CN116189677A - Recognition method, system, device and storage medium of multi-model voice command words - Google Patents
Recognition method, system, device and storage medium of multi-model voice command wordsDownload PDFInfo
- Publication number
- CN116189677A CN116189677ACN202310174256.3ACN202310174256ACN116189677ACN 116189677 ACN116189677 ACN 116189677ACN 202310174256 ACN202310174256 ACN 202310174256ACN 116189677 ACN116189677 ACN 116189677A
- Authority
- CN
- China
- Prior art keywords
- command word
- model
- models
- command
- words
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images


Classifications
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/46—Multiprogramming arrangements
- G06F9/50—Allocation of resources, e.g. of the central processing unit [CPU]
- G06F9/5005—Allocation of resources, e.g. of the central processing unit [CPU] to service a request
- G06F9/5027—Allocation of resources, e.g. of the central processing unit [CPU] to service a request the resource being a machine, e.g. CPUs, Servers, Terminals
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/16—Speech classification or search using artificial neural networks
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L2015/088—Word spotting
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/22—Procedures used during a speech recognition process, e.g. man-machine dialogue
- G10L2015/223—Execution procedure of a spoken command
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Theoretical Computer Science (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Software Systems (AREA)
- General Physics & Mathematics (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Data Mining & Analysis (AREA)
- Life Sciences & Earth Sciences (AREA)
- Mathematical Physics (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Financial Or Insurance-Related Operations Such As Payment And Settlement (AREA)
- Image Analysis (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及语音识别领域,尤其涉及一种多模型语音命令词的识别方法、系统、设备及储存介质。The invention relates to the field of speech recognition, in particular to a method, system, device and storage medium for recognizing multi-model speech command words.
背景技术Background technique
命令词识别技术使得机器对语音指令进行识别和理解的人工只能技术。命令词识别技术已经广泛用在我们的生活当中,智能家居,穿戴设备,智能车载系统等等。Command word recognition technology is an artificial intelligence technology that enables machines to recognize and understand voice commands. Command word recognition technology has been widely used in our lives, smart homes, wearable devices, smart vehicle systems and so on.
传统的命令词识别技术需要语音端点检测(vad)后通过声学建模,wfst解码得到识别的内容,只能对命令词进行精准识别,命令词的前后如果有人声干扰或者说话人说的其他语音识别的性能会下降很多,虽然可以使用在建立wfst时前后加入filler来对额外的语音进行吸收,但是实际使用时会造成大量误识别的出现,同时这种解码识别需要加载包含所有命令词的模型,只能在一个CPU上运行,无法多核并行。The traditional command word recognition technology requires voice endpoint detection (vad) and then through acoustic modeling, wfst decoding to get the recognized content, and can only accurately recognize the command word, if there is voice interference or other voices spoken by the speaker before and after the command word The performance of recognition will drop a lot. Although you can add fillers before and after wfst to absorb additional speech, but in actual use, it will cause a lot of misrecognition. At the same time, this kind of decoding recognition needs to load a model containing all command words , can only run on one CPU, and cannot be multi-core parallel.
发明内容Contents of the invention
本发明目的是为了克服现有技术的不足而提供一种以命令词进行建模,然后通过模型对语音命令词进行识别,最后得到语音识别的结果快速且精准,同时能在不损失识别性能的前提下增加命令词的数量的多模型语音命令词的识别方法、系统、设备及储存介质。The purpose of the present invention is to overcome the deficiencies in the prior art and provide a method of modeling command words, and then recognize the speech command words through the model, and finally obtain the result of speech recognition quickly and accurately, and at the same time, it can be used without loss of recognition performance. A multi-model voice command word recognition method, system, device and storage medium for increasing the number of command words on the premise.
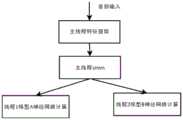
为达到上述目的,本发明采用的技术方案是:一种多模型语音命令词的识别方法,包括如下步骤:In order to achieve the above object, the technical solution adopted in the present invention is: a kind of recognition method of multi-model voice command word, comprises the steps:
基于需要支持的语音命令词划分后构建相应数量的模型以及各个模型支持的命令词;Construct a corresponding number of models and command words supported by each model based on the division of speech command words that need to be supported;
根据划分的结果得出系统运行时需要并行的模型最大数量,根据模型的最大数量创建线程池,加载需要运行的模型,每个模型从线程池中分配一个单独的线程;According to the results of the division, the maximum number of models that need to be parallelized when the system is running is obtained, and a thread pool is created according to the maximum number of models, and the models that need to be run are loaded, and each model is allocated a separate thread from the thread pool;
主线程对音频输入进行特征提取及公共部分的计算,其余的多个线程分别由对应模型的神经网络进行计算;The main thread performs feature extraction and calculation of the common part on the audio input, and the rest of the threads are calculated by the neural network of the corresponding model;
当只有一个模型识别到命令词时,对误识别做过滤得到最终识别结果;当多个模型同一时间检测到命令词时,根据命令词的得分最高的作为最终的识别结果。When only one model recognizes the command word, filter the misrecognition to get the final recognition result; when multiple models detect the command word at the same time, the one with the highest score of the command word is used as the final recognition result.
进一步的,语音命令词按照功能或者类别和命令词的长度进行划分。Further, the voice command words are divided according to the function or category and the length of the command words.
进一步的,每个模型的命令词个数不超过10个。Furthermore, the number of command words for each model does not exceed 10.
进一步的,命令词的得分的计算方式如下:Further, the calculation method of the score of command words is as follows:

进一步的,对不同的模型设置不同的长度限制,由于相近长度的命令词分在了一组,当选中的命令词片段的时长未达到设置的长度时将其认为是误识别。Furthermore, different length limits are set for different models. Since command words of similar length are grouped together, when the duration of the selected command word segment does not reach the set length, it is considered as a misrecognition.
进一步的,所述语音命令词包括主命令词,在每个所述主命令词下划分有依次层层分级的次级命令词;Further, the voice command words include main command words, and each of the main command words is divided into sub-command words that are graded layer by layer;
其中,每个次级命令词构建的模型在使用场景上是主命令词或上一个次级命令词构建模型的具体功能的命令词。Wherein, the model constructed by each secondary command word is the command word of the specific function of the model constructed by the main command word or the previous secondary command word in the usage scenario.
一种多模型语音命令词的识别系统,包括:A recognition system for multi-model speech command words, comprising:
分组建模模块:基于需要支持的语音命令词划分后构建相应数量的模型以及各个模型支持的命令词;Group modeling module: build corresponding number of models and the command words supported by each model based on the voice command words that need to be supported;
线程池构建模块:基于系统运行时需要并行的模型最大数量来创建线程池,加载需要运行的模型,每个模型从线程池中分配一个单独的线程;Thread pool building block: Create a thread pool based on the maximum number of models that need to be parallelized when the system is running, load the models that need to be run, and allocate a separate thread from the thread pool for each model;
并行解码模块:主线程对音频输入进行特征提取及公共部分的计算,其余的多个线程分别由对应模型的神经网络进行计算;Parallel decoding module: the main thread performs feature extraction and common part calculation on the audio input, and the remaining multiple threads are calculated by the neural network of the corresponding model;
获取识别结果模块:当只有一个模型识别到命令词时,对误识别做过滤得到最终识别结果;当多个模型同一时间检测到命令词时,根据命令词的得分最高的作为最终的识别结果。Obtain recognition result module: When only one model recognizes the command word, filter the misrecognition to get the final recognition result; when multiple models detect the command word at the same time, the highest score of the command word is used as the final recognition result.
一种处理设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序;其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现前述的方法。A processing device comprising: one or more processors; a memory for storing one or more programs; wherein, when the one or more programs are executed by the one or more processors, the One or more processors implement the aforementioned methods.
一种可读存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行前述的方法。A readable storage medium, wherein a computer program is stored in the storage medium, wherein the computer program is configured to execute the aforementioned method when running.
由于上述技术方案的运用,本发明与现有技术相比具有下列优点:Due to the application of the above-mentioned technical solution, the present invention has the following advantages compared with the prior art:
本发明方案的多模型语音命令词的识别方法、系统、设备及储存介质,首先不需要语音端点检测,输出层参数量更小,得到模型结果后不需要进行wfst解码只需要简单的后处理既可以得到识别的结果;能够在不损失识别性能的前提下增加命令词的数量,多线程并行计算也能带来效率的提高,同时在使用和后期维护更新时更加的灵活;另外,在后续添加或者删除命令词时只需要做局部的调整,不需要对所有的模型重新训练。The recognition method, system, equipment and storage medium of the multi-model speech command word of the present invention, at first do not need speech endpoint detection, output layer parameter quantity is smaller, after obtaining model result, do not need to carry out wfst decoding and only need simple post-processing. Recognition results can be obtained; the number of command words can be increased without loss of recognition performance, multi-threaded parallel computing can also improve efficiency, and at the same time, it is more flexible in use and later maintenance and updates; in addition, in subsequent additions Or you only need to make local adjustments when deleting command words, and you don't need to retrain all the models.
附图说明Description of drawings
下面结合附图对本发明技术方案作进一步说明:Below in conjunction with accompanying drawing, technical solution of the present invention will be further described:
图1为本发明一实施例的流程示意图;Fig. 1 is a schematic flow chart of an embodiment of the present invention;
图2为本发明一实施例中构建命令词后进行语音命令词识别的流程示意图;Fig. 2 is the schematic flow chart that carries out speech command word recognition after constructing command word in an embodiment of the present invention;
图3为本发明的步骤S3中以主命令词构建的两个模型A和B并行运行的流程图。Fig. 3 is a flow chart of parallel operation of two models A and B constructed with main command words in step S3 of the present invention.
具体实施方式Detailed ways
下面结合附图及具体实施例对本发明作进一步的详细说明。The present invention will be further described in detail below in conjunction with the accompanying drawings and specific embodiments.
参阅图1,本发明实施例所述的一种多模型语音命令词的识别方法,包括如下步骤:Referring to Fig. 1, the recognition method of a kind of multi-model voice command word described in the embodiment of the present invention, comprises the steps:
S1基于需要支持的语音命令词划分后构建相应数量的模型以及各个模型支持的命令词;S1 builds a corresponding number of models and command words supported by each model based on the division of speech command words that need to be supported;
S2根据划分的结果得出系统运行时需要并行的模型最大数量,根据模型的最大数量创建线程池,加载需要运行的模型,每个模型从线程池中分配一个单独的线程;S2 obtains the maximum number of models that need to be parallelized when the system is running according to the division results, creates a thread pool according to the maximum number of models, loads the models that need to be run, and allocates a separate thread for each model from the thread pool;
S3主线程对音频输入进行特征提取及公共部分的计算,其余的多个线程分别由对应模型的神经网络进行计算;The S3 main thread performs feature extraction and common part calculation on the audio input, and the rest of the multiple threads are calculated by the neural network of the corresponding model;
S4当只有一个模型识别到命令词时,对误识别做过滤得到最终识别结果;当多个模型同一时间检测到命令词时,根据命令词的得分最高的作为最终的识别结果。S4 When only one model recognizes the command word, filter the misrecognition to obtain the final recognition result; when multiple models detect the command word at the same time, the one with the highest score of the command word is used as the final recognition result.
作为本发明的进一步的优选实施例,在步骤S1中,语音命令词按照功能和命令词的长度或者按照类别和命令词的长度进行划分,将命令词长度相近或者相同的划分为一组;同时,由于相近长度的命令词分在了一组,还可以对不同的模型设置不同的长度限制,当选中的命令词片段的时长未达到设置的长度时将其认为是误识别,提升了识别的精准度。As a further preferred embodiment of the present invention, in step S1, the voice command word is divided according to the length of the function and the command word or according to the length of the category and the command word, and the command words with similar or identical lengths are divided into a group; at the same time , since the command words of similar length are grouped together, different length limits can also be set for different models. When the length of the selected command word fragment does not reach the set length, it is considered as a misrecognition, which improves the recognition accuracy. precision.
另外,为了保证模型识别的精准,所以每个模型的命令词个数不超过10个。In addition, in order to ensure the accuracy of model recognition, the number of command words for each model does not exceed 10.
作为本发明的进一步的优选实施例,在步骤S2中,由于线程池的数量等于系统运行时最大的模型并行数量,这样在需要使用某一个模型时,从线程池中拿出空闲的线程进行计算,卸载时,回收模型对应的线程到线程池里去,从而尽可能的节省系统的开销。As a further preferred embodiment of the present invention, in step S2, since the number of thread pools is equal to the maximum model parallel number when the system is running, when a certain model needs to be used, take out idle threads from the thread pool for calculation , when unloading, recycle the thread corresponding to the model to the thread pool, so as to save system overhead as much as possible.
作为本发明的进一步的优选实施例,在步骤S4中,命令词的得分的计算方式如下:As a further preferred embodiment of the present invention, in step S4, the computing mode of the score of command word is as follows:

通过命令词的得分来决定最终的识别效果,这样的识别准确率高。The final recognition effect is determined by the score of the command word, and the recognition accuracy is high.
作为本发明的进一步的优选实施例,语音命令词包括主命令词,在每个所述主命令词下划分有依次层层分级的次级命令词;其中,每个次级命令词构建的模型在使用场景上是主命令词或上一个次级命令词构建模型的具体功能的命令词。As a further preferred embodiment of the present invention, the voice command words include a main command word, and under each of the main command words, there are sub-command words that are graded successively; wherein, the model constructed by each sub-command word In the usage scenario, it is the command word of the specific function of the main command word or the previous secondary command word to build the model.
具体来说,语音命令词可以包括多个主命令词,主命令词的下设有多个第一次级命令词,第一次级命令词下设有多个第二次级命令词,依次类推,可以有多个次级命令词;其中,第一次级命令词构建的模型在使用场景上是主命令词构建模型的具体功能的命令词,第二次级命令词构建的模型在使用场景上是第一次级命令词构建模型的具体功能的命令词。Specifically, voice command words can include a plurality of main command words, a plurality of first secondary command words are arranged under the main command words, and a plurality of second secondary command words are arranged under the first secondary command words, and successively By analogy, there can be multiple secondary command words; among them, the model constructed by the first secondary command word is the command word of the specific function of the model constructed by the main command word in the usage scenario, and the model constructed by the second secondary command word is in use The scene is the command word of the specific function of the first-level command word construction model.
参阅图2为本发明一实施例的具体工作流程图,本实施例中以主命令词的长度构建了两个模型A和B来进行使用,同时还具有由主命令词的下一级命令词构成的C,D,E三个模型,其中C和D在使用场景上是实现模型A的具体功能的命令词,E是实现B的具体功能的命令词;C和D也是按照长度划分的。Referring to Fig. 2, it is a specific work flow diagram of an embodiment of the present invention. In this embodiment, two models A and B have been constructed with the length of the main command word for use, and simultaneously there are subordinate command words of the main command word Three models C, D, and E are formed, where C and D are command words to realize the specific functions of model A in usage scenarios, and E is a command word to realize specific functions of B; C and D are also divided according to length.
系统启动时,A和B两个初始模型并行运行,当识别结果是A的命令词时,切换到C和D并行;识别结果是B的命令词时切换到E,如果A和B或者C和D同时抛出识别结果会对两个结果打分选择最佳的结果,当然,图2只是举了某个特定的例子,实际使用时可以任意的去组合使用:比如初始模型的数量为三个或多个,主命令词的下一级命令词构建的模型为二个、三个或者四个。When the system starts, the two initial models A and B run in parallel. When the recognition result is the command word of A, switch to C and D in parallel; when the recognition result is the command word of B, switch to E. If A and B or C and D throwing the recognition results at the same time will score the two results and select the best result. Of course, Figure 2 is just a specific example, which can be used in any combination in actual use: for example, the number of initial models is three or multiple, the model constructed by the subordinate command word of the main command word is two, three or four.
综上所述,本发明中建模的单元是命令词,然后对每个由命令词构建的模型单独分配一个线程,最后通过模型对命令词来进行识别,当有多个模型检测到同一命令词时,通过命令词的最高得分来最为最终的识别结果。To sum up, the unit of modeling in the present invention is the command word, and then assign a thread to each model constructed by the command word, and finally identify the command word through the model, when multiple models detect the same command words, the final recognition result is obtained by the highest score of the command word.
参阅图3,其是对步骤S3的一个具体实施例的描述,其以主命令词构建的两个模型A和B并行为例进行应用,可以推广到多个模型并行。Referring to FIG. 3 , it is a description of a specific embodiment of step S3 , which is applied in parallel with two models A and B constructed by the main command word, and can be extended to multiple models in parallel.
本发明的识别方法具有如下优点:首先不需要语音端点检测,输出层参数量更小,得到模型结果后不需要进行wfst解码只需要简单的后处理既可以得到识别的结果;能够在不损失识别性能的前提下增加命令词的数量,多线程并行计算也能带来效率的提高,同时在使用和后期维护更新时更加的灵活;另外,在后续添加或者删除命令词时只需要做局部的调整,不需要对所有的模型重新训练。The recognition method of the present invention has the following advantages: firstly, it does not need speech endpoint detection, and the output layer parameter quantity is smaller. After obtaining the model result, it is not necessary to carry out wfst decoding, and only simple post-processing is required to obtain the recognition result; Increase the number of command words under the premise of performance, and multi-threaded parallel computing can also improve efficiency. At the same time, it is more flexible in use and later maintenance and updates; in addition, only partial adjustments need to be made when adding or deleting command words , there is no need to retrain all models.
本发明还公开了一种多模型语音命令词的识别系统,包括:The invention also discloses a recognition system for multi-model speech command words, comprising:
分组建模模块:基于需要支持的语音命令词划分后构建相应数量的模型以及各个模型支持的命令词;Group modeling module: build corresponding number of models and the command words supported by each model based on the voice command words that need to be supported;
线程池构建模块:基于系统运行时需要并行的模型最大数量来创建线程池,加载需要运行的模型,每个模型从线程池中分配一个单独的线程;Thread pool building block: Create a thread pool based on the maximum number of models that need to be parallelized when the system is running, load the models that need to be run, and allocate a separate thread from the thread pool for each model;
并行解码模块:主线程对音频输入进行特征提取及公共部分的计算,其余的多个线程分别由对应模型的神经网络进行计算;Parallel decoding module: the main thread performs feature extraction and common part calculation on the audio input, and the remaining multiple threads are calculated by the neural network of the corresponding model;
获取识别结果模块:当只有一个模型识别到命令词时,对误识别做过滤得到最终识别结果;当多个模型同一时间检测到命令词时,根据命令词的得分最高的作为最终的识别结果。Obtain recognition result module: When only one model recognizes the command word, filter the misrecognition to get the final recognition result; when multiple models detect the command word at the same time, the highest score of the command word is used as the final recognition result.
本发明另一实施例还提供一种电子设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序;其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现前述所述的方法。Another embodiment of the present invention also provides an electronic device, including: one or more processors; a memory for storing one or more programs; wherein, when the one or more programs are used by the one or more When the processors are executed, the one or more processors are made to implement the aforementioned methods.
本发明另一实施例还提供一种可读存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行前述所述的多模型语音命令词的识别方法。Another embodiment of the present invention also provides a readable storage medium, in which a computer program is stored, wherein the computer program is set to execute the aforementioned multi-model voice command word recognition method when running.
以上仅是本发明的具体应用范例,对本发明的保护范围不构成任何限制。凡采用等同变换或者等效替换而形成的技术方案,均落在本发明权利保护范围之内。The above are only specific application examples of the present invention, and do not constitute any limitation to the protection scope of the present invention. All technical solutions formed by equivalent transformation or equivalent replacement fall within the protection scope of the present invention.
Claims (9)

Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310174256.3ACN116189677B (en) | 2023-02-28 | 2023-02-28 | Method, system, equipment and storage medium for identifying multi-model voice command words |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310174256.3ACN116189677B (en) | 2023-02-28 | 2023-02-28 | Method, system, equipment and storage medium for identifying multi-model voice command words |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN116189677Atrue CN116189677A (en) | 2023-05-30 |
| CN116189677B CN116189677B (en) | 2025-07-08 |
Family
ID=86448400
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202310174256.3AActiveCN116189677B (en) | 2023-02-28 | 2023-02-28 | Method, system, equipment and storage medium for identifying multi-model voice command words |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN116189677B (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116825108A (en)* | 2023-08-25 | 2023-09-29 | 深圳市友杰智新科技有限公司 | Voice command word recognition method, device, equipment and medium |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5895448A (en)* | 1996-02-29 | 1999-04-20 | Nynex Science And Technology, Inc. | Methods and apparatus for generating and using speaker independent garbage models for speaker dependent speech recognition purpose |
| CN110648659A (en)* | 2019-09-24 | 2020-01-03 | 上海依图信息技术有限公司 | Voice recognition and keyword detection device and method based on multitask model |
| CN110808036A (en)* | 2019-11-07 | 2020-02-18 | 南京大学 | An Incremental Voice Command Word Recognition Method |
| WO2020226213A1 (en)* | 2019-05-09 | 2020-11-12 | 엘지전자 주식회사 | Artificial intelligence device for providing voice recognition function and method for operating artificial intelligence device |
| CN114631102A (en)* | 2019-11-05 | 2022-06-14 | 辉达公司 | Back-propagated distributed weight update for neural networks |
- 2023
- 2023-02-28CNCN202310174256.3Apatent/CN116189677B/enactiveActive
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5895448A (en)* | 1996-02-29 | 1999-04-20 | Nynex Science And Technology, Inc. | Methods and apparatus for generating and using speaker independent garbage models for speaker dependent speech recognition purpose |
| WO2020226213A1 (en)* | 2019-05-09 | 2020-11-12 | 엘지전자 주식회사 | Artificial intelligence device for providing voice recognition function and method for operating artificial intelligence device |
| CN110648659A (en)* | 2019-09-24 | 2020-01-03 | 上海依图信息技术有限公司 | Voice recognition and keyword detection device and method based on multitask model |
| CN114631102A (en)* | 2019-11-05 | 2022-06-14 | 辉达公司 | Back-propagated distributed weight update for neural networks |
| CN110808036A (en)* | 2019-11-07 | 2020-02-18 | 南京大学 | An Incremental Voice Command Word Recognition Method |
Non-Patent Citations (1)
| Title |
|---|
| 吴鹏飞;凌震华;: "基于多普勒雷达的发音动作检测与命令词识别", 小型微型计算机系统, no. 02, 15 February 2020 (2020-02-15)* |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116825108A (en)* | 2023-08-25 | 2023-09-29 | 深圳市友杰智新科技有限公司 | Voice command word recognition method, device, equipment and medium |
| CN116825108B (en)* | 2023-08-25 | 2023-12-08 | 深圳市友杰智新科技有限公司 | Voice command word recognition method, device, equipment and medium |
Also Published As
| Publication number | Publication date |
|---|---|
| CN116189677B (en) | 2025-07-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN108172213B (en) | Surge audio identification method, surge audio identification device, surge audio identification equipment and computer readable medium | |
| CN112749344B (en) | Information recommendation method, device, electronic device, storage medium and program product | |
| US20230004809A1 (en) | Method and Device for Model Compression of Neural Network | |
| CN112560985B (en) | Neural network search method, device and electronic equipment | |
| US20180068652A1 (en) | Apparatus and method for training a neural network language model, speech recognition apparatus and method | |
| CN113327584A (en) | Language identification method, device, equipment and storage medium | |
| CN113823265B (en) | A speech recognition method, device and computer equipment | |
| CN116189677A (en) | Recognition method, system, device and storage medium of multi-model voice command words | |
| CN110163151B (en) | Training method and device of face model, computer equipment and storage medium | |
| CN105279524A (en) | High-dimensional data clustering method based on unweighted hypergraph segmentation | |
| CN108776833A (en) | A kind of data processing method, system and computer readable storage medium | |
| CN110852082A (en) | Synonym determination method and device | |
| CN114861758A (en) | Multi-modal data processing method and device, electronic equipment and readable storage medium | |
| CN113010642A (en) | Semantic relation recognition method and device, electronic equipment and readable storage medium | |
| WO2021134231A1 (en) | Computing resource allocation method and apparatus based on inference engine, and computer device | |
| CN110175588B (en) | A meta-learning-based few-sample facial expression recognition method and system | |
| CN106529679A (en) | Machine learning method and system | |
| CN118762193A (en) | A connector detection method based on image recognition | |
| CN117636843A (en) | Speech recognition method, device, electronic equipment and storage medium | |
| CN114694659B (en) | Audio processing method, device, electronic device and storage medium | |
| CN114005459B (en) | Human voice separation method and device and electronic equipment | |
| CN116628203A (en) | Dialogue emotion recognition method and system based on dynamic complementary graph convolution network | |
| CN106971731B (en) | Correction method for voiceprint recognition | |
| CN116360960A (en) | Memory allocation method and memory allocation device based on many-core chip | |
| CN111767735B (en) | Method, apparatus and computer readable storage medium for executing tasks |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |