CN115455949A - Chinese grammar error correction method and system, storage medium and terminal - Google Patents
Chinese grammar error correction method and system, storage medium and terminalDownload PDFInfo
- Publication number
- CN115455949A CN115455949ACN202211234582.0ACN202211234582ACN115455949ACN 115455949 ACN115455949 ACN 115455949ACN 202211234582 ACN202211234582 ACN 202211234582ACN 115455949 ACN115455949 ACN 115455949A
- Authority
- CN
- China
- Prior art keywords
- chinese
- error correction
- grammar
- semantic information
- text
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/253—Grammatical analysis; Style critique
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/205—Parsing
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/232—Orthographic correction, e.g. spell checking or vowelisation
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Machine Translation (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本发明涉及中文语法纠错的技术领域,特别是涉及一种中文语法纠错方法及系统、存储介质及终端。The invention relates to the technical field of Chinese grammar error correction, in particular to a Chinese grammar error correction method and system, a storage medium and a terminal.
背景技术Background technique
由于用户习惯、电脑输入法等原因,在网络上发布中文时难免会出现一些中文语法错误,如多字错误、少字错误、语义重复、句式杂糅等。其中,多字错误如“人数超过100个”被误写为“人人数超过100个”;少字错误如“中国的首都是北京”被误写为“中国的都是北京”;语义重复如“人数超过100”被误写为“人数超过100以上”。Due to user habits, computer input methods, etc., it is inevitable that there will be some Chinese grammatical errors when publishing Chinese on the Internet, such as many-character errors, few-character errors, semantic repetition, and mixed sentence patterns. Among them, many word mistakes such as "the number of people exceeds 100" are mistakenly written as "the number of people exceeds 100"; few word mistakes such as "China's capital is Beijing" are mistakenly written as "China's capital is Beijing"; semantic repetition such as "The number of people exceeds 100" is mistakenly written as "the number of people exceeds 100 or more".
中文语法错误诊断(Chinese Grammatical Error Diagnosi)是中文自然语言处理(Natural Language Processing,NLP)中的一项基本任务,旨在自动检测和纠正中文句子中的语法错误。现有技术中,中文语法错误诊断方法主要包括以下两种:Chinese Grammatical Error Diagnosi (Chinese Grammatical Error Diagnosi) is a basic task in Chinese Natural Language Processing (NLP), which aims to automatically detect and correct grammatical errors in Chinese sentences. In the prior art, Chinese grammatical error diagnosis methods mainly include the following two types:
(1)基于词库和规则的语法纠错方法(1) Grammatical error correction method based on thesaurus and rules
该方法需要耗费大量人力资源去维护一个规则库,泛化性较差。同时,随着时间的推移,规则越来越多,规则之间可能会出现各种各样的问题。比如传统中文语法纠错方法经常会由于无法理解语义而做出一些错误的行为。例如在多字错误中将“山西西部地区出现降雨” 修改成 “山西部地区出现降雨”。这是因为‘山西西’容易被不严谨的规则判断有问题。This method requires a lot of human resources to maintain a rule base, and its generalization is poor. At the same time, as time goes by, there are more and more rules, and various problems may arise between the rules. For example, traditional Chinese grammar error correction methods often make some wrong behaviors because they cannot understand the semantics. For example, in the multi-word error, "rainfall occurs in western Shanxi" is changed to "rainfall occurs in western Shanxi". This is because "Shanxi West" is easily judged to be problematic by loose rules.
(2)基于深度学习的方法(2) Method based on deep learning
该方法能够提升一定的泛化能力。现有的深度学习方法通常使用基于GPT(Generative Pre Training)的自回归网络模型进行语法纠错。但是,该网络模型的网络速度比较慢,在实际生产使用的过程中会消耗大量的时间和资源。This method can improve the generalization ability to a certain extent. Existing deep learning methods usually use an autoregressive network model based on GPT (Generative Pre Training) for grammatical error correction. However, the network speed of this network model is relatively slow, and it will consume a lot of time and resources in the process of actual production use.
发明内容Contents of the invention
鉴于以上所述现有技术的缺点,本发明的目的在于提供一种中文语法纠错方法及系统、存储介质及终端,基于多任务深度学习算法实现有效的中文语法纠错,具有良好的泛化能力。In view of the shortcomings of the prior art described above, the purpose of the present invention is to provide a Chinese grammar error correction method and system, storage medium and terminal, based on a multi-task deep learning algorithm to achieve effective Chinese grammar error correction, with good generalization ability.
为实现上述目的及其他相关目的,本发明提供一种中文语法纠错方法,包括以下步骤:基于自编码网络模型获取中文输入文本的语义信息,基于所述语义信息生成所述中文输入文本的语法纠错文本;基于语言模型对所述语法纠错文本进行合理性判断,以获取最终中文文本。In order to achieve the above object and other related objects, the present invention provides a method for correcting Chinese grammar, comprising the following steps: obtaining semantic information of Chinese input text based on an autoencoder network model, and generating grammar of the Chinese input text based on the semantic information Error correction text: making a reasonable judgment on the grammatical error correction text based on the language model to obtain the final Chinese text.
于本发明一实施例中,基于多层语义编码器获取中文输入文本的语义信息。In an embodiment of the present invention, the semantic information of the Chinese input text is obtained based on a multi-layer semantic encoder.
于本发明一实施例中,所述语义编码器采用Transformer blocks模型。In an embodiment of the present invention, the semantic encoder adopts a Transformer blocks model.
于本发明一实施例中,基于所述语义信息生成所述中文输入文本的语法纠错文本包括以下步骤:In an embodiment of the present invention, generating the grammatical error correction text of the Chinese input text based on the semantic information includes the following steps:
基于所述语义信息检测所述中文输入文本的语法错误;detecting grammatical errors of the Chinese input text based on the semantic information;
基于所述语义信息和所述语法错误对所述中文输入文本进行纠正,获取语法纠错文本。Correcting the Chinese input text based on the semantic information and the grammatical error to obtain grammatical error-corrected text.
于本发明一实施例中,基于所述语义信息和所述语法错误对所述中文输入文本进行纠正,获取语法纠错文本包括以下步骤:In an embodiment of the present invention, the Chinese input text is corrected based on the semantic information and the grammatical error, and obtaining the grammatical error correction text includes the following steps:
基于所述语义信息和所述语法错误,生成所述中文输入文本的每个文字的标签;其中,对于不存在语法错误的文字,标签设置为第一预设符号;对于存在语法错误的文字,根据所述语义信息需删除时,标签设置为第二预设符号;对于存在语法错误的文字,根据所述语义信息需在后面增加文字时,标签设置为第三预设符号和所增加的文字;Based on the semantic information and the grammatical errors, generate a label for each word of the Chinese input text; wherein, for words without grammatical errors, the label is set to the first preset symbol; for words with grammatical errors, When the semantic information needs to be deleted, the label is set to the second preset symbol; for the text with grammatical errors, when the text needs to be added later according to the semantic information, the label is set to the third preset symbol and the added text ;
将所述中文输入文本的每个文字的标签依次映射为对应的文字,以获取所述语法纠错文本。The label of each character in the Chinese input text is mapped to the corresponding character in turn, so as to obtain the grammatical error correction text.
于本发明一实施例中,基于所述语义信息检测所述中文输入文本的语法错误时,采用语法错误检测深度学习模型;基于所述语义信息和所述语法错误对所述中文输入文本进行纠正,获取语法纠错文本时,采用语法纠正深度学习模型。In an embodiment of the present invention, when detecting grammatical errors of the Chinese input text based on the semantic information, a grammatical error detection deep learning model is used; based on the semantic information and the grammatical errors, the Chinese input text is corrected , when obtaining the grammatical error correction text, use the grammatical correction deep learning model.
于本发明一实施例中,所述语言模型采用N-Gram语言模型、GPT语言模型、ELMO语言模型中的一种或多种组合。In an embodiment of the present invention, the language model adopts one or more combinations of N-Gram language model, GPT language model, and ELMO language model.
本发明提供一种中文语法纠错系统,包括纠错模块和判断模块;The invention provides a Chinese grammar error correction system, including an error correction module and a judgment module;
所述纠错模块用于基于自编码网络模型获取中文输入文本的语义信息,基于所述语义信息生成所述中文输入文本的语法纠错文本;The error correction module is used to obtain the semantic information of the Chinese input text based on the self-encoding network model, and generate the grammatical error correction text of the Chinese input text based on the semantic information;
所述判断模块用于基于语言模型对所述语法纠错文本进行合理性判断,以获取最终中文文本。The judging module is used to judge the rationality of the grammatical error correction text based on the language model, so as to obtain the final Chinese text.
本发明提供一种存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述的中文语法纠错方法。The present invention provides a storage medium on which a computer program is stored, and when the program is executed by a processor, the above Chinese grammar error correction method is realized.
本发明提供一种中文语法纠错终端,包括:处理器及存储器;The invention provides a Chinese grammar error correction terminal, comprising: a processor and a memory;
所述存储器用于存储计算机程序;The memory is used to store computer programs;
所述处理器用于执行所述存储器存储的计算机程序,以使所述中文语法纠错终端执行上述的中文语法纠错方法。The processor is configured to execute the computer program stored in the memory, so that the Chinese grammar error correction terminal executes the above Chinese grammar error correction method.
如上所述,本发明所述的中文语法纠错方法及系统、存储介质及终端,具有以下有益效果。As mentioned above, the Chinese grammar error correction method and system, storage medium and terminal of the present invention have the following beneficial effects.
(1)基于多任务深度学习算法实现有效的中文语法纠错,不依赖于规则和词库,具有良好的泛化能力。(1) Realize effective Chinese grammar error correction based on multi-task deep learning algorithm, does not depend on rules and thesaurus, and has good generalization ability.
(2)采用大规模语料训练语言模型来提取语义特征,采用语义特征来进行中文语法纠错,节省了大量资源。(2) Large-scale corpus is used to train the language model to extract semantic features, and semantic features are used to correct Chinese grammar errors, which saves a lot of resources.
(3)相对于基于GPT类的自回归模型,所采用的基于Bert的自编码模型实现了纠错速度的大幅提升,有效提升了效率。(3) Compared with the GPT-based autoregressive model, the Bert-based autoencoder model adopted has greatly improved the error correction speed and effectively improved the efficiency.
附图说明Description of drawings
图1显示为本发明的中文语法纠错方法于一实施例中的流程图。FIG. 1 is a flowchart of an embodiment of the Chinese grammar error correction method of the present invention.
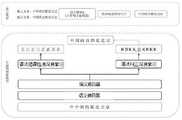
图2显示为本发明的中文语法纠错方法于一实施例中的示意图。FIG. 2 is a schematic diagram of an embodiment of the Chinese grammar error correction method of the present invention.
图3显示为本发明的中文语法纠错系统于一实施例中的结构示意图。FIG. 3 is a schematic structural diagram of an embodiment of the Chinese grammar error correction system of the present invention.
图4显示为本发明的中文语法纠错终端于一实施例中的结构示意图。FIG. 4 is a schematic structural diagram of a Chinese grammar error correction terminal in an embodiment of the present invention.
具体实施方式detailed description
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。Embodiments of the present invention are described below through specific examples, and those skilled in the art can easily understand other advantages and effects of the present invention from the content disclosed in this specification. The present invention can also be implemented or applied through other different specific implementation modes, and various modifications or changes can be made to the details in this specification based on different viewpoints and applications without departing from the spirit of the present invention. It should be noted that, in the case of no conflict, the following embodiments and features in the embodiments can be combined with each other.
需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。It should be noted that the diagrams provided in the following embodiments are only schematically illustrating the basic ideas of the present invention, and only the components related to the present invention are shown in the diagrams rather than the number, shape and shape of the components in actual implementation. Dimensional drawing, the type, quantity and proportion of each component can be changed arbitrarily during actual implementation, and the component layout type may also be more complicated.
本发明的中文语法纠错方法及系统、存储介质及终端通过采用自编码网络模型和语言模型相结合的多任务深度学习算法,实现了精准有效的中文语法纠错,具有良好的泛化能力,极具实用性。The Chinese grammar error correction method and system, storage medium and terminal of the present invention realize accurate and effective Chinese grammar error correction by adopting a multi-task deep learning algorithm combining a self-encoding network model and a language model, and have good generalization ability, Very practical.
如图1所示,于一实施例中,本发明的中文语法纠错方法包括以下步骤。As shown in FIG. 1 , in one embodiment, the Chinese grammar error correction method of the present invention includes the following steps.
步骤S1、基于自编码网络模型获取中文输入文本的语义信息,基于所述语义信息生成所述中文输入文本的语法纠错文本。Step S1. Obtain semantic information of the Chinese input text based on the self-encoding network model, and generate grammatical error correction text of the Chinese input text based on the semantic information.
具体地,自编码网络模型是另一种无监督学习方法,可以自动从无标注的数据中学习特征,是一种通过对信息进行”编码-解码”来完成信息的恢复重建,从而形成模型。自编码网络模型可以给出比原始数据更好的特征描述,具有较强的特征学习能力。在本发明中,应用基于Bert的自编码网络模型对中文输入文本进行纠错,从而获取对应的语法纠错文本,且纠错速度快,效率高。Specifically, the self-encoding network model is another unsupervised learning method that can automatically learn features from unlabeled data. It is a method of restoring and reconstructing information by "encoding-decoding" information to form a model. The self-encoding network model can give a better feature description than the original data, and has a strong feature learning ability. In the present invention, a Bert-based self-encoding network model is used to correct errors in Chinese input texts, thereby obtaining corresponding grammatical error-corrected texts, and the error correction speed is fast and the efficiency is high.
于本发明一实施例中,所述自编码网络模型包括多层语义编码器、语法错误检测深度学习模型和语法纠正深度学习模型。In an embodiment of the present invention, the self-encoding network model includes a multi-layer semantic encoder, a deep learning model for grammatical error detection, and a deep learning model for grammatical correction.
基于所述多层语义编码器获取中文输入文本的语义信息,从而使得所述自编码网络模型能够更容易学习所述中文输入文本中的语义信息。优选地,所述语义编码器采用Transformer blocks模型。如图2所示,当所述中文输入文本为“中中国的都是北京”时,通过所述多层语义编码器来识别其语义信息,即中国的首都是北京。The semantic information of the Chinese input text is obtained based on the multi-layer semantic encoder, so that the self-encoding network model can learn the semantic information in the Chinese input text more easily. Preferably, the semantic encoder adopts a Transformer blocks model. As shown in FIG. 2 , when the Chinese input text is "China is Beijing", its semantic information is recognized through the multi-layer semantic encoder, that is, the capital of China is Beijing.
基于所述语法错误检测深度学习模型和所述语法纠正深度学习模型,根据所述语义信息生成所述中文输入文本的语法纠错文本,从而实现中文输入文本的精准语法纠错。Based on the grammatical error detection deep learning model and the grammatical correction deep learning model, a grammatical error correction text of the Chinese input text is generated according to the semantic information, thereby realizing precise grammatical error correction of the Chinese input text.
于本发明一实施例中,基于所述语义信息生成所述中文输入文本的语法纠错文本包括以下步骤。In an embodiment of the present invention, generating the grammatical error correction text of the Chinese input text based on the semantic information includes the following steps.
11)基于所述语义信息检测所述中文输入文本的语法错误。11) Detecting grammatical errors of the Chinese input text based on the semantic information.
具体地,通过所述语法错误检测深度学习模型,基于所述语义信息检测所述中文输入文本的语法错误。如图2所示,对于所述中文输入文本“中中国的都是北京”,所述语法错误检测深度学习模型可检测出第二个文字和第四个文字存在语法错误,其余文字正确。Specifically, the grammatical errors of the Chinese input text are detected based on the semantic information through the grammatical error detection deep learning model. As shown in FIG. 2 , for the Chinese input text "Everything in China is Beijing", the grammatical error detection deep learning model can detect grammatical errors in the second and fourth characters, and the rest of the characters are correct.
12)基于所述语义信息和所述语法错误对所述中文输入文本进行纠正,获取语法纠错文本。12) Correct the Chinese input text based on the semantic information and the grammatical errors, and obtain grammatical error-corrected texts.
具体地,通过所述语法纠正深度学习模型,基于所述语义信息和所述语法错误对所述中文输入文本进行纠正,获取语法纠错文本。如图2所示,对于所述中文输入文本“中中国的都是北京”,由于第二个文字和第四个文字存在语法错误,根据“中国的首都是北京”这一语义,可针对所述第二个文字和所述第四个文字进行修改,从而获取语法纠正文本“中国的首都是北京”。Specifically, the Chinese input text is corrected based on the semantic information and the grammatical errors through the grammatical correction deep learning model, and the grammatical error-corrected text is obtained. As shown in Figure 2, for the Chinese input text "Everything in China is Beijing", due to grammatical errors in the second and fourth characters, according to the semantics of "China's capital is Beijing", all The above-mentioned second text and the above-mentioned fourth text are modified to obtain the grammatically corrected text "The capital of China is Beijing".
于本发明一实施例中,基于所述语义信息和所述语法错误对所述中文输入文本进行纠正,获取语法纠错文本包括以下步骤。In an embodiment of the present invention, correcting the Chinese input text based on the semantic information and the grammatical errors, and obtaining the grammatical error-corrected text includes the following steps.
121)基于所述语义信息和所述语法错误,生成所述中文输入文本的每个文字的标签;其中,对于不存在语法错误的文字,标签设置为第一预设符号;对于存在语法错误的文字,根据所述语义信息需删除时,标签设置为第二预设符号;对于存在语法错误的文字,根据所述语义信息需在后面增加文字时,标签设置为第三预设符号和所增加的文字。121) Based on the semantic information and the grammatical error, generate a label for each character of the Chinese input text; wherein, for a character without a grammatical error, the label is set as the first preset symbol; for a character with a grammatical error When the text needs to be deleted according to the semantic information, the label is set to the second preset symbol; for the text with grammatical errors, when the text needs to be added later according to the semantic information, the label is set to the third preset symbol and the added Text.
如图2所示,对于所述中文输入文本“中中国的都是北京”,需将第二个文字删除,故其对应的标签为D;需在第四个文字后增加一个“首”字,故其对应的标签为A_首;其他文字需保持不变,故对应的标签均为K。As shown in Figure 2, for the Chinese input text "All in China is Beijing", the second word needs to be deleted, so its corresponding label is D; a word "first" needs to be added after the fourth word , so the corresponding label is A_first; other text needs to remain unchanged, so the corresponding label is K.
122)将所述中文输入文本的每个文字的标签依次映射为对应的文字,以获取所述语法纠错文本。122) Mapping the labels of each character in the Chinese input text to corresponding characters in turn, so as to obtain the grammatical error correction text.
如图2所示,根据标签“KDKA_首KKKK” 对所述中文输入文本“中中国的都是北京”进行对应的映射处理,可得语法纠错文本“中国的首都是北京”。As shown in FIG. 2 , according to the label "KDKA_初KKKK", the corresponding mapping process is performed on the Chinese input text "All in China is Beijing", and the grammatical error correction text "The capital of China is Beijing" can be obtained.
步骤S2、基于语言模型对所述语法纠错文本进行合理性判断,以获取最终中文文本。Step S2, making a rationality judgment on the grammatical error correction text based on the language model, so as to obtain the final Chinese text.
具体地,基于语言模型对所述语法纠错文本进行合理性判断。这是因为当对所述中文输入文本进行语法纠错后,需要判断该纠错行为的合理性,防止误报现象的发生。其中,所述语言模型能够计算所述语法纠错文本的通顺度,选择最通顺的表达作为最终中文文本。如图2所示,所述语言模型针对输入文本“ 中中国的都是北京”进行通顺度计算,判断其为合理表述,则最终输出文本“ 中国的首都是北京”。Specifically, a rationality judgment is performed on the grammatical error correction text based on a language model. This is because after grammatical error correction is performed on the Chinese input text, the rationality of the error correction action needs to be judged to prevent false positives from occurring. Wherein, the language model can calculate the smoothness of the grammatical error correction text, and select the most smooth expression as the final Chinese text. As shown in FIG. 2 , the language model calculates the fluency of the input text "All in China is Beijing", and judges that it is a reasonable expression, then finally outputs the text "The capital of China is Beijing".
于本发明一实施例中,所述语言模型采用N-Gram语言模型、GPT(Generative Pre-Training)语言模型、ELMO(Embedding from Language Model)语言模型中的一种或多种组合。所述N-Gram语言模型能够预计或者评估一个句子是否合理,以及评估两个字符串之间的差异程度。所述GPT语言模型采用了Pre-training + Fine-tuning的训练模式,可用于分类、推理、问答、相似度等任务。所述ELMO语言模型可以更好地捕捉到语法和语义层面的信息且不限制词汇量。In an embodiment of the present invention, the language model adopts one or more combinations of N-Gram language model, GPT (Generative Pre-Training) language model, and ELMO (Embedding from Language Model) language model. The N-Gram language model is capable of predicting or evaluating whether a sentence is reasonable, and evaluating the degree of difference between two character strings. The GPT language model adopts the training mode of Pre-training + Fine-tuning, which can be used for tasks such as classification, reasoning, question answering, and similarity. The ELMO language model can better capture information at the grammatical and semantic levels without limiting the vocabulary.
如图3所示,于一实施例中,本发明的中文语法纠错系统包括纠错模块31和判断模块32。As shown in FIG. 3 , in one embodiment, the Chinese grammar error correction system of the present invention includes an
所述纠错模块31用于基于自编码网络模型获取中文输入文本的语义信息,基于所述语义信息生成所述中文输入文本的语法纠错文本。The
具体地,自编码网络模型是另一种无监督学习方法,可以自动从无标注的数据中学习特征,是一种通过对信息进行”编码-解码”来完成信息的恢复重建,从而形成模型。自编码网络模型可以给出比原始数据更好的特征描述,具有较强的特征学习能力。在本发明中,应用基于Bert的自编码网络模型对中文输入文本进行纠错,从而获取对应的语法纠错文本,且纠错速度快,效率高。Specifically, the self-encoding network model is another unsupervised learning method that can automatically learn features from unlabeled data. It is a method of restoring and reconstructing information by "encoding-decoding" information to form a model. The self-encoding network model can give a better feature description than the original data, and has a strong feature learning ability. In the present invention, a Bert-based self-encoding network model is used to correct errors in Chinese input texts, thereby obtaining corresponding grammatical error-corrected texts, and the error correction speed is fast and the efficiency is high.
于本发明一实施例中,所述自编码网络模型包括多层语义编码器、语法错误检测深度学习模型和语法纠正深度学习模型。In an embodiment of the present invention, the self-encoding network model includes a multi-layer semantic encoder, a deep learning model for grammatical error detection, and a deep learning model for grammatical correction.
基于所述多层语义编码器获取中文输入文本的语义信息,从而使得所述自编码网络模型能够更容易学习所述中文输入文本中的语义信息。优选地,所述语义编码器采用Transformer blocks模型。如图2所示,当所述中文输入文本为“中中国的都是北京”时,通过所述多层语义编码器来识别其语义信息,即中国的首都是北京。The semantic information of the Chinese input text is obtained based on the multi-layer semantic encoder, so that the self-encoding network model can learn the semantic information in the Chinese input text more easily. Preferably, the semantic encoder adopts a Transformer blocks model. As shown in FIG. 2 , when the Chinese input text is "China is Beijing", its semantic information is recognized through the multi-layer semantic encoder, that is, the capital of China is Beijing.
基于所述语法错误检测深度学习模型和所述语法纠正深度学习模型,根据所述语义信息生成所述中文输入文本的语法纠错文本,从而实现中文输入文本的精准语法纠错。Based on the grammatical error detection deep learning model and the grammatical correction deep learning model, a grammatical error correction text of the Chinese input text is generated according to the semantic information, thereby realizing precise grammatical error correction of the Chinese input text.
于本发明一实施例中,基于所述语义信息生成所述中文输入文本的语法纠错文本包括以下步骤。In an embodiment of the present invention, generating the grammatical error correction text of the Chinese input text based on the semantic information includes the following steps.
11)基于所述语义信息检测所述中文输入文本的语法错误。11) Detecting grammatical errors of the Chinese input text based on the semantic information.
具体地,通过所述语法错误检测深度学习模型,基于所述语义信息检测所述中文输入文本的语法错误。如图2所示,对于所述中文输入文本“中中国的都是北京”,所述语法错误检测深度学习模型可检测出第二个文字和第四个文字存在语法错误,其余文字正确。Specifically, the grammatical errors of the Chinese input text are detected based on the semantic information through the grammatical error detection deep learning model. As shown in FIG. 2 , for the Chinese input text "Everything in China is Beijing", the grammatical error detection deep learning model can detect grammatical errors in the second and fourth characters, and the rest of the characters are correct.
12)基于所述语义信息和所述语法错误对所述中文输入文本进行纠正,获取语法纠错文本。12) Correct the Chinese input text based on the semantic information and the grammatical errors, and obtain grammatical error-corrected texts.
具体地,通过所述语法纠正深度学习模型,基于所述语义信息和所述语法错误对所述中文输入文本进行纠正,获取语法纠错文本。如图2所示,对于所述中文输入文本“中中国的都是北京”,由于第二个文字和第四个文字存在语法错误,根据“中国的首都是北京”这一语义,可针对所述第二个文字和所述第四个文字进行修改,从而获取语法纠正文本“中国的首都是北京”。Specifically, the Chinese input text is corrected based on the semantic information and the grammatical errors through the grammatical correction deep learning model, and the grammatical error-corrected text is obtained. As shown in Figure 2, for the Chinese input text "Everything in China is Beijing", due to grammatical errors in the second and fourth characters, according to the semantics of "China's capital is Beijing", all The above-mentioned second text and the above-mentioned fourth text are modified to obtain the grammatically corrected text "The capital of China is Beijing".
于本发明一实施例中,基于所述语义信息和所述语法错误对所述中文输入文本进行纠正,获取语法纠错文本包括以下步骤。In an embodiment of the present invention, correcting the Chinese input text based on the semantic information and the grammatical errors, and obtaining the grammatical error-corrected text includes the following steps.
121)基于所述语义信息和所述语法错误,生成所述中文输入文本的每个文字的标签;其中,对于不存在语法错误的文字,标签设置为第一预设符号;对于存在语法错误的文字,根据所述语义信息需删除时,标签设置为第二预设符号;对于存在语法错误的文字,根据所述语义信息需在后面增加文字时,标签设置为第三预设符号和所增加的文字。121) Based on the semantic information and the grammatical error, generate a label for each character of the Chinese input text; wherein, for a character without a grammatical error, the label is set as the first preset symbol; for a character with a grammatical error When the text needs to be deleted according to the semantic information, the label is set to the second preset symbol; for the text with grammatical errors, when the text needs to be added later according to the semantic information, the label is set to the third preset symbol and the added Text.
如图2所示,对于所述中文输入文本“中中国的都是北京”,需将第二个文字删除,故其对应的标签为D;需在第四个文字后增加一个“首”字,故其对应的标签为A_首;其他文字需保持不变,故对应的标签均为K。As shown in Figure 2, for the Chinese input text "All in China is Beijing", the second word needs to be deleted, so its corresponding label is D; a word "first" needs to be added after the fourth word , so the corresponding label is A_first; other text needs to remain unchanged, so the corresponding label is K.
122)将所述中文输入文本的每个文字的标签依次映射为对应的文字,以获取所述语法纠错文本。122) Mapping the labels of each character in the Chinese input text to corresponding characters in turn, so as to obtain the grammatical error correction text.
如图2所示,根据标签“KDKA_首KKKK” 对所述中文输入文本“中中国的都是北京”进行对应的映射处理,可得语法纠错文本“中国的首都是北京”。As shown in FIG. 2 , according to the label "KDKA_初KKKK", the corresponding mapping process is performed on the Chinese input text "All in China is Beijing", and the grammatical error correction text "The capital of China is Beijing" can be obtained.
所述判断模块32与所述纠错模块31相连,用于基于语言模型对所述语法纠错文本进行合理性判断,以获取最终中文文本。The judging
具体地,基于语言模型对所述语法纠错文本进行合理性判断。这是因为当对所述中文输入文本进行语法纠错后,需要判断该纠错行为的合理性,防止误报现象的发生。其中,所述语言模型能够计算所述语法纠错文本的通顺度,选择最通顺的表达作为最终中文文本。如图2所示,所述语言模型针对输入文本“ 中中国的都是北京”进行通顺度计算,判断其为合理表述,则最终输出文本“ 中国的首都是北京”。Specifically, a rationality judgment is performed on the grammatical error correction text based on a language model. This is because after grammatical error correction is performed on the Chinese input text, the rationality of the error correction action needs to be judged to prevent false positives from occurring. Wherein, the language model can calculate the smoothness of the grammatical error correction text, and select the most smooth expression as the final Chinese text. As shown in FIG. 2 , the language model calculates the fluency of the input text "All in China is Beijing", and judges that it is a reasonable expression, then finally outputs the text "The capital of China is Beijing".
于本发明一实施例中,所述语言模型采用N-Gram语言模型、GPT(Generative Pre-Training)语言模型、ELMO(Embedding from Language Model)语言模型中的一种或多种组合。所述N-Gram语言模型能够预计或者评估一个句子是否合理,以及评估两个字符串之间的差异程度。所述GPT语言模型采用了Pre-training + Fine-tuning的训练模式,可用于分类、推理、问答、相似度等任务。所述ELMO语言模型可以更好地捕捉到语法和语义层面的信息且不限制词汇量。In an embodiment of the present invention, the language model adopts one or more combinations of N-Gram language model, GPT (Generative Pre-Training) language model, and ELMO (Embedding from Language Model) language model. The N-Gram language model is capable of predicting or evaluating whether a sentence is reasonable, and evaluating the degree of difference between two character strings. The GPT language model adopts the training mode of Pre-training + Fine-tuning, which can be used for tasks such as classification, reasoning, question answering, and similarity. The ELMO language model can better capture information at the grammatical and semantic levels without limiting the vocabulary.
需要说明的是,应理解以上装置的各个模块的划分仅仅是一种逻辑功能的划分,实际实现时可以全部或部分集成到一个物理实体上,也可以物理上分开。且这些模块可以全部以软件通过处理元件调用的形式实现,也可以全部以硬件的形式实现,还可以部分模块通过处理元件调用软件的形式实现,部分模块通过硬件的形式实现。例如:x模块可以为单独设立的处理元件,也可以集成在上述装置的某一个芯片中实现。此外,x模块也可以以程序代码的形式存储于上述装置的存储器中,由上述装置的某一个处理元件调用并执行以上x模块的功能。其它模块的实现与之类似。这些模块全部或部分可以集成在一起,也可以独立实现。这里所述的处理元件可以是一种集成电路,具有信号的处理能力。在实现过程中,上述方法的各步骤或以上各个模块可以通过处理器元件中的硬件的集成逻辑电路或者软件形式的指令完成。以上这些模块可以是被配置成实施以上方法的一个或多个集成电路,例如:一个或多个特定集成电路(Application Specific Integrated Circuit,简称ASIC),一个或多个微处理器(Digital Signal Processor,简称DSP),一个或者多个现场可编程门阵列(Field Programmable Gate Array,简称FPGA)等。当以上某个模块通过处理元件调度程序代码的形式实现时,该处理元件可以是通用处理器,如中央处理器(CentralProcessing Unit,简称CPU)或其它可以调用程序代码的处理器。这些模块可以集成在一起,以片上系统(System-on-a-chip,简称SOC)的形式实现。It should be noted that it should be understood that the division of each module of the above device is only a division of logical functions, and may be fully or partially integrated into one physical entity or physically separated during actual implementation. Moreover, these modules can be implemented in the form of calling software through processing elements, or can be implemented in the form of hardware, or some modules can be implemented in the form of calling software through processing elements, and some modules can be implemented in the form of hardware. For example, the x module can be a separate processing element, and can also be integrated in a chip of the above-mentioned device. In addition, the x module can also be stored in the memory of the above-mentioned device in the form of program code, and can be invoked by a certain processing element of the above-mentioned device to execute the function of the above-mentioned x module. The implementation of other modules is similar. All or part of these modules can be integrated together, and can also be implemented independently. The processing element mentioned here may be an integrated circuit with signal processing capabilities. In the implementation process, each step of the above method or each module above can be completed by an integrated logic circuit of hardware in the processor element or an instruction in the form of software. The above modules may be one or more integrated circuits configured to implement the above method, for example: one or more specific integrated circuits (Application Specific Integrated Circuit, referred to as ASIC), one or more microprocessors (Digital Signal Processor, DSP for short), one or more Field Programmable Gate Arrays (Field Programmable Gate Array, FPGA for short), etc. When one of the above modules is implemented in the form of a processing element scheduling program code, the processing element may be a general-purpose processor, such as a central processing unit (Central Processing Unit, CPU for short) or other processors that can call program codes. These modules can be integrated together and realized in the form of System-on-a-chip (SOC for short).
本发明的存储介质上存储有计算机程序,该程序被处理器执行时实现上述的中文语法纠错方法。优选地,所述存储介质包括:ROM、RAM、磁碟、U盘、存储卡或者光盘等各种可以存储程序代码的介质。A computer program is stored on the storage medium of the present invention, and when the program is executed by a processor, the above-mentioned Chinese grammar error correction method is realized. Preferably, the storage medium includes: various media capable of storing program codes such as ROM, RAM, magnetic disk, U disk, memory card or optical disk.
如图4所示,于一实施例中,本发明的中文语法纠错终端包括:处理器41和存储器42。As shown in FIG. 4 , in one embodiment, the Chinese grammar error correction terminal of the present invention includes: a
所述存储器42用于存储计算机程序。The
所述存储器42包括:ROM、RAM、磁碟、U盘、存储卡或者光盘等各种可以存储程序代码的介质。The
所述处理器41与所述存储器42相连,用于执行所述存储器存储的计算机程序,以使所述中文语法纠错终端执行上述的中文语法纠错方法。The
优选地,所述处理器41可以是通用处理器,包括中央处理器(Central ProcessingUnit,简称CPU)、网络处理器(Network Processor,简称NP)等;还可以是数字信号处理器(Digital Signal Processor,简称DSP)、专用集成电路(Application SpecificIntegrated Circuit,简称ASIC)、现场可编程门阵列(Field Programmable Gate Array,简称FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。Preferably, the
综上所述,本发明的中文语法纠错方法及系统、存储介质及终端基于多任务深度学习算法实现有效的中文语法纠错,不依赖于规则和词库,具有良好的泛化能力;采用大规模语料训练语言模型来提取语义特征,采用语义特征来进行中文语法纠错,节省了大量资源;相对于基于GPT类的自回归模型,所采用的基于Bert的自编码模型实现了纠错速度的大幅提升,有效提升了效率。因此,本发明有效克服了现有技术中的种种缺点而具高度产业利用价值。In summary, the Chinese grammar error correction method and system, storage medium and terminal of the present invention realize effective Chinese grammar error correction based on a multi-task deep learning algorithm, do not depend on rules and thesaurus, and have good generalization ability; Large-scale corpus training language model to extract semantic features, using semantic features to correct Chinese grammar, saving a lot of resources; compared with the GPT-based autoregressive model, the Bert-based autoencoder model adopted achieves faster error correction The substantial improvement has effectively improved the efficiency. Therefore, the present invention effectively overcomes various shortcomings in the prior art and has high industrial application value.
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。The above-mentioned embodiments only illustrate the principles and effects of the present invention, but are not intended to limit the present invention. Anyone skilled in the art can modify or change the above-mentioned embodiments without departing from the spirit and scope of the present invention. Therefore, all equivalent modifications or changes made by those skilled in the art without departing from the spirit and technical ideas disclosed in the present invention should still be covered by the claims of the present invention.
Claims (10)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211234582.0ACN115455949A (en) | 2022-10-10 | 2022-10-10 | Chinese grammar error correction method and system, storage medium and terminal |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211234582.0ACN115455949A (en) | 2022-10-10 | 2022-10-10 | Chinese grammar error correction method and system, storage medium and terminal |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN115455949Atrue CN115455949A (en) | 2022-12-09 |
Family
ID=84308486
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202211234582.0APendingCN115455949A (en) | 2022-10-10 | 2022-10-10 | Chinese grammar error correction method and system, storage medium and terminal |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115455949A (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116070629A (en)* | 2023-04-06 | 2023-05-05 | 北京蜜度信息技术有限公司 | Chinese text word order checking method, system, storage medium and electronic equipment |
| CN119830898A (en)* | 2024-12-10 | 2025-04-15 | 中电信人工智能科技(北京)有限公司 | Chinese smoothness detection method and device, electronic equipment and readable medium |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20150093016A (en)* | 2014-02-06 | 2015-08-17 | 삼성전자주식회사 | Dispaly apparatus and controlling method thereof |
| CN111452616A (en)* | 2020-03-30 | 2020-07-28 | 广州小鹏汽车科技有限公司 | Information display control method and device and vehicle |
| CN114444479A (en)* | 2022-04-11 | 2022-05-06 | 南京云问网络技术有限公司 | End-to-end Chinese speech text error correction method, device and storage medium |
| CN114742039A (en)* | 2022-03-31 | 2022-07-12 | 上海蜜度信息技术有限公司 | A Chinese spelling error correction method and system, storage medium and terminal |
| CN114881010A (en)* | 2022-04-26 | 2022-08-09 | 上海师范大学 | Chinese grammar error correction method based on Transformer and multitask learning |
- 2022
- 2022-10-10CNCN202211234582.0Apatent/CN115455949A/enactivePending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20150093016A (en)* | 2014-02-06 | 2015-08-17 | 삼성전자주식회사 | Dispaly apparatus and controlling method thereof |
| CN111452616A (en)* | 2020-03-30 | 2020-07-28 | 广州小鹏汽车科技有限公司 | Information display control method and device and vehicle |
| CN114742039A (en)* | 2022-03-31 | 2022-07-12 | 上海蜜度信息技术有限公司 | A Chinese spelling error correction method and system, storage medium and terminal |
| CN114444479A (en)* | 2022-04-11 | 2022-05-06 | 南京云问网络技术有限公司 | End-to-end Chinese speech text error correction method, device and storage medium |
| CN114881010A (en)* | 2022-04-26 | 2022-08-09 | 上海师范大学 | Chinese grammar error correction method based on Transformer and multitask learning |
Non-Patent Citations (2)
| Title |
|---|
| 张金宏: "基于Transformer模型的中文语法错误诊断研究", 《万方学位论文》, 15 August 2022 (2022-08-15), pages 1 - 66* |
| 汪权彬;谭营;: "基于数据增广和复制的中文语法错误纠正方法", 智能系统学报, vol. 15, no. 01, 31 January 2020 (2020-01-31)* |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116070629A (en)* | 2023-04-06 | 2023-05-05 | 北京蜜度信息技术有限公司 | Chinese text word order checking method, system, storage medium and electronic equipment |
| CN119830898A (en)* | 2024-12-10 | 2025-04-15 | 中电信人工智能科技(北京)有限公司 | Chinese smoothness detection method and device, electronic equipment and readable medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN110888966B (en) | Natural language question and answer | |
| CN111738004A (en) | A training method for a named entity recognition model and a method for named entity recognition | |
| CN112036162B (en) | Adaptation method, device, electronic device and storage medium for text error correction | |
| CN110223675B (en) | Method and system for screening training text data for voice recognition | |
| CN111310441A (en) | Text correction method, device, terminal and medium based on BERT (binary offset transcription) voice recognition | |
| CN112052329A (en) | Text abstract generation method and device, computer equipment and readable storage medium | |
| WO2023184633A1 (en) | Chinese spelling error correction method and system, storage medium, and terminal | |
| CN115455949A (en) | Chinese grammar error correction method and system, storage medium and terminal | |
| CN112883713B (en) | Evaluation object extraction method and device based on convolutional neural network | |
| CN113935331A (en) | Abnormal semantic truncation detection method, device, equipment and medium | |
| CN119599137B (en) | Detection and repair method and system for large language model output hallucination | |
| CN116956824A (en) | Aspect-level emotion analysis method and system based on dependency type and phrase structure tree | |
| CN109885821B (en) | Article writing method and device based on artificial intelligence, and computer storage medium | |
| CN112580351B (en) | Machine-generated text detection method based on self-information loss compensation | |
| CN117743599A (en) | Model detection method, device, medium and electronic equipment | |
| CN115982369A (en) | An Improved Text Classification Method Incorporating Label Semantics | |
| US20250103803A1 (en) | Training method for text combination determining model and text combination determining method | |
| CN114298032A (en) | Text punctuation detection method, computer equipment and storage medium | |
| CN112131879A (en) | A relation extraction system, method and apparatus | |
| CN119166754A (en) | A process standard entity relationship extraction method integrating deep learning and dependency syntax | |
| CN116227496B (en) | A method and system for extracting power public opinion entity relationship based on deep learning | |
| CN110377753B (en) | Relation extraction method and device based on relation trigger word and GRU model | |
| CN117112743A (en) | Answerability assessment method, system and storage medium for automatically generated text questions | |
| CN115526172A (en) | A coreference resolution method, device, equipment and readable storage medium | |
| CN115238052A (en) | Model generation method, dialogue generation method, device, and electronic device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |