability to distinguish different categories.
Uperhead的整个过程包括金字塔池化模块(PPM)、级联添加架构和融合块。在PPM模块中,使用不同池化尺度(1、2、3、6)的全局池化来获取不同感受野的信息,从而增强模型对不同类别的区分能力。接着,C4特征图通过PPM后变成了特征图F4。级联添加架构通过逐步加法操作来融合不同阶段的输出。具体来说,它将F4(1/32)上采样并添加到输入C3(1/16)以获得融合特征F3(1/16),然后通过相同的操作获得F2(1/8)和F1(1/4)。这种逐步添加的方法可以确保不同分辨率的特征图能够得到有效融合,从而提高模型的性能。最后,融合块将F1、F2、F3和F4的特征图融合在一起,生成具有1/4分辨率的融合特征。这些特征经过卷积层进行维度映射,得到最终的分割图。这个过程中,使用了级联加法架构和金字塔池化模块来融合不同分辨率的特征图,使模型能够更好地理解对象的纹理和类别,从而提高分割的准确率和鲁棒性。The whole process of Uperhead includes pyramid pooling module (PPM), cascade addition architecture and fusion block. In the PPM module, global pooling with different pooling scales (1, 2, 3, 6) is used to obtain information of different receptive fields, thereby enhancing the model's ability to distinguish different categories. Then, the C4 feature map is transformed into feature map F4 after passing through PPM. The cascade addition architecture fuses the outputs of different stages through a step-by-step addition operation. Specifically, it upsamples F4 (1/32) and adds it to the input C3 (1/16) to obtain the fused feature F3 (1/16), and then obtains F2 (1/8) and F1 (1/4) through the same operation. This step-by-step addition method ensures that feature maps of different resolutions can be effectively fused, thereby improving the performance of the model. Finally, the fusion block fuses the feature maps of F1, F2, F3 and F4 together to generate a fused feature with a resolution of 1/4. These features are dimensionally mapped through the convolutional layer to obtain the final segmentation map. In this process, the cascade addition architecture and pyramid pooling module are used to fuse feature maps of different resolutions, enabling the model to better understand the texture and category of the object, thereby improving the accuracy and robustness of the segmentation.
经过实验对比,Uperhead的提出使语义分割任务中的特征融合更加高效和准确。它使用了不同池化尺度的全局池化和逐步加法操作来融合不同分辨率的特征图,从而使模型能够更好地理解对象的纹理和类别。After experimental comparison, Uperhead makes feature fusion in semantic segmentation tasks more efficient and accurate. It uses global pooling and step-by-step addition operations of different pooling scales to fuse feature maps of different resolutions, so that the model can better understand the texture and category of the object.
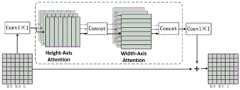
S35,采用残差轴向注意力机制方法来弥补边缘损失。RAA与主干块分层对应,使用双线性插值上采样使每个块级联起来,能够增强骨干网络的边界约束,弥补局部的空间上下文信息为了克服计算复杂性。注意力机制被分解为两个attention模块。第一个模块在特征图高度轴上执行自注意力,第二个模块在宽度轴上运行。具体步骤如下:S35, adopts the residual axial attention mechanism method to compensate for edge loss. RAA corresponds to the backbone block layer by layer, and uses bilinear interpolation upsampling to cascade each block, which can enhance the boundary constraints of the backbone network and compensate for the local spatial context information in order to overcome computational complexity. The attention mechanism is decomposed into two attention modules. The first module performs self-attention on the height axis of the feature map, and the second module operates on the width axis. The specific steps are as follows:
参考图5,对于竖直条纹轴向注意力(Height-AxisAAttention),X被均匀地划分为等宽度sw的非重叠水平条纹[X 1,..,XM],并且每个条纹包含(sw×W)个tokens。这里,sw是条带宽度,可以手动调整以平衡学习能力和计算复杂度。那么竖直条纹注意力的输出定义为:Referring to Figure 5, for Height-AxisAAttention, X is evenly divided into non-overlapping horizontal stripes [
X=[X1,X2,…XM];X=[X1 ,X2 ,…XM ];
Zi=Attention(XiWQ,XiWK,XiWV),Zi =Attention(Xi WQ ,Xi WK ,Xi WV ),
Hattention=[Z1,Z2,…,Zi]Hattention =[Z1 ,Z2 ,…,Zi ]
其中i=1,2,…M;FC代表线性映射;WQ,WK,WV分别代表X投影的查询、键、值的权重;Zi表示第i个竖直条纹的注意力图输出值。Where i = 1, 2, … M; FC represents linear mapping; WQ , WK , WV represent the weights of query, key, and value of X projection respectively;Zi represents the output value of the attention map of the i-th vertical stripe.
经过竖直轴(高度轴)注意力特征后将特征图重新进行合并,输入进水平轴(宽度轴)注意力(Width-Axis Attention)进行水平方向的特征聚合,只需对进行水平划分,后面过程同竖直轴注意力求解。After the vertical axis (height axis) attention features, the feature maps are merged again and input into the horizontal axis (width axis) attention (Width-Axis Attention) for horizontal feature aggregation. It only needs to be divided horizontally, and the subsequent process is the same as the vertical axis attention solution.
在语义分割任务中很难识别边缘。首先,很难准确标记边目标类别的边界像素。其次,在遥感图像获取过程中,相机与地面物体存在相对运动,导致物体产生一定的畸变问题。为了解决这个问题,提出了用残差轴向注意力机制(为方便介绍下文使用ARR代替)来对特征图进行边界增强,从而进一步提高高分辨率遥感图像的分割精度。图5给出了残差轴向注意力的作用原理图。It is difficult to identify edges in semantic segmentation tasks. First, it is difficult to accurately mark the boundary pixels of edge target categories. Second, during the acquisition of remote sensing images, there is relative motion between the camera and the ground objects, which causes certain distortion problems of the objects. To solve this problem, it is proposed to use the residual axial attention mechanism (ARR is used instead for convenience in the following introduction) to enhance the boundaries of the feature map, thereby further improving the segmentation accuracy of high-resolution remote sensing images. Figure 5 shows the working principle of residual axial attention.
在常用的空间注意力机制作用下,要得到这个目标像素点的上下文关系,需要计算整幅图像的注意力关系,所以计算复杂度是输入图像大小的二次复杂度。为了克服计算的计算复杂性,RAA被分解为两个模块,分别是一个模块特征图垂直轴模块和水平轴模块上执行自注意力。最后通过残差连接将输入特征图和注意力输出特征合并得到模块的最终的输出。而在ARR中,采用了一种特殊的注意力设计设计,将一个交叉区域在水平和垂直方向上拆分为两个条状区域,注意力在这两个条状区域分别计算。计算过程如下:Under the commonly used spatial attention mechanism, in order to obtain the contextual relationship of this target pixel, it is necessary to calculate the attention relationship of the entire image, so the computational complexity is the quadratic complexity of the input image size. In order to overcome the computational complexity of the calculation, RAA is decomposed into two modules, one module feature map vertical axis module and the other one performs self-attention on the horizontal axis module. Finally, the input feature map and the attention output feature are merged through the residual connection to obtain the final output of the module. In ARR, a special attention design is adopted to split an intersection area into two strip areas in the horizontal and vertical directions, and the attention is calculated separately in these two strip areas. The calculation process is as follows:
给定输入张量


然后将




其中查询项qo=WQxo、键项ko=WKxo、值项Vo=WVxo都是输入





具体实现是将多个条状注意力进行并行的运算,对输入xo(i,j);即有

然后进行水平轴方向注意力机制计算时,只需要将切分方向调整便可容易得到水平轴注意力的输出:Then, when calculating the horizontal axis attention mechanism, we only need to adjust the segmentation direction to easily obtain the output of the horizontal axis attention:


Y=Conv(YW,Ckernezsize=1)+X#Y=Conv(YW , Ckernezsize =1)+X#
YW中已经包含了竖直方向的注意力掩码,最终经过1×1的卷积将通道还原到输入大小C,经过残差连接获得ARR的最终输出结果Y。应用高度和宽度轴的轴向注意力有效地模拟了地物目标的空间线性关系,具有更好的计算效率。经过实验验证,高效的残差轴向注意力机制更加侧重局部的边界对齐,设计上也降低了计算成本,这表明RAA是一种更高效的设计。YW already contains the vertical attention mask, and finally the channel is restored to the input size C through 1×1 convolution, and the final output result Y of ARR is obtained through residual connection. The axial attention of the height and width axes effectively simulates the spatial linear relationship of the ground objects and has better computational efficiency. Experimental verification shows that the efficient residual axial attention mechanism focuses more on local boundary alignment and reduces the computational cost in design, which shows that RAA is a more efficient design.
具体的方案,残差轴向注意力详细计算过程如下所示:The specific solution and detailed calculation process of residual axial attention are as follows:
给定输入张量


然后将




其中查询项qo=WQxo、键项ko=WKxo、值项Vo=WVxo都是输入





具体实现是将多个条状注意力进行并行的运算,对输入xo(i,j);即有

然后进行水平轴方向注意力机制计算时,只需要将切分方向调整便可容易得到水平轴注意力的输出:Then, when calculating the horizontal axis attention mechanism, we only need to adjust the segmentation direction to easily obtain the output of the horizontal axis attention:


Y=Conv(YW,C,kernelsize=1)+X#Y=Conv(YW , C, kernelsize =1)+X#
YW中已经包含了竖直方向的注意力掩码,最终经过1×1的卷积将通道还原到输入大小C,经过残差连接获得ARR的最终输出结果Y。YW already contains the vertical attention mask. Finally, the channel is restored to the input size C through a 1×1 convolution, and the final output result Y of ARR is obtained through a residual connection.
S36,将Uperhead分割头与RAA结果进行concat融合,送入1×1卷积进行通道合并,最后经过softmaxt归一化处理,得到目标类别的预测值,组合成预测分割图,用以评价分割性能。S36, concat the Uperhead segmentation head with the RAA result, send it to 1×1 convolution for channel merging, and finally undergo softmaxt normalization to obtain the predicted value of the target category, which is combined into a predicted segmentation map to evaluate the segmentation performance.
其中,Swin transformer主干的结构如图8所示。整体框架由一个切片分块(PatchPartition)模块和四个级联阶段组成,以产生四个分辨率输出。stage1包含线性嵌入(Linear Embedding)和两个SwinTransformer块,其余阶段包含一个切片重组(PatchMerging)模块和每个阶段中的偶数块(例如,×2)。每两个块由一个窗口多头自注意(W-MSA)块和一个移位窗口多头自注意(SW-MSA)块组成,用于计算全局注意力。具体的W-MSA块包含层规范化(LN)、W-MSA模块和多层感知器(MLP)。LN对特征进行归一化处理,使训练过程更加稳定,W-MSA和SW-MSA用于计算像素间的注意力关系,MLP包含大量可学习参数,记录W-MSA学习到的系数。具体过程如下所示,给定一个H×W×C的输入。Patch Partition模块首先将图像分割成若干个

图8显示了Swintransformer微型版本,每个阶段分别有2、2、6、2个块。通过调整每个阶段的块数和改变维度C的值,文中提供了四个版本的Swintransformer,即tiny、small、base和large,缩写为Swin-T、Swin-S、Swin-B、和Swin-L,表示模型的规模由小变大。Swintransformer的具体创新设计是窗口自注意力机制(W-MSA),相比于传统自注意力机制(MSA)在整个H×W图像尺寸上计算关系,W-MSA在多个7×7大小窗口尺寸上计算注意力关系,大大减少了计算量。然而,这样的过程也减少了感受野,不利于大物体的分割。因此,Swin transformer增添了另一种巧妙的设计,使用移动窗口自注意力(SW-MSA)来解决这个问题(如图3所示)。通过对两个transformer块之间的特征图进行划分合并,将局部感受野扩展到全局感受野。Swin transformer共有四个阶段,在每一阶段的PatchMerging层进行


为了方便介绍,接下来采用ESWin缩写代替Efficient Swin transformer。详细的模型结构如图3所示,与Swin transformer结构相比,存在四个不同点。For the convenience of introduction, ESWin is used to replace Efficient Swin transformer. The detailed model structure is shown in Figure 3. Compared with the Swin transformer structure, there are four differences.
1)使用卷积运算进行切片初始化组合代替Swin transformer中Patch Partition操作。通过卷积核为7×7,步长为4的卷积层将输入H×W×3(3代表RGB通道)大小的图片被分成4×4个大小为
2)在每个transformer块之前,使用大小为3×步幅为2的卷积(Conv S2)来进行切片重组和对特征图进行下采。具体是将上层特征图分辨率下降一半,而通道数变为原来的2倍。2) Before each transformer block, a convolution with a size of 3× stride 2 (Conv S2) is used to reorganize the slices and downsample the feature maps. Specifically, the resolution of the upper feature map is reduced by half, and the number of channels is doubled.
3)在每个ESWin块中,使用一个隧深卷积(DWConv)进行位置嵌入来学习每个像素的位置信息,取代原Swintransformer中的相对位置嵌入。3) In each ESWin block, a deep tunnel convolution (DWConv) is used for position embedding to learn the position information of each pixel, replacing the relative position embedding in the original Swin transformer.
4)使用输入大小为h'×w'的更轻的ESWin块,应用全连接层(FC)进行降维和矩阵乘法计算注意力关系,LN和MLP采用传统的transformer设计。4) Using a lighter ESWin block with an input size of h'×w', a fully connected layer (FC) is applied for dimensionality reduction and matrix multiplication to calculate the attention relationship, and the LN and MLP adopt the traditional transformer design.
通过应用这种结构,ESWin可以达到与Swin transformer相当的精度,但计算复杂度较低。接下来将详细介绍ESWin模块。By applying this structure, ESWin can achieve comparable accuracy to the Swin transformer, but with lower computational complexity. Next, the ESWin module will be introduced in detail.
在计算机视觉中应用transformer结构的挑战性问题之一是高计算负荷。一个自注意块的计算复杂度可以表示为:One of the challenging issues in applying transformer architecture in computer vision is the high computational load. The computational complexity of a self-attention block can be expressed as:
ΩMSA=4HWC2+2(HW)2C#ΩMSA = 4HWC2 + 2(HW)2 C#
其中C代表特征图的维度,一般在几十到几百之间。由上式可知,自注意力机制的计算复杂度主要由图像的大小,其计算复杂度是图像尺寸的平方,训练自注意力模块需要巨大的计算开销。在保证精度的情况下,如何针对图片的输入大小进行有效的压缩成为轻量化设计该结构的首选,因此,Swintransformer将一张H×W大小的图像分成M×M个切片(patches),经过切割后最终的计算复杂度变表示为:Where C represents the dimension of the feature map, which is generally between tens and hundreds. As can be seen from the above formula, the computational complexity of the self-attention mechanism is mainly determined by the size of the image. Its computational complexity is the square of the image size. Training the self-attention module requires huge computational overhead. While ensuring accuracy, how to effectively compress the input size of the image becomes the first choice for lightweight design of the structure. Therefore, Swintransformer divides an H×W image into M×M patches. After cutting, the final computational complexity becomes:
ΩW-MSA=4HWC2+2M2HWC#ΩW-MSA = 4HWC2 + 2M2 HWC#
通过简单的手工设计将二次复杂度转化成线性复杂度。The quadratic complexity is transformed into linear complexity through simple manual design.
但是进行高分辨率遥感图像语义分割任务时,由于数据集本身尺度较大,为了保护空间信息连贯性和大目标类样本的完整性,需要尽可能大的输入图像来提高分割精度,因此M的大小设定被限制在一定的范围内。为了进一步提高高分辨率遥感影像的分割的分割效率,本文介绍的ESWin的注意力机制(如图3所示)将H×W大小的输入通过映射到更小的h′×w′来建立局部和全局注意力关系,从而大大减少计算量。当h′×w′足够小时,ESWin会比Swin transformer更加高效的进行训练,但性能也会受到一定影响;经过实验效果对比,本文将h'和w'设置为


此外,在分割任务相对容易时,可以进一步减少C的块数和维数,从而降低模型复杂度、避免过拟合问题并减少计算资源的消耗。实验结果表明,在不损失精度的情况下,该方法可以显著降低模型复杂度。In addition, when the segmentation task is relatively easy, the number of blocks and dimensions of C can be further reduced, thereby reducing model complexity, avoiding overfitting problems, and reducing the consumption of computing resources. Experimental results show that this method can significantly reduce model complexity without losing accuracy.
本发明实施例还提供了一种分层次Transformer的高分辨率遥感图像语义分割,所述系统用于实现如前所述的分层次Transformer的高分辨率遥感图像语义分割方法,包括:The embodiment of the present invention further provides a hierarchical Transformer high-resolution remote sensing image semantic segmentation system, and the system is used to implement the hierarchical Transformer high-resolution remote sensing image semantic segmentation method as described above, including:
图像获取模块,用于获取原始遥感影像,进行初步处理得到统一大小的高分辨率遥感图像;The image acquisition module is used to acquire the original remote sensing images and perform preliminary processing to obtain high-resolution remote sensing images of uniform size;
数据预处理模块,用于数据预处理构建样本集;Data preprocessing module, used for data preprocessing to construct sample sets;
模型建立模块,用于搭建分层次高效Transformer的高分辨率遥感图像语义分割模型;Model building module, used to build a hierarchical and efficient Transformer model for high-resolution remote sensing image semantic segmentation;
模型训练模块,用于对高分辨遥感图像语义分割模型按照预先设定好的训练方案进行训练,得到改进模型;The model training module is used to train the semantic segmentation model of high-resolution remote sensing images according to a pre-set training scheme to obtain an improved model;
语义分割模块,用于将需要进行分割处理的高分遥感图像按固定尺寸裁切后加载到改进模型中实现快速分割。The semantic segmentation module is used to crop the high-resolution remote sensing images that need to be segmented into fixed sizes and load them into the improved model to achieve fast segmentation.
请参阅图6为本发明实施例提供的电子设备的实施例示意图。如图6所示,本发明实施例提了一种电子设备,包括存储器1310、处理器1320及存储在存储器1310上并可在处理器1320上运行的计算机程序1311,处理器1320执行计算机程序1311时实现以下步骤:S1,获取原始遥感影像,进行初步处理得到统一大小的高分辨率遥感图像;Please refer to FIG6 for a schematic diagram of an embodiment of an electronic device provided by an embodiment of the present invention. As shown in FIG6, an embodiment of the present invention provides an electronic device, including a
S2,数据预处理构建样本集;S2, data preprocessing to construct sample set;
S3,搭建分层次高效Transformer的高分辨率遥感图像语义分割模型;S3, builds a hierarchical and efficient Transformer model for high-resolution remote sensing image semantic segmentation;
S4,对高分辨遥感图像语义分割模型按照预先设定好的训练方案进行训练,得到改进模型;S4, training the semantic segmentation model of the high-resolution remote sensing image according to a pre-set training scheme to obtain an improved model;
S5,将需要进行分割处理的高分遥感图像按固定尺寸裁切后加载到改进模型中实现快速分割。S5, the high-resolution remote sensing image that needs to be segmented is cropped to a fixed size and loaded into the improved model to achieve fast segmentation.
请参阅图7为本发明提供的一种计算机可读存储介质的实施例示意图。如图7所示,本实施例提供了一种计算机可读存储介质1400,其上存储有计算机程序1411,该计算机程序1411被处理器执行时实现如下步骤:S1,获取原始遥感影像,进行初步处理得到统一大小的高分辨率遥感图像;Please refer to FIG7 for a schematic diagram of an embodiment of a computer-readable storage medium provided by the present invention. As shown in FIG7, this embodiment provides a computer-
S2,数据预处理构建样本集;S2, data preprocessing to construct sample set;
S3,搭建分层次高效Transformer的高分辨率遥感图像语义分割模型;S3, builds a hierarchical and efficient Transformer model for high-resolution remote sensing image semantic segmentation;
S4,对高分辨遥感图像语义分割模型按照预先设定好的训练方案进行训练,得到改进模型;S4, training the semantic segmentation model of the high-resolution remote sensing image according to a pre-set training scheme to obtain an improved model;
S5,将需要进行分割处理的高分遥感图像按固定尺寸裁切后加载到改进模型中实现快速分割。S5, the high-resolution remote sensing image that needs to be segmented is cropped to a fixed size and loaded into the improved model to achieve fast segmentation.
需要说明的是,在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详细描述的部分,可以参见其它实施例的相关描述。It should be noted that in the above embodiments, the description of each embodiment has its own emphasis, and for parts that are not described in detail in a certain embodiment, reference can be made to the relevant descriptions of other embodiments.
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包括这些改动和变型在内。Obviously, those skilled in the art can make various changes and modifications to the present invention without departing from the spirit and scope of the present invention. Thus, if these modifications and variations of the present invention fall within the scope of the claims of the present invention and their equivalents, the present invention is also intended to include these modifications and variations.
Claims (10)
Translated fromChinese



Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310298438.1ACN116258976A (en) | 2023-03-24 | 2023-03-24 | A Hierarchical Transformer Semantic Segmentation Method and System for High Resolution Remote Sensing Images |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310298438.1ACN116258976A (en) | 2023-03-24 | 2023-03-24 | A Hierarchical Transformer Semantic Segmentation Method and System for High Resolution Remote Sensing Images |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN116258976Atrue CN116258976A (en) | 2023-06-13 |
Family
ID=86682540
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202310298438.1APendingCN116258976A (en) | 2023-03-24 | 2023-03-24 | A Hierarchical Transformer Semantic Segmentation Method and System for High Resolution Remote Sensing Images |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN116258976A (en) |
Cited By (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116863223A (en)* | 2023-07-05 | 2023-10-10 | 南京邮电大学 | Method for classifying remote sensing image scenes by embedding semantic attention features into Swin transform network |
| CN116977872A (en)* | 2023-07-19 | 2023-10-31 | 电子科技大学 | CNN+ transducer remote sensing image detection method |
| CN116993756A (en)* | 2023-07-05 | 2023-11-03 | 石河子大学 | Method for dividing verticillium wilt disease spots of field cotton |
| CN117274608A (en)* | 2023-11-23 | 2023-12-22 | 太原科技大学 | Remote sensing image semantic segmentation method based on space detail perception and attention guidance |
| CN117372701A (en)* | 2023-12-07 | 2024-01-09 | 厦门瑞为信息技术有限公司 | Interactive image segmentation method based on Transformer |
| CN117593716A (en)* | 2023-12-07 | 2024-02-23 | 山东大学 | Lane line identification method and system based on unmanned aerial vehicle inspection image |
| CN117849903A (en)* | 2023-12-05 | 2024-04-09 | 中国人民解放军国防科技大学 | A global ocean environment forecasting method based on multi-level feature aggregation |
| CN118195947A (en)* | 2024-04-23 | 2024-06-14 | 重庆理工大学 | Low-light image enhancement method and system based on global-local illumination perception |
| CN118365882A (en)* | 2024-04-29 | 2024-07-19 | 安徽大学 | Optical remote sensing image segmentation method based on VMamba model |
| CN118429808A (en)* | 2024-05-10 | 2024-08-02 | 北京信息科技大学 | Remote sensing image road extraction method and system based on lightweight network structure |
| CN118887226A (en)* | 2024-07-12 | 2024-11-01 | 成都理工大学 | A pyrite SEM image segmentation method and device |
| CN119274084A (en)* | 2024-12-06 | 2025-01-07 | 广东省林业调查规划院 | Method, system and storage medium for monitoring pine wood nematode diseased trees based on remote sensing satellites |
- 2023
- 2023-03-24CNCN202310298438.1Apatent/CN116258976A/enactivePending
Cited By (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116863223A (en)* | 2023-07-05 | 2023-10-10 | 南京邮电大学 | Method for classifying remote sensing image scenes by embedding semantic attention features into Swin transform network |
| CN116993756A (en)* | 2023-07-05 | 2023-11-03 | 石河子大学 | Method for dividing verticillium wilt disease spots of field cotton |
| CN116977872A (en)* | 2023-07-19 | 2023-10-31 | 电子科技大学 | CNN+ transducer remote sensing image detection method |
| CN117274608A (en)* | 2023-11-23 | 2023-12-22 | 太原科技大学 | Remote sensing image semantic segmentation method based on space detail perception and attention guidance |
| CN117274608B (en)* | 2023-11-23 | 2024-02-06 | 太原科技大学 | Semantic segmentation method of remote sensing images based on spatial detail perception and attention guidance |
| CN117849903A (en)* | 2023-12-05 | 2024-04-09 | 中国人民解放军国防科技大学 | A global ocean environment forecasting method based on multi-level feature aggregation |
| CN117593716A (en)* | 2023-12-07 | 2024-02-23 | 山东大学 | Lane line identification method and system based on unmanned aerial vehicle inspection image |
| CN117372701B (en)* | 2023-12-07 | 2024-03-12 | 厦门瑞为信息技术有限公司 | Interactive image segmentation method based on Transformer |
| CN117372701A (en)* | 2023-12-07 | 2024-01-09 | 厦门瑞为信息技术有限公司 | Interactive image segmentation method based on Transformer |
| CN118195947A (en)* | 2024-04-23 | 2024-06-14 | 重庆理工大学 | Low-light image enhancement method and system based on global-local illumination perception |
| CN118365882A (en)* | 2024-04-29 | 2024-07-19 | 安徽大学 | Optical remote sensing image segmentation method based on VMamba model |
| CN118429808A (en)* | 2024-05-10 | 2024-08-02 | 北京信息科技大学 | Remote sensing image road extraction method and system based on lightweight network structure |
| CN118887226A (en)* | 2024-07-12 | 2024-11-01 | 成都理工大学 | A pyrite SEM image segmentation method and device |
| CN119274084A (en)* | 2024-12-06 | 2025-01-07 | 广东省林业调查规划院 | Method, system and storage medium for monitoring pine wood nematode diseased trees based on remote sensing satellites |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN116258976A (en) | A Hierarchical Transformer Semantic Segmentation Method and System for High Resolution Remote Sensing Images | |
| CN113688813B (en) | Multi-scale feature fusion remote sensing image segmentation method, device, equipment and memory | |
| Wang et al. | A review of image super-resolution approaches based on deep learning and applications in remote sensing | |
| US11830246B2 (en) | Systems and methods for extracting and vectorizing features of satellite imagery | |
| CN108596248B (en) | A Remote Sensing Image Classification Method Based on Improved Deep Convolutional Neural Network | |
| CN109903301B (en) | An Image Contour Detection Method Based on Multi-level Feature Channel Optimal Coding | |
| CN105551036B (en) | A kind of training method and device of deep learning network | |
| CN108647639A (en) | Real-time body's skeletal joint point detecting method | |
| WO2021184891A1 (en) | Remotely-sensed image-based terrain classification method, and system | |
| CN110298387A (en) | Incorporate the deep neural network object detection method of Pixel-level attention mechanism | |
| CN106446936B (en) | Hyperspectral data classification method based on convolutional neural network combined spatial spectrum data to waveform map | |
| CN110070091B (en) | Semantic segmentation method and system based on dynamic interpolation reconstruction and used for street view understanding | |
| CN101271525A (en) | A Fast Method for Obtaining Feature Saliency Maps of Image Sequences | |
| CN114862871B (en) | A method for extracting wheat planting areas from remote sensing images based on SE-UNet deep learning network | |
| CN114419430A (en) | A method and device for extracting cultivated land blocks based on SE-U-Net++ model | |
| CN111161271A (en) | An Ultrasound Image Segmentation Method | |
| CN115937704B (en) | Remote sensing image road segmentation method based on topology perception neural network | |
| CN116645592B (en) | A crack detection method and storage medium based on image processing | |
| He et al. | Remote sensing image super-resolution using deep–shallow cascaded convolutional neural networks | |
| CN115546649A (en) | A multi-task prediction method for single-view remote sensing image height estimation and semantic segmentation | |
| Yu et al. | LFPNet: Lightweight network on real point sets for fruit classification and segmentation | |
| CN114529832A (en) | Method and device for training preset remote sensing image overlapping shadow segmentation model | |
| CN116012395A (en) | Multi-scale fusion smoke segmentation method based on depth separable convolution | |
| Dou et al. | Medical image super-resolution via minimum error regression model selection using random forest | |
| CN116128792A (en) | Image processing method and related equipment |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| CB03 | Change of inventor or designer information | ||
| CB03 | Change of inventor or designer information | Inventor after:Wu Honglin Inventor after:Fu Yongquan Inventor after:Jia Yong Inventor before:Fu Yongquan Inventor before:Wu Honglin Inventor before:Jia Yong |