CN115329085A - A social robot classification method and system - Google Patents
A social robot classification method and systemDownload PDFInfo
- Publication number
- CN115329085A CN115329085ACN202211039150.4ACN202211039150ACN115329085ACN 115329085 ACN115329085 ACN 115329085ACN 202211039150 ACN202211039150 ACN 202211039150ACN 115329085 ACN115329085 ACN 115329085A
- Authority
- CN
- China
- Prior art keywords
- target
- topic
- model
- social robot
- data set
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images







Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/951—Indexing; Web crawling techniques
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/953—Querying, e.g. by the use of web search engines
- G06F16/9536—Search customisation based on social or collaborative filtering
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/30—Semantic analysis
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/08—Learning methods
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q50/00—Information and communication technology [ICT] specially adapted for implementation of business processes of specific business sectors, e.g. utilities or tourism
- G06Q50/01—Social networking
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/237—Lexical tools
- G06F40/247—Thesauruses; Synonyms
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Databases & Information Systems (AREA)
- General Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Business, Economics & Management (AREA)
- Artificial Intelligence (AREA)
- Computational Linguistics (AREA)
- Computing Systems (AREA)
- Economics (AREA)
- General Business, Economics & Management (AREA)
- Human Resources & Organizations (AREA)
- Marketing (AREA)
- Primary Health Care (AREA)
- Strategic Management (AREA)
- Tourism & Hospitality (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Life Sciences & Earth Sciences (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Evolutionary Computation (AREA)
- Molecular Biology (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Description
Translated fromChinese技术领域technical field
本发明涉及社交机器人检测技术领域,特别是涉及一种社交机器人分类方法及系统。The invention relates to the technical field of social robot detection, in particular to a social robot classification method and system.
背景技术Background technique
随着推特、微博、微信、直播等社交网络的兴起,人们可以随时在社交网络上就不同的话题进行广泛的交流和分享。与此同时,人工智能技术的快速发展,社交机器人应运而生。With the rise of social networks such as Twitter, Weibo, WeChat, and live broadcasts, people can communicate and share extensively on different topics on social networks at any time. At the same time, with the rapid development of artificial intelligence technology, social robots came into being.
由于社交机器人形形色色,真假难辨。因此,开展对社交机器人进行检测和分类的研究是十分必要的。一方面可以帮助监管部门溯本清源,另一方面监管部门可以对不同类型的社交机器人采取不同的管控措施。对于具有正面影响的社交机器人允许它们在一定的范围内,正常开展业务和服务。而对于具有负面影响的社交机器人进行重点管控,限制其滋生和发展。从而更好的为真实用户营造一个健康、安全的网络环境,促进社会的和谐和稳定。Due to the variety of social robots, it is difficult to distinguish between true and false. Therefore, it is necessary to conduct research on the detection and classification of social robots. On the one hand, it can help the regulatory authorities to trace the source, and on the other hand, the regulatory authorities can adopt different control measures for different types of social robots. For social robots with positive influence, they are allowed to carry out business and services normally within a certain range. And focus on the control of social robots with negative impacts to limit their breeding and development. So as to better create a healthy and safe network environment for real users, and promote social harmony and stability.
目前,针对社交网络中社交机器人分类问题的研究较少,已有的研究主要通过选取社交机器人的账号特征,然后采用分类器分类,主要有以下几种:At present, there are few studies on the classification of social robots in social networks. The existing research mainly selects the account characteristics of social robots, and then uses classifiers to classify them. There are mainly the following types:
第一,有文献将异常用户分为产品营销广告发布者、发布内容与话题标签信息不符的内容污染者以及攻击、谩骂等不良言论发布者,对社交网络数据集提取用户内容、行为、属性、关系特征,选择可以有效利用多维特征并且在样本集严重不均衡时依然有效的极端梯度提升(eXtreme Gradient Boosting, XGBoost)算法构建分类模型。First, there are literatures that divide abnormal users into product marketing advertisement publishers, content polluters whose content does not match the hashtag information, and publishers of bad speech such as attacks and abuse, and extract user content, behaviors, attributes, Relational features, choose an extreme gradient boosting (eXtreme Gradient Boosting, XGBoost) algorithm that can effectively use multi-dimensional features and is still effective when the sample set is severely unbalanced to build a classification model.
第二,有文献将社交账号分为主动骚扰型垃圾用户、过度关注型垃圾用户、重复发送型垃圾用户、营销广告型垃圾用户和正常用户,首先选择一对多支持向量机(SupportVectorMachine,SVM)来构造多类分类器,然后采用模糊聚类来进行模糊处理,以解决一对多SVM中的漏分问题。Second, some literature divides social accounts into active harassment spam users, excessive attention spam users, repetitive spam users, marketing and advertising spam users, and normal users. First, one-to-many support vector machine (Support Vector Machine, SVM) To construct a multi-class classifier, and then use fuzzy clustering to perform fuzzy processing to solve the problem of missing points in one-to-many SVM.
第三,有文献提出了一种同时考虑良性机器人和恶意机器人的分类方法。将社交机器人分为广播机器人、消费机器人和垃圾邮件机器人三类。广播机器人由特定组织管理,主要用于信息传播目的。消费机器人用于聚合来自不同来源的内容并提供更新服务,而垃圾邮件机器人用于传递恶意内容,主要涵盖恶意机器人。该文首先通过绘制几个关键属性的累积分布函数(CDF),以便了解机器人和人类账户的活动模式。然后提出相应的分类特征,最后采用朴素贝叶斯、随机森林、支持向量机和逻辑回归模型进行分类。Third, some literature proposes a classification method that considers both benign and malicious bots. Divide social robots into three categories: broadcasting robots, consumer robots and spam robots. Broadcast bots are managed by specific organizations and are mainly used for information dissemination purposes. Consumption bots are used to aggregate content from different sources and provide update services, while spam bots are used to deliver malicious content and mainly cover malicious bots. The paper begins by plotting the cumulative distribution function (CDF) of several key attributes in order to understand the activity patterns of bot and human accounts. Then the corresponding classification features are proposed, and finally the naive Bayesian, random forest, support vector machine and logistic regression models are used for classification.
第四,有文献将社交账号分为正常用户、认证用户、推广员和趋势劫持者。其中,推广员包括发布包含恶意url信息的账户。趋势劫持者包括为了宣传特定的产品或服务,发布与主题事件不相关推文的账户,以及为了意见操纵和政治宣传,发布与主题事件相关推文的账户。该文献根据相似账户的共享应用程序链接相似账户,并在生成的相似图上构建马尔可夫随机场模型以进行分类。Fourth, some literature divides social accounts into normal users, authenticated users, promoters, and trend hijackers. Among them, promoters include accounts that publish information containing malicious URLs. Trend hijackers include accounts that tweet unrelated to a topical event in order to promote a specific product or service, as well as accounts that tweet about a topical event for the purposes of opinion manipulation and political propaganda. This paper links similar accounts based on their shared applications and builds a Markov random field model on the generated similarity graph for classification.
以上文献均通过调研提取各种账号特征,然后进行特征选择或绘制CDF 曲线检验选取的特征是否有效,最后采用机器学习方法进行多分类。但是,这些文献没有明确地给出不同类别的划分标准,也没有提出针对性的特征以区分不同类别的社交机器人,可解释性较差。The above literatures extract various account features through research, then perform feature selection or draw CDF curves to test whether the selected features are valid, and finally use machine learning methods for multi-classification. However, these literatures do not clearly give the classification criteria for different categories, nor do they propose targeted features to distinguish different categories of social robots, and the interpretability is poor.
第五,有文献通过分析每一类社交机器人发布推文的特点,提出了更具有针对性的检测特征。将社交机器人分为机器人、电子人和人类垃圾邮件发送者。其中机器人的推文使用的词汇非常有限,推文遵循一种非常结构化的模式。电子人倾向于从其他来源复制内容,它们的词汇量比普通机器人大得多。垃圾邮件发送者滥用算法发布一系列几乎无法区分的推文,以欺骗Twitter的垃圾邮件检测协议。相较于选择普通账号特征的方法,该类方法深入分析了不同类型机器人的差异,总结规律并提取特征,进一步推进了社交机器人分类方法的研究。Fifth, some literature proposes more targeted detection features by analyzing the characteristics of tweets issued by each type of social robot. Divide social bots into bots, cyborgs, and human spammers. The bot's tweets use a very limited vocabulary, and the tweets follow a very structured pattern. Cyborgs tend to copy content from other sources, and their vocabularies are much larger than regular bots. Spammers abused algorithms to post a series of nearly indistinguishable tweets in order to fool Twitter's spam detection protocols. Compared with the method of selecting the characteristics of ordinary accounts, this type of method deeply analyzes the differences of different types of robots, summarizes the rules and extracts features, and further promotes the research on classification methods of social robots.
综上可以发现,现有研究都是依据社交机器人的行为表现和博文内容提取特征以进行分类,但是机器人账号的行为和言论可能会依据检测机制、生成技术的变化而做出调整。因此,现有分类方案不能很好的识别与模型范例形式不同的社交机器人,只能学习已有类型机器人的特征,无法随时间进化应变。所以,设计一个能够适应不断变化的社交机器人的分类方法是至关重要的。To sum up, it can be found that the existing research is based on the behavior performance of social robots and the characteristics of blog content extraction to classify, but the behavior and speech of robot accounts may be adjusted according to changes in detection mechanisms and generation technologies. Therefore, existing classification schemes cannot well identify social robots that are different from the model paradigm, and can only learn the characteristics of existing types of robots, and cannot evolve and adapt over time. Therefore, it is crucial to design a taxonomy that can adapt to changing social robots.
发明内容Contents of the invention
基于此,本发明实施例提供一种社交机器人分类方法及系统,以提高分类方法的通用性和可解释性。Based on this, an embodiment of the present invention provides a social robot classification method and system, so as to improve the versatility and explainability of the classification method.
为实现上述目的,本发明提供了如下方案:To achieve the above object, the present invention provides the following scheme:
一种社交机器人分类方法,包括:A method for classifying social robots, comprising:
获取目标社交机器人关于目标话题的博文内容;Obtain the blog post content of the target social robot on the target topic;
将所述目标社交机器人关于目标话题的博文内容输入社交机器人分类模型中,得到所述目标社交机器人的类别;所述类别包括内容污染者、知识传播者和新闻评论者;所述社交机器人分类模型包括话题相关性目标模型和观点句识别目标模型;Input the blog post content of the target social robot about the target topic into the social robot classification model to obtain the category of the target social robot; the category includes content polluters, knowledge disseminators and news commentators; the social robot classification model Including topic relevance target model and opinion sentence recognition target model;
所述内容污染者表示所述目标社交机器人发布的博文内容与所述目标话题不相关;所述知识传播者表示所述目标社交机器人发布的博文内容与所述目标话题相关,且发表意见以及表达观点;所述新闻评论者表示所述目标社交机器人发布的博文内容与所述目标话题相关,且传播信息以及说明客观事件;The content polluter indicates that the content of blog posts published by the target social robot is not related to the target topic; the knowledge spreader indicates that the content of blog posts published by the target social robot is related to the target topic, and expresses opinions and Opinion: The news commentator indicates that the content of the blog post published by the target social robot is related to the target topic, and disseminates information and explains objective events;
其中,所述社交机器人分类模型的确定方法为:Wherein, the determination method of the social robot classification model is:
基于迁移学习的方法构建源域数据集;所述源域数据集包括第一类数据集和第二类数据集;所述第一类数据集包括在微博平台上爬取的在设定话题下的账号发布的原创博文内容、在与设定话题相关的话题下的账号发布的原创博文内容以及对应分类标签;所述分类标签包括所述账号属于内容污染者或者所述账号数据知识传播者;所述第二类数据集包括由社交机器人样本数据生成模型生成的已标注为新闻评论者的账号发布的观点型博文;The source domain data set is constructed based on the method of transfer learning; the source domain data set includes the first type of data set and the second type of data set; the first type of data set includes crawling on the Weibo platform in the set topic The original blog post content published by the account under the set topic, the original blog post content published by the account under the topic related to the set topic, and the corresponding classification tags; the classification tags include whether the account belongs to a content polluter or the account data knowledge disseminator ; The second type of data set includes opinion-type blog posts issued by accounts marked as news reviewers generated by the social robot sample data generation model;
基于社交机器人识别模型确定目标域数据集;所述目标域数据集包括已标注类别的社交机器人真实博文内容;Determine the target domain data set based on the social robot identification model; the target domain data set includes the real blog post content of the social robot that has marked the category;
对所述源域数据集中的设定话题进行扩充和话题内容压缩,得到话题扩充序列;Expanding and compressing topic content in the set topic in the source domain data set to obtain a topic expansion sequence;
根据所述源域数据集、所述目标域数据集、所述话题扩充序列和孪生网络,确定所述话题相关性目标模型;所述话题相关性目标模型用于识别内容污染者;Determine the topic relevance target model according to the source domain dataset, the target domain dataset, the topic expansion sequence and the Siamese network; the topic relevance target model is used to identify content polluters;
根据所述源域数据集、所述目标域数据集、基于规则的观点句识别方法以及文本分类模型,确定所述观点句识别目标模型;所述观点句识别目标模型用于知识传播者和新闻评论者。According to the source domain dataset, the target domain dataset, the rule-based viewpoint sentence recognition method and the text classification model, determine the viewpoint sentence recognition target model; the viewpoint sentence recognition target model is used for knowledge disseminator and news Comment by.
可选地,所述根据所述源域数据集、所述目标域数据集、所述话题扩充序列和孪生网络,确定所述话题相关性目标模型,具体包括:Optionally, the determining the topic relevance target model according to the source domain data set, the target domain data set, the topic expansion sequence and the twin network specifically includes:
将所述源域数据集和所述话题扩充序列输入孪生网络,以均方差误差函数最小为目标对所述孪生网络进行初步训练,确定所述孪生网络的相似度阈值;所述源域数据集中的账号属于内容污染者时,所述原创博文内容与所述话题扩充序列的相似度小于所述相似度阈值;Input the source domain data set and the topic expansion sequence into the twin network, and conduct preliminary training on the twin network with the goal of minimizing the mean square error function, and determine the similarity threshold of the twin network; When the account belongs to the content polluter, the similarity between the original blog post content and the topic expansion sequence is less than the similarity threshold;
初步训练确定好相似度阈值的孪生网络为话题相关性源模型;Preliminary training to determine the similarity threshold Siamese network as the source model of topic relevance;
采用所述目标域数据集和对应的目标域话题填充序列,对所述话题相关性源模型的相似度阈值进行微调;Fine-tuning the similarity threshold of the topic correlation source model by using the target domain data set and the corresponding target domain topic filling sequence;
将相似度阈值微调后的话题相关性源模型确定为所述话题相关性目标模型。The topic correlation source model after fine-tuning the similarity threshold is determined as the topic correlation target model.
可选地,所述根据所述源域数据集、所述目标域数据集、基于规则的观点句识别方法以及文本分类模型,确定所述观点句识别目标模型,具体包括:Optionally, the determining the viewpoint sentence recognition target model according to the source domain dataset, the target domain dataset, the rule-based viewpoint sentence recognition method and the text classification model specifically includes:
提取所述源域数据集的句子特征;所述句子特征包括关键词特征、位置特征、语义特征和长度特征;Extracting the sentence features of the source domain data set; the sentence features include keyword features, location features, semantic features and length features;
对所述句子特征进行归一化处理并加权求和,得到每条句子的观点句得分;Carry out normalization processing and weighted summation to described sentence feature, obtain the viewpoint sentence score of each sentence;
根据所述观点句得分确定基于规则的观点句识别模型的观点句阈值;Determine the opinion sentence threshold based on the opinion sentence recognition model of the rule according to the opinion sentence score;
采用所述目标域数据集中观点句得分小于所述观点句阈值的数据对卷积神经网络进行训练,并将训练好的卷积神经网络确定为文本分类模型;Using the opinion sentence score in the target domain data set to train the convolutional neural network with a score less than the opinion sentence threshold, and determine the trained convolutional neural network as a text classification model;
观点句阈值确定的基于规则的观点句识别模型和所述文本分类模型构成观点句识别源模型;The rule-based viewpoint sentence recognition model and the text classification model determined by the viewpoint sentence threshold value constitute a viewpoint sentence recognition source model;
采用所述目标域数据集对所述观点句识别源模型中的观点句阈值和卷积神经网络参数进行微调;Using the target domain data set to fine-tune the viewpoint sentence threshold and convolutional neural network parameters in the viewpoint sentence recognition source model;
将微调后的观点句识别源模型确定为所述观点句识别目标模型。The fine-tuned viewpoint sentence recognition source model is determined as the viewpoint sentence recognition target model.
可选地,所述对所述源域数据集中的设定话题进行扩充和话题内容压缩,得到话题扩充序列,具体包括:Optionally, the step of expanding and compressing topic content in the set topic in the source domain data set to obtain a topic expansion sequence specifically includes:
爬取与所述设定话题相关的话题的导语内容,并将所有相关话题的导语内容生成扩充文档;Crawling the lead content of topics related to the set topic, and generating extended documents for the lead content of all related topics;
采用用于文本的基于图的排序算法对所述扩充文档抽取关键词,得到话题扩充序列。A graph-based sorting algorithm for text is used to extract keywords from the expanded document to obtain a topic expanded sequence.
可选地,所述基于社交机器人识别模型确定目标域数据集,具体包括:Optionally, the determining the target domain data set based on the social robot recognition model specifically includes:
采用社交机器人识别模型检验得到社交机器人类型的真实数据;Use the social robot identification model test to get the real data of the social robot type;
对所述真实数据进行人工标注和博文去重后,得到有效社交机器人数据;After manual labeling and deduplication of blog posts on the real data, effective social robot data is obtained;
将所述有效社交机器人数据确定为目标域数据集。The effective social robot data is determined as a target domain data set.
可选地,所述孪生网络为预训练过的基于Transformer的双向编码器。Optionally, the Siamese network is a pre-trained Transformer-based bidirectional encoder.
可选地,所述将所述目标社交机器人关于目标话题的博文内容输入社交机器人分类模型中,得到所述目标社交机器人的类别,具体包括:Optionally, inputting the blog post content of the target social robot on the target topic into the social robot classification model to obtain the category of the target social robot, specifically includes:
将所述目标社交机器人关于目标话题的博文内容输入话题相关性目标模型,识别所述目标社交机器人是否为内容污染者;Input the blog post content of the target social robot about the target topic into the topic relevance target model, and identify whether the target social robot is a content polluter;
若所述目标社交机器人不为内容污染者,则将所述目标社交机器人关于目标话题的博文内容输入所述观点句识别目标模型,识别所述目标社交机器人是否为知识传播者或为新闻评论者。If the target social robot is not a content polluter, then input the blog post content of the target social robot on the target topic into the opinion sentence recognition target model to identify whether the target social robot is a knowledge disseminator or a news commentator .
本发明还提供了一种用于实现上述所述方法的社交机器人分类系统,包括:The present invention also provides a social robot classification system for realizing the method described above, including:
博文内容获取模块,用于获取目标社交机器人关于目标话题的博文内容;The blog post content acquisition module is used to obtain the blog post content of the target social robot on the target topic;
分类识别模块,用于将所述目标社交机器人关于目标话题的博文内容输入社交机器人分类模型中,得到所述目标社交机器人的类别;所述类别包括内容污染者、知识传播者和新闻评论者;所述社交机器人分类模型包括话题相关性目标模型和观点句识别目标模型;Classification recognition module, is used for inputting the blog post content of described target social robot about target topic in social robot classification model, obtains the category of described target social robot; Said category includes content polluter, knowledge spreader and news reviewer; The social robot classification model includes a topic relevance target model and an opinion sentence recognition target model;
所述内容污染者表示所述目标社交机器人发布的博文内容与所述目标话题不相关;所述知识传播者表示所述目标社交机器人发布的博文内容与所述目标话题相关,且发表意见以及表达观点;所述新闻评论者表示所述目标社交机器人发布的博文内容与所述目标话题相关,且传播信息以及说明客观事件;The content polluter indicates that the content of blog posts published by the target social robot is not related to the target topic; the knowledge spreader indicates that the content of blog posts published by the target social robot is related to the target topic, and expresses opinions and Opinion: The news commentator indicates that the content of the blog post published by the target social robot is related to the target topic, and disseminates information and explains objective events;
分类模型确定模块,用于确定所述社交机器人分类模型;A classification model determination module, configured to determine the classification model of the social robot;
所述分类模型确定模块,具体包括:The classification model determination module specifically includes:
源域数据集构建单元,用于基于迁移学习的方法构建源域数据集;所述源域数据集包括第一类数据集和第二类数据集;所述第一类数据集包括在微博平台上爬取的在设定话题下的账号发布的原创博文内容、在与设定话题相关的话题下的账号发布的原创博文内容以及对应分类标签;所述分类标签包括所述账号属于内容污染者或者所述账号数据知识传播者;所述第二类数据集包括由社交机器人样本数据生成模型生成的已标注为新闻评论者的账号发布的观点型博文;The source domain data set construction unit is used to construct the source domain data set based on the method of transfer learning; the source domain data set includes the first type data set and the second type data set; the first type data set is included in the microblog The original blog post content published by the account under the set topic, the original blog post content published by the account under the topic related to the set topic, and the corresponding classification tags crawled on the platform; the classification tags include that the account belongs to content pollution or the knowledge disseminator of the account data; the second type of data set includes opinion-type blog posts published by accounts marked as news commentators generated by the social robot sample data generation model;
目标域数据集构建单元,用于基于社交机器人识别模型确定目标域数据集;所述目标域数据集包括已标注类别的社交机器人真实博文内容;The target domain data set construction unit is used to determine the target domain data set based on the social robot recognition model; the target domain data set includes the real blog post content of the social robot that has marked the category;
话题扩充及压缩模块,用于对所述源域数据集中的设定话题进行扩充和话题内容压缩,得到话题扩充序列;The topic expansion and compression module is used to expand and compress topic content in the set topic in the source domain data set to obtain a topic expansion sequence;
话题相关性目标模型确定模块,用于根据所述源域数据集、所述目标域数据集、所述话题扩充序列和孪生网络,确定所述话题相关性目标模型;所述话题相关性目标模型用于识别内容污染者;Topic correlation target model determination module, used to determine the topic correlation target model according to the source domain data set, the target domain data set, the topic expansion sequence and the twin network; the topic correlation target model To identify content polluters;
观点句识别目标模型确定模块,用于根据所述源域数据集、所述目标域数据集、基于规则的观点句识别方法以及文本分类模型,确定所述观点句识别目标模型;所述观点句识别目标模型用于知识传播者和新闻评论者。The viewpoint sentence recognition target model determination module is used to determine the viewpoint sentence recognition target model according to the source domain data set, the target domain data set, the rule-based viewpoint sentence recognition method and the text classification model; the viewpoint sentence Recognition target models are used for knowledge disseminator and news commentator.
与现有技术相比,本发明的有益效果是:Compared with prior art, the beneficial effect of the present invention is:
本发明实施例提出了一种社交机器人分类方法及系统,所述方法包括:获取目标社交机器人关于目标话题的博文内容;将博文内容输入社交机器人分类模型得到目标社交机器人的类别;社交机器人分类模型包括话题相关性目标模型和观点句识别目标模型;社交机器人分类模型的确定方法为:基于迁移学习构建源域数据集;基于社交机器人识别模型确定目标域数据集;对源域数据集中的设定话题进行扩充和内容压缩;根据源域数据集、目标域数据集、压缩后的话题扩充序列和孪生网络确定话题相关性目标模型;根据源域数据集、目标域数据集、基于规则的观点句识别方法和文本分类模型确定观点句识别目标模型。本发基于迁移学习实现社交机器人的分类,对社交机器人发布的博文内容进行文本挖掘,提高了分类方法的通用性和可解释性。The embodiment of the present invention proposes a social robot classification method and system, the method comprising: obtaining the blog post content of the target social robot on the target topic; inputting the blog post content into the social robot classification model to obtain the category of the target social robot; the social robot classification model Including topic relevance target model and opinion sentence recognition target model; the determination method of social robot classification model is: constructing source domain data set based on transfer learning; determining target domain data set based on social robot recognition model; setting of source domain data set Topic expansion and content compression; according to the source domain data set, target domain data set, compressed topic expansion sequence and twin network to determine the topic relevance target model; according to the source domain data set, target domain data set, rule-based opinion sentence The recognition method and text classification model determine the target model of opinion sentence recognition. The present invention realizes the classification of social robots based on migration learning, and performs text mining on the content of blog posts published by social robots, which improves the versatility and interpretability of the classification method.
附图说明Description of drawings
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。In order to more clearly illustrate the technical solutions in the embodiments of the present invention or the prior art, the following will briefly introduce the accompanying drawings required in the embodiments. Obviously, the accompanying drawings in the following description are only some of the present invention. Embodiments, for those of ordinary skill in the art, other drawings can also be obtained according to these drawings without paying creative labor.
图1为本发明实施例提供的社交机器人分类方法的流程图;Fig. 1 is the flowchart of the social robot classification method provided by the embodiment of the present invention;
图2为本发明实施例提供的社交机器人分类模型的确定方法的流程图;Fig. 2 is a flowchart of a method for determining a social robot classification model provided by an embodiment of the present invention;
图3为本发明实施例提供的社交机器人分类方法的整体过程图;3 is an overall process diagram of a social robot classification method provided by an embodiment of the present invention;
图4为本发明实施例提供的话题相关性模型框架图;FIG. 4 is a framework diagram of a topic correlation model provided by an embodiment of the present invention;
图5为本发明实施例提供的SBERT模型架构图;Fig. 5 is the SBERT model architecture diagram provided by the embodiment of the present invention;
图6为本发明实施例提供的知识传播者和新闻评论者识别流程图;FIG. 6 is a flowchart for identifying knowledge disseminators and news commentators provided by an embodiment of the present invention;
图7为本发明实施例提供的基于网络的深度迁移学习模型框架图;FIG. 7 is a framework diagram of a network-based deep migration learning model provided by an embodiment of the present invention;
图8为本发明实施例提供的社交机器人分类系统的结构图。Fig. 8 is a structural diagram of a social robot classification system provided by an embodiment of the present invention.
具体实施方式Detailed ways
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。The following will clearly and completely describe the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some, not all, embodiments of the present invention. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。In order to make the above objects, features and advantages of the present invention more comprehensible, the present invention will be further described in detail below in conjunction with the accompanying drawings and specific embodiments.
术语解释:Explanation of terms:
社交机器人:社交机器人是目前活跃于社交网络上的一种虚拟机器人,它实际上是一种自动化程序,能够利用社交账号,运用人工智能等相关技术模仿人类行为在社交网络中活动。Social robot: A social robot is a virtual robot that is currently active on social networks. It is actually an automated program that can use social accounts and use artificial intelligence and other related technologies to imitate human behavior in social networks.
内容污染者:内容污染者是指发布与话题不相关博文的社交机器人账号。Content Polluter: A content polluter is a social robot account that posts irrelevant blog posts.
新闻评论者:新闻评论者是指发布内容与话题相关且发表意见、表达观点的社交机器人账号。News commenters: News commenters refer to social robot accounts that publish content related to topics and express opinions and opinions.
知识传播者:知识传播者是指发布内容与话题相关且传播信息、说明事件客观情况的社交机器人账号。Knowledge disseminator: Knowledge disseminator refers to a social robot account that publishes content related to the topic, disseminates information, and explains the objective situation of the event.
SBERT(Sentence Embeddings using Siamese BERT-Networks):基于预训练过的BERT的孪生网络模型。SBERT模型的子网络都使用BERT模型,且两个BERT模型共享参数。当对比A,B两个句子相似度时,它们分别输入BERT 网络,输出是两组表征句子的向量,然后计算二者的相似度。SBERT (Sentence Embeddings using Siamese BERT-Networks): A twin network model based on pre-trained BERT. The sub-networks of the SBERT model all use the BERT model, and the two BERT models share parameters. When comparing the similarity of the two sentences of A and B, they are respectively input into the BERT network, and the output is two sets of vectors representing the sentences, and then the similarity between the two is calculated.
TextCNN:文本分类模型,利用卷积神经网络(CNN)来对处理文本分类问题。TextCNN: Text classification model, using convolutional neural network (CNN) to deal with text classification problems.
TextRank算法:一种用于文本的基于图的排序算法,其基本思想是将文档看作一个词的网络,该网络中的链接表示词与词之间的语义关系。TextRank 算法主要包括:关键词抽取、关键短语抽取、关键句抽取。TextRank algorithm: a graph-based sorting algorithm for text, its basic idea is to regard the document as a network of words, and the links in the network represent the semantic relationship between words and words. The TextRank algorithm mainly includes: keyword extraction, key phrase extraction, and key sentence extraction.
BERT(BidirectionalEncoder Representations from Transformer):基于Transformer的双向编码器表示,是一个预训练的语言表征模型。BERT (BidirectionalEncoder Representations from Transformer): Transformer-based bidirectional encoder representation is a pre-trained language representation model.
pooling操作:池化操作,是CNN中非常常见的一种操作,池化操作通常也叫做子采样(Subsampling)或降采样(Downsampling),在构建卷积神经网络时,往往会用在卷积层之后,通过池化来降低卷积层输出的特征维度,有效减少网络参数的同时还可以防止过拟合现象。Pooling operation: Pooling operation is a very common operation in CNN. Pooling operation is usually also called subsampling (Subsampling) or downsampling (Downsampling). When building a convolutional neural network, it is often used in the convolutional layer. After that, pooling is used to reduce the feature dimension of the output of the convolutional layer, effectively reducing network parameters and preventing overfitting.
MEAN策略:mean-pooling(平均池化)是池化策略的一种。MEAN strategy: mean-pooling (average pooling) is a kind of pooling strategy.
Word2Vec词向量模型:Word2Vec是一种基于神经网络的语言模型,也是一种词汇表征方法。Word2Vec包括两种结构:skip-gram(跳字模型)和CBOW (连续词袋模型),但本质上都是一种词汇降维的操作。Word2Vec word vector model: Word2Vec is a neural network-based language model and a vocabulary representation method. Word2Vec includes two structures: skip-gram (skip word model) and CBOW (continuous bag of words model), but they are essentially a vocabulary reduction operation.
由于每个社交机器人的目的是唯一不变的,一切的行为都是为了达到最终的目的。所以,相比于分析行为以提取形式特征的方法,直接研究社交机器人的目的将更加有效。不同类型的社交机器人为达到自身的目的,针对同一事件会采取不同的行动,发表不同的言论,对事件的发展趋势做出不同的贡献。Since the purpose of each social robot is unique and constant, all behaviors are to achieve the ultimate purpose. Therefore, it will be more effective to study the purpose of social robots directly than to analyze behaviors to extract formal features. In order to achieve their own goals, different types of social robots will take different actions for the same event, make different remarks, and make different contributions to the development trend of the event.
因此,针对现有技术中的上述不足,本发明提供了一种基于迁移学习的社交机器人分类方法,对社交机器人发布的博文进行文本挖掘,通过文本挖掘结果判定社交机器人在特定事件中所发挥的作用,由此完成社交机器人的分类。Therefore, in view of the above-mentioned deficiencies in the prior art, the present invention provides a social robot classification method based on transfer learning, which performs text mining on blog posts issued by social robots, and judges the role played by social robots in specific events through text mining results. function, thus completing the classification of social robots.
针对已有文献分类方法无法适应新型社交机器人分类任务的问题,本发明将从社交机器人的目的这个角度来考虑,提出更具有通用性、可解释性的社交机器人类别划分方法。并且,现有社交机器人分类研究还普遍存在严重的样本不足问题,所以,本发明还将研究如何在样本数据有限的情况下设计效果更好的社交机器人分类方法。Aiming at the problem that existing literature classification methods cannot adapt to the classification tasks of new social robots, the present invention will consider from the perspective of the purpose of social robots, and propose a more general and interpretable classification method for social robots. Moreover, the existing social robot classification research generally has a serious problem of insufficient samples. Therefore, the present invention will also study how to design a social robot classification method with better effect in the case of limited sample data.
针对新浪微博平台特定话题下的博文相关性判断任务中话题文本语义稀疏且话题文本与微博文本长度相差较大的问题,本发明将在已有文本相关性判断模型的基础上提出更有效的相关性判别方法,从而丰富话题文本的语义信息,更准确的识别出内容污染者。Aiming at the problem that the semantics of the topic text is sparse and the length of the topic text and the microblog text differ greatly in the task of judging the relevance of blog posts under a specific topic on the Sina Weibo platform, the present invention will propose a more effective method based on the existing text correlation judgment model. The correlation discrimination method can enrich the semantic information of the topic text and identify content polluters more accurately.
针对依据社交机器人观点句生成原理生成的观点句缺乏人类写作技巧并不具有很好的观点句特征,难以用现有的观点句识别方法进行检测的问题,本发明将制定适当的观点句识别规则,构建观点句识别模型,从重点关注语料库关键词角度进行识别,弥补因为生成观点句不流畅、信息不全而难以用现有方法识别的缺点,由此提高观点句识别的准确率。Aiming at the problem that the opinion sentences generated based on the principle of social robot opinion sentence generation lack human writing skills and do not have good opinion sentence characteristics, and are difficult to detect with existing opinion sentence recognition methods, the present invention will formulate appropriate opinion sentence recognition rules , build an opinion sentence recognition model, focus on the key words of the corpus, and make up for the shortcomings of existing methods that are difficult to identify because the generated opinion sentences are not smooth and have incomplete information, thereby improving the accuracy of opinion sentence recognition.
图1为本发明实施例提供的社交机器人分类方法的流程图。参见图1,本实施例的社交机器人分类方法,包括:Fig. 1 is a flowchart of a social robot classification method provided by an embodiment of the present invention. Referring to Fig. 1, the social robot classification method of the present embodiment includes:
步骤101:获取目标社交机器人关于目标话题的博文内容。Step 101: Obtain blog post content of a target social robot on a target topic.
步骤102:将所述目标社交机器人关于目标话题的博文内容输入社交机器人分类模型中,得到所述目标社交机器人的类别;所述类别包括内容污染者、知识传播者和新闻评论者;所述社交机器人分类模型包括话题相关性目标模型和观点句识别目标模型。Step 102: Input the blog post content of the target social robot on the target topic into the social robot classification model to obtain the category of the target social robot; the categories include content polluters, knowledge disseminators and news commentators; the social robot The robot classification model includes a topic relevance target model and an opinion sentence recognition target model.
所述内容污染者表示所述目标社交机器人发布的博文内容与所述目标话题不相关;所述知识传播者表示所述目标社交机器人发布的博文内容与所述目标话题相关,且发表意见以及表达观点;所述新闻评论者表示所述目标社交机器人发布的博文内容与所述目标话题相关,且传播信息以及说明客观事件。The content polluter indicates that the content of blog posts published by the target social robot is not related to the target topic; the knowledge spreader indicates that the content of blog posts published by the target social robot is related to the target topic, and expresses opinions and Opinion: The news commentator indicates that the content of the blog post published by the target social robot is related to the target topic, and disseminates information and explains objective events.
所述步骤102,具体包括:The
将所述目标社交机器人关于目标话题的博文内容输入话题相关性目标模型,识别所述目标社交机器人是否为内容污染者。Input the target social robot's blog post content on the target topic into the topic relevance target model to identify whether the target social robot is a content polluter.
若所述目标社交机器人不为内容污染者,则将所述目标社交机器人关于目标话题的博文内容输入所述观点句识别目标模型,识别所述目标社交机器人是否为知识传播者或为新闻评论者。If the target social robot is not a content polluter, then input the blog post content of the target social robot on the target topic into the opinion sentence recognition target model to identify whether the target social robot is a knowledge disseminator or a news commentator .
图2为本发明实施例提供的社交机器人分类模型的确定方法的流程图。参见图2,所述社交机器人分类模型的确定方法为:FIG. 2 is a flowchart of a method for determining a social robot classification model provided by an embodiment of the present invention. Referring to Fig. 2, the determination method of described social robot classification model is:
步骤201:基于迁移学习的方法构建源域数据集;所述源域数据集包括第一类数据集和第二类数据集。所述第一类数据集包括在微博平台上爬取的在设定话题下的账号发布的原创博文内容、在与设定话题相关的话题下的账号发布的原创博文内容以及对应分类标签;所述分类标签包括所述账号属于内容污染者或者所述账号数据知识传播者;所述第二类数据集包括由社交机器人样本数据生成模型生成的已标注为新闻评论者的账号发布的观点型博文。Step 201: Construct a source domain dataset based on a transfer learning method; the source domain dataset includes a first-type dataset and a second-type dataset. The first type of data set includes the original blog post content published by the account under the set topic crawled on the Weibo platform, the original blog post content published by the account under the topic related to the set topic, and the corresponding classification labels; The classification label includes that the account belongs to a content polluter or the knowledge disseminator of the account data; the second type of data set includes the opinion type generated by the social robot sample data generation model that has been marked as a news reviewer’s account. blog post.
步骤202:基于社交机器人识别模型确定目标域数据集;所述目标域数据集包括已标注类别的社交机器人真实博文内容。Step 202: Determine the target domain data set based on the social robot recognition model; the target domain data set includes the real blog post content of the social robot that has been labeled.
步骤202,具体包括:Step 202 specifically includes:
采用社交机器人识别模型检验得到社交机器人类型的真实数据。The real data of social robot types are obtained by using the social robot identification model test.
对所述真实数据进行人工标注和博文去重后,得到有效社交机器人数据。After manual labeling and deduplication of blog posts on the real data, effective social robot data is obtained.
将所述有效社交机器人数据确定为目标域数据集。The effective social robot data is determined as a target domain data set.
步骤203:对所述源域数据集中的设定话题进行扩充和话题内容压缩,得到话题扩充序列。Step 203: Expanding and compressing the content of the topic set in the source domain dataset to obtain a topic expansion sequence.
步骤203,具体包括:Step 203 specifically includes:
爬取与所述设定话题相关的话题的导语内容,并将所有相关话题的导语内容生成扩充文档。Crawling lead content of topics related to the set topic, and generating extended documents from lead content of all related topics.
采用用于文本的基于图的排序(TextRank)算法对所述扩充文档抽取关键词,得到话题扩充序列。A graph-based ranking (TextRank) algorithm for text is used to extract keywords from the expanded document to obtain a topic expanded sequence.
步骤204:根据所述源域数据集、所述目标域数据集、所述话题扩充序列和孪生网络,确定所述话题相关性目标模型;所述话题相关性目标模型用于识别内容污染者。Step 204: Determine the topic relevance target model according to the source domain dataset, the target domain dataset, the topic expansion sequence and the Siamese network; the topic relevance target model is used to identify content polluters.
步骤204,具体包括:Step 204 specifically includes:
构建孪生网络;所述孪生网络为预训练过的基于Transformer的双向编码器(SBERT)。Construct a twin network; the twin network is a pre-trained Transformer-based bidirectional encoder (SBERT).
将所述源域数据集和所述话题扩充序列输入孪生网络,以均方差误差函数最小为目标对所述孪生网络进行初步训练,确定所述孪生网络的相似度阈值;所述源域数据集中的账号属于内容污染者时,所述原创博文内容与所述话题扩充序列的相似度小于所述相似度阈值。Input the source domain data set and the topic expansion sequence into the twin network, and conduct preliminary training on the twin network with the goal of minimizing the mean square error function, and determine the similarity threshold of the twin network; When the account of is a content polluter, the similarity between the original blog post content and the topic expansion sequence is less than the similarity threshold.
初步训练确定好相似度阈值的孪生网络为话题相关性源模型。The Siamese network whose similarity threshold is determined by preliminary training is the source model of topic relevance.
采用所述目标域数据集和对应的目标域话题填充序列,对所述话题相关性源模型的相似度阈值进行微调。The similarity threshold of the topic correlation source model is fine-tuned by using the target domain data set and the corresponding target domain topic filling sequence.
将相似度阈值微调后的话题相关性源模型确定为所述话题相关性目标模型。The topic correlation source model after fine-tuning the similarity threshold is determined as the topic correlation target model.
步骤205:根据所述源域数据集、所述目标域数据集、基于规则的观点句识别方法以及文本分类模型(TextCNN),确定所述观点句识别目标模型;所述观点句识别目标模型用于知识传播者和新闻评论者。Step 205: According to the source domain dataset, the target domain dataset, the rule-based viewpoint sentence recognition method and the text classification model (TextCNN), determine the viewpoint sentence recognition target model; the viewpoint sentence recognition target model is used For knowledge disseminators and news commentators.
步骤205,具体包括:Step 205 specifically includes:
提取所述源域数据集的句子特征;所述句子特征包括关键词特征、位置特征、语义特征和长度特征。Sentence features of the source domain data set are extracted; the sentence features include keyword features, position features, semantic features and length features.
对所述句子特征进行归一化处理并加权求和,得到每条句子的观点句得分。The sentence features are normalized and weighted and summed to obtain the opinion sentence score of each sentence.
根据所述观点句得分确定基于规则的观点句识别模型的观点句阈值。The viewpoint sentence threshold of the rule-based viewpoint sentence recognition model is determined according to the viewpoint sentence score.
采用所述目标域数据集中观点句得分小于所述观点句阈值的数据对卷积神经网络进行训练,并将训练好的卷积神经网络确定为文本分类模型。The convolutional neural network is trained by using the data whose opinion sentence score in the target domain data set is less than the opinion sentence threshold, and the trained convolutional neural network is determined as a text classification model.
观点句阈值确定的基于规则的观点句识别模型和所述文本分类模型构成观点句识别源模型。The rule-based viewpoint sentence recognition model determined by the viewpoint sentence threshold and the text classification model constitute a viewpoint sentence recognition source model.
采用所述目标域数据集对所述观点句识别源模型中的观点句阈值和卷积神经网络参数进行微调。Fine-tuning the viewpoint sentence threshold and convolutional neural network parameters in the viewpoint sentence recognition source model by using the target domain data set.
将微调后的观点句识别源模型确定为所述观点句识别目标模型。The fine-tuned viewpoint sentence recognition source model is determined as the viewpoint sentence recognition target model.
在实际应用中,上述社交机器人分类方法的一个更为具体的实现过程如下:In practical applications, a more specific implementation process of the above social robot classification method is as follows:
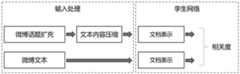
本具体实例在前期社交机器人识别的基础上,提出了一种社交机器人分类方法。首先,采用话题相关导语进行话题扩充,在此基础上应用SBERT (Sentence-BERT)模型对博文和扩充话题做相关性判断,以识别内容污染者。然后,提出一种将社交机器人观点句生成规则与深度学习模型TextCNN相结合的观点句识别方法,以进一步区分新闻评论者和知识传播者。最后,为了提高模型的分类效果,利用迁移学习方法,借助大量来自微博普通账号的博文数据进行模型训练,由此更好的提升社交机器人的分类效果。对比实验结果表明,通过扩充话题可以有效提高SBERT模型对博文话题相关性的分类结果;通过分析社交机器人观点博文生成规则,着重关注表达观点的关键词,较好地解决了由于社交机器人生成观点句质量不高导致的观点句识别难的问题;通过引入迁移学习,有效缓解了社交机器人数据量不足的问题,较大幅度的提升了社交机器人的分类效果。社交机器人分类方法的整体过程如图3所示。This specific example proposes a social robot classification method based on the previous social robot identification. First, the topic-related lead is used to expand the topic, and on this basis, the SBERT (Sentence-BERT) model is used to judge the relevance of the blog post and the expanded topic to identify content polluters. Then, an opinion sentence recognition method combining social robot opinion sentence generation rules with deep learning model TextCNN is proposed to further distinguish news commentators from knowledge disseminators. Finally, in order to improve the classification effect of the model, the transfer learning method is used to train the model with a large amount of blog post data from ordinary Weibo accounts, thereby better improving the classification effect of social robots. The results of comparative experiments show that the SBERT model can effectively improve the classification results of the topic relevance of blog posts by expanding the topic; by analyzing the generation rules of social robot opinion blog posts, focusing on the keywords expressing opinions, it is better to solve the problems caused by the generation of opinion sentences by social robots. The problem of difficult recognition of opinion sentences caused by low quality; through the introduction of transfer learning, the problem of insufficient data volume of social robots is effectively alleviated, and the classification effect of social robots is greatly improved. The overall process of the social robot classification method is shown in Figure 3.
本示例中社交机器人分类方法的具体实现步骤为:The specific implementation steps of the social robot classification method in this example are:
步骤1、构造数据集。
源域数据集由两部分数据组成:第一部分,通过编写爬虫代码进行数据采集。爬取微博平台上“#XXXX#”及其相关话题下的所有账号发布的原创博文内容,并通过人工标注方式标明400条内容与话题不相关的博文以及400 条新闻型博文,分别作为内容污染者和知识传播者的源数据;第二部分,通过社交机器人样本数据生成模型生成1200条观点型博文,作为新闻评论者的源数据。由此完成了迁移学习的源域数据集构造。The source domain data set consists of two parts of data: the first part is data collection by writing crawler code. Crawl the content of original blog posts published by all accounts under “#XXXX#” and related topics on the Weibo platform, and manually mark 400 blog posts whose content is not related to the topic and 400 news-type blog posts as content respectively The source data of polluters and knowledge disseminators; the second part, 1200 opinion-type blog posts are generated through the social robot sample data generation model as the source data of news commentators. This completes the construction of the source domain dataset for transfer learning.
目标域数据集为通过社交机器人识别模型检验得到的188个机器人类型的真实数据,经过人工标注和博文去重后,包括139个有效的社交机器人数据。其中有59个内容污染者、63个新闻评论者和17个知识传播者。The target domain data set is the real data of 188 robot types obtained through the social robot recognition model test. After manual labeling and deduplication of blog posts, it includes 139 valid social robot data. Among them are 59 content polluters, 63 news commentators and 17 knowledge disseminators.
步骤2、内容污染者识别。采用SBERT模型对博文的扩展话题和文本进行相关性判断,将发布与话题不相关博文的账号标为内容污染者,由此完成对内容污染者的识别,如图4所示,整体流程如下:Step 2. Identification of content polluters. The SBERT model is used to judge the relevance of the extended topics and texts of blog posts, and the accounts that publish unrelated blog posts are marked as content polluters, thus completing the identification of content polluters, as shown in Figure 4, the overall process is as follows:
步骤21、话题扩充模块包括话题扩充和文本压缩两部分。首先,搜集话题相关内容并进行扩充,使得话题的语义信息更加完整。然后,对扩充后的话题进行压缩,提取重要关键短语,由此避免数据稀疏的问题。最后,采用SBERT 模型计算扩充话题和博文的相关度。Step 21, the topic expansion module includes two parts: topic expansion and text compression. First, collect topic-related content and expand it to make the semantic information of the topic more complete. Then, the expanded topics are compressed to extract important key phrases, thereby avoiding the problem of data sparsity. Finally, the SBERT model is used to calculate the correlation between the augmented topics and blog posts.
步骤22、在话题扩充部分,本发明采用与该话题相关的话题内容以及话题导语部分进行内容扩充。以前期成为热点话题的“XXXX”事件为例。首先,在微博搜索包含“XXXX”的话题,爬取首页所有的#XX#的导语内容,将这些话题的导语作为一篇文档组织在一起。因为这些文字都是对每一个话题的介绍,并且经过了微博核查,因此都是与XXXX主题相关的句子。Step 22. In the topic expansion part, the present invention uses the topic content and topic lead part related to the topic to expand the content. Take the "XXXX" event that became a hot topic in the early days as an example. First, search for topics containing "XXXX" on Weibo, crawl all the lead content of #XX# on the homepage, and organize the leads of these topics as a document. Because these texts are introductions to each topic and have been verified by Weibo, they are all sentences related to the theme of XXXX.
步骤23、在文本压缩部分,本发明采用TextRank算法对扩充后的话题内容抽取关键词。TextRank算法的基本思想来源于谷歌的PageRank算法,通过将微博文本分割成若干组成单元(单词、句子)来建立图模型。微博文本中的重要成分通过投票机制进行排序,仅利用单个微博文本的信息,就可以实现关键词提取。Step 23. In the text compression part, the present invention uses the TextRank algorithm to extract keywords from the expanded topic content. The basic idea of the TextRank algorithm comes from Google's PageRank algorithm, which establishes a graph model by dividing the microblog text into several components (words, sentences). The important components in the microblog text are sorted through the voting mechanism, and keyword extraction can be realized only by using the information of a single microblog text.
TextRank算法提取导语关键词的过程如下:The process of TextRank algorithm extracting lead keywords is as follows:
1)对由导语扩充的话题内容按照完整的句子进行分割。1) Segment the topic content expanded by the introduction according to complete sentences.
2)对于每个句子,依次进行结巴分词、词性标注以及去掉停止词等操作。2) For each sentence, operations such as stammering word segmentation, part-of-speech tagging, and removing stop words are performed in turn.
3)构造一个话题候选关键字图G=(V,E),其中V是节点集,由第二步生成的话题候选关键字组成,然后采用共现关系构造任意两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个词语。TextRank算法的设计原理就是将相邻的词链接起来,借助相邻词的得分计算该词的得分,因此要构造边,从而得到词之间的邻接关系。再后续步骤中,每个词根据所在边中的其他词的得分更新自己的得分。3) Construct a topic candidate keyword graph G=(V,E), where V is a node set, which is composed of topic candidate keywords generated in the second step, and then use the co-occurrence relationship to construct an edge between any two points. There are edges between nodes only if their corresponding words co-occur in a window of length K, where K represents the window size, that is, at most K words co-occur. The design principle of the TextRank algorithm is to link adjacent words and calculate the score of the word with the help of the scores of adjacent words. Therefore, it is necessary to construct edges to obtain the adjacency relationship between words. In subsequent steps, each word updates its own score based on the scores of other words in the edge.
4)根据TextRank公式,迭代传播每个节点的分数,直到收敛。4) According to the TextRank formula, the score of each node is iteratively propagated until convergence.

其中,Vi、Vj表示不同的节点;WS(Vi)表示节点Vi的重要程度;d是阻尼系数,取值范围为0到1,代表从图中某一特定点指向其他任意点的概率,一般取值为0.85;In(Vi)为指向点Vi的点集合(入链集合),Out(Vj)为点Vj指向的点集合(出链集合)。|Out(Vj)|是出链的数量,且每一个词要将他们自身的分数平均的分给每一个出链,
5)对第4)步得到的节点分数进行排序,将最重要的k个词作为导语的关键词,由此完成话题扩充序列的构造。5) Sort the node scores obtained in step 4), and use the most important k words as the keywords of the lead, thus completing the construction of the topic expansion sequence.
步骤24、采用SBERT模型进行话题相关性判断,如图5所示,过程如下:Step 24, use the SBERT model to judge topic relevance, as shown in Figure 5, the process is as follows:
1)输入博文text和扩展话题topic,经过BERT编码后得到两个代表句子的特征向量u和v。1) Input the blog post text and the extended topic topic, and obtain two feature vectors u and v representing sentences after BERT encoding.
2)采用MEAN策略进行pooling操作,获取序列最后一层的所有输出向量,计算其平均值作为句子向量。2) Use the MEAN strategy to perform pooling operations, obtain all output vectors of the last layer of the sequence, and calculate their average value as the sentence vector.
3)采用均方误差函数作为优化的目标函数,对得到的句子向量通过计算 u和v的余弦相似度来衡量话题和博文的相似程度。当相似度大于相似度阈值时,判别为话题和博文相关。由于不同的阈值最终会产生不同的结果,取准确率最高的阈值作为最终阈值。3) The mean square error function is used as the optimized objective function, and the cosine similarity between u and v is calculated for the obtained sentence vector to measure the similarity between the topic and the blog post. When the similarity is greater than the similarity threshold, it is determined that the topic is related to the blog post. Since different thresholds will eventually produce different results, the threshold with the highest accuracy is taken as the final threshold.
步骤3、新闻评论者与知识传播者识别。针对博文提取观点句特征进行首次观点句识别,再利用TextCNN模型完成进一步观点句识别。根据博文是否与话题相关且是否具有观点完成新闻评论者和知识传播者的分类,如图6所示,整体流程如下:Step 3. Identification of news commentators and knowledge disseminators. The first opinion sentence recognition is carried out by extracting the features of opinion sentences from blog posts, and then the TextCNN model is used to complete further opinion sentence recognition. According to whether the blog posts are related to the topic and whether they have opinions, the classification of news commentators and knowledge disseminators is completed, as shown in Figure 6. The overall process is as follows:
步骤31、基于生成规则的观点句识别。从社交机器人生成文本的角度考虑,为了使新闻评论者表达特定的观点,生成者通常采用包含特定关键词的语料库。具体地,可以通过输入特定事件语料库的观点句示例,然后采用同义词变形的方式生成新的观点句。也可以通过输入通用语料库的观点句示例,提取句式特征,然后按照给定的关键词、给定的情感生成有关特定事件的观点句。因此,本发明按照社交机器人观点句生成规则,从关键词特征、位置特征、语义特征和长度特征四个角度进行观点句的识别,过程如下:Step 31. Recognition of opinion sentences based on generation rules. From the perspective of social robots generating text, in order to make news commentators express specific views, the generator usually uses a corpus containing specific keywords. Specifically, a new opinion sentence can be generated by inputting an opinion sentence example of a specific event corpus, and then adopting a synonym transformation method. It is also possible to extract sentence pattern features by inputting opinion sentence examples in the general corpus, and then generate opinion sentences about specific events according to given keywords and given emotions. Therefore, the present invention carries out the identification of opinion sentences from four angles of keyword feature, position feature, semantic feature and length feature according to the social robot opinion sentence generation rule, and the process is as follows:
1.将每条社交机器人博文分割为n个句子,d={s1,s2,...,sn}。然后将每个句子分割为l个词语,si={wi1,wi2,...,wil}。由此,通过对每个句子的4个特征进行加权求和,即可得到句子观点句分数,如公式(2)所示。其中λ1,λ2,λ3,λ4分别代表4个特征的权重,且四者之和为1。可根据情况适当调节λ1,λ2,λ3,λ4的值。1. Divide each social robot blog post into n sentences, d={s1 ,s2 ,...,sn }. Then divide each sentence into l words, si ={wi1 ,wi2 ,...,wil }. Thus, by weighting and summing the four features of each sentence, the score of the sentence opinion sentence can be obtained, as shown in formula (2). Among them, λ1 , λ2 , λ3 , and λ4 respectively represent the weights of the four features, and the sum of the four features is 1. The values of λ1 , λ2 , λ3 , and λ4 can be adjusted appropriately according to the situation.
f(si)=λ1fkeyword(si)+λ2fposition(si)+λ3fsemantics(si)+λ4flength(si) (2)f(si )=λ1 fkeyword (si )+λ2 fposition (si )+λ3 fsemantics (si )+λ4 flength (si ) (2)
2.提取关键词特征、位置特征、语义特征和长度特征。2. Extract keyword features, location features, semantic features and length features.
关键词特征:利用TextRank算法对全部社交机器人发布的博文抽取词性为名词、动词的关键词。在选取关键句时,如果句子中出现关键词,那么该句成为观点句的概率将会很大。因此,关键词特征的得分函数如下:Keyword features: Use the TextRank algorithm to extract keywords whose parts of speech are nouns and verbs from all blog posts published by social robots. When selecting key sentences, if keywords appear in the sentence, the probability of the sentence becoming an opinion sentence will be high. Therefore, the score function of keyword features is as follows:

位置特征:在一段表达观点的博文中,中心观点一般处在开头或者结尾。因此,博文的首句或尾句是观点句的可能性更高,位置特征的得分函数如下:Location characteristics: In a blog post expressing an opinion, the central idea is generally at the beginning or end. Therefore, the first or last sentence of a blog post is more likely to be an opinion sentence, and the score function of the position feature is as follows:

其中,n为文本中的句子个数,i为句子在文本中的位置,a、b和c为系数。从函数表达式可以看出,文本中间位置句子的得分低,而位于开头与结尾句子的得分较高。Among them, n is the number of sentences in the text, i is the position of the sentence in the text, and a, b, and c are coefficients. It can be seen from the function expression that the score of the sentence in the middle of the text is low, while the score of the sentence at the beginning and the end is higher.
语义特征:在观点句中,往往会出现表达观点的词以及主观性、总结性、转折性较强的词。典型的表达观点的词比如:“支持、反对、抵制、同意、相信、力挺”等。表示主观性的词比如:“我、认为、估计、应该、也许、大概”等。表示总结性的词如:“因此、总之、所以、综上、综上所述、由此可见”等。表示转折性的词如:“但是、尽管、虽然、然而”等。因此,语义特征的得分函数如下:Semantic features: In opinion sentences, there are often words expressing opinions and words with strong subjectivity, summary, and transition. Typical words expressing opinions such as: "support, oppose, resist, agree, believe, support" and so on. Words expressing subjectivity such as: "I, think, estimate, should, maybe, probably" and so on. Conclusive words such as: "so, in short, so, in summary, in summary, it can be seen from this" and so on. Words that express turning point, such as: "however, despite, although, however" and so on. Therefore, the score function of semantic features is as follows:

长度特征:考虑到这一事实,即知识传播者发布的新闻博文大多是针对事件的客观事实描述,因此博文大多长度较长,而新闻评论者根据规则生成的观点句则相对简短。因此,本发明将长度特征作为观点句识别的一个特征,长度特征的得分函数如下:Length feature: Considering the fact that most of the news blog posts published by knowledge disseminators are objective factual descriptions of events, so most of the blog posts are long in length, while the opinion sentences generated by news commentators according to the rules are relatively short. Therefore, the present invention regards the length feature as a feature of opinion sentence recognition, and the score function of the length feature is as follows:

3.通过对句子的四个特征进行归一化处理并加权求和,得到社交机器人博文的每条句子的观点句得分f(si)。设定观点句阈值θ∈(0,1),当句子得分 f(si)>θ,则判定为观点句,如果一条博文中出现多个句子得分大于θ,则取分数最高的句子作为观点句,由此完成基于规则的观点句识别。并且,对于博文中存在观点句的账号判断为新闻评论者。3. By normalizing the four features of the sentence and weighting the summation, the opinion sentence score f(si ) of each sentence in the blog post of the social robot is obtained. Set the opinion sentence threshold θ∈(0,1). When the sentence score f(si ) > θ, it is judged as an opinion sentence. If there are multiple sentences with scores greater than θ in a blog post, take the sentence with the highest score as the opinion sentence, thus completing the rule-based opinion sentence recognition. In addition, an account with an opinion sentence in a blog post is judged as a news commentator.
步骤32、基于TextCNN的观点句识别。为了更加全面的识别观点句,本发明将判断为不包含观点句的博文,输入到TextCNN模型中进行进一步的观点句判断。具体识别过程如下:Step 32. Recognition of opinion sentences based on TextCNN. In order to identify opinion sentences more comprehensively, the present invention inputs blog posts that do not contain opinion sentences into the TextCNN model for further judgment of opinion sentences. The specific identification process is as follows:
1)使用Word2Vec词向量模型对博文进行表征,将得到单词向量作为嵌入层的输入。1) Use the Word2Vec word vector model to represent the blog post, and the word vector will be used as the input of the embedding layer.
2)通过不同的滤波器抽取到博文特征的向量化表示。2) Extract the vectorized representation of blog post features through different filters.
3)经过池化操作筛选出最显著的特征向量。3) The most significant feature vectors are screened out through the pooling operation.
4)通过一个全连接层转化为分类问题,由此完成观点句识别。4) Transform it into a classification problem through a fully connected layer, thereby completing the recognition of opinion sentences.
上述识别的四个步骤分别对应观点句识别模型(Word2Vec模型)的嵌入层、卷积层、池化层、全连接层+softmax层,是该识别模型结构的四个层次。The above four steps of recognition correspond to the embedding layer, convolution layer, pooling layer, fully connected layer + softmax layer of the opinion sentence recognition model (Word2Vec model), which are the four levels of the recognition model structure.
步骤4、基于迁移学习的社交机器人分类。由于深度学习模型对数据量要求很高,而能够获得的社交机器人的数据量较为有限。因而,通过迁移人类的微博数据,完成社交机器人分类模型的训练,进而实现社交机器人的分类,整体流程如下:Step 4. Classification of social robots based on migration learning. Since the deep learning model requires a high amount of data, the amount of data that can be obtained for social robots is relatively limited. Therefore, by migrating human microblog data, the training of the social robot classification model is completed, and then the classification of social robots is realized. The overall process is as follows:
首先使用源域的大量人类数据预训练深度神经网络,然后将网络结构和网络参数迁移至目标域。由于本发明目标数据较少,并且社交机器人博文是仿照人类博文生成的文本,与人类博文的相似度很高,因此二者不论是浅层网络特征还是深层网络特征都比较相近。所以本发明冻结除输出层的其他所有网络的参数,使用社交机器人训练数据对输出层进行微调,最后使用测试数据测试模型的分类效果,如图7所示,具体过程如下:First, a deep neural network is pre-trained using a large amount of human data in the source domain, and then the network structure and network parameters are transferred to the target domain. Since the target data of the present invention is less, and social robot blog posts are texts generated by imitating human blog posts, and have a high similarity with human blog posts, both shallow network features and deep network features are relatively similar. Therefore, the present invention freezes all other network parameters except the output layer, fine-tunes the output layer using the social robot training data, and finally uses the test data to test the classification effect of the model, as shown in Figure 7, the specific process is as follows:
步骤41、将源域数据集按照8:2的比例随机划分为源域训练集和源域测试集,同样的目标域数据集划分为目标域训练集和目标域测试集;Step 41. Randomly divide the source domain data set into a source domain training set and a source domain test set according to a ratio of 8:2, and divide the same target domain data set into a target domain training set and a target domain test set;
步骤42、采用源域数据集训练和测试话题相关性模型、观点句识别模型,并保存测试效果最好的模型参数,得到话题相关性源模型、观点句识别源模型;Step 42, using the source domain data set to train and test the topic relevance model and opinion sentence recognition model, and save the model parameters with the best test effect to obtain the topic relevance source model and opinion sentence recognition source model;
步骤43、采用目标域数据集微调话题相关性源模型、微调观点句识别源模型,由此得到话题相关性目标模型、观点句识别目标模型;Step 43, using the target domain data set to fine-tune the source model of topic relevance and fine-tuning the source model of opinion sentence recognition, thereby obtaining the target model of topic relevance and the target model of opinion sentence recognition;
步骤44、将话题相关性目标模型和观点句识别目标模型组合即得到社交机器人多分类模型,根据两个分类模型得到的4种组合分类结果,相关观点句、相关非观点句、不相关观点句、不相关非观点句,将社交机器人分为内容污染者、新闻评论者与知识传播者。Step 44. Combining the topic relevance target model and the viewpoint sentence recognition target model to obtain a multi-classification model for social robots. According to the four combined classification results obtained by the two classification models, relevant viewpoint sentences, relevant non- viewpoint sentences, and irrelevant viewpoint sentences , Irrelevant and non-opinion sentences, and divide social robots into content polluters, news commentators and knowledge disseminators.
上述实施例的社交机器人分类方法,具有如下优点:The social robot classification method of the foregoing embodiment has the following advantages:
(1)针对微博文本与话题长度相差较大,导致出现数据稀疏的问题,提出了话题扩充,并建立了基于话题扩展模块的话题博文相关性识别模型。首先利用相关话题的导语文本扩充话题;然后采用TextRank提取关键词得到话题扩充序列,使得话题能够更加丰富、有效的表达事件内容;最后,采用SBERT 模型对话题扩充序列和博文序列计算文本相关度,实现内容污染者的识别。对比实验结果表明,话题扩充模块能够更加丰富、有效的表达事件内容,提升话题博文相关性判断的效果。(1) Aiming at the problem of data sparsity due to the large difference in the length of microblog text and topic, a topic expansion is proposed, and a topic blog post correlation identification model based on topic expansion module is established. First, use the lead text of related topics to expand the topic; then use TextRank to extract keywords to obtain the topic expansion sequence, so that the topic can express the content of the event more richly and effectively; finally, use the SBERT model to calculate the text relevance of the topic expansion sequence and blog post sequence, Enables identification of content polluters. The results of comparative experiments show that the topic expansion module can express event content more abundantly and effectively, and improve the effect of judging the relevance of topic blog posts.
(2)结合生成规则和深度学习实现观点句识别。首先从新闻评论类社交机器人的观点句生成原理出发,对博文提取关键词特征、位置特征、语义特征和长度特征,根据特征值加权求和计算句子的观点句得分并与阈值做比较,若大于阈值,则提前识别出明显具有关键词的观点句,若为小于阈值,则通过建立TextCNN模型,进行观点句识别(采用基于规则的方法提前识别出明显具有观点关键词的观点句,然后再通过建立TextCNN模型,对剩余句子进行观点句识别)。实验结果表明,基于组合的方法可以充分发挥两种方法各自的优势。通过关键词可精准的识别出符合社交机器人博文生成规则的、可能并不通顺的部分观点句;通过TextCNN模型可进一步识别出尽可能多的剩余观点句,大大提高了社交机器人观点句识别的准确率。(2) Combining generation rules and deep learning to realize opinion sentence recognition. First, starting from the idea sentence generation principle of news commentary social robots, extract keyword features, location features, semantic features and length features for blog posts, calculate the opinion sentence score of the sentence according to the weighted sum of the feature values and compare it with the threshold value, if it is greater than Threshold, then identify the opinion sentences that obviously have keywords in advance, if it is less than the threshold, then through the establishment of TextCNN model, carry out opinion sentence recognition (using the method based on rules to identify the opinion sentences that obviously have opinion keywords in advance, and then pass Establish a TextCNN model to identify the remaining sentences for opinion sentences). Experimental results show that the combination-based method can fully exploit the respective advantages of the two methods. Key words can be used to accurately identify some opinion sentences that meet the social robot blog post generation rules and may not be smooth; the TextCNN model can further identify as many remaining opinion sentences as possible, which greatly improves the accuracy of social robot opinion sentence recognition Rate.
(3)设计了基于社交机器人目的进行类别划分的策略。通过对社交机器人博文进行文本挖掘,进一步根据社交机器人在某一话题下的不同作用,将其分为内容污染者、新闻评论者和知识传播者三类。在该策略的基础上,针对社交机器人数据稀少和检测准确率不高的问题,还设计了基于迁移学习的社交机器人分类方法。借助迁移学习技术,可以将大量普通账号的博文数据训练结果迁移到社交机器人的分类模型,提高了分类方法的通用性和可解释性。对比实验结果证明,借助迁移学习技术进行训练,得到了更加准确的社交机器人分类模型。(3) A strategy for classifying social robots based on their purpose is designed. Through the text mining of social robot blog posts, social robots are further divided into three categories according to their different roles in a certain topic: content polluters, news commentators and knowledge disseminators. On the basis of this strategy, a social robot classification method based on migration learning is also designed to solve the problems of social robot data scarcity and low detection accuracy. With the help of transfer learning technology, the training results of blog post data of a large number of ordinary accounts can be transferred to the classification model of social robots, which improves the versatility and interpretability of the classification method. The results of comparative experiments prove that a more accurate social robot classification model can be obtained by training with transfer learning technology.
(4)当攻击者设定的社交机器人行为特征发生变化时,本实施例的方法依然适用于对变化后的社交机器人进行分类。并且,正是由于提出的社交机器人类别划分策略依赖于文本挖掘技术,使得迁移学习的源数据可以使用易于采集且数量丰富的正常用户博文数据,避免了社交机器人相似样本账号难以获得,从而无法进行正常学习的难题。(4) When the behavior characteristics of the social robot set by the attacker change, the method of this embodiment is still applicable to classify the changed social robot. Moreover, it is precisely because the proposed classification strategy of social robots relies on text mining technology that the source data of transfer learning can use easy-to-collect and abundant normal user blog post data, which avoids the difficulty of obtaining similar sample accounts of social robots, which makes it impossible to carry out Difficulties in normal learning.
此外,除上述实施例具体实现方式外,也可以通过采用其他模型进行博文话题相关性判断以识别内容污染者,通过采用其他模型进行观点句判断以识别新闻评论者和知识传播者,由此进行社交机器人分类。In addition, in addition to the specific implementation of the above-mentioned embodiments, it is also possible to identify content polluters by using other models to judge the relevance of blog posts, and to identify news commentators and knowledge disseminators by using other models to judge opinion sentences. Taxonomy of social robots.
本发明还提供了一种用于实现上述所述方法的社交机器人分类系统,参见图8,所述系统,包括:The present invention also provides a social robot classification system for implementing the above method, see FIG. 8, the system includes:
博文内容获取模块801,用于获取目标社交机器人关于目标话题的博文内容。The blog post
分类模型确定模块802,用于确定所述社交机器人分类模型。The classification
分类识别模块803,用于将所述目标社交机器人关于目标话题的博文内容输入社交机器人分类模型中,得到所述目标社交机器人的类别;所述类别包括内容污染者、知识传播者和新闻评论者;所述社交机器人分类模型包括话题相关性目标模型和观点句识别目标模型。The
所述内容污染者表示所述目标社交机器人发布的博文内容与所述目标话题不相关;所述知识传播者表示所述目标社交机器人发布的博文内容与所述目标话题相关,且发表意见以及表达观点;所述新闻评论者表示所述目标社交机器人发布的博文内容与所述目标话题相关,且传播信息以及说明客观事件。The content polluter indicates that the content of blog posts published by the target social robot is not related to the target topic; the knowledge spreader indicates that the content of blog posts published by the target social robot is related to the target topic, and expresses opinions and Opinion: The news commentator indicates that the content of the blog post published by the target social robot is related to the target topic, and disseminates information and explains objective events.
所述分类模型确定模块802,具体包括:The classification
源域数据集构建单元,用于基于迁移学习的方法构建源域数据集;所述源域数据集包括第一类数据集和第二类数据集;所述第一类数据集包括在微博平台上爬取的在设定话题下的账号发布的原创博文内容、在与设定话题相关的话题下的账号发布的原创博文内容以及对应分类标签;所述分类标签包括所述账号属于内容污染者或者所述账号数据知识传播者;所述第二类数据集包括由社交机器人样本数据生成模型生成的已标注为新闻评论者的账号发布的观点型博文。The source domain data set construction unit is used to construct the source domain data set based on the method of transfer learning; the source domain data set includes the first type data set and the second type data set; the first type data set is included in the microblog The original blog post content published by the account under the set topic, the original blog post content published by the account under the topic related to the set topic, and the corresponding classification tags crawled on the platform; the classification tags include that the account belongs to content pollution or the account data knowledge disseminator; the second type of data set includes opinion-type blog posts published by accounts marked as news commentators generated by the social robot sample data generation model.
目标域数据集构建单元,用于基于社交机器人识别模型确定目标域数据集;所述目标域数据集包括已标注类别的社交机器人真实博文内容。The target domain data set construction unit is used to determine the target domain data set based on the social robot recognition model; the target domain data set includes the real blog post content of the social robot that has been labeled.
话题扩充及压缩模块,用于对所述源域数据集中的设定话题进行扩充和话题内容压缩,得到话题扩充序列。The topic expansion and compression module is used for expanding and compressing topic content in the set topic in the source domain data set to obtain a topic expansion sequence.
话题相关性目标模型确定模块,用于根据所述源域数据集、所述目标域数据集、所述话题扩充序列和孪生网络,确定所述话题相关性目标模型;所述话题相关性目标模型用于识别内容污染者。Topic correlation target model determination module, used to determine the topic correlation target model according to the source domain data set, the target domain data set, the topic expansion sequence and the twin network; the topic correlation target model Used to identify content polluters.
观点句识别目标模型确定模块,用于根据所述源域数据集、所述目标域数据集、基于规则的观点句识别方法以及文本分类模型,确定所述观点句识别目标模型;所述观点句识别目标模型用于知识传播者和新闻评论者。The viewpoint sentence recognition target model determination module is used to determine the viewpoint sentence recognition target model according to the source domain data set, the target domain data set, the rule-based viewpoint sentence recognition method and the text classification model; the viewpoint sentence Recognition target models are used for knowledge disseminator and news commentator.
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。Each embodiment in this specification is described in a progressive manner, each embodiment focuses on the difference from other embodiments, and the same and similar parts of each embodiment can be referred to each other. As for the system disclosed in the embodiment, since it corresponds to the method disclosed in the embodiment, the description is relatively simple, and for the related information, please refer to the description of the method part.
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。In this paper, specific examples have been used to illustrate the principle and implementation of the present invention. The description of the above embodiments is only used to help understand the method of the present invention and its core idea; meanwhile, for those of ordinary skill in the art, according to the present invention Thoughts, there will be changes in specific implementation methods and application ranges. In summary, the contents of this specification should not be construed as limiting the present invention.
Claims (8)
Translated fromChinesePriority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211039150.4ACN115329085B (en) | 2022-08-29 | 2022-08-29 | A social robot classification method and system |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202211039150.4ACN115329085B (en) | 2022-08-29 | 2022-08-29 | A social robot classification method and system |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN115329085Atrue CN115329085A (en) | 2022-11-11 |
| CN115329085B CN115329085B (en) | 2025-09-05 |
Family
ID=83927528
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202211039150.4AActiveCN115329085B (en) | 2022-08-29 | 2022-08-29 | A social robot classification method and system |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115329085B (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115577707A (en)* | 2022-12-08 | 2023-01-06 | 中国传媒大学 | A Word Segmentation Method for Multilingual News Topic Words |
| CN117251556A (en)* | 2023-11-17 | 2023-12-19 | 北京遥领医疗科技有限公司 | Patient screening system and method in registration queue |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109472027A (en)* | 2018-10-31 | 2019-03-15 | 北京邮电大学 | A social robot detection system and method based on blog post similarity |
| CN111428116A (en)* | 2020-06-08 | 2020-07-17 | 四川大学 | Microblog social robot detection method based on deep neural network |
| US20210089579A1 (en)* | 2019-09-23 | 2021-03-25 | Arizona Board Of Regents On Behalf Of Arizona State University | Method and apparatus for collecting, detecting and visualizing fake news |
- 2022
- 2022-08-29CNCN202211039150.4Apatent/CN115329085B/enactiveActive
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109472027A (en)* | 2018-10-31 | 2019-03-15 | 北京邮电大学 | A social robot detection system and method based on blog post similarity |
| US20210089579A1 (en)* | 2019-09-23 | 2021-03-25 | Arizona Board Of Regents On Behalf Of Arizona State University | Method and apparatus for collecting, detecting and visualizing fake news |
| CN111428116A (en)* | 2020-06-08 | 2020-07-17 | 四川大学 | Microblog social robot detection method based on deep neural network |
Non-Patent Citations (1)
| Title |
|---|
| 王雅晗: "社交机器人检测技术研究及实现", 《硕士电子期刊》, 15 August 2019 (2019-08-15)* |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115577707A (en)* | 2022-12-08 | 2023-01-06 | 中国传媒大学 | A Word Segmentation Method for Multilingual News Topic Words |
| CN117251556A (en)* | 2023-11-17 | 2023-12-19 | 北京遥领医疗科技有限公司 | Patient screening system and method in registration queue |
Also Published As
| Publication number | Publication date |
|---|---|
| CN115329085B (en) | 2025-09-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Eke et al. | Sarcasm identification in textual data: systematic review, research challenges and open directions | |
| Neelakandan et al. | A gradient boosted decision tree-based sentiment classification of twitter data | |
| Li et al. | Document representation and feature combination for deceptive spam review detection | |
| CN113378565B (en) | Event analysis method, device, device and storage medium for multi-source data fusion | |
| CN103793503B (en) | Opinion mining and classification method based on web texts | |
| CN111310476B (en) | A public opinion monitoring method and system using aspect-based sentiment analysis method | |
| CN108052593A (en) | A kind of subject key words extracting method based on descriptor vector sum network structure | |
| CN112749274A (en) | Chinese text classification method based on attention mechanism and interference word deletion | |
| CN115017887B (en) | Chinese rumor detection method based on graph convolution | |
| CN113934835B (en) | Retrieval type reply dialogue method and system combining keywords and semantic understanding representation | |
| Mohawesh et al. | Fake or genuine? contextualised text representation for fake review detection | |
| Chen et al. | From symbols to embeddings: A tale of two representations in computational social science | |
| Rezaei et al. | Early multi-class ensemble-based fake news detection using content features | |
| Liu et al. | Correlation identification in multimodal weibo via back propagation neural network with genetic algorithm | |
| Jawad et al. | Combination of convolution neural networks and deep neural networks for fake news detection | |
| CN115329085A (en) | A social robot classification method and system | |
| Polignano et al. | Identification Of Bot Accounts In Twitter Using 2D CNNs On User-generated Contents. | |
| WO2025060268A1 (en) | Long text matching method combining noise filtering and divide-and-conquer strategy | |
| Tao et al. | News text classification based on an improved convolutional neural network | |
| Ahamed et al. | Bidirectional Deep Learning and Extended Fuzzy Markov Model for Sentiments Recognition | |
| Sharma et al. | An optimized approach for sarcasm detection using machine learning classifier | |
| Gan et al. | Microblog sentiment analysis via user representative relationship under multi-interaction hybrid neural networks | |
| Sun et al. | Improving the Performance of Answers Ranking in Q&A Communities: A Long-text Matching technique and Pre-trained Model | |
| Khabbazan et al. | Classifying the clarity of questions in cqa networks: A topic based approach | |
| Bhawal et al. | Fake News Detection in Urdu Language using BERT. |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |