CN115641849A - Voice recognition method and device, electronic equipment and storage medium - Google Patents
Voice recognition method and device, electronic equipment and storage mediumDownload PDFInfo
- Publication number
- CN115641849A CN115641849ACN202211199117.8ACN202211199117ACN115641849ACN 115641849 ACN115641849 ACN 115641849ACN 202211199117 ACN202211199117 ACN 202211199117ACN 115641849 ACN115641849 ACN 115641849A
- Authority
- CN
- China
- Prior art keywords
- speech
- voice
- confidence
- information
- utterance
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images








Landscapes
- Machine Translation (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本申请涉及语音处理技术领域,尤其涉及一种语音识别方法、装置、电子设备及计算机可读存储介质。The present application relates to the technical field of speech processing, and in particular to a speech recognition method, device, electronic equipment and computer-readable storage medium.
背景技术Background technique
目前,语音识别设备由于其使用的简便性已在不同地点或不同场合都得到了广泛应用,语音识别设备大多利用某种标准化语音(例如普通话)训练的模型去识别其他语音,包括标准化语音或非标准化语音(例如某地域方言),当下语音识别设备一般基于语音识别引擎实现语音识别,但由于不同地域的人会有不同的口音,因此,利用基于标准化语音的语音识别引擎对非标准化语音的说话人进行语音识别时,引擎的识别正确率较低。而相关技术中,对于如何提高标准化语音识别引擎的语音识别正确率尚无有效解决方案。At present, speech recognition devices have been widely used in different places or occasions due to their ease of use. Most speech recognition devices use a model trained on a standardized speech (such as Mandarin) to recognize other speech, including standardized speech or Standardized voice (such as a certain regional dialect), the current voice recognition equipment generally realizes voice recognition based on the voice recognition engine, but because people in different regions have different accents, therefore, use the voice recognition engine based on standardized voice to speak to non-standardized voice When humans perform speech recognition, the recognition accuracy of the engine is low. However, in the related art, there is no effective solution for how to improve the speech recognition accuracy rate of the standardized speech recognition engine.
发明内容Contents of the invention
有鉴于此,本申请的主要目的在于提供一种语音识别方法、装置、电子设备及计算机可读存储介质,能够提高语音识别引擎的语音识别正确率。In view of this, the main purpose of the present application is to provide a speech recognition method, device, electronic equipment and computer-readable storage medium, which can improve the speech recognition accuracy rate of the speech recognition engine.
为达到上述目的,本申请的技术方案是这样实现的:In order to achieve the above object, the technical solution of the present application is achieved in this way:
第一方面,本申请实施例提供一种语音识别方法,包括:In the first aspect, the embodiment of the present application provides a speech recognition method, including:
获取原始语音信息包含的至少两个属于不同发声对象的语音片段;Obtaining at least two speech segments belonging to different utterance objects included in the original speech information;
确定所述至少两个语音片段中每一个语音片段对应的发声对象的语音置信度;determining the voice confidence of the utterance object corresponding to each voice segment in the at least two voice segments;
识别出所述至少两个语音片段对应的至少两个文本信息,并利用目标语音置信度对应发声对象的文本信息修正其他语音置信度对应发声对象对应的文本信息,其中,所述目标语音置信度高于其他语音置信度;Recognizing at least two text information corresponding to the at least two speech segments, and using the text information corresponding to the utterance object with the target speech confidence degree to modify the text information corresponding to the utterance object with other speech confidence degrees, wherein the target speech confidence degree Higher than other speech confidence;
输出所述修正后的至少两个文本信息。Outputting the at least two text messages after modification.
在上述方案中,所述利用目标语音置信度对应发声对象的文本信息修正其他语音置信度对应发声对象对应的文本信息,包括:In the above solution, the use of the text information corresponding to the target voice confidence level to modify the text information corresponding to the other voice confidence level corresponding to the voice target includes:
确定所述至少两个文本信息中属于不同发声对象且满足目标相似度的至少两个词语,利用目标语音置信度对应发声对象对应的文本信息中的词语修正其他语音置信度对应发声对象对应的文本信息中的词语。Determine at least two words in the at least two text information that belong to different utterance objects and satisfy the target similarity, and use the words in the text information corresponding to the utterance object corresponding to the target speech confidence level to modify other texts corresponding to the utterance object corresponding to the speech confidence level words in the message.
在上述方案中,所述确定所述至少两个文本信息中属于不同发声对象且满足目标相似度的至少两个词语,包括:In the above solution, the determining at least two words in the at least two text messages that belong to different utterance objects and satisfy the target similarity includes:
对所述至少两个文本信息中的每一个文本信息进行分词处理,得到每一个文本信息包含的关键词语;performing word segmentation processing on each of the at least two text information to obtain key words contained in each text information;
确定属于不同文本信息包含的所述关键词语之间的第一相似度;determining a first similarity between the key words contained in different text information;
从所述至少两个文本信息中各文本信息包含的关键词语中获得所述第一相似度满足目标相似度的至少两个关键词;所述至少两个关键词为所述至少两个文本信息中属于不同发声对象且满足目标相似度的至少两个词语。Obtain at least two keywords whose first similarity meets the target similarity from keywords contained in each text information in the at least two text information; the at least two keywords are the at least two text information At least two words that belong to different utterance objects and meet the target similarity.
在上述方案中,所述原始语音信息包括按照第一时间间隔依次采集的至少一个子语音信息,所述获取原始语音信息包含的至少两个属于不同发声对象的语音片段,包括:In the above solution, the original voice information includes at least one sub-voice information sequentially collected according to the first time interval, and the obtained original voice information includes at least two voice segments belonging to different utterance objects, including:
对采集到的所述至少一个子语音信息中的任一第一子语音信息进行预处理,得到利用所述第一子语音信息的语音特征表示的第二子语音信息;Preprocessing any first sub-voice information in the at least one collected sub-voice information to obtain second sub-voice information represented by the voice features of the first sub-voice information;
对所述第二子语音信息进行分割和聚类处理,获得所述第一子语音信息包含的至少两个属于不同发声对象的子语音片段;Segmenting and clustering the second sub-speech information to obtain at least two sub-speech segments belonging to different utterance objects included in the first sub-speech information;
将每一个第一子语音信息中属于同一发声对象的子语音片段进行聚类处理,获得所述原始语音信息包含的至少两个属于不同发声对象的语音片段。Perform clustering processing on the sub-speech segments belonging to the same utterance object in each first sub-speech information, and obtain at least two speech segments belonging to different utterance objects included in the original speech information.
在上述方案中,所述对所述第二子语音信息进行分割和聚类处理,获得所述第一子语音信息包含的至少两个属于不同发声对象的子语音片段,包括:In the above solution, performing segmentation and clustering processing on the second sub-speech information to obtain at least two sub-speech segments belonging to different utterance objects included in the first sub-speech information, including:
对所述第二子语音信息进行分割和聚类处理,获得属于不同发声对象的至少两个中间语音片段;Segmenting and clustering the second sub-speech information to obtain at least two intermediate speech segments belonging to different utterance objects;
在至少一个所述中间语音片段包含至少两个不同的发声对象的情况下,重新对所述至少两个中间语音片段中的每一个中间语音片段进行分割和聚类处理,直到获得的所述至少两个属于不同发声对象的子语音片段中的每一个子语音片段仅包含一个发声对像为止。In the case that at least one intermediate speech segment contains at least two different sounding objects, each intermediate speech segment in the at least two intermediate speech segments is re-segmented and clustered until the obtained at least Each sub-speech segment of the two sub-speech segments belonging to different utterance objects contains only one utterance object.
在上述方案中,所述确定所述至少两个语音片段中每一个语音片段对应的发声对象的语音置信度,包括:In the above solution, the determining the voice confidence of the utterance object corresponding to each voice segment in the at least two voice segments includes:
对所述至少两个语音片段中的任一第一语音片段进行语句划分,得到所述第一语音片段包含的多个语句;performing sentence division on any first speech segment in the at least two speech segments to obtain a plurality of sentences contained in the first speech segment;
对所述多个语句中的任一第一语句进行识别,得到所述第一语句对应的语句置信度;Identifying any first sentence in the plurality of sentences to obtain a sentence confidence degree corresponding to the first sentence;
基于每一个所述语句置信度确定所述第一语音片段对应的语音置信度。The speech confidence corresponding to the first speech segment is determined based on each sentence confidence.
在上述方案中,所述对所述多个语句中的任一第一语句进行识别,得到所述第一语句对应的语句置信度,包括:In the above solution, the identifying any first sentence in the plurality of sentences to obtain the sentence confidence corresponding to the first sentence includes:
确定所述第一语句的类型;所述第一语句为所述多个语句中的任一句;Determine the type of the first sentence; the first sentence is any one of the plurality of sentences;
将所述第一语句输入到与所述类型对应的识别模型,获得所述第一语句被正确识别的概率;Inputting the first sentence into a recognition model corresponding to the type to obtain the probability that the first sentence is correctly recognized;
基于所述概率得到所述第一语句对应的语句的置信度。Obtain the confidence of the statement corresponding to the first statement based on the probability.
第二方面,本申请实施例还提供一种语音识别装置,包括:In the second aspect, the embodiment of the present application also provides a speech recognition device, including:
获取模块、确定模块、修正模块和输出模块,其中;acquisition module, determination module, correction module and output module, wherein;
所述获取模块,用于获取原始语音信息包含的至少两个属于不同发声对象的语音片段;The obtaining module is used to obtain at least two speech segments belonging to different utterance objects included in the original speech information;
所述确定模块,用于确定所述至少两个语音片段中每一个语音片段对应的发声对象的语音置信度;The determination module is configured to determine the voice confidence of the utterance object corresponding to each voice segment in the at least two voice segments;
所述修正模块,用于识别出所述至少两个语音片段对应的至少两个文本信息,并利用目标语音置信度对应发声对象的文本信息修正其他语音置信度对应发声对象对应的文本信息,其中,所述目标语音置信度高于其他语音置信度;The correction module is configured to identify at least two text information corresponding to the at least two speech segments, and use the text information corresponding to the utterance object with the target speech confidence degree to modify the text information corresponding to the utterance object corresponding to other speech confidence degrees, wherein , the target speech confidence is higher than other speech confidences;
所述输出模块,用于输出所述修正后的至少两个文本信息。The output module is configured to output the at least two text messages after modification.
第三方面,本申请实施例还提供一种电子设备,包括:In a third aspect, the embodiment of the present application further provides an electronic device, including:
存储器,用于存储可执行指令;处理器,用于执行所述存储器中存储的可执行指令时,实现上述语音识别方法。The memory is used to store executable instructions; the processor is used to implement the above speech recognition method when executing the executable instructions stored in the memory.
第四方面,本申请实施例还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现上述语音识别方法的步骤。In a fourth aspect, the embodiment of the present application further provides a computer-readable storage medium, on which a computer program is stored, and when the computer program is executed by a processor, the steps of the above speech recognition method are implemented.
本申请实施例提供的语音识别方法、装置、电子设备及计算机可读存储介质。其中,所述方法包括:获取原始语音信息包含的至少两个属于不同发声对象的语音片段,确定至少两个语音片段中每一个语音片段对应的发声对象的语音置信度,识别出至少两个语音片段对应的至少两个文本信息,利用语音置信度高的发声对象的文本信息修正语音置信度低的发声对象的文本信息。本申请提供的语音识别方法,通过识别出原始语音信息中各发声对象对应的语音片段,并确定各发声对象对应的语音置信度,利用高语音置信度的语音片段对应的文本信息修正其他语音片段对应的文本信息,如此,在语音识别过程中,利用即时获取的原始语音信息中的某些语音片段去修正其他语音片段的方式,可以提高语音识别的正确率,并且节省了通过大量已知数据获得标准语音识别引擎的训练时间,提高了语音识别的效率。The speech recognition method, device, electronic equipment, and computer-readable storage medium provided by the embodiments of the present application. Wherein, the method includes: acquiring at least two speech segments belonging to different utterance objects included in the original speech information, determining the speech confidence of the utterance object corresponding to each of the at least two speech segments, and identifying at least two speech segments For the at least two pieces of text information corresponding to the segment, use the text information of the speaking object with high speech confidence to modify the text information of the speaking object with low speech confidence. The speech recognition method provided by this application, by identifying the speech segments corresponding to each utterance object in the original speech information, and determining the speech confidence corresponding to each utterance object, using the text information corresponding to the speech segment with high speech confidence to correct other speech segments Corresponding text information, in this way, in the process of speech recognition, using some speech fragments in the instantly acquired original speech information to modify other speech fragments can improve the accuracy of speech recognition and save a large amount of known data. Gain the training time of standard speech recognition engines and improve the efficiency of speech recognition.
附图说明Description of drawings
图1是本申请实施例提供的语音识别方法的应用场景示意图;FIG. 1 is a schematic diagram of an application scenario of a speech recognition method provided in an embodiment of the present application;
图2A-图2F是本申请实施例提供的语音识别方法的一个可选的流程示意图;FIG. 2A-FIG. 2F are schematic flowcharts of an optional speech recognition method provided by the embodiment of the present application;
图3是本申请实施例提供的语音识别结果示例图;FIG. 3 is an example diagram of speech recognition results provided by the embodiment of the present application;
图4是本申请实施例提供的一种语音识别装置的结构示意图;FIG. 4 is a schematic structural diagram of a speech recognition device provided by an embodiment of the present application;
图5是本申请实施例提供的电子设备的组成结构示意图。FIG. 5 is a schematic diagram of the composition and structure of an electronic device provided by an embodiment of the present application.
具体实施方式Detailed ways
为了更清楚地阐述本申请实施例的目的、技术方案及优点,以下将结合附图对本申请实施例的实施例进行详细的说明。应当理解,下文对于实施例的描述旨在对本申请实施例的总体构思进行解释和说明,而不应当理解为是对本申请实施例的限制。在说明书和附图中,相同或相似的附图标记指代相同或相似的部件或构件。为了清晰起见,附图不一定按比例绘制,并且附图中可能省略了一些公知部件和结构。In order to more clearly illustrate the purpose, technical solutions, and advantages of the embodiments of the present application, the embodiments of the embodiments of the present application will be described in detail below in conjunction with the accompanying drawings. It should be understood that the following description of the embodiments is intended to explain and describe the general concept of the embodiments of the present application, and should not be construed as limiting the embodiments of the present application. In the specification and drawings, the same or similar reference numerals refer to the same or similar parts or components. For the sake of clarity, the drawings are not necessarily drawn to scale, and some well-known components and structures may be omitted from the drawings.
目前为提高语音识别引擎的语音识别正确率,一种方法是采集大量的带口音的语音数据训练标准声学模型,以增强标准声学模型的泛化性,从而提高语音识别正确率;另一种方法是采集一部分带口音的语音数据,在基于标准语音训练的标准声学模型上,采用说话人自适应技术,对标准声学模型进行修正,但上述方法存在以下问题:At present, in order to improve the accuracy rate of speech recognition of the speech recognition engine, one method is to collect a large amount of speech data with accents to train the standard acoustic model, so as to enhance the generalization of the standard acoustic model, thereby improving the accuracy rate of speech recognition; another method It is to collect a part of voice data with an accent, and use speaker adaptive technology to correct the standard acoustic model on the standard acoustic model based on standard voice training, but the above method has the following problems:
1、不具有普遍性,上述两种方式均需要事先准备带口音的数据,包括语音数据和语音数据对应的文本信息,以此来改进标准声学模型的性能,但是语音识别设备在出厂时并不确定将来要在何地域使用,也无法知晓该地域的标准口音,因此改进标准声学模型对地域的针对性较强,并不具有普遍性。1. It is not universal. Both of the above two methods need to prepare data with accents in advance, including voice data and text information corresponding to the voice data, so as to improve the performance of the standard acoustic model, but the voice recognition equipment does not leave the factory. To determine the region to be used in the future, it is impossible to know the standard accent of the region. Therefore, the improved standard acoustic model is more specific to the region and is not universal.
2、影响标准语音识别的正确率,以不同口音的数据训练标准声学模型或在标准声学模型上进行修正,在一定程度上能够提高非标准语音的识别正确率,但同时也会降低对标准语音的识别正确率。2. Affect the correct rate of standard speech recognition. Training the standard acoustic model with data of different accents or modifying the standard acoustic model can improve the recognition rate of non-standard speech to a certain extent, but it will also reduce the accuracy of standard speech. recognition accuracy.
基于相关技术中存在的问题,本申请实施例提供一种语音识别方法,通过获取原始语音信息包含的至少两个属于不同发声对象的语音片段,确定至少两个语音片段中每一个语音片段对应的发声对象的语音置信度,识别出至少两个语音片段对应的至少两个文本信息,利用语音置信度高的发声对象的文本信息修正语音置信度低的发声对象的文本信息。本申请提供的方法通过识别出原始语音信息包括的各语音片段对应的发声对象的语音置信度,并利用高语音置信度对应的文本信息对低语音置信度对应的文本信息进行修正,从而提高语音识别引擎的语音识别正确率。本申请利用即时获取的原始语音信息中的某些语音片段去修正其他语音片段,不需要事先准备大量带口音的语音数据对标准声学模型进行训练,因此也不会影响语音识别引擎对标准语音的识别正确率。Based on the problems existing in the related technology, the embodiment of the present application provides a speech recognition method, by obtaining at least two speech segments belonging to different utterance objects included in the original speech information, and determining the corresponding speech segment of each speech segment in the at least two speech segments The speech confidence of the speaking object is to identify at least two text information corresponding to at least two speech segments, and use the text information of the speaking object with high speech confidence to correct the text information of the speaking object with low speech confidence. The method provided by the present application recognizes the voice confidence of the utterance object corresponding to each voice segment included in the original voice information, and uses the text information corresponding to the high voice confidence to modify the text information corresponding to the low voice confidence, thereby improving the voice quality. The speech recognition accuracy rate of the recognition engine. This application uses some speech fragments in the original speech information obtained immediately to modify other speech fragments, and does not need to prepare a large amount of speech data with accents in advance to train the standard acoustic model, so it will not affect the speech recognition engine's ability to standard speech recognition accuracy.
下面说明本申请实施例提供的电子设备的示例性应用,本申请实施例提供的电子设备可以实施为笔记本电脑、平板电脑、台式计算机、移动设备等各种类型的终端,也可以实施为服务器。The following describes an exemplary application of the electronic device provided by the embodiment of the present application. The electronic device provided by the embodiment of the present application can be implemented as various types of terminals such as notebook computers, tablet computers, desktop computers, and mobile devices, and can also be implemented as a server.
图1是本申请实施例提供的语音识别方法的应用场景示意图,如图1所示,本申请实施例提供的语音识别系统100中包括识别终端1001、网络1002和输出终端1003,其中,识别终端1001可基于麦克风等语音采集设备采集发声对象产生的语音信息,其中还运行有识别语音信息的计算机程序,当识别终端1001同时具备识别和显示功能时,识别终端1001可以采用本申请实施例的方法得到语音识别结果并输出,向用户进行展示;当识别终端1001仅具备识别功能时,识别终端可通过网络1002,以无线或有线的方式将识别结果发送至具有显示功能的输出终端1003进行显示。也就是说,识别终端1001和输出终端1003在硬件实现上可以在一个装置内,也可以在不同的装置内。Fig. 1 is a schematic diagram of the application scenario of the speech recognition method provided by the embodiment of the present application. As shown in Fig. 1001 can collect the voice information generated by the vocal object based on voice collection equipment such as a microphone, and a computer program for recognizing voice information is also running in it. When the recognition terminal 1001 has both recognition and display functions, the recognition terminal 1001 can adopt the method of the embodiment of this application The speech recognition result is obtained and output, and displayed to the user; when the recognition terminal 1001 only has the recognition function, the recognition terminal can send the recognition result to the output terminal 1003 with display function through the network 1002 in a wireless or wired manner for display. That is to say, the identification terminal 1001 and the output terminal 1003 may be implemented in one device or in different devices in terms of hardware implementation.
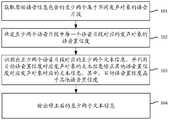
参见图2,图2是本申请实施例提供的语音识别方法的一个可选的流程示意图,将结合图2示出的步骤进行说明。Referring to FIG. 2 , FIG. 2 is a schematic flowchart of an optional speech recognition method provided by an embodiment of the present application, which will be described in conjunction with the steps shown in FIG. 2 .
步骤101:获取原始语音信息包含的至少两个属于不同发声对象的语音片段。Step 101: Obtain at least two speech segments belonging to different utterance objects included in the original speech information.
在一些实施例中,所述原始语音信息可以是指利用语音采集设备,例如麦克风,采集的至少两个发声对象产生的对话语音。其中,所述发声对象可以是具有不同口音的发声对象,例如,所述发声对象可以是普通话口音的发声对象;所述发声对象还可以是具有湖北口音的发声对象。原始语音信息可以包括按照第一时间间隔依次采集的至少一个子语音信息。In some embodiments, the original voice information may refer to dialogue voices generated by at least two utterance objects collected by a voice collection device, such as a microphone. Wherein, the utterance object may be an utterance object with a different accent, for example, the utterance object may be an utterance object with a Mandarin accent; the utterance object may also be an utterance object with a Hubei accent. The original voice information may include at least one piece of sub-voice information sequentially collected according to the first time interval.
对于图2A示出的步骤101,可以通过图2B中步骤1011至步骤1013实现,下面分别说明。Step 101 shown in FIG. 2A can be implemented through
步骤1011、对采集到的所述至少一个子语音信息中的任一第一子语音信息进行预处理,得到利用所述第一子语音信息的语音特征表示的第二子语音信息。Step 1011: Perform preprocessing on any first sub-speech information in the at least one sub-speech information collected to obtain second sub-speech information represented by the speech features of the first sub-speech information.
在实际处理过程中,语音识别系统可以针对每次采集的语音信息进行处理,也可以针对一段时间采集的语音信息统一处理,因此,所述原始语音信息可以包括至少一个子语音信息,该子语音信息即为语音识别系统一次能够采集到的语音信息。所述第一时间间隔可以根据语音识别系统的处理能力而人为设置,比如,所述第一时间间隔可以为5秒(s)。由于对于原始语音信息中的每一子语音信息的处理方式是一样的,因此,本申请仅采用对第一子语音信息处理为例进行说明。In the actual processing process, the speech recognition system can process the speech information collected each time, and can also process the speech information collected for a period of time. Therefore, the original speech information can include at least one sub-speech information, and the sub-speech information The information is the voice information that the voice recognition system can collect once. The first time interval may be artificially set according to the processing capability of the speech recognition system, for example, the first time interval may be 5 seconds (s). Since the processing method for each sub-voice information in the original voice information is the same, this application only uses the processing of the first sub-voice information as an example for illustration.
在一些实施例中,在对所述第一子语音信息进行语音识别之前,需要对采集得到的第一子语音信息进行预处理,以将第一子语音信息转化为便于后续识别的利用语音特征表示的第二子语音信息。其中,所说的预处理可以包括对第一子语音信息进行滤波、分帧、加窗等处理。所述的语音特征可以基于梅尔频率倒谱系数(Mel-Frequency CepstralCoefficients,MFCC)或线性预测(Perceptual Linear Predictive,PLP)等表示。In some embodiments, before performing speech recognition on the first sub-speech information, it is necessary to preprocess the collected first sub-speech information, so as to convert the first sub-speech information into speech features for subsequent recognition. Indicates the second sub-speech information. Wherein, the preprocessing may include filtering, framing, windowing and other processing on the first sub-speech information. The speech features may be expressed based on Mel-Frequency Cepstral Coefficients (Mel-Frequency Cepstral Coefficients, MFCC) or linear prediction (Perceptual Linear Predictive, PLP).
步骤1012、对所述第二子语音信息进行分割和聚类处理,获得所述第一子语音信息包含的至少两个属于不同发声对象的子语音片段。Step 1012: Segment and cluster the second sub-speech information to obtain at least two sub-speech segments belonging to different utterance objects included in the first sub-speech information.
在一些实施例中,参见图2C,图2B示出的步骤1012,可以通过图2C中步骤10121至步骤10122实现,下面分别说明。In some embodiments, referring to FIG. 2C ,
步骤10121、对所述第二子语音信息进行分割和聚类处理,获得属于不同发声对象的至少两个中间语音片段。Step 10121: Segment and cluster the second sub-speech information to obtain at least two intermediate speech segments belonging to different utterance objects.
在具体实施中,对第二子语音信息进行分割时,可以根据实际需求以逐渐减小的时长对第二子语音信息进行至少一次分割,并对分割得到的语音片段进行聚类,得到属于不同发声对象的至少两个中间语音片段。例如,以第一单位时长进行第一次分割,以第二单位时长进行第二次分割,以第三单位时长进行第三次分割等,其中,第一单位时长大于第二单位时长大于第三单位时长。将每一次分割得到的结果进行聚类得到每一次聚类对应的多个中间语音片段。In a specific implementation, when segmenting the second sub-speech information, the second sub-speech information can be segmented at least once with a gradually decreasing duration according to actual needs, and the segmented speech segments are clustered to obtain At least two intermediate speech segments of the speaking subject. For example, the first division is performed with the first unit duration, the second division is performed with the second unit duration, the third division is performed with the third unit duration, etc., wherein the first unit duration is longer than the second unit duration and is longer than the third unit duration. unit duration. The results obtained by each division are clustered to obtain a plurality of intermediate speech segments corresponding to each cluster.
步骤10122、在至少一个所述中间语音片段包含至少两个不同的发声对象的情况下,重新对所述至少两个中间语音片段中的每一个中间语音片段进行分割和聚类处理,直到获得的所述至少两个属于不同发声对象的子语音片段中的每一个子语音片段仅包含一个发声对像为止。
这里,当中间语音片段包括多个发声对象时,则代表还需要以更小单位时长对该中间语音片段继续进行分割。在具体实施中,若以单位时长进行分割的次数达到了设定次数后,例如10次,得到的中间语音片段仍然包含至少两个不同的发声对象,则可以以帧为单位时长对中间语音片段进行分割并聚类,以使每一个子语音片段仅包含一个发声对像。Here, when the intermediate speech segment includes multiple utterance objects, it means that the intermediate speech segment needs to be further segmented with a smaller unit duration. In a specific implementation, if the number of divisions per unit duration reaches the set number of times, for example, 10 times, the obtained intermediate speech segment still contains at least two different utterance objects, then the intermediate speech segment can be divided with the unit duration of the frame Segmentation and clustering are performed so that each subspeech contains only one vocalizing object.
为了更好地说明本过程,结合以下示例对本申请实施例进行举例,例如对第二子语音信息进行分割和聚类时,先以第一单位时长自动分割,例如1s,然后对分割得到的各语音段进行识别所属的发声对象,并对各语音段按照发声对象进行聚类,得到多个第一中间语音片段;若判断所述多个第一中间语音片段中存在包含不同发声对象的至少一个第一中间语音片段,则以第二单位时长,例如0.5s,对所述多个第一中间语音片段中的每一个第一中间语音片段进行重新分割并聚类,获得多个第二中间语音片段;若判断所述多个第二中间语音片段中存在包含不同发声对象的至少一个第二中间语音片段,则以第三单位时长(比如,0.1s)对所述多个第二中间语音片段继续进行分割并聚类,以逐渐减小的分割单位时长迭代上述过程,直至分割得到的各中间语音片段仅包含一个发声对像,此时各中间语音片段即为各子语音片段。In order to better illustrate this process, the following example is used to illustrate the embodiment of the present application. For example, when segmenting and clustering the second sub-speech information, it is first automatically segmented with the first unit duration, for example, 1s, and then each of the segmented sub-voice information is automatically segmented. The speech segment is identified to belong to the utterance object, and each speech segment is clustered according to the utterance object to obtain a plurality of first intermediate speech segments; if it is determined that at least one of the plurality of first intermediate speech segments contains different utterance objects For the first intermediate speech segment, each of the plurality of first intermediate speech segments is re-segmented and clustered with a second unit duration, such as 0.5s, to obtain a plurality of second intermediate speech segments Segment; if it is judged that there is at least one second intermediate speech segment that contains different utterance objects in the plurality of second intermediate speech segments, then the plurality of second intermediate speech segments is processed with a third unit duration (for example, 0.1s). Continue to perform segmentation and clustering, and iterate the above process with a gradually decreasing segmentation unit duration, until each intermediate speech segment obtained by segmentation contains only one utterance object, at this time, each intermediate speech segment is each sub-speech segment.
步骤1013、将每一个第一子语音信息中属于同一发声对象的子语音片段进行聚类处理,获得所述原始语音信息包含的至少两个属于不同发声对象的语音片段。Step 1013: Perform clustering processing on the sub-speech segments belonging to the same utterance object in each first sub-speech information, and obtain at least two speech segments belonging to different utterance objects contained in the original speech information.
这里,按照步骤10121至步骤10122的方法对每一个第一子语音信息进行处理,即对整个原始语音信息进行处理后,将同一发声对象对应的子语音片段聚类在一起,即可得到原始语音信息包括的至少两个属于不同发声对象的语音片段。Here, each first sub-speech information is processed according to the method from
继续参见图2A,步骤102:确定所述至少两个语音片段中每一个语音片段对应的发声对象的语音置信度。Continuing to refer to FIG. 2A , step 102: Determine the voice confidence of the utterance object corresponding to each of the at least two voice segments.
需要说明的是,目前的标准声学模型大都是采用普通话训练的标准声学模型,因而,利用目前的标准声学模型识别具有普通话口音的语音而获得的识别结果,相对于识别具有其他口音的语音而获得的识别结果,具有更高的置信度;或者说,与标准声学模型发音标准越接近的语音,采用目前的标准声学模型识别获得的识别结果具有较高的语音置信度。It should be noted that most of the current standard acoustic models are standard acoustic models trained in Mandarin. Therefore, the recognition results obtained by using the current standard acoustic model to recognize speech with a Mandarin accent are lower than those obtained by recognizing speech with other accents. The recognition result has a higher degree of confidence; in other words, the closer the standard acoustic model pronunciation standard is to the speech, the recognition result obtained by using the current standard acoustic model recognition has a higher degree of speech confidence.
在实际应用过程中,由于语音片段可包含多个语句,对于语音片段的识别,通常以语句为单位利用标准声学模型进行识别,因此,在一些实施例中,继续参见图2B,图2A示出的步骤102,可以通过图2B中步骤1021至步骤1023实现,下面分别说明。In the actual application process, since a speech segment can contain multiple sentences, the recognition of a speech segment is usually performed using a standard acoustic model in units of sentences. Therefore, in some embodiments, continue to refer to FIG. 2B, and FIG. 2A shows
步骤1021、对所述至少两个语音片段中的任一第一语音片段进行语句划分,得到所述第一语音片段包含的多个语句。Step 1021: Sentence division is performed on any first speech segment among the at least two speech segments to obtain multiple sentences contained in the first speech segment.
这里,在对第一语音片段进行语句划分时,可以说话人的停顿作为语句划分的标志,也可以说话人的两处停顿作为语句划分的标志,本实施例对语句划分的标志不加以限定。Here, when the first speech segment is divided into sentences, the pause of the speaker can be used as the mark of sentence division, and the two pauses of the speaker can also be used as the mark of sentence division. This embodiment does not limit the mark of sentence division.
步骤1022、对所述多个语句中的任一第一语句进行识别,得到所述第一语句对应的语句置信度。Step 1022: Identify any first sentence in the plurality of sentences, and obtain a sentence confidence degree corresponding to the first sentence.
在一些实施例中,参见图2D,图2B示出的步骤1022,可以通过图2D中步骤10221至步骤10223实现,下面分别说明。In some embodiments, referring to FIG. 2D ,
步骤10221、确定所述第一语句的类型;所述第一语句为所述多个语句中的任一句。
这里,第一语句的类型可为英语或汉语或是其他语言。Here, the type of the first sentence may be English or Chinese or other languages.
步骤10222、将所述第一语句输入到与所述类型对应的识别模型,获得所述第一语句被正确识别的概率。
需要说明的是,输入到标准声学模型中的任意语句都会在标准声学模型中的建模单元存在相应分值,具体实施中,以第一语句被正确识别的概率表示该分值,该分值越高,表明该语句的置信度越高,作为示例,参见图3,图3是本申请实施例提供的语音识别结果示例图,图3中发声对象spk0的口音为普通话口音,spk1的口音为湖北口音,由于词语“业主”在湖北口音中的发音语调和普通话的发音语调存在较大差别,因此,利用以普通话训练的标准声学模型进行语音识别时,发声对象spk0的语句的分值较大,相应地,发声对象spk0的语音置信度大于发声对象spk1的语音置信度。It should be noted that any sentence input into the standard acoustic model will have a corresponding score in the modeling unit in the standard acoustic model. In the specific implementation, the score is represented by the probability that the first sentence is correctly recognized, and the score The higher it is, the higher the confidence level of the statement is. As an example, see FIG. 3, which is an example diagram of the speech recognition result provided by the embodiment of the present application. In FIG. 3, the accent of the utterance object spk0 is a Mandarin accent, and the accent of spk1 is Hubei accent, because the pronunciation intonation of the word "proprietor" in Hubei accent is quite different from that of Mandarin, therefore, when the standard acoustic model trained in Mandarin is used for speech recognition, the score of the speech object spk0 is higher , correspondingly, the voice confidence of the utterance object spk0 is greater than the voice confidence of the utterance object spk1.
在具体实施中,标准声学模型中的建模单元会根据第一语句的类型,采用与类型相应的识别模型对第一语句进行识别,以得到所述第一语句对应的分值。例如,当第一语句的类型为汉语时,将第一语句输入到汉语识别模型进行识别,汉语识别模型的评估方式是基于拼音的声母或韵母实现的,例如当第一语句为“你好”时,对应声母或韵母为“n,i,h,ao”,识别时,识别模型会给出每一帧输出的声母或韵母的概率,针对上述示例,若第一帧输出结果为“n”的概率为0.98,“l”的概率为0.95,第二帧输出“i”的概率为0.98,第三帧输出“h”的概率为0.98,第四帧输出“ao”的概率为0.98,汉语识别模型输出上述四次识别结果为其他声母或韵母的概率均为0,按照该方法在得到四次识别的输出结果后,计算输出结果对应的平均概率,可得到“nihao”的概率为0.98,“lihao”的概率为0.9725,进而得到“你好”被正确识别的概率为0.98,同时,第一语句“你好”对应的分值也为0.98。In a specific implementation, the modeling unit in the standard acoustic model will, according to the type of the first sentence, use a recognition model corresponding to the type to recognize the first sentence, so as to obtain the score corresponding to the first sentence. For example, when the type of the first sentence is Chinese, input the first sentence into the Chinese recognition model for recognition, and the evaluation method of the Chinese recognition model is realized based on the initials or finals of Pinyin, for example, when the first sentence is "Nihao" , the corresponding initials or finals are "n, i, h, ao". During recognition, the recognition model will give the probability of the initials or finals output in each frame. For the above example, if the output result of the first frame is "n" The probability of outputting "l" is 0.98, the probability of "l" is 0.95, the probability of outputting "i" in the second frame is 0.98, the probability of outputting "h" in the third frame is 0.98, the probability of outputting "ao" in the fourth frame is 0.98, Chinese The probability that the recognition model outputs the above four recognition results as other initials or finals is 0. According to this method, after obtaining the output results of the four recognitions, the average probability corresponding to the output results can be calculated, and the probability of "nihao" can be obtained as 0.98. The probability of "lihao" is 0.9725, and then the probability of "hello" being correctly recognized is 0.98. At the same time, the score corresponding to the first sentence "hello" is also 0.98.
步骤10223、基于所述概率得到所述第一语句对应的语句置信度。
在一些实施例中,可将第一语句被正确识别的概率直接作为第一语句对应的语句的置信度。In some embodiments, the probability of the first sentence being correctly recognized may be directly used as the confidence level of the sentence corresponding to the first sentence.
继续参见图2B,步骤1023、基于每一个所述语句置信度确定所述第一语音片段对应的语音置信度。Continue referring to FIG. 2B ,
在一些实施例中,通过标准声学模型中的建模单元对每一个语句给出的分值,即语句置信度后,进一步可根据多个语句中每一个语句对应的语句置信度得出多个语句对应的平均语音置信度,并将平均语音置信度作为第一语音片段的语音置信度。In some embodiments, after the score given to each statement by the modeling unit in the standard acoustic model, that is, the statement confidence, multiple statements can be further obtained according to the statement confidence corresponding to each statement in the multiple statements The average speech confidence level corresponding to the sentence, and the average speech confidence level is used as the speech confidence level of the first speech segment.
继续参见图2A,步骤103:识别出所述至少两个语音片段对应的至少两个文本信息,并利用目标语音置信度对应发声对象的文本信息修正其他语音置信度对应发声对象对应的文本信息,其中,所述目标语音置信度高于其他语音置信度。Continue to refer to FIG. 2A, step 103: identify at least two text information corresponding to the at least two speech segments, and use the text information corresponding to the utterance object with the target speech confidence to modify the text information corresponding to the utterance object with other speech confidence, Wherein, the target speech confidence is higher than other speech confidences.
在一些实施例中,利用标准声学模型对至少两个语音片段进行解码,可得到语音片段对应的文本信息,由于每一个语音片段对应不同发声对象,而发声对象可能来自不同地域,具有不同的口音,因此,不同语音片段对应有不同的语音置信度。在具体实施中,语音片段的语音置信度越高,则代表该语音片段对应的发声对象的口音越接近标准口音,因此可利用语音置信度高的语音片段对应的文本信息对语音置信度低的语音片段对应的文本信息进行修正。In some embodiments, the standard acoustic model is used to decode at least two speech segments, and the text information corresponding to the speech segments can be obtained, because each speech segment corresponds to a different utterance object, and the utterance objects may come from different regions and have different accents , therefore, different speech segments correspond to different speech confidence levels. In a specific implementation, the higher the voice confidence of the voice segment, the closer the accent of the utterance object corresponding to the voice segment is to the standard accent. Therefore, the text information corresponding to the voice segment with high voice confidence can be used to identify the voice with low voice confidence. The text information corresponding to the speech segment is corrected.
在一些实施例中,参见图2E,图2E是本申请实施例提供的语音识别方法的一个可选的流程示意图,图2A示出的步骤103中,利用目标语音置信度对应发声对象的文本信息修正其他语音置信度对应发声对象对应的文本信息的步骤,可以通过图2E中步骤1031实现。In some embodiments, referring to FIG. 2E, FIG. 2E is an optional flowchart of the voice recognition method provided by the embodiment of the present application. In
步骤1031、确定所述至少两个文本信息中属于不同发声对象且满足目标相似度的至少两个词语,利用目标语音置信度对应发声对象对应的文本信息中的词语修正其他语音置信度对应发声对象对应的文本信息中的词语。Step 1031: Determine at least two words in the at least two text information that belong to different utterance objects and satisfy the target similarity, and use the words in the text information corresponding to the utterance object with the target speech confidence level to modify other speech confidence level corresponding utterance objects words in the corresponding text information.
这里,基于一个文本信息包含的任一词语,可计算该词语与其他文本信息包含的词语间的相似度,若两词语间的相似度满足目标相似度,则利用置信度高的文本信息对应的词语修正置信度低的文本信息对应的词语。例如,存在两个文本信息为A文本信息和B文本信息,A文本信息为:准备好明天开会需要的文件,其中包含有词语“文件”;B文本信息为:已经准备好了,共有三份文章,其中包含有词语“文章”。若识别得出A文本信息对应的语音置信度大于B文本信息对应的语音置信度,且词语“文件”和“文章”的相似度满足目标相似度,则将B文本信息中包含的词语“文章”替换为“文件”,完成修正。Here, based on any word contained in a piece of text information, the similarity between the word and words contained in other text information can be calculated. If the similarity between the two words meets the target similarity, then use the text information with high confidence The words corresponding to the text information with low confidence are corrected. For example, there are two text information A text information and B text information, the A text information is: prepare the documents needed for the meeting tomorrow, which contains the word "file"; the B text information is: ready, there are three copies Articles, which contain the word "article". If it is recognized that the speech confidence corresponding to the A text information is greater than the speech confidence corresponding to the B text information, and the similarity between the words "file" and "article" meets the target similarity, then the word "article" contained in the B text information "Replace with "file" to complete the correction.
进一步参见图2F,图2F是本申请实施例提供的语音识别方法的一个可选的流程示意图,图2E示出的步骤1031中,确定所述至少两个文本信息中属于不同发声对象且满足目标相似度的至少两个词语的步骤,可以通过图2F中步骤10311至步骤10313实现,下面分别说明。Further referring to FIG. 2F, FIG. 2F is an optional flow chart of the speech recognition method provided by the embodiment of the present application. In
步骤10311、对所述至少两个文本信息中的每一个文本信息进行分词处理,得到每一个文本信息包含的关键词语。Step 10311: Perform word segmentation processing on each of the at least two text information to obtain key words contained in each text information.
在一些实施例中,关键词语为进行分词处理得到的各词语的统称。在进行分词处理时,可以一个语素为单位对文本信息进行分词处理,语素为语言中最小的音义结合体,有发音且有意义,没有实际意义的词不能称为一个语素,例如呢、啊等语气词。In some embodiments, the key words are a general term for words obtained through word segmentation processing. When performing word segmentation processing, text information can be segmented in units of one morpheme. A morpheme is the smallest combination of sound and meaning in a language. It has pronunciation and is meaningful. A word without practical meaning cannot be called a morpheme, such as what, ah, etc. Modal.
步骤10312、确定属于不同文本信息包含的所述关键词语之间的第一相似度。
步骤10313、从所述至少两个文本信息中各文本信息包含的关键词语中获得所述第一相似度满足目标相似度的至少两个关键词;所述至少两个关键词为所述至少两个文本信息中属于不同发声对象且满足目标相似度的至少两个词语。
在一些实施例中,以任一文本信息包含的第一关键词语,计算该第一关键词语与其他文本信息包含的第二关键词语之间的第一相似度。第一关键词语为选定的文本信息包含的各关键词语中的任意关键词,第二关键词语为除选定文本信息之外的其他文本信息包含的各关键词语中的任意关键词。当选定的文本信息包含的第一关键词语处理完之后,继续选择下一个未处理的文本信息作为选定的文本信息,重复上述操作对其他文本信息包含的关键词进行处理,直至将所有文本信息包含的关键词语处理完毕。In some embodiments, a first key word included in any text information is used to calculate a first similarity between the first key word and a second key word included in other text information. The first key word is any key word among the key words included in the selected text information, and the second key word is any key word among the key words included in other text information except the selected text information. After the first keyword contained in the selected text information has been processed, continue to select the next unprocessed text information as the selected text information, and repeat the above operations to process the keywords contained in other text information until all text information is processed. The key words contained in the information have been processed.
继续参见图2A,步骤104:输出所述修正后的至少两个文本信息。Continue referring to FIG. 2A , step 104: output the at least two text messages after modification.
在一些实施例中,当修正的对象为单个字或词语时,输出时可直接输出字或词所在的语句,在另一些实施例中,修正后的至少两个文本信息在输出时,可在一个或多个具有显示功能的设备上进行输出,该设备可以是集修正、显示功能为一体的电子设备,也可以是仅提供显示功能的电子设备。In some embodiments, when the corrected object is a single word or phrase, the sentence where the word or word is located can be directly output during output, and in other embodiments, at least two text messages after correction can be output in Output on one or more devices with display function, the device may be an electronic device that integrates correction and display functions, or an electronic device that only provides display functions.
本申请实施例提供的语音识别方法,通过获取原始语音信息包含的至少两个属于不同发声对象的语音片段,确定至少两个语音片段中每一个语音片段对应的发声对象的语音置信度,识别出至少两个语音片段对应的至少两个文本信息,利用语音置信度高的发声对象的文本信息修正语音置信度低的发声对象的文本信息。如此,本申请提供的语音识别方法,通过确定语音片段对应发声的语音置信度,利用高语音置信度对应的文本信息对低语音置信度对应的文本信息进行修正,从而提高了标准语音识别引擎的语音识别正确率。The speech recognition method provided by the embodiment of the present application obtains at least two speech segments belonging to different utterance objects contained in the original speech information, determines the speech confidence of the utterance object corresponding to each of the at least two speech segments, and recognizes The at least two text information corresponding to the at least two speech segments are used to modify the text information of the speaking object with low speech confidence by using the text information of the speaking object with high speech confidence. In this way, the speech recognition method provided by the present application, by determining the speech confidence degree corresponding to the utterance of the speech segment, uses the text information corresponding to the high speech confidence degree to modify the text information corresponding to the low speech confidence degree, thereby improving the performance of the standard speech recognition engine. Speech recognition accuracy.
与相关技术相比,本申请实施例提出的语音识别方法,不需要针对不同地域设置不同的语音识别设备,基于标准声学模型,只需利用置信度高的文本信息对置信度低的文本信息进行修正,即可将带口音的语音信息修正为标准口音对应的语音信息,因而不受地域控制从而更具普遍性;另外,由于本申请实施例无需利用带口音的语音对标准声学模型进行训练,因此也不会降低对标准语音的识别正确率。Compared with related technologies, the speech recognition method proposed in the embodiment of the present application does not need to set up different speech recognition devices for different regions. Based on the standard acoustic model, it only needs to use text information with high confidence to perform text information with low confidence. Correction means that the voice information with an accent can be corrected to the voice information corresponding to a standard accent, so it is not subject to regional control and thus more universal; in addition, since the embodiment of the present application does not need to use the voice with an accent to train the standard acoustic model, Therefore, the recognition accuracy rate of the standard speech will not be reduced.
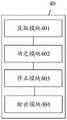
基于相同的发明构思,本申请实施例还提供一种语音识别装置,参考图4,图4为本申请实施例提供的一种语音识别装置的结构示意图。所述装置40包括:获取模块401、确定模块402、修正模块403和输出模块404,其中;Based on the same inventive concept, the embodiment of the present application further provides a speech recognition device, refer to FIG. 4 , which is a schematic structural diagram of a speech recognition device provided in the embodiment of the present application. The
所述获取模块401,用于获取原始语音信息包含的至少两个属于不同发声对象的语音片段;The obtaining module 401 is configured to obtain at least two speech segments belonging to different utterance objects included in the original speech information;
所述确定模块402,用于确定所述至少两个语音片段中每一个语音片段对应的发声对象的语音置信度;The determination module 402 is configured to determine the voice confidence of the utterance object corresponding to each voice segment in the at least two voice segments;
所述修正模块403,用于识别出所述至少两个语音片段对应的至少两个文本信息,并利用目标语音置信度对应发声对象的文本信息修正其他语音置信度对应发声对象对应的文本信息,其中,所述目标语音置信度高于其他语音置信度;The correction module 403 is configured to identify at least two text information corresponding to the at least two speech segments, and use the text information corresponding to the utterance object with the target speech confidence degree to modify the text information corresponding to the utterance object corresponding to other speech confidence degrees, Wherein, the target speech confidence is higher than other speech confidences;
所述输出模块404,用于输出所述修正后的至少两个文本信息。The output module 404 is configured to output the at least two text messages after modification.
在一些实施例中,所述修正模块403还用于确定所述至少两个文本信息中属于不同发声对象且满足目标相似度的至少两个词语,利用目标语音置信度对应发声对象对应的文本信息中的词语修正其他语音置信度对应发声对象对应的文本信息中的词语。In some embodiments, the correction module 403 is further configured to determine at least two words in the at least two text information that belong to different utterance objects and satisfy the target similarity, and use the target speech confidence to correspond to the text information corresponding to the utterance object The words in modify the words in the text information corresponding to the utterance object corresponding to the other speech confidence.
在一些实施例中,所述修正模块403还用于对所述至少两个文本信息中的每一个文本信息进行分词处理,得到每一个文本信息包含的关键词语;确定属于不同文本信息包含的所述关键词语之间的第一相似度;从所述至少两个文本信息中各文本信息包含的关键词语中获得所述第一相似度满足目标相似度的至少两个关键词;所述至少两个关键词为所述至少两个文本信息中属于不同发声对象且满足目标相似度的至少两个词语。In some embodiments, the correction module 403 is further configured to perform word segmentation processing on each text information in the at least two text information to obtain key words contained in each text information; determine all the words belonging to different text information The first similarity between the key words; at least two keywords whose first similarity meets the target similarity are obtained from the key words contained in each text information in the at least two text information; the at least two The keywords are at least two words in the at least two text messages that belong to different utterance objects and satisfy the target similarity.
在一些实施例中,所述原始语音信息包括按照第一时间间隔依次采集的至少一个子语音信息,所述获取模块401还用于对采集到的所述至少一个子语音信息中的任一第一子语音信息进行预处理,得到利用所述第一子语音信息的语音特征表示的第二子语音信息;对所述第二子语音信息进行分割和聚类处理,获得所述第一子语音信息包含的至少两个属于不同发声对象的子语音片段;将每一个第一子语音信息中属于同一发声对象的子语音片段进行聚类处理,获得所述原始语音信息包含的至少两个属于不同发声对象的语音片段。In some embodiments, the original voice information includes at least one sub-voice information sequentially collected according to a first time interval, and the acquiring module 401 is further configured to perform any first sub-voice information in the at least one collected sub-voice information Preprocessing a sub-speech information to obtain second sub-speech information represented by the speech features of the first sub-speech information; performing segmentation and clustering processing on the second sub-speech information to obtain the first sub-speech information At least two sub-speech segments belonging to different utterance objects included in the information; performing clustering processing on the sub-speech segments belonging to the same utterance object in each first sub-speech information, and obtaining at least two sub-speech segments contained in the original speech information belonging to different utterance objects; The speech segment of the speaking object.
在一些实施例中,所述获取模块401还用于对所述第二子语音信息进行分割和聚类处理,获得属于不同发声对象的至少两个中间语音片段;在至少一个所述中间语音片段包含至少两个不同的发声对象的情况下,重新对所述至少两个中间语音片段中的每一个中间语音片段进行分割和聚类处理,直到获得的所述至少两个属于不同发声对象的子语音片段中的每一个子语音片段仅包含一个发声对像为止。In some embodiments, the acquiring module 401 is further configured to segment and cluster the second sub-speech information to obtain at least two intermediate speech segments belonging to different utterance objects; in at least one of the intermediate speech segments In the case of including at least two different utterance objects, re-segment and cluster each intermediate speech segment in the at least two intermediate speech segments until the obtained at least two intermediate speech segments belonging to different utterance objects Each sub-speech segment in the speech segment contains only one utterance object.
在一些实施例中,所述确定模块402还用于对所述至少两个语音片段中的任一第一语音片段进行语句划分,得到所述第一语音片段包含的多个语句;对所述多个语句中的任一第一语句进行识别,得到所述第一语句对应的语句置信度;基于每一个所述语句置信度确定所述第一语音片段对应的语音置信度。In some embodiments, the determining module 402 is further configured to divide any first speech segment in the at least two speech segments into sentences to obtain multiple sentences contained in the first speech segment; Recognizing any first sentence in the plurality of sentences to obtain a sentence confidence degree corresponding to the first sentence; determining a speech confidence degree corresponding to the first speech segment based on each sentence confidence degree.
在一些实施例中,所述确定模块402还用于确定所述第一语句的类型;所述第一语句为所述多个语句中的任一句;将所述第一语句输入到与所述类型对应的识别模型,获得所述第一语句被正确识别的概率;基于所述概率得到所述第一语句对应的语句的置信度。In some embodiments, the determining module 402 is also used to determine the type of the first sentence; the first sentence is any sentence in the plurality of sentences; the first sentence is input to the The recognition model corresponding to the type obtains the probability that the first sentence is correctly recognized; and obtains the confidence degree of the sentence corresponding to the first sentence based on the probability.
需要说明的是,本申请实施例装置的描述,与上述方法实施例的描述是类似的,具有同方法实施例相似的有益效果,因此不做赘述。对于本装置实施例中未披露的技术细节,请参照本申请方法实施例的描述而理解。It should be noted that the description of the device in the embodiment of the present application is similar to the description of the above-mentioned method embodiment, and has similar beneficial effects to the method embodiment, so details are not repeated here. For the technical details not disclosed in the device embodiment of this application, please refer to the description of the method embodiment of this application for understanding.
需要说明的是,本申请实施例中,如果以软件功能模块的形式实现上述的屏幕分享方法,并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请实施例的技术方案本质上或者说对相关技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台终端执行本申请各个实施例所述方法的全部或部分。而前述的存储介质包括:U盘、移动硬盘、只读存储器(ROM,Read Only Memory)、磁碟或者光盘等各种可以存储程序代码的介质。这样,本申请实施例不限制于任何特定的硬件和软件结合。It should be noted that, in the embodiment of the present application, if the above screen sharing method is implemented in the form of software function modules and sold or used as an independent product, it can also be stored in a computer-readable storage medium. Based on this understanding, the essence of the technical solutions of the embodiments of the present application or the part that contributes to the related technologies can be embodied in the form of software products. The computer software products are stored in a storage medium and include several instructions to make One terminal executes all or part of the methods described in the various embodiments of the present application. The aforementioned storage medium includes: various media capable of storing program codes such as U disk, mobile hard disk, read only memory (ROM, Read Only Memory), magnetic disk or optical disk. Thus, embodiments of the present application are not limited to any specific combination of hardware and software.
本申请实施例还提供一种电子设备,图5是本申请实施例提供的电子设备的组成结构示意图,如图5所示,所述电子设备50至少包括:处理器501和配置为存储可执行指令的计算机可读存储介质502,其中处理器501通常控制所述电子设备的总体操作。计算机可读存储介质502配置为存储由处理器501可执行的指令和应用,还可以缓存待处理器501和电子设备50中各模块待处理或已处理的数据,可以通过闪存或随机访问存储器(RAM,RandomAccess Memory)实现。The embodiment of the present application also provides an electronic device. FIG. 5 is a schematic diagram of the composition and structure of the electronic device provided in the embodiment of the present application. As shown in FIG. A computer-readable storage medium of
本申请实施例提供一种存储有可执行指令的存储介质,其中存储有可执行指令,当可执行指令被处理器执行时,将引起处理器执行本申请实施例提供的语音识别方法,例如,如图2A示出的方法。The embodiment of the present application provides a storage medium storing executable instructions, wherein the executable instructions are stored, and when the executable instructions are executed by the processor, it will cause the processor to execute the voice recognition method provided in the embodiment of the present application, for example, The method shown in Figure 2A.
在一些实施例中,存储介质可以是计算机可读存储介质,例如,铁电存储器(FRAM,Ferromagnetic Random Access Memory)、只读存储器(ROM,Read Only Memory)、可编程只读存储器(PROM,Programmable Read Only Memory)、可擦除可编程只读存储器(EPROM,Erasable Programmable Read Only Memory)、带电可擦可编程只读存储器(EEPROM,Electrically Erasable Programmable Read Only Memory)、闪存、磁表面存储器、光盘、或光盘只读存储器(CD-ROM,Compact Disk-Read Only Memory)等存储器;也可以是包括上述存储器之一或任意组合的各种设备。In some embodiments, the storage medium may be a computer-readable storage medium, for example, a ferroelectric memory (FRAM, Ferromagnetic Random Access Memory), a read-only memory (ROM, Read Only Memory), a programmable read-only memory (PROM, Programmable Read Only Memory), Erasable Programmable Read Only Memory (EPROM, Erasable Programmable Read Only Memory), Electrically Erasable Programmable Read Only Memory (EEPROM, Electrically Erasable Programmable Read Only Memory), flash memory, magnetic surface memory, optical disc, Or a memory such as a CD-ROM (Compact Disk-Read Only Memory); it may also be various devices including one or any combination of the above-mentioned memories.
在一些实施例中,可执行指令可以采用程序、软件、软件模块、脚本或代码的形式,按任意形式的编程语言(包括编译或解释语言,或者声明性或过程性语言)来编写,并且其可按任意形式部署,包括被部署为独立的程序或者被部署为模块、组件、子例程或者适合在计算环境中使用的其它单元。In some embodiments, executable instructions may take the form of programs, software, software modules, scripts, or code written in any form of programming language, including compiled or interpreted languages, or declarative or procedural languages, and its Can be deployed in any form, including as a stand-alone program or as a module, component, subroutine or other unit suitable for use in a computing environment.
作为示例,可执行指令可以但不一定对应于文件系统中的文件,可以可被存储在保存其它程序或数据的文件的一部分,例如,存储在超文本标记语言(HTML,Hyper TextMarkup Language)文档中的一个或多个脚本中,存储在专用于所讨论的程序的单个文件中,或者,存储在多个协同文件(例如,存储一个或多个模块、子程序或代码部分的文件)中。作为示例,可执行指令可被部署为在一个计算设备上执行,或者在位于一个地点的多个计算设备上执行,又或者,在分布在多个地点且通过通信网络互连的多个计算设备上执行。As an example, executable instructions may, but do not necessarily correspond to files in a file system, may be stored as part of a file that holds other programs or data, for example, in a Hyper Text Markup Language (HTML) document in one or more scripts of the program in question, in a single file dedicated to the program in question, or in multiple cooperating files (for example, files that store one or more modules, subroutines, or sections of code). As an example, executable instructions may be deployed to be executed on one computing device, or on multiple computing devices located at one site, or alternatively, on multiple computing devices distributed across multiple sites and interconnected by a communication network. to execute.
需要说明的是,本申请实施例各实施例所记载的技术方案中各技术特征之间,在不冲突的情况下,可以任意组合。It should be noted that the technical features in the technical solutions described in the embodiments of the present application can be combined arbitrarily if there is no conflict.
应理解,说明书通篇中提到的“一个实施例”或“一实施例”意味着与实施例有关的特定特征、结构或特性包括在本申请的至少一个实施例中。因此,在整个说明书各处出现的“在一个实施例中”或“在一实施例中”未必一定指相同的实施例。此外,这些特定的特征、结构或特性可以任意适合的方式结合在一个或多个实施例中。应理解,在本申请的各种实施例中,上述各过程的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本申请实施例的实施过程构成任何限定。上述本申请实施例序号仅仅为了描述,不代表实施例的优劣。It should be understood that reference throughout the specification to "one embodiment" or "an embodiment" means that a particular feature, structure, or characteristic related to the embodiment is included in at least one embodiment of the present application. Thus, appearances of "in one embodiment" or "in an embodiment" in various places throughout the specification are not necessarily referring to the same embodiment. Furthermore, the particular features, structures or characteristics may be combined in any suitable manner in one or more embodiments. It should be understood that, in various embodiments of the present application, the sequence numbers of the above-mentioned processes do not mean the order of execution, and the execution order of the processes should be determined by their functions and internal logic, and should not be used in the embodiments of the present application. The implementation process constitutes any limitation. The serial numbers of the above embodiments of the present application are for description only, and do not represent the advantages and disadvantages of the embodiments.
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法或者装置不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法或者装置所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者装置中还存在另外的相同要素。在本申请所提供的几个实施例中,应该理解到,所揭露的设备和方法,可以通过其它的方式实现。以上所描述的设备实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,如:多个单元或组件可以结合,或可以集成到另一个系统,或一些特征可以忽略,或不执行。It should be noted that, in this document, the terms "comprising", "comprising" or any other variation thereof are intended to cover a non-exclusive inclusion such that a process, method or apparatus comprising a series of elements includes not only those elements, but also Other elements not expressly listed are included, or elements inherent in such process, method, or apparatus are included. Without further limitations, an element defined by the phrase "comprising a ..." does not preclude the presence of additional identical elements in the process, method, article, or apparatus comprising that element. In the several embodiments provided in this application, it should be understood that the disclosed devices and methods may be implemented in other ways. The device embodiments described above are only illustrative. For example, the division of the units is only a logical function division. In actual implementation, there may be other division methods, such as: multiple units or components can be combined, or May be integrated into another system, or some features may be ignored, or not implemented.
以上所述,仅为本申请的实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以所述权利要求的保护范围为准。The above is only the embodiment of the present application, but the scope of protection of the present application is not limited thereto. Anyone familiar with the technical field can easily think of changes or substitutions within the technical scope disclosed in the present application, and should covered within the scope of protection of this application. Therefore, the protection scope of the present application should be determined by the protection scope of the claims.
Claims (10)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211199117.8ACN115641849B (en) | 2022-09-29 | 2022-09-29 | Speech recognition method, device, electronic equipment and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211199117.8ACN115641849B (en) | 2022-09-29 | 2022-09-29 | Speech recognition method, device, electronic equipment and storage medium |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN115641849Atrue CN115641849A (en) | 2023-01-24 |
| CN115641849B CN115641849B (en) | 2025-09-19 |
Family
ID=84942378
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202211199117.8AActiveCN115641849B (en) | 2022-09-29 | 2022-09-29 | Speech recognition method, device, electronic equipment and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115641849B (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN120496529A (en)* | 2025-07-09 | 2025-08-15 | 中电信人工智能科技(北京)有限公司 | Text correction method, device and electronic device |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20170229122A1 (en)* | 2011-02-22 | 2017-08-10 | Speak With Me, Inc. | Hybridized client-server speech recognition |
| JP2019144310A (en)* | 2018-02-16 | 2019-08-29 | キヤノンマーケティングジャパン株式会社 | Information processor, information processing system, control method and program |
| CN110800046A (en)* | 2018-06-12 | 2020-02-14 | 深圳市合言信息科技有限公司 | Speech recognition and translation method and translation device |
| CN110875039A (en)* | 2018-08-30 | 2020-03-10 | 阿里巴巴集团控股有限公司 | Speech recognition method and apparatus |
| CN112599114A (en)* | 2020-11-11 | 2021-04-02 | 联想(北京)有限公司 | Voice recognition method and device |
| CN114420123A (en)* | 2022-03-16 | 2022-04-29 | 深存科技(无锡)有限公司 | Voice recognition optimization method and device, computer equipment and storage medium |
- 2022
- 2022-09-29CNCN202211199117.8Apatent/CN115641849B/enactiveActive
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20170229122A1 (en)* | 2011-02-22 | 2017-08-10 | Speak With Me, Inc. | Hybridized client-server speech recognition |
| JP2019144310A (en)* | 2018-02-16 | 2019-08-29 | キヤノンマーケティングジャパン株式会社 | Information processor, information processing system, control method and program |
| CN110800046A (en)* | 2018-06-12 | 2020-02-14 | 深圳市合言信息科技有限公司 | Speech recognition and translation method and translation device |
| CN110875039A (en)* | 2018-08-30 | 2020-03-10 | 阿里巴巴集团控股有限公司 | Speech recognition method and apparatus |
| CN112599114A (en)* | 2020-11-11 | 2021-04-02 | 联想(北京)有限公司 | Voice recognition method and device |
| CN114420123A (en)* | 2022-03-16 | 2022-04-29 | 深存科技(无锡)有限公司 | Voice recognition optimization method and device, computer equipment and storage medium |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN120496529A (en)* | 2025-07-09 | 2025-08-15 | 中电信人工智能科技(北京)有限公司 | Text correction method, device and electronic device |
Also Published As
| Publication number | Publication date |
|---|---|
| CN115641849B (en) | 2025-09-19 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11373633B2 (en) | Text-to-speech processing using input voice characteristic data | |
| US20220189458A1 (en) | Speech based user recognition | |
| US20230317074A1 (en) | Contextual voice user interface | |
| US11043213B2 (en) | System and method for detection and correction of incorrectly pronounced words | |
| US11810471B2 (en) | Computer implemented method and apparatus for recognition of speech patterns and feedback | |
| US10176809B1 (en) | Customized compression and decompression of audio data | |
| KR20210146368A (en) | End-to-end automatic speech recognition for digit sequences | |
| US8494853B1 (en) | Methods and systems for providing speech recognition systems based on speech recordings logs | |
| KR20200015418A (en) | Method and computer readable storage medium for performing text-to-speech synthesis using machine learning based on sequential prosody feature | |
| CN112651247B (en) | Dialogue system, dialogue processing method, translation device and translation method | |
| US11676572B2 (en) | Instantaneous learning in text-to-speech during dialog | |
| CN113593523B (en) | Speech detection method and device based on artificial intelligence and electronic equipment | |
| CN110853669B (en) | Audio identification method, device and equipment | |
| CN112562640A (en) | Multi-language speech recognition method, device, system and computer readable storage medium | |
| CN112599114A (en) | Voice recognition method and device | |
| CN114999463A (en) | Voice recognition method, device, equipment and medium | |
| CN114387950A (en) | Speech recognition method, apparatus, device and storage medium | |
| CN113421587A (en) | Voice evaluation method and device, computing equipment and storage medium | |
| CN115641849B (en) | Speech recognition method, device, electronic equipment and storage medium | |
| CN117711376A (en) | Language identification method, system, equipment and storage medium | |
| EP4287178A1 (en) | Improved performance evaluation of automatic speech recognition engines | |
| CN116052655A (en) | Audio processing method, device, electronic equipment and readable storage medium | |
| CN114822538A (en) | Method, device, system and equipment for training and voice recognition of re-grading model | |
| CN114048714A (en) | Method and device for standardizing reverse text | |
| CN117594060B (en) | Audio signal content analysis method, device, equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |