CN115526172A - A coreference resolution method, device, equipment and readable storage medium - Google Patents
A coreference resolution method, device, equipment and readable storage mediumDownload PDFInfo
- Publication number
- CN115526172A CN115526172ACN202211242338.9ACN202211242338ACN115526172ACN 115526172 ACN115526172 ACN 115526172ACN 202211242338 ACN202211242338 ACN 202211242338ACN 115526172 ACN115526172 ACN 115526172A
- Authority
- CN
- China
- Prior art keywords
- entity
- coreference
- label
- pair
- model
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images


Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
- G06F40/295—Named entity recognition
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Artificial Intelligence (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Software Systems (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Data Mining & Analysis (AREA)
- Evolutionary Computation (AREA)
- Medical Informatics (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Machine Translation (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本申请涉及自然语言处理领域,特别是涉及一种共指消解方法、装置、设备及可读存储介质。The present application relates to the field of natural language processing, in particular to a coreference resolution method, device, equipment and readable storage medium.
背景技术Background technique
随着人工智能的发展,对自然语言处理的研究日趋重要,在自然语言处理中,指代是一种常见的语言现象,广泛存在于自然语言的各种表达中。一般情况下,指代分为2种:回指(也称指示性指代)和共指(也称同指)。回指是指当前的照应语与上文出现的词、短语或句子(句群)存在密切的语义关联性,指代依存于上下文语义中,在不同的语言环境中可能指代不同的实体,具有非对称性和非传递性;共指主要是指2个名词(包括代名词、名词短语)指向真实世界中的同一参照体,这种指代脱离上下文仍然成立。With the development of artificial intelligence, the research on natural language processing is becoming more and more important. In natural language processing, reference is a common language phenomenon that exists widely in various expressions of natural language. In general, there are two types of reference: anaphora (also known as indicative reference) and coreference (also known as co-reference). Anaphora refers to the close semantic correlation between the current anaphora and the words, phrases or sentences (sentence groups) appearing above. The reference depends on the context semantics and may refer to different entities in different language environments. It is asymmetric and non-transitive; coreference mainly means that two nouns (including pronouns and noun phrases) point to the same reference in the real world, and this kind of reference still holds true out of context.
共指消解,是指对文本进行处理以识别在文本中哪些指代指的是现实世界中的同一个实体。换言之,共指消解的目的是找到文本中的作为指称词的名词、名词短语、代词、代词短语等实体并将它们进行归类,得到文本中指向相同实体的指代簇,例如,“[陈小小],英文名[Allen],1988年8 月出生,[他]是当今乐坛的当红歌手。”这句话中,[陈小小]、[Allen]、[他]这3个表述都指向“歌手陈小小”这一实体。而一篇文章中往往包括多种实体,在共指消解时会形成多个指代簇,由此以指示文章中的共指关系。Coreference resolution refers to the processing of text to identify which references in the text refer to the same entity in the real world. In other words, the purpose of coreference resolution is to find entities such as nouns, noun phrases, pronouns, and pronoun phrases as referents in the text and classify them, so as to obtain reference clusters pointing to the same entity in the text, for example, “[Chen Xiao Xiao], English name [Allen], born in August 1988, [he] is a popular singer in today's music scene.” In this sentence, the three expressions [Chen Xiaoxiao], [Allen], [he] are all Point to the entity "Singer Chen Xiaoxiao". An article often includes multiple entities, and multiple referential clusters will be formed during coreference resolution, thereby indicating the coreference relationship in the article.
现有的技术存在基于深度学习的实体对模型(mention pair model),模型能够识别到不同的实体对,并对实体对进行相关性判别,这种判别可以是二分类,也可以是聚类。或者,基于生成的方法进行句子重写,对句子进行编码器编码,然后进行解码,将代词替换成对应先行词。但是上述方法均需要大量的数据进行训练,他们所能够识别的实体类型大多构建在训练数据的实体类型上,而对新场景的实体,特别是当新场景仅有少量样本或无样本的情况时,对相同实体的不同表述的共指消解能力较差。Existing technology has a deep learning-based entity pair model (mention pair model), which can identify different entity pairs and perform correlation discrimination on entity pairs. This discrimination can be binary classification or clustering. Alternatively, a generative-based approach is used for sentence rewriting, where the sentence is encoded by an encoder and then decoded to replace pronouns with their corresponding antecedents. However, the above methods require a large amount of data for training, and most of the entity types they can recognize are built on the entity types of the training data, and for entities in new scenes, especially when there are only a few samples or no samples in the new scene , the coreference resolution ability for different representations of the same entity is poor.
发明内容Contents of the invention
基于上述问题,本申请提供了一种共指消解方法、装置、设备及可读存储介质,解决小样本场景下的共指消解问题。Based on the above problems, the present application provides a coreference resolution method, device, equipment and readable storage medium to solve the problem of coreference resolution in a small sample scenario.
第一方面,本申请公开了一种共指消解方法,包括:In the first aspect, the present application discloses a coreference resolution method, including:
根据输入文本中的内容进行实体识别;Entity recognition based on the content in the input text;
根据所述识别的实体组成实体对;forming entity pairs from said identified entities;
基于提示模型对所述实体对进行共指检测获得第一实体对标签;performing coreference detection on the entity pair based on the prompt model to obtain a first entity pair label;
基于所述第一实体对标签获得多实体的共指簇。A coreference cluster of multiple entities is obtained based on the first entity pair label.
可选地,所述根据输入文本中的内容进行实体识别,包括:Optionally, the performing entity recognition according to the content in the input text includes:
采用特征提取编码器和解码器对输入文本中的内容进行实体识别。Entity recognition is performed on the content in the input text using a feature extraction encoder and decoder.
可选地,所述根据输入文本中的内容进行实体识别,包括:Optionally, the performing entity recognition according to the content in the input text includes:
根据输入文本中的代词及实体类型进行实体识别。Entity recognition based on pronouns and entity types in the input text.
可选地,所述基于提示模型对所述实体对进行共指检测获得第一实体对标签,包括:Optionally, the coreference detection of the entity pair based on the hint model to obtain the first entity pair label includes:
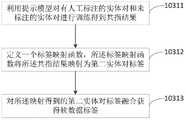
构建人工标注的提示模型;所述提示模型数量至少一个;所述提示模型用于输出实体对的共指结果;Constructing a manual-labeled prompt model; the number of the prompt model is at least one; the prompt model is used to output the coreference result of the entity pair;
利用提示模型对实体对的共指结果进行检测获得实体对标签。Using the hint model to detect the coreference results of entity pairs to obtain entity pair labels.
可选地,所述利用提示模型对实体对的共指结果进行预测获得第一实体对标签,包括:Optionally, using the hint model to predict the coreference result of the entity pair to obtain the first entity pair label includes:
利用提示模型对有人工标注的实体对和未标注的实体对进行训练得到软标签数据;Use the hint model to train the manually labeled entity pairs and unlabeled entity pairs to obtain soft label data;
基于所述软标签数据获得所述第一实体对标签。Obtaining the first entity pair labels based on the soft label data.
可选地,所述利用提示模型对有人工标注的实体对和未标注的实体对进行训练得到软标签数据,包括:Optionally, said using the prompt model to train the manually labeled entity pairs and unlabeled entity pairs to obtain soft label data, including:
利用提示模型对有人工标注的实体对和未标注的实体对进行训练得到共指结果;Use the prompt model to train the manually labeled entity pairs and unlabeled entity pairs to obtain the coreference result;
定义一个标签映射函数,所述标签映射函数将所述共指结果映射为第二实体对标签;defining a tag mapping function that maps the coreference result to a second entity pair tag;
对所述映射得到的第二实体对标签融合获得软数据标签。The soft data labels are obtained by fusing the labels of the second entity pairs obtained through the mapping.
可选地,基于所述实体对标签获得多实体的共指簇,包括:Optionally, obtaining a multi-entity coreference cluster based on the entity pair label includes:
基于所述第一实体对标签进行共指融合,获得多实体的共指簇。Based on the first entity, coreference fusion is performed on tags to obtain a coreference cluster of multiple entities.
第二方面,本申请公开了一种共指消解装置,包括:In the second aspect, the present application discloses a coreference resolution device, including:
识别模块,根据输入文本中的内容进行实体识别;The recognition module performs entity recognition according to the content in the input text;
组成模块,根据所述识别的实体组成实体对;a composition module for forming entity pairs according to the identified entities;
第一获取模块,基于提示模型对所述实体对进行共指检测获得实体对标签;The first acquisition module, based on the prompt model, performs coreference detection on the entity pair to obtain the entity pair label;
第二获取模块,基于所述实体对标签获得多实体的共指簇。The second obtaining module obtains the coreference clusters of multiple entities based on the entity pair labels.
第三方面,本申请公开了一种共指消解设备,包括:处理器、存储器、系统总线;In a third aspect, the present application discloses a coreference resolution device, including: a processor, a memory, and a system bus;
所述处理器以及所述存储器通过所述系统总线相连;The processor and the memory are connected through the system bus;
所述存储器用于存储一个或多个程序,所述一个或多个程序包括指令,所述指令当被所述处理器执行时使所述处理器执行上述共指消解方法的任一种实现方式。The memory is used to store one or more programs, and the one or more programs include instructions, and the instructions, when executed by the processor, cause the processor to perform any implementation of the above coreference resolution method .
第四方面,本申请公开了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当所述指令在终端设备上运行时,使得所述终端设备执行上述共指消解方法的任一种实现方式。In a fourth aspect, the present application discloses a computer-readable storage medium, where instructions are stored in the computer-readable storage medium, and when the instructions are run on a terminal device, the terminal device is made to execute the above-mentioned coreference resolution method any implementation method.
相较于现有技术,本申请具有以下有益效果:Compared with the prior art, the present application has the following beneficial effects:
本申请公开了一种共指消解方法,根据输入文本中的内容进行实体识别,根据所述识别的实体组成实体对,基于提示模型对所述实体对进行共指检测获得实体对标签,基于所述实体对标签获得多实体的共指簇。本申请通过命名实体识别,由于命名实体识别数据相对容易获取,对共指消解任务进行了拆分,优化小样本场景下的共指消解问题,并且以引入提示模型的方式,将需要大量训练数据的共指检测任务转换与预训练相似的形式,即掩码预测或者生成形式,达到零样本或者小样本学习的效果。利用大规模预训练语言模型的内在知识,能够在少量训练数据的情况下,达到大规模语料训练相近的效果,从而解决了小样本场景下的共指消解问题。The present application discloses a coreference resolution method, which performs entity recognition according to the content in the input text, forms entity pairs based on the identified entities, and performs coreference detection on the entity pairs based on the prompt model to obtain the entity pair labels. Entity-to-tags are used to obtain coreference clusters of multiple entities. This application uses named entity recognition. Since named entity recognition data is relatively easy to obtain, the coreference resolution task is split to optimize the coreference resolution problem in small sample scenarios, and a large amount of training data will be required by introducing a prompt model. The coreference detection task is transformed into a form similar to pre-training, that is, mask prediction or generation, to achieve the effect of zero-sample or small-sample learning. Using the internal knowledge of large-scale pre-trained language models, it can achieve similar effects to large-scale corpus training with a small amount of training data, thus solving the problem of coreference resolution in small-sample scenarios.
附图说明Description of drawings
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。In order to more clearly illustrate the technical solutions in the embodiments of the present application or the prior art, the following will briefly introduce the drawings that need to be used in the description of the embodiments or the prior art. Obviously, the accompanying drawings in the following description are only These are some embodiments of the present application. Those skilled in the art can also obtain other drawings based on these drawings without any creative effort.
图1为本申请实施例提供的一种共指消解方法的流程图;FIG. 1 is a flowchart of a coreference resolution method provided in an embodiment of the present application;
图2为本申请实施例步骤103B一种可选的实现方式流程图;FIG. 2 is a flow chart of an optional implementation of step 103B in the embodiment of the present application;
图3为本申请实施例步骤1031一种可选的实现方式流程图;FIG. 3 is a flow chart of an optional implementation of
图4为本申请实施例提供了一种共指消解装置的结构示意图。FIG. 4 provides a schematic structural diagram of a coreference resolution device according to an embodiment of the present application.
具体实施方式detailed description
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。In order to enable those skilled in the art to better understand the solution of the present application, the technical solution in the embodiment of the application will be clearly and completely described below in conjunction with the accompanying drawings in the embodiment of the application. Obviously, the described embodiment is only It is a part of the embodiments of this application, not all of them. Based on the embodiments in this application, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the scope of protection of this application.
正如前文描述,目前的现有技术存在基于深度学习的实体对模型 (mention pairmodel),模型能够识别到不同的实体对,并对实体对进行相关性判别,这种判别可以是二分类,也可以是聚类。或者,基于生成的方法进行句子重写,对句子进行编码器编码,然后进行解码,将代词替换成对应先行词。但是上述方法均需要大量的数据进行训练,他们所能够识别的实体类型大多构建在训练数据的实体类型上,而对新场景的实体,特别是当新场景仅有少量样本或无样本的情况时,对相同实体的不同表述的共指共指消解能力较差。As described above, there is a deep learning-based entity pair model (mention pair model) in the current existing technology. The model can identify different entity pairs and judge the relevance of entity pairs. This discrimination can be binary classification or is clustering. Alternatively, a generative-based approach is used for sentence rewriting, where the sentence is encoded by an encoder and then decoded to replace pronouns with their corresponding antecedents. However, the above methods require a large amount of data for training, and most of the entity types they can recognize are built on the entity types of the training data, and for entities in new scenes, especially when there are only a few samples or no samples in the new scene , the coreference resolution ability of different representations of the same entity is poor.
经过研究发现,大规模预训练语言模型中存储了大量知识,目前的常见范式是预训练+大量数据的训练,因此目前的范式预训练之后需要大量的训练数据,提示学习将下游任务转换成与预训练任务相似的形式,即掩码预测或生成形式,达到激发预训练模型内在知识,达到零样本或小样本学习的效果。After research, it is found that a large amount of knowledge is stored in a large-scale pre-trained language model. The current common paradigm is pre-training + training with a large amount of data. Therefore, the current paradigm requires a large amount of training data after pre-training. The similar form of pre-training tasks, that is, mask prediction or generation, can stimulate the intrinsic knowledge of the pre-training model and achieve the effect of zero-sample or small-sample learning.
本申请实施例提供了一种共指消解方法,根据输入文本中的内容进行实体识别,根据所述识别的实体组成实体对,基于提示模型对所述实体对进行共指检测获得实体对标签,基于所述实体对标签获得多实体的共指簇。本申请通过命名实体识别,由于命名实体识别数据相对容易获取,对共指消解任务进行了拆分,优化小样本场景下的共指检测问题,并且以引入提示模型的方式,将需要大量训练数据的共指检测任务转换与预训练相似的形式,即掩码预测或者生成形式,达到零样本或者小样本学习的效果,利用大规模预训练语言模型的内在知识,能够在少量训练数据的情况下,达到大规模语料精调相近的效果,从而解决了小样本场景下的共指消解问题。The embodiment of the present application provides a coreference resolution method, which performs entity recognition according to the content in the input text, forms an entity pair according to the identified entity, performs coreference detection on the entity pair based on the prompt model to obtain the entity pair label, A coreference cluster of multiple entities is obtained based on the entity pair labels. This application uses named entity recognition. Since named entity recognition data is relatively easy to obtain, the coreference resolution task is split to optimize the coreference detection problem in small sample scenarios, and a large amount of training data will be required by introducing a prompt model. The coreference detection task is converted into a form similar to pre-training, that is, mask prediction or generation, to achieve the effect of zero-sample or small-sample learning. Using the internal knowledge of a large-scale pre-trained language model, it can be used in the case of a small amount of training data. , to achieve a similar effect to large-scale corpus fine-tuning, thus solving the problem of coreference resolution in small-sample scenarios.
具体实施例specific embodiment
参见图1,该图为本申请实施例提供的一种共指消解方法的流程图。结合图1所示,本申请实施例提供的共指消解方法,可以包括:Referring to FIG. 1 , this figure is a flow chart of a method for coreference resolution provided by an embodiment of the present application. As shown in Figure 1, the coreference resolution method provided by the embodiment of the present application may include:
步骤101,根据输入文本中的内容进行实体识别。
在本实施例中,整体方案采用pipeline的方式,所述pipeline管道机制,可以理解为就像水管一样,数据就像水一样,在管道之间流动,pipeline的每一步就将一节节水管,数据经由这节水管流到下一节水管,流向下一节水管的就是经由上一节水管处理后的数据。需要说明的是,由于小样本的影响,端到端模型一般需要较大规模的训练数据(特别是共指消解的数据集较少,而特定领域的共指消解更少,里面需要包含关系标注,标注难度大)。利用pipeline,把共指消解任务分为命名实体识别和共指识别两部分,命名实体识别的数据一般较容易获得,即使是新领域,标注成本也会降低。In this embodiment, the overall solution adopts the pipeline method. The pipeline pipeline mechanism can be understood as water pipes, and data flows between the pipelines like water. Each step of the pipeline will save a water pipe. The data flows through this water-saving pipe to the next water-saving pipe, and what flows to the next water-saving pipe is the data processed by the previous water-saving pipe. It should be noted that due to the impact of small samples, end-to-end models generally require larger training data (especially less data sets for coreference resolution, and fewer coreference resolutions in specific fields, which need to contain relationship annotations , labeling is difficult). Using the pipeline, the coreference resolution task is divided into two parts: named entity recognition and coreference recognition. The data for named entity recognition is generally easier to obtain, and even for new fields, the labeling cost will be reduced.
可选地,根据输入文本中的内容进行实体识别,包括:采用特征提取编码器和解码器对输入文本中的内容进行实体识别;所述特征提取编码器为Spanbert;所述解码器为Globalpointer。Optionally, performing entity recognition according to content in the input text includes: using a feature extraction encoder and a decoder to perform entity recognition on the content in the input text; the feature extraction encoder is Spanbert; and the decoder is Globalpointer.
在一个具体的实施例中,在本申请中进行实体识别时,采用特征提取编码器和解码器的结构,需要说明是的,命名实体识别可以是LSTM+CRF,其中LSTM(Long Short-TermMemory,长短期记忆网络)可以被替换成其他类的预训练模型,如Bert、Roberta,Macbert、Ernie等等。BERT的全称为Bidirectional Encoder Representation from Transformers,是一个预训练的语言表征模型,强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的基于掩码的语言模型(masked language model,MLM),以致能生成深度的双向语言表征。In a specific embodiment, when performing entity recognition in this application, the structure of a feature extraction encoder and a decoder is used. It should be noted that yes, named entity recognition can be LSTM+CRF, where LSTM (Long Short-TermMemory, Long short-term memory network) can be replaced by other types of pre-trained models, such as Bert, Roberta, Macbert, Ernie, etc. The full name of BERT is Bidirectional Encoder Representation from Transformers. It is a pre-trained language representation model. It emphasizes that it is no longer the traditional one-way language model or the method of shallow splicing two one-way language models for pre-training. , but adopt a new mask-based language model (masked language model, MLM), so as to be able to generate deep bidirectional language representation.
本申请采用的Spanbert编码器是对BERT模型进行了如下改进:(1) 对随机的邻接分词(span)而非随机的单个词语(token)添加掩码;(2) 通过使用分词边界的表示来预测被添加掩码的分词的内容,不再依赖分词内单个token的表示。SpanBert能够对分词进行更好地表示和预测。The Spanbert encoder used in this application is to improve the BERT model as follows: (1) add a mask to a random adjacent word (span) instead of a random single word (token); (2) use the representation of the word segmentation boundary to Predicting the content of a masked segment no longer depends on the representation of a single token within the segment. SpanBert can better represent and predict word segmentation.
CRF(Conditional Random Field,条件随机场)是自然语言处理的解码方式基础模型,也可以是Biaffine、Lattice、以及Globalpointer解码器。本申请采用的Globalpointer解码器是一种基于span分类的解码方法,与 Spanbert编码器组合,可以提高命名实体识别的准确性。CRF (Conditional Random Field, Conditional Random Field) is the basic model of the decoding method of natural language processing, and it can also be Biaffine, Lattice, and Globalpointer decoders. The Globalpointer decoder used in this application is a decoding method based on span classification, which can improve the accuracy of named entity recognition when combined with the Spanbert encoder.
可选地,根据输入文本中的内容进行实体识别,包括:根据输入文本中的代词及实体类型进行实体识别。Optionally, performing entity recognition according to content in the input text includes: performing entity recognition according to pronouns and entity types in the input text.
在本实施例中,根据输入文本中的代词及实体类型进行实体识别,可以理解的是,由于共指消解的目的是找到文本中的作为指称词的名词、名词短语、代词、代词短语等实体并将它们进行归类,得到文本中指向相同实体的指代簇,因此,实体识别是对文本中的名词、名词短语、代词、代词短语等实体进行类型识别,例如:常见的类型是人物、地点、电影、音乐等。In this embodiment, entity recognition is performed according to pronouns and entity types in the input text. It can be understood that the purpose of coreference resolution is to find entities such as nouns, noun phrases, pronouns, and pronoun phrases as referents in the text. And classify them to get reference clusters pointing to the same entity in the text. Therefore, entity recognition is to identify the types of entities such as nouns, noun phrases, pronouns, and pronoun phrases in the text. For example: common types are people, Locations, movies, music, and more.
步骤102,根据所述识别的实体组成实体对。
在本实施例中,基于步骤101识别的实体,组成实体对,若两个实体组成的实体对指向真实世界中的同一实体,则所述实体对存在共指关系,若两个实体组成的实体对指向真实世界中的同一实体,则所述实体对不存在共指关系,可以理解的是,上述步骤中识别的任意实体均可自由组合成实体对,在本申请中实施例中不做限制。In this embodiment, an entity pair is formed based on the entities identified in
步骤103,基于提示模型对所述实体对进行共指检测获得第一实体对标签;
在本实施例中,通过提示模型,对实体对是否共指于同一实体进行共指检测。需要说明的是,由于小样本的局限,为了提高识别的准确率,在本实施例中所述提示模型是人工构建的。以X代表输入的句子,m1、m2 代表检测到的两个实体,MASK1、MASK2代表需要模型预测的词语,可以构建如下模型:[X]。在前面的句子里,[m1]指的是[m2],正确还是错误?[MASK1][MASK2],示例:你肯定认识倪大大,看过倪大大的作品,某电影看过吧他就参演了啊。在前面的句子里,他指的是倪大大,正确还是错误?[][]; []内是需要模型预测的词语,如[正][确]。In this embodiment, a coreference detection is performed on whether an entity pair corefers to the same entity through a hint model. It should be noted that due to the limitation of small samples, in order to improve the accuracy of recognition, the prompt model in this embodiment is constructed manually. Let X represent the input sentence, m1 and m2 represent the two detected entities, MASK1 and MASK2 represent the words that need to be predicted by the model, and the following model can be constructed: [X]. In the previous sentence, [m1] refers to [m2], correct or incorrect? [MASK1][MASK2], example: You must know Ni Da, you have seen Ni Da’s works, you have seen a certain movie and he participated in it. In the previous sentence, he was referring to Ni Dada, correct or incorrect? [][]; Inside [] are the words that need to be predicted by the model, such as [正][正].
基于上述提示模型,对实体对进行共指检测,获得所述实体对的第一实体对标签,需要说明是的,第一实体对标签即标识进行共指检测的实体对所指示的实体是否为同一个现实生活中实体,例如:相关/不相关。Based on the above prompt model, perform coreference detection on entity pairs, and obtain the first entity pair label of the entity pair. It needs to be explained that yes, whether the entity indicated by the entity pair indicated by the first entity pair label, that is, the identifier, is The same real-life entity, eg: related/unrelated.
步骤104,基于所述第一实体对标签获得多实体的共指簇。Step 104: Obtain a multi-entity coreference cluster based on the first entity pair label.
在本实施例中,基于每个实体对获得的第一实体对标签,将多个实体对进行判别后均会得到相应的标签,通过多个第一实体对标签获得多实体的共指簇,即把指代相同的放在同一个簇中。In this embodiment, based on the first entity pair label obtained by each entity pair, corresponding labels will be obtained after discriminating multiple entity pairs, and the coreference cluster of multiple entities is obtained through multiple first entity pair labels, That is, put the same reference in the same cluster.
可选地,基于所述第一实体对标签进行共指融合,获得多实体的共指簇。Optionally, performing coreference fusion on tags based on the first entity to obtain a coreference cluster of multiple entities.
上述实施例通过命名实体识别,由于命名实体识别数据相对容易获取,对共指消解任务进行了拆分,优化小样本场景下的共指检测问题,并且以引入提示模型的方式,将需要大量训练数据的共指检测任务转换与预训练相似的形式,即掩码预测或者生成形式,达到零样本或者小样本学习的效果,解决了小样本场景下的共指消解问题。The above-mentioned embodiment uses named entity recognition, and since named entity recognition data is relatively easy to obtain, the task of coreference resolution is split to optimize the problem of coreference detection in a small sample scenario, and a large amount of training will be required by introducing a prompt model The data coreference detection task is converted into a form similar to pre-training, that is, mask prediction or generation, to achieve the effect of zero-sample or small-sample learning, and to solve the problem of coreference resolution in small-sample scenarios.
一个具体的实施例中,上述步骤103基于提示模型对所述实体对进行共指检测获得第一实体对标签,包括:In a specific embodiment, the
步骤103A,构建人工标注的提示模型;所述提示模型数量至少一个;所述提示模型用于输出实体对的共指结果。Step 103A, constructing a manually labeled hint model; the number of the hint model is at least one; the hint model is used to output the coreference result of the entity pair.
在本实施例中,通过构建人工标注的提示模型,输出实体对的共指结果,需要说明的是,在构建人工标注的提示模型的过程中,为了提高模型的准确率,构建多个提示模型进行训练,例如:接上述举例,还可以是(1) [X]中,[m1]等价于[m2],正确吗?[MASK1][MASK2];(2)、[X]。[m1]的含义是[m2],是否[MASK1][MASK2];(3)有下列句子[X],其中[m1]说的是[m2],正确还是错误?[MASK1][MASK2]。In this embodiment, the coreference results of entity pairs are output by constructing a manually-labeled prompt model. It should be noted that, in the process of constructing a manually-labeled prompt model, in order to improve the accuracy of the model, multiple prompt models are constructed Carry out training, for example: following the above example, it can also be (1) in [X], [m1] is equivalent to [m2], correct? [MASK1][MASK2]; (2), [X]. The meaning of [m1] is [m2], whether it is [MASK1][MASK2]; (3) There is the following sentence [X], where [m1] refers to [m2], correct or incorrect? [MASK1][MASK2].
步骤103B,利用提示模型对实体对的共指结果进行检测获得第一实体对标签。Step 103B, using the hint model to detect the coreference result of the entity pair to obtain the first entity pair label.
在本实施例中,通过提示模型对实体对的共指结果进行检测,基于共指结果,获得对应实体对的第一实体对标签。In this embodiment, the coreference result of the entity pair is detected through the prompt model, and based on the coreference result, the first entity pair label of the corresponding entity pair is obtained.
在上述实施例中,通过构建多个提示模型,对于共指结果进行多个维度的检测,提升模型的稳定性,提高了共指消解的准确率。In the above-mentioned embodiment, by constructing multiple prompting models, the coreference result is detected in multiple dimensions, the stability of the model is improved, and the accuracy of coreference resolution is improved.
在一个具体的实施例中参见图2,图2为上述步骤103B利用提示模型对实体对的共指结果进行检测获得第一实体对标签一种可选的实现方式流程图。Referring to FIG. 2 in a specific embodiment, FIG. 2 is a flowchart of an optional implementation manner of obtaining the label of the first entity pair by using the hint model to detect the coreference result of the entity pair in the above step 103B.
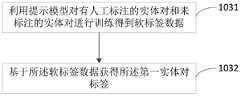
步骤1031,利用提示模型对有人工标注的实体对和未标注的实体对进行训练得到软标签数据。
在本实施例中,为保持综合准确率,构造提示模型,用有标注数据对提示模型进行训练,并将这个提示模型对未标注数据进行预测,预测结果进行融合得到软数据标签,需要说明的是,一般的标签被称为硬标签,例如:1代表相关,0代表不相关。在模型蒸馏中,经常使用软标签数据,软标签一般使用在模型蒸馏和某些数据集的训练中,可以让模型学习到样本整体类别分布,同时软标签与硬标签相比,软标签可以防止模型过拟合,例如:模型输出某个类别的概率,将这个概率当作标签,例如,将0.65作为相关程度标签。而伪标签(Pseudo Label)是半监督学习中的一个概念,能够帮助模型更好的从无标注的信息中进行学习,与完全的无监督学习相比,半监督学习拥有部分的标注数据和大量的未标注数据,这种形式也更加适合在现实场景,即标注数据少,未标注数据多的场景中使用,可以理解的是,本申请的标签,即是伪标签,也是软标签。In this embodiment, in order to maintain the comprehensive accuracy rate, a prompt model is constructed, the prompt model is trained with labeled data, and the prompt model is used to predict unlabeled data, and the prediction results are fused to obtain soft data labels. What needs to be explained Yes, general tags are called hard tags, for example: 1 means relevant, 0 means irrelevant. In model distillation, soft label data is often used. Soft labels are generally used in model distillation and training of certain data sets, allowing the model to learn the overall category distribution of samples. At the same time, compared with hard labels, soft labels can prevent Model overfitting, for example: the model outputs the probability of a certain category, and this probability is used as a label, for example, 0.65 is used as the degree of correlation label. Pseudo Label is a concept in semi-supervised learning, which can help the model learn better from unlabeled information. Compared with complete unsupervised learning, semi-supervised learning has part of the labeled data and a large amount of This form is also more suitable for use in real-world scenarios where there is less labeled data and more unlabeled data. It can be understood that the labels in this application are both pseudo-labels and soft labels.
在一个具体的实施例中,参见图3,图3为上述步骤1031利用提示模型对有人工标注的实体对和未标注的实体对进行训练得到软标签数据一种可选的实现方式流程图。In a specific embodiment, referring to FIG. 3 , FIG. 3 is a flow chart of an optional implementation of the
步骤10311:利用提示模型对有人工标注的实体对和未标注的实体对进行训练得到共指结果。Step 10311: Use the hint model to train the manually labeled entity pairs and unlabeled entity pairs to obtain coreference results.
在本实施例中,重复构造N个提示模型,用k条(如k=5)有标注数据对N个提示模型进行训练,并将这N个提示模型对M条(如M=1000) 未标注数据进行共指结果预测。In this embodiment, N prompt models are repeatedly constructed, and k (such as k=5) labeled data are used to train the N prompt models, and these N prompt models are used for M (such as M=1000) unreported Annotated data for coreference prediction.
步骤10312:定义一个标签映射函数,所述标签映射函数将所述共指结果映射为第二实体对标签。Step 10312: Define a label mapping function, the label mapping function maps the coreference result into a label of the second entity pair.
在本实施例中,通过定义一个标签映射函数,将共指结果映射为第二实体对标签,例如:把标签[正确][是#]映射为标签[相关],把标签[错误][否 #]映射为标签[不相关]。In this embodiment, by defining a label mapping function, the coreference result is mapped to the label of the second entity, for example: label [correct] [yes#] is mapped to label [relevant], and label [error] [no #] maps to the label [irrelevant].
步骤10313:对所述映射得到的第二实体对标签融合获得软数据标签。Step 10313: Fusing the second entity pair labels obtained through the mapping to obtain soft data labels.
在本实施例中,接上述步骤1031举例,对预测到的共指结果进行如下融合:In this embodiment, following the example of

其中Z为模板数,p为模板,x为输入样本,l为预测标签,sp(l|x)代表单个提示模型的预测概率分布,ω(p)为权重,权重可以设置为1,或根据在开发集上的准确率来进行设置。Where Z is the number of templates, p is the template, x is the input sample, l is the predicted label,sp(l|x) represents the predicted probability distribution of a single prompt model, ω(p) is the weight, and the weight can be set to 1, or Set according to the accuracy rate on the development set.
步骤1032,基于所述软标签数据获得所述第一实体对标签。Step 1032: Obtain the label of the first entity pair based on the soft label data.
在本实施例中,当获得大量软标签数据后,训练一个实体共指的二分类模型。其输入为[CLS]X[SEQ]m1[SEQ]m2[SEQ],输出为0/1,代表相关 /不相关,其中[CLS]是句子开始的标志,[CLS]标志放在第一个句子的首位,经过BERT得到的的表征向量C可以用于后续的分类任务;m1、m2 代表检测到的两个实体。示例:[CLS]你肯定认识倪大大,看过倪大大的作品, 某电影看过吧他就参演了啊。[SEQ]他[SEQ]倪大大[SEQ],输出1,为相关。也即获得第一实体对标签,重复上述操作,对实体对进行逐个判别,获得相应标签。在本实施例中,该方法把共指消解问题转化为一个二分类问题,简化了处理过程的同时可以保证共指消解的准确率。In this embodiment, after obtaining a large amount of soft label data, a binary classification model of entity coreference is trained. Its input is [CLS]X[SEQ]m1[SEQ]m2[SEQ], and the output is 0/1, representing relevant/irrelevant, where [CLS] is the sign of the beginning of the sentence, and the [CLS] sign is placed first At the first place of the sentence, the representation vector C obtained by BERT can be used for subsequent classification tasks; m1 and m2 represent the two detected entities. Example: [CLS] You must know Dada Ni, you have seen Dada Ni’s works, you have seen a certain movie and he participated in it. [SEQ] He [SEQ] Ni Da [SEQ], output 1, which is related. That is, the label of the first entity pair is obtained, the above operation is repeated, and the entity pairs are identified one by one to obtain the corresponding label. In this embodiment, the method converts the coreference resolution problem into a binary classification problem, which simplifies the processing process and ensures the accuracy of the coreference resolution.
图4是本申请实施例提供了一种共指消解装置结构示意图,包括:Fig. 4 is a schematic structural diagram of a coreference resolution device provided by an embodiment of the present application, including:
识别模块201,用于根据输入文本中的内容进行实体识别;A
组成模块202,根据所述识别的实体组成实体对;
第一获取模块203,基于提示模型对所述实体对进行共指检测获得第一实体对标签;The
第二获取模块204,基于所述第一实体对标签获得多实体的共指簇。The second obtaining
可选地,所述识别模块201包括:Optionally, the
第一识别单元,用于采用特征提取编码器和解码器对输入文本中的内容进行实体识别;The first recognition unit is used to use a feature extraction encoder and a decoder to perform entity recognition on the content in the input text;
第二识别单元,用于根据输入文本中的代词及实体类型进行实体识别。The second recognition unit is used for performing entity recognition according to pronouns and entity types in the input text.
可选地,所述第一获取模块203包括:Optionally, the first obtaining
构建单元,用于构建人工标注的提示模型;所述提示模型数量至少一个;所述提示模型用于输出实体对的共指结果;A construction unit, configured to construct a manual-labeled prompt model; the number of the prompt model is at least one; the prompt model is used to output the coreference result of the entity pair;
第一训练单元,用于利用提示模型对有人工标注的实体对和未标注的实体对进行训练得到软标签数据;The first training unit is used to use the prompt model to train the entity pairs with manual labeling and unlabeled entity pairs to obtain soft label data;
第一获取单元,用于基于所述软标签数据获得所述第一实体对标签;a first obtaining unit, configured to obtain the first entity pair label based on the soft label data;
第二训练单元,用于利用提示模型对有人工标注的实体对和未标注的实体对进行训练得到共指结果;The second training unit is used to use the prompt model to train manually labeled entity pairs and unlabeled entity pairs to obtain coreference results;
定义单元,用于定义一个标签映射函数,所述标签映射函数将所述共指结果映射为第二实体对标签;A definition unit, configured to define a tag mapping function, the tag mapping function maps the coreference result to a second entity pair tag;
第二获取单元,用于对所述映射得到的第二实体对标签融合获得软数据标签;The second acquisition unit is configured to fuse the second entity pair labels obtained by the mapping to obtain soft data labels;
检测单元,利用提示模型对实体对的共指结果进行检测获得第一实体对标签。The detection unit detects the coreference result of the entity pair by using the hint model to obtain the first entity pair label.
本发明实施例还提供一种共指消解设备,其特征在于,包括:处理器、存储器、系统总线;The embodiment of the present invention also provides a coreference resolution device, which is characterized in that it includes: a processor, a memory, and a system bus;
所述处理器以及所述存储器通过所述系统总线相连;The processor and the memory are connected through the system bus;
所述存储器用于存储一个或多个程序,所述一个或多个程序包括指令,所述指令当被所述处理器执行时使所述处理器执行上述共指消解方法的任一种实现方式。The memory is used to store one or more programs, and the one or more programs include instructions, and the instructions, when executed by the processor, cause the processor to perform any implementation of the above coreference resolution method .
本发明实施例还提供一种计算机可读存储介质,其特征在于,所述计算机可读存储介质中存储有指令,当所述指令在终端设备上运行时,使得所述终端设备执行上述共指消解方法的任一种实现方式。An embodiment of the present invention also provides a computer-readable storage medium, which is characterized in that instructions are stored in the computer-readable storage medium, and when the instructions are run on a terminal device, the terminal device executes the above coreference Any implementation of the digestion method.
需要说明的是,本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于装置及设备实施例而言,由于其基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。以上所描述的装置及设备实施例仅仅是示意性的,其中作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元提示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。It should be noted that each embodiment in this specification is described in a progressive manner, the same and similar parts of each embodiment can be referred to each other, and each embodiment focuses on the differences from other embodiments. place. In particular, for the device and device embodiments, since they are basically similar to the method embodiments, the description is relatively simple, and for relevant parts, please refer to part of the description of the method embodiments. The device and device embodiments described above are only illustrative, and the units described as separate components may or may not be physically separated, and the components indicated as units may or may not be physical units, that is, they may be located in One place, or it can be distributed to multiple network elements. Part or all of the modules can be selected according to actual needs to achieve the purpose of the solution of this embodiment. It can be understood and implemented by those skilled in the art without creative effort.
以上所述,仅为本申请的一种具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应该以权利要求的保护范围为准。The above is only a specific implementation of the present application, but the protection scope of the present application is not limited thereto. Any person familiar with the technical field can easily think of changes or Replacement should be covered within the protection scope of this application. Therefore, the protection scope of the present application should be based on the protection scope of the claims.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211242338.9ACN115526172A (en) | 2022-10-11 | 2022-10-11 | A coreference resolution method, device, equipment and readable storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211242338.9ACN115526172A (en) | 2022-10-11 | 2022-10-11 | A coreference resolution method, device, equipment and readable storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN115526172Atrue CN115526172A (en) | 2022-12-27 |
Family
ID=84700827
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202211242338.9APendingCN115526172A (en) | 2022-10-11 | 2022-10-11 | A coreference resolution method, device, equipment and readable storage medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115526172A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025007425A1 (en)* | 2023-07-04 | 2025-01-09 | 之江实验室 | Coreference resolution method and apparatus based on reference to external knowledge |
- 2022
- 2022-10-11CNCN202211242338.9Apatent/CN115526172A/enactivePending
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2025007425A1 (en)* | 2023-07-04 | 2025-01-09 | 之江实验室 | Coreference resolution method and apparatus based on reference to external knowledge |
| JP2025525269A (en)* | 2023-07-04 | 2025-08-05 | 之江実験室 | Anaphora resolution method and device that references external knowledge |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN113255755B (en) | Multi-modal emotion classification method based on heterogeneous fusion network | |
| CN110489760B (en) | Automatic text proofreading method and device based on deep neural network | |
| CN107729309B (en) | A method and device for Chinese semantic analysis based on deep learning | |
| WO2022022163A1 (en) | Text classification model training method, device, apparatus, and storage medium | |
| CN111950296B (en) | Comment target emotion analysis based on BERT fine tuning model | |
| CN113255320A (en) | Entity relation extraction method and device based on syntax tree and graph attention machine mechanism | |
| CN110209832B (en) | Method, system and computer equipment for judging upper and lower relationship | |
| CN113887215A (en) | Text similarity calculation method, device, electronic device and storage medium | |
| CN113723105A (en) | Training method, device and equipment of semantic feature extraction model and storage medium | |
| CN116661805B (en) | Code representation generation method and device, storage medium and electronic equipment | |
| Xue et al. | A better way to attend: Attention with trees for video question answering | |
| CN113553850A (en) | An Entity Relation Extraction Method Based on Coded Pointer Network Decoding of Ordered Structure | |
| CN112612871B (en) | Multi-event detection method based on sequence generation model | |
| CN113268592B (en) | A sentiment classification method for short text objects based on multi-level interactive attention mechanism | |
| CN114444481B (en) | Sentiment analysis and generation method of news comment | |
| CN112395876A (en) | Knowledge distillation and multitask learning-based chapter relationship identification method and device | |
| CN115080750B (en) | Weakly supervised text classification method, system and device based on fusion cue sequence | |
| CN114861601B (en) | Event joint extraction method based on rotary coding and storage medium | |
| CN116384403A (en) | A Scene Graph Based Multimodal Social Media Named Entity Recognition Method | |
| Zeng et al. | Correcting the bias: Mitigating multimodal inconsistency contrastive learning for multimodal fake news detection | |
| CN118296135A (en) | Cross-domain migration-oriented aspect-level emotion triplet extraction method | |
| CN115982369A (en) | An Improved Text Classification Method Incorporating Label Semantics | |
| Xu et al. | Research on depression tendency detection based on image and text fusion | |
| CN114330350B (en) | Named entity recognition method and device, electronic equipment and storage medium | |
| CN115688703A (en) | Specific field text error correction method, storage medium and device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |