CN116064683A - Gene editing system and its application in preparation of SCN5A gene mutation arrhythmia model pig nuclear transfer donor cells - Google Patents
Gene editing system and its application in preparation of SCN5A gene mutation arrhythmia model pig nuclear transfer donor cellsDownload PDFInfo
- Publication number
- CN116064683A CN116064683ACN202211011552.3ACN202211011552ACN116064683ACN 116064683 ACN116064683 ACN 116064683ACN 202211011552 ACN202211011552 ACN 202211011552ACN 116064683 ACN116064683 ACN 116064683A
- Authority
- CN
- China
- Prior art keywords
- scn5a
- protein
- arrhythmia
- grna2
- grna3
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images







Classifications
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
- C12N15/90—Stable introduction of foreign DNA into chromosome
- C12N15/902—Stable introduction of foreign DNA into chromosome using homologous recombination
- C12N15/907—Stable introduction of foreign DNA into chromosome using homologous recombination in mammalian cells
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- C07K14/47—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/70—Vectors or expression systems specially adapted for E. coli
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/79—Vectors or expression systems specially adapted for eukaryotic hosts
- C12N15/85—Vectors or expression systems specially adapted for eukaryotic hosts for animal cells
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N5/00—Undifferentiated human, animal or plant cells, e.g. cell lines; Tissues; Cultivation or maintenance thereof; Culture media therefor
- C12N5/06—Animal cells or tissues; Human cells or tissues
- C12N5/0602—Vertebrate cells
- C12N5/0652—Cells of skeletal and connective tissues; Mesenchyme
- C12N5/0656—Adult fibroblasts
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/16—Hydrolases (3) acting on ester bonds (3.1)
- C12N9/22—Ribonucleases [RNase]; Deoxyribonucleases [DNase]
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/5005—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving human or animal cells
- G01N33/5008—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving human or animal cells for testing or evaluating the effect of chemical or biological compounds, e.g. drugs, cosmetics
- G01N33/5044—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving human or animal cells for testing or evaluating the effect of chemical or biological compounds, e.g. drugs, cosmetics involving specific cell types
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/02—Fusion polypeptide containing a localisation/targetting motif containing a signal sequence
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/09—Fusion polypeptide containing a localisation/targetting motif containing a nuclear localisation signal
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/20—Fusion polypeptide containing a tag with affinity for a non-protein ligand
- C07K2319/21—Fusion polypeptide containing a tag with affinity for a non-protein ligand containing a His-tag
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/35—Fusion polypeptide containing a fusion for enhanced stability/folding during expression, e.g. fusions with chaperones or thioredoxin
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/50—Fusion polypeptide containing protease site
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/20—Type of nucleic acid involving clustered regularly interspaced short palindromic repeats [CRISPR]
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2503/00—Use of cells in diagnostics
- C12N2503/02—Drug screening
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2510/00—Genetically modified cells
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2800/00—Nucleic acids vectors
- C12N2800/10—Plasmid DNA
- C12N2800/106—Plasmid DNA for vertebrates
- C12N2800/107—Plasmid DNA for vertebrates for mammalian
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2500/00—Screening for compounds of potential therapeutic value
- G01N2500/10—Screening for compounds of potential therapeutic value involving cells
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Chemical & Material Sciences (AREA)
- Biomedical Technology (AREA)
- Organic Chemistry (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biotechnology (AREA)
- Wood Science & Technology (AREA)
- Molecular Biology (AREA)
- General Engineering & Computer Science (AREA)
- Biochemistry (AREA)
- General Health & Medical Sciences (AREA)
- Microbiology (AREA)
- Biophysics (AREA)
- Physics & Mathematics (AREA)
- Cell Biology (AREA)
- Plant Pathology (AREA)
- Immunology (AREA)
- Medicinal Chemistry (AREA)
- Toxicology (AREA)
- Urology & Nephrology (AREA)
- Hematology (AREA)
- Tropical Medicine & Parasitology (AREA)
- Rheumatology (AREA)
- Mycology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Gastroenterology & Hepatology (AREA)
- Food Science & Technology (AREA)
- Analytical Chemistry (AREA)
- General Physics & Mathematics (AREA)
- Pathology (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
Abstract
Translated fromChineseDescription
Translated fromChinese技术领域Technical Field
本发明属于基因编辑技术领域,具体涉及基因编辑系统及其在制备SCN5A基因突变的心率失常模型猪核移植供体细胞中的应用。The present invention belongs to the technical field of gene editing, and in particular relates to a gene editing system and an application thereof in preparing arrhythmia model pig nuclear transplantation donor cells with SCN5A gene mutation.
背景技术Background Art
心率失常是一种心肌收缩率的紊乱,或者是正常心跳节律或速率的任何变异。它包括规则或不规则的异常节律,以及节律的丧失。心律失常与离子通道基因表达异常明确相关,多个离子通道基因的突变可引起各种心律失常。目前,已知绝大多数的原发性心电异常都是由编码各主要离子通道亚单位的基因突变引起的,因此,这类病可称为“离子通道病”。Nav1.5通道是人类主要的心脏钠离子通道类型,负责动作电位的起始和传播,由SCN5A基因编码。Arrhythmia is a disorder of the myocardial contraction rate, or any variation in the normal heartbeat rhythm or rate. It includes regular or irregular abnormal rhythms, as well as the loss of rhythm. Arrhythmias are clearly associated with abnormal expression of ion channel genes, and mutations in multiple ion channel genes can cause various arrhythmias. At present, it is known that the vast majority of primary ECG abnormalities are caused by mutations in genes encoding the major ion channel subunits, so this type of disease can be called "ion channel disease." Nav1.5 channels are the main type of cardiac sodium ion channels in humans, responsible for the initiation and propagation of action potentials, and are encoded by the SCN5A gene.
研究心率失常的发生发展机制及研发相应的药物均需要在动物模型的基础上进行,目前常用的动物模型为小鼠模型,在SCN5A基因敲除的小鼠中观察到了明显的心率失常,然而小鼠不论从体型、器官大小、生理、病理等方面都与人相差巨大,不能真实地模拟人类正常的生理、病理状态。猪作为大动物,其体型大小和生理功能与人类近似,易于大规模繁殖饲养,而且在伦理道德及动物保护等方面要求较低,是理想的人类疾病模型动物。The study of the occurrence and development mechanism of arrhythmia and the development of corresponding drugs need to be based on animal models. The commonly used animal model is the mouse model. Obvious arrhythmia was observed in mice with SCN5A gene knockout. However, mice are very different from humans in terms of body shape, organ size, physiology, pathology, etc., and cannot truly simulate the normal physiological and pathological state of humans. As a large animal, pigs are similar in size and physiological functions to humans, easy to breed and raise on a large scale, and have low requirements in ethics and animal protection. They are ideal human disease model animals.
基因编辑是近年来不断取得重大发展的一种生物技术,其包括从基于同源重组的基因编辑到基于核酸酶的ZFN、TALEN、CRISPR/Cas9等编辑技术,其中CRISPR/Cas9技术是当前最先进的基因编辑技术。目前,基因编辑技术被越来越多地应用到动物模型的制作上。Gene editing is a biotechnology that has made significant progress in recent years. It includes gene editing based on homologous recombination to nuclease-based ZFN, TALEN, CRISPR/Cas9 and other editing technologies. Among them, CRISPR/Cas9 technology is the most advanced gene editing technology. At present, gene editing technology is increasingly being used in the preparation of animal models.
同源重组(HDR)是通过序列同源性交换DNA序列信息:即修复模板中包含所需插入片段,修复模板的两端则是与插入位点附近具有序列同源性的重组臂。过去通常使用双链DNA(dsDNA)作为修复模板,但最近的研究揭示了单链寡核苷酸脱氧核苷酸(ssODN)作为HDR供体模板的优越性。首先,ssODN作为供体模板比dsDNA模板的插入位点特异性高,dsDNA模板容易产生随机插入。其次,ssODN对同源重组臂的长度要求比dsDNA模板更短,单侧30-60个碱基的重组臂设计可以获得高效且稳定的HDR,相比类似的dsDNA模板,其提供的插入效率更高。第三,dsDNA容易被NHEJ修复途径合并,从而导致同源臂的复制或者dsDNA模板的部分整合,而ssODN就不易产生这种现象。另外,dsDNAs对培养的细胞是有害的,线型或者质粒dsDNAs的转染效率较低,并使细胞产生不良反应,而ssODN模板在这些方面就更有优势。Homologous recombination (HDR) is the exchange of DNA sequence information through sequence homology: that is, the repair template contains the desired insertion fragment, and the two ends of the repair template are recombination arms with sequence homology near the insertion site. In the past, double-stranded DNA (dsDNA) was usually used as a repair template, but recent studies have revealed the superiority of single-stranded oligodeoxynucleotide (ssODN) as a donor template for HDR. First, ssODN as a donor template has higher insertion site specificity than dsDNA templates, and dsDNA templates are prone to random insertion. Secondly, ssODN requires a shorter length of homologous recombination arms than dsDNA templates. The design of a recombination arm of 30-60 bases on one side can obtain efficient and stable HDR, and it provides higher insertion efficiency than similar dsDNA templates. Third, dsDNA is easily incorporated by the NHEJ repair pathway, resulting in duplication of homologous arms or partial integration of dsDNA templates, while ssODN is not prone to this phenomenon. In addition, dsDNAs are harmful to cultured cells. The transfection efficiency of linear or plasmid dsDNAs is low and they can cause adverse reactions in cells, while ssODN templates have more advantages in these aspects.
发明内容Summary of the invention
本发明的目的是提供基因编辑系统及其在制备SCN5A基因突变的心率失常模型猪核移植供体细胞中的应用。The purpose of the present invention is to provide a gene editing system and its application in preparing SCN5A gene mutation arrhythmia model pig nuclear transplantation donor cells.
本发明提供了一种制备重组猪细胞的方法,包括如下步骤:用SEQ ID NO:18所示的DNA分子取代猪细胞的染色体DNA中SEQ ID NO:19所示的DNA分子,得到重组猪细胞。The present invention provides a method for preparing a recombinant pig cell, comprising the following steps: replacing the DNA molecule shown in SEQ ID NO: 19 in the chromosome DNA of the pig cell with the DNA molecule shown in SEQ ID NO: 18 to obtain the recombinant pig cell.
用SEQ ID NO:18所示的DNA分子取代猪细胞的染色体DNA中SEQ ID NO:19所示的DNA分子的实现方式为:将SCN5A-gRNA2、SCN5A-gRNA3、SCN5A-mutant-ss153和NCN蛋白共转染猪细胞。The method for replacing the DNA molecule shown in SEQ ID NO: 19 in the chromosomal DNA of pig cells with the DNA molecule shown in SEQ ID NO: 18 is: SCN5A-gRNA2, SCN5A-gRNA3, SCN5A-mutant-ss153 and NCN protein are co-transfected into pig cells.
猪细胞、SCN5A-gRNA2、SCN5A-gRNA3、SCN5A-mutant-ss153和NCN蛋白的配比依次为:10万个猪细胞:0.8-1.2μg SCN5A-gRNA2:0.8-1.2μg SCN5A-gRNA3:1.8-2.2μgSCN5A-mutant-ss153:3-5μg NCN蛋白。The ratios of pig cells, SCN5A-gRNA2, SCN5A-gRNA3, SCN5A-mutant-ss153 and NCN protein are as follows: 100,000 pig cells: 0.8-1.2μg SCN5A-gRNA2: 0.8-1.2μg SCN5A-gRNA3: 1.8-2.2μg SCN5A-mutant-ss153: 3-5μg NCN protein.
猪细胞、SCN5A-gRNA2、SCN5A-gRNA3、SCN5A-mutant-ss153和NCN蛋白的配比依次为:10万个猪细胞:1μg SCN5A-gRNA2:1μg SCN5A-gRNA3:2μg SCN5A-mutant-ss153:4μgNCN蛋白。The ratios of pig cells, SCN5A-gRNA2, SCN5A-gRNA3, SCN5A-mutant-ss153 and NCN protein are: 100,000 pig cells: 1μg SCN5A-gRNA2: 1μg SCN5A-gRNA3: 2μg SCN5A-mutant-ss153: 4μg NCN protein.
所述共转染具体采用电击转染的方式。The co-transfection specifically adopts the method of electroporation transfection.
电击转染的参数设置具体可为:1450V、10ms、3pulse。The specific parameters for electroporation transfection can be set as: 1450V, 10ms, 3pulse.
所述共转染具体可采用哺乳动物核转染试剂盒(Neon kit,Thermofisher)与NeonTM transfection system电转仪。The co-transfection can be specifically carried out using a mammalian nuclear transfection kit (Neon kit, Thermofisher) and a NeonTM transfection system electroporator.
本发明还保护一种试剂盒,包括SCN5A-gRNA2、SCN5A-gRNA3、SCN5A-mutant-ss153和NCN蛋白。The present invention also protects a kit, comprising SCN5A-gRNA2, SCN5A-gRNA3, SCN5A-mutant-ss153 and NCN protein.
本发明还保护一种试剂盒,包括SCN5A-gRNA2、SCN5A-gRNA3、SCN5A-mutant-ss153和PRONCN蛋白。The present invention also protects a kit, comprising SCN5A-gRNA2, SCN5A-gRNA3, SCN5A-mutant-ss153 and PRONCN protein.
本发明还保护一种试剂盒,包括SCN5A-gRNA2、SCN5A-gRNA3、SCN5A-mutant-ss153和特异质粒。The present invention also protects a kit, comprising SCN5A-gRNA2, SCN5A-gRNA3, SCN5A-mutant-ss153 and a specific plasmid.
所述试剂盒还包括大肠杆菌BL21(DE3)。The kit also includes Escherichia coli BL21 (DE3).
以上任一所述试剂盒还包括猪细胞。Any of the above kits further comprises pig cells.
本发明提供了SCN5A-gRNA2、SCN5A-gRNA3、SCN5A-mutant-ss153和NCN蛋白在制备试剂盒中的应用。The present invention provides use of SCN5A-gRNA2, SCN5A-gRNA3, SCN5A-mutant-ss153 and NCN protein in preparing a kit.
本发明还提供了SCN5A-gRNA2、SCN5A-gRNA3、SCN5A-mutant-ss153和PRONCN蛋白在制备试剂盒中的应用。The present invention also provides the use of SCN5A-gRNA2, SCN5A-gRNA3, SCN5A-mutant-ss153 and PRONCN protein in preparing a kit.
本发明还提供了SCN5A-gRNA2、SCN5A-gRNA3、SCN5A-mutant-ss153和特异质粒在制备试剂盒中的应用。The present invention also provides the use of SCN5A-gRNA2, SCN5A-gRNA3, SCN5A-mutant-ss153 and a specific plasmid in preparing a kit.
以上任一所述试剂盒的用途为如下(a)或(b)或(c):(a)制备重组猪细胞;(b)制备心率失常模型猪;(c)制备心率失常细胞模型或心率失常组织模型或心率失常器官模型。The use of any of the above kits is as follows (a) or (b) or (c): (a) preparing recombinant pig cells; (b) preparing arrhythmia model pigs; (c) preparing an arrhythmia cell model or an arrhythmia tissue model or an arrhythmia organ model.
SCN5A-gRNA2、SCN5A-gRNA3、SCN5A-mutant-ss153和NCN蛋白的配比依次为:0.8-1.2μg SCN5A-gRNA2:0.8-1.2μg SCN5A-gRNA3:1.8-2.2μg SCN5A-mutant-ss153:3-5μgNCN蛋白。The ratios of SCN5A-gRNA2, SCN5A-gRNA3, SCN5A-mutant-ss153 and NCN protein are: 0.8-1.2μg SCN5A-gRNA2: 0.8-1.2μg SCN5A-gRNA3: 1.8-2.2μg SCN5A-mutant-ss153: 3-5μg NCN protein.
SCN5A-gRNA2、SCN5A-gRNA3、SCN5A-mutant-ss153和NCN蛋白的配比依次为:1μgSCN5A-gRNA2:1μg SCN5A-gRNA3:2μg SCN5A-mutant-ss153:4μg NCN蛋白。The ratios of SCN5A-gRNA2, SCN5A-gRNA3, SCN5A-mutant-ss153 and NCN protein are: 1μg SCN5A-gRNA2: 1μg SCN5A-gRNA3: 2μg SCN5A-mutant-ss153: 4μg NCN protein.
猪细胞、SCN5A-gRNA2、SCN5A-gRNA3、SCN5A-mutant-ss153和NCN蛋白的配比依次为:10万个猪细胞:0.8-1.2μg SCN5A-gRNA2:0.8-1.2μg SCN5A-gRNA3:1.8-2.2μgSCN5A-mutant-ss153:3-5μg NCN蛋白。The ratios of pig cells, SCN5A-gRNA2, SCN5A-gRNA3, SCN5A-mutant-ss153 and NCN protein are as follows: 100,000 pig cells: 0.8-1.2μg SCN5A-gRNA2: 0.8-1.2μg SCN5A-gRNA3: 1.8-2.2μg SCN5A-mutant-ss153: 3-5μg NCN protein.
猪细胞、SCN5A-gRNA2、SCN5A-gRNA3、SCN5A-mutant-ss153和NCN蛋白的配比依次为:10万个猪细胞:1μg SCN5A-gRNA2:1μg SCN5A-gRNA3:2μg SCN5A-mutant-ss153:4μgNCN蛋白。The ratios of pig cells, SCN5A-gRNA2, SCN5A-gRNA3, SCN5A-mutant-ss153 and NCN protein are: 100,000 pig cells: 1μg SCN5A-gRNA2: 1μg SCN5A-gRNA3: 2μg SCN5A-mutant-ss153: 4μg NCN protein.
以上任一所述SCN5A-gRNA2为sgRNA,其靶序列结合区如SEQ ID NO:16中第3-22位核苷酸所示。Any of the above-mentioned SCN5A-gRNA2 is an sgRNA, and its target sequence binding region is shown in nucleotides 3 to 22 in SEQ ID NO: 16.
具体的,所述SCN5A-gRNA2如SEQ ID NO:16所示。Specifically, the SCN5A-gRNA2 is shown in SEQ ID NO: 16.
具体的,所述SCN5A-gRNA2如SEQ ID NO:11所示。Specifically, the SCN5A-gRNA2 is shown in SEQ ID NO: 11.
以上任一所述SCN5A-gRNA3为sgRNA,其靶序列结合区如SEQ ID NO:17中第3-22位核苷酸所示。Any of the above-mentioned SCN5A-gRNA3 is an sgRNA, and its target sequence binding region is shown in nucleotides 3 to 22 in SEQ ID NO: 17.
具体的,所述SCN5A-gRNA3如SEQ ID NO:17所示。Specifically, the SCN5A-gRNA3 is shown in SEQ ID NO: 17.
具体的,所述SCN5A-gRNA3如SEQ ID NO:12所示。Specifically, the SCN5A-gRNA3 is shown in SEQ ID NO: 12.
具体的,所述SCN5A-mutant-ss153为SEQ ID NO:18所示的单链DNA分子。Specifically, the SCN5A-mutant-ss153 is a single-stranded DNA molecule shown in SEQ ID NO:18.
以上任一所述NCN蛋白为Cas9蛋白或具有Cas9蛋白的融合蛋白。Any of the above-mentioned NCN proteins is a Cas9 protein or a fusion protein with a Cas9 protein.
具体的,所述NCN蛋白如SEQ ID NO:3所示。Specifically, the NCN protein is shown in SEQ ID NO:3.
以上任一所述猪细胞为猪成纤维细胞。Any of the above pig cells is a pig fibroblast.
以上任一所述猪细胞为猪原代成纤维细胞。Any of the above pig cells is a primary pig fibroblast.
以上任一所述猪细胞为获自初生猪的猪原代成纤维细胞。Any of the above pig cells is a primary pig fibroblast obtained from a newborn pig.
所述NCN蛋白的制备方法包括如下步骤:The preparation method of the NCN protein comprises the following steps:
(1)将质粒pKG-GE4导入大肠杆菌BL21(DE3),得到重组菌;(1) Introducing plasmid pKG-GE4 into Escherichia coli BL21 (DE3) to obtain recombinant bacteria;
(2)采用液体培养基30℃培养所述重组菌,然后加入IPTG并进行25℃诱导培养,然后收集菌体;(2) culturing the recombinant bacteria in a liquid medium at 30° C., then adding IPTG and inducing the culture at 25° C., and then collecting the bacteria;
(3)将收集的菌体进行菌体破碎,收集粗蛋白溶液;(3) crushing the collected bacterial cells and collecting the crude protein solution;
(4)采用亲和层析从所述粗蛋白溶液中纯化具有His6标签的融合蛋白;(4) purifying the fusion protein with the His6 tag from the crude protein solution using affinity chromatography;
(5)采用具有His6标签的肠激酶酶切具有His6标签的融合蛋白,然后采用Ni-NTA树脂去除具有His6标签的蛋白,得到纯化的NCN蛋白;(5) using enterokinase with a His6 tag to digest the fusion protein with a His6 tag, and then using Ni-NTA resin to remove the protein with the His6 tag to obtain a purified NCN protein;
质粒pKG-GE4中具有SEQ ID NO:1中第5209-9852位核苷酸所示的融合基因。Plasmid pKG-GE4 contains the fusion gene shown by nucleotides 5209 to 9852 in SEQ ID NO:1.
所述NCN蛋白的制备方法具体包括如下步骤:The preparation method of the NCN protein specifically comprises the following steps:
(1)将质粒pKG-GE4导入大肠杆菌BL21(DE3),得到重组菌。(1) The plasmid pKG-GE4 was introduced into Escherichia coli BL21 (DE3) to obtain recombinant bacteria.
(2)将步骤(1)得到的重组菌接种至含氨苄青霉素的液体LB培养基,振荡培养;(2) inoculating the recombinant bacteria obtained in step (1) into a liquid LB medium containing ampicillin and culturing with shaking;
(3)将步骤(2)得到的菌液接种至液体LB培养基,30℃、230rpm振荡培养至OD600nm值=1.0,然后加入IPTG并使其在体系中的浓度为0.5mM,然后25℃、230rpm振荡培养12小时,然后离心收集菌体;(3) The bacterial solution obtained in step (2) was inoculated into liquid LB medium, and cultured at 30° C. and 230 rpm with shaking until the OD600 nm value was 1.0, and then IPTG was added to a concentration of 0.5 mM in the system, and then cultured at 25° C. and 230 rpm with shaking for 12 hours, and then the bacteria were collected by centrifugation;
(4)取步骤(3)得到的菌体,用PBS缓冲液洗涤;(4) Take the bacterial cells obtained in step (3) and wash them with PBS buffer;
(5)取步骤(4)得到的菌体,加入粗提缓冲液并悬浮菌体,然后进行菌体破碎,然后离心收集上清液,采用0.22μm孔径滤膜过滤,收集滤液;(5) taking the bacterial cells obtained in step (4), adding a crude extraction buffer to suspend the bacterial cells, and then crushing the bacterial cells, and then collecting the supernatant by centrifugation, filtering with a 0.22 μm pore size filter membrane, and collecting the filtrate;
(6)采用亲和层析从步骤(5)得到的滤液中纯化具有His6标签的融合蛋白(SEQ IDNO:2所示的融合蛋白);(6) Purifying the fusion protein with the His6 tag (the fusion protein shown in SEQ ID NO: 2) from the filtrate obtained in step (5) by affinity chromatography;
(7)取步骤(6)收集的过柱后溶液,使用超滤管浓缩,然后用25mM Tris-HCl(pH8.0)稀释;(7) taking the column solution collected in step (6), concentrating it using an ultrafiltration tube, and then diluting it with 25 mM Tris-HCl (pH 8.0);
(8)将具有His6标签的重组牛肠激酶加入到步骤(7)得到的溶液中,酶切;(8) adding recombinant bovine enterokinase with a His6 tag to the solution obtained in step (7) and performing enzyme digestion;
(9)将完成步骤(8)的溶液与Ni-NTA树脂混匀,孵育,然后离心收集上清液;(9) mixing the solution obtained in step (8) with Ni-NTA resin, incubating, and then centrifuging to collect the supernatant;
(10)取步骤(9)得到的上清液,使用超滤管浓缩,然后加入酶贮存液中,即为NCN蛋白溶液。(10) The supernatant obtained in step (9) is concentrated using an ultrafiltration tube and then added to the enzyme storage solution to obtain the NCN protein solution.
采用亲和层析从步骤(5)得到的滤液中纯化具有His6标签的融合蛋白的具体方法如下:The specific method of purifying the fusion protein with the His6 tag from the filtrate obtained in step (5) by affinity chromatography is as follows:
首先采用5个柱体积的平衡液平衡Ni-NTA琼脂糖柱(流速为1ml/min);然后上样50ml步骤(5)得到的滤液(流速为0.5-1ml/min);然后用5个柱体积的平衡液洗涤柱子(流速为1ml/min);然后用5个柱体积的缓冲液洗涤柱子(流速为1ml/min),以去除杂蛋白;然后用10个柱体积的洗脱液以0.5-1ml/min的流速洗脱,收集过柱后溶液(90-100ml)。First, use 5 column volumes of equilibration solution to equilibrate the Ni-NTA agarose column (flow rate is 1 ml/min); then load 50 ml of the filtrate obtained in step (5) (flow rate is 0.5-1 ml/min); then wash the column with 5 column volumes of equilibration solution (flow rate is 1 ml/min); then wash the column with 5 column volumes of buffer (flow rate is 1 ml/min) to remove impurities; then elute with 10 column volumes of eluent at a flow rate of 0.5-1 ml/min, and collect the post-column solution (90-100 ml).
以上任一所述PRONCN蛋白自上游至下游依次包括如下元件:信号肽、分子伴侣蛋白、蛋白标签、蛋白酶酶切位点、核定位信号、Cas9蛋白、核定位信号。Any of the above PRONCN proteins includes the following elements from upstream to downstream: a signal peptide, a molecular chaperone protein, a protein tag, a protease cleavage site, a nuclear localization signal, a Cas9 protein, and a nuclear localization signal.
所述信号肽的功能为促进蛋白分泌表达。所述信号肽可选自大肠杆菌碱性磷酸酶(phoA)信号肽、金黄色葡萄球菌蛋白A信号肽、大肠杆菌外膜蛋白(ompa)信号肽或任何其他原核基因的信号肽,优选为碱性磷酸酶信号肽(phoA signal peptide)。碱性磷酸酶信号肽用来引导目的蛋白分泌表达至细菌周质腔中,从而与细菌胞内蛋白分离,且分泌到细菌周质腔中的目的蛋白为可溶性表达,可被细菌周质腔中的信号肽酶裂解。The function of the signal peptide is to promote protein secretion expression. The signal peptide can be selected from the Escherichia coli alkaline phosphatase (phoA) signal peptide, the Staphylococcus aureus protein A signal peptide, the Escherichia coli outer membrane protein (ompa) signal peptide or any other prokaryotic gene signal peptide, preferably an alkaline phosphatase signal peptide (phoA signal peptide). The alkaline phosphatase signal peptide is used to guide the secretion expression of the target protein into the bacterial periplasmic cavity, thereby separating it from the bacterial intracellular protein, and the target protein secreted into the bacterial periplasmic cavity is soluble and can be cleaved by the signal peptidase in the bacterial periplasmic cavity.
所述分子伴侣蛋白的功能为增加蛋白的可溶性。所述分子伴侣可为任何帮助形成二硫键的蛋白,优选为硫氧还原蛋白(TrxA蛋白)。硫氧还原蛋白,其能作为分子伴侣帮助所共表达的目的蛋白(例如Cas9蛋白)形成二硫键,提高蛋白的稳定性、折叠的正确性,增加目的蛋白的溶解性及活性。The function of the molecular chaperone protein is to increase the solubility of the protein. The molecular chaperone can be any protein that helps to form disulfide bonds, preferably thioredoxin (TrxA protein). Thioredoxin can act as a molecular chaperone to help the co-expressed target protein (such as Cas9 protein) form disulfide bonds, improve the stability of the protein, the correctness of folding, and increase the solubility and activity of the target protein.
所述蛋白标签的功能为用于蛋白纯化。所述标签可为His标签(His-Tag,His6蛋白标签)、GST标签、Flag标签、HA标签、c-Myc标签或其他任何蛋白标签,进一步优选为His标签。His标签能与Ni柱结合,可以通过一步法Ni柱亲和层析纯化目的蛋白,可极大地简化目的蛋白的纯化流程。The function of the protein tag is to purify the protein. The tag may be a His tag (His-Tag, His6 protein tag), a GST tag, a Flag tag, an HA tag, a c-Myc tag or any other protein tag, more preferably a His tag. The His tag can bind to a Ni column, and the target protein can be purified by one-step Ni column affinity chromatography, which can greatly simplify the purification process of the target protein.
所述蛋白酶酶切位点的功能为纯化后用于切除非功能区段,以释放天然形式Cas9蛋白。所述蛋白酶可选自肠激酶(Enterokinase)、因子Xa(Factor Xa)、凝血酶(Thrombin)、TEV蛋白酶(TEV protease)、HRV 3C蛋白酶(HRV 3C protease)、WELQut蛋白酶或任何其他内切蛋白酶,进一步优选为肠激酶。EK为肠激酶酶切位点,便于使用肠激酶切除所融合的TrxA-His区段,得到天然形式的Cas9蛋白。本申请使用带His标签的商品肠激酶酶切融合蛋白后,可通过一次亲和层析除去TrxA-His区段及带His标签的肠激酶,得到天然形式的Cas9蛋白,避免了多次纯化透析对目的蛋白的伤害和损耗。The function of the protease cleavage site is to be used to cut off the non-functional segment after purification to release the natural form of Cas9 protein. The protease can be selected from enterokinase, factor Xa, thrombin, TEV protease, HRV 3C protease, WELQut protease or any other endoprotease, and enterokinase is further preferred. EK is an enterokinase cleavage site, which is convenient for using enterokinase to remove the fused TrxA-His segment to obtain a natural form of Cas9 protein. After the commercial enterokinase with a His tag is used to cut the fusion protein, the TrxA-His segment and the enterokinase with a His tag can be removed by one affinity chromatography to obtain a natural form of Cas9 protein, avoiding damage and loss to the target protein by multiple purification dialysis.
所述核定位信号可为任何核定位信号,优选为SV40核定位信号和/或nucleoplasmin核定位信号。NLS为核定位信号,在Cas9的N端及C端分别设计了一个NLS位点,使Cas9能更有效地进入细胞核进行基因编辑。The nuclear localization signal can be any nuclear localization signal, preferably an SV40 nuclear localization signal and/or a nucleoplasmin nuclear localization signal. NLS is a nuclear localization signal, and an NLS site is designed at the N-terminus and the C-terminus of Cas9, respectively, so that Cas9 can more effectively enter the cell nucleus for gene editing.
所述Cas9蛋白可为saCas9或spCas9,优选为spCas9蛋白。The Cas9 protein may be saCas9 or spCas9, preferably spCas9 protein.
PRONCN蛋白具体如SEQ ID NO:2所示。The PRONCN protein is specifically shown in SEQ ID NO:2.
以上任一所述特异质粒自上游至下游依次包括如下元件:启动子、操纵子、核糖体结合位点、PRONCN蛋白的编码基因、终止子。Any of the above-mentioned specific plasmids includes the following elements from upstream to downstream: a promoter, an operator, a ribosome binding site, a gene encoding PRONCN protein, and a terminator.
所述启动子具体可为T7启动子。T7启动子为原核表达强启动子,能高效驱动外源基因的表达。The promoter may specifically be a T7 promoter, which is a strong promoter for prokaryotic expression and can efficiently drive the expression of exogenous genes.
所述操纵子具体可为Lac操纵子。Lac操纵子为乳糖诱导表达的调控元件,可在细菌生长至一定数量后,再用IPTG在低温下诱导目的蛋白的表达,可避免目的蛋白过早表达对宿主菌生长的影响,低温下诱导表达也显著提高所表达的目的蛋白的可溶性。The operon may specifically be the Lac operon. The Lac operon is a regulatory element for lactose-induced expression. After the bacteria have grown to a certain number, IPTG can be used to induce the expression of the target protein at low temperature, which can avoid the effect of premature expression of the target protein on the growth of the host bacteria. Inducing expression at low temperature also significantly improves the solubility of the expressed target protein.
所述核糖体结合位点是蛋白翻译时的核糖体结合位点,对蛋白质的翻译是必要的。The ribosome binding site is a ribosome binding site during protein translation and is necessary for protein translation.
所述终止子具体可为T7终止子。T7终止子可在目的基因的末端有效终止基因转录,避免目的基因之外的其他下游序列得到转录和翻译。The terminator may specifically be a T7 terminator. The T7 terminator can effectively terminate gene transcription at the end of the target gene to prevent other downstream sequences other than the target gene from being transcribed and translated.
对于spCas9蛋白的密码子,本申请对其密码子进行了优化,使之完全适应本申请所选用的大肠杆菌高效表达菌株E.coli BL21(DE3)的密码子偏好,从而提高Cas9蛋白的表达水平。For the codons of the spCas9 protein, the present application optimizes the codons to make them fully adapt to the codon preference of the Escherichia coli high-efficiency expression strain E. coli BL21 (DE3) selected in the present application, thereby improving the expression level of the Cas9 protein.
T7启动子如SEQ ID NO:1中第5121-5139位核苷酸所示。The T7 promoter is shown as nucleotides 5121-5139 in SEQ ID NO:1.
Lac操纵子如SEQ ID NO:1中第5140-5164位核苷酸所示。The lac operon is shown in nucleotides 5140-5164 of SEQ ID NO:1.
核糖体结合位点如SEQ ID NO:1中第5178-5201位核苷酸所示。The ribosome binding site is shown in nucleotides 5178-5201 of SEQ ID NO:1.
碱性磷酸酶信号肽的编码序列如SEQ ID NO:1中第5209-5271位核苷酸所示。The coding sequence of the alkaline phosphatase signal peptide is shown in nucleotides 5209-5271 in SEQ ID NO:1.
TrxA蛋白的编码序列如SEQ ID NO:1中第5272-5598位核苷酸所示。The coding sequence of TrxA protein is shown in nucleotides 5272-5598 in SEQ ID NO:1.
His-Tag的编码序列如SEQ ID NO:1中第5620-5637位核苷酸所示。The coding sequence of His-Tag is shown in nucleotides 5620-5637 in SEQ ID NO:1.
肠激酶酶切位点的编码序列如SEQ ID NO:1中第5638-5652位核苷酸所示。The coding sequence of the enterokinase cleavage site is shown in nucleotides 5638-5652 in SEQ ID NO:1.
核定位信号的编码序列如SEQ ID NO:1中第5656-5670位核苷酸所示。The coding sequence of the nuclear localization signal is shown in nucleotides 5656-5670 in SEQ ID NO:1.
spCas9蛋白的编码序列如SEQ ID NO:1中第5701-9801位核苷酸所示。The coding sequence of the spCas9 protein is shown in nucleotides 5701-9801 in SEQ ID NO:1.
核定位信号的编码序列如SEQ ID NO:1中第9802-9849位核苷酸所示。The coding sequence of the nuclear localization signal is shown in nucleotides 9802-9849 of SEQ ID NO:1.
T7终止子如SEQ ID NO:1中第9902-9949位核苷酸。The T7 terminator is shown as nucleotides 9902-9949 in SEQ ID NO:1.
具体的,所述特异质粒为质粒pKG-GE4。Specifically, the specific plasmid is plasmid pKG-GE4.
质粒pKG-GE4中具有SEQ ID NO:1中第5121-9949位核苷酸所示的DNA分子。Plasmid pKG-GE4 contains the DNA molecule represented by nucleotides 5121 to 9949 in SEQ ID NO:1.
具体的,以上任一所述质粒pKG-GE4如SEQ ID NO:1所示。Specifically, any of the above plasmids pKG-GE4 is shown as SEQ ID NO:1.
本发明还保护以上任一所述方法制备得到的重组猪细胞。The present invention also protects the recombinant pig cells prepared by any of the above methods.
所述重组猪细胞为靶位点突变的双等位基因相同突变型重组细胞。The recombinant pig cell is a recombinant cell with identical mutations of both alleles at the target site.
靶位点突变的双等位基因相同突变型,即两条同源染色体均完成了单链DonorDNA的替换。The target site mutation has the same biallelic mutation type, that is, both homologous chromosomes have completed the replacement of single-stranded DonorDNA.
单链Donor DNA的替换,即用SEQ ID NO:18所示的DNA分子取代了染色体DNA中SEQID NO:19所示的DNA分子。The replacement of the single-stranded Donor DNA means that the DNA molecule shown in SEQ ID NO: 18 replaces the DNA molecule shown in SEQ ID NO: 19 in the chromosomal DNA.
SEQ ID NO:19所示的DNA分子位于猪细胞的染色体DNA中的SCN5A基因。The DNA molecule represented by SEQ ID NO: 19 is located in the SCN5A gene in the chromosomal DNA of pig cells.
猪SCN5A基因信息:编码电压门控钠离子通道α亚基5;位于13号染色体;Gene ID为100152567,Sus scrofa。Pig SCN5A gene information: encoding voltage-gated sodium channel alpha subunit 5; located on chromosome 13; Gene ID is 100152567, Sus scrofa.
猪SCN5A基因编码的蛋白质如NCBI中XP_020927335.1(13-MAY-2017)所示。The protein encoded by the porcine SCN5A gene is shown in NCBI as XP_020927335.1 (13-MAY-2017).
猪SCN5A基因编码的蛋白质具有SEQ ID NO:8所示的蛋白区段。The protein encoded by the porcine SCN5A gene has a protein segment shown in SEQ ID NO:8.
猪SCN5A基因具有SEQ ID NO:9所示的DNA区段。The porcine SCN5A gene has the DNA segment shown in SEQ ID NO:9.
本发明还保护所述重组猪细胞在制备心率失常模型猪中的应用。The present invention also protects the use of the recombinant pig cells in preparing arrhythmia model pigs.
将所述重组猪细胞作为核移植供体细胞进行体细胞克隆,可以得到克隆猪,即为心率失常模型猪。The recombinant pig cells are used as nuclear transplant donor cells for somatic cell cloning to obtain cloned pigs, namely, arrhythmia model pigs.
本发明还保护利用所述重组猪细胞制备的模型猪的猪组织,即心率失常组织模型。The present invention also protects the pig tissue of the model pig prepared by using the recombinant pig cell, that is, the arrhythmia tissue model.
本发明还保护利用所述重组猪细胞制备的模型猪的猪器官,即心率失常器官模型。The present invention also protects the pig organ of the model pig prepared by using the recombinant pig cell, that is, the arrhythmia organ model.
本发明还保护利用所述重组猪细胞制备的模型猪的猪细胞,即心率失常细胞模型。The present invention also protects pig cells of a model pig prepared by using the recombinant pig cells, namely, a cell model of arrhythmia.
本发明还保护所述重组细胞、所述心率失常组织模型、所述心率失常器官模型、所述心率失常细胞模型或者所述心率失常模型猪的应用,为如下(d1)或(d2)或(d3)或(d4):The present invention also protects the use of the recombinant cell, the arrhythmia tissue model, the arrhythmia organ model, the arrhythmia cell model or the arrhythmia model pig, which is as follows (d1) or (d2) or (d3) or (d4):
(d1)筛选治疗心率失常的药物;(d1) Screening for drugs to treat cardiac arrhythmias;
(d2)进行心率失常药物的药效评价;(d2) Evaluate the efficacy of drugs for arrhythmia;
(d3)进行心率失常的基因治疗和/或细胞治疗的疗效评价;(d3) Evaluate the efficacy of gene therapy and/or cell therapy for cardiac arrhythmia;
(d4)研究心率失常的发病机制。(d4) Study the pathogenesis of arrhythmias.
以上任一所述猪具体可为从江香猪。Any of the above-mentioned pigs can specifically be Congjiang Xiang pigs.
以上任一所述猪具体可为初生从江香猪。Any of the above-mentioned pigs can specifically be newborn Congjiang Xiang pigs.
以上任一所述猪具体可为巴马香猪。Any of the above-mentioned pigs can specifically be Bama Xiang pigs.
以上任一所述猪具体可为初生巴马香猪。Any of the above-mentioned pigs can specifically be newborn Bama Xiang pigs.
与现有技术相比,本发明至少具有如下有益效果:Compared with the prior art, the present invention has at least the following beneficial effects:
(1)本发明研究对象(猪)比其他动物(大小鼠、灵长类)具有更好的应用性。(1) The research object of the present invention (pig) has better applicability than other animals (rat, mouse, and primate).
大小鼠等啮齿类动物不论从体型、器官大小、生理、病理等方面都与人相差巨大,无法真实地模拟人类正常的生理、病理状态。研究表明,95%以上在大小鼠中验证有效的药物在人类临床试验中是无效的。就大动物而言,灵长类是与人亲缘关系最近的动物,但其体型小、性成熟晚(6-7岁开始交配),且为单胎动物,群体扩繁速度极慢,饲养成本很高。另外,灵长类动物克隆效率低、难度大、成本高。Rodents such as mice and rats are very different from humans in terms of body shape, organ size, physiology, and pathology, and cannot truly simulate the normal physiological and pathological conditions of humans. Studies have shown that more than 95% of drugs that have been proven effective in mice and rats are ineffective in human clinical trials. As far as large animals are concerned, primates are the animals that are most closely related to humans, but they are small in size, mature late (mating begins at 6-7 years old), and are single-birth animals. The population expansion rate is extremely slow, and the breeding cost is very high. In addition, primate cloning is inefficient, difficult, and costly.
而猪作为模型动物就没有上述缺点,猪是除灵长类外与人亲缘关系最近的动物,其体型、体重、器官大小等与人相近,在解剖学、生理学、免疫学、营养代谢、疾病发病机制等方面与人类极为相似。同时,猪的性成熟早(4-6个月),繁殖力高,一胎多仔,在2-3年内即可形成一个较大群体。另外,猪的克隆技术非常成熟,克隆及饲养成本也较灵长类低得多。因此猪是非常适合作为人类疾病模型的动物。As a model animal, pigs do not have the above disadvantages. They are the animals that are most closely related to humans except primates. Their body shape, weight, organ size, etc. are similar to those of humans. They are very similar to humans in anatomy, physiology, immunology, nutritional metabolism, and disease pathogenesis. At the same time, pigs mature early (4-6 months), have high fertility, and can produce many offspring per litter. A large group can be formed within 2-3 years. In addition, pig cloning technology is very mature, and the cost of cloning and raising is much lower than that of primates. Therefore, pigs are very suitable animals as models of human diseases.
(2)发明所构建的载体,使用了能够高效表达目的蛋白的强启动子T7-lac来进行目的蛋白的表达,用细菌周质蛋白碱性磷酸酶(phoA)的信号肽来引导目的蛋白分泌表达至细菌周质腔中,从而与细菌胞内蛋白分离,且分泌到细菌周质腔中的目的蛋白为可溶性表达。同时还采用硫氧还原蛋白TrxA与Cas9蛋白融合表达,TrxA能帮助所共表达的目的蛋白形成二硫键,提高蛋白的稳定性、折叠的正确性,增加目的蛋白的溶解性及活性。为了方便目的蛋白的纯化,设计了His标签,可以通过一步法Ni柱亲和层析纯化目的蛋白,极大地简化了目的蛋白的纯化流程。同时在His标签后设计了一个肠激酶酶切位点,便于切除所融合的TrxA-His多肽片段,得到天然形式的Cas9蛋白。利用带His标签的肠激酶酶切融合蛋白后,可通过一次亲和层析除去TrxA-His多肽片段及带His标签的肠激酶,得到天然形式的Cas9蛋白,避免了多次纯化透析对目的蛋白的伤害和损耗。同时,本发明也在Cas9的N端及C端分别设计了一个NLS位点,使Cas9能更有效地进入细胞核进行基因编辑。另外,本发明选择了E.coli BL21(DE3)为目的蛋白表达菌株,该菌株可高效表达克隆于含有噬菌体T7启动子的表达载体(如pET-32a)的外源基因。同时,对于Cas9蛋白的密码子,本发明进行了密码子优化,使之完全适应表达菌株的密码子偏好,从而提高目的蛋白的表达水平。另外,本发明在细菌生长至一定数量后,再用IPTG在低温下诱导目的蛋白的表达,可避免目的蛋白过早表达对宿主菌生长的影响,低温下诱导表达也显著提高所表达的目的蛋白的可溶性。经过上述各项优化设计及实验实施,所得到的Cas9蛋白活性比商品Cas9蛋白有了极显著的提高。(2) The vector constructed by the invention uses a strong promoter T7-lac that can efficiently express the target protein to express the target protein, and uses the signal peptide of bacterial periplasmic protein alkaline phosphatase (phoA) to guide the secretion and expression of the target protein into the bacterial periplasmic cavity, thereby separating it from the bacterial intracellular protein, and the target protein secreted into the bacterial periplasmic cavity is soluble. At the same time, the thioredoxin TrxA and Cas9 protein are fused and expressed. TrxA can help the co-expressed target protein to form a disulfide bond, improve the stability of the protein, the correctness of folding, and increase the solubility and activity of the target protein. In order to facilitate the purification of the target protein, a His tag is designed, and the target protein can be purified by one-step Ni column affinity chromatography, which greatly simplifies the purification process of the target protein. At the same time, an enterokinase cleavage site is designed after the His tag to facilitate the removal of the fused TrxA-His polypeptide fragment to obtain a natural form of the Cas9 protein. After the fusion protein is cleaved by enterokinase with a His tag, the TrxA-His polypeptide fragment and the enterokinase with a His tag can be removed by an affinity chromatography to obtain a natural form of Cas9 protein, avoiding the damage and loss of the target protein by multiple purification dialysis. At the same time, the present invention also designs an NLS site at the N-terminus and C-terminus of Cas9, so that Cas9 can more effectively enter the nucleus for gene editing. In addition, the present invention selects E.coli BL21 (DE3) as the target protein expression strain, which can efficiently express the exogenous gene cloned in the expression vector (such as pET-32a) containing the phage T7 promoter. At the same time, for the codons of the Cas9 protein, the present invention performs codon optimization to fully adapt to the codon preference of the expression strain, thereby improving the expression level of the target protein. In addition, after the bacteria grow to a certain number, the present invention uses IPTG to induce the expression of the target protein at low temperature, which can avoid the influence of premature expression of the target protein on the growth of the host bacteria, and the induced expression at low temperature also significantly improves the solubility of the expressed target protein. After the above-mentioned optimization designs and experimental implementation, the activity of the obtained Cas9 protein was significantly improved compared with the commercial Cas9 protein.
(3)采用本发明构建并表达的Cas9高效蛋白联合体外转录的gRNA进行基因编辑,并对Cas9和gRNA的最佳用量配比进行了优化,配合合成的ssODN作为Donor DNA,最终获得靶位点突变的单细胞克隆比率高达21.3%,远高于常规的点突变效率(<5%)。(3) The Cas9 high-efficiency protein constructed and expressed by the present invention was combined with in vitro transcribed gRNA for gene editing, and the optimal dosage ratio of Cas9 and gRNA was optimized. Synthetic ssODN was used as Donor DNA, and the single-cell clone rate of target site mutation was finally obtained as high as 21.3%, which is much higher than the conventional point mutation efficiency (<5%).
(4)利用本发明所得到的靶位点突变的单细胞克隆进行体细胞核移植动物克隆可直接得到含靶位点突变的克隆猪,并且该突变可稳定遗传。(4) Using the single cell clone with target site mutation obtained by the present invention to carry out somatic cell nuclear transplantation animal cloning can directly obtain cloned pigs containing target site mutation, and the mutation can be stably inherited.
在小鼠模型制作中采用的受精卵显微注射基因编辑材料后再进行胚胎移植的方法,因其直接获得点突变后代的概率非常低(低于1%),需要进行后代的杂交选育,这不太适用于妊娠期较长的大动物(如猪)模型制作。因此,本发明采用技术难度大、挑战性高的原代细胞体外编辑以及ssODN同源重组并筛选阳性编辑单细胞克隆的方法,后期再通过体细胞核移植动物克隆技术直接获得相应疾病模型猪,可大大缩短模型猪制作周期并节省人力、物力、财力。The method of microinjecting gene editing materials into fertilized eggs and then performing embryo transplantation in mouse model preparation has a very low probability of directly obtaining offspring with point mutations (less than 1%), and requires hybrid breeding of offspring, which is not suitable for model preparation of large animals (such as pigs) with long gestation periods. Therefore, the present invention adopts a method of in vitro editing of primary cells and ssODN homologous recombination and screening of positive edited single cell clones, which are technically difficult and challenging, and then directly obtains corresponding disease model pigs through somatic cell nuclear transplantation animal cloning technology in the later stage, which can greatly shorten the model pig production cycle and save manpower, material resources and financial resources.
本发明采用CRISPR/Cas9技术联合ssODN同源重组技术进行了SCN5A基因的基因编辑,模拟心率失常的自然发病遗传特征,并获得了SCN5A基因精确点突变的单细胞克隆,为后期通过体细胞核移植动物克隆技术培育心率失常模型猪奠定了基础。该模型猪将为研究心率失常的发病机制及药物研发提供有力的实验工具。The present invention uses CRISPR/Cas9 technology combined with ssODN homologous recombination technology to edit the SCN5A gene, simulate the natural genetic characteristics of arrhythmia, and obtain single-cell clones with precise point mutations in the SCN5A gene, laying the foundation for the later breeding of arrhythmia model pigs through somatic cell nuclear transplantation animal cloning technology. The model pig will provide a powerful experimental tool for studying the pathogenesis of arrhythmia and drug development.
本发明为通过基因编辑手段获得SCN5A基因突变的心率失常模型猪奠定了坚实的基础,将有助于研究并揭示SCN5A基因突变导致心率失常的发病机制,也可用于进行药物筛选、药效检测、基因治疗及细胞治疗等研究,能够为进一步的临床应用提供有效的实验数据,进而为成功治疗人类心率失常提供有力的实验手段。本发明对于研发心率失常药物的研发及揭示该病的发病机制具有重大应用价值。The present invention lays a solid foundation for obtaining arrhythmia model pigs with SCN5A gene mutations by gene editing, which will help study and reveal the pathogenesis of arrhythmia caused by SCN5A gene mutations, and can also be used for drug screening, drug efficacy testing, gene therapy and cell therapy research, and can provide effective experimental data for further clinical applications, thereby providing a powerful experimental means for the successful treatment of human arrhythmia. The present invention has great application value for the research and development of arrhythmia drugs and revealing the pathogenesis of the disease.
附图说明BRIEF DESCRIPTION OF THE DRAWINGS
图1为质粒pET-32a的结构示意图。FIG1 is a schematic diagram of the structure of plasmid pET-32a.
图2为质粒pKG-GE4的结构示意图。FIG. 2 is a schematic diagram of the structure of plasmid pKG-GE4.
图3为实施例2中gRNA与NCN蛋白用量配比优化的电泳图。Figure 3 is an electrophoresis diagram of the optimized dosage ratio of gRNA and NCN protein in Example 2.
图4为实施例2中NCN蛋白与商品Cas9蛋白的基因编辑效率比较的电泳图。FIG4 is an electrophoretic diagram comparing the gene editing efficiency of NCN protein and commercial Cas9 protein in Example 2.
图5为实施例3中用命名为BX4的猪的耳组织提取基因组作为模板采用不同引物对进行PCR扩增的电泳图。FIG. 5 is an electrophoretic diagram of PCR amplification using different primer pairs using the genome extracted from the ear tissue of a pig named BX4 as a template in Example 3.
图6为实施例3中分别以10只猪的基因组DNA为模板采用SCN5A-E11-JDF186和SCN5A-E11-JDR593组成的引物对进行PCR扩增的电泳图。FIG6 is an electrophoretic diagram of PCR amplification performed using the primer pair consisting of SCN5A-E11-JDF186 and SCN5A-E11-JDR593 using the genomic DNA of 10 pigs as templates in Example 3.
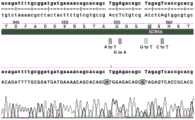
图7为编号为38的单细胞克隆的正向测序与SCN5A-mutant-ss153序列的比对结果。FIG. 7 is the comparison result of the forward sequencing of the single cell clone numbered 38 and the SCN5A-mutant-ss153 sequence.
图8为编号为24的单细胞克隆的正向测序与SCN5A-mutant-ss153序列的比对结果。FIG8 is the comparison result of the forward sequencing of the single cell clone numbered 24 and the SCN5A-mutant-ss153 sequence.
具体实施方式DETAILED DESCRIPTION
下面结合具体实施方式对本发明进行进一步的详细描述,给出的实施例仅为了阐明本发明,而不是为了限制本发明的范围。以下提供的实施例可作为本技术领域普通技术人员进行进一步改进的指南,并不以任何方式构成对本发明的限制。The present invention is further described in detail below in conjunction with specific embodiments, and the examples provided are only for illustrating the present invention, rather than for limiting the scope of the present invention. The examples provided below can be used as a guide for further improvements by those of ordinary skill in the art, and do not constitute a limitation of the present invention in any way.
下述实施例中的实验方法,如无特殊说明,均为常规方法,按照本领域内的文献所描述的技术或条件或者按照产品说明书进行。下述实施例中所用的材料、试剂等,如无特殊说明,均可从商业途径得到。实施例中构建的重组质粒,均已进行测序验证。商品Cas9-A蛋白为市售的效果好的Cas9蛋白。商品Cas9-B蛋白为市售的效果好的Cas9蛋白。完全培养液(%为体积比):15%胎牛血清(Gibco)+83%DMEM培养基(Gibco)+1%Penicillin-Streptomycin(Gibco)+1%HEPES(Solarbio)。细胞培养条件:37℃,5%CO2、5%O2的恒温培养箱。The experimental methods in the following examples, unless otherwise specified, are conventional methods, and are carried out according to the techniques or conditions described in the literature in the art or according to the product instructions. The materials, reagents, etc. used in the following examples, unless otherwise specified, can be obtained from commercial sources. The recombinant plasmids constructed in the examples have all been sequenced and verified. The commercial Cas9-A protein is a commercially available Cas9 protein with good effects. The commercial Cas9-B protein is a commercially available Cas9 protein with good effects. Complete culture medium (% is volume ratio): 15% fetal bovine serum (Gibco) + 83% DMEM medium (Gibco) + 1% Penicillin-Streptomycin (Gibco) + 1% HEPES (Solarbio). Cell culture conditions: 37°C, 5% CO2 , 5% O2 constant temperature incubator.
实施例2中采用的猪原代成纤维细胞是用初生从江香猪耳组织制备得到的。实施例3和实施例4中采用的猪原代成纤维细胞均是用初生巴马香猪耳组织制备得到的。用猪耳组织制备猪原代成纤维细胞的方法:①取猪耳组织0.5g,去除毛发及骨组织,然后用75%酒精浸泡30-40s,然后用含5%(体积比)Penicillin-Streptomycin(Gibco)的PBS缓冲液洗涤5次,然后用PBS缓冲液洗涤一次;②用剪刀将组织剪碎,采用5mL 0.1%胶原酶溶液(Sigma),37℃消化1h,然后500g离心5min,弃上清;③将沉淀用1mL完全培养液重悬,然后铺入含10mL完全培养液并已用0.2%明胶(VWR)封盘的直径为10cm的细胞培养皿中,培养至细胞长满皿底60%左右;④完成步骤③后,采用胰蛋白酶消化并收集细胞,然后重悬于完全培养液。用于进行后续电转实验。The porcine primary fibroblasts used in Example 2 were prepared from ear tissues of primary Congjiang Xiang pigs. The porcine primary fibroblasts used in Examples 3 and 4 were prepared from ear tissues of primary Bama Xiang pigs. Method for preparing primary porcine fibroblasts from pig ear tissue: ① Take 0.5g of pig ear tissue, remove hair and bone tissue, then soak in 75% alcohol for 30-40s, then wash 5 times with PBS buffer containing 5% (volume ratio) Penicillin-Streptomycin (Gibco), and then wash once with PBS buffer; ② Cut the tissue into pieces with scissors, digest with 5mL 0.1% collagenase solution (Sigma), digest at 37℃ for 1h, then centrifuge at 500g for 5min, and discard the supernatant; ③ Resuspend the precipitate with 1mL complete culture medium, and then spread it into a cell culture dish with a diameter of 10cm containing 10mL complete culture medium and sealed with 0.2% gelatin (VWR), and culture until the cells cover about 60% of the bottom of the dish; ④ After completing step ③, digest and collect the cells with trypsin, and then resuspend them in complete culture medium. Used for subsequent electroporation experiments.
质粒pKG-GE3,为环形质粒,如专利申请202010084343.6中的SEQ ID NO:2所示。专利申请202010084343.6中的SEQ ID NO:2中,第395-680位核苷酸组成CMV增强子,第682-890位核苷酸组成EF1a启动子,第986-1006位核苷酸编码核定位信号(NLS),第1016-1036位核苷酸编码核定位信号(NLS),第1037-5161位核苷酸编码Cas9蛋白,第5162-5209位核苷酸编码核定位信号(NLS),第5219-5266位核苷酸编码核定位信号(NLS),第5276-5332位核苷酸编码多肽P2A(多肽P2A的氨基酸序列为“ATNFSLLKQAGDVEENPGP”,断裂位置为C端开始第一个氨基酸残基和第二个氨基酸残基之间),第5333-6046位核苷酸编码EGFP蛋白,第6056-6109位核苷酸编码多肽T2A(多肽T2A的氨基酸序列为“EGRGSLLTCGDVEENPGP”,断裂位置为C端开始第一个氨基酸残基和第二个氨基酸残基之间),第6110-6703位核苷酸编码Puromycin蛋白(简称Puro蛋白),第6722-7310位核苷酸组成WPRE序列元件,第7382-7615位核苷酸组成3’LTR序列元件,第7647-7871位核苷酸组成bGH poly(A)signal序列元件。专利申请202010084343.6中的SEQ ID NO:2中,第911-6706位核苷酸形成融合基因,表达融合蛋白。由于自剪切多肽P2A和自裂解多肽T2A的存在,融合蛋白自发形成如下三个蛋白:具有Cas9蛋白的蛋白、具有EGFP蛋白的蛋白和具有Puro蛋白的蛋白。Plasmid pKG-GE3 is a circular plasmid, as shown in SEQ ID NO: 2 in patent application 202010084343.6. In SEQ ID NO: 2 in patent application 202010084343.6, nucleotides 395-680 constitute the CMV enhancer, nucleotides 682-890 constitute the EF1a promoter, nucleotides 986-1006 encode the nuclear localization signal (NLS), nucleotides 1016-1036 encode the nuclear localization signal (NLS), nucleotides 1037-5161 encode the Cas9 protein, nucleotides 5162-5209 encode the nuclear localization signal (NLS), nucleotides 5219-5266 encode the nuclear localization signal (NLS), and nucleotides 5276-5332 encode the polypeptide P2A (the amino acid sequence of polypeptide P2A is "ATNFSLLKQAGDVEENPGP", and the break position is The nucleotides at positions 5333-6046 encode EGFP protein, the nucleotides at positions 6056-6109 encode polypeptide T2A (the amino acid sequence of polypeptide T2A is "EGRGSLLTCGDVEENPGP", and the break position is between the first amino acid residue and the second amino acid residue at the C-terminus), the nucleotides at positions 6110-6703 encode Puromycin protein (abbreviated as Puro protein), the nucleotides at positions 6722-7310 constitute the WPRE sequence element, the nucleotides at positions 7382-7615 constitute the 3'LTR sequence element, and the nucleotides at positions 7647-7871 constitute the bGH poly (A) signal sequence element. In SEQ ID NO: 2 in patent application 202010084343.6, the nucleotides at positions 911-6706 form a fusion gene to express a fusion protein. Due to the presence of the self-cleaving polypeptide P2A and the self-cleaving polypeptide T2A, the fusion protein spontaneously forms the following three proteins: a protein with Cas9 protein, a protein with EGFP protein, and a protein with Puro protein.
pKG-U6gRNA载体即质粒pKG-U6gRNA,为环形质粒,如专利申请202010084343.6中的SEQ ID NO:3所示。专利申请202010084343.6中的SEQ ID NO:3中,第2280-2539位核苷酸组成hU6启动子,第2558-2637位核苷酸用于转录形成gRNA骨架。使用时,将20bp左右的DNA分子(用于转录形成gRNA的靶序列结合区)插入质粒pKG-U6gRNA,形成重组质粒,在细胞中重组质粒转录得到gRNA。The pKG-U6gRNA vector, i.e., the plasmid pKG-U6gRNA, is a circular plasmid, as shown in SEQ ID NO: 3 in patent application 202010084343.6. In SEQ ID NO: 3 in patent application 202010084343.6, nucleotides 2280-2539 constitute the hU6 promoter, and nucleotides 2558-2637 are used to transcribe to form the gRNA backbone. When used, a DNA molecule of about 20 bp (used to transcribe the target sequence binding region of the gRNA) is inserted into the plasmid pKG-U6gRNA to form a recombinant plasmid, and the recombinant plasmid is transcribed in the cell to obtain the gRNA.
实施例1、NCN蛋白的制备和纯化Example 1. Preparation and purification of NCN protein
一、原核Cas9高效表达载体的构建1. Construction of prokaryotic Cas9 efficient expression vector
质粒pET-32a的结构示意图见图1。The schematic diagram of the structure of plasmid pET-32a is shown in Figure 1.
质粒pKG-GE4是以质粒pET-32a为出发质粒进行改造得到的。质粒pET32a-T7lac-phoA:SP-TrxA-His-EK-NLS-spCas9-NLS-T7ter(简称质粒pKG-GE4),如SEQ ID NO:1所示,为环形质粒,结构示意图见图2。Plasmid pKG-GE4 is obtained by transforming plasmid pET-32a as the starting plasmid. Plasmid pET32a-T7lac-phoA:SP-TrxA-His-EK-NLS-spCas9-NLS-T7ter (referred to as plasmid pKG-GE4), as shown in SEQ ID NO: 1, is a circular plasmid, and the schematic diagram of the structure is shown in Figure 2.
SEQ ID NO:1中,第5121-5139位核苷酸组成T7启动子,第5140-5164位核苷酸编码Lac操纵子(lac operator),第5178-5201位核苷酸组成核糖体结合位点(RBS),第5209-5271位核苷酸编码碱性磷酸酶信号肽(phoA signal peptide),第5272-5598位核苷酸编码TrxA蛋白,第5620-5637位核苷酸编码His-Tag(又称为His6标签),第5638-5652位核苷酸编码肠激酶酶切位点(EK酶切位点),第5656-5670位核苷酸编码核定位信号,第5701-9801位核苷酸编码spCas9蛋白,第9802-9849位核苷酸编码核定位信号,第9902-9949位核苷酸组成T7终止子。编码spCas9蛋白的核苷酸已进行针对大肠杆菌BL21(DE3)菌株的密码子优化。In SEQ ID NO: 1, nucleotides 5121-5139 constitute a T7 promoter, nucleotides 5140-5164 encode a Lac operator, nucleotides 5178-5201 constitute a ribosome binding site (RBS), nucleotides 5209-5271 encode an alkaline phosphatase signal peptide (phoA signal peptide), nucleotides 5272-5598 encode a TrxA protein, nucleotides 5620-5637 encode a His-Tag (also known as a His6 tag), nucleotides 5638-5652 encode an enterokinase cleavage site (EK cleavage site), nucleotides 5656-5670 encode a nuclear localization signal, nucleotides 5701-9801 encode a spCas9 protein, nucleotides 9802-9849 encode a nuclear localization signal, and nucleotides 9902-9949 constitute a T7 terminator. The nucleotide encoding the spCas9 protein has been codon-optimized for the Escherichia coli BL21(DE3) strain.
质粒pKG-GE4的主要改造如下:①保留了TrxA蛋白的编码区域,TrxA蛋白可以帮助所表达的目的蛋白形成二硫键、增加目的蛋白的溶解性及活性;在TrxA蛋白的编码区域之前加入碱性磷酸酶信号肽的编码序列,碱性磷酸酶信号肽可以引导所表达的目的蛋白分泌至细菌的膜周质腔中并可被原核周质信号肽酶酶切;②在TrxA蛋白的编码序列之后增加His-Tag的编码序列,His-Tag可用于所表达的目的蛋白的富集;③在His-Tag的编码序列下游增加肠激酶酶切位点DDDDK(Asp-Asp-Asp-Asp-Lys)的编码序列,纯化出的蛋白将在肠激酶作用下去除His-Tag和上游所融合的TrxA蛋白;④插入密码子优化后的适宜大肠杆菌BL21(DE3)菌株表达的Cas9基因,同时在该基因的上游和下游均增加核定位信号编码序列,增加后期纯化出的Cas9蛋白的核定位能力。The main modifications of plasmid pKG-GE4 are as follows: ① The coding region of TrxA protein is retained. TrxA protein can help the expressed target protein to form disulfide bonds and increase the solubility and activity of the target protein; the coding sequence of alkaline phosphatase signal peptide is added before the coding region of TrxA protein. The alkaline phosphatase signal peptide can guide the expressed target protein to be secreted into the membrane periplasmic cavity of bacteria and can be cleaved by prokaryotic periplasmic signal peptidase; ② The coding sequence of His-Tag is added after the coding sequence of TrxA protein. His-Tag can be used for ③ Add the coding sequence of the enterokinase cleavage site DDDDK (Asp-Asp-Asp-Asp-Lys) downstream of the His-Tag coding sequence. The purified protein will remove the His-Tag and the TrxA protein fused upstream under the action of enterokinase; ④ Insert the codon-optimized Cas9 gene suitable for expression in the Escherichia coli BL21 (DE3) strain, and add the nuclear localization signal coding sequence upstream and downstream of the gene to increase the nuclear localization ability of the Cas9 protein purified later.
质粒pKG-GE4中的融合基因如SEQ ID NO:1中第5209-9852位核苷酸所示,编码SEQID NO:2所示的融合蛋白(融合蛋白TrxA-His-EK-NLS-spCas9-NLS,简称为PRONCN蛋白)。由于碱性磷酸酶信号肽以及肠激酶酶切位点的存在,融合蛋白被肠激酶酶切后形成SEQ IDNO:3所示的蛋白质,将SEQ ID NO:3所示的蛋白质命名为NCN蛋白。The fusion gene in the plasmid pKG-GE4 is shown in nucleotides 5209-9852 of SEQ ID NO: 1, encoding the fusion protein shown in SEQ ID NO: 2 (fusion protein TrxA-His-EK-NLS-spCas9-NLS, referred to as PRONCN protein). Due to the presence of the alkaline phosphatase signal peptide and the enterokinase cleavage site, the fusion protein is cleaved by enterokinase to form the protein shown in SEQ ID NO: 3, and the protein shown in SEQ ID NO: 3 is named NCN protein.
二、诱导表达2. Inducible Expression
1、将质粒pKG-GE4导入大肠杆菌BL21(DE3),得到重组菌。1. Introduce plasmid pKG-GE4 into Escherichia coli BL21 (DE3) to obtain recombinant bacteria.
2、将步骤1得到的重组菌接种至含100μg/ml氨苄青霉素的液体LB培养基,37℃、200rpm振荡培养过夜。2. The recombinant bacteria obtained in
3、将步骤2得到的菌液接种至液体LB培养基,30℃、230rpm振荡培养至OD600nm值=1.0,然后加入异丙基硫代半乳糖苷(IPTG)并使其在体系中的浓度为0.5mM,然后25℃、230rpm振荡培养12小时,然后4℃、10000g离心15分钟,收集菌体。3. The bacterial solution obtained in step 2 was inoculated into liquid LB medium, and cultured at 30°C and 230 rpm with shaking until the OD600nm value = 1.0, and then isopropylthiogalactoside (IPTG) was added to a concentration of 0.5 mM in the system, and then cultured at 25°C and 230 rpm with shaking for 12 hours, and then centrifuged at 4°C and 10000 g for 15 minutes to collect the bacteria.
4、取步骤3得到的菌体,用PBS缓冲液洗涤。4. Take the bacteria obtained in step 3 and wash them with PBS buffer.
三、融合蛋白TrxA-His-EK-NLS-spCas9-NLS的纯化3. Purification of fusion protein TrxA-His-EK-NLS-spCas9-NLS
1、取步骤二得到的菌体,加入粗提缓冲液并悬浮菌体,然后采用均质机进行菌体破碎(1000par循环三次),然后4℃、15000g离心30min,收集上清液,上清液采用0.22μm孔径滤膜过滤,收集滤液。本步骤中,每g湿重的菌体配比10ml粗提缓冲液。粗提缓冲液:含20mMTris-HCl(pH8.0)、0.5M NaCl、5mM Imidazole、1mM PMSF,余量为ddH2O。1. Take the bacterial cells obtained in step 2, add crude extraction buffer and suspend the bacterial cells, then use a homogenizer to break the bacterial cells (1000par cycle three times), then centrifuge at 4℃, 15000g for 30min, collect the supernatant, filter the supernatant with a 0.22μm pore size filter membrane, and collect the filtrate. In this step, 10ml crude extraction buffer is added for every gram of wet weight of bacterial cells. Crude extraction buffer: contains 20mMTris-HCl (pH8.0), 0.5M NaCl, 5mM Imidazole, 1mM PMSF, and the balance isddH2O .
2、采用亲和层析纯化融合蛋白。2. Purify the fusion protein using affinity chromatography.
首先采用5个柱体积的平衡液平衡Ni-NTA琼脂糖柱(流速为1ml/min);然后上样50ml步骤1得到的滤液(流速为0.5-1ml/min);然后用5个柱体积的平衡液洗涤柱子(流速为1ml/min);然后用5个柱体积的缓冲液洗涤柱子(流速为1ml/min),以去除杂蛋白;然后用10个柱体积的洗脱液以0.5-1ml/min的流速洗脱,收集过柱后溶液(90-100ml)。First, use 5 column volumes of equilibration solution to equilibrate the Ni-NTA agarose column (flow rate is 1 ml/min); then load 50 ml of the filtrate obtained in step 1 (flow rate is 0.5-1 ml/min); then wash the column with 5 column volumes of equilibration solution (flow rate is 1 ml/min); then wash the column with 5 column volumes of buffer (flow rate is 1 ml/min) to remove impurities; then elute with 10 column volumes of eluent at a flow rate of 0.5-1 ml/min, and collect the post-column solution (90-100 ml).
Ni-NTA琼脂糖柱:金斯瑞,L00250/L00250-C,填料为10ml。Ni-NTA agarose column: GenScript, L00250/L00250-C, filler volume 10 ml.
平衡液:含20mM Tris-HCl(pH 8.0)、0.5M NaCl、5mM Imidazole,余量为ddH2O。Balance solution: contains 20 mM Tris-HCl (pH 8.0), 0.5 M NaCl, 5 mM Imidazole, and the balance is ddH2 O.
缓冲液:含20mM Tris-HCl(pH 8.0)、0.5M NaCl、50mM Imidazole,余量为ddH2O。Buffer: Contains 20 mM Tris-HCl (pH 8.0), 0.5 M NaCl, 50 mM Imidazole, and the balance is ddH2 O.
洗脱液:含20mM Tris-HCl(pH 8.0)、0.5M NaCl、500mM Imidazole,余量为ddH2O。The eluent contained 20 mM Tris-HCl (pH 8.0), 0.5 M NaCl, 500 mM Imidazole, and the balance was ddH2 O.
四、融合蛋白TrxA-His-EK-NLS-spCas9-NLS的酶切与NCN蛋白的纯化IV. Enzyme cleavage of fusion protein TrxA-His-EK-NLS-spCas9-NLS and purification of NCN protein
1、取15ml步骤三收集的过柱后溶液,使用Amicon超滤管(Sigma,UFC9100,容量为15ml)将其浓缩至200μl,然后用25mM Tris-HCl(pH8.0)稀释至1ml。采用6个超滤管,共得到6ml。1. Take 15 ml of the post-column solution collected in step 3, concentrate it to 200 μl using an Amicon ultrafiltration tube (Sigma, UFC9100, capacity 15 ml), and then dilute it to 1 ml with 25 mM Tris-HCl (pH 8.0). Use 6 ultrafiltration tubes to obtain a total of 6 ml.
2、将商品来源的具有His6标签的重组牛肠激酶(生工生物,C620031,重组牛肠激酶轻链,具有His6标签,Recombinant Bovine Enterokinase Light Chain,His)加入到步骤1得到的溶液(约6ml)中,25℃酶切16小时。每50μg蛋白量配比加入2个单位的肠激酶。2. Add commercially available recombinant bovine enterokinase with a His6 tag (Sangon Biotech, C620031, Recombinant Bovine Enterokinase Light Chain, with a His6 tag, Recombinant Bovine Enterokinase Light Chain, His) to the solution obtained in step 1 (about 6 ml), and digest at 25°C for 16 hours. Add 2 units of enterokinase for every 50 μg of protein.
3、取完成步骤2的溶液(约6ml),与480μl Ni-NTA树脂(金斯瑞,L00250/L00250-C)混匀,在室温下旋转混匀15min,然后7000g离心3min,收集上清液(4-5.5ml)。3. Take the solution from step 2 (about 6 ml), mix it with 480 μl Ni-NTA resin (GenScript, L00250/L00250-C), rotate and mix at room temperature for 15 min, then centrifuge at 7000 g for 3 min and collect the supernatant (4-5.5 ml).
4、取步骤3得到的上清液,使用Amicon超滤管(Sigma,UFC9100,容量为15ml)将其浓缩至200μl,然后加入酶贮存液中,调整蛋白浓度为5mg/ml,即为NCN蛋白溶液。酶贮存液(pH7.4):含10mM Tris,300mM NaCl,0.1mM EDTA,1mM DTT,50%(体积比)甘油,余量为ddH2O。经测序,NCN蛋白溶液中的蛋白质,N端15个氨基酸残基如SEQ ID NO:3第1至15位所示,即NCN蛋白。4. Take the supernatant obtained in step 3, use Amicon ultrafiltration tube (Sigma, UFC9100, capacity 15ml) to concentrate it to 200μl, then add it to the enzyme storage solution, adjust the protein concentration to 5mg/ml, that is, NCN protein solution. Enzyme storage solution (pH7.4): contains 10mM Tris, 300mM NaCl, 0.1mM EDTA, 1mM DTT, 50% (volume ratio) glycerol, and the balance is ddH2 O. After sequencing, the protein in the NCN protein solution has 15 amino acid residues at the N-terminus as shown in SEQ ID NO: 3,
用于后续实施例的NCN蛋白由NCN蛋白溶液提供。The NCN protein used in the subsequent examples was provided as an NCN protein solution.
实施例2、NCN蛋白的性能Example 2: Performance of NCN protein
选择靶向TTN基因的2个gRNA靶点如下:The two gRNA targets targeting the TTN gene were selected as follows:
TTN-gRNA1靶点:AGAGCACAGTCAGCCTGGCG;TTN-gRNA1 target: AGAGCACAGTCAGCCTGGCG;
TTN-gRNA2靶点:CTTCCAGAATTGGATCTCCG。TTN-gRNA2 target: CTTCCAGAATTGGATCTCCG.
用于鉴定包含TTN基因中gRNA的靶点片段的引物如下:The primers used to identify the target fragment containing the gRNA in the TTN gene are as follows:
TTN-F55:TACGGAATTGGGGAGCCAGCGGA;TTN-F55: TACGGAATTGGGGAGCCAGCGGA;
TTN-R560:CAAAGTTAACTCTCTGTGTCT。TTN-R560: CAAAGTTAACTCTCTGTGTCT.
一、制备gRNA1. Preparation of gRNA
1、制备TTN-T7-gRNA1转录模板和TTN-T7-gRNA2转录模板1. Preparation of TTN-T7-gRNA1 and TTN-T7-gRNA2 transcription templates
TTN-T7-gRNA1转录模板为双链DNA分子,如SEQ ID NO:4所示。The TTN-T7-gRNA1 transcription template is a double-stranded DNA molecule, as shown in SEQ ID NO:4.
TTN-T7-gRNA2转录模板为双链DNA分子,如SEQ ID NO:5所示。The TTN-T7-gRNA2 transcription template is a double-stranded DNA molecule, as shown in SEQ ID NO:5.
2、体外转录得到gRNA2. Obtain gRNA by in vitro transcription
取TTN-T7-gRNA1转录模板,采用Transcript Aid T7 High Yield TranscriptionKit(Fermentas,K0441)进行体外转录,然后用MEGA clearTMTranscription Clean-Up Kit(Thermo,AM1908)进行回收纯化,得到TTN-gRNA1。TTN-gRNA1为单链RNA,如SEQ ID NO:6所示。The TTN-T7-gRNA1 transcription template was taken and in vitro transcription was performed using Transcript Aid T7 High Yield Transcription Kit (Fermentas, K0441), and then recovered and purified using MEGA clearTM Transcription Clean-Up Kit (Thermo, AM1908) to obtain TTN-gRNA1. TTN-gRNA1 is a single-stranded RNA, as shown in SEQ ID NO:6.
取TTN-T7-gRNA2转录模板,采用Transcript Aid T7 High Yield TranscriptionKit(Fermentas,K0441)进行体外转录,然后用MEGA clearTMTranscription Clean-Up Kit(Thermo,AM1908)进行回收纯化,得到TTN-gRNA2。TTN-gRNA2为单链RNA,如SEQ ID NO:7所示。The TTN-T7-gRNA2 transcription template was taken, and in vitro transcription was performed using Transcript Aid T7 High Yield Transcription Kit (Fermentas, K0441), and then recovered and purified using MEGA clearTM Transcription Clean-Up Kit (Thermo, AM1908) to obtain TTN-gRNA2. TTN-gRNA2 is a single-stranded RNA, as shown in SEQ ID NO:7.
二、gRNA与NCN蛋白用量配比优化2. Optimization of the ratio of gRNA to NCN protein
1、共转染猪原代成纤维细胞1. Co-transfection of primary porcine fibroblasts
第一组:将TTN-gRNA1、TTN-gRNA2和NCN蛋白共转染猪原代成纤维细胞。配比:约10万个猪原代成纤维细胞:0.5μg TTN-gRNA1:0.5μg TTN-gRNA2:4μg NCN蛋白。Group 1: TTN-gRNA1, TTN-gRNA2 and NCN protein were co-transfected into porcine primary fibroblasts. Ratio: about 100,000 porcine primary fibroblasts: 0.5μg TTN-gRNA1: 0.5μg TTN-gRNA2: 4μg NCN protein.
第二组:将TTN-gRNA1、TTN-gRNA2和NCN蛋白共转染猪原代成纤维细胞。配比:约10万个猪原代成纤维细胞:0.75μg TTN-gRNA1:0.75μg TTN-gRNA2:4μg NCN蛋白。Group 2: TTN-gRNA1, TTN-gRNA2 and NCN protein were co-transfected into porcine primary fibroblasts. Ratio: about 100,000 porcine primary fibroblasts: 0.75μg TTN-gRNA1: 0.75μg TTN-gRNA2: 4μg NCN protein.
第三组:将TTN-gRNA1、TTN-gRNA2和NCN蛋白共转染猪原代成纤维细胞。配比:约10万个猪原代成纤维细胞:1μg TTN-gRNA1:1μg TTN-gRNA2:4μg NCN蛋白。Group 3: TTN-gRNA1, TTN-gRNA2 and NCN protein were co-transfected into porcine primary fibroblasts. Ratio: about 100,000 porcine primary fibroblasts: 1μg TTN-gRNA1: 1μg TTN-gRNA2: 4μg NCN protein.
第四组:将TTN-gRNA1、TTN-gRNA2和NCN蛋白共转染猪原代成纤维细胞。配比:约10万个猪原代成纤维细胞:1.25μg TTN-gRNA1:1.25μg TTN-gRNA2:4μg NCN蛋白。Group 4: TTN-gRNA1, TTN-gRNA2 and NCN protein were co-transfected into porcine primary fibroblasts. Ratio: about 100,000 porcine primary fibroblasts: 1.25μg TTN-gRNA1: 1.25μg TTN-gRNA2: 4μg NCN protein.
第五组:将TTN-gRNA1和TTN-gRNA2共转染猪原代成纤维细胞。配比:约10万个猪原代成纤维细胞:1μg TTN-gRNA1:1μg TTN-gRNA2。Group 5: TTN-gRNA1 and TTN-gRNA2 were co-transfected into porcine primary fibroblasts. Ratio: about 100,000 porcine primary fibroblasts: 1 μg TTN-gRNA1: 1 μg TTN-gRNA2.
共转染采用电击转染的方式,采用哺乳动物核转染试剂盒(Neon kit,Thermofisher)与Neon TM transfection system电转仪(参数设置为:1450V、10ms、3pulse)。Co-transfection was performed by electroporation using a mammalian nuclear transfection kit (Neon kit, Thermofisher) and a Neon TM transfection system electroporator (parameter settings: 1450 V, 10 ms, 3 pulses).
2、完成步骤1后,采用完全培养液培养12-18小时,然后更换新的完全培养液进行培养。电转后培养总时间为48小时。2. After completing
3、完成步骤2后,采用胰蛋白酶消化并收集细胞,提取基因组DNA,采用TTN-F55和TTN-R560组成的引物对进行PCR扩增,然后进行1%琼脂糖凝胶电泳。3. After completing step 2, digest and collect the cells with trypsin, extract genomic DNA, perform PCR amplification using a primer pair consisting of TTN-F55 and TTN-R560, and then perform 1% agarose gel electrophoresis.
电泳图见图3。505bp条带为野生型条带(WT),254bp左右(野生型条带505bp理论缺失251bp)为缺失突变条带(MT)。The electrophoresis pattern is shown in Figure 3. The 505 bp band is the wild-type band (WT), and the 254 bp band (the wild-type band is 505 bp and theoretically lacks 251 bp) is the deletion mutation band (MT).
基因缺失突变效率=(MT灰度/MT条带bp数)/(WT灰度/WT条带bp数+MT灰度/MT条带bp数)×100%。第一组基因缺失突变效率为19.9%,第二组基因缺失突变效率为39.9%,第三组基因缺失突变效率为79.9%,第四组基因缺失突变效率为44.3%。第五组未发生突变。Gene deletion mutation efficiency = (MT grayscale/MT band bp number)/(WT grayscale/WT band bp number + MT grayscale/MT band bp number) × 100%. The gene deletion mutation efficiency of the first group was 19.9%, the second group was 39.9%, the third group was 79.9%, and the fourth group was 44.3%. No mutation occurred in the fifth group.
结果表明,当两个gRNA与NCN蛋白的质量配比为1:1:4,实际用量为1μg:1μg:4μg时基因编辑效率最高。因此,确定两个gRNA与NCN蛋白的最适用量为1μg:1μg:4μg。The results showed that the gene editing efficiency was highest when the mass ratio of the two gRNAs to the NCN protein was 1:1:4 and the actual dosage was 1μg:1μg:4μg. Therefore, the optimal dosage of the two gRNAs to the NCN protein was determined to be 1μg:1μg:4μg.
三、NCN蛋白与商品Cas9蛋白的基因编辑效率比较3. Comparison of gene editing efficiency between NCN protein and commercial Cas9 protein
1、共转染猪原代成纤维细胞1. Co-transfection of primary porcine fibroblasts
Cas9-A组:将TTN-gRNA1、TTN-gRNA2和商品Cas9-A蛋白共转染猪原代成纤维细胞。配比:约10万个猪原代成纤维细胞:1μg TTN-gRNA1:1μg TTN-gRNA2:4μg Cas9-A蛋白。Cas9-A group: TTN-gRNA1, TTN-gRNA2 and commercial Cas9-A protein were co-transfected into porcine primary fibroblasts. Ratio: about 100,000 porcine primary fibroblasts: 1μg TTN-gRNA1: 1μg TTN-gRNA2: 4μg Cas9-A protein.
pKG-GE4组:将TTN-gRNA1、TTN-gRNA2和NCN蛋白共转染猪原代成纤维细胞。配比:约10万个猪原代成纤维细胞:1μg TTN-gRNA1:1μg TTN-gRNA2:4μg NCN蛋白。pKG-GE4 group: TTN-gRNA1, TTN-gRNA2 and NCN protein were co-transfected into porcine primary fibroblasts. Ratio: about 100,000 porcine primary fibroblasts: 1μg TTN-gRNA1: 1μg TTN-gRNA2: 4μg NCN protein.
Cas9-B组:将TTN-gRNA1、TTN-gRNA2和商品Cas9-B蛋白共转染猪原代成纤维细胞。配比:约10万个猪原代成纤维细胞:1μg TTN-gRNA1:1μg TTN-gRNA2:4μg Cas9-B蛋白。Cas9-B group: TTN-gRNA1, TTN-gRNA2 and commercial Cas9-B protein were co-transfected into porcine primary fibroblasts. Ratio: about 100,000 porcine primary fibroblasts: 1μg TTN-gRNA1: 1μg TTN-gRNA2: 4μg Cas9-B protein.
Control组:将TTN-gRNA1、TTN-gRNA2共转染猪原代成纤维细胞。配比:约10万个猪原代成纤维细胞:1μg TTN-gRNA1:1μg TTN-gRNA2。Control group: TTN-gRNA1 and TTN-gRNA2 were co-transfected into porcine primary fibroblasts. Ratio: about 100,000 porcine primary fibroblasts: 1μg TTN-gRNA1: 1μg TTN-gRNA2.
共转染采用电击转染的方式,采用哺乳动物核转染试剂盒(Neon kit,Thermofisher)与Neon TM transfection system电转仪(参数设置为:1450V、10ms、3pulse)。Co-transfection was performed by electroporation using a mammalian nuclear transfection kit (Neon kit, Thermofisher) and a Neon TM transfection system electroporator (parameter settings: 1450 V, 10 ms, 3 pulses).
2、完成步骤1后,采用完全培养液培养12-18小时,然后更换新的完全培养液进行培养。电转后培养总时间为48小时。2. After completing
3、完成步骤2后,采用胰蛋白酶消化并收集细胞,提取基因组DNA,采用TTN-F55和TTN-R560组成的引物对进行PCR扩增,然后进行1%琼脂糖凝胶电泳。3. After completing step 2, digest and collect the cells with trypsin, extract genomic DNA, perform PCR amplification using a primer pair consisting of TTN-F55 and TTN-R560, and then perform 1% agarose gel electrophoresis.
电泳图见图4。采用商品Cas9-A蛋白的基因缺失突变效率为28.5%,采用NCN蛋白的基因缺失突变效率为85.6%,采用商品Cas9-B蛋白的基因缺失突变效率为16.6%。The electrophoresis diagram is shown in Figure 4. The gene deletion mutation efficiency using the commercial Cas9-A protein was 28.5%, the gene deletion mutation efficiency using the NCN protein was 85.6%, and the gene deletion mutation efficiency using the commercial Cas9-B protein was 16.6%.
结果表明,与采用商品的Cas9蛋白相比,采用本发明制备的NCN蛋白使得基因编辑效率显著提高。The results show that compared with commercial Cas9 protein, the NCN protein prepared by the present invention significantly improves the gene editing efficiency.
实施例3、SCN5A基因高效gRNA靶点的筛选Example 3: Screening of efficient gRNA targets for the SCN5A gene
猪SCN5A基因信息:编码电压门控钠离子通道α亚基5;位于13号染色体;Gene ID为100152567,Sus scrofa。猪SCN5A基因编码的蛋白质如NCBI中XP_020927335.1(13-MAY-2017)所示。猪SCN5A基因编码的蛋白质的部分区段氨基酸序列如SEQ ID NO:8所示。猪基因组DNA中,SCN5A基因共有27个外显子,第11编码外显子及其上下游各100bp如SEQ ID NO:9所示。Pig SCN5A gene information: Encodes voltage-gated sodium channel alpha subunit 5; located on chromosome 13; Gene ID is 100152567, Sus scrofa. The protein encoded by the pig SCN5A gene is shown in XP_020927335.1 (13-MAY-2017) in NCBI. The amino acid sequence of a portion of the protein encoded by the pig SCN5A gene is shown in SEQ ID NO: 8. In the pig genomic DNA, the SCN5A gene has a total of 27 exons, and the 11th coding exon and its upstream and downstream 100bp are shown in SEQ ID NO: 9.
一、SCN5A基因预设突变位点及邻近基因组序列保守性分析1. Conservative analysis of the SCN5A gene pre-specified mutation site and adjacent genomic sequences
10只初生巴马香猪,其中雌性6只(分别命名为BC1、BC2、BC3、BC4、BC5、BC6)、雄性4只(分别命名为BX1、BX2、BX3、BX4)。There were 10 newborn Bama Xiang pigs, including 6 females (named BC1, BC2, BC3, BC4, BC5, and BC6) and 4 males (named BX1, BX2, BX3, and BX4).
SCN5A-E11-JDF186:AATCGCTTCAGCATCACCCA;SCN5A-E11-JDF186: AATCGCTTCAGCATCACCCA;
SCN5A-E11-JDR593:GGATCTGCCTGGCATAGCAT;SCN5A-E11-JDR593:GGATCTGCCTGGCATAGCAT;
SCN5A-E11-JDF99:AAGTTGAGCTGGGGTGGATG;SCN5A-E11-JDF99:AAGTTGAGCTGGGGTGGATG;
SCN5A-E11-JDR457:CAGTCCACAGTGCTGTTCCT。SCN5A-E11-JDR457: CAGTCCACAGTGCTGTCCT.
用命名为BX4的猪的耳组织提取基因组作为模板,采用不同引物对进行PCR扩增,然后进行1%琼脂糖凝胶电泳。电泳图见图5。图5中:组1:采用SCN5A-E11-JDF99和SCN5A-E11-JDR457组成的引物对;组2:采用SCN5A-E11-JDF99和SCN5A-E11-JDR593组成的引物对;组3:采用SCN5A-E11-JDF186和SCN5A-E11-JDR457组成的引物对;组4:采用SCN5A-E11-JDF186和SCN5A-E11-JDR593组成的引物对。结果表明,优选采用SCN5A-E11-JDF186和SCN5A-E11-JDR593组成的引物对进行目的片段扩增。The genome was extracted from the ear tissue of a pig named BX4 as a template, and different primer pairs were used for PCR amplification, followed by 1% agarose gel electrophoresis. The electrophoresis diagram is shown in Figure 5. In Figure 5: Group 1: a primer pair consisting of SCN5A-E11-JDF99 and SCN5A-E11-JDR457 was used; Group 2: a primer pair consisting of SCN5A-E11-JDF99 and SCN5A-E11-JDR593 was used; Group 3: a primer pair consisting of SCN5A-E11-JDF186 and SCN5A-E11-JDR457 was used; Group 4: a primer pair consisting of SCN5A-E11-JDF186 and SCN5A-E11-JDR593 was used. The results showed that the primer pair consisting of SCN5A-E11-JDF186 and SCN5A-E11-JDR593 was preferably used to amplify the target fragment.
分别以10只猪的基因组DNA为模板,采用SCN5A-E11-JDF186和SCN5A-E11-JDR593组成的引物对进行PCR扩增,然后进行1%琼脂糖凝胶电泳。电泳图见图6。回收PCR扩增产物并进行测序,将测序结果与公共数据库中的SCN5A基因序列进行比对分析。选择10只猪中共有的保守区进行gRNA靶点的设计。The genomic DNA of 10 pigs was used as a template, and the primer pair consisting of SCN5A-E11-JDF186 and SCN5A-E11-JDR593 was used for PCR amplification, followed by 1% agarose gel electrophoresis. The electrophoresis diagram is shown in Figure 6. The PCR amplification product was recovered and sequenced, and the sequencing results were compared and analyzed with the SCN5A gene sequence in the public database. The conserved regions common to the 10 pigs were selected for the design of gRNA targets.
二、筛选靶点2. Target Screening
通过筛选NGG(避开可能的突变位点)初步筛选到若干靶点,经过预实验进一步从中筛选到4个靶点。By screening NGG (avoiding possible mutation sites), several targets were initially screened, and 4 targets were further screened after preliminary experiments.
4个靶点分别如下:The four targets are as follows:
SCN5A-E11-gRNA1靶点:TGATGAAAACAGCACAGCAG;SCN5A-E11-gRNA1 target: TGATGAAAACAGCACAGCAG;
SCN5A-E11-gRNA2靶点:ATGATGAAAACAGCACAGCA;SCN5A-E11-gRNA2 target: ATGATGAAAACAGCACAGCA;
SCN5A-E11-gRNA3靶点:GCACCAGCAGAGACGTGCGG;SCN5A-E11-gRNA3 target: GCACCAGCAGAGACGTGCGG;
SCN5A-E11-gRNA4靶点:AAGGCACCAGCAGAGACGTG。SCN5A-E11-gRNA4 target: AAGGCACCAGCAGAGACGTG.
三、制备重组质粒3. Preparation of recombinant plasmid
取质粒pKG-U6gRNA,用限制性内切酶BbsI进行酶切,回收载体骨架(约3kb的线性大片段)。The plasmid pKG-U6gRNA was taken and digested with restriction endonuclease BbsI to recover the vector backbone (a large linear fragment of about 3 kb).
分别合成SCN5A-E11-gRNA1-S和SCN5A-E11-gRNA1-A,然后混合并进行退火,得到具有粘性末端的双链DNA分子。将具有粘性末端的双链DNA分子和载体骨架连接,得到质粒pKG-U6gRNA(SCN5A-E11-gRNA1)。质粒pKG-U6gRNA(SCN5A-E11-gRNA1)表达SEQ ID NO:10所示的sgRNASCN5A-E11-gRNA1。SCN5A-E11-gRNA1-S and SCN5A-E11-gRNA1-A were synthesized separately, then mixed and annealed to obtain double-stranded DNA molecules with sticky ends. The double-stranded DNA molecules with sticky ends were connected to the vector backbone to obtain plasmid pKG-U6gRNA (SCN5A-E11-gRNA1). Plasmid pKG-U6gRNA (SCN5A-E11-gRNA1) expresses sgRNASCN5A-E11-gRNA1 shown in SEQ ID NO: 10.
sgRNASCN5A-E11-gRNA1(SEQ ID NO:10):sgRNASCN5A-E11-gRNA1 (SEQ ID NO: 10):
UGAUGAAAACAGCACAGCAGguuuuagagcuagaaauagcaaguuaaaauaaggcuaguccguuaucaacuugaaaaaguggcaccgagucggugcuuuuUGAUGAAAACAGCACAGCAGguuuuagagcuagaaauagcaaguuaaaauaaggcuaguccguuaucaacuugaaaaaguggcaccgagucggugcuuuu
分别合成SCN5A-E11-gRNA2-S和SCN5A-E11-gRNA2-A,然后混合并进行退火,得到具有粘性末端的双链DNA分子。将具有粘性末端的双链DNA分子和载体骨架连接,得到质粒pKG-U6gRNA(SCN5A-E11-gRNA2)。质粒pKG-U6gRNA(SCN5A-E11-gRNA2)表达SEQ ID NO:11所示的sgRNASCN5A-E11-gRNA2。SCN5A-E11-gRNA2-S and SCN5A-E11-gRNA2-A were synthesized separately, then mixed and annealed to obtain double-stranded DNA molecules with sticky ends. The double-stranded DNA molecules with sticky ends were connected to the vector backbone to obtain plasmid pKG-U6gRNA (SCN5A-E11-gRNA2). Plasmid pKG-U6gRNA (SCN5A-E11-gRNA2) expresses sgRNASCN5A-E11-gRNA2 shown in SEQ ID NO: 11.
sgRNASCN5A-E11-gRNA2(SEQ ID NO:11):sgRNASCN5A-E11-gRNA2 (SEQ ID NO: 11):
AUGAUGAAAACAGCACAGCAguuuuagagcuagaaauagcaaguuaaaauaaggcuaguccguuaucaacuugaaaaaguggcaccgagucggugcuuuuAUGAUGAAAACAGCACAGCAguuuuagagcuagaaauagcaaguuaaaauaaggcuaguccguuaucaacuugaaaaaguggcaccgagucggugcuuuu
分别合成SCN5A-E11-gRNA3-S和SCN5A-E11-gRNA3-A,然后混合并进行退火,得到具有粘性末端的双链DNA分子。将具有粘性末端的双链DNA分子和载体骨架连接,得到质粒pKG-U6gRNA(SCN5A-E11-gRNA3)。质粒pKG-U6gRNA(SCN5A-E11-gRNA3)表达SEQ ID NO:12所示的sgRNASCN5A-E11-gRNA3。SCN5A-E11-gRNA3-S and SCN5A-E11-gRNA3-A were synthesized separately, then mixed and annealed to obtain double-stranded DNA molecules with sticky ends. The double-stranded DNA molecules with sticky ends were connected to the vector backbone to obtain plasmid pKG-U6gRNA (SCN5A-E11-gRNA3). Plasmid pKG-U6gRNA (SCN5A-E11-gRNA3) expressed sgRNASCN5A-E11-gRNA3 shown in SEQ ID NO: 12.
sgRNASCN5A-E11-gRNA3(SEQ ID NO:12):sgRNASCN5A-E11-gRNA3 (SEQ ID NO: 12):
GCACCAGCAGAGACGUGCGGguuuuagagcuagaaauagcaaguuaaaauaaggcuaguccguuaucaacuugaaaaaguggcaccgagucggugcuuuuGCACCAGCAGAGACGUGCGGguuuuagagcuagaaauagcaaguuaaaauaaggcuaguccguuaucaacuugaaaaaguggcaccgagucggugcuuuu
分别合成SCN5A-E11-gRNA4-S和SCN5A-E11-gRNA4-A,然后混合并进行退火,得到具有粘性末端的双链DNA分子。将具有粘性末端的双链DNA分子和载体骨架连接,得到质粒pKG-U6gRNA(SCN5A-E11-gRNA4)。质粒pKG-U6gRNA(SCN5A-E11-gRNA4)表达SEQ ID NO:13所示的sgRNASCN5A-E11-gRNA4。SCN5A-E11-gRNA4-S and SCN5A-E11-gRNA4-A were synthesized separately, then mixed and annealed to obtain double-stranded DNA molecules with sticky ends. The double-stranded DNA molecules with sticky ends were connected to the vector backbone to obtain plasmid pKG-U6gRNA (SCN5A-E11-gRNA4). Plasmid pKG-U6gRNA (SCN5A-E11-gRNA4) expressed sgRNASCN5A-E11-gRNA4 shown in SEQ ID NO: 13.
sgRNASCN5A-E11-gRNA4(SEQ ID NO:13):sgRNASCN5A-E11-gRNA4 (SEQ ID NO: 13):
AAGGCACCAGCAGAGACGUGguuuuagagcuagaaauagcaaguuaaaauaaggcuaguccguuaucaacuugaaaaaguggcaccgagucggugcuuuuAAGGCACCAGCAGAGACGUGguuuuagagcuagaaauagcaaguuaaaauaaggcuaguccguuaucaacuugaaaaaguggcaccgagucggugcuuuu
SCN5A-E11-gRNA1-S:caccgTGATGAAAACAGCACAGCAG;SCN5A-E11-gRNA1-S: caccgTGATGAAAACAGCACAGCAG;
SCN5A-E11-gRNA1-A:aaacCTGCTGTGCTGTTTTCATCAc;SCN5A-E11-gRNA1-A:aaacCTGCTGTGCTGTTTTCATCAc;
SCN5A-E11-gRNA2-S:caccgATGATGAAAACAGCACAGCA;SCN5A-E11-gRNA2-S:caccgATGATGAAAACAGCACAGCA;
SCN5A-E11-gRNA2-A:aaacTGCTGTGCTGTTTTCATCATc;SCN5A-E11-gRNA2-A:aaacTGCTGTGCTGTTTTCATCATc;
SCN5A-E11-gRNA3-S:caccGCACCAGCAGAGACGTGCGG;SCN5A-E11-gRNA3-S:caccGCACCAGCAGAGACGTGCGG;
SCN5A-E11-gRNA3-A:aaacCCGCACGTCTCTGCTGGTGC;SCN5A-E11-gRNA3-A:aaacCCGCACGTCTCTGCTGGTGC;
SCN5A-E11-gRNA4-S:caccgAAGGCACCAGCAGAGACGTG;SCN5A-E11-gRNA4-S: caccgAAGGCACCAGCAGAGACGTG;
SCN5A-E11-gRNA4-A:aaacCACGTCTCTGCTGGTGCCTTc。SCN5A-E11-gRNA4-A:aaacCACGTCTCTGCTGGTGCCTTc.
SCN5A-E11-gRNA1-S、SCN5A-E11-gRNA1-A、SCN5A-E11-gRNA2-S、SCN5A-E11-gRNA2-A、SCN5A-E11-gRNA3-S、SCN5A-E11-gRNA3-A、SCN5A-E11-gRNA4-S、SCN5A-E11-gRNA4-A均为单链DNA分子。SCN5A-E11-gRNA1-S, SCN5A-E11-gRNA1-A, SCN5A-E11-gRNA2-S, SCN5A-E11-gRNA2-A, SCN5A-E11-gRNA3-S, SCN5A-E11-gRNA3-A, SCN5A-E11-gRNA4-S, and SCN5A-E11-gRNA4-A are all single-stranded DNA molecules.
四、不同靶点的编辑效率比较4. Comparison of editing efficiency of different targets
1、共转染1. Co-transfection
第一组:将质粒pKG-U6gRNA(SCN5A-E11-gRNA1)、质粒pKG-GE3共转染猪原代成纤维细胞。配比:约20万个猪原代成纤维细胞:0.92μg质粒pKG-U6gRNA(SCN5A-E11-gRNA1):1.08μg质粒pKG-GE3。Group 1: Co-transfect porcine primary fibroblasts with plasmid pKG-U6gRNA (SCN5A-E11-gRNA1) and plasmid pKG-GE3. Ratio: about 200,000 porcine primary fibroblasts: 0.92μg plasmid pKG-U6gRNA (SCN5A-E11-gRNA1): 1.08μg plasmid pKG-GE3.
第二组:将质粒pKG-U6gRNA(SCN5A-E11-gRNA2)、质粒pKG-GE3共转染猪原代成纤维细胞。配比:约20万个猪原代成纤维细胞:0.92μg质粒pKG-U6gRNA(SCN5A-E11-gRNA2):1.08μg质粒pKG-GE3。Group 2: Plasmid pKG-U6gRNA (SCN5A-E11-gRNA2) and plasmid pKG-GE3 were co-transfected into porcine primary fibroblasts. Ratio: about 200,000 porcine primary fibroblasts: 0.92μg plasmid pKG-U6gRNA (SCN5A-E11-gRNA2): 1.08μg plasmid pKG-GE3.
第三组:将质粒pKG-U6gRNA(SCN5A-E11-gRNA3)、质粒pKG-GE3共转染猪原代成纤维细胞。配比:约20万个猪原代成纤维细胞:0.92μg质粒pKG-U6gRNA(SCN5A-E11-gRNA3):1.08μg质粒pKG-GE3。Group 3: Plasmid pKG-U6gRNA (SCN5A-E11-gRNA3) and plasmid pKG-GE3 were co-transfected into porcine primary fibroblasts. Ratio: about 200,000 porcine primary fibroblasts: 0.92μg plasmid pKG-U6gRNA (SCN5A-E11-gRNA3): 1.08μg plasmid pKG-GE3.
第四组:将质粒pKG-U6gRNA(SCN5A-E11-gRNA4)、质粒pKG-GE3共转染猪原代成纤维细胞。配比:约20万个猪原代成纤维细胞:0.92μg质粒pKG-U6gRNA(SCN5A-E11-gRNA4):1.08μg质粒pKG-GE3。Group 4: Plasmid pKG-U6gRNA (SCN5A-E11-gRNA4) and plasmid pKG-GE3 were co-transfected into porcine primary fibroblasts. Ratio: about 200,000 porcine primary fibroblasts: 0.92μg plasmid pKG-U6gRNA (SCN5A-E11-gRNA4): 1.08μg plasmid pKG-GE3.
第五组:猪原代成纤维细胞,同等电转参数不加质粒进行电转操作。Group 5: Porcine primary fibroblasts, electroporated with the same electroporation parameters but without adding plasmids.
共转染采用电击转染的方式,采用哺乳动物核转染试剂盒(Neon kit,Thermofisher)与Neon TM transfection system电转仪(参数设置为:1450V、10ms、3pulse)。Co-transfection was performed by electroporation using a mammalian nuclear transfection kit (Neon kit, Thermofisher) and a Neon TM transfection system electroporator (parameter settings: 1450 V, 10 ms, 3 pulses).
2、完成步骤1后,采用完全培养液培养12-18小时,然后更换新的完全培养液进行培养。电转后培养总时间为48小时。2. After completing
3、完成步骤2后,采用胰蛋白酶消化并收集细胞,裂解细胞,提取基因组DNA,采用SCN5A-E11-JDF186和SCN5A-E11-JDR593组成的引物对进行PCR扩增,然后进行1%琼脂糖凝胶电泳。将目的产物切胶回收后送测序公司进行测序,然后将测序结果利用网页版Synthego ICE工具分析测序峰图得出不同靶点的基因编辑效率。第一组至第四组的基因编辑效率依次为74%、79%、85%、75%,第五组未发生基因编辑。结果表明,SCN5A-E11-gRNA2和SCN5A-E11-gRNA3编辑效率较高。3. After completing step 2, trypsin was used to digest and collect cells, cells were lysed, genomic DNA was extracted, and PCR amplification was performed using a primer pair consisting of SCN5A-E11-JDF186 and SCN5A-E11-JDR593, followed by 1% agarose gel electrophoresis. The target product was excised and recovered and sent to a sequencing company for sequencing. The sequencing results were then analyzed using the web version of the Synthego ICE tool to analyze the sequencing peak graph to obtain the gene editing efficiency of different targets. The gene editing efficiencies of the first to fourth groups were 74%, 79%, 85%, and 75%, respectively, and no gene editing occurred in the fifth group. The results showed that SCN5A-E11-gRNA2 and SCN5A-E11-gRNA3 had high editing efficiencies.
实施例4、制备SCN5A基因定向突变的重组细胞Example 4: Preparation of recombinant cells with targeted mutation of SCN5A gene
选用实施例3中筛到的两个高效gRNA靶点(SCN5A-E11-gRNA2和SCN5A-E11-gRNA3)。The two highly efficient gRNA targets (SCN5A-E11-gRNA2 and SCN5A-E11-gRNA3) screened in Example 3 were selected.
一、制备gRNA1. Preparation of gRNA
1、制备SCN5A-T7-gRNA2转录模板和SCN5A-T7-gRNA3转录模板1. Preparation of SCN5A-T7-gRNA2 and SCN5A-T7-gRNA3 transcription templates
SCN5A-T7-gRNA2转录模板为双链DNA分子,如SEQ ID NO:14所示。The SCN5A-T7-gRNA2 transcription template is a double-stranded DNA molecule, as shown in SEQ ID NO:14.
SCN5A-T7-gRNA3转录模板为双链DNA分子,如SEQ ID NO:15所示。The SCN5A-T7-gRNA3 transcription template is a double-stranded DNA molecule, as shown in SEQ ID NO: 15.
2、体外转录得到gRNA2. Obtain gRNA by in vitro transcription
取SCN5A-T7-gRNA2转录模板,采用Transcript Aid T7 High YieldTranscription Kit(Fermentas,K0441)进行体外转录,然后用MEGA clearTMTranscriptionClean-Up Kit(Thermo,AM1908)进行回收纯化,得到SCN5A-gRNA2。SCN5A-gRNA2为单链RNA,如SEQ ID NO:16所示。The SCN5A-T7-gRNA2 transcription template was taken and in vitro transcribed using Transcript Aid T7 High Yield Transcription Kit (Fermentas, K0441), and then recovered and purified using MEGA clearTM Transcription Clean-Up Kit (Thermo, AM1908) to obtain SCN5A-gRNA2. SCN5A-gRNA2 is a single-stranded RNA, as shown in SEQ ID NO: 16.
取SCN5A-T7-gRNA3转录模板,采用Transcript Aid T7 High YieldTranscription Kit(Fermentas,K0441)进行体外转录,然后用MEGA clearTMTranscriptionClean-Up Kit(Thermo,AM1908)进行回收纯化,得到SCN5A-gRNA3。SCN5A-gRNA3为单链RNA,如SEQ ID NO:17所示。The SCN5A-T7-gRNA3 transcription template was taken, and in vitro transcription was performed using Transcript Aid T7 High Yield Transcription Kit (Fermentas, K0441), and then recovered and purified using MEGA clearTM Transcription Clean-Up Kit (Thermo, AM1908) to obtain SCN5A-gRNA3. SCN5A-gRNA3 is a single-stranded RNA, as shown in SEQ ID NO: 17.
SCN5A-gRNA2(SEQ ID NO:16):SCN5A-gRNA2 (SEQ ID NO: 16):
GGAUGAUGAAAACAGCACAGCAGUUUUAGAGCUAGAAAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGCUUUUGGAUGAUGAAAACAGCACAGCAGUUUUAGAGCUAGAAAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCAACUUGAAAAAGUGGCACCGAGUCGGGUGCUUUU
SCN5A-gRNA3(SEQ ID NO:17):SCN5A-gRNA3 (SEQ ID NO: 17):
GGGCACCAGCAGAGACGUGCGGGUUUUAGAGCUAGAAAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCAACUUGAAAAAGUGGCACCGAGUCGGUGCUUUUGGGCACCAGCAGAGACGUGCGGGUUUUAGAGCUAGAAAUAGCAAGUUAAAAUAAGGCUAGUCCGUUAUCAACUUGAAAAAGUGGCACCGAGUCGGGUGCUUUU
二、合成具有SCN5A基因突变的单链Donor DNA2. Synthesis of single-stranded Donor DNA with SCN5A gene mutation
与心率失常相关的SCN5A基因突变(SCN5A基因中编码第558位氨基酸残基E的密码子GAG突变为终止密码子TAG),对应于猪SCN5A基因第11外显子。The SCN5A gene mutation associated with arrhythmia (the codon GAG encoding the 558th amino acid residue E in the SCN5A gene mutates to the stop codon TAG) corresponds to exon 11 of the porcine SCN5A gene.
合成单链Donor DNA,该单链Donor DNA除上述点突变(G突变为T)外,还含有SCN5A-E11-gRNA2和SCN5A-E11-gRNA3的靶点PAM或邻近PAM的3’端序列同义突变。该单链Donor DNA命名为SCN5A-mutant-ss153。A single-stranded Donor DNA was synthesized, which contained, in addition to the above point mutation (G mutated to T), a synonymous mutation of the 3' end sequence of the target PAM or adjacent PAM of SCN5A-E11-gRNA2 and SCN5A-E11-gRNA3. The single-stranded Donor DNA was named SCN5A-mutant-ss153.
SCN5A-mutant-ss153如SEQ ID NO:18所示。SCN5A-mutant-ss153 is shown as SEQ ID NO:18.
SCN5A-mutant-ss153(SEQ ID NO:18):SCN5A-mutant-ss153 (SEQ ID NO: 18):
ttttcaccttccgccggcgagacctgggttccgaaacagattttgcggatgatgaaaacagcacagcTggAgacagcTagagTcaccgcacgtctctgctggtgccttggcccctgcgccggcctagtgtccagggacagcccagtcccggagttttcaccttccgccggcgagacctgggttccgaaacagattttgcggatgatgaaaacagcacagcTggAgacagcTagagTcaccgcacgtctctgctggtgccttggcccctgcgccggcctagtgtccagggacagcccagtcccggag
野生型猪原代成纤维细胞染色体DNA中对应于单链Donor DNA的DNA区段如SEQ IDNO:19所示。The DNA segment corresponding to the single-stranded Donor DNA in the chromosomal DNA of wild-type pig primary fibroblasts is shown as SEQ ID NO:19.
SEQ ID NO:19SEQ ID NO: 19
ttttcaccttccgccggcgagacctgggttccgaaacagattttgcggatgatgaaaacagcacagcaggggacagcgagagccaccgcacgtctctgctggtgccttggcccctgcgccggcctagtgtccagggacagcccagtcccggagttttcaccttccgccggcgagacctgggttccgaaacagattttgcggatgatgaaaacagcacagca ggggacagcgagagccaccgcacgtctctgctggtgc cttggcccctgcgccggcctagtgtccagggacagcccagtcccggag
三、转染猪原代成纤维细胞3. Transfection of primary porcine fibroblasts
1、将SCN5A-gRNA2、SCN5A-gRNA3、SCN5A-mutant-ss153和NCN蛋白共转染猪原代成纤维细胞。配比:约10万个猪原代成纤维细胞:1μg SCN5A-gRNA2:1μg SCN5A-gRNA3:2μgSCN5A-mutant-ss153:4μg NCN蛋白。共转染采用电击转染的方式,采用哺乳动物核转染试剂盒(Neon kit,Thermofisher)与Neon TM transfection system电转仪(参数设置为:1450V、10ms、3pulse)。1. Co-transfect SCN5A-gRNA2, SCN5A-gRNA3, SCN5A-mutant-ss153 and NCN protein into porcine primary fibroblasts. Ratio: about 100,000 porcine primary fibroblasts: 1μg SCN5A-gRNA2: 1μg SCN5A-gRNA3: 2μg SCN5A-mutant-ss153: 4μg NCN protein. Co-transfection was performed by electroporation, using a mammalian nuclear transfection kit (Neon kit, Thermofisher) and a Neon TM transfection system electroporator (parameter settings: 1450V, 10ms, 3pulse).
2、完成步骤1后,采用完全培养液培养16-18小时,然后更换新的完全培养液进行培养。电转后培养总时间为48小时。2. After completing
3、完成步骤2后,采用胰蛋白酶消化并收集细胞,然后用完全培养液洗涤,然后用完全培养液重悬,然后分别挑取各个单克隆转移到96孔板中(每个孔1个细胞,每个孔中装有100μl完全培养液),培养2周(每2-3天更换新的完全培养液)。3. After completing step 2, digest and collect the cells with trypsin, then wash with complete culture medium, resuspend with complete culture medium, and then pick each monoclonal clone and transfer it to a 96-well plate (1 cell per well, 100 μl complete culture medium in each well), and culture for 2 weeks (replace new complete culture medium every 2-3 days).
4、完成步骤3后,采用胰蛋白酶消化并收集细胞(每孔得到的细胞,约2/3接种到装有完全培养液的6孔板中,剩余的1/3收集在1.5mL离心管中)。4. After completing step 3, use trypsin to digest and collect the cells (about 2/3 of the cells obtained in each well are inoculated into a 6-well plate filled with complete culture medium, and the remaining 1/3 are collected in a 1.5 mL centrifuge tube).
5、取步骤4的6孔板,培养直至细胞长至80%汇合度,采用胰蛋白酶消化并收集细胞,使用细胞冻存液(90%完全培养基+10%DMSO,体积比)将细胞冻存。5. Take the 6-well plate from step 4 and culture the cells until they grow to 80% confluence, digest and collect the cells using trypsin, and freeze the cells using cell freezing solution (90% complete culture medium + 10% DMSO, volume ratio).
6、取步骤4的离心管,取细胞,进行细胞裂解并提取基因组DNA,采用SCN5A-E11-JDF186和SCN5A-E11-JDR593组成的引物对进行PCR扩增,然后进行电泳。将猪原代成纤维细胞作为野生型对照(WT)。6. Take the centrifuge tube from step 4, take the cells, lyse the cells and extract genomic DNA, perform PCR amplification using the primer pair consisting of SCN5A-E11-JDF186 and SCN5A-E11-JDR593, and then perform electrophoresis. Use porcine primary fibroblasts as wild-type control (WT).
7、完成步骤6后,回收PCR扩增产物并测序。7. After completing step 6, recover the PCR amplification product and sequence it.
猪原代成纤维细胞的测序结果只有一种,其基因型为野生型(也可称为纯合野生型)。如果某一单细胞克隆的测序结果有两种,一种与猪原代成纤维细胞的测序结果一致,另一种与猪原代成纤维细胞的测序结果相比发生了突变(突变包括一个或多个核苷酸的缺失、插入或替换),该单细胞克隆的基因型为杂合型;如果某一单细胞克隆的测序结果为两种,均与猪原代成纤维细胞的测序结果相比发生了突变(突变包括一个或多个核苷酸的缺失、插入或替换),该单细胞克隆的基因型为双等位基因不同突变型;如果某一单细胞克隆的测序结果为一种,且与猪原代成纤维细胞的测序结果相比发生了突变(突变包括一个或多个核苷酸的缺失、插入或替换),该单细胞克隆的基因型为双等位基因相同突变型;如果某一单细胞克隆的测序结果为一种,且与猪原代成纤维细胞的测序结果一致,该单细胞克隆的基因型为野生型(也可称为纯合野生型)。There is only one sequencing result of primary porcine fibroblasts, and its genotype is wild type (also called homozygous wild type). If there are two sequencing results for a single cell clone, one is consistent with the sequencing result of primary porcine fibroblasts, and the other is mutated compared with the sequencing result of primary porcine fibroblasts (mutation includes deletion, insertion or substitution of one or more nucleotides), the genotype of the single cell clone is heterozygous; if there are two sequencing results for a single cell clone, both of which are mutated compared with the sequencing result of primary porcine fibroblasts (mutation includes deletion, insertion or substitution of one or more nucleotides), the genotype of the single cell clone is biallelic different mutation type; if there is one sequencing result for a single cell clone, and it is mutated compared with the sequencing result of primary porcine fibroblasts (mutation includes deletion, insertion or substitution of one or more nucleotides), the genotype of the single cell clone is biallelic identical mutation type; if there is one sequencing result for a single cell clone, and it is consistent with the sequencing result of primary porcine fibroblasts, the genotype of the single cell clone is wild type (also called homozygous wild type).
结果见表1。编号为42的单细胞克隆的基因型为野生型。编号为9、11、16、17、25、26、28、33、38、39、40、41、44、46的单细胞克隆的基因型为杂合型。编号为2、3、4、5、6、7、8、10、21、22、34、37、45、47的单细胞克隆的基因型为双等位基因不同突变型。编号为1、12、13、14、15、18、19、20、23、24、27、29、30、31、32、35、36、43的单细胞克隆的基因型为双等位基因相同突变型。得到SCN5A基因编辑单细胞克隆的比率为97.9%。The results are shown in Table 1. The genotype of the single cell clone numbered 42 is wild type. The genotype of the single cell clones numbered 9, 11, 16, 17, 25, 26, 28, 33, 38, 39, 40, 41, 44, and 46 is heterozygous. The genotype of the single cell clones numbered 2, 3, 4, 5, 6, 7, 8, 10, 21, 22, 34, 37, 45, and 47 is a double allele different mutation type. The genotype of the single cell clones numbered 1, 12, 13, 14, 15, 18, 19, 20, 23, 24, 27, 29, 30, 31, 32, 35, 36, and 43 is a double allele identical mutation type. The ratio of SCN5A gene editing single cell clones was 97.9%.
编号为38、44的单细胞克隆为靶位点突变的杂合型(即两条同源染色体中的一条完成了单链Donor DNA的替换,另一条为野生型)。编号为3、4、5、8、34、37的单细胞克隆为靶位点突变的双等位基因不同突变型(即两条同源染色体中的一条完成了单链Donor DNA的替换,另一条发生了其他突变)。编号为24、30的单细胞克隆为靶位点突变的双等位基因相同突变型(即两条同源染色体均完成了单链Donor DNA的替换)。得到靶位点突变的单细胞克隆(即编号为3、4、5、8、24、30、34、37、38、44的单细胞克隆)的比率为21.3%。Single cell clones numbered 38 and 44 are heterozygous for target site mutations (i.e., one of the two homologous chromosomes has completed the replacement of the single-stranded Donor DNA, and the other is wild type). Single cell clones numbered 3, 4, 5, 8, 34, and 37 are biallelic different mutations for target site mutations (i.e., one of the two homologous chromosomes has completed the replacement of the single-stranded Donor DNA, and the other has other mutations). Single cell clones numbered 24 and 30 are biallelic identical mutations for target site mutations (i.e., both homologous chromosomes have completed the replacement of the single-stranded Donor DNA). The ratio of single cell clones with target site mutations (i.e., single cell clones numbered 3, 4, 5, 8, 24, 30, 34, 37, 38, and 44) is 21.3%.
示例性的测序比对结果见图7和图8。图7是编号为38的单细胞克隆的正向测序与SCN5A-mutant-ss153序列的比对结果,为靶位点突变的杂合型。图8是编号为24的单细胞克隆的正向测序与SCN5A-mutant-ss153序列的比对结果,为靶位点突变的双等位基因相同突变型。Exemplary sequencing comparison results are shown in Figures 7 and 8. Figure 7 is the comparison result of the forward sequencing of the single cell clone numbered 38 and the SCN5A-mutant-ss153 sequence, which is a heterozygous mutation of the target site. Figure 8 is the comparison result of the forward sequencing of the single cell clone numbered 24 and the SCN5A-mutant-ss153 sequence, which is a biallelic identical mutation of the target site mutation.
表1 SCN5A基因编辑单细胞克隆的基因型测定结果Table 1 Genotyping results of SCN5A gene-edited single-cell clones


注:靶位点突变指的是完成了单链Donor DNA的替换;即用SEQ ID NO:18所示的DNA分子取代了染色体DNA中SEQ ID NO:19所示的DNA分子。Note: Target site mutation refers to the completion of the replacement of single-stranded Donor DNA; that is, the DNA molecule shown in SEQ ID NO: 18 replaces the DNA molecule shown in SEQ ID NO: 19 in the chromosomal DNA.
靶位点突变的双等位基因相同突变型(即两条同源染色体均完成了单链DonorDNA的替换)的单细胞克隆,即表1中编号为24、30的单细胞克隆,为目标单细胞克隆。将目标单细胞克隆作为核移植供体细胞进行体细胞克隆,可以得到克隆猪,即为心率失常模型猪。Single cell clones with the same mutation type of double alleles of the target site mutation (i.e., both homologous chromosomes have completed the replacement of single-stranded DonorDNA), i.e., single cell clones numbered 24 and 30 in Table 1, are target single cell clones. Using the target single cell clones as nuclear transplant donor cells for somatic cell cloning, cloned pigs, i.e., arrhythmia model pigs, can be obtained.
以上对本发明进行了详述。对于本领域技术人员来说,在不脱离本发明的宗旨和范围,以及无需进行不必要的实验情况下,可在等同参数、浓度和条件下,在较宽范围内实施本发明。虽然本发明给出了特殊的实施例,应该理解为,可以对本发明作进一步的改进。总之,按本发明的原理,本申请欲包括任何变更、用途或对本发明的改进,包括脱离了本申请中已公开范围,而用本领域已知的常规技术进行的改变。按以下附带的权利要求的范围,可以进行一些基本特征的应用。The present invention has been described in detail above. It will be apparent to those skilled in the art that the present invention may be implemented in a wide range under equivalent parameters, concentrations and conditions without departing from the spirit and scope of the present invention and without the need for unnecessary experimentation. Although the present invention provides specific embodiments, it should be understood that further improvements may be made to the present invention. In short, according to the principles of the present invention, this application is intended to include any changes, uses or improvements to the present invention, including changes made by conventional techniques known in the art that depart from the scope disclosed in this application. Applications of some of the basic features may be made within the scope of the following appended claims.
Claims (15)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211011552.3ACN116064683B (en) | 2022-08-23 | Gene editing system and application thereof in preparation of arrhythmia model pig nuclear transfer donor cells with SCN5A gene mutation |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211011552.3ACN116064683B (en) | 2022-08-23 | Gene editing system and application thereof in preparation of arrhythmia model pig nuclear transfer donor cells with SCN5A gene mutation |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN116064683Atrue CN116064683A (en) | 2023-05-05 |
| CN116064683B CN116064683B (en) | 2025-10-17 |
Family
ID=
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1176197A1 (en)* | 2000-06-16 | 2002-01-30 | Vlaams Interuniversitair Instituut voor Biotechnologie vzw. | A transgenic animal model for cardiac arrhythmias |
| CN104593422A (en)* | 2015-01-08 | 2015-05-06 | 中国农业大学 | Method of cloning reproductive and respiratory syndrome resisting pig |
| CN108048405A (en)* | 2018-01-15 | 2018-05-18 | 上海市东方医院 | Stablize cell model for expressing human endogenous INav and its preparation method and application |
| CN112442515A (en)* | 2019-09-02 | 2021-03-05 | 南京启真基因工程有限公司 | Application of gRNA target combination in construction of hemophilia model pig cell line |
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1176197A1 (en)* | 2000-06-16 | 2002-01-30 | Vlaams Interuniversitair Instituut voor Biotechnologie vzw. | A transgenic animal model for cardiac arrhythmias |
| CN104593422A (en)* | 2015-01-08 | 2015-05-06 | 中国农业大学 | Method of cloning reproductive and respiratory syndrome resisting pig |
| CN108048405A (en)* | 2018-01-15 | 2018-05-18 | 上海市东方医院 | Stablize cell model for expressing human endogenous INav and its preparation method and application |
| CN112442515A (en)* | 2019-09-02 | 2021-03-05 | 南京启真基因工程有限公司 | Application of gRNA target combination in construction of hemophilia model pig cell line |
Non-Patent Citations (3)
| Title |
|---|
| DAVID S. PARK等: "Genetically engineered SCN5A mutant pig hearts exhibit conduction defects and arrhythmias", J CLIN INVEST, vol. 125, no. 1, 31 January 2015 (2015-01-31), pages 408* |
| MA, X等: "Cas9[Plant multiplex genome editing vector pYLCRISPR/Cas9Pubi-H] ACCESSION:AKE81011v", GENBANK, 5 May 2015 (2015-05-05), pages 1 - 2* |
| 倪磊等: "SCN5A基因L812Q突变体细胞模型的建立与细胞定位", 山西医科大学学报, no. 07, 26 July 2016 (2016-07-26), pages 585 - 588* |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2021042470A1 (en) | Use of combination of grna targets in constructing cell lines of porcine models of haemophilia a, b and ab | |
| CN108285906B (en) | A construction method of site-directed integration of exogenous DNA transgenic pigs | |
| CN105463027A (en) | Method for preparing high muscle content and hypertrophic cardiomyopathy model cloned pig | |
| CN111575319B (en) | Efficient CRISPR RNP and donor DNA co-location mediated gene insertion or replacement method and application thereof | |
| CN114231533B (en) | Preparation method of miniature pig with human complement regulatory protein knocked in at Rosa26 site by fixed point | |
| CN114908097B (en) | A Dox-regulated lineage tracing technique for recording porcine tissue differentiation and organogenesis | |
| CN106148406B (en) | Porcine ApoE gene knockout vector and its construction method and application | |
| CN116103339A (en) | Kit and application thereof in construction of pig nuclear transfer donor cells of COL2A1 gene mutation type II collagen disease model | |
| CN115806981A (en) | Gene editing system and its application in the construction of psoriasis model pig nuclear transfer donor cells with TNIP1 gene mutation | |
| CN111549070B (en) | Methods of editing multiple copies of X chromosome genes to achieve animal sex control | |
| CN115927320A (en) | Application of gene editing system in preparation of SLC13A1 gene mutation hyposulfatemia model pig nuclear transplantation donor cells | |
| CN106244556B (en) | Method for site-directed mutation of ApoE gene | |
| WO2022062055A1 (en) | Crispr system and use thereof in preparation of severe-immunodeficiency cloned pig nuclear donor cells with multiple genes jointly knocked out | |
| CN116064683B (en) | Gene editing system and application thereof in preparation of arrhythmia model pig nuclear transfer donor cells with SCN5A gene mutation | |
| CN116064683A (en) | Gene editing system and its application in preparation of SCN5A gene mutation arrhythmia model pig nuclear transfer donor cells | |
| CN116179543B (en) | CRISPR-specific targeting pig Cavin-1 gene-based sgRNA and application thereof | |
| CN116064661A (en) | The gene editing system and its application of constructing NF1 gene mutation type I neurofibromatosis model pig nuclear transfer donor cells | |
| CN116004715A (en) | Application of gene editing system in preparation of SMN1 gene mutation spinal muscular atrophy model pig nuclear transfer donor cells | |
| CN116064473A (en) | A kit for constructing ataxia-telangiectasia model pig nuclear transplantation donor cells with ATM gene mutation | |
| CN115976018A (en) | Kit for constructing ABCA12 gene-mutated ichthyosis mottled model pig nuclear transplantation donor cells and its application | |
| CN115927456A (en) | The gene editing system and its application of constructing the donor cells of phenylketonuria model pig nuclear transplantation with PAH gene mutation | |
| CN115927193A (en) | Method for preparing pure hair and toenail type ectodermal dysplasia model pig nuclear transplantation donor cell and special gene editing system thereof | |
| CN110283851A (en) | Target spot MYO9B relevant to malignant pleural effusion and its application | |
| CN116064523A (en) | Gene editing system and application thereof in construction of HPS1 gene mutation sea PRS model pig nuclear transfer donor cells | |
| CN116064524A (en) | Application of gene editing system in construction of CFTR gene mutation cystic fibrosis model pig nuclear transfer donor cells |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant |