CN115527253A - A lightweight facial expression recognition method and system based on attention mechanism - Google Patents
A lightweight facial expression recognition method and system based on attention mechanismDownload PDFInfo
- Publication number
- CN115527253A CN115527253ACN202211145376.2ACN202211145376ACN115527253ACN 115527253 ACN115527253 ACN 115527253ACN 202211145376 ACN202211145376 ACN 202211145376ACN 115527253 ACN115527253 ACN 115527253A
- Authority
- CN
- China
- Prior art keywords
- convolution
- attention
- feature map
- model
- feature
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images





Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/16—Human faces, e.g. facial parts, sketches or expressions
- G06V40/174—Facial expression recognition
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/764—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using classification, e.g. of video objects
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/16—Human faces, e.g. facial parts, sketches or expressions
- G06V40/168—Feature extraction; Face representation
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/16—Human faces, e.g. facial parts, sketches or expressions
- G06V40/172—Classification, e.g. identification
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Oral & Maxillofacial Surgery (AREA)
- Multimedia (AREA)
- General Health & Medical Sciences (AREA)
- General Physics & Mathematics (AREA)
- Physics & Mathematics (AREA)
- Human Computer Interaction (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Computing Systems (AREA)
- Software Systems (AREA)
- Medical Informatics (AREA)
- Evolutionary Computation (AREA)
- Databases & Information Systems (AREA)
- Artificial Intelligence (AREA)
- Image Analysis (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及计算机视觉人脸图像处理领域,更具体地,涉及一种基于注意力机制的轻量级人脸表情识别方法和系统。The present invention relates to the field of computer vision human face image processing, and more specifically, to a lightweight human facial expression recognition method and system based on an attention mechanism.
背景技术Background technique
机器分辨人的情绪,最主要的方式就是通过检测人脸全局信息,然后筛选表情相关的关键信息进行分析。因此,如何快速、准确的提取人脸表情的关键信息是当前表情识别领域亟需解决的一个问题。The most important way for a machine to distinguish human emotions is to detect the global information of the face, and then filter the key information related to the expression for analysis. Therefore, how to quickly and accurately extract the key information of facial expressions is a problem that needs to be solved urgently in the field of expression recognition.
早期的人脸表情识别大都是使用传统图像处理方法和机器学习方法,然而这些方法存在无法提取表情图像深层次特征的缺陷,尤其是当表情图像含有一些复杂的背景信息时,识别的准确率将会大大地降低,已经无法满足当前的表情识别任务需求。近年来,随着深度学习技术在计算机视觉领域的大力发展,大量优秀的卷积神经网络模型被用于表情识别,通过堆叠卷积层数、添加注意力机制、改进损失函数等都取得了不错的识别成绩,但这些卷积神经网络方法的参数通常都非常的多,模型结构也比较复杂。对表情识别这种实时性要求高的任务而言,已有方法均不是一种好的选择。Most of the early facial expression recognition methods used traditional image processing methods and machine learning methods. However, these methods have the disadvantage of being unable to extract deep-level features of expression images, especially when the expression images contain some complex background information, the recognition accuracy will be reduced. It will be greatly reduced, and it can no longer meet the current expression recognition task requirements. In recent years, with the vigorous development of deep learning technology in the field of computer vision, a large number of excellent convolutional neural network models have been used for expression recognition, and good results have been achieved by stacking convolutional layers, adding attention mechanisms, and improving loss functions. However, the parameters of these convolutional neural network methods are usually very large, and the model structure is also relatively complicated. None of the existing methods is a good choice for facial expression recognition, a task with high real-time requirements.
现有的技术中,中国发明专利提供了一种获取表情识别模型的方法及装置、表情识别方法及装置、存储介质及电子装置,其中,获取表情识别模型的方法包括:获取多组第一训练数据,其中,所述多组第一训练数据中的每组数据包括:图像、与图像对应的人脸以及与人脸对应的表情;基于人脸识别模型构造表情识别初始模型;使用所述多组第一训练数据通过深度学习对所述表情识别初始模型进行训练,以得到表情识别模型。通过本发明,解决了相关技术中存在的由于表情识别模型导致的人脸表情识别准确率低,泛化性差,稳定性差的问题,但是无法排除无关因素的干扰,其中模型的参数量多,建模运算繁琐。In the existing technology, the Chinese invention patent provides a method and device for obtaining an expression recognition model, an expression recognition method and device, a storage medium, and an electronic device, wherein the method for obtaining an expression recognition model includes: obtaining multiple sets of first training data, wherein each set of data in the multiple sets of first training data includes: an image, a human face corresponding to the image, and an expression corresponding to the human face; constructing an initial model for expression recognition based on a face recognition model; using the multiple The first set of training data trains the expression recognition initial model through deep learning to obtain an expression recognition model. Through the present invention, the problems of low accuracy rate, poor generalization and poor stability of facial expression recognition caused by the expression recognition model in the related art are solved, but the interference of irrelevant factors cannot be ruled out, and the model has many parameters. The modulo operation is cumbersome.
发明内容Contents of the invention
本发明为解决现有的表情识别中无关因素干扰大,模型参数量多的技术缺陷,提供了一种基于注意力机制的轻量级人脸表情识别方法和系统。The present invention provides a light-weight human facial expression recognition method and system based on an attention mechanism in order to solve the technical defects of large interference of irrelevant factors and large amount of model parameters in the existing expression recognition.
为实现以上发明目的,采用的技术方案是:For realizing above-mentioned purpose of the invention, the technical scheme that adopts is:
一种基于注意力机制的轻量级人脸表情识别方法,包括以下步骤:A lightweight facial expression recognition method based on an attention mechanism, comprising the following steps:
S1:建立卷积模型,对数据集的图片进行裁剪,并对图片进行预处理,将预处理后的图片输入卷积模型中;S1: Establish a convolutional model, crop the images in the data set, and preprocess the images, and input the preprocessed images into the convolutional model;
S2:图片在卷积模型中进行轻量级Ghost卷积特征提取、注意力机制重标定、和下采样操作,得到最终输出的特征图;S2: The image is subjected to lightweight Ghost convolution feature extraction, attention mechanism recalibration, and downsampling operations in the convolution model to obtain the final output feature map;
S3:将特征图中的向量进行表情分类,得到识别结果;S3: classify the vectors in the feature map for expression classification, and obtain the recognition result;
S4:建立损失函数模型,使用识别结果训练模型参数并测试,完成人脸表情识别。S4: Establish a loss function model, use the recognition results to train model parameters and test, and complete facial expression recognition.
上述方案中,引入Ghost卷积减少逐点卷积的参数量,为了消除表情无关因素的干扰,设计了注意力机制能够同时关注表情图像的位置信息和上下文信息,从而增大人脸表情图像关键区域的权重,提高识别的性能,相较于常规表情识别方法,模型参数量更少,识别准确率更高。In the above scheme, Ghost convolution is introduced to reduce the parameter amount of point-by-point convolution. In order to eliminate the interference of expression-independent factors, an attention mechanism is designed to pay attention to the position information and context information of the expression image at the same time, thereby increasing the key area of the facial expression image. Compared with conventional expression recognition methods, the model parameters are less and the recognition accuracy is higher.
优选的,在步骤S1中,将输入图片进行随机裁剪为48×48,并进行小角度旋转和水平翻转。Preferably, in step S1, the input picture is randomly cropped to 48×48, and rotated at a small angle and flipped horizontally.
上述方案中,本首先对数据集的图片进行调整,将图片大小裁剪为48×48并对图片进行预处理,即使用一系列的数据增广操作增加训练数据。图片大小裁剪具体是将输入图片进行随机裁剪,小角度旋转,水平翻转,防止因训练数据少而造成过拟合的现象。In the above solution, Ben first adjusted the pictures in the data set, cut the picture size to 48×48 and preprocessed the pictures, that is, used a series of data augmentation operations to increase the training data. Image size cropping is specifically to randomly crop the input image, rotate it at a small angle, and flip it horizontally to prevent overfitting due to the lack of training data.
优选的,在步骤S2中,轻量级特征提取包括以下步骤:使用1×3和3×1的卷积提取特征,然后用Ghost卷积提取特征;重复上述操作,再与输入的图片拼接得到特征图;然后对通道进行混洗操作,得到最终的输出特征图。Preferably, in step S2, the lightweight feature extraction includes the following steps: using 1×3 and 3×1 convolution to extract features, and then using Ghost convolution to extract features; repeating the above operations, and then splicing with the input image to obtain Feature map; then the channel is shuffled to get the final output feature map.
优选的,在步骤S2中,下采样操作包括以下步骤:使用3×3,步长为2的深度卷积,进行下采样操作,输出的特征图尺寸减半;使用全局平均池化层和1×1卷积代替最后的下采样操作,得到输出特征图1024×1×1。Preferably, in step S2, the downsampling operation includes the following steps: use a 3×3 deep convolution with a step size of 2 to perform a downsampling operation, and halve the size of the output feature map; use a global average pooling layer and 1 The ×1 convolution replaces the final downsampling operation, resulting in an output feature map of 1024×1×1.
上述方案中,首先使用一个3×3的卷积,提取浅层特征,输入为3通道,输出为32通道的特征图;进入轻量级特征提取模块LFE:使用1×3和3×1的卷积提取特征,然后用Ghost卷积模块代替逐点卷积提取特征。重复一遍上述操作,再与输入的特征图拼接得到特征图,然后对通道进行混洗操作,加强信息交流,得到最终的输出特征图;进入改进的注意力模块LCA,对输入的特征进行重标定;之后使用3×3,步长为2的深度卷积,进行下采样操作,最终输出的特征图尺寸减半;在模型的末端使用全局平均池化层和一个1×1卷积代替最后的下采样模块,得到最终的输出特征图为1024×1×1。In the above scheme, first use a 3×3 convolution to extract shallow features, the input is 3 channels, and the output is a feature map of 32 channels; enter the lightweight feature extraction module LFE: use 1×3 and 3×1 Convolution extracts features, and then replaces point-by-point convolution with Ghost convolution module to extract features. Repeat the above operation, and then splicing with the input feature map to obtain the feature map, and then perform shuffling operation on the channel, strengthen information exchange, and obtain the final output feature map; enter the improved attention module LCA, and recalibrate the input features ; Then use a 3×3 deep convolution with a step size of 2 for downsampling, and the final output feature map size is halved; use a global average pooling layer and a 1×1 convolution at the end of the model instead of the final Downsampling module, the final output feature map is 1024×1×1.
优选的,在步骤S3中,将全局平均池化层得到的特征送入全连接层,具体操作为:将1024个向量映射为7个向量送入分类器进行表情分类,得到最终的识别结果。Preferably, in step S3, the features obtained by the global average pooling layer are sent to the fully connected layer, and the specific operation is: 1024 vectors are mapped into 7 vectors and sent to the classifier for expression classification to obtain the final recognition result.
优选的,在步骤S4中,所述函数模型使用Pytorch框架搭建,使用Fer2013数据集验证函数模型,且使用损失函数进行监督,具体为:Preferably, in step S4, the function model is built using the Pytorch framework, the function model is verified using the Fer2013 data set, and the loss function is used for supervision, specifically:

其中e表示表情的类别数,N为总样本数,W是权重参数,y为标签,x为输入数据。Where e represents the number of categories of expressions, N is the total number of samples, W is the weight parameter, y is the label, and x is the input data.
一种基于注意力机制的轻量级人脸表情识别系统,运用了所述的一种基于注意力机制的轻量级人脸表情识别方法的步骤S2,步骤S2的卷积模型包括特征提取模块、注意力模块和下采样模块;所述特征提取模块的输出端与所述注意力模块的输入端电性连接;所述注意力模块的输出端与所述下采样模块的输入端电性连接。A lightweight facial expression recognition system based on an attention mechanism, using the step S2 of the lightweight facial expression recognition method based on an attention mechanism, the convolution model of the step S2 includes a feature extraction module , an attention module and a down-sampling module; the output end of the feature extraction module is electrically connected to the input end of the attention module; the output end of the attention module is electrically connected to the input end of the down-sampling module .
优选的,在所述特征提取模块中,首先将3×3的普通卷积进行分解,使用两个分解卷积1×3和3×1进行串联代替,将深度卷积之后的1×1逐点卷积也进行替换,使用Ghost卷积大幅降低参数,最后将两者进行拼接。Preferably, in the feature extraction module, the 3×3 ordinary convolution is firstly decomposed, and two decomposed convolutions 1×3 and 3×1 are used to replace them in series, and the 1×1 after the depth convolution is gradually The point convolution is also replaced, using Ghost convolution to greatly reduce the parameters, and finally splicing the two.
上述方案中,首先将3×3的普通卷积进行分解,使用两个分解卷积1×3和3×1进行串联代替,为了进一步减少网络的参数量,将深度卷积之后的1×1逐点卷积也进行替换,使用一个新颖的Ghost卷积大幅降低参数,该卷积工作原理:首先对输入的特征图进行1×1卷积,此时的卷积核数量为输入通道的1/2,生成特征图x1∈RC/2×H×W,然后使用3×3的深度卷积进行特征提取,得到特征图x2∈RC/2×H×W,最后将两者进行拼接,公式描述如下:F=concat(g(x1),g(x2)),F∈RC×H×W。使用这种新颖的Ghost卷积代替1×1卷积,在减少网络参数量的同时,丰富了网络的感受野,更利于网络提取面部细节信息。In the above scheme, the 3×3 ordinary convolution is decomposed first, and two decomposed convolutions 1×3 and 3×1 are used to replace them in series. In order to further reduce the parameter amount of the network, the 1×1 after the depth convolution The point-by-point convolution is also replaced, and a novel Ghost convolution is used to greatly reduce the parameters. The working principle of this convolution is: firstly, 1×1 convolution is performed on the input feature map, and the number of convolution kernels at this time is 1 of the input channel. /2, generate feature map x1∈RC/2×H×W , and then use 3×3 deep convolution for feature extraction, get feature map x2∈RC/2×H×W , and finally splicing the two , the formula is described as follows: F=concat(g(x1), g(x2)), F∈RC×H×W . Using this novel Ghost convolution instead of 1×1 convolution not only reduces the amount of network parameters, but also enriches the receptive field of the network, which is more conducive to the network to extract facial detail information.
为了提取深度特征,本模块重复堆叠两次上述卷积过程,最后生成的特征图为Fo∈RC×H×W。为了更好的融合浅层的特征,将本模块的输入特征Fi∈RC×H×W与输出特征Fo∈RC×H×W进行拼接融合得到输出特征Mo∈R2C×H×W。使用拼接的目的,一是为了进行通道升维,二是减少逐像素的相加操作,可以加快模型的识别速度。最后对特征Mo使用通道混洗加强特征间信息的交流,增强特征表达能力。In order to extract deep features, this module repeats the above convolution process twice, and the final generated feature map is Fo∈RC×H×W . In order to better fuse shallow features, the input feature Fi∈RC×H×W of this module is spliced and fused with the output feature Fo∈RC×H×W to obtain the output feature Mo∈R2C×H×W . The purpose of using stitching is to increase the dimension of the channel, and to reduce the pixel-by-pixel addition operation, which can speed up the recognition speed of the model. Finally, channel shuffling is used for feature Mo to enhance the communication of information between features and enhance the ability of feature expression.
一个普通卷积参数量计算公式为:K×K×Ci×Co,本模块的卷积计算公式为:1×K×Ci+K×1×Ci+Ci×Ci/2+K×K×Ci/2。K为卷积核大小,Ci为输入通道数,Co为输出通道数。通过上述的公式可知,本发明所提方法极大的减少了参数量。The calculation formula of an ordinary convolution parameter is: K×K×Ci×Co, the convolution calculation formula of this module is: 1×K×Ci+K×1×Ci+Ci×Ci/2+K×K×Ci /2. K is the size of the convolution kernel, Ci is the number of input channels, and Co is the number of output channels. It can be seen from the above formula that the method proposed in the present invention greatly reduces the amount of parameters.
优选的,所述注意力模块包括上下文特征提取分支和坐标注意分支;Preferably, the attention module includes a context feature extraction branch and a coordinate attention branch;
对于坐标注意力分支,首先经过自适应全局最大池化和平均池化,获取特征信息,然后将两者的特征进行拼接,并使用1×1卷积生成特征图,然后将特征图拆分为两个方向的特征,并使用1×1卷积重新编码信息,最后使用Sigmoid函数生成注意力映射图;For the coordinate attention branch, firstly, through adaptive global maximum pooling and average pooling, feature information is obtained, and then the features of the two are spliced, and a feature map is generated using 1×1 convolution, and then the feature map is split into Features in two directions, and use 1×1 convolution to re-encode the information, and finally use the Sigmoid function to generate an attention map;
对于上下文特征提取分支,首先使用膨胀卷积提取上下文特征,然后使用1×1卷积聚合通道的相关信息,生成特征图;最后将生成的注意力的特征图与坐标注意分支特征图融合,具体方式为将两者的特征图按元素相乘。For the context feature extraction branch, first use dilated convolution to extract context features, then use 1×1 convolution to aggregate channel-related information to generate a feature map; finally, fuse the generated attention feature map with the coordinate attention branch feature map, specifically The method is to multiply the feature maps of the two element-wise.
上述方案中,使用的注意力主要包括两个平行的分支:上下文特征提取分支和坐标注意分支。对于坐标注意力分支,首先经过自适应全局最大池化和平均池化,获取特征信息Za,Zm,然后将两者的特征进行拼接,并使用1×1卷积生成特征图Mc=F1×1(concat(Za,Zm)),然后将特征图拆分为两个方向的特征,并使用1×1卷积重新编码信息,最后使用Sigmoid函数生成注意力映射图:Ch=F1×1(fh),Cw=F1×1(fw)。其中Ch∈RC×H×1,Cw∈RC×1×W。In the above scheme, the attention used mainly includes two parallel branches: the context feature extraction branch and the coordinate attention branch. For the coordinate attention branch, firstly through adaptive global maximum pooling and average pooling, feature information Za, Zm are obtained, and then the features of the two are spliced, and the feature map Mc=F1× is generated using 1×1 convolution1 (concat(Za,Zm)), then split the feature map into features in two directions, and use 1×1 convolution to re-encode the information, and finally use the Sigmoid function to generate the attention map: Ch=F1×1 (fh), Cw=F1×1 (fw). Among them Ch∈RC×H×1 , Cw∈RC×1×W .
对于上下文特征提取分支,首先使用膨胀卷积提取上下文特征,膨胀卷积不增加网络的参数量,同时可以增大感受野,然后使用1×1卷积聚合通道的相关信息,生成特征图Mg=F1×1(Fdilated(x)),Mg∈R1×H×W。最后将生成的注意力特征图Mg与坐标注意分支特征图融合,具体方式为将两者的特征图按元素相乘:Ao=Ch*Cw*Mg,Ao∈RC×H×W。For the context feature extraction branch, first use the dilated convolution to extract the context features, the dilated convolution does not increase the parameter amount of the network, and can increase the receptive field, and then use the 1×1 convolution to aggregate the relevant information of the channel to generate the feature map Mg= F1×1 (Fdilated (x)), Mg∈R1×H×W . Finally, the generated attention feature map Mg is fused with the coordinate attention branch feature map by multiplying the two feature maps element by element: Ao=Ch*Cw*Mg, Ao∈RC×H×W .
本发明改进的坐标注意力不仅能够捕捉通道相关性,编码特征的位置信息,而且使用了膨胀卷积提取上下文特征,有利于提升模型的整体性能。The improved coordinate attention of the present invention can not only capture the channel correlation, encode the location information of the feature, but also use the dilated convolution to extract the context feature, which is beneficial to improve the overall performance of the model.
优选的,在所述下采样模块中,使用3×3的深度卷积代替池化层,之后卷积输出特征图。Preferably, in the downsampling module, a 3×3 deep convolution is used instead of the pooling layer, and then the convolution outputs the feature map.
上述方案中,本发明所提模型使用3×3的深度卷积代替池化层,使用少量的计算代价解决因为使用池化层造成的关键信息丢失的问题,此卷积输出的特征图为:D=F3×3(Ao),D∈RC×H/2×W/2。In the above solution, the model proposed in the present invention uses 3×3 deep convolution instead of the pooling layer, and uses a small amount of calculation cost to solve the problem of key information loss caused by the use of the pooling layer. The feature map output by this convolution is: D=F3×3 (Ao), D∈RC×H/2×W/2 .
与现有技术相比,本发明的有益效果是:Compared with prior art, the beneficial effect of the present invention is:
本发明提供的一种基于注意力机制的轻量级人脸表情识别方法和系统,引入Ghost卷积减少逐点卷积的参数量,为了消除表情无关因素的干扰,改进了坐标注意力机制能够同时关注表情图像的位置信息和上下文信息,从而增大人脸表情图像关键区域的权重,提高识别的性能,相较于常规表情识别方法,模型参数量更少,识别准确率更高。A lightweight facial expression recognition method and system based on the attention mechanism provided by the present invention introduces Ghost convolution to reduce the parameter amount of point-by-point convolution. In order to eliminate the interference of expression-independent factors, the coordinate attention mechanism is improved. At the same time, it pays attention to the position information and context information of the expression image, thereby increasing the weight of the key area of the facial expression image and improving the recognition performance. Compared with the conventional expression recognition method, the number of model parameters is less, and the recognition accuracy is higher.
附图说明Description of drawings
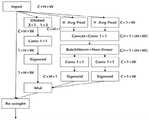
图1为本发明的方法流程图;Fig. 1 is method flowchart of the present invention;
图2是本发明的整体操作流程图;Fig. 2 is the whole operation flowchart of the present invention;
图3是本发明的总体模型结构图;Fig. 3 is an overall model structural diagram of the present invention;
图4是本发明改进的注意力模块图;Fig. 4 is an improved attention module diagram of the present invention;
图5是本发明的特征提取模块图;Fig. 5 is a feature extraction module diagram of the present invention;
图6是本发明引入的Ghost卷积示意图。Fig. 6 is a schematic diagram of Ghost convolution introduced in the present invention.
具体实施方式detailed description
附图仅用于示例性说明,不能理解为对本专利的限制;The accompanying drawings are for illustrative purposes only and cannot be construed as limiting the patent;
以下结合附图和实施例对本发明做进一步的阐述。The present invention will be further elaborated below in conjunction with the accompanying drawings and embodiments.
实施例1Example 1
如图1和图2所示,一种基于注意力机制的轻量级人脸表情识别方法,包括以下步骤:As shown in Figure 1 and Figure 2, a lightweight facial expression recognition method based on the attention mechanism includes the following steps:
S1:建立卷积模型,对数据集的图片进行裁剪,并对图片进行预处理,将预处理后的图片输入卷积模型中;S1: Establish a convolutional model, crop the images in the data set, and preprocess the images, and input the preprocessed images into the convolutional model;
S2:图片在卷积模型中进行特征提取、注意力机制重标定、和下采样操作,得到最终输出的特征图;S2: The image is subjected to feature extraction, attention mechanism recalibration, and downsampling operations in the convolution model to obtain the final output feature map;
S3:将特征图中的向量进行表情分类,得到识别结果;S3: classify the vectors in the feature map for expression classification, and obtain the recognition result;
S4:建立损失函数模型,使用识别结果训练模型参数并测试,完成人脸表情识别。S4: Establish a loss function model, use the recognition results to train model parameters and test, and complete facial expression recognition.
上述方案中,引入Ghost卷积减少逐点卷积的参数量,为了消除表情无关因素的干扰,改进了坐标注意力机制能够同时关注表情图像的位置信息和上下文信息,从而增大人脸表情图像关键区域的权重,提高识别的性能,相较于常规表情识别方法,模型参数量更少,识别准确率更高。In the above scheme, Ghost convolution is introduced to reduce the parameter amount of point-by-point convolution. In order to eliminate the interference of expression-independent factors, the coordinate attention mechanism is improved to pay attention to the position information and context information of the expression image at the same time, thereby increasing the key points of the facial expression image. The weight of the region improves the recognition performance. Compared with the conventional expression recognition method, the number of model parameters is less, and the recognition accuracy is higher.
优选的,在步骤S1中,将输入图片进行随机裁剪为48×48,并进行小角度旋转和水平翻转。Preferably, in step S1, the input picture is randomly cropped to 48×48, and rotated at a small angle and flipped horizontally.
上述方案中,首先对数据集的图片进行调整,将图片大小裁剪为48×48并对图片进行预处理,即使用一系列的数据增广操作增加训练数据。图片大小裁剪具体是将输入图片进行随机裁剪,小角度旋转,水平翻转,防止因训练数据少而造成过拟合的现象。In the above solution, firstly adjust the pictures in the data set, cut the picture size to 48×48 and preprocess the pictures, that is, use a series of data augmentation operations to increase the training data. Image size cropping is specifically to randomly crop the input image, rotate it at a small angle, and flip it horizontally to prevent overfitting due to the lack of training data.
优选的,在步骤S2中,轻量级特征提取包括以下步骤:使用1×3和3×1的卷积提取特征,然后用Ghost卷积提取特征;重复上述操作,再与输入的图片拼接得到特征图;然后对通道进行混洗操作,得到最终的输出特征图。Preferably, in step S2, the lightweight feature extraction includes the following steps: using 1×3 and 3×1 convolution to extract features, and then using Ghost convolution to extract features; repeating the above operations, and then splicing with the input image to obtain Feature map; then the channel is shuffled to get the final output feature map.
优选的,在步骤S2中,下采样操作包括以下步骤:使用3×3,步长为2的深度卷积,进行下采样操作,输出的特征图尺寸减半;使用全局平均池化层和1×1卷积代替最后的下采样操作,得到输出特征图1024×1×1。Preferably, in step S2, the downsampling operation includes the following steps: use a 3×3 deep convolution with a step size of 2 to perform a downsampling operation, and halve the size of the output feature map; use a global average pooling layer and 1 The ×1 convolution replaces the final downsampling operation, resulting in an output feature map of 1024×1×1.
上述方案中,首先使用一个3×3的卷积,提取浅层特征,输入为3通道,输出为32通道的特征图;进入轻量级特征提取模块LFE:使用1×3和3×1的卷积提取特征,然后用Ghost卷积模块代替逐点卷积提取特征。重复一遍上述操作,再与输入的特征图拼接得到特征图,然后对通道进行混洗操作,加强信息交流,得到最终的输出特征图;进入改进的注意力模块LCA,对输入的特征进行重标定;之后使用3×3,步长为2的深度卷积,进行下采样操作,最终输出的特征图尺寸减半;在模型的末端使用全局平均池化层和一个1×1卷积代替最后的下采样模块,得到最终的输出特征图为1024×1×1。In the above scheme, first use a 3×3 convolution to extract shallow features, the input is 3 channels, and the output is a feature map of 32 channels; enter the lightweight feature extraction module LFE: use 1×3 and 3×1 Convolution extracts features, and then replaces point-by-point convolution with Ghost convolution module to extract features. Repeat the above operation, and then splicing with the input feature map to obtain the feature map, and then perform shuffling operation on the channel, strengthen information exchange, and obtain the final output feature map; enter the improved attention module LCA, and recalibrate the input features ; Then use a 3×3 deep convolution with a step size of 2 for downsampling, and the final output feature map size is halved; use a global average pooling layer and a 1×1 convolution at the end of the model instead of the final Downsampling module, the final output feature map is 1024×1×1.
优选的,在步骤S3中,将全局平均池化层得到的特征送入全连接层,具体操作为:将1024个向量映射为7个向量送入分类器进行表情分类,得到最终的识别结果。Preferably, in step S3, the features obtained by the global average pooling layer are sent to the fully connected layer, and the specific operation is: 1024 vectors are mapped into 7 vectors and sent to the classifier for expression classification to obtain the final recognition result.
优选的,在步骤S4中,所述函数模型使用Pytorch框架搭建,使用Fer2013数据集验证函数模型,且使用损失函数进行监督,具体为:Preferably, in step S4, the function model is built using the Pytorch framework, the function model is verified using the Fer2013 data set, and the loss function is used for supervision, specifically:

其中e表示表情的类别数,N为总样本数,W是权重参数,y为标签,x为输入数据。Where e represents the number of categories of expressions, N is the total number of samples, W is the weight parameter, y is the label, and x is the input data.
实施例2Example 2
如图3~图6所示,一种基于注意力机制的轻量级人脸表情识别系统,运用了所述的一种基于注意力机制的轻量级人脸表情识别方法的步骤S2,步骤S2的卷积模型包括特征提取模块、注意力模块和下采样模块;所述特征提取模块的输出端与所述注意力模块的输入端电性连接;所述注意力模块的输出端与所述下采样模块的输入端电性连接。As shown in Figures 3 to 6, a lightweight facial expression recognition system based on the attention mechanism uses the step S2 of the lightweight facial expression recognition method based on the attention mechanism. The convolution model of S2 includes a feature extraction module, an attention module, and a downsampling module; the output end of the feature extraction module is electrically connected to the input end of the attention module; the output end of the attention module is connected to the The input terminal of the down-sampling module is electrically connected.
优选的,在所述特征提取模块中,首先将3×3的普通卷积进行分解,使用两个分解卷积1×3和3×1进行串联代替,将深度卷积之后的1×1逐点卷积也进行替换,使用Ghost卷积大幅降低参数,最后将两者进行拼接。Preferably, in the feature extraction module, the 3×3 ordinary convolution is firstly decomposed, and two decomposed convolutions 1×3 and 3×1 are used to replace them in series, and the 1×1 after the depth convolution is gradually The point convolution is also replaced, using Ghost convolution to greatly reduce the parameters, and finally splicing the two.
上述方案中,首先将3×3的普通卷积进行分解,使用两个分解卷积1×3和3×1进行串联代替,为了进一步减少网络的参数量,将深度卷积之后的1×1逐点卷积也进行替换,使用一个新颖的Ghost卷积大幅降低参数,该卷积工作原理:首先对输入的特征图进行1×1卷积,此时的卷积核数量为输入通道的1/2,生成特征图x1∈RC/2×H×W,然后使用3×3的深度卷积进行特征提取,得到特征图x2∈RC/2×H×W,最后将两者进行拼接,公式描述如下:F=concat(g(x1),g(x2)),F∈RC×H×W。使用这种新颖的Ghost卷积代替1×1卷积,在减少网络参数量的同时,丰富了网络的感受野,更利于网络提取面部细节信息。In the above scheme, the 3×3 ordinary convolution is decomposed first, and two decomposed convolutions 1×3 and 3×1 are used to replace them in series. In order to further reduce the parameter amount of the network, the 1×1 after the depth convolution The point-by-point convolution is also replaced, and a novel Ghost convolution is used to greatly reduce the parameters. The working principle of the convolution is: first, the input feature map is 1×1 convolution, and the number of convolution kernels at this time is 1 of the input channel. /2, generate feature map x1∈RC/2×H×W , and then use 3×3 deep convolution for feature extraction, get feature map x2∈RC/2×H×W , and finally splicing the two , the formula is described as follows: F=concat(g(x1), g(x2)), F∈RC×H×W . Using this novel Ghost convolution instead of 1×1 convolution not only reduces the amount of network parameters, but also enriches the receptive field of the network, which is more conducive to the network to extract facial detail information.
为了提取深度特征,本模块重复堆叠两次上述卷积过程,最后生成的特征图为Fo∈RC×H×W。为了更好的融合浅层的特征,将本模块的输入特征Fi∈RC×H×W与输出特征Fo∈RC×H×W进行拼接融合得到输出特征Mo∈R2C×H×W。使用拼接的目的,一是为了进行通道升维,二是减少逐像素的相加操作,可以加快模型的识别速度。最后对特征Mo使用通道混洗加强特征间信息的交流,增强特征表达能力。In order to extract deep features, this module repeats the above convolution process twice, and the final generated feature map is Fo∈RC×H×W . In order to better fuse shallow features, the input feature Fi∈RC×H×W of this module is spliced and fused with the output feature Fo∈RC×H×W to obtain the output feature Mo∈R2C×H×W . The purpose of using stitching is to increase the dimension of the channel, and to reduce the pixel-by-pixel addition operation, which can speed up the recognition speed of the model. Finally, channel shuffling is used for feature Mo to enhance the communication of information between features and enhance the ability of feature expression.
一个普通卷积参数量计算公式为:K×K×Ci×Co,本模块的卷积计算公式为:1×K×Ci+K×1×Ci+Ci×Ci/2+K×K×Ci/2。K为卷积核大小,Ci为输入通道数,Co为输出通道数。通过上述的公式可知,本发明所提方法极大的减少了参数量。The calculation formula of an ordinary convolution parameter is: K×K×Ci×Co, the convolution calculation formula of this module is: 1×K×Ci+K×1×Ci+Ci×Ci/2+K×K×Ci /2. K is the size of the convolution kernel, Ci is the number of input channels, and Co is the number of output channels. It can be seen from the above formula that the method proposed in the present invention greatly reduces the amount of parameters.
优选的,所述注意力模块包括上下文特征提取分支和坐标注意分支;Preferably, the attention module includes a context feature extraction branch and a coordinate attention branch;
对于坐标注意力分支,首先经过自适应全局最大池化和平均池化,获取特征信息,然后将两者的特征进行拼接,并使用1×1卷积生成特征图,然后将特征图拆分为两个方向的特征,并使用1×1卷积重新编码信息,最后使用Sigmoid函数生成注意力映射图;For the coordinate attention branch, firstly, through adaptive global maximum pooling and average pooling, feature information is obtained, and then the features of the two are spliced, and a feature map is generated using 1×1 convolution, and then the feature map is split into Features in two directions, and use 1×1 convolution to re-encode the information, and finally use the Sigmoid function to generate an attention map;
对于上下文特征提取分支,首先使用膨胀卷积提取上下文特征,然后使用1×1卷积聚合通道的相关信息,生成特征图;最后将生成的注意力的特征图与坐标注意分支特征图融合,具体方式为将两者的特征图按元素相乘。For the context feature extraction branch, first use dilated convolution to extract context features, then use 1×1 convolution to aggregate channel-related information to generate a feature map; finally, fuse the generated attention feature map with the coordinate attention branch feature map, specifically The method is to multiply the feature maps of the two element-wise.
上述方案中,使用的注意力主要包括两个平行的分支:上下文特征提取分支和坐标注意分支。对于坐标注意力分支,首先经过自适应全局最大池化和平均池化,获取特征信息Za,Zm,然后将两者的特征进行拼接,并使用1×1卷积生成特征图Mc=F1×1(concat(Za,Zm)),然后将特征图拆分为两个方向的特征,并使用1×1卷积重新编码信息,最后使用Sigmoid函数生成注意力映射图:Ch=F1×1(fh),Cw=F1×1(fw)。其中Ch∈RC×H×1,Cw∈RC×1×W。In the above scheme, the attention used mainly includes two parallel branches: the context feature extraction branch and the coordinate attention branch. For the coordinate attention branch, first through adaptive global maximum pooling and average pooling, feature information Za, Zm are obtained, and then the features of the two are spliced, and the feature map Mc=F1× is generated using 1×1 convolution1 (concat(Za,Zm)), then split the feature map into features in two directions, and use 1×1 convolution to re-encode the information, and finally use the Sigmoid function to generate the attention map: Ch=F1×1 (fh), Cw=F1×1 (fw). Among them Ch∈RC×H×1 , Cw∈RC×1×W .
对于上下文特征提取分支,首先使用膨胀卷积提取上下文特征,膨胀卷积不增加网络的参数量,同时可以增大感受野,然后使用1×1卷积聚合通道的相关信息,生成特征图Mg=F1×1(Fdilated(x)),Mg∈R1×H×W。最后将生成的注意力特征图Mg与坐标注意分支特征图融合,具体方式为将两者的特征图按元素相乘:Ao=Ch*Cw*Mg,Ao∈RC×H×W。For the context feature extraction branch, first use the dilated convolution to extract the context features, the dilated convolution does not increase the parameter amount of the network, and can increase the receptive field, and then use the 1×1 convolution to aggregate the relevant information of the channel to generate the feature map Mg= F1×1 (Fdilated (x)), Mg∈R1×H×W . Finally, the generated attention feature map Mg is fused with the coordinate attention branch feature map by multiplying the two feature maps element by element: Ao=Ch*Cw*Mg, Ao∈RC×H×W .
本发明改进的注意力不仅能够捕捉通道相关性,编码特征的位置信息,而且使用了膨胀卷积提取上下文特征,有利于提升模型的整体性能。The improved attention of the present invention can not only capture the channel correlation, encode the location information of the feature, but also use the dilated convolution to extract the context feature, which is beneficial to improve the overall performance of the model.
优选的,在所述下采样模块中,使用3×3的深度卷积代替池化层,之后卷积输出特征图。Preferably, in the downsampling module, a 3×3 deep convolution is used instead of the pooling layer, and then the convolution outputs the feature map.
上述方案中,本发明所提模型使用3×3的深度卷积代替池化层,使用少量的计算代价解决因为使用池化层造成的关键信息丢失的问题,此卷积输出的特征图为:D=F3×3(Ao),D∈RC×H/2×W/2。In the above solution, the model proposed in the present invention uses 3×3 deep convolution instead of the pooling layer, and uses a small amount of calculation cost to solve the problem of key information loss caused by the use of the pooling layer. The feature map output by this convolution is: D=F3×3 (Ao), D∈RC×H/2×W/2 .
实施例3Example 3
函数模型的数据及参数如下:The data and parameters of the function model are as follows:
使用Pytorch框架搭建本发明模型,使用Fer2013数据集验证本发明的有效效果,该数据集总共包含35887张表情图片,其中训练集为28709张,测试集为3589张图片,总共包含7类表情,分别是:开兴,愤怒,厌恶,恐惧,悲伤,中立,惊讶。Use the Pytorch framework to build the model of the present invention, and use the Fer2013 data set to verify the effective effect of the present invention. The data set contains a total of 35,887 expression pictures, of which 28,709 are training sets and 3,589 pictures are testing sets, including 7 types of expressions in total, respectively. Are: happy, angry, disgusted, fearful, sad, neutral, surprised.
模型训练阶段通过观察验证集的损失来调整网络的超参数,并采用带动量的SGD作为优化器,动量为0.9,权重衰减系数为5e-4。In the model training stage, the hyperparameters of the network are adjusted by observing the loss of the verification set, and SGD with momentum is used as the optimizer, the momentum is 0.9, and the weight decay coefficient is 5e-4.
训练阶段使用随机失活Dropout函数,防止网络过拟合,提高模型的泛化性能。In the training phase, the random inactivation Dropout function is used to prevent the network from over-fitting and improve the generalization performance of the model.
采用损失函数进行监督训练,最后保存训练好的模型,在测试集上进行验证。The loss function is used for supervised training, and finally the trained model is saved for verification on the test set.
损失函数计算公式为:The calculation formula of the loss function is:

其中e表示表情的类别数,N为总样本数,W是权重参数,y为标签,x为输入数据。Where e represents the number of categories of expressions, N is the total number of samples, W is the weight parameter, y is the label, and x is the input data.
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。Apparently, the above-mentioned embodiments of the present invention are only examples for clearly illustrating the present invention, rather than limiting the implementation of the present invention. For those of ordinary skill in the art, other changes or changes in different forms can be made on the basis of the above description. It is not necessary and impossible to exhaustively list all the implementation manners here. All modifications, equivalent replacements and improvements made within the spirit and principles of the present invention shall be included within the protection scope of the claims of the present invention.
Claims (10)

Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211058230 | 2022-08-31 | ||
| CN2022110582304 | 2022-08-31 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN115527253Atrue CN115527253A (en) | 2022-12-27 |
Family
ID=84696817
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202211145376.2APendingCN115527253A (en) | 2022-08-31 | 2022-09-20 | A lightweight facial expression recognition method and system based on attention mechanism |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115527253A (en) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116452981A (en)* | 2023-04-24 | 2023-07-18 | 浙江中烟工业有限责任公司 | Tobacco leaf automatic grading method, system, equipment and storage medium |
| CN116563908A (en)* | 2023-03-06 | 2023-08-08 | 浙江财经大学 | Face analysis and emotion recognition method based on multitasking cooperative network |
| CN116636855A (en)* | 2023-03-13 | 2023-08-25 | 武汉大学 | System and method for monitoring and classifying driver's electrocardiogram state |
| CN117894058A (en)* | 2024-03-14 | 2024-04-16 | 山东远桥信息科技有限公司 | Smart city camera face recognition method based on attention enhancement |
- 2022
- 2022-09-20CNCN202211145376.2Apatent/CN115527253A/enactivePending
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116563908A (en)* | 2023-03-06 | 2023-08-08 | 浙江财经大学 | Face analysis and emotion recognition method based on multitasking cooperative network |
| CN116636855A (en)* | 2023-03-13 | 2023-08-25 | 武汉大学 | System and method for monitoring and classifying driver's electrocardiogram state |
| CN116452981A (en)* | 2023-04-24 | 2023-07-18 | 浙江中烟工业有限责任公司 | Tobacco leaf automatic grading method, system, equipment and storage medium |
| CN117894058A (en)* | 2024-03-14 | 2024-04-16 | 山东远桥信息科技有限公司 | Smart city camera face recognition method based on attention enhancement |
| CN117894058B (en)* | 2024-03-14 | 2024-05-24 | 山东远桥信息科技有限公司 | Smart city camera face recognition method based on attention enhancement |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN115527253A (en) | A lightweight facial expression recognition method and system based on attention mechanism | |
| CN110728628A (en) | A face de-occlusion method based on conditional generative adversarial network | |
| CN113763417B (en) | A Target Tracking Method Based on Siamese Network and Residual Structure | |
| CN110852383A (en) | Target detection method and device based on attention mechanism deep learning network | |
| CN112507920A (en) | Examination abnormal behavior identification method based on time displacement and attention mechanism | |
| CN113486700A (en) | Facial expression analysis method based on attention mechanism in teaching scene | |
| CN111062329B (en) | Unsupervised person re-identification method based on augmented network | |
| CN113936295B (en) | Character detection method and system based on transfer learning | |
| CN111489405A (en) | Face sketch synthesis system for generating confrontation network based on condition enhancement | |
| CN113297956A (en) | Gesture recognition method and system based on vision | |
| CN112037225A (en) | A convolutional neural-based image segmentation method for marine ships | |
| CN117392017A (en) | A face restoration method based on feature points and deformable hybrid attention adversarial network | |
| CN113592715A (en) | Super-resolution image reconstruction method for small sample image set | |
| CN115131218A (en) | Image processing method, apparatus, computer readable medium and electronic device | |
| CN114359675A (en) | A saliency map generation method for hyperspectral images based on semi-supervised neural network | |
| CN112580502A (en) | SICNN-based low-quality video face recognition method | |
| CN113920171A (en) | Dual-modal target tracking algorithm based on feature-level and decision-level fusion | |
| CN109766918A (en) | Salient object detection method based on multi-level context information fusion | |
| Jakka et al. | Deepfake Video Detection using Deep Learning Approach | |
| CN114663965B (en) | Testimony comparison method and device based on two-stage alternative learning | |
| CN117475322A (en) | A method of constructing a joint encoding-decoding deep neural network for sea and land segmentation of remote sensing images | |
| CN116485654A (en) | Lightweight single-image super-resolution reconstruction method combining convolutional neural network and transducer | |
| CN113255704B (en) | A Pixel Difference Convolution Edge Detection Method Based on Local Binary Pattern | |
| CN115761848A (en) | An occluded face recognition method based on a two-stream prototype in a small-sample scene | |
| CN115273089A (en) | An Optical Character Restoration Method Based on Conditional Generative Adversarial Networks |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |