CN116091413A - A visual relationship detection method and device guided by contextual knowledge - Google Patents
A visual relationship detection method and device guided by contextual knowledgeDownload PDFInfo
- Publication number
- CN116091413A CN116091413ACN202211585880.4ACN202211585880ACN116091413ACN 116091413 ACN116091413 ACN 116091413ACN 202211585880 ACN202211585880 ACN 202211585880ACN 116091413 ACN116091413 ACN 116091413A
- Authority
- CN
- China
- Prior art keywords
- visual
- context
- object pair
- knowledge
- semantic
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images




Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/0002—Inspection of images, e.g. flaw detection
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T7/00—Image analysis
- G06T7/70—Determining position or orientation of objects or cameras
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/70—Labelling scene content, e.g. deriving syntactic or semantic representations
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Quality & Reliability (AREA)
- Computational Linguistics (AREA)
- Multimedia (AREA)
- Image Analysis (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明属于计算机视觉和机器人技术领域,具体涉及一种语境知识引导的视觉关系检测方法和装置。The invention belongs to the field of computer vision and robot technology, and in particular relates to a visual relationship detection method and device guided by contextual knowledge.
背景技术Background technique
在机器人运行过程中,需要对场景进行分析,检测人与人、人与物体、物体与物体之间的视觉关系,通过视觉关系来构建场景图,以更好地完成视觉语言导航、视觉语言标定、视觉问答等任务。During the operation of the robot, it is necessary to analyze the scene, detect the visual relationship between people and people, people and objects, and objects and objects, and construct a scene graph through visual relationships to better complete visual language navigation and visual language calibration. , visual question answering and other tasks.
然而,目前的视觉关系检测方法往往是直接从图像中去提取关系特征进行预测,如文献《Hengyue Liu,Ning Yan,Masood Mortazavi,and Bir Bhanu.Fullyconvolutional scene graph generation.In Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition,CVPR,2021.》公开的方法,或者融入外部构建的知识图谱,如文献《Zareian A,Karaman S,Chang S F.Bridgingknowledge graphs to generate scene graphs.In Proceedings of the EuropeanConference on Computer Vision,ECCV,2020.》公开的方法,但是这些关系视觉关系检测方式忽略了语境知识在关系检测中的重要地位。However, current visual relationship detection methods often extract relationship features directly from images for prediction, such as the document "Hengyue Liu, Ning Yan, Masood Mortazavi, and Bir Bhanu. Fully convolutional scene graph generation. In Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition, CVPR, 2021. "Disclosed methods, or integrated into externally constructed knowledge graphs, such as the literature "Zareian A, Karaman S, Chang S F.Bridging knowledge graphs to generate scene graphs.In Proceedings of the European Conference on Computer Vision, ECCV, 2020. "published methods, but these visual relationship detection methods ignore the important position of contextual knowledge in relationship detection.
发明内容Contents of the invention
鉴于上述,本发明的目的是提供一种语境知识引导的视觉关系检测方法和装置,通过语境知识引导提升视觉关系检测的准确性。In view of the above, the object of the present invention is to provide a visual relationship detection method and device guided by contextual knowledge, which improves the accuracy of visual relationship detection through contextual knowledge guidance.
为实现上述发明目的,实施例第一方面提供了一种语境知识引导的视觉关系检测方法,包括以下步骤:In order to achieve the purpose of the above invention, the first aspect of the embodiment provides a visual relationship detection method guided by contextual knowledge, including the following steps:
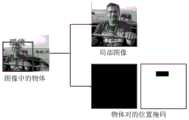
获取场景图像,确定场景图像中物体对的语义向量和语境向量,从场景图像中提取包含物体对的局部图像并确定物体对的位置掩码;Obtain the scene image, determine the semantic vector and context vector of the object pair in the scene image, extract the partial image containing the object pair from the scene image and determine the position mask of the object pair;
利用包含语境知识生成模块、视觉特征提取模块、语义特征提取模块、视觉关系检测模块以及综合判断模块的视觉关系检测模型进行视觉关系检测,包括:利用语境知识生成模块根据物体对的语境向量生成物体对的语境知识,利用视觉特征提取模块根据局部图像和物体对的位置掩码提取物体对的视觉特征,利用语义特征提取模块根据物体对的语义向量提取物体对的语义特征,利用视觉关系检测模块根据物体对的视觉特征和语义特征计算物体对的视觉预测结果,利用综合判断模块依据视觉预测结果与物体对的语境知识综合判断得到语境知识引导的物体对的视觉关系。Use the visual relationship detection model including the contextual knowledge generation module, visual feature extraction module, semantic feature extraction module, visual relationship detection module and comprehensive judgment module to detect the visual relationship, including: using the contextual knowledge generation module according to the context of the object pair The vector generates the contextual knowledge of the object pair, using the visual feature extraction module to extract the visual features of the object pair according to the local image and the position mask of the object pair, and using the semantic feature extraction module to extract the semantic features of the object pair according to the semantic vector of the object pair, using The visual relationship detection module calculates the visual prediction result of the object pair according to the visual features and semantic features of the object pair, and uses the comprehensive judgment module to comprehensively judge the visual prediction result and the contextual knowledge of the object pair to obtain the visual relationship of the object pair guided by contextual knowledge.
在一个实施例中,所述确定场景图像中物体对的语义向量和语境向量,包括:In one embodiment, the determining the semantic vector and the context vector of the object pair in the scene image includes:
检测场景图像中物体的位置和类别,将表示位置的包围框角点坐标和包围框中心点坐标组成位置向量,将类别转换成词向量作为语义向量;Detect the position and category of the object in the scene image, form the position vector with the coordinates of the corner points of the bounding box representing the position and the coordinates of the center point of the bounding box, and convert the category into a word vector as a semantic vector;
两个物体的语义向量拼接组成物体对的语义向量;The semantic vectors of the two objects are concatenated to form the semantic vector of the object pair;
将物体的位置向量和语义向量拼接组成语境向量,再将两个物体的语境向量拼接组成物体对的语境向量,或将两个物体的位置向量拼接组成物体对的位置向量,再将物体对的位置向量和语义向量拼接组成物体对的语境向量。The position vector and semantic vector of the object are concatenated to form the context vector, and then the context vectors of the two objects are concatenated to form the context vector of the object pair, or the position vectors of the two objects are concatenated to form the position vector of the object pair, and then The position vector and semantic vector of the object pair are concatenated to form the context vector of the object pair.
在一个实施例中,所述从场景图像中提取包含物体对的局部图像并确定物体对的位置掩码,包括:In one embodiment, the extracting the partial image containing the object pair from the scene image and determining the position mask of the object pair includes:
检测场景图像中物体的位置,依据两个物体位置的包围框截取包含物体对的局部图像;Detect the position of the object in the scene image, and intercept the partial image containing the object pair according to the bounding box of the two object positions;
在局域图像中,将每个物体的包围框内区域置于1,其他区域置于0,得到每个物体的位置掩码,两个物体的位置掩码组成物体对的位置掩码。In the local image, the area inside the bounding box of each object is set to 1, and the other areas are set to 0 to obtain the position mask of each object, and the position masks of the two objects form the position mask of the object pair.
在一个实施例中,所述利用语境知识生成模块根据物体对的语境向量提取物体对的语境知识,包括:In one embodiment, the context knowledge generating module using the context knowledge to extract the context knowledge of the object pair according to the context vector of the object pair includes:
将物体对的语境向量输入至语境知识生成模块,经过计算输出所有关系类别的语境概率,依据阈值筛选高语境概率置为1,剩下所有语境概率置为0,语境概率为1的关系类别和语境概率为1的关系类别组成物体对的语境知识。Input the context vector of the object pair to the context knowledge generation module, and output the context probabilities of all relationship categories after calculation, set the high context probability to 1 according to the threshold screening, set all the remaining context probabilities to 0, and set the context probability to 0. The relationship category with a context probability of 1 and the relationship category with a context probability of 1 constitute the contextual knowledge of the object pair.
在一个实施例中,所述利用视觉关系检测模块根据物体对的视觉特征和语义特征进行物体对的视觉预测,包括:In one embodiment, the visual prediction of the object pair according to the visual features and semantic features of the object pair by using the visual relationship detection module includes:
将物体对的视觉特征和语义特征输入至视觉关系检测模块,经过计算输出关系类别的视觉概率作为视觉预测结果;Input the visual features and semantic features of the object pair to the visual relationship detection module, and calculate the visual probability of the output relationship category as the visual prediction result;
所述利用综合判断模块依据视觉预测结果与物体对的语境知识综合判断得到物体对的视觉关系,包括:The use of the comprehensive judgment module to comprehensively judge the visual relationship of the object pair according to the visual prediction result and the context knowledge of the object pair includes:
将视觉预测结果与物体对的语境知识按照关系类别进行相乘,得到通过语境知识引导的关系类别的预测结果,依据预测结果确定物体对的视觉关系。The visual prediction result is multiplied by the contextual knowledge of the object pair according to the relationship category, and the prediction result of the relationship category guided by the contextual knowledge is obtained, and the visual relationship of the object pair is determined according to the prediction result.
在一个实施例中,所述语境知识生成模块采用第一全连接网络,所述视觉特征提取模块采用卷积网络,所述语义特征提取模块采用第二全连接网络,所述视觉关系检测模块采用第三全连接网络。In one embodiment, the contextual knowledge generation module uses a first fully connected network, the visual feature extraction module uses a convolutional network, the semantic feature extraction module uses a second fully connected network, and the visual relationship detection module Adopt the third fully connected network.
在一个实施例中,所述视觉关系检测模型被应用之前需要经过参数优化,参数优化时采用的总损失函数包括依据物体对的语境知识确定的标签中标记关系类别的激活损失、依据物体对的语境知识和视觉预测结果确定的标签中不正确关系类别的激活损失。In one embodiment, the visual relationship detection model needs to undergo parameter optimization before being applied, and the total loss function used in parameter optimization includes the activation loss of the label relationship category in the label determined according to the contextual knowledge of the object pair, and the activation loss according to the object pair Activation loss for incorrect relation categories in labels determined by contextual knowledge and visual prediction results.
在一个实施例中,所述方法还包括:通过位置随机扰动来增加物体对的位置多样性,进而得到多样性的语境向量、局部图像以及位置掩码,利用多样性的语境向量、局部图像以及位置掩码对视觉关系检测模型进行参数优化。In one embodiment, the method further includes: increasing the position diversity of the object pair by randomly perturbing the position, thereby obtaining diverse context vectors, local images, and position masks, using diverse context vectors, local Image and location masks for parameter optimization of visual relationship detection models.
为实现上述发明目的,实施例第二方面提供了一种语境知识引导的视觉关系检测装置,包括预处理单元和视觉关系检测单元,In order to achieve the purpose of the above invention, the second aspect of the embodiment provides a visual relationship detection device guided by contextual knowledge, including a preprocessing unit and a visual relationship detection unit,
所述预处理单元用于获取场景图像,确定场景图像中物体对的语义向量和语境向量,从场景图像中提取包含物体对的局部图像并确定物体对的位置掩码;The preprocessing unit is used to obtain the scene image, determine the semantic vector and the context vector of the object pair in the scene image, extract the partial image containing the object pair from the scene image and determine the position mask of the object pair;
所述视觉关系检测单元用于利用包含语境知识生成模块、视觉特征提取模块、语义特征提取模块、视觉关系检测模块以及综合判断模块的视觉关系检测模型进行视觉关系检测,包括:利用语境知识生成模块根据物体对的语境向量提取物体对的语境知识,利用视觉特征提取模块根据局部图像和物体对的位置掩码提取物体对的视觉特征,利用语义特征提取模块根据物体对的语义向量提取物体对的语义特征,利用视觉关系检测模块根据物体对的视觉特征和语义特征计算物体对的视觉预测结果,利用综合判断模块依据视觉预测结果与物体对的语境知识综合判断得到物体对的视觉关系。The visual relationship detection unit is used to perform visual relationship detection using a visual relationship detection model including a contextual knowledge generation module, a visual feature extraction module, a semantic feature extraction module, a visual relationship detection module and a comprehensive judgment module, including: using contextual knowledge The generation module extracts the contextual knowledge of the object pair according to the context vector of the object pair, uses the visual feature extraction module to extract the visual features of the object pair according to the local image and the position mask of the object pair, and uses the semantic feature extraction module according to the semantic vector of the object pair Extract the semantic features of the object pair, use the visual relationship detection module to calculate the visual prediction result of the object pair according to the visual characteristics and semantic features of the object pair, and use the comprehensive judgment module to comprehensively judge the visual prediction result and the contextual knowledge of the object pair to obtain the object pair. visual relationship.
为实现上述发明目的,实施例第三方面提供了一种电子设备,包括一个或多个处理器、存储一个或多个程序存储器,当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现上述语境知识引导的视觉关系检测方法的步骤。In order to achieve the purpose of the above invention, the third aspect of the embodiment provides an electronic device, including one or more processors, storing one or more program memories, when the one or more programs are processed by the one or more The processor is executed, so that the one or more processors implement the steps of the above context knowledge-guided visual relationship detection method.
为实现上述发明目的,实施例第四方面提供了一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现上述语境知识引导的视觉关系检测方法的步骤。To achieve the purpose of the above invention, the fourth aspect of the embodiment provides a computer-readable storage medium, on which a computer program is stored, and when the program is executed by a processor, the steps of the above-mentioned visual relationship detection method guided by contextual knowledge are implemented.
与现有技术相比,本发明具有的有益效果至少包括:Compared with the prior art, the beneficial effects of the present invention at least include:
在获得场景图像并提取物体对的语义向量、语境向量以及位置编码的基础上,根据语境向量生成语境知识,然后依据语义向量、位置编码以及局部图像来计算视觉预测结果,将语境知识作为引导信息,引导到视觉预测结果上,以综合判断得到物体对的视觉关系,这样提升了视觉关系检测的准确性。On the basis of obtaining the scene image and extracting the semantic vector, context vector and position code of the object pair, the context knowledge is generated according to the context vector, and then the visual prediction result is calculated according to the semantic vector, position code and local image, and the context Knowledge is used as guiding information to guide the visual prediction results, and the visual relationship between object pairs can be obtained through comprehensive judgment, which improves the accuracy of visual relationship detection.
附图说明Description of drawings
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动前提下,还可以根据这些附图获得其他附图。In order to more clearly illustrate the embodiments of the present invention or the technical solutions in the prior art, the following will briefly introduce the drawings that need to be used in the description of the embodiments or the prior art. Obviously, the accompanying drawings in the following description are only These are some embodiments of the present invention. Those skilled in the art can also obtain other drawings based on these drawings without creative work.
图1是实施例提供的语境知识引导的视觉关系检测方法的流程图;Fig. 1 is the flowchart of the visual relationship detection method guided by the contextual knowledge provided by the embodiment;
图2是实施例提供的物体对的语境向量的构建流程图;Fig. 2 is the construction flowchart of the context vector of the object pair provided by the embodiment;
图3是实施例提供的物体对的位置掩码的构建流程图;Fig. 3 is the construction flowchart of the location mask of object pair provided by the embodiment;
图4是实施例提供的利用视觉关系检测模型进行视觉关系检测的流程图;FIG. 4 is a flowchart of visual relationship detection using a visual relationship detection model provided by an embodiment;
图5是实施例提供的物体位置随机扰动的流程图;Fig. 5 is a flowchart of the random disturbance of object position provided by the embodiment;
图6是实施例提供的语境知识引导的视觉关系检测装置的结构示意图。Fig. 6 is a schematic structural diagram of a visual relationship detection device guided by contextual knowledge provided by an embodiment.
具体实施方式Detailed ways
为使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不限定本发明的保护范围。In order to make the object, technical solution and advantages of the present invention clearer, the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present invention, and do not limit the protection scope of the present invention.
研究发现,即使没有看到图像,在语境描述中也能提取到有用的知识来引导视觉关系检测。对于人类来说,给定物体和物体的类别和相对位置,已经能够大致猜测出物体之间的关系。例如,人类知道人和自行车两种物体类别和相对位置,人类就能通过已有的知识猜测,人和自行车之间可以是‘骑着’、‘在…上’、‘在…旁边’等关系,而不可能是‘穿着’,‘镶嵌于’等关系。当人类真实看到场景中人和自行车两种物体时,再基于已有的知识猜测和视觉所见判断关系。基于此发现,实施例提供了语境知识引导的视觉关系检测方法和装置,通过从物体类别和相对位置中学到语境知识,来指导对视觉关系的判断,以解决现物体对视觉关系检测准确率较低以及机器人对场景理解能力的不足的问题。We find that useful knowledge can be extracted in contextual descriptions to guide visual relationship detection even without seeing the images. For humans, given objects and their categories and relative positions, they have been able to roughly guess the relationship between objects. For example, human beings know the categories and relative positions of two types of objects, people and bicycles. Humans can guess based on the existing knowledge that the relationship between people and bicycles can be 'riding', 'on...', 'beside...', etc. , rather than 'wearing', 'embedded in' and other relationships. When humans actually see the two objects in the scene, people and bicycles, they then guess the relationship based on existing knowledge and visual observations. Based on this discovery, the embodiment provides a visual relationship detection method and device guided by contextual knowledge, which guides the judgment of visual relationship by learning contextual knowledge from object categories and relative positions, so as to solve the problem of accurate detection of visual relationship between objects and objects. The low rate and the insufficient ability of the robot to understand the scene.
图1是实施例提供的语境知识引导的视觉关系检测方法的流程图。如图1所示,实施例提供的视觉关系检测方法,包括以下步骤:Fig. 1 is a flowchart of a visual relationship detection method guided by contextual knowledge provided by an embodiment. As shown in Figure 1, the visual relationship detection method provided by the embodiment includes the following steps:
S110,获取场景图像,确定场景图像中物体对的语义向量和语境向量,从场景图像中提取包含物体对的局部图像并确定物体对的位置掩码。S110. Acquire a scene image, determine a semantic vector and a context vector of an object pair in the scene image, extract a partial image containing the object pair from the scene image, and determine a position mask of the object pair.
实施例中,获得的场景图像中包含多个物体。通过对场景图像进行分析计算来确定场景图像中物体对的语义向量和语境向量,如图2所示,包括以下步骤:In an embodiment, the obtained scene image contains multiple objects. Determine the semantic vector and context vector of the object pair in the scene image by analyzing and calculating the scene image, as shown in Figure 2, including the following steps:
检测场景图像中物体的位置和类别,将表示位置的包围框角点坐标和包围框中心点坐标组成位置向量,将类别转换成词向量作为语义向量;将两个物体的语义向量拼接组成物体对的语义向量;将物体的位置向量和语义向量拼接组成语境向量,再将两个物体的语境向量拼接组成物体对的语境向量,当然,也可以将两个物体的位置向量拼接组成物体对的位置向量,再将物体对的位置向量和语义向量拼接组成物体对的语境向量。Detect the position and category of the object in the scene image, the coordinates of the corner points of the bounding box representing the position and the coordinates of the center point of the bounding box form a position vector, convert the category into a word vector as a semantic vector; stitch the semantic vectors of two objects to form an object pair The semantic vector of the object; the position vector and the semantic vector of the object are concatenated to form the context vector, and then the context vectors of the two objects are concatenated to form the context vector of the object pair. Of course, the position vectors of the two objects can also be concatenated to form an object The position vector of the object pair, and then the position vector and semantic vector of the object pair are spliced to form the context vector of the object pair.
物体的位置通过包围框(x1,y1,x2,y2)表示,基于该包围框(x1,y1,x2,y2)可以计算物体位置的包围框中心点(xc=(x1+x2)/2,yc=(y1+y2)/2),拼接该包围框(x1,y1,x2,y2)和包围框中心点xc即可以得到物体的位置向量。The position of the object is represented by a bounding box (x1 , y1 , x2 , y2 ), based on the bounding box (x1 , y1 , x2 , y2 ), the center point of the bounding box (xc =(x1 +x2 )/2,yc =(y1 +y2 )/2), splicing the bounding box (x1 ,y1 ,x2 ,y2 ) and the center point xc of the bounding box is The position vector of the object can be obtained.
实施例中,还可以通过从场景图像中提取包含物体对的局部图像并确定物体对的位置掩码,如图3所示,包括以下步骤:依据两个物体位置的包围框截取包含物体对的局部图像,具体地,对于物体1的位置包围框



根据物体1和物体2的位置包围框,在局域图像中,将每个物体的包围框内区域置于1,其他区域置于0,得到每个物体的位置掩码,物体1和物体2的位置掩码组成物体对的位置掩码。According to the position bounding boxes of
通过对场景图像分析得到的局部图像,物体对的语义向量、语境向量以及位置掩码均作为视觉关系检测的数据源。The local image obtained by analyzing the scene image, the semantic vector, the context vector and the position mask of the object pair are all used as the data source for visual relationship detection.
S120,利用包含语境知识生成模块、视觉特征提取模块、语义特征提取模块、视觉关系检测模块以及综合判断模块的视觉关系检测模型进行视觉关系检测。S120. Perform visual relationship detection using a visual relationship detection model including a contextual knowledge generation module, a visual feature extraction module, a semantic feature extraction module, a visual relationship detection module, and a comprehensive judgment module.
实施例中,语境知识生成模块作为语境知识生成阶段,用于根据物体对的语境向量生成物体对的语境知识,具体地,将物体对的语境向量输入至语境知识生成模块,经过计算输出所有关系类别的语境概率,依据阈值筛选高语境概率置为1,剩下所有语境概率置为0,语境概率为1的关系类别和语境概率为1的关系类别组成物体对的语境知识。实施例中,语境知识生成模块可以采用第一全连接网络。In the embodiment, the contextual knowledge generation module is used as the contextual knowledge generation stage for generating the contextual knowledge of the object pair according to the context vector of the object pair, specifically, inputting the contextual vector of the object pair into the contextual knowledge generation module , after calculating and outputting the contextual probabilities of all relationship categories, the high contextual probability is set to 1 according to the threshold screening, and all remaining contextual probabilities are set to 0, the relationship categories with contextual probability of 1 and the relationship categories with contextual probability of 1 Contextual knowledge of the constituent object pairs. In an embodiment, the contextual knowledge generation module may use the first fully connected network.
如图4所示,语境知识生成模块依据物体对的语境向量计算输出例如拥有(has),穿戴(wears),和(with),使用(using),在上面(on),漂浮(flying in)等所有关系类别的语境概率,然后依据设定的阈值,例如阈值为0.7,筛选高于阈值的语境概率重新设置为1,其余语境概率设为0,如图4中,拥有,穿戴,和,使用这四类关系类别的语境概率为1,其余在上面,漂浮等所关系类别的语境概率为0,理解为has、wears、with、using关系是有可能存在的高概率关系,而on、flying in关系是不可能的低概率关系。这样语境概率为1的关系类别与语境概率为0的关系类别组成物体对的语境知识,该语境知识作为关系类别的知识掩码,用于对视觉关系检测的知识引导。As shown in Figure 4, the contextual knowledge generation module calculates the output according to the contextual vector of the object pair, such as having (has), wearing (wears), and (with), using (using), above (on), floating (flying) in) and other contextual probabilities of all relationship categories, and then according to the set threshold, for example, the threshold is 0.7, and the contextual probabilities above the threshold are reset to 1, and the remaining contextual probabilities are set to 0, as shown in Figure 4, with , wearing, and, the contextual probability of using these four types of relationship categories is 1, and the contextual probability of the rest of the above, floating and other related categories is 0. It is understood that the relationship of has, wears, with, and using is likely to exist. Probability relationship, while on and flying in relationships are impossible low-probability relationships. In this way, the relationship category with a contextual probability of 1 and the relationship category with a contextual probability of 0 constitute the contextual knowledge of the object pair, and the contextual knowledge is used as the knowledge mask of the relationship category for knowledge guidance for visual relationship detection.
实施例中,视觉特征提取模块、语义特征提取模块、视觉关系检测模块以及综合判断模块作为视觉关系检测阶段,用于视觉关系检测计算。如图4所示,具体包括:In the embodiment, the visual feature extraction module, the semantic feature extraction module, the visual relationship detection module and the comprehensive judgment module are used as the visual relationship detection stage for the visual relationship detection calculation. As shown in Figure 4, specifically include:
利用视觉特征提取模块根据局部图像和物体对的位置掩码提取物体对的视觉特征。实施例中,视觉特征提取模块可以采用卷积神经网络。局域图像和物体对的位置掩码拼接后输入至卷积神经网络,经过计算输出物体对的视觉特征。A visual feature extraction module is used to extract the visual features of the object pair based on the partial image and the position mask of the object pair. In an embodiment, the visual feature extraction module may use a convolutional neural network. The local image and the position mask of the object pair are spliced and input to the convolutional neural network, and the visual features of the object pair are output after calculation.
利用语义特征提取模块根据物体对的语义向量提取物体对的语义特征。实施例中,语义特征提取模块可以采用第二全连接网络。物体对的语义向量输入至第二全连接网络,经过计算输出物体对的语义特征。The semantic feature of the object pair is extracted by using the semantic feature extraction module according to the semantic vector of the object pair. In an embodiment, the semantic feature extraction module may use the second fully connected network. The semantic vector of the object pair is input to the second fully connected network, and the semantic features of the object pair are output after calculation.
利用视觉关系检测模块根据物体对的视觉特征和语义特征计算物体对的视觉预测结果。实施例中,视觉关系检测模块可以采用第三全连接网络。将物体对的视觉特征和语义特征输入至第三全连接网络,经过计算输出关系类别的视觉概率作为视觉预测结果。The visual prediction result of the object pair is calculated according to the visual feature and semantic feature of the object pair by using the visual relationship detection module. In an embodiment, the visual relationship detection module may use a third fully connected network. The visual features and semantic features of object pairs are input to the third fully connected network, and the visual probability of the output relationship category is calculated as the visual prediction result.
利用综合判断模块依据视觉预测结果与物体对的语境知识综合判断得到语境知识引导的物体对的视觉关系,具体包括:将视觉预测结果与物体对的语境知识按照关系类别进行相乘,得到通过语境知识引导的关系类别的预测结果,依据预测结果确定物体对的视觉关系。Using the comprehensive judgment module to comprehensively judge the visual relationship between the object pair guided by the contextual knowledge based on the visual prediction result and the contextual knowledge of the object pair, specifically including: multiplying the visual prediction result and the contextual knowledge of the object pair according to the relationship category, The prediction result of the relationship category guided by the contextual knowledge is obtained, and the visual relationship of the object pair is determined according to the prediction result.
实施例中,语境知识是由语境概率为1的关系类别与语境概率为0的关系类别组成,也就是每个关系类别拥有1或0的语境概率。视觉预测结果为视觉概率,且每个关系类别拥有一个在0-1范围内的视觉概率,这样将每个关系类别的语境概率和视觉概率相乘即可以得到每个关系类别的最终预测结果。然后再从所有关系类别的预测结果中提取概率值最大的关系类别作为物体对的最终视觉关系。In an embodiment, the context knowledge is composed of a relationship category with a context probability of 1 and a relationship category with a context probability of 0, that is, each relationship category has a context probability of 1 or 0. The visual prediction result is a visual probability, and each relationship category has a visual probability in the range of 0-1, so that the final prediction result of each relationship category can be obtained by multiplying the contextual probability and visual probability of each relationship category . Then, the relationship category with the highest probability value is extracted from the prediction results of all relationship categories as the final visual relationship of the object pair.
如图4所示,has、wears、with、using、on、flying in漂浮这些关系类型的视觉概率为0.63,0.89,0.83,0.50,0.92,0.05,将这些视觉概率与对应语境概率相乘后,得到概率值分别为0.63,0.89,0.83,0.50,0,0。As shown in Figure 4, the visual probabilities of relationship types such as has, wears, with, using, on, and flying in are 0.63, 0.89, 0.83, 0.50, 0.92, and 0.05. After multiplying these visual probabilities with the corresponding contextual probabilities , the obtained probability values are 0.63, 0.89, 0.83, 0.50, 0, 0 respectively.
在物体对的语境知识中,on的关系类别被认为是一个低概率关系,其值为0,而在物体对的视觉预测中,on的视觉概率是最高的;将物体对的视觉概率与物体对的语境知识相乘,on的关系被消除了,最终物体对的关系既是在语境知识中值为1的高概率关系,又是在物体对的视觉预测中概率最大的关系类别,即wears。In the contextual knowledge of object pairs, the relation category of on is considered as a low-probability relation with a value of 0, while in the visual prediction of object pairs, the visual probability of on is the highest; comparing the visual probability of object pairs with The contextual knowledge of the object pair is multiplied, the on relationship is eliminated, and the final object pair relationship is both a high-probability relationship with a value of 1 in the context knowledge, and the relationship category with the highest probability in the visual prediction of the object pair, Namely wears.
实施例中,视觉关系检测模型被应用之前需要经过参数优化,参数优化时采用的总损失函数包括依据物体对的语境知识确定的标签中标记关系类别的激活损失Lpos、依据物体对的语境知识和视觉预测结果确定的标签中不正确关系类别的激活损失Lneg,分别表示为:In the embodiment, the visual relationship detection model needs to be optimized before being applied. The total loss function used in the parameter optimization includes the activation loss Lpos of the labeled relationship category in the label determined based on the contextual knowledge of the object pair, and the language based on the object pair. The activation loss Lneg of incorrect relation categories in labels determined by contextual knowledge and visual prediction results, respectively, is expressed as:


其中,ReLu(·)表示ReLu激活函数,Rknow表示物体对的语境知识,Rvision表示物体对的视觉预测结果,r=rt代表关系类别为标签中标记的关系类别,r≠rt代表关系类别为标签中未标记的关系类别。具体训练时,依据Lpos+Lneg对视觉关系检测模型进行参数优化。Among them, ReLu( ) represents the ReLu activation function, Rknow represents the contextual knowledge of the object pair, Rvision represents the visual prediction result of the object pair, r=rt represents the relationship category marked in the label, r≠rt Represents the relationship category as the unmarked relationship category in the label. During specific training, the parameters of the visual relationship detection model are optimized according to Lpos + Lneg .
为了提升视觉关系检测模型的预测性能。还通过使用位置随机扰动方法在训练过程中生成多样化的语境向量,如图5所示,包括:对于场景图像中检测到的物体位置和类别,针对位置包围框(x1,y1,x2,y2),采用随机扰动方法在位置包围框上增加随机位置偏移,得到多样化的位置包围框(x1+ε,y1+ε,x2+ε,y2+ε),ε为一个小的随机数;利用多样化的的位置包围框生成的扰动的位置向量,利用扰动的位置向量和语义向量,生成多样化的语境向量,同时依据多样化的位置包围框生成多样化的局部图像以及位置掩码,然后利用多样性的语境向量、局部图像以及位置掩码对视觉关系检测模型进行参数优化。To improve the predictive performance of visual relationship detection models. Also by using the location random perturbation method to generate diverse context vectors during the training process, as shown in Figure 5, including: for the object location and category detected in the scene image, for the location bounding box (x1 , y1 , x2 , y2 ), using the random perturbation method to add a random position offset to the position bounding box to obtain a diverse position bounding box (x1 +ε,y1 +ε,x2 +ε,y2 +ε) , ε is a small random number; use the disturbed position vector generated by the diversified position bounding box, use the disturbed position vector and semantic vector to generate a diversified context vector, and generate according to the diversified position bounding box Diverse local images and position masks, and then use diverse context vectors, local images and position masks to optimize the parameters of the visual relationship detection model.
针对传统的视觉关系检测的训练图片获取困难,本发明在语境层面可以通过简单的位置扰动来轻松地扩充语境描述进行训练,进而来挖掘物体对语境描述中的语境知识,来引导视觉关系的检测过程,获得更好的视觉关系检测结果。In view of the difficulty in obtaining training pictures for traditional visual relationship detection, the present invention can easily expand the context description for training through simple position perturbation at the context level, and then mine the context knowledge in the object-to-context description to guide The detection process of visual relationship, to obtain better visual relationship detection results.
现有的视觉关系检测方式往往直接从场景图像中提取物体的视觉特征,而忽略语境描述的信息。而本发明实施例中将语义向量和位置向量拼接起来,组成语境向量作为语境描述,在不依靠视觉的情况下,仅通过语境描述来预测每个关系类别的语境概率。从语境概率中选择出高概率的关系类别作为语境知识。当通过视觉判断物体对关系时,通过语境知识引导,这样只关注语境知识认为的高概率关系,忽略语境知识认为的低概率关系,提高了对物体对视觉关系判断的准确率。本发明实施例适用于提高服务机器人在运行过程中对场景的分析和判断能力。Existing visual relationship detection methods often directly extract the visual features of objects from scene images, while ignoring contextual description information. However, in the embodiment of the present invention, the semantic vector and the position vector are spliced together to form a context vector as a context description, and the context probability of each relationship category is predicted only through the context description without relying on vision. From contextual probabilities, high-probability relation categories are selected as contextual knowledge. When judging the relationship between objects through vision, it is guided by contextual knowledge, so that only the high-probability relationship considered by contextual knowledge is paid attention to, and the low-probability relationship considered by contextual knowledge is ignored, which improves the accuracy of judging the object-to-visual relationship. The embodiments of the present invention are suitable for improving the ability of the service robot to analyze and judge the scene during operation.
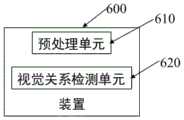
基于同样的发明构思,实施还提供了一种语境知识引导的视觉关系检测装置,如图6所示,装置600包括预处理单元610和视觉关系检测单元620,Based on the same inventive concept, the implementation also provides a visual relationship detection device guided by contextual knowledge. As shown in FIG. 6 , the
预处理单元610用于获取场景图像,确定场景图像中物体对的语义向量和语境向量,从场景图像中提取包含物体对的局部图像并确定物体对的位置掩码;The
视觉关系检测单元620用于利用包含语境知识生成模块、视觉特征提取模块、语义特征提取模块、视觉关系检测模块以及综合判断模块的视觉关系检测模型进行视觉关系检测。The visual
具体地,在视觉关系检测单元620中,进行视觉关系检测包括:利用语境知识生成模块根据物体对的语境向量提取物体对的语境知识,利用视觉特征提取模块根据局部图像和物体对的位置掩码提取物体对的视觉特征,利用语义特征提取模块根据物体对的语义向量提取物体对的语义特征,利用视觉关系检测模块根据物体对的视觉特征和语义特征计算物体对的视觉预测结果,利用综合判断模块依据视觉预测结果与物体对的语境知识综合判断得到物体对的视觉关系。Specifically, in the visual
需要说明的是,上述实施例提供的语境知识引导的视觉关系检测装置在进行视觉关系检测时,应以上述各功能单元的划分进行举例说明,可以根据需要将上述功能分配由不同的功能单元完成,即在终端或服务器的内部结构划分成不同的功能单元,以完成以上描述的全部或者部分功能。另外,上述实施例提供的语境知识引导的视觉关系检测装置与语境知识引导的视觉关系检测方法实施例属于同一构思,其具体实现过程详见语境知识引导的视觉关系检测方法实施例,这里不再赘述。It should be noted that, when the visual relationship detection device guided by contextual knowledge provided in the above embodiment performs visual relationship detection, the division of the above-mentioned functional units should be used as an example for illustration, and the above-mentioned functions can be assigned to different functional units as required. Completion means that the internal structure of the terminal or server is divided into different functional units to complete all or part of the functions described above. In addition, the contextual knowledge-guided visual relationship detection device provided in the above embodiment and the contextual knowledge-guided visual relationship detection method embodiment belong to the same concept, and its specific implementation process is detailed in the contextual knowledge-guided visual relationship detection method embodiment, I won't go into details here.
基于同样的发明构思,实施例还提供了一种电子设备,包括一个或多个处理器、存储一个或多个程序存储器,当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现上述语境知识引导的视觉关系检测方法的S110和S120。Based on the same inventive concept, the embodiment also provides an electronic device, including one or more processors, storing one or more program memories, when the one or more programs are executed by the one or more processors , so that the one or more processors implement S110 and S120 of the above context knowledge-guided visual relationship detection method.
基于同样的发明构思,实施例还提供了计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现上述语境知识引导的视觉关系检测方法的S110和S120。Based on the same inventive concept, the embodiment also provides a computer-readable storage medium, on which a computer program is stored, and when the program is executed by a processor, S110 and S120 of the above context knowledge-guided visual relationship detection method are implemented.
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。The serial numbers of the above embodiments of the present invention are for description only, and do not represent the advantages and disadvantages of the embodiments.
在本发明的上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。In the above-mentioned embodiments of the present invention, the descriptions of each embodiment have their own emphases, and for parts not described in detail in a certain embodiment, reference may be made to relevant descriptions of other embodiments.
在本申请所提供的实施例中,应该理解到,所揭露的技术内容,可通过其它的方式实现。其中,以上所描述的装置实施例仅仅是示意性的,例如所述单元的划分,可以为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,单元或模块的间接耦合或通信连接,可以是电性或其它的形式。In the embodiments provided in this application, it should be understood that the disclosed technical content can be realized in other ways. Wherein, the device embodiments described above are only illustrative. For example, the division of the units may be a logical function division. In actual implementation, there may be other division methods. For example, multiple units or components may be combined or may be Integrate into another system, or some features may be ignored, or not implemented. In another point, the mutual coupling or direct coupling or communication connection shown or discussed may be through some interfaces, and the indirect coupling or communication connection of units or modules may be in electrical or other forms.
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。The units described as separate components may or may not be physically separated, and the components displayed as units may or may not be physical units, that is, they may be located in one place, or may be distributed to multiple units. Part or all of the units can be selected according to actual needs to achieve the purpose of the solution of this embodiment.
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。In addition, each functional unit in each embodiment of the present invention may be integrated into one processing unit, each unit may exist separately physically, or two or more units may be integrated into one unit. The above-mentioned integrated units can be implemented in the form of hardware or in the form of software functional units.
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可为个人计算机、服务器或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、只读存储器(ROM,Read-Only Memory)、随机存取存储器(RAM,Random Access Memory)、移动硬盘、磁碟或者光盘等各种可以存储程序代码的介质。If the integrated unit is realized in the form of a software function unit and sold or used as an independent product, it can be stored in a computer-readable storage medium. Based on such an understanding, the essence of the technical solution of the present invention or the part that contributes to the prior art or all or part of the technical solution can be embodied in the form of a software product, and the computer software product is stored in a storage medium , including several instructions to make a computer device (which may be a personal computer, a server, or a network device, etc.) execute all or part of the steps of the methods described in various embodiments of the present invention. The aforementioned storage media include: U disk, read-only memory (ROM, Read-Only Memory), random access memory (RAM, Random Access Memory), mobile hard disk, magnetic disk or optical disc, etc., which can store program codes. .
以上所述的具体实施方式对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的最优选实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。The above-mentioned specific embodiments have described the technical solutions and beneficial effects of the present invention in detail. It should be understood that the above-mentioned are only the most preferred embodiments of the present invention, and are not intended to limit the present invention. Any modifications, supplements and equivalent replacements made within the scope shall be included in the protection scope of the present invention.
Claims (11)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211585880.4ACN116091413B (en) | 2022-12-09 | 2022-12-09 | A method and device for visual relationship detection guided by contextual knowledge |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211585880.4ACN116091413B (en) | 2022-12-09 | 2022-12-09 | A method and device for visual relationship detection guided by contextual knowledge |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN116091413Atrue CN116091413A (en) | 2023-05-09 |
| CN116091413B CN116091413B (en) | 2025-08-08 |
Family
ID=86205442
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202211585880.4AActiveCN116091413B (en) | 2022-12-09 | 2022-12-09 | A method and device for visual relationship detection guided by contextual knowledge |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN116091413B (en) |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102138140A (en)* | 2008-07-01 | 2011-07-27 | 多斯维公司 | Information processing with integrated semantic contexts |
| CN111626291A (en)* | 2020-04-07 | 2020-09-04 | 上海交通大学 | Image visual relationship detection method, system and terminal |
| CN113240033A (en)* | 2021-05-25 | 2021-08-10 | 清华大学深圳国际研究生院 | Visual relation detection method and device based on scene graph high-order semantic structure |
| US20210357646A1 (en)* | 2019-07-26 | 2021-11-18 | Zro Inc. | Method and Computing Device in which Visual and Non-Visual Semantic Attributes are Associated with a Visual |
- 2022
- 2022-12-09CNCN202211585880.4Apatent/CN116091413B/enactiveActive
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN102138140A (en)* | 2008-07-01 | 2011-07-27 | 多斯维公司 | Information processing with integrated semantic contexts |
| US20210357646A1 (en)* | 2019-07-26 | 2021-11-18 | Zro Inc. | Method and Computing Device in which Visual and Non-Visual Semantic Attributes are Associated with a Visual |
| CN111626291A (en)* | 2020-04-07 | 2020-09-04 | 上海交通大学 | Image visual relationship detection method, system and terminal |
| CN113240033A (en)* | 2021-05-25 | 2021-08-10 | 清华大学深圳国际研究生院 | Visual relation detection method and device based on scene graph high-order semantic structure |
Non-Patent Citations (1)
| Title |
|---|
| JINGHUI PENG 等: "Visual Relationship Detection With Image Position and Feature Information Embedding and Fusion", IEEE ACCESS, 30 November 2022 (2022-11-30)* |
Also Published As
| Publication number | Publication date |
|---|---|
| CN116091413B (en) | 2025-08-08 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6893233B2 (en) | Image-based data processing methods, devices, electronics, computer-readable storage media and computer programs | |
| CN112673381B (en) | A method for identifying an adversarial sample and a related device | |
| JP2022177232A (en) | Image processing method, text recognition method and device | |
| CN116308754B (en) | Bank credit risk early warning system and method thereof | |
| CN115223020B (en) | Image processing method, apparatus, device, storage medium, and computer program product | |
| CN111597884A (en) | Facial action unit identification method and device, electronic equipment and storage medium | |
| CN110879963B (en) | A sensitive emoticon package detection method, device and electronic equipment | |
| CN110008343A (en) | Text classification method, apparatus, device, and computer-readable storage medium | |
| CN116226785A (en) | Target object recognition method, multi-mode recognition model training method and device | |
| CN113837257A (en) | Target detection method and device | |
| CN114155244B (en) | Defect detection method, device, equipment and storage medium | |
| CN112926700A (en) | Class identification method and device for target image | |
| US20210326383A1 (en) | Search method and device, and storage medium | |
| CN114399729B (en) | Monitoring object movement identification method, system, terminal and storage medium | |
| CN118172546B (en) | Model generation method, detection device, electronic equipment, medium and product | |
| CN114332288A (en) | A method and network for generating images from text based on phrase-driven generative adversarial networks | |
| CN118570868A (en) | Zero-sample potential risk behavior detection method and device based on multi-mode large model | |
| WO2024179575A1 (en) | Data processing method, and device and computer-readable storage medium | |
| CN119156647A (en) | Performing computer vision tasks by generating sequences of tokens | |
| US20230036812A1 (en) | Text Line Detection | |
| CN112380861B (en) | Model training method and device and intention recognition method and device | |
| Ding et al. | Visual grounding of remote sensing images with multi-dimensional semantic-guidance | |
| US12300007B1 (en) | Automatic image cropping | |
| CN116091413A (en) | A visual relationship detection method and device guided by contextual knowledge | |
| CN112949672A (en) | Commodity identification method, commodity identification device, commodity identification equipment and computer readable storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |