CN116246653A - Voice endpoint detection method, device, electronic device and storage medium - Google Patents
Voice endpoint detection method, device, electronic device and storage mediumDownload PDFInfo
- Publication number
- CN116246653A CN116246653ACN202211643948.XACN202211643948ACN116246653ACN 116246653 ACN116246653 ACN 116246653ACN 202211643948 ACN202211643948 ACN 202211643948ACN 116246653 ACN116246653 ACN 116246653A
- Authority
- CN
- China
- Prior art keywords
- signals
- time
- sensor
- abscissa
- signal
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images






Classifications
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/03—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters
- G10L25/18—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters the extracted parameters being spectral information of each sub-band
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/27—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the analysis technique
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/48—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 specially adapted for particular use
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Measurement Of Velocity Or Position Using Acoustic Or Ultrasonic Waves (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本公开涉及语音处理技术领域,尤其涉及一种语音端点的检测方法、装置、电子设备和存储介质。The present disclosure relates to the technical field of voice processing, and in particular to a voice endpoint detection method, device, electronic equipment and storage medium.
背景技术Background technique
目前,随着人工智能、自然语言处理等技术的发展,语音处理在智能家电、机器人语音交互、车载终端等领域得到了广泛应用。语音端点检测可包括从采集的原始信号中识别是否存在语音信号,以及语音信号的开始时间、终止时间等,对语音处理至关重要。然而,相关技术中的语音端点检测方法,存在效率低、准确性低的问题。At present, with the development of technologies such as artificial intelligence and natural language processing, speech processing has been widely used in fields such as smart home appliances, robot voice interaction, and vehicle terminals. Speech endpoint detection may include identifying whether there is a speech signal from the collected original signal, as well as the start time and end time of the speech signal, which is crucial to speech processing. However, the speech endpoint detection method in the related art has the problems of low efficiency and low accuracy.
发明内容Contents of the invention
本公开提供一种语音端点的检测方法、装置、电子设备、计算机可读存储介质、计算机程序产品,以至少解决相关技术中的语音端点检测方法,存在效率低、准确性低的问题。本公开的技术方案如下:The present disclosure provides a voice endpoint detection method, device, electronic equipment, computer-readable storage medium, and computer program product to at least solve the problems of low efficiency and low accuracy in the voice endpoint detection method in the related art. The disclosed technical scheme is as follows:
根据本公开实施例的第一方面,提供一种语音端点的检测方法,包括:获取传感器阵列中多个传感器采集的原始信号;对多个所述原始信号进行波束形成,得到波束信号;对所述波束信号进行语音端点检测,得到语音信号的初始时间;基于所述初始时间,得到多个传感器对应的语音信号的目标时间。According to the first aspect of the embodiments of the present disclosure, there is provided a voice endpoint detection method, including: acquiring original signals collected by multiple sensors in the sensor array; performing beamforming on the multiple original signals to obtain beam signals; The voice endpoint detection is performed on the beam signal to obtain the initial time of the voice signal; based on the initial time, the target time of the voice signal corresponding to the plurality of sensors is obtained.
在本公开的一个实施例中,所述对多个所述原始信号进行波束形成,得到波束信号,包括:对声源进行方位估计,得到所述声源和所述传感器阵列之间的方位角;基于所述方位角对多个所述原始信号进行波束形成,得到所述波束信号。In an embodiment of the present disclosure, performing beamforming on a plurality of the original signals to obtain beam signals includes: performing azimuth estimation on a sound source to obtain an azimuth angle between the sound source and the sensor array ; performing beamforming on a plurality of the original signals based on the azimuth angles to obtain the beam signals.
在本公开的一个实施例中,所述对多个所述原始信号进行波束形成,得到波束信号,包括:响应于所述原始信号为宽带信号,对多个所述原始信号进行频域上的波束形成,得到频域波束信号;或者,响应于所述原始信号为单频信号,对多个所述原始信号进行时域上的波束形成,得到时域波束信号。In an embodiment of the present disclosure, performing beamforming on a plurality of original signals to obtain a beam signal includes: performing frequency domain processing on a plurality of original signals in response to the fact that the original signals are broadband signals Beamforming to obtain frequency-domain beam signals; or, in response to the fact that the original signal is a single-frequency signal, performing beamforming in the time domain on multiple original signals to obtain time-domain beam signals.
在本公开的一个实施例中,所述对所述波束信号进行语音端点检测,得到语音信号的初始时间,包括:对所述波束信号进行分帧处理,得到多帧波束信号;获取每帧波束信号的能熵比;基于所述能熵比,得到所述初始时间;其中,所述初始时间包括初始开始时间和/或初始结束时间。In an embodiment of the present disclosure, the performing speech endpoint detection on the beam signal to obtain the initial time of the speech signal includes: performing frame division processing on the beam signal to obtain a multi-frame beam signal; obtaining each frame beam The energy entropy ratio of the signal; the initial time is obtained based on the energy entropy ratio; wherein the initial time includes an initial start time and/or an initial end time.
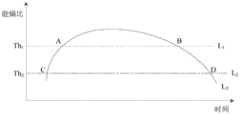
在本公开的一个实施例中,所述基于所述能熵比,得到所述初始时间,包括:基于多帧波束信号的能熵比,得到能熵比曲线,其中,所述能熵比曲线的横坐标为时间,纵坐标为能熵比;获取所述能熵比曲线与第一参考线之间的第一交点和第二交点,以及获取所述能熵比曲线与第二参考线之间的第三交点和第四交点,其中,所述第一交点的横坐标小于所述第二交点的横坐标;响应于所述第三交点的横坐标小于所述第一交点的横坐标,将所述第三交点的横坐标确定为语音信号的初始开始时间;和/或,响应于所述第四交点的横坐标大于所述第二交点的横坐标,将所述第四交点的横坐标确定为语音信号的初始结束时间;其中,所述初始时间包括所述初始开始时间和/或所述初始结束时间。In an embodiment of the present disclosure, the obtaining the initial time based on the energy entropy ratio includes: obtaining an energy entropy ratio curve based on the energy entropy ratio of multi-frame beam signals, wherein the energy entropy ratio curve The abscissa is time, and the ordinate is the energy entropy ratio; obtain the first intersection point and the second intersection point between the energy entropy ratio curve and the first reference line, and obtain the energy entropy ratio curve and the second reference line Between the third point of intersection and the fourth point of intersection, wherein the abscissa of the first point of intersection is smaller than the abscissa of the second point of intersection; in response to the abscissa of the third point of intersection being smaller than the abscissa of the first point of intersection, determining the abscissa of the third intersection point as the initial start time of the voice signal; and/or, in response to the abscissa of the fourth intersection point being greater than the abscissa of the second intersection point, setting the abscissa of the fourth intersection point to The coordinates are determined as an initial end time of the speech signal; wherein, the initial time includes the initial start time and/or the initial end time.
在本公开的一个实施例中,所述第一参考线、所述第二参考线均与横轴平行,所述第一参考线上的点的纵坐标均为第一门限,所述第二参考线上的点的纵坐标均为第二门限,所述第二门限小于所述第一门限。In one embodiment of the present disclosure, both the first reference line and the second reference line are parallel to the horizontal axis, the ordinates of the points on the first reference line are the first threshold, and the second The ordinates of the points on the reference line are all the second threshold, and the second threshold is smaller than the first threshold.
在本公开的一个实施例中,所述基于所述初始时间,得到多个传感器对应的语音信号的目标时间,包括:获取所述传感器对应的时差;将所述初始时间延后所述时差,得到所述传感器对应的语音信号的目标时间。In an embodiment of the present disclosure, the obtaining the target time of the voice signals corresponding to the multiple sensors based on the initial time includes: obtaining the time difference corresponding to the sensor; delaying the initial time by the time difference, The target time of the voice signal corresponding to the sensor is obtained.
在本公开的一个实施例中,所述获取所述传感器对应的时差,包括:对所述传感器采集的原始信号和所述波束信号进行互相关处理,得到互相关曲线;将所述互相关曲线的峰值对应的时间,确定为所述传感器对应的时差。In an embodiment of the present disclosure, the obtaining the time difference corresponding to the sensor includes: performing cross-correlation processing on the original signal collected by the sensor and the beam signal to obtain a cross-correlation curve; The time corresponding to the peak value is determined as the time difference corresponding to the sensor.
在本公开的一个实施例中,所述获取所述传感器对应的时差,包括:对声源进行方位估计,得到所述声源和所述传感器阵列之间的方位角;基于所述方位角、所述传感器与参考传感器之间的距离,得到所述传感器对应的时差。In an embodiment of the present disclosure, the obtaining the time difference corresponding to the sensor includes: performing an azimuth estimation on the sound source to obtain an azimuth between the sound source and the sensor array; based on the azimuth, The distance between the sensor and the reference sensor is used to obtain the time difference corresponding to the sensor.
根据本公开实施例的第二方面,提供一种语音端点的检测装置,包括:采集模块,被配置为执行获取传感器阵列中多个传感器采集的原始信号;处理模块,被配置为执行对多个所述原始信号进行波束形成,得到波束信号;检测模块,被配置为执行对所述波束信号进行语音端点检测,得到语音信号的初始时间;获取模块,被配置为执行基于所述初始时间,得到多个传感器对应的语音信号的目标时间。According to a second aspect of an embodiment of the present disclosure, there is provided a device for detecting a voice endpoint, including: a collection module configured to acquire raw signals collected by multiple sensors in a sensor array; a processing module configured to perform processing on multiple The original signal is beamformed to obtain a beam signal; the detection module is configured to perform voice endpoint detection on the beam signal to obtain the initial time of the voice signal; the acquisition module is configured to perform based on the initial time to obtain The target time of the speech signal corresponding to multiple sensors.
在本公开的一个实施例中,所述处理模块,还被配置为执行:对声源进行方位估计,得到所述声源和所述传感器阵列之间的方位角;基于所述方位角对多个所述原始信号进行波束形成,得到所述波束信号。In an embodiment of the present disclosure, the processing module is further configured to perform: performing azimuth estimation on the sound source to obtain an azimuth between the sound source and the sensor array; performing beamforming on each of the original signals to obtain the beam signal.
在本公开的一个实施例中,所述处理模块,还被配置为执行:响应于所述原始信号为宽带信号,对多个所述原始信号进行频域上的波束形成,得到频域波束信号;或者,响应于所述原始信号为单频信号,对多个所述原始信号进行时域上的波束形成,得到时域波束信号。In an embodiment of the present disclosure, the processing module is further configured to perform: in response to the fact that the original signal is a broadband signal, performing beamforming in the frequency domain on a plurality of the original signals to obtain a frequency domain beam signal ; or, in response to the fact that the original signal is a single-frequency signal, performing beamforming in the time domain on multiple original signals to obtain a time domain beam signal.
在本公开的一个实施例中,所述检测模块,还被配置为执行:对所述波束信号进行分帧处理,得到多帧波束信号;获取每帧波束信号的能熵比;基于所述能熵比,得到所述初始时间;其中,所述初始时间包括初始开始时间和/或初始结束时间。In an embodiment of the present disclosure, the detection module is further configured to: perform frame processing on the beam signal to obtain multi-frame beam signals; obtain the energy entropy ratio of each frame of beam signals; entropy ratio to obtain the initial time; wherein, the initial time includes an initial start time and/or an initial end time.
在本公开的一个实施例中,所述检测模块,还被配置为执行:基于多帧波束信号的能熵比,得到能熵比曲线,其中,所述能熵比曲线的横坐标为时间,纵坐标为能熵比;获取所述能熵比曲线与第一参考线之间的第一交点和第二交点,以及获取所述能熵比曲线与第二参考线之间的第三交点和第四交点,其中,所述第一交点的横坐标小于所述第二交点的横坐标;响应于所述第三交点的横坐标小于所述第一交点的横坐标,将所述第三交点的横坐标确定为语音信号的初始开始时间;和/或,响应于所述第四交点的横坐标大于所述第二交点的横坐标,将所述第四交点的横坐标确定为语音信号的初始结束时间;其中,所述初始时间包括所述初始开始时间和/或所述初始结束时间。In an embodiment of the present disclosure, the detection module is further configured to: obtain an energy entropy ratio curve based on the energy entropy ratio of the multi-frame beam signal, wherein the abscissa of the energy entropy ratio curve is time, The ordinate is the energy entropy ratio; obtain the first intersection point and the second intersection point between the energy entropy ratio curve and the first reference line, and obtain the third intersection point and the second intersection point between the energy entropy ratio curve and the second reference line A fourth point of intersection, wherein the abscissa of the first point of intersection is smaller than the abscissa of the second point of intersection; in response to the abscissa of the third point of intersection being smaller than the abscissa of the first point of intersection, the third point of intersection and/or, in response to the abscissa of the fourth intersection point being greater than the abscissa of the second intersection point, determining the abscissa of the fourth intersection point as the initial start time of the speech signal An initial end time; wherein, the initial time includes the initial start time and/or the initial end time.
在本公开的一个实施例中,所述第一参考线、所述第二参考线均与横轴平行,所述第一参考线上的点的纵坐标均为第一门限,所述第二参考线上的点的纵坐标均为第二门限,所述第二门限小于所述第一门限。In one embodiment of the present disclosure, both the first reference line and the second reference line are parallel to the horizontal axis, the ordinates of the points on the first reference line are the first threshold, and the second The ordinates of the points on the reference line are all the second threshold, and the second threshold is smaller than the first threshold.
在本公开的一个实施例中,所述获取模块,还被配置为执行:获取所述传感器对应的时差;将所述初始时间延后所述时差,得到所述传感器对应的语音信号的目标时间。In an embodiment of the present disclosure, the acquisition module is further configured to: acquire the time difference corresponding to the sensor; delay the initial time by the time difference to obtain the target time of the voice signal corresponding to the sensor .
在本公开的一个实施例中,所述获取模块,还被配置为执行:对所述传感器采集的原始信号和所述波束信号进行互相关处理,得到互相关曲线;将所述互相关曲线的峰值对应的时间,确定为所述传感器对应的时差。In an embodiment of the present disclosure, the acquisition module is further configured to execute: performing cross-correlation processing on the original signal collected by the sensor and the beam signal to obtain a cross-correlation curve; The time corresponding to the peak value is determined as the time difference corresponding to the sensor.
在本公开的一个实施例中,所述获取模块,还被配置为执行:对声源进行方位估计,得到所述声源和所述传感器阵列之间的方位角;基于所述方位角、所述传感器与参考传感器之间的距离,得到所述传感器对应的时差。In an embodiment of the present disclosure, the acquisition module is further configured to execute: performing azimuth estimation on the sound source to obtain an azimuth between the sound source and the sensor array; based on the azimuth, the The distance between the sensor and the reference sensor is used to obtain the time difference corresponding to the sensor.
根据本公开实施例的第三方面,提供一种电子设备,包括处理器;用于存储处理器可执行指令的存储器;其中,所述处理器被配置为实现本公开实施例第一方面所述方法的步骤。According to a third aspect of the embodiments of the present disclosure, there is provided an electronic device, including a processor; a memory for storing instructions executable by the processor; wherein the processor is configured to implement the first aspect of the embodiments of the present disclosure. method steps.
根据本公开实施例的第四方面,提供一种计算机可读存储介质,其上存储有计算机程序指令,该程序指令被处理器执行时实现本公开实施例第一方面所述方法的步骤。According to a fourth aspect of the embodiments of the present disclosure, there is provided a computer-readable storage medium, on which computer program instructions are stored, and when the program instructions are executed by a processor, the steps of the method described in the first aspect of the embodiments of the present disclosure are implemented.
根据本公开实施例的第五方面,提供一种计算机程序产品,包括计算机程序,其特征在于,所述计算机程序被电子设备的处理器执行时实现如本公开实施例第一方面所述方法的步骤。According to a fifth aspect of the embodiments of the present disclosure, there is provided a computer program product, including a computer program, wherein when the computer program is executed by a processor of an electronic device, the method described in the first aspect of the embodiments of the present disclosure is implemented. step.
本公开的实施例提供的技术方案至少带来以下有益效果:可对多个传感器采集的原始信号进行波束形成,得到波束信号,并对波束信号进行语音端点检测,得到初始时间,以得到多个传感器对应的目标时间,相较于相关技术中大多单独对每个传感器采集的原始信号进行语音端点检测,本方案中仅需对波束信号进行语音端点检测,大大减少了语音端点检测的次数,有助于提升传感器阵列的语音端点检测的效率,且波束信号的信噪比较高,有助于提高语音端点检测的准确性。The technical solutions provided by the embodiments of the present disclosure bring at least the following beneficial effects: Beamforming can be performed on the original signals collected by multiple sensors to obtain beam signals, and voice endpoint detection is performed on the beam signals to obtain the initial time to obtain multiple The target time corresponding to the sensor, compared with the original signal collected by each sensor in the related art, the voice endpoint detection is performed separately. In this solution, only the voice endpoint detection is required for the beam signal, which greatly reduces the number of voice endpoint detections. It helps to improve the efficiency of the voice endpoint detection of the sensor array, and the signal-to-noise ratio of the beam signal is high, which helps to improve the accuracy of the voice endpoint detection.
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。It is to be understood that both the foregoing general description and the following detailed description are exemplary and explanatory only and are not restrictive of the present disclosure.
附图说明Description of drawings
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理,并不构成对本公开的不当限定。The accompanying drawings here are incorporated into the specification and constitute a part of the specification, show embodiments consistent with the disclosure, and are used together with the description to explain the principle of the disclosure, and do not constitute an improper limitation of the disclosure.
图1是根据一示例性实施例示出的一种语音端点的检测方法的流程图。Fig. 1 is a flowchart showing a method for detecting a voice endpoint according to an exemplary embodiment.
图2是根据一示例性实施例示出的一种语音端点的检测方法的示意图。Fig. 2 is a schematic diagram showing a method for detecting a voice endpoint according to an exemplary embodiment.
图3是根据另一示例性实施例示出的一种语音端点的检测方法的流程图。Fig. 3 is a flow chart of a method for detecting a voice endpoint according to another exemplary embodiment.
图4是根据一示例性实施例示出的一种语音端点的检测方法中能熵比曲线、第一参考线、第二参考线的示意图。Fig. 4 is a schematic diagram of an energy-entropy ratio curve, a first reference line, and a second reference line in a speech endpoint detection method according to an exemplary embodiment.
图5是根据另一示例性实施例示出的一种语音端点的检测方法的流程图。Fig. 5 is a flow chart of a method for detecting a voice endpoint according to another exemplary embodiment.
图6是根据一示例性实施例示出的一种语音端点的检测系统的框图。Fig. 6 is a block diagram of a system for detecting a voice endpoint according to an exemplary embodiment.
图7是根据一示例性实施例示出的一种语音端点的检测装置的框图。Fig. 7 is a block diagram of an apparatus for detecting a voice endpoint according to an exemplary embodiment.
图8是根据一示例性实施例示出的一种电子设备的框图。Fig. 8 is a block diagram of an electronic device according to an exemplary embodiment.
具体实施方式Detailed ways
为了使本领域普通人员更好地理解本公开的技术方案,下面将结合附图,对本公开实施例中的技术方案进行清楚、完整地描述。In order to enable ordinary persons in the art to better understand the technical solutions of the present disclosure, the technical solutions in the embodiments of the present disclosure will be clearly and completely described below in conjunction with the accompanying drawings.
需要说明的是,本公开的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本公开的实施例能够以除了在这里图示或描述的那些以外的顺序实施。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置和方法的例子。It should be noted that the terms "first" and "second" in the specification and claims of the present disclosure and the above drawings are used to distinguish similar objects, but not necessarily used to describe a specific sequence or sequence. It is to be understood that the data so used are interchangeable under appropriate circumstances such that the embodiments of the disclosure described herein can be practiced in sequences other than those illustrated or described herein. The implementations described in the following exemplary examples do not represent all implementations consistent with the present disclosure. Rather, they are merely examples of apparatuses and methods consistent with aspects of the present disclosure as recited in the appended claims.
本公开技术方案中对数据的获取、存储、使用、处理等均符合国家法律法规的相关规定。The acquisition, storage, use, and processing of data in the disclosed technical solutions all comply with the relevant provisions of national laws and regulations.
图1是根据一示例性实施例示出的一种语音端点的检测方法的流程图,如图1所示,本公开实施例的语音端点的检测方法,包括以下步骤。Fig. 1 is a flowchart showing a method for detecting a voice endpoint according to an exemplary embodiment. As shown in Fig. 1 , the method for detecting a voice endpoint in an embodiment of the present disclosure includes the following steps.
S101,获取传感器阵列中多个传感器采集的原始信号。S101. Acquire raw signals collected by multiple sensors in a sensor array.
需要说明的是,本公开实施例的语音端点的检测方法的执行主体为电子设备,电子设备包括手机、笔记本、台式电脑、车载终端、智能家电等。本公开实施例的语音端点的检测方法可以由本公开实施例的语音端点的检测装置执行,本公开实施例的语音端点的检测装置可以配置在任意电子设备中,以执行本公开实施例的语音端点的检测方法。It should be noted that the voice endpoint detection method in the embodiment of the present disclosure is executed by an electronic device, and the electronic device includes a mobile phone, a notebook, a desktop computer, a vehicle-mounted terminal, and a smart home appliance. The voice endpoint detection method of the embodiment of the disclosure can be executed by the voice endpoint detection device of the embodiment of the disclosure, and the voice endpoint detection device of the embodiment of the disclosure can be configured in any electronic device to execute the voice endpoint of the embodiment of the disclosure detection method.
本公开的实施例中,传感器阵列包括多个传感器。对传感器阵列中多个传感器的分布方式不做过多限定,比如,可在至少一个设定方向上设置多个传感器,相邻两个传感器之间间隔设定距离,对设定方向不做过多限定,比如,以xy二维坐标系为例,可分别在x轴、y轴方向上设置多个传感器。In an embodiment of the present disclosure, the sensor array includes a plurality of sensors. The distribution of multiple sensors in the sensor array is not limited too much. For example, multiple sensors can be set in at least one set direction, and there is a set distance between adjacent two sensors. Multiple limitations, for example, taking the xy two-dimensional coordinate system as an example, multiple sensors can be set in the x-axis and y-axis directions respectively.
在一些例子中,传感器阵列包括传感器1至20,传感器1至20设置在x轴方向上,相邻两个传感器之间间隔20厘米。In some examples, the sensor array includes
需要说明的是,传感器用于采集声音。对传感器不做过多限定,比如,可包括MIC(Microphone,麦克风)、声纳、雷达等。It should be noted that the sensor is used to collect sound. The sensor is not limited too much, for example, it may include MIC (Microphone, microphone), sonar, radar and so on.
需要说明的是,原始信号包括语音信号,且由于环境、震动等因素影响,导致原始信号还包括噪声信号。对原始信号的SNR(Signal Noise Ratio,信噪比)不做过多限定,比如,可为-3dB。It should be noted that the original signal includes a speech signal, and due to factors such as environment and vibration, the original signal also includes a noise signal. The SNR (Signal Noise Ratio, signal-to-noise ratio) of the original signal is not limited too much, for example, it may be -3dB.
可以理解的是,不同的传感器,会采集不同的原始信号。It can be understood that different sensors will collect different original signals.
在一种实施方式中,可控制传感器按照设定采样率采集原始信号。应说明的是,对设定采样率不做过多限定,比如,设定采样率可为8kHz(千赫兹)。In one embodiment, the sensor can be controlled to collect the original signal at a set sampling rate. It should be noted that the set sampling rate is not limited too much, for example, the set sampling rate may be 8kHz (kilohertz).
在一些例子中,传感器阵列包括M个传感器,每个传感器采集的原始信号包括N个采样点信号,则M个传感器采集的原始信号包括M*N个采样点信号。应说明的是,采样点信号与采样时间一一对应,其中,M、N均为正整数。In some examples, the sensor array includes M sensors, and the original signal collected by each sensor includes N sampling point signals, then the original signal collected by the M sensors includes M*N sampling point signals. It should be noted that there is a one-to-one correspondence between the sampling point signal and the sampling time, where M and N are both positive integers.
可以理解的是,采样时间可包括t1、t2至tN,第i个传感器采集的原始信号包括Si1、Si2至SiN,其中,Si1、Si2至SiN均为采样点信号,Si1、Si2至SiN对应的采样时间依次为t1、t2至tN。1≤i≤M,i为正整数。It can be understood that the sampling time may include t1 , t2 to tN , and the original signal collected by the i-th sensor includes Si1 , Si2 to SiN , where Si1 , Si2 to SiN are all sampling points The sampling times corresponding to the signals Si1 , Si2 to SiN are t1 , t2 to tN in turn. 1≤i≤M, i is a positive integer.
S102,对多个原始信号进行波束形成,得到波束信号。S102. Perform beamforming on multiple original signals to obtain beam signals.
本公开的实施例中,可对多个传感器采集的原始信号进行波束形成,得到波束信号。应说明的是,对波束形成的具体方式不做过多限定,比如,可采用相关技术中的任一波束形成算法来实现。In the embodiments of the present disclosure, beamforming may be performed on raw signals collected by multiple sensors to obtain beam signals. It should be noted that the specific manner of beamforming is not limited too much, for example, any beamforming algorithm in the related art may be used for implementation.
在一些例子中,传感器阵列包括M个传感器,每个传感器采集的原始信号包括N个采样点信号,对多个原始信号进行波束形成,得到波束信号,包括对任一采样时间下的M个采样点信号进行加权求和,得到任一采样时间下的波束信号。则波束信号包括N个采样时间下的波束信号。In some examples, the sensor array includes M sensors, the original signal collected by each sensor includes N sampling point signals, and beamforming is performed on multiple original signals to obtain beam signals, including M samples at any sampling time Point signals are weighted and summed to obtain beam signals at any sampling time. Then the beam signals include beam signals at N sampling times.
比如,以M=5,N=5为例,采样时间可包括t1、t2至t5,第i个传感器采集的原始信号包括Si1、Si2至Si5,其中,Si1、Si2至Si5均为采样点信号,Si1、Si2至Si5对应的采样时间依次为t1、t2至t5。1≤i≤5,i为正整数。For example, taking M=5, N=5 as an example, the sampling time may include t1 , t2 to t5 , and the original signal collected by the i-th sensor includes Si1 , Si2 to Si5 , where Si1 , Si2 to Si5 are sampling point signals, and the sampling times corresponding to Si1 , Si2 to Si5 are t1 , t2 to t5 in sequence. 1≤i≤5, i is a positive integer.
以采样时间t1为例,可对采样时间t1下的采样点信号S11、S21、S31、S41、S51进行加权求和,得到采样时间t1下的波束信号。其中,S11为第1个传感器在采样时间t1下采集的采样点信号,S21为第2个传感器在采样时间t1下采集的采样点信号,S31为第3个传感器在采样时间t1下采集的采样点信号,S41为第4个传感器在采样时间t1下采集的采样点信号,S51为第5个传感器在采样时间t1下采集的采样点信号。Taking the sampling time t1 as an example, the weighted summation can be performed on the sampling point signals S11 , S21 , S31 , S41 , and S51 at the sampling time t1 to obtain the beam signal at the sampling time t 1. Among them,S11 is the sampling point signal collected by the first sensor at sampling timet1 ,S21 is the sampling point signal collected by the second sensor at sampling timet1 ,S31 is the sampling point signal collected by the third sensor at sampling time Sampling point signal collected att1 ,S41 is the sampling point signal collected by the fourth sensor at sampling timet1 ,S51 is the sampling point signal collected by the fifth sensor at sampling timet1 .
需要说明的是,采样时间t2至t5下的波束信号的获取过程,可参照上述采样时间t1下的波束信号的获取过程,这里不再赘述。It should be noted that, the acquisition process of the beam signal at the sampling timet2 tot5 may refer to the acquisition process of the beam signal at the sampling timet1 above, which will not be repeated here.
在一种实施方式中,对多个原始信号进行波束形成,得到波束信号,包括对声源进行方位估计,得到声源和传感器阵列之间的方位角,基于方位角对多个原始信号进行波束形成,得到波束信号。由此,该方法中可考虑到声源和传感器阵列之间的方位角,来对多个原始信号进行波束形成,得到波束信号。In one embodiment, beamforming is performed on a plurality of original signals to obtain beam signals, including estimating the azimuth of the sound source, obtaining the azimuth between the sound source and the sensor array, and performing beamforming on the plurality of original signals based on the azimuth Formed to get the beam signal. Therefore, in this method, the azimuth angle between the sound source and the sensor array can be considered to perform beamforming on multiple original signals to obtain beam signals.
需要说明的是,方位角可为任一角度,也可为角度区间,这里不做过多限定。比如,如图2所示,方位角θ为声源方向与垂直方向之间的夹角。It should be noted that the azimuth angle may be any angle, and may also be an angle interval, which is not limited here too much. For example, as shown in Figure 2, the azimuth θ is the angle between the direction of the sound source and the vertical direction.
需要说明的是,对声源进行方位估计的具体方式不做过多限定,比如,可采用CBF(Conventional Beamforming,传统波束形成)、MVDR(Minimum Variance DistortionlessResponse,最小方差无失真响应)、MUSIC(Multiple Signal Classification,多重信号分类)、CS(Compressed Sensing,压缩感知)等方位估计算法来实现。It should be noted that the specific method of estimating the direction of the sound source is not too limited. For example, CBF (Conventional Beamforming, traditional beamforming), MVDR (Minimum Variance Distortionless Response, minimum variance distortion-free response), MUSIC (Multiple Signal Classification, multiple signal classification), CS (Compressed Sensing, compressed sensing) and other orientation estimation algorithms to achieve.
在一种实施方式中,对多个原始信号进行波束形成,得到波束信号,包括响应于原始信号为宽带信号,对多个原始信号进行频域上的波束形成,得到频域波束信号,或者,响应于原始信号为单频信号,对多个原始信号进行时域上的波束形成,得到时域波束信号。由此,该方法中可考虑到原始信号为宽带信号或者单频信号,对多个原始信号进行频域或者时域上的波束形成,提高了波束形成的灵活性。In one embodiment, performing beamforming on multiple original signals to obtain beam signals includes performing beamforming on multiple original signals in the frequency domain in response to the fact that the original signals are broadband signals, to obtain frequency domain beam signals, or, In response to the fact that the original signal is a single-frequency signal, beamforming in the time domain is performed on the multiple original signals to obtain a time domain beam signal. Therefore, in this method, considering that the original signal is a broadband signal or a single-frequency signal, beamforming in the frequency domain or time domain may be performed on multiple original signals, thereby improving the flexibility of beamforming.
需要说明的是,对频域、时域上的波束形成的具体方式均不做过多限定,比如,频域上的波束形成,可采用相关技术中的任一频域波束形成算法来实现,时域上的波束形成,可采用相关技术中的任一时域波束形成算法来实现。It should be noted that the specific methods of beamforming in the frequency domain and time domain are not too limited. For example, the beamforming in the frequency domain can be realized by using any frequency domain beamforming algorithm in the related art. The beamforming in the time domain may be implemented by using any time domain beamforming algorithm in the related art.
在一些例子中,对多个原始信号进行频域上的波束形成,得到频域波束信号,包括基于方位角,对多个原始信号进行频域上的波束形成,得到频域波束信号。In some examples, performing beamforming in the frequency domain on the multiple original signals to obtain the beam signal in the frequency domain includes performing beamforming in the frequency domain on the multiple original signals based on the azimuth angle to obtain the beam signal in the frequency domain.
在一些例子中,对多个原始信号进行时域上的波束形成,得到时域波束信号,包括基于方位角,对多个原始信号进行时域上的波束形成,得到时域波束信号。In some examples, performing time-domain beamforming on multiple original signals to obtain time-domain beam signals includes performing time-domain beamforming on multiple original signals based on azimuth angles to obtain time-domain beam signals.
S103,对波束信号进行语音端点检测,得到语音信号的初始时间。S103. Perform voice endpoint detection on the beam signal to obtain an initial time of the voice signal.
需要说明的是,对波束信号进行语音端点检测的具体方式不做过多限定,比如,可采用相关技术中的任一语音端点检测算法来实现。It should be noted that the specific manner of performing voice endpoint detection on the beam signal is not too limited, for example, any voice endpoint detection algorithm in the related art may be used for implementation.
可以理解的是,波束信号包括语音信号和噪声信号,对波束信号进行语音端点检测,得到语音信号的初始时间,上述语音信号的初始时间指的是波束信号中的语音信号的时间,可包括波束信号中的语音信号的初始开始时间和/或初始结束时间。It can be understood that the beam signal includes a voice signal and a noise signal, and the voice endpoint detection is performed on the beam signal to obtain the initial time of the voice signal. The initial time of the voice signal refers to the time of the voice signal in the beam signal, which may include beam The initial start time and/or initial end time of the speech signal in the signal.
在一种实施方式中,对波束信号进行语音端点检测,得到语音信号的初始时间,包括对波束信号进行分帧处理,得到多帧波束信号,获取每帧波束信号的目标参数,基于目标参数,得到初始时间。其中,初始时间包括初始开始时间和/或初始结束时间。应说明的是,对目标参数不做过多限定,比如,目标参数可包括音量、过零率、谱熵值、能熵比等。In one embodiment, the voice endpoint detection is performed on the beam signal to obtain the initial time of the voice signal, including performing frame processing on the beam signal to obtain a multi-frame beam signal, and obtaining the target parameter of each frame of the beam signal. Based on the target parameter, Get the initial time. Wherein, the initial time includes an initial start time and/or an initial end time. It should be noted that the target parameters are not limited too much. For example, the target parameters may include volume, zero-crossing rate, spectral entropy value, energy entropy ratio, and the like.
需要说明的是,对分帧处理的具体方式不做过多限定,比如,可采用相关技术中的任一分帧处理算法来实现。It should be noted that the specific manner of the frame division processing is not limited too much, for example, any frame division processing algorithm in the related art may be used for implementation.
在一些例子中,基于目标参数,得到初始时间,包括基于多帧波束信号的目标参数,得到目标曲线,其中,目标曲线的横坐标为时间,纵坐标为目标参数,获取目标曲线与设定参考线之间的第五交点和第六交点,其中,第五交点的横坐标小于第六交点的横坐标,设定参考线上的点的纵坐标均为设定门限,将第五交点的横坐标确定为语音信号的初始开始时间,将第六交点的横坐标确定为语音信号的初始结束时间。应说明的是,设定参考线与横轴平行,对设定门限不做过多限定。In some examples, based on the target parameters, the initial time is obtained, including the target parameters based on the multi-frame beam signal, and the target curve is obtained, wherein the abscissa of the target curve is time, and the ordinate is the target parameter, and the acquisition of the target curve and the setting reference The fifth point of intersection and the sixth point of intersection between the lines, wherein, the abscissa of the fifth point of intersection is less than the abscissa of the sixth point of intersection, the vertical coordinates of the points on the reference line are set thresholds, and the abscissa of the fifth point of intersection The coordinates are determined as the initial start time of the speech signal, and the abscissa of the sixth intersection point is determined as the initial end time of the speech signal. It should be noted that the setting reference line is parallel to the horizontal axis, and there is no excessive limitation on the setting threshold.
S104,基于初始时间,得到多个传感器对应的语音信号的目标时间。S104. Based on the initial time, the target time of the voice signals corresponding to the multiple sensors is obtained.
可以理解的是,传感器对应的语音信号的目标时间,指的是传感器采集的原始信号中的语音信号的时间,可包括原始信号中的语音信号的目标开始时间和/或目标结束时间。It can be understood that the target time of the voice signal corresponding to the sensor refers to the time of the voice signal in the original signal collected by the sensor, and may include the target start time and/or target end time of the voice signal in the original signal.
可以理解的是,不同的传感器,对应的语音信号的目标时间可能不同。It can be understood that, for different sensors, the target time of the corresponding voice signal may be different.
在一种实施方式中,基于初始时间,得到多个传感器对应的语音信号的目标时间,包括基于初始开始时间,得到多个传感器对应的语音信号的目标开始时间,和/或,基于初始结束时间,得到多个传感器对应的语音信号的目标结束时间。In one embodiment, obtaining the target time of the speech signals corresponding to the multiple sensors based on the initial time includes obtaining the target start time of the speech signals corresponding to the multiple sensors based on the initial start time, and/or, based on the initial end time , to obtain the target end time of the voice signals corresponding to multiple sensors.
在一种实施方式中,基于初始时间,得到多个传感器对应的语音信号的目标时间,包括获取传感器对应的时差,将初始时间延后时差,得到传感器对应的语音信号的目标时间。可以理解的是,不同的传感器可对应不同的时差,时差指的是传感器对应的语音信号的目标时间和初始时间之间的时差。In one implementation, based on the initial time, obtaining the target time of the voice signals corresponding to the multiple sensors includes acquiring the time difference corresponding to the sensors, and delaying the initial time by the time difference to obtain the target time of the voice signal corresponding to the sensors. It can be understood that different sensors may correspond to different time differences, and the time difference refers to the time difference between the target time and the initial time of the speech signal corresponding to the sensor.
比如,如图2所示,传感器阵列包括传感器1至4,传感器1至4对应的时差依次为0秒、1秒、2秒、3秒。若初始时间包括初始开始时间t1秒、初始结束时间t2秒,则传感器1对应的语音信号的目标开始时间为t1秒,目标结束时间为t2秒,传感器2对应的语音信号的目标开始时间为(t1+1)秒,目标结束时间为(t2+1)秒,传感器3对应的语音信号的目标开始时间为(t1+2)秒,目标结束时间为(t2+2)秒,传感器4对应的语音信号的目标开始时间为(t1+3)秒,目标结束时间为(t2+3)秒。For example, as shown in FIG. 2 , the sensor array includes
在一些例子中,获取传感器对应的时差,包括对声源进行方位估计,得到声源和传感器阵列之间的方位角,基于方位角、传感器与参考传感器之间的距离,得到传感器对应的时差。In some examples, obtaining the time difference corresponding to the sensor includes estimating the azimuth of the sound source, obtaining the azimuth between the sound source and the sensor array, and obtaining the time difference corresponding to the sensor based on the azimuth and the distance between the sensor and the reference sensor.
比如,继续以图2为例,参考传感器可为距离声源最近的传感器1,若传感器1对应的时差为0秒,传感器2对应的时差Δt2=(d*sinθ)/c,传感器3对应的时差Δt3=(2d*sinθ)/c,传感器4对应的时差Δt3=(3d*sinθ)/c。其中,d为相邻两个传感器之间的距离,θ为方位角,c为介质的声速。For example, continuing to take Figure 2 as an example, the reference sensor can be
本公开的实施例提供的语音端点的检测方法,获取传感器阵列中多个传感器采集的原始信号,对多个原始信号进行波束形成,得到波束信号,对波束信号进行语音端点检测,得到语音信号的初始时间,基于初始时间,得到多个传感器对应的语音信号的目标时间。由此,可对多个传感器采集的原始信号进行波束形成,得到波束信号,并对波束信号进行语音端点检测,得到初始时间,以得到多个传感器对应的目标时间,相较于相关技术中大多单独对每个传感器采集的原始信号进行语音端点检测,本方案中仅需对波束信号进行语音端点检测,大大减少了语音端点检测的次数,有助于提升传感器阵列的语音端点检测的效率,且波束信号的信噪比较高,有助于提高语音端点检测的准确性。The voice endpoint detection method provided by the embodiments of the present disclosure obtains the original signals collected by multiple sensors in the sensor array, performs beamforming on the multiple original signals to obtain beam signals, and performs voice endpoint detection on the beam signals to obtain the voice signal. The initial time, based on the initial time, the target time of the voice signals corresponding to the multiple sensors is obtained. In this way, beamforming can be performed on the original signals collected by multiple sensors to obtain beam signals, and voice endpoint detection is performed on the beam signals to obtain the initial time to obtain the target time corresponding to multiple sensors. The voice endpoint detection is performed on the original signal collected by each sensor separately. In this solution, only the voice endpoint detection is required for the beam signal, which greatly reduces the number of voice endpoint detections and helps to improve the efficiency of the voice endpoint detection of the sensor array, and The high signal-to-noise ratio of the beam signal helps improve the accuracy of voice endpoint detection.
图3是根据另一示例性实施例示出的一种语音端点的检测方法的流程图,如图3所示,本公开实施例的语音端点的检测方法,包括以下步骤。Fig. 3 is a flow chart of a method for detecting a voice endpoint according to another exemplary embodiment. As shown in Fig. 3 , the method for detecting a voice endpoint in an embodiment of the present disclosure includes the following steps.
S301,获取传感器阵列中多个传感器采集的原始信号。S301. Acquire raw signals collected by multiple sensors in the sensor array.
S302,对多个原始信号进行波束形成,得到波束信号。S302. Perform beamforming on multiple original signals to obtain beam signals.
S303,对波束信号进行分帧处理,得到多帧波束信号。S303. Perform frame division processing on the beam signal to obtain multi-frame beam signals.
步骤S301-S303的相关内容,可参见上述实施例,这里不再赘述。Relevant content of steps S301-S303 can be referred to the above-mentioned embodiment, and will not be repeated here.
S304,获取每帧波束信号的能熵比。S304. Obtain the energy entropy ratio of the beam signal of each frame.
需要说明的是,对获取能熵比的具体方式不做过多限定,比如,可采用相关技术中的任一能熵比计算算法来实现。It should be noted that the specific method for obtaining the energy entropy ratio is not limited too much, for example, any energy entropy ratio calculation algorithm in the related art may be used to realize it.
在一种实施方式中,获取每帧波束信号的能熵比,包括获取任一帧波束信号的短时能量和短时谱熵,基于短时能量和短时谱熵,得到任一帧波束信号的能熵比。In one embodiment, obtaining the energy entropy ratio of each frame beam signal includes obtaining the short-term energy and short-time spectral entropy of any frame beam signal, and obtaining any frame beam signal based on the short-term energy and short-time spectral entropy energy entropy ratio.
在一些例子中,获取每帧波束信号的能熵比,可通过下述公式来实现:In some examples, the energy entropy ratio of each frame beam signal can be obtained by the following formula:

LEq=log(1+Eqa)LEq = log(1+Eq a)




其中,Sq(k)为第q帧波束信号在第k个频点下的信号分量,Eq为第q帧波束信号的短时能量,Yq(k)为第q帧波束信号在第k个频点下的能量,pq(k)为第q帧波束信号在第k个频点下的归一化谱概率密度函数,Hq为第q帧波束信号的短时谱熵,Qq为第q帧波束信号的能熵比。Among them, Sq (k) is the signal component of the qth frame beam signal at the k frequency point, Eq is the short-term energy of the qth frame beam signal, and Yq (k) is the qth frame beam signal at the The energy at k frequency points, pq (k) is the normalized spectral probability density function of the qth frame beam signal at the kth frequency point, Hq is the short-term spectral entropy of the qth frame beam signal, Qq is the energy entropy ratio of the beam signal in the qth frame.
其中,N/2表示只取正频率部分,a为设定系数。Among them, N/2 means that only the positive frequency part is taken, and a is the setting coefficient.
S305,基于多帧波束信号的能熵比,得到能熵比曲线,其中,能熵比曲线的横坐标为时间,纵坐标为能熵比。S305. Obtain an energy entropy ratio curve based on the energy entropy ratio of the multi-frame beam signal, where the abscissa of the energy entropy ratio curve is time, and the ordinate is the energy entropy ratio.
在一些例子中,基于多帧波束信号的能熵比,得到能熵比曲线,包括基于多帧波束信号的能熵比进行曲线拟合,得到能熵比曲线。应说明的是,对曲线拟合的具体方式不做过多限定,比如,可采用线性拟合、最小二乘法等。In some examples, obtaining an energy entropy ratio curve based on the energy entropy ratio of the multi-frame beam signals includes performing curve fitting based on the energy entropy ratio of the multi-frame beam signals to obtain the energy entropy ratio curve. It should be noted that the specific method of curve fitting is not limited too much, for example, linear fitting, least square method, etc. may be used.
S306,获取能熵比曲线与第一参考线之间的第一交点和第二交点,以及获取能熵比曲线与第二参考线之间的第三交点和第四交点,其中,第一交点的横坐标小于第二交点的横坐标。S306. Obtain the first intersection point and the second intersection point between the energy entropy ratio curve and the first reference line, and obtain the third intersection point and the fourth intersection point between the energy entropy ratio curve and the second reference line, wherein the first intersection point The abscissa of is smaller than the abscissa of the second intersection point.
S307,响应于第三交点的横坐标小于第一交点的横坐标,将第三交点的横坐标确定为语音信号的初始开始时间。S307. In response to the fact that the abscissa of the third intersection point is smaller than the abscissa of the first intersection point, determine the abscissa of the third intersection point as the initial start time of the voice signal.
S308,响应于第四交点的横坐标大于第二交点的横坐标,将第四交点的横坐标确定为语音信号的初始结束时间。S308. In response to the fact that the abscissa of the fourth intersection point is greater than the abscissa of the second intersection point, determine the abscissa of the fourth intersection point as the initial end time of the voice signal.
需要说明的是,对第一参考线、第二参考线均不做过多限定。It should be noted that neither the first reference line nor the second reference line is too limited.
在一种实施方式中,如图4所示,第一参考线L1、第二参考线L2均与横轴平行,第一参考线L1上的点的纵坐标均为第一门限Th1,第二参考线L2上的点的纵坐标均为第二门限Th2,第二门限Th2小于第一门限Th1。即第一参考线L1位于第二参考线L2的上方,对第一门限Th1、第二门限Th2均不做过多限定,比如,第一门限Th1可为噪声信号能量的1.5倍,第二门限Th2可为噪声信号能量。In one implementation, as shown in Figure 4, the first reference line L1 and the second reference line L2 are both parallel to the horizontal axis, and the vertical coordinates of the points on the first reference line L1 are the first threshold Th1. The ordinates of the points on the second reference line L2 are all the second threshold Th2 , and the second threshold Th2 is smaller than the first threshold Th1 . That is, the first reference line L1 is located above the second reference line L2 , and the first threshold Th1 and the second threshold Th2 are not too limited. For example, the first threshold Th1 can be 1.5 of the energy of the noise signal. times, the second threshold Th2 may be noise signal energy.
在一些例子中,第一门限Th1、第二门限Th2如下:In some examples, the first threshold Th1 and the second threshold Th2 are as follows:
Th1=α1D+σnTh1 =α1 D+σn
Th2=α2D+σnTh2 =α2 D+σn
α1<α2α1 < α2
其中,D为语音信号与噪声信号的能量差值,σn为预先采集的噪声信号能量,或者,σn可为无声帧的平均能量,D、σn可预先设置,也可实时更新,这里不做过多限定。Among them, D is the energy difference between the speech signal and the noise signal, σn is the noise signal energy collected in advance, or, σn can be the average energy of the silent frame, D and σn can be preset or updated in real time, here Don't be too restrictive.
其中,α1、α2为设定系数。Among them, α1 and α2 are setting coefficients.
在一些例子中,如图4所示,能熵比曲线L3与第一参考线L1之间的第一交点、第二交点分别为A、B,能熵比曲线L3与第二参考线L2之间的第三交点、第四交点分别为C、D,对点A、B、C、D按照横坐标从小到大进行排序,排序结果为点C、A、B、D,可将点C的横坐标确定为语音信号的初始开始时间,将点D的横坐标确定为语音信号的初始结束时间。In some examples, as shown in Figure 4, the first intersection point and the second intersection point between the energy entropy ratio curve L3 and the first reference line L1 are respectively A and B, and the energy entropy ratio curve L3 and the second
本公开的实施例提供的语音端点的检测方法,对波束信号进行分帧处理,得到多帧波束信号,获取每帧波束信号的能熵比,基于多帧波束信号的能熵比,得到能熵比曲线,综合考虑到第一门限和第二门限,来得到语音信号的初始时间。The voice endpoint detection method provided by the embodiments of the present disclosure performs frame division processing on beam signals to obtain multi-frame beam signals, obtains the energy entropy ratio of each frame beam signal, and obtains energy entropy based on the energy entropy ratio of multi-frame beam signals Ratio curve, taking into account the first threshold and the second threshold, to obtain the initial time of the speech signal.
图5是根据另一示例性实施例示出的一种语音端点的检测方法的流程图,如图5所示,本公开实施例的语音端点的检测方法,包括以下步骤。Fig. 5 is a flow chart of a method for detecting a voice endpoint according to another exemplary embodiment. As shown in Fig. 5 , the method for detecting a voice endpoint in an embodiment of the present disclosure includes the following steps.
S501,获取传感器阵列中多个传感器采集的原始信号。S501. Acquire raw signals collected by multiple sensors in a sensor array.
S502,对多个原始信号进行波束形成,得到波束信号。S502. Perform beamforming on multiple original signals to obtain beam signals.
S503,对波束信号进行语音端点检测,得到语音信号的初始时间。S503. Perform voice endpoint detection on the beam signal to obtain an initial time of the voice signal.
步骤S501-S503的相关内容,可参见上述实施例,这里不再赘述。Relevant content of steps S501-S503 can be referred to the foregoing embodiments, and will not be repeated here.
S504,对传感器采集的原始信号和波束信号进行互相关处理,得到互相关曲线。S504. Perform cross-correlation processing on the original signal collected by the sensor and the beam signal to obtain a cross-correlation curve.
S505,将互相关曲线的峰值对应的时间,确定为传感器对应的时差。S505. Determine the time corresponding to the peak value of the cross-correlation curve as the time difference corresponding to the sensor.
需要说明的是,对互相关处理的具体方式不做过多限定,比如,可采用相关技术中的任一互相关算法来实现。It should be noted that the specific manner of cross-correlation processing is not limited too much, for example, any cross-correlation algorithm in the related art may be used for implementation.
需要说明的是,互相关曲线的横坐标为时间,纵坐标为相关参数,相关参数用于表征原始信号和波束信号在某一时刻的相关性,若相关参数较大,表明原始信号和波束信号在某一时刻的相关性较强,若相关参数较大,表明原始信号和波束信号在某一时刻的相关性较高,反之,若相关参数较小,表明原始信号和波束信号在某一时刻的相关性较弱。It should be noted that the abscissa of the cross-correlation curve is time, and the ordinate is the relevant parameter. The relevant parameter is used to represent the correlation between the original signal and the beam signal at a certain moment. If the correlation parameter is large, it indicates that the original signal and the beam signal The correlation at a certain moment is strong. If the correlation parameter is large, it indicates that the correlation between the original signal and the beam signal is high at a certain moment. On the contrary, if the correlation parameter is small, it indicates that the original signal and the beam signal are at a certain moment. correlation is weak.
继续以图2为例,可对传感器1采集的原始信号和波束信号进行互相关处理,得到互相关曲线E1,将互相关曲线E1的峰值对应的时间,确定为传感器1对应的时差。Continuing to take Figure 2 as an example, the original signal collected by
可对传感器2采集的原始信号和波束信号进行互相关处理,得到互相关曲线E2,将互相关曲线E2的峰值对应的时间,确定为传感器2对应的时差。The original signal collected by the
可对传感器3采集的原始信号和波束信号进行互相关处理,得到互相关曲线E3,将互相关曲线E3的峰值对应的时间,确定为传感器3对应的时差。The original signal collected by the
可对传感器4采集的原始信号和波束信号进行互相关处理,得到互相关曲线E4,将互相关曲线E4的峰值对应的时间,确定为传感器4对应的时差。The original signal collected by the
需要说明的是,互相关曲线E1至E4在图2中未示出。It should be noted that the cross-correlation curves E1 to E4 are not shown in FIG. 2 .
S506,将初始时间延后时差,得到传感器对应的语音信号的目标时间。S506. Delay the initial time by the time difference to obtain the target time of the voice signal corresponding to the sensor.
步骤S506的相关内容,可参见上述实施例,这里不再赘述。Relevant content of step S506 can be referred to the above-mentioned embodiment, and will not be repeated here.
本公开的实施例提供的语音端点的检测方法,可对传感器采集的原始信号和波束信号进行互相关处理,得到互相关曲线,将互相关曲线的峰值对应的时间,确定为传感器对应的时差,以实现传感器的时差的获取。The speech endpoint detection method provided by the embodiments of the present disclosure can perform cross-correlation processing on the original signal collected by the sensor and the beam signal to obtain a cross-correlation curve, and determine the time corresponding to the peak value of the cross-correlation curve as the time difference corresponding to the sensor. In order to realize the acquisition of the time difference of the sensor.
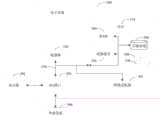
在上述任一实施例的基础上,如图6所示,语音端点的检测系统100,包括传感器阵列110、方位估计模块120、波束形成模块130、端点检测模块140、时延估计模块150和时延处理模块160。On the basis of any of the above-mentioned embodiments, as shown in FIG. 6 , the
传感器阵列110包括多个传感器,传感器用于采集原始信号,方位估计模块120用于对声源进行估计,得到声源和传感器阵列110之间的方位角,波束形成模块130用于对传感器阵列110中多个传感器采集的原始信号进行波束形成,得到波束信号,端点检测模块140用于对波束信号进行语音端点检测,得到语音信号的初始时间,时延估计模块150用于获取传感器对应的时差,时延处理模块160用于对初始时间延后时差,得到传感器对应的语音信号的目标时间。The
在一些例子中,时延估计模块150还用于对传感器采集的原始信号和波束信号进行互相关处理,得到互相关曲线,将互相关曲线的峰值对应的时刻,确定为传感器对应的时差。In some examples, the time
在一些例子中,时延估计模块150还用于根据方位角、传感器与参考传感器之间的距离,得到传感器对应的时差。In some examples, the time
图7是根据一示例性实施例示出的一种语音端点的检测装置的框图。参照图7,本公开实施例的语音端点的检测装置200,包括:采集模块210、处理模块220、检测模块230和获取模块240。Fig. 7 is a block diagram of an apparatus for detecting a voice endpoint according to an exemplary embodiment. Referring to FIG. 7 , the voice
采集模块210被配置为执行获取传感器阵列中多个传感器采集的原始信号;The
处理模块220被配置为执行对多个所述原始信号进行波束形成,得到波束信号;The
检测模块230被配置为执行对所述波束信号进行语音端点检测,得到语音信号的初始时间;The
获取模块240被配置为执行基于所述初始时间,得到多个传感器对应的语音信号的目标时间。The obtaining
在本公开的一个实施例中,所述处理模块220还被配置为执行:对声源进行方位估计,得到所述声源和所述传感器阵列之间的方位角;基于所述方位角对多个所述原始信号进行波束形成,得到所述波束信号。In an embodiment of the present disclosure, the
在本公开的一个实施例中,所述处理模块220还被配置为执行:响应于所述原始信号为宽带信号,对多个所述原始信号进行频域上的波束形成,得到频域波束信号;或者,响应于所述原始信号为单频信号,对多个所述原始信号进行时域上的波束形成,得到时域波束信号。In an embodiment of the present disclosure, the
在本公开的一个实施例中,所述检测模块230还被配置为执行:对所述波束信号进行分帧处理,得到多帧波束信号;获取每帧波束信号的能熵比;基于所述能熵比,得到所述初始时间。其中,所述初始时间包括初始开始时间和/或初始结束时间。In an embodiment of the present disclosure, the
在本公开的一个实施例中,所述检测模块230还被配置为执行:基于多帧波束信号的能熵比,得到能熵比曲线,其中,所述能熵比曲线的横坐标为时间,纵坐标为能熵比;获取所述能熵比曲线与第一参考线之间的第一交点和第二交点,以及获取所述能熵比曲线与第二参考线之间的第三交点和第四交点,其中,所述第一交点的横坐标小于所述第二交点的横坐标;响应于所述第三交点的横坐标小于所述第一交点的横坐标,将所述第三交点的横坐标确定为语音信号的初始开始时间;和/或,响应于所述第四交点的横坐标大于所述第二交点的横坐标,将所述第四交点的横坐标确定为语音信号的初始结束时间;其中,所述初始时间包括所述初始开始时间和/或所述初始结束时间。In an embodiment of the present disclosure, the
在本公开的一个实施例中,所述第一参考线、所述第二参考线均与横轴平行,所述第一参考线上的点的纵坐标均为第一门限,所述第二参考线上的点的纵坐标均为第二门限,所述第二门限小于所述第一门限。In one embodiment of the present disclosure, both the first reference line and the second reference line are parallel to the horizontal axis, the ordinates of the points on the first reference line are the first threshold, and the second The ordinates of the points on the reference line are all the second threshold, and the second threshold is smaller than the first threshold.
在本公开的一个实施例中,所述获取模块240还被配置为执行:获取所述传感器对应的时差;将所述初始时间延后所述时差,得到所述传感器对应的语音信号的目标时间。In an embodiment of the present disclosure, the acquiring
在本公开的一个实施例中,所述获取模块240还被配置为执行:对所述传感器采集的原始信号和所述波束信号进行互相关处理,得到互相关曲线;将所述互相关曲线的峰值对应的时间,确定为所述传感器对应的时差。In an embodiment of the present disclosure, the
在本公开的一个实施例中,所述获取模块240还被配置为执行:对声源进行方位估计,得到所述声源和所述传感器阵列之间的方位角;基于所述方位角、所述传感器与参考传感器之间的距离,得到所述传感器对应的时差。In an embodiment of the present disclosure, the
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。Regarding the apparatus in the foregoing embodiments, the specific manner in which each module executes operations has been described in detail in the embodiments related to the method, and will not be described in detail here.
本公开的实施例提供的语音端点的检测装置,获取传感器阵列中多个传感器采集的原始信号,对多个原始信号进行波束形成,得到波束信号,对波束信号进行语音端点检测,得到语音信号的初始时间,基于初始时间,得到多个传感器对应的语音信号的目标时间。由此,可对多个传感器采集的原始信号进行波束形成,得到波束信号,并对波束信号进行语音端点检测,得到初始时间,以得到多个传感器对应的目标时间,相较于相关技术中大多单独对每个传感器采集的原始信号进行语音端点检测,本方案中仅需对波束信号进行语音端点检测,大大减少了语音端点检测的次数,有助于提升传感器阵列的语音端点检测的效率,且波束信号的信噪比较高,有助于提高语音端点检测的准确性。The voice endpoint detection device provided by the embodiments of the present disclosure acquires the original signals collected by multiple sensors in the sensor array, performs beamforming on the multiple original signals to obtain beam signals, and performs voice endpoint detection on the beam signals to obtain the voice signal. The initial time, based on the initial time, the target time of the voice signals corresponding to the multiple sensors is obtained. In this way, beamforming can be performed on the original signals collected by multiple sensors to obtain beam signals, and the voice endpoint detection is performed on the beam signals to obtain the initial time, so as to obtain the target time corresponding to multiple sensors. The voice endpoint detection is performed on the original signal collected by each sensor separately. In this solution, only the voice endpoint detection is required for the beam signal, which greatly reduces the number of voice endpoint detections and helps to improve the efficiency of the voice endpoint detection of the sensor array, and The high signal-to-noise ratio of the beam signal helps improve the accuracy of voice endpoint detection.
图8是根据一示例性实施例示出的一种电子设备300的框图。Fig. 8 is a block diagram of an
如图8所示,上述电子设备300包括:As shown in FIG. 8, the above-mentioned
存储器310及处理器320,连接不同组件(包括存储器310和处理器320)的总线330,存储器310存储有计算机程序,当处理器320执行所述程序时实现本公开实施例所述的语音端点的检测方法。A
总线330表示几类总线结构中的一种或多种,包括存储器总线或者存储器控制器,外围总线,图形加速端口,处理器或者使用多种总线结构中的任意总线结构的局域总线。举例来说,这些体系结构包括但不限于工业标准体系结构(ISA)总线,微通道体系结构(MAC)总线,增强型ISA总线、视频电子标准协会(VESA)局域总线以及外围组件互连(PCI)总线。
电子设备300典型地包括多种电子设备可读介质。这些介质可以是任何能够被电子设备300访问的可用介质,包括易失性和非易失性介质,可移动的和不可移动的介质。
存储器310还可以包括易失性存储器形式的计算机系统可读介质,例如随机存取存储器(RAM)340和/或高速缓存存储器350。电子设备300可以进一步包括其它可移动/不可移动的、易失性/非易失性计算机系统存储介质。仅作为举例,存储系统360可以用于读写不可移动的、非易失性磁介质(图8未显示,通常称为“硬盘驱动器”)。尽管图8中未示出,可以提供用于对可移动非易失性磁盘(例如“软盘”)读写的磁盘驱动器,以及对可移动非易失性光盘(例如CD-ROM,DVD-ROM或者其它光介质)读写的光盘驱动器。在这些情况下,每个驱动器可以通过一个或者多个数据介质接口与总线330相连。存储器310可以包括至少一个程序产品,该程序产品具有一组(例如至少一个)程序模块,这些程序模块被配置以执行本公开各实施例的功能。
具有一组(至少一个)程序模块370的程序/实用工具380,可以存储在例如存储器310中,这样的程序模块370包括——但不限于——操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。程序模块370通常执行本公开所描述的实施例中的功能和/或方法。A program/
电子设备300也可以与一个或多个外部设备390(例如键盘、指向设备、显示器391等)通信,还可与一个或者多个使得用户能与该电子设备300交互的设备通信,和/或与使得该电子设备300能与一个或多个其它计算设备进行通信的任何设备(例如网卡,调制解调器等等)通信。这种通信可以通过输入/输出(I/O)接口392进行。并且,电子设备300还可以通过网络适配器393与一个或者多个网络(例如局域网(LAN),广域网(WAN)和/或公共网络,例如因特网)通信。如图8所示,网络适配器393通过总线330与电子设备300的其它模块通信。应当明白,尽管图中未示出,可以结合电子设备300使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理单元、外部磁盘驱动阵列、RAID系统、磁带驱动器以及数据备份存储系统等。The
处理器320通过运行存储在存储器310中的程序,从而执行各种功能应用以及数据处理。The
需要说明的是,本实施例的电子设备的实施过程和技术原理参见前述对本公开实施例的语音端点的检测方法的解释说明,此处不再赘述。It should be noted that, for the implementation process and technical principle of the electronic device in this embodiment, refer to the foregoing explanations of the voice endpoint detection method in the embodiment of the present disclosure, which will not be repeated here.
本公开实施例提供的电子设备,可以执行如前所述的语音端点的检测方法,获取传感器阵列中多个传感器采集的原始信号,对多个原始信号进行波束形成,得到波束信号,对波束信号进行语音端点检测,得到语音信号的初始时间,基于初始时间,得到多个传感器对应的语音信号的目标时间。由此,可对多个传感器采集的原始信号进行波束形成,得到波束信号,并对波束信号进行语音端点检测,得到初始时间,以得到多个传感器对应的目标时间,相较于相关技术中大多单独对每个传感器采集的原始信号进行语音端点检测,本方案中仅需对波束信号进行语音端点检测,大大减少了语音端点检测的次数,有助于提升传感器阵列的语音端点检测的效率,且波束信号的信噪比较高,有助于提高语音端点检测的准确性。The electronic device provided by the embodiments of the present disclosure can execute the voice endpoint detection method as described above, obtain the original signals collected by multiple sensors in the sensor array, perform beamforming on the multiple original signals, obtain beam signals, and perform beam formation on the beam signals The voice endpoint detection is performed to obtain the initial time of the voice signal, and based on the initial time, the target time of the voice signal corresponding to the multiple sensors is obtained. In this way, beamforming can be performed on the original signals collected by multiple sensors to obtain beam signals, and voice endpoint detection is performed on the beam signals to obtain the initial time to obtain the target time corresponding to multiple sensors. The voice endpoint detection is performed on the original signal collected by each sensor separately. In this solution, only the voice endpoint detection is required for the beam signal, which greatly reduces the number of voice endpoint detections and helps to improve the efficiency of the voice endpoint detection of the sensor array, and The high signal-to-noise ratio of the beam signal helps improve the accuracy of voice endpoint detection.
为了实现上述实施例,本公开还提出一种计算机可读存储介质,其上存储有计算机程序指令,该程序指令被处理器执行时实现本公开提供的语音端点的检测方法的步骤。In order to realize the above-mentioned embodiments, the present disclosure also proposes a computer-readable storage medium, on which computer program instructions are stored. When the program instructions are executed by a processor, the steps of the voice endpoint detection method provided in the present disclosure are implemented.
可选的,计算机可读存储介质可以是ROM、随机存取存储器(RAM)、CD-ROM、磁带、软盘和光数据存储设备等。Alternatively, the computer-readable storage medium may be ROM, random access memory (RAM), CD-ROM, magnetic tape, floppy disk, optical data storage device, and the like.
为了实现上述实施例,本公开还提供一种计算机程序产品,包括计算机程序,其特征在于,所述计算机程序被电子设备的处理器执行时实现如前所述的语音端点的检测方法。In order to implement the above embodiments, the present disclosure further provides a computer program product, including a computer program, wherein, when the computer program is executed by a processor of an electronic device, the method for detecting a voice endpoint as described above is implemented.
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其它实施方案。本公开旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由下面的权利要求指出。Other embodiments of the present disclosure will be readily apparent to those skilled in the art from consideration of the specification and practice of the invention disclosed herein. The present disclosure is intended to cover any modification, use or adaptation of the present disclosure. These modifications, uses or adaptations follow the general principles of the present disclosure and include common knowledge or conventional technical means in the technical field not disclosed in the present disclosure. . The specification and examples are to be considered exemplary only, with a true scope and spirit of the disclosure being indicated by the following claims.
应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限制。It should be understood that the present disclosure is not limited to the precise constructions which have been described above and shown in the drawings, and various modifications and changes may be made without departing from the scope thereof. The scope of the present disclosure is limited only by the appended claims.
Claims (20)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211643948.XACN116246653A (en) | 2022-12-20 | 2022-12-20 | Voice endpoint detection method, device, electronic device and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211643948.XACN116246653A (en) | 2022-12-20 | 2022-12-20 | Voice endpoint detection method, device, electronic device and storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN116246653Atrue CN116246653A (en) | 2023-06-09 |
Family
ID=86633991
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202211643948.XAPendingCN116246653A (en) | 2022-12-20 | 2022-12-20 | Voice endpoint detection method, device, electronic device and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN116246653A (en) |
Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20080317259A1 (en)* | 2006-05-09 | 2008-12-25 | Fortemedia, Inc. | Method and apparatus for noise suppression in a small array microphone system |
| CN103426440A (en)* | 2013-08-22 | 2013-12-04 | 厦门大学 | Voice endpoint detection device and voice endpoint detection method utilizing energy spectrum entropy spatial information |
| CN105532017A (en)* | 2013-03-12 | 2016-04-27 | 谷歌技术控股有限责任公司 | Apparatus and method for beamforming to obtain voice and noise signals |
| CN109243457A (en)* | 2018-11-06 | 2019-01-18 | 北京智能管家科技有限公司 | Voice-based control method, device, equipment and storage medium |
| CN112349297A (en)* | 2020-11-10 | 2021-02-09 | 西安工程大学 | Depression detection method based on microphone array |
| US20210043223A1 (en)* | 2019-08-07 | 2021-02-11 | Magic Leap, Inc. | Voice onset detection |
| KR20210091034A (en)* | 2020-01-10 | 2021-07-21 | 시냅틱스 인코포레이티드 | Multiple-source tracking and voice activity detections for planar microphone arrays |
| US20220086564A1 (en)* | 2020-09-17 | 2022-03-17 | Bose Corporation | Systems and methods for adaptive beamforming |
| CN114420108A (en)* | 2022-02-16 | 2022-04-29 | 平安科技(深圳)有限公司 | A speech recognition model training method, device, computer equipment and medium |
| CN114598962A (en)* | 2020-12-07 | 2022-06-07 | 湾流航空航天公司 | Microphone array on the aircraft that determines the location and steers the transducer beam to that location |
- 2022
- 2022-12-20CNCN202211643948.XApatent/CN116246653A/enactivePending
Patent Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20080317259A1 (en)* | 2006-05-09 | 2008-12-25 | Fortemedia, Inc. | Method and apparatus for noise suppression in a small array microphone system |
| CN105532017A (en)* | 2013-03-12 | 2016-04-27 | 谷歌技术控股有限责任公司 | Apparatus and method for beamforming to obtain voice and noise signals |
| CN103426440A (en)* | 2013-08-22 | 2013-12-04 | 厦门大学 | Voice endpoint detection device and voice endpoint detection method utilizing energy spectrum entropy spatial information |
| CN109243457A (en)* | 2018-11-06 | 2019-01-18 | 北京智能管家科技有限公司 | Voice-based control method, device, equipment and storage medium |
| US20210043223A1 (en)* | 2019-08-07 | 2021-02-11 | Magic Leap, Inc. | Voice onset detection |
| KR20210091034A (en)* | 2020-01-10 | 2021-07-21 | 시냅틱스 인코포레이티드 | Multiple-source tracking and voice activity detections for planar microphone arrays |
| US20220086564A1 (en)* | 2020-09-17 | 2022-03-17 | Bose Corporation | Systems and methods for adaptive beamforming |
| CN112349297A (en)* | 2020-11-10 | 2021-02-09 | 西安工程大学 | Depression detection method based on microphone array |
| CN114598962A (en)* | 2020-12-07 | 2022-06-07 | 湾流航空航天公司 | Microphone array on the aircraft that determines the location and steers the transducer beam to that location |
| CN114420108A (en)* | 2022-02-16 | 2022-04-29 | 平安科技(深圳)有限公司 | A speech recognition model training method, device, computer equipment and medium |
Non-Patent Citations (1)
| Title |
|---|
| 王晓雪: "《麦克风阵列的语音增强算法研究》", 中国优秀硕士学位论文全文数据库 信息科技辑, no. 01, 15 January 2020 (2020-01-15)* |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN109597022B (en) | Method, device and equipment for sound source azimuth calculation and target audio positioning | |
| CN110992974B (en) | Speech recognition method, apparatus, device and computer readable storage medium | |
| Majumder et al. | Few-shot audio-visual learning of environment acoustics | |
| CN110970053B (en) | A multi-channel and speaker-independent speech separation method based on deep clustering | |
| Georgiou et al. | Alpha-stable modeling of noise and robust time-delay estimation in the presence of impulsive noise | |
| Ren et al. | A novel multiple sparse source localization using triangular pyramid microphone array | |
| CN114788304B (en) | Method for reducing errors in an ambient noise compensation system | |
| CN110503971A (en) | Time-frequency mask neural network based estimation and Wave beam forming for speech processes | |
| WO2022257499A1 (en) | Sound source localization method and apparatus based on microphone array, and storage medium | |
| CN108922553B (en) | Direction-of-arrival estimation method and system for sound box equipment | |
| CN111429939B (en) | Sound signal separation method of double sound sources and pickup | |
| CN110709929B (en) | Processing sound data to separate sound sources in a multi-channel signal | |
| JP2017530396A (en) | Method and apparatus for enhancing a sound source | |
| CN118486318B (en) | A method, medium and system for eliminating noise in outdoor live broadcast environment | |
| CN112687276B (en) | Audio signal processing method and device and storage medium | |
| CN106537501A (en) | Reverberation estimator | |
| CN108231085A (en) | A kind of sound localization method and device | |
| CN113189544A (en) | Multi-sound-source positioning method for removing outliers by weighting of activity intensity vectors | |
| CN111179959B (en) | A method and system for estimating the number of competing speakers based on speaker embedding space | |
| CN118899005B (en) | Audio signal processing method, device, computer equipment and storage medium | |
| CN116110417A (en) | Data enhancement method and device for ultrasonic voiceprint anti-counterfeiting | |
| Ferreira et al. | Real-time blind source separation system with applications to distant speech recognition | |
| Guan et al. | Low complexity DOA estimation based on weighted noise component subtraction for smart-home application | |
| Parisi et al. | Source localization in reverberant environments by consistent peak selection | |
| CN116246653A (en) | Voice endpoint detection method, device, electronic device and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |