CN115718478A - SVG parameter optimization identification method based on SAC deep reinforcement learning - Google Patents
SVG parameter optimization identification method based on SAC deep reinforcement learningDownload PDFInfo
- Publication number
- CN115718478A CN115718478ACN202211466562.6ACN202211466562ACN115718478ACN 115718478 ACN115718478 ACN 115718478ACN 202211466562 ACN202211466562 ACN 202211466562ACN 115718478 ACN115718478 ACN 115718478A
- Authority
- CN
- China
- Prior art keywords
- value
- svg
- network
- parameter
- sac
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000000034methodMethods0.000titleclaimsabstractdescription59
- 230000002787reinforcementEffects0.000titleclaimsabstractdescription48
- 238000005457optimizationMethods0.000titleclaimsabstractdescription28
- 230000035945sensitivityEffects0.000claimsabstractdescription52
- 238000012549trainingMethods0.000claimsabstractdescription23
- 238000013178mathematical modelMethods0.000claimsabstractdescription6
- 238000012216screeningMethods0.000claimsabstractdescription3
- 230000009471actionEffects0.000claimsdescription44
- 238000004364calculation methodMethods0.000claimsdescription42
- 230000001052transient effectEffects0.000claimsdescription27
- 238000004422calculation algorithmMethods0.000claimsdescription23
- 230000006870functionEffects0.000claimsdescription23
- 238000013528artificial neural networkMethods0.000claimsdescription15
- 238000004088simulationMethods0.000claimsdescription9
- 238000011156evaluationMethods0.000claimsdescription6
- 230000008859changeEffects0.000claimsdescription5
- 230000006872improvementEffects0.000claimsdescription4
- 210000002569neuronAnatomy0.000claimsdescription3
- 238000005070samplingMethods0.000claimsdescription3
- 238000005259measurementMethods0.000abstractdescription3
- 238000010586diagramMethods0.000description12
- 239000002245particleSubstances0.000description7
- 230000001186cumulative effectEffects0.000description5
- 238000005516engineering processMethods0.000description5
- 238000012360testing methodMethods0.000description5
- 230000008901benefitEffects0.000description4
- 230000008569processEffects0.000description4
- 238000011160researchMethods0.000description4
- 238000004458analytical methodMethods0.000description2
- 230000006399behaviorEffects0.000description2
- 230000007613environmental effectEffects0.000description2
- 230000003993interactionEffects0.000description2
- 238000012986modificationMethods0.000description2
- 230000004048modificationEffects0.000description2
- 230000004044responseEffects0.000description2
- 230000003068static effectEffects0.000description2
- ORILYTVJVMAKLC-UHFFFAOYSA-NAdamantaneNatural productsC1C(C2)CC3CC1CC2C3ORILYTVJVMAKLC-UHFFFAOYSA-N0.000description1
- 230000005540biological transmissionEffects0.000description1
- 238000004891communicationMethods0.000description1
- 238000013135deep learningMethods0.000description1
- 238000001514detection methodMethods0.000description1
- 230000004069differentiationEffects0.000description1
- 238000002474experimental methodMethods0.000description1
- 230000001939inductive effectEffects0.000description1
- 238000009434installationMethods0.000description1
- 238000013507mappingMethods0.000description1
- 239000000463materialSubstances0.000description1
- 239000011159matrix materialSubstances0.000description1
Images






Classifications
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y02—TECHNOLOGIES OR APPLICATIONS FOR MITIGATION OR ADAPTATION AGAINST CLIMATE CHANGE
- Y02E—REDUCTION OF GREENHOUSE GAS [GHG] EMISSIONS, RELATED TO ENERGY GENERATION, TRANSMISSION OR DISTRIBUTION
- Y02E40/00—Technologies for an efficient electrical power generation, transmission or distribution
- Y02E40/10—Flexible AC transmission systems [FACTS]
Landscapes
- Supply And Distribution Of Alternating Current (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及电力信息技术领域,尤其是涉及基于SAC深度强化学习的SVG参数优化辨识方法。The invention relates to the field of electric power information technology, in particular to an SVG parameter optimization identification method based on SAC deep reinforcement learning.
背景技术Background technique
柔性交流输电技术FACTS的出现为提升电网可靠性和经济性提供了新的技术手段。静止无功发生器(SVG)作为FACTS家族的重要成员,在改善电力系统电压质量及提高系统运行稳定性方面得到广泛应用。准确的SVG控制器模型参数对电力系统仿真分析的正确性尤为重要,而很多厂商由于技术保密不提供相应的SVG控制参数,因此SVG控制器参数辨识很有必要。目前,对SVG控制器参数辨识的研究很少,更多的是对其控制器模型和工作原理的研究,由于SVG控制器参数众多,所以对SVG控制器进行参数辨识要花费许多时间。因此,研究出适当的方法对SVG控制器进行参数辨识并得出准确的参数具有工程意义和研究价值。The emergence of flexible AC transmission technology FACTS provides a new technical means for improving the reliability and economy of the power grid. As an important member of the FACTS family, static var generator (SVG) has been widely used in improving power system voltage quality and improving system operation stability. Accurate SVG controller model parameters are very important to the correctness of power system simulation analysis, and many manufacturers do not provide corresponding SVG control parameters due to technical confidentiality, so SVG controller parameter identification is necessary. At present, there are few researches on parameter identification of SVG controller, and more researches on its controller model and working principle. Due to the large number of parameters of SVG controller, it takes a lot of time to identify the parameters of SVG controller. Therefore, it is of engineering significance and research value to develop an appropriate method to identify the parameters of the SVG controller and obtain accurate parameters.
文献“Zheng Qiang Guan,Si Jing Liu,Xing Hua Liu.Static Var GeneratorTechnology and its Applications[J].Applied Mechanics and Materials,2014,2963(494-495):”对SVG控制器的工作原理以及无功电流的检测方法作了详细介绍,但对于SVG控制器参数辨识问题的研究较少。文献“夏天华,马骏超,黄弘扬,彭琰,肖修林,陈皓,郭瑞鹏.基于RTDS硬件在环测试的SVG控制器参数辨识[J].电力系统保护与控制,2020,48(13):110-116”提出了一种基于控制器硬件的在环测试的参数辨识方法,采用的粒子群算法虽然简单,但容易陷入局部最优解。文献“曹斌,丛雨,原帅,张晓琳,王琪,王立强,赵永飞.基于控制器硬件在环的SVG模型参数测试方法[J].电器与能效管理技术,2021(06):63-66+78.”提出了一种基于RTDS硬件的在环测试的参数辨识方法,将测试得到的SVG响应数据作为实测数据,对于不同的控制器参数组合,采用BPA软件进行暂态仿真,根据暂态仿真结果与实测数据的最小二乘指标进行参数辨识,能够准确对SVG控制器参数进行辨识,但是SVG控制器参数众多,对每个参数进行辨识耗时较大。文献“Sutton R S,Barto A G.Reinforcementlearning:An introduction[M].Cambridge,MA:MIT press,2018.”针对风电场随机特性引起的辨识结果不准确问题,综合低风速模型算法和高风速模型算法的优点,提出一种多方式混合辨识算法。The document "Zheng Qiang Guan, Si Jing Liu, Xing Hua Liu. Static Var Generator Technology and its Applications [J]. Applied Mechanics and Materials, 2014, 2963 (494-495):" on the working principle of SVG controller and reactive current The detection method of SVG controller has been introduced in detail, but there are few researches on the problem of parameter identification of SVG controller. Literature "Xia Hua, Ma Junchao, Huang Hongyang, Peng Yan, Xiao Xiulin, Chen Hao, Guo Ruipeng. Parameter identification of SVG controller based on RTDS hardware-in-the-loop test [J]. Power System Protection and Control, 2020,48(13):110 -116" proposed a parameter identification method based on controller hardware in-the-loop test. Although the particle swarm algorithm adopted is simple, it is easy to fall into local optimal solution. Literature "Cao Bin, Cong Yu, Yuan Shuai, Zhang Xiaolin, Wang Qi, Wang Liqiang, Zhao Yongfei. SVG model parameter testing method based on controller hardware in the loop [J]. Electrical Appliances and Energy Efficiency Management Technology, 2021(06):63-66 +78." proposed a parameter identification method for in-the-loop testing based on RTDS hardware, using the SVG response data obtained from the test as the actual measurement data, and using BPA software for transient simulation for different controller parameter combinations. The parameter identification of the simulation results and the least squares index of the measured data can accurately identify the parameters of the SVG controller. However, there are many parameters of the SVG controller, and it takes a long time to identify each parameter. In the literature "Sutton R S, Barto A G. Reinforcement learning: An introduction[M]. Cambridge, MA: MIT press, 2018." Aiming at the problem of inaccurate identification results caused by the random characteristics of wind farms, the low wind speed model algorithm and the high wind speed model algorithm were integrated Based on the advantages, a multi-mode hybrid identification algorithm is proposed.
强化学习主要关注智能体如何对环境的刺激做出决策,以取得最大的平均累积回报,从而形成一种从状态到动作的映射关系。强化学习方法与一般的数学优化算法和现代进化算法相比有很多优势。第一,强化学习在寻优的过程中不需要精确模型,甚至不需要对模型进行任何描述。因此,强化学习方法具有较强的通用性。第二,强化学习对策略的优化仅仅依靠于在不同状态或行为下环境反馈的奖励或惩罚信号,不需要计算目标函数的梯度信息。因此,强化学习方法可避免对目标函数连续、可导、凸性等要求,也避免了求微分和矩阵求逆等复杂运算,很大程度降低了计算的时间和复杂度。Reinforcement learning mainly focuses on how the agent makes decisions about the stimuli of the environment in order to obtain the maximum average cumulative return, thus forming a mapping relationship from state to action. Reinforcement learning methods have many advantages over general mathematical optimization algorithms and modern evolutionary algorithms. First, reinforcement learning does not require an accurate model, or even any description of the model, in the process of optimization. Therefore, reinforcement learning methods have strong versatility. Second, the optimization of strategies by reinforcement learning only relies on the reward or punishment signals of environmental feedback in different states or behaviors, and does not need to calculate the gradient information of the objective function. Therefore, the reinforcement learning method can avoid the requirements of continuous, differentiable, and convexity of the objective function, and also avoid complex operations such as differentiation and matrix inversion, which greatly reduces the time and complexity of calculation.
强化学习通过智能体感知环境状态信息,通过反复试错不断修正智能体行为策略,从而获得最大化的平均累积回报。强化学习具有对环境的先验要求低的优点,是一种可以应用到实时环境中的在线学习方法,因此在电力系统领域有着广泛的应用。在电力系统无功优化领域,文献“Shang X,Li M,Ji T,et al.Discrete reactive poweroptimization considering safety margin by dimensional Q-learning[A].In:2015IEEE Innovative Smart Grid Technologies-Asia(ISGTASIA)[C],2015.1–5.”采用强化学习对电力系统无功进行优化。文献“Shang X,Li M,Ji T,et al.Discrete reactivepower optimization considering safety margin by dimensional Q-learning[A].In:2015IEEE Innovative Smart GridTechnologies-Asia(ISGTASIA)[C],2015.1–5.”提出了一种基于分维搜索的强化学习算法,其奖励函数设计采用罚函数形式将电压安全问题和发电机无功出力限制考虑在内。文献“尚筱雅.基于改进强化学习算法的终端电网在线等值建模方法及其应用[D].华南理工大学,2018.”提出一种ERL(Enhanced ReinforcementLearning)算法对区域负荷时变系统进行参数辨识,该算法能对模型参数进行准确快速的跟踪。文献“Wang Siqi et al.On Multi-Event Co-Calibration of Dynamic ModelParameters Using Soft Actor-Critic[J].IEEE TRANSACTIONS ON POWER SYSTEMS,2021,36(1):521-524.”提出了一种基于最大熵、soft actor critic(SAC)的非策略深度强化学习(DRL)算法的参数校准方法,以自动调整不正确的参数集,同时考虑多个事件,可以节省大量的劳动力。Reinforcement learning uses the agent to perceive the state information of the environment, and continuously corrects the agent's behavior strategy through trial and error, so as to obtain the maximum average cumulative return. Reinforcement learning has the advantage of low prior requirements on the environment, and it is an online learning method that can be applied to real-time environments, so it has a wide range of applications in the field of power systems. In the field of power system reactive power optimization, the literature "Shang X, Li M, Ji T, et al. Discrete reactive poweroptimization considering safety margin by dimensional Q-learning[A].In:2015IEEE Innovative Smart Grid Technologies-Asia(ISGTASIA)[ C], 2015.1–5.” Using Reinforcement Learning to Optimize Power System Reactive Power. The document "Shang X, Li M, Ji T, et al.Discrete reactivepower optimization considering safety margin by dimensional Q-learning[A].In:2015IEEE Innovative Smart Grid Technologies-Asia(ISGTASIA)[C],2015.1–5." A reinforcement learning algorithm based on fractal search is proposed, and its reward function is designed in the form of a penalty function, taking voltage safety issues and generator reactive output constraints into consideration. Literature "Shang Xiaoya. Online Equivalent Modeling Method and Application of Terminal Power Grid Based on Improved Reinforcement Learning Algorithm [D]. South China University of Technology, 2018." Proposed an ERL (Enhanced Reinforcement Learning) algorithm for regional load time-varying systems Parameter identification, the algorithm can accurately and quickly track the model parameters. The document "Wang Siqi et al.On Multi-Event Co-Calibration of Dynamic ModelParameters Using Soft Actor-Critic[J].IEEE TRANSACTIONS ON POWER SYSTEMS,2021,36(1):521-524." proposed a method based on the maximum Parameter calibration methods for entropy, soft actor critic (SAC) off-policy deep reinforcement learning (DRL) algorithms to automatically tune incorrect parameter sets while considering multiple events can save a lot of labor.
综上,本发明考虑将强化学习应用到SVG控制器参数辨识,克服传统方法计算量大的缺陷,通过soft actor critic(SAC)深度强化学习算法对SVG参数进行准确快速估计。In summary, the present invention considers the application of reinforcement learning to the identification of SVG controller parameters, overcomes the disadvantage of large amount of calculation in traditional methods, and accurately and quickly estimates SVG parameters through the soft actor critic (SAC) deep reinforcement learning algorithm.
发明内容Contents of the invention
本发明的目的是提供一种基于SAC深度强化学习的SVG参数优化辨识方法,解决以上所述的问题。The purpose of the present invention is to provide a method for optimal identification of SVG parameters based on SAC deep reinforcement learning to solve the above-mentioned problems.
为实现上述目的,本发明提供了一种基于SAC深度强化学习的SVG参数优化辨识方法,其特征在于:包括以下步骤:In order to achieve the above object, the present invention provides a SVG parameter optimization identification method based on SAC deep reinforcement learning, which is characterized in that: comprising the following steps:
步骤一,建立与SVG实测曲线运行环境相同的SVG接入单机无穷大系统的等值数学模型;
步骤二,利用扰动法计算各参数的无功功率轨迹灵敏度、电压轨迹灵敏度以及电流轨迹灵敏度并进行筛选;Step 2, using the perturbation method to calculate the reactive power trajectory sensitivity, voltage trajectory sensitivity and current trajectory sensitivity of each parameter and perform screening;
步骤三,建立基于BPA的SAC的环境;Step 3, establishing a BPA-based SAC environment;
步骤四,搭建SAC智能体;Step 4, build the SAC agent;
步骤五,开始SVG参数辨识训练,得到最终辨识结果。Step five, start the SVG parameter identification training, and obtain the final identification result.
优选的,SVG实测曲线为RTDS实测曲线,所使用的仿真工具PSD-BPA。Preferably, the SVG measured curve is the RTDS measured curve, and the used simulation tool PSD-BPA.
优选的,步骤二的具体方法为:Preferably, the specific method of step 2 is:
SVG参数存于暂态数据文件中的VG/VG+卡,待辨识参数以BPA暂态数据文件中VG/VG+卡的值作为参数初始值进行潮流计算,设置短路故障,进行暂态计算,记录接有SVG母线处的无功曲线,电流曲线以及电压曲线;将选定参数在初始值的基础上增加5%,再一次进行暂态计算,得到输出曲线,然后计算选定参数的无功轨迹灵敏度、电流轨迹灵敏度、电压轨迹灵敏度,计算公式如下:The SVG parameters are stored in the VG/VG+ card in the transient data file. The parameters to be identified use the value of the VG/VG+ card in the BPA transient data file as the initial value of the parameter for power flow calculation, set short-circuit fault, perform transient calculation, and record connection There are reactive power curves, current curves and voltage curves at the SVG bus; increase the selected parameters by 5% on the basis of the initial value, and perform transient calculations again to obtain output curves, and then calculate the reactive power trajectory sensitivity of the selected parameters , current track sensitivity, and voltage track sensitivity, the calculation formulas are as follows:

式中:
优选的,步骤三的具体方法为:Preferably, the specific method of step three is:
针对辨识的每个SVG参数,确定参数的范围,SVG参数的值作为状态st,SVG参数值的改变量为动作at,做出动作后的下一次状态为For each identified SVG parameter, determine the range of the parameter, the value of the SVG parameter is the statet , the change of the SVG parameter value is the action at , and the next state after the action is
st+1→st+atst+1 →st +at
根据BPA中的暂态文件SWI文件格式,将状态st+1即SVG参数的值写入暂态文件SWI中,然后进行一次暂态计算,得到结果文件SWX,然后从结果文件SWX中读出当前状态下的无功功率Q,随后计算奖励R为:According to the format of the transient file SWI in BPA, write the state st+1 , that is, the value of the SVG parameter, into the transient file SWI, and then perform a transient calculation to obtain the result file SWX, and then read it from the result file SWX The reactive power Q in the current state, and then calculate the reward R as:
R=-(Q-QRTDS)2R=-(QQRTDS )2
其中QRTDS为RTDS实测无功功率数据;Where QRTDS is RTDS measured reactive power data;
SAC给出的动作at使得下一次的状态超过设定的SVG参数范围,给予SAC模型惩罚,使奖励R为-20,下一次的状态st+1在范围之内,则正常训练;The action at given by SAC makes the next state exceed the set SVG parameter range, and the SAC model is punished so that the reward R is -20, and the next state st+1 is within the range, then normal training;
最终得到当前状态st,当前动作at,下一次的状态st+1和奖励R,然后将(st,at,st+1,R)并存入集合D中用于后面训练,奖励R的大小作为评价指标,每次训练观察奖励R的值是否满足目标。Finally get the current statest , current action at , next state st+1 and reward R, and then save (stt , at ,st+1 , R) into the set D for later training , the size of the reward R is used as an evaluation index, and each training observes whether the value of the reward R meets the target.
优选的,步骤四的具体方法为:Preferably, the specific method of step 4 is:
SAC智能体中的神经网络选取MLP多层感知机,MLP神经网络的结构包括输入层、隐藏层和输出层,目标值网络


SAC智能体中状态价值网络


其中

然后训练动作价值网络





其中,







目标值网络




得到每个网络的误差函数之后,开始计算各个网络误差函数的梯度


优选的,步骤五的具体方法为:Preferably, the specific method of step five is:
首先初始化基于BPA的暂态计算环境,并初始化SVG参数和参数范围,然后初始化SAC模型,并初始化网络参数
因此,本发明采用上述基于SAC深度强化学习的SVG参数优化辨识方法,利用电力系统仿真软件BPA对SVG进行建模仿真,然后根据轨迹灵敏度筛选出对SVG无功动态曲线影响较大的SVG主要参数,采用这种方法能够减少参与辨识的参数数目,减少参数辨识时间。其次设定SVG参数的范围,用Tensorflow搭建SAC模型,然后通过SVG实测曲线和SAC智能体训练,最终得到辨识出RTDS的SVG参数,解决传统算法中经常出现的稳定性较差和难以收敛的问题,减少参数辨识的复杂度,提高对控制器影响较大的参数的辨识精度,提高辨识效率。Therefore, the present invention adopts the above-mentioned SAC deep reinforcement learning-based SVG parameter optimization identification method, uses the power system simulation software BPA to model and simulate SVG, and then screens out the main parameters of SVG that have a greater impact on the SVG reactive power dynamic curve according to the trajectory sensitivity , using this method can reduce the number of parameters involved in the identification and reduce the parameter identification time. Secondly, set the range of SVG parameters, use Tensorflow to build the SAC model, and then through the SVG measured curve and SAC agent training, finally get the SVG parameters that identify the RTDS, and solve the problems of poor stability and difficult convergence that often occur in traditional algorithms , reduce the complexity of parameter identification, improve the identification accuracy of parameters that have a greater impact on the controller, and improve the identification efficiency.
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。The technical solutions of the present invention will be described in further detail below with reference to the accompanying drawings and embodiments.
附图说明Description of drawings
图1为本发明基于SAC深度强化学习的SVG参数优化辨识方法流程图;Fig. 1 is the flow chart of the SVG parameter optimization identification method based on SAC deep reinforcement learning in the present invention;
图2为本发明SVG控制器模型图;Fig. 2 is the SVG controller model diagram of the present invention;
图3为本发明接有SVG的单机无穷大系统模型图;Fig. 3 is that the present invention is connected with the stand-alone infinite system model figure of SVG;
图4为本发明强化学习原理图;Fig. 4 is the schematic diagram of reinforcement learning of the present invention;
图5为本发明SAC结构图;Fig. 5 is the structural diagram of SAC of the present invention;
图6为本发明粒子群优化算法的辨识结果图;Fig. 6 is the identification result figure of particle swarm optimization algorithm of the present invention;
图7为本发明SAC深度强化学习方法得到的辨识结果图。Fig. 7 is a diagram of the identification results obtained by the SAC deep reinforcement learning method of the present invention.
具体实施方式Detailed ways
以下通过附图和实施例对本发明的技术方案作进一步说明。The technical solutions of the present invention will be further described below through the accompanying drawings and embodiments.
除非另外定义,本发明使用的技术术语或者科学术语应当为本发明所属领域内具有一般技能的人士所理解的通常意义。本发明中使用的“第一”、“第二”以及类似的词语并不表示任何顺序、数量或者重要性,而只是用来区分不同的组成部分。“包括”或者“包含”等类似的词语意指出现该词前面的元件或者物件涵盖出现在该词后面列举的元件或者物件及其等同,而不排除其他元件或者物件。术语“设置”、“安装”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。“上”、“下”、“左”、“右”等仅用于表示相对位置关系,当被描述对象的绝对位置改变后,则该相对位置关系也可能相应地改变。Unless otherwise defined, the technical terms or scientific terms used in the present invention shall have the usual meanings understood by those skilled in the art to which the present invention belongs. "First", "second" and similar words used in the present invention do not indicate any order, quantity or importance, but are only used to distinguish different components. "Comprising" or "comprising" and similar words mean that the elements or items appearing before the word include the elements or items listed after the word and their equivalents, without excluding other elements or items. The terms "setting", "installation" and "connection" should be understood in a broad sense, for example, it can be fixed connection, detachable connection, or integral connection; it can be mechanical connection or electrical connection; it can be direct It can also be connected indirectly through an intermediary, or it can be the internal communication of two elements. "Up", "Down", "Left", "Right" and so on are only used to indicate the relative positional relationship. When the absolute position of the described object changes, the relative positional relationship may also change accordingly.
实施例Example
图1为本发明基于SAC深度强化学习的SVG参数优化辨识方法流程图;图2为本发明SVG控制器模型图;图3为本发明接有SVG的单机无穷大系统模型图;图4为本发明强化学习原理图;图5为本发明SAC结构图;图6为本发明粒子群优化算法的辨识结果图;图7为本发明SAC深度强化学习方法得到的辨识结果图。Fig. 1 is the flow chart of the SVG parameter optimization identification method based on SAC deep reinforcement learning of the present invention; Fig. 2 is a model diagram of the SVG controller of the present invention; Fig. 3 is a model diagram of a stand-alone infinite system connected with SVG in the present invention; Fig. 4 is a diagram of the present invention Reinforcement learning principle diagram; Fig. 5 is the SAC structure diagram of the present invention; Fig. 6 is the identification result diagram of the particle swarm optimization algorithm of the present invention; Fig. 7 is the identification result diagram obtained by the SAC deep reinforcement learning method of the present invention.
如图所示,本发明所述的一种基于SAC深度强化学习的SVG参数优化辨识方法,包括以下步骤:As shown in the figure, a SAC deep reinforcement learning-based SVG parameter optimization identification method described in the present invention includes the following steps:
步骤一,建立与SVG实测曲线运行环境相同的SVG接入单机无穷大系统的等值数学模型。其中SVG实测曲线采用RTDS实测曲线,建立等值数学模型使用仿真工具PSD-BPA(简称BPA),是电力系统计算分析的综合电力仿真软件,在国内电力调度运行机构和电力系统规划相关单位及各高校中都得到了广泛应用,具有潮流计算、暂态稳定仿真计算、短路计算、小干扰稳定计算等功能。潮流计算:潮流计算文件格式为DAT,潮流数据文件是为潮流运算提供数据与指令、按照BPA定义的DAT文本文件,可直接编辑、修改参数。暂态计算:暂态计算文件格式为SWI。与潮流数据文件类似,元件动态参数、故障操作、计算和输出控制均以卡片形式输入,并可通过设置相关卡片的参数进行不同干扰方式下的稳定计算。Step 1: Establish an equivalent mathematical model of the SVG access stand-alone infinite system with the same operating environment as the SVG measured curve. Among them, the SVG measured curve adopts the RTDS measured curve, and the equivalent mathematical model is established using the simulation tool PSD-BPA (BPA for short), which is a comprehensive power simulation software for power system calculation and analysis. It has been widely used in colleges and universities, and has functions such as power flow calculation, transient stability simulation calculation, short circuit calculation, and small disturbance stability calculation. Power flow calculation: The file format of power flow calculation is DAT, and the power flow data file is a DAT text file that provides data and instructions for power flow calculation and is defined in accordance with BPA. It can be directly edited and modified parameters. Transient calculation: The format of the transient calculation file is SWI. Similar to power flow data files, component dynamic parameters, fault operations, calculations, and output control are all input in the form of cards, and stable calculations under different disturbance modes can be performed by setting the parameters of related cards.
图1为SVG控制器模型图,图中:V为SVG输出端电压,VREF为参考电压,VSCS为辅助信号,VT为系统侧电压,IS为SVG输出电流,T1为滤波器和测量回路的时间常数,T2、T3分别为第一级超前时间常数和第二级滞后时间常数,T4、T5分别为第二级超前时间常数和第三级滞后时间常数,TP为比例环节时间常数,TS为SVG响应延迟,KP为比例环节放大倍数,KI为积分环节的放大倍数,KD为SVG的V-I特性曲线的斜率,XT为SVG与系统之间的等值电抗。图中还有六个限幅环节:VMAX为电压限幅环节的上限,VMIN为电压限幅环节的下限,ICMAX为最大容性电流,ILMAX为最大感性电流,比例和积分环节输出的限幅VSMAX和VSMIN的计算公式如下:Figure 1 is a model diagram of the SVG controller, in which: V is the voltage at the SVG output terminal, VREF is the reference voltage, VSCS is the auxiliary signal, VT is the system side voltage, IS is the SVG output current, and T1 is the filter and the time constant of the measurement circuit, T2 and T3 are the first-level leading time constant and the second-level lagging time constant respectively, T4 and T5 are the second-level leading time constant and the third-level lagging time constant respectively, TP is the time constant of the proportional link, TS is the response delay of SVG, KP is the magnification of the proportional link, KI is the magnification of the integral link, KD is the slope of the VI characteristic curve of SVG, and XT is the distance between SVG and the system equivalent reactance. There are six limiting links in the figure: VMAX is the upper limit of the voltage limiting link, VMIN is the lower limit of the voltage limiting link, ICMAX is the maximum capacitive current, ILMAX is the maximum inductive current, and the proportional and integral link output The limiting formulas of VSMAX and VSMIN are as follows:

图2为经典的单机无穷大模型,将SVG接入该模型进行后续仿真计算。Figure 2 is a classic stand-alone infinite model, and SVG is connected to the model for subsequent simulation calculations.
步骤二,利用扰动法计算各参数的无功功率轨迹灵敏度、电压轨迹灵敏度以及电流轨迹灵敏度,探究不同观测量下的轨迹灵敏值,设定阈值,筛选出轨迹灵敏度大于设定阈值的参数。Step 2: Use the perturbation method to calculate the reactive power trajectory sensitivity, voltage trajectory sensitivity, and current trajectory sensitivity of each parameter, explore the trajectory sensitivity values under different observations, set thresholds, and screen out parameters with trajectory sensitivities greater than the set thresholds.
1、根据BPA中的SVG控制器模型,初始待辨识参数有[T1,T2,T3,T4,T5,TS,TP,KP,KI,KD,VMAX,VMIN,ICMAX,ILMAX](XT为系统等值电抗,根据厂家给定值确定后不作辨识。)以暂态数据文件中的VG/VG+卡中的参数值作为初始值,(各初始值为T1=0.005,T2=T3=T4=T5=1,TP=0.5,TS=0.003,KP=0.05,KI=600,KD=0.02,VMAX=1,VMIN=-1,ICMAX=ILMAX=1.1),t=0.072时,在图2的SVG母线处设置三相短路故障,故障在0.1秒后切除,进行暂态计算,记录SVG装置的输出无功功率值、电流值以及电压值。1. According to the SVG controller model in BPA, the initial parameters to be identified are [T1 , T2 , T3 , T4 , T5 , TS , TP , K P, KI , KD , VMAX , VMIN , ICMAX , ILMAX ] (XT is the equivalent reactance of the system, which will not be identified after being determined according to the manufacturer's given value.) The parameter values in the VG/VG+ card in the transient data file are used as initial values, (each The initial values are T1 =0.005, T2 =T3 =T4 =T5 =1, TP =0.5, TS =0.003, KP =0.05, KI =600, KD =0.02, VMAX = 1, VMIN =-1, ICMAX =ILMAX =1.1), when t=0.072, a three-phase short-circuit fault is set at the SVG busbar in Figure 2, and the fault is removed after 0.1 second, and the transient state calculation is performed to record the SVG device The output reactive power value, current value and voltage value.
2、将T1增加5%,其余参数保持不变,重复与上步相同的计算。将其余每个参数分别增加5%,(一个参数变化时,其余参数保持不变),分别得到每个参数在变化后的仿真无功曲线、电流曲线、电压曲线。2. Increase T1 by 5%, keep the other parameters unchanged, and repeat the same calculation as the previous step. Increase each of the other parameters by 5% respectively (when one parameter changes, the other parameters remain unchanged) to obtain the simulated reactive power curve, current curve, and voltage curve of each parameter after the change.
3、根据公式分别计算各参数的无功功率轨迹灵敏度、电压轨迹灵敏度以及电流轨迹灵敏度。无功轨迹灵敏度、电流轨迹灵敏度、电压轨迹灵敏度,计算公式如下:3. Calculate the reactive power trajectory sensitivity, voltage trajectory sensitivity and current trajectory sensitivity of each parameter according to the formula. Reactive track sensitivity, current track sensitivity, voltage track sensitivity, the calculation formula is as follows:

式中:
根据上述步骤,编写程序计算轨迹灵敏度,计算结果如表1所示。According to the above steps, write a program to calculate the trajectory sensitivity, and the calculation results are shown in Table 1.

表1参数轨迹灵敏度Table 1 Parameter trajectory sensitivity
由表1可得,各参数电压灵敏度比较接近,较难比较,而且电压灵敏度相对于电流灵敏度和无功灵敏度较小,因此电压灵敏度不作为判断指标。而电流灵敏度与无功灵敏度得出的各参数灵敏度大小结果相同,因此,在后续计算中只选取SVG输出的无功功率作为判断灵敏度大小的指标。It can be seen from Table 1 that the voltage sensitivity of each parameter is relatively close, and it is difficult to compare, and the voltage sensitivity is smaller than the current sensitivity and reactive power sensitivity, so the voltage sensitivity is not used as a judgment index. However, the sensitivity results of each parameter derived from current sensitivity and reactive power sensitivity are the same. Therefore, in the subsequent calculation, only the reactive power output by SVG is selected as the index for judging the sensitivity.
根据轨迹灵敏度计算结果可得,参数VMAX、VMIN的轨迹灵敏度为0;参数KP、TP的轨迹灵敏度较小,接近于0,在后续辨识中,这四个参数即用初始值,不作辨识。根据轨迹灵敏度筛选后的所需辨识参数为:[T1,T2,T3,T4,T5,TS,KI,KD,ICMAX]。According to the trajectory sensitivity calculation results, the trajectory sensitivity of the parameters VMAX and VMIN is 0; the trajectory sensitivity of the parameters KP and TP is small and close to 0. In the subsequent identification, the initial values of these four parameters are used. No identification is made. The required identification parameters screened according to the trajectory sensitivity are: [T1 , T2 , T3 , T4 , T5 , TS , KI , KD , ICMAX ].
步骤三,建立基于BPA的SAC的环境。The third step is to establish the environment of the BPA-based SAC.
接下来用SAC深度强化学习来辨识SVG参数。SAC模型包含环境和智能体,首先要进行环境的搭建。SVG参数[T1,T2,T3,T4,T5,TS,KI,KD,ICMAX]作为待辨识参数,各参数范围为:T1:0.005-0.071,T2-T5:0.9-1.1,TS:0.005-0.007,KI:700-900,KD:0.02-0.04,ICMAX:1.1-1.13。针对辨识的每个SVG参数,确定参数的范围,SVG参数的值作为状态st,SVG参数值的改变量为动作at(训练时,动作at由SAC智能体给出),做出动作后的下一次状态为Next, SAC deep reinforcement learning is used to identify SVG parameters. The SAC model includes the environment and agents, and the environment must be constructed first. SVG parameters [T1 , T2 , T3 , T4 , T5 , TS , KI , KD , ICMAX ] are used as parameters to be identified, and the range of each parameter is: T1 : 0.005-0.071, T2 - T5 : 0.9-1.1, Ts : 0.005-0.007, KI : 700-900, KD : 0.02-0.04, ICMAX : 1.1-1.13. For each SVG parameter identified, determine the range of the parameter, the value of the SVG parameter as the statet , the change of the SVG parameter value is the action at (during training, the action at is given by the SAC agent), and make an action The next state after
st+1=st+at (3)st+1 =st +at (3)
根据BPA中的暂态文件SWI文件格式,将状态st+1即SVG参数的值写入暂态文件SWI中,然后进行一次暂态计算,得到结果文件SWX。然后从结果文件SWX中读出当前状态下的无功功率Q,随后计算奖励R为:According to the format of the transient file SWI in BPA, the statest+1 , that is, the value of the SVG parameter, is written into the transient file SWI, and then a transient calculation is performed to obtain the result file SWX. Then read the reactive power Q in the current state from the result file SWX, and then calculate the reward R as:
R=-(Q-QRTDS)2 (4)R=-(QQRTDS )2 (4)
其中QRTDS为RTDS实测无功功率数据。Among them, QRTDS is the measured reactive power data of RTDS.
如果SAC给出的动作at使得下一次的状态超过设定的SVG参数范围,则给予SAC模型一个大的惩罚,使奖励R为-20。如果下一次的状态st+1在范围之内,则正常训练。If the action at given bySAC makes the next state exceed the set SVG parameter range, a large penalty is given to the SAC model, so that the reward R is -20. If the next state st+1 is within the range, train normally.
最终得到当前状态st,当前动作at,下一次的状态st+1和奖励R,然后将(st,at,st+1,R)并存入集合D中用于后面训练,奖励R的大小作为评价指标,每次训练观察奖励R的值是否满足目标。Finally get the current statest , current action at , next state st+1 and reward R, and then save (stt , at ,st+1 , R) into the set D for later training , the size of the reward R is used as an evaluation index, and each training observes whether the value of the reward R meets the target.
步骤四,搭建SAC智能体。Step 4, build the SAC agent.
强化学习是一种通过智能体与环境进行交互,通过环境反馈不断地对其策略进行修正的一种学习算法,其最终目的是获得最大平均累积回报。Reinforcement learning is a learning algorithm that continuously modifies its strategy through the interaction between the agent and the environment through environmental feedback, and its ultimate goal is to obtain the maximum average cumulative return.
标准RL(ReinforcementLearning)的目标是学习一个π*函数使累加的奖励期望值最大,而SAC训练了一个带有最大熵的π*函数,这代表着它不仅最大化了奖励期望,而且要求策略π的熵也要最大化。最大熵maximumentropy的核心思想就是不会遗落任意一个有用的动作,这就意味着神经网络需要去探索所有可能的最优路径,这使得SAC获得更强的探索能力和更强的鲁棒性。SAC的最优策略π*为要求累加的奖励和熵的期望值最大:The goal of standard RL (Reinforcement Learning) is to learn a π* function to maximize the cumulative reward expectation, while SAC trains a π* function with maximum entropy, which means that it not only maximizes the reward expectation, but also requires the strategy π Entropy is also maximized. The core idea of maximum entropy maximumentropy is not to leave any useful action, which means that the neural network needs to explore all possible optimal paths, which makes SAC gain stronger exploration ability and stronger robustness. The optimal strategy of SAC π* is to require the maximum expected value of cumulative reward and entropy:

H(π(at|st))=-logπ(at|st) (6)H(π(at |st ))=-logπ(at |st ) (6)
其中H(π(at|st))是状态st时策略的熵,计算公式如公式(6)所示。π(at|st)为SAC的策略函数,R(st,at)为状态为st,动作为at时的奖励,
SAC(soft actor critic)是强化学习中一种基于最大熵的非策略强化学习算法,它将强化学习跟深度学习结合起来,用神经网络来模拟策略、状态价值函数和动作价值函数。SAC模型中智能体和环境的交互如图3所示,SAC模型中包含两个网络,actor网络和critic网络,actor网络仅包含一个策略网络πφ(at|st),而critic网络中包含四个网络,一个状态价值网络


SAC深度强化学习的网络结构如图4所示。SAC智能体中的神经网络选取MLP多层感知机,MLP神经网络的结构包括输入层、隐藏层和输出层。目标值网络


表2参数值Table 2 parameter values
SAC智能体中状态价值网络


其中







其中,













得到每个网络的误差函数之后,开始计算各个网络误差函数的梯度


SAC算法的网络参数更新流程如下:The network parameter update process of the SAC algorithm is as follows:
第一步,初始化参数向量ψ,
第二步,得到初始状态st,动作at~πφ(at|st),根据公式(3)得到St+1~(st,at),根据公式(4)计算奖励R(st,at),将(st,at,st+1,R)存入replaybuffer D中。The second step is to get the initial state st , the action at ~πφ (at |st ), get St+1 ~(st ,at) according to the formula (3), and calculate the reward according to the formula (4) R(st , at ), store (st , at , st+1 , R) in replaybuffer D.
第三步,k满足设定次数30之后,从D中取得存储的样本数据,根据公式(13)计算策略网络πφ(at|st),动作价值网络


第四步,根据公式(12)更新参数
第五步,返回第二步。The fifth step, return to the second step.
步骤五,开始SVG参数辨识训练,得到最终辨识结果。Step five, start the SVG parameter identification training, and obtain the final identification result.
首先建立基于BPA的暂态计算环境,并初始化SVG参数和参数范围,然后建立SAC模型,并初始化网络参数
实验是在NVIDIA GeForce RTX 3060Laptop GPU上进行的,使用Tensorflow搭建神经网络并进行训练,优化器选择Adam。本专利方法的训练流程图如图5所示,当仿真的无功功率跟RTDS实测无功功率数据误差小于允许值时,输出SVG当前参数值,即为辨识结果。The experiment was carried out on NVIDIA GeForce RTX 3060Laptop GPU, and Tensorflow was used to build and train the neural network, and Adam was selected as the optimizer. The training flow chart of the patented method is shown in Figure 5. When the error between the simulated reactive power and the RTDS measured reactive power data is less than the allowable value, the current parameter value of the SVG is output, which is the identification result.
使用SAC深度强化学习对系统参数进行估计的主要目的是减少参数辨识的计算量,缩短计算时间,但前提是要保证参数预测结果的准确度,必须在验证这种辨识方法的准确可行之后才能进一步讨论其对于效率的提升。因此,实验结果主要关注准确度和时间两个方面。同时,将本方法与粒子群优化方法作对比,以展现基于SAC深度强化学习参数辨识的优势。The main purpose of using SAC deep reinforcement learning to estimate system parameters is to reduce the calculation amount of parameter identification and shorten the calculation time, but the premise is to ensure the accuracy of the parameter prediction results, and it is necessary to verify the accuracy and feasibility of this identification method before proceeding. Discuss its improvement in efficiency. Therefore, the experimental results mainly focus on the two aspects of accuracy and time. At the same time, this method is compared with the particle swarm optimization method to demonstrate the advantages of parameter identification based on SAC deep reinforcement learning.
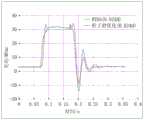
图6、7中RTDS曲线为实测曲线。图6中优化曲线为使用粒子群优化方法得到的辨识曲线,图7中BPA曲线为使用本文所提SAC深度强化学习方法得到的辨识结果曲线。由仿真曲线可看出本文方法辨识精度更高,从时间上看本文方法辨识速度也更快,辨识效率更高。辨识结果及精度对比如表3所示:The RTDS curves in Figures 6 and 7 are measured curves. The optimization curve in Figure 6 is the identification curve obtained by using the particle swarm optimization method, and the BPA curve in Figure 7 is the identification result curve obtained by using the SAC deep reinforcement learning method proposed in this paper. It can be seen from the simulation curve that the method in this paper has higher identification accuracy, and the method in this paper has faster identification speed and higher identification efficiency in terms of time. The identification results and accuracy comparison are shown in Table 3:
(a)(a)

(b)(b)
表3辨识结果对比Table 3 Comparison of identification results
从时间上看,本文方法的参数辨识过程只用了12.39min,优于粒子群优化方法。从该点上看,使用SAC深度强化学习算法的参数辨识能大大缩短辨识过程的时间,并且能够保证较高的辨识精度。In terms of time, the parameter identification process of the method in this paper only takes 12.39 minutes, which is better than the particle swarm optimization method. From this point of view, the parameter identification using the SAC deep reinforcement learning algorithm can greatly shorten the time of the identification process, and can ensure a high identification accuracy.
因此,本发明采用上述基于SAC深度强化学习的SVG参数优化辨识方法,利用电力系统仿真软件BPA对SVG进行建模仿真,然后根据轨迹灵敏度筛选出对SVG无功动态曲线影响较大的SVG主要参数,采用这种方法能够减少参与辨识的参数数目,减少参数辨识时间。其次设定SVG参数的范围,用Tensorflow搭建SAC模型,然后通过SVG实测曲线和SAC智能体训练,最终得到辨识出RTDS的SVG参数,解决传统算法中经常出现的稳定性较差和难以收敛的问题,减少参数辨识的复杂度,提高对控制器影响较大的参数的辨识精度,提高辨识效率。Therefore, the present invention adopts the above-mentioned SAC deep reinforcement learning-based SVG parameter optimization identification method, uses the power system simulation software BPA to model and simulate SVG, and then screens out the main parameters of SVG that have a greater impact on the SVG reactive power dynamic curve according to the trajectory sensitivity , using this method can reduce the number of parameters involved in the identification and reduce the parameter identification time. Secondly, set the range of SVG parameters, use Tensorflow to build the SAC model, and then through the SVG measured curve and SAC agent training, finally get the SVG parameters that identify the RTDS, and solve the problems of poor stability and difficult convergence that often occur in traditional algorithms , reduce the complexity of parameter identification, improve the identification accuracy of parameters that have a greater impact on the controller, and improve the identification efficiency.
最后应说明的是:以上实施例仅用以说明本发明的技术方案而非对其进行限制,尽管参照较佳实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对本发明的技术方案进行修改或者等同替换,而这些修改或者等同替换亦不能使修改后的技术方案脱离本发明技术方案的精神和范围。Finally, it should be noted that the above embodiments are only used to illustrate the technical solutions of the present invention and not to limit them. Although the present invention has been described in detail with reference to the preferred embodiments, those of ordinary skill in the art should understand that: it still Modifications or equivalent replacements can be made to the technical solutions of the present invention, and these modifications or equivalent replacements cannot make the modified technical solutions deviate from the spirit and scope of the technical solutions of the present invention.
Claims (6)
Translated fromChinese
































Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211466562.6ACN115718478A (en) | 2022-11-22 | 2022-11-22 | SVG parameter optimization identification method based on SAC deep reinforcement learning |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211466562.6ACN115718478A (en) | 2022-11-22 | 2022-11-22 | SVG parameter optimization identification method based on SAC deep reinforcement learning |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN115718478Atrue CN115718478A (en) | 2023-02-28 |
Family
ID=85255947
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202211466562.6APendingCN115718478A (en) | 2022-11-22 | 2022-11-22 | SVG parameter optimization identification method based on SAC deep reinforcement learning |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115718478A (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116470522A (en)* | 2023-03-31 | 2023-07-21 | 中国电力科学研究院有限公司 | Control parameter identification method and device for SVG universal electromagnetic transient model |
| CN118862661A (en)* | 2024-07-04 | 2024-10-29 | 国网江苏省电力有限公司 | A method for constructing proxy model of reactive support equipment near DC drop point based on hybrid machine learning |
| CN119628117A (en)* | 2024-12-30 | 2025-03-14 | 山东大学 | Active load shedding optimization control method, system, device and storage medium for wind farm |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112632860A (en)* | 2021-01-04 | 2021-04-09 | 华中科技大学 | Power transmission system model parameter identification method based on reinforcement learning |
| CN113406434A (en)* | 2021-05-14 | 2021-09-17 | 杭州电子科技大学 | SVG dynamic parameter segmentation optimization identification method based on parameter fault characteristics |
| CN114740730A (en)* | 2022-04-26 | 2022-07-12 | 杭州电子科技大学 | SVG parameter optimization identification method based on convolutional neural network |
| WO2022167600A1 (en)* | 2021-02-04 | 2022-08-11 | Deepmind Technologies Limited | Temporal difference scaling when controlling agents using reinforcement learning |
| US20220315219A1 (en)* | 2021-04-03 | 2022-10-06 | Northwestern Polytechnical University | Air combat maneuvering method based on parallel self-play |
- 2022
- 2022-11-22CNCN202211466562.6Apatent/CN115718478A/enactivePending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112632860A (en)* | 2021-01-04 | 2021-04-09 | 华中科技大学 | Power transmission system model parameter identification method based on reinforcement learning |
| WO2022167600A1 (en)* | 2021-02-04 | 2022-08-11 | Deepmind Technologies Limited | Temporal difference scaling when controlling agents using reinforcement learning |
| US20220315219A1 (en)* | 2021-04-03 | 2022-10-06 | Northwestern Polytechnical University | Air combat maneuvering method based on parallel self-play |
| CN113406434A (en)* | 2021-05-14 | 2021-09-17 | 杭州电子科技大学 | SVG dynamic parameter segmentation optimization identification method based on parameter fault characteristics |
| CN114740730A (en)* | 2022-04-26 | 2022-07-12 | 杭州电子科技大学 | SVG parameter optimization identification method based on convolutional neural network |
Non-Patent Citations (3)
| Title |
|---|
| 刘抚楷: "基于深度强化学习的船舶路径规划方法研究", 《中国优秀硕士学位论文全文数据库》, 15 September 2021 (2021-09-15)* |
| 胡键雄: "直流输电系统参数测辨与在线校正方法研究", 《中国优秀硕士学位论文全文数据库 工程科技II辑》, no. 3, 15 March 2022 (2022-03-15), pages 2 - 7* |
| 齐欣: "基于强化学习的辨识算法超参数优化方法研究", 《中国优秀硕士学位论文全文数据库 基础科学辑》, no. 3, 15 March 2022 (2022-03-15), pages 16 - 23* |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116470522A (en)* | 2023-03-31 | 2023-07-21 | 中国电力科学研究院有限公司 | Control parameter identification method and device for SVG universal electromagnetic transient model |
| CN116470522B (en)* | 2023-03-31 | 2024-05-03 | 中国电力科学研究院有限公司 | A control parameter identification method and device for SVG universal electromagnetic transient model |
| CN118862661A (en)* | 2024-07-04 | 2024-10-29 | 国网江苏省电力有限公司 | A method for constructing proxy model of reactive support equipment near DC drop point based on hybrid machine learning |
| CN119628117A (en)* | 2024-12-30 | 2025-03-14 | 山东大学 | Active load shedding optimization control method, system, device and storage medium for wind farm |
| CN119628117B (en)* | 2024-12-30 | 2025-07-08 | 山东大学 | Active load shedding optimization control method, system and equipment for wind farm and storage medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN115718478A (en) | SVG parameter optimization identification method based on SAC deep reinforcement learning | |
| CN111900731B (en) | A PMU-based Power System State Estimation Performance Evaluation Method | |
| CN103326358B (en) | Electric power system dynamic state estimation method based on synchronous phase-angle measuring device | |
| CN110363334B (en) | Grid line loss prediction method for photovoltaic grid-connected based on gray neural network model | |
| CN112330488B (en) | Power grid frequency situation prediction method based on transfer learning | |
| CN113406434B (en) | SVG dynamic parameter segmentation optimization identification method based on parameter fault characteristics | |
| CN108448568A (en) | Hybrid State Estimation Method of Distribution Network Based on Measurement Data of Multiple Time Periods | |
| CN112865109B (en) | Data-driven power system power flow calculation method | |
| CN105429134A (en) | Grid voltage stability prediction method based on power big data | |
| CN114626769B (en) | Operation and maintenance method and system for capacitor voltage transformer | |
| CN108233356B (en) | A photovoltaic inverter controller consistency evaluation method and evaluation platform | |
| CN103544546A (en) | Method for online prediction of quiescent voltage stability limit of electric system | |
| CN108090615A (en) | Low-limit frequency Forecasting Methodology after electric power system fault based on cross entropy integrated study | |
| CN117057284A (en) | Conversion data processing equivalent adjustment method and device for electromagnetic transient model | |
| CN111654033A (en) | Method and system for assessing static voltage stability situation of large power grid based on linear deduction | |
| CN115907526A (en) | Power grid voltage sag evaluation method and system, storage medium and computing device | |
| CN115374938A (en) | A distribution network voltage prediction method based on XGBoost | |
| CN119070306A (en) | Evaluation method and system for improving transmission capacity of key sections by grid-connected energy storage | |
| CN102542076B (en) | Correction method of simulation track of power grid frequency dynamic process | |
| CN117434379A (en) | A multi-scenario low-voltage distribution network abnormal line loss tracing method, system and equipment | |
| CN112134274B (en) | New energy collection region reactive power configuration method based on big data mining | |
| CN111756031A (en) | A method and system for estimating power grid operation trend | |
| CN115425768A (en) | PyTorch-based LCC-S type WPT system load and self-mutual inductance identification method and system | |
| CN115796336A (en) | A Line Loss Prediction Method in Station Area Based on Feature Selection and GRU Network | |
| Huang | Line loss prediction of distribution network based on BP Neural Network |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |