CN115186133A - Video generation method, device, electronic device and medium - Google Patents
Video generation method, device, electronic device and mediumDownload PDFInfo
- Publication number
- CN115186133A CN115186133ACN202210863915.XACN202210863915ACN115186133ACN 115186133 ACN115186133 ACN 115186133ACN 202210863915 ACN202210863915 ACN 202210863915ACN 115186133 ACN115186133 ACN 115186133A
- Authority
- CN
- China
- Prior art keywords
- video
- characteristic information
- text
- videos
- visual
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images







Classifications
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/70—Information retrieval; Database structures therefor; File system structures therefor of video data
- G06F16/78—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually
- G06F16/783—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually using metadata automatically derived from the content
- G06F16/7844—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually using metadata automatically derived from the content using original textual content or text extracted from visual content or transcript of audio data
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/70—Information retrieval; Database structures therefor; File system structures therefor of video data
- G06F16/75—Clustering; Classification
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/70—Information retrieval; Database structures therefor; File system structures therefor of video data
- G06F16/78—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually
- G06F16/783—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually using metadata automatically derived from the content
- G06F16/7847—Retrieval characterised by using metadata, e.g. metadata not derived from the content or metadata generated manually using metadata automatically derived from the content using low-level visual features of the video content
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
- G06F40/289—Phrasal analysis, e.g. finite state techniques or chunking
- G06F40/295—Named entity recognition
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/40—Scenes; Scene-specific elements in video content
- G06V20/41—Higher-level, semantic clustering, classification or understanding of video scenes, e.g. detection, labelling or Markovian modelling of sport events or news items
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/40—Scenes; Scene-specific elements in video content
- G06V20/46—Extracting features or characteristics from the video content, e.g. video fingerprints, representative shots or key frames
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Multimedia (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Library & Information Science (AREA)
- General Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Computational Linguistics (AREA)
- Software Systems (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Audiology, Speech & Language Pathology (AREA)
- General Health & Medical Sciences (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
Translated fromChinese
Description
Translated fromChinese技术领域technical field
本申请属于人工智能技术领域,具体涉及一种基于视频生成方法、装置、电子设备及介质。The present application belongs to the technical field of artificial intelligence, and specifically relates to a video-based generation method, device, electronic device and medium.
背景技术Background technique
随着深度神经网络的快速发展,视频生成相关方向的算法也越来越多样化,使得根据文字表述直接生成与之意思相符的视频成为可能。With the rapid development of deep neural networks, the algorithms related to video generation are becoming more and more diverse, making it possible to directly generate videos that match the meaning of textual expressions.
在相关技术中,在基于文本生成视频的过程中,通常是将文本输入网络模型后,先使用该网络模型的文本模态提取该文本对应的文本特征,然后通过该网络模型的视频模态直接基于该文本特征生成视频。In the related art, in the process of generating a video based on text, after inputting the text into a network model, first use the text mode of the network model to extract the text features corresponding to the text, and then directly use the video mode of the network model to directly extract the text features of the text. Generate a video based on this text feature.
然而,由于上述方案是通过网络模型直接基于提取出的文本特征生成视频,因此,在该网络模型的文本模态和视频模态存在信息差时,可能无法准确的进行特征提取,从而导致生成的视频与文本描述不匹配。However, since the above solution directly generates videos based on the extracted text features through the network model, when there is information difference between the text mode and the video mode of the network model, the feature extraction may not be performed accurately, resulting in the generated video Video does not match text description.
发明内容SUMMARY OF THE INVENTION
本申请实施例的目的是提供一种视频生成方法、装置、电子设备及介质,能够解决生成的视频与文本描述不匹配的问题。The purpose of the embodiments of the present application is to provide a video generation method, apparatus, electronic device and medium, which can solve the problem that the generated video does not match the text description.
为了解决上述技术问题,本申请是这样实现的:In order to solve the above technical problems, this application is implemented as follows:
第一方面,本申请实施例提供了一种视频生成方法,该方法包括:提取第一文本中的行为描述词和视觉描述词;从N个第一视频中确定与上述行为描述词匹配的目标视频片段,以及从该N个第一视频中确定与上述视觉描述词匹配的目标视频帧;基于上述目标视频片段和上述目标视频帧,生成目标视频;其中,上述N个第一视频为视频库中与上述第一文本相似的N个视频;N为大于1的整数。In a first aspect, an embodiment of the present application provides a video generation method, the method includes: extracting behavior descriptors and visual descriptors in a first text; determining a target matching the above behavior descriptors from N first videos A video clip, and a target video frame matching the above-mentioned visual descriptor is determined from the N first videos; a target video is generated based on the above-mentioned target video clip and the above-mentioned target video frame; wherein, the above-mentioned N first videos are a video library N videos that are similar to the first text above; N is an integer greater than 1.
第二方面,本申请实施例提供了一种视频生成装置,该装置包括:提取模块、确定模块和生成模块;其中,提取模块,用于提取第一文本中的行为描述词和视觉描述词;确定模块,用于从N个第一视频中确定与上述行为描述词匹配的目标视频片段,以及从上述N个第一视频中确定与上述视觉描述词匹配的目标视频帧;生成模块,用于基于确定模块确定的上述目标视频片段和上述目标视频帧,生成目标视频;其中,上述N个第一视频为视频库中与上述第一文本相似的N个视频;N为大于1的整数。In a second aspect, an embodiment of the present application provides a video generation device, the device includes: an extraction module, a determination module, and a generation module; wherein, the extraction module is used to extract behavior descriptors and visual descriptors in the first text; A determination module, for determining a target video segment matching the above-mentioned behavior descriptor from the N first videos, and determining a target video frame matching the above-mentioned visual descriptor from the above-mentioned N first videos; a generation module, for Based on the target video segment and the target video frame determined by the determining module, a target video is generated; wherein the N first videos are N videos similar to the first text in the video library; N is an integer greater than 1.
第三方面,本申请实施例提供了一种电子设备,该电子设备包括处理器和存储器,所述存储器存储可在所述处理器上运行的程序或指令,所述程序或指令被所述处理器执行时实现如第一方面所述的方法的步骤。In a third aspect, an embodiment of the present application provides an electronic device, the electronic device includes a processor and a memory, the memory stores a program or an instruction that can be executed on the processor, and the program or instruction is processed by the processor The steps of the method as described in the first aspect are implemented when the device is executed.
第四方面,本申请实施例提供了一种可读存储介质,所述可读存储介质上存储程序或指令,所述程序或指令被处理器执行时实现如第一方面所述的方法的步骤。In a fourth aspect, an embodiment of the present application provides a readable storage medium, where a program or an instruction is stored on the readable storage medium, and when the program or instruction is executed by a processor, the steps of the method according to the first aspect are implemented .
第五方面,本申请实施例提供了一种芯片,所述芯片包括处理器和通信接口,所述通信接口和所述处理器耦合,所述处理器用于运行程序或指令,实现如第一方面所述的方法。In a fifth aspect, an embodiment of the present application provides a chip, the chip includes a processor and a communication interface, the communication interface is coupled to the processor, and the processor is configured to run a program or an instruction, and implement the first aspect the method described.
第六方面,本申请实施例提供一种计算机程序产品,该程序产品被存储在存储介质中,该程序产品被至少一个处理器执行以实现如第一方面所述的方法。In a sixth aspect, an embodiment of the present application provides a computer program product, where the program product is stored in a storage medium, and the program product is executed by at least one processor to implement the method according to the first aspect.
在本申请实施例中,在基于文本生成视频时,电子设备可以先提取第一文本中的行为描述词和视觉描述词,然后从视频库中的与该第一文本相似的N个第一视频中确定与行为描述词匹配的目标视频片段和与视觉描述词匹配的目标视频帧,最后基于该目标视频片段和该目标视频帧,生成目标视频;其中,N为大于1的整数。如此,通过利用文本中用于描述主体行为的行为描述词,从第一视频中查找到与该主体行为匹配的视频片段,并利用文本中用于描述视觉呈现画面的视觉描述词,从第一视频中查找到与该视觉呈现画面匹配的视频帧,这样,将上述匹配到的视频片段和视频帧进行融合后,便可得到更加切题和真实的目标视频,保证了最终生成的视频的视频质量。In this embodiment of the present application, when generating a video based on text, the electronic device may first extract behavior descriptors and visual descriptors in the first text, and then select N first videos similar to the first text from the video library. Determine the target video segment that matches the behavior descriptor and the target video frame that matches the visual descriptor, and finally generate the target video based on the target video segment and the target video frame; where N is an integer greater than 1. In this way, by using the behavior descriptors used to describe the subject's behavior in the text, a video segment matching the subject's behavior is found from the first video, and using the visual descriptors used to describe the visual presentation in the text, from the first video Find a video frame that matches the visual presentation picture in the video, so that after the above-mentioned matched video clip and video frame are fused, a more relevant and real target video can be obtained, which ensures the video quality of the final generated video. .
附图说明Description of drawings
图1是本申请实施例提供的一种视频生成方法的流程示意图;1 is a schematic flowchart of a video generation method provided by an embodiment of the present application;
图2是本申请实施例提供的一种多模态特征提取模型的结构示意图;2 is a schematic structural diagram of a multimodal feature extraction model provided by an embodiment of the present application;
图3是本申请实施例提供的一种多模态特征提取模型的处理流程图之一;3 is one of the processing flow charts of a multimodal feature extraction model provided by an embodiment of the present application;
图4是本申请实施例提供的一种多模态特征提取模型的处理流程图之二;4 is the second processing flow chart of a multimodal feature extraction model provided by an embodiment of the present application;
图5是本申请实施例提供的一种多模态特征提取模型的处理流程图之三;5 is the third processing flow chart of a multimodal feature extraction model provided by an embodiment of the present application;
图6是本申请实施例提供的一种视频生成装置的结构示意图;6 is a schematic structural diagram of a video generation apparatus provided by an embodiment of the present application;
图7是本申请实施例提供的一种电子设备的结构示意图;7 is a schematic structural diagram of an electronic device provided by an embodiment of the present application;
图8是本申请实施例提供的一种电子设备的硬件示意图。FIG. 8 is a schematic diagram of hardware of an electronic device provided by an embodiment of the present application.
具体实施方式Detailed ways
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚地描述,显然,所描述的实施例是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员获得的所有其他实施例,都属于本申请保护的范围。The technical solutions in the embodiments of the present application will be clearly described below with reference to the accompanying drawings in the embodiments of the present application. Obviously, the described embodiments are part of the embodiments of the present application, but not all of the embodiments. Based on the embodiments in this application, all other embodiments obtained by those of ordinary skill in the art fall within the protection scope of this application.
本申请的说明书和权利要求书中的术语“第一”、“第二”等是用于区别类似的对象,而不用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便本申请的实施例能够以除了在这里图示或描述的那些以外的顺序实施,且“第一”、“第二”等所区分的对象通常为一类,并不限定对象的个数,例如第一对象可以是一个,也可以是多个。此外,说明书以及权利要求中“和/或”表示所连接对象的至少其中之一,字符“/”,一般表示前后关联对象是一种“或”的关系。The terms "first", "second" and the like in the description and claims of the present application are used to distinguish similar objects, and are not used to describe a specific order or sequence. It is to be understood that the data so used are interchangeable under appropriate circumstances so that the embodiments of the present application can be practiced in sequences other than those illustrated or described herein, and distinguish between "first", "second", etc. The objects are usually of one type, and the number of objects is not limited. For example, the first object may be one or more than one. In addition, "and/or" in the description and claims indicates at least one of the connected objects, and the character "/" generally indicates that the associated objects are in an "or" relationship.
下面结合附图,通过具体的实施例及其应用场景对本申请实施例提供的视频生成方法、装置、电子设备及介质进行详细地说明。The video generation method, apparatus, electronic device, and medium provided by the embodiments of the present application will be described in detail below with reference to the accompanying drawings through specific embodiments and application scenarios thereof.
在相关技术中,电子设备在基于文本生成视频的过程中,所使用的方案大致分为两种:In the related art, in the process of generating video based on text, electronic devices use two schemes:
一种方案是,采用多模态学习生成方法,使用单独训练完备的文本模态模型对用户输入的文本提取文本特征后,再将该文本特征输入生成式对抗网络生成视频。而这种方法所运用的文本模态模型和视频模态模型的特征维度可能不同,导致最终提取的特征存在信息差,没办法很好的匹配,或者当其中一个模态模型的有效信息少时模型无法提取到有用的特征,从而导致生成的视频与文本描述不匹配。One solution is to use a multi-modal learning generation method to extract text features from the text input by the user by using a separately trained text modality model, and then input the text features into a generative adversarial network to generate a video. However, the feature dimensions of the text modal model and the video modal model used in this method may be different, resulting in poor information in the final extracted features, which cannot be well matched, or when one of the modal models has less effective information. No useful features could be extracted, resulting in a mismatch between the generated video and the textual description.
另一种方案中,通常会将一个完整的视频分成多帧图像,然后在处理每帧图像时,在文本参数池中选一个固定的配置加载至该图像的特定部位,单帧图像可以多个部位组合配置,然后再将处理后的多帧图像拼接生成定制视频。然而,这种生成方法会导致生成的视频缺乏连贯性和真实性,丢失了空间信息。In another solution, a complete video is usually divided into multiple frames of images, and then when each frame of image is processed, a fixed configuration is selected from the text parameter pool to load into a specific part of the image, and a single frame of image can be multiple parts. Combine configurations and then stitch the processed multi-frame images to generate a custom video. However, this generative method leads to the lack of coherence and authenticity of the generated videos, and the loss of spatial information.
在本申请实施例提供的视频生成方法、装置、电子设备及介质中,在基于文本生成视频时,电子设备可以先提取第一文本中的行为描述词和视觉描述词,然后从视频库中的与该第一文本相似的N个第一视频中确定与行为描述词匹配的目标视频片段和与视觉描述词匹配的目标视频帧,最后基于该目标视频片段和该目标视频帧,生成目标视频;其中,N为大于1的整数。如此,通过利用文本中用于描述主体行为的行为描述词,来从第一视频中查找到与该主体行为匹配的视频片段,并利用文本中用于描述视觉呈现画面的视觉描述词,来从第一视频中查找到与该视觉呈现画面匹配的视频帧,这样,将上述匹配到的视频片段和视频帧进行融合后,便可得到更加切题和真实的目标视频,保证了最终生成的视频的视频质量。In the video generation method, device, electronic device, and medium provided in the embodiments of the present application, when generating a video based on text, the electronic device can first extract the behavior descriptor and visual descriptor in the first text, and then extract the behavior descriptor and visual descriptor from the video library. Determine the target video segment matched with the behavior descriptor and the target video frame matched with the visual descriptor in the N first videos similar to the first text, and finally generate the target video based on the target video segment and the target video frame; Wherein, N is an integer greater than 1. In this way, by using the behavior descriptor in the text for describing the subject's behavior, a video segment matching the subject's behavior is found from the first video, and using the visual descriptor in the text for describing the visual presentation picture, to obtain a video clip from the first video. A video frame matching the visual presentation picture is found in the first video. In this way, after the above-mentioned matched video clips and video frames are fused, a more relevant and real target video can be obtained, which ensures the final video quality. video quality.
本实施例提供的视频生成方法的执行主体可以为视频生成装置,该视频生成装置可以为电子设备,也可以为该电子设备中的控制模块或处理模块等。以电子设备为例来对本申请实施例提供的技术方案进行说明。The executive body of the video generation method provided in this embodiment may be a video generation apparatus, and the video generation apparatus may be an electronic device, or a control module or a processing module in the electronic device. The technical solutions provided by the embodiments of the present application are described by taking an electronic device as an example.
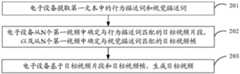
本申请实施例提供一种视频生成方法,如图1所示,该视频生成方法可以包括如下步骤201至步骤203:An embodiment of the present application provides a video generation method. As shown in FIG. 1 , the video generation method may include the
步骤201:电子设备提取第一文本中的行为描述词和视觉描述词。Step 201: The electronic device extracts behavior descriptors and visual descriptors in the first text.
在本申请实施例中,上述行为描述词可以为第一文本中用于描述主体行为的词,例如,奔跑、跳高、飞行、游泳等。In this embodiment of the present application, the above-mentioned behavior descriptors may be words used to describe the behavior of the subject in the first text, for example, running, high jumping, flying, swimming, and the like.
在本申请实施例中,上述视觉描述词可以为第一文本中用于描述视觉呈现画面的词,例如,穿红衣服的人、白色的小狗、蔚蓝色的大海等。In this embodiment of the present application, the above-mentioned visual descriptors may be words used to describe the visually presented picture in the first text, for example, a person in red, a white dog, a blue sea, and the like.
在本申请实施例中,电子设备在获取到第一文本后,可以先对文本进行分词,将分词进行词性拆解,分别提取出视觉描述词与行为描述词。In this embodiment of the present application, after acquiring the first text, the electronic device may firstly segment the text, and then perform part-of-speech disassembly on the segmented words to extract visual descriptors and behavior descriptors respectively.
在本申请实施例中,第一文本中可以包含至少一个行为描述词。In this embodiment of the present application, the first text may include at least one behavior descriptor.
在本申请实施例中,第一文本中可以包含至少一个视觉描述词。In this embodiment of the present application, the first text may include at least one visual descriptor.
步骤202:电子设备从N个第一视频中确定与行为描述词匹配的目标视频片段,以及从N个第一视频中确定与视觉描述词匹配的目标视频帧。Step 202: The electronic device determines from the N first videos a target video segment matching the behavior descriptor, and determines a target video frame matching the visual descriptor from the N first videos.
其中,N为大于1的整数。Wherein, N is an integer greater than 1.
在本申请实施例中,上述N个第一视频为视频库中与第一文本相似的N个视频。In the embodiment of the present application, the above-mentioned N first videos are N videos similar to the first text in the video library.
在本申请实施例中,上述视频库中预存有多个视频,每个视频由至少一个视频片段和/或至少两帧视频帧组成。In the embodiment of the present application, a plurality of videos are pre-stored in the above-mentioned video library, and each video is composed of at least one video segment and/or at least two video frames.
在本申请实施例中,当存在多个与行为描述词匹配的视频片段时,上述目标视频片段可以为与行为描述词相似度最高的视频片段。In this embodiment of the present application, when there are multiple video clips matching the behavior descriptor, the above-mentioned target video clip may be the video clip with the highest similarity with the behavior descriptor.
在本申请实施例中,在第一文本中包含多个行为描述词的情况下,电子设备可以从第一视频中查找每个行为描述词对应的视频片段。示例性地,上述目标视频片段可以包括:该多个行为描述词中每个行为描述词各自对应的视频片段。或者,上述目标视频片段可以包括:部分行为描述词对应的视频片段。In this embodiment of the present application, when the first text contains multiple behavior descriptors, the electronic device may search the first video for a video segment corresponding to each behavior descriptor. Exemplarily, the above target video segment may include: a video segment corresponding to each behavior descriptor in the plurality of behavior descriptors. Alternatively, the above-mentioned target video clips may include: video clips corresponding to some behavior descriptors.
在本申请实施例中,在第一文本中包含多个视觉描述词的情况下,电子设备可以从第一视频中查找每个视觉描述词对应的视频帧。示例性地,上述目标视频片段可以包括:该多个视觉描述词中每个视觉描述词各自对应的视频帧。或者,上述目标视频帧可以包括:部分视觉描述词对应的视频帧。In this embodiment of the present application, when the first text contains multiple visual descriptors, the electronic device may search the first video for a video frame corresponding to each visual descriptor. Exemplarily, the target video segment may include: a video frame corresponding to each visual descriptor in the plurality of visual descriptors. Alternatively, the above target video frame may include: video frames corresponding to some visual descriptors.
步骤203:电子设备基于目标视频片段和目标视频帧,生成目标视频。Step 203: The electronic device generates a target video based on the target video segment and the target video frame.
在本申请实施例中,电子设备在确定出目标视频片段和目标视频帧后,可以目标视频片段与目标视频帧进行融合,从而生成目标视频。In this embodiment of the present application, after determining the target video clip and the target video frame, the electronic device may fuse the target video clip and the target video frame to generate the target video.
可选地,在本申请实施例中,在上述目标视频片段包括多个视频片段。上述步骤203中“电子设备基于目标视频片段和目标视频帧,生成目标视频”可以包括步骤203a和步骤203b:Optionally, in this embodiment of the present application, the above-mentioned target video segment includes multiple video segments. In the
步骤203a:电子设备按照行为描述词在第一文本中的语序,对多个视频片段进行排序。Step 203a: The electronic device sorts the plurality of video clips according to the word order of the behavior description words in the first text.
在本申请实施例中,电子设备可以按照第一文本中的行为描述词的原始语序,对确定出的视频片段进行排序,以使其在时间顺序上具有连贯性和真实性。In this embodiment of the present application, the electronic device may sort the determined video clips according to the original word order of the behavior description words in the first text, so that the video clips have coherence and authenticity in time order.
步骤203b:电子设备按照视觉描述词在第一文本中的语序,将目标视频帧与排序后的多个视频片段融合,生成目标视频。Step 203b: According to the word order of the visual descriptor in the first text, the electronic device fuses the target video frame with the sorted video clips to generate the target video.
在本申请实施例中,电子设备可以将目标视频帧输入通用检测模型,以获得主体信息和背景信息,然后按照视觉描述词在第一文本中的语序,使用3D渲染技术将主体信息和目标视频片段融合,使目标视频帧中的主体动起来,再与背景信息进行拼接,生成目标视频。In this embodiment of the present application, the electronic device may input the target video frame into the general detection model to obtain subject information and background information, and then use 3D rendering technology to combine the subject information and the target video according to the word order of the visual descriptor in the first text Fragment fusion makes the subject in the target video frame move, and then splices with the background information to generate the target video.
示例性地,上述通用检测模型可以为:一种对图像中检测到的对象执行多标签分类的(yolov3)检测模型在计算机视觉系统识别项目(imagenet)数据集上训练收敛的模型,其用于提取文本中的主体特征信息。Exemplarily, the above-mentioned general detection model may be: a (yolov3) detection model that performs multi-label classification on the objects detected in the image is trained and converged on the computer vision system recognition project (imagenet) data set, which is used for Extract the subject feature information in the text.
示例性地,电子设备通过在视频库中找到与该文本最相似的多个第一视频。然后,从该多个第一视频中查找与第一文本中的行为描述词匹配的目标视频片段,提取选出该目标视频片段对应的运动信息,按照行为描述词在上述第一文本中的先后顺序,依次拼接选出的视频片段的运动信息。同时,在上述选出的多个视频中找到与视觉描述词最相似的帧,然后,使用通用检测模型得到主体和背景,最后,使用3D渲染技术将主体和运动信息融合后与背景拼接生成视频。Exemplarily, the electronic device finds a plurality of first videos most similar to the text in the video library. Then, search for a target video segment that matches the behavior descriptor in the first text from the plurality of first videos, extract and select the motion information corresponding to the target video segment, and follow the sequence of the behavior descriptor in the first text. sequence, the motion information of the selected video segments is spliced in sequence. At the same time, find the frame most similar to the visual descriptor in the above selected videos, then use the general detection model to get the subject and background, and finally use 3D rendering technology to fuse the subject and motion information and splicing with the background to generate a video .
如此,由于电子设备是按照第一文本中的语序,来对上述目标视频片段和目标视频帧融合,从而保证了目标视频片段和目标视频帧的连贯性,进而在保证最终生成的视频能够切合第一文本的文本内容的情况下,保证了该视频的空间信息的准确性。In this way, since the electronic device fuses the target video clip and the target video frame according to the word order in the first text, the coherence of the target video clip and the target video frame is ensured, thereby ensuring that the final generated video can meet the requirements of the first text. In the case of a textual content of text, the accuracy of the spatial information of the video is guaranteed.
在本申请实施例提供的视频生成方法中,在基于文本生成视频时,电子设备可以先提取第一文本中的行为描述词和视觉描述词,然后从视频库中的与该第一文本相似的N个第一视频中确定与行为描述词匹配的目标视频片段和与视觉描述词匹配的目标视频帧,最后基于该目标视频片段和该目标视频帧,生成目标视频;其中,N为大于1的整数。如此,通过利用文本中用于描述主体行为的行为描述词,来从第一视频中查找到与该主体行为匹配的视频片段,并利用文本中用于描述视觉呈现画面的视觉描述词,来从第一视频中查找到与该视觉呈现画面匹配的视频帧,这样,将上述匹配到的视频片段和视频帧进行融合后,便可得到更加切题和真实的目标视频,保证了最终生成的视频的视频质量。In the video generation method provided in this embodiment of the present application, when generating a video based on text, the electronic device may first extract behavior descriptors and visual descriptors in the first text, and then extract behavior descriptors and visual descriptors from the video library similar to the first text. In the N first videos, determine the target video segment that matches the behavior descriptor and the target video frame that matches the visual descriptor, and finally generate the target video based on the target video segment and the target video frame; wherein, N is greater than 1. Integer. In this way, by using the behavior descriptor in the text for describing the subject's behavior, a video segment matching the subject's behavior is found from the first video, and using the visual descriptor in the text for describing the visual presentation picture, to obtain a video clip from the first video. A video frame matching the visual presentation picture is found in the first video. In this way, after the above-mentioned matched video clips and video frames are fused, a more relevant and real target video can be obtained, which ensures the final video quality. video quality.
可选地,在本申请实施例中,上述步骤201中“电子设备提取第一文本中的行为描述词和视觉描述词”可以包括步骤201a和步骤201b:Optionally, in this embodiment of the present application, in the
步骤201a:电子设备将第一文本输入命名实体识别模型后,对第一文本进行分词,得到多个分词。Step 201a: After the electronic device inputs the first text into the named entity recognition model, it performs word segmentation on the first text to obtain multiple word segmentations.
在本申请实施例中,上述命名实体识别模型可以为:命名实体识别(Named EntityRecognition,NER)。进一步地,上述NER是指能够将文本中的实体词识别并提取出来的模型。In this embodiment of the present application, the above named entity recognition model may be: Named Entity Recognition (NER). Further, the above-mentioned NER refers to a model that can identify and extract entity words in text.
步骤201b:电子设备基于命名实体识别模型,对多个分词中的每个分词进行词性识别,确定出第一文本中的行为描述词和视觉描述词。Step 201b: Based on the named entity recognition model, the electronic device performs part-of-speech recognition on each of the multiple word segments, and determines the behavior descriptor and the visual descriptor in the first text.
在本申请实施例中,电子设备可以使用NER模型先将第一文本切分成多个分词,再分别提取出该多个分词中的视觉描述词与行为描述词。In this embodiment of the present application, the electronic device may use the NER model to first divide the first text into multiple word segments, and then separately extract visual descriptors and behavior descriptors in the multiple word segments.
如此,电子设备通过将第一文本输入实体识别模型,先对第一文本进行分词,再确定出多个分词中的行为描述词和视觉描述词,可以使电子设备更加准确的获取到第一文本所包含的特征信息。In this way, by inputting the first text into the entity recognition model, the electronic device first performs word segmentation on the first text, and then determines the behavior descriptors and visual descriptors in the multiple word segmentations, so that the electronic device can obtain the first text more accurately. Included feature information.
可选地,在本申请实施例中,上述视频库包括多个视频以及多个视频中的每个视频的视频特征信息。Optionally, in this embodiment of the present application, the foregoing video library includes multiple videos and video feature information of each video in the multiple videos.
以下将对本申请实施例中每个视频的视频特征信息的提取过程进行说明:The process of extracting the video feature information of each video in the embodiments of the present application will be described below:
可选地,在本申请实施例中,在上述步骤202之前,本申请实施例提供的视频生成方法还可以包括如下步骤301至步骤302:Optionally, in this embodiment of the present application, before the
步骤301:电子设备将视频库中的多个视频输入多模态特征提取模型进行特征提取,输出多个视频中的每个视频的视频特征信息。Step 301: The electronic device inputs multiple videos in the video library into a multi-modal feature extraction model to perform feature extraction, and outputs video feature information of each video in the multiple videos.
在本申请实施例中,上述视频库还可以包括视频附属信息列表,进一步地,上述附属信息列表包括每个视频的视频名称和每个视频主体的类型。In this embodiment of the present application, the above-mentioned video library may further include a list of video auxiliary information, further, the above-mentioned auxiliary information list includes the video name of each video and the type of each video subject.
步骤302:电子设备将每个视频的视频特征信息存入视频库中。Step 302: The electronic device stores the video feature information of each video in the video library.
在本申请实施例中,电子设备可以使用多模态特征提取模型提取视频库中的所有视频的视频特征信息,然后将所有视频特征信息载入检索引擎,并将视频名称和视频主体所属类型记录至附属信息列表。In this embodiment of the present application, the electronic device can use the multimodal feature extraction model to extract the video feature information of all videos in the video library, then load all the video feature information into the retrieval engine, and record the video name and the type of the video subject. to the attached information list.
如此,直接利用多模态特征提取模型提取视频库中每个视频的视频特征信息,从而使得后续电子设备可以直接将待使用的文本的文本特征与该视频库中的视频特征信息直接进行匹配,提高了匹配效率。In this way, the multimodal feature extraction model is directly used to extract the video feature information of each video in the video library, so that the subsequent electronic device can directly match the text feature of the text to be used with the video feature information in the video library. Improve matching efficiency.
可选地,在本申请实施例中,电子设备在提取到第一文本的视觉描述词后,可以提取视觉描述词中的主体,然后,查询类别映射表来确定该第一文本中视觉描述词中的主体的主体类型,最后,基于该主体类型从视频库中筛选出与该主体类型匹配的视频类型所对应的视频,从而组成新视频特征检索库。Optionally, in this embodiment of the present application, after extracting the visual descriptor of the first text, the electronic device may extract the subject in the visual descriptor, and then query the category mapping table to determine the visual descriptor in the first text. Finally, based on the subject type, the video corresponding to the video type matching the subject type is filtered out from the video library, so as to form a new video feature retrieval library.
示例性地,电子设备可以使用命名实体识别模型(如,NER预训练模型)来提取视觉描述词中的主体。Illustratively, the electronic device may use a named entity recognition model (eg, a NER pretrained model) to extract subjects in visual descriptors.
举例说明,上述类别映射表可以如下表1所示。需要说明的是,表1中仅仅示出了部分主体类型以及主题类型所对应的部分详细类别。在实际应用中,上述类别映射表可以包含更多的主体类型以及相应的详细类别,此处不再赘述。For example, the above category mapping table may be shown in Table 1 below. It should be noted that, Table 1 only shows some subject types and some detailed categories corresponding to the subject types. In practical applications, the above category mapping table may include more subject types and corresponding detailed categories, which will not be repeated here.
表1Table 1
如此,缩小了电子设备检索视频的范围,提高了电子设备的检索效率。In this way, the scope of video retrieval by the electronic device is narrowed, and the retrieval efficiency of the electronic device is improved.
以下将对如何基于该视频库实现本申请提供的技术方案进行说明:The following will describe how to implement the technical solution provided by this application based on the video library:
可选地,在本申请实施例中,在上述步骤202之前,本申请实施例提供的视频生成方法还可以包括如下步骤A1至步骤A3:Optionally, in the embodiment of the present application, before the
步骤A1:电子设备将第一文本输入多模态特征提取模型后,将第一文本转换为至少一个文本特征信息。Step A1: After the electronic device inputs the first text into the multimodal feature extraction model, the electronic device converts the first text into at least one text feature information.
在本申请实施例中,上述多模态特征提取模型可以为:多级注意力对齐模型(Muti-attention-alignment-model,MAAM)。进一步地,上述MAAM是端到端的多模态视频文本检索模型。In the embodiment of the present application, the above-mentioned multi-modal feature extraction model may be: a multi-level attention alignment model (Muti-attention-alignment-model, MAAM). Further, the above MAAM is an end-to-end multimodal video text retrieval model.
在本申请实施例中,上述至少一个文本特征信息可以包括文本特征向量。例如文本对应的token。In this embodiment of the present application, the above-mentioned at least one text feature information may include a text feature vector. For example, the token corresponding to the text.
步骤A2:从至少一个文本特征信息中,确定关键文本特征信息。Step A2: Determine key text feature information from at least one text feature information.
在本申请实施例中,上述关键文本特征信息可以为:上述至少一个文本特征信息中文本特征向量满足预定条件的文本特征信息。In this embodiment of the present application, the key text feature information may be: text feature information whose text feature vector satisfies a predetermined condition in the at least one text feature information.
步骤A3:调用视频库,对关键文本特征信息和每个视频的视频特征信息进行聚类,得到第一视频特征信息,并将第一视频特征信息对应的视频,作为所述第一视频。Step A3: Invoke the video library to cluster key text feature information and video feature information of each video to obtain first video feature information, and use the video corresponding to the first video feature information as the first video.
在本申请实施例中,上述第一视频特征信息与上述关键文本特征信息间的相似度满足第一条件。In the embodiment of the present application, the similarity between the first video feature information and the key text feature information satisfies the first condition.
在本申请实施例中,上述第一视频特征信息可以包括视频特征向量。例如视频对应的token。In this embodiment of the present application, the above-mentioned first video feature information may include a video feature vector. For example, the token corresponding to the video.
需要说明的是,token用于表示将特征转换为固定维度的序列特征向量,序列中每一个原子特征就是一个token。It should be noted that the token is used to represent the sequence feature vector that converts the feature into a fixed dimension, and each atomic feature in the sequence is a token.
在本申请实施例中,电子设备在提取到第一文本特征向量,以及从视频库中获取到视频特征向量之后,通过计算向量值,得到每个视频对应的分数,以此来得到第一文本与每个视频间地相似度。In the embodiment of the present application, after extracting the first text feature vector and acquiring the video feature vector from the video library, the electronic device obtains the score corresponding to each video by calculating the vector value, so as to obtain the first text Similarity with each video.
在本申请实施例中,上述第一条件可以为:与关键文本特征向量相似度值最高的视频特征向量。In the embodiment of the present application, the above-mentioned first condition may be: the video feature vector with the highest similarity value with the key text feature vector.
如此,电子设备通过将提取出的关键文本特征信息与视频库中的视频特征信息计算相似度,并将相似度值最高的视频确定为第一视频,提高了电子设备确定第一视频的准确度。In this way, the electronic device calculates the similarity between the extracted key text feature information and the video feature information in the video library, and determines the video with the highest similarity value as the first video, which improves the accuracy with which the electronic device determines the first video. .
举例说明,以多模态特征提取模型为MAAM为例。来对多模态特征提取模型的提取过程进行示例性说明。As an example, take the multimodal feature extraction model as MAAM as an example. To exemplify the extraction process of the multimodal feature extraction model.
示例性地,如图2所示,该MAAM模型分别由视觉模块、文本模块两部分组成。其中,上述视觉模块包括Vision-transformer模型(图文预训练模型中的视觉模型)和引导学习模块(Guide-Study-Module,GSM),上述文本模块包括Text-transformer模型(图文预训练模型中的文本模型)和GSM。该GSM模块由注意力(Attention)模块和聚类对齐(ClusterAlignment)模块组成,其中聚类对齐模块为共享模块。Exemplarily, as shown in Figure 2, the MAAM model is composed of two parts: a vision module and a text module. Wherein, the above-mentioned visual module includes a Vision-transformer model (visual model in the graphic and text pre-training model) and a guided learning module (Guide-Study-Module, GSM), and the above-mentioned text module includes a Text-transformer model (in the graphic and text pre-training model) text model) and GSM. The GSM module consists of an attention module and a cluster alignment module, wherein the cluster alignment module is a shared module.
需要说明的是,上述Attention模块用于引导模型只关注可区分特征的模块。It should be noted that the above Attention module is used to guide the model to only focus on modules with distinguishable features.
示例性地,上述GSM旨在获取各模态中各自具有区分度的特征信息,并将提取出的显著性特征向量统一映射到新的特征空间,使各模态特征向量在新的空间中处于同一语义维度,消除模态间的语义信息差。Exemplarily, the above-mentioned GSM aims to obtain the feature information with distinguishing degree in each modality, and uniformly map the extracted salient feature vector to a new feature space, so that each modality feature vector is in the new space. The same semantic dimension eliminates the difference in semantic information between modalities.
示例性地,如图3所示,上述GSM中的Attention模块用于提取关键信息,将Vision-transformer和Text-transformer倒数第二层的输出token数由n个减少为k个,k为一种新型模型结构(transformer)内自注意力头的个数。L为transformer结构的层数,al为transformer模型的第l层注意力权重,其中l的取值范围为transformer结构的第一层至倒数第二层,最后一层不参与注意力权重计算,al结构如(公式1)所示,Exemplarily, as shown in Figure 3, the Attention module in the above-mentioned GSM is used to extract key information, and the number of output tokens of the penultimate layer of Vision-transformer and Text-transformer is reduced from n to k, where k is a The number of self-attention heads in the new model structure (transformer). L is the number of layers of the transformer structure, al is the attention weight of the first layer of the transformer model, where the value of l ranges from the first layer to the penultimate layer of the transformer structure, and the last layer does not participate in the calculation of the attention weight, The structure of al is shown in (Formula 1),

其中,

Attention模块中,(1,L-1)中所有层注意力权重进行矩阵乘,如(公式3)所示:In the Attention module, the attention weights of all layers in (1, L-1) are matrix multiplied, as shown in (Formula 3):
afinal=∏al (公式3)afinal =∏al (Equation 3)
afinal与transformer结构倒数第二层aL-1做矩阵乘运算,得到aselect注意力向量如(公式4)所示:afinal and the penultimate layer aL-1 of the transformer structure do matrix multiplication to obtain aselect attention vector as shown in (Equation 4):
aselect=afinal*aL-1 (公式4)aselect = afinal *aL-1 (Equation 4)
对aL-1层的k个分量中的每一个分量取最大值,

为了方便展示,将第k个注意力头选取的max分量值记为取值

示例性地,如图4所示,聚类对齐模块用于:将文本Attention模块输出的k个token与视觉Attention模块输出的k个token进行聚类,得到p个共享中心{c1,c2,…,cp}。使用p个共享中心对每个token重新表示,文本模型的token与视觉模型的token使用同样的一组向量基进行表达,使两个模态之间的语义差得到进一步的弱化。Exemplarily, as shown in Figure 4, the cluster alignment module is used to: cluster the k tokens output by the text Attention module and the k tokens output by the visual Attention module to obtain p shared centers {c1 ,c2 ,…,cp }. Each token is re-represented using p shared centers, and the token of the text model and the token of the visual model are represented by the same set of vector bases, which further weakens the semantic difference between the two modalities.
其中,文本模型和视觉模型中的每个token与共享中心的每个分量计算点积,乘积经过softmax函数将输出转换为置信度,表示当前共享中心的分量对指定token的贡献的重要程度,以表示token在共享中心构成的新特征空间的数据分布,如(公式7)所示:Among them, the dot product of each token in the text model and the visual model and each component of the shared center is calculated, and the product is converted into a confidence level through the softmax function, which indicates the importance of the contribution of the current shared center component to the specified token, with Represents the data distribution of the new feature space composed of tokens in the sharing center, as shown in (Equation 7):

其中,

示例性地,如图3所示,上述MAAM模型进行特征向量提取的过程包括如下步骤S1至S4:Exemplarily, as shown in FIG. 3 , the process of extracting feature vectors by the above-mentioned MAAM model includes the following steps S1 to S4:
步骤S1:将文本通过Text-transformer模型获得m个token,其中分类token(cls-token)记为clsg。再将该m个tokem经过GSM中的Attention模块,将token数减少为k+1个。Step S1: Obtain m tokens from the text through the Text-transformer model, wherein the classification token (cls-token) is denoted as clsg . The m tokens are then passed through the Attention module in GSM to reduce the number of tokens to k+1.
步骤S2:将视频均匀采样16帧(Frame),每一帧通过Vision-transformer模型获得n个token,取每帧对应的cls-token与新增cls-token拼接成新的token序列特征向量,其中新增cls-token记为clsa。再将该新的token序列特征向量输入GSM中的Attention模块提取关键信息,将token数减少为k+1个。Step S2: uniformly sample the video for 16 frames (Frame), each frame obtains n tokens through the Vision-transformer model, and splices the cls-token corresponding to each frame and the newly added cls-token into a new token sequence feature vector, where The newly added cls-token is recorded as clsa . Then input the new token sequence feature vector into the Attention module in GSM to extract key information, and reduce the number of tokens to k+1.
步骤S3:文本模态和视频模态各自输出去除cls-token的k个attention token,再经过cluster alignment模块得到p维空间表征。Step S3: The text modality and the video modality respectively output k attention tokens that remove the cls-token, and then obtain the p-dimensional space representation through the cluster alignment module.
步骤S4:整体训练损失如(公式9)所示,经过多损失联合优化,使模型可以学习到视频模态与文本模态最具有代表性的注意力特征向量。Step S4: The overall training loss is shown in (Formula 9), and after joint optimization of multiple losses, the model can learn the most representative attention feature vectors of the video modality and the text modality.
L=Lg+La+Lc (公式9)L=Lg +La +Lc (Equation 9)
Lg是通过全局对齐模块(Global alignment)计算全局损失(global alignmentloss)如(公式10)所示:Lg is calculated by the global alignment module (Global alignment) as shown in (Equation 10):








La为注意力损失(Attention alignment loss)如(公式12)所示,Sim(zi,zj)表示样本i、j对应attention特征向量之间的余弦相似度;La is the attention loss (Attention alignment loss). As shown in (Formula 12), Sim(zi ,zj ) represents the cosine similarity between the attention feature vectors corresponding to samples i and j;


Lc为聚类损失(cluster alignment loss)如(公式13)所示,


可选地,在本申请实施例中,上述步骤202中“电子设备从N个第一视频中确定与行为描述词匹配的目标视频片段”可以包括步骤B1至步骤B3:Optionally, in this embodiment of the present application, in the
步骤B1:电子设备将行为描述词和N个第一视频输入多模态特征提取模型后,将行为描述词转换为至少一个行为特征信息,并将N个第一视频转化为至少一个视频特征信息。Step B1: After the electronic device inputs the behavior descriptor and the N first videos into the multimodal feature extraction model, converts the behavior descriptor into at least one behavior feature information, and converts the N first videos into at least one video feature information .
在本申请实施例中,上述至少一个行为特征信息可以包括行为特征向量。例如行为对应的token。In this embodiment of the present application, the at least one behavior feature information may include a behavior feature vector. For example, the token corresponding to the behavior.
步骤B2:从至少一个行为特征信息中,确定关键行为特征信息,并从至少一个视频特征信息中,确定第一关键视频特征信息。Step B2: Determine key behavior feature information from at least one behavior feature information, and determine first key video feature information from at least one video feature information.
在本申请实施例中,上述关键行为特征信息是指,在上述至少一个行为特征信息中起决定性作用的行为特征信息。In this embodiment of the present application, the above-mentioned key behavior feature information refers to behavior feature information that plays a decisive role in the above-mentioned at least one behavior feature information.
步骤B3:根据关键行为特征信息,从第一关键视频特征信息中,确定第二视频特征信息,并将第二视频特征信息对应的视频片段,作为目标视频片段。Step B3: Determine the second video feature information from the first key video feature information according to the key behavior feature information, and use the video segment corresponding to the second video feature information as the target video segment.
在本申请实施例中,上述第二视频特征信息与上述关键行为特征信息间的相似度满足第二条件。In the embodiment of the present application, the similarity between the second video feature information and the key behavior feature information satisfies the second condition.
在本申请实施例中,电子设备在提取到第一关键视频特征向量,以及提取到行为描述词对应的关键行为特征向量后,通过计算向量值,得到每个第一视频中的视频片段对应的分数,以此来得到行为描述词与每个视频片段间的相似度。In the embodiment of the present application, after extracting the first key video feature vector and extracting the key behavior feature vector corresponding to the behavior descriptor, the electronic device calculates the vector value to obtain the corresponding video clip in each first video. score to get the similarity between the behavior descriptor and each video clip.
在本申请实施例中,上述第二条件可以为:与上述关键行为特征向量相似度值最高的第一关键视频特征向量。In this embodiment of the present application, the above second condition may be: the first key video feature vector with the highest similarity value with the above key behavior feature vector.
在本申请实施例中,上述视频片段为上述第一视频中的视频片段。一个第一视频对应至少一个视频片段。In this embodiment of the present application, the above-mentioned video clip is a video clip in the above-mentioned first video. A first video corresponds to at least one video segment.
示例1,以第一视频为5个视频为例,电子设备将每个行为描述词与该5个视频送入MAAM提取行为特征向量后,将每个行为描述词与5个选出的视频的特征向量计算聚类损失Lc,取出Lc最小的视频中视觉模块中的k个Attention token对应位置的视频帧,若选出的视频帧不是相邻的,则将第一个选中的视频帧到最后一个选中的视频帧区间内的所有视频帧按照时间顺序排列,组成视频片段。如图5所示,将文本模态与视频模态在通过Attention模块后输出的Attention token分别标记为31与31,取32对应位置的原始视频帧组成与当前行为描述词最相关的视频动作片段。视频片段内的所有视频帧使用关键点检索模型提取主体关键点位置信息,相邻视频帧中,主体对应关键点计算位置差,n帧视频片段,得到n-1组关键点位置差记为运动信息。Example 1, taking the first video as an example of 5 videos, the electronic device sends each behavior descriptor and the 5 videos into MAAM to extract the behavior feature vector, and then compares each behavior descriptor with the 5 selected videos. The feature vector calculates the clustering loss Lc , and takes out the video frames corresponding to the k Attention tokens in the visual module in the video with the smallest Lc . If the selected video frames are not adjacent, the first selected video frame All video frames in the interval to the last selected video frame are arranged in chronological order to form a video segment. As shown in Figure 5, the attention tokens output by the text modality and the video modality after passing through the Attention module are marked as 31 and 31 respectively, and the original video frame corresponding to 32 is taken to form the most relevant video action segment with the current behavior descriptor. . All the video frames in the video clip use the key point retrieval model to extract the position information of the subject key points. In the adjacent video frames, the position difference of the subject corresponding to the key points is calculated, and the position difference of n-1 sets of key points is obtained for n video clips and recorded as motion. information.
如此,电子设备通过将提取出的关键行为特征信息与第一视频中的第一关键视频特征信息计算相似度,并将相似度值最高的视频片段确定为目标视频片段,进一步提高了电子设备确定视频片段的准确度。In this way, the electronic device calculates the similarity between the extracted key behavior feature information and the first key video feature information in the first video, and determines the video segment with the highest similarity value as the target video segment, which further improves the determination of the electronic device. The accuracy of the video clip.
可选地,在本申请实施例中,上述步骤202中“电子设备从N个第一视频中确定与视觉描述词匹配的目标视频帧”可以包括步骤C1至步骤C3:Optionally, in the embodiment of the present application, in the
步骤C1:电子设备将视觉描述词和N个第一视频输入多模态特征提取模型后,将视觉描述词转换为至少一个视觉特征信息,并将N个第一视频转化为至少一个视频特征信息。Step C1: After the electronic device inputs the visual descriptors and the N first videos into the multimodal feature extraction model, converts the visual descriptors into at least one visual feature information, and converts the N first videos into at least one video feature information .
在本申请实施例中,上述至少一个视觉特征信息可以包括视觉特征向量。例如视觉对应的token。In this embodiment of the present application, the at least one piece of visual feature information may include a visual feature vector. For example, the visual corresponding token.
步骤C2:从至少一个视觉特征信息中,确定关键视觉特征信息,并从至少一个视频特征信息中,确定第二关键视频特征信息。Step C2: Determine key visual feature information from at least one piece of visual feature information, and determine second key video feature information from at least one piece of video feature information.
在本申请实施例中,上述关键视觉特征信息是指,在上述至少一个视觉特征信息中起决定性作用的视觉特征信息。In the embodiment of the present application, the above-mentioned key visual feature information refers to the visual feature information that plays a decisive role in the above-mentioned at least one piece of visual feature information.
步骤C3:根据关键视觉特征信息,从第二关键视频特征信息中,确定第三视频特征信息,并将第三视频特征信息对应的视频帧,作为目标视频帧。Step C3: Determine the third video feature information from the second key video feature information according to the key visual feature information, and use the video frame corresponding to the third video feature information as the target video frame.
在本申请实施例中,上述第三视频特征信息与上述关键视觉特征信息间的相似度满足第三条件。In the embodiment of the present application, the similarity between the third video feature information and the key visual feature information satisfies the third condition.
在本申请实施例中,电子设备在提取到第二关键视频特征向量,以及提取到视觉描述词对应的关键视觉特征向量后,通过计算向量值,得到每个第一视频中的视频帧对应的分数,以此来得到视觉描述词与每个视频帧间的相似度。In the embodiment of the present application, after extracting the second key video feature vector and extracting the key visual feature vector corresponding to the visual descriptor, the electronic device calculates the vector value to obtain the corresponding video frame in each first video. score to get the similarity between the visual descriptor and each video frame.
在本申请实施例中,上述第三条件可以为:与上述关键视觉特征向量相似度值最高的第二关键视频特征向量。In the embodiment of the present application, the above third condition may be: the second key video feature vector with the highest similarity value with the above key visual feature vector.
在本申请实施例中,上述视频帧为上述第一视频中的视频帧。一个第一视频对应至少两个视频帧。In this embodiment of the present application, the above-mentioned video frame is a video frame in the above-mentioned first video. One first video corresponds to at least two video frames.
示例2,结合示例1,电子设备将每个视觉描述词与上述5个视频送入MAAM提取视觉特征向量后,将每个视觉描述词与5个选出的视频中所有的Attention token(共5*k个)计算余弦相似度,取相似度最大的一个Attention token对应的视频帧,作为目标视频帧,即该目标视频帧为最符合视觉描述词的视觉形象。Example 2, combined with Example 1, the electronic device sends each visual descriptor and the above 5 videos to MAAM to extract the visual feature vector, and then combines each visual descriptor with all the Attention tokens in the 5 selected videos (a total of 5). *k) Calculate the cosine similarity, and take the video frame corresponding to the Attention token with the largest similarity as the target video frame, that is, the target video frame is the visual image that best matches the visual descriptor.
如此,电子设备通过将提取出的关键视觉特征信息与第一视频中的第二关键视频特征信息计算相似度,并将相似度值最高的视频帧确定为目标视频帧,进一步提高了电子设备确定视频帧的准确度。In this way, the electronic device calculates the similarity between the extracted key visual feature information and the second key video feature information in the first video, and determines the video frame with the highest similarity value as the target video frame, which further improves the determination of the electronic device. Video frame accuracy.
在相关技术中,多模态特征提取模型训练方案通常分为同步训练和异步训练两种。其中:In the related art, the multimodal feature extraction model training scheme is usually divided into two types: synchronous training and asynchronous training. in:
异步训练即单个模态单独训练,各模态训练完备的模型提取特征后直接相似度匹配,这种训练方式得到的视觉模态模型和文本模态模型的特征维度不同,各模态模型学习出的特征存在信息差,没办法很好的匹配。或者,当其中一个模态有效信息较少时模型学不到有用信息。Asynchronous training means that a single modality is trained separately, and the models with complete training of each modality are directly matched for similarity after feature extraction. The visual modality model obtained by this training method and the text modality model have different feature dimensions. There is poor information in the features of , and there is no way to match them well. Or, the model cannot learn useful information when one of the modalities has less useful information.
同步训练即多个模态共同训练,每个模态模型关注的信息受另一个模态模型的影响,各模态模型更倾向于学习出能与其他模态模型特征更为相关的特征。但仅协同训练也是不够的,在视频模态和文本模态都包含了大量的冗余信息,各模态模型很难学习到关键信息,模型无法捕捉到文本以及视频内想要表达的重点内容。Synchronous training is the joint training of multiple modalities. The information concerned by each modal model is affected by another modal model, and each modal model is more inclined to learn features that are more relevant to the features of other modal models. However, only collaborative training is not enough. Both video modalities and text modalities contain a lot of redundant information. It is difficult for each modal model to learn key information, and the model cannot capture the text and the key content that the video wants to express. .
在本申请实施例中,多模态特征提取模型(如MAAM)的设计过程如下:In this embodiment of the present application, the design process of a multimodal feature extraction model (such as MAAM) is as follows:
首先,MAAM中的文本模态模型使用已有预训练text-transformer模型结构作为基础网络结构,并使用MAAM中的视频模态模型等间隔采样16帧视频帧,然后,每帧视频帧使用已有预训练vision-transformer模型结构作为基础网络结构。并且,为了去除冗余信息的干扰,在两个基础网络结构后引入GSM,指导各模态模型更加关注模态间相关信息。应注意的是,该GSM模块由Attention模块和Cluster Alignment模块组成。具体的,在GSM模块中的各模态原有倒数第二层输出后,接入Attention模块,在各自的模态中选出k个最有区分度的token,与分类token拼接成k+1个token序列,替换倒数第二层输出,然后,经最后一层transformer后得到k+1个注意力特征token。First, the text modality model in MAAM uses the existing pre-trained text-transformer model structure as the basic network structure, and uses the video modality model in MAAM to sample 16 video frames at equal intervals. The pre-trained vision-transformer model structure is used as the basic network structure. Moreover, in order to remove the interference of redundant information, GSM is introduced after the two basic network structures to guide each modal model to pay more attention to the inter-modal related information. It should be noted that this GSM module consists of an Attention module and a Cluster Alignment module. Specifically, after the original penultimate layer output of each modal in the GSM module, access the Attention module, select the k most distinguishing tokens in their respective modalities, and spliced with the classification token to form k+1 A sequence of tokens, replace the output of the penultimate layer, and then obtain k+1 attention feature tokens after the last layer of transformer.
其次,为了更好的对齐文本模态模型与视频模态模型特征,可以将除分类token外的k个注意力特征token送入Cluster Alignment模块,使用相同基向量表示视频模态模型与文本模态模型的特征,使视频模态模型与文本模态模型在新的特征空间可以消除之间的信息差。同时,为了提升两个模态特征的一致性,引入注意力对齐损失(Attentionalignment loss)与聚类对齐损失(Cluster alignment loss),使视频模态模型与文本模态模型从局部到全局的一致性最大化。Secondly, in order to better align the features of the text modality model and the video modality model, k attention feature tokens other than the classification token can be sent to the Cluster Alignment module, and the same base vector is used to represent the video modality model and the text modality. The features of the model enable the information difference between the video modality model and the text modality model to be eliminated in the new feature space. At the same time, in order to improve the consistency of the two modal features, attention alignment loss and cluster alignment loss are introduced to make the video modality model and the text modality model consistent from local to global. maximize.
如此,相比于相关技术中所提出的多模态特征提取模型训练方案,本申请提供的训练方案通过在多模态特征提取模型中新增一个GSM模块,使得训练出的多模态特征提取模型在提取特征信息时,能够更精准的捕捉到文本或视频中所包含的关键特征信息。In this way, compared with the multi-modal feature extraction model training scheme proposed in the related art, the training scheme provided by the present application adds a GSM module to the multi-modal feature extraction model, so that the multi-modal feature extraction model trained is extracted When the model extracts feature information, it can more accurately capture the key feature information contained in the text or video.
本申请实施例提供的视频生成方法,执行主体可以为视频生成装置。本申请实施例中以视频生成装置执行视频生成方法为例,说明本申请实施例提供的视频生成装置。In the video generation method provided by the embodiments of the present application, the execution body may be a video generation device. In the embodiment of the present application, the video generation device provided by the embodiment of the present application is described by taking the video generation device executing the video generation method as an example.
本申请实施例提供一种视频生成装置,如图6所示,该视频生成装置400包括:提取模块401、确定模块402和生成模块403,其中:上述提取模块401,用于提取第一文本中的行为描述词和视觉描述词;上述确定模块402,用于从N个第一视频中确定与上述行为描述词匹配的目标视频片段,以及从上述N个第一视频中确定与上述视觉描述词匹配的目标视频帧;上述生成模块403,用于基于确定模块402确定的上述目标视频片段和上述目标视频帧,生成目标视频;其中,上述N个第一视频为视频库中与上述第一文本相似的N个视频;N为大于1的整数。An embodiment of the present application provides a video generation device. As shown in FIG. 6 , the
可选地,在本申请实施例中,上述提取模块401,具体用于将第一文本输入命名实体识别模型后,对该第一文本进行分词,得到多个分词;基于上述命名实体识别模型,对上述多个分词中的每个分词进行词性识别,确定出上述第一文本中的行为描述词和视觉描述词。Optionally, in the embodiment of the present application, the above-mentioned
可选地,在本申请实施例中,上述视频库包括多个视频以及该多个视频中的每个视频的视频特征信息;上述确定模块402,还用于在从N个第一视频中确定与上述行为描述词匹配的目标视频片段,以及从上述N个第一视频中确定与上述视觉描述词匹配的目标视频帧之前,将上述第一文本输入多模态特征提取模型后,将上述第一文本转换为至少一个文本特征信息;从该至少一个文本特征信息中,确定关键文本特征信息;调用上述视频库,对上述关键文本特征信息和上述每个视频的视频特征信息进行聚类,得到第一视频特征信息,并将该第一视频特征信息对应的视频,作为上述第一视频;其中,上述第一视频特征信息与上述关键文本特征信息间的相似度满足第一条件。Optionally, in this embodiment of the present application, the above-mentioned video library includes multiple videos and video feature information of each video in the multiple videos; the above-mentioned determining
可选地,在本申请实施例中,上述确定模块402,具体用于将上述行为描述词和上述N个第一视频输入多模态特征提取模型后,将上述行为描述词转换为至少一个行为特征信息,并将上述N个第一视频转化为至少一个视频特征信息;从上述至少一个行为特征信息中,确定关键行为特征信息,并从上述至少一个视频特征信息中,确定第一关键视频特征信息;根据上述关键行为特征信息,从上述第一关键视频特征信息中,确定第二视频特征信息,并将该第二视频特征信息对应的视频片段,作为上述目标视频片段;其中,上述第二视频特征信息与上述关键行为特征信息间的相似度满足第二条件。Optionally, in this embodiment of the present application, the
可选地,在本申请实施例中,上述确定模块402,具体用于将上述视觉描述词和上述N个第一视频输入多模态特征提取模型后,将上述视觉描述词转换为至少一个视觉特征信息,并将上述N个第一视频转化为至少一个视频特征信息;从上述至少一个视觉特征信息中,确定关键视觉特征信息,并从上述至少一个视频特征信息中,确定第二关键视频特征信息;根据上述关键视觉特征信息,从上述第二关键视频特征信息中,确定第三视频特征信息,并将该第三视频特征信息对应的视频帧,作为上述目标视频帧;其中,上述第三视频特征信息与上述关键视觉特征信息间的相似度满足第三条件。Optionally, in this embodiment of the present application, the above-mentioned determining
可选地,在本申请实施例中,上述提取模块401,还用于在确定模块402从N个第一视频中确定与上述行为描述词匹配的目标视频片段,以及从上述N个第一视频中确定与上述视觉描述词匹配的目标视频帧之前;将上述视频库中的上述多个视频输入多模态特征提取模型进行特征提取,输出上述多个视频中的每个视频的视频特征信息;将该视频特征信息存入上述视频库中。Optionally, in this embodiment of the present application, the above-mentioned
可选地,在本申请实施例中,上述目标视频片段包括多个视频片段;上述生成模块403,具体用于按照上述行为描述词在上述第一文本中的语序,对上述多个视频片段进行排序;按照上述视觉描述词在上述第一文本中的语序,将上述目标视频帧与排序后的上述多个视频片段融合,生成目标视频。Optionally, in the embodiment of the present application, the above-mentioned target video clips include multiple video clips; the above-mentioned
本申请实施例提供的视频生成装置中,在基于文本生成视频时,该视频生成装置可以先提取第一文本中的行为描述词和视觉描述词,然后从视频库中的与该第一文本相似的N个第一视频中确定与行为描述词匹配的目标视频片段和与视觉描述词匹配的目标视频帧,最后基于该目标视频片段和该目标视频帧,生成目标视频;其中,N为大于1的整数。如此,通过利用文本中用于描述主体行为的行为描述词,来从第一视频中查找到与该主体行为匹配的视频片段,并利用文本中用于描述视觉呈现画面的视觉描述词,来从第一视频中查找到与该视觉呈现画面匹配的视频帧,这样,将上述匹配到的视频片段和视频帧进行融合后,便可得到更加切题和真实的目标视频,保证了最终生成的视频的视频质量。In the video generation device provided by the embodiment of the present application, when generating a video based on text, the video generation device may first extract the behavior descriptors and visual descriptors in the first text, and then extract the behavior descriptors and visual descriptors in the first text, and then extract from the video library similar to the first text. Determine the target video segment that matches the behavior descriptor and the target video frame that matches the visual descriptor in the N first videos of the integer. In this way, by using the behavior descriptor in the text for describing the subject's behavior, a video segment matching the subject's behavior is found from the first video, and using the visual descriptor in the text for describing the visual presentation picture, to obtain a video clip from the first video. A video frame matching the visual presentation picture is found in the first video. In this way, after the above-mentioned matched video clips and video frames are fused, a more relevant and real target video can be obtained, which ensures the final video quality. video quality.
本申请实施例中的视频生成装置可以是电子设备,也可以是电子设备中的部件,例如集成电路或芯片。该电子设备可以是终端,也可以为除终端之外的其他设备。示例性的,电子设备可以为手机、平板电脑、笔记本电脑、掌上电脑、车载电子设备、移动上网装置(Mobile Internet Device,MID)、增强现实(augmented reality,AR)/虚拟现实(virtualreality,VR)设备、机器人、可穿戴设备、超级移动个人计算机(ultra-mobile personalcomputer,UMPC)、上网本或者个人数字助理(personal digital assistant,PDA)等,还可以为服务器、网络附属存储器(Network Attached Storage,NAS)、个人计算机(personalcomputer,PC)、电视机(television,TV)、柜员机或者自助机等,本申请实施例不作具体限定。The video generating apparatus in this embodiment of the present application may be an electronic device, or may be a component in the electronic device, such as an integrated circuit or a chip. The electronic device may be a terminal, or may be other devices other than the terminal. Exemplarily, the electronic device may be a mobile phone, a tablet computer, a notebook computer, a palmtop computer, a vehicle-mounted electronic device, a Mobile Internet Device (MID), an augmented reality (AR)/virtual reality (VR) Devices, robots, wearable devices, ultra-mobile personal computers (UMPCs), netbooks or personal digital assistants (PDAs), etc., and can also be servers, network attached storages (NAS) , a personal computer (personal computer, PC), a television (television, TV), a teller machine or a self-service machine, etc., which are not specifically limited in the embodiments of the present application.
本申请实施例中的视频生成装置可以为具有操作系统的装置。该操作系统可以为安卓(Android)操作系统,可以为iOS操作系统,还可以为其他可能的操作系统,本申请实施例不作具体限定。The video generating apparatus in the embodiment of the present application may be an apparatus having an operating system. The operating system may be an Android (Android) operating system, an iOS operating system, or other possible operating systems, which are not specifically limited in the embodiments of the present application.
本申请实施例提供的视频生成装置能够实现图1至图5的方法实施例实现的各个过程,为避免重复,这里不再赘述。The video generation apparatus provided in the embodiment of the present application can implement each process implemented by the method embodiments in FIG. 1 to FIG. 5 , and to avoid repetition, details are not described here.
可选地,如图7所示,本申请实施例还提供一种电子设备600,包括处理器601和存储器602,存储器602上存储有可在所述处理器601上运行的程序或指令,该程序或指令被处理器601执行时实现上述视频生成方法实施例的各个步骤,且能达到相同的技术效果,为避免重复,这里不再赘述。Optionally, as shown in FIG. 7 , an embodiment of the present application further provides an
需要说明的是,本申请实施例中的电子设备包括上述所述的移动电子设备和非移动电子设备。It should be noted that the electronic devices in the embodiments of the present application include the aforementioned mobile electronic devices and non-mobile electronic devices.
图8为实现本申请实施例的一种电子设备的硬件结构示意图。FIG. 8 is a schematic diagram of a hardware structure of an electronic device implementing an embodiment of the present application.
该电子设备100包括但不限于:射频单元101、网络模块102、音频输出单元103、输入单元104、传感器105、显示单元106、用户输入单元107、接口单元108、存储器109、以及处理器110等部件。The
本领域技术人员可以理解,电子设备100还可以包括给各个部件供电的电源(比如电池),电源可以通过电源管理系统与处理器110逻辑相连,从而通过电源管理系统实现管理充电、放电、以及功耗管理等功能。图8中示出的电子设备结构并不构成对电子设备的限定,电子设备可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置,在此不再赘述。Those skilled in the art can understand that the
其中,上述处理器110,用于提取第一文本中的行为描述词和视觉描述词;从N个第一视频中确定与上述行为描述词匹配的目标视频片段,以及从上述N个第一视频中确定与上述视觉描述词匹配的目标视频帧;基于上述目标视频片段和上述目标视频帧,生成目标视频;其中,上述N个第一视频为视频库中与上述第一文本相似的N个视频;N为大于1的整数。The
可选地,在本申请实施例中,上述处理器110,具体用于将第一文本输入命名实体识别模型后,对该第一文本进行分词,得到多个分词;基于上述命名实体识别模型,对上述多个分词中的每个分词进行词性识别,确定出上述第一文本中的行为描述词和视觉描述词。Optionally, in this embodiment of the present application, the above-mentioned
可选地,在本申请实施例中,上述视频库包括多个视频以及该多个视频中的每个视频的视频特征信息;上述处理器110,还用于在从N个第一视频中确定与上述行为描述词匹配的目标视频片段,以及从上述N个第一视频中确定与上述视觉描述词匹配的目标视频帧之前,将上述第一文本输入多模态特征提取模型后,将上述第一文本转换为至少一个文本特征信息;从该至少一个文本特征信息中,确定关键文本特征信息;调用上述视频库,对上述关键文本特征信息和上述每个视频的视频特征信息进行聚类,得到第一视频特征信息,并将该第一视频特征信息对应的视频,作为上述第一视频;其中,上述第一视频特征信息与上述关键文本特征信息间的相似度满足第一条件。Optionally, in this embodiment of the present application, the above-mentioned video library includes multiple videos and video feature information of each video in the multiple videos; the above-mentioned
可选地,在本申请实施例中,上述处理器110,具体用于将上述行为描述词和上述N个第一视频输入多模态特征提取模型后,将上述行为描述词转换为至少一个行为特征信息,并将上述N个第一视频转化为至少一个视频特征信息;从上述至少一个行为特征信息中,确定关键行为特征信息,并从上述至少一个视频特征信息中,确定第一关键视频特征信息;根据上述关键行为特征信息,从上述第一关键视频特征信息中,确定第二视频特征信息,并将该第二视频特征信息对应的视频片段,作为上述目标视频片段;其中,上述第二视频特征信息与上述关键行为特征信息间的相似度满足第二条件。Optionally, in this embodiment of the present application, the
可选地,在本申请实施例中,上述处理器110,具体用于将上述视觉描述词和上述N个第一视频输入多模态特征提取模型后,将上述视觉描述词转换为至少一个视觉特征信息,并将上述N个第一视频转化为至少一个视频特征信息;从上述至少一个视觉特征信息中,确定关键视觉特征信息,并从上述至少一个视频特征信息中,确定第二关键视频特征信息;根据上述关键视觉特征信息,从上述第二关键视频特征信息中,确定第三视频特征信息,并将该第三视频特征信息对应的视频帧,作为上述目标视频帧;其中,上述第三视频特征信息与上述关键视觉特征信息间的相似度满足第三条件。Optionally, in this embodiment of the present application, the above-mentioned
可选地,在本申请实施例中,上述处理器110,还用于在从N个第一视频中确定与上述行为描述词匹配的目标视频片段,以及从上述N个第一视频中确定与上述视觉描述词匹配的目标视频帧之前;将上述视频库中的上述多个视频输入多模态特征提取模型进行特征提取,输出上述多个视频中的每个视频的视频特征信息;将该视频特征信息存入上述视频库中。Optionally, in this embodiment of the present application, the above-mentioned
可选地,在本申请实施例中,上述目标视频片段包括多个视频片段;上述处理器110,具体用于按照上述行为描述词在上述第一文本中的语序,对上述多个视频片段进行排序;按照上述视觉描述词在上述第一文本中的语序,将上述目标视频帧与排序后的上述多个视频片段融合,生成目标视频。Optionally, in this embodiment of the present application, the above-mentioned target video clip includes multiple video clips; the above-mentioned
在本申请实施例提供的电子设备中,在基于文本生成视频时,电子设备可以先提取第一文本中的行为描述词和视觉描述词,然后从视频库中的与该第一文本相似的N个第一视频中确定与行为描述词匹配的目标视频片段和与视觉描述词匹配的目标视频帧,最后基于该目标视频片段和该目标视频帧,生成目标视频;其中,N为大于1的整数。如此,通过利用文本中用于描述主体行为的行为描述词,来从第一视频中查找到与该主体行为匹配的视频片段,并利用文本中用于描述视觉呈现画面的视觉描述词,来从第一视频中查找到与该视觉呈现画面匹配的视频帧,这样,将上述匹配到的视频片段和视频帧进行融合后,便可得到更加切题和真实的目标视频,保证了最终生成的视频的视频质量。In the electronic device provided in this embodiment of the present application, when generating a video based on text, the electronic device may first extract behavior descriptors and visual descriptors in the first text, and then extract the behavior descriptors and visual descriptors in the first text, and then select N similar to the first text from the video library Determine the target video segment matching the behavior descriptor and the target video frame matching the visual descriptor in the first video, and finally generate the target video based on the target video segment and the target video frame; wherein, N is an integer greater than 1 . In this way, by using the behavior descriptor in the text for describing the subject's behavior, a video segment matching the subject's behavior is found from the first video, and using the visual descriptor in the text for describing the visual presentation picture, to obtain a video clip from the first video. A video frame matching the visual presentation picture is found in the first video. In this way, after the above-mentioned matched video clips and video frames are fused, a more relevant and real target video can be obtained, which ensures the final video quality. video quality.
应理解的是,本申请实施例中,输入单元104可以包括图形处理器(GraphicsProcessing Unit,GPU)1041和麦克风1042,图形处理器1041对在视频捕获模式或图像捕获模式中由图像捕获装置(如摄像头)获得的静态图片或视频的图像数据进行处理。显示单元106可包括显示面板1061,可以采用液晶显示器、有机发光二极管等形式来配置显示面板1061。用户输入单元107包括触控面板1071以及其他输入设备1072中的至少一种。触控面板1071,也称为触摸屏。触控面板1071可包括触摸检测装置和触摸控制器两个部分。其他输入设备1072可以包括但不限于物理键盘、功能键(比如音量控制按键、开关按键等)、轨迹球、鼠标、操作杆,在此不再赘述。It should be understood that, in this embodiment of the present application, the
存储器109可用于存储软件程序以及各种数据。存储器109可主要包括存储程序或指令的第一存储区和存储数据的第二存储区,其中,第一存储区可存储操作系统、至少一个功能所需的应用程序或指令(比如声音播放功能、图像播放功能等)等。此外,存储器109可以包括易失性存储器或非易失性存储器,或者,存储器109可以包括易失性和非易失性存储器两者。其中,非易失性存储器可以是只读存储器(Read-Only Memory,ROM)、可编程只读存储器(Programmable ROM,PROM)、可擦除可编程只读存储器(Erasable PROM,EPROM)、电可擦除可编程只读存储器(Electrically EPROM,EEPROM)或闪存。易失性存储器可以是随机存取存储器(Random Access Memory,RAM),静态随机存取存储器(Static RAM,SRAM)、动态随机存取存储器(Dynamic RAM,DRAM)、同步动态随机存取存储器(Synchronous DRAM,SDRAM)、双倍数据速率同步动态随机存取存储器(Double Data Rate SDRAM,DDRSDRAM)、增强型同步动态随机存取存储器(Enhanced SDRAM,ESDRAM)、同步连接动态随机存取存储器(Synch link DRAM,SLDRAM)和直接内存总线随机存取存储器(Direct Rambus RAM,DRRAM)。本申请实施例中的存储器109包括但不限于这些和任意其它适合类型的存储器。The
处理器110可包括一个或多个处理单元;可选的,处理器110集成应用处理器和调制解调处理器,其中,应用处理器主要处理涉及操作系统、用户界面和应用程序等的操作,调制解调处理器主要处理无线通信信号,如基带处理器。可以理解的是,上述调制解调处理器也可以不集成到处理器110中。The
本申请实施例还提供一种可读存储介质,所述可读存储介质上存储有程序或指令,该程序或指令被处理器执行时实现上述视频生成方法实施例的各个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。Embodiments of the present application further provide a readable storage medium, where a program or an instruction is stored on the readable storage medium, and when the program or instruction is executed by a processor, each process of the foregoing video generation method embodiment can be achieved, and the same can be achieved. In order to avoid repetition, the technical effect will not be repeated here.
其中,所述处理器为上述实施例中所述的电子设备中的处理器。所述可读存储介质,包括计算机可读存储介质,如计算机只读存储器ROM、随机存取存储器RAM、磁碟或者光盘等。Wherein, the processor is the processor in the electronic device described in the foregoing embodiments. The readable storage medium includes a computer-readable storage medium, such as computer read-only memory ROM, random access memory RAM, magnetic disk or optical disk, and the like.
本申请实施例另提供了一种芯片,所述芯片包括处理器和通信接口,所述通信接口和所述处理器耦合,所述处理器用于运行程序或指令,实现上述视频生成方法实施例的各个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。An embodiment of the present application further provides a chip, where the chip includes a processor and a communication interface, the communication interface is coupled to the processor, and the processor is configured to run a program or an instruction to implement the above video generation method embodiments Each process can achieve the same technical effect. In order to avoid repetition, it will not be repeated here.
应理解,本申请实施例提到的芯片还可以称为系统级芯片、系统芯片、芯片系统或片上系统芯片等。It should be understood that the chip mentioned in the embodiments of the present application may also be referred to as a system-on-chip, a system-on-chip, a system-on-a-chip, or a system-on-a-chip, or the like.
本申请实施例提供一种计算机程序产品,该程序产品被存储在存储介质中,该程序产品被至少一个处理器执行以实现如上述视频生成方法实施例的各个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。The embodiments of the present application provide a computer program product, the program product is stored in a storage medium, and the program product is executed by at least one processor to implement the various processes in the foregoing video generation method embodiments, and can achieve the same technical effect , in order to avoid repetition, it will not be repeated here.
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者装置不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者装置所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者装置中还存在另外的相同要素。此外,需要指出的是,本申请实施方式中的方法和装置的范围不限按示出或讨论的顺序来执行功能,还可包括根据所涉及的功能按基本同时的方式或按相反的顺序来执行功能,例如,可以按不同于所描述的次序来执行所描述的方法,并且还可以添加、省去、或组合各种步骤。另外,参照某些示例所描述的特征可在其他示例中被组合。It should be noted that, herein, the terms "comprising", "comprising" or any other variation thereof are intended to encompass non-exclusive inclusion, such that a process, method, article or device comprising a series of elements includes not only those elements, It also includes other elements not expressly listed or inherent to such a process, method, article or apparatus. Without further limitation, an element qualified by the phrase "comprising a..." does not preclude the presence of additional identical elements in a process, method, article or apparatus that includes the element. In addition, it should be noted that the scope of the methods and apparatus in the embodiments of the present application is not limited to performing the functions in the order shown or discussed, but may also include performing the functions in a substantially simultaneous manner or in the reverse order depending on the functions involved. To perform functions, for example, the described methods may be performed in an order different from that described, and various steps may also be added, omitted, or combined. Additionally, features described with reference to some examples may be combined in other examples.
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分可以以计算机软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如ROM/RAM、磁碟、光盘)中,包括若干指令用以使得一台终端(可以是手机,计算机,服务器,或者网络设备等)执行本申请各个实施例所述的方法。From the description of the above embodiments, those skilled in the art can clearly understand that the method of the above embodiment can be implemented by means of software plus a necessary general hardware platform, and of course can also be implemented by hardware, but in many cases the former is better implementation. Based on such understanding, the technical solutions of the present application can be embodied in the form of computer software products, which are essentially or contribute to the prior art, and the computer software products are stored in a storage medium (such as ROM/RAM, magnetic disk , CD-ROM), including several instructions to make a terminal (which may be a mobile phone, a computer, a server, or a network device, etc.) execute the methods described in the various embodiments of the present application.
上面结合附图对本申请的实施例进行了描述,但是本申请并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本申请的启示下,在不脱离本申请宗旨和权利要求所保护的范围情况下,还可做出很多形式,均属于本申请的保护之内。The embodiments of the present application have been described above in conjunction with the accompanying drawings, but the present application is not limited to the above-mentioned specific embodiments, which are merely illustrative rather than restrictive. Under the inspiration of this application, without departing from the scope of protection of the purpose of this application and the claims, many forms can be made, which all fall within the protection of this application.
Claims (16)
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210863915.XACN115186133A (en) | 2022-07-21 | 2022-07-21 | Video generation method, device, electronic device and medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210863915.XACN115186133A (en) | 2022-07-21 | 2022-07-21 | Video generation method, device, electronic device and medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN115186133Atrue CN115186133A (en) | 2022-10-14 |
Family
ID=83518658
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210863915.XAPendingCN115186133A (en) | 2022-07-21 | 2022-07-21 | Video generation method, device, electronic device and medium |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN115186133A (en) |
Cited By (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116127131A (en)* | 2022-12-02 | 2023-05-16 | 百度在线网络技术(北京)有限公司 | Video generation method, device, equipment and storage medium |
| CN116664726A (en)* | 2023-07-26 | 2023-08-29 | 腾讯科技(深圳)有限公司 | Video acquisition method and device, storage medium and electronic equipment |
| CN117544833A (en)* | 2023-11-17 | 2024-02-09 | 北京有竹居网络技术有限公司 | Methods, apparatus, equipment and media for generating video |
| CN117835013A (en)* | 2023-12-27 | 2024-04-05 | 北京智象未来科技有限公司 | Multi-scene video generation method, device, equipment and storage medium |
| WO2024199145A1 (en)* | 2023-03-24 | 2024-10-03 | 浪潮电子信息产业股份有限公司 | Text information processing method, system and device, and non-volatile readable storage medium |
Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108470036A (en)* | 2018-02-06 | 2018-08-31 | 北京奇虎科技有限公司 | A kind of method and apparatus that video is generated based on story text |
| CN108986186A (en)* | 2018-08-14 | 2018-12-11 | 山东师范大学 | The method and system of text conversion video |
| US20200394216A1 (en)* | 2018-08-07 | 2020-12-17 | Beijing Sensetime Technology Develpmen Co., Ltd. | Method and device for video processing, electronic device, and storage medium |
| CN112115299A (en)* | 2020-09-17 | 2020-12-22 | 北京百度网讯科技有限公司 | Video searching method and device, recommendation method, electronic device and storage medium |
| CN112231515A (en)* | 2020-10-28 | 2021-01-15 | 王志晓 | Mass surveillance video quick retrieval system and retrieval method |
| CN114329068A (en)* | 2021-08-11 | 2022-04-12 | 腾讯科技(深圳)有限公司 | Data processing method and device, electronic equipment and storage medium |
| CN114390217A (en)* | 2022-01-17 | 2022-04-22 | 腾讯科技(深圳)有限公司 | Video synthesis method and device, computer equipment and storage medium |
| US20220189173A1 (en)* | 2020-12-13 | 2022-06-16 | Baidu Usa Llc | Generating highlight video from video and text inputs |
- 2022
- 2022-07-21CNCN202210863915.XApatent/CN115186133A/enactivePending
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN108470036A (en)* | 2018-02-06 | 2018-08-31 | 北京奇虎科技有限公司 | A kind of method and apparatus that video is generated based on story text |
| US20200394216A1 (en)* | 2018-08-07 | 2020-12-17 | Beijing Sensetime Technology Develpmen Co., Ltd. | Method and device for video processing, electronic device, and storage medium |
| CN108986186A (en)* | 2018-08-14 | 2018-12-11 | 山东师范大学 | The method and system of text conversion video |
| CN112115299A (en)* | 2020-09-17 | 2020-12-22 | 北京百度网讯科技有限公司 | Video searching method and device, recommendation method, electronic device and storage medium |
| CN112231515A (en)* | 2020-10-28 | 2021-01-15 | 王志晓 | Mass surveillance video quick retrieval system and retrieval method |
| US20220189173A1 (en)* | 2020-12-13 | 2022-06-16 | Baidu Usa Llc | Generating highlight video from video and text inputs |
| CN114329068A (en)* | 2021-08-11 | 2022-04-12 | 腾讯科技(深圳)有限公司 | Data processing method and device, electronic equipment and storage medium |
| CN114390217A (en)* | 2022-01-17 | 2022-04-22 | 腾讯科技(深圳)有限公司 | Video synthesis method and device, computer equipment and storage medium |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN116127131A (en)* | 2022-12-02 | 2023-05-16 | 百度在线网络技术(北京)有限公司 | Video generation method, device, equipment and storage medium |
| WO2024199145A1 (en)* | 2023-03-24 | 2024-10-03 | 浪潮电子信息产业股份有限公司 | Text information processing method, system and device, and non-volatile readable storage medium |
| CN116664726A (en)* | 2023-07-26 | 2023-08-29 | 腾讯科技(深圳)有限公司 | Video acquisition method and device, storage medium and electronic equipment |
| CN116664726B (en)* | 2023-07-26 | 2024-02-09 | 腾讯科技(深圳)有限公司 | Video acquisition method and device, storage medium and electronic equipment |
| WO2025020659A1 (en)* | 2023-07-26 | 2025-01-30 | 腾讯科技(深圳)有限公司 | Video generation method and apparatus, storage medium and electronic device |
| CN117544833A (en)* | 2023-11-17 | 2024-02-09 | 北京有竹居网络技术有限公司 | Methods, apparatus, equipment and media for generating video |
| CN117835013A (en)* | 2023-12-27 | 2024-04-05 | 北京智象未来科技有限公司 | Multi-scene video generation method, device, equipment and storage medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN113762322B (en) | Video classification method, device and equipment based on multi-modal representation and storage medium | |
| CN114398961B (en) | Visual question-answering method based on multi-mode depth feature fusion and model thereof | |
| CN111797893B (en) | Neural network training method, image classification system and related equipment | |
| CN110717017B (en) | Method for processing corpus | |
| CN115186133A (en) | Video generation method, device, electronic device and medium | |
| US20190034814A1 (en) | Deep multi-task representation learning | |
| WO2020228376A1 (en) | Text processing method and model training method and apparatus | |
| CN113836992B (en) | Label identification method, label identification model training method, device and equipment | |
| CN113095346A (en) | Data labeling method and data labeling device | |
| CN114390217A (en) | Video synthesis method and device, computer equipment and storage medium | |
| CN117033609B (en) | Text visual question-answering method, device, computer equipment and storage medium | |
| CN113221882B (en) | Image text aggregation method and system for curriculum field | |
| CN113392179B (en) | Text annotation method and device, electronic device, and storage medium | |
| CN110162639A (en) | Knowledge figure knows the method, apparatus, equipment and storage medium of meaning | |
| CN111445545B (en) | Text transfer mapping method and device, storage medium and electronic equipment | |
| CN114661951B (en) | Video processing method, device, computer equipment and storage medium | |
| US20200143211A1 (en) | Learning representations of generalized cross-modal entailment tasks | |
| CN117556067B (en) | Data retrieval method, device, computer equipment and storage medium | |
| CN111797936A (en) | Image emotion classification method and device based on saliency detection and multi-level feature fusion | |
| CN117649567B (en) | Data labeling method, device, computer equipment and storage medium | |
| CN110705490A (en) | Visual Emotion Recognition Methods | |
| WO2024255641A1 (en) | Model training method, training data acquisition method, and related device | |
| Wu et al. | Sentimental visual captioning using multimodal transformer | |
| He et al. | Deep learning in natural language generation from images | |
| Jishan et al. | Bangla language textual image description by hybrid neural network model |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination |