CN116016986A - Rendering method and device for virtual human interaction video - Google Patents
Rendering method and device for virtual human interaction videoDownload PDFInfo
- Publication number
- CN116016986A CN116016986ACN202310025137.1ACN202310025137ACN116016986ACN 116016986 ACN116016986 ACN 116016986ACN 202310025137 ACN202310025137 ACN 202310025137ACN 116016986 ACN116016986 ACN 116016986A
- Authority
- CN
- China
- Prior art keywords
- video
- body movement
- lip
- broadcast
- voice
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



Landscapes
- Processing Or Creating Images (AREA)
- User Interface Of Digital Computer (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及虚拟人交互技术领域,特别涉及一种虚拟人互动视频的渲染方法和装置。The invention relates to the technical field of virtual human interaction, in particular to a rendering method and device for virtual human interactive video.
背景技术Background technique
虚拟人互动视频,是指具有如下特征的视频:视频画面中显示有三维的人物模型,视频播放时,该人物模型的肢体(包括四肢和躯干)以及唇部会随着视频输出的语音而变化。A virtual human interaction video refers to a video with the following characteristics: a three-dimensional character model is displayed on the video screen, and when the video is played, the limbs (including limbs and torso) and lips of the character model will change with the voice output from the video.
人机交互时,设备可以播放虚拟人互动视频来模拟真人说话,改善交互体验。因此,虚拟人互动视频越来越多地在如智能导购、智能导览、智能前台、手机助手等场景中应用。During human-computer interaction, the device can play virtual human interaction videos to simulate real people speaking and improve the interactive experience. Therefore, virtual human interaction videos are increasingly used in scenarios such as smart shopping guides, smart tour guides, smart front desks, and mobile assistants.
上述场景中,虚拟人互动视频所输出的语音通常携带大量随时变化的实时信息,如时间、天气、股票、业务状态、个人信息等,所以虚拟人互动视频必须进行实时渲染,即需要在获得用户输入后短时间内生成虚拟人互动视频并输出。In the above scenario, the voice output by the virtual human interaction video usually carries a large amount of real-time information that changes at any time, such as time, weather, stock, business status, personal information, etc. After a short period of input, a virtual human interaction video is generated and output.
然而,实时渲染含三维人物模型的视频所需的计算量很大,特别是随着建模技术的发展,三维人物模型的精度越来越高,导致渲染相应视频所需的计算量也越来越大。这一问题极大的增加了虚拟人互动视频的应用成本,限制了该项技术的应用范围和应用场景。However, real-time rendering of videos with 3D character models requires a lot of calculations, especially with the development of modeling technology, the accuracy of 3D character models is getting higher and higher, resulting in an increasing amount of calculations required to render corresponding videos. bigger. This problem greatly increases the application cost of virtual human interactive video, and limits the application scope and application scenarios of this technology.
发明内容Contents of the invention
针对上述现有技术的缺点,本发明提供一种虚拟人互动视频的渲染方法和装置,以减少实时渲染虚拟人互动视频所需计算量。Aiming at the above-mentioned shortcomings of the prior art, the present invention provides a method and device for rendering an interactive video of an avatar, so as to reduce the amount of computation required for real-time rendering of an interactive video of an avatar.
本申请第一方面提供一种虚拟人互动视频的渲染方法,包括:The first aspect of the present application provides a method for rendering a virtual human interaction video, including:
获得待播报语音;并选取肢体动作视频库中与所述待播报语音匹配的肢体动作数据作为目标肢体动作数据;其中,所述目标肢体动作数据包括基于虚拟人的肢体动作预先渲染的肢体动作视频,所述肢体动作视频的唇部位置信息和唇部姿态信息;Obtain the speech to be broadcast; and select the body movement data matching the speech to be broadcast in the body movement video library as the target body movement data; wherein, the target body movement data includes the body movement video pre-rendered based on the body movement of the virtual person , lip position information and lip gesture information of the body movement video;
根据所述唇部姿态信息和所述待播报语音,渲染唇部视频;Render lip video according to the lip gesture information and the voice to be broadcast;
基于所述唇部位置信息,融合所述唇部视频和所述肢体动作视频,得到用于输出所述待播报语音的虚拟人互动视频。Based on the lip position information, the lip video and the body movement video are fused to obtain a virtual human interaction video for outputting the speech to be broadcast.
可选的,所述根据所述唇部姿态信息和所述待播报语音,渲染唇部视频,包括:Optionally, the rendering of the lip video according to the lip gesture information and the voice to be broadcast includes:
将所述肢体动作视频的时间轴和所述待播报语音的时间轴同步;Synchronizing the time axis of the body movement video with the time axis of the voice to be broadcast;
针对所述待播报语音中每一音频帧,从所述唇部姿态信息中获取和所述音频帧对应的动作视频帧的唇部姿态数据,并根据所述音频帧和所述唇部姿态数据渲染得到所述音频帧对应的唇部视频帧;其中,所述动作视频帧指代所述肢体动作视频的视频帧;所述唇部视频帧指代组成所述唇部视频的视频帧。For each audio frame in the speech to be broadcast, the lip gesture data of the action video frame corresponding to the audio frame is obtained from the lip gesture information, and according to the audio frame and the lip gesture data A lip video frame corresponding to the audio frame is obtained by rendering; wherein, the action video frame refers to a video frame of the body action video; and the lip video frame refers to a video frame forming the lip video.
可选的,所述基于所述唇部位置信息,融合所述唇部视频和所述肢体动作视频,得到用于输出所述待播报语音的虚拟人互动视频,包括:Optionally, based on the lip position information, the lip video and the body movement video are fused to obtain a virtual human interaction video for outputting the speech to be broadcast, including:
针对每一所述动作视频帧,从所述唇部位置信息中获取所述动作视频帧的唇部位置数据,并将所述动作视频帧对应的唇部视频帧,叠加在所述动作视频帧中所述唇部位置数据所指示的位置,得到所述动作视频帧对应的互动视频帧;其中,连续的多个所述互动视频帧组成所述虚拟人互动视频。For each action video frame, the lip position data of the action video frame is obtained from the lip position information, and the lip video frame corresponding to the action video frame is superimposed on the action video frame In the position indicated by the lip position data, an interactive video frame corresponding to the action video frame is obtained; wherein, a plurality of consecutive interactive video frames form the virtual human interactive video.
可选的,所述选取肢体动作视频库中与所述待播报语音匹配的肢体动作数据作为目标肢体动作数据,包括:Optionally, selecting the body movement data in the body movement video library that matches the voice to be broadcast as the target body movement data includes:
确定与所述待播报语音的语音内容相匹配的目标肢体动作;Determining a target body movement that matches the voice content of the voice to be announced;
选取肢体动作视频库中,与所述目标肢体动作对应的肢体动作数据作为目标肢体动作数据。Select the body movement data corresponding to the target body movement in the body movement video library as the target body movement data.
可选的,所述肢体动作数据包括表情标签,所述表情标签表征渲染肢体动作视频时的虚拟表情;Optionally, the body movement data includes an expression tag, and the expression tag represents a virtual expression when rendering the body movement video;
所述选取肢体动作视频库中,与所述目标肢体动作对应的肢体动作数据作为目标肢体动作数据,包括:In the selected body movement video library, the body movement data corresponding to the target body movement is used as the target body movement data, including:
选取所述肢体动作视频库中,与所述目标肢体动作对应,并且具有和所述待播报语音相同的表情标签的肢体动作数据作为目标肢体动作数据;其中,所述待播报语音的表情标签根据所述待播报语音的语音内容确定。In the body movement video library, the body movement data corresponding to the target body movement and having the same expression label as the voice to be broadcast is selected as the target body movement data; wherein, the expression label of the voice to be broadcast is according to The voice content of the voice to be broadcast is determined.
本申请第二方面提供一种虚拟人互动视频的渲染装置,包括:The second aspect of the present application provides a virtual human interactive video rendering device, including:
获取单元,用于获得待播报语音;并选取肢体动作视频库中与所述待播报语音匹配的肢体动作数据作为目标肢体动作数据;其中,所述目标肢体动作数据包括基于虚拟人的肢体动作预先渲染的肢体动作视频,所述肢体动作视频的唇部位置信息和唇部姿态信息;The acquisition unit is used to obtain the speech to be broadcast; and select the body movement data matching the speech to be broadcast in the body movement video library as the target body movement data; wherein, the target body movement data includes the body movement based on the virtual person A rendered body movement video, lip position information and lip gesture information of the body movement video;
渲染单元,用于根据所述唇部姿态信息和所述待播报语音,渲染唇部视频;A rendering unit, configured to render lip video according to the lip gesture information and the voice to be broadcast;
融合单元,用于基于所述唇部位置信息,融合所述唇部视频和所述肢体动作视频,得到用于输出所述待播报语音的虚拟人互动视频。The fusion unit is configured to fuse the lip video and the body movement video based on the lip position information to obtain a virtual human interaction video for outputting the speech to be broadcast.
可选的,所述渲染单元根据所述唇部姿态信息和所述待播报语音,渲染唇部视频时,具体用于:Optionally, when the rendering unit renders the lip video according to the lip posture information and the voice to be broadcast, it is specifically used for:
将所述肢体动作视频的时间轴和所述待播报语音的时间轴同步;Synchronizing the time axis of the body movement video with the time axis of the voice to be broadcast;
针对所述待播报语音中每一音频帧,从所述唇部姿态信息中获取和所述音频帧对应的动作视频帧的唇部姿态数据,并根据所述音频帧和所述唇部姿态数据合成所述音频帧对应的唇部视频帧;其中,所述动作视频帧指代所述肢体动作视频的视频帧;所述唇部视频帧指代组成所述唇部视频的视频帧。For each audio frame in the speech to be broadcast, the lip gesture data of the action video frame corresponding to the audio frame is obtained from the lip gesture information, and according to the audio frame and the lip gesture data Synthesizing a lip video frame corresponding to the audio frame; wherein, the action video frame refers to a video frame of the body action video; the lip video frame refers to a video frame forming the lip video.
可选的,所述融合单元基于所述唇部位置信息,融合所述唇部视频和所述肢体动作视频,得到用于输出所述待播报语音的虚拟人互动视频时,具体用于:Optionally, when the fusion unit fuses the lip video and the body movement video based on the lip position information to obtain the virtual human interaction video for outputting the speech to be broadcast, it is specifically used for:
针对每一所述动作视频帧,从所述唇部位置信息中获取所述动作视频帧的唇部位置数据,并将所述动作视频帧对应的唇部视频帧,叠加在所述动作视频帧中所述唇部位置数据所指示的位置,得到所述动作视频帧对应的互动视频帧;其中,连续的多个所述互动视频帧组成所述虚拟人互动视频。For each action video frame, the lip position data of the action video frame is obtained from the lip position information, and the lip video frame corresponding to the action video frame is superimposed on the action video frame In the position indicated by the lip position data, an interactive video frame corresponding to the action video frame is obtained; wherein, a plurality of consecutive interactive video frames form the virtual human interactive video.
可选的,所述获取单元选取肢体动作视频库中与所述待播报语音匹配的肢体动作数据作为目标肢体动作数据时,具体用于:Optionally, when the acquisition unit selects the body movement data in the body movement video library that matches the voice to be broadcast as the target body movement data, it is specifically used for:
确定与所述待播报语音的语音内容相匹配的目标肢体动作;Determining a target body movement that matches the voice content of the voice to be announced;
选取肢体动作视频库中,与所述目标肢体动作对应的肢体动作数据作为目标肢体动作数据。Select the body movement data corresponding to the target body movement in the body movement video library as the target body movement data.
可选的,所述肢体动作数据包括表情标签,所述表情标签表征渲染肢体动作视频时的虚拟表情;Optionally, the body movement data includes an expression tag, and the expression tag represents a virtual expression when rendering the body movement video;
所述获取单元选取肢体动作视频库中,与所述目标肢体动作对应的肢体动作数据作为目标肢体动作数据时,具体用于:When the acquisition unit selects the body movement data corresponding to the target body movement in the body movement video library as the target body movement data, it is specifically used for:
选取所述肢体动作视频库中,与所述目标肢体动作对应,并且具有和所述待播报语音相同的表情标签的肢体动作数据作为目标肢体动作数据;其中,所述待播报语音的表情标签根据所述待播报语音的语音内容确定。In the body movement video library, the body movement data corresponding to the target body movement and having the same expression label as the voice to be broadcast is selected as the target body movement data; wherein, the expression label of the voice to be broadcast is according to The voice content of the voice to be broadcast is determined.
本申请提供一种虚拟人互动视频的渲染方法和装置,方法包括,获得待播报语音;并选取肢体动作视频库中与待播报语音匹配的肢体动作数据作为目标肢体动作数据;目标肢体动作数据包括基于虚拟人的肢体动作预先渲染的肢体动作视频,肢体动作视频的唇部位置信息和唇部姿态信息;根据唇部姿态信息和待播报语音,渲染唇部视频;基于唇部位置信息融合唇部视频和肢体动作视频,得到用于输出待播报语音的虚拟人互动视频。本方案只需要实时渲染唇部视频,就可以将唇部视频和预渲染的肢体动作视频合成为完成的虚拟人互动视频,显著减少了实时渲染虚拟人互动视频所需计算量。The present application provides a method and device for rendering a virtual human interactive video. The method includes obtaining the voice to be broadcast; and selecting the body movement data matching the voice to be broadcast in the body movement video library as the target body movement data; the target body movement data includes Based on the pre-rendered body movement video of the virtual human body movement, the lip position information and lip posture information of the body movement video; render the lip video according to the lip posture information and the voice to be broadcast; fuse the lips based on the lip position information video and body movement video to obtain a virtual human interaction video for outputting the voice to be broadcast. This solution only needs to render the lip video in real time, and can synthesize the lip video and the pre-rendered body movement video into a completed virtual human interaction video, which significantly reduces the amount of calculation required for real-time rendering of virtual human interactive video.
附图说明Description of drawings
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。In order to more clearly illustrate the technical solutions in the embodiments of the present invention or the prior art, the following will briefly introduce the drawings that need to be used in the description of the embodiments or the prior art. Obviously, the accompanying drawings in the following description are only It is an embodiment of the present invention, and those skilled in the art can also obtain other drawings according to the provided drawings without creative work.
图1为本申请实施例提供的一种虚拟人互动视频的渲染方法的流程图;FIG. 1 is a flow chart of a method for rendering a virtual human interaction video provided by an embodiment of the present application;
图2为本申请实施例提供的一种唇部姿态数据的示意图;Fig. 2 is a schematic diagram of a kind of lip posture data provided by the embodiment of the present application;
图3为本申请实施例提供的一种唇部位置数据的示意图;Fig. 3 is a schematic diagram of lip position data provided by the embodiment of the present application;
图4为本申请实施例提供的一种虚拟人互动视频的渲染装置的结构示意图。FIG. 4 is a schematic structural diagram of a virtual human interactive video rendering device provided by an embodiment of the present application.
具体实施方式Detailed ways
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。The following will clearly and completely describe the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some, not all, embodiments of the present invention. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
本申请实施例提供一种虚拟人互动视频的渲染方法,请参见图1,为该方法的流程图,该方法可以包括如下步骤。An embodiment of the present application provides a method for rendering a virtual human interaction video. Please refer to FIG. 1 , which is a flow chart of the method. The method may include the following steps.
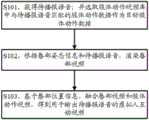
S101,获得待播报语音;并选取肢体动作视频库中与待播报语音匹配的肢体动作数据作为目标肢体动作数据。S101. Obtain the speech to be broadcast; and select body movement data matching the speech to be broadcast in the body movement video library as target body movement data.
其中,目标肢体动作数据包括基于虚拟人的肢体动作预先渲染的肢体动作视频,肢体动作视频的唇部位置信息和唇部姿态信息。Wherein, the target body movement data includes a body movement video pre-rendered based on the virtual human body movement, lip position information and lip posture information of the body movement video.
待播报语音的获得方法如下:The method of obtaining the voice to be broadcast is as follows:
首先,根据输入的用户指令确定待合成文本。用户指令的形式不作限定,可以是语音形式的指令,也可以是文本形式的指令。First, the text to be synthesized is determined according to the input user instruction. The form of the user instruction is not limited, and may be an instruction in a voice form or an instruction in a text form.
示例性的,用户说出一个问题后,终端设备采集用户说话时的语音,将该语音确定为用户的语音指令,获得该语音指令后,通过语音识别技术识别出用户所提的问题,接着根据该问题查找出预设的答案文本,或者利用人工智能算法根据该问题生成对应的答案文本,将该答案文本确定为用户指令对应的待合成文本。Exemplarily, after the user utters a question, the terminal device collects the voice of the user when speaking, determines the voice as the user's voice command, and after obtaining the voice command, recognizes the question raised by the user through voice recognition technology, and then Find a preset answer text for the question, or use an artificial intelligence algorithm to generate a corresponding answer text based on the question, and determine the answer text as the text to be synthesized corresponding to the user instruction.
获得待合成文本后,就可以利用语音合成技术生成用于播报待合成文本的待播报语音。语音合成是通过机械的、电子的方法,基于特定文本产生人造语音的技术,该项技术可以将计算机设备产生的、或者外部输入的文字信息转变为可以听得懂的、流利的汉语口语输出。本实施例所提供的方法,可以利用任意一种现有的语音合成技术,或者语音合成器来合成待播报语音。After the text to be synthesized is obtained, speech synthesis technology can be used to generate the speech to be broadcast for broadcasting the text to be synthesized. Speech synthesis is a technology that generates artificial voice based on specific text through mechanical and electronic methods. This technology can convert text information generated by computer equipment or external input into understandable and fluent spoken Chinese output. The method provided in this embodiment can use any existing speech synthesis technology or a speech synthesizer to synthesize the speech to be broadcast.
下面对肢体动作视频库进行说明。The body movement video library is described below.
肢体动作视频库包括多个肢体动作数据,每一肢体动作数据都对应于一种特定的肢体动作。一份肢体动作数据,可以包括以下内容:一段三维人物模型(以下简称虚拟人)执行特定肢体动作的肢体动作视频,用于描述该段肢体动作视频中唇部所在位置的唇部位置信息,以及用于描述该段肢体动作视频中唇部姿态的唇部姿态信息。The body movement video library includes multiple body movement data, and each body movement data corresponds to a specific body movement. A piece of body movement data may include the following content: a body movement video of a three-dimensional character model (hereinafter referred to as virtual person) performing specific body movements, lip position information used to describe the position of the lips in the body movement video, and Lip pose information used to describe the lip pose in the body action video.
在一种可选的实施例中,所有肢体动作视频中虚拟人可以保持默认表情且唇部静默无动作的状态。默认表情可以是微笑表情,也可以是其他表情,不做限定。In an optional embodiment, in all body movement videos, the avatar can maintain a default expression and a state of silence and no movement of lips. The default emoticon can be a smiling emoticon, or other emoticons, which are not limited.
以默认表情为微笑为例,在构建肢体动作视频库时,可以利用虚拟人的完整材质贴图,二维或三维场景贴图以及相关道具贴图等素材,对呈现微笑表情且唇部静默的虚拟人执行一个肢体动作的过程进行渲染,从而得到该肢体动作对应的一段肢体动作视频,同时在渲染过程中,实时记录肢体动作视频的每一视频帧的唇部位置数据,以及唇部姿态数据。渲染完成后,该肢体动作视频中所有视频帧的唇部位置数据的集合,就是该肢体动作视频对应的唇部位置信息,该肢体动作视频中所有视频帧的唇部姿态数据的集合,就是该肢体动作视频对应的唇部姿态信息,由此即可获得一个肢体动作对应的一份肢体动作数据。针对预设的虚拟人可执行的每一种肢体动作重复上述过程,就可以得到每一肢体动作对应的肢体动作数据,从而获得肢体动作视频库。Taking the default expression of smiling as an example, when building a body movement video library, you can use the complete material map, 2D or 3D scene map, and related props maps of the virtual person to execute the action on a virtual person with a smiling expression and silent lips. A body movement process is rendered to obtain a body movement video corresponding to the body movement. At the same time, during the rendering process, the lip position data and lip posture data of each video frame of the body movement video are recorded in real time. After the rendering is completed, the collection of lip position data of all video frames in the body movement video is the lip position information corresponding to the body movement video, and the collection of lip posture data of all video frames in the body movement video is the The lip posture information corresponding to the body movement video, so that a piece of body movement data corresponding to a body movement can be obtained. By repeating the above process for each body movement that can be performed by the preset virtual human, the body movement data corresponding to each body movement can be obtained, thereby obtaining the body movement video library.
在另一种可选的实施例中,不同肢体动作视频中虚拟人可以保持唇部静默无动作的状态,并且具有不同的表情。例如,一部分肢体动作视频中虚拟人呈现微笑表情,另一部分肢体动作视频中虚拟人呈现严肃表情。In another optional embodiment, in different body movement videos, the avatar can keep its lips silent and without movement, and have different expressions. For example, in some body movement videos, the avatar presents a smiling expression, while in another part of the body movement videos, the avatar presents a serious expression.
这种情况下,构建肢体动作视频库时需要预先指定不同肢体动作视频对应的表情标签,在渲染肢体动作视频时,按照表情标签所指示的表情进行虚拟人的渲染,并且在渲染结束后,需要将表情标签加入到对应的肢体动作数据中。也就是说,当不同肢体动作视频中虚拟人的表情不相同时,肢体动作数据可以包括肢体动作视频,唇部位置信息,唇部姿态信息和表征视频中虚拟人表情的表情标签。In this case, it is necessary to pre-specify the expression tags corresponding to different body action videos when building the body action video library. Add the expression label to the corresponding body movement data. That is to say, when the expressions of the avatars in different body movement videos are different, the body movement data may include body movement videos, lip position information, lip posture information and expression labels representing the expressions of the avatars in the videos.
示例性的,假设渲染某肢体动作对应的肢体动作视频时,指定该视频中虚拟人的表情为“严肃”,则渲染过程中控制虚拟人呈现严肃表情,渲染完肢体动作视频后,将该肢体动作视频,对应的唇部位置信息和唇部姿态信息,以及“严肃”标签确定为该肢体动作对应的一份肢体动作数据。For example, suppose that when rendering a body action video corresponding to a certain body action, specify the expression of the avatar in the video as "serious", then control the avatar to show a serious expression during the rendering process, and after rendering the body action video, set the The action video, the corresponding lip position information and lip posture information, and the "serious" label are determined as a piece of body action data corresponding to the body action.
请参见图2,虚拟人的唇部姿态,定义为其法线方向与全局坐标的天顶角和方位角。具体地,唇部区域,定义为口轮匝肌外沿内的部分,其法线为垂直于该口轮匝肌外沿形成的平面,朝向嘴唇面向的方向。使用球坐标系定义其方向,分别为法线方向与z轴的夹角为天顶角(如图2所示,记为角A),在x-y平面的投影和x轴的夹角为方位角(如图2所示,记为角B)。其中,角A控制唇部的仰俯,当A=π/2时,虚拟人为平视状态,当A<π/2时唇部为仰头状态,当A>π/2时虚拟人为低头状态;角B控制唇部的朝向,当B=0时,为面向正前方,当0<B<π时为朝向虚拟人左边,当π<B<2π时为朝向虚拟人自己右边。Please refer to Figure 2, the lip pose of the virtual human is defined as its normal direction and the zenith angle and azimuth angle of the global coordinates. Specifically, the lip region, defined as the portion inside the outer edge of the orbicularis muscle, has a normal that is perpendicular to the plane formed by the outer edge of the orbicularis muscle, toward the direction in which the lips face. Use the spherical coordinate system to define its direction, respectively, the angle between the normal direction and the z-axis is the zenith angle (as shown in Figure 2, denoted as angle A), and the angle between the projection on the x-y plane and the x-axis is the azimuth angle (As shown in Figure 2, denoted as angle B). Among them, the angle A controls the pitching of the lips. When A=π/2, the virtual person is in the state of looking up, when A<π/2, the lips are in the state of raising the head, and when A>π/2, the virtual person is in the state of bowing the head; Angle B controls the orientation of the lips. When B=0, it is facing the front, when 0<B<π, it is toward the left of the virtual person, and when π<B<2π, it is toward the right of the virtual person.
由此,肢体动作视频中一个视频帧的唇部姿态数据,可以是该视频帧中天顶角A的角度和方位角B的角度。示例性的,一个视频帧的唇部姿态数据可以是:角A为π/4,角B为π/3。Thus, the lip posture data of a video frame in the body action video may be the angle of the zenith angle A and the angle of the azimuth angle B in the video frame. Exemplarily, the lip pose data of a video frame may be: angle A is π/4, and angle B is π/3.
请参见图3,虚拟人的唇部位置,定义为虚拟人口轮匝肌外沿中心点的全局三维坐标。对应的,肢体动作视频中一个视频帧的唇部位置数据,可以是该视频帧中,口轮匝肌外沿中心点的坐标数据,即该点的(x,y,z)坐标。Please refer to FIG. 3 , the lip position of the virtual human is defined as the global three-dimensional coordinates of the center point of the outer edge of the orbicularis muscle of the virtual human. Correspondingly, the lip position data of a video frame in the body movement video may be the coordinate data of the center point of the outer edge of the orbicularis oris muscle in the video frame, that is, the (x, y, z) coordinates of the point.
可选的,步骤S101中选取肢体动作视频库中与待播报语音匹配的肢体动作数据作为目标肢体动作数据的过程,可以包括:Optionally, in step S101, the process of selecting the body movement data in the body movement video library that matches the voice to be broadcast as the target body movement data may include:
首先确定与待播报语音的语音内容相匹配的目标肢体动作;First determine the target body movement that matches the speech content of the speech to be broadcast;
然后选取肢体动作视频库中,与目标肢体动作对应的肢体动作数据作为目标肢体动作数据。Then select the body movement data corresponding to the target body movement in the body movement video library as the target body movement data.
语音内容和肢体动作之间的匹配关系可以预先设定,示例性的,当语音内容为指示用户点击设备的某个部位时,匹配的肢体动作可以是用手指向该部位所在方向,当语音内容为向用户打招呼时,匹配的肢体动作可以是点头并招手。The matching relationship between voice content and body movements can be preset. For example, when the voice content is to instruct the user to click a certain part of the device, the matching body movement can be to point the finger in the direction of the part. When the voice content When greeting the user, the matching body movements may be nodding and beckoning.
需要说明的是,一段待播报语音可以涉及多方面的语音内容,因此也可以匹配一个目标肢体动作或者多个目标肢体动作。对应的,一段待播报语音对应的目标肢体动作数据,可以是一个动作对应的一份数据,也可以是多个动作对应的多份数据。It should be noted that a piece of speech to be broadcast may involve various speech contents, so it may also match one target body movement or multiple target body movements. Correspondingly, the target body movement data corresponding to a piece of speech to be broadcast can be one piece of data corresponding to one movement, or multiple pieces of data corresponding to multiple movements.
在确定目标肢体动作后,就可以在肢体动作视频库中,找到目标肢体动作数据。目标肢体动作数据的视频中,虚拟人执行的动作和目标肢体动作一致。After the target body movement is determined, the target body movement data can be found in the body movement video library. In the video of the target body movement data, the actions performed by the virtual human are consistent with the target body movement.
如前所述,在一些实施例中,不同肢体动作视频中虚拟人可以有不同表情,此时,肢体动作数据包括表情标签,表情标签表征渲染肢体动作视频时的虚拟表情。As mentioned above, in some embodiments, avatars in different body movement videos may have different expressions. At this time, the body movement data includes expression tags, and the expression tags represent the virtual expressions when rendering the body movement videos.
这种情况下,在选取目标肢体动作数据时,就需要同时考虑肢体动作和表情标签,换言之,选取肢体动作视频库中,与目标肢体动作对应的肢体动作数据作为目标肢体动作数据,可以包括:In this case, when selecting the target body movement data, it is necessary to consider both the body movement and expression labels. In other words, select the body movement data corresponding to the target body movement in the body movement video library as the target body movement data, which may include:
选取肢体动作视频库中,与目标肢体动作对应,并且具有和待播报语音相同的表情标签的肢体动作数据作为目标肢体动作数据;其中,待播报语音的表情标签根据待播报语音的语音内容确定。In the body movement video library, body movement data corresponding to the target body movement and having the same expression label as the voice to be broadcast is selected as the target body movement data; wherein, the expression label of the voice to be broadcast is determined according to the voice content of the voice to be broadcast.
S102,根据唇部姿态信息和待播报语音,渲染唇部视频。S102. Render the lip video according to the lip gesture information and the speech to be broadcast.
步骤S102和S103中所涉及的肢体动作视频,均指代S101选取的目标肢体动作数据所包含的肢体动作视频。同理,步骤S102和S103中所涉及的唇部位置信息和唇部姿态信息,均指代S101选取的目标肢体动作数据所包含的唇部位置信息和唇部姿态信息。The body movement videos involved in steps S102 and S103 both refer to the body movement videos contained in the target body movement data selected in S101. Similarly, the lip position information and lip posture information involved in steps S102 and S103 refer to the lip position information and lip posture information contained in the target body movement data selected in S101.
可选的,步骤S102的执行过程可以包括:Optionally, the execution process of step S102 may include:
A1,将肢体动作视频的时间轴和待播报语音的时间轴同步;A1, synchronize the time axis of the body movement video with the time axis of the speech to be broadcast;
A2,针对待播报语音中每一音频帧,从唇部姿态信息中获取和音频帧对应的动作视频帧的唇部姿态数据,并根据音频帧和唇部姿态数据渲染得到音频帧对应的唇部视频帧;其中,动作视频帧指代肢体动作视频的视频帧;唇部视频帧指代组成唇部视频的视频帧。A2, for each audio frame in the speech to be broadcast, obtain the lip posture data of the action video frame corresponding to the audio frame from the lip posture information, and render the lip corresponding to the audio frame according to the audio frame and lip posture data A video frame; wherein, an action video frame refers to a video frame of a body movement video; a lip video frame refers to a video frame forming a lip video.
步骤A1的具体执行过程如下:The specific execution process of step A1 is as follows:
如果仅确定出一份目标肢体动作数据,则A1中只需要同步一个肢体动作视频,这种情况下,将该肢体动作视频的起始时刻设定为待播报语音的起始时刻,将该肢体动作视频的结束时刻设定为待播报语音的结束时刻;If only one piece of target body movement data is determined, only one body movement video needs to be synchronized in A1. In this case, set the starting moment of the body movement video as the starting moment of the speech to be broadcast, The end moment of the action video is set as the end moment of the voice to be broadcast;
完成上述设定后,如果该肢体动作视频的时长和待播报语音的时长一致,则时间轴同步成功,步骤A1结束;如果该肢体动作视频的时长大于待播报语音的时长,则可以通过加快视频播放速度,删除视频中若干个视频帧的方式缩短肢体动作视频的时长,使得两者时长一致;如果该肢体动作视频的时长小于待播报语音的时长,则可以通过减慢视频播放速度,复制视频中若干视频帧并将复制的视频帧插入原视频等方式延长肢体动作视频的时长,使得两者时长一致,在两者时长一致后,时间轴同步成功,步骤A1结束。After completing the above settings, if the duration of the body movement video is the same as the duration of the speech to be broadcast, the time axis synchronization is successful, and step A1 ends; if the duration of the body movement video is longer than the duration of the speech to be broadcast, you can speed up the video Play speed, shorten the duration of the body movement video by deleting several video frames in the video, so that the duration of the two is the same; if the duration of the body movement video is shorter than the duration of the voice to be broadcast, you can slow down the video playback speed to copy the video Add some video frames and insert the copied video frames into the original video to extend the duration of the body movement video, so that the durations of the two are consistent. After the durations of the two are consistent, the time axis synchronization is successful, and step A1 ends.
如果S101中确定出多个目标肢体动作数据,则A1中需要同步多个肢体动作视频,这种情况下,首先确定多个肢体动作视频的播放先后顺序,例如根据语音内容可以确定动作1先执行,动作2后执行,那么动作1对应的肢体动作视频先播放,动作2对应的肢体动作视频后播放,接着按照播放先后顺序将多个肢体动作视频依次拼接得到一个拼接视频。If multiple target body movement data are determined in S101, multiple body movement videos need to be synchronized in A1. In this case, first determine the playing sequence of multiple body movement videos. For example, according to the voice content, it can be determined that action 1 is executed first. , execute after action 2, then the body action video corresponding to action 1 is played first, and the body action video corresponding to action 2 is played later, and then multiple body action videos are spliced in sequence according to the playing sequence to obtain a spliced video.
获得拼接视频后,就可以按照前述单个视频的同步方式,将该拼接视频的时间轴和待播报语音的时间轴同步,具体构成请参见前文,不再赘述。After obtaining the spliced video, you can synchronize the time axis of the spliced video with the time axis of the voice to be broadcast according to the synchronization method of the aforementioned single video. For the specific composition, please refer to the previous section and will not repeat it here.
在步骤A2中,针对待播报语音中每一音频帧,可以将该音频帧,以及该音频帧对应的动作视频帧的唇部姿态数据,输入到口型实时合成器中进行口型渲染,得到该音频帧对应的唇部视频帧。In step A2, for each audio frame in the speech to be broadcast, the audio frame and the lip gesture data of the action video frame corresponding to the audio frame can be input into the mouth-shaped real-time synthesizer for lip-shape rendering to obtain The lip video frame to which this audio frame corresponds.
其中口型实时合成器,用于根据语音信号和唇部姿态数据,计算出在特定唇部姿态下,发出特定语音时的唇形。Among them, the lip shape real-time synthesizer is used to calculate the lip shape when a specific voice is uttered under a specific lip posture based on the voice signal and lip posture data.
S103,基于唇部位置信息,融合唇部视频和肢体动作视频,得到用于输出待播报语音的虚拟人互动视频。S103, based on the lip position information, fusing the lip video and the body movement video to obtain a virtual human interaction video for outputting the voice to be broadcast.
可选的,步骤S103的执行过程可以包括:Optionally, the execution process of step S103 may include:
针对每一动作视频帧,从唇部位置信息中获取动作视频帧的唇部位置数据,并将动作视频帧对应的唇部视频帧,叠加在动作视频帧中唇部位置数据所指示的位置,得到动作视频帧对应的互动视频帧;其中,连续的多个互动视频帧组成虚拟人互动视频。For each action video frame, the lip position data of the action video frame is obtained from the lip position information, and the lip video frame corresponding to the action video frame is superimposed on the position indicated by the lip position data in the action video frame, The interactive video frame corresponding to the action video frame is obtained; wherein, a plurality of continuous interactive video frames form the virtual human interactive video.
在S102中,肢体动作视频的时间轴已经和待播报语音的时间轴同步,因此,待播报语音的每一音频帧均对应于肢体动作视频中的一个动作视频帧,待播报语音的音频帧和肢体动作视频的动作视频帧一一对应。In S102, the time axis of the body movement video has been synchronized with the time axis of the speech to be broadcast, therefore, each audio frame of the speech to be broadcast corresponds to an action video frame in the body movement video, and the audio frame of the speech to be broadcast and There is a one-to-one correspondence between the action video frames of the body action video.
唇部视频中每一唇部视频帧,均由待播报语音合成得到的,待播报语音的音频帧和唇部视频的唇部视频帧也一一对应。由此,可以在唇部视频的每一唇部视频帧和肢体动作视频的每一动作视频帧之间确定一一对应的关系。Each lip video frame in the lip video is synthesized from the speech to be broadcast, and the audio frame of the speech to be broadcast corresponds to the lip video frame of the lip video. Thus, a one-to-one correspondence relationship can be determined between each lip video frame of the lip video and each action video frame of the body action video.
基于上述对应关系,在步骤S103中,就可以在渲染唇部视频时,实时地将每一唇部视频帧和对应的动作视频帧,基于该动作视频帧的唇部位置数据进行叠加融合,获得互动视频帧。由连续的多个互动视频帧组成的视频,就是用于输出待播报语音的互动视频。Based on the above correspondence, in step S103, when rendering the lip video, each lip video frame and the corresponding action video frame can be superimposed and fused based on the lip position data of the action video frame in real time to obtain Interactive video frames. A video composed of multiple consecutive interactive video frames is an interactive video used to output the voice to be broadcast.
上述互动视频可以在支持虚拟人互动视频的终端设备上播放。The above interactive video can be played on a terminal device that supports virtual human interactive video.
本实施例提供的方法,可以在云端由服务器执行。服务器通过执行上述方法,实时生成互动视频,并将互动视频以视频流的形式推送给终端设备展示。The method provided in this embodiment can be executed by a server on the cloud. By executing the above method, the server generates the interactive video in real time, and pushes the interactive video to the terminal device in the form of video stream for display.
本实施例提供的方法,也可以由终端设备执行。终端设备可以预先从服务器下载肢体动作视频库到本地,然后基于下载好的肢体动作视频库执行上述方法,在本地实时生成互动视频并播放。The method provided in this embodiment may also be executed by a terminal device. The terminal device can download the body movement video library from the server to the local in advance, and then execute the above method based on the downloaded body movement video library, and generate and play the interactive video locally in real time.
本申请提供一种虚拟人互动视频的渲染方法,方法包括,获得待播报语音;并选取肢体动作视频库中与待播报语音匹配的肢体动作数据作为目标肢体动作数据;目标肢体动作数据包括基于虚拟人的肢体动作预先渲染的肢体动作视频,肢体动作视频的唇部位置信息和唇部姿态信息;根据唇部姿态信息和待播报语音,渲染唇部视频;基于唇部位置信息融合唇部视频和肢体动作视频,得到用于输出待播报语音的虚拟人互动视频。本方案只需要实时渲染唇部视频,就可以将唇部视频和预渲染的肢体动作视频合成为完成的虚拟人互动视频,显著减少了实时渲染虚拟人互动视频所需计算量。The present application provides a method for rendering a virtual human interactive video. The method includes: obtaining the voice to be broadcast; and selecting the body movement data matching the voice to be broadcast in the body movement video library as the target body movement data; Pre-rendered body movement video of human body movement, lip position information and lip posture information of body movement video; render lip video according to lip posture information and voice to be broadcast; fuse lip video and lip position information based on lip position information The body movement video is used to obtain the virtual human interaction video for outputting the voice to be broadcast. This solution only needs to render the lip video in real time, and can synthesize the lip video and the pre-rendered body movement video into a completed virtual human interaction video, which significantly reduces the amount of calculation required for real-time rendering of virtual human interactive video.
根据本申请实施例提供的虚拟人互动视频的渲染方法,本申请实施例提供一种虚拟人互动视频的渲染装置,请参见图4,为该装置的结构示意图,该装置可以包括如下单元。According to the rendering method of virtual human interactive video provided in the embodiment of the present application, the embodiment of the present application provides a rendering device of virtual human interactive video. Please refer to FIG. 4 , which is a schematic structural diagram of the device. The device may include the following units.
获取单元401,用于获得待播报语音;并选取肢体动作视频库中与待播报语音匹配的肢体动作数据作为目标肢体动作数据;其中,目标肢体动作数据包括基于虚拟人的肢体动作预先渲染的肢体动作视频,肢体动作视频的唇部位置信息和唇部姿态信息;The
渲染单元402,用于根据唇部姿态信息和待播报语音,渲染唇部视频;The
融合单元403,用于基于唇部位置信息,融合唇部视频和肢体动作视频,得到用于输出待播报语音的虚拟人互动视频。The
可选的,渲染单元402根据唇部姿态信息和待播报语音,渲染唇部视频时,具体用于:Optionally, when the
将肢体动作视频的时间轴和待播报语音的时间轴同步;Synchronize the time axis of the body movement video with the time axis of the speech to be broadcast;
针对待播报语音中每一音频帧,从唇部姿态信息中获取和音频帧对应的动作视频帧的唇部姿态数据,并根据音频帧和唇部姿态数据合成音频帧对应的唇部视频帧;其中,动作视频帧指代肢体动作视频的视频帧;唇部视频帧指代组成唇部视频的视频帧。For each audio frame in the speech to be broadcast, the lip posture data of the action video frame corresponding to the audio frame is obtained from the lip posture information, and the lip video frame corresponding to the audio frame is synthesized according to the audio frame and the lip posture data; Wherein, an action video frame refers to a video frame of a body action video; a lip video frame refers to a video frame forming a lip video.
可选的,融合单元403基于唇部位置信息,融合唇部视频和肢体动作视频,得到用于输出待播报语音的虚拟人互动视频时,具体用于:Optionally, when the
针对每一动作视频帧,从唇部位置信息中获取动作视频帧的唇部位置数据,并将动作视频帧对应的唇部视频帧,叠加在动作视频帧中唇部位置数据所指示的位置,得到动作视频帧对应的互动视频帧;其中,连续的多个互动视频帧组成虚拟人互动视频。For each action video frame, the lip position data of the action video frame is obtained from the lip position information, and the lip video frame corresponding to the action video frame is superimposed on the position indicated by the lip position data in the action video frame, The interactive video frame corresponding to the action video frame is obtained; wherein, a plurality of continuous interactive video frames form the virtual human interactive video.
可选的,获取单元401选取肢体动作视频库中与待播报语音匹配的肢体动作数据作为目标肢体动作数据时,具体用于:Optionally, when the
确定与待播报语音的语音内容相匹配的目标肢体动作;Determine the target body movement that matches the voice content of the voice to be broadcast;
选取肢体动作视频库中,与目标肢体动作对应的肢体动作数据作为目标肢体动作数据。Select the body movement data corresponding to the target body movement in the body movement video library as the target body movement data.
可选的,肢体动作数据包括表情标签,表情标签表征渲染肢体动作视频时的虚拟表情;Optionally, the body movement data includes an expression tag, which represents a virtual expression when rendering the body movement video;
获取单元401选取肢体动作视频库中,与目标肢体动作对应的肢体动作数据作为目标肢体动作数据时,具体用于:When the
选取肢体动作视频库中,与目标肢体动作对应,并且具有和待播报语音相同的表情标签的肢体动作数据作为目标肢体动作数据;其中,待播报语音的表情标签根据待播报语音的语音内容确定。In the body movement video library, body movement data corresponding to the target body movement and having the same expression label as the voice to be broadcast is selected as the target body movement data; wherein, the expression label of the voice to be broadcast is determined according to the voice content of the voice to be broadcast.
本实施例提供的虚拟人互动视频的渲染装置,其具体工作原理可以参见本申请实施例提供的虚拟人互动视频的渲染方法中相关步骤,此处不再赘述。For the rendering device of the virtual human interactive video provided in this embodiment, for the specific working principle, please refer to the relevant steps in the rendering method of the virtual human interactive video provided in the embodiment of the present application, which will not be repeated here.
本申请提供一种虚拟人互动视频的渲染装置,装置包括,获取单元401获得待播报语音;并选取肢体动作视频库中与待播报语音匹配的肢体动作数据作为目标肢体动作数据;目标肢体动作数据包括基于虚拟人的肢体动作预先渲染的肢体动作视频,肢体动作视频的唇部位置信息和唇部姿态信息;渲染单元402根据唇部姿态信息和待播报语音,渲染唇部视频;融合单元403基于唇部位置信息融合唇部视频和肢体动作视频,得到用于输出待播报语音的虚拟人互动视频。本方案只需要实时渲染唇部视频,就可以将唇部视频和预渲染的肢体动作视频合成为完成的虚拟人互动视频,显著减少了实时渲染虚拟人互动视频所需计算量。The present application provides a rendering device for a virtual human interactive video, the device includes: the
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。Finally, it should also be noted that in this text, relational terms such as first and second etc. are only used to distinguish one entity or operation from another, and do not necessarily require or imply that these entities or operations, any such actual relationship or order exists. Furthermore, the term "comprises", "comprises" or any other variation thereof is intended to cover a non-exclusive inclusion such that a process, method, article, or apparatus comprising a set of elements includes not only those elements, but also includes elements not expressly listed. other elements of or also include elements inherent in such a process, method, article, or device. Without further limitations, an element defined by the phrase "comprising a ..." does not exclude the presence of additional identical elements in the process, method, article or apparatus comprising said element.
需要注意,本发明中提及的“第一”、“第二”等概念仅用于对不同的装置、模块或单元进行区分,并非用于限定这些装置、模块或单元所执行的功能的顺序或者相互依存关系。It should be noted that concepts such as "first" and "second" mentioned in the present invention are only used to distinguish different devices, modules or units, and are not used to limit the sequence of functions performed by these devices, modules or units or interdependence.
专业技术人员能够实现或使用本申请。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本申请的精神或范围的情况下,在其它实施例中实现。因此,本申请将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。Those skilled in the art can realize or use this application. Various modifications to these embodiments will be readily apparent to those skilled in the art, and the general principles defined herein may be implemented in other embodiments without departing from the spirit or scope of the application. Therefore, the present application will not be limited to the embodiments shown herein, but is to be accorded the widest scope consistent with the principles and novel features disclosed herein.
Claims (10)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310025137.1ACN116016986A (en) | 2023-01-09 | 2023-01-09 | Rendering method and device for virtual human interaction video |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202310025137.1ACN116016986A (en) | 2023-01-09 | 2023-01-09 | Rendering method and device for virtual human interaction video |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN116016986Atrue CN116016986A (en) | 2023-04-25 |
Family
ID=86019051
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202310025137.1APendingCN116016986A (en) | 2023-01-09 | 2023-01-09 | Rendering method and device for virtual human interaction video |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN116016986A (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN117058286A (en)* | 2023-10-13 | 2023-11-14 | 北京蔚领时代科技有限公司 | Method and device for generating video by using word driving digital person |
| CN117475986A (en)* | 2023-07-11 | 2024-01-30 | 北京航空航天大学 | Real-time conversational digital separation generating method with audiovisual perception capability |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113194348A (en)* | 2021-04-22 | 2021-07-30 | 清华珠三角研究院 | Virtual human lecture video generation method, system, device and storage medium |
| CN113538641A (en)* | 2021-07-14 | 2021-10-22 | 北京沃东天骏信息技术有限公司 | Animation generation method and device, storage medium, electronic device |
| CN114866807A (en)* | 2022-05-12 | 2022-08-05 | 平安科技(深圳)有限公司 | Avatar video generation method and device, electronic equipment and readable storage medium |
| CN114998489A (en)* | 2022-05-26 | 2022-09-02 | 中国平安人寿保险股份有限公司 | Virtual character video generation method, device, computer equipment and storage medium |
| CN115052197A (en)* | 2022-03-24 | 2022-09-13 | 北京沃丰时代数据科技有限公司 | Virtual portrait video generation method and device |
- 2023
- 2023-01-09CNCN202310025137.1Apatent/CN116016986A/enactivePending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113194348A (en)* | 2021-04-22 | 2021-07-30 | 清华珠三角研究院 | Virtual human lecture video generation method, system, device and storage medium |
| CN113538641A (en)* | 2021-07-14 | 2021-10-22 | 北京沃东天骏信息技术有限公司 | Animation generation method and device, storage medium, electronic device |
| CN115052197A (en)* | 2022-03-24 | 2022-09-13 | 北京沃丰时代数据科技有限公司 | Virtual portrait video generation method and device |
| CN114866807A (en)* | 2022-05-12 | 2022-08-05 | 平安科技(深圳)有限公司 | Avatar video generation method and device, electronic equipment and readable storage medium |
| CN114998489A (en)* | 2022-05-26 | 2022-09-02 | 中国平安人寿保险股份有限公司 | Virtual character video generation method, device, computer equipment and storage medium |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN117475986A (en)* | 2023-07-11 | 2024-01-30 | 北京航空航天大学 | Real-time conversational digital separation generating method with audiovisual perception capability |
| CN117058286A (en)* | 2023-10-13 | 2023-11-14 | 北京蔚领时代科技有限公司 | Method and device for generating video by using word driving digital person |
| CN117058286B (en)* | 2023-10-13 | 2024-01-23 | 北京蔚领时代科技有限公司 | Method and device for generating video by using word driving digital person |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2021193599A (en) | Virtual object figure synthesizing method, device, electronic apparatus, and storage medium | |
| CN112669417B (en) | Virtual image generation method and device, storage medium and electronic equipment | |
| WO2022001593A1 (en) | Video generation method and apparatus, storage medium and computer device | |
| US9667574B2 (en) | Animated delivery of electronic messages | |
| JP2022531057A (en) | Interactive target drive methods, devices, devices, and recording media | |
| CN101364309B (en) | Cartoon generating method for mouth shape of source virtual characters | |
| US11005796B2 (en) | Animated delivery of electronic messages | |
| EP3014619A2 (en) | System, apparatus and method for movie camera placement based on a manuscript | |
| CN116016986A (en) | Rendering method and device for virtual human interaction video | |
| WO2024244666A1 (en) | Animation generation method and apparatus for avatar, and electronic device, computer program product and computer-readable storage medium | |
| CN114245099A (en) | Video generation method and device, electronic equipment and storage medium | |
| CN112673400A (en) | Avatar animation | |
| CN115497448A (en) | Method and device for synthesizing voice animation, electronic equipment and storage medium | |
| EP4459561A1 (en) | Special effect display method and apparatus, device, storage medium, and program product | |
| US12361621B2 (en) | Creating images, meshes, and talking animations from mouth shape data | |
| JP2022531056A (en) | Interactive target drive methods, devices, devices, and recording media | |
| CN115115753B (en) | Animation video processing method, device, equipment and storage medium | |
| CN116524087A (en) | Audio-driven speaker video synthesis method and system fusing neural radiation fields | |
| CN119274534B (en) | Text-driven lip-sync digital human generation method, device, equipment and medium | |
| CN118537455A (en) | Animation editing method, playing method, medium, electronic device, and program product | |
| CN118710779A (en) | Animation playback method, device, medium, electronic equipment and program product | |
| CN112348932A (en) | Mouth shape animation recording method and device, electronic equipment and storage medium | |
| Perng et al. | Image talk: a real time synthetic talking head using one single image with chinese text-to-speech capability | |
| CN115766971A (en) | Demonstration video generation method, device, electronic device and readable storage medium | |
| CN119383425B (en) | An intelligent video animation generation system based on AIGC |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |