CN115619463A - Target user determination method, device, storage medium and electronic equipment - Google Patents
Target user determination method, device, storage medium and electronic equipmentDownload PDFInfo
- Publication number
- CN115619463A CN115619463ACN202211295508.XACN202211295508ACN115619463ACN 115619463 ACN115619463 ACN 115619463ACN 202211295508 ACN202211295508 ACN 202211295508ACN 115619463 ACN115619463 ACN 115619463A
- Authority
- CN
- China
- Prior art keywords
- user
- vector
- feature
- seed
- advertisement
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images






Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q30/00—Commerce
- G06Q30/02—Marketing; Price estimation or determination; Fundraising
- G06Q30/0241—Advertisements
- G06Q30/0251—Targeted advertisements
- G06Q30/0269—Targeted advertisements based on user profile or attribute
Landscapes
- Business, Economics & Management (AREA)
- Engineering & Computer Science (AREA)
- Accounting & Taxation (AREA)
- Development Economics (AREA)
- Strategic Management (AREA)
- Finance (AREA)
- Game Theory and Decision Science (AREA)
- Entrepreneurship & Innovation (AREA)
- Economics (AREA)
- Marketing (AREA)
- Physics & Mathematics (AREA)
- General Business, Economics & Management (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Management, Administration, Business Operations System, And Electronic Commerce (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本公开涉及人工智能技术领域,具体而言,涉及一种目标用户确定方法、目标用户确定装置、计算机可读存储介质以及电子设备。The present disclosure relates to the technical field of artificial intelligence, and in particular, relates to a method for determining a target user, a device for determining a target user, a computer-readable storage medium, and electronic equipment.
背景技术Background technique
随着网络技术的发展,广告投放已经成为网络领域中的重要组成部分。在广告投放场景下,往往有对投放人群进行扩展的需求。With the development of network technology, advertising has become an important part of the network field. In the advertising delivery scenario, there is often a need to expand the advertising audience.
例如,进行线下广告投放时,主要基于用户的历史行为信息和广告主的诉求通过人工进行人群圈选,效率较低。而且,人工进行人群圈选非常依赖item(物料)对应user(用户)的历史行为信息,容易造成广告投放中的“马太效应”。例如,对于冷门但质量较高的长尾内容,可能会被认定为具有较低的投放优先级,从而无法得到有效的投放。For example, when placing offline advertisements, it is mainly based on the historical behavior information of users and the demands of advertisers through manual crowd selection, which is inefficient. Moreover, manual crowd selection is very dependent on the historical behavior information of the item (material) corresponding to the user (user), which is likely to cause the "Matthew effect" in advertising. For example, unpopular but high-quality long-tail content may be deemed to have a lower delivery priority, so that it cannot be effectively delivered.
因此,为了保证广告的有效投放,提供一种精准高效的目标用户确定方法是非常必要的。Therefore, in order to ensure effective delivery of advertisements, it is very necessary to provide an accurate and efficient method for determining target users.
需要说明的是,在上述背景技术部分公开的信息仅用于加强对本公开的背景的理解,因此可以包括不构成对本领域普通技术人员已知的现有技术的信息。It should be noted that the information disclosed in the above background section is only for enhancing the understanding of the background of the present disclosure, and therefore may include information that does not constitute the prior art known to those of ordinary skill in the art.
发明内容Contents of the invention
本公开的目的在于提供一种目标用户确定方法、目标用户确定装置、计算机可读存储介质以及电子设备,进而在一定程度上克服由于相关技术的限制和缺陷而导致相似人群扩展的效率和精准率均较低的问题。The purpose of the present disclosure is to provide a method for determining target users, a device for determining target users, a computer-readable storage medium, and electronic equipment, so as to overcome the efficiency and accuracy of expanding similar groups of people due to the limitations and defects of related technologies to a certain extent lower average problem.
根据本公开的第一方面,提供一种目标用户确定方法,包括:According to a first aspect of the present disclosure, a method for determining a target user is provided, including:
获取多个用户的多维特征数据,并根据所述多维特征数据生成用户特征向量和广告特征向量,其中,所述多个用户包括种子用户和候选用户;Acquiring multi-dimensional feature data of multiple users, and generating user feature vectors and advertisement feature vectors according to the multi-dimensional feature data, wherein the multiple users include seed users and candidate users;
将所述用户特征向量和所述广告特征向量输入用户表征模型中,生成用户表征向量,所述用户表征向量包括第一种子用户向量和第一候选用户向量;Inputting the user feature vector and the advertisement feature vector into a user characterization model to generate a user characterization vector, the user characterization vector including a first seed user vector and a first candidate user vector;
将所述第一种子用户向量和所述第一候选用户向量输入相似度预估模型中,生成第二种子用户向量和第二候选用户向量,并计算所述第二种子用户向量和所述第二候选用户向量之间的相似度;inputting the first seed user vector and the first candidate user vector into a similarity estimation model, generating a second seed user vector and a second candidate user vector, and calculating the second seed user vector and the first The similarity between the two candidate user vectors;
根据所述相似度确定所述候选用户中的目标用户。A target user among the candidate users is determined according to the similarity.
在本公开的一种示例性实施例中,所述种子用户包括历史投放广告的种子用户和待投放广告的种子用户中的一种;所述获取多个用户的多维特征数据之前,包括:In an exemplary embodiment of the present disclosure, the seed users include one of the seed users who have placed advertisements in the past and the seed users who are to be placed advertisements; before acquiring the multi-dimensional feature data of multiple users, it includes:
获取待投放广告的第一广告特征向量和历史投放广告的第二广告特征向量;Acquiring the first advertisement feature vector of the advertisement to be delivered and the second advertisement feature vector of the historically delivered advertisement;
计算所述第一广告特征向量和所述第二广告特征向量之间的相似度,并根据所述相似度确定所述历史投放广告中与所述待投放广告相似的目标投放广告;calculating the similarity between the first advertisement feature vector and the second advertisement feature vector, and determining a target advertisement similar to the advertisement to be delivered among the historical advertisements according to the similarity;
基于所述目标投放广告的种子用户构建所述待投放广告的种子用户。The seed users to be advertised are constructed based on the target advertised seed users.
在本公开的一种示例性实施例中,所述多维特征数据包括用户特征数据和广告特征数据;所述根据所述多维特征数据生成用户特征向量和广告特征向量,包括:In an exemplary embodiment of the present disclosure, the multi-dimensional feature data includes user feature data and advertisement feature data; generating the user feature vector and the advertisement feature vector according to the multi-dimensional feature data includes:
对所述用户特征数据进行向量化处理,生成所述用户特征向量;Carrying out vectorization processing on the user feature data to generate the user feature vector;
对所述广告特征数据进行向量化处理,生成所述广告特征向量。Vectorizing the advertisement feature data to generate the advertisement feature vector.
在本公开的一种示例性实施例中,所述用户特征数据包括离散特征数据和连续特征数据中的至少一种;所述对所述用户特征数据进行向量化处理,生成所述用户特征向量,包括:In an exemplary embodiment of the present disclosure, the user feature data includes at least one of discrete feature data and continuous feature data; performing vectorization processing on the user feature data to generate the user feature vector ,include:
对各所述离散特征数据进行统计,得到多个第一特征数据;performing statistics on each of the discrete feature data to obtain a plurality of first feature data;
编码各所述第一特征数据,生成多个第一特征向量;Encoding each of the first feature data to generate a plurality of first feature vectors;
归一化各所述连续特征数据,生成多个第二特征向量;normalizing each of the continuous feature data to generate a plurality of second feature vectors;
将所述多个第一特征向量和所述多个第二特征向量进行拼接,生成所述用户特征向量。Splicing the multiple first feature vectors and the multiple second feature vectors to generate the user feature vector.
在本公开的一种示例性实施例中,所述用户表征模型至少包括第一全连接层和第一注意力层;所述将所述用户特征向量和所述广告特征向量输入用户表征模型中,生成用户表征向量,包括:In an exemplary embodiment of the present disclosure, the user characterization model includes at least a first fully connected layer and a first attention layer; the inputting the user feature vector and the advertisement feature vector into the user characterization model , to generate user representation vectors, including:
利用所述第一全连接层对所述用户特征向量和所述广告特征向量进行特征降维,得到用户中间向量和广告中间向量;Using the first fully connected layer to perform feature dimensionality reduction on the user feature vector and the advertisement feature vector to obtain a user intermediate vector and an advertisement intermediate vector;
基于所述用户中间向量和所述广告中间向量,通过所述第一注意力层生成所述第一种子用户向量和所述第一候选用户向量。Based on the user intermediate vector and the advertisement intermediate vector, the first seed user vector and the first candidate user vector are generated by the first attention layer.
在本公开的一种示例性实施例中,所述相似度预估模型包括两个网络分支,各网络分支至少包括第二全连接层和第二注意力层;所述将所述第一种子用户向量和所述第一候选用户向量输入相似度预估模型中,生成第二种子用户向量和第二候选用户向量,包括:In an exemplary embodiment of the present disclosure, the similarity prediction model includes two network branches, and each network branch includes at least a second fully connected layer and a second attention layer; the first seed The user vector and the first candidate user vector are input into the similarity estimation model, and the second seed user vector and the second candidate user vector are generated, including:
利用所述第二全连接层对所述第一种子用户向量和所述第一候选用户向量进行特征降维,得到种子用户中间向量和候选用户中间向量;Using the second fully connected layer to perform feature dimensionality reduction on the first seed user vector and the first candidate user vector to obtain a seed user intermediate vector and a candidate user intermediate vector;
基于所述种子用户中间向量和所述候选用户中间向量,通过所述第二注意力层生成所述第二种子用户向量和所述第二候选用户向量。Based on the seed user intermediate vector and the candidate user intermediate vector, the second seed user vector and the second candidate user vector are generated by the second attention layer.
在本公开的一种示例性实施例中,所述方法还包括:In an exemplary embodiment of the present disclosure, the method further includes:
获取第一训练样本,各所述第一训练样本为候选用户的用户特征向量和广告特征向量;Obtaining first training samples, each of which is a user feature vector and an advertisement feature vector of a candidate user;
将各所述候选用户的用户特征向量和广告特征向量输入所述用户表征模型中,得到对应的用户表征向量和广告表征向量;Inputting the user feature vectors and advertisement feature vectors of each candidate user into the user characterization model to obtain corresponding user characterization vectors and advertisement characterization vectors;
根据所述用户表征向量和所述广告表征向量构建第一目标函数;Constructing a first objective function according to the user characterization vector and the advertisement characterization vector;
基于所述第一目标函数,对所述用户表征模型的参数进行迭代更新,当满足迭代终止条件时,完成对所述用户表征模型的训练。Based on the first objective function, the parameters of the user representation model are iteratively updated, and when an iteration termination condition is met, the training of the user representation model is completed.
在本公开的一种示例性实施例中,所述方法还包括:所述方法还包括:In an exemplary embodiment of the present disclosure, the method further includes: the method further includes:
获取第二训练样本,各所述第二训练样本为种子用户向量和目标用户向量组成的向量对;Obtaining second training samples, each of which is a vector pair composed of a seed user vector and a target user vector;
通过所述相似度预估模型确定所述种子用户向量和所述目标用户向量的相似度;determining the similarity between the seed user vector and the target user vector through the similarity estimation model;
根据所述种子用户向量和所述目标用户向量的相似度构建第二目标函数;Constructing a second objective function according to the similarity between the seed user vector and the target user vector;
基于所述第二目标函数,对所述相似度预估模型的参数进行迭代更新,当满足迭代终止条件时,完成对所述相似度预估模型的训练。Based on the second objective function, the parameters of the similarity prediction model are iteratively updated, and when the iteration termination condition is met, the training of the similarity prediction model is completed.
根据本公开的第二方面,提供一种目标用户确定装置,包括:According to a second aspect of the present disclosure, an apparatus for determining a target user is provided, including:
特征向量生成模块,用于获取多个用户的多维特征数据,并根据所述多维特征数据生成用户特征向量和广告特征向量,其中,所述多个用户包括种子用户和候选用户;A feature vector generating module, configured to acquire multi-dimensional feature data of multiple users, and generate user feature vectors and advertisement feature vectors according to the multi-dimensional feature data, wherein the multiple users include seed users and candidate users;
表征向量生成模块,用于将所述用户特征向量和所述广告特征向量输入用户表征模型中,生成用户表征向量,所述用户表征向量包括第一种子用户向量和第一候选用户向量;A characterization vector generation module, configured to input the user feature vector and the advertisement feature vector into a user characterization model to generate a user characterization vector, the user characterization vector including a first seed user vector and a first candidate user vector;
相似度计算模块,用于将所述第一种子用户向量和所述第一候选用户向量输入相似度预估模型中,生成第二种子用户向量和第二候选用户向量,并计算所述第二种子用户向量和所述第二候选用户向量之间的相似度;a similarity calculation module, configured to input the first seed user vector and the first candidate user vector into a similarity estimation model, generate a second seed user vector and a second candidate user vector, and calculate the second the similarity between the seed user vector and the second candidate user vector;
目标用户确定模块,用于根据所述相似度确定所述候选用户中的目标用户。A target user determining module, configured to determine a target user among the candidate users according to the similarity.
根据本公开的第三方面,提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任意一项所述的方法。According to a third aspect of the present disclosure, there is provided a computer-readable storage medium, on which a computer program is stored, and when the computer program is executed by a processor, the method described in any one of the above is implemented.
根据本公开的第四方面,提供一种电子设备,包括:处理器;以及存储器,用于存储所述处理器的可执行指令;其中,所述处理器配置为经由执行所述可执行指令来执行上述任意一项所述的方法。According to a fourth aspect of the present disclosure, there is provided an electronic device, including: a processor; and a memory for storing executable instructions of the processor; wherein the processor is configured to execute the executable instructions to Perform any of the methods described above.
本公开示例性实施例可以具有以下部分或全部有益效果:Exemplary embodiments of the present disclosure may have some or all of the following beneficial effects:
在本公开示例实施方式所提供的目标用户确定方法中,通过获取多个用户的多维特征数据,并根据多维特征数据生成用户特征向量和广告特征向量;将用户特征向量和广告特征向量输入用户表征模型中,生成第一种子用户向量和第一候选用户向量;将第一种子用户向量和第一候选用户向量输入相似度预估模型中,生成第二种子用户向量和第二候选用户向量,并计算第二种子用户向量和第二候选用户向量之间的相似度;根据相似度确定候选用户中的目标用户。一方面,通过用户表征模型对不同特征域进行充分地学习组合以生成用户表征向量,该用户表征向量可以更加准确地反映用户的潜在兴趣,便于精准地确定种子用户的相似人群。而且,利用相似度预估模型输出的种子用户向量和候选用户向量可以更准确地计算种子用户和候选用户的相似度,进一步提高了相似人群扩展的精确率,进而提高广告投放的准确率;另一方面,通过用户表征模型和相似度预估模型即可确定目标用户,而无需进行人工圈选,提高了相似人群扩展的效率。In the target user determination method provided by the exemplary embodiments of the present disclosure, the multi-dimensional feature data of multiple users is obtained, and the user feature vector and the advertisement feature vector are generated according to the multi-dimensional feature data; the user feature vector and the advertisement feature vector are input into the user representation In the model, generate the first seed user vector and the first candidate user vector; input the first seed user vector and the first candidate user vector into the similarity estimation model, generate the second seed user vector and the second candidate user vector, and Calculating the similarity between the second seed user vector and the second candidate user vector; determining a target user among the candidate users according to the similarity. On the one hand, different feature domains are fully learned and combined through the user representation model to generate a user representation vector, which can more accurately reflect the potential interests of users and facilitate the accurate determination of similar groups of seed users. Moreover, using the seed user vectors and candidate user vectors output by the similarity prediction model can more accurately calculate the similarity between seed users and candidate users, further improving the accuracy of similar population expansion, thereby improving the accuracy of advertising; On the one hand, the target user can be determined through the user representation model and the similarity prediction model without manual selection, which improves the efficiency of similar group expansion.
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。It is to be understood that both the foregoing general description and the following detailed description are exemplary and explanatory only and are not restrictive of the present disclosure.
附图说明Description of drawings
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理。显而易见地,下面描述中的附图仅仅是本公开的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。The accompanying drawings, which are incorporated in and constitute a part of this specification, illustrate embodiments consistent with the disclosure and together with the description serve to explain the principles of the disclosure. Apparently, the drawings in the following description are only some embodiments of the present disclosure, and those skilled in the art can also obtain other drawings according to these drawings without creative efforts.
图1示出了可以应用本公开实施例中的目标用户确定方法及装置的示例性系统架构的示意图;FIG. 1 shows a schematic diagram of an exemplary system architecture to which the target user determination method and device in the embodiments of the present disclosure can be applied;
图2示意性示出了根据本公开实施例中的一种目标用户确定方法的流程图;FIG. 2 schematically shows a flow chart of a method for determining a target user according to an embodiment of the present disclosure;
图3示意性示出了根据本公开实施例中用户表征模型的一种结构示意图;Fig. 3 schematically shows a schematic structural diagram of a user representation model according to an embodiment of the present disclosure;
图4示意性示出了根据本公开实施例中相似度预估模型的一种结构示意图;FIG. 4 schematically shows a schematic structural diagram of a similarity prediction model according to an embodiment of the present disclosure;
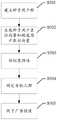
图5示意性示出了根据本公开实施例中的一种线下广告定向投放的流程图;Fig. 5 schematically shows a flow chart of targeted delivery of offline advertisements according to an embodiment of the present disclosure;
图6示意性示出了根据本公开实施例的目标用户确定装置的框图;Fig. 6 schematically shows a block diagram of an apparatus for determining a target user according to an embodiment of the present disclosure;
图7示意性示出了适于用来实现本公开实施例的电子设备的计算机系统的结构示意图。Fig. 7 schematically shows a structural diagram of a computer system suitable for implementing the electronic device of the embodiment of the present disclosure.
具体实施方式detailed description
现在将参考附图更全面地描述示例实施方式。然而,示例实施方式能够以多种形式实施,且不应被理解为限于在此阐述的范例;相反,提供这些实施方式使得本公开将更加全面和完整,并将示例实施方式的构思全面地传达给本领域的技术人员。所描述的特征、结构或特性可以以任何合适的方式结合在一个或更多实施方式中。在下面的描述中,提供许多具体细节从而给出对本公开的实施方式的充分理解。然而,本领域技术人员将意识到,可以实践本公开的技术方案而省略所述特定细节中的一个或更多,或者可以采用其它的方法、组元、装置、步骤等。在其它情况下,不详细示出或描述公知技术方案以避免喧宾夺主而使得本公开的各方面变得模糊。Example embodiments will now be described more fully with reference to the accompanying drawings. Example embodiments may, however, be embodied in many forms and should not be construed as limited to the examples set forth herein; rather, these embodiments are provided so that this disclosure will be thorough and complete and will fully convey the concept of example embodiments to those skilled in the art. The described features, structures, or characteristics may be combined in any suitable manner in one or more embodiments. In the following description, numerous specific details are provided in order to give a thorough understanding of embodiments of the present disclosure. However, those skilled in the art will appreciate that the technical solutions of the present disclosure may be practiced without one or more of the specific details being omitted, or other methods, components, devices, steps, etc. may be adopted. In other instances, well-known technical solutions have not been shown or described in detail to avoid obscuring aspects of the present disclosure.
此外,附图仅为本公开的示意性图解,并非一定是按比例绘制。图中相同的附图标记表示相同或类似的部分,因而将省略对它们的重复描述。附图中所示的一些方框图是功能实体,不一定必须与物理或逻辑上独立的实体相对应。可以采用软件形式来实现这些功能实体,或在一个或多个硬件模块或集成电路中实现这些功能实体,或在不同网络和/或处理器装置和/或微控制器装置中实现这些功能实体。Furthermore, the drawings are merely schematic illustrations of the present disclosure and are not necessarily drawn to scale. The same reference numerals in the drawings denote the same or similar parts, and thus repeated descriptions thereof will be omitted. Some of the block diagrams shown in the drawings are functional entities and do not necessarily correspond to physically or logically separate entities. These functional entities may be implemented in software, or in one or more hardware modules or integrated circuits, or in different network and/or processor means and/or microcontroller means.
图1示出了可以应用本公开实施例的一种目标用户确定方法及装置的示例性系统架构的示意图。Fig. 1 shows a schematic diagram of an exemplary system architecture of a method and device for determining a target user according to an embodiment of the present disclosure.
如图1所示,系统架构100可以包括终端设备101、102、103中的一个或多个,网络104和服务器105。网络104用以在终端设备101、102、103和服务器105之间提供通信链路的介质。网络104可以包括各种连接类型,例如有线、无线通信链路或者光纤电缆等等。终端设备101、102、103可以是具有显示屏的各种电子设备,包括但不限于台式计算机、便携式计算机、智能手机和平板电脑等等。应该理解,图1中的终端设备、网络和服务器的数目仅仅是示意性的。根据实现需要,可以具有任意数目的终端设备、网络和服务器。比如服务器105可以是多个服务器组成的服务器集群等。As shown in FIG. 1 , the
本公开实施例所提供的目标用户确定方法可以由服务器105执行,相应地,目标用户确定装置可以设置于服务器105中,服务器可以将用户特征向量、广告特征向量、用户表征向量和目标用户等发送至终端设备,并由终端设备向工作人员进行展示。但本领域技术人员容易理解的是,本公开实施例所提供的目标用户确定方法也可以由终端设备101、102、103执行,相应的,目标用户确定装置也可以设置于终端设备101、102、103中,例如,由终端设备执行后可以将用户特征向量、广告特征向量、用户表征向量和目标用户等直接显示在终端设备的显示屏上,以向工作人员进行展示,本示例性实施例中对此不做特殊限定。The target user determination method provided by the embodiment of the present disclosure can be executed by the
以下对本公开实施例的技术方案进行详细阐述:The technical solutions of the embodiments of the present disclosure are described in detail below:
本公开示例实施方式中,以物流行业中的线下广告投放为例进行说明。目前,进行线下广告投放时,主要基于用户的历史行为信息和广告主的诉求通过人工进行人群圈选,效率较低。而且,人工进行人群圈选非常依赖item(物料)对应user(用户)的历史行为信息,容易造成广告投放中的“马太效应”。例如,对于冷门但质量较高的长尾内容,可能会被认定为具有较低的投放优先级,从而无法得到有效的投放。In the exemplary implementation manner of the present disclosure, offline advertisement placement in the logistics industry is taken as an example for illustration. At present, when placing offline advertisements, crowd selection is performed manually based on historical behavior information of users and advertisers' appeals, which is inefficient. Moreover, manual crowd selection is very dependent on the historical behavior information of the item (material) corresponding to the user (user), which is likely to cause the "Matthew effect" in advertising. For example, unpopular but high-quality long-tail content may be deemed to have a lower delivery priority, so that it cannot be effectively delivered.
基于上述一个或多个问题,本示例实施方式提供了一种目标用户确定方法,建立了一种基于Attention(注意力)机制的Look-alike模型,可以实现线下物流广告人群的精确扩展。其中,look-alike技术可以根据少量的种子用户,通过大数据分析以及机器学习扩展出和种子用户相似的人群,也就是根据种子人群的共有属性进行自动化扩展,以扩大潜在用户覆盖面,提升营销/广告效果。Based on one or more of the above problems, this exemplary embodiment provides a method for determining target users, and establishes a Look-alike model based on an Attention mechanism, which can realize accurate expansion of offline logistics advertising crowd. Among them, look-alike technology can expand the population similar to seed users based on a small number of seed users through big data analysis and machine learning. Ad Performance.
需要声明的是,本公开示例实施方式中获取用户的多维特征数据的方法和途径是合规合法的。参考图2所示,该目标用户确定方法可以包括以下步骤S210至步骤S240:It should be declared that the method and approach for obtaining the user's multi-dimensional feature data in the example implementations of the present disclosure are compliant and legal. Referring to FIG. 2, the target user determination method may include the following steps S210 to S240:
步骤S210.获取多个用户的多维特征数据,并根据所述多维特征数据生成用户特征向量和广告特征向量,其中,所述多个用户包括种子用户和候选用户;Step S210. Obtain multi-dimensional feature data of multiple users, and generate user feature vectors and advertisement feature vectors according to the multi-dimensional feature data, wherein the multiple users include seed users and candidate users;
步骤S220.将所述用户特征向量和所述广告特征向量输入用户表征模型中,生成用户表征向量,所述用户表征向量包括第一种子用户向量和第一候选用户向量;Step S220. Input the user feature vector and the advertisement feature vector into a user characterization model to generate a user characterization vector, the user characterization vector includes a first seed user vector and a first candidate user vector;
步骤S230.将所述第一种子用户向量和所述第一候选用户向量输入相似度预估模型中,生成第二种子用户向量和第二候选用户向量,并计算所述第二种子用户向量和所述第二候选用户向量之间的相似度;Step S230. Input the first seed user vector and the first candidate user vector into the similarity estimation model, generate a second seed user vector and a second candidate user vector, and calculate the second seed user vector and the similarity between the second candidate user vectors;
步骤S240.根据所述相似度确定所述候选用户中的目标用户。Step S240. Determine a target user among the candidate users according to the similarity.
在本公开示例实施方式所提供的目标用户确定方法中,通过获取多个用户的多维特征数据,并根据多维特征数据生成用户特征向量和广告特征向量;将用户特征向量和广告特征向量输入用户表征模型中,生成第一种子用户向量和第一候选用户向量;将第一种子用户向量和第一候选用户向量输入相似度预估模型中,生成第二种子用户向量和第二候选用户向量,并计算第二种子用户向量和第二候选用户向量之间的相似度;根据相似度确定候选用户中的目标用户。一方面,通过用户表征模型对不同特征域进行充分地学习组合以生成用户表征向量,该用户表征向量可以更加准确地反映用户的潜在兴趣,便于精准地确定种子用户的相似人群。而且,利用相似度预估模型输出的种子用户向量和候选用户向量可以更准确地计算种子用户和候选用户的相似度,进一步提高了相似人群扩展的精确率,进而提高广告投放的准确率;另一方面,通过用户表征模型和相似度预估模型即可确定目标用户,而无需进行人工圈选,提高了相似人群扩展的效率。In the target user determination method provided by the exemplary embodiments of the present disclosure, the multi-dimensional feature data of multiple users is obtained, and the user feature vector and the advertisement feature vector are generated according to the multi-dimensional feature data; the user feature vector and the advertisement feature vector are input into the user representation In the model, generate the first seed user vector and the first candidate user vector; input the first seed user vector and the first candidate user vector into the similarity estimation model, generate the second seed user vector and the second candidate user vector, and Calculating the similarity between the second seed user vector and the second candidate user vector; determining a target user among the candidate users according to the similarity. On the one hand, different feature domains are fully learned and combined through the user representation model to generate a user representation vector, which can more accurately reflect the potential interests of users and facilitate the accurate determination of similar groups of seed users. Moreover, using the seed user vectors and candidate user vectors output by the similarity prediction model can more accurately calculate the similarity between seed users and candidate users, further improving the accuracy of similar population expansion, thereby improving the accuracy of advertising; On the one hand, the target user can be determined through the user representation model and the similarity prediction model without manual selection, which improves the efficiency of similar group expansion.
下面,对于本示例实施方式的上述步骤进行更加详细的说明。Next, the above-mentioned steps of this exemplary embodiment will be described in more detail.
在步骤S210中,获取多个用户的多维特征数据,并根据所述多维特征数据生成用户特征向量和广告特征向量,其中,所述多个用户包括种子用户和候选用户。In step S210, multi-dimensional feature data of multiple users are obtained, and user feature vectors and advertisement feature vectors are generated according to the multi-dimensional feature data, wherein the multiple users include seed users and candidate users.
物流行业中的线下广告投放是指将广告物料分发给仓库,从而通过仓库将广告投放给用户。线下广告投放的形式可以是随包裹广告、外包装广告等,投放过程依赖于仓库中订单任务的物流包裹而实现。例如,可以将广告单粘贴于包裹外包装上,用户收取包裹并通过广告单中的链接对商品进行浏览、点击等操作,可以视为线下广告的成功投放。利用Look-alike模型确定广告投放人群时,可以获取种子用户,并扩展出和种子用户相似的人群。其中,种子用户可以是一个用户,也可以是一群用户。例如,种子用户可以是点击/分享/购买某商品的100万个用户。候选用户可以是用户池中的未投放过该商品的广告的多个用户,如年龄介于15岁至50岁之间的2000万个用户。Offline advertising in the logistics industry refers to the distribution of advertising materials to warehouses, so that advertisements are delivered to users through warehouses. Offline advertisements can be placed in the form of package advertisements, outer packaging advertisements, etc. The delivery process depends on the logistics package of the order task in the warehouse. For example, an advertisement flyer can be pasted on the outer package of the package, and the user receives the package and browses and clicks on the product through the link in the advertisement flyer, which can be regarded as the successful delivery of offline advertising. When the Look-alike model is used to determine the audience for advertising, seed users can be obtained and people similar to seed users can be expanded. Wherein, the seed user may be one user or a group of users. For example, seed users can be 1 million users who clicked/shared/purchased a product. Candidate users may be multiple users in the user pool who have not placed an advertisement for the product, for example, 20 million users whose ages are between 15 and 50 years old.
用户的多维特征数据可以包括用户特征数据和广告特征数据,用户特征数据又可以包括属性特征数据、行为特征数据等多个维度的特征数据,广告特征数据可以是指用户物流订单中的物料信息等。其中,属性特征数据可以包括用户的画像信息,如年龄、性别、学历、职业等信息,还可以包括用户的常用地址、兴趣偏好等信息。行为特征数据可以为用户的浏览、点击、咨询、加购、收藏等行为特征。广告特征数据可以包括商品SKU(stockkeeping unit,库存量单位)、商品所属品类等数据。The user's multi-dimensional feature data can include user feature data and advertisement feature data, and user feature data can include attribute feature data, behavior feature data, and other multi-dimensional feature data. Advertisement feature data can refer to material information in user logistics orders, etc. . Among them, the attribute feature data may include the portrait information of the user, such as information such as age, gender, education background, occupation, etc., and may also include information such as the user's usual address and interest preferences. Behavior feature data can be user behavior features such as browsing, clicking, consulting, additional purchases, and favorites. The advertisement characteristic data may include data such as commodity SKU (stockkeeping unit, stock keeping unit), category to which the commodity belongs, and the like.
获取种子用户的多维特征数据和候选用户的多维特征数据后,可以对各维度的特征数据进行向量化处理,得到用户特征向量和广告特征向量。示例性的,可以对用户特征数据进行向量化处理,生成用户特征向量,对广告特征数据进行向量化处理,生成广告特征向量。例如,可以利用用户的画像信息和用户的多个行为特征来表征用户,可以利用用户的多个行为特征中包含的物料信息和商品SKU、商品所属品类等来表征广告。After obtaining the multi-dimensional feature data of the seed user and the multi-dimensional feature data of the candidate user, the feature data of each dimension can be vectorized to obtain the user feature vector and the advertisement feature vector. Exemplarily, user feature data may be vectorized to generate a user feature vector, and advertisement feature data may be vectorized to generate an advertisement feature vector. For example, user portrait information and user behavior characteristics can be used to characterize users, and material information contained in user behavior characteristics, product SKU, product category, etc. can be used to represent advertisements.
以用户特征数据为例,用户特征数据又可以包括离散特征数据和连续特征数据中的至少一种。其中,用户浏览、点击、咨询、加购、收藏等行为特征数据为连续特征数据,用户的年龄、性别、学历、商品所属品类等为离散特征数据。示例性的,可以对各离散特征取值进行统计,统计每个特征数据出现的频次,作为第一特征数据,并对第一特征数据进行编码,得到第一特征向量。例如,将第一特征数据编码为one-hot(独热编码)特征。对于连续特征数据,可以对连续特征数据进行归一化处理,生成第二特征向量。归一化连续特征可以将不同量级的特征转化为相同量级的特征,以避免数值不同级给模型带来的影响。例如,可以将每一维特征线性映射到目标范围,若映射到[0,1]或[-1,1],也可以用标准差进行归一化,本公开对此不做限定。Taking user feature data as an example, the user feature data may include at least one of discrete feature data and continuous feature data. Among them, the user's browsing, clicking, consulting, additional purchase, collection and other behavioral feature data are continuous feature data, and the user's age, gender, education, product category, etc. are discrete feature data. Exemplarily, the values of each discrete feature may be counted, and the occurrence frequency of each feature data may be counted as the first feature data, and the first feature data may be encoded to obtain the first feature vector. For example, the first feature data is encoded as a one-hot (one-hot encoding) feature. For continuous feature data, normalization processing may be performed on the continuous feature data to generate a second feature vector. Normalizing continuous features can transform features of different magnitudes into features of the same magnitude to avoid the impact of different magnitudes on the model. For example, the feature of each dimension can be linearly mapped to the target range. If it is mapped to [0, 1] or [-1, 1], the standard deviation can also be used for normalization, which is not limited in the present disclosure.
本公开示例实施方式中,可以利用pipeline管道机制将各维度特征数据的向量化过程串行,以实现对多个第一特征向量和多个第二特征向量的拼接,从而生成各个用户的特征向量。可以看出,各个用户的特征向量由归一化后的连续特征数据和编码后的离散特征数据组成。其中,Pipeline管道机制是一种批处理技术,可以提高数据处理效率。In the exemplary implementation of the present disclosure, the pipeline mechanism can be used to serialize the vectorization process of the feature data of each dimension, so as to realize the splicing of multiple first feature vectors and multiple second feature vectors, thereby generating feature vectors for each user . It can be seen that the feature vector of each user is composed of normalized continuous feature data and encoded discrete feature data. Among them, the Pipeline pipeline mechanism is a batch processing technology that can improve data processing efficiency.
类似的,向量化广告特征数据时,也可以对用户的所有广告特征取值进行统计,如将每个广告特征的枚举众数或平均数作为处理后的特征数据。还可以通过统计用户的平均收藏、加购、下单商品单价等数据来刻画用户的购买力,通过统计用户在某一时间段内的平均浏览时长和下单次数来衡量用户的忠诚度。同样的,可以对广告特征数据中的类别特征进行编码,将广告特征数据中的数值特征进行归一化,并通过pipeline管道机制汇总得到广告特征向量。生成广告特征向量的过程与生成用户特征向量的过程类似,此处不再详细赘述。Similarly, when vectorizing advertisement characteristic data, it is also possible to make statistics on all advertisement characteristic values of the user, such as taking the enumerated mode or average of each advertisement characteristic as the processed characteristic data. It is also possible to describe the purchasing power of users by counting the data of users' average favorites, additional purchases, and unit prices of ordered products, and to measure the loyalty of users by counting the average browsing time and number of orders placed by users within a certain period of time. Similarly, the category features in the advertisement feature data can be encoded, the numerical features in the advertisement feature data can be normalized, and the advertisement feature vector can be obtained by summarizing through the pipeline mechanism. The process of generating the advertisement feature vector is similar to the process of generating the user feature vector, and will not be described in detail here.
其中,为了增加广告特征的多样性,可以对用户浏览、加购、收藏的商品信息和商品SKU等特征数据进行中文切词,切分为更细粒度的范围属性,形成新特征。示例性的,可以基于词典进行切词,也可以基于统计进行切词,还可以基于规则进行切词,本公开对此不做具体限定。例如,通过对商品SKU进行切词,可以得到商品的颜色特征。Among them, in order to increase the diversity of advertising features, Chinese word segmentation can be performed on feature data such as user browsing, additional purchases, and favorite product information and product SKUs, and segment them into finer-grained range attributes to form new features. Exemplarily, the word segmentation may be performed based on a dictionary, may also be performed based on statistics, and may also be performed based on rules, which is not specifically limited in the present disclosure. For example, by segmenting the SKU of a product, the color feature of the product can be obtained.
重要的是,在本公开示例实施方式中,目标用户的确定可以包括人群扩展和潜客挖掘两种场景。人群扩展是指旧广告投放场景下,对历史投放人群进行扩展。潜客挖掘是指新广告投放场景下,对用户池中的用户进行挖掘,以确定潜在客户。对应的,种子用户可以是历史投放广告的种子用户和待投放广告的种子用户中的一种。在旧广告投放场景中,可以根据广告主成功投放的历史广告信息,建立不同三级品类商品的种子用户群。例如,对于不同品牌的手机广告,可以建立多个种子用户群。而在新广告投放场景中,没有历史投放信息可参考,因此,可以进行广告物料的相似度召回,将相似商品进行广告投放的种子用户群作为待投放广告的种子用户群。Importantly, in the exemplary implementation of the present disclosure, the determination of target users may include two scenarios of crowd expansion and potential customer mining. Crowd expansion refers to the expansion of historical advertising audiences in the old advertising delivery scenario. Potential customer mining refers to the mining of users in the user pool in the new advertising scenario to determine potential customers. Correspondingly, the seed user may be one of a seed user who has delivered advertisements in the past and a seed user who is to deliver advertisements. In the old advertising scenario, based on the historical advertising information successfully placed by the advertiser, a seed user group of different tertiary categories can be established. For example, for mobile phone advertisements of different brands, multiple seed user groups can be established. In the new advertising scenario, there is no historical information to refer to. Therefore, the similarity of advertising materials can be recalled, and the seed user group for similar products to be advertised is used as the seed user group to be advertised.
示例性的,可以获取待投放广告的第一广告特征向量和历史投放广告的第二广告特征向量,并计算第一广告特征向量和第二广告特征向量之间的相似度,以根据相似度确定历史投放广告中与待投放广告相似的目标投放广告。最后,可以基于目标投放广告的种子用户构建待投放广告的种子用户。举例而言,可以根据待投放广告中的商品SKU、商品所属品类等多个域的特征得到第一广告特征向量,根据历史投放广告中的商品SKU、商品所属品类等多个域的特征得到第二广告特征向量。通过计算第一广告特征向量和第二广告特征向量之间的距离,得到两个向量之间的相似度。例如,可以计算第一广告特征向量和第二广告特征向量之间的余弦距离、欧式距离等。通过计算待投放广告和多个历史投放广告之间的相似度,可以将与待投放广告相似度最大的历史投放广告作为目标投放广告。可以理解的是,目标投放广告的种子用户有较大的概率会对待投放广告中的商品感兴趣,因此,可以将该目标投放广告的种子用户作为待投放广告的种子用户,以便于利用该种子用户实现在新广告投放场景下的潜客挖掘。Exemplarily, the first advertisement feature vector of the advertisement to be delivered and the second advertisement feature vector of the previously served advertisement may be obtained, and the similarity between the first advertisement feature vector and the second advertisement feature vector is calculated, so as to determine Advertisements that are similar to the advertisements to be delivered in the past delivery advertisements. Finally, the seed users to be advertised can be constructed based on the seed users for target advertising. For example, the first advertisement feature vector can be obtained according to the characteristics of multiple domains such as the commodity SKU and the category of the commodity in the advertisement to be placed, and the second advertisement feature vector can be obtained according to the characteristics of multiple domains such as the commodity SKU and the category of the commodity in the advertisement to be placed in the past. Two ad feature vectors. By calculating the distance between the first advertisement feature vector and the second advertisement feature vector, the similarity between the two vectors is obtained. For example, a cosine distance, a Euclidean distance, etc. between the first advertisement feature vector and the second advertisement feature vector can be calculated. By calculating the similarity between the advertisement to be delivered and multiple historical delivery advertisements, the historical delivery advertisement with the greatest similarity to the advertisement to be delivered can be used as the target delivery advertisement. It can be understood that the seed user for the target advertisement has a high probability of being interested in the product in the advertisement. Therefore, the seed user for the target advertisement can be used as the seed user for the advertisement to be placed, so as to utilize the seed user Users can discover potential customers in the new advertising scenario.
该示例中,通过积累成功的历史投放广告的种子用户群,并利用该种子用户群在新广告投放场景中进行知识指导,可以弥补人工经验的不足,并实现潜客精准挖掘。In this example, by accumulating a seed user group with successful historical advertising and using this seed user group to provide knowledge guidance in new advertising scenarios, it can make up for the lack of manual experience and realize accurate mining of potential customers.
在步骤S220中,将所述用户特征向量和所述广告特征向量输入用户表征模型中,生成用户表征向量,所述用户表征向量包括第一种子用户向量和第一候选用户向量。In step S220, the user feature vector and the advertisement feature vector are input into a user characterization model to generate a user characterization vector, and the user characterization vector includes a first seed user vector and a first candidate user vector.
由于用户包括种子用户和候选用户,对应的,根据各用户的多维特征数据生成的用户特征向量可以包括种子用户特征向量和候选用户特征向量。一种示例实施方式中,用户表征模型可以是改进后的YouTube DNN(深度语义)模型,该模型至少包括第一全连接层和第一注意力层。示例性的,可以利用第一全连接层对用户特征向量和广告特征向量进行特征降维,得到用户中间向量和广告中间向量。进一步的,基于用户中间向量和广告中间向量,可以通过第一注意力层生成第一种子用户向量和第一候选用户向量。Since users include seed users and candidate users, correspondingly, the user feature vector generated according to the multi-dimensional feature data of each user may include seed user feature vectors and candidate user feature vectors. In an exemplary embodiment, the user representation model may be an improved YouTube DNN (Deep Semantics) model, which at least includes a first fully connected layer and a first attention layer. Exemplarily, the first fully connected layer may be used to perform feature dimensionality reduction on the user feature vector and the advertisement feature vector to obtain the user intermediate vector and the advertisement intermediate vector. Further, based on the user intermediate vector and the advertisement intermediate vector, the first sub-user vector and the first candidate user vector may be generated through the first attention layer.
参考图3所示,给出了融合Attention机制的YouTube DNN模型的一种结构示意图。该模型中包含3个隐层的DNN结构,分别为输入层310、隐藏层320和输出层330。其中,输入层310用于对输入特征进行处理,例如,可以将输入的用户特征和广告特征分别进行拼接处理或平均池化处理,并将处理后的用户特征和广告特征输入全连接层1(301)中进行空间转化。隐藏层320又包括全连接层1(301)、全连接层2(303)和全连接层3(304),每个全连接层连接一个激活函数,如ReLU(Rectified Linear Units,修正线性单元)激活函数,并且在全连接层1(301)和全连接层2(303)中间添加了第一注意力层(302),第一注意力层(302)可以对不同特征域进行充分地学习组合。输出层330可以对应的输出一个用户特征向量和广告特征向量。可以理解的是,为了利用注意力层获取局部特征显著性,通常是将注意力层添加至浅层全连接层。其它示例中,也可以将注意力层添加至深层全连接层,如可以在全连接层2(303)和全连接层3(304)中间添加第一注意力层(302),本公开对此不做限定。Referring to Figure 3, a schematic diagram of the structure of the YouTube DNN model that incorporates the Attention mechanism is given. The model includes a DNN structure with three hidden layers, namely an
示例性的,可以将通过Pipeline管道机制得到的用户特征向量和广告特征向量输入如图3所示的YouTube DNN模型中。具体地,将用户特征向量和广告特征向量分别进行平均池化后转入全连接层1(301),可以利用全连接层1(301)平均池化后的用户特征向量和广告特征向量进行特征降维,得到用户中间向量和广告中间向量。然后,将用户中间向量和广告中间向量输入第一注意力层(302),通过第一注意力层(302)可以捕捉广告中间向量的组成情况,对与用户中间向量相似的广告中间向量进行加权,从而可以提高广告中间向量的表达能力。对应的,从第一注意力层(302)输出两个多维向量后,可以依次通过全连接层2(303)和全连接层3(304)对两个多维向量进行空间再转化,得到用户表征向量和广告表征向量。其中,用户表征向量可以包括第一种子用户向量和第一候选用户向量。Exemplarily, the user feature vector and advertisement feature vector obtained through the Pipeline pipeline mechanism may be input into the YouTube DNN model as shown in FIG. 3 . Specifically, the user feature vector and the advertisement feature vector are averagely pooled and transferred to the fully connected layer 1 (301), and the user feature vector and the advertisement feature vector after the average pooling of the fully connected layer 1 (301) can be used for feature Dimensionality reduction, get the user intermediate vector and advertisement intermediate vector. Then, the user intermediate vector and the advertisement intermediate vector are input into the first attention layer (302), the composition of the advertisement intermediate vector can be captured by the first attention layer (302), and the advertisement intermediate vector similar to the user intermediate vector is weighted , so that the expression ability of the intermediate vector of the advertisement can be improved. Correspondingly, after outputting two multi-dimensional vectors from the first attention layer (302), the space of the two multi-dimensional vectors can be re-transformed through the fully connected layer 2 (303) and the fully connected layer 3 (304) in turn to obtain the user representation vector and ad representation vector. Wherein, the user characterization vector may include a first seed user vector and a first candidate user vector.
该示例中,在YouTube DNN模型中融合了Attention机制,Attention机制可以使得深度模型拥有能够在繁多的信息中自动关注重点特征的能力。并采用模型最后一层隐层的输出作为用户表征向量,不同维度的低阶特征都能够在该空间聚合,因此,该用户表征向量可以准确地反映用户潜在兴趣,便于后续精准地实现人群扩展。In this example, the Attention mechanism is integrated in the YouTube DNN model. The Attention mechanism can enable the deep model to have the ability to automatically focus on key features in a variety of information. The output of the last hidden layer of the model is used as the user characterization vector, and low-level features of different dimensions can be aggregated in this space. Therefore, the user characterization vector can accurately reflect the potential interests of users, which is convenient for the subsequent accurate realization of crowd expansion.
在步骤S230中,将所述第一种子用户向量和所述第一候选用户向量输入相似度预估模型中,生成第二种子用户向量和第二候选用户向量,并计算所述第二种子用户向量和所述第二候选用户向量之间的相似度。In step S230, input the first seed user vector and the first candidate user vector into the similarity estimation model to generate a second seed user vector and a second candidate user vector, and calculate the second seed user vector The similarity between the vector and the second candidate user vector.
参考图4所示,给出了相似度预估模型的一种结构示意图。其中,相似度预估模型为双塔结构,即包括两个网络分支,各网络分支至少包括第二全连接层(401)和第二注意力层(402),分别用于对种子用户表征向量和候选用户表征向量进行处理。示例性的,可以利用各第二全连接层对第一种子用户向量和第一候选用户向量进行特征降维,得到种子用户中间向量和候选用户中间向量。进一步的,可以基于种子用户中间向量和候选用户中间向量,通过第二注意力层生成第二种子用户向量和第二候选用户向量。最后,通过计算第二种子用户向量和第二候选用户向量之间的相似度,以确定候选用户中的目标用户,并向目标用户进行线下广告投放。Referring to FIG. 4 , a schematic structural diagram of a similarity estimation model is given. Among them, the similarity estimation model is a double-tower structure, that is, it includes two network branches, and each network branch includes at least the second fully connected layer (401) and the second attention layer (402), which are respectively used to characterize the seed user vector and candidate user representation vectors for processing. Exemplarily, each second fully connected layer may be used to perform feature dimensionality reduction on the first seed user vector and the first candidate user vector to obtain the seed user intermediate vector and the candidate user intermediate vector. Further, the second seed user vector and the second candidate user vector may be generated through the second attention layer based on the seed user intermediate vector and the candidate user intermediate vector. Finally, the target user among the candidate users is determined by calculating the similarity between the second seed user vector and the second candidate user vector, and offline advertisement is delivered to the target user.
例如,可以将第一种子用户向量输入相似度预估模型的第一分支中,通过第一分支中的第二全连接层(401)和与第二全连接层(401)连接的激活函数进行空间转化。然后,可以将降维后的第一种子用户向量输入第二注意力层(402),以得到第二种子用户向量。其中,激活函数可以是PReLU(Parametric Rectified Linear Unit,带参数的ReLU)激活函数。类似的,可以将第一候选用户向量输入相似度预估模型的第二分支中进行同样的处理,得到第二候选用户向量,具体的处理过程此处不再详细赘述。可以理解的是,通过注意力机制可以从种子用户表征向量中挑选出相对于当前候选用户中更有价值的向量特征,因此,可以提高种子用户表征向量的表达能力,进而可以更准确地计算种子用户和候选用户的相似度。For example, the first seed user vector can be input into the first branch of the similarity prediction model, and the second fully connected layer (401) in the first branch and the activation function connected with the second fully connected layer (401) are used to perform space transformation. Then, the dimensionally reduced first seed user vector may be input into the second attention layer (402) to obtain a second seed user vector. Wherein, the activation function may be a PReLU (Parametric Rectified Linear Unit, ReLU with parameters) activation function. Similarly, the first candidate user vector can be input into the second branch of the similarity estimation model to perform the same processing to obtain the second candidate user vector, and the specific processing process will not be described in detail here. It can be understood that, through the attention mechanism, more valuable vector features can be selected from the seed user characterization vector than the current candidate user. Therefore, the expressive ability of the seed user characterization vector can be improved, and the seed user characterization vector can be calculated more accurately. The similarity between the user and the candidate user.
得到第二种子用户向量和第二候选用户向量后,可以计算两个向量之间的相似度,以根据相似度确定与种子用户相似的候选用户。例如,可以计算两个向量之间的余弦距离,也可以计算两个向量之间的欧式距离、马氏距离等,以得到两个向量的相似度得分。需要说明的是,可以将各候选用户与当前种子用户的相似度得分归一化到0~1之间,便于根据归一化后的相似度得分对候选用户进行筛选,以确定多个与种子用户相似的目标用户。其它示例中,也可以计算各候选用户与多个种子用户之间的相似度,将多个相似度得分进行加权平均,并将计算结果作为各候选用户最终的相似度得分,进而根据相似度得分确定候选用户中的目标用户。After the second seed user vector and the second candidate user vector are obtained, the similarity between the two vectors may be calculated, so as to determine a candidate user similar to the seed user according to the similarity. For example, the cosine distance between two vectors can be calculated, and the Euclidean distance, Mahalanobis distance, etc. between two vectors can also be calculated to obtain the similarity score of the two vectors. It should be noted that the similarity scores between each candidate user and the current seed user can be normalized to between 0 and 1, so that the candidate users can be screened according to the normalized similarity score to determine multiple seed users. User lookalike target users. In other examples, it is also possible to calculate the similarity between each candidate user and multiple seed users, carry out weighted average of multiple similarity scores, and use the calculation result as the final similarity score of each candidate user, and then according to the similarity score Identify target users among candidate users.
一种示例实施方式中,在线预测目标用户之前,可以预先对用户表征模型和相似度预估模型分别进行训练。对于用户表征模型,以融合Attention机制的YouTube DNN模型为例。示例性的,可以获取第一训练样本,各第一训练样本为候选用户的用户特征向量和广告特征向量。可以将各候选用户的用户特征向量和广告特征向量输入用户表征模型中,得到对应的用户表征向量和广告表征向量,根据用户表征向量和广告表征向量构建第一目标函数。基于该第一目标函数,对用户表征模型的参数进行迭代更新,当满足迭代终止条件时,完成对该模型的训练。其中,第一目标函数可以是NCE(Noise ContrastiveEstimation,噪音对比估计)损失函数。可以理解的是,训练样本中用户对应完成商品链接跳转的为正样本,未触达或者触达后未完成商品链接跳转的为负样本,其它处于中间环节的部分样本为无效数据。In an example implementation, before online prediction of target users, the user representation model and the similarity prediction model may be trained separately in advance. For the user representation model, take the YouTube DNN model integrated with the Attention mechanism as an example. Exemplarily, first training samples may be acquired, and each first training sample is a user feature vector and an advertisement feature vector of a candidate user. The user feature vector and advertisement feature vector of each candidate user may be input into the user representation model to obtain the corresponding user representation vector and advertisement representation vector, and construct the first objective function according to the user representation vector and the advertisement representation vector. Based on the first objective function, the parameters of the user representation model are iteratively updated, and when the iteration termination condition is satisfied, the training of the model is completed. Wherein, the first objective function may be an NCE (Noise ContrastiveEstimation, noise contrastive estimation) loss function. It can be understood that in the training samples, the users corresponding to complete the product link jump are positive samples, those who have not been touched or have not completed the product link jump after being touched are negative samples, and some samples in the middle link are invalid data.
例如,可以将第一训练样本按照比例分为训练集、验证集和测试集,如比例为7:1:2。其中,训练集用于训练模型参数,验证集用于观察模型训练过程的性能变化,避免出现欠拟合或者过拟合,测试集用于评估模型效果。对用户表征模型的参数进行调优时,以融合Attention机制的YouTube DNN模型为例,可以包括模型参数初始化、最大迭代次数、激活函数的选择、优化器选择、早停条件和学习率等的设定。对该模型的参数进行训练时,当各参数均趋于收敛,或者满足一定迭代次数时训练终止。对模型参数调优的过程中,还包括对模型特征进行调优,可以根据特征之间的相似度进行评估,并且尽可能减少特征维度,避免出现过拟合。For example, the first training sample may be divided into a training set, a verification set and a test set according to a ratio, such as a ratio of 7:1:2. Among them, the training set is used to train the model parameters, the verification set is used to observe the performance changes of the model training process to avoid underfitting or overfitting, and the test set is used to evaluate the model effect. When tuning the parameters of the user representation model, taking the YouTube DNN model integrated with the Attention mechanism as an example, it can include model parameter initialization, maximum number of iterations, activation function selection, optimizer selection, early stopping conditions, and learning rate settings. Certainly. When training the parameters of the model, the training terminates when each parameter tends to converge or meets a certain number of iterations. The process of tuning the model parameters also includes tuning the features of the model, which can be evaluated based on the similarity between features, and feature dimensions should be reduced as much as possible to avoid overfitting.
对于相似度预估模型,训练该模型时,可以获取第二训练样本,各第二训练样本为种子用户向量和目标用户向量组成的向量对。通过相似度预估模型确定种子用户向量和目标用户向量的相似度,根据种子用户向量和目标用户向量的相似度构建第二目标函数,基于第二目标函数,对相似度预估模型的参数进行迭代更新,当满足迭代终止条件时,完成对该模型的训练。其中,相似度预估模型为一个多分类任务,需要预测每个候选用户对应的种子用户群的类别,因此,第二目标函数可以是多组交叉熵损失函数。类似的,也可以将第二训练样本按照如7:1:2的比例分为训练集、验证集和测试集。该模型的预测结果为每个候选用户隶属于种子用户群的概率。当该模型中的各参数均趋于收敛,或者满足一定迭代次数时训练终止。For the similarity estimation model, when training the model, second training samples may be obtained, and each second training sample is a vector pair composed of a seed user vector and a target user vector. Determine the similarity between the seed user vector and the target user vector through the similarity estimation model, construct a second objective function according to the similarity between the seed user vector and the target user vector, and based on the second objective function, perform a similarity estimation model parameter Iterative update, when the iteration termination condition is satisfied, the training of the model is completed. Wherein, the similarity estimation model is a multi-classification task, which needs to predict the category of the seed user group corresponding to each candidate user. Therefore, the second objective function may be multiple sets of cross-entropy loss functions. Similarly, the second training sample may also be divided into a training set, a verification set, and a test set according to a ratio of, for example, 7:1:2. The prediction result of this model is the probability that each candidate user belongs to the seed user group. When each parameter in the model tends to converge or meets a certain number of iterations, the training terminates.
用户表征模型和相似度预估模型训练完成后,可以使用测试集对各模型的模型性能进行评估。例如,可以使用AUC(Area Under Curve,ROC曲线下与坐标轴围成的面积)、精确率、召回率、prec@k和F1值等指标进行评估。其中,AUC是排序模型评价中常用的度量标准,其中ROC曲线又称为接收者操作特征曲线。以正样本的评估为例:AUC为遍历数据中的正负样本对,其中正样本预测值大于负样本的概率。After the user representation model and similarity prediction model are trained, the model performance of each model can be evaluated using the test set. For example, indicators such as AUC (Area Under Curve, the area under the ROC curve and the coordinate axis), precision rate, recall rate, prec@k and F1 value can be used for evaluation. Among them, AUC is a commonly used metric in the evaluation of ranking models, and the ROC curve is also called the receiver operating characteristic curve. Take the evaluation of positive samples as an example: AUC is the probability of positive and negative sample pairs in the traversal data, where the predicted value of the positive sample is greater than that of the negative sample.
Pre为模型的精确率,其中,TP表示把正样本成功预测为正的数据,FP表示把负样本错误预测为正的数据,TP+FP表示所有预测为正样本的数据,即:Pre is the accuracy rate of the model, where TP represents the data that successfully predicts positive samples as positive, FP represents the data that incorrectly predicts negative samples as positive, and TP+FP represents all the data that are predicted to be positive samples, namely:

Rec为模型的召回率,其中,TP表示把正样本成功预测为正的数据,FN表示把正样本错误预测为负的数据,TP+FN表示所有的正样本数据,即:Rec is the recall rate of the model, where TP represents the data that successfully predicts positive samples as positive, FN represents the data that incorrectly predicts positive samples as negative, and TP+FN represents all positive sample data, namely:

F1为模型精确率和召回率的调和平均数,其中,Pre为模型的精确率,Rec为模型的召回率,即:F1 is the harmonic mean of model precision and recall, where Pre is the precision of the model and Rec is the recall of the model, namely:

prec@k为推荐的排名前k的广告类目用户实际触达的比例。prec@k is the proportion of users actually reached by the top k recommended advertising categories.
该示例中,在用户表征模型和相似度预估模型中引入了注意力机制,该注意力机制使得同一组种子用户向量在对不同的候选用户进行兴趣预测时提供不同的加权,从而提高了种子用户向量的表达能力,进而提高了模型预测的准确性。In this example, an attention mechanism is introduced in the user representation model and the similarity prediction model. This attention mechanism enables the same set of seed user vectors to provide different weights when predicting the interest of different candidate users, thereby improving the seed The expressiveness of user vectors improves the accuracy of model predictions.
在步骤S240中,根据所述相似度确定所述候选用户中的目标用户。In step S240, a target user among the candidate users is determined according to the similarity.
示例性的,可以根据相似度得分将所有候选用户进行降序排序,并选取前一定数量(例如20个)候选用户作为目标用户。也可以根据相似度得分将所有候选用户进行升序排序,并选取后一定数量(例如20个)候选用户作为目标用户。还可以预先设置一个相似度阈值,将满足相似度阈值的候选用户作为目标用户,如相似度阈值可以设置为0.5,也可以设置为0.7,本公开对此不做具体限定。例如,可以将相似度得分大于相似度阈值的候选用户作为目标用户。Exemplarily, all candidate users may be sorted in descending order according to similarity scores, and a certain number (for example, 20) of candidate users before are selected as target users. All candidate users may also be sorted in ascending order according to similarity scores, and a certain number (for example, 20) of candidate users may be selected as target users. A similarity threshold can also be set in advance, and candidate users meeting the similarity threshold can be used as target users. For example, the similarity threshold can be set to 0.5 or 0.7, which is not specifically limited in the present disclosure. For example, candidate users whose similarity scores are greater than a similarity threshold may be used as target users.
确定目标用户后,可以根据目标用户的数量实现广告定量投放。还可以结合广告主的诉求和相似度分布实现成本阈值控制投放。例如,相似度阈值设置为0.5时,仅有1/3的目标用户的相似度得分大于0.7,此时,可以仅向相似度得分大于0.7的目标用户进行广告投放,以调整广告投放成本的下限。在广告投放过程中,可以结合需要展示的广告媒介形式(如面单广告、自提柜等)向目标用户的包裹或者所在社区媒介定向投放广告,实现精准的人群圈选和潜客挖掘,并触达目标用户群体。After determining the target users, the quantitative delivery of advertisements can be realized according to the number of target users. It can also combine advertisers' demands and similarity distribution to realize cost threshold control delivery. For example, when the similarity threshold is set to 0.5, only 1/3 of the target users have a similarity score greater than 0.7. At this time, you can only place advertisements to target users with a similarity score greater than 0.7 to adjust the lower limit of the advertising cost . In the process of advertising, it is possible to combine the forms of advertising media that need to be displayed (such as face-to-face advertising, self-pickup cabinets, etc.) Reach target user groups.
本公开示例实施方式中,基于广告前期的成功投放经验,结合用户物流场景下大量的历史行为信息等,可以利用融合Attention机制的YouTube DNN模型得到种子用户的精准行为表征。另外,在线上实时预测时,可以计算用户池中的各候选用户的行为表征与聚类后的种子用户聚类中心之间的相似度得分,并根据该得分精准地圈选出目标扩展人群。例如,可以对种子用户进行K-means聚类、均值漂移聚类和基于密度的聚类等方法,以达到减少模型计算量的目的,本实施例对此不做限定。In the exemplary embodiment of the present disclosure, based on the successful advertising experience in the early stage, combined with a large amount of historical behavior information in the user logistics scenario, the accurate behavior representation of the seed user can be obtained by using the YouTube DNN model integrated with the Attention mechanism. In addition, during online real-time prediction, the similarity score between the behavior representation of each candidate user in the user pool and the clustered seed user cluster center can be calculated, and the target expansion group can be accurately circled based on the score. For example, methods such as K-means clustering, mean shift clustering, and density-based clustering can be performed on seed users to achieve the purpose of reducing the amount of model calculation, which is not limited in this embodiment.
一种示例实施方式中,参考图5所示,可以根据步骤S501至步骤S505完成广告的定向投放。In an example implementation, as shown in FIG. 5 , targeted delivery of advertisements may be completed according to steps S501 to S505.
步骤S501.建立种子用户群:基于广告前期的成功投放经验,建立不同三级品类商品的种子用户群。对于旧广告投放场景,可以直接获取种子用户群。对于新广告投放场景,可以根据i2i(计算item-item相似度)做广告物料的相似度召回,将相似品的种子用户用于当前广告的潜客挖掘;Step S501. Establishing seed user groups: Based on the successful advertising experience in the early stage, establish seed user groups for different tertiary categories of commodities. For the old advertising scenario, the seed user group can be obtained directly. For new advertising scenarios, the similarity of advertising materials can be recalled according to i2i (calculation of item-item similarity), and the seed users of similar products can be used for potential customer mining of current advertisements;
步骤S502.生成种子用户表征向量和候选用户表征向量:通过融合Attention机制的YouTube DNN模型学习用户特征的高阶表示,得到种子用户表征向量和候选用户表征向量;Step S502. Generate seed user characterization vectors and candidate user characterization vectors: learn high-level representations of user features through the YouTube DNN model that integrates the Attention mechanism, and obtain seed user characterization vectors and candidate user characterization vectors;
步骤S503.相似度预估:将种子用户表征向量和候选用户表征向量作为基础模型(全连接层和PReLU激活函数)的输入,经过注意力层进行向量空间再转化后,计算两个向量之间的余弦相似度,得到相似度预估得分;Step S503. Estimation of similarity: the seed user representation vector and the candidate user representation vector are used as the input of the basic model (full connection layer and PReLU activation function), after the vector space is reconverted by the attention layer, the distance between the two vectors is calculated. The cosine similarity of , get the estimated similarity score;
步骤S504.确定目标人群:得到候选用户与种子用户的相似度预估得分后,可以根据广告主的资金或者投放量需求,确定满足相似度阈值的多个候选用户作为当前广告投放的目标群体池;Step S504. Determine the target group: After obtaining the estimated similarity scores between the candidate users and the seed users, multiple candidate users that meet the similarity threshold can be determined as the target group pool for the current advertisement according to the advertiser's funds or delivery volume requirements ;
步骤S505.线下广告投放:每个用户对应一类或者多类线下广告触达媒介,在广告主资金约束下,可以通过求解多维规划问题获取累计相似度最大化的实际广告投放人群和对应的线下触达媒介,以保证当前投放广告的增益最大化。Step S505. Offline advertising: each user corresponds to one or more types of offline advertising media. Under the constraints of the advertiser's funds, the actual advertising population and the corresponding advertising population with the largest cumulative similarity can be obtained by solving multidimensional programming problems. offline media to ensure the maximum gain of the current advertising.
在本公开示例实施方式所提供的目标用户确定方法中,通过获取多个用户的多维特征数据,并根据多维特征数据生成用户特征向量和广告特征向量;将用户特征向量和广告特征向量输入用户表征模型中,生成第一种子用户向量和第一候选用户向量;将第一种子用户向量和第一候选用户向量输入相似度预估模型中,生成第二种子用户向量和第二候选用户向量,并计算第二种子用户向量和第二候选用户向量之间的相似度;根据相似度确定候选用户中的目标用户。一方面,通过用户表征模型对不同特征域进行充分地学习组合以生成用户表征向量,该用户表征向量可以更加准确地反映用户的潜在兴趣,便于精准地确定种子用户的相似人群。而且,利用相似度预估模型输出的种子用户向量和候选用户向量可以更准确地计算种子用户和候选用户的相似度,进一步提高了相似人群扩展的精确率,进而提高广告投放的准确率;另一方面,通过用户表征模型和相似度预估模型即可确定目标用户,而无需进行人工圈选,提高了相似人群扩展的效率。In the target user determination method provided by the exemplary embodiments of the present disclosure, the multi-dimensional feature data of multiple users is obtained, and the user feature vector and the advertisement feature vector are generated according to the multi-dimensional feature data; the user feature vector and the advertisement feature vector are input into the user representation In the model, generate the first seed user vector and the first candidate user vector; input the first seed user vector and the first candidate user vector into the similarity estimation model, generate the second seed user vector and the second candidate user vector, and Calculating the similarity between the second seed user vector and the second candidate user vector; determining a target user among the candidate users according to the similarity. On the one hand, different feature domains are fully learned and combined through the user representation model to generate a user representation vector, which can more accurately reflect the potential interests of users and facilitate the accurate determination of similar groups of seed users. Moreover, using the seed user vectors and candidate user vectors output by the similarity prediction model can more accurately calculate the similarity between seed users and candidate users, further improving the accuracy of similar population expansion, thereby improving the accuracy of advertising; On the one hand, the target user can be determined through the user representation model and the similarity prediction model without manual selection, which improves the efficiency of similar group expansion.
应当注意,尽管在附图中以特定顺序描述了本公开中方法的各个步骤,但是,这并非要求或者暗示必须按照该特定顺序来执行这些步骤,或是必须执行全部所示的步骤才能实现期望的结果。附加的或备选的,可以省略某些步骤,将多个步骤合并为一个步骤执行,以及/或者将一个步骤分解为多个步骤执行等。It should be noted that although the various steps of the methods of the present disclosure are depicted in the drawings in a particular order, this does not require or imply that the steps must be performed in that particular order, or that all illustrated steps must be performed to achieve the desired the result of. Additionally or alternatively, certain steps may be omitted, multiple steps may be combined into one step for execution, and/or one step may be decomposed into multiple steps for execution, etc.
进一步的,本示例实施方式中,还提供了一种目标用户确定装置,该装置可以应用于一服务器或终端设备。参考图6所示,该目标用户确定装置600可以包括特征向量生成模块610、表征向量生成模块620、相似度计算模块630和目标用户确定模块640,其中:Further, in this exemplary embodiment, an apparatus for determining a target user is also provided, and the apparatus can be applied to a server or a terminal device. Referring to FIG. 6, the target
特征向量生成模块610,用于获取多个用户的多维特征数据,并根据所述多维特征数据生成用户特征向量和广告特征向量,其中,所述多个用户包括种子用户和候选用户;A feature
表征向量生成模块620,用于将所述用户特征向量和所述广告特征向量输入用户表征模型中,生成用户表征向量,所述用户表征向量包括第一种子用户向量和第一候选用户向量;A characterization
相似度计算模块630,用于将所述第一种子用户向量和所述第一候选用户向量输入相似度预估模型中,生成第二种子用户向量和第二候选用户向量,并计算所述第二种子用户向量和所述第二候选用户向量之间的相似度;A
目标用户确定模块640,用于根据所述相似度确定所述候选用户中的目标用户。A target
在一种可选的实施方式中,所述种子用户包括历史投放广告的种子用户和待投放广告的种子用户中的一种;目标用户确定装置600还包括:In an optional implementation manner, the seed user includes one of a seed user who has delivered advertisements in history and a seed user who is to deliver advertisements; the target
特征向量获取模块,用于获取待投放广告的第一广告特征向量和历史投放广告的第二广告特征向量;A feature vector acquisition module, configured to acquire the first advertisement feature vector of the advertisement to be placed and the second advertisement feature vector of the historical placed advertisement;
目标广告确定模块,用于计算所述第一广告特征向量和所述第二广告特征向量之间的相似度,并根据所述相似度确定所述历史投放广告中与所述待投放广告相似的目标投放广告;A target advertisement determination module, configured to calculate the similarity between the first advertisement feature vector and the second advertisement feature vector, and determine which of the historically served advertisements is similar to the advertisement to be delivered according to the similarity targeted advertising;
种子用户确定模块,用于基于所述目标投放广告的种子用户构建所述待投放广告的种子用户。The seed user determination module is configured to construct the seed users to be advertised based on the target advertised seed users.
在一种可选的实施方式中,所述多维特征数据包括用户特征数据和广告特征数据;特征向量生成模块610包括:In an optional implementation manner, the multidimensional feature data includes user feature data and advertisement feature data; feature
第一向量化模块,用于对所述用户特征数据进行向量化处理,生成所述用户特征向量;A first vectorization module, configured to perform vectorization processing on the user feature data to generate the user feature vector;
第二向量化模块,用于对所述广告特征数据进行向量化处理,生成所述广告特征向量。The second vectorization module is configured to perform vectorization processing on the advertisement feature data to generate the advertisement feature vector.
在一种可选的实施方式中,所述用户特征数据包括离散特征数据和连续特征数据中的至少一种;第一向量化模块包括:In an optional implementation manner, the user feature data includes at least one of discrete feature data and continuous feature data; the first vectorization module includes:
第一特征数据处理子模块,用于对各所述离散特征数据进行统计,得到多个第一特征数据;The first feature data processing sub-module is used to perform statistics on each of the discrete feature data to obtain a plurality of first feature data;
第一特征向量生成子模块,用于编码各所述第一特征数据,生成多个第一特征向量;The first feature vector generating submodule is used to encode each of the first feature data to generate multiple first feature vectors;
第二特征向量生成子模块,用于归一化各所述连续特征数据,生成多个第二特征向量;The second feature vector generating submodule is used to normalize each of the continuous feature data to generate multiple second feature vectors;
第一向量生成子模块,用于将所述多个第一特征向量和所述多个第二特征向量进行拼接,生成所述用户特征向量。The first vector generating submodule is configured to splice the plurality of first feature vectors and the plurality of second feature vectors to generate the user feature vector.
在一种可选的实施方式中,所述用户表征模型至少包括第一全连接层和第一注意力层;表征向量生成模块620包括:In an optional implementation manner, the user representation model includes at least a first fully connected layer and a first attention layer; the representation
第一特征降维子模块,用于利用所述第一全连接层对所述用户特征向量和所述广告特征向量进行特征降维,得到用户中间向量和广告中间向量;The first feature dimensionality reduction sub-module is used to use the first fully connected layer to perform feature dimensionality reduction on the user feature vector and the advertisement feature vector to obtain a user intermediate vector and an advertisement intermediate vector;
第二向量生成子模块,用于基于所述用户中间向量和所述广告中间向量,通过所述第一注意力层生成所述第一种子用户向量和所述第一候选用户向量。The second vector generating submodule is configured to generate the first seed user vector and the first candidate user vector through the first attention layer based on the user intermediate vector and the advertisement intermediate vector.
在一种可选的实施方式中,所述相似度预估模型包括两个网络分支,各网络分支至少包括第二全连接层和第二注意力层;相似度计算模块630包括:In an optional implementation manner, the similarity prediction model includes two network branches, and each network branch includes at least a second fully connected layer and a second attention layer; the
第二特征降维子模块,用于利用所述第二全连接层对所述第一种子用户向量和所述第一候选用户向量进行特征降维,得到种子用户中间向量和候选用户中间向量;The second feature dimensionality reduction sub-module is configured to use the second fully connected layer to perform feature dimensionality reduction on the first seed user vector and the first candidate user vector to obtain a seed user intermediate vector and a candidate user intermediate vector;
第三向量生成子模块,用于基于所述种子用户中间向量和所述候选用户中间向量,通过所述第二注意力层生成所述第二种子用户向量和所述第二候选用户向量。The third vector generating submodule is configured to generate the second seed user vector and the second candidate user vector through the second attention layer based on the seed user intermediate vector and the candidate user intermediate vector.
在一种可选的实施方式中,目标用户确定装置600还包括第一模型训练模块,所述第一模型训练模块被配置为用于获取第一训练样本,各所述第一训练样本为候选用户的用户特征向量和广告特征向量;将各所述候选用户的用户特征向量和广告特征向量输入所述用户表征模型中,得到对应的用户表征向量和广告表征向量;根据所述用户表征向量和所述广告表征向量构建第一目标函数;基于所述第一目标函数,对所述用户表征模型的参数进行迭代更新,当满足迭代终止条件时,完成对所述用户表征模型的训练。In an optional implementation manner, the target
在一种可选的实施方式中,目标用户确定装置600还包括第二模型训练模块,所述第二模型训练模块被配置为用于获取第二训练样本,各所述第二训练样本为种子用户向量和目标用户向量组成的向量对;通过所述相似度预估模型确定所述种子用户向量和所述目标用户向量的相似度;根据所述种子用户向量和所述目标用户向量的相似度构建第二目标函数;基于所述第二目标函数,对所述相似度预估模型的参数进行迭代更新,当满足迭代终止条件时,完成对所述相似度预估模型的训练。In an optional implementation manner, the target
上述目标用户确定装置中各模块的具体细节已经在对应的目标用户确定方法中进行了详细的描述,因此此处不再赘述。The specific details of each module in the above target user determining apparatus have been described in detail in the corresponding target user determining method, so details are not repeated here.
上述装置中各模块可以是通用处理器,包括:中央处理器、网络处理器等;还可以是数字信号处理器、专用集成电路、现场可编程门阵列或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。各模块也可以由软件、固件等形式来实现。上述装置中的各处理器可以是独立的处理器,也可以集成在一起。Each module in the above-mentioned device can be a general-purpose processor, including: a central processing unit, a network processor, etc.; it can also be a digital signal processor, an application-specific integrated circuit, a field programmable gate array or other programmable logic devices, discrete gates or transistors Logic devices, discrete hardware components. Each module may also be implemented by software, firmware, and other forms. Each processor in the above device may be an independent processor, or may be integrated together.
本公开的示例性实施方式还提供了一种计算机可读存储介质,其上存储有能够实现本说明书上述方法的程序产品。在一些可能的实施方式中,本公开的各个方面还可以实现为一种程序产品的形式,其包括程序代码,当程序产品在电子设备上运行时,程序代码用于使电子设备执行本说明书上述“示例性方法”部分中描述的根据本公开各种示例性实施方式的步骤。该程序产品可以采用便携式紧凑盘只读存储器(CD-ROM)并包括程序代码,并可以在电子设备,例如个人电脑上运行。然而,本公开的程序产品不限于此,在本文件中,可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。Exemplary embodiments of the present disclosure also provide a computer-readable storage medium on which a program product capable of implementing the above-mentioned method in this specification is stored. In some possible implementations, various aspects of the present disclosure can also be implemented in the form of a program product, which includes program code. When the program product is run on the electronic device, the program code is used to make the electronic device execute the above-mentioned functions of this specification. Steps according to various exemplary embodiments of the present disclosure described in the "Exemplary Methods" section. The program product may take the form of a portable compact disc read-only memory (CD-ROM) and include program code, and may run on an electronic device, such as a personal computer. However, the program product of the present disclosure is not limited thereto. In this document, a readable storage medium may be any tangible medium containing or storing a program, and the program may be used by or in combination with an instruction execution system, apparatus or device.
程序产品可以采用一个或多个可读介质的任意组合。可读介质可以是可读信号介质或者可读存储介质。可读存储介质例如可以为但不限于电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、光纤、便携式紧凑盘只读存储器(CD-ROM)、光存储器件、磁存储器件、或者上述的任意合适的组合。A program product may take the form of any combination of one or more readable media. The readable medium may be a readable signal medium or a readable storage medium. The readable storage medium may be, for example, but not limited to, an electrical, magnetic, optical, electromagnetic, infrared, or semiconductor system, device, or device, or any combination thereof. More specific examples (non-exhaustive list) of readable storage media include: electrical connection with one or more conductors, portable disk, hard disk, random access memory (RAM), read only memory (ROM), erasable programmable read-only memory (EPROM or flash memory), optical fiber, portable compact disk read-only memory (CD-ROM), optical storage devices, magnetic storage devices, or any suitable combination of the foregoing.
计算机可读信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了可读程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。可读信号介质还可以是可读存储介质以外的任何可读介质,该可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。A computer readable signal medium may include a data signal carrying readable program code in baseband or as part of a carrier wave. Such propagated data signals may take many forms, including but not limited to electromagnetic signals, optical signals, or any suitable combination of the foregoing. A readable signal medium may also be any readable medium other than a readable storage medium that can transmit, propagate, or transport a program for use by or in conjunction with an instruction execution system, apparatus, or device.
可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于无线、有线、光缆、RF等等,或者上述的任意合适的组合。Program code embodied on a readable medium may be transmitted using any appropriate medium, including but not limited to wireless, wireline, optical fiber cable, RF, etc., or any suitable combination of the foregoing.
可以以一种或多种程序设计语言的任意组合来编写用于执行本公开操作的程序代码,程序设计语言包括面向对象的程序设计语言—诸如Java、C++等,还包括常规的过程式程序设计语言—诸如“C”语言或类似的程序设计语言。程序代码可以完全地在用户计算设备上执行、部分地在用户设备上执行、作为一个独立的软件包执行、部分在用户计算设备上部分在远程计算设备上执行、或者完全在远程计算设备或服务器上执行。在涉及远程计算设备的情形中,远程计算设备可以通过任意种类的网络,包括局域网(LAN)或广域网(WAN),连接到用户计算设备,或者,可以连接到外部计算设备(例如利用因特网服务提供商来通过因特网连接)。Program code for performing the operations of the present disclosure may be written in any combination of one or more programming languages, including object-oriented programming languages—such as Java, C++, etc., as well as conventional procedural programming Language - such as "C" or similar programming language. The program code may execute entirely on the user's computing device, partly on the user's device, as a stand-alone software package, partly on the user's computing device and partly on a remote computing device, or entirely on the remote computing device or server to execute. In cases involving a remote computing device, the remote computing device may be connected to the user computing device through any kind of network, including a local area network (LAN) or a wide area network (WAN), or may be connected to an external computing device (e.g., using an Internet service provider). business to connect via the Internet).
本公开的示例性实施方式还提供了一种能够实现上述方法的电子设备。下面参照图7来描述根据本公开的这种示例性实施方式的电子设备700。图7显示的电子设备700仅仅是一个示例,不应对本公开实施方式的功能和使用范围带来任何限制。Exemplary embodiments of the present disclosure also provide an electronic device capable of implementing the above method. An
如图7所示,电子设备700可以以通用计算设备的形式表现。电子设备700的组件可以包括但不限于:至少一个处理单元710、至少一个存储单元720、连接不同系统组件(包括存储单元720和处理单元710)的总线730和显示单元740。As shown in FIG. 7,
存储单元720存储有程序代码,程序代码可以被处理单元710执行,使得处理单元710执行本说明书上述“示例性方法”部分中描述的根据本公开各种示例性实施方式的步骤。例如,处理单元710可以执行图2和图5中任意一个或多个方法步骤。The
存储单元720可以包括易失性存储单元形式的可读介质,例如随机存取存储单元(RAM)721和/或高速缓存存储单元722,还可以进一步包括只读存储单元(ROM)723。The
存储单元720还可以包括具有一组(至少一个)程序模块725的程序/实用工具724,这样的程序模块725包括但不限于:操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。
总线730可以为表示几类总线结构中的一种或多种,包括存储单元总线或者存储单元控制器、外围总线、图形加速端口、处理单元或者使用多种总线结构中的任意总线结构的局域总线。
电子设备700也可以与一个或多个外部设备800(例如键盘、指向设备、蓝牙设备等)通信,还可与一个或者多个使得用户能与该电子设备700交互的设备通信,和/或与使得该电子设备700能与一个或多个其它计算设备进行通信的任何设备(例如路由器、调制解调器等等)通信。这种通信可以通过输入/输出(I/O)接口750进行。并且,电子设备700还可以通过网络适配器760与一个或者多个网络(例如局域网(LAN),广域网(WAN)和/或公共网络,例如因特网)通信。如图所示,网络适配器760通过总线730与电子设备700的其它模块通信。应当明白,尽管图中未示出,可以结合电子设备700使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理单元、外部磁盘驱动阵列、RAID系统、磁带驱动器以及数据备份存储系统等。The
通过以上的实施方式的描述,本领域的技术人员易于理解,这里描述的示例实施方式可以通过软件实现,也可以通过软件结合必要的硬件的方式来实现。因此,根据本公开实施方式的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是CD-ROM,U盘,移动硬盘等)中或网络上,包括若干指令以使得一台计算设备(可以是个人计算机、服务器、终端装置、或者网络设备等)执行根据本公开示例性实施方式的方法。Through the description of the above implementations, those skilled in the art can easily understand that the example implementations described here can be implemented by software, or can be implemented by combining software with necessary hardware. Therefore, the technical solutions according to the embodiments of the present disclosure can be embodied in the form of software products, and the software products can be stored in a non-volatile storage medium (which can be CD-ROM, U disk, mobile hard disk, etc.) or on the network , including several instructions to cause a computing device (which may be a personal computer, a server, a terminal device, or a network device, etc.) to execute the method according to the exemplary embodiment of the present disclosure.
此外,上述附图仅是根据本公开示例性实施方式的方法所包括的处理的示意性说明,而不是限制目的。易于理解,上述附图所示的处理并不表明或限制这些处理的时间顺序。另外,也易于理解,这些处理可以是例如在多个模块中同步或异步执行的。In addition, the above-mentioned drawings are only schematic illustrations of processes included in the method according to the exemplary embodiments of the present disclosure, and are not intended to be limiting. It is easy to understand that the processes shown in the above figures do not imply or limit the chronological order of these processes. In addition, it is also easy to understand that these processes may be executed synchronously or asynchronously in multiple modules, for example.
应当注意,尽管在上文详细描述中提及了用于动作执行的设备的若干模块或者单元,但是这种划分并非强制性的。实际上,根据本公开的实施方式,上文描述的两个或更多模块或者单元的特征和功能可以在一个模块或者单元中具体化。反之,上文描述的一个模块或者单元的特征和功能可以进一步划分为由多个模块或者单元来具体化。It should be noted that although several modules or units of the device for action execution are mentioned in the above detailed description, this division is not mandatory. Actually, according to the embodiment of the present disclosure, the features and functions of two or more modules or units described above may be embodied in one module or unit. Conversely, the features and functions of one module or unit described above can be further divided to be embodied by a plurality of modules or units.
应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限制。It should be understood that the present disclosure is not limited to the precise constructions which have been described above and shown in the drawings, and various modifications and changes may be made without departing from the scope thereof. The scope of the present disclosure is limited only by the appended claims.
Claims (11)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211295508.XACN115619463A (en) | 2022-10-21 | 2022-10-21 | Target user determination method, device, storage medium and electronic equipment |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211295508.XACN115619463A (en) | 2022-10-21 | 2022-10-21 | Target user determination method, device, storage medium and electronic equipment |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN115619463Atrue CN115619463A (en) | 2023-01-17 |
Family
ID=84864178
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202211295508.XAPendingCN115619463A (en) | 2022-10-21 | 2022-10-21 | Target user determination method, device, storage medium and electronic equipment |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115619463A (en) |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105550903A (en)* | 2015-12-25 | 2016-05-04 | 腾讯科技(深圳)有限公司 | Target user determination method and apparatus |
| CN110162703A (en)* | 2019-05-13 | 2019-08-23 | 腾讯科技(深圳)有限公司 | Content recommendation method, training method, device, equipment and storage medium |
| CN112712418A (en)* | 2021-03-25 | 2021-04-27 | 腾讯科技(深圳)有限公司 | Method and device for determining recommended commodity information, storage medium and electronic equipment |
| CN112905897A (en)* | 2021-03-30 | 2021-06-04 | 杭州网易云音乐科技有限公司 | Similar user determination method, vector conversion model, device, medium and equipment |
| CN113888211A (en)* | 2021-09-23 | 2022-01-04 | 北京奇艺世纪科技有限公司 | An advertisement push method, device, electronic device and storage medium |
| CN115131052A (en)* | 2021-03-29 | 2022-09-30 | 腾讯科技(深圳)有限公司 | A data processing method, computer equipment and storage medium |
- 2022
- 2022-10-21CNCN202211295508.XApatent/CN115619463A/enactivePending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105550903A (en)* | 2015-12-25 | 2016-05-04 | 腾讯科技(深圳)有限公司 | Target user determination method and apparatus |
| CN110162703A (en)* | 2019-05-13 | 2019-08-23 | 腾讯科技(深圳)有限公司 | Content recommendation method, training method, device, equipment and storage medium |
| CN112712418A (en)* | 2021-03-25 | 2021-04-27 | 腾讯科技(深圳)有限公司 | Method and device for determining recommended commodity information, storage medium and electronic equipment |
| CN115131052A (en)* | 2021-03-29 | 2022-09-30 | 腾讯科技(深圳)有限公司 | A data processing method, computer equipment and storage medium |
| CN112905897A (en)* | 2021-03-30 | 2021-06-04 | 杭州网易云音乐科技有限公司 | Similar user determination method, vector conversion model, device, medium and equipment |
| CN113888211A (en)* | 2021-09-23 | 2022-01-04 | 北京奇艺世纪科技有限公司 | An advertisement push method, device, electronic device and storage medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN113268656B (en) | User recommendation method, device, electronic device and computer storage medium | |
| US10354184B1 (en) | Joint modeling of user behavior | |
| CN112163676B (en) | Method, device, equipment and storage medium for training multitasking service prediction model | |
| US11869021B2 (en) | Segment valuation in a digital medium environment | |
| CN112905897B (en) | Similar user determination method, vector conversion model, device, medium and equipment | |
| CN109471978B (en) | Electronic resource recommendation method and device | |
| CN113763019A (en) | User information management method and device | |
| CN111429161B (en) | Feature extraction method, feature extraction device, storage medium and electronic equipment | |
| CN112905885B (en) | Method, apparatus, device, medium and program product for recommending resources to user | |
| CN117573973B (en) | Resource recommendation method, device, electronic device, and storage medium | |
| CN119205259A (en) | Data recommendation method, device, computer equipment and storage medium | |
| CN115564517A (en) | Commodity recommendation method, prediction model training method and related equipment | |
| CN113778979B (en) | A method and device for determining click rate of live broadcast | |
| CN117540078A (en) | Optimization method and device for recommendation reason generation model | |
| CN115033801A (en) | Item recommendation method, model training method and electronic device | |
| CN113553501A (en) | Method and device for user portrait prediction based on artificial intelligence | |
| CN118586979A (en) | Product recommendation model training and application method, electronic equipment | |
| CN113094584A (en) | Method and device for determining recommended learning resources | |
| CN114579867A (en) | Method and apparatus for resource recommendation, electronic device and storage medium | |
| CN113792952A (en) | Method and apparatus for generating a model | |
| CN115619463A (en) | Target user determination method, device, storage medium and electronic equipment | |
| CN114519114B (en) | Method, device, server and storage medium for constructing multimedia resource classification model | |
| CN116308641A (en) | Product recommendation method, training device, electronic equipment and medium | |
| CN115187313A (en) | Data processing method, data processing device, storage medium and electronic equipment | |
| CN114266622A (en) | Resource recommendation method and device, electronic equipment and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |