CN115346023A - Method and system for realizing virtual scene by radio station, storage medium and terminal - Google Patents
Method and system for realizing virtual scene by radio station, storage medium and terminalDownload PDFInfo
- Publication number
- CN115346023A CN115346023ACN202110524540.XACN202110524540ACN115346023ACN 115346023 ACN115346023 ACN 115346023ACN 202110524540 ACN202110524540 ACN 202110524540ACN 115346023 ACN115346023 ACN 115346023A
- Authority
- CN
- China
- Prior art keywords
- virtual
- anchor
- virtual scene
- voiceprint
- scene
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images





Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T19/00—Manipulating 3D models or images for computer graphics
- G06T19/006—Mixed reality
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/60—Information retrieval; Database structures therefor; File system structures therefor of audio data
- G06F16/63—Querying
- G06F16/635—Filtering based on additional data, e.g. user or group profiles
- G06F16/636—Filtering based on additional data, e.g. user or group profiles by using biological or physiological data
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/60—Information retrieval; Database structures therefor; File system structures therefor of audio data
- G06F16/63—Querying
- G06F16/638—Presentation of query results
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/60—Information retrieval; Database structures therefor; File system structures therefor of audio data
- G06F16/68—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually
- G06F16/683—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually using metadata automatically derived from the content
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/60—Information retrieval; Database structures therefor; File system structures therefor of audio data
- G06F16/68—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually
- G06F16/683—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually using metadata automatically derived from the content
- G06F16/685—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually using metadata automatically derived from the content using automatically derived transcript of audio data, e.g. lyrics
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Multimedia (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Library & Information Science (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Physiology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Molecular Biology (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computer Graphics (AREA)
- Computer Hardware Design (AREA)
- Software Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及车辆技术领域,尤其涉及一种电台实现虚拟场景的方法及系统、存储介质、终端。The present invention relates to the technical field of vehicles, in particular to a method and system, a storage medium, and a terminal for a radio station to realize a virtual scene.
背景技术Background technique
随着生活水平的不断改善,汽车在人们的生活中越来越普遍,逐步成为城市和乡村的人们生活中不可或缺的交通工具之一。With the continuous improvement of living standards, automobiles are becoming more and more common in people's lives, and gradually become one of the indispensable means of transportation in people's lives in cities and villages.
同时,人们不再简单的定义汽车为交通运输工具与代步工具,汽车的安全性、环保性、舒适性以及娱乐性等方面的需求越来越大。但是,现有常用的汽车一般只能实现简单的使用、搭载功能,无法给用户提供更多的智能体验。At the same time, people no longer simply define cars as means of transportation and means of transportation, and the demand for safety, environmental protection, comfort and entertainment of cars is increasing. However, the existing commonly used cars generally can only realize simple use and carrying functions, and cannot provide users with more intelligent experience.
例如,目前车载电台在进行播放时,仅在中控显示屏中展示电台频谱或是数字,无法根据电台播放的内容显示当前的播报内容的环境模型或是电台节目的主播的角色模型,导致用户体验较差。For example, at present, when the vehicle-mounted radio station is playing, it only displays the radio frequency spectrum or numbers on the central control display, and cannot display the current environment model of the broadcast content or the role model of the anchor of the radio program according to the content played by the radio station, causing users The experience is poor.
发明内容Contents of the invention
本发明解决的技术问题是提供一种电台实现虚拟场景的方法及系统、存储介质、终端,根据电台节目的内容以及电台节目的主播显示对应的虚拟场景,有效提升用户的体验度。The technical problem solved by the present invention is to provide a method, system, storage medium, and terminal for a radio station to realize a virtual scene, which can effectively improve user experience by displaying corresponding virtual scenes according to the content of the radio program and the anchor of the radio program.
为解决上述问题,本发明提供一种电台实现虚拟场景的方法,包括:接收电台节目;加载虚拟场景数据库,所述虚拟场景数据库中包括虚拟环境模型集、虚拟主播模型集、以及每个虚拟主播模型所关联的虚拟主播行为集;将所述电台节目与所述虚拟场景数据库进行联动。In order to solve the above problems, the present invention provides a method for a radio station to realize a virtual scene, including: receiving a radio station program; loading a virtual scene database, which includes a virtual environment model set, a virtual anchor model set, and each virtual anchor The virtual anchor behavior set associated with the model; the radio program is linked with the virtual scene database.
可选的,所述虚拟场景数据库中还包括:每个虚拟主播模型所关联的一个或多个第一声纹音色信息。Optionally, the virtual scene database further includes: one or more first voiceprint timbre information associated with each virtual anchor model.
可选的,将所述电台节目与所述虚拟场景数据库进行联动的方法包括:根据所述虚拟场景数据库获取所述电台节目的主播对应的虚拟主播模型。Optionally, the method for linking the radio program with the virtual scene database includes: acquiring a virtual anchor model corresponding to the anchor of the radio program according to the virtual scene database.
可选的,根据所述虚拟场景数据库获取所述电台节目的主播对应的虚拟主播模型的方法包括:获取所述电台节目的主播的第二声纹音色信息;将所述第二声纹音色信息与所述虚拟场景数据库中的若干所述第一声纹音色信息进行对比;当所述第二声纹音色信息与若干所述第一声纹音色信息中的一个所述第一声纹音色信息对比相同时,则将对比相同的所述第一声纹音色信息所关联的虚拟主播模型作为所述电台节目的主播的虚拟主播模型。Optionally, the method for obtaining the virtual anchor model corresponding to the anchor of the radio program according to the virtual scene database includes: acquiring the second voiceprint timbre information of the anchor of the radio program; Compared with the first voiceprint timbre information in the virtual scene database; when the second voiceprint timbre information is compared with one of the first voiceprint timbre information If the comparison is the same, the virtual anchor model associated with the same first voiceprint and timbre information will be used as the virtual anchor model of the anchor of the radio program.
可选的,所述虚拟场景数据库中还包括:每个虚拟主播情绪所关联的一个或多个第一声纹情绪信息。Optionally, the virtual scene database further includes: one or more first voiceprint emotion information associated with each virtual anchor emotion.
可选的,将所述电台节目与所述虚拟场景数据库进行联动的方法还包括:根据所述虚拟场景数据库获取所述电台节目的主播对应的虚拟主播行为。Optionally, the method for linking the radio program with the virtual scene database further includes: acquiring the behavior of the virtual anchor corresponding to the anchor of the radio program according to the virtual scene database.
可选的,根据所述虚拟场景数据库获取所述电台节目的主播对应的虚拟主播行为的方法包括:获取电台节目的主播的第二声纹情绪信息;将所述第二声纹情绪信息与所述虚拟场景数据库中的若干第一声纹情绪信息进行对比;当所述第二声纹情绪信息与若干所述第一声纹情绪信息中的一个所述第一声纹情绪信息对比相同时,则将对比相同的所述第一声纹情绪信息所关联的虚拟主播动作作为电台节目的主播对应的虚拟主播行为。Optionally, the method for obtaining the virtual anchor behavior corresponding to the anchor of the radio program according to the virtual scene database includes: acquiring second voiceprint emotion information of the anchor of the radio program; combining the second voiceprint emotion information with the compare the first voiceprint emotion information in the virtual scene database; when the second voiceprint emotion information is the same as one of the first voiceprint emotion information, Then compare the virtual anchor action associated with the same first voiceprint emotion information as the virtual anchor behavior corresponding to the anchor of the radio program.
可选的,所述虚拟场景数据库中还包括:每个虚拟场景模型所关联的一个或多个第一场景关键词。Optionally, the virtual scene database further includes: one or more first scene keywords associated with each virtual scene model.
可选的,将所述电台节目与所述虚拟场景数据库进行联动的方法还包括:根据所述虚拟场景数据库获取所述电台节目的内容对应的虚拟环境模型。Optionally, the method for linking the radio program with the virtual scene database further includes: acquiring a virtual environment model corresponding to the content of the radio program according to the virtual scene database.
可选的,根据所述虚拟场景数据库获取所述电台节目的内容对应的虚拟环境模型的方法包括:获取电台节目的内容的音频数据;对所述音频数据进行语义解析,获取所述音频数据中的第二场景关键词;将所述第二场景关键词与所述虚拟场景数据库中的若干第一场景关键词进行对比;当所述第二场景关键词与若干所述第一场景关键词中的一个所述第一场景关键词对比相同时,则将对比相同的所述第一场景关键词所关联的虚拟场景模型作为电台节目的内容对应的虚拟环境模型。Optionally, the method for acquiring the virtual environment model corresponding to the content of the radio program according to the virtual scene database includes: acquiring audio data of the content of the radio program; performing semantic analysis on the audio data, and acquiring the second scene keywords; compare the second scene keywords with several first scene keywords in the virtual scene database; when the second scene keywords are compared with some of the first scene keywords When one of the first scene keywords is compared the same, the virtual scene model associated with the same first scene keyword is used as the virtual environment model corresponding to the content of the radio program.
可选的,当车辆处于在线状态时,加载虚拟场景数据库的方法包括:从云端服务器获取实时的虚拟场景数据库。Optionally, when the vehicle is online, the method for loading the virtual scene database includes: obtaining a real-time virtual scene database from a cloud server.
可选的,当车辆处于离线状态时,加载虚拟场景数据库的方法包括:从电台获取本地预置的虚拟场景数据库。Optionally, when the vehicle is offline, the method for loading the virtual scene database includes: obtaining a locally preset virtual scene database from the radio station.
相应的,本发明的技术方案中还提供了一种电台实现虚拟场景的系统,包括:电台节目获取模块,用于接收电台节目;数据库加载模块,用于加载虚拟场景数据库,所述虚拟场景数据库中包括虚拟环境模型集、虚拟主播模型集、以及每个虚拟主播模型所关联的虚拟主播行为集;联动模块,用于将所述电台节目与所述虚拟场景数据库进行联动。Correspondingly, the technical solution of the present invention also provides a system for a radio station to realize a virtual scene, including: a radio program acquisition module, used to receive a radio program; a database loading module, used to load a virtual scene database, and the virtual scene database It includes a virtual environment model set, a virtual anchor model set, and a virtual anchor behavior set associated with each virtual anchor model; a linkage module is used to link the radio program with the virtual scene database.
可选的,所述虚拟场景数据库中还包括:每个虚拟主播模型所关联的一个或多个第一声纹音色信息。Optionally, the virtual scene database further includes: one or more first voiceprint timbre information associated with each virtual anchor model.
可选的,所述联动模块包括:主播模型获取模块,用于根据所述虚拟场景数据库获取所述电台节目的主播对应的虚拟主播模型。Optionally, the linkage module includes: an anchor model acquiring module, configured to acquire a virtual anchor model corresponding to the anchor of the radio program according to the virtual scene database.
可选的,所述主播模型获取模块包括:声纹音色获取模块,用于获取电台节目的主播的第二声纹音色信息;声纹音色对比模块,用于将所述第二声纹音色信息与所述虚拟场景数据库中的若干所述第一声纹音色信息进行对比;主播模型选定模块,用于当所述第二声纹音色信息与若干所述第一声纹音色信息中的一个所述第一声纹音色信息对比相同时,则将对比相同的所述第一声纹音色信息所关联的虚拟主播模型作为电台节目的主播的虚拟主播模型。Optionally, the anchor model acquisition module includes: a voiceprint timbre acquisition module, configured to acquire second voiceprint timbre information of the anchor of the radio program; a voiceprint timbre comparison module, used to compare the second voiceprint timbre information Compared with the first voiceprint timbre information in the virtual scene database; the anchor model selection module is used to compare the second voiceprint timbre information with one of the first voiceprint timbre information When the first voiceprint timbre information is the same, the virtual anchor model associated with the same first voiceprint timbre information is used as the virtual anchor model of the anchor of the radio program.
可选的,所述虚拟场景数据库中还包括:每个虚拟主播情绪所关联的一个或多个第一声纹情绪信息。Optionally, the virtual scene database further includes: one or more first voiceprint emotion information associated with each virtual anchor emotion.
可选的,所述联动模块还包括:主播行为获取模块,用于根据所述虚拟场景数据库获取所述电台节目的主播对应的虚拟主播行为。Optionally, the linkage module further includes: an anchor behavior acquisition module, configured to acquire the virtual anchor behavior corresponding to the anchor of the radio program according to the virtual scene database.
可选的,所述主播行为获取模块包括:声纹情绪获取模块,用于获取电台节目的主播的第二声纹情绪信息;情绪信息对比模块,用于将所述第二声纹情绪信息与所述虚拟场景数据库中的若干第一声纹情绪信息进行对比;主播行为选定模块,用于当所述第二声纹情绪信息与若干所述第一声纹情绪信息中的一个所述第一声纹情绪信息对比相同时,则将对比相同的所述第一声纹情绪信息所关联的虚拟主播动作作为电台节目的主播对应的虚拟主播行为。Optionally, the anchor behavior acquisition module includes: a voiceprint emotion acquisition module, configured to acquire second voiceprint emotion information of an anchor of a radio program; an emotion information comparison module, configured to compare the second voiceprint emotion information with Comparing several first voiceprint emotional information in the virtual scene database; the anchor behavior selection module is used to compare the second voiceprint emotional information with one of the first voiceprint emotional information. When the voiceprint emotion information is the same, the virtual anchor action associated with the same first voiceprint emotion information is taken as the virtual anchor behavior corresponding to the anchor of the radio program.
可选的,所述虚拟场景数据库中还包括:每个虚拟场景模型所关联的一个或多个第一场景关键词。Optionally, the virtual scene database further includes: one or more first scene keywords associated with each virtual scene model.
可选的,所述联动模块还包括:环境模型获取模块,用于根据所述虚拟场景数据库获取所述电台节目的内容对应的虚拟环境模型。Optionally, the linkage module further includes: an environment model acquisition module, configured to acquire a virtual environment model corresponding to the content of the radio program according to the virtual scene database.
可选的,所述环境模型获取模块包括:音频获取模块,用于获取电台节目的内容的音频数据;音频解析模块,用于对所述音频数据进行语义解析,获取所述音频数据中的第二场景关键词;场景关键词对比模块,用于将所述第二场景关键词与所述虚拟场景数据库中的若干第一场景关键词进行对比;场景选定模块,用于当所述第二场景关键词与若干所述第一场景关键词中的一个所述第一场景关键词对比相同时,则将对比相同的所述第一场景关键词所关联的虚拟场景模型作为电台节目的内容对应的虚拟环境模型。Optionally, the environment model acquisition module includes: an audio acquisition module, configured to acquire audio data of the content of radio programs; an audio analysis module, configured to perform semantic analysis on the audio data, and acquire the first audio data in the audio data. Two scene keywords; a scene keyword comparison module, used to compare the second scene keyword with some first scene keywords in the virtual scene database; a scene selection module, used when the second scene keyword When the scene keyword is the same as one of the first scene keywords in a plurality of the first scene keywords, the virtual scene model associated with the same first scene keyword will be used as the content corresponding to the radio program. virtual environment model.
可选的,当车辆处于在线状态时,所述数据库加载模块用于从云端服务器加载实时的虚拟场景数据库。Optionally, when the vehicle is online, the database loading module is used to load the real-time virtual scene database from the cloud server.
可选的,当车辆处于离线状态时,所述数据库加载模块用于从电台加载本地预置的虚拟场景数据库。Optionally, when the vehicle is offline, the database loading module is used to load a locally preset virtual scene database from the radio station.
可选的,电台节目获取模块包括车载收音机。Optionally, the radio program acquisition module includes a car radio.
相应的,本发明的技术方案中还提供了一种存储介质,其上存储有计算机指令,所述计算机指令运行时执行上述任一项所述方法的步骤。Correspondingly, the technical solution of the present invention also provides a storage medium, on which computer instructions are stored, and the steps of any one of the methods described above are executed when the computer instructions are executed.
相应的,本发明的技术方案中还提供了一种终端,包括存储器和处理器,所述存储器上存储有能够在所述处理器上运行的计算机指令,所述处理器运行所述计算机指令时执行上述任一项所述方法的步骤。Correspondingly, the technical solution of the present invention also provides a terminal, including a memory and a processor, the memory stores computer instructions that can be run on the processor, and when the processor runs the computer instructions performing the steps of any one of the methods described above.
与现有技术相比,本发明的技术方案具有以下优点:Compared with the prior art, the technical solution of the present invention has the following advantages:
本发明的技术方案的方法中,通过接收电台节目;获取虚拟场景数据库,所述虚拟场景数据库中包括虚拟环境模型集、虚拟主播模型集、以及每个虚拟主播模型所关联的虚拟主播行为集;以及将所述电台节目与所述虚拟场景数据库进行联动。根据电台节目的内容以及电台节目的主播显示对应的虚拟场景,有效提升用户的体验度。In the method of the technical solution of the present invention, by receiving radio programs; obtaining a virtual scene database, the virtual scene database includes a virtual environment model set, a virtual anchor model set, and a virtual anchor behavior set associated with each virtual anchor model; And linking the radio program with the virtual scene database. According to the content of the radio program and the anchor of the radio program, the corresponding virtual scene is displayed, which effectively improves the user experience.
本发明的技术方案的系统中,包括:电台节目获取模块,用于接收电台节目;数据库加载模块,用于加载虚拟场景数据库,所述虚拟场景数据库中包括虚拟环境模型集、虚拟主播模型集、以及每个虚拟主播模型所关联的虚拟主播行为集;联动模块,用于将所述电台节目与所述虚拟场景数据库进行联动。根据电台节目的内容以及电台节目的主播显示对应的虚拟场景,有效提升用户的体验度。In the system of the technical solution of the present invention, it includes: a radio program acquisition module for receiving radio programs; a database loading module for loading a virtual scene database, which includes a virtual environment model set, a virtual anchor model set, and a virtual anchor behavior set associated with each virtual anchor model; a linkage module, used to link the radio program with the virtual scene database. According to the content of the radio program and the anchor of the radio program, the corresponding virtual scene is displayed, which effectively improves the user experience.
附图说明Description of drawings
图1是本发明实施例中一种电台实现虚拟场景的方法流程示意图;Fig. 1 is a schematic flow chart of a method for realizing a virtual scene by a radio station in an embodiment of the present invention;
图2是本发明实施例中获取虚拟主播模型的方法流程示意图;Fig. 2 is a schematic flow diagram of a method for obtaining a virtual anchor model in an embodiment of the present invention;
图3是本发明实施例中获取虚拟主播行为的方法流程示意图;Fig. 3 is a schematic flow diagram of a method for obtaining the behavior of a virtual anchor in an embodiment of the present invention;
图4是本发明实施例中获取虚拟环境模型的方法流程示意图;Fig. 4 is a schematic flowchart of a method for obtaining a virtual environment model in an embodiment of the present invention;
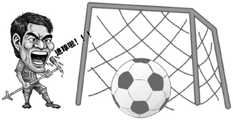
图5是本发明实施例中“进球”虚拟环境模型示意图;Fig. 5 is a schematic diagram of the "goal" virtual environment model in the embodiment of the present invention;
图6是本发明实施例中一种电台实现虚拟场景的系统结构示意图。Fig. 6 is a schematic structural diagram of a radio station implementing a virtual scene in an embodiment of the present invention.
具体实施方式Detailed ways
为了便于理解本发明,下面将参照相关附图对本发明进行更全面的描述。附图中给出了本发明的典型实施例。但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容更加透彻全面。In order to facilitate the understanding of the present invention, the present invention will be described more fully below with reference to the associated drawings. Typical embodiments of the invention are shown in the drawings. However, the present invention can be embodied in many different forms and is not limited to the embodiments described herein. Rather, these embodiments are provided so that the disclosure of the present invention will be thorough and complete.
除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。Unless otherwise defined, all technical and scientific terms used herein have the same meaning as commonly understood by one of ordinary skill in the technical field of the invention. The terms used herein in the description of the present invention are for the purpose of describing specific embodiments only, and are not intended to limit the present invention.
图1是本发明实施例的一种电台实现虚拟场景的方法的流程示意图。Fig. 1 is a schematic flowchart of a method for a radio station to implement a virtual scene according to an embodiment of the present invention.
请参考图1,本实施例所述的电台实现虚拟场景的方法包括如下步骤:Please refer to FIG. 1, the method for implementing a virtual scene by a radio station described in this embodiment includes the following steps:
步骤S100,接收电台节目;Step S100, receiving radio programs;
步骤S200,加载虚拟场景数据库,所述虚拟场景数据库中包括虚拟环境模型集、虚拟主播模型集、以及每个虚拟主播模型所关联的虚拟主播行为集;Step S200, loading a virtual scene database, which includes a virtual environment model set, a virtual anchor model set, and a virtual anchor behavior set associated with each virtual anchor model;
步骤S300,将所述电台节目与所述虚拟场景数据库进行联动。Step S300, linking the radio program with the virtual scene database.
在步骤S100的具体实施过程中,通过车载收音机接收所述电台节目。During the specific implementation of step S100, the radio program is received through the car radio.
在步骤S200的具体实施过程中,加载虚拟场景数据库分为两种情况,即车辆处于在线状态和车辆处于离线状态。In the specific implementation process of step S200, the loading of the virtual scene database is divided into two situations, that is, the vehicle is in the online state and the vehicle is in the offline state.
在本实施例中,当车辆处于在线状态时,加载虚拟场景数据库的方法包括:从云端服务器获取实时的虚拟场景数据库。由于车辆处于在线状态,因此可以通过互联网络接收实时更新的虚拟场景数据库,以带给用户最新的体验。In this embodiment, when the vehicle is online, the method for loading the virtual scene database includes: obtaining a real-time virtual scene database from a cloud server. Since the vehicle is online, it can receive a real-time updated virtual scene database through the Internet to bring users the latest experience.
在本实施例中,当车辆处于离线状态时,加载虚拟场景数据库的方法包括:从电台获取本地预置的虚拟场景数据库。虽然电台本地预置的虚拟场景数据库并不是实时更新的数据库,但是依然可以通过已存储的虚拟场景数据库,并根据电台节目的内容以及电台节目的主播显示对应的虚拟场景,提升用户的体验度。In this embodiment, when the vehicle is offline, the method for loading the virtual scene database includes: acquiring a locally preset virtual scene database from the radio station. Although the locally preset virtual scene database of the radio station is not a real-time updated database, the stored virtual scene database can still be used to display the corresponding virtual scene according to the content of the radio program and the anchor of the radio program to improve the user experience.
在本实施例中,所述虚拟场景数据库还包括:每个虚拟主播模型所关联的一个或多个第一声纹音色信息、每个虚拟主播情绪所关联的一个或多个第一声纹情绪信息、以及每个虚拟场景模型所关联的一个或多个第一场景关键词。In this embodiment, the virtual scene database further includes: one or more first voiceprint timbre information associated with each virtual anchor model, one or more first voiceprint emotions associated with each virtual anchor emotion information, and one or more first scene keywords associated with each virtual scene model.
通过存储以上信息的目的是为后续将所述电台节目与所述虚拟场景数据库进行联动提供基础数据支撑。The purpose of storing the above information is to provide basic data support for subsequent linkage between the radio program and the virtual scene database.
在步骤S300的具体实施过程中,将所述电台节目与所述虚拟场景数据库进行联动的方法包括:根据所述虚拟场景数据库获取所述电台节目的主播对应的虚拟主播模型。In the specific implementation process of step S300, the method for linking the radio program with the virtual scene database includes: acquiring a virtual anchor model corresponding to the anchor of the radio program according to the virtual scene database.
请参考图2,在本实施例中,根据所述虚拟场景数据库获取所述电台节目的主播对应的虚拟主播模型的方法包括:Please refer to FIG. 2. In this embodiment, the method for obtaining the virtual anchor model corresponding to the anchor of the radio program according to the virtual scene database includes:
步骤S301a,获取所述电台节目的主播的第二声纹音色信息;Step S301a, acquiring the second voiceprint timbre information of the anchor of the radio program;
步骤S302a,将所述第二声纹音色信息与所述虚拟场景数据库中的若干所述第一声纹音色信息进行对比;Step S302a, comparing the second voiceprint timbre information with the first voiceprint timbre information in the virtual scene database;
步骤S303a,当所述第二声纹音色信息与若干所述第一声纹音色信息中的一个所述第一声纹音色信息对比相同时,则将对比相同的所述第一声纹音色信息所关联的虚拟主播模型作为所述电台节目的主播的虚拟主播模型。Step S303a, when the second voiceprint timbre information is the same as one of the first voiceprint timbre information, compare the same first voiceprint timbre information The associated virtual anchor model serves as the virtual anchor model of the anchor of the radio program.
在一个场景中,如所述电台节目的主播是一个女性主播,所述虚拟场景数据库中已经采集存储有所述女性主播的第一声纹音色信息,并根据所述第一声纹音色信息制作了对应的虚拟主播模型,并存储在所述虚拟场景数据库中。当用户在收听所述女性主播的电台节目时,会获取到所述女性主播的实时声纹信息,并通过对所述声纹信息进行处理,获取所述女性主播的声纹信息中的第二声纹音色信息,通过将实时获取的第二声纹音色信息在所述虚拟场景数据库中进行对比,当所述女性主播的实时第二声纹音色信息与所述虚拟场景数据库中已存储的所述女性主播的第一声纹音色信息对比相同时,则从所述虚拟场景数据库中调取所述女性主播对应的虚拟主播模型,并在车载中控显示屏上播放。In one scenario, if the anchor of the radio program is a female anchor, the first voiceprint timbre information of the female anchor has been collected and stored in the virtual scene database, and the first voiceprint timbre information is created based on the first voiceprint timbre information. A corresponding virtual anchor model is created and stored in the virtual scene database. When the user is listening to the radio program of the female anchor, the real-time voiceprint information of the female anchor will be obtained, and the second part of the voiceprint information of the female anchor will be obtained by processing the voiceprint information. Voiceprint timbre information, by comparing the second voiceprint timbre information acquired in real time in the virtual scene database, when the real-time second voiceprint timbre information of the female anchor is compared with all stored in the virtual scene database When the first voiceprint and timbre information of the female anchors are the same, the virtual anchor model corresponding to the female anchor is retrieved from the virtual scene database, and played on the vehicle-mounted central control display.
需要说明的是,每个人的声纹音色信息都是唯一的,因此通过上述的声纹音色信息对比才能够获取唯一的主播虚拟模型。It should be noted that each person's voiceprint timbre information is unique, so the unique anchor virtual model can only be obtained through the above-mentioned voiceprint timbre information comparison.
在上述场景中描述的是一个第一声纹音色信息对应的一个虚拟主播模型,在其他的场景中,对于那些不是很知名的主播来说,还可以采用多个第一声纹音色信息对应一个虚拟主播模型,进而能够有效的降低建立所述虚拟场景数据库的周期和成本。What is described in the above scenario is a virtual anchor model corresponding to the first voiceprint timbre information. In other scenarios, for those less well-known anchors, multiple first voiceprint timbre information can also be used The virtual anchor model can effectively reduce the period and cost of establishing the virtual scene database.
在本实施例中,将所述电台节目与所述虚拟场景数据库进行联动的方法还包括:根据所述虚拟场景数据库获取所述电台节目的主播对应的虚拟主播行为。In this embodiment, the method for linking the radio program with the virtual scene database further includes: acquiring the behavior of the virtual anchor corresponding to the anchor of the radio program according to the virtual scene database.
请参考图3,在本实施例中,根据所述虚拟场景数据库获取所述电台节目的主播对应的虚拟主播行为的方法包括:Please refer to FIG. 3. In this embodiment, the method for obtaining the virtual anchor behavior corresponding to the anchor of the radio program according to the virtual scene database includes:
步骤S301b,获取电台节目的主播的第二声纹情绪信息;Step S301b, obtaining the second voiceprint emotion information of the anchor of the radio program;
步骤S302b,将所述第二声纹情绪信息与所述虚拟场景数据库中的若干第一声纹情绪信息进行对比;Step S302b, comparing the second voiceprint emotion information with a plurality of first voiceprint emotion information in the virtual scene database;
步骤S303b,当所述第二声纹情绪信息与若干所述第一声纹情绪信息中的一个所述第一声纹情绪信息对比相同时,则将对比相同的所述第一声纹情绪信息所关联的虚拟主播动作作为电台节目的主播对应的虚拟主播行为。Step S303b, when the second voiceprint emotion information is the same as one of the first voiceprint emotion information among several first voiceprint emotion information, compare the same first voiceprint emotion information The associated virtual anchor acts as the corresponding virtual anchor behavior of the anchor of the radio program.
在一个场景中,所述虚拟场景数据库中已经采集存储有所述主播的第一声纹情绪信息,并根据所述第一声纹情绪信息制作了对应的虚拟主播行为,其中第一声纹情绪信息中包括喜悦、兴奋、沮丧、悲伤等。当所述主播在用比较兴奋的情绪播报节目时,通过从所述主播的声纹信息中获取所述主播兴奋时所对应的第二声纹情绪信息。通过将实时获取的第二声纹情绪信息在所述虚拟场景数据库中进行对比,当所述主播的实时第二声纹情绪信息与所述虚拟场景数据库中已存储的所述主播的第一声纹情绪信息对比相同时,则从所述虚拟场景数据库中调取所述主播对应的虚拟主播行为,并在车载中控显示屏上播放。In one scenario, the first voiceprint emotion information of the anchor has been collected and stored in the virtual scene database, and the corresponding virtual anchor behavior is produced according to the first voiceprint emotion information, wherein the first voiceprint emotion Messages include joy, excitement, frustration, sadness, etc. When the anchor is broadcasting a program with a relatively excited emotion, the second voiceprint emotion information corresponding to when the anchor is excited is obtained from the voiceprint information of the anchor. By comparing the second voiceprint emotion information acquired in real time in the virtual scene database, when the real-time second voiceprint emotion information of the anchor is compared with the first voice of the anchor already stored in the virtual scene database, When the emotional information of the patterns is the same, the behavior of the virtual anchor corresponding to the anchor is retrieved from the virtual scene database, and played on the vehicle-mounted central control display.
需要说明的是,每个人的声纹情绪信息也都是唯一的,因此通过上述的声纹情绪信息对比才能够获取唯一的主播虚拟行为。It should be noted that each person's voiceprint emotional information is also unique, so the unique anchor virtual behavior can only be obtained through the above-mentioned voiceprint emotional information comparison.
同样,在上述场景中描述的是一个第一声纹情绪信息对应的一个虚拟主播行为,在其他的场景中,对于那些不是很知名的主播来说,还可以采用多个第一声纹情绪信息对应一个虚拟主播行为,进而能够有效的降低建立所述虚拟场景数据库的周期和成本。Similarly, what is described in the above scenario is the behavior of a virtual anchor corresponding to the emotional information of the first voiceprint. In other scenarios, for those anchors who are not very well-known, multiple first voiceprint emotional information can also be used Corresponding to a virtual anchor behavior, and thus can effectively reduce the period and cost of establishing the virtual scene database.
在本实施例中,将所述电台节目与所述虚拟场景数据库进行联动的方法还包括:根据所述虚拟场景数据库获取所述电台节目的内容对应的虚拟环境模型。In this embodiment, the method for linking the radio program with the virtual scene database further includes: acquiring a virtual environment model corresponding to the content of the radio program according to the virtual scene database.
请参考图4,在本实施例中,根据所述虚拟场景数据库获取所述电台节目的内容对应的虚拟环境模型的方法包括:Please refer to FIG. 4. In this embodiment, the method for obtaining the virtual environment model corresponding to the content of the radio program according to the virtual scene database includes:
步骤S301c,获取电台节目的内容的音频数据;Step S301c, obtaining the audio data of the content of the radio program;
步骤S302c,对所述音频数据进行语义解析,获取所述音频数据中的第二场景关键词;Step S302c, perform semantic analysis on the audio data, and obtain the second scene keywords in the audio data;
步骤S303c,将所述第二场景关键词与所述虚拟场景数据库中的若干第一场景关键词进行对比;Step S303c, comparing the second scene keyword with several first scene keywords in the virtual scene database;
步骤S304c,当所述第二场景关键词与若干所述第一场景关键词中的一个所述第一场景关键词对比相同时,则将对比相同的所述第一场景关键词所关联的虚拟场景模型作为电台节目的内容对应的虚拟环境模型。Step S304c, when the second scene keyword is the same as one of the first scene keywords, compare the virtual scene associated with the same first scene keyword The scene model serves as a virtual environment model corresponding to the content of the radio program.
请参考图5,在一个场景中,如电台节目的内容与足球相关的,在所述虚拟场景模型中已经存储有很多虚拟环境模型,每个虚拟环境模型都关联有对应的第一场景关键词,如所述第一场景关键词为“进球”,对应关联的虚拟环境模型则为足球冲进球门的画面。当电台主播在播放节目时,会实时的获取电台主播的音频数据,并对所述音频数据进行语义解析。当通过语义解析获取到电台主播播报的“进球”第二场景关键词时,则通过将实时获取的第二场景关键词在所述虚拟场景数据库中进行对比,当所述第二场景关键词与所述虚拟场景数据库中已存储的所述第一场景关键词对比相同时,则从所述虚拟场景数据库中调取对应的“进球”的虚拟环境模型,并在车载中控显示屏上播放。Please refer to Fig. 5, in a scene, if the content of the radio program is related to football, many virtual environment models have been stored in the virtual scene model, and each virtual environment model is associated with a corresponding first scene keyword , if the keyword of the first scene is "goal", the corresponding associated virtual environment model is a picture of a football rushing into a goal. When the radio anchor is playing a program, the audio data of the radio anchor will be obtained in real time, and semantic analysis is performed on the audio data. When the second scene keyword of "goal" broadcast by the radio anchor is obtained through semantic analysis, then by comparing the second scene keyword acquired in real time in the virtual scene database, when the second scene keyword When compared with the first scene keywords stored in the virtual scene database, the corresponding virtual environment model of "goal" is retrieved from the virtual scene database and displayed on the vehicle-mounted central control display screen. play.
在上述场景中描述“进球”第一场景关键词对应的是一个“进球”虚拟环境模型,对于其他的第一场景关键词如“跑步”或“奔跑”,则可以将这两个第一场景关键词关联一个虚拟环境场景。进而能够有效的降低建立所述虚拟场景数据库的周期和成本。In the above scenario, the first scene keyword of "goal" corresponds to a virtual environment model of "goal". For other first scene keywords such as "running" or "running", these two second scene keywords can be combined A scene keyword is associated with a virtual environment scene. Furthermore, the period and cost of establishing the virtual scene database can be effectively reduced.
在本实施例中,通过接收电台节目;获取虚拟场景数据库,所述虚拟场景数据库中包括虚拟环境模型集、虚拟主播模型集、以及每个虚拟主播模型所关联的虚拟主播行为集;以及将所述电台节目与所述虚拟场景数据库进行联动。根据电台节目的内容以及电台节目的主播显示对应的虚拟场景,有效提升用户的体验度。In this embodiment, by receiving radio programs; obtaining a virtual scene database, which includes a virtual environment model set, a virtual anchor model set, and a virtual anchor behavior set associated with each virtual anchor model; The radio program is linked with the virtual scene database. According to the content of the radio program and the anchor of the radio program, the corresponding virtual scene is displayed, which effectively improves the user experience.
相应的,本发明的实施例中,还提供了一种电台实现虚拟场景的系统,请参考图6,包括:电台节目获取模块100,用于接收电台节目;数据库加载模块200,用于加载虚拟场景数据库,所述虚拟场景数据库中包括虚拟环境模型集、虚拟主播模型集、以及每个虚拟主播模型所关联的虚拟主播行为集;联动模块300,用于将所述电台节目与所述虚拟场景数据库进行联动。Correspondingly, in the embodiment of the present invention, there is also provided a system for a radio station to realize a virtual scene, please refer to FIG. The scene database, the virtual scene database includes a virtual environment model set, a virtual anchor model set, and a virtual anchor behavior set associated with each virtual anchor model; the
在本实施例中,根据电台节目的内容以及电台节目的主播显示对应的虚拟场景,有效提升用户的体验度。In this embodiment, the corresponding virtual scene is displayed according to the content of the radio program and the host of the radio program, effectively improving the user experience.
在本实施例中,所述虚拟场景数据库中还包括:每个虚拟主播模型所关联的一个或多个第一声纹音色信息。In this embodiment, the virtual scene database further includes: one or more first voiceprint timbre information associated with each virtual anchor model.
在本实施例中,所述联动模块300包括:主播模型获取模块301,用于根据所述虚拟场景数据库获取所述电台节目的主播对应的虚拟主播模型。In this embodiment, the
在本实施例中,所述主播模型获取模块301包括:声纹音色获取模块3011,用于获取电台节目的主播的第二声纹音色信息;声纹音色对比模块3012,用于将所述第二声纹音色信息与所述虚拟场景数据库中的若干所述第一声纹音色信息进行对比;主播模型选定模块3013,用于当所述第二声纹音色信息与若干所述第一声纹音色信息中的一个所述第一声纹音色信息对比相同时,则将对比相同的所述第一声纹音色信息所关联的虚拟主播模型作为电台节目的主播的虚拟主播模型。In this embodiment, the anchor
在本实施例中,所述虚拟场景数据库中还包括:每个虚拟主播情绪所关联的一个或多个第一声纹情绪信息。In this embodiment, the virtual scene database further includes: one or more first voiceprint emotion information associated with each virtual anchor emotion.
在本实施例中,所述联动模块300还包括:主播行为获取模块302,用于根据所述虚拟场景数据库获取所述电台节目的主播对应的虚拟主播行为。In this embodiment, the
在本实施例中,所述主播行为获取模块302包括:声纹情绪获取模块3021,用于获取电台节目的主播的第二声纹情绪信息;情绪信息对比模块3022,用于将所述第二声纹情绪信息与所述虚拟场景数据库中的若干第一声纹情绪信息进行对比;主播行为选定模块3023,用于当所述第二声纹情绪信息与若干所述第一声纹情绪信息中的一个所述第一声纹情绪信息对比相同时,则将对比相同的所述第一声纹情绪信息所关联的虚拟主播动作作为电台节目的主播对应的虚拟主播行为。In this embodiment, the anchor
在本实施例中,所述虚拟场景数据库中还包括:每个虚拟场景模型所关联的一个或多个第一场景关键词。In this embodiment, the virtual scene database further includes: one or more first scene keywords associated with each virtual scene model.
在本实施例中,所述联动模块300还包括:环境模型获取模块303,用于根据所述虚拟场景数据库获取所述电台节目的内容对应的虚拟环境模型。In this embodiment, the
在本实施例中,所述环境模型获取模块303包括:音频获取模块3031,用于获取电台节目的内容的音频数据;音频解析模块3032,用于对所述音频数据进行语义解析,获取所述音频数据中的第二场景关键词;场景关键词对比模块3033,用于将所述第二场景关键词与所述虚拟场景数据库中的若干第一场景关键词进行对比;场景选定模块3034,用于当所述第二场景关键词与若干所述第一场景关键词中的一个所述第一场景关键词对比相同时,则将对比相同的所述第一场景关键词所关联的虚拟场景模型作为电台节目的内容对应的虚拟环境模型。In this embodiment, the environment
在本实施例中,当车辆处于在线状态时,所述数据库加载模块200用于从云端服务器加载实时的虚拟场景数据库。In this embodiment, when the vehicle is online, the
在本实施例中,当车辆处于离线状态时,所述数据库加载模块200用于从电台加载本地预置的虚拟场景数据库。In this embodiment, when the vehicle is offline, the
在本实施例中,电台节目获取100模块为车载收音机。In this embodiment, the radio
相应的,本发明实施例中还提供了一种存储介质,其上存储有计算机指令,所述计算机指令运行时执行上述方法的步骤。Correspondingly, an embodiment of the present invention also provides a storage medium on which computer instructions are stored, and the steps of the above method are executed when the computer instructions are run.
相应的,本发明实施例中还提供了一种终端,包括存储器和处理器,所述存储器上存储有能够在所述处理器上运行的计算机指令,所述处理器运行所述计算机指令时执行上述方法的步骤。Correspondingly, an embodiment of the present invention also provides a terminal, including a memory and a processor, the memory stores computer instructions that can run on the processor, and when the processor runs the computer instructions, it executes steps of the method described above.
虽然本发明披露如上,但本发明并非限定于此。任何本领域技术人员,在不脱离本发明的精神和范围内,均可作各种更动与修改,因此本发明的保护范围应当以权利要求所限定的范围为准。Although the present invention is disclosed above, the present invention is not limited thereto. Any person skilled in the art can make various changes and modifications without departing from the spirit and scope of the present invention, so the protection scope of the present invention should be based on the scope defined in the claims.
Claims (27)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110524540.XACN115346023A (en) | 2021-05-13 | 2021-05-13 | Method and system for realizing virtual scene by radio station, storage medium and terminal |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202110524540.XACN115346023A (en) | 2021-05-13 | 2021-05-13 | Method and system for realizing virtual scene by radio station, storage medium and terminal |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN115346023Atrue CN115346023A (en) | 2022-11-15 |
Family
ID=83946885
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202110524540.XAPendingCN115346023A (en) | 2021-05-13 | 2021-05-13 | Method and system for realizing virtual scene by radio station, storage medium and terminal |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115346023A (en) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116506650A (en)* | 2023-03-31 | 2023-07-28 | 广州方硅信息技术有限公司 | Live broadcast-based virtual resource configuration method, computer equipment and storage medium |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20170087474A1 (en)* | 2015-09-30 | 2017-03-30 | Sports Maximization Inc. | System for generating scenarios to evaluate their analytical ability on the scenarios raised during the virtual game |
| CN106648096A (en)* | 2016-12-22 | 2017-05-10 | 宇龙计算机通信科技(深圳)有限公司 | Virtual reality scene-interaction implementation method and system and visual reality device |
| CN110062267A (en)* | 2019-05-05 | 2019-07-26 | 广州虎牙信息科技有限公司 | Live data processing method, device, electronic equipment and readable storage medium storing program for executing |
| CN111383346A (en)* | 2020-03-03 | 2020-07-07 | 深圳创维-Rgb电子有限公司 | Interaction method and system based on intelligent voice, intelligent terminal and storage medium |
| CN111739507A (en)* | 2020-05-07 | 2020-10-02 | 广东康云科技有限公司 | AI-based speech synthesis method, system, device and storage medium |
| CN112153600A (en)* | 2020-09-23 | 2020-12-29 | 博泰车联网(南京)有限公司 | Audio management method, device and system and computer storage medium |
- 2021
- 2021-05-13CNCN202110524540.XApatent/CN115346023A/enactivePending
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20170087474A1 (en)* | 2015-09-30 | 2017-03-30 | Sports Maximization Inc. | System for generating scenarios to evaluate their analytical ability on the scenarios raised during the virtual game |
| CN106648096A (en)* | 2016-12-22 | 2017-05-10 | 宇龙计算机通信科技(深圳)有限公司 | Virtual reality scene-interaction implementation method and system and visual reality device |
| CN110062267A (en)* | 2019-05-05 | 2019-07-26 | 广州虎牙信息科技有限公司 | Live data processing method, device, electronic equipment and readable storage medium storing program for executing |
| CN111383346A (en)* | 2020-03-03 | 2020-07-07 | 深圳创维-Rgb电子有限公司 | Interaction method and system based on intelligent voice, intelligent terminal and storage medium |
| CN111739507A (en)* | 2020-05-07 | 2020-10-02 | 广东康云科技有限公司 | AI-based speech synthesis method, system, device and storage medium |
| CN112153600A (en)* | 2020-09-23 | 2020-12-29 | 博泰车联网(南京)有限公司 | Audio management method, device and system and computer storage medium |
Non-Patent Citations (2)
| Title |
|---|
| H. GEBHARD .ETAL: "Virtual Inernet broadcasting", IEEE, 30 June 2001 (2001-06-30)* |
| 袁海波 等: "虚拟博物馆中基于场景语义的三维交互", 微计算机信息, no. 27, 25 September 2009 (2009-09-25)* |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116506650A (en)* | 2023-03-31 | 2023-07-28 | 广州方硅信息技术有限公司 | Live broadcast-based virtual resource configuration method, computer equipment and storage medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| DE112021001301T5 (en) | DIALOGUE-BASED AI PLATFORM WITH RENDERED GRAPHIC OUTPUT | |
| CN111326147B (en) | Speech recognition method, device, electronic equipment and storage medium | |
| CN109920422A (en) | Voice interaction method and device, vehicle-mounted voice interaction device and storage medium | |
| CN116168125A (en) | Virtual image and scene control method and system, intelligent cabin and vehicle | |
| WO2018095195A1 (en) | Method and device for customizing packaging box | |
| CN114092669A (en) | Information display method, device, equipment, medium and product | |
| CN117290605A (en) | Vehicle-mounted intelligent scene recommendation method, device, equipment and medium | |
| CN115346023A (en) | Method and system for realizing virtual scene by radio station, storage medium and terminal | |
| CN117618890A (en) | Interactive methods, devices, electronic devices and computer-readable storage media | |
| WO2025161799A1 (en) | Method and apparatus for generating scenario, and electronic device and storage medium | |
| CN110929078A (en) | Automobile voice image reloading method, device, equipment and storage medium | |
| CN111966221B (en) | In-vehicle interaction processing method and device | |
| US20240207735A1 (en) | Interactive information display method, apparatus, electronic device and storage medium | |
| CN111866578A (en) | Data processing method and device, electronic equipment and computer readable storage medium | |
| CN110415015A (en) | Product degree of recognition analysis method, device, terminal and computer readable storage medium | |
| CN114710553B (en) | Information acquisition method, information pushing method and terminal equipment | |
| CN112061058B (en) | Scene triggering method, device, equipment and storage medium | |
| CN115527542A (en) | Design method and device of vehicle-mounted voice assistant, terminal equipment and storage medium | |
| CN114398135A (en) | Interaction method, apparatus, electronic device, storage medium and program product | |
| CN114449297A (en) | Multimedia information processing method, computing equipment and storage medium | |
| CN115396839A (en) | Multi-person interaction method, storage medium and electronic terminal based on Internet of Vehicles | |
| US20250310283A1 (en) | Configuration method and apparatus of dialogue robot, electronic device, medium and product | |
| Li et al. | Beyond voice assistants: Exploring advantages and risks of an in-car social robot in real driving scenarios | |
| CN114302239B (en) | Car machine end voice broadcasting configuration method, device and equipment | |
| CN119517028A (en) | A method, system, device and storage medium for determining intelligent cockpit interaction mode |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| CB02 | Change of applicant information | ||
| CB02 | Change of applicant information | Country or region after:China Address after:Room 3701, No. 866 East Changzhi Road, Hongkou District, Shanghai, 200080 Applicant after:Botai vehicle networking technology (Shanghai) Co.,Ltd. Address before:201815 208, building 4, No. 1411, Yecheng Road, Jiading Industrial Zone, Jiading District, Shanghai Applicant before:Botai vehicle networking technology (Shanghai) Co.,Ltd. Country or region before:China |