CN115688775A - An Attention Mechanism-Based Method for Named Entity Recognition in Power Grid Inspection Field - Google Patents
An Attention Mechanism-Based Method for Named Entity Recognition in Power Grid Inspection FieldDownload PDFInfo
- Publication number
- CN115688775A CN115688775ACN202211164862.9ACN202211164862ACN115688775ACN 115688775 ACN115688775 ACN 115688775ACN 202211164862 ACN202211164862 ACN 202211164862ACN 115688775 ACN115688775 ACN 115688775A
- Authority
- CN
- China
- Prior art keywords
- word
- power grid
- named entity
- vector
- inspection
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



Classifications
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y04—INFORMATION OR COMMUNICATION TECHNOLOGIES HAVING AN IMPACT ON OTHER TECHNOLOGY AREAS
- Y04S—SYSTEMS INTEGRATING TECHNOLOGIES RELATED TO POWER NETWORK OPERATION, COMMUNICATION OR INFORMATION TECHNOLOGIES FOR IMPROVING THE ELECTRICAL POWER GENERATION, TRANSMISSION, DISTRIBUTION, MANAGEMENT OR USAGE, i.e. SMART GRIDS
- Y04S10/00—Systems supporting electrical power generation, transmission or distribution
- Y04S10/50—Systems or methods supporting the power network operation or management, involving a certain degree of interaction with the load-side end user applications
Landscapes
- Machine Translation (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及了一种电网运检文本处理识别方法,尤其是涉及了一种基于注意力机制的电网运检领域命名实体识别方法。The invention relates to a text processing and recognition method for grid operation inspection, in particular to an attention mechanism-based named entity recognition method in the field of grid operation inspection.
背景技术Background technique
随着经济社会的发展和全球能源短缺的问题,电网技术的发展也遇到了新的瓶颈。面对当前的挑战和问题,不少国家相继开展了智能电网技术的研究工作。智能电网的建设目标是使用信息化和数字化的方法优化发电、输电、用电的各个步骤。当前,我国已基本完成国家智能电网的初步构建,智能电网的建设多集中在智能硬件、特高压智能电网建设、数据智能可视化监控等领域。而在电网运检领域,运检系统积累了体量大且增长迅速的缺陷故障文档记录。在处理这些问题时,存在操作经验依赖严重、标准文件依赖纸质化、过于依靠专家经验、无法形成有效的知识库和做出智能化决策等问题和痛点。With the development of economy and society and the problem of global energy shortage, the development of power grid technology has also encountered new bottlenecks. Facing the current challenges and problems, many countries have successively carried out research work on smart grid technology. The goal of smart grid construction is to use information and digital methods to optimize each step of power generation, power transmission, and power consumption. At present, my country has basically completed the initial construction of the national smart grid, and the construction of the smart grid is mostly concentrated in the fields of smart hardware, UHV smart grid construction, and data intelligent visualization monitoring. In the field of power grid operation inspection, the operation inspection system has accumulated a large volume of defect and fault documentation records that are growing rapidly. When dealing with these problems, there are problems and pain points such as the heavy reliance on operating experience, the reliance on paper-based standard documents, the over-reliance on expert experience, and the inability to form an effective knowledge base and make intelligent decisions.
知识图谱的本质是一种结构化的知识表示方式,是使用人工智能技术和图结构存储多种实体和关系的知识网络结构。知识图谱能有效利用大数据和机器学习的优势,为运检指挥人员提供辅助决策,提升应对异常和故障的处置能力。在智能电网的建设中,知识图谱针对图像监控设备故障、检修编排、文本挖掘等领域都有较好的应用效果。命名实体识别作为知识图谱中较为关键的一环,可以从大量文本语料中提取出相关信息实体,完成智能电网的结构化数据建设,有效提高运维人员的效率。The essence of knowledge graph is a structured knowledge representation method, which is a knowledge network structure that uses artificial intelligence technology and graph structure to store various entities and relationships. The knowledge map can effectively use the advantages of big data and machine learning to provide auxiliary decision-making for the inspection commanders and improve the ability to deal with abnormalities and failures. In the construction of smart grids, knowledge graphs have good application effects in areas such as image monitoring equipment failure, maintenance arrangement, and text mining. As a key part of the knowledge map, named entity recognition can extract relevant information entities from a large amount of text corpus, complete the structured data construction of the smart grid, and effectively improve the efficiency of operation and maintenance personnel.
近年来多采用深度学习的方法进行命名实体识别。其中大致分为三个框架,分别为:输入的分布式表示模块、上下文特征提取模块和标签解码模块。一般使用BiLSTM+CRF的方法来进行实体识别。本发明在此基础上加入了BERT嵌入层、多头注意力机制层和字词联合嵌入的方法,通过这些方法有进一步明确实体边界,提升实体识别的准确性。In recent years, deep learning methods have been used for named entity recognition. It is roughly divided into three frameworks, namely: input distributed representation module, context feature extraction module and label decoding module. Generally, the BiLSTM+CRF method is used for entity recognition. On this basis, the present invention adds a BERT embedding layer, a multi-head attention mechanism layer, and a joint word embedding method, through which the entity boundary can be further clarified and the accuracy of entity recognition can be improved.
发明内容Contents of the invention
为了解决背景技术中存在的问题,本发明提出了一种基于注意力机制的电网运检领域命名实体识别方法,能够利用这些数据进行命名实体识别以支持电网领域知识图谱的建设,最终实现电网运检领域的智能化控制和运行。In order to solve the problems existing in the background technology, the present invention proposes a named entity recognition method in the field of power grid operation inspection based on attention mechanism, which can use these data for named entity recognition to support the construction of knowledge graphs in the power grid field, and finally realize power grid operation. Intelligent control and operation in the inspection field.
为了实现上述目的,本发明的技术方案是:In order to achieve the above object, technical scheme of the present invention is:
方法建立电网运检识别模型,根据预先已经标注命名实体的电网系统运检文本输入到电网运检识别模型中进行训练,再利用训练后的电网运检识别模型对待测的电网系统运检文本进行处理获得对应的命名实体。Methods The power grid operation inspection recognition model is established, and the grid system operation inspection text that has been marked with the named entity is input into the power grid operation inspection recognition model for training, and then the power grid operation inspection recognition model after training is used to carry out Process to obtain the corresponding named entity.
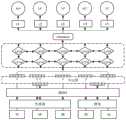
如图1所示,所述的电网运检识别模型包括嵌入层Embedding、双向长短期记忆模型层BiLSTM、注意力机制层attention、条件随机场层CRF的依次进行的四个部分;As shown in Figure 1, the power grid operation inspection recognition model includes four parts that are sequentially carried out in the embedding layer Embedding, the bidirectional long-short-term memory model layer BiLSTM, the attention mechanism layer attention, and the conditional random field layer CRF;
电网系统运检文本先输入到嵌入层中处理获得每个字的关键向量,进而将各个字的关键向量经双向长短期记忆模型层处理获得每个字对应的语义序列,再将每个字对应的语义序列经注意力机制层处理设置上注意力权重,最后将各个字对应的语义序列及其注意力权重结合输入到条件随机场层CRF预测输出各个字的命名实体分类,将命名实体同一类且相关的字组建成一个命名实体。The power grid system operation inspection text is first input into the embedding layer to obtain the key vector of each word, and then the key vector of each word is processed by the two-way long-term short-term memory model layer to obtain the semantic sequence corresponding to each word, and then each word is corresponding to The semantic sequence of each word is processed by the attention mechanism layer to set the attention weight, and finally the semantic sequence corresponding to each word and its attention weight are combined and input to the conditional random field layer CRF to predict and output the named entity classification of each word, and the named entities of the same class And related words are combined into a named entity.
所述的嵌入层能够将文本转化为带有关键语义信息的向量表示。The embedding layer can convert text into a vector representation with key semantic information.
所述的嵌入层,具体为:The embedding layer is specifically:
先通过中文分词框架对输入的电网系统运检文本进行分词,经过分词后生成一个分词向量W=(w1,w2,…,wm),其中m为分词后的词语数量,wm表示第m个词语;First, use the Chinese word segmentation framework to segment the input power grid system operation inspection text, and generate a word segmentation vector W=(w1 ,w2 ,…,wm ) after word segmentation, where m is the number of words after word segmentation, and wm represents the mth word;
同时采用基于变换器的双向编码器表示模块BERT对电网系统运检文本的每一句话进行处理获得以每个字为单位的向量作为字的向量,表示为E=(e1,e2,…,en),其中E表示字总向量,en表示第n个字的向量;At the same time, the converter-based bidirectional encoder representation module BERT is used to process each sentence of the power grid system operation inspection text to obtain a vector of each word as a word vector, expressed as E=(e1 ,e2 ,… , en ), where E represents the total word vector, and en represents the vector of the nth word;
然后对电网系统运检文本的每个字进行遍历,当且仅当每个字ci位于分词后的词语中,对词语内所有的字ci的向量进行平均计算,得到一个长度为n的平均词向量Ew,最后将平均词向量Ew拼接到字ci的向量后面形成作为该字ci的关键向量。对两个嵌入向量进行拼接操作,如图2所示。Then traverse each word of the power grid system operation inspection text, if and only if each word ci is in the word after word segmentation, calculate the average vector of all the words ci in the word, and obtain a length n The average word vector Ew , and finally the average word vector Ew is spliced behind the vector of the wordci to form the key vector of the wordci . The splicing operation is performed on the two embedding vectors, as shown in Figure 2.
从而将每个字为单位的向量进行平均作为词的向量,每个字的向量拼接上所在词的向量获得关键向量。Therefore, the vectors of each word as a unit are averaged as the vector of the word, and the vector of each word is concatenated with the vector of the word where it is located to obtain the key vector.
在电网运检维护领域的自然语言处理任务一直都面临着数据资源丰富性低、知识领域性强、知识门槛性高的特点。在运检维护领域,常常涉及到变压器的各个专业部件和故障术语,这也给智慧化改造带来了一定的难题。例如,故障报告,“#2主变有载轻瓦斯动作未复归”、“#1主变110kV开关低气压报警”。其中有诸如“有载”、“轻瓦斯”等专业术语,这给命名实体识别带来了挑战。本发明方法通过上述的嵌入层进行处理能够有机结合字符和词语的双重信息,能进一步明确实体边界信息,提升电网运检领域的实体识别效果。Natural language processing tasks in the field of power grid inspection and maintenance have always faced the characteristics of low abundance of data resources, strong knowledge domain, and high knowledge threshold. In the field of operation inspection and maintenance, various professional components and fault terms of transformers are often involved, which also brings certain difficulties to intelligent transformation. For example, fault report, "#2 main transformer has load light gas action not reset", "#1 main transformer 110kV switch low pressure alarm". Among them are technical terms such as "on-load", "light gas", etc., which pose a challenge for named entity recognition. The method of the present invention can organically combine the dual information of characters and words through the above-mentioned embedding layer to process, can further clarify entity boundary information, and improve the entity recognition effect in the field of power grid inspection.
在处理电网运检文本的嵌入层之后,本发明选择BiLSTM作为后续的解析层。所述的双向长短期记忆模型层采用循环神经网络(Recurrent Neural Network,RNN)。After processing the embedding layer of the power grid inspection text, the present invention selects BiLSTM as the subsequent parsing layer. The two-way long-short-term memory model layer adopts a recurrent neural network (Recurrent Neural Network, RNN).
通过循环神经网络表示当前输入的每个字的关键向量与序列信息之间的关系,在处理序列特征的数据上效果显著。循环神经网络同时使用正向LSTM和反向LSTM,解决了LSTM前后序列权重偏差的问题。The relationship between the key vector of each word currently input and the sequence information is represented by a cyclic neural network, which has a remarkable effect on processing sequence feature data. The cyclic neural network uses forward LSTM and reverse LSTM at the same time, which solves the problem of sequence weight deviation before and after LSTM.
具体实施中,通过对电网系统运检文本的定量分析发现,很多实体分布较为分散。另一方面,很多运检维护人员记录的文本前后标准不一,描述不规范,文本中的无用词较多,从一定程度上稀释了文本中的真正有用信息。本发明通过设置注意力机制层让算法模型在训练的过程中更加注重于关键信息,起到了强化特征的作用,解决文本前后标准不一、描述不规范、文本中的无用词较多的问题,实现真正有用的信息识别和提取。In the specific implementation, through the quantitative analysis of the power grid system operation inspection text, it is found that many entities are relatively scattered. On the other hand, the texts recorded by many transportation inspection and maintenance personnel have different standards before and after, the descriptions are not standardized, and there are many useless words in the texts, which dilutes the really useful information in the texts to a certain extent. The present invention allows the algorithm model to pay more attention to key information during the training process by setting the attention mechanism layer, which plays a role in strengthening features, and solves the problems of inconsistent standards before and after the text, irregular descriptions, and many useless words in the text. Realize the identification and extraction of really useful information.
所述的注意力机制层中,对不同的字分配注意力权重,分配的注意力权重a如下式:In the described attention mechanism layer, different words are assigned attention weights, and the attention weight a of distribution is as follows:

其中,ai表示第j个字的注意力权重,yi代表从双向长短期记忆模型层输出的第i个字对应的语义序列,bij表示第i个字和第j个字之间的相关性概率,i、j表示第i个字和第j个字的不同字的序号,N表示字的总数;Among them, ai represents the attention weight of the j-th word, yi represents the semantic sequence corresponding to the i-th word output from the two-way long-term short-term memory model layer, bij represents the distance between the i-th word and the j-th word Correlation probability, i, j represent the sequence numbers of the different words of the i word and the j word, and N represents the total number of words;
相关性概率bij按照以下公式计算:The correlation probability bij is calculated according to the following formula:

其中,wi和wj为文本分词后第i个字和第j个字所在的词语,n为词语总数量,f(·)表示计算词语之间的相似性函数,exp()表示以自然常数e为底的指数函数。Among them, wi and wj are the words where the i-th word and j-th word are located after the text segmentation, n is the total number of words, f(·) means to calculate the similarity function between words, and exp() means to use natural Exponential function with constant e as base.
在经过注意力机制层的输出后,利用条件随机场层对其进行标注输出,且设置任何约束,以避免产生不合逻辑的预测结果。例如在BIO标注法的约定中,一个以I标签开头的实体并没有实际的语义信息。After the output of the attention mechanism layer, use the conditional random field layer to mark the output, and set any constraints to avoid illogical prediction results. For example, in the BIO notation convention, an entity beginning with an I tag has no actual semantic information.
图1中,c1~c5为条件随机场最优化处理输出的标签序列表示,b-p——故障位置的序列开头,i-p——故障位置的序列其他位置,b-f、i-f分别表示故障类型的序列开头和故障类型的序列其他位置In Fig. 1, c1~c5 are the label sequence representations output by conditional random field optimization processing, b-p—the beginning of the sequence of the fault location, i-p—the other positions of the sequence of the fault location, b-f, i-f respectively represent the beginning and the beginning of the sequence of the fault type Elsewhere in the sequence of failure types
所述的条件随机场层采用经典的概率图模型,输出每个字的命名实体分类,本发明使用CRF层对上层的输出结果进行约束,防止语义序列特征出现不存在的依赖关系。The conditional random field layer adopts a classic probability graph model to output the named entity classification of each word. The present invention uses the CRF layer to constrain the output results of the upper layer to prevent non-existent dependencies of semantic sequence features.
本发明是针对电网系统运检文本而提出的一种命名实体识别方法,可以有效地对各类电力设备故障案例文本的实体信息进行抽取,将非结构化数据转化为结构化数据,再利用提取出的实体构建电网运检知识图谱用于指导电网运检的实际生产中,提升运维人员的工作效率。The invention is a named entity recognition method proposed for power grid system inspection texts, which can effectively extract entity information of various power equipment failure case texts, convert unstructured data into structured data, and then use the extracted The obtained entity constructs the power grid operation inspection knowledge map to guide the actual production of power grid operation inspection and improve the work efficiency of operation and maintenance personnel.
电网系统运检文本,是在电网运检维修中产生的记录运检维修信息的文本。The grid system inspection text is the text generated during the grid inspection and maintenance to record the inspection and maintenance information.
所述的命名实体是指电网运检维修中对于运检维修有意义的、电网运检维修所关注的对象词。The named entities refer to object words that are meaningful to the inspection and maintenance of the power grid and are concerned by the inspection and maintenance of the power grid.
通常例如故障位置、故障类型的感兴趣关键词。Typically keywords of interest such as fault location, fault type.
本发明的有益效果是:The beneficial effects of the present invention are:
本发明是一种融合注意力机制和字词联合嵌入向量的基于BERT+BiLSTM+CRF的命名实体识别算法,该算法模型能很好的抽取出电力系统的运检维修文本中的各类实体,将这些原始的非结构化数据转化为可以进行后续操作的结构化数据。The present invention is a named entity recognition algorithm based on BERT+BiLSTM+CRF that combines the attention mechanism and word joint embedding vector. The algorithm model can well extract all kinds of entities in the inspection and maintenance text of the power system. Transform these raw unstructured data into structured data for subsequent operations.
本发明针对电网垂直领域中资源低下、标准不统一的问题,设计了一种基于注意力机制和字词联合嵌入向量的方法,其可以有效解决在垂直领域下传统预训练模型不能解决的实体边界不明确、专业术语识别度不高的问题,在命名实体识别准确率上得到了提升。Aiming at the problems of low resources and non-uniform standards in the vertical field of the power grid, the present invention designs a method based on the attention mechanism and the joint embedding vector of words, which can effectively solve the entity boundary that cannot be solved by the traditional pre-training model in the vertical field The accuracy of named entity recognition has been improved for problems that are not clear and the recognition of technical terms is not high.
附图说明Description of drawings
图1为本发明的系统架构示意图;Fig. 1 is a schematic diagram of the system architecture of the present invention;
图2为本发明的字词联合嵌入图;Fig. 2 is the word joint embedding figure of the present invention;
图3为本发明的系统架构实施流程图;Fig. 3 is the implementation flowchart of the system framework of the present invention;
图4为本发明的算法效率对比实验图;Fig. 4 is the comparison experiment figure of algorithmic efficiency of the present invention;
表1为本发明的模型综合对比实验。Table 1 is a model comprehensive comparison experiment of the present invention.
具体实施方式Detailed ways
下面根据附图详细说明本发明。The present invention will be described in detail below according to the accompanying drawings.
按照本发明完整方案实施的实施例的具体实施过程包括数据处理、模型构建、模型训练、评价输出指标等过程,如图3所示:The specific implementation process of the embodiment implemented according to the complete scheme of the present invention includes processes such as data processing, model construction, model training, and evaluation output indicators, as shown in Figure 3:
(1)数据处理(1) Data processing
本发明实验采用的实验数据来自于某电网公司大约16年的缺陷运检维护记录,运检维护记录一般包括发生站点、故障位置、故障类型等信息。经过处理后,共得到大约15余万字符,将其按照6:2:2的比例划分为训练集、验证集与测试集。本发明选择BiLSTM+CRF作为本发明命名实体识别的基线模型(baseline)The experimental data used in the experiment of the present invention comes from about 16 years of fault inspection and maintenance records of a power grid company. The inspection and maintenance records generally include information such as the site where the fault occurred, the location of the fault, and the type of fault. After processing, a total of more than 150,000 characters were obtained, which were divided into training set, verification set and test set according to the ratio of 6:2:2. The present invention selects BiLSTM+CRF as the baseline model (baseline) for named entity recognition of the present invention
(2)模型构建(2) Model construction
本发明选择BiLSTM+CRF作为本发明命名实体识别的基线模型(baseline),该模型被广泛应用到文本分类、词性标注、命名实体识别等自然语言处理任务中。The present invention selects BiLSTM+CRF as the baseline model (baseline) of named entity recognition in the present invention, and this model is widely used in natural language processing tasks such as text classification, part-of-speech tagging, and named entity recognition.
为了比较BERT模型和传统的词嵌入方式,设计了BERT+BiLSTM+CRF的对比实验。同时,为了检验加入字词联合向量的实体抽取效果,对之前的模型加入了字词联合嵌入层。In order to compare the BERT model and the traditional word embedding method, a comparative experiment of BERT+BiLSTM+CRF was designed. At the same time, in order to test the entity extraction effect of adding word joint vectors, a word joint embedding layer was added to the previous model.
对于分词结果也设计了是否有字典参与的对照实验。该字典记录了大约110条电网系统常见故障缺陷,部分条目示例如下表。最后,为了对比注意力机制层的作用,本发明还设计了加入注意力机制的最终算法模型。For word segmentation results, a control experiment with or without the participation of a dictionary is also designed. The dictionary records about 110 common faults and defects in power grid systems, and some examples of entries are shown in the table below. Finally, in order to compare the effect of the attention mechanism layer, the present invention also designs the final algorithm model adding the attention mechanism.
(3)评价指标(3) Evaluation index
本发明采用精确率P、召回率R和平衡函数F1作为评价标准。精确率可以评价准确识别出各类实体类别的能力,召回率可以评价找到所有实体类别的能力,而平衡函数F1值则可以作为两者之综合来评价算法模型的能力。The present invention uses precision rate P, recall rate R and balance functionF1 as evaluation criteria. The precision rate can evaluate the ability to accurately identify various entity categories, the recall rate can evaluate the ability to find all entity categories, and the balance function F1 value can be used as a combination of the two to evaluate the ability of the algorithm model.
(4)模型综合对比实验(4) Model comprehensive comparison experiment
本发明对一共五种模型进行了综合对比实验,汇总得到的实验结果如表1所示。The present invention has carried out comprehensive contrast experiment to altogether five kinds of models, and the experimental result that summarizes is shown in Table 1.
表1Table 1

上表中可看出加入BERT模型后,识别的精确率、召回率、F1值均有提升。It can be seen from the above table that after adding the BERT model, the recognition accuracy, recall rate, and F1 value are all improved.
BERT模型在任意字符间计算注意力,可以很好地通过字符之间的上下文环境动态决定词嵌入向量。The BERT model calculates attention between arbitrary characters, and can dynamically determine the word embedding vector through the context between characters.
另一方面,本发明提出的字词联合嵌入向量在模型优化上也有不错的表现。可以看出字词联合嵌入向量可以起到提升实体识别的准确性,同时配合字典的分词结果也能提升实体边界的识别效果。On the other hand, the word joint embedding vector proposed by the present invention also has a good performance in model optimization. It can be seen that the word joint embedding vector can improve the accuracy of entity recognition, and at the same time cooperate with the word segmentation results of the dictionary to improve the recognition effect of entity boundaries.
最后,本发明在模型中加入的注意力机制的最终也提高了实体识别的准确度,其F1值相较之前的模型提升了4.06、3.62、2.56、1.27个百分点。对各种模型的算法训练收敛情况进行分析,如图4所示,图中的模型代号参考表1中所示。可以看出,传统的BiLSTM+CRF的训练收敛速度最慢,大约130次迭代才可以收敛,本发明提出的新模型在收敛速度也有一定优势,大约在50次迭代就可以达到收敛。Finally, the attention mechanism added to the model of the present invention finally improves the accuracy of entity recognition, and its F1 value is increased by 4.06, 3.62, 2.56, and 1.27 percentage points compared with the previous model. The algorithm training convergence of various models is analyzed, as shown in Figure 4, and the model codes in the figure are shown in Table 1. It can be seen that the traditional BiLSTM+CRF has the slowest training convergence speed, which can only be converged after about 130 iterations. The new model proposed by the present invention also has certain advantages in the convergence speed, and can reach convergence after about 50 iterations.
(4)模型分类对比实验(4) Model classification comparison experiment
本发明针对电网系统运检文本设置了三种不同实体,为了进一步评价各种算法模型实体识别的能力,分别对站点、错误位置、错误类型3类不同实体进行识别实验,实验结果如表2所示,其中代号参见表1所示。The present invention sets three different entities for the power grid system operation inspection text. In order to further evaluate the ability of various algorithm model entity recognition, three different entities of site, error location, and error type are respectively subjected to recognition experiments. The experimental results are shown in Table 2. , where the codes are shown in Table 1.
表2模型分类对比实验Table 2 Model classification comparison experiment
Table4 Model classification comparison experimentTable4 Model classification comparison experiment

从分类识别实验结果可以看出,在3类实体中,站点实体在所有模型的表现里精确率、召回率和F1值都很高。观察原始的运检记录文本可以发现,站点实体在其中类似于半结构数据,其位置多处于运检记录的开端,实体特征较为明显,因此即使通过简单的时序模型也很容易抽取出该实体类型,故而本发明提出的模型在此实体的提升效果不大。而其他两种类型在文本中的位置与上下文边界较为多样,因此本发明提出的算法模型在识别错误位置和错误类型的效果提升较为显著。如在识别错误位置实体上,本发明的算法模型相较之前的模型的F1值提升了6.79、4.56、3.22、0.25个百分点;在识别错误类型实体上,本发明的算法模型F1值则提升了9.21、4.93、3.28、4.22个百分点。It can be seen from the results of classification and recognition experiments that among the three types of entities, the site entities have high precision, recall and F1 values in the performance of all models. Observing the original inspection record text, it can be found that the site entity is similar to semi-structured data, and its position is mostly at the beginning of the inspection record, and the entity characteristics are more obvious, so it is easy to extract this entity type even through a simple time series model , so the model proposed by the present invention has little improvement effect on this entity. However, the positions and context boundaries of the other two types in the text are relatively diverse, so the algorithm model proposed by the present invention can significantly improve the effect of identifying error positions and error types. For example, in identifying the wrong position entity, the F1 value of the algorithm model of the present invention has improved by 6.79, 4.56, 3.22, 0.25 percentage points compared with the previous model; in identifying the wrong type entity, the F1 value of the algorithm model of the present invention has then improved 9.21, 4.93, 3.28, 4.22 percentage points.
(5)实验总结(5) Experiment summary
综合上述实验,本发明提出的模型算法创新性的在原有模型上引入了注意力机制和字词联合嵌入层,使得算法不仅在训练收敛速度上,抑或是在识别的准确率上都取得了不错的改良效果。考虑到智能电网中智能运检系统的后续建设,提升错误位置和类型的识别率有着更具建设性的作用,这也印证了本发明所提出算法模型的有效性和可行性。Based on the above experiments, the model algorithm proposed by the present invention innovatively introduces the attention mechanism and word joint embedding layer on the original model, so that the algorithm not only achieves good results in training convergence speed, but also in recognition accuracy. improvement effect. Considering the subsequent construction of the intelligent inspection system in the smart grid, improving the recognition rate of error locations and types has a more constructive effect, which also confirms the validity and feasibility of the algorithm model proposed in the present invention.
Claims (5)
Translated fromChinese

Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211164862.9ACN115688775A (en) | 2022-09-23 | 2022-09-23 | An Attention Mechanism-Based Method for Named Entity Recognition in Power Grid Inspection Field |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211164862.9ACN115688775A (en) | 2022-09-23 | 2022-09-23 | An Attention Mechanism-Based Method for Named Entity Recognition in Power Grid Inspection Field |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN115688775Atrue CN115688775A (en) | 2023-02-03 |
Family
ID=85063357
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202211164862.9APendingCN115688775A (en) | 2022-09-23 | 2022-09-23 | An Attention Mechanism-Based Method for Named Entity Recognition in Power Grid Inspection Field |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115688775A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN118520304A (en)* | 2024-07-19 | 2024-08-20 | 国网山西省电力公司营销服务中心 | Deep learning multilayer active power distribution network situation awareness and assessment method and system |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2020232861A1 (en)* | 2019-05-20 | 2020-11-26 | 平安科技(深圳)有限公司 | Named entity recognition method, electronic device and storage medium |
| CN112163689A (en)* | 2020-08-18 | 2021-01-01 | 国网浙江省电力有限公司绍兴供电公司 | Short-term load quantile probability prediction method based on deep Attention-LSTM |
| CN113595998A (en)* | 2021-07-15 | 2021-11-02 | 广东电网有限责任公司 | Bi-LSTM-based power grid information system vulnerability attack detection method and device |
| CN114091460A (en)* | 2021-11-24 | 2022-02-25 | 长沙理工大学 | Multitask Chinese entity naming identification method |
| CN114564950A (en)* | 2022-03-02 | 2022-05-31 | 东北电力大学 | Electric Chinese named entity recognition method combining word sequence |
| CN114648029A (en)* | 2022-03-31 | 2022-06-21 | 河海大学 | A Named Entity Recognition Method in Electric Power Field Based on BiLSTM-CRF Model |
| CN114970528A (en)* | 2021-12-20 | 2022-08-30 | 昆明理工大学 | Chinese named entity recognition method based on BERT and Attention mechanism |
- 2022
- 2022-09-23CNCN202211164862.9Apatent/CN115688775A/enactivePending
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2020232861A1 (en)* | 2019-05-20 | 2020-11-26 | 平安科技(深圳)有限公司 | Named entity recognition method, electronic device and storage medium |
| CN112163689A (en)* | 2020-08-18 | 2021-01-01 | 国网浙江省电力有限公司绍兴供电公司 | Short-term load quantile probability prediction method based on deep Attention-LSTM |
| CN113595998A (en)* | 2021-07-15 | 2021-11-02 | 广东电网有限责任公司 | Bi-LSTM-based power grid information system vulnerability attack detection method and device |
| CN114091460A (en)* | 2021-11-24 | 2022-02-25 | 长沙理工大学 | Multitask Chinese entity naming identification method |
| CN114970528A (en)* | 2021-12-20 | 2022-08-30 | 昆明理工大学 | Chinese named entity recognition method based on BERT and Attention mechanism |
| CN114564950A (en)* | 2022-03-02 | 2022-05-31 | 东北电力大学 | Electric Chinese named entity recognition method combining word sequence |
| CN114648029A (en)* | 2022-03-31 | 2022-06-21 | 河海大学 | A Named Entity Recognition Method in Electric Power Field Based on BiLSTM-CRF Model |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN118520304A (en)* | 2024-07-19 | 2024-08-20 | 国网山西省电力公司营销服务中心 | Deep learning multilayer active power distribution network situation awareness and assessment method and system |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11656298B2 (en) | Deep parallel fault diagnosis method and system for dissolved gas in transformer oil | |
| CN110222188B (en) | Company notice processing method for multi-task learning and server | |
| CN119396975A (en) | A knowledge question answering system based on large language model | |
| CN119961388A (en) | Knowledge question answering optimization system in the power field based on large model retrieval enhancement generation and instruction supervision fine-tuning | |
| CN118277957A (en) | Data extraction method, system and storage medium based on deep learning | |
| CN113487194A (en) | Electric power system dispatcher grade evaluation system based on text classification | |
| CN115688775A (en) | An Attention Mechanism-Based Method for Named Entity Recognition in Power Grid Inspection Field | |
| CN118940832A (en) | Power equipment defect knowledge extraction system and method based on transfer learning | |
| Lin et al. | Entity recognition of railway signal equipment fault information based on RoBERTa-wwm and deep learning integration | |
| CN117875706A (en) | An AI-based digital management method for grading process | |
| CN116975161A (en) | Entity relation joint extraction method, equipment and medium of power equipment partial discharge text | |
| CN117034941A (en) | Method for identifying named entity of Internet enterprise equipment | |
| Cai et al. | Evaluation Model of Learner's Cognitive Level Based on RoBERTa Fused with CNN | |
| Jiang et al. | A Lightweight Named Entity Recognition Method for Chinese Power Equipment Defect Text | |
| CN119691154B (en) | Entity identification-based power grid defect detection method, electronic equipment and program product | |
| Zhang et al. | Named Entity Recognition for Smart Grid Operation and Inspection Domain using Attention Mechanism | |
| Yang et al. | An Intelligent Risk Assessment Model Based on NLP | |
| Dong | Equipment Defects Based on Transfer Learning | |
| Chao et al. | Research on Test Case Generation Method of Airborne Software Based on NLP. | |
| Dong et al. | Knowledge Extraction Method of Electric Power Equipment Defects Based on Transfer Learning | |
| Yue | Design and Implementation of Digital Language Translation Software based on LSTM Algorithm | |
| Huang et al. | Inference method for power large-scale model operation based on distributed computing resource scheduling | |
| Xiao et al. | Power grid fault handling plan matching method based on a hybrid neural network | |
| Zhao et al. | An overlapping entity relation extraction method for electricity marketing audit information | |
| CN120611776A (en) | Knowledge graph construction and retrieval method based on multi-source heterogeneous equipment operation and maintenance data |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| TA01 | Transfer of patent application right | Effective date of registration:20250704 Address after:312000 Shaoxing Shengli Road, Zhejiang, No. 58 Applicant after:SHAOXING DAMING ELECTRIC POWER CONSTRUCTION Co.,Ltd. Country or region after:China Applicant after:STATE GRID ZHEJIANG ELECTRIC POWER CO., LTD. SHAOXING POWER SUPPLY Co. Address before:Room 107, building 7, 1056 Chengnan Avenue, Yuecheng District, Shaoxing City, Zhejiang Province, 312000 Applicant before:Shaoxing Jianyuan Electric Power Group Co.,Ltd. Daxing electric power loading branch Country or region before:China Applicant before:STATE GRID ZHEJIANG ELECTRIC POWER CO., LTD. SHAOXING POWER SUPPLY Co. | |
| TA01 | Transfer of patent application right |