CN116129207A - A Method for Image Data Processing with Multi-Scale Channel Attention - Google Patents
A Method for Image Data Processing with Multi-Scale Channel AttentionDownload PDFInfo
- Publication number
- CN116129207A CN116129207ACN202310414590.1ACN202310414590ACN116129207ACN 116129207 ACN116129207 ACN 116129207ACN 202310414590 ACN202310414590 ACN 202310414590ACN 116129207 ACN116129207 ACN 116129207A
- Authority
- CN
- China
- Prior art keywords
- global
- input data
- channel attention
- local
- features
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images


Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/7715—Feature extraction, e.g. by transforming the feature space, e.g. multi-dimensional scaling [MDS]; Mappings, e.g. subspace methods
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/77—Processing image or video features in feature spaces; using data integration or data reduction, e.g. principal component analysis [PCA] or independent component analysis [ICA] or self-organising maps [SOM]; Blind source separation
- G06V10/80—Fusion, i.e. combining data from various sources at the sensor level, preprocessing level, feature extraction level or classification level
- G06V10/806—Fusion, i.e. combining data from various sources at the sensor level, preprocessing level, feature extraction level or classification level of extracted features
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V2201/00—Indexing scheme relating to image or video recognition or understanding
- G06V2201/07—Target detection
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Evolutionary Computation (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- General Health & Medical Sciences (AREA)
- Software Systems (AREA)
- Computing Systems (AREA)
- Artificial Intelligence (AREA)
- Health & Medical Sciences (AREA)
- Databases & Information Systems (AREA)
- Medical Informatics (AREA)
- Multimedia (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Computational Linguistics (AREA)
- Data Mining & Analysis (AREA)
- Molecular Biology (AREA)
- General Engineering & Computer Science (AREA)
- Mathematical Physics (AREA)
- Image Analysis (AREA)
- Facsimile Image Signal Circuits (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及计算机视觉领域,尤其涉及一种多尺度通道注意力的图像数据处理方法。The invention relates to the field of computer vision, in particular to an image data processing method of multi-scale channel attention.
背景技术Background technique
通道注意力机制能够显著地提高模型的表现力和泛化能力,且具有较低的计算成本,容易被集成到现有的卷积神经网络结构中。而由于这些优点,通道注意力机制也已经被广泛应用于图像分类、目标检测、语义分割等深度学习应用领域。The channel attention mechanism can significantly improve the expressiveness and generalization ability of the model, and has a low computational cost, and is easy to be integrated into the existing convolutional neural network structure. Due to these advantages, the channel attention mechanism has been widely used in deep learning applications such as image classification, object detection, and semantic segmentation.
通道注意力机制的本质是对不同通道的特征进行加权平均,从而得到更加丰富、稳定、可靠的特征表达。The essence of the channel attention mechanism is to weight and average the features of different channels, so as to obtain more abundant, stable and reliable feature expressions.
现有的通道注意力有SE,ECA,CA等,这些通道注意力仅仅关注某一局部特征中的细节信息或者全局特征中的语义信息,而没有同时关注细节信息与语义信息,导致不够丰富的通道维度的特征表达。The existing channel attention includes SE, ECA, CA, etc. These channel attention only focus on the detailed information in a certain local feature or the semantic information in the global feature, but do not pay attention to the detailed information and semantic information at the same time, resulting in insufficient richness. Feature representation of the channel dimension.
发明内容Contents of the invention
本发明的目的是为了提供一种多尺度通道注意力的图像数据处理方法。The purpose of the present invention is to provide a multi-scale channel attention image data processing method.
本发明所要解决的问题是:The problem to be solved by the present invention is:
提出一种多尺度通道注意力的图像数据处理方法,提取输入数据中的全局特征和局部特征,从而使得卷积神经网络对输入数据的整体信息以及局部细节特征更加关注,从而缓解复杂场景中出现的目标聚集与目标遮挡问题。A multi-scale channel attention image data processing method is proposed to extract the global features and local features in the input data, so that the convolutional neural network pays more attention to the overall information and local detail features of the input data, thereby alleviating the occurrence of complex scenes. The problem of target aggregation and target occlusion.
一种多尺度通道注意力的图像数据处理方法采用的技术方案如下:A technical scheme adopted by an image data processing method of multi-scale channel attention is as follows:
一种多尺度通道注意力的图像数据处理方法A Method for Image Data Processing with Multi-Scale Channel Attention
S21:对输入数据(原始图像或特征图)进行数字化处理,将提取到的特征转换为数字化,并通过张量矩阵存储,经过归一化处理使卷积神经网络收敛加快;S21: Digitize the input data (original image or feature map), convert the extracted features into digits, store them in a tensor matrix, and speed up the convergence of the convolutional neural network after normalization;
S22:使用全局通道注意力机制与局部通道注意力机制相结合的方法,对输入数据进行特征提取和特征融合;S22: Use the method of combining the global channel attention mechanism and the local channel attention mechanism to perform feature extraction and feature fusion on the input data;
S23:在全局通道注意力机制内使用全局平均池化、自适应选择卷积核大小的一维卷积层和Sigmoid激活函数,全局通道注意力可以通过对特征图的全局平均池化和逐元素变换,自适应地调整不同通道的权重,使得模型能够关注更重要的特征,提高模型的分类性能和鲁棒性,其中全局平均池化的计算公式为:,其中表示全局平均池化结果,为输入图像,其尺寸为W×H×C,W、H和C分别表示输入图像的宽、高和通道,i和j分别代表宽和高上的像素点位置;S23: In the global channel attention mechanism, global average pooling, one-dimensional convolution layer with adaptive selection of convolution kernel size and Sigmoid activation function are used. Global channel attention can be achieved through global average pooling of feature maps and element-by-element Transformation, adaptively adjust the weights of different channels, so that the model can focus on more important features, improve the classification performance and robustness of the model, and the calculation formula of the global average pooling is: ,in Indicates the global average pooling result, is the input image, its size is W×H×C, W, H and C represent the width, height and channel of the input image respectively, and i and j represent the pixel position on the width and height respectively;
自适应选择的计算公式为:,其中表示一维卷积的卷积核大小,表示通道数,表示k只能取奇数,和用于改变和之间的比例,本发明中和分别取2和1;The calculation formula for adaptive selection is: ,in Represents the convolution kernel size of one-dimensional convolution, Indicates the number of channels, Indicates that k can only take odd numbers, and used to change and The ratio between, in the present invention and Take 2 and 1 respectively;
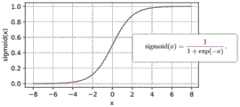
Sigmoid激活函数也称为S型生长曲线,计算公式为:,其中为输入;The Sigmoid activation function is also known as the S-type growth curve, and the calculation formula is: ,in for input;
S24:在局部通道注意力机制中采用的是二维卷积实现的多层感知机MLP,用于提取局部特征,MLP架构为卷积核大小为1的两个二维卷积以及中间的ReLU函数激活,输入数据经二维卷积后仅改变其通道数,第一个卷积操作的输出通道数为输入通道数的十六分之一,第二个卷积操作的输出通道数与嵌入位置通道数一致,局部通道注意力则可以帮助模型更好地捕捉输入特征中的局部信息;S24: In the local channel attention mechanism, a multi-layer perceptron MLP implemented by two-dimensional convolution is used to extract local features. The MLP architecture is two two-dimensional convolutions with a convolution kernel size of 1 and a ReLU in the middle. Function activation, the input data only changes its number of channels after two-dimensional convolution, the number of output channels of the first convolution operation is one-sixteenth of the number of input channels, the number of output channels of the second convolution operation is the same as the embedding The number of position channels is the same, and the local channel attention can help the model better capture the local information in the input features;
S25:ReLU函数通过将相应的活性值设为0,仅保留正元素并丢弃所有负元素;S25: The ReLU function keeps only positive elements and discards all negative elements by setting the corresponding activity value to 0;
S26:将全局注意力与局部注意力的输出进行融合操作,并使用Sigmoid函数激活数据得到最终的注意力权重,然后将激活后的数据与输入数据进行逐像素相乘;S26: Fuse the output of the global attention and the local attention, and use the Sigmoid function to activate the data to obtain the final attention weight, and then multiply the activated data and the input data pixel by pixel;
S27:通过Sigmoid函数进行压缩,它将已有数据根据其范围,将任意输入压缩到区间(0, 1)中的某个值,以保证归一化;S27: Compress through the Sigmoid function, which compresses any input to a certain value in the interval (0, 1) according to the existing data according to its range, so as to ensure normalization;
S28:对输入数据与激活后的数据进行逐像素相乘操作,用来完成对输入数据的不同位置加权操作,从而更关注全局特征和局部特征。S28: Perform a pixel-by-pixel multiplication operation on the input data and the activated data to complete weighting operations on different positions of the input data, so as to pay more attention to global features and local features.
进一步的,上述输入数据通过上述步骤S24中二维卷积后仅改变其通道数,且在整个MLP架构内,对输入数据的通道以一种先收缩后扩张的方式估计通道间的注意力,其中的收缩系数为r,收缩后特征尺度为H×W×C/r,使用ReLU激活函数,扩张后特征尺度为H×W×C。Further, the above-mentioned input data only changes the number of channels after the two-dimensional convolution in the above-mentioned step S24, and in the entire MLP architecture, the channel of the input data is estimated in a way of shrinking first and then expanding, The shrinkage coefficient is r, the feature scale after shrinkage is H×W×C/r, and the ReLU activation function is used, and the feature scale after expansion is H×W×C.
进一步的,上述步骤S23和S24中分别通过全局通道注意力机制中全局平均池化的方式和局部通道注意力机制中多层感知机MLP的方式分别提取输入数据中的全局特征和局部特征,并通过上述步骤S26对步骤S23与步骤S24的全局通道注意力机制的输出与局部通道注意力机制的输出进行融合操作即对不同特征进行特征融合,从而使得卷积神经网络对输入数据的整体信息以及局部细节特征更加关注,从而缓解复杂场景中出现的目标聚集与目标遮挡问题。Further, in the above steps S23 and S24, the global features and local features in the input data are respectively extracted by means of global average pooling in the global channel attention mechanism and the multi-layer perceptron MLP in the local channel attention mechanism, and Through the above step S26, the output of the global channel attention mechanism of step S23 and step S24 is fused with the output of the local channel attention mechanism, that is, the feature fusion of different features is performed, so that the convolutional neural network can understand the overall information of the input data and Local detail features are more concerned, thereby alleviating the problems of target aggregation and target occlusion in complex scenes.
本发明的有益效果:复杂场景下的小目标检测的大量聚集和严重的遮挡等特点带来的检测精度不高、漏检率高等问题,可以通过多尺度通道注意力的图像数据处理方法进一步缓解,多尺度通道注意力的图像数据处理方法通过提取数据中的全局特征和局部特征并对不同特征进行特征融合,从而使得卷积神经网络对输入数据的整体信息以及局部细节特征更加关注,从而缓解复杂场景中出现的目标聚集及目标遮挡问题。Beneficial effects of the present invention: the problems of low detection accuracy and high missed detection rate caused by the large number of small target detection and serious occlusion in complex scenes can be further alleviated by the image data processing method of multi-scale channel attention , the image data processing method of multi-scale channel attention extracts the global features and local features in the data and performs feature fusion on different features, so that the convolutional neural network pays more attention to the overall information of the input data and local detail features, thereby alleviating Target aggregation and target occlusion problems in complex scenes.
附图说明Description of drawings
图1为本发明中多尺度通道注意力的图像数据处理方法示意图;Fig. 1 is a schematic diagram of an image data processing method of multi-scale channel attention in the present invention;
图2为本发明中ReLU函数修正线性示意图;Fig. 2 is a linear schematic diagram of ReLU function modification in the present invention;
图3为本发明中sigmoid函数数据归一化示意图。Fig. 3 is a schematic diagram of normalization of sigmoid function data in the present invention.
具体实施方式Detailed ways
下面结合说明书附图对本发明进一步清楚完整说明,但本发明的保护范围并不仅限于此。The present invention will be further clearly and completely described below in conjunction with the accompanying drawings, but the protection scope of the present invention is not limited thereto.
实施例Example
如图1至图3所示,一种多尺度通道注意力的图像数据处理方法,包括以下步骤:As shown in Figures 1 to 3, an image data processing method for multi-scale channel attention includes the following steps:
S21:对输入数据(原始图像或特征图)进行数字化处理,将提取到的特征转换为数字化,并通过张量矩阵存储,经过归一化处理使卷积神经网络收敛加快;S21: Digitize the input data (original image or feature map), convert the extracted features into digits, store them in a tensor matrix, and speed up the convergence of the convolutional neural network after normalization;
S22:使用全局通道注意力机制与局部通道注意力机制相结合的方法,如图1所示,对输入数据进行特征提取和特征融合;S22: Use a method combining the global channel attention mechanism and the local channel attention mechanism, as shown in Figure 1, to perform feature extraction and feature fusion on the input data;
S23:在全局通道注意力机制内使用全局平均池化、自适应选择卷积核大小的一维卷积层和Sigmoid激活函数,如图1左列所示,全局通道注意力可以通过对特征图的全局平均池化和逐元素变换,自适应地调整不同通道的权重,使得模型能够关注更重要的特征,提高模型的分类性能和鲁棒性,其中全局平均池化的计算公式为:,其中表示全局平均池化结果,为输入图像,其尺寸为W×H×C,W、H和C分别表示输入图像的宽、高和通道,i和j分别代表宽和高上的像素点位置;S23: In the global channel attention mechanism, use global average pooling, one-dimensional convolution layer with adaptive selection of convolution kernel size and Sigmoid activation function, as shown in the left column of Figure 1, global channel attention can be passed to the feature map The global average pooling and element-by-element transformation adaptively adjust the weights of different channels so that the model can focus on more important features and improve the classification performance and robustness of the model. The calculation formula of the global average pooling is: ,in Indicates the global average pooling result, is the input image, its size is W×H×C, W, H and C represent the width, height and channel of the input image respectively, and i and j represent the pixel position on the width and height respectively;
自适应选择的计算公式为:,其中表示一维卷积的卷积核大小,表示通道数,表示k只能取奇数,和用于改变和之间的比例,本发明中和分别取2和1;The calculation formula for adaptive selection is: ,in Represents the convolution kernel size of one-dimensional convolution, Indicates the number of channels, Indicates that k can only take odd numbers, and used to change and The ratio between, in the present invention and Take 2 and 1 respectively;
Sigmoid激活函数也称为S型生长曲线,如图3所示,计算公式为:,其中为输入;The Sigmoid activation function is also called the S-type growth curve, as shown in Figure 3, the calculation formula is: ,in for input;
S24:在局部通道注意力机制中采用的是二维卷积实现的多层感知机MLP,用于提取局部特征,MLP架构为卷积核大小为1的两个二维卷积以及中间的ReLU函数激活,ReLU函数激活使一部分神经元的输出为0,减少了参数的相互依存关系,缓解了过拟合问题的发生,输入数据经二维卷积后仅改变其通道数,第一个卷积操作的输出通道数为输入通道数的十六分之一,第二个卷积操作的输出通道数与嵌入位置通道数一致,局部通道注意力则可以帮助模型更好地捕捉输入特征中的局部信息,如图1右列所示;S24: In the local channel attention mechanism, a multi-layer perceptron MLP implemented by two-dimensional convolution is used to extract local features. The MLP architecture is two two-dimensional convolutions with a convolution kernel size of 1 and a ReLU in the middle. Function activation, ReLU function activation makes the output of some
S25:ReLU函数通过将相应的活性值设为0,如图2所示,仅保留正元素并丢弃所有负元素;S25: The ReLU function sets the corresponding activity value to 0, as shown in Figure 2, only retains positive elements and discards all negative elements;
S26:将全局注意力与局部注意力的输出进行融合操作,并使用Sigmoid函数激活数据得到最终的注意力权重,然后将激活后的数据与输入数据进行逐像素相乘;S26: Fuse the output of the global attention and the local attention, and use the Sigmoid function to activate the data to obtain the final attention weight, and then multiply the activated data and the input data pixel by pixel;
S27:通过Sigmoid函数进行压缩,它将已有数据根据其范围,将任意输入压缩到区间(0, 1)中的某个值,以保证归一化,如图1所示;S27: Compress through the Sigmoid function, which compresses any input to a certain value in the interval (0, 1) according to the range of the existing data to ensure normalization, as shown in Figure 1;
S28:对输入数据与激活后的数据进行逐像素相乘操作,用来完成对输入数据的不同位置加权操作,从而更关注全局特征和局部特征如图1所示。S28: Perform a pixel-by-pixel multiplication operation on the input data and the activated data to complete weighting operations on different positions of the input data, so as to pay more attention to global features and local features, as shown in Figure 1 .
上述输入数据通过上述步骤S24中二维卷积后仅改变其通道数,且在整个MLP架构内,对输入数据的通道以一种先收缩后扩张的方式估计通道间的注意力,其中的收缩系数为r,收缩后特征尺度为H×W×C/r,使用ReLU激活函数,扩张后特征尺度为H×W×C。The above-mentioned input data only changes the number of channels after the two-dimensional convolution in the above-mentioned step S24, and in the entire MLP architecture, the channels of the input data are first contracted and then expanded to estimate the attention between channels, where the contraction The coefficient is r, the feature scale after shrinkage is H×W×C/r, and the ReLU activation function is used, and the feature scale after expansion is H×W×C.
所述步骤S23和S24中分别通过全局通道注意力机制中全局平均池化的方式和局部通道注意力机制中多层感知机MLP的方式分别提取输入数据中的全局特征和局部特征,并通过所述步骤S26对步骤S23与步骤S24的全局通道注意力机制的输出与局部通道注意力机制的输出进行融合操作即对不同特征进行特征融合,从而使得卷积神经网络对输入数据的整体信息以及局部细节特征更加关注,从而缓解复杂场景中出现的目标聚集与目标遮挡问题。In the steps S23 and S24, the global features and local features in the input data are respectively extracted by means of the global average pooling in the global channel attention mechanism and the multi-layer perceptron MLP in the local channel attention mechanism, and through the The above step S26 performs a fusion operation on the output of the global channel attention mechanism and the output of the local channel attention mechanism in steps S23 and S24, that is, performs feature fusion on different features, so that the convolutional neural network can fully understand the overall information and local information of the input data. More attention is paid to detailed features, thereby alleviating the problems of target aggregation and target occlusion in complex scenes.
本发明的实施例公布的是较佳的实施例,但并不局限于此,本领域的普通技术人员,极易根据上述实施例,领会本发明的精神,并做出不同的引申和变化,但只要不脱离本发明的精神,都在本发明的保护范围内。The embodiments of the present invention disclose preferred embodiments, but are not limited thereto. Those skilled in the art can easily comprehend the spirit of the present invention based on the above-mentioned embodiments, and make different extensions and changes. But as long as it does not deviate from the spirit of the present invention, it is within the protection scope of the present invention.
Claims (3)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310414590.1ACN116129207B (en) | 2023-04-18 | 2023-04-18 | A Method for Image Data Processing with Multi-Scale Channel Attention |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310414590.1ACN116129207B (en) | 2023-04-18 | 2023-04-18 | A Method for Image Data Processing with Multi-Scale Channel Attention |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN116129207Atrue CN116129207A (en) | 2023-05-16 |
| CN116129207B CN116129207B (en) | 2023-08-04 |
Family
ID=86301329
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202310414590.1AActiveCN116129207B (en) | 2023-04-18 | 2023-04-18 | A Method for Image Data Processing with Multi-Scale Channel Attention |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN116129207B (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116894836A (en)* | 2023-07-31 | 2023-10-17 | 浙江理工大学 | Yarn defect detection method and device based on machine vision |
| CN118094343A (en)* | 2024-04-23 | 2024-05-28 | 安徽大学 | Attention mechanism-based LSTM machine residual service life prediction method |
| CN118397281A (en)* | 2024-06-24 | 2024-07-26 | 湖南工商大学 | Image segmentation model training method, segmentation method and device based on artificial intelligence |
| CN119252334A (en)* | 2024-10-14 | 2025-01-03 | 山东合成生物技术有限公司 | A screening method and system for synthetic biological probiotics |
Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180231871A1 (en)* | 2016-06-27 | 2018-08-16 | Zhejiang Gongshang University | Depth estimation method for monocular image based on multi-scale CNN and continuous CRF |
| CN110853051A (en)* | 2019-10-24 | 2020-02-28 | 北京航空航天大学 | Cerebrovascular image segmentation method based on multi-attention densely connected generative adversarial network |
| CN111489358A (en)* | 2020-03-18 | 2020-08-04 | 华中科技大学 | A 3D point cloud semantic segmentation method based on deep learning |
| CN112017198A (en)* | 2020-10-16 | 2020-12-01 | 湖南师范大学 | Right ventricle segmentation method and device based on self-attention mechanism multi-scale features |
| CN112784764A (en)* | 2021-01-27 | 2021-05-11 | 南京邮电大学 | Expression recognition method and system based on local and global attention mechanism |
| CN113627295A (en)* | 2021-07-28 | 2021-11-09 | 中汽创智科技有限公司 | Image processing method, device, equipment and storage medium |
| CN114842553A (en)* | 2022-04-18 | 2022-08-02 | 安庆师范大学 | Behavior detection method based on residual shrinkage structure and non-local attention |
| CN115240201A (en)* | 2022-09-21 | 2022-10-25 | 江西师范大学 | A Chinese character generation method using Chinese character skeleton information to alleviate the problem of network model collapse |
| CN115761258A (en)* | 2022-11-10 | 2023-03-07 | 山西大学 | Image direction prediction method based on multi-scale fusion and attention mechanism |
| CN115880225A (en)* | 2022-11-10 | 2023-03-31 | 北京工业大学 | Dynamic illumination human face image quality enhancement method based on multi-scale attention mechanism |
- 2023
- 2023-04-18CNCN202310414590.1Apatent/CN116129207B/enactiveActive
Patent Citations (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20180231871A1 (en)* | 2016-06-27 | 2018-08-16 | Zhejiang Gongshang University | Depth estimation method for monocular image based on multi-scale CNN and continuous CRF |
| CN110853051A (en)* | 2019-10-24 | 2020-02-28 | 北京航空航天大学 | Cerebrovascular image segmentation method based on multi-attention densely connected generative adversarial network |
| CN111489358A (en)* | 2020-03-18 | 2020-08-04 | 华中科技大学 | A 3D point cloud semantic segmentation method based on deep learning |
| CN112017198A (en)* | 2020-10-16 | 2020-12-01 | 湖南师范大学 | Right ventricle segmentation method and device based on self-attention mechanism multi-scale features |
| CN112784764A (en)* | 2021-01-27 | 2021-05-11 | 南京邮电大学 | Expression recognition method and system based on local and global attention mechanism |
| CN113627295A (en)* | 2021-07-28 | 2021-11-09 | 中汽创智科技有限公司 | Image processing method, device, equipment and storage medium |
| CN114842553A (en)* | 2022-04-18 | 2022-08-02 | 安庆师范大学 | Behavior detection method based on residual shrinkage structure and non-local attention |
| CN115240201A (en)* | 2022-09-21 | 2022-10-25 | 江西师范大学 | A Chinese character generation method using Chinese character skeleton information to alleviate the problem of network model collapse |
| CN115761258A (en)* | 2022-11-10 | 2023-03-07 | 山西大学 | Image direction prediction method based on multi-scale fusion and attention mechanism |
| CN115880225A (en)* | 2022-11-10 | 2023-03-31 | 北京工业大学 | Dynamic illumination human face image quality enhancement method based on multi-scale attention mechanism |
Non-Patent Citations (4)
| Title |
|---|
| ABHINAV SAGAR ET.AL: "DMSANet: Dual Multi Scale Attention Network", 《ARXIV:2106.08382V2 [CS.CV]》, pages 1 - 10* |
| GANG LIU ET.AL: "Multiple Dirac Points and Hydrogenation-Induced Magnetism of Germanene Layer on Al (111) Surface", 《 JOURNAL OF PHYSICAL CHEMISTRY LETTE》, pages 4936 - 4942* |
| 章予希: "基于多尺度特征联合注意力的声纹识别模型研究", 《中国优秀硕士学位论文全文数据库 信息科技辑》, pages 136 - 362* |
| 高丹;陈建英;谢盈;: "A-PSPNet:一种融合注意力机制的PSPNet图像语义分割模型", 中国电子科学研究院学报, no. 06, pages 28 - 33* |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116894836A (en)* | 2023-07-31 | 2023-10-17 | 浙江理工大学 | Yarn defect detection method and device based on machine vision |
| CN118094343A (en)* | 2024-04-23 | 2024-05-28 | 安徽大学 | Attention mechanism-based LSTM machine residual service life prediction method |
| CN118397281A (en)* | 2024-06-24 | 2024-07-26 | 湖南工商大学 | Image segmentation model training method, segmentation method and device based on artificial intelligence |
| CN119252334A (en)* | 2024-10-14 | 2025-01-03 | 山东合成生物技术有限公司 | A screening method and system for synthetic biological probiotics |
Also Published As
| Publication number | Publication date |
|---|---|
| CN116129207B (en) | 2023-08-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN116129207B (en) | A Method for Image Data Processing with Multi-Scale Channel Attention | |
| CN114119638B (en) | Medical image segmentation method integrating multi-scale features and attention mechanisms | |
| CN111402129B (en) | Binocular stereo matching method based on joint up-sampling convolutional neural network | |
| CN109255755B (en) | Image super-resolution reconstruction method based on multi-column convolutional neural network | |
| CN110852383B (en) | Target detection method and device based on attention mechanism deep learning network | |
| WO2020056791A1 (en) | Method and apparatus for super-resolution reconstruction of multi-scale dilated convolution neural network | |
| CN110136062B (en) | A Super-Resolution Reconstruction Method for Joint Semantic Segmentation | |
| CN114764868A (en) | Image processing method, image processing device, electronic equipment and computer readable storage medium | |
| CN115222998A (en) | An image classification method | |
| CN115082675B (en) | A transparent object image segmentation method and system | |
| CN114170634A (en) | Gesture image feature extraction method based on DenseNet network improvement | |
| CN111507359A (en) | An Adaptive Weighted Fusion Method for Image Feature Pyramid | |
| CN115171052B (en) | Crowded crowd attitude estimation method based on high-resolution context network | |
| CN116645598A (en) | Remote sensing image semantic segmentation method based on channel attention feature fusion | |
| CN109740552A (en) | A Target Tracking Method Based on Parallel Feature Pyramid Neural Network | |
| CN116758407A (en) | Underwater small target detection method and device based on CenterNet | |
| CN117711023A (en) | Human body posture estimation method based on scale feature and hierarchical feature fusion | |
| Wang et al. | Global contextual guided residual attention network for salient object detection | |
| CN116012602A (en) | On-line positioning light-weight significance detection method | |
| CN117830703A (en) | Image recognition method based on multi-scale feature fusion, computer device and computer-readable storage medium | |
| CN110633706A (en) | A Semantic Segmentation Method Based on Pyramid Network | |
| CN110210419A (en) | The scene Recognition system and model generating method of high-resolution remote sensing image | |
| CN114492755A (en) | Object Detection Model Compression Method Based on Knowledge Distillation | |
| CN118733807A (en) | Multi-type building image retrieval method and system based on convolutional multi-head attention | |
| CN118470327A (en) | A remote sensing image semantic segmentation method, device, system, and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |