CN115910113A - Voice activity detection model construction method, device and electronic equipment - Google Patents
Voice activity detection model construction method, device and electronic equipmentDownload PDFInfo
- Publication number
- CN115910113A CN115910113ACN202211353534.3ACN202211353534ACN115910113ACN 115910113 ACN115910113 ACN 115910113ACN 202211353534 ACN202211353534 ACN 202211353534ACN 115910113 ACN115910113 ACN 115910113A
- Authority
- CN
- China
- Prior art keywords
- modal
- data
- features
- feature
- model
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



Classifications
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02D—CLIMATE CHANGE MITIGATION TECHNOLOGIES IN INFORMATION AND COMMUNICATION TECHNOLOGIES [ICT], I.E. INFORMATION AND COMMUNICATION TECHNOLOGIES AIMING AT THE REDUCTION OF THEIR OWN ENERGY USE
- Y02D10/00—Energy efficient computing, e.g. low power processors, power management or thermal management
Landscapes
- Image Analysis (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本公开实施例涉及计算机技术领域,尤其涉及一种语音活动检测模型构建方法、装置及电子设备。Embodiments of the present disclosure relate to the field of computer technology, and in particular, to a method, device, and electronic device for constructing a voice activity detection model.
背景技术Background technique
语音活动检测(voice activity detection,简称VAD)的作用是在一段音频中检测出语音。在远场语音交互场景中,当前现有的VAD技术存在一些难题,包括如何成功检测到最低能量的语音,也即是如何提高VAD的敏感度和准确率。如何在带噪环境下成功检测到语音,也即是如何提高VAD的漏检率/虚检率。Voice activity detection (VAD) is used to detect speech in a piece of audio. In the far-field voice interaction scenario, there are some difficulties in the existing VAD technology, including how to successfully detect the lowest energy voice, that is, how to improve the sensitivity and accuracy of VAD. How to successfully detect speech in a noisy environment, that is, how to improve the missed detection rate/false detection rate of VAD.
也正是因为目前的VAD技术依然存在上述问题,导致VAD的应用还不够广泛,很多对于语音检测要求非常高的场景应用效果也不是很理想。It is precisely because the current VAD technology still has the above-mentioned problems that the application of VAD is not widespread enough, and the application effect of many scenarios with very high requirements for voice detection is not very ideal.
发明内容Contents of the invention
本公开提供了一种语音活动检测模型构建方法、装置及电子设备,以解决现有技术中部分或全部技术问题。The present disclosure provides a voice activity detection model construction method, device and electronic equipment to solve some or all technical problems in the prior art.
第一方面,本公开提供了一种语音活动检测模型构建方法,包括:In a first aspect, the present disclosure provides a method for constructing a voice activity detection model, including:
获取多模态数据,其中,多模态数据至少包括音频数据和视频数据;Acquire multimodal data, where the multimodal data includes at least audio data and video data;
分别对多模态数据中每一模态数据进行特征提取,获取与每一模态数据分别对应的模态特征;performing feature extraction on each modality data in the multimodal data respectively, and obtaining modality features respectively corresponding to each modality data;
当多种模态数据中的一种或多种模态数据对应的模态特征不符合预设对齐标准时,对一种或多种模态数据对应的模态特征进行特征对齐处理;When the modal features corresponding to one or more modal data in the plurality of modal data do not meet the preset alignment standard, perform feature alignment processing on the modal features corresponding to one or more modal data;
将特征对齐后的所有模态特征进行融合,获取融合特征;All the modal features after feature alignment are fused to obtain the fused features;
利用融合特征,对预构建的初始模型进行迭代训练,直至经过训练后的模型达到预设条件时,确定达到预设条件后的模型为最终的语音活动检测模型。The fusion feature is used to iteratively train the pre-built initial model until the trained model reaches the preset condition, and the model after the preset condition is determined to be the final voice activity detection model.
本公开实施例提供的该方法,获取多模态数据,其中多模态数据至少包括音频数据和视频数据,多模态数据也可以至少包括音频数据和图像数据。分别对多模态数据中每一模态数据进行特征提取,或与每一模态数据分别对应的模态特征,然后将多模态数据中的一种或多种模态数据对应的模态特征进行特征对齐处理,以便所有的模态特征对齐,然后将特征对齐后的所有模态特征进行融合,获取融合特征,并利用融合特征对预构建的初始模型进行迭代训练,直至经过训练后的模型达到预设条件时,确定达到预设条件后的模型为最终的语音活动检测模型。整个过程中,因为涉及了语音数据和视频数据,经过不断对初始模型进行迭代训练后,模型的语音识别能力和图像识别能力都将会提高。那么,在语音识别能力提高的情况下,就可以间接提高VAD的敏感度和准确率,而且通过视频数据的检测,例如检测到面部肌肉的动作,就可以进一步佐证是否存在用户说话,也就可以再次验证是否存在语音数据,进而提高VAD的敏感度和准确率。而且,也可以降低VAD漏检率。即使噪声很大,VAD无法通过语音数据检测到有人说话的情况下,也可以通过图像特征识别确实有用户在说话,因此可以降低漏检率。再者,即使通过语音数据识别到有说话声,但是通过图像识别可以判定当前时刻没有任何人脸部肌肉有动作的情况下,也可以识别到实际上当前没有人说话,可能是其他设备发出的人声,那么,这种情况下VAD依然可以确定没有人说话,也即是可以降低虚检率。当然,如果多模态数据中还包括其他模态数据,也可以进一步提升VAD的检测准确率。因此,在本申请文件中,多模态数据至少包括音频数据和视频数据。The method provided by the embodiment of the present disclosure acquires multimodal data, where the multimodal data includes at least audio data and video data, and the multimodal data may also include at least audio data and image data. Feature extraction is performed on each modality data in the multimodal data, or the modality features corresponding to each modality data, and then the modality corresponding to one or more modality data in the multimodal data The features are subjected to feature alignment processing so that all the modal features are aligned, and then all the modal features after feature alignment are fused to obtain the fused features, and the pre-built initial model is iteratively trained using the fused features until the trained model When the model meets the preset condition, it is determined that the model that meets the preset condition is the final voice activity detection model. During the whole process, because speech data and video data are involved, after continuous iterative training of the initial model, the speech recognition ability and image recognition ability of the model will be improved. Then, when the voice recognition ability is improved, the sensitivity and accuracy of VAD can be improved indirectly, and through the detection of video data, such as the detection of facial muscle movements, it can further prove whether there is user speech, which can also Verify again whether there is voice data, thereby improving the sensitivity and accuracy of VAD. Moreover, the VAD missed detection rate can also be reduced. Even if the noise is very large and VAD cannot detect someone speaking through the voice data, it can also identify the user speaking through the image feature, so the missed detection rate can be reduced. Furthermore, even if there is a voice recognized through the voice data, but it can be determined through image recognition that there is no facial muscle movement at the current moment, it can also be recognized that no one is actually speaking at the moment, and it may be from other devices. Human voice, then, in this case, VAD can still determine that no one is speaking, that is, it can reduce the false detection rate. Of course, if the multimodal data also includes other modal data, the detection accuracy of VAD can be further improved. Therefore, in this document, multimodal data includes at least audio data and video data.
第二方面,本公开提供了一种语音活动检测模型构建装置,该装置包括:In a second aspect, the present disclosure provides a device for constructing a voice activity detection model, the device comprising:
获取模块,用于获取多模态数据,其中,多模态数据至少包括音频数据和视频数据;An acquisition module, configured to acquire multimodal data, where the multimodal data includes at least audio data and video data;
提取模块,用于分别对多模态数据中每一模态数据进行特征提取,获取与每一模态数据分别对应的模态特征;The extraction module is used to perform feature extraction on each modal data in the multimodal data respectively, and obtain the modal features corresponding to each modal data;
处理模块,用于当多种模态数据中的一种或多种模态数据对应的模态特征不符合预设对齐标准时,对一种或多种模态数据对应的模态特征进行特征对齐处理;A processing module, configured to perform feature alignment on the modal features corresponding to one or more modal data when the modal features corresponding to one or more modal data in the multiple modal data do not meet the preset alignment standard deal with;
融合模块,用于将特征对齐后的所有模态特征进行融合,获取融合特征;The fusion module is used to fuse all the modality features after feature alignment to obtain fusion features;
训练模块,用于利用融合特征,对预构建的初始模型进行迭代训练,直至经过训练后的模型达到预设条件时,确定达到预设条件后的模型为最终的语音活动检测模型。The training module is used to iteratively train the pre-built initial model by using the fusion feature until the trained model reaches the preset condition, and then determine that the model that meets the preset condition is the final voice activity detection model.
本公开实施例提供的语音活动检测模型构建装置,获取多模态数据,其中多模态数据至少包括音频数据和视频数据,多模态数据也可以至少包括音频数据和图像数据。分别对多模态数据中每一模态数据进行特征提取,或与每一模态数据分别对应的模态特征,然后将多模态数据中的一种或多种模态数据对应的模态特征进行特征对齐处理,以便所有的模态特征对齐,然后将特征对齐后的所有模态特征进行融合,获取融合特征,并利用融合特征对预构建的初始模型进行迭代训练,直至经过训练后的模型达到预设条件时,确定达到预设条件后的模型为最终的语音活动检测模型。整个过程中,因为涉及了语音数据和视频数据,经过不断对初始模型进行迭代训练后,模型的语音识别能力和图像识别能力都将会提高。那么,在语音识别能力提高的情况下,就可以间接提高VAD的敏感度和准确率,而且通过视频数据的检测,例如检测到面部肌肉的动作,就可以进一步佐证是否存在用户说话,也就可以再次验证是否存在语音数据,进而提高VAD的敏感度和准确率。而且,也可以降低VAD漏检率。即使噪声很大,VAD无法通过语音数据检测到有人说话的情况下,也可以通过图像特征识别确实有用户在说话,因此可以降低漏检率。再者,即使通过语音数据识别到有说话声,但是通过图像识别可以判定当前时刻没有任何人脸部肌肉有动作的情况下,也可以识别到实际上当前没有人说话,可能是其他设备发出的人声,那么,这种情况下VAD依然可以确定没有人说话,也即是可以降低虚检率。当然,如果多模态数据中还包括其他模态数据,也可以进一步提升VAD的检测准确率。因此,在本申请文件中,多模态数据至少包括音频数据和视频数据。The voice activity detection model building device provided by the embodiments of the present disclosure acquires multi-modal data, wherein the multi-modal data includes at least audio data and video data, and the multi-modal data may also include at least audio data and image data. Feature extraction is performed on each modality data in the multimodal data, or the modality features corresponding to each modality data, and then the modality corresponding to one or more modality data in the multimodal data The features are subjected to feature alignment processing so that all the modal features are aligned, and then all the modal features after feature alignment are fused to obtain the fused features, and the pre-built initial model is iteratively trained using the fused features until the trained model When the model meets the preset condition, it is determined that the model that meets the preset condition is the final voice activity detection model. During the whole process, because speech data and video data are involved, after continuous iterative training of the initial model, the speech recognition ability and image recognition ability of the model will be improved. Then, when the voice recognition ability is improved, the sensitivity and accuracy of VAD can be improved indirectly, and through the detection of video data, such as the detection of facial muscle movements, it can further prove whether there is user speech, which can also Verify again whether there is voice data, thereby improving the sensitivity and accuracy of VAD. Moreover, the VAD missed detection rate can also be reduced. Even if the noise is very large and VAD cannot detect someone speaking through the voice data, it can also identify the user speaking through the image feature, so the missed detection rate can be reduced. Furthermore, even if there is a voice recognized through the voice data, but it can be determined through image recognition that there is no facial muscle movement at the current moment, it can also be recognized that no one is actually speaking at the moment, and it may be from other devices. Human voice, then, in this case, VAD can still determine that no one is speaking, that is, it can reduce the false detection rate. Of course, if the multimodal data also includes other modal data, the detection accuracy of VAD can be further improved. Therefore, in this document, multimodal data includes at least audio data and video data.
第三方面,提供了一种电子设备,包括处理器、通信接口、存储器和通信总线,其中,处理器,通信接口,存储器通过通信总线完成相互间的通信;In a third aspect, an electronic device is provided, including a processor, a communication interface, a memory, and a communication bus, wherein the processor, the communication interface, and the memory complete mutual communication through the communication bus;
存储器,用于存放计算机程序;memory for storing computer programs;
处理器,用于执行存储器上所存放的程序时,实现第一方面任一项实施例的语音活动检测模型构建方法的步骤。The processor is configured to implement the steps of the voice activity detection model building method in any one embodiment of the first aspect when executing the program stored in the memory.
第四方面,提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被电子设备执行时实现如第一方面任一项实施例的语音活动检测模型构建方法、装置及电子设备的步骤。In the fourth aspect, a computer-readable storage medium is provided, on which a computer program is stored, and when the computer program is executed by an electronic device, the voice activity detection model construction method, device and electronic device according to any embodiment of the first aspect are implemented. A step of.
附图说明Description of drawings
图1为本公开提供的一种语音活动检测模型构建方法流程示意图;FIG. 1 is a schematic flow chart of a method for constructing a voice activity detection model provided by the present disclosure;
图2为本公开提供的一种双塔结构的示意图;Fig. 2 is a schematic diagram of a double-tower structure provided by the present disclosure;
图3为本公开提供的另一种语音活动检测模型构建装置结构示意图;FIG. 3 is a schematic structural diagram of another voice activity detection model building device provided by the present disclosure;
图4为本公开实施例提供的一种电子设备结构示意图。Fig. 4 is a schematic structural diagram of an electronic device provided by an embodiment of the present disclosure.
具体实施方式Detailed ways
为使本公开实施例的目的、技术方案和优点更加清楚,下面将结合本公开实施例中的附图,对本公开实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本公开一部分实施例,而不是全部的实施例。基于本公开中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本公开保护的范围。In order to make the purpose, technical solutions and advantages of the embodiments of the present disclosure clearer, the technical solutions in the embodiments of the present disclosure will be clearly and completely described below in conjunction with the drawings in the embodiments of the present disclosure. Obviously, the described embodiments It is a part of the embodiments of the present disclosure, but not all of them. Based on the embodiments in the present disclosure, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present disclosure.
为便于对本公开实施例的理解,下面将结合附图以具体实施例做进一步的解释说明,实施例并不构成对本公开实施例的限定。In order to facilitate the understanding of the embodiments of the present disclosure, the following will further explain and illustrate with specific embodiments in conjunction with the accompanying drawings, and the embodiments are not intended to limit the embodiments of the present disclosure.
针对背景技术中所提及的技术问题,本公开实施例提供了一种语音活动检测模型构建方法、装置及电子设备。Aiming at the technical problems mentioned in the background art, the embodiments of the present disclosure provide a voice activity detection model building method, device and electronic equipment.
下面将详细介绍具体的语音活动检测模型构建的方法步骤,可以参见本公开实施例提供的附图,图1为本公开实施例提供的一种语音活动检测模型构建方法流程示意图。该方法步骤包括:The specific method steps for building a voice activity detection model will be described in detail below, and reference can be made to the accompanying drawings provided by the embodiments of the present disclosure. FIG. 1 is a schematic flowchart of a method for building a voice activity detection model provided by an embodiment of the present disclosure. The method steps include:
步骤110,获取多模态数据。
现有技术中,目前主流的VAD通常是基于音频的VAD,也即是只用到基于音频的信息,而在现实生活中,设备的传感器可以采集到各种各样的信号,并不局限于音频信号。那么,如果将这些多模态信号都利用起来,则可以预计VAD的检测效果,通常会相较于仅仅基于音频信号的检测结果更加准确。即使在带噪环境下,也能够大大提高声音检测的敏感度和准确率,漏检率和虚检率也会相对更低一些。In the existing technology, the current mainstream VAD is usually audio-based VAD, that is, only audio-based information is used. In real life, the sensor of the device can collect various signals, not limited to audio signal. Then, if these multi-modal signals are utilized, it can be expected that the detection effect of VAD will usually be more accurate than the detection results based only on audio signals. Even in a noisy environment, the sensitivity and accuracy of sound detection can be greatly improved, and the missed detection rate and false detection rate will be relatively lower.
多模态数据,顾名思义,就是指多种不同形式的数据。例如,音频数据、视频数据、图像数据、红外数据、激光数据等等都属于不同模态的数据,在本公开中,多模态数据至少包括音频数据和视频数据,或者,多模态数据也可以至少包括音频数据和图像数据。下文中,以多模态数据包括音频数据和视频数据为例进行说明,至于其他模态数据,处理方式类似,这里不再过多赘述。Multimodal data, as the name suggests, refers to data in many different forms. For example, audio data, video data, image data, infrared data, laser data, etc. all belong to data of different modalities. In this disclosure, multimodal data includes at least audio data and video data, or multimodal data also includes At least audio data and image data may be included. In the following, multi-modal data including audio data and video data is taken as an example for illustration. As for other modal data, the processing methods are similar, and details will not be repeated here.
步骤120,分别对多模态数据中每一模态数据进行特征提取,获取与每一模态数据分别对应的模态特征。
具体的,假设多模态数据包括音频数据和视频数据。那么,针对音频数据的特征提取,所获取的模态特征就是音频特征。对于视频数据进行特征提取,所获取的模态特征就是图像特征。具体的特征提取方式可以采用现有技术中比较常规的技术手段实现,因此这里不再过多的解释说明。Specifically, it is assumed that the multimodal data includes audio data and video data. Then, for feature extraction of audio data, the obtained modality features are audio features. For feature extraction of video data, the acquired modality features are image features. The specific feature extraction method can be realized by relatively conventional technical means in the prior art, so too much explanation will not be given here.
步骤130,当多种模态数据中的一种或多种模态数据对应的模态特征不符合预设对齐标准时,对一种或多种模态数据对应的模态特征进行特征对齐处理。
具体的,在执行特征对齐处理的过程中,可以事先设定一个对齐标准。如果多模态数据中某些模态数据对应的模态特征已经符合预设对齐标准,那么则不需要执行特征对齐处理。当存在一种或多个模态数据对应的模态特征不符合预设对齐标准时,则需要将多模态数据中的一种或多种模态数据对应的模态特征进行特征对齐处理。Specifically, during the process of performing feature alignment, an alignment standard may be set in advance. If the modal features corresponding to some modal data in the multimodal data already meet the preset alignment standard, then feature alignment processing does not need to be performed. When there is one or more modal features corresponding to the modal data that do not meet the preset alignment standard, it is necessary to perform feature alignment processing on the modal features corresponding to one or more modal data in the multimodal data.
因此,首先要判断每一种模态数据对应的模态特征,是否符合预设对齐标准,然后再确定该模态数据是否需要执行特征对齐处理操作。Therefore, it is first necessary to determine whether the modal feature corresponding to each modal data meets the preset alignment standard, and then determine whether the modal data needs to perform feature alignment processing.
可选的,在一个具体的例子中,预设对齐标准用以指示单位时间内对应预设特征数量。Optionally, in a specific example, the preset alignment standard is used to indicate the number of corresponding preset features per unit time.
在具体判断每一种模态数据对应的模态特征,是否符合预设对齐标准时,可以通过如下方式实现:When specifically judging whether the modal characteristics corresponding to each modal data meet the preset alignment standards, it can be achieved in the following ways:
具体的,获取每一种模态数据在单位时间内对应的特征数量,然后将该特征数量与预设对齐标准进行比较,如果二者相等,则不需要执行特征对齐处理,如果不相等,则需要执行特征对齐处理。Specifically, the number of features corresponding to each mode data in unit time is obtained, and then the number of features is compared with the preset alignment standard. If the two are equal, there is no need to perform feature alignment processing; if they are not equal, then A feature alignment process needs to be performed.
具体执行的特征对齐处理方式,可以根据单位时间内模态特征数量预设对齐标准共同确定。The specific implementation of the feature alignment processing method can be jointly determined according to the preset alignment standard of the number of modal features per unit time.
并在根据预设对齐标准,和第一模态数据在单位时间内对应的特征数量,确定对第一模态数据的模态特征执行的特征对齐处理方式后,按照与第一模态数据的模态特征对应的特征对齐处理方式,完成对第一模态数据对应的模态特征进行特征对齐处理,其中,特征对齐处理方式包括对模态特征进行上采样处理,或进行下采样处理,第一模态数据为一种或多种模态数据中的任一种模态数据。And after determining the feature alignment processing method performed on the modal features of the first modal data according to the preset alignment standard and the number of features corresponding to the first modal data per unit time, according to the alignment with the first modal data The feature alignment processing method corresponding to the modal feature completes the feature alignment processing of the modal feature corresponding to the first modal data, wherein the feature alignment processing method includes performing up-sampling processing or down-sampling processing on the modal feature. A modal data is any one of one or more modal data.
步骤140,将特征对齐后的所有模态特征进行融合,获取融合特征。
步骤150,利用融合特征,对预构建的初始模型进行迭代训练,直至经过训练后的模型达到预设条件时,确定达到预设条件后的模型为最终的语音活动检测模型。In
具体的,将多种模态特征进行融合后,来训练模型,可以方便模型更多的识别多种不同类型的数据特征,进而根据不同类型的数据特征综合识别是否存在语音活动,例如同时检测到有人的嘴在动,同时检测到说话声,则可以说明存在语音活动,有人正在说话。Specifically, after merging multiple modal features to train the model, it is convenient for the model to identify more different types of data features, and then comprehensively identify whether there is voice activity based on different types of data features, such as simultaneously detecting If someone's mouth is moving and speaking is detected at the same time, it can indicate that there is voice activity and someone is speaking.
进一步可选的,在本申请文件中,侧重提取的图像特征是人的面部特征,包括但不局限于唇部的活动检测。更包括人的面部肌肉运动、面部表情等的特征提取。用以提高对语音活动检测的准确度。Further optionally, in this application document, the image features that focus on extraction are human facial features, including but not limited to lip activity detection. It also includes feature extraction of human facial muscle movements and facial expressions. To improve the accuracy of voice activity detection.
在这种情况下,即使用户口被遮住(无法通过嘴型确定用户是否说话的情况)、偏头等情况下,也可以通过局部面部肌肉或局部面部表情等提取的特征,来识别是否是当前用户正在说话。In this case, even if the user's mouth is covered (it is impossible to determine whether the user is speaking through the shape of the mouth), or the head is tilted, etc., it is possible to identify whether the user is currently User is talking.
而且,通过结合图像特征等多模态特征,也可以避免例如手机铃声等虽然存在“人声”,但是并非现场人员说话等的情况被误检测到。Moreover, by combining multi-modal features such as image features, it is also possible to avoid false detection of situations such as mobile phone ringtones that have "human voices" but are not speaking by on-site personnel.
当然,即使存在噪音的情况下,也可以通过图像特征等模态特征进行辅助识别,以免噪声被误认为是“人声”的情况发生。Of course, even in the presence of noise, modal features such as image features can be used to assist in identification, so as to prevent noise from being mistaken for "human voice".
该模型构建后,也可以广泛的增加VAD的应用场景,即使对于检测敏感度、漏检率和虚检率等要求比较高的应用场景,也完全可以适用。After the model is constructed, the application scenarios of VAD can also be widely increased, even for application scenarios with relatively high requirements such as detection sensitivity, missed detection rate and false detection rate, etc., it is completely applicable.
本公开实施例提供的语音活动检测模型构建方法,获取多模态数据,其中多模态数据至少包括音频数据和视频数据,多模态数据也可至少包括音频数据和图像数据。分别对多模态数据中每一模态数据进行特征提取,或与每一模态数据分别对应的模态特征,然后将多模态数据中的一种或多种模态数据对应的模态特征进行特征对齐处理,以便所有的模态特征对齐,然后将特征对齐后的所有模态特征进行融合,获取融合特征,并利用融合特征对预构建的初始模型进行迭代训练,直至经过训练后的模型达到预设条件时,确定达到预设条件后的模型为最终的语音活动检测模型。整个过程中,因为涉及了语音数据和视频数据,经过不断对初始模型进行迭代训练后,模型的语音识别能力和图像识别能力都将会提高。那么,在语音识别能力提高的情况下,就可以间接提高VAD的敏感度和准确率,而且通过视频数据的检测,例如检测到面部肌肉的动作,就可以进一步佐证是否存在用户说话,也就可以再次验证是否存在语音数据,进而提高VAD的敏感度和准确率。而且,也可以降低VAD漏检率。即使噪声很大,VAD无法通过语音数据检测到有人说话的情况下,也可以通过图像特征识别确实有用户在说话,因此可以降低漏检率。再者,即使通过语音数据识别到有说话声,但是通过图像识别可以判定当前时刻没有任何人脸部肌肉有动作的情况下,也可以识别到实际上当前没有人说话,可能是其他设备发出的人声,那么,这种情况下VAD依然可以确定没有人说话,也即是可以降低虚检率。当然,如果多模态数据中还包括其他模态数据,也可以进一步提升VAD的检测准确率。因此,在本申请文件中,多模态数据至少包括音频数据和视频数据。The voice activity detection model construction method provided by the embodiments of the present disclosure acquires multi-modal data, wherein the multi-modal data includes at least audio data and video data, and the multi-modal data may also include at least audio data and image data. Feature extraction is performed on each modality data in the multimodal data, or the modality features corresponding to each modality data, and then the modality corresponding to one or more modality data in the multimodal data The features are subjected to feature alignment processing so that all the modal features are aligned, and then all the modal features after feature alignment are fused to obtain the fused features, and the pre-built initial model is iteratively trained using the fused features until the trained model When the model meets the preset condition, it is determined that the model that meets the preset condition is the final voice activity detection model. During the whole process, because speech data and video data are involved, after continuous iterative training of the initial model, the speech recognition ability and image recognition ability of the model will be improved. Then, when the voice recognition ability is improved, the sensitivity and accuracy of VAD can be improved indirectly, and through the detection of video data, such as the detection of facial muscle movements, it can further prove whether there is user speech, which can also Verify again whether there is voice data, thereby improving the sensitivity and accuracy of VAD. Moreover, the VAD missed detection rate can also be reduced. Even if the noise is very large and VAD cannot detect someone speaking through the voice data, it can also identify the user speaking through the image feature, so the missed detection rate can be reduced. Furthermore, even if there is a voice recognized through the voice data, but it can be determined through image recognition that there is no facial muscle movement at the current moment, it can also be recognized that no one is actually speaking at the moment, and it may be from other devices. Human voice, then, in this case, VAD can still determine that no one is speaking, that is, it can reduce the false detection rate. Of course, if the multimodal data also includes other modal data, the detection accuracy of VAD can be further improved. Therefore, in this document, multimodal data includes at least audio data and video data.
在上述实施例的基础上,本公开还提供了另一种语音活动检测模型构建方法,与上述实施例中相同或类似的内容,这里将不再赘述。下面将详细介绍如何根据预设对齐标准,确定对第一模态数据对应的特征对齐处理方式。On the basis of the above embodiments, the present disclosure also provides another method for constructing a voice activity detection model, which is the same as or similar to the above embodiments, and will not be repeated here. The following will introduce in detail how to determine the feature alignment processing method corresponding to the first modality data according to the preset alignment standard.
具体参见如下内容所示,包括:For details, see the following content, including:
当第一模态数据对应的语音特征在单位时间内对应的特征数量大于预设特征数量时,确定对第一模态数据的模态特征执行的特征对齐处理方式为下采样处理;When the number of features corresponding to the speech features corresponding to the first modal data is greater than the preset number of features per unit time, it is determined that the feature alignment processing method performed on the modal features of the first modal data is down-sampling processing;
或,当多模态数据中第一模态数据对应的语音特征在单位时间内对应的特征数量小于预设特征数量时,确定对第一模态数据的模态特征执行的特征对齐处理方式为上采样处理。Or, when the number of features corresponding to the speech features corresponding to the first modal data in the multimodal data is less than the preset number of features per unit time, it is determined that the feature alignment processing method performed on the modal features of the first modal data is Upsampling processing.
具体的,假设预设对齐标准为在单位时间内,例如每秒内的特征数量为50帧;Specifically, it is assumed that the preset alignment standard is within a unit time, for example, the number of features per second is 50 frames;
而对于音频信号而言,例如通过麦克风阵列采集到的音频信号,假设使用的采样频率是16kHz,经过离散傅里叶变换等方法提取音频特征后,每秒钟是100帧。As for the audio signal, for example, the audio signal collected by the microphone array, assuming that the sampling frequency used is 16kHz, after the audio features are extracted by methods such as discrete Fourier transform, there are 100 frames per second.
对于摄像头采集的视频,经过图像特征提取后,每秒钟对应25帧图像特征。为了使二者能够对齐,则可以对音频特征执行下采样处理,对图像特征执行上采样处理。For the video captured by the camera, after image feature extraction, each second corresponds to 25 frames of image features. In order to align the two, downsampling can be performed on audio features and upsampling on image features.
在一个具体的例子中,上采样例如可以使用相邻两帧线性插值/或非线性插值等方式,当然也可以采用其他上采样方式,这里不做任何限定。In a specific example, the upsampling may use, for example, two adjacent frames of linear interpolation and/or nonlinear interpolation. Of course, other upsampling methods may also be used, which are not limited here.
针对图像特征,例如可以采用随机下采样方法,或者通过双塔结构完成对数据的(上)下采样处理。For image features, for example, a random down-sampling method may be used, or the (up) and down-sampling processing of data may be completed through a double-tower structure.
当然,双塔结构除了可以对图像特征执行采样处理外,还可以包括对音频特征执行采样处理。Of course, in addition to performing sampling processing on image features, the two-tower structure may also include performing sampling processing on audio features.
在一个可选的例子中,例如当多模态数据包括第一模态数据和第二模态数据。第一模态数据为语音数据,第二模态数据为视频数据。当第一模态数据对应的语音特征在单位时间内对应的特征数量大于预设特征数量,第二模态数据对应的视频特征在单位时间内对应的特征数量小于预设特征数量时,该方法还可以包括如下步骤:In an optional example, for example, when the multimodal data includes first modality data and second modality data. The first modal data is voice data, and the second modal data is video data. When the number of features corresponding to the voice features corresponding to the first modal data per unit time is greater than the preset number of features, and the number of features corresponding to the video features corresponding to the second modal data is less than the preset number of features per unit time, the method The following steps may also be included:
将语音特征和视频特征分别输入至预构建的特征对齐模型中。The speech features and video features are fed into the pre-built feature alignment model separately.
根据上文中所介绍的根据预设对齐标准,确定对第一模态数据对应的特征对齐处理方式的方法步骤可知,在特征对齐模型中需要对语音特征的下采样处理,以及视频特征执行上采样处理。使得经过处理后的语音特征与经过处理后的视频特征对齐,其中,特征对齐模型包括至少两个特征对齐处理通道,语音特征和视频特征分别输入到特征对齐模型中的不同特征对齐处理通道。According to the method steps of determining the feature alignment processing method corresponding to the first modality data according to the preset alignment standard described above, it can be known that in the feature alignment model, it is necessary to perform down-sampling processing on speech features and up-sampling on video features deal with. The processed speech features are aligned with the processed video features, wherein the feature alignment model includes at least two feature alignment processing channels, and the speech features and video features are respectively input into different feature alignment processing channels in the feature alignment model.
也即是,需要将语音特征输入到特征对齐模型中的其中一个特征对齐处理通道执行下采样处理。以及将视频特征输入到特征对齐模型中的另一个特征对齐处理通道执行上采样处理。That is, one of the feature alignment processing channels that input speech features into the feature alignment model needs to perform downsampling. And another feature alignment processing pass that feeds video features into the feature alignment model performs upsampling processing.
其中,特征对齐模型例如可以是双塔结构特征提取模型。Wherein, the feature alignment model may be, for example, a two-tower structure feature extraction model.
在一个具体的例子中,双塔结构具体参见图2所示,图2中示意出一种双塔结构的结构框图。In a specific example, the double-tower structure is shown in FIG. 2 . FIG. 2 shows a structural block diagram of a double-tower structure.
在图2中左侧的编码器1中输入语音特征,右侧的编码器2中输入图像特征。在编码器中对音频特征执行下采样处理,对图像特征执行上采样处理。最终在图2中的两个编码器的输出层,实现两个编码器的帧数对齐,也即是完成特征对齐操作。可以理解的是,图2中左侧的编码器1可以理解为特征对齐模型(双塔结构)中的其中一个特征对齐处理通道,而图2中右侧的编码器2则可以理解为特征对齐模型中的另一个特征对齐处理通道。具体采用双塔结构中的编码器完成特征对齐操作的过程属于现有技术,因此这里不做过多的介绍。Speech features are input into encoder 1 on the left in Figure 2, and image features are input into encoder 2 on the right. The encoder performs downsampling on audio features and upsampling on image features. Finally, in the output layer of the two encoders in Figure 2, the frame number alignment of the two encoders is realized, that is, the feature alignment operation is completed. It can be understood that encoder 1 on the left in Figure 2 can be understood as one of the feature alignment processing channels in the feature alignment model (two-tower structure), while encoder 2 on the right in Figure 2 can be understood as feature alignment Another feature alignment processing pass in the model. The specific process of using the encoders in the double-tower structure to complete the feature alignment operation belongs to the prior art, so it will not be introduced too much here.
可选的,与上述内容不同的是,如果将音频特征在每秒内的特征数量,例如100帧作为对齐标准,那么可以不对音频特征进行对齐处理,而是直接对图像这种执行上采样处理即可。Optionally, different from the above content, if the number of audio features per second, for example, 100 frames, is used as the alignment standard, then the audio features can not be aligned, but directly perform upsampling on the image. That's it.
不论上述哪种方式,都可以完成特征对齐处理,以便后续的特征融合。Regardless of the above methods, the feature alignment process can be completed for subsequent feature fusion.
在本公开的另一个实施例中,将特征对齐后的所有模态特征进行融合,获取融合特征,可以通过多种方式实现,例如本公开如下例子中所列举的任一种可实现方式。In another embodiment of the present disclosure, all the modal features after feature alignment are fused to obtain the fused features, which may be implemented in a variety of ways, for example, any of the implementable ways listed in the following examples of the present disclosure.
第一种,将特征对齐后的所有模态特征进行拼接处理,获取融合特征。The first one is to splice all the modal features after feature alignment to obtain fusion features.
第二种,将特征对齐后的所有模态特征进行点乘处理,获取融合特征。The second is to perform dot product processing on all modal features after feature alignment to obtain fusion features.
虽然,这两种实现方式都可以实现获取融合特征。但是在一个优选的实施例中,推荐使用点乘方式完成对所有模态特征的融合处理。Although, both of these implementations can achieve fusion features. However, in a preferred embodiment, it is recommended to use the dot product method to complete the fusion processing of all modal features.
具体而言,经过实验数据统计,可以得出点乘操作,更加有助于模型的收敛。而且,点乘后所生成的融合特征的特征维度,相较于特征拼接后所生成的融合特征维度,会更小一些,那么对于模型训练过程中的计算量而言,将会大大减小,降低模型计算量,提高模型训练的效率。Specifically, through the statistics of experimental data, it can be concluded that the dot product operation is more conducive to the convergence of the model. Moreover, the feature dimension of the fusion feature generated after dot multiplication will be smaller than the fusion feature dimension generated after feature splicing, so the calculation amount during the model training process will be greatly reduced. Reduce the amount of model calculations and improve the efficiency of model training.
可选的,在本公开的另一个实施例中,还提供了另一种语音活动检测模型构建方法实施例,与上述任一实施例相同或类似的内容,这里将不再赘述。Optionally, in another embodiment of the present disclosure, another embodiment of a method for constructing a voice activity detection model is provided, which is the same as or similar to any of the above embodiments, and will not be repeated here.
在本实施例中,将详细说明将特征对齐后的所有模态特征进行融合,获取融合特征后,方法还包括如下方法步骤:In this embodiment, all modal features after feature alignment will be fused in detail. After the fused features are obtained, the method further includes the following method steps:
利用注意力机制,对融合特征执行注意力机制训练,确定融合特征中的不同模态特征的权重系数。Using the attention mechanism, perform attention mechanism training on the fusion features, and determine the weight coefficients of different modal features in the fusion features.
具体的,可以通过注意力机制,增强神经网络对输入的不同模态特征中某些部分的权重,同时减弱其他部分的权重。注意力机制是人工神经网络中一种模仿认知注意力的技术。Specifically, the attention mechanism can be used to enhance the weight of some parts of the input different modal features of the neural network, while weakening the weight of other parts. The attention mechanism is a technique that mimics cognitive attention in artificial neural networks.
例如,增加人的面部肌肉、表情、动作,唇部动作等特征中一种或多种的权重,用以根据面部肌肉、表情(神态)、动作等的变化、唇部动作的变化等,来预测用户是否说话。增加语音特征的权重,通过提高上述特征的权重,用以提高语音识别的敏感度和准确率,同时也可以辅助降低虚检率和漏检率等。而对于其他部分特征,例如环境噪音等无关紧要的特征,则尽量的降低这些特征的权重系数,以免对语音活动检测过程中的敏感度、准确率等造成影响,也可以避免虚检率和漏检率的升高。For example, increase the weight of one or more of the features of people's facial muscles, expressions, movements, lip movements, etc., to determine the Predict whether the user will speak or not. Increase the weight of speech features. By increasing the weight of the above features, it is used to improve the sensitivity and accuracy of speech recognition, and it can also help reduce the false detection rate and missed detection rate. For other features, such as insignificant features such as environmental noise, the weight coefficients of these features should be reduced as much as possible, so as not to affect the sensitivity and accuracy of the voice activity detection process, and can also avoid false detection rate and omission. increase in detection rate.
也即是,加入注意力机制,就是方便后续根据融合特征对初始模型进行迭代训练时,利用注意力机制,确定融合特征中的不同模态特征的权重系数。进而根据权重系数,提高可以准确识别语音活动的特征的权重,提高语音活动检测的敏感度和准确率,以及降低虚检率和漏检率等。That is to say, the addition of the attention mechanism is to facilitate subsequent iterative training of the initial model based on the fusion features, using the attention mechanism to determine the weight coefficients of different modal features in the fusion features. Furthermore, according to the weight coefficient, the weight of the feature that can accurately identify the voice activity is increased, the sensitivity and accuracy of voice activity detection are improved, and the false detection rate and missed detection rate are reduced.
需要说明的是,本公开侧重想要介绍的是如何构建一个能够提高语音活动检测的准确度,敏感度和准确率,以及降低虚检率和漏检率等的语音活动检测模型。至于后续的应用过程,完全类似于其他模型构建后的应用情形,所以,这里没有再对后续的应用做详细的介绍和说明。同样的,通过本公开中上述任一实施例构建语音活动检测模型后,无须每次都执行训练以后才可以应用到具体的应用场景,而是只要构建完成后(或经过测试合格后),即可应用于各种应用场景中,例如噪音嘈杂的场景,比如大规模的会议场景,比如外部环境嘈杂的室外场景等等,或者用户面部被局部遮挡的场景等,尤其是口被遮挡的情况。It should be noted that this disclosure focuses on how to construct a voice activity detection model that can improve the accuracy, sensitivity, and accuracy of voice activity detection, and reduce the false detection rate and missed detection rate. As for the subsequent application process, it is completely similar to the application situation after the construction of other models, so there is no detailed introduction and explanation for the subsequent application here. Similarly, after the voice activity detection model is constructed by any of the above-mentioned embodiments in the present disclosure, it is not necessary to perform training every time before it can be applied to a specific application scenario, but as long as the construction is completed (or after passing the test), that is It can be applied to various application scenarios, such as noisy scenes, such as large-scale conference scenes, such as outdoor scenes with noisy external environment, etc., or scenes where the user's face is partially occluded, especially when the mouth is occluded.
以上,为本公开所提供的语音活动检测模型构建对应的方法实施例,下文中则介绍说明本公开所提供的语音活动检测模型构建对应的其他实施例,具体参见如下。The above is the embodiment of the method corresponding to the construction of the voice activity detection model provided by the present disclosure. The following describes other embodiments corresponding to the construction of the voice activity detection model provided by the present disclosure. For details, refer to the following.
图3为本公开实施例提供的一种语音活动检测模型构建装置的结构示意图,该装置包括:获取模块301、提取模块302、处理模块303、融合模块304,以及训练模块305。FIG. 3 is a schematic structural diagram of a device for constructing a voice activity detection model provided by an embodiment of the present disclosure. The device includes: an
获取模块301,用于获取多模态数据,其中,多模态数据至少包括音频数据和视频数据;An
提取模块302,用于分别对多模态数据中每一模态数据进行特征提取,获取与每一模态数据分别对应的模态特征;The
处理模块303,用于当多种模态数据中的一种或多种模态数据对应的模态特征不符合预设对齐标准时,对一种或多种模态数据对应的模态特征进行特征对齐处理;A
融合模块304,用于将特征对齐后的所有模态特征进行融合,获取融合特征;The fusion module 304 is used to fuse all the modality features after feature alignment to obtain fusion features;
训练模块305,用于利用融合特征,对预构建的初始模型进行迭代训练,直至经过训练后的模型达到预设条件时,确定达到预设条件后的模型为最终的语音活动检测模型。The training module 305 is used to iteratively train the pre-built initial model by using the fused features until the trained model meets the preset condition, and determine that the model that meets the preset condition is the final voice activity detection model.
可选的,处理模块303具体用于,Optionally, the
根据预设对齐标准,和第一模态数据在单位时间内对应的特征数量,确定对第一模态数据的模态特征执行的特征对齐处理方式;According to the preset alignment standard and the number of features corresponding to the first modal data per unit time, determine the feature alignment processing method performed on the modal features of the first modal data;
按照与第一模态数据的模态特征对应的特征对齐处理方式,完成对第一模态数据对应的模态特征进行特征对齐处理,其中,特征对齐处理方式包括对模态特征进行上采样处理,或进行下采样处理,第一模态数据为一种或多种模态数据中的任一种模态数据。According to the feature alignment processing method corresponding to the modal features of the first modal data, the feature alignment processing of the modal features corresponding to the first modal data is completed, wherein the feature alignment processing method includes upsampling processing on the modal features , or perform down-sampling processing, the first modal data is any one of one or more modal data.
可选的,处理模块303,具体用于当第一模态数据对应的语音特征在单位时间内对应的特征数量大于预设特征数量时,确定对第一模态数据的模态特征执行的特征对齐处理方式为下采样处理;Optionally, the
或,当多模态数据中第一模态数据对应的语音特征在单位时间内对应的特征数量小于预设特征数量时,确定对第一模态数据的模态特征执行的特征对齐处理方式为上采样处理。Or, when the number of features corresponding to the speech features corresponding to the first modal data in the multimodal data is less than the preset number of features per unit time, it is determined that the feature alignment processing method performed on the modal features of the first modal data is Upsampling processing.
可选的,处理模块303,具体用于:当多模态数据包括第一模态数据和第二模态数据,且第一模态数据对应的语音特征在单位时间内对应的特征数量大于预设特征数量,第二模态数据对应的视频特征在单位时间内对应的特征数量小于预设特征数量时,将语音特征和视频特征分别输入至预构建的特征对齐模型中,以便在特征对齐模型中执行对语音特征的下采样处理,以及执行对视频特征的上采样处理,使得经过处理后的语音特征与经过处理后的视频特征对齐,其中,特征对齐模型包括至少两个特征对齐处理通道,语音特征和视频特征分别输入到特征对齐模型中的不同特征对齐处理通道。Optionally, the
可选的,融合模块304,具体用于将特征对齐后的所有模态特征进行拼接处理,获取融合特征。Optionally, the fusion module 304 is specifically configured to splice all the modal features after feature alignment to obtain fusion features.
可选的,融合模块304,具体用于将特征对齐后的所有模态特征进行点乘处理,获取融合特征。Optionally, the fusion module 304 is specifically configured to perform dot product processing on all modal features after feature alignment to obtain fusion features.
可选的,训练模块305还用于利用注意力机制,对融合特征执行注意力机制训练,确定融合特征中的不同模态特征的权重系数。Optionally, the training module 305 is further configured to use the attention mechanism to perform attention mechanism training on the fused features, and determine weight coefficients of different modal features in the fused features.
本公开实施例提供的语音活动检测模型构建装置中各部件所执行的功能均已在上述方法实施例中做了详细的描述,因此这里不再赘述。The functions performed by each component in the device for constructing a voice activity detection model provided by the embodiments of the present disclosure have been described in detail in the above method embodiments, so details are not repeated here.
本公开实施例提供的一种语音活动检测模型构建装置,获取多模态数据,其中多模态数据至少包括音频数据和图像数据。分别对多模态数据中每一模态数据进行特征提取,或与每一模态数据分别对应的模态特征,然后将多模态数据中的一种或多种模态数据对应的模态特征进行特征对齐处理,以便所有的模态特征对齐,然后将特征对齐后的所有模态特征进行融合,获取融合特征,并利用融合特征对预构建的初始模型进行迭代训练,直至经过训练后的模型达到预设条件时,确定达到预设条件后的模型为最终的语音活动检测模型。整个过程中,因为涉及了语音数据和视频数据,经过不断对初始模型进行迭代训练后,模型的语音识别能力和图像识别能力都将会提高。那么,在语音识别能力提高的情况下,就可以间接提高VAD的敏感度和准确率,而且通过视频数据的检测,例如检测到面部肌肉的动作,就可以进一步佐证是否存在用户说话,也就可以再次验证是否存在语音数据,进而提高VAD的敏感度和准确率。而且,也可以降低VAD漏检率。即使噪声很大,VAD无法通过语音数据检测到有人说话的情况下,也可以通过图像特征识别确实有用户在说话,因此可以降低漏检率。再者,即使通过语音数据识别到有说话声,但是通过图像识别可以判定当前时刻没有任何人脸部肌肉有动作的情况下,也可以识别到实际上当前没有人说话,可能是其他设备发出的人声,那么,这种情况下VAD依然可以确定没有人说话,也即是可以降低虚检率。当然,如果多模态数据中还包括其他模态数据,也可以进一步提升VAD的检测准确率。因此,在本申请文件中,多模态数据至少包括音频数据和视频数据。An apparatus for constructing a voice activity detection model provided by an embodiment of the present disclosure acquires multimodal data, wherein the multimodal data includes at least audio data and image data. Feature extraction is performed on each modality data in the multimodal data, or the modality features corresponding to each modality data, and then the modality corresponding to one or more modality data in the multimodal data The features are subjected to feature alignment processing so that all the modal features are aligned, and then all the modal features after feature alignment are fused to obtain the fused features, and the pre-built initial model is iteratively trained using the fused features until the trained model When the model meets the preset condition, it is determined that the model that meets the preset condition is the final voice activity detection model. During the whole process, because speech data and video data are involved, after continuous iterative training of the initial model, the speech recognition ability and image recognition ability of the model will be improved. Then, when the voice recognition ability is improved, the sensitivity and accuracy of VAD can be improved indirectly, and through the detection of video data, such as the detection of facial muscle movements, it can further prove whether there is user speech, which can also Verify again whether there is voice data, thereby improving the sensitivity and accuracy of VAD. Moreover, the VAD missed detection rate can also be reduced. Even if the noise is very large and VAD cannot detect someone speaking through the voice data, it can also identify the user speaking through the image feature, so the missed detection rate can be reduced. Furthermore, even if there is a voice recognized through the voice data, but it can be determined through image recognition that there is no facial muscle movement at the current moment, it can also be recognized that no one is actually speaking at the moment, and it may be from other devices. Human voice, then, in this case, VAD can still determine that no one is speaking, that is, it can reduce the false detection rate. Of course, if the multimodal data also includes other modal data, the detection accuracy of VAD can be further improved. Therefore, in this document, multimodal data includes at least audio data and video data.
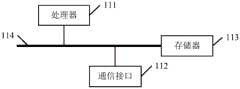
如图4所示,本公开实施例提供了一种电子设备,包括处理器111、通信接口112、存储器113和通信总线114,其中,处理器111,通信接口112,存储器113通过通信总线114完成相互间的通信。As shown in FIG. 4 , an embodiment of the present disclosure provides an electronic device, including a
存储器113,用于存放计算机程序;
在本公开一个实施例中,处理器111,用于执行存储器113上所存放的程序时,实现前述任意一个方法实施例提供的语音活动检测模型构建方法,该方法包括:In one embodiment of the present disclosure, the
获取多模态数据,其中,多模态数据至少包括音频数据和视频数据;Acquire multimodal data, where the multimodal data includes at least audio data and video data;
分别对多模态数据中每一模态数据进行特征提取,获取与每一模态数据分别对应的模态特征;performing feature extraction on each modality data in the multimodal data respectively, and obtaining modality features respectively corresponding to each modality data;
当多种模态数据中的一种或多种模态数据对应的模态特征不符合预设对齐标准时,对一种或多种模态数据对应的模态特征进行特征对齐处理;When the modal features corresponding to one or more modal data in the plurality of modal data do not meet the preset alignment standard, perform feature alignment processing on the modal features corresponding to one or more modal data;
将特征对齐后的所有模态特征进行融合,获取融合特征;All the modal features after feature alignment are fused to obtain the fused features;
利用融合特征,对预构建的初始模型进行迭代训练,直至经过训练后的模型达到预设条件时,确定达到预设条件后的模型为最终的语音活动检测模型。The fusion feature is used to iteratively train the pre-built initial model until the trained model reaches the preset condition, and the model after the preset condition is determined to be the final voice activity detection model.
可选的,预设对齐标准用以指示单位时间内对应预设特征数量;当多种模态数据中的一种或多种模态数据对应的模态特征不符合预设对齐标准时,对一种或多种模态数据对应的模态特征进行特征对齐处理,具体包括:Optionally, the preset alignment standard is used to indicate the number of corresponding preset features per unit time; when the modal features corresponding to one or more modal data in the multiple modal data do not meet the preset alignment standard, a The modal features corresponding to one or more modal data are subjected to feature alignment processing, including:
根据预设对齐标准,和第一模态数据在单位时间内对应的特征数量,确定对第一模态数据的模态特征执行的特征对齐处理方式;According to the preset alignment standard and the number of features corresponding to the first modal data per unit time, determine the feature alignment processing method performed on the modal features of the first modal data;
按照与第一模态数据的模态特征对应的特征对齐处理方式,完成对第一模态数据对应的模态特征进行特征对齐处理,其中,特征对齐处理方式包括对模态特征进行上采样处理,或进行下采样处理,第一模态数据为一种或多种模态数据中的任一种模态数据。According to the feature alignment processing method corresponding to the modal features of the first modal data, the feature alignment processing of the modal features corresponding to the first modal data is completed, wherein the feature alignment processing method includes upsampling processing on the modal features , or perform down-sampling processing, the first modal data is any one of one or more modal data.
可选的,根据所述预设对齐标准,和第一模态数据在单位时间内对应的特征数量,确定对第一模态数据的模态特征执行的特征对齐处理方式,具体包括:Optionally, according to the preset alignment standard and the number of features corresponding to the first modal data per unit time, determine the feature alignment processing method performed on the modal features of the first modal data, specifically including:
当第一模态数据对应的语音特征在单位时间内对应的特征数量大于预设特征数量时,确定对第一模态数据的模态特征执行的特征对齐处理方式为下采样处理;When the number of features corresponding to the speech features corresponding to the first modal data is greater than the preset number of features per unit time, it is determined that the feature alignment processing method performed on the modal features of the first modal data is down-sampling processing;
或,当多模态数据中第一模态数据对应的语音特征在单位时间内对应的特征数量小于预设特征数量时,确定对第一模态数据的模态特征执行的特征对齐处理方式为上采样处理。Or, when the number of features corresponding to the speech features corresponding to the first modal data in the multimodal data is less than the preset number of features per unit time, it is determined that the feature alignment processing method performed on the modal features of the first modal data is Upsampling processing.
可选的,当多模态数据包括第一模态数据和第二模态数据,且第一模态数据对应的语音特征在单位时间内对应的特征数量大于预设特征数量,第二模态数据对应的视频特征在单位时间内对应的特征数量小于预设特征数量时,方法包括:Optionally, when the multimodal data includes the first modal data and the second modal data, and the number of features corresponding to the speech features corresponding to the first modal data per unit time is greater than the preset number of features, the second modal When the number of features corresponding to the video features corresponding to the data is less than the preset number of features per unit time, the methods include:
将语音特征和视频特征分别输入至预构建的特征对齐模型中,以便在特征对齐模型中执行对语音特征的下采样处理,以及执行对视频特征的上采样处理,使得经过处理后的语音特征与经过处理后的视频特征对齐,其中,特征对齐模型包括至少两个特征对齐处理通道,语音特征和视频特征分别输入到特征对齐模型中的不同特征对齐处理通道。Input the speech features and video features into the pre-built feature alignment model, so as to perform down-sampling processing on the speech features in the feature alignment model, and perform up-sampling processing on the video features, so that the processed speech features and The processed video features are aligned, wherein the feature alignment model includes at least two feature alignment processing channels, and the speech features and video features are respectively input into different feature alignment processing channels in the feature alignment model.
可选的,将特征对齐后的所有模态特征进行融合,获取融合特征,具体包括:Optionally, all modal features after feature alignment are fused to obtain fused features, specifically including:
将特征对齐后的所有模态特征进行拼接处理,获取融合特征。All the modal features after feature alignment are spliced to obtain fusion features.
可选的,将特征对齐后的所有模态特征进行融合,获取融合特征,具体包括:Optionally, all modal features after feature alignment are fused to obtain fused features, specifically including:
将特征对齐后的所有模态特征进行点乘处理,获取融合特征。All modal features after feature alignment are processed by point multiplication to obtain fusion features.
可选的,将特征对齐后的所有模态特征进行融合,获取融合特征后,方法还包括:Optionally, all the modal features after feature alignment are fused, and after obtaining the fused features, the method further includes:
利用注意力机制,对融合特征执行注意力机制训练,确定融合特征中的不同模态特征的权重系数。Using the attention mechanism, perform attention mechanism training on the fusion features, and determine the weight coefficients of different modal features in the fusion features.
本公开实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被电子设备执行时实现如前述任一方法实施例提供的语音活动检测模型构建方法的步骤。An embodiment of the present disclosure also provides a computer-readable storage medium, on which a computer program is stored. When the computer program is executed by an electronic device, the steps of the method for constructing a voice activity detection model as provided in any of the foregoing method embodiments are implemented.
需要说明的是,在本文中,诸如“第一”和“第二”等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括要素的过程、方法、物品或者设备中还存在另外的相同要素。It should be noted that in this article, relative terms such as "first" and "second" are only used to distinguish one entity or operation from another entity or operation, and do not necessarily require or imply these No such actual relationship or order exists between entities or operations. Furthermore, the term "comprises", "comprises" or any other variation thereof is intended to cover a non-exclusive inclusion such that a process, method, article, or apparatus comprising a set of elements includes not only those elements, but also includes elements not expressly listed. other elements of or also include elements inherent in such a process, method, article, or device. Without further limitations, an element defined by the phrase "comprising a ..." does not preclude the presence of additional identical elements in the process, method, article, or apparatus that includes the element.
以上仅是本公开的具体实施方式,使本领域技术人员能够理解或实现本公开。对这些实施例的多种修改对本领域的技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本公开的精神或范围的情况下,在其它实施例中实现。因此,本公开将不会被限制于本文所示的这些实施例,而是要符合与本文所申请的原理和新颖特点相一致的最宽的范围。The above are only specific implementation manners of the present disclosure, so that those skilled in the art can understand or implement the present disclosure. Various modifications to these embodiments will be readily apparent to those skilled in the art, and the general principles defined herein may be implemented in other embodiments without departing from the spirit or scope of the present disclosure. Therefore, the present disclosure will not be limited to the embodiments shown herein, but is to be accorded the widest scope consistent with the principles and novel features claimed herein.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211353534.3ACN115910113A (en) | 2022-10-31 | 2022-10-31 | Voice activity detection model construction method, device and electronic equipment |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211353534.3ACN115910113A (en) | 2022-10-31 | 2022-10-31 | Voice activity detection model construction method, device and electronic equipment |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN115910113Atrue CN115910113A (en) | 2023-04-04 |
Family
ID=86471695
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202211353534.3APendingCN115910113A (en) | 2022-10-31 | 2022-10-31 | Voice activity detection model construction method, device and electronic equipment |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115910113A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116975696A (en)* | 2023-08-30 | 2023-10-31 | 杭州海康威视数字技术股份有限公司 | Task processing method and device, electronic equipment and storage medium |
- 2022
- 2022-10-31CNCN202211353534.3Apatent/CN115910113A/enactivePending
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116975696A (en)* | 2023-08-30 | 2023-10-31 | 杭州海康威视数字技术股份有限公司 | Task processing method and device, electronic equipment and storage medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110909613B (en) | Video character recognition method and device, storage medium and electronic equipment | |
| CN112889108B (en) | Speech classification using audiovisual data | |
| CN112686048B (en) | Emotion recognition method and device based on fusion of voice, semantics and facial expressions | |
| US11508366B2 (en) | Whispering voice recovery method, apparatus and device, and readable storage medium | |
| WO2024000867A1 (en) | Emotion recognition method and apparatus, device, and storage medium | |
| CN112329748B (en) | Automatic lie detection method, device, device and medium for interactive scene | |
| CN107346661B (en) | Microphone array-based remote iris tracking and collecting method | |
| CN113611308B (en) | A speech recognition method, device, system, server and storage medium | |
| CN113920560B (en) | Method, device and equipment for identifying multi-mode speaker identity | |
| CN112992191A (en) | Voice endpoint detection method and device, electronic equipment and readable storage medium | |
| CN111970471A (en) | Participant scoring method, device, equipment and medium based on video conference | |
| WO2024032159A1 (en) | Speaking object detection in multi-human-machine interaction scenario | |
| CN112232276A (en) | A kind of emotion detection method and device based on speech recognition and image recognition | |
| CN113129867B (en) | Training method of voice recognition model, voice recognition method, device and equipment | |
| CN111370004A (en) | Man-machine interaction method, voice processing method and equipment | |
| CN112489662B (en) | Method and apparatus for training speech processing model | |
| CN115910113A (en) | Voice activity detection model construction method, device and electronic equipment | |
| CN116405633A (en) | A sound source localization method and system for virtual video conferencing | |
| CN114283493A (en) | Artificial intelligence-based identification system | |
| CN115937726A (en) | Speaker detection method, device, equipment and computer readable storage medium | |
| CN117708752A (en) | Emotion recognition method and system based on video and audio information fusion | |
| CN111798849A (en) | Robot instruction identification method and device, electronic equipment and storage medium | |
| CN109782900A (en) | Man-machine interaction method and device | |
| CN116453539A (en) | Speech separation method, device, equipment and storage medium for multiple speakers | |
| CN115620713A (en) | Dialog intention recognition method, device, equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |